Windows Azure and Cloud Computing Posts for 11/10/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- AppFabric: Access Control and Service Bus
- Windows Azure Virtual Network, Connect, and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA) and Hyper-V Cloud
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Tip: If you encounter articles from MSDN or TechNet blogs that are missing screen shots or other images, click the empty frame to generate an HTTP 404 (Not Found) error, and then click the back button to load the image.
Azure Blob, Drive, Table and Queue Services
The Windows Azure Team reported a Breaking Change for Windows Azure Drive Beta in Guest OS 1.8 and 2.0 on 11/10/2010:
Windows Azure drives support the use of a local cache to improve performance of drives. With the upcoming Guest OS 1.8 and 2.0 releases, there’s a breaking change in the way this local cache is allocated.
Background
A Windows Azure application can request local storage in its service definition (.csdef). Here’s an example:
<LocalResources> <LocalStorage name="DriveCache" cleanOnRoleRecycle="true" sizeInMB="1000" /> </LocalResources>This example ensures that Windows Azure allocates 1000MB to a local storage resource called “DriveCache” for each role instance. When an application uses Windows Azure Drives, it can use such a local storage resource to allocate a cache for all Drives that are mounted. Here’s a typical snippet of code that does that:
LocalResource localCache = RoleEnvironment.GetLocalResource("DriveCache"); CloudDrive.InitializeCache(localCache.RootPath, localCache.MaximumSizeInMegabytes);Finally, when mounting a Windows Azure Drive, the instance can specify the amount of space to be allocated for that Drive, as follows:
driveLetter = drive.Mount(driveCacheSize, DriveMountOptions.None);The Breaking Change
Prior to Windows Azure Guest OS 1.8 and 2.0, the Windows Azure Drive cache was allocated as lazily as Drives were used. With these new Guest OS releases, the entire cache is allocated up-front, and if there isn’t enough space in the local resource for the cache, the call to
Mount()will fail with the errorD000007F.Due to an issue with how local storage resources are allocated, some of the requested space is unavailable for cache usage. That means that if your application declares a 1000MB local resource and then tries to allocate the full 1000MB across your Windows Azure Drive caches, the allocation will likely fail.
The workaround is to specify a local resource that’s 20MB larger than what the application uses. Here’s an example of allocating space for a Windows Azure Drive that uses 1000MB of cache space:
<LocalResources> <LocalStorage name="DriveCache" cleanOnRoleRecycle="true" sizeInMB="1020" /> </LocalResources> LocalResource localCache = RoleEnvironment.GetLocalResource("DriveCache"); CloudDrive.InitializeCache(localCache.RootPath, localCache.MaximumSizeInMegabytes); driveLetter = drive.Mount(1000, DriveMountOptions.None);Applications that would like to preserve the previous cache allocation behavior can specify an earlier Guest OS version. Here’s an example to specify Guest OS version 1.7:
<ServiceConfiguration serviceName="MyService" osVersion=" WA-GUEST-OS-1.7_201009-01 "> <Role name="MyRole"> … </Role> </ServiceConfiguration>We are working on making sure local storage resource allocation always gives you the full amount of space requested, and we expect to have a fix in an upcoming Guest OS release.
<Return to section navigation list>
SQL Azure Database and Reporting
Gavin Clarke asserted “'New generation' of Visual Studio tools promised” as a preface to his Microsoft unveils cloud-mounting SQL Server post of 11/9/2010 to The Register:
The next installment of Microsoft's SQL Server story starts Tuesday, with plans for easier-to-use programming apps for on-site servers and the cloudy SQL Azure.
Microsoft is scheduled to make available for download the first preview of Denali, the code name for the next version of SQL Server, to subscribers on MSDN and TechNet. The Community Technology Preview will be released at the annual Professional Association for SQL Server conference in Seattle, Washington.
Denali introduces Juneau, what Microsoft is calling a "new-generation" Visual Studio development tool for SQL Server that will bridge the gap between building and deploying apps for on-site and on cloud.
Quentin Clark, general manager Microsoft SQL Server Database Systems Group, said the goal is to make developing for SQL Azure and on-site SQL exactly the same, and to do so as soon as possible.
"We have this surface area of T-SQL, but in Danali we are starting to add very specific model and build capabilities in the development tools to let people develop to one surface area that's deployable on and off premises," Clark told The Reg.
SQL Server and SQL Azure share a core relational database management system (RDBMS), but programming apps for them is slightly different. If you are very prescriptive in how your SQL Server app should work, it likely will hit problems in SQL Azure.
If you use Data Definition Language (DDL) to specify where a log file should go in SQL Server on premises, for example, your app likely won't work in the Azure cloud because SQL Azure already takes care of where log files should be deployed. That's because Microsoft has tried to abstract away such details to make programming for its cloud easier.
Juneau — which will be demonstrated at PASS on Tuesday — will let devs do offline validation of apps, and will feature a table designer and query function that'll work with Visual Studio's Intellisense. Developers will be able to tell in real time as they build or package an application what potential problems they might hit when moving their app to the cloud, Clark promised.
Juneau will initially ship as a set of plug-ins to Visual Studio 2010, and will be folded into the next edition of Microsoft's development environment.
Denali chucks in some other cloud wrapping, but the real meat is in improved mission-critical performance for apps and some new business intelligence (BI) capabilities.
There's new columnar technology called Apollo, which Clark claimed could boost certain queries by between 10 and 50 times. Apollo puts algorithms into the database engine from the VertiPak storage engine used in Excel to compress and manage millions of rows of data in memory.
And then there's Crescent, a web-based data visualization and presentation feature to let the suits easily built interactive charts, graphs, and reports. It provides a reporting element to the work done in SQL Server 2008 R2's Project Gemini for "self-service" BI, which became SQL Server PowerPivot for SharePoint 2010 — an Excel plug-in for SQL Server 2008 R2.
A new service. SQL Server AlwaysOn, is an online support and analysis tool that provides best practices and is designed to help SQL Sever users troubleshoot configuration problems. It covers high-availability and disaster recovery, spanning reliable secondaries, multiple secondaries, faster failover and better reconnect and retry.
Also, Microsoft has announced a planned service codenamed Atlanta that will allow users to oversee their SQL Server configuration to — Microsoft said — ensure best operational practices.
While it looks to Denali, Microsoft is also finishing up on the most recent release of SQL Server. Microsoft will announce general availability of its SQL-Server appliance, SQL Server R2 Parallel Data Warehouse edition, targeting customers with hundreds of terabytes of data running on pre-configured iron from server giants. Coming with Data Warehouse edition is Microsoft's Critical Advantage Program, which provides dedicated support.
Bootnote
Denali is the Native American name for Alaska's Mount McKinley and Juneau is a city in Alaska. While clearly seeking inspiration for its codenames above the lower 48 on SQL Server, we should at least be grateful that Microsoft didn't turn to the state's other claims to fame besides oil and outstanding wilderness, the Palins, and go with "Todd" and "Sarah".
The SQL Server “Denali” page is here. Download the first “Denali” CTP here.
The SQL Server Team reported Parallel Data Warehouse is now available! from PASS on 11/9/2010:
Today, Microsoft announced General Availability of SQL Server 2008 R2 Parallel Data Warehouse (formerly Project “Madison”), its first Appliance for high end Data Warehousing. For customers with the most demanding Data Warehouses, SQL Server 2008 R2 Parallel Data Warehouse offers massive scalability to hundreds of terabytes and enterprise class performance through a massively parallel processing (MPP) architecture. With Parallel Data Warehouse, Microsoft provides the most complete Data Warehouse platform with a complementary toolset for ETL, BI, MDM and real-time Data Warehousing.
Parallel Data Warehouse offers customers:
- Massive scalability to hundreds of terabytes. The largest appliance scales to over 500TB of user data capacity and has up to 40 compute nodes
- Enterprise class performance – Parallel Data Warehouse delivers up to 10X data throughput and 100X faster query performance than an SMP Data Warehouse
- Latest generation of industry standard hardware with 2-socket servers that use 6-core Intel® Westmere processors
- Low cost with appliances starting from approximately $13K per terabyte
- First-class integration with Microsoft BI tools such as PowerPivot, SQL Server Analysis Services, Reporting Services and Integration Services
- Reduced risk through pretested configurations. Parallel Data Warehouse is also built on a mature SQL Server platform with ten releases of technology
Over sixteen customers, from 6 industries participated in the technology previews for Parallel Data Warehouse. These customers saw between 40 and 200 times improvement in query performance when compared to existing scale up data warehouses.
