Windows Azure and Cloud Computing Posts for 6/2/2011+
| A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Updated 6/2/2011 2:00 PM PDT and later with articles marked • by Bruce Guptil, Patrick Wood, Victoria Reitano, Carl Brooks, the Windows Azure Team, Jervis from ASPHostPortal, Mike Benkovich, Adam Grocholski, Chris Hoff, Gavin Clarke and Joe Panettieri.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructur and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
Brian Prince (@brianhprince) explained Using the Queuing Service in Windows Azure in a 6/2/2011 post to the DeveloperFusion blog:
Windows Azure is Microsoft’s cloud computing platform, and it is comprised of a series of services. The storage family of services is REST based, making it available to any developer on any platform. These services include
- BLOB storage, for your files,
- Tables for your structured, non-relational data, and
- Queues to store messages that will be picked up later.
The Windows Azure Platform also offers SQL Azure for relational data. SQL Azure, while a way to store data in Windows Azure, is not technically part of Windows Azure Storage, it is its own product. SQL Azure is also not based on REST, but on TDS.
In this article we are going to focus on the easiest of these services to work with, the Queues. We will also look at when and how you might use Queues in your application.
What are Queues?
A queue is simply a list of messages. The messages flow from the bottom of the queue to the top of the queue in the order they were added to the queue. It is known by computer scientists as a FIFO data structure. FIFO stands for First In-First Out.
You can think of a queue like a line at the bank. As customers enter the bank, they enter the bottom of the queue (or the back of the line). As the single teller finishes with each customer, the line moves forward, and people eventually get to the head of the line, and get their turn with the teller.
Just like how a bank may have many sets of doors that a customer may arrive through, a queue may have several message producers adding messages to the queue. These producers may have nothing to do with each other, and in some instances may create messages with different content and purposes.
A bank may, when the line gets long enough, open up more teller windows, and you application can do the same. You can change how many consumers you have taking messages off of the queue and processing the data.
Queues in and of themselves are pretty simple beasts, and have been around for a long time as a technology. They are also relatively simple to work with, highly reliable and performant: a single queue in Windows Azure can handle 500 operations per second, including putting, getting, and removing messages.
Windows Azure uses a storage container to hold your data - . You can create a storage account as part of your Windows Azure subscription. Each subscription can have up to five storage accounts by default. The limit can be increased by calling tech support.
A storage container will have a name, for example, OrdersData, and a storage key. The storage key is a private key of a certificate which acts as your password into that storage account. If anyone has both the name and the key, they will have full permissions to your storage, so you want to protect these.
A single storage account can hold any combination of data from Blobs, Queues, and Tables, up to a total capacity of 100TB. Any data stored in a storage container is replicated three times to provide for high availability and reliability. Each Windows Azure subscription can have many different storage accounts.
Starting the Sample
We are going to create a sample comprised of two console applications. One will be the consumer, and put messages on the queue. These messages are meant to be commands for a robot. The other console application will play the role of the robot, the consumer.
To get started, you will need to install the Windows Azure Tools for Microsoft Visual Studio. The current version is 1.4, and that is the version we will be using. You can download it from http://www.microsoft.com/windowsazure/sdk/.
Once you have the SDK installed, start the storage emulator. You should find it as Start > All Programs > Windows Azure SDK v1.4 > Storage Emulator. You must run this as an Administrator. The emulator runs a simulation of the real Windows Azure storage services locally for development purposes.
Now open Visual Studio 2010, also in Admin mode. The Windows Azure SDK requires Admin mode because of how the Windows Azure emulator works behind the scenes.
- Create a new blank solution.
- Add a C# Console Application Project to it. We will name this first console project Producer because it will be our little application for producing messages and adding them to the queue.
- Add a reference to the Microsoft.WindowsAzure.StorageClient assembly to the new project. You’ll find it in %ProgramFiles%\Windows Azure SDK\v1.4\bin.
- Add a second reference to the System.configuration assembly.
- Add an app.config file to your solution.
When app.config appears in Visual Studio, add the following appSettings element. This tells the Storage Client knows where to connect. This is a lot like providing a connection string to a database. We are using a connection string that will connect to and use the local storage emulator instead of connecting to the real Queue service in the cloud.
<?xml version="1.0" encoding="utf-8" ?> <configuration> <appSettings> <add key="DataConnectionString" value="UseDevelopmentStorage=true" /> </appSettings> </configuration>Now open program.cs if it isn’t open already and add the following using statements
using Microsoft.WindowsAzure.StorageClient; using Microsoft.WindowsAzure; using System.Configuration; using System.Threading;Now we start writing our application in the Main method of Program.cs. To begin with, we need to tell the Windows Azure Storage Client not to look in the Windows Azure project for its configuration details. There isn’t a Windows Azure project in this solution as this code will run on our local PC instead of in the cloud, so we have to add a few lines of code that tell it to look in app.config for its configuration.
private static void Main(string[] args) { CloudStorageAccount.SetConfigurationSettingPublisher((configName, configSetter) => { configSetter(ConfigurationManager.AppSettings[configName]); });The next step is to get a reference to our queue. In order to connect to the queue we need to first connect to the Storage Account, and then your Queue service. They live in a hierarchy. The queue is contained in the Queue service, which is contained inside your Storage Account in Windows Azure.
Once we have done that we will get a reference to the queue itself. The trick here is that you can get a reference to a queue, even when it doesn’t exist yet. This is how you create a queue. It seems weird, but you will get used to it. The FromConfigurationSetting() method will look in your cloud service configuration file for the DataConnectionString configuration value. Of course you can name the configuration element anything you would like.
var storageAccount = CloudStorageAccount.FromConfigurationSetting("DataConnectionString"); var queueClient = storageAccount.CreateCloudQueueClient(); var queue = queueClient.GetQueueReference("robotcommands"); queue.CreateIfNotExist();In our case, the queue named ‘robotcommands’ doesn’t exist yet.
It is important to note that all queue names must be lower case. You will forget this one day, and you will spend hours figuring out why your code isn’t working, and then you will remember me saying over and over again that the queue name must be lower case.
The CreateIfNotExist() method will see if the queue really does exist in Windows Azure, and if it doesn’t it will create it for you. This code will leave you with a queue object (of type CloudQueue) that will let you work with the queue you have selected or created.
What are Messages?
So now that we have a queue, what do we put in it? Well, messages of course. Messages in Windows Azure queues are meant to be very small, limited to 8KB in size. This is to help make sure the queue can stay super-fast, and make it easy for these messages to travel over the wire as part of REST.
Creating a message is fairly simple. You create a CloudQueueMessage with the contents of the message, and then add it to the queue object from above. You can put any text in the message that you want, including encoded binary data. In our sample, we are now going to create a message, and add it to the queue. We will use some user entered input as the contents of the message. We are using an infinite loop to continuously receive input from the user. If the user enters ‘exit’ then we will break the loop and end the program.
string enteredCommand = string.Empty; Console.WriteLine("Welcome to the robot command queue system. Enter 'exit' to stop sending commands."); while (true) { Console.Write("Enter a command to be queued up for the robot:"); enteredCommand = Console.ReadLine(); if (enteredCommand != "exit") { queue.AddMessage(new CloudQueueMessage(enteredCommand)); Console.WriteLine("Command sent."); } else break; }The important line here is the queue.AddMessage() line. In this line we create a new CloudQueueMessage passing in the data entered by the users. This creates the message we want to send. We then hand that message to the AddMessage method which sends it to the queue.
That’s all we need to do to create our producer application. We can now send messages, through a queue, to our robot.
Writing the Consumer Application
We now need to write the application that will represent our robot. It will continually check the queue for any messages that have been sent to it, and assumedly execute them somehow.
- In Visual Studio, click File > Add > New Project.
- Select Console Application, set its name to Consumer and hit OK.
- Add references to the Microsoft.WindowsAzure.StorageClient and System.configuration assemblies as you did for the Producer solution.
- Add an app.config file to the Consumer project and add the same appSettings element to this file as you did for the Producer solution.
Now open program.cs for the consumer solution if it isn’t already open. Initially, this application needs to do the same configuration and queue setup as the producer application, so our first additions replicate those made in the Starting the Sample section.
namespace Consumer { using System; using System.Linq; using Microsoft.WindowsAzure.StorageClient; using Microsoft.WindowsAzure; using System.Configuration; using System.Threading; public static class Program { private static void Main(string[] args) { CloudStorageAccount.SetConfigurationSettingPublisher((configName, configSetter) => { configSetter(ConfigurationManager.AppSettings[configName]); }); var storageAccount = CloudStorageAccount.FromConfigurationSetting("DataConnectionString"); var queueClient = storageAccount.CreateCloudQueueClient(); var queue = queueClient.GetQueueReference("robotcommands"); queue.CreateIfNotExist(); } } }Now to move on to the guts of our consumer application. The consumer of the queue will connect to the queue just like the message producer code. Once you have a reference to the queue you can call GetMessage(). A consumer will normally do this from within a polling loop that will never end. An example of this type of loop, without all of the error checking that you would normally include, is below.
