Windows Azure and Cloud Computing Posts for 7/26/2011+
A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles.

• Update 7/26/2011: Full coverage of Microsoft’s Visual Studio LightSwitch release to manufacturing (RTM) with new articles marked • by Mike Tillman, Tim Anderson, Kathleen Richards, Microsoft Global Foundation Services, Joe Panattieri and Bruce Kyle.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
Chris Shaw described My First Experience with SQL Azure in a 7/2011 post to the SS
There is so much news around the SQL Server world right now. If you haven’t been keeping up with it, you may be missing one of the largest jumps in technology in the last 10 years. News of SQL Azure has been around a little while, but not until the last year have I had the opportunity to put it to use. SQL Azure is the database in the “cloud,” meaning the install is located on servers hosted by Microsoft and all you have to do is connect to the server. There are some obvious benefits to this, most notably the cost. You don’t have to buy a server, SAN or even the licenses to run SQL Server or Windows. You do have to pay for the use of the database, and with a couple options, it is less expensive than purchasing all that hardware.
My situation that got me to look at SQL Azure included a small database for our local user group. The group has a little bit of money, but for the most part, we have to watch each and every penny. We wanted a database that would support an application that people can use on their mobile devices. If we were to look for a SQL Server host, we would have taken on some added costs. If we would have used a server that someone in the group owns, we may have issues with uptime or access to the machine. In place of a SQL Server with a local install, we signed up for a SQL Azure account from Microsoft.
Signing up for SQL Azure
I have been hearing stories on how easy it is to start using SQL Azure. There have been a number of workshops around Colorado that cost me nothing to attend. I just determined that it was going to be much more difficult than I had heard. With help of one of the board members in my local user group for the payment portion, we were up and running in less than an hour.You can find out more on signing up for SQL Azure here:
http://www.microsoft.com/windowsazure/. And more on the costs here:
http://www.microsoft.com/windowsazure/pricing/.First Steps with SQL Azure
After logging on, I was able to create a database and start quickly creating objects. I found out if I used the online tool, there is a user interface to help with object design. My preference is to use Management Studio to connect to my SQL Azure database. There were a couple learning curves, such as the USE statement doesn’t work as it does with a standard install. In addition, I was happy to see that PKs were required on all my tables.Benefits
There are so many benefits to SQL Azure that I am not sure that I can do them justice in this short article. The key benefit that I believe most people can appreciate is the cost savings. Considering that bringing a small database online with a server class machine would typically cost no less than $3,000 for strictly hardware, my first SQL Azure database is going to run me $10.00 a month. For that database, I am sure I will see the cost savings right away.I’m also looking forward to the lack of upgrades and patches. Think of your SQL Azure database as a database that you have on another DBA’s machine. That other DBA, or in the case Microsoft, is going to maintain your server. New features will be added and patches will be applied without having to come up with roll plans, rollback plans and change control items.
In addition to the upgrades, you don’t need to back up your system. All the work that you are doing is going to be focused on making your existing systems better, rolling out new features and improving queries. I cannot explain how weird it was to me to set up a new SQL Server and not run right over and start to make adjustments for my backups. I can’t say that, beyond a shadow of doubt, that SQL Azure is maintenance free. But from this point, I believe my database is just fine.
Personal Surprises
I couldn’t believe how easy and quick I was able to get my SQL Azure database online. I was also pleasantly surprised at how much information I was able to find as far as help files and tutorials. Buck Woody has a collection of great SQL Azure help information in the form of a learning plan that can be found here.Stumbling Blocks
There are a couple levels of configuration that I was able to navigate quickly, but I’m not sure what it initially meant. Each level had different configuration options. Because there is no Server level or distinct all databases level like I am used to seeing in the Management Studio, there will be some additional research for me.
One of the first stumbling blocks that I ran into dealt with access levels and the IP that I was presenting from my machine. I have three major locations where I might want to connect to the server, making sure that I knew all the potential ranges was a bit of a pain. I want to stress that this is more of an issue with me understanding my requirements than it was with SQL Azure.Summary
My question with SQL Azure has always come back to, “is it a game-changer?”
I believe we are sitting in the middle right now. It feels to me like there are a number of databases that could be moved over to Azure with no issues at all. As a matter of fact, I think it could be better for the database to be on SQL Azure in some cases. I believe there are many databases where the question of where the data is and security of the physical database resides may always come into question. I believe working with SQL Azure is a good first step for DBAs to work in the cloud, but it will become important to know about, in order to stay competitive in the job market.

<Return to section navigation list>
MarketPlace DataMarket and OData
Liam Cavanagh (@liamca) reported about Eye on Earth at the Esri User Conference and Windows Azure Marketplace Data Market in a 7/26/2011 post:
At the Esri User Conference in San Diego we talked about the our Eye on Earth project which consists of a joint partnership between the European Environmental Agency, Esri and Microsoft to build a “Solution Builder” that will allow governments and organizations around the world to upload their enviromnental data to the cloud and then create spatial visualizations for that data in an extremely simple way. This solution will use a combination of ArcGIS Online as well as Windows Azure and SQL Azure for the storage. Here is a link to the current version of Eye on Earth service. In the current version users can visualize and comment on Air and Water quality across Europe. The hope is that this will extend to all kinds of different environmental data (biodiversity, invasive plant species, etc.) for countries all around the world. [Emphasis added.]
Another key piece of this solution will be DataMarket which will allow these organizations to also share (and in some cases sell) the native data for others to use. This will help increase scientists ability to do statistical analysis on the data.
I will talk more about this solution as we move forward, but for now we have a little more information included in my presentations from the Esri user conference.

Bruce Kyle recommends that you Sell Your SaaS Applications, Data Through Windows Azure Marketplace in a 7/26/2011 post:
Windows Azure Marketplace has added the capability for you to sell finished applications built on Windows Azure in US markets.
Offerings are currently available within the United States with other countries being added in the next few months.
Benefits of the Windows Azure Marketplace include:
Global Reach
- Premium Experiences
- Secure Platform
Click here to read the full press release to learn more about this announcement.
How to Get Started Selling Your App Online
How does publishing an Application on the Marketplace work?
It’s simple:
- You control your business you decide what types of subscriptions you make available, the terms of use associated with the app, and the price customers should pay to use the app.
- We will expose your offering(s) in our marketplace, make it easy for customers to discover, and handle the customer subscriptions, provisioning and billing.
What Do I Need to Add to My App?
The application must be updated to react to events when users purchase a subscription to the application and cancel a subscription to the application. For more information download the App Publishing Kit.
For More Information
Click here to explore Windows Azure Marketplace and click here to learn more on how to get involved with the Windows Azure Marketplace.
For more information, see the Azure Team blogs post, Just Announced: Windows Azure Marketplace Expands Application Selling Capabilities In US Markets.

