Windows Azure and Cloud Computing Posts for 8/27/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |
![AzureArchitecture2H_thumb31[1]](file:///C:/Users/Administrator.OAKLEAF.000/AppData/Local/Temp/WindowsLiveWriter-429641856/supfiles635E56E/AzureArchitecture2H5.png "AzureArchitecture2H_thumb31[1]")
• Updated 8/29/2010 with new articles marked •
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA)
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Tip: If you encounter articles from MSDN or TechNet blogs that are missing screen shots or other images, click the empty frame to generate an HTTP 404 (Not Found) error, and then click the back button to load the image.
 Azure Blob, Drive, Table and Queue Services
Azure Blob, Drive, Table and Queue Services
James Senior delivered a guided tour of New: Windows Azure Storage Helper for WebMatrix in this 00:13:21 Channel9 video segment:

Hot on the heels of the OData Helper for WebMatrix, today we are pushing a new helper out into the community. The Windows Azure Storage Helper makes it ridiculously easy to use Windows Azure Storage (both blob and table) when building your apps. If you’re not familiar with “cloud storage,” I recommend you take a look at this video where my pal Ryan explains what it’s all about. In a nutshell, it provides infinitely simple yet scalable storage, which is great if you are a website with lots of user generated content and you need your storage to grow auto-magically with the success of your apps. Tables aren’t your normal relational databases—but they are great for simple data structures and they are super fast.
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
• Beth Massi recommends that you Add Some Spark to Your OData: Creating and Consuming Data Services with Visual Studio and Excel 2010 in an article for the September/October 2010 issue of CoDe Magazine:
The Open Data Protocol (OData) is an open REST-ful protocol for exposing and consuming data on the web. Also known as Astoria, ADO.NET Data Services, now officially called WCF Data Services in the .NET Framework. There are also SDKs available for other platforms like JavaScript and PHP. Visit the OData site at www.odata.org.
With the release of .NET Framework 3.5 Service Pack 1, .NET developers could easily create and expose data models on the web via REST using this protocol. The simplicity of the service, along with the ease of developing it, make it very attractive for CRUD-style data-based applications to use as a service layer to their data. Now with .NET Framework 4 there are new enhancements to data services, and as the technology matures more and more data providers are popping up all over the web. Codename “Dallas” is an Azure cloud-based service that allows you to subscribe to OData feeds from a variety of sources like NASA, Associated Press and the UN. You can consume these feeds directly in your own applications or you can use PowerPivot, an Excel Add-In, to analyze the data easily. Install it at www.powerpivot.com.
As .NET developers working with data every day, the OData protocol and WCF data services in the .NET Framework can open doors to the data silos that exist not only in the enterprise but across the web. Exposing your data as a service in an open, easy, secure way provides information workers access to Line-of-Business data, helping them make quick and accurate business decisions. As developers, we can provide users with better client applications by integrating data that was never available to us before or was clumsy or hard to access across networks.
In this article I’ll show you how to create a WCF data service with Visual Studio 2010, consume its OData feed in Excel using PowerPivot, and analyze the data using a new Excel 2010 feature called sparklines. I’ll also show you how you can write your own Excel add-in to consume and analyze OData sources from your Line-of-Business systems like SQL Server and SharePoint.
Creating a Data Service Using Visual Studio 2010
Let’s quickly create a data service using Visual Studio 2010 that exposes the AdventureWorksDW data warehouse. You can download the AdventureWorks family of databases here: http://sqlserversamples.codeplex.com/. Create a new Project in Visual Studio 2010 and select the Web node. Then choose ASP.NET Empty Web Application as shown in Figure 1. If you don’t see it, make sure your target is set to .NET Framework 4. This is a new handy project template to use in VS2010 especially if you’re creating data services.
Figure 1: Use the new Empty Web Application project template in Visual Studio 2010 to set up a web host for your WCF data service.
Click OK and the project is created. It will only contain a web.config. Next add your data model. I’m going to use the Entity Framework so go to Project -> Add New Item, select the Data node and then choose ADO.NET Entity Data Model. Click Add and then you can create your data model. In this case I generated it from the AdventureWorksDW database and accepted the defaults in the Entity Model Wizard. In Visual Studio 2010 the Entity Model Wizard by default will include the foreign key columns in the model. You’ll want to expose these so that you can set up relationships easier in Excel.
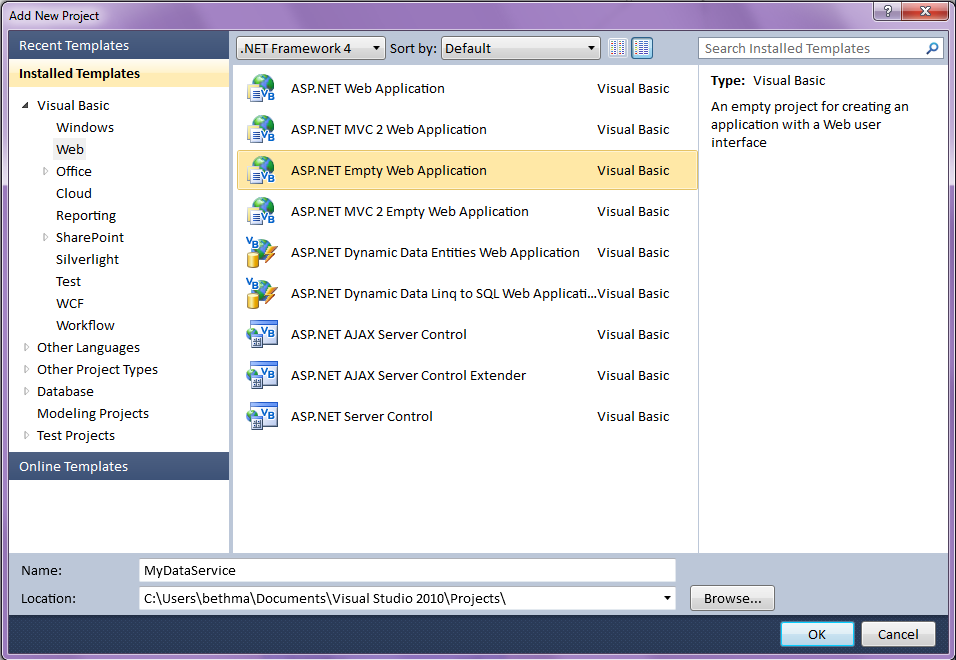
Next, add the WCF Data Service (formerly known as ADO.NET Data Service in Visual Studio 2008) as shown in Figure 2. Project -> Add New Item, select the Web node and then scroll down and choose WCF Data Service. This item template is renamed for both .NET 3.5 and 4 Framework targets so keep that in mind when trying to find it.
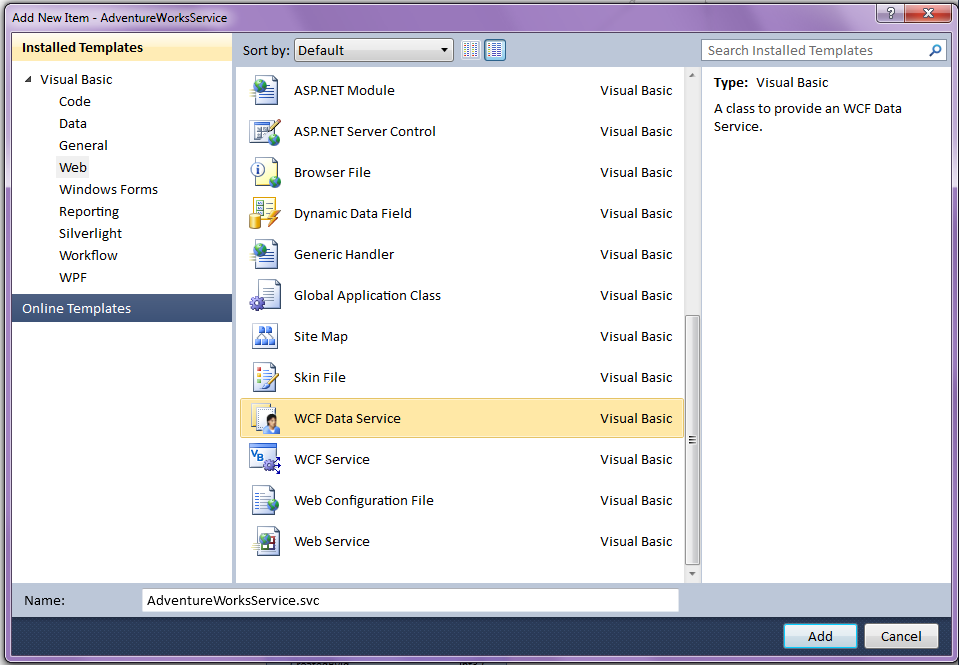
Figure 2: Select the WCF Data Service template in Visual Studio 2010 to quickly generate your OData service.
Now you can set up your entity access. For this example I’ll allow read access to all my entities in the model:
Public Class AdventureWorksService
Inherits DataService(
Of AdventureWorksDWEntities)
' This method is called only once to
' initialize service-wide policies.
Public Shared Sub InitializeService(
ByVal config As DataServiceConfiguration)
' TODO: set rules to indicate which
'entity sets and service operations
' are visible, updatable, etc.
config.SetEntitySetAccessRule("*",
EntitySetRights.AllRead)
config.DataServiceBehavior.
MaxProtocolVersion =
DataServiceProtocolVersion.V2
End Sub
End ClassYou could add read/write access to implement different security on the data in the model or even add additional service operations depending on your scenario, but this is basically all there is to it on the development side of the data service. Depending on your environment this can be a great way to expose data to users because it is accessible anywhere on the web (i.e., your intranet) and doesn’t require separate database security setup. This is because users aren’t connecting directly to the database, they are connecting via the service. Using a data service also allows you to choose only the data you want to expose via your model and/or write additional operations, query filters, and business rules. For more detailed information on implementing WCF Data Services, please see the MSDN library.
You could deploy this to a web server or the cloud to host for real or you can keep it here and test consuming it locally for now. Let’s see how you can point PowerPivot to this service and analyze the data a bit.
Article Pages: 1 2 3 - Next Page: 'Using PowerPivot to Analyze OData Feeds' >>
• Kevin Fairs points out a problem when using SqlBulkCopy with SQLAzure in this 8/29/2010 post:
Using SqlBulkCopy (.NET 4.0) with SQL Azure (10.25.9386) gives the error:
A transport-level error has occurred when receiving results from the server. (provider: TCP Provider, error: 0 - An existing connection was forcibly closed by the remote host.)
The SqlBulkCopy class is recommended by Microsoft for migration in their General Guidelines and Limitations (SQL Azure Database) document. However, it is clear to me that this does not work having tried many approaches, generally of the form:
Using cn As SqlConnection = New SqlConnection("connection string") cn.Open() Using BulkCopy As SqlBulkCopy = New SqlBulkCopy(cn) BulkCopy.DestinationTableName = "table" BulkCopy.BatchSize = 5000 BulkCopy.BulkCopyTimeout = 120 Try BulkCopy.WriteToServer(ds.Tables(0)) Catch ex As Exception End Try End Using End UsingAlternatives
- Use a traditional row at a time insert.
- Write a wrapper around BCP which works fine.
Or use George Huey’s SQL Azure Migration Wizard.
Wayne Walter Berry (@WayneBerry) issued a warning on 8/27/2010 about a problem with the original version of his Transferring a SQL Azure Database:
The original blog post doesn’t work as written, since the destination user executing the CREATE DATABASE must have exactly the same name as SQL Azure Portal Administrator name on the source database; i.e. you can only copy from a database where you know the SQL Azure Portal administrator name and password.
I will be revisiting this topic of how to transfer a SQL Azure database between two different parties in another blog post.
Dare Obasanjo (@Carnage4Life) posted Lessons from Google Wave and REST vs. SOAP: Fighting Complexity of our own Choosing on 8/27/2010:
Software companies love hiring people that like solving hard technical problems. On the surface this seems like a good idea, unfortunately it can lead to situations where you have people building a product where they focus more on the interesting technical challenges they can solve as opposed to whether their product is actually solving problems for their customers.
I started being reminded of this after reading an answer to a question on Quora about the difference between working at Google versus Facebook where Edmond Lau wrote
Culture:
Google is like grad-school. People value working on hard problems, and doing them right. Things are pretty polished, the code is usually solid, and the systems are designed for scale from the very beginning. There are many experts around and review processes set up for systems designs.Facebook is more like undergrad. Something needs to be done, and people do it. Most of the time they don't read the literature on the subject, or consult experts about the "right way" to do it, they just sit down, write the code, and make things work. Sometimes the way they do it is naive, and a lot of time it may cause bugs or break as it goes into production. And when that happens, they fix their problems, replace bottlenecks with scalable components, and (in most cases) move on to the next thing.
Google tends to value technology. Things are often done because they are technically hard or impressive. On most projects, the engineers make the calls.
Facebook values products and user experience, and designers tend to have a much larger impact. Zuck spends a lot of time looking at product mocks, and is involved pretty deeply with the site's look and feel.
It should be noted that Google deserves credit for succeeding where other large software have mostly failed in putting a bunch of throwing a bunch of Ph.Ds at a problem at actually having them create products that impacts hundreds of millions people as opposed to research papers that impress hundreds of their colleagues. That said, it is easy to see the impact of complexophiles (props to Addy Santo) in recent products like Google Wave.
If you go back and read the Google Wave announcement blog post it is interesting to note the focus on combining features from disparate use cases and the diversity of all of the technical challenges involved at once including
“Google Wave is just as well suited for quick messages as for persistent content — it allows for both collaboration and communication”
“It's an HTML 5 app, built on Google Web Toolkit. It includes a rich text editor and other functions like desktop drag-and-drop”
“The Google Wave protocol is the underlying format for storing and the means of sharing waves, and includes the ‘live’ concurrency control, which allows edits to be reflected instantly across users and services”
“The protocol is designed for open federation, such that anyone's Wave services can interoperate with each other and with the Google Wave service”
“Google Wave can also be considered a platform with a rich set of open APIs that allow developers to embed waves in other web services”
The product announcement read more like a technology showcase than an announcement for a product that is actually meant to help people communicate, collaborate or make their lives better in any way. This is an example of a product where smart people spent a lot of time working on hard problems but at the end of the day they didn't see the adoption they would have liked because they they spent more time focusing on technical challenges than ensuring they were building the right product.
It is interesting to think about all the internal discussions and time spent implementing features like character-by-character typing without anyone bothering to ask whether that feature actually makes sense for a product that is billed as a replacement to email. I often write emails where I write a snarky comment then edit it out when I reconsider the wisdom of sending that out to a broad audience. It’s not a feature that anyone wants for people to actually see that authoring process.
Some of you may remember that there was a time when I was literally the face of XML at Microsoft (i.e. going to http://www.microsoft.com/xml took you to a page with my face on it ). In those days I spent a lot of time using phrases like the XML<-> objects impedance mismatch to describe the fact that the dominate type system for the dominant protocol for web services at the time (aka SOAP) actually had lots of constructs that you don’t map well to a traditional object oriented programming language like C# or Java. This was caused by the fact that XML had grown to serve conflicting masters. There were people who used it as a basis for document formats such as DocBook and XHTML. Then there were the people who saw it as a replacement to for the binary protocols used in interoperable remote procedure call technologies such as CORBA and Java RMI.
The W3C decided to solve this problem by getting a bunch of really smart people in a room and asking them to create some amalgam type system that would solve both sets of completely different requirements. The output of this activity was XML Schema which became the type system for SOAP, WSDL and the WS-* family of technologies. This meant that people who simply wanted a way to define how to serialize a C# object in a way that it could be consumed by a Java method call ended up with a type system that was also meant to be able to describe the structural rules of the HTML in this blog post.
Thousands of man years of effort was spent across companies like Sun Microsystems, Oracle, Microsoft, IBM and BEA to develop toolkits on top of a protocol stack that had this fundamental technical challenge baked into it. Of course, everyone had a different way of trying to address this “XML<-> object impedance mismatch which led to interoperability issues in what was meant to be a protocol stack that guaranteed interoperability. Eventually customers started telling their horror stories in actually using these technologies to interoperate such as Nelson Minar’s ETech 2005 Talk - Building a New Web Service at Google and movement around the usage of building web services using Representational State Transfer (REST) was born.
In tandem, web developers realized that if your problem is moving programming language objects around, then perhaps a data format that was designed for that is the preferred choice. Today, it is hard to find any recently broadly deployed web service that doesn’t utilize
onJavascript Object Notation (JSON) as opposed to SOAP.
The moral of both of these stories is that a lot of the time in software it is easy to get lost in the weeds solving hard technical problems that are due to complexity we’ve imposed on ourselves due to some well meaning design decision instead of actually solving customer problems. The trick is being able to detect when you’re in that situation and seeing if altering some of your base assumptions doesn’t lead to a lot of simplification of your problem space then frees you up to actually spend time solving real customer problems and delighting your users. More people need to ask themselves questions like do I really need to use the same type system and data format for business documents AND serialized objects from programming languages?
I well remember learning about .NET 1.0’s XML support from Dare when he was literally the face of XML at Microsoft.
Wade Wegner (@WadeWegner) explained Using the ‘TrustServerCertificate’ Property with SQL Azure and Entity Framework in this 8/26/2010 post:
I’ve spent the last few days refactoring a web application to leverage SQL Server via Entity Framework 4.0 (EF4) in preparation for migrating it to SQL Azure. It’s a neat application, and a great example of how to fully encapsulate your data tier (the previous version had issues due to tight coupling between the data and web tier). More on this soon.
A connection was successfully established with the server, but then an error occurred during the pre-login handshake. (provider: SSL Provider, error: 0 – The certificate’s CN name does not match the passed value.)
I was caught off guard by this error, as I was pretty sure my connection string was valid – after all, I had copied it directly from the SQL Azure portal. Then I realized that this was the first time I had attempted to use EF4 along with SQL Azure; my first thought was, “oh crap!”
After a little bit of frantic research I found the following question on the SQL Azure forums. Raymond Li of Microsoft made the suggestion to set the ‘TrustServerCertificate’ property to True. So, I updated my connection string from …

