Windows Azure and Cloud Computing Posts for 3/15/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Updated 3/15/2011, 4:00 PM PDT with new articles by the Windows Azure Team, Beth Massi, Mary Jo Foley and Jeffrey Schwartz marked •.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4
- Windows Azure Infrastructur and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
Ike Ellis and Scott Read compared Microsoft SQL Azure vs. Amazon RDS in a 3/2011 article for DevelopMentor with my comments added in square brackets:
Microsoft SQL Azure and Amazon RDS are marketed remarkably similarly. Both companies claim that their cloud database product makes it easy to migrate from on-premise servers to their database-as-a-service cloud offerings; simply migrate your schema and data to the cloud, then change a connection string in your application, and it works. They also emphasize that the same management tools used with an on-premise database can be used in the cloud. The emphasis on these similarities seems to imply that the main competition facing the two companies is on-premise offerings, rather than each other. An examination of both products shows that it is very difficult to directly compare them because the two vendors have taken an entirely different approach to architecture. The key difference arises from the fact that Amazon dedicates hardware resources to the user, while Microsoft shares resources among users. Perhaps the most significant result of this difference is the consequent disparity in pricing. However there are also other differences that may influence the decision of a consumer, and these are examined below.
PRICING
WINNER: SQL Azure
Due to architectural differences, the two companies have setup their own way of charging for their offerings. SQL Azure only charges by the amount of data stored (database size). There is no cost for dedicated CPU compute time or for memory used. In contrast, the Amazon offering charges for CPU time, regardless of the size of the database. SQL Azure can be priced between $10 - $500/month, while RDS can cost between $84 - $2100/month. As the chart shows below, SQL Azure can cost significantly less than RDS, but it depends on the particular situation. By zooming in on the graph, you can see that RDS will actually cost less when dealing with a small CPU and memory allocation and having more than 10GB of data. This pricing difference is significant enough that many organizations will make the choice solely on price.
[RJ comment: The graph is missing.]
BACKUP/RESTORE
WINNER: RDS
Have you ever gotten this phone call? “Uh, I accidentally deleted all the customers in the customer table… in production.” That’s when point in time restore will save your life. Well, maybe not your life, but it will definitely save your job. This category was an easy one to call because RDS offers backup/restore, while SQL Azure does not. RDS’s backup strategy allows for eight days of backups. It will also backup the logs and restore those logs to a point in time. The SQL Azure solution must be configured manually using existing on-premise tools which causes additional bandwidth charges. This is a significant drawback to SQL Azure which may prevent companies from migrating to this product.
[RJ comment: SQL Azure maintains an original and two replicas of the data in the same data center and automatically restores the data in the event of a failure.]
SCALING
WINNER: RDS
When scaling a database you have two choices, “scaling up” or “scaling out.” “Scaling up” is adding more CPUs or memory to one box, allowing it to process requests faster. “Scaling out” is partitioning the database into smaller chunks to put it on more servers which also increases the I/O throughput. Because RDS runs on dedicated hardware, it allows you to scale-up by choosing how much processing power and memory your instance uses. Although that is expensive, it is available. SQL Azure doesn’t offer the option of scaling up. Neither product offers an in-the-box scale out solution, but third-party software is available for both.
[RJ comment: SQL Azure scales up with added resources as you increase database size. SQL Azure will enable scaling out to multiple databases when SQL Azure Federation arrives later in 2011. See my Build Big-Data Apps in SQL Azure with Federation article in the March 2011 issue of Visual Studio Magazine.]
DATABASE SIZE
WINNER: RDS
RDS allows you to have up to a 1TB database size, while SQL Azure has a maximum capacity of 50GB. This will prohibit some companies from moving to SQL Azure.
[RJ comment: SQL Azure Federation will enable scaling out by automatic sharding later in 2011.]
PERFORMANCE
WINNER: RDS
We ran our own rudimentary performance tests from San Diego. We ran INSERTs and SELECTs against both products. RDS was significantly faster on INSERT performance, while SQL Azure was slightly faster on SELECT performance. Since Amazon’s datacenter is in Northern California, while Microsoft’s datacenter is in San Antonio, our location may account for some of the performance difference. It might also be because RDS runs on dedicated hardware, while Microsoft is a shared service. We were running RDS on the smallest allotment of CPU and memory, so had we been willing to pay more, RDS could be even faster. Again, that option isn’t available on SQL Azure.
[RJ comment: Given the choice between SELECT and INSERT performance, I’ll almost always choose SELECT because data returning queries usually are much more prevalent than INSERT operations.]
FEATURE SET
WINNER: RDS
RDS runs as an instance of a full-blown MySQL installation. As a result, RDS has every MySQL feature there is. RDS users can also choose a specific MySQL version to deploy. SQL Azure has a subset of the features that ship with SQL Server 2008. While SQL Server 2008 is arguably more full-featured than MySQL; feature for feature SQL Azure is might come out ahead, users who are used to particular features from SQL Server 2008 may find that they are not available in SQL Azure. For example, SQL Azure does not support XML indexes, CLR objects, or SQL Server Profiler.
[RJ comment: SQL Azure still beats MySQL in features, disregarding the lack of XML indexes, CLR objects or SQL Server Profiler; MySQL doesn’t offer these features.]
TOOLING
WINNER: SQL Azure
As previously stated, both vendors enable the user to use tools that they are already comfortable with. SQL Azure can be managed using SQL Server Management Studio 2008 R2. We were also able to connect using SQLCMD, Visual Studio 2010, and BCP. We used MySQL Workbench 5.2 to manage RDS, but all of the existing MySQL tools are available. All the tools for both products worked seamlessly and without incident. Because the cloud allows users to experiment with different technologies and platforms without the burden of management, installation, and licensing, we felt that a cloud database should provide some management software as a service (SaaS). This would allow novices to get comfortable with a new environment. Microsoft addresses this with a Silverlight database tool called Database Manager (formally Project Houston). Using this simple and small-featured tool, anyone can get started creating tables, adding data, and creating stored procedures without installing local software. We ran it using Internet Explorer on Windows 7 and using Chrome on Mac OSX. While the fact that it even exists is superior to RDS, Microsoft’s tooling could be improved. For example, SQL Server Management Studio doesn’t have any designers when creating objects while connected to SQL Azure, whereas Workbench does when connected to RDS.
DISASTER RECOVERY
WINNER: SQL Azure
RDS allows you to create a standby replica of your database, but this is not done automatically. SQL Azure automatically creates standby servers when you create a new database. RDS’s standby replicas can be in a different data center in the same geographic region (called a multiple availability zone deployment), unlike SQL Azure. In SQL Azure, there is no additional cost for standby replicas, while RDS replicas can double or even triple the cost.
FUTURE ROADMAP
WINNER: SQL Azure
The future of SQL Azure assures an even stronger cloud database offering. Well-published roadmaps promise new features including SQL Azure Reporting Services, SQL Azure Data Sync Services, and SQL Azure OData support. With a little digging we found that Microsoft is addressing their woeful backup shortcomings and their limited maximum database size. In videos from PDC and TechEd Berlin, we found references to SQL Server Analysis Services in the cloud, SQL Server Integration Services in the cloud, and dedicated compute and memory SLAs. Meanwhile, Amazon has said that in Q2-2011, they will offer RDS using Oracle 11g as well as MySQL. While that is compelling, we expect this to raise their prices even higher due to the licensing costs. We weren’t able to find any other details on their future plans.
[RJ comment: “SQL Azure Reporting Services, SQL Azure Data Sync Services, and SQL Azure OData support” were available as Community Technical Previews (CTPs) in March 2011 when this comparison published.]
CONCLUSION
There are two major differences between the Microsoft SQL Azure and Amazon RDS platforms: pricing and capabilities. If price is no object and the user wants full features and high performance, then RDS is the obvious choice. If the user is more cost-conscious, SQL Azure has enough features and is good enough for many use-cases. The two exceptions are if a user has a database larger than 50GB, or needs a mature backup system. These are not possible with SQL Azure. That said, in most instances, Microsoft developers will favor SQL Azure because of their comfort level with the T-SQL syntax and the Microsoft tooling. Ruby and Java developers who have written MySQL applications will be inclined to choose RDS. With that in mind, perhaps these products aren’t competing with one another after all.
[RJ comments: I have never found that “price is no object” in a commercial programming environment.]
Shaun Xu announced SQL Azure Reporting Limited CTP Arrived in a 2/16/2011 post (missed when published):
It’s about 3 months later when I registered the SQL Azure Reporting CTP on the Microsoft Connect after TechED 2010 China. Today when I checked my mailbox I found that the SQL Azure team had just accepted my request and sent the activation code over to me. So let’s have a look on the new SQL Azure Reporting.
Concept
The SQL Azure Reporting provides cloud-based reporting as a service, built on SQL Server Reporting Services and SQL Azure technologies. Cloud-based reporting solutions such as SQL Azure Reporting provide many benefits, including rapid provisioning, cost-effective scalability, high availability, and reduced management overhead for report servers; and secure access, viewing, and management of reports. By using the SQL Azure Reporting service, we can do:
- Embed the Visual Studio Report Viewer ADO.NET Ajax control or Windows Form control to view the reports deployed on SQL Azure Reporting Service in our web or desktop application.
- Leverage the SQL Azure Reporting SOAP API to manage and retrieve the report content from any kinds of application.
- Use the SQL Azure Reporting Service Portal to navigate and view the reports deployed on the cloud.
Since the SQL Azure Reporting was built based on the SQL Server 2008 R2 Reporting Service, we can use any tools we are familiar with, such as the SQL Server Integration Studio, Visual Studio Report Viewer. The SQL Azure Reporting Service runs as a remote SQL Server Reporting Service just on the cloud rather than on a server besides us.
Establish a New SQL Azure Reporting
Let’s move to the Windows Azure Deveploer Portal and click the Reporting item from the left side navigation bar. If you don’t have the activation code you can click the Sign Up button to send a requirement to the Microsoft Connect. Since I already recieved the received code mail I clicked the Provision button.
Then after agree the terms of the service I will select the subscription for where my SQL Azure Reporting CTP should be provisioned. In this case I selected my free Windows Azure Pass subscription.
Then the final step, paste the activation code and enter the password of our SQL Azure Reporting Service. The user name of the SQL Azure Reporting will be generated by SQL Azure automatically.
After a while the new SQL Azure Reporting Server will be shown on our developer portal. The Reporting Service URL and the user name will be shown as well. We can reset the password from the toolbar button.
Deploy Report to SQL Azure Reporting
If you are familiar with SQL Server Reporting Service you will find this part will be very similar with what you know and what you did before. Firstly we open the SQL Server Business Intelligence Development Studio and create a new Report Server Project.
Then we will create a shared data source where the report data will be retrieved from. This data source can be SQL Azure but we can use local SQL Server or other database if it opens the port up. In this case we use a SQL Azure database located in the same data center of our reporting service. In the Credentials tab page we entered the user name and password to this SQL Azure database.
The SQL Azure Reporting CTP only available at the North US Data Center now so that the related SQL Server and hosted service might be better to select the same data center to avoid the external data transfer fee.
Then we create a very simple report, just retrieve all records from a table named Members and have a table in the report to list them. In the data source selection step we choose the shared data source we created before, then enter the T-SQL to select all records from the Member table, then put all fields into the table columns. The report will be like this as following
In order to deploy the report onto the SQL Azure Reporting Service we need to update the project property. Right click the project node from the solution explorer and select the property item. In the Target Server URL item we will specify the reporting server URL of our SQL Azure Reporting. We can go back to the developer portal and select the reporting node from the left side, then copy the Web Service URL and paste here. But notice that we need to append “/reportserver” after pasted.
Then just click the Deploy menu item in the context menu of the project, the Visual Studio will compile the report and then upload to the reporting service accordingly. In this step we will be prompted to input the user name and password of our SQL Azure Reporting Service. We can get the user name from the developer portal, just next to the Web Service URL in the SQL Azure Reporting page. And the password is the one we specified when created the reporting service. After about one minute the report will be deployed succeed.
View the Report in Browser
SQL Azure Reporting allows us to view the reports which deployed on the cloud from a standard browser. We copied the Web Service URL from the reporting service main page and appended “/reportserver” in HTTPS protocol then we will have the SQL Azure Reporting Service login page.
After entered the user name and password of the SQL Azure Reporting Service we can see the directories and reports listed. Click the report will launch the Report Viewer to render the report.
View Report in a Web Role with the Report Viewer
The ASP.NET and Windows Form Report Viewer works well with the SQL Azure Reporting Service as well. We can create a ASP.NET Web Role and added the Report Viewer control in the default page. What we need to change to the report viewer are
- Change the Processing Mode to Remote.
- Specify the Report Server URL under the Server Remote category to the URL of the SQL Azure Reporting Web Service URL with “/reportserver” appended.
- Specify the Report Path to the report which we want to display. The report name should NOT include the extension name. For example my report was in the SqlAzureReportingTest project and named MemberList.rdl then the report path should be /SqlAzureReportingTest/MemberList.
And the next one is to specify the SQL Azure Reporting Credentials. We can use the following class to wrap the report server credential.
1: private class ReportServerCredentials : IReportServerCredentials2: {3: private string _userName;4: private string _password;5: private string _domain;6:7: public ReportServerCredentials(string userName, string password, string domain)8: {9: _userName = userName;10: _password = password;11: _domain = domain;12: }13:14: public WindowsIdentity ImpersonationUser15: {16: get17: {18: return null;19: }20: }21:22: public ICredentials NetworkCredentials23: {24: get25: {26: return null;27: }28: }29:30: public bool GetFormsCredentials(out Cookie authCookie, out string user, out string password, out string authority)31: {32: authCookie = null;33: user = _userName;34: password = _password;35: authority = _domain;36: return true;37: }38: }And then in the Page_Load method, pass it to the report viewer.
1: protected void Page_Load(object sender, EventArgs e)2: {3: ReportViewer1.ServerReport.ReportServerCredentials = new ReportServerCredentials(4: "<user name>",5: "<password>",6: "<sql azure reporting web service url>");7: }Finally deploy it to Windows Azure and enjoy the report.
Summary
In this post I introduced the SQL Azure Reporting CTP which had just available. Likes other features in Windows Azure, the SQL Azure Reporting is very similar with the SQL Server Reporting. As you can see in this post we can use the existing and familiar tools to build and deploy the reports and display them on a website. But the SQL Azure Reporting is just in the CTP stage which means
- It is free.
- There’s no support for it.
- Only available at the North US Data Center [I believe it’s only available at the South Central US data center].
You can get more information about the SQL Azure Reporting CTP from the links following:
You can download the solutions and the projects used in this post here.











I’m still waiting for Shaun’s promised descriptive material about his Partition-Oriented Data Access project, which he described in his Happy Chinese New Year! post of 1/31/2011:
If you have heard about the new feature for SQL Azure named SQL Azure Federation, you might know that it’s a cool feature and solution about database sharding. But for now there seems no similar solution for normal SQL Server and local database. I had created a library named PODA, which stands for Partition Oriented Data Access which partially implemented the features of SQL Azure Federation. I’m going to explain more about this project after the Chinese New Year but you can download the source code here.
<Return to section navigation list>
MarketPlace DataMarket and OData
Richard Prodger described Travel Advisor – A Windows Azure DataMarket and Windows Phone 7 integration exercise on 3/10/2011 (missed when posted):
Over the last couple of months, I been leading a small project looking at extending the reach of the cloud to handheld devices. To test this out, we’ve built a Windows Phone 7 application that consumes data feeds from Windows Azure DataMarket, Bing, twitter and others. The app, known as “Travel Advisor”, went live on the Windows Phone 7 MarketPlace today.
What is it?
The application is ideal for people travelling abroad, perfect for the adventurous or regular traveller, the app provides up to the minute travel advice and warnings on every country listed by the UK Foreign and Commonwealth office. Travel Advisor provides embassy contact information, entry requirements, local customs information, local health advice, vaccination recommendations and much more. In addition the app provides language translation services, currency conversion and local weather forecasts. Live integration with the forums of GapYear.com provides access to a community of extreme travellers and the location aware Twitter integration allows you to keep your social network up to date with your adventures.
How does it work?
The UK Foreign and Commentwealth Office publishes travel advisory data as RSS feeds from their web site. We’ve created a Windows Azure worker role hosted application that monitors the RSS feeds and updates a SQL Azure database with the latest advice. The Windows Azure DataMarket then provides a discoverable interface for consuming this data in OData format. Our Windows Phone 7 application connects to the DataMarket and retrieves the data on demand. To augment the travel advice, the phone app also consumes weather data hosted on the DataMarket by Weather Central. In addition to the the DataMarket data, the phone app makes use of Bing services for language translation and currency conversion. With twitter integration, you can use the app to tweet a location message to your feed. The app makes use of the built in GPS to automatically select the appropriate country when you are outside the UK.
Watch a video demo here.
If you have a Windows Phone 7, please download the app from the MarketPlace and let us know what you think. It’s free!

