Windows Azure and Cloud Computing Posts for 5/18/2010+
 | Windows Azure, SQL Azure Database and related cloud computing topics now appear in this weekly series. |

Update: Most Azure-related MSDN blog posts are missing until Friday due to a change of MSDN’s blog posting platform. For details, see During the upgrade of the blogging platform... (Thanks to @BethMassi for the heads up.)
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now download and save the following two online-only chapters in Microsoft Office Word 2003 *.doc format by FTP:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available from the book's Code Download page; these chapters will be updated in May 2010 for the January 4, 2010 commercial release.
Azure Blob, Drive, Table and Queue Services
In case you missed Karsten Januszewski’s Tips & Tricks for Accessing and Writing to Azure Blob Storage of 4/16/2010, here it is again:
Lately I’ve been doing a lot with Azure Blob Storage for an upcoming Twitter-related Mix Online lab, and wanted to share what I’ve learned.
Creating An In Memory .xls File And Uploading It To Blob Storage
I needed to create a .xls file on the fly and get it into Azure Storage. Here’s how I did it:
private void SaveAsCSV()
{
CloudStorageAccount account = CloudStorageAccount.FromConfigurationSetting("DataConnectionString");
CloudBlobClient client = account.CreateCloudBlobClient();
CloudBlobContainer tweetContainer = client.GetContainerReference("archive");
CloudBlob csv = tweetContainer.GetBlobReference(searchTermId.ToString() + "/data/master.xls");
string header = "id\tusername\tdate\ttime\tstatus\tlang\timage\tsource";
MemoryStream stream = new MemoryStream();
using (StreamWriter streamWriter = new StreamWriter(stream))
{
streamWriter.WriteLine(header);
foreach (TwitterSearchStatus t in masterStatuses)
{
string line = t.Id + "\t" + t.FromUserScreenName + "\t" + t.CreatedDate.ToShortDateString() +
"\t" + t.CreatedDate.ToShortTimeString() + "\t" + t.Text.Replace("\r\n", "").Replace("\n", "").Replace("\r", "").Replace("\t", "") + "\t" + t.IsoLanguageCode + "\t" +
t.ProfileImageUrl + "\t" + t.Source + "\t";
streamWriter.WriteLine(line);
}
streamWriter.Flush();
stream.Seek(0, SeekOrigin.Begin);
csv.UploadFromStream(stream);
}
A few things to note here: First, I wired up all the various cloud accounts, clients, containers and blobs I needed. Pretty straightforward.
Then, I created a MemoryStream and used a StreamWriter to populate my XLS file. Note that I had to flush the StreamWriter and seek back to the beginning of the memory stream before uploading it to Azure. I also uploaded the stream inside the using statement with the UploadFromStream method.
Azure handles create or update automatically, so you don’t have to worry if that blob is being created for the first time, or being overwritten. Nifty.
You also might notice all the string replace that I did on the text of the tweet itself. This gets rid of line breaks in the tweet, so the .xls file doesn’t get screwed up.
If you’re wondering where the TwitterSearchStatus class came from, it’s from the most excellent TweetSharp library, which I use for serializaing and deserializing tweets. I also use the TweetSharp library to do OAuth with Twitter, but that’s a topic for a different lab note. :)
Creating and Unzipping a .Zip File From A MemoryStream In Azure
My .xls files started getting pretty big so I decided to zip them up to help with IO. At first I was using GZipStream from the System.IO.Compression library, but I switched to the DotNetZip library so users could more easily unzip the files. I’m real happy with this library; it’s fast and easy to use. Hats off to the folks who wrote it.
Here’s the code I used to seek back in the MemoryStream (already in the memory of the .xls file), write it to a .zip file and upload it to Azure:
memStream.Seek(0, SeekOrigin.Begin);
//have to wrap GZip in using
//because it does some writes on dispose
using (MemoryStream compressedStream = new MemoryStream())
using (ZipFile zip = new ZipFile())
//using (GZipStream gZipStream = new GZipStream(compressedStream, CompressionMode.Compress))
{
ZipEntry entry = zip.AddEntry("master.xls", memStream);
zip.Save(compressedStream);
compressedStream.Seek(0, SeekOrigin.Begin);
var csvCompressed = tweetContainer.GetBlobReference(searchTermId.ToString() + "/data/master.zip");
csvCompressed.UploadFromStream(compressedStream);
}
Nothing fancy here. The DotNetZip library handles streams well.
Downloading and unzipping the file within Azure is also straightforward:
MemoryStream stream = new MemoryStream();
WebClient webClient = new WebClient();
using (Stream compressedStream = webClient.OpenRead(Urls.blobURL + searchTermId.ToString() + "/data/master.zip"))
{
using (MemoryStream holdingStream = new MemoryStream())
{
compressedStream.CopyTo(holdingStream);
holdingStream.Seek(0, SeekOrigin.Begin);
using (ZipFile zipfile = ZipFile.Read(holdingStream))
{
ZipEntry entry = zipfile["master.xls"];
entry.Extract(stream);
}
}
}
stream.Seek(0, SeekOrigin.Begin);
Again, nothing fancy here, although you might be wondering where the CopyTomethod came from. That’s an extension to the Stream class, which looks like this:
public static class StreamExtensions
{
public static void CopyTo(this System.IO.Stream src, System.IO.Stream dest)
{
if (src == null)
throw new System.ArgumentNullException("src");
if (dest == null)
throw new System.ArgumentNullException("dest");
System.Diagnostics.Debug.Assert(src.CanRead, "src.CanRead");
System.Diagnostics.Debug.Assert(dest.CanWrite, "dest.CanWrite");
int readCount;
var buffer = new byte[8192];
while ((readCount = src.Read(buffer, 0, buffer.Length)) != 0)
dest.Write(buffer, 0, readCount);
}
}
Using WebClient To Access Blobs vs. CloudBlobClient– Benchmarking Time
In the above samples, you may have noticed that I used just a raw WebClient request to download blobs, whereas I used the CloudBlobClient for uploading. At first, I was using the CloudBlobClient to do gets on blobs. But I found that using WebClient was slightly faster. In fact, I did some benchmarking to compare:
DateTime startDownload = DateTime.Now;
Stream stream = null;
WebClient webClient = new WebClient();
stream = webClient.OpenRead(blobURL + currentArchive.SearchTerm.search_term_id.ToString() + "/data/master");
string content = null;
using (StreamReader sr = new StreamReader(stream))
{
content = sr.ReadToEnd();
}
DateTime endDownload = DateTime.Now;
ViewData["DownloadTime"] = endDownload - startDownload;
startDownload = DateTime.Now;
CloudStorageAccount account = CloudStorageAccount.FromConfigurationSetting("DataConnectionString");
CloudBlobClient client = account.CreateCloudBlobClient();
CloudBlobContainer tweetContainer = client.GetContainerReference("archive");
CloudBlob csv = tweetContainer.GetBlobReference(currentArchive.SearchTerm.search_term_id.ToString() + "/data/master");
content = csv.DownloadText();
endDownload = DateTime.Now;
ViewData["DownloadTimeAzureClient"] = endDownload - startDownload;
Now, if you require permissions to do gets on your blobs, this won’t work because you have to pass authentication parameters in the HTTP header. Using the CloudBlobClient works great for this. That’s why I use CloudBlobClient for doing writes to blob storage.
