Windows Azure and Cloud Computing Posts for 3/9/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructur and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
Kevin Cox and Michael Thomassy published Linked Servers to SQL Azure to the Microsoft SQL Server Customer Advisory Team blog on 3/8/2011:
Overview
Connecting directly to a SQL Azure database from a reporting tool (like Microsoft Excel and PowerPivot, or SQL Server Reporting Services) from your desktop or local data center is possible using a data source that looks like:
[YourAzureServr@database.windows.net].[YourDatabase].[YourSchema].[YourTable]
This is useful if you have a single database on SQL Azure that you need to query. What if you have reached the 50GB limit that is currently the top size of a SQL Azure database? The solution is to split your database into many databases containing the same schema. See this paper on database sharding with SQL Azure.
Expecting the users to always define multiple data sources to connect to multiple databases is cumbersome and may not perform well. For example, a PowerPivot user would have to open a separate link to every SQL Azure database individually. This paper describes a solution using a local SQL Server that can ease the access to all these databases and will usually give better performance. The solution is called Partitioned Views and is implemented using Linked Servers. Since customers don’t usually like to expose their databases to the internet, we are proposing a separate server that contains no actual data and only contains the views necessary for applications to get an internet link to SQL Azure databases. This is not the only solution because you can implement stored procedures using OPENROWSET or OPENQUERY for solutions that need more logic.
A read-only solution is the easiest to implement. If modifications must be made to the SQL Azure tables via the Distributed Partitioned Views, you must read the restrictions in SQL Server Books Online. It also helps to read about how to implement a partitioned view. Using the check constraints on the tables as shown in the examples in this link is essential if you want the optimizer to only touch the right tables when you use the constrained columns in a WHERE clause in your queries.
How does this work?
This concept relies on the linked server feature of SQL Server. Since ADO.NET, ODBC, PHP and JDBC are the only providers currently supported by SQL Azure, ODBC data source names (DSN) are required.
Setting up an ODBC DSN
Run odbcad32.exe to setup a system DSN using SQL Server Native Client. Or go into Control Panel\System and Security\Administrative Tools and click on Data Sources (ODBC). Each database you create on SQL Azure needs a separate DSN and a separate linked server definition. Use TCP, not named pipes because you will be communicating to the SQL Azure servers through the internet.
Scale the creation of ODBC connections to multiple databases by modifying & importing a .REG file into the registry (regedit.exe) patterned after this sample:
[HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC.INI]
[HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC.INI\Azure_ODBC1]
"Driver"="C:\\Windows\\system32\\sqlncli10.dll"
"Server"="YourAzureServer"
"LastUser"="YourLogin"
"Database"="YourDatabaseName"
[HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC.INI\ODBC Data Sources]
"Azure_ODBC1"="SQL Server Native Client 10.0"
SQL Server Linked Server
An ODBC DSN and an associated Linked Server need to be created for each Database that will be queried. Here are two sample T-SQL commands that will create a linked server and associated login:
EXEC master.dbo.sp_addlinkedserver @server = N'Azure_ODBC1',@srvproduct=N'Any', @provider=N'MSDASQL', @datasrc=N'Azure_ODBC1'
GO
/* For security reasons the linked server remote logins password is changed to ######## */
EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'Azure_ODBC1',
@useself=N'False',@locallogin=NULL,@rmtuser=N'yourlogin@YourAzureServer',@rmtpassword=’#####'
GO
SQL Azure Limits
By default, SQL Azure allows 149 databases per server. To exceed this threshold, either 1) create databases in other servers, or 2) contact the Azure business desk and request that your limit be increased from the default threshold. Each database can be a maximum of 50GB, giving a default total 7.45TB of storage per Server. Remember to factor in index sizes when planning your total data needs. The 50GB limit has to cover both data and index space. Log space is considered separate from the 50GB limit.
Distributed Partitioned View
In order to make all your SQL Azure databases appear as one data source, you need to create a distributed partitioned view (DPV) in your local, on-premise SQL Server database. This database must be at least Enterprise edition because DPVs are not supported in Standard Edition or less.
This example statement creates the view with two SQL Azure databases on a local SQL Server:
CREATE VIEW dbo.dpv_Test AS SELECT * FROM Azure_ODBC0.test0.dbo.fact UNION ALL SELECT * FROM Azure_ODBC1.test1.dbo.fact;This is an example of a simple select using a four-part name. More complex statements are allowed, such as adding joins and where clauses. Joins should use four part names in all table references to keep the join work on the same machine. The worst performance occurs when cross server joins are implemented.
The simple example above will return all rows from these tables in all databases. This may be your intention if, for example, you want to bring all the data into PowerPivot for aggregations and pivoting. Be mindful of the cost for bandwidth of returning all the rows. To estimate cost, go to the main Windows Azure pricing site. The appendix provides a query that can be used at any time to get the current billing estimate. Be mindful that the billing values reflect current pricing which you are likely to be modified as Azure matures.
Notes: It is not the view that is partitioned in a distributed partitioned view, it is the data the view points to that is partitioned. The data does not have to be partitioned, this view can point to one database and can contain one select. The tables being referenced in the view can exist in both SQL Azure and local databases as long as the correct permissions are granted for the appropriate users.
Use Linked Server to SQL Azure
There is a simple method for running a query against a single table directly on a SQL Azure server from your application (without using the DPV). As an example, if you open a query window on your local SQL Server Management Studio, while connected to a local instance, you can follow the sample:
SELECT * FROM [YourAzureServer@database.windows.net].[YourDatabase].[YourSchema].[YourTable]To query all the tables on your Azure server from a local server, simply use the view created above:
SELECT * FROM dpv_TestWrite to a table through the view:
INSERT INTO dpv_Test VALUES (1, ‘Test’, 1)The first time the view is invoked, either through a select or insert/update/delete command, it will cache the table constraints on the local server. This gives the view some information about where the insert should be directed and it will only touch that database. And if the constraints are used in the WHERE clause of a query, the optimizer will do partition elimination and only touch the databases it needs to touch.
Note: Beware that distributed partitioned views have several restrictions that are well documented in B Online. (This link is one of many to read, use it as a launch point for the other related pages.)
Linked Server Properties
Linked Servers are only available in SQL Server Enterprise Edition or higher.
If your view spans multiple Azure data centers, you need to be aware of one more thing before you get started. On your local server you need to set the Lazy Schema Validation option to TRUE so that the query is not sent to every server for every command. The schema check will defer to run time and may fail if the result set formats are incompatible. :
EXEC sp_serveroption 'LocalServerName', 'lazy schema validation', true GO EXEC sp_serveroption ‘RemoteServerName’, ‘lazy schema validation’, true GOAnother server level setting that can help performance is to ensure that the collation settings are compatible on all servers. This is an optimization option and is not required. What can happen if the collations are not compatible is the filters supplied by the WHERE clauses do not get applied on the remote server. Instead, all data is returned by the query and the WHERE clause gets applied on the local machine.
Downsides and potential pitfalls
This solution is not perfect and at times it can be a struggle. Most of the difficulties have been mentioned in this blog, but the two main ones are summarized here for convenience. The blog contains the solutions/workarounds to these problems so it is worth reading.
1. Optimizer sometimes ignores your WHERE clause and sends the query to every server, every database. The solution is to put constraints on your SQL Azure tables so the optimizer can determine which shard to touch and which to eliminate.
2. Non-remotable query where all data comes back to the local server without being filtered by the remote database.
What if one database is not available?
If the view needs to touch all the databases and one is not available, the query will fail. If the view has determined that it can do partition elimination and does not need the unavailable database, then the query will succeed. The only exception to this is the first time a DPV is executed after a restart of your local SQL Server, it needs to touch every destination database to get the constraints and store them locally (in memory). Remember to turn on lazy schema validation so that every query after the first one does not get sent to each database just to check the schema.
Leveraging Constraints for Partition Elimination
How does SQL Server know which databases to touch? To test this scenario, create the different databases on SQL Azure so that your main table contains data from each month of a certain year. Perhaps create the databases called AppDB2010_01 and AppDB2010_02 to make it easier for you to remember what the database contains. These names are meaningless and have no bearing on what you actually store in the database. Create a table, perhaps call it FACT and make sure it has a DATE or DATETIME (or any other date oriented data type). The key to making this solution work efficiently is to create a constraint on this DATE field so that SQL Server knows it only contains data within a certain range. In this example, it will only contain data for a certain month of a certain year; i.e. January 2010. This constraint is what gets cached on your local server after the first use of the DPV so that SQL Server knows which tables to touch during a query. Now test to confirm using a query such as:
SELECT * FROM dpv_Test WHERE datefield = ‘2010-01-15’.How do you know a query did not touch a certain database? Since SQL Profiler does not work in SQL Azure, the only way to know which queries ran on a certain server is to use certain DPVs to see what plans have been generated. The following query will return a list of recently generated statistics and plans for a server:
SELECT * FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) ORDER BY last_execution_time DESC;Summary
It is possible to use a local SQL Server to simplify access to a multiple SQL Azure database. The performance may be better than individual links from a front end tool when partition elimination is used.
Appendix: SQL Azure Billing Summary
Thanks to Lubor Kollar for creating these queries.
SELECT * FROM sys.Database_Usage SELECT * FROM sys.Bandwidth_Usage SELECT SKU, SUM ( CASE WHEN USAGE.SKU = 'Web' THEN (Quantity * 9.99/31) WHEN USAGE.SKU = 'Business' THEN (Quantity * 99.99/31) END ) AS CostInDollars FROM sys.Database_Usage USAGE WHERE datepart(yy, TIME) = datepart(yy, GetUTCDate()) AND datepart(mm, TIME) = datepart(mm, GetUTCDate()) GROUP BY SKU SELECT USAGE.Time_Period, USAGE.Direction, CASE WHEN USAGE.Direction = 'Egress' THEN 0.15 * USAGE.BandwidthInKB/(1024*1024) WHEN USAGE.DIRECTION = 'Ingress' THEN 0.10 * USAGE.BandwidthInKB/(1024*1024) END AS CostInDollars FROM ( SELECT Time_Period, Direction, SUM(Quantity) AS BandwidthInKB FROM sys.Bandwidth_Usage WHERE datepart(yy, TIME) = datepart(yy, GetUTCDate()) AND datepart(mm, TIME) = datepart(mm, GetUTCDate()) AND class = 'External' GROUP BY Time_Period, Direction ) AS USAGE
Credits:
- Authors: Kevin Cox & Michael Thomassy
- Contributors: Lubor Kollar
- Technical Reviewers: Shaun Tinline-Jones, Chuck Heinzelman, Steve Howard, Kun Cheng, Jimmy May
The Unbreakable Cloud blog described ScaleBase – A Database Load Balancer for Cloud in a 3/8/2011 post:
ScaleBase offers a cloud based service which can give better availability and scalability for SQL databases whether they are Oracle, MySQL, IBM DB2 or Microsoft SQL Server databases. It is an extremely sophisticated load balancer that provides your databases with as much cloud elasticity as you need by enabling significantly more concurrent user connections and SQL commands for any type of SQL database application! According to ScaleBase, the ScaleBase Database Load Balancer™ enables you to use your own databases on your own servers, and gives you total control over your database machines. Almost all database types are supported. Whether you use MySQL, Oracle Database, IBM DB2 or Microsoft SQLServer, ScaleBase can help you achieve the scalability you require.
