Windows Azure and Cloud Computing Posts for 7/31/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Updated 8/1/2010: See SQL Azure Database, Codename “Dallas” and OData, Live Windows Azure Apps, APIs, Tools and Test Harnesses, Cloud Computing Events and Other Cloud Computing Platforms and Services sections for articles marked •.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA)
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Azure Blob, Drive, Table and Queue Services
David Needle wrote Cloud Storage Poised to Save Enterprises Money: Report for Datamation’s Hot Topics section on 7/30/2010:
Public cloud storage services are fast becoming a more attractive option for the enterprise, according to a new report by research firm Ovum.
In its "Clouds Open for Enterprise Storage" report, Ovum said that a new generation of services is emerging in public clouds that can handle live data generated by applications running on customers' premises. These storage services are designed to be used separately from other cloud services and are attractively priced compared to traditional, on-premises storage systems.
"Not only do they relieve the burden of storing data on customers' premises, but they also have the multiplying effect of transferring to the cloud provider the responsibility of backing up that data," Ovum senior analyst Timothy Stammers said in a statement.
Vendors have been pitching online storage services to IT for over a decade, but they never reached their potential or won significant adoption."Considerable investments were made in these companies, and industry observers predicted that they would thrive. But the opposite happened, and the [online storage service provider] movement collapsed within a few years," Ovum said in its report.
Cost was a big factor in that failure. Because the online storage service providers were using the same enterprise storage systems as their customers, their services weren't significantly cheaper than what customers were paying for their own in-house storage. Stammers also noted that these providers faced hefty network bandwidth costs and resistance from customers still unfamiliar with the emerging concept of public cloud services.
But a lot has changed over the past several years. The price of network bandwidth has plummeted and, with IT budgets under considerable pressure in a shaky economy, CIOs are looking for ways to effectively cut costs. Also, far from being a foreign concept, cloud computing has become far more established with the success of Amazon (NASDAQ: AMZN), Salesforce (NYSE: CRM) and other well-known providers.
Ovum also said service providers are starting to use a new generation of object-oriented storage technology, which stores very large volumes of data at far lower cost than conventional enterprise storage systems.
In an interview with InternetNews.com, Stammers pointed to several startups that already offer these new cloud services, including Nirvanix, Nasumi and Ctera. "Nirvanix is the oldest with about 700 customers in three years, which is pretty impressive," Stammers said.
He also noted that many of these new cloud storage providers aren't even operating the storage systems themselves. Instead, they leverage giant storage clouds run by Amazon, Microsoft (NASDAQ: MSFT) or RackSpace (NYSE: RAX) to get further economy of scale.
These companies offer enterprise customers a gateway system that translates traditional file structures to the object-oriented storage.
"To the customer it still looks like ordinary storage and there's caching to alleviate latency issues," Stammers said. "Typically these systems also provide their own backup, but companies may also choose to do that on their own for an extra level of protection."
Related Articles
Top 10 Reasons Cloud Computing Deployments Fail SaaS Market Growing by Leaps and Bounds: Gartner Cloud Computing's Effect on the Hosting Industry Google's Government Deal Shows Cloud Promise, Challenges SAP: Private Clouds Have a Role in the Enterprise
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
Updated My Test Drive Project Houston CTP1 with SQL Azure tutorial on 7/31/2010 by using the Northwind database (ww0h28tyc2.database.windows.net) published by the SQL Azure Houston team (@SQLHouston) on 7/31/2010 with read/write and EXEC permissions for Database: nwind, Login: nwind, Password: #SQLHouston. See Tweet1 and Tweet2:

This means you can test SQL Azure Houston without having a SQL Azure account. (Repeated from Windows Azure and Cloud Computing Posts for 7/29/2010+.)
Niall Best analyzes Backup options for SQL Azure in this 7/23/2010 post (missed when posted). See my clarification below:
SQL Azure makes the move to using Windows Azure easy for many people. Lots of companies use SQL server and have existing databases and applications in SQL server. It’s much less daunting moving your SQL server database than re-coding the storage in Windows Azure tables.
One major sticking point with SQL Azure is that there is no native backup.
Microsoft do backup your database on your behalf from time to time but it is not user accessible and Microsoft say that they use this only to restore your data in severe cases of hardware failure.*
Realistically nobody is going to run anything other than a tech demo without a backup solution for their SQL database in Azure, so what can be done?
Back in the early SQL Azure beta days the SQL Azure migration wizard was the only real way to get data in and out of the cloud databases. Sure you could use raw BCP but the Migration Wizard is built on top of it.
It’s a good tool, especially considering it’s free and seems to have been continually developed. My main issue was that it was slow, and in older versions I had to copy the entire database every time rather than taking update snapshots. This leads nicely onto the next backup option.
Red Gate make, amongst other things, excellent SQL server productivity tools. I had been a fan of SQL Data Compare for years syncing up staging and production databases. I originally tested their standard SQL Data Compare tool with SQL Azure and it didn’t work, I was initially crushed.
Over a few weeks of emails and some calls expressing how useful their tools would be if SQL Azure was supported Red Gate started a beta program for SQL Data Compare and SQL Compare (schema compare) Sign up to the beta here
SQL Data Compare is my favourite SQL Azure backup tool as it’s very fast. Rather than copying all the data, you compare the differences between your last local backup SQL database and your SQL Azure database. The software then snapshots the differences and updates the local database to reflect the changes from the database in the cloud.
There are a whole host of options when comparing the databases, you can select individual tables and columns and even write your own compare where statements to get super granular backups.
Some people may worry about the cost once it comes out of beta but trust me it’s the best tool a DBA can have, it just works, very, very well.
Data Sync for SQL Azure has been around since November ’09 and it’s pretty much the same as the Migration Wizard. Its build on top of the Sync Framework 2.0 but it’s not as customisable as SQL Data Compare from RedGate, but it does allow scheduling of synchronisation so feels more like a backup tool.
The best of a bad situation?
I know many people are waiting for the traditional SQL backup / restore interface and the ability to store their SQL Azure backups in the local data centre blob storage. I guess due to the multi tenancy of the SQL Azure setup this isn’t easy (or they would have done it already, right?)
All three tools are free (or in beta) when this was posted so try all three. My personal favourite are the Red Gate tools are they are so much more than just a backup tool, but then they are also the most expensive.
* Clarification: SQL Azure maintains three database replicas, each of which is stored on an individual physical machine. In the event of data loss or corruption, the defective replica is replaced by a new duplicate. The issue is that SQL Azure doesn’t offer a streamlined means to create archival backups. In my opinion, SQL Azure Data Sync comes close to that goal by providing automated incremental backups to an on-premises SQL Server instance.
Lubor Kollar and George Varghese explain Loading data to SQL Azure the fast way in a 7/31/2010 post to the Microsoft SQL Server Development Customer Advisory Team:
Introduction
There are various data migration tools available, such as the SQL Server BCP Utility, SQL Server Integration Services (SSIS), Import and Export Data and SQL Server Management Studio (SSMS). You could even use the Bulk Copy API to author your own customized data upload application. An example of one such custom data migration application that is based on BCP is the SQL Azure Migration Wizard.
In this blog we discuss
1. Tools you have to maximize data upload speeds to SQL Azure
2. Analysis of results from data upload tests
3. Best Practices drawn from the analysis to help choose the option that works best for you
Choose the right Tool
Here are some popular tools that are commonly used for bulk upload.
BCP: This is a utility available with the SQL command line utilities that is designed for high performing bulk upload to a single SQL Server/Azure database.
SSIS: This is a powerful tool when operating on multiple heterogeneous data sources and destinations. This tool provides support for complex workflow and data transformation between the source and destination.
In some cases it is a good idea to use a hybrid combination of SSIS for workflow and BCP for bulk load to leverage the benefits of both the tools.
Import & Export Data: A simple wizard that does not offer the wide range of configuration that SSIS provides, but is very handy for schema migration and smaller data uploads.
SSMS: This tool has the option of generating SQL Azure schema and data migration scripts. It is very useful for schema migration, but is not recommended for large data uploads.
Bulk Copy API: In the case where you need to build your own tool for maximum flexibility of programming, you could use the Bulk Copy API. This API is highly efficient and provides bulk performance similar to BCP.
Set Up
To standardize this analysis, we have chosen to start with a simple flat-file data source with 1GB of data and 7,999,406 rows.
The destination table was set up with one clustered index. It had a size of 142 bytes per row.
We have focused this analysis on the two distinct scenarios of having data located inside and outside Windows Azure.
After sampling the various tools, we have identified BCP and SSIS as the top two performing tools for this analysis. These tools were used under various scenarios to determine the setup that provides fastest data upload speeds.
When using BCP, we used the –F and –L options to specify the first and last rows of the flat file for the upload. This was useful to avoid having to physically split the data file to achieve multiple stream upload.
When using SSIS, we split source data into multiple files on the file system. These were then referenced by Flat File Components in the SSIS designer. Each input file was connected to a ADO .Net Component that had the Use Bulk Insert when possible flag checked.
Approach
SQL Azure must be accessed from local client tool over the Internet. This network has three properties that impact the time required to load data to SQL Azure.
- Latency: The delay introduced by the network in getting the data packets to the server.
- Bandwidth: The capacity of the network connection.
- Reliability: Prone to disconnects due to external systems.
Latency causes an increase in time required to transfer data to SQL Azure. The best way to mitigate this effect is to transfer data using multiple concurrent streams. However, the efficiency of parallelization is capped by the bandwidth of your network.
In this analysis, we have studied the response of SQL Azure to concurrent data streams so as to identify the best practices when loading data to SQL Azure.
Results & Analysis
The chart below shows the time taken to transfer 1GB of data to a SQL Azure table with one clustered index.

The columns are grouped by the data upload tool used and the location of the data source. In each grouping we compare the performance of single versus multiple streams of data.
From the results we observed the fastest transfer time when loading data from Windows Azure to SQL Azure. We see that using multiple streams of data clearly improved the overall usage of both tools. Moreover, using multiple streams of data helped achieve very similar transfer times from both outside and inside Windows Azure.
BCP allows you to vary the batch size (number of rows committed per transaction) and the packet size (number of bytes per packet sent over the internet). From the analysis it was evident that although these parameters can greatly influence the time to upload data, their optimum values depend on the unique characteristics of your data set and the network involved.
For our data set and network that was behind a corporate firewall
Tool Observation BCP Best performance at 5 streams, with a batch size of 10,000 and default packet size of 4K. SSIS Best performance at 7 streams. We had the Use bulk upload when possible check box selected on the ADO .NET destination SQL Azure component. Best Practices for loading data to SQL Azure
- When loading data to SQL Azure, it is advisable to split your data into multiple concurrent streams to achieve the best performance.
- Vary the BCP batch size option to determine the best setting for your network and dataset.
- Add non clustered indexes after loading data to SQL Azure.
- Two additional indexes created before loading the data increased the final database size by ~50% and increased the time to load the same data by ~170%.
- If, while building large indexes, you see a throttling-related error message, retry using the online option.
Appendix: Destination Table Schema

Using the TPC DbGen utility to generate test Data
The data was obtained using the DbGen utility from the TPC website. We generated 1 GB of Data for the Lineitem table using the command dbgen –T L -s 4 -C 3 -S 1.
Using the –s option, we set the scale to 4 that generates a Lineitem table of 3GB. Using the –C option we split the table into 3 portions, and then using the –S option we chose only the first 1GB portion of the Lineitem table.
Unsupported Tools
The Bulk Insert T-SQL statement is not supported on SQL Azure. Bulk Insert expects to find the source file on the database server’s local drive or network path accessible to the server. Since the server is in the cloud, we do not have access to put files on it or configure it to access network shares.

