Windows Azure and Cloud Computing Posts for 8/27/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

• Updated 8/28/2011 9:00 AM PDT with added articles marked • by Brian Gracely, Hassaan Khan, Derrick Harris, Bill Wilder, Dhananjay Kumar, Michael Washam, and Glenn Gailey.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
No significant articles today.
<Return to section navigation list>
MarketPlace DataMarket and OData
Arlo Belshee started an OData for Objective C thread on the OData Mailing List on 8/26/2011:
We've had consistent feedback that the Objective C library isn't meeting users' needs in terms of either quality or design. We want to get that fixed as soon as possible.
To that end, I propose the following plan:
- Turn the project into a full, community-driven, OSS project, so that anyone can easily contribute. It'll start with the current public code, which I think we should term v0.1.
- A team at Microsoft has a set of improvements. We want to submit those to the project, as a v0.2.
- Build a community to get to 1.0.
The set of improvements we've got fix a number of bugs and increase capabilities of the library. However, they still don't fix the design. The library fundamentally doesn't feel native to an experienced Objective C programmer.
That's why we need step 3. My first goal is to get a better version out quickly so that people can use it. After that, I want to find a couple of experienced Objective C developers who can work together to design how the library should really feel. We'll (I do intend to remain involved with this project) form the core community for getting to 1.0.
We started this project more than a year ago, to see how OData would work on another platform. Now OData is a lot more mature, and it is time to make it really shine on the mobile platforms. OData4J seems to do a good job at Android, and Microsoft is supporting it on Windows Phone, but it is up to us to make the Objective C library really shine on iOS.
We're currently working through the legal stuff required to make this a full community project. We've gotten agreement from all the business people; we just need time for the lawyers to transfer ownership out of Microsoft. Please be patient as we go through this. It'll take time, but not too much.
We'll have this library open for everyone to contribute soon.
Thoughts?
Arlo Belshee, Sr. Program Manager, OData, Microsoft

See the Michael Stiefel will present W7 What is Windows Azure Marketplace DataMarket? at 1105 Media’s Visual Studio Live Orlando 2011 conference on 12/7/2011 at 10:45 AM to 12:00 PM EST article in the Cloud Computing Events section below.
<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
• Glenn Gailey (@ggailey777) described EF 4.1 Code First and WCF Data Services Part 2: Service Operation Considerations in an 8/27/2011 post:
In my previous post (Entity Framework 4.1: Code First and WCF Data Services), I demonstrated how to use the strongly-typed DbContext from a Code First Northwind data model as the provider for a data service implementation. As you might recall from that post, WCF Data Services doesn’t know what to do with a DbContext (it expects EF providers that derive from ObjectContext), so we needed to manually override the CreateDataSource method and return the ObjectContext from the DbContext (NorthwindEntities in our Code First example).
This is all well and good for accessing feeds from the data service and executing queries, but (as one of my readers pointed out) there is an unexpected side-effect to our little trick. Because we provide the WCF Data Services runtime with an ObjectContext, the DataService<T>.CurrentDataSource property also returns an ObjectContext instead of the usual strongly-typed DbContext. Generally when using the EF provider, this method returns a strongly-typed ObjectContext, loaded with nice entity set properties that return IQueryable<T>. When creating service operations, this is a great way to query the EF model using the same (already open) EF connection and context.
Because the plain-old ObjectContext we get back from CurrentDataSource doesn’t have these nice code-generated properties, we again need to do a bit more work to access Code First entity sets in a service operation. The trick is to use the ObjectContext.GetObjectSet<T> method to access a specific entity set, as in the following example that returns a filtered set of Product entities:
// Service operation that returns non-discontinued products. [WebGet] public IQueryable<Product> GetCurrentProducts() { var context = this.CurrentDataSource; return context.CreateObjectSet<Product>() .Where(p=>p.Discontinued == false) .AsQueryable<Product>(); }Note that the AsQueryable() method lets us return the entities as an IQueryable<T>, which enables clients to further compose the results of this service operation.

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Dhananjay Kumar (@Debug_Mode) described Creating and updating [an] Excel file in [a] Windows Azure Web Role using Open XML SDK in an 8/28/2011 post to his Debug Mode blog:
Problem Statement
You need to create and upload Excel file in Windows Azure Web Role. Since there is no MS Office present on Azure VM so you cannot use Office InterOp Dll. So you are left with option of Open XML SDK to create and update the Excel file.
Solution Approach
- Create and update Excel file using Open XML SDK
- Upload Excel Template in Azure BLOB
- Download Excel template in azure web role local storage
- Read and update excel file from azure web role local storage
- Upload updated excel in Azure BLOB.
Create a Local Storage in Azure Web Role
I have created local storage called ExcelStorage. We will download Template Excel file in this local memory to update the records.
Uploading template in BLOB
I have created an Excel file called TestBLOB.xlsx as below template and uploaded in a container called debugmodestreaming
There are two columns in the excel file. I am going to update these two columns. You can have any number of columns. I have uploaded this excel file manually using Storage Explorer tool.
Include below Namespaces to work with BLOB, local storage and Open XML SDK,
using System; using System.Collections.Generic; using System.Linq; using DocumentFormat.OpenXml.Packaging; using DocumentFormat.OpenXml.Spreadsheet; using Microsoft.WindowsAzure; using Microsoft.WindowsAzure.StorageClient; using Microsoft.WindowsAzure.ServiceRuntime;Download template from BLOB and save on web role local storage
LocalResource myConfigStorage = RoleEnvironment.GetLocalResource("ExcelStorage"); account = CloudStorageAccount.Parse (RoleEnvironment.GetConfigurationSettingValue("DataString")); blobClient = account.CreateCloudBlobClient(); container = blobClient.GetContainerReference("debugmodestreaming"); blob = container.GetBlobReference("TestBLOB.xlsx"); blob.DownloadToFile(myConfigStorage.RootPath + "dj.xlsx");In above code,
- Creating reference of local storage ExcelStorage . In previous step we created this local storage.
- DataString is name of the connection string for Azure storage. I assume you know to create connection string for azure storage
- Debugmodestreaming is name of the container.
- Reading excel template file TestBLOB.xlsx and saving it to file called dj.xlsx on web role local storage.
Creating Data to be saved on Excel file
List<Student> GetData() { List<Student> lstStudents = new List<Student> { new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name ="Dhananjay Kumar", RollNumber="2"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"} }; return lstStudents; } } class Student { public string Name { get; set; } public string RollNumber { get; set; } }I have created a class called Student and some dummy data to be saved in the Excel file.
Writing to Excel file using Open XML SDK
Note: Writing to EXCEL file code I binged and got it from somewhere. I want to thank to the real author of this code. I am sorry that could not locate his/her blog url and name. But this code is from that author. Thanks
var result = GetData(); int index = 2; using (SpreadsheetDocument myWorkbook = SpreadsheetDocument.Open(myConfigStorage.RootPath + "dj.xlsx", true)) { WorkbookPart workbookPart = myWorkbook.WorkbookPart; WorksheetPart worksheetPart = workbookPart.WorksheetParts.First(); SheetData sheetData = worksheetPart.Worksheet.GetFirstChild<SheetData>(); foreach (var a in result) { string territoryName = a.Name; string salesLastYear = a.RollNumber; Row contentRow = CreateContentRow(index, territoryName, salesLastYear); index++; sheetData.AppendChild(contentRow); } workbookPart.Workbook.Save(); }Only one point to be noted is, we are opening file to write from local storage. Dj.xlsx is the file we saved on local storage from BLOB.Uploading updated Excel file back to BLOB
blob.UploadFile(myConfigStorage.RootPath + "dj.xlsx"); blob.Properties.ContentType = "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"; blob.SetProperties(); BlobRequestOptions options = new BlobRequestOptions(); options.AccessCondition = AccessCondition.None;Again we are reading updated excel sheet from local storage and uploading it to BLOB. Make sure content type is set properly.
This is all we need to do to work with Excel file in Windows Azure.
For your reference full source code at one place is as below,




