Windows Azure and Cloud Computing Posts for 8/16/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table and Queue Services
Jim O’Neil (@jimoneil) continued his deep-dive series with Photo Mosaics Part 4: Tables in an 8/16/2011 post:
In this continuation of my deep-dive look at the Azure Photo Mosaics application I built earlier this year, we’ll take a look at the use of Windows Azure Table storage. If you’re just tuning in, you may want to catch up on the other posts of the series or at least the overview of the application.
In the application, Windows Azure Tables are the least prevalent aspect of storage and primarily address the cross-cutting concerns of logging/diagnostics and maintaining a history of application utilization. In the diagram below, the two tables – jobs and status – are highlighted, and the primary integrations points are shown. The status table in particular is accessed from just about every method in the roles running on Azure.
Windows Azure Table Storage Primer
Before I talk about the specific tables in use for the application, let’s review the core concepts of Windows Azure tables.
- Size limitations
- max of 100TB (this is the maximum for a Windows Azure Storage account, and can be subdivided into blobs, queues, and tables as needed). If 100TB isn’t enough, simply create an additional storage account!
- unlimited number of tables per storage account
- up to 252 user-defined properties per entity
- maximum of 1MB per entity (referencing blob storage is the most common way to overcome this limitation).
- Performance
- up to 5,000 entities per second across a given table or tables in a storage account
- up to 500 entities per second in a single table partition (where partition is defined by the PartitionKey value, read on!)
- latency of about 100ms when access is via services in the same data center (a code-near scenario)
- Structured but non-schematized. This means that tables have a structure, rows and columns if you will, but ‘rows’ are really entities and ‘columns’ are really properties. Properties are strongly typed, but there is no requirement that each entity in a table have the same properties, hence non-schematized. This is a far stretch from the relational world many of us are familiar with, and in fact, Windows Azure Table Storage is really an example of a key-value implementation of NoSQL. I often characterize it like an Excel spreadsheet: the row and column structure is clear, but there’s no rule that says column two has to include integers or row four has to have the same number of columns as row three.
- Singly indexed. Every table in Windows Azure Storage must have three properties:
- PartitionKey – a string value defining the partition to which the data is associated,
- RowKey – a string value, which when combined with the PartitionKey, provides the one unique index for the table, and
- Timestamp – a readonly, DateTime value.
The selection of partition key (and row key) are the most important decisions you can make regarding the scalability of your table. Data in each partition is serviced by a single processing node, so extensive concurrent reads and writes from the same partition can be a bottleneck for your application. For guidance, I recommend consulting the whitepaper on Windows Azure Tables authored by Jai Haridas, Niranjan Nilakantan, and Brad Calder. Jai also has a number of presentations on the subject from past Microsoft conferences that are available on-line.
- REST API. Access to Windows Azure Storage is via a REST API that is further abstracted for developer consumption by the Windows Azure Storage Client API and the WCF Data Services Client Library. All access to table storage must be authenticated via Shared Key or Shared Key Lite authentication.
The Programming Model
The last bullet above mentions that access to Windows Azure Storage is via a RESTful API, and that’s indeed true, but the programmatic abstraction you’ll most likely incorporate is a combination of the Windows Azure Storage Client API and the WCF Data Services Client Library.
In the Storage Client API there are four primary classes you’ll use. Three of these have analogs or extend classes in the WCF Data Services Client Library, which means you’ll have access to most of the goodness of OData, entity tracking, and constructing LINQ queries in your cloud applications that access Windows Azure Table Storage.
Class Purpose CloudTableClient authenticate requests against Table Storage and perform DDL (table creation, enumeration, deletion, etc.) CloudTableQuery a query to be executed against Windows Azure Table Storage TableServiceContext a DataServiceContext specific to Windows Azure Table Storage a class representing an entity in Windows Azure Table Storage If you’ve built applications with WCF Data Services (over the Entity Framework targeting on-premises databases), you’re aware of the first-class development experience in Visual Studio: create a WCF Data Service, point it at your Entity Framework data model (EDM), and all your required classes are generated for you.
It doesn’t work quite that easily for you in Windows Azure Table Storage. There is no metadata document produced to facilitate tooling – and that actually makes sense. Since Azure tables have flexible schemas, how can you define what column 1 is versus column 2 when each row (entity) may differ?! To use WCF Data Services Client functionality you have to programmatically enforce a schema to create bit of order over the chaos. You could still have differently shaped entities in a single table, but you’ll have to manage how you select data from that table and ensure that it’s selected into a entity definition that matches it.
