Windows Azure and Cloud Computing Posts for 10/28/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

- Updated 10/30/2011 with new articles marked ••.
- Updated 10/29/2011 with new articles marked •.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
McKinsey & Co. announced Complimentary Access to Their Latest McKinsey Quarterly Tablet [and PC] Edition in a 10/28/2011 email:
The fourth Quarterly issue of 2011 provides a state-of-the-art CEO's guide to navigating the era of "big data." McKinsey experts present a series of questions and thought-provoking examples intended to concentrate busy leaders' minds on the implications of big data. Also weighing in are Massachusetts Institute of Technology professor Erik Brynjolfsson, Cloudera cofounder Jeff Hammerbacher, AstraZeneca senior executive Mark Lelinski, and Butler University men's basketball coach Brad Stevens. …
Your tablet edition (iPad or Android software version 2.2 or higher) is available through Zinio, a leading online digital newsstand and bookstore. Use the Zinio reading platform to navigate between videos, audio, and articles within your issue of McKinsey Quarterly.
Not sure how to access our iPad edition? Please visit mckinseyquarterly.com for step-by-step directions.
Don't have an iPad? You can still read the issue on your computer (PC or Mac) or iPhone or Android phone. If you're not a Zinio subscriber, you can join and download our complimentary issue after a free, one-time registration.

No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
•• Cihan Biyikoglu (@cihangirb) began a new series with Federation Metadata in SQL Azure Part 1 – Federations and Federation Members on 10/29/2011:
One of the great value propositions of federations is the ability to represent all the data distribution on the server side for both your schema (for example which parts of your schema you want to scale out and using what keys etc) and your runtime layout (for example whether you need 30 or 300 federation members at any one time to handle your workload).
The annotations you put in to express your design and runtime decisions are represented in a number of system views. In part 1, we will take a look at the basic views that represent federations itself and members. In future parts of the series, we’ll take a look at other metadata that allow you to monitor ongoing federation operations, federation error reporting views as well as view a history of all the federation events, and connection metadata for federations and how to use that.
Alright lets get started…
Federations and Federation Members
Definition of a federation is represented by 2 system views which capture the federation distribution scheme;
- sys.federations represent the federations in a database.
- sys.federation_distributions represent the definition of the federation distribution scheme for federations. Yes, in v1 a federation only allow a single federation distribution key but the normalization is there to allow for multiple federation distribution keys in future.
Federation member metadata is quite symmetric except it represents additional runtime information the distribution information.
- sys,federation_members represent members of the federations
- sys.federation_member_distribution provides the distribution details per federation distribution key per member.
These views are available in all databases, root and members. Root contains the full set of rows for all federations and members. They only display the information related to the member you are connected to. For example, sys.federations would return all federation in ‘salesdb’, the root database, lets say we have federations f1 and f2 with 20 members each. However if you switch over to a federation member 2 of f1, sys.federation* system views will only contain federation f1 and member information for only member 2 that you are connected to. This is much like how sys.databases work in SQL Azure master database and user databases.
Besides the federation membership information, sys.databases contain the is_federation_member column to signify if a database is a federation member or a user database.
Lets look at a few examples that can help work out some common queries;
A few on db type;
-- am I a member db? select is_federation_member from sys.databases where name=db_name() -- am I a root db? select (~ is_federation_member) & (select cast(count(*) as bit) from sys.federations) from sys.databases where name=db_name() -- am I a db but not a root? select (~ is_federation_member) & ( select ~ cast(count(*) as bit) from sys.federations) from sys.databases where name=db_name() goHere are a few more about federation information for root dbs;
-- count of members each federation contain? use federation root with reset GO select f.name, count(fm.member_id) from sys.federations f join sys.federation_members fm on f.federation_id=fm.federation_id group by f.name GOand a few for members dbs;
-- which federation is this member a part of? select * from sys.federations where (select is_federation_member from sys.databases where name=db_name())=1 GO -- what are my low and high ranges? select range_low, range_high from sys.federation_member_distributions GO -- what is member db name and root db name? select db_name() go use federation root with reset go select db_name() goIf there are other examples you’d like to suggest, you can always leave a comment.



• My (@rogerjenn) Microsoft PinPoint Entry for the SQL Azure Reporting Services Preview Live Demo post of 10/29/2011 begins:
I created the following Microsoft PinPoint entry for the SQL Azure Reporting Services Preview live demo described in my PASS Summit: SQL Azure Reporting Services Preview and Management Portal Walkthrough - Part 3 article of 10/23/2011:


• Mark Scurrell (@mscurrell) described a SQL Azure Data Sync Webcast Overview webcast series in a 10/28/2011 post:
I've just posted the first in a series of webcasts for SQL Azure Data Sync over on Channel 9 here.
This first webcast provides a high-level overview of the service. There's a couple of slides to introduce the service, but most of the webcast is a demo of the service.
- More detailed walkthroughs for syncing between local SQL Server and SQL Azure as well as between SQL Azure databases.
- Scenarios where you can use Data Sync in conjunction with other services, such as Reporting Services.
- Deep dives into specific areas, such as filtering, provisioning, security considerations, best practices, conflicts, and so on.
Feel free to leave a comment with topics you'd like to see us cover in future webcasts.
It's been a few weeks now since we released the Data Sync Preview. If you've been using the service then please provide us feedback using the feature voting site here. If you haven't tried out CTP3, then why not? :-)

For more details about SQL Azure Data Sync, see my PASS Summit: SQL Azure Sync Services Preview and Management Portal Demo post of 10/19/2011.
Michael K. Campbell posted Microsoft Azure and the Allure of 100 Percent Application Availability to the DevProConnections blog on 10/28/2011:
Michael K. Campbell takes Microsoft's SQL Azure for a spin in hopes of achieving 100 percent application availability.
In sizing up SQL Azure as an option for my solution, one thing I did have to do was gauge how much downtime I could potentially expect when using SQL Azure. As much as the hype from all cloud vendors would have you believe that cloud solutions are always on, that's commonly not the case. As such, I went ahead and did some homework on overall uptime for SQL Azure within the last year to get a feel for what I could potentially expect going forward.
More specifically, in looking at the detailed statistics on cloudharmony.com, it turns out that SQL Azure was down a little under 33 minutes for an entire year. Not bad, but not 100 percent uptime either.
Because the highly distributed application I'm building uses SQL Server persistence only during the startup of each node and to periodically write tiny amounts of data that can be eventually consistent, I decided that even if SQL Azure was to double its failure rates in the next year, having a SQL Azure database along with a mirror SQL Server database hosted somewhere else would be good enough for me to work with. As such, what I've done is settled on using SQL Azure as my primary data storage mechanism because pricing and uptime are great. Then I've gone ahead and actually set up a secondary mirrored database for redundancy purposes.
This approach obviously wouldn't work for many applications that are database-centric, but this solution will probably only ever get to be around 2GB in size, only read about 2MB of data when an individual node starts up, and only make periodic writes. Consequently, instead of using a data repository, I've actually gone ahead and created a redundant data repository that pushes all writes to both databases (that uses an Amazon Simple Queue Service persistence mechanism to queue writes against either database if it's down) and tries to read from the failover or secondary database when the primary database doesn't respond quickly enough during node startup.
So far this approach is working well. And although creating a redundant repository did add some additional complexity to my application, the amount of complexity paled in comparison to what I would have had to do had I not written my application against a semi-permanent centralized data store. This meant that I could avoid coding up true peer-to-peer semantics that would have made my simple solution a nightmare.
As such, I think I might actually have a shot at hitting that coveted 100 percent uptime— even if 100 percent uptime is theoretically impossible and crazy to pursue.

Following is a screen capture of the CloudHarmony data Michael used for his article

I don’t understand why Michael “created a redundant data repository that pushes all writes to both databases (that uses an Amazon Simple Queue Service persistence mechanism to queue writes against either database if it's down) and tries to read from the failover or secondary database when the primary database doesn't respond quickly enough during node startup.” He could have used SQL Azure Sync Services to keep a secondary database in another region synchronized with his primary database. (See my PASS Summit: SQL Azure Sync Services Preview and Management Portal Demo post of 10/19/2011.) Putting another cloud provider (AWS) in the loop doesn’t sound to me like the optimum solution.
Herve Roggero (@hroggero) described How to Detect If You Are Connected To A Federation Root in a 10/27/2011 post:
If you develop applications in SQL Azure, you may end up in a situation where your code needs to know if it is operating in the root database or in a Federation Member, or if it is connected to a regular user database. Two ways can be used to make this determination: using system tables, or using the USE FEDERATION command.
Using System Tables
Here is the statement you would use:
SELECT is_federation_member FROM sys.databases WHERE name = db_name()
If you are currently connected to a federation member, is_federation_member will be 1; otherwise it will be 0.
Note that as of this writing, running the above statement in SQL Azure will throw an error because the is_federation_member column is not yet available in regular SQL Azure user databases. However, if you connect to a federation, the SQL code above will run.
Using the USE FEDERATION Command
Alternatively you can also use code in .NET to make that determination. Connect to the database as usual, using the SqlConnection class for example, then perform the following tasks:
- Execute the USE FEDERATION ROOT WITH RESET command, which forces the connection back to the root database (in case you are not current in the root database)
- Execute SELECT db_name() which fetches the name of the database of the root database
- Compare the original database name you connected to with the one returned by the previous call; if the names are the same, you originally connected to the root database
Here is the sample code:
string sql = "USE FEDERATION ROOT WITH RESET"; string sql2 = "SELECT db_name()"; bool isFederationRoot = false; try { SqlConnection sqlConn = new...; // Your connection string goes here sqlConn.Open(); ( new SqlCommand(sql, sqlConn)).ExecuteNonQuery(); // connect to the root db SqlDataReader dr = (new SqlCommand(sql2, sqlConn)).ExecuteReader(); // Get the db_name() if (dr.Read()) isFederationRoot = (dr[0].ToString().ToLower() == dbName.ToLower()); dr.Close(); } catch { }

<Return to section navigation list>
MarketPlace DataMarket and OData
• The Team Foundation Server Group made ODataForTFS2010v1.0.exe available for download on 10/26/2011 (missed when published):
Overview
The purpose of this project is to help developers work with data from Team Foundation Server on multiple types of devices (such as smartphones and tablets) and operating systems. OData provides a great solution for this goal, since the existing Team Foundation Server 2010 object model only works for applications developed on the Windows platform. The Team Foundation Server 2010 application tier also exposes a number of web services, but these are not supported interfaces and interaction with these web services directly may have unintended side effects. OData, on the other hand, is accessible from any device and application stack which supports HTTP requests. As such, this OData service interacts with the client object model in the SDK (it does not manipulate any web services directly).
For a video demonstration of this service please click here.
We are interested in your feedback on this release, and we are excited to hear about the types of experiences you create with it. You can email us at TFSOData@Microsoft.com.
System requirements
Supported Operating Systems: Windows 7, Windows Server 2008, Windows Server 2008 R2, Windows Vista
There are several components of this sample, and the software requirements depend on how you would like to use it. The list of required software may include the following:
For additional details, please consult the documentation which is included with this release.
- Microsoft Visual Studio 2010
- Microsoft Visual Studio Team Explorer 2010
- Microsoft Visual Studio Team Foundation Server 2010 (or access to a project hosted on a Team Foundation Server instance hosted by CodePlex.com)
- Microsoft .NET Framework 4; WCF Data Services Toolkit (aka ODataContrib); Internet Information Services 7 (IIS7)
- Windows Azure Tools for Microsoft Visual Studio 2010 (November 2010 or greater)
- (Optional) Windows Phone Developer Tools; (Optional) Microsoft WebMatrix
• Turker Keskinpala (@tkes) announced an OData Service Validation Tool Update: New feature and rules in a 10/25/2011 post to the OData.org wiki (missed when published):
We pushed another update to http://validator.odata.org and the Codeplex project:
- Added the crawling feature with UI support
- Added 2 new rules for Metadata
- Minor bug fixes for 3 rules
- Changed XML rules version definition
If you enter enter a URL to a service document and select the crawling checkbox, the validation engine will automatically validate the service doc, the metadata document (if available), the top feed in the service document and the top entry in the feed. In addition to those we also send a bad request to generate an OData error payload and validate that as well.
As always we’d like to hear your feedback. Please check the new feature out and let us know what you think either on the mailing list or on the discussions page on the Codeplex site.
Turker is a program manager on the OData team.
<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
•• Rick Garibay (@rickggaribay) posted an Azure Service Bus Relay Load Balancing Demo on 10/30/2011:
This week, the highly anticipated support for load balancing relay endpoints was released to the Azure Service Bus messaging fabric as first hinted by Velery Mizonov and later officially announced by Avkash Chauhan.
Richard Seroter and Sam Vanhoutte posted some very helpful walkthroughs of the functionality, so I thought I would follow up with a quick webcast to show Azure Service Bus Relay load balancing in action.
In the demo, I show starting three relay endpoints using the NetTcpRelayBinding with no address already in use exceptions and firing a series of messages over the bus which arrive at one of the 3 endpoints.
This is a feature that many customers and the community has been clamoring for for some time and it is great to see this live!
Steve Marx (@smarx) and Wade Wegner (@WadeWegner) produced Episode 63 - Securely Sharing Files with Windows Azure of the CloudClover show on 10/28/2011:
Join Wade and Steve each week as they cover the Windows Azure Platform. You can follow and interact with the show at @CloudCoverShow.
In the news:
How to Clean Up Old Windows Azure Diagnostics
- Windows Azure Toolkit for Windows Phone v1.3.1
- How to Block Un-validated Windows Azure Deployments
- How to Easily Enable Windows Azure Diagnostics Remotely
- Editing a Local Windows Azure Project with the Emulator Running
- BlobShare on Codeplex
- Packaging an Executable as a Windows Azure Application From the Command Line