Jon Galloway and Jesse Liberty produced a 00:39:39 Full-Stack Video Webcast: Windows Phone Development with TDD and MVVM segment:
In this episode of The Full Stack, Jesse and Jon reboot their windows phone client project using Test Driven Development (TDD) and the Model View ViewModel (MVVM) pattern.
Previous episodes focused on getting different technologies such as Windows Phone, WCF, and OData, connected. With a better understanding of the technology and some working code, we decided it's time to restructure the project using some sustainable practices and patterns.
Watch the video segment here.
<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
Vittorio Bertocci (@vibronet) continued his Fabrikam series with Fun with FabrikamShipping SaaS II: Creating an Enterprise Edition Instance on 3/14/2011:
I finally found (read: made) the time to get back to the “Fun with FabrikamShipping SaaS” series. As in the first installment (where I provided a “script” for going through the creation and use of a small business edition instance) here I will walk you through the onboarding and use of a new Enterprise instance of FabrikamShipping SaaS without going in the implementation details. Later posts (I hate myself when I commit like this) will build on those walkthroughs for explaining how we implemented certain features. I would suggest you skim through the Small Business walkthrough before jumping to this one, as there are few things that I covered at length there and I won’t repeat here.
Demoing the Enterprise edition is a bit more demanding than the Small Business edition, mostly because in the enterprise case we require the customer to have a business identity provider available. Also, every new subscription requires us to spin a new dedicated hosted service, hence we approve very few new ones in the live instance of the demo. The good news is that we provide you with helpers which allow you to experience the demo end to end without paying the complexity costs that the aforementioned two points entail: the enterprise companion and a pre-provisioned enterprise subscription. In this walkthrough I will not make use of any special administrative powers, but I will instead use those two assets exactly in the way in which you would. And without further ado…
Subscribing to an Enterprise Edition instance of FabrikamShipping
Today we’ll walk a mile in the shoes of Joe. Joe handles logistic for AdventureWorks, a mid-size enterprise which crafts customized items on-demand. AdventureWorks invested in Active Directory and keeps its users neatly organized in organizational and functional groups.
AdventureWorks needs to streamline its shipment practices, but does not want to develop an in-house solution; Joe is shopping for a SaaS application which can integrate with AdventureWorks infrastructure and processes, and lands on FabrikamShipping SaaS. The main things about FabrikamShipping which capture Joe’s interest are:
- The promise of easy Single Sign On for all AdventureWorks’ employees to the new instance
- The exclusive use of resources: enterprise instances of FabrikamShipping are guaranteed to run on dedicated compute and DB resources that are not shared with any other enterprise customer, with all the advantages which come with it (complete isolation, chance to fine-tune the amount of instances on which the service runs according to demand, heavy customizations are possible, and so on)
- The possibility to reflect in the application’s access rights the existing hierarchy and attributes defined in AdventureWorks’ AD
- The existence of REST-based programmatic endpoints which would allow the integration of shipment and management capabilities in existing tools and processes
And all this in full SaaS tradition: a new customized instance of FabrikamShipping can be provisioned simply by walking through an online wizard, and after that all that is required for accessing the application is a browser.
The feature set of the Enterprise edition fits the bill nicely, hence Joe goes ahead and subscribes at https://fabrikamshipping.cloudapp.net/. The first few steps are the same ones we saw for the small biz edition.
(here I am using Live ID again, but of course you can use google or facebook just as well. Remember the note about subscriptions being unique per admin subscriber)
Once signed in, you land on the first page of the subscription wizard.
Compared to the corresponding screen in the subscription wizard for the Small Biz edition, you’ll notice two main differences:
- The “3. Users” tab is not present. In tis place there are two tabs, “3. Single Sign On” and “4. Access Policies”. We’ll see the content of both in details, here I’d just like to point out that our general purpose visualization engine is the same and here it is simply reflecting the different kind of info we need to gather for creating an enterprise-type instance.
- There’s a lot more text: that’s for explaining some behind-the-scenes of the demo and setting expectations. I’ll pick up some of those points in this walkthrough
Who reads all that text anyway? Let’s just hit Next.
The Company Data step is precisely the same as the one in the Small Biz edition, all the same considerations apply; to get to something interesting we have to hit Next one more time.
Now things start getting interesting. Rather than paraphrasing, let me paste here what I wrote in the UI:
One of the best advantages of the Enterprise Edition of FabrikamShipping is that it allows your employees to access the application with their corporate credentials: depending on your local setups, they may even be able to gain access to FabrikamShipping without even getting prompted, just like they would access an intranet portal.
The subscription wizard can automatically configure FabrikamShipping to recognize users from your organization, but for doing so it requires a file which describes your network setup. If your company uses Active Directory Federation Services 2.0 (ADFS 2.0) that file is named FederationMetadata.xml: please ask your network administrator to provide it to you and upload it here using the controls below.
If you are not sure about the authentication software used in your organization, please contact your network administrator before going further in the subscription wizard and ask if your infrastructure supports federation or if a different subscription level may better suit your needs.Modern federation tools such as ADFS2.0 can generate formal descriptions of themselves: information such as which addresses should be used, which certificate should be used to verify signatures and which claims you are willing to disclose about your users can be nicely packaged in a well-known format, in this case WS-Federation metadata. Such descriptions can be automatically consumed by tools and APIs, so that trust relationships can be established automatically without exposing administrators to any of the underlying complexity. As a result, you can set up single sign on between your soon-to-be new instance of FabrikamShipping and your home directory just by uploading a file.
What happens here is that the subscription wizard does some basic validation on the uploaded metadata - for example it verifies that you are not uploading metadata which are already used for another subscriber - then it saves it along with all the other subscription info. At provisioning time, at the end of the wizard, the provisioning engine will use the federation metadata to call some ACS APIs for setting up AdventureWorks as an Identity Provider.
That’s a very crisp demonstration of the PaaS nature of the Windows Azure platform: I don’t have to manage a machine with a federation product on top of it in order to configure SSO, I can just call an API to configure the trust settings and the platform will take care of everything else. That’s pure trust on tap, and who cares about the pipes.
Note 1: You don’t have an ADFS2.0 instance handy? We’ve got you covered! Jump to the last section of the post to learn how to use SelfSTS as a surrogate for this demo.
Note 2: If you use ADFS2.0 here, you’ll need to configure the new instance as a valid relying party. Once your instance will be ready, you’ll get all the necessary information via email.
Also: the claims that FabrikamShipping needs are email, given name, surname name, other phone and group. You can use any claim type as long as they contain the same information, however if you use the schemas.xmlsoap.org URIs things will be much easier (FabrikamShipping will automatically create mappings: see the next screen).Let’s say that Joe successfully uploaded the metadata file and can now hit Next.
The Access Policies screen is, in my opinion, the most interesting of the entire wizard. Here you decide who in your org can do what in your new instance.
FabrikamShipping instances recognize three application roles:
- Shipping Creators, who can create (but not modify) shipments
- Shipping Managers, who can create AND modify shipments
- Administrators, who can can do all that the Shipping Managers can do and in addition (in a future version of the demo) will have access to some management UI
Those roles are very application-specific, and asking the AdventureWorks administrators to add them in their AD would be needlessly burdening them (note that they can still do it if they choose to). Luckily, they don’t have to: In this screen Joe can determine which individuals in the existing organization will be awarded which application role.
FabrikamShipping is, of course, using claims-based identity under the hood, but the word “claim” never occur on the page. Note how the UI is presenting to the user very easy and intuitive choices: for every role there’s the option to assign it to all users or none, there’s no mention of claims or attributes. If Joe so chooses, he can pick the Advanced option and have access to a further level of sophistication: in that case, the UI offers the possibility of defining more fine-grained rules which assign the application roles only when certain claims with certain values are present. Note that the claim types list has been obtained directly from AdventureWork’s metadata.
Once again, you can see PaaS in action. All the settings Joe is entering here will end up being codified as ACS rules at provisioning time, via management API.
The lower area on the screen queries Joe about how to map the claims coming from AdventureWorks in the user attributes that FabrikamShipping needs to know in order to perform its function (for example, for filling the sender info for shipments). One of the advantages of claims based identity is that often there is no need to pre-provision users, as the necessary user info can be obtained just in time directly at runtime together with the authentication token. In this case AdventureWorks claims are a perfect match for FabrikamShipping, but it may not always be the case (for example instead of having Surname your ADFS2 may offer Last Name, which contains the same info but it is codified as a different claim type).
Once the settings are all in, hitting Next will bring to the last screen of the wizard.
This is again analogous to the last screen in the subscription wizard for Small Biz, in also in this case I am going to defer the explanation for the Windows Azure-PayPal integration to a future post.
Let’s click on the link for monitoring the provisioning status.
Now that’s a surprise! Whereas the workflow for the Small Biz provisioning was just 3 steps long, here the steps are exactly twice that number. But more importantly, some of the steps here are significantly more onerous. You can refer to the session I did at TechEd Europe about details on the provisioning, or to a future post (I feel for my future self, I am really stacking up A LOT of those
) but let me just mention here that one Enterprise Edition instance requires the manual creation of a new hosted service, the dynamic creation of a new Windows Azure package and deployment, the startup of a new web role and so on. That’s all stuff which require resources and some time, which is why we accept very few new Enterprise subscriptions. However! Walking through the provisioning wizard is useful per se, for getting a feeling of how onboarding for an enterprise type SaaS application may look like and for better understanding the source code.
If instead you are interested to play with the end result, we got you covered as well! You can access a pre-provisioned Enterprise instance of FabrikamShipping, named (surprise surprise) AdventureWorks. All the nécessaire for accessing that instance is provided in the FabrikamShipping SaaS companion\, which I’ll cover in the next section.
For the purpose of this walkthrough, however, let’s assume that the subscription above gets accepted and processed. After some time, Joe will receive an email containing the text below:
Your instance of FabrikamShipping Enterprise Edition is ready!
The application is available at the address https://fs-adventureworks1.cloudapp.net/. Below you can find some instructions that will help you to get started with your instance.
You can manage your subscription by visiting the FabrikamShipping management console <https://fabrikamshipping.cloudapp.net/SubscriptionConsole/Management/Index>
. Please make sure to use the same account you used when you created the subscription.
Single Sign On
If you signed up using SelfSTS, make sure that the SelfSTS endpoint is active when you access the application. SelfSTS should use the same signing certificate that was active at subscription time. If you configured your tenant using the companion package <http://code.msdn.microsoft.com/fshipsaascompanion> , the SelfSTS should already be configured for you.
If you indicated your ADFS2.0 instance (or equivalent product) at sign-up time, you need to establish Relying Party Trust with your new instance before using it. You can find the federation metadata of the application at the address https://fabrikamshipping.accesscontrol.appfabriclabs.com/FederationMetadata/2007-06/FederationMetadata.xml
Expiration
Your instance will be de-provisioned within 2 days. Once the application is removed we will notify you.
_____
If you want a demonstration of how to use FabrikamShipping, please refer to the documentation at www.fabrikamshipping.com <http://www.fabrikamshipping.com/> . If you want to take a peek at what happens behind the scenes, you can download the FabrikamShipping Source Package <http://code.msdn.microsoft.com/fshipsaassource> which features the source code of the entire demo.
For any question or feedback, please feel free to contact us at fshipsupport@microsoft.com.
Thank you for your interest in the Windows Azure platform, and have fun with FabrikamShipping!
Sincerely,
the Windows Azure Platform Evangelism Team
Microsoft C 2010
The first part of the mail communicates the address at which the new instance is now active. Note the difference between the naming schema we used for Small Business, https://fabrikanshipping-smallbiz.cloudapp.net/<subscribercompany>, and the one we use here, .cloudapp.net">https://fs-<subscribercompany>.cloudapp.net. The first schema betrays its (probably) multitenant architecture, whereas here it’s pretty clear that every enterprise has its own exclusive service. Among the many differences between the two approaches, there is the fact that in the small biz case you use a single SSL certificate for all tenants, whereas here you need to change it for everyone (no wildcards). As you can’t normally obtain a <something>.cloudapp.net certificate, we decided to just use self-signed certs and have the red bar show so that you are aware of what’s going on in there. In a real life app FabrikamShipping would likely offer a “vanity URL” service instead of the naming schema used here, which would eliminate the certificate problem here. Anyway, long story short: later you’ll see a red bar in the browser, and that’s by design.
The Single Sign On section gives indications on how to set up the Relying Party Trust toward FabrikamShipping on your ADFS; of course what you are really doing is pointing to the ACS namespace that FabrikamShipping is leveraging. Once you’ve done that, Joe just needs to follow the link at the beginning of the mail to witness the miracle of federation & SSO unfold in front of his very eyes.
Accessing the AdventureWorks Instance with the Enterprise Companion
When we deployed the live instance of FabrikamShipping, we really thought hard how to make it easy for you guys to play with the demo. For the Small Biz it was easy, all you need is a browser, but the Enterprise posed challenges. Just how many developers have access to one ADFS2 instance to play with? And if they do, just how long they’ll have to wait between their subscription wizard run and when we have time to provision their subscription?
In order to ease things for you, we attached the problem on two fronts:
- We created a self contained WS-Federation STS surrogate, which does not require installation, supports federation metadata generation, uses certificates form the file system and has some limited claim editing capabilities. That’s the (now) well known SelfSTS.
- We used one pre-defined SelfSTS instance to provision one Enterprise edition instance, which we named (surprise!) AdventureWorks, then we made that pre-configured SelfSTS available for download so that everybody can run it on their local machine, pretend that it is the AdventureWorks’s ADFS2 and use it to access the aforementioned pre-provisioned FabrikamShipping SaaS instance.
All that stuff (and more) ended up in the package we call the Enterprise Companion, which (just like the source code package) can be downloaded from code gallery.
Once you download and install the companion, check out the StartHere.htm page: it contains the basic instructions for playing with the AdventureWorks instance (and more, which I will cover in the next “Fun with..” installment).
In fact, all you need to do is to launch the right SelfSTS and navigate to the instance’s address. Let’s do that!
Assuming that you unpacked the companion in the default location, you’ll find the SelfSTS in C:\FabrikamShippingSaaS_Companion\assets\OAuthSample\AdventureWorks.SelfSTS\SelfSTS.exe. The name already gives away the topic of the next “Fun with” post. If you launch it and you click on Edit Claim Types and Values you’ll see which claims are being sent. You can change the values, but remember that the AdventureWorks instance has been set with this set of claim types: if you change the types, you won’t be able to access the instance.
Close the Edit Claims window, and hit the green button Start; the button will turn red, and SelfSTS will begin listening for requests. At this point you just need to navigate to https://fs-adventureworks1.cloudapp.net/ and that’s it! If you want to verify that the federation exchange is actually taking place, you can use your standard inspection tools (Fiddler, HttpWatch, IE9 dev tools) to double check; below I am using HttpWatch. Remember what I said above about the browser’s red bar being by design here.
…and that’s pretty much it! Taken out of context this is just a web site federating with a WS-Federation IP thru ACS, but if you consider that this instance has been entirely generated from scratch starting from the company info provided during the subscription wizard, just leveraging the management APIs of Windows Azure, SQL Azure and ACS, and that the same machinery can be used again and again and again for producing any custom instance you want, that’s pretty damn impressive. Ah, and of course the only things that are running on premise here are the STS and the user’s browser; everything else is in the cloud.
You don’t have ADFS2.0 but you want to sign-up for a new Enterprise Instance?
In the part of the walkthrough covering the subscription wizard I assumed that you have an ADFS2 instance handy from where you could get the required FederationMetadata.xml document, but as I mentioned in the last section we know that it is not always the case for developers. In order to help you to sign up for a new instance even if you don’t have ADFS2 (remember the warnings about us accepting very few new instances), in addition to the AdventureWorks SelfSTS we packed in the Enterprise companion a SECOND SelfSTS instance, that you can modify to your heart’s content and use as a base for creating a new subscription. The reason for which we have two SelfSTSes is that no two subscription can refer to the same IP metadata (for security reasons), hence if you want to create a new subscription you cannot reuse the metadata that come in the SelfSTS described in the last section as those are already tied to the preprovisioned AdventureWorks instance. At the same time, we don’t want to force you to modify that instance of SelfSTS as it would make impossible to you to get to AdventureWorks again (unless you re-download the companion).
The second SelfSTS, which you can find in C:\FabrikamShippingSaaS_Companion\assets\SelfSTS\SelfSTS\bin\Release, out of the box is a copy of the AdventureWorks one. There was no point making it different, because you have to modify it anyway (remember, you are sharing the sample with everybody else who downloaded the companion hence you all need to have different metadata if you want to create new subscriptions). Creating different metadata is pretty simple, in fact all you need to do is to generate a new certificate (the introductory post about SelfSTS explains how) and you’re done.
The last thing you need to do before being ready to use that copy of SelfSTS in the new subscription wizard is to generate the metadata file itself. I often get feature requests about generating the metadata document file from the SelfSTS, but in fact it is very simple tog et one already with today’s UI:
- Click Start on the SelfSTS UI
- Hit the “C” button on the right of the Metadata filed; that will copy on the clipboard the address from which SelfSTS serves the metadata document
- Open notepad, File->Open, paste the metadata address: you’ll get the metadata bits
- Save in a file with .XML extension
Et voila’! Metadata document file a’ la carte, ready to be consumed by the subscription wizard. By the way, did I mention that we provision really few enterprise instances and if you want to experience the demo there’s a preprovisoned instance you can go thru? Ah right, that was 1/2 the post so I did mention that. I’m sorry, it must be the daylight savings
Neext?
Phew, long post is long. This was the second path you can take through FabrikamShipping SaaS to experience how the demo approached the tradeoffs entailed in putting together a SaaS solution. There is a third one, and it’s in fact a sub-path of the Enterprise edition: it shows how an Enterprise instance of FabrikamShipping SaaS offers not only web pages, but also web services which can be used to automate some aspects of the shipping processes. The web services aren’t too interesting per se, what is interesting is how they are secured: using OAuth2 and the autonomous profile for bridging between a business IP and REST services, all going through ACS, of course still being part of the dynamic provisioning that characterized the generation of the instance as a whole. That scenario is going to be the topic of the third and last installment of the “Fun with FabrikamShipping SaaS” series: after those, I’ll start slicing the sample to reach the code and uncover the choices we made, the solutions we found and the code you can reuse for handling the same issues in your own solutions.














