Windows Azure and Cloud Computing Posts for 5/24/2010+
 | Windows Azure, SQL Azure Database and related cloud computing topics now appear in this daily series. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now download and save the following two online-only chapters in Microsoft Office Word 2003 *.doc format by FTP:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available from the book's Code Download page; these chapters will be updated in June 2010 for the January 4, 2010 commercial release.
Azure Blob, Drive, Table and Queue Services
Mark Nischalke describes his Windows Azure Storage post of 5/24/2010 to The Code Project as “A simple look at what Windows Azure Storage is and how it can be used”:
Introduction
Windows Azure, Microsoft's cloud computing offering, has three type of storage available, blob, table and queue. This article will demonstrate a semi-practical usage for each of these types to help you understand each and how they could be used. The application will contain two roles, a Web Role for the user interface and Worker Role for some background processing. The Web Role will have a simple Web application to upload images to blob storage and some metadata about them to table storage. It will then add a message to a queue which will be read by the Worker Role to add a watermark to the uploaded image.
A Windows Azure account is not necessary to run this application since it will make use of the development environment.
Prerequisites: To run the sample code in this article you will need:
- Visual Studio 2008 or higher, Visual Studion 2010 is preferred.
- Windows Azure SDK (http://msdn.microsoft.com/en-us/library/dd179367.aspx)
- Windows Azure Tools for Visual Studio (http://www.microsoft.com/downloads/details.aspx?FamilyID=5664019e-6860-4c33-9843-4eb40b297ab6&DisplayLang=en)
- SQL Server. You will need to run DSInit fromAzure SDK to configure the database.

Mark continues with descriptions of Azure Roles and Storage, and explains “Building the storage methods” with narrative and C# code.
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
Wayne Walter Berry’s Generating Scripts for SQL Azure post of 5/24/2010 outlines a 16 step process for generating scripts to upload SQL Server databases to SQL Azure with SQL Server Management Studio 2008 R2:
When moving a SQL Server database to SQL Azure the first step is to generate a script that will transfer the schema of your SQL Server database to SQL Azure. SQL Server Management Studio 2008 R2 easily does this with a newly added advanced setting that allows you to target SQL Azure as you engine type. …
In order to use SSIS or BCP to transfer your SQL Server data to SQL Azure you need to have the schema is place on SQL Azure including your clustered indexes. Another option to upload data is changing the settings on the Generate and Publish Scripts dialog to include data generation. INSERT statements will be added to the script increasing the overall size of the script – this only works well for small databases.
I find it easier to use George Huey’s SQL Azure Migration Wizard, as described in my Using the SQL Azure Migration Wizard v3.1.3/3.1.4 with the AdventureWorksLT2008R2 Sample Database post updated 1/23/2010. The latest version is v3.2.2 of 5/16/2010.
Mamoon Yunis asserts “SQL Azure provides affordable and rapid collaboration across SOA Test teams using SOAPSonar” in his Using SQL Azure for SOA Quality Testing post of 5/24/2010:
I. INTRODUCTION
Throwing its hat in the Platform as a Service (PaaS) ring, Microsoft has joined the likes for Salesforce.com and Google with its annoucement of Microsoft Azure Platform. Microsoft Windows Azure Platform provides three primary components:
- Windows Azure: A cloud services operating system that serves as the development, service hosting and service management environment for the Windows Azure platform.
- SQL Azure: A cloud hosted relational database that removes the burdens of RDBMS installation, patching, upgrades and overall software management for relational databases.
- AppFabric: A platform that enables users to build and manage applications easily both on-premises and in the cloud.
To better understand the components offered by MS Azure, we registered for MS Azure Platform and browsed through the three components. SQL Azure turned out to be the easiest one to configure and do something useful with, so we built a mashup that utilizes MS SQL Azure as a centeral repository for SOA Testing. In this article, we share our impressions of SQL Azure and how to automate SOA quality assurance by building test cases that use data from a SQL Azure instance.
II. BENEFITS OF USING SQL AZURE FOR SOA TESTING
By using a cloud-based RDBMS, such as MS SQL Azure, developer and testors can gain the following benefits:
- Better Collaboration across testors by sharing test data within and across enterprise boundaries and geographies.
- Ease of Management by eliminating the burden of downloading, installing, patching and managing a Database used for storing SOA test data values.
- Increased Nimbleness by eliminating resources contention and scheduling bottlenecks by "spinning up" new instance of Database servers within minutes for SOA Testing teams.
- Cost Reduction inherently associated with on-demand and elastic nature of cloud computing by eliminating on-premise hardware and software.
III. SETUP AND INSTALLATION OVERVIEW
To understand SQL Azure and its utility for collaborative SOA Testing, we built a mash up between SQL Azure, a target web service IsValidEmail(email address) and SOAPSonar, a SOA Testing tool from Crosscheck Network. Figure 1 shows the overall setup scenario where SQL Azure is used to maintain and share test data consumed by geographically disparate SOA testers tasked with testing services for a SOA deployment.
Figure 1: SQL Azure setup for collaborative SOA testing
We started by registering for an Azure account and creating a SQL Azure Database. After setting firewall rules that permit remote access, we installed Microsoft SQL Management Studio and connected to the SQL Azure Database. With SQL Management Studio, we were able to create tables and insert data into the tables. We then installed SOAPSonar and imported the publicly available WSDL containing a single test service, IsValidOperation(email), that checks for the validity of an email address. The details of SQL Azure setup and data automation for SOA testing configuration are provided below along with details of issues that we encountered along the way. …

Mamo0n continues with the additional details. He is the founder of Forum Systems and a pioneer in Web Services Security Gateways & Firewalls.
Pradeep Chandraker’s RIA Services - exposing OData service article of 5/24/2010 for the C# Corner site shows you how to enable OData in RIA Services:
Open Data Protocol (OData) is a web protocol which is used for querying and updating data. OData is being used to expose and access information from a variety of sources, including relational databases, file systems, content management systems, and traditional web sites. OData applies web technologies like http, Atom publishing protocol and JSON to provide access to information from different applications and services. It is emerging set of extensions for the Atom protocol.
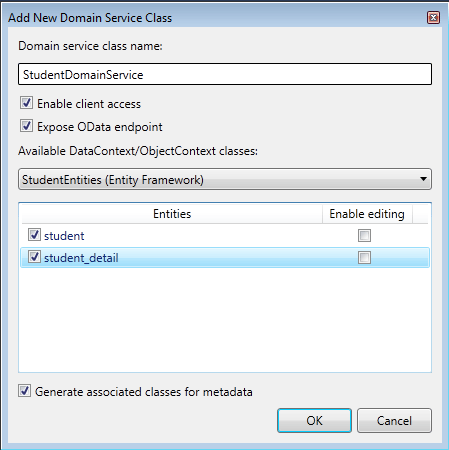
In RIA Service it is easy to enable Odata service. When you add Domain Service, check the "Expose OData endpoint" checkbox in "Add New Domain Service Class" dialog box (you can go through my article RIA Services - using Entity Framework to see how to create domain service).
