Windows Azure and Cloud Computing Posts for 3/24/2011+
| A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Updated 3/26/2011 with articles marked • from Patrick Butler Monterde, Nick J. Trough, Alik Levin, Steef-Jan Wiggers, Me, Vijay Tewari, Thomas Claburn, Jeff Wettlauter, Adam Hall, System Center Team, Michael Crump, Srinivasan Sundara Rajan, Changir Biyikoglu, SQL Server Team, Bernardo Zamora, David Linthicum, Jonathan Rozenblit, Todd Hoff, and Nicole Hemsoth.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructur and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
• Changir Biyikoglu announced a session about SQL Azure Federations at Teched 2011 in a 3/26/2011 post:
See you all in Atlanta at TechEd in May 2011 [for a session described here:]
DBI403 Building Scalable Database Solutions Using Microsoft SQL Azure Database Federations
- Session Type: Breakout Session
- Level: 400 - Expert
- Track: Database & Business Intelligence
- Speaker(s): Cihan Biyikoglu
SQL Azure provides an information platform that you can easily provision, configure and use to power your cloud applications. In this session we explore the patterns and practices that help you develop and deploy applications that can exploit the full power of the elastic, highly available, and scalable SQL Azure Database service. The session details modern scalable application design techniques such as sharding and horizontal partitioning and dives into future enhancements to SQL Azure Databases.
- Product/Technology: Microsoft® SQL Azure™
- Key Learning: SQL Azure Federations
- Key Learning: Building scalable solutions on SQL Azure
- Key Learning: Developing multi-tenant solutions on SQL Azure
Changir Biyikoglu explained Moving to Multi-Tenant Database Model Made Easy with SQL Azure Federations in a 3/23/2011 post:
- In some cases the capacity requirements of a small tenant could scale down below the minimum capacity database available in SQL Azure. Assume you have tenants with MBs of data. Consuming a GB database wastes valuable $s. You may ask why there is a scale-down limit on a database in SQL Azure and it is a long discussion but the short answer is this; there is a constant cost to a database and a smaller database does not improve much in cost to provide benefits. In future we may be able make optimizations but for now, 1GB Web Edition database size is the smallest database you can buy.
- When the tenant count is large, managing very large number of independent surfaces causes issues. Here are a few; with 100K tenants, if you were to create 100K databases for them, you would find that operations that are scoped globally to address all your data such as schema deployments or queries that need to report size usage per tenant across all databases would take excessively long to compute. The reason is the sheer number of connects and disconnects that you have to perform.
- Apps that have to work with such large number of databases end up causing connection pool fragmentations. I touched on this on previous post as well but to reiterate; assuming that your middle tier that can get a request to route its query to any one of the 100K tenants, the app server ends up maintaining 100K pools with a single connection in each pool. Since each app server does not always get a request for each 100K tenant frequently enough, many times, the app finds no connection in the pool thus need to establish a cold connection from scratch.
Having multiple tenants in a single database with federations solves all these issues;
- Multi-tenant database model with federations allow you to dynamically adjust the number of tenants per database at any moment in time. Repartitioning command like SPLIT allow you to perform these operations without any downtime.
- Simply rolling multiple tenant into a single database, optimizes the management surface and allows batching of operations for higher efficiency.
- With federations you can connect through a single endpoint and don’t have to worry about connection pool fragmentation for your applications regular workload. SQL Azure’s gateway tier does the pooling for you.
What’s the catch? Isn’t there any downside to multi-tenancy?
Sure there are downsides to implementing multi-tenancy in general. The most important one is database isolation. With multi-tenant database model, you don’t get strict security isolation of data between tenants. For example, you can no longer have a user_id that can only access a specific tenant in that database in SQL Azure with a multi-tenant database. You have to govern access always through a middle tier to ensure that isolation is protected. Access to data through open protocols like OData or WebServices can solve these issues.
Another complaint I hear often is the need to monitor and provide governance between tenants in your application in the multi-tenant case. Imagine a case where you have 100 tenants in a single database and one of these tenants consume excessive amount of resources. Your next query from a well-behaving tenant may get slowed-down/blocked/throttled in the database. In v1, federations provide no help here. Without app level governance you cannot create a fair system between these tenants in federations v1. The solutions to governance problem tends to be app specific anyways so I’d argue you would want this logic in the app tier and not in the db tier anyways. Here is why; with all governance logic, it is best to engage and deny/slow-down the work as early as possible in its execution lifetime. So pushing this logic higher in the stack to app tier for evaluation is a good principle to follow. That is not to say db should not participate in the governance decision. SQL Azure can contribute by providing data about a tenant’s workload and in future versions we may help with that.
Yes, there are issue to consider… But multi-tenancy has been around for a while and there are also good compromises and workarounds in place.
How does federation help with posting single-database-per-tenant (single-tenant) apps to multi-tenant model?
Lets switch gears and assume you are sold… Multi-tenancy it is… Lets see how federations help.
In a single-tenant app, the query logic in application is coded with the assumption that all data in a database belongs to one tenant. With multi-tenant apps that work with identical schemas, refactored code simply injects tenant_id into the schema (tables, indexes etc) and every query the app issues, contains the tenant_id=? predicate. In a federation, where tenant_id is the federation key, you are asked to still implement the schema changes. However federations provide a connection type called a FILTERING connection that automatically injects this tenant_id predicate without requiring app refactoring. Our data-dependent routing sets up a FILTERING connection by default. Here is how;
1: USE FEDERATION orders_federation(tenant_id=155) WITH RESET, FILTERING=ONSince SQL Azure federations know about your schema and your federation key, you can simply continue to issue the “SELECT * FROM dbo.orders” query on a filtered connection and the algebrizer in SQL Azure auto-magically injects “WHERE tenant_id=155” into your query. This basically means that connection to federations do the app logic refactoring for you…You don’t need to rewrite business logic and fully validate this code to be sure that you have tenant_id injected into every query.
With federations there is still good reasons to use UNFILTERING connections. FILTERING connections cannot do schema updates or does not work well when you’d like to fan out a query. So, “FILTERING=OFF” connections come with no restrictions and can help with efficiency. Here is how you get an UNFILTERING connection.
1: USE FEDERATION orders_federation(tenant_id=155) WITH RESET, FILTERING=OFFExistence of two modes of connection however create also an issue; what happens when TSQL intended for FILTERING connections is executed on an UNFILTERING connection? We can help here; federation provide a way for you to detect the connection type; in sys.dm_exec_sessions you can query the federation_filtering_state field to detect the connection state.
1: IF (select federation_filtering_state from sys.dm_exec_sessions2: where @@SPID=session_id)=13: BEGIN4: EXEC your single-tenant logic …5: END6: ELSE7: BEGIN8: RAISERROR ..., "Not on a filtering connection!"9: ENDThere are many other ways to ensure this does not happen but defensive programming is still the best approach to ensure robust results.
So net net, multi-tenancy is great for a number of reasons and you can move applications with heavy business logic coded in single-tenant model, with smaller work into a multi-tenant model with federations. I specifically avoid saying this is a transparent port due to issues I discussed and you still need to consider compromises in your code.
When federations become available this year, we’ll have more examples of how to move single-tenant applications over to multi-tenant model with federations but for those of you dreading the move, there is help coming.
The question is when is the “help coming” in the form of a SQL Azure Federation CTP?
Edu Lorenzo explained How to Move Data to [SQL] Azure on 3/23/2011:
Here is a short blog [post] on how to move data to Azure. This is just part of a longer blog on how to publish a databound app so bear with me.
Create an azure database. Call it whatever you want.
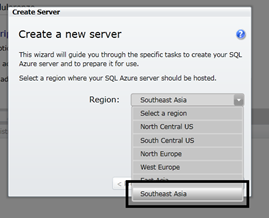
Create a new server that will house your database. I suggest choosing an area near you geographically. I chose Southeast Asia as that is the nearest to me the last time I checked :p
Fill in credentials for your database Admin. I used “eduadmin” as the admin name and “M!cR0$0f+” as password… yeah right
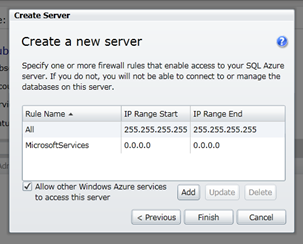
Then we add some rules. This is going to be your connectivity rules.
You now will have a database server with a master database
It is now time to click CREATE to create a new DB. I click Create then type in “adventureworks” as the database name.
- You now have an empty database called “adventureworks” up in the cloud.
- Now to put some data in it. I will use SQLServer2008R2′s management studio so I can show you some new stuff that you can use to migrate data.
Open up Management studio and use the Fully Qualified DNS Name that Azure gives you as the server and the credentials you entered earlier so you can connect your management studio directly to the azure database that you have. Take note of how I wrote the username.
My management studio is now connected to both my local version of the Adventureworks database and my cloud based database
Then I script out the data and schema from my local copy of adventureworks using Management Studio while taking note of some advanced options
As you can see, we can now (using R2) script data out to an azure friendly format.
- And then I run the script against my azure version of adventureworks
And the database has been created
To double check, I use the browser based azure database manager
And that’s it. A lot of things I did not indicate. This is a quickie blog [post].









Buck Woody (@buckwoody) described a SQL Azure Use Case: Department Application Data Store by moving Access tables to SQL Azure on 3/22/2011:
This is one in a series of posts on when and where to use a distributed architecture design in your organization's computing needs. You can find the main post here: http://blogs.msdn.com/b/buckwoody/archive/2011/01/18/windows-azure-and-sql-azure-use-cases.aspx
Description:
Most organizations use a single set of enterprise applications where employees do their work. This system is designed to be secure, safe, and to perform well. It is attended and maintained by a staff of trained technical professionals. But not all business-critical work is contained in these systems. Users who have installed software such as Microsoft Office often set up small data-stores and even programs to do their work. This is often because the system is “bounded” - the data or program only affects an individual’s work.
The issue arises when an individual’s data system is shared with other users. In effect the user’s system becomes a server.
There are many issues with this arrangement. The “server” in this case is not secure, safe and does not perform well at higher loads. It may have design issues, and is normally cannot be accessed from outside the office. Users might even install insecure software to allow them to access the system when they are on the road, adding to the insecurity. When the system becomes unavailable or has a design issue, IT may finally become aware of the application’s existence, and it’s criticality.
Implementation:
There are various options to correct this situation. The first and most often used is to bring the system under IT control, re-write or adapt the application to a better design, and run it from a proper server that is backed up, performs well, and is safe and secure. Depending on how critical the application is, how many users are accessing it, and the level of effort, this is often the best choice.
But this means that IT will have to assign resources, including developer and admin time,licenses, hardware and other infrastructure and development resources, and this takes time and adds to budget.
Another advantage to this arrangement is that the user’s department can set up the subscription to SQL Azure, which shifts the cost burden to the department that uses the data, rather than to IT.
Microsoft Access is only one example - many programs can use an ODBC connection as a source, and since SQL Azure uses this as a connection method, to the application it appears as any other database. The application then can be used in any location, not just from within the building, so there’s no need for a VPN into the building - the front end application simply goes with the user.
Another option for a front-end is to have the power-user create a LightSwitch application. More of a pure development environment than Microsoft Access, it still offers an easy process for a technical business user to create applications. Pairing this environment with SQL Azure makes for a mobile application that is safe and secure, paid for by the department. Interestingly, if designed properly, the data store can serve multiple kinds of front-end programs simultaneously, allowing a great deal of flexibility and the ability to transfer the data to an enterprise system at a later date if that is needed.
Resources:
Example process of moving a Microsoft Access data back-end to SQL Azure: http://www.informit.com/guides/content.aspx?g=sqlserver&seqNum=375


