Windows Azure and Cloud Computing Posts for 7/1/2011+
| A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
Mark Kromer (@mssqldude) posted a list of links to his Complete Microsoft Cloud BI Series on 7/1/2011:
I completed my 5 part series on Microsoft Cloud BI for the SQL Server Magazine BI Blog today. To read the entire series from start to finish, these are the links to each of the pieces:
Thanks, Mark

<Return to section navigation list>
Marketplace DataMarket and OData
The Windows Azure Team (@WindowsAzure) asked and answered Love Baseball? Check Out The MLB Head-to-Head Stats Dashboard On Windows Azure DataMarket on 7/1/2011:
Are you a baseball fan? Would you like to know the best Major League Baseball (MLB) players right now or compare real-time stats for two MLB teams head-to-head? What if you could see it all in a real-time dashboard for free? Sound Good? Then we have great news for you: welcome to the MLB Head-to-Head Stats Dashboard!
The MLB Head-to-Head Stats Dashboard is built on Windows Azure and the STATS.com datasets available on the Windows Azure Marketplace DataMarket, The dashboard allows you to compare MLB player performance and see stats and insights about the current season -- all in real-time. Information is continually updated with the latest game data so the dashboard always shows the latest statistics. A free trial mode is available that enables you to compare two MLB teams; a full STATS account will allow you to compare head-to-head stats of all MLB players.
Click here to learn more and sign up for your free trial.


<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
Steve Marx (@smarx) posted Cloud Cover Episode 49 - Access Control in the Windows Azure Toolkit for Windows Phone 7 on 7/1/2011:
Join Wade and Steve each week as they cover the Windows Azure Platform. You can follow and interact with the show at @CloudCoverShow.
In this episode, Vittorio Bertocci joins Steve as they discuss the role of Windows Azure Access Control in the Windows Azure Toolkit for Windows Phone 7.
In the news:
- New Windows Azure Traffic Manager Features Ease Visibility Into Hosted Service Health
- Rock, Paper, Azure! - The Grand Tournament
- Hosting Services with WAS and IIS on Windows Azure
- Porting Node to Windows with Microsoft's Help
Be sure to check out http://windowsazure.com/events to see events where Windows Azure will be present!

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
Avkash Chauhan explained the relationship between Windows Azure VM Role and SYSPREP in a 7/1/2011 post:
When someone prepare[s] VHD for VM Role, they might have the question if SYSPREP is really necessary or not.
First I would describe some of very important VM Role Image configuration achieved using SYSPREP as below:
VM image should be clean and in generalized state which is considered default image. Using a generalized image is the cleanest and most reliable method for deploying a Windows OS image on new hardware.
- VM should not have hardware configuration embedded in it. A generalized VM Image allows Windows Setup to properly re-evaluate the hardware to run smoothly. When VM runs on guest OS it configure itself to run based on Guest OS hardware and because the target hardware where your VM role will be running will be different from your own hardware where you have created the VM image so you need SYSPREP to setup OS in hardware neutral mode, so when it runs first time, it can actively re-evaluate the hardware environment.
- SYSPREP is prerequisite for cloning and duplicating machines. Through this process, each VM Image receive a fresh identity. If you are to create more than one instance from the parent, SYSPREP ensures that there are no ugly side effects.
- VM image “machine name” does matter when same image is used to deploy multiple instances as needed. SYSPREP erases the machine name to a state in which new name is given when VM is deployed. If the image is not SYSPREP, the machine name will remain the same and during multiple instances, duplicate machine name creates several conflicts.
- SYSPREP sets to image to non-activated state (or called default most – VL Activation) so when it is deployed or started, it can be activated depend on the environment . When VM Role image is deployed in cloud, the Windows Azure Integration Components are used to activate the VM Role image OS for Volume Licensing, regardless of which product key is present in the image.
- SYSPREP sets base OS locale to EN-US.
- VM Role image must be set to UTC time zone. SYSPREP is used to set this accurately.
- You must understand then Windows Azure does deploy instance or multiple instances form your VHD deployment. So it is must that your based VHD should be clean, and in such state that it can be used to deploy instances after instances as needed. SYSPREP is the best way to bring VM Image to this state.
- SYSPREP also sets up Administrator account to default state
As you can see SYSPREP really does help to create a VM Role image which can be effectively used for deploying multiple instances as needed so i would say SYSPREP indeed is needed.
Read more:

<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses

I had a hard time trying to get some diagnostics from a RoleEntryPoint.
I was doing some setup in this entry point and getting some errors.
So I tought, mmmm: this is a Task for the super Azure DiagnosticMonitor.
What happenned!!!
I took me a while to get to it. So
This is the things. I had to do.
1. First add a file called WaIISHost.exe.config
2. Add the Azure Diagnostics Trace Listener
<?xml version="1.0"?> <configuration> <system.diagnostics> <trace> <listeners> <add name="AzureDiagnostics" type="Microsoft.WindowsAzure.Diagnostics.DiagnosticMonitorTraceListener, Microsoft.WindowsAzure.Diagnostics, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35"> <filter type="" /> </add> </listeners> </trace> </system.diagnostics> </configuration>3. And very very important, you must go to Copy to Output Directory property for this file and set it to Copy Always.
4. And another thing that you need is a lot of patience. The Diagnostics infraestructure takes a while.
So you add a Thread.Sleep after the Start callDiagnosticMonitor.Start(storageAccount, configuration);
Thread.Sleep(10000);5. After you do that you will be able to collect some information from the WADLogsTables

Tony Bailey (a.k.a. tbtechnet) posted Getting a Start on Windows Azure Pricing on 6/30/2011:
The Windows Azure Platform Pricing Calculator is pretty neat to help application developers get a rough initial estimate of their Windows Azure usage costs. But where to start? What sort of numbers do you plug in? We've taken a crack at some use cases so you can get a basic idea. We've put the Windows Azure Calculator Category Definitions at the bottom of the post.
- Get free technical support for your Windows Azure development. Just click on Windows Azure Platform under Technologies
1. E-commerce application
a. An application developer is going to customize an existing Microsoft .NET e-commerce application for a national chain, US-based florist. The application needs to be available all the time, even during usage spikes, scale for peak periods such as Mother’s Day and Valentine’s Day
b. You can use the Azure pricing data to figure out what elements of your application are likely to cost the most, and then examine optimization and different architecture options to reduce costs. For example, storing data in binary large object (BLOB) storage will increase the number of storage transactions. You could decrease transaction volume by storing more data in the SQL Azure database and save a bit on the transaction costs. Also, you could reduce the number of compute instances from two to one for the worker role if it’s not involved in anything user-interactive—it can be offline for a couple minutes during an instance reboot without a negative impact on the e-commerce application. Doing this would save $90.00 per month in compute instances (three instead of four instances in use).
2. Asset Tracking Application
a. A building management company needs to track asset utilization in its properties worldwide. Assets include equipment related to building upkeep, such as electrical equipment, water heaters, furnaces, and air conditioners. The company needs to maintain data about the assets and other aspects of building maintenance and have all necessary data available for quick and effective analysis.
b. Hosting applications like this asset tracking system on Windows Azure can make a lot of sense financially and as a strategic move. For about $6,500.00 in the first year, this building management company can improve the global accessibility, reliability, and availability of their asset tracking system. They gain access to a scalable cloud application platform with no capital expenses and no infrastructure management costs, and they avoid the internal cost of configuring and managing an intricate relational database. Even the pay-as-you-go annual cost of about $9,000.00 is a bargain, given these benefits.
3. Sales Training Application
a. A worldwide technology corporation wants to streamline its training process by distributing existing rich-media training materials worldwide over the Internet.
b. Hosting applications like this sales training system on Windows Azure can make a lot of sense financially and as a strategic move. Using the high estimate, for a little less than $10,000.00 a year, this technology company can avoid the cost of managing and maintaining its own CDN while taking advantage of a scalable cloud application platform with no capital expenses and no infrastructure management.
4. Social Media Application
a. A national restaurant chain has decided to use social media to connect directly with its customers. They hire an application developer that specializes in social media to develop a web application for a short-term marketing campaign. The campaign’s goal is to generate 500,000 new fans on a popular social media site.
b. Choosing to host applications on Windows Azure can make financial sense for short-term marketing campaigns that use social media applications because you don’t have to spend thousands of dollars buying hardware that will sit idle after the campaign ends. It also gives you the ability to rapidly scale the application in or out, up or down depending on demand. As a long-term strategic decision, using Azure lets you architect applications that are easy to repurpose for future marketing campaigns.
Windows Azure Calculator Category Definitions
Azure Calculator Category
How does this relate to my application?
What does this look like on Azure?
Measured by
This is the raw computing power needed to run your application.
A compute instance consists of CPU cores, memory, and disk space for local storage resources—it’s a pre-configured virtual machine (VM). A small compute instance is a VM with one 1.6 GHz core, 1.75 GB of RAM, and a 225 GB virtual hard drive. You can scale your application out by adding more small instances, or up by using larger instances.
Instance size:
Extra small
Small
Medium
Large
Extra large
If you application uses a relational database such as Microsoft SQL Server, how large is your dataset excluding any log files?
A SQL Azure Business Edition database. You choose the size.
GB
This is the data your application stores—product catalog information, user accounts, media files, web pages, and so on.
The amount of storage space used in blobs, tables, queues, and Windows Azure Drive storage
GB
Storage Transactions
These are the requests between your application and its stored data: add, update, read, and delete.
Requests to the storage service: add, update, read, or delete a stored file. Each request is analyzed and classified as either billable or not-billable based on the ability to process the request and the request’s outcome.
# of transactions
Data Transfer
This is the data that goes between the external user and your application (e.g., between a browser and a web site).
The total amount of data going in and out of Azure services via the internet. There are two data regions: North America/Europe and Asia Pacific.
GB in/GB out
Content Delivery Network (CDN)
This is any data you host in datacenters close to your users. Doing this usually improves application performance by delivering content faster. This can include media and static image files.
The total amount of data going in and out of Azure CDN via the internet. There are two CDN regions: North America/Europe and other locations.
GB in/GB out
Service Bus Connections
These are connections between your application and other applications (e.g., for off-site authentication, credit card processing, external search, third-party integration, and so on).
Establishes loosely-coupled connectivity between services and applications across firewall or network boundaries using a variety of protocols.
# of connections
Access Control Transactions
These are the requests between your application and any external applications.
The requests that go between an application on Azure and applications or services connected via the Service Bus.
# of transactions








Jonathan Rozenblit (@jrozenblit) posted What’s In the Cloud: Canada Does Windows Azure - Scanvee on 6/30/2011:
Since it is the week leading up to Canada day, I thought it would be fitting to celebrate Canada’s birthday by sharing the stories of Canadian developers who have developed applications on the Windows Azure platform. A few weeks ago, I started my search for untold Canadian stories in preparation for my talk, Windows Azure: What’s In the Cloud, at Prairie Dev Con. I was just looking for a few stores, but was actually surprised, impressed, and proud of my fellow Canadians when I was able to connect with several Canadian developers who have either built new applications using Windows Azure services or have migrated existing applications to Windows Azure. What was really amazing to see was the different ways these Canadian developers were Windows Azure to create unique solutions.
This week, I will share their stories.
Leveraging Windows Azure for Mobile Applications
Today, we’ll see how Tony Vassiliev from Gauge Mobile and his team used Windows Azure as the backend for their mobile application.
Gauge Mobile
by
Gauge Mobile’s focus lies in mobile communications solutions. Scanvee, their proprietary platform, provides consumers, business and agencies the ability to create, manage, modify and track mobile barcode (ie. QR codes) and Near Field Communication (NFC) campaigns. Scanvee offers various account options to accommodate all business needs, from a basic free account to a fully integrated enterprise solution. Essentially, Gauge Mobile helps businesses of all sizes communicate more effectively with their consumers through mobile devices. They provide the tools to track and analyze their activities and make improvement in future communications.
Jonathan: When you guys were designing Scanvee, what was the rationale behind your decision to develop for the Cloud, and more specifically, to use Windows Azure?
Tony: Anything in the cloud makes more sense for a start-up. The advantages which equally apply to mobility can always be summed up to: affordability, scalability, and risk mitigation by reducing administrative requirements and increasing reliability. Microsoft has a definitive advantage when it comes to supporting their developer community. Windows Azure integration into existing development environments such as Visual Studio and SQL Server makes it easier and more efficient to develop for Azure. As well, naturally, utilization of existing technologies such as .Net framework and SQL Server are beneficial. Lastly, Platform-as-a-service model works better for us as a start-up than infrastructure-as-a-service offerings such as Amazon EC2. Azure offers turnkey solutions for load balancing, project deployment, staging environments and automatic upgrades. In conjunction with SQL Azure which replicates SQL Server in the cloud, total risk and administration costs of Azure solutions are less than an investment in EC2 where we still need to setup, configure and maintain our development and production environments internally.
Jonathan: What Windows Azure services are you using? How are you using them?
Tony: We are using a Windows Azure compute services - a web role (to which the mobile application connects) at the moment and we have a worker role in the works for background processing of large data inputs, outputs, invoice generation and credit card processing. We are also using one business SQL Azure database to hold the application's data and one for QA. We will be using sharding once we are at a point where we need to scale. Access Control and SQL Azure Reporting are two other features that we have on our roadmap. Access Control for integration into third party social networks and SQL Azure Reporting for our analytics. We may also end up using SQL Azure Sync depending on the state of SQL Azure and upcoming features for back up and point in time restores..
Jonathan: During development, did you run into anything that was not obvious and required you to do some research? What were your findings? Hopefully, other developers will be able to use your findings to solve similar issues.
Tony: There were few minor hiccups but nothing significant, everything was pretty straight forward!
Jonathan: Lastly, how did you and your team ramp up on Windows Azure? What resources did you use? What would you recommend for other Canadian developers to do in order to ramp up and start using Windows Azure??
Tony: Our senior engineer and architect is a .NET expert who had previously heard of Azure. He came equipped with all of Microsoft's development tools which provide good integration for Azure development. We started with a free account on Azure, created a prototype web role, deployed it, and sure enough it was a very simple and elegant procedure and we have continued to use Azure since.
As you can see, when it comes to mobile platforms, Windows Azure offers you an easy way to add backend services for your applications without having to put strain on the device. If your application has intensive processing and data requirements, such as Scanvee, you’ll need the infrastructure capacity in the backend to be able to support those requirements. Windows Azure can do that for you in a matter of a few clicks with no upfront infrastructure or configuration costs. Check out Connecting Windows Phone 7 and Slates to Windows Azure on the Canadian Mobile Developers’ Blog to get a deeper understand of how these platforms can work together. Once you’ve done that, get started by downloading the Windows Azure Toolkit for Windows Phone 7 or for iOS and working through Getting Started With The Windows Azure Toolkit for Windows Phone 7 and iOS.
I’d like to take this opportunity to thank Tony for sharing his story. For more information on Gauge Mobile, check out their site, follow them on Twitter, Facebook, and LinkedIn.
Tomorrow – another Windows Azure developer story.
Join The Conversation
What do you think of this solution’s use of Windows Azure? Has this story helped you better understand usage scenarios for Windows Azure? Join the Ignite Your Coding LinkedIn discussion to share your thoughts.
Previous Stories
Missed previous developer stories in the series? Check them out here.


