Windows Azure and Cloud Computing Posts for 3/6/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
David Robinson will present SQL Azure: Big Data - Sharding/Federation to the Victoria .NET Users Group on 3/8/2011 5:30 PM at Microsoft Theatre, 5/4 Freshwater Place, Southbank, Melbourne, Victoria 3006, Australia:
Sharding or application-aware partitioning is an integral part of the scale-out strategy for SQL Server, starting with SQL Azure later in 2011. In this session Dave presents an introduction to sharding patterns, and explores how some existing large scale applications already benefit from sharding. Dave will then discuss the design and capabilities of the SQL Azure Federations sharding platform, examining how this platform helps address some of the hard challenges that devs and admins face when implementing a sharding solution on their own and with existing libraries. Time permitting, Dave will touch on Microsoft’s vision for federations past v1 and how federations will co-exist with future scale-out solutions.
About David Robinson
David Robinson is a Senior Program Manager on the SQL Azure team. David is responsible for a multitude of things including driving product features, code samples, and most importantly demonstrating to customers the value that SQL Azure and cloud computing provides. David enjoys getting out in the community, presenting on SQL Azure, gathering feedback, and helping to ensure SQL Azure meets whatever workloads you throw at it. David has also written for MSDN magazine on developing solutions against SQL Azure. Before joining the SQL Azure team, David was a Solutions Architect on Microsoft's Health and Life Sciences team. Before joining Microsoft, David held various senior positions with a variety of software and consulting companies. David got his start as a developer at Computer Associates in the early 90's When not working, David enjoys spending time with his wife and helping her corral their 4 young daughters.
Dave is the technical editor of my Computing with the Windows Azure Platform book.
Mark Kromer (@mssqldude) posted SQL Saturday Philly: SSAS vs PowerPivot Cubes on 3/6/2011:
Thank you to all of those who joined me for my Philly SQL Saturday session on building SQL Server cubes in SSAS, PowerPivot and Denali. We can use this thread for follow-up questions, discussions and links related to the topic.
Ok, that transitions nicely into the PowerPivot portion of the talk yesterday. To review, PowerPivot is new with SQL Server 2008 R2 and requires Excel 2010. If you wish to try out PowerPivot, all you need are the evaluation version of Excel 2010 and the PowerPivot add in, if you are not already using Excel 2010. In order to truely experience the collaboration nature of PowerPivot models, though, you will need SharePoint 2010 with SQL Server 2008 R2 to persist the in-memory cubes as they are hydrated by SharePoint.
The sample PowerPivot that I used which gives you the exact same results as the SSAS cube that I built is available as a download here. PowerPivot makes it even easier to build solutions than the cube method that I demo’d with SSAS because the cube is processed immediately in memory and is abstracted away from the model power-user. But it has many limitations in V1 that you need to make your decisions based on which Microsoft technology to use for your BI solution based on a knowledge and understanding of the impact of those limitations. For example, you cannot build explicit hierarchies in PowerPivot like you can in SSAS. The role-based security is not available in the Excel version like you have in SQL Server and the advanced capabilities outside of what I showed yesterday such as partitioning or many-to-many are not available to you.
Now, you may not need those for your solution. And as I stated several times on Saturday, I am a true believer in smaller departmental cubes as opposed to mondo big enterprise cubes. So PowerPivot will work nicely in those circumstances. Go to http://www.powerpivot.com for more examples and tutorials.
Lastly, we did not get a chance to talk about this too much, but the SQL Server Denali CTP 2, which will be made available publicly soon, will give you a first-glance chance to preview and try out the new BIDS environment which is a convergence of the PowerPivot and SSAS technologies. What this means is that if you are intimidated by MDX, you can build cubes in BIDS with DAX instead. DAX is the PowerPivot scripting language and uses Excel syntax and is much more familiar to users of Excel functions that you find in statistics, math and finance. This makes sense to me because the primary users of business intelligence are, after all, experts in math, stats & finance.
But if you are really good at making fast, efficient, complicated cubes in SSAS, you can still use the UDM model, use MDX and there will be new features add for those developers as well. But you won’t get the quick, immediate feedback on your cube through the Vertipaq technology that PowerPivot brings to the table. Instead, you have to process your cubes and worry about storage techniques as you do now. I think of this direction in SQL Server as bringing the power of the PowerPivot compression engine and in-memory analysis server to all BI developers. Very powerful stuff.
Probably the best source of information about this direction in SSAS future is directly from the SSAS product team on their blog, which you can read here.
I probably did not hit all areas in this blog post that everyone wanted as follow-up from the session. So please send in your comments and feedback and we’ll keep the thread going. My goal here is to see you all using Microsoft SQL Server in one fashion or another for your BI solutions. Let me know what I can do to help. And your feedback on the session, presentaiton, contents, etc. is also greatly appreciated.
Roberto Bonini described Deploying your Database to SQL Azure (and using ASP.Net Membership with it) in a 3/5/2011 post:
Its been quite quiet around here on the blog. And the reason for that is the fact that I got asked by a Herbalife Distributor to put a little e-commerce site together (its called Flying SHAKES). So its been a very busy few weeks here, and hopefully as things settle down, we can get back to business as usual. I’ve badly neglected the blog and the screencast series.
I have a few instructive posts to write about this whole experience, as it presented a few unique challenges.
But we’ll start from the beginning. Now I’m assuming here that your database is complete and ready for deployment.
Step 0: Sign up for Windows Azure (if you haven’t already) and provision a new database. Take note of the servers fully qualified DNS address and remember your username and password. You’ll need it in a bit.
Step 1 Attach your database to to your local SQL Server. Use SQL Server Management Studio to do that.
At this point we have our two databases and we need to transfer the schema and data from one to the other. To do that, we’ll use a helpful little Codeplex project called SQL Azure Migration Wizard. Download it and unzip the files.
Run the exe. I chose Analyse and Migrate:
Enter your Local SQL Server details:
Hit Next until it asks if you’re ready to generate the SQL Scripts. This is the screen you get after its analyse the database and complied the scripts.
Now you get the second login in screen that connects you to your newly created SQL Azure Database.
This is the crucial bit. You have to replace SERVER with your server name in both the server name box and the Username box, replacing username with your username in the process. You need to have @SERVER after your username or the connection will fail.
Fill in the rest of your details and hit Connect. Press next and at the next screen you’ll be ready to execute the SQL scripts against your SQL Azure database.
And its that easy.
All you have to do is to go ahead and change your connection string from the local DB to the one hosted on SQL Azure.
There is one last thing to do. When you first deploy your site and try and run it against SQL Azure, it won’t work. the reason being is that you have to set a firewall rule for your SQL Azure Database by IP Address range. So you should receive an error message saying that IP address such and such is not authorised to access the database. So you just need to go ahead and set the appropriate rule in the Management Portal. You’ll need to wait a while before those settings take effect.
And you should be good to go.
The ASP.Net Membership Database
In the normal course of events, you can setup Visual Studio to run the SQL Scripts against whatever database you have specified in your connection string when you Publish your project. However, there is a big gotcha. The SQL Scripts that ship with Visual Studio will not run against SQL Azure. This is because SQL Azure is restricted.
Even if you log into your SQL Azure database using SQL Management Studio you’ll see that your options are limited as to what you can do with the database from within SQL Management Studio. And if you try and run the scripts manually, they still wont run.
However, Microsoft has published a SQL Azure friendly set of scripts for ASP.net.
So we have two options: We can run the migrate tool again, and use the ASP.net Membership database to transfer over Schema and Data. Or we can run the scripts against the database.
For the sake of variety, I’ll go through the scripts and run them against the database.
- Open SQL Management Studio and log into your SQL Azure Database.
- Go File-> Open and navigate to the folder the new scripts are in.
- Open InstallCommon.sql and run it. You must run this before running any of the others.
- For ASP.net Membership run the scripts for Roles, Personalisation, Profile and Membership.
At this point I need to point out that bad things will happen if you try running your website now, even if your connection string has been changed.
ASP.net will try and create a new mdf file for the membership database. You get this error:
An error occurred during the execution of the SQL file ‘InstallCommon.sql’. The SQL error number is 5123 and the SqlException message is: CREATE FILE encountered operating system error 5(failed to retrieve text for this error. Reason: 15105) while attempting to open or create the physical file ‘C:\USERS\ROBERTO\DOCUMENTS\VISUAL STUDIO 2010\PROJECTS\FLYINGSHAKESTORE\MVCMUSICSTORE\APP_DATA\ASPNETDB_TMP.MDF’. CREATE DATABASE failed. Some file names listed could not be created. Check related errors. Creating the ASPNETDB_74b63e50f61642dc8316048e24c7e499 database…
Now, the problem with all this is the machine.config file where all of these default settings actually reside. See internally, it has a LocalSQLServer connection string. And by default, the RoleManager will use it because its a default setting. Here’s what it looks like:

So, we have to overwrite those settings in our own web.config file like so:

Now, what we are doing here is simply replacing the connectionstringaname attribute in each of these providers with our own connection string name. Before that, however, we put “<clear/>” to dump the previous settings defined in the machine.config file and force it to use our modified settings.
That should allow the role manager to use the our SQL Azure database instead of trying to attach its own. Things should run perfectly now.
Finally
The Azure Management Portal has a very nice UI for managing and editing your database. You can add and remove tables, columns rows etc. Its really good. And rather welcome. I thought I’d have to script every change and alteration.





<Return to section navigation list>
MarketPlace DataMarket and OData
Rhett Clinton described his Dynamics CRM 2011 OData Query Designer in a 3/6/2011 post:
I’ve developed the CRM 2011 OData Query Designer as a Silverlight 4 application that is packaged as a Managed CRM 2011 Solution. This tool allows you to build OData queries by selecting filter criteria, selecting attributes and ordering by attributes. The tool also allows you to Execute the query and view the ATOM and JSON data returned. Once the managed solution is imported into CRM 2011 it is accessible from the Settings area under Customizations .
You can download the CRM 2011 OData Query Designer from codeplex.
Create Query tab:

Results (ATOM) Tab:

Results (JSON) Tab:


Glenn Gailey (@ggailey777) described Handling [WCF Data] Service Operation Exceptions in a 3/6/2011 post:
In responding to a customer post on the WCF Data Services forum, I ran across an interesting behavior when raising exceptions in a service operation. When creating a data service, you are supposed to use the DataServiceException class when raising exceptions. This is because the data service knows how to map properties of this exception object to correctly to the HTTP response message. There is even a HandleException method on DataService<T> that you can override to return other kinds of exceptions as DataServiceException.
The way to deal with this is to override the HandleException method and unpack the DataServiceException from the TargetInvocationException. Since the HandleException method is invoked when any exception is raised, we need to be sure to only handle the right kinds of errors (although it’s also a good practice to handle other non-data service exceptions in this method too). The following is an example implementation of HandleException that unpacks the DataServiceException and returns it as the top-level error:
// Override to manage returned exceptions.
protected override void HandleException(HandleExceptionArgs args)
{
// Handle exceptions raised in service operations.
if (args.Exception.GetType() ==
typeof(TargetInvocationException)
&& args.Exception.InnerException != null)
{
if (args.Exception.InnerException.GetType()
== typeof(DataServiceException))
{
// Unpack the DataServiceException.
args.Exception = args.Exception.InnerException;
}
else
{
// Return a new DataServiceException as "400: bad request."
args.Exception =
new DataServiceException(400,
args.Exception.InnerException.Message);
}
}
}[WebGet]
public void RaiseError()
{
throw new DataServiceException(500,
"My custom error message.");
}(Note that the RaiseError service operation simply raises an error to test the implementation.) This implementation also handles other kinds of errors raised in service operations.
You may also be interested in the fact that one of the nifty things about HandleExceptionArgs is that it has a UseVerboseErrors property, which enables you to return inner exception information at runtime even when verbose errors are turned off for the data service (when it is safe to do so).
The Community Megaphone reported Chris Koenig will present OData and The Communication Stack in Window Phone 7 on 3/9/2011 6:00 PM to the D/FW Connected Systems User Group at Improving Enterprises, Dallas:
Abstract:
Speaker Bio:
Chris Koenig is a Senior Developer Evangelist with Microsoft, based in Dallas, TX. Chris focuses on building, growing, and enhancing the developer communities in Texas, Oklahoma, Arkansas and Louisiana while specializing in Windows Phone 7 and Silverlight development.Meeting Details
- Meeting: OData and The Communication Stack in Window Phone 7
- Date: Wednesday, March 9, 2011
- Time: 6:00PM
- Where: Improving Enterprises, Dallas (One Hanover Park, 16633 Dallas Parkway, Suite 100, Addison, TX 75001)
- Maps: Bing, Google
- Cost: It's free thanks to our sponsors!
- RSVP: rsvp@dfwcsug.com or via the Eventbrite meeting announcement.
<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
Alik Levin described How To: Configure Windows Azure Web Role ASP.NET Web application for Federation with Access Control Service (ACS) v2 in a 3/3/2011 post:
This post outlines how to create basic Windows Azuer Web Role ASP.NET application configured for federation with Access Control Service (ACS) v2. This is only collection of resources that were tested individually but not in the sequence as presented below. I am collecting required raw materials to start with. The end goal is to build end-to-end walkthrough and test it. But that’s for another post.
Summary of steps:
- Create a basic Windows Azure Web Role ASP.NET project
- Create and configure ASP.NET web application as relying party in ACS v2 Management Portal
- Configure Windows Azure Web Role ASP.NET project for federation with ACS v2
- Make modifications related to specifically to Azure/ACS v2.
- Deploy your solution to Windows Azure
- Test your solution
The rest of the post is the details for each step.
Create basic Windows Azure Web Role ASP.NET project
To create Windows Azure Web Role ASP.NET project use the following topic - Code Quick Launch: Create and deploy an ASP.NET application in Windows Azure. Relevant section is To create and run an ASP.NET service for Windows Azure.
Create and configure ASP.NET web application as relying party in ACS v2 Management Portal
To create and configure relying party use the following topic - How To: Create My First Claims Aware ASP.NET application Integrated with ACS v2. Relevant steps are:
Step 1 - Create a Windows Azure AppFabric Project
- Step 2 - Add a Service Namespace to a Windows Azure AppFabric Project
- Step 3 – Launch the ACS v2.0 Management Portal
- Step 4 – Add Identity Providers
- Step 5 - Setup the Relying Party Application
- Step 6 - Create Rules
- Step 7 - View Application Integration Section
Configure Windows Azure Web Role ASP.NET project for federation with ACS v2
To create configure Windows Azure Web Role ASP.NET project for federation with ACS v2 use the following topic - How To: Create My First Claims Aware ASP.NET application Integrated with ACS v2. Relevant steps are:
- Step 9 - Configure trust between the ASP.NET Relying Party Application and ACS v2.0
Make modifications related to specifically to Azure/ACS v2.
To make relevant modifications related to ASP.NET project to be deployed to Windows Azure and configured for federation with ACS v2. use the following topic - Windows Azure Web Role ASP.NET Application and Access Control Service (ACS) V2 – Quick Checklist. You will need to configure certificates to enable your Windows Azure Web Role ASP.NET application to work with Windows Identity Foundation (WIF). Good start outlined here Exercise 1: Enabling Federated Authentication for ASP.NET applications in Windows Azure – relevant section is Task 1 – Creating a Windows Azure project and Preparing it for Using Windows Identity Foundation.
Deploy your solution to Windows Azure
To deploy your ASP.NET web application configured for federation with ACS v2 to Windows Azure Web Role use the following topic - Code Quick Launch: Create and deploy an ASP.NET application in Windows Azure. Relevant section is To deploy the service to Windows Azure.
Related Info
- Windows Identity Foundation (WIF) and Azure AppFabric Access Control (ACS) Service Survival Guide
- Video: What’s Windows Azure AppFabric Access Control Service (ACS) v2?
- Video: What Windows Azure AppFabric Access Control Service (ACS) v2 Can Do For Me?
- Video: Windows Azure AppFabric Access Control Service (ACS) v2 Key Components and Architecture
- Video: Windows Azure AppFabric Access Control Service (ACS) v2 Prerequisites
- Windows Azure AppFabric Access Control Service 2.0 Documentation
- Windows Identity Foundation (WIF) Fast Track
- Windows Identity Foundation (WIF) Code Samples
- Windows Identity Foundation (WIF) SDK Help Overhaul
- Windows Identity Foundation (WIF) Questions & Answers
Damir Dobric answered meetrohitpatil_hotmail.com’s Windows Server AppFabric to Windows Azure AppFabric![]() migration question on 2/24/2011 (missed when posted):
migration question on 2/24/2011 (missed when posted):
A: As Jason already mentioned, these two products are at the moment not identical, but both provide a number of more or less same features.
a) If your current solution consists of WCF and/or WF, you will be able to migrate it. At the moment, running of WF is still bit tricky, but this will be changed.
b) If your solution makes use of AppFabric Cache, it can be migrated if regions and tags are not used.
c) Note that monitoring features in Win Azure AppFabric use at the moment different monitoring mechanism. But this is a hosting feature which is provided a different way than in Windows Server AppFabric.
