Windows Azure and Cloud Computing Posts for 10/6/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table and Queue Services
Bruno Terkaly (@BrunoTerkaly) continued his series with Supporting Billions of entities/rows for Mobile – Android Series - Part 6–Reading and Writing to Windows Azure (Cloud-based) Tables using standard HTTP and Fiddler on 10/5/2011:
Past Posts in this series:
The last post was about …
In the last post I illustrated how to create a RESTful service using .NET technologies. Here is the diagram from the last post:
This post is to illustrate that you can go directly to the Storage Service with HTTP bypassing .NET
Although it is not recommended for this particular application, it is possible communicate directly with the Storage Service. Direct communication with Azure tables requires some advanced techniques, working with request headers and request bodies. Later in this post you will learn what makes this technique somewhat challenging.

We need to able to:1. Create a table
2. Insert into a table
3. Query a tableWe need do this using all standard http without any .NET whatsoever. We will use Fiddler to get this done. We can also use the Azure Storage Explorer.
Azure Storage Explorer
Azure Storage Explorer is a useful GUI tool for inspecting and altering the data in your Windows Azure Storage storage projects including the logs of your cloud-hosted applications.
All 3 types of cloud storage can be viewed and edited: blobs, queues, and tables.
Description Link Home page on CodePlex for Azure Storage Explorer http://azurestorageexplorer.codeplex.com/



Login to http://windows.azure.portal and choose Hosted Services, Storage Accounts & CDN.
Now you need your storage access keys.

Copy the storage access keys to the clipboard.

Now are are ready to configure the Azure Storage Explorer.

As expected, there are no tables and no data. That is the next step.
Adding a Table Object with Storage ExplorerFollow these steps to add a table object:
1. Click Tables
2. Click New
3. Enter a table name
Adding EntitiesEach table can have many Entities. You can think of an entity as a row in a table. But in reality an entity is a collection of name-value pairs. Notice under the Storage Type panel you can see the Tables button. Click tables before following the rest of the steps.
Notice that a PartitionKey and RowKey are required columns.
Querying the tableYou can also hit the query button to see the entities in the table. Later, when we create the Android client, you will be able to use LINQ to query the entities.
Using HTTP to interact with Azure TablesHTTP is the most generic way to interact with Azure tables. I will be using Fiddler add new records and to query the data in Azure tables.

You can download Fiddler here.Authentication
The Table service requires that each request be authenticated. Both Shared Key and Shared Key Lite authentication are supported.More information can be found here.
Entering an HTTP Request in Fiddler
Step 1 - Click on Request Builder
Step 2 - Enter the URL and select GET
Step 3 - Enter the Request Header (you cannot do this without my tool explained below. See “Generating the Request Header” section below).
Step 4 - Hit Execute

The Request Header is going to require you to generate a Shared Key Lite.
Viewing the Result in FiddlerAfter hitting Execute in Step 4 above, results will appear.
Viewing the results (see above)Step 1 – Double click the result item in the upper left window. This brings up results window in the lower right pane of Fiddler
Step 2 – Click on TextView to see the results in AtomPub format.
Step 3 – View the data. Notice you can see Bruno and Haybusa that we added previously with the Azure Storage Explorer.
Generating the Request Header

If you look carefully, you will notice the SharedKeyLite authorization signature. This isn’t trivial to generate, since you need to compute a Hash-based Message Authentication Code (HMAC) using the SHA256 hash function.
Luckily I’ve done that for you.
A Simple Windows Forms Application
You are looking at a custom application that I wrote. I am providing the code below in case you want to do this yourself. You typically would use the ADO.NET Data Services library in C# or VB.
But if you want to interact with Azure Tables from non-.NET clients, you will need to master the techniques I am illustrating here. You can learn more at [this link.]
The trick is understanding the code behind the Make Request button, which fills in all the boxes you see above. The ones to paste into fiddler are:
1. URI
2. HttpHeader













Source code elided for brevity.
You can even add data using this technique
Notice that this time I added a PartitionKey and RowKey in Steps 1 and 2 below.

Now we need to copy the Response Body in addition to the previous fields. The XML below was generated by my tool. Notice the partitionkey and rowkey from the form above.<?xml version="1.0" encoding="utf-8"?>
<entry xmlns:d="http://schemas.microsoft.com/ado/2007/08/dataservices" xmlns:m="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata" xmlns="http://www.w3.org/2005/Atom">
<title />
<author>
<name />
</author>
<updated>2011-10-04T15:28:55.7259928Z</updated>
<id />
<content type="application/xml">
<m:properties>
<d:PartitionKey>Bruno</d:PartitionKey>
<d:RowKey>GSXR1000</d:RowKey>
<d:Timestamp m:type="Edm.DateTime">0001-01-01T00:00:00</d:Timestamp>
</m:properties>
</content>
</entry>
Notice the Make Header tool creates the 3 core pieces of information you will need to paste into Fiddler’s Request Builder:
1. URI
2. Request Header
3. Request Body
When adding date, you will need to do a POST. Here is a table that explains the HTTP verbs and how they relate to operations:


In Fiddler do the following:Step 1 – Change from GET to POST
Step 2 – Paste in the new Request headers from the tool above
Step 3 – Paste in the Request Body from the tool above
Step 4 – Hit execute
Step 5 – Realize that you just added data to your table using a PURE http protocol

Notice that we have added the data. You can see the GSXR1000 data in Azure Storage Explorer.
ConclusionsThis post was important for several reasons. First, it introduced the Windows Azure Portal and addressed the Hosted Service and Storage Account and how they related to your RESTful service and to your infinitely scaled Azure Table Service Storage.




<Return to section navigation list>
SQL Azure Database and Reporting
David Aiken (@TheDavidAiken) asked you to Please scale your storage too in a 10/6/2011 post:
Everyone understands the concept of scaling out compute when building applications for Windows Azure, but many times I’m seeing storage left out of the equation. The results are applications that don’t scale because they are tied to a single database. In this post I will explain how you need to start thinking about storage in the cloud.
Storage on-premises
If you think about how you build big applications on premises and how you approach data in general is very different. Typically you have a database or storage standard. This could be SQL Server, or some other relational database. The law of the enterprise is usually “all data shall be stored in <insert your enterprise database here>”. There is no other choice.
The second big difference is how you approach scale. Typically to get scale, you build the biggest most elaborate database server you can. I remember years ago, tuning everything from the hardware, through to how the disks were partitioned and where the file groups in SQL Server were located and used. Machines typically had multiple CPU’s with multiple cores, multiple disk controllers, disks and a bucket full of RAM.
If you also needed high availability, that was easy. You typically built a second monster machine and configured an Active/Passive setup, or hot standby,
How the cloud changes storage
The first thing about using storage in the cloud is that there are zero setup costs. You can just as easily create a SQL Azure database or 7. Create multiple storage accounts, tables etc. You pay for what you consume. Setup is free. This means you have less reason to put all your data in one place. You can start thinking about which data source is right for what data. It is not unusual to have multiple data sources used.
The second big thing is that we don’t have that big huge server with lots of cores and ram and fancy stuff. At least not tuned to the extent you would for your workload. Instead we have “commodity hardware”. To achieve “scale” you have to think about using lots of little storage things, rather than a single huge one. This is the exact same thing you do with compute.
If you have 50GB of data, you may be better served by 50 x 1GB databases than 1 x 50GB. The cost is comparable too. Except you now have 50 of those servers running your database. Guess which model will be able to run more databases?
There is a tax in thinking about, designing and implementing this – however if done right, you can scale out as far as your compute (and credit card) will let you.
This might have been a rant. Apologies.
THIS POSTING IS PROVIDED “AS IS” WITH NO WARRANTIES, AND CONFERS NO RIGHTS