Visit us at PASS Summit
This week, Microsoft is showcasing Parallel Data Warehouse at PASS Summit 2010. Come to Booth # 208 to see a real Parallel Data Warehouse appliance!
Learn more:
- SQL Server 2008 R2 Parallel Data Warehouse: http://www.microsoft.com/sqlserver/en/us/solutions-technologies/data-warehousing/pdw.aspx
- Register Now to attend Microsoft Data Warehouse Virtual Launch Event on November 16, 2010
- SQL Server 2008 R2: http://www.microsoft.com/sqlserver/en/us/default.aspx

So when can we expect the CTP of SQL Azure Parallel Data Warehouse?
The SQL Server Team published a List of in depth PASS sessions on SQL Server Code-Named “Denali” on 11/9/2010:
PASS Attendees: now you’ve heard about the new features coming in SQL Server Code-Named “Denali” (featured in Ted Kummert’s keynote), don’t miss the sessions that explore Denali in depth:

Same question: The date for SQL Azure Denali CTP?
<Return to section navigation list>
Marketplace DataMarket and OData
Beth Massi will present Consuming Odata Services for Business Applications to the San Francisco User Group tonight (11/10/2010) at 6:30 PM PST:
The Open Data Protocol (OData) is a REST-ful protocol for exposing and consuming data on the web and is becoming the new standard for data-based services.
In this session you will learn how to easily create these services using WCF Data Services in Visual Studio 2010 and will gain a firm understanding of how they work as well as what new features are available in .NET 4 Framework.
You’ll also see how to consume these services and connect them to other public data sources in the cloud to create powerful BI data analysis in Excel 2010 using the PowerPivot add-in.
Finally, we'll build our own Office add-ins that consume OData services exposed by SharePoint 2010.
Speaker: Beth Massi is a Senior Program Manager on the Visual Studio BizApps team at Microsoft and a community champion for business application developers. She has over 15 years of industry experience building business applications and is a frequent speaker at various software development events. You can find Beth on a variety of developer sites including MSDN Developer Centers, Channel 9, and her blog www.BethMassi.com
Follow her on Twitter @BethMassi
Steve Michelotti recommended that you Create a FULL Local NuGet Repository with PowerShell in this 11/10/2010 post:
NuGet is simply awesome. Despite its relative infancy, it has already established itself as the standard for .NET package management. You can easily add packages from the public feed or even from a local directory on your machine. Phil Haack already has an excellent post describing how you set up a local feed. His post does a great job of explaining *how* to set up the feed, but how do you get packages (that you didn’t create locally) to put in there in the first place? One way is to simply install a package and then grab the *.nupkg file locally and then copy/paste it into whatever folder you’ve designated as your local NuGet feed. For example, if I’ve added the AutoMapper package, I can just grab it from here:
Notice how the <content> tag shows me the URI that I need to hit in order to download the file? That makes life easy. Now all we need is a few lines of PowerShell to put everything in a single local directory:
1: $webClient = New-Object System.Net.WebClient2: $feed = [xml]$webClient.DownloadString("http://feed.nuget.org/ctp2/odata/v1/Packages")3: $destinationDirectory = "C:\development\LocalNuGetTest"4:5: $records = $feed | select -ExpandProperty feed | select -ExpandProperty entry | select -ExpandProperty content6:7: for ($i=0; $i -lt $records.Length; $i++) {8: $url = $records[$i].src9: $startOfQuery = $url.IndexOf("?p=") + 310: $fileName = $url.Substring($startOfQuery, $url.Length - $startOfQuery)11: $fullPath = ($destinationDirectory + "\" + $fileName)12: $webClient.DownloadFile($records[$i].src, ($destinationDirectory + "\" + $fileName))13: }I specify my destination directory on line 3. Then I expand the XML elements into an object that PowerShell understands. After that it’s a simple matter of string parsing and downloading the files with the WebClient.
Now that you have all the packages locally, you can work offline even when you don’t have access to the public feed.


Marcus McElhaney posted Netflix Browser for Windows Phone 7 - Part 2 – CodeProject on 10/9/2010:
This article is the second, and final, part of the Netflix Browser for Windows Phone 7 article. Part 1 focused on exploring the Pivot and Panorama controls in general, and demonstrated the first steps of the demo application walkthrough. We learned how to add the controls to a project, and how to work with the Pivot and Panorama templates. In this part, we will continue with the walk-through of the demo application, and in particular we will look at OData and how to consume OData in a Windows Phone application. We will also explore the Silverlight Toolkit’s WrapPanel control, page navigation and the progress bar.
Netflix Browser for Windows Phone 7 - Part 2 - CodeProject
Related articles
- Windows Phone 7 Users: Netflix streaming is now yours [TNW Microsoft] (thenextweb.com)
- Windows Phone 7 is the Mobile Reset Microsoft So Desperately Needed (readwriteweb.com)
- What's the fuss about Silverlight (csharperimage.jeremylikness.com)
- Windows Phone 7 Devices On Sale Now: See Comparison Chart (pcworld.com)
<Return to section navigation list>
AppFabric: Access Control and Service Bus
Wade Wegner posted TechEd EMEA: A Lap Around the Windows Azure AppFabric (ASI205) on 11/10/2010:
Not only is this my first time at TechEd EMEA, but it’s also my first time to Berlin. While exhausting, it’s been a ton of fun! I haven’t had a much time to explore the city yet, but I’ve spent a lot of time talking to customers about the Windows Azure Platform.
Today I am delivering the presentation A Lap Around the Windows Azure AppFabric.
A Lap Around the Windows Azure AppFabric
Here’s the description:
Come learn how to use services in the Windows Azure AppFabric (such as Service Bus, Access Control, and Caching) as building blocks for Web-based and Web-hosted applications, and how developers can leverage these services to create and extend applications in the cloud while also connecting them with on-premises systems.
I’ll post links to the video and code downloads when they become available.
<Return to section navigation list>
Windows Azure Virtual Network, Connect, and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Bruce Kyle (pictured below) described Rob Tiffany’s series about How to Move Your Line of Business Apps to Phone + Cloud in an 11/10/2010 post to the ISV Developer Community blog:
Rob Tiffany has put together a series of blog posts describing how to move data to your Phone applications from the cloud. Issues for your apps include slow service connections. For device apps to be successful, they must pre-fetch the data they need and cache it offline so a user can keep working when the network is not around. This is not typical SOA, calling Web Services on-demand to help drive your application.
And you’d like to be able to connect to data in Windows Azure or on your on-premises database, store it on the Phone so you can have a disconnected story too. And you want to do this efficiently.
If you’ve looked at the Networking in Silverlight for Windows Phone 7 documentation on MSDN, you might have noticed that a number of things are missing, such as WCF RIA Services, WCF Data Services (OData), Duplex Communication over HTTP, Sockets, UDP Multicast Client, NTLM Auth, RSS/ATOM Feeds, Custom Bindings, JSON Serialization.
So what is left? How does that work?
And what are the steps, trick, and tips? Here’s the view:
Step 1. Build a WCF REST + JSON Service
Rob’s article describes what is on the Phone, in particular SOAP and REST + Basic Authentication. And he makes the case of JSON as a preferred data format for the wire. Next he shows how to build out a sample Web Service and how to add the attributes so your data is serialized. He writes the class that holds the data in a way that can be used on both Windows Phone and on your server.
He defines the contracts for a public interface for the Web Service that will generate JSON on the server. And he provides code to get all or a part of the list of data from the Web Service. He finishes off the service with the configuration files that set up the server to provide data using REST.
See Building a WCF REST + JSON Service.
By the way, this solution works whether you are hosted on Windows Server or Windows Azure.
Step 2. Move Your Web Service to Windows Azure
And then to test and debug the Azure-based Web Service. And you’ll see the data returning the data objects in wireless-friendly JSON format.
See Moving your WCF REST + JSON Service to Windows Azure.
Step 3. Consume You Web Service on the Phone
Rob begins by leveraging the Web Service code to create a Phone app that cpnsumes the Web Service. Next he shows how to build your Phone application in Visual Studio that will access the Web Service in Azure all on your development computer.
He illustrates how your Phone application will make an asynchronous call to the Web Service, and how to store the data on the Phone. He uses a Database class to connect to an ObservableCollection and the DataContractJsonSerializer used to de-serialize JSON-encoded Customer objects that are downloading over the air.
And finally, he shows how to access the table of your in-memory database.
See Consuming an Azure WCF REST + JSON Service.
Step 4. Working with the In-Memory Database
In this post, Rob shows how to query this new in-memory database using LINQ and I’ll show you how to save the data in your local tables to Isolated Storage so you can keep using your apps even when the network has disappeared.
