Windows Azure and Cloud Computing Posts for 5/25/2010+
 | Windows Azure, SQL Azure Database and related cloud computing topics now appear in this daily series. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now download and save the following two online-only chapters in Microsoft Office Word 2003 *.doc format by FTP:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available from the book's Code Download page; these chapters will be updated in June 2010 for the January 4, 2010 commercial release.
Azure Blob, Drive, Table and Queue Services
OakLeaf Systems recommends that you exercise the live OakLeaf Systems Azure Table Services Sample Project that’s running on Microsoft’s South Central US (San Antonio, TX) Data Center and demonstrates Azure Table Services paging, bulk entity deletion and creation, etc.:

Check out the Azure Storage Services Test Harness: Table Services 1 – Introduction and Overview and the six later later episodes in this Azure Table Services tutorial:
Captain Codeman explains Running MongoDb on Microsoft Windows Azure with CloudDrive in this 5/24/2010 post:
I’ve been playing around with the whole CQRS approach and think MongoDb works really well for the query side of things. I also figured it was time I tried Azure so I had a look round the web to see if there we’re instructions on how to run MongoDb on Microsoft’s Azure cloud. It turned out there were only a few mentions of it or a general approach that should work but no detailed instructions on how to do it. So, I figured I’d give it a go and for a total-Azure-newbie it didn’t turn out to be too difficult.
Obviously you’ll need an Azure account which you may get with MSDN or you can sign-up for their ‘free’ account which has a limited number of hours included before you have to start paying. One thing to be REALLY careful of though – just deploying an app to Azure starts the clock running and leaving it deployed but turned off counts as hours so be sure to delete any experimental deployments you make after trying things out!!
First of all though it’s important to understand where MongoDb would fit with Azure. Each web or worker role runs as a virtual machine which has an amount of local storage included depending on the size of the VM, currently the four pre-defined VMs are:
- Small: 1 core processor, 1.7GB RAM, 250GB hard disk
- Medium: 2 core processors, 3.5GB RAM, 500GB hard disk
- Large: 4 core processors, 7GB RAM, 1000GB hard disk
- Extra Large: 8 core processors, 15GB RAM, 2000GB hard disk
This local storage is only temporary though and while it can be used for processing by the role instance running it isn’t available to any others and when the instance is moved, upgraded or recycled then it is lost forever (as in, gone for good).
For permanent storage Azure offers SQL-type databases (which we’re not interested in), Table storage (which would be an alternative to MongoDb but harder to query and with more limitations) and Blob storage.
We’re interested in Blob storage or more specifically Page-Blobs which support random read-write access … just like a disk drive. In fact, almost exactly like a disk drive because Azure provides a new CloudDrive which uses a VHD drive image stored as a Page-Blob (so it’s permanent) and can be mounted as a disk-drive within an Azure role instance.
The VHD images can range from 16Mb to 1Tb and apparently you only pay for the storage that is actually used, not the zeroed-bytes (although I haven’t tested this personally).
So, let’s look at the code to create a CloudDrive, mount it in an Azure worker role and run MongoDb as a process that can use the mounted CloudDrive for it’s permanent storage so that everything is kept between machine restarts. We’ll also create an MVC role to test direct connectivity to MongoDb between the two VMs using internal endpoints so that we don’t incur charges for Queue storage or Service Bus messages.
The Captain continues with a detailed tutorial and sample code to get MongoDB up and running in Windows Azure.
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
Gavin Clarke reports a “VoltDB shocker” in his Database daddy goes non-relational on NoSQL fanbois post of 5/25/2010 about Michael Stonebraker’s new in-memory database:
Postgres and Ingres father Michael Stonebraker is answering NoSQL with a variant of his relational baby for web-scale data — and it breaks some of the rules he helped pioneer.
On Tuesday, Stonebraker’s VoltDB company is due to release its eponymous open-source OLTP in-memory database. It ditches just enough DBMS staples to be faster than NoSQL while staying on the right side of the critical ACID database compliance benchmark for atomicity, consistency, isolation and durability of data.
VoltDB claimed that the database is between five and ten times faster than NoSQL’s Cassandra on a Dell PowerEdge R610 cluster based on Intel’s Xeon 5550, and it said that VoltDB is 45 times faster than an Oracle relational database on the same hardware, with near-linear scaling on a 12-node cluster.
VoltDB is the fruit of the H-Store-project, a collaboration between MIT (Stonebraker’s academic home), Brown University, Yale University and Hewlett-Packard Labs that sought to build a next-generation transaction processing engine. An early H-Store prototype could out-perform a commercial DBMS by a factor of 80 on OLTP workloads, it was claimed.
VoltDB co-founder and chief technology officer Stonebraker ran afoul of web data movement while brewing H-Store, when he compared Google’s MapReduce to RDBMS and dared to say it was lacking.
He and computer science professor David DeWitt were pilloried by Google fanbois for “not getting” data in the cloud, after the two of them said MapReduce ignored many of the developments in parallel DBMS technology over the last 25 years.
It now seems that Stonebraker — the main architect on Ingres and Postgres and an adjunct professor of computer science at MIT — has answered the fans by reaching for the cloud without offering yet another NoSQL variant to an already crowded field. VoltDB is currently under test with 200 beta customers, and it has one paying user.
Like NoSQLers, VoltDB has bumped its speed by moving data into memory and off disc, and dumping features such as logging, locking, latching and buffer management that hinder performance and scalability in big deployments. VoltDB also adds distributed data partitioning for speed, with performance further helped by multi-core processors on chips and the additional memory in today’s servers.
To retain ACID compliance, VoltDB uses single-threaded partitions that run autonomously while the data itself is replicated in a cluster for high availability.