Herve Roggero (@hroggero) explained Solving Schema Separation Challenges in a multi-tenant database in a 10/5/2011 post to Geeks with Blogs:
Introduction
To save on hosting costs and simplify maintenance, Software as a Service (SaaS) providers typically rely on schema separation to host multiple customers' records. This implementation relies on a specific SQL Server and SQL Azure feature called a schema object. A schema object behaves like a container, or a namespace in programmatic terms, allowing multiple tables (and other objects) to be stored with the same name in a single database.
Basics of Schema Separation
Let's assume you have two customers, and you need to track historical information. So you need to create a table called tbl_history for each customer. You could either create a database for each customer with the tbl_history table in each database (the linear shard pattern), or create a schema container for each customer in a single database, and create the tbl_history table in each schema container (the compressed shard pattern). For a description of sharding patterns review this white paper: http://www.bluesyntax.net/files/EnzoFramework.pdf.
Here is an example of a schema-based storage for different customers. A database is created with 2 schema containers (cust1 and cust2). The tbl_history table is then added to each schema container. The following script assumes that the database has already been created.
CREATE SCHEMA cust1 GO CREATE SCHEMA cust2 GO CREATE TABLE cust1.tbl_history(id int identity(1,1) primary key, dateadded datetime default (getdate()), productid int, quantity int) CREATE TABLE cust2.tbl_history(id int identity(1,1) primary key, dateadded datetime default (getdate()), productid int, quantity int) INSERT INTO cust1.tbl_history(productid, quantity) values (1, 5) INSERT INTO cust1.tbl_history(productid, quantity) values (2, 7) INSERT INTO cust2.tbl_history(productid, quantity) values (107, 22) SELECT * FROM cust1.tbl_history SELECT * FROM cust2.tbl_historyAt this point we have two tables with the same name, each in a different schema container, but within a single database. Here is more information about schema containers: http://msdn.microsoft.com/en-us/library/ms189462.aspx
Securing Access
An important feature of schema containers is their support for security. You could easily create a user (mapped to a login account) and grant that user SELECT rights to cust1. The following statements should be executed against the master database in SQL Azure.
CREATE LOGIN logincust1 WITH PASSWORD = 'p@ssw0rd001' CREATE LOGIN logincust2 WITH PASSWORD = 'p@ssw0rd002'Then back in the user database, create two users.
CREATE USER user1 FOR LOGIN logincust1 CREATE USER user2 FOR LOGIN logincust2Finally, you need to authorize each user to execute statements against the history table. We will authorize user1 to use all the objects in schema cust1, and user2 in cust2.
GRANT SELECT, EXECUTE ON SCHEMA::cust1 TO user1 GRANT SELECT, EXECUTE ON SCHEMA::cust2 TO user2At this point, user1 can only select and execute stored procedures in the cust1 schema. user1 cannot access schema cust2. Here is more information about the Create Login statement: http://msdn.microsoft.com/en-us/library/ee336268.aspx
Customer Accounts vs. Service Accounts
The previous section discusses the creation of logins and users that provide security to each schema container. It should be noted that each login/user account created in the user database should be treated as a service account, not an actual customer account. Indeed, if you create customer accounts in SQL Azure directly you could negatively impact connection pooling, and hence performance. You should authorize users first, using a specific application authentication component (such as ASP.NET Membership), then map the customer account to the service account to use.
You typically implement the mapping (from customer account to service account) using a separate customer account database. A column in your customer account table would store the database connection string, which would contain the service account to use. Here is an example:
CREATE TABLE custmapping(customerid int primary key, custconnection nvarchar(255) NOT NULL)Note that in a production environment, you would likely encrypt the connection string. The above table does not implement encryption to illustrate a simple scenario.
You would then add a record for each customer:
INSERT INTO custmapping VALUES (1, 'server=....;UID=logincust1;PWD=p@ssw0rd001') INSERT INTO custmapping VALUES (2, 'server=....;UID=logincust2;PWD=p@ssw0rd002')When a customer logins with their account, your code would read the custmapping table to retrieve the connection string to use for the duration of the session.
Moving A Schema
If a customer grows significantly, or is abusing your SaaS application, you may be facing the need to move that customer's data to a different database so that the other customers (called tenants in SaaS terms) are not affected negatively by the increase in resources needed by that customer.
There are very few options available today to move a single schema container, and its associated objects, from one database to another. You could manually create the schema container and its objects first, then use BCP or SSIS to move the data. However this can be error prone and lengthy.
A tool recently released by Blue Syntax, called Enzo Backup for SQL Azure, provides the ability to backup a single schema. This tool will backup the associated users in addition to the related objects (tables, stored procedures and so forth). The restore process will recreate the schema in the chosen database server and all the objects (and data) in that schema. Here is more information about this tool: http://www.bluesyntax.net/backup.aspx
Multitenant Frameworks
Due to the level of complexity in building multitenant environments, certain companies are turning to specialized frameworks. Although these frameworks can require some learning curve, they provide certain capabilities that would be difficult to build, such as fan-out, caching, and other capabilities. Here are a few .NET frameworks:
- The Enzo Sharding Library (open-source); also supports Data Federation: http://enzosqlshard.codeplex.com/releases/view/72791
- The CloudNinja project (open-source): http://cloudninja.codeplex.com/
- The Enzo Multitenant Framework: http://www.bluesyntax.net/scale.aspx
Schema Separation and Data Federation
Data Federation is an upcoming feature of SQL Azure that will provide a new mechanism to distribute data. In a way, Data Federation allows SaaS vendors to design a monolithic database, in which all customers are located, and distribute records of one or more tables across databases when the time comes. Data Federation is essentially a compressed shard, similarly to schema separation, with the added benefit of tooling support and easier repartitioning based on performance and storage needs. In addition, Data Federation can help you distribute data on almost any dimension; not just customer id.
Data Federation and Schema Separation are not competing solutions for SaaS vendors. Each have specific benefits and challenges. SaaS vendors will need to determine which one serves their needs best, or even use both.
Using both Schema Separation and Data Federation delivers even greater flexibility. For example, if the history table of customer 2 becomes too large, you could leverage Data Federation to split that table, without affecting customer 1. A specific use of this technique could be to use Data Federation to split tables across databases every year for all customers (or only those that have a lot of records). This dual layering technique (using schema separation for customer records, and data federation for archiving) can deliver remarkable performance results and scalability.
Conclusion
Many vendors have successfully built a SaaS solution using schema separation. While tooling has been lacking, some vendors are adding schema separation support in their products. Understanding the options available at your finger tips, including the frameworks already developed, and how to combine sharding models can give you a significant advantage when building your SaaS solutions.