Samidip Basu (@samidip) posted Updating OData data source from WP7: Part 2 on 7/24/2011:
This post is a continuation of the first part (here) on Updating the underlying data behind an OData service.
So, we continue from where we left off. We have a SQL Azure table called “Team” which has its data exposed as an OData service. This can obviously be read easily by various clients; but what about updates? In the last post, we talked about how we can host a WCF Service in Azure that allows us CRUD operations on the underlying SQL Azure data. This does work; but what if you did not want to add a Service Reference to your project? Isn’t the promise of OData to be able to make plain HTTP requests to perform CRUD on data?
Yes, you are right. In this post, we see how to insert records into the SQL Azure DB table through OData by simply doing native HTTP Posts at the correct URL. Now, I will do this from a Windows Phone app, that is, Silverlight. This brings in the asynchronous factor since we cannot lock up the UI thread. Essentially, we need to open a Request channel at the right URL, write some byte content into the request stream & then expect a response back. In Silverlight, this means jumping through two different threads before coming back to the main UI thread. Check out this wonderful post on why we need to do this (here).
Now, in addition to the thread-hopping, our HTTP Post request needs to be formatted correctly in header & content for the OData endpoint to honor it. Here’s some code using the native “HttpWebRequest” from a Windows Phone app. Essentially, I am making an HTTP Post request against my SQL Azure OData service to insert a new Team member to our DB table:
private void SubmitPost() { HttpWebRequest myRequest = (HttpWebRequest)WebRequest.Create(new Uri("YourODataEndpoint")); myRequest.Method = "POST"; myRequest.Accept = "application/atom+xml"; myRequest.ContentType = "application/atom+xml;type=entry"; myRequest.BeginGetRequestStream(new AsyncCallback(GetRequestStreamCallback), myRequest); } private void GetRequestStreamCallback(IAsyncResult asynchronousResult) { HttpWebRequest request = (HttpWebRequest)asynchronousResult.AsyncState; System.IO.Stream postStream = request.EndGetRequestStream(asynchronousResult); XNamespace ds = "http://schemas.microsoft.com/ado/2007/08/dataservices"; XNamespace dsmd = "http://schemas.microsoft.com/ado/2007/08/dataservices/metadata"; var content = new XElement(dsmd + "properties", new XElement(ds + "Name", "Test"), new XElement(ds + "TwitterHandle", "@Test") ); XNamespace atom = "http://www.w3.org/2005/Atom"; var entry = new XElement(atom + "entry", new XElement(atom + "title", "A new team member"), new XElement(atom + "id", string.Format("urn:uuid:{0}", Guid.NewGuid())), new XElement(atom + "updated", DateTime.Now), new XElement(atom + "author", new XElement(atom + "name", "Sam")), new XElement(atom + "content", new XAttribute("type", "application/xml"), content) ); byte[] postContentBytes = Encoding.UTF8.GetBytes(entry.ToString()); postStream.Write(postContentBytes, 0, postContentBytes.Length); postStream.Close(); request.BeginGetResponse(new AsyncCallback(GetResponseCallback), request); } private void GetResponseCallback(IAsyncResult asynchronousResult) { HttpWebRequest request = (HttpWebRequest)asynchronousResult.AsyncState; HttpWebResponse response = (HttpWebResponse)request.EndGetResponse(asynchronousResult); Stream streamResponse = response.GetResponseStream(); StreamReader streamRead = new StreamReader(streamResponse); string responseString = streamRead.ReadToEnd(); // Update some UI if needed. streamResponse.Close(); streamRead.Close(); response.Close(); }In addition to the native “HttpWebRequest”, the “WebClient” class also seems to get the job done; but you need to set the “WebClient.Headers” property correctly to make the right HTTP request. Check out this post (here) on details about HTTP communication from the Silverlight world. Anyway, here’s the corresponding code using WebClient class:
private void PostUsingWebClient() { WebClient client = new WebClient(); client.UploadStringCompleted += new UploadStringCompletedEventHandler(client_UploadStringCompleted); XNamespace ds = "http://schemas.microsoft.com/ado/2007/08/dataservices"; XNamespace dsmd = "http://schemas.microsoft.com/ado/2007/08/dataservices/metadata"; var content = new XElement(dsmd + "properties", new XElement(ds + "Name", "Test"), new XElement(ds + "TwitterHandle", "@Test") ); XNamespace atom = "http://www.w3.org/2005/Atom"; var entry = new XElement(atom + "entry", new XElement(atom + "title", "A new team member"), new XElement(atom + "id", string.Format("urn:uuid:{0}", Guid.NewGuid())), new XElement(atom + "updated", DateTime.Now), new XElement(atom + "author", new XElement(atom + "name", "Sam")), new XElement(atom + "content", new XAttribute("type", "application/xml"), content) ); client.UploadStringAsync(new Uri("YourODataEndpoint", UriKind.Absolute), entry.ToString()); } void client_UploadStringCompleted(object sender, UploadStringCompletedEventArgs e) { if (e.Error != null) { // Oops } else { // Success } }So, that’s it. Performing CRUD operations against an OData service isn’t all that bad, is it?

<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
Vittorio Bertocci (@vibronet) posted A Digression on ACS and Rules on 7/25/2011:
As you know, ACS offers a simple-yet-powerful rule engine which you can use for processing incoming claims and keep out of your application a considerable chunk of logic: claims set normalization, occasional policy decision point, and so on. The primitive there is the claim mapping rule: if an incoming claim matches the premise of a rule then the conclusion (in form of output claim) is added to the token that ACS will issue. Classic modus ponens, for the first-order logic aficionados among you. In inference rule notation:
Simply put, that means that I can codify logic such as “if you see a claim coming from Google, of type ‘email’ and with value ‘johndoenet64@gmail.com’ please add to the output token a claim of type ‘role’ and value ‘hairdresser’”. There are variations, for example I can omit claim type and/or value if I want my rule to be triggered for a wider range of inputs (i.e. I might want a rule which gets triggered every time I get something from Google, regardless of which claims are provided: the system rule adding identity provider info is a good example of that), but that’s pretty much it.
One interesting fact you may not be aware of is that ACS rules can be chained: that is, you can create rules which will be triggered by the output of other rules. All you need to do is create a rule whose input claim has ACS itself as issuer.
For example: you could create a rule which assigns to all the users in the role “hairdresser” to the role “cashier” and “authorized shipment slips signer”, two roles associated to the hairdresser position.
The advantages of the chained approach to the “enumeration” one is obvious. If both John and Pamela are hairdressers, with the chaining I need just 4 rules (two for assigning the hairdresser role to the users, two for adding the extra roles to the hairdresser role (which starts looking more like a group)) versus the 6 I’d need without chaining (three rules with email premise and role conclusion per user). That’s N+2 vs 3N… they diverge pretty quickly

