Windows Azure and Cloud Computing Posts for 7/29/2011+
A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles.

• Updated 7/30/2011 with new articles marked • by Gartner, Louis Columbus, Larry Franks, Aaron Marisi, and Alik Levin
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Apps, Access Control, Caching, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table and Queue Services
Avkash Chauhan described Programatically deleting older blobs in Windows Azure Storage in a 7/29/2011 post:
When you use Windows Azure Storage to dump your diagnostics data, it may possible that you have lots of blobs which are old and you dont have any use of those blobs. You can delete them manually however you know how much it will take so to expedite the older blob deletion you can write some code which will do it automatically for you depend on your blob selection criteria.
To make your job simple, the best thing is that each blob has a property which indicate when the particular blob was last modified. This value can tell you how old this blob is. And using this value you can select older blobs and delete them.
Most Importantly "There is no way to do batch operations on blobs" so you will have to delete them one by one or you can run the code in loop to select all the blobs and delete them.
For example you can choose to delete blobs which are older then a week or two weeks or a month. So you can choose what blob selection criteria you will use to select the blobs and then delete them.
CloudBlobClient blobClient = connectionManager.GetBlobServiceClient(storageUri);
// Next lets select then container which you are looking for your old blobs.
CloudBlobContainer container = blobClient.GetContainerReference(this.WadBlobContainerName);
// Now we will select blob query object which will give us the list of selected filtered blobs
BlobRequestOptions blobQuery = new BlobRequestOptions();
blobQuery.BlobListingDetails = BlobListingDetails.None;
blobQuery.UseFlatBlobListing = true;
// Now we will setup Blob access condition option which will filter all the blobs which are not modified for X (this.DaysToKeep) amount of days
blobQuery.AccessCondition = AccessCondition.IfNotModifiedSince(DateTime.UtcNow.AddDays(-1 * this.DaysToKeep));
// Lets Query to do its job
IEnumerable<IListBlobItem> blobs = container.ListBlobs(blobQuery);
foreach (IListBlobItem blob in blobs)
{
CloudBlob cloudBlob = container.GetBlobReference(blob.Uri.ToString());
cloudBlob.DeleteIfExists(blobQuery);
}Thats it!!
Brent Stineman (@BrentCodeMonkey) explained Uploading Image Blobs–Stream vs Byte Array (Year of Azure Week 4) in a 7/28/2011 post:
OK, I promised you with when I started some of this Year of Azure project that some of these would be short. Its been a busy week so I’m going to give you a quickly based on a question posted on MSDN Azure forums.
- MemoryStream streams = new MemoryStream();
- // create storage account
- var account = CloudStorageAccount.DevelopmentStorageAccount;
- // create blob client
- CloudBlobClient blobStorage = account.CreateCloudBlobClient();
- CloudBlobContainer container = blobStorage.GetContainerReference("guestbookpics");
- container.CreateIfNotExist(); // adding this for safety
- string uniqueBlobName = string.Format("image_{0}.jpg", Guid.NewGuid().ToString());
- CloudBlockBlob blob = container.GetBlockBlobReference(uniqueBlobName);
- blob.Properties.ContentType = "image\\jpeg";
- System.Drawing.Image imgs = System.Drawing.Image.FromFile("waLogo.jpg");
- imgs.Save(streams, ImageFormat.Jpeg);
- byte[] imageBytes = streams.GetBuffer();
- blob.UploadFromStream(streams);
- imgs.Dispose();
- streams.Close();
Now the crux of the problem was that the resulting image in storage was empty (zero bytes). And Steve Marx correctly pointed out, the key thing missing is the resetting the buffer to position zero. So the corrected code would look like this. Note the addition of line 22. If fixes things just fine.
- MemoryStream streams = new MemoryStream();
- // create storage account
- var account = CloudStorageAccount.DevelopmentStorageAccount;
- // create blob client
- CloudBlobClient blobStorage = account.CreateCloudBlobClient();
- CloudBlobContainer container = blobStorage.GetContainerReference("guestbookpics");
- container.CreateIfNotExist(); // adding this for safety
- string uniqueBlobName = string.Format("image_{0}.jpg", Guid.NewGuid().ToString());
- CloudBlockBlob blob = container.GetBlockBlobReference(uniqueBlobName);
- blob.Properties.ContentType = "image\\jpeg";
- System.Drawing.Image imgs = System.Drawing.Image.FromFile("waLogo.jpg");
- imgs.Save(streams, ImageFormat.Jpeg);
- byte[] imageBytes = streams.GetBuffer();
- streams.Seek(0, SeekOrigin.Begin);
- blob.UploadFromStream(streams);
- imgs.Dispose();
- streams.Close();
But the root issue I still have here is that the original code sample is pulling a byte array but not doing anything with it. But a byte array is still a valid method of uploading the image. So I reworked the sample a bit to support this..
- MemoryStream streams = new MemoryStream();
- // create storage account
- var account = CloudStorageAccount.DevelopmentStorageAccount;
- // create blob client
- CloudBlobClient blobStorage = account.CreateCloudBlobClient();
- CloudBlobContainer container = blobStorage.GetContainerReference("guestbookpics");
- container.CreateIfNotExist(); // adding this for safety
- string uniqueBlobName = string.Format("image_{0}.jpg", Guid.NewGuid().ToString());
- CloudBlockBlob blob = container.GetBlockBlobReference(uniqueBlobName);
- blob.Properties.ContentType = "image\\jpeg";
- System.Drawing.Image imgs = System.Drawing.Image.FromFile("waLogo.jpg");
- imgs.Save(streams, ImageFormat.Jpeg);
- byte[] imageBytes = streams.GetBuffer();
- blob.UploadByteArray(imageBytes);
- imgs.Dispose();
- streams.Close();
We pulled out the reset of the stream and replaced UploadFromStream and replaced it with UploadByteArray.
Funny part is that while both samples work, the resulting blobs are different size. And since these aren’t the only way to upload files, there might be other sizes available. But I’m short on time so maybe we’ll explore that a bit further another day. The mysteries of Azure never cease.
Next time!

<Return to section navigation list>
SQL Azure Database and Reporting
• Larry Franks (@larry_franks) described Connecting to SQL Azure from Ruby Applications in a 7/19/2011 article for the TechNet Wiki (missed when published):
This article discusses the methods of connecting to SQL Azure from the Ruby language. While this article discusses several gems that can be used to connect to SQL Azure, it is by no means a comprehensive listing of all gems that provide this functionality.
NOTE: The procedures listed in this article may not work on all operating systems due to availability of ODBC drivers, differences in compilation process, etc. Currently this article contains information based on the Windows 7 operating system and the Windows Azure web or worker role hosting environment.
Table of Contents
Initial Preparation
This article assumes that you are familiar with the Ruby language. It also assumes that you have the following:
- Ruby 1.8.7, or 1.9.2
- Windows Azure Platform subscription
- SQL Azure database
- Firewall settings that allow connectivity from your client IP address
NOTE: For more information on Ruby, visit http://www.ruby-lang.org. For more information on the Windows Azure Platform, specifically for getting started with SQL Azure, see http://social.technet.microsoft.com/wiki/contents/articles/getting-started-with-the-sql-azure-database.aspx.
Ruby Database Connectivity
For connectivity to SQL Azure, we will be using the Ruby ODBC, TinyTDS, and Ruby OData gems. While there are other database connectivity methods available for the Ruby language, not all provide connectivity to SQL Azure.
All three gems can be installed through the gem command (http://docs.rubygems.org/read/book/2) by issuing the following commands:
gem install ruby-odbc gem install tiny_tds gem install ruby_odataNOTE: Don’t install the tiny_tds gem using this command line format, as it will not be capable of connecting to SQL Azure. For more details on how to install this package with support for SQL Azure, see Using TinyTDS.
Using Ruby ODBC
Ruby ODBC provides access to ODBC data sources, including SQL Azure. This gem relies on your systems ODBC drivers for connectivity, so you must first ensure you have a working ODBC connection to your SQL Azure database. Perform the following steps to configure and test an ODBC connection:
To Configure ODBC on Windows 7
- From the start menu, enter ‘ODBC’ in the Search field. This should return a Data Sources (ODBC) program; select this entry.
- In the Data Sources program, select the User DSN tab, and then click Add.
- Select SQL Server Native Client 10.0, and then click Finish.
- Enter a name for this DSN, enter the fully qualified DNS name for your SQL Azure database, and then click Next.
- Select ‘With SQL Server authentication’ and enter the login ID and password you created when your database was provisioned. The username must be entered in the following format: ‘username@servername.database.windows.net’. When finished, click Next.
- Select ‘Change the default database to’ and then select a database other than master. When finished, click Next.
- Check ‘Use strong encryption for data’ to ensure that data passed between your client and SQL Azure is encrypted. When finished, click Finish.
- Click Test Data Source to ensure that you can connect.
To Connect to SQL Azure using Ruby ODBC
The following code is an example of using Ruby ODBC to connect to a SQL Azure database specified by a DSN named ‘azure’, perform a select against the ‘names’ table, and return the value of the ‘fname’ field.
require 'odbc' sql='select * from [names]' datasource='azure' username='user@servername.database.windows.net' password='password' ODBC.connect(datasource,username,password) do |dbc| results = dbc.run(sql) results.fetch_hash do |row| puts row['fname'] end endActive Record can also use Ruby ODBC to connect to a SQL Azure database. The following is an example database.yml for using an ODBC connection with Active Record.
development: adapter: sqlserver mode: ODBC dsn: Driver={SQL Server};Server=servername.database.windows.net;Uid=user@servername.database.windows.net;Pwd=password;Database=databasenameNOTE: user, password, databasename and servername in the above examples must be replaced with valid values for your SQL Azure database.
NOTE: All tables in SQL Azure require a clustered index. If you receive an error stating that tables without a clustered index are not supported, add a :primary_key field. For more information, see Inside SQL Azure.
NOTE: The [schema_migrations] table will need a clustered index, and will return an error when you first attempt a migration (rake db:migrate). You can run the following command against your SQL Azure database to create a clustered index for this table after receiving this error:
CREATE CLUSTERED INDEX [idx_schema_migrations_version] ON [schema_migrations] ([version])After creating the clustered index, rerun the migration and it should succeed.
Using TinyTDS
TinyTDS does not rely on ODBC to connect to SQL Azure; instead it directly uses the FreeTDS library. While TinyTDS can be installed using the gem install command, the version that is installed by default does not currently support connectivity to SQL Azure (it will work fine for SQL Server.) In order to communicate with SQL Azure, TinyTDS requires a version of FreeTDS that has been compiled with OpenSSL support. While providing a version of this via gem install is on the TODO list (https://github.com/rails-sqlserver/tiny_tds,) you can currently compile your own version of FreeTDS to enable SQL Azure connectivity.
NOTE: While the following steps worked for me, I can make no guarantees that they will work in your specific environment. If you have a better process, please help improve this article by sharing it.
To Build FreeTDS on Windows 7
Environment:
- Ruby 1.9.2-p180 from http://rubyinstaller.org/
- DevKit-tdm-32-4.5.1-20101214-1400-sfx.exe from http://rubyinstaller.org/
- OpenSSL 0.9.8h (GnuWin32 binary distribution)
- LibIconv 1.9.2 (GnuWin32 binary distribution)
To build FreeTDS with OpenSSL support
- After installing Ruby, follow the DevKit installation and test steps at https://github.com/oneclick/rubyinstaller/wiki/Development-Kit.
- Download a current build of FreeTDS from FreeTDS.org. I used freetds-0.91rc.
- Download and install a Win32 version of OpenSSL and LibIconv. I used the GnuWin32 binary distribution that includes the libraries and header files, however other distributions may also work. Alternatively you may wish to download the source and build your own versions.
- Install or compile OpenSSL and LibIconv on your system, and then extract the FreeTDS source. To extract the FreeTDS package, you will need a utility that understands the .tgz format, such as 7Zip.
- In the directory where you have unzipped FreeTDS, find the ‘Configure’ file and edit it. NOTE: Notepad will not correctly recognize the linefeeds at the end of each line, so you may want to use a utility such as Notepad++ so that the file is more readable while editing it.
Search for –lssl –lcrypto. These should occur on a line similar to the following:NETWORK_LIBS="$NETWORK_LIBS –lssl –lcrypto"For my environment, I had to change this line toNETWORK_LIBS="$NETWORK_LIBS –lssl32 –leay32 –lwsock32 –lgdi32"in order to successfully compile the project.- From the DevKit folder, launch msys.bat. This will launch an sh.exe command window.
- Change directories to the location where you extracted the FreeTDS source. Note that while cd d: may work, the actual path reflected by this shell is a UNIX style path of /d. When specifying directories for the ./configure command later, I recommend specifying the paths using the /driveletter/folder format.
- From the FreeTDS source directory, run the following command:
./configure –prefix=<path to install FreeTDS to> —with-libiconv-prefix=<path to iconv> —with-openssl=<path to ssl>For example, if libiconv was installed to c:\libiconv and OpenSSL was installeld to c:\OpenSSL, the command would be./configure –prefix=/c/freetds –with-libiconv-prefix=/c/libiconv –with-openssl=/c/openssl- After the configuration process completes, run the following command: make
- Once the make process completes, run make install. This should copy the FreeTDS libraries to the directory specified by –prefix= during configuration.
- Add the <freetds install directory>\bin folder to the system path environment. This will allow the system to find the FreeTDS dll’s. NOTE: you must also add the OpenSSL\bin folder to the system path.
To build tiny_tds using the local FreeTDS library
From a command prompt, type the following:gem install tiny_tds -platform=ruby -- --with-freetds-dir=<FreeTDS installation folder>NOTE: If you receive an error about a duplicate definition of DBBIGINT, open <FreeTDS install folder\include\sybdb.h and search for the following line:
typedef tds_sysdep_int64_type DBBIGINT;Place // at the beginning of the line to comment out this statement, and then run the gem install command again.To connect to SQL Azure using TinyTDS
The following code is an example of connecting to SQL Azure using the tiny_tds gem:
require 'tiny_tds' client=TinyTds::Client.new(:username=>’user’, :password=> ‘password’, :dataserver=>’servername.database.windows.net', :port=>1433, :database=>’databasename’, :azure=>true) results=client.execute("select * from [names]") results.each do |row| puts row endNOTE: If you receive an error when stating that it cannot load ssleay32.dll when you run the above code, make a copy of the ssl32.dll file in the OpenSSL/bin folder and name the copy ssleay32.dll.
Tiny_tds can also be used with ActiveRecord. The following is an example database.yml for using a dblib connection to SQL Azure using the tiny_tds gem.
development: adapter: sqlserver mode: dblib dataserver: 'servername.database.windows.net' database: databasename username: user password: password timeout: 5000 azure: trueNOTE: All tables in SQL Azure require a clustered index. If you receive an error stating that tables without a clustered index are not supported, add a :primary_key field.
NOTE: The [schema_migrations] table will need a clustered index, and will return an error when you first attempt a migration (rake db:migrate). You can run the following command against your SQL Azure database to create a clustered index for this table after receiving this error:
CREATE CLUSTERED INDEX [idx_schema_migrations_version] ON [schema_migrations] ([version])After creating the clustered index, rerun the migration and it should succeed.Using Ruby OData
The Ruby OData gem allows you to connect to an OData service. OData is a RESTful method of accessing data over the internet, using standards such as JSON, AtomPub, and HTTP. For more information on OData, see http://www.odata.org/.
To configure SQL Azure for OData
OData support for SQL Azure is currently a Community Technical Preview (CTP) and can be accessed at http://www.sqlazurelabs.com. To enable OData for an existing database, perform the following steps:
- Using your browser, navigate to https://www.sqlazurelabs.com and select the OData link. You must sign in with the login associated with your Windows Azure subscription.
- Enter the name of the SQL Azure server that your database resides on, along with the administrator login and password. Select Connect to continue.
- Select a database, and then check 'Enable OData'.
- Either select an account to use for anonymous access, or click Add to add a federated user. You will finally be presented with the URL for the new OData service.
To connect to the OData service using Ruby OData
The following code will connect to an OData service that contains a database named 'testdb'. The code will then select rows from a table named 'People', and will display the contents of the 'fname' and 'email' fields.
require 'ruby_odata' svc=OData::Service.new "https://odata.sqlazurelabs.com/OData.svc/v0.1/servername/testdb" svc.People people=svc.execute people.each {|person| puts "#{person.fname} can be contacted at #{person.email}" }References
- https://github.com/rails-sqlserver/activerecord-sqlserver-adapter/wiki/Using-Azure
- http://www.java2s.com/Code/Ruby/Database/ODBCconnection.htm
- http://metaskills.net/2010/10/18/tinytds-a-modern-simple-and-fast-freetds-library-for-ruby-using-db-library/
- http://blogs.visoftinc.com/2010/06/12/Introducing-a-Ruby-OData-Client-Library/
See Also