Jas Sandhu (@jassand) reported Windows Azure Supports NIST Use Cases using Java in a 6/29/2011 post to the Interoperability @ Microsoft blog:
We've been participating in creating a roadmap for adoption of cloud computing throughout the federal government, with the National Institute for Standards and Technology (NIST) , an agency of the U.S. Department of Commerce, and the United States first federal physical science research laboratory. NIST is also known for publishing the often-quoted Definition of Cloud Computing, used by many organizations and vendors in the cloud space.
Microsoft is participating in the NIST initiative to jumpstart the adoption of cloud computing standards called Standards Acceleration to Jumpstart the Adoption of Cloud Computing, (SAJACC).The goal is to formulate a roadmap for adoption of high-quality cloud computing standards. One way they do this is by providing working examples to show how key cloud computing use cases can be supported by interfaces implemented by various cloud services available today. Microsoft worked with NIST and our partner, Soyatec, to demonstrate how Windows Azure can support some of the key use cases defined by SAJACC using our publicly documented and openly available cloud APIs.
By using the Windows Azure Service Management REST APIs we are able to manage services and run simple operations including simple CRUD operations, solve simple authentication and authorizations using certificates. Our Service management components are built with RESTful principles and support multiple languages and runtimes including Java, PHP and .NET as well as IDEs including Eclipse and Visual Studio.
It also provides rich interfaces and functionality that provide scalable access to public, private and hosted clouds. All of the SDKs are available as open source too. With the Windows Azure Storage Service REST APIs we can use 3 sets of APIs that provide storage management support for Tables, Blobs and Queues with the same RESTful principles using the same set of languages. These APIs as well are available as open source.
We also have an example that we have created called SAJACC use case drivers to demonstrate this code in action. In this demonstration written in Java we show the basic functionality demonstrated for the NIST Sample. We created the following scenarios and corresponding code …
1. Copying Data Objects into a Cloud, the user is able to copy items on their local machine (client) and copy to the Windows Azure Storage without any change in the file; the assumptions are to have credential with a pair of account name and key. The scenario involves generating a container with a random name in each test execution to avoid possible name conflicts. The container uses the Windows Azure API. With the credential previously created the user prepares the Windows Azure Storage execution context. Then a blob container is created, with optional custom network connection timeout and retry policy, you are able to easily recover from network failure. Then we will create a block blob and transfer a local file to it. We will then compute a MD5 hash for the local file, get one for the blob and compare it to show there are equivalent and no data was lost
2. Copying Data Objects Out of a Cloud, repeats what we do from the first use case, Copying Data Objects into a Cloud. Additionally we will include another scenario, where set public access to the blob container and get its public URL; we will then as an un-identified (public) user retrieve the blob using an http GET request and save it to the local file system. We will then generate a MD5 hash for this file and compare it to the originals we used previously
3. Erasing Data Objects in a Cloud erases a data object on behalf of a user. With the credentials and data you created in the previous examples we will use the public URL of the blob and delete it by using its blob name. We will verify by using an http GET request to confirm that it has been erased.
4. VM Control: Allocating VM Instance, the user is able to create a VM image to compute on that is secure and performs well. The scenario involves creating a Java Keystore and Truststore from a user certificate to support SSL transport (described below). We will also create Windows Azure management execution context to issue commands from and create a hosted service using it. We will then prepare a Windows Azure service package and copy it to the blob we created in the first use case. We will then deploy in the hosted service using its name and service configuration information including the URL of the blob and the number of instances. We can then change the instance count to as many roles we want to execute using what we deploy and verify the change by getting status information from it.
5. VM Control: Managing Virtual Machine Instance State, the user is able to stop, terminate, reboot, and start the state of a virtual instance. We will first prepare an app to run as the Web Role in Windows Azure. The program will add a Windows Azure Drive to keep some files persistent when the VM is killed or rebooted. We will have two web pages, one where a random file is created inside the mounted drive, and another to list all the files on the drive. Then we will build and package the program and deploy the Web Role create as a hosted service on Window Azure using the portal. We will then create another program to manage the VM instance state similar to what we had done before in the previous use case, VM Control: Allocating VM Instance. We will use http GET requests to visit the first web page to create a random file on the Windows Azure Drive and the second web page to lists the files to show that they are not empty. We will then use the management execution context to stop the VM and disassociate the IP address and confirm this by visiting the second web page which will not be available. We will then use the same management execution context to restart the VM and confirm that the files in the drive are persistent between the restarts of the VM.
6. Copying Data Objects between Cloud-Providers, the user is able to copy data objects from one Windows Azure Storage account to another. This example involves creating a program to run as a worker role where a storage execution context is created. We will use the container as per the first use case, Copying Data Objects into a Cloud. We will download the blob to a local file system. We will then then create a second storage execution context and transfer the downloaded file to this new storage execution context. Then as per the first use case we will create a new program and deploy it to retrieve the two blobs and compare and verify the contents MD5 hashes are the same.
Java code to test the Service Management API
Test Results
Managing API Certificates
For the Java examples (use cases 4-6), we need to have key credentials. In our download we demonstrate the Service Management API being called with an IIS certificate. We will take you through generating an X509 certificate for the Windows Azure Management API. We show the management console for IIS7 and certificate manager in Windows. Creating the self-signed server certificates and exporting them to the Windows Azure portal and generate a JKS format key store for the Java Azure SDK. We will then upload it to the Azure account and converting the keys for use in the Java Keystore and for calling the Service Management API from Java.
We then demonstrate the Service Management API using the Java Key tool Certificates. We will use the Java Keystore and export an X.509 certificate to the Windows Azure Management API. Then we upload certificate to an Azure account. We will then construct a new Service Management Rest object with the specific parameters and end by testing the Services Management API from Java
To get more information, the Windows Azure Storage Services REST API Reference and the Windows Azure SDK for PHP Developers are useful resources to have. You may also want to explore more with the following tutorials:
- Table Storage service, offers structured storage in the form of tables. The Table service API is a REST API for working with tables and the data that they contain.
- Blob Storage service, stores text and binary data. The Blob service offers the following three resources: the storage account, containers, and blobs
- Queue Service, stores messages that may be read by any client who has access to the storage account. A queue can contain an unlimited number of messages, each of which can be up to 8 KB in size
With the above tools and Azure cloud services, you can implement most of the Use Cases listed by NIST for use in SAJACC. We hope you find these demonstrations and resources useful, and please send feedback!
Resources:

![clip_image003[1]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-15-67-metablogapi/1050.clip_5F00_image0031_5F00_056C35C2.jpg "clip_image003[1]")
![clip_image005[1]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-15-67-metablogapi/8103.clip_5F00_image0051_5F00_7FB11C1B.jpg "clip_image005[1]")
![clip_image006[1]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-01-15-67-metablogapi/3404.image_5F00_2435769B.png "clip_image006[1]")
Patrick Butler Monterde described Developing and Debugging Azure Management API CmdLets in a 6/29/2011 post:
The Azure Management API Cmdlets enable you to use PowerShell Cmdlets to manage your Azure projects. You can access this project from the following link: http://wappowershell.codeplex.com/
Working with the Azure Management API Cmdlets
2. Installing a certificate is needed for executing the Cmdlets:
For creating the certificate follow this instructions: http://blogs.msdn.com/b/avkashchauhan/archive/2010/12/30/handling-issue-csmanage-cannot-establish-secure-connection-to-management-core-windows-net.aspx
Viewing Certificates: http://windows.microsoft.com/en-US/windows-vista/View-or-manage-your-certificates
Lessons Learned
Install the certificate your are going to be using as the Azure Management API certificate in the computer you are using for Execution/development. If this is not done you will get errors like this one: Windows Azure PowerShell CMDLET returns "The HTTP request was forbidden with client authentication scheme 'Anonymous'" error message. Link: http://blogs.msdn.com/b/avkashchauhan/archive/2011/06/13/what-to-do-when-windows-azure-powershell-cmdlet-returns-quot-the-http-request-was-forbidden-with-client-authentication-scheme-anonymous-quot-error-message.aspx
Developing and Debugging Recommendations
1. Closing the PowerShell Windows for Compiling
The PowerShell shell windows will lock the build and rebuild of the project because it using the Azure Management Cmdlets compiled libraries. You need to close any PowerShell window you may have open before Building the Azure Cmdlets project and for un-installation of the Cmdlets.
2. Streamline Testing
Create a text file with the variables and values, open a PowerShell window and copy and paste the variables. The variables will be available for the entire life of the window. Example:
$RolName = "WebRole1_IN_0"
$RolName2= "WebRole1_IN_1"
$Slot = "Production"
$ServiceName = "Mydemo"
$SubId = "6cad9315-45a8-3e4r4e-8bdc-3e3rfdeerrrf"
$Cert = "C:\certs\AzureManagementAPICertificate.cer"Reboot-RoleInstance -RoleInstanceName $RolName -Slot $Slot -SubscriptionId $SubId -Certificate $Cert -ServiceName $ServiceName
ReImage-RoleInstance -RoleInstanceName $RolName2 -Slot $Slot -SubscriptionId $SubId -Certificate $Cert -ServiceName $ServiceName
Visual studio Azure Management Cmdlets debugging Steps:
- Open the Azure Management Cmdlets Solution in Visual Studio
- Close all open PowerShell windows
- Open a CMD Windows and Run the Cmdlets Uninstall script:
- Run the script “uninstallPSSnapIn.bat”
- Find location “C:\AzureServiceManagementCmdlets\setup\dependency_checker\scripts\tasks”
- Recompile the project in Visual studio
- (as needed) Put your breakpoints
- On the CMD Window Run the Cmdlets installation script: installPSSnapIn.cmd
- Find location “C:\AzureServiceManagementCmdlets\setup\dependency_checker\scripts\tasks”
- Run the script “installPSSnapIn.cmd”
- Open a PowerShell Window. Run the following commands in the PowerShell window
- Add-PSSnapin AzureManagementToolsSnapIn
- Get-Command -PSSnapin AzureManagementToolsSnapIn
- Go back to Visual studio and Attach the Debugger to the PowerShell
- Tools Tab –> Attach to Process… –> Attach to the PowerShelll process.
- Go back to the the PowerShell Window
- Setup the variables you may need:
$RolName = "WebRole1_IN_0"
$RolName2= "WebRole1_IN_1"
$Slot = "Production"
$ServiceName = "Mydemo"
$SubId = "6cad9315-45a8-3e4r4e-8bdc-3e3rfdeerrrf"
$Cert = "C:\certs\AzureManagementAPICertificate.cer- Run the CmdLet you want to debug >> The execution will stop on the BreakPoint in Visual Studio
- For Example: Reboot-RoleInstance -RoleInstanceName $RolName -Slot $Slot -SubscriptionId $SubId -Certificate $Cert -ServiceName $ServiceName
Running the Commands:
Thanks to David Aiken for the PowerShell tips and tricks.