I posted this because I was about to ask the same question.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
Jason Chen answered Roger NZ’s Official date of the production release of Azure Connect and Service Bus of AppFabric V2 question on 3/2/2011 (missed when posted):
Q: Anyone from Microsoft can let us know the date of the production release of Azure Connect and Service Bus of AppFabric V2?
Because we have a product that uses both of them scheduled to be released soon and we would like to use the production version instead of the CTP version. The official release date of Azure Connect and Service Bus will impact our project plan.
A: Hi Roger, the production release date for Windows Azure Connect is first half of 2011.
Jason Chen, Windows Azure PM
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Marius Oiaga (@mariusoiaga) posted Windows Azure Platform Training Kit Refresh for Windows 7 SP1 RTM Users to the Softpedia blog on 3/2/2011:
Microsoft has refreshed a collection of resources that it’s offering free of charge to customers looking to start using Windows Azure and associated services.
Those interested in learning more about the software giant’s Cloud platform need to head over to the Microsoft Download Center and get the February Update for the Windows Azure Platform Training Kit.Various components of the company’s Cloud offerings are covered by the learning resources, including Windows Azure, SQL Azure, and the Windows Azure AppFabric.
What the kit brings to the table is a collection of technical content which will make it easier for customers to get started using Windows Azure.
As its Cloud platform evolves from one month to another, Microsoft is careful to always provide updates to the Windows Azure Platform Training Kit.
However, the latest refresh is designed to reflect not only changes to Windows Azure, but also to the operating system customers might be running such as Windows 7.
On February 22nd, 2011, Microsoft launched Windows 7 Service Pack 1 RTM to all customers worldwide. Windows Azure Platform Training Kit - February Update comes to make sure that those running Windows 7 SP1 RTM will be able to continue leveraging the technical content without any issues.
In this regard, the software giant revealed that it has introduced a number of fixes related to the demos and labs included in the kit.
In addition, “the setup scripts for all hands-on labs and demo scripts have also been updated so that the content can easily be used on a machine running Windows 7 SP1,” the company stated.
Microsoft also highlighted a number of additional changes to the kit, including:
- [Updated] Hands-on Lab - Building Windows Azure Apps with the Caching service
- [Updated] Hands-on Lab – Using the Access Control Service to Federate with Multiple Business Identity Providers
- [Updated] Hands-on Lab – Introduction to the AppFabric Access Control Service V2
- [Updated] Hands-on Lab - Introduction to the Windows Azure AppFabric Service Bus Futures
- [Updated] Hands-on Lab - Advanced Web and Worker Roles – fixed PHP installer script
- [Updated] Demo Script – Rafiki PDC Keynote Demo.”
Windows Azure Platform Training Kit - February Update is available for download here.Windows 7 Service Pack 1 (SP1) RTM Build 7601.17514.101119-1850 and Windows Server 2008 R2 Service Pack 1 (SP1) RTM are available for download here.
Steve Apiki described Building a Facebook Marketing App on Azure in an undated post to the Internet.com Cloud Computing Showcase (sponsored by Microsoft):
When your Facebook app hits it big, how will it scale? Very nicely, thank you, if you build on Windows Azure and design with scaling out in mind. We step through the creation of a simple Facebook 'viral' marketing app on Azure, using the Windows Azure Toolkit and the Facebook C# SDK, both on CodePlex, to make the job a lot easier.
Sample Code
The sample code is a snapshot of how this was done at the time the article was written. Download the sample code (Azure Article Example) for this article.
Visit http://facebooksdk.codeplex.com/ to stay up to date on all releases.But simply running on Azure doesn't guarantee scalability. An Azure app still needs to be designed to scale well, using methods like partitioning into multiple roles, and using simple, scalable storage structures.
In this article, we'll build a scalable Facebook marketing app on Azure. This sample app draws inspiration from the hugely successful Bloomin' Onion Facebook Campaign built for Outback Steakhouse in late 2009 by Thuzi. It's also built on two toolkits created by those same Thuzi developers: the Windows Azure Toolkit and the Facebook C# SDK. The Windows Azure Toolkit started out as a one-stop-shop for building Facebook apps on Azure, but has since evolved into a general-purpose Azure development toolkit. When we use the Windows Azure Toolkit in this app for storage and queue management, those techniques can be applied to any applications on the Azure platform.
What it Does
We'll build the app as a Facebook canvas application, setting the canvas URL to point to the application running on Azure. The first time the customer runs the app ("AzureSample"), they see a permissions request form that asks that the app be allowed to read information such as the customer's date of birth from Facebook.
Figure 1. Since the application will need to access the customer's date of birth, Facebook presents this permission screen before starting the app. The application declares what permissions it requires through an attribute supplied by the Facebook C# SDK.
Assuming the customer grants the necessary permissions, we start AzureSample and start gathering customer information.
Figure 2. The first page from the application's canvas URL collects customer information. When the page is opened, first name, last name, and date of birth are pre-filled with information read from Facebook.
The customer's first name, last name, and date of birth are read from Facebook and used to pre-fill the appropriate fields in the form. The customer needs to fill in the email address and zip code fields to continue to the next page.
Figure 3. The store selection page. The customer is presented with a list of up to three stores within 50 miles of the zip code they entered on the previous page and asked to select a favorite.
The next page shows a list of up to three nearby stores, keyed off of the zip code entered by the customer in the previous step. These are the three nearest stores within a 50 mile radius of the customer's zip code. (For the example, I just generated a list of 1000 stores in random zip codes to use as sample data.) At this point, we've gathered all of the customer information that we wanted. AzureSample starts a background task to send an email with the customer premium to the customer, and to migrate the contact information from fast Azure table storage to more-easily-queried SQLAzure. At this point, all that's left is to show the completion page.
Figure 4. The thank-you page. The customer is also automatically redirected here if they run the app again after signing up.
Project Structure
On Facebook, the application is known as AzureSample, because apps on Facebook can't include the string "facebook." If you were to install the application, you would probably give it a more meaningful name on Facebook, such as "SignUpFreeX." In Visual Studio, the solution is called AzureFacebookSample, and it includes four projects.
Figure 5. AzureFacebookSample in Visual Studio's Solution Explorer, showing the four projects within the solution.
AzureFacebookSample.Cloud is the main Azure application project. It includes two roles, the web role and a single worker role. The web role is implemented by the AzureFacebookSample.Web project, and the worker role, unsurprisingly, is implemented by AzureFacebookSample.Worker.
The web role is an ASP.NET MVC project and includes views for all of the application screens and the associated controller logic. The worker role is responsible for sending off the premium email and for migrating contact information from Azure table storage to SQL Azure.
AzureFacebookSample.Domain is a class library project that includes data models, queues, and data repositories shared by both the web and worker roles. The web and worker roles get to domain objects in Azure storage, Azure queues, and SQLAzure through the domain project.
AzureFacebookSample demonstrates how you might structure a production Facebook app on Azure, but it doesn't do several of the things you would need to do were you to implement a viral marketing app of your own. First, the worker role doesn't actually send an email. In a real application, the worker role would need to contact an external service that was capable of generating the quantity of email required by the marketing campaign. Contacting that web service is stubbed out in AzureFacebookSample. Second, you might need an additional worker role to handle email bounces from the mail service and to contact customers on Facebook to try to get a corrected email address (so that the premium can be sent). Finally, AzureFacebookSample doesn't attempt to drive Facebook "likes" to a company page or prompt the customer to notify Facebook friends about the app.
Read More: Next Page: First Canvas Page





