Windows Azure and Cloud Computing Posts for 11/25/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

•• Update 11/28/2010: New articles marked •• (OData, SQL Azure and Office 365 topics)
• Update 11/27/2010: New articles marked •
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control and Service Bus
- Windows Azure Virtual Network, Connect, and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA) and Hyper-V Cloud
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Tip: If you encounter articles from MSDN or TechNet blogs that are missing screen shots or other images, click the empty frame to generate an HTTP 404 (Not Found) error, and then click the back button to load the image.
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
•• Jason Sparapani interviewed Microsoft’s Mark Kromer (@mssqldude) in a Q&A: Staying aloft in SQL Azure development post of 11/16/2010 for SearchSQLServer.com (missed when posted):
It's been an eventful year for SQL Azure. In fact, with announcements regarding Windows Azure and SQL Azure at last month's 2010 Professional Developers Conference (PDC) on the Microsoft campus in Redmond, Wash., and at last week's Professional Association for SQL Server (PASS) Summit in Seattle, it's been an eventful few weeks. In this edition of our “SQL in Five” series, SearchSQLServer.com asks Mark Kromer, a data platform technology specialist at Microsoft, how recent developments such as new reporting services for SQL Azure and the upcoming SQL Server release, code-named Denali, might affect who will next turn to the cloud. …
Do Microsoft’s new reporting services for SQL Azure bring the company closer to getting SQL Azure to function like on-premises SQL Server? How?
Mark Kromer: It is probably more accurate to say that SQL Azure and SQL Server have a lot of similarities today. Microsoft is adding more of the traditional on-premise SQL Server capabilities into SQL Azure, as announced earlier this month at the PDC, and there were similar announcements last week at the PASS Summit. Capabilities being added to SQL Azure include the (limited CTP [community technology preview]) reporting feature, similar to SSRS' [SQL Server Reporting Services'] capability and data synchronization updates to provide SQL data replication, Data Sync CTP2. But I still suggest to customers that they carefully assess which workloads to prototype and then move into the cloud with SQL Azure. For example, if you have applications on SQL Server today that make large use of CLR [Common Language Runtime] functions or table partitioning, you will need to look at modifying those database applications or look at starting your migration into the cloud by starting with development, test, staging or other smaller workload databases to SQL Azure.
How does SQL Azure Data Sync, which enables tables in SQL Azure to be synchronized with tables in SQL Server, fit in to that objective?
Kromer: I think this is best described with an example. With SQL Azure Data Sync (CTP2), you could use the sync technology to implement a scaled-out read/write SQL Server architecture by using your local on-premises SQL Server instances and syncing those up to multiple SQL Azure databases that can be geographically dispersed and contain different or replicated data sets. The previous CTP1 of Data Sync did not have these native capabilities to sync on-premises to cloud SQL Azure databases. This way, you can scale-out your application with multiple SQL Server databases without needing to stand up multiple SQL Servers in geographically dispersed data centers and instead rely on the Microsoft Azure data centers and infrastructure to do that work for you. The CTP2 of Data Sync provides that ability to create sync groups from our data center SQL Servers to the cloud.
What’s still missing in terms of on-premise functionality in SQL Azure? And what’s on the burner for improvements?
Kromer: With the announcements at PDC and PASS of the SQL Azure reporting infrastructure, it is clear that Microsoft's cloud BI [business intelligence] story is going to be a big part of the data management story and will continue to grow with Denali (SQL Server 2011) and beyond. The Microsoft self-service BI features have been a huge success with SQL Server 2008 R2, and the current SQL Azure functionality is very much aligned to BI workloads in the cloud. Even without the SQL Azure Reporting CTP, you can still build cloud-based BI solutions with SQL Azure by utilizing SSIS [SQL Server Integration Services], SSRS and SSAS [SQL Server Analysis Services] on-premise using SQL Azure connection strings. SQL Azure databases in that scenario act just like an on-premise SQL Server 2008 R2 database. But it is important to keep in mind the database-as-a-service approach of SQL Azure. DBAs [database administrators] will not need to have to have the worries or responsibilities around maintaining the core infrastructure required for SQL Server instances, high-availability, patching, etc. So the functionality in SQL Azure will always have different lifecycles than the features required for on-premise SQL Server infrastructures.
IT managers still stress over trusting an outside entity with their data. How is Microsoft addressing that concern in regards to SQL Azure? Will Azure’s new Enhanced Access Control, which lets a company’s customers use their own Active Directory systems instead of log in to the company’s system, affect SQL Azure?
Kromer: Yes, I do think that the ability to federate identities in Azure with your company’s identity system like Active Directory will be helpful in that regard. But overall, the mindset of platform as a service with Azure requires a modification and a realization that giving patching, infrastructure and other controlling mechanisms to Microsoft data center teams is the understanding that businesses need to contend with. Doing so will result in increased ROI through reduced cap-ex expenditures from IT and data centers, and I am hopeful that such federated identity mechanisms can help in that regard.
Two other new Azure offerings are its VM role, which lets end users set policies to govern the operations of a virtual machine, and Azure Caching Service, which lets applications store used data in RAM for quicker access. Will SQL Azure users make use of these new features? If not, are there plans to make these available in SQL Azure?
Kromer: Certainly Windows Azure applications will want to use features like the Windows Azure AppFabric caching, and Windows Azure Storage provides developers with a very efficient and easy mechanism to use, store and retrieve blobs [binary large objects]. But SQL Azure is very much a leader in the market of cloud databases, much unlike the classic Amazon model of generating VMs in the cloud that run your company’s databases. With SQL Azure, the product line is likely to continue to evolve as a service-based platform for data management and BI and become a much stronger platform as more and more businesses realize the cost savings, reliability and security of the SQL Azure platform. That is really providing a different service than Windows Azure and AppFabric offerings.
Mark is the Microsoft data platform technology specialist for the mid-Atlantic region and the author of the MSSQLDUDE blog.
• Johan Åhlén answered SQL Azure - why use it and what makes it different from SQL Server? on 11/23/2010 (missed when posted):
I've so far not seen any article on why anyone should use SQL Azure so I thought it is time someone writes about that. This article is an introduction to why you might be interested in a cloud database and a summary of the differences compared to "ordinary" SQL Server. Finally I've included links to some useful resources.
Why would you need a cloud database?
Maybe you've read the story about the unknown IT multi-millionaire Markus Persson? If not, here is an article (in Swedish only). He's not so unknown any longer but I think he never imagined what a tremendous success his game Minecraft would be. Even if he haven't spent a single dollar on marketing it became so successful that the server capacity was not sufficient for the all the new paying players.
Of course it is very hard to predict how popular an online game or service will be. It can also change dramatically if you get good publicity (or bad). How can you then make sure you always have the right server capacity for your users?
This is where Azure and the cloud comes in. It is an elastic platform which provides you the means to instantly increase or decrease your server capacity. You only pay for what you use and don't have to estimate capacity needs and buy a reserve capacity. You won't run into the problem of "how can I do database maintenance when I always have millions of players online".
Database-as-a-service vs physical databases
What kind of demands can you make on a database? Why would anyone use a database? Would it not be easier to just write data to files instead?
I can give you at least four reasons why you should in most applications use a database:
Availability - let's say you are running business critical applications (like in healthcare). Then you don't want to rely on a single computer or disk. SQL Server comes with built-in support for high availability such as clustering, database mirroring, etc which can be configured by a DBA. With SQL Azure you automatically get high availability with zero configuration.
Security - with a database you have a much finer control of security than on a file. You can also audit the usage, who has accessed what and who has updated what. Auditing has become increasingly important since the last financial crisis.
Correctness - you can enforce consistency on a database through foreign keys, unique indexes, check constraints, etc. Also you can use transaction isolation to prevent chaos when thousands of users work with the database simultaneously. In almost any OLTP application you need to use transactions if you want the application to work correctly with many users.
Performance - databases have several mechanisms to optimize performance such as caching, query optimizers, etc.
I'm not saying that the above features cannot be achived by files and custom code, but with a database you needn't reinvent the wheel every time.
As a developer you just want the database features but probably don't want to spend time setting up clustering, applying security patches, worry about disk space, etc. Those are the things a DBA does for you.
With SQL Azure you get at least three physical databases for every single database your create. That is how SQL Azure ensures you get the 99.9% uptime. Also you don't need to spend any time on security patches, disk space, moving databases between different servers to handle increased load, etc.
SQL Server Consolidation
It has become increasingly popular to consolidate SQL Server databases, because it can save you money on hardware, licenses and maintenance work.
I've seen three main methods to consolidate databases:
Virtualization - which simply means moving physical machines to virtual machines. The easiest way, but also gives the least savings because every virtual machine needs its own OS and occupy a lot of resources.
Instance consolidation - which means that you move several SQL Server instances to the same physical server and let them share the OS. Better efficiency than virtualization, but still resources are not shared between instances.
Database consolidation - where you merge SQL Server instances. Even more efficient than instance consolidation.
I've added SQL Azure as a method in the picture above. It takes more effort than any of the other methods because SQL Azure is a bit different from a physical database but it also gives you the biggest savings.
Some differences between SQL Server and SQL Azure
So what really are the differences between SQL Server and SQL Azure? You can find a list of unsupported features in SQL Azure here. But what are the fundamental differences?
In SQL Server you usually rely on Integrated Security. In SQL Azure you have to use SQL Server authentication.
In SQL Server an idle connection almost never goes down. If it does, there is usually a serious error. In SQL Azure an idle connection goes down after 5 minutes and can go down for a lot of other reasons than timeout. You need to think about this especially if you use connection pooling.
The default transaction isolation level in SQL Azure is READ_COMMITTED_SNAPSHOT while it is READ_COMMITTED in SQL Server. That can make applications behave differently.
There is no SQL Server Agent in SQL Azure. Therefore it does not provide any functionality that relies on the SQL Server agent, such as CDC or similar.
You cannot currently backup a SQL Azure database. However you can easily copy them instead. But you don't have access to transaction log backups so you won't be able to restore the database to an arbitrary state in time.
Heap tables are not supported in SQL Azure (except in tempdb). A heap table is a table which does not have a clustered index. This is not a big issue since clustered indexes almost always are a much better choice than heap tables.
You cannot write cross-database references in SQL Azure. In SQL Server you can combine data from databases in the same instance.
Also you cannot access linked servers in SQL Azure.
Default database collation in SQL Azure is SQL_LATIN_1 and cannot be changed. However Microsoft has promised support for other default database collations in the future.
Fulltext indexing is currently not supported in SQL Azure.
The above list may look long, but most existing applications that use SQL Server would work well also on SQL Azure. The most common issue I think will be connection pooling and handling of lost connections. The second most common issue (for people who live outside of US like me) will probably be the default database collation.
Tempdb in SQL Azure
When you start using SQL Azure you will notice that you automatically get a master database. Do you also get a tempdb database?
Yes, there is a tempdb database. However there are some limitations how you can access it. Which of the following queries do you think works?
CREATE TABLE tempdb.dbo.Test ( col1 int not null )
CREATE TABLE #Test ( col1 int not null )
CREATE TABLE ##Test ( col1 int not null )
Only the second option works. As mentioned earlier you cannot write cross-database references (like the first option). The third option is forbidden because you cannot create global tempdb objects.
Can you have heap tables (non clustered) in tempdb? Yes you can. Still it doesn't support the SELECT INTO statement, which I believe was disabled because it creates heap tables.
Summary
SQL Azure is very useful for applications where you don't know how many users you will have in the future, since it provides you with the ability to scale up and down on demand. Especially with the new SQL Azure Federation support (that I will write about later). Also it is of course a very useful storage platform for Windows Azure based applications.
Links and resources