In this while loop we will get the next message on the queue. If the queue is empty, the GetMessage() method will return a null. If we get a null then we want to sleep for some period of time. In this example we are sleeping for five seconds before we poll again. Sometimes you might sleep a shorter period of time (speeding up the poll loop and fetching messages more aggressively), and sometimes you might want to slow the poll loop down. We will look at how to do this later in this article.
The pattern you should follow in this loop is:
- Get Message
- If no message available, sleep for five seconds
- Process the Message
- Delete the Message
The code that will do this is as follows. Add it to the Main() method after the call to queue.CreateIfNotExist().
CloudQueueMessage newMessage = null; double secondsToDelay = 5; Console.WriteLine("Will start reading the command queue, and output them to the screen."); Console.WriteLine(string.Format("Polling queue every {0} second(s).", secondsToDelay.ToString())); while (true) { newMessage = queue.GetMessage(); if (newMessage != null) { Console.WriteLine(string.Format("Received Command: {0}", newMessage.AsString)); queue.DeleteMessage(newMessage); } else Thread.Sleep(TimeSpan.FromSeconds(secondsToDelay)); }If there is a message found we will then want to process it. This is whatever work you have for that message to do. Messages generally follow what is called the Work Ticket pattern. This means that the message includes key data for the work to be done, but not the real data that is needed. This keeps the message light and easy to move around. In this case the message is just simple commands for the robot to process.
After the work is completed we want to remove the message from the queue so that it is not processed again. This is accomplished with the DeleteMessage() method. In order to do this we need to pass in the original message, because the service needs to know the message id and the pop receipt (more on this in The Message Lifecycle section) to perform the delete. And then the loop continues on with its polling and processing.
Running the Sample
You should now have a Visual Studio solution that has two projects in it. A console application called Producer that will generate robot commands and submit them to your queue. You will also have a second console application called Consumer that plays the role of the robot, consuming messages from the queue.
We need to run both of these console applications at the same time, which you can’t normally do with f5 in Visual Studio. The trick to running both is to right click on each project name, select the debug menu, and then select ‘start new instance’. It doesn’t matter which one you start first.
After you do this you will have two DOS windows open, one for each application. Use the Producer application to start creating messages to be sent to the queue. Here is what it looks like. Make sure the storage emulator from the Windows Azure SDK is already running before you start the applications.

The Message Lifecycle
The prior section mentioned something called a pop receipt. The pop receipt is an important part of the lifecycle of a message in the queue. When a message is grabbed from the top of the queue it is not actually removed from the queue. This doesn’t happen until DeleteMessage is called later. The message stays on the queue but is marked invisible. Every time a message is retrieved from the queue, the consumer can determine how long this timeout of invisibility should be, based on their processing logic. This defaults to 30 seconds, but can be as long as two hours. The consumer is also given a unique pop receipt for that get operation. Once a message is marked as invisible, and the time out clock starts ticking, there isn’t a way to end it quicker. You must wait for the full timeout to expire.
When the consumer comes back, within the timeout window, with the proper receipt id, the message can then be deleted.
If the consumer does not try to delete the message within the timeout window, the message will become visible again, at the position it had in the queue to begin with. Perhaps during this window of time the server processing the message crashed, or something untoward happened. The queue remains reliable by marking the message as visible again so another consumer can pick the message up and have a chance to process it. In this way a message can never be lost, which is critical when using a queuing system. No one wants to lose the $50,000 order for pencils that just came in from your best customer.
This does lead us to one small problem. Let’s say our message was picked up by server A, but server A never returned to delete it, and the message timed out. The message then became visible again, and our second server, server B, finds the message, picks it up and processes it. When it picks up the message it receives a new pop receipt, making the pop receipt originally given to server A invalid.
During this time, we find out that server A didn’t actually crash, it just took longer to process the message than we predicted with the timeout window. It comes back after all of its hard work and tries to delete the message with its old pop receipt. Because the old pop receipt is invalid server A will receive an exception telling it that the message has been picked up by another processor.
This failure recovery process rarely happens, and it is there for your protection. But it can lead to a message being picked up more than once. Each message has a property, DequeueCount, that tells you how many times this message has been picked up for processing. In our example above, when server A first received the message, the dequeuecount would be 0. When server B picked up the message, after server A’s tardiness, the dequeuecount would be 1. In this way you can detect a poison message and route it to a repair and resubmit process. A poison message is a message that is somehow continually failing to be processed correctly. This is usually caused by some data in the contents that causes the processing code to fail. Since the processing fails, the messages timeout expires and it reappears on the queue. The repair and resubmit process is sometimes a queue that is managed by a human, or written out to Blob storage, or some other mechanism that allows the system to keep on processing messages without being stuck in an infinite loop on one message. You need to check for and set a threshold for this dequeuecount for yourself. For example:
if (newMessage.DequeueCount > 5) { routePoisonMessage(newMessage); }Word of the Day: Idempotent
Since a message can actually be picked up more than once, we have to keep in mind that the queue service guarantees that a message will be delivered, AT LEAST ONCE.
This means you need to make sure that the ‘do work here’ code is idempotent in nature. Idempotent means that a process can be repeated without changing the outcome. For example, if the ATM was not idempotent when I deposited $10, and there was a failure leading to the processing of my deposit more than once, I would end up with more than ten dollars in my account. If the ATM was idempotent, then even if the deposit transaction is processed ten times, I still get only ten dollars deposited into my account.
You need to make sure that your processing code is idempotent. There are several ways to do this. Most usually you should just build it into the nature of the backend systems that are consuming the messages. In our robot example we wouldn’t want the robot to execute a single ‘Turn Left’ command twice because it is accidentally handling the same message twice. In this scenario we might track the message id of each message processed, and check that list before we execute a command to make sure we haven’t processed it.
When Queues are Useful
We can see that Windows Azure Queues are very simple to use. Queues become an important tool when we try to decouple parts of our system from each other. They provide an excellent way for two components (either in the same system, or in different systems altogether) to communicate (in a single-directional manner) without having any dependencies on each other.
These two sides of the communication (the producer and the consumer of the messages) don’t have to be running in Windows Azure. Perhaps the producer is a laptop application that is used by the field sales force to process and submit orders back to corporate. The consumer could be a mainframe behind the firewall at corporate that then reaches out and pulls down the messages in the queue to process them.
This is a great way to reduce the dependency from the sender on the receiver, giving you much more flexibility in your architecture, and reducing brittleness. If that mainframe is ever updated to a .NET application running on servers in the corporate datacentre, the producers of the message never need to know or care.
Other Queue Tips
We mentioned earlier that you may want to adjust how often you poll the queue. How often you poll the queue will mostly depend on how you need to consume the messages. In our mainframe example, we might be tied to a nightly batch process. In this case the mainframe is only connecting once an evening to pull down all of the orders that built up during the day. This is called a long queue, because you expect messages to stay in the queue for a longer period of time before they are processed.
Other queue polling techniques rely on self-adjusting the delay in the loop. A common algorithm for this is called the Truncated Exponential Back Off. This approach is taken from how TCP manages the to the sending and receiving of packets over the network. You can read more about the TCP scenario at http://en.wikipedia.org/wiki/Retransmission_(data_networks).
With this algorithm you will define a minimum polling delay (perhaps 1 second) and a maximum delay (perhaps 60 seconds). We will vary the delay of the polling loop over time. Each time the queue is found to be empty we will double the current delay. As the queue remains empty we will poll less and less often. First delaying the loop by 1 second per poll, then 2, then 4, 8, 16, 32, and so on until we reach our maximum delay of 60 seconds.
If we ever find a message in the queue, then we know that there is some traffic and we should speed up our polling loop. There are two approaches to take in this case. The first is that you start to gradually speed up the loop by cutting the delay in half each time you find a message. In this manner your delay would go from 60 to 30, to 15, and eventually back down to 1 second if there is enough messages in the queue. The alternative approach is to immediately shorten your polling delay to 1 second as soon as you find a message in the queue. This is useful when you know the message pattern involves groups of messages, instead of lone messages.
Summary
In this article we have explained how queues work, and how we can use them to decouple our systems, provide the robustness to our architecture we often need. Using messages is quite easy, with simple methods for putting and getting messages onto and off of the queue. There are many ways you can use a queue in your system, and we looked at only a few possibilities including a regular polling loop, a long queue used for infrequent use, and truncated exponential back off polling that allows our queue to speed up and slow down depending on usage.