<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
•• Avkash Chauhan (@avkashchauhan) described Communication between Windows Azure Roles in a 10/30/2011 post:
When building Windows Azure application you may have a collection of multiple web & worker role and depend on your application architecture you would need to establish a secure communication between your roles. For example I will use the following image from MSDN article (http://msdn.microsoft.com/en-us/library/gg433033.aspx):
The very first rule of Connectivity:
Only role instances that are part of the same Windows Azure application can communicate with each other and this communication could occur only over ports declared as internal endpoints within your Windows Azure Application.
So if your objective is to established communication between two separate Windows Azure application roles then the answer is no, it is not possible. If you can merge your separate applications into a single Windows Azure application which includes all roles then you sure can establish a secure connection between these roles of same application.
Now let’s discuss what could not be an option for our solution:
- Azure Connect: Establishing connectivity between Azure Roles and computers outside Azure
- Azure Service Bus: It didn’t provide direct network connectivity between Windows Azure Roles
Yes, you sure can setup a secure network connection between roles of a same Windows Azure Application and to set up network traffic rules to control role communication please visit the following article at MSDN:
- Getting Started with Enabling Role Communication


•• Microsoft’s Photosynth Team reported Photosynth Loves Windows Azure in a 10/18/2011 post (missed when published):
Photosynth stores a LOT of data. Today we have more than a million synths and panos, and the number is rising rapidly. So far we've accumulated more than 40 terabytes (TB) of data representing more than 100 terapixels.
It started this morning. Right now 1/2 the uploads are being directed to Azure, and served worldwide via Azure's CDN. If all goes well, we'll increase this to 100% within a few days, and then start migrating the 40 TB of existing content from our partner's data center into Azure. That process will likely take a number of weeks, but should not interfere with your ability to view old synths/panos or upload new ones.
You shouldn't be able to tell the difference between a synth or pano hosted on Azure verses our old storage system, but just in case there are some glitches in the worldwide CDN, I've included 3 comparisons below. Please leave a comment on this page or send an email to photosynth@live.com if you see any significant differences (particularly in loading speed) between the two storage solutions.
Medium-Sized Synth on Azure
Yes --in case you were wondering, this one does appear to be a forensics class homework assignment! Check out the other synths on this account: http://photosynth.net/userprofilepage.aspx?user=bchsforensicsci.

The post continues with the following sample Photosynths:
- Medium-Sized Synth on Old Storage System
- Desktop Panorama on Azure
- Desktop Panorama on Old Storage System
- Mobile Panorama on Azure
- Mobile Panorama on Old Storage System
Please leave us a comment if you see any significant difference in loading performance or speed to "resolve" the image when you zoom in, and please tell us what city and country you tried this from.
Thanks to Mary Jo Foley (@maryjofoley) for the heads-up in her Microsoft to eat its own cloud dog food with Photosynth post of 10/30/2011 to ZDNet’s All About Microsoft blog.
• Andy Cross (@andybareweb) explained Configuring Multiple Windows Azure Trace Sources in a 10/29/2011 post:
I was asked a question by Bruce (a commenter on my Forum post about Fluent Windows Azure Diagnostics) regarding how to configure the tracing of multiple applications in Windows Azure. The answer to this is to use Trace Sources in order to separate out the messages. This post details the technique needed to make this happen.
An application component writes its messages to the trace listeners that are configured to listen to them. Whilst this may seem obvious, it is important to note that if you write an application component to write messages globally and configure trace listeners to listen globally then you lose the granularity required to distinguish between the components of an application writing the messages. For example, if Class1 and Class2 both use Trace.TraceInformation(“hello”), the global Trace.Listeners will get “hello” traces from two components, but it will not differentiate between them.
In order to maintain the granularity of the Tracing Information, we must ensure that applications trace to a Trace Source, allowing us to distinguish the application component that is writing the trace message.
using System.Diagnostics; namespace BareWeb.Application1.Tracer { public class TraceOriginApp1 { private readonly TraceSource _ts; public TraceOriginApp1() { _ts = new TraceSource("BareWeb.Application1.Tracer"); } public void Run() { while (true) { this._ts.TraceInformation("This is Application1"); System.Threading.Thread.Sleep(1000); } } } }Compare this to the “global” approach of Trace.TraceInformation, and you can see that the named TraceSource instance variable is used to distinguish the origin of the message. The TraceSource is given its own TraceListeners, separate from the Trace.Listeners collection, which receive messages only from that TraceSource.
We can configure the TraceSources’ listeners in code or in configuration. Configuration is the preferred solution as it can be easily modified without recompilation. For brevity I have used the programmatic approach, the reason for this is that I want to configure TraceListeners that write a Text log to a certain location, and I want that location to be the dynamic result of “RoleEnvironment.GetLocalResource(“logtype”).RootPath”. This is possible to achieve through configuration but it is outside of the scope of this post. This is quite contrived, the correct implementation may use a Startup Task in order or modify the initializeData attribute of the TraceListeners in the config file.
In code, we simply create a Trace Source, and use that source as the instance that we call TraceInformation on, rather than using the Trace static methods.
TraceSource traceSourceApp1 = new TraceSource("BareWeb.Application1.Tracer");In our simplified programmatic approach, we pass this trace source across to the application that is going to do the logging. In a full implementation, these TraceListeners would be configured in App.Config and so you would not need to instantiate the listeners manually.
In the code we then use Fluent Windows Azure Diagnostics in order to setup Windows Azure Diagnostics;
// use Fluent Azure Diagnostics in order to move the directories into blob storage var azureDiagnostics = new BareWeb.FluentAzureDiagnostics.DiagnosticsCapture(CloudStorageAccount.DevelopmentStorageAccount); azureDiagnostics.Current().WithLogs().WhereLogsAreAbove(LogLevel.Verbose).TransferLogsEvery(TimeSpan.FromMinutes(1D)) .WithDirectory(RoleEnvironment.GetLocalResource("Trace1").RootPath, "app1", 256) .WithDirectory(RoleEnvironment.GetLocalResource("Trace2").RootPath, "app2", 256) .TransferDirectoriesEvery(TimeSpan.FromMinutes(1D)) .Commit();Since the Trace Sources are configured to use TextWriterTraceListeners and write to those Local Storage Resources (Trace1 and Trace2), Windows Azure Diagnostics are able to pick up the traces individually and place them in separate blob containers (in this case app1 and app2).
Multiple Trace Outputs
As always, source is provided: MultipleTraceSources

Avkash Chauhan (@avkashchauhan) described How to upgrade only one specific role from your Windows Azure Application in a 10/28/2011 post:
If you have more than one role in your Windows Azure application, and you decide to update only one role you sure can do that. To do that you will still need to build your full Azure application (included all role) and then only update the specific role via Windows Azure Portal. Here is what you would do:
- Build you package (CSPKG) which includes updated code for specific role you would want to update along with other roles.
- Now login Windows Azure portal and select specific role you would want to update. Please remember two important things here
- If you will select deployment first and choose "Upgrade" then all roles will be updated
- If you select only "web role" or "worker role" first from your service and the choose "Upgrade" then only select role will be updated even when you are using full CSPKG file to update on specific role.
- When you will choose “Upgrade” option you would ask to provide CSPKG and CSCFG files, please provide both and start the update progress.


Robert Nelson asserted Nokia & Microsoft Will Be Giving Away 85,000 Windows Phone Devices [To Help Spread The Word On Windows Phone, Microsoft & Nokia Announce Latest Offering -- 85,000 Free Phones Going To Developers & Other Influencers] in a 10/28/2011 post to the TFTS Hi-Tech News Portal:
We have seen quite a bit in terms of the Nokia Lumia handsets lately, which of course only seems natural given Nokia World 2011 began a few days back. And well, in addition to the announcement of the Nokia Lumia line of handsets, it looks like Nokia will be giving away quite a few free phones.
Sounds like a good way to help spread the word and put the handset in the hands of those who can help ‘encourage’ others to actually make a purchase. As for getting a free phone, those are said to be going to developers as well as to bloggers and other “cultural influencers.”
It was noted that Nokia will be giving away a total of 85,000 devices. In terms of the breakdown, it looks like 25,000 will be going to developers and the remaining 60,000 will be going to the bloggers and influencers. As for the developers, so far we are unsure just how those will be chosen, however it was said that they will go to developers who “commit” to building Windows Phone apps. And in that respect, it sort of makes sense. After all, one of the more often heard complaints about Windows Phone comes in with the lack of apps.
Moving onto the remaining free phones. This looks like it will include a mix of phones simply being handed out as well as some “staged outdoor happenings.” In this case there was not any mention as to how those lucky individuals will be chosen, but we suspect it safe to say that they will be those with bigger followings. You know, those who will be able to spread the word a bit easier.
In the end, it looks like a rather nice way to get some phones out into the public. Now, lets just hope that their plan works because these Windows Phone running Nokia devices are staring to get some serious hype. Or maybe more important, lets hope these handsets live up to the hype.


Wade Wegner (@WadeWegner) announced the Windows Azure Platform Training Kit – October Release on 10/27/2011:
Today we published the Windows Azure Platform Training Kit – October Release. The Windows Azure Platform Training Kit includes hands-on labs, presentations, and samples to help you understand how to build applications that utilize Windows Azure, SQL Azure, and the Windows Azure AppFabric.
- Browse the hands-on labs: Alternatively, you can browse through the individual hands-on labs on the MSDN site here: http://bit.ly/WAPCourse
The October 2011 update of the training kit includes the following updates:
- [New Hands-On Lab] SQL Azure Data-tier Applications
- [New Hands-On Lab] SQL Azure Data Sync
- [New Hands-On Lab] SQL Azure Federations
- [New Demo] Provisioning Logical Servers using Cmdlets Demo
- [New Demo] Parallel Computing on Azure – Travelling Salesman Demo
- [Updated] SQL Azure Labs and Demos with the new portal and tooling experience
- Applied several minor fixes in content
As with the September release, we have shipped an (updated) preview of our web installer. The training kit web installer is a very small application weighing in at 2MB. The web installer enables you to select and download just the hands-on labs, demos, and presentations that you want instead of downloading the entire training kit. As new or updated hands-on labs, presentations, and demos are available they will automatically show up in the web installer – so you won’t have to download it again.
You can now download the training kit web installer preview release from here.
We really try to make these training resources valuable to you, so please be sure to provide feedback if you find a bug, mistake, or feel as if we should including something else in the kit.