Steve Apiki is senior developer at Appropriate Solutions, Inc. of Peterborough, NH.
Shawn Cicoria posted Running Jetty under Windows Azure Using RoleEntryPoint in a Worker Role on 3/3/2011 (missed when posted):
This post is built upon the work of Mario Kosmiskas and David C. Chou’s prior postings – from here:
- http://blogs.msdn.com/b/mariok/archive/2011/01/05/deploying-java-applications-in-azure.aspx
- http://blogs.msdn.com/b/dachou/archive/2010/03/21/run-java-with-jetty-in-windows-azure.aspx
There were things I liked especially about Mario’s post – specifically, the ability to pull down the JRE and Jetty runtimes at role startup and instantiate the process using the extracted bits. The way Mario initialized the java process (and Jetty) was to take advantage of a role startup task configured as part of the service definition. This is a great quick way to kick off processes or tasks prior to your role entry point. However, if you need access to service configuration values or role events, that’s where RoleEntryPoint comes in. For this PoC sample I moved the logic for retrieving the bits for the jre and jetty to the worker roles OnStart – in addition to moving the process kickoff to the OnStart method. The Run method at this point is there to loop and just report the status of the java process. Beyond just making things more parameterized, both Mario’s and David’s articles still form the essence of the approach.
The solution that accompanies this post provides all the necessary .NET based Visual Studio project. In addition, you’ll need:
- Jetty 7 runtime http://www.eclipse.org/jetty/downloads.php
- JRE http://www.oracle.com/technetwork/java/javase/downloads/index.html
Once you have these the first step is to create archives (zips) of the distributions. For this PoC, the structure of the archive requires that the root of the archive looks as follows:
JRE6.zip
jetty---.zip
Upload the contents to a storage container (block blob), and for this example I used /archives as the location. The service configuration has several settings that allow, which is the advantage of using RoleEntryPoint, the ability to provide these things via native configuration support from Azure in a worker role.
Storage Explorer
You can use development storage for testing this out – the zipped version of the solution is configured for development storage. When you’re ready to deploy, you update the two settings – 1 for diagnostics and the other for the storage container where the /archives are going to be stored.

For interacting with Storage you can use several tools – one tool that I like is from the Windows Azure CAT team located here: http://appfabriccat.com/2011/02/exploring-windows-azure-storage-apis-by-building-a-storage-explorer-application/ and shown in the prior picture
At runtime, during role initialization and startup, Azure will call into your RoleEntryPoint. At that time the code will do a dynamic pull of the 2 archives and extract – using the Sharp Zip Lib <link> as Mario had demonstrated in his sample. The only different here is the use of CLR code vs. PowerShell (which is really CLR, but that’s another discussion).
At this point, once the 2 zips are extracted, the Role’s file system looks as follows:
Worker Role approot
From there, the OnStart method (which also does the download and unzip using a simple StorageHelper class) kicks off the Java path and now you have Java!
Task Manager
Jetty Sample Page
A couple of things I’m working on to enhance this is to extract the jre and jetty bits not to the appRoot but to a resource location defined as part of the service definition.
ServiceDefinition.csdef

As the concept matures a bit, being able to update dynamically the content or jar files as part of a running java solution is something that is possible through continued enhancement of this simple model.
The Visual Studio 2010 Solution is located here: HostingJavaSln_NDA.zip






Peter Kellner described Hosting The Same Windows Azure Web Project With Two Different Configurations in a 3/5/2011 post:
The Problem
In my scenario, I have the same web project that I want to host in two different Windows Azure Data Centers (BTW, Steve Marx let me know it’s “Windows Azure” and not “Azure” at MVP Summit so I’ll try and keep my terminology right as much as I can). Each Windows Azure Data Center has it’s own azure account (Azure Credential). It resolves to a different domain name and as part of that scenario, has different properties in the ServiceConfiguration.csfg file.
What Happens By Default
Adding Another Web Role Pointing At Same Web Project
So, here we go.
First, add a new cloud project / web role as follows:
Add the project:
Add the Web Role
Now, associate this role with the original web project “Web” and notice that a new web site has been created by the previous step. Our plan will be to delete the one that just got created.
That seems to have worked, so now let’s remove the WebRole1 project and then delete it from the directory.
Now, I believe we have what we want as shown below.
The final thing I need to do is simply update my ServiceConfiguration and ServiceDefinition files with what I want that is specific to AzureWebRoleConnectionRoadCom.
My plan is to do this for all my different deployments of the same project. If things don’t continue to go swimmingly, I’ll add some notes to this post to indicate that maybe this wasn’t the best possible plan, but for now, I’m keeping my fingers crossed that this will work.







Nick Beaugeard (@nickbeau) reported the availability of a preview of HubOne Pty. Ltd.’s corporate Website live on Windows Azure in a 3/6/2011 tweet:

Lindsay Holloway interviewed David Pallman in a 3/5/2011 post to the Examiner blog:
This week, Redmond, Washington, was host to a group of MVPs—not the most valuable players in basketball or football, though. From February 28 to March 2, Microsoft’s Most Valuable Professionals congregated for their annual summit at the mammoth software company’s headquarters. Microsoft’s MVPs, which consists of programmers, tech experts, professionals and small-business owners alike, gathers every year to network, discuss the latest in technology and discover the newest Microsoft developments.
Neudesic, which does IT consulting and development for small businesses, supports all Microsoft programs, but Azure is an especially important one, Pallman says. “We decided right away it would be highly strategic for us.” Because of the company’s relationship with Microsoft as a Microsoft Gold Partner and National Systems Integrator and its many MVPs on staff, Pallman and his team got to work with Azure a year before it was available to the general public. “[As] MVPs, we get certain perks,” he explains. “It gives us an elite status.”
Because Pallman is on the forefront of Microsoft’s products, he’s able to pass the knowledge and solutions onto his small-business clients. A big focus area for Pallman and Neudesic’s customers is cloud computing. “I think it’s the biggest thing to hit in years, but people are intimidated by it,” he says. “They hear about it all the time and they don’t want to bypass the opportunity. They just don’t know how to pursue it.” So the team helps them find the best system for their specific needs. Pallman estimates that customers end up saving 30 percent to 40 percent on their IT costs by leveraging cloud computing.
Microsoft’s half of the MVP deal means extensive firsthand insight and feedback from all of its members. Access to this sort of information is priceless for helping produce the best software solutions for its customers, and it’s also why the annual summit is so important. The event brings together MVPs from all over the world—a number that totals nearly 5,000.
“These summits are a two-way street,” Pallman says. “Microsoft gives us a lot of info, but we also give them valuable feedback.” He participated in a panel on scalability as well as networked and mingled with tech cohorts old and new. “There are many people we’ve never met because we’re spread around the world,” he explains. “But we’re like a band of brothers, with females, though. We may be competitors in the real world, but when we have our MVP hats on, we help each other out.”
Mawtex posted Free tool moves Composite C1 CMS sites to Windows Azure to the CMS Report blog on 3/2/2011 (missed when posted):
A new free migration tool and Windows Azure let you reach your global customer base with Composite C1 CMS. Making your website cloud powered and serving customers across multiple locations has now become painless. With the combination of free open source .NET CMS Composite C1, Windows Azure's scalability features and the easy migration path open source CMS in the cloud has become a perfect match.
Cloud power your CMS in minutes
Windows Azure is a Microsoft cloud platform offering that enables customers to deploy applications and data into the cloud. Composite C1 is a modern and fully featured free open source CMS available via Windows Web App Gallery and CodePlex.
Getting from zero to cloud without pain
"The architecture of Composite C1 lends itself well to cloud based computing and with this migration tool we believe we have a Windows Azure CMS that is unrivaled in both ease of use and flexibility for web professionals. If you are considering running your .NET CMS powered website in the cloud, Composite C1 definitely has something special to offer" says Marcus Wendt, Program Manager on the Composite C1 project. "The fact that you can build up a website using local components like WebMatrix, IIS or Visual Studio 2010 and then push your site to the cloud in a matter of minutes is something that brings real value to web professionals and this makes us unique in the .NET CMS space."
With Microsoft WebMatrix and the migration tool you can get from zero to cloud CMS without any .NET development or website configuration. Once in the cloud you can maintain your website and content online, or you can continuously publish your local website, even to multiple servers at multiple locations around the world.
From Seattle to Sidney
"With Windows Azure you simply choose the geographical regions that should host your website, making it really easy to deliver fast response times to your customers no matter what part of the world they come from. Being able to effectively serve your customers from Seattle to Sidney is what cloud computing is all about and with the release of this free tool we have positioned Composite C1 as the number one .NET CMS within cloud powered computing" says Composite CEO Oskar Lauritzen.
Read more and get cloud powered for free
Microsoft's trial and MSDN offers and the free CMS and migration tool make it possible to try out the cloud based CMS experience for free. You can download the migration tool and read more at http://docs.composite.net/Azure.
<Return to section navigation list>
Visual Studio LightSwitch
Beth Massi (@BethMassi) continues on the stump circuit with another Build Business Applications Quickly with Visual Studio LightSwitch presentation to the East Bay .NET Users Group on 3/9/2011 6:45 PM at the University of Phoenix, 2481 Constitution Drive, Room 105, Livermore, CA:
Build Business Applications Quickly with Visual Studio LightSwitch—Beth Massi
Microsoft Visual Studio LightSwitch is the simplest way to build business applications for the desktop and the cloud. In the session you will see how to build and deploy an end-to-end business application that federates multiple data sources. You’ll see how to create sophisticated UI, how to implement middle tier application logic, how to interact with Office, and much more without leaving the LightSwitch development environment. We’ll also discuss architecture and additional extensibility points as well demonstrate how to author custom controls and data sources that LightSwitch can consume using Visual Studio Professional+ and your existing Silverlight and .Net skills.
FUNdamentals Series
Enterprise Requirements for Cloud Computing—Adwait Ullal
Agenda
6:00 - 6:30 .NET FUNdamentals
6:30 - 6:45 check-in and registration
6:45 - 7:00 tech talk; announcements and open discussion
7:00 - 9:00 main presentation and give awaysPresenter's Bio
Beth Massi
Beth Massi is a Senior Program Manager on the Microsoft Visual Studio BizApps team who build the Visual Studio tools for Azure, Office, SharePoint as well as Visual Studio LightSwitch. Beth is a community champion for business application developers and is responsible for producing and managing online content and community interaction for the BizApps team. She has over 15 years of industry experience building business applications and is a frequent speaker at various software development events. You can find her on a variety of developer sites including MSDN Developer Centers, Channel 9, and her blog www.bethmassi.com/. Follow her on twitter @BethMassi
Adwait Ullal (FUNdamentals speaker)
Adwait Ullal has over 25 years of software development experience in diverse technologies and industries. Adwait is currently an independent consultant who helps companies, large and small with their IT strategy, methodology and processes. Adwait also maintains a jobs blog at http://dotnetjobs.posterous.com/.
Return to section navigation list>
Windows Azure Infrastructure
Aaron Saenz posted Costs of DNA Sequencing Falling Fast – Look At These Graphs! to the Singularity Hub blog on 3/5/2011:
The price of genomes is falling! This is the first step towards a genetically enabled future.
You may know that the cost to sequence a human genome is dropping, but you probably have no idea how fast that price is coming down. The National Human Genome Research Institute, part of the US National Institute of Health, has compiled extensive data on the costs of sequencing DNA over the past decade and used that information to create two truly jaw-dropping graphs. NHGRI’s research shows that not only are sequencing costs plummeting, they are outstripping the exponential curves of Moore’s Law. By a big margin. You have to see this information to really understand the changes that have occurred. Check out the original NHGRI graphs below. With costs falling so quickly we will soon be able to afford to produce a monumental flood of DNA data. The question is, will we know what to do with it once it arrives?
The Costs per Megabase (million base pairs) graph reflects the production costs of generating raw, unassembled sequence data. For The Costs per Genome, NHGRI considered a 3000 Mb genome (i.e. humans) with appropriate levels of redundancy necessary to assemble the long strain in its entirety. Both graphs show some amazing drop offs.
Keep in mind that these graphs use a logarithmic scale on the Y-axis so that steady decline in the beginning of each graph represents accelerating change in the field. From 2001 to 2007, first generation techniques (dideoxy chain termination or ‘Sanger’ sequencing) for sequencing DNA were already following an exponential curve. Starting around January of 2008, however, things go nuts. That’s the time when, according to the NHGRI, a significant part of production switched to second generation techniques. Look how quickly costs plummet. We’ve discussed before how retail costs for genome sequencing are dropping thanks to efforts from companies like Complete Genomics and Illumina. What these graphs show is that those retail prices reflect more than the genius of these companies – it’s a general crash of prices in the industry as a whole. Things are going to continue in this fashion. We’ve already seen newer sequencing technologies start to emerge, and there are institutions all over the world that are dedicated to pursuing genetic information in all its forms.
Just so you know, there’s no sleight of hand here. NHGRI’s explanation of their cost calculations reveal they did a very thorough job, especially when parsing what should be included in production costs and what shouldn’t. You can see all the details on their site.
One of the costs that NHGRI (rightfully) doesn’t include in production is the massive amounts of research investments the industry needs to fund to make any of this DNA data worthwhile. With the falling costs of sequencing we will have enormous amounts of raw data, but still very little understanding of what it means. As Daniel MacArthur (lately of Genetic Futures, now of Wired) points out in his discussion, production is outstripping research. What does the 897324989th base pair of your genome do? If you don’t know, why do you care if it reads A, C, T, or G? As we’ve seen with retail sequencing of single nucleotide polymorphisms (SNPs), giving a customer a look at parts of their DNA can be fun, but it’s not particularly enlightening.
Yet.
With falling genome prices we should be able to perform ever larger studies to correlate genes with medical histories. Already we’ve seen insurance companies and universities assemble large stores of genetic information in preparation for the days when such research will be financially possible. The stage is set for a great revolution in genetics fueled by plummeting sequencing prices. One day soon we should have an understanding of our genomes such that getting everyone sequenced will make medical sense. But that day hasn’t arrived yet. As we look at these amazing graphs we should keep in mind that falling prices are simply the first step in generating the future of medicine that genetics has promised us. The best science is still ahead of us. Get ready for it.
[image credits: NHGRI at NIH]
[citation: Wetterstrand KA. DNA Sequencing Costs: Data from the NHGRI Large-Scale Genome Sequencing Program Available at: www.genome.gov/sequencingcosts. Accessed March 1, 2011]Related Posts:
- Complete Genomics Secures New Customers, 500+ Orders for Whole Genome Sequences
- Yale Scientists Diagnose Illness Through Genome Sequencing
- Bid To Have Your Whole Genome Sequenced On Ebay
- Get Your Entire Genome From Complete Genomics For $5000
- Complete Genomics and ISB Team Up for Huge Whole Genome Study