… to …

… and voilà! It worked!
Turns out that when Encryt=True and TrustServerCertificate=False, the driver will attempt to validate the SQL Server SSL certificate. By setting the property TrustServerCertificate=True the driver will not validate the SQL Server SSL certificate.
Of course, once I learned/tried this, I came across an article on MSDN called How to: Connect to SQL Azure Using ADO.NET[, which] says to set the TrustServerCertificate property to False and the Encrypt property to True to prevent any man-in-the-middle attacks, so I guess I should include the following disclaimer: Use at your own risk!
Michael Otey wrote SQL Server vs. SQL Azure: Where SQL Azure is Limited for SQL Server Magazine on 8/26/2010:
Cloud computing is one of Microsoft’s big pushes in 2010, and SQL Azure is its cloud-based database service. Built on top of SQL Server, it shares many features with on-premises SQL Server.
For example, applications connect to SQL Azure using the standard Tabular Data Stream (TDS) protocol. SQL Azure supports multiple databases, as well as almost all of the SQL Server database objects, including tables, views, stored procedures, functions, constraints, and triggers.
7. SQL Azure Requires Clustered Indexes
When you first attempt to migrate your applications to SQL Azure, the first thing you’re likely to notice is that SQL Azure requires all tables to have clustered indexes. You can accommodate this by building clustered indexes for tables that don’t have them. However, this usually means that most databases that are migrated to SQL Azure will usually require some changes before they can be ported to SQL Azure.
6. SQL Azure Lacks Access to System Tables
Because you don’t have access to the underlying hardware platform, there’s no access to system tables in SQL Azure. System tables are typically used to help manage the underlying server and SQL Azure does not require or allow this level of management. There's also no access to system views and stored procedures.
5. SQL Azure Requires SQL Server Management Studio 2008 R2
To manage SQL Azure databases, you must use the new SQL Server Management Studio (SSMS) 2008 R2. Older versions of SSMS can connect to SQL Azure, but the Object Browser won’t work. Fortunately, you don’t need to buy SQL Server 2008 R2. You can use the free version of SSMS Express 2008 R2, downloadable from Microsoft's website.
4. SQL Azure Doesn't Support Database Mirroring or Failover Clustering
SQL Azure is built on the Windows Azure platform which provides built-in high availability. SQL Azure data is automatically replicated and the SQL Azure platform provides redundant copies of the data. Therefore SQL Server high availability features such as database mirroring and failover cluster aren't needed and aren't supported.
3. No SQL Azure Support for Analysis Services, Replication, Reporting Services, or SQL Server Service Broker
The current release of SQL Azure provides support for the SQL Server relational database engine. This allows SQL Azure to be used as a backend database for your applications. However, the other subsystems found in the on-premises version of SQL Server, such as Analysis Services, Integration Services, Reporting Services, and replication, aren't included in SQL Azure. But you can use SQL Azure as a data source for the on-premises version of Analysis Services, Integration Services, and Reporting Services.
2. SQL Azure Offers No SQL CLR Support
Another limitation in SQL Azure is in the area of programmability: It doesn't provide support for the CLR. Any databases that are built using CLR objects will not be able to be moved to SQL Azure without modification.
1. SQL Azure Doesn't Support Backup and Restore
To me, one of the biggest issues with SQL Azure is the fact that there no support for performing backup and restore operations. Although SQL Azure itself is built on a highly available platform so you don’t have to worry about data loss, user error and database corruption caused by application errors are still a concern. To address this limitation, you could use bcp, Integration Services, or the SQL Azure Migration Wizard to copy critical database tables.
Michael’s “limitations” are better termed “characteristics” in my opinion. Note that a new Database Copy backup feature is available, as announced in the SQL Azure Team’s Backing Up Your SQL Azure Database Using Database Copy post of 8/25/2010.
Wayne Walter Berry (@WayneBerry) described Creating a Bing Map Tile Server from Windows Azure on 8/26/2010:
There is another option for drawing pushpins, using JavaScript the Bing Map Ajax Controls allow you draw pushpins. However, after about 200 push pins on a map, the performance slows when using JavaScript. So if you have a lot of pushpins, draw them server side using a tile server.
Windows Azure is a perfect solution to use when creating a tile server, since it can scale to meet the traffic needs of the web site serving the map. SQL Azure is a perfect match to hold the latitude and longitude points that we want to draw as push pins because of the spatial data type support.
The tricky part of writing about this application is assembling all the knowledge about these disjointed technologies in the space of a blog post. Because of this, I am going to be off linking to articles about Bing Maps, Windows Azure, and writing mostly about SQL Azure.

Bing Maps
In order to embed a Bing Map in your web page you need to get a Bing Map Developer Account and Bing mapping keys, You can do that here at the Bing Map Portal. Once you have your keys, read this article about getting started with the Bing Maps AJAX control. This is what I used in the example to embed the Bing Map in my web page. Since we are going to build our own Bing Map Tile Server, you will want to read up on how Bing organizes tiles, and the JavaScript you need to add to reference a tile server from an article entitled: Building Your Own Tile Server. Or you can just cut and paste my HTML for a simple embedded map looks like this:
See original post for code snippet.
Notice that I am using my local server for the tile server. This allows me to quickly test the tile server in the Windows Azure development fabric without having to deploy it to Windows Azure every time I make a programming change to the ASP.NET code.
Windows Azure
Once you have created your web role in your cloud project, add an ASP.NET page entitled tile.aspx. Even though an ASP.NET page typically serves HTML, in this case we are going to serve an image as a PNG from the ASP.NET page. The Bing Map AJAX Control calls the tile.aspx page with the quadkey in the query string to get a tile (which is an image); this is done roughly 4 times with 4 different tile identifiers for every zoom level displayed. More about the quadkey can be found here. The example ASP.NET code uses the quadkey to figure out the bounding latitude/longitude of the tile. With this information we can make a query to SQL Azure for all the points that fall within the bounding latitude and longitude. The points are stored as a geography data type (POINT) in SQL Azure and we use a Spatial Intersection query to figure out which ones are inside the tile.
SQL Azure
CREATE TABLE [dbo].[Points]( [ID] [int] IDENTITY(1,1) NOT NULL, [LatLong] [geography] NULL, [Name] [varchar](50) NULL, CONSTRAINT [PrimaryKey_2451402d-8789-4325-b36b-2cfe05df04bb] PRIMARY KEY CLUSTERED ( [ID] ASC ) )It is nothing fancy, just a primary key and a name, along with a geography data type to hold my latitude and longitude. I then inserted some data into the table like so:
INSERT INTO Points (Name, LatLong) VALUES ('Statue of Liberty', geography::STPointFromText('POINT(-74.044563 40.689168)', 4326)) INSERT INTO Points (Name, LatLong) VALUES ('Eiffel Tower', geography::STPointFromText('POINT(2.294694 48.858454)', 4326)) INSERT INTO Points (Name, LatLong) VALUES ('Leaning Tower of Pisa', geography::STPointFromText('POINT(10.396604 43.72294)', 4326)) INSERT INTO Points (Name, LatLong) VALUES ('Great Pyramids of Giza', geography::STPointFromText('POINT(31.134632 29.978989)', 4326)) INSERT INTO Points (Name, LatLong) VALUES ('Sydney Opera House', geography::STPointFromText('POINT( 151.214967 -33.856651)', 4326)) INSERT INTO Points (Name, LatLong) VALUES ('Taj Mahal', geography::STPointFromText('POINT(78.042042 27.175047)', 4326)) INSERT INTO Points (Name, LatLong) VALUES ('Colosseum', geography::STPointFromText('POINT(41.890178 12.492378)', 4326))The code is only designed to draw pinpoint graphics at points, it doesn’t handle the other shapes that the geography data type supports. In other words make sure to only insert POINTs into the LatLong column.
One thing to note is that SQL Azure geography data type takes latitude and longitudes in the WKT format which means that Longitudes are first and then Latitudes. In my C# code, I immediately retrieve the geography data type as a string, strip out the latitude and longitude and reverse it for my code.
Now that we have a table and data, the application needs to be able to query the data, here is the stored procedure I wrote:
CREATE PROC [dbo].[spInside]( @southWestLatitude float, @southWestLongitude float, @northEastLatitude float, @northEastLongitude float) AS DECLARE @SearchRectangleString VARCHAR(MAX); SET @SearchRectangleString = 'POLYGON((' + CONVERT(varchar(max),@northEastLongitude) + ' ' + CONVERT(varchar(max),@southWestLatitude) + ',' + CONVERT(varchar(max),@northEastLongitude) + ' ' + CONVERT(varchar(max),@northEastLatitude) + ',' + CONVERT(varchar(max),@southWestLongitude) + ' ' + CONVERT(varchar(max),@northEastLatitude) + ',' + CONVERT(varchar(max),@southWestLongitude) + ' ' + CONVERT(varchar(max),@southWestLatitude) + ',' + CONVERT(varchar(max),@northEastLongitude) + ' ' + CONVERT(varchar(max),@southWestLatitude) + '))' DECLARE @SearchRectangle geography; SET @SearchRectangle = geography::STPolyFromText(@SearchRectangleString, 4326) SELECT CONVERT(varchar(max),LatLong) 'LatLong' FROM Points WHERE LatLong.STIntersects(@SearchRectangle) = 1The query takes two corners of a box, and creates a rectangular polygon, then is queries to find all the latitude and longitudes that are in the Points table which fall within the polygon. There are a couple subtle things going on in the query, one of which is that the rectangle has to be drawn in a clock-wise order, and that the first point is the last point. The second thing is that the rectangle must only be in a single hemisphere, i.e. either East or West of the dateline, but not both and either North or South of the equator, but not both. The code determines if the rectangle (called the bounding box in the code) is a cross over and divides the box into multiple queries that equal the whole.
The Code
To my knowledge there is only a couple complete, free code examples of a Bing tile server on the Internet. I borrowed heavily from both Rob Blackwell’s “Roll Your Own Tile Server” and Joe Schwartz’s “Bing Maps Tile System”.
I had to make a few changes, one of which is to draw on more than one tile for a single push pin. The push pin graphic is both wide and tall and if you draw it on the edge of a tile, it will be cropped by the next tile over in the map. That means for push pins that land near the edges, you need to draw it partially on both tiles. To accomplish this you need to query the database for push pins that are slightly in your tile, as well as the ones in your tiles. The downloadable code does this.
Caching
The whole example application could benefit from caching. It is not likely that you will need to update the push pins in real time, which means that based on your application requirements, you could cache the tiles on both the server and the browser. Querying SQL Azure, drawing bitmaps in real-time for 4 tiles per page would be a lot of work for a high traffic site with lots of push pins. Better to cache the tiles to reduce the load on Windows Azure and SQL Azure; even caching them for just a few minutes would significantly reduce the workload.
Another technique to improve performance is not to draw every pin on the tile when there are a large number of pins. Instead come up with a cluster graphic that is drawn once when there are more than X numbers of pins on a tile. This would indicate to the user that they need to zoom in to see the individual pins. This technique would require that you query the database for a count of rows within the tile, to determine if you are need to use the cluster graphic.
You can read more about performance and load testing with Bing Maps here.
- Attachment: BingMapTileServer.zip
- Code Sample, C#, T-SQL
Mike Godfrey explains how to remove the web server from a web application for searching a remote OData source in his JQuery and OData post of 8/26/2010:
A common model enabling a web application to search a remote source for data could be as follows.
The HTTP POST method allows the data set of an HTML form to be sent to a processing agent, typically a web server. The web server is responsible for querying a remote data source, typically a database. This can be achieved using a variety of techniques, such as old-fashioned ADO.Net in the ASP.Net page code behind or by more up-to-date ORM technologies. The web server will use the result of the data source query to re-render the HTML page and send it back to the browser.
There are several steps here making the model more complicated than it might need to be. Why do we need to POST to the web server? After all, is it not essentially acting as an intermediary between the browser and the data source? Is it possible to remove the web server from this model?
That’s the introduction finished with, let’s look at an example using the Netflix OData service (http://developer.netflix.com/docs/oData_Catalog).
See original post for code snippet.
Here I’ve set up a very basic page containing a form to search with and an empty div to display the results in. Using JQuery to hook into the submission of the form I’ve set up a fairly standard ajax call that will get the top 10 Titles from the Netflix catalogue. Because the Netflix OData service is on a different domain to my script I need to use JSONP to call it. This is where the added url complexity comes from, if the service was on the same domain as my script the url would be much simpler (e.g. “http://odata.netflix.com/Catalog/Titles?$top=10&$format=json”) and we would not need to specify the jsonpCallback parameter. I specify a success callback function to do something with the JSON result, I simply spit out a few properties to screen in the results div – but it’s easy to imagine more funky examples! Finally I return false to prevent the standard form submission from occurring.
If you look into the OData protocol you will notice that there are many many things that can make up the url:- $filter, $orderby, $skip, $expand, $select and $inlinecount come to mind in addition to the possibility of calling service operations. This makes handcrafting the url potentially complex and time consuming.
After a quick bit of research I discovered a small OData plugin that already exists for JQuery - http://wiki.github.com/egil/jquery.odata/. It removes the need to handcraft the urls – replacing them with more intuitive function calls – as well as hiding the potentially nasty ajax call setup.
See original post for Code Snippet
JQuery.OData makes it much easier to work with OData services but still allows you pass through many options as per normal JQuery plugin patterns, above I pass through a dataType property set to JSONP to be used in the ajax call. The success callback is pretty much identical, JQuery.OData does wrap up result.d into a more friendly result.data.
We’re currently using this plugin in a project at iMeta and have been pleased with it so far. If you find yourself with the need call an OData service and don’t want to perform full page postbacks, I thoroughly recommend giving JQuery.OData a go!
If you’re unfortunate enough to be supporting IE6 then give me a ping as I’ve spent many an hour so far debugging it and had to make a couple of tweaks to get JQuery.OData to play nice with it.
Other than that, the Fiddler web debugging tool is your friend when working with OData services, studying the request and response headers has proved to be a vital skill.
The SQL Azure Services Team recently updated its Codename “Dallas” Catalog with a list of services migrated from CPT2 to CPT3:
Announcing CTP3!
The following datasets are available in the Microsoft Codename “Dallas” catalog. Click Subscribe to add the dataset to your subscriptions.
Only the Associated Press, Government of the USA, Gregg London Consulting, and InfoUSA had migrated data to CTP3 as of 8/27/2010.

