Windows Azure and Cloud Computing Posts for 3/1/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Updated 3/2/2011 11:30 AM with additional 3/1/2011 articles marked •
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
I (@rogerjenn) recommended “Get ready to scale out SQL Azure databases beyond today's 50GB limit with the Transact-SQL and ADO.NET elastic sharding features, which are coming in the 2011 SQL Azure Federation Community Technology Previews” in a deck for my Build Big-Data Apps in SQL Azure with Federation cover article for Visual Studio Magazine’s March 2011 issue:
An urban myth that relational databases and SQL can't achieve Internet-scale of terabytes -- or petabytes -- has fostered a growing "NoSQL" developer community and a raft of new entity-attribute-value, also known as key value, data stores. The Microsoft SQL Azure team gave credence to the myth by limiting the maximum size of the initial Business Edition of the cloud database to just 10GB. SQL Azure adds a pair of secondary data replicas to assure high availability, and the team cited performance issues with replication as the early size-limiting factor.
Today, you can rent a 50GB SQL Azure database for $499.95 per month, but the SQL Azure Team isn't talking publicly about future scale-up options. Instead, Microsoft recommends that you scale out your SQL Azure databases by partitioning them horizontally into smaller instances, called shards, running on individual SQL Azure database instances, and group the shards into federations.
Sharding increases database capacity and query performance, because each added SQL Azure database brings its own memory and virtual CPU. Microsoft Software Architect Lee Novik first described SQL Azure sharding details in his "Building Scale-Out Applications with SQL Azure" session at the Microsoft Professional Developers Conference 2010, held last October in Redmond.
Horizontal partitioning isn't new to SQL Server. Horizontally partitioning SQL Server 7.0 and later tables to multiple files and filegroups improves performance by reducing average table and index size. Placing each filegroup on an individual disk drive speeds T-SQL queries. Partitioning also streamlines backup and maintenance operations by reducing their time-window length.
SQL Server 2005 automated the process with the CREATE PARTITION FUNCTION command, which lets you automatically map the rows of a table or index into specified partitions based on the values of a specified column. You design a CREATE PARTITION SCHEME to determine how to assign partitioned files to filegroups. SQL Server partitioned views make rows of all partitions appear as a single table; distributed partitioned views enable partitioning data across multiple linked servers, not just filegroups, for scaling out. SQL Server 2000 introduced updateable distributed views with distributed transactions, and SQL Server 2000 SP3 used OLE DB to optimize query-execution plans for distributed partitioned views.
A group of linked servers that participates in distributed partitioned views is called a "federation." The partitioning column, whose values determine the partition to which the row belongs, must be part of the primary key and can't be an identity, timestamp or default column.
New Taxonomy
Scaling out SQL Azure with federated database instances follows a pattern similar to that for on-premises SQL Server, but is subject to several important limitations. For example, SQL Azure doesn't support linked servers, CREATE PARTITION FUNCTION, CREATE PARTITION SCHEME, cross-database joins, distributed (cross-database) transactions, OLE DB or the T-SQL NewSequentialID function. These restrictions require architectural changes for SQL Azure federations, starting with this new taxonomy:
- Federation consists of a collection of all SQL Azure database instances that contain partitioned data having the same schema. The T-SQL script in "How to Create a Federation with Customers, Orders and OrderItems Tables" shows a T-SQL script to create an Orders_Federation with a schema based on three tables of the Northwind sample database.
- Federation Members comprise the collection of SQL Azure databases that contain related tables with partitioned data, called Federated Tables. A Federation Member also can contain replicated lookup tables (Products) that provide supplementary data that's not dependent on the Federation Key.
- Federation Key is the primary key value (CustomerID) that determines how data is partitioned among Federated Tables, each of which must contain the Federation Key in their primary key, which can be a big integer (bigint, a 64-bit signed integer) or GUID (uniqueidentifier) data type. For example, the Orders and OrderItems tables have composite primary keys (OrderID + CustomerID and OrderID + ProductID + CustomerID, respectively).
- Atomic Unit (AU)is a cluster of a single parent table (Customers) row and all related rows of its dependent tables (Orders and OrderItems). AU clusters can't be separated in the partitioning (sharding) process or when moving data between Federation Members.
- Federation Root is the initial database that contains metadata for specifying the Partitioning (sharding) Method, range of valid values for the Federation Key, and minimum/maximum Federation Key value ranges for each Federation Member.
- Partitioning Method determines whether the Federation Key is generated by the application or the data tier. For this article's example, the data tier uniqueidentifier data type provides random 128-bit (16-byte) GUID values, which balance additions across multiple Federation Members. Sequential bigint values are easier to read, but require a feature similar to the SQL Server Denali Sequence object to generate identity values that are unique over multiple Federated Tables.
The SQL Azure Team plans to release SQL Azure Federation features in piecemeal fashion starting with a Community Technology Preview (CTP) of version 1 in 2011. The current plan is for the CTP 1 to support partitioning by uniqueidentifier FederationKey values only; a post-CTP 1 drop will add bigint FederationKeys (see Table 1).

• Amazon.com published an item on 3/1/2011 for Jayaram Krishnaswamy’s Microsoft SQL Azure Enterprise Application Development book from Pakt Publishing:

Sam Vanhoutte (@SamVanhoutte) posted Using SQL Azure Data Sync to his CODit blog on 3/1/2011:
Lately, a lot of CTP’s came available on the Windows Azure platform. My goal is to try them all out. I blogged on two of these technologies already:
This time, we’re getting on the data side, with SQL Azure Data Sync. This data synchronization service is built on the Microsoft Sync Framework technologies. It provides bi-directional data synchronization and data management capabilities allowing data to be easily shared across SQL Azure databases within multiple data centers.
A very good and detailed overview on Data Sync can be found on the TechNet Wiki: http://social.technet.microsoft.com/wiki/contents/articles/sql-azure-data-sync-overview.aspx
Scenarios
This SQL Azure Data Sync service is a very promising and interesting feature that opens a lot of great scenarios:
- For development/testing purposes: provide data in your local database (on development) and synchronize with the Azure database to feed the cloud instances.
- Synchronizing configuration or master data across databases in a very easy way.
- Use SQL Azure Reporting Services on ‘local’ data.
Registration for CTP
Since this feature is still in CTP, you need to register first to get an invitation code. To do all this, just browse to http://datasync.azure.com and sign in with your live id. After this, you can enter your e-mail and other details and you should receive an invitation code some time later. With that registration code, you can log on to the full features.
Concepts
The following concepts are important in setting up Data Sync:
- Sync group: a sync group is a group of databases that can be synchronized together
- Database: a database that gets registered for SQL Azure Data Sync
- Agent: an agent is a Windows Service that performs and orchestrates the actual synchronization
Configuring data synchronization
Step 1: download the Sync Agent
A Sync agent is only required when synchronizing data from an on-premise database. If the synchronization is set up from Cloud to Cloud, then it is not required to download the Agent, since the synchronization logic will be run in the Cloud.
For this example, I will synchronize a local database with a SQL Azure database.
On the Data Sync portal, click the Agents tab page and download the Agent installer at the bottom of the page. After running the installer (and providing credentials for the Data Sync windows service), you can open a local configuration tool, through the Start menu: SQL Azure Data Sync Agent CTP2.
This tool allows you to configure local databases for synchronization. The following screenshot shows the default configuration window, after installation. To join this agent to a Windows Azure subscription, it is important to configure the Agent Key first. This can be done by clicking the Edit Agent Key button and providing the key that can be copied from the Data Sync Portal.
Once this is configured, it should be possible to Ping the Azure Sync Service, by clicking the Ping Sync Service button.

Step 2: Add your local database
Now we have the local agent installed, we will add a local (on premise) database to the configuration tool, so that it can be synchronized later.
In this example, I am using a custom database with 3 tables: Customer, OrderLines, OrderEvents.

- I will add this database in the SQL Azure Data Sync Agent tool, by clicking the ‘Add Member’ button at the left. This pops up a configuration window where the server, database and the authentication method need to be selected. (1)
- The Data Sync services have some limitations on supported data types, etc. It is possible to check the database for issues, by clicking the ‘Check Member Schema’ button. (2).
- I added a field with an unsupported data type (geography) to the customer table and the Schema validation provided a warning that indicated that this column would be skipped. (3) This is because geography is not supported in Windows Azure at this point in time.
- It is very important to start the Windows Service of the Azure Data Sync Agent, in order to register the client database with the Windows Azure subscriptions.

Step 3: Add the SQL Azure database
Adding a SQL Server database to the Data Sync subscription is much easier and can be done on the Data Sync management portal, by clicking the Databases tab and clicking the Add button. In the pop up, you just need to provide the server, database and credentials, before saving.
In my example, I am just adding a new empty database, here.

Step 4: Set up the synchronization, through a Sync Group
- In the management portal, click the New Sync Group button in the Sync Groups tab. And add all the databases you want to synch together to the database list(1) and click Next.
- In the next screen, you can add the tables, per database that you want to synchronize. For this demo, I want to synchronize everything, except the events table. (2) You can also enable a schedule for the synchronization (expressed in minutes).
- Once the group is created, you can synchronize the group easily.


Testing the data synchronization
Now I have the databases configured for synchronization, it’s time to play around with it a bit. To execute the synchronization, you can either rely on the synchronization schedule , when configured on the Sync group, or you can manually trigger the synchronization.

