Windows Azure and Cloud Computing Posts for 8/24/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

• Updated 8/24/2011 4:30 PM PDT with additional articles marked • by Cihan Biyikoglu, Avkash Chauhan, and Larry Franks
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Apps, Access Control, WCF, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table and Queue Services
Ryan Dunn (@dunnry) reported Handling Continuation Tokens in Windows Azure - Gotcha in an 8/24/2011 post:
I spent the last few hours debugging an issue where a query in Windows Azure table storage was not returning any results, even though I knew that data was there. It didn't start that way of course. Rather, stuff that should have been working and previously was working, just stopped working. Tracing through the code and debugging showed me it was a case of a method not returning data when it should have.
Now, I have known for quite some time that you must handle continuation tokens and you can never assume that a query will return data always (Steve talks about it waaaay back when here). However, what I did not know was that different methods of enumeration will give you different results. Let me explain by showing the code.
var q = this.CreateQuery().Where(filter).Where(f => f.PartitionKey.CompareTo(start.GetTicks()) > 0).Take(1).AsTableServiceQuery();var first = q.FirstOrDefault();if (first != null){return new DateTime(long.Parse(first.PartitionKey));}In this scenario, you would assume that you have continuation tokens nailed because you have the magical AsTableServiceQuery extension method in use. It will magically chase the tokens until conclusion for you. However, this code does not work! It will actually return null in cases where you do not hit the partition server that holds your query results on the first try.
I could easily reproduce the query in LINQPad:
var q = ctx.CreateQuery<Foo>("WADPerformanceCountersTable").Where(f => f.RowKey.CompareTo("9232a4ca79344adf9b1a942d37deb44a") > 0 && f.RowKey.CompareTo("9232a4ca79344adf9b1a942d37deb44a__|") < 0).Where(f => f.PartitionKey.CompareTo(DateTime.Now.AddDays(-30).GetTicks()) > 0).Take(1).AsTableServiceQuery().Dump();Yet, this query worked perfectly. I got exactly 1 result as I expected. I was pretty stumped for a bit, then I realized what was happening. You see FirstOrDefault will not trigger the enumeration required to generate the necessary two round-trips to table storage (first one gets continuation token, second gets results). It just will not force the continuation token to be chased. Pretty simple fix it turns out:
var first = q.AsEnumerable().SingleOrDefault();Hours wasted for that one simple line fix. Hope this saves someone the pain I just went through.

<Return to section navigation list>
SQL Azure Database and Reporting
• Cihan Biyikoglu reported Federations Migration Wizard Now Available! in an 8/24/2011 post:
One of the most popular tools for migrating your databases to SQL Azure is the SQL Azure Migration Assistant. Good friend George Huey finished off the extensions to it recently and now, it has a version of the tool that can help move large data into SQL Azure databases with Federations. You can start using the tool if you have access to the preview of the Federations technology.
Here is the link: http://sqlazurefedmw.codeplex.com/
Thank you George!

For more information about the new SQL Azure Federation Migration Wizard, see my Windows Azure and Cloud Computing Posts for 8/19/2011+ post.
Roger Hart described To The Cloud: Moving Red Gate Tools to SQL Azure in an 8/23/2011 post to Developer Fusion:
Red Gate make a lot of tools for SQL Server. Two of our most popular are SQL Compare, which compares and synchronizes schemas, and SQL Data Compare, which does the same for data.
Well over a year ago now, when we first got our hands on SQL Azure, we did the eager, mindlessly optimistic, and utterly predictable thing: “Let’s point SQL Compare at it, and see what happens!” It didn’t work, and that’s not massively surprising. More surprising, perhaps, is how simple it was to make it work.
None of the developers I spoke to who’d worked on one of our Azure projects had anything really bad to say about SQL Azure, or could recall anything big, hairy, and challenging.
So what was there? What did we do with Azure, and what did we learn from it?
We’ve built six Azure-compatible products to date: thee existing tools now support SQL Azure, and there are three small new widgets for working with it.
- SQL Compare and SQL Data Compare 8 and onwards now support migrating changes to, from, and between SQL Azure databases
- SQL Prompt 5.1 can connect to an Azure database and offer basic intellisense.
The new bits are largely spun out of frustrations we’ve had ourselves:
- CloudTally is a billing notification service
- SQL Azure Backup does what it says on the tin
- Query Anywhere is a Down Tools Week project, a browser-based SQL editor – SSMS light for Azure
I talked to the guys who built these, and the story each time was about most of the effort being in the edge cases, the UI, and around a few recurring issues I’ll tell you about.
Updating Apps For Azure
Getting SQL Compare and SQL Data Compare up and running for Azure began as a user request. Emmanuel Huna asked us to do it on our forums, and after a bit of back and forth, we got an early access build together. The project took about a month – two sprints, which is significantly less than any previous SQL Server version compatibility update. In fact, it took less time than developing some of the smaller SQL Compare features; object filtering, for example.
The main initial sources of confusion for the team were all around the way of working – you’ve got to be careful about how you create databases and move data around, because doing things in Azure costs money.
Debugging Azure Apps For As Little As Possible
It’s true that payment and setup are more admin problems than a development ones, but they did require some tweaks. The standard testing setup we use for our comparison tools creates and drops databases all over the place, and that’s going to get expensive pretty fast. So we had to re-architect a bit; first off so the automated tests didn’t spend all our money, and secondly so they didn’t rely on restoring backups (an impossibility under SQL Azure).
Unit tests were configured to run under each developer’s own Azure account, thereby making the most of the free allowances, and the big overnight integration tests we have set up for SQL Compare were moved over to relying on creation scripts. None of this is difficult, but it leaves you with a slightly disquieting feeling that anything you do might suddenly and unexpectedly cost you money. It’s an odd experience when you’re a developer used to throwing stuff around in a sandbox. Which is basically why we built CloudTally. Of course, once we’ve got SQL Compare working in Azure, we can just develop locally, and migrate. But we had to build it first.
The body of the work in getting SQL Compare and Data Compare to work with SQL Azure fell into two areas: accounting for the differences between Microsoft’s desktop and Azure flavours of T-SQL, and sorting out connection resilience.
It’s also worth noting that the SQL Azure update schedule is a lot more rapid than for on-premises SQL Server. This can really bite you, as Richard describes on his blog
T-SQL : Azure vs Desktop
The developer to take the first crack at Azure-ing up the comparison engine assures me that under the hood we’re basically looking at SQL Server 2008 with some features chopped off, and some object types missing. So you don’t have:
- Application Roles
- Assemblies
- Asymmetric Keys
- Certificates
- Contracts
- Defaults
- Event Notifications
- Full Text Catalogs
- Message Types
- Partition Functions
- Partition Schemes
- Queues
- Application Roles
- Routes
- Rules
- Services
- Service Bindings
- Extended Stored Procedures
- Numbered Stored Procedures
- Symmetric Keys
- Remote Synonyms
- User-Defined Types
- XML Schema Collections
- Common Language Runtime (CLR) User-Defined Types
- Large User-Defined Types (UDTs)
Some of the more administrative features are out, too, for example:
- Backups
- Database mirroring
- Distributed queries
- Distributed transactions
- Filegroup management
- Global temporary tables
- SQL Server configuration options
- SQL Server Service Broker
- System tables
- Trace Flags
That sounds like a lot, and we’ve summarised some of this information on our website. It’s covered in the Microsoft documentation, too:
- Learning SQL Compare 9.0 - Synchronizing to SQL Azure
- SQL Server Feature Limitations (SQL Azure Database)
- Transact-SQL Support (SQL Azure Database)
One thing that really caught us out is that tables now require a clustered index before you can insert data. Because SQL Compare often drops indexes at the beginning of a synchronization, and re-creates them at the end, this meant that for tables with data, our scripts would fail. So we had to add a few more table rebuilds than we typically like.
In the case of object types that no longer exist, there’s not a lot we can do. SQL Compare can’t create them if they’re not supported, so we just provide a warning and check for dependencies. For the syntax that’s different, we had to go through it on a case by case basis. The real issue was where information we were used to depending on was missing.
So, for example, SQL Compare needs to know a database’s compatibility level, and uses sp_dbcmptlevel to get it. This isn’t available in SQL Azure. But (and, boringly, this has been our Azure experience in microcosm) we didn’t have to do anything very complex or interesting to deal with it. Since SQL Azure is at compatibility level 100 we just needed to make sure SQL Compare determines the SQL Server version first. It didn’t take a lot, but it’s typical of the little tweaks we had to make all over the place.
Connection Resilience
The next issue was connections. Everybody complained about this, and there are two issues: connecting to multiple databases, and transient connection errors.
Under the desktop editions of SQL Server, you connect to a server, and can access as many databases as you have permissions for. Under SQL Azure, you connect to one database at a time, and USE statements just aren’t going to happen. Usually, when comparing databases, SQL Compare will query the Master database for login details. But under Azure you can’t chop and change the database you’re connected to. This gave us a bit of a headache.
In the end, the solution wasn’t elegant. SQL Compare just tries to create logins regardless, and to fail nicely if they already exist. Is it pretty? Frankly, no, but we’ve had surprisingly few error reports, and this approach did let us ship quickly.
Transient connectivity issues and resilience, by contrast, we just had to deal with. Microsoft is well aware of these issues with Azure. It’s documented, and they’ve even produced a “Transient Conditions Handling Framework” to help developers build resilience into their applications. But even using it, the error reports came in for connection issues. We knew, because one of the first things we did was hook in SmartAssembly, our detailed error reporting tool.
It tells us precisely where users are hitting issues, and they were hitting them around connection resilience. For example, with some connection interruptions, the early versions of SQL Data Compare would transactionally roll back an entire synchronization, and for a lot of data, that’s decidedly less than ideal. So we had to implement some of our own logic to cover more cases.
So, while executing the synchronization scripts, we keep track of where the current transaction began, and if we get an Exception which indicates a temporary problem (such as 40501 in the Microsoft documentation) we go back to the start of the failed transaction and start again. If we get disconnected 5 times in the same transaction we stop trying. Essentially, we keep going in the face of disconnections as long as we are still making progress.
Doing more for SQL Azure
Once we’d got the comparison tools up and running, we could tackle the other issue everybody had raised: backups. Microsoft offers the ability to copy an Azure database, and plenty of assurance about failover, but there are plenty of cases in which you want a backup too. Or, as Richard, who wrote our SQL Azure backup tool put it, after some frustration hosting websites on Azure: “To be honest, stuff it – I just want a backup solution!”
Here it is:
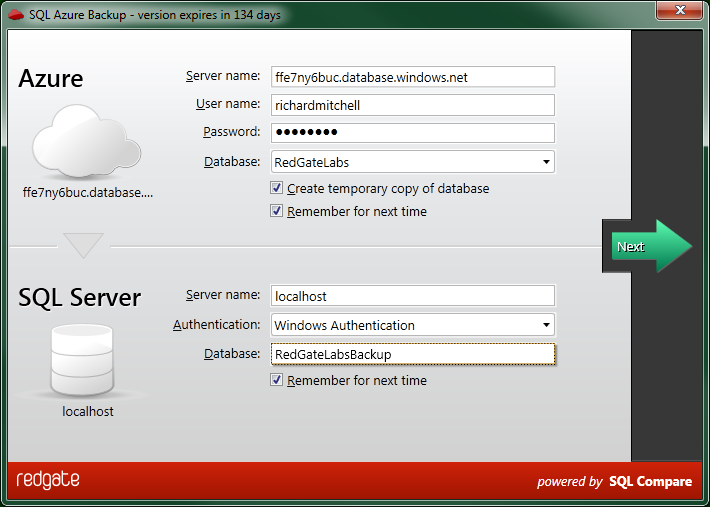
Richard brushed up against the mandatory clustered indexes, and some problems with deployment being slow from Visual Studio, but otherwise he had the prototype up and running in about half a day. SQL Azure Backup uses the SQL Data Compare engine to copy your data down to a new local database, so it was very nearly just a case of wrapping a UI around the existing SDK. The main gotcha was matching the new local database to the properties of the SQL Azure one.
For instance, in SQL Azure the default collation is SQL_LATIN1_GENERAL_CP1_CI_AS, and collation can only be set at column and expression level. There’s no server level or database level collation. So when SQL Azure Backup first tried to create a database on a local SQL Server instance, it would fail if the collations didn’t match. This isn’t much of a problem – the local database SQL Azure Backup creates just has to specify Azure-friendly collation, rather than accepting the server level default. But it’s the kind of little difference that can surprise you when moving to Azure.
You can take a look at SQL Azure Backup here It’s currently in free beta, and Richard is working on the next version (with a “big new feature” he refuses to tell me about) right now.
And that’s basically the state of it. Creating working ports of our tools to SQL Azure wasn’t a massive challenge. In fact, the experience was surprisingly smooth, given how new the platform is. With transience dealt with, the bulk of the effort is in working through and accounting for small differences, and a heck of a lot of testing.

