Windows Azure and Cloud Computing Posts for 8/4/2011+
A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles.

• Updated 8/4/2011 4:30 PM PDT with articles marked • by Beth Massi and Matias Woloski.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table and Queue Services
Matthew Weinberger (@MattNLM) reported Microsoft Windows Azure Gets Cloud Storage Analytics in an 8/4/2011 post to the TalkinCloud blog:
Developers and administrators leveraging the Microsoft Windows Azure Storage cloud are now privvy to detailed logs and metrics that help track usage and troubleshoot problems in blobs, queues and tables.
According to the Windows Azure team blog entry, it works exactly like it says on the tin: Storage logs are placed in a special container called $logs, where each entry in the blob corresponds to “a request made to the service and contains information like request id, request URL, http status of the request, requestor account name, owner account name, server side latency, E2E latency, source IP address for the request etc.”
The benefits, as noted above, lie largely in debugging. Developers can make sure access requests make it to the network, or see who or what deleted a container, or track the number of anonymous requests, and so on.
Meanwhile, the new Azure storage metrics include the following, as per that blog entry:
- Request information: Provides hourly aggregates of number of requests, average server-side latency, average E2E latency, average bandwidth, total successful requests and total number of failures and more. These request aggregates are provided at a service level and per API level for APIs requested in that hour. This is available for Blob, Table and Queue service.
- Capacity information: Provides daily statistics for the space consumed by the service, number of containers and number of objects that are stored in the service. Note, this is currently only provided for the Windows Azure Blob service.
Users can also set retention policies, to make sure the logs and metrics are deleted after a certain date for management’s sake. And both logs and metrics are retrievable from any application that can make and receive HTTP/HTTPS requests.
This should make Azure Storage some fans in the cloud ISV world. Keep watching TalkinCloud for more.
Read More About This Topic


For more details in depth about Windows Azure Storage analytics see my Windows Azure and Cloud Computing Posts for 8/3/2011+ post.
<Return to section navigation list>
SQL Azure Database and Reporting
Todd Hoff asserted that Jim Starkey is Creating a Brave New World by Rethinking Databases for the Cloud in an 8/4/2011 post to the High Scalability blog:
Jim Starkey, founder of NuoDB, in this thread on the Cloud Computing group, delivers a masterful post on why he thinks the relational model is the best overall compromise amongst the different options, why NewSQL can free itself from the limitations of legacy SQL architectures, and how this creates a brave new lock free world....
I'll [Jim Starkey] go into more detail later in the post for those who care, but the executive summary goes like this: Network latency is relatively high and human attention span is relatively low. So human facing computer systems have to perform their work in a small number of trips between the client and the database server. But the human condition leads inexorably to data complexity. There are really only two strategies to manage this problem. One is to use coarse granularity storage, glombing together related data into a single blob and letting intelligence on the client make sense of it. The other is storing fine granularity data on the server and using intelligence on the server to aggregate data to be returned to the client.
NoSQL uses the former for a variety of reasons. One is that the parallel nature of scalable implementations make maintaining consistent relationship among data elements problematic at best. Another is that clients are easy to run in parallel on multiple nodes, so moving computation from servers to clients makes sense. The downside is that there is only one efficient way to view data. A shopping cart application, for example, can store everything about a single user session in a single blob that is easy to store, fetch, and contains just about every necessary take an order to completion. But it also makes it infeasible to do reporting without moving vast quantities of unnecessary data.
SQL databases support ACID transactions that makes consistent fine granularity data possible, but also requires server side intelligence to manage the aggregation. The SQL language, ugly as it may be, performs the role with sufficient adequacy (we could do better, but not significantly better). Stored procedures using any sort of data manipulation language also works. But distributed intelligence, declarative or procedural, pretty much requires regularity of data. Hence schemas. They don't have to be rigid or constraining, but whatever intelligence is going to operate on bulk data needs a clue of what it looks like and what the relationships are.
So that's the short version. The long version requires a historical understanding of how we got from an abstract to structured views of data.
On of the earliest high performance database systems (they weren't called that yet) was a mainframe product, circa 1969, whose name eventually settled on Model 204 (person node: I did the port from DOS/360 to OS/360 MVT). Model 204 had records that were arbitrary collections of attribute/value pairs. The spooks loved it -- dump everything you know into cauldron and throw queries at it. But it couldn't handle relationships among records without a lot of procedural code.
There were two data models that attempted to capture data structure (relationships). One was the hierarchical model, IBM's IMS and the ARPAnet Datacomputer (personal note here, too). The other was the CODASYL (aka network) data model where individual records "owned" chains of other records. IDMS, the premier CODASYL product roamed the earth in the late Jurassic period until an alternative emerged from the primordial swamps (sigh, I was on the team that ported IDBMS to the PDP-11, often likened to an elephant on a bicycle). Both the hierarchical and network models required data manipulation languages that an orc's mother couldn't love.
Codd's relational model, once stripped of the unnecessary mathematical trappings, was a very happy compromise between simple regular tables and ad hoc joins for inter-table relationships. And it made for straightforward transactional semantics as well. It was a hit when the first commercial implementation came out and has persevered (I put out DEC's first relational database, Rdb/ELN, in 1984).
The OO data model (encapsulated objects and pointer) pops up and dies with great regularity, as does its close relative, object/relational mapping. Neither is particularly suited for the distributed world, however, but the refugees can generally find work in other companies.
Over the years I've had a professional affiliations with the amorphous data model (Model 204), hierachical (Datacomputer), CODASYL (DBMS-11), and relational (Rdb/ELN, Interbase, Firebird, MySQL, and NimbusDB). And my friend Tom Atwood started at least half of the OO database companies. So, if I can't claim objectivity, I can at least claim in depth personal experience.
Everything is a compromise. And I deeply believe that the relational model is the best compromise among simplicity, power, performance, and flexibility of implementation. It does require data description, but so do all other useful database management systems regardless of what it is called.
The scale problems with legacy relational databases have nothing to do with SQL, the relational model, or ACID transactions. The essence of the problem is theoretical -- the conflation of consistency and serializability. Serializability is a sufficient condition for database consistency but not a necessary condition. The NewSQL generation of products recognize this and refuse to be limited by lock managers of any ilk.
It's a brave new world out there, ladies and gentlemen.
If this seems like magic, take a look at How NimbusDB Works for more details. Are Cloud Based Memory Architectures The Next Big Thing? has a lot of clarifying quotes from Jim Starkey as well.
Related Articles
- Is NoSQL A Premature Optimization That's Worse Than Death? Or The Lady Gaga Of The Database World?
- Thoughts from GigaOM Structure 2011
- NimbusDB Presents at Under the Radar
- Databases in 21st Century: NimbusDB and the Cloud by Jim Starkey
- 2011 New England Database Summit Video on Facebook
- Jim Starkey: Introducing Falcon (the video and the podcast)
- Special Relativity and the Problem of Database Scalability by Jim Starkey (audio)


NuoDB was NimbusDB until 8/1/2011. According to the firm’s NuoDB is the new NimbusDB post of 8/1/2011:
NimbusDB, the thought leader in cloud database technology, announced today that the company has chosen to change its name to NuoDB. NuoDB is a NewSQL database system, a new category of databases designed to deliver horizontally scalable ACID transactions within the industry-standard SQL database model. “Nuo” derives from a Chinese word meaning “graceful”.
“Our NuoDB product is in Beta release and as the company gets ready for delivery to production users it is appropriate to adopt a more distinctive identity that reflects the essence of our culture and product”, said Barry Morris, Founder and CEO of NuoDB, Inc. “Early users see it as a major advantage that they can gracefully add and delete computer nodes to a running NuoDB database, which is really one of the key ideas of the cloud and our technology.”
The NuoDB product is an elastically scalable SQL database that supports ACID transactions.
Cloud computing is delivering enormous benefits to users that need computing services on a convenient utility model. Cloud computing does however create a substantial challenge for traditional database systems. Modern demands on databases are unprecedented and unpredictable both in terms of data volumes and user concurrency. Furthermore, the modern cloud data center is populated with small commodity machines connected by commodity networks, not large monolithic computers. What is needed is a new category of database system that delivers elastic scalability on networks of commodity computers but that does not require an enterprise to change its business models, processes, tools, skill bases, etc.
“The NewSQL wave of database systems is a consequence of the failure of traditional, monolithic SQL systems”, added Barry Morris. “What has worked for the last 30 years will not work for the next 30 years, obviously. NuoDB paves the way by creating a new vision of SQL databases that deliver increased or decreased performance as you assign different numbers of machines to a running database. No-one else can do that.”
On the topic of the new name, Morris noted “We liked NimbusDB as a name. It refers to the cloud, and that is what we do. But if you GOOGLE ‘Nimbus’ you’ll get hits that include breweries, toothbrushes, motorcycles, Harry Potter’s flying broom, and a good number of technology companies. NuoDB, on the other hand, gets at who we are and what we do, and distinguishes the company. We’re here to build a long-term business and I want us to do so with a distinctive position in the market. ‘Nuo’ derives from ‘graceful’ in Chinese and in the end gracefully scaling to meet demand is the heart of the cloud data challenge.”
Patrick Wood described How to Use Microsoft Access to Create Logins in a SQL Azure Database in an 8/1/2011 post:
In this article we will demonstrate how you can use a Pass-through query in Access with VBA code to create SQL Azure Logins. Microsoft Access can then use the Login and Password to gain access to SQL Azure Tables, Views, and Stored Procedures. We will create a Login using SQL in Access similar to the following Transact-SQL (T-SQL):
CREATE LOGIN MyLoginName WITH password = ‘zX/w3-q7jU’
Thankfully, a user would never have to memorize that password! Because this Login and password would only be used by my Access application the user never sees it and does not even know it exists.
There are several steps involved in creating a Login and Password for SQL Azure. And although most T-SQL that is used in SQL Azure is exactly the same as that used with SQL Server there are some critical differences which we will address in the following steps.
1) Create a Strong Password that Meets the Requirements of the Password Policy.
It is very important to use Strong Passwords because the extra security is needed since we cannot use Windows Authentication with SQL Azure. Passwords must be at least 8 characters long and contain at least one number or special character such as -/~^&.
2) Use Characters That Do Not Conflict With ODBC Connection Strings.
To avoid errors we should not use these ODBC connection string characters []{}(),;?*!@ in our Login Name and Password.
3) Build a Transact-SQL Statement Which Will Create the Login.
We will use the T-SQL CREATE LOGIN statement in a Pass-through query to create the Login. Since Pass-through queries “pass” the SQL unaltered to SQL Azure most of the time the SQL is just like what we would in SQL Server Management Studio (SSMS) and as seen here:
CREATE LOGIN MyLoginName WITH password = ‘zX/w3-q7jU’
Another requirement of the CREATE LOGIN statement is that it must be the only statement in a SQL batch. So we are only going to create one Login at a time.
4) Ensure the Login and Password Are Created In the master Database.
This is required because “USE master” does not work in SQL Azure as it does with SQL Server because the USE statement is not supported in SQL Azure. But with Access we can create the Login in the master database by specifying the master database in our Connection String: “DATABASE=master;”. We use a Function like the one below to get the Connection String with an obfuscated name to keep it more secure.
Public Function obfuscatedFunctionName() As String obfuscatedFunctionName = "ODBC;" _ & "DRIVER={SQL Server Native Client 10.0};" _ & "SERVER=tcp:MyServerName.database.windows.net,1433;" _ & "UID=MyUserName@MyServerName;" _ & "PWD=MyPassword;" _ & "DATABASE=master;" _ & "Encrypt=Yes" End FunctionSee my article Building Safer SQL Azure Cloud Applications with Microsoft Access for more information about securing your Access application.
5) Create a Function to Execute the SQL and Create the Login.
Place the ExecuteMasterDBSQL Function below in a Standard Module. This Function executes our CREATE LOGIN statement. It can be used any time you want to execute a T-SQL statement in the SQL Azure master database that does not return records. The Function returns True if the SQL was executed successfully or False if the SQL fails to be executed.