<Return to section navigation list>
MarketPlace DataMarket and OData
• My (@rogerjenn) Windows Azure and OData Sessions at MIX11 post updated 3/26/2011 lists 15 sessions for a search on Azure and 4 (2 duplicates) for a search on OData.
MIX11 will be held 4/12 through 4/14/2011 at the Mandalay Bay hotel, Las Vegas, NV. Hope to see you there.
• Michael Crump announced on 3/24/2011 a new series with a Producing and Consuming OData in a Silverlight and Windows Phone 7 application (Part 1) post:
I have started a new series on SilverlightShow.net called Producing and Consuming OData in a Silverlight and Windows Phone 7 application. I decided that I wanted to create a very simple and easy to understand article that not only guides you step-by-step but includes a video and full source code. I personally believe this is the best way to teach someone something and I hope you enjoy the series. I also want to thank SilverlightShow for giving me this opportunity to help other developers get up to speed quickly with OData.
The table of contents for the series is listed below. I will be adding parts 2 and 3 shortly.
- Producing and Consuming OData in a Silverlight and Windows Phone 7 application. (Part 1) – Creating our first OData Data Source and querying data through the web browser and LinqPad.
- Producing and Consuming OData in a Silverlight and Windows Phone 7 application. (Part 2 ) – Consuming OData in a Silverlight Application.
- Producing and Consuming OData in a Silverlight and Windows Phone 7 application. (Part 3) – Consuming OData in a Windows Phone 7 Application.
What is OData?
The Open Data Protocol (OData) is simply an open web protocol for querying and updating data. It allows for the consumer to query the datasource (usually over HTTP) and retrieve the results in Atom, JSON or plain XML format, including pagination, ordering or filtering of the data.
In this series of articles, I am going to show you how to produce an OData Data Source and consume it using Silverlight 4 and Windows Phone 7. Read the complete series of articles to have a deep understanding of OData and how you may use it in your own applications.
The Full Article
The full article is hosted on SilverlightShow and you can access it by clicking here. Don’t forget to rate it and leave comments or email me [michael[at]michaelcrump[dot]net if you have any problems.
<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
• Alik Levin continued his series with Windows Azure Web Role WCF Service Federated Authentication Using AppFabric Access Control Service (ACS) v2 – Part 2 on 3/25/2011:
This is a continuation to Windows Azure Web Role WCF Service Federated Authentication Using AppFabric Access Control Service (ACS) v2 – Part 1.
Step 2 – Create and configure WCF Service as relying party in ACS v2 Management Portal
The content in this step is adapted from How To: Authenticate with Username and Password to the WCF Service Protected by Windows Azure AppFabric Access Control Service Version 2.0.
In the next procedures you will create create and configure a relying party using the ACSv2.0 management portal. A relying party application is the WCF services that you want to use to implement the federated authentication for using the ACS.
To create and a configure a relying party
- Navigate to https://portal.appfabriclabs.com and authenticate using Live ID.
- Click on Service Buss, Access Control & Caching tab.
- Click on Access Control node in the treeview under the AppFabric root node. List of your namespaces should appear.
- Select your namespace by clicking on it and then click on Access Control Service ribbon. New browser tab should open an Access Control Service page.
- Click the Relying Party Applications link in the Trust Relationships section.
- On the Relying Party Applications page, click the Add link.
- On the Add Relying Party Application page specify the following information:
In the Relying Party Application Settings section:
- Name—Specify the display name for this relying party. For example, Windows Azure Username Binding Sample RP.
- Mode—Choose the Enter settings manually option.
- Realm—Specify the realm of your WCF service. For example, http://localhost:7000/Service/Default.aspx.
- Return URL—Leave blank.
- Error URL—Leave blank.
- Token format—Choose the SAML 2.0 option.
- Token encryption policy—Choose the Require encryption option.
- Token lifetime (secs) —Leave the default of 600 seconds.
In the Authentication Settings section:
- Identity providers—Leave all unchecked.
- Rule groups—Check the Create New Rule Group option.
In the Token Signing Options section:
- Token signing—Choose the Use a dedicated certificate option.
- Certificate:
- File—Browse for an X.509 certificate with a private key (.pfx file) to use for signing.
- Password—Enter the password for the .pfx file in the field above.
In the Token Encryption section:
- Certificate:
- File—Browse to load the X.509 certificate (.cer file) for the token encryption for this relying party application. It should be the certificate without private key, the one that will be used for SSL protection of your WCF service.
- Click Save.
- Saving your work also triggers creating a rule group. Now you need to generate rules for the rule group.
To generate rules in the rule group
- Click the Rule Groups link.
- On the Rule Groups page, click the Default Rule Group for Windows Azure Username Binding Sample RP rule group.
- On the Edit Rule Group page, click the Add link at the bottom.
- On the Add Claim Rule page, in the If section, choose the Access Control Service option. Leave the default values for the rest of the options.
- Click Save.
In the next procedures you will create and configure the service identity to respond to a token request based on a username and password.
To configure the service identity for using username and password credentials
- Navigate to https://portal.appfabriclabs.com and authenticate using Live ID.
- Click on Service Buss, Access Control & Caching tab.
- Click on Access Control node in the treeview under the AppFabric root node. List of your namespaces should appear.
- Select your namespace by clicking on it and then click on Access Control Service ribbon. New browser tab should open an Access Control Service page.
- Click the Service Identities link in the Service Settings section.
- On the Service Identities page, click the Add link.
- On the Add Service Identity page provide a Name. You will use it as a username for your username and password pair when requesting a token.
- Optionally, add a description in the Description section.
- Click Save. The page title should change to Edit Service Identity.
- Click the Add link in the Credentials section. You should be redirected to the Add Credentials page.
- On the Add Credentials page, provide the following information:
- Type—Choose Password from drop-down list.
- Password—Enter your desired password. You will use it as a password for your username and password pair when requesting a token.
- Effective date—Enter the effective date for this credential.
- Expiration date—Enter the expiration date for this credential.
- Click Save.
Related Materials
- Windows Azure Web Role WCF Service Federated Authentication Using AppFabric Access Control Service (ACS) v2 – Part 1
- Widows Azure Content And Guidance Map For Developers – Part 1, Getting Started
- Securing Windows Azure Distributed Application Using AppFabric Access Control Service (ACS) v2 – Scenario and Solution Approach
- Windows Azure Web Role ASP.NET Application Federated Authentication Using AppFabric Access Control Service (ACS) v2 – Part 1
- Windows Azure Web Role ASP.NET Application Federated Authentication Using AppFabric Access Control Service (ACS) v2 – Part 2
- Windows Azure Web Role ASP.NET Application Federated Authentication Using AppFabric Access Control Service (ACS) v2 – Part 3
- Securing Windows Azure Web Role ASP.NET Web Application Using Access Control Service v2.0 (same as above on one page)
Alik’s post might have benefitted from a few screen captures.
• Eugenio Pace (@eugenio_pace) began a new series with Authentication in WP7 client with REST Services–Part I on 3/24/2011:
In the last drop, we included a sample that demonstrates how to secure a REST web service with ACS, and a client calling that service running in a different security realm:
This is just a technical variation of the original sample we had in the book, that was purely based on SOAP web services (WS-Trust/SAML only):
But we have another example in preparation which is a Windows Phone 7 Client. Interacting with REST based APIs is pretty popular with mobile devices. In fact is what we decided to use when building the sample for our Windows Phone 7 Developer Guide.
There’s no WIF for the phone yet, so implementing this in the WP7 takes a little bit of extra work. And, as usual, there’re many ways to solve it.
The “semi-active” way:
This is a very popular approach. In fact, it’s the way you’re likely to see this done with the phone in many samples. It essentially involves using an embedded browser (browser = IE) and delegate to it all token negotiation until it gets the token you want. This negotiation is nothing else than the classic “passive” token negotiation, based on HTTP redirects that we have discussed ad infinitum, ad nauseam.
The trick is in the “until you get the token you want”. Because the browser is embedded in the host application (a Silverlight app in the phone), you can handle and react to all kind of events raised by it. A particular useful event to handle is Navigating. This signals that the browser is trying to initiate an HTTP request to a server. We know that the last interaction in the token negotiation (passive) is actually posting the token back the the relying party. That’s the token we want!
So if we have a way of identifying the last POST attempt by the browser, then we have the token we need. There are many ways of doing this, but most look like this:
In this case we are using the “ReplyTo” address, that has been configured in ACS with a specific value “break_here” and then extract the token with the browser control SaveToString method. The Regex functions you see there, simply extract the token from the entire web page.
Once you’ve got the token, then you use it in the web service call and voila!
With this approach your phone code is completely agnostic of how you actually get the final token. This works with any identity provider, and any protocol supported by the browser.
Here’re some screenshots of our sample:


The first one is the home screen (SL). The second one shows the embedded browser with a login screen (adjusted for the size of the phone screen) and the last one the result of calling the service.
JavaScript in the browser control in the phone has to be explicitly enabled:
If you don’t do this, the automatic redirections will not happen and you will see this:
You will have to click on the (small) button for the process to continue. This is exactly the same behavior that happens with a browser on a desktop (only that in most cases scripting is enabled).
In next post I’ll go into more detail of the other option: the “active” client. By the way, this sample will be posted to our CodePlex site soon.









• Eugenio Pace (@eugenio_pace) announced Drop #2 of Claims Identity Guide on CodePlex on 3/22/2011:
- All 3 samples for ACS v2: ("ACS as a Federation Provider", "ACS as a FP with Multiple Business Partners" and "ACS and REST endpoints"). These samples extend all the original "Federation samples" in the guide with new capabilities (e.g. protocol transition, REST services, etc.)
- Two new ACS specific chapters and a new appendix on message sequences
The 2 additions to the appendix are:
Message exchanges between Client/RP/ACS/Issuer:
And the Single-Sign-Out process (step 10 below):
You will also find the Fiddler sessions with explained message contents.
Feedback always welcome!


Clemens Vasters (@clemsensv) delivered a 00:07:51 What I do at work – Cloud and Service Bus for Normal People video segment on 3/25/2011:

David Chou posted Internet Service Bus and Windows Azure AppFabric on 3/24/2011:
Microsoft’s AppFabric, part of a set of ”application infrastructure” (or middleware) technologies, is (IMO) one of the most interesting areas on the Microsoft platform today, and where a lot of innovations are occurring. There are a few technologies that don’t really have equivalents elsewhere, at the moment, such as the Windows Azure AppFabric Service Bus. However, its uniqueness is also often a source of confusion for people to understand what it is and how it can be used.
Internet Service Bus
At first look, the term “Internet Service Bus” almost immediately draws an equal sign to ‘Enterprise Service Bus’ (ESB), and aspects of other current solutions, such as ones mentioned above, targeted at addressing issues in systems and application integration for enterprises. Indeed, Internet Service Bus does draw relevant patterns and models applied in distributed communication, service-oriented integration, and traditional systems integration, etc. in its approaches to solving these issues on the Internet. But that is also where the similarities end. We think Internet Service Bus is something technically different, because the Internet presents a unique problem domain that has distinctive issues and concerns that most internally focused enterprise SOA solutions do not. An ISB architecture should account for some very key tenets, such as:
- Heterogeneity – This refers to the set of technologies implemented at all levels, such as networking, infrastructure, security, application, data, functional and logical context. The internet is infinitely more diverse than any one organization’s own architecture. And not just current technologies based on different platforms, there is also the factor of versioning as varying implementations over time can remain in the collective environment longer than typical lifecycles in one organization.
- Ambiguity – the loosely-coupled, cross-organizational, geo-political, and unpredictable nature of the Internet means we have very little control over things beyond our own organization’s boundaries. This is in stark contrast to enterprise environments which provide higher-levels of control.
- Scale – the Internet’s scale is unmatched. And this doesn’t just mean data size and processing capacity. No, scale is also a factor in reachability, context, semantics, roles, and models.
- Diverse usage models – the Internet is used by everyone, most fundamentally by consumers and businesses, by humans and machines, and by opportunistic and systematic developments. These usage models have enormously different requirements, both functional and non-functional, and they influence how Internet technologies are developed.
For example, it is easy to think that integrating systems and services on the Internet is a simple matter of applying service-oriented design principles and connecting Web services consumers and providers. While that may be the case for most publicly accessible services, things get complicated very quickly once we start layering on different network topologies (such as through firewalls, NAT, DHCP and so on), security and access control (such as across separate identity domains), and service messaging and interaction patterns (such as multi-cast, peer-to-peer, RPC, tunneling). These are issues that are much more apparent on the Internet than within enterprise and internal SOA environments.
On the other hand, enterprise and internal SOA environments don’t need to be as concerned with these issues because they can benefit from a more tightly controlled and managed infrastructure environment. Plus integration in the enterprise and internal SOA environments tend to be at a higher-level, and deal more with semantics, contexts, and logical representation of information and services, etc., organized around business entities and processes. This doesn’t mean that these higher-level issues don’t exist on the Internet; they’re just comparatively more “vertical” in nature.
In addition, there’s the factor of scale, in terms of the increasing adoption of service compositions that cross on-premise and public cloud boundaries (such as when participating in a cloud ecosystem). Indeed, today we can already facilitate external communication to/from our enterprise and internal SOA environments, but to do so requires configuring static openings on external firewalls, deploying applications and data appropriate for the perimeter, applying proper change management processes, delegate to middleware solutions such as B2B gateways, etc. As we move towards a more inter-connected model when extending an internal SOA beyond enterprise boundaries, these changes will become progressively more difficult to manage collectively.
An analogy can be drawn from our mobile phones using cellular networks, and how its proliferation changed the way we communicate with each other today. Most of us take for granted that a myriad of complex technologies (e.g., cell sites, switches, networks, radio frequencies and channels, movement and handover, etc.) is used to facilitate our voice conversations, SMS, MMS, and packet-switching to Internet, etc. We can effortlessly connect to any person, regardless of that person’s location, type of phone, cellular service and network, etc. The problem domain and considerations and solution approaches for cellular services, are very different from even the current unified communications solutions for enterprises. The point is, as we move forward with cloud computing, organizations will inevitably need to integrate assets and services deployed in multiple locations (on-premises, multiple public clouds, hybrid clouds, etc.). To do so, it will be much more effective to leverage SOA techniques at a higher-level and building on a seamless communication/connectivity “fabric”, than the current class of transport (HTTPS) or network-based (VPN) integration solutions.
Thus, the problem domain for Internet Service Bus is more “horizontal” in nature, as the need is vastly broader in scope than current enterprise architecture solution approaches. And from this perspective Internet Service Bus fundamentally represents a cloud fabric that facilitates communication between software components using the Internet, and provides an abstraction from complexities in networking, platform, implementation, and security.
Opportunistic and Systematic Development
It is also worthwhile to discuss opportunistic and systematic development (as examined in The Internet Service Bus by Don Ferguson, Dennis Pilarinos, and John Shewchuk in the October 2007 edition of The Architecture Journal), and how they influence technology directions and Internet Service Bus.
Systematic development, in a nutshell, is the world we work in as professional developers and architects. The focus and efforts are centered on structured and methodical development processes, to build requirements-driven, well-designed, and high-quality systems. Opportunistic development, on the other hand, represents casual or ad-hoc projects, and end-user programming, etc.
This is interesting because the majority of development efforts in our work environments, such as in enterprises and internal SOA environments, are aligned towards systematic development. But the Internet advocates both systematic and opportunistic developments, and increasingly more so as influenced by Web 2.0 trends. Like “The Internet Service Bus” article suggests, today a lot of what we do manually across multiple sites and services, can be considered a form of opportunistic application; if we were to implement it into a workflow or cloud-based service.
And that is the basis for service compositions. But to enable that type of opportunistic services composition (which can eventually be compositing layers of compositions), technologies and tools have to be evolved into a considerably simpler and abstracted form such as model-driven programming. But most importantly, composite application development should not have to deal with complexities in connectivity and security.
And thus this is one of the reasons why Internet Service Bus is targeted at a more horizontal, and infrastructure-level set of concerns. It is a necessary step in building towards a true service-oriented environment, and cultivating an ecosystem of composite services and applications that can simplify opportunistic development efforts.
ESB and ISB
So far we discussed the fundamental difference between Internet Service Bus (ISB) and current enterprise integration technologies. But perhaps it’s worthwhile to discuss in more detail, how exactly it is different from Enterprise Service Bus (ESB). Typically, an ESB should provide these functions (core plus extended/supplemental):
- Dynamic routing
- Dynamic transformation
- Message validation
- Message-oriented middleware
- Protocol and security mediation
- Service orchestration
- Rules engine
- Service level agreement (SLA) support
- Lifecycle management
- Policy-driven security
- Registry
- Repository
- Application adapters
- Fault management
- Monitoring
In other words, an ESB helps with bridging differences in syntactic and contextual semantics, technical implementations and platforms, and providing many centralized management capabilities for enterprise SOA environments. However, as we mentioned earlier, an ISB targets concerns at a lower, communications infrastructure level. Consequently, it should provide a different set of capabilities:
- Connectivity fabric – helps set up raw links across boundaries and network topologies, such as NAT and firewall traversal, mobile and intermittently connected receivers, etc.
- Messaging infrastructure – provides comprehensive support for application messaging patterns across connections, such as bi-directional/peer-to-peer communication, message buffers, etc.
- Naming and discovery – a service registry that provides stable URI’s with a structured naming system, and supports publishing and discovering service end point references
- Security and access control – provides a centralized management facility for claims-based access control and identity federation, and mapping to fine-grained permissions system for services
A figure of an Internet Service Bus architecture is shown below.
And this is not just simply a subset of ESB capabilities; ISB has a couple of fundamental differences:
- Works through any network topology; whereas ESB communications require well-defined network topologies (works on top)
- Contextual transparency; whereas ESB has more to do with enforcing context
- Services federation model (community-centric); whereas ESB aligns more towards a services centralization model (hub-centric)
So what about some of the missing capabilities that are a part of ESB, such as transformation, message validation, protocol mediation, complex orchestration, and rules engine, etc.? For ISB, these capabilities should not be built into the ISB itself. Rather, leverage the seamless connectivity fabric to add your own implementation, or use one that is already published (can either be cloud-based services deployed in Windows Azure platform, or on-premises from your own internal SOA environment). The point is, in the ISB’s services federation model, application-level capabilities can simply be additional services projected/published onto the ISB, then leveraged via service-oriented compositions. Thus ISB just provides the infrastructure layer; the application-level capabilities are part of the services ecosystem driven by the collective community.
On the other hand, for true ESB-level capabilities, ESB SaaS or Integration-as-a-Service providers may be more viable options, while ISB may still be used for the underlying connectivity layer for seamless communication over the Internet. Thus ISB and ESB are actually pretty complementary technologies. ISB provides the seamless Internet-scoped communication foundation that supports cross-organizational and federated cloud (private, public, community, federated ESB, etc.) models, while ESB solutions in various forms provide the higher-level information and process management capabilities.
Windows Azure AppFabric Service Bus
The Service Bus provides secure messaging and connectivity capabilities that enable building distributed and disconnected applications in the cloud, as well hybrid application across both on-premise and the cloud. It enables using various communication and messaging protocols and patterns, and saves the need for the developer to worry about delivery assurance, reliable messaging and scale.
In a nutshell, the Windows Azure AppFabric Service Bus is intended as an Internet Service Bus (ISB) solution, while BizTalk continues to serve as the ESB solution, though the cloud-based version of BizTalk may be implemented in a different form. And Windows Azure AppFabric Service Bus will play an important role in enabling application-level (as opposed to network-level) integration scenarios, to support building hybrid cloud implementations and federated applications participating in a cloud ecosystem.


<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
• Steef-Jan Wiggers posted BizTalk AppFabric Connect: WCF-Adapter Service Stored Procedure on 3/24/2011:
In a post yesterday I [showed] a way to invoke a stored procedure in SQL Azure using WCF-SQL Adapter. There is another [way] to invoke a stored procedure using AppFabric Connect for Services functionality in BizTalk Server 2010. This new feature feature brings together the capabilities of BizTalk Server and Windows Azure AppFabric thereby enabling enterprises to extend the reach of their on-premise Line of Business (LOB) systems and BizTalk applications to cloud. To be able to bridge the capabilities of BizTalk Server and Windows Azure AppFabric you will need Biztalk Server 2010 Feature Pack.
I choose local database, stored procedure ADD_EMP_DETAILS (same as in previous posts) and click Next. In AppFabric Connect page, select the Extend the reach of the service on the cloud checkbox. In the Service Namespace text box, enter the service namespace that you must have already registered with the Service Bus.
Next step is configure the service behavior. You will have to configure the service behavior (for both on-premises and cloud-based services) and the endpoint behavior (for only endpoints on the Service Bus).
I enabled the EnableMetadatExchange to True, so the service metadata is available using standardized protocols, such as WS-Metadata Exchange (MEX). I not using security features as in certificates so the UseServiceCertificate is set to False. I enabled EndpointDiscovery, which makes the endpoints publicly discoverable. Next page is around configuring endpoints.
I accepted the the defaults for the on-premises endpoint and focus on configuring the Service Bus endpoints. I select netTcpRelayBinding for which the URL scheme is sb and set EnableMexEndPoint to True. Rest I accepted default values. After configuration you will have to click Apply. Then click and final screen will appear.
Finish and the wizard creates both on-premise and Service Bus endpoints for the WCF service.
Next steps involve publishing the service. In the Visual Studio project for the service, right-click the project in Solution Explorer and click Properties. On the Properties page, in the Web tab, under Servers category, select the Use Local IIS Web Server option.The Project URL text box is automatically populated and then click Create Virtual Directory.In Solution Explorer, right-click the project again and then click Build. When service is build you will have to configure it in IIS for auto-start. By right clicking the service, Manage WCF and WF Service and then configure you might run into this error (which you can ignore a this element is not present in intellisense).
In Auto-Start you can set it to enable. Next step is to verify if the Service Bus endpoints for the WCF service are published. You will have to view all the available endpoints in the Service Bus ATOM feed page for the specified service namespace:
.servicebus.windows.net/">https://<namespace>.servicebus.windows.net
I typed this URL in a Web browser and saw a list of the all the endpoints available under the specified service bus namespace. To be able to consume the WCF service to able to invoke the procedure you will need to build a client. I create a Windows Application to consume WCF Service, so inside my project I created a new project a Windows Forms Application and added a service reference using the URL for the relay metadata exchange endpoint.
In ServiceBus Endpoint the RelayClientAuthentication was set to RelayAccessToken, which means that the client will need to pass the authentication token to authenticate itself to the Service Bus. Therefore you will have to add following section in app.config.
<behaviors>
<endpointBehaviors>
<behavior name="secureService">
<transportClientEndpointBehavior credentialType="SharedSecret">
<clientCredentials>
<sharedSecret issuerName="<name>" issuerSecret="<value>" />
</clientCredentials>
</transportClientEndpointBehavior>
</behavior>
</endpointBehaviors>
</behaviors>You must get the values for issuerName and issuerSecret from the organization (e.g. your Azure account) that hosts the service. The endpoint configuration in app.config has to be changed to this:
<endpoint address="sb://contoso.servicebus.windows.net/Procedures_dbo/"
binding="netTcpRelayBinding" bindingConfiguration="Procedures_dboRelayEndpoint"
contract="ServiceReferenceSP.Procedures_dbo" name="Procedures_dboRelayEndpoint" behaviorConfiguration="secureService"/>Code for making this work (implementation of invoke button).
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using ExposeSPCloudTestClient.ServiceReferenceSP;namespace ExposeSPCloudTestClient
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}private void btnInvoke_Click(object sender, EventArgs e)
{
int returnValue = -1;Procedures_dboClient client = new Procedures_dboClient("Procedures_dboRelayEndpoint");
client.ClientCredentials.UserName.UserName = "sa";
client.ClientCredentials.UserName.Password = "B@rRy#06";try
{
Console.WriteLine("Opening client...");
Console.WriteLine();
client.Open();
client.ADD_EMP_DETAILS("Steef-Jan Wiggers", "Architect", 20000, out returnValue);
}
catch (Exception ex)
{
MessageBox.Show("Exception: " + ex.Message);
}
finally
{
client.Close();
}
txtResult.Text = returnValue.ToString();}
}
}Query employee table before execution of code above results as depicted below:
After invoking stored-procedure through consuming the service the new record is added.
As you can see I am added to employees table through adapter service called by the client.As you can see there is another way of invoking a stored-procedure making use of BizTalk AppFabric Connect Feature.













No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Patrick Butler Monterde described the Windows Azure Toolkit for Windows Phone 7 in a 3/25/2011 post:
Link: http://watoolkitwp7.codeplex.com/
Hello,
I am pleased to announce the Windows Azure Toolkit for Windows Phone 7. The toolkit is designed to make it easier for you to build mobile applications that leverage cloud services running in Windows Azure. The toolkit includes Visual Studio project templates for Windows Phone 7 and Windows Azure, class libraries optimized for use on the phone, sample applications, and documentation.
Windows Azure
Windows Azure is a cloud-computing platform that lets you run applications and store data in the cloud. Instead of having to worry about building out the underlying infrastructure and managing the operating system, you can simply build your application and deploy it to Windows Azure. Windows Azure provides developers with on-demand compute, storage, networking, and content delivery capabilities.
For more information about Windows Azure, visit the Windows Azure website. For developer focused training material, download the Windows Azure Platform Training Kit or view the online Windows Azure Platform Training Course.
Getting started: If you’re looking to try out the Windows Azure Platform free for 30-days—without using a credit card—try the Windows Azure Pass with promo code “CloudCover”. For more details, see Try Out Windows Azure with a Free Pass.
Content
- Setup and Configuration
- Toolkit Content
- Getting Started
- Troubleshooting
- Videos (coming soon)
Requirements
You must have the following items to run the project template and the sample solution included in this toolkit:
- Microsoft Visual Studio 2010 Professional (or higher) or both Microsoft Visual Web Developer 2010 Express and Microsoft Visual Studio
- 2010 Express for Windows Phone
- Windows Phone Developer Tools
- Internet Information Services 7 (IIS7)
- Windows Azure Tools for Microsoft Visual Studio 2010 (November Release)
• Jonathan Rozenblit asserted Connecting Windows Azure to Windows Phone Just Got A Whole Lot Easier in a 3/24/2011 post:

As of today, connecting Windows Azure to your application running on Windows Phone 7 just got a whole lot easier with the release of the Windows Azure Toolkit for Windows Phone 7 designed to make it easier for you to leverage the cloud services running in Windows Azure. The toolkit, which you can find on CodePlex, includes Visual Studio project templates for Windows Phone 7 and Windows Azure, class libraries optimized for use on the phone, sample applications, and documentation.
The toolkit contains the following resources:
- Binaries – Libraries that you can use in your Windows Phone 7 applications to make it easier to work with Windows Azure (e.g. a full storage client library for blobs and tables). You can literally add these libraries to your existing Windows Phone 7 applications and immediate start leveraging services such as Windows Azure storage.
- Docs – Documentation that covers setup and configuration, a review of the toolkit content, getting started, and some troubleshooting tips.
- Project Templates – VSIX (which is the unit of deployment for a Visual Studio 2010 Extension) files are available that create project templates in Visual Studio, making it easy for you to build brand new applications.
- Samples – Sample application that fully leverages the toolkit, available in both C# and VB.NET. The sample application is also built into one of the two project templates created by the toolkit.
There’s a really great article on how to get started in the wiki. Definitely check that out before you get started. To help make it even easier to get started with the toolkit, today’s (3/25) Cloud Cover episode will focus on the toolkit and how to get started using it. Over the next few weeks, videos, tutorials, demo scripts, and other great resources to go along with the toolkit will be released. Stay tuned here – I’ll keep you posted with all the new stuff as soon as it becomes available!
Want more?
If those resources aren’t enough to get you started, make sure to stop by Wade Wegner’s blog (a fellow evangelist) for a quick “how to get started" tutorial.Get Windows Azure free for 30 days
As a reader of the Canadian Mobile Developers’ blog, you can get free access to Windows Azure for 30 days while you’re trying out the toolkit. Go to windowsazurepass.com, select Canada as your country, and enter the promo code CDNDEVS.
If you think you need more than 30 days, no problem. Sign up for the Introductory Special instead. From now until June 30, you’ll get 750 hours per month free!
If you have an MSDN subscription, you have Windows Azure hours included as part of your benefits. Sign in to MSDN and go to your member’s benefits page to activate your Windows Azure benefits.
Next Steps
Download the toolkit and get your app connected to Windows Azure.This post is also featured on the Canadian Mobile Developers’ Blog.
Steve Marx (@smarx) and Wade Wegner (@WadeWegner) produced a Cloud Cover Episode 41 - Windows Azure Toolkit for Windows Phone 7 on 3/25/2011:
Join Wade and Steve each week as they cover the Windows Azure Platform. You can follow and interact with the show @CloudCoverShow.

In this episode, Steve and Wade walk through the new Windows Azure Toolkit for Windows Phone 7, which is designed to make it easier to build phone applications that use services running in Windows Azure. Wade explains why it was built, where to get it, and how it works.
- Highlight the new Eclipse Plugin CTP for Windows Azure
- Show a neat way to get MVC 3 project types to the cloud service wizard
- Describe the ease LightSwitch Beta 2 brings to Windows Azure and SQL Azure development
Windows Azure Toolkit for Windows Phone 7
Microsoft delivers toolkit for using Windows Azure to build Windows Phone 7 apps
Windows Azure Toolkit for Windows Phone 7 Released

Wade also introduces his new son, Ethan James Wegner, born last Saturday:

Patriek van Dorp described Updates and Patches in Windows Azure in a 3/25/2011 post:
My latest post on “When to deploy a VM Role in Windows Azure?” triggered a discussion on when the Fabric Controller brings down your Windows Azure Role instances. Someone said that updates and patches were only automatically deployed on Web Roles and Worker Roles and not on VM Roles so VM Roles wouldn’t be subject to the monthly updates. He was half right and to understand what happens you need to know what happens under the hood in the Windows Azure Fabric.
Depending on the number of cores a physical server has (this will always be in multiples of 8), a number of so called Host VM’s are running per server. Each Host VM utilizes 8 physical cores (this is also the number of cores of the largest Guest VM size). Each Host VM hosts 0 to 8 Guest VM’s, which are the VM’s we configure in our Azure Roles. These Guest VM’s can be of different sizes; Small (1 core), Medium (2 cores), Large (4 cores) and Extra Large (8 cores). (For the sake of simplicity I’ll omit the Extra Small instance which shares cores amongst instances)
Figure 1 shows how Guest VM’s are allocated amongst different Host VM’s on the same server.
Figure 1: Hardware, Host VM and Guest VM situated on top of each other
Now, Guest VM instances of VM Roles are not updated automatically by the Fabric Controller. The Host VM, on the other hand ís automatically updated on “patch Tuesday” once a month (this is not necessarily on Tuesday). This will affect all Guest VM instances that are hosted on that Host VM. This also means any instances of a VM Role that happen to be hosted on that particular Host VM.
Additionally Web Roles and Worker Roles are also affected by the automatic Guest VM OS updates.

<Return to section navigation list>
Visual Studio LightSwitch
Beth Massi (@BethMassi) posted a LightSwitch Beta 2 Content Rollup on 3/25/2011:
Well, it’s been 10 days since we released Visual Studio LightSwitch Beta 2 and we’ve been working really hard to get all of our samples, “How Do I” videos, articles and blog posts updated to reflect Beta 2 changes. Yes, that’s right. We’re going through all of our blog posts and updating them so folks won’t get confused when they find the posts later down the road. You will see notes at the top of them that indicate whether the information only applies to Beta 1 or has been updated to Beta 2 (if there’s no notes, then it applies to both). Check them out, a lot of the techniques have changed. I especially encourage you to watch the “How Do I” videos again.
So here’s a rollup of Beta 2 content that’s been done, reviewed, or completely redone from the team. You will find all this stuff categorized nicely on the new LightSwitch Learning Center into Getting Started, Essential and Advanced Topics. We add more each week!
Developer Center:
- Learning Center Redesign for Beta 2
- What's New in Beta 2
- Community Page (Started)
- "What is LightSwitch?"
How Do I Videos:
#1 - How Do I: Define My Data in a LightSwitch Application?
#2 - How Do I: Create a Search Screen in a LightSwitch Application?
#3 - How Do I: Create an Edit Details Screen in a LightSwitch Application?
#4 - How Do I: Format Data on a Screen in a LightSwitch Application?
#5 - How Do I: Sort and Filter Data on a Screen in a LightSwitch Application?
#6 - How Do I: Create a Master-Details (One-to-Many) Screen in a LightSwitch Application?
#7 - How Do I: Pass a Parameter into a Screen from the Command Bar in a LightSwitch Application?
#8 - How Do I: Write business rules for validation and calculated fields in a LightSwitch Application?
#9 - How Do I: Create a Screen that can Both Edit and Add Records in a LightSwitch Application?
#10 - How Do I: Create and Control Lookup Lists in a LightSwitch Application?
#11 - How Do I: Set up Security to Control User Access to Parts of a Visual Studio LightSwitch Application?Blogs:
Data
- Using Both Remote and Local Data in a LightSwitch Application
- How to Create a Many-to-Many Relationship
- Getting the Most out of LightSwitch Summary Properties
- How Do I: Import and Export Data to/from a CSV file
Screens
- How to Create a Screen with Multiple Search Parameters in LightSwitch
- Creating a Custom Search Screen in Visual Studio LightSwitch
- How to Programmatically Control LightSwitch UI
Queries
- Query Reuse in Visual Studio LightSwitch
- How Do I: Create and Use Global Values In a Query
- How Do I: Filter Items in a ComboBox or Modal Window Picker in LightSwitch
Office
- How to Send Automated Appointments from a LightSwitch Application
- How To Create Outlook Appointments from a LightSwitch Application
- How To Send HTML Email from a LightSwitch Application
- Using Microsoft Word to Create Reports For LightSwitch (or Silverlight)
Deployment
- Deployment Guide: How to Configure a Web Server to Host LightSwitch Applications
- Step-by-Step: How to Publish to Windows Azure
Tips, Tricks & Gotchas
- LightSwitch Gotcha: How To Break Your LightSwitch Application in Less Than 30 Seconds
- Where Do I Put My Data Code In A LightSwitch Application?
- Validating Collections of Entities (Sets of Data) in LightSwitch
Security
- Filtering data based on current user in LightSwitch apps
- How to reference security entities in LightSwitch
Architecture
- The Anatomy of a LightSwitch Application Series Part 1 - Architecture Overview
- The Anatomy of a LightSwitch Application Series Part 2 – The Presentation Tier
- The Anatomy of a LightSwitch Application Part 3 – the Logic Tier
- The Anatomy of a LightSwitch Application Part 4 – Data Access and Storage
Customization & Extensibility
- Using Custom Controls to Enhance Your LightSwitch Application UI - Part 1
- LightSwitch Beta 2 Extensibility “Cookbook”
Samples:
- LightSwitch Course Manager End-to-End Application
- Visual Studio LightSwitch Vision Clinic Walkthrough & Sample
- LightSwitch Beta 2 Extensibility “Cookbook”
Training:
Channel 9:

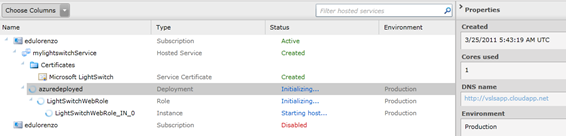
Edu Lorenzo described Publishing a Visual Studio LightSwitch App to Windows Azure on 3/24/2011:
So here goes!!!!
Off the top of my head, I think I will need both a hosted storage and a database because VS-LS apps are mostly data driven. Hmmm…. I’ll make one of both.
Then I create a lightswitch app and publish!
Of course you should publish it as a web app
And tell Lightswitch that it is to be deployed to Windows Azure
I supply the subscription ID and create a certificate for it
Upload the certificate I just made to my azure portal
I click next on the Lightswitch Publish wizard and choose appropriate values
Create a new Certificate
Connect to my Database
Then
And publish!
Watch as your management portal is being updated..
Wait for it… … …
And you now have.. a LightSwitch app deployed on azure!









Beth Massi (@BethMassi) provided a detailed and lavishly illustrated Deployment Guide: How to Configure a Web Server to Host LightSwitch Applications on 3/23/2011:
Note: This information applies to LightSwitch Beta 2.
If you select a desktop application you can choose to host the application services locally on the same machine. This creates a two-tier application where all the components (client + middle-tier) are installed on the user’s Windows computer and they connect directly to the database. This type of deployment avoids the need for a web server and is appropriate for smaller deployments on a local area network (LAN) or Workgroup. In this situation, the database can be hosted on one of the clients as long as they can all connect directly.
Both desktop and browser-based clients can be deployed to your own (or web hoster’s) Internet Information Server (IIS) or hosted in Azure. This sets up a three-tier application where all that is installed on the client is a very small Silverlight runtime and the application services (middle-tier) are hosted on a web server. This is appropriate if you have many users and need more scalability and/or you need to support Web browser-based clients over the internet.
(click images to enlarge)