<Return to section navigation list>
MarketPlace DataMarket and OData
Arthur Greef contributed an OData Query Service post to the Dynamics AX Integration using AIF blog on 8/24/2011:
Microsoft Dynamics AX 2012 hosts an OData Query Service that uses the Open Data Protocol (OData) protocol to execute queries that are modeled in the Application Object Tree (AOT). The OData protocol is a HTTP protocol for querying and updating data. Microsoft Dynamics AX 2012 supports data query scenarios (with some limitations listed below), but does not support data update scenarios. The following example describes how to read data from the Currency table. The sample assumes that the Application Object Server (AOS) is installed on a machine named ‘aoshost’.
Set up an AOT query that can be executed by the OData Query Service
- Open the Microsoft Dynamics AX 2012 development environment.
- Under AOT, click the Queries node, and then create a new query node. Either (1) Select File > New or (2) Right-click the Queries node, and then select New Query.
- Change the name the new query node to “CurrencyQuery”.
- Under AOT, click Queries > CurrencyQuery > Data Sources node, and then create a new data source node. Either: (1) SelectFile > New. or (2) Right-click the Data Sources node, and then select New Data Source.
- Select the new data source node Currency_1, and then on the Table property in the property sheet, select Currency
- Open the Microsoft Dynamics AX 2012 Windows Client.
- Click Organization Administration > Setup > Document management > Document data sources.
- In the Document data sources form, click New or press CTRL+N to add a new document data source.
i. No specific value is required in the Module column.
ii. In the Data source type column, select Query.
iii. In the Data source name column, select or enter the CurrencyQuery.
iv. Select the Activated check box to activate the query as a document data source.
v. Close the Document data sources form.
Using the OData Query Service with Windows Internet Explorer
- Open Internet Explorer.
- Enter the following URL to return the OData Query Service definition: http://aoshost:8101/DynamicsAx/Services/ODataQueryService/. The service will display the name CurrencyQuery. The Application Object Server (AOS) host name and the services port are provided when installing and configuring each AOS and can be found in the AX32Serv.exe.config file created under the file system folder created for the AOS.
- Enter the following URL to return the OData Query Service metadata definition: http://aoshost:8101/DynamicsAx/Services/ODataQueryService/$metadata
- Enter the following URL to execute the CurrencyQuery query: http://aoshost:8101/DynamicsAx/Services/ODataQueryService/CurrencyQuery
Note: If Internet Explorer formats the results as a feed, then right-click on the HTML page, and select View source to open the result in Notepad.
Using the OData Query Service with Microsoft PowerPivot
- Install Microsoft Excel.
- Install Microsoft PowerPivot.
- Open Microsoft Excel.
- Click the PowerPivot tab.
- On the PowerPivot tab, in the Launch group, click the PowerPivot Window button. A PowerPivot window opens.
- On the Home tab, in the Get External Data group, click the From Data Feeds button.
- In the Data Feed Url field, enter the following URL: http://aoshost:8101/DynamicsAx/Services/ODataQueryService/
- Click the Next button to view the CurrencyQuery OData data source.
- Click the Finish button to import the currency data into PowerPivot.
- Click the Close button to view the currency data.
Using the OData Query Service with Microsoft Visual Studio
- Install Microsoft Visual Studio.
- Create a new Console Application.
- Right-click the project References node in the Solution Explorer window, and then select the Add Service Reference… menu item.
- Enter the following Url into the Address field and click Go: http://aoshost:8101/DynamicsAx/Services/ODataQueryService/
- Click OK to add the service reference to the project.
OData Query Service paging
The OData Query Service returns data in pages that have a length specified in the AX32Serv.exe.config file created under the file system folder created for the AOS. The page size can be modified by editing the configuration file and by restarting the AOS. The default page size is shown in the following XML document fragment.
<add key="ODataQueryPageSize" value="1000" />
OData Query Service limitations
- OData protocol filters are not supported.
- OData protocol create and update operations are not supported.
- Each record in an OData query response must have a unique primary key. AOT queries with View data sources are therefore not OData query candidates and will not be displayed in an OData metadata request.
- Only queries that support “Value-based paging” are executed. AOT queries whose FetchMode property value is “1:n” will generate an error message in the Windows Event Log
OData Query Service notes
- You may need to replace the AOS host machine name with an IP address in the OData Query Service Url when accessing OData Query Services remotely.
- Some applications require a slash mark (/) at the end of the service definition URL. For example: http://aoshost:8101/DynamicsAx/Services/ODataQueryService/
This posting is provided "AS IS" with no warranties, and confers no rights.
PRNewswire reported Outercurve Foundation Announces Contribution of OData Validation Project in an 8/24/2011 press release:
Renamed DLSI Gallery now hosts four open source projects focused on access to and integration of data
WAKEFIELD, Mass., Aug. 24, 2011 /PRNewswire/ -- The Outercurve Foundation today announced the acceptance of the OData Validation project into the Data, Language and System Interoperability (DLSI) Gallery. The OData Service Validation Tool project is the fourth project contributed to the gallery. The open source project was contributed by Microsoft, the foundation's primary sponsor.
The DLSI Gallery hosts open source projects that promote interoperability at the data format, language/runtime and system layers. The focus is on projects that enable greater interoperability between Microsoft platforms and other technologies and platforms. The gallery was formerly known as the Systems Infrastructure and Integration Gallery.
OData is a widely used Web protocol with many adopters in the industry such as SAP, Netflix, the Department of Labor and IBM. A wide range of applications and libraries can consume an OData service. The OData Service Validation tool aims to foster the existing OData ecosystem by enabling OData service authors to validate their implementations against the OData specification to ensure the services interoperate well with any OData client.
"Integration and interoperability are important goals, but when access to data is added, everyone benefits," said Paula Hunter, Executive Director, Outercurve Foundation. "This project will help developers gain access to data, regardless of the silos created by applications or systems, to enable emerging technology trends such as cloud and mobile computing.
"As we looked at this project, we realized that the goals of the Systems Infrastructure and Integration Gallery were expanding," continued Hunter. "We are renaming the gallery as the Data, Language and System Interoperability (DLSI) Gallery to reflect the evolution of the scope of the projects we are exploring. We expect the gallery to host projects around cloud computing, multi-platform development and data exchange, with the goal of providing developers and IT professionals with more solutions and choices to promote cross-platform integration and interoperability."
The Outercurve Foundation has three galleries and 13 projects. Galleries include the ASP.NET Open Source Gallery, the Research Accelerators Gallery and the Data, Language and System Interoperability Gallery.
For more information on the OData Validation project, the Data, Language and System Interoperability Gallery or the Outercurve Foundation please visit www.Outercurve.org.
About The Outercurve Foundation
The Outercurve Foundation is a not-for-profit foundation providing software IP management and project development governance to enable and encourage organizations to develop software collaboratively in open source communities for faster results. The Outercurve Foundation is the only open source foundation that is platform, technology, and license agnostic. For more information about the Outercurve Foundation contact info@Outercurve.org

The Outercurve Foundation folks neglected to mention the Microsoft contributed the open-source OData specification to OData.org.
<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WCF, WIF and Service Bus
• Avkash Chauhan explained Enabling WCF Tracing in Windows Azure WCF Web Role in an 8/24/2011 post:
When you create a Windows Azure WCF Web Role you will see that WCF tracking is disabled by default. The original web.config looks like as below:
<?xml version="1.0"?>
<configuration>
<!-- To collect diagnostic traces, uncomment the section below.
To persist the traces to storage, update the DiagnosticsConnectionString setting with your storage credentials.
To avoid performance degradation, remember to disable tracing on production deployments.
<system.diagnostics>
<sharedListeners>
<add name="AzureLocalStorage" type="WCFServiceWebRole.AzureLocalStorageTraceListener, WCFServiceWebRole"/>
</sharedListeners>
<sources>
<source name="System.ServiceModel" switchValue="Verbose, ActivityTracing">
<listeners>
<add name="AzureLocalStorage"/>
</listeners>
</source>
<source name="System.ServiceModel.MessageLogging" switchValue="Verbose">
<listeners>
<add name="AzureLocalStorage"/>
</listeners>
</source>
</sources>
</system.diagnostics> -->
<system.diagnostics>
<trace>
<listeners>
<add type="Microsoft.WindowsAzure.Diagnostics.DiagnosticMonitorTraceListener, Microsoft.WindowsAzure.Diagnostics, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35"
name="AzureDiagnostics">
<filter type="" />
</add>
</listeners>
</trace>
</system.diagnostics>
<system.web>
<compilation debug="true" targetFramework="4.0" />
</system.web>
<system.serviceModel>
<behaviors>
<serviceBehaviors>
<behavior>
<!-- To avoid disclosing metadata information, set the value below to false and remove the metadata endpoint above before deployment -->
<serviceMetadata httpGetEnabled="true"/>
<!-- To receive exception details in faults for debugging purposes, set the value below to true. Set to false before deployment to avoid disclosing exception information -->
<serviceDebug includeExceptionDetailInFaults="false"/>
</behavior>
</serviceBehaviors>
</behaviors>
<serviceHostingEnvironment multipleSiteBindingsEnabled="true" />
</system.serviceModel>
<system.webServer>
<modules runAllManagedModulesForAllRequests="true"/>
</system.webServer>
</configuration>
WCF Service Web Role implements WCF tracing by default and puts it in the local storage To enable, WCF tracing you would need to modify web.config as below:
- Enable SharedListeners -> AzureLocalStorage
- Configure messageLogging with following properties:
<diagnostics>
<messageLogging maxMessagesToLog="3000" logEntireMessage="true" logMessagesAtServiceLevel="true" logMalformedMessages="true" logMessagesAtTransportLevel="true" />
</diagnostics>
The final web.config looks as below:
<?xml version="1.0"?>
<configuration>
<!-- To collect diagnostic traces, uncomment the section below.
To persist the traces to storage, update the DiagnosticsConnectionString setting with your storage credentials.
To avoid performance degradation, remember to disable tracing on production deployments. -->
<system.diagnostics>
<sharedListeners>
<add name="AzureLocalStorage" type="WCFServiceWebRole.AzureLocalStorageTraceListener, WCFServiceWebRole"/>
</sharedListeners>
<sources>
<source name="System.ServiceModel" switchValue="Verbose, ActivityTracing">
<listeners>
<add name="AzureLocalStorage"/>
</listeners>
</source>
<source name="System.ServiceModel.MessageLogging" switchValue="Verbose">
<listeners>
<add name="AzureLocalStorage"/>
</listeners>
</source>
</sources>
</system.diagnostics>
<system.diagnostics>
<trace>
<listeners>
<add type="Microsoft.WindowsAzure.Diagnostics.DiagnosticMonitorTraceListener, Microsoft.WindowsAzure.Diagnostics, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35"
name="AzureDiagnostics">
<filter type="" />
</add>
</listeners>
</trace>
</system.diagnostics>
<system.web>
<compilation debug="true" targetFramework="4.0" />
</system.web>
<system.serviceModel>
<diagnostics>
<messageLogging maxMessagesToLog="3000" logEntireMessage="true" logMessagesAtServiceLevel="true" logMalformedMessages="true" logMessagesAtTransportLevel="true" />
</diagnostics>
<behaviors>
<serviceBehaviors>
<behavior>
<!-- To avoid disclosing metadata information, set the value below to false and remove the metadata endpoint above before deployment -->
<serviceMetadata httpGetEnabled="true"/>
<!-- To receive exception details in faults for debugging purposes, set the value below to true. Set to false before deployment to avoid disclosing exception information -->
<serviceDebug includeExceptionDetailInFaults="false"/>
</behavior>
</serviceBehaviors>
</behaviors>
<serviceHostingEnvironment multipleSiteBindingsEnabled="true" />
</system.serviceModel>
<system.webServer>
<modules runAllManagedModulesForAllRequests="true"/>
</system.webServer>
</configuration>