When you enable OData endpoint for domain service you will notice two changes.
First for each query methods you want to expose using OData are marked with default query
[EnableClientAccess()] public class StudentDomainService : LinqToEntitiesDomainService<studententities> { [Query(IsDefault = true)] public IQueryableGetStudents() { return this.ObjectContext.students; } [Query(IsDefault = true)] public IQueryable GetStudent_detail() { return this.ObjectContext.student_detail; } } And second, the endpoint for OData is added into domainService section of Web.config.
<domainServices> <endpoints> <add name="OData" type="System.ServiceModel.DomainServices.Hosting.ODataEndpointFactory, System.ServiceModel.DomainServices.Hosting.OData, Version=4.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" /> </endpoints> </domainServices>Now to see the Atom feed hit the below URL (change port number to port number the application is currently running in your system)
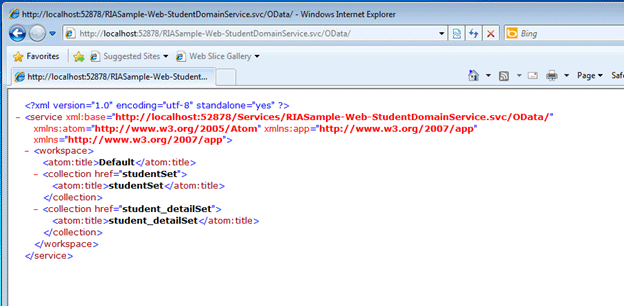
http://localhost:52878/RIASample-Web-StudentDomainService.svc/OData/
The URL is combination of namespace and domain service name. When you hit above URL you will get this output.
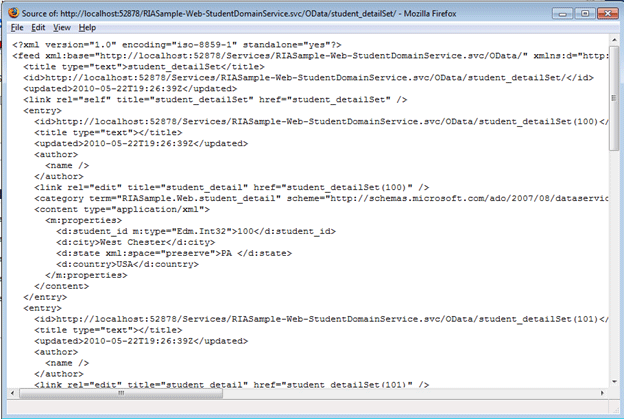
If you can to see student detail set you can specify that in URL.
http://localhost:52878/RIASample-Web-StudentDomainService.svc/OData/student_detailSet/
Output in Firefox view source:
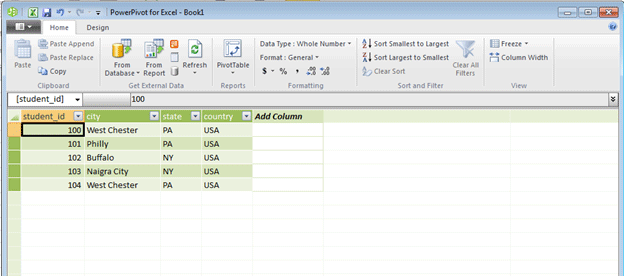
Output in Microsoft PowerPivot for Excel:
Microsoft currently supports the Open Data Protocol (OData) in SharePoint Server 2010, Excel 2010 (through SQL Server PowerPivot for Excel), Windows Azure Storage, SQL Server 2008 R2, Visual Studio 2008 SP1.
Marcelo Lopez Ruiz explains Consuming OData with Office VBA - Part IV (Access) in this February 19 article, which I missed when posted:
Check out parts one, two and three if you haven't - good stuff there!
In today's post, we're going to import data into Microsoft Access. I'm going to focus on having the building blocks in place, although in real-life use, you would either make this more general or more specific - more on this later.
If we're going to import data into a table, the first thing to do is to be able to figure out what columns we should create. Once we've downloaded some data, we can look at what the names are in for the values in our records, represented as dictionaries in a collection. The following code makes sure we gather all the names from all the records, in case some of them are missing. That won't be the case for today's example, but some other OData sources might do that.
Once we have our table, it's a simple matter to just add all of our dictionaries into it.
Finally, we're going to put all of the pieces together into a routine we can call to recreate the table and add data to it. We'll make use of a helper CollectionContains function to check whether the table exists in case we want to start with a fresh table every time.
Now to put together a sample, this is how we can use the code we just wrote to import the dataset from the OGDI site for New American Foundation's Funding, student demographics, and achievement data at state level data. If you create an empty Access database and put here all the code we've written so far, you should be able to see the table in your database and double-click it to browse the data (you may need to refresh the list of tables if the EdmFundDemo table doesn't show up immediately).
If you wanted to make this a real general-pupose import library, you would probably want to add data types and key information. On the other hand, if you were more precise, you could mess with the schema beforehand and only append certain columns. Scripting makes all these changes easy - that's what's great about being able to have an environment available with Microsoft Office to tweak things to your specific needs.




Visit Marcelo’s blog to copy code to paste to your Access VBA module. Following are the previous posts in this series:
- Consuming OData with Office VBA - Part I (2/16/2010)
- Consuming OData with Office VBA - Part II (2/17/2010)
- Consuming OData with Office VBA - Part III Excel (2/19/2010)
<Return to section navigation list>
AppFabric: Access Control and Service Bus
Alex James’ OData and Authentication - Part 3 - ClientSide Hooks post of 5/24/2010 discusses OAuth WRAP:
So far in this series we’ve looked at Windows Authentication.
For both Windows and Basic Authentication, Data Services does the authentication handshake and subsequent sending of authentication headers – all without you directly setting a http header.
It can do this because there is a higher level abstraction – the Credentials property – that hides the implementation details from you.
All this works great for Windows and Basic Authentication. However if you are using a different authentication scheme, for arguments sake OAuth WRAP, the Credentials property is of no use. You have to get back down to the request and massage the headers directly.
You might need to set the request headers for all sorts of reasons, but probably the most common is Claims Based Authentication.
So before we look into how to set the headers, a little background…
Claims based Authentication 101
The basic idea of Claims Based Auth, is that you authenticate against an Identity Provider and request an ‘access token’ which you can use to make requests against a server of protected resources.
The server – essentially the gatekeeper – looks at the ‘access token’ and verifies it was issued by an Identity Provider it trusts, and if so, allows access to the resources.
Keeping the claim private
Any time you send a token on the wire it should be encrypted, so that it can’t be discovered and re-used by others. This means claims based authentication – at least in the REST world – generally uses HTTPS.
Many Authentication Topologies
While the final step – setting the access token – is very simple, the process of getting an authentication token can get much more complicated, with things like federated trust relationships, delegated access rights etc.
In fact, there are probably hundreds of ‘authentication topologies’ that can leverage claims based authentication. And each topology will involve a different process to acquire a valid ‘access token’.