TableServiceContext
As a developer you’ll define at least one TableServiceContext class per storage account within your application. TableServiceContext actually extends DataServiceContext, one of the primary classes in WCF Data Services, with which you may already be familiar. The TableServiceContext has two primary roles:
- authenticate access, via account name and key, and
- broker access between the data source (Windows Azure Table Storage) and the in-memory representation of the entities, tracking changes made so that the requisite commands can be formulated and dispatched to the data source when an update is requested
You will also typically use the TableServiceContext to help implement a Repository pattern to decouple you application code from the backend storage scheme, which is particularly helpful when testing.
In the Azure Image Processor, the TableAccessor class (through which the web and worker roles access storage) is essentially an Repository interface, and encapsulates a reference to the TableServiceContext. Since this application only has two tables, the context class itself is quite simple:
1: public class TableContext : TableServiceContext 2: { 3: 4: public TableContext(String baseAddress, StorageCredentials credentials) 5: : base(baseAddress, credentials) 6: { 7: } 8: 9: public IQueryable<StatusEntry> StatusEntries 10: { 11: get 12: { 13: return this.CreateQuery<StatusEntry>("status"); 14: } 15: } 16: 17: public IQueryable<JobEntry> Jobs 18: { 19: get 20: { 21: return this.CreateQuery<JobEntry>("jobs"); 22: } 23: } 24: }The ‘magic’ here is that each of the method returns an IQueryable, which means that you can further compose queries, such as you can see in the highlighted method of TableAccessor below:1: public class TableAccessor 2: { 3: private CloudTableClient _tableClient = null; 4: 5: private TableContext _context = null; 6: public TableContext Context 7: { 8: get 9: { 10: if (_context == null) 11: _context = new TableContext(_tableClient.BaseUri.ToString(), _tableClient.Credentials); 12: return _context; 13: } 14: } 15: 16: public TableAccessor(String connectionString) 17: { 18: _tableClient = CloudStorageAccount.Parse(connectionString).CreateCloudTableClient(); 19: } 20: 21: public IEnumerable<StatusEntry> GetStatusEntriesForJob(Guid jobId) 22: { 23: if (_tableClient.DoesTableExist("status")) 24: { 25: CloudTableQuery<StatusEntry> qry = 26: (from s in Context.StatusEntries 27: where s.RequestId == jobId 28: select s).AsTableServiceQuery<StatusEntry>(); 29: return qry.Execute(); 30: } 31: else 32: return null; 33: } 34: 35: // remainder elided for brevityIn Lines 6ff, you can see the reference to the TableServiceContext, and in Lines 26ff the no-frills StatusEntries property from the context is further narrowed via LINQ to WCF Data Services to return only the jobs corresponding to an input id. If you’re wondering what CloudTableQuery and AsTableServiceQuery are, we’ll get to those shortly.TableServiceEntity
What’s missing here? Well in the code snippet above, it’s the definition of StatusEntry, and of course, there’s the JobEntry class as well. Both of these extend the TableServiceEntity class, which predefines those three required properties of every Windows Azure Table: PartitionKey, RowKey, and Timestamp. Below is the definition for StatusEntry, and you can crack open the code to look at JobEntry.
1: public class StatusEntry : TableServiceEntity 2: { 3: public Guid RequestId { get; set; } 4: public String RoleId { get; set; } 5: public String Message { get; set; } 6: 7: public StatusEntry() { } 8: 9: public StatusEntry(Guid requestId, String roleId, String msg) 10: { 11: this.RequestId = requestId; 12: this.RoleId = roleId; 13: this.Message = msg; 14: 15: this.PartitionKey = requestId.ToString(); 16: this.RowKey = String.Format("{0}|{1}", DateTime.UtcNow.Ticks, Guid.NewGuid()); 17: } 18: }Note that I’ve set the PartitionKey to be the requestId; that means all of the status entries for a given image processing job are within the same partition. In the Windows Forms client application, this data is queried by requestId, so the choice is logical, and the query will return quickly since it’s being handled by a single processing node associated with the given partition.Where this choice could be a poor one though is if there are rapid fire inserts into the status table. Assume for instance that every line executed in the web and worker role code results in a status update. Since the table is partitioned by the job id, only one processing node can access it, and so a bottleneck may occur, and performance suffers. An alternative would be to partition based on a hash of say the tick count at which the status message was written, thus fanning out the handling of status messages to different processing nodes.
In this application, we don’t expect the status table to be a hot spot, so it’s not of primary concern, but I did want to underscore that how your data is used contextually may affect your choice of partitioning. In fact, it’s not unheard of to duplicate data in order to provide different indexing schemes for different uses of that data. Of course, in that scenario you bear the burden of keeping the data in sync to the degree necessary for the successful execution of the application.
