Windows Azure and Cloud Computing Posts for 8/4/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA)
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Azure Blob, Drive, Table and Queue Services
See Black Hat Briefings USA 2010 distributed Grant Bugher’s Secure Use of Cloud Storage PDF whitepaper of July 2010, which covers Windows Azure Table storage and Amazon S3/SimpleDB security in the Cloud Security and Governance section below.
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
Wayne Walter Berry (@WayneBerry) posted Using SQL Azure for Session State on 8/4/2010:
Hypertext Transfer Protocol (HTTP) is a stateless protocol; the advantage of a stateless protocol is that web servers do not need to retain information about users between requests. However, in some scenarios web site developers want to maintain state between page requests to provide consistency to the web application. To create state from a stateless protocol, ASP.NET has the concept of a session which is maintained from the user’s first request to their last request for that visit to the web site.
By default, ASP.NET session is maintained in the RAM of the running web server. However, Windows Azure is a stateless platform, web role instances have no local storage; at any time the web role instance could be moved to a different server in the data center. When the web role instance is moved, the session state is lost. To have a perceived sense of state with a stateless protocol on a stateless web server, you need permanent server side storage that persists even if the web role instance is moved. In this article I will discuss how to use SQL Azure to create persistent storage for an ASP.NET session in Windows Azure.
SQL Azure is a perfect fit for maintaining session in Windows Azure, because there is already a SqlSessionStateStore; a Microsoft session state provider developed for on-premise SQL Server installations. The SQL server provider was developed for local IIS installations across multiple web servers in a web farm that wanted to maintain the user’s state across machines.
Creating the Tables
If we are going to use the SqlSessionStateStore provider on Windows Azure against SQL Azure, we are going to need to create the appropriate tables and stored procedures. Typically this would be done with the InstallSqlState.sql script that ships with the .NET framework (or Aspnet_regsql.exe's –sstype), however this script doesn’t work for SQL Azure, because of Transact-SQL differences. Instead we have to use a modified script (see download at the bottom of this blog post).
Here are the instructions to create the databases, stored procedures, and tables needed to store session state on SQL Azure
- Download a modified Transact-SQL script called ASPStateInstall.sql that will create the ASPState database.
- Execute the ASPStateInstall.sql script from SQL Server Management Studio on the master database, read more about connecting to SQL Azure with SQL Server Management Studio here.
- Reconnect SQL Server Management Studio to the ASPState database that you just created.
- Execute the InstallSqlState.sql script from the download from SQL Server Management Studio on the ASPState database.
Modifying the web.config
Next thing to do is modify the web.config so that Windows Azure uses SQL Azure as storage for the session state. Your web.config should look something like this:
<sessionState mode="SQLServer" sqlConnectionString="Server=tcp:...;Trusted_Connection=False;Encrypt=True;" cookieless="false" timeout="20" allowCustomSqlDatabase="true" />Make sure to modify the sqlConnectionString to match the SQL Azure connection string from the SQL Azure Portal for the ASPState database. If you are trying this on an on-premise installation of IIS, the same modification to the web.config will work.
Doing the Clean Up
When installing ASP.NET SQL Session State Management provider with an on-premise SQL Server the install creates a job that the SQL Server Agent executes which cleans up the old session data. SQL Azure doesn’t have the concept of a SQL Server Agent; instead we can use a Windows Azure worker role to clean-up the SQL Azure database. For more information see our SQL Server Agent blog series (Part 1, Part 2, and Part 3). The InstallSqlState.sql script that you ran to setup the database contains a DeleteExpiredSessions. Trimming the expired sessions is as easy as calling this script from the worker role. Here is what the code looks like:
public override void Run() { // This is a sample worker implementation. Replace with your logic. Trace.WriteLine("WorkerRole1 entry point called", "Information"); while (true) { Thread.Sleep(60000); // Create a SqlConnection Class, the connection isn't established // until the Open() method is called using (SqlConnection sqlConnection = new SqlConnection( ConfigurationManager.ConnectionStrings["ASPState"]. ConnectionString)) { try { // Open the connection sqlConnection.Open(); SqlCommand sqlCommand = new SqlCommand( "DeleteExpiredSessions", sqlConnection); sqlCommand.CommandType = System.Data.CommandType.StoredProcedure; sqlCommand.ExecuteNonQuery(); } catch (SqlException) { // WWB: Don't Fail On SQL Exceptions, // Just Try Again After the Sleep } } } }Make sure to add the ASPState connection string to the worker role’s app.config or the worker role will never completely initialize when you deploy to Windows Azure. Here is what it will look like:
<?xml version="1.0" encoding="utf-8" ?> <configuration> <connectionStrings> <add name="ASPState" connectionString="Server=tcp:…;Trusted_Connection=False;Encrypt=True;"/> </connectionStrings>If you cut and paste the code above, make sure to modify the connectionString attribute to match the SQL Azure connection string from the SQL Azure Portal.
Dinakar Nethi’s four-page Sync Framework for SQL Azure whitepaper became available for download on 8/4/2010. From the summary:
The whitepaper primarily addresses:
Guidelines for efficient Scoping:
- Each scope has one thread allocated to it from the OS. So distributing the tables across multiple scopes will help parallelize the data migrations
- Put static/changing at a very low rate tables in one scope and reduce their sync frequency
- Group frequently changing tables in different scopes
- Put logical related tables (Primary Key-Foreign key dependency or logical dependency) in one scope
- Scopes that are only read on the client should be marked as download only as this streamlines the sync workflow and decreases sync times
- It is better to minimize the number of clients that are in each scope with the best case being a different scope for each client. This minimizes contention on the server and is ideal for the hub-spoke case where all changes flow through a single server vs. being synced between clients
- Initialize via snapshots vs. full initialization wherever possible to improve initial sync time by an order of magnitude
For a detailed walkthrough of SQL Azure Data Sync, see my
Franz Bouma compares LightSwitch and Visual Studio with Squire and Stratocaster guitars in his Microsoft LightSwitch: a [Squire] which will never be a Fender in this 8/4/2010 post:
Yesterday, Microsoft announced a new Visual Studio tool: Microsoft LightSwitch. LightSwitch is a tool which allows you to create Line of Business (LoB) applications by using a visual tool, similar to Microsoft Access, although LightSwitch can also produce applications for the web and can pull data from various sources instead of its own build-in database.