<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
• The Windows Azure Team suggested on 3/15 that you Register Now for Webinar This Thursday, March 17, "Windows Azure CDN - New Features":
If you want to learn more about the new and upcoming features of the Windows Azure Content Delivery Network (CDN), don't miss the free Academy Live Webinar this Thursday, March 17 at 8:00 AM PDT, "Windows Azure CDN - New Features." Hosted by Windows Azure CDN program management lead Jason Sherron, this session will include a quick review of the Windows Azure CDN, as well as an overview of new and soon-to-be released features. There will be time for Q&A during and following the presentation.
Click here to learn more about this session and to register.
Shaun Xu described CDN on Hosted Service in Windows Azure in a 3/10/2011 post (missed when posted):
- Move the static content, the images, CSS files, etc. into the blob storage.
- Enable the CDN on his storage account.
- Change the URL of those static files to the CDN URL.
I think these are the very common steps when using CDN. But this morning I found that the new Windows Azure SDK 1.4 and new Windows Azure Developer Portal had just been published announced at the Windows Azure Blog. One of the new features in this release is about the CDN, which means we can enabled the CDN not only for a storage account, but a hosted service as well. Within this new feature the steps I mentioned above would be turned simpler a lot.
Enable CDN for Hosted Service
To enable the CDN for a hosted service we just need to log on the Windows Azure Developer Portal. Under the “Hosted Services, Storage Accounts & CDN” item we will find a new menu on the left hand side said “CDN”, where we can manage the CDN for storage account and hosted service. As we can see the hosted services and storage accounts are all listed in my subscriptions.
To enable a CDN for a hosted service is veru simple, just select a hosted service and click the New Endpoint button on top.
In this dialog we can select the subscription and the storage account, or the hosted service we want the CDN to be enabled. If we selected the hosted service, like I did in the image above, the “Source URL for the CDN endpoint” will be shown automatically. This means the windows azure platform will make all contents under the “/cdn” folder as CDN enabled. But we cannot change the value at the moment.
The following 3 checkboxes next to the URL are:
- Enable CDN: Enable or disable the CDN.
- HTTPS: If we need to use HTTPS connections check it.
- Query String: If we are caching content from a hosted service and we are using query strings to specify the content to be retrieved, check it.
Just click the “Create” button to let the windows azure create the CDN for our hosted service. The CDN would be available within 60 minutes as Microsoft mentioned. My experience is that about 15 minutes the CDN could be used and we can find the CDN URL in the portal as well.
Put the Content in CDN in Hosted Service
Let’s create a simple windows azure project in Visual Studio with a MVC 2 Web Role. When we created the CDN mentioned above the source URL of CDN endpoint would be under the “/cdn” folder. So in the Visual Studio we create a folder under the website named “cdn” and put some static files there. Then all these files would be cached by CDN if we use the CDN endpoint.
The CDN of the hosted service can cache some kind of “dynamic” result with the Query String feature enabled. We create a controller named CdnController and a GetNumber action in it. The routed URL of this controller would be /Cdn/GetNumber which can be CDN-ed as well since the URL said it’s under the “/cdn” folder. In the GetNumber action we just put a number value which specified by parameter into the view model, then the URL could be like /Cdn/GetNumber?number=2.
1: using System;2: using System.Collections.Generic;3: using System.Linq;4: using System.Web;5: using System.Web.Mvc;6:7: namespace MvcWebRole1.Controllers8: {9: public class CdnController : Controller10: {11: //12: // GET: /Cdn/13:14: public ActionResult GetNumber(int number)15: {16: return View(number);17: }18:19: }20: }And we add a view to display the number which is super simple.
1: <%@ Page Title="" Language="C#" MasterPageFile="~/Views/Shared/Site.Master" Inherits="System.Web.Mvc.ViewPage<int>" %>2:3: <asp:Content ID="Content1" ContentPlaceHolderID="TitleContent" runat="server">4: GetNumber5: </asp:Content>6:7: <asp:Content ID="Content2" ContentPlaceHolderID="MainContent" runat="server">8:9: <h2>The number is: <%1: : Model.ToString()%></h2>10:11: </asp:Content>Since this action is under the CdnController the URL would be under the “/cdn” folder which means it can be CDN-ed. And since we checked the “Query String” the content of this dynamic page will be cached by its query string. So if I use the CDN URL, http://az25311.vo.msecnd.net/GetNumber?number=2, the CDN will firstly check if there’s any content cached with the key “GetNumber?number=2”. If yes then the CDN will return the content directly; otherwise it will connect to the hosted service, http://aurora-sys.cloudapp.net/Cdn/GetNumber?number=2, and then send the result back to the browser and cached in CDN.
But to be notice that the query string are treated as string when used by the key of CDN element. This means the URLs below would be cached in 2 elements in CDN:
- http://az25311.vo.msecnd.net/GetNumber?number=2&page=1
- http://az25311.vo.msecnd.net/GetNumber?page=1&number=2
The final step is to upload the project onto azure.
Test the Hosted Service CDN
After published the project on azure, we can use the CDN in the website. The CDN endpoint we had created is az25311.vo.msecnd.net so all files under the “/cdn” folder can be requested with it. Let’s have a try on the sample.htm and c_great_wall.jpg static files.
Also we can request the dynamic page GetNumber with the query string with the CDN endpoint.
And if we refresh this page it will be shown very quickly since the content comes from the CDN without MCV server side process.
The style of this page was missing. This is because the CSS file was not includes in the “/cdn” folder so the page cannot retrieve the CSS file from the CDN URL.
Summary
In this post I introduced the new feature in Windows Azure CDN with the release of Windows Azure SDK 1.4 and new Developer Portal. With the CDN of the Hosted Service we can just put the static resources under a “/cdn” folder so that the CDN can cache them automatically and no need to put then into the blob storage. Also it support caching the dynamic content with the Query String feature. So that we can cache some parts of the web page by using the UserController and CDN. For example we can cache the log on user control in the master page so that the log on part will be loaded super-fast.
There are some other new features within this release you can find here. And for more detailed information about the Windows Azure CDN please have a look here as well.







<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Yasser Abdel Kader announced the March Update for Visual Studio 2010 and .NET Framework 4 Training Course Just Released with Windows Azure features on 3/15/2011:
Microsoft just released the March update for the VS 2010 and .Net 4.0 Training Kit. It includes Videos, Hands-on-Labs for: C# 4.0, Visual Basic 10, F#, ASP.NET 4, parallel computing, WCF, Windows Workflow, WPF, Silverlight and Windows Azure. The kit now contains 50 labs, 22 demos, 16 presentations and 12 videos.
For Silverlight, there are new Hands on Lab for Migrating Windows Forms / ASP.Net Web Forms Applications to Silverlight, Working with Panels, XAML and Controls, Silverlight Data Binding, Migrating Existing Applications to Out-of-Browser, Great UX with Blend, Web Services and Silverlight, Using WCF RIA Services, Deep Dive into Out of Browser and Using the MVVM Pattern in Silverlight Applications
Steve Plank (@plankytronixx) posted Windows Azure and Open Source Applications on 3/14/2011:
Whenever most of us think of OSS, we think in terms of a stack with Linux at the bottom, providing the OS platform and say PHP at the top with say a CMS app atop that. It’s often forgotten of course, that there’s a healthy and thriving community of developers who write OSS code to run on Windows (and therefore Windows Azure).
For Windows Azure developers, there is a tool called the Windows Azure Companion. It’s now in its March 2011 CTP release and can downloaded from here. I’m mentioning all this because it appears to be a fantastically well-guarded secret among the cloud community. Pretty well known among OSS and interop folks, but it’s a really cool piece of cloud technology I think deserves a much wider audience. I wonder how many people know there is an installer that can install most of your favourite OSS web applications, plus platform-level components such as say, MySQL, on to your Windows Azure subscription for you…
One important reason to load the March CTP, if you happen to already have the old version of the companion, is because it’s built using the recent refresh of the SDK (v 1.4).
It works like this:
- Download the .cspkg file from the Windows Azure Companion site. This file contains all the application code needed to run the installer.
- Download the .cscfg file from the Windows Azure Companion site.
- This contains not only the configuration for the installer but also points to the list of apps you want to install. You need to edit the file to point at the app feed file.
- Edit the .cscfg file to point to the app feed file
- The app feed file point to the applications you want to deploy, for example, this entry points to Drupal
- …and this entry points to MySQL
- Once you have deployed the .cspkg and .cscfg to Windows Azure, an installer will fire up on port 8080 at your specified URL, say http://myDrupal.cloudapp.net:8080. It has to run on port 8080 because the actual application (say Drupal) you want to install, will run on port 80, later. All you have deployed at this stage is the installer itself.
- The installer gets some configuration information from the .cscfg that you edited in step 3. It consults the app feed and displays a list of applications and platform level packages you might want to install (as defined in the app feed).
- The installer installs the application(s), in this case Drupal.
- The application is installed – you can go to the application’s URL, say, http://myDrupal.cloudapp.net on port 80 and there you have it, a fully deployed OSS application on Windows Azure.
Above is a video, put together by the “Interop Technologies” Microsoft Evangelist Craig Kitterman which shows how simple these steps are. In fact, one piece of the hard work has already been done in the video – the creation of the app feed file. The “Cloud/Web Famous” Maarten Balliauw has already broken that ground for us! Thanks Maarten.
To learn more, download the code, engage in forums etc, go to the Windows Azure Companion site.


David Chou described Cloud-optimized architecture and Advanced Telemetry in a 3/14/2011 post:
One of the projects I had the privilege of working with this past year, is the Windows Azure platform implementation at Advanced Telemetry. Advanced Telemetry offers an extensible, remote, energy-monitoring-and-control software framework suitable for a number of use case scenarios.
One of their current product offerings is EcoView™, a smart energy and resource management system for both residential and small commercial applications. Cloud-based and entirely Web accessible, EcoView enables customers to view, manage, and reduce their resource consumption (and thus utility bills and carbon footprint), all in real-time via the intelligent on-site control panel and remotely via the Internet.
Much more than Internet-enabled thermostats and device end-points, “a tremendous amount of work has gone into the core platform, internally known as the TAF (Telemetry Application Framework) over the past 7 years” (as Tom Naylor, CEO/CTO of Advanced Telemetry wrote on his blog), which makes up the server-side middleware system implementation, and provides the intelligence to the network of control panels (with EcoView being one of the applications), and an interesting potential third-party application model.
- Energy Monitoring Firm Saves Money, Scales Business with Hosted Computing Platform
- Startup Uses Cloud Computing to Change Business Model, Becomes Instantly Profitable
- SQL Azure team blog’s Interview with Tom Naylor, CTO of Advanced Telemetry
- Windows Azure AppFabric team blog’s How Advanced Telemetry became instantly profitable after migrating to the Windows Azure Platform
- Channel 9 Video - Building on Azure: Advanced Telemetry
The Move to the Cloud
As pointed out by the first case study, the initial motivation to adopt cloud computing was driven by the need to reduce operational costs of maintaining an IT infrastructure, while being able to scale the business forward.
“We see the Windows Azure platform as an alternative to both managing and supporting collocated servers and having support personnel on our side dedicated to making sure the system is always up and the application is always running,” says Tom Naylor. “Windows Azure solves all those things for us effectively with the redundancy and fault tolerance we need. Because cost is based on usage, we’ll also be able to much more accurately assess our service fees. For the first time, we’ll be able to tell exactly how much it costs to service a particular site.”
For instance, in the Channel 9 video, Tom mentioned that replicating the co-located architecture from Rackspace to Windows Azure platform resulted in approximately 75% cost reduction on a monthly basis in addition to other benefits. One of the major ‘other’ benefits is agility, which arguably is much more valuable than the cost reduction normally associated with cloud computing benefits. In fact, as the second case study pointed out, in addition to breaking ties to an IT infrastructure, Windows Azure platform become a change enabler that supported to shift to a completely different business model for Advanced Telemetry (from a direct market approach to that of an original equipment manufacturer (OEM) model). The move to Windows Azure platform provided the much needed scalability (of the technical infrastructure), flexibility (to adapt to additional vertical market scenarios), and manageability (maintaining the level of administrative efforts while growing the business operations). The general benefits cited in the case study were:
- Opens New Markets with OEM Business Model
- Reduces Operational Costs
- Gains New Revenue Stream
- Improves Customer Service
Cloud-Optimized Architecture
However, this is not just another simple story of migrating software from one data center to another data center. Tom Naylor understood well the principles of cloud computing, and saw the value in optimizing the implementation for the cloud platform instead of just using it as a hosting environment for the same thing from somewhere else. I discussed this in more detail in a previous post Designing for Cloud-Optimized Architecture. Basically, it is about leveraging cloud computing as a way of computing and as a new development paradigm. Sure, conventional hosting scenarios do work in cloud computing, but there is more value and benefits to gain if an application is designed and optimized specifically to operate in the cloud, and built using unique features from the underlying cloud platform.
In addition to the design principles around “small pieces, loosely coupled” fundamental concept I discussed previously, another aspect of the cloud-optimized approach is to think about storage first, as opposed to thinking about compute. This is because, in cloud platforms like Windows Azure platform, we can build applications using the cloud-based storage services such as Windows Azure Blob Storage and Windows Azure Table Storage, which are horizontally scalable distributed storage systems that can store petabytes and petabytes of data and content without requiring us to implement and manage the infrastructure. This is in fact, one of the significant differences between cloud platforms and traditional outsourced hosting providers.
In the Channel 9 video interview, Tom Naylor said “what really drove us to it, honestly, was storage”. He mentioned that the Telemetry Application Platform currently handles about 200,000 messages per hour, each containing up to 10 individual point updates (which roughly equates to 500 updates per second). While this level of traffic volume isn’t comparable to the top websites in the world, it still poses significant issues for a startup company to store and access the data effectively. In fact, the data required the Advanced Telemetry team to cull the data periodically in order to maintain a relatively workable size for the operational data.
“We simply broke down the functional components, interfaces and services and began replicating them while taking full advantage of the new technologies available in Azure such as table storage, BLOB storage, queues, service bus and worker roles. This turned out to be a very liberating experience and although we had already identified the basic design and architecture as part of the previous migration plan, we ended up making some key changes once unencumbered from the constraints inherent in the transitional strategy. The net result is that in approximately 6 weeks, with only 2 team members dedicated to it (yours truly included), we ended up fully replicating our existing system as a 100% Azure application. We were still able to reuse a large percentage of our existing code base and ended up keeping many of the database-driven functions encapsulated in stored procedures and triggers by leveraging SQL Azure.” Tom Naylor described the approach on his blog.
The application architecture employed many cloud-optimized designs, such as:
- Hybrid relational and noSQL data storage – SQL Azure for data that is inherently relational, and Windows Azure Table Storage for historical data and events, etc.
- Event-driven design – Web roles receiving messages act as event capture layer, but asynchronously off-loads processing to Worker roles
Lessons Learned
In the real world, things rarely go completely as anticipated/planned. And it was the case for this real-world implementation as well. :) Tom Naylor was very candid about some of the challenges he encountered:
- Early adopter challenges and learning new technologies – Windows Azure Table and Blob Storage, and Windows Azure AppFabric Service Bus are new technologies and have very different constructs and interaction methods
- “The way you insert and access the data is fairly unique compared to traditional relational data access”, said Tom, such as the use of “row keys, combined row keys in table storage and using those in queries”
- Transactions - initial design was very asynchronous; store in Windows Azure Blob storage and put in Windows Azure Queue, but that resulted in a lot of transactions and significant costs based on the per-transaction charge model for Windows Azure Queue. Had to leverage Windows Azure AppFabric Service Bus to reduce that impact
The end result is a an application that is horizontally scalable, allowing Advanced Telemetry to elastically scale up or down the deployments of individual layers according to capacity needs, as different application layers are nicely decoupled from each other, and the application is decoupled from horizontally scalable storage. Moreover, the cloud-optimized architecture supports both multi-tenant and single-tenant deployment models, enabling Advanced Telemetry to support customers who have higher data isolation requirements.