See my Nicole Hemsoth reported DRC Energizes Smith-Waterman, Opens Door to On-Demand Service in a 2/9/2011 post to the HPC in the Cloud blog post here for details about new developments in online gene sequencing.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
Itzik Spitzen will present Moving Client/Server and Windows Forms Applications to Windows Azure Cloud with Visual WebGui Instant CloudMove (CSD106CAL) on 3/8/2011 at 8:00 to 9:00 AM PST:
The Cloud and SaaS models are changing the face of enterprise IT in terms of economics, scalability and accessibility . Visual WebGui Instant CloudMove transforms your Client / Server application code to run natively as .NET on Windows Azure and enables your Azure Client / Server application to have a secured-by-design plain Web or Mobile browser based accessibility. Watch this session to learn how Gizmox helped customers move their Client/Server to Windows Azure Cloud.
Visual WebGui (VWG) provides the shortest path from Client/Server business applications to Windows Azure allowing to step up to the SaaS delivery model and enjoy the Cloud’s economics and scalability at minimal cost and time. In this session we will explain how VWG bridges the gap between Client/Server applications’ richness, performance, security and ease of development and the Cloud’s economics & scalability.
Then we will introduce the unique migration and modernization tools which empower customers like Advanced Telemetry, Communitech, and others, to transform their existing Client/Server business applications to native Web Applications (Rich ASP.NET) and then deploy them on Windows Azure which allows accessibility from any browser (or mobile if desired by the customer).
Register for the event here.
BEvents.com announced the free, one-day Cloud Computing World Forum Middle East and Africa will take place on 3/9/2011 at the Grand Millennium Hotel, Dubai:

Show highlights will include:
- 1 Day Conference on Cloud Computing and SaaS
- Featuring presentations on Cloud Computing, SaaS, Applications, IaaS, Virtualization and PaaS
Keynote theatre featuring leading industry speakers
More case studies than any other like event
- 1/2 Day pre-show complimentary workshop available to all - Click Here
Learn from the key players offering leading products and services
Pre-show online meeting planner
Evening networking reception for all attendees
I find it strange that no one from Microsoft is speaking. (TechEd 2011 Middle East opens the same day.)
See The Community Megaphone reported Chris Koenig will present OData and The Communication Stack in Window Phone 7 on 3/9/2011 6:00 PM to the D/FW Connected Systems User Group at Improving Enterprises, Dallas in the Marketplace DataMarket and OData section above.
See Beth Massi (@BethMassi) continues on the stump circuit with another Build Business Applications Quickly with Visual Studio LightSwitch presentation to the East Bay .NET Users Group on 3/9/2011 6:45 PM at the University of Phoenix, 2481 Constitution Drive, Room 105, Livermore, CA in the Visual Studio LightSwitch section above.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Reuven Cohen (@ruv) described The Rise of The Cloud Aggregator in a 3/6/2011 post:
Recently there has been a lot of renewed talk of "Cloud Aggregators" a term that has been thrown around quite bit of the the last few years. But what is a cloud aggregator really? How does one define this segement? How do you qualify a company or service as a cloud aggregator? It's time for my turn to attempt to define this some-what vague term.
First, more generally what is a aggregator? One of the best descriptions I could find is described as "a system or service that combines data or items with similar characteristics (geographic area, target market, size, etc.) into larger entities. Value is derived from cost savings, or the ability to reach a larger market and charge higher prices from bundling multiple goods or services."
I'm not sure I agree with the higher prices part, but I do think the key point is the value in assembling "a system or service" that brings together a group of formally distinct components or web services. For example Google at its heart is an aggregator, all those websites found on the Internet would and do exist regardless of Google, but easy access to all of them through a simple, power and effient interface had previously not existed (at least not in a way that was relevant). Then there are marketplace aggregators such as Ebay, in this case without the ebay platform each of these vendors could not exist beyond potentially a physical storefront. Ebay provided both the aggregation, facilitation (which makes tasks for others easy) and fulfillment (completing the transaction).
So using Google and Ebay as two ends of the aggregator spectrum. You have Google the market disrupter versus ebay the market maker. Each important, but important for very different reasons. Both share common traits in that they provide easy access to something that was previously not very easily accessible. Yet each derive their true value in completely different ways. Google brought order to chaos through the use of advanced algorithms and massive computational power and ebay created a structured marketplace that had never existed in an area that needed it.
Now back to cloud aggregators. Here's my definition.
Cloud Aggregator - a platform or service that combines multiple clouds with similar characteristics (geographic area, cost, technology size, etc.) into a single point of access, format, and structure. Value is derived from cost savings and greater efficiency found from the ability to easily leverage multiple services providers.
James Hamilton described Yahoo! Compute Coop Design in a 3/5/2011 post:
Chris Page, Director of Climate & Energy Strategy at Yahoo! spoke at the 2010 Data Center Efficiency Summit where he presented Yahoo! Compute Coop Design.
The primary attributes of the Yahoo! design are: 1) 100% free air cooling (no chillers), 2) slab concrete floor, 3) use of wind power to augment air handling units, and 4) pre-engineered building for construction speed.
Chris reports the idea to orient the building such that the wind force on the external wall facing the dominant wind direction and use this higher pressure to assist the air handling units was taken from looking at farm buildings in the Buffalo, New York area. An example given was the use of natural cooling in chicken coops.
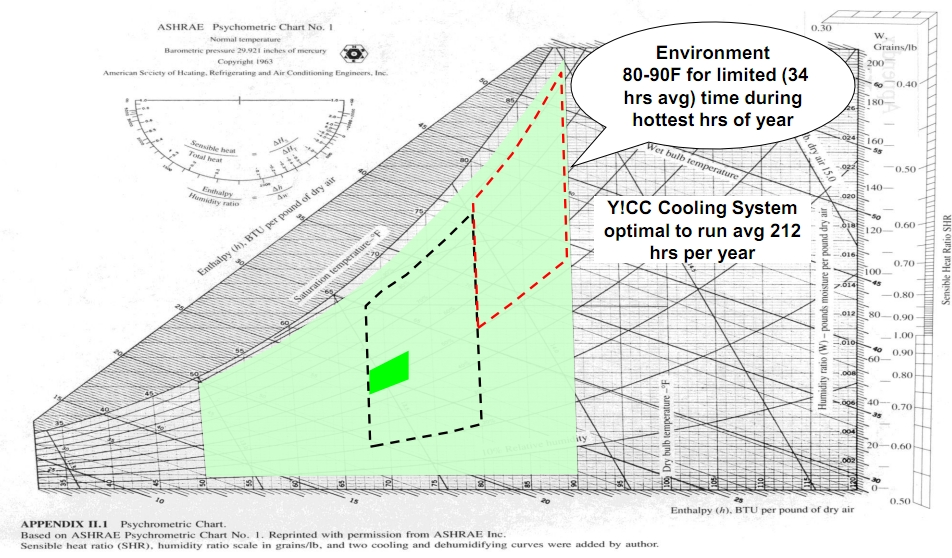
Chiller free data centers are getting more common (Chillerless Data Center at 95F) but the design approach is still far from common place. The Yahoo! team reports they run the facility at 75F and use evaporative cooling to attempt to hold the server approach temperatures down below 80F using evaporative cooling. A common approach and the one used by Microsoft in the chillerless datacenter at 95F example is install low efficiency coolers for those rare days when they are needed on the logic that low efficiency is cheap and really fine for very rare use. The Yahoo! approach is to avoid the capital cost and power consumption of chillers entirely by allowing the cold aisle temperatures to rise to 85F to 90F when they are unable to hold the temperature lower. They calculate they will only do this 34 hours a year which is less than 0.4% of the year.
Reported results:
- PUE at 1.08 with evaporative cooling and believe they could do better in colder climates
- Saves ~36 million gallons of water / yr, compared to previous water cooled chiller plant w/o airside economization design
- Saves over ~8 million gallons of sewer discharge / yr (zero discharge design)
- Lower construction cost (not quantified)
- 6 months from dirt to operating facility
Chris’ slides: http://dcee.svlg.org/images/stories/pdf/DCES10/airandwatercafe130.pdf (the middle slides of the 3 slide deck set)
Thanks to Vijay Rao for sending this my way.

