Windows Azure and Cloud Computing Posts for 10/7/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

• Updated 10/8/2011 10:30 AM PDT with additional articles marked • by David Pallman, Lydia Leong, Rajasekhar Pediredla, Robin Shahan (@RobinDotNet), Tom Hollander, Matthew Weinberger, Scott M. Fulton, III, Ranjith Pallath, Jo Maitland, Christine Drake, Brent Stineman and Avkash Chauhan.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table and Queue Services
• Avkash Chauhan (@avkashchauhan) described Handling ERROR_AZURE_DRIVE_DEV_PATH_NOT_SET when mounting a cloud drive in a 10/7/2011 post:
If you have the same code running in ASP.NET (within a web role you may not hit the problem) however if you try to do this outside role code or from a standalone app you have much more chances to hit this error.
Couple of months back, I have written a sample on how to mount a cloud drive using a standalone app as below:
http://mountvhdazurevm.codeplex.com/
Today when I used my own sample, I got error as “ERROR_AZURE_DRIVE_DEV_PATH_NOT_SET” so I was kind of surprised.. but I also had a chance to dig further, which I like most.
With SDK 1.5 based application, I verified that RoleEnvironment was somehow not available, even the code was running inside a VM which already have Web Role running fine.
I did spend some time to understand why RoleEnvironment is not available and loop through the following function until it is try and within few seconds I could get my cloud drive mounted…
if (RoleEnvironment.IsAvailable) { // Code will only work if Windows Azure role environment is ready }Not sure why (still looking for that) however you if you want to mount a cloud drive do the following to solve such errors:
- Before calling any Cloud drive related code, be sure to have RoleEnvironment.IsAvailable return as true
- If #1 is not available then loop through the code because cloud drive specific code will work only when Azure runtime environment is ready

• Avkash Chauhan (@avkashchauhan) described How to list millions of blob[s] from Windows Azure Storage in [the least] amount of time? in a 10/6/2011 post:
In a situation when you have millions of blobs in a Azure Storage container, it may take hours to list all of your blobs. This is mostly because [of the] huge bandwidth overhead due to uncompressed XML about container/blob data.
Depending on the names of your blobs, you’ll want to choose the right set of requests to make in parallel.
Example 1:
If all your blobs were named with random GUID’s:
- Call ListBlobsWithPrefix(“container/0”)”
- You will get a list all blobs that have names starting with a 0.
Example 2:
For a huge list of blobs you can, in parallel, issue the same request for “container/1”, “container/2”, …, “container/f”.
This way all hexadecimal letters will be covered and you will get a list if blobs starting from each hexadecimal character.
Example 3:
If your blob list contains a collection of English words
- You can choose to make one request for each letter of the alphabet.
Please be sure that he prefix (with ListBlobsWithPrefix API) can be multiple characters so you could allow the deserialization to occur in parallel, taking advantages of multiple cores if your Azure VM has multiple CPU cores or the machine where this code is running had multiple cores.

Scott M. Fulton III (@SMFulton3) showed how to Manage Amazon AWS, Azure BLOB Storage Like a Hard Drive in a 10/7/2011 post to the ReadWriteCloud blog:
When you're developing services in the cloud, you often deploy them directly from your development environment - in the case of Windows Azure, from Visual Studio. When your services involve massive files like videos, those services will need to support what the cloud calls binary large objects, a phrase created just so we can call them BLOBs. Inevitably, you will find yourself having to manage BLOBs. Writing one-off programs just to send commands to the cloud service to manage your files, isn't exactly the way self-service should work.
In cloud-based storage, BLOBs were created to handle any-length strings of bytes, and were originally intended for containing large databases whose contents the system should preferably leave alone. What distinguishes a BLOB from an ordinary file is its variable degree of accessibility through simple HTTP. Almost immediately they became the perfect storage containers for things like small videos, which conceivably can be managed in the browser rather than being streamed. In any event, an HTTP address does point to a BLOB - not specifically to where it's stored (because remember, this is the cloud) but rather to an address which the server may resolve dynamically to determine where it's stored at the moment.
But from CloudBerry Explorer's vantage point, the BLOB is analogous to a file and its container analogous to a folder. Once you give the program the shared access key to your cloud storage on Amazon S3, Google Cloud, or Azure (depicted at right), you can create a container (or what S3 calls a bucket, as depicted below) and then drag-and-drop files into that container (you can't just drag a folder into open space, I found out, because creating a container is a drawn-out process for the server).
This is not a substitute for file hosting services like Dropbox or Skydrive, which are already supremely convenient and some of which tie in directly to Windows. Instead, CloudBerry makes BLOB management simpler for developers to write C# functions to do these same things. The freeware version offers basic file management functions and the ability to generate capacity reports - pie charts representing the total storage utilization for your containers. Meanwhile, the Pro version ($39.95) also enables you to synchronize a local storage folder and a cloud-based container, although the sync process is mainly convenient when you run CloudBerry in the background.
One feature added to the Pro edition for Azure is support for Microsoft's Storage Analytics tool, which lets Azure developers monitor and report on how efficiently their storage and bandwidth are being used. Storage Analytics provides reports on such metrics as number of object requests per hour, average server-side and end-to-end latencies, and total number of successful and failed requests.



<Return to section navigation list>
SQL Azure Database and Reporting
• The SQL Azure Team updated the Forms-Based Authentication with SQL Azure topic on 10/5/2011:
Author: http://msdn.microsoft.com/en-us/library/windowsazure/hh307537.aspx
Learn more about RBA Consulting.
Forms-Based Authentication with SQL Azure
This authentication model uses the SqlMembershipProvider and the SqlRoleProvider to authenticate users of an ASP.NET web application that is hosted in Windows Azure against data that is stored in a SQL Azure database.
This section looks at the benefits and concerns associated with this model and provides guidance on when the model should be used.
- The SqlMembershipProvider and the SqlRoleProvider is that they ship with the .NET Framework, which means that they have been extensively tested and are officially supported by Microsoft. There is a considerable amount of product documentation and samples available to help developers.
- User data that is stored in SQL Azure is relational, which makes it easily consumable by other applications and reporting frameworks.
- There are no transaction costs for using SQL Azure to store user data.
- If the ASP.NET application (that is hosted in Windows Azure) and the SQL Azure database are hosted in the same data center, the latency between the two is very low.
- When authentication is performed, credentials will be passed over the wire from the client to the ASP.NET application. To prevent these credentials from being compromised, they should be protected during the authentication process by using SSL to secure the communication channel between the client and the server.
- In cases where an existing user data store does not exist, a new store will have to be built. This means that there is an additional, one-time, administrative cost, which could be significant depending on the number of users in the system.
- In cases where an existing user store does exist, a migration strategy must be designed and implemented to move the data from the existing store into the SQL Azure store.
- SQL Azure has size limitations. Currently, SQL Azure limits the size of databases to a maximum of 50 GB. If the database exceeds 50 GB, you must design and implement a partitioning strategy to distribute user data across multiple databases.
- This model does not allow for run-time changes to authentication logic. As a result, if the ASP.NET application's authentication code requires an update, the application will have to be redeployed to the Windows Azure environment.
- Connectivity to SQL Azure is much more prone to transient errors compared to on-premises databases. Leveraging the built-in membership classes does not account for such transient conditions. This means it is much more likely to encounter intermittent connectivity errors during authentication. When using SQL Azure in general, the connecting client should implement logic that handles such conditions as per http://blogs.msdn.com/b/appfabriccat/archive/2010/10/28/best-practices-for-handling-transient-conditions-in-sql-azure-client-applications.aspx.
- ASP.NET applications with authentication and authorization requirements that can be defined in terms of user names and roles are a good fit for this model. User names and roles are supported by the SqlMembershipProvider and SqlRoleProvider. If the application has more advanced authentication and authorization requirements, select a different security model.
- If the ASP.NET application requires analysis of user data, then consider using this model because the relational structure of the data lends itself to complex analysis.
- It is a good choice if the authentication logic is limited to the scope of ASP.NET application and does not have to be shared with other applications.
- Consider this model when an existing ASP.NET application that uses the SqlMembershipProvider and the SqlRoleProvider is being moved to the Windows Azure environment. Given that the application is already using these established and well-tested providers, it makes sense to keep them in place.
The following figure illustrates how forms-based authentication between an ASP.NET application in Windows Azure and a SQL Azure database works.

The client's browser connects to the ASP.NET application to perform authentication. The connection is made over port 443, which is secured with HTTPS and SSL. All non-secure communication between the client's browser and the ASP.NET application use HTTP, and communicate through port 80.
The ASP.NET application's Web.config file specifies the following information.
- The application's authentication mode is set to Forms.
- The logon page that is used by the application for forms authentication.
- The membership provider is set to the SqlMembershipProvider.
- The role provider is set to the SqlRoleProvider.
- The connection string that is used to connect to the SQL Azure user store.
SQL Azure stores the following pieces of information.
- User data such as user names and encrypted passwords that are used by the ASP.NET application.
- The names of roles that are used by the ASP.NET application to secure application resources.
- The associations of users with roles.
The following figure illustrates the schema that is used by SQL Azure to store this information.

Note that this is the same schema used by SQL Server on-premises.
The ASP.NET application connects to the SQL Azure hosted user store. It uses port 1433, just as it would with any other SQL database. The TDS that is used for application-to-database communication in SQL Azure is encrypted to provide an additional layer of security. If you want finer-grained security, the firewall to SQL Azure can be configured to filter connections based on the requesting application's IP address. By default, the SQL Azure firewall is configured to deny all incoming requests. The firewall can be configured to allow only traffic from other Windows Azure services. This configuration prevents any traffic that is outside of the Windows Azure data center from obtaining a connection to SQL Azure. The firewall can also be configured to allow IP addresses that fall within known ranges to obtain connections to SQL Azure. …

Read more: The topic continues with detailed “How to Implement the Model” and other sections.
Mike Krieger (@mikeyk) described PostgreSQL Sharding & IDs at Instagram in a 10/1/2011 post (missed when published):
With more than 25 photos & 90 likes every second, we store a lot of data here at Instagram. To make sure all of our important data fits into memory and is available quickly for our users, we’ve begun to shard our data—in other words, place the data in many smaller buckets, each holding a part of the data.
Our application servers run Django with PostgreSQL as our back-end database. Our first question after deciding to shard out our data was whether PostgreSQL should remain our primary data-store, or whether we should switch to something else. We evaluated a few different NoSQL solutions, but ultimately decided that the solution that best suited our needs would be to shard our data across a set of PostgreSQL servers.
Before writing data into this set of servers, however, we had to solve the issue of how to assign unique identifiers to each piece of data in the database (for example, each photo posted in our system). The typical solution that works for a single database—just using a database’s natural auto-incrementing primary key feature—no longer works when data is being inserted into many databases at the same time. The rest of this blog post addresses how we tackled this issue.
Before starting out, we listed out what features were essential in our system:
- Generated IDs should be sortable by time (so a list of photo IDs, for example, could be sorted without fetching more information about the photos)
- IDs should ideally be 64 bits (for smaller indexes, and better storage in systems like Redis)
- The system should introduce as few new ‘moving parts’ as possible—a large part of how we’ve been able to scale Instagram with very few engineers is by choosing simple, easy-to-understand solutions that we trust.
Existing solutions
Many existing solutions to the ID generation problem exist; here are a few we considered:
Generate IDs in web application
This approach leaves ID generation entirely up to your application, and not up to the database at all. For example, MongoDB’s ObjectId, which is 12 bytes long and encodes the timestamp as the first component. Another popular approach is to use UUIDs.
Pros:
- Each application thread generates IDs independently, minimizing points of failure and contention for ID generation
- If you use a timestamp as the first component of the ID, the IDs remain time-sortable
Cons:
- Generally requires more storage space (96 bits or higher) to make reasonable uniqueness guarantees
- Some UUID types are completely random and have no natural sort
Generate IDs through dedicated service
Ex: Twitter’s Snowflake, a Thrift service that uses Apache ZooKeeper to coordinate nodes and then generates 64-bit unique IDs
Pros:
- Snowflake IDs are 64-bits, half the size of a UUID
- Can use time as first component and remain sortable
- Distributed system that can survive nodes dying
Cons:
- Would introduce additional complexity and more ‘moving parts’ (ZooKeeper, Snowflake servers) into our architecture
DB Ticket Servers
Uses the database’s auto-incrementing abilities to enforce uniqueness. Flickr uses this approach, but with two ticket DBs (one on odd numbers, the other on even) to avoid a single point of failure.
Pros:
- DBs are well understood and have pretty predictable scaling factors
Cons:
- Can eventually become a write bottleneck (though Flickr reports that, even at huge scale, it’s not an issue).
- An additional couple of machines (or EC2 instances) to admin
- If using a single DB, becomes single point of failure. If using multiple DBs, can no longer guarantee that they are sortable over time.
Of all the approaches above, Twitter’s Snowflake came the closest, but the additional complexity required to run an ID service was a point against it. Instead, we took a conceptually similar approach, but brought it inside PostgreSQL.
Our solution
Our sharded system consists of several thousand ‘logical’ shards that are mapped in code to far fewer physical shards. Using this approach, we can start with just a few database servers, and eventually move to many more, simply by moving a set of logical shards from one database to another, without having to re-bucket any of our data. We used Postgres’ schemas feature to make this easy to script and administrate.
Schemas (not to be confused with the SQL schema of an individual table) are a logical grouping feature in Postgres. Each Postgres DB can have several schemas, each of which can contain one or more tables. Table names must only be unique per-schema, not per-DB, and by default Postgres places everything in a schema named ‘public’.
Each ‘logical’ shard is a Postgres schema in our system, and each sharded table (for example, likes on our photos) exists inside each schema.
We’ve delegated ID creation to each table inside each shard, by using PL/PGSQL, Postgres’ internal programming language, and Postgres’ existing auto-increment functionality.
Each of our IDs consists of:
- 41 bits for time in milliseconds (gives us 41 years of IDs with a custom epoch)
- 13 bits that represent the logical shard ID
- 10 bits that represent an auto-incrementing sequence, modulus 1024. This means we can generate 1024 IDs, per shard, per millisecond
Let’s walk through an example: let’s say it’s September 9th, 2011, at 5:00pm and our ‘epoch’ begins on January 1st, 2011. There have been 1387263000 milliseconds since the beginning of our epoch, so to start our ID, we fill the left-most 41 bits with this value with a left-shift:
id = 1387263000 << (64-41)Next, we take the shard ID for this particular piece of data we’re trying to insert. Let’s say we’re sharding by user ID, and there are 2000 logical shards; if our user ID is 31341, then the shard ID is
31341 % 2000 -> 1341. We fill the next 13 bits with this value:
id |= 1341 << (64-41-13)Finally, we take whatever the next value of our auto-increment sequence (this sequence is unique to each table in each schema) and fill out the remaining bits. Let’s say we’d generated 5,000 IDs for this table already; our next value is 5,001, which we take and mod by 1024 (so it fits in 10 bits) and include it too:
id |= (5001 % 1024)We now have our ID, which we can return to the application server using the
RETURNINGkeyword as part of theINSERT.Here’s the PL/PGSQL that accomplishes all this (for an example schema insta5):
CREATE OR REPLACE FUNCTION insta5.next_id(OUT result bigint) AS $$ DECLARE our_epoch bigint := 1314220021721; seq_id bigint; now_millis bigint; shard_id int := 5; BEGIN SELECT nextval('insta5.table_id_seq') %% 1024 INTO seq_id; SELECT FLOOR(EXTRACT(EPOCH FROM clock_timestamp()) * 1000) INTO now_millis; result := (now_millis - our_epoch) << 23; result := result | (shard_id << 10); result := result | (seq_id); END; $$ LANGUAGE PLPGSQL;And when creating the table, we do:
CREATE TABLE insta5.our_table ( "id" bigint NOT NULL DEFAULT insta5.next_id(), ...rest of table schema... )And that’s it! Primary keys that are unique across our application (and as a bonus, contain the shard ID in them for easier mapping). We’ve been rolling this approach into production and are happy with the results so far. Interested in helping us figure out these problems at scale? We’re hiring!