1st synchronization: Creating tables in the cloud.
The first synchronization I did created the two synchronized tables on my empty Cloud database and added the data there. One thing to notice is that the Location column (with the spatial data type) was not created on the SQL Azure database.
2nd synchronization: Adding data locally, synchronizing to the cloud.
In this test, I added two customers and some order lines to the local database and synchronized with the Cloud database, to find out that everything was copied without problems.
3rd synchronization: Adding data in the cloud, synchronizing locally.
In this test, I added a customer to the cloud database and synchronized with the on premise database, to find out that everything was copied without problems.
4th synchronization: Adding data on premise and in the cloud, synchronizing bi-directionally
In this test, I added customers in both databases before synchronization to find out that the data was synchronized correctly.
Data conflicts
Now, I wanted to simulate some conflicts to find out how the Data Sync would handle them.
Adding or updating data in both databases, with the same primary key.
I added two different customers, but with the same primary key in both databases. But, surprisingly, the synchronization happened without any issue, but my local customer was overridden by the cloud customer, resulting in lost data.
- Both records (local + cloud) were normally marked as new, so it should be possible to detect this.
- I was looking to find out if the ‘most recent’ record won, but in all scenarios, the data from the cloud database survived the synchronization. (probably, because this database was added first)
Maybe something for a next CTP?
Deleting data that is being referenced by a non-synchronized table
Another interesting test was to delete an order line on my cloud database. But this order line was being referenced by a record in my local database (OrderEvent). Knowing that the OrderEvent table is not being synchronized, this should result in a conflict.
Here I did not receive an exception, but I also noticed that my record on my local database still existed, where my cloud record was deleted. So here my data was out of synch.
Maybe something for a next CTP?
Adding a third database
The last test I did, was adding a new empty (cloud) database to the sync group and after the synchronization, everything seemed to work automagically. Great!
Underlying design
- When configuring a table for synchronization, triggers are being created for the three actions: insert, update, delete. They have the following name structure: [TableName]_dss_[action]_trigger.
- These triggers add the data in new tables that are being created during configuration of the sync group. For every data table, a sync table is being added with the following name: DataSync.[TableName]_dss_tracking
- Next to that, we can also see that a lot of new stored procedures are getting created
Conclusion
This CTP looks already very stable and the sychronization (between multiple databases) is very smooth. I am just hoping that there will be a better view or configuration for synchronization exceptions (like explained in the conflicts section).









Yves Goeleven (@Yves Goeleven) reported NServiceBus on Sql Azure, sometimes stuff just works on 2/28/2011:
It just works
Microsoft has put a tremendous amount of effort into Sql Azure to ensure that it works the same way as Sql Server on premises does. The fruits of all this labor are now reaped by us, in order to persist NServiceBus data, such as subscriptions and saga’s for example, on Sql Azure all you got to do is change your connection string.
To show this off, I’ve included a version of the Starbucks sample in the trunk of NServiceBus which has been configured to store it’s information on Sql Azure. You may recall this sample from my previous article so I’m not going to explain the scenario again, I’ll just highlight the differences.
Configuring the sample
In order to configure NServiceBus for Sql Azure, you have to configure it as you would for Sql Server using the DBSubscriptionStorage and the NHibernateSagaPersister configuration settings for respectively subscriptions and saga’s:
Configure.With() .Log4Net() .StructureMapBuilder(ObjectFactory.Container) .AzureConfigurationSource() .AzureMessageQueue().XmlSerializer() .DBSubcriptionStorage() .Sagas().NHibernateSagaPersister().NHibernateUnitOfWork() .UnicastBus() .LoadMessageHandlers() .IsTransactional(true) .CreateBus() .Start();In your application configuration file you also need to include the NHibernate connection details using the DBSubscriptionStorageConfig and NHibernateSagaPersisterConfig configuration sections.
<section name="DBSubscriptionStorageConfig" type="NServiceBus.Config.DBSubscriptionStorageConfig, NServiceBus.Core" /> <section name="NHibernateSagaPersisterConfig" type="NServiceBus.Config.NHibernateSagaPersisterConfig, NServiceBus.Core" />Furthermore you need to provide the details for your NHibernate connection, like the connection provider, the driver, the sql dialect and finally your connection string. Be sure to format your connection string using the sql azure recognized format and naming conventions.
<DBSubscriptionStorageConfig> <NHibernateProperties> <add Key="connection.provider" Value="NHibernate.Connection.DriverConnectionProvider"/> <add Key="connection.driver_class" Value="NHibernate.Driver.SqlClientDriver"/> <add Key="connection.connection_string" Value="Server=tcp:[yourserver].database.windows.net;Database=NServiceBus;User ID=[accountname]@[yourserver];Password=[accountpassword];Trusted_Connection=False;Encrypt=True;"/> <add Key="dialect" Value="NHibernate.Dialect.MsSql2005Dialect"/> </NHibernateProperties> </DBSubscriptionStorageConfig> <NHibernateSagaPersisterConfig> <NHibernateProperties> <add Key="connection.provider" Value="NHibernate.Connection.DriverConnectionProvider"/> <add Key="connection.driver_class" Value="NHibernate.Driver.SqlClientDriver"/> <add Key="connection.connection_string" Value="Server=tcp:[yourserver].database.windows.net;Database=NServiceBus;User ID=[accountname]@[yourserver];Password=[accountpassword];Trusted_Connection=False;Encrypt=True;"/> <add Key="dialect" Value="NHibernate.Dialect.MsSql2005Dialect"/> </NHibernateProperties> </NHibernateSagaPersisterConfig>Alright, that was it, validate your other settings, like the azure storage account used as a transport mechanism and hit F5, it just works!
<Return to section navigation list>
MarketPlace DataMarket and OData
• Matt Stroshane (@mattstroshane) continued his series with Introducing the OData Client Library for Windows Phone, Part 2 on 3/1/2011:
This is the second part of the 3-part series, Introducing the OData Client Library. In today’s post, we’ll cover how to set up your application to use the proxy classes that were created in part one of the series. We’ll also cover visualizing the proxy classes and discuss the data service context and collection classes. This post is also part of the OData + Windows Phone blog series.
Prerequisites
Introducing the OData Client Library for Windows Phone, Part 1
How to Set Up Your Application
To set up your application, you need to configure references to two things: the proxy classes that you created in part one, and the OData client assembly named System.Data.Services.Client.dll.
Add Reference
The System.Data.Services.Client.dll assembly contains “helper” methods that allow you to work with your proxy classes. After you’ve unzipped the OData Client Library for Windows Phone download, you can add this assembly to your project just like any assembly. Open the Add Reference dialog by right-clicking the project in Solution Explorer and clicking Add Reference. From the Add Reference dialog, use the Browse tab to locate the file.

Add Reference to the OData Client Library for Windows Phone (click to zooom)
Note for VB apps, after adding a reference: In Solution Explorer, you’ll need to click the Show All Files button to see the References folder that contains the assembly System.Data.Services.Client.dll file.
Add Data Models
To add the proxy classes file, right-click the project again and select Add, and then Existing Item. Then, locate the generated code file, NorthwindModel.vb, and click Add. When you do this, Visual Studio makes a copy of the file and saves it in the project folder.
A Note about Namespace Differences
It’s important to note that the proxy classes do not have the same namespace as the client library assembly, System.Data.Services.Client.dll. Instead, the proxy classes namespace will be the same as the name that you gave the proxy class file. In this case, NorthwindModel:

This means that when you make references to the proxy classes and OData client library assembly in code, you will need two different imports statements (using for C#). In this example, WindowsPhoneApplication1 is the name of the application:

Visualizing the Northwind Proxy Classes
The DataSvcUtil.exe utility creates proxy classes for each of the tables that are exposed by this service. For example, a customer class is created for the customer table in the Northwind database. If you have a professional version of Visual Studio 2010, you can see all of the classes graphically, as shown in this image:

Northwind OData proxy class diagram (click to zoom)
To create a diagram like this, right-click NorthwindMode.vb and click View Class Diagram to generate a visual representation of all the proxy classes in the NorthwindModel namespace.
Data Service Context and Collections
The two most important classes of the OData client library are the DataServiceContext and the DataServiceCollection classes. The
DataServiceContext, the “context,” is a class that represents the data service itself. You use the context to load your proxy class objects into a DataServiceCollection object.The DataServiceCollection is a collection (an ObserveableCollection) that provides notifications when items get added or removed, or if the list gets updated. You can bind your list-based Silverlight controls to the DataServiceCollection object.
Next
In Introducing the OData Client Library for Windows Phone Part 3, we’ll discuss how to load data from the Northwind OData service.
See Also: Community Content
Netflix Browser for Windows Phone 7 – Part 1, Part 2
OData v2 and Windows Phone 7
Data Services (OData) Client for Windows PHone 7 and LINQ
Learning OData? MSDN and I Have the videos for you!
OData and Windows Phone 7, OData and Windows Phone 7 Part 2
Fun with OData and Windows Phone
Developing a Windows Phone 7 Application that consumes OData
Lessons Learnt building the Windows Phone OData browserSee Also: Documentation
Open Data Protocol (OData) Overview for Windows Phone
How to: Consume an OData Service for Windows Phone
Connecting to Web and Data Services for Windows Phone
Open Data Protocol (OData) – Developers
WCF Data Services Client Library
WCF Data Service Client Utility (DataSvcUtil.exe)