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Larry Franks (@larry_franks) described Getting Started with Ruby on Windows Azure in an 8/24/2011 post:
In this post, I’ll talk about hot to get started developing Ruby applications for Windows Azure. I'll go over the basic things I’ll be using, optional things that are nice to have, and why I’m using some things instead of others.
If you have something that you think I’m missing that is useful when working with Ruby on Windows Azure, or that’s an alternative to one of the things I mention, leave a comment and I’ll add it to my list.Basic Requirements
The Ruby language
There are several versions of the Ruby language, as well as variants such as IronRuby, JRuby, or Rubinius. For most of my blog posts I’ll be using plain old MRI Ruby. Specifically I’ll be using RubyInstaller 1.9.2 and DevKit for my Windows environment and the MRI/YARV version that Ruby Version Manager installs for OS X. If there’s a lot of interest in Ruby 1.8.7, IronRuby, JRuby, etc., I can write about those also (please leave a comment if you'd like me to). But, I believe the things I’ll be explaining should work mostly the same between recent versions and distributions.
A Windows Azure subscription
In order to use Windows Azure, you need a subscription. There are a variety of offers, as well as a free trial. http://www.microsoft.com/windowsazure/pricing/ has pricing information and links to the free trial and http://msdn.microsoft.com/en-us/library/gg433024.aspx provides information on the subscription process.
A web framework
Hosting an application on Windows Azure means hosting a service, generally a web service. When I hear ‘Ruby’ and ‘web application’, I usually think Ruby on Rails. Rails is a web framework that lets you quickly and easily create websites in Ruby.
There are other web frameworks though, such as Sinatra, which provides a more bare bones framework. I will try to keep my examples generic so that the concept can be used from whatever framework you’re developing with.
A web browser that runs Silverlight
The Windows Azure Management portal is a Silverlight web application that allows you to provision Windows Azure services and deploy applications. You can bypass the portal to a certain extent by using REST APIs to provision services, or the waz-cmd tool that wraps some of the APIs and provides a command line interface for management tasks. Currently you can’t access everything through REST though, so the browser isn’t optional (yet.)
(Optional) a non-Azure Windows Installation
In general, a local version of Windows is optional. Since Ruby isn’t a .NET language, and since you can access most of the services the Windows Azure platform provides via REST APIs or other HTTP based methods, you usually don’t need Windows for testing. However, if you’re application uses a gem that includes a binary and you plan on deploying to Windows Azure, you can install the gems in question on a Windows environment and see if there are any problems.
A local Windows install also allows you to install the tools + SDK from http://www.microsoft.com/windowsazure/learn/getstarted/, which gives you Visual Studio 2010 and the Windows Azure Development environment. The development environment provides a compute (hosting) emulator and a storage emulator that are useful for testing deployment packages before deploying to Windows Azure.
(Optional) Visual Studio 2010
Visual Studio is also optional thanks to pre-packaged deployment solutions like Smarx Role and AzureRunMe. These solutions generally make it easier to run Ruby applications in Windows Azure buy allowing you to customize the command line to run your application, pull your application code in from a .zip file, or even download it from a Git repository. However if you want to customize either of these solutions you’ll need Visual Studio.
I’ll either be using Smarx Role or AzureRunMe to deploy my code to Windows Azure. I’ll save a discussion of both deployment options in a later post.
Other stuff
- Waz-cmd: A gem that exposes some Windows Azure management APIs to the command line
- Waz-storage: A gem that encapsulates the Windows Azure Storage Services REST APIs
- TinyTDS: A FreeTDS library for connecting to SQL Server and SQL Azure. NOTE: Currently requires a manual build sequence in order to work with SQL Azure.
Setting everything up
Here’s the steps to install the basics that I’ll be using:
- Install a Ruby distribution for your operating system. For example, on Windows I’ll install RubyInstaller, then DevKit, then follow the steps at https://github.com/oneclick/rubyinstaller/wiki/Development-Kit to configure and test DevKit.
- Download Small.cspkg and ServiceConfiguration.cscfg from http://smarxrole.codeplex.com/releases/view/68772.
- Download AzureRuneMe.cspkg and ServiceConfiguration.cscfg from https://github.com/RobBlackwell/AzureRunMe.
To verify that you’ve successfully installed Ruby, create a file named hello.rb containing the following text:
puts ‘Hello world!’
To run this application, type ruby hello.rb. You should see “Hello world!” returned.
In the next post I’ll go into detail on deploying web applications to Windows Azure using the Smarx Role and AzureRunMe projects, and why you need these projects in the first place.

Larry a writer working on content for Windows Azure Platform technologies, with a focus on SQL Azure.
Nathan Totten (@ntotten) described Node.JS on Windows Azure in an 8/24/2011 post:
We have been working on some enhancements to the Windows Azure Toolkit for Social Games in the past few weeks. One of the enhancements has been to include support for Web Sockets to enable faster real time communication between the different players of a game. There are a lot of choices out there for running Web Sockets, but the one we liked best was Socket.IO on Node.JS. Node.JS is getting to the point where it runs almost as well on Windows as is does on Linux and it is improving weekly. This post will show you the most basic setup of how to run Node.JS on Windows Azure.
Create our cloud project:
Add our worker role:
Now we need to add node.exe to our worker role. You can download the current Windows build for Node.JS on www.nodejs.org.
I am going to add node.exe to the root of my worker role. When you add it, make sure you set the Copy To Output Directory property to “Copy if newer”.

Next, we need to add our app.js file. This will be our node applications entry point. While I am at it I will also create a folder called “node_modules”. This folder will be used for any modules I want to include in the project. I am not going to show that in this post, but you will need to download modules manually because Node Package Manager does not yet work on Windows. You will need to make sure you set your app.js file and any module files to “Copy if newer” as well.
Now we need to do is modify our worker role entry point to start the node.exe process.
public class WorkerRole : RoleEntryPoint { Process proc; public override void Run() { proc.WaitForExit(); } public override bool OnStart() { proc = new Process() { StartInfo = new ProcessStartInfo( Environment.ExpandEnvironmentVariables(@"%RoleRoot%\approot\node.exe"), "app.js") { UseShellExecute = false, CreateNoWindow = true, WorkingDirectory = Environment.ExpandEnvironmentVariables(@"%RoleRoot%\approot\"), } }; proc.Start(); return base.OnStart(); } }We will take the most basic example of a node app and add that code to our app.js file.
var http = require('http'); http.createServer(function (req, res) { res.writeHead(200, { 'Content-Type': 'text/plain' }); res.end('NodeJS.exe running on Windows Azure!'); }).listen(8080);Next, we need to make sure we open up the ports we are using in node. In this case we are listening on port 8080. This change is made in our worker role cloud configuration.
Now we are ready to deploy the application to Windows Azure. After your application is deployed you can navigate to your cloudapp.net host and see your node.js server in action. You can see my sample deployed here: http://simplenodejs.cloudapp.net:8080/ and you can download the sample code here: https://ntotten.blob.core.windows.net/shared/SimpleNodeJSSample.zip
Let me know how you plan on using Node.JS in Windows Azure.







Anže Vodovnik posted Autoscaling Windows Azure applications with the Enterprise Library on 8/24/2011 to the Studio Pešec Lab blog:
Microsoft’s Grigori Melnik has posted some insight on the upcoming Windows Azure Integration Pack for Enterprise Library [see post below]. An interesting read into the detailed thinking behind the process. After a quick read, it seems our cloud applications will now (finally) be ready to scale, true to the marketing promises from the initial years.