Similar pros and cons apply to creading shard IDs for SQL Azure and other relational databases.
<Return to section navigation list>
MarketPlace DataMarket and OData
Alex James (@adjames) asserted “Actions will provide a way to inject behaviors into an otherwise data-centric model without confusing the data aspects of the model, while still staying true to the resource oriented underpinnings of OData” in an introduction to his Actions in OData post of 10/7/2011:
Motivation:
When a client GETs a resource over HTTP it learns about the content type (perhaps HTML) via a header in the response. Clients that understand this content type can then discover possible next steps encoded by the server. For example in HTML these next steps include things like images you can download, stylesheets you should use to render the content, links you can follow, or even forms you can render and fill out. These possible next steps are simply hypermedia actions that you can take using regular HTTP methods, often GET, sometimes POST, less frequently PUT and DELETE.
Looking at OData through this lens we see that OData servers encode many possible hypermedia actions when a resource is retrieved. For example links that you can follow to GET related resources, a link you can use to update (via a PUT or PATCH) or delete (via a DELETE) the current resource. But there is one glaring omission from OData, in OData there is no hypermedia action that can be used to kick off a related server process (that isn’t CRUD). HTML allows this via HTML forms, which allow the client to both discover (via GET) and invoke (via GET or POST) arbitrary server processes. HTML forms are nothing more than a HTML encoding of a flexible hypermedia action related to the current resource.
Clearly it would be nice to have something similar in OData. But what would the equivalent hypermedia action look like in OData?
Now in a purely RESTful system the server uses hypermedia to expose applicable actions (think of this as a workflow) and the client invokes the actions it wants by passing the information (i.e. state) required to the address advertised by the server.
For example to checkout a movie you post a ‘checkoutmovie’ request (similar to the body of a HTML form) to a uri that essentially represents a process or queue, where the ‘checkoutmovie’ request provides all the state needed to ‘checkout’ the movie.
Thinking like this leads you to the ‘pit of success’.
Today in OData the only way to achieve something similar would be to model Actions as Entities, but that is a low fidelity experience with additional baggage. “Actions” will provide a way to inject behaviors into an otherwise data centric model without confusing the data aspects of the model, while still staying true to the resource oriented underpinnings of OData.
Design:
Actions will be advertised in payloads just like navigation properties today, with two differences:
- You can't just follow a link to an action; they have side-effects so a POST is required.
- Sometime actions need additional parameters too.
So we need something a little different from a standard link.
Also note that the availability of an action may be dependent upon the state of the entity, i.e. you can't always Checkout a movie and you can't always Withdraw from a bank account.
The proposal for atom is <m:action> elements that are peers of an Entry's links:
<m:action rel="MyEntities.Checkout" target="Movies(6)/Checkout" title="Checkout Donnie Darko" />
And in JSON we stash this away under the metadata, so as not to confuse Actions and the rest of the data:
"__metadata": {
…,
"actions": {
"MyEntities.Checkout": [
{ "target": "http://server/service.svc/Movies(6)/Checkout", "title": "Checkout Donnie Darko" }
]
}
}The identity or rel of the action (or the actions property name in JSON) is the EntityContainer qualified Name of a FunctionImport in $metadata that describes the action. This means given a particular rel if you know the URL of $metadata you can find the FunctionImport that describes the parameters, which could optionally be annotated with vocabularies that tell you more about the Action's semantics.
Note too that in these examples rel is relative to the current $metadata, it is however possible that an Action isn't described in the current $metadata, so we also allow you to use absolute urls, like this:
<m:action rel="http://otherserver/$metadata#MyEntities.Checkout"
target="Movies(6)/Checkout"
title="Checkout Donnie Darko" />I guess you can imagine where this is going?
The contract here is that what comes before the # must be a $metadata endpoint, and what comes after the # is again an EntityContainer qualified FunctionImport that represents the action.
Finally notice that in JSON we use an array, because while generally there will be just one binding of an action to an entity, it is possible to advertise an action twice, with different targets or titles. A good example would be a ‘Call’ action that is bound to phone numbers, when a person has more than one phone number.
Addressable vs Queryable Metadata:
Given the current thread on the mailing list about Queryable Metadata it is important to point out that our rels are using 'Addressable Metadata' here. Where Addressable metadata is different from queryable metadata because it doesn't support arbitrary query, it only supports pointing at individual things in the model like EntityTypes, EntitySets and FunctionImports.
The use of # is there to highlight that this is an 'anchor' inside a larger document rather than a completely separate document.
One of the key goals here is to create something simple enough that it is possible to quickly create clients that can implement this by themselves - queryable metadata on the other hand is clearly something much richer and much harder to implement in a client framework.
In metadata:
Actions, like ServiceOperations, are described in $metadata as FunctionImports. Here is the Checkout action:
<EntityContainer Name="MyEntities" m:IsDefaultEntityContainer="true">
…
<FunctionImport Name="Checkout" ReturnType="Edm.Boolean"
IsBindable="true"
IsSideEffecting="true"
m:IsAlwaysBindable="false">
<Parameter Name="movie" Type="Namespace.Movie" Mode="In" />
<Parameter Name="noOfDays" Type="Edm.Int16" Mode="In" />
</FunctionImport>
…
</EntityContainer>There are some new attributes:
- IsSideEffecting indicates this is an Action (as opposed to a function which I'll post about soon ...) which means it requires a POST operation to execute. IsSideEffecting defaults to true if omitted.
- IsBindable indicates that this can 'occasionally' be appended to Urls representing the first parameter, sort like a C# extension method. IsBindable defaults to false if omitted.
- m:IsAlwaysBindable indicates that this Action is available independently of state. This is useful because it allows servers to omit these actions from an efficient format payload, which will be highly dependent upon metadata, and have the client still know that the action can be invoked. IsAlwaysBindable is only allowed if IsBindable is true, at which point it defaults to false if omitted.
Notice that Actions can be distinguished from a legacy ServiceOperation because the legacy m:HttpMethod, which was previously required, is omitted.
Invoking the Action:
In our example movie entry, the server has indicated that the 'MyEntities.Checkout' action can be invoked via a POST to this URL:
http://server/service.svc/Movies(6)/Checkout
However we don't yet know what to POST.
Using the rel of the action ('MyEntities.Checkout') we know the 'Checkout' FunctionImport in the 'MyEntities' EntityContainer describes the action, and we can see that our action requires two parameters: movie and noOfDays.
Because the action is advertised (or bound) in an entity we known that the movie (or binding) parameter is provided 'by reference' in the target URL. However we still need to provide a value for noOfDays. All other parameters are always passed in the payload of the POST in JSON format.
So to Checkout Movie(6) for 7 days you need to make a request like this:
POST /service.svc/Movies(6)/Checkout
{
"noOfDays": 7
}It is important to notice that establishing required parameters etc. can done once and cached, indeed you could even generate methods, in C# for example, to capture this information.
Of course caching this information introduces coupling to a particular version of the server, so there is a trade off here.
Once the server receives this request it will attempt to invoke the Action by passing the movie referenced by /Movies(6), and the value 7 for the number of days, into the actual implementation of the Checkout action. In our case the returnType is a bool, but the return type could be any standard OData type, Collection or MultiValue, and the shape of the response will be exactly what you would expect for that ReturnType; i.e. a Single Entry, a Feed, an OData collection etc.
Summary:
“Actions” is a big feature that adds significant power to the OData protocol, and has me for one very excited. Actions allow you to model behavior with high fidelity and without compromise, and their conditional availability leaves the server in full control nudging OData further towards HATEOAS.
Actions though are a big topic, and this post only scratches the surface, in future posts I'll talk about topics like:
- Supported Parameters types
- Conditional Execution (i.e. ETags)
- Composition
- Functions (i.e. like actions but without Side Effects).
That said I hope this is enough to whet your appetite.
Please let me know what you think via the OData.org mailing list.

I believe OData Actions will be a great new feature.
Himanshu Singh reported Windows Azure Marketplace Now Available in 26 Countries, Support 17 Currencies in a 10/7/2011 post:
As we announced at //BUILD/ 2011 last month, Windows Azure Marketplace is now available in 26 countries and supports 17 currencies. With this release we have delivered on the promise to provide a global marketplace for cloud applications and data, with a secure commerce platform. Customers in these new markets can now discover, explore and subscribe to premium data and applications on the Windows Azure Marketplace.
Countries available (26): US, Austria, Belgium, Canada, Czech, Denmark, Finland, France, Germany, Hungary, Ireland, Italy, Netherlands, Norway, Poland, Portugal, Spain, Sweden, Switzerland, UK, Australia, Hong Kong, Japan, Mexico, New Zealand, Singapore.


<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
• Tom Hollander described Using Service Bus Queues with WCF in a 10/6/2011 post with a link to source code:
In 2008 I posted a series of blog articles about how to use MSMQ, WCF and IIS together. I chose to use this architecture as it combined the scalability and resiliency benefits of durable asynchronous messaging, with the simplicity and power of the WCF programming model and IIS hosting model. Over the last year I’ve spent much of my time working with Windows Azure. While Windows Azure has long provided a durable queuing mechanism, there was no integration with WCF or IIS, meaning developers were responsible for writing code to poll the queue, read and dispatch the messages.
Thankfully this has changed with the September 2011 release of Windows Azure AppFabric Service Bus . This release has significantly expanded on the capabilities of the previous release with support for Queues, Topics and Subscriptions plus the ability to integrate with WCF and IIS using the NetMessagingBinding.
In this post I’ll provide a simple example of how to use a Service Bus Queue to enable asynchronous messaging between a single client and a service. The full sample can be downloaded here. In a later post I’ll extend this sample to use Topics and Subscriptions to support a publisher-subscriber pattern.
Creating the Queue
To use the Service Bus, you first need to have a Windows Azure subscription. If you don’t yet have one, you can sign up for a free trial. Once you have a subscription, log into the Windows Azure Portal, navigate to Service Bus, and create a new Service Namespace. You can then create one or more queues directly from the portal, however in my sample I built a small library that lets you define your queues (and topics and subscriptions) in a configuration file so they can be created when needed by the application:
<serviceBusSetup> <credentials namespace="{your namespace here}" issuer="owner" key="{your key here}" /> <queues> <add name="samplequeue" /> </queues> </serviceBusSetup>Note that for any interactions with Service Bus, you’ll need to know your issuer name (“owner” by default) and secret key (a bunch of Base64 gumph), as well as your namespace, all which can be retrieved from the portal. For my sample, this info needs to go in a couple of places in each configuration file.
Defining the Contract
As with any WCF service, you need to start with the contract. Queuing technologies are inherently one-way, so you need to use the IsOneWay property on the OperationContract attribute. I chose to use a generic base interface that accepts any payload type, which can be refined for specific concrete payloads. However if you don’t want to do this, a simple single interface would work just fine.
[ServiceContract] public interface IEventNotification<TLog> { [OperationContract(IsOneWay = true)] void OnEventOccurred(TLog value); }[ServiceContract] public interface IAccountEventNotification : IEventNotification<AccountEventLog> { } [DataContract] public class AccountEventLog { [DataMember] public int AccountId { get; set; } [DataMember] public string EventType { get; set; } [DataMember] public DateTime Date { get; set; } }Building and Hosting the Service
The service is implemented exactly the same way as any other WCF service. You could build your own host, but I choose to host the service in IIS via a normal .svc file and associated code-behind class file. For my sample, whenever I receive a message I write a trace message and also store the payload in a list in a static variable. (I also built a web page to view this list using my horrendous web development skills, but let’s not look at this in any detail
).
public class Service1 : IAccountEventNotification { public void OnEventOccurred(AccountEventLog log) { Trace.WriteLine(String.Format(
"Service One received event '{0}' for account {1}", log.EventType, log.AccountId)); Subscriber.ReceivedEvents.Add(log); } }The magic of wiring this service up to the Service Bus all happens in configuration. First, make sure you’ve downloaded and referenced the latest version of the Microsoft.ServiceBus.dll – NuGet is the easiest way to get this (just search for “WindowsAzure.ServiceBus”).
Now it’s just a matter of telling WCF about the service, specifying the NetMessagingBinding and correct URL, and configuring your authentication details. Since I haven’t got the SDK installed, the definitions for the bindings are specified directly in my web.config file instead of in machine.config.
<system.serviceModel> <!-- These <extensions> will not be needed once our sdk is installed--> <extensions> <bindingElementExtensions> <add name="netMessagingTransport" type="Microsoft.ServiceBus.Messaging.Configuration.NetMessagingTransportExtensionElement, Microsoft.ServiceBus, Version=1.5.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35"/> </bindingElementExtensions> <bindingExtensions> <add name="netMessagingBinding" type="Microsoft.ServiceBus.Messaging.Configuration.NetMessagingBindingCollectionElement, Microsoft.ServiceBus, Version=1.5.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35"/> </bindingExtensions> <behaviorExtensions> <add name="transportClientEndpointBehavior" type="Microsoft.ServiceBus.Configuration.TransportClientEndpointBehaviorElement, Microsoft.ServiceBus, Version=1.5.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35"/> </behaviorExtensions> </extensions> <behaviors> <endpointBehaviors> <behavior name="securityBehavior"> <transportClientEndpointBehavior> <tokenProvider> <sharedSecret issuerName="owner" issuerSecret="{your key here}" /> </tokenProvider> </transportClientEndpointBehavior> </behavior> </endpointBehaviors> </behaviors> <bindings> <netMessagingBinding> <binding name="messagingBinding" closeTimeout="00:03:00" openTimeout="00:03:00"
receiveTimeout="00:03:00" sendTimeout="00:03:00" sessionIdleTimeout="00:01:00"
prefetchCount="-1"> <transportSettings batchFlushInterval="00:00:01" /> </binding> </netMessagingBinding> </bindings> <services> <service name="ServiceBusPubSub.ServiceOne.Service1"> <endpoint name="Service1" address="sb://{your namespace here}.servicebus.windows.net/samplequeue" binding="netMessagingBinding" bindingConfiguration="messagingBinding" contract="ServiceBusPubSub.Contracts.IAccountEventNotification" behaviorConfiguration="securityBehavior" /> </service> </services> </system.serviceModel>One final (but critical) thing to note: Most IIS-hosted WCF services are automatically “woken up” whenever a message arrives. However this does not happen when working with the Service Bus—in fact it only starts listening to the queue after it’s already awake. During development (and with the attached sample) you can wake up the service by manually browsing to the .svc file. However for production use you’ll obviously need a more resilient solution. For applications hosted on Windows Server, the best solution is to use Windows Server AppFabric to host and warm up the service as documented in this article. If you’re hosting your service in Windows Azure, you’ll need to use a more creative solution to warm up the service, or you could host in a worker role instead of IIS. I’ll try to post more on possible solutions sometime in the near future.
Building the Client
Once again, building the client is just the same as for any other WCF application. I chose to use a ChannelFactory so I could reuse the contract assembly from the service, but any WCF proxy approach should work fine. An abridged version of the code is shown below.
var factory = new ChannelFactory<IAccountEventNotification>("Subscriber"); var clientChannel = factory.CreateChannel(); ((IChannel)clientChannel).Open(); clientChannel.OnEventOccurred(accountEventLog); ((IChannel)clientChannel).Close(); factory.Close();Again, the interesting part is the configuration, although it matches the service pretty closely:
<system.serviceModel> <extensions> <bindingElementExtensions> <add name="netMessagingTransport" type="Microsoft.ServiceBus.Messaging.Configuration.NetMessagingTransportExtensionElement, Microsoft.ServiceBus, Version=1.5.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35"/> </bindingElementExtensions> <bindingExtensions> <add name="netMessagingBinding" type="Microsoft.ServiceBus.Messaging.Configuration.NetMessagingBindingCollectionElement, Microsoft.ServiceBus, Version=1.5.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35"/> </bindingExtensions> <behaviorExtensions> <add name="transportClientEndpointBehavior" type="Microsoft.ServiceBus.Configuration.TransportClientEndpointBehaviorElement, Microsoft.ServiceBus, Version=1.5.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35"/> </behaviorExtensions> </extensions> <behaviors> <endpointBehaviors> <behavior name="securityBehavior"> <transportClientEndpointBehavior> <tokenProvider> <sharedSecret issuerName="owner" issuerSecret="{your key here}"/> </tokenProvider> </transportClientEndpointBehavior> </behavior> </endpointBehaviors> </behaviors> <bindings> <netMessagingBinding> <binding name="messagingBinding" sendTimeout="00:03:00" receiveTimeout="00:03:00"
openTimeout="00:03:00" closeTimeout="00:03:00" sessionIdleTimeout="00:01:00" prefetchCount="-1"> <transportSettings batchFlushInterval="00:00:01" /> </binding> </netMessagingBinding> </bindings> <client> <endpoint name="Subscriber"
address="sb://{your namespace here}.servicebus.windows.net/samplequeue"
binding="netMessagingBinding"
bindingConfiguration="messagingBinding"
contract="ServiceBusPubSub.Contracts.IAccountEventNotification"
behaviorConfiguration="securityBehavior" /> </client> </system.serviceModel>Summary
That should be it! With just some minor changes to your WCF configuration, some code (or manual processes) to create a queue, and a bit of work around activation, you can get a client and service happily communicating via a Windows Azure AppFabric Service Bus Queue.
In the next post, we’ll take this one step further by integrating Topics and Subscriptions to allow multiple subscribers to process the same (or even different) messages from the publisher.