VoltDB vice president of marketing Andy Ellicott told The Reg: “The challenge is to remove all the overhead, but — unlike the NoSQL key value store guys — keep ACID properties, to make sure the database maintains integrity of data automatically and make sure the database can be accessed by the SQL.
“We will work between partitions in an ACID way — that separates us from the sharders, as opposed to writing roll-back logic. It’s true ACID.”
While VoltDB has followed the NoSQL key-value crowd by ditching DBMS features, it has held on to the relational data model. It has also hidden the underlying complexity of VoltDB that programmers would have encountered by writing their software to different clusters. The problem with other projects is that by dumping the relational model, they're forcing architects to find new ways of building their applications.
Programming to VoltDB is done through Java stored procedures, while VoltDB routes queries to different servers without the programmer’s application needing to know the topology of the cluster.
VoltDB is available as a community edition (free under a GPL license) and a commercial license, which costs $15,000 for a four-server cluster on an annual subscription. That price buys you roadmap updates, patches, and services. Each additional server is priced at $3,000. Updates to VoltDB are planned within the next year to let you automatically add clusters and repartitioning. ®
The commercial version appears a bit pricey. Wondering about the registered trademark (®) symbol at the end.
See Scott Hanselman reports that he presented OData Basics - At the AZGroups "Day of .NET" with ScottGu in this 5/24/2010 post and Webcast in the Cloud Computing Events section below.
<Return to section navigation list>
AppFabric: Access Control and Service Bus
The NetSqlServiceTeam posted IIS Hosted WCF Services using AppFabric Service Bus to the Windows Azure Platform AppFabric Team Blog on 5/25/2010:
Through a number of customer engagements we’ve heard time and again how extending current SOA investments to the cloud, through the use of Windows Azure AppFabric, has been transformative for our customer’s businesses.
Customers have accrued value in many areas, but one theme that gets repeated over and over again is taking current back-end systems and connecting those systems to AppFabric Service Bus.
Whether companies are extending high-value on-premises systems to the cloud for mobile workforce access or partner access, AppFabric Service Bus, coupled with AppFabric Access Control, has allowed these customers to extend the life of their systems with new cloud-enabled scenarios. The really interesting part here is that these customers have been able to cloud-enable existing systems without the cost and risk of rewriting and hosting them in the cloud.
In cases where customers are aggressively moving their software assets to the cloud, they too have leveraged the connectivity provided by Windows Azure AppFabric to keep their Tier 1 applications running in their own datacenters. With AppFabric, they are able to maintain control of these business critical systems, letting them run in their own datacenter(s), managed by their own IT staff, but cloud-enable them through AppFabric.
In an effort to further cloud-enable existing systems, one of our team members wrote a whitepaper that shows how to take WCF services hosted in IIS 7.5 and connect them up to the AppFabric Service Bus. This has been a frequently requested feature, so we’re excited to get this whitepaper out.
If you have WCF services hosted in IIS 7.5 and want to connect them to the cloud, this whitepaper will show you how to enable that scenario.
This appears to be an update to or replacement for the 5/19/2010 post of the same name.
Eugenio Pace’s Windows Azure Architecture Guide – Part 2 – TailSpin Surveys – AuthN and AuthZ post of 5/24/2010 explains authorization methods:
Tailspin Surveys is a multitenant, SaaS solution, targeting many different customers. Some of these customers might be “enterprise” with “Big-IT” and are likely to demand advanced integration capabilities for identity (e.g. identity federation). Others, potentially smaller, are likely to not require these. Even smaller companies (e.g. someone working from home) might even want to reuse one of their existing identities (their e-mail provider, their LiveID, etc)
These 3 possibilities are illustrated above:
- Adatum (the “big company”) uses ADFS to issue tokens for TailSpin Surveys. They want their employees (e.g. John) to have SSO between their own applications (potentially on-premises, but not necessarily). TailSpin Surveys will just trust their identity provider (ADFS in the example). Tokens issued by Adatum’s identity provider are therefore accepted in Tailspin Surveys.
- Fabrikam (the “small company”). It has AD, but no ADFS (or any other equivalent infrastructure). The can’t issue tokens that TailSpin can understand and they have no desire to change anything from their side. For customers like Fabrikam, TailSpin provides an identity provider of their own that they can use (they federate with themselves). The biggest drawback is that Fabrikam users will have to remember another username/password, but…not many employees in Fabrikam use Surveys anyway. With this architecture however, TailSpin prepares better for the future. When Fabrikam upgrades their infrastructure, they would simply change the trust relationship.
- Mark working from Home (a super small company). Mark doesn’t have an ADFS under his desk. It is likely that Mark does most of his work from a single PC, with quite a bit of software being delivered to him as a service (like Surveys). Mark however, already uses LiveID for mail (e.g.Hotmail) and various other things. For people like Mark, TailSpin offers the opportunity to associate this external identities with the application.
What’s important is that the application (Surveys) is completely agnostic of how the users authenticates. All this is delegated. trust is established as part of the on-boarding process when a new tenant subscribes to Surveys. This of course can be highly automated or completely manual.
If all this sounds familiar to you, don’t worry. You are not crazy :-). We have covered this same scenario many times already:
- Exploring the Service Provider track – First station: Fabrikam Shipping – Part I (the scenario & challenges)
- Exploring the Service Provider track – Fabrikam Shipping Part II (Solution)
Fortunately, most of the design needed for TailSpin is already covered in the “Claims Identity Guide”. There’s quite a bit we are reusing from it. Since Surveys is an MVC application we will be using exactly the same approach for securing it with claims. This other post describes how it works:WIF and MVC – How it works.

