Windows Azure and Cloud Computing Posts for 5/4/2010+
 | Windows Azure, SQL Azure Database and related cloud computing topics now appear in this weekly series. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now download and save the following two online-only chapters in Microsoft Office Word 2003 *.doc format by FTP:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available from the book's Code Download page; these chapters will be updated for the January 4, 2010 commercial release in April 2010.
Azure Blob, Table and Queue Services
David Aiken reminds developers that address is not the same as Address with Azure table storage in this 5/4/2010 post:
When using Windows Azure table storage – keep in mind the property names are case sensitive!
Yesterday one of our developers was working on refactoring some code. As is standard practice, they changed the class properties on the table storage entity classes from a lower case address to an [initial-letter] upper case Address. This worked fine in the developer fabric, but when we pushed to the cloud the app broke. Upon investigation it turned out each entity now had an address property as well as the new Address property.
Easy fix, we changed everything back to [all] lower case.
THIS POSTING IS PROVIDED “AS IS” WITH NO WARRANTIES, AND CONFERS NO RIGHTS EVEN IF YOU HAVE A NOTE FROM YOUR MUM
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
Stephen O’Grady asks The Future of Open Data Looks Like…Github? in this 5/4/2010 post:
When we’re talking about data, we typically start with open data. What we mean, in general, is access and availability. The ability to discover and procure a given dataset with a minimum of friction. Think Data.gov or Data.gov.uk.
The next logical direction is commerce. And while this idea isn’t high profile at the moment, at least outside of data geek circles, it will be. Startups like Data Marketplace, Factual, and Infochimps perceive the same opportunity that SAP does with its Information On Demand or Microsoft, with Project Dallas.
What follows commerce? What’s the next logical step for data? Github, I think. Or something very like it.
In the open source world, forking used to be an option of last resort, a sort of “Break Glass in Case of Emergency” button for open source projects. What developers would do if all else failed. Github, however, and platforms with decentralized version control infrastructures such as Launchpad or, yes, Gitorius, actively encourage forking (coverage). They do so primarily by minimizing the logistical implications of creating and maintaining separate, differentiated codebases. The advantages of multiple codebases are similar to the advantages of mutation: they can dramatically accelerate the evolutionary process by parallelizing the development path.
The question to me is: why should data be treated any different than code? Apart from the fact that the source code management tools at work here weren’t built for data, I mean. The answer is that it shouldn’t.
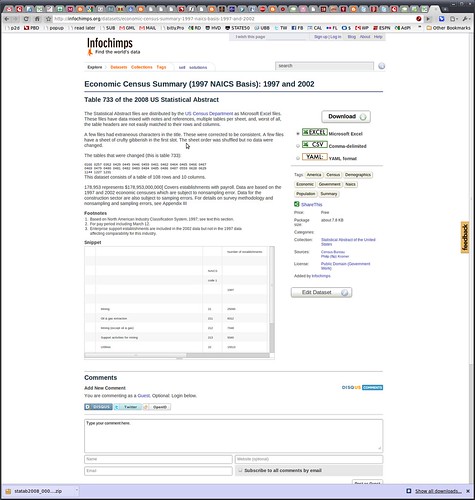
Consider the dataset above from the US Census Department, hosted by Infochimps. Here’s the abstract, in case you can’t read it:
The Statistical Abstract files are distributed by the US Census Department as Microsoft Excel files. These files have data mixed with notes and references, multiple tables per sheet, and, worst of all, the table headers are not easily matched to their rows and columns.
A few files had extraneous characters in the title. These were corrected to be consistent. A few files have a sheet of crufty gibberish in the first slot. The sheet order was shuffled but no data were changed.
Translation: it’s useful data, but you’ll have to clean it up before you go to work on it. …
Stephen continues with a discussion of forking: “What if, however, we had a Github-like “fork” button?”
Muhammad Mosa (a.k.a. Moses of Egypt) shows you How-To: Open Data Protocol [OData] Visualizer Extention for VS2010 in this 5/4/2010 post to the OData Primer wiki:
This is a How-To video on how to download, install and start working with OData Visualizer Extension for Visual Studio.Net 2010.
OData Visualizer is an extension for VS2010 made by Microsoft Data Modeling team
Its a 10 min video presented by Muhammad Mosa.Download the video.
