Windows Azure and Cloud Computing Posts for 7/18/2011+
A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles.

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
Sudhir Hasbe posted Windows Azure Storage Architecture Overview on 7/19/2011:
Found this good article on Windows Azure Storage Architecture. Good read if you are planning use storage in cloud.
In this posting we provide an overview of the Windows Azure Storage architecture to give some understanding of how it works. Windows Azure Storage is a distributed storage software stack built completely by Microsoft for the cloud.
Before diving into the details of this post, please read the prior posting on Windows Azure Storage Abstractions and their Scalability Targets to get an understanding of the storage abstractions (Blobs, Tables and Queues) provided and the concept of partitions.
3 Layer Architecture
The storage access architecture has the following 3 fundamental layers:
- Front-End (FE) layer – This layer takes the incoming requests, authenticates and authorizes the requests, and then routes them to a partition server in the Partition Layer. The front-ends know what partition server to forward each request to, since each front-end server caches a Partition Map. The Partition Map keeps track of the partitions for the service being accessed (Blobs, Tables or Queues) and what partition server is controlling (serving) access to each partition in the system.
- Partition Layer – This layer manages the partitioning of all of the data objects in the system. As described in the prior posting, all objects have a partition key. An object belongs to a single partition, and each partition is served by only one partition server. This is the layer that manages what partition is served on what partition server. In addition, it provides automatic load balancing of partitions across the servers to meet the traffic needs of Blobs, Tables and Queues. A single partition server can serve many partitions.
- Distributed and replicated File System (DFS) Layer – This is the layer that actually stores the bits on disk and is in charge of distributing and replicating the data across many servers to keep it durable. A key concept to understand here is that the data is stored by the DFS layer, but all DFS servers are (and all data stored in the DFS layer is) accessible from any of the partition servers.
These layers and a high level overview are shown in the below figure:
Here we can see that the Front-End layer takes incoming requests, and a given front-end server can talk to all of the partition servers it needs to in order to process the incoming requests. The partition layer consists of all of the partition servers, with a master system to perform the automatic load balancing (described below) and assignments of partitions. As shown in the figure, each partition server is assigned a set of object partitions (Blobs, Entities, Queues). The Partition Master constantly monitors the overall load on each partition sever as well the individual partitions, and uses this for load balancing. Then the lowest layer of the storage architecture is the Distributed File System layer, which stores and replicates the data, and all partition servers can access any of the DFS severs.

Robin Shahan (@RobinDotNet) described how to Host your ClickOnce deployment in Azure for pennies per month in a 7/18/2011 post:
A while back, I wrote an article that shows you how to host your ClickOnce deployment in Windows Azure Blob Storage. The article assumed that you already had a Windows Azure account.
Since prequels are so popular in Hollywood (Star Wars I-III, anyone?), I thought I would write a prequel to explain how much it costs to host your deployment in Azure, and how to sign up for an Azure account and create the storage account. Hopefully, this article will be more popular than Jar Jar Binks.
Show me the money
How much does it cost to host your ClickOnce deployment in Windows Azure Storage? Well, for a pay-as-you-go account, here are the costs as of today, which I found by going to here and clicking on “Pay-As-You-Go”.
Windows Azure Storage
- $0.15 per GB stored per month
- $0.01 per 10,000 storage transactions
Data Transfers
- North America and Europe regions
- $0.15 per GB out
- Asia Pacific Region
- $0.20 per GB out
- All inbound data transfers are at no charge.
Let’s take an example. Let’s say we have a deployment consisting of 150 files and a total size of 30MB. We have 100 customers, and we are going to publish a new version every month, starting in January, and all 100 customers are going to update to every version. At the end of the year, how much will this have cost us?
Put your mathlete hats on and get out your calculators. Ready? Here we go…
The storage cost for one month = $0.15 / GB * 30MB * 1GB/1000MB = $.0045. So January will be (1*value), February will be (2*value) because we’ll have two versions. March will be (3*value), and so on until December when it hits (12*value) because we have 12 versions stored. After calculating that out for the whole year, the total cost of storing the deployment files for the year will cost $0.2475. This is affordable for most people.
Let’s talk about the storage transactions. If you have a file bigger than 32MB, it is one transaction per 4MB and one at the end of the list of blocks. If the file is smaller than 32MB, it’s 1 transaction for that file. All of the files in our case are less than 32MB. So when we upload a new version of the deployment, here are the costs:
Storage Transaction cost when uploading once = 30 files * $.01/10000 = $0.00003.
Data Transfer costs are free going up, so nothing to calculate there. How about coming back down to your customer?
Transaction cost when downloading once = 30 files * $.01/10000 = $0.00003.
Data transfer cost when downloading once = 30 MB * 1GB/1000MB * $0.15/GB = $0.0045
Now you’re wishing you’d paid attention in all of those math classes, aren’t you? And we’re not done yet. Let’s calculate our total for the entire year.
- $0.00036 = Storage Transaction cost for uploading 12 versions throughout the year.
- $0.00 = Data Transfer cost for uploading 12 versions.
- $0.2475 = Storage for 12 versions uploaded once per month and retained throughout the year.
- $0.036 = Storage Transaction cost for downloading 12 versions for 100 customers.
- $5.40 = Data Transfer cost when downloading 12 versions for 100 customers.
So our grand total is $5.68386, which is an average of 47 cents per month.
For more detailed information on Windows Azure storage costs, check out this blog entry from the Windows Azure Storage Team; it was written before they eliminated the Data Transfer cost of uploading to blob storage so don’t include that cost. Thanks to Neil McKenzie for clarification, and for providing the link to the Windows Azure Storage Team blog.
Hook me up with an Azure account
You have three basic options.
- If you have an MSDN subscription either through your company or because you are a bizspark customer, you probably get an MSDN benefit that more than covers your ClickOnce deployment costs. The basic mechanism for signing up will be similar, but the way you set up your storage account will be the same, so that information below should work for you as well as for those who have no MSDN account. You will have to give your credit card to cover any charges over the free usage benefit.
- If you want to try this out for free without giving your credit card, you can sign up for a free 30-day Azure pass. At the end of 30 days, you will have to delete the storage account and set it up on a real account if you want to continue using it. (If you use the same storage account name on the new account, the URL will be the same and your users will be able to pick up updates even though you changed accounts.)
- If you sign up for a pay-as-you-go account, you have to give your credit card, but you get a free benefit which would make my deployment example free for the first 3 months. Then at the end of 3 months, it will start charging your credit card, and you will not have to move your storage account. Let’s take a look at how to sign up for this type of account.
Go to http://www.microsoft.com/windowsazure/offers/ This should take you to the Windows Azure Platform Offers shown in Figure 1.

Figure 1: Windows Azure Platform OffersClick on the Pay-As-You-Go tab and then click the Buy button on the right. Next, you will be given a choice to sign up for a new Windows Live account, or use one you already have (Figure 2).
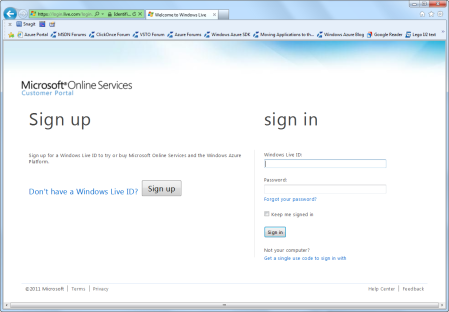
Figure 2: Sign up or sign in.They are going to send you e-mail on this account, so be sure it’s an account you actually check periodically. After logging in with your Windows Live account, you will be prompted for your profile information (Figure 3).
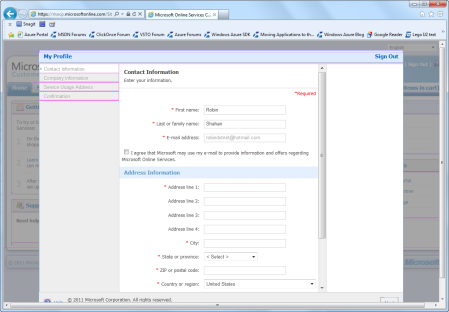
Figure 3: Profile information.Fill in your address and phone number and click the Next button. You will be prompted for company information (Figure 4). I think you’ll find that a lot of people work for “n/a”. I doubt Microsoft looks at that information, but you can amuse yourself by putting in the name of the most popular fruit in America, just in case someone IS looking at the company names — give them a surprise. Although, it is widely reported that Apple uses Windows Azure Storage for their new iCloud service, so it might not surprise them at all. (Google would definitely surprise them!)
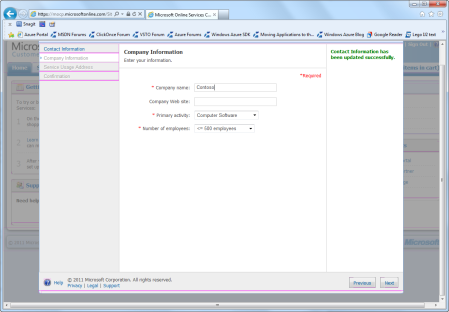
Figure 4: Company informationNow they will ask for your Service Usage Address. (You can check the box to use the information you filled in on the profile page.) This is displayed in Figure 5.
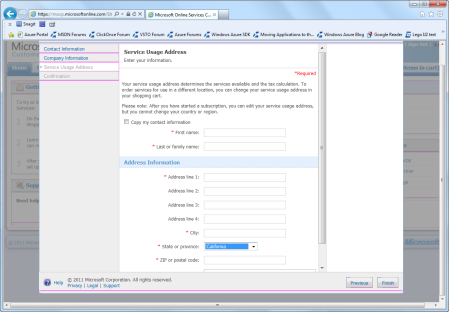
Figure 5: Service Usage Address.Fill in the information and click Finish. Next you will get directions to close this page and go to the Services page. You will find yourself at the Customer Portal for the Microsoft Online Services (Figure 6).