<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Bob Familiar reports ARCast.TV - SOASTA uses Windows Azure to offer CloudTest Solutions in this 5/25/2010 post to the Innovations Showcase blog:
SOASTA, based in California, … offers both internally installed and cloud-based testing applications. SOASTA developed a cloud-based testing application that it now deploys on the Windows Azure platform.
Their CloudTest Service Helps Performance-Testing Firm Simulate Real-World Internet Traffic. With the Windows Azure platform SOASTA has easy access to servers all over the world under a pay-as-you-go pricing model.
The company recently demonstrated its CloudTest® application in a case-study test of Office.com for Microsoft.
In this episode, Hong Choing talks to Tom Lounibos, CEO of SOASTA, and Brad Johnson, VP of Business Development, about their elastic CloudTest services on Windows Azure, partnership with CSC, and their views on Cloud computing trends and business impact.
ARCast.TV - SOASTA uses Windows Azure to offer CloudTest Solutions
More details, here.

Bruce Kyle’s ISV Video: Nubifer Expands Enterprise Mashups to Azure post of 5/25/2010 to the US ISV Developer blog describes Nubifer’s Cloud:Link application:
Cloud:Link from Nubifer monitors cloud-based applications and any URI in an enterprise from Windows Azure .It monitors your enterprise systems in real time, and strengthens interoperability with disparate owned and leased SaaS systems includes Windows Azure.
Nubifer Cloud:Link monitors your enterprise systems in real time, and strengthens interoperability with disparate owned and leased SaaS systems. When building "Enterprise Mash-ups" , custom addresses and custom source codes are created by engineers to bridge "the white space", or "electronic hand-shakes", between the various enterprise applications within your organization. By using Nubifer Cloud:Link, you gain a real time and historic view of system based interactions.
Cloud:Link is designed and configured via robust admin tools to monitor custom "Enterprise Mash-ups" and deliver real time notifications, warning and performance metrics of your separated, but interconnected business systems. Cloud:Link offers the technology and functionality to help your company monitor and audit your enterprise system configurations.
Video Link: Nubifer cloud solution on Windows Azure
Suresh Sreedharan talks with Chad Collins, CEO at Nubifer Inc. about Nubifer's cloud offering on the Windows Azure platform.
About Nubifer
Nubifer provides mid to large size companies with scalable cloud hosted enterprise applications - SaaS (software as a service), PaaS (platform as a service), HRIS (human resource information systems), CRM (customer resource management) and data storage offerings. In addition, Nubifer provide our noted consulting support and cloud infrastructure consulting services.

Aashish Dhamdhere said We Want to Showcase Your 'Building Block' Solutions for Windows Azure in this 5/25/2010 post to the Windows Azure blog:
One of the core benefits of Windows Azure is how it increases developers' agility to get their ideas to market faster. We believe the 'building block' components and services that our community of developers is building illustrates this benefit by helping address particular scenarios and making the process of developing compelling and complete solutions on Windows Azure easier and faster.
'Building block' components and services are designed to be incorporated by other developers into their applications (e.g. a billing engine that developers can use to quickly add paid subscriptions to their web application). Other examples include (but are not limited to) management tools, UI controls, and email services.
As one of the people responsible for marketing Windows Azure, I'm always on the lookout for the latest and greatest community-built components and services to help us showcase the unique benefits of Windows Azure. So if you've built a component, service, or application that helps make development on Windows Azure easier or faster, I want to hear from you. If you're interested in learning more, please drop me an email and I'll follow up with you.
This appears to be a repeat of a previous post that might have been updated or redated.
R. Bonini’s Running Windows Communication Foundation on Windows Azure post of 5/24/2010 describes how to munge config files to use IIS hosting of WCF in Azure:
In general, WCF can be run in a number of ways.
- The First is to use IIS to host your service for you. IIS will take care of port mapping between internal and external ports.
- The Second is to self host. This means that your process will create a ServiceHost, passing in the appropriate class. Your service is responsible for error handling and termination of the WCF service. The service class itself can contain the Service behaviour attributes or you can stick them in the app.config file. This also means that you have to ensure that the WCF service is listening on the correct port when you create it.
In Windows Azure terms, the first method would be a Web role, and the second method would be a worker role.
It should be noted that all of the above methods and code patterns are perfectly legitimate ways to create and host a WCF service. The question here is, which of these ways will run on Windows Azure.
Programming for Windows Azure is generally an easy thing so long as your application start up code is correct. If there are any exceptions in your start up code, the role will cycle between Initializing, Busy and Stopping. Its enough to drive you mad. Therefore, if you choose to self host, you need to be sure that your worker role code runs perfectly.
For all your Windows Azure applications its also a good idea to create a log table using Windows Azure tables to assist you in debugging your service.
Now, before you begin any WCF Azure work, you need to install a patch. WCF can exhibit some strange behaviour when deployed behind a load balancer.Since all Windows Azure service instances are behind a LB by default, we need to install this patch. This patch is also installed in the cloud.
You can find the patch, as well a thorough run down of all the WCF issues in Azure here. While I’m not attempting to tackle all of the problems, and indeed the solutions to them, i do aim to get a basic service working with as little fuss as possible.
IIS Hosting
It must be said that i did try all sorts of settings in the config file. It turns out that the one with almost no actual settings is the one that works. basically this forces us to rely on IIS to do the configurations for us. On one hand this is a good thing, saving us the hassle. On the other, there is some loss of control that the programmer in me does not like.
Bonini shows the config file’s <system.servicemodel> section and then explains that self-hosting WCF works in the Development Fabric but not in the Cloud Fabric.
Ammalgam asserts Makes perfect sense – Wordpress and Windows Azure integration in this 5/24/2010 post to the Cloud Computing Zone blog:
A free and open source plugin developed by Microsoft is the latest example of PHP and Windows Azure interoperability to come from the company, after various other offerings, including a PHP software development kit for the Cloud platform.
By leveraging the plugin, customers running WordPress will be able to take advantage of the storage capacity offered by the software giant’s Cloud operating system. Essentially, the plugin was designed to bridge WordPress with the Windows Azure Storage Service, enabling customers to host media content in the Cloud, Jean-Christophe Cimetiere, Microsoft Sr. technical evangelist, revealed.
“The Windows Azure Storage plugin for WordPress allows developers running their own instance of WordPress to take advantage of the Windows Azure Storage services, including the Content Delivery Network (CDN) feature. It provides a consistent storage mechanism for WordPress Media in a scale-out architecture where the individual web servers don’t share a disk.
Note that this scenario goes beyond WordPress and could also be very compelling any other web application where there’s a need to load balance across a number of web servers without shared disk,” Cimetiere explained.
Windows Azure Storage for WordPress is, of course, available for download free of charge, as it is an open source project hosted in the WordPress repository. Users already familiar with the WordPress blogging platform are undoubtedly also familiar with the process of installing a plugin, and will be able to deploy Windows Azure Storage for WordPress without any problems.
The web page describes the plugin this way…
This WordPress plugin allows you to use Windows Azure Storage Service to host your media for your WordPress powered blog. Windows Azure Storage is an effective way to scale storage of your site without having to go through the expense of setting up the infrastructure for a content delivery.