What puzzles me with LightSwitch is: what's the target audience? Who is supposed to use this tool instead of another tool? Is this a tool to sell more Sharepoint licenses, more Azure licenses? I have no idea. The main problem is that there's some friction in the image of LightSwitch. Microsoft says LightSwitch is aimed at the tech-savvy non-developer who wants to create a LoB application without needing to hire a truck full of professional developers. In short: a tool for an amateur who wants to 'Do It Him/Herself'. The friction is in the level of knowledge a person apparently has to have: what's a database, what's a table, what's an entity, what's a screen, what's validation etc.. So is it really an amateur tool for amateurs or is it an amateur tool for professionals?
The 'Do It Yourself' remark is familiar: a lot of people try to fix things around the house themselves before they call in the pro's, and sometimes they even succeed wonderfully. These 'do-it-yourself' people buy off-the-shelve cheap powertools to help them with the job and if you close your eyes a bit, the end result looks OK, as if a professional did the work. However, how many of those 'do-it-yourself' people will successfully install a full electrical circuit in the house, or create a new bathroom, with bath, plumbing, fancy mirrors etc.? Not many, they'll call the professionals, who have different tools and different skills and don't create a dangerous train-wreck.
I didn't want to compare LightSwitch to an el-cheapo power-drill, so I have chosen a different metaphore: an electrical guitar. A beginner will buy a beginner's guitar. A professional will buy a professional's guitar. Let's look at two brand examples: [Squire] and Fender. pSquire] is a brand from Fender actually and under that brand, Fender sells el-cheapo knock-offs of its expensive equipment, like the [T]elecaster and the [S]tratocaster. A [Squire Stratocaster] costs below 200 [E]uros, a Fender USA made [S]tratocaster costs 1400+ [E]uros. Why's that? They both have 6 strings, pick-ups (the 'elements' below the strings) and produce sound, and look almost the same: what's the difference?
As an amateur rock-guitarist, I can only try to describe the difference, but I hope it will show you what I mean. I played on el-cheapo guitars for some time, maybe 2 years or so, and one day I was offered to play a couple of hours on a real Fender telecaster (which costs over 1300 [E]uros). I still can't believe the difference in sound that guitar made. It played like a dream, the sustain (the time a note continues to sound) was endless, the pickups were able to produce much deeper sound than I had ever heard from my [los]-cheapos. Did it make my own compositions at that time sound better (warmth, depth)? Yes absolutely. Did it make my compositions better? No. Did it make me a better guitar player? No.
An amateur guitarist will sound like an amateur guitarist, no matter the equipment. A professional guitarist will sound like a professional, no matter the equipment. Don't make the mistake that by using a more expensive guitar you suddenly are Jeff Kollman of Cosmosquad (one of the best guitarists in the world, see below): the notes you'll play perhaps sound better, but the overall music will still be at the amateur level.
Microsoft LightSwitch is a tool for amateurs to produce stuff amateurs will produce. It's a mistake to think the stuff produced with LightSwitch will be usable by professional developers later on to extend it / maintain it or will appeal to professionals. See LightSwitch as that el-cheapo [Squire] Telecaster: it looks like a real Fender Telecaster guitar, it produces guitar sound, but a professional will choose for the real deal, for reasons a professional understands. Is that bad or arrogant? No: a professional is a professional and knows his/her field and has skills an amateur doesn't have and therefore doesn't understand. In these videos on Youtube (Part 1 | Part 2) (12 minutes combined) Jeff Kollman / Cosmosquad is interviewed and plays a Fender Telecaster in a custom tuning. It's very advanced stuff, but it shows what a professional can do with a tool for professionals.
In guitar-land things are pretty much settled down, amateurs use amateur material/tools, professionals use professional material/tools. In developer-land, let's see it the same way. The only fear I have is that in a few years time, the world is 'blessed' with applications created by amateurs using a tool meant for amateurs and us professionals have to 'fix the problems'. You can't bend a [Squire] to become a Fender, it will stay a [Squire]: amateurs of the world, please do realize that.
C programmers similarly denigrated Visual Basic 1.0 when it arrived in May 1991. I wonder if Frans received an early copy of the Beta, which won’t be available to MSDN Subscribers until 8/23/2010. If not, his condemnation of the framework appears to me to be premature.
Gavin Clarke reported “Microsoft may submit its OData web data protocol for standards ratification, but seems eager to avoid the bruising it received on OOXML” in his OOXML and open clouds: Microsoft's lessons learned From conflation to inflation post of 8/3/2010 to The Register:
Microsoft may submit its OData web data protocol for standards ratification, but seems eager to avoid the bruising it received on OOXML.
Jean Paoli, Microsoft's interoperability strategy general manager and one of the co-inventors of the original XML whose work ultimately went into OOXML, told The Reg that Microsoft might submit OData to the W3C or OASIS.
OData is on a list of both Microsoft and non-Microsoft technologies that the company is touting as one answer to moving data between clouds and providing interoperability. Data interoperability is a major cause of concern as the initial euphoria of the cloud evaporates leaving a headache of practical concerns such as: how do I move my data to a new cloud should I choose?
Paoli, speaking after Microsoft unveiled its four principles of cloud interoperability recently, said Microsoft and the industry should reuse existing standards as much as possible to solve interoperability problems.
He also believes, though, that the cloud will create new situations in the next three to five years that people can't currently foresee and that'll need new standards to manage. "With the cloud there's new scenarios we don't know about," Paoli said.
The last time Microsoft got involved with portability of data it was about document formats, and things turned nasty given that Microsoft is the biggest supplier of desktop productivity apps with Office, and SharePoint is increasingly Microsoft's back-end data repository.
While open sourcers, IBM, Red Hat, Sun Microsystems and others lined up to establish the Open Document Format (ODF) as an official standard, Microsoft predictably went its own way.
Rather than open Office to ODF, Microsoft instead proposed Office Open XML (OOXML) in a standards battle that saw accusations flying that Microsoft had loaded the local standards voting processes to force through OOXML so it wouldn't have to fully open up.