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework v4
• Beth Massi (@bethmassi) posted Visual Studio LightSwitch Beta 2 Released! on 3/15/2011 at 12:58 PM PDT:
Wow, what a busy morning! I’m super excited that we announced the release of Visual Studio LightSwitch Beta 2 today! Check out the team blog post for details:
Visual Studio LightSwitch Beta 2 Released with Go Live License!
We've also got a lot of new content and a fresh look for the LightSwitch Developer Center on MSDN so check it out! Whether you are just beginning or have been using LightSwitch for a while, we've got something for you.
We've also done a major overhaul to the LightSwitch Developer Learning Center in order to organize learning topics, blog articles, tips & tricks, and documentation better and allows us to easily roll out more training content each week. You can access training, samples, How Do I Videos, articles and more here.
We'll also be updating the Training Kit (that you can also access from the Learning Center) on Thursday for the public release. Also check out our team blogs and bloggers for more information on LightSwitch. We're in the process of updating all our Beta 1 blog posts to Beta 2 so keep checking back.
- LightSwitch Team Blog
- Beth Massi's Blog
- Robert Green's Blog
- Matt Thalman's Blog
- See the Dev Center Commuity page for more from the community
Also make sure to ask questions in the LightSwitch Forums, we have the majority of the team hanging out there ready to answer any questions or issues you are having.

Michael Desmond asserted “The second pre-release version of Microsoft's wizard-based, rapid business application development tool adds cloud and extensibility features” in a deck for his Microsoft Releases LightSwitch Beta 2 report of 3/15/2011:
Microsoft today announced at its Developer Tools Partner Summit in Redmond that Beta 2 of the Visual Studio LightSwitch rapid business application development tool is available for immediate download [see article below]. LightSwitch Beta 1 was announced at the Visual Studio Live! event in August 2010. Dave Mendlen, senior director of Developer Marketing at Microsoft said the final shipping version of LightSwitch will be released "later this year."
The new pre-release version of LightSwitch offers two significant new capabilities, Mendlen said.
"With Beta 2 we've introduced some new functionality. The first is we added Windows Azure publishing, which is now fully integrated. The second is extensibility. Anyone with a copy of Visual Studio Pro can, starting with LightSwitch Beta 2, build extensions for LightSwitch," Mendlen said.
LightSwitch Beta 2 also addresses an incompatibility between the earlier pre-release version of LightSwitch (Beta 1) and the recently released Visual Studio 2010 Service Pack 1 (SP1). Visual Studio developers who have upgraded to VS2010 SP1 must upgrade to LightSwitch Beta 2 to work with LightSwitch. Also, LightSwitch Beta 2 will not work with the RTM version of VS2010.
Extensions and Cloud
The new capabilities in LightSwitch Beta 2 draw the tool into line with Microsoft's broad cloud computing strategy. Windows Azure publishing will enable LightSwitch developers to easily deploy their applications to either the desktop or the cloud. Mendlen described the tool as offering "simple and fast" LOB application creation "for desktop and cloud."LightSwitch Beta 2 support for extensions will certainly appeal to attendees at the Developer Tools Partner Summit, an invitation-only event for Microsoft ecosystem partners that build and market tools for the Microsoft development stack. Mendlen said LightSwitch extensions can include screens, business templates, data sources, business types and controls. He singled out a pair of working LightSwitch extensions as examples: An Infragistics custom shell extension that enables a Windows Phone 7 Metro-like, touch-enabled UI, and a ComponentOne pivot table control that offers Excel-like data manipulation.
Mendlen said the focus was to build a robust ecosystem of third-party providers around LightSwitch. "Don't go crazy trying to make a pivot table. Just go buy one and you'll have that functionality for you," he said, adding. "We have more extensibility points and more places to monetize than just the traditional control vendor model."
Visual Studio LightSwitch is aimed at business analysts and power users who today often create ad-hoc business logic in applications like FileMaker Pro or Microsoft Excel and Access. Based on Visual Studio, LightSwitch offers a visual, wizard-driven UI that allows business users to craft true, .NET-based applications with rich data bindings. Unlike ad-hoc development, the .NET code produced by LightSwitch can be seamlessly imported into Visual Studio for professional developers to inspect, edit and extend.
Also announced at the Developer Tools Partner Summit was a program that gives Visual Studio Ultimate Edition license holders free access to unlimited virtual users with Microsoft's load testing tool and agent. Ultimate Edition users will get a license key to generate unlimited users with the Visual Studio 2010 Load Test Feature Pack, without having to buy the Visual Studio Load Test Virtual User Pack 2010. The Load Test Virtual User Pack normally costs $4499 per pack supporting 1000 virtual users.
"I saw an estimate from one customer that this could be a million dollars in cost savings for them. It's massive," said Mendlen. "It's free and we're making it available to Ultimate customers forever. If you have Ultimate you get this value."
The Visual Studio LightSwitch Team announced Visual Studio LightSwitch Beta 2 Released with Go Live License! on 3/15/2011 at 10:02 AM:
We are extremely happy to announce the release of Microsoft® Visual Studio® LightSwitch™ Beta 2! MSDN subscribers can access LightSwitch Beta 2 today and public availability will be Thursday, March 17th. Please see Jason Zander’s post that walks through some of the new features.
- MSDN Subscribers download LightSwitch Beta 2 now!
- The general public can download Beta 2 on Thursday at 10AM PST here
Read What’s New in Beta 2 for information on new capabilities in this release. We’d also like to announce that Beta 2 comes with a “Go Live” license which means you can now start using Visual Studio LightSwitch for production projects!
We’ve also done some major updates to the LightSwitch Developer Center with How Do I videos based on Beta 2 as well as a new and improved Learning Center and Beta 2 samples to get you up to speed fast, whether you’re a beginner or advanced developer. We’ll be rolling out more in-depth content and training in the coming weeks so keep checking back.
INSTALLATION NOTES: Visual Studio 2010 Express, Professional, Premium, Test Professional or Ultimate users must install Visual Studio 2010 SP1 before installing Visual Studio LightSwitch Beta 2. Visual Studio LightSwitch Beta 1 users should uninstall Beta 1 before installing Beta 2. Also see the Beta 2 readme for late breaking issues. These are known incompatible releases with Visual Studio LightSwitch Beta 2 (see links for details on compatibility and workarounds):
- Visual Studio Async CTP - known compatibility details(see *Async CTP Issues with VS2010 SP1* announcement)
- Windows SDK 7.1 - known compatibility details
- Help Viewer Power Tool – known compatibility details
PROJECT UPGRADE NOTES: Due to the many improvements in Beta 2, projects created in Beta 1 cannot be opened or upgraded. You will need to recreate your projects and copy over any user code that you have added. You can get to the user code files by switching to File View in the Solution Explorer. Please note that some APIs have changed so you may need to update some of your code appropriately. At this point we do not plan to introduce breaking changes post-Beta 2 that will cause you to need to recreate your Beta 2 projects.
We want to hear from you! Please visit the LightSwitch Forums to ask questions and interact with the team and community. Have you found a bug? Please report them on Microsoft Connect.
Have fun building business applications with Visual Studio LightSwitch!
Jason Zander posted Announcing Microsoft® Visual Studio® LightSwitch™ Beta 2 on 3/15/2011 at 10:00 AM:
I’m happy to announce that as of 10:00 AM PDT today Microsoft® Visual Studio® LightSwitch™ Beta 2 is available for download! MSDN subscribers using Visual Studio 2010 can download the beta immediately with general availability on Thursday, March 17.
- Download LightSwitch Beta 2 (MSDN Subscribers with Visual Studio 2010)
- Thursday's 10:00 AM PDT general availability download will be here.
We are happy to announce that Beta 2 comes with a “Go Live” license which means you can now start using Visual Studio LightSwitch for production projects!
Since the launch of Beta 1, the team has been heads down in working through your feedback and has made some improvements that I think you’ll agree are pretty cool.
- Publish to Azure: the Publish Wizard now provides the ability to publish a LightSwitch desktop or browser application to Windows Azure, including the application’s database to SQL Azure. The team is planning a detailed tutorial of this experience that will get posted on the team blog later this week.
- Improved runtime and design-time performance: Build times are 50% faster in Beta 2 and we have made the build management smarter to improve iterative F5 scenarios by up to 70%. LightSwitch Beta 2 applications will startup up to 30% faster than Beta 1. New features like static spans will include related data in a single query execution and improve the time to load data on a screen by reducing the total number of server round-trips. The middle tier data load/save pipeline has been optimized to improve throughput by up to 60%.
- Runtime UI improvements: Auto-complete box, better keyboard navigation, and improved end-user experience for long-running operations.
- Allow any authenticated Window user: When Windows authorization was selected in a LightSwitch app, you previously needed to add the Windows users who are allowed to use the application into the User Administration screen of the running application. This is cumbersome in installations where there are a large number of Windows users and when you just wanted to open the app up to all Windows users. The project properties UI now allows you to authenticate any Windows user in a LightSwitch application while still using the LightSwitch authorization subsystem for determining user permissions for specific users.
LightSwitch Architectural Overview
Applications you build with LightSwitch follow n-tier best practices and use common .NET technologies that you are probably building upon yourself today. For an overview of LightSwitch architecture, please see "The Anatomy of a LightSwitch Application Series" on the team blog.
I've included a detailed walk through below, to help you get your first LightSwitch application up and running using Beta 2. You may also find the following links useful as you explore LightSwitch:
- LightSwitch Developer Center
- LightSwitch Team Blog
- LightSwitch Feature Matrix
- LightSwitch Forums
- Feedback: Visual Studio Connect
Now on to building your first application!
Tutorial
In this tutorial we are going to build a student-course registration application to be used at a local college. There are six parts to this tutorial.
- Part 1 – Installation
- Part 2 – Creating a New Project
- Part 3 – Starting with Data
- Part 4 – Creating Screens
- Part 5 – Adding Relationships
- Part 6 – Writing Some Code
- Summary
Let’s get going!
Part 1 – Installation
Visual Studio 2010 Professional, Premium, Test Professional or Ultimate users must install Visual Studio 2010 SP1 before installing Visual Studio LightSwitch Beta 2. Visual Studio LightSwitch Beta 1 users should uninstall Beta 1 before installing Beta 2. Also see the Beta 2 readme for late breaking issues. For information on known incompatible releases with Visual Studio LightSwitch Beta 2, please check out the team post.
There are two installation options available from the download link above, a web installer and a DVD ISO image:
- Visual Studio LightSwitch, Beta 2 (x86) – DVD (English). This is an ISO image which can be burned to a disc and used by multiple users (or mounted using a utility).
- Visual Studio LightSwitch, Web Install Beta 2 (x86) – (English). This is a web installer that will download all components incrementally and install them on a single machine.
Unless you plan to take the bits with you or hand around a DVD to co-workers, I recommend using the web installer which will lower your bandwidth requirements and eliminate the need to burn a DVD or mount an ISO.
A goal of LightSwitch is to remove the need for configuration, so all you have to do is click “Install Now” to get going. After all components are installed, you can simply click the [Launch] button:
Note: if you had Visual Studio 2010 already installed, you will find the new LightSwitch templates in your installation.
Part 2 – Creating a New Project
In this example, I am building a simple course registration application for the staff at the Office of Registrar of a local college. This application will allow the staff to easily register courses for new or existing students.
To get started, choose File, New Project. If you installed Visual Studio 2010, you will need to select the LightSwitch templates:
You can choose from Visual Basic or C#. I’m going to pick Visual Basic and call the application “LightSwitchDemo.” Then hit [OK]. After a few moments your new project will come up and we can start adding data.
Part 3 - Starting with Data
To get started we need to track students. Because working with data is such a basic operation, the initial designer gives you these options right away. We’ll get started by clicking on [Create new table].
This will bring up the table designer. Start by changing the name of the table to “Student”, which you can do by simply typing in the title bar.
Next, edit the fields for the table to store typical data about a student. Note the usage of domain types like Email Address and Phone Number, which provide built-in validation logic and customizable UI on the screens we create in later steps.
To ensure each student record will have a unique email address- click Select Email field and check the “Include in Unique Index” in Properties. This is a new Beta 2 feature.
Next we will need a table for courses. To get started, click “New Table” button in the command bar.

Edit the table name to “Course” and add new columns.
At this point we need to create some UI for our application to allow us to edit table data.
Part 4 - Creating Screens
The most common activities for business applications are layout out your data and create screens to work with that data. In this step we will create a couple of screens to allow us to edit the table data. To start, right click the Screens folder in the Solution Explorer and choose "Add Screen".

There are a very common set of screen patterns for working with data and LightSwitch includes those patterns by default. Screen templates are also an extensibility option for LightSwitch, so you should expect Visual Studio partners to add new patterns in the future (or you can create your own with Visual Studio Professional).For our application let’s create a “New Data Screen” so we can edit our student list. On the Add New Screen dialog, select “New Data Screen”, then select "Student" from the Screen Data combo box:
Notice that as you select the Student table, the default Screen Name updates itself to give you a reasonable unique screen name. You can always choose to update this name yourself, if you have your own naming pattern to follow. Once you have made the changes, click [OK].

The Screen Designer now appears. For now, let’s just add another screen for the Course table. Again, right click the Screens folder in the Solution Explorer and choose "Add Screen". On the Add New Screen dialog, select “New Data Screen”, then select "Course" from the Screen Data combo box:

Click [OK]. Then hit F5 (or Debug, Start Debugging from the menu). This will kick off a build of the application and start the running app:

By default your application will be a Windows desktop application. If you have experimented with Beta 1, you will notice that Beta 2 has improved the application start time and performance. The default Office-like theme is more refined and user-friendly. It also provides a better use of the screen real estate. You can now collapse both the task list and the ribbon. In Beta 2, we also set the display name of a field based on camel casing convention. For example, FirstName of the Student table will have “First Name” as its display name by default.The application shell is another extension option for LightSwitch and we have Visual Studio partners working on creating new ones. This means in the future you’ll be able to select from a set of shells to build an application that looks cool (kind of like selecting PowerPoint slide deck templates).
I’ll start by adding my personal information to the database. When done, just click the "Save" ribbon button.
Go ahead and add a few more student and course records.
The two screens make it easy to create new data, but they’re not designed to browse and find existing records. Let’s add a screen to search for students. Close the running application to exit debug mode and return to the Visual Studio IDE. Right click the Screens folder in Solution Explorer and choose "Add Screen".

Select the “Search Data Screen” template and then select the “Students” table from Screen Data combo box, and then hit [OK]. Once again the screen designer will appear. Let’s just hit F5 again.

When you select “Search Student” from the task list, you will get the list of all the student data you have entered. Because we picked the Search template, we have searching, sorting, and paging capabilities built into the screen by default.

Another default feature of the desktop application is Office integration. In this case, I can click on the Excel icon and get my data opened as an Excel spreadsheet.
Notice that First Name is shown as a link, by default. The link takes you to an auto generated details screen for the student. We will show you how to customize the details screen in a bit. For now, I’d like to customize the search column order and make Last Name appear as a link as well. To do this, click “Design Screen” button in the upper right hand corner of the running app to enter the runtime screen designer.

One of the features of LightSwitch is that it allows you to make quick UI changes while the app is running in debug mode. As you change the UI tree, you get an instant preview of what your screen will look like.Select "Last Name" under Data Grid Row and check “Show as link” in Properties (which is new in Beta 2). You will see the links show up in the preview pane.

Let’s also move the "Last Name" column before the "First Name" column by using the up arrow in the command bar.

Hit [Save]We have now exited the runtime designer and returned to the running screen. We can see our UI changes reflected in the running app.
As a side note, if the app user resizes the grid columns, LightSwitch will remember the user setting next time he/she runs the app again. This is also something we introduced in Beta 2.
So far my application is looking pretty decent and LightSwitch is doing all the work for me. One unfortunate behavior we have to deal with is that by default our app opens the Create New Student screen every time we launch the application. The college staff won’t be creating a student that often so let’s customize that.
Close the running app and return to the Visual Studio IDE. Double-click the Properties node that’s just under the application node in the Solution Explorer.

