Windows Azure and Cloud Computing Posts for 10/5/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

• Updated 10/6/2011 with five new sessions added to my list of sessions related to Windows Azure at the SharePoint Conference 2011 at the top of the Live Windows Azure Apps, APIs, Tools and Test Harnesses section below.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
Cihan Biyikoglu reported a New sample shows how to build multi-tenant apps with Federations in SQL Azure in a 10/4/2011 post:
Nice fresh sample from Full Scale180’s guys called Cloud Ninja.
“The Cloud Ninja - SQL Azure Federations Project is a sample demonstrating the use of SQL Azure Federations in creating multi-tenant solutions. SQL Azure Federations can be a useful tool for migrating existing single tenant solutions to multi-tenant cloud solutions, as well as building new multi-tenant internet scale solutions. In this project we demonstrate the migration of an existing solution to SQL Azure Federations and further leveraging SQL Azure Federation features in our multi-tenant solutions.”
You can download the code here; http://shard.codeplex.com/

See post below.
Trent Swanson posted a Multi-tenant SQL Azure Federations Sample to CodePlex on 10/4/2011:
Project Description
This is a sample application demonstrating the use of SQL Azure Federations in a multi-tenant solution.
The Cloud Ninja - SQL Azure Federations Project is a sample demonstrating the use of SQL Azure Federations in creating multi-tenant solutions. SQL Azure Federations can be a useful tool for migrating existing single tenant solutions to multi-tenant cloud solutions, as well as building new multi-tenant internet scale solutions. In this project we demonstrate the migration of an existing solution to SQL Azure Federations and further leveraging SQL Azure Federation features in our multi-tenant solutions.
In addition to our multi-tenant applicaiton, we have implemented a simple dashboard to provide a visual of the federation information, as well as perform a SPLIT operation on the tenant federation member.
Cloud Ninja Federations View

Team
- David Makogon
- Bhushan Nene
- Ercenk Keresteci (Full Scale 180)
- Trent Swanson (Full Scale 180)
Prerequisites
- Visual Studio 2010 SP1
- Windows Azure SDK 1.5
- Windows Azure Subscription
- SQL Azure Federations
- DNS configured with wildcard subdomain (alternatively you could test using hosts file and simply add a bunch of tenant hosts)
Trent Swanson is a founder at Full Scale 180.
<Return to section navigation list>
MarketPlace DataMarket and OData
Himanshu Singh (pictured below) posted a Real World Windows Azure: Interview with Marc Slovak and Manish Bhargava at LexisNexis to the Windows Azure blog on 10/5/2011:
As part of the Real World Windows Azure customer interview series, I talked to Marc Slovak, Vice President Product Technology, and Manish Bhargava, Product Manager, at LexisNexis about their new offerings on Windows Azure Marketplace. Here’s what they had to say:
Himanshu Kumar Singh: Tell me about LexisNexis.
Marc Slovak: LexisNexis is a leading global provider of content-enabled workflow solutions designed specifically for professionals in the legal, risk management, corporate, government, law enforcement, accounting, and academic markets. We serve customers in more than 100 countries with more than 15,000 employees worldwide with access to billions of searchable documents and records from more than 45,000 legal, news and business sources.
HKS: What is Lawyers.com?

Manish Bhargava: Lawyers.com is a free service from LexisNexis Martindale-Hubbell designed specifically for individuals and small businesses. Lawyers.com provides a variety of services:
- Accurate and reliable profiles of over one million lawyers and firms worldwide
- A wealth of information that helps users better understand the law, make more informed personal legal choices and identify high quality legal representation
- Helpful tips on selecting an attorney, preparing to meet with an attorney and working with an attorney
- An interactive discussion community of individuals and lawyers covering hundreds of legal topics
- Consumer friendly explanations of major areas of law, articles on current legal topics, links to legal resources on the web, a glossary of 10,000 legal terms, and more
HKS: What’s the issue you’ve had to address?
MB: Lawyers.com has more than 3,000 consumer-facing legal articles authored by lawyers themselves, with more added daily. These articles are written in a manner that’s authoritative and informative, yet easy enough for a non-lawyer to understand. Articles pertain to sought-after areas of practice, including child custody, divorce, immigration, bankruptcy, employment and so on. We get over two million visitors every month looking for legal information.
All this is great. The problem is that these valuable articles are housed within lawyers.com, which means consumers and small business users have to somehow find these articles and read them on lawyers.com. This requires us to do a damn good job on search engine optimization (SEO). We thought, what if we also allow external clients to take these articles and host it on their websites via web services? This would increase 'eyeballs' on our content. To do this we either needed to build our own API layer, which is a big investment and an area with which we are not yet comfortable, or use Windows Azure Marketplace to host our dataset. It was a no-brainer for us to choose to go the Microsoft route.
HKS: Tell us about your offerings on Windows Azure Marketplace.
MB: The Lawyers.com consumer legal articles dataset allows you to search for articles based on area of law. For each article result, you get access to the title, excerpt and a link back to Lawyers.com page where your end consumers can get more details. We have built a sample application that uses the Microsoft’s OData API layer, which gives you access to our dataset. Here you’re able to specify an area of law and find all related articles available in the offering. You can also download the code, which will enable you to quickly leverage it in your website. In the future, we have plans on building a javascript widget, which will allow you to quickly integrate the consumer articles into your website by simply dropping in couple of lines of code. Details of future releases related to LexisNexis APIs and Widget can be found here.
HKS: Your other offering is for the LexisNexis Communities. What are they?
MS: The LexisNexis Communities are places where tens of thousands of legal professionals explore the latest legal trends, information, and resources available for FREE. Our online content includes blog posts (written by prominent legal professionals), podcasts, video, commentary and the latest news on emerging issues and top cases in sixteen practice areas including Bankruptcy Law, Insurance Law, Patents and Trademarks, Environmental Law, and Real Estate Law to name a few. Our most recently released community addresses Immigration Law. In addition to our practice area communities we have professional communities that provide resources and support to librarians, paralegals, new associates and government information workers.
HKS: Why are you making this content available on Windows Azure Marketplace?
MS: Many of our members have asked about reproducing our content on their intranets or their public facing websites. We made the decision to make our blog posts and podcasts available through the Windows Azure Marketplace to satisfy this need. Windows Azure Marketplace provides a variety of tools and resources to access and use our content in a variety of ways.

HKS: Is there a sample application similar to the one Manish described for Lawyers.com?
MS: Absolutely. Since the content we are providing is not tabular data we felt that it was important to illustrate techniques for accessing and using the content. The idea behind our sample site is to provide a use case and the sample code used to create the site. There are some differences between this site and the Lawyers.com implementation so the two examples taken together illustrate a substantial amount of functionality derived through the OData API layer.
Learn more about the Lawyers.com Consumer Legal Articles data on the Windows Azure Marketplace
Learn more about the LexisNexis Legal Communities data on the Windows Azure Marketplace.
Read more Windows Azure customer success stories.