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
Josh Einstein shows you how to Trick WCF Data Services into supporting $format = json in this 5/18/2010 post:
In the OData specification, the $format parameter can be passed on the query string of the request to tell the server that you would like the response to be serialized as JSON. Normally, to get JSON-formatted data, you have to specify "application/json" in your "Accept" header. The query string feature is handy in situations when it’s not easy or possible to modify the request headers.
Unfortunately, if you try to pass $format on a WCF Data Services query, you will get a response that looks like:
<errorxmlns="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata"><code/><messagexml:lang="en-US">The query parameter '$format' begins with a system-reserved'$' character but is not recognized.</message></error>Unfortunately, WCF Data Services doesn’t support this OData convention. But with a little bit of trickery, you can make it work by modifying the request in an ASP.NET HTTP module.
The trick is to check for the query string parameter before the request gets to WCF Data Services and modify the request headers accordingly. Normally, the Request.Headers collection is read-only. You’ll need to use some simple reflection to make it writable but once you do, it’s just a matter of setting the appropriate Accept header, then rewriting the URL to remove the $format parameter so WCF Data Services doesn’t bitch and moan.
Josh continues with a complete source code listing.
v-waberr repeats posts about SQL Server 2008 R2 Management Studio being able connect to SQL Azure in a SQL Server Management Studio to SQL Azure post to the SQL Azure Team blog of 5/18/2010:
Starting with SQL Server 2008 R2, SQL Server Management Studio can connect directly to SQL Azure. The minimum install to do this is SQL Server Management Studio Express Edition (download here for free); however any version of SQL Server (except SQL Server Express) that includes the SQL Server Management Studio will work.
Here is how to us SQL Server Management Studio to attach to SQL Azure:
1. The first step is to figure out your server name, to do this go to the SQL Azure Portal.
2. Login with your Windows Live Id
3. Click on your project name.
4. You should be at the Server Administration page.

5. Highlight the server name in the browser and copy (Ctrl-C) in your clipboard.
6. Now open SQL Server Management Studio 2008 R2. By default it will open the Connect to Server dialog.
7. Paste in the full DNS of the server stored in the clipboard into Server Name.
8. In the login box enter in your Administrator username for SQL Azure, this was on the Server Administration page where you got the full DNS of the server from.
9. The password is your SQL Azure password.
10. Click on Options >>
11. This will take you to the Connection Properties tab, check the Encrypt connection box. You should always encrypt your connection, see this previous blog post for why.
12. Press the Connect button.
It is that easy to start administrating SQL Azure using SQL Server Management Studio 2008 R2. Do you have questions, concerns, comments? Post them below and we will try to address them.


Nothing new that I can find here, except that SQL Server 2008 R2 has RTM’d.
<Return to section navigation list>
AppFabric: Access Control and Service Bus
Scott Hanselman’s Windows Server and Azure AppFabric virtual launch May 20th announces Thursday’s RTW of these two application servers:
I spent 7 years at a large e-Finance company working on an Application Server for Windows with a team of very smart folks. When we'd go and sell our application server/component container to banks, we'd have to say things like "Windows doesn't really have an actual App Server like jBoss or WebSphere, so we wrote our own." However, remember that we were in banking, not in appserver-writing, so I always thought this was cheesy. As Microsoft came out with different subsystems that did stuff we'd already done, we'd evaluate them and "refactor via subtraction," removing our stuff and moving over to the MS stuff when appropriate. Still, the lack of an AppServer was an irritant.
AppFabric is the Windows Application Server. For web applications, AppFabric gets you caching (remember "Velocity?") for scale as well as high-availability of in-memory data. That means replicated, in-memory distributed hashtables, effectively, with PowerShell administration. I showed this at TechEd in Dubai, it's pretty cool.
For composite apps, on the business tier, AppFabic gets you services to support Windows Workflow and Windows Communication Foundation (WCF) apps. That means, workflows and web services get supporting services for scale. (remember "Dublin?"). For all apps, you get nice instrumentation in MMC that will live alongside your IIS7 management snapins, so you don't have to run around in multiple places to manage apps.
Windows Server AppFabric will be launched on May 20th, and you can get the iCal for the Virtual Launch event at http://www.appinfrastructure.com and put it on your calendar. There's also Azure AppFabric for cloud apps that give you a Service Bus, Access Control and Federation. This means, AppFabric is the app server both for Windows and the Cloud.
Most of these links, training and sample, show Beta 2 today, but will be updated soon to the final bits, I hear. There's lot more coming, and I'll do my best to collect the info in as clear a way as possible.
Related Links
- MSDN Developer Center on Windows Server AppFabric
- AppFabric Marketing Site with overviews, download links, etc.
- AppFabric SDK and AppFabric LABS
- Install AppFabric with the Web Platform Installer
- Workflow, Services and AppFabric for the Web Developer
- Tutorial Using the Windows Server AppFabric Interface
- Tail Spin Travel - Nice sample from Jonathan Carter. I showed this at TechEd Dubai with Soma.
If you're building BIG stuff of scale, as I did for 15+ years, AppFabric should prove pretty useful. I'm going to spend some time digging into it and I'll try to get the inside scoop from the team in the coming months. I'm also going to look into how well this all plays with Open Source libraries and subsystems.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Brian Hitney describes how to set the Windows Azure Guest OS in this 5/18/2010 post:
In a Windows Azure project, you can specify the Guest OS version for your VM. This is done by setting the osVersion property inside the ServiceConfiguration file:
If you don’t specify a version explicitly, the latest Guest OS is chosen for you. For production applications, it’s probably best to always provide an explicit value, and I have a real world lesson that demonstrates this!