On the property designer page, select "Screen Navigation" which will allow us to edit the menu structure for the application.

We want to make the Search Student the default start screen which will avoid trying to add a new record every time we execute the application. To do this, select the "Search Student" task then click [Set] button to make it the startup screen. Let’s also move it up in the task list by clicking the up arrow. When you are done, the designer should look like the following:

Now when we run the application, the student list comes up first and we do not get a new student screen unless we explicitly click on that task.Part 5 - Adding Relationships
At this point, we have a Student and Course table but we have no way to connect them. Each student can register many courses; and each course can have many students in it. This is a classic many to many relationship which will require a new table to track instances of student-course pairs. Once again we will right click the "Data Sources" folder and choose "Add Table":
Name the table “Enrollment” by editing the title.
Next we need to add a relationship to the Student table. Click the “+ Relationship…” tool bar button.
Using the Add New Relationship dialog is one of those things that remind me why I like LightSwitch so much: it’s just easier to use than other complicated dialogue boxes. When the dialog comes up, simply change the To column of the Name row to our target table "Student".

Notice that the dialog now shows you both the relational diagram of many to 1, as well as plain, old fashioned text to explain what you just did. Having worked on two databases and three database API sets I know how to edit this stuff by hand using SQL syntax, but this is just easier. After your edits are complete, hit the [OK] button to save the relationship. LightSwitch now automatically adds a new column for the relationship and updates the Student table for the foreign key:

Let’s repeat the step again for the Course table by clicking the + Relationship… toolbar button. Now change the target Name to Course to establish the relationship:

Now click [OK] and our many-to-many relationship has been set up through the Enrollment table.

If you double click the Student table item on the designer your focus will change to that table and you can see that the Enrollment column which has been added for you.Now let’s add a screen for the Enrollment table. As we did before, right click the Screens folder and add a new screen. Select the New Data Screen template and change the Screen Data to the table Enrollment.
Let’s name the screen RegisterCourse, then click [OK].
After the screen is created, hit F5 to run the application. Click the Register Course on the task list to open the screen. We will see an auto-complete box for Student and one for Course.

Auto-complete box is another new Beta 2 feature that LightSwitch provides by default. It greatly improves the keyboard navigation experience for data entry tasks.We now have a functional application without writing a single line of code! We can create new students, search existing students, and register courses for students. To further optimize the workflow- imagine handling a phone call for an existing student. We’d want to enable a user to find the student via the Search Student screen. Wouldn’t it be nice if we could open the Register Course screen with the student auto complete box already filled out?
Part 6 - Writing Some Code
To do this, we need to provide the Register Course screen with an optional screen parameter. If the parameter is set, we could use it to prefill the student information.
Close the running application and go back to the Visual Studio IDE. Double click on the RegisterCourse screen on the Solution Explorer to open the screen designer. To add a parameter to this screen, click “Add Data Item… “ button in the command bar.

In the Add Data Item dialog, select Local Property, Integer type, and uncheck “Is Required” to make it an optional property. Name the property StudentId and click [OK].

Then select the newly created StudentId in the Screen Designer.

Check “Is Parameter” in the property pane indicating this is a screen parameter.

We now have an optional screen parameter. Next, we need to write some code to check its value when the screen is being initialized. Use the “Write Code” dropdown button in the command bar and select RegisterCourse_InitializeDataWorkspace.

LightSwitch now takes you to the code editor for the Register Course screen:Private Sub RegisterCourse_InitializeDataWorkspace(saveChangesTo As System.Collections.Generic.List(Of Microsoft.LightSwitch.IDataService))
' Write your code here.
Me.EnrollmentProperty = New Enrollment()
End Sub
InitializeDataWorkspace is called before the data on the screen is being loaded. We want to check for its value and find the corresponding student record. Let’s add the following code:
Private Sub RegisterCourse_InitializeDataWorkspace(saveChangesTo As System.Collections.Generic.List(Of Microsoft.LightSwitch.IDataService))
' Write your code here.
Me.EnrollmentProperty = New Enrollment()
' MY CODE: StudentId is an optional parameter. Check if it has a value. If so, run a query to fetch the student record and prefill the EnrollmentProperty
If (StudentId.HasValue) Then
Me.EnrollmentProperty.Student = DataWorkspace.ApplicationData.Students_Single(StudentId)
End If
End Sub
That’s all we need to do for the Register Course screen. Next, we need to customize the student details screen to include a launch point that opens the Register Course screen with a parameter.
To do this let’s create a details screen for the students. Once again right click the Screens folder and choose Add Screen. Select the Details Screen template and then select the Student table from the Screen Data.

Make sure “Use as Default Details Screen” is checked and click [OK]. The screen designer for the details screen appears.Let’s add a new ribbon button to the student details screen. Right click on the Screen Command Bar in the content tree and select “Add Button…”
In the Add Button dialog, name the method RegisterCourse and click [OK].

With the newly created button selected, go to Properties and click “Choose Image…” link.
In the Select Image dialog, import an image from your computer for this ribbon button and click [OK].
Double clicking on the Register Course button will take us to the corresponding screen code. Add the following code:
Private Sub RegisterCourse_Execute()
' MY CODE: open the Register Course screen with the student id as its screen parameter
Application.ShowRegisterCourse(Student.Id)
End Sub
Now hit F5 and see it in action. In the "Search Students" screen, click on one of the student links.

It will take us to the details screen we just created. As you can see, we’ve added a new ribbon button called “Register Course.”Now click on the “Register Course” ribbon button. It will take us to the Register Course screen with the student field already pre-set to Jason. To register a course, you only need to select a course from the auto-complete box and save the screen.
Summary
In this tutorial we’ve created our first working LightSwitch application completely from scratch. We took advantage of some of Beta 2’s new features, along with adding some simple coding. The team is publishing additional walkthroughs that will go into more detail, as well as, providing guidance on publishing to Azure.
With the addition of the Go Live license for Beta 2, you can see we are well on our way towards releasing the final version of LightSwitch. We are really looking forward to your feedback on Beta 2 which will help us get over the finish line.



























Julia Kornich described EF Feature CTP5: Code First Model with Master-Detail WPF Application in a detailed 3/8/2011 post to the ADO.NET Team blog (missed when posted):
This post provides an introduction to creating your model using Code First development and then using the types defined in the model as data sources in the “master-detail” WPF application.
In this walkthrough, the model defines two types that participate in one-to-many relationship: Category (principal\master) and Product (dependent\detail). Then, the Visual Studio tools are used to bind the types defined in the model to the WPF controls. The WPF data-binding framework enable navigation between related objects: selecting rows in the master view causes the detail view to update with the corresponding child data. Note, that the data-binding process does not depend on what approach is used to define the model (Code First, Database First, or Model First).
In this walkthrough the default Code First conventions are used to map your .NET types to a database schema and create the database the first time the application runs. You can override the default Code First conventions by using Data Annotations or the Code First Fluent API. For more information see: EF Feature CTP5: Code First Walkthrough (section 9 - Data Annotations) and EF Feature CTP5: Fluent API Samples.
Install EF CTP5
If you haven’t already done so then you need to install Entity Framework Feature CTP5.
Create a solution and a class library project to which the model will be added
1. Open Visual Studio 2010.
2. From the menu, select File -> New -> Project… .
3. Select “Visual C#” from the left menu and then select “Class Library” template.
4. Enter CodeFirstModel as the project name and CodeFirstWithWPF as the solution name. Note, to be able to specify different names for the project and the solution names must check the “Create directory for solution” option (located on the right bottom corner of the New Project dialog).
5. Select OK.
Create a simple model
When using the Code First development you usually begin by writing .NET classes that define your domain model. The classes do not need to derive from any base classes or implement any interfaces. In this section you will define your model using C# code.
1. Remove the default source code file that was added to the CodeFirstModel project (Class1.cs).
2. Add reference to the EntityFramework assembly. To add a reference do:
2.1. Press the right mouse button on the CodeFirstModel project, select Add Reference…
2.2. Select the “.NET” tab.
2.3. Select EntityFramework from the list.
2.4. Click OK .
3. Add new class to the CodeFirstModel. Enter Product for the class name.
4. Replace the Product class definition with the code below.
public class Product { public int ProductId { get; set; } public string Name { get; set; } public virtual Category Category { get; set; } public int CategoryId { get; set; } }5. Add another new class. Enter Category for the class name.
6. Implement the Category class as follows:
using System.Collections.ObjectModel; public class Category { public Category() { this.Products = new ObservableCollection<Product>(); } public int CategoryId { get; set; } public string Name { get; set; } public virtual ObservableCollection<Product> Products { get; private set; } }The Products property on the Category class and Category property on the Product class are navigation properties. Navigation properties in the Entity Framework provide a way to navigate an association\relationship between two entity types, returning either a reference to an object, if the multiplicity is either one or zero-or-one, or a collection if the multiplicity is many.
The Entity Framework gives you an option of loading related entities from the database automatically whenever you access a navigation property. With this type of loading (called lazy loading), be aware that each navigation property that you access results in a separate query executing against the database if the entity is not already in the context.
When using POCO entity types, lazy loading is achieved by creating instances of derived proxy types during runtime and then overriding virtual properties to add the loading hook. To get lazy loading of related objects, you must declare navigation property getters as public, virtual (Overridable in Visual Basic), and not sealed (NotOverridable in Visual Basic). In the code above, the Category.Products and Product.Category navigation properties are virtual.
Create a derived context
In this step we will define a context that derives from System.Data.Entity.DbContext and exposes a DbSet<TEntity> for the classes in the model. The context class manages the entity objects during runtime, which includes retrieval of objects from a database, change tracking, and persistence to the database. A DbSet<TEntity> represents the collection of all entities in the context of a given type.
1. Add reference to the EntityFramework assembly. That is where DbContext and DbSet are defined. To add a reference do:
1.1. Press the right mouse button on the CodeFirstModel project, select Add Reference…
1.2. Select the “.NET” tab.
1.3. Select EntityFramework from the list.
1.4. Click OK.
2. Add new class to the CodeFirstModel. Enter ProductContext for the class name.
3. Implement the class definition as follows:
using System.Data.Entity; public class ProductContext : DbContext { public DbSet<Category> Categories { get; set; } public DbSet<Product> Products { get; set; } }4. Build the project.
In the code above we use a “convention over configuration” approach. When using this approach you rely on common mapping conventions instead of explicitly configuring the mapping. For example, if a property on a class contains “ID” or “Id” string, or the class name followed by Id (Id can be any combination of upper case and lower case) the Entity Framework will treat these properties as primary keys by convention. This approach will work in most common database mapping scenarios, but the Entity Framework provides ways for you to override these conventions. For example, if you explicitly want to set a property to be a primary key, you can use the [Key] data annotation. For more information about mapping conventions, see the following blog: Conventions for Code First.
Create a WPF application
In this step we will add a new WPF application to the CodeFirstWithWPF solution.
1. Add a new WPF application to the CodeFirstWithWPF solution.
1.1. Press the right mouse button on the CodeFirstWithWPF solution and select Add -> New Project…
1.2. Select “WPF Application” template. Leave the default name (WpfApplication1).
1.3. Click OK.
2. Add reference to the CodeFirstModel class library project. That is where our model and the object context are defined.
2.1. Press the right mouse button on the project and select Add Reference…
2.2. Select the “Projects” tab.
2.3. Select CodeFirstModel from the list.
2.4. Click OK.
3. Add reference to the EntityFramework assembly.
4. Add the classes that are defined in the model as data sources for this WPF application.
4.1. From the main menu, select Data -> Add New Data Source…
4.2. Select Objects and click Next.
4.3. In the “What objects do you want to bind to” list click to open the CodeFirstModel until you see the list of data sources, select Category. There no need to select the Product data source, because we can get to it through the Product’s property on the Category data source.
4.4. Click Finish.
5. Show the data sources (from the main menu, select Data -> Show Data Sources). By default the Data Sources panel is added on the left of the Visual Studio designer.
6. Select the Data Sources tab and press the pin icon, so the window does not auto hide. You may need to hit the refresh button if the window was already visible.
7. Select the Category data source and drag it on the form. Let’s see what happened when we dragged this source:
7.1. By default, the CollectionViewSource categoryViewSource resource and the DataGrid categoryDataGrid control are added to XAML. For more information about DataViewSources, see http://bea.stollnitz.com/blog/?p=387.
7.2. The categoryViewSource resource serves as a binding source for the outer\parent Grid element. The binding source is specified by setting the parent Grid element DataContext property to "{StaticResource categoryViewSource }". The inner Grid elements then inherit the DataContext value from the parent Grid (categoryDataGrid’s ItemsSource property is set to "{Binding}").
<Window.Resources> <CollectionViewSource x:Key="categoryViewSource" d:DesignSource="{d:DesignInstance my:Category, CreateList=True}" /> </Window.Resources> <Grid DataContext="{StaticResource categoryViewSource}"> <DataGrid AutoGenerateColumns="False" EnableRowVirtualization="True" Height="132" HorizontalAlignment="Left" ItemsSource="{Binding}" Name="categoryDataGrid" RowDetailsVisibilityMode="VisibleWhenSelected" VerticalAlignment="Top" Width="321"> <DataGrid.Columns> <DataGridTextColumn x:Name="categoryIdColumn" Binding="{Binding Path=CategoryId}" Header="Category Id" Width="SizeToHeader" /> <DataGridTextColumn x:Name="nameColumn" Binding="{Binding Path=Name}" Header="Name" Width="SizeToHeader" /> </DataGrid.Columns> </DataGrid> </Grid>8. Select the Products property from under the Category data source and drag it on the form. The categoryProductsViewSource resource and productDataGrid grid are added to XAML. The binding path for this resource is set to Products. WPF data-binding framework will do its magic so that only Products related to the selected Category show up in productDataGrid.
9. Add a button to the form and set the Name property to buttonSave and the Content property to Save.
10. The form should look similar to this:
11. Add the event handler for the save button by double-clicking on the button. This will add the event handler and bring you to the code behind for the form. The code for the buttonSave_Click event handler will be added in the next section.
Add the code that handles data interaction
In this section you will create a WPF client application that queries the conceptual model, updates entity objects, and saves the data to the database.
1. Implement the code behind class (MainWindow.xaml.cs) as follows. The code comments explain what the code does.
using CodeFirstModel; using System.Data.Entity; /// <summary> /// Interaction logic for MainWindow.xaml /// </summary> public partial class MainWindow : Window { private ProductContext _context = new ProductContext(); public MainWindow() { InitializeComponent(); } private void Window_Loaded(object sender, RoutedEventArgs e) { System.Windows.Data.CollectionViewSource categoryViewSource = ((System.Windows.Data.CollectionViewSource)(this.FindResource("categoryViewSource"))); // Load is an extension method on IQueryable, defined in the System.Data.Entity namespace. // This method enumerates the results of the query, much like ToList but without creating a list. // When used with Linq to Entities this method creates the entity instances and adds to the context. _context.Categories.Load(); // Load is defined in the System.Data.Entity namespace. // After the data is loaded call the DbSet<T>.Local property to use the DbSet<T> as a binding source. categoryViewSource.Source = _context.Categories.Local; } private void buttonSave_Click(object sender, RoutedEventArgs e) { // When you delete an object from the related entities collection (in our case Products), // The Entity Framework doesn’t mark these child entities as deleted. // Instead, it removes the relationship between the parent and the child // by setting the parent reference to null. // So we manually have to delete the products that have a Category reference set to null. // The following code uses LINQ to Objects against the Local collection of Products. // The ToList call is required because otherwise the collection will be modified // by the Remove call while it is being enumerated. // In most other situations you can do LINQ to Objects directly against the Local property without using ToList first. foreach (var product in _context.Products.Local.ToList()) { if (product.Category == null) { _context.Products.Remove(product); } } _context.SaveChanges(); // Refresh the grids so the database generated values show up. this.categoryDataGrid.Items.Refresh(); this.productsDataGrid.Items.Refresh(); } protected override void OnClosing(System.ComponentModel.CancelEventArgs e) { base.OnClosing(e); this._context.Dispose(); } }Test the WPF application
When you run the application the first time, the Entity Framework uses the default conventions to create the database on the localhost\SQLEXPRESS instance and names it after the fully qualified type name of the derived context (CodeFirstModel.ProductContext). The subsequent times, unless the model changes, the existing database will be used. You can change the default behavior by overriding the Code First default conventions. For more information, see EF Feature CTP5: Code First Walkthrough.
1. Set the WpfApplication1 project as a startup project.
1.1. Click the right mouse button on the WpfApplication1 project and select “Set as StartUp project”.
2. Compile and run the application.
3. Enter a category name in the top grid and product names in the bottom grid. (Do not enter anything in ID columns, because the primary key is generated by the database).
4. Press the Save button to save the data to the database. After the call to DbContext’s SaveChanges(), the IDs are populated with the database generated values. Because we called Refresh() after SaveChanges() the DataGrid controls are updated with the new values as well.
Summary
In this post we demonstrated how to create a model using Code First development and then use the types (that participate in the inheritance hierarchy) defined in the model as data sources in the “master-detail” WPF application.