Dan Woods (@danwoodscito) posted The Technology Of SAP's Open Strategy to his Forbes column on 10/4/2011:
There is an old joke in the world of business software that ERP is a roach motel where data goes to die. Like most jokes, this one is rooted in pain. Since the dawn of the modern era of business software, companies have spent huge amounts of time and money entering data into applications like ERP, CRM, SCM, HR, PLM and then struggling to get it out.
The multi-billion dollar world of business intelligence software is a fundamental response to this problem. Ornate mechanisms have been created to get data out, clean it, massage it, optimize it, and deliver it at high speed to those who need it to support decisions or the execution of processes. But the world of BI too has longstanding complaints: it is too hard and expensive to manage and support all the infrastructure needed. In addition, when new questions arise, they cannot be answered fast enough. Experts are always involved and they become a bottleneck.
All large software vendors are intimately familiar with these concerns. At SAP TechEd in Las Vegas in mid-September, I listened to a variety of presentations outlining SAP’s broad response to opening up its products so that people can more easily get to data and roll their own solutions. Of course, this process has been going on for years, but SAP is moving in some new directions that are worth a close look. If you are an executive paying a hefty bill for SAP, it may be time to reopen the conversation with your SAP experts about what is possible. Some things that have been frustratingly difficult in the past are now much easier. Other things that were unimaginable have become possible.
As I pointed out in a previous column (How SAP is Betting its Growth on Partnerships), this openness is not only a matter of making customers happy. SAP’s goals for expansion and growth require openness so that partners can adapt the company’s products to meet the needs of new markets and new types of users. Unless SAP gives partners the tools to tailor its products and create new ones, the company has little hope of growing from €12.5 billion in revenue in 2010 to €20 billion in 2015. In addition, openness should drive sales to existing customers, which should be able to solve more problems by extending the platform.
Here are the technologies SAP is betting on to make itself more open to innovation.
A Simpler Gateway
SAP NetWeaver Gateway will probably have the widest impact in the short term in opening up SAP products to new uses. SAP NetWeaver Gateway is a product that takes a new approach to moving data in and out of SAP. Here are the highlights:
Simpler data model: Many of the techniques that allow access to data in SAP applications provided access database tables that were designed to serve the needs of programmers. In other words, the data structures are highly abstract and not friendly to average business users. With SAP NetWeaver Gateway, a simplified data model is presented that is far easier to understand.
Cross version support: SAP NetWeaver Gateway works the same way no matter if you are back in the stone age of SAP R/3 or using the latest release of the SAP Business Suite that includes ERP, CRM, and several other applications. For companies that have many different versions of SAP applications, and mergers and acquisitions have left more than a few in this state, this is a massive benefit.


Read more: Page 2, 3, Next Page »
SAP office graphic from Wikipedia.
Frank Martinez reported RMC OData to be presented at InfoCamp 2011 in a 10/4/2011 post:
More on InfoCamp 2011.
InfoCamp 2011, which will be held on 10/8 and 10/9/2011 at the University of Washington’s Mary Gates Hall, is sold out.
Here’s Microsoft Research’s FAQ for RMC OData:
- What is RMC OData? RMC OData is a queryable version of research.microsoft.com (RMC) data, produced in the OData protocol (see odata.org for more information about the OData protocol). RMC data provides metadata about assets currently published on research.microsoft.com, such as publications, projects, and downloads.
- Asset collections that queries can be performed against:
- Downloads – Applications and tools which can be installed on your own machine or data sets which you can use in your own experiments. Downloads are created by groups from all Microsoft Research labs.
- Events – Events occurring in different locations around the world hosted by or in collaboration with Microsoft Research, with different themes and subject focus.
- Groups – Groups from all Microsoft Research labs; groups usually contains a mix of researchers and engineering staff.
- Labs – Microsoft Research locations around the world.
- Projects – Projects from all Microsoft Research labs.
- Publications – Publications authored by or in collaboration with researchers from all Microsoft Research labs.
- Series – Collections of videos created by Microsoft Research, grouped by event or subject focus.
- Speakers – Speakers for Microsoft Research videos; in many cases speakers are not Microsoft Research staff.
- Users – Microsoft Research staff; predominantly researchers but also includes staff from other teams and disciplines within Microsoft Research.
- Videos – Videos created by Microsoft Research; subjects include research lectures and marketing/promotional segments, some with guest lecturers and visiting speakers.
- Example queries:
http://odata.research.microsoft.com/odata.svc/Downloads/
- This query returns all Microsoft Research Downloads.
http://odata.research.microsoft.com/odata.svc/Videos/
- This query returns all Microsoft Research Videos.
http://odata.research.microsoft.com/odata.svc/Downloads(77034)/
- This query returns the metadata for a specific Microsoft Research Download, in this case for asset ID 77034. Note that some browsers return a .part file, which can be opened in text editors or other tools to examine. Generally this workflow is unnecessary when querying for specific assets from applications.
http://odata.research.microsoft.com/odata.svc/Videos(154104)/
- This query returns the metadata for the specific Microsoft Research Video 154104.
http://odata.research.microsoft.com/odata.svc/Downloads(77034)/Users/
- This query returns all Microsoft Research staff related to Microsoft Research Download 77034.
http://odata.research.microsoft.com/odata.svc/Videos(154104)/Speakers/
- This query returns all speakers related to Microsoft Research Video 154104.
http://odata.research.microsoft.com/odata.svc/Projects/?$filter=substringof('cloud', Description) eq true
- This query returns Microsoft Research Projects which contain ‘cloud’ in in their metadata.
http://odata.research.microsoft.com/odata.svc/Videos/?$select=Url,Duration,Name&$orderby=Duration desc&$filter=Duration ge 4900
- This query returns only the name, duration, and URL of the Microsoft Research Videos with duration greater than 4900 seconds, ordered by descending duration.
http://odata.research.microsoft.com/odata.svc/Videos/?$filter=year(DateRecorded) eq 2011
- This query returns Microsoft Research Videos which were recorded in 2011.
http://odata.research.microsoft.com/odata.svc/Videos/?search=farming
- This query returns Microsoft Research Videos with ‘farming’ in the metadata.
http://odata.research.microsoft.com/odata.svc/Series/?$expand=Videos
- This query returns all Microsoft Research Videos for all Series; includes the relationship to other assets for each video.
http://odata.research.microsoft.com/odata.svc/Series(150350)/?$expand=Videos
- This query returns all Microsoft Research Videos related to Series 150350.For complete information about the system query options supported by the OData protocol, refer to http://www.odata.org/developers/protocols/uri-conventions#OrderBySystemQueryOption.
- Where do I send feedback about RMC OData?
Feedback on RMC OData can be sent to rmcodata-feedback@microsoft.com.
Here’s the metadata for RMC OData:

Don’t forget to temporarily disable Feeds in IE to display query result sets.
<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
Steve Peschka (@speschka) posted a link to his Facebook DataView WebPart Code from SharePoint Conference on 10/4/2011:
For those of you who attended my SPC 351 session at SharePoint Conference today (Hitting the Ground Running with Claims Authentication), there was a request for some source code. As promised, I'm attaching a zip file with the source to the Facebook DataView WebPart I demonstrated. It's based on using ACS to log into a SharePoint site with Facebook authentication, and then using the Facebook Access Token (that comes in a special SAML claim) to make a request out to Facebook for the user's public profile info. [Emphasis added.]
The source code is attached for your use and enjoyment. Hopefully the recorded SPC sessions will be posted somewhere; if not and there is sufficient demand (by my random estimate of your interest based on comments to this post) I may try and find a place to post a separate recording I did of the demo...my backup in case of network connectivity issues.
Alan Smith (@alansmith) posted a CTP Version of The Developers Guide to AppFabric on 10/3/2011 to his CloudCasts blog:
I’ve just published a CTP version of “The Developers Guide to AppFabric”. Any feedback on the content would be great, and I will include it in the full release next week.
“The Developer’s Guide to AppFabric” is a free e-book for developers who are exploring and leveraging the capabilities of the Azure AppFabric platform.
The CTP version, published on the 3th October 2011, marks seven years to the day since the first version of “The Blogger’s Guide to BizTalk” was published.
The first section will provide an introduction to the brokered messaging capabilities available in the Azure AppFabric September 2011 release. The next section will go into a lot more depth and explore the brokered messaging feature set. Future sections will cover the Access Control Service, relayed messaging, and cache. Features like the application model and integration services will be covered as they emerge and are released.
The book will always be free to download and available in CHM and PDF format, as well as a web based browsable version. The planned release schedule for the remainder of 2011 is to update the guide with new content monthly, around the start of each month. Updates will be made available on the website and announced through my blog and twitter.
Developer’s Guide to AppFabric: devguide.cloudcasts.net
Twitter: @alansmith
The feedback form is here.