Darryl K. Taft (@darrylktaft) reported Nokia Giving Away 25,000 Free Windows Phones to Developers in a 10/27/2011 post to eWeek.com’s Application Development News blog:
At Nokia World 2011, Nokia and Microsoft announced that the handset maker will give away 25,000 free Lumia Windows Phones to help to seed the phone and its operating system in the marketplace.
Nokia plans to give away 25,000 new Lumia 800 smartphones based on the Microsoft Windows Phone operating system to developers, and the cell phone company, in conjunction with Microsoft, hopes to sign up 100,000 developers between now and June 2012.
At the Nokia World 2011 conference here, Marco Argenti, senior vice president of developer experience and marketplace at Nokia, said Nokia plans to give away the phones starting right then on Oct. 27.
“There are literally trucks outside right now full of Windows Phones,” said Matt Bencke, general manager of developer and marketplace at Microsoft. “This is one of the largest seeding programs I’ve ever heard of,” said Brandon Watson, senior director of Windows Phone 7 development at Microsoft.
Nokia and Microsoft are not just wantonly giving away the phones; they are focusing on committed developers, Watson said.
Argenti said analysts estimate that 44 percent of smartphone users are considering “upgrading” to Windows Phone. “I hope it’s going to be a ‘real Windows Phone,’” he said alluding to Nokia CEO Stephen Elop’s comment that the Nokia Lumia is the “first real Windows Phone.” Argenti also noted that some analysts have projected that Windows Phone could reach 19.5 percent adoption by 2015.
Moreover, since Nokia and Microsoft teamed up eight months ago, they have seen 330 percent growth in the number of apps available for the platform. “In the Nokia Store we have over 90,000 apps,” Argenti said.
Bencke explained that Nokia and Microsoft are building a new “third” ecosystem together and are helping with the development, marketing, merchandising, designing, providing a marketplace and other issues required for an ecosystem.
“For instance, we’re working with Nokia to understand local markets so developers’ great apps can be discovered,” Bencke said. “We’re also working to make payment more readily available. Nokia has 131 payment processing centers around the globe.”
Microsoft and Nokia also have 1,600 evangelists around the world spreading the word about Windows Phone on Nokia, Bencke added.
Chris Klug described Dynamic IP-address filtering for Azure in a 10/27/2011 post:
Putting applications in the cloud is great, and offers a lot of benefits (as well as some complications). We get great scalability, elasticity, low cost of ownership etc. One problem however, is that the cloud is very public. I guess this isn’t a problem in most cases, but if what you are putting up there is supposed to be secret, or at least needs to limit who gets to use it, it becomes an issue.
I am currently working on a project like this. I am not going to talk about the project as such as it is under NDA, but the fact that it is is a service in the cloud that should only be used by certain clients is not uncommon.
The service has a front end that consists of WCF services, hosted in a web role, which is what we need to secure. The worker roles behind the web roles are by default secure as they do not communicate with the outside world at all.
We are using basicHttpBindings for different reasons, and have decided to secure the communication using BasicHttpSecurityMode.TransportWithMessageCredential. We have also decided that due to the limited amount of clients, and their static locations, IP-address filtering would add another layer of security. It isn’t fail safe, but it is at least another layer that you would need to get through.
Setting up IP-address filtering isn’t hard on a local IIS, but require a bit more work in the cloud. Why? Well, the feature isn’t installed by default. And to adding to that, we need to be able to reconfigure the IP-addresses without having to redeploy.
But let’s start with enabling the IP-address filtering module in IIS, which is done using a startup task. The IP-address whitelisting can wait for now. One thing at the time.
A startup task is a cmd-file that is run when the role is being set up. You can find a lot more information about these tasks on the interwebs. This information will tell you that you can run them as background tasks and foreground tasks and probably do all sorts of things. In this case, we can ignore that…
Let’s start by creating a startup task. I do this by creating a new text file called Startup.cmd (name doesn’t matter). I do however make sure it is saved as a UTF-8 encoded file without a byte order mark. VS doesn’t do this easily, so create the file using Notepad instead. I put it in the root of my application, but it can probably be anywhere…(I didn’t read up on all the startup task features, but I assume you can just change the path to it…)
Also, make sure to set the “Build Action” in VS to none, and the “Copy to Output Directory” setting to “Copy always” or “Copy if newer”. This will make sure that the file is included in the package, but isn’t embedded.
Inside the file, we can place any command that we want to run on the server. In this case, we need to install the "IPv4 Address and Domain Restrictions" feature, and unlock the IP-security section in the configuration. I have blatantly stolen this script somewhere on the web, but I can’t remember where. I have however seen it in a LOT of different places when looking for it, so I assume it is ok for me to use it as well…
@echo off
@echo Installing "IPv4 Address and Domain Restrictions" feature
%windir%\System32\ServerManagerCmd.exe -install Web-IP-Security
@echo Unlocking configuration for "IPv4 Address and Domain Restrictions" feature
%windir%\system32\inetsrv\AppCmd.exe unlock config -section:system.webServer/security/ipSecurityAs you can see, it uses ServerManagerCmd.exe to install the feature, and AppCmd.exe to unlock the config section for modification. Without unlocking it, we are not allowed to make changes to it…which we need to do…
To get the startup task to run, I open the ServiceDefinition.csdef and add the following fragment to the WebRole element
<Startup>
<Task commandLine="Startup.cmd" executionContext="elevated" taskType="simple" />
</Startup>As you can see, I am telling it to run my Startup.cmd from the root of the project, using elevated privileges.
If you were to run this, it would just work. Well…kind of… It would install the feature alright, but it wouldn’t do any filtering. To get it to actually do something, you would have to change the web.config file to till IIS to actually filter. This is done in the configuration/system.webServer/security element. You can find more information about it here for example.
But in this case, I need to make it a bit more complicated. I can’t put up a list of IP-addresses like this. It needs to be able to be configured using the Azure config instead. The reason? Well, they can be changed on a running instance, while the web.config can’t. A web.config change requires a redeploy of the application. This last part proved to be a bit more complicated than I thought though.
I just want to add a disclaimer here! This is the solution I came up with. It does not reflect the opinion of my employer, parents, wife etc. I have no idea if it is a good practice or not. I take no responsibility for any destroyed servers in Microsoft’s data centers. Basically I take no responsibility for anything if you use it, but it seems to work. If you have a better way, please let me know! And if you know more than me and still believe it is an OK way to do it, please let me know then as well. In that case I can remove this disclaimer…
Ok, so let’s go ahead now that the disclaimer is out of the way! So far it has not blown up anything, an it worked in the cloud on the first attempt…
First thing first. I need to get the configuration from the Azure config into my startup task. Luckily, Steve Marx had a post that showed how that was done. The short story being that you can use xPath expressions to get information from the role configuration into your startup task, where they show up as environment variables.
He however used a simple bool to turn a task on or off. In my case, I needed a list, but who cares. A semicolon separated list of IP-addresses probably works the same... So I added the following to my startup task configuration XML.
<Startup>
<Task commandLine="Startup.cmd" executionContext="elevated" taskType="simple">
<Environment>
<Variable name="ADDRESSES">
<RoleInstanceValue xpath="/RoleEnvironment/CurrentInstance/ConfigurationSettings/ConfigurationSetting[@name='WhiteListedIPs']/@value" />
</Variable>
</Environment>
</Task>
</Startup>I also added a new configuration setting definition called WhiteListedIPs in the service definition, and updated each of the role configurations.
I then set about trying to use the string in my cmd-file. However, after having failed several times, I came to the conclusion that I sucked at writing cmd-files…and in a vain attempt to explain why, I just want to say that I wasn’t interested in computers when cmd-files where common. So I really have very little knowledge about how you author cmd-files. I am however quite good at building C# apps, and also at coming up with cowboy-ways of solving problems.
In this case, I decided to create another project in my solution. A console application project. I then added a reference from my web project to that project. Yes, a reference from a web project to a console application project. Sweet! Cowboyness…check!
This way, the exe-file created from the new project will be copied to the bin folder of the web project, where it ends up sitting right next to my cmd-file. Just what I needed.
Next, I modified my cmd-file to start the new exe-file, and pass the string of IP-addresses to it as a command line parameter, making the cmd-file look like this
@echo off
@echo Installing "IPv4 Address and Domain Restrictions" feature
%windir%\System32\ServerManagerCmd.exe -install Web-IP-Security
@echo Unlocking configuration for "IPv4 Address and Domain Restrictions" feature
%windir%\system32\inetsrv\AppCmd.exe unlock config -section:system.webServer/security/ipSecurity
SetUpRestrictedAccess.exe "%ADDRESSES%"I then went and looked at the console application. It is fairly simple. It uses the ServerManager class from the Microsoft.Web.Administration assembly to get hold of the IP security config section for the host.
I admit that changing the host config instead of the individual web.config file seems a little little shooting mosquitos with a cannon, but it was the way I did it. And it works…
Next, I make sure to set the allowUnlisted parameter to false. Then I go ahead and clean out the existing addresses and configured the allowed IP-addresses.
Do NOT forget to add 127.0.0.1 as well. If you do, debugging will fail. I also had some issues when not setting the subnet mask to a “wider” value. But changing that made debugging work. Don’t ask me why, but please tell me why if you know! This can of course be skipped by using Marx’s emulated trick…I did however find that a bit too late, and had already messed up my host config… It might also be a case of me effing up the config while trying different ways of doing this… But once again, it works like this…
After the local address is added, I split the list of IP-addresses that were passed in, and add them one at the time. Finishing the whole thing off with a call to CommitChanges().
using (var serverManager = new ServerManager())
{
var config = serverManager.GetApplicationHostConfiguration();
var ipSecuritySection = config.GetSection("system.webServer/security/ipSecurity");
var ipSecurityCollection = ipSecuritySection.GetCollection();
ipSecuritySection["allowUnlisted"] = false;
ipSecurityCollection.Clear();
var addElement = ipSecurityCollection.CreateElement("add");
addElement["ipAddress"] = @"127.0.0.1";
addElement["subnetMask"] = @"255.0.0.0";
addElement["allowed"] = true;
ipSecurityCollection.Add(addElement);
var addresses = args[0].Split(new [] { ";" }, StringSplitOptions.RemoveEmptyEntries);
foreach (var address in addresses)
{
addElement = ipSecurityCollection.CreateElement("add");
addElement["ipAddress"] = address;
addElement["subnetMask"] = @"255.255.255.255";
addElement["allowed"] = true;
ipSecurityCollection.Add(addElement);
}
serverManager.CommitChanges();
}Running this will cause the startup task to runs before the role starts, which in turn calls the console application that adds the desired IP-addresses to the whitelist and blocks everyone else.
There is one more thing that needs to be done though. We need to make sure that we update the configuration if the Azure config is changed. This is easy to do, just make sure that you watch the RoleEnvironment.Changed event, and run through the above code again if it is raised.
In my case, I placed the above code in a common library that could be used both from the console app, and the web role when the role config changed. DRY dude, DRY!
Ok, so why didn’t I just modify the IP-filtering config in the OnStart of the WebRole? Well…I initially did…and then I got a bit surprised. The application actually starts responding to requests before the OnStart method is called. This obviously leaves a gap in the security for a short period of time. Not a big gap, but big enough to feel wrong. So we decided to make sure we got it configured in time.
That’s it! As usual, I hope you got some info you needed. There are a lot of samples on how to run startup tasks out there. There are even a bunch about setting up IP-filtering. But I couldn’t find one that could take the configuration from the Azure config, and thus couldn’t be changed at runtime.
In a different scenario with more frequent IP-changes, I would probably have put the IP-addresses in a DB instead, and have a WCF service method that could be called to make the change. But since the IP-address changes are very likely to be infrequent in this project, this sufficed.
No code this time…sorry!