<Return to section navigation list>
SQL Azure Database and Reporting
• Patrick Wood questioned Microsoft Access DSN-Less Linked Tables: TableDef.Append or TableDef.RefreshLink? for SQL Azure in a 6/2/2011 post:
When it came to creating DSN-Less Linked Tables I had always used a procedure that deleted the TableDef and appended a new one until a problem occurred. The code I was using to save Linked Tables as DSN-Less Tables was not working with some of the Views in SQL Azure. This was a serious problem because the application I was developing would be distributed to clients who would then distribute it to their clients. We did not want to use a DSN file. But now the code that normally worked without a hitch was failing.
Because I was developing for SQL Azure, I had to use SQL Azure Security which includes the Username and Password in the Connection string. Even though I explicitly set the dbAttachSavePWD (Enum Value: 131072) when I appended the new TableDefs the Connection Property of my views still did not include my Username and Password. So I quickly wrote some code to loop through the TableDef properties to see if I could discover the problem.
Sub ListODBCTableProps() Dim db As DAO.Database Dim tdf As DAO.TableDef Dim prp As DAO.Property Set db = CurrentDb For Each tdf In db.TableDefs If Left$(tdf.Connect, 5) = "ODBC;" Then Debug.Print "----------------------------------------" For Each prp In tdf.Properties 'Skip NameMap (dbLongBinary) and GUID (dbBinary) Properties here If prp.Name <> "NameMap" And prp.Name <> "GUID" Then Debug.Print prp.Name & ": " & prp.Value End If Next prp End If Next tdf Set tdf = Nothing Set db = Nothing End Sub
I discovered that the TableDef Attributes of the Views for which my code was not working was 536870912 but for the Tables and Views that were working it was 537001984. After checking the TableDefAttributeEnum Enumeration values I was puzzled. The Attributes value for the Views which were not working was 537001984 which is the value for dbAttachedODBC (Linked ODBC database table). And the value of the Attribute for the Tables and Views that were working was 536870912 which is not in the list. After a few moments I figured it out. I saw that if you add the dbAttachedODBC value of 536870912 to the dbAttachSavePWD value of 131072 it equals the 537001984 Attributes value of the DSN-Less Tables and Views that were set properly. This made sense since the documentation Description for dbAttachSavePWD is “Saves user ID and password for linked remote table”. Apparently the Views needed both Attributes. But how could I set it?
Even though my code explicitly set the Attributes value to dbAttachSavePWD when creating the new TableDefs it was not working. Eventually I found some code that used the TableDef.RefreshLink Method, added the TableDefs Attributes dbAttachSavePWD (131072) value, and tested it. This solution worked. Below is the code I used.
Function SetDSNLessTablesNViews() As Boolean Dim db As DAO.Database Dim tdf As DAO.TableDef Dim strConnection As String SetDSNLessTablesNViews = False 'Default Value Set db = CurrentDb 'Use a Function to get the Connection string 'Note: In actual use I never use "Connection" in my Variables or Procedure names. 'I disguise them to make it hard for a hacker to use code to get my Connection string strConnection = GetCnnString() 'Loop through the TableDefs Collection For Each tdf In db.TableDefs 'Verify the table is an ODBC linked table If Left$(tdf.Connect, 5) = "ODBC;" Then 'Skip System tables If Left$(tdf.Name, 1) <> "~" Then Set tdf = db.TableDefs(tdf.Name) tdf.Connect = strConnection tdf.Attributes = dbAttachSavePWD 'dbAttachSavePWD = 131072 tdf.RefreshLink End If End If Next tdf SetDSNLessTablesNViews = True Set tdf = Nothing Set db = Nothing End FunctionI felt better about using the tdf.RefreshLink Method rather than deleting the TableDefs and appending them again. I read that you could delete your TableDefs and not be able to append a new one if there is an error in the Connection string at this page on Doug Steele’s website at the bottom of the page.
I found an interesting discussion about whether to delete and then append a new TableDef or use the RefreshLink Method on Access Monster. However the latest Developer’s Reference documentation settles the matter for me when it states the TableDef.RefreshLink Method “Updates the connection information for a linked table (Microsoft Access workspaces only).”
You may also want to see the sample code from The Access Web by Dev Ashish using the RefreshLink Method.
Below is an example of the code used to get the Connection string. As I stated in the procedure notes I never use “Connection” in Constants, Variables, or Procedure names. Nor do I use cnn, con, cnnString, etc. Instead I disguise the name of my Procedure to make it hard for a hacker to use to get my Connection string. Constants and Procedure names, along with some variables, are easily seen by opening up even an accde or mde file with a free Hex editor unless you have encrypted the database file. If I can see the name of your Constant I can very easily get its value.
'Don't forget to change the name of this procedure Function GetCnnString() As String GetCnnString = "ODBC;" _ & "DRIVER={SQL Server Native Client 10.0};" _ & "SERVER=MyServerName;" _ & "UID=MyUserName;" _ & "PWD=MyPassW0rd;" _ & "DATABASE=MySQLDatabaseName;" _ & "Encrypt=Yes" End FunctionYou can see or download the code used in this article from our Free Code Samples page.
Get the free Demonstration Application that shows how effectively Microsoft Access can use SQL Azure as a back end.
Jason Bloomberg (@TheEbizWizard) engaged in “Rethinking data consistency” for his BASE Jumping in the Cloud article of 6/2/2011 for the Cloud Computing Journal:

Your CIO is all fired up about moving your legacy inventory management app to the Cloud. Lower capital costs! Dynamic provisioning! Outsourced infrastructure! So you get out your shoehorn, provision some storage and virtual machine instances, and forklift the whole mess into the stratosphere. (OK, there's more to it than that, but bear with me.)
Everything seems to work at first. But then the real test comes: the Holiday season, when you do most of your online business. You breathe a sigh of relief as your Cloud provider seamlessly scales up to meet the spikes in demand. But then your boss calls, irate. Turns out customers are swamping the call center with complaints of failed transactions.
You frantically dive into the log files and diagnostic reports to see what the problem is. Apparently, the database has not been keeping an accurate count of your inventory-which is pretty much what an inventory management system is all about. You check the SQL, and you can't find the problem. Now you're really beginning to sweat.
You dig deeper, and you find the database is frequently in an inconsistent state. When the app processes orders, it decrements the product count. When the count for a product drops to zero, it's supposed to show customers that you've run out. But sometimes, the count is off. Not always, and not for every product. And the problem only seems to occur in the afternoons, when you normally experience your heaviest transaction volume.
The Problem: Consistency in the Cloud
The problem is that while it may appear that your database is running in a single storage partition, in reality the Cloud provider is provisioning multiple physical partitions as needed to provide elastic capacity. But when you look at the fine print in your contract with the Cloud provider, you realize they offer eventual consistency, not immediate consistency. In other words, your data may be inconsistent for short periods of time, especially when your app is experiencing peak load. It may only be a matter of seconds for the issue to resolve, but in the meantime, customers are placing orders for products that aren't available. You're charging their credit cards and all they get for their money is an error page.From the perspective of the Cloud provider, however, nothing is broken. Eventual consistency is inherent to the nature of Cloud computing, a principle we call the CAP Theorem: no distributed computing system can guarantee (immediate) consistency, availability, and partition tolerance at the same time. You can get any two of these, but not all three at once.
Of these three characteristics, partition tolerance is the least familiar. In essence, a distributed system is partition tolerant when it will continue working even in the case of a partial network failure. In other words, bits and pieces of the system can fail or otherwise stop communicating with the other bits and pieces, and the overall system will continue to function.
With on-premise distributed computing, we're not particularly interested in partition tolerance: transactional environments run in a single partition. If we want ACID transactionality (atomic, consistent, isolated, and durable transactions), then we should stick with a partition intolerant approach like a two-phase commit infrastructure. In essence, ACID implies that a transaction runs in a single partition.
But in the Cloud, we require partition tolerance, because the Cloud provider is willing to allow that each physical instance cannot necessarily communicate with every other physical instance at all times, and each physical instance may go down unpredictably. And if your underlying physical instances aren't communicating or working properly, then you have either an availability or a consistency issue. But since the Cloud is architected for high availability, consistency will necessarily suffer.
The Solution: Rethink Your Priorities
The kneejerk reaction might be that since consistency is nonnegotiable, we need to force the Cloud providers to give up partition tolerance. But in reality, that's entirely the wrong way to think about the problem. Instead, we must rethink our priorities.As any data specialist will tell you, there are always performance vs. flexibility tradeoffs in the world of data. Every generation of technology suffers from this tradeoff, and the Cloud is no different. What is different about the Cloud is that we want virtualization-based elasticity-which requires partition tolerance.
If we want ACID transactionality then we should stick with an on-premise partition intolerant approach. But in the Cloud, ACID is the wrong priority. We need a different way of thinking about consistency and reliability. Instead of ACID, we need BASE (catchy, eh?)
BASE stands for Basic Availability (supports partial failures without leading to a total system failure), Soft-state (any change in state must be maintained through periodic refreshment), and Eventual consistency (the data will be consistent after a set amount of time passes since an update). BASE has been around for several years and actually predates the notion of Cloud computing; in fact, it underlies the telco world's notion of "best effort" reliability that applies to the mobile phone infrastructure. But today, understanding the principles of BASE is essential to understanding how to architect applications for the Cloud.