<Return to section navigation list>
AppFabric: Access Control and Service Bus
• The Endpoint.tv Team wants you to Vote on [AppFabric] show topics for endpoint.tv:
Got a great idea for endpoint.tv? Interested in Windows Server AppFabric and Windows Azure AppFabric? Want to see a sample, tip, technique, code, etc.? Let us know and vote for your favorites.
See the Atom feed here in your reader.
• Brian ? helps Understanding Windows Azure AppFabric Access Control via PHP in this 8/29/2010 post:
AppFabric Access Control Service (ACS) as a Nightclub
Before the nightclub is open for business, the bouncer tells the bartender that he will be handing out blue wristbands tonight to customers who are of legal drinking age.
Once the club is open, a customer presents a state-issued ID with a birth date that shows he is of legal drinking age.
The bouncer examines the ID and, when he’s satisfied that it is genuine, gives the customer a blue wristband.
Now the customer can go to the bartender and ask for a drink.
The bartender examines the wristband to make sure it is blue, then serves the customer a drink.
I would add one step that occurs before the steps above and is not shown in the diagram:
0. The state issues IDs to people and tells bouncers how to determine if an ID is genuine.

To draw the analogy to ACS, consider these ideas:
You, as a developer, are the State. You issue ID’s to customers and you tell the bouncer how to determine if an ID is genuine. You essentially do this (I’m oversimplifying for now) by giving giving both the customer and bouncer a common key. If the customer asks for a wristband without the correct key, the bouncer won’t give him one.
The bouncer is the AppFabric access control service. The bouncer has two jobs:
He issues tokens (i.e. wristbands) to customers who present valid IDs. Among other information, each token includes a Hash-based Message Authentication Code (HMAC). (The HMAC is generated using the SHA-256 algorithm.)
Before the bar opens, he gives the bartender the same signing key he will use to create the HMAC. (i.e. He tells the bartender what color wristband he’ll be handing out.)
The bartender is a service that delivers a protected resource (drinks). The bartender examines the token (i.e. wristband) that is presented by a customer. He uses information in the token and the signing key that the bouncer gave him to try to reproduce the HMAC that is part of the token. If the HMACs are not identical, he won’t serve the customer a drink.
The customer is any client trying to access the protected resource (drinks). For a customer to get a drink, he has to have a State-issued ID and the bouncer has to honor that ID and issue him a token (i.e. give him a wristband). Then, the customer has to take that token to the bartender, who will verify its validity (i.e. make sure it’s the agreed-upon color) by trying to reproduce a HMAC (using the signing key obtained from the bouncer before the bar opened) that is part of the token itself. If any of these checks fail along the way, the customer will not be served a drink.
To drive this analogy home, I’ll build a very simple system composed of a client (barpatron.php) that will try to access a service (bartender.php) that requires a valid ACS token.
Hiring a Bouncer (i.e. Setting up ACS)
In the simplest way of thinking about things, when you hire a bouncer (or set up ACS) you are simply equipping him with the information he needs to determine if a customer should be issed a wristband. Essentially, this means providing information to a customer that the bouncer will recognize as a valid ID. And, we also need to equip the bartender with the tools for validating the color of a wristband issued by the bouncer. I think this is worth keeping in mind as you work through the following steps.
To use Windows Azure AppFabric, you need a Windows Azure subscription, which you can create here:http://www.microsoft.com/windowsazure/offers/. (You’ll need a Windows Live ID to sign up.) I purchased theWindows Azure Platform Introductory Special, which allows me to get started for free as long as keep my usage limited. (This is a limited offer. For complete pricing details, see http://www.microsoft.com/windowsazure/pricing/.) After you purchase your subscription, you will have to activate it before you can begin using it (activation instructions will be provided in an e-mail after signing up).
After creating and activating your subscription, go to the AppFabric Developer Portal:https://appfabric.azure.com/Default.aspx (where you can create an access control service). To create a service…

Brian continues with a step-by-step PHP tutorial and ends with a link to the source code for Barterder.php and BarPatron.php: ACS_tutorial.zip.
Michael Gorsuch explained Using DotNetOpenAuth with Windows Azure in an 8/28/2010 post:
My project requires OpenID authentication, and I chose to use the DotNetOpenAuth library. Since I’m working with ASP.NET MVC, I implemented the example listed on their website.

I found that it works just fine in production and in any other MVC project, but it does not work with the Azure development fabric (this is what you use to run your projects locally before deploying to cloud). As soon as the redirect is called to send you out for authentication, the fabric crashes.
The offending line is as follows:
returnrequest.RedirectingResponse.AsActionResult();I do not know the precise nature of this error, and was not able to find a fix on the internets. Everyone who came across it proposed using a DEBUG switch to mock the transaction if you were in your development environment. While that’s probably okay, I’m rather new to federated authentication and am not entirely sure how to ‘fake it’.
Fortunately, I made a small ‘fix’. It’s more of a hack, in that I don’t fully understand the cause of this problem – I only know that this slight modification lets you get on with your life. I change the previously mentioned line to read:
stringlocation = request.RedirectingResponse.Headers["Location"];returnRedirect(location);For whatever reason, fashioning a redirect request from scratch works. I can only assume that the DotNetOpenAuth code is producing something that the Azure Dev environment finds offensive.
Hope this helps!
Brian Loesgen reported A New Blog is Born: Windows Server AppFabric Customer Advisory Team on 8/27/2010:
Microsoft’s Windows Server AppFabric Customer Advisory Team ( CAT) has launched a new blog focused on AppFabric (both Windows Server AppFabric and Azure AppFabric), WCF, WF, BizTalk, data modeling and StreamInsight. You can find the blog at http://blogs.msdn.com/b/appfabriccat/. [Emphasis added.]
If you read my blog, then these are technologies that will be of interest to you, and this promises to be a good source of information.
Thanks to the CAT team for putting this together!
Ryan Dunn (@dunnry) [left] and Steve Marx (@smarx) [center] put Wade Wegner (@WadeWegner) [right] through the wringer in this 00:40:52 Cloud Cover Episode 23 - AppFabric Service Bus:

In this episode:
- Wade Wegner joins us as we talk about what the Windows Azure AppFabric Service Bus is and how to use it.
- Discover the different patterns and bindings you can use with the AppFabric Service Bus.
- Learn a tip on how to effectively host your Service Bus services in IIS.
Show Links:
SQL Azure Support for Database Copy
Perfmon Friendly Viewer for Windows Azure MMC
Infographic: IPs, Protocols, & Token Flavours in the August Labs release of ACS
Wade's Funky Fresh Beat
AutoStart WCF Services to Expose them as Service Bus Endpoints
Host WCF Services in IIS with Service Bus Endpoints
Neil Mackenzie posted Messenger Connect Beta .Net Library to his Azurro blog on 8/26/2010:
Introduction
The Live Services group has now released the Windows Live Messenger Connect API Beta providing programmatic access to Live Services but without the synchronization that caused some confusion in the Live Framework API. This is a large offering encompassing ASP.Net sign in controls along with both JavaScript and .Net APIs. The Live Services team deserves credit for a solid offering – and this is particularly true of the documentation team which has provided unusually strong and extensive documentation for a product still in Beta.
The goal of this post is to provide a narrative guide through only the .Net portion of the Messenger Connect API.
OAuth WRAP
The Live Framework used Delegated Authentication to give user’s control over the way a website or application can access their Live Services information. Messenger Connect instead uses OAuth WRAP (Web Resource Authorization Protocol) an interim standard already been deprecated in favor of the not yet completed OAuth 2 standard. A number of articles – here and here - describe the politico-technical background of the move from OAuth 1 to OAuth2 via OAuth WRAP. From the perspective of the .Net API the practical reality is that this is an implementation detail burnt into the API so it is not necessary to know anything at all about the underlying standard being used.
Three core concepts from OAuth WRAP (and Delegated Authentication) are exposed in the Messenger Connect API:
- scopes
- access tokens
- refresh tokens
Authorization to access parts of a user’s information is segmented into scopes. For example, a user may give permission for an application to have read access but not write access to the photos uploaded to Live Services. An application typically requests access only for those scopes it requires. The user can manage the consent provided to an application and revoke that consent at any time through the consent management website at http://consent.live.com.
The Messenger Connect API supports various scopes grouped into public and restricted scopes. Public scopes are usable by any application while restricted scopes – allowing access to sensitive information such as email addresses and phone numbers – are usable only by specific agreement with Microsoft.
The public scopes are:
- WL_Activities.View
- WL_Activities.Update
- WL_Contacts.View
- WL_Photos.View
- WL_Profiles.UpdateStatus
- WL_Profiles.View
- Messenger.SignIn
The restricted scopes are:
- WL_Calendar.Update
- WL_Calendar.View
- WL_Contacts.Update
- WL_Contacts.ViewFull
- WL_Photos.Update
- WL_Profiles.ViewFull
The extent of these scopes is pretty apparent from their name with, for example, WL_Activities.Update being permission to add items to the activities stream of a user.
An application requests permission to some scopes and then initiates the sign in process which pops up a Windows Live sign-in page in which the user can view the scopes which have been requested. On successful sign-in Windows Live returns an access token and a refresh token. The access token is a short-lived token the application uses to access the user’s information consistent with the scopes authorized by the user. The refresh token is a long-lived token an application uses to reauthorize itself without involving the user and to generate a new access token – it essentially allows the application to continue accessing the user’s information without continually asking the user for permission. The access token is valid for the order of hours while the refresh token lasts substantially longer (very helpful, I know). …
Neil continues with a detailed analysis of the API beta.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Humphrey Scheil described Umbraco CMS - complete install on Windows Azure (the Microsoft cloud) in this 8/29/2010 post:
We use the Umbraco CMS a lot at work - it's widely regarded as one of (if not the) best CMSs out there in the .NET world. We've also done quite a bit of R&D work on Microsoft Azure cloud offering and this blog post shares a bit of that knowledge (all of the other guides out there appear to focus on getting the Umbraco database running on SQL Azure, but not how to get the Umbraco server-side application itself up and running on Azure). The cool thing is that Umbraco comes up quite nicely on Azure, with only config changes needed (no code changes).
So, first let's review the toolset / platforms I used:
- Umbraco 4.5.2, built for .NET 3.5
- Latest Windows Azure Guest OS (1.5 - Release 201006-01)
- Visual Studio 2010 Professional
- Azure SDK 1.2
- SQL Express 2008 Management Studio
- .NET 3.5 sp1
Then use these steps to make your Umbraco project "Azure-aware." Again, test your installation by deploying to the Azure Dev Compute and Storage Fabric on your local machine and testing that Umbraco works as it should before going to production. The Azure Dev environment is by no means perfect (see below) or a true synonym for Azure Production, but it's a good check nonetheless.
Now we need to use the SQL Azure Migration Wizard tool to migrate the Umbraco SQL Express database. I used v3.3.6 (which worked fine with SQL Express contrary to some of the comments on the site) to convert the Umbraco database to its SQL Azure equivalent - the only thing the migration tool has to change is add a clustered index on one of the tables (dbo.Users) as follows - everything else migrates over to SQL Azure easily:
CREATE CLUSTERED INDEX [ci_azure_fixup_dbo_umbracoUserLogins] ON [dbo].[umbracoUserLogins] ([userID]) WITH (IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) GOThen create a new database in SQL Azure and re-play the script generated by AzureMW into it to create the db schema and standing data that Umbraco expects. To connect to it, you'll replace a line like this in the Umbraco web.config:
<add key="umbracoDbDSN" value="server=.\SQLExpress; database=umbraco452;user id=xxx;password=xxx" />with a line like this:
<add key="umbracoDbDSN" value="server=tcp:<<youraccountname>> .database.windows.net;database=umbraco;user id=<<youruser>> @<<youraccount>>;password=<<yourpassword>>" />So we now have the Umbraco database running in SQL Azure, and the Umbraco codebase itself wrapped using an Azure WebRole and deployed to Azure as a package. If we do this using the Visual Studio tool set, we get:
- 19:27:18 - Preparing...
- 19:27:19 - Connecting...
- 19:27:19 - Uploading...
- 19:29:48 - Creating...
- 19:31:12 - Starting...
- 19:31:52 - Initializing...
- 19:31:52 - Instance 0 of role umbraco452_net35 is initializing
- 19:38:35 - Instance 0 of role umbraco452_net35 is busy
- 19:40:15 - Instance 0 of role umbraco452_net35 is ready
- 19:40:16 - Complete.
Note the total time taken - Azure is deploying a new VM image for you when it does this, it's not just deploying a web app to IIS, so the time taken is always ~ 13 minutes, give or take. I wish it was quicker..
Final comments
If you deploy and it takes longer than ~13 minutes, then double check the common Azure gotchas. In my experience they are:
1. Missing assemblies in production - so your project runs fine on the Dev Fabric and just hangs in Production on deploy - for Umbraco you need to make sure that Copy Local is set to true for cms.dll, businesslogic.dll and of course umbraco.dll so that they get packaged up.
2. Forgetting to change the default value of DiagnosticsConnectionString in ServiceConfiguration.cscfg (by default it wants to persist to local storage which is inaccessible in production - you'll need to use an Azure storage service and update the connection string to match, e.g. your ServiceConfiguration.cscfg should look something like this:
<?XML:NAMESPACE PREFIX = [default] http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration NS = "http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration" /> <?xml version="1.0"?> <ServiceConfiguration serviceName="UmbracoCloudService" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration"> <Role name="umbraco452_net35"> <Instances count="1" /> <ConfigurationSettings> <Setting name="DiagnosticsConnectionString" value="DefaultEndpointsProtocol=https;AccountName=travelinkce;AccountKey=pIiMwawlZohZSmgrQr8tUPL5DRPE31Sg/9lqJog11Y3FdXTG7HnRSlVNXMNGLbZyCsG3JX1DlbqYtBBrce1w7g==" /> </ConfigurationSettings> </Role> </ServiceConfiguration>The Azure development tools (Fabric etc.) are quite immature in my opinion - very slow to start up (circa one minute) and simply crash when you've done something wrong rather than give a meaningful error message and then exit (for example, when trying to access a local SQL Server Express database (which is wrong - fair enough), the loadbalancer simply crashed with a System.Net.Sockets.SocketException{"An existing connection was forcibly closed by the remote host"}. I have the same criticism of the Azure production system - do a search to see how many people spin their wheels waiting for their roles to deploy with no feedback as to what is going / has gone wrong. Azure badly needs more dev-friendly logging output.
I couldn't get the .NET 4.0 build of Umbraco to work (and it should, .NET 4.0 is now supported on Azure). The problem appears to lie in missing sections in the machine.config file on my Azure machine that I haven't had the time or inclination to dig into yet.
You'll also find that the following directories do not get packaged up into your Azure deployment package by default: xslt, css, scripts, masterpages. To get around this quickly, I just put an empty file in each directory to force their inclusion in the build. If these directories are missing, you will be unable to create content in Umbraco.
Exercises for the reader
- Convert the default InProc session state used by Umbraco to SQLServer mode (otherwise you will have a problem once you scale out beyond one instance on Azure). Starting point is this article - http://blogs.msdn.com/b/sqlazure/archive/2010/08/04/10046103.aspx, but Google for errata to the script - the original script supplied does not work out of the box.
- Use an Azure XDrive or similar to store content in one place and cluster Umbraco
• Roberto Bonini continues his Windows Azure Feed Reader series with a 00:45:00 Windows Azure Feed Reader Episode 4: The OPML Edition post and video segment on 8/29/2010:
As you’ve no doubt surmised from the title, this weeks episode deals almost entirely with the OPML reader and fitting it in with the rest of our code base.
If you remember, last week I showed a brand new version of the OPML reader code using LINQ and Extension Methods. This week, we begin by testing said code. Given that its never been been tested before, bugs are virtually guaranteed. Hence we debug the code, make the appropriate changes and fold the changes back into our code base.
The fact is that a) making the show any longer would bust my Vimeo Basic upload limit and b) I couldn’t think of anything else to do that could be completed in ~10 minutes.
The good thing is that we’re back to our 45 minute-ish show time, after last weeks aberration.
Don’t forget, you can head over to Vimeo to see the show in all its HD glory: http://www.vimeo.com/14510034
After last weeks harsh lessons in web-casting, file backup and the difference between 480p and 720p when displaying code, this weeks show should go perfectly well.
Enjoy.
Remember, the code lives at http://windowsazurefeeds.codeplex.com
• Ankur Dave describes his work on Windows Azure Clustering as an intern for Microsoft Research’s Extreme Computing Group (XCG) in this Looking back at my summer with Microsoft post of 8/24/2010:
I spent the summer working on the Azure Research Engagement project within the Cloud Computing Futures (CCF) team at Microsoft Research’s eXtreme Computing Group (XCG). My project was to design and build CloudClustering, a scalable clustering algorithm on the Windows Azure platform. CloudClustering is the first step in an effort by CCF to create an open source toolkit of machine learning algorithms for the cloud. My goal within this context was to lay the foundation for our toolkit and to explore how suitable Azure is for data-intensive research.
Unfortunately, high school ends late and Berkeley starts early, so the internship was compressed into just seven weeks. In the first week, I designed the system from scratch, so I got to control its architecture and scope. I spent the next two weeks building the core clustering algorithm, and three weeks implementing and benchmarking various optimizations, including multicore parallelism, data affinity, efficient blob concatenation, and dynamic scalability.