• Johan Åhlén posted SQL Azure some more tips and tricks on 11/5/2010 (missed when posted):
Data-tier applications (DACs)
There are two main options on how to deploy your database solutions to SQL Azure, unless you want to do it manually. These options are to use Data-tier applications or to use the SQL Azure Migation Wizard. The latter is an open source tool that copies your database (including the data) in any direction. Data-tier applications however is a new feature in SQL Server 2008 R2 and SQL Azure that enables you to develop a database in Visual Studio like you would develop a C# applications or similar. Existing databases can easily be converted to a Data-tier applications as long as you don't use any features that are not supported (such as XML).
Deploying a Data-tier application in SQL Azure
You can't deploy it from Visual Studio. Instead build your project, connect to SQL Azure through SQL Server Management Studio, right-click on your instance and choose "Deploy Data-tier Application..." in the menu. Click Next in the wizard and browse to your .dacpac file.
Upgrading a Data-tier application in SQL Azure is a manual process. You'll need to deploy it under a new name, copy the data manually from the old database and rename it. How to rename a SQL Azure database? Issue the T-SQL statement: "ALTER DATABASE database_name MODIFY NAME = new_database_name".
To add logins and users in your Data-tier application you need to create the login with the MUST_CHANGE password option.
CREATE LOGIN [username] WITH PASSWORD='' MUST_CHANGE, CHECK_EXPIRATION=OFF, CHECK_POLICY=OFF
You map it to a database user in the same way as "ordinary" SQL Server:
CREATE USER [username] FOR LOGIN [username] WITH DEFAULT_SCHEMA=[dbo]
Then you need to add it to one or more roles by executing this T-SQL statement within your database (make sure you don't execute it within the master database):
EXEC sp_addrolemember N'my_db_role', N'username'
Finally you need to assign a password and enable the login by executing the following T-SQL statement on the master database.
ALTER LOGIN [username] WITH PASSWORD='mypassword'
GO
ALTER LOGIN [username] ENABLEChanging the edition of your SQL Azure database or increasing the size
You can increase or decrease the size of the database or change the edition at any time. Just issue the following T-SQL statement on the master database.
ALTER DATABASE database_name
MODIFY (MAXSIZE = x GB, EDITION = 'x')Edition can currently be either web or business. Database size can currently be either 1, 5, 10, 20, 30, 40 or 50 GB.
Resizing or changing the edition of your database takes almost no time so you can easily start with a smaller database and increase it on demand (like you should be able to with a cloud database).
Josh Reuben delivered a detailed SQL Azure and Windows Azure Together post with tips and tricks on 11/25/2010:
The SQL Azure Firewall needs tweaking to work between these two stacks – 90% of your teething problems will be here.
Step 1) create your SQL Azure project – from the Azure Portal
Add a DB
Test connectivity – it will fail – you need to add a Firewall rule – you may need to wait a few minutes for this to work
Add a DB and test connectivity with userid & password – connectivity will now succeed:
Get your connection string from the portal.
Next, you need to manage your DB – you must have SQL 2008 R2 Management Studio – note the R2
Make sure you open port 1433 outgoing on your local firewall
Specify the server name from your DB – it should be something like XXX.database.windows.net.
Use SQL Server Authentication to connect
Supprisingly, connection fails!
Its that pesky SQL Azure firewall again – you are going out on 1433 and your ISP NAT probably has a different mapping – jot down this IP and add another firewall rule to the SQL Azure portal:
Now you can connect
But note: its not your regular SQL Management Studio interface – try right click on Tables > New Table: you wont get a designer, its back to TSQL (reduced) for you!
-- =========================================
-- Create table template SQL Azure Database
-- =========================================
IF OBJECT_ID('<schema_name, sysname, dbo>.<table_name, sysname, sample_table>', 'U') IS NOT NULL
DROP TABLE <schema_name, sysname, dbo>.<table_name, sysname, sample_table>
GO
CREATE TABLE <schema_name, sysname, dbo>.<table_name, sysname, sample_table>
(
<columns_in_primary_key, , c1> <column1_datatype, , int> <column1_nullability,, NOT NULL>,
<column2_name, sysname, c2> <column2_datatype, , char(10)> <column2_nullability,, NULL>,
<column3_name, sysname, c3> <column3_datatype, , datetime> <column3_nullability,, NULL>,
CONSTRAINT <contraint_name, sysname, PK_sample_table> PRIMARY KEY (<columns_in_primary_key, , c1>)
)
GO
Step 2) Create a Web Role to access the SQL Azure DB
You need a service Façade over your data – in Visual Studio, you need to create a Cloud project that contains a WCF Service Web Role
Alternatively, you could also expose your SQL Azure DB via OData: https://www.sqlazurelabs.com/ConfigOData.aspx
The concept is to first test the Web Role from your local dev fabric against your cloud storage model, then publish and test from there.
Add an ADO.NET Entity Data Model – just get your connection string from SQL Azure and point to your SQL Azure DB
Add a WCF Data Service
public class WcfDataService1 : DataService< /* TODO: put your data source class name here */ >
{
// This method is called only once to initialize service-wide policies.
public static void InitializeService(DataServiceConfiguration config)
{
// TODO: set rules to indicate which entity sets and service operations are visible, updatable, etc.
// Examples:
// config.SetEntitySetAccessRule("MyEntityset", EntitySetRights.AllRead);
// config.SetServiceOperationAccessRule("MyServiceOperation", ServiceOperationRights.All);
config.DataServiceBehavior.MaxProtocolVersion = DataServiceProtocolVersion.V2;
}
}Test locally – create a test client
var x = new ServiceReference1.CloudValueEntities(new Uri(uriProd));
try
{
var r = new Registrations()
{
CompanyName = "xxx",
EmailAddress = "XXX",
FullName = "XXX",
HowDidYou = "XXX",
PhoneNumber = "XXX"
};
x.AddToRegistrations(r);
x.SaveChanges();
Console.WriteLine("New product added with ID {0}.", r.ID);
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
Console.ReadLine();
Or use Fiddler Request Builder to test non-GET HTTP verbs:
Step 3) Publish
From visual studio:
Specify that you want to deploy directly:
You will see this screen: you need to setup credentials
To do this, there are some prerequisites!
- You must have an Azure account
- You must have an Azure storage account and hosted service setup – if not, after you setup your credentials, then the 2nd and 3rd dropdowns above will not find a deployment target!!!
Select the 1st dropdown to create your credential
Then click copy the full path link and go to the developer portal accounts to upload your certificate:
Now deployment can proceed
Note: although it is stated that this should take approx. 60 seconds, its more like 20 minutes! Bah!
Step 4) Troubleshooting
But it works on my machine!
Because you cant debug directly into a deployed web role, it's a good idea to expose a service operation that tries to do a basic version of your operation in a try catch, and returns an exception message on failure. Like so:
public string GetDataCount()
{
string retval;
try
{
using (var context = new CloudValueEntities())
{
retval = context.Registrations.Count().ToString();
}
}
catch (Exception ex)
{
retval = ex.Message;
}
return retval;
}Check your web.config file – publishing may have mangled it. If you are exposing WCF over EF, make sure
aspNetCompatibilityEnabled="false"and
MultipleActiveResultSets=False
Open up your SQL Azure firewall to check that this is not causing the problem – just because your local machine IP is allowed through, doesn't mean that your published web role Windows Azure host can get through!
You should see your service exposed as such:
And Bobs your uncle!

























Ike Ellis explained how to handle an SQL Azure Connection Error with SSIS, SSAS on 11/21/2010:
"Test Connection failed because of an error in initializing provider. Server Name cannot be deteremined. It must appear as the first segment of the server's dns name (servername.database.windows.net.) Some libraries do not send the server name, in which case the server name must be included as part of the user name (username@servername). In addition, if both formats are used, the server names must match."
I solved this the way the error says to solve it, by adding what was in the server name field after the user name in the user name field. I also noticed that it can be solved by switching to the native .NET provider, and not using the server name in the user name. I played with the data source in SSIS, too, and it works the same way. Interestingly, SSRS chooses a native .NET SQL provider by default, and therefore doesn't have this problem.
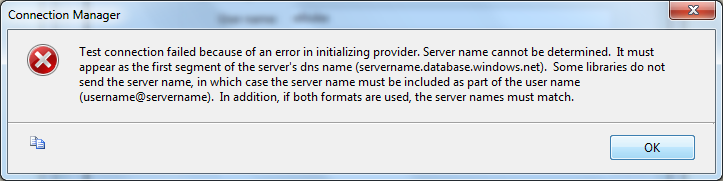
When in doubt, always use username@servername as the login.
<Return to section navigation list>
Dataplace DataMarket and OData
•• Gurnam Madan posted a brief, graphic description of WCF Data Services on 11/28/2010:
It often becomes difficult (if not painful) to share data beyond its original intent. As systems continue to become more interconnected, the need to reuse information also grows and the value of any given data becomes greater the more it can be shared and accessed by other systems.
The Open Data Protocol, referred to as OData, is a new data-sharing standard that breaks down silos and fosters an interoperative ecosystem for data consumers (clients) and producers (services) that is far more powerful than currently possible. WCF Data Services, is the Microsoft technology to support the Open Data Protocol. Microsoft now also supports OData in SQL Server 2008 R2, Windows Azure Storage, Excel 2010 (through PowerPivot), and SharePoint 2010.
In addition to client libraries that simplify working with OData, the Data Services framework builds on the general WCF capabilities to provide a solution for creating OData services for the web. Data Services enable you to expose data models to the Web in a RESTful way, with rich built-in data access capabilities such as flexible querying, paging, and association traversal.
The Data Services framework facilitates the creation of flexible data services that are naturally integrated with the web. WCF Data Services use URIs to point to pieces of data and use simple, well-known formats to represent that data, such as JSON and ATOM (XML-based feed format). This results in the data service being surfaced as a REST-style resource collection that is addressable with URIs and with which agents can interact using standard HTTP verbs such as GET, POST, PUT or DELETE.
For examples and quick start guides on WCF Data Services, go to this link. Also, read more about OData protocol here.

•• K. Scott Morrison described Securing OData (with Layer 7 Technologies’ CloudSpan gateway) in this 11/27/2010 post:
One emerging technology that has recently caught our attention here at Layer 7 is the Open Data Protocol, or OData for short. You can think of OData as JDBC/ODBC for the web. Using OData, web developers can query data sources in much the same way they would use SQL. It builds on the basic CRUD constructs of REST, adding the Atom Publishing Protocol to help flesh out the vision under a very standards-oriented approach. OData’s major promoter is Microsoft, but the company is clearly intent on making this protocol an important community-driven initiative that provides value to all platforms.
Most applications are designed to constrain a user’s view of data. Any modern relational database has the ability to apply access control and limit a user’s view to the records to which they are entitled. More often than not, however, the enforcement of these entitlements is a task delegated not to the database, but to the application that interacts with it.
Consider, for example, a scenario, where a database makes a JDBC or ODBC connection directly available to clients outside of the corporate firewall:
It can be extremely risky to permit direct outside connections into a database.
People avoid doing this for a good reason. It is true that you can secure the connection with SSL and force the incoming user to authenticate. However, if an attacker was able to compromise this connection (perhaps by stealing a password), they could explore or alter the database at will. This is a gangster’s paradise.
A simple web application is really a security buffer zone between the outside world and the database. It restricts the capabilities of the user through the constraints imposed by elements that make up each input form. Ultimately, the application tier maps user interactions to explicit SQL statements, but a well-designed system must strictly validate any incoming parameters before populating any SQL templates. From this perspective, web applications are fundamentally a highly managed buffer between the outside world and the data—a buffer that has the capability of applying a much more customizable and rigorous model of access control than a RDMS could.
The Web application tier as security buffer between the database and the Internet.
However, this is also why SQL injection can be such an effective vector of attack. An application that fails to take the necessary precautions to validate incoming data can, in effect, extend the SQL connection right outside to the user. And unconstrained SQL can open up the entire database to examination or alteration. This attack vector was very popular back in the PowerBuilder days, but lately it has made a startling resurgence because its effectiveness when applied to badly designed web apps.
OData, of course, is the data source connection, so injection isn’t an issue—just getting a hold of it in the first place is enough. So what is critically important with OData is to strictly manage what this connection is capable of doing. OData servers need to provide not just authentication, authorization, and audit of the connection, but wholesale constraint of protocol function and data views as well. Web security demands that you assume the worst—and in this case, the worst is certainly compromise of the connection. The best way to manage this risk is to limit your exposure to what an attacker can do.
In SQL-terms, this is like limiting the functions that a user can access, and restricting them to the views to which they are entitled (and they shouldn’t be entitled to much). The danger with OData is that some of the tools make it much too easy to simply open a connection to the data (“click here to make the database available using OData”); this can have widespread negative consequences if an attacker is able to compromise a legitimate user’s account. If the data source cannot itself impose the necessary constraints on the connection, then an intermediate security layer is mandatory.
This is where Layer 7 can help. CloudSpan is fully compatible with OData, and can act as an independent security layer between the OData client (which may be a browser-resident application) and the OData server. It can offer not just AAA on the connection, but can narrow the OData API or mask query results based on an individual user’s entitlement.
CloudSpan Gateways managing access to OData data sources.
Here’s a real example that Julian Phillips, one of Layer 7’s architects, put together. Jules constructed a policy using the Netflix OData API, which is an experimental service the company has made available on the net. The Netflix API allows you to browse selections in their catalog. It has it’s own constraints built in—it’s already read-only, for example—but we are going to show how CloudSpan could be deployed to further constrain the API to implement stricter security protocols, and even enforce business rules governing access.
Jules’ policy is activated on all URI’s that match the /Catalog* patternthe entry point into the Netflix OData API. This shows up in CloudSpan under the service browser:
What we are going to do here is add some security constraints, and then a business rule that restricts the ability of minors to only view movie titles with a rating of G or PG-13. Minors can build perfectly valid Netflix OData queries and submit them to the API; however, these will be trapped by the CloudSpan gateway before they get to the actual OData server.
Jules’ basic policy is quite simple. We’ve collapsed some details into folders to make the basic flow easier to understand:
First off, the policy throws an explicit audit to capture both the URI and the query string for debugging purposes. We then ensure that the connection uses SSL (and subject to the cipher suite constraints currently in effect), and we mine HTTP basic credentials from the connection. Need Kerberos or SSL client-side certificate authentication instead? Just drag the assertions implementing either of these into the policy and you are good to go.
The gateway then authenticates the user against a directory, and from this interaction we determine whether this user is an adult or a minor based on their group membership. If the user is indeed an adult, the gateway passes their OData query to the server unchanged. However, if the user is a minor, the gateway adds constraints to the query to ensure that the server will only return G or PG-13 movies. For reference, the full policy is below (click to expand):
This example is somewhat contrived, but you should be able to see how the intermediate security gateway can add critical constraint to the scope of OData protocol. OData shows a lot of promise. But like many new technologies, it needs to be managed with care. If deployed securely, OData can become an essential tool in any web developer’s toolkit.






Scott is the Chief Technology Officer and Chief Architect at Layer 7 Technologies
Azret Botash explained WPF Scheduling Control – Binding to OData in this 11/24/2010 post with a video link:
In this video, Azret Botash covers the advanced binding options of the WPF Scheduler.
Source: Devexpress Channel
A while back I have showed you how to bind a Scheduler Control to OData. You can do the same with the WPF Scheduler Control. Watch this video where I show you how to this step by step.
Mario Szpuszta presented a WCF Data Services - A Practical Deep-Dive! session (01:08:06) at TechEd Europe 2010:
(Slow news day.)
<Return to section navigation list>
Windows Azure AppFabric: Access Control and Service Bus
•• Steve Plank (@plankytronixx, Planky) posted Single-sign-on between on-premise apps, Windows Azure apps and Office 365 services on 11/27/2010:
A lot of people don’t realise there will be 2 very interesting features in Office 365 which makes connecting the dots with your on-premise environment and Windows Azure easy. The 2 features are directory sync and federation. It means you can use your AD account to access local apps in your on-premise environment; just like you always have. You can also use the same user account and login process to access Office 365 up in the cloud, and you could either use federation or a domain-joined application running in Azure to also use the same AD account and achieve single-sign-on.
Let’s take them all one at a time:
On-Premise
Not much to be said about these applications. If they are written to use integrated windows authentication, they’ll just work through the miracle that is Kerberos. It is worth reviewing, very briefly what happens with an on-premise logon, just to get an understanding of how the moving parts fit together.