'This procedure executes Action Query SQL in the SQL Azure master database. 'Example usage: Call ExecuteMasterDBSQL(strSQL) or If ExecuteMasterDBSQL(strSQL) = False Then ' Function ExecuteMasterDBSQL(strSQL As String) As Boolean On Error GoTo ErrHandle Dim db As DAO.Database Dim qdf As DAO.QueryDef ExecuteMasterDBSQL = False 'Default Value Set db = CurrentDb 'Create a temporary unnamed Pass-through QueryDef. This is a 'practice recommended in the Microsoft Developer Reference. 'The order of each line of code must not be changed or the code will fail. Set qdf = db.CreateQueryDef("") 'Use a function to get the SQL Azure Connection string to the master database qdf.Connect = obfuscatedFunctionName 'Set the QueryDef's SQL as the strSQL passed in to the procedure qdf.SQL = strSQL 'ReturnsRecords must be set to False if the SQL does not return records qdf.ReturnsRecords = False 'Execute the Pass-through query qdf.Execute dbFailOnError 'If no errors were raised the query was successfully executed ExecuteMasterDBSQL = True ExitHere: 'Cleanup for security and to release memory On Error Resume Next Set qdf = Nothing Set db = Nothing Exit Function ErrHandle: MsgBox "Error " & Err.Number & vbCrLf & Err.Description _ & vbCrLf & "In procedure ExecuteMasterDBSQL" Resume ExitHere End Function6) Use a Form to Enter the Login Name and Password
We can make it easy for users to create a Login by using a form. To do this we need to add two text boxes and a command button to the form. Both text boxes need to be unbound. Name the text box for the Login Name txtLoginName. Name the text box for the Password txtPassword. Name the command button cmdCreateLogin. The form should look something like this, but without the extra touches for appearance sake.
Add the code below to the command button’s Click event. After the code verifies that a Login Name and Password has been entered, it calls the ExecuteMasterDBSQL Function to create the Login in our SQL Azure master database.
Private Sub cmdCreateLogin_Click() 'Prepare a Variable to hold the SQL statement Dim strSQL As String 'Build the SQL statement strSQL = "CREATE LOGIN " & Me.txtLoginName & " WITH password = '" & Me.txtPassword & "'" 'Verify both a Login Name and a Password has been entered. If Len(Me.txtLoginName & vbNullString) = 0 Then 'A Login Name has not been entered. MsgBox "Please enter a value in the Login Name text box.", vbCritical Else 'We have a Login Name, verify a Password has been entered. If Len(Me.txtPassword & vbNullString) = 0 Then 'A Password has not been entered. MsgBox "Please enter a value in the Password text box.", vbCritical Else 'We have a Login Name and a Password. 'Create the Login by calling the ExecuteMasterDBSQL Function. If ExecuteMasterDBSQL(strSQL) = False Then MsgBox "The Login failed to be created.", vbCritical Else MsgBox "The Login was successfully created.", vbInformation End If End If End If End SubThe code in the Form checks the return value of the ExecuteMasterDBSQL Function and informs us whether or not the Login was successfully created. Once we have created a Login we can create a Database User for the Login and grant the User access to the data in the SQL Azure Database. Creating a Database User for the Login appears to be a good subject for another article.
Get the free Demonstration Application that shows how effectively Microsoft Access can use SQL Azure as a back end.
More Free Downloads:
Us or UK/AU Pop-up Calendar
Report Date Dialog Form in US or UK/AU Version.
Free Church Management Software with Contributions management.
Code SamplesGet the Access and Outlook Appointment Manager to manage all of your Outlook Calendar Appointments and Access dated information.
Happy computing,
Patrick (Pat) Wood
Gaining Access
http://gainingaccess.net



It’s unfortunate that Access Web Databases don’t support VBA, which is necessary for Patrick’s approaches outline above.
<Return to section navigation list>
MarketPlace DataMarket and OData
Users are encountering issues with Jonathan Carter’s (@LostInTangent) WCF Data Services Toolkit post to CodePlex on 5/8/2011 as last reported in the Issue Tracker page on 8/3/2011. From the Home page:
Elevator Pitch
The WCF Data Services Toolkit is a set of extensions to WCF Data Services (the .NET implementation of OData) that attempt to make it easier to create OData services on top of arbitrary data stores without having deep knowledge of LINQ.
It was born out of the needs of real-world services such as Netflix, eBay, Facebook, Twitpic, etc. and is being used to run all of those services today. We've proven that it can solve some interesting problems, and it's working great in production, but it's by no means a supported product or something that you should take a hard commitment on unless you know what you're doing.
In order to know whether you qualify for using the toolkit to solve your solution, you should be looking to expose a non-relational data store (EF + WCF Data Services solves this scenario beautifully) as an OData service. When we say "data store" we really do mean anything you can think of (please be responsible though):
- An XML file (or files)
- An existing web API (or APIs)
- A legacy database that you want to re-shape the exposed schema dramatically without touching the database
- A proprietary software system that provides its data in a funky one-off format
- A cloud database (e.g. SQL Server) mashed up with a large schema-less storage repository (e.g. Windows Azure Table storage)
- A CSV file zipped together with a MySQL database
- A SOAP API combined with an in-memory cache
- A parchment scroll infused with Egyptian hieroglyphics
That last one might be a bit tricky though...Further Description
WCF Data Services provides the functionality for building OData services and clients on the .NET Framework. It makes adding OData on top of relational and in-memory data very trivial, and provides the extensibility for wrapping OData on top of any data source. While it's possible, it currently requires deep knowledge of LINQ (e.g. custom IQueryables and Expression trees), which makes the barrier of entry too high for developing services for many scenarios.
After working with many different developers in many different industries and domains, we realized that while lots of folks wanted to adopt OData, their data didn't fit into that "friendly path" that was easily achievable. Whether you want to wrap OData around an existing API (SOAP/REST/etc.), mash-up SQL Azure and Windows Azure Table storage, re-structure the shape of a legacy database, or expose any other data store you can come up with, the WCF Data Services Toolkit will help you out. That doesn't mean it will make every scenario trivial, but it will certainly help you out a lot.
In addition to this functionality, the toolkit also provides a lot of shortcuts and helpers for common tasks needed by every real-world OData service. You get JSONP support, output caching, URL sanitization, and more, all out of the box. As new scenarios are learned, and new features are derived, we'll add them to the toolkit. Make sure to let us know about any other pain points you're having, and we'll see how to solve it.

Jason Bloomberg (@TheEbizWizard) posted REST-Based SOA: an Iconoclastic Approach to the ZapThink blog on 8/4/2011:
At ZapThink we’re proud to be iconoclasts. After all, building agile architectures requires critical appraisal—and frequent dismissal—of traditionally held beliefs. We know this role places us among the heretics who dare challenge established dogma.
In fact, the whole notion of agility has long suffered this battle between iconoclasm and dogmatism. As we discuss in our Licensed ZapThink Architect course, the Agile Manifesto embodies an iconoclastic approach to software development dogma – and yet, so many people have become dogmatic about the Agile Manifesto itself, entirely missing its point!
ZapThink once more jumped into this iconoclasm-masquerading-as-dogma fray with our recent ZapFlash, How I Became a REST “Convert.” We explained how you can implement SOA following REST principles, and how such an approach introduces important simplifications and efficiencies as compared to a Web Services-based approach.
Get out the torches and pitchforks! ZapThink is at it again! Not only are we flying in the face of established SOA dogma, we’re taking on REST dogma as well! Never mind that the original vision for REST movement was inherently iconoclastic. In fact, it’s no wonder that RESTafarians use religious metaphors in their discussions (although Rastafarianism is a far cry indeed from the Catholic metaphors we’re leveraging in this ZapFlash).
To quote our beloved Agile Manifesto, we want to favor responding to change over following a plan—even if that plan is how SOA or even REST is “supposed to be done.” The goal is stuff that actually addresses the business problem, not some adherence to official dogma (another Agile principle, in case you didn’t notice). Therefore, it came as no surprise to us when an organization contacted us and let us know that they are taking the REST-based SOA approach we discussed in the ZapFlash, and that it actually works.
The Iconoclastic REST-based SOA of the US Coast Guard
We recently spoke with the US Coast Guard (USCG) about their SPEAR (Semper Paratus: Enterprise Architecture Realization) initiative. The SPEAR approach to SOA centers on document-centric, event-driven, loosely coupled, asynchronous, message-based Business Services. Now, there’s nothing particularly iconoclastic about event-driven SOA—after all, we debunked that notion back in 2004—but their story doesn’t end there. Another central characteristic of their SOA approach is their document-centricity. While it’s true that document style interfaces are the norm for Web Services, the USCG takes the notion to a new level.
In the Web Services world, when a WSDL file specifies a document style interface, then the constraints on the input and output messages fall into one or more schema definitions, instead of the SOAP message structure itself. As far as SOAP is concerned, the body of the SOAP message contains a payload consisting of whatever document you like. The advantage of the document style over the tightly coupled remote procedure call (RPC) style is it allows for flexible versioning of Services: many changes to a Service do not force a new contract version.
However, as anyone who has monkeyed with Web Services can attest, the operations of a Service still cause issues, even when it’s a document style interface. We can’t seem to get away from Web Services’ tightly coupled RPC heritage. And furthermore, XML schemas are strongly typed, which introduces a further undesirable level of tight coupling.
To resolve such issues, REST moves the operations out of any formal contract, instead relying upon the GET, POST, PUT and DELETE operations best known from HTTP. Even so, there’s no requirement in REST that resources are necessarily documents. True, URLs that point to documents are a common and familiar pattern, but URLs could as easily point to abstracted method calls as well.
SPEAR takes document-centricity to the next level. For SPEAR, the document is the interface. It has meaning both for human and machine consumption. It’s self-describing and removes the need for defining a specific, formal contract. Instead, the USCG provides a basic header/body document structure. The header contains elements like requester, type, ID, timestamps, and status (request, response, publication or error, for example). The body contains different parts depending upon the type of Service. Request/response Services, for example, include elements like request, response, publication, and exception. As a result, SPEAR’s Service contracts (if you even decide to call them that) consist of a simple document structure and core REST operations—nothing more.
Maintaining State the Service-Oriented Way
For example, take a straightforward request/response Service that executes a simple database query. The Service simply populates the response field in the request document and returns the entire document to the requester. As a result, the document still contains the timestamped request. The ESB can now publish the document or put it on a queue, and the document itself acts as its own cache.
This approach to state is a simple example of a new trend in REST-based state management: Hypermedia as the Engine of Application State (HATEOAS). With HATEOAS, documents and the hyperlinks they contain represent all the state information a distributed environment requires. Want to know the next step in a process? Simply follow the appropriate link.
In the case of SPEAR, the USCG has established an internal standard URI representation: domain://provider:context/resource. For example, service://uscg.mda.vesselCrew:test/sla. The domain represents a taxonomy of resource types, including system://, organization://, geography://, and service://. The provider component represents the address to the provider of the resource. The context (squeezed in where ports go in a URL), represents the business context like :test, :dev, :stage, etc.
The ESB then resolves URIs to the physical endpoint references, acting as a routing engine that delivers the Business Service abstraction. Any hyperlink to such a URI, therefore, points to a document that contains all the state information the system requires, and furthermore, the architecture offers late binding to Services as a key feature. There is no build time mapping to any particular resource. Instead of using strongly typed schemas, they rely upon dynamic, loose typing in the documents. Such an approach is decidedly not Web Services-friendly.
It’s also important to note that state maintenance in the Web Services world has always been problematic. There are basically three ways to main state information in interactions among inherently stateless Services: rely upon the Service consumer to maintain a correlation ID (either not broadly adopted or relies upon an underlying protocol like HTTP cookies); rely upon the underlying execution environment (vendor dependent), or place state information into the message. Unfortunately, Web Services offer no standard way of accomplishing the latter task, requiring SOA teams to customize their SOAP headers—which is usually a deal killer.
The SPEAR approach, however, includes state information in the message, because, of course, the message is the document. As a result, they are taking a fully Service-oriented approach to maintaining state. They are able to do so in spite of leveraging an ESB because they selected the Fiorano ESB, which has long maintained state in a fully message-centric manner, instead of spawning threads to keep track of state as in other vendors’ ESBs.