<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework
Joe Kunk (@JoeKunk) asserted “Learn how to extend support for Microsoft C#-only BlankExtension/BizType projects to Visual Basic” in a deck for his An Encrypted String Data Type for Visual Studio LightSwitch article for the July 2001 edition of Visual Studio Magazine’s On VB column:
In my recent article, "Is Visual Studio LightSwitch the New Access?", I looked at the suitability of LightSwitch as a replacement tool for departmental applications developed in Microsoft Access. LightSwitch is being positioned as a tool for the power user to develop Microsoft .NET Framework applications without having to face the substantial learning curve of the full .NET technology stack. I described each of the six extension types available to add the functionality to LightSwitch that an experienced .NET developer might want to use to make development in LightSwitch easier, or that a designer may want to use to build a visually appealing application.
This article demonstrates the usefulness of LightSwitch extension points by showing how to build a custom business data type to provide automatic encryption to a database string field. Once installed, the "Encrypted String" field data type can be available for use in any table in a LightSwitch project with the extension enabled. When a field of the Encrypted String data type is used in a LightSwitch screen, the field automatically decrypts itself when the cursor enters the field and automatically encrypts itself whenever the cursor leaves the field. The LightSwitch developer can store sensitive information in the database in encrypted form with no more effort than selecting the "Encrypted String" data type when designing the table.
Figure 1 shows an example of a LightSwitch grid with two rows of data, each row having User Name and Password as the Encrypted String data type. The cursor is in the Password field of the first row, so it's shown and editable as plain text -- which is automatically encrypted when the cursor leaves the field. The Comments column shows the decrypted value of each field. The database sees and saves the field value in its encrypted form; be sure to allow sufficient length in the database field for the encrypted string value.
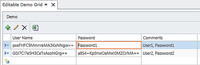
[Click on image for larger view.]Figure 1. The Encrypted String business type being edited in a LightSwitch screen.
Installing and Using the Encrypted String Business Type
In order to run LightSwitch, you must be using Visual Studio Professional or higher with Service Pack 1 installed, and also the Visual Studio LightSwitch beta 2 (available for download here). Beta 1 must be uninstalled before installing beta 2.To install the Encrypted String business type into LightSwitch, download the code from this article and extract all files. Close all instances of Visual Studio. Double-click the Blank.Vsix.vsix file found in the Blank.VSIX\bin folder. You'll see the Visual Studio Extension Installer dialog box. Make sure the Microsoft LightSwitch checkbox is checked and click the Install button. You'll see an Installation Complete confirmation dialog box once the install is done. The Visual Studio Extension Manager will now show Encrypted String Extension in the Installed Extensions list.
The Encrypted String extension must be enabled in any LightSwitch project that wishes to use it. In the LightSwitch project, right-click on the project's properties and choose the Extensions tab. Click on the Encrypted String Extension item to activate it for the project, as shown in Figure 2. Now the Encrypted String data type is available for use when creating a table in the same manner as an Integer, Date Time or String field.
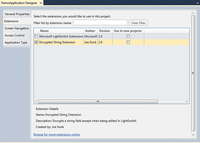
[Click on image for larger view.]Figure 2. Including the Encrypted String Extension in the LightSwitch project.
To remove existing LightSwitch extensions, go to the Extension Manager in Visual Studio. Choose Tools and then Extension Manager, then select the extension and choose Uninstall. Close Visual Studio for the change to take effect.
Creating the Custom Business Type Extension
On March 16, 2011, the LightSwitch team published the "LightSwitch Beta 2 Extensibility Cookbook". In addition to the Cookbook document, the post has a BlankExtension.zip file, which is the completed version of the Cookbook's instructions to create a sample extension of each type in the Cookbook. This completed sample will serve as the starting point to create the Encrypted String custom business type extension. The instructions in this section serve as a guide for how you can modify this sample project to implement your own custom business type, as I did.Download the BlankExtension.zip file and extract the "Blank Extension - BizType" project to a location of your choosing. Load the BlankExtension solution into Visual Studio. Examine each project in the Blank Extension solution to ensure all LightSwitch references are correct in the Blank.Client, Blank.ClientDesign and Blank.Common projects. Note that the LightSwitch beta 2 product does not install into the Global Assembly Cache, or GAC, but instead into the C:\Program Files\Microsoft Visual Studio 10.0\Common7\IDE\LightSwitch\1.0 folder. Remove any incorrect references and browse to the needed assemblies in the Client subfolder of the LightSwitch folder.


Julie Lerman (@julielerman) described Entity Framework June 2011 CTP: TPT Inheritance Query Improvements in a 7/1/2011 post to her Don’t Be Iffy blog:
I want to look at some of the vast array of great improvements coming to EF that are part of the June 2011 CTP that was released yesterday.
Everyone’s going on and on about the enums.
There’s a lot more in there. Not sure how many I’ll cover but first up will be the TPT store query improvements.
I’ll use a ridiculously simple model with code first to demonstrate and I’ll share with you a surprise discovery I made (which began with some head scratching this morning).
Beginning with one base class and a single derived class.
public class Base { public int Id { get; set; } public string Name { get; set; } } public class TPTA: Base { public string PropA { get; set; } }By default, code first does TPH and would create a single database table with both types represented. So I use a fluent mapping to force this to TPT. (Note that you can’t do this configuration with Data Annotations).
public class Context: DbContext { public DbSet<Base> Bases { get; set; } protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Entity<Base>().Map<TPTA>(m => m.ToTable("TPTTableA")); } }Here’s my query:
from c in context.Bases select new {c.Id, c.Name};Notice I’m projecting only fields from the base type.
And the store query that results:
SELECT [Extent1].[Id] AS [Id], [Extent1].[Name] AS [Name] FROM [dbo].[Bases] AS [Extent1]Not really anything wrong there. So what’s the big deal? (This is where I got confused…
)
Now I’ll add in another derived type and I’ll modify the configuration to accommodate that as well.
public class TPTB: Base { public string PropB { get; set; } } modelBuilder.Entity<Base>().Map<TPTA>(m => m.ToTable("TPTTableA"))
.Map<TPTB>(m => m.ToTable("TPTTableB"));Execute the query again and look at the store query now!
SELECT [Extent1].[Id] AS [Id], [Extent1].[Name] AS [Name] FROM [dbo].[Bases] AS [Extent1] LEFT OUTER JOIN (SELECT [Extent2].[Id] AS [Id] FROM [dbo].[TPTTableA] AS [Extent2] UNION ALL SELECT [Extent3].[Id] AS [Id] FROM [dbo].[TPTTableB] AS [Extent3]) AS [UnionAll1] ON [Extent1].[Id] = [UnionAll1].[Id]Egad!
Now, after switching to the new bits (retargeting the project and removing EntityFramework.dll (4.1) and referencing System.Data.Entity.dll (4.2) instead)
The query against the new model (with two derived types) is trimmed back to all that’s truly necessary:
SELECT [Extent1].[Id] AS [Id], [Extent1].[Name] AS [Name] FROM [dbo].[Bases] AS [Extent1]Here’s some worse ugliness in EF 4.0. Forgetting the projection, I’m now querying for all Bases including the two derived types. I.e. “context.Bases”.
SELECT CASE WHEN (( NOT (([UnionAll1].[C2] = 1) AND ([UnionAll1].[C2] IS NOT NULL)))
AND ( NOT (([UnionAll1].[C3] = 1) AND ([UnionAll1].[C3] IS NOT NULL)))) THEN '0X' WHEN (([UnionAll1].[C2] = 1)
AND ([UnionAll1].[C2] IS NOT NULL)) THEN '0X0X' ELSE '0X1X' END AS [C1], [Extent1].[Id] AS [Id], [Extent1].[Name] AS [Name], CASE WHEN (( NOT (([UnionAll1].[C2] = 1) AND ([UnionAll1].[C2] IS NOT NULL))) AND ( NOT (([UnionAll1].[C3] = 1)
AND ([UnionAll1].[C3] IS NOT NULL)))) THEN CAST(NULL AS varchar(1)) WHEN (([UnionAll1].[C2] = 1)
AND ([UnionAll1].[C2] IS NOT NULL)) THEN [UnionAll1].[PropA] END AS [C2], CASE WHEN (( NOT (([UnionAll1].[C2] = 1) AND ([UnionAll1].[C2] IS NOT NULL))) AND ( NOT (([UnionAll1].[C3] = 1)
AND ([UnionAll1].[C3] IS NOT NULL)))) THEN CAST(NULL AS varchar(1)) WHEN (([UnionAll1].[C2] = 1)
AND ([UnionAll1].[C2] IS NOT NULL)) THEN CAST(NULL AS varchar(1)) ELSE [UnionAll1].[C1] END AS [C3] FROM [dbo].[Bases] AS [Extent1] LEFT OUTER JOIN (SELECT [Extent2].[Id] AS [Id], [Extent2].[PropA] AS [PropA], CAST(NULL AS varchar(1)) AS [C1], cast(1 as bit) AS [C2], cast(0 as bit) AS [C3] FROM [dbo].[TPTTableA] AS [Extent2] UNION ALL SELECT [Extent3].[Id] AS [Id], CAST(NULL AS varchar(1)) AS [C1], [Extent3].[PropB] AS [PropB], cast(0 as bit) AS [C2], cast(1 as bit) AS [C3] FROM [dbo].[TPTTableB] AS [Extent3]) AS [UnionAll1] ON [Extent1].[Id] = [UnionAll1].[Id]And now with the new CTP:
SELECT CASE WHEN (( NOT (([Project1].[C1] = 1) AND ([Project1].[C1] IS NOT NULL)))
AND ( NOT (([Project2].[C1] = 1) AND ([Project2].[C1] IS NOT NULL)))) THEN '0X' WHEN (([Project1].[C1] = 1)
AND ([Project1].[C1] IS NOT NULL)) THEN '0X0X' ELSE '0X1X' END AS [C1], [Extent1].[Id] AS [Id], [Extent1].[Name] AS [Name], CASE WHEN (( NOT (([Project1].[C1] = 1) AND ([Project1].[C1] IS NOT NULL))) AND ( NOT (([Project2].[C1] = 1)
AND ([Project2].[C1] IS NOT NULL)))) THEN CAST(NULL AS varchar(1)) WHEN (([Project1].[C1] = 1)
AND ([Project1].[C1] IS NOT NULL)) THEN [Project1].[PropA] END AS [C2], CASE WHEN (( NOT (([Project1].[C1] = 1) AND ([Project1].[C1] IS NOT NULL))) AND ( NOT (([Project2].[C1] = 1)
AND ([Project2].[C1] IS NOT NULL)))) THEN CAST(NULL AS varchar(1)) WHEN (([Project1].[C1] = 1)
AND ([Project1].[C1] IS NOT NULL)) THEN CAST(NULL AS varchar(1)) ELSE [Project2].[PropB] END AS [C3] FROM [dbo].[Bases] AS [Extent1] LEFT OUTER JOIN (SELECT [Extent2].[Id] AS [Id], [Extent2].[PropA] AS [PropA], cast(1 as bit) AS [C1] FROM [dbo].[TPTTableA] AS [Extent2] ) AS [Project1] ON [Extent1].[Id] = [Project1].[Id] LEFT OUTER JOIN (SELECT [Extent3].[Id] AS [Id], [Extent3].[PropB] AS [PropB], cast(1 as bit) AS [C1] FROM [dbo].[TPTTableB] AS [Extent3] ) AS [Project2] ON [Extent1].[Id] = [Project2].[Id]At first glance you may think “but it’s just as long and just as ugly” but look more closely:
Notice that the first query uses a UNION for the 2nd derived type but the second uses another LEFT OUTER JOIN. Also the “Cast 0 as bit” is gone from the 2nd query. I am not a database performance guru but I’m hoping/guessing that all of the work involved to make this change was oriented towards better performance. Perhaps a DB guru can confirm. Google wasn’t able to.
I did look at the query execution plans in SSMS. They are different but I’m not qualified to understand the impact.
Here’s the plan from the first query (from EF 4 with the unions)
and the one from the CTP generated query:




The ADO.NET Team published Announcing the Microsoft Entity Framework June 2011 CTP on 6/30/2011:
We are excited to announce the availability of the Microsoft Entity Framework June 2011 CTP. This release includes many frequently requested features for both the Entity Framework and the Entity Framework Designer within Visual Studio.
What’s in Entity Framework June 2011 CTP?
The Microsoft Entity Framework June 2011 CTP introduces both new runtime and design-time features. Here are some of the new runtime features:
- The Enum data-type is now available in the Entity Framework. You can use either the Entity Designer within Visual Studio to model entities that have Enum properties, or use the Code First workflow to define entities that have Enum objects as properties. You can use your Enum property just like any other scalar property, such as in LINQ queries and updates.
- Two new spatial data-types for Geography and Geometry are now natively supported by the Entity Framework. You can use these types and methods on these types as part of LINQ queries, for example to find the distance between two locations as part of a query.
- You can now add table-valued functions to your entity data model. A table-valued function is similar to a stored procedure, but the result of executing the table-valued function is composable, meaning you can use it as part of a LINQ query.
- Stored procedures can now have multiple result sets in your entity data model.
- The Entity Framework June 2011 CTP includes several SQL generation improvements, especially around optimizing queries over models with table-per-type (TPT) inheritance.
- LINQ queries are now automatically compiled and cached to improve query performance. In previous releases of the Entity Framework, you could use the CompiledQuery class to compile a LINQ query explicitly but in this CTP this happens automatically for LINQ queries.
There are several new features for the Entity Framework Designer within Visual Studio:
- The Entity Designer now supports creation of Enums, spatial data-types and table-value functions from the designer surface.
- You can now create multiple diagrams for each entity data model. Each diagram can contain entities and relationships to make visualizing your model easier. You can switch between diagrams using the Model Browser and include related entities on each diagram as an optional command.
- The StoreGeneratedPattern for key columns can now be set on an entity Properties window and this value will propagate from your entity model down to the store definition.
- Diagram information is now stored in a separate file from the edmx or entity code files.
- When you import stored procedures using the Entity Model Wizard, you can now batch import your stored procedures as function imports. The result shape of each stored procedure will automatically become a new complex type in your entity model. This makes getting started with stored procedures very easy.
- The Entity Designer surface now supports selection driven highlighting and entity shape coloring.
Getting the Microsoft Entity Framework June 2011 CTP
The Microsoft Entity Framework June 2011 CTP is available on the Microsoft Download Center and there are three separate installers. You will need to have Visual Studio 2010 SP1 to install and use the new Entity Designer. All three installers are available here and should be installed in the following order:
- Download and install the runtime installer for the Entity Framework 2011 CTP runtime components.
- Download and install the WCF Data Services 2011 CTP installer to use new features in WCF Data Services with the Entity Framework.
- Download and install the designer installer to use the new Entity Framework 2011 CTP entity designer within Visual Studio 2010 SP1.
Getting Started
There are a number of resources to help you get started with this CTP.
Targeting the Microsoft Entity Framework June 2011 CTP Runtime
The easiest way to use the CTP is to set your project’s target framework to Microsoft Entity Framework June 2011 CTP. This target framework allows use of the CTP versions of the Entity Framework assemblies in addition to the standard .NET 4.0 RTM assemblies.
To re-target a C# project:
- Right-click the project in the Solution Explorer and choose Properties or select <Project> Properties from the Project menu.
- On the Application tab, select Microsoft Entity Framework June 2011 CTP or Microsoft Entity Framework June 2011 CTP Client Profile from the Target framework dropdown.

- A dialog box will appear indicating that the project needs to be closed and reopened to retarget the project. Click Yes.

To re-target a VB.NET project:
- Right-click the project in the Solution Explorer and choose Properties or select <Project> Properties from the Project menu.
- Select the Compile tab and click the Advanced Compile Options… button on the bottom left of the dialog.
- Select Microsoft Entity Framework June 2011 CTP or Microsoft Entity Framework June 2011 CTP Client Profile from the Target framework dropdown.