Figure 6: Customer Portal for Microsoft Online ServicesNow you get to pick a plan. If you pick the Windows Azure Platform Introductory Special, they provide some benefit for free for the first 90 days. This benefit covers our ClickOnce deployment example above, so it would be free for the first three months, and then would cost you as noted above. If you’re nuts and you don’t like free stuff and just want to pay now, You can select the Windows Azure Platform Consumption. Click the Buy Now button on your selection; you will be prompted to log in again and then taken to the Pricing and Online Subscription Agreement screen (Figure 7).
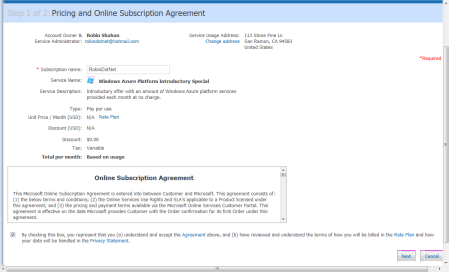
Figure 7: Pricing and Online Subscription Agreement.Fill in your subscription name. Pick something that you like and can remember. Then read the Online Subscription agreement as carefully as you read all of these things, check the box and hit the Next button. If you don’t read it carefully, and Microsoft comes to your house to pick up your firstborn child, don’t say I didn’t warn you.
Next comes the hard part. Fill in your credit card information and click the Submit button. If your credit card information is correct, you will be sent to the Azure portal (Figure 8).
I now have an Azure account! How do I set up my new storage account?
This is the Windows Azure Portal, which you can reach through this URL: http://windows.azure.com
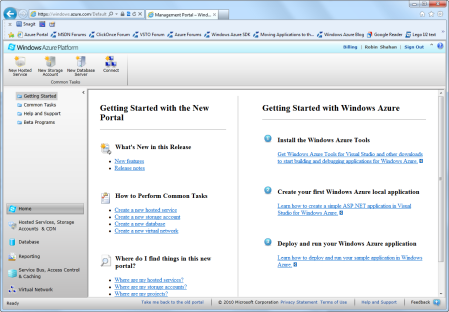
Figure 8: Windows Azure PortalThis screen is where you manage all of your Azure services. You can define services, set up databases, and set up storage accounts, which is what we’re here to do. Click on the ‘New Storage Account’ icon at the top of the screen as shown in Figure 9.
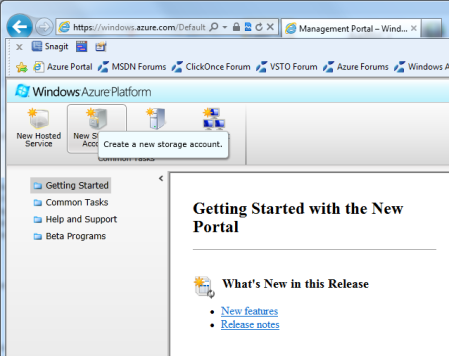
Figure 9:Create a new storage accountNext you will be prompted for your new storage account name (Figure 10). This will be used in the URLs for accessing your deployment, so you should probably think twice before making it something like “myapplicationsux” or “mypornpix”. The name must have only lowercase letters and numbers. After you fill it in, it will tell you if it’s already used. If it doesn’t give you any errors, it’s available.
In regards to the region, you will be asked to either choose a region, choose an affinity group, or create a new affinity group. This is not something you can change later, so choose wisely. (Unlike Walter Donovan in Indiana Jones and the Last Crusade, if you choose poorly, you will not instantly grow ancient and disintegrate.)
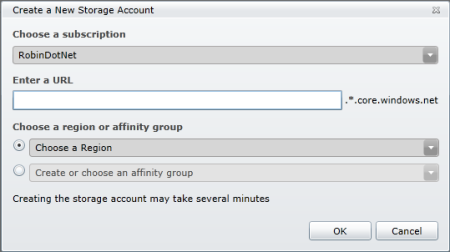
Figure 10: Create a new storage accountAn affinity group is basically specifying a location and naming it. You can then choose the affinity group when setting up other services to ensure that your compute instances and your data are in the same region, which will make them as performant as possible.
Just in case you ever want to use this account for something other than Blob Storage, I recommend setting up an affinity group. Select the radio button for “Create or choose an affinity group”, and then select the dropdown. Then you can select the location – be sure to use the dropdown. Mine defaulted to “anywhere in the US”, but it’s better to select a specific region, such as North Central or South Central, or whatever region is closest to you. Then click OK to go ahead and create the storage account. You should now see your storage account in the Windows Azure Portal (Figure 11).
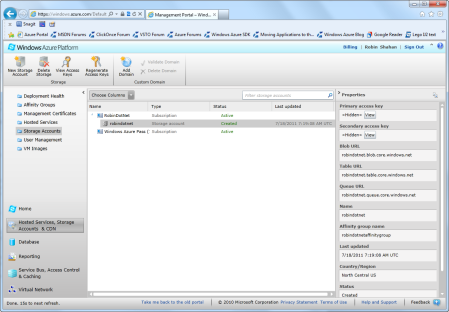
Figure 11: Storage AccountYou can assign a custom DNS entry to your storage account by clicking the Add Domain button on the top of the screen and following the instructions.
The URL for accessing your blob storage is on the right side of the screen. Mine is robindotnet.blob.core.windows.net. On the right are also the View buttons for retrieving the primary access key that you will need to set up a client application to access your blob storage. With these two pieces of information, you should be able to view your data.
For uploading and maintaining your files in blob storage, I use Cloud Storage Studio from Cerebrata which is excellent, but not free. There are free storage explorers available, such as the Azure Storage Explorer from CodePlex and the Cloudberry Explorer for Azure Blob Storage.
You should be good to go. Now go read the article on how to actually put your ClickOnce deployment in your new storage account, and start racking up those pennies.

<Return to section navigation list>
SQL Azure Database and Reporting
Cihan Biyikoglu explained Data Consistency Models - Referential Integrity with Federations in SQL Azure on 7/19/2011
Referential Integrity in Federations
Federation provide a great scale-out model with independent member databases. Even thought many local referential integrity rules are supported, federations place restrictions on costly referential integrity rules across federation members. Let me expand on that sentence; you can set up your familiar referential integrity with foreign keys between Customer, Orders and OrderDetails. All you need to do is ensure the federation distribution column is part of your federation key. Here is what the T-SQL would look like; Line# 24 and 36 defines the foreign key relationships.
1: -- Create Orders Federation 2: USE FEDERATION ROOT WITH RESET 3: GO 4: CREATE FEDERATION Orders_Federation(cid BIGINT RANGE) 5: GO 6: -- Deploying Schema for Orders_Federation 7: USE FEDERATION Orders_Federation(cid = 0) WITH RESET, FILTERING=OFF 8: GO 9: -- Deploy Customer, Orders and OrderDetails 10: CREATE TABLE customers( 11: customerid BIGINT, 12: customername nvarchar(256), 13: ... 14: primary key (customerid)) 15: FEDERATED ON (cid = customerid) 16: GO 17: CREATE TABLE orders( 18: customerid BIGINT, 19: orderid bigint, 20: odate datetime, 21: primary key (orderid, customerid)) 22: FEDERATED ON (cid = customerid) 23: GO 24: ALTER TABLE orders 25: ADD CONSTRAINT orders_fk1 FOREIGN KEY(customerid) 26: REFERENCES customers(customerid) 27: GO 28: CREATE TABLE orderdetails( 29: customerid BIGINT, 30: orderdetailid bigint, 31: orderid bigint, 32: inventoryid uniqueidentifier, 33: primary key (orderdetailid, customerid)) 34: FEDERATED ON (cid = customerid) 35: GO 36: ALTER TABLE orderdetails 37: ADD CONSTRAINT orderdetails_fk1 FOREIGN KEY(orderid,customerid) 38: REFERENCES orders(orderid,customerid) 39: GOTake a look at line#32; the “inventoryid” column; “invetoryid” identifies each part instance individually in the inventory table and lets the app track each shipped item back to each individual part instance through production and delivery. Also imagine that inventory, much like orders, is a large table with high traffic. You want to scale out inventory as well. However inventory table does not align with the partitioning style of orders. The way you mainly access the inventory table is through a partid to place the order or to produce the part. So… you create another federation in your “salesdb” to scale out the inventory table. Here is the T-SQL for the schema;
1: -- Create Inventory Federation 2: USE FEDERATION ROOT WITH RESET 3: GO 4: CREATE FEDERATION Inventory_Federation(pid UNIQUEIDENTIFIER RANGE) 5: GO 6: -- Deploying Schema for Inventory_Federation 7: USE FEDERATION Orders_Federation(cid = 0) WITH RESET, FILTERING=OFF 8: GO 9: -- Deploy Inventory 10: CREATE TABLE inventory( 11: inventoryid uniqueidentifier, 12: partid uniqueidentifier, 13: warehouseid bigint, 14: arrivaldatetime datetimeoffset, 15: .... 16: primary key (inventoryid, partid)) 17: FEDERATED ON (pid = partid) 18: GO 19: ALTER TABLE inventory 20: ADD CONSTRAINT inventory_fk1 FOREIGN KEY(warehouseid) 21: REFERENCES warehouses(warehouseid) 22: GO 23: CREATE TABLE warehouses( 24: warehouseid bigint 25: zipcode int, 26: address nvarchar(4096), 27: ... 28: ) 29: GOIn a single database without federations, one would naturally setup the foreign key relationship between the orderdetails table and the inventory table.1: ALTER TABLE orderdetails 2: ADD CONSTRAINT orderdetails_fk2 FOREIGN KEY(inventoryid) 3: REFERENCES inventory(inventoryid) 4: GOHowever the T-SQL above does not work with federations. Federations do not allow foreign key relationships across federation members. SQL Azure does not support distributed transactions yet and such large scale distributed transactions will likely cause scalability issues. The cost of the enforcement is generally proportional to the # rows involved in the transaction and complexity of the relationships.Imagine a case where you bulk insert 100 orders that needs to transact across many parts in the inventory table. That could is a single transaction that potentially involve 100s of parts and 100s of members would need to participate in that transaction and that would consume large amount of system resources and would not likely succeed. So what is the solution for federations?
Strictly vs. Eventually Consistent Data Models
Referential integrity in classic database applications is a powerful way to ensure full and strict consistency of data between normalized pieces of data. You can ensure that no order will be created for a customer that does not exist or a customer won’t be dropped while orders for that customer still exists in the system. However, complex consistency checks can be resource intensive to validate. One can find many references to this added cost in the database literature. For example; you regularly will see references to disabling or turning off constraints and referential integrity for bulk data processing etc.
The cost of enforcement is amplified in scale-out systems given that the local transactions turn into distributed transactions. It is common to find either no support for referential integrity or restrictions in many scale-out systems around such expensive constraints.
Given all this, many web-scale databases choose to loosen consistency requirements for the app and gain scale and perf. Apps instrument to detect and gracefully handle cases where data inconsistencies are found. Many systems implement offline data consistency checking through consistency-checkers which scan the data structure and check data based on logical consistency rules of the app.
Consistency checkers are fairly commonplace in most system software; SQL Server exposes it through DBCC command (DBCC stands for database consistency checker. You can see DBCC CHECKDB etc for information on how SQL Server does this for its lower level structures such as pages and extents). Your application can do the same and in it “DBCC”, it can auto fix or manually fix consistency issues much like the SQL Server version does.
Overall, in absence of support for cross-member referential integrity, I recommend adapting the eventual consistency model. It does place some additional load on the developers but this model allows better scale for the system.