Thinking in a BASE Way
Let's put the BASE principles in simple terms.
- Basic availability: stuff happens. We're using commodity hardware in the Cloud. We're expecting and planning for failure. But hey, we've got it covered.
- Soft state: the squeaky wheel gets the grease. If you don't keep telling me where you are or what you're doing, I'll assume you're not there anymore or you're done doing whatever it is you were doing. So if any part of the infrastructure crashes and reboots, it can bootstrap itself without any worries about it being in the wrong state.
- Eventual consistency: It's OK to use stale data some of the time. It'll all come clean eventually. Accountants have followed this principle since Babylonian times. It's called "closing the books."
So, how would you address your inventory app following BASE best effort principles? First, assume that any product quantity is approximate. If the quantity isn't near zero you don't have much of a problem. If it is near zero, set the proper expectation with the customer. Don't charge their credit card in a synchronous fashion. Instead, let them know that their purchase has probably completed successfully. Once the dust settles, let them know if they got the item or not.
Of course, this inventory example is an oversimplification, and every situation is different. The bottom line is that you can't expect the same kind of transactionality in the Cloud as you could in a partition intolerant on-premise environment. If you erroneously assume that you can move your app to the Cloud without reworking how it handles transactionality, then you are in for an unpleasant surprise. On the other hand, rearchitecting your app for the Cloud will improve it overall.
The ZapThink Take
Intermittently stale data? Unpredictable counts? States that expire? Your computer science profs must be rolling around in their graves. That's no way to write a computer program! Data are data, counts are counts, and states are states! How could anything work properly if we get all loosey-goosey about such basics?Welcome to the twenty-first century, folks. Bank account balances, search engine results, instant messaging buddy lists-if you think about it, all of these everyday elements of our wired lives follow BASE principles in one way or another.
And now we have Cloud computing, where we're bundling together several different modern distributed computing trends into one neat package. But if we mistake the Cloud for being nothing more than a collection of existing trends then we're likely to fall into the "horseless carriage" trap, where we fail to recognize what's special about the Cloud.
The Cloud is much more than a virtual server in the sky. You can't simply migrate an existing app into the Cloud and expect it to work properly, let alone take advantage of the power of the Cloud. Instead, application migration and application modernization necessarily go hand in hand, and architecting your app for the Cloud is more important than ever.
Of course, the alternative is to take advantage of the transactional consistency features of cloud-based, enterprise-scale relational databases, such as SQL Azure to manage inventory data.
Jason is Managing Partner and Senior Analyst at Enterprise Architecture advisory firm ZapThink LLC.
The AppFabricCAT Team posted SQL Azure Federations – First Look on 5/31/2011:
At Microsoft TechEd 2011, the SQL Azure Database Federations feature was announced and that the product evaluation program was now open for nominations. You can read more about the program here.
Create the Federation
A federation is a collection of database partitions that are defined by a federation scheme. To create the federation scheme you must execute the ‘CREATE FEDERATION’ command. In this example we have a federation named Visitor_Fed with a distribution name of range_id followed by a RANGE partition type of BIGINT. Only RANGE partitions are supported for this release. Range types can be BIGINT, UNIQUEIDENTIFIER OR VARBINARY(n) where n can be up to 900.
CREATE FEDERATION Visitor_Fed (range_id BIGINT RANGE) GOConnect to a Federation
Connection to a federation member is performed with the ‘USE FEDERATION’ statement. In the statement below we connect to the Visitor_Fed federation member with range_id distribution name equal to 0. This connects us to the first for now only federation in this example. The FILTERING=OFF option denotes that the connection is scoped to the federation member’s full range. Setting FILTERING=ON scopes the connection to a particular federation key instance within a federation member. The RESET keyword is required and is used explicitly reset the connection after use.
USE FEDERATION Visitor_Fed (range_id = 0) WITH FILTERING = OFF, RESET GOCreate a Table
The syntax to create a table has a new enhancement, the ‘FEDERATED ON’ clause which allows the table to be included in multiple federation members. Only one FEDERATE ON column is supported on any given table and it must refer the federation key. Another stipulation, all unique indexes on federated tables must contain the federation column, in this case the visitor_id is defined as the federated column and has a primary key associated with it.
CREATE TABLE visitor ( visitor_id BIGINT PRIMARY KEY, col2 varchar(10) ) FEDERATED ON (range_id = visitor_id) GOSplit a Federation
A federation member is split using the ‘ALTER FEDERATION name SPLIT AT’ command. In the example below, we connect to the root member and perform a SPLIT of the Visitor_Fed federation at the value 100, thus creating two federation members. We can see by querying the sys.federation_member_distributions DMV and from table 1 that we have a two members, member_id=65537 and member_id=65538. The ranges are aligned at a split value of 100 and thus we have a member from the min to 100 and another from 100 to max. A visitor_id value of 100 is included in the second member.
USE FEDERATION ROOT WITH RESET GO ALTER FEDERATION Visitor_Fed SPLIT AT (range_id = 100) GO

Table 1 Federation Member Distributions
Inserting/Querying
Connect to the appropriate federation member. Insert/delete/update/select as one would typically do if not utilizing federations.
USE FEDERATION Visitor_Fed (range_id = 0) WITH FILTERING = OFF, RESET GO INSERT INTO visitor VALUES (1, 'visitor 1') INSERT INTO visitor VALUES (2, 'visitor 2') GO USE FEDERATION Visitor_Fed (range_id = 100) WITH FILTERING = OFF, RESET GO INSERT INTO visitor VALUES (100, 'visitor 100') INSERT INTO visitor VALUES (101, 'visitor 101') GO
<Return to section navigation list>
MarketPlace DataMarket and OData
Alex James (@adjames) will present Using OData to create your web-api to the Aarhus International Software Development Conference in Aarhus, Denmark on 10/10/2011 at 13:20 to 13:40:
This session will explore using OData (odata.org) to power your Web API. Given the trend towards the web as a platform, OData is often ideal for building Web APIs that are powerful, flexible and predictable. You’ll also learn how OData uses appropriate web-standards and idioms, and can be integrated with authentication protocols like OAuth 2.0. But perhaps most importantly you’ll see how OData can extend the reach of your Web API out to most major platforms and form factors, through its built-in support for both JSON and ATOM formats and most major development platforms.
Biography: Alex James
Alex is the Senior Program Manager on the OData team at Microsoft. He is responsible designing new features in the OData protocol and working with the OData community.
Prior to that Alex worked on the Entity Framework team for a couple of years, helping create the vastly improved v2.
Before joining Microsoft Alex created 2 object relational mappers, a relational file-system, dabbled in his own startup, and consulted for about 10 years, so he is something of a veteran in the data programmability space.
His vision is a world of devices and software that are simple enough even for his mum.
Twitter: http://twitter.com/adjames
Blog: http://blogs.msdn.com/b/alexj
Other Links: http://odata.org
<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
• Victoria Reitano (@giornalista515) reported DotNetOpenAuth joins the Outercurve stable in a 6/2/2011 post to the SD Times on the Web blog:
DotNetOpenAuth, created by Andrew Arnott, was accepted to the Outercurve Foundation’s ASP.NET gallery today. The open-source project is a free, community-based library of standards-based authentication and authorization protocols used in websites and Web applications for .NET developers and others.
The project is housed on SourceForge, and will continue to be hosted and maintained by Andrew Arnott and the DotNetOpenAuth community. Outercurve will provide IT support where needed along with a larger community, according to Stephen Walli, technical director at Outercurve, a not-for-profit foundation that hosts three galleries and 12 projects, with DotNetOpenAuth being the sixth in the ASP.NET gallery.
“Andrew assigned the copyright to us and we manage the software intellectual property. We will provide services and help him grow the project, and encourage the community’s growth,” Walli said, adding that commercial interests are much more likely to become involved with the project now that it has been accepted by the foundation.
Walli explained that this is initially how software foundations came to be created, such as Apache in the late 1990s. He said that commercial companies are often anxious about working with projects maintained by individuals as individuals cannot offer assurances that the work will not contribute to a competitors’ success, something many vendors do not want to do.
Walli said mobile vendors will probably be the first to look into the project, as that is where much of the growth in the tech industry is happening—particularly with security.
“The Web is maturing; we’re finally hitting the next wave and [DotNetOpenAuth] is really timely," said Walli. "We’re just stepping into a new space, with SaaS projects and offerings, and to incorporate these authorization and authentication protocols is a fabulous opportunity for the ASP.NET world."
Paula Hunter, executive director of Outercurve, said that the project was presented to the foundation a few weeks ago. Outercurve does not have a classic incubation stage; instead gallery managers find, vet and present the projects to the board. Hunter said Bradley Millington, the ASP.NET gallery's manager, has done well in “spreading the word in the .NET open-source community” to attract new contributors and committers, which is how he recruited Arnott and his DotNetOpenAuth project and community.