Diagram 1: The AD Kerberos authentication exchange
Look at the numbered points in diagram 1 and follow along:
The user hits Ctrl-Alt-Del and enters their credentials. This causes an…
…authentication exchange between the client computer and the Domain Controller (which in Kerberos parlance is a Kerberos Distribution Centre or KDC). Note that the password itself never actually traverses the network, even in encrypted form. But the user proves to the KDC that they have knowledge of the password. If you want to understand more about how this is possible, read my crypto primer. A successful authentication results in…
A Kerberos Ticket Granting Ticket or TGT being issued to the user. This will live in the user’s ticket-cache. I’ll explain this ticket using a real life example. In the 80s, my wife (girlfriend at the time) and I did a backpacking trip round China. In Guangzhou railway station we dutifully joined the long queue at the “Destination Shanghai” booth. Once at the head of the queue, the official said, effectively “Do you have your TGT?”. The answer was no – we wanted tickets to Shanghai. She informed us she couldn’t sell a ticket to Shanghai unless we had a “TGT” to give her. “How do you get one of those?” I asked and she pointed to an incredibly long queue. We joined that queue and eventually we were given a ticket; a “TGT”. This gave us the right to queue up at a booth to buy a train ticket. We then joined the “Destination Shanghai” queue again. When we got to the head of it, we exchanged our TGT (plus some money!) for a Shanghai ticket.
Some time later, maybe hours later, the user tries to connect to IIS on a server.
The server, requests a Kerberos Service Ticket (ST). This causes the client to…
…send its TGT (which it could only have got by successfully authenticating and proving knowledge of the password) to the KDC. The KDC validates the TGT, and if succesful…
..issues a service ticket for the IIS server.
The client forwards the service ticket to the IIS Server. The server has enough crypto material to check the validity of the service ticket. It effectively says “this is valid and there’s only one way you could have got it – you must have successfully authenticated at some stage. You are a friend!”. The result is…
…the web page gets delivered to the user.
Extending the model to the cloud
Windows Azure Connect (soon to be released to CTP) allows you to not only create virtual private networks between machines in your on-premise environment and instances you have running in Windows Azure, but it also allows you to domain-join those instances to your local Active Directory. In that case, the model I described above works exactly the same, as long as Windows Azure Connect is configured in a way to allow the client computer to communicate with the web server (which is hosted as a domain-joined machine in the Windows Azure data centre). The diagram would look like this and you can followed the numbered points using the list above:

Diagram 2: Extending AD in to Windows Azure member servers
Office 365
Office 365 uses federation to “extend” AD in to the Office 365 Data Centre. If you know nothing of federation, I’d recommend you read my federation primer to get a feel for it.
The default way that Office 365 runs, is to use identities that are created by the service administrator through the MS Online Portal. These identities are stored in a directory service that is used by Sharepoint, Exchange and Lync. They have names of the form:
planky@plankytronixx.emea.microsoftonline.com
However if you own your own domain name you can configure it in to the service, and this might give you:
planky@plankytronixx.com
…which is a lot more friendly. The thing about MSOLIDs that are created by the service administrator, is that they store a password in the directory service. That’s how you get in to the service.
Directory Synchronization
However you can set up a service to automatically create the MSOLIDs in to the directory service for you. So if your Active Directory Domain is named plankytronixx.com then you can get it to automatically create MSOLIDs of the form planky@plankytronixx.com. The password is not copied from AD. Passwords are still mastered out of the MSOLID directory.

Diagram 3: Directory Sync with on-premise AD and Office 365
The first thing that needs to happen, is that user entries made in to the on-premise AD, need to have a corresponding entry made in to the directory that Office 365 uses to give users access. These IDs are known as Microsoft Online IDs or MSOLIDs. This is achieved through directory synchronization. Whether directory sync is configured or not – the MS Online Directory Service (MSODS) is still the place where passwords and password policy is managed. MS Online Directory Sync needs to be installed on-premise.
When a user uses either Exchange Online, Sharepoint Online or Lync, the Identities come from MSODS and authentication is performed by the identity platform. The only thing Directory Sync really does in this instance is to ease the burden on the administrator to use the portal to manually create each and every MSOLID.
One of the important fields that is synchronised from AD to the MSODS is the user’s AD ObjectGUID. This is a unique immutable identifier that we’ll come back to later. It’s rename safe, so although the username, UPN, First Name, Last Name and other fields may change, the ObjectGUID will never change. You’ll see why this is important.
The Microsoft Federation Gateway
I’ve written quite a few posts in my blog about Active Directory Federation Services (ADFS) 2.0 and Windows Azure’s AppFabric: Access Control Service (ACS). These are both examples of Security Token Services (STSes) and they enable federation. The Microsoft Federation Gateway (MFG) is a similar service. It’s not a general purpose feature for use with any service, any organisation, in the way ADFS 2.0 and AppFab:ACS are. It’s a federation service that is aimed specifically at MS Online Services. It is therefore much easier to configure as much of it is already done for you by the virtue of it being used for Office 365 only.
The MFG can federate with your on-premise ADFS Server. The authentication of the MSOLID will take place using the local Active Directory account in your on-premise AD. This will be done by Kerberos and the ADFS Server (which authenticates over Kerberos as detailed in diagram 1). Office 365 services are only delivered through MSOLIDs – setting up federation doesn’t change that. An MSOLID (which still exists in the MSODS) is the entity to which a mailbox or a Sharepoint site is assigned; the entity to which you might set the mailbox size or Sharepoint site size. It is not assigned to the AD account. Simply a collection of attributes from the AD account are synchronized to the MSOLID account. The key join-attribute, the attribute the identity platform uses to link a successful authentication from your on-premise AD, to the correct MSOLID, is the AD ObjectGUID. Remember this is synchronised from AD to MSODS. Let’s have a look at how this works. First a federation trust is set up between the MFG in the cloud and a local instance of ADFS you have installed that sits atop your AD:

Diagram 4: Federation trust: MFG (Cloud) to ADFS (on-premise)
This involves the exchange of certificates and URL information. To understand more about federation trusts, read my primer. Creating a federation trust is a one-time setup. If certificates expire, it may need to be reset. But each service, ADFS and the MFG, publish metadata URLs where information like certificates and URLs can be extracted from. This means as long as each service’s metadata is updated (such as expired certificates), the opposite, corresponding service can poll its federation partner regularly and get automatic updates.
Notice in Diagram 4 how the IdP – the Identity Provider, has now moved from the MS Online Services Identity Platform, to your local AD. That’s because the identity information that is actually used is from your AD. Let’s walk through the scenario, having removed some of the components for simplicity:

Diagram 5: Office 365 federated authentication – stage 1.
The MSOLIDs that were synced in to the MSODS have mailboxes assigned to them. There is an internal linkage in Exchange Online between the MSOLID and the mailbox (or any other service/resource, such as Sharepoint Sites and MSOLIDs) owned by the MSOLID.
The user in the on-premise environment has already logged in to AD and is in possession of a Kerberos TGT (see step 3 in Diagram 1). She attempts to open a mailbox in Exchange Online. Exchange Online notices the access request is un-authenticated.
Exchange Online therefore redirects her browser to its local federation service, the MFG. Exchange Online only trusts the local MFG, it doesn’t have a trust relationship with any other federation service.
The MFG notices this user is un-authenticated, so it redirects the user’s browser to their own local federation service – the ADFS server they have installed on-premise.
As soon at the user hits the ADFS URL, the Kerberos authentication steps (steps 4 to 8 in Diagram 1) kick off to ensure only a user with a valid account and knowledge of the password can get access to its services. Note – at this point the user is not prompted for credentials because of the way Kerberos works (Diagram 1) but they do have authenticated access to ADFS. In this step, the user is requesting a SAML (Security Assertion Markup Language) Token. For more information on this, read the federation primer.

Diagram 6: Office 365 federated authentication – stage 2.
Now the user is authenticated, the ADFS Server creates, encrypts and digitally signs a SAML Token which contains, among many other attributes, the user’s AD ObjectGUID.
The user’s web browser is redirected, along with the signed and encrypted SAML Token back to the MFG. If you need to understand signatures and encryption, read the crypto primer.
The MFG validates the signature on the incoming SAML token to ensure it did truly come from its federation partner. It decrypts the token and then creates a new token.
Among many other attributes, it copies the AD ObjectGUID from the incoming SAML Token to the outgoing SAML Token. The SAML Token is signed and encrypted.
The user’s web browser is now redirected, with the new SAML Token, to Exchange Online.
Exchange Online validates the signature to ensure it was truly issued by the MFG, decrypts it and extracts among many other attributes the AD ObjectGUID. It uses this as a “primary key” on the set of MSOLIDs in the Directory. When it finds the correct MSOLID user, it can then check whether the mailbox or other resource that is being asked for, either has the correct permissions for the MSOLID or is owned by that MSOLID. Remember in the directory sync stage (Diagram 3), the AD ObjectGUID was one of the attributes copied.
If everything checks out – the email is passed to the user.
Note in this process that it’s still the MSOLID that owns or has permissions to the resources in Office 365. Nothing is assigned directly to the AD user. However, if the user forgets their password, it’s the AD helpdesk that sorts the problem out. The password policy is set by the AD administrator. The glue that links the on-premise AD environment to the in-cloud Office 365 environment is the AD ObjectGUID. You can now see why it is you can’t just authenticate with federation alone, you also need Directory sync because at its core, Office 365 uses MSOLIDs to determine access.
Is this blanket-SSO?
Yes – using Windows Azure Connect to domain-join you Azure Instances (and ensure you are deploying Windows Integrated Authentication applications to them!) alongside Office 365 with its attendant Directory Sync and Federation features will give you SSO across all the on-premise apps that implement Integrated Authentication and Office 365 services (through federated access). As mentioned above, Windows Azure Connect (formerly codenamed Project Sydney) is a virtual network that allows you to domain-join instances in the cloud. But you can also federate with Windows Azure based applications. When would you want to federate and when would you want to domain-join? Well, I’ve written a post to give some guidance on that.
If you’d like to understand a little more about federating your Azure apps to your AD, this post and this post will give you the architectural guidance you need.
Planky
Rachael Collier recommended that you Get started with Windows Azure AppFabric in this 11/25/2010 post from the UK:
Windows Azure AppFabric provides a comprehensive cloud middleware platform for developing, deploying and managing applications on the Windows Azure Platform. This rather handy resource page on MSDN will get you started nicely, with ‘How do I?’ videos, the AppFabric sessions from PDC10, downloads and a lot more besides.
Get started with Windows Azure AppFabric here.
Vittorio Bertocci (@vibronet) posted Intervista con Giorgio sul Corriere [della Sera] on 11/25/2007. Here’s Bing’s (Windows Live Search’s) translation to Interview with Giorgio on Corriere [della Sera]:
Here I am at the airport in Seattle, where I came after a guidatona dawn. Snowing since yesterday evening, and I do hope that the plane that I am going to take to succeed in bringing me on vacation as planned (a couple of days to Honolulu for Thanksgiving, after which andro straight to Beijing for the keynote of TechEd in China). [Link added.]
Amidst all this activity, I look at the post and what I? An article appeared today on seven, the dummy weekly Corriere della Sera, which faithfully reproduces a chat that George and I have done with Federico to a dinner here in Seattle. It is a wonderful article, which you can read in here digital format. A wonderful way to start the celebration of Thanksgiving:-)

Here’s the referenced article translated by Windows Live Search:
Vittorio sways her Crown by Rockstar and it fails to resist the quip: "more than brains would say that we're hair on the run". Then watch George, ben younger but also much more stempiato, adding: "well, at least for me." On the Microsoft Redmond campus exterminated, sites that now has a mythological world no longer only of hi-tech, there's a much nicer as tepid Sun unusual in a region average ingrata like Seattle, Washington State, land of grunge just steps from the cold Canada. To let us guide you in what since 1986 is the home of the largest software company in the world, two Italian computer with their abilities have established themselves as pillars of multinational, Vittorio Bertocci, genovese class ' 72, and Giorgio Sardo, 26 years old from Turin.
More than just meetings, the campus is a small town size – and sometimes even look-Gardaland, inhabited by over 30,000 employees, where you will find every type of structure by inland transport with vans hybrids – "The connector", the largest private service in the world-, basketball and football fields, until you get to the gym. Also this is the biggest, but "only" throughout North America. Between the various "buildings" brimming offices and laboratories, we then the "Commons", the leisure area with shops – also a biciclettaio-and especially restaurants with kitchens literally from any where. Here is the rule of self service "intercultural dialogue". The dishes that come from loudspeakers are filled with impossibly, and pairings only acceptable from an Anglo-Saxon: beside and above to a pizza "pepperoni" place a chicken wrap a slice of salmon with above the hummus and two wan tong fried, while a huge slice of meat covered with barbecue sauce goes to close the last spaces available along with two leaves of salad. The dish you pay $ 15 per pound (about half a kilo), regardless of the content. Coca Cola is practice, therefore free.
Living and eating here at least 5 days a week, one meal per day plus snacks, it's easy to see increase its circumference. Especially if the work involves the sitting in front of a computer at least 9-10 hours a day. Vittorio Bertocci after 5 years of Redmond is a strict diet for never ending u.s. statistics about overweight individuals. Between squirrels and pure air, seems a perfect trap to keep employees and managers as much as possible to the desk. "We are we to be in love of our work" says Vittorio. "And often by the company arrives the predicozzo that invites us to improve the work-life balance". Giorgio spalleggia him: "I do not feel at all trapped, on the contrary: our work is very flexible. Sometimes I do of the conference call that being directly to bed ". Smiles and closes the matter with a joke: "And then on campus is not served beer: how could an average American live there in?".
Work at Microsoft, in the heart of the multinational founded by Bill Gates, is a boast, more: a ever mission that is not tired. Not at random on the badges of Vittorio and Giorgio it says "Evangelist": their role in their respective fields of competence, is to spread the "verb" company, guidelines and direction of development of a multinational that alone has in fist over 90% of all computers in the world. "It's a huge responsibility", confirms proud Giorgio. "What we do here falls then the daily lives of millions and millions of people. Io e Vittorio not superheroes, but certainly our work changes the world a little every day ".
Vittorio Bertocci currently deals with privacy online with special focus on the world of cloud computing, digital technology that resides in the clouds of the network and not on the hard disk of our computer. "I joined Microsoft in Italy in 2001, one week before 9/11," he says. "When then came the call from Redmond, the decision to depart was immediate, also thanks to the thrust of my wife, Iwona, Polish: after a Ph.d. in computer science in Pisa urbanism yet to find a good job in Italy. Here in the United States after putting the curriculum online the first call came after a few hours ". Giorgio Sardo was "hooked" by Microsoft already when he was a student at the Politecnico di Torino. In 2006 he won the "Imagine Cup" of the company, a worldwide contest with over 60 thousand participants. "From there the road was marked", recounts the gaze cunning. "Concluded the master in 2007, was a Friday I remember, the Monday after I was behind my desk in Microsoft". Now works on Internet Explorer, what keeps us to remember "is the most popular programme".
From Italy Miss family and friends ("And the Basil", which according to Vittorio in United States "sucks, sa anise"). The urge to return there is also, but without excessive haste. "The quality of life here is very high", tells Vittorio. "Everything costs much less than in Italy, the shops are always open, services operate to wonder and the people are highly educated". Sometimes almost too, at the limit of coolness. "It's true, I just opened", admits the genovese. "But to live and put on family here is maximum: sometimes I come home on foot, along a river, where I see herons, storks, salmon, sometimes even Eagles and beavers."
Thing you would bring in Italy from the USA? Neither has no doubts: the work ethic. Giorgio synthesizes the thought: "in our country lacks merit-American system, where the youth if capable have equal opportunities compared to older workers. Here essentially come appreciated and respected for what you do, and not if you're a child or friend of someone ". But the whole of Italy is not to throw, indeed. "Meanwhile our country is beautiful, aesthetically, even in the little," says Vittorio. "Here you prefer the functional". "And then the Italy boasts a high level of education, light years away from what you find here," concludes Giorgio. "Here is difficult that someone manages to go beyond their own narrow professional and cultural. Sometimes during certain conversations ends that I feel embarrassed for them ". An excellence that then though, to be put to good use, needs to be carried elsewhere.