We’re not quite ready to cover these complexities yet, but we will revisit the specifics in a later post.
Still, at the end of the day, the client application simply needs to pass a valid access token to the server to gain access.
Example Scenario: OAuth WRAP
So if for example you have an OData service that uses OAuth WRAP for authentication the client would need to send a request like this:
GET /OData.svc/Products(1)
Authorization: WRAP access_token=”123456789”And the server would need to look at the Authorization header and decide if the provided access_token is valid or not.
Sounds simple enough.
The real question for today is how do you set these headers?
Client Side Hooks: Before making requests
On the client-side adding the necessary headers is pretty simple.
Both the Silverlight and the .NET DataServiceContext have an event called SendingRequest that you can hook up to. And in your event handler you can add the appropriate headers.
For OAuth WRAP your event handler might look something like this:
void OnSendingRequest(object sender, SendingRequestEventArgs e)
{
e.RequestHeaders.Add("Authorization","WRAP access_token=\"123456789\"");
}What if the Access Token is invalid or missing?
If the Access Token is missing or invalid the server will respond with a 401 unauthorized response, which your code will need to handle.
Unfortunately in the Data Services client today there is no place to hook into the HttpResponse directly, so you have to wait for an Exception.
You will get either a DataServiceQueryException or DataServiceRequestException depending on what you were doing, and both of those have a Response property (which is *not* a HttpResponse) that you can interrogate like this:
try
{
foreach (Product p in ctx.Products)
Console.WriteLine(p.Name);
}
catch (DataServiceQueryException ex)
{
var scheme = ex.Response.Headers["WWW-Authenticate"];
var code = ex.Response.StatusCode;
if (code == 401 && scheme == "WRAP")
DoSomethingToGetAnOAuthAccessToken();
}The problem with trying to get an Access Token when challenged like this, rather than up front before you make the request, is that you now have to go and acquire a valid token, and somehow maintain context too, so the user isn’t forced to start again.
It is also a little unfortunate that you can’t easily centralize this authentication failure code.
Summary
As you can see it is relatively easy to add custom headers to requests, which is ideal for integrating with various auth schemes on the client side.
It is however harder to look at the response headers. You can do it, but only if you put try / catch blocks into your code, and write code to handle the UI flow interruption.
So our recommendation is that you get the necessary tokens / claims etc – for example an OAuth access_token – before allowing users to even try to interact with the service.
In Part 4 we will look at the Server-Side hooks…

Eve Maler’s (@xmlgrrl) Comparing OAuth and UMA post of 5/23/2010 describes the current activities of UMAnitarians and user-managed access control:
![]()
The last few weeks have been fertile for the Kantara User-Managed Access work. First we ran a half-day UMA workshop (slides, liveblog) at EIC that included a presentation by Maciej Machulak of Newcastle University on his SMART project implementation; the workshop inspired Christian Scholz to develop a whole new UMA prototype the very same day. (And they have been busy bees since; you can find more info here.)
Then, this past week at IIW X, various UMAnitarians convened a series of well-attended sessions touching on the core protocol, legal implications of forging authorization agreements, our “Claims 2.0″ work, and how UMA is being tried out in a higher-ed setting — and Maciej and his colleague Łukasz Moreń demoed their SMART implementation more than a dozen times during the speed demo hour.
In the middle of all this, Maciej dashed off to Oakland, where the IEEE Symposium on Security and Privacy was being held, to present a poster on User-Managed Access to Web Resources (something of a companion to this technical report, all with graphic design by Domenico Catalano).
Through it all, we learned a ton; thanks to everyone who shared questions and feedback.
Because UMA layers on OAuth 2.0 and the latter is still under development, IIW and the follow-on OAuth interim F2F presented opportunities for taking stock of and contributing to the OAuth work as well.
Since lots of people are now becoming familiar with the new OAuth paradigm, I thought it might be useful to share a summary of how UMA builds on and differs from OAuth. (Phil Windley has a thoughtful high-level take here.) You can also find this comparison material in the slides I presented on IIW X day 1.
Terms
UMA settled on its terms before WRAP was made public; any overlap in terms was accidental. As we have done the work to model UMA on OAuth 2.0, it has become natural to state the equivalences below more boldly and clearly, while retaining our unique terms to distinguish the UMA-enhanced versions. If any UMA technology ends up “sedimenting” lower in the stack, it may make sense to adopt OAuth terms directly.
- OAuth: resource owner; UMA: authorizing user
- OAuth: authorization server; UMA: authorization manager
- OAuth: resource server; UMA: host
- OAuth: client; UMA: requester
Concepts
I described UMA as sort of unhooking OAuth’s authorization server concept from its resource-server moorings and making it user-centric.
- OAuth: There is one resource owner in the picture, on “both sides”. UMA: The authorizing user may be granting access to a truly autonomous party (which is why we need to think harder about authorization agreements).
- OAuth: The resource server respects access tokens from “its” authorization server. UMA: The host outsources authorization jobs to an authorization manager chosen by the user.
- OAuth: The authorization server issues tokens based on the client’s ability to authenticate. UMA: The authorization manager issues tokens based on user policy and “claims” conveyed by the requester.
Dynamic trust
UMA has a need to support lots of dynamic matchups between entities.
- OAuth: The client and server sides must meet outside the resource-owner context ahead of time (not mandated, just not dealt with in the spec). UMA: A requester can walk up to a protected resource and attempt to get access without having registered first.
- OAuth: The resource server meets its authorization server ahead of time and is tightly coupled with it (not mandated, just not dealt with in the spec). UMA: The authorizing user can mediate the introduction of each of his hosts to the authorization manager he wants it to use.
- OAuth: The resource server validates tokens in an unspecified manner, assumed locally. UMA: The host has the option of asking the authorization manager to validate tokens in real time.
Protocol
UMA started out life as a fairly large “application” of OAuth 1.0. Over time, it has become a cleaner and smaller set of profiles, extensions, and enhanced flows for OAuth 2.0. If any find wider interest, we could break them out into separate specs.
- OAuth: Two major steps: get a token (with multiple flow options), use a token. UMA: Three major steps: trust a token (host/authorization manager introduction), get a token, use a token.
- OAuth: User delegation flows and autonomous client flows. UMA: Profiles (TBD) of OAuth flows that add the ability to request claims to satisfy user policy.
- OAuth: Resource and authorization servers are generally not expected to communicate directly, vs. through the access token that is passed through the client. UMA: Authorization manager gives host its own access token; host uses it to supply resource details and request token validation.
Much work remains to be done; please consider joining us (it’s free!) if you’d like to help us make user-managed access a reality.

Yes, Oakland is hosting an IEEE Symposium at the Claremont Hotel and Spa, half of which is in Berkeley. The preceding graphic is part of Maciej Machulak’s poster presentation. (Click to see the entire poster.)
Notes from the Internet Identity Workshop (IIW) 2010 held at San Jose’s (CA) Computer History Museum on 5/17 through 5/20/2010 are available here.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Eugenio Pace announced Windows Azure Architecture Guide – Part 1 – Release Candidate Documents updated in this 5/24/2010 post:
I just uploaded new versions of the docs that make up our guide. No major changes, but some wordsmithing and professional graphics.