Subscribe to ODataPrimer YouTube Channel.
Stacey Higginbotham claims Clustrix Builds the Webscale Holy Grail: A Database That Scales in her 5/3/2010 post to the GigaOm blog:
Clustrix, a Y Combinator graduate from 2006, launched today with the claim that it’s built a transaction database with MySQL-like functionality and reliability that can scale to billions of entries. Clustrix plans to sell its appliance (which consists of more than a terabyte of memory and its proprietary software) to web firms that don’t want to take on the complicated task of sharding their data (replicating it across multiple databases), or moving to less robust database options like Cassandra or a key value store such as what’s provided by Twitter.
This is big stuff. Indeed, Paul Mikesell — CEO of Clustrix and the former co-founder of storage system success story Isilon — said the goal is to use its appliance to solve a growing problem for companies managing large amounts of data, such as big travel, e-commerce and social websites. As the web grows more social, companies are trying to keep track of more pieces of data about users and their relationships to other users. This creates complicated and large databases that can slow down access to user information, and thus the end user experience.
We’ve written about myriad attempts to solve these data scalability problems, attempts that have spawned appliance startups and whole branches of code designed to help sites scale their data, from Hadoop to Cassandra to Twitter’s Gizzard. Mikesell said the product could replace the need for caching appliances such as those offered by Schooner or Northscale, but could also work in conjunction with them.
As for some of the open source options, new programming languages like Bloom, or cloud-based scalable databases such as Microsoft’s SQL Azure or Rackspace’s partnership with FathomDB, Mikesell is confident that the ability to replicate the functionality of a relational database at webscale without sharding or tweaking the existing code is powerful enough that customers would pay $80,000 for a 3-node machine containing the software. There are plenty of companies reluctant to trust the open-source spin-outs from companies like Twitter and Facebook.
The market is clearly there for scalable relational database products (GigaOM Pro, sub req’d), so if Clustrix can take the $18 million invested in it from Sequoia, ATA Ventures and US Venture Partners and turn it into an Isilon-like exit, more power to it.

I wonder how many enterprises will purchase hardware appliances from cloud startups, no matter how well-funded they are in their early stages.
Abi Iyer and Dinakar Nethi are co-authors of the illustrated, 13-page Microsoft SQL Azure FAQ whitepaper of 5/3/2010:
SQL Azure Database is a cloud based relational database service from Microsoft. SQL Azure provides relational database functionality as a utility service. Cloud-based database solutions such as SQL Azure can provide many benefits, including rapid provisioning, cost-effective scalability, high availability, and reduced management overhead. This paper provides an architectural overview of SQL Azure Database, and describes how you can use SQL Azure to augment your existing on-premises data infrastructure or as your complete database solution.


<Return to section navigation list>
AppFabric: Access Control and Service Bus
Wade Wegner announced his New Role: Technical Evangelist for Azure AppFabric in this 5/4/2010 post:
I am excited to share that I’m taking the role of Technical Evangelist for the Windows Azure platform, focused on the Azure AppFabric. I’m joining James Conard’s team that focuses on Windows Azure platform evangelism, working with David Aiken, Ryan Dunn, Zach Owens, and Vittorio Bertocci – truly an all-star team! Oh, and I hope to spend a lot more time with Jack Greenfield, Clemens Vasters, Justin Smith, and everyone else on the AppFabric team!
So, what is the Windows Azure platform AppFabric (other than a mouthful)?
That’s one of the things I hope to de-mystify in my new role. Expect to see me talking a lot about it in the future.
The best part about focusing on the Azure AppFabric is that it doesn’t restrict me to just one technology – because the Azure AppFabric is the glue that integrates and secures applications across the Internet, I’ll get to leverage the entire Windows Azure platform, various mobile platforms, web technologies, and almost everything else in our technology stack – not to mention interoperability with other platforms!
So, what does taking this role mean?
- I’m moving the entire family to Redmond, WA. Incidentally, want to buy a house in Glen Ellyn, IL?
- I hope to spend more time in Visual Studio than in Outlook.
- I’m going to spend a lot more time writing blog posts and recording screen casts. Lots of really neat things to share.
