Windows Azure and Cloud Computing Posts for 3/3/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Updated 3/3/2011 with new articles after 3:30 PM marked •
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
• The Windows Azure Storage Team has been quiet lately, so we’ve republished Brad Calder’s 4.5-star Windows Azure Storage Architecture Overview of 12/30/2011 because of the large number of forum questions it answers:
In this posting we provide an overview of the Windows Azure Storage architecture to give some understanding of how it works. Windows Azure Storage is a distributed storage software stack built completely by Microsoft for the cloud.
Before diving into the details of this post, please read the prior posting on Windows Azure Storage Abstractions and their Scalability Targets to get an understanding of the storage abstractions (Blobs, Tables and Queues) provided and the concept of partitions.
3 Layer Architecture
The storage access architecture has the following 3 fundamental layers:
- Front-End (FE) layer – This layer takes the incoming requests, authenticates and authorizes the requests, and then routes them to a partition server in the Partition Layer. The front-ends know what partition server to forward each request to, since each front-end server caches a Partition Map. The Partition Map keeps track of the partitions for the service being accessed (Blobs, Tables or Queues) and what partition server is controlling (serving) access to each partition in the system.
- Partition Layer – This layer manages the partitioning of all of the data objects in the system. As described in the prior posting, all objects have a partition key. An object belongs to a single partition, and each partition is served by only one partition server. This is the layer that manages what partition is served on what partition server. In addition, it provides automatic load balancing of partitions across the servers to meet the traffic needs of Blobs, Tables and Queues. A single partition server can serve many partitions.
- Distributed and replicated File System (DFS) Layer – This is the layer that actually stores the bits on disk and is in charge of distributing and replicating the data across many servers to keep it durable. A key concept to understand here is that the data is stored by the DFS layer, but all DFS servers are (and all data stored in the DFS layer is) accessible from any of the partition servers.
These layers and a high level overview are shown in the below figure:
Here we can see that the Front-End layer takes incoming requests, and a given front-end server can talk to all of the partition servers it needs to in order to process the incoming requests. The partition layer consists of all of the partition servers, with a master system to perform the automatic load balancing (described below) and assignments of partitions. As shown in the figure, each partition server is assigned a set of object partitions (Blobs, Entities, Queues). The Partition Master constantly monitors the overall load on each partition sever as well the individual partitions, and uses this for load balancing. Then the lowest layer of the storage architecture is the Distributed File System layer, which stores and replicates the data, and all partition servers can access any of the DFS severs.
Lifecycle of a Request
To understand how the architecture works, let’s first go through the lifecycle of a request as it flows through the system. The process is the same for Blob, Entity and Message requests:
- DNS lookup – the request to be performed against Windows Azure Storage does a DNS resolution on the domain name for the object’s Uri being accessed. For example, the domain name for a blob request is “<your_account>.blob.core.windows.net”. This is used to direct the request to the geo-location (sub-region) the storage account is assigned to, as well as to the blob service in that geo-location.
- Front-End Server Processes Request – The request reaches a front-end, which does the following:
- Perform authentication and authorization for the request
- Use the request’s partition key to look up in the Partition Map to find which partition server is serving the partition. See this post for a description of a request’s partition key.
- Send the request to the corresponding partition server
- Get the response from the partition server, and send it back to the client.
- Partition Server Processes Request – The request arrives at the partition server, and the following occurs depending on whether the request is a GET (read operation) or a PUT/POST/DELETE (write operation):
- GET – See if the data is cached in memory at the partition server
- If so, return the data directly from memory.
- Else, send a read request to one of the DFS Servers holding one of the replicas for the data being read.
- PUT/POST/DELETE
- Send the request to the primary DFS Server (see below for details) holding the data to perform the insert/update/delete.
- DFS Server Processes Request – the data is read/inserted/updated/deleted from persistent storage and the status (and data if read) is returned. Note, for insert/update/delete, the data is replicated across multiple DFS Servers before success is returned back to the client (see below for details).
Most requests are to a single partition, but listing Blob Containers, Blobs, Tables, and Queues, and Table Queries can span multiple partitions. When a listing/query request that spans partitions arrives at a FE server, we know via the Partition Map the set of partition servers that need to be contacted to perform the query. Depending upon the query and the number of partitions being queried over, the query may only need to go to a single partition server to process its request. If the Partition Map shows that the query needs to go to more than one partition server, we serialize the query by performing it across those partition servers one at a time sorted in partition key order. Then at partition server boundaries, or when we reach 1,000 results for the query, or when we reach 5 seconds of processing time, we return the results accumulated thus far and a continuation token if we are not yet done with the query. Then when the client passes the continuation token back in to continue the listing/query, we know the Primary Key from which to continue the listing/query.
Fault Domains and Server Failures
Now we want to touch on how we maintain availability in the face of hardware failures. The first concept is to spread out the servers across different fault domains, so if a hardware fault occurs only a small percentage of servers are affected. The servers for these 3 layers are broken up over different fault domains, so if a given fault domain (rack, network switch, power) goes down, the service can still stay available for serving data.
The following is how we deal with node failures for each of the three different layers:
- Front-End Server Failure – If a front-end server becomes unresponsive, then the load balancer will realize this and take it out of the available servers that serve requests from the incoming VIP. This ensures that requests hitting the VIP get sent to live front-end servers that are waiting to process requests.
- Partition Server Failure – If the storage system determines that a partition server is unavailable, it immediately reassigns any partitions it was serving to other available partition servers, and the Partition Map for the front-end servers is updated to reflect this change (so front-ends can correctly locate the re-assigned partitions). Note, when assigning partitions to different partition servers no data is moved around on disk, since all of the partition data is stored in the DFS server layer and accessible from any partition server. The storage system ensures that all partitions are always served.
- DFS Server Failure – If the storage system determines a DFS server is unavailable, the partition layer stops using the DFS server for reading and writing while it is unavailable. Instead, the partition layer uses the other available DFS servers which contain the other replicas of the data. If a DFS Server is unavailable for too long, we generate additional replicas of the data in order to keep the data at a healthy number of replicats for durability.
Upgrade Domains and Rolling Upgrade
A concept orthogonal to fault domains is what we call upgrade domains. Servers for each of the 3 layers are spread evenly across the different fault domains, and upgrade domains for the storage service. This way if a fault domain goes down we lose at most 1/X of the servers for a given layer, where X is the number of fault domains. Similarly, during a service upgrade at most 1/Y of the servers for a given layer are upgraded at a given time, where Y is the number of upgrade domains. To achieve this, we use rolling upgrades, which allows us to maintain high availability when upgrading the storage service.
The servers in each layer are broken up over a set of upgrade domains, and we upgrade a single upgrade domain at a time. For example, if we have 10 upgrade domains, then upgrading a single domain would potentially upgrade up to 10% of the servers from each layer at a time. A description of upgrade domains and an example of using rolling upgrades is in the PDC 2009 talk on Patterns for Building Scalable and Reliable Applications for Windows Azure (at 25:00).
We upgrade a single domain at a time for our storage service using rolling upgrades. A key part for maintaining availability during upgrade is that before upgrading a given domain, we proactively offload all the partitions being served on partition servers in that upgrade domain. In addition, we mark the DFS servers in that upgrade domain as being upgraded so they are not used while the upgrade is going on. This preparation is done before upgrading the domain, so that when we upgrade we reduce the impact on the service to maintain high availability.
After an upgrade domain has finished upgrading we allow the servers in that domain to serve data again. In addition, after we upgrade a given domain, we validate that everything is running fine with the service before going to the next upgrade domain. This process allows us to verify production configuration, above and beyond the pre-release testing we do, on just a small percentage of servers in the first few upgrade domains before upgrading the whole service. Typically if something is going to go wrong during an upgrade, it will occur when upgrading the first one or two upgrade domains, and if something doesn’t look quite right we pause upgrade to investigate, and we can even rollback to the prior version of the production software if need be.
Now we will go through the lower to layers of our system in more detail, starting with the DFS Layer.
DFS Layer and Replication
Durability for Windows Azure Storage is provided through replication of your data, where all data is replicated multiple times. The underlying replication layer is a Distributed File System (DFS) with the data being spread out over hundreds of storage nodes. Since the underlying replication layer is a distributed file system, the replicas are accessible from all of the partition servers as well as from other DFS servers.
The DFS layer stores the data in what are called “extents”. This is the unit of storage on disk and unit of replication, where each extent is replicated multiple times. The typical extent sizes range from approximately 100MB to 1GB in size.
When storing a blob in a Blob Container, entities in a Table, or messages in a Queue, the persistent data is stored in one or more extents. Each of these extents has multiple replicas, which are spread out randomly over the different DFS servers providing “Data Spreading”. For example, a 10GB blob may be stored across 10 one-GB extents, and if there are 3 replicas for each extent, then the corresponding 30 extent replicas for this blob could be spread over 30 different DFS servers for storage. This design allows Blobs, Tables and Queues to span multiple disk drives and DFS servers, since the data is broken up into chunks (extents) and the DFS layer spreads the extents across many different DFS servers. This design also allows a higher number of IOps and network BW for accessing Blobs, Tables, and Queues as compared to the IOps/BW available on a single storage DFS server. This is a direct result of the data being spread over multiple extents, which are in turn spread over different disks and different DFS servers, since any of the replicas of an extent can be used for reading the data.
For a given extent, the DFS has a primary server and multiple secondary servers. All writes go through the primary server, which then sends the writes to the secondary servers. Success is returned back from the primary to the client once the data is written to at least 3 DFS servers. If one of the DFS servers is unreachable when doing the write, the DFS layer will choose more servers to write the data to so that (a) all data updates are written at least 3 times (3 separate disks/servers in 3 separate fault+upgrade domains) before returning success to the client and (b) writes can make forward progress in the face of a DFS server being unreachable. Reads can be processed from any up-to-date extent replica (primary or secondary), so reads can be successfully processed from the extent replicas on its secondary DFS servers.
The multiple replicas for an extent are spread over different fault domains and upgrade domains, therefore no two replicas for an extent will be placed in the same fault domain or upgrade domain. Multiple replicas are kept for each data item, so if one fault domain goes down, there will still be healthy replicas to access the data from, and the system will dynamically re-replicate the data to bring it back to a healthy number of replicas. During upgrades, each upgrade domain is upgraded separately, as described above. If an extent replica for your data is in one of the domains currently being upgraded, the extent data will be served from one of the currently available replicas in the other upgrade domains not being upgraded.
A key principle of the replication layer is dynamic re-replication and having a low MTTR (mean-time-to-recovery). If a given DFS server is lost or a drive fails, then all of the extents that had a replica on the lost node/drive are quickly re-replicated to get those extents back to a healthy number of replicas. Re-replication is accomplished quickly, since the other healthy replicas for the affected extents are randomly spread across the many DFS servers in different fault/upgrade domains, providing sufficient disk/network bandwidth to rebuild replicas very quickly. For example, to re-replicate a failed DFS server with many TBs of data, with potentially 10s of thousands of lost extent replicas, the healthy replicas for those extents are potentially spread across hundreds to thousands of storage nodes and drives. To get those extents back up to a healthy number of replicas, all of those storage nodes and drives can be used to (a) read from the healthy remaining replicas, and (b) write another copy of the lost replica to a random node in a different fault/upgrade domain for the extent. This recovery process allows us to leverage the available network/disk resources across all of the nodes in the storage service to potentially re-replicate a lost storage node within minutes, which is a key property to having a low MTTR in order to prevent data loss.
Another important property of the DFS replication layer is checking and scanning data for bit rot. All data written has a checksum (internal to the storage system) stored with it. The data is continually scanned for bit rot by reading the data and verifying the checksum. In addition, we always validate this internal checksum when reading the data for a client request. If an extent replica is found to be corrupt by one of these checks, then the corrupted replica is discarded and the extent is re-replicated using one of the valid replicas in order to bring the extent back to healthy level of replication.
Geo-Replication
Windows Azure Storage provides durability by constantly maintaining multiple healthy replicas for your data. To achieve this, replication is provided within a single location (e.g., US South), across different fault and upgrade domains as described above. This provides durability within a given location. But what if a location has a regional disaster (e.g., wild fire, earthquake, etc.) that can potentially affect an area for many miles?
We are working on providing a feature called geo-replication, which replicates customer data hundreds of miles between two locations (i.e., between North and South US, between North and West Europe, and between East and Southeast Asia) to provide disaster recovery in case of regional disasters. The geo-replication is in addition to the multiple copies maintained by the DFS layer within a single location described above. We will have more details in a future blog post on how geo-replication works and how it provides geo-diversity in order to provide disaster recovery if a regional disaster were to occur.
Load Balancing Hot DFS Servers
Windows Azure Storage has load balancing at the partition layer and also at the DFS layer. The partition load balancing addresses the issue of a partition server getting too many requests per second for it to handle for the partitions it is serving, and load balancing those partitions across other partition servers to even out the load. The DFS layer is instead focused on load balancing the I/O load to its disks and the network BW to its servers.
The DFS servers can get too hot in terms of the I/O and BW load, and we provide automatic load balancing for DFS servers to address this. We provide two forms of load balancing at the DFS layer:
- Read Load Balancing - The DFS layer maintains multiple copies of data through the multiple replicas it keeps, and the system is built to allow reading from any of the up to date replica copies. The system keeps track of the load on the DFS servers. If a DFS server is getting too many requests for it to handle, partition servers trying to access that DFS server will be routed to read from other DFS servers that are holding replicas of the data the partition server is trying to access. This effectively load balances the reads across DFS servers when a given DFS server gets too hot. If all of the DFS servers are too hot for a given set of data accessed from partition servers, we have the option to increase the number of copies of the data in the DFS layer to provide more throughput. However, hot data is mostly handled by the partition layer, since the partition layer caches hot data, and hot data is served directly from the partition server cache without going to the DFS layer.