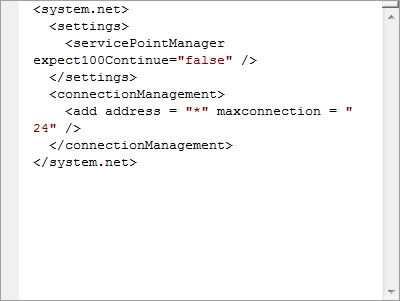
The Cennest group offers Bulb Flash:- Few tips to Reduce Cost and Optimize performance in Azure! in this 5/15/2010 post:
- Perform better at
- Lesser cost.
-
expect100Continue:- The first change switches off the ‘Expect 100-continue’ feature. If this feature is enabled, when the application sends a PUT or POST request, it can delay sending the payload by sending an ‘Expect 100-continue’ header. When the server receives this message, it uses the available information in the header to check whether it could make the call, and if it can, it sends back a status code 100 to the client. The client then sends the remainder of the payload. This means that the client can check for many common errors without sending the payload. If you have tested the client well enough to ensure that it is not sending any bad requests, you can turn off the ‘Expect 100-continue’ feature and reduce the number of round-trips to the server. This is especially useful when the client sends many messages with small payloads, for example, when the client is using the table or queue service.
-
maxconnection:-The second configuration change increases the maximum number of connections that the web server will maintain from its default value of 2. If this value is set too low, the problem manifests itself through "Underlying connection was closed" messages.
WCF Data Optimizations(When using Azure Storage)
If you are not making any changes to the entities that WCF Data Services retrieve set the MergeOption to “NoTracking”
Implement paging. Use the ContinuationToken and the ResultSegment class to implement paging and reduce in/out traffic.
These are just a few of the aspects we at Cennest keep in mind which deciding the best deployment model for a project..
Applications deployed on [A]zure are meant to
As a software developer its inherently your job to ensure this holds true..
Here are a few pointers to keep in mind when deploying applications on Azure to make sure your clients are happy:-)
Application Optimizations
Cloud is stateless , so if migrating an existing ASP.NET site and you are expecting to have multiple web roles up there then you cannot use the default in memory Session state..You basically have 2 options now
Use ViewState instead . Using ASP.NET view state is an excellent solution so long as the amount of data involved is small. But if the data is huge you are increasing your data traffic , not only affecting the performance but also accruing cost… remember..inword traffic is $.10/GB and outgoing $0.15/GB.
Second option is to persist the state to server side storage that is accessible from multiple web role instances. In Windows Azure, the server side storage could be either SQL Azure, or table and blob storage. SQL Azure storage is relatively expensive as compared to table and blob storage. An optimum solution uses the session state sample provider that you can download from http://code.msdn.microsoft.com/windowsazuresamples. The only change required for the application to use a different session state provider is in the Web.config file.
Remove expired sessions from storage to reduce your costs. You could add a task to one of your worker roles to do this .
Don’t go overboard creating multiple worker roles which do small tasks. Remember you pay for each role deployed so try to utilize each node’s compute power to its maximum. You may even decide to go for a bigger node instead of creating a new worker role and have the same role do multiple tasks.
Storage Optimization
Choosing the right Partition and Row key for your tables is crucial.Any process which needs to tablescan across all your partitions will be show. basically if you are not being able to use your partition key in the “Where” part of your LINQ queries then you went wrong somewhere..
Configuration Changes
See if you can make the following system.configuration changes..
Return to section navigation list>
Windows Azure Infrastructure
James Hamilton reports PUE is Still Broken and I still use it in this 5/24/2010 post:
PUE is still broken and I still use it. For more on why TPUE has definite flaws, see: PUE and Total Power Usage Efficiency. However, I still use it because it’s an easy to compute summary of data center efficiency. It can be gamed endlessly but it’s easy to compute and it does provide some value.
Improvements are underway in locking down of the most egregious abuses of PUE. Three were recently summarized in Technical Scribblings RE Harmonizing Global Metrics for Data Center Energy Efficiency. In this report from John Stanley, the following were presented:
- Total energy to include all forms of energy whether electric or otherwise (e.g. gas fired chiller must include chemical energy being employed). I like it but It’ll be a challenge to implement
- Total energy should include lighting, cooling, and all support infrastructure. We already knew this but its worth clarifying since it’s a common “fudge” employed by smaller operators
- PUE energy should be calculated using source energy. This is energy at the source prior to high voltage distribution losses and including all losses in energy production. For example, for gas plants, it’s the fuel energy used including heat losses and other inefficiencies. This one seems hard to compute with precision and I’m not sure how I could possibly figure out source energy where some power is base load power and some is from peak plants and some is from out of state purchases. This recommendation seems a bit weird.
As with my recommendations in PUE and Total Power Usage Efficiency, these proposed changes add complexity while increasing precision. Mostly I think the increased complexity is warranted although the last, computing source energy, looks hard to do and I don’t fully buy that the complexity is justified.
It’s a good short read: Technical Scribblings RE Harmonizing Global Metrics for Data Center Energy Efficiency.
David Gristwood posted his 00:10:57 Conversations with David Chappell about Windows Azure and Cloud Computing Webcast to Channel9 on 5/25/2010:
David Gristwood engages David Chappell in conversation about Windows Azure and cloud computing, and explore which applications are great candidates for Windows Azure, and, interestingly which ones don’t, as well as discussing the differences between Infrastructure vs Platform as a Service, and the role of private vs public cloud.

Edwin Yapp quotes [Steve] Ballmer: Make cloud easy to access in Malasia in this 5/25/2010 post to ZDNet Asia:
PUTRAJAYA--Small and midsize businesses (SMBs) in Malaysia will likely only embrace cloud computing services if technology providers make them easy to implement, according to Microsoft CEO Steve Ballmer.
Speaking to the media Tuesday during the launch of its cloud computing services here in the country's administrative capital, Ballmer noted that SMBs are "change resistant" and this is true not only in emerging countries such as Malaysia but also in other developed nations.
"SMBs typically have nobody responsible for IT and even midsize businesses have few resources to handle IT," he said. "Malaysia has over 600,000 SMBs that have yet to automate or are currently under automated. For many, it's a first step for them, if we can make it simple enough."
Ballmer noted that SMBs want to be in control of their business, including their IT infrastructure and data. "But being in control does not necessarily mean their IT infrastructure is well managed. So the top issue [in my mind] is to get people over the notion of [needing to have] control," said Ballmer.
In this aspect, he said Microsoft will have to work to ensure it does not feed the natural concerns and trepidations that these businesses have over cloud computing.
He noted that if SMBs in Malaysia can overcome their natural fear of not having control of their IT infrastructure and embrace what cloud computing has to offer, they would stand to benefit greatly.
Microsoft cloud in Malaysia
Malaysian businesses can now access Microsoft's full range of cloud computing capabilities, delivered over the vendor's Windows Azure platform.
Microsoft also launched here today its cloud computing suite called Business Productivity Online Suite (BPOS), which encompasses SharePoint Online, Exchange Online, Office Life Meeting and Office Communications Online.Ballmer added that for cloud computing to be deployed successfully, a country must have a strong broadband infrastructure.
"Malaysia has a decent broadband infrastructure and given the government's commitment to make it a national priority, we're betting that the broadband infrastructure will [eventually] get there," he said.