Then there were the real-world battles, as government bodies began to mandate they'd only accept documents using ODF. Things came to a head in the cradle of the American revolution, Massachusetts, which declared for ODF but then also accepted OOXML following intense political lobbying by Microsoft, while the IT exec who'd made the call for ODF resigned his post.
The sour grapes of ODF ratification, followed by the bitter pills of local politics, left people feeling Microsoft had deliberately fragmented data openness to keep a grip through Office.
Paoli was once one of Microsoft's XML architects who designed the XML capabilities of Office 2003, the first version of Office to implement OOXML. Today he leads a team of around 80 individuals who work with other Microsoft product groups on interoperability from strategy to coding.
What lessons did Microsoft lean from OOXML that it can apply to pushing data portability in the cloud?
"I think collaboration is important in general and communication," Paoli said. "I think we did a very poor job of communications a long time ago and I think we need to communicate better. People did not understand what we were trying to do [on OOXML]."
This time Paoli said that Microsoft is going into the standards bodies and open-source communities to discuss ways of working together on cloud interoperability, identity, and application deployment. Results from conversations will be posted back to a new Microsoft site listing those four principles of cloud interoperability here.
On OData, Paoli was keen to point out how the technology uses the existing and widely accepted HTTP, JSON, and AtomPub. "We want to deepen the conversation with the industry," he said.
For all the we're-all-in-this-together stuff, there's still a sense that Microsoft is promoting its own Azure cloud as much as trying to champion a common cause.
Microsoft's new site makes great play about how Windows Azure use HTTP, SOAP, and REST, that you can mount and dismount server drives in Azure clouds using NTFS, and the availability of GUI tools for Eclipse and Windows Azure SDKs for Java and Ruby. On the upstanding-citizen side, the site also lists the standards bodies in which Microsoft is participating.
Yet, concerning OData, things have a decidedly Microsoft feel.
OData might be "open" but it's Microsoft products — SharePoint 2010, SQL Azure, Windows Azure table storage and SQL reporting services — that mostly expose data as OData.
IBM's WebSphere does, too, and PHP, Java, JavaScript, and the iPhone can consume OData — but it looks like you're mostly moving data between Microsoft's applications and cloud services.
One major user of OData is Netflix, whose entire catalog is available in OData — Netflix is a premier customer of Microsoft technology already, using Silverlight on its site.
In a world of circular logic, Microsoft needs to get more applications and services using OData to justify Azure's use of it, while OData is important to help sell more copies of SharePoint 2010 on the basis of interoperability with the cloud — Microsoft's cloud, specifically.
Does this mean that Microsoft has an agenda — and should it be trusted? Trust is something Microsoft always has to work hard to achieve thanks to its history and periodic outbursts on things like patents in open source — a community Microsoft is courting to support Azure.
Paoli says skeptics will always exist, but today Microsoft is part of the community through work on things like Stonehenge at the Apache Software Foundation (ASF).
"I'm very, very pragmatic. It reminds me of when I moved from France and was hired by Microsoft... everyone was asking me: 'Hey, wow, is Microsoft really into XML? I said 'yeah'. There was always some skepticism, and that was 14 years ago. We implemented XML — we helped created the basic standards, we had a lot of partners.
"The best approach is to work with people pragmatically and work with people on technology issues and just move on."
He reckons, too, that Microsoft has learned its lessons about dealing with open sourcers — people it's relying on to deploy PHP and Ruby apps on Azure. Microsoft's mistake in the past was to conflate Linux and open source products and the developer community — a community Paoli said Microsoft feels at home in. And we know how much Microsoft loves developers, developers, developers.
"We know the world is a mixed IT environment — this is really ingrained in our thinking," Paoli claimed.
It's early days for cloud and Microsoft's role in shaping it, but the strategy sounds different.
Ten years ago, before OOXML, Microsoft decided it would lead with IBM a push to shape the future of web services, a foundation of cloud, with the WS-* specs. WS-* proved inflexible, and developers moved on to better technologies. On OOXML, Microsoft led again but was left looking isolated and awakard.
Microsoft's needs OData as much as it did the ideas behind WS-* and OOXML. This time, Microsoft seems to be searching for a subtler way to advance its cause.
John Alioto shows you Three ways to interact with SQL Azure … in this 8/3/2010 post:
There are several different tools that one can use to interact with a SQL Azure database. Each tool has scenerios that it is best for and an audience to whom it will appeal. Here are three along with some thoughts on each.
Method #1: Tried and True, SSMS [2008 R2]

This method is great for heavy-duty management and creation of databases. It’s also great because it’s the tool we’re all most familiar with. I’m just using the AdventureWorks sample for Azure which has a nice little installer and I can interact with my database as normal …

Method #2: Project Codename “Houston”
The team over at SQL Azure Labs has created a very nice Silverlight tool they are calling Houston. This is a lighter weight tool than SSMS. You can’t do all the database management that you can with the full Management Studio, but that’s okay as this is a tool more targeted at developers (which I am, so that’s good!) You will see it has a great Silverlight interface that is easy to use (spinning cubes are hotness!)

You can select multiple rowsets, click to zoom (ctrl-click to zoom out), save queries and more. You just have to get out of the habit of using F5 to execute your query! :)

Take a look at this blog post by my buddy Richard Seroter for more detailed walkthrough. [See my Test Drive Project Houston CTP1 with SQL Azure post (updated 7/31/2010) for an even more detailed walkthrough.]
Method #3: Quadrant
Quadrant is a graphical tool for manipulating data. In order to get Quadrant, you need to download and install the SQL Server Modeling CTP – November 2009 (as of this writing, check for updates depending on when you read this.) Quadrant is a very different data manipulation experience. It is simple, beautiful and powerful.
In order to connect to a SQL Azure database with Quadrant, you create a new Session (File->New Session). You need to look under the “More” drop down, as you must connect to SQL Azure with SQL Server Authentication

If all is well, you are greeted with a simple canvas upon which to manipulate your data.

The first thing you will notice is that this is a WPF application, so you have great things like Mouse Wheel in/out for zoom. You can simply open your explorer and start dragging tables onto the canvas. It’s quite an amazing experience – watch some videos about the UI and I think you will quickly see just how compelling this experience can be.