- Click Ok.
- A dialog box will appear indicating that the project needs to be closed and reopened to retarget the project. Click Yes.
Walkthroughs
For assistance in using the new design-time and runtime features please refer to the following walkthroughs [see posts below]:
Support
The Entity Framework Pre-Release Forum can be used for questions relating to this release.
Uninstalling
We recommend installing the Microsoft Entity Framework June 2011 CTP in a non-production environment to avoid any risk associated with installing and uninstalling pre-release software. If the CTP is uninstalled, existing functionality installed with Visual Studio 2010 (such as the Entity Designer) may no longer be available. To restore the features that were removed, complete the following steps:
- Locate the Visual Studio 2010 installation DVD and insert it into your computer. If you are using an Express SKU of Visual Studio and don’t have the installation media, you can obtain new media here
- Launch an administrative-level command prompt and execute one of the following commands. These commands restore versions of the EF Tools files that were initially shipped with Visual Studio 2010.
With Ultimate, Pro, or other non-Express SKUs:
[DVD drive letter]:\WCU\EFTools\ADONETEntityFrameworkTools_enu.msi USING_EXUIH=1With C# Express, VB Express, and Visual Web Developer Express SKUs:
[DVD drive letter]:\[VBExpress, VCSExpress, or VWDExpress]\WCU\EFTools\ADONETEntityFrameworkTools_enu.msi USING_EXUIH=1
- To update the EF Tools with what shipped with Visual Studio Service Pack 1, there are two options:
- To run an update only for EF Tools, create a DVD with Visual Studio Service Pack 1 and execute the following command from an administrative-level command prompt. This update will only take a few minutes to complete.
msiexec /update [DVD drive letter]:\VS10sp1-KB983509.msp /package {14DD7530-CCD2-3798-B37D-3839ED6A441C}
- To avoid creating a DVD, reapply SP1. Launch the Uninstall/Change programs applet in the Control Panel, double-click on Microsoft Visual Studio 2010 Service Pack 1, and then choose the option to “Reapply Microsoft Visual Studio Service Pack 1.” This approach will take longer since all of SP1 will be applied, not just the EF Tools file updates.
What’s Not in the Entity Framework June 2011 CTP?
There are a number of commonly requested features that did not make it into this CTP of the Entity Framework. We appreciate that these are really important to you and our team has started work on a number of them already. We will be reaching out for your feedback on these features soon:
- Stored Procedure or table-valued function support in Code First
- Migration support in Code First
- Customizable conventions in Code First
- Unique constraints support
- Batching create-update-delete statements during save
- Second level caching
Thank You
It is important for us to hear about your experience using the Entity Framework and we appreciate any and all feedback you have regarding this CTP or other aspects of the Entity Framework. We thank you for giving us your valuable input and look forward to working together on this release.
ADO.NET Entity Framework Team



Pedro Ardila described Walkthrough: Spatial (June CTP) on 6/30/2011:
Spatial data is one of the new features in Entity Framework June 2011 CTP. Spatial data allows users to represent locations on a map as well as points, geometric shapes, and other data which relies on a coordinate system. There are two main types of spatial data: Geography and Geometry. Geography data takes the ellipsoid nature of the earth into account while Geometry bases all measurements and calculations on Euclidean data. Please see this blog post if you would like to understand more about the Spatial design in EF.
In this walkthrough we will see how to use EF to interact with spatial data in a SQL Server database. We will create a console application in Visual Studio using the Code First and Database First Approach. Our application will use a LINQ query to find all landmarks within a certain distance of a person’s location.
Pre-requisites
- Visual Studio 2010 Express and SQL Server 2008 R2 Express or Higher. Click here to download the Express edition of VS and SQL Server Express
- Microsoft Entity Framework June 2011 CTP. Click here to download.
- Microsoft Entity Framework Tools June 2011 CTP. Click here to download.
- Microsoft SQL Server 2008 Feature Pack. This pack contains the SQL Spatial Types assembly used by Entity Framework. Click here to download.
- You can also get the types by installing SQL Server Management Studio Express or higher. You can download Express here.
- Your Visual Studio 2010 setup might include these types already, in which case you won’t need to install additional components.
- SeattleLandmarks database. You can find it at the bottom of this post.
Setting up the Project
- Launch Visual Studio and create a new C# Console application named SeattleLandmarks.
- Make sure you are targeting the Entity Framework June 2011 CTP. Please see the EF June 2011 CTP Intro Post to learn how to change the target framework.
Code First Approach
We will first see how to create our application using Code First. You could alternatively use a Database First approach, which you will see below.
Creating Objects and Context
First we must create the classes we will use to represent People and Landmarks, as well as our context. For the sake of this walkthrough, we will create these in Program.cs. Normally you would create these in separate files. The classes will look as follows:
public class Person { public int PersonID { get; set; } public string Name { get; set; } public DbGeography Location { get; set; } } public class Landmark { public int LandmarkID { get; set; } public string LandmarkName { get; set; } public DbGeography Location { get; set; } public string Address { get; set; } } public class SeattleLandmarksEntities : DbContext { public DbSet<Person> People { get; set; } public DbSet<Landmark> Landmarks { get; set; } }
Database InitializerWe will use a database initializer to add seed data to our Landmarks and People tables. To do so, create a new class file called SeattleLandmarksSeed.cs. The contents of the file are the following:
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Data.Entity; using System.Data.Spatial; namespace SeattleLandmarks { class SeattleLandmarksSeed : DropCreateDatabaseAlways<SeattleLandmarksEntities> { protected override void Seed(SeattleLandmarksEntities context) { var person1 = new Person { PersonID = 1, Location = DbGeography.Parse("POINT(-122.336106 47.605049)"), Name = "John Doe" }; var landmark1 = new Landmark { LandmarkID = 1, Address = "1005 E. Roy Street", Location = DbGeography.Parse("POINT(-122.31946 47.625112)"), LandmarkName = "Anhalt Apartment Building" }; var landmark2 = new Landmark { LandmarkID = 2, Address = "", Location = DbGeography.Parse("POINT(-122.296623 47.640405)"), LandmarkName = "Arboretum Aqueduct" }; var landmark3 = new Landmark { LandmarkID = 3, Address = "815 2nd Avenue", Location = DbGeography.Parse("POINT(-122.334571 47.604009)"), LandmarkName = "Bank of California Building" }; var landmark4 = new Landmark { LandmarkID = 4, Address = "409 Pike Street", Location = DbGeography.Parse("POINT(-122.336124 47.610267)"), LandmarkName = "Ben Bridge Jewelers Street Clock" }; var landmark5 = new Landmark { LandmarkID = 5, Address = "300 Pine Street", Location = DbGeography.Parse("POINT(-122.338711 47.610753)"), LandmarkName = "Bon Marché" }; var landmark6 = new Landmark { LandmarkID = 6, Address = "N.E. corner of 5th Avenue & Pike Street", Location = DbGeography.Parse("POINT(-122.335576 47.610676)"), LandmarkName = "Coliseum Theater Building" }; var landmark7 = new Landmark { LandmarkID = 7, Address = "", Location = DbGeography.Parse("POINT(-122.349755 47.647494)"), LandmarkName = "Fremont Bridge" }; var landmark8 = new Landmark { LandmarkID = 8, Address = "", Location = DbGeography.Parse("POINT(-122.335197 47.646711)"), LandmarkName = "Gas Works Park" }; var landmark9 = new Landmark { LandmarkID = 9, Address = "", Location = DbGeography.Parse("POINT(-122.304482 47.647295)"), LandmarkName = "Montlake Bridge" }; var landmark10 = new Landmark { LandmarkID = 10, Address = "1932 2nd Avenue", Location = DbGeography.Parse("POINT(-122.341529 47.611693)"), LandmarkName = "Moore Theatre" }; var landmark11 = new Landmark { LandmarkID = 11, Address = "200 2nd Avenue N./Seattle Center", Location = DbGeography.Parse("POINT(-122.352842 47.6186)"), LandmarkName = "Pacific Science Center" }; var landmark12 = new Landmark { LandmarkID = 12, Address = "5900 Lake Washington Boulevard S.", Location = DbGeography.Parse("POINT(-122.255949 47.549068)"), LandmarkName = "Seward Park" }; var landmark13 = new Landmark { LandmarkID = 13, Address = "219 4th Avenue N.", Location = DbGeography.Parse("POINT(-122.349074 47.619589)"), LandmarkName = "Space Needle" }; var landmark14 = new Landmark { LandmarkID = 14, Address = "414 Olive Way", Location = DbGeography.Parse("POINT(-122.3381 47.612467)"), LandmarkName = "Times Square Building" }; var landmark15 = new Landmark { LandmarkID = 15, Address = "5009 Roosevelt Way N.E.", Location = DbGeography.Parse("POINT(-122.317575 47.665229)"), LandmarkName = "University Library" }; var landmark16 = new Landmark { LandmarkID = 16, Address = "1400 E. Galer Street", Location = DbGeography.Parse("POINT(-122.31249 47.632342)"), LandmarkName = "Volunteer Park" }; context.People.Add(person1); context.Landmarks.Add(landmark1); context.Landmarks.Add(landmark2); context.Landmarks.Add(landmark3); context.Landmarks.Add(landmark4); context.Landmarks.Add(landmark5); context.Landmarks.Add(landmark6); context.Landmarks.Add(landmark7); context.Landmarks.Add(landmark8); context.Landmarks.Add(landmark9); context.Landmarks.Add(landmark10); context.Landmarks.Add(landmark11); context.Landmarks.Add(landmark12); context.Landmarks.Add(landmark13); context.Landmarks.Add(landmark14); context.Landmarks.Add(landmark15); context.Landmarks.Add(landmark16); context.SaveChanges(); } } }
Adding Entities containing Spatial Data
In the code above, we added a number of landmarks containing spatial data. Note that to initialize a spatial property we use the DbGeography.Parse method which takes WellKnownText. In this case, we passed a point with a longitude and latitude.Invoking the Initializer
Now, to make sure the Initializer gets invoked, we must add the following lines to App.config inside <configuration>:
<appSettings> <add key="DatabaseInitializerForType SeattleLandmarks.SeattleLandmarksEntities, SeattleLandmarks" value="SeattleLandmarks.SeattleLandmarksSeed, SeattleLandmarks" /> </appSettings>Writing the App (Code First)
- Open Program.cs and enter the following code:
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Data.Spatial; using System.Data.Entity; namespace ConsoleApplication4 { class Program { static void Main(string[] args) { using (var context = new SeattleLandmarksEntities()) { var person = context.People.Find(1); var distanceInMiles = 0.5; var distanceInMeters = distanceInMiles * 1609.344; var landmarks = from l in context.Landmarks where l.Location.Distance(person.Location) < distanceInMeters select new { Name = l.LandmarkName, Address = l.Address }; Console.WriteLine("\nLandmarks within " + distanceInMiles + " mile(s) of " + person.Name + "'s location:"); foreach (var loc in landmarks) { Console.WriteLine("\t" + loc.Name + " (" + loc.Address + ")"); } Console.WriteLine("Done! Press ENTER to exit."); Console.ReadLine(); } } } public class Person { public int PersonID { get; set; } public string Name { get; set; } public DbGeography Location { get; set; } } public class Landmark { public int LandmarkID { get; set; } public string LandmarkName { get; set; } public DbGeography Location { get; set; } public string Address { get; set; } } public class SeattleLandmarksEntities : DbContext { public DbSet<Person> People { get; set; } public DbSet<Landmark> Landmarks { get; set; } } }The first thing we do is create a context. Then we create distance and person variables. In line 14, we use the Find method in DbSet to retrieve the first person. We use both of these in the LINQ query in line 19. In this query we select all the locations within a half mile of the given person’s location. To compute the distance, we use the Distance method in System.Data.Spatial.DbGeography. You can explore the full list of methods by browsing through the System.Data.Spatial namespace in the Class View window.The output is the following:
Landmarks within 0.5 mile(s) of John Doe's location:
Bank of California Building (815 2nd Avenue)
Ben Bridge Jewelers Street Clock (409 Pike Street)
Bon Marché (300 Pine Street)
Coliseum Theater Building (N.E. corner of 5th Avenue & Pike Street)
Done! Press ENTER to exit.
Database First Approach
Here are the steps to follow if you would like to use Database First:
Attaching the Seattle Landmarks Database
- Launch SQL Server Management Studio and connect to your instance of SQL Express.
- Right click on the Databases node and select Attach…
- Under Databases to attach, click Add… and then browse to the location of SeattleLandmarks.mdf. Click Add and then click OK.
Creating a Model
- Add a new ADO.NET Entity Data Model to your project by right clicking on the project and navigating to Add > New Item.
- In the Add New Item window, click Data, and then click ADO.NET Entity Data Model. Name your model ‘SeattleLandmarksModel’ and click Add.
- The Entity Data Model Wizard will open. Click on Generate from database and then click Next>.
- Select New Connection… on the Wizard. Under Server name, enter the name of your SQL Server instance (if you installed SQL Express, the server name should be .\SqlExpress)
- Under Connect to a database, select SeattleLandmarks from the first dropdown menu.
- The Connection Properties window should look as follows. Click OK to proceed