using System; using System.Collections.Generic; using System.Linq; using DocumentFormat.OpenXml.Packaging; using DocumentFormat.OpenXml.Spreadsheet; using Microsoft.WindowsAzure; using Microsoft.WindowsAzure.StorageClient; using Microsoft.WindowsAzure.ServiceRuntime; namespace WebRole1 { public partial class _Default : System.Web.UI.Page { private static CloudStorageAccount account; private static CloudBlobClient blobClient; private static CloudBlobContainer container; private static CloudBlob blob; protected void Button1_Click1(object sender, EventArgs e) { LocalResource myConfigStorage = RoleEnvironment.GetLocalResource("ExcelStorage"); account = CloudStorageAccount.Parse (RoleEnvironment.GetConfigurationSettingValue("DataString")); blobClient = account.CreateCloudBlobClient(); container = blobClient.GetContainerReference("debugmodestreaming"); blob = container.GetBlobReference("TestBLOB.xlsx"); blob.DownloadToFile(myConfigStorage.RootPath + "dj.xlsx"); var result = GetData(); int index = 2; using (SpreadsheetDocument myWorkbook = SpreadsheetDocument.Open(myConfigStorage.RootPath + "dj.xlsx", true)) { WorkbookPart workbookPart = myWorkbook.WorkbookPart; WorksheetPart worksheetPart = workbookPart.WorksheetParts.First(); SheetData sheetData = worksheetPart.Worksheet.GetFirstChild<SheetData>(); foreach (var a in result) { string territoryName = a.Name; string salesLastYear = a.RollNumber; Row contentRow = CreateContentRow(index, territoryName, salesLastYear); index++; sheetData.AppendChild(contentRow); } workbookPart.Workbook.Save(); } blob.UploadFile(myConfigStorage.RootPath + "dj.xlsx"); blob.Properties.ContentType = "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"; blob.SetProperties(); BlobRequestOptions options = new BlobRequestOptions(); options.AccessCondition = AccessCondition.None; } string[] headerColumns = new string[] { "A", "B" }; Row CreateContentRow(int index, string territory, string salesLastYear) { Row r = new Row(); r.RowIndex = (UInt32)index; Cell firstCell = CreateTextCell(headerColumns[0], territory, index); r.AppendChild(firstCell); Cell c = new Cell(); c.CellReference = headerColumns[1] + index; CellValue v = new CellValue(); v.Text = salesLastYear.ToString(); c.AppendChild(v); r.AppendChild(c); return r; } Cell CreateTextCell(string header, string text, int index) { Cell c = new Cell(); c.DataType = CellValues.InlineString; c.CellReference = header + index; InlineString inlineString = new InlineString(); Text t = new Text(); t.Text = text; inlineString.AppendChild(t); c.AppendChild(inlineString); return c; } List<Student> GetData() { List<Student> lstStudents = new List<Student> { new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name ="Dhananjay Kumar", RollNumber="2"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"}, new Student { Name = "Dj ", RollNumber = "1"} }; return lstStudents; } } class Student { public string Name { get; set; } public string RollNumber { get; set; } } }
• Michael Washam (@MWashamMS) described Debugging a Random Crash in Windows Azure with ADPlus.exe in an 8/22/2011 post (missed when published):
Everyone has ran into the problem where their application has this random crash when the moon is blue. The question is how do you track these issues down?
Instrumenting your application to log exceptions as they occur is usually a good start. However, there is still that case where a crash occurred outside of your execption handler. The tried and true method of track these issues down is using post-mortem debugging with a dump file.
Windows Azure is tricky here though. How do you attach the debugger? If you have 10 instances of a role do you login and attach 10 seperate places?
The answer is YES and No.. Yes that you need to attach to all 10 instances if you wish to track down the exception and NO that you don’t have to actually login and attach to each machine.
I’ve put together a startup script that will automate this task for you on deployment.
Contents of start-adplus.ps1
param( $LocalResourceName, $ProcessnameNoExe ) $scriptDir = Split-Path -Parent $MyInvocation.MyCommand.Path $debuggerPath = $scriptDir + "\Debugger\adplus.exe" # wait until the process is running then attach # Get-Process doesn't expect the .exe while(-not (Get-Process -name $ProcessnameNoExe -erroraction silentlycontinue)) { Start-Sleep -s 5 } # Start-Process does expect the .exe though so put it back $ProcessnameNoExe = $ProcessnameNoExe + ".exe" # Trick to identify the local resource path [void]([System.Reflection.Assembly]::LoadWithPartialName("Microsoft.WindowsAzure.ServiceRuntime")) $localResourcePath = ([Microsoft.WindowsAzure.ServiceRuntime.RoleEnvironment]::GetLocalResource($LocalResourceName)).RootPath.TrimEnd('\\') #construct the arguments to adplus.exe for crash mode, the process name, and the local resource path as the output directory $debuggerarguments = " -crash -pn " + $ProcessnameNoExe + " -o " + $localResourcePath # start the process start-process -filepath $debuggerpath -argumentlist $debuggerargumentsTo configure the startup task to run I created a folder in my project called Startup. I created a folder within startup named Debugger.
You will need to add all of the files from the \Program Files\Debugging Tools for Windows folder to this folder and mark all files as Content and Copy Always to make sure they are deployed with your project.
Next you will need to create a bat file to kick off the powershell script.
Here I have passed a localresource named called crashresource and the process I want to debug waworkerhost.Contents of crashmode.bat
REM TIP %~dp0 is a batch file variable that returns the path of the currently executing script powershell -ExecutionPolicy Unrestricted -File "%~dp0start-adplus.ps1" -LocalResourceName crashresource -ProcessName waworkerhost REM Exit and tell Windows Azure we are complete exit /b 0


Finally, configure the service definition file to run your startup task and configure the local resource to hold the dump files.
Modifications to serviceDefinition.csdef
<LocalResources> <LocalStorage cleanOnRoleRecycle="false" name="crashresource" sizeInMB="1000" /> </LocalResources> <Startup> <Task commandLine="Startup\crashmode.bat" executionContext="elevated" taskType="background" /> </Startup>You should then configure the diagnostics system to transfer the files from the crashresource local resource to storage.
How to get started: http://msdn.microsoft.com/en-us/library/gg433039.aspxDisclaimer: This should ONLY be done as a last resort. Configuring your application for diagnostics and properly instrumenting your application will isolate most issues without resorting to the debugger.
Subscribed.
• Michael Washam (@MWashamMS) reported Deployment to Windows Azure Fails with Profiling Enabled in an 8/10/2011 post:
With the new 1.4 Tools if you try to deploy a project that has the profiler enabled and a VM Role as one of your Azure roles you will receive an error on deployment.
11:04:55 AM – HTTP Status Code: 400/nError Message: One or more configuration settings are specified for this deployment configuration but are not defined in the service definition file:
MortgageRatesPDFService:Profiling.ProfilingConnectionString, MortgageRatesPDFService:CloudToolsDiagnosticAgentVersion./nOperation Id: f7423416-9f32-4a9f-9c3f-9766d859d2bf
.CSCFG
<Setting name="Profiling.ProfilingConnectionString" value="SomeBogusValue"/> <Setting name="CloudToolsDiagnosticAgentVersion" value="1.4"/>.CSDEF
<ConfigurationSettings> <Setting name="CloudToolsDiagnosticAgentVersion"/> <Setting name="Profiling.ProfilingConnectionString"/> </ConfigurationSettings>This should allow the deployment to proceed.. Happy profiling!