Chris “Woody” Woodruff posted OData Workshop Screencast–Producing OData Feeds, the second in his OData screen cast series, on 7/29/2010:

Don Demsak (@donxml) wrote Introducing SO-Aware – Bringing Service Oriented Awareness to the Enterprise about an OData-based repository replacement for long-gone UDDI on 7/28/2010:
So, you are a .Net developer, and you gone and built some services for your enterprise applications. You’ve spent the time building and deploying the services. You might have written them using ASP.Net, or you went all out and built them “the right way” with WCF. But for some reason, you are not seeing the return on investment. Sure, your applications are more modular, and reusable, but it takes a bit more work building the services, and other applications don’t seem to be taking advantage of the services you built. And if they are using your services, now you have to monitor them, and make sure that any changes you make will not break the other applications that use your services.
There are a couple of things they don’t warn you about when hyping service orientation:
- Service Configuration – If you are using WCF, a MEX endpoint will only take you so far, and WCF doesn’t make it easy to share configuration across services, easily. .Net 4.0 is a step in the right direction, but it is still only shares bindings and behaviors within a machine.
- Service Discoverability – You might have built a great service, but unless other applications (or developers) know about your service, they can’t use it.
Service Monitoring – Now that the service is out there, how do you know how often it is being used, and which operations are the most popular. Microsoft has AppFabric, but it only goes so far, and you are not ready to make the jump to AppFabric.
- Service Testing – Once your service becomes wildly used, how do you go about making sure that your changes, especially changes to configuration, do not break the clients using your services.
Successful services depend on these 4 aspects of Service Orientation, but they depend on more than just developers. Architects, other developers, testers, and operation support want visibility into them.
So, to take full advantage of all the hard work you put into your services you need a repository to store all this info. And not just any repository, but one that is extremely easy to use and find the information within it. If you are an old time service developer, you might have heard about this thing call UDDI – Universal Data Discovery and Integration. It was supposed to be the way the find out and use services, but it has proven to be incredibly complex and hard to use. So, no one really used it. A much easier solution would be an REST (Resource State Transfer) based service solution. REST service tend to be much easier to use, because they are HTTP based, but because there are so many different flavors of REST implementations, discovery (querying) the data within tended to be custom for each implementation. That is until Microsoft released OpenData (OData) as an open specification. With OData, it becomes just as easy to query a repository as it is to consume it.
SO-Aware does this all for you. You can think of it as 3 separate repositories all exposed using the RESTful OData protocol. It contains:
- Service Configuration Repository: this is where you store all your metadata about your service. If you have a WCF service, this is where your WSDL and your bindings and behaviors are stored. If it is an ODate service, you can put all your OData service documents here. Or if you are using a custom ASP.Net REST service implementation, you can put the details about your service here.
- Service Monitoring Repository: If you are using a WCF service, all the usage information about your service is stored here.
- Service Testing Repository: We all need to make sure to test our services. This is where you can store the service tests, and the test results.
Sounds great, but what’s in it for you, the developer? Well, the we all know that WCF configuration isn’t easy. Sure, Microsoft has made it a little easier with 4.0, but you still need to fight the WCF Configuration Editor to get the Service configuration correct, and once you do that, do you really remember how to update it when you need to? And how do you tell the operation folks to maintain it, and deploy the configurations to the service farm? Well that is where putting the configuration into a repository really pays off. With SO-Aware, you get a custom Service Host Factory, which will automatically pull the latest service configuration out of the repository for you, and reconfigures the service automatically. Need to make a change to the config, no more updating the config locally, and then trying to put a change control request into operations, or hoping that operations updates the configuration correctly, and then deploy it to all the servers. No more trying to keep the compliance documentation in sync with what is deployed on the services. Instead, those very same changes can be made via the SO-Aware portal, using templates built buy WCF experts, making it so much easier to maintain your WCF configurations.
And what is even better than configuring the service? Well that would be configuring all the clients, too. With SO-Aware, the consumers of your services have it just as easy as you do (even easier, since odds are they know even less about WCF). They can point their client proxies to the SO-Aware repository and automatically configure the client side WCF configuration. Now, there is no reason for .Net developers to be afraid of consuming WCF services. The configuration just happens for them, and they don’t even have to know about how to do it, or how to update it when it changes. All they need is what version of the service they wish to use, and it gets automatically configured for them.
Now that you have your services built and deployed (even to the test environment), as a good enterprise developer, you need to test the services, especially the binding and behavior configuration changes. Well, SO-Aware has you covered there, too. You can put your service tests into the SO-Aware Service Testing Repository via the Management Portal. Since the configuration is in the repository, and SO-Aware is written in .Net, you can sure that your Service Testing tool works with whatever bindings and behaviors you used, no matter how customized you got them. This is where most generic Service Testing tools fall down. They either only support the simplest of WS-* specifications, or don’t align with the versions implemented in WCF. With SO-Aware that isn’t the case, so you don’t have to do things like expose unsecured endpoints to work with your service testing tool. And to make things even easier, to execute your test, since SO-Aware is RESTful, all you have to do is an http get on the url for the test, and it will execute it for you. So, integrating into whatever testing framework or build management tool is a breeze.
So, we have configuration and testing covered, now onto Service Monitoring. Do you have SLAs? Or maybe you just want to know how often your service is called, and which operations are used the most. Or maybe you have a rogue request coming in and you want to record the request and response. Because your services are configured to use the SO-Aware Service Host Factory to get the configuration from the repository, it can also monitor the service and asynchronously publish that information to the SO-Aware Monitoring Repository. You can then review all this data in the SO-Aware Management Portal.
Now you are asking yourself, this tool sounds great, but I’m not sure if my company will be willing to purchase something like this. Maybe you’ve run across other Service Governance applications, and you got a little sticker shock. Or, maybe you just don’t know how valuable a tool like this would be in your enterprise, so you want to try it out in production for a while first. It really doesn’t matter, because Tellago Studios has a number of Microsoft MVPs, and we know how valuable the .Net developer community is. So, we are giving away the Express Edition of SO-Aware. With the Express Edition, you have a fully functioning product, that can be used in production. It isn’t a trial version. The only limit on the Express Edition is that you can only register five services. That, it is it. Well, there is one more thing. If you do use SO-Aware Express Edition in your organization, we would love to get feedback on the product from you. Your feedback will only serve to make future version a better product.
To get your free SO-Aware Express Edition, please fill out the Express Edition Registration Form and we will email you an activation key along with details on how to get and install the SO-Aware Express Edition.
SO-Aware sounds good to me, especially the Express Edition.
Pablo M. Cibraro (@cibrax) posted WCF configuration simplification with SO-Aware on 7/30/2010:
As I discussed in the previous post, everything in SO-Aware is exposed as resources via OData. You can simply take a look at this by browsing at the main feed of the service repository.
It’s always very useful for the enterprise to have a catalog of services and available operations into the repository for documentation purposes, and also for testing and monitoring.
The following code illustrates how a new SOAP service can be imported into the repository using the OData api (The example uses a WCF Data service generated proxy).
Importing a service from an existing WSDL
1: var repository = new ResourceRepositoryContext(RepositoryUri); 2: 3: var service = new Service 4: { 5: Name = "Customers", 6: Namespace = "http://soaware/demo", 7: Style = "SOAP" 8: }; 9: 10: repository.AddToServices(service); 11: 12: var serviceDescription = new SoapDescription 13: { 14: MetadataURI = "http://localhost:8080/?wsdl" 15: };Associate the WSDL to an specific service version
1: var serviceVersion = new ServiceVersion
2: {
3: MajorVersion = 1,
4: MinorVersion = 0,
5: };
6:
7: repository.AddToServiceVersions(serviceVersion);
8:
9: repository.SetLink(serviceVersion, "Soap", serviceDescription);
10: repository.SetLink(serviceVersion, "Service", service);The code above is creating a new version (1.0) for the service, and associating the WSDL and all the inferred entities (endpoint, contracts, operations and schemas) to that version.
Associate a WCF binding to the imported endpoints
1: var endpoint = serviceDescription.Endpoints.First(); 2: var binding = repository.Bindings.Where(b => b.Name == "kerberos").First(); 3: 4: repository.SetLink(endpoint, "Binding", binding); 5: 6: repository.SaveChanges(SaveChangesOptions.Batch);Configuring the service host
As you can see, we are getting an existing binding “kerberos” from the repository for using message security with kerberos (SO-Aware already ships with a bundle of pre-configured bindings for supporting different scenarios), and associating that binding to the imported endpoint. Therefore, next time you restart the service host for that service, it will start using the selected binding for that endpoint.
Ok, so far we have imported a service into the repository. As next step, something you can do is to configure and specific service host that we provide for automatically get the service configuration from the repository (in the example above, the new endpoint configuration with the “kerberos” binding)
In order to do that, you need to use a custom service host “Tellago.ServiceModel.Governance.ConfigurableServiceHost” or the custom service host factory “Tellago.ServiceModel.Governance.ConfigurableServiceHostFactory” in you case you are hosting WCF in IIS.
1: ServiceHost host = new ConfigurableServiceHost(typeof(Customers), 2: new Uri("http://localhost:8080")); 3: 4: host.Open();This “ConfigurableServiceHost” uses an specific configuration section to know how to map the service type “Customers” to the service version in the repository.
1: <serviceRepository url="http://localhost/SoAware/ServiceRepository.svc"> 2: <services> 3: <service name="ref:Customers(1.0)" type="CustomerService.Customers, CustomerService"/> 4: </services> 5: </serviceRepository>The prefix “ref:” tells the host to look for that service into the repository. This is when you want to download the complete service configuration and all the associated endpoints from the repository. However, this service host also supports another syntax in the configuration section for downloading only specific bindings or behaviors.
1: <serviceRepository url="http://localhost/SoAware/ServiceRepository.svc"> 2: <services> 3: <service name="CustomerService.Customers"> 4: <endpoint name="Customers_WindowsAuthentication" binding="ws2007HttpBinding" bindingConfiguration="ref:kerberos" contract="CustomerService.ICustomers"/> 5: <endpoint address="mex" binding="mexHttpBinding" contract="IMetadataExchange" /> 6: </service> 7: </services> 8: </services> 9: </serviceRepository>The example above only tells the configurable host to download the “kerberos” binding from the repository, and not the rest of the service configuration.
Configuring the client application
The configuration on the client side is also very trivial. We provide a class for automatically configuring a proxy, “Tellago.ServiceModel.Governance.ServiceConfiguration.ConfigurableProxyFactory”, or a class “Tellago.ServiceModel.Governance.ServiceConfiguration.ConfigurationResolver” for resolving individual WCF configuration objects like endpoints, bindings or behaviors that you want to inject in your existing proxy.
The following code illustrates how the ConfigurableProxyFactory can be used to invoke the service without having a single line of configuration.
1: class Program 2: { 3: static Uri RepositoryUri = new Uri("http://localhost/SOAware/ServiceRepository.svc"); 4: 5: static void Main(string[] args) 6: { 7: var factory = new ConfigurableProxyFactory<ICustomers>(RepositoryUri, "Customers(1.0)"); 8: var proxy = factory.CreateProxy(); 9: 10: try 11: { 12: var customer = proxy.GetCustomer(1); 13: 14: Console.WriteLine("Customer received {0}", customer.FistName); 15: } 16: finally 17: { 18: factory.Dispose(); 19: } 20: } 21: }As can see, everything was inferred from the configuration in the repository, even the endpoint address and the configured binding.
Download the sample code from this location.