Jon Brodkin counts “Cloud apps are free, will put you out of work, and other misconceptions” among his Six misconceptions about cloud apps in this 5/25/2010 five-page article for NetworkWorld’s Data Center blog:
Cloud computing is all the rage in the IT industry these days, but there's still plenty of confusion about how cloud applications work and what kind of long-term impact they will have on business technology.
In this article we'll take a look at six common misconceptions IT pros and users have about cloud apps, related to performance, security, management, cost and the long-term effect on IT staffing.
1. Cloud computing will put IT pros out of a job
It's true that shifting internal IT functions to cloud applications lessens the need for a business to have a huge IT staff. Some organizations have moved to cloud services such as Google Apps because they no longer had the staff to handle an internal e-mail and collaboration system. This cause-and-effect may be switched in other cases, with layoffs occurring because of a move to outsourcing.
But the long-term risk to IT employees may not be as terrible as it might first appear, analysts say. For a business that uses many cloud apps, internal IT staff is still needed to manage and integrate the services. Some IT managers may start to see themselves more as vendor managers.
"There's no question it could reduce the demand for traditional IT skills," says analyst Jeff Kaplan, managing director of Thinkstrategies. "But that doesn't mean there can't be a whole new generation of requirements around vendor management, to properly evaluate, select, monitor, manage and contract with these cloud computing companies."
These "traditional" IT pros might find their roles shifting to business unit support, making sure every employee has the right cloud tools to do his or her job. Another obvious point is that, over time, as technology resources shift from customers to vendors, the vendors will have a greater need for IT pros, creating more jobs on the vendor side.
If you're an IT administrator managing servers, applications and other in-house systems today, a shift to cloud computing could force you to learn new skills or eventually find a job elsewhere. But smart tech people already know their industry undergoes constant change, and should be ready to adapt.
2. The cloud is free (or at least incredibly inexpensive)
The Google Apps business version is $50 per user per year. Microsoft's online services start at $120 per year, and both Google and Microsoft offer free versions to home users.
That sounds inexpensive, because it is, but users and analysts are quick to point out that licensing is not the only cost of using a cloud service.
"One of the biggest preconceived notions you have is that it's free. It's out there, it's not a big deal, just sign up and everything's great," says Scott Weidig, who is a technology coordinator at Schaumberg High School in Illinois and uses a variety of cloud apps for business and personal use, including Zoho and Google Apps.
Some customers report having to upgrade Internet bandwidth to take advantage of cloud services (more on that later in this article).
Jon continues with details of the following misconceptions:
3. Cloud performance is never a problem …
4. You can replace Microsoft Office with Google, or Zoho, or…
5. The cloud is easy to set up and manage …
6. Security is [fill in the blank] …

<Return to section navigation list>
Cloud Security and Governance
Lydia Leong claimed Lightweight Provisioning != Lightweight Process in this 5/25/2010 post to her Cloud Pundit: Massive-Scale Computing blog:
Congratulations, you’ve virtualized (or gone to public cloud IaaS) and have the ability to instantly and easily provision capacity.
Now, stop and shoot yourself in the foot by not implementing a lightweight procurement process to go with your lightweight provisioning technology.
That’s all too common of a story, and it highlights a critical aspect of movement towards a cloud (or just ‘cloudier’ concepts). In many organizations, it’s not actually the provisioning that’s expensive and lengthy. It’s the process that goes with it.
You’ll probably have heard that it can take weeks or months for an enterprise to provision a server. You might even work for an organization where that’s true. You might also have heard that it takes thousands of dollars to do so, and your organization might have a chargeback mechanism that makes that the case for your department.
Except that it doesn’t actually take that long, and it’s actually pretty darn cheap, as long as you’re large enough to have some reasonable level of automation (mid-sized businesses and up, or technology companies with more than a handful of servers). Even with zero automation, you can buy a server and have it shipped to you in a couple of days, and build it in an afternoon.
What takes forever is the procurement process, which may also be heavily burdened with costs.
When most organizations virtualize, they usually eliminate a lot of the procurement process — getting a VM is usually just a matter of requesting one, rather than going through the whole rigamarole of justifying buying a server. But the “request a VM” process can be anything from a self-service portal to something with as much paperwork headache as buying a server — and the cost-savings and the agility and efficiency that an organization gains from virtualizing is certainly dependent upon whether they’re able to lighten their process for this new world.
There are certain places where the “forever to procure, at vast expense” problems are notably worse. For instance, subsidiaries in companies that have centralized IT in the parent company often seem to get shafted by central IT — they’re likely to tell stories of an uncaring central IT organization, priorities that aren’t aligned with their own, and nonsensical chargeback mechanisms. Moreover, subsidiaries often start out much more nimble and process-light than a parent company that acquired them, which leads to the build-up of frustration and resentment and an attitude of being willing to go out on their own.
And so subsidiaries — and departments of larger corporations — often end up going rogue, turning to procuring an external cloud solution, not because internal IT cannot deliver a technology solution that meets their needs, but because their organization cannot deliver a process that meets their needs.
When we talk about time and cost savings for public cloud IaaS vs. the internal data center, we should be careful not to conflate the burden of (internal, discardable/re-engineerable) process, with what technology is able to deliver.
Note that this also means that fast provisioning is only the beginning of the journey towards agility and efficiency. The service aspects (from self-service to managed service) are much more difficult to solve.