I presented my work to XCG in the last week, in a talk entitled "CloudClustering: Toward a scalable machine learning toolkit for Windows Azure." Here are the slides in PowerPoint [with the script] and PDF, and here’s the video of the talk. On my last day, it was very gratifying to receive a request from the Azure product group to give this talk at a training session for enterprise customers :)
- Introduction by Roger Barga, my manager - http://www.youtube.com/watch?v=Sy6MyB_w0fs
- General introduction - http://www.youtube.com/watch?v=djkiyhG0e4A
- Technical introduction - http://www.youtube.com/watch?v=N9BsoXze61Y
- Algorithm and implementation - http://www.youtube.com/watch?v=MpAGwyFQqHw
- Optimizations (Part 1) - http://www.youtube.com/watch?v=bU43KnbCfxs
- Optimizations (Part 2) and Results - http://www.youtube.com/watch?v=vxucDtIpttI
These seven weeks were some of the best I've ever had -- and for that I especially want to thank my mentors, Roger Barga and Wei Lu. I'd love to come back and work with them again next year! :)
Unfortunately, the link to Ankur Dave’s talk is missing.
Jenna Pitcher reported Computershare’s infrastructure turns Azure in this 8/27/2010 article for Delimiter.com.au:

Australian investor services giant Computershare this week revealed that it had rebuilt its most highly trafficked sites on Microsoft’s Azure cloud computing platform, sending them live in the first week of August.
Speaking at Microsoft’s Tech.Ed conference on the Gold Coast this week, Computershare architect Peter Reid explained the company’s online investor services to corporations were quite seasonal and “spikey” because of the nature of financial reporting.
The company immediately saw several benefits from moving to Microsoft’s cloud computing platform, the first being that it no longer needed to keep extra hardware provisioned for its high traffic events.
“The other one is that we would like to protect our normal business — traditional employee and investor side business from these unusual events,” said Reid. Previously, the “spikey” applications had affected all of the other services running on the same software.
Reid said that he did not look at other hosting options because the team already had the tools and knowledge to go forward. “We had the application written in .NET, we already had the skills base of the development staff on .NET,” he said.
Computershare has a priority projects group of five employees which takes on interesting projects within the organisation. Four of them were assigned to the Azure project for a month and worked closely with Microsoft. This computer development team worked closely with Microsoft’s Technical Adoption Program (TAP).
“We were kind of guided through the process by the Azure TAP guys,” Reid said. Computershare touched base with the Azure experts at least once a week with a phone call. But no real re-education of the Computershare developers was needed, given they had a lot of the .NET knowledge already.
One other benefit Reid touched on was scalability. “We were really interested in looking at the the flexible deployment side of the Azure framework,” he said. “So the ability to scale up and scale down automatically without having to touch it.”
Reid said that other cloud computing options didn’t have Azure’s abilities in this area. “Ssome of the other providers — where you have infrastructure as a service with [virtual machines] in the cloud — didn’t give us that flexible ability to spin up extra web servers on demand and spin them back down as we needed,” he said.
The GFC
One of the main motivations for the switch was also the changing nature of the financial sector. In 2007 and 2008 Computershare had some load issues due to a lot of initial public offering launches coming in from Hong Kong. But then everything changed due to the GFC — the IPOs dried up.However, Reid’s team noticed early this year that the market was getting set to ramp up again — and they knew they would have another big season on their doorstep very soon. “We knew it was imminent, that we were going to have these big IPOs coming on board,” the architect said. “We just got the application Azure two weeks before we had to go live the first time.”
Reid stated that the data centres for the project were located in South East Asia — whereas normally they would use their Brisbane and Melbourne facilities. This location worked out being better for the Hong Kong listings. And the cheaper processing architecture also drove savings.
There was only one pressing issue that Computershare came up against — the ability to monitor the infrastructure.
“They really wanted to know how they were going to monitor this application in the cloud,” said Reid. Not all the needed tools were available out of the box, so there was a bit of work to do in that area, with some tools needing to be built in-house.
In terms of the future, Reid said Computershare was currently looking at all of its applications and working out which ones it would make sense to run in the cloud. Computershare is also looking a content management system, an edge network and caching technology.
“So if you go to our website, we send you the page and the images out of our datacentre,” said Reid of the current situation, noting Computershare wanted to shift to a system where a browser’s closest local datacentre would actually serve the traffic.
One last aspect of the project which Reid highlighted as being important was that of its impact on the environemnt,
“Its important for us to deliver our website in the most efficient way we can,” he said. “Running these kind of servers all year round wasting energy is adding to our carbon foot print and one thing we would like to do is wipe those loads and turn off the servers as soon as we can can so we don’t end up killing the environment unnecessarily by running idle machines that are not doing anything.”
However, the architect has not estimated how much the Azure project has reduced the company’s carbon footprint.
“We don’t have any figures of how much carbon we are burning at the moment but it is certainly something I want to do,” he said.
Image credit: TechFlash Todd, Creative Commons
Delimiter’s Jenna Pitcher is attending Tech.Ed this week as a guest of Microsoft, with flights, accommodation and meals paid for.
Patrick Butler Monterde posted Code Contracts – Best Practices to Azure on 8/26/2010:

Code Contracts provide a language-agnostic way to express coding assumptions in .NET programs. The contracts take the form of pre-conditions, post-conditions, and object invariants. Contracts act as checked documentation of your external and internal APIs.
- Runtime Checking. Our binary rewriter modifies a program by injecting the contracts, which are checked as part of program execution. Rewritten programs improve testability: each contract acts as an oracle, giving a test run a pass/fail indication. Automatic testing tools, such as Pex, take advantage of contracts to generate more meaningful unit tests by filtering out meaningless test arguments that don't satisfy the pre-conditions.
- Static Checking. Our static checker can decide if there are any contract violations without even running the program! It checks for implicit contracts, such as null dereferences and array bounds, as well as the explicit contracts. (Premium Edition only.)
- Documentation Generation. Our documentation generator augments existing XML doc files with contract information. There are also new style sheets that can be used with Sandcastle so that the generated documentation pages have contract sections.
Code Contracts comes in two editions:
- Code Contracts Standard Edition: This version installs if you have any edition of Visual Studio other than the Express Edition. It includes the stand-alone contract library, the binary rewriter (for runtime checking), the reference assembly generator, and a set of reference assemblies for the .NET Framework.
- Code Contracts Premium Edition: This version installs only if you have one of the following: Visual Studio 2008 Team System, Visual Studio 2010 Premium Edition, or Visual Studio 2010 Ultimate Edition. It includes the static checker in addition to all of the features in the Code Contracts Standard Edition.
The Visual Studio ALM Rangers uploaded a Visual Studio Database Guide to CodePlex on 8/12/2010 (missed when posted):
Project Description
Practical guidance for Visual Studio 2010 Database projects, which is focused on 5 areas:This release includes common guidance, usage scenarios, hands on labs, and lessons learned from real world engagements and the community discussions.
- Solution and Project Management
- Source Code Control and Configuration Management
- Integrating External Changes with the Project System
- Build and Deployment Automation with Visual Studio Database Projects
- Database Testing and Deployment Verification
The goal is to deliver examples that can support you in real world scenarios, instead of an in-depth tour of the product features.Visual Studio ALM Rangers
This guidance is created by the Visual Studio ALM Rangers, who have the mission to provide out of band solutions for missing features or guidance. This content was created with support from Microsoft Product Group, Microsoft Consulting Services, Microsoft Most Valued Professionals (MVPs) and technical specialists from technology communities around the globe, giving you a real-world view from the field, where the technology has been tested and used.
For more information on the Rangers please visit http://msdn.microsoft.com/en-us/vstudio/ee358786.aspx and for more a list of other Rangers projects please see http://msdn.microsoft.com/en-us/vstudio/ee358787.aspx.What is in the package?
The content is packaged in 3 separate zip files to give you the choice of selective downloads, but the default download is the first of the listed packages:
- Visual Studio Guidance for Database Projects --> Start here
- Visual Studio Database Projects Hands-On-Labs document
- Hands-On-Labs (HOLs), including:
- Solution and Project Management
- Refactoring a Visual Studio Database Solution to Leverage Shared Code
- Source Code Control and Configuration Management
- Single Team Branching Model
- Multiple Team Branching Model
- Integrating External Changes with the Project System
- Maintaining Linked Servers in a Visual Studio Database Project
- Complex data movement
- Build and Deployment Automation
- WiX-Integration with deployment of databases
- The Integrate with Team Build Scenario
- Building and deploying outside team build
- Database Testing and Deployment Verification
- The “Basic” Create Unit Test Scenario
- The “Advanced” Create Unit Test Scenario
- Find Model drifts Scenario
Team
- Contributors
- Shishir Abhyanker (MSFT), Chris Burrows (MSFT), David V Corbin (MVP), Ryan Frazier (MSFT), Larry Guger (MVP), Barclay Hill (MSFT), Bob Leithiser (MSFT), Pablo Rincon (MSFT), Scott Sharpe (MSFT), Jens K. Süßmeyer (MSFT), LeRoy Tuttle (MSFT)
- Reviewers
- Christian Bitter (MSFT), Regis Gimenis (MSFT), Rob Jarrat (MSFT), Bijan Javidi (MSFT), Mathias Olausson (MVP), Willy-Peter Schaub (MSFT)
How to submit new ideas?
The recommended method is to simply post ideas to the Discussions page or to contact the Rangers at http://msdn.microsoft.com/en-us/teamsystem/ee358786.aspx
Return to section navigation list>
VisualStudio LightSwitch
The Video Studio Lightswitch Team announced MSDN Radio: Visual Studio LightSwitch with John Stallo and Jay Schmelzer on MSDN Radio at 8/30/3010 9:00 to 9:30 AM PDT:
Tune in on Monday, August 30, 2010 from 9:00-9:30 AM Pacific Time for MSDN Radio. This week they’ll be interviewing LightSwich team members! It’s your chance to call in and ask us questions about LightSwitch.
About MSDN Radio: “MSDN Radio is a weekly Developer talk-show that helps answer your questions about the latest Microsoft news, solutions, and technologies. We dive into the challenges of deciphering today’s technology stack. Register today and have a chance to call-in and talk with the experts on the air, or just tune in to the show.”
Register here: MSDN Radio: Visual Studio LightSwitch with John Stallo and Jay Schmelzer
Matt Thalman showed How to: designing one LightSwitch screen to create or edit an entity in this 8/26/2010 post (Click an empty image frame to generate a 404 error and then click Back to view the screen captures):
Create an entity to work with. For the purposes of this tutorial, I’ve created a Customers table.
- Create a Details Screen for Customer:

- Rename the Customer property on the screen to CustomerQuery:

- Click the “Add Data Item…” button in the command bar and create a local Customer property:

- Delete the current content on the screen bound to the CustomerQuery. We want to replace the content in the screen to be bound to the Customer property, not the CustomerQuery.

- In its place, we want to bind the Customer property onto the screen:

- Change the control type of the Customer to be a Vertical Stack. By default, this will add controls for each of the fields defined in Customer which is exactly what we want.