ScaleBase guarantees the ACID compliance which are typically with SQL based RDBMS. There is no need for any application rewrites, redesign or changes. All you have to do is run a five-step wizard and then direct your database connections to the ScaleBase Database Load Balancer™ IP address! ScaleBase can be combined with NoSQL databases to give the tremendous performance and scalability for cloud based databases. To explore more on ScaleBase, please visit www.scalebase.com.
<Return to section navigation list>
MarketPlace DataMarket and OData
Howard Dierking asked How Can I Make This (OData SSIS Component) More Testable? on 3/9/2011:
I’ve been going through a refactoring exercise recently with my SSIS data source component for OData (or WCF data services to be more specific). The primary goals of the refactoring were:
- Move as much logic as possible out of the SSIS adapter code, which I look at as the equivalent of presentation code, and move it into my domain.
- Simplify the domain (ideally improving maintainability and future extensibility) by doing a better job of focusing each class around a single responsibility (or getting closer than I was)
- Improve testability – both unit level and end-to-end
I’m pretty happy with how the code is turning out (though I would welcome your general thoughts and feedback) with one major exception.
The crux of the problem is the SSIS object model. For a bit more context, here’s the part of my domain that makes an OData response (typically an Atom feed) available to SSIS.
The problem is in the SetPipelineValue method on the Result class. The purpose of the Result class is to make a row of data available to an SSIS pipeline buffer. Because SSIS has its own data types, and sets values on the buffer through its own get and set functions, I created this method to encapsulate the logic necessary to get from Atom result to .NET type to SSIS type to getting set on a buffer. The code looks like the following:
publicclassResult : IResult
{
privatestaticIDictionary<DataType, Action<PipelineBuffer,int,object>> typeAssignmentFcnMap =newDictionary<DataType, Action<PipelineBuffer,int,object>> {
{ DataType.DT_NTEXT, (buffer, index, val) => buffer.AddBlobData(index, Encoding.Unicode.GetBytes(val.ToString())) },
{ DataType.DT_WSTR, (buffer, index, val) => buffer.SetString(index, (string)val) },
{ DataType.DT_R8, (buffer, index, val) => buffer.SetDouble(index, (double)val) },
{ DataType.DT_I4, (buffer, index, val) => buffer.SetInt32(index, (Int32)val) },
{ DataType.DT_BOOL, (buffer, index, val) => buffer.SetBoolean(index, (bool) val) },
{ DataType.DT_GUID, (buffer, index, val) => buffer.SetGuid(index,(Guid)val) },
{ DataType.DT_DBTIMESTAMP, (buffer, index, val) => buffer.SetDateTime(index, (DateTime)val) },
{ DataType.DT_I2, (buffer, index, val) => buffer.SetInt16(index, (Int16)val)},
{ DataType.DT_I8, (buffer, index, val) => buffer.SetInt64(index, (Int64)val)},
{ DataType.DT_DECIMAL, (buffer, index, val) => buffer.SetDecimal(index, (decimal)val)}
};
publicvoidSetPipelineValue(stringpropertyName, PipelineBuffer ssisBuffer,intssisPositionInBuffer, DataType ssisDataType) {
var index = GetPropertyIndex(propertyName);
var fieldValue = _values[index];
typeAssignmentFcnMap[ssisDataType](ssisBuffer, ssisPositionInBuffer, fieldValue);
}
}The problem comes when I’m trying to write tests to verify that the buffer was set with the correct values of the correct SSIS data type. As you can see, the buffer is represented by the PipelineBuffer class – this is a concrete class with no interface or virtual members to make it mockable. As such, I can’t send in a mock buffer and then verify that the appropriate values are set (or at the very least, verify that the appropriate methods were called).
At this point, the best solution that I’ve got is to wrap the PipelineBuffer in a class (and the the SetXx methods) and then mock that class in testing. I’m ok with the additional code here because it will enable me to run end to end tests (at the moment, I can’t inspect the final values to be set on the buffer) – but wanted to see whether anybody had a different approach for this problem.

<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
See The Windows Azure Team reported NOW AVAILABLE: Updated Windows Azure SDK and Windows Azure Management Portal v1.4 in a 3/9/2010 2:30 PM PST post in the Live Windows Azure Apps, APIs, Tools and Test Harnesses section below for updates to the Window Azure Connect, RDP and CDN features.
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
The Windows Azure Team reported NOW AVAILABLE: Updated Windows Azure SDK and Windows Azure Management Portal v1.4 in a 3/9/2010 2:30 PM PST post:
We're pleased to announce that new versions of the Windows Azure Software Development Kit (SDK) and Windows Azure Management Portal are now available to developers. The 1.4 version of the Windows Azure SDK includes new features for both Windows Azure Connect and the Windows Azure Content Delivery Network (CDN). It also includes enhancements to improve the stability and robustness of Remote Desktop to Windows Azure Roles, as well as other bug fixes.
The new features we are enabling today include:
- Windows Azure Connect:
- Multiple administrator support on the Admin UI.
- An updated Client UI with improved status notifications and diagnostic capabilities.
- The ability to install the Windows Azure Connect client on non-English versions of Windows.
- Windows Azure CDN:
- Windows Azure CDN for Hosted Services: Developers can now use the Windows Azure Web and VM roles as "origin" for objects to be delivered at scale via the Windows Azure CDN. Static content in a website can be automatically edge-cached at locations throughout the United States, Europe, Asia, Australia and South America to provide maximum bandwidth and lower latency delivery of website content to users.
- Serve secure content from the Windows Azure CDN: A new checkbox option in the Windows Azure management portal enables delivery of secure content via HTTPS through any existing Windows Azure CDN account.
In addition, the new version of the Windows Azure Management Portal has been enhanced to make the UI more responsive.
To learn more about and download the new Windows Azure SDK please click here. To start using the new Windows Azure Management Portal, click here.
Bruce Kyle reported Visual Studio SP1, TFS Project Server Integration, Load Test Pack Available Today in a 3/9/2011 post to the US ISV Evangelism blog:
The new service pack to Visual Studio will be available today to MSDN subscribers from their subscriber downloads. If you're not an MSDN subscriber, you can get the update on Thursday, March 10.
New features improve several areas, including IntelliTrace, unit testing, and Silverlight profiling.
The announcements were made by S Somasegar, Senior Vice President, Developer Division, in his blog post Visual Studio 2010 enhancements.
TFS-Project Server Integration Feature Pack
Also available for Visual Studio Ultimate with MSDN subscribers via Download Center today is the TFS-Project Server Integration Feature Pack. Integration between Project Server and Team Foundation Server enables teams to work more effectively together using Visual Studio, Project, and SharePoint and coordinates development between teams using disparate methodologies, such as waterfall and agile, via common data and metrics.
Visual Studio Load Test Feature Pack
Also introduced today Visual Studio 2010 Load Test Feature Pack is available to all Visual Studio 2010 Ultimate with MSDN subscribers. With this feature pack, you can simulate as many virtual users as you need without having to purchase additional Visual Studio Load Test Virtual User Pack 2010 licenses.
Visual Studio LightSwitch Beta 2
Visual Studio LightSwitchoffers a simple way to develop line of business applications for the desktop and cloud. LightSwitch reaches Beta 2.
There is no indication in the New Downloads | Visual Studio 2010 category’s Downloads list that Visual Studio LightSwitch Beta 2 is available as of 3/8/2010. Only the Beta 1 version (8/18/2010) is listed. (I have a Visual Studio 2010 Ultimate with MSDN subscription.)
Maarten Balliauw (@maartenballiauw) recommended that you Put your cloud on a diet (or: Windows Azure and scaling: why?) on 3/9/2011:
One of the key ideas behind cloud computing is the concept of scaling.Talking to customers and cloud enthusiasts, many people seem to be unaware about the fact that there is great opportunity in scaling, even for small applications. In this blog post series, I will talk about the following:
- Windows Azure and scaling: how? (.NET)
- Windows Azure and scaling: how? (PHP)
Windows Azure and scaling: why?
Both for small and large project, scaling your application’s capacity to meet the actual demand can be valuable. Imagine a local web application that is being used mostly during office hours, with peak demand from 6 PM to 8 PM. It consists of 4 web role instances running all day, which is enough to cope with peaks. Also, the number can be increased over time to meet actual demand of the web application.
Let’s do a cost breakdown of that… In short, one small instance on Windows Azure will cost $ 0.12 per hour per instance, totaling $ 11.52 per day for this setup. If you do this estimation for a month, costs will be somewhere around $ 345.14 for the compute demand of this application, not counting storage and bandwidth.
Flashback one paragraph: peak load is during office hours and from 6 PM to 8 PM. Interesting, as this may mean the application can be running on less instances for the hours off-peak. Even more interesting: there are no office hours in the weekend (unless, uhmm, Bill Lumbergh needs you to come and work). Here’s a closer estimate of the required number of instances, per hour of day:
Interesting! If these values are extrapolated to a month, costs will be somewhere around $ 219.31 for the compute demand of this application, not counting storage and bandwidth. That’s more than a $ 100 difference with the “always 4 instances” situation. Or over $ 1200 yearly. Imagine having a really big project and doing this: that’s a lot of beer difference :-)
Of course, this is a rough estimation, but it clearly shows there is value in scaling up and down at the right moments. The example I gave is based on a local application with clear demand differences during each day and could be scaled based on the time of day. And that’s what I will be demonstrating in the next 2 blog posts of this series: how to scale up and down automatically using the current tooling available for Windows Azure. Stay tuned!
PS: The Excel sheet I used to create the breakdown can be found here: Scaling.xlsx (11.80 kb)


Andy Cross (@andybareweb) described a Workaround: WCF Trace logging in Windows Azure SDK 1.3 in a 3/9/2011 post:
This post shows a workaround to the known issue in Windows Azure SDK 1.3 that prevents the capture of WCF svclog traces by Windows Azure Diagnostics. The solution is an evolution of the work by RobinDotNet’s on correcting IIS logging.
This manifests itself in a malfunctioning Windows Azure Diagnostics setup – log files may be created but they are not transferred to Blob Storage, meaning they become difficult to get hold of, especially in situations where multiple instances are in use.
The workaround is achieved by adding a Startup task to the WCF Role that you wish to collect service level tracing for. This Startup task then sets ACL permissions on the folder that the logs will be written to, and creates a null (zero-byte) file with the exact filename that the WCF log is going to assume. This explicitly creates the file and prevents errors that occur when the file is not created – namely that it is created by a different process to WAD-Agent and this process sets permissions that exclude the agent.