• The TechEd 2011 North America team (@TechEd_NA) reported the following MarketPlace DataMarket session will be presented in Atlanta, GA:
COS307 Building Applications with the Windows Azure DataMarket
Session Type: Breakout Session
- Level: 300 - Advanced
- Track: Cloud Computing & Online Services
- Speaker(s): TBD
This session shows you how to build applications that leverage DataMarket as part of Windows Azure Marketplace. We are going to introduce the development model for DataMarket and then immediately jump into code to show how to extend an existing application with free and premium data from the cloud. Together we will build an application from scratch that leverages the Windows Phone platform, data from DataMarket and the location APIs, to build a compelling application that shows data around the end-user. The session will also show examples of how to use JavaScript, Silverlight and PHP to connect with the DataMarket APIs.Key Learning: Building applications on top of the Windows Azure Marketplace DataMarket infrastructure.
Azret Botash continued his DevExpress series with OData and OAuth - Part 4 – Managing Identities on 2/28/2011:
We’re almost ready to implement an OAuth 1.0 Service provider. But first, let’s make sure our member accounts are properly password protected. Since we allow to sign in using different credentials into the same account, we need a place to store all those different identities.
AuthenticationType
Specified the type of the identity.
Hash
A unique value given to an identity by the provider. We must make sure that this value is unique per provider/authentication type.
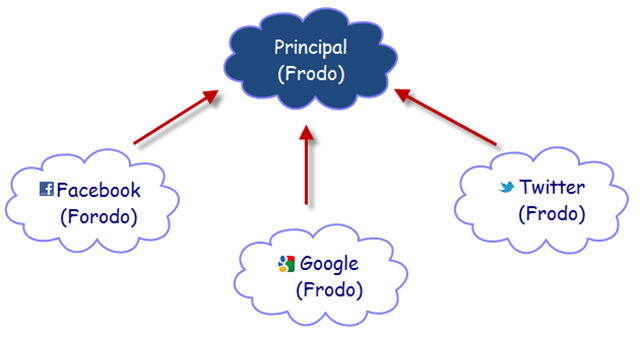
- AuthenticationType.Principal: We use “Principal” + Email address
- AuthenticationType.Google: We use “Google” + Email address. Google does not let users change their email address so this value is unique.
- AuthenticationType.Facebook: We use “Facebook” + ID. Facebook does allow users to change their email address. If we were to hash “Facebook” + Email address, and the user changes the email at a later time, we will not be able to resolve the identity after the change. So ID is what we need.
- AuthenticationType.Twitter: We use “Twitter” + ID. Twitter doesn’t even provide email addresses but provides a screen name and an ID. Screen names can be changed so we can’t use them either. So ID is what we need.
Note: Examine the FromTwitter, FromGoogle and FromFacebook methods in the AuthenticationService.cs
To compute the hash value we use MixedAuthenticationTicket.GetHashCode:
public string GetHashCode(string identitySecret) { using (HMACSHA1 hash = new HMACSHA1(Encoding.ASCII.GetBytes(identitySecret))) { return Convert.ToBase64String( hash.ComputeHash(Encoding.ASCII.GetBytes( this.AuthenticationType.ToLowerInvariant() + this.Identity.ToLowerInvariant()))); } }The “identitySecret” - a hash key, we’ll configure in Web.config.
<appSettings> <add key="Identity_Private_Key" value="tR3+Ty81lMeYAr/Fid0kMTYa/WM=" /> </appSettings>Token & Secret
This is where we store the latest access token and token secret that were issued by the provider. And in the case of AuthenticationType.Principal, we store the hashed password and the password hash key (salt).
Principal
An ID of the Principal object to resolve to.
Putting it Together
The new sign up page:
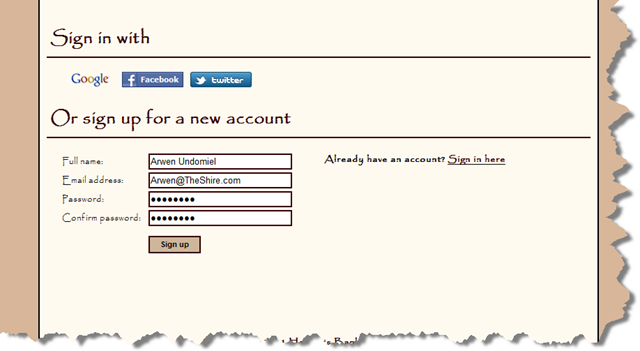
[HttpPost] public ActionResult Signup(Signup model, string returnUrl) { if (!ModelState.IsValid) { return View(model); } try { MembershipCreateStatus createStatus; MixedAuthenticationTicket ticket = MembershipService.CreatePrincipal( model.Email, /* We use email as our primary identity */ model.Email, model.FullName, model.Password, out createStatus); if (createStatus == MembershipCreateStatus.Success) { MixedAuthentication.SetAuthCookie(ticket, true, null); return RedirectToAction("", "home"); } ModelState.AddModelError("", MembershipService.ErrorCodeToString(createStatus)); return View(model); } catch (Exception e) { ModelState.AddModelError("", e); return View(model); } }Updated sign in page:
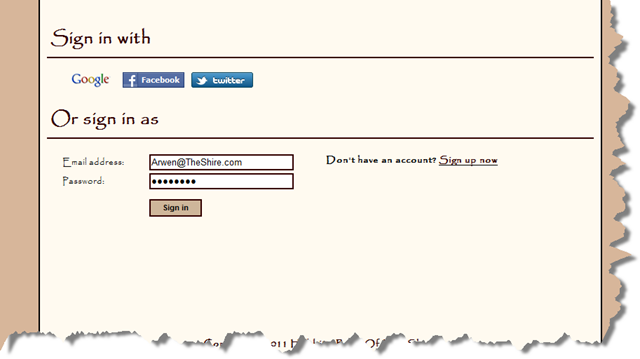
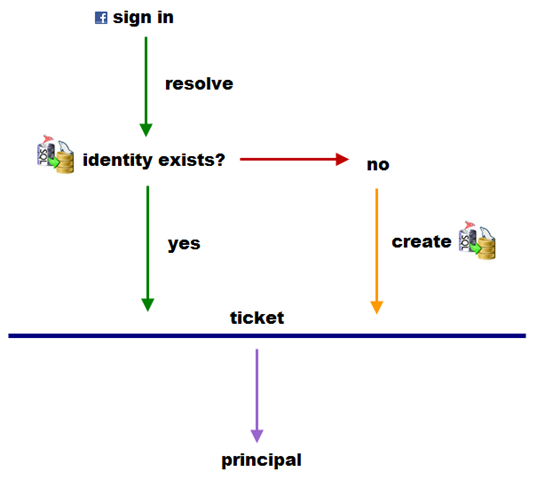
[HttpPost] public ActionResult Signin(Signin model, string returnUrl) { if (!ModelState.IsValid) { return View(model); } try { if (Impersonate(MembershipService.ResolvePrincipalIdentity( model.Email, model.Password), true)) { return RedirectToAction("", "home"); } ModelState.AddModelError("", "Email address or Password is incorrect."); return View(model); } catch (Exception e) { ModelState.AddModelError("", e); return View(model); } }public MixedAuthenticationTicket ResolvePrincipalIdentity(string identity, string password) { MixedAuthenticationTicket ticket = new MixedAuthenticationTicket("Principal", identity.ToLowerInvariant(), String.Empty, Guid.Empty, String.Empty); using (Session session = _Global.CreateSession()) { string identityCode = ticket.GetHashCode(ConfigurationManager.AppSettings["Identity_Private_Key"]); Identity identityRecord = session.FindObject<Identity>( new BinaryOperator( "Hash", identityCode) ); if (identityRecord == null) { return MixedAuthenticationTicket.Empty; } string encodedPassword = HMACSHA1(password, identityRecord.Secret); if (!encodedPassword.Equals(identityRecord.Token)) { return MixedAuthenticationTicket.Empty; } ticket.Principal = identityRecord.Principal; return ticket; } }For our own (Principal) authentication everything is straightforward and simple. For federated authentication it’s tricky. What should we do when someone signs in for example using Facebook for the first time? Should we auto create the identity and principal? Should we auto create the identity, redirect to the “confirm account” page and only than create the principal? Or should we keep the credentials in the cookie and only create persistent records when the user confirms the account?. My preference is toward option #2 for the following reasons:
- Storing tokens (or any sensitive information) on the client side is not a good practice (even if we encrypt ticket cookie). And we need to keep track of the issued tokens so we have performs actions on user’s behalf.
- The sign-in identity is unique (and will remain that way) and we’re going to persist it at some point anyway. So why not create it right away? (right after we acquired the token). You can put an expiration timestamp on auto created identities and GC them periodically.
- Auto-creating principals without user’s confirmation is also not an option. What if one ha an account already and wants to associate this *new* login with that *existing* account.
in other words:
public MixedAuthenticationTicket ResolveFederatedIdentity( MixedAuthenticationTicket ticket, IToken accessToken) { if (!ticket.IsAuthenticated) { return MixedAuthenticationTicket.Empty; } using (Session session = _Global.CreateSession()) { session.BeginTransaction(); DateTime utcNow = DateTime.UtcNow; string identityCode = ticket.GetHashCode(ConfigurationManager.AppSettings["Identity_Private_Key"]); Identity identityRecord = session.FindObject<Identity>( new BinaryOperator( "Hash", identityCode) ); if (identityRecord != null) { if (identityRecord.Token == accessToken.Value && identityRecord.Secret == accessToken.Secret) { ticket.Principal = identityRecord.Principal; return ticket; } } if (identityRecord == null) { identityRecord = new Identity(session); identityRecord.Created = utcNow; identityRecord.Hash = identityCode; } identityRecord.Modified = utcNow; identityRecord.Token = accessToken.Value; identityRecord.Secret = accessToken.Secret; switch (ticket.AuthenticationType) { case "Google": identityRecord.AuthenticationType = AuthenticationType.Google; break; case "Facebook": identityRecord.AuthenticationType = AuthenticationType.Facebook; break; case "Twitter": identityRecord.AuthenticationType = AuthenticationType.Twitter; break; default: throw new ArgumentException("Authentication type is not supported.", "ticket"); } identityRecord.Save(); session.CommitTransaction(); ticket.Principal = identityRecord.Principal; return ticket; } }
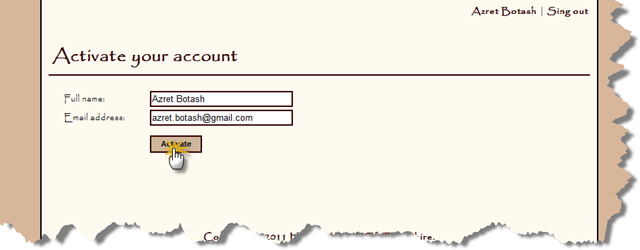
Now we need to confirm the account and create the principal:
public MixedAuthenticationTicket ActivatePrincipal( MixedAuthenticationTicket ticket, out MembershipCreateStatus status) { status = MembershipCreateStatus.ProviderError; using (Session session = _Global.CreateSession()) { session.BeginTransaction(); string identityCode = ticket.GetHashCode(ConfigurationManager.AppSettings["Identity_Private_Key"]); Identity identityRecord = session.FindObject<Identity>( new BinaryOperator( "Hash", identityCode) ); if (identityRecord == null) { return MixedAuthenticationTicket.Empty; } /* Update or Create Principal */ Principal principalRecord = null; if (identityRecord.Principal.HasValue && identityRecord.Principal.Value != Guid.Empty) { principalRecord = session.GetObjectByKey<Principal>(identityRecord.Principal.Value); } DateTime utcNow = DateTime.UtcNow; if (principalRecord == null) { principalRecord = new Principal(session); principalRecord.ID = Guid.NewGuid(); principalRecord.Created = utcNow; } principalRecord.FullName = ticket.FullName; principalRecord.Email = ticket.Email; principalRecord.Modified = utcNow; /* Update Identity */ identityRecord.Principal = principalRecord.ID; identityRecord.Modified = utcNow; /* Commit */ principalRecord.Save(); identityRecord.Save(); session.CommitTransaction(); status = MembershipCreateStatus.Success; ticket.Email = principalRecord.Email; ticket.Principal = principalRecord.ID; ticket.FullName = principalRecord.FullName; return ticket; } }
What’s next
Download source code for Part 4
- Part 1: Introduction
- Part 2: FormsAuthenticationTicket & MixedAuthentication
- Part 3: Understanding OAuth 1.0 and OAuth 2.0, Federated logins using Twitter, Google and Facebook
- Part 4: Managing Identities
- Part 5: Implementing OAuth 1.0 Service Providers (storing and caching tokens, distributed caches (memcached, velocity))
- Part 6: Securing OData feeds without query interceptors
- Part 7: Client Apps
<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
• Francois Lascelle explained Selecting a token format for your Web APIs, RESTful web services on 3/1/2011:
The most important token format that you need to support for your web apis and RESTful web services these days is: anything. So many platforms define their own authentication/authorization mechanism with what seems to be little concern for standardized formats: API keys here, HMAC signatures there, various OAuth interpretation, etc. Simple does trump standards. For the integration-focused enterprise architect, this reality creates a need for flexible infrastructure supporting arbitrary token formats.
About a year ago, I was proposing a simple approach for enabling RESTful web service requesters with SAML-based tokens for authentication/authorization. The pattern enabling a REST client to access a service using a SAML token is illustrated below.