- I’ll continue speaking at events like PDC, TechEd, and MIX, and hope to hit even more online and local events.
- I want to work with all of you to find new and interesting ways to leverage the Azure AppFabric.
I am leaving an amazing group of people here in Central Region DPE. I want to thank everyone on my team – both local and extended – for making my time as an Architect Evangelist enjoyable and fulfilling. …

<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
The Windows Azure Team reported on 5/4/2010 Windows Azure CloudPoll for Facebook Now Available:
In late March 2010, we announced the availability of the Windows Azure Toolkit for Facebook. We're now happy to announce the launch of CloudPoll on Facebook, a new application hosted on Windows Azure and built using the Windows Azure Toolkit for Facebook. Available for free to all Facebook users, CloudPoll allows you to create, manage, and evaluate all kinds of polls for your pages using blob storage, SQL Azure, and compute hosted in Windows Azure. CloudPoll was built by Thuzi in collaboration with Microsoft and incorporates best practices for the rapid development of flexible, scalable, and architecturally sound Facebook applications.
To learn how to get started, read Microsoft Architect Bruce D. Kyle's blog post, or check out Thuzi Jim Zimmerman's session at MIX10, Building Facebook Apps with Microsoft .NET and Deploying to Windows Azure.
You can download the Windows Azure Toolkit for Facebook from Codeplex here. In addition to the framework, you can download the Simple-Poll sample application that will show you how to connect your Facebook Application to Windows Azure, blob storage, and SQL Azure.

Bill Zack’s Refactoring to the Cloud post of 5/4/2010 to the Innovation Showcase blog reported:
In talking to customers one of the questions that I get asked repeatedly is how to migrate a legacy application into Window Azure. In the first of this this multipart screen cast series Brian Hitney from Microsoft’s Developer and Platform Evangelism group explores the basics of migrating existing ASP.NET web sites to Windows Azure.
Using a real-world example (his popular Worldmaps application) Brian performs a step-by-step conversion of Worldmaps from ASP.NET to Windows Azure and SQL Azure.
See more here…

David Lavrinc reports Ford's cloud-computing future starts with students [w/video] and links to a Ford press release in this 5/4/2010 post to autoblog:
Ford's American Journey 2.0 – Click above for high-res image gallery
If you're even marginally interested in mobile technology, you know the future is in the cloud. Remote servers store your data, allowing you to access everything from contacts to music from a range of devices. That technology has largely been limited to mobile phones and PCs, but Ford's pioneering a new system that's set to connect the cloud to your car.
Six teams of students enrolled in Cloud Computing in the Commute at the University of Michigan have partnered with Ford's Research and Advanced Engineering program to develop a handful of applications utilizing real-time vehicle data, GPS and social networking to create a connected in-car experience like no other.
The software, dubbed "Fiestaware" and built atop Windows 7 and Microsoft's Robotics Developer Studio, allowed the teams to create services and software that utilize the vehicle's on-board internet connection to deliver a variety of information to the driver.
Each team created an app they felt would best utilize the available services, and the programs included everything from a real-time fuel consumption tool to traffic alerts and point-of-interest sharing. All the programs were tested and honed by Ford's user interface engineers, and a panel judges from FoMoCo, U-M and Microsoft picked one app as the winner.
Caravan Track (pictured above) allows drivers to set a route on a website, track participating vehicles and send the driver hazard notifications, along with a host of other information. The team that created the program will get to test out their app on the road when they depart from Ann Arbor, MI on May 14th and drive cross-country to the Maker Faire in San Mateo, CA in a kitted-out Fiesta.
Judging by the pace of development and Ford's continued innovations in the infotainment space, expect similar cloud-based services to be included in future Blue Oval products. A data-over-voice system will be available on the 2011 Fiesta and upgrades to the SYNC system are sure to make connectivity even easier going forward. Get all the details on the system, the teams and their creations, along with a video, after the jump.
Ford’s press release, on which the preceding article is based, observes:
In the class, the students explored and built applications based on access to Ford's developmental application platform built on Windows 7 and Microsoft Robotics Developer Studio, dubbed "Fiestaware," that enabled them to harness the power of social networks that safely and responsibly connect to the cloud. The software system is the first of its kind, and provides access to vehicle performance data, networking services, voice recognition, social networking tools and other data, as well as the Windows Azure cloud services platform. Students in the class were able to use the platform to conceptualize and build a new class of applications as class projects. [Emphasis added.]