Julia is a programming writer on the ADO.NET team.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
David Linthicum asserted The US Government Needs to Move from the Tactical to the Strategic When Considering Cloud in a 3/15/2011 post to ebizQ’s Where SOA Meets Cloud blog:
As presented in Network World, "The Equal Employment Opportunity Commission (EEOC) expects to save 40% over the next five years by switching its financial management application to a cloud computing vendor -- a sign of the massive savings to come from the U.S. federal government's shift to the software-as-a-service model." Good, but not great.
The reality is that US government has a lot of IT fat that can be cut through the use of cloud computing, with leveraging SaaS-based applications being the low hanging fruit. What's great about SaaS is that that the business case is obvious, and the savings are typically between 40 and 60 percent. However, what's not so great about SaaS is that you're only dealing with a single application domain and not the architecture holistically.
While the savings that the US government, and we as taxpayers, can enjoy from cloud computing is significant perhaps tactical moves such as leveraging a single SaaS application only masks larger more systemic issues. Indeed, what's truly needed is an overall strategy around the use of cloud, and the architectural steps to get there. This includes the use of other cloud solutions, such as IaaS and PaaS, as well as SaaS.
The problem is that architectural change around the use of new technology, such as cloud computing, is hard while just migrating from a single on premise application to a SaaS app is easy and quick. However, the former offers many more efficiencies and cost savings when considering both the economies of the technologies as well as the agility their use brings.
So, when government agencies think cloud they need to thing long term and strategic, and not short term and tactical. We will all be much happier with the end result.
Yahoo Finance reported Gartner Says 2011 Will Be the Year of Platform as a Service, “Gartner Special Report Examines Key Issues Facing the PaaS Marketplace” from a 3/14/2011 BusinessWire press release:
All the leading enterprise software vendors, as well as large cloud specialists, will introduce new platform-as-a-service (PaaS) offerings this year, making 2011 the year of PaaS, according to Gartner, Inc. These leading vendors are expected to deliver new or strongly expanded PaaS service offerings and cloud-enabled application infrastructure products.
"By the end of 2011, the battle for leadership in PaaS and the key PaaS segments will engulf the software industry," said Yefim Natis [pictured at right], vice president and distinguished analyst at Gartner. "Early consolidation of specialized PaaS offerings into PaaS suites will also be evident. New vendors will enter the market through acquisitions or in-house development. Users can expect a wave of innovation and hype. It will be harder to find a consistent message, standards or clear winning vendors."
PaaS is a common reference to the layer of cloud technology architecture that contains all application infrastructure services, which are also known as "middleware" in other contexts. PaaS is the middle layer of the software stack "in the cloud." It is the technology that intermediates between the underlying system infrastructure (operating systems, networks, virtualization, storage, etc.) and overlaying application software. The technology services that are part of a full-scope PaaS include functionality of application containers, application development tools, database management systems, integration brokers, portals, business process management and many others — all offered as a service.
Today's PaaS offerings come in a over a dozen of specialized types; however, during the next three years, the variety of PaaS specialist-subset offerings will consolidate to a few major application infrastructure service suites, and, over a longer time, comprehensive, full-scale PaaS offerings will emerge as well.
Gartner believes that during the next five years, the adoption of PaaS in most midsize and large organizations will not lead to a wholesale transition to cloud computing. Instead, it will be an extension of the use patterns of on-premises application infrastructures to hybrid computing models where on-premises application infrastructures and PaaS will coexist, interoperate and integrate.
"The cloud computing era is just beginning, and the prevailing patterns, standards and best practices of cloud software engineering have not yet been established. This represents an opportunity for new software providers to build a leading presence in the software solutions market," said Mr. Natis. "It is also a major technical and business challenge to the established software vendors — to retain their leadership by extending into the new space without undermining their hard-earned strength in the dominant on-premises computing market."
During the next five years, the now-fragmented and uncertain space of cloud application infrastructure will experience rapid growth through technical and business innovation. Large vendors will grow through in-house development, partnerships and acquisitions, while small vendors will grow through partnerships and specialization. Users will be driven into cloud computing as business application services (e.g., SaaS) and advanced platform services (e.g., PaaS) reach acceptable levels of maturity and offer new innovative technological and business model features that will become increasingly hard to resist.
"During the next two years, the fragmented, specialized PaaS offerings will begin to consolidate into suites of services targeting the prevailing use patterns for PaaS," Mr. Natis said. "Making use of such preintegrated, targeted suites will be a more attractive proposition than the burdensome traditional on-premises assembly of middleware capabilities in support of a project. By 2015, comprehensive PaaS suites will be designed to deliver a combination of most specialized forms of PaaS in one integrated offering."
Gartner predicts that by 2015, most enterprises will have part of their run-the-business software functionally executing in the cloud, using PaaS services or technologies directly or indirectly. Most such enterprises, will have a hybrid environment in which internal and external services are combined.
More information is available in the report "PaaS Road Map: A Continent Emerging" which can be found on Gartner's website at http://www.gartner.com/resId=1521622. This research is part of the Special Report on PaaS, which can be found at: http://www.gartner.com/technology/research/cloud-computing/report/paas-cloud.jsp. The Special Report includes links to more than 20 reports related to PaaS, as well as webinar replays, and a video with Mr. Natis.
Jo Maitland asked Is cloud computing the carriers' to lose? and asserted “When it comes to trust, IT pros will choose the service provider” in a 3/14/2011 post to SearchCloudComputing.com:
IT pros might not like their telecom provider, but they do trust them to deliver service without interruption. And that gives these carriers a huge advantage over online book seller Amazon.com and other cloud computing providers desperately wooing corporate customers.
But just how smart is the carriers' strategy to delve into cloud computing?
There's no question enterprise IT departments are interested in cloud computing services. Our latest cloud computing survey, which polled over 300 IT professionals from companies of all sizes, revealed that almost 70% have budget for cloud services in 2011. So can the carriers deliver?
Randy Bias, founder and CEO of CloudScaling, said the U.S. carriers have the idea that there's a business model adjacent to Amazon Web Services (AWS) called enterprise cloud computing. It's built on expensive products from legacy IT vendors and so far there hasn't been much adoption. Terremark's enterprise cloud services are priced higher than those of AWS and there's a monthly commitment on pricing instead of the "pay as you go" model.
Bias is adamant that there isn't a separate enterprise cloud business model, just one winning formula: the AWS model of commodity cloud computing. Ironically, of all the companies that have a shot at dominating the cloud, it's the carriers that really understand commodity services. But Bias said the problem is that they aspire to more.
How will the carriers conquer cloud?
CloudScaling built the cloud computing infrastructure for Korea Telecom, Korea's largest fixed-line operator. It's built with standard, low-margin hardware, uses open source software and is designed for failover, rapid horizontal scaling and high server-to-admin ratios, like AWS. Verizon-Terremark took the opposite approach and built its cloud infrastructure on VMware software and EMC hardware.Tom Nolle, founder and principal analyst at Cimi Corp, said it might take the U.S. carriers some time to get their act together -- they are giant organizations, after all -- but once they do, he believes they are the natural suppliers of enterprise cloud services.
The added value they bring on top of basic IT infrastructure services -- through integration of mobile users and applications, secure network resources, billing systems, SLA knowledge and geographic reach -- is more than Amazon can offer, he said.
And when it comes to trust, IT pros will choose the service provider. When their job has been to keep the lights on for 20 years, they'll stand by the vendor they know, not the risky operator with no track record.
But if Amazon Web Services continues at its current rate of growth, it will be sitting on a $10 billion infrastructure cloud services business by 2016, according to Forrester Research. That's a utility computing service like we've never seen before.
More on carriers and the cloud:

Jo is the Senior Executive Editor of SearchCloudComputing.com.
Full disclosure: I’m a paid contributor to SearchCloudComputing.com.
John Treadway (@cloudbzz) described “How the Meek Shall Inherit The Data Center, Change The Way We Build and Deploy Applications, And Kill the Public Cloud Virtualization Market” in a preface to his SeaMicro: Atom and the Ants post of 3/14/2011:
The tiny ant. Capable of lifting up to 50 times its body weight, an ant is an amazing workhorse with by far the highest “power to weight” ratio of any living creature. Ants are also among the most populous creatures on the planet. They do the most work as well – a bit at a time Ants can move mountains.
Atom chips (and ARM chips too) are the new ants of the data center. They are what power our smartphones, tablets and ever more consumer electronics devices. They are now very fast, but surprisingly thrifty with energy – giving them the highest computing power to energy weight ratio of any microprocessor.
I predict that significantly more than half of new data center compute capacity deployed in 2016 and beyond will be based on Atoms, ARMs and other ultra-low-power processors. These mighty mites will change much about how application architectures will evolve too. Lastly, I seriously believe that the small, low-power server model will eliminate the use of virtualization in a majority of public cloud capacity by 2018. The impact in the enterprise will be initially less significant, and will take longer to play out, but in the end it will be the same result.
So, let’s take a look at this in more detail to see if you agree.
This week I had the great pleasure to spend an hour with Andrew Feldman, CEO and founder of SeaMicro, Inc., one of the emerging leaders in the nascent low-power server market. SeaMicro has had quite a great run of publicity lately, appearing twice in the Wall Street Journal related to their recent launch of their second-generation product – the SM10000-64 based on a new dual-core 1.66 GHz 64-bit Atom chip created by Intel specifically for SeaMicro.
SeaMicro: 512 Cores, 1TB RAM, 10 RU
Note – the rest of this article is based on SeaMicro and their Atom-based servers. Calxeda is another company in this space, but uses ARM chips instead.
These little beasties, taking up a mere 10 rack units of space (out of 42 in a typical rack), pack an astonishing 256 individual servers (512 cores), 64 SATA or SSD drives, up to 160GB of external network connectivity (16 x 10GigE), and 1.024 TB of DRAM. Further, SeaMicro uses ¼ of the power, ¼ the space and costs a fraction of a similar amount of capacity in a traditional 1U configuration. Internally, the 256 servers are connected by a 1.28 Tbps “3D torus” fabric modeled on the IBM Blue Gene/L supercomputer.
The approach to using low-power processors in a data center environment is detailed in a paper by a group of researchers out of Carnegie Mellon University. In this paper they show that cluster computing using a FAWN (“Fast Array of Wimpy Nodes”) approach, overall, are “substantially more energy efficient than conventional high-performance CPUs” at the same level of performance.
The Meek Shall Inherit The Earth
A single rack of these units would boast 1,024 individual servers (1 CPU per server), 2,048 cores (total of 3,400 GHz of compute), 4.1TB of DRAM, and 256TB of storage using 1TB SATA drives, and communicate at 1.28Tbps at a cost of around half a million dollars (< $500 per server).$500/server – really? Yup.
Now, let’s briefly consider the power issue. SeaMicro saves power through a couple of key innovations. First, they’re using these low power chips. But CPU power is typically only 1/3 of the load in a traditional server. To get real savings, they had to build custom ASICs and FPGAs to get 90% of the components off of a typical motherboard (which is now the size of a credit card, with 4 of them on each “blade”). Aside from capacitors, each motherboard has only three types of components – the Atom CPU, DRAM, and the SeaMicro ASIC. The result is 75% less power per server. Google has stated that, even at their scale, the cost of electricity to run servers exceeds the cost to buy them. Power and space consumes >75% of data center operating expense. If you save 75% of the cost of electricity and space, these servers pay for themselves – quickly.
If someone just gave you 256 1U traditional servers to run – for free – it would be far more expensive than purchasing and operating the SeaMicro servers.
Think about it.
Why would anybody buy traditional Xeon-based servers for web farms ever again? As the saying goes, you’d have to pay me to take a standard server now.
This is why I predict that, subject to supply chain capacity, more than 50% of new data center servers will be based on this model in the next 4-5 years.
Atoms and Applications
So let’s dig a bit deeper into the specifics of these 256 servers and how they might impact application architectures. Each has a dual-core 1.66GHz 64-bit Intel Atom N570 processor with 4GB of DRAM. These are just about ideal Web servers and, according to Intel, the highest performance per watt of any Internet workload processer they’ve every built.They’re really ideal “everyday” servers that can run a huge range of computing tasks. You wouldn’t run HPC workloads on these devices – such as CAD/CAM, simulations, etc. – or a scale-up database like Oracle RAC. My experience is that 4GB is actually a fairly typical VM size in an enterprise environment, so it seems like a pretty good all-purpose machine that can run the vast majority of traditional workloads.
They’d even be ideal as VDI (virtual desktop servers) where literally every running Windows desktop would get their own dedicated server. Cool!
Forrester’s James Staten, in a keynote address at CloudConnect 2011, recommended that people write applications that use many small instances when needed vs. fewer larger instances, and aggressively scale down (e.g. turn off) their instances when demand drops. That’s the best way to optimize economics in metered on-demand cloud business models.
So, with a little thought there’s really no need for most applications to require instances that are larger than 4GB of RAM and 1.66GHz of compute. You just need to build for that.
And databases are going this way too. New and future “scale out” database technologies such as ScaleBase, Akiban, Xeround, dbShards, TransLattice, and (at some future point) NimbusDB can actually run quite well in a SeaMicro configuration, just creating more instances as needed to meet workload demand. The SeaMicro model will accelerate demand for scale-out database technologies in all settings – including the enterprise.
In fact, some enterprises are already buying SeaMicro units for use with Hadoop MapReduce environments. Your own massively scalable distributed analytics farm can be a very compelling first use case.
This model heavily favors Linux due to the far smaller OS memory footprint as compared with Windows Server. Microsoft will have to put Windows Server on a diet to support this model of data center or risk a really bad TCO equation. SeaMicro is adding Windows certification soon, but I’m not sure how popular that will be.
If I’m right, then it would seem that application architectures will indeed be impacted by this – though in the scheme of things it’s probably pretty minor and in line with current trends in cloud.
Virtualization? No Thank You… I’ll Take My Public Cloud Single Tenant, Please!
SeaMicro claims that they can support running virtualization hosts on their servers, but for the life of me I don’t know why you’d want to in most cases.What do you normally use virtualization for? Typically it’s to take big honking servers and chunk them up into smaller “virtual” servers that match application workload requirements. For that you pay a performance and license penalty. Sure, there are some other capabilities that you get with virtualization solutions, but these can be accomplished in other ways.
With small servers being the standard model going forward, most workloads won’t need to be virtualized.
And consider the tenancy issue. Your 4GB 1.66GHz instance can now run on its own physical server. Nobody else will be on your server impacting your workload or doing nefarious things. All of the security and performance concerns over multi-tenancy go away. With a 1.28 Tbps connectivity fabric, it’s unlikely that you’ll feel their impact at the network layer as well. SeaMicro claims 12x available bandwidth per unit of compute than traditional servers. Faster, more secure, what’s not to love?
And then there’s the cost of virtualization licenses. According to a now-missing blog post on the Virtualization for Services Providers blog (thank you Google) written by a current employee of the VCE Company, the service provider (VSPP) cost for VMware Standard is $5/GB per month. On a 4GB VM, that’s $240 per year – or 150% the cost of the SeaMicro node over three years! (VMware Premier is $15/GB, but in fairness you do get a lot of incremental functionality in that version). And for all that you get a decrease in performance having the hypervisor between you and the bare metal server.
Undoubtedly, Citrix (XenServer), RedHat (KVM), Microsoft (Hyper-V) and VMware will find ways to add value to the SeaMicro equation, but I suspect that many new approaches may emerge that make public clouds without the need for hypervisors a reality. As Feldman put it, SeaMicro represents a potential shift away from virtualization towards the old model of “physicalization” of infrastructure.
The SeaMicro approach represents the first truly new approach to data center architectures since the introduction of blades over a decade ago. You could argue – and I believe you’d be right – that low-power super-dense server clusters are a far more significant and disruptive innovation than blades ever were.
Because of the enormous decrease in TCO represented by this model, as much as 80% or more overall, it’s fairly safe to say that any prior predictions of future aggregate data center compute capacity are probably too low by a very wide margin. Perhaps even by an order of magnitude or more, depending on the price-elasticity of demand in this market.
Whew! This is some seriously good sh%t.
It’s the dawn of a new era in the data center, where the ants will reign supreme and will carry on their backs an unimaginably larger cloud than we had ever anticipated. Combined with hyper-efficient cloud operating models, information technology is about to experience a capacity and value-enablement explosion of Cambrian proportions.
What should you do? Embrace the ants as soon as possible, or face the inevitable Darwinian outcome.
The ants go marching one by one, hurrah, hurrah…