<Return to section navigation list>
MarketPlace DataMarket and OData
No significant articles today.
<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
Clemens Vasters (@clemensv) began a Achieving Transactional Behavior with Messaging series on 10/6/2011:
Elastic and dynamic multitenant cloud environments have characteristics that make traditional failure management mechanisms using coordinated 2-phase transactions a suboptimal choice. The common 2-phase commit protocols depend on a number of parties enlisted into a transaction making hard promises on the expected outcome of their slice a transaction. Those promises are difficult to keep in an environment where systems may go down at any time with their local state vanishing, where not all party trust each other, where significant latency may be involved, and network connectivity cannot be assumed to be reliable. 2-phase-commit is also not a good choice for operations that take significant amounts of time and span a significant amount of resources, because such a coordinated transaction may adversely affect the availability of said resources, especially in cases where the solution is a high-density multitenant solution where virtualized, and conceptually isolated resources are collocated on the same base resources. In such a case, database locks and locks on other resources to satisfy coordinated transaction promises may easily break the isolation model of a multitenant system and have one tenant affect the other.
Therefore, failure management – and this is ultimately what transactions are about – requires a somewhat different approach in cloud environments and other scalable distributed systems with similar characteristics.
To find a suitable set of alternative approaches, let’s quickly dissect what goes on in a distributed transaction:
To start, two or more parties ‘enlist’ into a shared transaction scope performing some coordinated work that’s commonly motivated by a shared notion of a ‘job’ that needs to be executed. The goal of having a shared transaction scope is that the overall system will remain correct and consistent in both the success and the failure cases. Consistency in the success case is trivial. All participating parties could complete their slice of the job that had to be done. Consistency in the failure case is more interesting. If any party fails in doing their part of the job, the system will end up in a state that is not consistent. If you were trying to book a travel package and ticketing with the airline failed, you may end up with a hotel and a car, but no flight. In order to prevent that, a ‘classic’ distributed transaction asks the participants to make promises on the outcome of the transaction as the transaction is going on.
As all participating parties have tentatively completed but not finalized their work, the distributed transaction goes into a voting phase where every participant is asked whether it could tentatively complete its portion of the job and whether it can furthermore guarantee with a very high degree of certainty that it can finalize the job outcome and make it effective when asked to do so. Imagine a store clerk who puts an item on the counter that you’d like to purchase – you’ll show him your $10 and ask for a promise that he will hand you the item if you give him the money – and vice versa.
Finally, once all parties have made their promises and agreed that the job can be finalized, they are told to do so.
There are two big interesting things to observe about the 2-phase-commit (2PC) distributed transaction model that I just described: First, It’s incredibly simple from a developer’s perspective because the transaction outcome negotiation is externalized and happens as ‘magic’. Second, it’s not resembling anything that happens in real life and that should be somewhat suspicious. You may have noticed that there was no neutral escrow agent present when you bought the case of beverages at the store for $10 two paragraphs earlier.
The grand canonical example for 2PC transactions is a bank account transfer. You debit one account and credit another. These two operations need to succeed or fail together because otherwise you are either creating or destroying money (which is illegal, by the way). So that’s the example that’s very commonly used to illustrate 2PC transactions. The catch is – that’s not how it really works, at all. Getting money from one bank account to another bank account is a fairly complicated affair that touches a ton of other accounts. More importantly, it’s not a synchronous fail-together/success-together scenario. Instead, principles of accounting apply (surprise!). When a transfer is initiated, let’s say in online banking, the transfer is recorded in form of a message for submission into the accounting system and the debit is recorded in the account as a ‘pending’ transaction that affects the displayed balance. From the user’s perspective, the transaction is ’done’, but factually nothing has happened, yet. Eventually, the accounting system will get the message and start performing the transfer, which often causes a cascade of operations, many of them yielding further messages, including booking into clearing accounts and notifying the other bank of the transfer. The principle here is that all progress is forward. If an operation doesn’t work for some technical reason it can be retried once the technical reason is resolved. If operation fails for a business reason, the operation can be aborted – but not by annihilating previous work, but by doing the inverse of previous work. If an account was credited, that credit is annulled with a debit of the same amount. For some types of failed transactions, the ‘inverse’ operation may not be fully symmetric but may result in extra actions like imposing penalty fees. In fact, in accounting, annihilating any work is illegal – ‘delete’ and ‘update’ are a great way to end up in prison.
As all the operations occur that eventually lead to the completion or failure of the grand complex operation that is a bank transfer, the one thing we’ll be looking to avoid is to be in any kind of ‘doubt’ of the state of the system. All participants must be able to have a great degree of confidence in their knowledge about the success or failure of their respective action. No shots into the dark. There’s no maybe. Succeed or fail.
That said, “fail” is a funny thing is distributed systems because it happens quite a bit. In many cases “fail” isn’t something that a bit of patience can’t fix. Which means that teaching the system some patience and tenacity is probably a good idea instead of giving up too easily. So if an operation fails because it runs into a database deadlock or the database is offline or the network is down or the local machine’s network adapter just got electrocuted that’s all not necessarily a reason to fail the operation. That’s a reason to write an alert into a log and call for help for someone to fix the environment condition.
If we zoom into an ‘operation’ here, we might see a message that we retrieve from some sort of reliable queue or some other kind of message store and subsequently an update of system state based on message. Once the state has been successfully updated, which may mean that we’ve inserted a new database record, we can tell the message system that the message has been processed and that it can be discarded. That’s the happy case.
Let’s say we take the message and as the process wants to walk up the database the power shuts off. Click. Darkness. Not a problem. Assuming the messaging system supports a ‘peek/lock’ model that allows the process to first take the message and only remove it from the queue once processing has been completed, the message will reappear on the queue after the lock has expired and the operation can be retried, possibly on a different node. That model holds true for all failures of the operation through to and in the database. If the operation fails due to some transient condition (including the network card smoking out, see above), the message is either explicitly abandoned by the process or returns into the queue by ways of a lock timeout. If the operation fails because something is really logically wrong, like trying to ship a product out of the inventory that’s factually out of stock, we’ll have to take some forward action to deal with that. We’ll get to that in a bit.
Assuming the operation succeeded, the next tricky waypoint is failure after success, meaning that the database operation succeeded, but the message subsequently can’t be flagged as completed and thus can’t be removed from the queue. That situation would potentially lead to another delivery of the message even though the job has already been completed and therefore would cause the job to be executed again – which is only a problem if the system isn’t expecting that, or, in fancier terms, if it’s not ‘idempotent’. If the job is updating a record to absolute values and the particular process/module/procedure is the only avenue to perform that update (meaning there are no competing writers elsewhere), doing that update again and again and again is just fine. That’s natural idempotency. If the job is inserting a record, the job should contain enough information, such as a causality or case or logical transaction identifier that allows the process to figure out whether the desired record has already been inserted and if that’s the case it should do nothing, consider its own action a duplicate and just act as if it succeeded.
Checkpoint: With what I said in the last two paragraphs, you can establish pretty good confidence about failure or success of individual operations that are driven by messages. You fail and retry, you fail and take forward action, or you succeed and take steps to avoid retrying even if the system presents the same job again. There’s very little room for doubt. So that’s good.
The ‘forward action’ that results from failure is often referred to as ‘compensation’, but that’s a bit simplistic. The forward action resulting from running into the warehouse with the belief that there’s still product present while the shelf is factually empty isn’t to back out and cancel the order (unless you’re doing a firesale of a touch tablet your management just killed). Instead, you notify the customer of the shipping delay, flag a correction of the inventory levels, and put the item on backorder. For the most part, pure ‘compensation’ doesn’t really exist. With every action, the system ends up in a consistent state. It’s just that some states are more convenient than others and there are some state for which the system has a good answer and some states for which it doesn’t. If the system ends up in a dead end street and just wants to sit down and cry because nobody told it what to do now, it should phone home and ask for human intervention. That’s fine and likely a wise strategy in weird edge cases.
Initiating the ‘forward action’ and, really, any action in a system that’s using messaging as its lifeline and as a backplane for failure resilience as I’m describing it here is not entirely without failure risk in itself. It’s possible that you want to initiate an action and can’t reach the messaging system or sending the message fails for some other reason. Here again, patience and tenacity are a good idea. If we can’t send, our overall operation is considered failed and we won’t flag the initiating message as completed. That will cause the job to show up again, but since we’ve got idempotency in the database that operation will again succeed (even if by playing dead) or fail and we will have the same outcome allowing us to retry the send. If it looks like we can send but sending fails sometime during the operation, there might be doubt about whether we sent the message. Since doubt is a problem and we shouldn’t send the same message twice, duplicate detection in the messaging system can help suppressing a duplicate so that it never shows up at the receiver. That allows the sender to confidently resend if it’s in doubt about success in a prior incarnation of processing the same message.
Checkpoint: We now also can establish pretty good confidence about initiating forward action or any other action in the system given if the ‘current’ action is following the principles described above.
So far I’ve talked about individual actions and also about chains of actions, albeit just in the failure case. Obviously the same applies to success cases where you want to do something ‘next’ once you’re done with ‘this’.
Now let’s assume you want to do multiple things in parallel, like updating multiple stores as part of executing a single job – which gets us back to the distributed transaction scenario discussed earlier. What helps in these cases is if the messaging system supports ‘topics’ that allow dropping a message (the job) into the messaging system once and serve the message to each participant in the composite activity via their own subscription on the topic. Since the messaging system is internally transactional it will guarantee that each message that is successfully submitted will indeed appear on each subscription so it ensures the distribution. With that, the failure handling story for each slice of the composite job turns into the same model that I’ve been explaining above. Each participant can be patient and tenacious when it comes to transient error conditions. In hard failure cases, the forward action can be a notification to the initiator that will then have to decide how to progress forward, including annulling or otherwise invoking forward actions activities that have been executed in parallel. In the aforementioned case of a ticketing failure that means that the ticketing module throws its hands up and the module responsible for booking the travel package either decides to bubble the case to the customer or an operator leaving the remaining reservations intact or to cancel the reservations for the car and the hotel that have been made in parallel. Should two out of three or more participants’ operations fail and each report up to the initiator, the initiator can either keep track of whether it already took corrective forward action on the third participant or, in doubt, the idempotency rule should avoid doing the same thing twice.
The model described here is loosely based on the notion of ‘Sagas’, which were first described in a 1987 ACM paper by Hector Garcia-Molina and Kenneth Salem, so this isn’t grand news. However, the notion of such Sagas is only now really gaining momentum with long-running and far distributed transactions becoming more commonplace, so it’s well worth to drag the model further out into the limelight and give it coverage. The original paper on Sagas is still assuming that the individual steps can be encapsulated in a regular transaction, which may not even be the case in the cloud and with infrastructures that don’t have inherent transaction support. The role of the messaging system with the capabilities mentioned above is to help creating compensate for the absence of that support.
… to be continued …