Apart from the sheer number of rules, there’s also the manageability of the system. Onboarding Pamela as hairdresser, or changing her position later on, entails just adding (or changing) one single rule. If the hairdresser responsibilities change over time, all you need to do is changing the rules that have role-hairdresser as premise. Neat-o.
The above is a schema of how the usual rules work. A is the set of all possible claim types/values from the A issuer, O is the set of the claims issued by ACS (B is there just for showing that there can be multiple IPs). The blue arrow from A to O represent rules of the first type, the blue arrow that loops from O to O represents the chained rules. Let’s abuse this notation a bit and give a representation of the two rule styles above.
In the version without chaining, we have 6 rules (all of the form {A,O} predicate) which assign to John and Pamela to the 3 roles.
In the version with chaining, we have two rules of the form {A,O} and two of the form {O,O}. Welcome to the exciting world of predicates.
See what we have done here? The blue rule assigned Joe and Pamela to the set of the hairdressers; the red and green rules got chained and indirectly assigned Joe and Pamela to the set of the signers and the set of the cashiers, too.The case above is a fairly unfortunate case, as the defining property we are using for determining that a user belongs to a given set (hairdressers) is unique to every element (every user has a different email address) hence in order to define our first set we need to add as many rule as there are users.
If our users would come from an identity provider that supplies more structured info, such as the directory for a cosmetology school, we could be in a better shape. For example students may be subdivided in groups according to the specialties they elected: hair stylist, skin care, nail technology and so on. Why did I pick up this sample again? Now I have to play along, tho
Anyway, let’s say that those students all go to work in a salon during the summer break, and that salon uses an application secured via ACS. At this point the rule could be “if you see a claim coming from the cosmetology school AD, of type ‘group’ and with value ‘hair stylist’ please add to the output token a claim of type ‘role’ and value ‘hairdresser’”. That rule would instantly cover all the students satisfying the criteria, as opposed to just one as before. You can even extend those sets by boolean union, for example adding a rule which establishes that the Barbering students are also in the Hairdresser role.
The chaining technique would have the same value, refining the properties of one set instead of having to recreate it; but never really doing anything for altering the number of elements affected.Now what if, instead of the union of sets, we’d want to target the intersection? This is a very, very common requirement. For example, let’s say that the salon will employ only hair stylist students who are at the last year of the course. With the current {A, O} and {O, O} set of predicates, the answer is simple: you can’t. Or better, you can if you “cheat”. You can go by enumeration: if you know in advance that Rudy is a last year student in the hair stylist track, you can provision him by email and do the same with everybody else. That is not always possible, of course, and it’s not very efficient or manageable.
The other possibility is to rely on the directory administration of the school, and ask him/her to create a group “employed at salon A” that can can be used by ACS for assigning the hairdresser role to the correct group. There will be occasions in which you’ll be able to do it, but most often than not you should take as little dependency from the incoming source as possible (no guarantees they are willing to help, or will reliably and timely do so).As mentioned here, from today ACS offers a new type of rule which allows you to identify the intersection of two sets. By allowing you to define two input claim conditions in logical AND from the same IP, that is to say a predicate of the form {A&A,O} you can effectively express that
“if you see a claim coming from the cosmetology school AD, of type ‘group’ and with value ‘hair stylist’ AND
you see a claim coming from the cosmetology school AD, of type ‘group’ and with value ‘last year student’
please add to the output token a claim of type ‘role’ and value ‘hairdresser’”.
In other “words”, our diagram earns an extra predicate with different arity:
..and adding a bit of notation abuse, we can see how this new predicate effectively gives you the power of identifying intersections:
Now, you may raise the fact that some conditions may require intersection with more than two sets. That’s fair. The good news is that you can add extra conditions, by feeding the result of one rule as one of the two inputs of another. In other words, you can write rules of the form {A&O, O} (of course the order of A and O in the premise does not matter, as AND is commutative). So if you want one of the students you employ to be allowed to operate a cashier machine only if older than 21, you can cascade the former cashier rule by modifying it as follows:
basically that means we added a predicate of the form shown in red:
Here you can see one case in which no student is actually allowed to operate the cashier:
There is one guy in the “adults” group, but that group has empty intersection with the hairdresser role (which was itself the intersection of the hair stylists and the last year students groups). You can iterate as many times you want, and you can even do intersections entirely in the O domain (with predicates of the form {O&O, O}).
Well, it’s the 3rd blog post I write this weekend, and it’s technically Monday morning now the time is up, I better get some sleep.
The hair salon scenario is perhaps not the most common SaaS application you’ll find around, but I hope this was useful for you to think about how to use ACS rules. If you have feedback on how ACS rules, don’t be shy!

![image_thumb[4]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-00-26-94-metablogapi/2477.image_5F00_thumb4_5F00_4C2981A0.png "image_thumb[4]")

![image_thumb[7]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-00-26-94-metablogapi/0827.image_5F00_thumb7_5F00_61C3BA3D.png "image_thumb[7]")
![image_thumb[9]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-00-26-94-metablogapi/7608.image_5F00_thumb9_5F00_7570A3D1.png "image_thumb[9]")
![image_thumb[10]](http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-00-26-94-metablogapi/0246.image_5F00_thumb10_5F00_74983DE7.png "image_thumb[10]")






<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Bruce Kyle reported Updated Developer Training Kit Integrates SharePoint, Azure, SQL Azure in a 7/26/2011 post:
The developer training kit that show you how to combine the power of both SharePoint 2010 and Windows Azure has been updated.
SharePoint 2010 provides many ways to integrate with Windows Azure. From simple SQL Azure data-centric applications to complex workflow that leverages custom Azure services, there is great potential to integrate these two growing technologies. The kit contains twelve modules that include PowerPoint decks, hands-on labs and source code that shows how the SharePoint 2010 platform and Windows Azure platform can work together.
You can view the online MSDN version of the training course here: http://msdn.microsoft.com/en-us/SPAzureTrainingCourse
You can also download an offline version of the course here http://go.microsoft.com/?linkid=9762346 which allows you to store the hands-on labs and presentations on your local computer.
SharePoint + Azure Dev Training Units
- Windows Azure Development Overview. This unit provides an overview of the Windows Azure Platform, to understand the services Microsoft is providing as part of the Windows Azure Platform, the key concepts, and how to get started.
- SharePoint 2010 Development Overview. This unit will help you get started with development for SharePoint 2010 using Visual Studio 2010.
- Getting Started with Integrating SharePoint 2010 and Windows Azure This unit introduces some of the ways in which you can integrate SharePoint 2010 and Windows Azure.
- Integrating Windows Azure Web Services with SharePoint 2010. This unit describes key Windows Azure components and features and identifies integration points and common solution patterns for combining SharePoint 2010 and Windows Azure.
- Integrating jQuery, SharePoint 2010 and WCF Services in Windows Azure. In this unit you will learn how SharePoint AJAX Enabled Web Parts can communicate with Windows Azure Services using JQuery.
- Integrating Windows Azure in Office 2010 Solutions. This unit covers the different ways you can integrate Office 2010 with the cloud.
- Using Bing Maps in SharePoint 2010 with SQL Azure and Business Connectivity Services. This unit provides an introduction to working with SQL Azure, SharePoint 2010 and the Bing Maps Platform.
- Securing Windows Azure Services for SharePoint 2010. This unit provides a background on how to use Windows Identity Foundation for securing Windows Azure Services on SharePoint 2010.
- Using Windows Azure Blob Storage with SharePoint 2010. This unit provides an overview of Windows Azure Data Storage and various Blob storage related artifacts and interfaces. It also explains how to integrate Azure Blobs with SharePoint 2010 for elastic storage.
- Azure Hosted Application Design Pattern for SharePoint. This unit explains the Windows Azure Hosted Application Design Pattern and associated development patterns. It also explains the SharePoint 2010 Sandbox Solutions and challenges associated with it.
- Using Windows Azure with SharePoint Event Handlers. This unit introduces Azure Worker Roles and details how to call and communicate with Worker Roles from a SharePoint Event Handler.
- Using Windows Azure with SharePoint Workflow. This unit explains how to call and communicate with Worker Roles from a Workflow. It also introduces Pluggable Services and how to use it with Azure Worker Roles.
US Training Events at Conferences
We’ll be conducting one-day developer training workshops on “SharePoint & Windows Azure” using this kit at various locations including the below conferences.
- SharePoint Saturday Conference in Washington DC on August 11
- SharePoint Conference (SPC) in Anaheim on October 6

• Mike Tillman (@MiTillman) posted Just Released: New Windows Azure Tutorials and Tutorial Landing Pages to the Windows Azure Team blog on 7/26/2011:
We’re pleased to announce four new Getting Started Tutorials that will help developers and IT pros who are interested in trying out Windows Azure to get up-and-running quickly. In addition to these tutorials, we just launched a new tutorials section on the Windows Azure product website that catalogs tutorial content covering all aspects of the Windows Azure platform.
The new getting started tutorials cover several common scenarios:
- Installing the SDK and Getting a Subscription walks through the process of setting up a Windows Azure development environment and registering for a Windows Azure subscription.
- Deploying a Windows Azure Sample Application describes how to deploy and configure a pre-packaged Windows Azure application.
- Developing a Windows Azure Hello World Application Using ASP.NET MVC 3 describes how to create a basic web application and deploy it to Windows Azure.
- Developing a Windows Azure Data Application Using Code First and SQL Azure expands on the Hello World application by using the Entity Framework Code First feature to add a SQL Azure database component.
The new tutorial landing pages bring together the best Windows Azure tutorials from across several Microsoft sites and group them by task and experience level to make it easy to identify the tutorial that best meets your needs. For example, if you want to move an existing application to Windows Azure, check out Migrate Services and Data Tutorials; if you need to add authentication to an existing Windows Azure application, try Control Access Tutorials.
We would love to get your feedback about the new pages or any of the content on the Windows Azure product website. Send us your thoughts at: azuresitefeedback@microsoft.com.