• Rajasekhar Pediredla described Azure Access Control – Authenticating with Google Account in a 10/3/2011 post to the Code Project blog:
Access Control provides an easy way to provide identity and access control to web applications and services, while integrating with standards-based identity providers, including enterprise directories such as Active Directory, and web identities such as Windows Live ID, Google, Yahoo! and Facebook.
Introduction
Generally most of the web applications require some authentication process, and it can use custom or any existing web identity. Here we can authenticate the cloud applications using existing Google account. So, whoever having the Google account, they can login to the cloud application. We need to perform some following steps to complete this sample application.
Step1: Create a service namespace for AppFabric in Azure portal
Step2: Configure ACS (Access Control Services) for Google account relay service
Step3: Create a Cloud project with a Web Role
Step4: Configuring Access Control Services (ACS)
Step5: Configuring the application to use ACS with Federation Authentication
Step6: Test the application locally
Step7: Modifying the existing application to deploy into Azure portal
Step8: Modifying the ACS portal settings for production environment
Step9: Publish the cloud application into Azure portal
Step10: Run the cloud application using DNS URL of the production deployment

Rajasekhar continues with a fully illustrated, step-by-procedural description.
Mike Wood (@mikewo) continued his Tips for Working with the Windows Azure AppFabric Caching Service – Part II of III series on 10/6/2011 (see below for Part I):
This post continues our series on tips [for] working with the Windows Azure AppFabric Caching Service. In our first post we discussed tips on some of the differences between the Windows Azure AppFabric Caching Service and the Windows Server AppFabric Caching Service available for your own data center. These differences could help drive decisions on where and what you decide to cache in your Windows Azure solutions.
For this post we will focus on how best to choose the size of cache for Windows Azure AppFabric Caching. This post may refer to the Windows Azure AppFabric Caching as simply the Caching Service. References to the Windows Server AppFabric Caching will be called out specifically.
Cache Size Choice is important, and not just for cost
Windows Azure AppFabric Caching is a service offering which you can include in your Windows Azure applications. As a service offering it comes with a tiered pricing model. Which tier you select is based on the size of cache you need, how much load you plan on pushing across the service and just how many consumer machines will be using the service. The table below provides the current options on cache size the quotas that are set for each size tier.
* data from http://msdn.microsoft.com/en-us/library/gg602420.aspx and is subject to change.
As you can see there are several variables that you need to consider when selecting a cache size. The size of the cache is usually pretty straightforward to guess at. You decide what the size is of the items you are storing in cache, how many of them will be in there at any given time on average and do a little math plus some wiggle room for spikes in usage, etc.; however, it isn’t necessarily as simple as that when factoring in the other considerations. For example, let’s say we are simply caching some shared reference data and we know that we will be well under the 128 MB cache size, but we expect our site traffic to require about 500,000 transactions to the service an hour. We’ll have to select a tier higher than the 128 MB in order to make sure we can deal with the load. The transactions and bandwidth per hour is on an hourly, wall-clock basis and is reset at approximately the top of each hour.
Hitting one of the quotas will result in your code receiving a DataCacheException that is very specific to which quote you exceeded. For example you may receive an exception that states:
“ErrorCode<ERRCA0017>:SubStatus<ES0009>:There is a temporary failure. Please retry later.
(The request failed, because you exceeded quota limits for this hour. If you experience this often, upgrade your subscription to a higher one). Additional Information : Throttling due to resource : Bandwidth.”This very specifically spells out that you’ve hit the bandwidth quota. The only exception (no pun intended) to this rule is if you exceed the cache size. The system will simply start asynchronously purging the least recently used data from the cache to bring you back into the size limit you’ve selected.
Don’t take the transaction quotas to be a reflection of the actual throughput the Caching service is capable of. These quotas are placed here to balance the usage of the shared resources of the cache clusters that is backing up the service. In tests for a proof of concept we were able to easily see 10,000 cache operations per second in a five minute test from traffic against two web roles, which equates to an hourly throughput of 36 million transactions! This test so far surpassed what our target goals were that we didn’t try to see the actual limits, so there is likely more capability than that with the service. Also note that if you use local cache then accessing that local cache does not count against the transaction or bandwidth quotas as it is already on the local machine. It is calls to the service itself that are metered.
The one quota that people usually get surprised by is concurrent connections. Just looking at the table above, which came from the Windows Azure AppFabric FAQ page, the definition of concurrent connection isn’t really clear. The first assumption most people make is that it is the number of users who can be performing operations on the cache at any one time, which is technically true, but in this case it is what is meant by “user” that is important. The Cache service is accessed through a DataCache object in your code, which is often referred to as the Cache Client. Each DataCache object has a connection to the cache service, so the quota is really on the number of instances of DataCache that can be active at any one time. DataCache can be accessed by many threads concurrently, so a single web role could create an instance of DataCache and use that to service all requests to that web role. In fact, this is how the ASP.NET Session Providers for AppFabric Cache are implemented. The lesson here is to make sure there is one instance of DataCache per process and to not just go create new instances of this object for each request.
So, you can look at the concurrent connections quota more from the stand point of how many web roles, or processes using the cache, can you have at any one time. Like the majority of the other quotas this is a hard limit. The service will simply return an exception to any instance of DataCache beyond the allotted amount. If you are using caching in your web role at the 128 MB tier and you increase your web role instance count from five to six then the new instance coming on will start getting the exception whereas the first five instances will still be able to use the cache with no problems. The obvious implication to this is that as you scale the number of roles, or processes using a specific cache, keep in mind that you may need to scale your cache tier as well.
In our final post in this series we’ll cover more considerations about scaling your solution and how the Caching Service is affected.


Mike Wood (@mikewo) started a Tips for Working with the Windows Azure AppFabric Caching Service – Part I of III series with a 10/5/2011 post to the Cumulux blog (see below for Part I):
Windows Azure AppFabric is first and foremost a set of middleware services running on top of the Windows Azure Platform that you can use in your own applications. While the services offered includes the Windows Azure Service Bus and Access Control features as well, in this series of tips we will focus on some key points to keep in mind when working with the Windows Azure AppFabric Caching Service, which is an in-memory, distributed cache for your solutions in the cloud.
The Windows Azure AppFabric Caching Service is similar to the Windows Server AppFabric Caching (code named Velocity) services that you can install and run on-premise in your own data centers. Note that we say it is similar and not “the same as”. While the two share the same API they do not share the same implementation in some cases and, more to the point, the cloud version does not have all the same features that the on-premise version has. This is very important to keep in mind when you are looking to migrate an existing on-premise application that may already using the on-premise Windows Server AppFabric Caching. These tips may refer to the Windows Azure AppFabric Caching as simply the Caching Service. References to the Windows Server AppFabric Caching will be called out specifically.
Choosing what you cache, and where, is just as important as choosing to cache in the first place
Caching is an optimization. We use caching because it’s faster than going back to a persisted store to get or calculate the data for each request, and it takes load off that persisted store so that it can service even more requests. This really works out great for data that is mostly read. For example, if your application showed the top 10 rated forum posts from the previous day in the sidebar of each page then there is no reason to calculate or look this up for every request. Simply cache the result from the first request for the rest of the day. So even though every page displays this data we can simply get it out of the cache in memory and reduce the hits to the persisted store. If you’re caching data that changes frequently then you’re having to make the decision of how long that data in the cache can be stale and still be meaningful.
There are many considerations to the decision of what to cache, but in Windows Azure AppFabric Caching making the decision of what to cache, or where to cache it, can be affected by the features of the service itself. For example, the on-premise Windows Server AppFabric Caching has notifications in which the consumer machines of the cache can get event like notifications from the cache cluster when items are added, removed from or replaced in the cache. This allows for each of the consumers of the cache to know when something has changed in the cache and is a pretty nice feature to have. In the cloud version of the Caching service notifications are not supported and so consumers of the cache cannot be notified of changes in the distributed cache. In both versions of the caching service a local cache feature can be set up to keep some of the cache data at the local consumer machine level so that it doesn’t even have to ask for the data from the cache cluster; however, in the on-premise Windows Server AppFabric Caching the notifications feature is used to invalidate data in that local cache as it changes in the cluster. Since the cloud version of the Caching service doesn’t support the notification it means that local caches will not invalidate items in the local cache unless they expire because of their set lifetime. This can mean that you may not choose to use the local cache feature in the cloud as much as you would in the on-premise version of the service for data that tends to change often, or you will choose to cache it for less time.
Another example of the differences between the on-premise and cloud Caching services is the on-premise Windows Server AppFabric Caching which has the capability to set a default for item expiration; the Windows Azure Caching service does not support default expiration in the same manner. By default in the cloud the data will remain in the cache until there is memory pressure on the cache, in which case the least recently accessed data in the cache will start to be pushed out. You can get around this by using overloads of the Add and Put methods which take an explicit expiration time for the object you are placing in cache to have more control on how long something lives in the cache.
When choosing to cache objects that are large you may also run into another difference between the cache services. For the cloud Caching Service there is an 8MB limit on the object that you cache. This is something to keep in mind when looking at the objects you want to cache. The on-premise version of the caching service does not have this limitation.
When looking at data for caching you need to think about how often the data changes, or how stale the data can be and still be useful to the users or consumers as well as if the data is shared across sessions or something that is specific to unique user sessions. Data that is slowly changing or shared across multiple users can get a lot of benefit from the local cache feature even with the limitations of cloud version as mentioned earlier; however, data that is user specific may not benefit much from local caching even if the data doesn’t change much. For example, if you have a Windows Azure solution that has two web role instances the load to those servers will be balanced and the likelihood of a user landing on either when requests come in is pretty equal. If there is some bit of data that is cached using the local cache feature it’s still pretty likely that this could be helpful over multiple requests. Once you scale up your instance count then the this benefit may fall given that the users are less likely to land on the same servers they have already been to, which would nullify the performance savings you get with local caching. If you have fifty web role instances it is very possible that a user may never hit the same server within a short session, in which the local caching would buy you nothing.
In our next tip we’ll talk about tips to help decide the size of Cache you need.

Vittorio Bertocci (@vibronet) posted TechEd 2011微软中国技术大会:下周与您相约 on 10/6/2011:
亲爱的中国读者,
我很高兴地宣布今年我也将会出席在北京的TechEd技术会议!
我将会在10月13日星期四演讲几个话题;其中的一个话题跟我在几周前的//Build会议上展示的比较相似,另外一个话题将会是基于claims身份架构的深入浅出。
不过我来北京最重要的原因其实是见到你们!我想向你们学习一切有关如何处理你们应用程序身份的问题,这样我才能够把你们的要求带回雷蒙德。我将会有空出席于TechEd 会场星期三(12日)以及星期五(14日)的会议,如果您感兴趣,请跟我联系吧。
谢谢!期待下周与您相约!
维托里奥
附言:十分感谢我的好朋友兼同事 王超 帮我翻译这篇博客。
P.P.S.: last year’s keynote recording:




Here’s the Bing translation:
Dear Chinese readers,
I am very pleased to announce that this year I also will take part in Beijing's TechEd Technical Conference!
I will speak at Thursday, October 13, several topics; one of the topic with me a few weeks ago//Build compare similar shows at the Conference, other topics will be based on claims of identity schemas easily comprehensible manner.
But I came to Beijing is the most important reason to meet you! I would like to learn from you all about how to handle identity problems in your application, so that I can bring your request back to Redmond. I will have time to attend TechEd Conference Wednesday (12th) and Friday (14th) session, if you are interested, please contact me about it.
Thank you! Looking forward to meet with you next week!
Dimensional torio
PS: thank you my good friend and colleague Wang Chao translate for me this blog.
A very readable translation but I have no idea what “Dimensional torio” means.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
• Ranjith Pallath presented a one-hour session entitled On-premises and Cloud via Windows Azure Connect which is available as recording from Microsoft Events:
Event ID: 1032493789
- Language(s): English.
- Product(s): Windows Azure.
- Audience(s): Pro Dev/Programmer.
- Potential usage
- Creation of applications by connecting on-premise applications and services to cloud services
- Different components of Windows Azure Connect
- Management overview
- Joining cloud-based virtual machines to Active Directory
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Andy Cross (@AndyBareWeb) reported the availability of Fluent Windows Azure Diagnostics with SDK 1.5 for download on 10/7/2011:
Windows Azure Diagnostics are a set of powerful tools for monitoring your applications running within Windows Azure.
Configuring Windows Azure Diagnostics is something of a hobby of mine… In my consultancy work I have been so fortunate as to be involved with many incubation projects with Windows Azure and one of the questions I get asked is “why aren’t my xyz logs being persisted?” Often the problem is with the way the Diagnostics Monitor has been configured (usually done on Start of a Role Instance), and the root cause is often that the API for doing so mirrors an underlying XML data structure, rather than being strictly intuitive.
The default manner of configuring Windows Azure Diagnostics is detailed here http://blog.bareweb.eu/2011/01/beginning-azure-diagnostics/ and here http://blog.bareweb.eu/2011/03/implementing-azure-diagnostics-with-sdk-v1-4/
As an example, you may have to do the following in order to configure Trace Logs to be transfered every minute:
string wadConnectionString = "Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString"; CloudStorageAccount storageAccount = CloudStorageAccount.Parse(RoleEnvironment.GetConfigurationSettingValue(wadConnectionString)); RoleInstanceDiagnosticManager roleInstanceDiagnosticManager = storageAccount.CreateRoleInstanceDiagnosticManager(RoleEnvironment.DeploymentId, RoleEnvironment.CurrentRoleInstance.Role.Name, RoleEnvironment.CurrentRoleInstance.Id); DiagnosticMonitorConfiguration config = DiagnosticMonitor.GetDefaultInitialConfiguration(); config.Logs.ScheduledTransferPeriod = TimeSpan.FromMinutes(1D); config.Logs.ScheduledTransferLogLevelFilter = LogLevel.Information; roleInstanceDiagnosticManager.SetCurrentConfiguration(config);Fluent Windows Azure Diagnostics attempts to simplify this, so:
var azureDiagnostics = new DiagnosticsCapture(CloudStorageAccount.DevelopmentStorageAccount); azureDiagnostics.Default() .WithLogs() .WhereLogsAreAbove(LogLevel.Verbose) .TransferLogsEvery(TimeSpan.FromMinutes(1D)) .Commit();The approach attempts to remain fluent (i.e. meaning conferred easily through speech) with even the most complex of statements:
var azureDiagnostics = new DiagnosticsCapture(CloudStorageAccount.DevelopmentStorageAccount); string logPath = RoleEnvironment.IsAvailable ? RoleEnvironment.GetLocalResource("mylocallogs").RootPath : @"C:\mylogs\"; azureDiagnostics.Current() .WithDirectory(logPath, "mylogs", 1024) .TransferDirectoriesEvery(TimeSpan.FromHours(2D)) .WithLogs() .WhereLogsAreAbove(LogLevel.Information) .WithPerformanceCounter(@"\Processor(*)\% Processor Time", TimeSpan.FromMinutes(1D)) .TransferPerformanceCountersEvery(TimeSpan.FromHours(1D)) .WithWindowsEventLog("Application!*") .WithWindowsEventLog("System!*") .TransferWindowsEventLogEvery(TimeSpan.FromHours(2D)) .CheckForConfigurationChangesEvery(TimeSpan.FromDays(1D)) .Commit();The library is provided open source on codeplex: http://fluentazurediag.codeplex.com/license
Feedback welcome.
Kurt Mackie asserted “The senior director of SharePoint product management at Microsoft takes some time during this week's SharePoint Conference 2011 to discuss what's coming for the Web application platform” as an introduction to his Q&A: Microsoft Talks SharePoint, BCS and Office 365 interview of Jared Spatero of 10/6/2011 for 1105 Media’s RedmondMag.com:
Nuances from the SharePoint Conference 2011 event were explained by Jared Spataro, a senior director of SharePoint product management at Microsoft.
During Microsoft's Monday keynote address, Spataro and other company representatives had described a new Business Connectivity Services (BCS) capability in SharePoint 2010 that's expected to arrive at end of this year. Microsoft also announced the launch of a Microsoft Certified Architect (MCA) program for SharePoint. Finally, Microsoft made the case for tapping Office 365 to get SharePoint as a service. I spoke with Spataro on Tuesday at the event, which was held in Anaheim, Calif.
What's the Microsoft view on public cloud, private cloud and hybrid deployments with SharePoint? We saw a demo during the keynote where Office 365 takes care of things such as failover clustering, for instance.
Jared Spataro: I would say that this idea of a hybrid deployment is one of the biggest differentiators in the enterprise space. Our perspective is "the cloud on your terms." We're not trying to push you to the cloud or stay on prem[ises]. We want you to make the right decision for your business. I think that's very different from the way our competitors have approached it. If it's important for you to run this in your own datacenter, SharePoint 2010, as it's architected, can go do that for you. It can do amazing things; it can scale in ways that no other system can out there. But if that's not what you're interested in, if you'd rather focus on other parts of SharePoint -- whether it's business applications or whatever you want to do -- we can take care of those problems for you, and that's what we call "Office 365."
Some surveys show Web site and document management as top uses for SharePoint. What is Microsoft seeing?
Spataro: We see a lot of different uses. [First,] we see a lot of people who are doing document management. The next one down was project management, so managing specific projects with an outcome and an end date. The third one down was enterprise search, so using it not just to search SharePoint but to search outside SharePoint. And that's become a bigger and bigger thing. People start to think of SharePoint as an information hub where they can manage not only the information that lives in it but the stuff that lives outside, which is pretty revolutionary. And the fourth one is publishing business intelligence, which makes a lot of sense if your close enterprise customers are kind of moving in that direction. There are a lot of others. To characterize what we found, it didn't drop off from there. In fact, business intelligence was used by 44 percent of customers, and from there, it looked in the forties and high thirties for the rest of the use cases. So the big takeaway from us is that SharePoint can do a lot, people are using it for a lot, and those top four were clearly the leaders, but beyond that, there's just a lot of capabilities.
What about compliance issues in moving to Office 365? An analyst told me that the hybrid solution currently isn't ready if an organization wants to keep the data local.
Spataro: The announcement that we made about BCS (Business Connectivity Services) actually opens up that scenario for the first time in a very wide type of way. So that's why that announcement was so significant. Prior to that announcement, you could have what you could characterize as an island of information -- a nice island, a very functional island, but you had to decide to put your information in the cloud in order to use the capabilities in the cloud, or you were going to move them on prem. This BCS announcement means that we can now create a connection between the cloud and any other data source -- other cloud data source or any on-prem data source -- and that means we can do what you are suggesting, which is the ability to tap into data. It is most useful in data than in documents. We don't have an equivalent that is sophisticated in what you'd call federated document management -- that's a pretty sophisticated use case.
Can you explain BCS?
Spataro: It stands for "Business Connectivity Services." The easiest way to think of it is that it is a mapping between an interface -- a "list" is what it is, actually, in SharePoint -- and data that lives someplace else. And it allows you to have a read-write connection between the lists in SharePoint and the data that sits in the back. So, pretend you're a sales organization and you wanted to get a list of customers. And you wanted to present that listing to your sales portal. And maybe say, I'm' showing up and I'm Jared and I get my list of customers just for me. I'd be able to use BCS to go down to my customer relationship management system to pull the list of customers just for Jared and display them up in a list so that it would feel like an integrated part of the experience. And if I then want to do something with that list of customers -- like update their status, change the spelling of a name -- because BCS is bidirectional, I can also write that back to the customer relationship management. So, what a lot people use it to do is they will create a kind of blended experience, where someone gets everything they need to work -- documents, list of their customers and other capabilities like social capabilities -- and get a really nice blended experience without having to open up separate applications. And that's kind of the best-use case scenario. …
Juozas Kaziukėnas (@juokaz) reported We built a cloud platform for PHP. Wait… what? on 10/3/2011 (missed when posted):
We built a cloud platform for PHP. Yep, you heard it correctly. We see a huge opportunity in the market and are willing to work hard to make deploying PHP projects very easy. However this is a different one and here is the story behind it and what it can do for you.
Why Azure?
Current workflow with Azure, original from XKCD
There is nothing specific about Azure that we wanted to leverage, but because so many existing PaaS providers are built on Amazon cloud it just made sense to try something else. Furthermore, I have a lot of experience with Windows and PHP so it all felt like a good plan. I think we are awesome enough to make Azure rock for PHP, because…
Azure is just impossible to use for PHP today. This is a fact. Doesn’t matter which way you look at it, it just su.. isn’t particularly good. The amount of steps you need to make, the knowledge you need to have and the fact that you can only deploy from Windows host are some of the things which make it a very painful experience. I had enough of this pain.
What is most important, I find Microsoft’s approach and tooling lacking in so many areas, that the only way I knew how to fix this was to build a service on top, rather than release Azure+ as a product or open source project. There was and still is no way I can change the 15-20 min. deploy time (try debugging a non-working app having to wait half hour before every retry), so we built something which overcomes it.
Oh God no, Windows?!
It’s not a big surprise that Azure is running on top of Windows, it’s a Microsoft cloud at the end of a day. I know a lot of PHP developers feel very negative about Microsoft and Windows specifically. Well, Internet Explorer 6 specifically, but Windows is not better either. But that is something what you would care if this was an infrastructure service.
Azure+ is Platform as a Service or PaaS in short. What that means is that you deploy apps to a cloud black box and the infrastructure it is running is completely irrelevant to you. There is more work to be completed to making it truly PaaS, but our goal is to make deploying to this service completely headache-free and to just make everything work*.
Important fact to note, this is not developed under any collaboration or affiliation with Microsoft and thus it’s our own decisions on where we’ll take it from here. I think PHP support on Windows is as good as on any other OS and all the PHP apps I tried (Zend Framework, Symfony2, Lithium) worked pretty much out of the box.
Features
First of all, PHP developers start by writing PHP code, because to start learning PHP you only need a Apache installed and that’s it. Hack on some code, click refresh and you see the result. That’s what PHP is. That’s why at least 15 minutes of wait is just something PHP developer wouldn’t want to do. We made it faster. How about 5 sec. or less deployment time?
Furthermore, in core we have mechanisms which allows us to support and change PHP configuration and version in the same short time. So you can try different PHP versions in a matter of one mouse click or switch off
display_errorswhen your app is ready to live. Currently you can only choose from two PHP versions and error reporting mode, but there is more to come.Speed of deployments and configuration freedom is a good building base to start with. But there is more baked in, like an API which allows pushing code directly and a service which will pull from a specified Git repository automatically. Right now we are working on adding MySQL support, so you can port pretty much any existing app. It’s a great core platform which allows adding new functionality very very easily.
Reception
It was an unbelievable journey so far and we learned insane amount of things about Azure itself and how to make PHP deployments blazing fast. Some things required hours to tackle, but in the end we made sure that our users are never going to have to deal with them. And believe me, there are a lot of things you can shoot yourself with when working with Windows.
This is a project which needs feedback and especially from people who know PHP, cloud stack etc. really well. I was running demos and giving access to some people I know and, I think, they were really impressed with the stack. Also because it relies heavily on Microsoft stack, I had spent past two weeks demoing it to a selected group of Microsoft friends and so far reception was amazing. To quote one:
I think you could single highhandedly revolutionize Azure
I think this is a great achievement for PHP community too, because a lot of the functionality we support is not available in some of the leading services so this should kick their asses a bit. We want to stay competitive and keep pushing the PHP ecosystem further, but when it comes to standards, we’ll adopt any upcoming specifications for PHP platforms.
Conclusion
Currently a group of 15 or so people is actively testing this and is sending us valuable feedback. Nevertheless it’s quite close to production-quality service and you’ll hear more about it very soon. If you feel like you’d like to test this (completely free of charge) and would be able to provide some good thoughts, feel welcome to write to me. You can find more details about Azure+ here.





Juozas (a.k.a. Joe) is CEO of @webspecies.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+

Return to section navigation list>
Windows Azure Infrastructure and DevOps
• David Pallman posted The Cloud Gourmet: Cooking with Windows Azure on 10/8/2011:
Today, October 08, 2011, 59 minutes ago | noreply@blogger.com (David Pallmann)


Bonjour and welcome to The Cloud Gourmet with your host, Chef Az-ure-D. Together we shall create delicious masterpieces in the cloud on the Windows Azure platform.
In this first post I want to share some of my favorite resources for cooking in the cloud. in subsequent posts we will explore individual recipes.
Now you may be thinking "chef, that's fine for you but I cannot cook!" Nonsense! Absurdité! Anyone can learn to cook in the cloud, and many items are simple to prepares. Together we shall learn. You will see.
Recipes
Of course we learn by doing, but sometimes you just need to get something accomplished and need guidance to ensure a successful outcome. That's why we have recipes. Let me share some of my favorite recipe sources with you.
Windows Azure Development Cookbook
Neil Mackenzie
http://www.packtpub.com/microsoft-windows-azure-development-cookbook/bookNeil Mackenzie (@mknz) is not only a Windows Azure MVP and respected blogger, he’s also the Julia Child of Windows Azure. His Microsoft Windows Azure Development Cookbook is just what it claims to be, a cookbook (available in print and Kindle editions). Neil’s cookbook is a step-by-step guide to accomplishing key development tasks on the Windows Azure platform with sample code all along the way. It includes chapters on access, blob storage, table storage, queue storage, hosted services, diagnostics, management, SQL Azure database, and AppFabric service.
Windows Azure How To Topics
Microsoft Documentation
http://msdn.microsoft.com/en-us/library/windowsazure/gg432998.aspxThere’s a lot of good information in the Windows Azure online documentation, and one of the best parts of that are the Windows Azure How To Topics pages and index. As you can see from this partial screen capture it covers a lot of tasks. Each how to page gives you the approach and steps to follow and shows sample code.
Windows Azure Training Kit
Microsoft
http://www.microsoft.com/windowsazure/learn/get-started/The Windows Azure Training Kit contains a nice collection of hands-on labs. With the investment of an hour or two, each lab shows you step-by-step how to build something that leverages one or more of the services in the Windows Azure platform.
Shows
There’s nothing like a cooking show to get inspired: an expert shares insights, shows you how something is done, and then pulls a finished version out of the oven to show you the outcome.The Cloud Cover Show
Steve Marx and Wade Wegner, Microsoft Channel 9
http://channel9.msdn.com/Shows/Cloud+Cover
Cloud Cover is your eye on the Microsoft Cloud. This weekly videocast by Microsoft evangelists Steve Marx (@smarx) and Wade Wegner (@WadeWegner) is excellent, educational, and entertaining. In each show they’ll take an area of Windows Azure and show it you close up as well as discussing its significance. Cloud Cover is also one of best ways to keep up with news about Windows Azure.
Session Videos from Microsoft Conferences

Microsoft puts on several large conferences each year including PDC, MIX, TechEd, and BUILD. The videos of the keynotes and technical sessions are usually kept online for a year on Microsoft Channel 9. In these you can hear from Microsoft product team members and developer evangelists.
Live Demonstrations
An in-person cooking demonstration is a real treat—especially if you get to cook alongside. These kind of events exist for Windows Azure. Keep an eye out for upcoming events in your area.
Windows Azure Bootcamps
http://azurebootcamp.comFrom time to time, Microsoft and the MVP community will put on Windows Azure bootcamps which are usually 1- or 2-day free events. Here, you’ll hear topical presentations and be guided through hands-on labs with assistance. These events are also a great opportunity to talk directly to an expert.
Code Camps
Regional code camps are another great way to see live Windows Azure presentation and development. Windows Azure is often a topic covered at these events.
The Personal Touch
On-site Training
You get what you pay for, no? Perhaps you want more than the occasional free regional event and want on-site training, which can be tailored to your needs, people, location, and schedule. Windows Azure training is offered by some Microsoft patterns including Neudesic. Think of on-site Windows Azure training for architects, developers, and IT professionals as the equivalent of sending your people to a culinary institute.
Consulting
There’s nothing like a personal chef, eh? If you retain the services of a knowledgeable and experienceD consultant you are in good hands. You can leverage a consultant in a number of ways: they can advise you, help with design, and/or perform the actual development work. You can use consultants to create your solutions for you, or even better you can cook alongside them so you learn. These days they can work on location and/or remote, with on-shore and/or off-shore resources as desired. Windows Azure consulting is offered by some Microsoft partners including we at Neudesic.My friends, this is by no means all. The Microsoft and community resources for Windows Azure are substantial. Once you have a feel for who in the community is working in areas that interest you, I urge you to follow their blogs and social network posts. I look forward to cooking in the cloud with you!






• Lydia Leong (@cloudpundit) published Introduction to the Future of the Data Center Market on 10/7/2011:
Earlier this year, I was part of a team at Gartner that took a futuristic view of the data center, in a scenario-planning exercise. The results of that work have been published as The Future of the Data Center Market: Four Scenarios for Strategic Planning (Gartner clients only). My blog entries today are by my colleague, project leader Joe Skorupa, and provide a glimpse into this research.
Introduction
As a data center focused provider, how do you formulate strategic plans when the pace and breadth of change makes the future increasingly uncertain? Historical trends and incremental extrapolations may provide guidance for the next few years, but these approaches rarely account for disruptive change. Many Gartner clients that sell into the data center requested help formulating long-range strategic plans that embrace uncertainty. To assist our clients, a team of 15 Gartner from across a wide range of IT disciplines employed the scenario-based planning process to develop research about the future of the data center market. Unlike typical Gartner research, we did not focus on 12-18 month actionable advice; we focused on potential market developments/disruptions in the 2016-2021 timeframe. As a result its primary audience is C-level executives that their staffs that are responsible for long-term strategic planning. Product line managers and competitive analysts may also find this work useful.
Scenario-based planning was adopted by the US Department of Defense in the 1960s and the formal scenario-based planning framework was developed at Royal Dutch Shell in the 1970s. It has been applied to many organizations, from government entities to private companies, around the world to identify major disruptors that could impact an organization’s ability to maintain or gain competitive advantage. For this effort we used the process to identify and assess major changes in social, technological, economic, environmental and political (STEEP) environments.
These scenarios are told as stories and are not meant to be predictive and the actual future will be some subset of one or more of the stories. However, they provide a basis for deriving company-specific implications and developing a strategy to enable your company to move forward and adapt to uncertainty as the future unfolds. Exploring alternative future scenarios that are created by such major changes should lead to the discovery of potential opportunities in the market or to ensure the viability of current business models that may be critical to meeting future challenges.
To anchor the research, we focused on the following question (the Focal Issue) and its corollary:
Focal Issue: With rapidly changing end-user IT/services needs and requirements, what will be the role of the data center in 2021 and how will this affect my company’s competitiveness?
Corollary: How will the role of the data center affect the companies that sell products or services into this market?
The next post describes the scenarios themselves.