Asynchronicity as the General Case
For many years, Gartner believed that SOA interactions were inherently synchronous, request/response—casting SOA as little more than next-gen client/server—until TIBCO twisted their arm into admitting that yes, SOA could be event driven. Nevertheless, SOA has always allowed for asynchronous as well as synchronous Service exchange patterns. (The whole Gartner event-driven SOA kerfuffle led to the SOA 2.0 fiasco, lest we forget.) In fact, ZapThink pointed out the importance of asynchronous behavior as early as 2002.
In the SPEAR architecture, the listener acts as the handler, retaining messages at their last stop. The senders simply fire and forget. Messages are sent to the Fiorano bus, not the destination, allowing for dynamic routing of messages as well as publish/subscribe. In this way the ESB routes, filters, and enforces policy via the URIs themselves.
Publish/subscribe is a broadcast push exchange pattern: many consumers can subscribe to the same topic, and the ESB pushes messages to subscribers as appropriate. Even when a single consumer queries a resource, the ESB follows a push pattern, putting documents onto a queue for the consumer to pick up. As a result, SPEAR can support different consumer behaviors, depending upon the use case. If the consumer is accessing Services via unreliable network connections, or simply requires low message volumes and can tolerate some latency, then the consumer can simply poll the Service. In other cases, when latency is an issue or when there are higher message volumes, the ESB can perform a true push to the consumer via a JMS interface.
OK, hold on just one minute. JMS? I thought we were talking about REST, you know, over HTTP. How can JMS fit into this picture?
Yes, the USCG is being iconoclastic once again. The ESB is abstracting the endpoint, while at the same time providing a push-based messaging infrastructure. If the consumer wants the resource to push a real-time stream of large messages to it, then the URI should resolve to a JMS endpoint. If not, or if the consumer doesn’t support JMS (typically when it’s running over HTTP), then the resource will resolve to an HTTP endpoint.
The ZapThink Take
Is the USCG implementing “pure” SOA or “pure” REST? I’m not even going to dignify those questions with a response, because the whole notion of a “pure” architectural approach is inherently dogmatic. What the USCG has done is implement an architecture that actually works for them—that is, it delivers loosely coupled, abstracted Business Services with the flexibility and performance they require. And remember, actually working trumps following a pre-determined set of best practices every time—especially when those best practices don’t actually solve the problems at hand.
There are two important morals here. First, REST-based SOA is alive and well, and offers straightforward solutions to many of the knottier problems that Web Services-based SOA has suffered from. But even more importantly, the success the USCG has achieved shows that any architectural approach is nothing more than a loose collection of best practices. It’s up to the architect to know which best practices are best for solving their particular problems. Avoid a dogmatic approach, and select the right tool for the job, even if that brands you as an iconoclast.

AllComputers.us described Integrating Silverlight, Windows Azure DataMarket, and SharePoint on 8/2/2011:
Silverlight is becoming an increasingly important web development technology, both because of the strength of its Rich Internet Application (RIA) design and development capabilities, and because of the tools that both designers (Microsoft Expression Blend) and developers (Visual Studio 2010) can use to build Silverlight applications.
SharePoint 2010 natively supports Silverlight applications. This means that you can build a Silverlight application and deploy it as a Silverlight-enabled Web Part—and it just works. SharePoint also provides a remote client API (SharePoint client object model) that lets you interact with SharePoint from within a Silverlight application (as well as from JavaScript and .NET Framework applications) to, for example, create, read, update, and delete (more commonly known as CRUD operations) list items.
In this section, you’ll continue to use the DATA.gov data feed, but instead of reading the data into a Visual Web Part, you’ll use a Silverlight application.
Let’s go ahead and create a Silverlight application that displays Windows Azure Marketplace DataMarket data and is deployed to SharePoint by using the native Silverlight Web Part.
1. Create a Silverlight Application to Display DataMarket Data and Deploy It to SharePoint
1.1. Create a Silverlight Application to Display DataMarket Data and Deploy It to SharePoint
Open Visual Studio 2010 and click File | New Project, and then select Silverlight. Provide a name for your application (for example, Dallas_Silverlight_Crime_App).
Clear the Host The Silverlight Application In A New Web Site check box and ensure that you’re using Silverlight 4.
You’ll see that when the project is created, there is a MainPage.xaml file and a MainPage.xaml.cs file. In this exercise, you will be working mainly with these two files.
Open the MainPage.xaml file, and add the bold code in the following snippet to your file. Also ensure that the height and width are 300 and 600 respectively for both the root UserControl and LayoutRoot. (Be sure to not just type in the XAML below; drag the controls from the Toolbox so the appropriate namespace references are added to the XAML file and reference libraries are added to the project.)
<UserControl x:Class="Dallas_Silverlight_Crime_App.MainPage" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" xmlns:d="http://schemas.microsoft.com/expression/blend/2008" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" mc:Ignorable="d" d:DesignHeight="300" d:DesignWidth="600" xmlns:sdk="http://schemas.microsoft.com/winfx/2006/xaml/presentation/sdk"> <Grid x:Name="LayoutRoot" Background="White" Width="600"> <sdk:DataGrid AutoGenerateColumns="True" Height="223" HorizontalAlignment="Left" Margin="12,33,0,0" Name="dataGridDallasCrimeData" VerticalAlignment="Top" Width="576" /> <sdk:Label Content="Dallas Crime Data" Height="15" HorizontalAlignment="Left" Margin="12,12,0,0" Name="lblTitle" VerticalAlignment="Top" Width="120" /> <Button Content="Get Data" Height="23" HorizontalAlignment="Left" Margin="12,265,0,0" Name="btnGetData" VerticalAlignment="Top" Width="75" Click="btnGetData_Click" /> </Grid> </UserControl>The preceding code is for the UI of the Silverlight application. If you haven’t yet created a Silverlight application, XAML is the declarative XML-based language that you use to build the UI. This UI is simple and contains only three controls: a DataGrid to display the retrieved data, a Label, and a Button to trigger the service call to get the data from the WCF service (and ultimately the DATA.gov data feed).
Note:
More Info For more information on Silverlight, go to http://www.silverlight.net/.
Right-click Reference, and select Add Service Reference.
Paste the URL you copied from the IIS service (for example, http://blueyonderdemo:6622/DallasCrimeData.svc), and click Go.
When the service definition successfully returns, name the service reference DallasCrimeDataService, and click OK.
For the MainPage.xaml.cs file, alter the code-behind with the bold code in the following code snippet:
using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Windows; using System.Windows.Controls; using System.Windows.Documents; using System.Windows.Input; using System.Windows.Media; using System.Windows.Media.Animation; using System.Windows.Shapes; using Dallas_Silverlight_Crime_App.DallasCrimeDataSvc; using System.Collections; using System.Collections.ObjectModel; namespace Dallas_Silverlight_Crime_App { public partial class MainPage : UserControl { public MainPage() { InitializeComponent(); } private void btnGetData_Click(object sender, RoutedEventArgs e) { DallasCrimeDataClient myWCFProxyFromAzure = new DallasCrimeDataClient(); myWCFProxyFromAzure.GetCrimeDataCompleted += new EventHandler <GetCrimeDataCompletedEventArgs>(myWCFProxyFromAzure_GetCrimeDataCompleted); myWCFProxyFromAzure.GetCrimeDataAsync(null); } void myWCFProxyFromAzure_GetCrimeDataCompleted(object sender, GetCrimeDataCompletedEventArgs e) { ObservableCollection<CrimeData> myCrimeData = e.Result; dataGridDallasCrimeData.ItemsSource = myCrimeData; } } }The preceding code creates an instance of the WCF service proxy, and then asynchronously calls the service to retrieve the results. Finally, it binds the results (which is an ObservableCollection of CrimeData objects) to the DataGrid. Notably, the myWCFProxyFromAzure.getCrimeDataCompleted manages the return data from the WCF service call by first mapping the results (e.Result) to the myCrimedata var object and then iterating through myCrimeData to ultimately populate a list collection, which is then bound to the DataGrid.
You’ll see some errors in your code; these occur because you have not yet added the service reference to the WCF service. Right-click the project, and select Add Service Reference.
Add the service URL from the IIS-deployed WCF service (http://localhost:6622/DallasCrimeData.svc) and click Go.
Name the service reference DallasCrimeDataServiceFromAzure, and click OK.
Before you deploy the Silverlight application to SharePoint, you need to make sure that you’ll be able to call cross-domain from the Silverlight application. To enable this, add the files clientaccesspolicy.xml (see Example 1) and crossdomain.xml (see Example 2) in your wwwroot folder (for example, C:\Inetpub\wwwroot).
Example 1. Client access policy XML file
<?xml version="1.0" encoding="utf-8"?> <access-policy> <cross-domain-access> <policy> <allow-from http-request-headers="*"> <domain uri="*"/> </allow-from> <grant-to> <resource path="/" include-subpaths="true"/> </grant-to> </policy> </cross-domain-access> </access-policy>Example 2. Cross-domain policy XML file
Now open your SharePoint site, and create a new document library called XAPS by clicking Site Actions | View All Site Content | Create, and Document Library. Provide a name (that is, XAPS), and click Create.
When the new document library is complete, click the Add Document link.
Click Browse, and then paste the .xap file bin folder location into Windows Explorer. Locate the .xap file. Then click Open and OK.
After adding the .xap file to the document library, right-click the link, and select Copy Shortcut to copy the Silverlight application shortcut to your Clipboard.
Return to the Web Part page, and then click Site Actions and Edit Page. Delete the other Web Parts on the page.
Click Add A Web Part. Navigate to the Media And Content category, and select the Silverlight Web Part. Click Add.
You’ll be prompted for a URL to the .xap file. Paste the shortcut into the URL field, and click OK.
After the Silverlight application is added, you can click the Get Data button and the Silverlight application will retrieve the Windows Azure data from the DataMarket and display it in the DataGrid.
The result will look similar to Figure 1.
Figure 1. Silverlight Web Part that displays Windows Azure DataMarket crime data.
Although this section deployed the WCF service to IIS, you can deploy that same WCF service to Windows Azure—and consume it in many different applications. For example, you could take the same code and create a cloud application by using the Windows Azure tools, and then deploy the application to Windows Azure. You’d also need to remember to include the crossdomain.xml and clientaccesspolicy.xml files with the service project—but the result would be very much the same as in Figure 2-8; the only difference would be that the service reference pointed to an instance of the service that lives in Windows Azure as opposed to living locally in IIS.
<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Matias Woloski posted the workaround for Not enough space on the disk – Windows Azure on 8/4/2011:
No, it’s not because Local Storage quota is low. That’s easy to fix by just increasing the quota in the SerivceDef. I hit this nasty issue while working with WebDeploy, but since you might get this in a different context as well I wanted to share it and get hours back of your life, dear reader.
Problem
WebDeploy throws an out of disk exception when creating a package
There is not enough space on the disk. at System.IO.__Error.WinIOError(Int32 errorCode, String maybeFullPath) at System.IO.FileStream.WriteCore(Byte[] buffer, Int32 offset, Int32 count) at System.IO.BinaryWriter.Write(Byte[] buffer, Int32 index, Int32 count) at Microsoft.Web.Deployment.ZipEntry.ReadFromFile(String path, Boolean shouldCompress, BinaryWriter tempWriter, Stream stream, FileAttributes attr, DateTime lastModifiedTime, String descriptor, Int64 size) at Microsoft.Web.Deployment.ZipEntry..ctor(String path, DeploymentObject source, ZipFile zipFile)
Analysis
WebDeploy uses a temp path to create temporary files during the package creation. This folder seems to have a 100MB quota according to MSDN, so if the package is more than that, the process will throw an IO exception because the “disk is full” even though there is plenty of space. Below a trace of Process Monitor running from the Azure Web Role showing the CreateFile returning DISK FULL.
By looking with Reflector, we can validate that WebDeploy is using Path.GetTempPath.