Mike is Managing Editor, Windows Azure.
Jonathan Rozenblit (@jrozenblit) analyzed Social Gaming Powered By Windows Azure in a 7/25/2011 post:
Social applications (games, sharing, and location-based applications and services) are very quickly becoming the most prominent types of applications. These social applications have the potential to grow from a few users to millions of users in an incredibly short period of time, and as such, they need a robust, scalable, and dependable platform on which to run to meet the growing demands of the users.
Social Gaming
In their January 2011 Social Gaming: Marketers Make Their Move report, eMarketer predicts that the social gaming market will increase to $1.32 billion in revenues by 2012, up from $856 million in 2010. As the social gaming market continues to grow and become more profitable, many companies are looking to take their games to the next level and platforms to allow them to do it.
If we take the founding principles of Windows Azure (on-demand scalable computing resources, storage, and geographic delivery) and apply them to the needs of social games, we can quickly see how Windows Azure and Social Gaming is a perfect match. Companies like Sneaky Games (the developers of the Facebook fantasy game Fantasy Kingdoms) and Playdom (the makers of Bola Social Soccer, a Facebook, Sonico, and Orkut game with over 5 million users) are already using Windows Azure as their backend platform.
Windows Azure Toolkit for Social Games
To make it even easier to develop social games with Windows Azure, the same folks who brought you the Windows Azure Toolkit for Windows Phone 7 and iOS have now released a preview of their latest toolkit, the Windows Azure Toolkit for Social Games. The toolkit allows you to quickly get started building new social games with Windows Azure. It includes accelerators, libraries, developer tools, and samples. It also has specific services and code to handle capabilities unique to games, such as storing user profiles, maintaining leader boards, in-app purchasing, and so forth.
Tankster
As a starting point, the toolkit also includes the source code for a game called Tankster, created by Grant Skinner and his team at gskinner.com. The game is built with HTML5 and comes complete with reusable service-side code and documentation. It also supports a variety of social interactions including messaging, wall posts, and comments while player achievements and game stats are presented on a live leaderboard so gamers can interact with each other.
Try your skills at a round of Tankster >>
Next Steps
So what’s next?
Then have a look at the samples and Tankster.
Deep dive into the architecture behind Tankster >>
If you’ve previously developed a game, see how you can overlay the functionality provided by the toolkit onto your game. If the toolkit doesn’t fit with your game, no worries. Think about your game’s architecture and where you can leverage Windows Azure’s on-demand compute, storage, and geographic delivery services to get your game in the Cloud. Either way, take this opportunity to see how you, too, can leverage the benefits of Windows Azure. If you don’t have an existing game, now’s the best time to sit down and design one!

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Tim Anderson (@timanderson) announced Microsoft releases Visual Studio LightSwitch: a fascinating product with an uncertain future in a 7/26/2011 post:
Microsoft has released Visual Studio LightSwitch, a rapid application builder for data-centric applications.
LightSwitch builds Silverlight applications, which may seem strange bearing in mind that the future of Silverlight has been hotly debated since its lack of emphasis at the 2010 Professional Developers Conference. The explanation is either that Silverlight – or some close variant of Silverlight – has a more important future role than has yet been revealed; or that the developer division invented LightSwitch before Microsoft’s strategy shifted.
Either way, note that LightSwitch is a model-driven tool that is inherently well-suited to modification for different output types. If LightSwitch survives to version two, it would not surprise me to see other application targets appear. HTML 5 would make sense, as would Windows Phone.
So LightSwitch generates Silverlight applications, but they do not run on Windows Phone 7 which has Silverlight as its development platform? That is correct, and yes it does seem odd. I will give you the official line on this, which is that LightSwitch is not aimed primarily at developers, but is for business users who run Windows and who want a quick and easy way to build database applications. They will not care or even, supposedly, realise that they are building Silverlight apps.
I do not believe this is the whole story. It seems to me that either LightSwitch is a historical accident that will soon be quietly forgotten; or it is version one of a strategic product that will build multi-tier database applications, where the server is either Azure or on-premise, and the client any Windows device from phone to PC. Silverlight is ideal for this, with its modern presentation language (XAML), its sandboxed security, and its easy deployment. This last point is critical as we move into the app store era.
LightSwitch could be strategic then, or it could be a Microsoft muddle, since the official marketing line is unconvincing. I have spent considerable time with the beta and doubt that the supposed target market will get on with it well. Developers will also have a challenge, since the documentation is, apparently deliberately, incomplete when it comes to writing code. There is no complete reference, just lots of how-to examples that might or might not cover what you wish to achieve.
Nevertheless, there are flashes of brilliance in LightSwitch and I hope, perhaps vainly, that it does not get crushed under Microsoft’s HTML 5 steamroller. I set out some of its interesting features in a post nearly a year ago.
Put aside for a moment concerns about Silverlight and about Microsoft’s marketing strategy. The truth is that Microsoft is doing innovative work with database tools, not only in LightSwitch with its model-driven development but also in the SQL Server database projects and “Juneau” tools coming up for “Denali”, SQL Server 2011, which I covered briefly elsewhere. LightSwitch deserves a close look, even it is not clear yet why you would want actually to use it.
Related posts:



• Kathleen Richards reported Microsoft Releases Visual Studio LightSwitch 2011 in a 7/26/2011 post to the Visual Studio Magazine News blog:
Microsoft today announced the release of Visual Studio LightSwitch 2011, a template-driven, self-service development tool for creating data-driven .NET applications that can be deployed to the desktop, Web or Azure cloud. LightSwitch enables power users and developers to create line of business .NET applications with little or no coding.
Microsoft has made LightSwitch available for immediate download to MSDN subscribers, with general availability for purchase set for Thursday July 28. A Visual Studio LightSwitch 2011 license is US $299. A free, 90-day trial version of LightSwitch is available immediately, though users will have to register the software after the first 30 days.
<a target="_blank" href="http://ad.doubleclick.net/click%3Bh%3Dv8/3b50/3/0/%2a/c%3B243457146%3B1-0%3B0%3B66880671%3B4307-300/250%3B41849540/41867327/1%3B%3B%7Efdr%3D243718845%3B0-0%3B1%3B42240652%3B4307-300/250%3B43100960/43118747/1%3B%3B%7Esscs%3D%3fhttps://www.ibm.com/services/forms/signup.do?source=gts-LITS-sdc-NA&S_PKG=601AS5FW&S_TACT=601AS8VW"><img src="http://s0.2mdn.net/3000209/Conversations_300x250.jpg" width="300" height="250" border="0" alt="Advertisement" galleryimg="no"></a> < a href="http://ad.doubleclick.net/jump/eof.vsm/;Topic=Visual_Studio_2010;Topic=NET;Topic=Development;item=4c0fd72e_bf0f_4c5f_a5f6_3102cce33b4c;pos=BOX_A3;tile=7;sz=336x280,300x250;ord=123456789?" target="_blank" >< img src="http://ad.doubleclick.net/ad/eof.vsm/;Topic=Visual_Studio_2010;Topic=NET;Topic=Development;item=4c0fd72e_bf0f_4c5f_a5f6_3102cce33b4c;pos=BOX_A3;tile=7;sz=336x280,300x250;ord=123456789?" border="0" alt="" />< /a>
Jason Zander, corporate vice president for the Visual Studio team at Microsoft, announced the LightSwitch release in his blog on Tuesday and explained the thinking behind the latest edition to the Visual Studio family of products:
[LightSwitch] starts with the premise that most business applications consist of data and the screens that users interact with. LightSwitch simplifies attaching to data with data source wizards or creating data tables with table designers. It also includes screen templates for common tasks so you can create clean interfaces for your applications without being a designer. Basic applications can be written without a line of code. However, you can add custom code that is specific to your business problem without having to worry about setting up classes and methods.OakLeaf Systems' principal Roger Jennings, who specializes in data development and Windows Azure, is a proponent of LightSwitch. Its use of the Azure cloud for deployment and data on the backend works as advertised, he said in an email interview. "It corresponds to .NET and Visual Studio as Microsoft Access’ RAD capabilities related to Visual Basic 6 and earlier. It’s likely to bring a lot of fledgling developers into the .NET programming fold and the Windows Azure Platform," said Jennings, who noted that, "SQL Azure eliminates the need for developers to have DBA skills."
LightSwitch Beta 2 shipped in March with a Go-Live license for internal production use. The first public beta of the technology was released to developers last August at the Visual Studio Live! conference. Early on LightSwitch received mixed reactions from developers, some of whom bemoaned potential IT and security issues from providing lower barriers to entry to nonprofessional programmers who are essentially creating forms-over-data apps in corporate environments.
The technology offers starter kits for common business applications, pre-configured screen templates, themes and components for building line of business solutions without requiring code for common data query, record-creation and maintenance tasks. LightSwitch data can be exported to Microsoft Office applications such as Excel and consumed from various data sources including SQL Server Express, SQL Server, SQL Azure, SharePoint 2010 Lists, Entity Data Framework and WCF RIA Services.
If custom coding is required, projects can be migrated to Visual Studio 2010 (with Service Pack 1) for further development in C# or VB.NET. The LightSwitch client technology is built on Silverlight 4 and a Model View ViewModel (MVVM) pattern, enabling LightSwitch applications to run in browsers as a plug-in or out of the browser as desktop applications.
Extensible Solutions
Microsoft is heavily promoting the extensibility of LightSwitch solutions in hopes of creating a third-party ecosystem of extensions. At the Beta 2 launch, Andrew Brust, founder and CEO of Blue Badge Insights, told the audience that the ecosystem in his view was "comparable to the opportunity when Visual Basic 1.0 was entering its final beta roughly 20 years ago," according to his Redmond Diary blog.ComponentOne, DevExpress, First Floor Software, Infragistics and RSSBus are offering extensions for LightSwitch on Tuesday as part of the launch. Infragistics released NetAdvantage for Visual Studio LightSwitch, a Silverlight-based toolset of data visualization UI controls, shells and themes specifically geared towards building out dashboards and enhancing line of business applications. A subset of the tooling is free, with the full version available to NetAdvantage Ultimate subscribers or as a standalone product.
Jason Beres, Infragistics' VP of product management, expects LightSwitch to offer a solution to business users whose requirements fit somewhere in between one and two-tier Microsoft Access applications and scalable solutions in Visual Studio. "LightSwitch is the sweet spot in between, where I don't really want to get into the guts of code but I want something scalable and that can actually stand the test of lots of users and that is built on a modern platform," said Beres. "So if I need to write code I can, but it would be desirable not to write code and our products fit into that."
LightSwitch extensions are available in the Visual Studio Gallery and accessible via the Extension Manager within the IDE, which enables users to select extensions for use in current projects. In Visual Studio LightSwitch 2011, the six extensibility points include business type, control, custom data source, screen templates, shell and theme. Developers can learn more about extensibility from the LightSwitch Extensibility Cookbook, released with LightSwitch Beta 2.
Kate is the editor of RedDevNews.com and executive editor of Visual Studio Magazine.
Full disclosure: I’m a contributing editor for Visual Studio Magazine.
The Visual Studio LightSwitch Team (@VSLightSwitch) opened the LightSwitch Release landing page at about 10:00 AM on Tuesday morning 7/26/2011:

There’s also a LightSwitch Developer Center on MSDN":

Update: The LightSwitch team responded with a link to the Buy Visual Studio LightSwitch 2011 page:

The Buy from Microsoft button won’t be active until 7/27/2011, but the license is US$299, according to the reply tweet I received from @VSLightSwitch.
David Rubenstein reported Infragistics rolls out UI tools for LightSwitch in a 7/26/2011 article for the SD Times on the Web blog:
As Microsoft prepares its Thursday Visual Studio LightSwitch release, UI tool company Infragistics today released a set of Silverlight-based tools to give “end-user developers” the power to create richer interactions with applications.
According to Jason Beres, vice president of product management at Infragistics, the company has taken its XAML controls and data visualizations and “made them LightSwitch-friendly,” which allows users to take advantage of Microsoft’s prewritten code to handle the routine tasks of an application.
LightSwitch, Beres said, falls in the middle of the spectrum between Access, the software business developers have been using to create line-of-business applications; and Visual Studio, where professional developers work. He added that LightSwitch will first find an uptick “with Visual Studio developers who want to do something quicker. As LightSwitch gets picked up with end-user developers, it will help there as well. There will be some learning [for the end-user developers], but I don’t think the curve will be that big.”
NetAdvantage for Visual Studio LightSwitch is an add-on to the Microsoft IDE that is composed of user experience controls and components that users can drag into a Visual Studio form designer, Beres explained.
The tool set includes a number of themes, including Metro, that users can select to change the look and feel of the application, he said. Also, the company took its Microsoft Outlook navigation bar and windowing controls, so screens show up as tiles in the main shell experience. “This gives applications a more interesting, immersive experience,” Beres said.Further, LightSwitch is compelling because applications can be deployed directly to Windows Azure. “It would be slick if LightSwitch deployed to HTML5,” Beres said, mentioning a path Microsoft is heading down for cross-platform application functionality.


According to Microsoft, LightSwitch will release on Tuesday, 7/26/2011 at about noon PDT.
Michael Washington (@ADefWebserver) explained Tracing: Debugging Your LightSwitch Application In Production in a 7/22/2011 post to his Visual Studio LightSwitch Help blog (missed when posted):
So you have deployed your LightSwitch application and everything is running fine. Then you get an email that a user is unable to perform a function. The problem you now have is that this is a problem that you can only see in production. When you need to preform debugging of a LightSwitch application in production, you want to use Tracing.
You can also read more about Tracing at this link: http://msdn.microsoft.com/en-us/library/wwh16c6c.aspx.
This article covers Tracing when your LightSwitch application is deployed as a “web application”.
Set-up Tracing Of Your Deployed Applications
Publish your LightSwitch application.
Open the web.config of your deployed application.
To enable Tracing, the Microsoft.LightSwitch.Trace.Enabled setting, and the trace enabled setting, must be set to true.
In this example, we will also set Microsoft.LightSwitch.Trace.LocalOnly to true (so Tracing will only work using ”http://localhost”), and Microsoft.LightSwitch.Trace.Level to verbose (so we will see more detailed information).
See the Dan Seefeldt article for an explanation of all the settings.
View Tracing In Your Web Browser
First open a web browser and navigate to your LightSwitch application.
Next, open another web browser, and go to the web address with ”/Trace.axd” at the end (for example: http://localhost/{Your LightSwitch Application}/Trace.axd).
If we look at the the screen that we have navigated to inside the LightSwitch screen designer, we can see that the collections on the left-hand side of the screen are called and show up in the Trace.
When we click View Details…
We will see some lines marked “A user implemented method does not exist”.
This refers to the the methods that are part of the “Save Pipeline” that you could have implemented code in but you did not.
Special Thanks
A special thanks to LightSwitch team member, Dan Seefeldt, for his assistance in creating this article.