• Lydia Leong (@cloudpundit) added What does the future of the data center look like to you? to her Cloud Pundit blog on 10/7/2011:
Earlier this year, I was part of a team at Gartner that took a futuristic view of the data center, in a scenario-planning exercise. The results of that work have been published as The Future of the Data Center Market: Four Scenarios for Strategic Planning (Gartner clients only). My blog entries today are by my colleague, project leader Joe Skorupa, and provide a glimpse into this research. See the introduction for more information.
The Scenarios
Scenarios are defined by the 4 quadrants that result from the intersection of the axes of uncertainty. In defining our scenarios we deliberately did not choose technology-related axes because they were too limiting and because larger macro forces were potentially more disruptive.
We focused on exploring how the different external factors outlined by the two axes would affect the environment into which companies would provide the products and services. Note that these external macro forces do contain technological elements.
The vertical axis describes the role and relevance of technology in the minds of the consumers and providers of technology while the horizontal axis describes availability of resources – human capital (workers with the right skill set), financial capital (investments in hardware, software, facilities or internal development) or natural resources, particularly energy — to provide IT. The resulting quadrants describe widely divergent possible futures.
- The “Tech Ration” Scenario
- This scenario describes the world in 2021 that is characterized by severely limited economic, energy, skill and technological resources needed to get the job done. People view technology as they used to think of the telephone – as a tool for a given purpose. After a decade of economic decline, wars, increasingly scarce resources and protectionist government reactions, most businesses are survival-focused.
Key Question: What would be the impact of a closed-down, localized view of the world on your strategic plans?
- The “Tech Pragmatic” Scenario
- This scenario presents a similar world of limited resources but where people are highly engaged with IT and it forms a key role in their lifestyles. Social networks and communities evolved over the decade into sources of innovation, application development and services. IT plays a major role in coordinating and orchestrating the ever-changing landscape of technology and services.
Key Question: Will your strategy be able to cope with a world of limited resources but the need for agility to meet user demands?
- The “Tech Fashion” Scenario
- This scenario continues the theme where the digital natives’ perspectives have evolved to where technology is an integral part of people’s lives. The decade preceding 2021 saw a social-media-led peace, a return to economic growth, and a flourishing of technology from citizen innovators. It is a world of largely unconstrained resources and limited government. Businesses rely on technology to maximize their opportunities. However, consumers demand the latest technology and expect it to be effective.
Key Question: How will a future where the typical IT consumer owns multiple devices and expects to access any application from every one of their devices affect your strategic planning?
- The “Tech Gluttony” Scenario
- This scenario continues in 2021 with unconstrained resources where people view technology as providing separate tools for a given purpose. Organizations developed situation-specific products and applications. Users and consumers view their technology tools as limited life one-offs. IT budgets become focused on integrating a constantly shifting landscape of tools.
Key Question: Does a world of excessive numbers of technological tools from myriad suppliers change your strategic planning?
The four scenario stories each depicts the journey to and a description of a plausible 2021 world. Of course the real future is likely to be a blend of two or more of the scenarions. To gain maximum value, you should treat each story as a history and description of the world as it is. To gain maximum benefit suspend disbelief, immerse yourself in the story, and take time to reflect on the implications for your business and enter into discussion on what plans would be most beneficial as the future unfolds.
ObPlug: Of course, Gartner analysts are available to assist in deriving specific implications for your business and formulating appropriate plans.
• Avkash Chauhan (@avkashchauhan) described What to do when Windows Azure Management Portal does not list any hosted services even when you are sure to have one or more in a 10/7/2011 post:
If you see this problem this is mainly because of a Silvelight cache issue.
To solve it please change your portal language to something else and then change back to "English" this will clear the cache and shows hosted service list.



• Brent Stineman (@BrentCodeMonkey) continued his series with Configuration in Azure (Year of Azure–Week 14) on 10/8/2011:
Another late post, and one that isn’t nearly what I wanted to do. I’m about a quarter of the way through this year of weekly updates and frankly, I’m not certain I’ll be able to complete it. Things continue to get busy with more and more distractions lined up. Anyways…
How do know where to load a configuration setting from?
So you’ve sat through some Windows Azure training and they explained that you have the service configuration and you should use it instead of the web.config and they covered using RoleEnvironment.GetConfigurationSettingValue. So you know how to get a setting from with location? This is where RoleEnvironment.IsAvailable comes into play.
Using this value, we an write code that will pull from the proper source depending on the environment our application is running in. Like the snippet below:
if (RoleEnvironment.IsAvailable) return RoleEnvironment.GetConfigurationSettingValue("mySetting"); else return ConfigurationManager.AppSettings["mySetting"].ToString();Take this a step further and you can put this logic into a property so that all your code can just reference the property. Simple!
But what about CloudStorageAccount?
Ok, but CloudStorageAccount has methods that automatically load from the service configuration. If I’ve written code to take advantage of this, they’re stuck. Right? Well not necessarily. Now you may have a seen a code snippet like this before:
CloudStorageAccount.SetConfigurationSettingPublisher( (configName, configSetter) => configSetter(RoleEnvironment.GetConfigurationSettingValue(configName)) );This is the snippet that needs to be done to help avoid the “SetConfigurationSettingPublisher needs to be called before FromConfigurationSetting can be used.” error message. But what is really going on here is that we are setting a handler for retrieving configuration settings. In this case, RoleEnvironment.GetConfigurationSettingValue.
But as is illustrated by a GREAT post from Windows Azure MVP Steven Nagy, you can set your own handler, and in this handler you can role your own provider that looks something like this:
public static Action<string, Func<string, bool>> GetConfigurationSettingPublisher() { if (RoleEnvironment.IsAvailable) return (configName, configSetter) => configSetter(RoleEnvironment.GetConfigurationSettingValue(configName)); return (configName, configSetter) => configSetter(ConfigurationManager.AppSettings[configName]); }Flexibility is good!
Where to next?
Keep in mind that these two examples both focus on pulling from configuration files already available to us. There’s nothing stopping us from creating methods that pull from other sources. There’s nothing stopping us from creating methods that can take a single string configuration setting that is an XML document and hydrate it. We can pull settings from another source, be it persistent storage or perhaps even another service. The options are up to us.
Next week, I hope (time available of course) to put together a small demo of how to work with encrypted settings. So until then!
PS – yes, I was renewed as an Azure MVP for another year! #geekgasm