He walks you through each of the steps to do CRUD (create, retrieve, update, and delete) your data using a listbox and buttons on the Phone. And then how shows how to store and retrieve the data from IsolatedStorage.
Jim O’Neill completed his Azure@home series with his Azure@home Part 11: Worker Role Run Method (concluded) post of 11/10/2010:
Well, it looks like eleven may be the magic number for this blog series. It’s been a couple of weeks, so to review: my last post focused on most of the processing inside of the Run method of the Azure@home WorkerRole – primarily the LaunchFoldingClientProcess implementation, which is responsible for steps 4 through 8 of the architecture diagram to the right. Steps 7 and 8 were touched upon, but not fully explored, and that’s the topic of this post, namely looking at how progress on a given Folding@home simulation is reported:
- to the local Azure table named workunit, and
- to the ‘overseer application,’ distributed.cloudapp.net, which keeps track of each of the individual Azure@home deployments.
The snippet of code from LaunchFoldingClientProcess we’re focused on is recreated below, and it’s specifically the pair of invocations at Lines 46-47 and Lines 61-62 that do the reporting. The first set handles reporting on a configurable interval of time (pollingInterval – by default every 15 minutes), and the second set handles the final report for a work unit immediately after its associated Folding@home client process has successfully completed.
C# source code elided for brevity.
UpdateLocalStatus
UpdateLocalStatus has an implementation that should appear fairly familiar if you’ve followed along with this blog series. Its role is to update the workunit table for each distinct deployment of Azure@home thus providing the status information for the WebRole’s status.aspx page (cf. Part 4 of this series).
More C# source code elided for brevity.
Passed into this method (and into UpdateServerStatus as well) is a simple class – FoldingClientStatus – that encompasses the information extracted from the unitinfo.txt file (Step 6 in the architecture diagram above).
The method ReadStatusFile in FoldingClientCore.cs contains the code that parses unitinfo.txt (we didn’t cover its implementation explicitly in this series). This Folding@home file format isn’t documented, so as a bit of defensive programming, the HasParseError flag was added to the status class. When a parsing error is detected, a message is written (via Azure Diagnostics) to the Azure log, and a default value is provided for the element that failed parsing. Granted, that could result in some inconsistent entries in the workunit table.
Code analysis and other text omitted.
Final(?) Words
Whether you’ve made it through the entire series front-to-back or just popped in on an article of interest or two, I hope the relatively deep coverage of the Azure@home project and relevant Azure topics has been helpful. While I honestly can’t think of anything significant that I’ve left untouched in this series, I’m certainly open to feedback if there’s some aspect of the project that you think deserves more attention in a blog post.
Given the recent announcements at PDC, the gears are already turning in my head in terms of how I might update this project to take advantage of some of the new features – like administrative access, the VM Role, and AppFabric caching. So don’t be surprised to see the series resurrected to explore these new aspects of the Windows Azure Platform!
Andy Robb explained How to take on the cloud – from Umbraco and Windows Azure in an 11/10/2010 post to the Underbelly blog:
The cloud can seem like a pretty intangible thing. From a consumer standpoint the ability to have your ‘stuff’ at your fingertips no matter where you are, or on what device is quite an inviting prospect. But when we translate that to customers and businesses it appears a very different beast. So when Umbraco (a .NET CMS) announced at PDC 2010 that it had a way of allowing small web devs a simple and quick way of deploying sites, and large enterprises more flexibility I wanted to find out more – in plain English.
What actually happened?
This first release of the accelerator is targeted at web developers, but there is no complex code to understand and only configuration is required in order to use the accelerator to run Umbraco on Windows Azure. There is a detailed usage guide available along with the accelerator which can be found on CodePlex.
Why did they do it?
“We wanted to find a way of reducing the technical requirements for great web design so that Umbraco can be used by a much wider audience, including hobbyists and other users who are not professional web developers,” says Paul Sterling, Partner with Umbraco. “The work required to get Umbraco implementations hosted and configured can be technically complex, particularly for potential users who do not have the time or expertise needed to deal with the IT infrastructure.”
Effectively they removed the administrative overhead and managed to get on improving the actual app itself.
What are the benefits?
First off this opens the door to huge markets as it removes the requirement for users to configure and deploy their own web server infrastructure. Second, enterprise customers can add features and benefits without needing to constantly assess its server strategy; as their application scales so does the unit that processes and supports it. Finally it reduces the need for constant licensing and other underlying IT infrastructure efforts.
Check out this site for more information from Umbraco themselves on the integration, or here to view more information on deploying Umbraco on Windows. Paul Sterling did a great video interview which you can also watch here.
Mike Champion announced WS-I Completes Web Services Interoperability Standards Work in an 11/10/2010 post to the Interoperability @ Microsoft blog:
The final three Web services profiles developed by the Web Services Interoperability Organization (WS-I) have been approved by WS-I’s membership. Approval of the final materials for Basic Profile (BP) 1.2 and 2.0, and Reliable Secure Profile (RSP) 1.0 marks the completion of the organization’s work. Since 2002, WS-I has developed profiles, sample applications, and testing tools to facilitate Web services interoperability. These building blocks have in turn served as the basis for interoperability in the cloud.
As announced today by the WS-I, stewardship over WS-I’s assets, operations and mission will transition to OASIS (Organization for the Advancement of Structured Information Standards).
It took a lot of work to get real products to fully interoperate using the standards. WS-I members have delivered an impressive body of work supporting deliverables in addition to the profiles (test tools, assertions, etc.). One might ask “why did it take so long, and what exactly did all this hard work entail?”
When WS-I started up, interoperability of the whole stack of XML standards was fragile, especially of the SOAP and WSDL specifications at the top of the stack. It was possible for a specification to become a recognized standard with relatively little hard data about whether implementations of the specs interoperated. Specs were written in language that could get agreement by committees rather than in terms of rigorous assertions about formats and protocols as they are used in conjunction with one another in realistic scenarios. In other words, the testing that was done before a spec became a standard was largely focused on determining whether the spec could be implemented in an interoperable way, and not on whether actual implementations interoperated.
At WS-I the web services community learned how to do this better. One of the first tasks was to develop profiles of the core specifications that turned specification language containing “MAY” and “SHOULD” descriptions of what is possible or desirable to “MUST” statements of what is necessary for interoperability, and removing altogether the features that weren’t widely implemented. We learned that it is important to do N-way tests of all features in a profile across multiple implementations, and not just piecewise testing of shared features. Likewise, since the SOAP based specs were designed to compose with one another, it is important to test specs in conjunction and not just in isolation. During this period of learning and evolving, it was really necessary to go through the profiling process before the market would accept standards as “really done.”
The underlying reality, especially in the security arena, is quite complex, a fact which also slowed progress. Different products support different underlying security technologies, and adopted the WS-* security-related standards at different rates. Also, there are many different ways to setup secure connections between systems, and it took considerable effort to learn how to configure the various products to interoperate. For example, even when different vendors support the same set of technologies, they often use different defaults, making it necessary to tweak settings in one or both products before they interoperate using the supported standards. The continuous evolution of security technology driven by the ‘arms race’ between security developers and attackers made things even more interesting.
This work was particularly tedious and unglamorous over the last few years, when the WS-* technologies are no longer hot buzzwords. But now, partly due to the growing popularity of test driven development in the software industry as a whole, but partly due to the hard-won lessons from WS-I, the best practices noted above are commonplace. Later versions of specifications, especially SOAP 1.2, explicitly incorporated the lessons learned in the Basic Profile work at WS-I. Other Standards Development Organization (SDO) such as OASIS and W3C have applied the techniques pioneered at WS-I, and newer standards are more rigorously specified and don’t need to be profiled before they can legitimately be called “done.” Newer versions of the WS-* standard as well as CSS, ECMAScript, and the W3C Web Platform (“HTML5”) APIs are much more tightly specified, better tested, and interoperable “out of the box” than their predecessors were 10 years ago.