Mechanical translation still leaves much to be desired, no? On the other hand, it’s been many years since I spoke broken Italian.
As of 11/26/2010, I was unable to find any EN-US translations of the ZH-CN Tech Ed China 2010 content.
<Return to section navigation list>
Windows Azure Virtual Network, Connect, and CDN
Nuno Filipe Godinho posted Understanding Windows Azure Connect – PDC10 Session Review on 11/25/2010:
Anthony Chavez – Director @ Windows Azure Networking Group
Introducing Windows Azure Connect
- Secure network connectivity between on-premises and cloud
- Supports standard IP protocols (TCP, UDP)
- Example use cases:
- Enterprise app migrated to Windows Azure that requires access to on-premise SQL Server
- Windows Azure app domain-joined to corporate Active Directory
- Remote administration and troubleshooting of Windows Azure roles
- Simple setup and management
Roadmap
- CTP release by end of 2010
- Support connect from Azure to non-Azure resources
- Supports Windows Server 2008 R2, Windows Server 2008, Windows 7, Windows Vista SP1, and up
- Future releases
- Enable connectivity using existing on-premises VPN devices
Closer Look
- Three steps to setup Windows Azure connect
- Enable Windows Azure (WA) roles for External connectivity via service Model
- Select only the roles that should be enabled for external connectivity
- Enable local computers for connectivity by installing WA Connect Agent
- Configure/Manage your network policy that defines which Azure roles and which Azure computers can communicate.
- defined using the Connect Portal
- After the Configuration/Management of the Network Polity, Azure Connect automatically setups secure IP-level network between connected role instances and local computers
- Tunnel firewall/NAT/s through hosted relay service
- Secured via end-to-end IPSec
- DNS name resolution
Windows Azure Service Deployment
- To use Connect for a Windows Azure Service, enable one or more of its Roles
- For Web & Worker Roles, include the connect plug-in as part of the Service Model (using .csdef file)
- For VM Roles, install the connect agent in VHD image using Connect VM Install package
- Connect agent will automatically be deployed for each new role instance that starts up
- Connect agent configuration is managed through the ServiceConfiguration (.cscfg file)
- One one configuration setting is required
- ActivationToken
- Unique per-subscription token, accessed from Admin UI
- Several Optional settings for managing AD domain-join and service availability
Deployment
On-Premise
- Local computers are enabled for connectivity by installing & activating the Connect Agent. It can be retrieved from:
- Web-based installation link
- Retrieved from the Admin Portal
- Contains per-subscription activation token embedded in the url
- Standalone install package
- Retrieved from the Admin Portal
- Enabled installation using existing software distribution tools
- Connect agent tray icon & client UI, enables us to:
- View activation state & connectivity status
- Refresh network policy
- Connect agent automatically manages network connectivity, by:
- Setting up a virtual network adapter
- “Auto-connecting” to Connect relay service as needed
- Configuring IPSec policy based on network policy
- Enabling DNS name resolution
- Automatically syncing latest network policies
Management of Network Policy
- Connect network policy managed through Windows Azure admin portal
- Managed on a per-subscription basis
- Local Computers are organized into groups
- Eg. “SQL Server Group”, “Laptops Group”, …
- A computer can only belong to a single group at a time
- Newly activated computers aren’t assigned to any group
- Windows Azure roles can be connected to groups
- Enabled network connectivity between all Role instances (VMs) and local computer in the Group
- Windows Azure connect doesn’t connect to other Windows Azure Roles
- Groups can be connected to other Groups
- Enabled network connectivity between computers in each group
- A group can be ‘interconnected’ – enables connectivity within the group
- Useful for ad-hoc & roaming scenarios
- Eg. your laptop having a secure connection back to a server that resides inside the corp net
Network Behavior
- Connect resources (Windows Azure role instances and external machines) have secure IP-level network connectivity
- Regardless of physical network topology (Firewall / NATs) as long as they support outbound HTTPs access to Connect Relay service
- Each connected machine has a routable IPv6 address
- Connect agent sets up the virtual network address
- No changes to existing networks
- Communication between resources is secured via end-to-end certificate-based IPSec
- Scoped to Connect Virtual network
- Automated management of IPSec certificates
- DNS name resolution for connected resources based on machine names
- Both directions are supported (Windows Azure to Local Computer or vice-versa)
Active Directory Domain Join
- Connect plug-in support domain-join of Windows Azure roles to on-premise Active Directory
- Eg. Scenarios:
- Log into Windows Azure using Domain Accounts
- Connect to on-premise SQL Server using Windows Integrated Authentication
- Migrate LOB apps to cloud that assume domain-join environment
- Process:
- Install Connect agent on DC/DNS servers
- Recommendation: create a dedicated site in the case of multiple DC environment
- Configure Connect plug-in to automatically join Windows Azure role instances to Active Directory
- Specify credentials used for domain-join operation
- Specify the target OU for Windows Azure roles
- Specify the list of domain users / groups to add to the local administrators group
- Configure the network policy to enable connectivity between Windows Azure roles and DC/DNS Servers
- Note: New Windows Azure role instances will automatically be domain-joined
Finally the recap of Windows Azure Connect
- Enables secure network connectivity between Windows Azure and on-premise resources
- Simple to Setup & Manage
- Enabled Windows Azure Roles using connect plug-in
- Install Connect agent on local computers
- Configure network policy
- Useful Scenarios:
- Remote administration & troubleshooting
- Windows Azure Apps Access to on-premise Servers
- Domain-join Windows Azure roles
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
•• On Windows described Resource: Volvo uses Microsoft cloud for Twilight [game] in an 11/28/2010 post to its Manufacturing sector:
Volvo Cars is a premium global car manufacturer recognised for its innovative safety systems and unique designs. Volvo was written into the original books that became the Twilight franchise, so there was a natural marketing partnership for movie releases.
As part of the latest movie, Eclipse, Volvo wanted to create a virtual world resembling the Twilight story where users from around the globe could participate in a chance to win a new Volvo XC 60. However, the existing technology infrastructure could not provide the scalability or level of security required.

Watch the video here.
• Jyoti Bansal explained Apps vs. Ops: How Cultural Divides Impede Migration to the Cloud in an 11/27/2010 post to Giga Om’s Structure blog:
Many groups within the IT organization have significant stakes in the decision-making process when it comes to moving production applications to virtualized servers or to the cloud. One group in particular, the application owners, can take opposing viewpoints when it comes to these two technologies.
Web applications, as we all know, are the lynch pin of most organizations today, serving as either mission-critical or revenue-critical functions of the business. The job of an application owner depends on making sure the critical business applications they oversee run smoothly and meet performance and availability goals. If an organization’s e-commerce web site has a four-hour performance outage, you can be sure its application owner will be in hot water. At the same time, however, application owners face constant pressure to get new functionality developed and rolled out quickly to meet the demands of the business.
This results in an interesting organizational dynamic. When it comes to virtualization, a technology usually seen as a key enabler of cloud computing, application owners typically are typically resistant to the change. They often cite performance degradation and scalability concerns as the primary reasons to refrain from moving mission-critical applications to virtualized infrastructures. IT operations teams, on the other hand, push for virtualization adoption to achieve cost savings through server consolidation and manageability gains.
At the same time, when it comes to moving a mission-critical application to the cloud, it’s the application owners who often drive the effort, while the IT operations teams are the ones resistant to change. Application owners look at cloud as the alternative to get new business functionality rolled out quickly, but the internal IT operations teams cite lack of control and uncertainty about SLAs as reasons to block the move critical applications to the cloud.
In both cases, other than the real technical issues related to security, performance and scalability, the IT culture plays a key role. This struggle in IT departments is based far more on tools, measurements and accountability rather than a fundamental divide. Because virtualization administrators’ superiors rate their underlings on the level of virtualization achieved, and because application owners’ superiors look for constant uptime and SLA adherence, it’s no wonder these two camps have become impenetrable silos. Both retain (and perhaps guard) their specialized knowledge and have no understanding of the measurements and standards by which the other functions.
Both virtualization and cloud are maturing from a technology perspective, and more and more mission-critical applications can gain from the advantages they bring. But the key for a virtualization- or cloud-migration project to succeed is paying attention to resolving the internal IT conflicts in addition to the technical issues.
Visibility, measurability and accountability are the most important factors that can help resolving these conflicts. Better visibility and measurability into application performance, both before and after the change, helps alleviate the fears about performance degradation that application owners have when virtualizing their apps. Similarly, real-time visibility and automated response abilities alleviate the concerns the IT operations teams have about losing control when moving apps to the cloud. When application owners are considering deploying an application in the cloud, they should definitely consider integrating the right tooling and reporting mechanism so that lack of accountability doesn’t become an organizational issue hindering the success of the project.
Jyoti Bansal is founder and CEO of App Dynamics.

• Steve Fox asked Azure, jQuery & SharePoint: Huh? in an 11/26/2010 post:
I’ve been spending a lot more time of late looking at how Azure integrates with SharePoint. You may have seen some earlier posts on this. A couple of weeks ago, I attended SharePoint Connections in Las Vegas. I delivered the opening keynote, where we (I was joined by Paul Stubbs) showed a few demos where we integrated SharePoint with the cloud. In the keynote, I specifically outlined three permutations of how SharePoint can map to or integrate with the cloud:
- Office 365 (with specific focus on SharePoint Online). Office 365 represents the next wave of hosted productivity applications (and includes Office 2010 Client, SharePoint Online, Lync Online, and Exchange Online).
- SharePoint WCM. Essentially, building Internet-facing web sites using SharePoint 2010.
- SharePoint integrating with wider cloud services. This might be leveraging Twitter or Facebook to harvest social data and creating ‘socially intelligent’ solutions in SharePoint or using Bing or Azure to create expansive applications that integrate/leverage the cloud.
During this conference (and also at PDC and TechEd EU), I also presented to more enthusiasts on SharePoint and the Cloud. We talked about a number of different patterns that cut across Twitter and SharePoint integration, oData and Office/SharePoint integration, Office Server-Side services, and SharePoint and Azure.
One pattern we discussed during the session was integrating jQuery and Azure in SharePoint. This pattern is interesting because you’re leveraging jQuery as a client technology in SharePoint and also using Excel Services, and you could potentially divorce yourself from server-side dependencies to integrate with Azure, thus no need to install assemblies on the server. This means that you have improved code reusability across SharePoint On-premises and SharePoint Online. I’m halfway through creating a pattern for this integration, so at the risk of showing you half the story I thought I’d go ahead and post current progress. I figured you may find some (or potentially all) of this useful.
First of all, I’m tackling this problem in two steps, the first of which is tested and shown in this blog post. I will post the second step when I complete the pattern. The figure below shows my rough thinking around how I’ll set things up to get a working prototype. Step 1 is complete and discussed in this blog; although, it still has the server-side dependency with the deployed ASMX service to IIS. The goal of trying Step 2 will be to remove the dependency on the ASMX to IIS to become a complete client-side service call/app. The value of the first step is if you want to use jQuery in an on-premises instance of SharePoint (say in an enterprise app), you can use this pattern to do do. The value of the second step is that you take a step away from the server dependency and operate completely on the client.
Scenario: Use an ASMX service to call a method called GetRate(), which simply returns an int value of 5. Then pass that value to be used to update an Excel Web Access data part—updating the data in the Excel Web Access view.
Okay, let’s jump in and discuss Step 1.
Step 1: The first step was to deploy a WCF service to Azure and then build a wrapper service to call the Azure-deployed WCF service from an ASMX service deployed in IIS. This was, in essence, a test run for the jQuery service call. With some client-side code and the jQuery library deployed into SharePoint (say to the Site Assets folder), you can interact with Azure via the ASMX service. Thus, the second step: calling the WCF service direct from jQuery from within SharePoint. You create a WCF Service using the VS 2010 tools and then deploy into Azure. You can reference this blog post to get a sense for how to deploy services to Azure: http://blogs.msdn.com/b/steve_fox/archive/2010/06/15/integrating-a-custom-azure-service-with-business-connectivity-services.aspx.
Service Contract
…
namespace WCFServiceWebRole1
{
[ServiceContract]
public interface IService1
{…
[OperationContract]
[WebGet]
int getRate();
}
}Service Method
…
namespace WCFServiceWebRole1
{
public class Service1 : IService1
{
…public int getRate()
{
int forecastRate = 5;
return forecastRate;
}}
}Step 2: Create an ASMX service that calls the WCF Azure service and deploy to IIS.
Web Method
…
[WebService(Namespace = "http://tempuri.org/")]
[WebServiceBinding(ConformsTo = WsiProfiles.BasicProfile1_1)]
[System.Web.Script.Services.ScriptService]
public class RateCall: System.Web.Services.WebService {[WebMethod]
public int GetRate()
{
int rate = 5;
return rate;
}
}Step 3: Create a new Empty SharePoint 2010 project in VS 2010. Add two modules to the project. Here you can see that I’ve called the one module AzureWebServiceCall (this contains the script that will call the ASMX service that calls the Azure service) and the other module JQueryCore, which contains the jQuery libraries. You can use a .txt or .js file; that is, AzureServiceCall.txt or AzureServiceCall.js will work as files that you can point to from a Content Editor Web Part).
For the JQueryCore module, you right-click and select Add and Existing Item and add the appropriate library to your project. For the AzureWebServiceCall code, you amend the text file with code that looks similar to the below. Note that the bolded code is relevant to the call into the web service. …