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Steve Peschka (@speschka) reported The [Claims Azure and SharePoint Integration] CASI Kit Announcement from SharePoint Conference is available for download on 10/6/2011:
Just wanted to update folks with the announcement made at the SharePoint Conference yesterday regarding the CASI Kit. I have decided to release everything for it - full source code to the base class, the web part, and all of the sample projects - up to CodePlex. If you go to casikit.codeplex.com now you can get everything that makes this toolkit. In addition to that you will find:
- A video that walks you through the process of building an application with the CASI Kit
- The sample project that I built out at SharePoint Conference - both the starting project and completed project - along with written step by step instructions for building it yourself. The CASI Kit is simple enough to use that the instructions for building the application fit on a single page!
- All of the written guidance for using the CASI Kit
The reasons for doing this primarily came down to this:
- By having the source code available, if you have any issues or find bugs, etc., you have the source code - you can put it in the debugger, you can step through code, you can make changes as needed. So you should have full comfort that you aren't just relying on a black box unsupported component; now you can see everything that's going on and how it's doing it.
- As features in the SharePoint product change over time, having the source code allows you to modify it and change it to stay in step with those changes. For example, if new ways are added to connect up SharePoint and other cloud services then you can modify the code to take advantage of those new platform features, or even transition off the CASI Kit in a prescriptive manner. With the source code, you're in control of adapting to those changes in the future.
- You now have the opportunity to build other solutions, whatever you want, using the CASI Kit as is or breaking it apart and using it as a really big building block to your own custom applications.
Hopefully you will find this source code and kit useful for connecting to Windows Azure and other cloud-based services going forward. Enjoy!