Return to section navigation list>
Windows Azure Infrastructure and DevOps
• The Microsoft Global Foundation Services team posted a 00:10:17 Microsoft Cloud Infrastructure YouTube video on 7/24/2011:
This video will provide a deeper look at how Microsoft uses secure, reliable, scalable and efficient best practices to deliver over 200 cloud services to more than a billion customers and 20 million businesses in over 70 countries.It provides an understanding at how we view our end-to-end cloud strategy from an infrastructure perspective.
Windows Azure (@WindowsAzure) North Central US data center topped CloudSleuth’s Response Time list and maintained 100% availability for the last 6 hours in a 7/26/2011 test:

Here are the same reports for the past 30 days:

Lori MacVittie (@lmacvittie) was Pondering the impact of cloud and Web 2.0 on traditional middleware messaging-based architectures and PaaS in her Web 2.0 Killed the Middleware Star post of 7/26/2011 to F5’s DevCentral blog:
It started out innocently enough with a simple question, “What exactly *is* the model for PaaS services scalability? If based on HTTP/REST API integration, fairly easy. If native middleware… input?” You’ll forgive the odd phrasing – Twitter’s limitations sometimes make conversations of this nature … interesting.
The discussion culminated in what appeared to be the sentiment that middleware was mostly obsolete with respect to PaaS.
THE OLD WAY
Very briefly for those of you who are more infrastructure / network minded than application architecture fluent, let’s review the traditional middleware-based application architecture.
Generally speaking, middleware – a.k.a. JMS, MQ Series and most recently, ESB – is leveraged as means to enable a publish-subscribe model of sharing data. Basically, it’s an integration pattern, but no one really likes to admit that because of the connotations associated with the evil word “integration” in the enterprise. But that’s what it’s used for – to integrate applications by sharing data. It’s more efficient than a point-to-point integration model, especially when one application might need to share data with two, three or more other applications. One application puts data into a queue and other applications pull it out. If the target of the “messages” is multiple applications or people, then the queue keeps the message for a specified period of time otherwise, it deletes or archives (or both) the message after the intended recipient receives it.
That pattern is probably very familiar to even those who aren’t entrenched in enterprise application architecture because it’s similar to most social networking software in action today. One person writes a status update, the message, and it’s distributed to all the applications and users who have subscribed (followed, put in a circle, friended, etc… ). The difference between Web-based social networking and traditional enterprise applications is two-fold:
- First – web-based applications were not, until the advent of Web 2.0 and specifically AJAX, well-suited to “polling for” or “subscribing to” messages (updates, statuses, etc…) thus the use of traditional pub-sub architectures for web applications never much gained traction.
- Second – Middleware has never scaled well using traditional scalability models (up or out). Web-based applications generally require higher capacity and transaction rates than traditional applications taking advantage of middleware, making middleware’s inability to scale problematic. It is unsuited to use in social networking and other high-volume data sharing systems, where rapidity of response is vital to success.
Moreover as James Urquhart
noted earlier in the conversation, although cloud computing and virtualization appear capable of addressing the scalability issue by scaling middleware at the VM layer – which is certainly viable and makes the solution scalable in terms of volume – this introduces issues with consistency, a.k.a. CAP, because persistence is not addressed and thus the consistency of messages across queues shared by users is always in question. Basically, we end up – as pointed out by James Saull
- with a model that basically kicks the problem to another tier – the scalable persistence service. Generally that means a database-based solution even if we use the power of virtualization and cloud computing to address the innate challenges associated with scaling messaging middleware. Mind you, that doesn’t mean an RDBMS is involved, but a data store of some kind and all data stores introduce similar architectural and technologically issues with consistency, reliability and scalability.
THE NEW WAY
Now this is not meant to say the concept of queuing, of pub-sub, is absent in web applications and social networking. Quite the contrary, in fact. The concept is seen in just about any social networking site today that bases itself on interaction (integration) of people. What’s absent is the traditional middleware as a means to manage the messages across those people (and applications). See, scaling middleware ran into the same issues as stateful applications – they required persistence or a shared-nothing architecture to ensure proper behavior. The problem as you added middleware servers became the same as other persistence-based issues seen in web applications, digital shopping carts and even today’s VDI implementations. How do you ensure that having been subscribed to a particular topic that you actually manage to get the messages when the load balancing solution arbitrarily directs you to the next available server?
You can’t. Hence the use of persistent stores to enable scalability of middleware. What you end up with is essentially 4 tiers – web, application, middleware and database. You might at this point begin to recognize that one of these tiers is redundant and, given the web-based constraints above, unnecessary. Three guesses which one it is, and the first two do not count.
Right. The middleware tier. Web 2.0 applications don’t generally use a middleware tier to facilitate messaging across users or applications. They use APIs and web-based database access methods to go directly to the source. Same concept, more scalable implementation, less complexity. As James put it later in the conversation, “the “proven” architecture seems to be Web2, which has its limitations.”
BRINGING IT BACK to PaaS
So how does this relate to PaaS? Well, PaaS is Platform as a Service which is really a nebulous way of describing developer services delivered in a cloud computing environment. Data, messaging, session management, libraries; the entire application development ecosystem. One of those components is messaging and, so it would seem, traditional middleware (as a service, of course). But the scalability issues with middleware really haven’t been solved and the persistence issues remain.
Adding pressure is the web development paradigm in which middleware has traditionally been excluded. Most younger developers have not had the experience (and they should count themselves lucky in this regard) of dealing with queuing systems and traditional pub-sub implementations. They’re a three-tier generation of developers who implement the concept of messaging by leveraging database connectivity directly and most recently polling via AJAX and APIs. Queueing may be involved but if it is, it’s implemented in conjunction with the database – the persistent store – and clients access via the application tier directly, not through middleware.
The ease with which web and application tiers are scaled in a cloud computing environment, moreover, meets the higher concurrent user and transaction volume requirements (not to mention performance) associated with highly integrated web applications today. Scaling middleware services at the virtualization layer, as noted above, is possible, but reintroduces the necessity of a persistent store. And if we’re going to use a persistent store, why add a layer of complexity (and cost) to the architecture when Web 2.0 has shown us it is not only viable but inherently more scalable to go directly to that source?
At the end of the day, it certainly appears that between cloud computing models and Web 2.0 having been forced to solve the shared messaging concept without middleware – and having done so successfully – that middleware as a service is obsolete. Not dead, mind you, as some will find a use case in which it is a vital component, but those will be few and far between. The scalability and associated persistence issues have been solved by some providers – take RabbitMQ for example – but that ignores the underlying reality that Web 2.0 forced a solution that did not require middleware and that nearly all web-based applications eschew middleware as the mechanism for implementing pub-sub and other similar architectural patterns. We’ve gotten along just fine on the web without it, why reintroduce what is simply another layer of complexity and costs in the cloud unless there’s good reason.
Viva la evolu[c]ion.