For the RowKey, I’ve opted for a concatenation of the Ticks and a GUID. Why both? First of all, the combination of PartitionKey and RowKey must be unique, and there is a chance, albeit slim, that two different roles processing a given job will write a message at the exact same tick value. As a result, I brought in GUID to differentiate the two. The use of tick also enforces the default sort order, so that (more-or-less) the status entries appear in order. This will certainly be the case for entries written from a given role instance, but clock drift across instances could result in out-of-order events. For this application, exact order is not required, but if it is for you, you’ll need to consider an alternative synchronization mechanism, or better yet (in the world of the cloud) reconsider if that requirement is really a ‘requirement’.
For JobEntry, by the way, the PartitionKey and RowKey are defined as follows:
this.PartitionKey = clientId; this.RowKey = String.Format("{0:D20}_{1}", this.StartTime.Ticks, requestId);The clientId is current a SID based on the execution of the Windows Forms client, but would be extensible to any token, such as an e-mail address that might be used in a OAuth type scenario. The RowKey is a concatenation of a Ticks value and the requestId (a GUID). Strictly speaking, the GUID value is enough to guarantee uniqueness – each job has a single entity (row) in the table - but I added the Ticks value to enforce a default sort order, so that when you select all the jobs of a given client they appear in chronological order versus GUID order (which would be non-deterministic).Be aware of the supported data types! Windows Azure Tables support eight data types, so the properties defined for your TableServiceEntity class need to align correctly, or you’ll get a rather generic DataServiceRequestException message:
An error occurred while processing this request.
with details in an InnerException indicating a 501 status code and the message:
The requested operation is not implemented on the specified resource. RequestId:ddf8af86-521e-4c5e-b817-2b3a9c07007e Time:2011-08-16T00:54:42.7881423ZIn my JobEntry class for instance, that’s why you’ll see the properties TileSize and Slices typed as Int32, whereas through the rest of the application they are of type Byte.
Curiously, I thought the same would be true of the Uri data, which I redefined to String explicitly, but on revisiting this, they seem to work. I’m assuming here there’s some explicit ToString going on to make it fly.DataServiceQuery/CloudTableQuery
Now that we’ve got the structure of the data defined and the context to map our objects to the the underlying storage, let’s take a look at the query construction. In an excerpt above, you saw the following query:
CloudTableQuery<StatusEntry> qry = (from s in Context.StatusEntries where s.RequestId == jobId select s).AsTableServiceQuery<StatusEntry>(); return qry.Execute();That bit in the middle looks like a standard LINQ query to grab from the StatusEntries collection only those entities with a given RequestId, and that’s precisely what it is (and more specifically it’s a DataServiceQuery). In Windows Azure Table Storage though, a DataServiceQuery isn’t always sufficient.When issuing a request to Windows Azure Table Storage (it’s all REST under the covers, remember), you will get at most 1000 entities returned in response. If there are more than 1000 entities fulfilling your query, you can get the next batch but it requires an explicit call along with a continuation token that is passed as part of the header and tells the Azure Storage engine where to pick up returning results. There are actually other instances where continuation tokens enter the picture even with less than 1000 entities, so it’s a best practice to always handle continuation tokens.
A DataServiceQuery does not handle continuation tokens, but you can use the extension method AsTableServiceQuery to convert the DataServiceQuery to a CloudTableQuery and get access to continuation token handling and some other Azure tables-specific functionality, such as:
- RetryPolicy enables you to specify how a request should be retried in cased where it times out or otherwise fails – remember, failure is a way of life in the cloud! There are a number of retry policies predefined (empirically the undocumented default, as of this writing, is RetryExponential(3, 3, 90, 2)), and you can create your own by defining a delegate of type RetryPolicy.
- Execute runs the query and traverses all of the continuation tokens to return all of the results. This is a convenient method to use, since it handles the continuation tokens transparently, but it can be dangerous in that it will return all of the results requested from 1 to 1 million (or more)!
- BeginExecuteSegmented and EndExecuteSegmented are also aware of continuation tokens, but requires you to loop over each ‘page’ of results. It’s a tad safer than the full-blown Execute and a good choice for a pagination scheme. In fact, I go through all the gory details in a blog post from my Azure@home series.
From the
qry.Execute()line above, you can see I took the easy way out by letting CloudTableQuery grab everything in one fell swoop. In this context, that’s fine, because the number of status entries for a given job will be on the order of 10-50 versus thousands.That’s pretty much it as far as the table access goes; next time we’ll cover the queues used by the Azure Photo Mosaic application.


<Return to section navigation list>
SQL Azure Database and Reporting
No significant articles today.