Lydia is an analyst at Gartner, where she covers Web hosting, colocation, content delivery networks, cloud computing, and other Internet infrastructure services.
Thomas Bittman posted IT Operations: From Day-Care to University to the Gartner blogs on 5/24/2010:
After spending the day discussing IT operations, here are some musings on the future of IT ops.
Traditionally, IT ops has been responsible for managing operationally "dumb" applications. These legacy applications are like infants – they need constant care and feeding. They can’t take care of themselves, and they rely entirely on others to survive. Actually, these dumb applications are even less capable than infants – at least infants cry when they’re hungry!
IT operations today is like day-care. Every infant is different, has different needs, signals their needs in different ways. There’s not much economies of scale here at all. Not a lot that can be automated. And new infants are being added daily!
There are three major paths for IT operations in the future – and each of them is very different:
(1) The Day-Care for Clones: Limit IT operations to management of a single (or small number of) applications. Knowing exactly how these applications work allows you to custom design IT operations/automation to their needs. This is what cloud providers typically do today, and application-centric environments (around Oracle, for example).
(2) The Smart Day-Care: The effort for years has been to make the day-care smarter, more adaptive, more on-demand. This has been a huge challenge, and will continue to be a huge challenge. One new concept has been the introduction of virtual machines, that can be used to encapsulate workloads – which doesn’t solve the problem, but it does enable more automation. Ideally, you still want to have metadata about what’s inside the virtual machine, which can describe service topology, security requirements, even service level requirements.
(3) The University: Expect more from the applications. They need to manage themselves, describe their requirements. They don’t "trust" infrastructure at all – if there are failures, the application is designed to be resilient and extremely self-reliant. On the other hand, IT operations still has a role. With "smart" applications, IT operations can’t necessarily trust them. The role of IT operations is to set constraints, manage the amount of resource that can be used, monitor behavior, look for changes in behavior.
The issue in IT operations is that these three paths are each viable, but each has very different skill, architecture, process, and management tool requirements. This confusion will take place inside enterprise IT – managing a mixed bag of “dumb” applications, “smart” applications, management of virtual machines, private clouds, and public clouds. Get ready for a bumpy ride!
Lori MacVittie asserts Training your data center “muscle memory” will ensure that when the pressure is on your network will make all the right moves as a preface to her Repetition is the Key to Network Automation Success post to the F5 DevCentral blog of 5/25/2010:
If you’ve ever taken dancing lessons – or musical lessons – or tried to teach yourself to type you know that repetition is the key to success. Or as your mom would tell you, “practice makes perfect.” The reason repetition is a key factor in the success of endeavors that require specific movements in a precisely orchestrated fashion is that it builds what instructors call “muscle memory.” You’re actually teaching your muscles to react to a thought or movement automatically. Once you’ve repeated the same movement over and over it becomes second nature, like a Pavlovian response.
To achieve the efficiencies associated with network automation you’ve got to build the data center’s “muscle memory”, as it were. You can’t jump from no automation to full automation in one day, just as you can’t go from the basic steps of a waltz to flying around the floor like a seasoned pro. It takes time and repetition.
Application developers may recognize this approach as an iterative, or agile one, with the key mantra being “test early, test often.”
THE DATA CENTER ORCHESTRATION DANCE
First, start by identifying two or three key tasks in an operation process and automate each of them individually. Test them (this is the practice part, by the way). Then tie them together and test again. And again. And again. Once you’re comfortable with the basic steps you can move on to adding one step at a time – always practicing the individual step first (automation) and then again as part of the operational orchestration.
As you continue to add to the orchestration through new individual steps you might start to see patterns emerging or redundant steps. This is one of the ways in which you can squeeze more efficiencies out of this new paradigm: streamline operational processes. Eliminate redundancies and, if patterns occur, abstract them into reusable operational tasks that can be leveraged across multiple orchestrations.
As you’re practicing (because you are testing and retesting, right?) and getting more proficient in the data center orchestration dance you’ll be able to start weaving together those patterns in different ways. You might find that step “a” leads more naturally into step “c” for you and, given performance data collected during practice it might even execute faster. If that’s the case, change the order around and … yes, test it again. Being light on your feet (agile) means the ability to change steps around quickly – but not at the cost of introducing errors, hence the need to practice whenever any individual step changes or the order in which steps are orchestration is modified.

OPERATIONAL EFFICIENCY
It is through automation and orchestration that a data center realizes the operational efficiencies associated with cloud computing and, to a lesser extent one of its key enabling technologies, virtualization. But that automation and orchestration requires a commitment to consistently practice (test) and refine those operational processes until they can execute in your sleep. Because that is one of the goals, after all: you can sleep at night without worrying about the availability or performance of applications being delivered over your network because your new network knows the right steps to take at the right time.
<Return to section navigation list>
Cloud Computing Events
tbTechnet reports In-person Windows Azure Boot Camps for public-sector applications in this 5/25/2010 post to the Windows Azure Platform, Web Hosting and Web Sevices blog:
If you’re a developer working on applications that provide solutions to local and regional public sector type organizations, like these applications:
- then there is great news. There are in-person Windows Azure boot camps taking place in several cities:
- Phoenix, AZ: May 26-27
- Dallas. TX: June 2-3
- Sacramento, CA: June 9-10
- Denver, CO: June 16-17
- New York, NY: June 2-3
- Austin, TX: June 23-24
- Boston, MA: June 9-10
Learn more here: http://www.azurebootcamp.com/publicsector. To submit a request to register, please email: askdpeps@microsoft.com.