I do enjoy doing the whiteboard like graphics, and we have kept that spirit in the guide, but we have them redone professionally by a graphics designer. So you will see this:
instead of this:
Or:
instead of:
We only have one extra color available in the guide (different shades of blue).
Although, I must confess: now that I see both versions side-by-side, my handwritten diagrams don’t look bad at all :-).





I’d say the graphic designer did a good job of emulating Eugenio’s drawings.
Travio’s Side-by-side they fall post of 5/24/2010 describes how to overcome problems with C/C++ isolated applications and side-by-side assemblies in Windows Azure projects:
The project I’m on at work finally went to actual Windows Azure over the weekend. This was the media server component which converts and thumbnails media that gets sent to it using a combination of ffmpeg, ImageMagick and Lokad.Cloud for message queuing. This was our first test in the full [A]zure environment and I found a very annoying problem. [Links added.]
We got ImageMagick working ages ago by putting the executables (convert.exe, identify.exe) in cloud storage, then when the application needed to use them, it would download them to local scratch storage (I’ll do a bigger post on this later). This works really well on my local machine but upon testing on actual Windows Azure convert.exe and identify.exe stopped working, quoting:
“The application has failed to start because its side-by-side configuration is incorrect.. Please see the application event log …”
My first thought was to follow the application event log, so I grabbed Azure Diagnostics Manager [http://www.cerebrata.com/products/AzureDiagnosticsManager/Default.aspx] and added some code to my WorkerRole.cs/WebRole.cs OnStart…
DiagnosticMonitorConfiguration dmc = DiagnosticMonitor.GetDefaultInitialConfiguration();
dmc.WindowsEventLog.DataSources.Add(Constants.ApplicationName);
dmc.WindowsEventLog.ScheduledTransferPeriod = TimeSpan.FromMinutes(1);
DiagnosticMonitor.Start(”DataConnectionString”, dmc);…and found nothing! I couldn’t get the event log and after a little bit of playing around I decided to give up path!
The problem is that every time you do small changes to [A]zure the deploy process takes AGES – like 5 minutes or so. So trying little things and failing them then having to wait 5 minutes between can get very frustrating. I’m sure if I read the full how-to post (http://blog.toddysm.com/2010/05/collecting-event-logs-in-windows-azure.html) I would have worked it out but I had a feeling that the event log wouldn’t tell me much regardless.
So back on track I looked into the side-by-side error and found some information about it. Basically side-by-side errors mean that some config/assemblies are missing (http://msdn.microsoft.com/en-us/library/ms235342.aspx). So I started along the long path of finding the missing references to ImageMagick. By the way, the actual problem is that the VS2008 C++ Redistrib packages didn’t exist on Azure whereas they existed on my system (ImageMagick download page states this at the very bottom http://www.imagemagick.org/www/binary-releases.html). I don’t think I can just install them on azure so I went about the problem by gathering all the required assemblies.
So, to investigate side-by-side issues you have to use the “sxstrace” tool. I set up a new blank Windows 7 VM to ensure vs2008 redistributable packages weren’t there, then ..
- Run cmd elevated (Start -> type “cmd” -> right click on cmd -> Run as Adminsitrator).
- cd into your executable directory
- Run “sxstrace trace -logfile:sxstrace.ctl” (without quotes)
- In another cmd, run your side-by-side failing program (identify.exe in my case)
- Press enter to stop tracing for sxstrace
- The trace is a binary file that needs to be parsed. Parse it: sxstrace parse -logfile:sxstrace.ctl -outfile:sxstrace.txt
- Open up sxstrace.txt and you’ll find your problem.
In my case, identify.exe required a couple of dlls and some .manifest files. You end up having to copy required manifests from c:\windows\winsxs\manifests to your executable folder then grabbing all those dlls. Run sxstrace again (as above) to find more problems. Here’s what I ended up with to get identify.exe and convert.exe working (my wordpress images directory isn’t working so the filenames are just given below):
convert.exe
identify.exe
identify.exe.manifest (not sure if this is needed)
Microsoft.VC90.OpenMP.MANIFEST (this was renamed from the respective manifest file in c:\windows\winsxs\manifests as I was looking specifically for this name from the sxstrace log)
mscvm90.dll
msvcp90.dll
msvcr90.dll
vcomp90.dll
x86_microsoft.vc90.crt_1fc8b3b9a1e18e3b_9.0.21022.8_none_bcb86ed6ac711f91.manifestHappy to provide more details if anyone needs.
Travio’s earlier posts about Windows Azure for managing images also might interest developers.
Andrea DiMaio’s US Federal Government Facelifts Its Cloud Initiative post of 5/24/2010 to the Gartner blogs analyzes the latest federal cloud RFQ:
Over the last week or so a few events have witnessed that the US Federal Government, and in particular the GSA, is in the process of accelerating its cloud computing initiative and making it more relevant after the launch of apps.gov (which went largely unnoticed from a procurement perspective) and a failed RFQ for infrastructure-as-a-service services.
The federal cloud computing initiative is now part of the recently renamed Office of Citizen Services and Innovative Technologies. and soon led by Sanjeev “Sonny” Bhagowalia, CIO at Department of Interior.
Last week the GSA launched an RFQ for IaaS, which replaced the one launched last year and canceled in February. Also, it launched info.apps.gov, which provides general information about cloud computing for federal agencies to get acquainted with concepts and examples. Also, as US CIO Vivek Kundra reminded last week, the federal cloud computing initiative keeps pursuing a standardization effort, especially in the area of security where the Federal Risk and Authorization Management Program (FedRAMP) should ease the Certification & Accreditation process required today for compliance with FISMA regulations.
It is clear that the feds are getting serious about cloud computing and are trying to address the legitimate concerns that federal agencies still have in adopting this model.
While most of the information on info.apps.gov is very helpful, there is still room for improvement in highlighting more clearly the full list of criteria to select cloud as an option, as well as to better position vendor and government
ownoffering[s].Gartner has just published a series of research notes dealing with all this. Clients can start from the introductory article Governments in the Cloud (login required)
Return to section navigation list>
Windows Azure Infrastructure
Aashish Dhamdhere reports We Want to Showcase Your ‘Building Block' Solutions for Windows Azure in this 5/24/2010 post to the Azure Team Blog:
One of the core benefits of Windows Azure is how it increases developers' agility to get their ideas to market faster. We believe the ‘building block' components and services that our community of developers is building illustrates this benefit by helping address particular scenarios and making the process of developing compelling and complete solutions on Windows Azure easier and faster.
‘Building block' components and services are designed to be incorporated by other developers into their applications (e.g. a billing engine that developers can use to quickly add paid subscriptions to their web application). Other examples include (but are not limited to) management tools, UI controls, and email services.