Solution
Since we can’t change WebDeploy code nor parameterize it to use a different path, the solution is to change the TEMP/TMP environment variables, as suggested here http://msdn.microsoft.com/en-us/library/gg465400.aspx#Y976. An excerpt…
Ensure That the TEMP/TMP Target Directory Has Sufficient Space
The standard Windows environment variables TEMP and TMP are available to code running in your application. Both TEMP and TMP point to a single directory that has a maximum size of 100 MB. Any data stored in this directory is not persisted across the lifecycle of the hosted service; if the role instances in a hosted service are recycled, the directory is cleaned.
If the temporary directory for the hosted service runs out of space, or if you need data to persist in the temporary directory across the lifecycle of the hosted service, you can implement one of the following alternatives:
You can configure a local storage resource, and access it directly instead of using TEMP or TMP. To access a local storage resource from code running within your application, call the RoleEnvironment.GetLocalResource method. For more information about setting up local storage resources, see How to Configure Local Storage Resources.
You can configure a local storage resource, and point the TEMP and TMP directories to point to the path of the local storage resource. This modification should be performed within the RoleEntryPoint.OnStart method.
The following code example shows how to modify the target directories for TEMP and TMP from within the OnStart method:
using System; using Microsoft.WindowsAzure.ServiceRuntime; namespace WorkerRole1 { public class WorkerRole : RoleEntryPoint { public override bool OnStart() { string customTempLocalResourcePath = RoleEnvironment.GetLocalResource("tempdir").RootPath; Environment.SetEnvironmentVariable("TMP", customTempLocalResourcePath); Environment.SetEnvironmentVariable("TEMP", customTempLocalResourcePath); // The rest of your startup code goes here… return base.OnStart(); } } }
Wade Wegner (@WadeWegner) described how to avoid a YSOD (yellow screen of death) in his Deploying the Windows Azure ASP.NET MVC 3 Web Role post of 8/4/2011:
Yesterday Steve Marx and I covered the new Windows Azure Tools for Visual Studio 1.4 release on the Cloud Cover Show (will publish on Friday, 8/5). Since the tools shipped the same day as the show we literally only had an hour or so before the show to pull together a demonstration of some of the new capabilities. I think we did a reasonably good job, but I’d like to further clarify a few things in this post.
One of the items I demonstrated on the show was deploying the new MVC 3 template to Windows Azure.
It’s great having this template built into the tools. No longer do I have to hit Steve Marx’s website to lookup the requisite MVC 3 assemblies.
Immediately after creating the projects I confirmed that my assemblies were all added and set to Copy Local = True by default (one of the nice aspects of having the template baked into the tools) and published to Windows Azure. I was a bit surprised when suddenly I got the YSOD:
Naturally, I updated my web.config file with <customErrors mode="Off" /> and redeployed to Windows Azure.
In case you don’t want to click the image, the error is:
A network-related or instance-specific error occurred while establishing a connection to SQL Server. The server was not found or was not accessible. Verify that the instance name is correct and that SQL Server is configured to allow remote connections. (provider: SQL Network Interfaces, error: 26 – Error Locating Server/Instance Specified)"
In retrospect, I should have expected this error as I received validation warnings within Visual Studio (one of the other nice updates in the 1.4 tools):
I was quite baffled as to why MVC 3 suddenly would require SQL Express (or any flavor of SQL for that matter), until Anders Hauge—a PM on the Visual Studio team—clued me in on the fact that they have shipped the ASP.NET Universal Providers within the MVC 3 template.
For information on these providers, see Introducing System.Web.Providers – ASP.NET Universal Providers for Session, Membership, Roles and User Profile on SQL Compact and SQL Azure by Scott Hanselman for a great introduction.
It turns out that, by default, the template uses the default session state provider in ASP.NET Universal Providers as the ASP.NET session state provider, which in turn uses SQL Express (by default) to store session state.
<sessionState mode="Custom" customProvider="DefaultSessionProvider"> <providers> <add name="DefaultSessionProvider" type="System.Web.Providers.DefaultSessionStateProvider, System.Web.Providers, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" connectionStringName="DefaultConnection" applicationName="/" /> </providers> </sessionState>Okay, so what’s the best way to get this to work?
Well, in my haste on the Cloud Cover Show, I simply uninstalled the ASP.NET Universal Provider package, which removed the custom session state provider. Of course, once I deployed, I no longer saw the YSOD. This is probably not the best way to go about fixing this, as the ASP.NET Universal Providers are really worth using. For a good analysis of the options, take a look at Nathan’s discussion on various ways to resolve this in his post Windows Azure Tools 1.4 Released.
In retrospect, I wish I had simply created a SQL Azure database and used it instead. It’s pretty easy to do:
In the Windows Azure Platform Management Portal, select Database and create a new database. I called mine UniversalProviders.
Select the database and click the View … button to grab/copy your connection string. Note: you’ll need to remember your SQL login password.
In your solution, update the ApplicationServies and DefaultConnection connection strings using your SQL Azure connection string. Note: you must set MultipleActiveResultSets=True in the connection string, so be sure to add it back if you’ve copied the SQL Azure connection string from the portal.
<connectionStrings> <add name="ApplicationServices" connectionString="Server=tcp:YOURDB.database.windows.net,1433;Database=UniversalProviders;User ID=YOURLOGIN@YOURDB;Password=YOURPWD;Trusted_Connection=False;Encrypt=True;MultipleActiveResultSets=True;" providerName="System.Data.SqlClient" /> <add name="DefaultConnection" connectionString="Server=tcp:YOURDB.database.windows.net,1433;Database=UniversalProviders;User ID=YOURLOGIN@YOURDB;Password=YOURPWD;Trusted_Connection=False;Encrypt=True;MultipleActiveResultSets=True;" providerName="System.Data.SqlClient" /> </connectionStrings>Deploy to Windows Azure.
Now, when we run the applications, it works!
In fact, I recommend you use Database Manager from the portal …
… to open up the database and see that, in fact, you now have a dbo.Sessions table in the database.
What’s more, if you then click Log On and setup a user, you’ll see all the membership & roles work within the MVC application in Windows Azure!
Wrapping up, apologies for not digging into this in greater depth on the show – hopefully this post helps to clarify a few things.
Shaun Xu announced New Version Avaliable - Windows Azure Tools for VS2010 and observe the same YSOD problem as Wade in an 8/4/2011 post from the PRC:
This morning I got the information that the Windows Azure Tools for Visual Studio 2010 - August 2011 Upgrade had been released. The version of this new upgrade is 1.4.40727.1601 with the Windows Azure SDK v1.4.20407.2049. This upgrade includes some awesome features that I was looking forward for a long time, which are:
Profiling the application running in Windows Azure.
New ASP.NET MVC 3 web role template.
Multi-configuration files in one cloud project.
More validation in the service package and deployment phase.
Download and Install
ASP.NET MVC 3 Web Role
After you installed the package we can find the new ASP.NET MVC 3 Web Role template available when creating a new cloud project.
In the solution explorer we can see the ASP.NET project had been created with the new Razor view engine and HTML5. And the assemblies related to MVC3 are all added and set the Copy Local = True by default.
And we can just press F5 to run the application under the local emulator.
Multiple Service Configurations
Under the cloud project we can find that there are two service configuration files (CSCFG) which are:
ServiceConfiguration.Cloud.cscfg
ServiceConfiguration.Local.cscfg
This is another good feature added in this upgrade. As a developer, normally we need to use different settings between development and deployment. For example, when developing in the local emulator I uses the local storage emulator, local SQL Server with 2 web role instances. But when deploying to the cloud I need to use the storage service, SQL Azure and 4 instances. This means I need to tweak the service configuration every time [I deploy] to the cloud. And this could be more complex if we have more environment such as development, local testing and cloud.
The Multiple Service Configurations feature can make the job simpler. With two configuration files enabled, we can choose which one will be the service configuration file when locally debugging, packaging and deploying. This means we can set different values in different file between local and cloud environment.
In the service setting windows, find the Service Configuration section, where we will choose which CSCFG file is going to be edited. And if I need to edit the Service Definition file (CSDEF) just select the All Configuration.
Let’s firstly select the All Configurations and navigate to the Settings tab to add the connection string to the storage the application is being used.
And then select the Local under the Service Configuration, we will use the storage emulator when locally developing and debugging.
Next, select Cloud and specify the storage account information when deploying to the cloud environment.
And if we opened the two CSCFG files we can find the settings had been updated in the related files.
If we need more service configuration files just select the Manage menu under the Service Configuration dropdown and create a copy from one of the existing. For example, I added a new configuration named TestServer which will be used when deploying to the local test server. And in the solution explorer a new CSCFG file had been created as well.
We can choose which configuration file should be used when debugging under the Visual Studio. Just right click the cloud project and open its property window. In Development tab we can choose which configuration should be used.
New Package and Publish Window
In the previous tool we choose to package or publish our windows azure project by selecting the radio button in the Publish window. In this upgrade the package and publish had been totally separated. In the context menu of the windows azure project we can create a package by using the Package menu, and use the Publish menu to deploy the application directly to the cloud.
In the package window we will be asked to select which service configuration should be used, which build configuration should be used and whether to enable the remote desktop.
In the publish windows, similar as what we did before, we need to select a proper management certificate, hosted service, storage service, and the service configuration, build configuration as well. We can also enable the IntelliTrace if we are using .NET 4.0 and VS2010 Ultimate, and enable the profiling feature, whcih is new in this upgrade.
More Validation
The different environment between the development machine and cloud instance introduced more work when first deployment. We need to verify which references should be set to Copy Local = True and which configuration should be changed. I also introduced a website which can help you to do the validation in this post. But now the Windows Azure Tool helps us to validation the project.
If we just publish this ASP.NET MVC3 web role to the cloud, we can see there is a warning in the error window said we are using a local database which might cause problem after deployed in the cloud.
And not only validating the database connection string, if we added some references which out of the .NET Framework package it will bring an error to indicate us to set the Copy Local = True on them.
Powered by ASP.NET Universal Providers
After deployed the ASP.NET MVC 3 application to the cloud we can open the website, but there’s an exception occurred.
This is because the ASP.NET MVC 3 application utilizes the ASP.NET Universal Providers, and it uses the default session state provider in ASP.NET Universal Providers as the ASP.NET session state provider, which means leverage the SQL Server to store the sessions.
To solve this problem, we can specify a proper SQL Azure connection string in web.config; or we can just use the InProc session provider if no need to scaling-out.
The ASP.NET Universal Providers extends the Session, Membership, Roles and Profile support to SQL Compact Edition and SQL Azure, which means as a developer, we can implement the business logic regardless which backend database we are using. For more information about this cool stuff please check the Scott’s blog post.
After fixed this problem we can see the ASP.NET MVC 3 application running in the Windows Azure.
Summary
The team is keeping improve the tools of Windows Azure Platform by listening the voice from the developers, to make it more convenient and simpler to work with Windows Azure. In this upgrade of Visual Studio Tool it brings not huge but many useful features to us, such as multi-configuration and ASP.NET MVC 3 web role. I personally strong recommended to upgrade to this version.
Microsoft added the Windows Azure Code Library on 8/3/2011:
Thomas Claburn asserted “Bad news for Microsoft extends far beyond mobile, developer survey says. But analysts don’t count Redmond out yet” as a deck for his Mobile Developers See Apple, Google Ruling Enterprise article of 8/3/2011 for InformationWeek:
Mobile developers see the heated competition between Apple's iOS and Google's Android operating systems reshaping the markets for cloud computing, enterprise IT, and social networking. Industry analysts, however, aren't quite ready to count Microsoft out.
A Q3 2011 survey of more than 2,000 mobile developers, conducted by cross-platform development toolmaker Appcelerator and research firm IDC, finds developers divided about whether iOS or Android will come to dominate the mobile enterprise market. Some 44% of respondents sided with Apple while another 44% sided with Google when asked which OS would prevail in the enterprise market. The chance of other operating systems becoming relevant to enterprises was deemed to be small: 7% said they believed Windows Phone 7 would emerge ahead, 4% bet on BlackBerry, and just 2% foresee webOS triumphant.