• Michael Washam (@MWashamMS) described Profiling Windows Azure Applications using the August 2011 Release of the Visual Studio Tools (1.4) in an 8/5/2011 post (missed when published):
For a recap of what is new in this release see my earlier post: What’s new in Windows Azure VS.NET Tools 1.4
Note: The tools can be downloaded here using the Web Platform Installer.
For this article I’ll use a simple but common performance problem: string concatenation.
I have three functions.
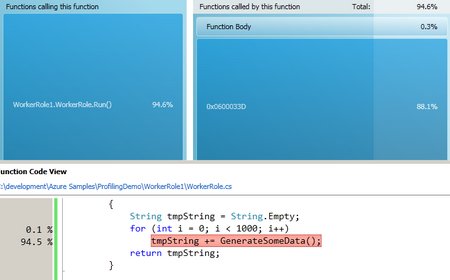
GenerateSomeData() just creates a new Guid and converts it to a string to return.
private string GenerateSomeData() { Guid g = Guid.NewGuid(); return g.ToString(); }DoVeryInefficientStringCopying() calls GenerateSomeData() 1000 times and concatenates the result into a string. String concatenation is very intensive because strings in C# are immutable (you can’t change a string once it is created) so each concatenation is actually creating a new string with the previous/new combined.
private string DoVeryInefficientStringCopying() { String tmpString = String.Empty; for (int i = 0; i < 1000; i++) tmpString += GenerateSomeData(); return tmpString;<br /> }DoMoreEfficientStringCopying() – accomplishes the same goal except it uses StringBuilder to append the string instead of using the string class’s += operator. The difference is StringBuilder is efficient and uses a buffer to grow the string instead of constantly creating new strings and copying memory.
private string DoMoreEfficientStringCopying() { System.Text.StringBuilder tmpSB = new System.Text.StringBuilder(); for (int i = 0; i < 1000; i++) tmpSB.Append(GenerateSomeData()); return tmpSB.ToString(); }I’m adding this code to a worker role I will deploy out to Azure with profiling enabled.
Here is the worker role code:
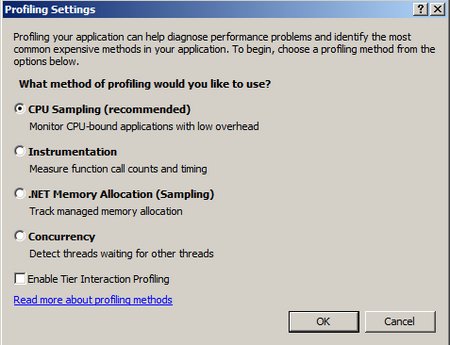
public override void Run() { // This is a sample worker implementation. Replace with your logic. Trace.WriteLine("WorkerRole1 entry point called", "Information"); while (true) { // Use the profiler to see which method is more efficient.. DoVeryInefficientStringCopying(); DoMoreEfficientStringCopying(); Thread.Sleep(10000); Trace.WriteLine("Working", "Information"); } }For profiling this simple problem I’m going to choose CPU Sampling:
Once the application is deployed and the scenario you are profiling has been reproduced you can analyze the profiling data.
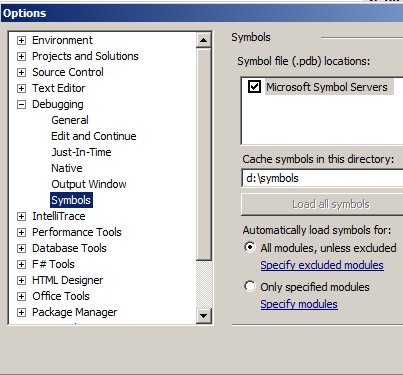
The first step is to configure your symbol paths. Within Visual Studio click tools -> options -> debugging. I have a debug build and I’m not calling any additional libraries so I don’t need to set anything here but if you have components with .pdb’s outside of this project you could reference them here as well as the Microsoft symbol servers.
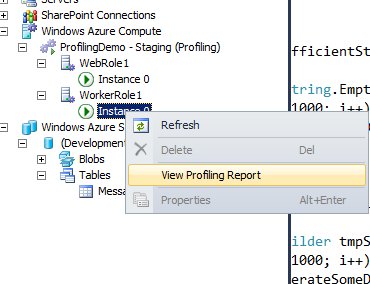
To analyze the profiling report expand the worker role from within server manager and select “View Profiling Report”:
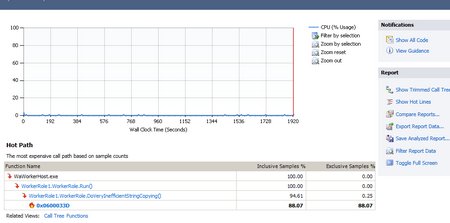
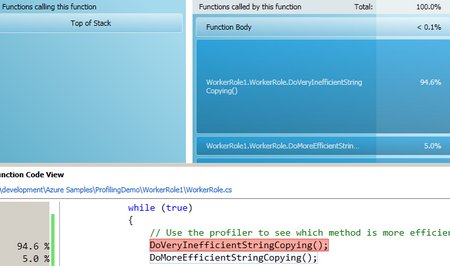
The initial screen shows my overall CPU usage which isn’t much considering my code is sleeping every 10 seconds. It also highlights a “hot path” which is the most expensive code path captured during the profiling session. Unsurprisingly, it is in the DoVeryInefficientStringCopying() method.
Clicking on the WorkerRole.Run() method drills in where I can actually compare and contrast the two methods:
It’s easy to see that 94.6% of our time was spent in the VeryIneffecient method compared to the Effecient version.
If I then click on the DoVeryInefficientStringCopying() method in the top window I can drill in further which gets us to the += operation causing all of the trouble.
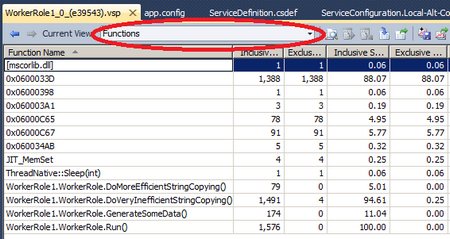
You can also change the view to a table layout of all the different functions to compare and contrast how much time was spent in each function and various other views.
For more information on analyzing the report data using Visual Studio 2010 Profiler see the following link: http://msdn.microsoft.com/en-us/library/ms182389.aspx.

Ben Lobaugh (@benlobaugh) explained How to deploy WordPress Multisite to Windows Azure using the WordPress scaffold in an 8/26/2011 post to the Interoperability Bridges blog:
Recommended Reading
Pre-Requisites
- Setup the Windows Azure development environment
- Setup the Windows Azure SDK for PHP
Synopsis
This article will show you how to use the scaffolding features of the Windows Azure SDK for PHP and the WordPress scaffold to quickly deploy an instance of WordPress Multisite optimized to run on Windows Azure. Though this article contains the steps needed to setup the multisite configuration it is recommended that you read the article on the WordPress Codex site to completely familiarize yourself with what is happening behind the scenes.`
Internet access is required for the WordPress scaffold to download several core components.
Windows Azure service setup
Before you will be able to run WordPress on Windows Azure you need to setup the following services:
- Hosted Service
- Storage account
- SQL Azure database
- Setup a database that WordPress can write to.
For more information on setting up these services see the following MSDN articles
Download the WordPress scaffold
A version of WordPress that is optimized to run on Windows Azure has been turned into a scaffold to allow for easy configuration and deployment to Windows Azure. The WordPress scaffold can be downloaded from:
https://github.com/Interop-Bridges/Windows-Azure-PHP-Scaffolders/tree/master/WordPress
The WordPress.phar file contains the packaged scaffold you need to run this tutorial. The WordPress folder contains the source of the scaffold which you can download and alter if you would like.
Place the WordPress.phar file into C:\temp for easy reference during the remainder of this article
Run the WordPress scaffold
When the WordPress scaffold is run the optimized version of WordPress will be built in a project location of your choosing, for this article we will be using C:\temp\WordPress.
Parameters
The WordPress scaffold requires several parameters when being run. The values of the given parameters will be used to populate the ServiceConfiguration.cscfg file.
- -DB_NAME - Name of the database to store WordPress data in
- -DB_USER - Username of user with access to the database. This will be in the form of user@db.host
- -DB_PASSWORD - Password of user with access to the database
- -DB_HOST - Hostname of database. This should be a fully qualified domain name.
- -WP_ALLOW_MULTISITE - Set to true to allow WordPress to operate in multisite mode
- -SUBDOMAIN_INSTALL - Optional, set to true if running WordPress Multisite with sub-domains. If you intend on using sub-directories for your blog network do not use this parameter.
- -sync_account - Endpoint of Windows Azure Storage account. NOTE: Inside of this storage account you will need to create a public container called 'wpsync'
- -sync_key - Access key of Windows Azure Storage account
Note: If you need to change the value of a parameter after running the scaffold you will not need to rerun the scaffold. Open the ServiceConfiguration.cscfg file for editing and you will see all the values you entered previously.
Additional Parameters
More parameters than those listed above are available in the WordPress scaffold. All additional parameters contain a default value that generally will not need to be changed. You can view all available parameters with the following command:
scaffolder help -s="C:\temp\WordPress.phar"Create the project
The WordPress scaffold can be run with the following command:
scaffolder run -s="C:\temp\WordPress.phar"-out="C:\temp\WordPress"-DB_NAME=**** -DB_USER=****@**** -DB_PASSWORD=**** -DB_HOST=****.database.core.windows.net -WP_ALLOW_MULTISITE=true-sync_key=**** -sync_account=****Running the WordPress scaffold may take several minutes. There are several critical operations happening:
- A WordPress archive is downloaded from http://wordpress.org and unpacked into the project directory
- The WordPress database abstraction plugin for SQL Azure is downloaded and added to the WordPress project files
- The Windows Azure Storage plugin for WordPress is downloaded and added to the WordPress project files
- WordPress is configured to work with Windows Azure services
- The Windows Azure service configuration file is setup
Open C:\temp\WordPress in a file browser and you should see the following files:
- WebRole/
- ServiceConfiguration.cscfg
- ServiceDefinition.csdef
The WordPress files are located inside of the WebRole folder.
Install the Windows Azure FileSystemDurabilityPlugin
The WordPress database abstraction plugin creates a database table mapping file inside of the wp-content directory that is required by the plugin when connecting to SQL Azure. Because this file is created on a running instance and is not inside the package uploaded to Windows Azure no other running instance will contain this file. To make WordPress operate properly with SQL Azure this file needs to be copied to all running and newly created instances. The Windows Azure FileSystemDurabilityPlugin was created to ensure the file exists across all running instances, however the plugin does not come packaged with the Windows Azure SDK by default.
The FileSystemDurabilityPlugin is hosted on Github. Just copy it into the Windows Azure SDK folder and configure it through the ServiceConfiguration.cscfg file before packaging.
- Download the FileSystemDurabilityPlugin from https://github.com/downloads/Interop-Bridges/Windows-Azure-File-System-Durability-Plugin/FileSystemDurabilityPlugin.zip
- Copy the FileSystemDurabilityPlugin folder you just downloaded to C:\Program Files\Windows Azure SDK\<YOUR VERSION>\bin\plugins
- Edit C:\Temp\WordPress\ServiceConfiguration.cscfg with your settings for the FileSystemDurabilityPlugin
For more information see the readme file located at https://github.com/Interop-Bridges/Windows-Azure-File-System-Durability-Plugin
Customize WordPress
WordPress writes directly to the file system when themes and plugins are installed. This will work in Windows Azure, however changes written to the file system are not durable and will be erased when the instance is restarted or upgraded. Also the file system is not shared across instances so if there are multiple instances running on the same WordPress installation they will not know of any changes made to the file system by any other running instance. Therefore the proper method of adding themes and plugins is to do it now before it is packaged and uploaded.
If you desire to upgrade or add additional files later it is recommended that the files be added to the project files on the development machine and WordPress repackaged.
Custom php.ini settings
If you need to add or change custom settings in the php.ini file this scaffold has support for that. Open the WebRoledirectory and you will find a php directory. Inside of that directory is a php.ini file. Whatever settings exist in here are automatically added to the installed PHP's php.ini at runtime.
Additionally if you have extension you would like to run they may be added to the ext folder and setup in thephp.ini. All files in the ext folder are copied to the installed PHP's ext folder at runtime and will be available for use.
Package the WordPress project
When you are finished customizing your WordPress installation you will need to package the project to deploy. The following command will create the package:
package create -in="C:\temp\WordPress"-out="C:\temp"-dev=falseDeploy the WordPress package
You now need to deploy the package files to Windows Azure to get the WordPress site running. If you have not deployed a Windows Azure package see the following articles:
Finalize the WordPress installation
The final step is to visit the URL you chose when creating the Hosted Service which the WordPress package is deployed on. When you visit the URL you will be presented with the standard WordPress form to fill in the details about your site and initial login information.
Setup the Multisite network
At this point your WordPress install is still setup as a single stand alone blog. The next step is to choose the type of network setup and make a couple configuration changes. To start navigate to the Tools menu and choose Network Setup.
Network Setup using sub-directories
Choose the subdirectories radio button. The Network Title and Admin E-mail Address will be filled in automatically based on information submitted when you setup WordPress. If you would like to make changes you can do so now. When you are done click the Install button.
Next you will be taken to a page asking you to alter setting in wp-config.php and the .htaccess file. Windows Azure uses IIS, IIS uses a Web.config file instead of a .htaccess file. The correct Web.config file was created for you when you ran the scaffolder. Instead of editing the wp-config.php file you will edit the service configuration file through the portal.
Edit the service configuration through the portal
The wp-config.php file in the WordPress scaffold reads configuration from the Windows Azure deployment service configuration. The following steps will need to be completed in order to finalize the network setup of your WordPress Multisite installation.
- Login to the Windows Azure Portal
- Choose your hosted service, click on it