MSDN currently has a Guest OS Version and SDK Compatibility Matrix page that is extremely helpful if you’re trying to figure out which versions offer what features. I recently ran into a problem when examining some of my performance counters – they were all zero (and shouldn’t have been)! Curious to find out why, I did some digging (which means someone internal told me what I was doing wrong).
In short, I had specified a performance counter to monitor like so: "\ASP.NET Applications(__Total__)\Requests/Sec". This had worked fine, but when I next redeployed some weeks later, the new Guest OS (with .NET Fx 4.0) took this to mean 4.0 Requests/Sec, because I didn’t specify a version. So, I was getting zero requests/sec because my app was running on the earlier runtime. This was fixed by changing the performance counter to "\ASP.NET Apps v2.0.50727(__Total__)\Requests/Sec".
For more information on this, check out this article on MSDN. And thanks to the guys in the forum for getting me up and running so quickly!

Maartin Balliauw explains Extension methods for PHP in this 5/18/2010 post:
The concept of “extension” methods will be nothing new to this blog’s .NET-related audience. For the PHP-related audience, this is probably something new. Let’s start with the official definition for extension methods: Extension methods enable you to "add" methods to existing types without creating a new derived type, recompiling, or otherwise modifying the original type. Extension methods are a special kind of static method, but they are called as if they were instance methods on the extended type.
Let’s visualize this. Imagine having the following class:
class HelloWorld
{
public function sayHello($to = 'World', $from = null)
{
$helloString = "Hello, " . $to . "!";
if (!is_null($from)) {
$helloString .= " From " . $from;
}echo $helloString . "\r\n";
}
}Not too difficult. There’s a sayHello() method that allows you to optionally pass who should be greeted and who the greeting is from. Imagine you would like to have a sayHelloTo() method as well, a shortcut to sayHello($to). And some other helper methods that use sayHello() under the hood. Wouldn’t it be nice to have the HelloWorld class concentrating on the real logic and defining the helper/utility functions somewhere else? …
Maarten goes on with a class named HelloExtensions and other examples.
Luke Puplett continues his analysis of Azure vs. a hosted Web server in Azure vs Hosting: Bang for Buck of 5/18/2010:
Following on from my last posting about the cost of running an Azure hosted little website I have done some more calculations.
As it turned out, my previous favourite, Fido.net had run out of servers and wanted more money than I was prepared to part with for the next rung up the server ladder.
Previously, I had toyed with the idea of running my own server. I can do this with Fido but they want me insured, and when I spoke to insurance people, they said that it was a waste of time as it would be incumbent on the OEM of the server that set fire to the building.
Redstation do co-lo and its cheap. You get a 100Mbit line and around 4Tb traffic cap, a 1U space in the rack and 8 IP addresses (5 usable), 24/7 access and free tea and coffee from the machine.
Couple them with a little server built here and I could be onto a sure fire value winner.
A custom PCN built 1U server with my own added reliable SSD drive will set me back $775. That's a quad core box with 8Gb RAM.
I can also load it up with my own BizSpark licensed software, which is not an option when you rent a server. Plus I can add another server some day and split out the SQL duties – although I’m getting ahead of myself.
Let's see how it all stacks up. Sorry for the micro text.
Unless I’m mistaken, and the point of a blog is much to do with airing thoughts so that others can give theirs, Windows Azure is exceptionally bad value.
I’m now using the Compute time as “time in existence” of the VM. And when the VMs are so puny, and the price is so large, 7p an hour for 1.6Ghz and 1.75Gb RAM, its not good.
When I first looked at Microsoft’s Azure platform, I thought it spelled the end for traditional hosters. Evidently not. I thought it was a low barrier to entry way for mobile app makers to get their apps into the cloud.
They have missed the opportunity to be truly disruptive in this market and charge a base rate plus the amount you use. Being MS, they own the OS and have the power to really accurately charge by utilisation, and auto provision at times or duress. At the moment, the value proposition is in the quick provisioning of servers and would benefit a company that gets massive influxes of traffic for short periods, like ticket sales.
Anyway, this is as much about Azure as it is about hosting options for a small website/service, and so it now looks like building a cheap server and paying for the rack space is the most cost-effective solution.
Until I sign a contract though, it could change. One thing that rented boxes provide is a little more peace of mind from driving down to the chilled room with a screwdriver at 2am. Although from my experience, hardware doesn’t fault that easily and its almost always a dodgy spindle.
With SSD drives, I hope to eliminate that.

Bruce Kyle links to an ISV Video: Datacastle Brings Data Protection From the Cloud in this 5/17/2010 post:
Datacastle provides a way for businesses to protect vulnerable data with backup, recovery, encryption, and even data shredding if laptops might be lost or stolen.
The data protection server console manage protection is both on premises and hosted in Windows Azure. It also includes a Web Services interface in the Windows Azure Platform that allows IT Pros to integrate with other management consoles. In addition data can be deleted based on a command given to the the admin console running in Windows Azure.
ISV Video LInk: Datacastle Brings Data Protection From the Cloud Using Windows Azure
Datacastle CEO Ron Faith talks with Bruce Kyle, ISV Architect Evangelist, about how users and IT Pros protect laptop data from in the cloud. He also describes the lessons learned in moving the server software to the cloud.
About Datacastle
Datacastle provides a way for businesses to protect high business impact information assets with data backup, recovery, encryption, and even data shredding if laptops are lost or stolen.
Datacastle RED includes secure data deduplication and is available as a hosted solution in Windows Azure or as an on premise implementation. Datacastle RED's features can be self-managed by end users or centrally-managed by IT using the administrative console that runs in Windows Azure. Datacastle's Web Services interface in the Windows Azure Platform also allows ITPros to integrate with other management and reporting consoles.
Other Videos about How ISVs Use Windows Azure
- David Bankston of INgage Networks, talks about social networking and Azure
- Gunther Lenz, Microsoft, chats with Michael Levy, SpeechCycle
- Gunther Lenz, Microsoft, chats with Guy Mounier, BA-Insight, about BA-Insight's next Generation solution levereging Windows Azure
- Aspect leverages storage + compute in call center application
- From Paper to the Cloud -- Epson's Cloud App for Printer, Scanner and Windows Azure
- Vidizmo - Nadeem Khan, President, Vidizmo talks about technology, roadmap and Microsoft partnership
- Murray Gordon talks with ProfitStars at a recent Microsoft event
Return to section navigation list>
Windows Azure Infrastructure
David Linthicum claims “It's time for cloud customers to vote with their dollars to get the openness and portability they've been promised” in his The cloud's conflict of interest over interoperability post of 5/18/2010 to InfoWorld’s Cloud Computing blog:
Interoperability is all the talk these days in the world of cloud computing. The PowerPoint presentations speak for themselves in their descriptions of the ability to move data, code, and even virtual machines and binary images among clouds, both private and public, with drag-and-drop ease.