Yung Chou posted Chou’s Theories of Cloud Computing: The 5-3-2 Principle to the TechNet blogs on 3/3/2011 (missed when published):
For discussing cloud computing, I recommend employing the following theories as a baseline.
Theory 1: You can not productively discuss cloud computing without first defining what it is.
The fact is that cloud computing is confusing since everyone seems to have a different definition of cloud computing. Notice the issue is not lack of definitions, nor the need for having an agreed definition. The issue is not having a well-thought-out, i.e. good, definition to operate upon. And without a good definition, a conversation of cloud computing will be non-productive since cloud computing touches infrastructure, architecture, development, deployment, operations, automation, optimization, manageability, cost, and very area of IT. And as explained below, it is indeed a transformation and generational shift of our computing platform from desktop to cloud. Without a good definition of cloud computing, a conversation of the subject will result in nothing more than an academic exercise.
Theory 2: The 5-3-2 principle defines the essence and scopes the subject domain of cloud computing.
Employ the 5-3-2 principle as a message framework to facilitate the discussions and improve the awareness of cloud computing. The description of cloud computing is however up to individuals to articulate. Staying with this framework will keep a cloud conversation aligned with the business values which IT is expected to and should deliver in a cloud solution.
Theory 3: The 5-3-2 principle of cloud computing describes the 5 essential characteristics, 3 delivery methods, and 2 deployment models of cloud computing.
The 5 characteristics of cloud computing, shown below, are the required attributes for an application to be classified as a cloud application. These are the differentiators. Questions like “I am running application X, do I still need cloud?” can be clearly answered by determining if these characteristics are needed.
The 3 delivery methods of cloud computing, as shown below, are the frequently heard: Software as a Service, Platform as a Service, and Infrastructure as a Service, namely SaaS, PaaS, and IaaS respectively. Here, a key is to first understand “what is a service.” All 3 delivery methods are presented as services in the context of cloud computing. Without a clear understanding of what is service, there is a danger of not grasping the fundamentals and becoming off-base.
The 2 deployment methods of cloud computing are public cloud and private cloud. Public cloud is the Internet and private cloud is a cloud (and notice a cloud should exhibit the 5 characteristics) which is dedicated to an organization. Private cloud although frequently assumed inside a private data center, as depicted below, can be on premises or hosted off premises by a 3rd party.
The 5-3-2 principle is a simple, structured, and disciplined way of conversing cloud computing. 5 characteristics, 3 delivery methods, and 2 deployment models explain the key aspects of cloud computing. A cloud discussion is to focus on how to deliver and maximize the 5 characteristics with the architecture, automation, optimization, etc. of a service delivered by SaaS, PaaS, or IaaS, regardless it is deployed in public cloud or private cloud. Under the framework provided by the 5-3-2 principle, now there is a structured way to navigate through the maze of cloud computing and define a path to an ultimate cloud solution. Cloud computing will be clear and easy to understand with the 5-3-2 principle as following:





<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Eric Knorr reported “Trend Micro CEO Eva Chen talks about the challenges facing enterprise security in the era of the cloud” in a deck for his What cloud security really means post to InfoWorld’s Security Central blog of 3/14/2011:
You can look at cloud security in two ways. For customers, cloud security means facing down added uncertainty and risk -- whether you're talking about the public or the private cloud, data moves across virtual machines and shared resources, increasing exposure. For vendors, on the other hand, cloud security means a massively scalable architecture to ramp up security technology in the endless war on threats.
Eva Chen, CEO of Trend Micro, makes it her business to address both sides of the cloud security equation. In a conversation with InfoWorld's Doug Dineley and me last week, she went to the whiteboard and dove right into virtualization security: "I think there are two challenges. First, there's the traditional security agent in a virtualization environment: What is the impact and how do you optimize it to make it work? Second, in a virtualization environment, what kind of new security challenges will you have?"
The first problem, says Chen, is that you can't have conventional antimalware technology running in every VM -- the I/O bandwidth required is too prohibitive. Instead, Trend Micro has created an agent that integrates with VMware to protect every virtual machine on the host.
That agent (and all other Trend Micro agents) connects to the company's Smart Protection Network, a reputation-based system that identifies malware, spam, and malicious websites, allowing the agent to intervene before they can prey on the client. This is the "supply side" of cloud security; Symantec, Webroot, and others have launched similar reputation-based plans using global networks of data centers. In Trend Micro's case, the company has pushed a considerable portion of the scanning process from the client to the cloud.
Another risk factor is multitenancy. Shared cloud infrastructure poses its own risk -- data supposedly deleted may inadvertently persist where it can be accessed by others, for example, or intruders posing as customers may discover ways to pry into other customers' data. Chen's answer to this is persistent public/private key encryption to protect cloud data -- and she believes that as we move into the cloud era, persistent data encryption will become the default. She may be right -- we're already at a point where the processing power is there.
Chen includes mobile devices as part of the cloud totality -- and as you've heard a million times by now, enterprises consider the proliferation of mobile devices as one of the greatest security threats. The ultimate answer to the challenge of mobile security, says Chen, must be a mobile gateway where you can enforce security policy down to the level of device capability (not allowing a camera to function, for example). That capability isn't available from Trend Micro or anyone else at this point, but the industry players are working on it.
Trend Micro was among the first vendors to build a reputation-based security network in the cloud. But Chen is determined to go beyond that. "Now we are going to securing the cloud," she asserts. "When customers want to use the cloud infrastructure or cloud application or storage, then how do we provide a tool to enable them to do that? That is our next journey to the cloud."
<Return to section navigation list>
Cloud Computing Events
• The Windows Azure Team suggested on 3/15 that you Register Now for Webinar This Thursday, March 17, "Windows Azure CDN - New Features":
Click here to learn more about this session and to register.
David Pallman (@davidpallman) announced his Webcast: Windows Azure Compute Architecture will occur on 3/16/2011 at 10:00 to 11:00 AM PDT:
Tomorrow (Wed 3/16/11) I'll be giving the first in a series of public webcasts on Windows Azure architecture. This initial webcast is on Windows Azure Compute.
In this webcast Windows Azure MVP and author David Pallmann will discuss the architecture of the Windows Azure Compute service, the area of the Windows Azure platform responsible for hosting. You'll learn why the execution environment in the cloud is different from the enterprise, pitfalls to avoid, and strengths you can leverage to your advantage. The session will include a tour of compute design patterns, along with demonstrations.
REGISTER
Windows Azure Compute Architecture Webcast
Wed., March 16, 2011
10:00 AM - 11:00 AM Pacific Time
• Mary Jo Foley (@maryjofoley) reported PDC 2011 will be held in Seattle and include a best Windows Azure appliation contest in her Microsoft PDC 2011: Seattle or bust? post of 3/15/2011 to ZDNet’s All About Microsoft blog:
I’ve mentioned previously that I’ve heard from various contacts of mine that Microsoft will hold another Professional Developers Conference (PDC) this year, most likely in September.
Now there’s new evidence — courtesy of the Microsoft India Web site — that this year’s PDC will be in Seattle again, as last year’s was. A contest for the best new Windows Azure applications will reward the top six creators all-expenses-paid trips to the PDC 2011 in Seattle, according to the Web site.

Microsoft has yet to announce officially if and when it plans to hold PDC this year. I’d guess the lack of information is related to Windows 8, something else the Softies still have said nothing about officially. I’ve noted that there’s been speculation that Microsoft is planning to deliver a first test build of Windows 8 at this year’s PDC.The PDC is held regularly, though not annually. The target audience is professional developers and software architects who build for Microsoft’s various platforms, including Windows, Windows Azure and Windows Phone. In the past few years, Microsoft has held PDCs in 2003 (Los Angeles), 2005 (Los Angeles), 2008 (Los Angeles), 2009 (Los Angeles) and 2010 (Seattle). The planned 2007 PDC was cancelled.
Back to the Azure developers contest with the PDC 2011 prize. It’s open to amateur and professional developers. Registrations must be completed by April 15, and entries must be received by April 30. Winners are slated to be announced by July 31, 2011.
I’ve asked Microsoft officials again for dates and the location of this year’s expected PDC. No word back so far. If/when I hear back, I’ll update this post.
Update: “Sorry, not commenting,” a Microsoft spokesperson responded to my inquiry via e-mail.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Jeffrey Schwartz (@JeffreySchwartz) reported HP Announces Big Plans for the Cloud in a 3/15/2011 post to Virtualization Review:
At Monday's annual HP analyst meeting, CEO Leo Apotheker announced that Hewlett-Packard Co. plans to launch a public cloud service.
The cloud, connectivity and software are integral to HP's strategy, Apotheker told analysts at the HP Summit 2011 event held in San Francisco. It was the first public appearance by Apotheker since he became CEO more than four months ago.
Observers have eagerly awaited Apotheker's remarks. Since taking over the top spot at HP after the abrupt departure of former CEO Mark Hurd, Apotheker has avoided public statements regarding the company's future strategy. Indeed, as expected, Apotheker's key message focused on his desire for HP to march forward into the cloud.
"We intend to be the platform for cloud and connectivity," Apotheker told analysts. "The opportunities in the cloud are extraordinary and we are positioned to lead with our portfolio and to lead with our customers who need a trusted partner to help navigate the journey ahead."
Apotheker talked of a world where end user devices are context-aware and the cloud becomes a point of convergence between those devices and the datacenter bringing together both personal and business information.
Still, he sees many customers embracing hybrid cloud infrastructures where data resides in datacenters but compute and storage and platform services come from a variety of sources, both internally and externally.
"Different customers will make this journey at different speeds. For many large enterprises, a hybrid environment, that combines traditional private and public cloud will be the pervading technology mode for a long, long time," he said.
HP executives suggested that the company has had this cloud strategy in place for some time. Indeed, the company in late January outlined its enterprise cloud strategy with the launch of its HP Enterprise Cloud Services-Compute and CloudSystem. With ECS Compute, enterprises will be able to provision their own servers through HP's outsourcing services, while CloudSystem is a premises-based turnkey cloud offering based on HP's BladeSystem Matrix hardware.
That said, Apotheker said HP is seeing increasing demand for a public cloud service. The service will initially appear in the form of a storage offering toward the end of this year or early next year, said chief technology officer Shane Robinson. That will be followed by a compute service, he said. Ultimately HP will offer platform-as-a-service.
"This is really driven by demand from our enterprise customers. Many of our enterprise customers are asking us to please provide this extension to what they're doing in their private cloud space, so they can seamlessly burst into a public cloud offering and deal with their peaks and loads and demands," Robinson said.
He said HP will build it using its intellectual property plus it will rely on partnerships. "We're not trying to do everything ourselves but we've got some really interesting things to bring to the party here," Robinson said. "We're going to enable an HP ecosystem of customers and partners and one of our key differentiators will be security and management controls. There's going to be a lot of focus on ease of use and we think there's some really interesting enterprise opportunities in the billing space and other normal business process support software applications so we can really engage with big enterprise customers."
HP also plans to launch a cloud marketplace that will be open to developers of consumer apps and an enterprise service catalog. The webOS platform will enable its connectivity strategy between devices and the cloud.
Todd Bradley, executive vice president of HP's Personal Systems Group, talked up an ambitious game plan for webOS, the operating system the company gained when it acquired Palm Inc. last year. In addition to powering a new crop of phones launched last month and a forthcoming tablet device, Bradley outlined plans for offering it with PCs and printers.
"The development teams across HP are working to bring the webOS experience to the Windows PCs," Bradley said, adding, "next year we will migrate tens of millions of Web connected printers into the ecosystem."
Bradley described webOS as the basis of HP's "connected ecosystem" for third-party and enterprise developers alike to build and share their applications through the marketplace. Synergy, the synchronization engine of webOS, is key in merging the information that resides on various devices and the cloud, Bradley said.
"We're open to both consumer and enterprise developers, content owners and service providers, and our catalog will support custom views of enterprise applications. We're making it as easy for these developers to participate in the growth of our ecosystem," Bradley said.
"With webOS, developers can now write an application once and deploy it across multiple applications, smart phones, TouchPads [and ultimately PCs]. They have unique integration opportunities that no other platform offers."
Lastly, Apthotheker talked up the pending acquisition of Vertica Systems, which will give it a big push into the business intelligence and analytics market. The company will offer the technology in a ready-made appliance offered in quarter, half and full rack configurations consisting of its BladeSystem Matrix hardware.
"Vertica brings big data analytics in real time, and the converged infrastructure delivers us a ready to go appliance with the shortest time to solution," Apotheker said. The company intends to offer the technology in the form of software and software-as-a-service, as well.
Still no mention of HP’s intentions for delivering the Windows Azure Platform Appliance (WAPA) per the company’s agreement with Microsoft announced at the Microsoft Worldwide Partner Conference last year.
Jeffrey Schwartz is executive editor of Redmond Channel Partner and an editor-at-large at Redmond magazine.
Full disclosure: Virtualization Review is an 1105 Media property and I’m a contributing editor for Visual Studio Magazine, which also is owned by 1105 Media.
Chris Hoff (@Beaker) analyzed AWS’ New Networking Capabilities – Sucking Less ;) on 3/15/2011:
I still haven’t had my coffee and this is far from being complete analysis, but it’s pretty darned exciting…
One of the biggest challenges facing public Infrastructure-as-a-Service cloud providers has been balancing the flexibility and control of datacenter networking capabilities against that present in traditional data center environments.
I’m not talking about complex L2/L3 configurations or converged data/storage networking topologies; I’m speaking of basic addressing and edge functionality (routing, VPN, firewall, etc.) Furthermore, interconnecting public cloud compute/storage resources in a ‘private, non-Internet facing role) to a corporate datacenter has been less than easy.
Today Jeff Barr ahsploded another of his famous blog announcements [see below], which goes a long way solving not only these two issues, but clearly puts AWS on-track for continuing to press VMware on the overlay networking capabilities present in their vCloud Director vShield Edge/App model.
The press release (and Jeff’s blog) were a little confusing because they really focus on VPC, but the reality is that this runs much, much deeper.
I rather liked Shlomo Swidler’s response to that same comment to me on Twitter
This announcement is fundamentally about the underlying networking capabilities of EC2:
Today we are releasing a set of features that expand the power and value of the Virtual Private Cloud. You can think of this new collection of features as virtual networking for Amazon EC2. While I would hate to be innocently accused of hyperbole, I do think that today’s release legitimately qualifies as massive, one that may very well change that way that you think about EC2 and how it can be put to use in your environment.
The features include:
- A new VPC Wizard to streamline the setup process for a new VPC.
- Full control of network topology including subnets and routing.
- Access controls at the subnet and instance level, including rules for outbound traffic.
- Internet access via an Internet Gateway.
- Elastic IP Addresses for EC2 instances within a VPC.
- Support for Network Address Translation (NAT).
- Option to create a VPC that does not have a VPC connection.
You can now create a network topology in the AWS cloud that closely resembles the one in your physical data center including public, private, and DMZ subnets. Instead of dealing with cables, routers, and switches you can design and instantiate your network programmatically. You can use the AWS Management Console (including a slick new wizard), the command line tools, or the APIs. This means that you could store your entire network layout in abstract form, and then realize it on demand.
That’s pretty bad-ass and goes along way toward giving enterprises a not-so-gentle kick in the butt regarding getting over the lack of network provisioning flexibility. This will also shine whcn combined with the VMDK import capabilities — which are albeit limited today from a preservation of networking configuration. Check out Christian Reilly’s great post “AWS – A Wonka Surprise” regarding how the VMDK-Import and overlay networking elements collide. This gets right to the heart of what we were discussing.
Granted, I have not dug deeply into the routing capabilities (support for dynamic protocols, multiple next-hop gateways, etc.) or how this maps (if at all) to VLAN configurations and Shlomo did comment that there are limitations around VPC today that are pretty significant: “AWS VPC gotcha: No RDS, no ELB, no Route 53 in a VPC and “AWS VPC gotcha: multicast and broadcast still doesn’t work inside a VPC,” and “No Spot Instances, no Tiny Instances (t1.micro), and no Cluster Compute Instances (cc1.*)” but it’s an awesome first step that goes toward answering my pleas that I highlighted in my blog titled “Dear Public Cloud Providers: Please Make Your Networking Capabilities Suck Less. Kthxbye”
Thank you, Santa.
On Twitter, Dan Glass’ assessment was concise, more circumspect and slightly less enthusiastic — though I’m not exactly sure I’d describe my reaction as that bordering on fanboi:
…to which I responded that clearly there is room for improvement in L3+ and security. I expect we’ll see some
In the long term, regardless of how this was framed from an announcement perspective, AWS’ VPC as a standalone “offer” should just go away – it will just become another networking configuration option.
While many of these capabilities are basic in nature, it just shows that AWS is paying attention to the fact that if it wants enterprise business, it’s going to have to start offering service capabilities that make the transition to their platforms more like what enterprises are used to using.
Great first step.
Now, about security…while outbound filtering via ACLs is cool and all…call me.
/Hoff
P.S. As you’ll likely see emerging in the comments, there are other interesting solutions to this overlay networking/connectivity solution – CohesiveF/T and CloudSwitch come to mind…
Related articles
- AWS – A Wonka Surprise ? (cloudave.com)
- The Benefits of a Virtualized Approach to Advanced-Level Network Services (blogs.cisco.com)
- VMware on Amazon Web Services or How the Cloud Becomes a Data Fabric (readwriteweb.com)
- CloudSwitch: Traitor To the [Public Cloud] Cause… (rationalsurvivability.com)
- CloudPassage & Why Guest-Based Footprints Matter Even More For Cloud Security (rationalsurvivability.com)
- Revisiting Virtualization & Cloud Stack Security – Back to the Future (Baked In Or Bolted On?) (rationalsurvivability.com)
- How VMware Differs from Amazon Web Services in its Approach to Importing Virtual Machines (readwriteweb.com)
- Amazon Launches CloudFormation To Simplify App Deployment (informationweek.com)