[Large block of sample code elided for brevity.]
Step 4: Deploy to SharePoint
To do this, right-click the top-level SharePoint project and click Deploy. This will deploy the modules into a folder called SiteAssets in SharePoint.
At this point the core jQuery libraries and JavaScript files are deployed. You now need to add an Excel document that will use the return value from the Azure service call to update the fields in the Excel document. In this Excel document, note the following quarterly aggregates with four named cells (e.g. Q1_Forecast, and so on).
If you look at the JavaScript code, you’ll notice that you’re using the ewa object to get the active workbook and a specific range in that workbook: cell = “Forecast!Q1_Forecast”. Thus, the code takes the return int from Azure and updates the Q1_Forecast cell with that value. The other fields are simply calculated fields that pivot off whatever value is in Q1_Forecast (e.g. Q2_Forecast = Q1_Forecast * .20).
//EWA code to update cells in active workbook
ewa.getActiveWorkbook().getRangeA1Async("'Forecast'!Q1_Forecast", getRangeComplete, [[Q1]]);
ewa.getActiveWorkbook().getRangeA1Async("'Forecast'!Q2_Forecast", getRangeComplete, [[Q2]]);
ewa.getActiveWorkbook().getRangeA1Async("'Forecast'!Q3_Forecast", getRangeComplete, [[Q3]]);
ewa.getActiveWorkbook().getRangeA1Async("'Forecast'!Q4_Forecast", getRangeComplete, [[Q4]]);An important note to the Excel Web Access code is that the ewa object will work only if there is one Excel Web Access web part on the page; if there is more than one, you’ll need to reference the web part by it’s specific ID. Dan Parish has a great write-up of this (along with some additional details on the EWA code) here: http://blogs.msdn.com/b/excel/archive/2007/10/29/excel-services-combining-the-ewa-and-api-using-ajax.aspx.
You need to make sure that when you create and upload the Excel document to a document library, that you then publish the named range (or other objects you’re using in the Excel document) to SharePoint using the Excel Services functionality. To do this, click the File tab, Save and Send, Save to SharePoint, and then select Publish Options. Select the items you want to expose to Excel Services and then click OK. The figure below shows the named ranges/cells that I’ve exposed through Excel Services.
Step 5: After the files are deployed and you’ve published your Excel document to SharePoint, you create a Content Editor Web Part to the page. Point the content editor web part to the location of the .txt file (with the JavaScript code above) in it—which if you followed along would be in the Site Assets library. To do this, click Insert, Web Part, Media and Content, and Content Editor, and click Add.
Then click Edit Web Part and add the link to the text file in the in the Content Link.
SharePoint now dynamically loads the .txt file with the jQuery/JavaScript in it. Again, you can use a .js file and it loads the same.
Step 6: You can now add the Excel Web Access web part on the web part page that loads the Excel document. To do this, click Insert, Web Part, Business Data, and Excel Web Access, and click Add. When the default web part loads, click ‘Click here to open tool pane.’ Add the link to the Excel Document in the Workbook field and add the name of the named range in the Named Item field.
You should now have something like the following loaded onto the page.
You can rearrange the web parts on the page as you desire, but when you click the Get Data button the following will happen:
1. jQuery calls the ASMX service deployed to IIS.
2. ASMX service calls WCF service deployed to Azure and then returns the int value of 5.
3. jQuery code takes the return SOAP package and extracts the returned int value.
4. JavaScript code leverages the returned int value and updates the calculated view (i.e. the Excel Web Access web part).
5. The percentages for each quarter in the Excel Web Access web part are updated from the one core return int of 5.
Summary
A long post, I know. Using jQuery is interesting; using it in the context of Azure service-calls to update views is compelling (think financial models that depend on a cloud-service that delivers daily integer values that have significant cascading effects on the model).
This post showed you how you could leverage an Azure WCF service call and wrap with an ASMX SOAP call, which you could then use in JavaScript and jQuery to update an Excel view. The next step would be to craft an app that will eventually live and act entirely in the cloud—i.e. it uses data stored in Azure and uses jQuery to interact with an Azure WCF service. As I move forward, I’m going to continue to bang away at this until I have something that is completely lives in the cloud without any on-premises dependencies. I welcome any thoughts from you the community.
In the meantime, grind the code!







• Bill Zack contributed Design Patterns, Anti-Patterns and Windows Azure on 11/26/2010:
A complete catalog of patterns (and anti-patterns) would list lots more than are listed here. Fortunately no catalog of design patterns is ever complete so the category is totally open ended. And as the Widows Azure platform evolves additional ones will emerge.
What follows is simply JMNSHO.
Patterns that work well
Web Farming
The use of more than two instances of a web role is a no-brainer and in fact at least two web role instances are required to receive our Service Level guarantee. The reason that I glorified this with the title Web Farming is because that is essentially what you are doing. Whether you create a web farm yourself on-premise with multiple web servers or deploy two instances of a web role you are creating a web farm. In a web farm, whether on premise or in Windows Azure, you have to worry about state since two request might come to different servers/instances and the state might be on the wrong machine. This means that you should make sure that your applications can work statelessly by storing persistence data external to the server/instance.
Inter role instance communications using Queues
This is the classic pattern of using a Windows Azure Queue and either Blob or Table Storage to communicate between web and worker role instances. With this pattern a web role stores a blob or a set of table storage entities in Windows Azure storage and enqueues a request that is later picked up by a worker role instance for further processing.
SQL Azure Database as a Service (DBaaS?)
Patterns that are more difficult
Inter role instance communications with WCF
If the Inter Role instance communications using queues pattern does not work for you then you can wire up your own inter role instance communications using WCF. You might want to do this if for instance you are implementing a map-reduce type of application where one role instance need to be different than the others, for instance where you need to have a controller instance that fires up and manages a variable set of worker roles cooperating on the partitioned solution of a problem. Of course you could use queues to communicate between them but that may not be performant enough.
Multi-threading within a role instance
In case it has escaped your notice, let me remind you that everything in Windows Azure costs money. You pay for every running instance of every role that you deploy based on the amount of time that it is deployed into Azure. In Windows Azure you have a wide variety of Compute Role types (Extra Small, Small, Medium, Large, Extra Large) that you can specify in your application. Each one has a different price. In some cases it may make sense to have fewer instances where the instances do their own multi-threading instead of having more instances running. You need to decide, probably by benchmarking your application, where the best approach and best value lies. Of course you can also implement dynamic scaling to optimize the process but that requires development effort. But then so does multi-threading.
Elevated Privileges and the VM Role
These features, coming “soon” to Windows Azure, include: Remote Desktop Support which enables connecting to individual service instances, Elevated Privileges which enables performing tasks with elevated privileges within a service instance and the full Virtual Machine (VM) Role which enables you to build a Windows Server virtual machine image off-line and upload it to Windows Azure.
For the ISV these features make it easier to port a legacy application that might use things like COM+ to Windows Azure. They also make it easier to peek inside of a live role instance to see what is happening.
But beware! the VM Role is definitely not Infrastructure as a Service (IaaS). Managing failures, patching the OS and persistence in the face of VM failures are your responsibility. Note that the VM Role is recommended only as a technique to be used to migrate an application to Azure. The real long-term answer is to re-architect your application to be stateless and fit the capabilities of the Windows Azure.
Building Hybrid on-Premise/In Cloud Applications
Building applications that are split between on-premise and in cloud components are inherently more difficult than building applications that live in one place or the other. But there is of course great value in building them in many cases. On-premise applications can leverage SQL Azure, Windows Azure Blob, Table and Queue Storage directly. Windows Azure applications can also, with a bit more difficulty, do the reverse leveraging things like SQL Server and other data sources located on-premise in the data center. The use of REST styled APIs in Azure makes this somewhat easier, however the features here are still evolving.
Patterns to be Avoided
The following should be considered anti-patterns (for now). Of course things could always change in subsequent releases. Azure is an evolving platform, but for now they should be avoided.
Running Legacy Servers using VM Roles
The VM Role is not IaaS (yet). Building your own clusters out of VM Roles to run servers like Exchange, SQL Server, SharePoint or an Active Directory Domain Controller is not a good idea even if you could set it up.
Remember that the VM Role still expects stateless apps so we are discounting the idea of legacy apps running in a VM Role. Most of our server software was not built with Azure in mind. You can run them in their own VM Role but any the thought of an Exchange or AD server being turned off and rolled back due to some failure should give you pause. Even if you create your own cluster architecture for this the difficulty of setting it up and maintaining it in the face of potential state loss would put it into the anti-pattern category
The VM role is really for software that has a fairly fragile or custom install experience. If what you are installing requires state to be maintained in the face of a failure it is really not well suited to The VM Role.
The same holds true for 3rd party servers such as MySQL, Oracle, DB/2, etc. Remember that, if you need a relational database like SQL Server SQL Azure, in general, is the best way to go.
Setting up a TFS Server in Azure
The same holds true here as for running other legacy server in Azure. However at PDC we demonstrated a port of TFS running in Windows Azure as a proof of concept. There was even talk of a CTP early next year of TFS as a Service. (TFSaaS?).
I realize that the list of anti-patterns is very thin and undoubtedly there are other patterns that you should not try to implement in Windows Azure as it stands today.

• Bertrand LeRoy described Deploying Orchard to Windows Azure in details on 11/17/2010 (missed when posted) and updated CodePlex documentation on 11/24/2010:
Orchard supports building and deploying to the Windows Azure environment. If you don't want or need to build the package by yourself, a binary version of the Windows Azure package is available on the CodePlex site. This topic describes the detailed steps you can take to build and deploy packages of Orchard to Azure.
[Ed. Note: The following About the Orchard Project section is taken from the project’s home page on CodePlex.]
Orchard is a free, open source, community-focused project aimed at delivering applications and reusable components on the ASP.NET platform. It will create shared components for building ASP.NET applications and extensions, and specific applications that leverage these components to meet the needs of end-users, scripters, and developers. Additionally, we seek to create partnerships with existing application authors to help them achieve their goals. Orchard is delivered as part of the ASP.NET Open Source Gallery under the Outercurve Foundation. It is licensed under a New BSD license, which is approved by the OSI. The intended output of the Orchard project is three-fold:
- Individual .NET-based applications that appeal to end-users , scripters, and developers
- A set of re-usable components that makes it easy to build such applications
- A vibrant community to help define these applications and extensions
In the near term, the Orchard project is focused on delivering a .NET-based CMS application that will allow users to rapidly create content-driven Websites, and an extensibility framework that will allow developers and customizers to provide additional functionality through modules and themes. You can learn more about the project on the Orchard Project Website
Table of Contents [Hide/Show]
Building and deploying to Azure
Redeploying to Azure
Changing the machine key
Deploying Orchard to Azure with optional modulesBuilding and deploying to Azure¶
First, install Windows Azure Tools for Microsoft Visual Studio 1.2 (June 2010), which includes the Windows Azure SDK.

You can build a deployable package for Azure from the Visual Studio 2010 command-line. You will need a source tree enlistment of Orchard to do this. Run "ClickToBuildAzurePackage.cmd" from the command-line to build the package.

When the command completes successfully, you will have an Azure package under the "artifacts" folder (artifacts\Azure\AzurePackage.zip).

Unzip the AzurePackage.zip file to edit the ServiceConfiguration.cscfg file. The content of this file will contain a sample configuration.

<?xml version="1.0"?> <ServiceConfiguration serviceName="OrchardCloudService" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration"> <Role name="Orchard.Azure.Web"> <Instances count="1" /> <ConfigurationSettings> <Setting name="DiagnosticsConnectionString" value="UseDevelopmentStorage=true" /> <Setting name="DataConnectionString" value="UseDevelopmentStorage=true" /> </ConfigurationSettings> </Role> </ServiceConfiguration>
Update it with your account details. Edit the "value" attribute for both the DiagnosticsConnectionString and DataConnectionString.<Setting name="DiagnosticsConnectionString" value="DefaultEndpointsProtocol=https; AccountName=your-account-name; AccountKey=your-account-key" /> <Setting name="DataConnectionString" value="DefaultEndpointsProtocol=https; AccountName=your-account-name; AccountKey=your-account-key" />
Log in to the Windows Azure Developer Portal.

On the home page, you can view your projects and services.

Click your project name.

You will need a SQL Azure Storage account as well as Windows Azure Storage service (blob). If you view the Windows Azure Storage service details, you can find your primary and secondary access keys (this is the account key that you copied to the DiagnosticsConnectionString and DataConnectionString in theServiceConfiguration.cscfg file).

View the details for your SQL Azure service.

Create a new SQL Azure database for Orchard. The example below assumes "orcharddb", but you can name it whatever you like.

View the details for your Windows Azure Hosted Service. From here you will deploy your package. Click "Deploy" for either the Staging or Production node.

Browse for the package and configuration files that you built from the Orchard command-line. Name the deployment, and click "Deploy".

The Azure Developer Portal will upload the files.

When the upload is complete, you will see that the deployment is in a "Stopped" state. Click the "Run" button to begin the deployment.

When the deployment is in progress, you will see the deployment progress from "Initializing" through a variety of other states.

Wait until the deployment reaches a "Ready" state (this can take a few minutes). Then click the link to view your running site.
If all went well, you will see the Orchard setup screen. In order to use Orchard in Azure, you need to configure it against the SQL Azure database (to ensure application state is retained as Azure recycles instances of your site during load balancing).

After completing the setup step, you should arrive on the familiar Orchard home page and can being configuring your site.
Redeploying to Azure¶
When you redeploy to Azure using the same storage, you should clean the contents of the SQL Azure database (or just delete it and re-create a new one). You will also need to delete the contents of you Windows Azure Storage (blob) to ensure a fresh state. Orchard uses blob storage to write your site settings (which would otherwise be stored on the file system under ~/App_Data in a non-Azure installation). You can access your blob storage from http://www.myazurestorage.com.

Changing the machine key¶
When deploying to Azure, it is recommended that you change the machine key from the web.config file in the Orchard.Azure.Web project before packaging and deploying.
Deploying Orchard to Azure with optional modules¶
The Azure package that you deploy to Azure does not need to be limited to the default modules that are distributed with Orchard. This is why we provide all the tools to build your own package.
It is possible to include third party modules, or even your own modules and deploy them to Orchard.
The only constraint is that the modules can't be installed dynamically from the gallery like you'd do with a regular deployment of Orchard because of the distributed nature of Azure: the local file system does not get automatically replicated across instances and they may get out of sync if we allowed for that.
In order to work around this constraint and allow you to deploy your own selection of modules to Azure, you need to build your own package with the modules that you need.This is done by editing the src/Azure.Orchard.sln solution file, adding the projects for the modules that you need to deploy, and finally referencing those modules from the Orchard.Azure.Web project. Once this is done, you may launch the build script exactly like described above. The resulting package should contain your additional modules.
Once you've deployed that new package to Azure, you can go to the features screen and enable the features in order to start using them.