The Startup task should have a command line that executes a powershell script. This allows much freedom on implementation, as powershell is a very rich scripting language. The Startup line should read like:
powershell -ExecutionPolicy Unrestricted .\FixDiagFolderAccess.ps1>>C:\output.txtThe main work then, is done by the file FixDiagFolderAccess.ps1. I will run through that script now – it is included in full with this post: http://blog.bareweb.eu/2011/03/implementing-and-debugging-a-wcf-service-in-windows-azure/
echo "Thank you RobinDotNet!" echo "Output from Powershell script to set permissions for IIS logging." Add-PSSnapin Microsoft.WindowsAzure.ServiceRuntime # wait until the azure assembly is available while (!$?) { echo "Failed, retrying after five seconds..." sleep 5 Add-PSSnapin Microsoft.WindowsAzure.ServiceRuntime } echo "Added WA snapin."This section of code sets up the Microsoft.WindowsAzure.ServiceRuntime cmdlets, a set of useful scripts that allow us access to running instances and information regarding them. We will use this to get paths of “LocalResource” – the writable file locations inside an Azure instance that will be used to store the svclog files.
# get the ######## WcfRole.svclog folder and the root path for it $localresource = Get-LocalResource "WcfRole.svclog" $folder = $localresource.RootPath echo "WcfRole.svclog path" $folderThis gets us the path to the local resource, for later use in creating placeholders and setting permissions.
# set the acl's on the FailedReqLogFiles folder to allow full access by anybody. # can do a little trial & error to change this if you want to. $acl = Get-Acl $folder $rule1 = New-Object System.Security.AccessControl.FileSystemAccessRule( "Administrators", "FullControl", "ContainerInherit, ObjectInherit", "None", "Allow") $rule2 = New-Object System.Security.AccessControl.FileSystemAccessRule( "Everyone", "FullControl", "ContainerInherit, ObjectInherit", "None", "Allow") $acl.AddAccessRule($rule1) $acl.AddAccessRule($rule2) Set-Acl $folder $aclAt this point we have just set the ACL for the folder that SVCLogs will go to. However this isn’t yet enough and we must also create a zero-byte file at the location that we will be saving our svclogs to – otherwise the permissions will be overwritten by the writing process.
It is important that the file is a zero-byte file, as otherwise the svclog file will have an invalid start to the file – and will not work in the svc viewer application.
## lets create the svclog too! $null | Set-Content $folder\WcfRole.svclogThat’s it – done!
You can find the source code and example in the following blog; http://blog.bareweb.eu/2011/03/implementing-and-debugging-a-wcf-service-in-windows-azure/
One further word of thanks to RobinDotNet – I wouldn’t have been able to complete this without the inspiration from the blog post on IIS Logs.
Andy Cross (@andybareweb) explained Implementing and Debugging a WCF Service in Windows Azure in a 3/8/2011 post:
To begin with, we must create a new Windows Azure Project using the Windows Azure SDK v1.3, and add to it a new WCF Role. This Role will be created in Visual Studio with some very useful basic settings and services. It is important to note that this isn’t the only way of creating a WCF Service, you can use a Web Role or a Worker Role (or even a VM role!). However, if we create a Service using the WCF Role template, it is a little easier. It is interesting to note that the approach taken using the WCF Role project type is the same as you would have for a Web Role and different to how you would create it for a Worker Role. The difference is that a WCF Role and a Web Role would both host a WCF service inside IIS, whereas with a Worker Role you would almost certainly use Self Hosting in a Windows Application. For more information on this, see here: http://msdn.microsoft.com/en-us/library/ms730158.aspx
Back to the task at hand, create a WCF Service Web Role for our project:
This creates a Web Application (the same as a Web Role would) but also adds in some basic code files.
Basic WCFRole structure
These are the fundamental pieces of a very basic WCF Service, and I will now go into a little detail as to what they are each for. Skip this section if you are an old hand at WCF!
- AzureLocalStorageTraceListener.cs – a derivation of XmlWriterTraceListener that collects logging information written with the System.Diagnostics.Trace class and outputs it as Xml. This is a XmlWriterTraceListener with a slight specialization – it always writes its Xml based Trace information to an area in LocalStorage; the writeable area of disk that Windows Azure allows a Role to write to. It is specialized in this way so that the file path can be written to but also so that the Windows Azure Diagnostics framework knows where to pick up the files from; the Windows Azure Diagnostics framework has to move them off the local instance of a role instance so that they are available commonly across for all Instances.
- IService1.cs – this class contains an interface and a class. Both are interesting as they are decorated with attributes over their definitions – the interface gains the attribute [ServiceContract] – meaning that the interface defines a service contract in the application; it can be used for WCF and both client and server agree to the methods that are available on the service provided the methods within are also similarly decorated as [OperationContract]. The class gains the attribute [DataContract] and its members [DataMember] – providing a way for client and server to agree on the details of any messages passed between client and server.
- Service1.svc (and expand it to see Service1.svc.cs) – this class implements the interface declared as IService1, meaning it is the actual logic that will execute when you connect to a WCF Service that uses the Service1.svc implementation of IService1. Note that in this case, the path to Service1.svc will always provide this funcationality, but in advanced WCF configuration you may replace the .svc file and use a purely configuration based approach for better flexibility.
- Web.config – the configuration for the web application; of particular note is that the AzureLocalStorageTraceListener is disabled by default and the system.serviceModel node which defines that we may use httpGet (a basic web request) to determine service metadata. This latter setting is useful since we can use a browser to explore the service in development.
- WebRole.cs – a RoleEntryPoint derived class that controls how the WCF Role is started by Windows Azure. The OnStart method configures the basics of how to transfer the Windows Azure Diagnostics information to blob storage – it will do so every 1 minute from the same location that the AzureLocalStorageTraceListener is configured to use. Note that the local storage configured is defined as :
<LocalStorage name=”WcfRole.svclog” sizeInMB=”1000″ cleanOnRoleRecycle=”false” />Making a few changes
Welcome back if you skipped the last summary of files.
We’re now going to make some changes to the basic project so that we can explore how to extend the solution, how to break it and how to find out why it was broken.
Firstly, I’ll add a new method to the Service so that we can see how to begin extending the Service. Go to the IService1 interface, and add the following code:
[OperationContract] float Divide(float dividend, float divisor);Now we have a new method on the interface that we have to implement. Go to Service1.svc.cs, and add the following code:
public float Divide(float dividend, float divisor) { if (divisor == 0F) { throw new DivideByZeroException(); } return dividend / divisor; }Now we have a new method and the ability to make things go awry!
Run it in Visual Studio (or debug) and you’ll see the following.
WCF Service Working
This reassures us that the WCF service is running, but we cannot invoke it using the browser. Instead, we will knock up a simple Worker Role client that can communicate with the WCF Service.
Start by adding a new Project to the Solution, right clicking on the Project:
Add WCF Client Project
This Worker Role then needs to be able to create a client to the WCF Service we previously created. To do this, add a Service Reference by right clicking on References:
Add Service Reference
This then allows us to browser for an existing service or one within the solution. For now we will stay using the internal Solution WCF service.
Discover Local Service
Find the local service
try { for (int i = 100; i >= 0; i--) { Trace.WriteLine(service1.Divide(100F, (float)i)); } } catch (Exception ex) { Trace.TraceError(ex.ToString()); }In practise it can often be easier to bind to a live Azure instance – this is because when binding locally your solution can get the wrong port number (the local IIS port rather than the one Windows Azure Emulator is running on – this Windows Azure Emulator port is also liable to change if you don’t shut down your debugging sessions carefully). As an example, the following shows an incorrect port number when discovering a local solution:
Erroneous config
To correct this, replace the port number with a manually configured port number for the InputEndpoint of your WCFRole. You can either configure this in the ServiceDefinition.csdef file or in by right clicking on the WCF Role and going to its properties page as I have here:
Set endpoint
Note that you must then change the <client><endpoint> address attribute so that its port matches the above. Any time that the Compute Emulator does not close properly you will need to reset these to make sure they match up, otherwise you will get an exception which states there is no endpoint listening at the port specified in the WCF Client configuration.
Our WorkerRole needs some code in order to successfully call the WCF Service. We will simply iterate from 100 down to 0 calling Divide on 100F, eventually getting to 0 where our code already intentionally throws a DivideByZeroException.
try { for (int i = 100; i >= 0; i—) { Trace.WriteLine(service1.Divide(100F, (float)i)); } } catch (Exception ex) { Trace.TraceError(ex.ToString()); }The output on the client side of the WCF communication receives a WCF exception, but does not contain the details.
snip... 10 11.11111 12.5 14.28571 16.66667 20 25 33.33333 50 100 [WaWorkerHost.exe] System.ServiceModel.FaultException: The server was unable to process the request due to an internal error. For more information about the error, either turn on IncludeExceptionDetailInFaults (either from ServiceBehaviorAttribute or from the <serviceDebug> configuration behavior) on the server in order to send the exception information back to the client, or turn on tracing as per the Microsoft .NET Framework 3.0 SDK documentation and inspect the server trace logs. Server stack trace: at System.ServiceModel.Channels.ServiceChannel.ThrowIfFaultUnderstood(Message reply, MessageFault fault, String action, MessageVersion version, FaultConverter faultConverter) at System.ServiceModel.Channels.ServiceChannel.HandleReply(ProxyOperationRuntime operation, ProxyRpc& rpc) at System.ServiceModel.Channels.ServiceChannel.Call(String action, Boolean oneway, ProxyOperationRuntime operation, Object[] ins, Object[] outs, TimeSpan timeout) at System.ServiceModel.Channels.ServiceChannel.Call(String action, Boolean oneway, ProxyOperationRuntime operation, Object[] ins, Object[] outs) at System.ServiceModel.Channels.ServiceChannelProxy.InvokeService(IMethodCallMessage methodCall, ProxyOperationRuntime operation) at System.ServiceModel.Channels.ServiceChannelProxy.Invoke(IMessage message) Exception rethrown at [0]: at System.Runtime.Remoting.Proxies.RealProxy.HandleReturnMessage(IMessage reqMsg, IMessage retMsg) at System.Runtime.Remoting.Proxies.RealProxy.PrivateInvoke(MessageData& msgData, Int32 type) at WcfClientRole.AzureWcfBasic.IService1.Divide(Single dividend, Single divisor) at WcfClientRole.AzureWcfBasic.Service1Client.Divide(Single dividend, Single divisor) in c:\dev\Blog\WCFBasic\WcfClientRole\Service References\AzureWcfBasic\Reference.cs:line 119 at WcfClientRole.WorkerRole.Run() in c:\dev\Blog\WCFBasic\WcfClientRole\WorkerRole.cs:line 31We could in theory turn on exception message details, but this isn’t regarded as a secure approach. In order to then debug this information then, we need to look at the earlier configured Windows Azure Diagnostics.