<Return to section navigation list>
MarketPlace DataMarket and OData
Database Trends and Applications posted Melissa Data Brings Address Check Service to Microsoft's DataMarket on 7/19/2011:
Melissa Data Corp, a developer of data quality and address management solutions, has announced that its Address Check Web Service is now available on Windows Azure Marketplace DataMarket for Microsoft's Data Quality Services (or any client that embeds the API). Address Check provides real-time address verification and standardization for U.S. and Canadian addresses. Users, from both small and large businesses, can easily add Address Check to their applications to save money on postage and reduce undeliverable mail and shipments by cleaning up inaccurate, incomplete, or undeliverable addresses at point of entry.
"It is basically on demand. As they need a service they can use Microsoft's Data Quality Services to link up to the marketplace and pick and choose the types of services almost on an à la carte type of menu," Greg Brown, director of marketing for Melissa Data, tells 5 Minute Briefing.
The Address Check service validates address data against the most current reference data from the U.S. Postal Service and Canada Post. The programming logic used by Address Check is CASS Certified by the USPS - ensuring that the highest quality of data is returned. The service includes DPV, LACSLink, SuiteLink, EWS (Early Warning System), and exclusive AddressPlus to add missing apartment numbers for increased deliverability.
With the new integration with Microsoft's platform, there is no development needed on the end user's part, says Brown. "This opens it up to whole realm of data stewards that can take advantage of what was once either web services or local APIs that needed to be integrated into an application."
In addition to providing address verification, appending missing ZIP + 4s, delivery points, and identifying addresses vacant 90 days or more, the Address Check service also returns suggestions (with rankings) for invalid or ambiguous addresses and will geocode addresses with accurate latitude/longitude coordinates. The service also includes intelligent entity recognition algorithms that can analyze name and address information from free form or un-fielded text data and assign the contents to the correct output property.
To request a free 30-day trial of Address Check or for more information, visit http://www.melissadata.com/datamarket.
Elijah Glover (@ElijahGlover) gave a 00:41:01 Data for a Connected World video presentation on 7/14/2011 (missed when posted to the Umbraco Video Archive):
Click here to watch the video.
Elijah claims to be a Level 2 Certified and Core Umbraco developer, IT generalist.
<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
The Windows Azure Team recommended Build Your Next Game with the Windows Azure Toolkit for Social Games on 7/20/2011:
Today at Seattle Casual Connect, we announced the Windows Azure Toolkit for Social Games. This toolkit includes accelerators, common libraries, and deployment tools to help developers quickly get started building social games. Additionally, the toolkit provides samples and guidance for other scenarios, such as using Facebook credits to monetize a game.
The Windows Azure Toolkit for Social Games also comes with a new proof-of-concept game call Tankster from industry innovator Grant Skinner and his team at gskinner.com. This game is built with HTML5 and comes complete with reusable server side code and documentation. It also supports a variety of ways gamers can interact with each other, such as messaging, wall posts, and comments; player achievements and game stats are presented on a live leaderboard. After all, what’s a social game without being able to talk a little trash?
The Windows Azure Toolkit for Social Games is available for .NET and HTML5; future updates will include support of additional languages.
eMarketer predicts the social gaming market will increase to $1.32 billion in revenues by 2012, up from $856 million in 2010. As the social gaming market continues to grow and become more profitable, many companies are looking for stable and scalable solutions for running their games. With Windows Azure, Microsoft makes it easier capitalize on the revenue possibilities with a scalable cloud platform that accelerates time to market and reduces backend cost and overhead.
The Windows Azure platform provides game developers with on-demand compute, storage, content delivery and networking capabilities so that they can focus on development as opposed to operational hurdles. The toolkit also provides unique capabilities for social gaming prerequisites, such as storing user profiles, maintaining leader boards, in-app purchasing and so on.
Although Microsoft is announcing the social gaming toolkit today, social gaming developers have already found success on Windows Azure. Here’s what they’re saying:
- "Windows Azure scales from one to twenty-two instances effortlessly to support our peak scalability needs. In the future, our platform will scale to serve thousands, or even millions, of gamers. Not only has Windows Azure streamlined our development and deployment process, it has also reduced our infrastructure management burden because we are not hosting and managing a VM somewhere. We are taking advantage of true Platform-as-a-Service" - David Godwin, CEO, Sneaky Games. Sneaky Games is the developer of Fantasy Kingdoms, a fantasy building game for Facebook that launched in April 2010.
- “Our Bola Social Soccer game, hosted on the Windows Azure platform, has experienced tremendous success since inception in January 2010 with over 5 million users per month, with peaks of up to 1.2 M unique users per day. The solution was integrated with Facebook, Sonico and Orkut and localized to 7 different languages. Using the Windows Azure platform, we were able to rapidly deploy Bola Social Soccer game and to handle the rapid growth due to the soccer world cup, and the best of all is that we just paid for what we used. Also, while using the Azure toolset we had a high level of productivity." - Pato Jutard, Engineering Manager, Three Melons. Three Melons is the Agentinian developer of Bola Social Soccer, which is integrated with Facebook, Sonico, and Orkut.
- “Using Windows Azure, TicTacTi has served 500 million in-game advertisements to games on behalf of our customers, helping everyone in the ecosystem monetize games with engaging and context appropriate product placement, rich media, branded campaigns, pre/post/mid roll, and contextual lead generation.” – Nir Hagshury, Chief Technical Officer, TicTacTi. Based in Tel Aviv, Israel and with offices in Europe and the United States, Tictacti offers technology for monetizing games and videos by providing interactive in-game and in-video advertising.
Whether you want to build social games as a hobby or you want to reach millions of gamers, the Windows Azure platform can help. If you haven’t signed up for the Windows Azure platform be sure to take advantage of our free trial offer. Click here to get started today.
Joe Panettieri described How A Media Company Cashed In On Windows Azure in a 7/19/2011 post the TalkinCloud blog:
Microsoft claims to have more than 41,000 cloud partners. But who are they, and which ones are truly profitable? I don’t have all the answers. In some ways, I think Microsoft’s numbers are inflated. But some anecdotal success stories are starting to merge. A key example: VRX Studios, a full-service photography company, has completely transformed its business using Windows Azure.
The story starts back in 2009, when VRX Studios — which serves 10,000 hotel clients — needed to replace an antiquated digital asset management system (DAMS). At the time, the system needed to handle 30 terabytes of data. Instead of partnering up for a solution, VRX Studios created its own DAMS — called MediaValet — running on Windows Azure.
VRX Studios claims that building MediaValet on Windows Azure and bringing it to market was 50 percent cheaper and faster than under the traditional software and on-premises model. Today, according to a spokeswoman, MediaValet is a standalone product available to all types of companies. The interesting twist: MediaValet is expected to surpass the success of VRX Studios within the next three years, according to the company spokeswoman.
Deeper Details?
But how do VRX Studios and MediaValet measure success? Annual revenues? Profits?
I hope to speak with David MacLaren, president and CEO of VRX Studios and MediaValet, within the next few days — once I hit a few other deadlines. If you have questions for MacLaren about his bet on Windows Azure feel free to post a comment or email me (joe [at] NineLivesMediaInc [dot] com).
In the meantime, I remain skeptical of some Microsoft numbers. Yes, it may be factually accurate for Microsoft to say it has 41,000 cloud partners. But how many of those partners actually support more than a dozen businesses and more than a few dozen end-users? My guess: Only a few hundred partners are in that category.
Still, I’m a long-term believer in Windows Azure. The VRX Studios story is one example of a company moving into a completely new business — thanks to the cloud. We’ll be sure to offer insights from MacLaren as soon as we coordinate our schedules.
Read More About This Topic


Scott Densmore suggested Enterprise Library Windows Azure Integration Pack - Vote for What You Want on 7/19/2011:
Grigori and team have opened up voting on there Enterprise Library Windows Azure Integration Pack. Go vote to provide the direction they should take.
Ben Kepes (@benkepes) took A Closer Look at Cloud-based Testing with Soasta in a 7/19/2011 post to the ReadWriteCloud blog:
One of the themes many of us commentators harp on about is the fact that barriers to entry for application developers have never been lower - the availability of cloud hosting, agile development methodologies, even this crazy frothy investment cycle we're in all combine to see lots of applications being created.
One of the flip sides of al this app development is the corresponding drag on testing - that horrible stage that no one really likes, but everyone needs to do. One player looking to aid in that stage of the process is Soasta (rhymes with toaster!)
Soasta bills themselves as the "cloud testing pioneer", providing Web testing services to test performance, scalability and reliability of both websites and Web applications by simulating traffic spikes for both testing and production applications. CloudTest has a number of different offerings including;
- CloudTest Mobile for mobile application performance testing
- CloudTest Enterprise integrated internal and external testing with clouds such as Amazon EC2, IBM, Microsoft Azure and Rackspace.
- CloudTest Professional (Pro) more control and scale than the enterprise product
- CloudTest Standard an internal testing tool
- CloudTest On-Demand a full product+service offerings for organizations with no testing team themselves.
To this lineup Soasta is today launching a free product, CloudTest Lite, a downloadable app that gives organizations the ability to run limited testing (up to 100 virtual users, single server and behind-firewall testing only) including;
- Testing of web and mobile applications, including applications using HTML5 to REST Web services
- Test building with visual test creation tools
- Integration of application, system, and network monitoring data
- Analysis of results in real-time through a dashboard
- Upgrade path to a more scalable CloudTest edition

Interestingly this release comes only days after Atlassian announced its own new testing tool, as Klint Finley covered. The Atlassian Bonfire product is a browser plugin tool that is linked with Atlassian's Jira bug tracking tool to give end to end testing/notification/tracking supports. As such bonfire seems much lighter weight than Soasta, focusing less on the testing and analysis of that testing and more on identifying bugs - Soasta on the other hand is a complete testing and performance tuning application. You can see some sample screen shots below:
In demos the CloudTest product had a simple and intuitive test builder functionality that makes it easier for a testing team to spend less time designing tests, and more time running them - and that's never a bad thing. App testing has never been more important - with this new freemium offering, Soasta is hoping it will gain more customers for its suite of testing products

Klint Finley (@Klintron) reported Microsoft Research Releases Another Hadoop Alternative for Azure in a 7/18/2011 post to the ReadWriteCloud blog:
Today Microsoft Research announced the availability of a free technology preview of Project Daytona MapReduce Runtime for Windows Azure. Using a set of tools for working with big data based on Google's MapReduce paper, it provides an alternative to Apache Hadoop.
Big Data Made Easy?
The team's goal was to make Daytona easy to use. Roger Barga, an architect in the eXtreme Computing Group, was quoted saying:
"'Daytona' has a very simple, easy-to-use programming interface for developers to write machine-learning and data-analytics algorithms. They don't have to know too much about distributed computing or how they're going to spread the computation out, and they don't need to know the specifics of Windows Azure."To accomplish this difficult goal (MapReduce is not known to be easy) Microsoft Research is including a set of example algorithms and other sample code along with a step-by-step guide for creating new algorithms.
Data Analytics as a Service
To further simplify the process of working with big data, the Daytona team has built an Azure-based analytics service called Excel DataScope, which enables developers to work with big data models using an Excel-like interface. According to the project site, DataScope allows the following:
- Users can upload Excel spreadsheets to the cloud, along with metadata to facilitate discovery, or search for and download spreadsheets of interest.
- Users can sample from extremely large data sets in the cloud and extract a subset of the data into Excel for inspection and manipulation.
- An extensible library of data analytics and machine learning algorithms implemented on Windows Azure allows Excel users to extract insight from their data.
- Users can select an analysis technique or model from our Excel DataScope research ribbon and request remote processing. Our runtime service in Windows Azure will scale out the processing, by using possibly hundreds of CPU cores to perform the analysis.
- Users can select a local application for remote execution in the cloud against cloud scale data with a few mouse clicks, effectively allowing them to move the compute to the data.
- We can create visualizations of the analysis output and we provide the users with an application to analyze the results, pivoting on select attributes.
This reminds me a bit of Google's integration between BigQuery and Google Spreadsheets, but Excel DataScope sounds much more powerful.
We've discussed data as a service as a future market for Microsoft previously.
Microsoft's Other Hadoop Alternative
Microsoft also recently released the second beta of its other Hadoop alternative LINQ to HPC, formerly known as Dryad. LINQ/Dryad have been used for Bing for some time, but not the tools are available to users of Microsoft Windows HPC Server 2008 clusters.
Instead of using MapReduce algorithms, LINQ to HPC enables developers to use Visual Studio to create analytics applications for big, unstructured data sets on HPC Server. It also integrates with several other Microsoft products such as SQL Server 2008, SQL Azure, SQL Server Reporting Services, SQL Server Analysis Services, PowerPivot, and Excel.
Microsoft also offers Windows Azure Table Storage, which is similar to Google's BigTable or Hadoop's data store Apache HBase.
More Big Data Initiatives from Microsoft
We've looked previously at Probase and Trinity, two related big data projects at Microsoft Research. Trinity is a graph database, and Probase is a machine learning platform/knowledge base.
We also covered Project Barcelona, an enterprise search system that will compete with Apache Solr.