As one of the people responsible for marketing Windows Azure, I'm always on the lookout for the latest and greatest community-built components and services to help us showcase the unique benefits of Windows Azure. So if you've built a component, service, or application that helps make development on Windows Azure easier or faster, I want to hear from you. If you're interested in learning more, please drop me an email and I'll follow up with you.

Aashish is a Microsoft Senior Product Manager for Windows Azure.
John Savageau asserts “Cloud Computing- the Divine Form” [of utility] in his “A Cloud Computing Epiphany” post of 5/22/2010:
One of the greatest moments a cloud evangelist indulges in occurs at that point a listener experiences an intuitive leap of understanding following your explanation of cloud computing. No greater joy and intrinsic sense of accomplishment.
Government IT managers, particularly those in developing countries, view information and communications technology (ICT) as almost a “black” art. Unlike the US, Europe, Korea, Japan, or other countries where Internet and network-enabled everything has diffused itself into the core of Generation “Y-ers,” Millennials, and Gen “Z-ers.” The black art gives IT managers in some legacy organizations the power they need to control the efforts of people and groups needing support, as their limited understanding of ICT still sets them slightly above the abilities of their peers.
But, when the “users” suddenly have that right brain flash of comprehension in a complex topic such as cloud computing, the barrier of traditional IT control suddenly becomes a barrier which must be explained and justified. Suddenly everybody from the CFO down to supervisors can become “virtual” data center operators – at the touch of a keyboard. Suddenly cloud computing and ICT becomes a standard tool for work – a utility.
The Changing Role of IT Managers
IT managers normally make marginal business planners. While none of us like to admit it, we usually start an IT refresh project with thoughts like, “what kind of computers should we request budget to buy?” Or “that new “FuzzPort 2000″ is a fantastic switch, we need to buy some of those…” And then spend the next fiscal year making excuses why the IT division cannot meet the needs and requests of users.
The time is changing. The IT manager can no longer think about control, but rather must think about capacity and standards. Setting parameters and process, not limitations.
Think about topics such as cloud computing, and how they can build an infrastructure which meets the creativity, processing, management, scaling, and disaster recovery needs of the organization. Think of gaining greater business efficiencies and agility through data center consolidation, education, and breaking down ICT barriers.
The IT manager of the future is not only a person concerned about the basic ICT food groups of concrete, power, air conditioning, and communications, but also concerns himself with capacity planning and thought leadership.
The Changing Role of Users
There is an old story of the astronomer and the programmer. Both are pursuing graduate degrees at a prestigious university, but from different tracks. By the end of their studies (this is a very old story), the computer science major focusing on software development found his FORTRAN skills were actually below the FORTRAN skills of the astronomer.
“How can this be” cried the programmer? “I have been studying software development for years, and you studying the stars?”
The astronomer replied “you have been studying FORTRAN as a major for the past three years. I have needed to learn FORTRAN and apply it in real application to my major, studying the solar system, and needed to learn code better than you just to do my job.”
There will be a point when the Millenials, with their deep-rooted appreciation for all things network and computer, will be able to take our Infrastructure as a Service (IaaS), and use this as their tool for developing great applications driving their business into a globally wired economy and community. Loading a LINUX image and suite of standard applications will give the average person no more intellectual stress than a “Boomer” sending a fax.
Revisiting the “4th” Utility
Yes, it is possible IT managers may be the road construction and maintenance crews of the Internet age, but that is not a bad thing. We have given the Gen Y-ers the tools they need to be great, and we should be proud of our accomplishments. Now is the time to build better tools to make them even more capable. Tools like the 4th utility which marries broadband communications with on-demand compute and storage utility.
The cloud computing epiphany awakens both IT managers and users. It stimulates an intellectual and organizational freedom that lets creative people and productive people explore more possibilities, with more resources, with little risk of failure (keep in mind with cloud computing your are potentially just renting your space).
If we look at other utilities as a tool, such as a road, water, or electricity – there are far more possibilities to use those utilities than the original intent. As a road may be considered a place to drive a car from point “A” to point “B,” it can also be used for motorcycles, trucks, bicycles, walking, a temporary hard stand, a temporary runway for airplanes, a stick ball field, a street hockey rink – at the end of the day it is a slab of concrete or asphalt that serves an open-ended scope of use – with only structural limitations.
Cloud computing and the 4th utility are the same. Once we have reached that cloud computing epiphany, our next generations of tremendously smart people will find those creative uses for the utility, and we will continue to develop and grow closer as a global community.
John Savageau is President of Pacific-Tier Communications dividing time between Honolulu and Long Beach, California.
Don Fornes contributes a Service Oriented Architectures (SOAs): A Plain English Guide as a 5/21/2010 article for the Software Advice Web site:
If you’ve been around the enterprise software industry the last few years, no doubt you’ve heard the term “service oriented architecture” (SOA). If you aren’t technical, it’s one of those terms that flies right over your head. That’s understandable, given that most definitions of SOA are rather dry. For example:
“A paradigm for organizing and utilizing distributed capabilities that may be under the control of different ownership domains. It provides a uniform means to offer, discover, interact with and use capabilities to produce desired effects consistent with measurable preconditions and expectations. (OASIS)”
Further complicating the topic is a dictionary-sized list of related technical acronyms such as SOAP, XML, CORBA, DCOM, .NET, J2EE, REST, BPEL and WS-CDL. The list goes on…
Allow me to try a more colloquial definition of SOA:
“A new and better way to get a bunch of different software programs to work together so people can do things that require information from each of those systems.”
We can also simplify the concept through an analogy: think of SOA as the information technology (IT) equivalent of managing a large, diverse workforce. To get stuff done in a big organization, you need to:
carefully define your goals and what constitutes success;
draw on the unique talents and knowledge of each individual;
get people to speak the same language and work together as a team; and,
measure where things stand and whether success is achieved.
SOA does all that for IT. It catalogs what systems are in place and what they can do (e.g. what data they own). It specifies a common language that they can all use to communicate, even if this common language is not each system’s “native tongue.” With those components in place, the organization can build new applications or processes that make use of the multi-system integration. Finally, a SOA coordinates and monitors the processes that span these systems.
Keep in mind that SOA is not a specific piece of technology. It’s really a strategy or model for how you go about achieving what I described above. Yes, there are many new technologies or standards (like .Net, J2EE, SOAP and XML) that play a critical role in SOA. SOA has also spawned hundreds of new software products that deliver various components of the SOA vision. And yes, there are many big IT companies that promote SOA a lot (IBM, Oracle and SAP come to mind). But SOA itself is an intangible strategy, just like Balanced Scorecard, Six Sigma and Total Quality Management are organizational management strategies.
But integrating software systems is nothing new, you say. True.
What’s new about SOA is that it’s now much easier to integrate systems. Moreover, SOA goes beyond just passing data back and forth. It actually manages and monitors complex processes that require multiple systems to work together in real-time (i.e., really quickly). It also defines standards for writing the next generation of systems so that the SOA vision is easier to achieve as the IT landscape evolves.