We at Microsoft and the other companies who did the work at WS-I learned a lot more about how to get our mutual customers applications to interoperate across our platforms than could be contained in the WS-I documents that were just released. And to support this effort we are compiling additional guidance under a dedicated website: http://msdn.microsoft.com/webservicesinterop
This has a set whitepapers that go into much more depth about how to get interoperability between our platform / products and those from other vendors and open source projects. Available whitepapers include:
- Data Type Interoperability Between .NET and Java: http://msdn.microsoft.com/en-us/netframework/gg413252.aspx
- Oracle WebLogic-to-WCF Secure Messaging Interoperability: http://msdn.microsoft.com/en-us/netframework/gg413253.aspx
- IBM WebSphere-to-WCF Secure Messaging Interoperability: http://msdn.microsoft.com/en-us/netframework/gg413262.aspx
- Standards-Based Interoperability between SAP NetWeaver and Microsoft .NET Framework http://msdn.microsoft.com/en-us/library/ff709807.aspx
- Metro to WCF Interoperability: http://msdn.microsoft.com/en-us/library/ff842400.aspx
Finally, it might be tempting to believe that the lessons of the WS-I experience apply only to the Web Services standards stack, and not the REST and Cloud technologies that have gained so much mindshare in the last few years. Please think again: First, the WS-* standards have not in any sense gone away, they’ve been built deep into the infrastructure of many enterprise middleware products from both commercial vendors and open source projects. Likewise, the challenges of WS-I had much more to do with the intrinsic complexity of the problems it addressed than with the WS-* technologies that addressed them. William Vambenepe made this point succinctly in his blog recently:
But let’s realize that while a lot of the complexity in WS-* was unnecessary, some of it actually was a reflection of the complexity of the task at hand. And that complexity doesn’t go away because you get rid of a SOAP envelope …. The good news is that we’ve made a lot of the mistakes already and we’ve learned some lessons … The bad news is that there are plenty of new mistakes waiting to be made.
We made some mistakes and learned a LOT of lessons at WS-I, and we can all avoid some new mistakes by a careful consideration of WS-I’s accomplishments.
-- Michael Champion, Senior Program Manager

See my Windows Azure and Cloud Computing Posts for 2/22/2010+ post for an earlier post about REST and WS-* APIs by William Vambenepe. I called the WS-* standards “SOAP Header Soup” in an early article for Visual Studio Magazine also.
Kevin Kell asserted Microsoft Azure Does Open Source in an 11/9/2010 post to the Learning Tree blog:
Yes, that’s right.
It may or may not be widespread knowledge but Microsoft has been quietly supporting open source for years. Many people continue to think of Microsoft as a company that sells proprietary software. They certainly are that but they are also involved heavily in open source. They do not, in my opinion, get enough credit for their efforts there.
PHP is a technology that is popular with the open source community. There are many freely available applications written in PHP that could be incorporated into a cloud based solution. With the latest release of the Windows Azure SDK for PHP and the Windows Azure Tools for Eclipse it is easier than ever for programmers to deploy their PHP applications to the Azure cloud.
The SDK gives PHP programmers a set of classes that can be used to program against Azure storage (blobs, tables and queues) and Service Management. There are also additional SDKs for App Fabric and OData as well as drivers for SQL Server. The Eclipse tools offer an end-to-end solution that enables the developer to program, test and deploy PHP solutions onto Azure.
Version 2.0 of the Eclipse Tools (developed by Soyatec) was announced at PDC10. This version offers many new features including integration with the Development Fabric, support for Worker Roles, MySQL integration and deployment from within the IDE.
In addition to the SDKs, drivers and Eclipse tools there is also support for the command line developer to leverage scripting skills in deployment of existing PHP applications. Finally, there is the Windows Azure Companion which makes it pretty easy to deploy finished open source community applications (such as WordPress, SugarCRM, Drupal and others) onto Windows Azure without having to know a lot about the underlying details.
The following screencast demonstrates creating a PHP Azure application from within Eclipse.
To learn more about Windows Azure consider attending Learning Tree’s Azure programming course. For an introduction to PHP you may like to come to Introduction to PHP for Web Development.
CloudVentures announced “We are now very active in developing a ‘Microsoft Cloud Solutions’ portfolio” in it’s Canadian Cloud Roadmap – Next Steps for Microsoft Cloud Solutions post of 11/9/2010:
As I have been profiling we are now very active in developing a ‘Microsoft Cloud Solutions’ portfolio, aka a Microsoft-based ‘Cloud in a Box’ for those who wish to roll their own Azure and cater for local markets.
This will be promoted into the USA and Canadian governments as a first step, based around development of a core Reference Architecture and Roadmap for Government Clouds.
Government Cloud Standards
Recently the USA Gov held their second Cloud Computing workshop where there is still early bird opportunity to be keenly involved in setting these types of standards:
http://www.nist.gov/itl/cloud/cloudworkshopii.cfm
The work we have begun with the Canadian Cloud Roadmap can be concluded and then put forward as a timely response to these requirements, which we’ll do via an in-depth Microsoft mapping program.
If you would like to have your products and services participate, feel free to add them here or contact me directly.
<Return to section navigation list>
Visual Studio LightSwitch
Beth Massi (@bethmassi) explained Creating a Custom Search Screen in Visual Studio LightSwitch in an 11/9/2010 post:
While I was on my speaking trip in Europe a couple folks asked me how they could create their own search screen instead of using the built-in search functionality that LightSwitch provides. Basically they wanted the search to come up blank until a user entered specific search criteria and they only wanted to search on a specific field. In this post I’ll explain a couple options you have that allow you to tweak the default search screens and then I’ll show you how easy it is to build your own. Let’s get started!
Creating a Search Screen
Creating search screens in LightSwitch is really easy – it takes about 5 seconds once you have your table defined. You just describe your data, create a new screen and then choose the “Search Screen” template. Take a look at this video here: How Do I: Create a Search Screen in a LightSwitch Application?
For instance, say we have a Patient table that we’ve created in LightSwitch (if you don’t know how to create a table in LightSwitch see this video):
To create a search screen for Patient just click the “Screen…” button at the top of the designer or right-click on the screens node in the Solution Explorer and select “Add Screen”. Then select the “Search Data Screen” template and choose the Patient table for the Screen Data:
Hit F5 to debug the application and open the search screen. Out of the box you automatically get searching across any string field as well as paging and exporting to Excel.
Specifying “Is Searchable”
By default all string fields in a table (a.k.a. properties on an entity) are searchable in LightSwitch. For instance if we enter “Beth” into the search screen above then it will return all the patients with the string “Beth” matching in any of the string fields in the Patient table. Sometimes we don’t want all the fields to be searched. For instance if we’re not displaying some of the string fields in the search grid that could look confusing to the user if a match was found in one of those fields – they may think the search is broken. Or if there are many rows in the table with a lot of string fields you can improve performance by not searching on all of them.
To prevent the user from searching on a field in a table, open the table designer (by double-clicking on the table in the Solution Explorer) and highlight the field you want. Then uncheck Is Searchable in the property window:
You can also specify whether the entire table should be searchable by default. If you select the table itself (by clicking on the name of the table at the top, in this case Patient) then you can toggle the Is Searchable property there as well. If you uncheck this, then anytime the table data is displayed in a grid in the system, there will be no search box on the top of the grid. However, what if we want to search on non-string fields? What if we want to show a blank search screen and require the user to enter some search criteria? We can create our own search screen very easily to accomplish this. First we need to write a query that takes a parameter.
Creating a Parameterized Query
For this example let’s create a search screen that searches for Patients older than a certain date that the user enters. In this case we will ask for the Patient’s birth date because we are storing a Birthdate field on the Patient table. To create a query that takes a parameter, right click on the table (in my case Patient) in the Solution Explorer and select “Add Query”. Another way to do that is if you have the Table Designer open you can just click the “Query…” button at the top of the designer. (For an intro to the Query Designer see this video: How Do I: Sort and Filter Data on a Screen in a LightSwitch Application?)
Name the query PatientsOlderThanDate, then add a “Where” filter condition and select Birthdate, <= (is less than or equal to), and then choose @parameter for the value type. Then choose “Add New” and a parameter will be created below for you. I’ll also add a sort on LastName then FirstName ascending.
Creating a Custom Search Screen
Now that we have a query that accepts a parameter we can create a screen based on this query. You actually don’t need to choose the Search Data Screen template, you can choose any template you want, but for this example I’ll stick with the search screen template. For the Screen Data, select the query we just created:
Now we need to tweak the screen a bit. One you pick a template the screen designer opens. You will see the query and its fields on the left of the screen and a hierarchal view of the screen controls in the center. On the right is your properties window. Since our query has a parameter, LightSwitch automatically has added a screen property called “Birthdate” which is used as the parameter to the query (this is indicated by the arrow from the query parameter to the screen property). However as it stands right now, this screen is never going to show up on the navigation menu because the Birthdate screen property is set to “Is Parameter” in the properties window. This means that this parameter must be passed in code to open the screen. In order for this to show up on the menu, select the BirthDate screen property and then uncheck the “Is Parameter”:
Next set the control for the Birthdate field in the center view to a Date Picker instead of a Date Viewer. This will allow the user to enter the Birthdate that will feed our query. Finally you can decide whether you still want to show the search box on the grid by selecting the PatientCollection and toggling the “Support search” property.