Microsoft Research posted Excel DataScope to its Azure Research Engagements blog on 7/18/2011:
Cloud-scale data analytics from Excel
From the familiar interface of Microsoft Excel, Excel DataScope enables researchers to accelerate data-driven decision making. It offers data analytics, machine learning, and information visualization by using Windows Azure for data and compute-intensive tasks. Its powerful analysis techniques are applicable to any type of data, ranging from web analytics to survey, environmental, or social data.
Complex Data Analytics via Familiar Excel Interface
We are beginning to see a new class of decision makers who are very comfortable with a variety of diverse data sources and an equally diverse variety of analytical tools that they use to manipulate data sets to uncover a signal and extract new insights. These decision makers want to invoke complex models, large-scale machine learning, and data analytics algorithms over their data collection by using familiar application, such as Microsoft Excel. They also want access to extremely large data collections that live in the cloud, to sample or extract subsets for analysis or to mash up with their local data sets.
Seamless Access to Cloud Resources on Windows Azure
Excel DataScope is a cloud service that enables data scientists to take advantage of the resources of the cloud, via Windows Azure, to explore their largest data sets from familiar client applications. Our project introduces an add-in for Microsoft Excel that creates a research ribbon that provides the average Excel user seamless access to compute and storage on Windows Azure. From Excel, the user can share their data with collaborators around the world, discover and download related data sets, or sample from extremely large (terabyte sized) data sets in the cloud. The Excel research ribbon also presents the user with new data analytics and machine learning algorithms, the execution of which transparently takes place on Windows Azure by using dozens or possibly hundreds of CPU cores.
Extensible Analytics Library
The Excel DataScope analytics library is designed to be extensible and comes with algorithms to perform basic transforms such as selection, filtering, and value replacement, as well as algorithms that enable it to identify hidden associations in data, forecast time series data, discover similarities in data, categorize records, and detect anomalies.
Excel DataScope Features
- Users can upload Excel spreadsheets to the cloud, along with metadata to facilitate discovery, or search for and download spreadsheets of interest.
- Users can sample from extremely large data sets in the cloud and extract a subset of the data into Excel for inspection and manipulation.
- An extensible library of data analytics and machine learning algorithms implemented on Windows Azure allows Excel users to extract insight from their data.
- Users can select an analysis technique or model from our Excel DataScope research ribbon and request remote processing. Our runtime service in Windows Azure will scale out the processing, by using possibly hundreds of CPU cores to perform the analysis.
- Users can select a local application for remote execution in the cloud against cloud scale data with a few mouse clicks, effectively allowing them to move the compute to the data.
- We can create visualizations of the analysis output and we provide the users with an application to analyze the results, pivoting on select attributes.
Analytics Algorithms Performed in the Cloud
Excel DataScope is a technology ramp between Excel on the user’s client machine, the resources that are available in the cloud, and a new class of analytics algorithms that are being implemented in the cloud. An Excel user can simply select an analytics algorithm from the Excel DataScope Research Ribbon without concern for how to move their data to the cloud, how to start up virtual machines in the cloud, or how to scale out the execution of their selected algorithm in the cloud. They simply focus on exploring their data by using a familiar client application.
Excel DataScope is an ongoing research and development project. We envision a future in which a model developer can publish their latest data analysis algorithm or machine learning model to the cloud and within minutes Excel users around the world can discover it within their Excel Research Ribbon and begin using it to explore their data collection.
Project Team

Roger Barga, ARCHITECT
Jared Jackson, SENIOR RSDE LEAD
Wei Lu,
RSDE
Jaliya Ekanayake, RSDE
Mohamed Fathalla, SENIOR RSDEThe original post has links to an Excel DataScope Overview Video, TechFest 2011 Demo, Cloud Data Analytics from Excel – poster 1, and Cloud Data Analytics from Excel – poster 2 from TechFest 2011, which is taking place the week of 7/18/2011.
Jim O’Neil (@jimoneil)described Photographic Mosaics in Windows Azure: A New Series in a 9/18/2011 post:
During our last Windows Azure live event series, the Azure TechJam, I structured a talk on using Windows Azure services – roles, storage, service bus – around an application I built to generate photographic mosaics in the cloud. It’s not an original idea by any means – check out for instance the Mosaic 23/25 site which likewise leveraged Windows Azure and Mosaicer 2.0 (in VB6!) which provided a starting point for the client UI. Disclaimers aside, the application has really provided me (and continues to provide) a great learning vehicle in how it pulls together many of the Windows Azure platform offerings into something a more substantial than “Hello World.”
Since that live event, I’ve been continually adding capabilities to the application, and although it’s still a work in progress, it’s in a reasonable state now for you to get it up and running to aid your own understanding of Windows Azure. So with this post, I’m kicking off a new blog series to do a deeper dive of the application architecture and hopefully spark a discussion around patterns and practices you may want to consider in your own cloud applications. I definitely invite and welcome your comments throughout this series, and together I’m hoping we can improve the existing implementation.
followingscreencast which shows the client application at work in the original post.The client application along with the Windows Azure cloud application and a utility application are all available for download, and the package includes a document with further instructions on the set up. The following steps though should get you up and running – e-mail me if you run into an issue or have questions on the setup - of course it all works great on my machine!
Windows Azure Account Requirements
While you can exercise most of the application features in the local development fabric on your own machine, at some point you’ll want to see this all live in Windows Azure. The application uses three roles (they can be small or extra-small), so you can use the Windows Azure trial (use promo code: DPEA01) to prop the application up in the cloud free of charge. If you are using other subscription offers, do be aware of the pricing for the various services so you do not incur unexpected charges.
You will need to setup the following three services in Windows Azure – be sure to select the same sub-region for all three!
- Windows Azure Storage account
- Windows Azure Hosted Service
- Windows Azure AppFabric namespace (select all three services and a cache size of 128 MB)
Storage Requirements
Once you set up your storage account, you’ll need to create a number of queues, tables, and blob containers for use by the application. The Storage Manager solution in the download is a Windows Forms application which creates these assets for you, given a WIndows Azure storage account name and key. You can run the application from within Visual Studio:
N.B.: Due to licensing, the Flickr functionality (i.e., populate a blob container with Flickr images) requires that you download the FlickrNet.dll and add a reference to it within the Storage Manager application. Without the reference, the Storage Manager application will not compile. You will also need to register for an API key and supply that API key in the app.config for the solution.
<userSettings><StorageManager.Properties.Settings><setting name="AccountName" serializeAs="String"><value>[Azure Storage Account]</value></setting><setting name="AccountKey" serializeAs="String"><value>[Storage Account Key]</value></setting><setting name="FlickrAPIKey" serializeAs="String"><value>[Optional Flickr API Key]</value></setting></StorageManager.Properties.Settings></userSettings>Cloud Application Configuration
Once you’ve created all of the required storage constructs, add the configuration values for the three Windows Azure Roles within the cloud application. Below is the entire ServiceDefinition.cscfg file, with highlighting to indicate the modifications needed..
1: <?xml version="1.0" encoding="utf-8"?>2: <ServiceConfiguration serviceName="AzureService" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration" osFamily="1" osVersion="*">3: <Role name="AzureJobController">4: <Instances count="1" />5: <ConfigurationSettings>6: <Setting name="ApplicationStorageConnectionString"value="DefaultEndpointsProtocol=https;AccountName={Acct. Name};AccountKey={Acct. Key}"/>7: <Setting name="Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString"value="DefaultEndpointsProtocol=https;AccountName={Acct. Name};AccountKey={Acct. Key}"/>8: </ConfigurationSettings>9: </Role>10: <Role name="AzureImageProcessor">11: <Instances count="1" />12: <ConfigurationSettings>13: <Setting name="ApplicationStorageConnectionString"value="DefaultEndpointsProtocol=https;AccountName={Acct. Name};AccountKey={Acct. Key}"/>14: <Setting name="Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString"value="DefaultEndpointsProtocol=https;AccountName={Acct. Name};AccountKey={Acct. Key}"/>15: <Setting name="EnableAppFabricCache" value="false" />16: </ConfigurationSettings>17: </Role>18: <Role name="AzureClientInterface">19: <Instances count="1" />20: <ConfigurationSettings>21: <Setting name="ApplicationStorageConnectionString"value="DefaultEndpointsProtocol=https;AccountName={Acct. Name};AccountKey={Acct. Key}"/>22: <Setting name="Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString"value="DefaultEndpointsProtocol=https;AccountName={Acct. Name};AccountKey={Acct. Key}"/>23: <Setting name="AppFabricNamespace" value="{Namespace}"/>24: <Setting name="ServiceBusIssuer" value="owner" />25: <Setting name="ServiceBusSecret" value="{Default Key}" />26: <Setting name="UserStorageAccountName" value="{Account Name}" />27: <Setting name="UserStorageAccountKey" value="{Account Key}" />28: </ConfigurationSettings>29: </Role>30: </ServiceConfiguration>
- Lines 6, 7, 13, 14, 21, and 22: provide the Storage Account Name and Key for your Windows Azure Storage account
- Line 23: provide the name of the App Fabric endpoint you created
- Line 25: provide the Default Key for the Service Bus
- Line 26: provide the name of your Windows Azure Storage Account (this can be a different storage account than in Line 6, but for now using the same account is fine)
- Line 27: provide the account key for the storage account used in Line 26
If you want to experiment with Windows Azure AppFabric Caching, you’ll also need to modify the app.config file of the AzureImageProcessor Worker Role to include the endpoint and Authentication token for the Caching service. (Note, we’ll look at caching in detail a bit later in the series, at which point I may modify this configuration).
1: <dataCacheClients>2: <dataCacheClient name="default">3: <hosts>4: <host name="{Service Bus NameSpace}.cache.windows.net" cachePort="22233" />5: </hosts>6: <securityProperties mode="Message">7: <messageSecurity8: authorizationInfo="{Authentication token}" >9: </messageSecurity>10: </securityProperties>11:12: <tracing sinkType="DiagnosticSink" traceLevel="Verbose"/>13: </dataCacheClient>14: </dataCacheClients>
Client Application Configuration
You’ve seen the client application in action already. The only configuration step needed here is to supply the endpoints for the WCF services hosted in WIndows Azure. You can modify these directly within the app.config file:
<client><endpoint address="http://127.0.0.1:81/StorageBroker.svc"binding="basicHttpBinding"contract="AzureStorageBroker.IStorageBroker"/><endpoint address="http://127.0.0.1:81/JobBroker.svc"binding="basicHttpBinding"contract="AzureJobBroker.IJobBroker"bindingConfiguration="JobBroker_BindingConfig"/></client>If you run the client application as a non-administrative user, an informational message will result indicating that the notification functionality is not available. This occurs because you do not have the permission to create an HTTP namespace for the self-hosted Service Bus service on your local machine; you can do so grant this permission via netsh in an elevated command prompt, or simply run the application as an administrator (which is fine for testing, but not advised for an application deployed to end-users)
Need Help?
Hopefully this blog post will get you up and running. If not, check out the README file that comes with the download; it’s a bit more explanatory. And finally don’t hesitate to forward your questions to me via this blog post. It’s quite possible I’ve overlooked some details or nuances of the setup!