If you don’t have your own web server or IT department then deploying to Azure is an attractive option. Check out the pricing options here as well as the Free Azure Trial. Last week Andy posted on the team blog how to publish your LightSwitch application to Azure, if you missed it see:
Step-by-Step: How to Publish to Windows Azure
In this post I’m going to show you how you can set up your own server to host the application as well as some configuration tips and tricks. First I’ll walk through details of configuring a web server for automatic deployment directly from the LightSwitch development environment and then move onto the actual publishing of the application. I’ll also show you how to create install packages for manual deployment later, like to an external web hoster. We’ll also cover Windows and Forms authentication. Finally I’ll leave you with some tips and tricks on setting up your own application pools, integrated security and SSL that could apply to not only LightSwitch applications, but any web site or service that connects to a database. Here’s what we’ll walk through:
Configuring a server for deployment
- Installing Prerequisites with Web Platform Installer
- Verifying IIS Settings, Features and Services
- Configuring Your Web Site and Database for Network Access
Deploying your LightSwitch application
- Direct Publishing a LightSwitch Application
- Creating and Installing a LightSwitch Application Package
- Deploying Applications that use Forms Authentication
- Deploying Applications that use Windows Authentication
Configuration tips & tricks
- Configuring Application Pools & Security Considerations
- Using Windows Integrated Security from the Web Application to the Database
- Using Secure Sockets Layer (SSL) for LightSwitch Applications
Keep in mind that once you set up the server then you can deploy multiple applications to if from LightSwitch. And if you don’t have a machine or the expertise to set this up yourself, then I’d suggest either a two-tier deployment for small applications, or looking at Azure as I referenced above. This guide is meant for developers and IT Pros that want to host LightSwitch web applications on premises.
So let’s get started!
Installing Prerequisites with Web Platform Installer
You can use the Web Platform Installer (WPI) to set up a Windows web server fast. It allows you to select IIS, the .NET Framework 4 and a whole bunch of other free applications and components. All the LightSwitch prerequisites are there which includes setting up IIS and the web deploy service properly as well as including SQL Server Express. This makes it super easy to set up a machine with all the stuff you need. Although you can do this all manually, I highly recommend you set up your LightSwitch server this way. You can run the Web Platform Installer on Windows Server 2008 (& R2), Windows 7, and Windows Server 2003. Both IIS 7.0 and IIS 6.0 are supported. If the server already has IIS 6.0 installed, IIS 7.0 will not be installed.
(Note that LightSwitch Beta 2 prerequisites have changed from Beta 1, they do not contain any assemblies that are loaded into the Global Assembly Cache anymore. Therefore you must uninstall any Beta 1 prerequisites before installing Beta 2 prerequisites.)
To get started, on the Web Platform tab select the Products link at the top then select Tools on the left and click the Add button for the Visual Studio LightSwitch Beta 2 Server Runtime. This will install IIS, .NET Framework 4, SQL Server Express 2008 and SQL Server Management Studio for you so you DO NOT need to select these components again.
If you already have one or more of these components installed then the installer will skip those. LightSwitch server prerequisites do not install any assemblies; they just make sure that the server is ready for deployment of LightSwitch applications so you have a smooth deployment experience for your LightSwitch applications. Here's the breakdown of the important dependencies that get installed:
- IIS 7 with the correct features turned on like ASP.NET, Windows Authentication, Management Services
- .NET Framework 4 + SP1
- Web Deployment Tool 1.1 and the msdeploy provider so you can deploy directly from the LightSwitch development environment to the server
- SQL Server Express 2008 (engine & dependencies) and SQL Server Management Studio (for database administration)(Note: LightSwitch will also work with SQL Server 2008 R2 but you will need to install that manually if you want that version)
The prerequisites are also used as a special LightSwitch-specific customization step for your deployed web applications. When deploying to IIS 7, they will:
- Make sure your application is in the ASP.NET v4.0 Application Pool
- Make sure matching authentication type has been set for the web application
- Adds an application administrator when your application requires one
So by installing these you don’t have to worry about any manual configuration of the websites after you deploy them. Please note, however, that if you already have .NET Framework 4 on the machine and then install IIS afterwards (even via WPI) then ASP.NET may not get configured properly. Make sure you verify your IIS settings as described below.
To begin, click the "I Accept" button at the bottom of the screen and then you'll be prompted to create a SQL Server Express administrator password. Next the installer will download all the features and start installing them. Once the .NET Framework is installed you'll need to reboot the machine and then the installation will resume. Once you get to the SQL Server Express 2008 setup you may get this compatibility message:
If you do, then just click "Run Program" and after the install completes, install SQL Server 2008 Service Pack 1.
Plan on about 30 minutes to get everything downloaded (on a fast connection) and installed.
Verifying IIS Settings, Features and Services
Once IIS is installed you’ll need to make sure some features are enabled to support LightSwitch (or any .NET web application). If you installed the Visual Studio LightSwitch Server Prerequisites on a clean machine then these features should already be enabled.
In Windows 2008 you can check these settings by going to Administrative Tools –> Server Manager and under Roles Summary click on Web Server (IIS). Then scroll down to the Role Services. (In Windows 7 you can see this information by opening “Add or Remove Programs” and selecting “Turn Windows features on or off”.) You will need to make sure to install IIS Management Service, Application Development: ASP.NET (this will automatically add additional services when you check it), and under Security: Windows Authentication.
Next we need to make sure the Web Deployment Agent Service is started. Open up Services and right-click on Web Deployment Agent Service and select Start if it’s not already started.
Configure Your Web Site and Database for Network Access
Now before moving on we should make sure we can browse to the default site. First, on the web server, you should be able to open a browser to http://localhost and see the IIS 7 logo. If that doesn’t happen something got hosed in your install and you should troubleshoot that in the IIS forums or the LightSwitch forums. Next we should test that other computers can access the default site. In order for other computers on the network to access IIS you will need to enable “World Wide Services (HTTP Traffic-In)” under Inbound Rules in your Windows Firewall. This should automatically be set up when you add the Web Server role to your machine (which happens when you install the prerequisites above).
At this point you should be able to navigate to http://<servername> from another computer on your network and see the IIS 7 logo. (Note: If you still can’t get it to work, try using the machine’s IP address instead of the name)
Next you need to make sure the SQL Server that you want to deploy the LightSwitch application database (which stores your application data, user names, permissions and roles) is available on the network. In this example I’m going to deploy the database to the same machine as the web server but you could definitely put the database on it’s own machine running either SQL Server or Express depending on your scalability needs. For smaller, internal, departmental applications running the database on the same machine is probably just fine. SQL 2008 Express is installed as part of the prerequisites above, you just need to enable a few things so that you can connect to it from another machine on your network.
Open up SQL Server Configuration Manager and expand the SQL Server Services and start the SQL Server Browser. You may need to right-click and select Properties to set the start mode to something other than Disabled. The SQL Server Browser makes the database instance discoverable on the machine. This allows you to connect via <servername>/<instancename> syntax to SQL Server across a network. This is going to allow us to publish the database directly from LightSwitch as well.
Next you need to enable the communication protocols so expand the node to expose the Protocols for SQLEXPRESS as well as the Client Protocols and make sure Named Pipes is enabled. Finally, restart the SQLEXPRESS service.