There are major differences in user experience among some of the top tablets. We take a deeper look at some of the strengths and weaknesses of Apple's iOS, Android/Honeycomb and RIM's QNX operating systems.
Developers projecting victories for iOS and Android cited different reasons for their assessment. Some 30% of developers see Android's ascendance following from its market share leadership. About 24% said they believe the ongoing consumerization of IT will ensure that iOS becomes the dominant force in enterprise mobility.
Consumer market relevance clearly influences how developers think about mobile platforms overall. Asked about what will affect the growth of mobile the most, the top two answers were Google+ (25%) and iCloud (22%).
Developers see Apple's iCloud reshaping the cloud computing market. Those planning to deploy cloud services in their apps over the next year say they're likely to choose: Amazon (51%), iCloud (50%), Microsoft Windows Azure (20%), VMWare (20%), and RedHat OpenShift (17%). [Emphasis added.]
In an email, Appcelerator's VP of marketing, Scott Schwarzhoff, suggested that the increasing symbiosis of mobile and cloud will define the post-PC landscape. "Platform players in this new space will need an integrated strategy to create maximum value," he said. "This integration creates ease-of-deployment from a business standpoint, which in turn creates the opportunity for greater adoption. This ease of integration explains the enthusiasm we see from developers for Apple iCloud. To compete, Microsoft needs to make Windows Azure similarly easy to deploy to non-Microsoft devices for marketshare reasons while at the same time offer Azure as a way to pull through demand--particularly in the enterprise--for Windows Phone 7 devices." [Emphasis added.]
Even so, there's an element of wishful thinking here: Developers, particularly those using Appcelerator's tools, prefer a simple world where they can write their code and have it work everywhere. Reality may not be so accommodating.
Appcelerator and IDC concede as much by questioning developer sentiment about Android in the enterprise. "Developer enthusiasm notwithstanding, Appcelerator and IDC believe that there may be a gap between CIO needs and developer perceptions when it comes to Android," the firms' report states. "Many CIOs today note that Android has a substantial way to go from a management tooling and security standpoint to see broad adoption in the enterprise."
At the same time, product gaps represent opportunities for third-parties. Witness Array Network's release of DesktopDirect for Android, which promises to solve some of the security issues associated with Android in the workplace. Just as the imperfections of Windows helped create a thriving ecosystem for third parties, the messiness of Android may create an incentive for third parties to build businesses that help Google's operating system rise and endure.
Certainly Apple, having build up its iOS business almost flawlessly, could become the next Microsoft if Android stumbles or becomes too expensive as a consequence of ongoing patent litigation. But not everyone believes that the mobile market can be reduced to two-horse race. Al Hilwa, IDC program director for applications development software, cautions that enterprise mobility has just begun to take off and that we have yet to see how well Microsoft will be able to leverage its might in the PC market to affect its mobile fortunes.
"The expectation is that enterprises will be going through a protracted cycle of reworking their apps to support mobility but many are waiting for Microsoft to play its hand with the PC since that is the de facto device that the overwhelming majority of enterprises buy for their employees," Hilwa wrote in an email. "The fact that Windows 8 will run on ARM and be more mobile will make mobility mainstream. I expect the synergies created between Windows 8 and Windows Phone to be very important in pushing WP7 into enterprise mobility."
Hilwa notes that Microsoft will have to resolve the differences in the application development models between Windows 8 and Windows Phone, which may happen at the forthcoming BUILD conference.
"If Windows 8 uses HTML5 and JavaScript as the primary UI development model and potentially for the Windows 8 app store, will a future version of Windows Phone also support that for its app stores?" he asks.
Apple and Google may be ahead, but it's too early still to declare the contest over.
Steve Fox noted new SharePoint content in his Windows Azure Platform Training Kit Update Releases Today post of 8/3/2011:
You’ve probably seen a few posts on my blog involving Windows Azure; more recently, I’ve been talking quite a bit about the integration between SharePoint and Windows Azure. However, of critical importance for the developer is to ensure you have access to good how-to docs and sample code. And of course if you want to teach others about Windows Azure, then it’s good to have some collateral on it. Well, today the latest release of the Windows Azure Platform Training Kit shipped.
http://www.microsoft.com/download/en/details.aspx?displaylang=en&id=8396
In this kit, you’ll find a set of comprehensive tutorials, code and decks that you can use to ramp up on Windows Azure. For you SharePoint developers who are looking to go deep on Windows Azure, this is a great kit to take a look at.
Enjoy!
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Beth Massi (@BethMassi) explained How to Create a Multi-Column Auto-Complete Drop-down Box in LightSwitch in an 8/4/2011 post:
In this post I’d like to address a very common usage of drop-downs (otherwise known as Combo-boxes or Auto-complete boxes) that allow users to pick from a list of values coming from a lookup or parent table, commonly referred to as “Lookup lists”. Typically these lists display one column like the “Name” of the item. But often times we want to display multiple columns of information to the user here. This is not only super-simple to do in Visual Studio LightSwitch, it’s incredibly flexible on what kind of layouts you can create.
In this post I will walk through a variety of common layouts using the Auto-complete box in LightSwitch. You should keep in mind that most of these techniques are not limited to the Auto-complete box at all. In fact you will see these layout controls are available to you almost anywhere on the screen. Let’s get started!
Setting up a Lookup List
For a video demonstration of this see How Do I: Create and Control Lookup Lists in a LightSwitch Application?
When you relate tables together in Visual Studio LightSwitch parent relationships are automatically presented on screens as an auto-complete box. For instance Products can belong to Categories so the Category table is the parent of the Product table.
When you create a Product screen, the Category is displayed in an auto-complete box which displays the Summary Property of the table. A summary property is used by LightSwitch to determine what to display when a row of data is represented on a screen. It not only applies to the auto-complete box but also anywhere in the system. For instance, search screens use this property to provide a link to the edit screen for the selected record. By default this is the first string property on the table but you can change this in the Properties window in the Data Designer.
Now when we create an Edit Detail screen for Product we automatically get an auto-complete box for the Category. If you build and run your application (F5) you will see something similar for your parent relationships that are displayed in the auto-complete box:
The summary property is being displayed by default and usually this is exactly what you would want. However, you are not limited to this. In fact, there are a lot of cool tricks you can do with the screen designer and its variety of layout controls (check out the Screen Designer Tips & Tricks Sheel wrote about on the team blog). Click the “Design Screen” button to go into the screen customization mode and expand the auto-complete box node to expose the Summary Control:
Displaying Multiple Columns
In order to display multiple columns in the auto-complete box, click the down arrow on the Summary Control and change it to a Columns Layout:
By default all the fields on the entity will show up. Delete the ones you don’t want to display in the auto-complete box and change the order how you like. In my example, the category has a Name, Description and Picture.
By default all the columns are set to 150 pixels wide. You can change this in the properties by setting the width to whatever you want. In this example I set the Description to “Auto-size” since I want that column to stretch. Now click Save on the customization mode and you can see the layout immediately updated.
For a video demonstration of how to do this see: How Do I: Show Multiple Columns in an Auto-Complete Dropdown Box?
Displaying Picture & Text
As you can see this is pretty easy. However if you’re going to want to display a picture here then there are better layout controls you can use for this specific purpose, the “Picture and Text” and “Text and Picture” layout controls. Here you select the picture and then three additional pieces of information you want to display. The (TITLE) is a larger font then the rest and (SUBTITLE) is larger than the (DESCRIPTION).
In my example I also set the width property of Name to “Auto-size”. When you save the customization mode now you will see a much nicer layout. As a matter of fact, you are not required to choose a picture so you can use this layout for displaying just text.
Displaying Links to Allow Editing
Sometimes you want to allow editing of the row right from the drop-down. This way users can make corrections to the data without having to open another screen manually. LightSwitch allows this by setting label controls to show up as “Links”. These links look like hyperlinks but they navigate the user to an edit screen for the record. For example go back into customization mode and we can select the Name property and set it to “Show as Link” in the properties below.
Click Save and now you will see that the Name appears like a hyperlink in the auto-complete box. If you click it, then a default edit screen for the Category will open to allow the user to edit the record. After they save their changes they can click “Refresh” at the bottom of the auto-complete box to see their changes.
As you can see there are a lot of flexible ways to lay out controls in Visual Studio LightSwitch and allowing editing of the items is super-easy. In my next post I’ll show you how you can add commands to the auto-complete box to allow adding a new item to the list, another very common user-productivity scenario in business applications.
Enjoy!
Return to section navigation list>
Windows Azure Infrastructure and DevOps
David Linthicum (@DavidLinthicum) asserted “Government regulation could have a chilling effect on cloud computing and complicate what should be simple and dynamic” as a deck for his Watch out: The feds want to regulate the cloud warning of 8/4/2011 in InfoWorld’s Cloud Computing blog:
On June 16, the Brookings Institution, one of the oldest think tanks in Washington, D.C., hosted a panel on the proposals in the Cloud Computing Act of 2011. According to the institute, "Discussion included an overview of the international policy implications as governments and firms adjust to a coherent legal framework, changes and innovations in public procurement, and challenges for private industry as it balances consumer needs and compliance with these proposed cloud computing safeguards."
Despite my years of cloud experience, I've never heard of any of the panelists who participated. Perhaps their well-funded PR and marketing teams got them in.
The danger is that the movement toward these types of regulations could happen in a vacuum, ducking most media scrutiny (the government's attempts to regulate cloud computing have gone woefully underreported) and without input from the truly knowledgeable experts. Industry thought leaders and major providers should be chiming in on this right now because the regulators don't seem to get it.
IT has leveraged cloudlike mechanisms for years. What's changed now is that cloud computing is mainstream, and many in the world of IT focus on it as the next big thing. Naturally, the government is interested in what that could mean.
As cloud computing becomes more of a force in government and the private sector, the feds will try to control its use, both nationally and internationally. For example, government officials could force IT shops to use a third party to maintain data deemed personal or private, and the third party will be required to implement defined policies and procedures. Such a requirement would eliminate the flexible value of leveraging the cloud.
Although the regulators' intentions are generally good -- as is pavement of the road to hell in the familiar saying -- they simply aren't sufficiently educated on the use of cloud computing and what it could mean to both business and government. The true value of the cloud is to simplify enterprise computing, as well as make it more cost-effective. Adding any type of regulation would make cloud computing more complex and expensive -- undoing its very value proposition.
So, federal government, please butt out. If policy makers have a legitimate role, it's what the Software and Information Industry Association is urging: a focus on promoting standards, not creating laws that would limit the value of cloud computing.
I believe most cloud-watchers know of Dan Reed, Corporate Vice President of Technology Policy and Strategy and Leader, eXtreme Computing Group, Microsoft Corp. The other panelists are mysteries to me, too.
In my view, regulators’ intentions seldom, if ever, are good. Their intentions usually are to regulate in support of objectives espoused by special-interest lobbyists.
Simon Munro (@simonmunro) posted Microscalability on 8/4/2011:
I like to talk and think about application scalability but sometimes feel that my ambitions just don’t stack up to ‘real’ scalability. I am in awe of the scalability issues that are discussed and dealt with by the usual scalability suspects – Facebook, Twitter and so on. My idea of scalability is a lot more modest, and at least practical, than some of the cases discussed on highscalability.com.
I was pleasantly surprised the other day when the when a smaller scalability problem was given the nod over at highscalability.com with the post Peecho Architecture – Scalability On A Shoestring. Even though it was a only guest post, and Todd ‘The Hoff’ Hoff and Lori ‘F5 Friday’ MacVittie are not talking about this kind of sclability, rubbing shoulders with bigger scalability concerns gives microscalability some credibility.
To me, a lot of the cloud principles are particularly relevant with microscalability. It is the smaller applications without huge budgets that cannot afford to put in, say, an Oracle grid, even though it is technically possible. Microscalability is where the patterns are learned and applied for most developers. Microscalability probably makes up the bulk of scalability instances, that collectively dwarf the problems of the big scalability case studies. People who work on cost effective platforms have to deal with pooling connections to databases, using cache effectively, referencing jquery libraries hosted elsewhere, optimising database access, degrading services during peak times – a whole host of little problems with big architectural implications, which they solve every day to make their systems more scalable.