SAML for REST
The fact that there are still no definitive SAML bindings targeting RESTful web services today does not seem to deter developers from leveraging SAML to control access to their RESTful web services. We encountered this again recently in the field in the form of a proof of technology project in which the main objective was to demonstrate the Layer 7 Gateway acting both as the token issuer for a REST client as well as an API proxy which controls access based on those very tokens. Two token formats were requested: SAML and OAuth.
For our gateway to authenticate RESTful requesters and issue tokens is a very common and straightforward process. In order for the REST client to be able to use this token however, it must be able to insert it in an Authorization header (the RESTful location for this token). In the case where the token is a SAML assertion, it can exceed in size the practical limit of what can be used as an HTTP header value (a rich SAML assertion with an XML digital signature can be quite verbose). This is where the Layer 7 Gateway policy language flexibility shines. By simply declaring the compression (gzip assertion) of the resulting SAML before sending it back to the client, the token has now been shrunk to a manageable size for the client. The reverse decompression at reception is just as straightforward using the reverse operation in our policy language.

SAML idp for REST with token compression
Note that although we could just as well create a session on the Gateway and return a cookie back to the requester, we are interacting with a REST client here; this is not a browser-driven interaction. Besides, server side sessions are not RESTful. If the client re-sends the token at each call, the authorization of the requester is validated each time through the evaluation of the SAML statements and this does not require any server-side session.
When implementing the same use case, but with a token format based on OAuth instead of SAML, this compression/decompression step is no longer needed. The rest of the configuration using our Gateway policy language is very similar. This compression is one of the technical tradeoffs when choosing between such token formats and relates to the so-called “open” vs “enterprise” identity camps. On one hand, you have a rich and standardized token format (SAML), which can be used to express a variety of statements about an identity. On the other hand you have a simple and lean token format but less standardized. On that last point, what constitutes an OAuth token format in this particular context is a bit of a moving target and various interpretations are not necessarily compatible.
In the end, choosing a token format should consider the requirements around authorization and the technical capabilites of the parties involved. Better yet, don’t narrow your support on a single format. Support and enable different token formats instead if that is what is needed.
When selecting supporting infrastructure to manage APIs and broker with cloud or partners, keep in mind this need to accommodate arbitrary authentication approaches. Although rich standard support provides value, the essential ingredient of an agile service gateway is its flexibility and its extensibility.


Vittorio Bertocci (@vibronet) described a New ACS Infographic in a 3/1/2011 post:
Back in August I tried to capture in a single view all the relevant aspects for token issuing of that LABS release of ACS: preconfigured identity providers, available issuer endpoints, credential types accepted, token types, and so on. Since then I’ve been using that infographic in various sessions, and it served me well to explain some of the hardest scenarios.
As I was revving one deck I stumbled in that slide, and found it outdated; hence I decided to align the content to what the service offers today, and explicitly add some of the elements that I often find myself drawing on top of the schema. So here it is! As usual, if you want to see a bigger version just click on the image.

I already explained in the last post the general structure of the diagram, and I won’t repeat it here as it remains largely unchanged: I just adjusted some labels according to feedback.
Other cumulative changes from the last 6 months:
- The area representing ACS is now subdivided in bands, indicating the functional layers that the claims traverse from input to output: a protocol layer receiving the token, a trust layer verifying it comes from one of the intended sources, the claims transformation core which executes all the rules that apply, again the trust layer to see if the intended RP is configured in the service, which crypto should be used with it, etc; finally, again the protocol layer to dispatch the issued token via the intended protocol
- I added icons for the application types that would typically use the endpoints (ie the WS-Federation endpoint is usually for web applications, WS-Trust for SOAP web services, etc) as the brackets on the left are slightly more generic (ie also include the intended client or usage scenario)
- The WS-Trust endpoint can spit SWT too now
- Certificates were added among the credentials that can be sued as service identities
- OpenID now appears among the possible identity providers (it is not in the portal, but an OpenID issuer can be set up via management service)
I briefly chatted with Caleb about if it was the case to include the protocols that ACS uses for connecting with the various preconfigured IPs (ie OpenID with google and yahoo, Oauth2 with Facebook, etc) but the conclusion was that this is exactly one of the details you can stop worrying about when you outsource trust management to ACS

So there you have it. Don’t take it all the once, but rather use it as a GPS when you feel the need to understand where you are in the service. Happy exploring!

Vittorio Bertocci (@vibronet) reported a New Topic on MSDN: WIF Configuration on 3/1/2011:
The WIF online documentation just got a brand-new section, which provides a great reference for the WIF configuration elements. It’s very well written & organized, and certainly beats digging in the config schema!
The Windows Azure AppFabric Team posted 3/1/2011 - Updated IP addresses for AppFabric Data Centers on 3/2/2011:
The addition is under United States (North/Central). Value added: 157.55.136.0/21
The Windows Azure AppFabric Team reported Access Control Service updated in Labs on 3/1/2011:
The Windows Azure AppFabric Team updated the Access Control Service Samples and Documentation (Labs) with Release Notes - February 2011 Labs Update on 3/1/2011:
Schema changes for OData client
Property name in schema
Type of change
Comments
*.SystemReserved [boolean, immutable]
Added
This property has been added to all OData objects, and indicates whether or not an object is reserved for exclusive use by the ACS namespace.
Important: If you are using the ACS management service to programmatically manage ACS, your management service client code must updated and recompiled to function correctly after February 28, 2011. No code changes are required other than recompiling the updated management service client code.
The February 9, 2011 Labs release of Access Control Service contains the following changes:
Management Portal Changes
The ACS management portal has been redesigned to match the look and feel of the new Windows Azure and AppFabric portals. The portal now features a new left-hand navigation menu that provides easy access to all sections of the portal.
Federated Sign Out
The home realm discovery JSON feed now features a LogoutURL property, which is populated for ADFS and Windows Live ID identity providers. This URL allows end-users to sign out of the ADFS or Windows Live ID identity provider that they signed in with.
Simplified Sign in for Windows Phone 7 Apps
An endpoint has been added to ACS to simplify retrieval of a security token from the website so it can be used in the WP7 app to authenticate to a protected resource. This endpoint can be used by calling the home realm discovery JSON feed with the protocol set to "javascriptnotify" and using the returned LoginUrl to redirect to the identity provider.
Known Issues
Below are known issues with some of the new features introduced in the February Labs release. These issues have fixes planned for a forthcoming release.
Launching the ACS portal from the AppFabric portal
In this release, users of the AppFabric portal at http://portal.appfabriclabs.com may need to disable their web browser’s pop-up blocker in order to launch the ACS management portal. The ACS management portal is launched by selecting “Manage Access Control Service” in the Access Control Service section of the AppFabric portal.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
Avkash Chauhan described Windows Azure VM Role - CSUPLOAD Error: Recovering from an unexpected error: The page range specified is invalid in a 3/1/2011 post:
When you use CSULOAD to upload VHD for VM Role, you may receive an error as below:
Found existing page blob. Resuming upload…
Recovering from an unexpected error: The page range specified is invalid.