SOA has a lot to do with the World Wide Web. In fact, “web services” is a form of SOA, or arguably, a synonym. It refers to multiple Web applications communicating over the Internet, or local network, to share data and processes. Online travel websites like Kayak or Orbitz are a great example of web service integration. They don’t own the reservation data and they don’t do the actual booking on their system.
Instead, they offer easy-to-use websites that manage incredibly complex processes behind the scenes by acting as “web service consumers.” That is, they pull data and execute transactions from numerous other systems that are owned by airlines, rental car agencies and hotels that are acting as “web services providers.” Those behind-the-scenes systems act as web services to the Orbitz or Kayak websites. …
Don continues with a tabular taxonomy/glossary for Service Oriented Architectures and concludes:
Is SOA for Real?
SOA sounds great, right? Yes, when implemented properly the vision of SOA can be realized and provide tremendous value. However, like all things IT, there is nothing easy about executing on the SOA model. It takes a disciplined IT department and substantial investment to make SOA work.
And now a slightly cynical definition of SOA:
A new three-letter acronym to describe incremental improvements to existing software development techniques, allowing systems to perhaps interoperate more effectively. Also used by highly acquisitive software companies to tell an optimistic story about how they’ll get their acquired products to work together.
SOA non-believers will often paint this new model as IT dreaming or clever marketing. To some extent they would be right, because SOA has become a popular buzzword tossed around by many software vendors. Moreover, SOA remains in its early stages and there are still concerns about:
systems running slower because of multiple layers of translation;
the challenge of getting disparate systems to share the context of their requests; and,
nascent standards that do not yet provide adequate security and reliability.
There is certainly reason to consider all of these issues. However, SOA is supported by a huge industry filled with developers that want to see its vision realized. Even if SOA is not a magic bullet, there is tremendous value to working toward the SOA vision and achieving just some of its ideals. The model holds great promise and provides a roadmap for moving beyond historical IT integration and development challenges. We like it.
Thanks to SOA visionary Sam Gentile for the heads-up. As Sam says, “It’s a recommended read.”
<Return to section navigation list>
Cloud Security and Governance
David Kearns reports “Version 4 unifies identity management across physical and virtual servers as well as cloud-based environments, both public and private” in his Novell unveils new version of Identity Manager post of 5/24/2010 to NetworkWorld’s Security blog:
Last week Novell brought BrainShare back to Europe after a four year absence. But the gathering in Amsterdam almost didn't happen, as the Icelandic ash cloud closed Amsterdam's Schiphol airport two days before the conference was to begin. I heard lots of stories about people scrambling for ways to get to the city. But it did get going on time and, I'm really happy to say, it looks like Novell is back. …
Novell chose BrainShare Europe (or, more correctly, BrainShare EMEA - Europe, Middle East, Africa) to reveal the next version of it's Identity Manager product -- now at version 4.
Of course, it isn't really a single product but a collection of technologies and services useful for implementing identity management for your organization. The company wanted to emphasize that this release unifies identity management across physical and virtual servers as well as cloud-based environments, both public and private.
While it's true that everyone, it seems, is touting their software as cloud-enabled (or cloud-enabling), in this instance Novell makes a strong case for their commitment to the cloud model. In fact, after listening to people use a lack of security as the excuse for why organizations aren't utilizing the many advantages that cloud-based services can offer (lower cost, efficient management, better control, improved ease of use, etc.) it was refreshing to hear Novell executives affirm that Identity Manager 4 offers the same level of trust in the cloud that it offers in the data center.
I want to get into more detail about Identity Manager 4 and what Jim Ebzery (senior vice president and general manager for Security, Management and Operating System Platforms) had to tell me about their product and its future but I'll save that for the next issue. For now, I just want to note that I'm impressed that John Dragoon is still CMO at Novell, after more than five years in the job. It's the longest I can remember anyone filling that role in the 25 years I've covered the company. Maybe their marketing is finally coming around.
<Return to section navigation list>
Cloud Computing Events
Glen Gordon announces Free 1/2 day OData class coming to Raleigh, Charlotte and Atlanta on 6/2 through 6/4/2010 in this 5/24/2010 post:
Heard about OData yet? It's a cool open format for accessing data on the web, based on aspects of HTTP, AtomPub and JSON. Best of all, it's interoperable with many technologies. You might have heard of Microsoft tools in the past that could generate and work with data in the OData format like project Astoria, and more recently WCF Data Services.
Register for the events here and read more about OData below!
The Open Data Protocol (OData) http://www.odata.org/ is an open protocol for sharing data. It provides a way to break down data silos and increase the shared value of data by creating an ecosystem in which data consumers can interoperate with data producers in a way that is far more powerful than currently possible, enabling more applications to make sense of a broader set of data. Every producer and consumer of data that participates in this ecosystem increases its overall value.
OData is consistent with the way the Web works - it makes a deep commitment to URIs for resource identification and commits to an HTTP-based, uniform interface for interacting with those resources (just like the Web). This commitment to core Web principles allows OData to enable a new level of data integration and interoperability across a broad range of clients, servers, services, and tools.
OData is released under the Open Specification Promise to allow anyone to freely interoperate with OData implementations.
In this talk Chris will provide an in depth knowledge to this protocol, how to consume a OData service and finally how to implement an OData service on Windows using the WCF Data Services product.

O’Reilly Media will host a Cloud Summit on 7/20/2010 in conjunction with its O’Reilly OSCON Open Source Conference 2010 to be held in Portland, OR, from 7/29 to 7/23/2010:
The Cloud Summit is full day exploration of the major topics around cloud computing. We examine what cloud computing means, its past, the future and the interaction with open source. The purpose of this track is to give the audience a sound understanding of the issues around cloud computing, to sort fact from fiction, to dispel some of the myths around cloud and to provide a common framework to understand what is happening in our industry.
The summit combines experts from the field of operation, security, enterprise architecture, technology change and open source as well as practitioners in the field of cloud computing to give a holistic view of cloud computing – today and tomorrow.
After the event, come and socialize with some of the leading lights of cloud computing and then join us for the O’Reilly Open Source Awards and Ignite OSCON, a fast-paced and fun evening of talks.
Register now for the Cloud Summit, or the Cloud Summit plus the full O’Reilly Open Source Convention (21-23 July).
Who Should Attend?
- CIOs, CTOs, Technical Architects and those wishing to get up to speed quickly with concepts of cloud computing.
- Practitioners and evangelists in the field wishing to understand where cloud computing is heading.
- Community leaders & local event organisers in the cloud computing space
- Open source community leaders
Benefits of Attending
- Gain an understanding of what cloud really means and where it is heading.
- Hear directly from key figures in the cloud computing industry.
- Share with others using cloud computing in practice.
- Build connections with local events and groups in cloud computing.
- Build connections with other companies using cloud computing.
- Find developers or employers with cloud computing experience
We want attendees to the Cloud Summit to get the most benefit from being together. To help this, we’ve created a Cloud Summit page on the OSCON Wiki where you can leave details of your user groups, projects or other cloud computing related topics.