- Write Load Balancing – All writes to a given piece of data go to a primary DFS server, which coordinates the writes to the secondary DFS servers for the extent. If any of the DFS servers becomes too hot to service the requests, the storage system will then choose different DFS servers to write the data to.
Why Both a Partition Layer and DFS Layer?
When describing the architecture, one question we get is why do we have both a Partition layer and a DFS layer, instead of just one layer both storing the data and providing load balancing?
The DFS layer can be thought of as our file system layer, it understand files (these large chunks of storage called extents), how to store them, how to replicate them, etc, but it doesn’t understand higher level object constructs nor their semantics. The partition layer is built specifically for managing and understanding higher level data abstractions, and storing them on top of the DFS.
The partition layer understands what a transaction means for a given object type (Blobs, Entities, Messages). In addition, it provides the ordering of parallel transactions and strong consistency for the different types of objects. Finally, the partition layer spreads large objects across multiple DFS server chunks (called extents) so that large objects (e.g., 1 TB Blobs) can be stored without having to worry about running out of space on a single disk or DFS server, since a large blob is spread out over many DFS servers and disks.
Partitions and Partition Servers
When we say that a partition server is serving a partition, we mean that the partition server has been designated as the server (for the time being) that controls all access to the objects in that partition. We do this so that for a given set of objects there is a single server ordering transactions to those objects and providing strong consistency and optimistic concurrency, since a single server is in control of the access of a given partition of objects.
In the prior scalability targets post we described that a single partition can process up to 500 entities/messages per second. This is because all of the requests to a single partition have to be served by the assigned partition server. Therefore, it is important to understand the scalability targets and the partition keys for Blobs, Tables and Queues when designing your solutions (see the upcoming posts focused on getting the most out of Blobs, Tables and Queues for more information).
Load Balancing Hot Partition Servers
It is important to understand that partitions are not tied to specific partition servers, since the data is stored in the DFS layer. The partition layer can therefore easily load balance and assign partitions to different partition servers, since any partition server can potentially provide access to any partition.
The partition layer assigns partitions to partition severs based on each partition’s load. A given partition server may serve many partitions, and the Partition Master continuously monitors the load on all partition servers. If it sees that a partition server has too much load, the partition layer will automatically load balance some of the partitions from that partition server to a partition server with low load.
When reassigning a partition from one partition server to another, the partition is offline only for a handful seconds, in order to maintain high availability for the partition. Then in order to make sure we do not move partitions around too much and make too quick of decisions, the time it takes to decide to load balance a hot partition server is on the order of minutes.
Summary
The Windows Azure Storage architecture had three main layers – Front-End layer, Partition layer, and DFS layer. For availability, each layer has its own form of automatic load balancing and dealing with failures and recovery in order to provide high availability when accessing your data. For durability, this is provided by the DFS layer keeping multiple replicas of your data and using data spreading to keep a low MTTR when failures occur. For consistency, the partition layer provides strong consistency and optimistic concurrency by making sure a single partition server is always ordering and serving up access to each of your data partitions.

I give Brad’s post six stars: 
![]()
![]()
![]()
![]()
![]()
![]()
<Return to section navigation list>
SQL Azure Database and Reporting
•• Cihan Biyikoglu posted “NoSQL” Genes in SQL Azure Federations on 3/3/2011:
It is great to see people catching onto the idea of federations. Recently, there has been a number of great articles and a new whitepaper that refer to how federations flip SQL Azure to “NoSQL” Azure. Aaaaand yes, it is true! Federation bring great benefits of NoSQL model into SQL Azure where it is needed most. I have a special love for RDMSs after having worked on 2, Informix and SQL Server but I also have a great appreciation for NoSQL qualities after having worked on challenging web platforms. These web platforms need flexible app models with elasticity to handle unpredictable capacity requirements and needed the ability to deliver great computational capacity to handle peaks and at the same time deliver that with great economics.
NoSQL does bring advantages in this space and I’d argue SQL Azure is inheriting some of these properties of NoSQL through federations. However, to bring in these traits of NoSQL, I think we need adjustments to the strict RDBMS viewpoint. Lets be more specific… Here is my list of NoSQL qualities and how federation provide us the quality.
Scale-out for Massive Parallelism
There are many models for scale-out. Some utilizing vertical partitioning… Others utilizing shared resource models… Most commercially available RDBMSs try to provide the full richness of the SQL app model with SQLs uncompromising consistency guarantees. However these implementation bottleneck as they try to maintain these guarantees and quickly exhaust capacity… With the increasing system resources spent on maintaining rich models, it is not a surprise that these implementations find themselves compromising on scalability targets. Instead, NoSQL spends little effort on sharing resources and coordinating across nodes… It compromises on consistency guarantees in favor of scale. The scale targets improve with NoSQL. Federations take a similar approach in SQL Azure. Federation decentralize and minimize coordination across nodes… With that, federations provide the ability to take advantage of the full computational power of a cluster to parallelize processing. By federating your workload, atomic-unit focused work (a.k.a OLTP work by many of the SQL minded folks), such as “placing an order” or “shopping cart management”, get parallelized to scale to massive concurrent user load… There is little coordination between nodes needed thus the full power of the cluster is focused on processing the user workload. Federations also allow greatly parallelizing complex query processing over large amount of data through fan-out queries, such as “most popular products sold” or “best customers”. Having many nodes participate in calculating aggregates result in lower latencies.
Loosened Consistency or Eventual Consistency
Very large databases suffer from the richness of the SQL programming model sometimes because of uncompromising consistency guarantees of a ‘database’. This definition of the ‘database’ is an interesting discussion but majority vote among commercial database systems define it with the following properties; database contain a single consistent schema, allow transaction semantics on all parts of its data and adheres to ACID properties with varying isolation levels for its query processing. However loosened and eventual consistency does provide benefits. With federations, each federation member and atomic unit provide the familiar local consistency guarantees of ‘databases’. However federations compromise on strict schema requirement. You can have divergence in schema between federation members. That is fine in federations. Federations also push to a looser model of consistency for query results across multiple federation members. When executing fan-out queries, the patterns trade in regular ACID rules and isolation levels common to databases in favor of better scalability.
Lightweight Local Storage Besides Reliable Storage
One of NoSQL traits is arguably the ability to move processing close to the data. SQL Azure and other RDBMSs provide great programmability capabilities close to data. Stored procedures and TSQL provide ability to move complex logic close to data. Federations are not different. You can continue to use stored procedures, triggers, tables, views indexes and all other objects you are used to, to take full advantage of the powerful programmability surface of SQL Azure. SQL Azure databases are not lightweight local stores however. They are highly available, none volatile, replicated and protected… However there is another local store; that is tempdb. With every federation member that is scaled out, you also get a portion of tempdb on that node. It isn’t replicated so it is purely local.
Unstructured or Semi Structured Data
Relational stores provide great methods for structured data storage and query processing. If you like key value pairs, databases provide that as well. SQL Azure also support hierarchy data type and indexing as well as XML data type for semi structured data. Blob types are there for completely unstructured data.
Obviously SQL Azure databases continue to provide the consistency model that you expect between the walls of a ‘database’. The root database and federations members are all SQL Azure databases. The above list is not exhaustive and I am sure you can come up with other NoSQL properties. However it is clear that with federations, NoSQL qualities are extending into SQL Azure.
•• My (@rogerjenn) Build Big-Data Apps in SQL Azure with Federation cover article for Visual Studio Magazine’s March 2011 issue recommended “Get ready to scale out SQL Azure databases beyond today's 50GB limit with the Transact-SQL and ADO.NET elastic sharding features, which are coming in the 2011 SQL Azure Federation Community Technology Previews.”
• [SQL Azure Database] [South Central US] [Red] Issue Investigation of 3/3/2011:
- Mar 3 2011 10:53PM Users are experiencing intermittent database connectivity issues and are unable to create servers. We are actively investigating.
- Mar 3 2011 11:15PM Normal service availability is fully restored for SQL Azure Database.
Mark Kromer (@mssqldude) explained Where SQL Server & SQL Azure Converge in a 3/3/2011 post:
Throughout 2011, with each new Microsoft CTP release of SQL Server Denali, updates to SQL Azure and service packs for SQL Server 2008 R2, you are going to see more & more convergence between the traditional on-premises database and the cloud database world, SQL Azure. Add to this mix, the advancements coming from Redmond this year with AppFabric and Windows Azure and you are starting to see these worlds blend together into the goal of optimized and effective IT data centers and workgroups where you seamlessly move data and applications between bare metal to private cloud to public cloud.
- SQL Azure Data Migration Wizard
- Data Sync Framework
- Data-Tier Applications
SQL Azure Data Migration Wizard
This is a free download tool from Codeplex (http://sqlazuremw.codeplex.com) and it is a very simple, easy-to-use and intuitive utility. It is a tool for engineers, so don’t look for fancy GUIs and Silverlight. But it does an awesome job of migrating your on-premises SQL Server database objects and data to SQL Azure. It handles a lot of the migration steps that you would need to do manually such as identifying unsupported SQL Azure objects and code as well as things like adding clustered indexes on every table (a current SQL Azure requirement). This is a great stop-gap tool to use until Data Sync is ready for prime time …
SQL Azure Data Sync
This is the Microsoft-sanctioned go-forward way to replicate data between on-prem SQL Server and SQL Azure, as well as scheduling data synchronization and replication across Azure data centers and SQL Azure databases. The problem is that the current publicly available version (https://datasync.sqlazurelabs.com) does not sync to or from SQL Server on-premises yet and the new version is still in CTP (beta), which you can sign-up for here.
SQL Server Data-Tier Application
This is functionality that is built into SQL Server 2008 R2 that allows developers and administrators to move units of code built in SQL Server databases, around instances and through a development lifecycle (i.e. dev, test, stage, prod). This is available today and you can deploy SQL Server database schemas that you’ve developed from Visual Studio 2010 to SQL Server 2008 R2 on-prem or to the cloud in SQL Azure.
Joe D’Antoni (Philly SQL Server UG VP) and I are presenting on all of these techniques at this Saturday’s SQL Saturday Philadelphia in Ft. Washington, PA (http://www.sqlsaturday.com). Our presentation material is available for you to view here.
Jonathan Gao updated the TechNet Wiki’s SQL Azure Content Index with my Build Big-Data Apps in SQL Azure with Federation article for Visual Studio Magazine on 3/2/2011:
Overview
SQL Azure is a cloud based relational database that is based on SQL Server technologies. The purpose of this page is to provide a centralized listing of all technical content pertaining to SQL Azure. Content on this page is organized into two groupings; by topic (scenario,) and by feature. Topics are broken down into broad scenarios such as getting started, administration, or troubleshooting, while features are broken down by product features such as SQL Azure Database, SQL Azure Data Sync, and SQL Azure Reporting.
For an index that contains only TechNet Wiki articles related to SQL Azure, see SQL Azure TechNet Wiki Articles Index.
Index
Topics
- Getting Started
- Connectivity
- Scaling
- Migration
- Security
- Performance
- Transactions
- Troubleshooting
- Administration
- Development
Features
- SQL Azure Database
- SQL Azure Data Sync
- SQL Azure Reporting
- Microsoft Access
- Entity Framework
- Microsoft Excel
Topics
Getting Started
Articles
- SQL Azure Database: Glossary of Terms
- SQL Azure Database Guide
- Overview of Microsoft SQL Azure Database
- SQL Azure Survival Guide
- Getting Started with SQL Azure Database
- Understanding Data Storage Offerings on Windows Azure
- MSDN Magazine: SQL Azure and Windows Azure Table Storage
- SQL Azure FAQ
- SQL Azure Data Sync Overview
- SQL Azure Data Sync FAQ
- Overview of Tools to Use with SQL Azure
- MSDN Magazine: Getting Started with SQL Azure Development
- Comparing SQL Server with SQL Azure
- SQL Azure Survival Guide
Videos
- MSDN: What is SQL Azure?
- MSDN: Introduction to SQL Azure
- Showcase: SQL Azure: Creating Your First Database
Training
Connectivity
Scaling
Articles
- Sharding with SQL Azure
- Inside SQL Azure
- Visual Studio Magazine: Build Big-Data Apps in SQL Azure with Federation [Emphasis added]
Videos
Migration
Articles
- Overview of Options for Migrating Data and Schema to SQL Azure
- Brute Force Migration of Existing SQL Server Databases to SQL Azure
- SQL Azure Data Migration Using SQL Server Import and Export Wizard
- Moving Access Data to the Cloud
- SQL Azure Data Sync - Cost Considerations
- SQL Azure Data Sync Scenario - SQL Azure-to-SQL Azure Synchronization
- SQL Azure Data Sync Scenario - SQL Server-to-SQL Azure Synchronization
- SQL Server to SQL Azure Synchronization
- SQL Azure to SQL Azure Synchronization
- SQL Azure Data Sync Overview
Videos
Security
Articles
Videos
- TechNet Videos: How Do I: Configure SQL Azure Security?