Using Fiestaware looks to me to be more dangerous than talking on a cellphone while driving.
Jason Farrell explains Using Worker Roles with Windows Azure in this 5/3/2010 post:
Windows Azure is considered to be a cloud based operating system which allows developers to leverage a network of computers to permit what amounts to infinite scaling. This scaling is all managed within data centers run by Microsoft. Of the many uses for Azure one is computation. With the ability to leverage so many computers the prospect of performing heavy computation becomes very attractive. For this purpose, Azure supports what are known as Worker roles which act as background processing agents.
If you have flirted with Azure at all, you know that one of the most popular uses is to host web applications and allow for “n” instances to be spun up and down at will, this allowing companies to hug the demand curve rather then planning for the highest usage point. The roles which carry this out are called Web roles. However, the other type of role, the one which carries out background processing is called a Worker role.
Worker roles are much like Web roles in that they have OnStart and OnEnd events, but a web role is, by default, externally accessible, a worker role is not. Think of a worker role as a messenger boy, they allow for communication.
I have constructed a rather simple example to show them in action. What we have is a simple guestbook which allows a guest to leave his name, a message, and a picture. All of this information is stored in a blob and saved to my local storage account, however, the worker role is ticking every second and if its see’s a message in the queue, it will process that message. In this case, the message will be the address to the blob and the action will be to create three images: one resized to half the width of the original, one resized to 1/4 of the original, and the final one is the original itself with all meta information.
Jason continues with the source code and concludes with a SkyDrive link to the sample project.
Vishwas Lele’s Monte Carlo Simulation on Azure post of 5/1/2010 describes his refactoring of an Excel Services Monte Carlo simulation to support Windows Azure:
Readers who are not already familiar with Windows Azure concepts may find it useful to review this [overview of Windows Azure service architecture] first.
This project was motivated by an article by Christian Stitch: In his article, Christian Stitch describes an approach for financial option valuation implemented with Monte Carlo simulation using Excel Services. Of course, with Windows Azure, we have now easy access to highly elastic computational capability. This prompted me to take Christian’s idea and refactor the code to run on the Windows Azure Platform.
Live Demo http://ais.cloudapp.net **
** To limit the cost of hosting this demo application, the availability is limited to regular business hours: 9:00 am to 5:00 pm EST. An on-premise utility, based on Windows Azure Service Management cmdlets,
is usedautomates the creation and removal of this application.Monte Carlo Simulations
You can read more about Monte Carlo Simulation on the Wikipedia page here. But here is an explanation from Christian’s article that I found succinct and useful:
“Monte Carlo simulations are extremely useful in those cases where no closed form solutions to a problem exist. In some of those cases approximations to the solution exist; however, often the approximations do not have sufficient accuracy over the entire range. The power of Monte Carlo simulations becomes obvious when the underlying distributions do not have an analytical solution. Monte Carlo simulations are extensively used in the physical and life sciences, engineering, financial modeling and many other areas.”
It is also important to note that there is no single Monte Carlo method of algorithm. For this project I follow these steps:
- Ask the user to define a domain of possible inputs (Mean, StdDev, Distribution, MinVal and MaxVal).
- Generate inputs using Box-Muller transform.
- Perform a deterministic computation using the inputs for number of iteration requested.
- Aggregate the results of the individual computations into the final result.
Why use the Windows Azure Platform?
Monte Carlo simulation results require a very large number of iterations to get the desired accuracy. As a result, access to elastic, cheap computational resources is a key requirement. This is where the Windows Azure Platform comes in. It is possible to dynamically add compute instances as needed (as you would imagine, you only pay for what you use). Furthermore, it is also possible to select from a set of small (2 cores), medium (4 cores) and large (6 cores) compute instances.
As part of my testing, I ran a simulation involving a billion iterations. In an unscientific test, running this simulation using 2 small compute instances took more than four hours. I was able to run the same simulation in minutes ( < 20 minutes ) by provisioning four large compute instances.