If you leave the search on the grid this means that you want to let users search within those results that are already displayed after executing our query. I find it to be a bit confusing to leave it on there but you may have your reasons. For this example, I’ll uncheck that. You can also change the display label for the search field to make it more intuitive and/or do other visual tweaks to the screen here or at runtime. If you want this search screen to be the default screen that opens when the application launches, from the main menu select Project –> Properties and then select the Screen Navigation tab and select the screen and click the “Set” button at the bottom of the page:
Now we can hit F5 to start debugging and we will see our custom search screen in the navigation menu. When we open the screen no records are displayed initially. You will also see the Birthdate field as a date picker on the top of the screen. When you enter a date and hit enter or tab, the query will automatically execute and display the results:
That’s it! It should literally take about 5 minutes to create your own custom search screen with Visual Studio LightSwitch.










Return to section navigation list>
Windows Azure Infrastructure
The Windows Azure Team announced a New White Paper Details the Windows Azure Programming Model on 11/10/2010:
If you want to better understand the Windows Azure programming model, you should read David Chappell's latest white paper, "The Windows Azure Programming Model", which is available now on WindowsAzure.com as a free download (located at the bottom of the 'Introductory / Overview Whitepapers' section). Also included in this white paper is guidance and typical examples of on-premises applications that are good candidates to move to Windows Azure.
Here’s the direct download link (requires site registration) and description of the *.pdf file:
The Windows Azure Programming Model
Millions of developers around the world know how to create applications using the Windows Server programming model. Yet applications written for Windows Azure, Microsoft’s cloud platform, don’t exactly use this familiar model. While most of a Windows developer’s skills still apply, Windows Azure provides its own programming model. This document will help you to understand the Windows Azure Platform as a Service programming model.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA) and Hyper-V Cloud
Alan Le Marquand continued his “Creating a Private Cloud” series with System Center Virtual Machine Manager Self-Service Portal 2.0 - Now Available! of 11/10/2010:
Following on from my previous posts on Creating a Private Cloud Part 1 and Part 2, System Center Virtual Machine Manager Self-Service Portal 2.0 (SSP) is now available.
For those who have not read the two posts yet, briefly the System Center Virtual Machine Manager Self-Service Portal 2.0 (SSP) is a fully supported, partner extensible solution that enables you to dynamically pool, allocate, and manage compute, network and storage resources to deliver a private cloud platform in you datacenter. Installed with System Center Virtual Machine Manager 2008 R2 and SQL Server 2008 or 2008 R2 the self-service portal consists of three components:
- VMMSSP website component. A web-based component that provides a user interface to the self-service portal.
- VMMSSP database component. A SQL Server database that stores information about configured assets and other information related to tasks performed in the portal.
- VMMSSP server component. A Windows service that runs default and customized virtual machine actions that the user requests through the VMMSSP website.
To Learn more about the System Requirements Visit the SSP page on TechNet.
Key Features:
- Automation and Guidance: To assess, plan and design your private cloud foundation infrastructure
- Customer/business unit on-boarding: Automated workflows to onboard business unit IT departments onto to your virtualized shared resource pool
- Dynamic provisioning engine: To rapidly provision virtualized infrastructure in conjunction with System Center and Hyper-V
- Self-Service portal: To empower consumers of IT to request and provision infrastructure for their apps/services
- Partner Extensibility: Enable partners to expose their unique hardware capabilities through familiar Microsoft scripting technologies while providing variety and flexibility to IT
Want more info?
- Visit the official Microsoft System Center VMM Self-Service Portal 2.0 blog.
- Read my two blogs at Creating a Private Cloud Part 1 and Part 2,
- Visit the Put the Cloud to Work For Your Organization site
- Visit the new Cloud Centre on TechNet
Questions or Comments?
Feel free to send your comments and feedback to sspfeedback@microsoft.com, or visit www.Microsoft.com/SSP.
Bruce Kyle asserted Hyper-V Cloud Fast Track Program Offers On Ramp for Private Clouds in an 11/9/2010 post to the ISV Developer Community blog:
If you're looking to get started implementing a Microsoft private cloud infrastructure, the Hyper-V Cloud Fast Track program can offer invaluable help by delivering pre-validated reference architectures.
Hyper-V Cloud Fast Track solutions are currently being offered by six Microsoft hardware partners, who cover a broad swath of the Windows Server hardware market.
Learn more at Private Cloud.
The San Francisco Chronicle’s SFGate.com published a VKernel and Microsoft Collaborate on Chargeback for Private Cloud Initiative press release on 11/9/2010:
Berlin, Germany (PRWEB) November 9, 2010. VKernel, an award-winning provider of capacity management products for virtualized data centers, today announced general availability of VKernel Chargeback 2.5 with Hyper-V. The latest version of VKernel's chargeback product was developed in collaboration with Microsoft to support private cloud computing environments based on Microsoft infrastructure. Chargeback 2.5 integrates with both Microsoft System Center Operations Manager and System Center Virtual Machine Manager Self Service Portal to help managers of private clouds easily charge for IT resources consumed or allocated at the departmental or divisional level.
Microsoft's self-service portal is a fully supported, partner-extensible solution built on top of Windows Server 2008 R2 Hyper-V and System Center Virtual Machine Manager 2008. IT professionals use the self-service portal to pool, allocate, and manage resources to offer infrastructure as a service and to deliver the foundation for a private cloud platform inside data centers.
To succeed with these private cloud platforms, chargeback or at least "show" back is a basic building block for success. VKernel's Chargeback 2.5 with Hyper-V enables cloud providers to quickly and easily deploy a chargeback solution for virtualized environments. By integrating with the self-service portal, Chargeback 2.5 will be able to retrieve deployment information about which customers have requested and deployed virtual machines. With its current integration to System Center Operation Center, Chargeback 2.5 can combine this deployment information with actual usage statistics of each Hyper-V instance. The result is an integrated view of resources allocated and consumed by self-service internal customer.
"Microsoft has been a great collaborator on this project," says Bryan Semple, Chief Marketing Officer, VKernel. "As cloud services gain traction, chargeback will be an increasingly important component of these initiatives. VKernel is ready to support the demands of these customers especially those deploying private cloud infrastructure with Microsoft."
"VKernel brings a strong set of charge-back capabilities to Microsoft customers," said Dai Vu Director of Solutions Marketing in the Windows Server and Cloud division at Microsoft Corp. "VKernel's charge-back expertise and ability to deliver immediate value to customers with their product suite meets our customer's requirements."
VKernel Chargeback 2.5 with support for Hyper-V is available for immediate download at www.vkernel.com/products/chargeback-hyper-v . Pricing starts at $299 per socket.
About VKernel
VKernel is the number one provider of virtualization capacity management solutions for VMware and Microsoft virtualized infrastructures. Our powerful, easy to use and affordable products simplify the complex and critical tasks of planning, monitoring and predicting capacity utilization and bottlenecks. Used by over 35,000 system administrators, the products have proven their ability to maximize capacity utilization, reduce virtualization costs and improve application performance.###
For the original version on PRWeb visit: www.prweb.com/releases/prwebvkernel-microsoft/private-cloud-chargeback/prweb4758824.htm
<Return to section navigation list>
Cloud Security and Governance
Lori MacVittie (@lmacvittie) asserted It’s about business continuity between the customer or user and your applications, and you only have control over half that equation as a preface to her Disaster Recovery: Not Just for Data Centers Anymore post of 11/10/2010 to F5’s Dev Center blog:
Back in the day (when they still let me write code) I was contracted to a global transportation firm where we had just completed the very first implementation of an Internet-enabled tracking system. We had five whole pilot customers and it was, to say the least, a somewhat fragile system. We were all just learning back then, after all, and if you think integration today is difficult and fraught with disaster, try adding in some CICS and some EDI-delivered data. Yeah – exactly.
In any case it was Saturday and I was on call and of course the phone rang. A customer couldn’t access the application so into the car I went and off to the office to see what was going on (remote access then wasn’t nearly as commonplace as it is now and yes, I drove uphill, both ways, to get there).
The thing was, the application was working fine. No errors, nothing in the logs; I was able to log in and cruise around without any problems whatsoever. So I pull out my network fu and what do I find? There’s a router down around Chicago.
Bleh. Trying to explain that to the business owner was more painful than giving birth and trust me, I’ve done both so I would know.
Through nearly a decade of use and abuse, the Internet itself has grown a lot more resilient and outages of core routers rarely, if ever, happen. But localized service (and its infrastructure) do experience outages and interruptions and there are just as many (if not more) folks out there who don’t understand the difference between “Internet problem” and “application problem.” And you won’t have any better luck explaining to them than I did a decade ago.