")




Tim Anderson (@timanderson) posted Azure: it's Windows but not as we know it to The Register on 7/18/2011:
Moving an application to the cloud
If Microsoft Azure is just Windows in the cloud, is it easy to move a Windows application from your servers to Azure?
The answer is a definite “maybe”. An Azure instance is just a Windows virtual server, and you can even use a remote desktop to log in and have a look. Your ASP.NET code should run just as well on Azure as it does locally.
Azure tables are a non-relational service that stores entities and properties. Azure blobs are for arbitrary binary data that can be served by a content distribution network. SQL Azure is a version of Microsoft’s SQL Server relational database.
Reassuringly expensive
While SQL Azure may seem the obvious choice, it is more expensive. Table storage currently costs $0.15 per GB per month, plus $0.01 per 10,000 transactions.
SQL Azure costs from $9.99 per month for a 1GB database, on a sliding scale up to $499.95 for 50GB. It generally pays to use table storage if you can, but since table storage is unique to Azure, that means more porting effort for your application.
What about applications that cannot run on a stateless instance? There is a solution, but it might not be what you expect.
The virtual machine (VM) role, currently in beta, lets you configure a server just as you like and run it on Azure. Surely that means you store state there if you want?
In fact it does not. Conceptually, when you deploy an instance to Azure you create a golden image. Azure keeps this safe and makes a copy which it spins up to run. If something goes wrong, Azure reverts the running instance to the golden image.
This applies to the VM role just as it does to the other instances, the difference being that the VM role runs exactly the virtual hard drive (VHD) that you uploaded, whereas the operating system for the other instant types is patched and maintained by Azure.
Therefore, the VM role is still stateless, and to update it you have to deploy a new VHD, though you can use differencing for a smaller upload.
If your application does expect access to persistent local storage, the solution is Azure Drive. This is a VHD that is stored as an Azure blob but mounted as an NTFS drive with a drive letter.
You pay only for the storage used, rather than for the size of the virtual drive, and you can use caching to minimise storage transaction and improve performance.
No fixed abode
The downside of Azure drive is that it can be mounted by only one instance, though you can have that instance share it as a network drive accessible by other instances in your service.
Another issue with Azure migrations is that the IP address of an instance cannot be fixed. While it often stays the same for the life of an instance, this is not guaranteed, and if you update the instance the IP address usually changes.
User management is another area that often needs attention. If this is self-contained and lives in SQL Server it is not a problem, but if the application needs to support your own Active Directory, you will need to set up Active Directory Federation Services (ADFS ) and use the .NET library called Windows Identity Framework to manage logins and retrieve user information. Setting up ADFS can be tricky, but it solves a big problem.
Azure applications are formed from a limited number of roles, web roles, worker roles and VM roles. This is not as restrictive as it first appears.
Conceptually, the three roles fulfill places for web applications, background processing and creating your own operating system build. In reality you can choose to run whatever you wish in those roles, such as installing Apache Tomcat and running Java-based web solution in a worker role.
For example, Visual Studio 2010 offers an ASP.NET MVC 2 role, but not the more recent ASP.NET MVC 3. It turns out you can deploy ASP.NET MVC 3 on Azure, provided the necessary libraries are fully included in your application. Even PHP and Java applications will run on Azure.
Caught in the middle
Middleware is more problematic. Azure has its own middleware, called AppFabric, which offers a service bus, an access control service and a caching service. At its May TechEd conference, Microsoft announced enhanced Service Bus Queues and publish/subscribe messaging as additional AppFabric services.
As Azure matures, there will be ways to achieve an increasing proportion of middleware tasks, but migration is a substantial effort.
Nick Hines [pictured at right] is chief technical officer of innovation at Thoughtworks, a global software developer and consultancy which is experimenting with Azure.
One migration Hines is aware of is an Australian company that runs an online accounting solution for small businesses. Hines says the migration to Azure was not that easy. The company found incompatibilities between SQL Azure and its on-premise SQL Server.
“While Microsoft claims you can just pick up an application and move it onto Azure, the truth is it’s not that simple,” Hines says.
“To really get the benefit, in terms of the scale-out and so on, designing it for Azure up front is probably a much better idea.
“But the same could be said for deploying an application on Amazon Web Services, to be fair to Microsoft.”


<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Beth Massi (@bethmassi) reported E-Book Available: Creating Visual Studio LightSwitch Custom Controls on 7/18/2011:
Visual Studio LightSwitch provides a rich extensibility model for the professional developer looking to customize LightSwitch beyond what you get out of the box. One of these extensibility points is the creation of custom UI controls. Yesterday MVP Michael Washington released an E-Book for the professional developer looking to extend LightSwitch with custom Silverlight controls. It will walk you through creating LightSwitch custom controls even if you are a total beginner and have not created a Silverlight control before.
E-Book: Creating Visual Studio LightSwitch Custom Controls (Beginner to Intermediate)
Michael is one of our LightSwitch community rock stars and has a whole site dedicated to helping people get the most out of LightSwitch business application development. I encourage you to check out his site and get involved:
Thanks for all you do!
And as always, you can find more from the LightSwitch Team here:
- LightSwitch Developer Center (http://msdn.com/lightswitch)
- LightSwitch Forums
- LightSwitch Team Blog
- LightSwitch Team on Facebook
- LightSwitch Team on Twitter
Enjoy!

Michael Washington (@ADefWebserver) published The Visual Studio LightSwitch Economy on 7/18/2011:
I wrote the E-Book Creating Visual Studio LightSwitch Custom Controls (Beginner to Intermediate), because I had to. I feel very passionate about the fact that LightSwitch is a much easier way to create professional Silverlight applications (and I have been creating Silverlight applications for a long time link, link, link). I had created Blog posts, but to properly demonstrate the power of LightSwitch, I needed a complete end-to-end book. So I wrote an E-Book and offered it to the current members of the site for only $5 (the regular price is $9.99). Then… wow sales have been good, hundreds of dollars in the first day!
This got me thinking, what do all those people want? Information, yes, but what they really want is to use LightSwitch to create applications that will help them… do “something”. It doesn’t matter what that “something” is, it is important to them. There are thousands of “hungry” people who need information to help them achieve their goals.
But, this Blog post is not about me, it’s about You. You can help the growing LightSwitch community get what they need. But they don’t just need E-Books, they also need:
- Shells
- Themes
- Control Extensions (not to be confused with Custom Controls that are covered in my E-Book)
- Custom Data Sources
- Screen Templates
Right now, we have only a few LightSwitch “extensions”. All the big control vendors have announced products, but there are only a few products from normal companies like the Document Toolkit. However it already has 2600 downloads.
My Offer To You
You can make LightSwitch products and easily sell them on the LightSwitch Help Website. If you want to create a LightSwitch extension, you can find information here: Microsoft Visual Studio LightSwitch Extensions Cookbook.doc (note however, the LightSwitch team has announced they will provide templates that are easier to use in the coming weeks so you may want to wait a bit for it).
When you do have a LightSwitch product to sell, Here is what you do:
- Create an Account on http://www.payloadz.com
- Create a listing for your product http://help.payloadz.com/creating_a_product.htm
- Set up the Affiliate information for your product (with at least a 10% affiliate payout): http://help.payloadz.com/Affiliate_System.htm
- Make an announcement with a link to your product in the LightSwitch Community Announcements Forum
- We will list your product on the LightSwitch Help Website Market Page (on a busy day the LightSwitch help Website gets about 400 visitors and 1500 page views)
A Win-Win Situation
Number one, the LightSwitch community wins because they want these things, because it helps them achieve their objectives. People don’t mind seeing products that they may be interested in, and if they are visiting the LightSwitch Help Website, they are interested.
You benefit because it’s a little extra money for you, and it is something that you are already interested in.
The LightSwitch Help Website makes a little extra revenue to pay for the server.
Also note Paul Patterson plans to open a LightSwitch Market so you can sell your LightSwitch products there too: http://www.lightswitchmarket.com/

Paul Patterson announced Microsoft LightSwitch – Yes, I To[o] will Write an eBook! on 7/18/2011:
Why create an eBook? Well… I don’t know. It seems to be the thing to do I guess.
Actually, I have been wanting to test the waters of writing something with a little more content than a blog post. I have acquired a lot of Microsoft Visual Studio LightSwitch knowledge, so I might as well put it to some use. Maybe even make a few extra bucks in the process.
Want a free copy of this eBook? Then subscribe to my newsletter (click the newsletter button on the right side of the page). Anyone who is subscribed, at the time when the eBook is first published, will get a free copy of the eBook.
The book is going to be titled “The Non-Programmers Guide to Microsoft Visual Studio LightSwitch”.
Here is a gratuitous image of the cover page
Tehe!