Direct Publishing a LightSwitch Application
Here is the official documentation on how to publish a LightSwitch application - How to: Deploy a 3-tier LightSwitch Application. As I mentioned, there’s a couple ways you can deploy to the server, one way is directly from the LightSwitch development environment, but the other way is by creating an application package and manually installing it on the server. I’ll show you both.
Now that we have the server set up, the Web Deployment Agent service running, and remote access to SQL Server, we can publish our application directly from the LightSwitch development environment. For this first example, I'm going to show how to deploy an application that does not have any role-based security set up. We’ll get to that in a bit. So back on your LightSwitch development machine, right-click on the project in the Solution Explorer and select “Publish”.
The Publish Wizard opens and the first question is what type of client application you want, desktop or Web (browser-based). I’ll select desktop for this example.
Next we decide where and how we want to deploy the application services (middle-tier). I want to host this on the server we just set up so select “IIS Server” option. For this first example, I will also choose to deploy the application directly to the server and since I installed the prerequisites already, I’ll leave the box checked “IIS Server has the LightSwitch Deployment Prerequisites installed”.
Next we need to specify the server details. Enter the URL to the web server and specify the Site/Application to use. By default, this will be set to the Default Web Site/AppName. Unless you have set up another website besides the default one leave this field alone. Finally, specify an administrator username and password that has access to the the server.
Next you need to specify a couple connection strings for the application database. The first one is the connection that the deployment wizard will use to create or update the database. This refers specifically to the intrinsic application database that is maintained by every LightSwitch application and exists regardless of whether you create new tables or attach to an existing database for your data. Make sure you enter the correct server and instance name in the connection string, in my case it’s called LSSERVER\SQLEXPRESS. Leaving the rest as integrated security is fine because I am an administrator of the database and it will use my windows credentials to connect to the database to install it. Regardless of what connection string you specify, the user must have dbcreator rights in SQL Server.
The second connection string will be the connection string the application uses at runtime. The middle-tier components connect to the database with this connection string and it is stored in the Web.config file. LightSwitch warns us here that this should not be using integrated security. This is because the web application is going to be set up in the ASP.NET v4.0 Application Pool which runs under a built-in identity that does not have access to the database. I’ll show you later how we can set up our own application pools, for now click the “Create Database Login…” button to create a login for the application. This will set up a least-privileged account with access to just the database and roles it needs.
Here I’ll specify the login name and password for this application.
Next you specify a certificate to use to sign the client application (.XAP file). This should be a valid certificate from a trusted Certificate Authority like VeriSign or if this is an internal application then you probably have certificates you use for enterprise deployment. If you don’t sign the application then users will see a warning message when installing the desktop application and they will not be able to get automatic updates if you update the application.
Click Next one last time and you will see a summary of all the setting we specified. If you run the publish wizard again, you will be taken to this page automatically and all the settings will be remembered.
Click Publish and it will take a few minutes to get everything installed on your remote server. You can see the status of the deployment by looking in the lower left hand side of Visual Studio LightSwitch. Once the publishing is done, open up your browser to http://<servername>/<applicationname> and in the case of a desktop application you will see an Install button. Click that to install and launch the desktop application.
Users of desktop applications will see an icon on their Windows desktop as well as the Start Menu to re-launch the application. And users can uninstall the application normally through Add or Remove Programs.
Creating and Installing a LightSwitch Application Package
Sometimes you don’t have direct access to the server where you want to host your LightSwitch application so direct deployment isn’t an option. In this case, you’ll need to create a package on disk which you can hand to an administrator to install manually. So back on your LightSwitch development machine, right-click on the project in the Solution Explorer and select “Publish” and click on the first page, Client Configuration. You can select Desktop or Web – I did Desktop before so this time I’ll select Web.
Again I’ll select IIS server that has our prerequisites installed.
Now on the publish output, this time select "Create a package on disk" and then enter a website name and specify a location to where you want the package created.
On the next page you specify the Database Configuration details. You can either create a new database or specify a database that needs to be updated. This refers specifically to the intrinsic application database that is maintained by every LightSwitch application and exists regardless of whether you create new tables or attach to an existing database for your data. For the first deployment of the application you are always going to want to select the New Database option as you won't have one created yet. If you are publishing an update to an existing application then you would select Update Existing option.
Just like in the case of direct deployment, you can specify a certificate to use to sign the client application (.XAP file). For a web application, this isn’t necessary.
Click Next and you will see a summary of all the setting we specified. Next click Publish and this will create a .ZIP file package in the publish location you specified. Copy that application package over to your web server then open up IIS Manager on the server and right-click on the Default Web Site and select Deploy –> Import Application. Note that you will need to be an administrator of the machine in order to install the package properly.
Browse to the .ZIP application package that we created then click Next. The contents of the package will then be displayed.
Similar to a direct deployment, when you install the package it’s going to ask for some database details. The first connection string will be used to create or update the database. Make sure you enter the correct server and instance name in the connection string, in my case it’s called LSSERVER\SQLEXPRESS. Using integrated security here is fine because I am an administrator of the database and it will use my windows credentials to connect to the database to install (or update) it.
The next four fields are used to create the connection string the application uses at runtime. The middle-tier components connect to the database this way and this information is stored in the Web.config file. By default you cannot specify an integrated security account because the web application is going to be set up in the ASP.NET v4.0 Application Pool which runs under a built-in identity and this identity does not have access to the database. (I’ll show you how to set up your own application pool using integrated security at the end.) Make sure you specify a least-privileged account with access to just the database it needs.
Click Next and this will kick off the installation that should be pretty quick. Once it completes, navigate your favorite browser to the website. Since I chose to deploy this as a Web application this time, the LightSwitch application will open like any other web site right inside the browser.
Deploying Applications that use Forms Authentication
Access control (checking user permissions) is a big feature in LightSwitch and there are hooks built in all over screens, queries and entities that allow you to easily check permissions you define. Here’s the library documentation to check out:
How to: Create a Role-based Application
and I also recommend this video:
You specify user permissions and the type of authentication you want to use on the Access Control tab of the Project –> Properties.
Here you define user permissions that you check in code in order to access resources (for details on how to do that see the video and article referenced above). You also specify what kind of Authentication you want to use which affects how to application is deployed. The web application on the server must have the corresponding IIS authentication enabled.
First let’s walk through Forms authentication. This means you will be storing usernames and passwords inside the LightSwitch database (LightSwitch uses the ASP.NET membership provider model). This type of authentication is appropriate for internet-based applications. Once you go to publish your application that uses Forms Authentication, there will be a new section in the Publish Wizard that allows you to specify how the administrator is deployed.
Direct Deployment – Forms Authentication
In the case of direct deployment you will see a screen that asks for the Administrator user name and password. This has nothing to do with the connection to the database so don’t get confused. This is just the first user that gets deployed as actual data into the users table so you can log into the application and start setting up other users and roles. If you are re-deploying (i.e. updating) an application that was already deployed with Forms Authentication then choose not to create the application admin again.
Creating an Application Package – Forms Authentication
If you are creating a package on disk, then the Publish Wizard will only ask you whether you want to create the Application Administrator or not. If this is the first time deploying, select yes, otherwise if you’ve already gone through this once select no. You will be asked to specify the details later when you deploy the package on the server.
So now when you import the application package you will see additional fields that you need to enter that set up this Application Administrator. (Remember that to install the package on the server in the first place you have to be an administrator of the machine, but these fields just specify what data gets deployed in the application’s users table).
After you publish the application, whether you do it directly or create a package, if you’ve installed the LightSwitch prerequisites you will see that the corresponding Forms Authentication is set up properly on your web site. This is required in order for the application to work properly.
And when you launch the application you will be prompted for the Application Admin username/password that you entered.
Deploying Applications that use Windows Authentication
Using Windows Authentication is appropriate if all your users are on the same network or domain, like in the case of an internal intranet-based line-of-business application. This means that no passwords are stored by your LightSwitch application. Instead the Windows logon credentials are used and passed to the application server. In this case you can also choose whether you want to set up specific users and roles or whether any authenticated user has access to the application.
Note that If you have permissions defined in your application and you are checking them in code, then those permissions will only be granted to users specified in the Users screen of the application. The "Allow any Windows authenticated user” setting will work, but users who are not also defined in the Users screen will not have any of the defined permissions. The best way to think of the two options for Windows authentication are:
- Give special permissions and roles to the Windows users that I administer within the application. (This is always on if you have selected Windows authentication)
- ALSO, let any Windows user access the unprotected parts of my application
In either case, the deployment and web application configuration is the same.
Direct Deployment – Windows Authentication
In the case of direct deployment you will see a screen that asks for the Application Administrator user. This should be a valid user on the domain where the application is hosted. Again, this is just the first user that gets deployed into the users table so they can open the application and start setting up other users and roles. If you are re-deploying (i.e. updating) an application that was already deployed with Windows Authentication then choose not to create the application admin again.
Creating an Application Package – Windows Authentication
If you are creating a package on disk, just like Forms Authentication above, the Publish Wizard will only ask you whether you want to create the Application Administrator or not. If this is the first time deploying, select yes, otherwise if you’ve already gone through this once select no. Again, you will be asked to specify the details when you deploy the package on the server. Here is where you will specify the application Admin user as a valid domain user.
After you publish the application, whether you do it directly or create a package, if you’ve installed the LightSwitch prerequisites you will see that the corresponding Windows Authentication is set up properly on your web site. This is required in order for the application to work properly.
And when you run the application you will see the authenticated user in the right-hand corner.
That’s it! We are now armed with the knowledge of how to deploy any type of LightSwitch application to a server. :-)
Configuring Application Pools & Security Considerations
Now that we know how to deploy LightSwitch Desktop and Web applications, next I want to talk a little bit about how application pools and Windows identities work. This will help you determine what is the best way for you to host any web application on a network. You don't actually have to know much about this stuff when deploying a LightSwitch application because the installation package will set up all of this for you. However, I think it's always a good thing to understand what's going on, especially if you are trying to troubleshoot issues. If you don't care, you can skip this section :-)
When you create a new website in IIS Manager you choose which application pool it should run under. When deploying applications with LigthSwitch your applications are deployed to the ASP.NET v4.0 app pool. Application pools give you isolation between worker processes (so if one web application crashes it can’t take others with it) but they also allow you to run under different identities. The built-in application pools use built-in accounts that they run under.
If you create your own application pool you can set it to run under a specific Windows Identity and you can allow access only to the resources that identity needs to run the application. In the case of a LightSwitch application, that additional resource will be the database. If you are already on a Windows domain it’s best to create a least-privilege domain user, set that user as the identity of the application pool, and grant access for that user to the database (which is probably on another machine, if so you’ll probably want to read this).
Since I am hosting the database on the same machine as IIS I can use a local machine account. Open up the Local Users and Groups console and create a local user called LightSwitchApp. Then add this user to the IIS_IUSRS group so that it has read access to web application files on disk under the wwwroot. Next open up IIS Manager, right-click on Application Pools and select “Add Application Pool....” Type a name for your App Pool, I called mine LightSwitchAppPool and select the .NET Framework version 4. Then click OK.
Next right-click on the LightSwitchAppPool and select Advanced Settings and change the Identity to the account you just created. (Once we update our LightSwitch web application to run in this pool, it will run under this identity to access resources.)
Now we can set the Application Pool of the LightSwitch application we deployed earlier. In IIS Manager right-click on the Web application and select Manage Application – Advanced Settings. Here you can change the application pool to the one we just created.
Note that if your web application files are physically deployed to somewhere other than under inetpub\wwwroot then you will also need to add read file access permissions to that directory for the LightSwitchApp user account. Because we used LightSwitch earlier to deploy our application, our application is located under C:\inetpub\wwwroot\OrderManagement.
There’s one last piece to set up if your application is going to use Windows Authentication. When you use a custom user identity as the application pool identity in this situation you need to either use the NTLM provider (not Kerberos) or you need to Enable support for Kerberos authentication. Another option is to use the Network Service identity as the app pool’s identity and add that account access to the database instead. To use the NTLM provider (which is what I’m going to do) select the web site and select Authentication under the IIS section on the main window of the IIS manager. Select the Windows Authentication (which is enabled), right-click and select “Providers…” and then move Negotiate down to the bottom of the list.
Using Windows Integrated Security from the Web Application to the Database
Like I mentioned earlier, typically you want to set up Windows Integrated security between your web application and database. It's a lot easier this way because you don't have to worry about managing user names and passwords in your application connection strings. It also is a lot more secure -- right now our username and password to the database is being stored in clear text on the web application's Web.config. Only administrators of the server can see this file, however, you may not trust other people that have access to the machine. Let’s face it, you’re paranoid. ;-)
We've configured our LightSwitchAppPool to run under the LightSwitchApp user identity so the next step is to grant this user access to the database. Open up SQL Server Management Studio and right-click on the Security node and choose New Login. On the General tab specify the local LightSwitchApp user account as the Login name, use Windows Authentication. On the User Mapping make sure you check off the database you want to grant access to, in my case OrderManagement. At minimum you will need to enable the following roles: aspnet_Membership*, aspnet_Roles*, db_datareader, db_datawriter, and public. Or you can grant the db_owner role which will include these.
Because we've configured our LightSwitchAppPool to run under the LightSwitchApp user identity we can now change the connection string in the Web.config to use integrated security and the middle-tier will connect to the database under this windows account instead. In IIS Manager right-click on the web application and select Explore to navigate to the physical folder. Open the Web.config in notepad and remove the uid and password and add Integrated Security=SSPI:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<appSettings> ... </appSettings>
<connectionStrings>
<add name="_IntrinsicData" connectionString="Data Source.\SQLEXPRESS;Database=OrderManagement;Integrated Security=SSPI;Pooling=True;Connect Timeout=30;User Instance=False" />
</connectionStrings>
<system.web> ...Save the file and now run your client application again and everything should be working, running under your own Application Pool and using Windows Integrated security to the database. As a tip, if you have trouble connecting to your database, double-check the connection string and also make sure the database user is a db_owner for the correct database.
Using Secure Sockets Layer (SSL) for LightSwitch Applications
To wrap up this post I’m going to leave you with some notes and recommendations on using Secure Sockets Layer with LightSwitch applications. As you’ve probably noticed by now, LightSwitch clients communicate with the server via HTTP which is the protocol used between web browsers and web servers. HTTP specifies that data be sent in clear-text, which means that a network eavesdropper could monitor the data exchanged between clients and servers. In any web application, including LightSwitch applications, if you want communications to be secure you need to use the HTTPS protocol. This hides the normal HTTP data in an encrypted tunnel called a Secure Sockets Layer (SSL).
In order to configure your web server to enable HTTPS, you use a certificate and set it up like any other secure web site. No LightSwitch-specific configuration is required on the IIS server in order to host LightSwitch applications with SSL. For information on setting up SSL see: How to Set Up SSL on IIS
When you enable SSL this protects not only the sensitive business data that is exchanged between client and server, but also the usernames and passwords when you are using Forms Authentication. It is a best practice to use HTTPS when using Forms authentication in conjunction with an IIS server exposed to the internet or when hosting in Azure. Otherwise, it is possible for an attacker to recover passwords and impersonate users. When using Windows authentication, an attacker cannot recover user passwords or impersonate users regardless of the protocol. However, business data transferred between client and server will still be subject to eavesdropping unless HTTPS is employed. (Note that HTTPS is not necessary when deploying a two-tier application because the client-server communication does not happen over the network – all LightSwitch assemblies are deployed locally on the same machine in this case.)
There may be situations where you want to host the same LightSwitch application using both HTTP and HTTPS, like if you have both internal (behind firewall) and external (internet) clients. By default in recent versions of IIS, the Default Web Site listens for both HTTP and HTTPS connections. You can also choose to force a LightSwitch application to require HTTPS and redirect any HTTP incoming connections to the HTTPS endpoint by modifying the Web.config of your LightSwitch application.
In the <appSettings> section of Web.config, you should see:
<!-- A value of true will indicate http requests should be re-directed to https –>
<add key="Microsoft.LightSwitch.RequireEncryption" value="false" />Set the value from “false” to “true”. You can configure this in Web.config after deploying, or from inside LightSwitch before deploying. To find your Web.config during development, in Solution Explorer switch to File View then enable Show All Files. It will be located in the Server Generated project.
Web servers that communicate via HTTPS rely on having a server certificate installed which does a couple things for you. The certificate verifies the identity of the server and also contains the secret key information used to encrypt any data sent to the client. For a web browser to be able to trust the identity of a server, the server’s certificate must be signed by a trusted Certificate Authority (CA) like VeriSign. Note that most CAs charge for this service and so it’s common during development for a server to use a test certificate which is a self-generated, unsigned -- and thus untrusted -- certificate.
If you connect to a LightSwitch web application via HTTPS and the server is using an untrusted certificate, the behavior depends on your web browser. At minimum your browser will tell you that there’s a certificate problem and ask if you’d like to proceed. This is what will happen if you have deployed a LightSwitch Web application. However, if you have a LightSwitch Desktop application and you want to use it over HTTPS, then your IIS server must be using a trusted certificate. This is because Silverlight, and thus LightSwitch, will not allow desktop applications to come from untrusted server certificates.
To fix this, you can either force your web browser to trust the server’s certificate by pre-installing it in the client’s certificate store, or you can replace the server’s certificate with one which has been signed by a trusted CA. Note that you should perform either of these steps before accessing the application for the first time from a client, otherwise it will appear to that client that the certificate has changed or been tampered with. If you’ve accidentally done just that then you will need to uninstall (via Add or Remove Programs) and then reinstall the client application.
Wrap Up
So I think that about covers it. Deployment of web applications can be tricky no matter what the technology, but LightSwitch makes this a lot easier on you especially when you use the WPI and install the LightSwitch Server Prerequisites. And you have a couple good options for deployment. You can either set up a web server for direct deployment by giving LightSwitch developers admin access to it (which is especially handy for testing and staging) or you can have them create packages that an administrator can easily install later. Now you should be a pro at 3-tier LightSwitch application deployment and all your applications should be running smooth. :-)
BTW, I’m working on some How Do I videos on 3-tier and Azure deployment so stay tuned.















