<Return to section navigation list>
MarketPlace DataMarket and OData
Xignite, Inc. posted a 00:10:30 Azure DataMarket Overview w/ Xignite video segment on 8/15/2011:
Wes Yanaga (Channel9) chats with Chas Cooper (Xignite) and Shoshanna Budzianowski (Microsoft) regarding the recent addition of Xignite data to the Azure DataMarket Marketplace.
SAP explained When to Use the OData Channel in a new documentation topic found 8/152011:
This section provides information to help you decide whether to use the Generic Channel or the OData channel of SAP NetWeaver Gateway.
Use the Generic Channel if:
The interfaces for data provisioning on a backend system already match the requirements, for example, if the RFCs already exist. In this case, a complete adaptation on SAP NetWeaver Gateway is feasible, as the adaptation wraps remote calls to the backend and converts data between the RFC’s tables and the SAP NetWeaver Gateway API.
You do not wish to write any code. In this case you can use one of the content generators (BOR, RFC, or Screen Scraping).
Rapid prototyping is required.
Use the OData Channel if:
Required remote interfaces do not exist, that is, adequate RFCs for data provisioning need to be developed on the backend. In this case adaptation would occur on both sides of the RFC: on the backend to create an RFC and on the Gateway to wrap and map that RFC to the GW API.
The remote interface between both components creates strong dependencies for development, versioning, and deployment, and hence increases cost.
You wish to have code only in the backend.
The developer requires more flexibility, for example, they do not have to rely on existing interfaces based on RFC or web services, but can fetch data locally in the Business Suite system.
You want to leverage the lifecycle management benefits, because all objects created can reside in the same software component and follow existing paths.

No significant articles today.
<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Eric Nelson (@ericnel) described Microsoft and Windows Azure - deploying a customer facing application in Six Weeks in an 11/16/2011 post to his IUpdatable blog:
I often get asked about how we are using Windows Azure internally and under NDA I can share some of the details – but its great to be able to point publicly at some of the excellent work that has been going on. And they are genuine technical case studies … hurrah! :-)
How Microsoft IT Deployed a Customer Facing Application to Windows Azure in Six Weeks
Technical Case StudyFrom:
To:
Architecting and Redeploying a Business Critical Application to Windows Azure
The Microsoft IT Volume Licensing team architected and redeployed a business critical application, with full security review and approval, to Windows Azure. The resulting solution delivers lower cost and improved scalability, performance, and reliability.
IT Pro Webcast | Technical Case StudyFrom:
To:
Related Links:
- Attend a FREE workshop September 12th
- Sign up to Microsoft Platform Ready for assistance on the Windows Azure Platform
- http://www.azure.com/offers
- http://www.azure.com/getstarted






<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
The Visual Studio LightSwitch Team (@VSLightSwitch) described on 8/16/2011 how to “Build useful and user-friendly applications that look and function like professional software” that Wow Your End Users:
Take your application beyond users' expectations
Microsoft Visual Studio LightSwitch 2011 offers tools and options that help users create applications that rival off-the-shelf solutions by using both included features and downloadable extensions.
Quickly and easily create common screens
Use screen templates as a guide to lay out your content, providing a professional look and maintaining consistency among your forms.
Write the code that only you can write
Build your application to do exactly what you need it to do. LightSwitch lets you create custom business logic and rules unique to your business, which means that you can provide a tailored experience that best meets your users' needs.
Extend and customize your application
Take advantage of components, data sources, and services that add functionality. LightSwitch applications are built on a set of extensible templates, so it's easy to share components from one application to the next, or to expand your application’s capabilities using LightSwitch extensions.
Video: Wow your end users
Return to section navigation list>
Windows Azure Infrastructure and DevOps
David Mills of the System Center Team announced the final release version of the System Center Operations Manager (SCOM) Monitoring Pack for Windows Azure applications is available in a Hey! You! Get ON My Cloud! post of 8/15/2011:
The final release version of the System Center Monitoring Pack for Windows Azure applications is now available. This monitoring pack enables you to monitor the availability and performance of applications that are running on Windows Azure. Previously available as a release candidate (RC), this new Operations Manager monitoring pack enables an integrated view into Windows Azure based applications running in your public cloud environment.
- Discover Windows Azure applications.
- Provide status of each role instance.
- Collect and monitor performance
information.- Collect and monitor Windows events.
- Collect and monitor the .NET Framework
trace messages from each role instance.- Groom performance, event, and the .NET
Framework trace data from Windows Azure storage account.- Change the number of role instances via
a task.
Download the final release version of this monitoring pack here and give it a try!
For more information on licensing System Center to manage public cloud environments, please refer to the Microsoft License Mobility through Software Assurance Customer Guide. [And see the below post.]