Hongli Lai describes performance problems with MongoDB shard rebalancing in his Union Station beta is back online, and here’s what we have been up to post of 3/4/2011 to the Phusion blog:
Union Station is our web application performance monitoring and behavior analysis service. Its public beta was launched on March 2.
Within just 12 hours after the public beta launch of Union Station we were experiencing performance issues. Users noticed that their data wasn’t showing up and that the site is slow. We tried to expand our capacity on March 3 without taking it offline, but eventually we were left with no choice but to do so anyway. Union Station is now back online and we’ve expanded our capacity three fold. Being forced to take it offline for scaling so soon is both a curse and a blessing. On the one hand we deeply regret the interruption of service and the inconvenience that it has caused. On the other hand we are glad that so many people are interested in Union Station that caused scaling issues on day 1.
In this blog post we will explain:
- The events that had led to the scaling issues.
- What capacity we had before scaling, how our infrastructure looked like and what kind of traffic we were expecting for the initial launch.
- How we’ve scaled Union Station now and how our infrastructure looks like now.
- What we’ve learned from it and what we will do to prevent similar problems in the future.
Preparation work before day 1
Even before the launch, our software architecture was designed to be redundant (no single point of failure) and to scale horizontally across multiple machines if necessary. The most important components are the web app, MySQL, MongoDB (NoSQL database), RabbitMQ (queuing server) and our background workers. The web app receives incoming data, validates them and puts them in RabbitMQ queues. The background workers listen on the RabbitMQ queues, transform the data into more usable forms and index them into MongoDB. The bulk of the data is stored in MongoDB while MySQL is used to for storing small data sets.
Should scaling ever be necessary then every component can be scaled to multiple machines. The web app is already trivially scalable: it is written in Ruby so we can just add more Phusion Passenger instances and hook them behind the HTTP load balancer. The background workers and RabbitMQ are also very easy to scale: each worker is stateless and can listen from multiple RabbitMQ queues so we can just add more workers and RabbitMQ instances indefinitely. Traditional RDBMSes are very hard to write-scale across multiple servers and typically require sharding at the application level. This is the primary reason why we chose MongoDB for storing the bulk of the data: it allows easy sharding with virtually no application-level changes. It allows easy replication and its schemaless nature fits our data very well.
In extreme scenarios our cluster would end up looking like this:

Abstract overview of the Union Station software architecture (updated)We started with a single dedicated server with an 8-core Intel i7 CPU, 8 GB of RAM, 2×750 GB harddisks in RAID-1 configuration and a 100 Mbit network connection. This server hosted all components in the above picture on the same machine. We explicitly chose not to use several smaller, virtualized machines in the beginning of the beta period for efficiency reasons: our experience with virtualization is that they impose significant overhead, especially in the area of disk I/O. Running all services on the bare metal allows us to get the most out of the hardware.
Update: we didn’t plan on running on a single server forever. The plan was to run on a single server for a week or two, see whether people are interested in Union Station, and if so add more servers for high availability etc. That’s why we launched it as a beta and not as a final.
During day 1 and day 2
Equipped with a pretty beefy machine like this we thought it would hold out for a while, allowing us to gauge whether Union Station will be a success before investing more in hardware. It turned out that we had underestimated the amount of people who would join the beta as well as the amount of data they have.
Within 12 hours of launching the beta, we had already received over 100 GB of data. Some of our users sent hundreds of request logs per second to our service, apparently running very large websites. The server had CPU power in abundance, but with this much data our hard disk started becoming the bottleneck: the background workers were unable to write the indexed data to MongoDB quickly enough. Indeed, ‘top’ showed that the CPUs were almost idle while ‘iotop’ showed that the hard disks were running at full speed. As a result the RabbitMQ queues started becoming longer and longer. This is the reason why many users who registered after 8 hours didn’t see their data for several minutes. By the next morning the queue had become even longer, and the background workers were still busy indexing data from 6 hours ago.
During day 2 we performed some emergency filesystem tweaks in an attempt to make things faster. This did not have significant effect, and after a short while it was clear: the server could no longer handle the incoming data quickly enough and we need more hardware. The plan in the short term was to order additional servers and shard MongoDB across all 3 servers, thereby cutting the write load on each shard by 1/3rd. During the afternoon we started ordering 2 additional servers with 24 GB RAM and 2×1500 GB hard disks each, which were provisioned within several hours. We setup these new harddisks in RAID-0 instead of RAID-1 this time for better write performance, and we formatted with the XFS filesystem because that tends to perform best with large database files like MongoDB’s. By the beginning of the evening, the new servers were ready to go.
Update: RAID-0 does mean that if one disk fails we lose pretty much all data. We take care of this by making separate backups and setting up replicas on other servers. We’ve never considered RAID-1 to be a valid backup strategy. And of course RAID-0 is not a silver bullet for increasing disk speed but it does help a little, and all tweaks and optimizations add up.
Update 2: Some people have pointed out that faster setups exist, e.g. by using SSD drives or by getting servers with more RAM for keeping the data set in memory. We are well aware of these alternatives, but they are either not cost-effective or couldn’t be provisioned by our hosting provider within 6 hours. We are well aware of the limitations of our current setups and should demand ever rise to a point where the current setup cannot handle the load anymore we will definitely do whatever is necessary to scale it, including considering SSDs and more RAM.
MongoDB shard rebalancing caveats
Unfortunately MongoDB’s shard rebalancing system proved to be slower than we hoped it would be. During rebalancing there was so much disk I/O we could process neither read nor write requests in reasonable time. We were left with no choice but to take the website and the background workers offline during the rebalancing.
After 12 hours the rebalancing still wasn’t done. The original server still had 60% of the data, while the second server had 30% of the data and the third server 10% of the data. Apparently MongoDB performs a lot of random disk seeks and inefficient operations during the rebalancing. Further down time was deemed unacceptable so after an emergency meeting we decided to take the following actions:
- Disable the MongoDB rebalancer.
- Take MongoDB offline on all servers.
- Manually swap the physical MongoDB database files between server 1 and 3, because the latter has both a faster disk array as well as more RAM.
- Change the sharding configuration and swap server 1 and 3.
- Put everything back online.
These operations were finished in approximately 1.5 hours. After a 1 hour testing and maintenance session we had put Union Station back online again.
Even though MongoDB’s shard rebalancing system did not perform to our expectations, we do plan on continuing to use MongoDB. Its sharding system – just not the rebalancing part – works very well and the fact that it’s schemaless is a huge plus for the kind of data we have. During the early stages of the development of Union Station we used a custom database that we wrote ourselves, but maintaining this database system soon proved to be too tedious. We have no regrets switching to MongoDB but have learned more about its current limits now. Our system administration team will take these limits in mind next time we start experiencing scaling issues.
Our cluster now consists of 3 physical servers:
- All servers are equipped with 8-core Intel i7 CPUs.
- The original server has 8 GB of RAM and 2×750 GB harddisks in RAID-1.
- The 2 new servers have 24 GB of RAM each and 2×1500 GB harddisks in RAID-0 and are dedicated database servers.
Application-level optimizations
We did not spend the hours only idly waiting. We had been devising plans to optimize I/O at the application level. During the down time we had made the following changes:
- The original database schema design had a lot of redundant data. This redundant data was for internal book keeping and was mainly useful during development and testing. However it turned out that it is unfeasible to do anything with this redundant data in production because of the sheer amount of it. We’ve removed this redundant data, which in turn also forced us to remove some development features.
- One of the main differentiation points of Union Station lies in the fact that it logs all requests. All of them, not just slow ones. It logs a lot of details like events that have occurred (as you can see in the request timeline) and cache accesses. As a result the request logs we receive can be huge.
- We’ve implemented application-level support for compression for some of the fields. We cannot compress all fields because we need to run queries on them, but the largest fields are now stored in gzip-compressed format in the database and are decompressed at the application level.
How we want to proceed from now
We’ve learned not to underestimate the amount of activity our users generate. We did expect to have to eventually scale but not after 1 day. In order to prevent a meltdown like this from happening again, here’s our plan for the near future:
- Registration is still closed for now. We will monitor our servers for a while, see how it holds up, and it they perform well we might open registration again.
- During this early stage of the open beta, we’ve made the data retention time 7 days regardless of which plan was selected. As time progresses we will slowly increase the data retention times until they match their paid plans. When the open beta is over we will honor the paid plans’ data retention times.