- On the Entity Data Model Wizard, click Next, then click on the Tables checkbox to include People and Landmarks on your model. Click Finish.
The resulting Model is very simple. It includes two entities named Landmark and Person. Each of these contains a Spatial Property called Location:
Writing the App (Database First)
Our program above would work against Database First with a few minor changes: On line 15. Rather than using the Find() method, we will use the Take() method in ObjectContext to retrieve the first person; Lastly, the entities and context we need are automatically generated by the VS tools when using Database First. Therefore, we don’t need the People, Landmarks, and SeattleLandmarksEntities classes defined from line 43 onwards.
How It Works
EF treats Geometry and Geography as primitive types. This allows us to use them in the same way we would use integers and strings as properties in an entity. The SSDL for our entities is the following:
<Schema Namespace="SeattleLandmarksModel.Store" Alias="Self" Provider="System.Data.SqlClient" ProviderManifestToken="2008" xmlns:store="http://schemas.microsoft.com/ado/2007/12/edm/EntityStoreSchemaGenerator" xmlns="http://schemas.microsoft.com/ado/2009/11/edm/ssdl"> <EntityContainer Name="SeattleLandmarksModelStoreContainer"> <EntitySet Name="Landmarks" EntityType="SeattleLandmarksModel.Store.Landmarks" store:Type="Tables" Schema="dbo" /> <EntitySet Name="People" EntityType="SeattleLandmarksModel.Store.People" store:Type="Tables" Schema="dbo" /> </EntityContainer> <EntityType Name="Landmarks"> <Key> <PropertyRef Name="LandmarkID" /> </Key> <Property Name="LandmarkID" Type="int" Nullable="false" StoreGeneratedPattern="Identity" /> <Property Name="LandmarkName" Type="nvarchar" MaxLength="50" /> <Property Name="Location" Type="geography" /> <Property Name="Address" Type="nvarchar" MaxLength="100" /> </EntityType> <EntityType Name="People"> <Key> <PropertyRef Name="PersonID" /> </Key> <Property Name="PersonID" Type="int" Nullable="false" StoreGeneratedPattern="Identity" /> <Property Name="Name" Type="nvarchar" MaxLength="50" /> <Property Name="Location" Type="geography" /> </EntityType> </Schema>Notice that the type for Location in both entities is geography. You can see this in the VS designer by right clicking on Location and selecting Properties.
Conclusion
In this walkthrough we have seen how to create an application which leverages spatial data using the Code First and Database First approaches. Using spatial functions, we calculated the distance between two locations. You can find out more about spatial types in EF here. Lastly, we appreciate your feedback, so please feel free to leave your questions and comments below.
Pedro Ardila
Program Manager – Entity Framework



Pawel Kadluczka posted a Walkthrough: Enums (June CTP) on 6/30/2011:
This post will provide an overview of working with enumerated types (“enums”) introduced in the Entity Framework June 2011 CTP. We will start from discussing the general design of the feature then I will show how to define an enumerated type and how to use it in a few most common scenarios.
Where to get the bits?
To be able to use any of the functionality discussed in this post you first need to download and install Entity Framework June 2011 CTP bits. For more details including links installation instructions see the Entity Framework June 2011 CTP release blog post.
Intro
Enumerated types are designed to be first class citizen in the Entity Framework. The ultimate goal is to enable them in most places where primitive types can be used. This is not the case in this CTP release (see Limitations in Entity Framework June 2011 CTP section) but we are working on addressing most of these limitations in post-CTP releases. In addition enumerated types are also supported by the designer, code gen and templates that ship with this CTP.
Design/Theory
As per MSDN enumerated types in the Common Language Runtime (CLR) are defined as “a distinct type consisting of a set of named constants”. Since enums in the Entity Framework are modeled on CLR enums this definition holds true in the EF (Entity Framework) as well. The EF enum type definitions live in conceptual layer. Similarly to CLR enums the EF enums have underlying type which is one of Edm.SByte, Edm.Byte, Edm.Int16, Edm.Int32 or Edm.Int64 with Edm.Int32 being the default underlying type if none has been specified. Enumeration types can have zero or more members. When defined, each member must have a name and can optionally have a value. If the value for the member is not specified then the value will be calculated based on the value of the previous member (by adding one) or set to 0 if there is no previous member. If the value for a given member is specified it must be in the range of its enum underlying type. It is fine to have values specified only for some members and it is fine to have multiple members with the same name but you can’t have more than one member with the same name (case matters). There are two main takeaways from this:
conceptually, the way you define enums in EF is very similar to the way you define enums in C# or VB.NET which makes mapping enum types defined in your program to EF enum types easy
if you happen to have at least one member without specified value then the order of the members matters, otherwise it does not
The last piece of information is that enumerated types can have “IsFlags” attribute. This attribute indicates if the type can be used as set of flags and is an equivalent of [Flags] attribute you can put on an enum type in your C# or VB.NET program. At the moment this attribute is only used for code generation.
Limitations in Entity Framework June 2011 CTP
The biggest limitations of Enums as shipped in the CTP are:
Properties that are of enumerated type cannot be used as keys
It is not possible to create EntityParameters that are enumerated types
System.Enum.HasFlag method is not supported in LINQ queries
EntityDataSource works with enums only in some scenarios
Properties that are of enum type cannot be used as conditions in the conceptual model (C-Side conditions)
It is not possible to specify enum literals as default values for properties in the conceptual model (C-Space)
Practice
Now that we know a bit about enums let’s see how they work in practice. To make things simple, in this walkthrough we will create a model that contains only one entity. The entity will have a few properties – including an enum property. In the walkthrough I will use “Model First” approach since it does not require having a database (note that there is no difference in how the tools in VS work for “Database First” approach). After creating a database we will populate it with some data and write some queries which will involve enum properties and values.
Preparing the model
- Properties that are of enumerated type cannot be used as keys
- Launch Visual Studio and create a new C# Console Application project (in VS File à New à Project or Ctrl + Shift + N) which we will call “EFEnumTest”
- Make sure you are targeting the new version of EF. To do so, right click on your project on the Solution Explorer and select Properties.
- Select Microsoft Entity Framework June 2011 CTP from the Target framework dropdown.
Figure 1. Targeting the in Entity Framework 4.2 June 2011 CTP
Press Ctrl + S to save the project. Visual Studio will ask you for permission to close and reopen the project. Click Yes
Add a new model to the project - right click EFEnumTest Project à Add New Item (or Ctrl + Shift + A), Select ADO.NET Data Entity Model from Visual C# Items and call it “EnumModel.edmx”. Then click Add.
Since we are focusing on “Model First” approach select Empty Model in the wizard and press Finish button.
Once the model has been created add an entity to the model. Go to Toolbox and double click Entity or right click in the designer and select Add New à Entity
Rename the entity to Product
Add properties to the Product entity:
- Id of type Int32 (should actually already be created with the entity)
- Name of type String
- Category of type Int32
- Change the type of the property to enum. The Category property is currently of Int32 type but it would make much more sense for this property to be of an enum type. To change the type of this property to enum right click on the property and select Convert to Enum option from the context menu as shown on Figure 2 (there is a small glitch in the tools at the moment that is especially visible when using “Model First” approach – the “Convert to Enum” menu option will be missing if the type of the property is not one of the valid underlying types. In “Model First” approach when you create a property it will be of String type by default and you would not be able to find the option to convert to the enum type in the menu – you would have to change the type of the property to a valid enum underlying type first – e.g. Int32 to be able to see the option).
Figure 2. Changing the type of a property to enum
Define the enum type. After selecting Conver to Enum menu option you will see a dialog that allows defining the enum type. Let’s call the type CategoryType, use Byte as the enum underlying type and add a few members:
- Beverage
- Dairy
- Condiments
We will not use this type as flags so let’s leave the IsFlag checkbox unchecked. Figure 3 shows how the type should be defined.
Figure 3. Defining an enum type
Press OK button to create the type.
This caused a few interesting things to happen. First the type of the property (if the properties of the property are not displayed right click the property and select Properties) is now CategoryType. If you open the Type drop down list you will see that the newly added enum type has been added to the list (by the way, did you notice two new primitive types in the drop down? Yes, Geometry and Geography are new primitive types that ship in CTP and make writing geolocation apps much simpler). You can see that on Figure 4.
Figure 4. The type of the property changed to "CategoryType"
Having enum types in this dropdown allows you changing the type of any non-key (CTP limitation) scalar property in your model to this enum type just by selecting it from the drop down list. Another interesting thing is that the type also appeared in the Model Browser, EnumModel à Enum Types node. Note that Enum Types node is new in this CTP and allows defining enum types without having to touch properties – you can just right click it and select Add Enum Type option from the menu. Enum types defined this way will appear in the Type drop down list and therefore can be used for any non-key (CTP limitation) scalar property in the model.
Save the model.
Inspecting the model
In the Solution Explorer right click on the EnumModel.edmx
Choose Open With… option from the context menu
Select Xml (Text) Editor from the dialog
Press OK button
Confirm that you would like to close the designer
Now you should be able to see the model in the Xml form (note that you will see some blue squiggles indicating errors. This is because the database has not been yet created and there is no mappings for the Product entity – you can ignore these errors at the moment)
Navigate to CSDL content - we are only interested in changes to conceptual part of the edmx file as there are no changes related to enums in SSDL and C-S mapping changes – and you should see something like:
<EntityType Name="Product"> <Key> <PropertyRef Name="Id" /> </Key> <Property Type="Int32" Name="Id" Nullable="false" annotation:StoreGeneratedPattern="Identity" /> <Property Type="String" Name="Name" Nullable="false" /> <Property Type="EnumModel.CategoryType" Name="Category" Nullable="false" /> </EntityType> <EnumType Name="CategoryType" UnderlyingType="Byte"> <Member Name="Beverage" /> <Member Name="Dairy" /> <Member Name="Condiments" /> </EnumType>What you can see in this fragment is the entity type and the enum type we created in the designer. If you look carefully at the Category property you will notice that the type of the property refers to the EnumModel.CategoryType which is our enum type.
Inspecting code generated for the model
In Solution Explorer double click EnumModel.Designer.cs
Expand Enums region in the file that opened. The definition for our enum type looks like this:
[EdmEnumTypeAttribute(NamespaceName="EnumModel", Name="CategoryType")] [DataContractAttribute()] public enum CategoryType : byte { /// <summary> /// No Metadata Documentation available. /// </summary> [EnumMemberAttribute()] Beverage = 0, /// <summary> /// No Metadata Documentation available. /// </summary> [EnumMemberAttribute()] Dairy = 1, /// <summary> /// No Metadata Documentation available. /// </summary> [EnumMemberAttribute()] Condiments = 2 }The underlying enum type is byte – as we chose when defining the type. All the members we defined are present.
Find the Category property on the Product entity:
[EdmScalarPropertyAttribute(EntityKeyProperty=false, IsNullable=false)] [DataMemberAttribute()] public CategoryType Category { get { return _Category; } set { OnCategoryChanging(value); ReportPropertyChanging("Category"); _Category = (CategoryType)StructuralObject.SetValidValue((byte)value, "Category"); ReportPropertyChanged("Category"); OnCategoryChanged(); } } private CategoryType _Category; partial void OnCategoryChanging(CategoryType value); partial void OnCategoryChanged();The code looks very similar to the code generated for primitive properties we know from the previous version of the Entity Framework. The only differences are additional casts required to make enum values work correctly.Creating the database
Double click EnumModel.edmx in the Solution Explorer to open the model in the designer
Confirm that you want to close the model opened in the Xml editor if prompted
Right click in the designer
Select Generate Database from Model… menu option to open a wizard which will guide you through the process
Click New Connection… button - Since we are using Model First approach we want to create a new connection to the database.
Enter the name of the database server you would like to use (e.g. “.\SQLExpress” if Sql Server Express edition is installed on your box) in the dialog that opened
Test the connection using Test Connection button
Press OK button if the connection worked
In the wizard click Next button. You should see a SQL script that will be used to create the database
Click Finish button – a new window containing the script will open in Visual Studio.
Click the Execute SQL icon in the toolbar (or use Ctrl + Shift + E key combination) to execute the script and create the database (note that this step may require administrator rights so you may need to restart Visual Studio as administrator)
Playing with enums
So far, so good. The model has been created. It contains an enum type and an entity type with a property of the enum type. Database has been also created. We need to populate the database with some data and will be ready to query the database with queries using enum types.
Create a method that adds a few entities to the database. Use the following code to do that:
private static void Seed() { using (var ctx = new EnumModelContainer()) { if (!ctx.Products.Any()) { ctx.AddToProducts(new Product() { Name = "Milk", Category = CategoryType.Dairy }); ctx.AddToProducts(new Product() { Name = "Seattle's Rain", Category = CategoryType.Beverage }); ctx.AddToProducts(new Product() { Name = "Cayenne Pepper", Category = CategoryType.Condiments }); ctx.AddToProducts(new Product() { Name = "Sour Cream", Category = CategoryType.Dairy }); ctx.AddToProducts(new Product() { Name = "Chevy Volt", Category = (CategoryType)255 }); ctx.SaveChanges(); } } }The method is pretty straightforward. It checks whether there are any entities in the database and if there aren’t it adds some default entities. Certainly, when creating entities we are able to use the members of the enum type we defined in the model. Interestingly however C# and VB.NET allow for kind of abusing enum types by allowing specifying a value that does not correspond to any of the specified members of the enum type (internally we call such a value “unnamed enum value/member”). This is what happens with the last entity – we did not have a category for this product so we used a number that is in range of the enum underlying type and cast it to the actual enum type
Create a helper method to display entities. It will just iterate over entities and print Id, Name and Category just like this:
private static void DisplayProducts(IEnumerable<Product> products) { Console.WriteLine("Products"); foreach (var p in products) { Console.WriteLine("Id: {0}, Name: {1}, Category: {2}", p.Id, p.Name, p.Category); } }
Modify Main function so that it invokes Seed method and then displays all entities we have in the database. Here is the code:
Products
Id: 1, Name: Milk, Category: Dairy
Id: 2, Name: Seattle's Rain, Category: Beverage
Id: 3, Name: Cayenne Pepper, Category: Condiments
Id: 4, Name: Sour Cream, Category: Dairy
Id: 5, Name: Chevy Volt, Category: 255
Press any key to continue . . .
The results seem correct. One interesting thing to note is that for named enum members the name of the member is displayed (e.g. Dairy, Beverage etc.) while for the unnamed enum values – the entity with Id = 5 – we got the value as a number
So, we were able to create entities with enum properties save them to database and then read them from the database (i.e. round tripping seems to work) and show to the user. In addition we were able to use a value that did not have any corresponding enum type member and nothing blew up. Nice. But this is not actually where enums really shine. The place where enums really shine are queries. It is much more natural to say “Get me all yellow sports cars I own” than “Get me all my sports cars whose color is 6”. So let’s do some queries.
In the Main method instead of showing all the results use a Linq query that returns only dairy products:
static void Main(string[] args) { Seed(); using (var ctx = new EnumModelContainer()) { var q = from p in ctx.Products where p.Category == CategoryType.Dairy select p; DisplayProducts(q); } }Here is the result:Products
Id: 1, Name: Milk, Category: Dairy
Id: 4, Name: Sour Cream, Category: Dairy
Press any key to continue . . .
Now let’s order our entities by category in descending order. Replace the previous query in the Main method with:
var q = from p in ctx.Products orderby p.Category descending select p;The result is:Products
Id: 5, Name: Chevy Volt, Category: 255
Id: 3, Name: Cayenne Pepper, Category: Condiments
Id: 4, Name: Sour Cream, Category: Dairy
Id: 1, Name: Milk, Category: Dairy
Id: 2, Name: Seattle's Rain, Category: Beverage
Press any key to continue . . .Using enum values in queries is very natural – queries are much easier to write and to understand. Moreover using enums does not change how queries work – we translate enum properties to corresponding database columns and enum values to corresponding values of the enum underlying type. As a result queries containing enum values or properties work the same way as queries containing only primitive properties as values – everything is translated to SQL and pushed to the database.
The above examples are just the most common scenarios where enum types can be used in EF. However enum types are also supported as properties on complex types, in ESQL queries, as parameters or return types of stored procedures or in TVFs (Table Valued Functions) – another new feature which ships with this CTP. Finally the CTP includes also an updated version of EF 4.1 that supports enums, so you are able to use enums with CodeFirst. We will cover how to use Enums with Code First in an upcoming blog post.
Summary
In the walkthrough we went through the process of creating and using enumerated types in the Entity Framework June 2011 CTP1. First we looked at a high level overview of the design of enum types in the EF. Then we created a model with an entity that contained a property of enum type. We inspected edmx file and the generated code for changes related to enums. From the model we prepared we generated a database. Finally, we added entities with enum properties to the database and used enum values when querying the database with LINQ.
Support and Feedback
As always we appreciate any feedback you may have on enumerated types in the Entity Framework or Entity Framework in general. For support please use the Entity Framework Pre-Release Forum