Performance
Transactions
Troubleshooting
Articles
Videos
Administration
Articles
- Billing Numbers Directly From Transact-SQL
- Current Options for Backing up Data with SQL Azure
- SQL Azure Backup and Restore Strategy
Videos
Development
Articles
Features: SQL Azure Database
- SQL Azure Database: Glossary of Terms
- SQL Azure Database Overview
- Getting Started with SQL Azure Database
- MSDN Magazine: Getting Started with SQL Azure Development
- Overview of Microsoft SQL Azure Database
- SQL Azure FAQ
- Overview of Tools to Use with SQL Azure
- Inside SQL Azure
- Sharding with SQL Azure
- Overview of Security in SQL Azure
- Security Guidelines for SQL Azure
- Gaining Performance Insight into SQL Azure
- Current Options for Backing up Data with SQL Azure
- Handling Transactions in SQL Azure
- Troubleshooting and Optimizing Queries with SQL Azure
- Connection Management in SQL Azure
- Billing Numbers Directly From Transact-SQL
- MSDN Magazine: SQL Azure and Windows Azure Table Storage
- MSDN Magazine: Getting Started with SQL Azure Development
SQL Azure Data Sync
Articles
- SQL Azure Data Sync Overview
- SQL Azure Data Sync FAQ
- SQL Azure Data Sync - Cost Considerations
- SQL Azure Data Sync Scenario - SQL Azure-to-SQL Azure Synchronization
- SQL Azure Data Sync Scenario - SQL Server-to-SQL Azure Synchronization
- SQL Server to SQL Azure Synchronization
- SQL Azure to SQL Azure Synchronization
Videos
SQL Azure Reporting
Microsoft Access
Entity Framework
Microsoft Excel
Greg Leake (@gregleake) posted Windows Azure, SQL Azure, Azure StockTrader and Configuration Service 5.0 on 3/1/2011:
This was my first Azure project, so will be publishing some information about the porting process itself. Luckily, and amazingly, zero lines of code in the StockTrader business logic had to change. I had to add one simple method to the data access tier to account for the connection model used by SQL Azure for a multi-tenant DB (about 20 lines of code); and call this method strictly from the SQLHelper class in about 6 places. This took only a few hours to accomplish! Of course, the StockTrader design pattern used originally made this easy, since all data access (in fact, every call to ADO.NET) channels through a single helper class-based on the Patterns and Practice's Data Access Block. So, save for these ~25 lines of code in this infratructure class, all the existing StockTrader code moved seamlessly, not a single query even had to be changed!
The Business Service tier and Order Processor tier, both WCF services, also moved very easily to Windows Azure--I created autonmous service domains for each. So, there will be a StockTrader sample in the cloud that everyone can check out very soon! In fact, it works quite nicely as a web site accessible from mobile devices including Windows Phone 7, IPhone, Android, etc.
I am just as excited about the new 5.0 Configuration Service. This handles the lifecycle of WCF services on Azure (both Web and Worker Roles), so that a single code-based can run on bare-metal clustered servers, private cloud environments such as Hyper-V with scale out across VMs, and now across Azure instances. StockTrader, via Configuration Service, also runs in hybrid setups--such as running the Web App in the cloud but connecting back into on-pemise datacenter through secure WCF messaging for the business tier, data tier, and order processing tier. Some highlights of next release:
1. Will include new projects for both on-premise StockTrader and Azure StockTrader, with fixes made especially to HTML for consistent rendering on all versions of IE, Firefox, Chrome, and their smart-phone equivalents. Also, new projects incorporate the new Config Service libraries/capabilities.
2. I will also be hosting ConfigWeb itself in the cloud (of course only I have the access authorization for my cloud-hosted implementations of StockTrader.
3. Some important fixes to Config Service for handling cross-service domain scenarios, especially when different connected service domains have different security/WCF bindings. I am using a mix of transport security, as well as message security via WCF.
4. Some new Config Service 5.0 features:
- Error logging to your own SQL or SQL Azure database, with new view log pages in ConfigWeb.
- SOA Map page now not only returns online status of on-premise clusters, but also Azure clusters. Plus it also returns some base level performance metrics across those instances, and aggregated up to the cluster level (asp.net req/sec, cpu utilization, wcf service req/sec)--folks could add others of course since source code will be again part of the download.
- Remoting across multiple service domains for error/audit log viewing from single admin sign on.
- Mapping of WCF endpoints to Azure endpoints, automatically. Just define the Azure endpoints in ConfigWeb.
- Upgrades to work better with external load balancers---just mark any endpoint (config or business endpoint) as externally load balanced with address/port in ConfigWeb. This works great with Azure fabric controller load balancing (or any other type of load balancer).
- Node service on Azure uses internal, private endpoints on your Azure services/web apps for synchronizing config updates across azure instances.
- Biggest thing is a single code base for Config Service that works with on-premise apps and Win Azure/SQL Azure apps. In fact, just by using SQL Azure for the config databases, you automatically get high availability since SQL Azure runs on an HA platform with online replicas automatically maintained for database failover. Very cool.
I also hope to add some Visual Studio project templates for VS 2010 to make it even easier to implement config services in customer apps.
Details on StockTrader’s previous version 4.0 are available from Greg’s New: StockTrader and Configuration Service 4.0 post of 8/6/2010.
Greg’s last post was Windows Server AppFabric and Microsoft .NET 4.0 vs. IBM eXtreme Scale 7.1 and IBM WebSphere 7 Benchmarks of 8/8/2010. He’s not a prolific blogger.
<Return to section navigation list>
MarketPlace DataMarket and OData
Matt Stroshane (@mattstroshane) completed OData for WP7 series with Introducing the OData Client Library for Windows Phone, Part 3 of 3/3/2011:
This is the third part of the 3-part series, Introducing the OData Client Library. In today’s post, we’ll cover how to load data from the Northwind OData service into the proxy classes that were created in part one of the series. This post is also part of the OData + Windows Phone blog series.
Prerequisites
Introducing the OData Client Library for Windows Phone, Part 1
Introducing the OData Client Library for Windows Phone, Part 2How to Load Data from Northwind
There are four steps for loading data with the OData Client Library for Windows Phone. The following examples continue with the Northwind “Customer” proxy classes that you created in part one. Exactly where this code is located in your program is a matter of style. Later posts will demonstrate different approaches to using the client library and proxy classes.
Note: Data binding implementation will vary depending on your programming style. For example, whether or not you use MVVM. To simplify the post, I will not address it here and assume that, one way or another, you will bind your control to the DataServiceCollection object.
1. Create the DataServiceContext Object
To create the data service context object, all you need to do is specify the service root URI of the Northwind OData service, the same URI that you used to create the proxy classes.
If you look inside the NorthwindModel.vb file, you’ll see that DataSvcUtil.exe created a class inheriting from DataServiceContext, named NorthwindEntities. This is the context class that is used in the following example:
'data service context
DimNorthwindContextAs_
NewNorthwindEntities(
NewUri("http://services.odata.org/Northwind/Northwind.svc/"))2. Create the DataServiceCollection Object
To create the data service collection object, you need to specify that you’ll be putting Customer objects in it, and that you will load the collection with our NorthwindEntities context. Because the collection contains Customer objects, the collection is named Customers in the following example:
'data service collection of customer classes
DimWithEventsCustomersAs_
NewDataServiceCollection(Of Customer)(NorthwindContext)Note: You’ll need to register for the Customers LoadCompleted event later on. In VB, you set up for this by using the WithEvents keyword. In C#, you typically register for the event handler in the next step, when the data is requested.
3. Request the Data
Now that you have your context and collection objects ready to go, you are ready to start loading the data. Because all networking calls on the Windows Phone are asynchronous, this has to happen in two parts. The first part involves requesting the data; the second part (next step) involves receiving the data. In the following example, you use the LoadAsync method of the DataServiceCollection to initiate the request.
Because the collection knows the context, and the context knows the root URI, all you have to do is specify the URI that is relative to the root. For example, the full URI of the Customers resource is:
http://services.odata.org/Northwind/Northwind.svc/Customers
Because the root URI is already known by the context, all you need to specify is the relative URI, /Customers. This is what’s used in the following code example:
'load customers collection asynchronously
Customers.LoadAsync(
NewUri("/Customers", UriKind.Relative))Note: The LoadAsync method can be called in a variety of places, for example, when you navigate to a page or click a “load” button.
4. Receive the Data
If you have a Silverlight control bound to the data service collection, it will automatically be updated when the first set of data comes back (the amount of which depends on your request and how that particular service is configured). Even with data binding, it is still important to handle the LoadCompleted event of the DataServiceCollection object. This allows you to handle errors from the data request. Additionally, the following example uses the Continuation property to check for more pages of data and automatically load them using the LoadNextPartialSetAsync() method.
'look for errors when the customer data finishes loading
PrivateSubcustomers_LoadCompleted(ByValsenderAsObject,
ByValeAsLoadCompletedEventArgs) _
HandlesCustomers.LoadCompleted
Ife.ErrorIsNothingThen
'handling for a paged data feed
IfCustomers.Continuation IsNotNothingThen
'automatically load next page of data
Customers.LoadNextPartialSetAsync()
EndIf
Else
'write error message
Debug.WriteLine(String.Format("!!! ERROR: {0}", e.Error.Message))
'notify user as appropriate
EndIf
EndSubNote: This is just one example for handling the LoadCompleted event. You’ll likely see many other types of implementations.
Choosing a Home for Your Code
If you have a single-page application that is not very complicated, it is just fine putting your DataServiceContext and DataServiceCollection in the code-behind page, for example MainPage.xaml.vb.
In the case of multi-page apps, the model-view-viewmodel (MVVM) programming pattern is a popular choice for Windows Phone apps. With MVVM, the data service context and collection are typically placed in the ViewModel code file, for example MainViewModel.vb.
Conclusion
This series covered the basics of getting started with the OData Client Library for Windows Phone.
The Microsoft development teams are always looking for ways to improve your programming experience, so I don’t expect it will stay this way forever. Keep an eye out for new features with each release of the Windows Phone development tools. The documentation will always detail changes in the topic What’s New in Windows Phone Developer Tools.
See Also: Community Content
Netflix Browser for Windows Phone 7 – Part 1, Part 2
OData v2 and Windows Phone 7
Data Services (OData) Client for Windows PHone 7 and LINQ
Learning OData? MSDN and I Have the videos for you!
OData and Windows Phone 7, OData and Windows Phone 7 Part 2
Fun with OData and Windows Phone
Developing a Windows Phone 7 Application that consumes OData
Lessons Learnt building the Windows Phone OData browserSee Also: Documentation
Open Data Protocol (OData) Overview for Windows Phone
How to: Consume an OData Service for Windows Phone
Connecting to Web and Data Services for Windows Phone
Open Data Protocol (OData) – Developers
WCF Data Services Client Library
WCF Data Service Client Utility (DataSvcUtil.exe)
PRNewswire reported “Company Recognized For Exceptional Windows Azure and DataMarket Applications” to introduce a 3/3/2011 Catapult Systems Wins Two Development Awards From The Code Project press release:
"Congratulations to Catapult Systems for winning recognition from The Code Project for their Windows Azure development capabilities," said Jenni Flinders, vice president Microsoft U.S. partner business. "Their drive to provide an award-winning employee performance management application to Windows Azure subscription holders is an example of how Microsoft partners are embracing the Microsoft cloud vision."
In addition to the recognition from The Code Project for development on Microsoft Azure platforms, Catapult Systems was recently recognized by Microsoft for achieving a record eight gold and 17 silver competencies. In addition, Microsoft named several Catapult consultants as "Most Valuable Professionals" (MVPs), a special designation given to the top Microsoft certified consultants from around the world.
Catapult Systems is a widely-recognized IT consulting services firm with nearly 20 years experience delivering Microsoft-based technology solutions to enterprises of all sizes. A Microsoft National Systems Integrator, the company is ranked in the top 0.05% of Microsoft partners globally. For more information, visit www.CatapultSystems.com.
About Catapult Systems, Inc.
Catapult Systems provides Microsoft IT consulting services in enterprise solutions, infrastructure and custom development. With offices in Austin, Dallas, Houston, San Antonio, Denver, Tampa and Washington D.C., Catapult implements secured, innovative technology solutions, enabling our clients to achieve their business priorities while deriving the maximum value from their Microsoft technology investments. A Microsoft National Systems Integrator (NSI), Catapult holds 8 gold and 17 silver Microsoft competencies, placing the company in the top 0.05% of Microsoft partners globally. For more information about Catapult visit www.CatapultSystems.com.
Catapult Systems is a trademark of Catapult Systems, Inc. All other company and product names mentioned are used only for identification and may be trademarks or registered trademarks of their respective companies.
Bruno Aziza [right] interviewed Moe Khosravy [left] in an 00:04:10 YouTube Video Segment on 3/1/2011:
Bruno wrote this tweet on 3/3/2010:
In 90 day[s] only, this #data market got 5K subs, 3M transactions, find out why @ http://ow.ly/46KZV #bitv #analytics #data #Azure #DataMarket
The WinnerHosts.com site posted a useful OData bibliography of early articles:
OData By Example
The Purpose Of The Open Data Protocol OData Is To Provide A RESTbased Protocol For CRUDstyle Operations Create Read Update And Read Against Resources Exposed from microsoft.com
OData Articles
OData By Example Using Microsoft ADONET Data ServicesNET Framework WCF Data Services Introducing The Microsoft Open Data Protocol Visualizer CTP1 from odata.org
Producing And Consuming OData Feeds An Endtoend Example Jon
Having Waxed Theoretical About The Open Data Protocol Its Time To Make Things More Concrete Ive Been Adding Instrumentation To Monitor The Health And Performance from jonudell.net
Practical OData Building Rich Internet Apps With The Open Data
If For Example Youre A Silverlight Developer Who Learns The OData Library For That Platform You Can Program Against Any OData Feed Beyond The OData Library For from microsoft.com
Simple Silverlight 4 Example Using OData And RX Extensions
A Simple Silverlight Application That Uses RX Extensions To Communicate With An OData Service Author Defwebserver Section Silverlight Chapter Web Development from codeproject.com
OData HOW TO Query An OData Service Using Ajax ASPNET Ajax
From Client Script You Can Query And Modify Data That Is Exposed By An OData Feed That Is Hosted In The Same Web Site As The Current Web Page The Example In This from asp.net
Simple Silverlight 4 Example Using OData And RX Extensions
This Is Part II To The Previous Blog HttpopenlightgroupnetBlogtabid58EntryId98ODataSimplifiedaspx Where We Looked A Simple OData Example from openlightgroup.net
Odata Osht And Some Examples Jason Rowe
My Head Is Spinning From Looking At Odata Tonight I Keep Going Back And Forth On If This Is The Coolest Thing In The World Or Just A Way To Browse Data from jasonrowe.com
Odata Examples
Any Examples Using Odata With Forms That Are Not Part Of A CRM Solution Such As Web Portal from microsoft.com
<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
Cennest Technologies published an Introduction into the world of “Claims”( Windows Identity Foundation & Azure App fabric Access Control!) on 3/1/2011:
Have you been working on a website or an application where you maintain a user database for people coming from different companies/domains? Someone is responsible for maintaining the consistency of this database? Also you as an application developer are required to write code to check for authorization rights allowing/disallowing visitors to visit only authorized sections of your site?