Eliot Horowitz provides more details on MongoDB sharding problems in his Foursquare outage post mortem post to the mongodb-user Google Group:
(Note: this is being posted with Foursquare’s permission.)
As many of you are aware, Foursquare had a significant outage this week. The outage was caused by capacity problems on one of the machines hosting the MongoDB database used for check-ins. This is an account of what happened, why it happened, how it can be prevented, and how 10gen is working to improve MongoDB in light of this outage.
It’s important to note that throughout this week, 10gen and Foursquare engineers have been working together very closely to resolve the issue.
* Some history
Foursquare has been hosting check-ins on a MongoDB database for some time now. The database was originally running on a single EC2 instance with 66GB of RAM. About 2 months ago, in response to increased capacity requirements, Foursquare migrated that single instance to a two-shard cluster. Now, each shard was running on its own 66GB instance, and both shards were also replicating to a slave for redundancy. This was an important migration because it allowed Foursquare to keep all of their check-in data in RAM, which is
essential for maintaining acceptable performance.The data had been split into 200 evenly distributed chunks based on user id. The first half went to one server, and the other half to the other. Each shard had about 33GB of data in RAM at this point, and the whole system ran smoothly for two months.
* What we missed in the interim
Over these two months, check-ins were being written continually to each shard. Unfortunately, these check-ins did not grow evenly across chunks. It’s easy to imagine how this might happen: assuming certain subsets of users are more active than others, it’s conceivable that their updates might all go to the same shard. That’s what occurred in this case, resulting in one shard growing to 66GB and the other only to 50GB. [1]* What went wrong
On Monday morning, the data on one shard (we’ll call it shard0) finally grew to about 67GB, surpassing the 66GB of RAM on the hosting machine. Whenever data size grows beyond physical RAM, it becomes necessary to read and write to disk, which is orders of magnitude slower than reading and writing RAM. Thus, certain queries started to become very slow, and this caused a backlog that brought the site down.We first attempted to fix the problem by adding a third shard. We brought the third shard up and started migrating chunks. Queries were now being distributed to all three shards, but shard0 continued to hit disk very heavily. When this failed to correct itself, we ultimately discovered that the problem was due to data fragmentation on shard0.
In essence, although we had moved 5% of the data from shard0 to the new third shard, the data files, in their fragmented state, still needed the same amount of RAM. This can be explained by the fact that Foursquare check-in documents are small (around 300 bytes each), so many of them can fit on a 4KB page. Removing 5% of these just made each page a little more sparse, rather than removing pages altogether.[2]
After the first day's outage it had become clear that chunk migration, sans compaction, was not going to solve the immediate problem. By the time the second day's outage occurred, we had already move 5% of the data off of shard0, so we decided to start an offline process to compact the database using MongoDB’s repairDatabase() feature. This process took about 4 hours (partly due to the data size, and partly because of the slowness of EBS volumes at the time). At the end of the 4 hours, the RAM requirements for shard0 had in fact been reduced by 5%, allowing us to bring the system back online.
* Afterwards
Since repairing shard0 and adding a third shard, we’ve set up even more shards, and now the check-in data is evenly distributed and there is a good deal of extra capacity. Still, we had to address the fragmentation problem. We ran a repairDatabase() on the slaves, and promoted the slaves to masters, further reducing the RAM needed on each shard to about 20GB.* How is this issue triggered?
Several conditions need to be met to trigger the issue that brought down Foursquare:1. Systems are at or over capacity. How capacity is defined varies; in the case of Foursquare, all data needed to fit into RAM for acceptable performance. Other deployments may not have such strict RAM requirements.
2. Document size is less than 4k. Such documents, when moved, may be too small to free up pages and, thus, memory.
3. Shard key order and insertion order are different. This prevents data from being moved in contiguous chunks.Most sharded deployments will not meet these criteria. Anyone whose documents are larger than 4KB will not suffer significant fragmentation because the pages that aren’t being used won’t be cached.
* Prevention
The main thing to remember here is that once you’re at max capacity, it’s difficult to add more capacity without some downtime when objects are small. However, if caught in advance, adding more shards on a live system can be done with no downtime.For example, if we had notifications in place to alert us 12 hours earlier that we needed more capacity, we could have added a third shard, migrated data, and then compacted the slaves.
Another salient point: when you’re operating at or near capacity, realize that if things get slow at your hosting provider, you may find yourself all of a sudden effectively over capacity.
* Final Thoughts
The 10gen tech team is working hard to correct the issues exposed by this outage. We will continue to work as hard as possible to ensure that everyone using MongoDB has the best possible experience. We are thankful for the support that we have received from Foursquare and our community during this unfortunate episode. As always, please let us know if you have any questions or concerns.[1] Chunks get split when they are 200MB into 2 100MB halves. This means that even if the number of chunks on each shard was the same, data size is not always so. This is something we are going to be addressing in MongoDB. We'll be making splitting balancing look for this imbalance so it can act upon it.
[2] The 10gen team is working on doing online incremental compaction of both data files and indexes. We know this has been a concern in non-sharded systems as well. More details about this will be coming in the next few weeks.
Roger Bodamer provides advice on scaling out MongoDB using replica sets and auto-sharding in this 00:50:43 Scaling with MongoDB video segment from InfoQ:
Roger Bodamer provides advice on scaling out MongoDB using replica sets and auto-sharding, plus tips for database deployment and scaling use cases.

Roger heads West Coast Operations for 10gen.
For the current lowdown on sharding SQL Azure databases, see my (@rogerjenn) recommendation to “Get ready to scale out SQL Azure databases beyond today's 50GB limit with the Transact-SQL and ADO.NET elastic sharding features, which are coming in the 2011 SQL Azure Federation Community Technology Previews” in the deck for my Build Big-Data Apps in SQL Azure with Federation cover article for Visual Studio Magazine’s March 2011 issue.
<Return to section navigation list>

















0 comments:
Post a Comment