Enabling Diagnostics
Much of the work with diagnostics has been done for us already. However we must remember that we have to add in the sharedListener for AzureLocalStorage. This is as simple as swapping which system.diagnostics node is commented out in Web.Config of the WCF Web Role.
Additionally, you must add in the following line to WebRole.cs:
DiagnosticMonitor.Start(CloudStorageAccount.DevelopmentStorageAccount, diagnosticConfig);I did find there was a problem transferring the logs to BlobStorage using SDK1.3. There are two solutions for this problem, which relates to permissions available on the files created as the SVCLog. Firstly, you can mimic the approach of RobinDotNet (http://robindotnet.wordpress.com/2011/02/16/azure-toolssdk-1-3-and-iis-logging/ – I will post on exactly how to do this later) or you may be able to remove the <Sites> node for ServiceDefinition.csdef entirely, meaning it will no longer run as full IIS. I went with the first option, and will post a quick summary of how I managed to get it to work later as a separate post. For now, if you have problems with this SDK 1.3 known issue, you can (using the Development Emulator) access the files directly by browsing to their file path or use Remote Desktop to access the logs in the Cloud.
If you are intrigued to use the WCF tracelogs immediately, you can open the attached project and see how it works for yourself – look at the FixDiagFolderAccess.ps1 powershell script. It creates some access control lists for the folder, and then importantly creates a NULL or completely empty placeholder for the file that we will eventually be overwriting.
This will give you the SVCLog definition, that contains all the details of bindings and exceptions. In here you will be able to find the DivideByZeroException and begin diagnosing the problem.
The file firstly appears on the hard disk:
WCF Log on disk
After a moment (note the times in this blog are not indicative!) the Windows Azure Diagnostics system transfers the file to blob storage into the WAD-TraceFiles container.
The WCF Log is transferred to the Blob Container
Following this, the log can be downloaded an inspected for errors. In this case we can scroll down until we find the details regarding Divide by zero, and we can find a red highlighted row, showing an exception occurred. Looking into more detail we can retrieve the actual stack trace of the error from the server:
Trace info including highlighted line with exception
Exception detail being shown
Source code for this blog is here: WCFBasic












<Return to section navigation list>
Visual Studio LightSwitch
Doug Seven published a Visual Studio LightSwitch Feature Matrix on 3/8/2011:
On his blog yesterday, Soma (Sr. VP of Developer Division at Microsoft), announced that Visual Studio LightSwitch Beta 2 will be coming soon. I can tell you, we are really excited about LightSwitch, and apparently you are too (you’ve downloaded over 100,000 copies of Beta 1).
One question that comes up a lot is, what can LightSwitch do versus what can Visual Studio Professional do? What’s the difference? Well, the difference is pretty clear.
Visual Studio LightSwitch is a specialist tool for building line-of-business applications for the desktop and cloud, while Visual Studio Professional is a generalist tool for building anything you can imaging for Microsoft platforms.
Take a look at this feature matrix and you’ll see what I mean (we’ll get a formal version of this up on http://www.microsoft.com/lightswitch soon).
Visual Studio LightSwitch
Visual Studio Professional
LightSwitch Runtime
Yes
Yes1
Visual Studio Project System
Yes
Yes
IntelliSense
Yes
Yes
Team Explorer (Team Foundation Server integration)
-2, 3
Yes3
LIGHTSWITCH APPLICATION DEVELOPMENT
Predefined Screen Templates
Yes
Yes1
Application Skinning and Theming
Yes
Yes1
Data Entity Designer
Yes
Yes1
Business-oriented Data Types (e.g. EmailAddress, PhoneNumber, etc.)
Yes
Yes1
Automatic Data Input Validation
Yes
Yes1
Windows Azure Deployment
Yes
Yes1
SQL Azure Support
Yes
Yes
LANGUAGES, EDITORS & COMPILERS
Visual Basic
Yes
Yes
Visual C#
Yes
Yes
Visual C++
-
Yes
Visual F#
-
Yes
HTML/JavaScript
-
Yes
Silverlight/XAML Editor
-
Yes
PROJECT TYPES
LightSwitch Application
Yes
Yes1
ASP.NET
-
Yes
ASP.NET AJAX
-
Yes
ASP.NET MVC
-
Yes
Console Application
-
Yes
Database Projects
-
Yes
Office Applications & Add-ins
-
Yes
Setup Projects
-
Yes
SharePoint Applications & WebParts
-
Yes
Test Projects
-
Yes
Visual Studio Add-ins
-
Yes
Windows Forms
-
Yes
Windows Phone
-
Yes
WCF
-
Yes
WPF
-
Yes
XNA Games
-
Yes
1 Only available for LightSwitch applications. Requires Visual Studio LightSwitch and Visual Studio Professional to both be installed.
2 Team Explorer will integrate with LightSwitch but must be installed separately.
3 Requires a Team Foundation Server Client Access License (CAL).I hope that helps!
Doug is Director of Product Management, Visual Studio.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
Robert Minnear asserted End-user requirements must take precedence in the decision to deploy applications in the cloud in a preface to his Latency: The Achilles Heel of Cloud Computing post of 3/9/2011:
Today, cloud computing is proliferating. For IT and corporate business units alike, there is strong interest in deploying applications in a cloud environment for its increased business flexibility and cost savings. However, common cloud computing solutions can introduce unexpected costs associated with the broader issue of latency from the cloud edge to the end user.
IT and individual business units tend to focus on the aspect of performance within the cloud environment when deploying applications to the cloud, rather than the question of performance and reliability of the overall application and content delivery chain from the cloud environment to the end user.
This is a serious miscalculation for two reasons. First, the cloud computing provider's choice of network carrier shouldn't penalize the cloud user when network performance is degraded. Second, end users will abandon applications and websites based on the smallest performance delays or downtime, jeopardizing the perceived value of the cloud initiative. For these reasons, it is critical that the discussion around cloud latency shift away from IT or business unit-defined acceptable levels of latency to end-user behavior judgments as to what level of latency is acceptable.
Using a systemic approach, CIOs and business unit executives can effectively gratify their end users when deploying their business-critical and revenue-centric applications in the cloud.
Slow or Unresponsive Application and Website Performance Matter to End Users
When it comes to end-user requirements for application and website performance, every millisecond counts. Numerous studies show that end users are unforgiving - they expect results quickly, or will click away, which has a direct impact on customer satisfaction, top line revenues and the bottom line. According to Equation Research, in a study commissioned by Gomez, a sub-par web experience results in lost revenue opportunity, a lower customer perception of your company, and can boost your competitor's bottom line.
- Seventy-eight percent of site visitors have gone to a competitor's site due to sub-par performance during peak times.
- Eighty-eight percent are less likely to return to a site after a poor user experience.
- Forty-seven percent left with a less positive perception of the company.
Aberdeen Group provides a similar snapshot of demanding user requirements for website performance in a recent study on the performance of web applications.
- One second delay reduces customer conversions by 7%.
- One second delay decreases customer satisfaction by 16%.
- One second delay decreases page views by 11%.
Latency across the Internet is typically the culprit behind slow or unresponsive applications and websites, and represents a major issue for cloud computing. Geography and network distance play a key role in determining latency - the further the cloud environment is from your internal network systems or the end user, the greater latency across the network.
A Narrow Focus on Cloud Infrastructure
IT and corporate business units have been focused on the performance and reliability of their applications deployed in the cloud infrastructure, and not beyond the cloud edge to their end user. Cloud computing's value proposition is generally not one of improved application performance, but increased flexibility and cost savings. This is clear from two recent studies compiled by KPMG and Aberdeen Group.KPMG surveyed current cloud adopters to identify realized benefits of cloud and what respondents would like to see improved. Neither "performance" nor "availability" was cited as realized benefits. Instead, both were identified as areas that should be improved. In the Aberdeen Group study on cloud infrastructure performance, only 5 percent of respondents indicated their applications experienced a performance improvement. Thus, IT and corporate business units want to see stronger performance and reliability within the cloud environment. Unfortunately, this focus on performance and availability within the cloud environment ignores the aspect of the "network" path by which latency and jitter affect the performance of application content delivery to end users.
Both aspects, the cloud computing platform and the network or "Internet," have the potential to adversely impact the end-user experience. The combined latency or degraded performance can manifest itself as a simple echo annoyance on a VoIP call, or can spell disaster for a Massive Multiplayer Online Game (MMOG) provider with thousands of users playing performance-sensitive games at any given time. When this happens, high latency within the cloud and/or across the network will cost your organization money.
Cloud infrastructure performance and the "network" must be given equal consideration. They are two sides of the same coin, and the ultimate success of any application deployment in the cloud relies on both aspects performing reliably at a level acceptable to the end-user.
Is Your Carrier the Weak Link in Application Performance in the Cloud?
It has long been standard practice for organizations seeking a reliable and consistent connection to the Internet to use multiple carriers for that connection. This "redundancy" served as insurance so that when one carrier's network failed, the other carrier would take on the organization's traffic and keep applications up and running. The use of multiple carriers to maintain a connection to the Internet speaks to the importance of the applications that are now placed there.The problem with this approach is that no one or combination of two (or three or four) carriers ensures an optimal connection to the Internet. Redundancy may keep the connections up, but they are not addressing a core need - which is optimal routing of traffic to reduce latency, jitter and packet loss. Indeed, brown outs or less-than-optimal network performance may cumulatively prove more costly to an organization over time than actual downtime during the same period.
Manually selecting a combination of carriers that somehow comprise a more efficient routing solution for web-based applications is a "hit or miss" proposition. Finding the optimal path across carriers is a fluctuating objective, if not incomprehensible to determine and manage due to standard networking practices like Border Gateway Protocol (BGP) and carrier SLAs.
Latency from the Cloud to Your End User
Both cloud customers and cloud providers must consider end-user behavior as it relates to application and website performance and downtime. To gather perspective, IT and corporate business units should apply the following formula:CL1 + NL2 = TSL
Where CL equals intra-cloud latency, NL equals network or Internet latency, and TSL equals total system or systemic latency.
It's important to recognize that network latency will be significantly greater than cloud-based latency as represented here:
L2 >> L1
Ultimately, TSL is the statistic that the application or website should be measured against in terms of end-user requirements as represented in the extension of the formula:
TSL < End-User Requirements
Is Your Cloud Provider's SLA Strong Enough for What Cloud Computing Requires?
Regarding downtime, it can be indicated by traditional percentage measures of availability over a given 12-month period. Though cloud providers will usually indicate their level of guaranteed uptime in their SLAs, it is still critical to measure uptime using independent tools. Understanding SLA definitions of downtime is important to identify gaps in what the IT organization's definition may be versus that of the cloud provider.
The critical questions that cloud customers should ask their providers when considering downtime include the following:
- What level of availability is your cloud service designed to provide? This question may be answered in terms of "durability" or a similar measure that communicates well over 5-9s of uptime.