Return to section navigation list>
Windows Azure Infrastructure and DevOps
Matthew Weinberger (@MattNLM) reported Capgemini to Offer International Microsoft Windows Azure Services in a 7/20/2011 post to the TalkinCloud blog:
Service provider titan Capgemini Group has announced a strategic partnership with Microsoft to deliver Windows Azure consulting, technology and outsourcing services to customers in 22 countries around the world. In other words, Microsoft has enlisted Capgemini to help clients make the jump into the Azure PaaS cloud.
According to Capgemini’s press release, the Windows Azure services will have a “first focus on the U.K., the Netherlands, the United States, Canada, France, Belgium and Brazil.” Together, the two companies plan on jointly putting together pitches for verticals including the public sector and financial institutions. The goal is to demonstrate the value of the cloud in general and the Windows Azure platform in specific for solving business challenges such as M&A and legacy replacements.
Here’s what John Brahim, Capgemini’s Application Services Europe Deputy CEO, had to say about the partnership in a prepared statement:
“Capgemini already has a very strong alliance with Microsoft and this further strengthens our relationship. We have a long history of customer collaboration and deep sector specific expertise and Microsoft offers innovative solutions to meet customer needs in the quickly growing domain of the cloud. Together we are well positioned to deliver cloud services that will help customers keep ahead of the technology curve, while at the same time reducing costs.”
Capgemini plans on upping its Microsoft game, with 1,500 architects and developers in branch offices around the world slated to receive Windows Azure training and several in-house solutions moving to Redmond’s cloud. Capgemini will also promote third-party solutions hosted on Azure to customers. But most interesting of all, Capgemini plans on developing the Windows Azure Center of Excellence in Mumbai, India, an “offshore center of expertise.”
At the recent Microsoft Worldwide Partner Conference, there was a definite emphasis on using partners to build momentum for the Microsoft Windows Azure Cloud. And getting an established partner such as Capgemini to leverage its global reach for migration services certainly fits the bill. We’ll be watching closely for updates.
Read More About This Topic


Simon Munro (@simonmunro) argued (with tongue in cheek) The cloud will have no impact on IT departments in a 7/19/2011 post:
I’m sure, if there was as much Internet ubiquity as today as twenty years ago, that there would have been much discussion about the impact that Excel would have on data processing departments (as they were called) at the beginning of the nineties. “Of course”, they would have argued, “our users will still come to us for data bases (two words), this spreadsheet ‘revolution’ is for small stuff and we will remain important”. They were right, and continue to be right, as data professionals continue to ignore the fact that most corporate information (not just data) is in spreadsheets while they sit in their data centres fondling their precious tables.
Much has been discussed recently on the impact of the cloud on IT departments. Some of them can even be considered quite detailed and thoughtful if your cognitive bias is towards traditional corporate data centres. I saw a presentation last week by a cloud consulting practice with its roots in data centres and even though the story on the slides looked okay, I came away with two messages. Firstly, the people involved have decades of experience in building and operating data centres, not applications, so have a tendency to get excited about data centre infrastructure and processes. Second, their overriding objectives were to sell more tin. Any ‘cloud’ solution put together by them will be biased towards a solution that builds on their collective data centre experience and high margin products from the same domain and era.
There is an understandable perception, amongst IT vendors and their IT media lackeys, that the cloud will be driven outwards from the corporate data centres via private clouds to end users who will embrace the marvel – a cloud ‘journey’, if you will, that starts with the IT department. But the cloud is driven by consumers, broadband at home, iPhone apps, DropBox and all sorts of applications that are (currently) on the periphery of corporate IT. The cloud is driven, not by the optimal use of computing resources, but by applications and the desire of people (not ‘users’) to build them and congregate towards them.
Corporate IT has virtually no role to play in this. IT departments of the early nineties that nodded to each other that their AS/400s were working well while being completely unaware of users loading up Quattro Pro for DOS (a spreadsheet for the youngsters) on their PCs – back in the day when viruses afflicted humans and PC security was irrelevant. IT departments of today are sitting in the same happy world of ignorance nodding contentedly that their virtualised ‘cloud’ data centre is doing well while their customers build and use applications on the public cloud. IT won’t even know about them and, in most cases, even care.
While some enterprises may find a balance of public cloud consumption, most won’t. They will continue to evolve their own style of infrastructure and applications. There is no point in trying to change. The cognitive dissonance is too great and the desire doesn’t exist. The big IT players still dominate and the marketing and media is still aligned towards the marketing budgets. Proponents of the cloud shouldn’t worry – there is enough to do without worrying about internal IT. Die-hard IT departments shouldn’t worry because their systems, from power all the way up the stack to their ERP applications, will still be there for a while yet. Just like Excel didn’t replace existing IT, but merely added a different kind of computing capability to peoples’ work life.
So IT departments aren’t going to change much. The impact will be low. Jobs will be protected and money will continue to be spent on specialised IT infrastructure. The cloud is simply going to create another market that is of no more concern to enterprise IT than the apps that people run on their personal mobiles or whether or not Excel is a good place to keep data.

David Linthicum (@DavidLinthicum) asserted “Many cloud vendors' oversimplified approaches are more likely to hurt than help” as a deck for his Beware the oversimplification of cloud migration article of 9/18/2011 for InfoWorld’s Cloud Computing blog:
I
get a pitch a day from [enter any PR firm here]. The details vary, but the core idea is the same: "We have defined the steps to migrate to the cloud, so follow us."
To be honest with you, I often bite. If nothing else, I'll take a look at the press release, white paper, or website. Often there is a list of pretty obvious things to do, such as "define the business objectives" and "define security," but the details are nowhere to be found. Why? Because the details are hard and complex, and the vendors would rather that their steps seem more approachable by the IT rank-and-file than ensure they will actually work.
Moving applications, systems, and even entire architectures to cloud-based platforms is no easy feat. In many cases it requires a core understanding of data, processes, APIs, services, and other aspects about the existing state of IT before planning the move. Yes, the details.
For those in IT who are charged with migrating to the cloud, this is often where they drop the ball. They jump right into standing up cloud instances and try to make the move without a full understanding of the project. Failed cloud project after failed cloud project can be attributed to this error being made by people who followed stepwise processes outlined by a cloud provider, technology vendor, or big consulting organization.
By the way, although it's more complex than most people understand, migrating to the cloud is not at all difficult. You need to understand this process for what it is: An architectural problem that requires both the as-is and to-be states to be defined so all issues are understood, including metadata, performance, security, compliance, and governance.
Understanding your problem domain leads to the right process for migration. If you know what you want to move and why you want to move it, you know how to test for security and compliance, and you understand how to create an effective migration plan that sweats the details rather than ignores them.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
David Mills announced System Center Operations Manager 2012 Beta is LIVE! in a 7/19/2011 post to the System Center Team blog:
Like most companies today, you rely on your IT infrastructure to keep your business running. You need to find out about and fix IT problems before they lead to any downtime or loss of productivity and revenue. This becomes even more challenging when you depend on a combination of physical, virtual, and cloud resources to run a diverse mix of operating systems (Windows, Linux, and Unix) that support any number of critical business applications. Microsoft understands these challenges and is dedicated to helping customers address these issues.
System Center Operations Manager 2012 provides the solution to the challenges mentioned above by:
- Delivering flexible and cost effective enterprise-class monitoring and diagnostics while reducing the total cost of ownership by leveraging commodity hardware with standard configurations to monitor heterogeneous environments.
- Helping to ensure the availability of business-critical applications and services through market-leading .NET application performance monitoring and diagnostics plus JEE application health monitoring.
- Providing a comprehensive view of datacenters, and private and public clouds.
Here’s what’s new
- Rich application performance monitoring and diagnostics for .NET applications plus JEE application health monitoring
- Support for monitoring heterogeneous environments
- Integrated network device monitoring and alerts
- Simplified management infrastructure
- Common console across datacenter and clouds with customizable dashboards
Download the beta here.
For more information, visit the new Operations Manager 2012 beta page

Cory Fowler (@SyntaxC4) posted [Info Graphic] Costs: Private vs. Public Cloud on 7/19/2011:
Here’s an interesting Info Graphic on Private vs. Public Cloud. My Favourite part is the following code snippet which is found on the left hand side of the graphic below the red light saber.
if ($CompanyWorth >= 1 billion dollar) { $PrivateCloud = "Yes." } else { $PrivateCloud = "Try the public cloud." } //end cloud computing evaluation.
via


The ServerAndCloudPlatformTeam reported availabilty of a “Windows Server 8” sneak preview on 7/18/2011:
If you’re in IT you are likely pulled between an almost infinite need for more computing power to deliver business solutions and the ever increasing demands for greater agility, higher efficiency and lower costs. Fortunately, you can now deliver on these seemingly contradictory demands by leveraging the benefits of cloud computing with our public and private cloud solutions. And they are only going to get better.
Today we are excited to give you a sneak peek at the next step in private cloud computing by showing you just two of hundreds of new capabilities coming in the next version of Windows Server, internally code-named “Windows Server 8.”
At 36:50 of this online video we demonstrate how Windows Server 8 virtual machines will help you build private clouds of greater scale by supporting (at least…) 16 virtual processors fully loaded with business critical workloads like SQL Server. Then we show you how you can deliver improved fault tolerance and flexibility, without the added tax or complexity of additional hardware, tools and software licenses, by using the new built-in Hyper-V Replica feature. All it takes is a few clicks, a network connection and Windows Server 8.
But this is just the beginning! We’re looking forward to sharing more about Windows Server 8 at Microsoft’s BUILD conference, September 13-16, in Anaheim.
Herman Mehling asserted “Recent studies find a painful truth among early cloud computing adopters: cloud-to-cloud integration is a major headache” as a deck for his Lessons from Cloud Adopters: Cloud-to-Cloud Integration Is a Challenge article of 7/18/2011 for DevX:
A recent report from cloud solution provider Appirio confirms what many IT people have long known, even feared: cloud-to-cloud integration is a major headache for cloud adopters.
Appirio's "State of the Public Cloud: The Cloud Adopters' Perspective," found that more than 75 percent of respondents consider cloud-to-cloud integration a priority, but that only 4 percent "had fully integrated their cloud applications."
The report was based on a survey of 155 IT decision-makers at mid- to large-sized North American companies that have adopted at least one software-as-a-service (SaaS) or public cloud application.
Another key finding was that most cloud adopters prefer cloud solutions over on-premise applications when it comes to availability, costs and time to value; and they are eager to expand their cloud strategies.
The key findings of Appirio's report dovetail with findings of a recent Gartner study on companies transitioning to SaaS and how it was working out for them. It found that many businesses were actually pulling their data back out of cloud-based applications and asked them why.
Gartner asked 270 executives, "Why is your organization currently transitioning from a SaaS solution to an on-premises solution?" For 56 percent of respondents, the number one reason they gave for transitioning back to on-premises solutions was the unexpectedly significant requirements of integration.
More than half of the people who tried moving their business to a cloud-based application and pulled back did so because integrating those applications with the rest of their businesses proved too challenging to make it worthwhile.
Gartner has predicted that at least 35 percent of all large and midsize organizations worldwide will be using one or more iPaaS (integration platform as a service) offerings by 2015.