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• My Sessions Related to Windows Azure at the SharePoint Conference 2011 post to the OakLeaf Systems blog of 10/5/2011 (updated 10/6/2011) provides links to and full descriptions of the following SPC 2011 sessions:
BA Insight: Enterprise Search and the Cloud: Unifying Information across SharePoint, O365, LOB systems, and more
- Building integrated SharePoint 2010 and CRM Online solutions.
- Customer Spotlight: Saying Goodbye to Paper - Building a Multi Million Document Repository to Save Time and Money
- Developing Cloud-Based Applications for SharePoint Online using Windows Azure
- Integrating Microsoft Office 2010 and Windows Phone 7
- Out of the Sandbox and into the cloud: Build your next SharePoint app on Azure
- Delivering Data as a Service using Azure platform and self service BI at Microsoft
Added 5/6/2011 (Thanks to Steve Fox):
- Building Business Applications on Azure using Office365 and Windows Azure AppFabric
- Developing LOB Connectors in SQL Azure and Business Connectivity Services
- Security Design with Claims Based Authentication
- SharePoint, Azure and Claims Integration for Developers
- Hit The Ground Running with Claims Authentication in SharePoint 2010
Steve Fox (@redmondhockey) described Using Windows Azure to Connect LOB Data to SharePoint Online using Business [Data] Connectivity Services in a 10/5/2011 post:
What’s New at SPC 2011
I’ve been hanging out here at the SharePoint Conference (SPC) 2011 in Anaheim, CA this week, and it’s been a blast. Earlier in the week, Jeff Teper announced a key innovation for the cloud: support for Business Connectivity Services (BCS) in SharePoint Online. For those that don’t know, BCS is an evolution of the Business Data Catalog functionality in SharePoint 2007 that enables you to integrate with line-of-business (LOB) data. The BCS, upgraded for SharePoint 2010, provides you with both a declarative way (using SharePoint Designer 2010) and a code-centric way (using Visual Studio 2010) to create what are called external content types (ECTs). An ECT represents a definition file that connects SharePoint to the LOB system and supports both Web-service based connections and ADO.NET connections. You can find out more about BCS here.
What’s significant about BCS is that it represents one of the primary ways in which LOB data is surfaced natively within SharePoint. And this is significant for reporting, LOB data management, and system integration. Further, having CRUD (create, read, update, and delete) capabilities built into the connection to your LOB is a productivity win; it means that you don’t need to jump across systems to manage updates to critical business data. (This integration harkens back to my OBA days.)
This functionality was not initially released with the RTW of Office 365; that is, SharePoint Online (SPO) was restricted to interacting with data at the site collection level (using the client object model and artifacts such as lists and libraries) or using client-side technologies such as JavaScript/jQuery and Silverlight to reach out (beyond the sandboxed solutions limitations of SharePoint Online—no external service calls or data queries) to integrate external data sources/services. With the announcements for BCS support in SPO, though, comes a native way to integrate LOB data with your cloud-based solutions. This is very significant for its usage and answers to what has been one of the top feature requests by SharePoint Online developers.
Integrating SPO & Windows Azure using BCS
The three core scenarios really are ‘categories’ of applications that have allowed me to easily describe the ways in which Windows Azure integrates with SharePoint and SharePoint Online (SPO). Realistically, these categories translate into other types of applications such as training solutions (e.g., in the context of Resource, for example, think about using your Office 365 as the collaborative experience around training and Windows Azure as the place to store your training videos and metadata). While my Reach discussion focused on existing or third party services (e.g. Windows Azure Marketplace DataMarket) and custom services (e.g. WCF services) that can be consumed in SharePoint Online, my Resource discussion focused on the new BCS and SPO story. What I addressed were a number of key points:
- There is now a native LOB connection supported in the cloud through BCS and SPO;
- You can use SharePoint Designer to declaratively create the external content type that is then imported into your SPO site;
- The way in which this connection is enabled is through a custom WCF service that you’ll need to deploy to Windows Azure;
- You can manage permissions against the external content type using native administration tools in SPO; and
- This WCF service, though, opens up a tremendous amount of possibilities to pull all types of LOB data into SPO.
The figure below provides a high-level view of what the architecture of the demo looked like. In the demo, I used SQL Server as my LOB, had a WCF talking to the SQL Server instance, had created an external content type using SharePoint Designer 2010 (created against my WCF service) which then enabled me to expose the external list in SharePoint Online. I should add here that Mark Kashman, who presented an overview on SharePoint Online a day earlier to me, had walked through the declarative or IT Pro experience for creating the external list.
If you’re wondering what the external list looked like in SPO, it was like any other native external list you’ve seen in SharePoint—shown in the figure below.
While Mark focused a lot on the ‘how do you declaratively create the external list,’ I focused on interacting with the external list programmatically—mine was a developer-focused talk, so I wanted to show uses of jQuery/JavaScript along with the SharePoint Client Object Model. Specifically, I showed developers how they could create an animated view of the external list data. While I’m still a fan of Silverlight, I also really like jQuery, mainly because of the growing controls, plug-ins and libraries that you can use and don’t have to recreate. For SPO, using jQuery UI is great as well because you can quickly test and change themes based on the CSS libraries. So, the proverbial question is: how?
Using the Client Object Model and jQuery to Display Data from SQL Azure in SPO
Once you’ve got an external list, it’s pretty easy to create a new face for it using jQuery and the Client Object Model. And because I was dealing with an already extant external list, I followed this process:
- Created a document library called JavaScript to house all of my jQuery libraries and CSS templates/images. You can download all of the themes from the jQuery UI link above and get the core jQuery libraries from here. (As a best practice, you would not want to expose this document library to end users.)
- Uploaded my jQuery libraries and CSS templates.
- I also created a JavaScript file that referenced these libraries—this was a TXT file I created in Visual Studio as an HTM file but could literally be created in Notepad if you wanted. (You can find the code that I added to this file below.)
- I then created a content editor web part (which you can find in the Media and Content category) that then referenced the .txt file by editing the web part and pasting the link to the TXT file in the Content Link field—see figure below .
The core code that I used to create the TXT file I uploaded is shown below. I used a button to trigger the load (which was a call to the BindEmployeeData function), but a cleaner method might be to use the $document.ready() function. (Note you’d need to add your own SPO domain in the script links referenced at the top of the HTML file—e.g. https://mysposite.site.com/…)





About 100 lines of source code elided for brevity.
To give you some idea of what the code is doing, let’s take a quick walk through some of it.
The first task you need to accomplish is getting the context for the SPO site and then getting the list data that you want to use/display. You can see this is done using the loosely-typed context object (which represents the SPO site context). For those of you that are familiar with the SharePoint Client Object Model, this will not be new; for those that aren’t, what’s happening here is that you get the context for the SPO site, get the list by its title (using the getByTitle method), define a query (which uses the queryString string as the query) and then get the items in the list by using the getItems method. You’ll notice that because we’re using JavaScript, this is an asynchronous call, so you manage this using the executeQueryAsync method and delegate functions.
…
More lines of source code elided for brevity.
With an object that now contains the employee data, you can now walk through the data object and begin to add content to the jQuery accordian control. This is fairly straightforward and just means using vars to retrieve data from the data object (i.e. empListItems) that you then format within some HTML and add as a content object to the accordian control using the append function. The result is a nicely formatted accordian control that loads the external list data that is stored in SQL Azure (and retrieved via an external content type that communicates with the WCF service). And this didn’t take too much coding to complete.
Summary
Overall, I’m very excited about this opportunity to connect LOB data with SPO using BCS. And it’s not just because you have a way to implement and surface LOB connections in the cloud; I’m more excited about the possibilities. That is, the WCF service that connects the LOB data endpoint to SPO is mediated by your custom CRUD WCF service, which means you have control over the modeling of the data you bring into SPO and the type/origin of data. And the mere fact that you can model your own LOB data connection means that you could connect to SQL Azure data, oDATA through REST endpoints, and even on-premises LOB data that is using a service bus connection through Windows Azure AppFabric—yes, on-premises data could be surfaced here. In short, there’s a ton of possibility here, and as intelligent developers you’ll figure out and test the parameters of this technology.
In closing, I do want to send a thanks to the team that pushed to get this feature out. There were a number of folks that worked very hard to ensure this feature saw the day of light—you guys know who you are. And with developers so passionate about seeing this as core to the SPO developer experience (passionate enough to pass around a petition for its inclusion in one of our developer workshops), I was thrilled to not only see it, but also talk about it this week at SPC 2011. So, nice work on this guys!
You’ll see more on this from Microsoft and me moving forward. The exact date of availability will be released through the formal Microsoft channels, but I would think it shouldn’t be too long before you can get your hands on this in the real world.