- What does your SLA guarantee to my business? Don't be surprised to see the number of "9s" drop off significantly here.
- Does the cloud service provider publish metrics for actual uptime obtained over the past 12 months?
In the end, it's not what the provider says it will do, or what the provider guarantees it will do, but what the provider actually has proven to deliver. Lost revenue will very likely far exceed any credits for downtime you may receive. As a result, it's much more critical to have a highly available cohesive cloud computing and network solution to minimize potential loss in the first place.
Of course, this aspect of the SLA doesn't address the issue of latency or delay in terms of measurable performance metrics and guarantees.
Today, SLAs across cloud providers fail to align with market realities that dictate the need for a highly responsive application or website experience. Often, the cloud provider will guarantee levels of uptime but won't guarantee any latency threshold. Some cloud vendors will go so far as to guarantee a threshold for latency, but this is calculated only for intra-cloud operations and completely ignore the aspect of application content delivery across the Internet which, by its nature, is harder to control.
Promises for performance, especially when they relate to such a complex system involving the cloud infrastructure and the network, must be backed by SLAs that mean something.
Take a Systemic Approach to Minimize Latency
End-user requirements must take precedence in the decision to deploy applications in the cloud. For any application deployment that is crucial to the organization's revenue model or business operations, the objective for IT and individual business units should be to optimize application processing and content delivery into a cohesive, optimized end-user experience. To achieve this, the organization must address latency across the entire cloud infrastructure and network solution with the end user in mind.The total latency should not exceed any estimated acceptable performance requirement from the end-user's perspective. Anything above acceptable performance levels raises the risk and likelihood that end users will penalize an application or website by abandonment.
Thus, enterprise organizations seeking a cloud service provider should do their due diligence to ensure their service is built on the following components:
- Reliable data center architecture with multiple layers of redundant infrastructure to remove single points of failure
- Capabilities that eliminate dependencies on any single carrier network
- High-performance cloud architecture
- Dynamic, intelligent traffic routing mechanism to reduce latency and improve reliability of IP traffic
- Measurement mechanism for performance across the entire "cloud to end-user" system
- Robust SLA with performance and availability guarantees, as well as proactive outage detection and crediting
Given the level of trust that customers must have to place applications and information in the cloud environment, cloud vendors must offer higher-level SLA and support models to address cloud performance/reliability and customer-related inquiries. Some key aspects of next-generation SLAs to look for include:
- Guarantees for performance and reliability from the cloud infrastructure across the network to the end user
- Transparent capture of how much downtime has occurred across the system
- Transparent capture of actual network performance compared to SLA latency guarantees
- Proactive, automated crediting mechanism when downtime SLA guarantees are exceeded.
- Robust customer support mechanisms that scale with the level of customer services commitment
Cloud Computing's Promise
Cloud computing represents a compelling solution for IT and individual businesses to increase flexibility and cut costs typically associated with the deployment of new platforms. However, the decision to move to the cloud must take into consideration the end user. Today, organizations have a growing number of choices as to which cloud computing and IP solutions they employ - selecting a cloud solution that minimizes latency across the Internet can yield benefits for IT and individual business units while addressing end-user requirements for application performance.Looking out into the not-too-distant future, cloud computing will no longer be considered innovative, but simply the way we deliver applications. The term "cloud" won't be used anymore - it won't be necessary.
This vision will be fully realized if we deploy a regimen across the Internet that serves to minimize latency where possible and accelerate IP traffic to a much greater level.



Robert (Bobby) Minnear is vice president of engineering at Internap.
Nati Shalom (@natishalom) posted Productivity vs. Control tradeoffs in PaaS to the High Scalability blog on 3/9/2011:
Gartner published recently an interesting paper: Productivity vs. Control: Cloud Application Platforms Must Split to Win
. (The paper requires registration.)
The paper does a pretty good job covering the evolution that is taking place in the PaaS market toward a more open platform and compares between the two main categories: aPaaS (essentially a PaaS running as a service) and CEAP (Cloud Enabled Application Platform) which is the *P* out of PaaS that gives you the platform to build your own PaaS in private or public cloud.
While I was reading through the paper I felt that something continued to bother me with this definition, even though I tend to agree with the overall observation. If I follow the logic of this paper than I have to give away productivity to gain control, hmm… that’s a hard choice.
The issue seem to be with the way we define productivity. Read the full details here.
Lori MacVittie (@lmacvittie) asserted The “what” is a dynamic data center infrastructure. Cloud is “how” to get there in a preface to her Cloud is the How not the What post of 3/9/2011 to F5’s DevCentral blog:
Admist the chatter and sound bites on Twitter coming from Cloud Connect this week are some interesting side conversations revolving around architecture and how cloud may or may not change the premises upon which those architectures are based. Architecture is, in the technology demesne, the “fundamental underlying design of computer hardware, software, or both.”
A data center architecture is the design of a data center, the underlying fundamental way in which compute, network and storage resources are provisioned and ultimately delivered to support the goal of delivering applications. Of supporting the business. But note that “cloud” is not the goal, it’s not what we’re hoping to achieve, it’s how we’re hoping to achieve.
CLOUD is ABOUT HOW we MANAGE RESOURCES
Naysayers of private/enterprise cloud, who firmly stand in the “it’s merely a transitory architecture”, believe that the economy of scale and thus the efficiency and cost savings associated with cloud can only be realized by the complete adoption of a public cloud deployment model. From the perspective of raw costs of resources – whether compute, network or storage – that view may be right. But this view, too, supports the underlying premise that public cloud is how you achieve economy of scale. The goal is not cloud, it’s efficiency. The same is true of a private/enterprise cloud – the goal is efficiency through aggregation and automation and ultimately liberation of the data center. The goal is a dynamic infrastructure designed to combat the rising costs and increasing gap between IT’s budget and its need to manage core data center resources.
Cloud is the means by which resources can be dynamically leveraged and scaled. It is part of a larger architecture – a data center design, one which has a goal of delivering applications, not clouds. The what is a data center architecture that is efficient, manageable, and less complex than its traditional predecessors. The what is processes that make it possible to achieve an economy of scale not just in growth of physical resources, but in virtual resources and human capital as well. The what is a dynamic infrastructure. How may be in part or in full a cloud computing framework that integrates private and public cloud computing resources as well as traditional (legacy) frameworks.
Cloud is about how resources are provisioned and managed, about how those resources are used to deliver the applications and services necessary to support IT as a Service. It’s not what we’re trying to do, it’s how we’re trying to do it.
Respondents were asked to rate their motivations to use cloud providers on a scale of one to five and the results ranked as follows: Elasticity 4.0; deployment speed 3.75; lower costs, 3.5; and a wide array of services offered by cloud providers, 3.25.
-- Survey Shows Businesses Interested, But Still Conflicted, About The Cloud, Network Computing Magazine (March 2011)
Notice the “motivations” – not one is “build a cloud.” Organizations are looking at cloud as a means to achieve operational goals – elasticity, rapid provisioning, and lower costs. Organizations aren’t trying to build a cloud for cloud’s sake; they’re trying to build an underlying framework and architect a data center that can adapt and support the increasing dynamism inherent in applications, in users, in clients, in business requirements. The entire ecosystem of the data center is changing, becoming more volatile day by day, pushed into supporting new and often unvetted technology due to consumerism of technology and a need to reduce costs across the entire data center – up and down the stack and across every business application.
Cloud is how we can address the challenges that naturally occur from such rapid changes, but it’s not what we’re trying to do.
We’ll debate private cloud and dig into some obstacles (and solutions) enterprises are experiencing in moving forward with private cloud computing in the Private Cloud Track at CloudConnect 2011. That’s today (March 9) – don’t miss it!

Kamesh Pemmaraju asserted “A new research study finds software execs are optimistic about their cloud business forecasts and the adoption of cloud apps and platforms, but identifies a need to work harder to meet customer expectations” in a preface to his Cloud Leaders Face a Changing Tide Opinion piece of 3/9/2011 for the SandHill blog:
What do senior software executives predict about cloud computing for the next three to five years? One thing is clear: the software industry is in the middle of a major inflection point not seen since the client-server days. The year 2011 is already proving to be a decisive one for cloud software and services vendors.
Like a tidal force's change in direction that affects the entire Earth, there are indicators that the world of software is shifting to the cloud. The new market reality is that—no matter their size—software vendors can no longer simply push customers to their products; rather, vendors' products need to be where their customers want to be—in the cloud.
As evident in the following excerpt, the findings of Sand Hill Group's new research study, "Leaders in the Cloud 2011," clearly show that the software leaders of the future are already making themselves very attractive in the cloud.
Executives Optimistic about Cloud Future
During January-February 2011, Sand Hill Group conducted a research study to gauge software vendors' cloud outlook for the coming year and beyond. The study utilized an online survey to gather executives' impressions on direction of the cloud market, their cloud strategies, and customer readiness for adoption. A total of 100 software CEOs and senior executives responded to the 24-question survey and provided insight about their cloud revenues today and next year, customer attitudes and readiness, and which products and services are gaining traction. The 2011 study updates the ground-breaking findings of the "Leaders in the Cloud" study from 2010.On the heels of a major recession and with robust indications that the economy has turned around, software executives surveyed expressed optimism about the growth of the cloud market.
A majority (85 percent) of the 100 software executive respondents said their company already has a cloud product/service offerings in the market. And 40 percent of the companies have had their cloud product or service in the market for more than 24 months.
Forty-three percent of the executives forecasted that their revenues will be dominated (81 - 100 percent) by cloud-based services and products in five years (see chart).

Doug Rehnstrom asserted Government Should Consider Windows Azure as Part of its “Cloud-First” Strategy in a 3/4/2011 post to the Learning Tree blog (missed when published):
Recently, the United States Chief Information Officer, Vivek Kundra, published a 25 point plan to reform the government’s IT management.
Point number 3 states that the government should shift to a “Cloud-First” policy. When describing that point, Mr. Kundra tells of a private company that managed to scale up from 50 to 4,000 virtual servers in three days, to support a massive increase in demand. He contrasts that with the government’s “Cash-For-Clunkers” program, which was overwhelmed by unexpected demand.
You might be interested in the entire report at this URL, http://www.cio.gov/documents/25-Point-Implementation-Plan-to-Reform-Federal%20IT.pdf.
Microsoft Windows Azure is perfect for this type of scenario. If your program is less successful than you hoped, you can scale down. If you’re lucky enough to be the next Twitter, you can scale up as much as you need to. Tune your application up or down to handle spikes in demand. You only pay for the resources that you use, and Microsoft handles the entire infrastructure for you. Scaling up or down is simply a matter of specifying the number of virtual machines required, in a configuration file.
Visual Studio and the .NET Framework make programming Windows Azure applications easy. Visual Studio automates much of the deployment of an Azure application. Web sites can be created using ASP.NET. Web services are easy with Windows Communication Foundation. There’s seamless integration of data using either Azure storage or SQL Azure. Plus, you can leverage the existing knowledge of your .NET developers.