In addition, OSCON offers attendee-organized Birds-of-a-Feather sessions, so why not go ahead and organize more Cloud Computing meetups during the evenings of OSCON?

The post continues with a schedule of brief (20-, 30- and 45-minute) sessions.
NextGenUG reports Mike Taulty will be presenting on OData at Fest10 on July 16th - covering - OData – What, Why, When and How? in this 5/21/2010 news article:
Mike Taulty will be lifting the lid on OData at Fest10 on July 16th 2010 on Bournemouth Pier. You may have heard of OData recently. At the PDC 2009, Microsoft put a big focus onto OData, launched odata.org and released OData under the Open Specification Promise.In this session we’ll explore what OData really is and what it might mean for your data-centric services and clients. We’ll poke around in the protocol a little and we’ll then take a deeper look at what technologies Microsoft has on both the client and server side for both producing and consuming OData services.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Lori MacVittie claims Salesforce and Google have teamed up with VMware to promote cloud portability but like beauty that portability is only skin deep in her Despite Good Intentions PaaS Interoperability Still Only Skin Deep post of 5/24/2010 to F5’s DevCentral blog:
VMware has been moving of late to form strategic partnerships that enable greater portability of applications across cloud computing providers. The latest is an announcement that Google and VMware have joined forces to allow Java application “portability” with Google’s App Engine.
It is important to note that the portability resulting from this latest partnership and VMware’s previous strategic alliance formed with Salesforce.com will be the ability to deploy Java-based applications within Google and Force.com’s “cloud” environments. It is not about mobility, but portability. The former implies the ability to migrate from one environment to another without modification while the latter allows for cross-platform (or in this case, cross-cloud) deployment. Mobility should require no recompilation, no retargeting of the application itself while portability may, in fact, require both. The announcements surrounding these partnerships is about PaaS portability and, even more limiting, targeting Java-based applications. In and of itself that’s a good thing as both afford developers a choice. But it is not mobility in the sense that Intercloud as a concept defines mobility and portability, and the choice afforded developers is only skin deep.
PaaS MOBILITY INHERENTLY LIMITED
The mobility of an application deployed atop a PaaS is exceedingly limited for two reasons. First, you are necessarily targeting a specific platform for applications: .NET, Java, PHP, Python, Ruby. If that was the only issue then alliances such as those between VMware and Google and Salesforce.com might be of broader appeal. But the second limiting factor with PaaS is the use of proprietary platform services such as those offered for data, queuing and e-mail.
Both announcements make mention of the ability to “tap into” or “leverage” platform services, which is ironic when mentioned within the context of a partnership that is intended to help customers avoid cloud “lock-in” because there is almost no way to avoid cloud “lock-in” when an organization commits to integrating with the proprietary services of a PaaS (Platform as a Service) solution.
None.
Such platform services are proprietary. Closed. Non-portable. They are services that, once your application is dependant upon, you are “locked in.” If you use Force.com’s “Chatter collaboration” your application is now dependent upon that service and is locked into that platform. If you tie yourself to any of Google App
Engine’s proprietary services (data store, e-mail services), you are locked into that platform. You can’t move the application else unless you extract the integration with those services and replace it with something else. The same is true for Amazon EC2 and its services (SQS, SNS, etc…). Integration with those services necessarily makes your application dependent on the service and thus that particular “cloud”. It locks you in.
This is the same problem suffered by IaaS (Infrastructure as a Service) providers today and is the same problem organizations developing on-premise cloud computing models will face when trying to migrate applications to or from off-premise cloud computing models: portability that is more than “skin” deep. It’s the same problem implementers face when trying to normalize infrastructure services: disparate vendor implementations of APIs and control planes make it impossible today to migrate easily between two like solutions because the services provided and thus integrated into the cloud management framework that enables automation are as different as night and day. If your on-premise cloud is integrated with your Load balancer to provide elastic scalability and you want to move to an off-premise cloud provider you can:
- Find a cloud provider that also uses that load balancer (and is willing to let customers integrate directly)
- Use a virtual network appliance version of the load balancer when deploying off-premise to enable the integration to continue working as is
- Use a physical-hybrid solution
- Employ off-premise cloud as a virtual private extension of your data center and continue to leverage your existing infrastructure
- Rewrite the integration to take advantage of whatever solution your chosen cloud provider has available, accepting that you might lose functionality in the process.
This is because the services upon which the integrations are built are not portable (just like the services available from PaaS vendors for data, messaging, and other traditional application integration points). They are not mobile; they are not interoperable. The portability offered between PaaS implementations now – and likely for the foreseeable future – is only skin deep.
DOES IT EVEN MATTER?
Now don’t get me wrong, this announcement is certainly a step in the right direction. After all, Spring developers will now have more options and more options is good. And for many organizations cloud “lock in” isn’t the problem some might think it is. After all, most organizations standardize on a development language and environment, a la “we’re a Microsoft shop” or “We’re a Java shop” or “We only deploy atop IBM WebSphere”. The difference between the two is subtle but has the same effect: lock-in to a particular environment. The difference is in who makes the choice: the vendor or the customer. If the former does it, it’s wrong. If the latter does it, it’s a choice.
The announcements also don’t go into a lot of detail, and it may be the case that VMware, Force.com, and Google will provide the means by which these proprietary service offerings in fact will be “portable”, even if only via an automatic refactoring mechanism. As it stands, this announcement appears to be furthering the goal of cloud/application portability. It allows an albeit limited choice of environments, but it is still a choice all the same. But does it really further the goal of cloud or application portability?
I guess it really depends on how you define “portability” and whether or not you buy into the additional “services” offered by the respective PaaS offerings.



If you’re a “Microsoft shop” you’re probably already locked into Windows clients and servers, as well as .NET development with Visual Studio. In this case, locking yourself into Windows Azure, which (incidentally) also offers PHP and Java SDKs, probably doesn’t matter. If you’re an SQL Server user, SQL Azure is a natural. It’s highly probable that Microsoft will maintain more than competitive features, pricing and service levels with other enterprise-scale PaaS (as well as IaaS) purveyors.
Geva Perry expands on his earlier LAMP-for-the-cloud post with Who Will Build the LAMP Cloud? And Who Cares? of 5/24/2010:
On Saturday, GigaOm published a blog post I wrote entitled Who Will Build the LAMP Cloud? Please read the full post, but I basically ask in it the title question and speculate on potential candidates and players including Google, Amazon, Microsoft, Heroku and Zend.
But apparently there may be a more fundamental question: does anyone want a LAMP cloud?
My rationale for asking the original question was as follows: There are platform-as-a-service plays for popular application stacks such as Java (VMForce.com and Google App Engine), .Net (Microsoft Azure) and Ruby-on-Rails (Heroku and Engine Yard), so why not the LAMP stack? After all, it is one of the most popular technology stacks on the web today.
But in the very first comment, Kiril Sheynkman questions the need for a LAMP cloud altogether, with the claim that LAMP is losing its relevance and being rapidly replaced by other components. For example, he lists MongoDB, CounchDB and Cassandra as alternatives to MySQL -- the M in LAMP.