<Return to section navigation list>
MarketPlace DataMarket and OData
• Aaron Marisi described Getting Started with igGrid, OData, and WCF Data Services in a 7/28/2011 article for the Infragistics blog:
The igGrid is a client-side data grid with paging, filtering, and sorting functionality. It can bind to local data including XML, JSON, JavaScript arrays, HTML tables and remote data returned through web services.
The most seamless way to bind the igGrid to remote data is to use it in conjunction with OData. OData, or Open Data Protocol, operates over HTTP and provides a means of querying and updating data in JSON and AtomPub formats through a set of common URL conventions. This means that you can provide the grid with a URL to the OData service, set one property, and all of the paging, filtering, and sorting can be done remotely on the server without any additional configuration.
This article shows how to setup a client-side jQuery grid with remote paging, filtering, and sorting by setting up a WCF Data Service in an ASP.NET Web Application and setting two options on the igGrid.
1. Open Visual Studio and create a new ASP.NET Empty Web Application called ‘igDataSourceWCFService’:
Note: this is a plain old ASP.NET Web Application – this is not ASP.NET MVC. NetAdvantage for jQuery is ‘server agnostic’, meaning it does not rely on any specific server-side architecture. While the product ships with built-in support for ASP.NET MVC, this server framework is not required to use the rich client-side functionality.
2. Add an App_Data folder to your project and add the AdventureWorks database into that folder:
Note: To obtain the AdventureWorks database, download it here.
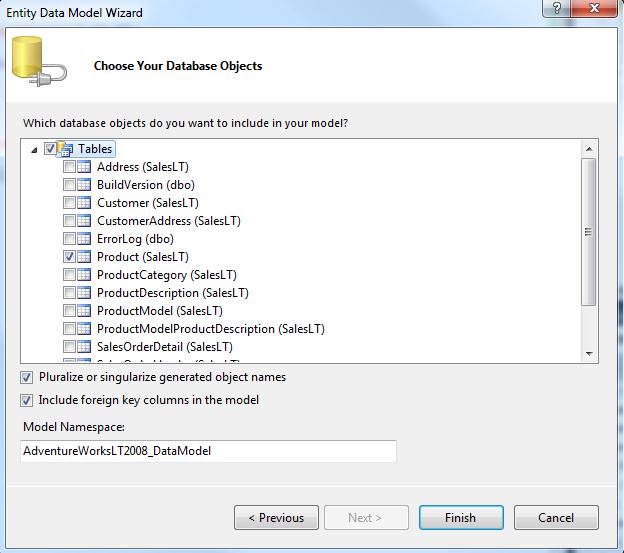
3. Next, add an ADO.NET Entity Data Model named AdventureWorksEntities.edmx to the project and point it to the AdventureWorks database:
4. Choose the Product table to be included in the Entity Data Model:
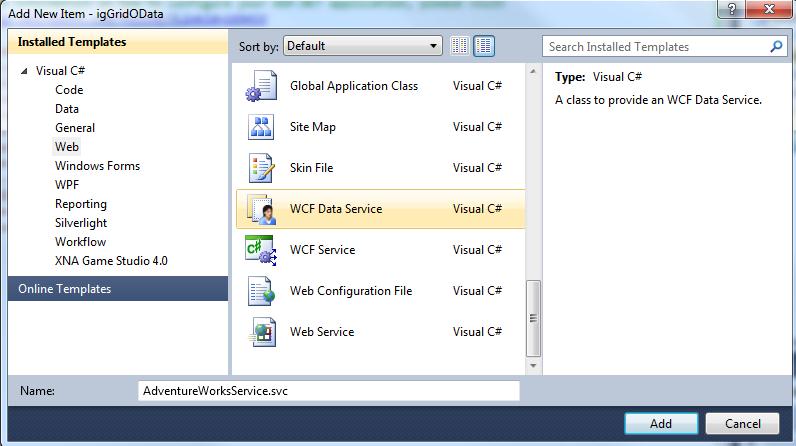
5. Next add a WCF Data Service to the project named ‘AdventureWorksService.svc’:
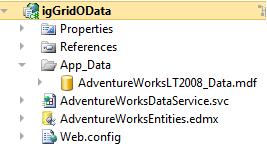
6. At this point your project should look like this:
7. Next, open the ‘AdventureWorksDataService’. This class derives from DataService<T> where T has not yet been defined. Specify the type of your Entity Data Model here:
- public class AdventureWorksDataService : DataService<AdventureWorksLT2008_DataEntities>
public class AdventureWorksDataService : DataService<AdventureWorksLT2008_DataEntities>8. Next, enable access to the Products table through the Data Service by adding this line of code within the InitializeService method:
- public static void InitializeService(DataServiceConfiguration config
- {
- config.SetEntitySetAccessRule("Products", EntitySetRights.AllRead);
- config.DataServiceBehavior.MaxProtocolVersion = DataServiceProtocolVersion.V2;
- }
public static void InitializeService(DataServiceConfiguration config { config.SetEntitySetAccessRule("Products", EntitySetRights.AllRead); config.DataServiceBehavior.MaxProtocolVersion = DataServiceProtocolVersion.V2; }9. WCF Data Services has native support for the Atom format. To enable JSON formatted data, you should download the JSONPSupportBehavior code file and include it in your application.
10. Once the JSONPSupportBehavior.cs file is included in your application, make sure to change the namespace to match the namespace used in your application. Also, add the JSONPSupportBehavior attribute to your AdventureWorksDataService class:
- [JSONPSupportBehavior]
- public class AdventureWorksDataService : DataService<AdventureWorksLT2008_DataEntities>
[JSONPSupportBehavior] public class AdventureWorksDataService : DataService<AdventureWorksLT2008_DataEntities>11. At this point, you can run the Web Application and access the data of the service so now it’s time to setup the igGrid.
12. You will need the NetAdvantage for jQuery combined and minified script file, ig.ui.min.js, which comes with the product. In addition, you will need the jQuery, jQuery UI, and jQuery templates scripts to run the sample. This help article discusses referencing the required scripts and where the combined and minified scripts can be found.
Note: You can download the full or trial product here. The jQuery templates script can be obtained here.
13. You should setup a scripts directory in your project and copy the JavaScript files into this folder.
14. Setup a styles directory and add the Infragistics themes directory to this folder. For more information on working with the jQuery themes for the igGrid, see this help topic.
15. Next you can setup the sample page. You are going to add a new html page to the application and call it ‘default.htm’. Once that is done your project will look like this:
16. Open the default.htm file and include CSS links and script tags for the jQuery resources:
<head> <link href="styles/themes/min/ig/jquery.ui.custom.min.css" rel="stylesheet" type="text/css" /> <link href="styles/themes/base/ig.ui.min.css" rel="stylesheet" type="text/css" /> <script src="scripts/jquery.min.js" type="text/javascript"></script> <script src="scripts/jquery-ui.min.js" type="text/javascript"></script> <script src="scripts/jquery.tmpl.min.js" type="text/javascript"></script> <script src="scripts/ig.ui.min.js" type="text/javascript"></script> </head>17. Next, add a TABLE element to the body of the HTML which will serve as the base element for the grid:
<body> <table id='tableProducts'></table> </body>18. Add another script tag to the HEAD and instantiate an igGrid and define columns:
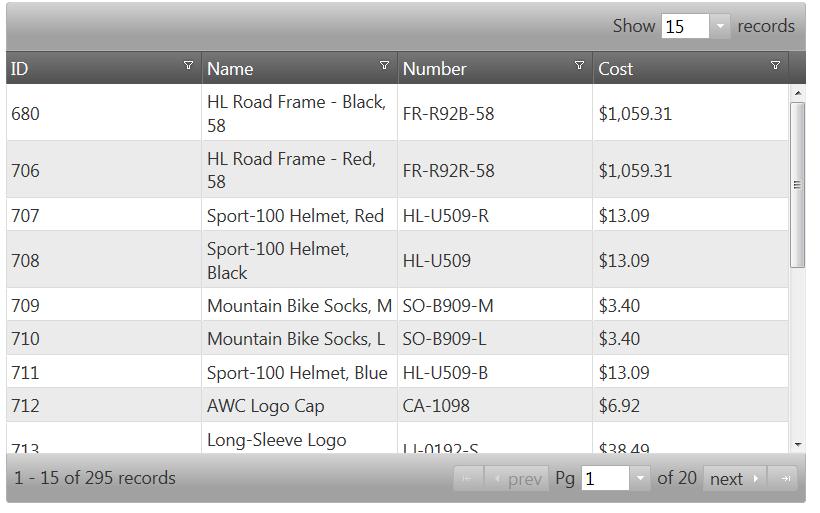
<script type="text/javascript"> $(window).load(function () { $('#tableProducts').igGrid({ height: '500px', width: '800px', autoGenerateColumns: false, columns: [ { headerText: 'ID', key: 'ProductID', dataType: 'number' }, { headerText: 'Name', key: 'Name', dataType: 'string' }, { headerText: 'Number', key: 'ProductNumber', dataType: 'string' }, { headerText: 'Cost', key: 'StandardCost', dataType: 'number', format: 'currency'} ] }); }); </script>19. To bind the igGrid to data, two options should be set to define the URL for the data and the responseDataKey:
Note: The value d.results is a standard response key for JSON data coming from a ‘V2’ OData service
responseDataKey: 'd.results', dataSource: 'AdventureWorksDataService.svc/Products?$format=json',20. Finally, enable the features of the grid including the option to make them operate remotely:
features: [ { name: 'Selection', mode: 'row', multipleSelection: true }, { name: 'Paging', type: 'remote', pageSize: 15 }, { name: 'Sorting', type: 'remote' }, { name: 'Filtering', type: 'remote', mode: 'advanced' } ]Run the sample and you will see the igGrid rendered. Combined with OData, the grid can filter, sort, and page data remotely by supplying a single URL as the datasource.
Note: The AdventureWorks database and NetAdvantage for jQuery resources are not included in the sample. Visit these links to obtain the software:

<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, Caching WIF and Service Bus
• Alik Levin described Windows Azure AppFabric Access Control Service (ACS) – New Content Published On MSDN in a 7/27/2011 post:
Quick update on newly available content our team just published on MSDN for Windows Azure AppFabric Access Control Service (ACS).
First of all the content can now be easily accessed using human friendly URL – http://msdn.com/acs.
We have made some changes to the high level structure of the content for better scanability:
Access Control Service 2.0
- Release Notes
- Differences between Access Control Service 1.0 and Access Control Service 2.0
- ACS Overview
- Getting Started with ACS
- ACS Components
- Scenarios and Solutions Using ACS
- ACS Functionality
- ACS Guidelines Index
- Troubleshooting ACS
- ACS How To's
- ACS Code Samples Index
- ACS Management Service API Reference
The newly added topics are:
- Certificates and Keys Management Guidelines
Deploying ACS Federated Applications and Services To Windows Azure
- How To: Authenticate with a Client Certificate to a WCF Service Protected by ACS
Suggestions for improvement are highly appreciated.
Related content
- Windows Azure AppFabric Access Control Service (ACS): WCF SAML/SOAP Client Certificate Scenario
- Windows Azure AppFabric Access Control Service (ACS): WCF SAML/SOAP Username/Password Scenario
- Windows Azure AppFabric Access Control Service (ACS): WCF SAML/SOAP ADFS Scenario
- Windows Azure AppFabric Access Control Service (ACS): WCF SWT/REST OAuth Scenario
- Windows Azure AppFabric Access Control Service (ACS): REST Web Services And OAuth 2.0 Delegation

An anonymous member of the AppFabricCAT Team posted Reaching stable performance in AppFabric Cache with a non-Idle cache channel on 7/30/2011:
While using Azure AppFabric Cache, you will notice that object-retrieval-time averages around 6 milliseconds. However, you may also notice some spikes which can be as high as 400 milliseconds, which by most accounts will be undesirable. The purpose of this article is to explain the reason behind this seemly mysterious latency points. To do this, first we need to look at the DataCacheFactory (DCF), as stated in a previous blog, its instantiation is required to establish the communication with your Azure AppFabric Cache service end-point, which under-the-hood is a WCF channels and as such leverages the CLR ThreadPool.
Here is where the problem resides, the CLR ThreadPool has a known issue, which manifests itself by releasing all of the I/O threads in the ThreadPool (except for one) after 15-seconds of inactivity , for further details on the issue, refer to this blog. This, in turn, destroys the WCF channel running on the released thread; the spikes are simply the result of trying to recover from the lost channel.
NOTE: This may also manifest in the Azure AppFabric Server (on-Prem) however it is less noticeable because idle times may not be as high since we have dedicated cluster, unlike the share cluster on the cloud. Either way, the recommendation below should be utilized in either on-Prem or on-cloud.
Not just a 15 second idle problem
Even after the 15 second I/O thread issue is fixed (a fix is being investigated for a future release, more details are not currently available), the fact still remains that Windows Azure load balancers (LB) will close idle connections after 60 seconds. Hence, you need to avoid either of these possible spikes.
Keeping a busy channel
In a system where DCF is always kept busy, NEITHER of these issues will be a concern because neither of those idle times will ever be reached, unless using local cache (see the “other considerations” title below). Similarly, for application that may incur this idle time, keeping them artificially busy, will avoid these performance spikes.
As described in the article above, a workaround will require changes on the service, which in this case; it will mean a QFE in Azure AppFabric Cache. And even then, it is uncertain that it will also fix the 60 second connection timeout from the LB (since the service is behind the LB). Either way, keeping an active channel, would avoid the problems and this can be done by simply doing an API call to Put a small object in intervals below 15 seconds – I will call this preserving an active channel.
Where to best preserve the active channel
My first reaction was to simply add a call to my static encapsulation of the DataCacheFactory class under the RoleEntryPoint.Run() method (in the public class WebRole : RoleEntryPoint) and do a Put() operation from a thread every 15 seconds. Unfortunately, even though I was invoking a static class, it needed to create another class instance (separate from the one used in the application) because the memory points at which the Session and the RoleEntryPoint ran are too far apart at the moment of their respective executions and hence they cannot both run a single static instance. So I ended up with two separate DataCacheFactories, one invoked in RoleEntryPoint.Run() and the other in the webpage, at the httpContext, which defeats the purpose.
This took me into the Global class (public class Global : System.Web.HttpApplication), implementing the thread under the Application_Start() method throw an exception. It turns out that since the DataCacheFactory requires ACS authentication which turns requires an HttpContext To finally make it work, the code had to be added into the session_start() method of the global class.
As you will see below, the interval is set to 11 seconds just to avoid any delay that will make the lapse go over 15 seconds. The Boolean initialized, is used to prevent the creation of several other threads. And lastly note the use of the TimerCallback thread, as it is the most adequate to handle thread that are dedicated to this type of task (waking up doing a task and then reviving after a given period of time). The following is how the code is implemented under the global.asax.cs
public class Global : System.Web.HttpApplication { //Make the time lapse just a little above 2/3 of the 15 seconds, to avoid time sync issues private const int PingChannelInterval = 11000; private const int DueTime = 1000; //Time to wait before thread starts public const string WakeNonLocalCacheChannelObjKey = "UTC time of last wake call to non-LocalCache channel"; private static bool initialized = false; //Thread to keep channel from idling. private static Timer t = null; void Application_End(object sender, EventArgs e) { //Now it is safe to dispose of the thread that kept the channel from idling //Reset initialized flag since thread has been disposed. t.Dispose(); initialized = false; } void Application_Error(object sender, EventArgs e) { //Now it is safe to dispose of the thread that kept the channel from idling //Reset initialized flag since thread has been disposed. t.Dispose(); initialized = false; } //Here is where the Thread to keep the channel from idling happens void Session_Start(object sender, EventArgs e) { //If a session has already started then no need to create another //Preserve channel thread, one is enough if (!initialized) { t = new Timer(PreserveActiveChannel, null, DueTime, PingChannelInterval); } } //Thread to keep channel from idling static void PreserveActiveChannel(object state) { try { //Stop any more thread from starting, we only need one running initialized = true; //Since I have 2 DataCacheFactories, store the flag of the one been used //either the one with localcache or the one without local cache bool StoreTypeOfFactoryBeenUsed = MyDataCache.CacheFactory.UseLocalCache; //Choose to work with the non-local Cache DataCacheFactory //since this is the only DataCacheFactory that will be kept warm MyDataCache.CacheFactory.UseLocalCache = false; //warm up only the non-localCache Factory, via a Put(), note that stored obj is a timestamp MyDataCache.CacheFactory.Put(WakeNonLocalCacheChannelObjKey, DateTime.UtcNow.ToString()); //Now that the warming is done, set the DataCacheFactory back to the one been previously used MyDataCache.CacheFactory.UseLocalCache = StoreTypeOfFactoryBeenUsed; } catch (Microsoft.ApplicationServer.Caching.DataCacheException exception) { //If things failed, reset initialization initialized = false; //Logic to gracefully handle this exception goes here } } }//end of classOther considerations
When running a DCF instance with local cache turn on, the cached objects stay in the local memory of client application and hence the WCF channel is not used and the idle timeout will likely take place. But this may not be apparent until a lapse of over 15 seconds, of only local cache activity, is followed by a trip to the AppFabric Cache service. Similarly, this will also happen after a local cache time out of over 15 seconds.
Another gotcha can be when IIS decides to recycle, the following two blogs go over some methods to avoid this but keep in mind that at the first time the DCF is used, the delay to create the channel has to be incurred, so this has to happen at least once.
Observing the behavior
The easiest way to observe the behavior is by hitting the service from outside the local Datacenter (DC), so below I am sharing the URL to a running web role with the project. It is deployed on the south/Central US region and consuming a service in the north/central US region. As such you will also see that the normal delay is not around 6 milliseconds but more around 30 milliseconds, which is expected since the request has to travel from one DC to the other.
Instructions
Since I am leveraging a project I used before, the basic instructions to understand the APIs can be found on this blog under the title “Running the Demos”.
URL to sample: http://test1perfofworkerrolecache.cloudapp.net.
Below is the interface you will be shown.
The interface exposes 2 DCFs, they can be picked from the drop down menu:
Choose the “Enabled” local cache DCF
Then press the button label “Get (optimistic)”, will show the lapsed in time in the Status box. The first click will be the longest at likely over 400 milliseconds the subsequent runs will reach around 30 milliseconds and then you will get 0 milliseconds once local cache kicks in. Now, do nothing for say 18 seconds and then do a Get again. The long elapse time will happen again (unless someone else happens to be running the exact same app at the same time, I am assuming this will be unlikely).
Choose the “Disable” local cache DCF
Then do the exact same steps as above and you will first noticed that since local cache is not use the elapse time will never go below 20 or so milliseconds but then if you do nothing for 15 or so seconds, the next hit will not incurred the 400 millisecond spike. To find out when was the last time the PreserveActiveChannel thread reached the service click on the “TimeStamp of last factory ping” button and it will retrieve the object been leverage to keep the channel warm which value contains the timestamp of the latest ping.
For reference
- More information on the RoleEnryPoint method
- This link will take you to the project’s code.
Reviewers: Rama Ramani, Mark Simms, Christian Martinez and James Podgorski