Subscribed.
Grigori Melnik (@gmelnik) described Autoscaling Windows Azure applications with an Autoscaling Enterprise Block in an 8/23/2011 post:
As I have previously announced, my team has been heads-down working on the new Windows Azure Integration Pack for Enterprise Library. Autoscaling came as one of the top-ranked stories for the pack (it is a frequently requested feature from the product group and it gathered a lot of votes on our backlog too). In this post, I’d like to provide an update on our thinking about the scenarios we are addressing and our implementation progress. Also, as you read this, please tell us what you think – validate our scenarios or make suggestions on what to revise – we are actively listening!
Why?
How?
We envision users to specify various autoscaling rules and then expect them to be enacted. We will provide a new block – the Autoscaling Application Block. It will contain mechanisms for collecting data, evaluating rules, reconciling rules and executing various actions across multiple targets.
Based on conversations with advisors, the primary persona for the Autoscaling Application block is the application operator, not the developer. We are constantly reminding ourselves of this when designing the ways for interacting with the block.
Importantly, the process of defining the rules is iterative as shown on the pic below.
The operation personnel will likely need to go through these stages multiple times to refine the rules.
Which rules are to be supported?
There are 2 types of rules we support:
1) constraint rules:
- are associated with a timetable; help respond to predicted increases/decreases of activities;
- proactively set limits on the minimum and maximum number of role instances in your Windows Azure application;
- help to guard your budget;
- have a rank to determine precedence if there are multiple overlapping rules;
- example: Rule with Rank 1 = Every last Friday of the month, set the range of the Worker Role A instances to be: min = 3, max = 82) reactive rules:
- are based on some KPI that can be defined for your app; KPIs can be defined using perf counters (e.g. CPU utilization) or business metrics (e.g. # of unprocessed purchase orders);
- reactively adjust the current count of role instances (by incrementing/decrementing the count by an absolute number or by a proportion) or perform some other action (action types are described below);
- help respond to unexpected bursts or collapses in your application’s workload and to meet your SLA.A reactive rule is based on a metric (an abstract concept that you will monitor for). The block will collect data points (which are effectively metric values with corresponding timestamps) at a specific sampling rate, which you can configure. A user will use a KPI aggregate function (such as AVERAGE, MIN, MAX, SUM, COUNT, LAST, TREND etc over data points over a period of time) and a KPI goal to define a KPI. A reactive rule will specify what action needs to be taken based on whether the KPI goal is met or not. For example:
Metric: CPU usage
Source: Worker Role A all instances
Target: Worker Role A
Data points: metric values [80%, 40%, 60%, 80%] collected every 10 secs (sampling rate) with corresponding timestamps;
KPI Aggregate function: AVERAGE (Data points) for the past 1 hr
KPI Goal: < 75%
KPI 1 (user-named): If KPI Aggregate function for specific Source meets the KPI Goal, then KPI status = green
Rule R1 (user-named): if KPI 1 status = red, then increment instance count of Target by 1This is good, but users told us that they don’t want to necessarily focus on low level performance counters, but rather on some business KPI. Here’s an example of such a reactive rule. We intend to enable such specifications that use custom KPIs and custom actions:
Metric: Work orders waiting for processing
Source: Application
Target: Specified in the custom action
Data points: [10,15,12,80,100,105,103] collected every 15 mins
KPI Aggregate function: TREND (Data points) over the past 3 hrs
KPI Goal: + 50%
KPI 2: If (KPI Aggregate Function (Source, Metric) > KPI Goal), then KPI status = red, otherwise KPI status = green
Rule R2: If KPI 2 status = red, then do Custom Action C (scan the queue, provision another queue for work orders with “low” priority, and move all “low” priority work orders to that queue; listen on the main queue, when the queue clears move the “low” priority work orders back and de-provision the queue)Which actions are to be supported?
In the rule type descriptions, I mentioned instance scaling actions. They are not the only ones we plan to support. Here are various kinds of actions we plan to support:
- Instance Scaling. The Autoscaling Application Block varies the number of role instances in order to accommodate variations in the load on the application. Note that instance scaling actions can span multiple host services/subscriptions.
- Throttling. Instead of spinning off new instances, the block limits or disables certain (relatively) expensive operations in your application when the load is above certain thresholds. I envision you will be able to define various modi operandi for your app. In our sample application (survey management system), advanced statistical functionality for survey owners may be temporarily disabled when the CPU utilization across all worker roles is higher than 80%, and the maximum number of the worker roles has been reached.
- Notifying. Instead of performing instance scaling or throttling, the user may elect to simply receive notifications about the load situations with no automatic scaling taking place. The block will still do all monitoring, rule evaluation and determination of what adjustments need to be made to your Windows Azure application short of actually making those adjustments. It would be up to the user to review the notification and to act upon it.
- Custom action. In the spirit of the Enterprise Library extensibility, we provide extension hooks for you to plug-in your custom actions.
What data can be reacted upon?
We plan to enable the Autoscaling Application block to pull data from the following sources:
- Windows Azure Diagnostics tables (e.g. CPU utilization)
- Windows Azure Storage API (e.g. # unprocessed orders on a queue)
- Windows Azure Storage Analytics (such as transaction statistics and capacity data)
- application data store (your custom metric)
- real-time data sources instrumented in the app (e.g. # active users, # tenants, # documents submitted)How will I configure the block?
Just like any other application block, the Autoscaling Application block can be configured both declaratively and programmatically.
There are actually two levels of configuration that you’ll need to do. One is the configuration of the block itself (e.g. where it should look for rules, how often to evaluate the rules, where to log, etc.) This is no different from configuring any other application block. Then, there’s configuration of the rules with corresponding actions, which are more like data managed by the operators (it/pros). With regard to declarative configuration, as a minimum, there will be an XML configuration file with a defined schema to get IntelliSense support when authoring the rules. We are also brainstorming other options, including PowerShell commandlets and basic SCOM integration.
Where will the block be hosted?
The Autoscaling Application block is a component, which you must host in a client. We envision that you will be able to use the block in different hosts:
- worker role
- windows service on-prem
- stand-alone app on-prem.Our sample application implementation will use the block from a worker role. However, there’s nothing the block design that forces you to do so.
When will the Autoscaling Application Block be available?
Our plan is to ship this fall. We’ll be making regular Codeplex drops for you to inspect the block more closely and to provide feedback. Don’t wait too long – we are moving fast!
Final notes for today
This initial post gives you a quick overview of what’s coming in the Autoscaling Application block. In the future posts, I intend to address the following topics:
1) Multiple rule interaction
2) Scale groups
3) Kinetic stabilizer for dealing with the high frequency oscillation problem
4) Specifying custom business rules
5) Declarative configuration
6) Programmatic configuration
7) Autoscaling trace trail/history
8) Autoscaling visualizationsI’d like to conclude with an important note. To take advantage of the Autoscaling Application block, your application needs to be designed for scalability. There are many considerations. For example, a simple web role may not be scalable because it uses a session implementation that is not web farm friendly. I’ll try to touch on these considerations in the future posts. But for now remember, the Autoscaling Application block doesn’t automatically make your application scalable!


Steve Peschka posted a detailed Windows Azure 1.4 Diagnostics All Up Overview to his MSDN blog on 8/23/2011:
I know that there have been a number of posts and articles out there about using diagnostics in Windows Azure. This, in fact, was part of the problem when I went to flesh out the details of what’s available recently. I found a bunch of different articles, but spread across many different releases of Azure so it was fairly time consuming to figure out what would work with the latest Azure SDK (1.4). So this post will hopefully just bring together the main points for using Azure diagnostics with the 1.4 version of the SDK.
In addition to all of the typical logging and debugging tools like those mentioned above, you can also configure your deployment to allow you to RDP into the Azure server hosting your application, as well as enable IntelliTrace for limited debugging and troubleshooting in an application that’s been deployed. Let’s walk through these different pieces.
To configure the different diagnostic components, such as how often they persist data to storage, how much storage should be allocated, which perfmon counters to capture, etc., it can most easily be done by writing some code in the WebRole.cs file that comes with a standard Web Role Azure application (and I think most Azure features other than VM role have something analogous to a WebRole class, like the WorkerRole.cs file with a Worker Role project). Before we start looking at code, you should go into your Azure Role project and check the box on the Configuration tab that says “Specify the storage account credentials for the Diagnostics results:”. Use the picker button there to select a storage account you have in Azure; do not use local development. This will save a new connection string to the project called Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString.
Now let’s look at the entire chunk of code in the web role class, and then I’ll break down some of the specifics:
public override bool OnStart() { // For information on handling configuration changes // see the MSDN topic at http://go.microsoft.com/fwlink/?LinkId=166357. try { //initialize the settings framework Microsoft.WindowsAzure.CloudStorageAccount.SetConfigurationSettingPublisher((configName, configSetter) => { configSetter(RoleEnvironment.GetConfigurationSettingValue(configName)); }); //get the storage account using the default Diag connection string CloudStorageAccount cs = CloudStorageAccount.FromConfigurationSetting( "Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString"); //get the diag manager RoleInstanceDiagnosticManager dm = cs.CreateRoleInstanceDiagnosticManager( RoleEnvironment.DeploymentId, RoleEnvironment.CurrentRoleInstance.Role.Name, RoleEnvironment.CurrentRoleInstance.Id); //get the current configuration DiagnosticMonitorConfiguration dc = dm.GetCurrentConfiguration(); //if that failed, get the values from config file if (dc == null) dc = DiagnosticMonitor.GetDefaultInitialConfiguration(); //Windows Azure Logs dc.Logs.BufferQuotaInMB = 10; dc.Logs.ScheduledTransferLogLevelFilter = LogLevel.Verbose; dc.Logs.ScheduledTransferPeriod = TimeSpan.FromMinutes(5); //Windows Event Logs dc.WindowsEventLog.BufferQuotaInMB = 10; dc.WindowsEventLog.DataSources.Add("System!*"); dc.WindowsEventLog.DataSources.Add("Application!*"); dc.WindowsEventLog.ScheduledTransferPeriod = TimeSpan.FromMinutes(15); //Performance Counters dc.PerformanceCounters.BufferQuotaInMB = 10; PerformanceCounterConfiguration perfConfig = new PerformanceCounterConfiguration(); perfConfig.CounterSpecifier = @"\Processor(_Total)\% Processor Time"; perfConfig.SampleRate = System.TimeSpan.FromSeconds(60); dc.PerformanceCounters.DataSources.Add(perfConfig); dc.PerformanceCounters.ScheduledTransferPeriod = TimeSpan.FromMinutes(10); //Failed Request Logs dc.Directories.BufferQuotaInMB = 10; dc.Directories.ScheduledTransferPeriod = TimeSpan.FromMinutes(30); //Infrastructure Logs dc.DiagnosticInfrastructureLogs.BufferQuotaInMB = 10; dc.DiagnosticInfrastructureLogs.ScheduledTransferLogLevelFilter = LogLevel.Verbose; dc.DiagnosticInfrastructureLogs.ScheduledTransferPeriod = TimeSpan.FromMinutes(60); //Crash Dumps CrashDumps.EnableCollection(true); //overall quota; must be larger than the sum of all items dc.OverallQuotaInMB = 5000; //save the configuration dm.SetCurrentConfiguration(dc); } catch (Exception ex) { System.Diagnostics.Trace.Write(ex.Message); } return base.OnStart(); }Now let’s talk through the code in a little more detail. I start out by getting the value of the connection string used for diagnostics, so I can connect to the storage account being used. That storage account is then used to get down to the diagnostic monitor configuration class. Once I have that I can begin configuring the various logging components.The Windows Azure Logs is where all of the Trace.* calls are saved. I configure it to store up to 10MB worth of data in the table that it uses, and to persist writes to the table every 5 minutes for all writes that are Verbose are higher. By the way, for a list of the different tables and queues that Windows Azure uses to store this logging data you can see here – http://msdn.microsoft.com/en-us/library/hh180875.aspx – and here – http://msdn.microsoft.com/en-us/library/microsoft.windowsazure.diagnostics.diagnosticmonitorconfiguration.aspx. Infrastructure logs and Diagnostics logs are virtually identical.
For event viewer entries, I have to add each log I want to capture to the list of DataSources for the WindowsEventLog class. The values that I could provide are Application!*, System!* or UserData!*. The other properties are the same as described for Windows Azure Logs.
For perfmon counters, you have to describe which counters you want to capture and how frequently they should sample data. In the example above, I added a counter for CPU and configured it to sample data every 60 seconds.
Finally, the last couple of things I did were to enable capturing crash dumps, changed the overall quota for all the logging data to approximately 5GB, and then I saved changes. It’s very important that you bump up the overall quota, or you will likely throw an exception that says you don’t have enough storage available to make the changes described above. So far 5GB has seemed like a safe value, but of course your mileage may vary.
Now it’s ready to go, so it’s time to publish the application. When you publish the application out of Visual Studio, there are a couple of other things to note:
In the Publish Settings dialog, you should check the box to Enable IntelliTrace; I’ll explain more on that later. In addition, I would recommend that you click on the link to Configure Remote Desktop connections…; at times I found this to be the only way I was able to solve an issue. Since the documentation on remote desktop has faded out of being current a bit, let me just suggest to you that you use this dialog rather than manually editing configuration files. It brings up a dialog that looks like this:
The main things to note here are:
- You can seemingly use any certificate for which you have a PFX file. Note that you MUST upload this certificate to your hosted service before publishing the application.
- The User name field is whatever you want it to be; a local account with that user name and password will be created.
So now you complete both dialogs and publish your application. Hit your application once to fire it up and make sure your web role code executes. Once you do that, you should be able to go examine the diagnostics settings for the application and see your customizations implemented, as shown here (NOTE: I am using the free CodePlex tools for managing Azure that can be downloaded from http://wapmmc.codeplex.com/):
After I have some code that has executed, and I’ve waited until the next Scheduled Transfer Period for the Windows Azure Logs, I can see my Trace.* calls showing up in the WADLogsTable as shown here:
Also, since I configured support for RDP into my application, when I click on the web role the option to make an RDP connection to it is enabled in the toolbar in the Azure Developer Portal:
So I have all the logs and traces from my application available to me now, and I can RDP into the servers if I need to investigate further. The other cool feature I enabled was IntelliSense. Describing IntelliSense is beyond the scope of this posting, but you can find out some great information about it here http://blogs.msdn.com/b/jnak/archive/2010/06/07/using-intellitrace-to-debug-windows-azure-cloud-services.aspx and here http://blogs.msdn.com/b/ianhu/archive/2010/03/16/intellitrace-what-we-collect.aspx. When IntelliTrace is enabled, it says so when I view my hosted service in the Visual Studio Server Explorer:
I can then right click on an instance in my application and select the View IntelliTrace logs menu item. That downloads the IntelliTrace logs from Azure and opens them up in Visual Studio, which looks like this:
As you can see from the picture, I can see the threads that were used, any exceptions that were raised, System Info, the modules that were loaded, etc. I simulated an exception to test this out by setting my overall storage allocation for diagnostic info to 50MB. You may recall that I mentioned needing more like 5GB. I made the change and published my application, and then a few minutes later downloaded the IntelliTrace logs. Sure enough I found the error highlighted here in the second page of logs:
So there you have it – a good overview of diagnostics in Windows Azure 1.4. We’re capturing Trace events, event logs, perf counters, IIS logs, crash dumps, and any custom diagnostic log files. I can RDP into the server for additional troubleshooting if needed. I can download IntelliTrace logs from my application and have a limited debugging experience in my local instance of Visual Studio 2010.
Attachment:
Windows Azure 1.4 Diagnostics All Up Overview.docx