Next Page: Lessons from Early Cloud Adopters
Paul Carmody sponsored a Why Enterprises Choose Private Cloud white paper with research from Gartner that was published by Itnernap IT on 7/18/2011 (site registration required to download). From the Introduction:
The potential advantages of cloud computing are well documented. If designed and provisioned properly, cloud deployments can lower capital and operating costs, increase flexibility, and improve service levels. Private cloud deployments are particularly important because they increasingly represent an enterprises’ first step toward the ultimate goal of dynamically matching IT service demand with IT service supply; a concept Gartner termed “real-time infrastructure” in the enclosed Gartner research report.
This research might serve as a useful starting point as you consider deploying a private cloud. Several important questions are asked and answered including: How quickly are enterprises adopting private cloud as part of their IT infrastructure? What variables determine the ultimate success or failure of a private cloud implementation? How should a private cloud deployment influence an enterprises’ overall data center strategy?
From Internap’s perspective, we firmly agree with Gartner’s recommendations that enterprises should be wary of vendors offering a cookie-cutter approach to private cloud implementations and with Gartner’s position that companies should examine the extent to which a service provider is investing in their infrastructure, processes, and technologies that support a comprehensive cloud strategy. We also believe that private cloud deployments should consider the applications’ performance and availability attributes all the way to the end-user.
Introduction
We recognize, however, that elegant technologies and reliable planning don’t substitute for a service provider’s attentiveness and willingness to collaborate. We also know that every organization’s approach to achieving their IT infrastructure objectives is different. Therefore, our commitment to service extends from the design consultation stage where our sales engineers help our customers determine what solutions fit with their broader data center and cloud strategies, through implementation and ongoing support.
Beyond the information you discover within this note, we invite you to engage with our team to understand how Internap can deliver value at every stage of your IT organization’s evolution toward the cloud.
We’re looking forward to hearing from you.
Since 1996, Internap has successfully delivered high-performance, highly-reliable IT infrastructure services to thousands of customers. Our entire business model, from the technologies and services we develop and sell, to the processes and people we employ, is built on providing the best performance, availability, and support to our customers. We continually invest significant resources in our platform of premium datacenters, cloud and hosting technologies, portfolio of intelligent connectivity solutions, and staff to ensure that we can continue to live up to this commitment.
In 2010, we opened an additional 30,000 square feet of performance-centric data center capacity designed to N+1 redundancy standards for power, cooling, and connectivity. With almost 40 percent of our data center footprint deployed within the last three years, we enable our customers to provision scalable private cloud solutions with power density requirements up to 12 kW per cabinet. We also recently brought to market a number of enhancements to our managed services and performance connectivity capabilities that increase the utility of our services to our private cloud customers. These enhancements range from a broad footprint roll-out of our TCP acceleration service, XIP™, to the launch of our open- source based Internap Cloud Storage. The common thread is our focus on features and functions that improve performance and increase reliability for a better end-user experience “in the cloud.”
Paul Carmody


Paul is Sr. Vice President, Product Management and Business Development, Internap Network Services Corporation.
<Return to section navigation list>
Cloud Security and Governance
<Return to section navigation list>
Cloud Computing Events
No significant articles today.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Damon Edwards (@damonedwards) posted Matt Ray talks Crowbar, Chef, and OpenStack integration for building private clouds (VIDEO) on 7/19/2011:
Also while in Austin, I stopped by Opscode's satellite offices to talk to Matt Ray about the integration work he is doing with Crowbar (a soon to be open source bare-metal provisioning tool from Dell), Chef, and OpenStack. This toolchain stretches the concept of infrastructure as code all the way from the bios to the provisioning of a private cloud... it's a "datacenter as code".
See the short (06:39) video here: Matt Ray talks Crowbar, Chef, and OpenStack integration from dev2ops.org on Vimeo.

Andy Edmonds, Thijs Metsch and Eugene Luster co-authored An Open, Interoperable Cloud article of 7/19/2011 for the InfoQ blog:
In this article we describe how through leveraging mature open standards (related to Clouds, Grids and Storage), interoperable clouds can be created now. We demonstrate the use of the major contemporary innovative cloud interface specifications to realise an open standards-based, interoperable, cloud offering.
The motivation for this article is to demonstrate that currently available features in cloud standards from various standard-developing organisations (SDOs) are enough to create a cloud offering as described in the following sections. This article can be seen as one of the first steps of an exploration into cloud standards integration, especially between Open Cloud Compute Interface (OCCI) [1], Open Virtualisation Format (OVF) [4] and CDMI [3]. Last but not least what is detailed in this document can be used to drive collaborations between OCCI and the Cloud Management Working Group (CMWG) [10] as well as efforts like cloud-standards.org, Standards and Interoperability for eInfrastructure Implementation Initiative (SIENA) [5], National Institute for Standards and Technology (NIST) [6] and others.
In order to describe how this integration of standards can happen, we will use a simple scenario. That scenario is one where a startup service provider wants to deploy, scale, migrate and redeploy their new Hadoop’s [7] based MapReduce service.
In order to implement/execute the scenario, the following enabling standards are used:
- DMTF’s OVF - providing a means to package virtual infrastructure deployments, which can be exported or imported into an infrastructure service offering.
- SNIA’s CDMI - providing an API that allows for the runtime management of storage infrastructure service offerings.
- OGF’s OCCI - providing an API that allows for the runtime management of infrastructure as service offerings.
It should be noted that aspects such as authorisation and authentication are not dealt with in this article. These issues are somewhat orthogonal and dealt with by other specifications and technologies (e.g. OAuth, OpenID, etc). OCCI and CDMI leverage the design considerations in the HTTP protocol suite with respect security.
The Scenario
The scenario is one where a startup company wishes to offer a MapReduce service to their clients. As the service offering is new it will be offered to a limited set of beta users. This limitation allows the startup company's architects to create an initial deployment architecture that suits the initial resource requirements to deliver the service. The service's deployment architecture is as follows:
Once the service has been deployed, the number of users makes it necessary that the service scales. This means additional resources must be added on the fly to serve the demand. Next to the scaling, migrations are considered part of the overall scenario. In case that the infrastructure provider suffers a major outage the startup is forced to migrate the service. This forms the final piece of the scenario in which the service provider moves the complete deployment over to a new more suitable infrastructure provider.
The scenario consists of two distinct phases:
- Service deployment and scaling
- Service migration and redeployment
To each of these phases there are a number of steps, which will be detailed in relation to the standards used to execute each step.
The overall goal of the startup is to utilise the infrastructure provider’s CDMI and OCCI interfaces and to supply the provider with OVF service descriptions, which it can understand. It is these provider-offered capabilities that enable interoperability for the startup. …

The authors continue with the following topics:
- Service Deployment and Scaling
- Integrating Cloud Standards
- Integrating Standards to Ensure Portability
- Related Work and Outlook
And came to the following Conclusions:
This article documented observations and action items of the OCCI working group’s perspective resulting from the collaborative efforts of attending SDO sessions at the DMTF Alliance Partner Technical Symposium (APTS). DMTF hosted this face-to-face event to investigate the possibility of integrating open cloud computing interoperability and portability standards efforts of OVF, CDMI and OCCI.
The scenario described in the first sections was used to step through different processes during the service’s lifetime, in particular migration and scaling of the service. It is intended to reflect a real-world service offering, albeit basic, and demonstrates that by using today’s standards it is possible to realise such a setup.
Further sections in the article discussed how the triplet of standards can be integrated and where open issues reside. The open issues requiring further investigation or improvement were shown and described. The overall integration is sufficient to achieve the complete deployment, migration and scaling of the service described in the scenario section using today available versions of those specifications.
It is noted here that bringing in a fourth currently available specification might be desirable. CSA’s CloudAudit has become accepted by the industry and adds important features to the scenario in this document. Auditing clouds and conformance levels was left out of scope in this document but would be useful to investigate further.
Although currently focusing more on the infrastructure level of the service deployment a more PaaS based scenario (like a Node.js or GAE service) using cloud standards could be described in future revisions of this document.
Acknowledgements
The authors would like to thank Mark Carlson (Oracle) and David Slik (NetApp) for inputs on the integration of CDMI and OCCI.
We would like to thank Winston Bumpus (VMware) and Jeff Wheeler (Huawei) for their help on OVF-related topics.
The following reviewers work was greatly appreciated while creating, editing and reviewing this document:
- Alexis Richardson (RabbitMQ)
- Lawrence Lamers (VMware)
- Sebastian Schoenberg (Intel)
- John Kennedy (Intel)
- Finian Rogers (Intel)
- Dr. Craig Lee (The Aerospace Corporation)
About the Authors
- Andy Edmonds is a researcher at Intel.
- Thijs Metsch is Senior Software Engineer, at Platform Computing, focusing on Grid and Cloud Technology.
- Eugene Luster is a Cloud Advocate at R2AD, focusing on Cloud Computing open standards development.
References
- Open Cloud Computing Interface working group community website
- Distributed Management Task Force website
- Cloud Data Management Interface website
- Open Virtualization Format
- Standards and Interoperability for eInfrastructure Implementation Initiative website
- NIST Cloud Computing Program
- Apache Hadoop website
- Open Cloud Computing Interface - Infrastructure, Open Grid Forum, GFD-P-R.184, 2011
- Cloud Data Management Interface, Storage Network Initiative Alliance, 2010
- Cloud Management Working Group website
Chris Czarnecki analyzed Amazon S3 Durability in a 7/19/2011 post to the Learning Tree blog:
When adopting cloud computing services, reliability availability and durability are key concerns. It is important to determine what level the cloud provider is offering for the above parameters. Lets take Amazon S3 as an example. S3 is described by Amazon as a highly durable storage infrastructure designed for mission critical and primary data storage. Amazon then highlight the following facts:
- Backed with the Amazon S3 Service Level Agreement.
- Designed to provide 99.999999999% durability and 99.99% availability of objects over a given year.
- Designed to sustain the concurrent loss of data in two facilities.
The above, quoted by Amazon, give us a feeling that durability is incredibly high. However, the wording is clever. It states that S3 is designed to provide 99.999999999% durability and 99.99% availability of objects over a given year. This is potentially very different to what is actually provided. Reading the Service Level Agreement highlights that the S3 SLA offers no guarantee of durability, just availability. Further, this availability is not at 99.99% but 99.9%. I quote the SLA below.
AWS will use commercially reasonable efforts to make Amazon S3 available with a Monthly Uptime Percentage (defined below) of at least 99.9% during any monthly billing cycle (the “Service Commitment”)
If the availability falls between >=99% and < 99.9% customers will receive 10% of the monthly charge in credit. Availability < 99% and customers receive a credit of 25% of the monthly charge.
The reason I write about this is not as a criticism of Amazon – I think their services are first class and use them widely. I write to highlight the fact that when considering moving to the cloud, the SLA's need to be read in detail so that there is no misunderstanding between what is actually being provided and what you think is being provided.