<Return to section navigation list>
AppFabric: Access Control and Service Bus
Sandeep J Alur claims The element of security that developers can leverage in Windows Azure is part of Windows Azure Platform App Fabric. The App Fabric has the capability to connect various systems whether on/off premise and provide secure access in the preface to his Securing Applications with Windows Azure of 8/1/2010 (in India):
Security has been one of the basic ingredients that have gone into making Microsoft's Application Platform. The frameworks/foundations that are part of .Net Framework enables building of secure applications. However, the question of 'Security' is something that one always ponders over during the course of the software development life cycle. Enterprises often standardize on a security model, but fail to embrace the same across, due to technology nuances, proprietary and silo implementations. The story gets complicated with mergers and acquisitions. Under such circumstances, variety of security models emanate thus making it overtly complicated for solution architects/developers to bring in a model & for end users to navigate through systems during access. The need of the hour is to centralize security for an enterprise, post which all systems will rely on the central mechanism to grant access. Be it on premise application or hosted in the Cloud, the same model is desired which provides security infrastructure to variety of applications independent of technology/platform. The one innovation that I have to talk about in the context of this article is related to 'Windows Identity Foundation' (WIF).
WIF, an add-on library to .Net Framework, simplifies the security model by externalizing the entire security infrastructure from an application. WIF positions a security infrastructure that centralizes storage of user credentials and provides end points for client applications via open standards (HTTP, SOAP, and REST based protocols). This aspect makes the solution to be highly interoperable and accessible across platforms and technologies. The crux of the solution relies on Claims based identity. From a .Net perspective, we are familiar with the concept of Principle and Identity objects. Now the Claims based Security model builds on the same theme and the infrastructure is enabled by WIF. It is important to understand this model as the same security principles are instilled & model available for applications hosted in Windows Azure. With this model, the entire authentication and authorization aspects are outsourced to an entity outside of the application domain.
The App Fabric
The element of security that developers can leverage in Windows Azure is part of Windows Azure Platform App Fabric. The App Fabric has the capability to connect various systems whether on/off premise and provide secure access. Again along the lines of 'Service Orientation', the building block that provides security in the cloud is called 'App Fabric Access Control'. Access Control simplifies the implementation of identity federation across services meant to function in unison. In reality, it is a daunting task to secure applications that cross organization boundary. Access Control provides a platform to federate the identity across systems/services built using standards based infrastructure. Leveraging Active Directory Federation Services 2.0 is a classic example of leveraging identity infrastructure and the same is available as an Identity store in the cloud. While this is being made available, let me take you through a scenario to understand the way claims based (federated) identity works in the Cloud. Along the lines, we will understand few technical jargons/terms that are of relevance while we demystify Access control.
Let us consider a scenario wherein Retail 'Company A' has put together an Inventory Management application, which typically gets used by vendors. Likewise, Company A has many applications which fall under the same operating paradigm. It really does not make sense for the applications to worry about security aspects. Hence the need to position a central security infrastructure that addresses the authentication and authorization needs of every application in the enterprise. All that the applications are expected to do is receive the security token and grant/deny access. ADFS 2.0 comes into rescue here by providing out of the box framework for providing secure tokens. Following is a detailed explanation of the overall process.
The Process
A.'Company A' has built an inventory application/service which gets invoked by a client (Vendor). When this happens, the application expects a security token as part of the client request. To indicate so, the inventory service exposes a policy that provides details of the expected claim. If the token is not present, the request gets routed to the service which authenticates and issues token. Hence inventory application is termed as a 'Relying Party', since it relies on the external authority to provide users claim. A claim is the one that contains encrypted details of a specific user requesting access like the user name, role/membership etc.
B.The service which issues token is termed as STS (Secure Token Service), which acts as issuing authority. Issuing authority can return right from Kerberos tickets to X509 certificates. In this claims based identity scenario, the STS issues a token that contains claims. ADFS 2.0 is a classic example of an STS that is considered an authentication & authorization authority. An STS infrastructure mostly issues tokens in an interoperable & industry recognized SAML (Security Assertion Markup Language) format.
C.In case of federated scenario where in more than one certifying authority or identity store is participating, the STS infrastructure will take care of federating the user identity across various applications. Irrespective of whether the applications reside on/off premise, Access Control in Windows Azure federates and routes security tokens across various participating services.
For anyone who intends to implement highly interoperable security infrastructure in the cloud, Access Control reduces the complexity of programming significantly and provides a platform to operate under a secure environment. 'Services' in Cloud are the future and hence need to have a scalable, yet loosely coupled security infrastructure. Windows Azure's App Fabric Access Control is a best fit for Enterprise scenarios wherein a user identity needs to be federated across various lines of business applications irrespective of its origin. The security model which has taken shape in the form of Windows Identity Foundation on the .Net Framework, has reached the pastures of blue (Azure) in shaping the security story for applications hosted in Windows Azure.

Sandeep works for Microsoft Corporation India as an Enterprise Architect Advisor. He can be reached @ saalur@microsoft.com.
Valery Mizonov’s WCF netTcpRelayBinding Streaming Gotcha post shows you how to avoid a specific “gotcha” with WCF streaming over netTcpRelayBinding in the Windows Azure AppFabric Service Bus:
Scenario
I’m currently leading the development efforts on a customer project where we are streaming large amounts of structured (XML) data from on-premise BizTalk Server 2010 environment all the way to a cloud-based inventory database hosted on SQL Azure. The message flow can be simplified to an extent where it can be described as follows:
Inventory files are being received from many EDI partners and transformed into a canonical inventory schema representation using BizTalk Server’s support for EDI interoperability and data mapping/transformation;
The canonical inventory schema instances are being picked up by a designated WCF-Custom Send Port configured with netTcpRelayBinding that talks to the Azure Service Bus;
The inventory data is relayed in streaming mode through the Service Bus to a WCF Service endpoint hosted in a worker role on the Windows Azure;
The WCF Service receives the data stream and relays it further to a SQL Azure database-based queue so that the data becomes available for processing.
Below is the depicted version of the message flow that we have implemented at the initial stage of the project:

The Windows Azure AppFabric Service Bus make the above scenario shine as it makes it easy to connect the existing on-premise BizTalk infrastructure with cloud-based service endpoints. While it’s truly an eye-opener, there are several observations that we have made as it relates to data streaming over TCP sockets.
Observations
As referenced above, the cloud-hosted WCF service exposes a streaming-aware operation that takes the inbound data stream and makes sure that it safely lands in a SQL Azure database. Specifically, we are reading the data from inbound stream into a memory buffer in chunks and then flush the buffer’s content into a varchar(max) field using the Write() mutator operation supported by the UPDATE command.
The code snippet implementing the above technique is shown below:
#region IPersistenceServiceContract implementation public Guid PersistDataStream(Stream data) { // Some unrelated content was omitted here and the code below was intentionally simplified for sake of example.// For best performance, we recommend that data be inserted or updated in chunk sizes that are
// multiples of 8040 bytes. int bufferSize = 8040 * 10; using (ReliableSqlConnection dbConnection = new ReliableSqlConnection(dbConnectionString)) using (SqlStream sqlStream = new SqlStream(dbConnection, readDataCommand, writeDataCommand, getDataSizeCommand)) { BinaryReader dataReader = new BinaryReader(data); byte[] buffer = new byte[bufferSize]; int bytesRead = 0; do { bytesRead = dataReader.Read(buffer, 0, bufferSize); if (bytesRead > 0) { TraceManager.CustomComponent.TraceInfo("About to write {0} bytes into SQL Stream", bytesRead); sqlStream.Write(buffer, 0, bytesRead); } } while (bytesRead > 0); } return Guid.NewGuid(); } #endregionDespite the fact that both the client and server WCF bindings were configured correctly and identically as and where appropriate, including such important configuration parameters as reader quotas, max buffer size, etc, we have noticed that the specified buffer size was not appreciated by the underlying WCF stream. This basically means that the chunk size returned from the Read method was never ever near the anticipated buffer size of 80400 bytes. The following trace log fragment supports the above observations (note the instrumentation event in the above code that we emit before writing data into a SQL database):

There is an explanation for the behavior in question.
First of all, some fluctuation is the read chunk size bubbled up by the OSI transport layer is expected on any TCP socket connection. With TCP streaming, the data is being made available immediately as it streams off the wire. The TCP sockets generally don’t attempt to fill the buffer in full, they do their best to supply as much data as they can as timely as they can.
Secondly, when we set the buffer size to 80400 bytes, we unintentionally attempted to ask the TCP stack to buffer up to 53 times of its Maximum Transmission Unit (MTU) value as well to potentially exceed the maximum TCP receive window size. This is an unrealistic ask.
So, why do these small incremental (sometimes appearing to be random) chunks project potential concerns to a developer? Well, in our example, we are writing data into a SQL Azure database and we want this operation to be as optimal as possible. Writing 2, 6, 255 or even 4089 bytes per each call doesn’t allow us to achieve the appropriate degree of efficiency. Luckily, a solution for this challenge comes across extremely well in the following simple approach.
Solution
Simply put, we need to make sure that the data will be continuously read from the inbound stream into a buffer until the buffer is full. This means that we will not stop after the first invocation of the Read method - we will be repetitively asking the stream to provide us with the data until we satisfied that we have received the sufficient amount. The easiest way of implementing this would be through an extension method in C#:
public static class BinaryReaderExtensions { public static int ReadBuffered(this BinaryReader reader, byte[] buffer, int index, int count) { int offset = 0; do { int bytesRead = reader.Read(buffer, index + offset, count); if (bytesRead == 0) { break; } offset += bytesRead; count -= bytesRead; } while (count > 0); return offset; } }Now we can flip the method name from Read to ReadBuffered in the consumer code leaving the rest unchanged:
do {
// Note the name changed from Read to ReadBuffered as we are now using the extension method. bytesRead = dataReader.ReadBuffered(buffer, 0, bufferSize); if (bytesRead > 0) { TraceManager.CustomComponent.TraceInfo("About to write {0} bytes into SQL Stream", bytesRead); sqlStream.Write(buffer, 0, bytesRead); } } while (bytesRead > 0);The end result is that we can now guarantee that each time we invoke a SQL command to write data into a varchar(max) field, we deal with fully filled-in buffers and data chunks the size of which we can reliably control:

As an extra benefit, we reduced the number of database transactions since we are now able to stream larger chunks of data as opposed to invoking the SQL command for a number of smaller chunks as it was happening before.
Conclusion
Streaming is a powerful and high-performance technique for large data transmission. Putting on the large Azure sun glasses, we can confidently say that the end-to-end streaming between on-premise applications and the Cloud unlocks extremely interesting scenarios that makes impossible possible.
In this article, we shared some observations from our recent Azure customer engagement and provided recommendations as to how to avoid a specific “gotcha” with WCF streaming over netTcpRelayBinding in the Windows Azure AppFabric Service Bus. When implemented, the recommendations help ensure that developers have control over the size of the data that comes out of the underlying WCF stream and reduce inefficiency associated with “smaller than expected” data chunks.
Additional Resources/References
For more information on the related topic, please visit the following resources:
- “Large Message Transfer with WCF-Adapters Part 1” article by Paolo Salvatori;
- “WCF Streams” article in the MSDN Library;
- “Large Data and Streaming” article in the MSDN Library;
- “How to Enable Streaming” article in the MSDN Library;
See Cloud Ventures claims to be “Harnessing the Identity Metasystem for Secure Cloud Services” in its Cloud Identity and Privacy post of 7/30/2010 in the Cloud Security and Governance section below.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Wely Lau begins a new Step-by-step: Migrating ASP.NET Application to Windows Azure blog series from Indonesia with Part 1 – Preparing the ASP.NET application of 8/1/2010:
(I assume you’ve successfully installed the Windows Azure Tools for Visual Studio. If you haven’t done so, go and download it here. At the time this article is written, the version of the VS Tools for Azure is 1.2 – June 2010)
Without further [ado], let’s start the migration:
1. Download and Install Personal Starter Kit
2. Having done the first step, start an empty solution in Visual Studio. I call it CloudPersonalSite.
3. Next, right click on the blank solution, select Add – New Project.
4. You may choose you preferred language (In this example, I’ll use C#), then select Cloud on the project types. Select Windows Azure Cloud Service as the template. Ultimately, fill-in the project name with CloudServicePersonal.
5. As immediate, the New Cloud Service Project will pop-up and ask you for the roles in your project. By default, there are 4 roles available. I’ll choose ASP.NET Web Role and rename it to PersonalWebRole.
6. As soon as you click OK, Visual Studio will generate 2 projects for you. The first one is CloudServicePersonal which is your Windows Azure Cloud Service Project. The second one is the ASP.NET Web Role called PersonalWebRole. Do note that the ASP.NET Web Role is basically an ordinary ASP.NET Web Application Project (NOT ASP.NET WEBSITE) with some modification on web.config files as well as the new added file called WebRole.cs / WebRole.vb.
7. The next step is to create the personal web site based on the installed template. To do that, right click on the project and select Add – New Website. Select Personal Web Site Starter Kit as the template and name the website WebSitePersonal.
![image_thumb[11][7]](http://netindonesia.net/blogs/wely/image_thumb117_thumb_6A76F50A.png "image_thumb[11][7]")
8. Since the template is actually created with .NET 2.0, Visual Studio will now prompt us whether to migrate it to .NET 3.5. To do that, click YES button.
You will now see the default page of the personal website, the welcome.html if you have successfully completed those steps above.
In the next post, I’ll continue to write how to modify the web site to be ready on the Web Role.
Stay tuned!






![image_thumb[14][10]](http://netindonesia.net/blogs/wely/image_thumb1410_1000726C.png "image_thumb[14][10]")
![image_thumb[11][7]](http://netindonesia.net/blogs/wely/image_thumb117_04B75E2F.png "image_thumb[11][7]")

• Wely Lau continues his Step-by-step: Migrating ASP.NET Application to Windows Azure blog series on 8/1/2010 with Part 2–Preparing SQL Azure Database:
If you notice the App_Data of the personal website, you will see the Personal.mdf file which is the database of the application.
However, by noticing the web.config file, there is also another database called aspnetdb.mdf. This database will be automatically created when we open-up the ASP.NET Administration portal. To do that, click on ASP.NET Configuration button to open up the web site administration tool.
I believe most of you are familiar with ASP.NET administrator tool. As it, I won’t go into the details of how to create roles and users. But in this example, create 2 roles (Administrators and Guests) and 1 user (admin).
When you are done, try to refresh the App_Data folder and you will see that the new aspnetdb.mdf file was created.
1. The first step is to prepare the SQL Azure database. To do that, go to http://sql.azure.com. I assume you have got the SQL Azure account in this step. Click on the project name and it will bring you to your server administration as shown below.
You will notice that some info above such as my server name, admin user, as well as server location which I’ve defined it earlier.
2. The next step is to create the database. To do that, click on the Create Database button and fill in the name (I name it PERSONAL). You may also want to specify the edition of your database (whether Web or Business) as well as the maximum size for your database. Click Create when you are ready.
Immediately, you will see the new created database.
3. Now the we’ll need to connect to the SQL Azure database from client. To do that, open up the SQL Server 2008 R2 Management Studio. (You’ll need to use the R2 version since the ability to connect to SQL Azure). Enter the server name as you could seen from your server administration, eg: [server name].database.windows.net. Subsequently enter your username and password as authentication. Click on option, and type the database name that you’ve been created just name (PERSONAL).

If anything goes well, you should see as following screenshot.
4. Now you are connected with the SQL Azure database, the Personal. The next step is to create tables and other objects from the on-premise database. Remembering that we have 2 database on local server, aspnetdb and personal. Now we are going to prepare the script of these two database. To do that, . Login to the your local database engine with your admin credential. I would recommend you to copy the mdf and ldf file of your database (in this sample aspnetdb and personal) to the SQL Server data folder in order to simplify the attach process.
Next, attached your database mdf file. Moreover, I rename the database to personal and aspnetdb from the long fullname. If everything goes well, you will see the following database in the explorer like mine.
5. The next step is to generate the script of each database. To do that, right click on the personal database and select Task – Generate Script.
I’ll select the script entire database objects on the “Choose Object” step.
6. On the Set Scripting Options steps, click on Advanced button. Modify the following properties:
- Types of data scripts : Schema and data.
- Script use database: falseClick OK to close the “Advanced scripting options”
Subsequently, Select “Save to file” and locate the file to your preferred location. (in this example, I save it to my documents\scripts.sql
Click Next and Next, Finish to finished.
7. Do note that the script that has been generated is not SQL-Azure-ready! It means that we’ll need to modify it first so that could be successfully compatible with SQL Azure. Thanks to community folks who have been developing the SQL Azure Migration Wizard to simplify the task. Download and open up the Migration Wizard.
Select Analyze Only (as we’ll do the migration manually) and TSQL file as the input. Click on Next to proceed.
8. You will notice that in the Result Summary, some of the sections are marked with these comments --~ CREATE DATABASE is not supported in current version of SQL Azure
From the Object Explorer, select our cloud database “Personal”. Click on New Query button. As the new query editor comes up. Just copy and paste all of the script from SQL Azure Migration Wizard to SQL Server Management Studio. For each block with those comment, delete it.
Run it immediately. If anything goes well, you will see the result as following.

9. Repeat step 4 to 8 with database aspnetdb. Do note that although the source comes from two database, we are only targeted to one destination on SQL Azure for simplicity purpose.
When you run the aspnetdb query, you might find the problem as below on the [aspnet_Membership_GetNumberOfUsersOnline] stored procedured. This is caused the SP uses nolock keyword which are deprecated features in SQL Server 2008 R2. To solve it, just delete the (NOLOCK) keyword.
10. If everything goes well, when you refresh the cloud personal database, you will see the tables and stored procedure are all there.
It means that we’ve successfully export our on-premise database to the cloud.
11. Now, to test whether the database is successfully created, we can connect our personal starter kit website to use SQL Azure database. To do that, modify connection string section in the web.config file as following.
<add name="Personal" connectionString="server=[server_name].database.windows.net;database=personal;uid=[username];pwd=[password]" providerName="System.Data.SqlClient"/>
<add name="LocalSqlServer" connectionString="server=[server_name].database.windows.net;database=personal;uid=[username];pwd=[password]"/>
12. Run our ASP.NET website and see whether it is successfully connected.
In the next post, I’ll show you how to migrate our ASP.NET website to ASP.NET Web role.
Stay tuned.
















The Voice of Innovation blog offered A Chance to Showcase Your Solutions on Microsoft Government Cloud Application Center on 7/30/2010:

If you're interested in this opportunity, profile your solution(s) on Microsoft Pinpoint using your Live ID. Once you've posted your solution and verified that you are accurately profiled (e.g., Windows Azure Platform, Hosting Services, Interactive Web, etc.), email us at info@voicesforinnovation.org, and we'll help you make the connections to list your offerings on the Microsoft Government Cloud Application Center.
By signing up, you can reach government customers as well as showcase your solutions and services to Microsoft personnel working with the public sector.
This is the first I’ve heard of the Government Cloud Application Center (and I’m a member of the Microsoft Partner Network.) FullArmor has listed an interesting collection of Azure-based applications and add-ins.
Kevin Kell posted Microsoft Azure … Beware the Sticker Shock! to Learning Tree International’s Cloud Computing blog on 7/30/2010:
With Azure you must realize that you pay for everything that is deployed whether it is being used or not. You pay for storage. You pay for computing. You pay for data transfers in and out. You pay for Service Bus transactions. You pay for Access Control requests. You pay for everything!
I was pretty actively using Azure in July. I was deploying applications left and right. I was increasing the number of worker and web roles to test scaling. I was migrating SQL Server databases. I was using Service Bus and Access Control services without a care in the world! I was happy. This was cool. Everything was working and it was all good!
Well, I just got my statement for the month. Let us just say … ahem … it was a bit more than I would have liked. I could have almost rented a small apartment (okay maybe not in New York or LA … but maybe in Tucson) for a month! Yes, I should have done all the cost analysis first. Yes, I should have considered the financial implications before I did anything. I didn’t. I got caught up in a kind of a geeky nirvana and just kind of lost track of the dollars and cents. That is the last time I will make that mistake!
For me the big killer was the compute service charges. You are charged $0.12 per hour per small VM instance regardless of whether it is doing anything or not. That doesn’t sound like much, right? However there are 720 hours in a 30 day month. That means a single VM instance, whether a web role or a worker role, costs about $86 per month if you choose the consumption payment model. If you have both a web role and a worker role in your application, which would not be uncommon, you are up to $172 per month. On top of that, Microsoft requires at least two instances of each “Internet facing” (i.e. web) role in order to ensure the 99.95% availability guaranteed in their Service Level Agreement. Throw in a SQL Azure database and are up to about $270 a month for a single application! Imagine if you have several!
Now, I am not saying that this is too much or too little. It all depends on your particular application. Indeed it probably was less expensive, and certainly a heck of a lot easier, than setting up the whole platform and infrastructure myself. What I am saying is be aware of how quickly things can add up.
Do your homework. Only deploy what you need. Only keep it deployed for as long as you need it. When you are done get rid of it.
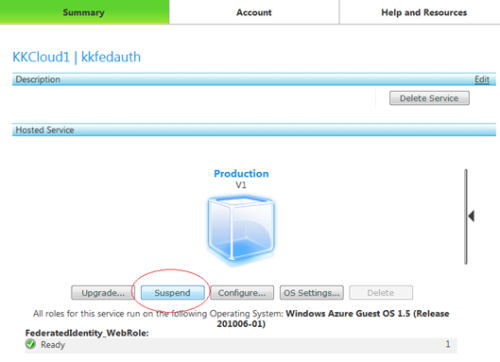
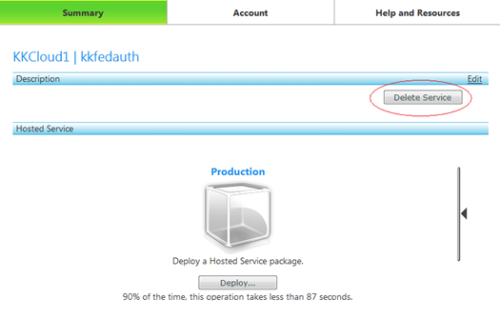
Here is how you delete a service on Microsoft Azure:
Suspend the deployment
Delete the suspended deployment
Delete the service
Azure is pretty cool and there is a lot you can do with it. Just remember that the meter is always running.