Following are recent OakLeaf posts about Azure analytics, monitoring, diagnostics and performance testing:
- OakLeaf Systems Windows Azure Table Services Sample Project Updated with Tools v1.4 and Storage Analytics 8/22/2011
- Load-Testing the OakLeaf Systems Azure Table Services Sample Project with up to 25 LoadStorm Users 11/18/2011
- Adding Trace, Event, Counter and Error Logging to the OakLeaf Systems Azure Table Services Sample Project 12/5/2010
Avkash Chauhan explained Windows Azure: Avoiding WCF Service Throttling by increasing maximum concurrent connection count in WCF service Configuration in an 8/23/2011 post:
Recently I was working on a WCF based Application running in Windows Azure however this WCF service was not able to connect more than 100 concurrent connections. We could consistently observed that when the service hits the limit of exactly 100 connections, then new clients cannot connect to the service endpoint.
The WCF service running in Windows Azure was being throttled by hitting maximum concurrent connections, that’s why when total number of concurrent connection hits the threshold value (in this case 100), service was not able to serve further connection to any client.
To solve this problem we needed to increase the concurrent connections in the service configuration. There are two ways to configure the service configuration:
(For example we are modifying the maximum concurrent connection from 100 to 200)
Option #1 Change Service Throttling (serviceThrottling) setting in web.config/app.config as below:
<configuration>
...
<system.serviceModel>
<services>
<service name="YourServiceName" behaviorConfiguration="Throttled">
<endpoint address="" binding="wsHttpBinding" contract="ISampleService">
<identity>
<dns value="localhost"/>
</identity>
</endpoint>
<endpoint address="mex" binding="mexHttpBinding" contract="IMetadataExchange"/>
</service>
</services>
<behaviors>
<serviceBehaviors>
<behavior name="Throttled">
<serviceMetadata httpGetEnabled="true"/>
<serviceDebug includeExceptionDetailInFaults="false"/>
<serviceThrottling maxConcurrentCalls="200" maxConcurrentSessions="200" />
</behavior>
</serviceBehaviors>
</behaviors>
</system.serviceModel>
</configuration>
Option #2: You can also change service throttling (serviceThrottling) directly in your Service Code by setting ServiceThrottlingBehavior properties to change the concurrent calls number as below:
// configure the service endpoint
host.AddServiceEndpoint(typeof(IServerWithCallback), binding, endpointurl, new Uri(listenurl));
// bump up the number of sessions supported by adding throttle behaviour
ServiceThrottlingBehavior throttle = host.Description.Behaviors.Find<ServiceThrottlingBehavior>();
if (throttle == null)
{
throttle = new ServiceThrottlingBehavior();
throttle.MaxConcurrentCalls = 10;
throttle.MaxConcurrentInstances = 200;
throttle.MaxConcurrentSessions = 200;
host.Description.Behaviors.Add(throttle);
}
// start the service endpoint
host.Open();
That's it.

Bill Wilder offered Four 4 tips for developing Windows Services more efficiently in an 8/21/2011 post:
Are you building Windows Services?
I recently did some work with Windows Services, and since it had been rather a long while since I’d done so, I had to recall a couple of tips and tricks from the depths of my memory in order to get my “edit, run, test” cycle to be efficient. The singular challenge for me was quickly getting into a debuggable state with the service. How I did this is described below.
Does Windows Azure support Windows Services?
Trivia Question: Does Windows Azure allow you to deploy your Windows Services as part of your application or cloud-hosted service?
Short Answer: Windows Azure is more than happy to run your Windows Services! While a more native approach is to use a Worker Role, a Windows Service can surely be deployed as well, and there are some very good use cases to recommend them.
More Detailed Answer: One good use case for deploying a Windows Service: you have legacy services and want to use the same binary on-premises and on-Azure. Maybe you are doing something fancy with Azure VM Roles. These are valid examples. In general – for something only targeting Azure – a Worker Role will be easier to build and debug. If you are trying to share code across a legacy Windows Service and a shiny new Windows Azure Worker Role, consider following the following good software engineering practice (something you may want to do anyway): factor out the “business logic” into its own class(es) and invoke it with just a few lines of code from either host (or a console app, a Web Service, a unit test (ahem), etc.).
Windows Services != Web Services
Most readers will already understand and realize this, but just to be clear, a Windows Service is not the same as a Web Service. This post is not about Web Services. However, Windows Azure is a full-service platform, so of course has great support for not only Windows Services but also Web Services. Windows Communication Foundation (WCF) is a popular choice for implementing Web Services on Windows Azure, though other libraries work fine too – including in non-.NET languages and platforms like Java.
Now, on to the main topic at hand…
Why is Developing with Windows Services Slower?
Developing with Windows Services is slower than some other types of applications for a couple of reasons:
- It is harder to stop in the Debugger from Visual Studio. This is because a Windows Service does not want to be started by Visual Studio, but rather by the Service Control Manager (the “scm” for short – pronounced “the scum”). This is an external program.
- Before being started, Windows Services need to be installed.
- Before being installed, Windows Services need to be uninstalled (if already installed).
Tip 1: Add Services applet as a shortcut
I find myself using the Services applet frequently to see which Windows Services are running, and to start/stop and other functions. So create a shortcut to it. The name of the Microsoft Management Console snapin is services.msc and you can expect to find it in Windows/System32, such as here: C:\Windows\System32\services.msc
A good use of the Services applet is to find out the Service name of a Windows Service. This is not the same as the Windows Services’s Display name you seen shown in the Name column. For example, see the Windows Time service properties – note that W32Time is the real name of the service:
Tip 2: Use Pre-Build Event in Visual Studio
Visual Studio projects have the ability to run commands for you before and after the regular compilation steps. These are known as Build Events and there are two types: Pre-build events and Post-build events. These Build Events can be accessed from your Project’s properties page, on the Build Events side-tab. Let’s start with the Pre-build event.
Use this event to make sure there are no traces of the Windows Service installed on your computer. Depending on where you install your services from (see Tip 3), you may find that you can’t even recompile your service until you’ve at least stopped it; this smooths out that situation, and goes beyond it to make the usual steps happen faster than you can type.
One way to do this is to write a command file – undeploy-service.cmd – and invoke it as a Pre-build event as follows:
undeploy-service.cmd
You will need to make sure undeploy-service.cmd is in your path, of course, or else you could invoke it with the path, as in c:\tools\undeploy-service.cmd.
The contents of undeploy-service.cmd can be hard-coded to undeploy the service(s) you are building every time, or you can pass parameters to modularize it. Here, I hard-code for simplicity (and since this is the more common case).
set ServiceName=NameOfMyService
net stop %ServiceName%
C:\WINDOWS\Microsoft.NET\Framework\v4.0.30319\installutil.exe /u %ServiceName%
sc delete %ServiceName%
exit /b 0Here is what the commands each do:
- Set a reusable variable to the name of my service (set ServiceName=NameOfMyService)
- Stop it, if it is running (net stop)
- Uninstall it (installutil.exe /u)
- If the service is still around at this point, ask the SCM to nuke it (sc delete)
- Return from this .cmd file with a success status so that Visual Studio won’t think the Pre-Build event ended with an error (exit /b 0 => that’s a zero on the end)
In practice, you should not need all the horsepower in steps 2, 3, and 4 since each of them does what the prior one does, plus more. They are increasingly powerful. I include them all for completeness and your consideration as to which you’d like to use – depending on how “orderly” you’d like to be.
Tip 3: Use Post-Build Event in Visual Studio
Use this event to install the service and start it up right away. We’ll need another command file – deploy-service.cmd – to invoke as a Post-build event as follows:
deploy-service.cmd $(TargetPath)
What is $(TargetPath) you might wonder. This is a Visual Studio build macro which will be expanded to the full path to the executable – e.g., c:\foo\bin\debug\MyService.exe will be passed into deploy-service.cmd as the first parameter. This is helpful so that deploy-service.cmd doesn’t need to know where your executable lives. (Visual Studio build macros may also come in handy in your undeploy script from Tip 2.)
Within deploy-service.cmd you can either copy the service executables to another location, or install the service inline. If you copy the service elsewhere, be sure to copy needed dependencies, including debugging support (*.pdb). Here is what deploy-service.cmd might contain:
set ServiceName=NameOfMyService
set ServiceExe=%1
C:\WINDOWS\Microsoft.NET\Framework\v4.0.30319\InstallUtil.exe %ServiceExe%net start %ServiceName%
Here is what the commands each do:
- Set a reusable variable to the name of my service (set ServiceName=NameOfMyService)
- Set a reusable variable to the path to the executable (passed in via the expanded $(TargetPath) macro)
- Install it (installutil.exe)
- Start it (net start)
Note that net start will not be necessary if your Windows Service is designed to start automatically upon installation. That is specified through a simple property if you build with the standard .NET template.
Tip 4: Use System.Diagnostics.Debugger in your code
If you follow Tip 2 when you build, you will have no trouble building. If you follow Tip 3, your code will immediately begin executing, ready for debugging. But how to get it into the debugger? You can manually attach it to a running debug session, such as through Visual Studio’s Debug menu with the Attach to Process… option.
I find it is often more productive to drop a directive right into my code, as in the following:
void Foo()
{
int x = 1;
System.Diagnostics.Debugger.Launch(); // use this…
System.Diagnostics.Debugger.Break(); // … or this — but not both
}System.Diagnostics.Debugger.Launch will launch into a into debugger session once it hits that line of code and System.Diagnostics.Debugger.Break will break on that line. They are both useful, but you only need one of them – you don’t need them both – I only show both here for illustrative purposes. (I have seen problems with .NET 4.0 when using Break, but not sure if .NET 4.0 or Break is the real culpret. Have not experienced any issues with Launch.)
This is the fastest way I know of to get into a debugging mood when developing Windows Services. Hope it helps!