If you prefer Java or PHP, Azure supports those as well. Most any program that will run on Windows will also run on Azure, as under the hood it’s just Windows Server 2008.
In point 3.2 of that report, it states that each agency must find 3 “must move” services to migrate to the cloud. If you’re a government IT worker or contractor trying to help meet that goal, you might be interested in learning more about Windows Azure. Come to Learning Tree course 2602, Windows Azure Platform Introduction: Programming Cloud-Based Applications.
There are many other cloud computing platforms and services besides Azure. These include Amazon EC2, Google App Engine and many others. To learn more about the broad range of cloud services and choices available, you might like to come to Learning Tree Course 1200: Cloud Computing Technologies.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Ben Kerschberg (@benkerschberg) published Cloud Computing Down to Earth: A Primer for Corporate Counsel to Law.com’s Corporate Counsel site on 2/28/2011 (missed when posted):
Cloud computing is the most exciting evolution in information technology today.
Defined by the National Institute of Standards and Technology ("NIST") as "a model for enabling convenient, on demand network access to a shared pool of configurable resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider intervention," cloud computing represents a fundamental change in the way that corporations conduct business today, a shift that is well underway.
Also See: FULL Expert Archive
Gartner Group predicts that spending on cloud computing applications worldwide will increase at an annual rate of 20 percent for years to come, thereby growing to a market of over $150 billion by 2013 — a staggering figure.
Corporate counsel must understand cloud computing.
They must master relevant law and protect corporate interests contractually. They must learn the language of the cloud so as to be prepared to advise senior management as to the myriad legal issues related thereto. And they must understand how certain cloud-driven business imperatives may affect their relationships with C-suite colleagues such as the chief information officer and others who support such strategic initiatives.
These topics and others were recently the subject of a highly informative webinar hosted by the International Technology Law Association and moderated by Jon Neiditz, a senior partner at Nelson Mullins Riley & Scarborough and the expert founder of the firm's Information Management Practice.
This article examines these issues in the following manner. First, it provides a primer that both explains the technology at the core of the cloud and why counsel must understand it in order to inform their work inside the corporation. Second, it outlines the legal issues raised by the cloud.
And third, it prescribes specific guidelines that counsel should — and indeed often must — implement both internally and vis-à-vis third parties such as outside counsel and cloud service providers in order to protect the corporation.
Understanding the Cloud
Cloud computing promises the ability to use Web-based applications on demand at any time, anywhere in the world ("location independent") and independently of any specific hardware (e.g., your work desktop or laptop). If you have Internet access, you can use the same basic cloud applications such as Google Apps for business, see infra — and thus access your work and data — as easily at corporate headquarters in Palo Alto as in an Internet café in Istanbul. For the corporation, cloud computing has many benefits, including, but not limited to, the following:
- Decreased costs of computing power and the ability to scale or decrease service at almost no marginal cost beyond that of the on-demand services, platforms or infrastructures themselves.
- Few (if any) upgrade purchases.
- Drastically reduced capital expenditures for hardware. IDC predicts that cloud computing will reduce the cost of owning IT infrastructure by 54 percent.
- Decreased maintenance and reduced IT support costs as a result of not having to maintain staff to keep infrastructure and software running locally.
- Usage-based pricing with no fixed contracts. Beware, however, for the need for highly structured contracts with cloud service providers is more important than ever, as discussed infra.
- Arguably improved security provided by mega vendors (e.g., Google, Microsoft) whose reputations are on the line around the clock 24-7-365. The extent of such security measures must be subject to strict scrutiny during counsel's due diligence of vendors, and also memorialized contractually, see infra.
The Underlying Cloud Model
The cloud model itself is a three-tiered structure based on (1) infrastructure-as-a-service (IaaS), (2) platform-as-a-service (PaaS), and (3) software-as-a-service (SaaS). Infrastructure and software are particularly important for corporate counsel to master.
Provisioning infrastructure from a third-party cloud vendor allows corporations to take advantage of processing, storage, networks and other fundamental computing resources on which its computers can run software, including platforms, Operating Systems, and applications.
As the NIST definition makes clear, "[t]he consumer does not manage or control the underlying infrastructure," but has control over what to deploy on it. An example of IaaS is Amazon's Elastic Compute Cloud (EC2). Corporate counsel must have an intimate understanding of — and must help define ex ante their corporation's business and IT strategies in this area — the nature of their company's cloud infrastructure.
At the platform level, an example of which is Salesforce, the cloud-based corporate platform can be built in-house or acquired from a third party to allow for the deployment and delivery of Operating Systems and SaaS. At the most granular software and user level, SaaS are the applications that are accessible from various client devices (e.g., desktop computers, mobile phones) through a Web browser.
Google Apps (Gmail, Calendar, Docs, etc.) for business is a quintessential example of a SaaS. It bears repeating here a portion of NIST's definition of SaaS: "The consumer does not manage or control the underlying cloud infrastructure, including network, servers, storage, or even individual application capabilities with the possible exception of limited user-specific application configuration settings."
In other words, individual corporate implementations of cloud computing that are either underway or will occur — and the question in early 2011 already is no longer "if," but rather only "when" — must be controlled and carefully monitored at every step by corporate counsel.
The Corporate Dynamics of Cloud Computing
Before turning to the legal issues raised by cloud computing, corporate counsel must understand why this paradigm already is or will soon become one of the most important issues on their radar.
First, Chief Information Officers ("CIOs") have emerged as executives increasingly valued for their alignment of corporate strategy and IT, and often use the latter to drive the former. As I have argued elsewhere, CIOs "must embrace and implement IT in order to meet short- and long-term strategic goals," thereby "effectively position[ing] themselves at the center of any corporate hierarchy."
Second, cloud computing is now an indispensible arrow in a CIO's quiver.
The cloud is no longer merely a cost-cutting IT luxury, but rather it has become a business (not just an IT) imperative. According to Silicon Valley-based Appirio, a highly respected cloud solution provider, 82 percent of surveyed cloud adopters report that cloud computing already has helped them achieve a specific business objective, with 83 percent reporting that cloud solutions have helped make their business more agile. This movement toward embracing cloud computing to stimulate innovation and corporate growth is well past its tipping point.
Corporate counsel must understand this confluence of factors in order to be able to judge appropriately potential conflicts between their ethical responsibilities and legal duties and strategic initiatives that may have the blessing of the most senior management. Corporate counsel may find this to be a difficult task not only per se, but also in light of the dual roles that they themselves juggle, which I described (as part of a larger ethical discussion) in a recent article here for CorpCounsel.com.
Specific Legal Issues and Concerns Raised by Cloud Computing
Corporate counsel may already be taking advantage of cloud computing's benefits in their own legal departments.
These include law department and practice management systems, storage platforms, secure document and information exchange servers, secure e-mail networks, and document management. As the American Bar Association's Request for Comments on "Issues Concerning Client Confidentiality and Lawyers' Use of Technology" (Sept. 20, 2010) ("ABA Request for Comments") makes clear, cloud computing raises "specific issues and possible concerns relating to the potential theft, loss, or disclosure of confidential information." Id. at 3.
These include:
- unauthorized access to confidential client information by a vendor's employees (or sub-contractors) or by outside parties (e.g., hackers) via the Internet, see id.;
- the storage of information on servers in countries with fewer legal protections for electronically stored information ("ESI"), see id. at 4, which can be especially problematic in regulated industries that have highly defined requirements with respect to the handling of ESI throughout its life cycle;
- a vendor's failure to back up data adequately, see id.;
- the ability to access corporate data using easily accessible software in the event that the corporation terminates its relationship with the cloud computing provider or the provider goes out of business, see id.;
- the provider's procedures for responding to (or when appropriate, resisting) government requests for access to information, see id. What if, for example, a government (domestic or foreign) seizes the actual servers (i.e. hardware) on which Corporation A's confidential and highly regulated data resides in order to take control of Corporation B's data, which resides on the same shared, multitenant server?;
- policies for notifying the corporation of security breaches, see id., so that counsel can immediately fulfill her duties with respect to client notification under Model Rule of Professional Conduct 1.4;
- insufficient data encryption, see id.;
- unclear policies regarding the corporation's ability to "control" its own data, which may result in a quandary if served with a request for production of materials under Rule 34 of the Federal Rules of Civil Procedure;
- policies for data destruction when the corporation no longer wants the relevant data available or transfers it to a different host, see id.
- the potential warrantless seizure of corporate electronic mail under the anachronistic Electronic Communications Privacy Act of 1986 ("ECPA"), 18 U.S.C. § 2510, which includes the Stored Communications Act, 18 U.S.C. §§ 2701-12. Signed into law in 1986, the ECPA established a procedural framework for law enforcement authorities to obtain wire and electronic information, including files stored on a computer. Think Miami Vice, not cloud computing. Only two months ago, the Sixth Circuit in United States v. Warshak (6th Cir. Dec 14, 2010), held valid based on the government's dubious reliance on the Stored Communications Act a warrantless seizure of corporate e-mails notwithstanding a lengthy and informed exposition on the relationship between technology and the Fourth Amendment, see id. slip op. at 14-29.
These legal issues are highly complex and demand the attention of corporate counsel.
Cloud Computing and eDiscovery
The legal issues set forth above are hardly the end of corporate counsel's legal concerns vis-à-vis the cloud.
By its very nature, cloud computing can significantly impact where ESI resides, thus impacting the traditional model of eDiscovery. As mentioned in the above "seizure of servers" hypothetical, most cloud computing hardware is multitenant, which allows many companies to share the same physical hardware while segregating — albeit insufficiently and dangerously at times — access to each company's information.
Why is this problematic?
Think back to your company before the cloud. ESI was stored locally on your own servers. You had complete control over where the information resided. Retention policies, backup practices, data restoration ability, and data destruction were all within the control of your IT department.
Cloud computing changes this entire landscape.
Suppose, for example, that the Department of Justice's Antitrust Division, with its sophisticated eDiscovery procedures, issues your company a Second Request. With your corporate ESI in the cloud — i.e. potentially on a server in China — you are now responsible for identifying precisely where your data physically resides.
In which server farm? On which server?
Shared with which other companies? How will you produce the requested data? The answers won't always be obvious or easy to come by. Counsel must thus insist on contractual terms and conditions that answer these questions to increase their certainty.
Getting Proactive About Cloud Computing
Cloud computing here is here to stay.
Corporate counsel must thus understand how and why it will impact their companies so as to provide sound legal advice that does not ignore the business realities of this paradigm shift when it is embraced at the highest levels of senior management. And counsel must be highly proactive when dealing with potential cloud solution providers so that their business relationships comport not only with their companies' specific needs, but also with industry regulations that govern their handling of corporate data.
The following advice is intended to provide a starting point for corporate counsel as they move to master the legal side of the cloud.