Pedro Ardila described a Walkthrough: Table-Valued Functions (June CTP)
Microsoft Entity Framework June 2011 CTP is bringing support for Table-Valued Functions. TVFs are store functions capable of returning table-shaped values. TVFs are similar to Stored Procedures in that they can have procedural code in their body. Unlike stored procedures however, TVFs are composable which means I can use them inside a classic query. In this walkthrough we will learn how to map entities to TVFs using the VS designer. Then we will see how to use TVFs in LINQ queries.
Pre-requisites
Microsoft Entity Framework June 2011 CTP. Click here to download.
- Microsoft Entity Framework Tools June 2011 CTP. Click here to download.
- Northwind Database. Click here to download.
The Database
1. After installing the Northwind msi, execute "C:\SQL Server 2000 Sample Databases\instnwnd.sql" against your SQL Server instance.
2. Now we will add a TVF which returns the details for a given order. Execute the following SQL Statement against the Northwind database.
CREATE FUNCTION [dbo].[GetDetailsForOrder](@Oid INT)RETURNS TABLE ASRETURN SELECT [OrderID], [ProductID], [UnitPrice], [Quantity], [Discount] FROM [dbo].[Order Details] WHERE OrderID = @OidDatabase First Approach
Setting up Project
Launch Visual Studio and create a new C# Console application.
- Make sure you are targeting the Entity Framework June 2011 CTP. Please see the EF June 2011 CTP Intro Post to learn how to change the target framework.
Creating a Model
Add a new ADO.NET Entity Data Model to your project by right clicking on the project and navigating to Add > New Item.
In the Add New Item window, click Data, and then click ADO.NET Entity Data Model. Name your model ‘NorthwindModel’ and click Add.
Select New Connection… on the Wizard. Under Server name, enter the name of your SQL Server instance (if you installed SQL Express, the server name should be .\SqlExpress)
Under Connect to a database, select Northwind from the first dropdown menu.
The Connection Properties window should look as follows. Click OK to proceed.
Click Next on the Entity Data Model Wizard, then expand the Tables node, then the dbo node. Select the checkboxes next to the Orders, Order Details, and Products tables. Now scroll down to find the Stored Procedures and Functions node, expand dbo, and select the checkbox next to GetDetailsForOrder from the list of functions. Click Finish.
The resulting Model includes three entities named Order, Order_Detail, and Product. There are one-to-many relationships between Order to Order_Detail, and between Product and Order_Detail.
Creating a FunctionImport for the TVF
- Open the Model Browser by right clicking on the designer and selecting Model Browser:
- Find the GetDetailsForOrder function under NorthwindModel.Store:
Double-click on the function to bring up the Add Function Import dialog.
Click on the Function Import is Composable? checkbox
Select GetDetailsForOrder from the Stored Procedure/Function Name checkbox.
Click the Entities radio button then select Order_Detail from the dropdown. The Add Function Import dialog should now look as follows:
Click OK to close the dialog and create the Function Import. You will see it on the Model Browser under the Function Imports node:
Writing the App
Open Program.cs and enter the following code:
using System;using System.Collections.Generic;using System.Linq;using System.Text; namespace NorthwindApp{ class Program { static void Main(string[] args) { using (var context = new NorthwindEntities()) { var OrderID = 10248; var MinUnitPrice = 10; //Retrieve the names of the products in order 1048 with a unit price over $10 var Products = from od in context.GetDetailsForOrder(OrderID) where od.UnitPrice > MinUnitPrice select od.Product.ProductName; Console.WriteLine("Products in order " + OrderID + " with unit price over $" + MinUnitPrice + ":"); foreach (var p in Products) { Console.WriteLine("\t" + p); } Console.WriteLine("Done! Press ENTER to exit."); Console.ReadLine(); } } } }In the code above we create a context, then we create variables for the OrderID and the Minimum unit price we are looking for. Note how we can follow the TVF call with a where clause. This demonstrates the composable nature of TVFs. The output of our program is the following:Products in order 10248 with unit price over $10:
Queso Cabrales
Mozzarella di Giovanni
Done! Press ENTER to exit.
How It Works
EDMX
A TVF is represented as a function in the storage layer. The function is marked as IsComposable=”True”, and a ReturnType is specified to be a collection of RowTypes. A FunctionImport is specified in the conceptual layer. Here we specify the parameters’ EDM Types, EntitySet and ReturnType that the function will map to. The mapping layer glues the Function and the FunctionImport together.
<!-- SSDL content --> <Function Name="GetDetailsForOrder" Aggregate="false" BuiltIn="false" NiladicFunction="false" IsComposable="true" ParameterTypeSemantics="AllowImplicitConversion" Schema="dbo"> <Parameter Name="Oid" Type="int" Mode="In" /> <ReturnType> <CollectionType> <RowType> <Property Name="OrderID" Type="int" Nullable="false" /> <Property Name="ProductID" Type="int" Nullable="false" /> <Property Name="UnitPrice" Type="money" Nullable="false" /> <Property Name="Quantity" Type="smallint" Nullable="false" /> <Property Name="Discount" Type="real" Nullable="false" /> </RowType> </CollectionType> </ReturnType> </Function> <!-- MSL content --> <FunctionImportMapping FunctionImportName="GetDetailsForOrder" FunctionName="NorthwindModel.Store.GetDetailsForOrder" /> <!-- CSDL content --> <FunctionImport Name="GetDetailsForOrder" IsComposable="true" EntitySet="Order_Details" ReturnType="Collection(NorthwindModel.Order_Detail)"> <Parameter Name="Oid" Mode="In" Type="Int32" /> </FunctionImport>.NET Layer
The Entity Framework tools generate a function stub so that the function can be used in LINQ queries:
[EdmFunction("NorthwindEntities", "GetDetailsForOrder")] public IQueryable<Order_Detail> GetDetailsForOrder(Nullable<global::System.Int32> oid){ ObjectParameter oidParameter; if (oid.HasValue) { oidParameter = new ObjectParameter("Oid", oid); } else { oidParameter = new ObjectParameter("Oid", typeof(global::System.Int32)); } return base.CreateQuery<Order_Detail>("[NorthwindEntities].[GetDetailsForOrder](@Oid)", oidParameter);}Code First Approach
Entity Framework June 2011 CTP does not include Code First support for TVFs. However, you can use DbContext against your TVFs. You can do this by adding the DbContext template to your model. The steps to add the template are the following:
Open NorthwindModel.edmx and right click on the canvas
Click on Add Code Generation Item…
Select ADO.NET DbContext Generator V4.2, enter a name for your template, and click Add
Conclusion
In this walkthrough we created a TVF in Northwind, then we created a FunctionImport and called the TVF within a LINQ query. If you would like to find out more about TVFs, please read the EF Design post about TVF Support. As always, we look forward to hearing from you so please leave your questions and comments below.
Pedro Ardila
Program Manager – Entity Framework






The Entity Framework Team posted Auto-Compiled LINQ Queries (Entity Framework June 2011 CTP) to the Entity Framework Team Design blog on 6/30/2011:
When you write a LINQ to Entities query today, the Entity Framework walks over the expression tree generated by the C#/VB compiler and translates (or compiles) that into SQL.
Compiling the expression tree into SQL involves some overhead though, particularly for more complex queries. In order to avoid having to pay this performance penalty every time the LINQ query is executed, the CompiledQuery class was introduced. This allows you to pay the overhead of compilation just once, and gives you back a delegate that points directly at the compiled version of the query in the Entity Framework cache.
static readonly Func<NorthwindEntities, IQueryable<string>> query = CompiledQuery.Compile<NorthwindEntities, IQueryable<string>>( db => from c in db.Customers where c.Country == "USA" select c.CompanyName);Each subsequent time you execute the query it’s now much faster.
Auto-Compiled LINQ to Entities Queries
The Entity Framework June 2011 CTP supports a new feature called Auto-Compiled LINQ Queries. Now every LINQ to Entities query that you execute automatically gets compiled and placed in EF’s query cache. Each additional time you run the query, EF will find it in its query cache and won’t have to go through the whole compilation process again.
This also provides a boost to queries issued using WCF Data Services, as it uses LINQ under the covers.
How Does it Work?
The Entity Framework will walk the nodes in the expression tree and create a hash which becomes the key used to place it in the query cache. If it does not find the query in the cache then it will go ahead and compile it and store the compiled query in the cache for subsequent use. Each subsequent time, the hash will be calculated and find the compiled query in the tree, thus saving the compilation overhead.
Turning off Query Caching
A new property on ObjectContext.ContextOptions has been introduced that allows you to control the default behavior of query compilation. By default this property is true, but you can set it to false to disable auto-compilation of LINQ queries:
db.ContextOptions.DefaultQueryPlanCachingSetting = false;
Note: If you’re using DbContext and need to get the ObjectContext instance, just cast to IObjectContextAdapter:
((IObjectContextAdapter)db).ObjectContext.ContextOptions.DefaultQueryPlanCachingSetting = false;
The value of this property gets propagated to the EnablePlanCaching property on each newly-created ObjectQuery for the ObjectContext. Note: There is a known limitation in the June 2011 CTP: while DefaultQueryPlanCachingSetting is propagated to the EnablePlanCaching setting of each new query, the EnablePlanCaching setting is not propagated when using LINQ operators.
Performance Guidance
Obviously when it comes to performance there’s no one-size-fits-all approach. The size/complexity of your application and queries will greatly influence how much of a performance boost your application will get from this. It’s important to measure your specific application with a good profiler.
It is worth noting that using the CompiledQuery class is still the fastest approach, as the delegate that you get back does not need to calculate a hash of the expression tree. Auto-compiled LINQ queries should be almost as fast though, and provide the benefit of not having to manually use the CompiledQuery class.
Feedback
We’d love to get your feedback on this feature and hear if it’s helping in your application. Please download the CTP today and let us know what you think!
Strange that this article was posted to a different MSDN blog.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
Carl Franklin and Richard Campbell (@richcampbell) interviewed Scott Guthrie (@scottgu) at the Norwegian Developers Conference (NDC) and posted the podcast to their DotNetRocks.com site on 6/30/2011:
Visit the site to listen to the podcast.
Fresh off his keynote at the Norwegian Developers Conference in Oslo, Norway, Scott Guthrie dropped into the fishbowl to talk to Carl and Richard about his new role with the Azure team. Scott digs into how Azure has evolved and his focus on improving the developer experience. The conversation wraps up with a chat about the upcoming Build conference.
Scott Guthrie is General Manager within the Microsoft Developer Division. He runs the development teams that build the Common Language Runtime (CLR), .NET Compact Framework, ASP.NET / Atlas, Windows Forms, Windows Presentation Foundation (aka "Avalon"), IIS 7.0, Commerce Server, Visual Web Developer, and Visual Studio Tools for WPF (aka "Cider")
Links from the Show