Avkash Chauhan (@avkashchauhan) reported Whats new in Windows Azure SDK 1.5 - Packages are no longer encrypted in a 10/27/2011 post:
In Windows Azure SDK 1.5 the packages are no longer encrypted since they are always transferred between the development machine and Windows Azure Portal over https.
Up to Windows Azure SDK 1.4 when you generate Service Package (CSPKG) file then file was encrypted using a certificate included Windows Azure SDK. There used to be environment variable flag which can be set as TRUE to disable encryption as below:
- _CSPACK_FORCE_NOENCRYPT_=true
Step 1: Copy/rename CSPKG file to ZIP file
Step 2: Inside ZIP file you will see another CSSX file as below, take it out from ZIP file.
Step 3: Renaming CSSX file to ZIP file, and unzipping it will give you all the contents in your package



Bruno Terkaly (@BrunoTerkaly) recommended that developers Download Toolkits for iOS and Android to connect to the Microsoft Cloud (Windows Azure) in a 10/26/2011 post:
Jump-Starting your iOS and Android Development for Windows Azure
The Windows Azure Toolkit for Android is a toolkit for developers to make it easy to work with Windows Azure from native Android applications. The toolkit can be used for native Android applications developed using Eclipse and the Android SDK.
The Windows Azure Toolkit for iOS is a toolkit for developers to make it easy to access Windows Azure storage services from native iOS applications. The toolkit can be used for both iPhone and iPad applications, developed using Objective-C and XCode.
First, download the Windows Azure SDK:
Toolkits for Android and iOS: https://github.com/microsoft-dpe/



<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Kostas Christodoulou continued his series with CLASS Extensions. Making of (Part II) on 10/29/2011:
Crashing your LightSwitch project with your extensions is a piece of cake. The first simplest thing I did was change the business type to handle integer values instead of string ones. But I changed “:String” to “:Int”. That was enough to do it. It should be “:Int32”.
So, after managing to create and use (declare as a type for an integer field in an entity) my business type, keeping my LightSwitch project in one piece, I had to work on my control. As I have already mentioned I had my custom control ready and tested, so, it should be easy.
I had used my custom control only in detail parts and although the expander used was “deforming” the layout when expanded (I have to fix this anyhow in the future) everything were going back to normal after collapsing the expander. This was not so for collections. Using my control in a grid the result after collapsing the color picker control was a grid row having a height of the expanded control. The reason is that the grid rows are auto-sized and have no specific height so…
I was only after having implemented a wrapper control to provide 2 different controls, one for collections and one for details, based on the reply by Justin Anderson to a thread initially intended to help me handle read-only controls, that I got an answer from Silverlight forum where I knew it was the right place to post my question. Either way, implementing what the reply suggested (although it works fine) required a lot of handling of transitions between expanded and collapsed. Also the “deform” in a grid when the control is expanded(even temporary) is, in my opinion, more annoying than in details.if ((this.DataContext as IContentItem).ContainerState.HasFlag(ContainerState.Cell)) { ColorControl control = new ColorControl(); control.DataContext = this.DataContext; control.SetBinding(ColorControl.IsReadOnlyProperty, new Binding("IsReadOnly")); MainGrid.Children.Add(control); } else { ColorPickerDrop control = new ColorPickerDrop(); control.DataContext = this.DataContext; control.SetBinding(ColorPickerDrop.IsReadOnlyProperty, new Binding("IsReadOnly")); MainGrid.Children.Add(control); }In the code above you can see selecting the control to “use” based on the ContainerState property of the IContentItem that is passed as DataContext. You can also see the attempt to make the control read-only. My attempt was to make the controls automatically read-only when “Use read-only controls” is checked from the designer. I was that close…
Also for some reason my control when implemented in extension tended to take too much space by default. I had to change alignment to left/top by hand. It was only after releasing the first (and only one available until now) version that I managed to handle this along with other issues regarding designer behavior.
Hopefully before the end of 2011 I will be able to publish the next version, which contains also one more business type (rating) and respective control.
In the next post I will discuss the read-only issue that I didn’t manage to deal with in the published version…
Beth Massi (@bethmassi) announced on 10/28/2011 that she’ll be Talking LightSwitch in the South Bay on Wednesday Nov. 2nd in Mountain View, CA:
I’ll be speaking about LightSwitch next Wednesday in Mountain View so if you’re in the area come on out and I’ll show you what LightSwitch can do for you! See how to build business applications in light speed….
Building Business Applications in Light Speed with Visual Studio LightSwitch
When: Wednesday, 11/2/2011 at 6:00 PM
Where: Hacker Dojo, 140A S Whisman Rd Mountain View, CA
Visual Studio LightSwitch is the simplest way to build business applications for the desktop and cloud for developers of all skill levels. LightSwitch simplifies the development process by letting you concentrate on the business logic, while LightSwitch handles the common tasks for you. In this demo-heavy session, you will see, end-to-end, how to build and deploy a data-centric business application using LightSwitch. You will also see how professional developers can enhance the LightSwitch experience by tapping into its rich extensibility model.
Hope to see you there!

Alessandro Del Sole (@progalex) explained Using Silverlight Pie Charts in Visual Studio LightSwitch in a 10/27/2011 post to The Code Project:
This article explains how to bind Pie Chart controls from the Silverlight Toolkit to a LightSwitch screen.
Introduction
Often you need to provide a visual representation of your data and it is not unusual to present information via charts. This is a very common business requirement. In Visual Studio LightSwitch there is not a built-in control to display charts, but you can easily take advantage of extensibility and use chart controls from the free Silverlight Toolkit, available on CodePlex. In this article you learn how to extend LightSwitch applications with custom Silverlight controls that embed Pie Chart controls and that are data-bound to screen collections.
Background
You need to download and install both theSilverlight Toolkit and the Northwind database, which is used as an external data source in order to keep the source code archive size smaller and because that database already includes a number of data. You also need a little bit of familiarity with Silverlight 4 or at least with XAML code and data-binding concepts. This also requires you to have Visual Studio 2010 Professional or higher. The sample application will display a simple list of products from the Northwind database and will display a chart based on the products' unit price. One entity and one screen will be used for this example; if you are not new to Silverlight, building the application described in this article takes less then half an hour.
LightSwitch
Basically the application uses a custom control, which is one of the LightSwitch extensibility points. I wrote the custom control myself, embedding charting controls from the Silverlight Toolkit. Notice that without LightSwitch creating a business application like this would require working with Silverlight 4 (or WPF) and writing all the plumbing code such as the data access layer, the user interface, code for binding data and so on. Using LightSwitch dramatically boosted my productivity and saved me a lot of time (and thus, business money).
Creating the Project
The first thing to do in Visual Studio 2010 is creating a new LightSwitch project:
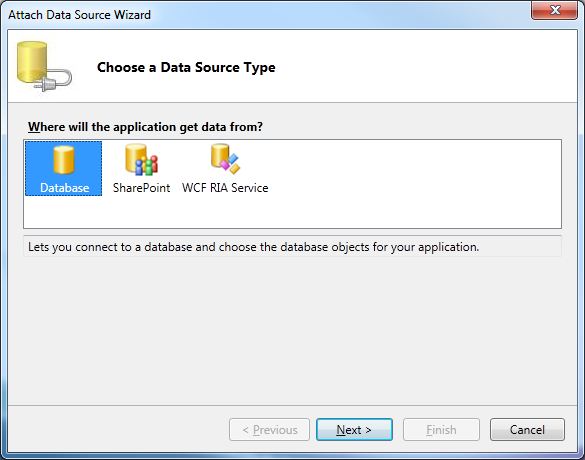
When the new project is ready, click Attach to external data source. In the Attach Data Source Wizard dialog, you first select the Database option:
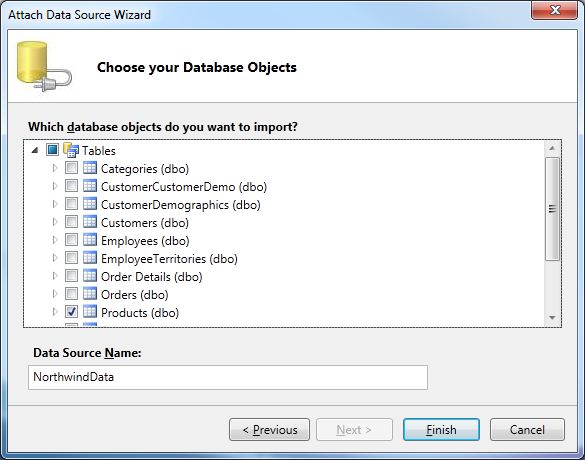
You will then specify the connection information to Northwind, and then you will be able to select your tables. Just select the
Productsone, which is enough:
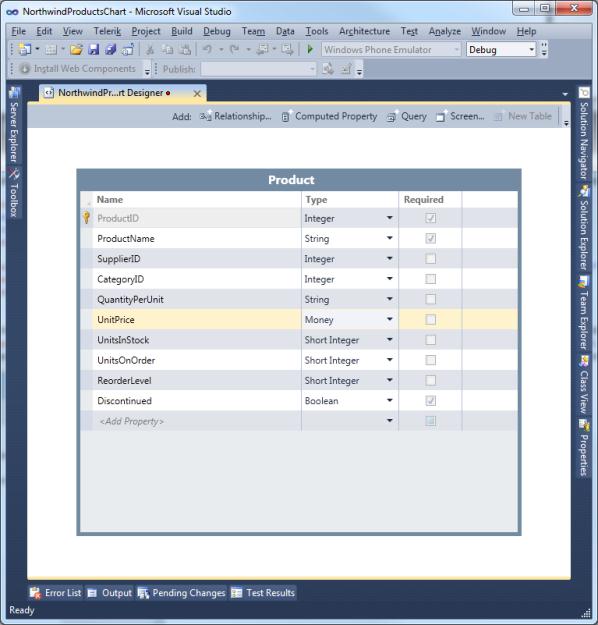
At this point Visual Studio LightSwitch generates a new
Productentity. Replace theDecimaltype with theMoneybusiness type, as represented in the following figure:
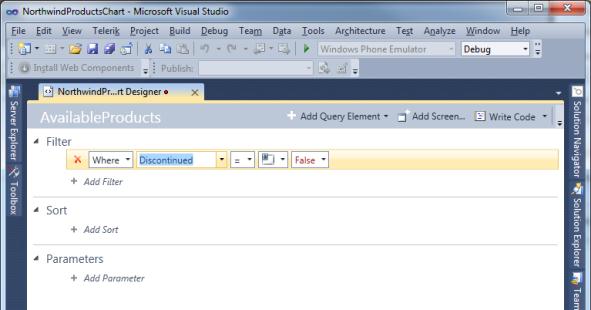
You will need a Search Screen at this point, but since the list of products is quite long you can filter the search result with a query that excludes discontinued products. To accomplish this, in the Designer click Query. Rename the new query as
AvailableProductsand specify aWherecondition like in the following example:
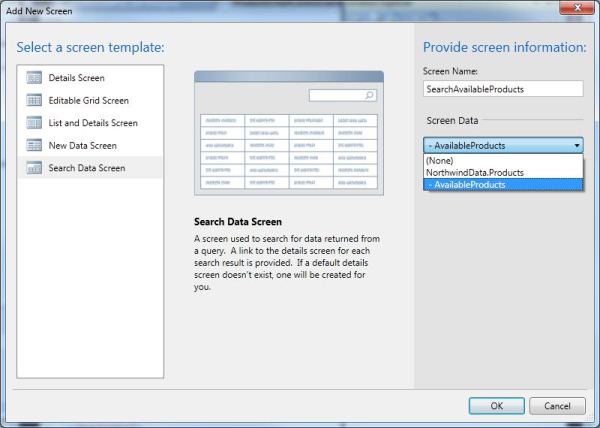
Now click Add Screen and add a new screen of type Search Screen that points to the query:
You will now implement a custom Silverlight control that draws pie charts based on the products list and you will later embed the control in the Search Screen.
Creating a custom Silverlight control to display charts
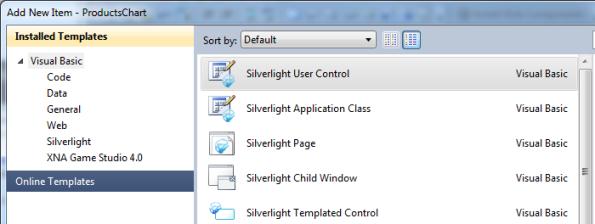
Select File, Add, New Projectand add a new project of type Silverlight Class Libraryto the Solution. When the new project is ready, remove the default code file (Class1.vb) and then add a new item of type Silverlight User Control calling this
ProductsChartControl.
At this point you need to add a reference to an assembly called System.Windows.Controls.Toolkit.dll, which is located under the Silverlight Toolkit's folder on disk. The goal now is implementing a custom control that displays pie charts based on products' names and unit prices. The following code demonstrates how to implement such a custom control:
Collapse | Copy Code
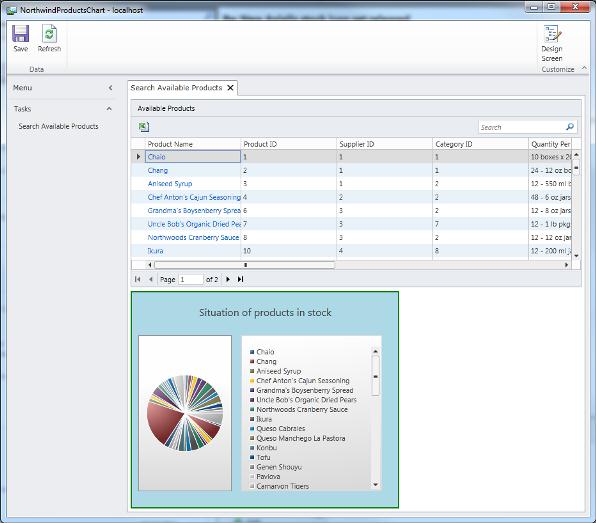
<UserControl x:Class="ProductsChart.ProductsChartControl" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" xmlns:d="http://schemas.microsoft.com/expression/blend/2008" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" mc:Ignorable="d" Width="420" Height="340" d:DesignHeight="300" d:DesignWidth="400" xmlns:toolkit="http://schemas.microsoft.com/winfx/2006/xaml/presentation/toolkit"> <Grid x:Name="LayoutRoot" Background="White"> <toolkit:Chart x:Name="unitsInStockChart" Background="LightBlue" BorderBrush="Green" BorderThickness="2" Title="Situation of products in stock" Grid.Column="0" > <toolkit:Chart.Series> <toolkit:PieSeries Name="PieSeries1" ItemsSource="{Binding Screen.AvailableProducts}" IsSelectionEnabled="False" IndependentValueBinding="{Binding ProductName}" DependentValueBinding="{Binding UnitPrice}" /> </toolkit:Chart.Series> </toolkit:Chart> </Grid> </UserControl>Basically the
Chartcontrol from the toolkit acts like a container of chart drawings. ThePieSeriescontrol is data-bound (ItemsSource) to the screen collection; theIndependentValueBindingproperty represents what you will see on the X axis of the chart, whereasDependentValueBindingrepresents what you will see on the Y axis. At this point simply compile the project.Using the custom control in LightSwitch
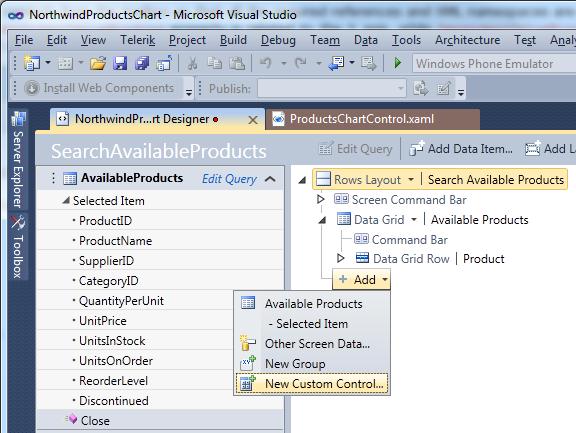
In Solution Explorer double-click the search screen you added before, so that it is opened in the Screen Designer. Expand the Add drop-down box located at the very bottom of the designer and then select New Custom Control:
At this point you will need to add first a reference to the class library project and then you will select the
ProductsChartControlcreated before:
You will notice that it is placed at the bottom of the screen's controls tree; you can choose to remove the control label in the Properties window.
Testing the Application
You can now press F5 to run the application. Once data are loaded, the chart control is also populated according to the data-bound properties specified before:
Points of Interest
Extensibility in Visual Studio LightSwitch allows adding interesting features and behaviors to application even when some functionalities or controls are not available out of the box. The Silverlight Toolkit offers a number of free, reusable controls that can be easily embedded in LightSwitch applications and add special effects with regard to data visualization as well.
License
This article, along with any associated source code and files, is licensed under The Microsoft Public License (Ms-PL)