Steve and James Petrosky presented SharePoint, Azure and Claims Integration for Developers, which described the CASI Kit at the SharePoint Conference 2011. See my Sessions Related to Windows Azure at the SharePoint Conference 2011 of 10/5/2011 (updated 10/6/2011) for more Azure content at SPC 2011.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
The Visual Studio LightSwitch team (@VSLightSwitch) reported Metro Theme Updated! in a 10/6/2011 post:
Back in August we released a theme called “Metro” that gives you a more modern look to your applications with simple colors and more emphasis on text. You can see some screen-shots here. Today we released an update that addresses some issues found by the community, most notably:
- Fixed issues where you cannot use commands with custom images
- Fixed issues where the AddNew button does not appear when overridden
- Fixed issues where screen does not load when using a custom control with a combobox
So check out the new version and let us know what you think.
 Download the Metro Theme for Visual Studio LightSwitch
Download the Metro Theme for Visual Studio LightSwitch
Beth Massi (@bethmassi) posted “I Command You!” - LightSwitch Screen Commands Tips & Tricks on 10/6/2011:
In this post I wanted to pull together some command tips that seem common when building features into the screens in your business applications. Some of them are floating around on the LightSwitch forums, community blogs, and samples but I thought having these in one place would be easier for folks. I use these techniques a lot when I’m building my own LightSwitch applications.
- How to Create a Command
- How to Open a Open Another Screen (with or without Parameters)
- How to Open a Modal Dialog or Window
- How to Open the Browser & Navigate to a URL
- How to Open the Calculator (or other Windows System Programs)
- How to Open an “Open File” Dialog
- How to Open the Default Program for a File (like Office Documents)
So let’s get started!
How to Create a Command
First off let me start by showing you what I mean by “screen commands”. Commands are buttons (or links) that users click to perform some sort of action. You can add commands to any control like grids & textboxes as well as the screen itself. Take a look at the documentation
How to: Add a Custom Command to a Screen. Commands show up in the model on the left-hand side of the screen designer and are indicated by the pink method icons. You always have three commands by default – Close, Refresh and Save. Refresh and Save also appear in the Screen Command Bar by default when running the application.
Creating commands has two main parts – creating the actual button (or link), then writing the code to execute the command in the command_Execute method. (You can also control whether the command buttons are enabled or disabled by writing code in command_CanExecute method.) Commands can be buttons or links and typically are located in the ribbon at the top of the screen (called the Screen Command Bar) as well as on Data Grids or topmost group controls (called Command Bar) and these are displayed by default when you create a screen. However, you can add commands to any control on a screen that you want so you have a lot of flexibility on the placement of your commands. Here is a screen with a variety of commands:
To add a command to the Screen Command Bar or Command Bar for a group just select it in the screen designer and click the +Add button. Depending on the control LightSwitch will present a set of pre-built commands. On group controls that display data from a single entity, you can add a prebuilt command “Delete” that will delete the current record. On data grids and lists that work with multiple entities you can select a from a variety of commands for adding, editing and deleting records. You can also overwrite the default behavior of these commands by right-clicking on them and selecting “Override Code”.
To create a new custom command, select “New button” and then give it a method name. At that point it will appear in the model on the left of the screen designer. Once you create the button, right click on it and select “Edit Execute Code” to write the code for the command.
If you don’t see a Command Bar on a control (like a label, textbox, date picker, autocomplete box, etc.) just right-click on the control and then on the menu you will see "Add Button…”. You can also click “Add Layout Item” at the top of the screen designer and select “Add Button…”. If you’re running the application in screen customization mode then select the control and click the “Add button” icon
at the top of the content tree. This gives you the flexibility to put commands anywhere on the screen you want.
Now that you understand how to create commands anywhere you want, here are some tips & tricks on some common code that you can write for your custom commands. Note that you can write this code in any of the screen methods, they are not limited to commands. Although that’s probably the most common place you will see custom code like this.
How to Open Another Screen (with or without Parameters)
This one is very common and very simple in LightSwitch. In order to open a screen you use the Application object to access all your screens and call one of the “Show” methods.
Private Sub OpenMyScreen_Execute() ' Write your code here. Me.Application.ShowCreateNewCustomer() End SubYou can also define optional and required parameters on screens. For instance if we create a screen based on a query that requires a parameter then LightSwitch will generate a screen field for us in the model that is used to feed the query. You can select this field and in the properties window you can indicate that it is a screen parameter as well as whether it is required or not.
Keep in mind that screens that have required parameters will not show up in the main navigation bar because they must be called in code.
Private Sub OpenMyScreen_Execute() ' Write your code here. Me.Application.ShowSearchCustomersByPostalCode("98052") End SubFor a couple video demonstrations to see this in action please watch:
- How Do I: Pass a Parameter into a Screen from the Command Bar in a LightSwitch Application?
- How Do I: Open a Screen After Saving Another Screen in a LightSwitch Application?
How to Open A Modal Dialog or Window
There are also a couple methods on screens that allow up to pop up modal message boxes and input boxes. To present a message to the user you write the following:
Me.ShowMessageBox("This is the message")You can also specify a caption and what kind of buttons you want on the message box like OK, OK and Cancel, Yes and No, etc. ShowMessageBox will return a value that indicates what the user chose. In this example I am want to ask the user if they are sure they want to delete a record. Since Delete is a pre-built command, just right-click on it in the screen designer and select “Override Code”. Then you can write the following:
Private Sub gridDeleteSelected_Execute() If Me.ShowMessageBox("Are you sure you want to delete this record?", "Delete", MessageBoxOption.YesNo) = Windows.MessageBoxResult.Yes Then Me.Customers.SelectedItem.Delete() End If End SubYou can also get input from the user by using an input box. This is handy for presenting a message and requesting a single answer from the user.
Private Sub Search_Execute() If Me.CustomerPostalCode = "" Then Me.CustomerPostalCode = Me.ShowInputBox("Please enter a postal code to search for:", "Search") End If Me.CustomersByPostalCode.Load() End SubYou can also open other modal windows that you create on the screen in the content tree. For instance, you may have a lot of fields on a record and you want to display the entire set of fields in a modal window when the user clicks a row command in a search screen instead of requiring them to scroll. Simply add the Selected Item to the bottom of your screen and then change the control type to a Modal Window. You can then lay out the fields exactly how you like. By default LightSwitch will create a button command for you to launch the modal window automatically but you can turn this off in the properties window by unchecking “Show Button”.
In order to launch this modal window from your own command you can call OpenModalWindow and pass it the Name of the Modal Window control:
Private Sub ShowAllFields_Execute() Me.OpenModalWindow("Customers_SelectedItem") End Sub
This video also shows a couple of these techniques:
How to Open the Browser & Navigate to a URL
This is a common one for sure. Maybe you want to open a browser to a specific site, or a report from SQL reporting services, or a SharePoint site. For instance say we have a textbox for our website address field. We can add a command to the control and then execute code to open the address. First you will need to add a reference to the System.Windows.Browser assembly. On the Solution Explorer flip to file view and then right-click on the Client project and select Add Reference.
Then on the .NET tab select System.Windows.Browser and then click OK.
Then you’ll need to add these imports at the very top of your code file:
Imports Microsoft.LightSwitch.Threading Imports System.Runtime.InteropServices.AutomationNow you can write code to open a browser to a specific URL:
Private Sub OpenSite_Execute() Dispatchers.Main.BeginInvoke( Sub() 'Dim uri As New Uri("http://www.bing.com") 'Go to a specific website Dim uri As New Uri(Me.Customer.WebSite) 'Go to website stored in the Customer.WebSite field If (AutomationFactory.IsAvailable) Then Dim shell = AutomationFactory.CreateObject("Shell.Application") shell.ShellExecute(uri.ToString) ElseIf (Not System.Windows.Application.Current.IsRunningOutOfBrowser) Then System.Windows.Browser.HtmlPage.Window.Navigate(uri, "_blank") End If End Sub) End SubNotice that we need to make sure we always call this code from the Main UI thread. If you don’t you will get an error if you are running LightSwitch as a browser application. When running in desktop mode the AutomationFactory.IsAvailable is true so that means we need to open the default browser. If we are already in the browser, then we can simply navigate to a new page.
You can also do a lot of other things in desktop mode like access the Windows file-system, open default programs, and use COM automation. Here’s some more tips for your desktop applications.
How to Open the Calculator (or other Windows System Programs)
This is based on a tip I saw from Paul Patterson that I thought was pretty clever: Open the System Calculator with Interop. This is a nice productivity feature for users working with numerical values on your screen. Just like the previous example that opens the browser, you can open any Windows system programs with ShellExecute in desktop mode (this will not work in browser mode). First add this import to the top of your code file:
Imports System.Runtime.InteropServices.AutomationThen you can simply pass to ShellExecute the name of the Windows program you want to open:
Private Sub OpenProgram_Execute() Try If (AutomationFactory.IsAvailable) Then Dim shell = AutomationFactory.CreateObject("Shell.Application") shell.ShellExecute("calc.exe") 'Open the calculator shell.ShellExecute("notepad.exe") 'Open notepad shell.ShellExecute("mspaint.exe") 'Open Paint End If Catch ex As Exception Me.ShowMessageBox(ex.ToString) End Try End SubHow to Open an “Open File” Dialog
You may want to request a file from a user and you need to present the Open File Dialog. Here’s how you can do that. First add these imports to the top of your code file:
Imports Microsoft.LightSwitch.Threading Imports System.Runtime.InteropServices.Automation Imports System.WindowsThen write this code to open the Open File Dialog which prompts the user for a file:
Private Function GetFile(fileFilter As String) As IO.FileInfo Dim file As IO.FileInfo = Nothing 'This only works in desktop mode in LightSwitch. If AutomationFactory.IsAvailable Then 'You need to open the file dialog on the main thread. Dispatchers.Main.Invoke( Sub() Dim dlg As New Controls.OpenFileDialog dlg.Filter = fileFilter If dlg.ShowDialog = True Then file = dlg.File End If End Sub) End If Return file End FunctionThen you could use this to guide the user into opening certain types of files by specifying a filter. Keep in mind that you can read from any file on the local machine but you are limited to writing or accessing the full path or details of the file to only those that come from trusted locations like the user’s My Document folder.
Private Sub FindFile_Execute() Try 'Request a text file: Dim myFile = GetFile("Text Files (*.txt)|*.txt") 'You can read from files anywhere on disk that the user has access to. ' However you can only write to files in trusted locations like My Documents. Using fs = myFile.OpenText() Me.ShowMessageBox(fs.ReadToEnd()) fs.Close() End Using 'Try to get the full path to the file. This will throw a SecurityException if ' the file is not from a trusted location like My Documents. Me.ShowMessageBox(myFile.FullName) Catch ex As System.Security.SecurityException Me.ShowMessageBox("Please select a file in your Documents, Music or Pictures folder.") Catch ex As Exception Me.ShowMessageBox(ex.ToString) End Try End SubAlso note that in LightSwitch opening the OpenFileDialog will only work in Desktop applications which have elevated permissions. If you try to directly launch the OpenFileDialog in a browser-based application you will get a “Dialogs must be user-initiated” error message. This is because Silverlight dialogs (like OpenFileDialog) can only be opened from “user actions”, like a button clicked event handler. The reason why this won’t work with LightSwitch is because we invoke the button logic asynchronously, so the code is not considered to be “user-initiated”. For a work-around see the “Add a Simple Silverlight dialog” section of Matt Sampson’s post: How Do I Import Data While Running a LightSwitch Web Application.
How to Open the Default Program for a File (like Office Documents)
If you want to open a file in it’s default program (specified by Windows) you can just use ShellExecute again. In this case you probably need to request the file from the user first so you can use the GetFile method in the previous tip above for that. Add these imports to the top of your code file:
Imports Microsoft.LightSwitch.Threading Imports System.Runtime.InteropServices.Automation Imports System.WindowsThen you can write code like this to request the file and then open it with the default program. Here’s a couple examples:
Private Sub OpenFile_Execute() Try If (AutomationFactory.IsAvailable) Then Dim shell = AutomationFactory.CreateObject("Shell.Application") 'Open a text file Dim textFile = GetFile("Text Files (*.txt)|*.txt") shell.ShellExecute(textFile.FullName) 'Open an Excel file Dim excelFile = GetFile("Excel Files (*.xlsx)|*.xlsx") shell.ShellExecute(excelFile.FullName) 'Open a Word Document Dim wordFile = GetFile("Word Files (*.docx)|*.docx") shell.ShellExecute(wordFile.FullName) End If Catch ex As System.Security.SecurityException Me.ShowMessageBox("Please select a file in your Documents, Music or Pictures folder.") Catch ex As Exception Me.ShowMessageBox(ex.ToString) End Try End SubWrap Up
I hope this post showed you some cool tips and tricks you can use on your screens and commands. Remember that you can put commands anywhere on your LightSwitch screens and there are a good set of prebuilt commands you can use for working with data. However if you need to provide users additional productivity features you can easily create custom commands and do almost anything you want.