<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
My (@rogerjenn) Live Silverlight PivotViewer for Protein Structures Runs on Windows Azure post of 7/30/2011 provides details about Microsoft Research’s Excel DataScope project:
The University of San Diego (UCSD) Supercomputer Center has made available a publicly accessible Silverlight PivotViewer Control running on the Windows Azure Platform at http://momcollection.cloudapp.net/. The PivotViewer performs filtering, sorting and Deep Zoom operations on a collection of 671 protein molecules from the RCSB Protein Data Bank maintained by the National Cancer Institute’s Pathway Interactive Database.
Eric Stollnitz and Joseph Joy introduced the Silverlight PivotViewer in their New Technologies for Immersive Content session at MIX10 on 4/14/2010. Microsoft Research’s new Excel DataScope project uses the PivotViewer for it’s UI (see section below).
Following is a summary of the RCSB Protein Data Bank’s archive:
The Protein Data Bank (PDB) archive currently contains the atomic coordinates, sequences, annotations, and experimental details of more than 70,000 proteins, nucleic acids and complex assemblies. Navigating and analyzing this large and rapidly expanding volume of structural information by sequence, structure, function and other criteria becomes increasingly difficult. The RCSB PDB website (http://www.pdb.org) provides powerful query, analysis and visualization tools to aid the user in mining the PDB. In addition, the RCSB PDB integrates structural data with information about taxonomy, biological function, protein domain structure, literature, Molecule of the Month articles and other resources, to present the data in a biological context. The three-dimensional (3D) structures make possible an atomic-level understanding of biological phenomena and diseases, and allow the design of new therapeutics.
The Molecule of the Month series is the source of the technical data about the molecules contained in the Silverlight PivotViewer Control’s *.cxml file. Images are stored in Deep Zoom format. You can learn more about the Silverlight PivotViewer Control in Chapter 12, PivotViewer of the team’s “Data & Networking” series.
Here’s a capture of the Azure control’s default view sorted by Macromolecule Type:
Clicking one of the tiles in the * DNA column opens a Deep-Zoom view of the simplified protein DNA structure with annotations from the Molecule of the Month article:
Steve Marx (@smarx) of the Windows Azure Team (@WindowsAzure) described Pivot, OData, and Windows Azure: Visual Netflix Browsing, upload a live demo with about 3,000 tiles to http://netflixpivot.cloudapp.net/ and provided downloadable source code for the C# project in his 6/19/2010 post.
Shortly after MIX10, Microsoft released an Excel add-in for the PivotViewer, described in the Silverlight Team’s 7/18/2011 Excel Tool page. Here’s a capture of the New Collection ribbon:
and a sample worksheet with added include names, links to Wikipedia articles, and Wikipedia descriptions:
Microsoft Research’s Excel DataScope Project
The Excel PivotViewer add-in is similar to that used by Microsoft Research’s first Excel DataScope Community CTP, which became publicly available on 6/15/2011. Here’s the DataScope File ribbon preparing to open a Workgroup stored in a Windows Azure blob:
A workspace contains both data and analytics and provides isolation for a group of data analysts to work together on shared data and data analysis models.
This ribbon appears after connecting to a Workgroup:
Once connected to a workspace the data analytics models and operators available in the cloud are displayed on the Excel DataScope Research Ribbon (these algorithms are implemented on Windows Azure).
Here’s the Dataset Import dialog connected to a blob in Azure storage:
Excel DataScope allows a user to sample from a data set in the cloud, which comes in handy when manipulating multiTB data sets in the cloud.
Here’s a geospatial cluster visualization with placeholders for image tiles not supplied:
An example of the data visualizations produced by DataScope after running K-means clustering on a cloud-scale data set of ocean sensor data. Each tile in the visualization is a data point in the collection. The visualization is interactive, users can ‘pivot’ on various attributes of the data and the collection is dynamically rendered.
Credit: Excel DataScope images and captions provided by Roger Barga, who currently works as an Architect and group lead in the Cloud Computing Futures (CCF) team. CCF is part of the eXtreme Computing Group (XCG), a new organization in Microsoft Research established to push the boundaries of computing.












Joel Forman posted Alert RSS Feed for Azure Applications Leveraging Windows Azure Diagnostics to the Slalom Consulting blog on 7/29/2011:
One important aspect to building scalable applications in the cloud is the ability to debug, troubleshoot, and monitor deployed services. In this post I will demonstrate how to add a simple RSS Feed for alerts to your cloud service that leverages the information being collected via Windows Azure Diagnostics.
WAD does a nice job of handing the collecting of diagnostics data. But it doesn’t provide monitoring or alerting capabilities to date. One simple way to generate some basic alerting capabilities is to add an RSS Feed to your Web Role that queries data collected by WAD and surfaces key information that you would want to know about. Here are some quick steps to create such a feed that will include any log message from any instance (web, worker, etc.) with the category of “Error” or “Critical”.
For this example, I started with a new cloud solution consisting of one ASP.NET MVC Web Role.
Make sure Windows Azure Diagnostics is enabled in the properties of your Web Role. Note that a configuration setting is added to your ServiceConfiguration.cscfg file designating the storage account where the diagnostics data is persisted. In this example, I am running locally so I am using development storage.
I modified the settings for WAD via the OnStart event for my Web Role to persist logs more frequently for this demo. I just recently read this post by Cory Fowler that shows how to do this via a configuration file as well.
I added a try/catch block that catches an exception and I am tracing that exception using Trace.TraceError. By default for my web role in my web.config, WAD has already been configured as a trace listener for me. This will show up in my diagnostics storage account, within a Table Storage table called WADLogsTable that gets generated by WAD.
Time to implement the feed. I did a quick search and found this solution for returning an RSS Feed from a Controller Action. (Thanks!)
I created a couple of classes to represent my TableServiceContext and TableServiceEntity that we will use in querying Windows Azure Table Storage via the Storage Client Library included in the Windows Azure SDK.
Finally, I added a new Controller and Action for my alert feed. Via LINQ I am able to query the logs table to retrieve the most recent messages with the level of “Error” or worse. Leveraging the Syndication classes included in the .NET framework, we can easily enumerate the log messages and return a feed.
I can subscribe to this feed from a feed reader on my mobile device, and/or add this feed to my Outlook inbox.
There are a lot of more advanced ways to accomplish monitoring and alerting via Windows Azure. This is just a simple solution to gain some real-time visibility into important events, without much overhead to implement.
You can download the source code for the Alert Feed Controller here.