Colbertz posted All-In-One Windows Azure Code Samples on 11/26/2010 to the new All-In-One Code Framework blog:
The Windows Azure platform is a flexible cloud–computing platform that lets you focus on solving business problems and addressing customer needs. The All-In-One Windows Azure code samples demonstrate the typical programming topics about Windows Azure. These topics are either frequently asked in MSDN forums and Microsoft Support, or are requested by many developers via our code sample request function. We want to alleviate the frustration felt by developers when they are developing Windows Azure projects.
Visual Studio 2008 Code Samples
Sample Description Download ReadMe CSAzureServiceBusSLRest Expose on-premises WCF service to an internet Silverlight client (C#) Download
ReadMe.txt CSAzureServiceBusWCFDS Access data on premise from Cloud via Service Bus and WCF Data Service (C#) ReadMe.txt CSAzureStorageRESTAPI Call raw List Blob REST API in C# ReadMe.txt CSAzureTableStorageWCFDS Expose data in Windows Azure Table Storage via WCF Data Services (C#) ReadMe.txt CSAzureWCFWorkerRole Host WCF in a Worker Role (C#) ReadMe.txt CSAzureWorkflowService35 Run WCF Workflow Service on Windows Azure (C#) ReadMe.txt VBAzureServiceBusSLRest Expose on-premises WCF service to an internet Silverlight client (VB.NET) ReadMe.txt VBAzureServiceBusWCFDS Access data on premise from Cloud via Service Bus and WCF Data Service (VB.NET) ReadMe.txt VBAzureStorageRESTAPI Call raw List Blob REST API in VB.NET ReadMe.txt VBAzureTableStorageWCFDS Expose data in Windows Azure Table Storage via WCF Data Services (VB.NET) ReadMe.txt VBAzureWCFWorkerRole Host WCF in a Worker Role (VB.NET) ReadMe.txt VBAzureWorkflowService35 Run WCF Workflow Service on Windows Azure (VB.NET) ReadMe.txt Visual Studio 2010 Code Samples
Sample Description Download ReadMe CSAzureTableStoragePaging Azure Table Stroage Paging (C#) ReadMe.txt CSAzureWorkflow4ServiceBus Expose WCF Workflow Service using Service Bus (C#) ReadMe.txt CSAzureXbap XBAP client app invokes a service in the cloud (C#) ReadMe.txt VBAzureTableStoragePaging Azure Table Stroage Paging (VB.NET) ReadMe.txt VBAzureWorkflow4ServiceBus Expose WCF Workflow Service using Service Bus (VB.NET) ReadMe.txt VBAzureXbap XBAP client app invokes a service in the cloud (VB) ReadMe.txt
I’m surprised that the Windows Azure Team isn’t promoting these code sample more widely.
Maarten Balliauw (@martinballiauw) announced on 11/26/2010 that he’s now Writing for the Windows Azure for PHP portal:
I actually just noticed it has been a while since I did a blog post. I also know that writing about this is not really a good idea in the blogosphere. Unless… it’s for a good reason!
The good reason for not being that active on my blog lately is the fact that I’m producing content for Microsoft’s Interoperability team. Have you ever wanted to start working with Windows Azure and PHP? No idea where to start? Meet the official portal: Developing Applications for Azure with PHP.
- Tutorial - Using the Windows Azure Tools for Eclipse with PHP
- Tutorial - Using the Windows Azure SDK for PHP
- Tutorial - Using Queue Service
- Scenario - Offloading static content to blob storage
So whenever you think I’m relaxing and doing nothing, check http://azurephp.interoperabilitybridges.com for new content. By the way, if you are doing PHP and Azure, drop me a line. It’s always good to know and maybe I can be of help.
Stay tuned for more on this!
Chris Czarnecki posted Microsoft Azure for ASP.NET MVC to the Learning Tree blog on 11/25/2010:
Through my consulting activity and teaching for Learning Tree I am continually surprised by the lack of awareness developers have of the facilities of Microsoft Azure. As this platform develops at a fast pace, maybe Microsoft is not making its developer community fully aware of the wide and rich feature set the platform provides. With this background I feel compelled to write to raise awareness of what this platform offers, in particular for Web developers using ASP.NET MVC.
Microsoft’s ASP.NET MVC solution enables developers to create clean, maintainable, highly scalable Web applications, which with hosting available in Azure provides an equivalent clean hands-free approach to deployment and server maintenance. Combine this with the instantaneous, self provision elastic scaling, I am at a loss to explain why more organisations are not exploiting this offering. My conclusion is that the general lack of clarity of what Cloud Computing is coupled with a lack of awareness and clarity of what Azure is/can offer is preventing companies from working in a more productive, cost efficient manner.
If you would like to know more about Cloud Computing, why not attend the Learning Tree Cloud Computing course, or for more details of Azure, try the excellent Azure training course, developed by renowned Azure expert Doug Rehnstrom. Equally, the ASP.NET MVC course may open a new approach to Web application development for you too!
tbtechnet reported Code Project’s Windows Azure Platform Contest $1,000 or Xbox with Kinect on 11/25/2010:
Looks like The Code Project is running another Windows Azure platform contest.
They’re offering money and Xbox with Kinect to developers.
On Windows posted a brief Cloud computing for connected devices article on 11/25/2010:
Microsoft, Siemens and Intel have been demonstrating the latest evolution of the Innovative Production Line (IPL) proof of concept (POC) at SPS/IPC/Drives in Nuremberg, Germany. [Link added].
This POC illustrates a real-world vision of how manufacturers can seamlessly connect the plant floor to the IT data centre.
The IPL also shows how Windows Azure coupled with the latest technologies from Windows Embedded can enable constant production process optimisation, reduce delays and increase overall factory productivity by supporting the analysis and execution of real-time factory floor data from enterprise applications.
This portal could then provide instant access to real-time information, enabling manufacturers to estimate supplemental energy requirements. For example, it can superimpose a weather map over the factory location to forecast when to purchase more energy from the grid, thus helping manufacturers establish a more environmentally friendly business.
Another new addition to the IPL is Intel’s Active Management Technology for monitoring from devices to services in the cloud. This intelligent device management enables users to monitor device health and identify if a device is faulty or needs to be rebooted, as well as reviewing read-out information in real time.
Microsoft PR also issued a Manufacturing Looks to Connected Devices and the Cloud to Drive Growth news release on 11/24/2010:
NUREMBERG, Germany — Nov. 24, 2010 — The manufacturing industry is thriving. A report out this week by the Engineering Employers Federation (EEF) shows that manufacturing is growing at the fastest rate since 1994 in the UK, with most businesses planning continued investments. The UK is not alone. Earlier this year, the U.S. manufacturing industry was touted as leading the economic rebound (The Telegraph, June 2010), and the latest data shows manufacturing accelerated for the first time in three months across Europe (International Business Times). As the industry starts to strengthen, manufacturers are looking for new, innovative ways to enhance efficiency, drive growth and meet other critical needs; the natural next step is to look to the cloud.
Microsoft provides manufacturers with a trusted, familiar and easy-to-use platform that allows them to instantly respond to their constantly changing environment and customer demands, positioning them favorably to be able to adapt and scale for growth.
This week at SPS/IPC/Drives in Nuremberg, Germany, Microsoft, Siemens and Intel will demonstrate the latest evolution of the Innovative Production Line (IPL) proof of concept (POC) to illustrate a real-world vision of how manufacturers can seamlessly connect the plant floor to the IT data center. Since it was last on display at Hannover Messe earlier this year, the IPL has evolved extensively and is now attached to the cloud via Windows Azure to showcase connectivity between industrial devices and cloud services, enabled by robust, flexible solutions that scale from end to end.
Another new addition to the IPL is Intel’s Active Management Technology (AMT) for monitoring from devices to services in the cloud. This intelligent device management enables users to monitor device health and identify if a device is faulty or needs to be rebooted, as well as reviewing read-out information in real time.
These are just a few of the scenarios being demonstrated at the Windows Embedded booth at SPS/IPC/DRIVES. Other scenarios include these:
Complete value chain tracking. To improve efficiencies, factory managers are able to review factory statistics and change production parameters to optimize production, ensuring materials are ordered from the supplier when stocks get below a certain point and adjusting the delivery of material to the production line.
Remote intelligent device management. Factory managers can monitor the health of individual devices and the factory line as a whole. A summary dashboard provides a quick snapshot for the factory manager to be able to see which devices are not working and get more details such as the device health history, predicted device failures, online presence and location personnel responsible for the maintenance of the device.
Factory online rebranding. All new branding is hosted on Windows Azure; users simply choose the brand they require, which is then pulled down by the Edge Storage Server and pushed to all devices. The devices automatically show all screens in the new branding once the new production starts.
If you are attending SPS/IPC/DRIVES this year, please check out the IPL at the Windows Embedded booth in Hall 7A, stand 150, or follow us on Twitter at @MSFTWEB for updates from the show. For further information you can also visit http://www.microsoft.com/windowsembedded/en-us/about/solutions/industrial-solutions.mspx.
 proof of concept (POC) at SPS/IPC/Drives in Nuremberg, Germany.")
Colbertz referenced J. D. Meier’s Blog in his Code Sample Maps and Scenario Maps in his 11/24/2010 post to the All-In-One Code Framework blog:
I stumbled upon J.D. Meier's blog, and see these interesting ideas of Code Sample Maps and Scenario Maps.
Code Sample Maps
For each area (ADO.NET, ASP.NET, etc.) we did a map of Code Samples pulling from All-in-One Code Framework, Channel9, CodePlex, Code Gallery, MSDN Dev Centers, and MSDN Library. You can see their code samples roundup at -- http://blogs.msdn.com/b/jmeier/archive/2010/11/01/code-sample-collections-roundup-for-ado-net-asp-net-silverlight-wcf-windows-azure-and-windows-phone.aspx.
Scenario Maps / Customer Needs
In J.D.Meier's words: "Scenario Maps are a simple way we collect, organize, and share user scenarios for a given problem space or technology. They serve as a fast and scannable index of the problems that users face. They are one of the most effective ways to see the forest from the trees. Rather than get lost in a single scenario, they are a step back and a look across all the key scenarios. This helps for ranking and prioritizing the problems for a given space. "
You are encouraged to scan the Scenarios Map and either share your scenarios in the comments or email your scenarios to feedbackandthought at live.com. Be sure to share your scenarios in the form of “how to blah, blah, blah …” – this makes it much easier to act on and update the map.
<Return to section navigation list>
Visual Studio LightSwitch
•• Glenn Wilson (@Mykre) posted LightSwitch Request Management System Part 1 on 11/28/2010:
Today I posted about Foreign Keys and LightSwitch and created a simple little application to work with, but thinking about it now, I have decided to continue with it and expand on what i have. I do not know how far I will go with it but it is a start and it will help me talk about different features of LightSwitch.
What I am going to work on is a small request Management System that say a small IT Department could use to manage support requests, or basically any type of area that has requests come in. When I was thinking about the idea I started to knock together a simple application and within about 30 minutes I had a fully working system that was functional and could do the job… and there is the speed at which you can develop applications with LightSwitch, but as most Bloggers I am going to drag it out over several posts.
Create the Base Tables
The First part is to create the base tables for the application, when creating the tables remember that the LightSwitch system will automatically add the id field for you. I have added to the tables only the values that need to change for the moment, for the remainder leave them as default.


With the last table created you should notice that the names of the tables get adjusted to have the Plural Name for the table, you are free to change this is you like but I just leave mine as they are.
The next stage is to set up the relationships between the Base Tables. Setting up the relationships can be done by pressing the
button inside the table designer.
RequestHistory Table


Changing the Display Names of Fields
That should do the Base Tables for now, next we need to start on the presentation of the objects and data to the user. The first stage of that is to customize how some of the data is displayed in the UI. for this we will start with the User Table. In the current design that we have we have several fields that are labelled so that the database can easily read them, but what good is that to the user.
With the Table Designer open to the user table select the FirstName field, now in the properties for that field you will see a Display Name option, Change the “FirstName” to be “Frist Name”. Once done do this for the remaining fields LastName, EmailAddress, PhoneNUmber and MobileNumber.
For Requests, Change RequestDate, RequestUser and AssignedUser. For RequestHistory, Change RequestDate.
Changing the Summary Field for a Table
Inside Many of the LightSwitch Screens you have the choice of displaying a summary value for the tables, sometimes this is used inside lookups, and for others it is the point to click to expand a record or jump to another screen. In regards to this application I want to create a summary item for the User which would be a formatted version of the Users Full Name, I would also like to have the Request Number formatted of which it would be based off the id value of the record in the database.
To change the summary value of the user we need to create a new property on the table. To do this open the User table in the designer and Click an empty field, Type”FullName” and set the Data type to String. In the properties section you will see a checkbox to convert this property to a computed column, select this and select the Edit Method link. This will open the code editor of the LightSwitch designer. At this point in the application this is the first point that you would be typing code into the application, even though you have almost finished the full data layer for the application.
Enter the code Below…
partial void FullName_Compute(ref string result)
{
// Set result to the desired field value
result = this.LastName + ", " + this.FirstName;
}Going back to the Designer you will see that you now have a computed filed in your table. This is shown in the designer like this.
Now back in the designer click on the table header and inside the properties section change the Summary Property to the “FullName”
Next is the Request Id, Jump into the Request Table through the designer and add a property called “RequestId”, set it as a computed field and select Edit Method.
Add the following Code…
public partial class Request
{
partial void RequestId_Compute(ref string result)
{
// Set result to the desired field value
result = "REQ" + this.Id.ToString("000000");
}
}At this stage you could say that we have finished the Base Data Layer for the application, time to move onto the UI.
Creating the First Screens
The first screen of the application that we are going to create is one that will allow us to add users to the system. To do this inside the solution Explorer right click on the screens tree and select “Add Screen”.
The Create Screen Wizard will appear, using the Screen shot fill out the information to Create the Screen.
In this case we selected the “New Data Screen” and selected the User table for the “Screen Data”, once done press of and let the designer do it’s thing. Once complete go to the Properties Window and change the Display Name to “Create New User” and finally inside the main designer window select the
and drag it towards the top and leave it just under th command bar in the “Top Row”. It should look like the Screen Shot Below.
At this point in time we now have the ability to execute the application and create users for the system, now we would like to have the ability to search the users and edit their details if needed.
Go back to the designer and create a new screen, this time select the “Search Data Screen” and select the Users as the “Screen Data”
Once the screen is created go to the Properties and change the Display name to “Search Users”, next inside the designer expand the “DataGridRow” item as seen in the screen shot.
Select the Summary Item and change the Display Name to “User Name”, next change the “UserCollection” to read “Search Application Users”.
If you run the application now you are presented with the create user screen as the default, what we would like to do is change it so that the user search screen is the default screen.
Setting the Search Screen as Default
To set the Default screen for startup we need to go to the application properties. To do this we go to the solution explorer and right click on the Application, in this case the application is “RequestManagement”
Once done inside the Designer select the Screen Navigation Tab.
Looking at the above you can see that the “Create New User” Screen is in Bold, this means that it is the default start up screen. Select the “Search Users” Screen and at the bottom press the “Set” Button.
This will set the “Search Users” Screen as the Default. Next I would like the “Search Users” Screen to appear above the “Create New User” screen. With the “Search User” Screen selected use the Arrows on the right to move the screen towards to top of the navigation.
Executing The Application
Now if you run the application you will be presented with the Basic User Screens.
The first step is to create a User, on the left side select the “Create New User” screen, this will present a simple screen where you can enter the user information.
In the screen above I have added my information, you can also see that the editor has changed the labels of the fields to be in bold, this means that those fields are a required field. If I save that screen and return to the “Search Users” Screen (You will have to hit Refresh), you should now see my user in the system.
The other thing that you should see is the summary field that we created for the user, it is also converted to a link. As LightSwitch is configured to handle this if you click on this screen it will automatically create a details screen for the user record. In the next article I will create this screen and add the users request information to it.
Hope you like this small article and I do plan on putting some more together, as we speak I am already working on the next article which will allow the application to add requests and assign them to users. The user will then be able to see what requests have been assigned to him or her. If you do find anything that you do not understand or would like more information on please drop a comment and I will get back to you.