Indeed, there is no real reason we can't move quickly in this direction. Many cloud providers use similar internal architectures and virtualization technology approaches, as well as similar API architectures. That provides the potential basis for interface and platform compatibility.
Yet there are no cloud offerings today that actually deliver on the true vision of cloud-to-cloud interoperability. What gives?
Although there are indeed several technology issues such as lack of standards that inhibit cloud interoperability, they're technically solvable. The core motivation behind the lack of cloud interoperability is based on a simpler rationale: greed. Cloud providers have a clear conflict of interesting in support interoperability, as it deprives them of the ability to lock in customers.
This conflict is hardly new or unique to the cloud. While technology providers over the years have publicly promoted standards and interoperability, their business interests push them away from the interoperability that would make it easy for customers to move to other providers. After all, if there is true interoperability, there is true commodity -- which means less perceived value and differentiation, and thus less money. No technology provider, including the cloud computing variety, wants to see that happen.
I don't care what the cloud providers tell you about being "open," having "no lock-in," and being able to "run anywhere," these words won't mean anything for some time. There is simply no business motivation to deliver on these promises. The trouble is that cloud providers' interests do not coincide with customers' interests, yet users and customers depend on the cloud providers to create both the interoperability standards and the mechanisms to implement it.
So what can you do? Vote with your dollars. If enough enterprises, and perhaps the government, refuse to support cloud providers that are more proprietary in nature and don't provide a clear path to interoperability, the providers will get the message quickly. By channeling your money to the more open providers, you will create the business case needed to implement and support standards and code, data, and binary interoperability. Then we can actually get the true value of the cloud.
Thomas Bittman’s Clarifying Private Cloud Computing post of 5/18/2010 to the Gartner Blogs continues the private-vs-public cloud controversy:
I continue to talk with clients who understand the concept of private cloud computing, they think they know it when they see it, but they can’t quite explain it in words. A year ago I described The Spectrum of Private to Public Cloud Services, but I didn’t put that in the form of a definition. Here’s a shot.
Gartner’s official definition of cloud computing is “A style of computing where scalable and elastic IT-enabled capabilities are delivered as a service to customers using Internet technologies.” We also describe five defining attributes of cloud computing: service-based, scalable and elastic, shared, metered by use, uses Internet technologies. A key to cloud computing is an opaque boundary between the customer and the provider. Graphically, that looks like this:
When the customer does not see the implementation behind the boundary, and the provider doesn’t care who the customer is, you have a public cloud service. So what is private cloud?
Private cloud is “A form of cloud computing where service access is limited or the customer has some control/ownership of the service implementation.”
Graphically, that means that either the provider tunnels through that opaque boundary and limits service access (e.g., to a specific set of people, enterprise or enterprises), or the customer tunnels through that opaque boundary through ownership or control of the implementation (e.g., specifying implementation details, limiting hardware/software sharing). Note that control/ownership is not the same as setting service levels – these are specific to the implementation, and not even visible through the service.
The ultimate example would be enterprise IT, building a private cloud service used only by its enterprise. But there are many other examples, such as a virtual private cloud (the same as the example above, except replace ‘enterprise IT’ with ‘third-party provider’), and community clouds (the same as a virtual private cloud, except opened up to a specific and limited set of different enterprises).
Still “foggy”, or is it “clear”?


Julie Bort claims “iPhone will never kill the PC” in her Dell CEO says IT will be about virtual desktops and cloud computing on mobile devices report of 5/18/2010:

Dell CEO Michael Dell contends that mobile devices will never kill the PC. Instead, he envisions a future where users own an increasing number and variety of devices, each capable of looking like the other via desktop virtualisation, served by virtual networks and the cloud.
"What's converging is the data, not the device," Dell told attendees of the Citrix Synergy user conference in San Francisco during a keynote speech. "It's not clear that one device replaces another."
He believes that each user will have many devices, each geared for a specific task. "Some are better for carrying with you. Others are for consuming content, others are better for creating content." This runs counter to the idea that a smartphone or other mobile device will eventually become the multi-function computer of choice for work, communication, social networking and entertainment. Since 2008, users have purchased about a quarter of a billion smartphones, reports market research firm Strategy Analytics. Many of them use their smartphone for traditional PC work tasks, be it composing a document or sending e-mail.
Yet, Dell said that the iPad confirms his view that users will want more devices, all accessing the same data (and even, perhaps the same virtual desktop).
"There is an application infrastructure growing up significantly around devices like the iPad. Does this create new uses, new demand, or does it replace something else? Seem to me it creates new uses," Dell said. …
Julie continues with Michael Dell quotations.
Lori MacVittie explains Architectural Multi-tenancy in this 5/18/2010 essay:
Almost every definition of cloud, amongst the myriad definitions that exist, include the notion of multi-tenancy, a.k.a. the ability to isolate customer-specific traffic, data, and configuration of resources using the same software and interfaces. In the case of SaaS (Software as a Service) multi-tenancy is almost always achieved via a database and configuration, with isolation provided at the application layer. This form of multi-tenancy is the easiest to implement and is a well-understood model of isolation.
In the case of IaaS (Infrastructure as a Service) this level of isolation is primarily achieved through server virtualization and configuration, but generally does not yet extend throughout the datacenter to resources other than compute or storage. This means the network components do not easily support the notion of multi-tenancy. This is because the infrastructure itself is only somewhat multi-tenant capable, with varying degrees of isolation and provisioning of resources possible. load balancing solutions, for example, support multi-tenancy inherently through virtualization of applications, i.e. Virtual IP Addresses or Virtual Servers, but that multi-tenancy does not go as “deep” as some might like or require. This model does support configuration-based multi-tenancy because each Virtual Server can have its own load balancing profiles and peculiar configuration, but generally speaking it does not support the assignment of CPU and memory resources at the Virtual Server layer.