Return to section navigation list>
Windows Azure Infrastructure and DevOps
Adam Hall of Microsoft’s Server and Cloud Platform Team described App Controller – Enabling Application Self Service in a 10/28/2011 post:
As announced on the Server and Cloud Platform Blog, System Center App Controller 2012 Beta is now available!
App Controller is a new member of the System Center family and provides a number of capabilities that enable Application Self Service across both private and public clouds. In this post, we will explore these key capabilities.
Before we dive into the details, let’s define what we mean by the term ‘application’ and what we mean by a ‘service’. In a cloud computing model, a service is a deployed instance of an application along with its associated configuration and virtual infrastructure. So, in this context, you will see that we talk about ‘applications’ but we manage them as ‘services’.
Enabling a Standardized Approach to Deploying Applications Across Private and Public Clouds
Windows Azure also operates on a template model, combining an Application Package with an associated Configuration.
App Controller allows a user to view, manage, and deploy services to both a private cloud (via Virtual Machine Manager) and the Public Windows Azure Cloud in a consistent template driven manner. As you can see in the screenshot below, at deployment time the user can choose to deploy the service to any cloud they have access to, as well as see the available quota they have left in that cloud.
The two screenshots below show the deployment of an Azure (top) and a VMM service (below). As you can see, the template diagram and configuration is very similar. This was a key design goal in order to make the deployment of a service consistent regardless of location.
A Unified Web Console to Simplify Management of Applications Across Private and Public Clouds
App Controller provides the ability to manage services running in on-premises private clouds and in Windows Azure Public Clouds. Users can see all of the services that they have access to in a simple, unified view.
In the screenshot below, this user has access to two private cloud instances and three Windows Azure subscriptions. This user can also see what the delegated resource quota utilization is for his or her private clouds.
The screenshot below shows the view a user has of running services.
Actions can be performed against the services, including start/stop the service, apply a new template to upgrade the application, or even delete it if the service is being decommissioned.
Manage and Maintain Application Resources
App Controller provides the user with an easy experience to upload, manage, and duplicate application resources. From receiving an updated application on a file share, to duplicating the application between clouds, to uploading a Windows Azure application package, App Controller provides a clean and simple management capability for all of these application resources.
Duplicating service templates is an easy copy/paste function between private clouds allowing the user to duplicate all content or map the template component to existing resources that exist in the destination cloud, as shown below.
Manage Multiple Windows Azure Subscriptions and Delegate Access to Them
App Controller allows you to connect to multiple Windows Azure subscriptions and then delegate subscription access out to users via their Active Directory credentials. This provides a common access model across the management of both private and public clouds and the services running in them.
Access to Windows Azure subscriptions is delegated on a per-subscription basis, as shown below.
Infrastructure Management, Reimagined
And, finally, App Controller also provides the ability to manage the individual Virtual Machines that are running within the services to which the user has access. All of the usual management capabilities are there: stopping, starting, mounting an ISO opening a remote desktop connection, and so on. But, we still provide that information in the context of the service, so the user always knows what he or she is working on.
Calls to Action!
So, what do you do now? Where can you find more information? Look no further – here is a list of links to all of the App Controller related content!
- Get involved in the Community Evaluation Program (CEP). We are running a private cloud evaluation program starting in November where we will step you through the entire System Center Private Cloud solution set, from Fabric and Infrastructure, through Service Delivery & Automation and Application Management. Sign up here.
- Online Documentation
- App Controller TechNet Forums
We hope you decide to take App Controller for a spin, and please provide us with feedback on your experiences.










Jo Maitland (@JoMaitlandTT) posted Azure updates may leave Windows shops wanting more to TechTarget’s SearchCloudComputing.com on 10/28/2011:
Windows shops taking the plunge into cloud computing can have faith in its more mature Azure Platform as a Service, but should keep an eye on unexpected costs.
“Microsoft's goal is to mirror what it does in Azure in the on-premises products, but it's not there yet.”
Rob Sanfilippo, research vice president, Directions on Microsoft
That's the sentiment independent analyst firm, Directions on Microsoft, provided in an update and Q&A session on some useful features added to Windows Azure that became available in the past month. Rob Sanfilippo, research vice president for developer tools and strategies at Directions on Microsoft, led the webinar.
Recent updates include a feature called server side in-memory caching (codenamed Velocity), which improves performance of hosted .NET applications. The cache can be shared across instances running on Azure, but it's charged as a separate service, so watch out for that, he noted.
Windows Azure storage has a new geo replication feature that automatically replicates data to a secondary data center in the same region at no extra cost. There is a charge for additional regions, though. And Traffic Manager provides various ways to handle the lack of availability of a hosted service.
In SQL Azure, Sanfilippo said, Microsoft added a federation service that automatically performs data sharding across databases. This means users can string together databases over the 150 GB limit and treat them logically as one database. This gets around the database size limitation criticisms SQL Azure has received.
On the pricing front, Sanfilippo said Azure's extra small compute instances were now $0.04 per hour, down from $0.05 per hour, putting it at a more competitive level with Amazon Web Services. And the Access Control feature in Windows Azure Appfabric, which can now handle authentication and authorization mapping between clients and applications, is free until January 1, 2012. It works with popular identity providers (ADFS, LiveID, Facebook and Google) to reduce the burden on developers to include security code in their applications. Sanfilippo said to try this out soon before Microsoft starts charging for it. He also liked the new Azure pricing calculator that lets users get a tally of what their monthly rate would if they were to deploy an app on Azure. …

Read more: Jo continues with “Q&A in which Sanfilippo took questions from Windows administrators and developers.”
Velocity is an IIS caching service. Most Azure developers use Windows Azure AppFabric Caching services. The Windows Azure Storage Team posted geo-replication details in Introducing Geo-replication for Windows Azure Storage on 9/15/2011.
Kevin Remde (@KevinRemde) reported Breaking News: More New System Center 2012 RCs and Betas Available Today on 10/27/2011:
Great news! More betas and release candidates of the System Center 2012 tools are available today for download! Like many of you, I have been waiting patiently for these gems, and I can’t wait to start playing with them. These round out the pre-releases of tools that allow you to support private and hybrid cloud solutions.
Released today:
System Center Configuration Manager 2012 Release Candidate (RC)
- System Center Endpoint Protection 2012 RC
- System Center Service Manager 2012 Beta
- System Center App Controller 2012 Beta (formerly codename “Concero”)
System Center Configuration Manager 2012 has already had a couple of betas, so it’s nice to see that it is now up to Release Candidate status. Some of the improvements:
- Diverse mobile device management support through Exchange ActiveSync including support for iOS, Android, Symbian as well as Windows mobile devices.
- User-centric application delivery across multiple devices
- Integrated settings management with auto-remediation
- Integrated desktop antivirus management with System Center 2012 Endpoint Protection
- An Improved, modern administration user interface with built in search concepts
Furthermore, new capabilities released in this RC release include:
- Improved endpoint protection functionality, with integrated setup, management and reporting for System Center 2012 Endpoint Protection.
- Improved application catalog design that provides a better, more responsive experience when requesting and downloading applications.
- New support for Windows Embedded devices, including Windows Embedded 7 SP1, POSReady 7, Windows 7 Think PC, and Windows Embedded Compact 7.
- Improved client health checks for Configuration Manager services and features
- Improved compliance enforcement and tracking, with the ability to create dynamic collections of baseline compliance and generate hourly compliance summaries.
- Platform support for deep mobile device management of Nokia Symbian Belle devices. Pending a platform update by Nokia later this calendar year for these devices, customers will be able to try out the management of Nokia devices with ConfigMgr.
- Additional scalability and performance improvements.
System Center Endpoint Protection 2012 is a name that you have never heard before today. That’s because it is an official re-branding of what was Forefront Endpoint Protection. “This name change better reflects the integration between management and security that we have been working towards…” says it pretty well. I think the fact that this solution is not only integrated with, it is “built upon” System Center Configuration Manager is a key part of this, too. It makes sense.
“Sounds great. Which betas are available today?”
The first of the two betas released today is System Center Service Manager 2012, which is, as the name implies, the service management part of the solution.
“You mean, like a help-desk support ticket manager?”
Yes, and much more. I know I’m just scratching the surface of all it can do when I say this – but think about how you will provide a self-service interface for your users and the business units you support. Service Manager is the tool that you will use to create that portal, and then to allow you to act upon requests; and not just manually. Those requests can be handled by you and your staff, or trigger some automation to take care of the request. (See System Center Orchestrator 2012). Also, Service Manager 2012 adds the tracking of SLAs. So if you have a service that you have promised a certain response time or up-time for, Service Manager can track your actual performance against those goals.
For a private cloud, you have to grant people the ability to request and acquire services without having to know the details of the underlying architecture (the “fabric” - Storage, Compute, Networking). Service Manager is one way to provide that interface. More details about the current version, Service Manager 2010, can be found here.
And the other beta available today, formerly known as codename “Concero”, is System Center App Controller 2012.
“Let me guess.. It controls your apps?”
Well.. yeah.. in a sense. More accurately, though; this is the tool that bridges the gap for the management of private and public cloud services. Once the fabric is configured, and the clouds are defined; meaning: once you folks in the datacenter have created the building blocks for the services you provide, and have defined the abstracted layer at which your users can request and manage services (See?! Sometimes it’s just easier to say “cloud”, isn’t it!), or through which you can make changes such as scaling-out your services. For example, adding more instances of the web-tier in a muli-tiered application, for example.
“Couldn’t I just use System Center Virtual Machine Manager to do that?”
Sure, you could – if that person has the VMM 2012 admin console installed. And if all of your clouds are local. But what the application owner doesn’t have that console installed? Or what they also manage multi-tiered applications (or call them “services”) running in some other cloud like Windows Azure?
“Wait.. what? I can manage my Windows Azure-based services with this?”
Yep. As I said, App Controller bridges that gap for you. It’s a self-service portal where the application owners can go to manage their applications that are running in your private and/or public cloud spaces. For those folks, it’s not about managing the infrastructure or the plumbing you’ve provided. For them, “It’s all about the app.”
You can find more details about System Center App Controller 2012 here.
“So.. the obvious question remains: When will these products be released?”
They are shooting for the first half of calendar year 2012.
---
DOWNLOAD and try these tools out. But wait just a minute and let me start my download first.