All issues i’ve mentioned so far are pretty common in a multi-tenant type of an applications(like SAAS) which caters to multiple companies . Usually you would have each user of your app create a new username/password and store it in your app database..here are the disadvantages of such an approach
1. Your users have to remember ANOTHER set of username/passwords
2. You end up storing not just their username/passwords but also other details like their role, reporting manager etc etc which is btw already present on their corp net so you are basically duplicating information
3.You are responsible for maintaining the duplicate information…if the person got promoted to a manager , your database needs to be updated also
4. What if the person leaves the company? He still has a login into your application until it is manually removed!
Even if your user’s don’t really come from a domain or a company, aren’t there enough “Identity Providers” like Live, Google, OpenID out there?. Why do you need to “authenticate” these users?. Why not just ask an existing Identity provider to check out the user’s authenticity and let you know more about the user?Basically “Outsource” your “authentication” work and focus on your core capability which is application logic..Sounds too good to be true?? Welcome to Claim based Architectures!!
Microsoft’s Windows Identity Foundation provides a framework for building such “Claim based applications”.My next sequence of blogs will be an attempt to demystify the “Claims based Identity Model”.
If you are still reading this you are probably saying demystify WHAT???
So lets start with what claims based identity model means..
When you build claims-aware applications, the user presents her identity to your application as a set of claims One claim could be the user’s name; another might be her email address. The idea here is that an external identity system is configured to give your application everything it needs to know about the user with each request she makes, along with cryptographic assurance that the identity data you receive comes from a trusted source.
Under this model, single sign-on is much easier to achieve, and your application is no longer responsible
for:
Authenticating users.
Storing user accounts and passwords.
Calling to enterprise directories to look up user identity details.
Integrating with identity systems from other platforms or companies.
Under this model, your application makes identity-related decisions based on claims supplied by the
user. This could be anything from simple application personalization with the user’s first name, to
authorizing the user to access higher valued features and resources in your application.Lets also define a few more key terms you would hear again and again..
Claims:- You can think of a claim as a bit of identity information, such as name, email address, age, membership in the sales role, and so on. The more claims your service receives, the more you’ll know about the user who is making the request. Claims are signed by an issuer, and you trust a set of claims only as much as you trust that issuer. Part of accepting a claim is verifying that it came from an issuer that you trust.There are steps as to how to establish a trust relationship between your application and an issuer. Will elaborate on those in another post..
Security Token:- A set of claims serialized and digitally signed by the issuer
This next one is confusing
Issuing Authority & Identity Provider
An issuing authority has two main features. The first and most obvious is that it issues security tokens. The second feature is the logic that determines which claims to issue. This is based on the user’s identity, the resource to which the request applies, and possibly other contextual data such as time of day.
Some authorities, such as Windows Live ID, know how to authenticate a user directly. Their job is to validate some credential from the user and issue a token with an identifier for the user’s account and possibly other identity attributes. These types of authorities are called identity providers
So basically not All Issuing Authorities are Identity Providers. Some of them just accept claims from Identity providers and convert them into claims acceptable by your application (Azure app fabric Access Control is such an example)..basically they don’t have authentication logic..just mapping logic.
Security Token Service(STS):- This is another confusing term as you will see people using Issuer and STS interchangeably.Basically A security token service (STS) is a technical term for the Web interface in an issuing authority that allows clients to request and receive a security token according to certain interoperable protocols
Relying Party:- When you build a service that relies on claims, technically you are building a relying party. Some synonyms that you may have heard are claims aware application, or claims-based application.
Pretty heavy definitions!!.. It took us some reading to finally find definitions that are easy to understand. Surprizingly the easiest definitions were not in “A Guide to Claims-based Identity” or “WindowsIdentityFoundationWhitepaperForDevelopers-RTW” but in “A Developer’s Guide to Access Control in Windows Azure platform AppFabric”
If you have reached this line then you are definitely on your way to building the next gen identity aware apps…so look forward to our next set of blogs!!

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
Fins Technology posted a copy of Microsoft’s Software Development Engineer, Senior Job requirement for a Windows Azure Connect SDE on 3/3/2011:
Company: Microsoft Corp.
- Location: Redmond, WA, US
- Job Type: Full Time
- Category: Software Development
- Yrs of Exp: 5+ to 7 years
- Posted: 3/2/2011
Job Description
Are you passionate about taking on big challenges? Does the prospect of solving the next-generation of networking problems for Cloud Computing interest you? Do you want to play a pivotal role is defining features of the Windows Azure Platform? Would you enjoy working in a fast-paced, startup environment that places a premium on shipping early and often? If you answered Yes to all of the questions, then the Windows Azure Connect team might be the place for you!
The successful candidate needs to have deep technical, design, and hands-on development/coding skills with a proven track record of shipping top-quality code (C, C++, or C#) and low-level systems components. The candidate must have the ability to ramp-up quickly on various technologies, patterns, and best practices and in many cases be able to define new ones as applicable to the problem at hand.
Qualifications:
• Solid hands-on experience with managed and native code
• Experience with networking / IPSec / Certificate management is a big plus
• Development experience (5+ years) delivering products from inception to release
• Good communication skills and a collaborative working style
• Comfortable in an agile setting
• BS/MS in Computer Science or equivalent experience
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
•• Jason Zander delivered a Performance Troubleshooting Article and VS2010 SP1 Change notice in his 3/3/2011 post:
We are getting very near to the final release of VS2010 SP1 (if we were landing a plane the wheels would be down right now with the runway in front of us). Thanks again for all your feedback and stay tuned for the imminent release of the product.
We’ve concentrated heavily on fixing issues you have reported, including those related to performance and reliability. The team has collected the most common scenarios we see that may cause issues and published it here:
One of the interesting patterns we have seen is that Windows XP users are twice as likely to hit hardware graphics related issues than those using Vista, Windows 7 or Windows Server. In some cases users report slower performance of VS2010 along with the potential for crashing behavior. Very frequently this turns out to be attributable to poor/old video drivers or other operating system components. You can manually turn off hardware acceleration in Visual Studio if you think this is impacting you. To do this, choose Tools, Options and turn off the automatic options:
Based on the number of machine reports we have found with video driver issues, we are taking the step of turning off hardware graphics acceleration in Visual Studio by default for Windows XP users when you install the final version of VS2010 SP1. This change will only impact the Visual Studio IDE, not other applications or your version of Windows. You can also easily turn hardware acceleration back on using the Tools, Options dialog above.
I generally really hate making setting changes like this; as a developer I don’t like it when my environment changes defaults. At the same time I’ve seen enough data about the issues people are hitting today and I want to ensure everyone has a good experience. I’m blogging about this change now to provide the background on the decision as early as possible.
Thanks again for your feedback on VS2010 SP1 and get ready for downloads!

• James Urquhart described Capacity aggregation: Cloud's great experiment in a 3/3/2010 post to C|Net News’ Wisdom of Clouds blog:
In my last post, I gave you an outline of what I see as the three biggest "killer apps" of cloud computing. There is, however, another facet to the cloud story that I think is very exciting right now: innovation on the core technical and operational models that form the basis of distributed computing.
What I mean by that is this: cloud has made new ways of acquiring and consuming infrastructure, platforms, and applications readily available to an increasingly broad market of potential users. The financial model--pay-as-you-go--makes failure much, much cheaper than it was with models in which the application owner had to lay out large amounts of capital up front to have somewhere to run their application.
That ease of access and experimentation makes cloud a new tool in the toolbox of technologists. And, as in any craft where useful new tools are introduced, those technologists are now trying to see if they can solve new problems that weren't possible before. Today, the cloud is a place where the so-called envelope is being pushed to new extremes.
One of the most important of these experiments today is the introduction of true compute capacity aggregators--market services where capacity is available on demand, from multiple providers, with price and service competition.
Achieving a true capacity market, in which capacity can be traded as a commodity product like wheat or energy is an extremely difficult problem to solve. In fact, I'm on record as saying it will be many years before the technical and legal barriers to such a model will be removed.
However, I may be proven wrong, if services like Enomaly's SpotCloud, ScaleUp's Cloud Management Platform (specifically it's new federation features), and stealth start-up ComputeNext (outlined by CloudAve blogger Krishnan Subraramian) have their way. These services aim to make the acquisition of compute capacity consistent across multiple sources, which is the beginning of an exchange market model.
The overall model is simple: those with capacity make it available to the service (though how that is done seems to vary by offering), and those that need capacity come to the service, find what they need, and consume it. SpotCloud is the most mature--you can play with it today--with the others coming online over the coming months, it appears.
The questions these experimental models hope to answer is two-fold. First, what model will the compute exchange market take? Both SpotCloud and ScaleUp take online travel industry models. (SpotCloud is modeled somewhat after travel clearinghouse Hotwire, and ScaleUp after aggregators like Orbitz or Travelocity.) According to Subraramian's post, ComputeNext is taking more of a search engine model, though how they monetize that is unclear.
Second, how does one run various kinds of applications in what is almost inherently a transient infrastructure model? Given the fact that there is little guarantee that any given capacity will be available on a long-term basis, what types of applications can consume it today, and what kinds of innovations will expand that target market?
SpotCloud, in fact, forces this question, as its capacity is transient by definition (though they recently added instance renewal recently). So, the question becomes, is it a limited tool, or will some software developer create new management tools that run a distributed, "fail ready" application on transient infrastructure, creating new instances to replace expired instances when required without losing performance or availability?
By the way, there is no guarantee that these aggregators will be the source of compute exchanges. Other application-level management tools, such as enStratus (disclaimer: I am an adviser) and RightScale could handle capacity evaluation and acquisition in the application management plane itself, rather than as an online service consumed by the application management tools.
However, the existence of aggregators is one model that has to be explored before we can pick a utility "standard."
There are many people who believe that some large portion of compute capacity will be provided in a utility model in the future. Are the early cloud aggregators of today the path to that vision? I'm not sure, but I can't wait to see how these experiments turn out.
Read more: http://news.cnet.com/8301-19413_3-20038926-240.html#ixzz1FaJVT8vi
• Joel Forman started a new series on the Slalom Works blog with Windows Azure Platform: March 1st Links of 3/1/2011:
I’m starting a new link listing series, which will list recent links that I have come across to valuable, interesting Windows Azure Platform material. Hopefully you will find some of these interesting as well…
- Windows Azure Code Samples Forum: Vote on what code samples you would like to see around the Windows Azure Platform. I thought this was interesting because of the top 2 samples requested: SSO Application and Windows Phone 7 and Windows Azure. There are some good samples for these already out there today. Sample around SSO (via ACS) and WP7 can be found in the updated Windows Azure Platform Training Kit. The Identity Training Kit and Online Course also has good identity-based labs.
- Cloud Cover on Channel9: Multiple Sites in a Web Role: I really enjoy this blog series, and the latest episode covers how to take advantage of the Full IIS features of the 1.3 SDK to run multiple web sites within a web role.
- Using MSBuild to Deploy to Multiple Windows Azure Environments: Tom Hollander has a nice blog post about using MSBuild with TFS 2010 and Visual Studio 2010 for Windows Azure projects.
- Introduction to the Windows Azure AppFabric Blog Series: The AppFabric team has a new series of blog posts that summarize the Windows Azure AppFabric offering. Here are links to Part 1, Part 2, and Part 3.
Happy reading…
Avkash Chauhan explained Migrating 32Bit ASP.NET application to Windows Azure Web Role in a 3/3/2011 post:
If you have a 32bit ASP.NET application and decided to port to Windows Azure application you will do the following:
- 1. Create a Web Role using Windows Azure SDK 1.3
- 2. Add existing Website (hosted on a 32-bits server) converted to Web Application.
- 3. Build
- 4. Test locally in Compute Emulator
- 5. Deploy it
Server Error in '/' Application.
is not a valid Win32 application. (Exception from HRESULT: 0x800700C1)
Description: An unhandled exception occurred during the execution of the current web request. Please review the stack trace for more information about the error and where it originated in the code.
Exception Details: System.BadImageFormatException: is not a valid Win32 application. (Exception from HRESULT: 0x800700C1)
Source Error:An unhandled exception was generated during the execution of the current web request. Information regarding the origin and location of the exception can be identified using the exception stack trace below. …
The reason for this problem is that the IIS server doesn't have 32bit application support enabled in Application Pool so to fix this error you will need to enable 32 bit applications in the Application pool. And to make it happen, you will need to create a "Startup Task" to enabled 32-Bit application support in IIS and this has to be done in your Windows Azure Application. Here are the detailed steps:
1. Create a BATCH file with proper command lines which can run the script to enable 32Bit application support in IIS as below:
File: Enable32BitAppPool.cmd
%windir%\system32\inetsrv\appcmd set config -section:applicationPools -applicationPoolDefaults.enable32BitAppOnWin64:true
2. Add this BATCH file into Windows Azure Application Startup Task by adding the following lines in ServiceDefinition.csdef to enable 32-bit application in IIS advance setting
File: ServiceDefinition.csdef
<Startup>
<Task commandLine="Enable32BitAppPool.cmd" executionContext="elevated" taskType="simple">
</Task>
</Startup>
3. St the file Enable32BitAppPool.cmd property to "Copy Local" as true so this batch file will be deployed to Azure Portal with your package.