One of the ways to “get around this” is believed to be the virtualization of the solution as part of the hardware solution. In other words, the hardware solution acts more like a physical server that can be partitioned via internal, virtualized instances of the solution*. That’s a lot harder than it sounds to implement for the vendor given constraints on custom hardware integration and adds a lot of overhead that can negatively impact the performance of the device. Also problematic is scalability, as this approach inherently limits the number of customers that can be supported on a single device. If you’re only supporting ten customers this isn’t a problem, but if you’re supporting ten thousand customers, this model would require many, many more hardware devices to implement. Taking this approach would drastically slow down the provisioning process, too, and impact the “on-demand” nature of the offering due to acquisition time in the event that all available resources have already been provisioned.

Resource pooling. The provider’s computing resources are pooled to serve multiple consumers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand. There is a sense of location independence in that the customer generally has no control or knowledge over the exact location of the provided resources but may be able to specify location at a higher level of abstraction (e.g., country, state, or datacenter). Examples of resources include storage, processing, memory, network bandwidth, and virtual machines.
And yet for IaaS to truly succeed the infrastructure must support multi-tenancy, lest customers be left with only compute and storage resources on-demand without the benefit of network and application delivery network (load balancing, caching, web application firewall, acceleration, protocol security) components to assist in realizing a complete on-demand application architecture.
What is left as an option, then, is to implement multi-tenancy architecturally, by combining the physical and virtualized networking components in a way that is scalable, secure, and fits into the provider’s data center.
ARCHITECTURAL MULTI-TENANCY
An architectural approach leverages existing networking components to provide shared services to all customers. Such services include virtual server layer failover, global application delivery, network and protocol security, and fault-tolerance. But to provide the customer-specific – application-specific, really – configuration and isolation required of a multi-tenant system the architecture includes virtual network appliance (VNA) versions of the networking components that can be provisioned on-demand and are specific to each customer.
This architecture ensures providers are able to easily scale the customer-specific networking services by taking advantage of the hardware components’ inherent scaling mechanisms while affording customers control over their application delivery configuration. Providers keep their costs to implement lower because they need fewer hardware components as a foundational technology in their data center while ensuring metering and billing of application delivery components at the customer level is easily achieved, often via the same “instance-based” model that is used today for server costing.
Customers need not be concerned that an excessively complex configuration from another customer will negatively impact the performance of their application because the application/customer-specific configuration resides on the VNA, not the shared hardware. All customers can benefit from a shared configuration on the hardware platform that provides non-specific security functions such as protocol and network-layer security, but application-specific security can reside with the application, alleviating concerns that “someone else’s” configuration will incur latency and delays on their application because of the use of layer 7 security inspections (often inaccurately called “deep packet inspection”). …

Lori continues with a description of an “architecture in which VNAs are leveraged to provide multi-tenancy also assists in maintaining mobility (portability) of the application” in private clouds.
Not to be one-upped by Chris Hoff (see below), Lori reports similar parody treatment in Novell Shoots at the Cloud and Scores of 5/18/2010:
It’s been described on Twitter as “reading like a Greek tragedy” but then again, Novell’s interpretive reading of one of Hoff’s cloud security posts was describe[d] in similar terms, so at least I’m in good company.
Novell deserves kudos for this humorous set of “interpretive” readings of a variety of cloud-focused blogs, including some of their own: "Get Your SaaS Off My Cloud" by Lori MacVittie from Novell, Inc. on Vimeo.
James Hamilton provides a detailed analysis of When Very Low-Power, Low-Cosr Servers Don't Make Sense in this 5/18/2010 post:
I am excited by very low power, very low cost servers and the impact they will have on our industry. There are many workloads where CPU is in excess and lower power and lower cost servers are the right answer. These are workloads that don’t fully exploit the capabilities of the underlying server. For these workloads, the server is out of balance with excess CPU capability (both power and cost). There are workloads were less is more. But, with technology shifts, it’s easy to get excited and try to apply the new solution too broadly.
We can see parallels in the Flash memory world. At first there was skepticism that Flash had a role to play in supporting server workloads. More recently, there is huge excitement around flash and I keep coming across applications of the technology that really don’t make economic sense. Not all good ideas apply to all problems. In going after this issue I wrote When SSDs make sense in Server applications and then later When SSDs Don’t Make Sense in Server Applications. Sometimes knowing where not to apply a technology is more important than knowing where to apply it. Looking at the negative technology applications is useful.
Returning to very low-cost, low-power servers, I’ve written a bit about where they make sense and why:
But I haven’t looked much at where very low-power, low-cost servers do not make sense. When aren’t they a win when looking at work done per dollar and work done per joule? Last week Dave DeWitt sent me a paper that looks the application of Wimpy (from the excellent FAWN, Fast Array of Wimpy Nodes, project at CMU) servers and their application to database workloads. In Wimpy Node Clusters: What About Non-Wimpy Workloads Willis Lang, Jignesh Patel, and Srinanth Shankar find that Intel Xeon E5410 is slightly better than Intel Atom when running parallel clustered database workloads including TPC-E and TPC-H. The database engine in this experiment is IBM DB2 DB-X (yet another new name for the product originally called DB2 Parallel Edition – see IBM DB2 for information on DB2 but the Wikipedia page is not yet caught up to the latest IBM name change).
These results show us that on complex, clustered database workloads, server processors can win over low-power parts. For those interested in probing the very low-cost, low-power processor space, the paper is worth a read: Wimpy Node Clusters: What About Non-Wimpy Workloads. …
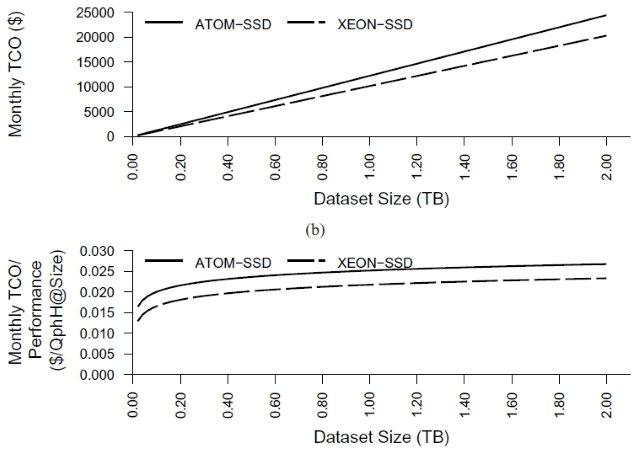
James continues with a definition of “Where very low-power, low-cost servers win is.”
Heather Clancy reports 4 power advantages of cloud computing from New York City’s Uptime Institute’s Symposium 2010 in her 5/17/2010 post to ZDNet’s GreenTech Pastures blog:
There has been some debate here on ZDnet in the past few months over the energy efficiency profile of the cloud, especially since Greenpeace came out blasting the high-tech industry at large for not thinking through the power equation properly.