Congrats on being renewed, Brent! Be sure to catch his latest [Windows Azure] Digest for October 7th, 2011.
Brian Swan (@brian_swan) said patterns & practices’ Introduction to the Windows Azure Platform “is the best overview of the Windows Azure Platform that I've come across” in his Pie in the Sky post of 10/7/2011 to the Windows Azure’s Silver Lining blog:
The Microsoft® Windows® Azure™ technology platform provides on-demand, cloud-based computing, where the cloud is a set of interconnected computing resources located in one or more data centers. Currently, the Windows Azure platform is available in data centers in the United States, Europe, and Asia. Developers can use the cloud to deploy and run applications and to store data. On-premises applications can still use cloud–based resources. For example, an application located on an on-premises server, a rich client that runs on a desktop computer, or one that runs on a mobile device can use storage that is located on the cloud.
Virtualization also allows you to have both vertical scalability and horizontal scalability. Vertical scalability means that, as demand increases, you can increase the number of resources, such as CPU cores or memory, on a specific VM. Horizontal scalability means that you can add more instances of VMs that are copies of existing services. All these instances are load balanced at the network level so that incoming requests are distributed among them.
At the time of this writing, the Windows Azure platform includes three main components: Windows Azure, the Windows Azure platform AppFabric, and SQL Azure.
Windows Azure provides the following capabilities:
- A Microsoft Windows® Server-based computing environment for applications
- Persistent storage for both structured and unstructured data, as well as asynchronous messaging
The Windows Azure platform AppFabric provides two services:
- Service Bus, which helps you to connect applications that are on-premises or in the public cloud, regardless of the network topology
- Access Control Service, which manages authorization and authentication for Representational State Transfer (REST)–based Web services with security tokens
SQL Azure is essentially SQL Server® provided as a service in the cloud.
The platform also includes various management services that allow you to control all these resources, either through a web-based user interface (a web portal) or programmatically. In most cases, there's REST-based API that can be used to define how your services will work. Most management tasks that can be performed through the web portal can also be done through the API. Finally, there's a comprehensive set of tools and software development kits (SDKs) that allow you to develop, test, and deploy your applications. For example, you can develop and test your applications in a simulated local environment, named the development fabric. Most tools are also integrated into development environments such as Microsoft Visual Studio®. In addition, there are also third-party management tools available.
The Windows Azure Platform
In Windows Azure, the compute environment processes requests, and the storage environment holds data reliably. An internal subsystem, known as the Windows Azure Fabric Controller (FC) manages all compute and storage resources, deploys new services, and monitors the health of each deployed service. When a service fails, the FC provisions the necessary resources and re-deploys the service. Another component of the Windows Azure platform is SQL Azure. SQL Azure is a relational database in the cloud. Essentially, SQL Azure is a large subset of SQL Server hosted by Microsoft and offered as a service. Although SQL Azure is complementary to Windows Azure storage services, they are not the same.
At the time of this writing, the Windows Azure platform AppFabric provides two services: the service bus and the access control services.
Bharath says:
The Windows Azure Fabric Controller and the Windows Azure platform AppFabric are not the same! The Fabric Controller is an internal system used by Windows Azure to provision, monitor, and manage services that run in Windows Azure.
The service bus allows you to connect applications and services, no matter where they are located. For example, you can connect an on-premises application that is behind the corporate firewall to a service that runs in the cloud. It implements common message and communications patterns, such as events, one-way messages, publish and subscribe, remote procedure call (RPC)–style message exchanges, and tunnels for streamed data. The access control service allows you to manage identity in the cloud for REST-based services. It implements a token-issuing service that also provides token transformation capabilities. The Windows Azure platform AppFabric isn't discussed in this guidance. For more information, see the references at the end of this chapter. Remember that the Windows Azure platform AppFabric is not the same as the Windows Azure Fabric Controller.
In addition to these components, the Windows Azure platform also provides diagnostics services for activities such as monitoring an application's health.
All storage and management subsystems in Windows Azure use REST-based interfaces. They are not dependent on any .NET Framework or Microsoft Windows® operating system technology. Any technology that can issue HTTP or HTTPS requests can access Windows Azure's facilities.
Typically, applications that run in Windows Azure have multiple instances. Each of these instances runs in a Windows Virtual Machine (VM) that is created and managed by Windows Azure. Currently, you cannot access these VMs the way you can if create a VM with an application such as Virtual Server or Virtual PC. Windows Azure controls them for you.
To get started with Windows Azure platform, go to http://www.windowsazure.com.
Windows Azure Compute
An application that runs on Windows Azure is referred to as a hosted service. Typically, a hosted service contains different computational resources that collectively process information and interact with each other and the external world. Hosted services in Windows Azure are said to contain roles, and there are currently two roles available: a worker role and a web role.
Worker roles are general-purpose code hosts. They are frequently used for long-running tasks that are non-interactive, but you can host any type of workload in them. Worker roles are general enough to host even complete application platforms such as Microsoft Internet Information Services (IIS) or Apache Tomcat. Windows Azure initiates worker roles and, like Windows services, they run all the time.
You can think of web roles as special cases of worker roles that have IIS 7 enabled by default. Therefore, they can host web applications and web services. Figure 1 illustrates web and worker roles.
Figure 1
Web roles and worker roles
Typically, a web role instance accepts incoming HTTP or HTTPS requests over ports 80 and 443. These public ports are referred to as public endpoints. All public endpoints are automatically load balanced at the network level. Both worker roles and web roles can make outbound TCP connections and can also open endpoints for incoming connections. In addition to the load-balanced public endpoints, instances can open internal endpoints. These internal endpoints are neither load-balanced, nor publically visible to the Internet. Instead, internal endpoints can be used for synchronous communication among instances and roles.
The VMs that run both web role and worker role instances also run a Windows Azure agent. This agent exposes an API that lets an instance interact with the Windows Azure FC. For example, an instance can use the agent to enumerate the public and internal endpoints in the VM instance it's running in or to discover run-time configuration settings.
An application deployed in a web role can be implemented with ASP.NET, Windows Communication Foundation (WCF), or any technology that works with IIS. For example, you can host a Hypertext Preprocessor (PHP) application on Windows Azure because IIS supports it through Fast CGI, which is a protocol that interfaces interactive applications with a web server. Most web role applications are optimized for workloads that follow a request-reply pattern, where the time between a request and a response is ideally very short.
A key consideration for the scalability of web roles is session management. In standard ASP.NET applications, there is some way to store session state. For example, an online store may keep track of a shopping cart. Similar to web farms, storing session state in memory on each server instance is a problem for web role–based websites because there's no guarantee that users will be directed to the same web role instance each time they make a request. Instead, you maintain state information in someplace other than the web role instance such as Windows Azure storage, SQL Azure, in a cookie that you pass back to the client, or in hidden form elements.
One of the most common application patterns in Windows Azure is for a web role to receive incoming requests and then use Windows Azure queues to pass them to the worker role to process. The worker role periodically looks in the queue for messages to see if there is any work to do. If there is, it performs the task. The web role typically retrieves completed work from persistent storage, such as a blob or a table. Figure 2 illustrates this typical design pattern.
Figure 2
Typical application pattern for web roles and worker roles
This is a simple and common interaction between a web role and a worker role, but there are many other possibilities. For example, you can use WCF to link web roles and worker roles.
Another function of the agent that runs on the web and worker roles is to maintain a heartbeat with the FC. The FC monitors the health of the VMs and the physical servers. If an application becomes unresponsive because of an error in its code, or if the underlying hardware of an instance fails, the FC takes whatever action is appropriate to recover. In the case of an application that crashes, the FC might simply restart the instance. In the more extreme case of a hardware error on the underlying physical host, the FC attempts to move the affected instances to another physical machine in the data center. At all times, the FC attempts to keep as many instances running as you specified when you configured the application. There currently are no auto-scaling capabilities. You are responsible for specifying the number of instances of any compute resource on Windows Azure, either through the web portal or with the management API.
Windows Azure Storage
Windows Azure provides scalable storage services that store both structured and unstructured data. The storage services are considered to be scalable for two reasons:
- An application can scale to store many hundreds of terabytes of data.
- The storage services can scale out your data access for better performance, depending on the usage pattern.
Storage services are independent of any hosted services, though they are often used in conjunction with them. Access to Windows Azure storage is with a REST-based API. This means that many clients that support the HTTP stack can access storage services. In practice, co-locating your data with services that run in Windows Azure achieves the best performance. Like hosted services, the storage services are also fault-tolerant and highly available. Each bit of data stored in Windows Azure storage is replicated both within the data center and the geographic region. Data is continuously scanned for bit decay and replicas of your data are maintained (currently, there are three copies).
All data is accessed with HTTP requests that follow REST conventions. The .NET Framework includes many libraries that interact with REST-based services at different abstraction levels, such as WCF Data Services, and direct HTTP calls through the WebRequest class. The Windows Azure SDK also contains specialized client libraries that provide domain models for all of the Windows Azure services. REST-based services are also used with many other platforms, such as JAVA, PHP, and Ruby. Almost every programming stack that can handle HTTP requests can interact with Windows Azure storage. There are four types of Windows Azure storage: blobs, drives, tables, and queues. To access Windows Azure storage, you must have a storage account that you create with the Windows Azure portal web interface at http://windows.azure.com.
A storage account is associated with a specific geographical location. Currently, each storage account can hold up to 100 terabytes of data, which can be made up of a combination of blobs, tables, queues, and drives. You can have as many storage accounts as you like, though, by default, you can create up to five accounts.
By default, all access to Windows Azure storage must be authenticated. Each storage account has two 256-bit symmetric keys.
Blobs
Generally, blobs provide storage for large pieces of data, such as images, video, documents, and code. Each storage account in a subscription can have any number of containers, where each container can hold any number of blobs. Storage is limited at the account level, not by any specific container or blob. Blobs are referenced with URLs that are created in the following format:
http(s)://<storage account name>.blob.core.windows.net/<container>/<blob name>
Windows Azure blob storage supports the notion of a root container. This is useful when you need to access blobs by specifying just the domain name. The reserved name $root denotes this special case. The following URL identifies a blob named "mypicture.jpg" that appears under an account named "myaccount":
http://myaccount.blob.core.windows.net/$root/mypicture.jpg
This is equivalent to the following:
http://myaccount.blob.core.windows.net/mypicture.jpg
Silverlight access policy files are a perfect example of where root containers are useful.
You can name blobs so that they appear to belong to a hierarchical namespace, but in reality, the namespace is flat. For example, the following is a blob reference that seems to imply a hierarchical structure:
http://myaccount.blob.core.windows.net/pictures/trips/seattle/spaceneedle.jpg
You could mistakenly assume a hierarchy or folder structure with folders named "pictures", "trips", and "seattle", but actually, all the path segments are the name of the blob itself. In other words, the container's name is "pictures" and the blob's name is "trips/seattle/spaceneedle.jpg".
Both containers and the blobs themselves can optionally store metadata in the form of a collection of name/value pairs, up to a maximum size of 8 kilobytes (KB). In addition to the Create, Update, and Delete operations, you can also perform more specialized operations on blobs such as Copy, Snapshot, or Lease.
Containers act as a security boundary in blob storage. By default, all access to blob storage requires knowledge of a secret key. However, you can set an access policy on the container to change this behavior to allow anonymous access. Valid access policies are the container-level access policy and the blob-only access policy. Container-level access allows you to enumerate and discover all blobs within the container. Blob-only access requires explicit knowledge of the blob Uniform Resource Identifier (URI). If the access policy is removed, the default behavior that requires knowledge of the key resumes.
Windows Azure provides a content delivery network (CDN) for efficient distribution of blob content. The CDN stores frequently accessed blobs closer to the application that uses it. For example, if a video is particularly popular with users in Asia, the CDN moves the blob to a server that is geographically close to these users. The CDN is an optional feature of blobs that you must explicitly enable. Using this feature may affect your billing.
Figure 3 illustrates how blobs are stored. An account holds blob containers. There can be more than one container associated with an account. The containers hold the blobs.
Figure 3
Blob storage
Blobs can be divided into two types: block blobs and page blobs.
Block Blobs
Each block blob can store up to 200 gigabytes (GB), which is divided into data blocks of up to 4 megabytes (MB) each. Block blobs are optimized for streaming workloads. They work well for large pieces of data such as streaming video, images, documents, and code. Block blob operations are optimized to safely upload large amounts of information. For example, you can use the API to upload blocks of data in parallel. Also, if there is a failure, you can resume uploads of specific blocks instead of the entire dataset.
For example, if you uploaded a 10 GB file to blob storage, you could split it into blocks of up to 4 MB in size. You would then use the PutBlock operation to upload each block independently (or possibly in parallel with other blocks for increased throughput). Finally, you would write all these blocks into a readable blob with the PutBlockList operation. Figure 4 illustrates this example.
Figure 4
Uploading a 10 GB file
Page Blobs
Page blobs have some predefined maximum size, up to 1 terabyte, and consist of an array of pages, where each page is 512 bytes. Page blobs are optimized for random access read/write I/O. Write operations, such as the PutPage method must be aligned to a page. This means that data is written to offsets that are multiples of 512 bytes. In contrast, read operations, such as the GetPage method, can occur on any address that is within a valid range. You are charged for page blobs by the amount of information that they actually contain, not by the amount of reserved space. If you provision a 1 GB page blob that contains 2 pages, you are only charged for 1 KB of data. Figure 5 illustrates basic page blob read and write operations.
Figure 5
Basic read and write operations
Windows Azure Drives
Windows Azure drives are page blobs that are formatted as NTFS single-volume virtual hard drives. A single role instance can mount a drive in exclusive read/write mode or many instances can mount a single drive in read-only mode. There is no way to combine the two options. Typically, one instance mounts the drive in read/write mode and periodically takes a snapshot of the drive. This snapshot can then be simultaneously mounted in read-only mode by other instances.
Because the underlying storage for a Windows Azure drive is a page blob, after the drive is mounted by a compute node, all information written by this node is persisted in the blob. Writing to a blob is possible after acquiring a lease on the drive. A lease is one of Windows Azure storage's concurrency control mechanisms. It is, in essence, a lock on a blob. Windows Azure drives are useful for legacy applications that rely on the NTFS file system and on standard I/O libraries. All operations on page blobs are also available for Windows Azure drives.
Figure 6 illustrates a Windows Azure drive.
Figure 6
Windows Azure drive
A Windows Azure drive is accessible to code that runs in a role. The data written to a Windows Azure drive is stored in a page blob that is defined within the Windows Azure Blob service and cached on the local file system.
Windows Azure Tables
Windows Azure tables provide scalable structured storage. Tables are associated with a storage account. Windows Azure tables are not like the tables in a typical relational database. They don't implement relationships and don't have a schema. Instead, each entity stored in a table can have a different set of properties made up of different types, such as string or int. Tables use optimistic concurrency, based on time stamps, for updates and deletions. Optimistic concurrency assumes that concurrency violations occur infrequently and simply disallows any updates or deletions that cause a concurrency violation. Figure 7 illustrates table storage.
Figure 7
Windows Azure table storage
There are three properties that all entities in a table have: a PartitionKey, a RowKey and the system-controlled property, LastUpdate. Entities are identified by the PartitionKey and the RowKey properties. The LastUpdate property is used for optimistic concurrency.
Windows Azure monitors the PartitionKey property and automatically scales tables if there is sufficient activity. It can potentially scale tables up to thousands of storage nodes by distributing the entities in the table. The PartitionKey also ensures that some set of related entities always stay together. This means that it is important to choose a good value for the key. The combination of the PartitionKey and the RowKey uniquely identifies any given entity instance in the table.
A query against a Windows Azure table that specifies both the PartitionKey and RowKey properties returns a single entity. Any other type of query could potentially return many entities because uniqueness is not guaranteed. Windows Azure table storage returns data in pages (currently, up to 1,000 entities are returned for each query). If there's more data to retrieve, the returned result set includes a continuation token that can be used to get the next page of data. Continuation tokens are returned until there's no more data available.
Tables don't currently support any aggregation functions, such as Sum or Count. Even though you can count rows or sum columns, most of these operations are resolved on the client side and involve scanning the entire table contents, which could be very expensive. You should consider other approaches, such as pre-computing and storing the values that you need, or providing approximations.
Transactions are supported within a single partition in a single table. For example, you can create, delete, and update entities in a single atomic operation. This is referred to as a batch operation. Batches are limited to 4 MB payloads.
There are various APIs available to interact with tables. The highest level ones use WCF Data Services. At the lowest level, you can use the REST endpoints that are exposed by Windows Azure.
Windows Azure Queues
Unlike blobs and tables, which are used to store data, queues serve another purpose. A primary use is to allow web roles to communicate with worker roles, typically for notifications and to schedule work. Queues provide persistent asynchronous messaging, where each message is up to 8 KB long.
Applications that retrieve messages from queues should be designed to be idempotent, because the messages can be processed more than once. Idempotency means that an operation can be performed multiple times without changing the result. Applications that retrieve messages should also be designed to handle poison messages. A poison message contains malformed data that causes the queue processor to throw an exception. The result is that the message isn't processed, stays in the queue, and the next attempt to process it once again fails.
Figure 8 illustrates queue storage. Accounts can contain queues that, in turn, contain messages.
Figure 8
Queue storage
The SDK includes a domain model that implements a higher-level abstraction of a queue. You can also interact with queues through a REST endpoint.
SQL Azure
SQL Azure is a cloud-based relational database management system (RDBMS). It currently focuses on the features required to perform transactions. For example, it provides indexes, views, triggers, and stored procedures. Applications that access SQL Server locally should be able to use SQL Azure with few, if any, changes. Customers can also use on-premises software, such as SQL Server Reporting Services, to work with SQL Azure.
You can connect to SQL Azure in a variety of ways, such as ADO.NET, PHP, and Open Database Connectivity (ODBC). This means that the way that you develop database applications today are the same as for SQL Azure. Essentially, if you have a database that you relocate to the cloud, you simply change the connection string.
Applications can either be located in the cloud, along with the database, or they can be located on-premises, and connect to a database that is in the cloud. The first option is known as code near and the second is known as code far.
No matter where the application is located, it accesses data with a protocol named Tabular Data Stream (TDS) over TCP/IP. This is the same protocol that is used to access a local SQL Server database.
SQL Azure includes a security feature that restricts access to the database to particular IP address ranges. You specify the IP addresses of the expected incoming connections and reject all others at the network level.
To access SQL Azure, you must create an account at http://sql.azure.com. Each account can have one or more logical servers, which are implemented as multiple physical servers within a geographical location. Each logical server can contain one or more logical databases, which are implemented as replicated, partitioned data across multiple physical servers.
You first create a database with the SQL Azure server administration interface, which is available on the web portal. You can also use tools such as SQL Server Management Studio to create databases, add elements such as user-defined objects, tables, views, and indexes, or to change the firewall settings.
SQL Azure is available in three database sizes: 1 GB, 10 GB, and 50 GB. Your bill is based on the size of the database, not on the amount of information you actually store.
Management Services
A main goal of Windows Azure is to make life simpler for application owners. One of the ways it does this is by providing a layer of automated service management. With this service, developers create the application and deploy it to the cloud. Developers also configure the service settings and constraints. After these tasks are performed, Windows Azure runs the service and maintains its health.
Windows Azure also provides capabilities to perform a number of operations, such as monitoring your applications and managing your storage accounts, hosted services, service deployments, and affinity groups. You can either use a web portal for these operations or perform them programmatically with a REST-based API. The API uses a different authentication mechanism than the web portal. All programmatic calls use X509 client certificates for authentication. Users can upload any valid X509 certificate to the Windows Azure developer portal and then use it as a client certificate when making API requests.
The Windows Azure management API described here is specifically for Windows Azure components such as compute and storage. Other services in the platform (such as SQL Azure and the AppFabric) have their own set of management interfaces.
Windows Azure Subscription and Billing Model
Figure 9 illustrates the current Windows Azure billing configuration for a standard subscription.
Figure 9
Windows Azure billing configuration for a standard subscription
To use Windows Azure, you first create a billing account by signing up for Microsoft Online Services, which manages subscriptions to all Microsoft services. Windows Azure is one of these, but there are others, such as Microsoft SharePoint® and hosted Exchange. You create a billing account on the Microsoft Online Services customer portal. Every billing account has a single account owner who is identified with a Windows Live® ID. The account owner can create and manage subscriptions, view billing information and usage data, and specify the service administrator for each subscription. The service administrator manages services and also deployments. There is one service administrator for each project. The account owner and the service administrator can be (and in many cases should be) different Live IDs.
After you have the billing account, you can select Windows Azure from the subscription offerings. When you buy a subscription, you enter a subscription name. This is the name of the Azure project. After buying the subscription, you can activate the Windows Azure service and specify the service administrator. For each billing account, you can have as many subscriptions as you want.
Next, go to the Windows Azure Portal at http://windows.azure.com and sign in. You will see the Windows Azure Portal home page with a project that has the name you gave when you created the subscription. On the home page, you can create services for your project. A service is either a hosted service or a storage account.
By default, each project is limited to twenty compute instances. Each project can have up to six hosted services. Hosted services are spaces where applications are deployed. Each hosted service has from one to five roles. These can be any combination of web roles and worker roles. In Visual Studio, you can configure a role for the number of instances and the size of the VM. VMs can be designated as small, medium, large, and extra large. The definitions of what these mean are located at http://msdn.microsoft.com/en-us/library/ee814754.aspx. Briefly, a small VM corresponds to 1 CPU core, a medium VM corresponds to 2 CPU cores, a large VM corresponds to 4 CPU cores, and an extra large VM corresponds to 8 CPU cores. A core is the processing portion of a CPU, exclusive of the cache. A hosted service is always associated with an URL.
A hosted service also has a staging environment and a production environment. Finally, a project can have up to five storage accounts. These are also shared among all the hosted services in the subscription. If you need more computing power or storage capacity, you can arrange this through Microsoft Online Services.
The number of CPU cores for a hosted service is number of roles X instance count X number of CPU cores for the selected VM size. For example, if you have one hosted service with two roles, where each role has one instance and is a small VM, the number of CPU cores is 1 x 2 x 1 = 2. As another example, if you have five hosted services, each with one role, two instances of that role and a medium VM, the number of CPU cores is 5 x 1 x 2 x 2 = 20. This is the default limit for CPU cores per project.
For storage, you can have up to five accounts, each of which can contain up to 100 terabytes of data. This can be any combination of blobs, tables, and queues.
Another point to remember is that you are billed for role resources that are used by a deployed service, even if the roles on those services are not running. If you don't want to get charged for a service, delete the deployments associated with the service.
Estimating Your Costs
Windows Azure charges for how you consume services such as compute time, storage, and bandwidth. Compute time charges are calculated by an hourly rate as well as a rate for the instance size. Storage charges are based on the number of gigabytes and the number of transactions. Prices for data transfer vary according to the region you are in and generally apply to transfers between the Microsoft data centers and your premises, but not on transfers within the same data center. There are also various purchasing models, such as the consumption model and the subscription model. For a description of the different pricing models and any special offers, go to http://www.microsoft.com/windowsazure/pricing/.
If you want to estimate your costs for using Windows Azure, you can use the Microsoft Windows Azure platform TCO and ROI Calculator, where TCO is total cost of ownership and ROI is return on investment. The tool is located at http://www.microsoft.com/windowsazure/tco/. Using information you provide about your company and the application, the tool can help you estimate the correct configuration and its costs, the costs of migrating an application to Windows Azure, and compare on-premises and Windows Azure application delivery costs.
More Information
There is a great deal of information about the Windows Azure platform in the form of documentation, training videos, and white papers. Here are some Webs sites you can visit to get started:
- The portal to information about Microsoft Windows Azure is at http://www.microsoft.com/windowsazure/. It has links to white papers, tools such as the Windows Azure SDK, and many other resources. You can also sign up for a Windows Azure account here.
- The Windows Azure platform Training Kit contains hands-on labs to get you quickly started. You can download it at http://www.microsoft.com/downloads/details.aspx?FamilyID=413E88F8-5966-4A83-B309-53B7B77EDF78&displaylang=en.
- [Wade Wegner]
Ryan Dunnand Steve Marx have a series of Channel 9 discussions about Azure at Cloud Cover, located at http://channel9.msdn.com/shows/Cloud+Cover/.- Find answers to your questions on the Windows Azure Forum at http://social.msdn.microsoft.com/Forums/en-US/windowsazure/threads.
- Steve Marx is a Windows Azure technical strategist. His blog is at http://blog.smarx.com/. It is a great source of news and information on Windows Azure.
- Ryan Dunn is [a former] Windows Azure technical evangelist. His blog is at http://dunnry.com/blog.
- Eugenio Pace, a program manager in the Microsoft patterns & practices group, is creating a series of guides on Windows Azure, to which this documentation belongs. To learn more about the series, see his blog at http://blogs.msdn.com/eugeniop.
- Scott Densmore, lead developer in the Microsoft patterns & practices group, writes about developing applications for Windows Azure on his blog at http://scottdensmore.typepad.com/.
- Jim Nakashima is a program manager in the group that builds tools for Windows Azure. His blog is full of technical details and tips. It is at http://blogs.msdn.com/jnak/.
- Code and documentation for the patterns & practice guidance project is available on the CodePlex Windows Azure Guidance site at http://wag.codeplex.com/.