Simon Munro (@simonmunro) posted TestOps, Scalability Engineers and other important roles to his CloudComments.net blog on 10/27/2011:
I was reminded yesterday of a project that is failing to go live right at the end because of unforeseen performance problems of a particular component. It should never have happened.
Why? Well, the architecture was built in such a way as to explicitly remove a dependency of an underperforming RDBMS, so it should never have become a problem. But architectural decay happens, so let’s let that slide. The main reason for being in that position is that assumptions were made about the performance/capacity of a component that were not perpetually tested. When building apps on a public cloud you cannot make any assumptions about performance of the underlying infrastructure – there are just too many variables and unknowns that get in the way. On premise you can always scale up, improve the storage i/o, decrease latency by changing the network, or any other infrastructure tweaks available. On the public cloud the only tool that you have is the ability to test continuously in a production environment.
Perpetual production testing allows the architecture to be adapted if bottlenecks are detected and completed code to be ‘reviewed’ against a production platform. This means that early on in the project you need infrastructure to run tests, something to monitor results (such as NewRelic), a strategy for perpetual testing, sample data, and people who ‘get it’.
Unfortunately current testers , don’t ‘get’ the opportunity that early testing presents, are too used to having to wait for the operational (QA) platform to be presented when ready and do not have sufficient infrastructural or development skills to coax a half-finished application to life. The developers meanwhile have little respect or interest in testing and, particularly in the cloud, are unfamiliar with the immediate feedback loop and significance of perpetual load and performance testing. Devops, well there are so few of them around that they are probably run ragged and don’t have time to look up from the infrastructure.
This results in a crucial gap in the cloud application development process that leads to surprise underperformance too late in the cycle to do anything about. Then all the finger pointing starts.
While many understand the importance of test skills (Microsoft has ‘Software Engineer in Test’ as a primary role), in most cases testers are little more than button pushers. I have only met an handful of testers that can rustle up a working Outlook rule (using the wizard), never mind being able to write a python script to make something happen on a production environment. Within development teams testers are seen as barely technical resources, and it is not an attitude that will change soon, if at all.
I was thinking that maybe the role should be TestOps, to borrow from the DevOps culture, being someone who does testing within a highly technical ops environment. More towards the development side is a ‘Software Scalability Engineer’, reflecting someone who writes code, but not necessarily features, and still has to do hands-on scripting, testing and moving data around.
Whatever the role is called, or even if it is rolled up in a single person, there is no doubt that the function exists. We desperately need people who can perpetually check to make sure that our promised scalability and availability is actually delivered – all of this on top of a public cloud platform that is subject to, erm, interesting behaviours.
David Linthicum (@DavidLinthicum) asserted “Several barriers keep the government from executing its stated 'cloud first' policy -- but three steps can overcome them” in a deck for his How to revive the feds' lifeless 'cloud first' policy article of 10/27/2011 for InfoWorld’s Cloud Computing blog:
Remember the federal government's "cloud first" policy? A year ago, the Washington Post reported, "The [General Services Administration, the main procurement agency] is the first federal agency to make the Internet switch, and its decision follows the Office of Management and Budget's declaration last month that the government is now operating under a 'cloud-first' policy, meaning agencies must give priority to Web-based applications and services."
Almost a year later, we're still waiting for cloud computing to show up in most government agencies. There are many reasons for the slow adoption of cloud computing in the federal government: the huge size of government IT, the long procurement cycles, and the lack of cloud computing talent in both government IT and its array of contractors.
Another issue is pushback from multiple entities against the use of cloud computing, including Congress questioning the "cloud first" policy. Congress is looking at the potential security risks of cloud computing. However, government IT and government contractors are relatively sure they can maintain enterprise security as the government looks to migrate to the cloud.
The backstory is not surprising to most in government IT. The policy does not have the teeth it needs to drive the change required for many federal agencies to get to cloud computing. Although the policy tells agencies that the economic savings from cloud computing is their incentive for adoption, those agencies need upfront funding to get moving in the right direction. That money is currently lacking.
Moreover, the government agencies need to think differently as to how they do IT going forward -- and that seems to be the largest hurdle. In the current federal approach to IT, sharing is not encouraged, but ownership of infrastructure and applications is. Thus, the number of data centers built and maintained by the government has exploded in recent years, as new requirements led to new systems, which led to more racks.
The solution to this problem takes three steps:
- Provide funding. You can't get to the value without change, and change costs money.
- Work on changing the cultures in government IT. Perhaps this is an impossible task, but if the cultures of server ownership and IT fiefdoms don't fall by the wayside, cloud computing won't have much of a chance.
- Set and hold to deadlines. There are cloud mandates in place now; make sure they are enforced.

Martin J. Logan (@martinjlogan) posted DevOps in the Cloud Explained to the DevOps.com blog on 10/23/2011:
This post was done by @martinjlogan and based on a presentation given by George Reese @GeorgeReese at Camp DevOps 2011
Time to throw some more buzzwords at you. Nothing makes peoples eyes roll back more quickly than saying DevOps and Cloud in the same sentence. This is going to be all about Cloud and DevOps.
The theory of DevOps is predicated on the idea that all elements of a technology infrastructure can be controlled through code. Without cloud that can’t be entirely true. Someone has to back the servers into the data center and so on. In pure cloud operations we get to this sort of nirvana where everything relating to technology is controllable purely through code.
A key thing with respect to DevOps plus Cloud that follows from the statements made above is that everything becomes repeatable. At some level that is the point of DevOps. You take the repeatable elements of Dev and apply them to Ops. Starting a server becomes a repeatable testable process.
Scalability; this is another thing you get with DevOps + Cloud. DevOpsCloud allows you to increase the server to admin ratio. No longer is provisioning a server kept as a long set of steps stored in a black binder somewhere. It is kept as actual software. This reduces errors tremendously.
DevOps + Cloud is self healing. What I mean by that is that when you get to a scenario where you entire infrastructure is governed by code, that code can become aware of anything that is going wrong within its domain. You can detect VM failures and automagically bring up a replacement VM for example. You know that the replacement is going to work the way you designed it. No more 3:00 AM pager alerts for many of your VM failures because this is all handled automatically. Some organizations even go so far as to have “chaos monkeys” these folks are paid to wreak havoc just to ensure/prove that the system is self healing.
Continuous integration and deployment. This means that your environments are never static. There is no fixed production environment with change management processes that govern how you get code into that environment. The walls between dev and ops fall down. We are running CI and delivering code continuously not just at the application level but at the infrastructure level when you fully go DevOps and Cloud.
CloudDevOpsNoSQLCoolness
DevOps needs these buzzwords. The reason it does is because DevOps only succeeds in so far as you are able to manage things through code. Anywhere you drop back to human behavior you are getting away from the value proposition that is represented by DevOps. What cloud and NoSQL bring into the mix is this ability, or ease, to treat all elements of your infrastructure as a programmable component that can be managed through DevOps processes.
I will start off with NoSQL. I am not saying that you can’t automate RDBMS systems, it is just that it is quite a bit easier to automate NoSQL systems because of their properties. It will make more sense in a bit. Let’s talk CAP theorem. CAP theorem is an over arching theorem about how you can manage consistency, availability and partition tolerance.
- Consistency – how consistent is your data for all readers in a system. Can one reader see a different value than another at times – for how long?
- Availability – how tolerant is the entire system of a failure of a single node
- Partition tolerance – a system that continuous to operate despite message loss between partitions.
Now all that was an oversimplification but lets just go with it for now. Cap theorem says that you can’t have more than 2 of the aforementioned properties at once. Relational DBs are essentially focused on consistency. It is very hard [impossible] to have a relational system that has nodes in Chicago and London and has nodes that are perfectly available and consistent. These distributed setups present some of the largest failure scenarios we see in traditional systems. These failures are the types of things we would want to handle automatically with a self healing system. Due to the properties of RDBMS systems, as we will see, this can be very difficult.
The deployment of a relational DB is fairly easy. This can be automated well enough. What gets hard is if you want to scale your reads based on autoscaling metrics. Lets say I have my reads spread across my slaves and I want the number of slaves to go up and down based on demand. The problem here is that each slave brought up needs to pull a ton of data in order to meet the consistency requirements of the system. This is not very efficient.
NoSQL systems go for something called eventual consistency. Most data that you are dealing with on a day to day basis can be eventually consistent. If, for example, if I update my Facebook status, delete it, and then add another it is ok if some people saw the first update and others only saw the second. Lots of data is this way. If you rely on eventual consistency things become a lot easier.
NoSQL systems by design can deal with node failures. In the SQL side if the master fails your application can’t do any writes until you solve the problem by bringing up a new master or promoting a slave. Many NoSQL systems have a peer to peer based relationship between its nodes. This lack of differentiation makes the system much more resistent to failure and much easier to reason about. Automating the recovery of these NoSQL systems is far easier than the RDBMS as you can imagine. At the end of the day, tools with these properties, being easy to reason about and being simple to automate are exactly the types of tools that we should prefer in our CloudDevOps type environments.
Cloud
Cloud is, for the purposes of this discussion, is sort of the pinnacle of SOA in that it makes everything controllable through an API. If it has no API it is not Cloud. If you buy into this then you agree that everything that is Cloud is ultimately programmable.
Virtualization is the foundation of Cloud but virtualization is not Cloud by itself. It certainly enables many of the things we talk about when we talk Cloud but it is not necessary sufficient to be a cloud. Google app engine is a cloud that does not incorporate virtualization. One of the reasons that virtualization is great is because you can automate the procurement of new boxes.
The Cloud platform has 2 key components to it that turn virtualization into Cloud. One of them is locational transparency. When you go into a vSphere console you are very aware of where the VM sits. With a cloud platform you essentially stop caring about that stuff. You don’t have to care anymore about where things lie which means that topology changes become much easier to handle in the scaling case or failure cases. Programming languages like Erlang have made heavy use of this property for years and have proven that this property is highly effective. Let’s talk now about configuration management.
Configuration management is one of the most fundamental elements allowing DevOps in the cloud. It allows you to have different VMs that have just enough OS that they can be provisioned, automatically through virtualization, and then through configuration management can be assigned to a distinct purpose within the cloud. The CM system handles turning the lightly provisioned VM into the type of server that it is intended to be. Orchestration is also a key part of management.
Orchestration is the understanding of the application level view of the infrastructure. It is knowing which apps need to communicate and interact in what ways. The orchestration system armed with this knowledge can then provision and manage nodes in a way consistent with that knowledge. This part of the system also does policy enforcement to please all the governance folks. Moving to an even higher level of abstraction and opinionatedness we will talk about Platform Clouds (PaaS) in the next section.
Platform Clouds (PaaS)
Platform clouds are a bit different. They are not VM focused but instead focus on providing resources and containers for automated scalable applications. Some examples of the type of resources that are provided by a PaaS system are database platforms including both RDBMS and NoSQL resource types. The platform allows you to spin up instances of these sorts of resources through an API on demand. Amazon SimpleDB is an example of this. Messaging components, things that manage communication between components are yet another example of the type of service that these sorts of systems provide. The management of these platforms and the resources provisioned within them is handled by the cloud orchestration and management systems. The systems are also highly effective at providing containers for resources that are user created.
The real power here is that you can package up your application, say a war file or some ruby on rails app, and then just hand it off to the cloud which has specific containers for encapsulating your code and managing things like security, fault tolerance, and scalability. You don’t have to think about it.
One caveat to be aware of though is that you can run into vendor lock in. Moving from one of these platforms, should you rely heavily on its services and resources, can be very difficult and require a lot of refactoring.
Cloud and DevOps
Cloud with your DevOps offers some fantastic properties. The ability to leverage all the advancements made in software development around repeatability and testability with your infrastructure. The ability to scale up as need be real time (autoscaling) and among other things being able to harness the power of self healing systems. DevOps better with Cloud.
Info
Twitter: @GeorgeReese
Email: george.reese at enstratus dot com