Microsoft’s new preferred name and three-letter abbreviation (TLE) for SharePoint BCS appears to be Business Data Connection (BDC) services.
Brian Swan (@brian_swan) reported An Auto-Scaling Module for PHP Applications in Windows Azure in a 10/5/2011 post to the Windows Azure’s Silver Lining blog:
One of the core value propositions of Windows Azure is the ability to have automatic, elastic scalability for your applications (i.e. automatically increase or decrease the number of instances on which your application is running based on some criteria). In this post, I’ll introduce you to a customizable PHP module that automatically scales an application based on performance counters. The source code for the module is available on GitHub here: https://github.com/brian-swan/PHP-Auto-Scaler.
Note: Much of code in this module is based on a 4-part series on scaling PHP applications that starts here: Scaling PHP Applications on Windows Azure, Part 1. I recommend reading through that series if you want to fill in some of the details about scaling that I’m omitting here.
Overview
This auto-scaling module is designed to work with any application running on any number of Windows Azure Web role instances. You simply need to configure it and deploy it in a Worker role as part of your application. Here’s how it works:
- You deploy your application to Windows Azure with Windows Azure Diagnostics turned on and the auto-scaling module running in a Worker role. (For more about diagnostics, see How to Get Diagnostics Info for Azure/PHP Applications–Part 1 and How to Get Diagnostics Info for Azure/PHP Applications–Part 2.)
- The Windows Azure Diagnostics Monitor writes diagnostics data (such as CPU usage, available memory, etc.) at regular intervals (configured by you) to your storage account (Table storage, to be specific).
- The worker role periodically reads data from your storage account and crunches the numbers. The module includes some default “crunching” logic (details below), but you will undoubtedly want to customize this logic. (For more about worker roles, see Support for Worker Roles in the Windows Azure SDK for PHP.)
- Based on the number crunching, the Worker role uses the Windows Azure Management API to increase or decrease (or leave the same) the number of instances on which your application is running.
- Steps 2-4 are automatically repeated.
Step-by-Step
Here, I’ll walk you through the steps for using the auto-scaling module while also explaining a bit about how it works.
1. Prerequisites
In order to use the scaling module, you’ll need to take care of a few things first:
- Create a Windows Azure subscription. Make note of your subscription ID.
- Create a storage account. Make note of your storage account name and private key.
- Create a hosted service. Make note of the URL prefix for your service.
- Create your PHP application.
2. Configure the scaling module
In the storageConfig.php file of the scaling module, you will need to define several constants:
define ('SUBSCRIPTION_ID', 'your subscription id');define("STORAGE_ACCOUNT_NAME", "your_storage_account_name");define("STORAGE_ACCOUNT_KEY", "your_storage_account_key");define('DNS_PREFIX', 'the dns prefix for your hosted service');define("PROD_SITE", true);define("EXCEPTION_TABLE", "ExceptionEntry");define("STATUS_TABLE", "StatusTable");define('ROLE_NAME', 'your web role name');define('DEPLOYMENT_SLOT', 'production or staging');define('MIN_INSTANCES', 2);define('MAX_INSTANCES', 20);define ('AVERAGE_INTERVAL', "-15 minutes");define('COLLECTION_FREQUENCY', 60); // in seconds$certificate = 'your_cert_name.pem';
- SUBSCRIPTION_ID, STORAGE_ACCOUNT_NAME, STORAGE_ACCOUNT_KEY, and DNS_PREFIX should all come from your notes in step 1.
- PROD_SITE should be set to true if your application will be run in the cloud. If you are testing the application locally, it should be set to false.
- EXCEPTION_TABLE and STATUS_TABLE are the names of tables in your storage account that data will be written to. Do not change these.
- ROLE_NAME is the name of your Web role. (More on this later.)
- DEPLOYMENT_SLOT is production or staging depending on whether you are deploying to the staging or production slot of your hosted service.
- MIN_INSTANCES and MAX_INSTANCES are the minimum and maximum number of instances on which you want your application running.
- AVERAGE_INTERVAL is the period over which you want performance counters averaged. The default value is 15 minutes, so when the module reads data from your storage account, it will look at and average data going back in time 15 minutes.
- COLLECTION_FREQUENCY determines how often the module collects performance data from your storage account. The default is 60 seconds.
- $certificate is the name of your .pem certificate, which is necessary when using the Windows Azure Management API. Your certificate needs to be included in the root directory of your Worker role. You can learn more about what you need to do in the Creating and uploading a service management API certificate section of this tutorial: Overview of Command Line Deployment and Management with the Windows Azure SDK for PHP.
3. Customize the scaling logic
Two functions, get_metrics and scale_check, in the scaling_functions.php file do the work of getting performance data from your storage account and determining what action should be taken based on the data. You will probably want to customize the logic in these functions.
The get_metrics function queries your storage account for entries going back in time 15 minutes (by default), and averages each of the performance counters you are watching (configured in the diagnostics.wadcfg file of your Web role):
function get_metrics($deployment_id, $ago = "-15 minutes") {$table = new Microsoft_WindowsAzure_Storage_Table('table.core.windows.net', STORAGE_ACCOUNT_NAME, STORAGE_ACCOUNT_KEY);// get DateTime.Ticks in past$ago = str_to_ticks($ago);// build query$filter = "PartitionKey gt '0$ago' and DeploymentId eq '$deployment_id'";// run query$metrics = $table->retrieveEntities('WADPerformanceCountersTable', $filter);$arr = array();foreach ($metrics AS $m) {// Global totals$arr['totals'][$m->countername]['count'] = (!isset($arr['totals'][$m->countername]['count'])) ? 1 : $arr['totals'][$m->countername]['count'] + 1;$arr['totals'][$m->countername]['total'] = (!isset($arr['totals'][$m->countername]['total'])) ? $m->countervalue : $arr['totals'][$m->countername]['total'] + $m->countervalue;$arr['totals'][$m->countername]['average'] = (!isset($arr['totals'][$m->countername]['average'])) ? $m->countervalue : $arr['totals'][$m->countername]['total'] / $arr['totals'][$m->countername]['count'];// Totals by instance$arr[$m->roleinstance][$m->countername]['count'] = (!isset($arr[$m->roleinstance][$m->countername]['count'])) ? 1 : $arr[$m->roleinstance][$m->countername]['count'] + 1;$arr[$m->roleinstance][$m->countername]['total'] = (!isset($arr[$m->roleinstance][$m->countername]['total'])) ? $m->countervalue : $arr[$m->roleinstance][$m->countername]['total'] + $m->countervalue;$arr[$m->roleinstance][$m->countername]['average'] = (!isset($arr[$m->roleinstance][$m->countername]['average'])) ? $m->countervalue : ($arr[$m->roleinstance][$m->countername]['total'] / $arr[$m->roleinstance][$m->countername]['count']);}return $arr;}If you want to collect and average other metrics, you may want to change the logic of this function.
The scale_check function essentially takes the output of the get_metrics function and returns 1, 0, or –1 depending on whether an instance needs to be added, the instance count needs no adjustment, or an instance needs to be subtracted. The logic used to determine this is simplistic (as you can see in the function). You will probably want to adjust the logic to suit your application. (Note that by default scaling logic is based on 3 performance counters: percent CPU usage, available memory, and the number of TCPv4 connections.)
function scale_check($metrics) {$percent_proc_usage = (isset($metrics['totals']['\Processor(_Total)\% Processor Time']['average'])) ? $metrics['totals']['\Processor(_Total)\% Processor Time']['average'] : null;$available_MB_memory = (isset($metrics['totals']['\Memory\Available Mbytes']['average'])) ? $metrics['totals']['\Memory\Available Mbytes']['average'] : null;$number_TCPv4_connections = (isset($metrics['totals']['\TCPv4\Connections Established']['average'])) ? $metrics['totals']['\TCPv4\Connections Established']['average'] : null;if(!is_null($percent_proc_usage)) {if( $percent_proc_usage > 75 )return 1;else if( $percent_proc_usage < 25)return -1;}if(!is_null($available_MB_memory)) {if( $available_MB_memory < 25 )return 1;else if( $available_MB_memory > 1000)return -1;}if(!is_null($number_TCPv4_connections)) {if( $number_TCPv4_connections > 120 )return 1;else if( $number_TCPv4_connections < 20)return -1;}return 0;}4. Package and deploy your application
Now you are ready to package and deploy your application. Instructions for doing so are in this blog post: Support for Worker Roles in the Windows Azure SDK for PHP. However, there are a couple of things you’ll need to know that aren’t included in that post:
- When you run the default scaffoler and specify a name for your Web role, that name will be the value of the ROLE_NAME constant in step 2 above. i.e. When you run this command…
scaffolder run -out="c:\path\to\output\directory" -web="WebRoleName" -workers="WorkerRoleName"…WebRoleName will be the value of ROLE_NAME.
- After you have run the default scaffolder and you have added your application source code to your Web role directory, you need to configure Windows Azure Diagnostics. Instructions for doing this are here: How to Get Diagnostics Info for Azure/PHP Applications – Part 1. As is shown in that post, the diagnostic information that the auto-scaling module relies on (by default) are three performance counters: CPU usage, available memory, and TCPv4 connections. You can collect different diagnostic information, but to leverage it for scaling decisions you will have to adjust the scaling logic in the scaling module (see step 3 above).
- In the Worker role directory, open the run.bat file and change it contents to php scale_module.php. This tells the worker role to run scale_module.php on start up.
- You will need to include the Windows Azure SDK for PHP library with your Worker role.
The Main Loop
Boiled down, the main loop (in the scale_module.php file) looks like this
while(1) {//Calls to management API here//based on metrics.sleep(COLLECTION_FREQUENCY);}It essentially repeatedly calls get_metrics and scale_check and makes calls to the management API (based on the return value of scale_check) to increase or decrease the number of instances. To avoid doing this too often, it pauses for COLLECTION_FREQUENCY seconds in each loop.
After the number of instances have been adjusted based on metrics, it takes some time for the new instance to be up and running. Another loop checks to make sure all instances are in the ready state before checking performance metrics again:
while($ready_count != $instance_count) {$ready_count = 0;foreach($deployment->roleinstancelist as $instance) {if ($instance['rolename'] == ROLE_NAME && $instance['instancestatus'] == 'Ready')$ready_count++;}sleep(10); // Avoid being too chatty.$scale_status = new ScaleStatus();$scale_status ->statusmessage = "Checking instances. Ready count = " . $ready_count . ". Instance count = " . $instance_count;$scale_status ->send();}I won’t post the rest of the main loop here (you can see it on GitHub here: https://github.com/brian-swan/PHP-Auto-Scaler/blob/master/scale_module.php), but I will point out two things about the code as it is now:
- You’ll see several calls that write to a table called ScaleStatus (as in the snippet above). These are there so I could see (in a table) what my scaling module was doing. I think these calls can be removed at some point in the future.
- You’ll see try…catch blocks around some of my code. In some cases I found that an exception was thrown when a timeout occurred. This information is currently written to table storage. Clearly, this needs to be improved.
So, there it is…an auto-scaling module in PHP. As I said in the introduction, this is very much proof-of-concept code, but I’ve tested it and it works as I’d expect it to. Instances are added when I hammer my application with traffic and instances are subtracted when the traffic backs off. However, as I also pointed out earlier, I know there is lots of room to improve on this…I’m looking forward to input from other.