.png")
.png")
.png")
.png")
.png")
.png")
.png")
.png")
.png")
I agree with Bryan that the preceding is the best and most up-to-date overall description of Windows Azure services that I’ve seen so far. Unfortunately, Jim Nakashima hasn’t posted to his Cloudy in Seattle blog in 11 months; I miss his writing.
Himanshu Singh recommended that you Download the Deploying and Managing Windows Azure Applications Evaluation in a 10/6/2011 post to the Windows Azure blog:
The folks over at the TechNet Evaluation Center have just released a new evaluation experience called Deploying And Managing Windows Azure Applications. In this evaluation, users will follow a step-by-step guide to deploy a sample application to Windows Azure and then use System Center Operations Manager (SCOM) to monitor and manage that application.
The evaluation is free and works with the existing Windows Azure free trial. Register for the Deploying and Managing Windows Azure Applications evaluation here.
The following components are included in the evaluation:
- Windows Azure Platform Trial - Sign up for a free trial of the Windows Azure platform or use your own account.
- Evaluation Guide - This step-by-step guide walks you through deploying and managing an application on Windows Azure.
- Windows Azure-ready Application - You will deploy this sample application on Windows Azure.
- System Center Operations Manager 2007 R2 VHD - This fully configured virtual machine provides the environment from which you will deploy the sample application on Windows Azure and demonstrates System Center Operations Manager's capabilities for managing applications and IT services in a Windows Azure public cloud environment.
- Windows Azure Application Monitoring Management Pack - The Windows Azure Application Monitoring Management Pack for System Center Operations Manager enables you to monitor the availability and performance of applications that are running on Windows Azure.
- Windows Azure Software Development Kit and Tools for Visual Studio - To further explore Windows Azure, these tools extend Visual Studio 2010 and Visual Web Developer 2010 Express Edition to enable you to create, build, debug, run, and package scalable services on Windows Azure.
Learn more and to register to access technical product resources, including forums, solution accelerators, white papers and webcast, at the Deploying and Managing Windows Azure Applications Resource Page.

My Configuring the Systems Center Monitoring Pack for Windows Azure Applications on SCOM 2012 Beta post of 9/7/2011 describes a similar process for SCOM 2012 (59 steps.)
Mike Wood (@mikewo) summarized Fall 2011 and BUILD Azure Related New Features in a 10/5/2011 post to the Cumulux blog:
Over the last few months there have been quite a few announcements and new features announced for Windows Azure. Many announcements came out of the BUILD conference in Anaheim, California, but the Windows Azure teams have been also releasing new features and tools regularly. Below is high level description and timeline on the key features and tools announced during the months of August and September.
Windows Azure Platform
- Updates to the Service Management API (available now)
- New operations have been added to the Service Management API which allow for the ability to rollback an in-progress service update or configuration change, invoke multiple “write” operations for an ongoing deployment and get more detailed information on deployed role instances and subscriptions.
- PowerShell Service Management Cmdlets (available now)
- Windows Azure Platform PowerShell Cmdlets V2 has been released. This version includes consolidating the ACS Cmdlets, support for SQL Azure Cmdlets and updates to existing Cmdlets. This is a must have for automation of administration of your Windows Azure
solutions.- Windows Azure SDK 1.5 (available now)
- The new Windows Azure 1.5 SDK includes updates to some of the SDK tools
- Updated Compute Emulator to bring the development compute emulator more in line with cloud environment. It also includes some improvements for performance of the compute emulator as well as the ability to allocate unique local loop back IPs to make ports more predictable.
- The CSUpload.exe tool has been updated with the ability to upload hosted service certificates (for RDP and SSL certificates). This improves the automation story for deployments.
- A new CSEncrypt command line tool has been created to allow for better automation of managing Remote Desktop certificate creation and password encrypting.
- The CSPack command line tool now no longer encrypts the package files being created. The packages are still uploaded over SSL for security, but the contents of the package are no longer encrypted, which can help with debugging packaging issues.
- Added new enhancements to the Service Definition such as:
- ProgramEntryPoint element for service definition to allow for direct launching of programs in worker roles.
- Enhanced ability to include local system directory content into a package using ProgramEntryPoint and NetFxEntryPoint elements.
- UpdateDomain setting now can be increased to 20.
- Windows Azure Tools for Visual Studio 2010 – Sept (Available now)
- A new version of the tools was announced the same day as the new 1.5 SDK. In August there was also a previous release for the tools that added a few new features.
- Added ability to create a Windows Azure Deployment project in most web based projects.
- Profiling support for Windows Azure projects was added in August.
- Validation of packages was added to warn developers of when they have a configuration that will be problematic in Windows Azure, or if they are missing assemblies that are required to be included in the package. Added in August.
- Included the ability to manage Service Configuration files for multiple environments added in August.
- Windows Azure Platform Training Kit (Available now)
- Updated in September for the changes to the Windows Azure Tools for Visual Studio 1.5 release the training kit has updated labs and a new lab for the Windows Azure Marketplace for Applications. This training kit is a great way to learn about the components of the Windows Azure Platform.
- Windows Azure Storage Enhancements (Available now)
- New updates and features were made to the Windows Azure Storage services.
- Geo-replication for disaster recovery for Azure Tables and BLOBs.
- Table changes include:
- Table Upsert Feature – Ability to insert or update in a single call. Also includes ability to perform merges in the update.
- Table Projections feature – Ability to select only specific properties in the query instead of pulling them all back.
- Improved BLOB HTTP headers in order to better support streaming and downloads for some browsers and media players.
- Queue changes include:
- Increased the queue message size from 8K to 64K.
- Ability to insert a message into the queue with future visibility time. This allows scheduling a message to be consumed in the future.
- Ability to update the content of a message while it is being processed to allow for progress to be recorded in the message.
- Ability to renew the invisibility time as it is being worked on. This allows for scenarios where a consumer can get a lease on a message and while it is being processed it can keep extending the lease. Previously a queue message must be processed within a maximum of 2 hours. This is now 7 days as long as the consumer processing it continues to renew the lease.
- Windows Azure Toolkit for Windows 8 (available now as CTP for the Windows 8 Developer preview)
- Building a cloud service to support rich Windows Metro style apps is even easier with the Windows Azure Toolkit for Windows 8. This toolkit has all the tools to make it easy to develop a Windows Azure service and deploy it to your users. In addition to documentation, this toolkit includes Visual Studio project templates for a sample Metro style app and a Windows Azure cloud project. This tool is designed to accelerate development so that developers can start enabling Windows 8 features, such as notifications, for their app with minimal time and experience. Use this toolkit to start building and customizing your own service to deliver rich Metro style apps.
Windows Azure AppFabric
- Windows Azure AppFabric SDK 1.5 (Available now)
- New features for the Service Bus that have been in CTP since May have now been released into the production environment and available to the AppFabric SDK 1.5. These improvements include:
- Improved publish/subscribe capabilities.
- Durable, or “brokered” messaging capabilities through features such as queues, topics and subscriptions.
Windows Azure Marketplace
- Availability of the marketplace in Additional countries. (Available in
Oct)
- The Marketplace will be available in 25 new countries. Customers in these new markets will be able to discover, explore and subscribe to premium data and applications on the Marketplace.
- Microsoft Translator APIs (Available now)
- The BING translation services are now available via the MarketPlace as a subscription service. You can add translation to your applications and solutions.
SQL Azure
- Q2 2011 Service Release (Available now)
- A new service update was pushed to SQL Azure in August. This update included many new features on the platform:
- Co Admin support to allow additional database administrator accounts.
- Increased capability for spatial data types.
- Additional built in functions
- New SQL Azure Management Portal (Available now)
- A replacement to the previous online management portal, the new portal has more features for managing your SQL Azure databases. The new portal also offers some new database lifecycle tools at the server level, such as creating new databases, deploying DAC packs, or extracting data.
- SQL Azure Import/Export Hosted (Available as CTP)
- There is a CTP of an export/import feature for SQL Azure that allows you to utilize the Data-Tier Application Framework to back up your databases to BLOB storage.
There have been a lot of changes over the last few months. One great thing about the cloud is that new features can be added much faster than traditional product development. Things that can come out so fast it can sometimes be hard to keep up. We hope this list will be a good start on what’s new.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Tim Anderson (@timanderson) described Hands On with Storage Spaces in Windows Server 8 in a 10/7/2011 post:
Storage Spaces is a new virtual storage feature in Windows Server 8. I have the developer preview installed, but it took me a while to get Storage Spaces working – you need one or more unused hard drives. I finally managed to find a spare 150GB SATA drive and tried it out. Note that I am going to create a 1.5TB drive on this using the magic of thin provisioning, with data deduplication thrown in for good measure.

Here I specify the pool name and the subsystem where it will find its disks. In my case it is the RAID controller built into the motherboard.

Success

Next task is to create a new volume. I’ve selected thin provisioning as I want a drive larger than the available space. If it runs out of real space, I will have to add another drive to the pool. I have also selected Simple layout, which means no resiliency. I am doing this for the demo as I only have one drive, but in reality I would always use one of the resilient options. They are apparently not RAID, even though they are like RAID.

Next I assign the new drive to a virtual folder, as I am bored with Windows drive letters.

I turn on data deduplication. This means that I can have several copies of the same file, but it will only occupy the space of one. If a file is mostly the same as another file, I will also save space.

Success again. Note that Windows formatted the new drive for me in a matter of minutes. It may help that most of the space does not really exist.

Here is my drive ready for use, with 1,572,730,876 KB free. Handy.

I am impressed with how easy Storage Spaces are to use, and that it works with cheap SATA drives.
Now, I remember that Windows Home Server had an easy to use storage system called Drive Extender. You could just add and remove drives. Is Storage Spaces a kind of grown up version of Drive Extender? I asked the Windows storage team and got a snooty reply. “We do not contrast our upcoming capabilities with those that might have been offered in the past as part of other Microsoft products.” However, the spokesperson did add:
Storage Spaces delivers a rich storage virtualization capability directly from within Windows. Two powerful new abstractions (Pools and Spaces) deliver multiple benefits including seamless and easy capacity aggregation and expansion ("just add drives to a pool"), optimal just-in-time allocation (via Thin Provisioning), resiliency to physical drive failures (via mirrored or parity spaces), continuous availability (via integration with failover clustering and cluster shared volumes), ease-of-management via integration with the rich new Windows Storage Management API (with WMI interfaces and associated PowerShell cmdlets), and "pay-for-play" via support for pools comprising heterogeneous media (e.g. SSDs and HDDs). Obviously, these are just a subset of features.
Obviously. I like Storage Spaces so far though, and the feature seems to bring some similar benefits to Windows Server users.
Related posts:









Virtualized storage with Mirror or Parity Layout will provide high availability storage for private and WAPA clouds. I plan to test 1TB redundant storage with my Intel DQ45CB motherboard, which supports five SATA and one eSATA drives (three 750GB drives are installed). I have Windows 8 Server Developer Preview installed as one of four boot devices.
Laura DiDio (@lauradidio) reported Microsoft Hyper-V gaining on VMware in the virtualization market in a 10/7/2011 post to TechTarget’s SearchServerVirtualization.com:
VMware is still indisputably the server virtualization market leader, but Microsoft Hyper-V has made significant strides in the last year.
Microsoft Hyper-V is used at 53% of the respondents’ organizations, compared with 59% who have VMware and 18% who use Citrix Systems XenServer, according to an Information Technology Intelligence Consulting (ITIC) independent survey of 400 global respondents. Microsoft Hyper-V usage jumped by 15 percentage points in the last 12 months, fueled by improvements in the hypervisor’s core functionality and the widespread adoption of Windows Server 2008 R2. The survey respondents -- which encompassed a relatively equal mix of companies from small to medium-sized businesses (SMBs) to enterprises from various industries -- also showed that XenServer deployments doubled from 9% in 2010 to 18% in the most recent survey.
Meanwhile, Oracle offerings -- which include Oracle VM as well as the former Sun Microsystems virtualization products -- saw a decline from 4% in 2010 to 2% in 2011.
Despite the gains of Hyper-V and XenServer, VMware is still the top virtualization vendor among companies with multiple platforms. Fifty-eight percent of the survey participants indicated that VMware is their primary virtualization platform, compared to 32% who said Microsoft Hyper-V and 8% who responded that Citrix XenServer was their most widely deployed hypervisor.
The survey results underscore the maturation of the server virtualization market. In the first wave of deployments, VMware was the dominant player with the most advanced features. The initial implementation of Hyper-V within Windows Server 2003 was rudimentary and lagged far behind VMware’s ESX Server, and Citrix Systems lacked the marketing muscle to effectively compete against VMware.
The virtualization market is vastly different today. Microsoft has made a concerted effort to match the performance and management capabilities of VMware vSphere. For example, the following Microsoft Hyper-V R2 features have significantly closed the gap with VMware:
- Hyper-V in Windows Server 2008 R2 now supports up to 64 logical processors in the host processor pool, delivering greater virtual machine (VM) density per host and IT administrators more flexibility in assigning CPU resources to VMs.
- Improvements in Hyper-V Live Migration enable organizations to perform live migrations across different CPU versions within the same processor family.
- The new Microsoft Hyper-V also adds enhancements that increase VM performance and power consumption while reducing the hypervisor processing load.
- The latest Hyper-V VMs consume approximately 20% to 30% less power on average (depending on individual configuration and workloads) thanks to the Core Parking feature implemented into Windows Server 2008 R2. …

Read more.
Full disclosure: I’m a paid contributor to TechTarget’s SearchCloudComputing.com.
<Return to section navigation list>
Cloud Security and Governance
Christine Drake posted Beyond Perimeter Defense to Data-Centric Security to the Trend Cloud Security blog on 10/7011:
Traditionally businesses have focused their IT security on perimeter defense—blocking threats before they enter the network. This protection is still important. But with today’s cloud computing, mobile devices, and advanced persistent threats (APTs), businesses need security that protects their data wherever it travels and in whatever type of device it resides, requiring new data-centric security.
Earlier this week, Trend Micro held its annual insight event for the analyst community and announced our new vision on data-centric security (see video clips of the event here and here). Back in 2008, Trend Micro launched our Smart Protection Network which correlates cloud-based email, web, and file reputation services. This global threat intelligence blocks threats before they enter the network. But with targeted attacks as well as cloud computing and mobile devices expanding network perimeters, companies need more than this “outside-in” approach to security. Businesses also need “inside-out” protection that focuses on the data. So we have made our Smart Protection Network even smarter—providing adaptable protection on the local level as well as from the cloud.
For businesses this means new sensors will be added to Trend Micro products that collect local threat intelligence and context-aware data usage (who, what, where, when) to create customized data protection. And this protection will be provided in a unified framework with a centralized view across the network along with policy and action options. By combining global threat intelligence and customized local protection, the new Smart Protection Network enables companies to create effective data usage policies and detect possible data breaches, even from advanced persistent threats, zero-day malware, or targeted attacks.
Trend Micro’s CEO, Eva Chen, gave a presentation on cloud computing at VMworld Las Vegas. Towards the end of that presentation she discusses this new security model (view a shorter version of the presentation in this video). When companies know their data is safe wherever it resides, they can be free to embrace consumerization to increase productivity in a mobile workforce. Or explore new infrastructure technologies such as cloud computing. You can read more about this data-centric security model on this Trend Micro web page.
<Return to section navigation list>
Cloud Computing Events
• Robin Shahan (@RobinDotNet) reported that she’s Speaking at Silicon Valley Code Camp–Oct 8 in a 10/7/2011 post:
This weekend I will be speaking at the Silicon Valley Code Camp in, well, Silicon Valley. To be more specific, it’s at Foothill College in Los Altos Hills, California, United States of America, Earth. Milky Way Galaxy. (Ok, enough of that.) My talks (parts 1 and 2) are at 3:30 and 5:00 on Saturday, October 8th.
I think this is the largest code camp in the US, with over 200 sessions, and over 3,000 people registered. They have sessions on pretty much everything from .NET and Azure to Java, HTML5, Google developer tools and platforms, mobile development, and even the new Metro UI programming from Microsoft coming with Windows 8 that was revealed at the recent build conference.
My talk is called Azure for Developers. I’m going to briefly cover the basic principles of Windows Azure, but the main purpose of the talk is to show you how to program something that will run in Windows Azure and talk about how I used the different features when I migrated my company’s entire infrastructure to Azure last year.
I’ll show how to migrate an existing SQLServer database to SQL Azure, then write a WCF service to access it (including the SQL Azure retry code), and show how to access the service from a desktop client. I’ll show how you can put requests on an Azure queue and then read from the queue with a worker role and write information to blob storage. I’ll also show you how to set up diagnostics so you can do diagnostics tracing, performance monitoring, etc.
This covers pretty much all the major stuff in Windows Azure except writing to Azure table storage. I found out today that the sessions are 75 minutes instead of 60, so I’m going to try to add a section to the presentation to show how to run the WCF service against Windows Azure table storage instead of using SQL Azure.
You should be able to take what you see and create your own Windows Azure applications. The integration of the development environment with Azure is a huge benefit, and if you’re already a .NET programmer, the leap to Azure is totally manageable, as you’ll see with all the familiar-looking code.
If you’re in the Bay Area this weekend, it would be great to see you. If you have any Azure questions, please bring them with you!