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Garth Fort, General Manager of the Management and Security Product Management Team, posted Announcing Private Cloud Community Evaluation Program on 10/27/2011:
You have heard the promise of what the Private Cloud can offer and it is about time that we owe you and ourselves a world class Private Cloud solution. With System Center 2012 and Windows Server Hyper-V, we are delivering on it. To help you understand how we do this, we are excited to announce the Private Cloud Community Evaluation Program (Private Cloud CEP). With our Private Cloud CEP, we will show you how and help you build your own Private Cloud infrastructure from scratch.
System Center 2012 combined with Windows Server Hyper-V helps you deliver flexible and cost effective private cloud infrastructure to your business units in a self-service model, while carrying forward your existing datacenter investments. Recognizing that applications are where core business value resides, System Center 2012 offers performance based monitoring and deep application insight which combined with a “service centric” approach helps you deliver predictable application service levels. System Center 2012 also empowers you to deliver and consume private and public cloud computing on your terms with common management experiences across your environments.
We have had great success running the Community Evaluation Programs for individual System Center products where we invite customers to join us virtually as we talk and demonstrate in great detail about all that is new with System Center 2012. Based on growing interest in Microsoft’s Private Cloud offering, we are ready to kick-off a new program that focuses on how the System Center 2012 products work together to help you create and manage a Private cloud in a very structured manner. As a part of this program you will have clear learning themes that will help you all the way from creating your Private Cloud infrastructure to deploying and monitoring applications in a self-service model. This program will provide you an opportunity to evaluate the products, with guidance from the product teams and understand how System Center 2012 and Windows Server Hyper-V will really change the way you look at Private Cloud.
The program begins on November 1st, 2011 at 1 PM PST and I will be doing the kick-off session. I invite you all to a guided journey to the Private Cloud and beyond. To learn more about the program and sign-up, please follow the link below.
Private Cloud CEP Application: Click Here
I’ve signed up.
<Return to section navigation list>
Cloud Security and Governance
Chris Hoff (@Beaker) exclaimed Oh, c’mon… in a 10/28/2011 in response to a NetworkWorld Article:
Story [Researchers find "massive" security flaws in cloud architectures] here from Network World.
Frankly, XML Signature-Wrapping and XSS don’t represent “massive security flaws in cloud architectures.”
They represent unfortunate vulnerabilities in authentication mechanism and web app security, but “cloud architecture?”
These vulnerabilities were also fixed. Quickly.
Further, while the attack vector will continue to play an important role when using Cloud (publicly) as a delivery model (that is, APIs,) this story is being over played.
Will this/could this/is this type of vulnerability pervasive? Certainly there are opportunities for abuse of Internet-facing APIs and authentication schemes, especially given the reliance on vulnerable protocols and security models?
Perhaps.
Is it scary?
Yes.
See: Cloudifornication and Cloudinomicon.
Related articles
- Researchers demo cloud security issue with Amazon AWS hijacking attack (infoworld.com)
- Shared security flaws of cloud computing (ritcyberselfdefense.wordpress.com)
- Hackers could have taken over AWS (theregister.co.uk)

Chris Hoff (@Beaker) posted The Killer App For OpenFlow and SDN? Security on 10/27/2011:
I spent yesterday at the PacketPushers/TechFieldDay OpenFlow Symposium. The event provided a good overview of what OpenFlow [currently] means, how it fits into the overall context of software-defined networking (SDN) and where it might go from here.
I’d suggest reading Ethan Banks’ (@ecbanks) overview here.
Many of us left the event, however, still wondering about what the “killer app” for OpenFlow might be.
Chatting with Ivan Pepelnjak (@ioshints) and Derrick Winkworth (@CloudToad,) I reiterated that selfishly, I’m still thrilled about the potential that OpenFlow and SDN can bring to security. This was a topic only briefly skirted during the symposium as the ACL-like capabilities of OpenFlow were discussed, but there’s so much more here.
I wrote about this back in May (OpenFlow & SDN – Looking forward to SDNS: Software Defined Network Security):
… “security” needs to be as programmatic/programmable, agile, scaleable and flexible as the workloads (and stacks) it is designed to protect. “Security” in this context extends well beyond the network, but the network provides such a convenient way of defining templated containers against which we can construct and enforce policies across a wide variety of deployment and delivery models.
So as I watch OpenFlow (and Software Defined Networking) mature, I’m really, really excited to recognize the potential for a slew of innovative ways we can leverage and extend this approach to networking [monitoring and enforcement] in order to achieve greater visibility, scale, agility, performance, efficacy and reduced costs associated with security. The more programmatic and instrumented the network becomes, the more capable our security options will become also.
I had to chuckle at a serendipitous tweet from a former Cisco co-worker (Stefan Avgoustakis, @savgoust) because it’s really quite apropos for this topic:
…I think he’s oddly right!
Frankly, if you look at what OpenFlow and SDN (and network programmability in general) gives an operator — the visibility and effective graph of connectivity as well as the multiple-tupule flow action capabilities, there are numerous opportunities to leverage the separation of control/data plane across both virtual and physical networks to provide better security capabilities in response to threats and at a pace/scale/radius commensurate with said threat.
To be able to leverage telemetry and flow tables in the controllers “centrally” and then “dispatch” the necessary security response on an as-needed basis to the network location ONLY that needs it, really does start to sound a lot like the old “immune system” analogy that SDN (self defending networks) promised.
The ability to distribute security capabilities more intelligently as a service layer which can be effected when needed — without the heavy shotgunned footprint of physical in-line devices or the sprawl of virtualized appliances — is truly attractive. Automation for detection and ultimately prevention is FTW.
Bundling the capabilities delivered via programmatic interfaces and coupling that with ways of integrating the “network” and “applications” (of which security is one) produces some really neat opportunities.
Now, this isn’t just a classical “data center core” opportunity, either. How about the WAN/Edge? Campus, branch…? Anywhere you have the need to deliver security as a service.
For non-security examples, check out Dave Ward’s (my Juniper colleague) presentation “Programmable Networks are SFW” where he details interesting use cases such as “service engineered paths,” “service appliance pooling,” “service specific topology,” “content request routing,” and “bandwidth calendaring” for example.
…think of the security ramifications and opportunities linked to those capabilities!
I’ve mocked up a couple of very interesting security prototypes using OpenFlow and some open source security components; from IDP to Anti-malware and the potential is exciting because OpenFlow — in conjunction with other protocols and solutions in the security ecosystem — could provide some of the missing glue necessary to deliver a constant, but abstracted security command/control (nee API-like capability) across heterogenous infrastructure.
NOTE: I’m not suggesting that OpenFlow itself provide these security capabilities, but rather enable security solutions to take advantage of the control/data plane separation to provide for more agile and effective security.
If the potential exists for OpenFlow to effectively allow choice of packet forwarding engines and network virtualization across the spectrum of supporting vendors’ switches, it occurs to me that we could utilize it for firewalls, intrusion detection/prevention engines, WAFs, NAC, etc.
Thoughts?
Related articles
- What’s OpenFlow’s killer app? (infoworld.com)
- OpenFlow and SDN: Networking’s future? (networkworld.com)
- Can OpenFlow Unlock More of Virtualization’s Potential? (informationweek.com)
- OpenFlow Tutorial: Next-Gen Networking Has Much To Prove (informationweek.com)
- Network Virtualization is like a big virtual chassis (bradhedlund.com)
- A Contentious Question: The Value Proposition & Target Market Of Virtual Networking Solutions? (rationalsurvivability.com)
- VMware’s vShield – Why It’s Such A Pain In the Security Ecosystem’s *aaS… (rationalsurvivability.com)
- (Physical, Virtualized and Cloud) Security Automation – An API Example (rationalsurvivability.com)
- SecurityAutomata: A Reference For Security Automation… (rationalsurvivability.com)

<Return to section navigation list>
Cloud Computing Events
Eric Nelson (@ericnel) explained Over 20 years in the industry… and I’m reduced to…
Creating this to start my Thursday
Related Links:
- Sign up for 6 weeks of FREE help to build a solution on the Windows Azure Platform


Martin Tantow (@mtantow) reported CloudTimes Announces Media Sponsorship for CloudBeat 2011 in a 10/27/2011 post to the CloudTimes blog:
CloudTimes is proud to announce a media partnership with VentureBeat on its CloudBeat 2011 conference in Redwood City, CA on Nov 30th – Dec 1st, 2011.
The event will be different from existing cloud conferences. Using a customer-centric approach (rather than vendor-centric), the event will hone in on 12 case studies, where we’ll dissect the most disruptive examples across all layers of the cloud.
These customer case studies will highlight the core components of the cloud revolution:
- security
- collaboration
- analytics
- mobile usage
- increased productivity
- integration
CloudTimes readers register here and use promo code “VB_Times” to get 20% off
The cloud is increasingly governing how companies manage themselves, and it’s giving them more flexibility, speed, and savings. At CloudBeat 2011 you’ll learn the best solutions that are changing the way businesses serve customers, empower employees, and deliver tangible value to investors. Participating industry leaders include:
Aaron Levie, Co-Founder & CEO, Box.net
- Lew Moorman, CSO & President, Cloud, Rackspace
- Javier Soltero, CTO, SaaS, VMware
- Andy McLoughlin, Co-Founder & EVP Strategy, Huddle
- Luis Robles, Venture Capitalist, Sequoia Capital
- Solomon Hykes, Co-Founder & CEO, dotCloud
- Jim McGeever, Chief Operating Officer, NetSuite
- Marten Mickos, CEO, Eucalyptus Systems
- Peter Fenton, General Partner, Benchmark Capital
- Michael Crandell, CEO, RightScale
Check out the full list here.
CloudBeat 2011 will also feature the first ever “Innovation Showdown.” We’re looking for companies with the freshest products or services that leverage the cloud to drive great outcomes for real world organizations. 10 finalists will make the cut, and will have four minutes to showcase their innovative cloud technologies live at CloudBeat 2011. For more info on the Showdown, or to apply, go here.
Join in for an information-packed two days that will offer actionable lessons and networking opportunities, as we explore revolutionary instances of enterprise adoption of the cloud.
CloudTimes readers register here and use promo code “VB_Times” to get 20% off