Richard Seroter (@rseroter, avartared below) continued his Interview Series: Four Questions With … Sam Vanhoutte about the AppFabric Service Bus on 6/2/2011:
Hello and welcome to my 31st interview with a thought leader in the “connected technology” space. This month we have the pleasure of chatting with Sam Vanhoutte who is the chief technical architect for IT service company CODit, Microsoft Virtual Technology Specialist for BizTalk and interesting blogger. You can find Sam on Twitter at http://twitter.com/#!/SamVanhoutte.
Microsoft just concluded their US TechEd conference, so let’s get Sam’s perspective on the new capabilities of interest to integration architects.
Q: The recent announcement of version 2 of the AppFabric Service Bus revealed that we now have durable messaging components at our disposal through the use of Queues and Topics. It seems that any new technology can either replace an existing solution strategy or open up entirely new scenarios. Do these new capabilities do both?
A: They will definitely do both, as far as I see it. We are currently working with customers that are in the process of connecting their B2B communications and services to the AppFabric Service Bus. This way, they will be able to speed up their partner integrations, since it now becomes much easier to expose their internal endpoints in a secure way to external companies.
But I can see a lot of new scenarios coming up, where companies that build Cloud solutions will use the service bus even without exposing endpoints or topics outside of these solutions. Just because the service bus now provides a way to build decoupled and flexible solutions (by leveraging pub/sub, for example).
When looking at the roadmap of AppFabric (as announced at TechEd), we can safely say that the messaging capabilities of this service bus release will be the foundation for any future integration capabilities (like integration pipelines, transformation, workflow and connectivity). And seeing that the long term vision is to bring symmetry between the cloud and the on-premise runtime, I feel that the AppFabric Service Bus is the train you don’t want to miss as an integration expert.
Q: The one thing I was hoping to see was a durable storage underneath the existing Service Bus Relay services. That is, a way to provide more guaranteed delivery for one-way Relay services. Do you think that some organizations will switch from the push-based Relay to the poll-based Topics/Queues in order to get the reliability they need?
A: There are definitely good reasons to switch to the poll-based messaging system of AppFabric. Especially since these are also exposed in the new ServiceBusMessagingBinding from WCF, which provides the same development experience for one-way services. Leveraging the messaging capabilities, you now have access to a very rich publish/subscribe mechanism on which you can implement asynchronous, durable services. But of course, the relay binding still has a lot of added value in synchronous scenarios and in the multi-casting scenarios.
And one thing that might be a decisive factor in the choice between both solutions, will be the pricing. And that is where I have some concerns. Being an early adopter, we have started building and proposing solutions, leveraging CTP technology (like Azure Connect, Caching, Data Sync and now the Service Bus). But since the pricing model of these features is only being announced short before being commercially available, this makes planning the cost of solutions sometimes a big challenge. So, I hope we’ll get some insight in the pricing model for the queues & topics soon.
Q: As you work with clients, when would you now encourage them to use the AppFabric Service Bus instead of traditional cross-organization or cross-departmental solutions leveraging SQL Server Integration Services or BizTalk Server?
A: Most of our customer projects are real long-term, strategic projects. Customers hire us to help designing their integration solution. And most of the cases, we are still proposing BizTalk Server, because of its maturity and rich capabilities. The AppFabric Services are lacking a lot of capabilities for the moment (no pipelines, no rich management experience, no rules or BAM…). So for the typical EAI integration solutions, BizTalk Server is still our preferred solution.
Where we are using and proposing the AppFabric Service Bus, is in solutions towards customers that are using a lot of SaaS applications and where external connectivity is the rule.
Next to that, some customers have been asking us if we could outsource their entire integration platform (running on BizTalk). They really buy our integration as a service offering. And for this we have built our integration platform on Windows Azure, leveraging the service bus, running workflows and connecting to our on-premise BizTalk Server for EDI or Flat file parsing.
Q [stupid question]: My company recently upgraded from Office Communicator to Lync and with it we now have new and refined emoticons. I had been waiting a while to get the “green faced sick smiley” but am still struggling to use the “sheep” in polite conversation. I was really hoping we’d get the “beating a dead horse” emoticon, but alas, I’ll have to wait for a Service Pack. Which quasi-office appropriate emoticons do you wish you had available to you?
A: I am really not much of an emoticon guy. I used to switch off emoticons in Live Messenger, especially since people started typing more emoticons than words. I also hate the fact that emoticons sometimes pop up when I am typing in Communicator. For example, when you enter a phone number and put a zero between brackets (0), this gets turned into a clock. Drives me crazy. But maybe the “don’t boil the ocean” emoticon would be a nice one, although I can’t imagine what it would look like. This would help in telling someone politely that he is over-engineering the solution. And another fun one would be a “high-five” emoticon that I could use when some nice thing has been achieved. And a less-polite, but sometimes required icon would be a male cow taking a dump.
Zoiner Tejada (@ZoinerTejada) claimed they’re “A portable way to reliably queue work between different clients and services” in his REST Easy with AppFabric Durable Message Buffers article of 6/1/2011 for DevProConnections:
Representational State Transfer (REST)–enabled HTTP programming platforms broaden the client base that can be used to interact with services beyond those that are purely based on the Microsoft .NET Framework or that support SOAP. The Azure AppFabric Service Bus Durable Message Buffers that are broadened in this way provide platform-level support for reliable and replicated message queuing.
In this article, I examine the updated version of the Durable Message Buffers feature as it applies to the Windows Azure AppFabric Community Technology Preview (CTP) February 2011 release. I will show the feature's capabilities and how to take advantage of them from REST-based .NET clients in a fashion that translates well to other REST-enabled HTTP programming platforms such as Silverlight, Flash, Ruby, and even web pages.
To take advantage of the new release, you need to access the Labs portal. Also, you need to download Windows Azure AppFabric SDK v2.0, samples. Optionally, you can download the offline CHM Help file. You might also consider using the RestMessageBufferClient class provided within the samples as a starting point for your own .NET helper classes because the SDK libraries currently do not include helper classes for a message buffer.
AppFabric Durable Message Buffers
The AppFabric Durable Message Buffers component gives you a message queuing service that uses replicated storage and provides an internal failover feature for increased reliability. That the component is exposed to a REST operation means that it is available to a large swath of clients.
Generally, the service can be divided into two major feature sets: management and runtime. The Management feature set lets you create, delete, get a description of, and list buffers. The Runtime feature set lets you send, retrieve, and delete messages. These features are accessed and secured separately by making requests to the following Uniform Resource Identifiers (URIs):
When you first provision your account, you select the service namespace to use, and that single namespace is used by both management and runtime operations. Interaction for both management and runtime centers on REST, where requests and responses comply with the HTTP/1.1 spec. Figure 1 shows a high-level flow of messages across the Durable Message Buffer.
- Management Address: http(s)://{serviceNameSpace}-mgmt.servicebus.appfabriclabs.com
- Runtime Address: http(s)://{serviceNameSpace}.servicebus.appfabriclabs.com
Figure 1: AppFabric Durable Message BuffersIn the current CTP, the maximum message size is 256KB. Each buffer can store up to 100MB of message payload data, and there is a limit of 10 buffers per account.
Using the Durable Message Buffers
To use the service, you need to create a namespace through the management portal. With a namespace in place, you can then programmatically manage buffers and interact with them.
I will examine the steps in detail to set up a namespace, create a buffer, send messages to the buffer, retrieve messages from the buffer, and delete the buffer. I will also briefly cover related functionality for how to get a buffer's description, list all buffers created under an account, perform atomic read/delete operations, and unlock messages that were examined but were not processed.
Namespaces, Service Accounts, and Tokens
To start, you need to create a namespace that scopes the buffers you will create. To do this, log on to the Windows Azure AppFabric Labs Management Portal, and click New Namespace. The Create a new Service Namespace dialog box appears. You will need to select an Azure subscription and provide a globally unique service namespace, region, and connection pack size. For this CTP, the region and connection pack size options are fixed, which Figure 2 shows. …
Figure 2: Creating a namespace


The AppFabricCAT Team posted How to best leverage Windows Azure AppFabric Caching Service in a Web role to avoid most common issues on 6/1/2011:
The method
Since I have created a blog that shows the concepts of the APIs used in AppFabric Cache, I went ahead and leveraged the same sample code to migrate the whole solution into a web role. Since both cache technologies (on-prem and in the cloud) are very similar and have kept API parity (some exceptions may exist, but that will be a topic in a different blog) then it follows that the transition from one to the other should also be simple, which is for the most part true. However, we are not just going from on-prem to cloud, but also from Windows forms to an ASP.Net page – we have two “bridges” to cross.
For reference on the difference between the on-prem and cloud technologies see this MSDN article.