The Windows Azure Team (@WindowsAzure) posted a Real World Windows Azure: Interview with David Holecek, Digital Strategy Manager at Volvo Car Corporation interview on 7/29/2011:
MSDN: Can you tell us more about Volvo and how you market to consumers?
Holecek: Volvo is one the car industry’s most-recognized brands and has a long history of innovative designs that take a human-centered approach. Beyond relying on our reputation of manufacturing cars with impeccable safety records, we also have to develop rich, digital marketing campaigns that transcend traditional paper-based marketing efforts.
MSDN: What were some of the challenges that Volvo faced with its marketing campaigns prior to adopting Windows Azure?
Holecek: We had a great opportunity to create a new marketing campaign with the release of the Twilight movie series because the films highlighted several Volvo cars. So, when the first two movies in the series came out, we started digital marketing campaigns that drove traffic to the Volvo website. However, at the campaigns’ peaks of popularity, we had up to 9,000 visitors every second, which, unfortunately, resulted in outages and sluggish performance of the campaign website—that meant unhappy customers, which is unacceptable for us as a customer-centric company. Our IT personnel were left scrambling trying to fix all of the performance issues. So, when the third Twilight movie, Eclipse, was to be released, we knew that we needed a solution that would provide us scalability and high performance.
MSDN: Why did you choose Windows Azure as your solution?
Holecek: The full-service digital marketing agency and Microsoft Gold Certified Partner that we work with, LBi, recommended Windows Azure based on previous experience with the cloud service. We were under a tight deadline to get the new campaign launched—just three months if we wanted to go live at the same time the movie premiered. We were already familiar with the Microsoft .NET Framework 4 and the Microsoft Visual Studio 2010 Professional development system, so we could use those existing skills to develop for Windows Azure.
MSDN: Can you describe how Volvo is using Windows Azure to address the need for scalability and high performance?
Holecek: We developed an interactive game where users try to navigate a course maze in a Volvo car in the fastest time and using the shortest route. The grand prize was a brand new Volvo XC60. The game was hosted in web roles in Windows Azure. As needed, we could quickly add new web roles and scale up to meet traffic demands. The webs roles also handled web-service requests that were triggered during game play, and data from those service requests was stored in Queue storage in Windows Azure. Worker roles in Windows Azure processed the service requests and game-play data was stored in Windows Azure Table Storage. We also took advantage of strategically placed Microsoft data centers across the globe, deploying instances of the game at multiple data centers across the United States and Europe so that customers who played the game accessed it from the instance closest to their physical proximity.
MSDN: What makes your solution unique?
Holecek: By using Windows Azure, we freed our creativity and focused on developing the most engaging experience possible. We weren’t limited by technology constraints, or worried about focusing our efforts on troubleshooting performance issues. The marketing promotion was successful at driving traffic to the Volvo website. It ran from June 3 to July 14, 2010, during which time more than one million unique visitors went to the website, more than 400,000 of whom actively played the game.
MSDN: What kinds of benefits did Volvo realize with Windows Azure?
Holecek: One of the most important outcomes of using Windows Azure is that, unlike with our previous campaigns, we had the level of scalability that we needed to handle a large volume of traffic. We could easily scale up to handle peaks, or scale down to right-size our infrastructure for any lulls. It was the most cost-effective solution, too, especially compared to building our own infrastructure to run a temporary marketing promotion like this. In fact, by using Windows Azure, we saved 85 percent compared to an on-premises infrastructure, thanks to the pay-as-you-go pricing model that it offers. In addition, Windows Azure helped us deliver the high-performance application that we wanted and we minimized any latency issues. In fact, we did not experience any downtown or other production-related disturbances with the campaign website.
Read the full story.
Click here to read more Windows Azure customer success stories.
David Pallman described Windows Azure Design Patterns, Part 1: Architectural Symbols in a 7/28/2011 post:
Today I am beginning a new article series on Windows Azure design patterns, which has been an interest of mine since Windows Azure debuted in 2008. Design patterns are usually expressed in a design pattern language which may also be accompanied by a symbology. In this first article we’ll describe the symbology we’ll be using in this series to represent Windows Azure design patterns in architectural diagrams, also used on my AzureDesignPatterns.com web site and in my upcoming book, The Windows Azure Handbook, Volume 2: Architecture.
A symbology is warranted because Windows Azure brings a number of concepts, artifacts, terms, and patterns that aren’t in our traditional vocabulary of enterprise architecture diagramming. Some good goals for a symbology are these:
1. Symbols should be simple enough they can be easily drawn by hand legibly on a whiteboard.
2. Symbols should be available to use in productivity tools such as Visio or PowerPoint.
3. Symbols should mesh well with established diagram conventions and traditional symbols.
4. Symbols should serve several levels of granularity, from high-level views down to detailed.
5. Pattern categories such as compute or data should be easy to pick out. We can use color for this. While we shouldn’t depend on color exclusively to communicate (it isn’t always available, and some people are color-blind), it is nevertheless very effective for reinforcement.
Service and Project Symbols
At a very high level, we might just want to reference we are using a particular service:
If we’re focusing on deployment details, showing the management projects (hosted service project, , storage account, AppFabric namespace) may be necessary. Use these file folder-derived symbols for that.
Compute Symbols
Windows Azure Compute gets a lot of attention in architectural diagrams. The service model is pattern-rich, and the other platform services often play a supporting role to hosted services. We’ll color-code compute symbols green. A hosted service consists of one or more roles, each of which contains instances. We can show a role like this, indicating the number of instances in the upper right--in this case 2 or more to maintain high availability--and show the minimum number of instances with discrete symbols. For each instance we have a symbol reflecting what is running in the role, and below it the VM size.
If our diagram is complex or we are short on space, we can condense the above notation to this:
We can use different instance symbols to distinguish a web role from a worker role from a VM role.
Web roles can host web sites (accessed by people) as well as web services (accessed by programs). It’s useful in architectural diagrams to make this distinction even though it makes no difference to Windows Azure. We can use a circle symbol for web sites and a triangular symbol for web services. When a web site and a web service are combined in a single web role, which is common in ASP.NET-WCF projects, we can superimpose the two.
Roles may have endpoints. We can show an input (public) endpoint with a load balancer like this. We also want to show our clients, which might be interactive users or programmatic clients. As we start to show the larger solution it becomes important to mark the data center boundary so it’s clear what is and isn’t in the cloud.
Storage Symbols
We’ll color code data patterns blue. Starting with blob storage, we can show a blob, multiple blobs, or a container of blobs like this. We might also want to relate storage artifacts to a storage account.
If we want more granularity, we can expand to this notation where we can show the count and/or size of blobs in a container, separated into categories. The example below shows the count of image, video, and XML blobs in a container named “media” whose total size is about 20GB.
Queues and messages can be shown in a similar way, with simple representations
or with expanded detail. This shows an order queue whose message payloads come in two types, web orders and phone orders.
Finally, we can take the same approach with table storage: simple representations
or expanded detail, which shows a table’s entity properties, partition key, and row key.
Relational Data Symbols
Keeping with our blue color-coding for data, these symbols represent SQL Azure relational database tables, databases, and virtual database servers.
To show the tables a database contains, we can go to this expanded notation. Alternatively, you can use an established data dictionary notation of your preference.
For SQL Azure reporting, we have these symbols to represent a report definition and a report endpoint.
For SQL Azure Data Sync, we need symbols for a sync group and to show that a database has a 1-way or 2-way sync connection.
We can show OData endpoints for the SQL Azure OData Service or a DataMarket subscription like this:
Communication & Networking Symbols
Communication and networking patterns are color-coded red. The AppFabric Service Bus symbols include service bus connection, service bus queue, message, message buffer, and service namespace.
For Windows Azure Connect virtual networks there are symbols for a virtual network, for a role group member, and for a machine group member.
Security Symbols
For security, we need symbols for the key actors: identity providers (IPs), relying party applications (RPs), and various directories (such as AD) and security token services (STSs)--including some well-known STSs such as the Access Control Service and ADFS. Security symbols are color-coded purple-gray.
To show that a communication channel or a data store is secure, we can annotate it with a lock symbol.
Combining these symbols, here’s how we can show an application (RP) accessing domain identity via ADFS. The Windows Azure web role is the relying party. The user is redirected to ADFS for an AD domain sign-in and upon valid authentication is redirected back to the cloud application with a security token.
A Software-as-a-Service Example
Let’s put all of this together and show what a moderately complex solution looks like using this symbology. Below you see Onboarded.com, a Windows Azure-hosted SaaS solution. This is a single deployment in the cloud that serves multiple corporate clients, with separate databases and Active Directory integration for each tenant. A “T” marks the areas of the diagram that are unique to each tenant.
Hopefully this diagram is easy and intuitive to digest at this point. In the cloud we have a web role and a worker role, both of which make use of Windows Azure storage, SQL Azure databases, and the AppFabric Service Bus (each with tenant-specific resources). The web role contains both a web site and a web service. Both corporate and field users can access this solution, signing in with their domain credentials which are verified through a Service Bus connection to an on-premise AD integration service.
You can download the icons here. Note, this is a work in progress so you can expect the set to grow and see refinement over time. You can use them freely, but I'd appreciate a reference to me, my Windows Azure book series, or my AzureDesignPatterns.com web site.
In our next installment, we’ll start to look at individual patterns topically, starting with compute.
























<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Beth Massi (@bethmassi) reported CodeCast: Launch of Visual Studio LightSwitch 2011 on 7/29/2011:
Check it out, I did a podcast with Ken Levy on Wednesday here on campus and he posted it yesterday evening. In this one I chat with him about the release of Visual Studio LightSwitch with the latest news and resources. Always a fun time chatting with Ken!
CodeCast Episode 109: Launch of Visual Studio LightSwitch 2011 with Beth Massi
Also check out these resources for more info on Visual Studio LightSwitch:
And get involved with the community:
- Ask questions in the LightSwitch Forums
- LightSwitch on Facebook
- LightSwitch on Twitter
- LightSwitch Team Blog
Enjoy!

The Visual Studio LightSwitch Team (@VSLightSwitch) announced NetAdvantage for Visual Studio LightSwitch on 7/20/2011:
Infragistics has released NetAdvantage for Visual Studio LightSwitch! They have created a great suite of custom controls, themes and custom shell extensions which give you a rich toolset to build code-free dashboards and engaging line of business applications with LightSwitch. See more here:
NetAdvantage for Visual Studio LightSwitch
They also offer a free version: NetAdvantage for Visual Studio LightSwitch “Light”. With the “Light: version, you will get their Numeric Editor, Mask Editor, Office 2010 Theme and Metro Theme! You can download NetAdvantage for Visual Studio LightSwitch directly from Infragistics. You can also install it from within Visual Studio LightSwitch via the Extension Manager or you download it from the Visual Studio Gallery.
Stay tuned for more extensions from our partners!
Return to section navigation list>
Windows Azure Infrastructure and DevOps
• Louis Columbus (@LouisColumbus) reported Gartner Releases Their Hype Cycle for Cloud Computing, 2011 in a 7/27/2011 post:
Calling the hype around cloud computing “deafening”, Gartner released their annual hype cycle for the 34 different technologies in a 75-page analysis today. You can find the Hype Cycle at the end of this post and I’ve provided several of the take-aways below:
- The industry is just beyond the Peak of Inflated Expectations, and headed for the Trough of Disillusionment. The further up the Technology Trigger and Peak of Inflated Expectations curve, the greater the chaotic nature of how technologies are being positioned with widespread confusion throughout markets. The team of analysts who wrote this at Gartner share that conclusion across the many segments of the Hype Cycle.
- Gartner states that nearly every vendor who briefs them has a cloud computing strategy yet few have shown how their strategies are cloud-centric. Cloudwashing on the part of vendors across all 34 technology areas is accelerating the entire industry into the trough of disillusionment. The report cites the Amazon Web Services outage in April, 2011 as a turning point on the hype cycle for example.
- Gartner predicts that the most transformational technologies included in the Hype Cycle will be the following: virtualization within two years; Big Data, Cloud Advertising, Cloud Computing, Platform-as-a-Service (PaaS), and Public Cloud computing between two and five years; and Community Cloud, DevOps, Hybrid Cloud Computing and Real-time Infrastructure in five to ten years.
- There continues to be much confusion with clients relative to hybrid computing. Gartner’s definition is as follows ”Hybrid cloud computing refers to the combination of external public cloud computing services and internal resources (either a private cloud or traditional infrastructure, operations and applications) in a coordinated fashion to assemble a particular solution”. They provide examples of joint security and management, workload/service placement and runtime optimization, and others to further illustrate the complex nature of hybrid computing.
- Big Data is also an area of heavy client inquiry activity that Gartner interprets as massive hype in the market. They are predicting that Big Data will reach the apex of the Peak of Inflated Expectations by 2012. Due to the massive amount of hype surrounding this technology, they predict it will be in the Trough of Disillusionment eventually, as enterprises struggle to get the results they expect.
- By 2015, those companies who have adopted Big Data and extreme information management (their term for this area) will begin to outperform their unprepared competitors by 20% in every available financial metric. Early use cases of Big Data are delivering measurable results and strong ROI. The Hype Cycle did not provide any ROI figures however, which would have been interesting to see.
- PaaS is one of the most highly hyped terms Gartner encounters on client calls, one of the most misunderstood as well, leading to a chaotic market. Gartner does not expect comprehensive PaaS offerings to be part of the mainstream market until 2015. The point is made that there is much confusion in the market over just what PaaS is and its role in the infrastructure stack.
- SaaS performs best for relatively simple tasks in IT-constrained organizations. Gartner warns that the initial two years may be low cost for any SaaS-based application, yet could over time be even more expensive than on-premise software.
- Gartner estimates there are at least 3M Sales Force Automation SaaS users globally today.
Bottom line: The greater the hype, the more the analyst inquiries, and the faster a given technology ascends to the Peak of Inflated Expectations. After reading this analysis it becomes clear that vendors who strive to be accurate, precise, real and relevant are winning deals right now and transcending the hype cycle to close sales. They may not being getting a lot of attention, but they are selling more because enterprises clearly understand their value.
Source: Gartner, Hype Cycle for Cloud Computing, 2011 David Mitchell Smith Publication Date: 27 July 2011 ID Number: G00214915 © 2011