James Urquhart picked up on this comment and posted Does cloud computing need LAMP? in which he writes:
“I have to say that Kirill's sentiments resonated with me. First of all, the LA of LAMP are two elements that should be completely hidden from PaaS users, so does a developer even care if they are used anymore? (Perhaps for callouts for operating system functions, but in all earnestness, why would a cloud provider allow that?)
“Second, as he notes, the MP of LAMP were about handling the vagaries of operating code and data on systems you had to manage yourself. If there are alternatives that hide some significant percentage of the management concerns, and make it easy to get data into and out of the data store, write code to access and manipulate that data, and control how the application meets its service level agreements, is the "open sourceness" of a programming stack even that important anymore?”
I agree with James that in a PaaS offering, the developer shouldn't care about the underlying infrastructure, and therefore, the L(inux) and A(pache) in the stack are less relevant. This brings me to something that may perhaps seem like a nuance, but may be important: perhaps my original question should have been: "Who is building the PHP cloud?" and not LAMP.
In fact, if you keep scrolling down in the comments to my GigaOm post, you'll see an interesting one from a fellow named Brian McConnell. Brian writes that he currently uses Google App Engine with Python. He goes on into some detail about the benefits of GAE, which are essentially the selling points of PaaS over IaaS. But he concludes with the following:
“I’ll probably stick with App Engine and Python for a while since things are working well and it ain’t broke, so it don’t need fixing, but if I am required to migrate in the future, or start another project, I’d like to be able to use PHP with the same level of simplicity.”
This anecdotal testimony gives some merit to the notion of a PHP-focused platform-as-a-service.
James' last question: "Is the 'open sourceness' of a programming stack even that important anymore?" is a good one, but orthogonal to the discussion about a LAMP/PHP cloud, in my mind.

My Windows Azure and Cloud Computing Posts for 5/23/2010+ post covered the original LAMP-for-the-cloud articles.
Mark Thiele asks “Why Haven’t All of You Adopted Amazon’s Cloud?” in this 5/24/2010 post to DataCenterPulse.com:
“Why Haven’t All of You Adopted Amazon’s Cloud?” seems like the question Werner Vogel keeps asking (http://bit.ly/9cw6RG). Over the last year he’s made it clear several times that there is no such thing as a private cloud (I still disagree to some extent), and also that we should all be adopting Amazon’s service.
I like Werner and I like Amazon, but I do think it’s a little arrogant to just assume that because we say that Amazon’s cloud is the “one true cloud option” (Hallelujah) that it makes it so. In fact Amazon might have the best option available today for some workloads, but the truth is there isn’t any one cloud that solves everyone’s problems.
The average CIO still is not convinced that the cloud providers in the market today care as much about their applications as they do. There’s also the question of security. While I generally agree that most hosted cloud solutions are safer than an enterprise environment, it takes time to prove that out to everyone’s unique comfort level.
There’s also the little fact that moving an application is often times very costly and potentially interruptive. In most cases CIOs are going to look for a natural evolutionary event to justify moving their key apps into the cloud instead of forcing the issue just because they can. The cost of maintaining an inefficient architecture in most cases is just a fraction of the cost of the potential business interruption and or the work of doing the migration.
Time will tell whether Amazon can solve everyone’s problems, but yelling at us about it won’t make it happen any sooner. In the mean time there will be a strong push by enterprises to gain as much benefit as they can from utilizing a combination of cloud solutions, including internal private cloud[s].

Mark King claims Google App Engine for Business: Too Many Promises, Not Enough Substance in his 5/24/2010 post to TechOat.com:
Google's new App Engine for Business has been beefed up with features to cater to enterprise markets--SMBs, in particular. It has a relatively low price point ($8 per application, per user, capped at $1000 per month), hosted SQL (one of the most popular business database platforms), and a partnership with VMware. Google's hungry to court business, but will SMBs, especially those not already devotees of Google's other business offerings, quickly jump aboard?
Not very likely. At least, not right now.
Google has to prove itself worthy of business. It's made baby steps into the corporate world with Google Apps and Google Docs, which currently claim approximately 4 percent of the business productivity suite market share. Still, it's still a rather measly adoption rate in the Microsoft-saturated business world. I'm not a programmer, so I'm not discussing which environment makes for the best development. But from an IT business stance, Microsoft is already so rooted in business that it makes sense that it's easier to integrate Web applications into typical Wintel infrastructures via Azure with the .NET platform rather than having to use App Engine's Java and Python supported platform.
There is no doubt that the low-cost, cloud-based model Google offers is the future; Web applications and cloud infrastructures, be they private or public, will continue to gain ground. Yet there's still too much risk and not enough reassurances with the new App Engine for Business.
Erick Knorr asserts “With over 70,000 companies now using Salesforce, Google has no quicker route to paying business customers” as he asks Will Google buy Salesforce next? in this 5/24/2010 article for InfoWorld Modernizing IT blog:
Google's valuation now stands at $124 billion. How big is that? For reference, IBM is worth $173 billion. Once the big, friendly St. Bernard of tech companies, Google has turned into Godzilla overnight. And it's better positioned than Microsoft ($204 billion) to capitalize on the Web-centric future, from mobile to social networking to converged TV to cloud computing.
With the EU and the FTC breathing down its neck, Google must be careful to avoid pushing its domination of search and online advertising into monopoly territory (the recent $750 million Google acquisition of AdMob, a mobile advertising startup, seemed to barely squeak by). So what other opportunities for growth does Google see in the near term? The recent Google ad campaign to induce Office users to forget about upgrading to Office 2010 and adopt Google Docs should give you an indication.
[ Read Robert Scheier's article "Can Google really hack it in business?" | Last October, the InfoWorld Test Center pitted Google Docs against Zoho and a beta version of Office Web Apps. ]
Up until now Google hasn't seemed terribly serious about the business software market. Gmail has made some headway in business, but the paid version of Google Apps -- which includes Docs, Gmail, Sites, Wave, and a three-nines SLA for $50 per seat per year -- can't be too successful, because Google still won't say how many customers have gone for it. We keep hearing about a the same high-profile wins at Genentech and the city of Los Angeles.
So assuming Google really does want to get serious, why not buy Salesforce? When it comes to successful SaaS (software as a service) applications, there's Salesforce and everyone else. One big reason is that, unlike most Web-centric companies, Salesforce really knows how to sell applications to business, something Google is just beginning to learn. Plus, thanks to an alliance struck in 2008, Google Apps is already integrated with Salesforce. …

Robert continues with page 2 of his essay, where he concludes:
…But if Google wants a piece of the action in this area, what other choices does it have? Microsoft is fighting back against Google Docs with Office Web Apps, due to come out of beta next month. And Google has no play at all in the enterprise application market, which according to the research firm AMR hovers somewhere north of $60 billion in size. Salesforce claims that it's "the CRM choice of 72,500 companies." If Google wants more than a token number of paying business customers in the near term, it's going to have to buy them.
<Return to section navigation list>
