It remains to be seen in my mind who this application is for. It certainly allows you to look and interact with data in a different way than the other two – perhaps a bit more right-brained.
There you have it, three very simple, very powerful ways to interact with your SQL Azure databases.







I haven’t tried Quadrant with SQL Azure, but will. John says he was raised in the Bay Area and lives in the East Bay. I wonder if he’s a member of San Francisco’s [in]famous Alioto clan (mayor, supervisor, attorney, et al.)
Brian Harry shares his take on LightSwitch in his Announcing Visual Studio LightSwitch! post of 8/3/2010:
Today at VSLive!, Jason Zander announced a new Visual Studio product called LightSwitch. It’s been in the works for quite some time now, as you might imagine. Beta 1 of LightSwitch will be available on August 23rd – I’ll post again with a link as soon as I have it. You can check out this link to learn more: http://www.microsoft.com/visualstudio/lightswitch
Basically LightSwitch is a new tool to make building business applications easier than ever before. It allows you to build local or browser hosted applications using SilverLight. Your apps can run on premise or in the cloud. In some ways, I draw an analogy with Microsoft Access in the sense that it is a radically simplified way to build business apps that enable you to have your app up and running within minutes or hours.
However, there are some key innovations. For one, your app is, by default, architected for the future – scalability and the cloud. Further when you hit the wall on the “simple” tool, which apps seem to do when the little departmental app suddenly becomes a smash hit, you have headroom. LightSwitch IS a Visual Studio based product. You can “go outside the box” and bring the full power of Visual Studio and Expression to bear to build a bullet proof, scalable app without throwing everything out and starting over.
LightSwitch provides a heavily “data-oriented” application design paradigm. It can consume and mash-up external data in Sharepoint or SQL (including SQL Azure) and provides quick and easy way to build the UI around it.
It’s a really awesome way to get started, yet ensure that there’s no ceiling for your app. If you find yourself automating a bunch of business processes, I strongly encourage you to give LightSwitch a try.
Jason’s blog has a nice walk through with a simple LightSwitch example: http://blogs.msdn.com/b/jasonz/archive/2010/08/03/introducing-microsoft-visual-studio-lightswitch.aspx.
Mike Taulty likened LightSwitch to Microsoft Access in his “Coming Soon”– Visual Studio LightSwitch of 8/3/2010:
A new version of Visual Studio called “LightSwitch” was announced at the VS Live conference today by Jason Zander.
At the moment, I don’t have any deep details to write about here but the essence is around a productive tool for building business applications with Silverlight for both the browser and the desktop which takes in cloud options as well.
It’s not necessarily targeted at every developer who’s building applications with .NET or Silverlight and undoubtedly there’s bound to be trade-offs that you make between [productivity/control] just as there are every time you adopt a [framework/toolset] but I think that this is a really interesting addition to Visual Studio.
It’s great to see Silverlight being used as the front-end here and ( as others have said ) in some ways the demos I’ve seen so far have a slight flavour of how Access was used to put together an app on top of a SQL store.
However, with the front end being Silverlight I can expect to run that cross-browser, cross-platform and in or out of the browser and, from the announcements, it looks like having SQL, SharePoint or SQL Azure data storage are key scenarios so I’ll perhaps ditch the “Access comparison” at that point

Either way – the best way to work it all out will be to try it out and, with that in mind, there’s a beta coming later in the month.
In the meantime, to get a few more details I’ve found ( in descending order from more detail to less detail );
- Channel 9 Video
- Jason’s Blog Post
- The Visual Studio LightSwitch home page ( only one short video right now but looks like it will grow )
- Soma’s Blog Post
- Brian Harry’s Blog Post
- LightSwitch Q&A at VS Live
<Return to section navigation list>
AppFabric: Access Control and Service Bus
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
No significant articles today.
Return to section navigation list>
Windows Azure Infrastructure
Lori MacVittie (@lmacvittie) observed An impassioned plea from a devops blogger and a reality check from a large enterprise highlight a growing problem with devops evolutions – not enough dev with the ops to set up her Will DevOps Fork? post of 8/4/2010 to F5’s DevCentral blog:
John E. Vincent offered a lengthy blog on a subject near and dear to his heart recently: devops. His plea was not to be left behind as devops gains momentum and continues to barrel forward toward becoming a recognized IT discipline. The problem is that John, like many folks, works in an enterprise. An enterprise in which not only the existence of legacy and traditional solutions require a bit more ingenuity to integrate but in which the imposition of regulations breaks the devops ability to rely solely on script-based solutions to automate operations.
The whole point of this long-winded post is to say "Don't write us off". We know. You're preaching to the choir. It takes baby steps and we have to pursue it in a way that works with the structure we have in place. It's great that you're a startup and don't have the legacy issues older companies have. We're all on the same team. Don't leave us behind.
John E. Vincent, “No operations team left behind - Where DevOps misses the mark”
But it isn’t just legacy solutions and regulations slowing down the mass adoption of cloud computing and devops, it’s the sheer rate of change that can be present in very large enterprise operations.
Scripted provisioning is faster than the traditional approach and reduces technical and human costs, but it is not without drawbacks. First, it takes time to write a script that will shift an entire, sometimes complex workload seamlessly to the cloud. Second, scripts must be continually updated to accommodate the constant changes being made to dozens of host and targeted servers.
"Script-based provisioning can be a pretty good solution for smaller companies that have low data volumes, or where speed in moving workloads around is the most important thing. But in a company of our size, the sheer number of machines and workloads we need to bring up quickly makes scripts irrelevant in the cloud age," said Jack Henderson, an IT administrator with a national transportation company based in Jacksonville, Fla.
More aggressive enterprises that want to move their cloud and virtualization projects forward now are looking at more advanced provisioning methods
Server provisioning methods holding back cloud computing initiatives
Scripting, it appears, just isn’t going to cut it as the primary tool in devops toolbox. Not that this is any surprise to those who’ve been watching or have been tackling this problem from the inevitable infrastructure integration point of view. In order to accommodate policies and processes specific to regulations and simultaneously be able to support a rapid rate of change something larger than scripts and broader than automation is going to be necessary.