So, it is perhaps natural that one of the keynote presentatations during the opening day of the Uptime Institute’s Symposium 2010 here in New York focused on the “Power-Related Advantages of Cloud Computing.”
According to Jonathan Koomey, who is a consulting professor for Stanford University and a project scientist at the Lawrence Berkeley National Laboratory, there are four primary reasons why cloud computing (at least philosophically speaking) should be a more power-efficient approach than an in-house data center. This is the order in which Koomey lists them.
- Workload diversity: Because you will have many different sorts of users making use of the cloud resources – different applications, different feature set preferences and different usage volumes – this will improve hardware utilization and therefore make better use of power that you’re using anyway to keep a server up and running.
- Economies of economies of scale: There are certain fixed costs associated with setting up any physical data center. According to Koomey, implementing technical and organization changes is cheaper per computation for larger organizations than for IT small shops. And because you will have more people using the infrastructure, again, you can spread those costs more efficiently.
- Power-management flexibility: Koomey postulates that it’s easier to manage virtual servers than physical servers from a power perspective. If hardware fails, the load can automatically be deployed elsewhere. Likewise, in theory, you could move all virtual loads to certain servers when loads are light and power-down or idle those that aren’t being used.
- You can pick the most efficient site possible: So, for example, if you are a business based in a state that uses primarily coal-powered electricity, do you really want to site your data center there? “If you have a data center in a place that is all coal-powered, this is a big business risk,” Koomey says. In a future where there might actually be a tax on the carbon your company produces, that would certainly be a risk indeed.
The 451 Group, which is now part of the Uptime Institute, has published a separate report on IT and the greening of the cloud. The point being that none of you should forget about power considerations when you’re evaluating a cloud service provider, even if you are “just” an IT manager.
<Return to section navigation list>
Cloud Security and Governance
Chris Hoff (@Beaker) reports Amazon Web Services Hires a CISO – Did You Know? on 5/18/2010:
Just to point out a fact many/most of you may not be aware of, but Amazon Web Services hired (transferred (?) since he was an AWS insider) Stephen Schmidt as their CISO earlier this year. He has a team that goes along with him, also.
That’s a very, very good thing. I, for one, am very glad to see it. Combine that with folks like Steve Riley and I’m enthusiastic that AWS will make some big leaps when it comes to visibility, transparency and interaction with the security community.
See. Christmas wishes can come true! Thanks, Santa!
You can find more about Mr. Schmidt by checking out his LinkedIn profile.
Hoff also points to this Novell Marketing Genius: Interpretive Reading Of One Of My Cloud Security Blog Posts… parody of 5/18/2010:
Speechless. … Direct link here.
“Cloud: Security Doesn’t Matter (Or, In Cloud, Nobody Can Hear You Scream)” by Chris Hoff from Novell, Inc. on Vimeo.
Hysterical.
<Return to section navigation list>
Cloud Computing Events
The Windows Azure Team reported Windows Azure FireStarter Sessions Now Available On Demand on 5/18/2010:
If you couldn't attend the recent Windows Azure Firestarter event, you can now see what you missed - recordings of all the event sessions are now available for viewing on-demand on Channel 9. For those who missed it, the Windows Azure Firestarter Event was an all-day live event we held last month at our Redmond, Washington campus to help developers learn more about how they can take full advantage of cloud services.
Topics covered included Microsoft's strategic vision for the cloud, an end-to-end overview of the Windows Azure platform from a developer's perspective, as well as how to migrate your data and existing applications (regardless of platform) onto the cloud. In addition to these sessions, you can also watch the Q&A that took place at the end of the day with the event's speakers.
Click the links below to watch each session:
The Microsoft Partner Network (Canada) offers a Windows Azure Platform - Technology Partner Technical Briefing in this SQL Server 2008 R2 Training Resources post of 5/18/2010 but doesn’t list the dates and venues (Toronto on 6/16/2010 and Vancouver BC on 6/18/2010):
Overview:
This one day course examines the three main technologies that constitute the Windows Azure™ technology platform: Windows Azure, SQL Azure, and Azure AppFabric. The session begins with an overview of cloud-based computing and the Windows Azure Platform offerings. Then, the course details each technology with code samples and demonstrations.
What can the Windows Azure Platform offer for:
- Developers - Quickly and easily create, manage and distribute web applications and services. Provides the tools and building blocks to help extend existing on-premises systems to the cloud.
- Independent Software Vendors - Offers the ability to provide customers a range of choices in user experience over the web or on connected PCs, servers and mobile devices.
- System Integrators – Offers the opportunity to both streamline your organization`s infrastructure investments and help your customers do the same.
Target Audience:
This custom course is designed for decision makers, IT architects and developers to get an overview of the Windows Azure Platform.Session Agenda:
Section I: Windows Azure - Platform Overview
Section II: Windows Azure
Section III: SQL Azure
Section IV: Azure AppFabricRegister here.
BusinessWire published the Cloudcor Inc Launches New Cutting Edge Cloud Computing Conference in Q4 2010 press release on 5/18/2010:
The Up 2010™ cloud computing conference is an annual review of cloud computing developments, on the cloud's impact on world economy and society, and an aggregation point for the study of future trends.
“We are delighted to launch UP 2010 Conference, which is a new and exciting complementary offerings to our growing Cloud portfolio. Our aim to help current mainstream users of ICT and particularly those”
Organized by leading experts and authorities of cloud computing, this five-day conference will highlight key findings, advancements and innovation by industry leaders, whose continued support and contributions are helping to shape the future of cloud computing.
The conference's hybrid approach will make the best use of both face-to-face meetings and virtual collaboration via the cloud, and is itself an example of how traditional and new media approaches can work together synergistically. Creators leverage deep knowledge of both physical & virtual (online) conference capabilities to produce a leading edge of collaboration within cloud computing.
UP 2010 provides public and private sector end users of Information & Communications Technology - (ICT), with insights into cutting edge research & development, and understanding of evolving ideas and best practices, and real-world business use cases. It will also provide a virtual platform to network with leading experts of cloud computing. …
When I commented on Twitter about the lack of physical venue information in the press release, the @UP_con folks sent me the following direct message:
UP_Con: We have multiple venues planned for UP2010. More Announcements will be made shortly. Stay tuned. Plz dont pollute the @UP_Con channel. Thks
Chutzpah, no?