The Interface
With these plans in mind, I went ahead and created a web role in Visual studio 2010 using the latest SDK and then removed all the default content (the one showing “Welcome to ASP.NET”) from the ASP.Net page. Then, I literally copied, via the traditional method of holding the Ctrl key while selecting, via mouse clicks, all the controls in the windows form from the old project (Form1.cs [Design] page). Then I released the keys and clicked “Ctrl + c”, and then pasted (Ctrl + v) all of the controls into the new web role project (Default.aspx file). Then I hit F5 and it worked! This meant that all my controls were going to have the same name. This only copied the interface and not the code behind. Below I show the old and new interface.
Figure 1: The windows form

Figure 2: The ASP.Net form
To break down my steps, instead of copying and pasting “all” of the code sections (in the windows form it is the Form1.cs file, and in the ASP.NET/web role it is the default.aspx.cs file), I only copied the code that updates the tStatus WebControls.TextBox and throw my own test exceptions (i.e. no cache code is used instead instrumented exceptions were thrown). At this point, I tested the interface, and received the following exceptions.
Figure 3: Dangerous request error

You will notice that the first action (say “Add”) will correctly update the text box with the instrumented exception, but the 2nd action will think that you are trying to do a post back to the server with the remaining information (the instrumented exception) from the status box and this is seen as a type of dangerous request. As per the message shown in the exception details above, one option is to change the request validation mode, but since we are not really trying to send any exception information to the server, the recommended approach is to disable the state of the text box to not perform a post back to the server. This can be achieved by changing the text box property from Enabled=True to Enabled=false, as shown in Figure 4.
Figure 4: Change to the TextBox property

Note that I have to do this since, for didactical purposes, I show the raw exception on the web UI but for production purposes, the exception should be handled in a separate class (anywhere but in the web UI), and probably put into a tracelog and in parallel throw a more friendly message, which will be shown to the Web UI on a stateless control (as per the property change mentioned above). Similar schemes can be created for value checking, such null return values from DataCacheItemVersion, all this with the goal of handling errors outside default.aspx.cs.
Another important thing to notice, which will become even more apparent later, is that the code within default.aspx.cs runs in the context of HttpHandler, which ASP.NET uses to map each HTTP request (one for every request in essence every web user). This means that every single line of code written in this context will be duplicated for every HTTP request. Hence, keep the amount of code in this context to a minimum (more code = more instances of that code repeatedly running), which will include but will not be limited to error tracing and validation. Notice, however, that I am not doing this in this sample for the purpose of simplicity and clarity.
Plugging the AppFabric Cache Code
The information on how to create and connect to a Windows Azure AppFabric Caching service can be found in a few blogs, here is one from MSDN. In essence, to use the AppFabric cache cloud Service, one takes the old code and modifies the way the DataCacheServerEndpoint is instantiated (use the cache end point name instead of the DNS name of a node or nodes) and then leverage the given ACS token to authenticate against the service, as shown below in Figure 5. Note that the same can be done using the Application Configuration file, for more on it, see this MSDN article.
Figure 5: Cloud (code on the left) vs. On-Prem (code on the right)

Now paste all the code, as is, from the old windows form project and the web role will serve a web forms that works, but only for the first one or two simple actions (e.g., adding, removing, etc…). Using local cache or version handles will throw exceptions of missing or uninitialized objects.
The issue is that the default.aspx.cs code is instantiated for each HTTP request, and hence the DataCacheFactory , the DataCacheItemVersion and DataCacheLockHandle objects are all instantiated many times on every request (on every HttpHandler). If by chance you somehow get the same instance that handled your previous request then things may work but we need to make the solution more predictable. In the case of simple operations like Add() the DataCacheFactory is only needed once so those may work. It worked great on the windows form because it maintains state (i.e. the same object instanced was the one used) but due to the nature of HttpHandler this state needs to be handle in a different manner.
The easy solution would be to simply label all of these objects to be private static, which will not keep only one instance of this object so in the case of the DataCacheFactory, it will minimize the amount of connections created against the Windows Azure AppFabric Caching service. As mentioned in my blog on the release of the product, this has direct influence on your maximum amount of connections quota. If you create many instances of the DataCacheFactory object, you will quickly fill your connections quota, which in turn will render the service unusable for the next hour (as per quota behavior), at which point the service will go back online until the connection quotas are quickly drained again.
Why did not we care so much about this when we were on-prem? The fact was that the same thing was taking place, but as long as the DataCacheFactory was not Disposed after every use (or in any frequency), then the effect may not have been noticed. But, the fewer cache factories you need to recreate the less performance penalty you will pay. AppFabric cache (in both on-prem and cloud) leverage WCF for its network traffic, which means that each time a cache factory is recreated, a new WCF channel is created and this can be expensive in terms of performance. I will show this in practice in my next blog.
As previously stated, the best performance will be reached by keeping as little code as possible under the default.aspx.cs file. The solution that you will find in the final project (which you can download from this link) is to encapsulate all of the AppFabric cache objects created, API usage and some validation, into a separate class, which in the sample is named the AFCache class. To keep things further “locked”, the AFCache Class is encapsulated into a static class of its own. In effect, it is made into a singleton. This class can be seen in Figure 5 above, which also shows how the code only differs a little bit in the constructor. Notice that for simplicity and encapsulation, at this point there are no static assignments. You can also see how to initialize a DataCacheServerEndpoint and how the ACS token is handled.
Another very important distinction is the added configuration line to assign MaxConnectionsToServer. By default, this is only one. If we had two, then AppFabric Cache client will allow itself to create up to two WCF channels, if needed. Hence, if you find that performance with one channel is not enough then increasing this value may be an option, but connection quotas should be always kept in mind, more so if several Web roles are used. Each webrole will need at least one cache factory, and as it is advised for redundancy. The minimum solution requires at least two web roles; hence you will need at least two connections. In this minimum case, I will recommend reserving at least 3 available connections since a drop in connection within one hour, may be assumed as a third connection.
The code below, shows the static encapsulation of the AFCache class
//Encapsulating the AFCache class to be used as a singleton public static class MyDataCache { private static AFCache _SingleCache = null; static MyDataCache() { _SingleCache = new AFCache(); } public static AFCache CacheFactory { get{ return _SingleCache; } } }Another important point is the encapsulation of AppFabric APIs within the AFCache class itself, here is how it is done in the sample, noticed how the highlighted areas indicate the action AppFabric Cache API.
public class AFCache { //...<Initializing cache factories and other private members>... public AFCache() { //...<Constructor, checking that cache factory is still alive>... } public DataCacheItemVersion Add(string myKey, string myObjectForCaching) { if (CheckOnFactoryInstance()) { return myDefaultCache.Add(myKey, myObjectForCaching); } return null; } public string Get(string myKey, out DataCacheItemVersion myDataCacheItemVersion) { if (!this.UseLocalCache && this.CheckOnFactoryInstance()) { return (string)myDefaultCache.Get(myKey, out myDataCacheItemVersion); } //Calling CheckOnLocalCacheFactoryInstance() will setup the local cache enable factory else if (this.UseLocalCache && this.CheckOnLocalCacheFactoryInstance()) { return (string)myDefaultCache.Get(myKey, out myDataCacheItemVersion); } else { myDataCacheItemVersion = null; } return null; } public DataCacheItemVersion Put(string myKey, string myObj) {...} public bool Remove(string myKey) {...} ... }Here is a sample of how the get method, which is wrapped within the cache AFCache class, is called from default.aspx.cs. This is triggered when the Get_Click()method is fired from the web form by the user
RetrievedStrFromCache = (string)MyDataCache.CacheFactory.Get(myKey, out myVersionBeforeChange)In Conclusion
Although parity does exist between the two versions of the technology (on-Prem and Cloud), there are small considerations that need to be seriously taken into account as part of the architecture. As a friend at work says, “we are making accountants out of coders”. That may be a little exaggerated, but it does illustrate the point that usability of the service is a concept that needs consideration. When working with cloud services, quotas have to be taken into account, which in turn makes the application take a more holistic, and even smarter approach to the usage of available services. This in turn, as in the case shown above, will also streamline execution – all and all, a good idea.





The AppFabricCAT Team described AppFabric Cache – Encrypting at the Client in a 5/31/2011 post:
Introduction
Implementation
Note: These tests are not meant to provide exhaustive coverage, but rather a probing of the feasibility and performance impact of using encryption to secure data saved into Azure AppFabric Cache.
Keeping things really simple, static methods were created to encrypt/decrypt the data. The test cases in the previous blog were enriched to include the encryption prior to sending it to the cache. SSL was used to secure the message transmission.
Cryptography Overview
.NET Framework 4 includes the System.Security.Cryptography namespace which provides cryptographic services, including those to secure data by encryption and decryption. The specific instrument used in this blog is the RijndaelManaged class, which greatly simplifies the amount of energy required to implement the encryption. The RijndaelManaged class can be used to encrypt/decrypt data according to the AES standard, but since encryption is a full topic in its own right; I will refer you to this blog or this generic MSDN sample for more details. I exploited the vanilla/default settings of the cryptography classes provided by .NET 4.