Rock on,
The Windows Azure Management Pack requires System Center Operations Manager 2007 R2 CU3 or newer to be installed on Windows Server 2008 or Windows Server 2008 R2.
For more details about Microsoft License Mobility to the cloud, see Doug Barney’s The Skinny on Microsoft's New Cloud Pricing article of 8/16/2011 for 1105 Media’s Virtualization Review blog:
Software licensing is way more complicated than it needs to be, and moving to the cloud, especially using your existing apps, offers a whole new wrinkle.
Microsoft, which is "all in the cloud," wants its customers equally in, and is tweaking its Software Assurance volume licensing program to ease the transition. The basic idea is through "license mobility" you can use what you already paid for to run on your servers and move that software to the cloud.
Analyst firm Directions on Microsoft analyzes license mobility, and their analyst John Cullen spoke to Microsoft watcher and Redmond magazine columnist Mary Jo Foley about all the gory details. Licensing comes easy to Cullen, who for half a decade crafted volume programs in Redmond.
According to Cullen, mobility is an attempt to lure IT to the cloud, but also a lifeline for Software Assurance, which could end up irrelevant as computing shifts off site.
The Microsoft side of the equation is not the most complicated part. The tricky area is continuing to pay Microsoft fees while at the same time negotiating new fees with a hosting company. It is unclear whether, in the final analysis, you'll save or lose money on this deal.
While I may have mentioned the Microsoft side is a bit less hairy than with hosters, it ain't exactly second grade math. Here's an example from Cullen:
"A scenario where you 'win' (licenses let you do more in the cloud than on-premises): We're running one SQL Server workload on a dual proc on-premises server licensed with two SQL Enterprise proc licenses. You can move the workload up to a multitenant hoster with a quad proc box, at times using more proc 'horsepower' than you did when on premises, and yet you only need to allocate ONE of your two SQL Enterprise proc licenses to do so."
Not exactly nuclear science, but not simple either, especially when you have multiple servers, multiple apps and myriad VMs to match. Break out your HP EasyCalc 300 to figure all that out!

Full disclosure: I’m a Contributing Editor of 1105 Media’s Visual Studio Magazine.
The Windows Azure Team (@WindowsAzure) announced Simplified Data Transfer Billing Meters and Swappable Compute Instances on 8/16/2011:
First, the price of extra small compute will be reduced by 20 percent. Additionally, the compute allocations for all of our offers will be simplified to small compute hours. To deliver additional flexibility to our customers, these hours can also be used for extra small compute at a ratio of 3 extra small compute hours per 1 hour of small compute. Customers can also utilize these hours for other compute sizes at the standard prescribed ratios noted in their rate plan. Additionally, current Introductory Special offer customers and customers who sign up for this offer prior to October 1 will receive both 750 extra small compute hours and 750 small compute hours for the months of August and September to ensure maximum value and flexibility in advance of this enhanced offer.
Details on compute allotment by offer can be found below:
Prior to October 1
Beginning on October 1
Offer
Extra Small
Small
Extra Small
Small
Extra Small Equivalent
Introductory Special*
750
750
-
750
2,250
Cloud Essentials
750
25
-
375
1,125
MSDN Professional
750
-
-
375
1,125
MSDN Premium
1,500
-
-
750
2,250
MSDN Ultimate
-
1,500
-
1,500
4,500
*Note: On August 1, we increased the number of small hours included in this offer from 25 to 750. For the months of August and September, Introductory Special users will get both 750 extra small compute hours and 750 small compute hours. Once small hours and extra-small hours are swappable beginning on October 1, Introductory Special will only include 750 small hours.
We are also simplifying our data transfer meters to utilize only two zones, “Zone 1” and “Zone 2”. The zone meter system will simplify the current meter system that includes multiple regions and separate meters for both standard data transfers and CDN. Data centers in Europe and North America will be reported and charged under Zone 1 and those for the rest of the world will be classified as Zone 2. This change will ease customer’s ability to monitor data transfers and understand billing charges. The price per GB for outbound data transfers will not change. Customers will also gain the flexibility to utilize CDN data transfers against any data transfer amounts included with their offer. For billing periods that overlap September and October, customers will see both the current regional and new Zone 1 and 2 meters on their invoice
These changes are part of our ongoing commitment to deliver world class services in a simple and flexible way to customers.
This information was delivered to Windows Azure Platform subscribers by email on 8/15/2011.
The new allocation for the Cloud Essentials offer still won’t let me run a high-availability application, which requires two instances (~1,500 hours/month.)