- Click Configure on the toolbar

- A dialog will pop up containing your service configuration. Find the configuration options specified on the WordPress Network Setup page and set their corresponding values in the service configuration. When you are finished click OK.
Note: You $base is also listed in the service configuration.
- It will take a few moments for your configuration information to refresh, then your WordPress Multisite setup will be complete.
You may need to logout of WordPress and log back in before you see the Network Admin panel.
Configure the Windows Azure Storage plugin
The very last step to complete in order to fully take advantage of the power of Windows Azure is to configure the Windows Azure Storage plugin. This plugin stores all your uploaded media files in blob storage. DO NOT SKIP THIS STEP! If you upload media files directly to the file system on your instance you will lose them when the role is recycled or updated.
Note: The Windows Azure Storage plugin was built for a single WordPress site and therefore at the current time it must be configured on a per site basis.
Login to your WordPress administration backend and navigate toPlugins. Click Activate on the Windows Azure Storage for WordPress plugin.
After activation navigate to Settings > Windows Azure. This page will bring up the Windows Azure Storage configuration settings. You will need the name of your storage endpoint as well as your primary connection key.
After you click Save Changes you will need to specify the Default Storage Container and check the Use Windows Azure Storage when uploading via WordPress' upload tabcheckbox to ensure all uploaded media files are transferred to durable blob storage.
You may now begin using your new WordPress installation to create content as you would any standalone WordPress install.
Congratulations on getting WordPress running on Windows Azure!













Martin Ingvar Kofoed Jensen (@IngvarKofoed) described a Composite C1 non-live edit multi instance Windows Azure deployment in an 8/25/2011 post (missed when published):
Introduction
This post is a technical description of how we made a non-live editing multi datacenter, multi instance Composite C1 deployment. A very good overview of the setup can be found here. The setup can be split into three parts. The first one is the Windows Azure Web Role. The second one is the Composite C1 “Windows Azure Publisher” package. And the third part is the Windows Azure Blob Storage. The latter is the common resource shared between the two first and, except for it usage, is self explaining. The rest of this blog post I will describe the first two parts of this setup in more technical detail. This setup also supports the Windows Azure Traffic Manager for handling geo dns and fall-over, which is a really nice feature to put on top!
The non-live edit web role
Because it is time consuming to download new files from the blob, the synchronization is done to a local folder and not the live website. This minimizes the offline time of the website. All the paths of downloaded and deleted files are kept in memory. When the synchronization is done the live website is put offline with the app_offline.htm and all downloaded files are copied to the website and all deleted files are also deleted from the website. After this, the website is put back online. All this extra work is done to keep the offline time as low as possible.
The web role writes its current status (Initialized, Ready, Updating, Stopped, etc) in a XML file located in the named work blob container. During the synchronization (updating), the web role also includes the progress in the xml file. This XML is read by the local C1’s Windows Azure Publisher and displayed to the user. This is a really nice feature because if a web role is located in a datacenter on the other side of the planet, it will take longer time before it is done with the synchronization. And this feature gives the user a full overview of the progress of each web role. See the movie below of how this feature looks like.
All needed for starting a new Azure instance with this, is to create a new blob storage or use and existing one and modified the blob connection string in the package configuration. This is also shown in the movie below.
Composite C1 Windows Azure Publisher
This Composite C1 package adds a new feature to an existing/new C1 web site. The package is installed on a local C1 instance and all development and future editing is done on this local C1 website. The package adds a way of configuring the Windows Azure setup and a way of publishing the current version of the website.
A configuration consists of the blob storage name and access key. It also contains two blob container names. One container is used to upload all files in the website and the other container is used for very simple communication between the web roles and the local C1 installation.
After a valid configuration has been done, it is possible to publish the website. The publish process is a local folder to blob container synchronization with the same optimization as the one I have described in this earlier blog post: How to do a fast recursive local folder to/from azure blob storage synchronization. Before the synchronization is started the C1 application is halted. This is done to insure that no changes will be made by the user while the synchronization is in progress. The first synchronization will obvious take some time because all files has to be uploaded to the blob. Ranging from 5 to 15 minutes or even more, depending on the size of the website. Consecutive synchronizations are much faster. And if no large files like movies are added a consecutive synchronization takes less than 1 minute!
The Windows Azure Publisher package also installs a feature that gives the user an overview of all the deployed web roles and their status. When a new publish is finished all the web roles will start synchronizing and the current progress for each web role synchronization is also displayed the overview. The movie below also shows this feature.
Here is a movie that shows: How to configure and deploy the Azure package, Adding the Windows Azure Traffic Manager, Installing and configuring the C1 Azure Publisher package, the synchronization process and overview and finally showing the result.
Related Posts:
- Microsoft.WindowsAzure.* assemblies not in GAC on Azure sites: I discovered something ord with Azure deployments. 99% of developers and Azure deployments will prob...
- Moving C1 to Azure (File I/O): This blog post focus on file I/O when moving a complex solution to the Azure platform.Composite C1 i...
- Azure and the REST API: Introduction In this post I’ll write about the interesting things i discovered when doing RES...


Dominick Pinter posted a live Webinar - Kentico Technical Learning: Installing and Management on Windows Azure on 8/24/2011 (missed when published):
The cloud is an amazing evolution in computing! This evolution requires changes in how we deploy and manage our applications and sites. What are the architecture patterns you need to think about? How do you install? How do you manage your site? These are just a few of the questions that we often hear from our customers. In this webinar Dominik Pinter, Senior Kentico Developer, will cover how to prepare your site for Windows Azure and then deploy it to the cloud. Once you have your site up we will cover how you can manage your site using both the Kentico CMS tools and the tools available from Windows Azure.
Slides for this webinar are available here.

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Yann Duran (@yannduran) described how to Add a Web Page URL to LightSwitch's Navigation Menu in an 8/26/2011 post to MSDN’s Samples library:
Introduction
In order to be able to display a web page in LightSwitch, we ususally have to resort to adding a button on a page somewhere, & launching a browser window in the button's Execute method.
Here I'll show you how you can add an item in the Navigation Menu, that will appear with all your screens, but will launch a browser instead of a page.
Credit for the original technique goes to the LightSwitch Teams's Matt Thalman, and Sheel Shah.
This technique, and other advanced techniques for LightSwitch 2011 are covered in the upcoming LightSwitchbook, Pro Visual Studio LightSwitch 2011 Development, written by Tim Leung & myself. The book is due to be published in December 2011, & is available for pre-purchase now through Amazon.
Building the Sample
The prerequisites for this sample are:
Description
The first step is to create a LightSwitch project.
To create a LightSwitch project:
On the Menu Bar in Visual Studio:
choose File
choose New Project
In the New Project dialog box
select the LightSwitch node
then select LightSwitch Application (Visual Basic)
in the Name field, type AddUrlToNavigationMenu as the name for your project
click the OK button to create a solution that contains the LightSwitch project
Next, we need to add a screen.
To add the screen:
In the Solution Explorer in:
right-click the Screens folder
select Add Screen (see figure 1)
select New Data Screen
use LaunchURL as the Screen Name
leave Screen Data set to (none)
click OK
Figure 1. Add new screen
- A new item has now been added to the Navigation Menu (see Figure 2)
Figure 2. LaunchURL screen added
Now we need to add a bit of code to the screen, to make it behave the way we want, that is to display a web page, instead of displaying the screen as it usually would.
To add the code:
We're going to need a reference to System.Windows.Browser, so let's do that now.
In Solution Explorer:
click the View button (see Figure 3)
select File View