Return to section navigation list>
Windows Azure Infrastructure and DevOps
David Strom reported Azure Tops Cloud Provider Performance Index in a 10/6/2011 post to the ReadWriteCloud blog:
Yes, you read that right: Microsoft's cloud service Azure topped the list of 25 different providers by CloudSleuth in a report out this week, just slightly edging out Google's App Engine. CloudSleuth uses the Gomez performance network to gauge the reliability and consistency of the most popular public IaaS and PaaS providers.
They run an identical sample ecommerce application on a variety of popular cloud service providers and measure the results over at least six months of historical data.
The report, which is available here, shows a marked difference between Azure servers running in the US (near Chicago) and those running in Singapore (which lagged the list).

Windows Azure led the pack of Australasian data centers, too. I’m still waiting for CloudSleuth to add the Windows Azure South Central US (San Antonio, TX) data center (where my demo app is located) to their test program. For the latest uptime and performance on my demo app, see Uptime Report for my Live OakLeaf Systems Azure Table Services Sample Project: September 2011 of 10/3/2011.
Ryan Bateman’s Cloud Provider Global Performance Ranking – 12 Month Average provides more details about the tests and adds “this chart to understand the trending global average performance of the top cloud service providers. The same rule applies here, we have at least 6 months of data to form an average and the outliers above 10s response times were removed.”

Fig 2. Twelve provider site response times averaged globally and mapped over time
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
<Return to section navigation list>
Cloud Computing Events
Bill Wilder listed October Azure Cloud Events in Boston Area on 10/3/2011:
Since this summary page is – by necessity – a point-in-time SNAPSHOT of what I see is going on, it will not necessarily be updated when event details change. So please always double-check with official event information!
Know of any more cloud events of interest to the Windows Azure community? Have any more information or corrections on the events listed? Please let us know in the comments.
Events are listed in the order in which they will occur.
1. Mongo Boston
- when: Mon 03-Sep-2011, 9:00-5:00 PM
- where: Hosted at NERD Center
- wifi: Wireless Internet access will be available
- food: Provided
- cost: $30
- what: The main Azure-related content is a talk by Jim O’Neilon using Mongo with the Windows Azure Platform – from the published program description: “MongoDB in the Cloud, Jim O’Neil - Developer Evangelist, Microsoft: MongoDB is synonomous with scale and performance, and, hey, so is cloud computing! It’s peanut butter and chocolate all over again as we take a look at why you might consider running MongoDB in the cloud in general and also look at the alpha release of MongoDB on Azure, a collaboration from 10gen and Microsoft.”
- more info: http://www.10gen.com/events/mongo-boston-2011
- register: http://www.10gen.com/events/mongo-boston-2011
- twitter: @mongodb
2. Cloud Camp
- when: Thu 06-Oct-2011, 5:15 – 8:30 PM (then after-party)
- where: CloudCamp Boston #5 is Co-located with the OpenStack Design Summit. Intercontinental Hotel, 510 Atlantic Ave, Salon A (between Congress St & Fort Hill Wharf), Boston, MA 02210
- wifi: (not sure)
- food: (not sure, though food and beer were offered last time)
- cost:
- what: (from the event description on cloudcamp.org) “CloudCamp is an unconference where early adopters of Cloud Computing technologies exchange ideas. With the rapid change occurring in the industry, we need a place where we can meet to share our experiences, challenges and solutions. At CloudCamp, you are encouraged to share your thoughts in several open discussions, as we strive for the advancement of Cloud Computing. End users, IT professionals and vendors are all encouraged to participate.”
- more info: http://www.cloudcamp.org/boston
- register: here
- twitter: (not sure)
3. Boston Azure User Group meeting: Topic TBD, but will be Azurey
when: Thu 27-Oct-2011, 6:00 – 8:30 PM
- where: Hosted at NERD Center
- wifi: Wireless Internet access will be available
- food: Pizza and drinks will be provided
- cost: FREE
- what: Details coming!
- more info: See our (new) Boston Azure Meetup.com site for more info
- register: http://www.meetup.com/bostonazure/events/35904052/
- twitter: #bostonazure
4. New England Code Camp #16
While not strictly an Azure-only event, there will be Azure content at this community-driven event. Hope to see you there!
- when: Saturday, October 29, 2011 9am–6pm
- where: Microsoft Office on Jones Road in Waltham
- wifi: (usually just for speakers)
- food: (usually pizza, sometimes donuts)
- cost: FREE
- what: It’s a Code Camp!
- more info: http://blogs.msdn.com/b/cbowen/archive/2011/08/24/new-england-code-camp-16-october-29th-save-the-date.aspx
- register (for speakers and all attendees): http://codecampboston.eventbrite.com/