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
David Linthicum (@DavidLinthicum) asserted “Moving to a private cloud is easier than you think” in a deck for his Building Private Clouds article of 8/16/2011 for the Cloudonomics Journal:
While the hype rages around cloud computing, most cloud implementations go the way of the private cloud and avoid the public clouds for now. Private clouds are exactly what they sound like. Your own instance of SaaS, PaaS, or IaaS that exists in your own data center, all tucked away, protected and cozy. You own the hardware, you can hug your server.
However, what defines a private cloud these days could also mean systems that are remotely hosted but dedicated to a single enterprise, and, in some cases, provided out of a public cloud data center as a virtual private cloud. Thus any cloud infrastructure that's dedicated to a single organization is getting the "private cloud" label. This includes the emerging relabeling of existing enterprise software and hardware solutions, looking to deliver cloud-in-a-box private clouds.
If this sounds confusing, it is. The technology vendors and the hype clearly load up the term "private cloud" with everything and anything. However, the concept of private cloud computing has the potential to bring a huge amount of value to enterprise IT. That is, if we understand the right approach, and how to leverage the right technology to create the building blocks of the private cloud.
Why Go Private?
Most enterprises are eager to leverage cloud computing, but not so eager to place core business processing and critical business data on public clouds. Indeed, there may even be legal restrictions on where data may exist, as we have seen in the financial and health verticals, where some types of data may not exist outside of the enterprise. Or, the risk of compromised or lost data outweighs the value that public cloud computing will bring.While the regulations are real, most of those who select private over public cloud computing do so around control issues. Many in enterprise IT don't like to give up control of core business systems since that is where they may place their own value. If these systems are controlled and managed by others outside of the enterprise, they feel their value will be diminished. In most cases these are false perceptions.
Security is another reason to go private cloud. Public clouds provide rudimentary security subsystems that have thus far had a good track record. However, most enterprises do not consider public clouds as secure as systems that exist on site or as those remotely hosted but completely under the enterprise's control. While public cloud security is getting better, private clouds do offer fewer security risks.
Finally, there are performance issues with public clouds that include the natural latency of leveraging the Internet. This is a matter of how the applications and systems are designed more than limitations of the clouds, but in some instances these are valid concerns in problem domains with a high amount of data transfer between the data server and the consumer.
What's a Private Cloud?
NIST defines a private cloud as "The cloud infrastructure is operated solely for an organization. It may be managed by the organization or a third party and may exist on premise or off premise." For the most part, that is the definition that many are running with. However, let's go a few steps farther to define the core attributes of private clouds, and cloud computing in general. They are:
- Multitenancy and resource pooling
- Self or auto-provisioning
- Use-based accounting
- Security
- Governance
First you'll notice that virtualization is not on the list despite the fact that those who leverage virtualization often call clusters of virtualized servers a private cloud. The reality is that virtualization is often used when building a private cloud, and it is described below as a building block. But simple virtualization does not a private cloud make, and you choose to leverage it or not. For example, Google's cloud systems do not leverage virtualization but Amazon's AWS does. …

David continues with definitions of the items in the preceding list and describes “Building Blocks of Private Cloud.” He concludes:
Best Practices
While private clouds are still very new in our world, some best practices are beginning to emerge around how to define, design, and implement a private cloud.The first best practice is to focus on the requirements before you begin your journey to a private cloud solution. Many tasked to deploy private clouds often skip the requirements, and thus take a shot in the dark around the best architecture and technology requirements, and thus they often miss the mark. As a rule, make sure to move from the requirements, to the architecture, and then to the solution. While the lure of a private cloud-in-a-box is sometimes too difficult to resist, most solutions require a bit more complex planning process to deliver the value.
Also recommended is the use of service oriented architecture (SOA) approaches around the definition and architecture of private clouds. Many find that the use of SOA concepts, which can deliver solutions as sets of services that can be configured into solutions, is a perfect match for those who design, build, and deploy private clouds.
The second best practice is to define the business value of the private cloud before the project begins. There should be a direct business benefit that is gained from this technology. Many private cloud deployments will cost many millions of dollars, and will thus draw questions from management. You need to be prepared to provide solid answers as to the ROI.
The final best practice is to work in small increments. While it may seem a good idea to fill half the data center with your new private cloud ... you'll need the capacity at some point right? Not now. You should only create private cloud instances with the capacity requirements for the next year. If you've designed your private cloud right, and have leveraged the right vendors, increasing capacity should be as easy as adding additional servers as needed.
In Your Future?