Jay Fry offers A new way to compare your cloud computing options in this 5/17/2010 post from CA World:
If cloud computing does what everyone is saying it’s going to do, organizations are going to end up with many, many ways to get the IT service they need to support their business. And choice is good.
But having thousands of choices with no clear way to decide (or even prioritize) is not a recipe for success. Three of the announcements I’m helping with at CA World in Las Vegas this week (#caworld on Twitter) are aimed at addressing that problem: finding smart ways for companies to make those choices – and ways to constantly challenge those choices. Read on for a bit of detail and commentary on the first two; I’ll post another blog after Chris O’Malley’s Cloud & SaaS Focus Area Opening to cover the third.
Answering the bigger questions
These announcements are the result of quite a bit of soul searching at CA (now called CA Technologies, a hint that significant change is afoot) about how the company could and should help fill in some key missing pieces for really getting utility out of cloud computing.
What we saw and heard from customer after customer was that there are a number of very important issues around the cloud, issues that everyone’s been talking about: security, assuring performance and availability, managing and automating underlying technologies like physical and virtual servers. And, to be sure, we (and others) have answers to a lot of those that are getting better and better all the time (including some announcements from us coming this week).
However, there was a bigger problem not getting answered.
Business users are realizing that the IT department is no longer the single source for delivering the IT service they need. They can go around IT. Or at least use cloud services, SaaS offerings, and the like as pretty strong bargaining chips in the negotiations with IT.
And IT has had a pretty difficult time putting what they can deliver side by side with what can be sourced from the cloud and doing a fact-based comparison so the business can make the right decision.
We also realized that there are things that CA Technologies could and should deliver to help answer some of these questions, and things that are better driven by others with relevant expertise and experience. So we are doing a mix of both.
Jay continues with more details about CA World 2010 and Cloud Commons.
Google announced Google's Largest Developer Event of the Year (Google I/O) will take place 5/19 and 5/20/2010 at San Francisco’s Moscone Center:
Join us for two days of deep technical content featuring Android, Google Chrome, Google APIs, GWT, App Engine, open web technologies, and more.
Google I/O features 80 sessions, more than 5,000 developers, and over 100 demonstrations from developers showcasing their technologies. Talk shop with engineers building the next generation of web, mobile, and enterprise applications.
Follow @googleio for the latest updates on I/O. (official hashtag: #io2010)
Watch the I/O keynotes live on the GoogleDevelopers YouTube channel. To view the schedule for the keynotes, check out the Agenda page.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Mary Jo Foley reports Microsoft sues Salesforce.com for alleged patent infringement in this 5/15/2010 post:
Details are scarce so far, but Microsoft has filed a lawsuit against Salesforce.com for allegedly infringing nine unspecified Microsoft CRM-related patents.
Microsoft posted a statement on its Web site acknowledging it had taken legal action on May 18. Here’s an excerpt from that statement from Horacio Gutierrez, corporate vice president and deputy general counsel of Intellectual Property and Licensing:
“Microsoft has filed an action today, in the U.S. District Court for the Western District of Washington, against Salesforce.com for infringement of nine Microsoft patents by their CRM product.”
I’ve asked Microsoft and Salesforce both for additional information. Salesforce officials said they have no comment. Microsoft is not commenting beyond the statement it released on its Web site.
Microsoft and Salesforce are rivals in the cloud-based CRM space. The two also compete in the CRM developer space, with Microsoft pushing its xRM platform as a rival to Salesforce’s Force.com platform.
Earlier this month, Salesforce hired a former Microsoft Vice President, Maria Martinez. At Salesforce, Martinez is Executive Vice President of Customers for Life. At Microsoft, she was Corporate Vice President of Worldwide Services.
Mary Jo continues with an update containing names of patents that Microsoft claims Salesforce.com infringes.
The “Executive Vice President of Customers for Life” title sounds suspiciously like lifelong bonded indenture to me.
Jason Kincaid claims Google To Launch Amazon S3 Competitor ‘Google Storage’ At I/O in this 5/18/2010 TechCrunch post:
Amazon’s cloud storage services are going to be getting another major competitor this week: Google. We hear that this week during its I/O conference
, Google will be announcing a new service that is a direct competitor with Amazon’s S3 cloud storage. Google’s service will be called Google Storage for Developers, or ‘GS’. We believe it will be available in a private beta initially. We also hear that the service will be positioned to make it very easy for existing S3 customers to make the switch to Google Storage.
Features will include a REST API, the ability to use Google accounts to offer authenticated downloads, and data redundancy. Developers will be able to use a command line tool to manage their data, and there will be a web interface as well.
We’d previously reported that Google was looking to expand its cloud service offerings, but that it would primarily be focused on ‘value-added’ services that took advantage of technology Google has been using internally, like its translation tools and video processing. We’re hearing that such value-added services will not be part of this launch, but it is highly likely that they will be coming in the future. And that’s the key here — competitors will have a hard time matching the array of technologies and infrastructure Google has spent years developing.
It will be interesting to compare Google’s feature set and pricing with Azure blog and table storage.
Alin Irimie explains Amazon CloudFront Streaming Access Logs in this 5/18/2010 post:
CloudFront delivers your static and streaming content using a global network of edge locations. Amazon CloudFront delivers your static and streaming content using a global network of edge locations. Requests for your objects are automatically routed to the nearest edge location, so content is delivered with the best possible performance. You can now enable logging for an Amazon CloudFront Streaming distribution Once enabled for a particular distribution, CloudFront logs all accesses to a designated Amazon S3 bucket. The information in the log files will let you know which of your streaming media files are the most popular and will also let you see which CloudFront Edge Location was used to stream the information.
Each log entry contains the following information:
- Date
- Time
- Edge Location
- Client IP Address
- Event (Connect, Play, Seek, Stop, Pause, Unpause, Disconnect, and so forth)
- Byte Count
- Status
- Client Id
- Request URI Stem
- URI Query
- Referrer
- Page URL
- User Agent
Additional information about the stream is logged for play, stop, pause, unpause, and seek events. Log entries are generated for both public and private streamed content.
The following applications and tools already have support for this new feature:
You can also use any application that understands log files in a W3C-compatible log format to manipulate or analyze the log files. Read the CloudFront documentation to learn more.

Paul Krill claims “The key forces behind Java, JRuby, and more have all left Oracle” in his “Sun's stars: Where are they now? And why did they leave?” post of 5/18/2010 to InfoWorld’s the Industry Standard blog:
Oracle, which spent $7.4 billion to acquire once-high-flying Sun Microsystems, has been losing prominent Sun technologists since shortly after the deal was forged. The acquisition was supposed to give Oracle control not only over such technologies as Sun's flagship Java implementation and Sun's Sparc hardware, but access to engineers and developers who were nothing short of celebrities in their field. But it has not worked out that way.