- Now we need to write some code to hook everything up. Click the Write Code button on the command bar at the top of the screen designer. Paste the following code into the generated class:
partial void CustomerDetail_Loaded()
{
if (!this.Id.HasValue)
{
this.Customer = new Customer();
}
else
{
this.Customer = this.CustomerQuery;
}
}
So what happens here is that the screen has a parameter called Id which represents the Id of the Customer. If that property is not set, we assume the screen should create and display a new customer. If that property is set, we simply set the Customer property to the return value of the CustomerQuery query which is actually bound to the Id property (the screen template did that work for us). Notice that we’re setting the Customer property here because that is what all of the screen content is bound to. So by setting this property, it updates the controls on the screen with the state from that entity.- Ok, how do we use this screen? Well, by default any customer displayed as Summary control defined as a link will automatically navigate to this screen. If you want to navigate to this screen through the use of a List, for example, just following the next set of steps.
- Create a List and Details Screen for Customers:

- Expand the Command Bar of the Customer List and override the code for the Add button:

- Paste the following code into the CustomerListAddAndEditNew_Execute method:
this.Application.ShowCustomerDetail(null);
This code passes null as the customer ID parameter to the screen which will cause the screen to create a new entity.- Go back to the screen designer and override the code for the Edit button in the same way you did for the Add button. Paste the following code into the CustomerListEditSelected_Execute method:
this.Application.ShowCustomerDetail(this.CustomerCollection.SelectedItem.Id);
This code passes the ID of the currently selected customer which will cause that customer to be loaded into the CustomerDetail screen.With these changes, you can now edit the CustomerDetail to behave however you want and you will have a consistent experience when creating a new customer or editing an existing customer.








The Visual Studio Lightswitch Team continued their introductory architecture series with The Anatomy of a LightSwitch Application Part 3 – the Logic Tier on 8/26/2010:
Just as a recap, the presentation tier is a Silverlight client application that can run as a desktop application (out-of-browser) or as a browser-hosted application. LightSwitch uses a 3-tier architecture where the client sends all requests to fetch and update data through a middle tier.
The primary job of the logic tier is data access and data processing. It is the go-between from the client to each of the data sources that have been added to the application. LightSwitch creates a data service in the logic tier for each data source. Each data service exposes a set of related entities via entity sets. There are query operations for fetching entities from the entity sets, and a single submit operation for sending added, modified and deleted entities for processing.
Each data service talks to its corresponding data source via a data source provider. These providers are implemented by LightSwitch. The LightSwitch developer doesn’t need to know about the underlying data access technologies employed in order to work with data or to write business logic.
Let’s dig into the details of data services, business logic, query operations, and submit operations. We’ll also look at some implementation details: data providers and transaction management.
Data Services
A data service encapsulates all access to a data source. A LightSwitch logic tier hosts any number of data services which are exposed as public service endpoints at the service boundary. Each data service exposes a number of queryable entity sets with operations for querying entities and an operation for submitting a change-set of added, updated and deleted entities. An entity set is a logical container for entities of the same entity type. Operations that fetch entities always fetch them from a given entity set. Likewise, operations that add, update, or delete entities update them through a given entity set.
If this terminology is new to you, you can think of an entity set as analogous to a SQL table. An entity instance is then analogous to a SQL row, and the properties of the entity type match the SQL columns. (Note that these are not equivalent concepts, but will help ground you in something familiar.)
At a more formal architectural level, LightSwitch chose to follow the Entity Data Model (EDM) for defining our data services. You can think of a LightSwitch data service as implementing an entity container having entity types, entity sets, association types, and association sets. We do not yet support complex types or function imports which are also part of the EDM. The LightSwitch developer needn’t be bothered with all these concepts. The LightSwitch tool makes importing or defining entity types and relationships straightforward and LightSwitch takes care of the rest.
To get a better understanding of the structure of a data service, let’s look at an example. The following diagram shows example
Northwinddata service with two entity sets,CustomersandOrders. Each entity set has the defaultAllandSinglequeries, and customers has an additional modeled query that selects theActivecustomers. It also has the defaultSaveChangesoperation.
Let’s now look at this in more detail. We’ll go over query operations, submit operations, custom operations, and how custom business logic is associated with the entity sets and operations.
Query Operations
A query operation requests a set of entities from an entity set in the data service, with optional filtering and ordering applied. Queries can have parameters and can return multiple or single results. A query can define specific filtering and ordering intrinsically. In addition to passing parameters, the caller can pass additional filter and ordering predicates to be performed by the query operation.
For each entity set, LightSwitch provides a default “All” and “Single” query. For example, for a
Customersentity set, LightSwitch will generateCustomers_Allto return all of the customers andCustomers_Singleto return one customer by key. You can define additional query operations for an entity set that defines its own parameters, filters and ordering.LightSwitch queries are composable so that new queries can be based on an existing one. For example you can define an
ActiveCustomers, based on the built-inCustomers_All, and then then defineActiveCustomersByRegion(string region)based on theActiveCustomersquery.Query operations can have parameters that are used in the filter (where) clauses. LightSwitch also supports optional parameters. Optional parameters are a special case of nullable parameters. If the parameter value is null at runtime, LightSwitch omits the query clause that uses it. Optional parameters are useful in building up screens where the end-user may or may not provider certain filter criteria. For example, say you are defining a search query for Customers. You want to return all the customers, but if the “active” parameter is specified, you return only the active or inactive customers. You define the filter clause in the designer as follows, designating the parameter as an optional Boolean type.
LightSwitch generates a nullable Boolean parameter and interprets the where clause as follows:
where (!active.HasValue || customer.IsActive == active.Value)A query can be designated as a singleton query by specifying “One” as the number of entities to return. A singleton query operation returns just one entity or null and the query is not further composable. The runtime behavior matches the LINQ
SingleOrDefaultbehavior. It will throw an exception at runtime if the query returns more than one record.Although a LightSwitch query operation can define filtering and ordering within the query, a client can compose additional query operators at the call site. For example, say you’ve defined the
ActiveCustomersquery which filters out only active customers and returns them ordered by the customer ID. Any LightSwitch business logic can then use LINQ to invoke this query and pass additional filters or ordering.
Dim query = From c As Customer In northwind.ActiveCustomersWhere c.State = “WA” OrderBy c.ZipCode
Note that the additional
WhereandOrderbyclauses get executed in the data service—not on the client. Not all of theIQueryableLINQ operators are supported—only those that we can serialize over WCF RIA Services. (SeeIDataServiceQueryablein the LightSwitch runtime API.)During execution of the query, the operation passes through the query pipeline, during which you can inject custom server-side code. Here is a quick summary of the query pipeline.
1. Pre-processing
a. CanExecute – called to determine if this operation may be called or not
b. Executing – called before the query is processed
c. Pre-process query expression – builds up the final query expression2. Execution – LightSwitch passes the query expression to the data provider for execution
3. Post-processing
a. Executed – after the query is processed but before returning the results
b. OR ExecuteFailed – if the query operation failedThe bolded elements represent points in the pipeline where you can customize the query by adding custom code. In CanExecute, you can test user permissions to access the operation, or any other logic to determine if the operation is available. (LightSwitch also checks the CanRead status for the underlying entity set.) In the Executing phase, you can modify the transaction scope semantics. This is very advanced and typically not necessary. During the pre-processing phase, you can append additional query operators using LINQ. This is helpful because some data providers support more complex query expressions than can be modeled in LightSwitch or serialized from the client.
During the Execution phase, LightSwitch transforms the query expression into one that can be used directly by the given data provider. In some cases this involves transforming the data types used from LightSwitch specific entity types to entity types used by the underlying provider. More on this in the section below on data providers.
Submit Operations
Each data service has a single built-in operation called
SaveChanges. This operation sends changed entities from the client to data service for processing.
SaveChangesoperates on a change set. The client’s data workspace tracks one change set per data service. (See data workspace in prior post.) The change set includes all of the locally added, updated and deleted entities for that data service. The change set is serialized, sent to the data service, and is deserialized into a server-side data workspace. (Note that locally changed entities associated with a different data source are not included in the change set.) Execution in the data service follows the submit pipeline, which looks like this.1. Pre-processing
a. SaveChanges_CanExecute – called to determine whether this operation is available or not
b. SaveChanges_Executing – called before the operation is processed2. Process modified entities
a. Entity Validation – the common property validation is called for each modified entity (the same validation code that runs on the client)
b. EntitySet_Validate – called for each modified entity
c. EntitySet_Inserting – called for each added entity
d. EntitySet_Updating – called for each updated entity
e. EntitySet_Deleting – called for each deleted entity3. Execution – LightSwitch passes all of the changes to the underlying data provider for processing
4. Post-process modified entities
a. EntitySet_Inserted
b. EntitySet_Updated
c. EntitySet_Deleted5. Post-processing
a. SaveChanges_Executed
b. OR SaveChanges_ExecuteFailedThe pipeline looks rather simple. Each modified entity in the change set gets processed once through the pipeline. But if code on in the data service makes additional changes, LightSwitch ensures that newly added, modified or deleted entities also pass through the pipeline. This helps to ensure that business logic is applied uniformly to all entities and entity sets. In addition to the pipeline functions above, the per-entity set
CanRead,CanInsert,CanUpdate,CanDeleteare also evaluated for affected entity sets.If the processing succeeds, any modified entities are serialized back to the client. In this way, the client can get updated IDs, or observe any other changes made by the data service code.
LightSwitch uses optimistic concurrency for updates. If a concurrency violation occurs, the concurrency error is returned to the client where it can observe the proposed, current and server values.
Custom Operations (future)
Many real-world scenarios require general purpose operations that cannot be classified as either an entity query or a submit operation. These operations may be data-intensive, long-running, or require access to data or services that are not otherwise accessible from the client.
Although custom operations are definitely a part of the LightSwitch architectural roadmap, they did not make it into the first release. This was a difficult trade-off. I’m writing this now just to ensure you that we won’t forget about the importance of this and that we intend to publish some workarounds that are possible in v1.
Transaction Management
Transactions in the data service are scoped per data workspace. Each operation invocation gets its own data workspace instance and, in the default case, each data workspace uses its own independent transaction and its own DB connection.
If an ambient transaction is available, the data workspace will use it and compose with other transactions within that transaction scope, but by default, there is no ambient transaction. The default isolation level for query operations is IsolationLevel.ReadCommitted. The default isolation level for submit operations is IsolationLevel.RepeatableRead. In neither case is DTC used by default.
The LightSwitch developer controls the default transaction scope, including enrollment in a distributed transaction, by creating his own transaction scope in the “Executing” phase of the pipeline, and then committing it in the “Executed” phase.
It is possible to transact changes to multiple different data sources simultaneously, but LightSwitch does not do this by default. We only save changes to a single data service, and thus to a single data source. If you need to save changes to a different data source within the current submit operation, you can create a new data workspace, make the changes there, and call its SaveChanges method. In this case, you can also control the transaction scope used by the new data workspace.
Note that changing the transaction scope within the query pipeline does not work in this release. This is an implementation limitation but may be fixed in a future release.
Data Providers
LightSwitch data workspaces aggregate data from different data sources. A single LightSwitch application can attach to many different kinds data sources. LightSwitch provides a single developer API for entities, queries and updates regardless of the data source kind. Internally, we have implemented three strategies to provide data access from the logic tier to the back-end storage tiers.
ADO.NET Entity Framework for access to SQL Server and SQL Azure
WCF Data Services for access to SharePoint 2010 via the OData protocol
A shim to talk to an in-memory WCF RIA DomainService for extensibilityLightSwitch uses existing .NET data access frameworks as a private implementation detail. We are calling them “data providers” in the abstract architectural sense. LightSwitch does not define a public provider API in the sense of ADO.NET data providers or Entity Framework providers. LightSwitch translates query expressions and marshals between the LightSwitch entity types and those used by the underlying implementation. (For access to SQL using Entity Framework, we use our entity types directly without further marshaling.)
For extensibility, we support calling into a custom RIA DomainService implementation. LightSwitch loads an instance of the DomainService class into memory. We call the instance directly from our data service implementation to perform queries and submit operations. The custom DomainService is not exposed as a public WCF service. The [EnableClientAccess] attribute should not be applied.
Using this mechanism, a developer can use Visual Studio Professional to create a DomainService that exposes its own entity types and implements the prescribed query, insert, update, and delete methods. LightSwitch infers a LightSwitch entity based on the exposed entity types and infers an entity set based on the presence of a “default” query.
Summary
The LightSwitch logic tier hosts one or more data services. The LightSwitch client accesses goes through the data service to access data in a data source, such as a SQL database or a SharePoint site. Data services expose entity sets and operations. A query operation fetches entities from entity sets. The submit operation saves modified entities to entity sets. The data service implements a query pipeline and a submit pipeline to perform application-specific business logic.
In the next post we’ll take a quick look at the storage tier. This will detail the data sources we support, which storage features of the data sources we support, and how we create and update the data schema for the application-owned SQL database.


<Return to section navigation list>
Windows Azure Infrastructure
• Rich Miller reported Microsoft Picks Virginia for Major Data Center in an 8/27/2010 post to the DatacenterKnowledge blog:

A recent version of the Microsoft IT-PAC container, which will be a key component of the new Microsoft data center.
[Link added.]
Microsoft’s decision is being welcomed by officials in Virginia, which engaged in a pitched battle with neighboring North Carolina to win the huge project, which will create 50 new jobs.
Boydton, a town of about 500 residents in Mecklenburg County, will become the unlikely home for one of the world’s most advanced new modular data centers. Microsoft’s new facility will feature the use of its container-based design known as an IT-PAC (short for Pre-Assembled Component). By using modular systems and repeatable designs, Microsoft can reduce the cost of building its data center.
Microsoft Adding Cloud Capacity
With the Virginia project, Microsoft continues to step up its data center construction program as it builds future capacity for its battle with Google and other leading players in cloud computing. In May the company began building a second data center in Quincy, Washington, and in June it confirmed plans to move forward with the construction of a new data center in West Des Moines, Iowa.“We are excited to announce that we will be building our latest state-of-the-art data center near Boydton, Virginia,” said Kevin Timmons, General Manager of Microsoft Datacenter Services. “My team and I look forward to engaging in the deployment of our latest modular solution in Virginia. This new data center will enable the best possible delivery of services to our current and future customers.”
Timmons also thanked state and local officials for their efforts during Microsoft’s site location process.
“Microsoft is a household name and securing this global project is a significant win for Virginia,” said Virginia Gov. Bob McDonnell. “The company’s search process was long and competitive, and a great team of players came together to show Microsoft that Mecklenburg County was the right fit for its new version of a state-of-the-art data center. The project represents the largest investment in Southern Virginia.
“It will further bolster the Commonwealth’s standing as a leader in the information technology sector, while creating new jobs for our citizens and spurring economic development throughout the region,” he continued.
Three States in the Running
Microsoft has been scouting sites in Virginia, North Carolina and at least one other state for about six months. At different times the company has been rumored to be considering sites in Christiansburg, Va. and near Greensboro, N.C. But in the end, sources say it came down to two locations – the Boydton location and a site in western North Carolina.The Boydton site has strong fiber connectivity from existing routes supporting a government data center in the region. The fiber optic network of the Mid-Atlantic Broadband Cooperative (MBC) was described as a”key component” in Microsoft’s decision to locate in Virginia.
Attention from the Governor
Virginia pulled out all the stops in the bid to win the Microsoft project. In mid-June McDonnell made an unannounced visit to Boydton to discuss the project with local officials. But there was plenty of competition. In July North Carolina legislators passed a bill expanding earlier measures to attract major data centers.But Microsoft apparently found the Boydton Industrial Park a compelling location. The 175-acre site features a 40-acre graded pad. The site is served by Dominion Virginia Power and its water utility is the Roanoke River Public Service Authority.
Grants from State Will Support Project
McDonnell approved a $2.1 million grant from the Governor’s Opportunity Fund to assist Mecklenburg County with the project. The Virginia Tobacco Indemnification and Community Revitalization Commission approved $4.8 million in funds. The Virginia Department of Business Assistance will provide training assistance through the Virginia Jobs Investment Program.At Microsoft, the IT-PAC serves as the foundation of a broader shift to a modular, component-based design that offers cost-cutting opportunities at almost every facet of the project. They are designed to operate in all environments, and employ a free cooling approach in which fresh air is drawn into the enclosure through louvers in the side of the container – which effectively functions as a huge air handler with racks of servers inside.
Next-Generation Data Center Design
This next-generation design gives Microsoft the ability to to forego the concrete bunker exterior seen in many data centers in favor of a steel and aluminum structure built around a central power spine. Microsoft’s decision to leave the facility open to the air was guided by a research project in which the company housed servers in a tent for eight months.Microsoft has built four huge data centers to support the growth of its online business, including its Windows Azure cloud computing platform. The sites in Chicago, Dublin, San Antonio and Quincy, Washington have each been in the neighborhood of 500,000 square feet.
Microsoft has been operating a pair of data centers in northern Virginia, where it has been one of the largest tenants in data centers operated by DuPont Fabros Technology (DFT).
• Scott Bekker asserts “CFO Peter Klein makes the case for Microsoft's financial upside in cloud computing at the Microsoft Financial Analyst meeting” and then attempts to answer What Is Microsoft Thinking? in this article dated 9/1/2010 for Redmond Channel Partner Online:
“As we build out the world's leading development platform in the cloud, we're going to attract many ISVs to build applications to that.”
Peter Klein, CFO, Microsoft [pictured at right]Steve Ballmer, Kevin Turner, Craig Mundie and other Microsoft executives emphasized the cloud in their keynotes, but they all talked about a broader range of Microsoft initiatives. Tellingly, Chief Financial Officer Peter Klein focused the bulk of his remarks on the central question for investors: How will a company that gets revenues almost entirely from software sales make a future in the cloud?
Klein told attendees July 29 that the cloud "gives us access to many, many hundreds of millions of customers, scenarios and products that we don't sell today." Top ways Microsoft will grow revenues and profits in the cloud, according to Klein's speech are:
- Make the Microsoft pie bigger. Currently, Microsoft addresses only the $400 billion software market. Going into the cloud gives Microsoft access to the entire IT market. "Because it allows us to deliver new capabilities and new scenarios, it should allow us to actually increase our share within the software segment."
- Add midmarket users. Klein estimated that there are 200 million to 300 million midmarket users, and that many of them aren't served by enterprise-class e-mail offerings. Upselling and cross-selling collaboration and communication services will also increase earnings per customer, he said.
- Add enterprise workers. In a pitch familiar from the initial Microsoft Business Productivity Online Suite rollout two years ago, Klein talked about all the deskless workers in the enterprise who can be served by the cloud. "We think this could be as much as 30 to 40 percent of the worldwide workforce."
- Save enterprises money. Using the Windows Azure platform has the capacity to offer enterprise customers substantial savings in datacenter hardware, hosting, maintenance and support while still increasing Microsoft's gross margins.
- Build it and they will come. Klein said the Windows Azure platform should accelerate Microsoft's momentum with ISVs. "As we build out the world's leading development platform in the cloud, we're going to attract many ISVs to build applications to that." Klein also said Windows Azure should be "hugely incremental" to Microsoft's development population.
Thomas Erl continues his Cloud Computing, SOA and Windows Azure - Part 3, “Windows Azure Roles,” on 8/28/2010:
A cloud service in Windows Azure will typically have multiple concurrent instances. Each instance may be running all or a part of the service's codebase. As a developer, you control the number and type of roles that you want running your service.
Web Roles and Worker Roles
- Web roles
- Worker roles
Web roles provide support for HTTP and HTTPS through public endpoints and are hosted in IIS. They are most comparable to regular ASP.NET projects, except for differences in their configuration files and the assemblies they reference.
Worker roles can also expose external, publicly facing TCP/IP endpoints on ports other than 80 (HTTP) and 443 (HTTPS); however, worker roles do not run in IIS. Worker roles are applications comparable to Windows services and are suitable for background processing.
Virtual Machines
Underneath the Windows Azure platform, in an area that you and your service logic have no control over, each role is given its own virtual machine or VM. Each VM is created when you deploy your service or service-oriented solution to the cloud. All of these VMs are managed by a modified hypervisor and hosted in one of Microsoft's global data centers.Each VM can vary in size, which pertains to the number of CPU cores and memory. This is something that you control. So far, four pre-defined VM sizes are provided:
- Small - 1.7ghz single core, 2GB memory
- Medium - 2x 1.7ghz cores, 4GB memory
- Large - 4x 1.7ghz cores, 8GB memory
- Extra large - 8x 1.7ghz cores, 16GB memory
Notice how each subsequent VM on this list is twice as big as the previous one. This simplifies VM allocation, creation, and management by the hypervisor.
Windows Azure abstracts away the management and maintenance tasks that come along with traditional on-premise service implementations. When you deploy your service into Windows Azure and the service's roles are spun up, copies of those roles are replicated automatically to handle failover (for example, if a VM were to crash because of hard drive failure). When a failure occurs, Windows Azure automatically replaces that "unreliable" role with one of the "shadow" roles that it originally created for your service. This type of failover is nothing new. On-premise service implementations have been leveraging it for some time using clustering and disaster recovery solutions. However, a common problem with these failover mechanisms is that they are often server-focused. This means that the entire server is failed over, not just a given service or service composition.
When you have multiple services hosted on a Web server that crashes, each hosted service experiences downtime between the current server crashing and the time it takes to bring up the backup server. Although this may not affect larger organizations with sophisticated infrastructure too much, it can impact smaller IT enterprises that may not have the capital to invest in setting up the proper type of failover infrastructure.
Also, suppose you discover in hindsight after performing the failover that it was some background worker process that caused the crash. This probably means that unless you can address it quick enough, your failover server is under the same threat of crashing.
Windows Azure addresses this issue by focusing on application and hosting roles. Each service or solution can have a Web frontend that runs in a Web role. Even though each role has its own "active" virtual machine (assuming we are working with single instances), Windows Azure creates copies of each role that are physically located on one or more servers. These servers may or may not be running in the same data center. These shadow VMs remain idle until they are needed.
Should the background process code crash the worker role and subsequently put the underlying virtual machine out of commission, Windows Azure detects this and automatically brings in one of the shadow worker roles. The faulty role is essentially discarded. If the worker role breaks again, then Windows Azure replaces it once more. All of this is happening without any downtime to the solution's Web role front end, or to any other services that may be running in the cloud.
Input Endpoints
Web roles used to be the only roles that could receive Internet traffic, but now worker roles can listen to any port specified in the service definition file. Internet traffic is received through the use of input endpoints. Input endpoints and their listening ports are declared in the service definition (*.csdef) file.Keep in mind that when you specify the port for your worker role to listen on, Windows Azure isn't actually going to assign that port to the worker. In reality, the load balancer will open two ports-one for the Internet and the other for your worker role. Suppose you wanted to create an FTP worker role and in your service definition file you specify port 21. This tells the fabric load balancer to open port 21 on the Internet side, open pseudo-random port 33476 on the LAN side, and begin routing FTP traffic to the FTP worker role.
In order to find out which port to initialize for the randomly assigned internal port, use the RoleEnvironment.CurrentRoleInstance.InstanceEndpoints["FtpIn"].IPEndpoint object.
Inter-Role Communication
Inter-Role Communication (IRC) allows multiple roles to talk to each other by exposing internal endpoints. With an internal endpoint, you specify a name instead of a port number. The Windows Azure application fabric will assign a port for you automatically and will also manage the name-to-port mapping.Here is an example of how you would specify an internal endpoint for IRC:
<ServiceDefinition xmlns=
"http://schemas.microsoft.com/ServiceHosting/2008/10/
ServiceDefinition" name="HelloWorld">
<WorkerRole name="WorkerRole1">
<Endpoints>
<InternalEndpoint name="NotifyWorker" protocol="tcp" />
</Endpoints>
</WorkerRole>
</ServiceDefinition>Example 1
In this example, NotifyWorker is the name of the internal endpoint of a worker role named WorkerRole1. Next, you need to define the internal endpoint, as follows:RoleInstanceEndpoint internalEndPoint =
RoleEnvironment.CurrentRoleInstance.
InstanceEndpoints["NotificationService"];
this.serviceHost.AddServiceEndpoint(
typeof(INameOfYourContract),
binding,
String.Format("net.tcp://{0}/NotifyWorker",
internalEndPoint.IPEndpoint));
WorkerRole.factory = new ChannelFactory<IClientNotification>(binding);Example 2
You only need to specify the IP endpoint of the other worker role instances in order to communicate with them. For example, you could get a list of these endpoints with the following routine:var current = RoleEnvironment.CurrentRoleInstance;
var endPoints = current.Role.Instances
.Where(instance => instance != current)
.Select(instance => instance.InstanceEndpoints["NotifyWorker"]);Example 3
IRC only works for roles in a single application deployment. Therefore, if you have multiple applications deployed and would like to enable some type of cross-application role communication, IRC won't work. You will need to use queues instead.Summary of Key Points
- Windows Azure roles represent different types of supported applications or services.
- There are two types of roles: Web roles and worker roles.
- Each role is assigned its own VM.
This excerpt is from the book, "SOA with .NET & Windows Azure: Realizing Service-Orientation with the Microsoft Platform", edited and co-authored by Thomas Erl, with David Chou, John deVadoss, Nitin Ghandi, Hanu Kommapalati, Brian Loesgen, Christoph Schittko, Herbjörn Wilhelmsen, and Mickie Williams, with additional contributions from Scott Golightly, Daryl Hogan, Jeff King, and Scott Seely, published by Prentice Hall Professional, June 2010, ISBN 0131582313, Copyright 2010 SOA Systems Inc. For a complete Table of Contents please visit: www.informit.com/title/0131582313
Microsoft Cloud Services debunks 13 cloud computing myths in its new Put the Cloud to Work for Your Organization TechNet page:

Click here to find out What Kind of Cloud Are You with simple questionnaires?
Ken Fromm (@frommww) explained Why Cloud Equals Better Outsourcing in a 8/27/2010 guest post to the ReadWriteCloud:
Business Week published an article recently that talked about changes in outsourcing. They got the cloud part right - massive disruptions and changes in the IT infrastructure stack both in technology and company power positions. But they got the outsourcing part wrong. Photo by Kevin.
There will be big changes for large and middle-tier outsourcing companies. But the large won't necessarily get larger. In fact, the combination of cloud and modern programming frameworks makes it perfect for small developers and medium IT shops to get a leg up on the big consulting firms, putting their models - and margins - at risk.
This post explains why cloud makes for better outsourcing. More specifically, why cloud lets you keep a better eye on outsourced development, lets you more quickly correct issues that might arise, and gives you more security when taking ownership of the work.
Most large firms don't go to large IT consulting shops to get their websites designed and developed. (At least, we hope they don't.) Design shops in combination with industrial strength content management systems (WordPress, Alfresco, and Drupal/Joomla/Zend combinations) let modest-size firms create robust sites for some of the largest companies. - and under modest budgets. The same is happening within Web app development. The combination of cloud infrastructure and programming frameworks lets a small team of developers compete on the same or even better terms than a large team of enterprise consultants and developers.
A Web application is not just a SaaS or Web 2.0 service built for multi-tenant use. The increasing ease of building them means that every application becomes a Web app and that almost every company can build or commission one. They can be utilities to extend your brand. They can be critical interfaces doing business with your customers and business partners. Or they can be for internal use built on top of open source business apps or as replacement for large complex business software.
Reason 1: Agility
The most pronounced advantage to developing in the cloud is agility - the ability to work faster and get more things done. In the case of outsourced development, agility translates into the ability to ramp up development of a project as well as identify if something is going off course.
The issue isn't so much the development of the look and feel because that's not tied to whether something is in the cloud or not (although the programming frameworks used for cloud development create common interface patterns that accelerate development). But when you start handling data and running algorithms to process the data - and when you modify the features to find out what works and what doesn't - that's where doing things in the cloud changes the game.
This is because build-test-deploy cycles are faster using cloud infrastructure and programming frameworks. The structure and flows for a Web app can be built in a few days or weeks. Data storage components can be brought on line quickly and multiple copies or versions of test data can be cycled in and out. Configuration and data management time is reduced, and so less time is spent messing with operating environments and copying and managing data stores - which means more time developing, testing code segments and algorithms, and making sure an application will work as intended.
And once you launch the application, this speed improvement extends to iterating on the design. No application is launched with the right features and flows - in fact, with minimal viable product approaches, the goal is not to get everything right, it's to get something to users to get data. Being able to rapidly iterate based on real-world data and to rapidly add or delete features (yes, deleting features is a part of popular design approaches) makes sure you get a viable product to users sooner rather than later.
Reason 2: Standard Architectures
Standard architectures and loosely coupled components are another benefit to using cloud infrastructure. Most IT consultants developing on managed servers will have likely have restrictions or gating factors with their infrastructure which will make development more serialized and the components more tightly configured.
The cloud enforces much looser coupling between application code, operating systems, Web and application tiers, and data storing and processing. Cloud developers are forced to compartmentalize and think in distributed terms.
This is in part due to the abstraction inherent in virtualization - more parts of systems are commoditized and therefore shielded from application code. Also, the components that are visible are accessed through increasingly standard distributed programming approaches.
This approach pays off because one or more pieces can be modified and then combined and relaunched in hours and minutes instead of half-days and more days. And because the elements launched are copies and created on the fly, instances can be started and stopped at will with little setup or clean up.
Developers can also build and test more asynchronously. Instead of running one version one day and another version another day, developers can run trials at the same time and share results the same day.
Reason 3: Transparency
A third reason for reduced risk with outsourcing development is the greater transparency provided by cloud development, meaning that a more logically separated architecture in combination with rapid launch-teardown-restart mentality makes it easier to know where things are, localize and identify problem areas, and take over ownership.
When you outsource development, you typically accept the language and the development environment that the IT shop specializes in. The big pieces - the operating system, Web server, database, and language - will be common and industrial strength. (Hopefully it's a form of LAMP stack.)
But with internally managed environments, the scripts that configure the system, the wiring of connections between components, and the side processes to maintain the system will all be largely custom and unique.
With a system in the cloud, a number of components are shielded by the virtualization layer. Any exposed connections typically work via standard interfaces. Configuration scripts and issues are either handled by third party software or services or at least widely documented and discussed. Configuration problems, scaling issues, and growing pains will still exist. But the enforced compartmentalization and the widely exposed connections reduces the complexity and administration of the system.
Cloud development and programming frameworks have led to the rapid acceptance of core design patterns. This means the application code and the system architecture will be recognizable to thousands of developers.
It also means that approaches and answers are available from a number of sources - which means you can more easily take over oversight and operation of the application with less of a learning curve and less risk.
Summary
Risks associated with developing applications - internally or using outside developers - will always remain. Things will go wrong regardless of the platform or method you're using. Teams can fall flat or deliver something other than what was intended. Algorithms might not quite work right. Data can get corrupted or overwritten. Bad programming and poor project management can touch any project.
But the combination of the cloud and common programming frameworks increases your chances of success - or at least, developing what you intend to develop.
Ken Fromm is a serial entrepreneur who has been a part of many innovation cycles. He co-founded two companies, Vivid Studios, one of the first interactive agencies in the Internet 1.0 days, and Loomia, a Web 2.0 recommendation and personalization company. He is currently working in business development for Appoxy, developing scalable cloud applications for others in the realtime and Internet of Things arenas. He can be found on Twitter at @frommww.
David Linthicum posted The Cloud and Connectivity on 8/27/2010 to ebizQ’s Where SOA Meets Cloud blog:
John C. Dvorak, who is anti cloud, had an interesting post entitled: The Cloud Fails Again. John lost his Internet connection for a while, and found himself dead in the water and thus another proof point that the cloud has a clear downside.
"Then along comes the Internet. The Internet brought with it a couple of interesting dimensions. First, it required everyone to get used to networking. The Internet was the world's biggest network. Anyone who wanted on needed to learn and accept computer networks as commonplace. The new mindset led to the reversal of computer evolution back toward mainframe computing--only now it's known as "cloud computing." The priests seem to have beaten back that trend toward individualism that began in 1975."
To be honest Dvorak has a point. One of the downsides of cloud computing is that it's dependent on connectivity. No connectivity, no cloud. At least public cloud.
I tell my clients the same thing I'm telling you. You have to plan for the loss of connectivity when considering leveraging cloud computing for your major business systems, and mediate the risks as much as you can. It's just a business continuity strategy with a few new dimensions.
So, how do you do that? First, plan on what needs to occur if connectivity is lost to your cloud or clouds. This typically means leveraging some sort of on premise system using data that's been recently synchronized from your cloud provider. Typically a laptop or two, or a single server left in the data center.
If you think this diminishes the value of cloud computing, to some extent you're right. It really goes to the value of the business application, or how much money is lost if you're down for any amount of time. If it's high, than you have to make sure to build the cost of data synchronization and maintaining a back-up on-site system when your router begins to blink red. Also, you should ask yourself in these situations if cloud computing is indeed a fit.
Fortunately, these days, connectivity issues are few and far between. However, you have to consider the risks involved in leveraging any type of computing model, cloud computing include. Then, you simple manage the risks. Nothing new about that.
In my experience, loss of significant Internet connectivity with my ATT DSL connection for the past two years has been less frequent than catastrophic disk crashes. (The headshot is of Linthicum, not Dvorak.)
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA)
Jeffrey Schwartz (@JeffreySchwartz) asserted “The Windows Azure Platform Appliance is coming this fall. While you can't buy one of these limited-production releases, it could portend the future of private clouds” in a deck for his feature-length Microsoft’s Cloud in a Box article for Redmond Channel Partner Online’s 9/1/2010 issue:
Microsoft's cloud in a box is coming this fall. And while only the company's three largest partners and one customer will be the first to deploy the new Windows Azure Platform Appliance, the successful implementation of these systems could re-define how the channel and services providers deliver IT in the years to come.
Microsoft further talked up the Appliance at last month's Financial Analyst Meeting (FAM), held in Redmond. While the average partner may not get their hands on something that resembles the Appliance anytime soon, Microsoft believes the Appliance could touch every ISV, systems integrator and managed services provider over time.
"It's a very real, very near-term thing and we will be expanding on that over the coming months and years as more and more customers and partners become involved," said Bob Muglia, president of the Microsoft server and tools business, speaking at a press briefing hours after taking the wraps off of the Appliance.
Just what is the Windows Azure Platform Appliance? It will initially consist of Windows Azure, SQL Azure and a Microsoft-specified configuration of servers, storage and networking gear. The emphasis is on Microsoft-specified. While OEMs Dell Inc., Fujitsu Ltd. and Hewlett-Packard Co. are the first partners that will be offering the Appliance as part of their managed services offerings, Microsoft determines the specs of those Appliances. Not only that, Microsoft remotely manages the Appliances, including providing platform software updates. Owners of the Appliances still can develop and deploy applications that run atop those Appliances.
Muglia uses the cable or satellite provider set-top-box analogy, where the user has no control over the software or hardware in the box but they can choose from a broad array of programming. "You just turn the TV on, and it works," he said in his WPC keynote address. "That set-top box is fully updated. That's exactly what we're doing with the Windows Azure Appliance."
[Click image for larger view.]"It's a very real, very near-term thing, and we'll be expanding on that over the coming months and years as more and more customers and partners become involved."
Bob Muglia, President, Server and Tools Business, MicrosoftThe Appliance will mirror the cloud service that Microsoft launched earlier this year. Anyone who has the Appliance can connect it to the Microsoft Windows Azure service. Microsoft says it will maintain a flow of new software to all of those Appliances to keep them up-to-date, just like set-top boxes are updated by cable or satellite providers.
"The customer still has control over things like when to actually update the software that's on there, what applications run, what sets of underlying operating system services and SQL services to run," Muglia said. "All of those are controlled by the customer, and one of the things we'd be doing is working pretty closely with our service providers to give them a fair amount of opportunity."
One of the reasons Microsoft technically is able to launch a cloud appliance is because it intends to run the same Appliances customers have in their datacenters in its own datacenters, says Robert Wahbe, Microsoft corporate vice president for server and tools marketing. "That's a very important element of being able to deliver the services platform," Wahbe says. "You can't really deliver on this notion unless you're in fact running a public cloud yourself. That's the only way you can test the scale of these configurations."
In addition to providing defined server, network and storage specifications, the Appliance will employ "innovative" power, cooling and automation technology, according to Microsoft. Customers who choose to buy the Appliance can address one of the key barriers to cloud computing: concerns about maintaining physical control of the systems, data sovereignty and compliance.
The first models deployed by Dell, Fujitsu, HP and eBay will weigh in at 880 servers -- certainly not aimed at the lightweight or moderate systems architecture. "This is not a small thing, it's designed for scale. It's very large; over time we'll make it both smaller and larger," Muglia told reporters and analysts.
Still, there are plenty of financial services firms, government and military agencies and other customers who simply won't entertain running their data in any public cloud service. "It's table stakes to get these customers to look at Windows Azure at all," says IDC analyst Al Gillen, who has looked at the Appliance closely both at the WPC and at the FAM.
The Appliance allows partners to bring it to those customers, and use the public cloud for non-mission-critical data or extended compute or platform services as needs require. While the total addressable market for the first crop of the Appliance will be small, Gillen believes the long-term success of Windows Azure is tied to the acceptance of the Appliance by large providers initially and others down the road. "This is the first step in taking this to a much more mainstream availability," Gillen says.

Ellen Rubin claimed hybrid clouds are The New Normal in Enterprise Infrastructure in this 8/26/2010 post to the CloudSwitch blog:
As we work with dozens of companies that are actively running pilots and doing early deployments in the cloud, it made me think about what the “new normal” will look like in enterprise IT infrastructure. A recent report from the Yankee Group shows that adoption of cloud is accelerating, with 24% of large enterprises already using IaaS, and another 37% expected to adopt IaaS within the next 24 months.
It’s clearly a time of major shifts in the IT world, and while we wait for the hype to subside and the smoke to clear, some early outlines of the new paradigm are emerging. Here’s what it looks like to us at CloudSwitch:
- Hybrid is the dominant architecture: on-prem environments (be they traditional data centers or the emerging private clouds) will need to be federated with public clouds for capacity on-demand. This is particularly true for spikey apps and use cases that are driven by short-term peaks such as marketing campaigns, load/scale testing and new product launches. The tie-back to the data center from external pools of resources is a critical component, as is maintaining enterprise-class security and control over all environments. Multiple cloud providers, APIs and hypervisors will co-exist and must be factored into the federation strategy.
- Applications are “tiered” into categories of workloads: just as storage has been tiered based on how frequently it’s accessed and how important it is to mission-critical operations, application workloads will be categorized based on their infrastructure requirements. In the end, app developers and users don’t really want to care about where and how the application is hosted and managed; they just want IT to ensure a specific QoS and meet specific business requirements around geography, compliance, etc. The cloud offers a new opportunity to access a much broader range of resources that can be “fit” against the needs of the business. In some cases, the current IT infrastructure is over-provisioning and over-delivering production gear for lower-importance/usage apps; in other cases it’s woefully under-delivering.
- IT becomes a service-enabler, not just a passive provider of infrastructure resources: IT is now in a position to provide self-service capabilities across a large set of resources, internally and externally, to developers, field and support teams. This requires a new set of skills, as we’ve blogged about before, but the cloud gives IT the opportunity to meet business needs in a much more agile and scalable way, while still maintaining control over who gets to use which resources and how.
- The channel shifts from resellers to service providers: as noted by Andrew Hickey at ChannelWeb, the opportunities for resellers will need to shift as companies reduce their large hardware and software buys in favor of the cloud. The new focus will be on providing services and consulting with an opex model and monthly payments, and expertise in change management and predictive use models will become core competencies. We’ve already started to see this shift at CloudSwitch with a new crop of cloud-focused consulting/SI boutiques springing up in the market to help CIOs plan their cloud deployments.
For many enterprises, these shifts are still being discussed at a high level as CIOs formulate their cloud strategies. Other organizations are diving right in and selecting a set of applications to showcase the benefits of cloud to internal stakeholders. We’ve been fortunate at CloudSwitch to work with some of the earliest cloud adopters and with our cloud provider partners to help define some of the “new normal.”
Dana Gardner reported on “Private and Hybrid Cloud Computing Models in the Enterprise” in his Trio of Cloud Companies Collaborate on Private Cloud Platform Offerings BriefingsDirect post of 8/26/2010:

A trio of cloud ecosystem companies have collaborated to offer an integrated technology platform that aims to deliver a swift on-ramp to private and hybrid cloud computing models in the enterprise.
newScale, rPath and Eucalyptus Systems are combining their individual technology strengths in a one-two-three punch that promises to help businesses pump up their IT agility through cloud computing. [Disclosure: rPath is a sponsor of BriefingsDirect podcasts.]
The companies will work with integration services provider MomentumSI to deliver on this enterprise-ready platform that relies on cloud computing, integrating infrastructure for private and hybrid clouds with enterprise IT self-service, and system automation.
No cloud-in-a-box
From my perspective, cloud solutions won’t come in a box, nor are traditional internal IT technologies and skills apt to seamlessly spin up mission-ready cloud services. Neither are cloud providers so far able to provide custom or "shrink-wrapped" offerings that conform to a specific enterprise’s situation and needs. That leaves a practical void, and therefore an opportunity, in the market.
This trio of companies is betting that self-service private and hybrid cloud computing demand will continue to surge as companies press IT departments to deliver on-demand infrastructure services readily available from public clouds like Amazon EC2. Since many IT organizations aren’t ready to make the leap, they don’t have the infrastructure or process maturity to transition to the public cloud. That’s where the new solution comes in.Incidentally, you should soon expect similar cloud starter packages of technology and services, including SaaS management capabilities, from a variety of vendors and partnerships. Indeed, next week's VWworld conference should be rife with such news.
The short list of packaged private cloud providers includes VMware, Citrix, TIBCO, Microsoft, HP, IBM, Red Hat, WSo2, RightScale, RackSpace, Progress Software and Oracle/Sun. Who else would you add to the list? [Disclosure: HP, Progress and WSO2 are sponsors of BriefingsDirect podcasts].
Well, add Red Hat, which this week preempted VWworld with news of its own path to private cloud offerings, saying only Red Hat and Microsoft can offer the full cloud lifecycle parts and maintenance. That may be a stretch, but Red Hat likes to be bold in its marketing.Behind the scenes
Here’s how the newScale, rPath and Eucalyptus Systems collaboration looks under the hood. newScale, which provides self-service IT storefronts, brings its e-commerce ordering experience to the table. newScale’s software lets IT run on-demand provisioning, enforce policy-based controls, manage lifecycle workloads and track usage for billing.
rPath will chip in its automating system development and maintenance technologies. With rPath in the mix, the platform can automate system construction, maintenance, and on-demand image generation for deployment across physical, virtual and cloud environments.
This trio of companies is betting that self-service private and hybrid cloud computing demand will continue to surge
For its part, Eucalyptus Systems, an open source private cloud software developer, will offer infrastructure software that helps organizations deploy massively scalable private and hybrid cloud computing environments securely. MomentumSI comes in on the back end to deliver the solution.
It's hard to imagine that full private and/or hybrid clouds are fully ready from any singe single vendor. And who would want that, and the inherent risk of lock-in, a one-stop cloud shop would entail? Best-of-breed and open source components work just as well for cloud as for traditional IT infrastructure approaches. Server, storage and network virtualization may make the ecosystem approach even more practical and cost-efficient for private clouds. Pervasive and complete management and governance are the real keys.
My take is that ecosystem-based solutions then are the first, best way that many organizations will likely actually use and deploy cloud services. The technology value triumvirate of newScale, rPath and Eucalyptus—with solution practice experience of MomentumSI—is an excellent example of the ecosystem approach most likely to become the way that private cloud models actually work for enterprises for the next few years.
BriefingsDirect contributor Jennifer LeClaire provided editorial assistance and research on this post. She can be reached at http://www.linkedin.com/in/jleclaire and http://www.jenniferleclaire.com.

<Return to section navigation list>
Cloud Security and Governance
David Pallman recommended and analyzed Threat Modeling the Cloud in this detailed 8/28/2010 post:
If there’s one issue in cloud computing you have to revisit regularly, it’s security. Security concerns, real or imagined, must be squarely addressed in order to convince an organization to use cloud computing. One highly useful technique for analyzing security issues and designing defenses is threat modeling, a security analysis technique long used at Microsoft.
To illustrate how threat modeling works in a cloud computing context, let’s address a specific threat. A common concern is that the use of shared resources in the cloud might compromise the security of your data by allowing it to fall into the wrong hands—what we call Data Isolation Failure. A data isolation failure is one of the primary risks organizations considering cloud computing worry about.
To create our threat model, we’ll start with the end result we’re trying to avoid: data in the wrong hands.

Next we need to think about what can lead to this end result that we don’t want. How could data of yours in the cloud end up in the wrong hands? It seems this could happen deliberately or by accident. We can draw two nodes, one for deliberate compromise and one for accidental compromise; we number the nodes so that we can reference them in discussions. Either one of these conditions is sufficient to cause data to be in the wrong hands, so this is an OR condition. We’ll see later on how to show an AND condition.
Let’s identify the causes of accidental data compromise (1.1). One would be human failure to set the proper restrictions in the first place: for example, leaving a commonly used or easily-guessed database password in place. Another might be a failure on the part of the cloud infrastructure to enforce security properly. Yet another cause might be hardware failure, where a failed drive is taken out of the data center for repair. These and other causes are added to the tree, which now looks like this:
We can now do the same for the deliberately compromised branch (1.2). Some causes include an inside job, which could happen within your business but could also happen at the cloud provider. Another deliberate compromise would be a hacker observing data in transmission. These and other causes could be developed further, but we’ll stop here for now.
If we consider these causes sufficiently developed, we can explore mitigations to the root causes, the bottom leaves of the tree. These mitigations are shown in circles in the diagram below (no mitigation is shown for the “data in transmission observed” node because it needs to be developed further). For cloud threat modeling I like to color code my mitigations to show the responsible party: green for the business, yellow for the cloud provider, red for a third party.
You should not start to identify mitigations until your threat tree is fully developed, or you’ll go down rabbit trails thinking about mitigations rather than threats. Stay focused on the threats. I have deliberately violated this rule just now in order to show why it’s important. At the start of this article we identified the threat we were trying to model as “data in the wrong hands”. That was an insufficiently described threat, and we left out an important consideration: is the data intelligible to the party that obtains it? While we don’t want data falling into the wrong hands under any circumstances, we certainly feel better off if the data is unintelligible to the recipient. The threat tree we have just developed, then, is really a subtree of a threat we can state more completely as: Other parties obtain intelligible data in cloud. The top of our tree now looks like this, with 2 conditions that must both be true. The arc connecting the branches indicates an AND relationship.
The addition of this second condition is crucial, for two reasons. First, failing to consider all of the aspects in a threat model may give you a false sense of security when you haven’t examined all of the angles. More importantly, though, this second condition is something we can easily do something about by having our application encrypt the data it stores and transmits. In contrast we didn't have direct control over all of the first branch's mitigations. Let’s develop the data intelligible side of the tree a bit more. For brevity reasons we’ll just go to one more level, then stop and add mitigations.Mitigation is much easier in this subtree because data encryption is in the control of the business. The business merely needs to decide to encrypt, do it well, and protect and rotate its keys. Whenever you can directly mitigate rather than depending on another party to do the right thing you’re in a much better position. The full tree that we've developed so far now looks like this.
Since the data intelligible and data in the wrong hands conditions must both be true for this threat to be material, mitigating just one of the branches mitigates the entire threat. That doesn’t mean you should ignore the other branch, but it does mean one of the branches is likely superior in terms of your ability to defend against it. This may enable you to identify a branch and its mitigation(s) as the critical mitigation path to focus on.
While this example is not completely developed I hope it illustrates the spirit of the technique and you can find plenty of reference materials for threat modeling on MSDN. Cloud security will continue to be a hot topic, and the best way to make some headway is to get specific about concerns and defenses. Threat modeling is a good way to do exactly that.