Business Wire posted a CLM Matrix Joins Microsoft in the Clouds press release on 7/29/2010:
Matrix-Online is a Software as a Service (SaaS) offering that runs on the Windows Azure and SQL Azure Platform as a Service (Paas). The solution provides a cloud-based contract management repository where companies can track, search and set alerts for all of your active contracts. No IT staff is needed, no additional licenses, access to all future upgrades and releases with minimal configuration.
As Microsoft signs up additional customers on the Azure platform, CLM Matrix intends to broaden their customer reach by having the Matrix-Online service fully enabled within the cloud environment.
“Matrix-Online is an ideal solution for companies who need to get a handle on their contractual relationships,” says Tim Sparks, CEO of CLM Matrix. "Companies that have diverse vendor, customer and partner relationships need a flexible and scalable solution that can meet their needs. Windows Azure and SQL Azure are the perfect cloud platform for our contract management service offering to reach a broader set of customers."
Matrix-Online allows users to set up alerts and notifications to establish reminders for future milestones (e.g. date expirations). The management reporting capabilities also allow companies to proactively manage their pipeline of expiring agreements and gain greater insight into governing terms and conditions that influence future business performance. …
Return to section navigation list>
Windows Azure Infrastructure
Surenda Reddy reported on 7/31/2010 that he’s working on a CloudMap – Layers, Technologies, and Players:
I have been trying to map the architectural layers of the infrastructure in the data center/enterprises, technologies that map to these layers, and players/providers who is offering solutions/technologies to help deliver these services. I have been embarked on a mission to find whitespaces/blue oceans to help enterprises to create/claim value from the “redwood” in their data center before it turn into “deadwood”.

Click image to expand
George Reese beat Surenda to the punch with his cloud-computing mind map, which is described at the end of this section.
James Urquhart recommends that you Hedge your bets in cloud computing in this 7/31/2010 post to C|Net’s The Wisdom of Clouds blog:
Debates flare up all the time about what is the "right" way to consume cloud computing. Public cloud providers push for ditching your data center in favor of pay-per-use services delivered over the network. Many hardware vendors claim that the enterprise's road to cloud computing is through the operation of private clouds. Still others argue that the whole concept is a crock of...well, you get the idea.
Which argument do you buy? How should you plan to deploy and operate your IT resources over the next 3, 5, even 10 years? In who's basket should you place your eggs?
In part, your answer will probably depend a bit on who you are, what your role is in IT delivery or consumption, and well-known factors such as sensitivity to data loss, regulatory requirements, and the maturity of your IT organization.
I would argue, however, that if you have existing IT investment, or you have requirements that push beyond the limits of today's cloud computing technology or business models, you should consider not choosing at all.
My argument starts with the simple fact that there are so many variables in the cloud computing equation, that no one can predict how the transition to cloud computing will take place--if it does at all. (I most certainly believe there will be a slow but inevitable change to IT, eventually dominated by public cloud services.)
If the public cloud providers are correct, and everything IT will be a public utility at some point, then predicting the next decade or two of transition is next to impossible.
If the vendors are right, and you must implement cloud in your existing facilities before understanding how to move mission critical systems to public clouds, then when and how to do so is itself complicated, and probably differs for each set of business requirements.
If the "cloud is a fad" crowd is right, then implementing any cloud experiments at all will be wasted investment.
The odds are almost certain that the actual result for most, if not all businesses, will be somewhere in the mix of traditional data center, private cloud, and public cloud environments. Think of it as landing somewhere in the "Hybrid IT Triangle."
So how does one do this? How does a modern IT organization formally change its ways to be flexible to the uncertain future of its operations model?
The simplest way to do this is to embrace a few basic principles, many of which have been known for decades, and some of which are being made painfully clear in the cloud computing model:
Focus on the application, not the server. In my earlier DevOps series, I laid out an argument for why virtualization and cloud are forcing both developers and operations teams to change their "unit of deployment" from the bare metal server to the application itself. This is a key concept, as you can manage the application in all three of the points on the triangle above.
What does that look like? Well, virtualization makes it much easier to do, as you can build VM images for a single application, or a single application partition or service. At that point, it's not the VM that's the unit being "operated," as much as it's the file system or even the application code itself running in that VM.
Thus, if you want to move the application from an internal VMware based environment to a Xen based cloud provider, your challenge is simply to get that same file system, or even just the application itself, running in the new infrastructure. Is this natural for most IT organizations today? No, but working to think this way has huge benefits in a hybrid IT environment.
Decouple payload operations from infrastructure operations. Another key argument of the DevOps series is that cloud is forcing a change in operations roles, from the traditional "server, network, and storage" siloes to more horizontal "applications" and "infrastructure" designations.
Infrastructure operators run the "hardscape" (servers, storage devices, switches, etc.) that makes up the data center, campus networks, and so on. They also manage the software systems that automate and monitor resource consumption, such as virtualization platforms and IT management systems.
Application operators focus much more on the code, data, and connectivity required to deliver software functionality to end users or other application systems. These are the men and women that must choose where to deploy applications, and how to operate them once they are deployed. As public cloud systems don't allow them access to the bare metal, they have to design processes that don't depend on access to that "hardscape."
Choose management tools that allow you to operate in all three options. There are so many management and governance options out there today that enable deploying, managing, and monitoring applications in virtualized data centers, private clouds, and public clouds. Use them.
One of the biggest concerns about the cloud today is so-called "lock-in." In the cloud, lock-in has an especially insidious side; if a cloud vendor goes out of business, your infrastructure may disappear. One way to mitigate this risk is to choose an application-centric (or, at the very least, VM-centric) management tool or service that will allow you to take your data and applications elsewhere--quickly--should such an event take place.
As cool as true portability between clouds and between virtualization platforms would be, relying on a management environment that can engineer solutions to portability is a much better transitional strategy. It's especially good if these tools or services help with things like backups, data syncronization, and disaster avoidance.
Now, the maturity of the tools and services on the market today might not make these strategies easy to implement, but I would argue that beginning the cultural and procedural changes behind these recommendations today will make your future life in a hybrid IT landscape much easier to deal with. Betting heavily on any one outcome, on the other hand, is a great way to miss out on the utility of the others.
Lori MacVittie (@lmacvittie) recommends Eliminating the overhead associated with active [load-balancer] health checks without sacrificing availability in her F5 Friday: Eavesdropping on Availability post to F5’s DevCentral blog:
One of the core benefits of cloud computing and application delivery (and primary purposes of load balancing) is availability. In the simplest of terms, achieving availability is accomplished by putting two or more servers (virtual or iron) behind a load balancing device. If one of the servers fails, the Load balancer directs users to the remaining server, ensuring the application being served from that server remains available.
The question then is this: how does the load balancer know when an application is not available? The answer is: health monitoring.
Every load balancer (and clustering solution) can do this at some level. It may be just an ICMP ping or a TCP three-way handshake or determining whether the HTTP and application response received are correct. It may be a combination of a variety of health monitoring options. Regardless of what the health check is doing, it’s getting done and an individual server may be taken out of rotation in the event that its health check response indicates a problem.
Now, interestingly enough there is more than one way to perform a health check. As you might have guessed the first way is to communicate out-of-band with the server and/or application. Every <user configured> time interval, the load balancer performs a check and then acts or doesn’t act upon the response. The advantage of this is that the load balancer can respond very quickly to problems provided the time interval is of sufficiently granular value. The disadvantage of this approach is that it takes up resources on the load balancer, the network, and the server. In a service-provider or cloud computing environment, the resources consumed by out-of-band health checks can be devastating to network performance and may well impact capacity of the server.
What else is there?
INBAND and PASSIVE MONITORING
While inband monitoring is relatively new, passive monitoring was pioneered by F5 many years ago. In fact, leveraging passive monitoring and inband monitoring together provides the means to more quickly address problems as they occur.
Inband monitoring
was introduced in BIG-IP v10. Inband monitors can be used with either a Standard or a Performance (Layer 4) type virtual server, and as a bonus can also be used with active monitors. What inband monitoring does is basically eavesdrop on the conversation between a client and the server to determine availability. The monitor, upon an attempt by a client to connect to a pool member, behaves as follows:
What inband monitoring does do – and does well – is eliminate all the extraneous traffic and connections consuming resources on servers and the network typically associated with active monitoring. But what it can’t do at this time is inspect or verify the correctness of the response. It’s operating strictly at the layer 4 (TCP). So if the server|application responds, the inband monitor thinks all is well. But we know that a response from a server does not mean that all is well; the content may not be what we expect. What we want is to mitigate the impact of monitoring on the network and servers but we don’t want to sacrifice application availability. That’s where passive monitoring comes in.
- If the pool member does not respond to a connection request after a user-specified number of tries within a user-specified time period, the monitor marks the pool member as down.
- After the monitor has marked the pool member as down , and after a user-specified amount of time has passed, the monitor tries again to connect to the pool member (if so configured).
Passive monitoring