Bill is a Windows Azure MVP.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+

Kean Walmsley (@keanw) posted Visual Studio LightSwitch 2011 – Part 2 to his Through the Interface blog on 8/24/2011:
After creating our basic LightSwitch project in the last post, today we’re going to add some real functionality.
To get warmed up, let’s take a look at some contents of the project we created last time. At the top level, we see there’s a new project type, along with some intriguing files:
Drilling down a level further, we see a number of sub-projects (Client, Server, Common) contain C# files:
To add some “screens” (the moniker used for dialogs in the LightSwitch runtime environment), it’s a simple matter of right-clicking the Screens item in the Solution Explorer and selecting Add Screen…:
We then get to choose the type of screen (whether to view a single item or a list of items, create a new item, etc.) and configure its options:
This builds a default list-view plus details screen, which, when we see it in the Designer, is structured based on its data – there’s no graphical design to manipulate.
When we’re running the application – with its single, default screen – from the debugger, we get the very nice option to edit the screen during the debug process:
When selected, we get to edit the layout with a very helpful preview capability:
I won’t go into the ins and outs of building the app, but suffice to say that I did some work to streamline the user interface for this application, and found it very interesting. After just a few hours of experimentation with an extremely powerful – yet straightforward – user interface, I was able to come up with a very elegant application for editing goals in our SharePoint system. And all without a single line of code (although I believe you can add some, if you really need to).
Here’s a screenshot, with some blurring, to protect the innocent. :-)
Now if only they’d address the many-to-many relationship issue… at which point I’d add an additional screen to create new goals, with their associated metadata. But still – a very interesting development system, all things considered.

Microsoft Access 2007 added the Lookup field data type to accommodate multi-select lists bound to linked SharePoint lists having Lookup fields. SQL Server doesn’t support this complex data type, so it’s not surprising that VS LightSwitch doesn’t handle it.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
Lori MacVittie (@lmacvittie) asserted “Cloud-based services for all things digital will either drive – or die by – bandwidth” in an introduction to her The Cloud and The Consumer: The Impact on Bandwidth and Broadband post of 8/24/2011 to F5’s DevCentral blog:
Consumers, by definition, consume. In the realm of the Internet, they consume far more than they produce. Or so it’s been in the past. Broadband connectivity across all providers have long offered asymmetric network feeds because it mirrored reality: an HTTP request is significantly smaller than its corresponding response, and in general web-based activity is heavily biased toward fat download and thin upload speeds. The term “broadband” is really a misnomer, as it focuses only on the download speed and ignores the very narrowband of a typical consumer’s upload speed.
Cloud computing , or to be more accurate, cloud-hosted services aimed at consumers may very well change the status quo by necessity. As providers continue to push the notion of storing all things digital “in the cloud”, network providers must consider the impact on them – and the satisfaction of their customer base with performance over their network services.
SPEED MATTERS
Today we’re hearing about the next evolutionary step in Internet connectivity services: wideband. It’s a magnitude faster than broadband (enabled by the DOCSIS 3.0 standard) and it’s
being pushed heavily by cable companies. Those with an eye toward the value proposition will quickly note that the magnitude of growth is nearly entirely on download speeds, with very little attention to growth on the upside of the connection. A fairly standard “wideband” package from provider Time Warner Cable, for example, touts “50 Mbps down X 5 Mbps up.” (DSL Reports, 2011)
Unfortunately, that’s not likely enough to satiate the increasing need for more upstream bandwidth created by the “market” for sharing high-definition video, large data, real-time video conferencing (hang out in Google+ anyone?) and the push to store all things digital in “the cloud.”
It’s suggested that “these activities require between 10 and 100 mbps upload and download speed.” (2010 Report on Internet Speeds in All 50 States, Speed Matters)
Wideband is certainly a step in the right direction; Speed Matters also reported that in 2010:
The median download speed for the nation in 2010 was 3.0 megabits per second (mbps) and the median upload speed was 595 kilobits per second (kbps).2 (1000 kilobits equal 1 megabit). These speeds are only slightly faster than the 2009 speedmatters.org results of 2.5 mbps download and 487 kbps upload. In other words, between 2009 and 2010, the median download speed increased by only 0.5 mbps (from 2.5 mbps to 3.0 mbps), and the average upload speed barely changed at all (from 487 kbps to 595kbps).
You’ll note that upload speeds are still being reported in kbps, which even converted is significantly below the 10 mbps threshold desired for today’s cloud and video-related activities. Even “wide”band offerings fall short of the suggested 10 mbps upload speeds.
WHERE DOES THAT LEAVE US?
This leaves us in a situation in which either Internet providers must narrow the gap between up- and down-stream speeds or cloud-based service providers may find their services failing in adoption by the consumer market. Consumers, especially the up and coming “digital” generations, are impatient. Unwilling to wait more than a few seconds, they are quick to abandon services which do not meet their exacting view of how fast the Internet should be.
Other options include a new focus for web and WAN optimization vendors – the client. Desktop and mobile clients for WAN optimization solutions that leverage deduplication and compression techniques as ways to improve performance over bandwidth constrained connections may be one option and it may be the best option for cloud-based service providers to avoid the middle-man and its likely increased costs to loosen bandwidth constraints. Another truth of consumerism is that while we want it faster, we don’t necessarily want to pay for the privilege. A client-service based WAN optimization solution bypasses the Internet service provider, allowing the cloud-based service provider to deploy a server-side WAN optimization controller and a client-side WAN optimization endpoint to enable deduplication and compression techniques to more effectively – and with better performance and reliability – transfer data to and from the provider.
This isn’t as easy as it sounds, however, as it requires a non-trivial amount work on the part of the provider to deploy and manage both the server and client-side components.
That said, the investment may be well worth increasing adoption among consumers – especially if the provider in question is banking on a cloud-based services offering as the core value proposition to its offerings.




Simon Munro (@simonmunro) provided Technical comparisons of AWS and Azure in an 8/24/2011 post:
AWS is the market leader of cloud computing, by virtue of its early entry, rapid innovation and monopolisation of the definition of cloud computing. Microsoft is a viable contender with their established customers, channels and developers as well as a sound offering backed by a company that is “All in”.
On the surface, a technical person can draw parallels. Windows Azure (AppFabric) Queues map to Amazon Simple Queue Service. SQL Azure maps to Amazon Relational Database Service and, more recently, Windows Azure AppFabric Caching maps to Amazon ElastiCache, and so on. But those are services offered on the platform, so while you can compare and map individual services, it becomes difficult to provide a technical comparison of the overall platforms.
The fundamental building block of AWS applications is the EC2 instance and on Windows Azure it is the compute role (mostly web and worker roles). EC2 is a fully fledged virtual machine and Azure roles are containers for compute resources. (Drawing parallels between EC2 and Windows Azure VM Roles does a disservice to EC2, as Azure VM roles are not the building block of Azure applications.)
The importance of EC2 as a basic building block breaks down most of the technical comparisons between the two platforms. One may, for example map Windows Azure Table Storage, as a NoSQL database, to Amazon SimpleDB. But, with EC2 as a building block, SimpleDB is not the popular NoSQL choice on AWS, where MongoDB and Redis run well. Also, EC2 allows anything to be run (although some may not be recommended), giving EC2 an unfair edge over Windows Azure. You can, for example, run SOLR on Linux for search on EC2 and it manifests itself as a first class service, whereas no search service exists on the Windows Azure platform.
In turn, Windows Azure roles, as the container for applications and the basic building block, have advantages over EC2. Windows Azure roles require significantly less hand holding, configuration and management than EC2. There is no Chef for Windows Azure. The Windows Azure AppFabric takes care of keeping the roles running smoothly. (AWS is catching up with CloudFormation and the Java oriented Elastic Beanstalk, but it still cannot be compared to the Windows Azure fabric controller).
It would be easy to say that Windows Azure is PaaS and Amazon Web Services is IaaS, so that is where the comparison should be made. But, firstly AWS is not IaaS, and secondly all cloud vendors are moving further up the stack, providing more services that can be consumed instead of the infrastructure services. Amazon’s ElastiCache is a good example of this, where a component that previously had to be hosted in EC2 instances is now made available as a service. AWS will continue, I am sure, to add more services and the infrastructure appearance of their model will be unimportant in a few years’ time. At the same time, Microsoft has the opportunity and engineering resources to add really good services and even entire application suites to their platform — further confusing the comparisons.
So when business asks for a comparison between the two, work with them to do a higher level comparison that makes sense in their particular environment. Don’t cheat by trying to map low level services, features and prices — they look eerily similar at that level and you won’t find the droids you are looking for. Rather try something like this,
- Map out a general architectural picture for each of the platforms
- Decide which components are less architecturally significant, so that compromises can be made (and there are always compromises)
- Factor in the business and internal IT attitude towards Microsoft, anti-Microsoft and Amazon
- Look at existing IT support processes and how they would fit in with each platform.
- Work out, more or less, what the development, hosting and support costs will be for each platform. Comparing EC2 pricing to Azure Role pricing is not enough.
- Look at the application roadmap to determine if it looks like it will add high degrees of specialisation, forcing it down the AWS route, or integration with existing services and applications, tending it more towards Windows Azure.
- Get internal IT on board, they probably won’t like either of them, so you need to get working on them early.