Scott’s bio here is as out of date as that in the Microsoft News Center, which was last updated 2/15/2008.
Michael Cote’ (@cote) claimed Despite much hope, PaaS momentum hasn’t blown the doors off yet in a 6/30/2011 post to his Red Monk blog:
Touted at the next thing in cloud, Platform as a Service is receiving much attention now. While PaaS has been far from a failure, it hasn’t been a mega success…yet.
I’ve been talking with several people about Platform as a Service use recently: with all the vendors (and us analysts as well!) going on about how great it is, I’ve been trying to assertion both current momentum and ongoing developer desire. The point of PaaS is to make a developer’s life even easier: you don’t need to manage your cloud deployments at the the lower level of IaaS, or even wire together your Puppet/Chef scripts. The promise of PaaS is similar to that of Java application servers: just write your applications (your business logic) and do magic deployment into the platform, where everything else is taken care of. Pioneers like Heroku have certainly proven that out, initially. Still, aside from that big name in the PaaS space, I very seldom hear developers tell me they’re using PaaS: they still prefer to use the lower-level of IaaS. Indeed, it seems that for many developers, the IaaS layer and tools around it are “good enough” for mow.
Taking Stock
Coming across PaaS usage numbers can be difficult. First, if they report at all, companies typically you how many applications, customers, and/or developers are using the PaaS. Customers is perhaps the only metric that’s not suspect: a paying customer, after all, is a committed customer who, at the very least, is providing revenue to the PaaS provider. Applications can be totally bunk: how many of those are simple “Hello, cloud!” applications, dead applications, duplicates, etc.? Developers is even worse: a “registered developer” could just be someone filling out a form and clicking submit.
I spent some time back in January of this year to round up some numbers, and I’ve found some additional figures which slightly updates those January ones. For example, number of applications deployed on various App Engine, Heroku, and Force.com:
Each of AppEngine, Force.com, and Heroku are at sub 300,000 applications deployed. Which, is a big number, sure. But how many applications are there in the world? It’s hard to know (and how many are just “Hello, world’s!” and Pet Shops), but:
- in 2010 Steve Ballmer claimed there were over 4,000,000 Windows applications
- there’s probably around 350,000 apps in the iTunes App Store, with Android quickly catching up if not already
- one estimate puts Facebook at 57,512 apps
- supposedly, there are 48,792,911 WordPress installs world-wide, with around half hosted at WordPress.com
With those baselines and the estimates of the number of applications in PaaSes, things look luke-warm for PaaS adoption currently.
When it comes to customers, Microsoft Azure and EngineYard are the only ones I can track down:
- Forrester estimates that there’s 31,000 Azure customers (check this PDF), while a June 7th, 2010 presentation from Microsoft TechEd 2010 boasted over 10,000.
- EngineYard claims over 2,000 paying customers, currently.
Check out the raw data for the number of developers, which is perhaps the least helpful figure: akin to tracking downloads in open source horse races.
Sentiment, anecdotes, and other fuzzy analysis
Overall, I don’t hear a lot of excitement about PaaS from developers I speak with. Most of them have used Heroku (I tend to skew towards people who would, though), but they seem to be doing “just fine” with a “build your own PaaS” approach. As one enterprise architect put it:
[My] ideal is we leverage Chef/Puppet and stick to IaaS systems whether our own internal VMWare cloud, a public AWS or OpenStack or Rackspace or whatever tomorrow brings. Scripting the build out of what we need. I think that is going to be the most portable from what I have seen. But we have to balance that against the time/complexity savings of being able to deploy to a CloudFoundry with “one line.”
I think the overall answer is “we don’t know yet.” We care about lock in. We worry about it. But I’m not sure we care enough to push us one way or the other.
You’ve got it all wrapped up there: flexibility and future-proofing vs. what you already have and productivity. As ever, they tend to be skitish about being restricted on which middleware they want to use. “What if I need to use node.js, or zeromq, or, I don’t know, Java?” they say.
These are all trade-offs, to be sure: to tautological, any technology choice means you’re using that technology and not others. The question for developers is how much flexibility they’ll have to add in what they need.
Offerings like Cloudfoundry seem to be addressing these concerns. The same EA said:
CloudFoundry is very intriguing to [our line of business] specifically from VMWare given our Spring heavy stack already. The idea of utilizing the open source version (or paid supported version) that we pull internal to our own VMWare stack could be very interesting. But again we need some more maturity in our [corporate IT] area [to start thinking along these "cloud" lines]. They are still relatively new (2 years) and are just maturing around how to support these various [programming models].
As another random data point, it’s notable that Accenture has a PaaS services offering now.
PaaS 3.0
Almost nothing works the first time it’s attempted. Just because what you’re doing does not seem to be working, doesn’t mean it won’t work. It just means that it might not work the way you’re doing it. If it was easy, everyone would be doing it, and you wouldn’t have an opportunity.
–Bob’s RulesStephen O’Grady suggests, in email, that there’s three waves of PaaS, each learning from the past and getting better:
- Azure, AppEngine, Force.com – each a bit too limited and narrow. Too much lock-in
- Heroku – Stephen describes PaaS in this phase as “built from off the shelf parts and practices, these were the “same idea, but with an important differentiation with respect to interoperability and standards.” Slightly more open, if standard.
- Cloundfoundry (which I praised), OpenShift – these are, as Stephen says, “composed of not only standardized components, but each of which supports multiple runtimes.” I tend to see these more as “bring your own PaaSes”
Stephen closed out our email discussion with this:
In essence, then, I think there’s very solid upside in PaaS plays, assuming they’re copying Heroku’s formula rather than, say, Force.com’s. Because really, what most of them become is hardware backed language framework targets – think djangy, Heroku or nodejitsu. And we know from experience that frameworks are leading language adoption. While the timeframe of their traction remains unclear, I am bullish on PaaS for all of the above.
Check out more of his PaaS thinking in his 2011 predictions note.
Indeed, while PaaS adoption hasn’t been going gang-busters of late, it’s not really possible to write-off the idea yet. In fact, it’s probably a good idea to assume there’ll be more of it, even if we don’t exactly know what form it will take.
Disclosure: VMware, Microsoft, RedHat, Salesforce, and others are clients.




The DevX blog asserted “When development and operations teams work together, software companies are able to get their products to market much more quickly” in a deck for its The Growing Trend Toward DevOps article of 6/30/2011:
Agile methodology has done much to improve the speed of development teams, but it doesn't address the performance of the other groups involved in the process of bringing software to market -- like operations, testing, security, etc. DevOps is an approach that helps solve some of these problems by encouraging better collaboration between the development and operations departments.
The DevOps community is starting to develop best practices related to the approach. In addition, open source tools like Puppet and Chef are helping to bridge the divide between server administrators and application developers.

The DevX post links to:
Bridging the Great Dev/Ops Divide By James Turnbull, TechNewsWorld
In today's hyper-competitive landscape, software consumers require their development requests to be responded to quickly, while providers want to demonstrate momentum and serve their markets with frequent software releases. These pressures demand software providers constantly offer new features and functionality. Older approaches to software development are being replaced. Enter DevOps.
Under the legacy approach to software development, developers write code, which is then frozen, tested by another group, released and ultimately supported by yet another team again. Under this highly structured approach, large enterprise software applications are typically updated every 6 to 12 months, and up to several years can pass between major operating system releases. In enterprises, risk appetite and the desire for stability typically drive these intervals.
This "silo" approach to software development practices (that has been used by development teams since the 1970s) is clearly out of synch with today's real-time-focused business world. In today's hyper-competitive landscape, internal and external software consumers and customers require their development requests to be responded to quickly, while providers want to demonstrate momentum and serve their markets with frequent software releases. These pressures demand software providers constantly offer new features and functionality, and as a result, older approaches to software development are being replaced with a development cycle based on continuous improvement and deployment.
While the advent of agile development has helped to bring software development to the market faster, it does not address the impact of faster cycles beyond the development organization; engineering, testing, security, operations and support teams are also deeply affected by a torrent of software releases. Many technology organizations are still plagued by developmental and operational inefficiencies, poor coordination, and a lack of clear accountability for delivery and management of products and services. How can software development, engineering and operational functions stay in synch?
Enter DevOps
DevOps aims to bridge this gap between development and operations and encourage better cooperation and inevitably provide agility in both environments.
Think of DevOps as a framework of ideas and principals to create more cooperation and coordination between development, testing, security and other operational groups. In a DevOps environment, developers and operational staff build relationships, processes and tools that allow them to better interact with each other, representing a new way of thinking between the people who make the software and the people tasked with ensuring its smooth operation.
DevOps breaks down the traditional silos between development and operations. This can include extending core tenets of Agile Development from application development into the realm of testing and production. In turn it's also important for operational teams to embed their production orientation into the application development lifecycle. They need to ensure their operational requirements are communicated clearly, widely and most importantly early to development.
Critical server functions -- including automation, monitoring, capacity planning and performance, backup and recovery, storage, security, networking and provisioning -- can all benefit from the DevOps model to enhance the nature and quality of interactions between development and operations teams.
Best Practices
Through the collective DevOps community, best practices have started to emerge and are shared, fostering large-scale improvement. It provides operational and development teams an opportunity to:
- Discuss which best practices are most effective
- Share the tools they tend to converge upon
- Apply these principles (such as version control, bug tracking, staging and production testing) across the entire software lifecycle.
To achieve DevOps fluidity between software development, testing, quality assurance and the operational teams, the environments used for each of these functions should be automated via the same means, and subject to the same processes. This allows software developers to understand the process of how an application is to be deployed, and the IT infrastructure that supports it. System administrators supporting operational functions also learn about the role of server administration in the development process. Open source tools like Puppet and Chef help bridge this divide, giving system administrators across the various functions a common platform for sharing knowledge.
Businesses expect technology organizations to deliver products and services in an efficient, cost-effective, reliable and timely manner. Failure to do so results in slow speed to market, lack of responsiveness to market requirements and reduced customer satisfaction. In many technology organizations, these failures are the result of process inefficiencies, poor coordination, and a lack of clear accountability across development, engineering and operations organizations.
The DevOps movement has created a rapidly emerging framework of ideas and principles designed to foster cooperation, learning and coordination between development and operational groups. In today's DevOps environment, developers and operations staff build relationships, processes and tools that allow them to better interact with each other, and ultimately better serve the customer.

James is vice president of technology operations at Puppet Labs.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Lori MacVittie (@lmacvittie) posted F5 Friday: Eliminating the Blind Spot in Your Data Center Security Strategy on 7/1/2011 to F5’s DevCentral blog:
Pop Quiz: In recent weeks, which of the following attack vectors have been successfully used to breach major corporation security? (choose all that apply)
Phishing
SQL Injection
SlowLoris
Parameter tampering
DDoS
Data leakage
If you selected them all, give yourself a cookie because you’re absolutely right. All six of these attacks have successfully been used recently, resulting in breaches across the globe:
- International Monetary Fund
- US Government – Senate
- CIA
- Citibank
- Malaysian Government
- Sony
- Brazilian governmentand Petrobraslatest LulzSecvictims
That’s no surprise; attacks are ongoing, constantly. They are relentless. Many of them are mass attacks with no specific target in mind, others are more subtle, planned and designed to do serious damage to the victim. Regardless, these breaches all have one thing in common: the breach was preventable. At issue is the reality that attackers today have moved up the stack and are attacking in the data center’s security blind spot: the application layer. Gone are the days of blasting the walls of the data center with packets to take out a site. Data center interconnects have expanded to the point that it’s nearly impossible to disrupt network infrastructure and cause an outage without a highly concerted and distributed effort. It does happen, but it’s more frequently the case that attackers are moving to highly targeted, layer 7 attacks that are far more successful using far fewer resources with a much smaller chance of being discovered.
The security-oriented infrastructure traditionally relied upon to alert on attacks is blind; unable to detect layer 7 attacks because they don’t appear to be attacks. They look just like “normal” users.
The most recent attack, against www.cia.gov, does not appear to be particularly sophisticated. LulzSec described that attack as a simple packet flood, which overwhelms a server with volume. Analysts at F5, which focuses on application security and availability, speculated that it actually was a Slowloris attack, a low-bandwidth technique that ties up server connections by sending partial requests that are never completed. Such an attack can come in under the radar because of the low volume of traffic it generates and because it targets the application layer, Layer 7 in the OSI model, rather than the network layer, Layer 3.
[emphasis added]
-- Ongoing storm of cyberattacks is preventable, experts say
It isn’t the case that organizations don’t have a sound security strategy and matching implementation, it’s that the strategy has a blind spot at the application layer. In fact, it’s been the evolution of network and transport layer security success that’s almost certainly driven attackers to climb higher up the stack in search of new and unanticipated (and often unprotected) avenues of opportunity.
ELIMINATING the BLIND SPOT
Too often organizations – and specifically developers – hear the words “layer 7” anything and immediately take umbrage at the implication they are failing to address application security. In many situations it is the application that is vulnerable, but far more often it’s not the application – it’s the application platform or protocols that is the source of contention, neither of which a developer has any real control over. Attacks designed to specifically leech off resources – SlowLoris, DDoS, HTTP floods – simply cannot be noticed or prevented by the application itself. Neither are these attacks noticed or prevented by most security infrastructure components because they do not appear to be attacks. In cases where protocol (HTTP) exploitation is leveraged, it is not possible to detect such an attack unless the right information is available in the right place at the right time.
The right place is a strategic point of control. The right time is when the attack begins. The right information is a combination of variables, the context carried with every request that imparts information about the client, network, and server-side status. If a component can see that a particular user is sending data at a rate much slower than their network connection should allow, that tells the component it’s probably an application layer attack that then triggers organizational policies regarding how to deal with such an attack: reject the connection, shield the application, notify an administrator.
Only a component that is positioned properly in the data center, i.e. in a strategic point of control, can properly see all the variables and make such a determination. Only a component that is designed specifically to intercept, inspect and act on data across the entire network and application stack can detect and prevent such attacks from being successfully carried out.
BIG-IP is uniquely positioned – topologically and technologically – to address exactly these kinds of multi-layer attacks. Whether the strategy to redress such attacks is “Inspect and Reject” or “Buffer and Wait”, the implementation using BIG-IP simply makes sense. Because of its position in the network – in front of applications, between clients and servers – BIG-IP has the visibility into both internal and external variables necessary. With its ability to intercept and inspect and then act upon the variables extracted, BIG-IP is perfectly suited to detecting and preventing attacks that normally wind up in most infrastructure’s blind spot.
This trend is likely to continue, and it’s also likely that additional “blind spots” will appear as consumerization via tablets and mobile devices continues to drive new platforms and protocols into the data center. Preventing attacks from breaching security and claiming victory – whether the intent is to embarrass or to profit – is the goal of a comprehensive organizational security strategy. That requires a comprehensive, i.e. multi-layer, security architecture and implementation. One without any blind spots in which an attacker can sneak up on you and penetrate your defenses.
It’s time to evaluate your security strategy and systems with an eye toward whether such blind spots exist in your data center. And if they do, it’s well past time to do something about it.
More Info on Attack Prevention on DevCentral



The CloudTweaks blog posted a The State of Data Security: Defending Against New Risks and Staying Compliant research report on 7/1/2011:
Today’s IT and business managers must take a hard look at the risks and costs of potential data loss. Creating a proactive data security plan arms you with the knowledge you need to manage the risk and helps you to stay compliant with data protection rules and regulations. We all know that data breaches are constantly in the news—in fact security breaches compromised more than 500 million U.S. records since 2005. Plus, lost data due to human error or negligence is just as much of a threat. Fortunately, it’s much less expensive to prevent a breach or other data loss incident, than it’s to respond to one and resolve it after the fact.
Recognize how your data can become vulnerable, including the latest issues stemming from unprotected data on mobile devices and social media sites. Understand the compliance issues involved, and identify data protection strategies you can use to keep your company’s information both safe and compliant.
CSO magazine’s 2011 CyberSecurity Watch Survey found that 81% of respondents’ organizations experienced a security event during the past 12 months, compared with 60% in 2010. Twenty-eight percent of respondents saw an increase in the number of security events as compared with the prior 12 months.
Today’s connected world makes it easier than ever to let companies collect personal information, often for completely legitimate reasons. Personal information is any information that someone can use to uniquely identify, contact, or locate a single person, or use with other sources to uniquely identify a single individual. This information typically must be protected by law. Credit card numbers from a retail sale, Social Security numbers on tax forms, bank account information for online bill payment, medical details from a doctor’s visit, and names, email addresses and birthdates entered on any Internet site registration—this data all resides in the databases of various companies, who often share it with third party vendors to perform a wide array of outsourced activities.