Steve Marx (@smarx) explained Controlling Application Pool Idle Timeouts in Windows Azure in a 3/2/2011 post:
A question I hear from time to time is whether it’s possible to change the idle timeout time for IIS application pools in Windows Azure. It is indeed possible, and fairly easy to do with a startup task.
To change the timeout to zero (which means “never”), add the following startup task declaration to
ServiceDefinition.csdef:<Startup> <Task commandLine="startup\disableTimeout.cmd" executionContext="elevated" /> </Startup>And add
disableTimeout.cmdin a folder calledstartup, with the following line of code (should be one line, split just for formatting):%windir%\system32\inetsrv\appcmd set config -section:applicationPools -applicationPoolDefaults.processModel.idleTimeout:00:00:00Be sure to mark
disableTimeout.cmd’s “Copy to Output Directory” setting to “Copy always”.
• Ryan Bateman posted Top 15 Cloud Service Providers – Ranked by Global Performance to ComputWare’s CloudSleuth blog on 2/28/2011:
I hope by now you’ve become acquainted with the Global Provider View (GPV) made available on CloudSleuth by Compuware Gomez (my employer). We’ve been pinning the major cloud service providers against one another through GPV for almost 11 months now and have some really awesome data to show for it. Here is a peek into the last few months. [see fig. 1]

Fig. 1
Q. How might this data be useful to you?
A1. Let’s say you’re an application owner and you’ve been getting pressure from your CXO to “check out that cloud thing” they’ve been hearing about. You’ve got users around the world that use your app today and usage is increasing while your user base is spreading geographically. How do you know which cloud service provider will provide optimal performance for the users in the regions you care about? See Fig.1 and work your way down from the top.
A2. It isn’t! Same scenario as above, CXO yelling at you about investigating cloud services for an app you own… except this time you AREN’T a huge Global 1000 company and your users are limited to a specific geography. This data might be too high-level for you. If you are looking for a more accurate representation of a service provider’s performance on a regional level, check out GPV. It features backbone performance test results from various regions around the world, allowing you to drill into the performance of providers at the city level. Drill in to the region that best represents the location of your users and work your way down the list from the top.
–P.S. Congratulations to Windows Azure for claiming the top spot.
The post continues with details of the test methodology.
• Compuware published a White Paper: "Performance in the Cloud" Survey Report on 3/1/2011:
Poor performance of cloud applications impacts revenue, delays rollouts
Almost 700 businesses across North America and Europe were surveyed to understand whether they are already experiencing the impact of poor application performance in their cloud application deployments, and how this is affecting their cloud strategies moving forward.
Results highlight the growing awareness that IT departments' ability to gaurantee the performance of cloud applications is severely restricted, and that more complex SLAs are required for issues such as Internet connection and performance as well as end-user experience.
Register to receive this white paper and learn how to effectively manage your applications' performance.
Downloading the whitepaper requires site registration.
Sten Sundberg wrote ARCHITECTURE RULES about the Windows Azure Architect Training Program on 2/28/2011 (missed when posted):
Some time ago Per and I had an interesting experience. We were benchmarking a hybrid application, changing its bandwidth resources and modifying its architectural design between test runs. It was a hybrid application, because part of it was running on-premises and part of it in the cloud.
The purpose of the application was to create and populate a number of example Windows Azure Tables for the program, deployed in Microsoft’s Northern Europe Data Center. It generated a number of person, organization, employment, product, lead and lead subject entities, saving them in different tables in Windows Azure Storage.
Fine-Grained (Typical) Architectural Design – Slow Connection
The first test run was designed the way I guess most of us would have designed it. It sent rather fine-grained messages to Windows Azure Storage, saying things such as save this person, save this organization, and so on. When we ran it on an 8 Mbit connection it took nearly 12 minutes to complete. This was very different from running it locally on the Storage Emulator, which took just 1 minute and 9 seconds. But that was expected, because as we all know there is no network latency when you work exclusively in your own computer.Using a Faster Connection
Anyway, 8 Mbit/second isn’t fast, so our next step was to run the same application, not changing neither design nor implementation, on a dramatically faster (100 Mbit) connection. The faster connection brought down the total time to eight and a half minute, saving three and a half minute, or nearly 30 %. We might have expected more improvement, but 30 % is what we got. And after all, network latency doesn’t affect all parts of the operation; other things that take time don’t change at all just because the connection gets faster.More Coarse-Grained Conversation Pattern
Our next step was to modify the architectural design by changing the conversation pattern used by the on-premises part and the cloud part of the application. We made the consumer change batches of new objects rather than one at a time, and we made the consumer ask for batch-oriented transactions rather than moving data to storage one entity object a time. We went back to the slow connection, because we wanted to see how well improved architecture should stand in relation to using a (dramatically) faster connection. It turned out that the improved architecture made more performance impact than the faster connection. The total time now went down to 6 minutes and 2 seconds. Where a 12 times faster connection could improve performance by 30 %, a smarter architectural design could improve it by close to 50 %.Shifting Responsibility Patterns
For our next test we made more considerable changes to the architecture. We moved parts of the on-premises application to the cloud, thereby placing the responsibility for data access closer to table storage. We were still ordering the work from the on-premises part, but much of the real operations now took place in a Windows Azure Worker Role in the cloud. That allowed us to make the conversation pattern even more coarse-grained. We kept using the slow connection, because that was more interesting than using the fast one. If we had used the fast connection only, questions about performance on a more commonly used and slower connection would still remain.The result was amazing. The entire job was now completed in 1 minute and 26 seconds, representing an 88 % improvement in relation to the original about 12 minutes.
You must keep your Worker Roles Stateless
We now wanted to see what kind of performance gain we could expect when running the application on three Worker Role instances rather than one. It turned out, however, that our application couldn’t take advantage of Windows Azure’s tremendous out-scaling capabilities. We had done what I think most of us unconsciously do; we had made our Worker Roles keep state. It wasn’t much, and we never thought about it as state, but that small amount of state, kept in each Worker Role instance, made it impossible for them to share the work between them.We modified the Worker Role by making it push that state down to table storage. This made an incredible impact on the number of table access operations our application had to do, so processing time went up to 2 minutes and 16 seconds. However, that was still a good result; it was an 82 % improvement over the original design which wasn’t bad in itself, but which was not based on Windows Azure know-how.
Scaling Out
Our last test involved adding two Worker Role instances, making it possible to share the work by three instances. Our now stateless Worker Roles had no problems with that, it worked like a charm. And the final time now was 1 minute and 34 seconds. That wasn’t the fastest time of all, but it was incredibly fast, and it used a design that could scale up to hundreds or thousands of Worker Role instances if needed. When compared with the original design it was 87 % faster.It was also interesting to notice that adding two Worker Role instances, going from one to three, didn’t triple – or even double – performance; it gave us a still impressive 31 % improvement. The reason, of course, is that with one single application sending out messages to a Worker Role, and when not all the steps in the process can be started until one or several specific tasks have been completed, it’s impossible to keep all three instances busy all the time. With several applications running, and with many users sending work request, we should come much closer to the theoretical 3 times improvement.
Conclusions
The most interesting conclusion is that a bit of knowledge about the characteristics of Windows Azure makes it possible to architecturally design for dramatic improvements in performance. Where using a 12 times faster connection could improve performance with less than 30 %, smarter architectural design could improve it with as much as 87 %.Another interesting conclusion is that without proper knowledge about how Windows Azure works it will be difficult to find an architectural design that both performs well, is stable and robust, and which can take advantage of Windows Azure’s scaling out capabilities.
That conclusion made us proud that we from the beginning decided to make the Windows Azure Architect program dive deeply into technical matters while not forgetting that architecture is about matching business requirements with technological opportunities.
Coming Up: SQL Azure
In an upcoming blog post I will present the results of a corresponding benchmark test where SQL Azure rather than Windows Azure Table Storage provides storage for the data. We will do the last test only, the one that takes advantage of Windows Azure scalability, but that will be enough to give us all some very interesting information.How fast is SQL Azure when compared to Windows Azure Tables? It goes without saying that I won’t be able to give you the final answer, but I will be able to tell you how each environment performed when solving exactly the same not entirely trivial problem.
More details about the US$1490 Windows Azure Architect Training Plan are here.
<Return to section navigation list>
Visual Studio LightSwitch
•• Edu Lorenzo demonstrated Adding Forms Authentication based Access Control to a Visual Studio LightSwitch Application on 3/3/2011:
Okay, so in my last blog, I showed how to configure an application made with Visual Studio LightSwitch to use and implement Access control following Windows Authentication. In this blog, I will show how to configure the same application to use Forms Authentication.
I start off by opening the application I have been working on, and by the way, I have added a few things here and there to it in between blogs.
First, I added several new access controls and enabled them by checking the “Granted for debug” checkbox for each. To put simply, I have set these properties to true, so that when I run, the logged in user can perform all the actions I have indicated. Let’s illustrate by unchecking the canReadPatient rule and running the application.
You will see here two things:
- The current user CAN see the patient screen, because we have not set that in the access control. We are still allowing the user to see the patient screen.
- But the current user cannot see the patient entity.
This illustrates how LightSwitch implements access control on the screen and on the entity levels separately.
By now, I believe you are wondering where we add or delete users and define roles. At first I thought I would have needed to add a new screen by myself but that is not the case with Visual Studio LightSwitch.
To do that, what we need to do is to check the Granted for debug checkbox for the Security Administration Module and then run the app again.
Upon running the app, we get:
Two new screens, one for defining users and another for defining roles! Both neatly tucked in, in their own dropdown menu item called Administration.
And in case you haven’t noticed yet, I have not gone into Forms Authentication while this blog’s title is related to Forms Authentication. The reason behind that, is that Visual Studio LightSwitch makes it so easy to move from Windows Authentication to Forms Authentication by just choosing the appropriate option button.
And that’s it!
Next time I’ll show how to add a new user control J

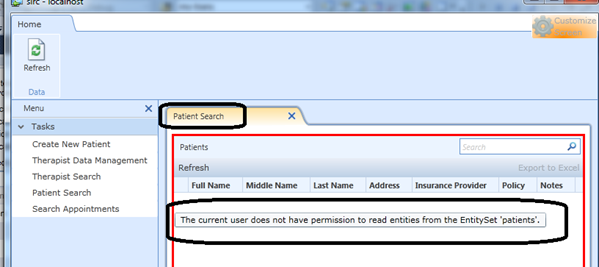



The MSDN Code Archive’s Visual Studio LightSwitch Samples were updated on 12/3/2010:
Files
LightSwitch Walkthrough Sample source code, 41327K, uploaded Dec 3 2010 - 12296 downloads
To download the file you must agree to a long-winded Ms-PL license. More than 100,000 downloads indicates more than casual interest in Visual Studio Lightswitch.
Return to section navigation list>
Windows Azure Infrastructure
Wolfgang Tonniger posted an Interview with David Chappell: Cloud Hype and Reality to the Business Ready Blog on 3/3/2011:
David Chappell [pictured at right], Chef von Chappell & Associates in San Francisco, ist Berater, Buchautor und begehrter Redner in Sachen Technologievermittlung und Technologiebewertung. Wir trafen David Chappel nach seiner Keynote für den Microsoft Virtualization Day 3.0 im Hotel Savoyen.
BIZofIT: Mr. Chappell, that cloud is one of the strongest hypes we have seen in IT-history is no secret anymore. What are the signs that it is more than that – a paradigm shift like client server was for mainframe computing?
David Chappell: Lets break the answer apart into three big pieces. 1) First of all cloud applications. Cloud apps are not hype because they made Marc Benioff a billionaire. Salesforce.com CRM is very successful and proofs that cloud apps can work. People love this product. The same holds true for Google apps and Microsoft BPOS (Business Productivity Online Suite, Office 365). In the app space we already have big succeess stories and more will come with e-mail and Exchange. The move to the cloud is happening right now. Like with 2) the private part of cloud platforms, the piece of IaaS (Infrastructure as a Service). If you have VMs today, I can tell you that you will have a private cloud in the next few years. Because both, VMware and Microsoft are moving their products into this direction. Why? Because it definitely makes sense and it´s a clear evolution.
… if you don´t like change, you better don´t work in IT!
3) In case of public cloud platforms – like Amazon EC2 and Windows Azure – things are a bit less clear, in part because Amazon doesn´t report revenues. But the estimates agree on that Amazon, who is the big fish here right now for revenue, will be a billion dollar business in the next couple of years. That means, they are meeting really customer demand and they are running usefull services. You don´t build a million dollar business with hype. It´s reality. I am not concerned anymore that the cloud is just hype. Yes, there is a lot of hype. But there is a lot of success too.
BIZofIT-2: When you talk about the cloud you say that the cloud helps to reduce complexity.
David Chappell (grinning): Did I say that? I doubt it.
BIZofIT: What I wanted to pose is that for companies the infrastructure tasks are becoming more and more complex and the cloud may help to reduce this complexity.
David Chappell: I think this is a fair statement, the cloud certainly can help reduce complexity. But it also can make complexity worse, at least in the short run. If I am moving some parts of my e-mail infrastructure into the cloud, I will have some apps in the datacenter and some in Windows Azure. This might be cheaper and better, but not necessarily less complex because I will have to manage both worlds. Anyway, it´s very hard to deal with this kind of broad generalizations about cloud technology because it always depends on what you are doing, and what you mean in each case – cloud apps, cloud platforms, public platforms, private platforms.