If your file is uploaded completely and then error occurred at the last it is possible this error occurred due to a mismatch between page blob upload. There are two things you can try:
1. Try the same command little later and it may work.
2. Use the following blog with entries as described after the blog:
<csupload
uploadBlockSizeInKb="512"
maxUploadThreads="1"
ignoreServerCertificateErrors="false"
maxVHDMountedSizeInMB="66560"
/>
If you try a few time this should fix your problem. As VM Role is still in BETA and work is being done to root out such issues.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Avkash Chauhan explained DiagnosticMonitor.Start() line in OnStart() method generates exception: The remote server returned an error: (409) Conflict in a 3/1/2011 post:
Recently I was working on an issue in which DiagnosticMonitor.Start() line in OnStart() method was generating exception as below:
Microsoft.WindowsAzure.StorageClient.StorageClientException was unhandled by user code
Message=The specified container already exists.
Source=Microsoft.WindowsAzure.StorageClient
StackTrace:
at Microsoft.WindowsAzure.StorageClient.EventHelper.ProcessWebResponse(WebRequest req, IAsyncResult asyncResult, EventHandler`1 handler, Object sender)
at Microsoft.WindowsAzure.StorageClient.CloudBlobClient.EndGetResponse(IAsyncResult asyncresult, WebRequest req)
at Microsoft.WindowsAzure.StorageClient.Tasks.WebRequestExtensions.<>c__DisplayClass1.<GetResponseAsync>b__0(IAsyncResult asyncresult)
at Microsoft.WindowsAzure.StorageClient.Tasks.APMTask`1.OnEnd(IAsyncResult ar)
InnerException: System.Net.WebException
Message=The remote server returned an error: (409) Conflict.
Source=System
StackTrace:
at System.Net.HttpWebRequest.EndGetResponse(IAsyncResult asyncResult)
at Microsoft.WindowsAzure.StorageClient.EventHelper.ProcessWebResponse(WebRequest req, IAsyncResult asyncResult, EventHandler`1 handler, Object sender)
InnerException:
I found that this exception was caused by following two properties:
1. I had “Just My Code” enabled in my [Tools > Options > Debugging > General dialog.]
2. My exception policy was set to “Break on uncaught exception in user code”.
The exception stopped appearing after I made following two chances in my VS2010 environment:
1. Tools > Options > Debugging > General > Enable Just My Code <------- Uncheck/Disable
2. Debug > Exceptions > Break on uncaught exception in user code <------- Uncheck/Disable
• The Windows Azure Team posted Windows Azure Platform Training Kit - February Update v2.4 on 3/1/2011:
Brief Description
Quick Details
- Version: February Update
- Date Published: 3/1/2011
- Language: English
Overview
The Windows Azure Platform Training Kit includes a comprehensive set of technical content including hands-on labs, presentations, and demos that are designed to help you learn how to use the Windows Azure platform, including: Windows Azure, SQL Azure and the Windows Azure AppFabric.
The February 2011 update of the Windows Azure Platform Training Kit includes several updates and bug fixes for the hands-on labs. Most of the updates were focused on supporting the new Windows Azure AppFabric February CTP and the new portal experience for AppFabric Caching, Access Control, and the Service Bus.
Some of the specific changes with the February update of the training kit includes:
- [Fixes] Several bug fixes in demos and labs
- [Updated] Hands-on Lab - Building Windows Azure Apps with the Caching service
- [Updated] Hands-on Lab – Using the Access Control Service to Federate with Multiple Business Identity Providers
- [Updated] Hands-on Lab – Introduction to the AppFabric Access Control Service V2
- [Updated] Hands-on Lab - Introduction to the Windows Azure AppFabric Service Bus Futures
- [Updated] Hands-on Lab - Advanced Web and Worker Roles – fixed PHP installer script
- [Updated] Demo Script – Rafiki PDC Keynote Demo
- [Fixes] The setup scripts for all hands-on labs and demo scripts have also been updated so that the content can easily be used on a machine running Windows 7 SP1.
Release: February Update
Version: 2.4System Requirements
- Supported Operating Systems:Windows 7;Windows Server 2008;Windows Server 2008 R2
The Windows Azure Platform Training Kit - February 2011 release has the following system requirements.
- .NET Framework 4.0
- Visual Studio 2010
- ASP.NET MVC 2.0
- Windows Powershell
- Microsoft Internet Information Server 7
- Windows Azure Tools for Microsoft Visual Studio 1.3
- Windows Azure platform AppFabric SDK V1.0 - October Update
- Windows Azure platform AppFabric SDK V2.0 CTP - February Update
- Microsoft SQL Server Express 2008 (or later)
- SQL Server Management Studio 2008 R2 Express Edition
- Microsoft Windows Identity Foundation Runtime
- Microsoft Windows Identity Foundation SDK
David Pallman posted Introducing The Windows Azure Handbook on 3/1/2011:
I’m excited to introduce my Windows Azure book series, The Windows Azure Handbook. The first volume is available now through Amazon.com and other channels.
• Volume 1: Planning & Strategy is for business and technical decision makers
• Volume 2: Architecture is for architects
• Volume 3: Development is for developers
• Volume 4: Management is for IT Workers

Volume 1, the yellow book, focuses on planning and strategy and is intended primarily for business and technical decision makers. With the information in this book you'll be equipped to responsibly evaluate Windows Azure, make a business case for it, determine technical suitability for your applications, plan for adoption, and formulate a cloud computing strategy.
Volume 2, the green book, covers architecture and includes design patterns for compute, storage, relational data, networking, communication, security, and applications. (Spring 2011)
Volume 3, the blue book, covers development and includes these topics: programming with Windows Azure compute, storage, database, communication, networking, and security services. (Summer 2011)
Volume 4, the purple book, covers management and includes these topics: operations monitoring, application management, scaling, and billing management. (Fall 2011)
What make the Windows Azure Handbook unique? To quote from the Introduction:
“Most books on cloud computing seem to be either business-focused and general or deeply technical and platform-specific. In my view, either level of focus is myopic: I’m a firm believer that when technology is applied both the business context and the technical context need to be jointly considered and in alignment. I also find the full lifecycle of cloud computing (planning, design, development, management) is rarely addressed in a single work. I see therefore a need and opportunity for a book series that tells the full story about cloud computing with Windows Azure.“I believe I’m in a unique position to tell that story well. As a Microsoft MVP I’m kept well-informed about where the platform is and where it is going and I’m exposed to industry thought leaders. As general manager of a consulting practice I and my colleagues are helping customers adopt cloud computing in the real world and are in tune with the best practices. My involvement in business activities such as cloud computing assessments has given me insight into the benefits, risks, and trade-offs companies must consider in evaluating and adopting cloud computing. My regular involvement in solution architecture and development allows me to speak about both from a position of hands-on experience. The big picture is a compelling one, and you’ll get a good sense of it from these books.”
You can find out more about The Windows Azure Handbook series on its book site at http://azurehandbook.com/.

Steve Marx (@smarx) described Controlling Application Pool Idle Timeouts in Windows Azure in a 3/1/2011 post:
A question I hear from time to time is whether it’s possible to change the idle timeout time for IIS application pools in Windows Azure. It is indeed possible, and fairly easy to do with a startup task.
The default idle timeout value is twenty minutes, which means your app pool is shut down after twenty minutes if it’s not being used. Some people want to change this, because it means their apps are a bit slow after twenty minutes of inactivity.
ServiceDefinition.csdef:<Startup> <Task commandLine="startup\disableTimeout.cmd" executionContext="elevated" /> </Startup>And add
disableTimeout.cmdin a folder calledstartup, with the following line of code (should be one line, split just for formatting):%windir%\system32\inetsrv\appcmd set config -section:applicationPools -applicationPoolDefaults.processModel.idleTimeout:00:00:00Be sure to mark
disableTimeout.cmd’s “Copy to Output Directory” setting to “Copy always”.
Chris Czarnecki described Deploying Java Applications to Azure in a 3/1/2011 post to the Learning Tree blog:
Windows Azure is typically considered as a Platform as a Service (PaaS) for .NET applications only. However, the platform is open to more programming languages than just .NET. For example, PHP developers can also deploy applications to Azure as Kevin Kell wrote about in a post last November. Little known, but definitely possible, Web applications for Azure can be written in Java using the Windows Azure Starter Kit for Java.
In addition to the vendors providing a Java PaaS, they also provide a rich set of API’s covering areas such as storage, messaging and scheduling to mention a few. Each of these API’s is vendor specific, although they offer similar areas of functionality. Choosing the correct vendor and platform is not an easy decision. Choice is good but making the correct choice is difficult yet vital for an organisation. Learning Trees’s Cloud Computing course discusses the products offered by the major Cloud Computing vendors, comparing and contrasting their features, advantages and disadvantages, equipping attendees with the knowledge required to make the correct choice for their organisations. If you are interested in using PaaS, why not consider attending, I am confident you will benefit a lot from the course.
<Return to section navigation list>
Visual Studio LightSwitch
• Danny Pugh posted VS 2010 LightSwitch Hosting :: How to create a LightSwitch Web Application on 3/1/2011:
Introduction:
In this article, we will see how to create a LightSwitch Web Application, such as a LightSwitch Desktop application; we need to do some steps to set it up.
Creating LightSwitch Web Project: Fire up the VS 2010, select the LightSwitch [No: 1] from Installed Template and Create the Project with name SampleLSWebApplication.
Preparing for Web Application: After successful creation of the LightSwitch project go to the Solution Explorer. Right click the solution and select the Properties option.

In the properties window you have to select the Application Type [No: 1] Menu Tab. In the Application Type Menu Tab, there will be three types of LightSwitch Application types. To create the Web Application [Browser Client] we have to select the third option i.e. Browser client, 3-tier deployment [No: 2].
The LightSwitch Web application needs the IIS Server to host the application on the local machine.
Adding new Table to the Screen: After creating the project, the first screen that appears is the DataSource selection screen.
In that screen, we have to select the Create New Table option to create the new table.
The second option is for creating the application that will use the external database as DataSource.Adding Fields to the Table: After creating the table, we have to add the fields. The LightSwitch gives the nice GUI to create the fields required. We can set the field type and can set the Required field option by checking the Required checkbox [No: 1].