Klint Finley (@Klintron) reported Microsoft Says It Will Give Your Data to the U.S. Government, Even If It's Not in the U.S. in a 6/30/2011 post to the ReadWriteCloud blog:
Microsoft has admitted that it will hand over data to the U.S. government, if properly requested, even if that data is stored somewhere other than the U.S.
The issue, according to ZDNet's Zack Whittaker, is that because Microsoft is a U.S. company it has to comply with the Patriot Act, and that means handing over data that may be offshore. The same rules would apply to Amazon Web Services and any other U.S. based cloud provider that has servers overseas.
The admission came during the Office 365 launch. According to Whittaker, Managing Director of Microsoft UK fielded a question about whether Microsoft could guarantee that data stored in the European Union would stay in the EU, even if it was requested by the U.S. government under the Patriot Act. Whittaker said Microsoft could not make that guarantee.
"Any data which is housed, stored or processed by a company, which is a U.S. based company or is wholly owned by a U.S. parent company, is vulnerable to interception and inspection by U.S. authorities," writes Whittaker. "While it has been suspected for some time, this is the first time Microsoft, or any other company, has given this answer."
Last week the FBI seized a server from Instapaper during an unrelated raid on colocation provider DigitalOne. Now Microsoft has made it clear that data housed in other countries might be subject to the same treatment.


Martin Tantau reported Apigee Launches First PCI-Compliant API Management Solution in the Cloud to the CloudTimes blog on 6/30/2011:
Apigee, a leading provider of API products and services which was formerly known as Sonoa Systems, announced their PCI-compliant Enterprise API management solution in the cloud. APIs are key in IT today and there are several organization competing for the lead on API management like Mashery, 3scale, Stratus Security or WebServius.
The new offering by Apigee enables organizations to deliver API interfaces that can be quickly and securely deployed on a public cloud. Apigee claims that their Enterprise Cloud PCI is the only cloud-based API management tool on the market that supports full compliance with the Payment Card Industry Data Security Standard (PCI-DSS). “With Apigee, businesses can, for the first time, easily tap the vast, affordable compute resources of “the cloud” to support their transactional API traffic with the confidence that all sensitive customer data remains protected.” Other players in related fields like Layer 7 have also PCI-DSS compliance for their API security & management suite as well.
“To fully protect critical customer credit card information, there’s an increased focus on compliance, especially as more e-commerce services shift to cloud computing and APIs,” said Chet Kapoor, Apigee CEO. “But the extensive time and resources necessary to comply with industry regulations has prevented many forward-thinking retailers from extending their e-commerce strategies with APIs. The Apigee Enterprise Cloud API also protects and screens sensitive data flowing between an application and an API residing on a public cloud, so businesses can now confidently broaden their e-commerce network with transactional APIs.”
Businesses today are increasingly relying on APIs to enable the development of rich third-party applications that utilize their data and services. APIs help organizations reach customers across thousands of platforms through a network of apps, and increasingly, smart APIs are replacing websites as the conduit for commerce. However, due to the high cost and other challenges associated with building and supporting scalable, secure PCI-compliant APIs, the vast majority of APIs offered today are for catalog-type applications that enable viewing data, but not transacting with it.
PCI compliance is becoming increasingly important as credit cards are being used more often. APIs as the interface between many systems are therefore required to be PCI-compliant as well. The payments and transaction space is getting more crowded (fortunately) as many new start-ups are entering the market – see e.g. Square that we reported about earlier. We are glad to see Apigee taking the lead here.
The new Apigee Enterprise Cloud PCI solution is deployed in PCI-compliant data centers, where cardholder information is protected according to PCI DSS. With Apigee Enterprise Cloud PCI, enterprises can:
- Quickly build and deploy a transactional API — in about a quarter of the time it would take to build it ‘from scratch’
- Maintain PCI compliance and data protection of all API traffic, including encryption and masking for cardholder information, regardless of whether the API is deployed on-premise or in the cloud
- For the first time, take advantage of the virtually limitless, on-demand compute resources of the cloud to dynamically scale APIs to meet traffic demands
For organizations that require on-premise solutions, Apigee Enterprise can also be deployed on site and delivers the same capabilities as Apigee Enterprise Cloud, while fitting into PCI-DSS compliant in-house deployment
<Return to section navigation list>
Cloud Computing Events
James Downey (@james_downey) posted Big Data and Hadoop: A Cloud Use Case on 7/1/2011:
Tuesday night I drove to Santa Clara for the Big Data Camp, learned more about Hadoop, and even ran into a few Dell colleagues. Thanks to Dave Nielson for organizing the camp and to Ken Krugler for his great overview of Hadoop.
While the phrase big data lacks precision, it is of growing importance to ever more enterprises. With data flooding in from web sites, mobile devices, and those ever present sensors, processing and deriving business value out of it all becomes ever more difficult. Data becomes big when it exceeds the storage and processing capabilities of a single computer. While an enterprise could spend lots of money on high-end, specialized hardware finely tuned for a specific database, at some point that hardware will become either inadequate or too expensive.
Once data exceeds the capabilities of a single computer, we face the problem of distributing its storage and processing. To solve this problem, big data innovators are using Hadoop, an open source platform capable of scaling across thousands of nodes of commodity hardware. Hadoop includes both a distributed file system (HDFS) and a mechanism for distributing batch processes. It is scalable, reliable, fault tolerant, and simple in its design.
Many enterprises, however, would only need to process big data periodically, perhaps daily or weekly. When running a big data batch job, an organization might want to distribute the load over hundreds or thousands of nodes to assure completion within a time window. But when the batch job completes, those nodes may not be needed for Hadoop until the time comes for the next batch job.
This use case—the dynamic expansion and contraction in the need for computing resources—fits well with the capabilities of cloud computing, whether private, public, or hybrid. (In this case, I mean cloud as in Infrastructure-as-a-Service.) A cloud infrastructure could spin up the nodes when needed and free the resources when that need goes away. In public cloud computing, that freeing of resources would directly impact cost.
During his presentation, Ken Krugler suggested that we think of Hadoop as a distributed operating system in that Hadoop enables many computers to store and process data as if they formed a single machine. I’d add that cloud computing—virtualization, automation, and processes that enable an agile infrastructure—may be needed to complete this operating system analogy so that this distributed operating system not only manages distributed resources but does so for maximum efficiency across a multitude of use cases.
Extra Credit Reading (Dell Resources on Hadoop):
Philippe Julio, Hadoop Architecture, http://www.slideshare.net/PhilippeJulio/hadoop-architecture
Joey Jablonski, Hadoop in the Enterprise, http://www.slideshare.net/jrjablo/hadoop-in-the-enterprise
Aurelian Dumitru, Hadoop Chief Architect, Dell’s Big Data Solutions including Hadoop Overview, http://www.youtube.com/watch?v=OTjX4FZ8u2s

That’s me on the left, Aurelian Dumitru, Dell’s Hadoop Chief Architect, in the center, Barton George, Director of Marketing for Dell’s Web & Tech vertical, on the right. Thanks to DJ Cline for the photo. See http://bit.ly/iHJJIl for more photos of the Big Data Camp.


Barton George (@barton808) posted Hadoop Summit: Talking to the CEO of Hortonworks on 6/30/2011:
Yesterday I attended the Hadoop Summit down in Santa Clara. The one-day event featured a morning of general sessions followed by three tracks of break outs in the afternoon. The event also featured displays by several dozen vendors.
The big topic of the day was Hortonworks, a Yahoo! spin-out that had been announced the day before. The company, which will officially come into being next month will be made up of 25 core Hadoop engineers from Yahoo! Leading this new venture as its CEO is Yahoo! veteran and until this week VP of Hadoop engineering, Eric Baldeschwieler.
In the afternoon I was able to get some time with Eric and learn more about his new gig.
Some of the ground Eric covers
- What is Hortonworks and what are its goals?
- (0:46) Who is the technical team that will be making up the new venture
- (1:48) Their president Rob Bearden, his open source experience and the business expertise he brings
- (2:24) Their customers
- (2:44) Which Hadoop engineers will remain at Yahoo!
- (3:37) The symbiotic relationship Hortonworks and Yahoo! will have and how they will help one another
Extra-credit reading
- Press release: Yahoo! and Benchmark Capital to Form Hortonworks to Increase Investment in Hadoop Technology and Accelerate Innovation and Adoption
- Hortonworks slide deck from Eric’s Hadoop summit keynote



<Return to section navigation list>
Other Cloud Computing Platforms and Services
Derrick Harris (@derrickharris) reported Battle on: MapR, Cloudera pimp their Hadoop products on 6/29/2011:
The fight for Hadoop dominance is officially on. The unveiling of Yahoo’s Hadoop spinoff Hortonworks will undoubtedly be the talk of today’s Hadoop Summit, but it’s not the only game in town. In fact, while Hortonworks is busy answering questions about its product strategy, Cloudera and MapR will demonstrate new versions of their distributions overflowing with bells and whistles.
I wrote yesterday about the importance of new tools designed to improve the Hadoop experience at a level above the distribution layer, but the distribution — the underlying code base that defines Hadoop’s core architecture and capabilities — is still king. Apache Hadoop is a set of open-source tools designed to enable the storage and processing of large amounts of unstructured data across a cluster of servers. Chief among those tools are Hadoop MapReduce and the Hadoop Distributed File System (HDFS), but there are numerous related ones, including Hive, Pig, HBase and ZooKeeper.
Most vendors try to distinguish their Hadoop distributions with MapReduce and HDFS. Some will try to tweak the core Apache features and architectures, while others will replace one component — generally HDFS — altogether.
EMC and IDC released their Digital Universe study this week, estimating we’ll create 1.8 zettabytes of data this year and data growth is outpacing Moore’s Law. Now that we’ve realized there’s value in all that information, we’re anxious to capture, analyze and use it, and that requires more and better big-data technology. As this diagram from Karmasphere illustrates, Hadoop is a very large part of the big data stack, which means we’re just getting started.
So many distributions, so little time
Cloudera. Cloudera, whose CDH was the first commercial Hadoop distribution, takes the approach of taking the full complement of available open-source components and integrating them into an enterprise-grade product. Its value isn’t so much in “improving” Hadoop as it is in making everything from Hadoop MapReduce to its own Sqoop (SQL to Hadoop) tool work well together out of the box.
Cloudera actually released CDH version 3.5 recently, but today it released a bunch of new features for its Cloudera Enterprise product, a suite of management tools designed to make it easier to operate CDH clusters. The coolest has to be something called SCM Express, which makes getting started with Hadoop easier. Cloudera’s Charles Zedlewski explained that SCM Express is a free tool that lets users provision and launch up to a 50-node Hadoop cluster “in about six clicks.”
MapR. However, Cloudera has lots of company, including the brand new MapR. That startup just released its first two products today: a free Hadoop distribution called M3 and a paid distribution called M5. MapR takes the Cloudera approach of integrating the entire spectrum of Hadoop tools into its distribution and including management functionality, but it also has made a number of significant changes to the MapReduce and HDFS components to improve performance.
MapR’s Jack Norris says the result is “probably the most comprehensive distribution,” which performs two to five times faster than the standard Apache Hadoop. A majority of MapR’s changes are to the storage layer, which it has reworked to be faster, easier, more reliable and more scalable than HDFS.
You can’t talk about MapR without talking about EMC, which announced last month that the Enterprise Edition of its Greenplum HD Hadoop distribution will be “powered by MapR.” Norris explained to me that the product, available later this year, will utilize MapR’s M5 version, which includes advanced storage capabilities around high availability and data protection. However, EMC’s line of Greenplum HD distributions, which also includes a free Community Edition, is actually centered around the specialized Hadoop code developed by and running within Facebook.
Of course, Hortonworks isn’t to be discounted, nor are DataStax with its Cassandra-based Brisk distribution or IBM, which has been promising its own Big-Blue-style Hadoop distribution for some time. But the most interesting thing about all this Hadoop activity might be the pace of it: As of mid-March, Cloudera stood alone as a commercial Hadoop provider. Now it has four competitors with more likely to come.
Feature image courtesy of Flickr user Joi.
Related content from GigaOM Pro (subscription req’d):







<Return to section navigation list>

















0 comments:
Post a Comment