In addition, to the elastic computation resources, Windows Azure also offers a variety of persistence options including Queues, Blobs and Tables that can be used to store any amount of data for any length of time.
Last but not the least, as a .NET/ C# developer, I was able to port the existing C# code with multi-threading, ASP.NET and other constructs, easily to Windows Azure.


Vishwas continues with “Logical View”, “Development View” and “Physical View” topics. He concludes:
Summary
Windows Azure Platform is a good fit for applications such as the Monte Carlo method that require elastic computational and storage resources. Azure Queue provides a simple scheme for implementing the asynchronous pattern. Finally, moving existing C# code – calculation algorithm, multithreading and other constructs to Azure is straightforward.
Return to section navigation list>
Windows Azure Infrastructure
Phil Wainwright’s Private Cloud as a Stepping Stone post of 3/4/2010 to the Enterprise Irregulars blog begins:
I’ve not been keen on the notion of private cloud — I think it’s often a misnomer, an attempt to pick-and-choose from the cloud computing model in a way that eliminates many of the benefits. But I have grudgingly come to accept that private cloud may have some uses as part of a strategy of introducing cloud computing into a largely on-premise enterprise IT infrastructure.
This formed the subject of my recent webinar discussion with IBM vice president Jerry Cuomo, who is CTO of Websphere, How Can the Cloud Fit Into Your Applications Strategy?, part of the Cloud QCamp online conference.
As I said in the webcast, most enterprises for the foreseeable future will continue to maintain important and substantial off-cloud assets. They can’t just switch off the lights, junk everything they’ve invested in and migrate it all to the cloud in one fell swoop. Instead, they’ll introduce cloud computing gradually into the mix of IT resources they draw upon, and as their usage of the cloud increases, they’ll find themselves managing a hybrid environment in which cloud-based assets will coexist and interact with on-premise IT assets.
In doing so, they’ll have to tackle three different integration challenges:
- Migration. Transferring software assets and processes between on-premise and cloud environments. They’ll need as far as possible to automate the process of migrating assets on and off the cloud, so that it can act as a seamless extension to the on-premise infrastructure.
- Integration. Data exchange and process workflow between cloud and on-premise systems. As a first step, they’ll probably rely initially on point-to-point integrations. But they will soon find a need to implement some form of mediation technology if the integration is to remain manageable and cost-effective…

That looks like two “different integration challenges” to me.
James Hamilton analyzes Dave Patterson’s keynote at Cloud Futures 2010 in Patterson on Cloud Computing of 5/4/2010:
Dave Patterson did a keynote at Cloud Futures 2010. I wasn’t able to attend but I’ve heard it was a great talk so I asked Dave to send the slides my way. He presented Cloud Computing and the Reliable Adaptive Systems Lab.
The Berkeley RAD Lab principal investigators include: Armando Fox, Randy Katz & Dave Patterson (systems/networks), Michael Jordan (machine learning), Ion Stoica (networks & P2P), Anthony Joseph (systems/security), Michael Franklin (databases), and Scott Shenker (networks) in addition to 30 Phd students, 10 undergrads, and 2 postdocs.
The talk starts by arguing that cloud computing actually is a new approach drawing material from the Above the Clouds paper that I mentioned early last year: Berkeley Above the Clouds. Then walked through why pay-as-you-go computing with small granule time increments allow SLAs to be hit without stranding valuable resources.
.jpg)
James continues with a few example slides from the deck.
Randy Bias wrote on 5/4/2010 a paean to James Hamilton’s recent MIX’10 presentation on economies of scale for large cloud providers in Understanding Cloud Datacenter Economies of Scale:
I was quite impressed by James Hamilton’s recent MIX’10 presentation on economies of scale for large cloud providers. James “gets it” like few others in the industry. If you haven’t watched his hour-long presentation, I suggest you do. I also recommend this excellent response from James Urquhart. My goal in this posting is to highlight, clarify and expand on a few of James Hamilton’s points. I will focus on Infrastructure-as-a-Service (IaaS) clouds, but the concepts are relevant for other kinds of cloud services.
In his presentation, James focuses on power: utilization, distribution, etc., and while an important element, like him, I don’t think it’s the most important factor.