Encryption Method
Shown below is the static method used to return a byte array of encrypted data. The EncryptData static method takes the byte array to be encrypted, the secret key to use for the symmetric algorithm, the initialization vector to use for the symmetric algorithm and returns an encrypted byte array. By default, the SymmetricAlgorithm.Create method creates an instance of the RijndaelManaged class. The CreateEncryptor method provides the encryption algorithm for an instance of CryptoStream which provides the cryptographic transformation link to the MemoryStream.
public static byte[] EncryptData(byte[] inb, byte[] rgbKey, byte[] rgbIV) { SymmetricAlgorithm rijn = SymmetricAlgorithm.Create(); byte[] bytes; using (MemoryStream outp = new MemoryStream()) { using (CryptoStream encStream = new CryptoStream(outp, rijn.CreateEncryptor(rgbKey, rgbIV), CryptoStreamMode.Write)) { encStream.Write(inb, 0, (int)inb.Length); encStream.FlushFinalBlock(); bytes = outp.ToArray(); } } return bytes; }Decryption Method
The DecryptData static method is the essentially the inverse of the EncryptData method, it takes in an encrypted by array and returns the decrypted representation. The only subtle difference is that we are using the CreateDecryptor method to provide a decryption algorithm to the CryptoStream.
public static byte[] DecryptData(byte[] inb, byte[] rgbKey, byte[] rgbIV) { SymmetricAlgorithm rijn = SymmetricAlgorithm.Create(); byte[] bytes; using (MemoryStream outp = new MemoryStream()) { using (CryptoStream encStream = new CryptoStream(outp, rijn.CreateDecryptor(rgbKey, rgbIV), CryptoStreamMode.Write)) { encStream.Write(inb, 0, (int)inb.Length); encStream.FlushFinalBlock(); bytes = outp.ToArray(); } } return bytes; }Key Generation
Key generation was straight forward. The default key generation methods of the RijndaelManaged class were used to generate the secret key and initialization vector. The keys were generated once and used for all encryption and decryption calls.
SymmetricAlgorithm alg = SymmetricAlgorithm.Create(); alg.GenerateIV(); alg.GenerateKey(); byte[] rgbKey = alg.Key; byte[] rgbIV = alg.IV;
Results
See the previous blog post for data model and a more comprehensive test case description. The average duration in milliseconds were computed. The test cases were run 3 times and the values grouped by test case. All Encryption test cases were run with SSL enabled. The keys for the tables are as follows.
- ProdCat – A ProductCategory object
- Product: A Product object
- ProdMode: A Product object which includes the ProductModel
- ProdDes: A Product object which includes ProductModel and ProductDescriptions
Time to ‘Get’ and Object
Figure 1 displays the time to retrieve an object from the AppFabric Cache. The AppFabric SDK call executed was DataCache.Get. The chart shows that there is a small impact securing your data, either with SSL or the encryption methods detailed in this blog.

Figure 1 Time to Get an Object from Cache
Time to ‘Add’ and Object
Figure 2 displays the time to put an object into the AppFabric Cache. The call made was DataCache.Add. From the table it is apparent that the numbers are quite comparable align with those retrieve an object from cache that has been encrypted.

Figure 2 Time to Add an Object to Cache
Conclusion
In this blog we enhanced our compression algorithms to include encryption to secure the Azure AppFabric data at rest. The results clearly indicate that encryption adds a level of overhead to the performance, particularly as the object size increases. Compressing those large objects before encrypting will afford you a measure of performance gain with the added bonus of less cache space used.
Reviewers : Jaime Alva Bravo


<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
• Mike Benkovich (@mbenko) and Adam Grocholski (@adamgrocholski) will present an MSDN Webcast: Windows Azure Boot Camp: Connecting to Windows Azure (Level 200) on 6/13/2011 at 12:00 Noon PDT:
- Event ID: 1032485093
- Language(s): English
- Product(s): Windows Azure.
- Audience(s): Pro Dev/Programmer.
Technology is changing rapidly, and nothing is more exciting than what's happening with cloud computing. Join us as we dive deeper into Windows Azure and cover requested topics during these sessions that extend the Windows Azure Boot Camp webcast series.
Try Azure Now: Try the cloud for 30 days for free! Enter promotional code: WEBCASTPASS
Presenters: Mike Benkovich, Senior Developer Evangelist, Microsoft Corporation and Adam Grocholski, Technical Evangelist, RBA Consulting
Energy, laughter, and a contagious passion for coding: Mike Benkovich brings it all to the podium. He's been programming since the late 1970s when a friend brought a Commodore CPM home for the summer. Mike has worked in a variety of roles, including architect, project manager, developer, and technical writer. Mike is a published author with WROX Press and APress Books, writing primarily about getting the most from your Microsoft SQL Server database. Since appearing in Microsoft's DevCast in 1994, Mike has presented technical information at seminars, conferences, and corporate boardrooms across America. This music buff also plays piano, guitar, and saxophone, but not at his MSDN events. For more information, visit www.BenkoTIPS.com.
Adam Grocholski is currently a technical evangelist at RBA Consulting. Recently he has been diving into the Windows Azure and Windows Phone platforms as well as some more obscure areas of the Microsoft .NET Framework (i.e., T4 and MEF). From founding and presenting at the Twin Cities Cloud Computing user group to speaking at the local .NET and Silverlight user groups, code camps, and a number conferences, Adam is committed to building a great community of well-educated Microsoft developers. When he is not working, he enjoys spending time with his three awesome daughters and amazing wife. You can catch up with his latest projects and thoughts about technology at http://thinkfirstcodelater.com, or if that's too verbose for your liking you can always follow him on twitter at http://twitter.com/agrocholski.
If you have questions or feedback, contact us.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• The Windows Azure Team announced the availabilty of New Content: Windows Azure Video Tutorials Now Available in a 6/2/2011 post:
InformationWeek::Analytics’ BS&T Staff published its Bank Systems & Technology Digital Issue: June 2011 on 6/2/2011 (Requires site registration):
THE AVCs OF DATA CENTER TRANSFORMATION: The data center stands as the single most important asset in a bank's ability to complete transactions and service customers. And as part of ongoing efforts to reduce expenses, improve efficiency and boost performance, the data center is in a constant state of reinvention. Today, it's difficult to talk data centers without talking about cloud computing. Bank Systems & Technology's June digital issue explores how banks are leveraging automation, virtualization and the cloud to transform their data centers and sharpen IT service and delivery. We look at lessons learned and a few cautionary tales, and offer best practices to help ensure a smooth transformation.
Table of Contents

- THE AVCs OF DATA CENTER TRANSFORMATION: The building blocks of data center transformation are automation, virtualization and cloud computing. But to successfully reinvent the data center, banks first must undergo an IT transformation.
- THE RISE OF CLOUD REGULATION: As cloud computing continues to gain momentum in financial services, regulators are certain to take notice - and action.
- BELLY UP TO THE BAR: Paying "by the drink" for cloud-based data center services makes more sense than investing in infrastructure, says MetLife Bank CIO Mark LaPenta in an exclusive Q&A with BS&T.
- 3 STEPS TO A SAFER FUTURE IN THE CLOUD: Banks have an opportunity to help shape the cloud computing business model and minimize the future risks of operating in the cloud, according to TowerGroup's Rodney Nelsestuen.
- PLUS: Danger Lurks in the Cloud
Room to Grow: Adding Capacity Via Virtualization
About the Author
Bank Systems & Technology's editorial mission is to provide banking executives involved in technology management -- whether in the IT organization or in line-of-business areas -- with the targeted and timely information and analysis they need to help their organizations reduce risk while improving customer retention, competitiveness and financial performance. Our content spans across multiple media platforms -- including a print publication, digital edition, Web site, e-newsletter, live events, virtual events, webcasts, video, blogs and RSS feeds -- so bank/financial services executives can access information via any channel/platform they prefer. BS&T’s audience comprises the key commercial banking segments, ranging from global banks to community banks and credit unions, covering both retail and wholesale banking. Key ongoing areas of focus include core systems, payments and cards, channel optimization, regulation/compliance, risk management, security, customer insight/business intelligence and architecture/infrastructure.
Robert Duffner posted Thought Leaders in the Cloud: Talking with Olivier Mangelschots, Managing Director at Orbit One Internet Solutions to the Windows Azure blog on 6/2/2011:
Olivier Mangelschots [pictured below] is Managing Director at Orbit One Internet Solutions, a systems integrator based in Belgium that is deeply involved in Microsoft technology.
In this interview we cover:
Identity management in hybrid environments
- The role of partners in providing customized cloud solutions
- SLAs and cloud outages
- Migrating to the cloud vs. building for the cloud
- Things in clouds work better together
Robert Duffner: Could you take a moment to introduce yourself and Orbit One?