K. Scott Morrison discusses a recent Yankee Group study about cloud security in his What, Me Worry? post of 8/26/2010:
According to Yahoo news Infrastructure Services Users Worry Less About Security. This article references a Yankee Group study that found although security remains a top barrier slowing the adoption of cloud services in the enterprise, most companies that have adopted Infrastructure-as-a-Service (IaaS) worry less about security once they begin using the technology.
Once they’ve made the leap into the cloud, the article suggests, users conclude that the security issues aren’t as significant as they had been led to believe. I find myself in partial agreement with this; the industry has created a level of hysteria around cloud security that isn’t necessarily productive. Taking pot shots at the security model in the cloud is pretty easy, and so many do—regardless of whether their aim is true (and for many, their aim is not).
Nevertheless, my interpretation of these results is that they are uncovering less a phenomenon of confidence genuinely earned and more a case of misplaced trust. The article makes an interesting observation about the source of this trust:
Twenty-nine percent of the companies in the survey viewed system integrators as their most trusted suppliers of cloud computing. But among early adopters of IaaS, 33 percent said they turn to telecom companies first.
Do you remember, back around the turn of the century, when large-scale PKI was first emerging? The prevailing wisdom was that state-sponsored PKI should be administered by the post offices because this organization above all was perceived as trustworthy (as well as being centralized and a national responsibility). Hong Kong, for instance, adopted this model. But in general, the postal-run PKI model didn’t take hold, and today few federal post services are in the business of administering national identity. Trust doesn’t transfer well, and trust with letters and packages doesn’t easily extend to trust with identity.
Investing generalized trust in the telcos reminds me of the early PKI experience. The market is immature, and because of this so too are our impressions. Truthfully, I think that the telcos will be good cloud providers—not because I have an inherent trust in them (I actively dislike my cell provider on most days), but because the telcos I’ve spoken to that have engaged in cloud initiatives are actually executing extremely well. Nevertheless, I don’t think I should trust them to secure my applications. This is ultimately my responsibility as a cloud customer, and because of I can’t reasonably trust any provider entirely, I must assume a highly defensive stance in how I secure my cloud-resident applications.
I hope my provider is good at security; but I need to assume he is not, and prepare myself accordingly.

<Return to section navigation list>
Cloud Computing Events
Credera announced Credera Hosts Webinar on "Microsoft Cloud Computing: A Deeper Dive into Windows Azure" on 8/31/2010 at 10:00 AM PDT:
Join us for a Webinar on August 31, 2010 at 12 PM CDT
Reserve your Webinar seat now at: https://www1.gotomeeting.com/register/585015272
Windows Azure, Microsoft SQL Azure and AppFabric are the key components of the Windows Azure platform. By adopting Azure, businesses will reap the following benefits:
- Agility
- Efficiency
- Focus on Priorities
- Reliable Service
- Simplicity
Join us to learn more about Azure and the value it can have on your business.
Title: "Microsoft Cloud Computing: A Deeper Dive into Windows Azure"
Date: Tuesday, August 31, 2010
Time: 12:00 - 1:00 PM CDT
After registering, you will receive a confirmation email containing information about joining the Webinar.
System Requirements
PC-based attendees
Required: Windows® 7, Vista, XP, 2003 Server or 2000
Macintosh®-based attendees
Required: Mac OS® X 10.4.11 (Tiger®) or newer )

Chris P_Intel announced upcoming Intel presentations in his Intel IT's Virtualization Journey post of 8/23/2010:
Next week VMware is hosting VMworld and what seems like the entire technology industry will be talking about virtualization ... like we haven't been for the past several years. Anyway, a few members of the Intel IT technology team will be on hand at VMworld in the Moscone Center next week to share what we are doing with virtualization in both the data center and on our client platforms.
Unlike the IT engineer in this video who is using a rocket to put his data center in the cloud, Intel IT is using an accelerated virtualization approach to lay the foundation for our enterprise private cloud. Next week Shesha Krishnapura (Principal Engineer, Intel IT) will co-present with Dylan Larson (Marketing Director, Intel Data Center Group) in a session titled "Virtualization Transitions: The Journey to Enterprise Cloud Computing". This session will occur Wed Sept 1 at 10:30 AM in Moscone North Room 135
Dylan will cover the technologies and capabilities required to take enterprises and service providers worldwide on their journey to cloud computing. They will outline and detail our technologies in compute, networking, and storage. They will cover the economics of cloud computing and Intel's vision to invest in technologies, people, and solutions through 2015. Shesha will discuss how Intel IT has gone from consolidating data centers to virtualizing infrastructures to setting the foundation for enterprise-wide cloud deployments.
In a separate session focused on client virtualization, Dave Buchholz (Principal Engineer, IT) will conduct several chalk talks on Enabling Device-Independent Mobility Using Client Virtualization. You can find Dave inside the Intel booth.
Dave will discuss an internal Intel IT Proof of Concept showing the future of client computing using device-independent mobility (DIM). We are evaluating implementing various client virtualization technologies and the use of virtual containers to abstract the OS; applications; corporate and personal data, workspaces and user-specific settings. In this model, users can access their applications and information from any device, anywhere, anytime. Our goal is to provide side-by-side personal and professional environments on the same hardware devices and remove many of the platform qualification and adoption roadblocks faced by many IT shops today.
If you are going to VMworld, we hope to see you there. If not, visit the http://www.intel.com/IT program website and explore our IT best practices on virtualization.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Ted Hoff asked is OpenStack - The Answer to: How do We Compete with Amazon? in this 8/27/2010 post to the High Scalability blog:

The Silicon Valley Cloud Computing Group had a meetup Wednesday on OpenStack, whose tag line is the open source, open standards cloud. I was shocked at the large turnout. 287 people registered and it looked like a large percentage of them actually showed up. I wonder, was it the gourmet pizza, the free t-shirts, or are people really that interested in OpenStack? And if they are really interested, why are they that interested? On the surface an open cloud doesn't seem all that sexy a topic, but with contributions from NASA, from Rackspace, and from a very avid user community, a lot of interest there seems to be.
The brief intro blurb to OpenStack is:
OpenStack allows any organization to create and offer cloud computing capabilities using open source software running on standard hardware. OpenStack Compute is software for automatically creating and managing large groups of virtual private servers. OpenStack Storage is software for creating redundant, scalable object storage using clusters of commodity servers to store terabytes or even petabytes of data.
This meeting seemed eerily familiar because oh so long ago, like just a few months ago, NASA presented on their internal cloud platform Nebula. And in that short a time everything changed. OpenStack was born, an active development community formed, and OpenStack is near its first official release. How quickly they grow up.
At the time I remember thinking about Nebula: wow, the government is really screwed up, good on these guys for trying to fix it, what a great job they are doing, not sure it would work for anyone else; going with an Amazon API compatibility strategy makes sense; and what a hodgepodge of different components, I bet it will be an operations nightmare.
I learned yesterday that the biggest change is that they are dumping Amazon compatibility mode. Since Amazon hasn't said it's OK to use their APIs it's risky legally to clone them. But I suspect the most important reason is the entrance of Rackspace into the mix. Instead of Amazon APIs they are moving to Rackspace APIs. This makes perfect sense and argues for the result actually working in a real-life cloud since Rackspace is a real-life cloud vendor. Rackspace is also very active in the open source movement, so this is a great match and should solidify adoption.
I imagine what Rackspace gets out of this is, that if successful, they will at least have some sort of leverage with Amazon. Amazon is a machine. Amazon executes to perfection and they release new features at a relentless pace with no signs of slowing down. They don't leave much of a door open for others to get into the game. With a real open cloud alternative it might allow a lot of people to play in the cloud space that would have been squeezed out before.
What Amazon can't match is the open cloud's capability of simultaneous supporting applications that can run seamlessly in a private cloud hosted in a corporate datacenter, in local development and test clouds, and in a full featured public cloud.
What I've heard is that this is a move by public cloud vendors to commoditize the cloud infrastructure, which then allows the concentration on selling managed services. This strategy can only work if the infrastructure is a true commodity. Amazon has the ability to keep adding high-end features that can potentially nullify the commodity argument. Can an open source cloud move fast enough to compete?
Every framework and every API is a form of lock-in, but this feels a lot less like a strangle-hold. Amazon is concerned enough at least to bother condemning private clouds as unworkable and completely unnecessary with Amazon around. It at least means they care.
Eucalyptus, an Amazon compatible clone, was once part of Nebula but was dropped in favor of building their own software and using Rackspace's work. Their reasoning was they had scaling problems with Eucalyptus and source code changes weren't being merged into the main release so they had to maintain a separate code base, which isn't a viable working relationship. So they opted for more control and are going their own way. Eucalyptus hasn't stayed single long. They are forming a new self-service private cloud along with newScale and rPath.
A key design point emphasized in the meeting is that the design is componentized. They want you to be able swap in and out different implementations so it can be customized for your needs. It should be able to work on your network topology and on your disks. If you want a different authentication system then that should be possible. It's still early though and their philosophy is make it work and then make it good, so it may be a while before they reach component nirvana, but that's the vision. Part of the win of partnering with Rackspace is they've been through these wars before and understand how to build this sort of architecture.
The other point they really really wanted you to take home from the meeting is that this is the most openest open source project you've ever seen. An Apache style license is used so the entire source base is open for use and abuse. They rejected an open core model, so all the source is available and all the features are available. You are without limits.
The other sense that the project is open is that it has a very active development community. Have you been frustrated by other open source projects that give you a big rejection notice when you try to contribute code because you haven't yet attained inner sanctum level 32? OpenStack promises to be different. They will actually merge your code in. How long this can last once real releases start happening, who knows, but it's something.
Sebastion Stadl, founder of both the cloud meetup and Scalr, said he will talk to the OpenStack folks about making Scalr the RightScale equivalent for OpenStack. This would be great. The feeling I got from the talk is that OpenStack will primarily work on the framework, not operations, monitoring, etc., which is a mistake IMHO, but having Scalr on the job would help patch that hole in the offering.
The vibe from the meeting was excited and enthusiastic, like something was happening. There wasn't a lot of technical detail in the presentations. This was much more of a coming-out party, the purpose of which is to inform society that there's a new force in the market. We'll see how many hearts get broken.
Lee Pender reported a Colorful Battle in Store Between Red Hat and Azure in this 8/26/2010 article for Redmond Channel Partner Online:
The darling of the open source world revealed this week that it has developed a Platform-as-a-Service (PaaS, of course -- but not that Paas, or even this one) offering, primarily aimed at companies looking to create "hybrid" clouds, or mixed Internet-service and on-premises IT environments.
In revealing its new platform, Red Hat did perhaps more than it realized to validate Microsoft's competitive offer. Quoth the news story linked above:
"Paul Cormier, executive vice-president and president of Red Hat's products and technologies unit, said that Red Hat and Microsoft are the only two companies that can offer the entire stack necessary to run a hybrid cloud-enabled IT environment. He added that some virtualization vendors lack the operating system and a 'credible middleware offering' to make this claim."
First of all, mee-ow! Take that, VMware! Of course, Cormier is probably right, but he might not realize how such a statement plays into Microsoft's hands. A pure-cloud environment, in which everything runs on an Internet-based platform hosted in a vendor's data center and is delivered to a company on a subscription basis, levels the playing field somewhat for companies trying to compete against Microsoft.
After all, if a company really is going to just chuck its whole IT infrastructure into the cloud, there's no reason for it not to consider a fresh start with a brand-new vendor. But nobody's doing that -- and Red Hat gets that (as does Microsoft). Companies are going to farm some functionality out to the cloud but continue to house some of it -- probably most of it -- within their own walls.
And that's where Microsoft should have the same old advantage it has had over Red Hat and other vendors for years: its massive installed base. It's the old pitch extended to a new model: Why mess around with multiple vendors when you can get everything from Redmond, both what you have in-house and what you need in a hosted model?
OK, so maybe the pitch isn't quite that simple, but it's not far off. And it is one big point in Microsoft's favor as the company begins in earnest to compete in the cloud with rivals such as Amazon, Google and now Red Hat. Plus ca change, as the French would say...The more things change, the more things stay the same.
What's your take on Microsoft competing with Red Hat in the cloud? How compelling does Red Hat's PaaS offer look at first blush compared to Azure? Send your thoughts to lpender@rcpmag.com.
Audrey Watters asked Deltacloud: Is This the Cloud API Standard We've Been Looking For? in an 8/26/2010 post to the ReadWriteCloud:
Despite Amazon's leadership and market share in cloud computing, many in the industry have been reluctant to crown Amazon S3's API as the standard, arguing it's too early and too vendor-specific.
And while the former may still be true, the latter could be addressed with yesterday's announcement by Red Hat that the company is open-sourcing its Deltacloud API. More importantly, perhaps, Red Hat has contributed Deltacloud to the Apache Software Foundation where it is currently an incubator project. This moves the API out of the control of a single vendor and under the supervision of an external governing body.
The Deltacloud core provides a REST API, support for all major cloud service providers (including Amazon, GoGrid, and Rackspace, and backwards compatibility across versions.
The main advantage of Deltacloud is, in the broadest sense, interoperability. Red Hat also lists the following as benefits of the API:
- The API can either be offered directly by the cloud provider, or by individual users running their own server
- Client libraries can easily be written in any number of computer languages, and are already available for popular ones
- The core API logic resides on the API server, enabling consistent behavior across all client libraries
- Support for new clouds can be added to the API without changes to clients
Red Hat has also submitted Deltacloud to the Distributed Management Task Force (DMTF) as a potential industry standard. According to Red Hat's press release, this move will enable "the portability and interoperability needed to realize the full promise of cloud computing. Open source, under an Apache model, enables a true community-driven solution - unique, and needed, in the cloud computing landscape."
With all the providers supported, this may be the best representation of what an API standard would look like. But the Deltacloud Initiative is also taking requests for what other features should be included.

<Return to section navigation list>

















0 comments:
Post a Comment