Avkash Chauhan explained Using ProgramEntryPoint element in Service Definition to use custom application as role entry point using Windows Azure SDK 1.5 in a 10/4/2011 post:
Part 1: Basics of running Nodes.js from command line:
You can download node.exe from the link below:
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, { 'Content-Type': 'text/html' });
res.write('<h1>Welcome. This is node.js page in Windows Azure</h1><br><br>');
res.write('<h2>Visit <a href="http://www.microsoft.com/windowsazure/">Windows Azure</a></h2>');
res.end();
}).listen(8080);Now launch nodejs server application as below:
- C:\node-v0.4.12\bin>node app.js
After that you can open http://localhost:8080/ url with your browser to verify it NodeJS server is running:
Part 2: Using nodes.js in Windows Azure
Now you can use the steps below to use nodes.js with Windows Azure:
- Create Windows Azure application with one Worker role
- Now you can include all of your nodes related files
- In this example you can just include node.exe and app.js (which you used above in Part 1)
- After that your can delete app.config and workerRole.cs as we are going to use ProgramEntryPoint elements released with Windows Azure SDK 1.5. Edit the following highlighted text in your Service Definition to run node.exe as worker role entry point application:
<?xml version="1.0" encoding="utf-8"?>
<ServiceDefinition name="AzureNodeJs15" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceDefinition">
<WorkerRole name="NodeJsWorkerRole" vmsize="Small">
<Runtime executionContext="limited">
<EntryPoint>
<ProgramEntryPoint commandLine="node.exe app.js" setReadyOnProcessStart="true" />
</EntryPoint>
</Runtime>
<Endpoints>
<InputEndpoint name="NodeJS" protocol="tcp" port="80" />
</Endpoints>
</WorkerRole>
</ServiceDefinition>Now you can just package your application and then deploy it to Windows Azure.


<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Jan van der Haegen (@janvanderhaegen) posted Skinning your LightSwitch application: intro on 10/6/2011:
I have been dropping hints here and there about an extension “with a little twist”, “that will blow your mind”, …
I have been working towards it since the early beta days, and I can now confidently announce that, in a couple of months, I will release the first, be it very rough, beta, alpha, 0.0.0.0.1-SNAPSHOT version of my LightSwitch skinning extension.
Why skinning?
Every LightSwitch application has that glowing button in the top right called “Design Screen”. When you ever have the joy of showing LightSwitch, click that button, the runtime editor pops up, and by simply selecting a Bing map control extension from a combo box and hitting save, change your static, auto-generated screen to a vivid and dynamic one. Stop right there.
Stop and take a good look at your audience. The unsuspecting LightSwitch virgins never see it coming, and usually have their mouth dropped open. I gave my 10th LightSwitch demo a couple of weeks ago, to the two newest members in my team, and one of them literally whispered in disbelief: “That’s… Amazing!”
The way I experience LightSwitch, the opposite is to be said on shell and theme extensions, unfortunately. The default implementation really is quite nice, but creating a shell or a decent theme extension is such a huge job in a barely documented maze of code, it feels like it requires a master in advanced nuclear engineering just to stay sane while doing it… What’s even worse, is that there is nothing vivid or dynamic about the end result.
So what is skinning then?
I have made it my mission to create one theme and one shell extension, that combined, offer the power of skinning a LightSwitch application to both the developer and the end-user. My functional requirements for this skinning extension are:
- A skin can be changed at runtime. A button (in the ribbon bar, next to the ‘Design Screen” one), takes the user to the skinning configuration screen. Here, the user can select a skin from a number of predefined skins, and it gets applied immediately, completely changing the look and feel of the entire application. No restarts should be required to see the result.
- A skin is a package that defines the look and feel of the entire LightSwitch application. It’s a theme extension that fully supports the default shell, screens, all of the control templates, … It’s also a shell extension, offering custom shell controls (navigation, commands, …).
- A skin can be fine tuned at runtime. The user can change the color or type of brush with just a few clicks for each of the brushes used in all of the control templates. The user can reposition the shell controls, and select which control template to use. Once again, all changes can be previewed and are applied immediately from the skinning configuration screen.
- A new skin can be downloaded without any hassle. Even in a deployed application, it should be possible for the user to download a new skin and apply it from the skinning configuration screen.
- A skin is user specific, user group specific, or company specific. The developer of the application can choose and modify the skin to be used, or just create a new, perhaps company specific one. He can choose to empower admin users of the application to change this default skin, set new skins for groups of users or specific individuals, and/or add the right to groups of users to pick their own, personal skin to apply.
There will be a time in the near future, at least, I hope that time will come, when people will talk about shell and theme extensions and say: “Granted, shells and themes were a good start, but they are SO 2011 aren’t they?”
You’re dreaming right?
Yes, I am. But there’s nothing wrong with that, is there?
As I said, I have a lot of working samples now, crossed every foreseeable obstacle at least once, so it’s “just a matter of time” now, recreating the 2k+ control templates used in LightSwitch, adding new control templates for the shell parts, creating the skin configuration screen, storing user specific skin settings, …
Justin Anderson (Microsoft MSFT) said:
Users will not be able to change the theme (a LightSwitch theme) of the application. LightSwitch themes are chosen by the developer during development. But I’m sure if a shell author want to get creative, a shell can provide their own customizability (not just limited to theming) at runtime by the end user.But as Cromanty suggested, please do add this as a suggested feature on Connect.
Justin Anderson, LightSwitch Development Team
Proposed As Answer byJustin AndersonMicrosoft EmployeeTuesday, August 16, 2011 8:25 AM
Marked As Answer byBeth MassiMicrosoft Employee, OwnerWednesday, August 17, 2011 10:10 PMChallenge accepted.