BIZofIT: The customers want the freedom of choice but like to blink the fact that going for a very individual mix of on-premise and cloud may also cause extra headaches.
David Chappell: You are right. More options can make your life better in various ways at the risk of raising complexity.
BIZofIT: Not to forget all these new vendors entering into an almost exploding cloud market. How companies can compare the cloud offerings and where are we in terms of standardization?
David Chappell: We are nowhere. Take cloud platforms. There aren´t any viable standards out there right now, nor will there be for some period of time. User groups can define whatever they want – as long as the vendors don´t support them, they are irrelevant.
BIZofIT: But how it comes that the IaaS offerings you mentioned in your keynote today are better to compare?
David Chappell: Simply because they are more similar and service is the same. It´s not because of standards. People are offering VMs on demand and it´s pretty clear, that it´s always a VM (virtual machine) that runs Linux or Windows. Whereas if you compare AppForce (Salesforce.com) to Windows Azure they are pretty different. They are both PaaS, but they have different kinds of apps, different languages – they are different in many ways. This variation you don´t see that much in IaaS. That´s what I meant. But in terms of real standards (defined by standardization bodies) there is nothing really happening in the cloud.
BIZofIT: Maybe this is also part of the hesitation coming from the customer side. That they are waiting for cloud standards.
David Chappell: I don´t think so. I´ve done hundreds of talks around Azure and other cloud platforms around the world – and I almost never was asked this question. People want to save money and want to have lower risks. What I´ve experienced so far, the driving forces are always security and cost issues.
BIZofIT: How you value forecasts which estimate a cloud engagement of almost 80% of the companies within some years?
David Chappell: Again. Talking about the cloud is inherently confusing. You have to make clear what you mean – cloud applications, public cloud platforms or private cloud platforms? If they mean that 80% of the companies will have private clouds, I totally agree. If they mean that 80% of the companies will do something in the public cloud, I totally agree. But to estimate that 80% of all applications will be run in the cloud within some years, is nuts.
BIZofIT: How you respond to people´s fear concerning the cloud?
David Chappell: Well, public cloud apps, public cloud platforms are threatening in many ways to inhouse IT departments. If your job is running Exchange for example and your company moves to „Exchange Online“ your job, as you know it, is gone – unless you´re willing to change. But this holds true to anybody who works in IT – whether as administrator, developer or whatever. Who thinks that his current skillset will last his whole carreer, is wrong. So, if you don´t like change, you better don´t work in IT.
BIZofIT: Thanks for the talk.
David is a frequent author of Microsoft-sponsored white papers about Windows Azure and cloud-computing topics.
David Linthicum (@DavidLinthicum) asserted “Microsoft has the entrenched advantage in this fight -- but it also has much more to lose” in a deck for his Why the Microsoft-Google cloud sniping won't stop soon article of 3/3/2011 for InfoWorld’s Cloud Computing blog:
The interminable sniping between Microsoft and Google over their respective cloud-based office productivity services may never end. The latest Microsoft shot at Google came around the final release of Google Cloud Connect for Microsoft Office last week.
Google Cloud Connect for Microsoft Office adds cloud and collaboration to Word, Excel, and PowerPoint in Microsoft Office 2003, 2007, and 2010 on Windows PCs, using Microsoft's Office APIs (available for Windows only -- thus, the lack of Mac support in Cloud Connect). The value is that multiple people may collaborate on the same file at the same time.
Of course, one good shot across the Microsoft bow will get a quick and snarky response: "Although it's flattering that Google is acknowledging customer demand for Office, we're not sure Google's heart is in the productivity business," Microsoft said in its statement.
This kind of silly back and forth will continue throughout 2011 and 2012 as the lines are drawn in the sand around the multi-billion-dollar office productivity market that Microsoft currently dominates and Google is desperate to penetrate. However, Microsoft has a vulnerability.
The issue is that most of us use Office and have a love-hate relationship with it. I suspect that we would have a love-hate relationship with any productivity application, even if we moved to Google Docs. But the idea that most people will move to Google and leave Office behind is a bit of a reach at this point.
The reason is simple: We know Office, it's relatively inexpensive, it has a migration path to the cloud (Office 365), and we don't want to learn new stuff. I suspect I'll continue to be an Office user no matter what Google does; it's not worth the hassle to learn a new product. Although I use Google Docs for sharing a collaborative project, most of my writing (including this blog) occurs in Office on my laptop. I think I'm in the majority.
However, Google could drive directly into the productivity market if Microsoft stumbles with Office 365 (the beta shows some real issues in its execution) or if Google can create a compelling set of features in Google Docs that are just too good to pass up. Thus far, though, that hasn't happened.
No significant articles today.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
•• Dan Power announced on 3/1/2011 a "Data Governance In The Cloud" Seminar, March 24th in Atlanta:
March 24, 2011 • 7:30-11:30AM
JW Marriott Buckhead
3300 Lenox Road,
Atlanta, GA 30326
Master Data Management (MDM) is key to driving revenue and achieving greater productivity with Salesforce.com. A clear data strategy and processes for collecting, aggregating, consolidating, and distributing data throughout an organization impacts your bottom line.
- Is bad data undermining your sales performance?
- Do you have data in disparate systems, fragmented — some in the cloud, some on-premise?
- Are your people, processes, and technologies not aligned properly to ensure data efficiency, access and consistency across your organization?
- Is your sales team spending more time searching for data than they are with customers?
If you’re experiencing any of these issues, attend Data Governance in the Cloud to get control of your data and an action plan for success.
Agenda Overview
- Introduction to the Fundamentals of Master Data Management
- How to Establish Data Governance within your Organization
- Introduction to CRM Process Modeling
- How to Develop a Sales & CRM Process Model
- Cloud Data Integration – Informatica
Seminar Sponsors
Key Insight from Proven Leaders in CRM… Attend this information packed morning and leave with an action plan to gain control of your data, empower your people, initiate processes, and learn which technologies can help you accomplish your goals.
Meet the Experts
Ernie Megazzini
VP, Cloud Technology
CoreMatrixDan Power
President
Hub DesignsDarren Cunningham
VP, Marketing
Informatica Cloud
Who Should AttendBusiness and IT executives and management responsible for consistent and proper handling of data across an organization.
Benefits of Attending
Attendees will leave with a clear understanding of how a company with a well defined, integrated MDM strategy can achieve greater revenues and increased productivity.
Attend this information packed seminar to get control of your data strategy and achieve success with your CRM solution




Bill Brenner asserted “The often-misused SAS 70 auditing standard is set to be replaced next year by SSAE 16” as a deck for his SAS 70 replacement: SSAE 16 post of 10/6/2010 (missed when posted):
The SAS 70 auditing standard has been a must for service providers to test internal security controls. But it hasn't been without critics, and SAS 70's replacement is at hand.
In June 2011, it will be replaced by Standards for Attestation Engagements (SSAE) No. 16. The Auditing Standards Board of the American Institute of Certified Public Accountants (AICPA) finalized SSAE 16 in April with an effective start date of June 15, 2011. Its purpose is to update the U.S. service organization reporting standard so it mirrors and complies with the new international service organization reporting standard known as ISAE 3402.
Holly Russo, senior manager for accounting firm Schneider Downs & Co. summed up what's different in SSAE 16 in a website note to clients. Key differences are:
The requirement of a "management assertion" section within the report - Under SSAE 16, management of service organizations are required to provide a written assertion in the body of the report about the fair presentation of the description of the service organization's system, the suitability of the design of the controls and, for Type 2 reports, the operating effectiveness of the controls. If a service organization uses subservice organization(s) and elects to use the inclusive method, the subservice organization(s) assertion must also accompany the auditors' report. Management's assertion must also specify the criteria used for its assessment. These assertions are similar in nature to SAS 70 audit management representation letters. A separate management representation letter is also still required. For Type II reports, the service auditors' opinion on fair presentation of the system and suitability of design will be for the period covered by the report. Under SAS 70, this is currently as of a point in time. With the clock ticking, CSO decided to take the temperature of those who have experienced and/or conducted SAS 70 audits. The goal is to see how well it has prepared companies for the broader auditing gauntlet to come. The four perspectives that follow are in response to our inquiries in various LinkedIn forums.
Scott Crawford, research director at Enterprise Management Associates (EMA) and former information security officer for the International Data Centre of the Comprehensive Nuclear-Test-Ban Treaty Organization in Vienna, Austria.
A SAS 70 audit is conducted according to objectives defined by the service organization for itself. In other words, SAS 70 is not itself a framework of objectives, but rather allows the organization to choose its objectives -- which begs the question of "audited to what?"
Bill is Senior Editor of CSOOnline.com. Thanks to Tom Olzak for the heads-up on2/28/010
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
PRNewsWire announced Cloudcor Names AMD as Elite Gold Partner for Cloud Slam'11 Cloud Computing Conference in a 3/3/2011 press release:

MOUNTAIN VIEW, Calif., March 3, 2011 /PRNewswire/ -- Cloudcor® announces AMD (NYSE: AMD), a leading cloud microprocessor provider, as a Gold Partner for Cloud Slam'11® - the world's Premier hybrid format Cloud Computing conference – Scheduled from April 18 - 22, 2011.
At the conference, AMD will showcase leading-edge cloud enabling technologies at the Day 1 Live event in Mountain View, California. Also, AMD Engineering Fellow Keith Lowery will deliver a virtual headline Keynote address, sharing best practices encompassing next-generation process and compute capabilities that are shaping the future of the Cloud industry.
"We are delighted to collaborate with AMD, as one of our elite partners for our Cloud Slam'11 conference," Cloudcor Chairman – Khazret Sapenov said. "AMD is helping public and private cloud providers deliver the future innovations. We are sure their contribution to this year's event will enlighten our Day 1 delegates in Silicon Valley and global audiences tuning in virtually.
"Cloud Slam'11 is an important event for the technology industry as we continue to see more and more organizations – both in the public and private sectors – moving their businesses into the cloud," said Margaret Lewis, director of commercial software solutions, AMD. "In 2010, we launched the AMD Opteron™ 4000 Series platform, the first server platform specifically designed to meet the requirements of cloud, hyperscale data center, and SMB customers who need highly flexible and power-efficient systems. Because those needs persist today, we're thrilled to be part of Cloud Slam – an event that's raising the bar in bringing technology leaders together to ensure the future success and evolution of the cloud."
How To Register for Cloud Slam'11
Admission to the conference is priced to fit any budget, starting from $99 dollars to $299 dollars; and can be accessed via http://cloudslam.org/register
About CloudSlam'11®
CloudSlam'11 - Produced by Cloudcor, is the premier Cloud Computing event. CloudSlam'11 will take place April 18-22 2011 delivered in hybrid format; Day 1 to be held in Mountain View Silicon, CA, Days 2 - 5 Virtual - For more information, visit http://cloudslam.org. Stay connected via Twitter @CloudSlam – http://twitter.com/cloudslam
CONTACT: Khazret Sapenov, CTO, Cloudcor Inc Phone: +1 510-894-6207 E-mail: k.sapenov@cloudcor.com
Full disclosure: I have (free) VIP press credentials to Cloud Slam 2011.
Chris Evans (@chrisavis) announced TechNet Systems Management and MSDN Azure Event Registration now open! on 3/2/2011:
Good News Everyone!
You can now start registering for the upcoming TechNet and MSDN events that we will be delivering around the western United States.
TechNet Events Presents: System Center Essentials 2010 – Manage Everything with One Server!!
Summary: System Center Essentials combines the deployment and configuration management features of System Center Configuration Manager with the alerting and reporting features of System Center Operations Manager into a single server solution for managing small to medium size networks. In addition, the System Center Virtual Machine Manager2008 R2 Console is built in which means you have full manageability of all your physical and virtual assets in one easy to use console.
We will spend time looking at the different features that SCE2010 offers including demos on Reporting, Update Management, and working with Virtual Machines.
Windows Intune: Managing your assets from “the cloud”
Summary: “The Cloud” – Every day we here how applications and even traditional physical assets are moving to the cloud. But where are the cloud based tools to help IT Professionals manage all of the client machines that are still on premise? Introducing cloud based management with Windows Intune. Windows Intune lets the IT Pro Windows Update, hardware and software inventory, alerting, reporting and more without having to install any additional servers on site. Simply connect to a secure web portal and get insight into all of your clients.
In this session, we will discuss what differentiates Windows Intune from other Microsoft management products as well as some great benefits you get when using Windows Intune.
Date
Location
Time
Registration Link
4/11/2011
Denver
9:00 AM – 12:00 PM
4/12/2011
San Francisco
9:00 AM – 12:00 PM
4/15/2011
Tempe
9:00 AM – 12:00 PM
4/18/2011
Bellevue
9:00 AM – 12:00 PM
4/19/2011
Portland
9:00 AM – 12:00 PM
4/20/2011
Irvine
9:00 AM – 12:00 PM
4/21/2011
Los Angeles
9:00 AM – 12:00 PM
MSDN Events Presents: Understanding Azure
Summary: Cloud Development is one of the fastest growing trends in our industry. Don’t get left behind. In this event, Rob Bagby and Bruno Terkaly will provide an overview of developing with Windows Azure. They will cover both where and why you should consider taking advantage of the various Windows Azure’s services in your application, as well as providing you with a great head start on how to accomplish it. This half-day event will be split up into 3 sections. The first section will cover the benefits and nuances of hosting web applications and services in Windows Azure, as well as taking advantage of SQL Azure. The second section will cover the ins and outs of Windows Azure storage, while the third will illustrate the Windows Azure AppFabric.