Microscalability may never be as glamorous as high scalability but it does deserve some attention. After all, of the thousands of customers being signed up by Amazon, Microsoft, Rackspace and other providers, very few of them need hundreds of servers, but almost all of them need to learn more about scalability.
Joel Foreman summarizes Windows Azure Platform: August 3rd Links in an 8/4/2011 post to the Slalom Consulting blog:
It has been a few weeks since my last post in my link-listing series regarding Windows Azure, but there have been several things that have caught my eye in that period. Happy to share with other Azure enthusiasts…
- Update for Windows Azure Toolkit for iOS: The toolkit for iOS now supports several new features such as integration with the Access Control Service. I see this as a great enabler for building federated authentication capabilities to AD, Google, Facebook, Yahoo, Live ID, other Open ID providers directly into native iPhone and iPad applications.
- Windows Azure Toolkit for Social Games: A new toolkit to enable game development on Windows Azure. Complete source code from an example game, Tankster, is available.
- Architecture of Tankster: Nathan Totten describes the architecture of the social game Tankster, built on Windows Azure, in a couple nice posts.
Here are a few recent posts from Cory Fowler, Windows Azure MVP, that I think are pretty useful:
- The Ultimate Windows Azure Development VM: This post is really useful, not just for building a complete developer machine with Windows Azure goodies, but also for finding some nice tools or references that you might not have known about.
- Must Have NuGet Packages for Windows Azure: Summary of some of the NuGet packages available for Windows Azure developers. Can be a great time-saver when starting new projects.
- Windows Azure Diagnostics Configuration File: A good tip for leveraging a configuration file to store all of the your settings around WAD. I didn’t realize you could do this until this post.
Here are some more links to great articles and materials, in no particular order:
- ScottGu on Windows Azure: Scott Guthrie gives one of his first interviews since joining the Windows Azure team on his appearance on Cloud Cover on Channel9.
- Windows Azure Security in a Single Post: Buck Woody gives a great summary of Windows Azure Security in a single blog post. A good read.
- Hosting Java Enterprise Applications on Windows Azure: Interesting article talking about the realities in deploying Java applications to Azure.
- Azure AppFabric Applications in CTP: In the current AppFabric CTP, you can play around with Windows Azure Applications. I was a little fuzzy on this at first, but after reading Neil McKenzie’s post and watching a Cloud Cover Episode on AppFabric Applications, I am seeing the vision. I could see building Azure applications this way, abstracting the underlying platform. Will be interesting to see where this goes. I downloaded the CTP and am experimenting a bit.
- Project Daytona: MapReduce runtime for Windows Azure announced.
- Architecture Symbols and Diagrams: David Pallman has created some great symbols and diagrams for use with modeling cloud applications.
Happy reading…
James Governor (@monkchips) posted his On Cloud Certification: EMC vs IBM analysis to his Monkchips blog on 8/4/2011:
Generally I prefer to avoid vendor spitting matches. If a company claims to have won a thousand customers from their arch-rival in a quarter, its funny how they haven’t counted the losses. Its actually called churn.
But cloud certification is kind of a big deal. Major waves in the tech industry tend to have an associated certification- think CNE, MCSE, ITIL and so on. Today a VMware Certified Professional commands a premium in the market. Simples.
But the Cloud market has yet to coalesce around a standard set of certifications.
Chuck Hollis documented EMC’s introductory play in this area December 2010, with a follow up in March 2011, calling it the “first ever cloud certification”. At that time 482 people were enrolled for classes.
I worked closely with IBM though on its Cloud Certification program, so I was a bit surprised when EMC claimed it was first to market – given IBM launched at Impact in May 2010. By March 2011 400 people had completed the course, and become IBM Certified Cloud Solution Advisors.
The obvious question is – why the hell did you wait til August to post about something that happened in March? You can blame WordPress draft mode for that…
More seriously, its not a big deal. Chuck is a good guy, and I suspect just had no idea IBM had already entered the market. The numbers of people going through the vendors’ courses were not that different at the time. No clear leader has emerged.
Of course other players are in the mix – including for example the Cloud Credential Council. Another obvious potential dominant player in cloud certification is Amazon Web Services. It is no surprise at all to see AWS pimping the University of Washington Certificate in Cloud Computing.
Meanwhile as far as I call tell Microsoft is so far focusing on Azure education rather than certification and authorisation. [Emphasis added.]
I will write a follow up in the Fall where I get the latest numbers from EMC and IBM. They will just be reported numbers though- I don’t have an elaborate methodology for testing claims. Any other certification programs I should be looking at?
Disclosure: IBM and Microsoft are both clients. VMware is too, but the EMC mothership not yet. Amazon is not a client.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Joseph Foran (@joseph_foran) posted Defining disaster recovery strategies in the cloud to TechTarget’s SearchCloudComputing.com site on 8/4/2011:
There's some confusion between traditional offsite disaster recovery and DR in the cloud. Knowing the difference and spelling out recovery requirements are the first stages in maintaining a solid DR strategy.
Whether or not DR is handled in the cloud, the steps for a successful disaster recovery plan remain the same:
- Plan for disaster
- Document your plan
- Test your backups
- Correct any problems
- Test again to ensure you fixed any problems
- Repeat frequently
The final step -- repeat -- is what keeps a disaster from becoming a catastrophe.
Disaster recovery has evolved from barely more than tape-based restores and rented data center space for recovery of essential services to nearly instant switchover from a downed site to a virtual failover site. Differences also exist in how cloud computing DR vendors manage the offsite component, or how they get an IT environment to the cloud. And what some people might say they believe is DR in the cloud, is not.
Most vendors insert a device into the client's IT infrastructure to acquire information, store it locally and then replicate it to the cloud. In nearly all cases, data isn't actually going to the cloud; data is actually transferred to the provider's data center. This method is similar to traditional backup. It's local, fast and allows you to recover data from the device in the event of a non-disastrous data loss. In the event of an actual disaster that takes the protected site offline, offsite data is brought back online and presented over the Internet.
Once you understand where data is housed in the event of a disaster, it's crucial for IT teams and business managers to determine recovery point objectives (RPO) and recovery time objectives (RTO) that meet the company's needs. While many companies may want always-on, never-down operations, often budget and the likelihood of a disaster occurring help them realize that's not necessarily what they need. It's important to set realistic DR goals.
For companies that depend on technology to generate revenue, a zero RPO/zero RTO rule holds true; paying for this DR plan is part of the cost of doing business. For others companies, cyber insurance and a high RPO/RTO will suffice. The larger the business is, the more complex the portfolio is, the more complex its RPO and RTO needs are -- from zero/zero to an 8 hour/24 hour setup to a more complex 24/24 requirement.
DR in the cloud options
Virtualization is the underlying technology of cloud-based disaster recovery. And this is where, later in this process, it becomes a true cloud service. Major vendors like IBM, Iron Mountain, CommVault, Simply Continuous and AppAssure provide commercial-grade cloud-based DR products designed to integrate with business standards and processes, report on activities and keep both IT teams and business units informed about the product's status.Virtual machines (VMs) that were created to recover the IT environment are no different from VMs you would bring up in a dedicated facility using physical machines. The only disparity is that these VMs are hosted in a third-party facility and are essentially operating from the cloud. When the lights go out at the protected facility and disaster protocols are invoked, those VMs replace both physical machines and virtual machines -- taking over as production machines.
This approach is SLA-friendly. Virtual machines that store DR data and applications can be brought up in a controlled manner. This allows you to manage capacity and cost. If a business unit has an RTO of four hours for a Web-based order-processing system and an RTO of 48 hours for a frequently used but nonessential historical archive of customer orders, the service-level agreement dictates that the DR product immediately recover the Web-based order processing systems and wait to recover historical archives. This hold on recovery serves two purposes: it reduces to cost associated with any compute time and gives harried IT staff time to ensure that more critical SLAs are met first.
A phased recovery plan also allows time for the disaster to dissipate or pass. It's common to plan for utter destruction; however, in many cases, a disaster is a simple case of evacuation. Once the evacuation orders have been lifted and the facility has been checked, you may not need to run the DR protocol for less critical SLAs.
More on DR in the cloud:
Full disclosure: I’m a paid contributor to SearchCloudComputing.com.
Jay Fry (@jayfry3) posted Boy, my new iPad and I are demanding a lot from IT -- and we're not alone to his Data Center Dialog blog on 8/3/2011:
I caved and joined the revolution this weekend. I bought an iPad.
And while it was very fun to do all the things that a newly minted Apple fan boy does (like downloading the app that turns the iPad into ones like they had on Star Trek: The Next Generation), that was just the beginning. I had yet to try to torment my internal IT department with my demands.First and foremost: I wanted to use my iPad as part of my normal work day. I'm certainly not the first to want this. The appearance of consumer-purchased devices that employees would like to have (must be!) supported by internal IT is getting an amazing amount of attention. Though not always from IT departments, if they can help it. In addition, it’s not just 1 or 2 folks who want to start using tablets, smartphones, and the like. It’s everyone.
What does “not supported” mean for my iPad?
So, first thing Monday, I tried my luck linking into our IT systems. It started off innocently enough: I easily connected to the in-office wireless network. The first real test was going to be whether I could get my corporate email and calendar.

IT had obviously been through this before; there is a document in place on our help system that explains how to do everything. Unfortunately, it starts like this: "Please check if this iPad was purchased for business purposes or if it was a personal purchase. Note: personal machines are not supported."
Hmmm. That sounded ominous. But, despite being “not supported,” it was really simple to enable email and calendar access. I had to add some security precautions, as you might expect, but it worked. My fingers are crossed that it continues to work, given the help I’m not going to get. And, of course, there are a multitude of our enterprise apps I’m not getting access to.But I’m satisfied. For now. But not everyone is. And corporations certainly shouldn’t be.
Cloud computing, intriguing mobile devices (and what you can do with them) are ganging up on IT
My process of tormenting IT with my iPad started Monday, but it’s guaranteed to last for a long time. And, as I said, the key issue is that I’m not alone.
People – and, yes, it’s about the people and what they (er, I) want to do – have devices that they love that give them easy, constant access. That should be good. There’s a blurring of the boundary between business and personal that businesses stand to gain from.
Cloud-based resources give organizations a fighting chance to scale sufficiently to keep up with the volume driven by these more-and-more-ubiquitous tablets and smartphones. But management and security are often thought of way too late.
In a piece posted at Forbes.com, Dan Woods, CTO and editor of CITO Research, noted that “the IT monopoly has ended but the need to ensure security, reliability, compliance, and integration has not. Most consumerization efforts are long on choice and short on ways to actually address that fact that IT’s responsibilities to manage the issues have not disappeared.”
Shirking management and security – or leaving it as an afterthought – will not cut it this time around, especially since users don’t think twice about going around the official IT channels, something that those official IT channels really can’t afford to have happen if they are going to get their jobs done.
The train is moving faster than you thought
In a study called “IT Consumers Transform the Enterprise: Are You Ready?” that IDC published a few weeks back (free copy without registration here; CA Technologies was a sponsor), they mention these needs – and the speed they need to be dealt with. “The train is moving faster than you thought. Adoption of public cloud, mobile, and social technologies in business operations has already reached high levels, often driven by ‘stealth IT.’”
IDC noted a “surprisingly high” (and concerning) level of personal and confidential information sharing. While the “consumerization of IT” introduces a bunch of new, innovative services and approaches into the enterprise, it also exposes the org to “business risk, compliance gaps, and security challenges if they are not managed.”
An InfoWorld article by Nancy Gohring noted another IDC study that found that even as more and more people are bringing their own tablets and smartphones to work, IT departments have been “slow to support them and may not even be aware of the trend.” Slow, I understand (given I just bought my first iPad a few days ago); not aware, however, is a recipe for big headaches ahead.
What are those ahead of the train doing to stay ahead?