GLOBAL APPLICATION DELIVERY to the RESCUE (SOMETIMES)
When most people hear the words “disaster” and “recovery” together their eyes either glaze over and they try to run from the room or they get very animated and start talking about all the backup-plans they have for when the alien space-craft lands atop their very own data center, complete with industrial strength tin-foil hat.
Okay, okay. There are people for whom disaster recovery is an imperative and very important, it’s just that we hope they never get to execute their plans. The thing is that their plans have a broader and more generalized use than just in the event of a disaster and in fact they should probably be active all the time and addressing what external “disasters” may occur on a daily basis.
Global application delivery (which grew out of global server load balancing (GSLB)) is generally the primary strategic component in any disaster recovery plan, especially when those plans involve multiple data centers. Now, global application delivery is also often leveraged as a means to provide GeoLocation-based load balancing across multiple application deployments as a way to improve performance and better distribute load across a global web application presence. If you expand that out just a bit, and maybe throw in some cloud, you can see that in a disaster recovery architecture, global application delivery is pretty key. It’s the decision maker, the router, the “thing” on the network that decides whether you are directed to site A or site B or site Z.
Because many outages today are often localized or regionalized, it’s often the case that a segment of your user population can’t access your applications/sites even though most others can. It’s possible then to leverage either regional clouds + global application delivery or multiple data centers + global application delivery to “route around” a localized outage and ensure availability for all users (mostly).
I keep saying “mostly” and “sometimes” because no system is 100%, and there’s always the chance that someone is going to be left out in the cold, no matter what.
The thing is that a router outage somewhere in Chicago doesn’t necessarily impact users trying to access your main data center from California or Washington. It does, however, impact those of us in the midwest for whom Chicago is the onramp to the Internet. If only the route between Chicago and the west coast is impacted, its quite possible (and likely) we can access sites hosted on the east coast. But if you only have one data center – on the west coast – well, then you are experiencing an outage, whether you realize it or not.
cloud computing MAKES MULTIPLE DATA CENTERS FEASIBLE
For many organizations dual-data centers was never a possibility because, well, they’re downright expensive – both to buy, build, and maintain. Cloud computing offers a feasible alternative (for at least some applications) and provides a potential opportunity to improve availability in the event of any disaster or interruption, whether it happens to your data center or five states away.
You don’t have control over the routes that make up the Internet and deliver users (and customers) to your applications, but you do have control over where you might deploy those applications and how you respond to an interruption in connectivity across the globe. Global application delivery enables a multi-site implementation that can be leveraged for more than just disaster recovery; such implementations can be used for localized service disruption as well as overflow (cloud bursting style) handling for seasonal or event-based spikes or to assist in maintaining service in the face of a DDoS attack. “Disaster recovery” isn’t just about the data center, anymore, it’s about the applications, the users, and maintaining connectivity between them regardless of what might cause a disruption – and where.
Patrick Harding and Gunnar Peterson posted their Cloud Security: The Federated Identity Factor paper to the HPC in the Cloud blog on 11/9/2010:
The Web has experienced remarkable innovation during the last two decades. Web application pioneers have given the world the ability to share more data in more dynamic fashion with greater and greater levels of structure and reliability, yet the digital security mechanisms that protect the data being served have remained remarkably static. We have finally reached the point where traditional web security can no longer protect our interests, as our corporate data now moves and rests between a web of physical and network locations, many of which are only indirectly controlled and protected by the primary data owner.
How have web applications evolved to de-emphasize security, and why has greater security become critical today? The answer comes by exploring common practices and comparing them to the best practices that are becoming the heir to throne of web application security: Federated Identity.
A Brief History of Web Applications
Commercial use of the World Wide Web began in the early 1990’s with the debut of the browser. The browser made the Web accessible to the masses, and businesses began aggressively populating the Web with a wealth of static HyperText Markup Language (HTML) content.
Recognizing the untapped potential of a worldwide data network, software vendors began to innovate. By the mid-1990’s, dynamic functionality became available via scripting languages like the Common Gateway Interface (CGI) and Perl. ”Front-end” Web applications accessed data stored on “back-end” servers and mainframes. The security practice of “armoring” servers and connections began here, by building firewalls to protect servers and networks, and creating SSL (Secure Sockets Layer) to protect connections on the wire.
The Web continued to grow in sophistication: Active Server Pages (ASP) and JavaServer Pages (JSP) allowed applications to become substantially more sophisticated. Purpose-built, transaction-oriented Web application servers emerged next, like Enterprise JavaBeans (EJB) and the Distributed Component Object Model (DCOM), making it easier to integrate data from multiple sources. The need to structure data became strong and protocols like Simple Object Access Protocol (SOAP) and the eXtensible Markup Language (XML) emerged in 1999.
From 2001 to present, services evolved as a delivery model that de-emphasized the physical proximity of servers to clients, and instead emphasized loosely coupled interfaces. Services-Oriented Architecture (SOA) and the Representational State Transfer (REST) architectures both allow interaction between servers, businesses and domains, and combined with advances in latency and performance that accompanied the Web 2.0 movement, the foundation was laid.
These innovations have all helped enable the “cloud.” The concept of a cloud has long been used to depict the Internet, but this cloud is different. It embodies the ability of an organization to outsource both virtual and physical needs. Applications that once ran entirely on internal servers are now provided via Software-as-a-Service (SaaS). Platforms and Infrastructure are now also available as PaaS and IaaS offerings, respectively.
During all of these advances, one aspect of the Web has remained relatively static: the layers of security provided by firewalls, and the Secure Socket Layer (SSL). To be sure, there have been advances in Web security. Firewalls have become far more sophisticated with Deep Packet Inspection and intrusion detection/prevention capabilities, and SSL has evolved into Transport Layer Security (TLS) with support for the Advanced Encryption Standard. But are these modest advances sufficient to secure today’s cloud?

Read more Page: 1 of 5: 2, 3, 4, 5, All »
<Return to section navigation list>
Cloud Computing Events
TechEd Europe 2010 session videos are beginning to show up in the Cloud Computing and Online Services category:

I captured the preceding screen on 11/10/2010 at 11:00 AM PST. Downloadable WMV and WMV High versions and slide decks are available for some (but not all) sessions.
I’ll update my Windows Azure, SQL Azure, OData and Office 365 Sessions at Tech*Ed Europe 2010 post of 11/9/2010 with active video links every few hours beginning at 12:00 PM PST.
Update 11/10/2010 11:00 AM PST: Four Latest Vitualization Videos are available:

Krip provided an independent overview of TechEd Europe 2010 in his At Tech Ed it's all about the cloud post of 11/9/2010:
From the massive posters that catch your eye when entering Messe for Tech Ed to the theme of the keynote to the hardware and software on display it’s clear Microsoft along with its partners is pushing the “cloud”. This includes both on-premise computing (private cloud) and platform as a service (Azure).
Response at the conference to these new features has been very positive. It’s joining Office programs with the inclusion of a task focused ribbon bar but that’s just icing on the cake. One click by the IT Pro you’ve authorised in your organisation and you have a new private cloud provisioned complete with applications. One tweeter referred to this as the “God button”. On the Azure front, SCOM will now keep an eye on the pulse of your systems there with the help of a new Management Pack. And the announcement of SCOM integration with Microsft’s recently acquired AVIcode means deep integration with .NET applications.
As revealed at PDC and reiterated at Tech Ed Microsoft is opening up Azure VMs for greater control by those hosting applications on them. You can direct that startup tasks be run that install 3rd party components. You will have full IIS capability meaning multiple websites not just one. You can RDP onto the VMs for complete visibility of the instance. A much richer portal along with an MMC snap-in for management are on the way. These are just to name a few of the enhancements on Azure. Microsoft is moving at lightning speed responding to customer requests.
So there’s lots to look forward to in cloud computing!
-Krip
John C. Stame published a comprehensive PDC 2010 Windows Azure Update Summary on 11/9/2010:
PDC 2010 (Microsoft Professional Developer Conference) was held in Redmond a couple of weeks ago and it marked a significant milestone for Windows Azure – One Year Anniversary since its production announcement at PDC 2009.
In review, the Windows Azure platform, composed of Windows Azure and SQL Azure, and Windows Azure AppFabric is supported by a rich set of development tools, management and services from Microsoft Corp. You can learn more here. It is a Platform as a service (PaaS) and is where Microsoft thinks developers and businesses will ultimately gain the true value of the cloud.