David Pallman lists upcoming Azure Bootcamps sposored by Neudesic in this 5/25/2010 post:
Microsoft's Azure Bootcamps are going strong! At an Azure bootcamp you get a full day of learning Azure through a combination of presentions and hands-on labs. Starting next week, Neudesic is sponsoring the following 12 Azure bootcamps across the country in 12 locations:
- New York - June 15 RSVP
- Washington DC - June 22 RSVP
- Dallas - June 8 RSVP
- Chicago - June 24-25 RSVP
- Denver - June 4 RSVP
- Salt Lake City - June 11 RSVP
- Portland - June 1 RSVP
- San Diego - June 1 RSVP
- Orange County - June 2 RSVP
- Los Angeles - June 3 RSVP
- San Francisco - June 15 RSVP
- Seattle - June 16 RSVP
The Boston Azure Users Group reports that The Thursday May 27, 2010 meeting of the Boston Azure User Group is fast approaching! in this 5/25/2010 update:
- When? Thursday May 27, 2010; see Meeting Topics for timing of specific activities.
- Where? At the Microsoft NERD at One Memorial Drive, Cambridge, MA 02142. Phone: 857-453-6000. Click here for directions, which includes getting there by public transportation or car. There is limited off-street parking in the area and a for-pay garage under the building for $10.
- Who is invited? Open to anyone interested in learning about the Windows Azure cloud computing platform.
- Cost? Free. Microsoft generously donates the space and provides the pizza.
- Food? Yes, there is pizza. And salad. Please RSVP so we can get an accurate count.
- WiFi? Yes, there is wireless. We will provide you the access code at the meeting.
- Meeting Topics:
6:00 PM - Members of the Boston Azure community have expressed a lot of interest in getting more "hands-on" at the meeetings. If you are interested in hacking on Windows Azure as a community, come hear Bill Wilder's proposal for a collaborative community hacking project. Bring your enthusiasm. We might have code available for download in case you want to bring your laptop. If ready, you could register and download the code while you are there.
- 6:30ish - When the food arrives, grab some pizza, some salad, a cold drink, ...
7:00 PM - The main speaker is Michael Stiefel, a local independent consultant who specializes in Microsoft technologies and Windows Azure. Abstract: When you put data in a computing cloud, the requirements of consistency, availability and partitioning can conflict. This means when building highly available and scalable applications, you may have to give up classic ACID database transactions and relational database features such as foreign keys, joins, and stored procedures. How do you then handle data versioning, and latency? The Microsoft cloud platform gives you two data technologies: Tables, and SQL Azure. When do you use one or the other? This talk will talk about how to architect, design, and implement data storage in this new world.
- 8:20 PM - Announcements, give-aways, general wrap up
- 8:30 PM - Done! See you next month!
To RSVP, please send email to: events@bostonazure.org
Please include "RSVP" in the subject line and your full name in the message body. Also include "SUBSCRIBE (your email addr)" in the body if you wish to be added to our mailing list.
Clemens Vasters offers the latest versions of his presentation slide decks in a NT Konferenca 2010 - Windows Azure Slidedecks post of 5/24/2010:
I put the slides for my talks at NT Konferenca 2010 on SkyDrive. The major difference from my APAC slides is that I had to put compute and storage into one deck due to the conference schedule, but instead of purely consolidating and cutting down the slide count, I also incorporated some common patterns coming out from debates in Asia and added slides on predictable and dynamic scaling as well as on multitenancy. Sadly, I need to rush through all that in 45 minutes today.
Scott Hanselman reports that he presented OData Basics - At the AZGroups "Day of .NET" with ScottGu in this 5/24/2010 post and Webcast:
Recently I had the pleasure to speak at the 7th Annual AZGroups.org event in Phoenix, colloquially known as the "Day of ScottGu." Scott talked for about 4 hours or so, then Jeffrey Palermo, then myself. Tough acts to follow! You can view ScottGu's and Jeffrey's talks at http://azgroups.nextslide.com, and mine is here via direct link
, and also embedded below.I spoke on OData and it was a great crowd. We had a blast. I'd encourage you to check out the talks, as there's lots of good information and demos. Thank you to Scott Cate for putting the whole thing together, and be sure to check out Scott Cate's VS Trips and Tricks videos, as he does tiny screencast versions of Sara Ford's VS tips. Is three Scotts enough for you?

Webcast: Open OData with Scott Hanselman on NextSlide
<Return to section navigation list>
Other Cloud Computing Platforms and Services
David Linthicum claims “Google's powerful Prediction API could make advanced predictive analytics accessible to rank-and-file developers -- for free” in his Google's new Predictive API gives cloud developers a big boost post of 5/25/2010 to InfoWorld’s Cloud Computing blog:
Google I/O last week left us with Google TV and IT-oriented Android OS news, but it was the release of the new APIs that interested me the most. Google clearly has its black belt in API development, and the current bunch of APIs continues that trend. Most interesting was the new Prediction API, which provides advanced analytic services for any Internet-connected applications, on premise or in the cloud.
Google says "the Prediction API allows you to get more from your data and makes its patterns more accessible. Specifically, the Prediction API leverages Google's machine-learning infrastructure to give you the tools to better analyze your data and reveal patterns that are often difficult to manually discover. The API also enables you to use those patterns to predict new outcomes, which facilitates the development of all types of software, from textual analysis systems to recommendation systems." …
You implement this API using a three-step process. First, upload the training data into Google Storage (Google's cloud storage service). Second, build the model from the data. Finally, make new predictions using that data -- for example:
POST www.googleapis.com/prediction/v1/query/${mybucket}%2F${mydata}For now, you can use the Prediction API for free, since Google considers it to be in beta. Access to the Prediction API is currently by invitation only. To request access you need to sign up on the Google waitlist. (I did so before writing this blog post.)
Predictive analytics is not new; those in the BI world have been doing things like this for years. However, that's with some very expensive hardware and software; thus, it's been out of reach of many smaller enterprises and certainly impractical for most common application development efforts.

James Hamilton quotes Vivek Kundra in a State of Public Sector Cloud Computing post of 10/25/2010:
Federal and state governments are prodigious information technology users. Federal Chief Information Security Office Vivek Kundra reports that the United States government is spending $76B annually on 10,000 different systems. In a recently released report, State of Public Sector Cloud Computing, Vivek Kundra summarizes the benefits of cloud computing:
There was a time when every household, town, farm or village had its own water well. Today, shared public utilities give us access to clean water by simply turning on the tap; cloud computing works in a similar fashion. Just like the water from the tap in your kitchen, cloud computing services can be turned on or off quickly as needed. Like at the water company, there is a team of dedicated professionals making sure the service provided is safe and available on a 24/7 basis. Best of all, when the tap isn’t on, not only are you saving water, but you aren’t paying for resources you don’t currently need.
§ Economical. Cloud computing is a pay-as-you-go approach to IT, in which a low initial investment is required to get going. Additional investment is incurred as system use increases and costs can decrease if usage decreases. In this way, cash flows better match total system cost.
§ Flexible. IT departments that anticipate fluctuations in user load do not have to scramble to secure additional hardware and software. With cloud computing, they can add and subtract capacity as its network load dictates, and pay only for what they use.
§ Rapid Implementation. Without the need to go through the procurement and certification processes, and with a near-limitless selection of services, tools, and features, cloud computing helps projects get off the ground in record time.
§ Consistent Service. Network outages can send an IT department scrambling for answers. Cloud computing can offer a higher level of service and reliability, and an immediate response to emergency situations.
§ Increased Effectiveness. Cloud computing frees the user from the finer details of IT system configuration and maintenance, enabling them to spend more time on mission-critical tasks and less time on IT operations and maintenance.
§ Energy Efficient. Because resources are pooled, each user community does not need to have its own dedicated IT infrastructure. Several groups can share computing resources, leading to higher utilization rates, fewer servers, and less energy consumption.
This document defines cloud computing and describes the federal government approach and then goes on to cover 30 case studies. The case studies are the most interesting part of the report in that they provide a sampling of the public sector move to cloud computing showing its real and project are underway and substantial progress is being made.
It’s good to see the federal government showing leadership at a time when the need for federal services are undiminished but the burgeoning federal deficit needs to be brought under control. The savings possible through cloud computing are substantial and the federal IT spending base is enormous, so its particularly good to be adopting this new technology delivery platform at scale.
- Document: State of Public Sector Cloud Computing
- Executive Summary: State of Public Sector Cloud Computing
Thanks to Werner Vogels for sending this article my way.