Scott Guthrie (@scottgu) resurfaced as a Windows Azure honcho “coming up to speed” in a 00:32:55 Episode 53 - Scott Guthrie Discusses Windows Azure video segment on 7/29/2011:
In this episode, Steve and Wade are joined by Scott Guthrie—Corporate Vice President, Server & Tools Business—who talks about what he's been focused on with Windows Azure. In this conversation, Scott talks about the good, the bad, and the ugly, and also shows code along the way.
In the news:
Brian Gracely (@bgracely) described The "21st Century Bits Factory" in a 7/30/2011 post:
Growing up in Detroit, I was always fascinated by the auto factories. Beyond the fact that I had tons of friends and relatives that worked there, I used to love to go on the tours to watch the massive machinery turn out these incredible pieces of automative art. But over time, the atmosphere in the factories changed as competition from European and Asian carmakers increased. Things become more automated, resources were brought in "just in time", parts were sourced from all over the world and in some cases actually came from competitors. Terms like "lean manufacturing" and "six sigma" began to flood into the vocabulary of anyone involved in manufacturing in the 70s, 80s or 90s.
For people working in IT, a similar transition is rapidly taking place. For some people, they may view the burst of new Data Center building announcements (here, here, here, here, here, and many more) as just a new phase in IT evolution. But I actually believe it's something bigger than simply the natural trends of Moore's Law.
I've been using the phrase "21st Century Bits Factory" for about six months now because I believe this new trend toward hyper-efficient Data Center facilities and operations is a similar tipping point to what we saw in the manufacturing industry decades ago. But instead of making cars or widgets, these giants factories are creating products, commerce and business value through 1s and 0s. The businesses they support are almost entirely driven by the value of this data, so the businesses are beginning to invest in their data centers with laser focus.
So what's all this mean to the IT industry?
- The New CIO had better have a strong grasp on both his internal and external bit factories. If they are looking for leading practices, facilities like SuperNAP (here, here) might be a good place to start their education. This will help them decide if they want to be a renter or an owner.
- New standards and recommendations (here, here) will emerge that attempt to take the learnings from the largest of bit factories and attempt to bring those back into mainstream IT operations are various sizes. CIOs should educate themselves on how this new thinking could impact their Data Centers now and in the future.
- The common separation of costs between IT and Facilities will need to be re-evaluated. It was understandable when IT owned a few floors of a building or a bunch of closets, but when they run the entire facility it will be in everyone's best interest to drive collaboration between those groups as Cloud Computing is now measured in ROI/watt as often as it's measured in ROI/$.
- CIOs should be looking to leverage the concepts within JIT, Lean and Six Sigma to potentially drive the operational efficiency that will allow IT services to be delivered at scale and at the pace of 21st century business.
- CIOs should be looking at ways to leverage Data Center efficiencies to drive tax breaks, energy efficiency tax credits or other forms of savings/rebates to offset other IT costs to the business.
Now every company will have the budgets to build new Data Centers in the near term. Consolidation of resources (unified networks, virtualization, etc.) might resolve immediate space/power/cooling challenges. But over time, just as we saw in the manufacturing industry years ago, most businesses will be faced with the question of how they will evolve their 21st century bits factories, whether they are owners or renters.

Brian is a Cloud Evangelist @Cisco and Co-Host of @thecloudcastnet.
Jay Fry (@jayfry3) claimed A service provider ecosystem gaining steam in the cloud is good news for enterprises in a 7/29/2011 post:
If you’re in enterprise IT, you (or that guy who sits next to you) are very likely looking to figure out how to start using cloud computing. You’ve probably done a fair bit of sleuthing around the industry to see what’s out there. Stats from a number of different analyst firms point overwhelmingly to the fact that enterprises are first and foremost trying to explore private cloud, an approach that gives them a lot of control and (hopefully) the ability to use their existing security and compliance implementations and policies.
And, all that sleuthing will most likely lead you to one pretty obvious fact: there are lots of approaches to building and delivering a private cloud.
So, here’s an additional thing to think about when picking how you’re going to deliver that private cloud: an ecosystem is even more valuable than a good product.While your current plans may call for a completely and utterly in-house cloud implementation, you just might want to expand your search criteria to include this “what if” scenario: what if at some point you’d like to send a workload or two out to an external provider, even if only on a limited basis?
That “what if” should get you thinking about the service provider partners that you will have to consider when that time comes. Or even a network of them.
The CA Technologies cloud product announcements on July 27 talked a lot about the offerings from CA Technologies (including those targeted for service providers specifically), but I wanted to make sure that the cloud service provider ecosystem that’s building steam around CA AppLogic got the attention it deserved as well.Kick-starting a cloud ecosystem
In the early days of cloud computing (and prior to being acquired by CA), 3Tera made a lot of headway with service providers. Over the 16 months since 3Tera came onboard, CA has been working to build on that. We’ve really seen why and how to work closely with our growing set of partners. You can’t just focus on technology, but you must also figure out how to enable your partner’s business. For service providers, that’s all about growing revenues and building margin.
We’re now seeing results from those efforts. In the first half of this year alone, we’ve announced new and extended partnerships with ScaleMatrix, Bird Hosting, StratITsphere, Digicor, and others around the world.A benefit to enterprises: service providers as a safety valve
Interestingly enough, enterprises view this ecosystem as a real benefit as they consider adopting a private cloud platform like CA AppLogic. Not only can they quickly get a private cloud up and running, but they have a worldwide network of service providers that they can rely on as a safety valve for new projects, cloud bursting for existing applications, plus the real-world expertise that comes with having done this many times before.A number of the partners and service providers using CA AppLogic to deliver cloud services to their customers joined in on the announcement of CA AppLogic 3.0 on July 27. Many posted blogs that talked about how they believed the new capabilities would prove useful for their own business – and why it would be intriguing for enterprise customers as well.
Here are a few highlights from their blog comments:
- Kevin Van Mondfrans of Layered Tech pointed to CA AppLogic’s continued innovation for application deployment “with its intuitive drag and drop application deployment interface.” The visual interface, he said, is the “hallmark of AppLogic,” and it “continues to differentiate this platform from the others. AppLogic enables complete deployment of entire application environments including virtual load balancers, firewalls, web servers, application server and databases in a single motion.”
The new AppLogic 3.0 capabilities “are interesting enhancements,” said Kevin in his post, “and they “enable a broader set of use cases for our customers with privacy requirement and who want to migrate VMware and Xen environments to the cloud.”- Mike Vignato of ScaleMatrix notes that he believes “having the ability to use VMware inside the AppLogic environment will turbo charge the adoption rate” of CA AppLogic as a cloud platform. Why? “It will allow enterprise CIOs to leverage their VMware investment while simplifying cloud computing and lowering overall costs.”
- DNS Europe thought the ability to import workloads from VMware or Xen using the Open Virtualization Format (OVF) import feature was a “further testament to CA's longstanding commitment to open standards. OVF import simplifies operations, increases agility, and liberates VMware- or Xen-based workloads for operation within AppLogic applications.” They also called out Roll-Based Access Control, as well as the new Global Fabric Controller: “Automatic detection and inventory functions further boost AppLogic as the number one ITSM friendly cloud platform.” (Go here for my interview with Stephen Hurford, their cloud services director.)
- Christoph Streit of ScaleUp posted this summary of what’s important to their business in AppLogic 3.0: “One of the most important new features from our perspective is the new VLAN tagging support. This has been a feature that most of our customers, who are mainly service providers, have been asking for. This new feature enables a service provider to offer their customers cloud-based compute resources (such as VMs or complete application stacks) in the same network segment as their co-located or dedicated servers. Also, this makes it possible for a service provider to segregate customer traffic more easily.”
- Mike Michalik, whose team at Cirrhus9 spent over 200 documented hours working with the beta code, agreed. The new VLAN capabilities, he writes, “will allow Cirrhus9 to basically build true multi-tenant grids for our MSP clients. This will give them the flexibility to have a single grid that has truly segregated clients on it, as opposed to having multiple grids for each one. It will also allow for easier system administration per client and geographically disperse data centers for the same overall grid.”
- ScaleMatrix’s Mark Ortenzi was on the same page. “The ability for CA AppLogic 3.0 to allow VLAN tagging support…is an amazing new feature that will really change the way MSPs can go to market.” (You can read a Q&A I did with Mark a few months back about their business here.)
- “The really cool thing I’m excited about,” writes Mike Michalik at Cirrhus9, “is the bandwidth metering. I like the flexibility that this option gives us now because we can have several billing models, if we choose to. Tiered billing can be in place for high consumption users while fixed billing options can be provided to clients that have set requirements that don’t vary much.”
The value of an ecosystem
ScaleUp’s Christoph Streit underscored the importance of these kinds of partnerships in the cloud space. He used ScaleUp and CA AppLogic as an example: “We can effectively show the value of cloud computing to everyone – IT departments, business users, developers, the CIO and, in some cases, even the CEO.”We’ll be working with these partners and many others even more actively as part of the CA Cloud Market Accelerator Program for Service Providers that we announced this week as well.
Watch this space for more updates on the ecosystem. For profiles on many for them, you can check out the Cloud Accelerator profiles we’ve created as well.


<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
• Thomas J. Bittman, George J. Weiss, Mark A. Margevicius and Philip Dawson co-authored Gartner’s Magic Quadrant for x86 Server Virtualization Infrastructure of May 26, 2011 (missed when published). From the “What You Need to Know,” “Magic Quadrant” and “Market Overview” sections:
What You Need to Know
As of mid-2011, at least 40% of x86 architecture workloads have been virtualized on servers; furthermore, the installed base is expected to grow five-fold from 2010 through 2015 (as both the number of workloads in the marketplace grow and as penetration grows to more than 75%). A rapidly growing number of midmarket enterprises are virtualizing for the first time, and have several strong alternatives from which to choose. Virtual machine (VM) and operating system (OS) software container technologies are being used as the foundational elements for infrastructure-as-a-service (IaaS) cloud computing offerings and for private cloud deployments. x86 server virtualization infrastructure is not a commodity market. While migration from one technology to another is certainly possible, the earlier that choice is made, the better, in terms of cost, skills and processes. Although virtualization can offer an immediate and tactical return on investment (ROI), virtualization is an extremely strategic foundation for infrastructure modernization, improving the speed and quality of IT services, and migrating to hybrid and public cloud computing.
Magic Quadrant

Market Overview
The x86 server virtualization infrastructure market is the foundation for two extremely important market trends: infrastructure modernization and cloud computing. For infrastructure modernization, virtualization is being used to improve resource utilization, improve the speed of resource delivery and encapsulate workload images in a way that enables automation. Virtualization is also being used as a basis for cloud computing — both private and public. In the last year, the number of server virtual containers and VMs more than doubled, due to:
Growth in workloads
Rapid growth in customer adoption
Increased use of hosted virtual desktops (HVDs; on servers)
Increased use of cloud IaaS
Significant growth in midmarket enterprises beginning to virtualize for the first time
Maturity of product offerings
Interoperability between service providers and enterprises is becoming more important, as enterprises plan to build architectures that can enable workload migration to and from cloud providers, and hybrid cloud computing ("cloudbursting").
x86 server virtualization infrastructure provides the foundation for new management and automation tools, new security architectures and new process methodologies. Although the technologies in the x86 server virtualization infrastructure market are simply enablers, these technologies will be used by vendors to drive customers to higher-level management and automation technologies. Choices made at the lower layers matter.
The market is becoming very competitive — both in terms of product offerings and in terms of overarching visions for the road map to cloud computing. VMware remains the market share and technology leader, but the market is growing rapidly, and competitors like Microsoft and Citrix Systems have a larger share now than they did a year ago. While the majority of Global 1000 enterprises have been virtualizing for several years, many smaller enterprises and those in emerging economies are just starting out, or haven't started yet. These enterprises have several viable alternatives from which to choose. In addition, as the cloud computing paradigm continues to evolve, cloud service providers offering IaaS want to make interoperability with their service offerings easy. A key trend in service providers is a shift to support better interoperability with existing enterprise virtualization infrastructures — in many cases, expanding their support for the same technologies that enterprises are using. …
The Windows Azure Team (@WindowsAzure) reported Fujitsu Announces the Global Availability of New Line of Middleware Products to Support Windows Azure on 7/29/2011:
Fujitsu announced the global availability of a new line of middleware products to support the Windows Azure Platform, which comes on the heels of their announcement of the Fujitsu Global Cloud Platform service, powered by Windows Azure. The middleware products launching today will run on both FGCP/A5 and the Windows Azure public cloud service, as well as provide customers around the world with the ability to build and deploy with Java and COBOL language runtime environments, migrate existing list applications, and coordinate job scheduling between on-premises and the Windows Azure Platform.