Figure3. File view
-
right-click the Client project
-
select Add Reference
-
find and click System.Windows.Browser (see Figure 4)
-
click OK
Figure 4. Adding System.Windows.Browser
Switch back to Logical View
click the View button (see Figure 5)
select Logical View
Figure 5. Selecting Logical view
In the Screen Designer (see Figure 6):
click the Write Code dropdown
select LaunchURL_Run
Figure 6. Selecting LaunchURL_Run method
Add the following code into LaunchURL_Run (see Listing 1):
Please Note: The Option Strict Off option isrequired for the line that executes the Shell.Application object.
Listing 1. LaunchURL_Run method code
Option Strict Off Imports System.Runtime.InteropServices.Automation Imports System.Windows.Browser Imports Microsoft.LightSwitch.Client Imports Microsoft.LightSwitch.Threading Namespace LightSwitchApplication Public Class Application Private Sub LaunchURL_Run(ByRef handled As Boolean) 'change this to launch the page you want Dim uri = New Uri("http://www.lightswitchcentral.net.au", UriKind.RelativeOrAbsolute) Dispatchers.Main.BeginInvoke( Sub() Try If AutomationFactory.IsAvailable _ Then Dim shell = AutomationFactory.CreateObject("Shell.Application") shell.ShellExecute(uri.ToString()) ElseIf (Not System.Windows.Application.Current.IsRunningOutOfBrowser) _ Then HtmlPage.Window.Navigate(uri, "_blank") Else Throw New InvalidOperationException() End If Catch ex As Exception 'handle the exception however you want End Try End Sub) ' Set handled to 'true' to stop further processing. handled = True End Sub End Class End Namespace
The first screen that gets added to a LightSwitch project become the startup screen. If we leave our screen set as the startup screen, it'll launch the web page as soon as the application runs.
So we need to fix that.
To prevent our screen from automatically running:
In Solution Explorer:
right-click the Screens folder
select Edit Screen Navigation (see Figure 7)

Figure 7. Edit screen navigation
click on the LaunchURL screen to select it
click the Clear button
notice that our screen is no longer the startup screen (see Figure 8)
Figure 8. No more startup screen
All that's left to do now, is to run the application.
If you've found this sample helpful, or even if you haven't, please rate it, & feel free to give meany feedback on it.
More Information
For more information on LightSwitch Development, see the LightSwitch Developer Center, or theLightSwitch Forum.
The Visual Studio LightSwitch Team (@VSLightSwitch) has added a Visual Studio LightSwitch UserVoice site:
Welcome to the Visual Studio LightSwitch UserVoice site. Let us know what you would like to see in future versions of Visual Studio LightSwitch. This site is for suggestions and ideas. If you need to file a bug, visit the Visual Studio LightSwitch Connect site: http://connect.microsoft.com/lightswitch.
We look forward to hearing from you!
Thanks –
The Visual Studio LightSwitch Team
Return to section navigation list>
Windows Azure Infrastructure and DevOps
• Bill Wilder (@codingoutloud) answered Azure FAQ: How frequently is the clock on my Windows Azure VM synchronized? in an 8/25/2011 post:
Q. How often do Windows Azure VMs synchronize their internal clocks to ensure they are keeping accurate time?
A. This basic question comes up occassionally, usually when there is concern around correlating timestamps across instances, such as for log files or business events. Over time, like mechanical clocks, computer clocks can drift, with virtual machines (especially when sharing cores) effected even more. (This is not specific to Microsoft technologies; for example, it is apparently an annoying issue on Linux VMs.)
I can’t find any official stats on how much drift happens generally (though some data is out there), but the question at hand is what to do to minimize it. Specifically, on Windows Azure Virtual Machines (VMs) – including Web Role, Worker Role, and VM Role - how is this handled?
According to this Word document - which specifies the “MICROSOFT ONLINE SERVICES USE RIGHTS SUPPLEMENTAL LICENSE TERMS, MICROSOFT WINDOWS SERVER 2008 R2 (FOR USE WITH WINDOWS AZURE)” – the answer is once a week. (Note: the title above includes “Windows Server 2008 R2″ – I don’t know for sure if the exact same policies apply to the older Windows Server 2008 SP2, but would guess that they do.)
Here is the full quote, in the context of which services you can expect will be running on your VM in Windows Azure:
Windows Time Service. This service synchronizes with time.windows.com once a week to provide your computer with the correct time. You can turn this feature off or choose your preferred time source within the Date and Time Control Panel applet. The connection uses standard NTP protocol.
So Windows Azure roles use the time service at time.windows.com to keep their local clocks up to snuff. This service uses the venerable Network Time Protocol (NTP), described most recently in RFC 5905.
UDP Challenges
The documentation around NTP indicates it is based on User Datagram Protocol (UDP). While Windows Azure roles do not currently support you building network services that require UDP endpoints (though you can vote up the feature request here!), the opposite is not true: Windows Azure roles are able to communicate with non-Azure services using UDP, but only within the Azure Data Center. This is how some of the key internet plumbing based on UDP still works, such as the ability to do Domain Name System (DNS) lookups, and – of course – time synchronization via NTP.
This may lead to some confusion since UDP support is currently limited, while NTP being already provided.
The document cited above mentions you can “choose your preferred time source” if you don’t want to use time.windows.com. There are other sources from which you can update the time of a computing using NTP, such as free options from National Institute for Standards and Technology (NIST).
Here are the current NTP Server offerings as seen in the Control Panel on a running Windows Azure Role VM (logged in using Remote Desktop Connection). The list includes time.windows.com and four options from NIST:
Interestingly, when I manually tried changing the time on my Azure role using a Remote Desktop session, any time changes I made were immediately corrected whenever I tried to make changes. Not sure if it was doing an automatic NTP correction after any time change, but my guess is something else was going on since the advertised next time it would sync via NTP did not change based on this.
When choosing a different NTP Server, it did not always succeed (sometimes would time out), but also I did see it succeed, as in the following:
The interesting part of seeing any successful sync with time.nist.gov is that it implies UDP traffic leaving and re-entering the Windows Azure data center. This, in general, is just not allowed – all UDP traffic leaving or entering the data center is blocked. To prove this for yourself another way, configure your Azure role VM to use a DNS server which is outside of the Azure data center; all subsequent DNS resolution will fail.
If “weekly” is Not Enough
If the weekly synchronization frequency is somehow inadequate, you could write a Startup Task to adjust the frequency to, say, daily. This can be done via the Windows Registry (full details here including all the registry settings and some tools, plus there is a very focused summary here giving you just the one registry entry to tweak for most cases).
How frequently is too much? Not sure about time.windows.com, but time.nist.gov warns:
All users should ensure that their software NEVER queries a server more frequently than once every 4 seconds. Systems that exceed this rate will be refused service. In extreme cases, systems that exceed this limit may be considered as attempting a denial-of-service attack.
Of further interest, check out the NIST Time Server Status descriptions:




They recommend against using any of the servers, at least at the moment I grabbed these Status values from their web site. I find this amusing since – other than the default time.windows.com, these are the only four servers offered as alternatives in the User Interface of the Control Panel applet. As I mentioned above, sometimes these servers timed out on an on-demand NTP sync request I issued through the applet user interface; this may explain why.
It may be possible to use a commercial NTP service, but I don’t know if the Windows Server 2008 R2 configuration supports it (at least I did not see it in the user interface), and if there was a way to specify it (such as in the registry), I am not sure that the Windows Azure data center will allow the UDP traffic to that third-party host. (They may – I just don’t know. They do appear to allow UDP requests/responses to NIST servers. Not sure if this is a firewall/proxy rule, and if so, is it for NTP, or just NTP to NIST?)
And – for the (good kind of) hacker in you – if you want to play around with accessing an NTP service from code, check out this open source C# code.
• Brian Gracely (@bgracely) asked Are there No Rules anymore, or New Rules everywhere? in the future of networking, storage, cloud management, application development and all-in-one vendors in an 8/28/2011 post to his Clouds of Change blog:
As I prepared to fly to Las Vegas for VMworld, I started thinking about which technologies I wanted to learn about, which start-ups I wanted to investigate and which strategic angles I needed to dig into more.
As I started thinking about various technology areas - networking, storage, cloud management, application development or usage (PaaS and SaaS) - it dawned on me that every one of those areas was under intense pressure to significantly change where it has been for the last 5-10 years. Technologies are always going through cycles of updates, but I can't remember a time when so many areas were going through potentially radical change at the same time.
Networking: The three biggest questions in networking today are focused on the server-access layer of the Data Center.
- Do new applications (web, big data, etc.) mandate a reduction of network layers &/or a simplicity of deployment/operations?
- Where do custom ASICs belong in the Data Center vs. "merchant silicon" from Broadcom or Fulcom Technologies?
- Where do L4-7 services (Load-Balancing, Firewall, IDS/IPS, DLP) belong in these new architectures, and how should they be deployed (application-level, virtual appliances, physical appliances or integrated services in switches)?
Storage: Virtualization rocked the storage world. 100%+ annual data growth is expanding the storage world. Big Data is making storage rethink data placement and caching capabilities. And Flash is turning storage economics completely upside down.
- The turbo-charging capabilities of FLASH (SSD, PCIe) can do amazing things to improve application performance, update metadata, eliminate bottlenecks. But where is the best place to put that capability? Should it reside in the server? Should it reside in the storage? Is it just a tier, or is it the core of the storage architecture? The answers are still to be determined. Some will be application specific, while others will change the architecture for broad usage models.
- What is the on-going role for the SAN? High visibility outages such as Amazon AWS EBS and Big Data architectures using onboard DAS are looming large. Massive unstructured data growth is unlocking new value for business.
Cloud Management: The best Cloud Computing companies in the world differentiate themselves through their cloud management technologies. And almost everyone of them are using homegrown tools, processes and capabilities. It's their Intellectual Property. But as the mass market looks to adopt Cloud Computing, many companies are trying to fill the void by creating cloud management that can be used by Enterprises, Governments, Service Providers or Commercial customers. It's a crowded market, filled with both proprietary and open-source options.
- Will OpenStack succeed, fail, stall or fork? This open-source project has the potential to become the LAMP stack of cloud management, if the community comes together in positive actions.
- How many CIOs will begin to leverage multi-cloud management to move from "managing budgets against 'no'" vs. making "yes" their default answer to all business <-> technology opportunities.
- Will we begin to see standardization of APIs between clouds or for specific cloud management functions, or are the industry still moving too fast to get bogged down in API standardization?
Application Development: When every person on the planet has a mobile device in their pocket, this leads to two interesting application challenges: (1) mobile, scalable, social applications are built differently, and (2) all those devices create a lot of data, and the analysis of that data is different than it was in the past.
- How quickly will the PaaS revolution take off? With so many PaaS options today (Cloud Foundry, Heroku, OpenShift, Google AppEngine, Microsoft Azure, Amazon AWS, etc.), how quickly will consolidation happen?
- With Enterprises only having 15-30% of their budgets available to drive innovation, will they have the resources to adopt these new application and services models?
- How do Enterprises manage the transition from legacy environments to new environments?
All-in-One Vendors: Back in the day, vendors fit nicely into certain silos. Network, database, storage, middleware. Those days are long gone. Now every major vendor is not only trying to become a one-stop shop for their customers, but are also balancing multi-partner coopetition environments. So what's a customer to do? Should they strive for best-of-breed, or use single-vendor solutions, or outsource to public clouds?
- How do you hire or transition the skill-set need of these new converged environments.
- Can vendors succeed in environments that are outside their core technology skills?
- How will the roles of Systems Integrators and Cloud Providers change to fill capability gaps?
After making this list, I quickly realized that we're right at the brink of potentially massive shifts in our industry. Both in terms of technologies and potentially the companies that succeed &/or fail. It means the potential for incredible opportunities for people that are willing to learn and take some chances.
It's going to be an amazing week of learning, and the next 12 months are going to have some major, long-term changes in our industry.


Brian is a cloud evangelist at Cisco, co-host of @thecloudcastnet amd a VMware vExpert.
Arjan de Jong asserted “Cloud Computing Providers Challenged to Dispel Security Concerns” as an introduction to his Benefits of Cloud Computing Realized by Increasing Number of [UK] Companies guest post of 8/27/2011 to the CloudTimes blog:
The adoption of cloud computing services has been swift for both large and small companies and satisfaction with cloud computing is very high, according to a recent study conducted by the Cloud Industry Forum in the UK www.cloudindustryforum.org. The study indicates that companies of all sizes are incorporating cloud computing into their overall IT strategies. Key drivers of this change seem to be flexibility, agility and cost savings.
More than 80 percent of the companies already using cloud services indicated they would likely increase their use of the cloud during the next year. This indicates a high level of satisfaction with cloud services by ad[o]ptors of the technology. Business applications companies are likely to move to the cloud are: email management, data back-up and disaster recovery, storage and web hosting services. Additional activities that users will move to the cloud are accounting, service management, CRM, security, and unified communications.
Businesses indicate that agility to deliver new services is their primary driver to adopt cloud computing. Companies are moving to the cloud because it offers them the flexibility they need to adapt to the ever changing business climate. The cloud makes it possible to access technology quickly and to offer solutions that they did not already have. At the same time, companies avoid the expense and hassle of owning and managing their own hardware.
Of the businesses surveyed that were not yet using cloud computing, nearly a third indicated that they anticipate adopting cloud services within the next year. It also appears that larger organizations are most likely to adopt cloud computing. Only 20 percent of companies with fewer than 20 employees are considering using cloud computing.
Within the IT Channel, cloud services are increasingly considered important, according to resellers surveyed. A large majority of resellers believe end users are ready to move to the cloud and the resellers are active in selling and supporting cloud services. There is still room for growth in this market, however, as almost one third of the resellers still do not actively engage with their customers about the relevance of cloud services versus on-premises technology.
In spite of the overall satisfaction of current cloud users and the number of companies that are considering adopting cloud services, there are still concerns that limit the growth of cloud computing. The issues that continue to create anxiety revolve around data security, privacy and the physical location of the data.
Because of these concerns, the vast majority of companies surveyed do not intend to move employee or customer information and accounts or financial data services to the cloud in the foreseeable future. Furthermore, regarding the location of data, companies feel more confident if their data is stored locally or nationally, as they are concerned about the potential impact of another country’s laws on data storage. It appears companies are more confident when data is maintained in their home country where the laws and legal system are familiar.
In response to these concerns, cloud computing providers must stress the security measures they have in place to protect data and educate current and potential customers about the actual, rather than perceived safety, of the cloud. When it comes to the location of data storage, cloud computing providers must offer variety and choices to customers. Clearly, a one-size for all, single location data center SaaS or IaaS solution, however attractive from a cost stand point, probably won’t deliver what the customer wants. Cloud computing customers do want value, but the savings should come from the hardware and redundant storage side of the equation, not at the expense of confidence and security.
Events such as the recent failure of Amazon Web Services’ European cloud due to lightning strikes can also cause some businesses to doubt the benefits of cloud computing or to believe that it is not a safe or reliable method of hosting data. Cloud computing providers must reassure potential customers that they are taking all the necessary steps to mitigate these types of disruptions.
Base on this important survey from the Cloud Industry Forum, cloud computing is gaining momentum fast in organizations of all types and sizes. There are major opportunities for expanding the cloud market alongside on-premise solutions, by encouraging companies to adopt cloud computing and guaranteeing safe storage of even more data and IT functionality into the cloud. Cloud computing companies need to be more than mere service providers but industry advocates dispelling misunderstandings and communicating to companies the very real benefits of being in the cloud.

Arjan is Marketing Manager at Jitscale.
James Kim posted Cutting the Cloud: Cloud Computing and Windows Azure to the MicrosofFeed blog on 8/25/2011:
Yes, we know, we have been beat over the head with cloud computing for the past year. Everything from online fax and office collaboration has evolved as a result of the newest cloud technology. But programs like Windows Azure are making it easier than ever to plug into the cloud.
Those familiar with Windows Azure Storage cloud are now able to track usage and troubleshoot problems in queues, tables, and blobs. It allows for much more efficient debugging. Azure’s ELMH (Error Logging Modules and Handlers) technology makes application-wide error logging easier than ever.
Azure metrics provide a summary of the “blobs, tables, and queues” statistics for an account. These logs and metrics can be accessed from any service running in Azure or directly over the internet.
Additional Microsoft is updating their billing structure for Microsoft Azure meaning, you guessed it, cheaper product! The price of extra small computer will be reduced by 20% starting October. Also, the new billing system will allow more flexibility in pricing.
If you haven’t already, look into Windows Azure to streamline your error logging and analysis. The cloud has never looked so good.
You may also like to check out:
- Top 10 Books for Windows Azure Development
- 10+ Beautiful Microsoft Windows Azure Wallpapers
- How to Install Windows Azure Developer Tools in 8 Easy Steps
- Windows Azure and Cloud Computing – An Introduction
- Windows Azure Toolkits for iOS, Android and Windows Phone Released!
- Scott Guthrie to join Windows Azure Group
- Download Windows Azure Toolkit for Windows Phone 7