CloudTimes reported Analyst Forecast 42% Annual Growth for Cloud Systems Management Software in a 7/26/2011 post:
A new report “Global Cloud Systems Management Software Market 2010-2014” was released by MarketResearch.com, which was prepared based on in-depth analysis of the market with inputs from industry experts. The report covers the current market landscape and growth prospects of the Cloud Systems Management Software market and focuses on the Americas, EMEA, and APAC regions.
The research methodology is based on primary research which includes in-depth interviews with industry experts, vendors, resellers and customers as well as secondary research which includes a research platform, industry publications, company reports, news articles, analyst reports, trade associations and the data published by Government agencies.
The report forecasts that the Global Cloud Systems Management Software (CSMS) market will grow at a CAGR of 42% over the period of 2010-2014. The increasing need to deploy hybrid cloud infrastructure is one of the key factors contributing to this market growth. The CSMS market has also been witnessing the emerging focus on interoperable cloud architecture. However, increasing concerns about data security in the cloud could hinder the growth of this market.
The vendors dominating the Global CSMS market space include IBM, HP, Microsoft, and Symantec.
David Linthicum (@DavidLinthicum) asserted “A recent report from the Carbon Discloser Project shines a green light on cloud computing, but an efficient cloud still could be using dirty power” as a deck for his Beware: Cloud computing's green claims aren't always true article of 7/26/2011 for InfoWorld’s Cloud Computing blog:
Cloud computing must be green. After all, those who provide cloud computing technology say so, most cloud advocates say so, and even those who check up on such things say so.
Take the Carbon Discloser Project, for example. It just published a report on cloud computing and carbon emissions, "Cloud Computing: The IT Solution for the 21st Century." The conclusions were exciting: "The results show that by 2020, large U.S. companies that use cloud computing can achieve annual energy savings of $12.3 billion and annual carbon reductions equivalent to 200 million barrels of oil -- enough to power 5.7 million cars for one year."
However, there are flaws in the report, according to GreenMonk analyst Tom Raftery and as reported in ReadWrite Web. Chief among those flaws is the assumption that energy savings necessarily equate to reduced carbon emissions. "If I have a company whose energy retailer is selling me power generated primarily by nuclear or renewable sources, for example, and I move my applications to a cloud provider whose power comes mostly from coal, then the move to cloud computing will increase, not decrease, my carbon emissions," Raftery says.
It's a valid point: The idea of becoming more cost-efficient typically means you're more carbon-efficient as well -- but not always. If you go green, then you need to hook up fewer and fewer computers to grids that are powered by coal, whether they are cloudlike or not.
To Raftery's point, sometimes using cloud computing will make it worse, like moving 1,000 local servers from a nuclear- or wind-powered grid to 500 servers in a cloud powered by coal. Although cloud computing typically means resource pooling, thus using fewer computers, it matters more where they run when you consider the greenness of cloud computing -- or any form of computing for that matter.
So, once again, things are not cut and dry. There are many "it depends" moments when we talk about the greenness of cloud computing. But reducing energy usage through the cloud's greater efficiency is still a good development overall.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
See the John Treadway (@CloudBzz) reported Dell Joins OpenStack Parade to the Enterprise… in a 7/26/2011 post to his CloudBzz blog article in the Other Cloud Computing Platforms and Services section below.
<Return to section navigation list>
Cloud Security and Governance
SD Times on the Web reported Open Cloud Initiative Launches to Drive Open Standards in Cloud Computing in a 7/26/2011 post:
Today the Open Cloud Initiative (OCI), a non-profit organization was established to advocate open standards in cloud computing, announced its official launch at the OSCON 2011 Open Source Convention. Its purpose is to provide a legal framework within which the greater cloud computing community of users and providers can reach consensus on a set of requirements for Open Cloud, as described in the Open Cloud Principles (OCP) document, and then apply those requirements to cloud computing products and services, again by way of community consensus.
The Open Cloud Initiative (OCI) has launched its official website at http://www.opencloudinitiative.org/ and commenced a 30-day final comment period on the Open Cloud Principles (OCP), which are designed to ensure user freedoms without impeding the ability of providers to do business. They are focused on interoperability, avoiding barriers to entry or exit, ensuring technological neutrality and forbidding discrimination. They define the specific requirements for Open Standards and mandate their use for formats and interfaces, calling for “multiple full, faithful and interoperable implementations”, at least one of which being Open Source. Full text of the Principles can be found at http://www.opencloudinitiative.org/principles.
“The primary purpose of the Open Cloud Initiative (OCI) is to define “Open Cloud” by way of community consensus and advocate for universal adoption of Open Standard formats and interfaces” said Sam Johnston [@samj], founder and president. “Inspired by the Open Source Initiative (OSI), we aim to find a balance between protecting important user freedoms and enabling providers to build successful businesses.”
The Open Cloud Initiative (OCI) is governed by a Board of Directors comprising leaders from the cloud computing and Open Source industries, including Rick Clark, Marc Fleischmann, Sam Johnston, Shanley Kane, Noirin Plunkett, Evan Prodromou, Sam Ramji, Thomas Uhl, John Mark Walker and Simon Wardley.
The Open Cloud Initiative (OCI) is being founded as a California public benefit corporation (non-profit) and intends to obtain federal tax exemption by way of 501(c)(3) educational and scientific charity status in due course.
For more information, including the Open Cloud Initiative (OCI) Articles of Association, Bylaws, Open Cloud Principles (OCP), or to participate in the community, please visit http://www.opencloudinitiative.org.



<Return to section navigation list>
Cloud Computing Events
Gartner Fellow and Managing VP Daryl C. Plummer will present a one hour Cloud Computing Strategies to Optimize Your IT Initiatives Webinar on 7/27/2011 at 11:00 AM PDT:
Cloud computing is moving from a new idea to the next big strategy for optimizing how IT is used. We'll establish the reality of cloud computing for enterprises and consumers, and examine the maturity of cloud computing, its direction and the markets it affects.
- How is the definition and enterprise perspective of cloud computing evolving?
- How are cloud computing markets growing and maturing?
- What markets, vendors and strategies will transform most by moving to the cloud?
Register here.

Wilshire Conferences annouced that the NoSQL Now! conference will be held on 8/23 to 8/25/2011 at the San Jose Convention Center, San Jose, CA:
NoSQL Now! is a new conference covering the dynamic field of NoSQL technologies (Not Only SQL). It is scheduled for:
San Jose Convention Center
San Jose, California
August 23-25, 2011It is a vendor-neutral forum celebrating the diversity of NoSQL technologies and helping businesses develop objective evaluation processes to match the right NoSQL solutions with the right business challenge.
NoSQL Now! is intended for every enterprise that needs to find better, faster and cheaper solutions to managing its fast growing databases and data stores. The educational program will be designed to accommodate all levels of technical understanding, from novice through expert, with an emphasis on the design and management needs of enterprise IT and big data applications.
The venue will also provide opportunities for CTOs, developers and software entrepreneurs to meet and mix with potential customers and investors.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Joe Panetteiri asked OpenStack: Will VARs Learn From Cloud Services Providers? in a 7/26/2011 post to the TalkinCloud blog:
OpenStack, the open source cloud standard, seems to be catching on with more and more cloud services providers (CSPs). But I wonder if VARs are paying enough attention to OpenStack — which could have major long-term implications for how public and private cloud applications are deployed.
Some folks think OpenStack is only for large cloud services providers working on massive public or private cloud projects. Earlier today, for instance, Dell announced the Dell OpenStack Cloud Solution, which integrates OpenStack, Dell PowerEdge C servers, the Dell-developed “Crowbar” OpenStack installer, and services from Dell and Rackspace Cloud Builders.
Despite such lofty announcements, OpenStack isn’t just for big cloud projects. Instead, OpenStack positions itself for a range of audiences — including VARs and SMB customers.
But where do VARs and smaller MSPs (managed services providers) fit into the OpenStack conversation? Here’s one answer to that question: Rackspace was one of the first OpenStack proponents. And it’s a safe bet that the most profitable Rackspace channel partners — including small VARs — over the long haul will master one or more of the three core OpenStack components:
- OpenStack Compute
- OpenStack Object Storage
- OpenStack Image Service
Some folks think OpenStack could disrupt traditional virtualization companies like VMware. But I think OpenStack is more about portability — potentially giving large and small customers the flexibility to more easily migrate their SaaS applications from one cloud services provider to another. I also think service providers running OpenStack will emerge as a major alternative to Amazon Web Services.
Over the past year, the OpenStack effort has grown from 25 companies to 80 companies, notes Huffington Post. The lineup includes everyone from giants (Cisco, Citrix, Dell, Intel) to industry upstarts (Canonical, Nephoscale).
But I still wonder: Will small VARs wake up to the OpenStack opportunity? Or will those VARs sit on the sideline as big cloud services providers march forward with OpenStack?
Read More About This Topic


John Treadway (@CloudBzz) reported Dell Joins OpenStack Parade to the Enterprise… in a 7/26/2011 post to his CloudBzz blog:
The OpenStack Parade is getting bigger and bigger. As predicted, enterprise vendors are starting to announce efforts to make OpenStack “Enterprise Ready.” Today Dell announced their support for OpenStack through their launch of the “Dell OpenStack Cloud Solution.” This is a bundle of hardware, OpenStack, a Dell-created OpenStack installer (“Crowbar”), and services from Dell and Rackspace Cloud Builders.
Dell joins Citrix as a “big” vendor supporting OpenStack to their customers. Startups such as Piston are also targeting the OpenStack space, with a focus on the enterprise.
Just one year old, the OpenStack movement is a real long-term competitor to VMware’s hegemoy in the cloud. I fully expect to see IBM, HP and other vendors jumping into the OpenStack Parade in the not too distant future.