Return to section navigation list>
Windows Azure Infrastructure and DevOps
No significant articles today.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Matthew Weinberger (@M_Wein) reported Symantec Cloud Survey: Customers Think Cloud Boosts Security in a 10/5/2011 post to the TalkinCloud blog:
Despite any number of outages and data breaches, a new study by Symantec shows as many as 87 percent of organizations think moving to cloud infrastructure will improve their overall security (or at least leave it unchanged). But at the same time, Symantec’s findings indicate security remains a roadblock to general cloud adoption — and many IT departments aren’t ready for a cloud migration, regardless.
The Symantec State of the Cloud 2011 survey “focused on various forms of cloud computing including Public and Private Software-as-a-Service, Hybrid Infrastructure or Platform-as-Service, as well as Public and Private Infrastructure or Platform-as-a-Service” and incorporated 5,300 responses from users in 38 countries and organizations of all sizes, according to the press release.
Other key findings from the survey include:
- Even though many expressed optimism about cloud security, it was also a top concern, with many expressing trepidation over malware and hack attacks.
- Only 15 percent to 18 percent of respondents indicated their IT staffs were “extremely ready” to tackle the cloud challenge, with almost half claiming their techs just aren’t ready at all.
- The upside of that last statistic for TalkinCloud readers: “3 in 4″ organizations are turning to VARs, service providers, systems integrators and other channel pros to tackle the migration.
- 75 percent to 81 percent of organizations are considering the cloud, with 73 percent implementing cloud services right now (security services are most popular as per the study, but since the report was generated by security giant Symantec, I take that part at least with a grain of salt). But only 20 percent have implemented every single one of the focus areas mentioned above.
- Reality and expectations aren’t quite dovetailing: 88 percent expected the cloud to boost IT agility, but only 47 percent say that it actually has, with ROI lower than expected, especially in the areas of disaster recovery, OpEx, efficiency and security.
Most of Symantec’s recommendations per the study results are pretty basic: Take the lead in the cloud migration and don’t dawdle; audit solutions and do your homework with quotes and solutions from many vendors so you get the cloud that’s right for you.
But the piece of advice that stuck with me was this:
You don’t have to take an all-or-nothing approach to cloud computing. Leveraging cloud services are an easy first step to moving to the cloud. While it may take time to prepare to move business-critical applications, you can start immediately with simpler applications and services.
I can’t agree more — one of the nice things about the so-called cloud revolution is that, despite the hype of tastemakers such as Google or Salesforce.com, SaaS and legacy applications can indeed live together in harmony. Choose the solution that works for you right now, and don’t feel pressured to jump in with both feet just because it’s what everyone else is doing.
Read More About This Topic

<Return to section navigation list>
Cloud Computing Events
Communauté .NET Montréal will present Samedi .NET - Azure Camp on 10/15/2011 at UQAM - Salle R-M110, 315 rue Sainte-Catherine Est, Montreal, QC:
Azure Camp: Une commandite de Microsoft Canada
Sujet: Débutez avec le Cloud et Windows Azure
Conférenciers:
- Guy Barrette, Microsoft Regional Director & MVP Azure
- Sébastien Warin, MVP Azure
- Cory Fowler, MVP Azure
Endroit: UQAM, Salle R-M110
Heure: 9h00 à 16h30Note: Les présentations de Cory seront en anglais.
NOTE: Un frais de $10 est exigé pour cette journée. Vous devez aussi avoir payé votre membership annuel de $25.
Vous êtes familier avec le développement Web avec ASP.Net ou MVC et vous désirez apprendre à migrer vos applications vers Windows Azure ou vous êtes tout simplement curieux et désirez mieux comprendre les enjeux du Cloud et du développement sous Azure ? Ce Samedi .NET est parfait pour vous. Lors de cette journée, vous verrez comment utiliser les grands modules offerts par Azure avec des démonstrations de type « hands-on ».
Programme de la journée (à confirmer):
09h00-09h10: Mot de bienvenue
09h10-09h40:Azure en 30 minutes (les seules slides de la journées)
09h40-10h30: Building Your First Windows Azure Application (Expérience développement, Émulateurs, Web Role,Table storage)
10h30-10h45: Pause
10h45-11h30: Background Processing with Worker Roles and Queues (Worker Role,Queues)
11h30-12h00: Publishing a Windows Azure Application Management Portal (Configuration des unités de stockage, Déploiement d'une application en staging et en production)
12h00-13h15: Lunch (non inclus)
13h15-14h00: Debugging an Application in the Cloud (Debugging et tracing)
14h00-15h00: Introduction to SQL Azure (Configuration d'une base de données SQL Azure, Création et gestion des tables, Gestion via Management Studio, Application Azure accédant SQL Azure)
15h15-15h30: Break
15h30-16h30: Moving a Web Application to the Cloud (Utilisation des providers ASP.NET Membership, Roles et des Sessions dans Azure)Code/Labs
La salle étant en forme d'amphithéatre avec tables, vous serez donc à l'aise pour prendre des notes. N'oubliez pas d'apporter papier et crayons. Il n'est pas nécessaire d'apporter un ordinateur. Pour ceux qui désirent apporter un ordinateur portatif, notez que nous ne garantissons pas que des prises électriques soient disponibles. Veuillez apporter une extension électrique. Notez qu'il n'y aura pas d'accès Internet.
Vous désirez suivre les présentations sur votre ordinateur portatif ou vous désirez tout simplement refaire les labs de retour à la maison ou au travail ? Fort simple: pour nos présentations, nous utiliserons les labs du Windows Azure Platform Training Kit.
Installez d'abord le SDK de Windows Azure
Installez ensuite le Azure Platform Training KitLunch
Le lunch n'est pas inclus. Des machines distributices ($) sont à proximité de la salle pour ceux qui désirent café, boissons gazeuses, eau et friandises. Pensez à apporter votre p'tit change ;-)Coûts
Cette activité sera ouverte pour les membres en règle de la Communauté seulement (ayant déboursé le membership de $25). Je suis déjà membre, dois-je débourser le $10? Oui car l'organisation de cette journée requiert la location d'une grande salle et l'utilisation de matériel audio-vidéo. Votre $10 sert donc à couvrir ces frais. Reste que pour une journée de formation sur Azure, $10 c'est pas tellement cher ;-)Conférenciers
Guy Barrette est un architecte de solutions basé à Montréal, Canada. Il est le directeur régional Microsoft pour la région de Montréal et un MVP Windows Azure. Il se spécialise dans les outils de développement Microsoft depuis la sortie de VB 3 en 1994. Guy aide les entreprises à bâtir de meilleures solutions avec les technologies Microsoft. Il a été conférencier lors d'événements MSDN et lors de conférences comme Microsoft TechDays et DevTeach. Depuis 2006, il co-anime le podcast Visual Studio Talk Show. Guy est président de la Communauté .NET Montréal et vous pouvez lire son blog sur guy.dotnet-expertise.com.
Sébastien Warin est issue de l'école SUPINFO, deux fois vainqueur de la finale française Microsoft Imagine Cup en 2008 et 2009 et gagnant de l'Innovation Award lors de la finale mondiale en 2008 et du Live Services Award en 2009, il est aujourd’hui responsable technique du laboratoire xBrainLab (centre de recherche et d'innovation) ainsi que du système d’information du groupe Wygwam – Usilink.
Speaker pour Microsoft sur différents événements, ses compétences couvrent aussi bien les domaines du développements (technologies .NET), de l’ IT (Infrastructure et Cloud Computing) ainsi que des réseaux (technologies Cisco) reconnues par différentes certifications (MCP, MCTS, MCPD, CCNA) et comme Microsoft MVP (Most Valuable Professionnal) sur Windows Azure.
Cory Fowler refers to himself as a ‘Developer as a Service’. He is a Technology Community Leader, Mentor and Speaker that enjoys sharing his passion for Software Development with others. Cory has been awarded with a Microsoft MVP award for his Focus on Windows Azure (Microsoft’s Cloud Computing Platform). Even with his head in the Clouds, Cory finds himself developing a wide range of Solutions including but not limited to Websites (with ASP.NET MVC & Silverlight), Windows Phone 7 Applications (with Silverlight & XNA) and other solutions using the C# Programming Language. Even though Cory works primarily on the Microsoft Stack, he has worked with Open Source Languages in the Past and supports a number of Open Source Software Projects.