Speakers: Bruno Terkaly & Rob Bagby
Date
Location
Time
Registration Link
4/11/2011
Denver
1:00 PM – 5:00 PM
4/12/2011
San Francisco
1:00 PM – 5:00 PM
4/15/2011
Tempe
1:00 PM – 5:00 PM
4/18/2011
Bellevue
1:00 PM – 5:00 PM
4/19/2011
Portland
1:00 PM – 5:00 PM
4/20/2011
Irvine
1:00 PM – 5:00 PM
4/21/2011
Los Angeles
1:00 PM – 5:00 PM


Mark Kromer (@mssqldude) reported that he and Joe D’Antoni (Philly SQL Server UG VP) will present at SQL Saturday Philadelphia on 3/5/2011 in Ft. Washington, PA:
- SQL Azure Data Migration Wizard
- Data Sync Framework
- Data-Tier Applications
Their presentation material is available for you to view here.
See the Mark Kromer (@mssqldude) explained Where SQL Server & SQL Azure Converge in a 3/3/2011 post in the SQL Azure Database and Reporting section above.
Forrester Research announced on 3/3/2011 its Forrester IT Forum to be held 5/25 to 5/27/2011 at The Palazzo hotel in Las Vegas, NV:
Forrester's IT Forum 2011 will bring together more than 1,000 IT professionals, Forrester analysts, global thought leaders, and solution providers to explore how to deliver business and technology alignment.
IN-DEPTH TRACK SESSIONS
Ten tracks of value-rich sessions allow you to tailor the Event experience to address your challenges and responsibilities. Tracks include content focusing most closely on these roles:
- Application Development & Delivery Professional: Faster Change.
- Business Process Professional: Transform Processes That Touch Your Customers.
- CIO: Leadership At The Intersection Of Business And Technology.
- Content & Collaboration Professional: Reinventing Your Workplace Experience.
- Enterprise Architecture Professional: Coupling Strategy, Information, and Technology.
- Infrastructure & Operations Professional: Reboot I&O To Support Empowered Employees.
- Security & Risk Professional: Security At The Intersection Of Business And Technology.
- Sourcing & Vendor Management Professional: Business And Technology's Intersection Brings New Vendors And Changing Relationships.
- Technology Marketing Professional: Empowering Customer Engagement In The Tech Industry.
- Vendor Strategy Professional: Growth And Disruption In The Tech Industry.
OTHER BENEFITS OF ATTENDING
- One-On-One Meetings with more than 80 Forrester analysts.
- Networking sessions with more than 1,000 attending executives.
- Solutions Showcase featuring leading solutions providers and emerging technologies.
- Practical advice includes short- and long-term recommendations as well as tools and frameworks that can be put immediately into action.
REGISTRATION INFORMATION
Early Bird Discount: Register by April 8 to receive our Early Bird rate, a $200 savings.
Notice that the word “cloud” doesn’t appear in Forrester’s promotional Web page. The main page for the event is here.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
•• Klint Finley (@klintron) reported Joyent Relaunches Node.js Service, Announces Cloud Analytics in a 3/3/2011 post to the ReadWriteCloud blog:
Cloud hosting provider Joyent re-launched its Node.js hosting service no.de this week. Joyent, the sponsor company of Node.js, is now offering versions 0.4.0 and 0.4.1 to no.de users. It also announced Cloud Analytics, a new service for finding problems with Node.js applications.
According to a blog post by Joyent's Dave Pacheco, Cloud Analytics is a " tool for real-time performance analysis of production systems and applications deployed in the cloud." So far it's only available for Node.js and most of the metrics require version 0.4.0.
Cloud Analytics can monitor:
- Node.js 0.4.x: HTTP server operations decomposed by method, URL, remote IP, remote port, and latency.
- Node.js 0.4.x: HTTP client operations decomposed by method, URL, server address, server port, and latency.
- Node.js 0.4.x: garbage collection operations decomposed by GC type and latency.
- Node.js 0.4.x: socket operations decomposed by type, remote host and port, size, and buffered data.
- Filesystem: logical filesystem operations decomposed by pid, application name, zone name (SmartMachine name), operation type, filesystem type, and latency.
- CPU: thread executions decomposed by pid, application name, zone name, runtime, and reason leaving CPU.
The Node.js hosting space continues to heat up. We've covered other entrant to the field including Nodejitsu, NodeSocket and Nodester. To understand the interest in Node.js, you might want to read our interview with Guillermo Rauch.
Also, Joyent's chief evangelist Tom Hughs-Croucher released a full preview of his book on Node.js today.

•• Joe Panettiere delivered a Memo From Cisco: MSPs Will Enjoy Early Cloud Computing Advantage in a 3/3/2011 post to the MSPMentor blog:
When it comes to cloud computing, successful managed services providers (MSPs) should have a leg up against traditional channel players. That’s the consensus among Cisco Systems executives who have helped to build the networking giant’s managed services channel program and cloud computing partner program. Moreover, roughly 100 MSPs that work with Cisco will instantly qualify to join the new Cisco Cloud Partner Program. Here’s the update, including an MSPmentor FastChat Video interview with Wendy Bahr, senior VP of global and transformational partnership at Cisco.
First, a little background: At Cisco Partner Summit this week in New Orleans, Senior VP and Channel Chief Edison Peres officially unveiled the Cisco Cloud Partner Program. It includes three areas of focus: Cloud Builder, Cloud Services Provider and Cloud Reseller. Aspiring cloud partners can pursue each or all of the designations, according to Surinder Brar, chief strategist for Cisco’s worldwide partner organization.
Brar reinforced the close relationship between Cisco’s managed services partner program and the cloud partner program. Indeed, Cisco’s Advanced and Master MSPs that have an existing cloud service will be grandfathered into the new Cloud Partner Program, Brar said. When the next anniversary of participation comes up, Cisco will audit the MSP to make sure the cloud services offerings remain in compliance. Using that approach, Brar estimates that roughly 100 MSPs will instantly qualify for the Cloud Partner Program.
Meanwhile, Cisco’s Bahr says MSPs could have an early advantage in cloud computing, thanks to MSP experience leveraging recurring revenue business models as well as the OPEX (operational expenses) vs. CAPEX (capital expenses) model. Bahr makes the point while providing some more background on the Cisco Cloud Partner Program in this FastChat Video:
Click here to view the embedded video.
That’s all for the moment. Catching a flight home soon. More analysis from Cisco Partner Summit 2011 on Friday.
• Ken Fromm (@frommww) [pictured below right] wrote Cloud + Machine-to-Machine = Disruption of Things: Part 1 as a guest author for the ReadWriteCloud blog:
Editor's note: This is the first in a two-part series on the advantages that cloud computing brings to the machine-to-machine space. It was first published as a white paper by Ken Fromm. Fromm is VP of Business Development at Appoxy, a Web app development company building high scale applications on Amazon Web Services. He can be found on Twitter at @frommww.
The use of cloud infrastructure and cloud services provides a low-cost means to create highly scalable applications. Even better, the cloud dramatically improves development speed and agility. Applications can be developed in much less time with much smaller teams. And as these benefits extend themselves in the machine-to-machine (M2M) space, companies creating M2M applications will see dramatic reduction in the cost of developing applications and provisioning services.
Articles on the Internet of Things (or Web of Things) are increasingly finding their way into mainstream news. Executives of large companies (such as the CEO of Sprint) and even government officials (such as the Chinese Premier) are speaking about the possibilities and opportunities of having ubiquitous sensors connected to the Internet.
The use of the cloud - in combination with the advent of low-cost sensors and high-availability M2M data transmission - will transform old industries and modify many business models.
Almost every major electronic device, vehicle, building component, and piece of equipment has the ability to become "smart" by connecting sensors to it. Most devices already do. The difference though is that moving data to the cloud and being able to process it in infinite combinations provides new capabilities in very low cost, transparent ways.
M2M Business Transformation
The case for what the Internet of Things might entail has been eloquently made here, here, and here. When devices and machines can send data to the cloud and have dashboards and interfaces on Web browsers, HDTV wallboards, mobile phones, and ipads, the impact becomes large.
This potential will affect almost every industry - just as the Internet, email, websites, e-commerce, and now Web 2.0 are touching every industry and every business process. The impact will be most noticeable at non-Web companies.
The change here will be dramatic - from where every device is by itself or controlled through a local device to where every device can be accessed anywhere (by authenticated users), where data streams can be "followed," and interfaces and dashboards improved on the fly to provide new views and device control. Does the concept of "following" a jet engine or a pneumatic thermostat have appeal to equipment makers and airlines or building owners? You bet it does.
Equipment, automobile, and device manufacturers need to beginning positioning themselves to gather realtime data on the performance of each product and use cloud processing and data storage to do it. Using this approach, they'll be able to rapidly improve their products, build direct connections with customers, and get ahead of customer and product issues. They'll also be able to offer service offerings and develop new revenues sources. Services will become a part of every product. Some as ways to improve customer support and customer connections. Others as revenue sources in and among themselves.
Want a quick diagnosis on your transmission? Go to CloudAutoDiagnostics.com and check in with your car's data feed. It will compare your data from the transmission sensors against others with similar transmissions. Yup, there's a issue but nothing serious. Want a 10% coupon for the service shop around the corner?
Below is a short list where the Internet of Things and M2M in the cloud will matter although it really could be just a single line that says anywhere where there is a sensor, an electronic device, or a machine.
- Personal Health and Fitness
- Medical Devices
- Automobiles
- Shipping, and Transportation
- Smart Grid and Smart Buildings
- Retail
- Architecture
- Agriculture
- Mining
- Natural Resource Management
The use of the cloud - in combination with the advent of low-cost sensors and high-availability M2M data transmission - will transform old industries and modify many business models. As is the case in each disruptive tech cycle, new companies will arise, existing market share will be threatened, and the separation between industries and channels will become blurred. Those in the M2M space who take advantage of what the cloud offers will not only be able to anticipate these changes but will lead the way into these new opportunities.
Key M2M Cloud Patterns
The goal of this paper is not to convince readers of what the future will like or even go through what new devices might look like. ReadWriteWeb and other tech publications will do a far better job there. The goal here is to list out the advantages that cloud computing brings to M2M applications.
Separation of Data Collection, Processing, Interface, and Control
The use of cloud computing means that data collection, processing, interface, and control can be separated and distributed to the most appropriate resource and device. Current M2M implementations combine data collection, processing, interface, and control. Either chips in sensor bodies or an onsite laptop or desktop PC tied within a local mesh network perform the data processing and determine the control logic.
Once data collection and processing moves to the cloud, however, most current limitations disappear. One of the more obvious ones is that data limits go away. Storing data in the cloud means that the data buffers within devices (whether its 500 or even 5,000 data points) no longer matter. Cloud storage is near limitless and so historic data can be saved for as long as its deemed valuable.
Not only is there access to super-fast processors, if there are server or storage bottlenecks, these can be addressed by on-demand launching of more servers or horizontally scaling storage. Using the cloud and dynamic languages and frameworks, the cost of ownership goes way down and the limitations go away.
The data can be used for showing readings, performance, or status for the last day, week, month, and even year. Individual nodes can be inspected as well as grouped together with similar data from other devices. Analysis can be performed quickly on specific groupings and filters - whether it's product line, region, demographic, or application use. The consumer Web understands the value of data and the many permutations that analysis can take. Once M2M data moves to the cloud, M2M companies begin to have the same realizations.
Applications are also not restricted by tiny processors, low-power consumption, and special purpose programming languages. Processing in the cloud brings best-of-breed programming capabilities. These include widely popular programming languages and frameworks, flexible data structures, and extensive algorithm libraries.
Not only is there access to super-fast processors, if there are server or storage bottlenecks, these can be addressed by on-demand launching of more servers or horizontally scaling storage. Using the cloud and dynamic languages and frameworks, the cost of ownership goes way down and the limitations go away. There's also a huge increase in the speed of product development.
Lastly, interfaces can move to Web browsers, wallboards, mobile phones and tablets, eliminating the need for either having screens a part of every devices or local computers permanently a part of installations. Medical devices no longer have to come with their own monitors. Separating the data input from the processing from the screen readout not only means lower costs (less components to the devices) but also easier upgrading of diagnostics and far better visualization capabilities.
An MRI or sonogram sent to the cloud, digitally refined using the latest algorithms distributed across multiple machines, and presented on an iPad or an HDTV screen is going to look a lot better and be more insightful than if displayed on existing monitors, no matter how new the device is. Separating the components and putting the data and processing in the cloud allows devices to keep getting smarter while not necessarily becoming more complex.
Data Virtualization
Data storage is one of the biggest advantages of using the cloud for M2M applications. The cloud not only offers simple and virtual ways to run applications, it also offers simple and virtual ways to store data. Cloud infrastructure companies are increasingly offering simple-to-use services to provision and maintain databases. These services even extend to offering databases as a service - meaning offering expandable data storage at the end of an IP address all the while masking or eliminating the management of servers, disks, backup and other operational issues. Examples include Amazon's SimpleDB and RDS service and Salesforce's Database.com offering.
Once transmitted to the cloud, data can be stored, retrieved and processed without having to address many of the underlying computing resources and processes traditionally associated with databases. For M2M applications, this type of virtualized data storage service is ideal.
Being able to seamlessly handle continuous streams of structured data from sensor sources is one of the more fundamental requirements for any distributed M2M application. As an example, Appoxy processes the data streams from network adapters from Plaster Networks, a fast-growing leader in the IP-over-power line space. Status inputs are sent by the adapters continuously to Plaster which runs its applications on one of the top cloud infrastructure providers. Appoxy processes these for use with the user dashboard running on the Web.
This console provides insights to users on the status and performance of the adapters and their networks (allowing users to see whether they are getting optimal performance out of their devices and networks). The data also provides valuable diagnostic information to Plaster, dramatically reducing support calls and improving device usage and customer satisfaction. The information is also invaluable for product development. Data on the performance of new products and features can be assessed in real-time, providing insights that would otherwise be unattainable from devices in field.