Rodrigo Flores recommended that you Dump the SLA. Service expectations matter more in an 8/21/2011 post to GigaOm’s Structure blog:
Like an annoying pop song, Service Level Agreements (SLAs) have been on my mind for a while. In most cases, they are not worth the digital bits sent to serve them up on the web. Yet they are important if we are comparing cloud service providers, because without taking into account an SLA, your business may spend far more time and effort trying to engineer around failures to prop up an inexpensive cloud.
Recently, I received an e-mail comparing a customer’s internal storage costs to Amazon’s. Of course, Amazon seems to be cheaper based on a pure gigabyte comparison. But it was a flawed analysis because it didn’t include the service level promised, never mind guaranteed.
Without that it’s impossible to compare costs. The enterprise gigabyte comes with a whole host of services around it, while Amazon’s does not. IT groups are terrible at explaining their offerings, so it seems like cost per gigabyte is a good measure, but it’s not. Here’s why.
Amazon’s Elastic Block Storage service has huge variations in performance that make the service range from good enough to completely useless. It’s so variable that it takes a lot of work to architect around it. This post by Orion and Mdash of Heroku delves into some of the work they did to get acceptable performance from EBS, such as use lots of disks, larger buffers, right file-systems, larger chunk sizes on the RAID, etc. Maybe they toss in a little unicorn powder.
I was struck by how much work they did as storage admins. That costs money in labor, hiring, and training. Add backups, multi-zone, multi-datacenter and the dollar-to-dollar comparison between private storage and public storage begins to be a fairer fight.
This is not a knock on EBS, which I use. But I did learn that when you use a cloud service, you always accept a service level, whether explicit or implied, and that brings a whole bunch of labor, labor that could be avoided if you consider someone offering a higher service level, instead of cutting them out because their gigabyte pricing is too high.
Getting to better SLAs.
To improve SLAs we need to work on two questions. First, what are the operational expectations I should have in terms of reliability, availability, performance, security? Unlike Heroku, (s crm), who owns their own code, an enterprise customer can’t rewrite Oracle (s orcl) or SAP or their existing 1000+ internal applications. Therefore, specific operational expectations are very important to determine the suitability of the infrastructure for a specific application. The Amazon service catalog description for EBS performance doesn’t provide any expectation, and Amazon doesn’t commit to any service level that allows the customer to carry out operations they might need to implement in order to recover from failures.
Below, for example, is a potential way to set expectations: service catalog options. Each offering has different levels and costs. The customer can easily see that Tier 1 Windows includes higher level support, while Tier 4 does not include support. The customer can select and make a trade-off between service level and labor that works for them.
The second question is related to the visibility and tooling for recovery that a customer has. I agree with Christian Reilly that the legalese in SLAs is useless. They are biased in favor of the vendor, the penalties (if any) cannot hope to equal the value lost and they’re operationally useless. It’s this last bit that better SLAs can change, and in doing so make SLAs operationally useful.
For example, EBS provides replication, but I can’t see or manipulate the replica, nor is there a service request a user can make to get a copy. Therefore, operationally speaking, the customer is in charge making replicas, snapshots, and back ups for when EBS fails. And cloud is made by humans. Trucks hit generators. Lighting strikes. And that means the cloud will fail and the customer may not have any recourse to have prevented his data from getting lost.
There are other cloud providers who do provide back ups, mirroring, snapshots and the tooling. And those services cost more because the cloud provider adds more labor, know-how and resources to deliver that service level. Otherwise, the customer is on the hook for that labor, which adds to that gigabyte cost comparison.
New SLAs mean new types of clouds.
In conclusion, the road to better service level agreements will require the vendor to articulate the service offering and expected performance clearly in a way that is visible, actionable by the customer and with clear metrics for recovery. So if the service includes back up, the customer understands the scope, can see when the backup failed, and can on their own recover from failure within the promised window (mean time to recover).
New SLAs will likely lead to two types of clouds –or at least make this bifurcation of clouds more visible. One cloud will be for apps designed for failure, scale out and mobility: perfect for single app startups coming out of Silicon Valley and some new field applications. Which makes sense because startups have more labor than money.
The other is built to bring existing enterprise applications into a more cloud-like operating model; meaning transitioning existing applications and workloads to be more on-demand, elastic and pay-per-consumption, using either a private cloud or an enterprise cloud provider. I call them “city clouds” because they have to work within existing infrastructure, follow rules, customs, and are constrained by other applications. And thanks to better SLAs customers can know what they are choosing and price that into their estimates.
Rodrigo Flores is a cloud enterprise architect at Cisco Systems and the former founder and CTO of newScale, which was acquired by Cisco in April 2011.


<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Jonathan Rozenblit (@jrozenblit) posted When It Comes to Cloud, First Things First - Strategy and Training on 8/24/2011 to the IT Manager Connection (Canada) blog:
By now you may have been told, through advertisements, videos, presentations, etc., that developing for the Cloud, specifically, Windows Azure, is simple if you are already doing any kind of .NET development – your team would be able to leverage the skills they already have and the tools they already know. While this is true (in relative context), you would be doing yourself and your team a disservice if you jump right in. When I speak to managers, such as yourself, about Cloud development, I always urge to take a step back and look at two things that, if done correctly, can virtually ensure the success of your organization’s journey to the Cloud – your cloud strategy and your architects’ and developers’ training plan.
Cloud Strategy
Strategizing your move to the Cloud will allow you to understand:
- Which of your applications are good candidates for moving to the Windows Azure
- Which of public cloud, hybrid cloud, or on-premise solutions would be better suited for each application’s needs
- The impact of security and privacy on your applications
Next week we’ll go deeper into Cloud strategies and show you how to get started with your own strategy.
Architect/Developer Training Plan
While those aspects cover off your applications, the next consideration is your team – your architects and your developers. They need to get up to speed on the intricacies of the platform’s services. Key word - intricacies. There are many ways to use the various services of the Windows Azure platform, but only a few (specific to each application’s functional and non-functional requirements) will allow your organization to truly capitalize on the benefits of the Cloud and Windows Azure. That is why training has to start long before you start looking at migrating or writing your first application. Developers need to learn how to use the services as well as the tools and toolkits that are available. Architects need to understand how application requirements map onto Windows Azure services and how each non-functional requirement ultimately affect which service to use when.
There are plenty of resources to get your team started (Windows Azure Platform Training Kit, Canadian Developer Connection to name a couple); however, resources (books, training kits, classes) can only teach the technical aspects of the platform. Knowledge gained from experience working with the platform – designing and building solutions that use it – will ensure that your organization’s Cloud implementation will be successful. Emphasizing once more – training is required, but experience will make the difference.
Bottom Line
Have your architects and developers start early, trying out learned concepts on smaller, less critical applications, to gain that experience. They will be able to see what works and what does not work in your environment, tweaking as necessary until an optimal solution is reached. While that is happening, you and other stakeholders in your organization can develop your Cloud strategy.
Straight Talk About Windows Azure
On the next episode of the AlignIT Manager Tech Talk (September 8, 2011, 12:00 PM – 12:30 PM EST), Joel Varty, Director of Research and Development at Agility CMS, joins Ruth and I for a straight talk discussion about Windows Azure – the problems that it can solve, the opportunities that it can surface, and the challenges and lessons of transitioning design and development teams from traditional development to the Cloud. Joel will share how he worked with his team of architects and developers to get up to speed on Cloud development and their strategy for moving their applications to the Cloud.
[Register to] Watch >>

<Return to section navigation list>
Cloud Computing Events
The Windows Azure Team (@WindowsAzure) reported Windows Azure and the Cloud Take Center Stage at Tech-Ed Australia August 30-September 2, 2011 in an 8/23/2011 post:
A recent survey of Australian IT organizations identified cloud computing as one of the most important technology trends right now. That’s why Tech-Ed Australia 2011, which will take place August 30 – September 2, 2011 at the Gold Coast Convention and Exhibition Centre, is diving deeply into the cloud. Attendees will hear from experts about where the market is headed and return to their organizations with an extended skill set to help them harness the full power of the cloud.
Tech-Ed offers 16 Technical Tracks with more than 160 learning opportunities ranging from understanding the latest business productivity solutions to diving deeper on Microsoft’s Virtualization strategy. The Cloud Computing and Online Services track offers 19 sessions focused on a variety of cloud-related topics from “To the Cloud! A Lap Around the Windows Azure Platform” to “Connecting Phone Applications to the Cloud”. Please visit the Session and Speaker Catalogue and filter by the “Cloud Computing and Online Services” track to see a list of all cloud-related sessions.
If you plan to attend Tech-Ed Australia and will be onsite Monday August 29, 2011, don’t miss the Pre-Conference Technical Training session*, 'How “the Cloud' Can Help You Integrate”.
Led by renowned integration experts, this two-day development workshop will provide delegates with an early opportunity to gain insight and hands-on experience with Windows Azure. It will focus on how to maximize existing integration technology investment, architectural design considerations, real world tips and techniques and hands-on experience with the integration tools available today.
Interested in attending Tech-Ed Australia but haven’t registered yet? It's not too late; register now.
*Note: There is a separate registration fee for the pre-conference session. Click here to learn more.