Return to section navigation list>
Windows Azure Infrastructure and DevOps
• Todd Hoff asked Did the Microsoft Stack Kill MySpace? in a 3/26/2011 to the High Scalability blog:
Robert Scoble wrote a fascinating case study, MySpace’s death spiral: insiders say it’s due to bets on Los Angeles and Microsoft, where he reports MySpace insiders blame the Microsoft stack on why they lost the great social network race to Facebook.
Does anyone know if this is true? What's the real story?
I was wondering because it doesn't seem to track with the MySpace Architecture post that I did in 2009, where they seem happy with their choices and had stats to back up their improvements. Why this matters is it's a fascinating model for startups to learn from. What does it really take to succeed? Is it the people or the stack? Is it the organization or the technology? Is it the process or the competition? Is the quality of the site or the love of the users? So much to consider and learn from.
Some conjectures from the article:
- Myspace didn't have programming talent capable of scaling the site to compete with Facebook.
- Choosing the Microsoft stack made it difficult to hire people capable of competing with Facebook. .Net programmers are largely Enterprise programmers who are not constitutionally constructed to create large scalable websites at a startup pace.
- Their system had " “hundreds of hacks to make it scale that no one wants to touch," which hamstrung their ability to really compete.
- Because of their infrastructure MySpace can’t change their technology to make new features work or make dramatically new experiences.
- Firing a lot of people nose dived morale and made hiring tough. (duh)
- Los Angeles doesn't have startup talent capable of producing a scalable social network system.
- Facebooks' choice of the LAMP stack allowed them to hire quicker and find people who knew how to scale.
Todd continues with “Some very interesting points in the comments (from the article, email, Hacker News).”
• Thomas Claburn asserted “Rivals Facebook, Google, and Microsoft, along with Cisco and IBM to name a few others, are overlooking their differences to promote programmable networking” as a deck for his Tech Giants Push Smart Networking Standard of 3/25/2011 for InformationWeek:
Seventeen major technology companies, including Deutsche Telekom, Facebook, Google, Microsoft, Verizon, and Yahoo, have banded together to develop and promote a new approach to networking called Software-Defined Networking (SDN) through a non-profit foundation, the Open Networking Foundation (ONF).
Other founding members of the ONF include: Broadcom, Brocade, Ciena, Cisco, Citrix, Dell, Ericsson, Force10, HP, IBM, Juniper Networks, Marvell, NEC, Netgear, NTT, Riverbed Technology, and VMware.
SDN promises to make network data handling more efficient and flexible through automation and programming. Existing network switches provide mechanisms for quality-of-service adjustments, allowing network data types to be differentiated or blocked. SDN offers a way to optimize the use of many of these capabilities and to deploy new ones. It could help network switches communicate to determine optimal solutions to network problems.
For example, SDN could assist with re-routing data flows dynamically during a particularly popular online event. It could be used to detect denial of service attacks more efficiently, or to provide the infrastructure to outsource the management of home networks.
"Software-Defined Networking will allow networks to evolve and improve more quickly than they can today," said Urs Hoelzle, ONF president and chairman of the board, and SVP of engineering at Google. "Over time, we expect SDN will help networks become both more secure and more reliable."
Arising from a six-year research collaboration between Stanford University and the University of California at Berkeley, SDN consists of two primary elements, a software component called OpenFlow and a set of management interfaces for network service providers.
The aim of the ONF initially will be to encourage the adoption of the OpenFlow standard through free licensing.
The nascent technology is already prompting some concern. In a message posted to David Farber's Interesting People mailing list, privacy advocate Lauren Weinstein observed that without a network neutrality framework, SDN could limit the services or options of Internet users.
"While the stated possible positives of such technology are real enough, the same mechanisms could be used to impose exactly the sorts of walled gardens, service degradations, and 'pay to play' limits that are at the heart of Net Neutrality concerns, as dominant ISPs in particular would be tempted to leverage this technology to further restrict user applications to the benefit of their own profit centers," he wrote.
Yet any technology can be misused. Absent a clear and present danger, technical innovation shouldn't be shunned because the politics of network management remain unsettled.
• Geva Perry (@gevaperry, pictured below) announced Video Interview on Zenoss's Cloud Management Blog in a 3/24/2011 post:
Josh Duncan at Zenoss, which makes cloud monitoring and management software, interviewed me over Skype for their Cloud Management Blog. We covered a pretty wide range of cloud-related topics and Josh split up the video interview into two parts.
The first part is now up on their blog here. (by the time I post this blog the second part may be up as well).
To quote from Josh:
Here’s what we cover in part 1 of Thinking Out Cloud with Geva Perry:
- “It’s happening now” – what are all the challenges and strategies to address
- The business case for the Cloud – from cost savings to business agility
- The operational challenges of Cloud computing
- “The CIO doesn’t matter” - democratization of IT (link to Forbes article)
See the video.
UPDATE: Part 2 is also avilable now at: http://blog.zenoss.com/2011/03/thinking-out-cloud-with-geva-perry-part-2/
• David Linthicum asserted “The cloud makes BI finally affordable and accessible, so businesses can actually take advantage of their intelligence” in a deck for his Cloud-based BI is a game-changer in a 3/24/2011 post to InfoWorld’s Cloud Computing blog:
Those who follow the world of business intelligence (BI) have probably noticed both an increase in new cloud BI providers and the movement of existing providers to the cloud.
The concept is simple: Your transactional information is copied to cloud-based storage, either to an ODS (operational data store) or a data warehouse. The information is structured in a way that's easy to understand, typically around major business entities such as sales, inventory, and payments. Once the data is in the cloud, you can run reports, create dashboards, and perform analytical operations that support core business decisions from a Web app.
The use of BI in the cloud is a game-changer, but not in that it adds any new BI capabilities. Instead, through the use of the cloud computing, BI is finally affordable and available to those who need access to this information.
Since the inception of these concepts years ago, data warehousing and BI have always been too expensive. You can count on $1 million minimum to get a basic system up and running, then expect to pay very expensive consultants and analysts to maintain it. Moreover, the users who needed these BI systems to make critical business decisions typically had no access, with IT citing cost and complexity of deploying and managing the front-end BI tools.
With the advent of cloud-based BI, the cost drops dramatically compared to that of traditional BI. You can also bring critical analytics to those who need them: line managers who can use the information to improve business operations when it counts, and not have to learn of problems weeks and even months after they appear, as is the case with many traditional BI systems.
Moreover, cloud-based BI provides better support for device-delivered information, such as to dashboards or reports intended for smartphones and tablets.
This is a case of the cloud providing access to flexible and elastic computing resources at an affordable price. At last, BI systems are available to those who actually need them.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
• Vijay Tewari posted ANNOUNCING System Center Project Codename “Concero” to the TechNet blogs on 3/25/2011:
At the Microsoft Management Summit on Tuesday, 3/22/11, Brad Anderson announced a new capability in System Center 2012 called Project Codename “Concero”. Before I actually talk about what it is, let me first talk about what the word “Concero” means. It’s a Latin word which means “connected”, which is at the heart of what “Concero” does.
System Center 2012 cloud and datacenter management solutions empower you with a common management toolset for your private and public cloud applications and services, thus helping you confidently deliver IT as a Service for your business. Our goal is to help you consume the full power of and deliver private and public cloud computing on your terms. System Center 2012 provides the ability for customers to create and manage their “Private Clouds” using the virtualization infrastructure provided by Windows Server 2008 R2, Hyper-V and other virtualization platforms. At his keynote, Brad outlined the key tenets for the cloud, one of which is “Self-Service”. This empowers the “Application Owners” to consume the cloud capacity in an agile manner. With System Center 2012, “Concero” provides a web based and simple experience for the application owner who will be consuming cloud capacity.
We recognize that customers will be in an environment where they will be consuming cloud capacity from multiple providers. The initial release of “Concero” will enable customers to deploy, manage and control applications and services deployed on private clouds built using System Center Virtual Machine Manager 2012 and in the public cloud offering of Windows Azure. This provides a consistent and simple user experience for service management across these clouds.
Some key capabilities of “Concero” are:
(a) Ability to access resources across multiple VMM Servers
(b) Ability to register and consume capacity from multiple Windows Azure subscriptions
(c) Deploy and manage Services and virtual machines on private clouds created within VMM 2012 and on Windows Azure
(d) Copy Service templates (and optional resources) from one VMM Server to another
(e) Copy Windows Azure configuration, package files and VHD’s from on-premises and between Windows Azure subscriptions
(f) Enable multiple users authenticated through Active Directory to access a single Windows Azure subscriptionBelow are some screen shots from “Concero”
We are excited that we can now talk about this capability. The MMS session BH04 provides more information on Concero. Enjoy!!


Vijay is Principal Group Program Manager, System Center Project Codename “Concero”
Ben Day described a workaround for a System Center Virtual Machine Manager (SCVMM), Refresh-VMHost, WMI Providers, and the Wifi Card problem on 3/25/2011:
Getting SCVMM installed was fine but when I went to associate my Hyper-V host (aka. The New Laptop) via SCVMM’s “Add Host”, I’d get get failure on the Refresh-VMHost step.
Error (2923)
A malformed response was received while trying to contact the VMM agent on borgomale.benday.local. (Unspecified error (0x80004005))
Recommended Action
1) Ensure the VMM agent is installed and that the VMMAgent service is running.
2) If the VMMAgent service is running, restart the service, and then verify that WS-Management is installed correctly and that the WinRM service is running.
3) Check the manufacturers’ Web sites to ensure that you have the latest drivers for your network adapters and other devices.
After months of fiddling around without any luck, I found this post a few days ago on the Korean MSDN site. In the post, Hariveer Singh from Microsoft suggests the following 4 queries to try from the command line.
winrm enumerate wmi/root/cimv2/Win32_NetworkAdapterSetting -r:machinename
winrm enumerate wmi/root/cimv2/win32_networkadapter -r:machinename
winrm enumerate wmi/root/cimv2/Win32_NetworkAdapterConfiguration -r:machinename
winrm enumerate wmi/root/cimv2/Win32_PerfRawData_Tcpip_NetworkInterface -r:machinenameWhen I ran the first 2, I got the following error:
WSManFault
Message
ProviderFault
WSManFault
Message = HRESULT = 0x80041013
ExtendedError
__ExtendedStatus
Description = null
Operation = ExecQuery
ParameterInfo = select * from Win32_NetworkAdapterSetting
ProviderName = WinMgmt
StatusCode = nullError number: -2147023537 0x8007054F
An internal error occurred.
A while back, I’d read on a different MSDN forum post that there were known problems with Broadcom network adapters. Unfortunately, my network adapters are both Intel so I was pretty much stuck until I had Haviveer’s winrm queries. Anyway, once I had the failing winrm queries, pretty much knew that there was a problem with the WMI provider for one of my NICs. From there, I tried using WBEMTEST.EXE to run the failing query (select * from Win32_NetworkAdapterSetting) directly against WMI. WBEMTEST.EXE is typically located at C:\Windows\System32\wbem.
When the query executed, I got a provider load failure with the 0x80041013 error number.
Many searches later, I found Mark Wolzak’s post about Win32_NetworkAdapter “Provider Load Failure”. This post walked me through the process of finding the actual answer and the actual fix. It all came down to isolating which network adapter was causing the provider load problem and then fixing it. For me, it meant that the Intel WiFi driver (C:\Program Files\Intel\WiFi\bin\WiFiWMIP.dll) for my Intel Centrino Ultimate-N 6300 AGN had problems. I uninstalled the driver for the wifi card and then re-ran the “winrm enumerate wmi/root/cimv2/Win32_NetworkAdapterSetting -r:machinename” query and this time IT WORKED! After that, I installed the latest version of the wifi driver from Intel’s site, re-ran the query, and it still worked. (Hallelujah!)
Finally, I re-tried the SCVMM Add Host operation and this time Refresh-VMHost worked.