I also want to dispel the myth that only the largest companies can achieve these economies of scale. Don’t get me wrong; providing a cloud service is a scale game. It requires a certain amount of buying power to compete. However,you don’t need to be MSFT, YHOO, AMZN, or GOOG to compete effectively. Buying power can be had at levels much lower than you might think.
In this article, I refer regularly to Jame’s comments in his presentation, so I suggest you watch his video first. In order to minimize confusion, I’ve borrowed some pictures from his slides and inserted them here for your reference. This is a long entry, but it will be worth the read as I’ve got numbers for you which I hope you will find interesting. …
Randy concludes:
It’s critical to understand the potential economies of scale for cloud providers. They can achieve these economies through size and focus. While larger players have some advantages, many businesses can afford to buy servers and network in enough bulk to see significant price savings. More important than sheer size is the ability to focus on innovation.
Public cloud providers have a core competency that involves delivering IT services at a very cost effective price point. They are the new IT utility companies of the near future. Their ability to focus and spend development resources to achieve ever newer economies of scale will be something that traditional businesses can’t compete with. Traditional enterprise IT vendors will likely continually be playing “catch up” and be unable to provide competitive solutions in time.
Economies of scale are why other business infrastructure in the past, e.g. railways, telecommunications, and shipping, have consolidated into businesses who focus on delivery of the infrastructure as a core competency. To think IT is any different is to bet against history.
Lori MacVittie analyzes the impending depletion of IPv4 addresses in her Apple iPad Pushing Us Closer to Internet Armageddon post of 5/4/2010:
Apple’s latest “i” hit over a million sales in the first 28 days it was available. Combine that with sales of other Internet-abled devices like the iPhone, Android, Blackberry, and other “smart” phones as well as the continued growth of Internet users in general (via cable and other broadband access technologies) and we are heading toward the impending cataclysm that is IPv4 address depletion. Sound like hyperbole?
It shouldn’t. The depletion of IPv4 addresses is imminent, and growing closer every day, and it is that depletion that will cause a breakdown in the ability of consumers to access the myriad services offered via the Internet, many of which they have come to rely upon. The more consumers, the more devices, the more endpoints just exacerbates the slide toward what will be, if we aren’t careful, a falling out between IPv6-only consumers and IPv4-only producers and vice-versa that will cause a breakdown in communication that essentially can only be called “Internet Armageddon.” …
Lori continues with an explanation of “WHAT’S THE BIG DEAL?” and “THE OPTIONS.”
The Leading Edge Forum (LEF) reported that it completed the final volume of its Cloud rEvolution series in a recent post about Cloud rEvolution: A Workbook for Cloud Computing in the Enterprise (Volume 4):
LEF Reports examine key technologies, best practices and the work of clients, CSC technologists and alliance partners.
Cloud rEvolution: A Workbook for Cloud Computing in the Enterprise (Volume 4)
This final volume in our Cloud rEvolution series takes the form of a practical, hands-on implementation guide produced by the LEF Executive Programme, based on their in-depth cloud computing research over the last two years. It encourages organizations to get up to speed on cloud computing and then run a workshop jointly with business and IT staff that:1. Examines cloud opportunities.
2. Reviews potential issues.
3. Considers where and how specific information should be processed.
4. Proposes a series of concrete steps organizations can take to begin doing business in the cloud.A Workbook for Cloud Computing in the Enterprise is the final volume in the four-volume Cloud rEvolution series. The series is as follows:
Volume 1: Cloud rEvolution: Laying the Foundation
Volume 2: Cloud rEvolution: The Art of Abstraction
Volume 3: Cloud rEvolution: The Cloud Effect
Volume 4: Cloud rEvolution: A Workbook for Cloud Computing in the Enterprise
<Return to section navigation list>
Cloud Security and Governance
David Linthicum claims “As IT focuses on refined encryption and identity management systems, it may be missing a big vulnerability: users” as a preface to his Users are the largest cloud computing security threat post of 5/4/2010 to InfoWorld’s Cloud Computing blog:
While it's been obvious to me for a long time, those moving to the cloud are coming to grips with the fact that the most considerable threat to cloud computing security is not from hackers sitting thousands of miles away, it's from the people in the office next door. This article on Bnet agrees:
“Once upon a time the world of computer security was divided into two zones, inside and outside, but the shift to cloud computing changed that. "How do you design a resilient security system when the source of the attacks are most likely people inside the system?" says Roger Grimes, a 20-year veteran of the security industry [and Security Adviser columnist at InfoWorld.com]. ‘How do you educate users to make sure they don't accidentally let an intruder in?’”