Private clouds are really a direct copy of the efficiency of public cloud computing architectures, repurposed for internal use within enterprises. The benefits are somewhat different, as is the technology, architecture, and the way private clouds are deployed. In many respects private clouds are just another internal system, but it's the patterns of use where the value of private clouds really shines through, including access to shared resources that can be allocated on-demand.Challenges that exist include the confusion around the term "private cloud," which is overused simply as way to push an existing software or hardware product as something that's now "a cloud," and thus relevant and cool. This cloud washing has been going on for some time with everything from disk drives, printers, and scanners being positioned within the emerging space of the private cloud as "clouds."
The only way to counter this confusion is to stick to our guns in terms of what a private cloud is, including its attributes and building blocks as discussed in this article. Without a clear understanding of the concept of a private cloud, and the best practices and approaches to build a private cloud, it won't provide the value we expect.
I’m surprised David didn’t address hybrid clouds.
<Return to section navigation list>
Cloud Security and Governance
David Linthicum (@DavidLinthicum) asserted “The use of the cloud could actually enhance your ability to manage IT successfully within complex regulations” in a deck for his The case for compliance as a cloud service article of 8/16/2011 for InfoWorld’s Cloud Computing blog:
IT must deal with an increasing number of regulations, many of which come with stiff legal and financial penalties for noncompliance. As cloud computing comes on the scene, it's no wonder that many in IT push back on its use, which in many instances forces you to give up direct control of systems that have to be maintained with these regulations in mind. As one client put it, "Why would I let somebody who does not work here get me arrested?"
But there's another, better way to think about this issue. There is no legal reason why the systems that have to maintain compliance can't exist in the cloud. In fact, it could be better to have some of those systems in the cloud. Unfortunately, many in IT don't see the possibility because of nightmares about a cloud provider's mistake leading to big trouble.
The trouble with regulations is that they constantly change, and thus need to be managed as if they were a consistently shifting set of users and/or business requirements. This affects how security subsystems function and how information is tracked around the interpretation of government or legal mandates. Therefore, many hundreds of IT shops figure out ways to maintain compliance, perhaps not all resulting in the same solutions -- and that means mistakes, inconsistencies, and wasted effort.
That's where cloud computing provides an opportunity. In many instances, the ability to comply with existing regulations or keep up with changing regulations can be outsourced to a cloud computing provider that can solve these problems for all subscribers. For example, a provider could offer a type of encryption that's now a government mandate or log transactions in specific ways to meet the letter of the law.
It's much cheaper and perhaps safer to use cloud providers for many of the services required of you to maintain compliance in your industry. Such centrally managed compliance based on the same rules is more effective and efficient. There are already some examples of this cloud-based compliance today, such as in industry-specific cloud services for health care, finance, and government.
More of these features should be provided from cloud services precisely because they can be centrally managed. That means better consistency and assurance about your actual compliance -- and less work to get there.

<Return to section navigation list>
Cloud Computing Events
The Windows Azure Team (@WindowsAzure) recommended in an 8/16/2011 post that you Don’t Miss Live Global Chat on Ortsbo with the Andretti Racing Family on Saturday, August 27, 2011 at 9:00 am PT:
A division of Intertainment Media, Ortsbo allows users around the world to communicate with family, friends and colleagues by enabling them to break down language and cultural barriers through an easy to use, language-centric interface.
Ortsbo’s new HTML alpha platform offers users the ability to connect to Facebook, MSN and Google Talk; other social networks will be added quickly. The HTML version of Ortsbo, combined with the power of Windows Azure, allows both commercial and consumer use of Ortsbo without the need to download a plug-in, facilitating real time translated chat for virtually all worldwide browser-enabled devices.
Presented by Andretti Autosport, together with INDYCAR and Ortsbo, the chat will be broadcast live to fans around the world from Infineon Raceway in Sonoma, Calif., which was the site of Marco Andretti's first win.
Eric Nelson (@ericnel) described FREE One Day Windows Azure Discovery Workshops for product authors - first is September 12th in an 8/16/2011 to his IUpdatable blog:
In September we will start to deliver monthly workshops on the Windows Azure Platform to help Microsoft partners who are developing software products and services and would like to explore the relevance and opportunities presented by the Windows Azure Platform for Cloud Computing.
Overview:
Who should attend:
These workshops are aimed at technical decision makers including CTOs, Technical Directors, senior architects and developers. Attendees should be from companies who create software products or services used by other organisations. For example Independent Software Vendors.
There are a maximum of 12 spaces per workshop and one space per partner.
Format:
This format is designed to encourage discussion and feedback and ensure you get any questions you have about the Windows Azure platform answered. There will be the opportunity for more detailed one to one conversations over lunch and into the afternoon.
Topics covered will include:
- Understanding Microsoft’s Cloud Computing Strategy
- Just what is the Windows Azure platform?