You are going to need orchestration, and that means you’re going to need integration. You’re going to need Infrastructure 2.0.
AUTOMATED OPERATIONS versus DATA CENTER ORCHESTRATION
In order to properly scale automation along with a high volume of workload you need more than just scripted automation. You need collaboration and dynamism, not
codified automation and brittle configurations. What scripts provide now is the ability to configure (and update) the application deployment environment and – if you’re lucky – piece of the application network infrastructure on an individual basis using primarily codified configurations. What we need is twofold. First, we need to be able to integrate and automate all applicable infrastructure components. This becomes apparent when you consider the number of network infrastructure components upon which an application relies today, especially those in a highly virtualized or cloud computing environment.
Second is the ability to direct a piece of infrastructure to configure itself based on a set of parameters and known operational states – at the time it becomes active. We don’t want to inject a new configuration every time a system comes up, we want to modify on the fly, to adapt in real-time, to what’s happening in the network, in the application delivery channel, in the application environment. While it may be acceptable (and it isn’t in very large environments but may be acceptable in smaller ones) to use a reset approach, i.e. change and reboot/reload a daemon to apply those changes, this is not generally an acceptable approach in the network. Other applications and infrastructure may be relying on that component and rebooting/resetting the core processes will interrupt service to those dependent components. The best way to achieve the goal desired – real-time management – is to use the APIs provided to do so.
On top of that we need to be able to orchestrate a process. And that process must be able to incorporate the human element if necessary, such as may be the case with regulations that require approvals or “sign-offs”. We need solutions that are based on open-standards and integrate with one another in such a way as to make it possible to arrive at a solution that can serve an organization of any size and any age and at any stage in the cloud maturity model.
Right now devops is heading down a path that relegates it to little more than automation operators, which is really not all that much different than what the practitioners were before. Virtualization and cloud computing have simply raised their visibility due to the increased reliance on automation as a means to an end. But treating automated operations as the end goal completely eliminates the “dev” in “devops” and ignores the concept of an integrated, collaborative network that is not a second-class citizen but a full-fledged participant in the application lifecycle and deployment process. That concept is integral to the evolution of highly virtualized implementations toward a mature, cloud-based environment that can leverage services whether they are local, remote, or a combination of both. Or that change from day to day or hour to hour based on business and operational conditions and requirements.
DEVOPS NEEDS to MANAGE INFRASTRUCTURE not CONFIGURATIONS
The core concept behind infrastructure 2.0 is collaboration between all applicable constituents – from the end user to the network to the application infrastructure to the application itself. From the provisioning systems to the catalog of services to the billing systems. It’s collaborative and dynamic, which means adaptive and able to change the way in which policies are applied – from routing to switching to security to load balancing – based on the application and its right-now needs. Devops is – or should be - about enabling that integration. If that can be done with a script, great. But the reality is that a single script or set of scripts that focus on the automation of components rather than systems and architectures is not going to scale well and will instead end up contributing to the diseconomy of scale that was and still is the primary driver behind the next-generation network.
Scripts are also unlikely to address the very real need to codify the processes that drive an enterprise deployment, and do not take into consideration the very real possibility that a new deployment may need to be “backed-out” if something goes wrong. Scripts are too focused on managing configurations and not focused enough on managing the infrastructure. It is the latter that will ultimately provide the most value and the means the which the network will be elevated to a first class citizen in the deployment process.
Infrastructure 2.0 is the way in which organizations will move from aggregation to automation and toward the liberation of the data center based on full stack interoperability and portability. A services-based infrastructure that can be combined to form a dynamic control plane that allows infrastructure services to be integrated into the processes required to not just automate and ultimately orchestrate the data center, but to do so in a way that scales along with the implementation.
Collaboration and integration will require development, there’s no way to avoid that. This should be obvious from the reliance on APIs (Application Programming Interface), a term which if updated to reflect today’s terminology would be called an ADI (Application Development Interface). Devops needs to broaden past “ops” and start embracing the “dev” as a means to integrate and enable the collaboration necessary across the infrastructure to allow the maturation of emerging data center models to continue. If the ops in devops isn’t balanced with dev, it’s quite possible that like many cross-discipline roles within IT, the concept of devops may have to fork in order to continue moving virtualization and cloud computing down its evolutionary path.


<Return to section navigation list>
Windows Azure Platform Appliance
David Linthicum claims “Data centers will spend double on server hardware by 2014 to power private clouds, and mobile usage will also boost server investments” in a preface to his Why cloud adoption is driving hardware growth, not slowing it post of 8/4/2010 to InfoWorld’s Cloud Computing blog:
The move to cloud computing is driving significant spending on data center hardware to support businesses' private cloud initiatives, says IDC. In fact, private cloud hardware spending will draw public cloud hardware spending, IDC predicts. IDC also forecasts that server hardware revenue for public cloud computing will grow from $582 million in 2009 to $718 million in 2014, and server hardware revenue for the larger private cloud market will grow from $2.6 billion to $5.7 billion in the same period.
The growth in private cloud computing hardware revenue is not surprising. Survey after survey has shown that enterprises moving to cloud computing are looking to move to private clouds first, which means many new boxes of servers are showing up in the lobby to build these private clouds. That said, I suspect some of these so-called private clouds are just relabeled traditional data center and won't have many built-in cloud computing features beyond simple virtualization. Cloudwashing comes to the data center.
An irony in all this is that cloud computing may drive up the number of servers in the data center, even though many organizations are looking to cloud computing to reduce the hardware footprint in that same area. But building all those new cloud services, both public and private, means building the platforms to run them. Ultimately, the adoption of cloud computing could diminish the number of servers deployed in proportion to the number of users served, but that won't happen until the late 2010s or even early 2020s.
Also driving this server growth is the increase in mobile platforms and applications, which are almost always based in the cloud. In all likelihood, mobile may drive much of the server hardware growth in the next two years.
Finally, the number of VC dollars driving new cloud computing startups will boost server sales in 2011 and beyond. Although many startups will use existing clouds for their infrastructure, such as the offerings from Amazon.com and Google, I suspect a significant number of the differentiated startups will have their own data center and server farms.
Just when you thought it was time to sell your hardware stocks due to the rise of cloud computing, the trend upends your expectations.