Glenn is a DirectX/XNA MVP, DBA by day and XNA, Windows Phone 7 Developer, and Gamer by night in Melbourne, Australia.
Allessandro Del Sole explained Visual Studio LightSwitch: Binding a Silverlight Pie Chart control to screens in an 11/26/2010 post:
As you know, it is easy to extend the user interface of screens in LightSwitch applications by adding custom Silverlight controls. The Silverlight Toolkit adds to your toolbox a number of new useful controls, especially for data visualization such as charts. In this post I will show you how to add a Pie Chart to a screen listing products.
Imagine you have an entity named Product, like the following which I grabbed from the Northwind database:
Now add to the solution a new project of type Silverlight Class Library. I assume you already performed these steps before, so I will not describe them in details. Remove the Class1.vb code file added by default and then add a new Silverlight User Control item to the project, calling it ProductsChartControl. The goal is displaying in the charts products by unit price. When the designer is ready, edit the default Grid container by adding the chart as follows:
<Grid x:Name="LayoutRoot" Background="White">
<toolkit:Chart x:Name="unitsInStockChart" Background="Yellow" BorderBrush="Green" BorderThickness="2"
Title="Situation of products in stock" Grid.Column="0" >
<toolkit:Chart.Series>
<toolkit:PieSeries Name="PieSeries1" ItemsSource="{Binding Screen.ProductCollection}" IsSelectionEnabled="False"
IndependentValueBinding="{Binding ProductName}" DependentValueBinding="{Binding UnitPrice}" />
</toolkit:Chart.Series>
</toolkit:Chart>
</Grid>Notice that it is a good idea dragging chart controls from the toolbox so that all the required references and XML namespaces are added for you. The chart is populated via the ItemsSource property assignment which points to the Screen.ProductCollection. Then the IndependentValueBinding property is related to the Y axis, while DependentValueBinding populates the pie chart. Build the project and then go back to the screen designer. Select the Vertical Stack|Search Product root element and then click Add Layout Item|Custom User Control. You will be asked to specify a new control, so click Add Reference and select the newly created user control:
Now run the application and run the search screen. As you can see the pie chart is populated via data-binding correctly:
This is a nice way to improve the way LightSwitch applications show data!




I’m not sure I’d select a pie chart for this visualization, but Alessandro’s instructions are very useful.
Mauricio Rojas described Lightswitch Experiences: Migrating Access to Microsoft Lightswitch in an 11/25/2010 post:
But Microsoft Access (despite all its good) is kind of an old technology and there was no clear alternative for a simple mortal [modern?] development environment… until Microsoft LightSwitch.
This series of posts illustrates the experiences of migrating Microsoft Access applications to LigthSwitch.
This post shows the result of migrating all Northwind Access example tables:
The following is Microsoft LightSwitch Solution explorer showing all Tables:
And these are some of the Northwind tables in LightSwitch
The migration process is straightforward. Text and Memo fields can be migrated to string, Numbers can be migrated to Int32 or Int64, Currency is map to Money. Yes\No can be mapped to boolean with a Value List.
There is support for specifying a caption (Display ID in Lightswitch), Description, and validation rules.
I will keep posting about Query migration, form migration and also report migration. Stay tuned.







Mauricio’s posts would be more useful if he described the migration process as well as the results. I assume he migrated the Northwind Access database to an SQL Server 2008 [R2] database with the SQL Server Migration Assistant for Access, because LightSwitch Beta 1 doesn’t support an Access *.accdb (or *.mdb) file as a data source.
Return to section navigation list>
Windows Azure Infrastructure
• Steve Plank (@plankytronixx, Planky) posted Windows Azure VM Role: Looking at it a different way on 11/27/2010:
The debate regarding PaaS vs. IaaS continues at pace. It seems as though no mention of this debate where Windows Azure is concerned, is complete without a frequently misunderstood notion of what the recently announced VM Role is. Many commentators are saying “It’s Microsoft’s IaaS offering”.
Let me put forward a way of explaining what it is:
When you hand over the package, it consist of all the files and resources needed to run the application. It’s rolled in to a file called a .cspkg file, a “cloud service package” file. The configuration or .cscfg accompanies the package. There is no guarantee of state for the application. If it fails for some reason, it must be capable of picking up where it left off and it’s down to the developer to work out how that is going to happen – perhaps by using persistent storage like blob or table storage.
The Windows Azure fabric has no knowledge of the internals of the application. Imagine a bug is identified – Windows Azure will not create and apply a patch to the application. We know that for the Web and Worker Roles, it will apply patches and fixes – ones that Microsoft has identified – to the operating system but not to the application itself.
The way to look at the VM Role is that the entire thing is a Windows Azure application. You don’t send a .cspkg file, but instead, the package is a .vhd file. Now, because these files are likely to be huge in comparison to a .cscfg, Windows Azure has created a method of updating with differencing disks, but that’s just an implementation detail. You can think of a VM Role application package as the .vhd file.
As is the case with the .cspkg, Windows Azure has no visibility to the internals of the application. Just as with a .cspkg application, it is the developer’s responsibility to keep it up to date, apply bug fixes, patches, updates etc. Only with an entire .vhd, the “application” updates are the patches, fixes and service packs of the OS itself plus any updates to the developer-built part of the “app”.
The application is still subject to the service model, it’s just the application package file-type that is diferent (.vhd) and the scope of the application is different (it includes the entire OS). Other than those differences, it’s a PaaS application that runs on Windows Azure, subject to the service model and all the other benefits and constraints, just like the Web and Worker Roles.
I hope this viewpoint helps describe VM Role as a PaaS offering and not the confusing IaaS that many folks think it mimics.
Planky
See also Bill Zack contributed Design Patterns, Anti-Patterns and Windows Azure on 11/26/2010 in the Live Windows Azure Apps, APIs, Tools and Test Harnesses section above.
Louis Columbus (@LouisColumbus, picture below) published Mark Russinovich on Windows Azure, Cloud Operating Systems and Platform as a Service on 11/26/2010:
Mark Russinovich is a Technical Fellow working on the Windows Azure team and is considered one of the leading experts on its architecture. He is currently working on the Windows Azure Fabric Controller, which handles kernel-level tasks for the platform. He explains the functions of the Fabric Controller in detail during the following video, illustrating concepts with references to data centers and legacy Microsoft operating systems.
Windows Azure: Platform as a Service
Mark Russinovich: Windows Azure, Cloud Operating Systems and Pla
This movie [was released on 11/25/2010, is 00:44:35 in length and] requires Adobe Flash for playback.
Source attribution: http://channel9.msdn.com/Shows/Going+Deep/Mark-Russinovich-Windows-Azure-Cloud-Operating-Systems-and-Platform-as-a-Service

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA) and Hyper-V Cloud
Hovhannes Avoyan [pictured below] predicted No Cloud Standards, Private Clouds Will Fail, Say Predictions for 2011 based on an earlier article by James Staten of Forrester Research:
Here are a few predictions about the Cloud for 2011 from an article I read that I thought I’d share with you. Some of them are quite startling. Here goes:
Don’t Expect Cloud Standards in 2011 – Yeah, there will be drafts of standards, and possibly some ratifications by groups such as DMTF, NIST and the Cloud Security Alliance. But actual adoption of any kind of standard won’t happen…and is still a few years off. That shouldn’t prevent you from using the Cloud however, especially when you can rely on technologies such as 24/7 cloud platform monitoring to make sure your database and apps are available and up and running.
More enterprises will build private clouds, and they’ll continue to fail. While nobody likes to see something fail, the article suggests that this is a good thing because then companies will learn that building a cloud is a very complex task. You shouldn’t start too grand or with something too highly visible. Start small; learn and then expand.
Hosted private clouds will outgrow internal clouds — by a factor of three to one. In 2011, private cloud service providers will be perfectly able to provide the consistent speed that a company’s employees need when turning to the cloud for performance. Why? Because they use standardized procedures that are executed by software — not your resident in-house VMware administrators.
Information is not just power; it’s also a profit center. Of course Cloud computing helps companies gain greater insight into their data. But next year it will increasingly help firms earn money, too. Just look at services such as Windows Azure DataMarket — designed to help enterprises leverage data sources more easily.
On that last point, the data that Monitis’ Web LoadTester provides your company is instrumental in maintaining profitability. We use cloud-computing power for instant web applications and network testing. Our on-demand Web Load Tester service helps ensure that your site’s Web pages will continue to work as designed when many visitors come — for example, the day after Thanksgiving, or Black Friday!
Why is this so important? Heavy user traffic is always good, unless your web system is under too much stress. Web LoadTester helps you determine how your system responds to that traffic. You can use the service at any time, day or night, to ensure that your websites and applications are ready for any number of visitors whenever they arrive.
Hovhannes is the CEO of Monitis, Inc., a provider of on-demand systems management and monitoring software to 50,000 users (inlcuding OakLeaf) spanning small businesses and Fortune 500 companies.
<Return to section navigation list>
Cloud Security and Governance
John Oates prefaced his Brussels talks clouds and privacy post of 11/25/2010 for the The Register with “Steely Neelie warns on security:”
Neelie Kroes, European Commissioner for the Digital Agenda, warned yesterday that moves to cloud computing must not endanger citizens' rights to privacy and proper data protection.
Kroes told the Université Paris-Dauphine that putting personal data on remote servers risked losing control of that data. She said the Commission was funding research to strengthen data protection but it was important that such security was put first when designing such systems.
She said legal systems also needed to adjusted as data increasingly flows out of the European Union to the rest of the world.
She said laws within the community needed to allow the free movement of data, as part of the Digital Single Market. But being "cloud-friendly" did not mean Europe should ignore security considerations.
She added that many cloud companies are small and medium businesses that needed help "to know exactly what is allowed and what is not".
Kroes said that some international companies assert that European privacy laws are merely a protectionist stance to favour local providers and to hold back the development of cloud computing.
She said this was untrue and used the car industry as a metaphor. She said that people mainly build cars to provide mobility, but that doesn't mean we should ignore safety features such as brakes and seatbelts.
Security and data protection were similarly "must-have" features of any cloud, she said.
She said European citizens and businesses should know two things about their cloud supplier - that they follow European data protection standards in a transparent way and secondly that places "where the cloud touches the earth" - the countries where the company's servers are located - have proper legal frameworks in place to enforce such standards.
The European Commission is collecting feedback on proposed improvements to European data protection.
Kroes said: "In conclusion, I wish to say to you that cloud computing may indeed become one of the backbones of our digital future. Securing workable data protection will help us to give shape to that digital future. Let us keep up the conversation about these and other digital issues. If we do that, we will deliver the better economy and better living that digital technologies make possible."
Kroes' full speech on cloud security is here. ®