<Return to section navigation list>
Other Cloud Computing Platforms and Services
David Linthicum (@DavidLinthicum) asserted “At OpenWorld this week, it's clear that Oracle is a follower rather than a leader in cloud computing” in a deck for his The ugly truth: Oracle still doesn't get the cloud post of 10/5/2011 to InfoWorld’s Cloud Computing blog:
Now that Oracle OpenWorld is under way, the press releases from Oracle will come fast and furious. This includes speculation that Oracle may unveil its own platform-as-a-service offering, setting it in competition with Microsoft's Azure, Salesforce.com's Heroku, and Engine Yard.
In other words, 2009 called. It wants its cloud strategy back.
The movement to the cloud has not been as easy as Oracle thought it would be when it jumped in last year. Despite Oracle's dominance in the enterprise database and platform space, many of those who move to the cloud (private, public, or hybrid) do not include Oracle in their plans.
This trend was validated in a GigaOm article noting the fact that most of those who move to the cloud are looking to avoid Oracle's hefty software and hardware bills. They opt instead for open source or other less costly solutions to build and deploy their clouds.
The core problems with Oracle's cloud computing strategy are that it is late to the party and doesn't really get the value of cloud computing. Cloud computing is about doing things differently, including how you manage data, processes, and storage. Oracle's goal is to make sure that things are done the same way, which means keeping customers on Oracle technology.
Oracle shoves its proprietary approaches to computing into boxes that are relabeled as "cloud," then it charges a fee that probably averages a million dollars for most of its customers for the privilege. Oracle's hope is that its customers are so hooked on the Oracle way of doing things that they will find this the easiest path to the cloud.
However, as enterprises define their cloud computing strategies, Oracle will be quickly forgotten. The enterprise software and hardware behemoth has been relegated to a legacy role. Its products are still peddled by quota-carrying salespeople who roam the halls of corporate America and the government. That's not how the cloud is sold.
How can Oracle fix this legacy problem? I assume it will snap up cloud technology providers like crazy until it has enough market share to be satisfied. However, I suspect even that won't buy Oracle a cloud pass.
Oracle needs to commit to being an innovator once again: focus on areas that have been ignored by IBM, Microsoft, and even the emerging public cloud providers. But it will likely remain business as usual at Oracle, and it'll be "me too"-ing its way to the cloud. If Oracle stays on this route, it will become irrelevant. Nobody will care. I know I won't.

Joe Brockmeier (@jzb) reported OpenStack Leaving Home: Foundation Coming in 2012 in a 10/5/2011 post to the ReadWriteCloud:
OpenStack is going to be taking another major step in open governance next year. According to Rackspace, the time has come to form an OpenStack Foundation. Rackspace president Lew Moorman will be discussing an OpenStack Founation during the "state of the union talk" tomorrow at the OpenStack Conference in Boston.
Why now? Today I spoke with Rackspace's Mark Collier and Jonathan Bryce, and their response was that now is the time given the level of contributions from other companies.
Influence, Not Control
Bryce, chairman of the project policy board, said that it's been talked about since the beginning. However, the fact that the last milestone release had 12 features from eight companies in the OpenStack project showed that OpenStack is "a living, breathing thing, not dependent on any one company."
The company has taken some criticism about heavy-handed governance while OpenStack was maturing. Rick Clark, one of the founding members of the Rackspace team guiding OpenStack, voiced concerns about Rackspace's control of the project when he left the company for Cisco. Clark, who took pains to make clear that he felt Rackspace meant the best for the project, said he was still concerned that Rackspace was controlling rather than influencing OpenStack. "Rackspace has a choice to make; they can try to control the project and eventually fail, or they choose to influence it and succeed."
Jonathan Bryce Talks Rackspace Governance Earlier This Year
It looks like, ultimately, Rackspace is choosing influence over control.
It's worth noting that Rackspace has gotten pretty strong positives from many in the OpenStack community on its management of the project. Piston Cloud Computing's CEO, Joshua McKenty said, "Rackspace has done an amazing job of shepherding this open source project through its infancy, and they have gradually handed off many of the
responsibilities for OpenStack to the broader community. The role of an OpenStack Foundation will be to manage the last of those responsibilities."McKenty also said that OpenStack has always functioned as a meritocracy. "I think the most fundamental marker of that will be over the coming months - when we see that this next step in the management and organization of the project has almost no impact on the day-to-day functioning of the community, which has relied on merit and so-called 'lazy consensus' since its inception."
Leaving Home
With OpenStack nearly ready to leave the nest, does Rackspace have any regrets? Collier said that the company had "absolutely no regrets," and that the project had actually been "nothing but positive" for Rackspace.
Before, Collier says that companies would plan strategy and come to Rackspace when they decided they needed third-party hosting. Now? Collier says that companies bring Rackspace in to discuss transforming their IT, automating processes, and so on. "It's a much higher level conversation."
Structure Still Unresolved
Collier said that Rackspace will be transitioning the trademark and other intellectual property to a foundation, but the actual makeup of the foundation is still up in the air. One key consideration, said Collier, is ensuring that the foundation has resources on par or better than what is currently provided by Rackspace. "We have a rough idea what resources are needed, the last thing we'd want to do is turn OpenStack over to an underfunded entity."
Beyond that, though, Bryce said that the structure for the foundation is to be determined. Why not set up the project with existing foundations, like Apache? Bryce said that it makes sense to have a standalone foundation that's "more like a tightly focused Apache foundation."
"OpenStack is made up of very closely related projects that make up a cloud operating system. There's tight coherence around release schedules, integration points, important things to maintain. It makes sense to have something that's just focused on OpenStack because of the tight integration around a broad set of technologies."
We'll be watching the foundation formation with great interest. How the project is staffed and funded are going to be crucial to its success. It will be interesting to see how much of the current Rackspace staff that's tasked with OpenStack transitions to the foundation, and where new blood comes from as well.
But generally, this looks like a good move. OpenStack has evolved very, very quickly. Mistakes have been made, but not fatal ones. What do you think? What suggestions do you have for the OpenStackers as the project moves towards more independence?