The conference included some announcements highlighting significant updates to the Windows Azure Platform. Here is a summary of those announcements with links to resources to learn more. Warning – long list / post!
Windows Azure Virtual Machine Role eases the migration of existing Windows Server applications to Windows Azure by eliminating the need to make costly application changes and enables customers to quickly access their existing business data from the cloud. Microsoft announced Virtual Machine Role support for Windows Server 2008 R2 in Windows Azure. A public beta will be available by the end of 2010.
Server Application Virtualization enables customers to deploy virtualized application images onto the Windows Azure worker role (single role, single instance) rather than the VM Role. Through this approach, customers can more easily migrate their traditional applications to Windows Azure without the need to rewrite them or to package them within a VM. Once the application is deployed with server application virtualization on Windows Azure, customers can benefit from the automated service management capabilities of Windows Azure including automatic configuration and ongoing operating system management. Server Application Virtualization for Windows Azure will be available as a community technology preview (CTP) before the end of 2010, and the final release will be available to customers in the second half of 2011
Constructing VM role images in the cloud. Microsoft is enabling developers and IT professionals to build VM images for VM role directly in the cloud. This will be offered as an alternative to the current approach of building images on-premises and uploading them over the Internet. This update will be available in 2011.
Support for Windows Server 2003 and Windows Server 2008 SP2 in the VM Role. Microsoft supports Windows Server 2008 R2 in the Guest OS. In 2011, Microsoft will add support for Windows Server 2003 and Windows Server 2008 SP2.
SQL Azure Reporting allows developers to embed reports into their Windows Azure applications, including rich data visualization and export to popular formats, such as Microsoft Word, Microsoft Excel and PDF, enabling the users of these applications to gain greater insight and act on their line-of-business data stored in SQL Azure databases. A CTP will be available to customers by the end of 2010. The final release of SQL Azure Reporting will be generally available in the first half of 2011.
SQL Azure Data Sync is another important building block service to help developers rapidly build cloud applications on the Windows Azure platform using Microsoft’s cloud database. It allows developers to build apps with geo-replicated SQL Azure data and synchronize on-premises with cloud and mobile applications. A CTP will be available by the end of 2010. A final release of SQL Azure Data Sync is set to be released in the first half of 2011.
Database Manager for SQL Azure is a new lightweight, Web-based database management and querying capability for SQL Azure. This capability was formerly referred to as “Project Houston,” and allows customers to have a streamlined experience within the Web browser without having to download any tools. Database Manager for SQL Azure will be generally available by the end of 2010.
Windows Azure AppFabric helps developers rapidly build cloud applications on the Windows Azure platform.
- AppFabric Caching, which helps developers accelerate the performance of their applications.
- AppFabric Service Bus enhancements will help developers build reliable, enterprise quality delivery of data or messages, to and from applications to third parties or mobile devices.
CTPs were available at PDC, and both of these important building-block technologies will be generally available the first half of 2011.
Windows Azure Marketplace is a single online marketplace for developers and IT professionals to share, find, buy and sell building block components, training, services, and finished services or applications needed to build complete and compelling Windows Azure platform applications.
DataMarket is best thought of as a market within the Windows Azure Marketplace. It provides developers and information workers with access to premium third-party data, Web services, and self-service business intelligence and analytics, which they can use to build rich applications. Today there are more than 35 data providers offering data on DataMarket, with over 100 more coming soon.
At PDC 2010, DataMarket (formerly code-named “Dallas”) was released to Web, and a Windows Azure Marketplace beta will be released by the end of the year.
TFS on Windows Azure. Microsoft demoed Team Foundation Server on Windows Azure, which shows that steps have been made toward cloud-hosted Application Lifecycle Management. A CTP will be available in 2011.
Windows Azure AppFabric
- Windows Azure AppFabric Access Control enhancements help customers build federated authorization into applications and services without the complicated programming that is normally required to secure applications beyond organizational boundaries. With support for a simple declarative model of rules and claims, Access Control rules can easily and flexibly be configured to cover a variety of security needs and different identity-management infrastructures. These enhancements are currently available to customers.
- Windows Azure AppFabric Connect allows customers to bridge existing line-of-business (LOB) integration investments over to Windows Azure using the Windows Azure AppFabric Service Bus, and connecting to on-premises composite applications running on Windows Server AppFabric. This new set of simplified tooling extends Microsoft BizTalk Server 2010 to help accelerate hybrid on- and off-premises composite application scenarios, which are critical for customers starting to develop hybrid applications. This service is freely available today.
Windows Azure Virtual Network. New functionality is being introduced under the Windows Azure Virtual Network name. Windows Azure Connect (previously known as “Project Sydney”) enables a simple and easy-to-manage mechanism to set up IP-based network connectivity between on-premises and Windows Azure resources. The first Windows Azure Virtual Network feature is called Windows Azure Connect. A CTP of Windows Azure Connect will be available by the end of 2010, and it will be generally available in the first half of 2011.
Extra Small Windows Azure Instance. Also announced was the Extra Small Instance, which will be priced at $0.05 per compute hour in order to make the process of development, testing and trial easier for developers. This will make it affordable for developers interested in running smaller applications on the platform. A beta of this role will be available before the end of 2010.
Remote Desktop enables IT professionals to connect to a running instance of their application or service to monitor activity and troubleshoot common problems. Remote Desktop will be generally available later this year.
Elevated Privileges. The VM role and Elevated Privileges functionality removes roadblocks that today prevent developers from having full control over their application environment. For small changes such as configuring Internet Information Service (IIS) or installing a Microsoft Software Installer (MSI), Microsoft recommends using the Elevated Privileges admin access feature. This approach is best suited for small changes and enables the developer to retain automated service management at the Guest OS and the application level. Elevated Privileges will be generally available to customers later this year.
Full IIS Support enables development of more complete applications using Windows Azure. The Web role will soon provide full IIS functionality, which enables multiple IIS sites per Web role and the ability to install IIS modules. The full IIS functionality enables developers to get more value out of a Windows Azure instance. Full IIS Support will be generally available to customers later this year.
Windows Server 2008 R2 Roles. Windows Azure will now support Windows Server 2008 R2 in its Web, worker and VM roles. This new support will enable customers to take advantage of the full range of Windows Server 2008 R2 features such as IIS 7.5, AppLocker, and enhanced command-line and automated management using PowerShell Version 2.0. This update will be generally available later this year.
Multiple Admins. Windows Azure will soon support multiple Windows Live IDs to have administrator privileges on the same Windows Azure account. The objective is to make it easy for a team to work on the same Windows Azure account while using their individual Windows Live IDs. The Multiple Admins update will be generally available later this year.
Dynamic Content Caching. With this new functionality, the Windows Azure CDN can be configured to cache content returned from a Windows Azure application. Dynamic Content Caching will be available to customers in 2011.
CDN SSL Delivery. Users of the Windows Azure CDN will now have the capability to deliver content via encrypted channels with SSL/TLS. This update will be available in 2011.
Improved global connectivity. Microsoft will add new Windows Azure CDN nodes in the Middle East and improve existing connectivity in the U.S. and Brazil in 2011.
Improved Java Enablement. Microsoft plans to make Java a first-class citizen on Windows Azure. This process will involve improving Java performance, Eclipse tooling and client libraries for Windows Azure. Customers can choose the Java environment of their choice and run it on Windows Azure. Improved Java Enablement will be available to customers in 2011.
Windows Azure AppFabric Composition Model and Composite App Service provides an end-to-end “composite” application development environment to help developers streamline the process of assembling, managing and deploying various home-grown and third-party services that span the Web, middle tier and database in the cloud. A CTP will be available in the first half of 2011.
Microsoft also announced the following developer and operator enhancements at PDC 2010:
- A completely redesigned Microsoft Silverlight-based Windows Azure portal to ensure an improved and intuitive user experience
- Access to new diagnostic information including the ability to click on a role to see type and deployment time
- A new sign-up process that dramatically reduces the number of steps needed to sign up for Windows Azure
- New scenario-based Windows Azure Platform forums to help answer questions and share knowledge more efficiently
These Windows Azure enhancements will be generally available by the end of 2010.
Finally, a great offer for partners:
“Windows Azure Platform Cloud Essentials for Partners” is an offer that replaces Microsoft’s existing partner offers. This offer will go live on Jan. 7, 2011, and provide free access to the Windows Azure platform, including 750 Extra Small Instance hours and a SQL Azure database per month at no additional charge. Partners can sign up for the Cloud Essentials Pack at Microsoft Cloud Partner.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Todd Hoff reported the availability of a Paper: Hyder - Scaling Out without Partitioning in an 11/9/2010 post to the High Scalability blog:
Partitioning is what differentiates scaling-out from scaling-up, isn't it? I thought so too until I read Pat Helland's blog post on Hyder, a research database at Microsoft, in which the database is the log, no partitioning is required, and the database is multi-versioned. Not much is available on Hyder. There's the excellent summary post from Mr. Helland and these documents: Scaling Out without Partitioning and Scaling Out without Partitioning - Hyder Update by Phil Bernstein and Colin Reid of Microsoft.