<Return to section navigation list>
Cloud Security and Governance
Dana Gardner asserted “Standards effort points to automation via common markup language O-ACEML for improved IT compliance, security” in a deck for his The O-ACEML Is a New Standard Creation and Effort article of 7/30/2011 for his BriefingsDirect blog:
This discussion examines the Open Automated Compliance Expert Markup Language (O-ACEML), a new standard creation and effort that helps enterprises automate security compliance across their systems in a consistent and cost-saving manner.
O-ACEML helps to achieve compliance with applicable regulations but also achieves major cost savings. From the compliance audit viewpoint, auditors can carry out similarly consistent and more capable audits in less time.
Here to help us understand O-ACEML and managing automated security compliance issues and how the standard is evolving are Jim Hietala, Vice President of Security at The Open Group, and Shawn Mullen, a Power Software Security Architect at IBM. The discussion is moderated by Dana Gardner, Principal Analyst at Interarbor Solutions. [Disclosure: The Open Group is a Sponsor of BriefingsDirect podcasts.]Here are some excerpts:
Hietala: One of the things you've seen in last 10 or 12 years -- since the compliance regulations have really come to the fore -- is that the more regulation there is, more specific requirements are put down, and the more challenging it is for organizations to manage. Their IT infrastructure needs to be in compliance with whatever regulations impact them, and the cost of doing so becomes significant.
So, anything that could be done to help automate, to drive out cost, and maybe make organizations more effective in complying with the regulations that affect them -- whether it’s PCI, HIPAA, or whatever -- there's lot of benefit to large IT organizations in doing that. That’s really what drove us to look at adopting a standard in this area.
Manual process
We're moving to] enable compliance of IT devices specifically around security constraints and the security configuration settings and to some extent, the process. If you look at how people did compliance or managed to compliance without a standard like this, without automation, it tended to be a manual process of setting configuration settings and auditors manually checking on settings. O-ACEML goes to the heart of trying to automate that process and drive some cost out of an equation.
Mullen: This has been going on a while, and we’re seeing it on both classes of customers. On the high-end, we would go from customer-to-customer and they would have their own hardening scripts, their own view of what should be hardened. It may conflict with what compliance organization wanted as far as the settings. This was a standard way of taking what the compliance organization wanted, and also it has an easy way to author it, to change it.
If your own corporate security requirements are more stringent, you can easily change the O-ACEML configuration, so that is satisfies your more stringent corporate compliance or security policy, as well as satisfying the regulatory compliance organization in an easy way to monitor it, to report, and see it.
In addition, on the low end, the small businesses don’t have the expertise to know how to configure their systems. Quite frankly, they don’t want to be security experts. Here is an easy way to print an XML file to harden their systems as it needs to be hardened to meet compliance or just the regular good security practices.
One of the things that we're seeing in the industry is server consolidation. If you have these hundreds, or in large organizations thousands, of systems and you have to manually configure them, it becomes a very daunting task. Because of that, it's a one-time shot at doing this, and then the monitoring is even more difficult. With O-ACEML, it's a way of authoring your security policy as it meets compliance or for your own security policy in pushing that out.
This allows you to have a single XML and push it onto heterogeneous platforms. Everything is configured securely and consistently and it gives you a very easy way to get the tooling to monitor those systems, so they are configured correctly today. You're checking them weekly or daily to ensure that they remain in that desired state.
[As an example], let's take a single rule, and we'll use a simple case like the minimum password length. In PCI the minimum password length, for example, is seven. Sarbanes-Oxley, which relies on COBiT password length would be eight.But with an O-ACEML XML, it's very easy to author a rule, and there are three segments to it. The first segment is, it's very human understandable, where you would put something like "password length equals seven." You can add a descriptive text with it, and that's all you have to author.
Actionable command
When that is pushed down on to the platform or the system that's O-ACEML-aware, it's able to take that simple ACEML word or directive and map that into an actionable command relevant to that system. When it finds the map into the actionable command, it writes it back into the XML. So that's completing the second phase of the rule. It executes that command either to implement the setting or to check the setting.The result of the command is then written back into the XML. So now the XML for particular rule has the first part, the authored high-level directive as a compliance organization, how that particular system mapped into a command, and the result of executing that command either in a setting or checking format.
Now we have all of the artifacts we need to ensure that the system is configured correctly, and to generate audit reports. So when the auditor comes in we can say, "This is exactly how any particular system is configured and we know it to be consistent, because we can point to any particular system, get the O-ACEML XML and see all the artifacts and generate reports from that."
What's interesting about O-ACEML -- and this is one of our differences from, for example, the security content automation protocol (SCAP) -- is that instead of the vendor saying, "This is how we do it. It has a repository of how the checking goes and everything like that," you let the end point make the determination. The end point is aware of what OS it is and it's aware of what version it is.
For example, with IBM UNIX, which is AIX, you would say "password check at this different level." We've increased our password strength, we've done a lot of security enhancements around that. If you push the ACEML to a newer level of AIX, it would do the checking slightly differently. So, it really relies on the platform, the device itself, to understand ACEML and understand how best to do its checking.We see with small businesses and even some of the larger corporations that they're maintaining their own scripts. They're doing everything manually. They're logging on to a system and running some of those scripts. Or, they're not running scripts at all, but are manually making all of these settings.
It's an extremely long and burdensome process, when you start considering that there are hundreds of thousands of these systems. There are different OSes. You have to find experts for your Linux systems or your HP-UX or AIX. You have to have all those different talents and skills in these different areas, and again the process is quite lengthy. …

Dana continues with his transcript. Read the rest of it here.
Chris Hoff (@Beaker) posted Unsafe At Any Speed: The Darkside Of Automation on 7/29/2011:
I’m a huge proponent of automation. Taking rote processes from the hands of humans & leveraging machines of all types to enable higher agility, lower cost and increased efficacy is a wonderful thing.
However, there’s a trade off; as automation matures and feedback loops become more closed with higher and higher clock rates yielding less time between execution, our ability to both detect and recover — let alone prevent — within a cascading failure domain is diminished.
Take three interesting, yet unrelated, examples:
- The premise of the W.O.P.R. in War Games — Joshua goes apeshit and almost starts WWIII by invoking a simulated game of global thermonuclear war
- The Airbus 380 failure – the luck of having 5 pilots on-board and their skill to override hundreds of cascading automation failures after an engine failure prevented a crash that would have killed hundreds of people.*
- The AWS EBS outage — the cloud version of Girls Gone Wild; automated replication caught in a FOR…NEXT loop
These weren’t “maliciously initiated” issues, they were accidents. But how about “events” like Stuxnet? What about a former Gartner analyst having his home automation (CASA-SCADA) control system hax0r3d!? There’s another obvious one missing, but we’ll get to that in a minute (hint: Flash Crash)
How do we engineer enough failsafe logic up and down the stack that can function at the same scale as the decision and controller logic does? How do we integrate/expose enough telemetry that can be produced and consumed fast enough to actually allow actionable results in a timeframe that allows for graceful failure and recovery (nee survivability.)
One last example that is pertinent: high frequency trading (HFT) — highly automated, computer driven, algorithmic-based stock trading at speeds measured in millionths of a second.
Check out how this works:
[Check out James Urquhart's great Wisdom Of the Clouds blog post: "What Cloud Computing Can Learn From Flash Crash"]
In the use-case of HFT, ruthlessly squeezing nanoseconds from the processing loops — removing as much latency as possible from every element of the stack — literally has implications in the millions of dollars.
Technology vendors are doing many very interesting and innovative things architecturally to achieve these goals — some of them quite audacious — and anything that gets in the way or adds latency is generally not considered “useful.” Security is usually one of them.
There are most definitely security technologies that allow for very low latency insertion of things like firewalls that have low single-digit microsecond latency figures (small packet,) but interestingly enough we’re also governed by the annoying laws of physics and things like propagation delay, serialization delay, TCP/IP protocol overhead, etc. all adds up.
Thus traditional approaches to “in-line” security — both detective and preventative — are not generally sustainable in these environments and thus require some deep thought so as to provide solutions that will scale as well as these HFT systems do…no short order.
I think this is another good use for “big data” and security data analytics. Consider very high speed side-band systems that function along with these HFT systems that could potentially leverage the logic in these transactional trading systems to allow us to get closer to being able to solve the challenges of these environments. Integrate these signaling and telemetry planes with “fabric-enabled” security capabilities and we might get somewhere useful.
This tees up nicely my buddy James Arlen’s talk at Blackhat on the insecurity of high frequency trading systems: “Security when nano seconds count” You should plan on checking it out…I know I will.


Carl Brooks (@eekygeeky) posted Regulated cloud computing -- our new national nightmare to SearchCloudComputing.com on 7/29/2011:
Two items in the extremely boring but very important arena of federal regulations came up this week that touch on cloud computing: A Brookings Institution report calling for clarity and additional regulation around cloud computing and export control, and a counterpoint report from the Software & Information Industry Association (SIIA) basically begging for that idea to be furiously ignored.
“The move to the cloud is one of the defining information technology trends of the early 21st century.”
John Villasenor, Brookings Institution
If you think that reporting on, reading about or examining federal regulation of the IT sector is hot stuff and not boring, I do not want to come to your cookout. However, it is incredibly important right now, in the same way a truck is incredibly important when you are standing on the highway. The Brookings Institution recently hosted a panel on the proposed "Cloud Computing Act of 2011." There are several other very far reaching bills on consumer data and identity privacy in the senate right now, like the Commercial Privacy Bill of Rights, the Consumer Privacy Protection Act, the Data Accountability and Trust Act and so on. None of these will be all that important, of course, because after next week we will all be eating each other's brains with teaspoons in the post-default apocalypse.
But assuming our native criminal class either gets their act together or suffers a TKO from the executive wing, you should care about this.
The DATA legislation, for example, would call for IT shops to "require each person engaged in interstate commerce that owns or possesses data containing personal information, or contracts to have any third-party entity maintain such data for such person, to establish and implement policies and procedures regarding information security practices for the treatment and protection of personal information."
No matter where you or your data resides, it is subject to audits on demand. Your data management tools can handle that in a snap, right? On no wait, they can't. Those tools don't exist. Looks like you'll be on your knees begging sales, HR, your payment processors, your vendors, your partners and your customers for all that crap -- and legal will still find a way to blame IT.
"The move to the cloud is one of the defining information technology trends of the early 21st century," says John Villasenor of the Brookings Institution. Therefore, he writes in part, the feds should probably clarify what it means to read regulated email or electronic documents on your phone while overseas.
Please, dear god, no. Do not do that. I've seen federal data standards in action. I know people with two phones and three computers they have to use for different federal requirements. They have to fill out paperwork if they send an email from the wrong device. It's like Kafka meets Cthulhu and the end result torments your soul in non-Euclidean email shape for the rest of eternity.
Meanwhile, SIIA attempts to lay out some reasonable policy goals for legislators that mostly focus around the fact that senators do not understand the "interwebs" and need to leave it the hell alone. Normally, I'm on the wrong side of SIIA; they're an anti-piracy group, which is a bit like trying to bail out the ocean with a tea cup while trying to annoy beachgoers by poking them with sticks. And normally, I like Brookings' positions on policy; they're reasonable, nuanced and, in this case, amazingly wrong.
Is it time to clarify what it means to open an email in international airspace? Time to make businesses responsible for ridiculous amounts of tangentially related material they either shouldn't have or shouldn't need? No. Hands off what you don't understand, please.
The cloud train is rolling, and locomotives (and their engineers) do not appreciate it when morons in suits barge in and start pulling levers for no earthly good reason. I'm all for consumer privacy and commercial accountability; pass laws that simply forbid bad actions, not make technologists and enterprises jump through crazy hoops.
Now you will promptly forget about the incredibly important decisions being made around cloud in Washington and head straight to YouTube when I tell you that the SIIA put out the "Don't Copy that Floppy" videos in 1992.