- First, be aware of any and all potential changes to the Model Rules of Professional Conduct by both the ABA and your respective state Bar Associations, which can enforce even stricter standards. The ABA has made clear that it is considering amending Rules 1.1 (competency), 1.6 (duty of confidentiality), and 1.15 (safeguarding client property) in order to "emphasize that lawyers have particular ethical duties to protect clients' electronic information beyond mere practice norms" in the cloud context. ABA Request for Comments at 3.
- Second, follow closely evolving industry standards in the cloud space separate and apart from, yet certainly as they relate to, the regulation of your own industry.
- Third, seriously consider mitigating your corporate risk by purchasing cyberinsurance and/or cyberliability insurance. The former provides coverage for some technology-related losses such as the cost of replacing infrastructure after a cyberattack. Cyberliability insurance, on the other hand, would cover a scenario arising out a cloud vendor's failure to protect your or your client's confidential information.
- Fourth, follow advances in technology. The New York Bar Associate Committee on Professional Ethics Opinion 842 (Sept. 10, 2010) ("New York Bar Opinion") addresses the use of third-party storage providers and confidential information. It provides strong guidance. Counsel "should stay abreast of technological advances to ensure" that its outside storage systems "remain sufficiently advance" to protect corporate data. The vendor landscape in the cloud is changing daily. Make sure that you are working with the best.
- Fifth, race to the top with it comes to implementing a compliance regime that protects your corporation's legal interests and discharges its legal duties as they pertain to the cloud and its intersection with your industry's regulations. These policies should have buy-in from the highest levels of management, including the board of directors, and they should be enforced as imperatives throughout the Legal Department, especially in terms of negotiating contractual terms and conditions with cloud solution providers. Ensure also that you constantly discharge your likely-to-change obligations with respect to confidential information under the Model Rules of Professional Conduct. This includes your obligation to notify your clients in the event of an unauthorized release of such information.
- Sixth, conduct meticulous due diligence on all potential cloud vendors and negotiate strict terms and conditions governing their stewardship of your data. The New York Bar again provides sound advice:
o Ensure that your online data provider has an enforceable obligation to preserve confidentiality and security, and that it will notify you in the event of any security breach (defined as broadly as possible) or if served with process that in any way relates to your data. See New York Bar Opinion at 4.o Investigate the cloud service provider's security measures, policies, recoverability methods, and other procedures to assess their adequacy. See id.o Ensure that said vendor is using the most appropriate technology to guard against "reasonably foreseeable attempts to infiltrate the data that is stored." Id.o Ensure that the cloud provider can "purge and wipe" any copies of the data and move it to a different host if necessary. Id.These are serious issues that demand serious action. One final concern comes to mind.
In any contractual negotiations with cloud vendors, insist upon security provisions based upon the data security requirements specific to your industry (e.g., credit card or health care information). For example, can your vendor provide verifiable assurances that it is HIPPA compliant or meets the standards of the Payment Card Industry Data Security Standards?
If not, then work with someone else, as the stakes are simply too high not to do so.
Conclusion
Cloud computing raises daunting legal issues. Yet corporate counsel have no choice but to master both the law and the technology itself. The cloud has become too important to strategic business initiatives to be ignored.
There may, of course, be times when counsel must strongly advise against the use of the cloud. However, sound practice also dictates mastering the paradigm so as to be able to both protect the corporation's legal interests and allow it to leverage the most powerful paradigm in IT to contribute to corporate growth
Ben Kerschberg has a JD from Yale Law School, where he was as a Coker Fellow and is a founder of Consero Group LLC
<Return to section navigation list>
Cloud Computing Events
Steve Plank (@plankytronixx) announced Cloud Track is part of UK Tech Days Conference in May in a 3/9/2011 post to his Plankytronixx site:
Tech Days is running again this year. 3 days of Cloud, Web, Client and Phone with tracks for both IT Pros and Developers. I’ll be presenting a few sessions, come up and say hello to me after a session, it’d be nice to put a few faces to the names of you guys who email me. Or even if yu already know me – still come up and say hello…
For the Tech Days web site and registration, go to this link.

Eric Nelson listed Upcoming events and training in March for the Windows Azure Platform in a 3/9/2011 post to the UK ISV Evangelism Blog:
This is a summary of the learning opportunities for the Windows Azure Platform from Microsoft UK in March (which still have space!).
We do have an events page but I felt a comparison table with a little commentary would help you decide.
When Where What Who Cost Register Notes 14th March Reading A small half day informal briefing for ISVs and SIs to get you up to speed on Windows Azure. Lots of discussion. Business decision makers, CTOs, senior architects and system designers FREE Read more We have delivered many of these over the last few months to between 5 and 15 attendees. Space is limited. 25th March London BizSpark Camp on Windows Azure. The afternoon is the technical bit. BizSpark Members FREE Read more This is the second of these. The first was lots of fun. 29th March Reading This is different. It is a small half day workshop where we want to listen a lot to understand ISVs concerns about the Cloud etc CTOs, senior architects and senior developers FREE Read more We are keeping it small – but if you want to be involved then please do contact us. 31st March Reading EDITORS CHOICE
Day long technical overview briefing on the Windows Azure Platform delivered by the partner team.This is targeted at developers and architects in software houses creating “Products” (e.g. ISVs) FREE Read more This will be excellent :-). If you are new to Azure and near to Reading then I would highly recommend you attend. It is a maximum of 50 people, hence plenty of opportunities to ask questions. 28th March to 31st Online Two Live Meetings separated by a lot of homework. We have funded QA Training to deliver this. Software developers FREE Register This is a “you get as much out as you put in” week.
Now… what did I forget?
Victor Philip Ortiz reported Microsoft focuses on New Era of Opportunities at Tech-Ed Middle East 2011 in an 3/9/2011 article for PC Magazine Middle & Near East:
S. Somasegar, Senior Vice President, Developer Division, Microsoft Corp today opened the second edition of Tech-Ed Middle East in Dubai with a keynote speech focusing on a new era of opportunities across the technology landscape. He addressed more than 1700 developers and IT professionals along with technology partners who came together at the start of Tech-Ed Middle East which Microsoft’s premier technology event is offering the region’s IT community a chance to explore Microsoft’s latest, ground-breaking technologies.
Somasegar pinpointed two overwhelming trends changing technology experiences today starting with proliferation of devices. The number of smartphones in the world is expected to exceed the number of desktops and laptops by 2012 accompanied by an explosion of applications and data flow. Cloud Computing was the second major trend e highlighted with 80% of enterprises evaluating cloud computing for reasons as simple as economics and the agility it can offer IT. The keynote covered how Proliferation of devices & Cloud Computing can enable more immersive and rich experiences to connect users around the world.
Speaking about developer opportunity around devices, Somasegar outlined an opportunity for game developers with the Kinect for Windows SDK (Software Development Kit) being made available within the next few months as a free download. This “starter kit” for developers makes it easier to create richer experiences using Kinect technology, giving them an opportunity to access key pieces of the Kinect system – like audio technology, system application programming interfaces and direct control of the Kinect sensor itself.
Expanding on his proliferation of devices theme, Somasegar touched upon how mobile phones are increasingly extending into the cloud realm. According to Somasegar, “At Microsoft we believe the best user experiences span multiple devices and form factors and we’re seeing more and more device scenarios where applications are synched and tethered to the cloud. With Windows Phone 7, for example, consumers will be able to access their Xbox via their smartphone and engage in a host of other online experiences.”
Since the launch of Microsoft’s Windows Phone 7 in 2010, over 1 million tools have been downloaded worldwide. Currently there are 8,271 apps available with over 100 new apps added very day. Focusing on the regional developer opportunity for Windows Phone 7, Somasegar announced the launch of Yalla Apps which is a solution for MEA developers to have Windows Phone 7 global marketplace access. Yalla Apps is a Windows Phone 7 marketplace which enables developers (Individuals, ISVs and students) to register, unlock their phones and submit their Apps to the Windows Phone 7Marketplace.
Touching upon the significance of Cloud Computing, Somasegar commented on the fact that Cloud Computing has the potential to accelerate the speed and lower the cost of IT while delivering reliable services.
Somasegar added: “Microsoft has the most comprehensive approach to cloud computing which gives customers the freedom to access the full power of the cloud on their terms. It’s important to Microsoft that our customers have options. So – whether in your datacenter, with a service provider, or from Microsoft datacenters – Microsoft provides the flexibility and control to consume IT as a Service whichever way best meets your unique business needs.”He concluded, “ One of the benefits of working with clouds powered by Microsoft technologies is that you will be able to use a common set of tools – the ones you’re already familiar with – across our private and public clouds. Microsoft has a common set of identity, management, and Developer tools.”
Commenting on the launch of new developer tools, Somasegar talked about the impending launch of Visual Studio LightSwitch Beta 2. Visual Studio LightSwitch Beta 2 demonstrates significant advancements from Beta 1, including the addition of the ability to deploy a LightSwitch application directly to Windows Azure. Visual Studio LightSwitch will give developers a simpler and faster way to create high-quality line-of-business applications for the desktop, the web, and the cloud by providing a simplified development model with tools that abstract away a majority of the code writing and technology decisions enabling them to focus on their business needs.
Brenda Michelson (pictured below) reported Cloud Connect 2011: Colin Clark introduces Cloud Event Processing in a 3/8/2011 post:
Session Abstract: In many ways, Big Data is what clouds were made for. Computing problems that are beyond the grasp of a single computer—no matter how huge—are easy for elastic platforms to handle. In this session, big data processing pioneer Colin Clark will discuss how to discover hidden signals and new knowledge within in huge streams of realtime data, applying event processing design patterns to events in real time.
Speaker – Colin Clark, CTO, Cloud Event Processing
Colin opens talking about high velocity, big data. Then, gives his Complex Event Processing Criteria:
- Domain Specific Language
- Continuous Query
- Time/Length Windows
- Pattern Matching
Example of what Colin is talking about: “Select * from everything where itsInteresting = toMe in last 10 minutes”
How much data does that return? How much processing will it take?
Limitations of current CEP solutions: memory bound, compute bound and black box. Using CEP, can analyze data in-flight, but have limitations. Other challenge is time series analysis.
A technique available for time series analysis is symbolic aggregate approximation (SAX).
Colin is describing the construction of a “SAX word” from a days worth of IBM trading. Then, search history for that same word, to find a pattern.
Getting closer to solving the high velocity, big data problem. But, still too much data to process. So, the next element in cloud event processing is Map/Reduce.
Still though, need to address the real-time (event-driven) aspect. Brings us to virtualized resources (cloud).
So, assuming I captured this correctly: High velocity, big data = CEP + SAX + Streaming Map/Reduce + virtualized resources, which equals Cloud Event Processing’s Darkstar.
Today, Darkstar is working on Wall Street, doing market surveillance at the exchange. Speaking with Colin in the hallway, we discussed non-capital market prospects as well.