Passive monitoring is real-time, it’s looking at real requests to determine actual availability and correctness of response. This is even more useful when you start considering how you might respond. The robust nature of iRules allows you to do some interesting manipulation of content and communication channel, so if you can think it up you can probably get it done with an iRule.
By combining inband with passive monitoring you end up with “inband passive monitoring”. This solution eliminates the overhead of active monitoring by eavesdropping on client-server conversations and ensures application availability by inspecting content.
For a great discussion of inband passive monitoring and a detailed scenario of how it might work in conjunction with a real application, check out Alan Murphy’s post on the subject, “BIG-IP v10: Passive Application Monitoring
Doug Rehnstrom claimed This Cloud Thing is Out of Control in a post to Learning Tree International’s Cloud Computing blog on 7/30/2010:
I heard we are supposed to have a “patch management process” and a “disaster recovery plan”. Who the heck is supposed to put those in place, and once in place who’s going to keep them current? I imagine we could create a process to periodically review the plan. Every so often, we could do a simulation and see if it works. We could just buy a few more servers to set up a test environment. Maybe we could have a committee who could report their findings to some IT manager who is responsible for the change-control process. Yeah, that’s the ticket.
I guess some companies are swimming in money and have people to do those things, but we sure don’t.
We are supposed to have redundant servers, load balancers and replicated databases. Those are expensive to set up, and they take smart people to keep working. Are the streets filled with qualified network administrators with nothing to do?
From my perspective, “losing control” is not a reason to resist the cloud. Rather, it’s a reason to embrace it.
I also keep hearing things like, “I’m not going to trust Microsoft with my data.” Well, everyone in my company runs a PC with Windows (except for me because I’m the geek with the Mac). We use Windows servers and store our data in a SQL Server database. All our programming is done in Microsoft .NET, and all our documents are created using Microsoft Office. Hmm, it seems to me that we already trust Microsoft with all our data. Moving to the cloud only means we don’t have to wipe the dust off our servers every couple years.
Windows Azure will actually cost us more money than what we’re currently spending. We are not buying virtual machines, though. We are buying better control over backups, replication, patches, security, and disaster recovery. Trust me, I think it’s worth it (from my perspective anyway).
To learn more about Windows Azure come to Learning Tree course 2602: Windows® Azure™ Platform Introduction.
Audrey Watters reported “Two thirds of businesses are considering adopting cloud computing” in her Survey Finds Gap in Attitudes Between the Cloud "Haves" and "Have-Nots" post of 7/30/2010 to the ReadWriteCloud blog:
London-based communications SaaS provider Mimecast has announced the results of its second annual Cloud Adoption Survey. The survey, conducted by independent research firm Loudhouse, assessed the attitudes of IT decision-makers in the U.S. and UK about cloud computing.
And the results are unsurprising, echoing the findings from elsewhere: the majority of organizations are now using some sort of cloud service, or considering moving to the cloud. Concerns about security and cost are cited as the major obstacles to adoption.
Some of the research highlights include:
- The majority of organizations now use some cloud-based services. The report found 51% are now using at least one cloud-based application. Adoption rates for U.S. businesses are slightly ahead of the UK with 56% of respondents using at least one cloud-based application, compared to 50% in the UK. This is a substantial increase from Mimecast's 2009 survey, when only 36% of U.S. businesses said they were using cloud services.
- Two thirds of businesses are considering adopting cloud computing. 66% of businesses say they are considering adopting cloud-based services in the future, with once again, U.S. businesses leaning more towards adoption than their UK peers (70% of U.S. businesses, and 50% of UK ones).
- Email, security, and storage are the most popular cloud services. 62% of the organizations that use cloud computing are using a cloud-based email application. Email services are most popular with mid-size businesses (250-1000 employees) with 70% of organizations this size using the cloud for email. Smaller businesses (under 250 employees) are most likely to use the cloud for security services, and larger enterprises (over 1000 employees) most likely to opt for cloud storage services.
Overall both users and non-users responded positively to the idea of the cloud, believing that the cloud creates better performance (61%), sustainability (62%), and smooth integration into existing systems (56%). But the report also points to some different attitudes between those who have adopted cloud technologies and those who haven't:
- Existing cloud users are satisfied. Security is not considered to be an issue by existing cloud users: 57% say that moving data to the cloud has resulted in better security, with 58% saying it has given them better control of their data. 73% say it has reduced the cost of their IT infrastructure and 74% believe the cloud has alleviated the internal resource pressures.
- Security fears are still a barrier. 62% of respondents believe that storing data on servers outside of the business is a significant security risk. Interestingly, this number was higher for users of cloud applications than it was for non-users (only 59% of non-users thought it was risky, while 67% of users did.)
- Some think the benefits of the cloud may be overstated.54% of respondents said the potential benefits of the cloud are overstated by the IT industry, and 58% indicated they believed that replacing legacy IT solutions will almost always cost more than the benefits of new IT.
"The research shows that there is a clear divide within the IT industry on the issue of cloud computing," says Mimecast CEO and co-founder Peter Bauer. "While those organisations that have embraced cloud services are clearly reaping the rewards, there are still a number who are put off by the 'cloud myths' around data security and the cost of replacing legacy IT. It is now up to cloud vendors to educate businesses and end users to ensure that these concerns do not overshadow the huge potential cost, security and performance benefits that cloud computing can bring."

George Reese published The Cloud Computing Mind Map to the O’Reilly Community blog on 6/30/2010 [missed when posted]:
Getting your brain around all of the components of cloud computing is a huge challenge. There are so many players, and a number of them are performing functions entirely new to IT. A few months ago, I put together a mind map of the cloud computing space I use to help people understand this space. It's reached a level of maturity that I now feel it appropriate to share it with a wider audience.
[If clicking the above image results in a non-scrollable window, click here to open the 2590 x 2293 pixel PNG image (905 KB) from Windows Live SkyDrive in its own window with scrollbars.]
The Cloud Stack
I have already written a blog entry on the cloud stack. This mind map mostly matches what I wrote in that article, though some of my thinking has evolved since then. First, the layer I used to call "orchestration" seems to be settling down as "cloud operating system". I dislike the term cloud operating system, but I'm not going to tilt against that windmill. Because I operate in the cloud management space, the details in cloud management are the most evolved.
Types of Clouds
There's nothing surprising in the list of types of clouds. I do further break down IaaS into Storage and Compute. I don't think that's terribly controversial.
Deployment Models
This area is straight from the NIST cloud computing definition. I'm done fighting the cloud definition wars. I'm all for taking the NIST definition and moving on with our lives. As a result, my cloud mind map takes the NIST definition as a given. I left out community clouds. I don't think they are that interesting, but that doesn't contradict NIST. It's just a willful omission.
Characteristics
The characteristics, as well, come straight from the NIST definition without any of the willful omissions.
Benefits and Barriers
I am sure I have left out items relevant to both the benefits and barriers of cloud computing. Perhaps the most interesting choice I made was including security as both a benefit and a barrier. I would guess most people think of security as a self-evident barrier to cloud computing. My view on security as a barrier is much more complex. I would, however, argue that security is actually a benefit of cloud computing. But that argument is for another blog entry.
The other benefits are fairly straightforward. On the barriers side, I opted to include jobs as one of the barriers. The cloud can represent a perceived (and in some cases, real) threat to IT jobs. Because of the threat to jobs, some people are reluctant to adopt cloud computing.
Vendors
I know for every vendor I have properly included here, there are 10 or 20 I left out that probably should be included. I apologize in advance for the omission. The purpose of the Vendors section is not to be comprehensive, but to help people intimidated by all of the "cloud" vendors to start making sense of where vendors fit in the scheme of things.
I had the hardest time classifying Cisco, CloudSwitch, and CohesiveFT. Cisco is everything and nothing all at once in the cloud space. CloudSwitch and CohesiveFT are in some sense competitive offerings with one another and in another sense very different. I'm not sure what you call the space they occupy. Network cloudification platforms? Cloud transplant tools? I don't know, but I do know they don't fit neatly into the rest of the picture I have painted.
Projects
The Projects section of the mind map goes through the elements of executing on a cloud-based project. It starts from the cloud decision and moves through managing a production cloud deployment. I think a lot more work needs to be done fleshing this part of the mind map out.
George Reese is the author of Cloud Application Architectures: Building Applications and Infrastructure in the Cloud.
If you're involved in planning IT infrastructure as a network or system architect, system administrator, or developer, this book will help you adapt your skills to work with these highly scalable, highly redundant infrastructure services. Cloud Application Architectures will help you determine whether and how to put your applications into these virtualized services, with critical guidance on issues of cost, availability, performance, scaling, privacy, and security.

<Return to section navigation list>
Windows Azure Platform Appliance
Rich Hewlett adds fuel to the private-vs-public-cloud fire with his Private Clouds Gaining Momentum post of 7/30/2010 that covers both the Windows Azure Platform Applicance and Rackspace’s OpenStack:
Well its been an interesting few weeks for cloud computing, mostly in the "private cloud" space. Microsoft have announced their Windows Azure Appliance enabling you to buy a Windows Azure cloud solution in a box (well actually many boxes as it comprises of hundreds of servers) and also the OpenStack cloud offering continues to grow in strength with RackSpace releasing its cloud storage offering under Apache 2.0 license with the OpenStack project.
OpenStack is an initiate to provide open source cloud computing and contains many elements from various organisations (Citrix, Dell etc) but the core offerings are Rackspace’s storage solution and the cloud compute technology behind NASA’s Nebula Cloud platform. To quote their web site…
“The goal of OpenStack is to allow any organization to create and offer cloud computing capabilities using open source software running on standard hardware. OpenStack Compute is software for automatically creating and managing large groups of virtual private servers. OpenStack Storage is software for creating redundant, scalable object storage using clusters of commodity servers to store terabytes or even petabytes of data.”
It is exciting to see OpenStack grow as more vendors outsource their offerings and integrate them into the OpenStack initiative. It provides an opportunity to run your own open source private cloud that will eventually enable you to consume the best of breed offerings from various vendors based on the proliferation of common standards.
“…a turnkey cloud platform that customers can deploy in their own datacentre, across hundreds to thousands of servers. The Windows Azure platform appliance consists of Windows Azure, SQL Azure and a Microsoft-specified configuration of network, storage and server hardware. This hardware will be delivered by a variety of partners.”
Whilst this is initially going to appeal to service providers wanting to offer Azure based cloud computing to their customers, it is also another important shift towards private clouds.
These are both examples in my eyes of the industry stepping closer to private clouds becoming a key presence in the enterprise and this will doubtless lead to the integration of public and private clouds. It shows the progression from hype around what cloud might offer, to organisations gaining real tangible benefits from the scalable and flexible cloud computing platforms that are at home inside or outside of the private data centre. These flexible platforms provide real opportunities for enterprises to deploy, run, monitor and scale their applications on elastic commodity infrastructure regardless of whether this infrastructure is housed internally or externally.
The debate on whether ‘Private clouds’ are true cloud computing can continue and whilst it is true that they don’t offer the ‘no- capital upfront’ expenditure and pay as you go model I personally don’t think that excludes them from the cloud computing definition. For enterprises and organisations that are intent on running their own data centres in the future there will still be the drive for efficiencies as there is now, perhaps more so to compete with competitors utilising public cloud offerings. Data centre owners will want to reduce the costs of managing this infrastructure, and will need it to be scalable and fault tolerant. These are the same core objectives of the cloud providers. It makes sense for private clouds to evolve based on the standards, tools and products used by the cloud providers. the ability to easily deploy enterprise applications onto an elastic infrastructure and manage them in a single autonomous way is surely the vision for many a CTO. Sure the elasticity of the infrastructure is restricted by the physical hardware on site but the ability to shut down and re-provision an existing application instance based on current load can drive massive cost benefits as it maximises the efficiency of each node. The emergence of standards also provides the option to extend your cloud seamlessly out to the public cloud utilising excess capacity from pubic cloud vendors.
The Windows Azure ‘Appliance’ is actually hundreds of servers and there is no denying the fact that cloud computing is currently solely for the big boys who can afford to purchase hundreds or thousands of servers, but it won’t always be that way. Just as with previous computing paradigms the early adopters will pave the way but as standards evolve and more open source offerings such as OpenStack become available more and more opportunities will evolve for smaller more fragmented private and public clouds to flourish. For those enterprises that don’t want to solely use the cloud offerings and need to maintain a small selection of private servers the future may see private clouds consisting of only 5 to 10 servers that connect to the public cloud platforms for extra capacity or for hosted services. The ability to manage those servers as one collective platform offers efficiency benefits capable of driving down the cost of computing.
Whatever the future brings I think that there is a place for private clouds. If public cloud offerings prove to be successful and grow in importance to the industry then private clouds will no doubt grow too to compliment and integrate those public offerrings. Alternatively if the public cloud fails to deliver then I would expect the technologies involved to still make their way into the private data centre as companies like Microsoft move to capitalise on their assets by integrating them into their enterprise product offerings. Either way then, as long as the emergence of standards continues as does the need for some enterprises to manage their systems on site, the future of private cloud computing platforms seems bright. Only time will tell.
John Letzing reported Analysts encouraged by Microsoft's 'cloud' progress via MarketWatch on 7/30/2010:
Wall Street analysts came away from Microsoft Corp.'s annual gathering encouraged by the company's progress in adapting to a market in which software applications are increasingly delivered online, according to research reports published Friday.
Younger rivals including Google, Amazon.com and Salesforce.com Inc. have sought to expand the cloud-computing market, while Microsoft has endeavored to alter its own approach to keep pace.
Jefferies & Co. analyst Katherine Egbert pointed out that investors are shifting money out of Microsoft shares, based on concerns about how the company will develop new ways of making money.
Shares of Microsoft have fallen roughly 15% in the past three months, compared with a roughly 8% decline for the Nasdaq Composite Index over the same period. The stock closed Friday down slightly, at $25.81.
But Egbert wrote in a research note that concerns about Microsoft may be exaggerated, as the company has a history of adopting "technologies, mostly invented by others, to the mass market."
On Thursday Microsoft chief executive Steve Ballmer said Apple has sold more iPads than he would have liked, and discussed Microsoft's plans to improve the quality of tablet devices that run Windows 7 OS. WSJ's Marcelo Prince and MarketWatch's Rex Crum join Simon Constable on the Digits show to discuss Microsoft's strategy. Plus: Emily Maltby reports on affordable 3-D software for small businesses.
"Investors need to stop expecting from Microsoft innovation a la Apple and start expecting low-cost, mass-market, inexpensive adaptations of popular technologies a la China," Egbert wrote, in reference to Microsoft competitor Apple Inc.
Cloud evolution
"We're going to lead with the cloud," Microsoft Chief Operating Officer Kevin Turner said at the company's annual analyst meeting Thursday, while noting successes in vying for cloud-computing contracts against Google and International Business Machines Corp. /quotes/comstock/13*!ibm/quotes/nls/ibm (IBM 128.40, +0.38, +0.30%) . Read more about Microsoft's annual meeting.
Microsoft "appears to be holding their own competitively" in cloud computing, Deutsche Bank analyst Todd Raker told clients in a note. "The bottom line is we believe the cloud is evolving from a secular threat to an opportunity" for the company.
However, Raker also acknowledged that the timing of any significant economic benefit from Microsoft's cloud-computing effort remains "unclear," noting that "we get significant pushback from investors on near-term reasons to own the stock."
Some analysts argued that investors may not yet fully appreciate Microsoft's Windows Azure platform service, which includes cloud computing and storage for customers hosted at the company's data centers.
"While the buzz has picked up around Azure over the past 12 months, we do not believe the company gets enough credit," Oppenheimer analyst Brad Reback told clients in his own research note.
"Azure should be a net revenue and profit creator" as more corporate customers snap up the service, he said.
Matt Hester posted Windows Azure Bringing Developers and IT Pro’s of the World Together to TechNet’s Windows Server 2008 R2 Experts blog on 7/29/2010:

A lot of my posts have been focused on the IT Pro story of Microsoft Technologies. This post will be slightly different, and hopefully will help enhance communication with the developers in your organization. Some of you may be aware that we've been talking about Windows Azure as an application platform. In fact, Windows Azure is the first general purpose Cloud Platform - it is blurring the lines between your developers and your infrastructure. We've already talked about this in regards to Windows Server 2008 R2: : Windows Server 2008 R2: the Cloud is in Your Datacenter.
Your servers run your company's mission critical applications, and your developers are writing applications that run on those servers. In most cases your company's developers are going to be way ahead of you with Windows Azure. We've already discussed the benefits Windows Azure offers developers: Microsoft Pumps Windows Azure as Top Cloud Choice for Developers
“Google is a platform as a service, but it’s only restricted to two languages – Python and Java. You have to fit in with the way they do things. We’re being general purpose. Amazon is an infrastructure as a service; they provide no tools support. How you develop your applications is your concern. You’re on your own. We support any language and multiple frameworks. We provide a rich ecosystem of technology or you can use open source software like MySQL or Apache. Our approach is we don’t put any shackles on the developer.”
So if your developers haven't started to target Windows Azure, have them take a look at the articles in this post. For the IT Professional in all of us, we're excited to announce a great new platform for your world.
Microsoft announced the Windows Azure platform appliance, the first turnkey cloud services platform for deployment in customer and service provider datacenters. Dell, eBay, Fujitsu and HP are early adopters of a limited production release of the appliance, Microsoft said.
The appliance is an enabler for developers...
Whether your applications target the cloud or the appliance, Windows Azure lets your developers work better.

<Return to section navigation list>
Cloud Security and Governance
James Houghton addresses “The considerations and components of IT cost” in his Accounting for the Cloud post of 7/31/2010:

The past few weeks we have been discussing some of the mistakes made in early cloud deployments. As a refresher, here are the issues we outlined:
- Not understanding the business value
- Assuming server virtualization is enough
- Not understanding service dependencies
- Leveraging traditional monitoring
- Not understanding internal/external costs
This week we are discussing a key mistake that occurs fairly often; one that only manifests long after the solution is operational...blindly assuming that Cloud equals costs savings. Blasphemy, you say - how could it possibly not cost less? Let's take a look at the considerations and components of IT cost, and revisit this question at the end.
The unfortunate truth is that most enterprises have well-established IT cost allocation mechanisms, but few of these have any basis in actual consumption. Put simply, can you (or your users) confidently say that your IT bill reflects how much - or little - you use something? Traditional approaches to IT chargeback involve aggregating the net IT cost, and allocating it proportionally to business units based on head count, server count, or some other surrogate for allocating actual cost. This approach (sometimes affectionately referred to as ‘peanut butter' - you spread it around) has merit in its simplicity, but cannot be allowed to persist as we move toward Cloud operating models.
There may be some readers who don't have this issue - perhaps you are blessed with an accurate model, or lucky enough to be starting from scratch with no legacy IT systems. Congratulations - we're all jealous - go live long and prosper in the Cloud. But the other 99.9% should probably keep reading.
Delivering IT in a Cloud operating model - public or private - can absolutely be a powerful way to realize cost savings, but only if your organization understands exactly what the Cloud is replacing. When you move an application or service to the Cloud, can you confidently point to the person (labor), the server, the network, the UPS, and the CRAC unit that can be eliminated or reduced to offset the new cost of your Cloud service? If you can't answer that question, then the harsh reality is that your new Cloud service likely only increased your IT costs. Now you not only get an accurate usage-based bill for your Cloud service, through the miracle of ‘peanut butter' the costs for your remaining non-Cloud services just went up (fewer applications to spread the costs to).
Let's set aside the granular elements of IT total cost of ownership (TCO) for a minute and instead focus on the TCO differences between Cloud models. If you opt for a SaaS model, then you may be safe in assuming that most of the traditional IT responsibilities go away. You'll likely still need a modicum of IT support to monitor performance of the service and ensure any interfaces to your in-house systems are operational, but the rest goes away. Now let's contrast that to consuming an IaaS model...what functions are you, the accountable IT executive, no longer responsible for? Let's ask that from a different perspective: how many people in your organization today physically touch a server/storage device? In all likelihood very few, mostly the facilities team that's responsible for the rack and stack work. When you consume an IaaS you will still need some level of support from your server administrators, you'll still need an operations team armed with monitoring tools, and (if you like your job) you'll still need people planning and exercising disaster recovery and business continuity functions. And of course a PaaS model will fall somewhere in between. Still feel confident presenting your business case for Cloud adoption based on savings to the CFO?
Granular IT cost accounting is not fun (well, for most people anyway), but it is fast becoming a mandatory component for the IT environment of the future. Workload consumption metrics, harvested across multiple technology silos (network, server, storage) with robust metering tools are required. After all, if you don't understand how your applications and service workloads are consuming existing IT resources, then you won't know how to optimize when moving applications and services to the Cloud.
Cloud Ventures claims to be “Harnessing the Identity Metasystem for Secure Cloud Services” in its Cloud Identity and Privacy post of 7/30/2010:
Advances in Identity Management technologies will provide foundations for an "Identity Metasystem", providing the tools for securing information in a manner that greatly accelerates adoption of Cloud computing.
Secure Cloud Services
Typically conversations about Cloud Computing quickly lead to the perceived big roadblock holding back its adoption, data privacy and security.
Ask yourself how you would feel about having sensitive information, like your bank account or credit card details, stored "in the Cloud"? What does that even mean? Who owns and controls it? If the data resides on servers in the USA, can they be seized by the authorities?
As Eric Openshaw, U.S. Technology Leader at Deloittes highlights in his article 'Keeping Data Safe in the Cloud', these are the serious challenges that Cloud must answer before corporates and governments will leap on board, and it will require a combination of IT and services.
This means it is also a very fertile area for venture development. New technologies and processes that address these concerns will likely be very successful in the Cloud market.
For example the Esotera 'Cloud File System' that we profiled previously provides one essential ingredient, distributed encryption. What difference does it make if someone seizes a server if the data on it is only a useless fragment of the information, and it's encrypted?
Consultants firms provide audit services like SaS70, to ensure data-centre operations are suitably robust so that they can assure one aspect of information security, but technology is needed to guarantee its privacy through greater levels of granularity of features like this encryption.
Cloud Identity Metasystem
Although Cloud mainly refers to a type of software, it's also referred to in the context of the overall Internet, as "in the Cloud".
This means hosting applications with service providers like Amazon but this will also come to mean better data sharing between them by doing so. Plugging your app into the Cloud will mean engineering it to be better integrated with the Cloud, as well as using it for utility infrastructure.
A simple example is the hassles of having multiple usernames and passwords for each web site that you use, and how this can be addressed by using a single Internet username identity. The most popular standard that has emerged for this is OpenID, now used by millions.
This enables you to have a single username that works consistently across multiple web sites, eliminating this friction and is thus a great boon, but it's only the tip of the iceberg.
By doing this this will provide the technical features required to achieve the Information Assurance processes needed to certify Cloud services as being secure enough.
Matching these developments to government policy for their adoption will be the key to unlocking the floodgates. Kim writes in this paper how compliance with EU privacy laws can be achieved, and with the USA recently beginning their procedures to formalize recognition of them this is likely to act as a catalyst in accelerating levels of Cloud adoption.
Vendor profile: Cloud Identity
Insightfully named Cloud Identity is one vendor that offers this type of technology, and they highlight the key venture strategy to employ, namely that of identifying how corporate IT can leverage these advances to solve practical problems.
Cloud Identity provides software for automating user processes across multiple SaaS systems. Organizations employing temporary workers may have them use Salesforce and Webex for example, so they need to be automatically set up and removed from these accordingly.
With this software enterprises can leverage OpenID as a single identifier but control it according to corporate policies and integrate it with on-site Identity Management systems like Active Directory, providing for a secure 'bridge' from on-site to hosted applications.
Liz McMillan posited “Certificate of Cloud Security Knowledge (CCSK) Aimed at Promoting Secure Cloud Computing for All” as a preface to her Cloud Security Alliance Sets Industry Standard with New User Certification post of 7/29/2010:
The Cloud Security Alliance on Wednesday unveiled the industry's first user certification program for secure cloud computing. The Certificate of Cloud Security Knowledge (CCSK) is designed to ensure that a broad range of professionals with a responsibility related to cloud computing have a demonstrated awareness of the security threats and best practices for securing the cloud.
Cloud computing is being aggressively adopted on a global basis as businesses seek to reduce costs and improve their agility. Among the critical needs of the industry is to provide training and certification of professionals to assure that cloud computing is implemented responsibly with the appropriate security controls. The Cloud Security Alliance has developed a widely adopted catalogue of security best practices, the Security Guidance for Critical Areas of Focus in Cloud Computing, V2.1.
In addition, the European Network and Information Security Agency (ENISA) whitepaper "Cloud Computing: Benefits, Risks and Recommendations for Information Security" is an important contribution to the cloud security body of knowledge. The Certificate of Cloud Security Knowledge (CCSK) provides evidence that an individual has successfully completed an examination covering the key concepts of the CSA guidance and ENISA whitepaper. More information is available at www.cloudsecurityalliance.org/certifyme.
"Cloud represents the shift to compute as a utility and is ushering in a new generation of information technology. Critical services are now being provided via the cloud, which is creating a mandate for cloud security skills across the spectrum of IT-related professions," said Jim Reavis, CSA executive director. "The CSA is providing a low cost certification that establishes a robust baseline of cloud security knowledge. When combined with existing professional certifications, the CCSK helps provide necessary assurance of user competency in this important time of transition. We are also thrilled to have ENISA's support and their agreement to join our certification board."
"We have already been leveraging the CSA's ‘Security Guidance for Critical Areas in Cloud Computing' as a best practices manual for our information security staff," said Dave Cullinane, CISO and VP for eBay, Inc. "We now plan to make this certification a requirement for our staff, to ensure they have a solid baseline of understanding of the best practices for securing data and applications in the cloud."
"Security has been identified as the most significant issue associated with cloud computing adoption," said Melvin Greer, Chief Strategist, Cloud Computing, for Lockheed Martin. "The CSA Certificate of Cloud Security Knowledge (CCSK) will provide a consistent way of developing cloud security competency and provide both organizations and agencies the confidence they need to adopt secure cloud solutions."
"Cloud computing will undoubtedly have a profound effect on information security. Educating and developing talented thought-leaders is a key challenge in solving cloud security issues," said Jerry Archer, CSO for Sallie Mae. "The CSA, in providing a set of goals through the CCSK, is challenging security practitioners to become the cloud thought-leaders we need today and tomorrow to ensure safe and secure cloud environments. In developing the CCSK, CSA is "setting the bar" for security professionals and providing business executives a means to gauge the opinions and rhetoric associated with security in the cloud."
eBay, Lockheed Martin and Sallie Mae join many other companies, including ING, Symantec, CA, Trend Micro and Zynga in their commitment to adoption of the CCSK. Online testing will be available starting Sept 1st 2010. The CSA will offer discount pricing of $195 through Dec 31; regular pricing at $295 begins January 1.