I’m not sure why Bill included Mongo Boston, which occurred a month ago.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Jeff Barr (@jeffbarr) described a new AWS Integrated IAM Policy Generator in a 10/6/2011 post:
You can now create custom IAM (Identity and Access Management) policy documents from the IAM tab of the AWS Management Console. You can use a custom policy document to gain access to a number of advanced IAM features such as limiting access by user agent, time, or IP address, requiring a secure transport, or even enabling cross-account access to selected AWS resources.
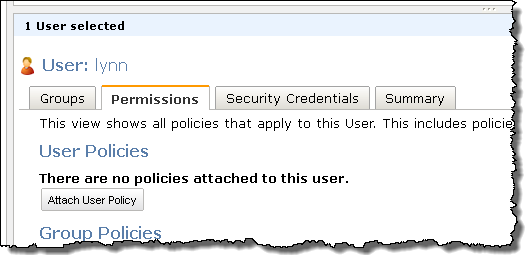
Here's a tour! The first step is to click on the Attach User Policy button (you can also do this for IAM groups):
There's a new Policy Generator option:
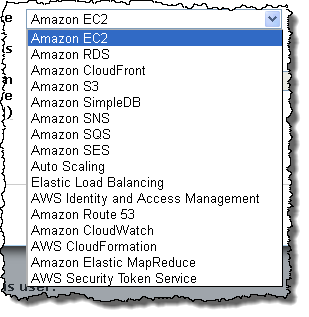
The Policy Generator allows you to create policy documents for any AWS service that is supported by IAM:
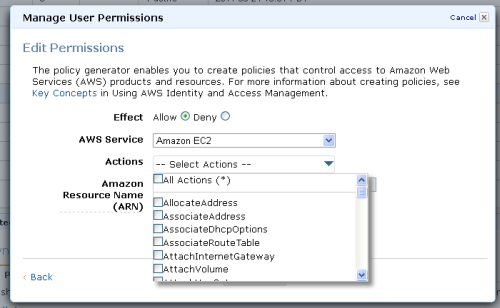
After selecting a service you can choose to allow or deny any number of actions in the policy document that you create:
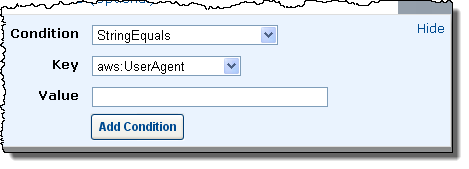
You can also attach any number of conditions to each of your policies:
If this looks like something that you could use, then I suggest that you head over to the AWS Management Console today and create some policies! I suggest that you review the Permissions and Policies section of the IAM documentation to make sure that you are taking advantage of the power and flexibility of IAM.

Jeff Doyle’s Strategy: Inside OpenFlow for InformationWeek:: Reports became available for download on 10/6/2011:
Inside OpenFlow
 Opportunity and disruption often go hand in hand. OpenFlow creates some distinct opportunities for commodity switch vendors to break into a market segment long dominated by bigger players with extensive feature support in their operating systems. It also creates opportunities for new vendors focused on network controllers, such as Big Switch Networks and Nicira Networks. Taking over the “brains” of the network means switch vendors excelling in low cost manufacturing can remove some of their R&D costs and zero in on hardware sales. But it’s also disruptive, to IT and the networking status quo.
Opportunity and disruption often go hand in hand. OpenFlow creates some distinct opportunities for commodity switch vendors to break into a market segment long dominated by bigger players with extensive feature support in their operating systems. It also creates opportunities for new vendors focused on network controllers, such as Big Switch Networks and Nicira Networks. Taking over the “brains” of the network means switch vendors excelling in low cost manufacturing can remove some of their R&D costs and zero in on hardware sales. But it’s also disruptive, to IT and the networking status quo.
 Ultimately, the success or failure of OpenFlow, and, more widely, software-defined networking depends on how well controllers integrate with switches and the breadth of availability of OpenFlow-capable switches. In this three-part report we’ll provide a market and technology overview, then InformationWeek Reports managing director Art Wittmann weighs in on the effects the protocol may have on the currently dominant players in the “big switch” market. We’ll close with a tutorial on OpenFlow.
Ultimately, the success or failure of OpenFlow, and, more widely, software-defined networking depends on how well controllers integrate with switches and the breadth of availability of OpenFlow-capable switches. In this three-part report we’ll provide a market and technology overview, then InformationWeek Reports managing director Art Wittmann weighs in on the effects the protocol may have on the currently dominant players in the “big switch” market. We’ll close with a tutorial on OpenFlow.
So far, Cisco and Juniper have both been public supporters of OpenFlow, and Juniper has demonstrated support in some of its products. “The real question about OpenFlow is not if it provides additional capabilities in any one device but whether it can deliver those capabilities across a heterogeneous network,” says Juniper’s Dave Ward.
The industry excitement around OpenFlow may be exaggerated, and it may be premature. It may trigger major shakeups among networking vendors, bringing important new players onto the field and changing the way established suppliers do business. Only time will tell. OpenFlow does, however, hold the promise of transforming the way we design and control our networks, and that alone makes it worth our attention. (S3631011)
Table of Contents
3 Author’s Bio
4 Executive Summary
5 OpenFlow Makes a Splash
5 Figure 1: Use of Virtualization Technologies
7 The Biggest Thing Since Ethernet?
8 Figure 2: Private Cloud Use
9 Figure 3: Private Cloud Adoption Drivers
11 Getting a Handle on OpenFlow
12 Figure 4: Central Network Command
13 Figure 5: Control Plane
14 Figure 6: The OpenFlow Model
15 Figure 7: Flow Entry Format
16 Figure 8: Group Entry Format
17 Figure 9: Pipeline Processing
18 Figure 10: Action Packets
20 Figure 11: Actions Switches Execute on Packets
21 Related Reports
About the Author
Jeff Doyle specializes in IP routing protocols, MPLS and IPv6 and has designed or assisted in the design of large-scale IP service provider networks throughout North America, Europe, Japan, Korea, Singapore and the People’s Republic of China. Over the past few years he has had extensive experience helping in the deployment of IPv6 in large networks around the world.
James Staten (@staten7) reported Oracle Finally Gets Serious About Cloud, But It's IaaS, Not PaaS in a 10/6/2011 post to his Forrester blog:
After three days of cloudwashing, cloud-in-a-box and erector set private cloud musings at Oracle OpenWorld in San Francisco this week, CEO Larry Ellison chose day four to take the wraps off a legitimate move into cloud computing.
Oracle Public Cloud is the unification of the company's long-struggling software-as-a-service (SaaS) portfolio with its Fusion applications transformation, all atop Oracle VM and Sun hardware. While Ellison spent much of his keynote taking pot shots at his former sales executive and now SaaS nemesis, Salesforce CEO Mark Benioff, the actual solution being delivered is more of a direct competitor to Amazon Web Services than Force.com. The strongest evidence is in Oracle's stance on multitenancy. Ellison adamantly shunned a tenancy model built on shared data stores and application models, which are key to the profitability of Salesforce.com (and most true SaaS and PaaS solutions), stating that security comes only through application and database isolation and tenancy through the hypervisor. Oracle will no doubt use its own Xen-based hypervisor, OracleVM rather than the enterprise standard VMware vSphere, but converting images between these platforms is quickly proving trivial.
While many enterprise infrastructure & operational professionals will applaud this approach, this IaaS-centric architecture is far more resource intensive for supporting multiple customers than the Benioff model. Microsoft seems to agree with Benioff, as its Windows Azure model applies tenancy at the application level as well. As does, frankly, Oracle’s own SaaS customer relationship management (CRM) solution, now known as Fusion CRM. Ellison’s investment portfolio, which includes other SaaS solutions such as NetSuite, also favor this tenancy model.
A big selling point for Ellison was the fact that the same Fusion middleware software sold on-premises was available in his cloud and that the programming model for Oracle Public Cloud was the same open standards-based languages of Java, BPEL and web services. This is in clear contrast to the walled gardens of most other PaaS offerings. Microsoft comes closest to this value proposition, as most open languages and web services are supported but the middleware services of Azure are not one-for-one with their on-premises equivalents.
No doubt I&O pros will laud this architectural consistency, as it significantly eases the migration of Java apps between on-premises and cloud.
While Ellison announced a collection of cloud services – four SaaS applications and 4 PaaS services – a subset of these appear visible on the cloud.oracle.com site. Only the company’s database and Java services are shown as PaaS services with the already pre-existing CRM and human capital management (HCM) SaaS applications; talent management and Fusion Financials (Oracle eBusiness Suite) are expected to follow at the SaaS layer with a data service to supposedly rival Azure DataMarket filling out the PaaS layer. Ellison called out a discrete security service at the PaaS layer, but I presume this is a core function of the platform rather than a discrete service forthcoming.
Enterprise developers and I&O pros expecting a PaaS solution when looking at Oracle Public Cloud should note that while middleware and application services will be exposed – and supposedly you will not be able to provision a raw VM – this exposure does not a PaaS make. This is IaaS, which means that each image is a standalone entity rather than an autoscaling web service. While Oracle may provide tools to make scaling easier, customers should be prepared to apply IaaS best practices to this environment.
Lots of unknowns remain for this service, the biggest being pricing. While Ellison talked about an AWS-like pay-per-use model he also stated the requirement of a subscription. And since every instance will include at least either an Oracle database or a WebLogic app server, you can expect each instance to cost far more than Amazon’s $0.08 for a small VM.
For a different take on this announcement, see Forrester vendor strategist analyst Stefan Ried's blog entry.