Jeff Barr (@jeffbarr) described New - Amazon S3 Server Side Encryption for Data at Rest in a 10/4/2011 post:
A lot of technical tasks that seem simple in theory are often very complex to implement. For example, let's say that you want to encrypt all of the data that you store in Amazon S3. You need to choose an encryption algorithm, create and store keys (while keeping the keys themselves safe from prying eyes), and "bottleneck" your code to ensure that encryption happens as part of every PUT operation and decryption happens as part of every GET operation. You must take care to store the keys in durable fashion, lest you lose them along with access to your encrypted data.
In order to save you from going through all of this trouble (and to let you focus on your next killer app), we have implemented Server Side Encryption (SSE) for Amazon S3 to make it easier for you to store your data in encrypted form. You can now request encrypted storage when you store a new object in Amazon S3 or when you copy an existing object. We believe that this important (and often-requested) new feature will be welcomed by our enterprise customers, perhaps as part of an overall strategy to encrypt sensitive data for regulatory or compliance reasons.
Amazon S3 Server Side Encryption handles all encryption, decryption, and key management in a totally transparent fashion. When you PUT an object and request encryption (in an HTTP header supplied as part of the PUT), we generate a unique key, encrypt your data with the key, and then encrypt the key with a master key. For added protection, keys are stored in hosts that are separate and distinct from those used to store your data. Here's a diagram of the PUT process for a request that specifies SSE:
Decryption of the encrypted data requires no effort on your part. When you GET an encrypted object, we fetch and decrypt the key, and then use it to decrypt your data. We also include an extra header in the response to the GET to let you know that the data was stored in encrypted form in Amazon S3.
We encrypt your data using 256-bit AES encryption, also known as AES-256, one of the strongest block ciphers available. You can apply encryption to data stored using Amazon S3's Standard or Reduced Redundancy Storage options. The entire encryption, key management, and decryption process is inspected and verified internally on a regular basis as part of our existing audit process.
You can use Amazon S3's bucket policies to allow, mandate, or forbid encryption at the bucket or object level. You can use the AWS Management Console to upload and access encrypted objects.
To learn more, check out the Using Encryption section of the Amazon S3 Developer Guide.


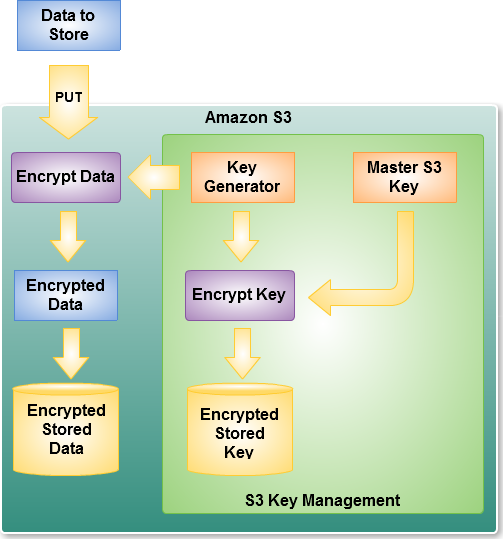
I’ve been lobbying (without success, so far) for enabling Transparent Data Encryption (TDE) on SQL Azure. Key management appears to be the primary issue.
Jeff Barr (@jeffbarr) reported Amazon S3 - 566 Billion Objects, 370,000 Requests/Second, and Hiring! in a 10/4/2011 post:
Our customers continue to make very heavy use of Amazon S3. We now process up to 370,000 S3 requests per second.
Many of these are PUT requests, representing new data that is flowing in to S3. As of the end of the third quarter of 2011, there are 566 billion (566,000,000,000) objects in S3. Here's a growth chart:
We've doubled the object count in just nine months (the other data points are from Q4). My math skills are a bit rusty but I definitely know exponential growth when I see it!
Designing, building, and running a large-scale distributed service like this isn't for the faint of heart. We're very proud of what we have done, but we have plans to do a whole lot more. If you are ready to push the state of the art in this area, consider applying for one of the open positions on the S3 team. Here's a sampling (these jobs are all based in Seattle):
- Software Development Manager - Simple Storage Service
- Software Development Engineer - Simple Storage Service
- Senior Software Development Engineer - Simple Storage Service
- Systems Engineer - Simple Storage Service
- Principal Product Manager - Simple Storage Service
- Director, Amazon S3
We also have a number of business development positions open:
- Business Development Manager - S3 Cloud Storage (Seattle)
- Business Development Representative - S3/Cloud Storage (Seattle)
- Sales Manager - S3 Cloud Storage (UK / Slough)
- Business Development Manager - S3 Cloud Storage (Paris)

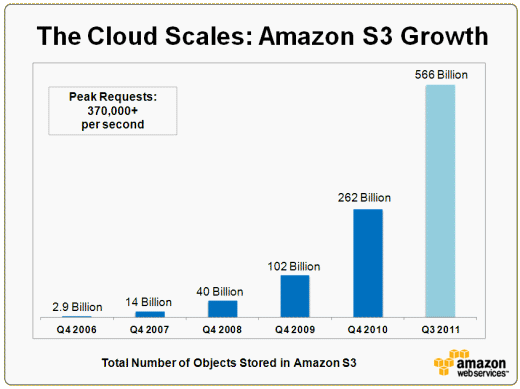

Will cloud computing solve the current unemployment crisis? Probably not, but it’s doing its part.
Rip Empson (@ripemp) reported Larry Ellison Cancels Marc Benioff’s Keynote at Oracle’s OpenWorld in a 10/4/2011 post to TechCrunch:
Well, well, well. The Oracle OpenWorld Conference is in full swing, and Salesforce CEO Marc Benioff was scheduled to be one of the keynote speakers tomorrow (Wednesday). “Was” being the operative word here. Thanks to a recent update from Benioff’s Twitter account, it seems that Oracle CEO Larry Ellison has cancelled Mr. Benioff’s keynote tomorrow.
Hmmm. Instead, Larry will be king of the stage, with a one hour and forty-five minute keynote, kicking off at 2:45 p.m. PST. No word as of yet on why Ellison cancelled the Salesforce CEO’s keynote. Not even Benioff was sure: …



As you might have garnered from his tweet, Benioff will likely instead be answering questions and interacting with the media at the Ame Restaurant in the St. Regis Hotel on Wednesday at 10:30 a.m PST. We’ll be there to cover, and will be sure to share any helpful words of advice Benioff has for the man who just gave him the early hook, as they say in showbiz.
Now, we’re not in the business of speculating here, but (at least according to Forbes) Benioff upstaged Ellison last year at OpenWorld, poking holes in Oracle’s strategy, in relation to cloud computing specifically, and so there’s very definitely the possibility that Ellison doesn’t want that kind of mockery on stage before he presents a potentially expansive talk on the state of the cloud. Then again, why invite the Salesforce CEO to the conference if you’re just going to un-invite him?
Especially considering that (as reported by the New York Times) a keynote speech at a top conference like OpenWorld can cost the speaker up to 1 million big ones. Earlier this week, Benioff published a series of blog posts deriding Ellison’s opening remarks at OpenWorld (and has, in the past, been incited by Ellison who posted slides of Benioff’s book “Behind The Cloud, altering it to “Way Behind The Cloud”), told the NYT that he got an email from Oracle this afternoon about the cancellation — and also offering Benioff his million dollars back. Wouldn’t be surprised if the email included “and don’t let the door hit you on the way out”. …

Read more.
<Return to section navigation list>

















0 comments:
Post a Comment