Adding Screens to the Application: Adding screens to the application is pretty cool. Just go to the solution explorer and there you can see the Screen folder like icon. Right click the icon and choose the Add Screen option.

As I said in the LightSwitch Desktop Application article, we can add the screens from a tabbed window also.
Selecting Screen Template and Assigning Screen Data:
For designing the screen, there are some screen templates available in the LightSwitch. So we can select the screen template for our application. In this sample application, we have selected New Data Screen [No: 1].
In the left side of the Design screen, we can give the name of the Screen in that first Textbox [No: 2].The Screen Data will be the table what we have created earlier. If we have created more than one table then the screen will be created as per the selection of the Screen Data [No: 3].
Changing the Control Type for the Table Fields:
After the creation of the screen, we can change the control type for the table fields.
As shown, the control for the ItemCode is Textbox. We can change the control as we want.LightSwitch Web Application in Running Mode:
If you run the LightSwitch Web Application, you will see the screen like the one above. The left side Panel is the Menu for the Application.To add the data you have to click on the Menu item [No: 1]. But by default one empty record will be created.
We can see that there are separate screens for each record so that we can easily navigate the records and edit the information.
Summary:
In this article, we have seen the basics of creating a LightSwitch Application. We will get deeper into the details in the future.






More interesting to me than the instructions to create the app was the LightSwitch Hosting advertisement. I’m still waiting for LightSwitch hosting details for Windows Azure, which (hopefully) will come in Beta 2.
• Amazon.com posted an item on 3/1/2011 for Alessandro Del Sole’s forthcoming Visual Studio LightSwitch Unleashed book from Sams Publishing:


By that time, maybe Beta 2 will be available.
Return to section navigation list>
Windows Azure Infrastructure
• The SearchCloudComputing.com staff compiled Cloud computing development for beginners, a list of recent articles on cloud computing topics, which begins with my Choosing from the major Platform as a Service providers article, on 3/1/2011:
Interested in using cloud computing services for testing and development? Then you’re in the right place. Although cloud development can require a different set of skills, it also offers distinct advantages, including the removal of any scalability concerns. And with the continued proliferation of Platform as a Service (PaaS) offerings, the idea of developing applications in the cloud has become even more enticing.
This guide provides information on a variety of cloud computing platforms available for application development, including Google App Engine and Salesforce.com's Force.com. It also offers best practices and helpful hints on working with cloud application programming interfaces (APIs), along with an overview of the costs and advantages associated with Microsoft's Azure platform.
Cloud Development Tips | Cloud Development News
CLOUD DEVELOPMENT TIPS AND TUTORIALS
Choosing from the major Platform as a Service providers
Many organizations are turning to Platform as a Service offerings for their cloud needs. Our expert compares and contrasts the major options from Google, Microsoft and Amazon.How Microsoft Azure actually works
Curious about how Azure works? Microsoft technical fellow Mark Russinovich offered a detailed overview of the cloud platform's innards.Snapshots in the cloud: The developer's friend
What cloud computing features will excite Java developers the most? The ability to take a seamless and nearly instantaneous virtual snapshot of an uncooperative application for troubleshooting purposes, for example, is just one of many things that should excite a skilled development team.Cloud computing programming API tutorial
With all of the options available to developers interested in creating cloud-based applications, it can be tough to make a choice. This guide gives an overview on application programming interfaces and other development resources from major cloud platforms like Google App Engine and Amazon’s Elastic Compute Cloud.Microsoft Azure tutorial: A look at the cloud platform
In just over a year, Microsoft's deep pockets and commitment to cloud strategies have established Azure as a major player in the development world. This Azure overview analyzes every aspect of the company's flagship cloud platform.How developing in the cloud is different
Developing Java applications in the cloud requires a different set of skills and presents a whole new set of challenges. Bhaskar Sunkara, director of engineering at AppDynamics, discusses what changes when you're developing applications in the cloud.An introduction to developing for Microsoft Azure
Microsoft’s cloud computing platform has its own operating system and developer services built in. This multi-part series gives new users the information they need to begin developing applications for Azure.Will Database.com appeal to cloud developers?
Ariel Kelman, vice president of product marketing for Force.com, said that the company's new Database.com cloud database service is available for developers writing in any language, on any platform and any device. The question is, will any developers care?Compatibility concerns in the evolution of cloud computing APIs
As cloud computing emerges, many enterprises are looking for compatibility between applications on different platforms. Unfortunately, users are often required to revise codes in order to get the most out of APIs associated with individual clouds.Windows Azure's hidden compute costs
Some developers feel that Azure's pricing model makes it difficult to experiment with the platform. How do Azure's costs compare to in-house systems and other cloud infrastructures?Google and VMware team on Java development platform
Facing increased pressure from Microsoft's fast-rising Azure platform, a cloud strategy from unlikely collaborators Google and VMware allows Java developers to build and run Spring-based Java applications on Google App Engine.Developer advantages and challenges of Microsoft's Azure
The long-stated goal of Microsoft's cloud strategy is to provide a seamless connection between Azure services and the company's development environments. This will certainly limit appeal, but developers in Microsoft shops will see distinct advantages.Salesforce.com legitimizes cloud strategy with Heroku purchase
Why did Salesforce.com spend $212 million on cloud development platform Heroku? With Microsoft gaining in the Platform as a Service (PaaS) market, Salesforce.com can now add Heroku to its Force.com and VMforce stable and legitimize its place as a PaaS leader.According to IBM, cloud computing development is moving on up
A recent IBM survey indicates that mobile and cloud platforms are becoming the places to go for IT delivery and application development. In fact, 91% of respondents think cloud will surpass on-premise computing in the next five years.How will Joyent's cloud platform affect the Web app world?
What's the big deal about Joyent launching a new PaaS offering? According to the cloud hoster's CTO, the service will offer ten times, maybe even 100 times, the performance of your Web app for the same amount of infrastructure.VMware and Salesforce.com take wraps off VMforce
VMforce, a PaaS from VMware and Salesforce.com, aims to entice SpringSource and Java application developers through the addition of Java support to Force.com.For more on cloud computing development, head to our development headquarters.
Full disclosure: I’m a paid contributor to SearchCloudComputing.com.
Andrew Brust (@andrewbrust) gave a thumbs-up to Windows Azure in his Microsoft, Windows Azure and Assisted Transitions “Redmond Review” column for March 2011:
I've been working on a big Windows Azure research project recently, and it's got me thinking. For well over a year now, developers have been inundated with cloud messaging and evangelism. The marketing, news and analysis make the on-premises model sound completely passé, and yet cloud development is still far from common.
We've been here before, with the launch of microcomputers, the advent of client/server databases, the growth of GUI technologies, the flight to object-oriented programming, the shift from 16-bit to 32-bit APIs, the emergence of the Web, the move to managed code and more. Each of these technology shifts brought huge burdens in learning, capital investment, application rewrites and more. I'm afraid the cloud-computing model -- for all its benefits -- will impose another round of these cyclical burdens.
Getting There from Here, and Vice Versa
For Microsoft developers, though, there's good news here. When it comes to easing these generational transitions, when it comes to bridging the gaps they introduce, when it's necessary to create new development environments that work intuitively for the experts in the older ones, Microsoft really shines. Think about it: When Windows reached prominence, Visual Basic gave QuickBASIC developers a chance at bat. When SQL Server came out, we could query it with the APIs we used with Access. When the Web became prominent, Active Server Pages let us use Visual Basic to program it. Successive versions of Visual Studio made ensuing changes more approachable, too.These transitioning aids are often themselves transitional: Not so many people use DAO against SQL Server anymore, and lots of people do their Web development in C# instead of Visual Basic. Our new code doesn't look like our old code, but with Microsoft, we had a path to get from old to new, and it was pretty smoothly paved.
This tradition continues. I've written about the value of the consistency of Windows Azure with on-premises Windows Server and the Microsoft .NET Framework; I've applauded SQL Azure and its symmetry with SQL Server. I've also discussed how the Professional Developers Conference 2010 Windows Azure announcements -- for things like the Extra Small Instance, AppFabric Caching, SQL Azure Reporting, the VM Role and SQL Azure Connect VPN access -- build on that symmetry and serve to further ease the transition from corporate datacenter to cloud.
But it's only with some significant hands-on research of late that I've really grown to appreciate just how important all of this is.
Déja Knew
Here's my take: Doing Windows Azure development feels like starting a new job, but in the same line of work. You use the same tools and techniques in your work, and draw on the same experience to do your job. Put another way: You'll still know the ropes and you'll maintain your confidence.This works on the business side, too. Windows Azure services are being integrated into MSDN subscriptions and corporate Enterprise Agreements, just like conventional software licenses. Windows Azure training comes from the same Microsoft and partner channels -- even the same trainers -- that you already know. You'll keep your account reps and your partner account managers, and you'll likely keep your consulting providers, too. But you're still getting the cloud, not just a bunch of on-premises stuff hosted on a virtual machine.
Does Microsoft have a self-interest in maintaining this continuity?
Of course. Change and retooling is expensive for Microsoft, as would be jettisoning the value and stability of the on-premises server platform Redmond has built over the last decade and more. That doesn't compromise the efficacy of Windows Azure, though -- in fact, it helps assure it. Microsoft needs a platform that's competitive, complete and mitigates disruption. So do you. After significant hands-on work with Windows Azure, I can safely say that's exactly what you get.
Andrew is Founder and CEO of Blue Badge Insights, an analysis, strategy and advisory firm serving Microsoft customers and partners. He also serves as CTO for Tallan, a Microsoft National Systems Integrator; is a Microsoft Regional Director and MVP; an advisor to the New York Technology Council; and co-author of "Programming Microsoft SQL Server 2008" (Microsoft Press, 2008).
No significant articles today.
David Linthicum asserted Big Consulting Missing the Cloud Computing and SOA Links in a 3/1/2011 post to ebizQ’s Where SOA Meets Cloud blog:
Consulting is a funny business. You have to remain relevant, so you have a tendency to follow the hype and follow the crowd. Cloud computing is the next instance of that, and many of the larger consulting organizations is chasing cloud computing as fast as they can.
However, many are not chasing cloud computing the right way, missing many of the architectural advantages. Instead they are just tossing things out of the enterprise onto private and public clouds and hoping for the best. Making things worse, many in larger enterprise clients are not seeing the forest through the trees, or in this case the architecture through the clouds. So, you have both parties taking a reactive versus a proactive approach to the cloud.
Missing is good architectural context supporting the use of cloud computing. Or, the ability to create an overall strategic plan and architectural framework, and then looking at how cloud computing fits into this framework now, and into the future. Typically that means leveraging SOA approaches and patterns.
That message seems to fall on death ears these days, and most disturbingly those death ears seem to be attached to consulting organizations that have the trust of enterprises to take their IT to the next level. The end result will be failed cloud computing projects, with the blame being put on the technology. It's really the lack of strategic planning and architecture that's at the heart of the problem.
The concept of SOA, as related to cloud computing is simple. You need to understand the existing and future state architecture before you begin selecting platforms and technology, including cloud computing. Once you have that understanding its relatively easy to figure out where SaaS, IaaS, and PaaS come into play, or not. Moreover, creating a roadmap for implementation and migration over time, typically a 3 to 5 year horizon.
We need to get good at this quick, else cloud computing will do is little good.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
James Governor posted EMC: Private/Public Cloud to Stabilise: 80/20 by 2015 to his Monkchips blog on 3/1/2011:

I went to an EMC event back in January, and of course the topics of discussion were cloud, cloud and uh cloud – after all what’s the biggest driver of storage today? But on the subject of cloud one slide really stuck in my mind. Enough that I am posting on it now. I am a private cloud skeptic – indeed I posted the 15 Ways to Tell Its Not Cloud Computing back in March 2008- so the idea we’ll have settled into a simple Pareto distribution by 2015 seemed kind of crazy. Are we really going to settle into a simple 80/20 for Private/Public cloud within four years or so?
Now EMC made it very clear this was just an “illustrative” example, but its certainly a pointer to how EMC sees the market playing out. I am pretty sure Amazon would have a very different view: maybe 20% private cloud to 80% public by 2020? Actually I would love to know what Amazon’s planning assumptions for AWS. One problem is its so hard to measure the cloud market – everything gets labeled private cloud these days – its kind of a placeholder for Enterprise IT.
Anyway – the point of this post is that really I’d like to know what you think. How do you see this stuff shaking out?
I’d say “this stuff” will shake out closer to the opposite of EMC’s prognostication: 80/20 public/private cloud by a common measure (billings/chargebacks).
See BusinessWire reported CEO Songnian Zhou to Discuss How To Get Started with Private Cloud Management and Build A Roadmap for Success in a preface to the Platform Computing Announced As Gold partner at Third Annual Cloud Slam’11 Conference press release of 3/1/2011: in the Cloud Computing Events section.
<Return to section navigation list>
Cloud Security and Governance
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
BusinessWire reported CEO Songnian Zhou to Discuss How To Get Started with Private Cloud Management and Build A Roadmap for Success in a preface to the Platform Computing Announced As Gold partner at Third Annual Cloud Slam’11 Conference press release of 3/1/2011:

TORONTO & SAN JOSE, Calif.--(BUSINESS WIRE)--Cloudcor announces Platform Computing, the leading independent private cloud management software provider, as a Gold Partner for Cloud Slam’11 - the world's Premier Hybrid Format Cloud Computing conference – scheduled from 18 - 22 April, 2011.
“We are looking forward to our third year in collaboration with Cloudcor and to participating again at the Cloud Slam’11 conference”
At the third annual Cloud Slam conference, Platform Computing will share insight into world class private cloud management strategies, based on Platform’s experience working with dozens of early adopter private cloud customers and the company’s 18 year history creating distributed computing models, the precursors to cloud. Topics discussed will include: the evolution of the private cloud market and future trends, key elements of cloud strategies, how to justify investments, how to build a real world implementation roadmap and customer case studies.
“We are delighted to continue our collaboration with Platform Computing, as one of our elite Gold partners for the third annual Cloud Slam’11 conference,” Cloud Slam’11 Chairman – Khazret Sapenov said. “Platform is leading the way in private cloud management technologies serving the enterprise space. Their expertise will once again educate, inform and enlighten our global audiences seeking efficiencies from the cloud.
“We are looking forward to our third year in collaboration with Cloudcor and to participating again at the Cloud Slam’11 conference,” said Jay Muelhoefer, VP Enterprise Marketing at Platform Computing. “While many are calling 2011 the year of the private cloud, the journey to adoption is still uncharted territory for most companies developing or re-examining their cloud strategies. We’re excited we have this opportunity to discuss strategies and best practices to ensure the success of enterprise private cloud projects and to share our customers’ experiences to illustrate how companies can achieve effective private cloud management.”
How To Register for Cloud Slam’11
Admission is priced to fit any budget, from $99 dollars to $299 dollars. Please visit http://www.cloudslam.org/register
About CloudSlam’11®
CloudSlam’11 - Produced by Cloudcor, Inc, is the premier Cloud Computing event. CloudSlam’11 will take place April 18-22 2011 delivered in hybrid format; Day 1 to be held in Mountain View Silicon, CA, Days 2 - 5 Virtual - For more information, visit http://cloudslam.org Stay connected via Twitter @CloudSlam – www.twitter.com/cloudslam
Contacts
Cloudcor®
Khazret Sapenov, 510-984-2312
k.sapenov@cloudslam.org
• The CloudTimes blog reported Cloudforce New York Opens This Week as The Second Largest Cloud Computing Event on 2/28/2011:
The Cloudforce event which starts this week on March 3 in New York, is expected to receive more than 4,000 attendees.
Cloudforce, salesforce.com’s second biggest event after Dreamforce, is a free one day event with 18 role-based breakout sessions for sales, customer service, developers, and IT.
Salesforce.com’s CEO Marc Benioff will deliver the keynote focused on the shift to Cloud 2, the next generation of cloud computing that is social, mobile and open.
The will be interesting sessions on Chatter, Sales/Service Cloud, Force.com platform and more. Attendees will be able to cover the full salesforce.com Cloud 2 ecosystem of apps, platform and collaboration. There will also be a Force.com Zone with 16 developer labs and 4 code consultation stations for hands on experiences for attendees.
Ping Identity and Symantec will host an Ensuring Trust in the Cloud: Delivering Cloud-Based Authentication with Single Sign-On Webinar on 3/3/2011 at 8:00 to 9:00 AM PST:
Over the last decade, cloud computing vendors have invested heavily in making Software-as-a-Service (SaaS) as secure as possible. However, as with any security framework, cloud computing security is only as good as its weakest link. And in many circumstances, that weakest link is the password used to access web-based applications.
Ping Identity, a leader in Internet Identity Security and Symantec, a global security leader, have partnered to help enterprises establish one online employee identity through secure Internet Single Sign-On (SSO) and Two-Factor Authentication. Together, we’re ensuring a seamless integration between Symantec’s VeriSign Identity Protection (VIP), and PingFederate®, our Internet Identity Security solution.
Join Chris Ceppi, Director of Strategic Alliances, Ping Identity and Jeff Burstein, Principal Product Manager, User Authentication, Symantec for this webinar, where they will provide more details on how we:
Register
- Combine Single Sign-On with Strong Authentication to enable secure employee access to internal as well as cloud-based solutions
- Mitigate security concerns and password issues due to the increased use of SaaS
- Work with your current infrastructure to achieve a flexible, cost-effective security solution
Cloud Connect 2011 will host a DevOps and Automation Conference on Thursday, 3/10/2011 at the Santa Clara Convention Center, Santa Clara, CA with Damon Edwards (pictured below) as the track chair:
Nearly everything about software development has changed. Clouds make it easy to experiment on the fly; they bring together the roles of development and operations; and they require new tools for deployment and validation. Agile engineering and the Devops movement are direct results of adaptive, on-demand platforms. In this track, we'll look at the changing face of application engineering, from the first line of code to the automation of massively distributed systems.
8:15 AM– 9:15 AM Moving from "Dev vs. Ops" to "DevOps" (Location: Grand Ballroom E)
Changing tools is easy when compared to changing people and process. How can you cultivate an organization’s culture to identify and solve DevOps problems? From both the bottom up and the top down, what are the effective strategies for implementing DevOps best practices?
Speaker - Andrew Shafer, VP of Engineering, Cloudscaling
Andrew Shafer is a lead engineer and infrastructure consultant at Cloudscaling where he helps organizations leverage and create next generation cloud computing resources and platforms. Since 2004, he has been a regular participant in the Salt Lake City Agile Roundtable and a team member or manager in an Agile setting. Andrew brings with him a background in computational science, embedded Linux, database administration, web frameworks, and operations. In addition to technical expertise, Andrew is focused on finding ways to balance prescriptive processes with the uniqueness of projects and teams.
Speaker - Lloyd Taylor, VP of Infrastructure, ngmoco:)
9:30 AM–10:30 AM
Automating the Gaps Between Development and Operations (Location: Grand Ballroom E)
In this session, you learn effective strategies for automating the core DevOps gap -- getting releases from code check-in in Development through to where it is running in Production Operations. While noting tools for your further research, speakers will focus on tool independent processes and best practices you can bring to your own organization.
Speaker - Juan Paul Ramirez, Vice President of Engineering, Shopzilla
Juan Paul is Vice President of Engineering at Shopzilla, having successfully lead or played a substantial role in the delivery of virtually every software application in the company, including the large scale affiliate program, and initial launch of the company’s latest products, beso and TaDa.
Earlier in his career, Juan Paul was the quintessential face of the DevOps role. Highlighting the need for software configuration management in the mid-90′s, blossoming internet economy allowed Juan Paul to bring Experian‘s credit reporting software quality into a modern age, create the successful initial public launch of the leading commercial real estate site in the country, Loopnet.com, and allow for Gateway to reposition it’s internet presence for PC sales. Juan Paul’s sites, and he speaks of them with great pride and ownership, account for millions of active visitors per day with nary a technical commonality except for a penchant for automation and unworldly quality standards.
Juan Paul holds a degree in Management Information Systems and Corporate Law and Public Policy from Syracuse University.Speaker - Alex Honor, Founder, ControlTier open source project
Alex Honor is the founder of the ControlTier open source automation project. Has been involved in the development and management of large scale online systems for over 15 years, including critical roles at E*TRADE, NASA Ames Research, Open Design, and DTO Solutions. He is a frequent speaker at regional user group meetings on issues of system scalability and deployment automation.
10:45 AM–11:45 AM Ask the Experts: The DevOps Panel (Location: Grand Ballroom E)
This lively session will feature a panel of DevOps experts discussing past victories, horror stories, and the future of DevOps. Come join in the discussion with any DevOps related questions or comments.
Moderator - Damon Edwards, Co-Founder and President, DTO Solutions
Damon Edwards is the co-founder and president of the DTO Solutions consulting group. DTO Solutions specializes in automated infrastructure and process improvement consulting for large-scale, mission critical IT operations, including Intuit, Dun & Bradsteet, E*Trade, LinkedIn, iControl, SilverSpring Networks, and AT&T. Damon is also a frequent contributor to the dev2ops.org blog, focusing on automation and process issues faced by cloud, software-as-a-service, and e-commerce organizations.
Panelist - John Willis, Vice President of Training & Services, Opscode
John has over three decades working in the IT trenches managing complex infrastructures. Prior to joining Opscode, he founded Gulf Breeze Software, an award winning IBM business partner, which specializes in deploying Tivoli technology for the enterprise. John has trained more than 10,000 people on IBM Tivoli products around the world and is recognized as an industry expert in enterprise systems management and monitoring. Willis has authored six IBM Redbooks for IBM on enterprise systems management and was the founder and chief architect at Chain Bridge Systems.
Panelist - Juan Paul Ramirez, Vice President of Engineering, Shopzilla
Juan Paul is Vice President of Engineering at Shopzilla, having successfully lead or played a substantial role in the delivery of virtually every software application in the company, including the large scale affiliate program, and initial launch of the company’s latest products, beso and TaDa.
Earlier in his career, Juan Paul was the quintessential face of the DevOps role. Highlighting the need for software configuration management in the mid-90′s, blossoming internet economy allowed Juan Paul to bring Experian‘s credit reporting software quality into a modern age, create the successful initial public launch of the leading commercial real estate site in the country, Loopnet.com, and allow for Gateway to reposition it’s internet presence for PC sales. Juan Paul’s sites, and he speaks of them with great pride and ownership, account for millions of active visitors per day with nary a technical commonality except for a penchant for automation and unworldly quality standards.
Juan Paul holds a degree in Management Information Systems and Corporate Law and Public Policy from Syracuse University.Panelist - Alex Honor, Founder, ControlTier open source project
Alex Honor is the founder of the ControlTier open source automation project. Has been involved in the development and management of large scale online systems for over 15 years, including critical roles at E*TRADE, NASA Ames Research, Open Design, and DTO Solutions. He is a frequent speaker at regional user group meetings on issues of system scalability and deployment automation.
Panelist - Andrew Shafer, VP of Engineering, Cloudscaling
Andrew Shafer is a lead engineer and infrastructure consultant at Cloudscaling where he helps organizations leverage and create next generation cloud computing resources and platforms. Since 2004, he has been a regular participant in the Salt Lake City Agile Roundtable and a team member or manager in an Agile setting. Andrew brings with him a background in computational science, embedded Linux, database administration, web frameworks, and operations. In addition to technical expertise, Andrew is focused on finding ways to balance prescriptive processes with the uniqueness of projects and teams.
Panelist - Lloyd Taylor, VP of Infrastructure, ngmoco:)
Panelist - James Urquhart, Market Strategist, Cloud Computing Service Provider Systems Unit, Cisco
James Urquhart manages cloud computing infrastructure strategy for the Server Provider Systems Unit of Cisco Systems. Named one of the ten most influential people in cloud computing by the MIT Technology Review, and author of the popular cloud computing blog, The Wisdom of Clouds (http://news.cnet.com/the-wisdom-of-clouds), Mr. Urquhart brings a deep understanding of these disruptive technologies and the business opportunities they afford. James has a Bachelor of Arts degree in Physics and Mathematics from Macalester College.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• The CloudTimes blog reported IBM’s New Software Virtualizes a Data Center in Minutes on 3/1/2011:
IBM revealed today (in beta) a new advanced virtual deployment software which enables organizations to build a cloud environment rapidly with greater ease of management than ever before. This IBM software has tremendous speed and can deploy a single virtual machine in seconds, dozens in a few minutes and hundreds or thousands at the unrivaled speed of under an hour.
“These new technologies deliver a definitive step forward in simplifying the way IT staff can manage the cloud,” said Ric Telford, vice president of Cloud Services, IBM. “They come at a critical time for businesses as the demand for computing resources and new services are becoming nearly insatiable, despite generally stagnate budgets. IBM is delivering again on our promise of leading cloud innovation with a focus on fundamentally transforming the economics of IT.”
IBM also announced three new breakthroughs for managing virtual environments in today’s press release.
If IBM “can deploy a single virtual machine in seconds,” why can’t Windows Azure spin up a new or updated compute deployment in the same timeframe?
• Alex Williams (@alexwilliams) described Scality and Parallels in his Two Companies That Turn Hosted Services into Infrastructure Providers article of 3/1/2011 for the ReadWriteCloud blog:
Object-based storage is gaining in popularity and is increasingly viewed as a core requirement for multi-tenant infrastructures. Its strength is in its capability to handle unstructured data, which is far more prevalent these days than structured data.
Amazon Web Services and Rackspace offer object-based storage. But outside the narrow field of massive infrastructure plays, there is a growing space for services that hosting providers integrate into their own environments so they may compete more effectively in the market.
Scality is an emerging hot company in the cloud-based storage space. Today it announced a $7 million "B" round. The money will go to opening a sales and service office in New York and the extension of its core services for data center environments.
I had a brief introduction to Scality last week, and what I saw impressed me. I am now more intrigued by the hosting market as it adopts technologies such as Parallels Automation and the Scality object-storage.
Scality and Parallels are partners in servicing the hosting market. Scality offers what it calls a RING. It's an application centric cloud storage system. It turns commodity x86 server hardware and Ethernet LANs into cloud storage.

Parallels provides a service that can turn a data center into an infrastructure environment. It's a modular system with APIs for application integration and billing services. I spoke to several people at the Parallels Summit who were integrating the technology for their hosting services.

Scality and Parallels have a common interest in serving the hosting market. They fit into a fast growing market space. They are enablers. They offer cloud-based storage and application environments that can transform how hosting services operate.
That's a potent combination for hosting providers as they help small businesses start making their own transitions to the cloud.
David Linthicum asserted “It's a good start, but technology that can do this trick among the clouds, not just within a single cloud, is needed” as a deck for his Amazon to provide 'formation' cloud computing post of 3/1/2011 to InfoWorld’s Cloud Computing blog:
Amazon.com just announced a new product called CloudFormation that allows those who use the AWS (Amazon Web Services) cloud to configure and manage resources as a single system by creating a template that describes the applications and resources that make up their system or architecture.
CloudFormation then takes care of provisioning, while taking into account any dependencies between resources, including server instances, database instances, and load balancers. The service also allows AWS users to configure and set triggers that automatically provision additional resources.
Once again, Amazon has built its stack in the right direction. Consider the features of CloudFormation and the fact that AWS has recently been on a tear with new features and products like Elastic Beanstalk and the recent Oracle offering in its cloud.
I would not put CloudFormation into the major feature category, but the ability to cobble together aspects of a cloud, such as storage, compute, and database, means you'll be able to deal with your cloud services in a much more holistic way. Today, by contrast, you have to keep in mind all of the resources at play and make sure enough are being allocated and de-allocated in support of your system.
What we really need is a way to do this across clouds, or intercloud, so those organizations using many clouds in their system can deal with them as a virtual single bundle of resources. Such intercloud management technology should remove the underlying granular provisioning mechanisms, so developers and admins can deal with hundreds, perhaps thousands of resources as a single, well-integrated whole, even though the services are scattered all over the place on many different clouds.
Read more: 2, next page ›
The UnbreakableCloud blog reported CloudBees, a first PaaS for Java apps in the cloud on 3/1/2011:
The CloudBees platform is the first Platform as a Service that lets companies build, test and deploy Java web applications in the cloud. CloudBees provides the leading Java Platform as a Service for both enterprises and ISVs, from development to production.
With CloudBees, Software teams can move their development and production activities instantly to the cloud, without restrictions or infrastructure costs. CloudBees’s PaaS went on GA recently at the end of January. CloudBees has aquired NetworkStax on Dec 14h positioning the company to take advantage on the fast growing cloud market. CloudBees was on stealth mode for sometime and came out of stealth mode on last year.
Please contact CloudBees for more information or to explore CloudBees PaaS platform for the cloud
I believe Amazon Web Services’ Elastic Beanstalk feature beat CloudBees by a couple of weeks.
<Return to section navigation list>

















0 comments:
Post a Comment