The idea behind Hyder as summarized by Pat Helland (see his blog for the full post):
Hyder is a software stack for transactional record management. It can offer full database functionality and is designed to take advantage of flash in a novel way. Most approaches to scale-out use partitioning and spread the data across multiple machines leaving the application responsible for consistency.In Hyder, the database is the log, no partitioning is required, and the database is multi-versioned. Hyder runs in the App process with a simple high-performance programming model and no need for client server. This avoids the expense of RPC. Hyder leverages some new hardware assumptions. I/Os are now cheap and abundant. Raw flash (not SSDs – raw flash) offers at least 10^4 more IOPS/GB than HDD. This allows for dramatic changes in usage patterns. We have cheap and high performance data center networks. Large and cheap 64-bit addressable memories are available. Also, with many-core servers, computation can be squandered and Hyder leverages that abundant computation to keep a consistent view of the data as it changes.
The Hyder system has individual nodes and a shared flash storage which holds a log. Appending a record to the log involves a send to the log controller and a response with the location in the log into which the record was appended. In this fashion, many servers can be pushing records into the log and they are allocated a location by the log controller. It turns out that this simple centralized function of assigning a log location on append will adjudicate any conflicts (as we shall see later).
The Hyder stack comprises a persistent programming language like LING or SQL, an optimistic transaction protocol, and a multi-versioned binary search tree to represent the database state. The Hyder database is stored in a log but it IS a binary tree. So you can think of the database as a binary tree that is kept in the log and you find data by climbing the tree through the log.
The Binary Tree is multi-versioned. You do a copy-on-write creating new nodes and replace nodes up to the root. The transaction commits when the copy-on-write makes it up to the root of the tree.
For transaction execution, each server has a cache of the last committed state. That cache is going to be close to the latest and greatest state since each server is constantly replaying the log to keep the local state accurate [recall the assumption that there are lots of cores per server and it’s OK to spend cycles from the extra cores]. So, each transaction running in a single server reads a snapshot and generates an intention log record. The transaction gets a pointer to the snapshot and generates an intention log record. The server generates updates locally appending them to the log (recall that an append is sent to the log controller which returns the log-id with its placement in the log). Updates are copy-on-write climbing up the binary tree to the root.
Log updates get broadcast to all the servers – everyone sees the log. Changes to the log are only done by appending to the log. New records and their addresses are broadcast to all servers. In this fashion, each server can reconstruct the tail of the log.
Performance of Hyder: The system scales without partitioning. The system-wide throughput of update transactions is bounded by the update pipeline. It is estimated this can perform 15K update transactions per second over a 1GB Ethernet and 150K update transactions per second over a 10GB Ethernet. Conflict detection and merge can do about 200K txs per second.
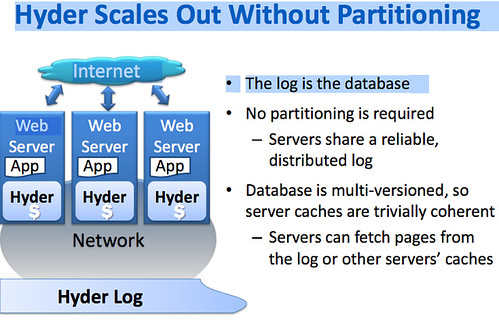
Mixpanel Engineering reported We’re moving [to Amazon]. Goodbye Rackspace on 11/8/2010:
At Mixpanel, where our hardware is and the platform we use to help us scale has become increasingly important. Unfortunately (or fortunately) our data processing doesn’t always scale linearly. When we get a brand new customer sometimes we have to scale by a step function; this has been a problem in the past but we’ve gotten better at this.
So what’s the short of it? We’re unhappy with the Rackspace Cloud and love what we’re seeing at Amazon.
Over the history we’ve used quite a few “cloud” offerings. First was Slicehost back when everything was on a single 256MB instance (yeah, that didn’t scale). Second was Linode because it was cheaper (money mattered to me at that point). Lastly, we moved over to the Rackspace Cloud because they cut a deal with YCombinator (one of the many benefits of being part of YC). Even with all the lock in we have with Rackspace (we have 50+ boxes and hiring if you want to help us move them!), it’s really not about the money but about the features and the product offering, here’s why we’re moving:
EBS
IO is a huge scaling problem that we have to think about very carefully. We’ve since deprecated Cassandra from our stack but Rackspace is a terrible provider if you’re using Cassandra in general. Your commit log and data directory should be on two different volumes–Rackspace does not make this easy or affordable. EBS is a godsend.
What happens when you need more disk space? You’re screwed -> resize your box and go down. Need more than 620G of space? You can’t do it.
EBS lets you mount volumes on to any node. This is awesome if you ever need to move your data to a bad node instead of having to scp it over.
Edit: Nobody is saying you get better IO performance on Amazon simply that EBS solves different IO challenges that Rackspace does not. IO is basically terrible everywhere on the cloud.
Instances
We’re super excited about the variety of instances that Amazon offers. The biggest money savers for us we foresee are going to be Amazon’s standard XL as well as the high CPU ones. Rackspace offers a more granular variety which is a benefit if you need to be thrifty but it bottlenecks fast as you begin to scale and realize what kind of hardware you need.
Uptime
Rackspace Cloud has had pretty atrocious uptime over the year there has been two major outages where half the internet broke. Everyone has their problems but the main issue is we see really bad node degradation all the time. We’ve had months where a node in our system went down every single week. Fortunately, we’ve always built in the proper redundancy to handle this. We know this will happen Amazon too from time to time but we feel more confident about Amazon’s ability to manage this since they also rely on AWS.
Control Panel
Rackspace’s control panel is the biggest pain in the ass thing to use. Their interface is clunky, bloated, and slow. In my experience, I can’t count how many times I’ve seen their Java exceptions while frantically trying to provision a new node to help scale Mixpanel.
Amazon has awesome and very well vetted command line tools that blow Rackspace out the water. I can’t wait to write a script and start up a node. I believe Rackspace has an SDK / command line tools now though–very early and beta however.
Quota limits
Probably the most frustrating thing on Rackspace is their insane requirement to post a ticket to get a higher memory quota. We’ve had fires where we needed to add extra capacity only to get an error when creating a new node that we can’t. Once you post a ticket, you have to wait for their people to answer your ticket in a 24-hour period. Now we just ask Rackspace for +100G increments way before we ever need it. I know Amazon doesn’t impose these limits to the same (annoying) extent.
Globalization
Amazon has a CDN and servers distributed globally. This is important to Mixpanel as websites all over the world are sending us data. There’s nothing like this on Rackspace. We have lots of Asian customers and speed matters.
Backups
Rackspace has a limit on their automatic backups: 2G. Our databases aren’t weak 2G memory bound machines–nobody’s is at scale. S3 is a store for everything and EBS is just useful for this kind of thing. Cloudfront on Rackspace is still in its infancy.
Backups on Amazon will be so much cleaner and straight forward.
Pricing
We’ve done a very methodical pricing comparison for our own hardware and have determined that the pricing is actually about the same across both services. We don’t know how well the hardware will scale on Amazon so we over-estimated to make up for crazy issues. Amazon came to about 5-10% cheaper but take that with a grain of salt. It’s probably closer to equal.
Here’s one huge thing though, Amazon in the long-run for our business will be drastically cheaper with the concept of Reserved instances and bidded instances. That’s extremely sexy to us.
Also? Amazon constantly reduces its prices. I’ve never seen Rackspace do that.
What’s the main reason for us?
Amazon just iterates on their product faster than anyone else and has the best one. We expect people to use us because of that in the long-run and we’ve taken note. Rackspace is extremely slow and as the person in charge of infrastructure and scalability we’re going to use the platform that knows how to keep guys like me happy by running fast and anticipating my needs.
Amazon’s products:
Rackspace cloud’s products:
If you have an opinion, express it. Tell us what you hate about Amazon and problems you’ve seen. We haven’t moved yet.
Want to work on fascinating big-data problems? Mixpanel is hiring lots of engineers in San Francisco: http://mixpanel.com/jobs


<Return to section navigation list>

















0 comments:
Post a Comment