Related posts:
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Matthew Weinberger reported Nimbula Cloud Operating System Gains Partner Ecosystem in a 3/9/2011 post to the TalkinCloud blog:
Nimbula, the self-described “Cloud Operating System Company” formed by veterans of the development team behind Amazon EC2, used this week’s Cloud Connect Conference to make two major announcements: the flagship Nimbula Director private cloud tool will be generally available within the next 30 days, and the company is launching a technology partner ecosystem to drive adoption.
Nimbula Director will be free for deployments under 40 cores. As TalkinCloud noted when Nimbula Director launched in a public beta in the final days on 2010, the product is designed to help optimize what the company would describe as ancient, plodding data centers with managable, flexible elasticity and scalable resources. And it’s based on the company’s better-established Nimbula Cloud Operating System technology.
A key advantage of Nimbula Director, says the press release, is the ability to federate workloads to Amazon EC2 with the same permissions control as the private cloud. And even if you’re on the free plan, Nimbula’s offering paid support options.
To help drive customer adoption of Director, Nimbula has entered into agreements with technology partners like Citrix Systems, Inc., Cloud Cruiser, enStratus, Opscode, Puppet Labs and Scalr. Citrix, for example, will be offering support for XenServer and NetScaler with Nimbula Director. And enStratus will use Nimbula Director to let customers deploy and manage their own cloud applications in their infrastructure.
TalkinCloud has its ear to the ground, so keep watching for more updates from the Cloud Connect Conference. …
Read More About This Topic
Jeff Barr (@jeffbar) described Even More EC2 Goodies in the AWS Management Console in a 3/9/2011 post to the Amazon Web Services blog:
We've added some new features to the EC2 tab of the AWS Management Console to make it even more powerful and even easier to use.
You can now change the instance type of a stopped, EBS-backed EC2 instance. This means that you can scale up or scale down as your needs change. The new instance type must be compatible with the AMI that you used to boot the instance, so you can't change from 32 bit to 64 bit or vice versa.
The Launch Instances Wizard now flags AMIs that will not incur any additional charges when used with an EC2 instance running within the AWS free usage tier:
You can now control what happens when an EBS-backed instance shuts itself down. You can choose to stop the instance (so that it can be started again later) or to terminate the instance:
You can now modify the EC2 user data (a string passed to the instance on startup) while the instance is stopped:
We'll continue to add features to the AWS Management Console to make it even more powerful and easier to use. Please feel free to leave us comments and suggestions.
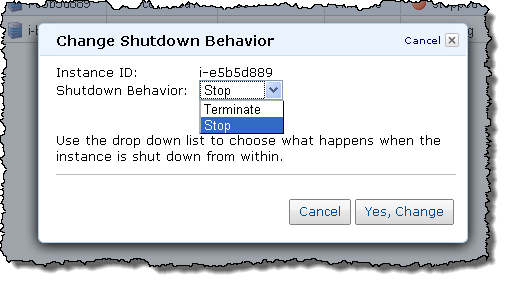
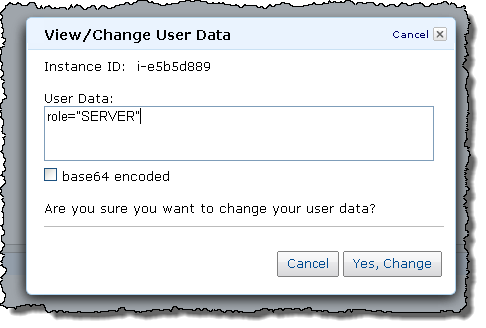
Jeff Barr (@jeffbar) announced that you can now Run SUSE Linux Enterprise Server on Cluster Compute Instances in a 3/9/2011 post to the AWS blog:
You can now run SUSE Linux Enterprise Server on EC2's Cluster Compute and Cluster GPU instances. As I noted in the post that I wrote last year when this distribution became available on the other instance types, SUSE Linux Enterprise Server is a proven, commercially supported Linux platform that is ideal for development, test, and production workloads. This is the same operating system that runs the IBM Watson DeepQA application that competed against a human opponent (and won) on Jeopardy just last month. [Emphasis added.]
After reading Tony Pearson's article (How to Build Your Own Watson Jr. In Your Basement), I set out to see how his setup could be replicated on an hourly, pay as you go basis using AWS. Here's what I came up with:
- Buy the Hardware. With AWS there's nothing to buy. Simply choose from among the various EC2 instance types. A couple of Cluster Compute Quadruple Extra Large instances should do the trick:
- Establish Networking. Tony recommends 1 Gigabit Ethernet. Create an EC2 Placement Group, and launch the Cluster Compute instances within it to enjoy 10 Gigabit non-blocking connectivity between the instances:
- Install Linux and Middleware. The article recommends SUSE Linux Enterprise Server. You can run it on a Cluster Compute instance by selecting it from the Launch Instances Wizard:
Launch the instances within the placement group in order to get the 10 Gigabit non-blocking connectivity:
You can use the local storage on the instance, or you can create a 300 GB Elastic Block Store volume for the reference data:
- Download Information Sources. Tony recommends the use of NFS to share files within the cluster. That will work just fine on EC2; see the Linux-NFS-HOWTO for more information. He also notes that you will need a relational database. You can use Apache Derby per his recommendation, or you can start up an Amazon RDS instance so that you don't have to worry about backups, scaling or other administrative chores (if you do this you might not need the 300 GB EBS volume created in the previous step):
You'll need some information sources. Check out the AWS Public Data Sets to get started.
- The Query Panel - Parsing the Question. You can download and install OpenNLP and OpenCyc as described in the article. You can run most applications (open source and commercial) on an EC2 instance without making any changes.
- Unstructured Information Management Architecture. This part of the article is a bit hand-wavey. It basically boils down to "write a whole lot of code around the Apache UIMA framework."
- Parallel Processing. The original Watson application ran in parallel across 2,880 cores. While this would be prohibitive for a basement setup, it is possible to get this much processing power from AWS in short order and (even more importantly) to put it to productive use. Tony recommends the use of the UIMA-AS package for asynchronous scale-out, all managed by Hadoop. Fortunately, Amazon Elastic MapReduce is based on Hadoop, so we are all set:
- Testing. Tony recommends a batch-based approach to testing, with questions stored in text files to allow for repetitive testing. Good enough, but you still need to evaluate all of the answers and decide if your tuning is taking you in the desired direction. I'd recommend that you use the Amazon Mechanical Turk instead. You could easily run A/B tests across multiple generations of results.
I really liked Tony's article because it took something big and complicated and reduced it to a series of smaller and more approachable steps. I hope that you see from my notes above that you can easily create and manage the same types of infrastructure, run the same operating system, and the same applications using AWS, without the need to lift a screwdriver or to max out your credit cards. You could also use Amazon CloudFormation to automate the entire setup so that you could re-create it on demand or make copies for your friends.
Read more about features and pricing on our SUSE Linux Enterprise Server page.
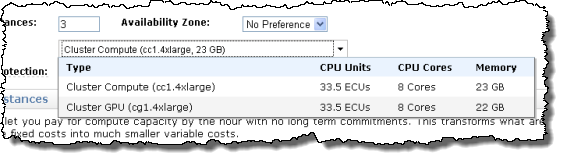
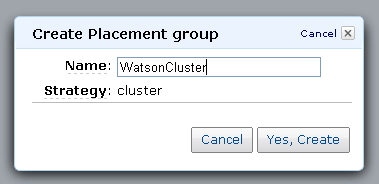

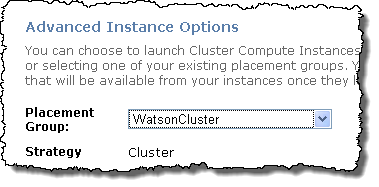
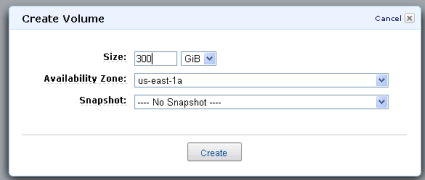
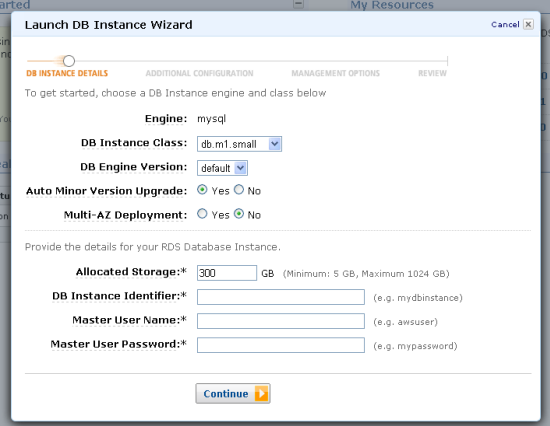
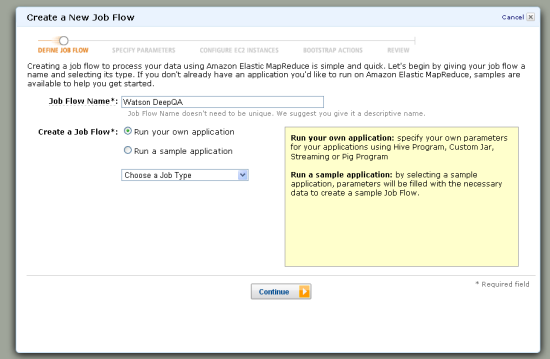
Q: Why is Jeff Barr smiling? A: Amazon Web Services is on a “new features roll.”
Andrew Shafer asserted “The rising tide raises all boats” as a preface to his Cloudbuilders At Arms to the Cloudscaling blog on 3/8/2011:
Today Rackspace announced a new OpenStack governance model and Cloudbuilders to provide commercial support and training for OpenStack.
Rackspace Cloudbuilders gives the OpenStack ecosystem a formal center of gravity for organizations needing help to work through the many choices the framework doesn’t make for them. Before Cloudbuilders, organizations were on their own to fill in many blanks. This can be overwhelming for organizations lacking domain expertise or the dynamics of open source projects. Acquiring either of those things can be a daunting task.
Cloudbuilders will accelerate OpenStack’s transition from a collection of code repositories with an ecosystem of developers to an ecosystem of organizations providing services. Organizations will no longer be left to their own devices, literally and figuratively.
This transition to more code running on real hardware providing production services will help to focus the OpenStack community on the real challenges we are all facing. Accelerating the community of OpenStack installations will enable us all to start finding solutions based on data.
Cloudscaling has built many relationships throughout Rackspace and with the great people formerly known as Anso Labs. Cloudscaling looks forward to working together with Cloudbuilders to build up the ecosystem and contribute to the body of knowledge about deploying and managing cloud infrastructures.
Now we have to get back to building…

The CloudTimes blog reported GigaSpaces Announces Second Generation Cloud-Enablement Platform on 3/8/2010:
<Return to section navigation list>

















0 comments:
Post a Comment