Alin Irimie reports AWS Management Console Now Supports Relational Database Service in this 5/24/2010 post to the Azure Journal – Cloud Computing blog:
Amazon Relational Database Service (Amazon RDS) is a web service that makes it easier to set up, operate, and scale a relational database in the cloud. It provides cost-efficient, resizable capacity for an industry-standard relational database and manages common database administration tasks.
Amazon RDS gives you access to the full capabilities of a familiar MySQL database. This means the code, applications, and tools you already use today with your existing MySQL databases work seamlessly with Amazon RDS. Amazon RDS automatically patches the database software and backs up your database, storing the backups for a user-defined retention period.
Starting today, there is a new tab in the AWS Management Console for the Amazon Relational Database Service.
You can now easily create, manage, and scale DB Instances:
You can also view the Amazon CloudWatch metrics for each of your instances:


Alin continues with a laundry list of Amazon RDS’ “service highlights.”
Bob Warfield asks How Much Uptime Does Your Application Need? in this 5/24/2010 post about Amazon’s spot pricing for EC2:

I was having an interesting discussion with a friend recently about Amazon’s spot instance pricing for EC2 that prompted me to write this post. Let me walk you through how it went, because I think it replays some of the thinking that all startups should go through about their online service. BTW, hat tip to Geva Perry for putting me on to the spot instances, which I hadn’t noticed.
To begin with, what is Amazon’s spot instance pricing? A spot instance is one where you bid, sort of auction style, what you’re willing to pay for an EC2 instance. The spot price moves up or down based on availability. For the most part, it is quite a bit less than the normal retail pricing for EC2, so one can get EC2 instances for considerably less. I think this is a very cool model. But, there is a catch. Amazon publishes the spot price, which is based on the availability of unused capacity. If the spot price goes above your bid, your EC2 instance will be immediately shut down. Note that you don’t pay your bid price either. Instead, you pay the spot price, which by definition has to be below your bid price right up until they shut you down for having bid too little.
Interesting model, no? I was remarking to my friend about how excited I was about it. You see, cost to deliver the service really matters for Cloud and SaaS businesses, and here was Amazon blazing an interesting new trail with the potential for interesting savings.
My friend’s reaction was pretty negative. He couldn’t imagine dedicating a production application to an opportunistic model like this where his app could go down at any moment due not to some catastrophic failure, but to the vagaries of this odd marketplace. It was a brief exchange, but I almost wondered if he thought it unsavory to do that to his users.
The thing is, most developers and businesses automatically assume that whatever software they are offering has to be up 24×7, five “9′s”, and with 100% efficacy. But is that really true?
No doubt it is for some apps, but probably not for a lot of apps. How do you know what is needed for your application? Your customers will tell you, but not because you asked. If you do ask, of course they want 100% uptime. They may even insist on it contractually. However, your service has almost certainly gone down and been unavailable. They all do, sooner or later. It has probably experienced outages that are so short, nobody noticed, or perhaps very few did. BTW, read the fine print carefully on those five “9′s” Cloud SLA’s. They’re all riddled with exclusions. For example, they may exclude outages caused by their Internet service provider. They may exclude outages lasting less than a certain length of time, or outages that had a certain amount of lead time warning. Those businesses have spent time understanding what their customers really demand and what they can really deliver.
Getting back to the story at hand, you’ve probably had outages. Let’s say you had a 10 minute outage. How many of your customers noticed and called or wrote? At Helpstream, when this happened, and it was seldom, a 10 minute outage would generally net contact by 1 to 3 customers. This despite having nearly 2 million seats using the software. The contact would boil down to, “What’s going on, we can’t access the service?” Usually, the service was back up before we could respond with an answer, and the customer had already lost interest in the outage.
Does this mean you can bombard customers with 10 minute outages with impunity? No, absolutely not. But in this case, a rare 10 minute outage was not causing a lot of trouble. Now look at spot pricing and Amazon. It typically took us 3 or 4 minutes to spin up a new server on EC2. So, if we had to convert all servers from spot price to normal instance pricing, that could be done in well under 10 minutes of outage. Consider that the worst case and consider that it might happen once every six months or so. What are some better cases?
There are many. You could envision cases where only part of the service was down, or perhaps where the service simply got a little slower because some, not all instances were using spot pricing on a highly distributed “scale out” architecture. While you may have an app that couldn’t tolerate a 10 minute service outage, how many couldn’t tolerate being slower for 10 minutes out of every 6 months?
Or, consider an opportunistic scenario for giving customers a better experience on a mission critical application. Take my old alma mater, Callidus Software. Callidus offers a transactional piece of enterprise software that computes sales compensation for some of the world’s largest companies. Take my word for it, payroll is mission critical. The transaction volumes on the system are huge, and a compensation payroll run can easily take hours. We used a grid computing array of worker processors, up to 120 cpu’s, to compute a typical run. These were restartable if one or more died during the run. Can you see where this is going? If the whole grid were done with spot priced instances, and the whole grid went down for 10 minutes, it would simply delay the overall run for 10 minutes or so. Not great, but not the end of the world. Now suppose Callidus offered 50% faster payroll processing because it could afford to throw more cpu’s at the problem. Buried in the fine print is a disclaimer that sometimes, even as often as once a quarter, your payroll run could be delayed 10 minutes. Yet overall, your payroll would be processed 50% faster. Does anyone care about the rare 10 minute delay? My sense is they would not.
My hobby involves machine tools, and machinists are constantly upset with drawings that specify too much precision in the part to be machined. It’s easy for a young engineer to call out every feature on the drawing with many digits of precision. But, each digit costs a lot more money to guarantee because it means a lot more work for the machinist. Up time is the same sort of thing. Specifying or offering SLA’s that are excessively harsh is very common in the IT world, but there is a cost associated with it. The moral of the story is, don’t just assume every service and every aspect of every service has to have five “9′s” of availability. Consider what you can do by trading a little of that away for the customers or for your bottom line. Chances are, you can offer something that customers will like at a lower delivery cost. Assuming your competitor’s haven’t thought of it, that might just be the edge you’re looking for.

<Return to section navigation list>
