Sorry about the late post, Robin, but your Atom or RSS feed didn’t update before yesterday’s cutoff.
David Aiken (@TheDavidAiken) reported Our datacenters are awesomeness in a box in a 10/7/2011 post:
Last week I attended the (first?) Seattle Windows Azure User Group meeting. One of the topics of conversation was around datacenters. (Tip: We typically don’t build them above bakeries).
We don’t as a rule talk very much about how awesome they are – although there are a few videos out there which are great for a Friday lunchtime watch.
A great animation of the ITPAC
Our recent GFS datacenter tour video
You can find more geeky videos on the Microsoft Global Foundation Services site at http://www.globalfoundationservices.com/infrastructure/videos.html.
Just a note, these are videos about our datacenters and not just Windows Azure.
BTW – if you are in the Seattle area, you should join the user group. People like Steve Marx & Vittorio Bertocci might even be there.
THIS POSTING IS PROVIDED “AS IS” WITH NO WARRANTIES, AND CONFERS NO RIGHTS

I’m not sure why David adds a weasel clause to his posts. Few, if any, other Windows Azure bloggers add them.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Jo Maitland (JoMaitlandTT) reported Oracle Public Cloud: The good and bad in a 10/7/2011 post to the SearchCloudComputing.com blog:
If an expensive, monolithic, late-to-market cloud is what you've been waiting for then Oracle Public Cloudappears to be the answer.
Unveiled at Oracle OpenWorld in San Francisco this week, the service includes the usual three tiers of a cloud computing model:
- Infrastructure as a Service -- Users can buy a virtual machine (VM) running on Oracle Solaris 11 and Oracle VM 3.0 virtualization
- Platform as a Service (PaaS) -- Users can buy Fusion middleware meaning a WebLogic application server and an Oracle database
- Software as a Service -- Users can buy three apps: Fusion CRM; Fusion HCM, a human resources app; and a new collaboration tool called Social Network
To date, Oracle has been a laggard in bringing cloud offerings to market. But the company said it is launching cloud services now -- years after everyone else -- because its survey results indicate that customers are ready. Asked how many were interested in building private cloud, 28.6% of Oracle customers answered yes in 2010, versus 37% in 2011 (a 28% increase). Regarding public cloud adoption, 13.8% of respondents said they were interested in 2010 versus 20.9% in 2011 (a 50% increase).
How cloud-like is Oracle Public Cloud?
The biggest surprise in the announcement of Oracle Public Cloud was the lack of multi-tenancy support in these services. Users get a separate VM and database per customer to guarantee isolation between a company's data and everyone else's, Oracle execs claimed. This immediately raises the question of cost, as cloud computing has been able to drive lower costs primarily by using shared data stores and a shared-application model. Oracle offered no pricing information for its cloud services, but expect premium.
And just to be clear, cloud computing as defined by the National Institute of Science and Technology (NIST) states, "The provider's computing resources are pooled to serve multiple customers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand." Oracle must have missed that part.
Oracle was fuzzy on the details of its PaaS offering, but it looks like there is no autoscaling capability today, which is a basic feature of Platform as a Service.
The sign-up process for Oracle Public Cloud doesn't quite meet the mark of a true cloud service, either. It's a monthly subscription versus pay-as-you-go. And before you can start using the service, you have to submit a request, wait for credentials via email and then sign in. Sounds like the old Oracle on-demand hosting model to me.
On the plus side, Oracle's Fusion middleware is the same product sold on the cloud as on-premises, and the programming model for Oracle Public Cloud uses the same open standards-based languages including Java, BPEL and Web services. So moving workloads to and from the cloudshould be straightforward.
Oracle cloud offerings meet mixed reaction
Oracle users at the conference offered mixed reactions to the news. Some said it might simplify deploying Oracle apps that traditionally have been complex and unwieldy to manage. But others said the Oracle Exadata and Exalogic engineered cloud-in-a-box systems were "mainframe cloud" and not what cloud computing is supposed to be about.Robert Shimp, group VP at Oracle, countered that, in the future, "all enterprise clouds will be built on engineered systems, not x86 boxes lashed together. That's going to seem like a crazy-bad idea over time."
More on public cloud:

Jo Maitland is the Senior Executive Editor of SearchCloudComputing.com.
Full disclosure: I’m a paid contributor to SearchCloudComputing.com.
• Matthew Weinberger (@M_Wein) asked (but didn’t answer) Oracle Public Cloud: Is Larry Ellison Innovating? in a 10/7/2011 post to the Talkin Cloud blog:
At Oracle OpenWorld, Oracle CEO Larry Ellison unveiled Oracle Public Cloud, the company’s first big IaaS foray into applications, middleware, and (of course) database solutions delivered as a service. In my opinion Oracle Public Cloud looks a lot like Salesforce.com – which may explain some of the fireworks between Ellison and Salesforce.com CEO Marc Benioff this week.
Let’s back up. As per the Oracle blog entry that details the offering, there are five key components to the Oracle Public Cloud suite:
Application Services
- Oracle Fusion CRM Cloud Service
- Oracle Fusion HCM Cloud Service
- Oracle Social Network Cloud Service
Platform Services
- Oracle Database Cloud Service
- Oracle Java Cloud Service
Among those five key components are 100 “modules,” providing for everything from compliance and governance to financial management to supply chain management and back. In other words, Oracle Public Cloud aims to take all of Ellison and company’s existing expertise and experience from decades in the enterprise IT world and make it into a compelling cloud play.
Also of note: Throughout Oracle OpenWorld, the company said its on-premise applications and cloud applications would leverage the exact same code. Ellison’s goal is to allow Oracle customers to mix and match their on-premise deployments with cloud offerings.
Predictably, Oracle Public Cloud is all built on the Fusion Applications platform, a project six years in the making, with baked-in BI/analytics, security, portability between legacy and cloud environments, service-oriented architecture, and the use of industry standards all given as key priorities.
Speaking of industry standards, Oracle Public Cloud unsurprisingly allows for applications to be built or extended into the cloud by way of common standards like Java EE and SQL, bringing it onto a par with many other public cloud providers and ensuring portability between them and on-premises applications.
Ellison singled out Oracle Public Cloud’s standards-based infrastructure and pursuant ease of data migration as a major edge over competitors like — you guessed it — Salesforce.com.
And naturally, the Oracle Public Cloud applications are designed to work in most mobile browsers – though I didn’t realize until it was pointed out that Ellison didn’t mention Google Android on stage. What’s more, Exalogic and Exadata are at the core of the Oracle Public Cloud offering, proving that TalkinCloud was correct in our hunch that the two platforms were destined for new life in the cloud.
Otherwise, Oracle is pitching the solution with all the usual cloud perks: predictable billing, scalability, self-service, and so forth.
I’m of two minds here:
- Oracle is the arms dealer of the cloud space, as my editor Joe Panettieri likes to say, and there are many, many SaaS providers out there who run Oracle databases and are looking for a compatible cloud solution. What’s more, the vast majority of public clouds already use Oracle databases and middleware behind the scenes, so even if this is Oracle’s first public IaaS play, it’s way more ingratiated with the cloud services channel than it may appear at first blush.
- But on the other hand, by taking the time to make so many slams on Salesforce.com on stage, and by allegedly barring Benioff from speaking at OpenWorld, and by taking so long to come out with this solution, Oracle looks like they envy Salesforce at a time when they need to energize their user base by appearing to be thought leaders and visionaries.
Needless to say, we’ll be watching Oracle Public Cloud under the microscope, so stay tuned.
Read More About This Topic

If “Oracle Public Cloud is all built on the Fusion Applications platform,” I believe that it’s a PaaS offering. The three Fusion services look to me to be SaaS products.
Scott M. Fulton, III (@SMFulton3) confused WSDL and SOAP in his Amazon Adds SQS Queue Administration to AWS Console post of 10/7/2011 to the ReadWriteCloud:
The XML-based language that the Web uses for sending small transactional messages and chunks of data between hosts is Web Services Description Language (WSDL). Essentially, it's a system for Web services to communicate almost anything between one another, first by defining the format of what it is they're communicating - a kind of manifest - and then by enclosing instances of the items defined inside XML tags.
What makes WSDL perfect for cloud services is that the message transport protocol is simple HTTP (thus the "W" for "Web" in its name). So hosts don't have to be joined together in the same network loop; it's the Internet that connects them. Cloud-based Web services geared to receive WSDL messages use their own message queues, often using the same MQ systems devised for middleware. For Amazon Web Services, the MQ is Simple Queue Service (SQS). Believe it or not, up until a few days ago, AWS customers could not access their SQS queues through the AWS Management Console.
Indeed, an independent developer named Kresimir Popovic had made his own SQS management tool, and AWS support personnel were suggested that customers download and use it.
This week, Amazon's AWS team announced on its blog that this little omission has finally been patched. The current version of AWS Management Console, deployed now, includes a complete set of tools for SQS queue management.

[screenshot courtesy Amazon Web Services]
As is typical for WSDL, messages are limited to 64K maximum size, so SQS is not an appropriate system for exchanging e-mail-sized messages. Instead, say you have an order processing system. Most likely, all the characters needed to represent the customer sign-up data can be compressed into one message. Streams of messages can then be directed to your SQS queue, where they'll wait for up to four days (more than enough time) for your service to get around to them.
With the new AWS Console features, you can create new queues, grant permissions to them with respect to whether their handlers can send or delete messages therein, send messages to queues manually, adjust the timeout period for waiting messages, and most importantly, look inside your queues to see what's waiting. "As you can see, this addition to the console provides you with a lot of insight into your SQS message queues, and it also provides you with a lot of control," writes Amazon's Jeff Barr.
Amazon Web Services was founded in 2002.
See Also


As I observed in a comment to Scott’s post:
I believe [Scott] confused WSDL (Web Services Description Language) documents, which provide descriptive contracts (related to a schema) for XML Web services, with the SOAP (no longer an acronym) protocol for messaging.
Also, there's no official or unofficial limit on the size of a WSDL schema or a SOAP message.
See the full text of Jeff Barr’s post below.
Navneet Joneja posted Google Cloud SQL: Your database in the cloud to the Google Developer and Google Code blogs on 10/6/2011:
One of App Engine’s most requested features has been a simple way to develop traditional database-driven applications. In response to your feedback, we’re happy to announce the limited preview of Google Cloud SQL. You can now choose to power your App Engine applications with a familiar relational database in a fully-managed cloud environment. This allows you to focus on developing your applications and services, free from the chores of managing, maintaining and administering relational databases. Google Cloud SQL brings many benefits to the App Engine community:
- No maintenance or administration - we manage the database for you.
- High reliability and availability - your data is replicated synchronously to multiple data centers. Machine, rack and data center failures are handled automatically to minimize end-user impact.
- Familiar MySQL database environment with JDBC support (for Java-based App Engine applications) and DB-API support (for Python-based App Engine applications).
- Comprehensive user interface for administering databases.
- Simple and powerful integration with Google App Engine.
The service includes database import and export functionality, so you can move your existing MySQL databases to the cloud and use them with App Engine. Cloud SQL is available free of charge for now, and we will publish pricing at least 30 days before charging for it. The service will continue to evolve as we work out the kinks during the preview, but let us know if you’d like to take it for a spin.


Navneet is a Google product manager.
Yet another MySQL derivative. Built-in replication to multiple data centers is a nice feature, if the replication is transactional. I’ve applied for a Cloud SQL test account.
Jeff Barr (@jeffbarr) reported AWS Management Console Now Supports the Simple Queue Service (SQS) on 10/6/2011:
The AWS Management Console now supports the Amazon Simple Queue Service (SQS). You can create, inspect, and modify queues. You can post new messages to queues and you can peek at the messages in the queues. Here is a tour:
You can see all of your message queues for the current region, along with the number of messages available and in flight, from the main window:
The following actions are available for each queue:
You can select one of your queues to see more information about it:
You have full control of the permissions associated with each of your queues:
You can create a new queue by filling in a form. You have control over the visibility timeout, message retention period, and the maximum message size:
You can also modify these settings for an existing queue:
You can send a message to any one of your queues:
You can also peek into any of your queues to see what's inside. The messages that you see will be hidden from other applications until the time period specified by the queue's visibility timeout has elapsed:
You can view messages for a desired period of time, or you can wait for the desired number of messages to appear:
You can click on the More Details link to see the entire message. In this particular case, I chose to encode the messages in JSON format:
As you can see, this addition to the console provides you with a lot of insight into your SQS message queues, and it also provides you with a lot of control.

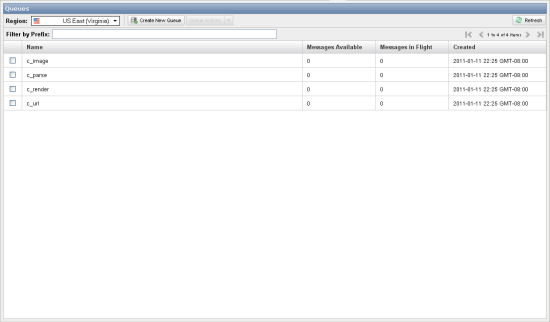
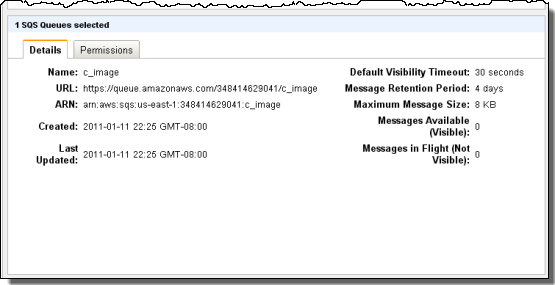
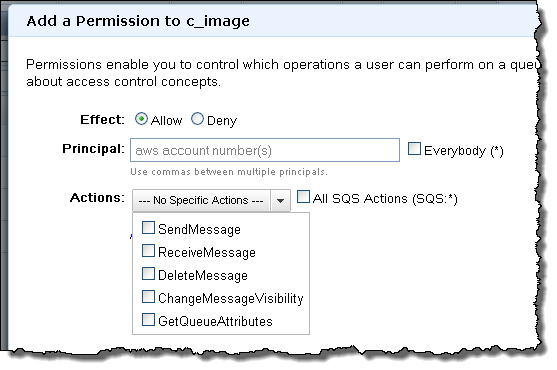

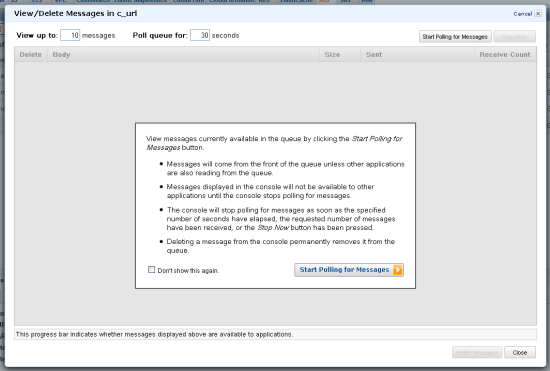
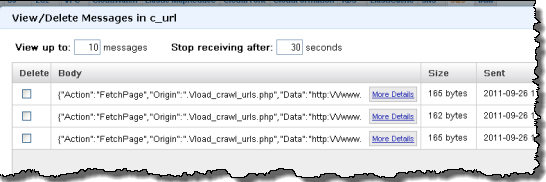
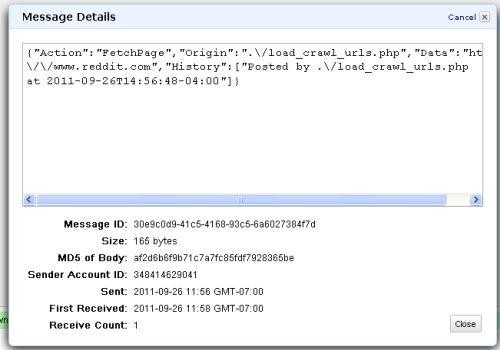
Simple and straightforward.
<Return to section navigation list>

















0 comments:
Post a Comment