<Return to section navigation list>
Cloud Security and Governance
Chris Hoff (@Beaker) makes suggestions If You Could Have One Resource For Cloud Security… in this 8/4/2010 post:
I got an interesting tweet sent to me today that asked a great question:
I thought about this and it occurred to me that while I would have liked to have answered that the Cloud Security Alliance Guidance was my first choice, I think the most appropriate answer is actually the following:
“Cloud Security and Privacy: An Enterprise Perspective on Risks and Compliance” by Tim Mather, Subra Kumaraswamy, and Shahed Latif is an excellent overview of the issues (and approaches to solutions) for Cloud Security and privacy. Pair it with the CSA and ENISA guidance and you’ve got a fantastic set of resources.
I’d also suggest George Reese’s excellent book “Cloud Application Architectures: Building Applications and Infrastructure in the Cloud”
I suppose it’s only fair to disclose that I played a small part in reviewing/commenting on both of these books prior to being published.
Black Hat Briefings USA 2010 distributed Grant Bugher’s Secure Use of Cloud Storage PDF whitepaper of July 2010, which covers Windows Azure Table storage and Amazon S3/SimpleDB security. From the Executive Summary and Introduction:
Executive Summary
Cloud storage systems like those offered by Microsoft Windows Azure and Amazon Web Services provide the ability to store large amounts of structured or unstructured data in a way that promises high levels of availability, performance, and scalability. However, just as with traditional data storage methods such as SQL‐based relational databases, the
interfaces to these data storage systems can exploited by an attacker to gain unauthorized access if they are not used correctly.
The query strings used by cloud providers of tabular data make use of query strings that are subject to SQL Injection‐like attacks, while the XML transport interfaces of these systems are themselves subject to injection in some circumstances.
In addition, cloud‐based databases can still be used for old attacks like persistent cross‐site scripting. Using cloud services to host public and semi‐public files may introduce new information disclosure vulnerabilities. Finally, owners of applications must ensure that the application’s cloud storage endpoints are adequately protected and do not allow
unauthorized access by other applications or users.Luckily for developers, modern development platforms offer mitigations that can make use of cloud services much safer.
Conducting database access via frameworks like Windows Communication Foundation and SOAP toolkits can greatly reduce the opportunity for attacks, and cloud service providers themselves are beginning to offer multifactor authentication and other protections for the back‐end databases. Finally, traditional defense‐in‐depth measures like input validation and output encoding remain as important as ever in the new world of cloud‐based data.
Introduction
This paper covers background on cloud storage, an overview of database attacks, and specific examples using two major cloud storage APIs – Windows Azure Storage and Amazon S3/SimpleDB – of exploitable and non‐exploitable applications. The purpose of this paper is to teach developers how to safely leverage cloud storage without creating vulnerable applications.
Grant Bugher is Lead Security Program Manager, Online Services Security and Compliance
Global Foundation Services, Microsoft Corporation.
Bruce Maches posted Validation of Public Cloud Infrastructure: Satisfying FDA Requirements While Balancing Risk Vs. Reward to HPC in the Clouds’ Behind the Cloud blog on 8/3/2010:
In a prior post I provided an overview of the 21 CFR Part 11 validation guidelines and the impact of these requirements on the validation of public cloud infrastructure services. The main thrust of that post was discussing how current industry validation practices are a potential impediment to the full-scale adoption of cloud computing in the life sciences. Especially in regards to the use of public cloud infrastructure related services for applications coming under Part 11 guidelines. See my May 5th post for additional background. I have received some feedback on potential approaches to validating public cloud based applications and thought I would provide some additional thoughts here.
The key word here is trust – if I am an FDA auditor how do I know I can trust the installation, operation and output of a particular system? The actual Part 11 compliance process for any application includes the hardware, software, operational environment and support processes for the system itself. This allows an IT group to answer the questions:
- Can I prove the entire system (hardware, software) was installed correctly?
- Can I prove the system is operating correctly?
- Can I prove the system is performing correctly to meet the user requirements as stated in the Design Qualification documents?
- Can I prove that the system environment is properly maintained by people with the requisite skills and that all changes are being properly documented?
The validation of public cloud offerings revolves primarily around the first and last question above. How do I ensure that the overall environment was designed, implemented and maintained per Part 11 guidelines? If a life science company wanted to leverage public cloud computing for validated applications it would have to take a hard look at the risks vs. rewards and develop a strategy for managing those risks while ensuring that the advantages of leveraging public cloud could can still be realized.
There are several steps a company can take to start down this path. The initial step would be to develop an internal strategy and supporting processes for how the organization is planning to meet Installation and Operational Qualification (IQ & OQ) portions of the Part 11 guidelines in a cloud environment. The strategy would be incorporated into the overall Validation Master Plan (VMP). This plan is the first stop for any auditor as it spells out the organizations overall validation strategy as to what systems will require validation and how that will be performed. For validating public cloud the VMP would need to address at a minimum such topics as:
- The actual hardware (IQ) piece, since a server serial number is not available what documentation of the system physical and operating environment is acceptable?
- What level of data center (i.e. SAS 70 Level II) is approved for use by the organization for public cloud applications and how is that certification proven?
- What documentation can the cloud vendor provide describing how they developed and implemented the data center environment?
- What training and certification documents are available for the vendor personnel who will be managing/maintaining the environment?
- How detailed and accurate are the vendors change management records and processes?
Any organization creating this type of a strategy would have to assess its appetite for potential risk and balance that against the gains and cost savings that are a part of the promise of cloud computing. There are no hard and fast rules on how this can be done as every organization is unique.
Another piece of the puzzle is with the OS and associated software being deployed. This portion of the environment can be easily validated with a documented IQ and a pre-qualified image built. This image can then be loaded up into the cloud as needed and used over and over again. A company can build a whole library of the pre-validated images and have them available for quick deployment which drastically cuts down the time it takes to bring a new environment on-line. There are a number of vendors who are building these pre-qualified images that provide choices in the OS (Windows, Linux) databases, and other portions of the software environment.