James is a writer for Choosewhat.com, which provides product reviews and test data for business services and products.
Dell Computer published Saugatuck Cloud IT Management Survey: Summary Research Results in 8/2011. From Summary Findings: Part 1:
• Adoption of Cloud-based solutions, including SaaS, will be widespread across all categories through 2014 when Collaboration, SaaS, IaaS and PaaS will all achieve over 70 percent adoption.
• Greater than 50 percent of enterprises plan on using Cloud or SaaS-based IT Management solutions to manage their IT environment. Most workloads will be on-premises-based, internal private Cloud, or hybrid/integrated workloads. A smaller percentage of enterprise respondents will be using Cloud-based tools to manage “Cloud-based only” workloads.
• The degree of current satisfaction with on-premises IT management tools is in the mediocre range (55 percent – 68 percent), by no means a ringing endorsement of the status quo. It is reasonable to expect enterprise buyers will acquire new SaaS-based IT management tools, given the aggressive Cloud acquisition timeframes expressed and the finding that enterprises expect to acquire SaaS IT management tools to manage complex, hybrid, Cloud and on-premises workloads.
• Responses of enterprise buyers indicate that a majority are aware that SaaS-based IT management solutions that can help them manage their IT environments and meet their business/technology objectives. The top four areas that enterprise buyers plan to deploy SaaS-based IT management tools are Data backup, Email
system, Email archiving and Communication tools (e.g., notification, event management).• The top benefits that enterprise buyers expect from SaaS-based IT management solutions are clearly focused on reducing the costs of infrastructure and IT support, as well as enabling faster, more rapid deployment, and to provide greater flexibility and agility.
• Security issues led the list of top concerns that enterprise buyers have associated with deploying SaaSbased IT management. While this is consistent with other Cloud surveys that Saugatuck has conducted over the past eight years, buyers are also now expressing concerns about data and regulatory requirements, lock in and service levels – all indicating a more evolved and SaaS-based management tools as they consider them

From Summary Findings – Part II:
• While 19 percent to 25 percent of enterprise buyers already have or will acquire SaaS-based IT management tools by YE2011 (depending on solution category), these same enterprise buyers appear ready to deploy SaaS-based IT management tools in even larger numbers in 2012 (23 percent) and 2013 (18 percent), generally across all categories. By YE2014, cumulative enterprise deployment of SaaS based IT management tools will range from 68 percent to 80 percent, across the various tools categories.
• Enterprise buyers strongly prefer an integrated suite of SaaS-based IT management solutions over “best of breed” SaaS solutions, by a margin of 59 percent to 41 percent. This is likely because of the preference for efficiency of managing the whole integrated suite over managing the parts.
• Enterprise buyers strongly prefer buying direct from a large, established provider, but also favor to some degree the option of buying from a managed services provider or a Cloud hosting provider. Local and regional VARs and SIs, Telco providers and business consultancies are the least-favored procurement
options.
Copyright 2011 ǀ Saugatuck Technology, Inc. ǀ All Rights Reserved www.saugatucktechnology.com.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
• Hassaan Khan asserted “For chip-maker Intel, cloud is both relevant and real, as the company has saved USD 17 million to date from their internal cloud efforts” in a deck for his Technology forecast: Intel steadfast on ‘cloud’ future article for the Express Tribune of 8/27/2011:
Cloud computing is the delivery of computing as a service rather than a product, whereby shared resources, software and information are provided to computers and other devices as a utility (like the electricity grid) over a network (typically the Internet).
Intel’s journey to the private cloud began in 2006, with the successful deployment of a global computing grid to support mission-critical design processes. Today, it is building an office and enterprise cloud on a virtualised infrastructure. As a first step to creating this infrastructure, the company has accelerated the pace of server virtualisation with 42% of the environment virtualised by the end of 2010. The chip maker also claims to be on track to virtualise 75% of their environment over the next few years.
Given that Intel is just mid-way in its journey to the private cloud; both its savings and growth numbers appear significant. “The cloud segment is up 50% in the first half of 2011 versus first half of last year demonstrating how fast that business continues to ramp. We believe that we are very early in the cloud build-out and Intel remains extremely well-positioned to profitably grow from the explosion of mobile devices and Internet-based services,” Intel president and CEO Paul Otellini said during the company’s Q2 2011 earnings call.
Intel has achieved a number of business benefits with their private cloud, which include immediate provisioning, higher responsiveness, lower business costs, flexible configurations, and secured infrastructure. “The provisioning time has reduced from 90 days to three hours and now on the way to minutes.” Liam Keating, IT Director, Intel APAC said at the recently-concluded Intel cloud summit in Malaysia.
Furthermore, Intel Labs has announced two new Intel Science and Technology Centers (ISTC) hosted at Carnegie Mellon University focused on cloud and embedded computing research.
Aimed at shaping the future of cloud computing and how increasing numbers of everyday devices will add computing capabilities, Intel Labs announced the latest Intel Science and Technology Centers (ISTC) both headquartered at Carnegie Mellon University.
These centers embody the next $30 million installment of Intel’s recently announced 5-year, $100 million ISTC program to increase university research and accelerate innovation in a handful of key areas.
“These new ISTCs are expected to open amazing possibilities,” said Justin Rattner, Intel Chief Technology Officer. “Imagine, for example, future cars equipped with embedded sensors and microprocessors to constantly collect and analyze traffic and weather data. That information could be shared and analysed in the cloud so that drivers could be provided with suggestions for quicker and safer routes.”
The ISTC forms a new cloud computing research community that broadens Intel’s “Cloud 2015″ vision with new ideas from top academic researchers, and includes research that extends and improves on Intel’s existing cloud computing initiatives.

<Return to section navigation list>
Cloud Security and Governance
Kevin Jackson reported FedPlatform.org Focuses on a Government PaaS in an 8/26/2011 post to the Cloud Interoperability Magazine blog:
With GSA now issuing ATOs and Amazon launching it's own government specific cloud, IaaS for government agencies is now a reality. This next step in this "Cloud First" march is a consistent platform on which agencies can securely develop their applications.
To focus on this requirement, FedPlatform.org has been formed as a collaborative initiative to help federal organizations safely learn about and evaluate PaaS technologies. The initiative supports the Federal Cloud Computing Strategy and the Federal CIO’s 25-Point Federal IT Reform Plan, which suggests that cloud technologies provide new efficiencies and substantial cost savings. The FedPlatform.org mission is to facilitate implementations that adhere to rapidly evolving cloud computing standards, with a heavy focus on interoperability, portability and security.
FedPlatform also aims to provide a common security model for federal software systems that leverages the platform. In doing so, it provides major security advantages over disparate stovepipe security models. [Emphasis added.]
Platforms as a Service incorporate a common role-based access control (RBAC) engine for managing users, workshops, roles, privileges, and memberships. It supports timeouts, strong passwords, password expirations, appropriate encryptions, and RSA tokens. SSL is also available. The hosting can be fully managed on Amazon’s EC2, a GSA IaaS platform or even on an agency's own infrastructure. They are also making available a collection of tools and resources to help advance organizations from prototyping through production environments on private, community, hybrid or public clouds.


<Return to section navigation list>
Cloud Computing Events
• Michael Washam (@MWashamMS) posted I’m speaking at BUILD on 8/26/2011:

I'm speaking at BUILD

Michael is a Technical Evangelist for Microsoft. He’s focused on private and public cloud computing, web development and server workloads.
See other posts by Michael about use of the Visual Studio Tools for Azure v1.4’s profiling feature in the Live Windows Azure Apps, APIs, Tools and Test Harnesses section above.
Michael Stiefel will present W7 What is Windows Azure Marketplace DataMarket? at 1105 Media’s Visual Studio Live Orlando 2011 conference on 12/7/2011 at 10:45 AM to 12:00 PM EST:
Dallas is a data information service built on Windows Azure. Dallas accesses a variety of data from government, news, financial, traffic, and other sources. By providing a uniform method and format for retrieving and offering data, Microsoft has created a data marketplace.
Both large and small data providers can provide access to data to large and small development organizations in an environment where otherwise it would be highly unlikely or impossible for these groups to partner. Potentially this could lead to the democratization of data, where data can be combined with other data, in ways that could not be foreseen by the original providers. Since this data is available through a REST API, the applications that consume the data do not have to run on any particular platform.
You will learn:
To use data provided by Microsoft Dallas in an application
- To integrate Microsoft Dallas data into an Excel spreadsheet for data analysis
- To make data available to others in Microsoft Dallas


Michael is president of Reliable Software, Inc.
The “Dallas” codename was retired months ago in favor of Windows Azure Marketplace DataMarket. On the whole, I prefer “Dallas.”
Full disclosure: I’m a contributing editor for 1105 Media’s Visual Studio Magazine. An illustrated list of my cover stores for VSM since 11/2003 is here.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Derrick Harris (@derrickharris) posted Verizon buys CloudSwitch to give itself a software play to Giga Om’s Structure blog on 8/25/2011 (missed when published):
Verizon is buying cloud computing startup CloudSwitch in a move that will give Verizon, as well as its cloud subsidiary Terremark, a software-development edge to complement its service-provider expertise. Terms of the deal were undisclosed, but CloudSwitch had raised $15.4 million prior to the acquisition, from Atlas Venture, Matrix Partners and Commonwealth Capital Ventures. CloudSwitch Co-founder and VP of Products Ellen Rubin told me the company was going to raise another round when the acquisition opportunity arose.
CloudSwitch, which launched at our Structure 2010 event, makes software that makes it easy for customers to move their applications to the cloud. It gives customers an interface to port applications to the Amazon Web Services, Terremark and Microsoft Windows Azure clouds while maintaining their corporate security policies, and it also protects data as it traverses the network. This will give Terremark customers another option for network security and control instead of leasing a dedicated pipe.
Rubin said the product’s multicloud support will remain intact and will continue to evolve, although CloudSwitch will have an inside track in terms of optimizing for Terremark’s collection of cloud and managed service offerings. That will help Terremark capitalize on customers’ desires to use multiple clouds for different applications, because it gets paid regardless of where CloudSwitch users are running their applications.
However, Rubin said, the ultimate benefit for Terremark, and parent company Verizon, might be CloudSwitch’s software expertise. CloudSwitch will lead software development within the company beyond its core product, which will give the traditionally service-oriented Verizon and Terremark additional software capabilities and intellectual property. If the CloudSwitch team wasn’t given an expanded software-development role, she said, “We would have been less excited [about the deal].”
The CloudSwitch team will report to Terremark President Kerry Bailey. For more on CloudSwitch’s business, check out this video interview I did with Rubin at Structure 2011:


Alex Popescu (@al3xandru) posted links to articles and a video about Running MongoDB on the Cloud to his MyNoSQL blog on 8/27/2011:
I’ve been posting a lot about deployments in the cloud and especially about deploying MongoDB in the Amazon cloud:
- MongoDB on Amazon EC2 with EBS Volumes
- MongoDB on EC2
- MongoDB in the Amazon Cloud
- Setting Up MongoDB Replica Sets on Amazon EC2
- MongoDB and Amazon: Why EBS?
- Amazon EBS vs SSD: Price, Performance, QoS
- Multi-tenancy and Cloud Storage Performance
In this video Jared Rosoff covers topics like scaling and performance characteristics of running MongoDB in the cloud and he also shares some best practices when using Amazon EC2.
MongoDB on EC2 and EBS from Jared Rosoff
This video was made available by 10gen, creators of MongoDB and organizers of the Mongo events.

Keith Hudgins (@keithhudgins) continued his Crowbar series with Infrastucture as Code, or insights into Crowbar, Cloud Foundry, and more as part 3 on 8/26/2011:
Note: This is part 3 of a series on Crowbar and Cloud Foundry and integrating the two. If you haven't yet, please go back and read part 1 and 2.
Over the last few days I've introduced you to Crowbar and Cloud Foundry. Both are fairly new tools in the web/cloud/DevOps orbit, and worth taking a look at, or even better, getting involved in the community efforts to flesh them out into full-featured pieces of kit that are easier to use, more stable, and closer to turnkey. Are either one ready for production? Oh heck yeah, but you'll have to be able to read the code and follow it well in order to figure out what either project's doing under the hood: they're both real new, and the documentation (and architecture, when it comes right down to it) are still being written.
So where are these projects going?
Let's start with Cloud Foundry:
Cloud Foundry works, right now. It's rough around the edges yet, and there's still some tooling and packaging that needs to be done to make it easier to run on your own infrastructure, but the bones are very solid and they work. VMWare is actively engaging partners to help expand the capabilities of the platform. Through its Community Leads program, the project has already gained application support for Python and PHP applications.
Just yesterday, the CF project announced Cloud Foundry Micro, which is a VMWare appliance image that you can use to set up a development box on your desktop. This is a neatly packaged box that allows you to test your applications before you deploy them into the Cloud Foundry PaaS. This is cool, but a little limited: it doesn't yet support PHP and Python, and it's a bit of a black box. Great for developers, but if you want to crack the hood and see the shiny engine, you'll need to roll your own.
You can do that (sort of) with the older developer instance installer, which was documented in my last article. (Link's here for convenience.) Very soon, VMWare will be releasing more robust Chef cookbooks that hopefully will come closer to a production style install library. The cookbooks inside that install package were the basis of the pending Cloud Foundry barclamp.
Since there are now three beta PaaS products based on Cloud Foundry, the future is looking bright. It's fully open source, and you can either use it or help build it.
So what about Crowbar?
I'm glad you asked! Crowbar is a much lower-level tool on the stack (Your users and/or customers will never see it!) and is being put together by a smaller team (for now), but it solves a very interesting problem (how do you go from a rack of powered-down servers to a running infrastructure?) and is just beginning an important shift in focus.
Crowbar, as we've seen before, was originally written to do one thing: install OpenStack on Dell hardware. Very soon, it will begin to install other application stacks (Cloud Foundry, to start) and is opening up to be more easily extendable. CentOS/RHEL support is in the works for client nodes (currently, only Ubuntu Maverick is supported). The initial code has been committed to enable third-party barclamps. There are a small handful of community developers, and (I've been assured) the door is open for more. Fork the project on github, read the docs (I've got some more here), and start hacking.
Bonus: I'm documenting how to create your own barclamp and the lessons I've learned so far. As I write this, it's a blank page. By the time I'm done , you'll be able to make a barclamp to deploy your own application by following my instructions.

Zen Kishimoto posted a detailed, illustrated report of presentations to a recent SVForum Cloud SIG meeting by OpenStack founders and contributors in an OpenStack: Open Source Cloud Computing Infrastructure as a Service post of 8/24/2011 to the NetHawk blog:
I’ve worked for MySQL and JBoss as a consultant and understand how open source works. After MySQL and JBoss were acquired, I stayed away from the open source area because I was not excited about it anymore with the two giants gone. I heard about OpenStack from time to time but did not take the time to really understand what it is and how it is doing. Like most people, I am interested in what’s happening with cloud computing. Many aspects of cloud computing are related to energy. One such aspect is energy efficiency because of economies of scale. Now combining open source and cloud computing has made me want to revisit open source.
Recently, I had a chance to attend a Cloud SIG meeting held in the heart of Silicon Valley. The following information is not very technical but includes some history and an overview of what OpenStack is doing now. Specifically, I wanted to show who is behind OpenStack’s efforts. Although there are many more people involved besides the speakers, their pictures may bring it closer to you. The whole session was videotaped by the Cloud SIG of SVForum and may become available later, along with the presentation slides.
As reported elsewhere, Rackspace and NASA got together and developed a set of open source infrastructure as a service (IaaS) software packages.
Six people heavily involved in OpenStack gave short presentations:
As expected, people move around from company to company, and without knowing a little bit about each speaker’s background, it is a bit confusing.
A Short Summary of OpenStack
Before getting into the meat of the discussion, let me summarize what constitutes OpenStack. There are three major components, but there are several more cooking. These are the three major pieces now:
- Compute (Nova), which manages things like provisioning to set up the computing environment.
- Object Storage (Swift), which provides something similar to AWS’ S3.
- Image Service (Glance), which manages virtual machine images.
Other projects are listed here.
They are written in Python, and several people asked why Python instead of Ruby or something else. Joshua referred to a classified report submitted to the White House and defended his language choice but did not elaborate.
OpenStack is gaining popularity, and the community, including companies, is growing:
The list is growing, so you may want to check the OpenStack website for the latest.
Two Japanese companies, NTT Data and Midokura, were listed as code contributors. I was surprised, because it is rare that Japanese companies get recognition for their contributions to open source efforts.
Speakers
Rick Clark, now with Cisco, was one of the guys at Rackspace who conceived the idea of OpenStack and initiated the work with NASA.
Rick Clark
Vish Ishaya was with NASA Ames (hired by Joshua McKenty) but is now with Rackspace.
Vish Ishaya
Vish is in charge of the compute piece. He joined NASA to work on OpenStack and was with NASA at the time of the project start. He described what it was like at the beginning working with Rackspace. As he said, it is a bit strange now that he works for Rackspace.
Joe Arnold is with Cloud Scaling and is working on object storage for OpenStack.
Joe Arnold
James Urquhart is with Cisco and speaks at many cloud computing conferences. He discussed how OpenStack relates to Cisco’s business.
James Urquhart
In short, service providers are their customers and by arming them with more comprehensive portfolios of services (supported by Cisco’s software and hardware), they sell more services to end users. So the key is to support the service providers. James also said that the current version of clouds does not have specific support for networking, i.e., network as a service (NaaS). NaaS is being developed as part of OpenStack; the project name is Quantum. He also referred to another project called Donabe (a Japanese word meaning earthenware pot), which is a container service, a group of resources created and/or managed as one unit, with an initial focus on network containers. This project is headed by Rick Clark.
Christian Reilly is with Citrix and discussed the company’s perspective on OpenStack.
Christian Reilly
His main topic was a Citrix project called Olympus, which is OpenStack on steroids, intended to bridge a gap between OpenStack and public and private clouds. See the following feature comparison chart:
Last but not least, Joshua McKenty took the stage. He was at NASA and played a major role in conceiving OpenStack. He denied being the father of OpenStack but admitted some blood relationship to it, like grandfather, uncle, or cousin. But the energy emanating from him when he talked about OpenStack convinced me that he must be its father.
Joshua McKenty
He showed us the number of developers working on different open source projects:
He and the rest of the speakers seemed to be genuinely excited with the OpenStack movement. This is something I felt when I was working with MySQL and JBoss. There are many more things for them to do to make OpenStack a viable solution for cloud computing, but the momentum seems to be working in their favor.
















<Return to section navigation list>

















0 comments:
Post a Comment