This is undoubtedly the reason we haven’t heard any news from Dell about their erstwhile Windows Azure Platform Appliance (WAPA) offering.
Barton George (@barton808) posted Dell announces availability of OpenStack solution; Open sources “Crowbar” software framework on 6/26/2011:
Today at OSCON we are announcing the availability of the Dell OpenStack Cloud Solution along with the open sourcing of the code behind our Crowbar software framework.
The Solution
Dell has been a part of the OpenStack community since day one a little over a year ago and today’s news represents the first available cloud solution based on the OpenStack platform. This Infrastructure-as-a-service solution includes a reference architecture based on Dell PowerEdge C servers, OpenStack open source software, the Dell-developed Crowbar software and services from Dell and Rackspace Cloud Builders.
Crowbar, keeping things short and sweet
Bringing up a cloud can be no mean feat, as a result a couple of our guys began working on a software framework that could be used to quickly (typically before coffee break!) bring up a multi-node OpenStack cloud on bare metal. That framework became Crowbar. What Crowbar does is manage the OpenStack deployment from the initial server boot to the configuration of the primary OpenStack components, allowing users to complete bare metal deployment of multi-node OpenStack clouds in a matter of hours (or even minutes) instead of days.
Once the initial deployment is complete, Crowbar can be used to maintain, expand, and architect the complete solution, including BIOS configuration, network discovery, status monitoring, performance data gathering, and alerting.
Code to the Community
As mentioned above, today Dell has released Crowbar to the community as open source code (you can get access to it the project’s GitHub site). The idea is allow users to build functionality to address their specific system needs. Additionally we are working with the community to submit Crowbar as a core project in the OpenStack initiative.
Included in the Crowbar code contribution is the barclamp list, UI and remote API’s, automated testing scripts, build scripts, switch discovery, open source Chef server. We are currently working with our legal team to determine how to release the BIOS and RAID which leverage third party components. In the meantime since it is free (as in beer) software, although Dell cannot distribute it, users can directly go the vendors and download the components for free to get that functionality.
More Crowbar detail
For those who want some more detail, here are some bullets I’ve grabbed from Rob “Mr. Crowbar” Hirschfeld’s blog:
Important notes:
- Crowbar uses Chef as it’s database and relies on cookbooks for node deployments
- Crowbar has a modular architecture so individual components can be removed, extended, and added. These components are known individually as “barclamps.”
- Each barclamp has it’s own Chef configuration, UI subcomponent, deployment configuration, and documentation.
On the roadmap:
- Hadoop support
- Additional operating system support
- Barclamp version repository
- Network configuration
- We’d like suggestions! Please comment on Rob’s blog!
Extra-credit reading
- THIS JUST IN: Dell Announces the Dell OpenStack Cloud Solution
- #Crowbar source released with #OpenStack Cloud install (#apache2 #opschef #Dell #cloud)
- How OpenStack installer (crowbar + chefops) works (video from 3/14 demo)
Pau for now…


Jeff Barr (@jeffbarr) announced Auto Scaling - Notifications, Recurrence, and More Control in a 7/25/2011 post to the Amazon Web Services blog:
We've made some important updates to EC2's Auto Scaling feature. You now have additional control of the auto scaling process, and you can receive additional information about scaling operations.
Here's a summary:
You can now elect to receive notification from Amazon SNS when Auto Scaling launches or terminates EC2 instances.
- You can now set up recurrent scaling operations.
- You can control the process of adding new launched EC2 instances to your Elastic Load Balancer group.
- You can now delete an entire Auto Scaling group with a single call to the Auto Scaling API.
- Auto Scaling instances are now tagged with the name of their Autos Scaling group.
Notifications
The Amazon Simple Notification Service (SNS) allows you to create topics and to publish notifications to them. SNS can deliver the notifications as HTTP or HTTPS POSTs, email (SMTP, either plain-text or in JSON format), or as a message posted to an SQS queue.You can now instruct Auto Scaling to send a notification when it launches or terminates an EC2 instance. There are actually four separate notifications: EC2_INSTANCE_LAUNCH, EC2_INSTANCE_LAUNCH_ ERROR, EC2_INSTANCE_TERMINATE, and EC2_INSTANCE_TERMINATE_ERROR. You can use these notifications to track the size of each of your Auto Scaling groups, or you can use them to initiate other types of application processing or bookkeeping.
George Reese, this feature is for you!
Recurrent Scaling Operations
Scheduled scaling actions for an Auto Scaling group can now include a recurrence, specified as a Cron string. If your Auto Scaling group manages a fleet of web services, you can scale it up and down to reflect expected traffic. For example, if you send out a newsletter each Monday afternoon and expect a flood of click-throughs, you can use a recurrent scaling event to ensure that you have enough servers running to handle the traffic. Or, you can use this feature to launch one or more servers to run batch processes on a periodic basis, such as processing log files each morning.Instance Addition Control
The Auto Scaling service executes a number of processes to manage each Auto Scaling group. These processes include instance launching and termination, and health checks (a full list of the processes and a complete description of each one can be found here).The SuspendProcesses and ResumeProcesses APIs give you the ability to suspend and later resume each type of process for a particular Auto Scaling group. In some applications, suspending certain Auto Scaling processes allows for better coordination with other aspects of the application.
With this release, you now have control of an additional process, AddToLoadBalancer. This can be particularly handy when newly launches EC2 instances must be initialized or verified in some way before they are ready to accept traffic.
Hassle-Free Group Deletion
You can now vanquish an entire Auto Scaling group to oblivion with a single call to DeleteAutoScalingGroup. You'll need to set the new ForceDelete parameter to true in order to do this. Before ForceDelete you had to wait until all instances in an Auto Scaling group were terminated before you were allowed to delete the Auto Scaling group. Auto Scaling will terminate all running instances in the group and obviates the waiting.Easier Identification
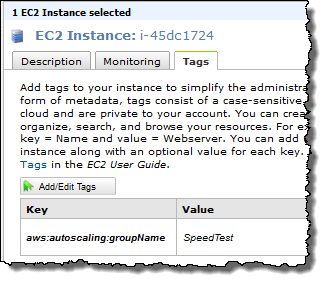
Instances launched by Auto Scaling are now tagged with the name of their Auto Scaling group so that you can find and manage them more easily. The Auto Scaling group tag is immutable and doesn’t count towards the EC2 limit of 10 tags per instance. Here is how the EC2 console would show an instance of the Auto Scaling group SpeedTest:
You can read more about these new features on the Auto Scaling page or in the Auto Scaling documentation.
These new features were implemented in response to feedback from our users. Please feel free to leave your own feedback in the EC2 forum.


These features would be welcome for Windows Azure.
<Return to section navigation list>

















{kind=link}
0 comments:
Post a Comment