As I have mentioned in several prior posts the possibilities for leveraging cloud computing in the life sciences are potentially enormous. From speeding up drug research and discovery, allowing for the rapid deployment of new systems, providing the needed compute power required by resource hungry scientific applications, to cutting costs and migrating legacy applications into the cloud there are a myriad of ways that life science CIO’s can leverage cloud environments, both public and private. As with any change, part of the CIO’s responsibility is to make sure that the organization has a clear and well thought out strategy for incorporating cloud computing into its overall IT strategic direction.
Bruce Maches is a former Director of Information Technology for Pfizer’s R&D division, current CIO for BRMaches & Associates and a contributing editor for HPC in the Cloud.
<Return to section navigation list>
Cloud Computing Events
Eric Nelson (@ericnel) posted a Call for speakers for UK Windows Azure Platform online conference on 20th of September on 8/4/2010:
I have decided to try and put together a top notch online conference delivered predominantly via UK based speakers, inspired by the very enjoyable and useful community driven MVC Conference http://mvcconf.com/ (see my write up)
The plan is:
- The conference will take place 10am to 5pm UK time, delivered using Live Meeting and recorded for on-demand access
- Two “rooms”(or three is we have loads of speakers/sessions!)
- which equates to 10 (or 15) session of 55mins with 5min breaks between
- One room will be more about introducing the Windows Azure Platform (lap around etc.), likely predominantly MS delivered.
- Aim is to help developers new to Azure.
- Second room is about detailed topics, learning, tips etc. Delivered by a mix of MS, community and early adopters.
- For developers who already understand the basics
- + panel Q&A
- + virtual goody bag
- + ?
- for FREE
What I am after is folks with strong knowledge of the Windows Azure Platform to propose a session (or two). All I need at this stage is a very short draft session proposal by ideally this Thursday (as I’m on holiday next week). This is a short proposal – I just need a one liner so I can start to think what works overall for the day. Please send to eric . nelson AT microsoft . com (without the spaces).
If you are not UK based, you are still welcome to propose but you need to be awake during UK time and speak good English.
And the wonderful bit is… you can present it from the comfort of your home or office :-)
P.S. I’m sure I don’t need to say it, but even if you don’t fancy speaking, do block of the 20th now as it promises to be a great day.
The International Supercomputing Conference on 8/4/2010 announced that the ISC Cloud’10 Conference to Help Attendees See the Cloud More Clearly will be held 10/28 to 10/29/2010 in Frankfurt, Germany:
The organizers of the International Supercomputing Conference (ISC), building on their 25 years of leadership and expertise in supercomputing events, introduce the inaugural ISC Cloud’10 conference to be held October 28-29, 2010 in Frankfurt, Germany.
The ISC Cloud’10 conference will focus on computing and data intensive applications, the resources they require in a computing cloud, and strategies for implementing and deploying cloud infrastructures. Finally, the conference will shed light on how cloud computing will impact HPC.
“Although cloud computing is already being addressed at other conferences, there is definitely a need for a dedicated international cloud computing event at which both researchers and industry representatives can share ideas and knowledge related to compute and data intensive services in the cloud,” said ISC Cloud General Chair Prof. Dr. Wolfgang Gentzsch, an international expert in Grids who now brings his expertise to the clouds.
Questions like “How will cloud computing benefit my organization?”, “What are the roadblocks I have to take into account (and remove)?”, “What kind of applications and services are suitable for clouds?”, “How does virtualization impact performance?”, “Will clouds replace supercomputers and Grids?”, “Can clouds finally help us deal with our data deluge?”, and “Replace our internal data vaults?”, will be addressed and answered at the conference.
ISC Cloud attendees will have a chance to participate in discussions, receive useful help for making decisions (taking cost-benefit, security, economics and other issues into account), clear up misconceptions, identify the limitations of cloud computing and, last but no less important, make contacts to facilitate decisions in this key field of IT.
Participants will also enjoy outstanding opportunities to network with leading minds from around the world.
The key topics of this conference are:
• Cloud computing models: private, public and hybrid clouds
• Virtualization techniques for the data center
• Perspective of scientific cloud computing
• Migrating large data sets into a cloud
• Trust in cloud computing: security and legal aspects
• Cloud computing success stories from industry and research; and
• Lessons learnt and recommendations for building your cloud or using cloud services.Among the renowned speakers are Kathy Yelick from Lawrence Berkeley National Laboratory, USA; Dan Reed from Microsoft; Matt Wood from Amazon and John Barr from the 451 Group on Cloud Computing. The presentations are available here.
The Details
ISC Cloud ’10 will be held Thursday, October 28 and Friday, October 29, at the Frankfurt Marriott Hotel. Participation will be limited and early registration is encouraged.
Registration will open on August 16. For more information, visit the ISC Cloud website.
About ISC Cloud’10
Organized by Prof. Hans Meuer and his Prometeus Team, ISC Cloud’10 brings together leading experts in cloud computing from around the world presenting valuable information about their own experience with designing, building, managing and using clouds, in a collegial atmosphere.
Subscribe to our newsletter to find out more about our conference and about cloud computing. Plus join our Facebook group to share your thoughts and follow us on twitter for latest updates.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
![image[2]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgCmO9A7r9SyRwSrRXxE7SC46aiBaQVTb7Hn91AH8fNkWG4kfhNwBJeoGWub15bo57MMyqh87A0TkF3TQhiC-nhMYJmTJLGVR2IQvTR5ZjwQZ1-kQ1vrzJMh8xvvOXy4ZWfJTpN6G6f/?imgmax=800 "image[2]")
Todd Hoff posted Dremel: Interactive Analysis of Web-Scale Datasets - Data as a Programming Paradigm to the High Scalability blog on 8/4/2010:

If Google was a boxer then MapReduce would be a probing right hand that sets up the massive left hook that is Dremel, Google's—scalable (thousands of CPUs, petabytes of data, trillions of rows), SQL based, columnar, interactive (results returned in seconds), ad-hoc—analytics system. If Google was a magician then MapReduce would be the shiny thing that distracts the mind while the trick goes unnoticed. I say that because even though Dremel has been around internally at Google since 2006, we have not heard a whisper about it. All we've heard about is MapReduce, clones of which have inspired entire new industries. Tricky.