Chris Kanaracus (pictured below) claimed “The new service's open design is far superior to Salesforce.com's 'roach motel,' according to Ellison” in a deck for his Ellison unveils new cloud, trashes Salesforce.com article of 10/6/2011 for InfoWorld’s Computing blog:
Oracle CEO Larry Ellison on Wednesday unveiled a public cloud service that will run its Fusion Applications and others, and while doing so delivered a withering broadside against competitors, with his harshest words for Salesforce.com.
"Our cloud's a little bit different. It's both platform as a service and applications as a service," he said during a keynote address at the OpenWorld conference in San Francisco, which was webcast. "The key part is that our cloud is based on industry standards and supports full interoperability with other clouds. Just because you go to the cloud doesn't mean you forget everything about information technology from the past 20 years."
In contrast, Salesforce.com's Force.com platform is the "roach motel" of cloud services, amounting to "the ultimate vendor lock-in" due to its use of custom programming languages like Apex. In contrast, the Oracle Public Cloud uses Java, SQL, XML, and other standards, Ellison said.
"You can check in but you can't check out" of Salesforce.com, Ellison said to laughter from the OpenWorld crowd. "It's like an airplane, you fly into the cloud and you never get out. It's not a good thing."
Salesforce.com may have bought Heroku, a cloud application platform that supports Java, but customers shouldn't be fooled, Ellison claimed.
"They say, 'Oh, we just bought Heroku. It runs Java.' [But] it's sort of like a Salesforce.com version of Java that only runs in Heroku. Don't try to move that [Java Enterprise Edition] application to the Salesforce.com cloud. It won't run. If you build something in Heroku you can't move it. It's a derivative of Java."
In contrast, "you can take any existing Oracle database you have and move it to our cloud," Ellison said. "You can just move it across and it runs unchanged. Oh by the way, you can move it back if you want to. You can move it to the Amazon cloud if you want to. You can do development and test on our cloud and go into production in your data center ... and nothing changes."
"Beware of false clouds," Ellison said, referring to a favorite saying of Salesforce.com CEO Marc Benioff. "That is such good advice. I could not have said it better myself."
Ellison even trashed Salesforce.com's and other SaaS (software-as-a-service) providers' use of multitenant architectures, wherein many customers share a single application instance with their data kept separate. The practice cuts down on system overhead as well as allows vendors to roll out patches and upgrades to many customers at once.

Read more: next page ›, 2
Having been a pilot for many years, I believe it’s correct to say “If you fly into a cloud you always come out.” Hopefully, in full control of your aircraft.
So far, nothing I’ve read about the Oracle “cloud” will distinguish it from current competitors, such as Windows Azure, when it launches sometime in the future. I’ve signed up to be kept informed of the progress. The Oracle Public Cloud landing page has more details.
Barb Darrow asked Top 5 questions out of Oracle OpenWorld 2011 in a 10/3/2011 post to the Giga Om blog:
As Oracle (s orcl) continues its stackapalooza at Oracle OpenWorld 2011 this week, here are my top five questions for the database-and-enterprise-apps giant as it forges into the cloud computing era.
1. How many companies are catching what Oracle’s pitching?
Monday morning, Oracle Co-President Mark Hurd once again touted the company’s soup-to-nuts stack. But his mantra, “Complete Stack, Complete Customer Choice” seems a bit oxymoronic on its face.
Oracle would love businesses to buy its upcoming Exalytic analytics appliance to massage their stats, Exadata for their database loads, Exalogic for their apps, and the newly announced Big Data Appliance to bring social network and other non-structured data into the fold. But that’s a pricey load of hardware.
There are companies that really want to source more of their IT hardware and software from fewer companies, if only to simplify procurement. But there are many more companies–among them some very big Oracle database shops–that really don’t want to devote more of their budget to a company with support and maintenance policies they deplore. For them, vendor lock-in is worrisome; vendor lock in to Oracle is unthinkable.
Analyst Ray Wang said Oracle is right that engineered systems work better, as proven by Apple in the consumer world. “The question is whether or not Oracle can convince non diehard ‘redstack’ customers that the price and performance benefits are worth becoming an Oracle customer,” said Wang, principal analyst and CEO of Constellation Research.
2. Just what is Oracle NoSQL anyway?
Is Oracle NoSQL based on Berkeley DB , the database company Oracle bought in 2006. Kinda. Here’s what a recent Oracle post has to say about that:
Oracle NoSQL Database leverages the Oracle Berkeley DB Java Edition High Availability storage engine to provide distributed, highly available key/value storage for large-volume, latency-sensitive applications or web services. It can also provide fast, reliable, distributed storage to applications that need to integrate with ETL processing.
3. Is a Sparc resurgence underway?
Most of Oracle’s fancy-pants appliances are, beneath it all, Intel machines. Exadata, Exalogic, Exalytics–all run Intel Xeon chips (they also run Linux as well as Solaris). But with the fast Sparc T-4 chips which power Oracle’s new Sparc Supercluster, some beleaguered Sparc fans see reason for hope.
Supercluster builds on four four-socket Sparc T4 server nodes; Infiniband switches; ZFS storage appliances; and comes in half-or full-rack configuration.
4. Is there room for independent business intelligence/analytics players?
With Oracle, SAP, and IBM all backing their own in-house or acquired BI and analytics, what happens to standalone players?
And by standalone players, I mean SAS Institute, the privately held pioneer in high-end analytics? IBM bought SPSS and Netezza; EMC bought GreenPlum; SAP bought BusinessObjects; and Oracle bought Hyperion (and has put Essbase into the new Exalytics box), so the field is otherwise pretty much clear.
5. How long will the era of peaceful co-opetition between Oracle and EMC last?
EMC Chairman Joe Tucci and Lieutenant Pat Gelsinger raised eyebrows talking about how many Oracle shops are heavily virtualized. Interesting, given how Oracle’s stated support policies pretty much leave VMware (s vmw) users out in the cold. Oracle supports virtualization, provided it’s Oracle virtualization.
Gelsinger, president and COO of EMC’s Information Infrastructure Product group, also helped show off a GreenPlum big data demo. When it comes to big data appliances, EMC and Oracle are on a collision course. Right now, Oracle CEO Larry Ellison is happy taking pot shots at IBM and HP(s hpq), but things could get interesting with EMC-Oracle relationship going forward.
Photo of [Mark Hurd] courtesy of Flickr user Emma, Michael and Elway’s Excellent Adventures

<Return to section navigation list>

















0 comments:
Post a Comment