Image by Wikipedia.
Jeff Barr (@jeffbarr) announced A New Approach to Amazon EC2 Networking on 3/14/2011:
You've been able to use the Amazon Virtual Private Cloud to construct a secure bridge between your existing IT infrastructure and the AWS cloud using an encrypted VPN connection. All communication between Amazon EC2 instances running within a particular VPC and the outside world (the Internet) was routed across the VPN connection.
Today we are releasing a set of features that expand the power and value of the Virtual Private Cloud. You can think of this new collection of features as virtual networking for Amazon EC2. While I would hate to be innocently accused of hyperbole, I do think that today's release legitimately qualifies as massive, one that may very well change the way that you think about EC2 and how it can be put to use in your environment.
The features include:
- A new VPC Wizard to streamline the setup process for a new VPC.
- Full control of network topology including subnets and routing.
- Access controls at the subnet and instance level, including rules for outbound traffic.
- Internet access via an Internet Gateway.
- Elastic IP Addresses for EC2 instances within a VPC.
- Support for Network Address Translation (NAT).
- Option to create a VPC that does not have a VPN connection.
You can now create a network topology in the AWS cloud that closely resembles the one in your physical data center including public, private, and DMZ subnets. Instead of dealing with cables, routers, and switches you can design and instantiate your network programmatically. You can use the AWS Management Console (including a slick new wizard), the command line tools, or the APIs. This means that you could store your entire network layout in abstract form, and then realize it on demand.
VPC Wizard
The new VPC Wizard lets you get started with any one of four predefined network architectures in under a minute:
The following architectures are available in the wizard:
- VPC with a single public subnet - Your instances run in a private, isolated section of the AWS cloud with direct access to the Internet. Network access control lists and security groups can be used to provide strict control over inbound and outbound network traffic to your instances.
- VPC with public and private subnets - In addition to containing a public subnet, this configuration adds a private subnet whose instances are not addressable from the Internet. Instances in the private subnet can establish outbound connections to the Internet via the public subnet using Network Address Translation.
- VPC with Internet and VPN access - This configuration adds an IPsec Virtual Private Network (VPN) connection between your VPC and your data center – effectively extending your data center to the cloud while also providing direct access to the Internet for public subnet instances in your VPC.
- VPC with VPN only access - Your instances run in a private, isolated section of the AWS cloud with a private subnet whose instances are not addressable from the Internet. You can connect this private subnet to your corporate data center via an IPsec Virtual Private Network (VPN) tunnel.
You can start with one of these architectures and then modify it to suit your particular needs, or you can bypass the wizard and build your VPC piece-by-piece. The choice is yours, as is always the case with AWS.
After you choose an architecture, the VPC Wizard will prompt you for the IP addresses and other information that it needs to have in order to create the VPC:
Your VPC will be ready to go within seconds; you need only launch some EC2 instances within it (always on a specific subnet) to be up and running.
Route Tables
Your VPC will use one or more Route Tables to direct traffic to and from the Internet and VPN Gateways (and your NAT instance, which I haven't told you about yet) as desired., based on the CIDR block of the destination. Each VPC has a default, or main routing table. You can create additional routing tables and attach them to individual subnets if you'd like:
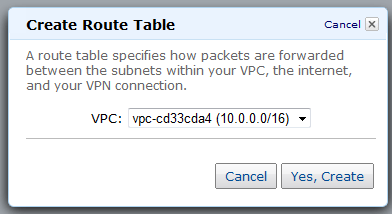
Internet Gateways
You can now create an Internet Gateway within your VPC in order to give you the ability to route traffic to and from the Internet using a Routing Table (see below). It can also be used to streamline access to other parts of AWS, including Amazon S3 (in the absence of an Internet Gateway you'd have to send traffic out through the VPN connection and then back across the public Internet to reach S3).
Network ACLs
You can now create and attach a Network ACL (Access Control List) to your subnets if you'd like. You have full control (using a combination of Allow and Deny rules) of the traffic that flows in to and out of each subnet and gateway. You can filter inbound and outbound traffic, and you can filter on any protocol that you'd like:
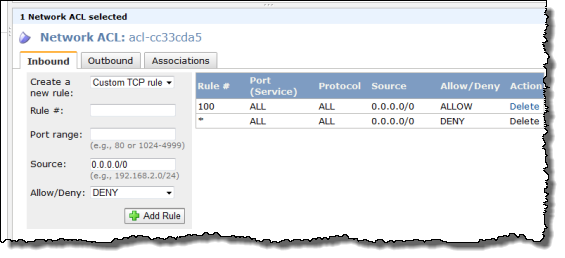
You can also use AWS Identity and Access Management to restrict access to the APIs and resources related to setting up and managing Network ACLs.
Security Groups
You can now use Security Groups on the EC2 instances that your launch within your VPC. When used in a VPC, Security Groups gain a number of powerful new features including outbound traffic filtering and the ability to create rules that can match any IP protocol including TCP, UDP, and ICMP.You can also change (add and remove) these security groups on running EC2 instances. The AWS Management Console sports a much-improved user interface for security groups; you can now make multiple changes to a group and then apply all of them in one fell swoop.
Elastic IP Addresses
You can now assign Elastic IP Addresses to the EC2 instances that are running in your VPC, with one small caveat: these addresses are currently allocated from a separate pool and you can't assign an existing (non-VPC) Elastic IP Address to an instance running in a VPC.
NAT Addressing
You can now launch a special "NAT Instance" and route traffic from your private subnet to it in. Doing this allows the private instances to initiate outbound connections to the Internet without revealing their IP addresses. A NAT Instance is really just an EC2 instance running a NAT AMI that we supply; you'll pay the usual EC2 hourly rate for it.ISV Support
Several companies have been working with these new features and have released (or are just about to release) some very powerful new tools. Here's what I know about:
The OpenVPN Access Server is now available as an EC2 AMI and can be launched within a VPC. This is a complete, software-based VPN solution that you can run within a public subnet of your VPC. You can use the web-based administrative GUI to check status, control networking configuration, permissions, and other settings.
CohesiveFT's VPN-Cubed product now supports a number of new scenarios.
By running the VPN-Cubed manager in the public section of a VPC, you can connect multiple IPsec gateways to your VPC.You can even do this using security appliances from vendors like Cisco, ASA, Juniper, Netscreen, and SonicWall, and you don't need BGP.
VPN-Cubed also lets you run grid and clustering products that depend on support for multicast protocols.
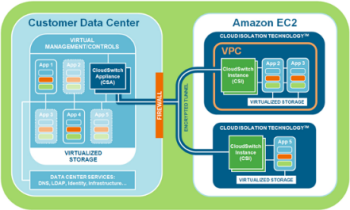
CloudSwitch further enhances VPC's security and networking capabilities. They support full encryption of data and rest and in transit, key management, and network encryption between EC2 instances and between a data center and EC2 instances. The net-net is complete isolation of virtual machines, data, and communications with no modifications to the virtual machines or the networking configuration.
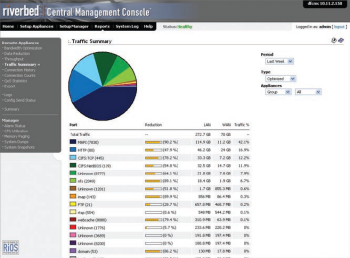
The The Riverbed® Cloud Steelhead® extends Riverbed’s WAN optimization solutions to the VPC, making it easier and faster to migrate and access applications and data in the cloud. Available on an elastic, subscription-based pricing model with a portal-based management system.
Pricing
I think this is the best part of the Virtual Private Cloud: you can deploy a feature-packed private network at no additional charge! We don't charge you for creating a VPC, subnet, ACLs, security groups, routing tables, or VPN Gateway, and there is no charge for traffic between S3 and your Amazon EC2 instances in VPC. Running Instances (including NAT instances), Elastic Block Storage, VPN Connections, Internet bandwidth, and unmapped Elastic IPs will incur our usual charges.
Internet Gateways in VPC has been a high priority for our customers, and I’m excited about all the new ways VPC can be used. For example, VPC is a great place for applications that require the security provided by outbound filtering, network ACLs, and NAT functionality. Or you could use VPC to host public-facing web servers that have VPN-based network connectivity to your intranet, enabling you to use your internal authentication systems. I'm sure your ideas are better than mine; leave me a comment and let me know what you think!

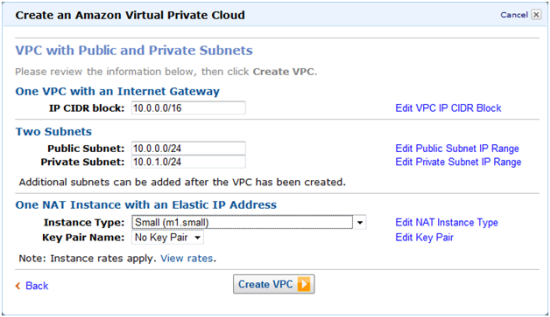
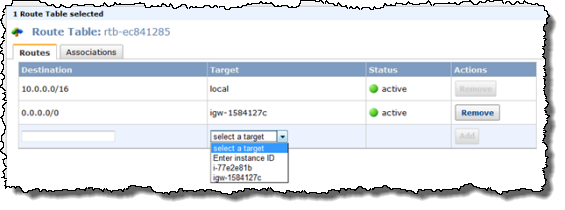
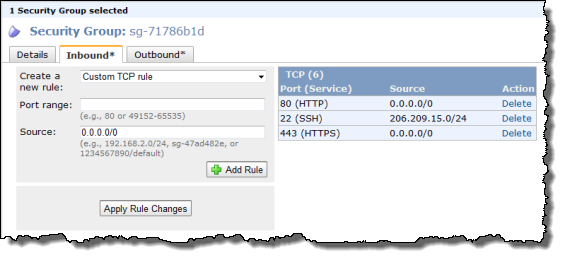
Matthew Weinberger reported Cloud.com Upgrades to 2.2, Promotes Hybrid Cloud in a 3/15/2011 post to the TalkinCloud blog:
Cloud.com‘s CloudStack, the open source cloud platform for public and private infrastructure-as-a-service clouds, has been upgraded to version 2.2. New in this release are better hypervisor support, advanced networking configurations, borderless scalability, streamlined administration, and – continuing a major Cloud.com trend for 2011 — hybrid cloud readiness. And apparently, that’s in addition to a hundred additional usability and functionality tweaks.
Here’s a point-by-point look at the new features in the Cloud.com CloudStack 2.2 release, with details taken from the official press release:
- Advanced Networking Configuration: By using the latest networking features like embedded software-based network management, VLAN and Direct Attach IP, administrators can get finer control over physical and virtual network integration.
- Borderless Scalability: CloudStack-powered clouds can now manage and federate infrastructure that’s geographically dispersed among different data centers. The CloudZones tool helps manage those different availability zones.
- Hypervisor Independence: The press release puts it better than I could: “CloudStack 2.2 comes with out-of-the-box support for VMware vSphere 4, Citrix XenServer 5.6 and the open source Kernel-based Virtual Machine (KVM) running simultaneously in a single cloud.”
- Streamlined Administration: A new, AJAX-powered web interface makes it easier to manage even thousands of guest VMs, with role-based access delegation giving self-service flexibility.
- Hybrid Cloud Ready: Cloud.com has included the new CloudBridge tool, which enables private cloud applications to interoperate with the Amazon EC2 compute cloud and Amazon S3 storage cloud, creating a true hybrid solution. And when the OpenStack API releases soon, CloudBridge will support that, too. And Cloud.com is leveraging their existing partnership with platform-agnostic cloud management vendor RightScale to help administrators keep it all under control.
Cloud.com’s made waves in the cloud services market of late, powering no less than two major public cloud offerings and contributing to the ever-growing OpenStack project.
Jonathan Feldman asserted “The open source cloud project known as OpenStack has been in the spotlight recently, thanks in part to corporate support from Rackspace. While such support is often necessary for projects like OpenStack, questions remain about the company's role in governing it” in a deck for his OpenStack Governance, Rackspace Stacked article of 3/15/2011 for InformationWeek:
Last week's Cloud Connect event prominently featured the OpenStack initiative. Elsewhere, the OpenStack page asked: "If there are other open source cloud projects, why start a new one?" Problem is, there are two answers on the OpenStack site, one of which makes it clear that Rackspace is driving the OpenStack bus, while the other is more toned down.
Here's the toned down version from the OpenStack FAQ:
We wanted a community where people with similar philosophies about cloud architecture and open-source software can openly collaborate together. We believe in open source, open design, open development and an open community that is fully transparent‹not a cathedral, a bazaar.
Sounds good. Now, here's the corporate Rackspace version from the Project page:
We've been eagerly watching these projects emerge, but unfortunately we've found most of them incapable of dealing with the tremendous scale we require. The one exception we found was the code that powers NASAs Nebula cloud. Rackspace and NASA share similar problems, including the need to manage huge datasets and thousands of instances of compute. With similar philosophies about cloud architecture and open source software, it was an easy decision to combine our projects into one new effort, now called OpenStack.
Which is it? The Rackspace-NASA effort combined into one new project, or an open-source, politically-correct "not a cathedral, a bazaar?"
All initiatives need funding. An effort like OpenOffice needed Sun's sponsorship to succeed; many initiatives have failed because they lacked financial and in-kind support, even if that in-kind support is permission for employees to work on the effort. In many ways, having Rackspace drive OpenStack could mean good news for the pragmatic shepherds of standards-based cloud computing.
But sometimes the balance between corporate support and pro bono is precarious. To wit: Cloud Connect also featured Rackspace Enterprise Strategy VP Andy Schroepfer as a keynote speaker; suddenly Rackspace was not only talking about Rackspace's "fanatical support" for their customers, but also exhibiting "fanatical salesmanship." (Check the #ccevent Twitter stream; the perception was that Schroepfer was over the top, selling from the stage instead of providing key insights for attendees. You can also watch Schrepfer's talk by clicking "play" in the video embedded below.)
Nebula was a carefully conceived and functional NASA effort dating back to 2009, well before the July 2010 announcement that Rackspace would be folding the Nebula technology into the OpenStack effort. The question is will the governance of OpenStack allow the community to steer the project, or will Rackspace exercise domination, acting like Oracle did governing OpenOffice. It's too early to tell; the absorption of Nebula occurred less than a year ago. But the governance of the project policy board, which includes four Rackspace appointees (along with five other elected members), seems a bit Rack-heavy for a project that enthusiastically states: "Backed by Rackspace, NASA, Dell, Citrix, Cisco, Canonical and over 50 other organizations."
Matthew Weinberger announced Gluster Signs On With OpenStack in a 3/15/2011 post to the TalkinCloud blog:
Gluster, which develops scale-out NAS solutions for public and private clouds, is the latest company to join the OpenStack community. As contributing developers, Gluster hopes to enhance the OpenStack Storage project with redundancy, better scale, and higher redundancy. The company is planning to present its first code contribution as soon as the OpenStack Developer Conference in April 2011.
When OpenStack’s most recent release dropped in early 2011, industry heavyweights like Cisco had thrown their support behind it. With over 50 developer partners already listing themselves as members of the OpenStack Alliance, Gluster is in good company.
Gluster itself is potentially a good fit for the OpenStack Alliance, given that the company is no stranger to both the cloud and open source. Gluster has already partnered with fellow OpenStack contributor RightScale for more manageable cloud storage, and the company has released Amazon Web Services-ready virtual appliances. Plus Gluster’s solutions are open source.
Still, we’re curious to see whether Rackspace rivals embraces OpenStack, since doing so requires cooperation amid competition.
<Return to section navigation list>

















{kind=link}
{kind=link}
0 comments:
Post a Comment