No significant articles today.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
James Urquhart (@jamesurquhart) analyzed Clouds, open source, and new network models: Part 3 in a 10/28/2011 post:
The most common question I get from those I brief about OpenStack's new network service is "How does Quantum relate to software defined networking?"
Especially confusing to many is the difference between these kinds of cloud networking services and the increasingly discussed OpenFlow open-networking protocol.
In part 1 of this series, I described what is becoming an increasingly ubiquitous model for cloud computing networks, namely the use of simple abstractions delivered by network systems of varying sophistication. In part 2, I then described OpenStack's Quantum network service stack and how it reflected that model.
Software defined networking (SDN) is an increasingly popular--but extremely nascent--model for network control, based on the idea that network traffic flow can be made programmable at scale, thus enabling new dynamic models for traffic management. Because it can create "virtual" networks in the form of custom traffic flows, it can be confusing to see how SDN and cloud network abstractions like Quantum's are related.
To help clarify the difference, I'd like to use one particular example of "software defined networking," which was discussed in depth this week at the PacketPushers/TechFieldDay OpenFlow Symposium. Initially developed for computer science research (and--rumor has it--national intelligence networks), OpenFlow is an "open" protocol to control the traffic flows of multiple switches from a centralized controller.
The whitepaper (PDF) on OpenFlow's Web site provides the following description of the protocol:
"OpenFlow provides an open protocol to program the flow-table in different switches and routers. A network administrator can partition traffic into production and research flows. Researchers can control their own flows--by choosing the routes their packets follow and the processing they receive. In this way, researchers can try new routing protocols, security models, addressing schemes, and even alternatives to IP. On the same network, the production traffic is isolated and processed in the same way as today."
(Credit: OpenFlow.org)
That last sentence is interesting. If a switch (or router) supports OpenFlow, it doesn't mean that every packet sent through the device has to be processed through the protocol. Standard "built-in" algorithms can be used for the majority of traffic, and specific destination addresses (or other packet characteristics) can be used to determine the subset that should be handled via OpenFlow.
What can OpenFlow be used for? Well, Ethan Banks of the Packet Pushers blog has a great post outlining the "state of the union" for OpenFlow. Today, it is very much a research project, but commercial networking companies (including both established vendors and startups) are interested in the possibility that it will allow innovation where innovation wasn't possible before.
But finding the "killer apps" for OpenFlow is proving elusive at this early, early stage. Chris Hoff, security architect at Juniper, thinks it is information security. However, the quote of the day may have come from Peter Christy, co-founder of the Internet Research Group, in this article:
"I completely embrace the disruptive potential but I'm still puzzled on how it will impact the enterprise. The enterprise is the biggest part of the networking market. Building a reliable SDN controller is a challenging task. Customers don't value reproducing the same thing with a new technology. There have been few OF/SDN 'killer' apps so far. SDN is not ready for the enterprise market yet."
That said, how does OpenFlow relate to Quantum? It's simple, really. Quantum is an application-level abstraction of networking that relies on plug-in implementations to map the abstraction(s) to reality. OpenFlow-based networking systems are one possible mechanism to be used by a plug-in to deliver a Quantum abstraction.
OpenFlow itself does not provide a network abstraction; that takes software that implements the protocol. Quantum itself does not talk to switches directly; that takes additional software (in the form of a plug-in). Those software components may be one and the same, or a Quantum plug-in might talk to an OpenFlow-based controller software via an API (like the Open vSwitch API).
I know this gets a little complicated if you don't understand networking concepts very well, but the point is that you shouldn't ever need to deal with this stuff, unless you are a network engineer. Quantum hides the complexity of the network from the application developer's perspective. The same is true of Amazon's VPC, as well various emerging products from networking companies.
However, powerful new ways of viewing network management are being introduced to allow for an explosion of innovation in how those "simple" network representations are delivered. In the end, that will create a truly game-changing marketplace for cloud services in the years to come.
That, when all is said and done, may be the network's role in cloud computing

Randy Bias (@randybias) asked Is Open Compute Ready for Prime Time? in a 10/28/2011 to his Cloudscaling blog:
I just returned from the Open Compute Project (OCP) Summit in NYC. It was an eye opening experience. I thought I would share my take aways plus talk about what I perceive as a core issue: can the Open Compute Project (OCP) grow beyond Facebook? By that, I mean there is a clear challenge right now. Most of the OCP Summit seemed to be Facebook telling vendors what they needed. That’s great for Facebook, but doesn’t advance the ball for the rest of us.
For those of you who may not have heard of the Open Compute Project, it’s an attempt to ‘open source’ hardware design and specifications, in much the way that software is open sourced. Here is the OCP mission statement:
The Open Compute Project Foundation is a rapidly growing community of engineers around the world whose mission is to design and enable the delivery of the most efficient server, storage and data center hardware designs for scalable computing. We believe that openly sharing ideas, specifications and other intellectual property is the key to maximizing innovation and reducing operational complexity in the scalable computing space. The Open Compute Project Foundation provides a structure in which individuals and organizations can share their intellectual property with Open Compute Projects.
Facebook hopes to gain by seeding a community and providing their own designs such that others will provide their own to that community in an open manner. In this way they will be able to learn and grow from the greater community over time. No one has ever really tried this before so it’s a big question mark if they will succeed.
My money is on the success of OCP and Cloudscaling has designs we hope to push back. But will Facebook accept designs of others? What if they aren’t ‘efficient’ enough or ‘cutting edge’ enough? Much of what Facebook has seeded the OCP with is impractical in today’s datacenters. For OCP to thrive it’s going to have to spread it’s arms wide while maintaining the high level of quality it appears to expect.
Let’s get into it.
OCP Summit Take Aways
The OCP Summit seemed to be a much better organized event than some of the other early open source events I attended. Most likely this is the effect of having a single primary driver in Facebook. There were a number of keynotes in the morning following by break out sessions in the afternoon. I am sure these are covered in other blogs, but what you should know is that the keynotes were composed of outstanding speakers from Facebook, AWS, RedHat, and Dell, while the breakout sessions appeared to be all, or mostly, Facebook employees.I had some observations while seeing the various presentations and Q&A sessions:
- Facebook seems to have a very FB-centric world view, which is to be expected; e.g. thinking on virtualization was completely missing and while it’s unlikely Facebook uses much virtualization in their system, any IaaS provider will find the current OCP designs seriously lacking
- OCP, in general, wants to set a high bar of professionalism and rigor; they want participants who participant in action, not just name; “we aren’t a marketing umbrella”
- Pragmatic thinking about the millions and millions of unused or underused square feet of already existing datacenter space was completely missing; how to retrofit, or how to get ‘part of the way’ towards the current OCP designs was missing
- Some of the designs being discussed are useful in the 3-5 or even 10 year time frame, but not now
- OCP is providing very clear guidelines on how to participate and incubate new projects, which is awesome
- There is some danger this community will be only Facebook and hardware vendors who want to sell to them
One thing that really struck me was how on one side you would see folks panning blade servers, but then advocating some very advanced and specialized designs like Open Rack, which are another kind of specialized design. Certainly the Open Rack project is not blade servers, but if there is one thing I feel like we should have learned from ATM, FDDI, Token Ring, blade servers, and a host of other specialized technologies it’s that ‘good enough’ + ‘cheap’ usually wins.
Now, the counter argument from folks would be that OCP is attempting to get the vendors to follow their lead and manufacture at scale such that the cost of these specialized solutions is competitive with standard 1U/2U rackmount servers; however, this hasn’t worked before, why would it now? This is a key chicken and egg problem and part of why rackmount servers are still the standard Field Replaceable Unit (FRU) for most large scale datacenters.
This is not to say I think the Open Rack design is bad, it’s just very forward thinking and I don’t think it has a lot of practical application any time soon.
Remember, 57% of large scale datacenter costs are servers, so paying *any* premium above what a rackmount server costs can’t be justified easily.
Practical Compute
Given the above, I’d like to call for those involved with OCP to start thinking about not just ‘open compute’, but ‘practical compute’. We have customers now who have many thousands of square feet of datacenter space that is a sunk cost. These facilities are largely paid for and can be retrofitted to some degree, but there are limits. DC space is 4-5% of overall costs, which is not insignificant, especially if that facility is already paid for.What’s more important? Designing a new 1.07 PUE datacenter for 100M or retrofitting 3-5 existing smaller DCs and getting them down from 2-3 PUE to 1.25-1.5 PUE for closer to 10M per DC [1]? To really bring this home, during Jame’s Hamilton’s keynote at OCP Summit, he specifically said that hot aisle containment could drop a 3 PUE facility to 2.5 or even 2 PUE.
My view is that over the 5-10 year time frame retrofitting existing empty DCs to have much better power, cooling, and more efficient servers is a more practical approach. There are a lot of customers who fit this bill. Unfortunately, the current OCP designs assume that everyone will build new DCs that are designed to wring the last oodle of efficiency out of every step of the process.
In some ways, this reminds me of how people approach ‘availability’ or ‘security’. There is almost an infinite amount of resource you can dump into either bucket, but you quickly reach a point of diminishing returns. Smart business people look very carefully at the risk/reward tradeoffs of availability and security and find a ‘sweet spot’ for those diminishing returns.
For Facebook that point is very different from many of the others who can benefit from the Open Compute Project (OCP).
OCP’s Future is Bright … I Hope
I believe OCP’s future is bright. As I said, we’re working on some designs we hope to push back. I am concerned that the focus on Facebook’s needs, the high bar that is being set, and some of the focus on forward thinking designs may blind the OCP community to the need for pragmatic designs for today’s datacenters. On the other hand, it is important for someone to hold us all to a higher standard when it comes to energy efficiency. We all want to be good citizens. Can OCP strike the right balance and become more broadly meaningful? I believe it can if it keeps in mind that retrofitting existing datacenters is an important short to medium term goal that needs attention.Big props to Facebook for continuing to open up OCP’s processes and providing guidance on how to participate. Here I think is the seed for how OCP can be wildly successful. We need more constituents with clear pragmatic designs that are based on real world usage and use cases, not overly futuristic thinking.
My message to the greater OCP community is that this is a great start, but the sooner there is a broad base of customers who are not Facebook within the Open Compute Project, the better. Let’s get some real practical computing designs out there for today’s datacenters. OCP could be a tremendous vehicle for change with more active participants with real world problems.
[1] Yes, I’m making these numbers up. It’s more of framing how to evaluate which approach to take rather than any particular facts or data I have. What’s important is that it’s a business evaluation, not an assumption that we need yet more datacenter space.


Jinesh Varia (@jinman) announced the availability of a New Whitepaper: Using AWS for Disaster Recovery in a 10/28/2011 post:
Disaster recovery (DR) is one of most important use cases that we hear from our customers. Having your own DR site in the cloud ready and on standby, without having to pay for the hardware, power, bandwidth, cooling, space and system administration and quickly launch resources in cloud, when you really need it (when disaster strikes in your datacenter) makes the AWS cloud the perfect solution for DR. You can quickly recover from a disaster and ensure business continuity of your applications while keeping your costs down.
Disaster recovery is about preparing for and recovering from a disaster. Any event that has a negative impact on your business’ continuity or finances could be termed a disaster. This could be hardware or software failure, a network outage, a power outage, physical damage to a building like fire or flooding, human error, or some other significant disaster.
In that regard, we are very excited to release Using AWS for Disaster Recovery Whitepaper. The paper highlights various AWS features and services that you can leverage for your DR processes and shows different architectural approaches on how to recover from a disaster. Depending on your Recovery Time Objective (RTO) and Recovery Point Objective (RPO) - two commonly used industry terms when building your DR strategy - you have the flexibility to choose the right approach that fits your budget. The approaches could be as minimum as backup and restore from the cloud or full-scale multi-site solution deployed in onsite and AWS with data replication and mirroring.
The paper further provides recommendations on how you can improve your DR plan and leverage the full potential of AWS for your Disaster Recovery processes.
Download Whitepaper (PDF) - (more whitepapers available at http://aws.amazon.com/whitepapers)
AWS cloud not only makes it cost-effective to do DR in the cloud but also makes it easy, secure and reliable. With APIs and right automation in place, you can fire up and test whether you DR solution really works (and do that every month, if you like) and be prepared ahead of time. You can reduce your recovery times by quickly provisioning pre-configured resources (AMIs) when you need them or cutover to already provisioned DR site (and then scaling gradually as you need). You can bake the necessary security best practices into an AWS CloudFormation template and provision the resources in an Amazon Virtual Private Cloud (VPC). All at the fraction of the cost of conventional DR.
How are you using the cloud for Disaster Recovery today? Please do share your general feedback about DR and any feedback regarding the whitepaper that you might have.
- Jinesh


Robert X. Cringely described Meg’s Revenge on 10/27/2011:
There is no joy in Round Rock.
Early this morning the database servers at Dell Computer went down hard. The company is unable to accept orders on its web site and almost 5,000 Dell sales reps trying to meet their quotas in the last week of the quarter are unable to book sales. Today’s loss for the company is already over $50 million and rising.
The database system in question is Oracle running atop NonStop Unix on a Tandem NonStop (now stopped — what an irony) system made, of course, by Hewlett Packard. So Michael Dell is pulling his hair out at this moment while he waits to be saved by HP.
It could be a long wait.
I guess NonStop means never having to say you’re sorry.

<Return to section navigation list>

















0 comments:
Post a Comment