Carl Brooks is the Senior Technology Writer for SearchCloudComputing.com.
Full disclosure: I’m a paid contributor to SearchCloudComputing.com
<Return to section navigation list>
Cloud Computing Events
Cory Fowler (@SyntaxC4) asked you to Join [him] at SDEC 2011 in Winnipeg on 10/17 to 10/19/2011:
If you’re going to be around Winnipeg between October 17-19, why not join me at the Software Development and Evolution Conference? [Register Today]
I’ll be giving two talks both, surprise surprise, on Windows Azure and Cloud Computing.
Windows Azure Sessions at SDEC 2011
The 7 Deadly Sins of Cloud Development
Are you a sinner, a saint, or a lost soul in your journey to the clouds? Come identify potential sins in your current/future cloud deployment, and discover ways to repent. In this session we will look at tools, code and architectural decisions that will lead you on the right path heading into the cloud.
Azure Deep Dive – Migrate an Application to Windows Azure
This is a hands on event so be sure to BRING YOUR LAPTOP loaded with the pre-requisite software below. Take an existing application and prepare it for the cloud. During this Dojo you’ll be able to register for your very own Windows Azure Account, or use one of the limited time accounts provided. Then take a guided tour to moving an existing application (provided) modify it so it’s "cloud ready", then deploy the application to Windows Azure. Required pre-requisite software:
- Visual Studio 2010
- SQL Server Management Studio 2008 R2
- Windows Azure Tools for Visual Studio 2010
- Windows Identity Foundation
[Or setup an Ultimate Windows Azure Development Environment]


<Return to section navigation list>
Other Cloud Computing Platforms and Services
My (@rogerjenn) Early Google Base Posts on the OakLeaf Systems Blog post updated on 7/30/2011 explains why I abandoned Google Base as a candidate for public access to relational data in late 2005:
Updated below on 7/30/2011 with reasons why I abandoned attempts to use Google for sharing data from relational tables.
Google opened a public beta version of Google Base to testers on 11/16/2005. According to program manager Bindu Reddy’s First Base post to the Official Google Blog:
Today we're excited to announce Google Base, an extension of our existing content collection efforts like web crawl, Google Sitemaps, Google Print and Google Video. Google Base enables content owners to easily make their information searchable online. Anyone, from large companies to website owners and individuals, can use it to submit their content in the form of data items. We'll host the items and make them searchable for free. There's more info here.
The following table lists my early posts to the OakLeaf Systems blog about a number of Google Base tests I ran in 2005, as well as a review of the DabbleDB beta in March 2006:
Date Post 11/16/2005 Google Base and Bulk Uploads with Microsoft Access 11/17/2005 Google Base and Atom 0.3 Bulk Uploads 11/27/2005 Bulk-Uploaded Items Disappear from Google Base 11/29/2005 Windows Live "Fremont" vs. Google Base Classifieds 12/5/2005 Problems Uploading a Google Base Custom Item Type from a TSV File 12/12/2005 Google Base and Blogger Items Missing from Google Search 3/19/2006 Dabble DB: The New Look in Web Databases It’s interesting to note that Google supported data insert operations using the Atom format before AtomPub became a standard. Microsoft later adopted AtomPub as the foundation of it’s Open Data Protocol (OData) for RESTful create, retrieve, update, and delete (CRUD) operations on Windows Azure storage, as well as SharePoint lists.
Added 7/30/2011: I abandoned my attempts to use Google Base for sharing database and spreadsheet tables at the end of 2005 because I encountered issues with severe latency (as long as a few hours to publish inserted data), limited data type repertoire, chancy (and slow) data upload techniques, and a cumbersome, unintuitive client UI.
Google removed Google Base’s search page on 10/8/2009 and abandoned Google Base in September 2010 by morphing it to the Google Merchant Center. Google announced on 12/17/2010 that Google Base's API had been deprecated in favor of a set of new APIs known as Google Shopping APIs. Google also abandoned its Google Health services that had database-backed services in June 2011. Microsoft currently is attempting to woo former Google Health users to its HealthVault service with a data conversion application.
Alex Handy described the Top five changes in Java SE 7 in a 7/29/2011 post to SD Times on the Web:
It's been a long time coming, Java SE 7. After years of development, one major company acquisition and at least a hundred thousand discussions over the future of Java, yesterday Oracle and the OpenJDK community finally released the updates they've been working on all this time. There are a lot of changes in this version, not the least of which is the switch in naming conventions: The OpenJDK is the basis of Java SE 7, and its the project where all work has been done on the language, rather than within the JCP.
So, let's all grab ourselves a nice symbolic cup of coffee to tide us over while we examine the biggest changes in Java SE 7.
Concurrency and collections updates (JSR 166y)
Core proliferation has been an issue for a while now. With every new PC and server including more cores than the last, developers are constantly receiving more horsepower for their applications. Unfortunately, as enterprises have learned over the last 10 years, developing parallel and concurrent software is not as easy as adding all those new cores to a server farm.
Doug Lea, the Java genius from SUNY Oswego, headed up the design of JSR 166y, also known as the Concurrency and collections update. He designed the Fork/Join functionality that's used in this update.
Perhaps the best way to describe the new functions is to take a clip from the project's wiki:
Parallel*Array (often referred to as PA) and its planned follow-ons for sets and maps, provide an easier/better way of routinely programming to take advantage of dozens to hundreds of processors/cores: If you can think about a programming problem in terms of aggregate operations on collections of elements, then we can automate parallel execution. This generally pays off if either you have lots of elements (in which case, it works well even if the operations are small/cheap), or if each of the operations are time-consuming (in which case it works well even if there are not a lot of elements). To take advantage of this, though, the aggregate processing must have a regular structure, which means that you must be able to express things in terms of apply, reduce, filter, map, cumulate, sort, uniquify, paired mappings, and so on.
So that's what Parallel*Array does. Some people (especially those with experience with either database programming or functional programming) like this style anyway, and might use this API even without the parallelism benefits. But in turn, the fact that this style can be awkward to write out has led to all the language extension controversies about closures, function types, and related syntactic support.
Like all lightweight-task frameworks, Fork/Join (FJ) does not explicitly cope with blocked IO: If a worker thread blocks on IO, then (1) it is not available to help process other tasks, and (2) other worker threads waiting for the task to complete (i.e., to join it) may run out of work and waste CPU cycles. Neither of these issues completely eliminates potential use, but they do require a lot of explicit care.
For example, you could place tasks that may experience sustained blockages in their own small ForkJoinPools. (The Fortress folks do something along these lines mapping fortress "fair" threads onto fork/join.) You can also dynamically increase worker pool sizes (we have methods to do this) when blockages may occur. All in all though, the reason for the restrictions and advice are that we do not have good automated support for these kinds of cases and don't yet know of the best practices, or whether it is a good idea at all.


Tim Anderson (@timanderson) posted Java Standard Edition 7 is done, but feels like an interim release on 7/28/2011:
Oracle has released Java SE 7:
Oracle today announced the availability of Java Platform, Standard Edition 7 (Java SE 7), the first release of the Java platform under Oracle stewardship.
What’s in Java SE 7? Despite the full version number increment, I am tempted to call this an interim release. In December 2010 the JCP approved the specification of both Java SE 7 and Java SE 8, with two of the more interesting features, Project Lambda and the Module system (Project Jigsaw), held back for Java SE 8. Java SE 7 does include the InvokeDynamic keyword which improves the performance of dynamic languages such as Ruby and Python running on the JVM, as well as most of the minor language enhancements known as “Project Coin”. There is also a Fork/Join framework to better support concurrent programming.
The good news is that Java SE 8 is set to follow in late 2012, not so long considering Java SE 6 was released in 2006 . You can see the roadmap summarised here. This post is from October 2010, but as far as I am aware it has not changed much since. 2012 is also when we can expect Java Enterprise Edition 7.
It is also worth mentioning JavaFX 2.0, set for release later this year. A handy summary of JavaFX 2.0 is here. Whereas JavaFX 1.0 was rushed out and features a new scripting language that in the end few wanted, JavaFX 2.0 is more promising. Dimitry Jemerov, developer of IntelliJ IDEA at JetBrains, told me earlier this year:
JavaFX is going to turn, when the version 2.0 is released, from a dead end resource sucker project into a set of distinct technologies of great immediate usefulness to many Java developers.
Is there still hope for Java on the client? Java is barred from Apple iOS which is a problem, and is no longer supplied as standard on Mac OS X, but it will still make sense for many business applications. Of course Java is also wildly successful in the context of Google Android, but that uses the Dalvik VM rather than the Java VM so is rather a different thing.
Update: As ever, upgrade critical machines with caution. In particular, Apache Lucene and Apache Solr do not work on Java 7 because of HotSpot optimization bugs.
Related posts:


Charles Babcock asserted “After two years of acquisitions, CA introduces 10 products to help customers plan and deliver private clouds that can use internal and external services” in a deck for his Fruit Of CA Cloud Acquisitions Adds Up article of 7/29/2011 for InformationWeek:
CA Technologies, sometimes identified with the mainframe, repositioned itself recently to help its customers move in pragmatic, discrete steps toward cloud computing.
Over the last two years, it's made a series of small firm acquisitions in the cloud arena, including 3Tera, Nimsoft, and Oblicore. The fruit of that effort was announced Wednesday as it offered a set of new products stemming from the acquisitions, combined with upgrades to existing products.
There are major differences in user experience among some of the top tablets. We take a deeper look at some of the strengths and weaknesses of Apple's iOS, Android/Honeycomb and RIM's QNX operating systems.
CA has been integrating the acquired technology into a broader cloud approach, particularly for customers with legacy systems. Such customers need to move in steps that allow them to plan, design, deliver, and secure cloud services, and also have a way to ensure they are performing as expected, Jay Fry, vice president of marketing for cloud computing, said in an interview.
CA AppLogic 3.0 is a result of the 3Tera acquisition in March 2010. AppLogic 3.0 allows a cloud user to model a service and drag components for it from a catalogue to assemble and deploy it on virtual servers. The service may be connected to other applications in the software infrastructure of the enterprise by drawing lines in the model to the target systems. Fry said AppLogic helps with the design and deliver steps of cloud computing with its graphical user interface. Services that may have taken days to construct previously may be built in a few hours, using the modeling process.
The 3.0 version allows services built in AppLogic to run both VMware ESX and Citrix Xen hypervisors on the same server cluster. Customers may also use the Open Virtual Format, a standardized virtual machine format recognized by both hypervisors, to import virtual machines needed to establish a service. Typical CA AppLogic deployments start at $100,000; it is also available through annual subscription, Fry said.
Enterprises often use a mix of internal and external services, but they don't always know how well they're performing, Ryan Shopp, senior director of product marketing, virtualization, said in an interview. CA Business Service Insight 8.0 stems from the Oblicore acquisition and has been upgraded to track what services are running, monitor their performance, and identify when they are not meeting service level agreements.
The monitoring tool is also geared to help IT administrators evaluate the tradeoffs between using internal and external services. The evaluation process is based on benchmarks established in the CA-sponsored Service Measurement Index, currently hosted at Cloud Commons.
The product helps in the planning stage and in assuring services are delivered as planned, said Shopp. Pricing for Business Service Insight varies based on several metrics, but the average sale is $200,000.
CA Automation Suite for Clouds 1.0 is a combined CA product aimed at allowing enterprises to securely provision cloud servers in the data center. It is a combination of several predecessors, including CA Server Automation, CA Virtual Automation, CA Process Automation, CA Configuration Automation and CA Service Catalogue. A base configuration in a 100-socket pack starts at $195,000.
CA announced a total of 10 new or upgraded products Wednesday, including some designed for cloud service providers as well as the enterprise.

No significant articles today.
<Return to section navigation list>
