Nothing really changes. Back in the day, I was asked to do penetration testing for a large minicomputer manufacturer. While password-guessing programs worked from time to time, the easiest way into the system was to call a user and ask for his or her user ID and password. We succeeded about one out of three times.
While there is certainly more education around these days and most people won't provide user IDs and passwords on the phone, this little trick still works. Try emailing everyone in the company and asking for the user ID and passwords for your cloud computing provider, perhaps talking about a "critical software upgrade." You'll still get one or two people to respond before corporate security is alerted. That's all it takes. …
Roger Grimes asserts “With frequent backups and stringent security policies, cloud vendors often run much tighter ships than other organizations” in a preface to his Cloud computing is more secure than you think post of 5/4/2010 to InfoWorld’s Security Advisor blog:
Recent security problems with Google's cloud offerings have sparked a flood of questions about whether or not cloud services are ready for prime time. Are they sophisticated enough to handle the world's mission-critical applications reliably and securely? In my view, the answer is a resounding yes. Choosing one or more cloud service could, in fact, reduce expense and security risks for the average company.
That view may come as a surprise in light of the dozens of stories that emerge each week summarizing various cloud failures. Those failures aren't the norm, though; it's just that the media makes more money when it reports bad news instead of good. How many articles have you read about cloud vendors with 99.999 percent uptime and availability? How many news alerts have you seen this year discussing the cloud products and services that experienced no significant security issues? Not many, I suspect. …
Over the last 10 years of my career, I've performed hundreds of security reviews at an array of organizations. In general, the average company has dozens of security gaps, many of them of the highest risk. It's never a surprise to the companies that have hired me. Heck, the participating staff usually knows of far more problems, but there's little incentive for them to volunteer information. It's common to find huge policy gaps, unpatched software on mission critical servers, bug-filled applications, spotty data restoration, and a myriad of maliciousness.
Most of the cloud providers I review, however, fall at the other end of the spectrum: They have highly focused and fairly locked-down environments. Instead of the 40- to 90-page report I typically deliver, my reports to cloud companies tend to be 5 to 20 pages long, citing only a few problems. The bigger the cloud vendor, the fewer problems I find on average. …
Gorka Sadowski continues his cloud-logging series with Logs for Better Clouds - Part 6 of 5/4/2010:

Log Collection and Reporting requirements
So far in this series we have addressed:
- Trust, visibility, transparency. SLA reports and service usage measurement.
- Daisy chaining clouds. Transitive Trust.
- Intelligent reports that don't give away confidential information.
- Logs. Log Management.
Now, not all Log Management solutions are created equal, so what are some high-level Log Collection and Reporting requirements that apply to Log Management solutions?
Log Collection
A sound Log Management solution needs to be flexible to collect logs from a wide variety of log sources, including bespoke applications and custom equipments. Universal Collection is important to collect, track and measure all of the possible metrics that are in scope for our use case, for example the number and size of mails scanned for viruses, or number and size of files encrypted and stored in a Digital Vault, or number of network packets processed, or number of Virtual CPU consumed...And collection needs to be as painless and transparent as possible. Log Management needs to be an enabler, not a disabler! In order for the solution to be operationally sound, it needs to be easily integrated even in complex environments.
Open Reporting Platform
In addition to an easy universal collection, the Log Management solution needs to be an Open Platform, allowing a Cloud Provider to define very specific custom reports on standard and non-standard types of logs.Many different types of reports will be used but they will fall under 2 categories.
External facing reports will be the ones shared with adjacent layers, for example service usage reporting, SLA compliance, security traceability, etc. These will have to show information about all the resources required to render a service while not disclosing information considered confidential.
Internal reports will deal with internal "housekeeping" needs, for example security monitoring, operational efficiency, business intelligence...
And for the sake of Trust, all of these reports need to be generated with the confidence that all data (all raw logs in our case) has been accounted for and computed.