Filtering by “Cloud Computing and Online Services” returns 19 sessions, which doesn’t indicate “cloud” being center-stage to me. Here’s a session list with links to descriptions (* indicates new or forthcoming Azure features):
- ARC-COS-MID208 | Architecting real-world Azure applications
- COS201 | Application Lifecycle Management for Windows Azure projects
- COS202 | Cloud Bursting using HPC and Azure for on Demand Analytics*
- COS203 | Developing with SQL Azure: Tools & Frameworks In Action
- COS204 | Migrating your applications to Azure
- COS211 | To The Cloud! A lap around the entire Windows Azure platform.
- COS212 | Go Large with SQL Azure Federations*
- COS309 | A Windows Azure Acid Test!
- COS-MID305 | Connecting Cloud and On-Premises Applications
- COS-MID306 | Introduction to Windows Azure AppFabric Composite Applications*
- COS-MID310 | Crossing the Rubicon - Integrating with the Cloud Is Here to Stay
- COS-OFC307 | Exploring the Office Developer Story in Microsoft Office 365
- COS-WPH208 | Connecting Phone Applications to the Cloud
- DEV-COS315 | The Essential Windows Azure Developers Toolkit
- OFS307 | High Octane Internet Sites on the SharePoint Platform
- SVR-COS-VIR315 | Modular Approach to Building the Private Cloud with HP
- VIR-COS301 | Best Practices for Private Cloud Implementation
- VOC-COS204 | The Challenges of moving Document Creation to the Cloud
- VOC-COS206 | Real World Windows Azure from GreenButton
Paul Patterson announced on 8/23/2011 that he’ll be Speaking at EDMUG on September 12, 2011 about LightSwitch 2011:
On September 12, 2011 I’ll be speaking at the Edmonton .Net User Group (EDMUG). I’ll be presenting an overview of the recently released Microsoft Visual Studio LightSwitch 2011. RSVP via the EDMUG Meetup site at www.EDMUG.net.
See you there?
The dev2ops blog reported DevOps HackDay at VMware featuring CloudFoundry in an 8/23/2011 post:
Start: 2011-09-08 09:00
- End: 2011-09-08 18:00
- Timezone: US/Pacific
Register now to spend a day hacking in the clouds with CloudFoundry. The focus of this hack is to get a few working applications up in the cloud the #devops way: a fully programmable infrastructure that extends from the OS through the application lifecycle.
We will be building a pipeline line that starts out in source control, flows through a build process, get packaged as Infrastructure as Code and ends up as a working application deployed to the CloudFoundry Open Source PaaS. The project will also include underlying instrumentation to collect data along the pipeline and also include an infrastructure for data storage and analysis.
The initial plan is implement this pipeline for a sample Java application. We'll be using Chef to automate the installation and configuration of the OS and middleware stack, then use CloudFoundry to automate application provisioning. Have a CloudFoundry ready app that you want to try out? Bring it along. Hopefully at the end of the day we will have a few Java, Ruby on Rails, and NodeJS applications up and running.
Some of the tools we'll be using:
- Source Control - GIT
- Build - Jenkins
- Artifacts - Nexus
- DNS - DynDNS
- Release - Rundeck
- Configuration - Chef
- Deployment - IaaS Cloud
- Data Collection: Zenoss
Whether you are coming to learn from the experts, have ideas you want to share, or just like the camaraderie of a good Hack Day -- Bring your laptop and come ready to participate.
DTO Solutions will lead this full day (9am-6pm) hands-on hackathon. We will have coffee/pastry in the morning, lunch, and a beer bash from 4-6pm with CloudFoundry/Layer 2 folks to discuss take-aways from the day.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Beth Periseau (@PariseauTT) asserted VMware Cloud Foundry vs. vFabric: the picture grows clearer in an 8/24/2011 post to the SearchCloudComputing.com blog:
Integration and differentiation between elements of VMware's cloud computing application development is taking shape. A timeline for full integration between vFabric services and Cloud Foundry Platform as a Service remains to be seen.
First, let's look at the integration. There were a couple open questions earlier this summer about how the various vFabric services, including RabbitMQ messaging and GemFire in-memory data management, fit with Cloud Foundry plans, and whether vFabric was supposed to be supplemental or competitive to them.
At least one of those questions was put to rest with the announcement of RabbitMQ integration into Cloud Foundry last week; VMware has now made the distributed messaging available as a service to which various applications can subscribe on the public Cloud Foundry platform. It now appears VMware means to integrate vFabric services separately into the PaaS, while continuing to offer an on-premises package of application services for enterprises with vFabric.
After that announcement, though, the question of differentiation still remained. How would the vFabric services package, revised with vFabric 5 in mid-June, differ from the Cloud Foundry Micro Cloud? Both products looked to offer the ability to download cloud application stacks into on-premises deployments, bundled, if desired, into a single virtual machine.
With the rollout of VMware's Micro Cloud Foundry beta this week, that answer is also becoming clear.
The main difference is one of scale -- while vFabric 5 technically can run all services in onevirtual machine (VM), that's not how it's intended to be used; it's still more likely that users will scale out the VMs within a vFabric deployment, VMware officials said.
While vFabric 5 is intended to run on virtual servers in a data center, Micro Cloud is meant to run on a developer's laptop, with VMware's Fusion or Workstation as the container. Micro Cloud application images can be transferred to Cloud Foundry's PaaS for wider scaling, but unlike the vFabric platform, Micro Cloud in itself does not scale to multiple instances.
Micro Cloud includes a mini version of the Cloud Foundry platform; its main focus is on delivering various application development frameworks like Spring, Rails or Node.js to individual developers working in coffee shops. vFabric 5, by contrast, is a platform for on-premises, production enterprise application development using the Spring framework.
There are still unanswered questions around these early-stage products, of course, the biggest one being when Cloud Foundry developers will get their hands on the full set of vFabric services. On that question, VMware says integration is on the roadmap, but it's keeping the timeframe strictly under wraps.
More on VMware and the cloud:
Beth is Senior News Writer for SearchServerVirtualization.com.
Full disclosure: I’m a paid contributor to SearchCloudComputing.com.
Derrick Harris (@derrickharris) reported VMware puts Cloud Foundry on laptops in an 8/224/2011 post to Giga Om’s Structure blog:
VMware has released Micro Cloud Foundry, a fully functional version of its open-source, Platform-as-a-Service software condensed into a virtual image that runs on developers’ personal computers or laptops. The aim is to make it easier to create and test cutting-edge applications all without having to download and configure the myriad components available within Cloud Foundry.
This might not seem like much, until you consider all that Cloud Foundry has to offer. As of its release, Micro Cloud Foundry supports Java on Spring, Ruby on Rails/Sinatra and Node.js, as well as MySQL, MongoDB and Redis. It also supports Dynamic DNS, so programmers can work on their applications wherever they happen to be, or so external services can connect to applications running within a Micro Cloud Foundry instance.
On his blog explaining the news, VMware CTO Steve Herrod writes that “VMware will provide frequent Micro Cloud Foundry updates to include additional frameworks and services.”
Micro Cloud Foundry works with VMware Fusion for Mac OS X, and with VMware Workstation and Player for PCs. Because it’s fully compatible with everything else Cloud Foundry, VMware Cloud Marketing Director Dave McJannet told me applications created using Micro Cloud Foundry can easily be pushed to any cloud running Cloud Foundry. Also, Micro Cloud Foundry will be regularly updated to ensure compatibility with the latest versions of the parent software.
The product is currently available as a beta service, and is free to download from micro.cloudfoundry.com.
Micro Cloud Foundry is a small step, but an important one, in making Cloud Foundry a PaaS platform capable of competing with more-established offerings for developers’ hearts, minds and dollars. For example, Heroku has ties to Salesforce.com, Windows Azure connects to other Microsoft software and services, and now VMware is leveraging its virtualization forte to make Cloud Foundry more appealing.
So early in the PaaS story, there’s already so much action and innovation. It’s hard to imagine where we’ll be even a year down the road, but it’s not hard to imagine PaaS becoming a legitimate rival to legacy application platforms even sooner than expected if the innovation keeps up.
Related research and analysis from GigaOM Pro:
Subscriber content. Sign up for a free trial.


Matthew Weinberger (@MattNLM) reported Rackspace Hosting Starts Multi-City OpenStack Training Tour on 8/24/2011:
Rackspace Hosting, together with NASA, started the OpenStack open source cloud operating system project. So who better to train developers and system administrators on the deployment, management, and troubleshooting of OpenStack clouds?
Leading a series hands-on workshops will be the Rackspace Cloud Builders, the arm of the hosting provider that specializes in getting service providers up to speed on cloud deployments. The first five-day course, “Fundamentals Training for OpenStack,” will spend two days on OpenStack Object Storage and three on OpenStack Compute, according to the press release.
The first leg of Rackspace’s big OpenStack training tour will hit Austin, Texas; Boston; London; and San Antonio before the end of 2011. And Rackspace is keeping enrollment limited to ensure a healthy student-to-teacher ratio.
Here’s what Jim Curry, GM of Rackspace Cloud Builders, had to say in a prepared statement:
“As powerful as the OpenStack software is, we know firsthand it takes a lot more than software to properly design, deploy and operate a cloud at scale. [...] Students of Rackspace Cloud Builders training will have exclusive access to the OpenStack experts at Rackspace, and will walk away from the training course with the experience and knowledge to install, run and operate an OpenStack system in production.”
Is there a larger story here? I think so. Rackspace likes to hype the concept that even though it largely designed OpenStack, it doesn’t own it. But despite the rapid adoption of the OpenStack standard on the part of the larger cloud community, Rackspace very often seems to dominate the conversation.
Of course, as one of the few cloud-focused billion-dollar titans of the technology world, Rackspace has a little more clout, too. Does great cloud power come with great cloud responsibility?
Read More About This Topic



Anuradha Shukla reported VMware Offers Micro Cloud Foundry as a Free Download in an 8/24/2011 post to the CloudTweaks blog:
VMware has announced the beta availability of Micro Cloud Foundry as a free download at http://micro.cloudfoundry.com.
Micro Cloud Foundry is a complete version of the industry’s first open Platform as a Service (PaaS) solution, Cloud Foundry. Cloud Foundry delivers access to modern, high productivity frameworks and a rich ecosystem of application services from VMware, third parties and the open source community. Micro Cloud Foundry runs on a developer’s Mac or PC and lets them build end-to-end cloud applications locally, without the hassles of configuring middleware. Developers can therefore greatly accelerate their application development process, says VMware.
Applications created on Micro Cloud Foundry can be deployed directly to www.cloudfoundry.com or other instances of Cloud Foundry. This solution also helps developers to scale their applications without changing a line of code.
“VMware recognizes there is a new generation of developers looking for a simpler approach to building and testing their applications,” said Charlotte Dunlap, senior analyst with Current Analysis. “With this technology, VMware supports the growing need for developers to work on their laptops with an open, lightweight platform that minimizes configuration requirements and speeds application development.”
“Today VMware is taking another significant step forward in delivering a modern cloud application platform ideal for the hybrid cloud environment, by delivering industry’s only PaaS solution that can be run on an individual developer’s laptop,” said Jerry Chen, vice president of cloud and application services, VMware. “Micro Cloud Foundry gives developers a full cloud development environment that combines all the flexibility of local development with the ability to deploy and scale their applications anywhere in the future. Micro CloudFoundry gives developers the ability to build cutting edge cloud applications while exploring the latest developer frameworks and application services without configuration hassles.“
VMware intends to provide regular Micro Cloud Foundry updates to include additional frameworks and services, looking forward.
Jerry Huang posted Amazon S3 User Identity Explained on 8/23/2011 to his Gladinet blog:
Amazon S3 was designed with developers as its audience. Developers create applications around the Amazon S3 and those applications are used by the end user.
Seeing the amazing growth from Amazon S3, we are also seeing more and more people from real estates, dental office and many other small and medium sized businesses started to use Amazon S3 directly since the aws.amazon.com web-front provides many basic functionalities.
Gladinet supports Amazon S3 from day one with functionalities like map a network drive to Amazon S3; backup to Amazon S3; leverage Amazon S3 as a PC-2-PC sync bridge and conduit. As long as you have your master Amazon S3 account credentials, you can use Gladinet software with Amazon S3.
Now, Amazon introduced IAM (identity and account management) in its aws.amazon.com web interface. This introduced new user identities in one single master account. So now, not only it is possible to have a set of master account credentials, normal S3 admins can also create sub-users for his/her team. It is very good in that it can support a group of users with one single Amazon S3 account and one single billing. However, it also introduced complexity because the sub-accounts have different permissions from the master-account.
All Powerful Master Account Identity
By default, the Amazon S3 master account has all the permissions as the default owner of the account. You can retrieve the master account credentials from the aws.amazon.com site by clicking the Account link
Once you are in the account page, click on the Security Credentials link.
Now under the Access Keys section, it is your master account credentials. This set of credentials by default will have all the access to the Amazon S3 account.
You can use this set of account credentials with any of the Gladinet software during the mounting process and it will work by default.
Locked Down IAM User Identity
Compared to the all powerful master account, the sub-user you created inside IAM is by default locked down, meaning it doesn’t have any access to Amazon S3 objects when created.
The users created in the IAM web interface will not be able to mount Amazon S3 buckets inside Gladinet software. No worry, there is a S3 Resource Manager that you can assign IAM users to buckets. So user Joe can have access to bucket acme_joe, user Alice can have access to bucket acme_alice. Check out this article about setting it up with the S3 Resource Manager.
Summary
The concept is similar to Windows users, the administrators by default can access all the files in the C Drive. The users by default have much less permissions and privileges. Once you got the concept that the Amazon S3 master identity has all the access and the IAM user has none of the access upon creation, the rest is simple.
Related Posts





<Return to section navigation list>

















0 comments:
Post a Comment