Tim Bray Simon PhippsIt was not unexpected that Sun CEO Jonathan Schwartz and Sun chairman and former CEO Scott McNealy did not make the switch to Oracle. Those high-ranking positions were already taken at the database giant. But the number of former Sun personnel residing in Oracle's top executive offices is sparse.
[ Also on InfoWorld: Paul Krill details Oracle's ambitious plans for Sun's technology. | Relive the rise and fall of Sun in our slideshow. ]
In fact, the only Sun alumni found on Oracle's Web listing of top executives are Executive Vice President John Fowler, who had dealt with Sun hardware; Senior Vice President Cindy Reese, who was a worldwide operations executive at Sun; and Vice President Mike Splain, who also was involved with Sun's hardware systems operations.
Key departures have included Java founder James Gosling, XML co-inventor Tim Bray, and Simon Phipps, Sun's chief open source officer. After serving as CTO of client software at Sun, Gosling worked for a couple months with the same title at Oracle before leaving in April under what appears to be acrimonious circumstances. Bray, who was director of Web technologies at Sun, also quickly left Oracle, becoming a developer advocate at Google. Phipps, never offered a job at Oracle, is open source strategy director at integrator and identity platform vendor ForgeRock.

James GoslingOther departures include Sun engineers Charles Nutter and Thomas Enebo, who shepherded the development of the JRuby programming language at Sun but joined Engine Yard last summer several months after the Oracle acquisition of Sun was announced. A key developer on the open source Hudson continuous build project, Kohsuke Kawaguchi left in April to form a company to continue working on Hudson.
Sun's tech leaders say why they didn't fit in at Oracle
In a blog post, Gosling noted his need for a lawyer after resigning. "I've spent an awful lot of time reading these [blog and other] messages and answering as many as I could. Between all this and spending quality time with my lawyer, resigning has been a full-time job (before I quit, several friends said I'd need a lawyer because 'this is Oracle we're talking about' ... sadly, they were right)," wrote Gosling, who has not indicated where his next employment would be.

Paul continues with quotes from Gosling and Nutter about their Oracle exits. Sound to me like serious brain drain.
James Governor expands on his responses to Paul Krill’s questions in On Sun Folks Leaving Oracle of 5/18/2010:

More often than you’d think, I’ve been asked about the cultural clunking between Sun and Oracle. Recently, several high profile departures of Sun people from Oracle have prompted a few of those questions again. It’s, of course, good to keep things in perspective: these are just a handful of folks being profiled out of the thousands who came over.
Last week, Paul Krill asked me for input on a story published today on the topic. In addition to the round-up of events and comments in the story, below my longer responses.
Culture Clash
It seems like the cultures of Oracle and Sun clash. What are the cultural (how the business desires reflect the way employees go about their jobs, day-to-day) differences at Oracle and Sun?
I think the assessment of cultures not fitting is pretty near the truth. Sun spent a good deal of engineering time doing something close to “applied research and development,” as with the dynamic language folks building on-top of the Java VM. While many technology companies – most, actually – focus on 6 to 12 months out, Sun in it’s last years kept it’s eyes in part a longer horizon calling for engineering talent that was exploratory and “cutting edge.” People like Google do this, of course, but they have a here and now revenue flow from the more pedestrian “making better junk mail” business model of selling online ads. Without here-and-now revenue flows like that, it’s difficult to keep up a large emphasis on emerging technology R&D.
Oracle, in contrast, has built its business model around creating and buying up existing, successful portfolios (database, Siebel, PeopleSoft, etc.) and honing their portfolio into classic enterprise software cash machines. The software is evolved and added to, but customer demands are more important than speculating and taking risks
on new ways using IT. Oracle’s guarded uptake of cloud is a nice example here. I suspect they’ll sort through Sun’s assets and follow the same practice. Oracle’s revenues and overall enterprise brand-value are the envy of many other vendors, so clearly the model works.Losing People
What’s the effect of losing these high-profile folks?
First, it means Oracle is probably not interested in the projects they were working on – Java aside (I’d say Gosling is a special case in all this: he’s probably well off enough that he can choose his employer and him leaving Oracle doesn’t really reflect on the Java commitment). I don’t expect to see much emphasis from Oracle on extending the
prominent languages that run on the VM aside from Java [though, as pointed out, Groovy might be a stands-out at Oracle, who knows?]. In contract, VMWare/Spring Source is very invested in getting groovy running on the VM, while languages like clojure are seeing quick fame.There’s still plenty of smart folks at Oracle – for example, they have a nice, pragmatic cloud asset in William Vambenepe who, despite Oracle’s flashy marketing that cloud is a lot of marketing claptrap is doing excellent work sussing out exactly how cloud technologies can start helping IT. Getting more Oracle-ites engaging to that degree would be great for Oracle to carry the positive nerdiness of the Sun/Java world that Oracle is well positioned to draw revenue from.
More Context
Related, be sure to check out RedMonk’s coverage of Oracle gobbling up Oracle: from me, from Stephen, and from James.
Disclosure: Sun was a long-time client, Oracle is not a client.
Jim Finkle reports “Former Sun Microsystems Chief Executive Jonathan Schwartz is taking the high road after getting a public tongue lashing from Silicon Valley's richest man, Larry Ellison” in his Ex-Sun CEO takes high road after Ellison attack story of 5/14/2010 for Reuters:
"The underlying engineering teams are so good, but the direction they got was so astonishingly bad that even they couldn't succeed," Ellison said in a recent interview with Reuters.
(Click here to see a Reuters special report)
When asked by Reuters if he wanted to respond, Schwartz replied in a cryptic email on Friday that would not be available to talk until after August.
"Until then, Larry's an outstandingly lovely, flawless man," Schwartz said.
He did not say why he won't talk now. But it might be because he is writing a book about life atop of Sun. In February, Schwartz sent a message to his followers on Twitter that he was thinking about penning such a memoir.
Sun, which specializes in making high-end computer servers, has never recovered from the dot-com bust and was sold to Oracle in January for $5.6 billion.
The best account we have from Schwartz on Sun's decline is a simple haiku that he Tweeted as he left the company in February: "Financial crisis/Stalled too many customers/CEO no more"
<Return to section navigation list>
