We can see that many internal and external facing reports need to be generated and precisely customized, and again this needs to be achieved easily. …
Mike Kirkwood describes Securing Google Apps: New Admin Feature Gives Real-Time Control in this 5/3/2010 post to the ReadWriteCloud blog:
Google has been working to harden Google Apps for its arrival into the enterprise. The tools bring browser based productivity into another dimension.
And, where people are productive, security is to be questioned. In this short review, we look at the new feature Google offers admins and look a bit closer at security in a browser-based world.
To further enable Google Apps administrators, the company has released a new cookie based reset tool for managing security between the client and the enterprise cloud. This functionality of Google Apps allows an administrator to flag a user for re-authentication on their next HTTP request to Google's cloud apps.
This new feature is targeted at environments where a user of the the Google Apps cloud loses an IT asset and the company wants to remove access to any current for future page requests.
This feature shows how mobile and personal computer are again creeping together in security needs for cloud data service use.
After reading a complete description of the feature, it seems to me that Windows Azure storage and Microsoft BPOS would benefit from a similar reset tool.
<Return to section navigation list>
Cloud Computing Events
Brenda Michelson reported that she’s @ ITLC 2010 Conference: Cloud Computing for the Trucking Industry on 5/13/2010:
I’m at the Information Technology & Logistics Council (ITLC) conference on Amelia Island in Florida. I was invited here to speak on SOA. Now, I’m sitting in on a cloud computing session. The format is three mini-presentations, followed by a panel discussion.
- Chris Rafter, Solution Services Group, Logicalis, Inc.
- Jackie Baretta, CIO, Con-Way Inc.
- Dave Tezler, Oracle
- Moderator: Steve Chaffee, Logicalis
Steve Chaffee opened quoting the Forrester paper by Gene Leganza on Enterprise Architects and Cloud Computing Adoption. He also mentioned the citizen development aspect of cloud, as familiarized by Gartner.
First up is Chris Rafter, Logicalis is an IT Services Company. Chris is starting with some Cloud Computing fundamentals. After some What is Cloud? Chris is talking about how cloud computing isn’t just an IT topic. It’s also a business topic and finance topic. The overall value prop: “Deliver the same application, with “good enough” quality of experience, for dramatically lower cost.” …
Brenda continues live-blogging the other panelists’ comments. (Amelia Island Plantation is a nice venue this time of year.)
Jonathan Wong from the Microsoft Innovation Centre Singapore presents the slide deck from his 4/26/2010 presentation to the Singapore PHP User Group in an Event Summary: Windows Azure @ PHP User Group post of 4/28/2010 to the Centre’s blog:
Last night, we hosted the Singapore PHP User Group (or the Philosophy in Programming Society, as they like to be called) at our office for their monthly meet-up.
There were two presentations during the event. I presented on using the Windows Azure Platform with PHP, and Chin Yong presented on APC (Alternative PHP Cache – no, not Armored Personnel Carrier)
Here are our presentation slides:
- You can also download my barebones Azure PHP code template here, if you are interested in trying to run your own PHP application on Windows Azure.
- Don’t forget that the one-stop location for everything you need to learn about and get started on Windows Azure is at this simple URL: www.windowsazure.com.
Quote of the night comes from Chin Yong’s last slide:
“The closest I have gotten to .net is php.net”
Umm, Chin Yong, you and I need to talk…
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Maureen O’Gara claims “Customers can now seamlessly connect their IT infrastructure via an encrypted IPsec VPN connection” in her Amazon Opens Virtual Private Cloud in Europe post of 5/4/2010:
Amazon has taken its Virtual Private Cloud (VPC) to Europe.
Customers can now seamlessly connect their IT infrastructure via an encrypted IPsec Virtual Private Network (VPN) connection to Amazon resources in the European Union, keeping their data in the EU and lowering latency.
Until Tuesday VPC, a bridge between a company's existing IT infrastructure and a set of isolated Amazon compute resources in the Amazon cloud, was only available in the US.
With VPC customers can use their existing management capabilities such as security services, firewalls and intrusion detection systems on their Amazon resources.
Jeff Barr provides more details in his Amazon Virtual Private Cloud Heads to Europe post of 5/3/2010.
