Andy Edmonds, Thijs Metsch and Eugene Luster co-authored An Open, Interoperable Cloud article of 7/19/2011 for the InfoQ blog:
In this article we describe how through leveraging mature open standards (related to Clouds, Grids and Storage), interoperable clouds can be created now. We demonstrate the use of the major contemporary innovative cloud interface specifications to realise an open standards-based, interoperable, cloud offering.
The motivation for this article is to demonstrate that currently available features in cloud standards from various standard-developing organisations (SDOs) are enough to create a cloud offering as described in the following sections. This article can be seen as one of the first steps of an exploration into cloud standards integration, especially between Open Cloud Compute Interface (OCCI) [1], Open Virtualisation Format (OVF) [4] and CDMI [3]. Last but not least what is detailed in this document can be used to drive collaborations between OCCI and the Cloud Management Working Group (CMWG) [10] as well as efforts like cloud-standards.org, Standards and Interoperability for eInfrastructure Implementation Initiative (SIENA) [5], National Institute for Standards and Technology (NIST) [6] and others.
In order to describe how this integration of standards can happen, we will use a simple scenario. That scenario is one where a startup service provider wants to deploy, scale, migrate and redeploy their new Hadoop’s [7] based MapReduce service.
In order to implement/execute the scenario, the following enabling standards are used:
- DMTF’s OVF - providing a means to package virtual infrastructure deployments, which can be exported or imported into an infrastructure service offering.
- SNIA’s CDMI - providing an API that allows for the runtime management of storage infrastructure service offerings.
- OGF’s OCCI - providing an API that allows for the runtime management of infrastructure as service offerings.
It should be noted that aspects such as authorisation and authentication are not dealt with in this article. These issues are somewhat orthogonal and dealt with by other specifications and technologies (e.g. OAuth, OpenID, etc). OCCI and CDMI leverage the design considerations in the HTTP protocol suite with respect security.
The Scenario
The scenario is one where a startup company wishes to offer a MapReduce service to their clients. As the service offering is new it will be offered to a limited set of beta users. This limitation allows the startup company's architects to create an initial deployment architecture that suits the initial resource requirements to deliver the service. The service's deployment architecture is as follows:
Once the service has been deployed, the number of users makes it necessary that the service scales. This means additional resources must be added on the fly to serve the demand. Next to the scaling, migrations are considered part of the overall scenario. In case that the infrastructure provider suffers a major outage the startup is forced to migrate the service. This forms the final piece of the scenario in which the service provider moves the complete deployment over to a new more suitable infrastructure provider.
The scenario consists of two distinct phases:
- Service deployment and scaling
- Service migration and redeployment
To each of these phases there are a number of steps, which will be detailed in relation to the standards used to execute each step.
The overall goal of the startup is to utilise the infrastructure provider’s CDMI and OCCI interfaces and to supply the provider with OVF service descriptions, which it can understand. It is these provider-offered capabilities that enable interoperability for the startup. …
The authors continue with the following topics:
- Service Deployment and Scaling
- Integrating Cloud Standards
- Integrating Standards to Ensure Portability
- Related Work and Outlook
And came to the following Conclusions:
This article documented observations and action items of the OCCI working group’s perspective resulting from the collaborative efforts of attending SDO sessions at the DMTF Alliance Partner Technical Symposium (APTS). DMTF hosted this face-to-face event to investigate the possibility of integrating open cloud computing interoperability and portability standards efforts of OVF, CDMI and OCCI.
The scenario described in the first sections was used to step through different processes during the service’s lifetime, in particular migration and scaling of the service. It is intended to reflect a real-world service offering, albeit basic, and demonstrates that by using today’s standards it is possible to realise such a setup.
Further sections in the article discussed how the triplet of standards can be integrated and where open issues reside. The open issues requiring further investigation or improvement were shown and described. The overall integration is sufficient to achieve the complete deployment, migration and scaling of the service described in the scenario section using today available versions of those specifications.
It is noted here that bringing in a fourth currently available specification might be desirable. CSA’s CloudAudit has become accepted by the industry and adds important features to the scenario in this document. Auditing clouds and conformance levels was left out of scope in this document but would be useful to investigate further.
Although currently focusing more on the infrastructure level of the service deployment a more PaaS based scenario (like a Node.js or GAE service) using cloud standards could be described in future revisions of this document.
Acknowledgements
The authors would like to thank Mark Carlson (Oracle) and David Slik (NetApp) for inputs on the integration of CDMI and OCCI.
We would like to thank Winston Bumpus (VMware) and Jeff Wheeler (Huawei) for their help on OVF-related topics.
The following reviewers work was greatly appreciated while creating, editing and reviewing this document:
- Alexis Richardson (RabbitMQ)
- Lawrence Lamers (VMware)
- Sebastian Schoenberg (Intel)
- John Kennedy (Intel)
- Finian Rogers (Intel)
- Dr. Craig Lee (The Aerospace Corporation)
About the Authors
- Andy Edmonds is a researcher at Intel.
- Thijs Metsch is Senior Software Engineer, at Platform Computing, focusing on Grid and Cloud Technology.
- Eugene Luster is a Cloud Advocate at R2AD, focusing on Cloud Computing open standards development.
References
- Open Cloud Computing Interface working group community website
- Distributed Management Task Force website
- Cloud Data Management Interface website
- Open Virtualization Format
- Standards and Interoperability for eInfrastructure Implementation Initiative website
- NIST Cloud Computing Program
- Apache Hadoop website
- Open Cloud Computing Interface - Infrastructure, Open Grid Forum, GFD-P-R.184, 2011
- Cloud Data Management Interface, Storage Network Initiative Alliance, 2010
- Cloud Management Working Group website
Jeff Barr (@jeffbarr) reported Amazon S3 - More Than 449 Billion Objects on 7/19/2011:
As of the end of the second quarter of 2011, Amazon S3 holds more than 449 billion objects and processes up to 290,000 requests per second for them at peak times. Here's a chart:
No matter how you look at it, that's a lot of objects! Here are a few ways to put it into perspective:
- 1,440 objects for every resident of the United States (source: US Population Clock).
- 64 objects for each person on Planet Earth (source: World Population Clock).
- 4 objects for every neuron in your brain (source: Wikipedia / Neuron).
- About as many S3 objects as there are stars in the Milky Way (source: Wikipedia / Milky Way).


John Considine asserted “Citrix and VMware have been competing in the virtualization space for years” in a introduction to his Cloud Wars Heat Up post of 7/18/2011 to the CloudSwitch blog:
Last week I wrote about the Cloud.com acquisition and what it means for Citrix, Rackspace, OpenStack and the industry. Next, I’d like to dig into the VMware announcement about their cloud infrastructure suite. Citrix clearly wanted to announce their news just prior to VMware’s, and for a good reason – Citrix is hitting VMware in a weak spot of their cloud strategy. It’s pretty clear that VMware is not getting the vCloud adoption they were anticipating from service providers and even enterprises.
In Paul Maritz’s presentation, he mentioned that VMware “…has been working closely with service providers because you need the same stacks on both sides [the private cloud and public cloud] to be able to ‘slide’ applications to the cloud…and back again.” At CloudSwitch we are dedicated to the notion that you don’t have to have identical infrastructure stacks between the data center and the cloud. You have to expect that what a cloud provider chooses will not necessarily be the same as what the enterprise has chosen, or that they will work together in lock-step. VMware seems committed to the strategy that they will provide the complete solution on both sides of the cloud, and that all parties will work together to stay coordinated. This is very different from Citrix’s positioning around more open and heterogeneous solutions.
Citrix and VMware have been competing in the virtualization space for years with a battle of features (mostly Citrix catching up with VMware and trying to gain share in the enterprise virtualization market), but the scope of the competition has been growing thanks to cloud computing. Cloud computing expands the server virtualization fight from hypervisor features to integrated stacks for deploying/managing infrastructure. The hypervisors remain important, but the new frontier contains everything from core networking to storage management, to large scale deployments to self-service IT. In this new battle, Citrix has some real strength in networking (Netscaler, etc.) and application delivery, and with their Cloud.com acquisition, they are capturing some proven orchestration technologies.
VMware is investing huge resources to expand their cloud offerings (Maritz claims a million man hours). Their focus is on adding features to their hypervisor and layers to their stack (vSphere+vCenter SRM+vCenter Operations+vShield+vCloud Director). They have lots of expertise in this area and direct interaction with enterprise customers and requirements. On the service provider side, they are dependent on feedback from VMware-based partners to provide input and learn how to build and run large-scale infrastructure clouds. We’ll have to see how this approach plays out vs. Citrix’s CloudStack.
In the end, this competition is great for all of us as well as for CloudSwitch specifically. The competition in the cloud space will continue to drive innovation, new features, and simplification of deployment for this great new platform called cloud computing. CloudSwitch is all about choice and giving enterprises control and flexibility in their cloud architectures. As the world of cloud computing evolves, we love to see different options, technologies, and capabilities – because a world filled with different cloud choices needs a CloudSwitch to connect all of the pieces.

Jeff Barr (@jeffbarr) reported Amazon Simple Email Service Now Supports Attachments on 7/18/2011:
You can now use the Amazon Simple Email Service to send email message that include attachments such as images or documents.
There are no new "attachment" APIs. Instead, you simply use the existing SendRawEmail function to send a message that includes one or more MIME parts. Each part of the message must be of a MIME type that is supported by SES. Document and image formats are supported; executable files and archives are not. Consult the SES documentation for a complete list of supported MIME types.
Messages that include attachments incur an additional cost of $0.12 per GB of attachment data. This is in addition to the $0.10 cost for every 1000 messages and the usual cost for outbound data transfer (see the SES page for details).
I spent a few minutes putting together some PHP code to create and send a message with an attachment. I installed and configured the latest version of the AWS SDK for PHP, the Mail_Mime package, and wrote a little bit of code. Here's what I ended up with:
Load the MIME package and the AWS SDK for PHP:
#!/bin/env php
<?php
include('Mail/mime.php');
include('sdk.class.php');Create a MIME message with text and HTML bodies, and a PDF attachment:
$mail_mime = new Mail_mime(array('eol' => "\n"));
$mail_mime->setTxtBody("Hello Jeff, here's your invoice.\n");
$mail_mime->setHTMLBody("<p>Hello Jeff, here's your invoice.</p>");
$mail_mime->addAttachment("/tmp/invoice.pdf", "application/pdf");Retrieve the complete message body in MIME format, along with the headers:
$body = $mail_mime->get();
$headers = $mail_mime->txtHeaders(array('From' => 'jbarr@amazon.com', 'Subject' => "Invoice for Jeff"));Assemble the message using the headers and the body:
$message = $headers . "\r\n" . $body;
Send the message (which must be base 64 encoded):
$ses = new AmazonSES();
$r = $ses->send_raw_email(array('Data' => base64_encode($message)), array('Destinations' => 'jbarr@amazon.com'));Report on status:
if ($r->isOK())
{
print("Mail sent; message id is " . (string) $r->body->SendRawEmailResult->MessageId . "\n");
}
else
{
print("Mail not sent; error is " . (string) $r->body->Error->Message . "\n");
}Close up shop:
?>
As you can see, this is pretty straightforward. Per the usual operating protocol for SES, you'll need to verify the email addresses that you use for testing, and you'll need to request and receive production access in order to start sending to arbitrary addresses.


Azure developers have been agitating for an SES equivalent for more than a year.
<Return to section navigation list>

















1 comments:
Before choosing your cloud hosting you consider above all the points means you get it reliable and cheapest web hosting services.web site hosting
Post a Comment