Nicole Hemsoth reported Microsoft “Targets” Virtualization Goals of Mega-Retailers in a 3/25/2011 post to the HPC in the Cloud blog:
Microsoft has made a series of cloud power plays that have ramped up in frequency and ferocity since the turn of the year. Under the umbrella of their cloud push are not only new features to extend Azure, but also added virtualization-related services, including this week’s introduction of System Center 2012, which targets private cloud-building.
According to Microsoft, Target has virtualized nearly every aspect of its business-critical operations, including inventory, point of sale, supply chain management, asset protection, in-store digital input and other processes using Windows Server 3008 R2 Hyper-V and Microsoft System Center.
The feat to merge together a distributed infrastructure with over 300,000 endpoints, which include not only servers (15,000) and workstations (29,000), but also registers (52,000), mobile devices (70,000) and even a range of kiosks at different points throughout Target’s 1,755 locations is no small one. The move will eliminate 8,650 servers by 2012 and will adhere to a “two servers per store” policy.
Fritz DeBrine, who heads up Target’s Server Technology and Enterprise Storage division noted that the prime motivation behind the two-server policy boiled down to cost as prior to building their virtualized army, there were several servers, most often seven, dedicated to different tasks in each store. DeBrine said that the power, maintenance and refresh costs were quite hefty.
A Targeted Tale of Virtualization
Although Target didn’t begin the virtualization process until 2006, general server sprawl following rapid expansion and an increasing complex, distributed system were management challenges that the company first identified in 2004. At that time their first idea was to replace outdated servers that supported their pharmacy operations, which ran on IBM AIX.
Brad Thompson, Target’s Director of Infrastructure Engineering claimed that at this point in 2004, “the hardware we had been using for the pharmacy solution was no longer available. At the same time, we didn’t want to replace a lot of the hardware as that would cost us millions of dollars. By this point, virtualization had become a viable alternative to simply deploying more servers and would allow us to make better use of existing server capacity and reduce infrastructure management.”
The migration toward virtualization was not something that happened overnight, certainly, but the process has been rolling since 2006 when IT leaders at Target decided to roll with Microsoft Virtual Server. Like other large enterprises that make the decision to examine virtualization routes, DeBrine stated that the goal from the outset was to reduce the number of servers. He explained that before the virtualization process the company operated under a buy a server when you build a new application model—one that is cost and operationally inefficient.
DeBrine claims that they carefully weighed their options at this early point, examining the offerings of VMware closely before finally settling on Microsoft. He notes that at that time, the first VM they deployed was “a SUSE Linux instance running our pharmacy application. Things were running well and created three additional workloads on MSVS over the next 18 months” and kept adding more applications to the mix.
Page: 1 of 2
Read more: 2, Next >
• Jeffrey Schwartz (@Jeffrey Schwartz) reported SCCVM 2012 Test Release To Get Server App-V for Windows Azure Beta in a 3/24/2011 article for Application Development Trends:
Microsoft's Server Application Virtualization tool for Windows Azure was included in a System Center Virtual Machine Manager 2012 beta version, released earlier this week.
According to Microsoft, Server App-V builds on the technology used in the company's client application virtualization software, available via the Microsoft Desktop Optimization Pack, Microsoft Application Virtualization for Terminal Services and MSDN.
"This process allows existing, on-premises applications to be deployed directly onto Windows Azure, providing yet more flexibility in how organizations can take advantage of Microsoft's cloud capabilities," Owens noted.
That will allow applications mobility, simplified management and lower operational costs, Owens explained. The apps are converted into "Xcopyable" images, without requiring code changes to the apps "allowing you to host a variety of Windows [Server] 2008 apps on the Windows Azure worker role."
Microsoft released the first community technology preview (CTP) of Server App-V in December and plans a final release by the end of the year. The Server App-V documentation is available for download here.
• Jeff Wettlauter announced System Center Configuration Manager Beta 2 in a 3/24/2011 post to the TechNet blogs:
This week we are extremely pleased to release Beta 2 of Configuration Manager 2012. We thought it would be helpful to provide a technical introduction to the product, and share with you some places and programs you can use to get your hands on it.
The main engineering investments for ConfigMgr 2012 are:
- Unify Infrastructure – In order to truly deliver many new features but at the same time reducing infrastructure footprint, and complexity, ConfigMgr 2012 integrates device, virtualization and security management. From treating devices as first class citizens in places like the application model, to integrating true virtualization delivery mechanisms, and aligning Forefront Endpoint Protection in 1 pane of glass, will ensure organizations experience a simpler infrastructure. In addition, new features like Role Based Administration, new Client Agent settings at the Collection level, and investments in SQL will enable organizations to flatten their hierarchy, reduce server footprint, and simplify their architectures. All of this adds up to some significant improvements for the administrator, and the organization.
- Simplify Administration – Through the automation of tasks like software update deployment, and the auto remediation of non compliant settings, ConfigMgr 2012 will reduce mouse clicks, and processes that Administrators typically go through. Software Update Management now has a capability called Auto Deployment Rules, that allow automation from the point of update availability to flow through the infrastructure to the target systems. These rules can be defined at any level an update is categorized. Product, Language, Severity are examples of how updates might be categorized. Building on a feature from ConfigMgr 2007 called DCM (Desired Configuration Management) ConfigMgr 2012 will now add the ability to remediate non compliant CI’s, or entire Baselines. Much like how Group Policy behaves, ConfigMgr 2012 Settings Management will enable organizations to define how an OS, App or setting should be configured, and simply allow that 1 time setting to remain in constant compliance. Efficiency is driven at 2 levels. Efficiency for the Administrator, and new efficiencies for the actual network infrastructure. Both of these drive time, cost and other resource savings that are worth checking out.
We hope you can take a look at ConfigMgr 2012. This beta 2 release is full of new features, capabilities and efficiencies. Check out our new console, the cool ribbon 1 click actions, and the new enhancements around our capabilities. Here are some resources for you to get going today:
- Introduction to Configuration Manager 2012 - link
- What’s New in Configuration Manager 2012 - link
- Fundamentals of Configuration Manager 2012 - link
- Download the ConfigMgr Beta 2 here
- Join our 800 friends in the Community Evaluation Program here
- Check out our Virtual Labs on Technet here (currently based on Beta 1, update coming soon)
- Download a pre configured Virtual Machine here (currently based on Beta 1, update coming soon)
• The SQL Server Team posted Microsoft Announces Additional Details about System Center Advisor (formerly codename “Atlanta”) on 3/24/2011:
At the Professional Association for SQL Server (PASS) Summit last November, Microsoft announced System Center codename “Atlanta.” Since then, you have told us how excited you are about this new service; a cloud-based service that enables IT pros to assess their SQL Server configuration and proactively avoid problems. This excitement showed in your tremendous participation during the beta program. With that, today we’re excited to share more news about project Atlanta.
At this week’s Microsoft Management Summit conference, Microsoft announced the following details about System Center codename “Atlanta:”
- System Center codename “Atlanta” is now named System Center Advisor
- The Release Candidate of System Center Advisor is now available
- With commercial availability targeted for the second half of calendar year 2011, System Center Advisor will only be available as a benefit of Software Assurance for entitled server products, including SQL Server. That means, this service brings new support and maintenance value to Software Assurance coverage at no additional cost!
As huge fans of SQL Server, we’re very excited about the value System Center Advisor brings to our customers’ environments. The following sums up the key benefits you can experience with System Center Advisor:
- Proactively avoid problems: Increase awareness and proactively avoid problems with server deployments through ongoing assessment and alerting of configuration from a cloud service
- Help resolve issues faster: Resolve issues faster by providing Microsoft or internal support staff current and historical views into configuration to get up to date solutions for any issues
- Help reduce downtime: Help reduce downtime and improve performance of servers through proactive scanning for known configuration issues and comparison with best practices.
For more information on System Center Advisor or to sign up for FREE access to the Release Candidate, visit http://www.systemcenteradvisor.com.
• Adam Hall posted Welcome to the family System Center Orchestrator! to the TechNet blogs on 3/24/2011:
I am very excited to be able to post this article, welcoming System Center Orchestrator to the System Center suite!
As was communicated by Brad Anderson in Tuesday’s MMS keynote and on the Nexus news bulletin, System Center Orchestrator is the official name for what we have been referring to previously as Opalis vNext.
There will be a lot of information posted over the coming weeks and months as we build to the Beta in a few months and the Final release expected later this year, however I wanted to provide a summary level list here.
- IT Pro - Authoring, Debugging & Scripting
- The Opalis product will be rebranded to System Center Orchestrator. We are working very hard to ensure that your existing investments in Opalis are maintained.
- A new PowerShell provider to allow Orchestrator to be integrated into scripts and provide a mechanism for remote execution of runbooks.
- Operator - Trigger, Monitor &Troubleshoot
- A new silverlight based dynamic web console to provide an easy way to start, monitor and investigate runbooks.
- Developer - Application integration
- A new rich OData based web service that exposes Orchestrator functionality and information in a standards based way.
- IT Business Manager - Report & Analyze
- A new mechanism for connecting your existing reporting investments to Orchestrator to extract, report and analyze what is happening inside Orchestrator.
In addition to the above investment areas, we are also completing a number of ‘housekeeping’ functions:
- A new Installer experience
- An Orchestrator Management Pack for Operations Manager
- Globalization of the Orchestrator release (Localization will follow in a future release)
- Updated versions of the Integration Packs, both for System Center as well as a number of the 3rd Party IP’s
As I mentioned above, we will be posting a lot of information about Orchestrator over the coming weeks and months. We are ramping up our early adopter TAP program at the moment, and later in the year we will be running a full Public Beta so you can all take the new functionality for a spin.
Keep an eye out for further information in the near future, and in the mean time, you can keep up with all the information by following @SC_Orchestrator on twitter or by using the #SCOrch tag.
And as always, I welcome any feedback you have.
• The System Center Team suggested that you Check out System Center Advisor on 3/24/2011:
This new cloud service enables customers to assess the configuration of their servers so they can proactively avoid problems. System Center Advisor helps customers resolve issues faster with the ability for support staff to access current and historical configuration data for their deployment. Additionally, System Center Advisor helps reduce downtime by providing suggestions for improvement, and notifying customers of key updates specific to their configuration.
Designed for IT professionals responsible for the management of Windows-based data centers, the core value of this new service is built on Microsoft’s experience supporting customers with their server deployments around the world. The Release Candidate available now (March 2011) helps IT Pros manage the configuration of SQL Servers as well as some Windows Server features. Advisor aims to extend and deepen its reach with new configuration analysis intelligence and server product support over time.
With targeted commercial availability in the second half of 2011, System Center Advisor will only be available as a benefit of Software Assurance for entitled server products. This service brings new support and maintenance value to Software Assurance coverage at no additional cost.
For more details, visit: http://www.microsoft.com/systemcenter/advisor
• Bernardo Zamora posted Virtualize SQL Server with Hyper-V and System Center on 3/22/2011 to the SQL Server Team blog(missed when posted):
At this week’s Microsoft Management Summit conference (MMS), we are discussing how we are taking virtualization beyond OS and Infrastructure, with SQL Server as a key workload and an important element of a Private Cloud Platform. And why wouldn’t customers virtualize SQL Server with Hyper-V and System Center? SQL Server is a core component of any virtualized environment and together with Hyper-V, delivers enhanced virtualization manageability through System Center, lowers database TCO, and provides a single point of contact for the service and support of the full Microsoft “stack.” But don’t take my word for it – check out these examples that are being highlighted at MMS this week:
- Target Corporation, (video and case study), a “Mega” customer from the Hyper-V Cloud Accelerate program, and their broad, 15,000+ VM deployment of Hyper-V and System Center to virtualize and manage key business critical workloads including SQL Server.
- 3rd party “break the box” performance testing results from Enterprise Strategy Group (ESG), which includes deep technical guidance resources, and published best practice guidance for SQL Server, SharePoint, and Exchange.
- Download the Stocktrader application that was shown in today’s MMS keynote demonstrating how high-scale applications can be optimized in private cloud environments. The demo can be found at https://azurestocktrader.cloudapp.net and all related source code can be downloaded at http://msdn.microsoft.com/stocktrader.
We are working with customers every day to provide guidance on what workloads to virtualize on SQL Server and Hyper-V. For more information, please download our recently published whitepaper, Hyper-V is the Best Solution for SQL Server. For additional information, please visit our Consolidation and Virtualization Page.
Go virtualize your database!
<Return to section navigation list>
Cloud Security and Governance
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
• My (@rogerjenn) Windows Azure and OData Sessions at MIX11 post updated 3/26/2011 lists 15 sessions for a search on Azure and 4 (2 duplicates) for a search on OData.
MIX11 will be held 4/12 through 4/14/2011 at the Mandalay Bay hotel, Las Vegas, NV. Hope to see you there.
• Nick J. Trough recommended on 3/25/2011 TechDays 2011 - Check out the sessions and build your own agenda to be held 4/26 through 4/28/2011 at Metropolis Antwerpen in Antwerp, Belgium:
Check out the live agenda and find out why you should attend TechDays 2011. Review the sessions and speakers and build your own personalized agenda. Today we already have more than 1200 registrations. Don’t lose time and register now before the event sells out!

If you haven't decided yet, we give you more than just a few reasons
why you should not miss this event.Developer Opening Keynote
We are happy to announce Scott Hanselman will be joining TechDays 2011 for the developer Opening Keynote this year.
The Main Conference
During the main conference on April 26th and 27th, six Developer and IT-Pro tracks bring you a mix of new technology and in-depth content on current technology with over 60 technical sessions planned.With the full agenda now published, you can filter sessions and build your personalized agenda for the event.
Deep Dives (post-conference)
On the third day of TechDays, on April 28th, we host a Deep Dive day with four different tracks for developers and IT-Professionals. As a developer you can choose between two tracks that go in-depth and focus on Best Practices : Visual Studio Application Lifecycle Management and Cloud (Windows Azure).
As an IT Professional you have the following two options : Virtual Desktop Infrastructure (by Corey Hynes) or Direct Access (by John Craddock).
Next to learning there is also the networking aspect of this conference. We give you the opportunity to connect with Product Managers from Redmond, meet your peers, talk to our user groups and much more.
Don't wait to register before it's too late!PS. You can also follow the TechDays on Twitter and/or Facebook.


<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Srinivasan Sundara Rajan described “Interoperability Patterns Between Windows Azure And VMware VFabric” in his Java EE and .NET Interoperability on the Cloud post of 3/25/2011:
Coexistence on Cloud
My recent article on Java EE and .NET PaaS for enterprises would have triggered the important ‘interoperability concerns' - if an enterprise continues to operate on two major platforms such as .NET and Java EE, how will the migration to Cloud ease their interoperability issues. Here are few options that are readily available.
For the sake of interoperability case studies:
.NET Cloud Platform: Microsoft Azure PaaS platform running on underlying Azure IaaS platform
Java EE Cloud Platform: VMware VFabric PaaS platform running on unspecified IaaS platform
The following are the various Interoperability Patterns that are possible and can be extended more.

Synchronous Interoperability Pattern
This involves direct calls from respective applications and the application will block till the response is retrieved. It's only suitable for very specific real-time applications where the response time is critical.

Back-End Interoperability Pattern As almost all the systems are driven by the data stored in their back end enterprise information tiers (EIS), this pattern involves direct connection to the respective back end data stores of the cloud platform and perform data transfers.
This pattern has the advantage of moving large amounts of data with minimal latency , also this pattern handles issues like Change data management. If properly implemented tight coupling can also be avoided in this pattern. However most of the back end interoperability APIs are proprietary than based on open standards.

Middleware Interoperability (Integration) Pattern
With the emergence ESB (Enterprise Service Bus), Orchestration Tools like Oracle BPEL Designer, Biztalk Integration , the role of middleware tools and frameworks play a larger role in enterprise application interoperability and play a role in Cloud interoperability too.From a classic definition of grammar, this pattern is more of an Integration pattern than an Interoperability pattern. However, this solves the needs of the enterprises in terms of connecting Java EE and .NET applications on the Cloud and hence this is mentioned here too.
My earlier articles on Cloud Integration Tools and Cloud Data Integration will go into details about the supporting tools and platforms for this pattern.
Summary
Tight budgets and go-to-market concerns and zero down time for critical applications prevent many enterprises from totally revamping their existing system and move on to the new frameworks. So even though we see that there are newer platforms for cloud, we require coexistence between multiple disparate systems. Java EE and .NET will continue to be dominant industry platforms as they existed in the last decade.However, interoperability between the applications can only be meaningful if the respective cloud platforms provide authentication, single sign on and other mechanisms. While platforms like Windows Azure provide them comprehensively, we need to analyze them from a interoperability point of view.
Srinivasan works at Hewlett Packard as a Solution Architect.
<Return to section navigation list>

















{kind=link}
0 comments:
Post a Comment