This type of smart device marks the beginning of the trend. It's a fair bet that all network devices will become smart and cloud-aware. Followed by all vehicles, manufacturing equipment and almost all machines of any substance.
The types of data stores available include SQL, NoSQL and block or file storage. SQL is useful for many application needs but the massive, parallel and continuous streams of M2M data lends itself well to the use of NoSQL approaches. These data stores operate by using key-value associations which allows for a flatter non-relational form of association. NoSQL databases can work without fixed table schemes, which makes it easy to store different data formats as well as evolve and expand formats over time.
NoSQL databases are also easy to scale horizontally. Data is distributed across many servers and disks. Indexing is performed by keys that route the queries to the datastore for the range that serves that key. This means different clusters respond to requests independently from other clusters, greatly increasing throughput and response times. Growth can be accommodated by quickly adding new servers, database instances and disks and changing the ranges of keys.
The NoSQL approach play well in M2M applications. Data for sensors or groups of sensors can be clustered together and accessed by an ever-expanding set of processes without adversely affecting performance. If a datastore gets too large or has too many requests, it can be split into smaller chunks or "shards." If there are many requests on the same data, it can be replicated into multiple data sets, with each process hitting different shards lessening the likelihood of request collisions.
Joe Panettieri reported Cisco Cloud VARs Embrace VCE, Vblock in a 3/3/2011 post to the TalkinCloud blog:
VCE — the joint VBlock venture between VMware, Cisco and EMC — is attracting influential cloud and data center partners attending Cisco Partner Summit. Moreover, VCE is preparing a formal channel partner program for solutions providers, according to four VARs at the summit.
The four VARs participated in a data center panel this morning. Initially, the VARs say, VCE was met with some skepticism. Some partners worried VCE would eliminate the value-add related to integrating VMware, Cisco and EMC solutions for customers. But under CEO Michael Capellas‘s leadership, VCE is evolving to help VARs shorten sales cycles for Vblock solutions.
Vblock, as you may recall, integrates virtualization, networking and storage in the data center. When Vblock first surfaced, partners say they had some trouble coordinating potential customer wins across Cisco, EMC and VMware. But VCE is addressing those concerns by providing a single point of contact for channel partners. Multiple sources say VCE is developing a formalized partner program that will provide VARs with dedicated channel account managers.
Now, some insights from each of the four VARs.
Cameron Bulanda, VP of specialty sales, Insight: “When VCE was first announced we were a little concerned. But when you look at the fact that you get a single point of contact, clearly VCE is a strategic offering. It’s a Ragu solution — it’s all in there. It’s vetted.”
William Padfield, CEO, Datacraft Asia: The company has consolidated three internal data centers down to one, swapping out Dell and Hewlett-Packard x86 servers for Cisco and VBlock solutions, saving power and energy. “We were the first company in Asia to promote a VCE on a road show. The best-in-class approach sounded interesting.” But, says Padfield, there was a danger: VCE could have turned into a three-headed beast, with poor coordination across VMware, Cisco and EMC. Instead, VCE is becoming useful because it truly is emerging as a dedicated business with its own employees, notes Padfield.
Adrian Foxall, Networking Business Line Director, ComputaCenter: “It’s not really about cannibalizing old server business. Instead it’s about the growth. about solution selling. There’s a consistency of message now from VCE. And we heartily embrace it. Having Capellas run it give us a degree of comfort because we knew him at Compaq.”
Mont Phelps, CEO, MWN Corp.: VCE represents “an integrated solution tested and backed by a single organization. They’re really young. We’re feeling good about their commitment. It’s better for the customer and better for us. If you’re going to drive a Vblock opportunity it simplifies how we interact” with VMware, Cisco and EMC solutions.
Also, notes Phelps, the VCE employees come from VMware, Cisco and EMC. But sometime in the near future it sounds like they are turning in their old employment badges — replaced by VCE employment badges.
Early in the Game
Of course, the VCE effort and Vblock solution are fairly young. Within weeks Hewlett-Packard is set to host its own partner summit — the HP Americas Partner Summit — where data center solutions will surely occupy portions of the spotlight. TalkinCloud will be sure to follow up with HP perspectives at that time. …
Read More About This Topic
Robert Duffner posted Thought Leaders in the Cloud: Talking with Erica Brescia, CEO of BitRock to the Windows Azure Team blog on 3/3/2011:
Erica Brescia [pictured at right] is the CEO of BitRock, a provider of multiplatform software deployment automation. Through the BitNami.org portal, it has simplified native, virtual, and cloud installations of popular open source software. Since joining the company in early 2005, Erica has been instrumental in earning the business of leading commercial open source vendors.
Prior to joining BitRock, Erica managed several sales teams for T-Mobile and served as a liaison to the mobile enthusiast community. In the past, she held positions as an analyst at Oakwood Worldwide and as a consultant with Chekiang First Bank in Hong Kong, where she helped plan the launch of its Internet banking service. Erica has a Bachelor of Science degree in Business Administration from the University of Southern California.
In this interview, we discuss:
- Growing interest in the cloud for production deployments
- Portability of virtual appliances to and in the cloud
- Projects that would have never succeeded were it not for the cloud
- The location of the datacenter matters for cloud hosted applications
- The ability of the cloud to provide dynamic scale up, not just scale out
Robert Duffner: Erica, take a moment and introduce yourself, BitRock, and what you're doing around cloud computing.
Erica Brescia: I'm the CEO of BitRock, which has been in business for seven years now, providing packaging services. We offer a cross-platform installation tool, and we also build the installers, virtual machine images, and cloud templates for a lot of the leading open source companies, such as Alfresco, SugarCRM, MySQL, Jaspersoft, GroundWork, and other companies.
A few years ago, we started a site called bitnami.org that provides a lot of open source packages in easy-to-deploy packages in the form of installers, VMs, and cloud templates. We're preparing to launch a new offering called BitNami Cloud Hosting, which makes it easy to deploy the packages we've prepared for apps like Drupal, DokuWiki, WordPress, Liferay, SugarCRM, and manage them on top of cloud.
Currently we support Amazon EC2, and we plan to add support for other clouds down the road based on customer demand.
Robert: Through BitNami, you support deployment across physical, virtual, and cloud. Obviously, cloud is at the forefront of the news, but what do you see as core scenarios for each of these deployment types?
Erica: For production deployments, we still see most people using the native installers. We have seen a huge increase in use of the virtual appliances within the last year or so, but mostly just for testing purposes. People want to try a new application, so they download the VM, which keeps it entirely separate from their system and makes it easy to test several different applications side by side.
We actually do that with the native installers as well, but VMs offer even more of a container-like approach.
Certainly with BitNami Cloud Hosting, we're seeing a lot more interest in using the cloud for production deployments. BitNami Cloud Hosting makes it much easier to do things like schedule automated backups, restore a server if it goes down, and get visibility into the server itself to make sure that the web server databases and everything are still running. You can also easily make clones and update things in the cloud.
So with the new offering, we're starting to see more production use of the cloud, but I think it's still very early. Most of the stories that we hear around cloud computing right now involve very specific applications, especially those that are resource-intensive only for certain amounts of time, like batch processing. Or sometimes a social networking game that has to scale up massively and then scale back down when people move on to the next big thing.
And what we see as the next wave are smaller companies that just want to move away from traditional hosting and get a little bit more control and flexibility over their servers. They are just starting to dip their toes into the cloud now.
We built BitNami Cloud Hosting to facilitate that and lower the barrier to adoption a little bit - many of the cloud platforms are still a little complex and have somewhat high technical barriers to adoption.
Robert: The virtual appliance obviously predates the cloud, and it seems like cloud provides it another distribution channel. How has that affected BitNami and BitRock?
Erica: We don't really even think of them as virtual appliances in the cloud anymore, even though that's what they are. [laughs]
The fact that we already had virtual appliances built for BitNami made it a very simple and streamlined process for us to move the cloud. We already have all the processes and technology in place to build completely self-contained images, whether it's a virtual appliance, an AMI, or a package for any other platform. So that transition has been pretty seamless for us.
In fact, we ported the entire BitNami library of 30 or so application stacks to Amazon, and we had all of the proofs of concept done in under a week because of the technology we already had developed for creating virtual appliances.
Robert: There's an obvious intersection between BitNami and infrastructure as a service, but do you see any future intersection between BitNami and platform as a service?
Erica: Right now, we see platform as a service as being mostly for people who want to develop custom applications and who are comfortable building them on top of a platform that may be difficult for them to move the application away from in the future. At this point, BitNami Cloud Hosting is really geared toward people who want to develop on top of or customize existing applications.. For example, people might be customizing a Drupal deployment or putting SugarCRM and Alfresco on a server and making some customizations there, as opposed to building applications from the ground up. They can also build on top of our Ruby on Rails or LAMP Stacks, which gives them more portability than they would get with a PaaS-based solution, but we're not seeing too much of that yet, since it is still early in the product's lifecycle.
We do see value in platform as a service for some use cases, but from a lot of our customers' perspectives, it gives them a level of lock in that they're not entirely comfortable with. This may change over time, but at this point, people still like the idea of having complete control over their environments and their servers, and being able to switch if necessary.
Robert: That's interesting, in light of virtual appliances for popular open source projects like Joomla and WordPress. Can you talk about BitNami for organizations that are looking to build new applications architected for the cloud?
Erica: We do provide LAMP and Ruby on Rails (and our Ruby on Rails stack is incredibly popular), but again, we're not really focused on people trying to build custom applications for our platform. We provide a base platform, and they can certainly build on top of our stack and then use our resources to monitor it and deploy new servers and facilitate updates and things like that.
Still, it's not built up to the same level as Heroku or similar solution that are very specific to one language. The benefit of using BitNami is that you get a lot more flexibility.
As I said before, if you build on top of platform as a service, you really architect your application for that specific platform. This offers a lot of benefits in the sense that it takes away a lot of the overhead of managing a deployment and handling updates, but many people aren't quite comfortable with that type of solution yet. With BitNami, they'd have to do more heavy lifting to use our platform, but would get more flexibility and control in terms of how they build their application.
Robert: An article was published a few weeks ago titled, "Cloud Computing: A Shift from IT Luxury to Business Necessity." The author says 83 percent of cloud adopters agree that cloud solutions have helped them respond more quickly to the needs of their business. Are you seeing projects that would have trouble being successful without the cloud?
Erica: Absolutely. In fact, I was just on the phone the other day with someone who told me it takes six to nine months for them to get access to new servers, and they needed to try out some new applications. They make open source applications accessible for blind people, and they need to stay up to date with the latest applications.
Drupal 7 just came out, and they couldn't get access to a server to deploy it and give this application a try, but the cloud let them just stick it on a credit card. IT management doesn't like to hear this, but it's incredibly easy, even for non-technical people, to use something like BitNami Cloud Hosting to deploy an application.
I was on the phone with somebody else who works for a major oil company who needed to get Redmine set up and said it was going to take nine months, and he needed it for his project now, and the cloud enabled him to do that. While putting technology into the hands of people who wouldn't have access to it otherwise may be a little frustrating for IT, it certainly enables people to get things done more quickly.
Robert: There's the notion that one advantage of cloud is that location doesn't matter. Do you view it that way, or do you think the cloud will actually give the customers more control over the location of their data and processing?
Erica: I think that location definitely matters, at least in terms of large chunks of geographic area. For example, in the beta BitNami Cloud Hosting, we've only supported the U.S. East zone on Amazon. And virtually everyone who's come to us from Europe or from Australia has asked to keep their data within their geographic area. In Australia's case, Singapore is the closest they have available.
It certainly is important for a lot of data protection laws here and in Europe, to have some control over where in the world your server's running, and there are also issues with latency.
I heard a very cool use case of a company that built a solution based on Amazon, and they were moving their servers around the globe based on the time of day to get the absolute best performance out of their application for their users.
On the other hand, I don't think more specific geographical control is generally important for people. As long as they know that it's within one half of the U.S. or within Europe, for example, people are comfortable.
Robert: Another advantage of the cloud, which of course Microsoft likes to talk about, is the idea of elasticity. Is elasticity also important with appliances, or is it more about portability?
Erica: We think of elasticity for our users in terms of being able to take a small server and make it very large when you need to and then make it small again, as opposed to being able to spin up a thousand servers very quickly, which is what most people refer to as elasticity.
You see a lot of use cases around things like web applications that may take off, and having the flexibility to scale very quickly is important for them, as well as for jobs that only may need to run once a month, like batch processing jobs that need a lot of servers at once. That's also relevant for testing across a huge pool of servers.
Those are not use cases that we're really focused on. We think that the next wave of cloud adoption is going to be by smaller companies that need to run five or 10 servers with various business applications. For them, scaling doesn't involve hundreds of servers; it just involves going from a small to an extra large server and back, or something similar to that.
Robert: When people think about cloud applications, they often think about software as a service. How are you seeing that evolve?
Erica: With traditional software as a service, you think of a big multi-tenant application like SalesForce. With BitNami Cloud Hosting and those platforms that make it easier to manage deployments on the cloud, you can offer more of a single-tenant approach to software as a service. That is very interesting for companies that have to do more customization or integration than you can do easily with a traditional software-as-a-service product.
A lot of companies that are looking at BitNami Cloud Hosting may have a traditional software-as-a-service offering, but they have a subset of customers for whom that's not appropriate. They may have requirements either around not using a multi-tenant application or around being able to integrate with other applications and have them all run together.
The cloud offers a cool opportunity for doing that and getting a lot of the benefits of software as a service, without losing some of the flexibility and control you get with managing your own servers. I don't hear that use case talked about much, but I think it is really interesting, and we are seeing a lot of interest in it.
Robert: Erica, thanks for your time.
Erica: Thank you.
<Return to section navigation list>

















0 comments:
Post a Comment