Not everyone, however, is behind the curve. Part of the IDC survey I mentioned earlier highlighted the top characteristics of leaders in this area – as in, what behaviors are they showing. The leaders are more likely to be those using IaaS, PaaS, and Saas; those who are interacting with customers using their smart mobile devices; those who are concerned about data protection, back-up, and end-to-end user experience. “Businesses that are being proactive about consumer-driven IT are more likely to realize greater benefits from investments made to address the consumerization of IT,” said IDC’s Liam Lahey in a recent blog that summarized their survey findings.
In addition, in Woods’ Forbes article, he pointed out some questions that need asking, many at an application level: “Supporting mobile workers adds a new dimension to every application in a company. Which applications should be supported on mobile devices? How much of each application should be available? When does it make sense to craft custom mobile solutions? How can consumer apps become part of the picture? What is [the] ROI for mobility? How much should be invested[?] None of these questions have obvious answers.” Another post of his has some good suggested approaches for IT.
My CA Technologies colleague Andi Mann did a good job of netting this all out in another recent post: “While a minority of leading organizations already ‘get it’, there is still a massive latent opportunity to establish new game-changing technologies, drive disruptive innovations, build exponential revenues, and beat your competitors.” In other words, having IT bury its head in the sand is going to mean missing some opportunities that don’t come along very often to reshape the competitive landscape.
Especially when you couple the support of these tablets and other mobile devices with the changes coming about with the rise of cloud computing.
Look in the mirror
In the end, says Andi, “it’s all about you! ...The bottom line is that you — as an individual, as a consumer, as an employee, as an IT professional — are responsible for a radical change affecting business, government, and IT. You are both driving this change as a consumer of social, mobile, and cloud applications; and being driven by this change as an IT professional adapting to these new customer behaviors.”Maybe TIME Magazine wasn’t wrong a few years back when they named You as their Person of the Year (congrats, by the way) with a big mirror-like thing on their front cover. It’s just that the revolution always takes longer than people think, and the results are never quite evenly distributed.
I’m a perfect example. I've been involved in cloud computing for many years, but didn’t join this particular part of the revolution -- the part where I expect flicking my fingers on a piece of glass will get me access to what I want -- until this past weekend.But I’ll probably be confounding IT departments left and right from now on. Make it so.
Jay is marketing and strategy VP for CA's cloud business.
<Return to section navigation list>
Cloud Computing Events
Jim Reavis announced on 8/3/2011 that the Cloud Security Alliance (CSA) will offer Certificate of Cloud Security CCSK Training on 8/16 in Falls Church, VA:
If you are interested and available, CSA's CCSK training is being held in Washington DC in 2 weeks.
- CCSK Basic - August 16 - http://ccsk-dc.eventbrite.com/ (All you need to pass the CCSK exam)
- CCSK Plus - August 16-17 - http://ccsk-plus-dc.eventbrite.com/ (Includes CCSK Basic plus a day of lab work)
There is also a special "train the trainer" session on August 18.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Jeff Barr (@jeffbarr) described New AWS Enterprise Features: VPC Everywhere, Direct Connect, Identity Federation in an 8/4/2011 post:
I often see blog posts that start by saying "with the announcement of ____, it is clear that AWS is now targeting the enterprise." These posts mention recent developments such as Reserved Instances, Dedicated Instances, VM Import, support for Oracle Database 11g, and the improvements to the EC2 networking model.
Today we are adding three major items to that list:
- VPC Everywhere - The Virtual Private Cloud (VPC) is now generally available, and can now be used in multiple Availability Zones of every AWS Region. VPCs can now span multiple Availability Zones, and each AWS account can now create multiple VPCs. Windows 2008 R2 is now supported, as are Reserved Instances for Windows with SQL Server.
- AWS Direct Connect - Enterprises can now create a connection to an AWS Region via dedicated 1 Gbit and 10 Gbit network circuits in order to enhance privacy and reduce network latency.
- Identity Federation - Enterprises can now create temporary security credentials for AWS to allow existing identities (from, for example, a LDAP server) to make use of IAM's fine-grained access controls.
I've written an entire post for each of these new features. Check them out, and let me know what you think! [See below]
It’s clear to me that Amazon is catching up with Windows Azure’s enterprise features.
Jeff Barr (@jeffbarr) explained AWS Direct Connect in an 8/4/2011 post:
The new AWS Direct Connect service allows enterprises to create a connection to an AWS Region via a dedicated network circuit. In addition to enhancing privacy, dedicated circuits will generally result in more predictable data transfer performance and will also increase bandwidth between your data center and AWS. Additionally, users of dedicated circuits will frequently see a net reduction in bandwidth costs.
AWS Direct Connect has one location available today, located at Equinix’s Ashburn, Virginia colocation facility. From this location, you can connect to services in the AWS US-East (Virginia) region. Additional AWS Direct Connect locations are planned for San Jose, Los Angeles, London, Tokyo, and Singapore in the next several months.
There are two ways to get started:
- If you already have your own hardware in an Equinix data center in Ashburn, Virginia, you can simply ask them to create a cross-connect from your network to ours. They can generally get this set up in 72 hours or less.
- If you don't have hardware in this data center, you can work with one of the AWS Direct Connect solution providers (our initial list includes AboveNet, Equinix, and Level 3) to procure a circuit to the same datacenter or obtain colocation space. If you procure a circuit, the AWS Direct Connect solution provider will take care of the cross-connect for you.
You can select 1 Gbit or 10 Gbit networking for each connection, and you can create multiple connections for redundancy if you'd like. Each connection can be used to access all AWS services. It can also be used to connect to one or more Virtual Private Clouds.
Billing will be based on the number of ports and the speed of each one. Data transfer out of AWS across the circuit will be billed at $0.02 / GB (2 cents per GB). There is no charge for data transfer in to AWS.
I expect to see AWS Direct Connect used in a number of different scenarios. Here are a few of them:
- Data Center Replacement - Migrate an existing data center to AWS and then use Direct Connect to link AWS to the corporate headquarters using a known private connection.
- Custom Hosting - Place some custom network or storage devices in a facility adjacent to an AWS Region, and enjoy high bandwidth low latency access to the devices from AWS.
- High Volume Data Transfer - Move extremely large amounts of data in and out of HPC-style applications.
In order to make the most of a dedicated high speed connection, you will want to look at a category of software often known as WAN optimization (e.g. Riverbed's Cloud Steelhead) or high speed file transfer (e.g. Aspera's On-Demand Direct for AWS). Late last month I saw a demonstration from Aspera. They showed me that that were able to achieve 700 Mbps of data transfer across a 1 Gbps line. At this rate they are able to transfer 5 Terabytes of data to AWS in 17 hours.
Jeff Barr (@jeffbarr) described AWS Identity and Access Management - Now With Identity Federation in an 8/4/2011 post:
In the past 6 months we have launched several AWS Identity and Access Management (IAM) features that have made it easier for our customers to control access to their AWS account. For example, we’ve launched support for IAM in the AWS Management Console, we've enabled users to log in to the AWS Management Console, and we announced general availability of IAM.
Identity Federation
Today we are enabling Identity Federation with IAM. This new capability allows existing identities (e.g. users) in your enterprise to access AWS APIs and resources using IAM's fine-grained access controls, without the need to create an IAM user for each identity.
Applications can now request temporary security credentials that can be used to sign requests to AWS. The temporary security credentials are comprised of short lived (1-36 hour) access keys and session tokens associated with the keys. Your enterprise users (or, to be a bit more precise, the AWS-powered applications that they run) can use the access keys the same way as before, as long as they pass the token along in the calls that they make to the AWS APIs. The permissions associated with temporary security credentials are at most equal to those of the IAM user who issued them; you can further restrict them by specifying explicit permissions as part of the request to create them. Moreover, there is no limit on the number of temporary security credentials that can be issued.
How it Works
Suppose that you want to allow each employee of a large organization to use a reporting application to store data files in their own slice of an S3 bucket. Before making any calls to S3, the application would use the new GetFederationToken function (one of two functions in the new Security Token Service) to create a set of temporary security credentials specific to the particular employee. Here is the general flow:
Let's go through this, one step at a time:
The Identity Broker
This flow presupposes the existence of an Identity Broker. The broker is responsible for mapping the employee identifier in to a set of AWS credentials. This could be implemented as a separate process or network service, or it could be embedded in the calling application. If the broker is running in a separate process, there is no need to embed an AWS credentials in the storage application.
We have put together a sample Identity Broker in order to show you how to build one of your own. The sample code implements a proxy using Microsoft Active Directory. The proxy issues temporary security credentials for access to Amazon S3 buckets and objects, using permissions that are tied to a particular Active Directory User. The code includes a sample Federation Proxy and a sample console application.
If you build an Identity Broker that works with another directory, let me know and I'll post an update to this blog.
An employee decides to use an AWS-powered reporting application to save some information in Amazon S3.
- The application calls an Identity Broker. The broker accepts an employee identifier as input.
- The Identity Broker uses the organization's LDAP directory to validate the employee's identity.
- The Identity Broker calls the new GetFederationToken function using IAM credentials. The call must include an IAM policy and a duration (1 to 36 hours), along with a policy that specifies the permissions to be granted to the temporary security credentials.
- The Security Token Service confirms that the policy of the IAM user making the call to GetFederationToken gives permission to create new tokens and then returns four values to the application: An access key, a secret access key, a token, and a duration (the token's lifetime).
- The Identity Broker returns the temporary security credentials to the reporting application.
- The data storage application uses the temporary security credentials (including the token) to make requests to Amazon S3.
- Amazon S3 uses IAM to verify that the credentials allow the requested operation on the given S3 bucket and key
- IAM provides S3 with the go-ahead to perform the requested operation.
The Security Token Service can elect to return a token that is valid for less than the duration requested in the call to GetFederationToken. The client application must track the expiration date and time of the token so that it can obtain a new token before the current one expires. Any request made with an expired token will fail.
The token can have any subset of the permissions granted to the caller (an IAM user) of GetFederationToken. This means that you can create an IAM user with access only to the APIs and resources that the application needs.
Identity Federation can be used with a number of AWS services including EC2, S3, SNS, and SQS. We expect to enable additional services over time.
The IAM Hotel
The latest version of the IAM documentation provides detailed information on how to use this new functionality, but I think it is worth showing you how it ties in with the rest of IAM using a simple metaphor:
Imagine that your AWS account is like a hotel and you are the innkeeper. In the early days of AWS our customers were often startups or individuals, essentially small groups for which basic security met their needs. So we offered a single master key granting unconditional access to all of your AWS resources.
Over time, our customer base grew more sophisticated, including more complex organizations and more significant resources to protect. The old model required sharing of the master key; this was not sufficient to meet the security needs of these larger organizations. With the introduction of IAM you can create the equivalent of ”access badges” for your hotel employees – housekeeping gets access to guest rooms, cooks get access to the kitchen, in effect allowing you to grow your business while giving you explicit control over the permissions granted to your employees. You, the owner, can define and enforce the appropriate level of access.
However, taking the hotel metaphor further, let’s think of your hotel guests. You could give them the same “access badges” as you give to your employees, but since their stay is short you would need to ensure that they return their badges when they leave. Or you could ask your hotel employees to help guests enter their room or access hotel facilities, but that level of personalized service would not scale as your business grows. Of course, we all know what the solution is to that problem: to enable your front desk to issue temporary “hotel access cards” to your guests for accessing only their room and hotel facilities.
As you can see, identity federation opens up new use cases for our enterprise customers. In the language of the hotel metaphor, you now have the ability to issue hotel cards to your guests. You can provision temporary security credentials for identities you are responsible for managing, with no limits on the number of identities you can represent or the number of credentials you can obtain.
Jeff Barr (@jeffbarr) asserted Amazon VPC - Far More Than Everywhere in an 8/4/2011 post:
Today we are marking the Virtual Private Cloud (VPC) as Generally Available, and we are also releasing a big bundle of new features (see my recent post, A New Approach to Amazon EC2 Networking for more information on the last batch of features including subnets, Internet access, and Network ACLs).
You can now build highly available AWS applications that run in multiple Availability Zones within a VPC, with multiple (redundant) VPN connections if you'd like. You can even create redundant VPCs. And, last but not least, you can do all of this in any AWS Region.