Dremel, according to Brian Bershad, Director of Engineering at Google, is targeted at solving BigData class problems:
While we all know that systems are huge and will get even huger, the implications of this size on programmability, manageability, power, etc. is hard to comprehend. Alfred noted that the Internet is predicted to be carrying a zetta-byte (1021 bytes) per year in just a few years. And growth in the number of processing elements per chip may give rise to warehouse computers of having 1010 or more processing elements. To use systems at this scale, we need new solutions for storage and computation.
How Dremel deals with BigData is describe in this paper, Dremel: Interactive Analysis of Web-Scale Datasets, which is the usual high quality technical paper from Google on the architecture and ideas behind Dremel. To learn more about the motivation behind Dremel you might want to take a look at The Frontiers of Data Programmability, a slide deck from a Key Note speech given by Dremel paper co-author, Sergey Melnik.
Why is a paper about Dremel out now? I assume it's because Google has released BigQuery, a web service that enables you to do interactive analysis of massively large datasets, which is based on Dremel. To learn more about what Dremel can do from an analytics perspective, taking a look at BigQuery would be a good start.
You may be asking: Why use Dremel when you have MapReduce? I think Kevin McCurley, a Google Research Scientist, answers this nicely:
The first step in research is to form a speculative hypothesis. The real power of Dremel is that you can refine these hypotheses in an interactive mode, constantly poking at massive amounts of data. Once you come up with a plausible hypothesis, you might want to run a more complicated computation on the data, and this is where the power of MapReduce comes in. These tools are complementary, and together they make a toolkit for rapid exploratory data intensive research.
So, Dremel is a higher level of abstraction than MapReduce and it fits as part of an entire data slice and dice stack. Another pancake in the stack is Pregel, a distributed graph processing engine. Dremel can be used against raw data, like log data, or together with MapReduce, where MapReduce is used to select a view of the data for deeper exploration.
Dremel occupies the interactivity niche because MapReduce, at least for Google, isn't tuned to return results in seconds. Compared to MapReduce, Dremel's query latency is two orders of magnitude faster. MapReduce is "slow" because it operates on records spread across a distributed file system comprised of many thousands of nodes. To see why, take an example of search clicks. Whenever you search and click on a link from the results, Google will store all the information it can about your interaction: placement on the page, content around the link, browser type, time stamp, geolocation, cookie info, your ID, query terms, and anything else they can make use of. Think about the hundreds of millions of people clicking on links all day every day. Trillions of records must be stored. This data is stored, in one form or another, in a distributed file system. Since that data is spread across thousands of machines, to run a query requires something like MapReduce, which sends little programs out to the data and aggregates the results through intermediary machines. It's a relatively slow process that requires writing a computer program to process the data. Not the most accessible or interactive of tools.
Instead, with Dremel, you get to write a declarative SQL-like query against data stored in a very efficient for analysis read-only columnar format. It's possible to write queries that analyze billions of rows, terabytes of data, trillions of records—in seconds.
Others think MapReduce is not inherently slow, that's just Google's implementation. The difference is Google has to worry about the entire lifecycle of data, namely handling incredibly high write rates, not just how to query already extracted and loaded data. In the era of BigData, data is partitioned and computation is distributed, bridges must be built to cross that gap.
It's interesting to see how the Google tool-chain seems to realize many of the ideas found in Frontiers of Data Programmability, which talks about a new paradigm where data management is not considered just as a storage service, but as a broadly applicable programming paradigm. In that speech the point is made that the world is full of potential data-driven applications, but it's still too difficult to develop them. So we must:
- Focus on developer productivity
- Broaden the notion of a “database developer” to target the long tail of developers
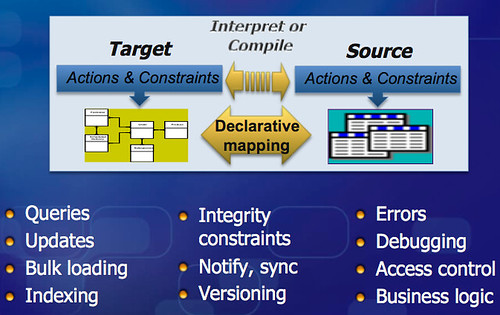
Productivity can be increased and broadened by using something called Mapping-Driven Data Access:
Unsurprisingly Google has created a data as a programming paradigm for their internal use. Some of their stack is also openish. The datastore layer is available through Google App Engine, as is the mapper part of MapReduce. BigQuery opens up the Dremel functionality. The open source version of the data stack is described in Meet the Big Data Equivalent of the LAMP Stack, but there doesn't appear to be a low latency, interactive data analysis equivalent to Dremel...yet. The key insight for me has been to consider data as a programming paradigm and where a tool like Dremel fits in that model.
Related Articles
- Dremel: Interactive Analysis of Web-Scale Datasets on Google Research
- Google’s Dremel – Or, Can MapReduce Itself Handle Fast, Interactive Querying? by Tasso Argyros from Aster Data
- MapReduce Online by lots of people from University of California, Berkeley.
- The Frontiers of Data Programmability by Sergey Melnik
- Product: SciDB - A Science-Oriented DBMS At 100 Petabytes
- Compiling Mappings to Bridge Applications and Databases
- Google I/O 2010 - BigQuery and Prediction APIs
- Running Large Graph Algorithms - Evaluation Of Current State-Of-The-Art And Lessons Learned
Mary Jo Foley reported on 8/4/2010 Salesforce pays Microsoft to settle patent infringement suit. From the summary:
Microsoft announced on August 4 that it has settled its patent infringement case with Salesforce. While the terms of the agreement aren’t being disclosed “Microsoft is being compensated by Salesforce.com,” according to a Microsoft press release.
<Return to section navigation list>
Technorati Tags: Windows Azure, Windows Azure Platform, Azure Services Platform, Azure Storage Services, Azure Table Services, Azure Blob Services, Azure Drive Services, Azure Queue Services, SQL Azure Database, SADB, Open Data Protocol, OData, Azure AppFabric, Server AppFabric, Cloud Computing, Amazon Web Services, Amazon S3, SimpleDB, Google Labs, BigQuery, Dremel, Google App Engine, MapReduce

















0 comments:
Post a Comment