<Return to section navigation list>
Cloud Computing Events
• Azure Services Brasil (@AzureServicesBr) reported on 8/1/2010 the following three CloudCamps will be held in August 2010:
August 10, 2010 in São Paulo, Brazil (co-located with Cloud Summit).
- August 14, 2010 in Belo Horizonte, Brazil (located at Assespro-MG)
- August 19, 2010 in Brasilia, Brazil (requires registration for CONSEGI)
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Brett Sheppard posted Meet Big Data equivalent of the LAMP Stack to the GigaOm blog on 8/1/2010:
Many Fortune 500 and mid-size enterprises are funding Hadoop test/dev projects for Big Data analytics, but question how to integrate Hadoop into their standard enterprise architecture. For example, Joe Cunningham, head of technology strategy and innovation at credit card giant Visa, told the audience at last year’s Hadoop World that he would like to see Hadoop evolve from an alpha/beta environment into mainstream use for transaction analysis, but has concerns about integration and operations management.
What’s been missing for Big Data analytics has been a LAMP (Linux, Apache HTTP Server, MySQL and PHP) equivalent. Fortunately, there’s an emerging LAMP-like stack for Big Data aggregation, processing and analytics that includes:
- Hadoop Distributed File System (HDFS) for storage
- MapReduce for distributed processing of large data sets on compute clusters
- HBase for fast read/write access to tabular data
- Hive for SQL-like queries on large data sets as well as a columnar storage layout using RCFile
- Flume for log file and streaming data collection, along with Sqoop for database imports
- JDBC and ODBC drivers to allow tools written for relational databases to access data stored in Hive
- Hue for user interfaces
- Pig for dataflow and parallel computations
- Oozie for workflow
- Avro for serialization
- Zookeeper for coordinated service for distributed applications
While that’s still a lot of moving parts for an enterprise to install and manage, we’re almost to a point where there’s an end-to-end “hello world” for analytical data management. If you download Cloudera’s CDH3b2, you can import data with Flume, write it into HDFS, and then run queries using Cloudera’s Beeswax Hive user interface.
With the benefit of this emerging analytical platform, data science is becoming more integral to businesses, and less a quirky, separate function. As an industry, we’ve come a long way since, industry visionary Jim Gray was famously thrown out of the IBM Scientific Center in Los Angeles for failure to adhere to IBM’s dress code.
Adobe’s infrastructure services team has scaled HBase implementations to handle several billion records with access times under 50 milliseconds. Their “Hstack” integrates HDFS, HBase and Zookeeper with a Puppet configuration management tool. Adobe can now automatically deploy a complete analytical data stack across a cluster.
Working with Hive, Facebook created a web-based tool, HiPal, that enables non-engineers to run queries on large data sets, view reports, and test hypotheses using familiar web browser interfaces.
For Hadoop to realize its potential for widespread enterprise adoption, it needs to be as easy to install and use as Lotus 1-2-3 or its successor Microsoft Excel. When Lotus introduced 1-2-3 in 1983, they chose the name to represent the tight integration of three capabilities: a spreadsheet, charting/graphing and simple database operations. As a high school student, I used it to manage the reseller database for a storage startup, Maynard Electronics. Even as a 15 year old, I found Lotus 1-2-3 easy to use. More recently, with Microsoft Excel 2010 and SQL Server 2008 R2, I can click on Excel ribbon buttons to load and prepare PowerPivot data, create charts and graphs using out-of-the-box templates, and publish on SharePoint for collaboration with colleagues.
The Fourth Paradigm quotes Jim Gray as saying “We have to do better producing tools to support the whole research cycle – from data capture and data curation to data analysis and data visualization.” As the Hadoop data stack becomes more LAMP-like, we get closer to realizing Jim’s vision and giving enterprises an end-to-end analytics platform to unlock the power of their Big Data with the ease of use of a Lotus 1-2-3 or Microsoft Excel spreadsheet.
Brett Sheppard is an executive director at Zettaforce.
• Steven Overly reported Google cloud-computing applications get certification for federal government use in the 8/2/2010 issue of the Washington Posts Capitol Business section (requires site registration):
Google wants the federal government to use its e-mail.
The company earned federal certification last week for its cloud-based e-mail, calendar and other collaboration applications after the General Services Administration determined they met moderate-level federal security requirements.
It's the first cloud-based suite to earn such accreditation and serves as an impetus for the Mountain View, Calif.-based giant to ramp up its sales efforts in Washington, said David Mihalchik, Google's federal business development executive.
"We hear them tell us that federal employees are clamoring for the same technology [at work that] they have at home," Mihalchik said. "What we've done is to certify Google Apps so that government has an apples-to-apples comparison of their existing system and Google Apps."
Once largely absent from Washington, Google has expanded its reach here in recent years, mainly to lobby on Internet and antitrust policies. Its offices in Reston and north of Metro Center currently contain about 30 employees each.
But the notion of the federal government as a potential customer has only begun to take shape as lawmakers and executives look to cut information technology costs with cloud computing, a burgeoning trend whereby organizations receive IT services and software via the Internet.
"This is a new technology paradigm," Mihalchik said. And "Google is a cloud computing company."
That shift has been slowed by lawmaker concerns about data security and privacy, said Deniece Peterson, the manager of industry analysis at Input, a Reston-based market research firm that follows federal contracts. She said last week's announcement may ease some trepidation.
Google's certification comes as various media outlets have said the company is vying with Microsoft to provide e-mail for GSA's 15,000 employees.
The Federal Information Security Management Act, or FISMA, requires agencies to establish security standards for information systems and hold any vendors to them, said Sahar Wali, a GSA spokeswoman.
Wali said FISMA certification is not required in order to win the bid, so accreditation may not give Google an outright advantage. But it is required to implement a new e-mail system, and prior approval could shorten the time it takes for that to happen.
But even as Google beats technology giants likes Microsoft and IBM to the finish line on a cloud suite that meets FISMA standards, Peterson said not to expect others will go "quietly into the night because Google has arrived."
CONTINUED 1 2 Next > (See page 2 for more from Microsoft.)
Sidebar: WASHINGTON, DC- July 28, 2010: David Mihalchik, Business Development Executive at Google at their Washington DC office photographed in the Liquid Galaxy. Described as a multi-screen immersive visualization chamber for Google Earth. Photograph made on July 28, 2010 in Washington,DC.( Photo by Jeffrey MacMillan ) Freelance Photo imported to Merlin on Wed Jul 28 17:16:04 2010 (Jeffrey Macmillan - Jeffrey Macmillan For Washington Post)
Old news but with more background than most articles. Note that nothing was said about FISMA certification of Google App Engine or Google App Engine for Business. I expect Microsoft to try for FISMA certification for BPOS and Windows Azure Services, including SQL Azure and App Fabric.
Maureen O’Gara asserted “It didn’t disclose terms but an Israeli press report put the price at $140 million” in a preface to her IBM Buys Storwize post of 7/30/2010:
IBM is buying Storwize, an Israeli start-up that does real-time data compression software that can reportedly cut physical storage requirements by up to 80%.
That facility in turn is supposed to lower the cost of making data available for analytics and other applications. It can scan more years of historical data from multiple sources without additional storage and compressing data in real-time is suppose to make it available up to four times faster for transaction workloads.
IBM didn't disclose terms but an Israeli press report put the price at $140 million.
Storwize, which has offices in Massachusetts, raised $40 million from Sequoia Capital, Bessemer Venture Partners, Tenaya Capital, Tamares Group and Tokyo Electron Device. The deal is supposed to close this quarter.
Storwize claims one hundred customers.
IBM says its patented Random Access Compression Engine (RACE) is "unique" in being able to compress primary data, or data that clients are actively using, regardless of type - anything from files to virtualization images to databases - in real-time while maintaining performance. It said other storage compression technologies only compress secondary or backup data.
By compressing primary data, Storwize users can store up to five times more data using the same amount of storage, prevent storage sprawl and lower power and cooling costs. "This is important now more than ever," IBM said, "as the world's data already vastly exceeds available storage space and enterprise demand for storage capacity worldwide is projected to grow at a compound annual growth rate of over 43% from 2008 to 2013, according to IDC."
Storwize's STN appliance will work with most people's NAS systems.

<Return to section navigation list>

















{kind=link}