Behind the Scenes!
There's a story behind the title of this post, and I thought I would share it with you. A few months ago the VPC Program Manager told me that they were working a project called "VPC Everywhere." The team was working to make the VPC available in multiple Availability Zones of every AWS Region. I added "VPC Everywhere" to my TODO list, and that was that.
Last month he pinged me to let me know that VPC Everywhere was getting ready to launch, and to make sure that I was ready to publish a blog post at launch time. I replied that I was ready to start, and asked him to confirm my understanding of what I had to talk about.
He replied that VPC Everywhere actually included quite a few new features and sent me the full list. Once I saw the list, I realized that I would need to set aside a lot more time in order to give this release the attention that it deserves. I have done so, and here's my post!
Here's what's new today:
- The Virtual Private Cloud has exited beta, and is now Generally Available.
- The VPC is available in multiple Availability Zones in every AWS Region.
- A single VPC can now span multiple Availability Zones.
- A single VPC can now support multiple VPN connections.
- You can now create more than one VPC per Region in a single AWS account.
- You can now view the status of each of your VPN connections in the AWS Management Console. You can also access it from the command line and via the EC2 API.
- Windows Server 2008 R2 is now supported within a VPC, as are Reserved Instances for Windows with SQL Server.
- The Yamaha RTX1200 router is now supported.
Let's take a look at each new feature!
General Availability
The "beta" tag is gone! During the beta period many AWS customers have used the VPC to create their own isolated networks within AWS. We've done our best to listen to their feedback and to use it to drive our product planning process.VPC Everywhere
You can now create VPCs in any Availability Zone in any of the five AWS Regions (US East, US West, Europe, Singapore, or Tokyo). Going forward, we plan to make VPC available at launch time when we open up additional Regions (several of which are on the drawing board already). Data transfer between VPC and non-VPC instances in the same Region, regardless of Availability Zone, is charged at the usual rate of $0.01 per Gigabyte.Multiple Availability Zone Support
You can now create a VPC that spans multiple Availability Zones in a Region. Since each VPC can have multiple subnets, you can put each subnet in a distinct Availability Zone (you can't create a subnet that spans multiple Zones though). VPN Gateways are regional objects, and can be accessed from any of the subnets (subject, of course, to any Network ACLs that you create). Here's what this would look like:
Multiple Connection Support
You can now create multiple VPN connections to a single VPC. You can use this new feature to configure a second Customer Gateway to create a redundant connection to the same external location. You can also use it to implement what is often described as a "branch office" scenario by creating VPN connections to multiple geographic locations. Here's what that would look like:
By default you can create up to 10 connections per VPC. You can ask for more connections using the VPC Request Limit Increase form.
Multiple VPCs per Region
You can now create multiple, fully-independent VPCs in a single Region without having to use additional AWS accounts. You can, for example, create production networks, development networks, staging networks, and test networks as needed. At this point, each VPC is completely independent of all others, to the extent that multiple VPCs in a single account can even contain overlapping IP address ranges. However, we are aware of a number of interesting scenarios where it would be useful to peer two or more VPCs together, either within a single AWS account or across multiple accounts owned by different customers. We're thinking about adding this functionality in a future release and your feedback would be very helpful.By default you can create up to 5 VPCs. You can ask for additional VPCs using the VPC Request Limit Increase form.
VPN Connection Status
You can now check the status of each of your VPN Connections from the command line or from the VPC tab of the AWS Management Console. The displayed information includes the state (Up, Down, or Error), descriptive error text, and the time of the last status change.Windows Server 2008 R2 and Reserved Instances for Windows SQL Server
Windows Server 2008 R2 is now available for use within your VPC. You can also purchase Reserved Instances for Windows SQL Server, again running within your VPC.Third-Party Support
George Reese of enStratus emailed me last week to let me know that they are supporting VPC in all of the AWS Regions with their cloud management and governance product.Bruno from Riverbed dropped me a note to tell me that their Cloud Steelhead WAN optimization product is now available in all of the AWS Regions and that it can be used within a VPC. Their product can be used to migrate data into and out of AWS and to move data between Regions.
Patrick from cohesiveFT sent along information about the vpcPLUS edition of their VPN-Cubed product. Among other things, you can use VPN-Cubed to federate VPCs running in multiple AWS Regions. The vpcPLUS page contains a number of very informative diagrams as well.
Keep Moving
Even after this feature-rich release, we still have plenty of work ahead of us. I won't spill all the beans, but I will tell you that we are working to support Elastic MapReduce. Elastic Load Balancing, and the Relational Database Service inside of a VPC.Would you be interested in helping to make this happen? It just so happens that we have a number of openings on the EC2 / VPC team:
- Software Development Manager- Amazon Virtual Private Cloud (Herndon, VA).
- Software Development Engineer - AWS (Herndon, VA).
And there you have it - VPC Everywhere, and a lot more! What do you think?
-- Jeff;
PS - The diagrams in this post were created using a tool called Cacoo, a very nice, browser-based collaborative editing tool that was demo'ed to me on my most recent visit to Japan. It runs on AWS, of course.
Barton George (@Barton808) posted Introducing the Dell | Cloudera solution for Apache Hadoop — Harnessing the power of big data on 8/4/2011:
Data continues to grow at an exponential rate and no place is this more obvious than in the Web space. Not only is the amount exploding but so is the form data’s taking whether that’s transactional, documents, IT/OT, images, audio, text, video etc. Additionally much of this new data is unstructured/ semi-structured which traditional relational databases were not built to deal with.
Enter Hadoop, an Apache open source project which, when combined with Map Reduce allows the analysis of entire data sets, rather than sample sizes, of structured and unstructured data types. Hadoop lets you chomp thru mountains of data faster and get to insights that drive business advantage quicker. It can provide near “real-time” data analytics for click-stream data, location data, logs, rich data, marketing analytics, image processing, social media association, text processing etc. More specifically, Hadoop is particularly suited for applications such as:
- Search Quality — search attempts vs. structured data analysis; pattern recognition
- Recommendation engine — batch processing; filtering and prediction (ie use information to predict what similar users like)
- Ad-targeting – batch processing; linear scalability
- Thread analysis for spam fighting and detecting click fraud — batch processing of huge datasets; pattern recognition
- Data “sandbox” – “dump” all data in Hadoop; batch processing (ie analysis, filtering, aggregations etc); pattern recognition
The Dell | Cloudera solution
Although Hadoop is a very powerful tool, it can be a bit daunting to implement and use. This fact wasn’t lost on the founders of Cloudera who set up the company to make Hadoop easier to used by packaging it and offering support. Dell has joined with this Hadoop pioneer to provide the industry’s first complete Hadoop Solution (aptly named “the Dell | Cloudera solution for Apache Hadoop”).
The solution is comprised of Cloudera’s distribution of Hadoop, running on optimized Dell PowerEdge C2100 servers with Dell PowerConnect 6248 switch, delivered with joint service and support. Dell offers two flavors of this big data solution: Cloudera’s distribution with the free download of Hadoop software, and Cloudera’s enterprise version of Hadoop that comes with a charge.
It comes with its own “crowbar” and DIY option
The Dell | Cloudera solution for Apache Hadoop also comes with Crowbar, the recently open-sourced Dell-developed software, which provides the necessary tools and automation to manage the complete lifecycle of Hadoop environments. Crowbar manages the Hadoop deployment from the initial server boot to the configuration of the main Hadoop components allowing users to complete bare metal deployment of multi-node Hadoop environments in a matter of hours, as opposed to days. Once the initial deployment is complete, Crowbar can be used to maintain, expand, and architect a complete data analytics solution, including BIOS configuration, network discovery, status monitoring, performance data gathering, and alerting.
The solution also comes with a reference architecture and deployment guide, so you can assemble it yourself, or Dell can build and deploy the solution for you, including rack and stack, delivery and implementation.
Extra-credit reading
- Rob’s Blog: Big Questions? Big Answers with #Dell #BigData solution (plus #Crowbar get #RHEL)
- Joseph’s blog: Big News: #Dell and #Cloudera Partner on #Hadoop Solution
- AD’s blog: Introducing the Dell | Hadoop Solution
- Hadoop Summit: Chatting with Cloudera’s VP of Product
- Hadoop Summit: Looking at the evolving Hadoop ecosystem with Ken Krugler
- In-database analytics explained by Forrester’s James Kobielus
- Dell announces availability of OpenStack solution; Open sources “Crowbar” software framework
Pau for now…
The Dell | Cloudera solution competes with Microsoft’s HPC Pack and LINQ for HPC for Windows Server 2008 R2 and Microsoft Research’s Project “Daytona” for automating MapReduce processes.
Jnan Dash (@JnanDash) described the Large Scale Hadoop Data Migration at Facebook in an 8/1/2011 post:
In 2010 Facebook had the largest Hadoop cluster in the world, with over 20PB of storage. Yes, that is 20 Petabytes or 20,000 Terabytes or 20 to the power of 15 bytes! By March 2011, the cluster had grown to 30 PB – that’s 3000 times the Library of Congress. As they ran out of power and space to add more nodes, a migration to a larger data center was needed. In a Facebook post Paul Yang describes how they accomplished this monumental task.
The Facebook infrastructure team chose a replication approach for this migration. Two steps were followed. First, a bulk copy transferred most of the data from the source cluster to the destination. Second all changes since the start of the bulk copy were captured via a cluster Hive plug-in that recorded the changes in an audit log. The replication system continuously polled the audit log and applied modified files to the destination. The plug-in also recorded Hive metadata changes. The Facebook Hive team developed both the plug-in and the replication system.
Remember, the challenge here is not to interrupt the 750 million Facebook users access to the data 24/7, while the migration was happening. It is like changing the engine of an airplane while flying 600 miles an hour at 36000 feet above ground. Quite a remarkable effort.
The big lesson learned was to develop a fast replication system that proved invaluable in addressing the issues. For example, corrupt files could easily be remedied with additional copy without affecting the schedule. The replication system became a potential disaster-recovery solution for warehouses using Hive. The Hadoop HDFS-based warehouses lack built-in data-recovery functionality usually found in traditional RDBMS systems.
Facebook’s next challenge will be to support a data warehouse distributed across multiple data centers.
<Return to section navigation list>
Technorati Tags: Windows Azure,Windows Azure Platform,Azure Services Platform,Azure Storage Services,Azure Table Services,Azure Blob Services,Azure Drive Services,Azure Queue Services,SQL Azure Database,SADB,Open Data Protocol,OData,Windows Azure AppFabric,Azure AppFabric,Windows Server AppFabric,Server AppFabric,Cloud Computing,Visual Studio LightSwitch,LightSwitch,Amazon Web Services,AWS,Amazon Connect,Amazon VPC,SharePoint 2010,Dell Computer,Cloudera,Hadoop,Windows Phone 7,WP7





























































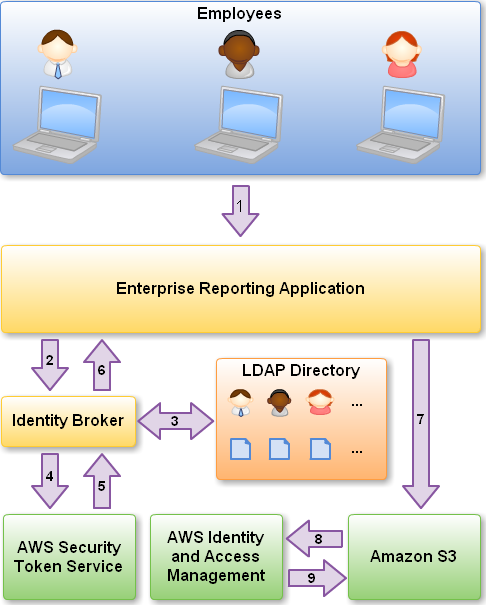






















0 comments:
Post a Comment