- Exploring why software product authors should be in interested in the Windows Azure Platform
- Understanding the Windows Azure Platform Pricing Model
- How partners are using the Windows Azure platform today
- Getting started building solutions that utilise the Windows Azure Platform
- Drilling into the key components – Windows Azure, SQL Azure, AppFabric
Registration is 9:30 for a 10am start. There will be lunch at around 1pm after which the formal part of the workshop will finish. The good news is the Microsoft team will remain to continue the discussion in a more informal format.
How to register:
If you are interested in attending, please email ukdev@microsoft.com with the following:
- Your Company Name
- Your Role
- Why you would like to attend
- You current knowledge/exposure to Cloud Computing and the Windows Azure Platform

<Return to section navigation list>
Other Cloud Computing Platforms and Services
Jeff Barr (@jeffbarr) described the AWS Toolkit for Eclipse - Version 2.0 in an 8/16/2011 post to the AWS Evangelist blog:
We have added a number of handy and useful features to the popular AWS Toolkit for Eclipse. The toolkit includes the AWS SDK for Java; you can use it to develop AWS applications for deployment directly on Amazon EC2 or via AWS Elastic Beanstalk.
The new features include a new AWS Explorer, support for multiple AWS accounts and identities, new editors for Amazon S3, Amazon SNS, and Amazon SQS, a new SimpleDB query editor, remote debugging for Elastic Beanstalk environments, and support for creating connections to databases hosted on Amazon RDS.
Here's a tour. The AWS Explorer displays all of your AWS resources in a single hierarchy:
You can expand any service node to see what's inside:
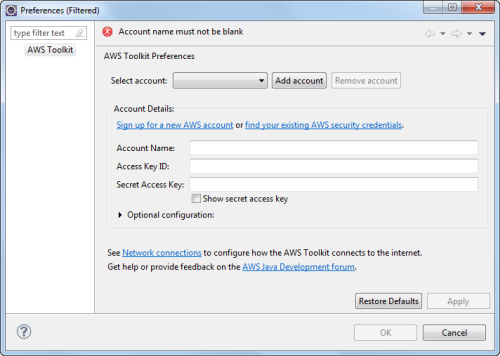
You can now add multiple AWS accounts or IAM user credentials, and you can easily activate any one of them as needed. You can now manage development, test, staging, and production services within a single session, using IAM users to control access to each:
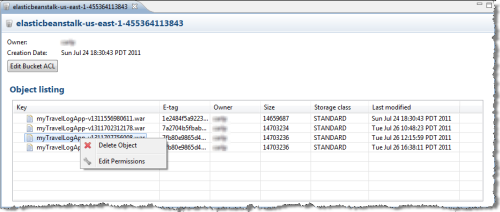
You can now view and edit the contents of any of your S3 buckets:
You can also take a look at any of your SQS queues:
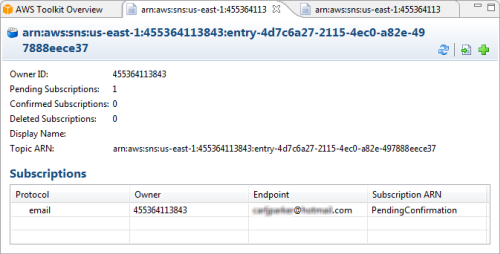
You can also view your SNS topics and subscriptions:
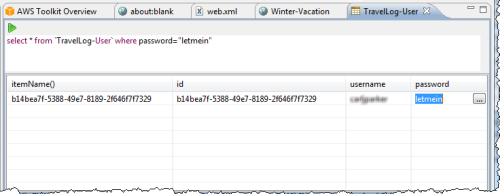
You can query any of your SimpleDB domains:
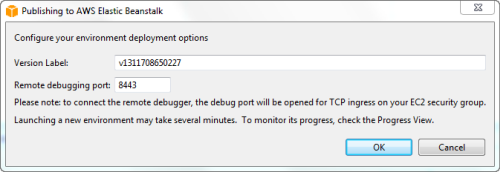
You can debug an Elastic Beanstalk application from within Eclipse. The toolkit will even automatically open up the proper remote debugging port for you:
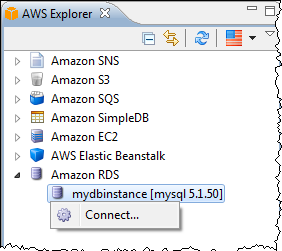
You can also connect to RDS Database Instances:
The newest AWS Toolkit for Eclipse can be downloaded here. We've also put together a brand new version of the Getting Started Guide.





<Return to section navigation list>

















0 comments:
Post a Comment