Another call to bolster Brussels’ burgeoning bureaucracy.
<Return to section navigation list>
Cloud Computing Events
•• The Cloud Computing World Forum announced Mobile Cloud Computing Forum Close to Selling Out in an 11/27/2010 press release:
There is less than a week remaining to book one of the limited places left at the Mobile Cloud Computing Forum taking place next Wednesday 1st December at RIBA, London.
The highly anticipated 1 day conference and exhibition will include an overview of the Mobile Cloud Computing Proposition and Marketplace, Mobile Cloud and Enterprise Applications, The Challenges for the Mobile Cloud and The Future of Mobile.
The event will embrace the full Mobile Cloud Computing supply chain including suppliers, integrators, analysts, journalists and end users giving the audience a complete overview of Mobile Cloud Computing and SaaS.
Key speakers confirmed include:
- Amir Lahat, Head of Global Business Ventures, Nokia Siemens Networks
- Peter Ranson, CIO, Oxfam
- Evangelos Kotsovinos, Vice President, Morgan Stanley
- Peter Judge, Editor, eWeek Europe UK
- Renaud Larsen, Director Cloud Computing Strategy, Alcatel-Lucent
- James Akrigg, Head of Technology for Partners (SMS&P), Microsoft Ltd
- Michael Crossey, VP Marketing, Aepona
- Justin Campbell, Senior Sales Specialist, O2
- Scott Petty, Business Products & Services Director, Vodafone
- David Jack, CIO, The Trainline
- John Lincoln, Vice President - Enterprise Marketing, Du
- Chris Hazelton, Research Director, Mobile & Wireless, The 451 Group
- Bob Tarzey, Analyst and Director, Quocirca
- Simon Bradshaw, Research Assistant, Queen Mary University of London
- Simon Stimpson, President and CEO, Life Champions
- David King, CTO, Logica
To register for the event please visit www.mobilecloudcomputingforum.com, or call the team on +44 (0)845 519 1230.
• Brian Loesgen announced San Diego Day of Azure II, Azure Discovery to be held 12/4/2010 from 8:00 AM to 5:00 PM at the AMN Healthcare Conference Center, 12400 High Bluff Drive, San Diego, CA:
So Azure has been in production for a while now and you have checked out the presentations at the 1st Day of Azure, or you have seen presentations at your local user group, or you have checked out a webcast. Maybe you have even played around and created your first Azure Application or your first SQL Azure database. And you are thirsty for more.
If that is the case then the Day of Azure II is the day for you. This is a single day, all-inclusive, with some of the best speakers you can possibly find on the topics, delivering the intermediate/advanced sessions on Azure development that you won't find at a Code Camp or User Group Presentation. Our format gives the presenters the capability to cover the material at a much deeper level than you will find at any other type of local event.
And this is all being brought to by Microsoft and the San Diego .Net User Group (including breakfast, lunch, and snacks) at a price that you just simply can't match. This is the type of information that you would normally being paying hundreds or thousands of dollars to attend a conference like PDC or Tech-ED. So don't hesitate and ensure your spot for this important day..
Andrew Karcher
Conference Opening
8:00 – 8:15
Brian Loesgen
Azure Discovery
Cloud technologies are transformational, and one of those rare paradigm shifts that we don’t see often. The Windows Azure platform represents a tremendous investment by Microsoft, one that developers can benefit from today to enable solutions that previously would have been impossible or prohibitively expensive to create. This session will go beyond an overview of Microsoft’s Windows Azure cloud platform, it will show you why Cloud computing is a seismic shift, and why the Windows Azure platform is a natural evolution for .NET (and other) developers. What’s going on under the hood? What’s in it for me? Why PaaS and not IaaS? Fabric? Blobs? CDNs? Geo-distribution? Hybrids? This far-ranging session will touch on many aspects of the Azure platform.
8:15 – 9:15
Break
9:15 – 9:30
Scott Reed
Creating an Azure app, from “file|new|project” on through deployment
Demo after demo this talk will walk through creating a new Cloud application and then utilizing each major feature of Windows Azure. From web roles to worker roles, internal and external communication, local storage as well as blobs, tables, and queues each aspect will be covered. Provides a great overview of the different features available now, as well as an in depth look at the APIs available for that feature.
9:30 – 11:30
Lunch
11:30 – 12:30
Henry Chan
Migrating an existing ASP.NET app to Windows Azure (live demo)
Henry Chan, Chief Cloud Architect for Nubifer Cloud Computing will demonstrate the process of converting a traditional ASP.NET application into a Windows Azure application. The application being converted is the popular “Nerd Dinner” ASP.NET MVC technology demonstration application written by Scott Hanselman. The live demonstration will cover creation/setup of a new project in Visual Studio 2010, importing existing code, updating the code to utilize Windows Azure technologies, and publishing the completed project.
12:30 – 1:30
Break
1:30 – 1:45
Lynn Langit, Ike Ellis
SQL Azure (approx. 1 hour on migration of existing DBs to SQL Az, and then Twitter-on-WA WA BI demo)
In this demo-filled session, Ike and Lynn will show how SQL Azure works. They will demonstrate working with SQL Azure storage in your application and discuss the option to connect a non-cloud hosted front end and/or a cloud-hosted front end to a SQL Azure back end solution. Ike and Lynn will also talk about migration strategies and best practices. In this talk, you will also learn recommended business scenarios for cloud-based storage. They will cover in detail features of SQL Server RDMS which are and are not supported in SQL Azure. Finally, Ike and Lynn will demonstrate several new enhancements Microsoft has added to SQL Azure based on the feedback received from the community since launching the service earlier this year.
1:45 – 3:45
Break
3:45 – 4:00
Brian Loesgen
Architectural patterns and best practices
Microsoft’s Windows Azure cloud platform is a full Platform-as-a-Service offering, and is much, MUCH more than “Hosting Version 2.0”. You could do things the way you always have, but as an architect or developer on the Windows Azure platform there are some exciting new architectural patterns that enable the next generation of software, and do things that would have been impossible just a few years ago. As an architect evangelist on the Microsoft Azure ISV team, I see new Windows Azure patterns and best practices regularly. The key takeaway from this session is “question everything”, come and see why.
4:00 – 5:00
Andrew Karcher
Raffle
5:00 - 5:15
About the presenters:
Scott Reed, DevelopMentor, Brain Hz
Scott's career in software began in 1993 at IBM. Along the way he has developed enterprise solutions for both Microsoft and Cardinal Health. In 2006, Scott founded Brain Hz Software, a company specializing in software architecture and agile development. He is an expert in all things .NET and is a .NET and WCF instructor for DevelopMentor. His interests range from data access technologies, multithreading, and communications as well as UI technologies.
Scott holds a B.S. in Computer Science and Mathematics from Virginia Tech. He is an active member of the local .NET community, regularly giving talks at user groups and code camps in Southern California.
Henry T. Chan, Nubifer
Henry Chan is a thought leader in Cloud Computing and has over 20 years of proven experience in architecting and building custom enterprise software applications, client server and system applications. Henry possesses extensive experience working with Fortune 500 companies, as well as with start-up companies. Henry maintains expertise in analysis, design and implementation of information systems using web and client-server technologies. He is heavily involved in design and development, with a special focus on the Windows Azure platform, leveraging technologies like T-SQL, C#, VB.NET, ASP.NET (both WebForms and MVC) with AJAX extensions, Javascript, jQuery, WPF, Silverlight, and XHTML technologies. Henry possesses a BS in Computer Science from the University of California, San Diego. To read some of the cloud computing research Henry has co-authored with the nubifer research team, visit0http://nubifer.wordpress.com.
Lynn Langit, Microsoft
Lynn Langit is a Developer Evangelist for Microsoft in Southern California. She has worked with SQL Server for 10 years and has published two technical books on SQL Server (both on Business Intelligence). In her spare time, Lynn works on creating courseware to get kids started in coding. She also personally volunteers on the largest electronic medical records project implemented in sub-saharan Africa - SmartCare. For more information check out her blog at http://blogs.msdn.com/SoCalDevGal.
Ike Ellis, DevelopMentor, EllisTeam
Ike is the Lead SQL Instructor and SQL Course Author for DevelopMentor. He first worked with Microsoft SQL Server in 1997. Ike started as an independent consultant and trainer in September, 2000. Recent projects include a planning and financial solution used by a major retailer, a SQL Server Analysis Services project for a top ten university, an attorney scorecard tool used by the oldest intellectual property law firm in the US, SQL performance tuning for a medical imaging company, and an enrollment and retention tool used by an online university.
Ike has been Microsoft Certified since the beginning. He currently holds the MCDBA, MCSE, MCSD, MCNE, and MCT certifications. Ike loves consulting, loves technology, and thoroughly enjoys teaching. He’s been doing all three since 1996. Ike is a popular code camp and user group speaker. In addition to his responsibilities at EllisTeam, he is the current chairperson for the Tech Immersion Group of the San Diego .NET User’s Group. He also volunteers his time with SQLPass and the San Diego .NET Developer’s Group. Ike blogs at http://ellisteam.blogspot.com/.
Brian Loesgen, Microsoft
Brian Loesgen is a Principal Architect Evangelist with Microsoft, on the Azure ISV team. Based in San Diego, Brian is a 6-time Microsoft MVP and has extensive experience in building sophisticated enterprise, ESB and SOA solutions. Brian was a key architect/developer of the “Microsoft ESB Guidance”, initially released by Microsoft in Oct 2006. He is a co-author of the SOA Manifesto, and is a co-author of 8 books, including “SOA with .NET and Windows Azure”, and is the lead author and currently working on “BizTalk Server 2010 Unleashed”. He has written technical white papers for Intel, Microsoft and others. Brian has spoken at numerous major technical conferences worldwide. Brian is a co-founder and past-President of the International .NET Association (ineta.org), and past-President of the San Diego .NET user group, where he continues to lead the Connected Systems SIG, and is a member of the Editorial Board for the .NET Developer’s Journal. Brian was also a member of the Microsoft Connected Systems Division Virtual Technical Specialist Team pilot, and is part of Microsoft’s Connected Systems Advisory Board. Brian has been blogging since 2003 at http://blog.BrianLoesgen.com.
• Steve Plank (@plankytronixx, Planky, pictured below right) posted VIDEO: Mark Rendle’s Talk at the inaugural Cloud Evening on 11/27/2010:
Cloud Evening is a UK-based Cloud Computing enthusiast’s group. It’s not aimed at majoring on any particular cloud provider or technology vendor. If you are UK-based, I’d encourage you to join the group and come along to the meetings. They are punctuated by the usual beer and pizza of course! The next meeting isn’t yet scheduled but it’ll be towards the end of Jan/beginning of Feb.
Click Here to watch Mark’s talk concerning the new Windows Azure features announced at the PDC.
Planky

Eric Nelson (@ericnel) posted Slides and links from the UK ISV Community Day on the 25th of November 2010 on 11/24/2010 for update on 11/25/2010:
[This is a placeholder – it will be updated after the 25th with all the presentations etc]
A big thanks to everyone who attended on the 25th and to my fellow speakers for doing a great job. Ok – they haven't presented yet but I know they will :-)
Microsoft Technology Roadmap – Eric Nelson (blog | twitter)
Technologies such as the Windows Azure Platform, Windows Phone 7, SharePoint 2010 and Internet Explorer 9.0 all present new opportunities to solve the needs of your customers in new and interesting ways. This session gave an overview of the latest technologies from Microsoft.
View more presentations from Eric Nelson.
Technology drill downs
Each session was 30 minutes
Windows Azure Platform – Eric Nelson
Windows Azure Platform in 30mins by ericnel
View more presentations from Eric Nelson.
Windows Phone 7 – Paul Foster
SQL Server 2008 R2 – Keith Burns
Links
Getting Help from Microsoft
- sign up to http://bit.ly/ukmprhome to get free developer support, training and additional benefits
- http://msdev.com for on-demand training
- http://channel9.msdn.com/learn for on-demand training
- Follow the UK ISV team blog and brand new twitter account
Misc
- IE 9.0 Beta and Platform Preview http://ie.microsoft.com/testdrive/
- http://www.odata.org/developers and http://www.powerpivot.com/index.aspx
- Silverlight and WPF and HTML from Mike Taulty
- UK VS Live Meetings etc http://www.microsoft.com/visualstudio/en-gb/visual-studio-events
Azure
- Download the free Windows Azure ebook (also includes details of how you can order the paper copy from lulu)
- For more resources and information http://bit.ly/startazure
- If you are an ISV intending to explore/adopt azure, sign up to http://bit.ly/ukmpr
- If you are an ISV in the UK, then pop along for a chat about Azure on December 13th
- If you are based in the UK, join http://ukazure.ning.com and check out all upcoming events
- Cloud Storage Studio http://www.cerebrata.com/
Windows Phone 7
SQL Server 2008 R2
No significant articles today.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Rob Gillen (@argodev) answered the Does Amazon’s Cluster Compute Platform Still Represent Cloud Computing? question on 11/17/2010 (missed due to RSS/Atom failure):
I’m sitting at the airport in New Orleans, after having attended the first half of the ACM/IEEE 2010 Super Computing conference. This was the first time I have attended this conference, and it was certainly interesting to participate.
During the workshop I participated in on Sunday (Petascale Data Analytics on Clouds: Trends, Challenges, and Opportunities), there arose a conversation regarding the Amazon EC2 “cluster compute instances” and their having reached a spot on the Top 500 list. What surprised me, however, was not that they were mentioned (I actually expected them to receive more attention than they did), but that they were described as not being “real” cloud computing. The point was made that they represented some sort of special configuration that was done just for the tests and that the offering was somehow significantly different than the rest of the general populous could acquire. The two primary individuals involved in the exchange have significant history in classic HPC and have, at least a degree of “anti-cloud” bias, but I am responsible for helping influence the viewpoint of one of these folks so I’ve been thinking a bit over the past few days about how to properly articulate the inaccuracies of the argument… and wondering if it really matters anyway.
Commodity Hardware – by this I mean that the platforms being utilized could be purchased/deployed by anyone… and, by “anyone”, I am thinking of a moderately skilled computer hobbyist. I’m referring, particularly, to the chip architectures, availability of the motherboards, etc. A quick glance at the specs for a given machine validates that anyone (with enough money) could easily assemble a similarly-configured machine. It is simply a quad-core Intel box with 24 GB of RAM and roughly 2TB of disk. One might argue that the newly-announced Cluster GPU Instance is specialized hardware, but then again, anyone with an extra $2,700 to spare could add one of these to their machine. The point is, that machines in this class are in the 5K range, not the 50K or 500K range.
Commodity Networking – now to some of you, 10GB non-blocking networks might seem specialized or exotic, but – at least in the HPC realm – it isn’t. Most serious HPC platforms utilize a network technology called InfiniBand (usually QDR) or something fancier (more expensive such as an IBM custom interconnect or CRAY’s Gemini. A quick search shows one could purchase 10GBE switches starting in the 2-3K range and going up from there whereas IB QDR switches are at least double that.
Broad Availability – this point gets a little stickier. The point is, that anyone can get access to CCI nodes at any point – simply using a credit card and visiting the AWS website. However, getting access to 880 of them (the number used in the Top 500 run) is likely to be more difficult. The reason is not an unwillingness on Amazon’s part to provide this (I’m sure, given the proper commitment, this would not be impossible), but rather a question of economics and scale. Their more “general” nodes have a large demand and use case… the scale of demand for CCI nodes is yet to be established although I’d imagine the sweet spot for these customers is in the 16-64 node range… folks who could really use a cluster some of the time, but certainly don’t need it all of the time. As such, I (and I have no inside knowledge of their supply/demand change) don’t imagine that the demand is currently so large that beyond the currently active nodes, they have ~1000 nodes of this instance type sitting around just waiting for you to request them (this will likely changes as demand grows).
Inexpensive + Utility-style Pricing – This is one area where this instance type represents all of the goodness we have become accustomed to in the cloud computing world. These nodes (remember I listed the above as starting around 5K) are available at $1.60/hour ($2.10/hour for the GPU-enabled nodes). This makes a significant computing platform available to almost anyone. For just over $100/hour, you can have a reasonably-well powered 64-node cluster on which to run your experiments… that is disruptive in my opinion. The best part about it, is that this price is the worst case scenario – meaning, this is the price with no special arrangement, or reservation, or volume discount, or anything. It represents no long term commitment… nothing beyond a commitment for the current hour.
So… what is different? – I have spent the majority of this post explaining how I think that these instance types are similar in many ways to other IaaS offerings and thereby deserve categorization as “regular” cloud computing, but that begs the question – what is unique about these nodes that would cause Amazon to promote them as better for HPC workloads? What facts formed the foundation for these rather experienced HPC experts to classify them as different? In my mind, there is really only 2 or three things here. The first is the networking – rather than being connected to a shared 1GBE network, you are given access to a 10GBE network, and guaranteed full bisection bandwidth node-to-node. It is this fact alone that makes the platform so interesting to the HPC folks as it makes it actually viable for network-heavy applications (think traditional MPI apps). Secondly, you have clear visibility to the hardware. Amazon tells you exactly what type of processors you are running on allowing you to optimize your codes for that particular processor (somewhat common in the HPC realm). Tightly coupled with this fact is that you can’t get a “part” of this instance type. You get the entire node (less the hypervisor) and, as such, are not contending with any other customers for node-local resources (RAM, ephemeral disks, network, etc). Finally, the fact that you can get nodes that have specialized hardware (NVidia GPUs) is unique… there are very few cloud providers currently offering this sort of feature set.
In the end, I think the Amazon offerings are very much representative of the “cloud” and, particularly, of where the cloud is going. I think we will continue to see a broad level of homogeneity (basic hardware abstractions) with comparatively small pockets of broad-domain specific assets. The key being that for a large number of researchers, the offerings announced by Amazon this summer (and additionally this week) make the decision as to whether or not to buy that new departmental cluster much more difficult – especially when a true TCO analysis is performed. These are similar to the arguments and justifications for “normal” cloud compute scenarios and as such, should be considered one and the same.
<Return to section navigation list>

















0 comments:
Post a Comment