Olivier Mangelschots: I'm Managing Director of Orbit One Internet Solutions. We have been in business since '95 here in a city called Gent, Belgium. Today, we have 18 people, and we mainly focus on developing web portals. We use technology such as SharePoint, Microsoft CRM, and Umbraco, which is an open source CMS based on ASP.NET.
We also try to help our customers realize the new world of work, making use of technology such as Microsoft Lync to be able to work from anywhere while staying in contact with their teams. We're really interested in the cloud and looking forward to this change.
Robert: You've been involved in building customer solutions since well before cloud computing. How have you seen the cloud impact the solution that you're providing to your customers?
Olivier: We've always tried to make solutions in such a way that the impact on the internal IT structure for the customer is as low as possible. Even as far back as 2000, the solutions that we've developed have mostly been hosted by us.
We try to minimize the need for customers to implement local servers, so they can focus on making the best use of the solutions instead of the technical infrastructure behind it.
Robert: Jericho Forum president Paul Simmonds says that new rules are needed for identity in the cloud and that passwords are broken. Can you talk about the challenges and solutions for identity management in the cloud? How is it different from traditional hosting?
Olivier: Identity is one of the key elements to make the cloud successful, and I think we've come a long way. Today, most cloud solutions are starting to incorporate identity management the way it should be done, using federated identity and single sign-on. In the past, an organization had to choose between doing everything on-premises or moving everything to the cloud.
It was difficult to have part in the cloud and part on-premises, because you had to manage users and synchronization separately. It was quite a pain. But now, large and small companies can move to the cloud and have centralized user management, so they are able to handle user services in a very transparent way.
It shouldn't matter for the users whether an application is hosted on-premises or hosted in a cloud at Microsoft or hosted at a partner, so long as everything is nicely integrated. Of course, the first thing the user notices is the fact that he has to enter a username and password, so that should be very transparent.
Robert: Customers can choose between cloud, on-premises, and partner hosting. How do you explain the differences between these options to the customers you work with?
In addition to saving on costs, they can make things happen more quickly. If they want to deploy something new, they can do so in a matter of hours in the cloud, where they would need days, weeks, or sometimes months for an on-premises deployment.
Partner hosting is still very important, mainly because not everything is possible in the public cloud. There are certain limitations with Azure and Office 365, for example. The price is very affordable, but you get what's in the box, and partners can offer customization.
In addition to offering more personalized solutions with regard to technical features, partners can also provide customization in terms of service-level agreements, security considerations, encryption, and those sorts of things, which are very important for some organizations.
Robert: At EMC's recent conference, CEO Joe Tucci said that hybrid clouds are becoming the de facto standard. Can you talk a little bit about hybrid solutions that may use a mix of options?
Olivier: As an example, one of the things that is very easy to migrate to a public cloud is an organization’s set of Exchange mailboxes with contacts, calendars, and so on. The level of customization that users need is quite small, and most people are happy with the product as it comes out of the box.
If you move the mailboxes to the cloud, users typically don’t even notice. They just keep using Outlook and Outlook Web Access, synchronizing their phones as they need to. Still, it saves a lot of costs, as well as allowing many companies to have much larger mailboxes than they would otherwise be able to.
This is one of the mixed situations we see, where companies are moving part of their services to the cloud, such as Exchange mailboxes, while keeping, for example, SharePoints sites internally because they need some custom modules in there that are not available in the cloud.
Mixing and matching in that way can be a smart approach, because it allows companies to save costs while also being more productive and agile.
Robert: Following the recent Amazon outage where full service wasn't restored for about four days, are you seeing customers question the reliability of the cloud? What do you think is the lesson learned from that?
Olivier: Almost all companies are a bit scared of moving their data away to some unknown location, because they have less control over those systems. The event at Amazon was, of course, very unfortunate. The cloud on a massive scale is still very new, and certain technologies should really be considered to be in a beta phase.
I think we have to be realistic about the fact that in an on-premises situation, uptime is not guaranteed at all. Many organizations have far more than four days of outages a year because of human error.
Many companies are not ready today to move certain critical applications to the cloud. I believe that, as the cloud grows bigger and more mature, service-level agreements will be available from cloud systems that are far more demanding than those that are possible from on-premises situations.
This is also where partner hosting can come into play. You can combine certain things in the public cloud for very affordable mass-usage scenarios while putting specific, mission-critical solutions at a partner that will do a custom replicated solution.
In the long term, I believe that the public cloud will come in several flavors, including an inexpensive mass market flavor and a more enterprise-focused flavor with high levels of redundancy and availability, which will cost more.
Robert: Lew Moorman, the chief strategy officer at Rackspace, likened the Amazon interruption to the computing equivalent of an airplane crash. It's a major episode with widespread damage, but airline travel is still safer than traveling in a car. He was using this as an analogy to cloud computing being safer than running data centers by individual companies. Do you think that analogy holds up?
Olivier: I think it does in certain scenarios, although not all. But I think you're absolutely right that when an airplane crash occurs, it garners a lot of attention, even though statistically, it is far safer than driving a car.
If a big cloud goes down, that’s a major news story, and everybody's talking about it. But actually, this almost never happens, and a very large scale public cloud can be much safer than environments run by individual companies.
At the same time, there is always a balance between how much you pay and what you get for it. I don't think it's possible to get the service with the maximum possible guarantees for a very low fee. If you're willing to pay more, you will get more possibilities.
Azure is a nice example, because you can choose what geographical area your data and services will be running in. And you're completely free, as a developer or as an architect, to create systems that are redundant over several parts of the Azure cloud, which allows you to go further than what's in the box.
Robert: Customers aren't always starting from scratch, and sometimes they have something existing that they want to move to the cloud. Can you talk a little bit about migration to the cloud and things that customers might need to be aware of?
Olivier: This is a major issue today. For certain services, migration to the cloud is more difficult than it should be. The issue is going to be addressed step by step. First, of course, you need to have the cloud. Then you can start building migration tools. When I look, for example, at Microsoft Exchange, it's very easy and there are lots of good tools to move from an on-premises or a partner-hosted solution to the cloud.
SharePoint, for example, or Dynamic CRM, is much harder to migrate. You need third-party tools, although Microsoft is working on creating its own tools. There is still work to do there.
Azure, I think, is a completely different beast, and you can’t just take an application and put it on Azure. To make it really take advantage of the Azure opportunities and added value, you need to redesign the application and make it Azure-aware. That can take quite some time to do, and it's a long-term investment for product developers.
Robert: As more people move to the cloud, there's the chance to integrate one cloud resource with another. I know you've been thinking about the combination of Office 365 and Azure. Can you tell us your thoughts on that?
Olivier: The combination of Office 365/Dynamics CRM Online with Windows Azure is a very interesting thing. For example, we have customers using CRM Online, which is kind of out of the box, you get what's in there. We combine it for them with custom Azure solutions to do things that are not foreseen in CRM.
To give you an example, there is a company called ClickDimensions that has an email marketing plug-in for Microsoft CRM. You can send out mass e-mails to people from CRM, and there is tracking functionality about who opens the e-mail and who clicks on your website. You have a whole history about your prospects and your leads.
Actually, all this is running in the Azure cloud. It's all custom-developed, and it's always up, piping this information through to your CRM system. This is a nice combination of using out-of-the-box standards, shared hosting products such as Office 365, and CRM Online, combined with custom-developed solutions running in Azure. You get the best of both worlds.
Robert: At Microsoft, we see cloud as a critical back-end for mobile applications. You probably saw the recent announcement around our Toolkits for Devices that includes support for the iOS, Android, and Windows Phone 7. Do you have any thoughts around the combination of cloud and mobile?
Olivier: I don't really have special thoughts, although cloud and mobile, of course, work very well together. On the other hand, I think that any application is nice to have in the cloud, and the nice thing about the combination of cloud and mobile is making sure it's available from anywhere, since mobile users can be coming from anywhere in the world.
It's very difficult to know when you roll out a mobile application how much people are going to use it, and hosting these kind of things on the cloud makes very much sense, because you can cope with the peaks, you can cope with identity issues, and you have a nice kind of platform to start with.
Robert: Was there anything else that you wanted to talk about or any other subject you want to discuss?
Olivier: Today, I see Azure as a tool kit, or a large system to build new applications and solutions, so the group using it is mostly developers and other technical people. It would be nice to see a layer between Azure and other scenarios, where Azure is the engine and Microsoft or other partners create front ends for it.
To give you an example, if I want to host simple websites running a CMS solution, I can choose any of a number of partners that have management modules that allow me to easily configure the website, hit start, and it's running. It would be great to see an integration between for example Microsoft WebMatrix and Azure, allowing less technical people to get their website running in Azure in a few clicks.
These extra layers on top of Azure are a big thing for partner opportunities, but I also think that Microsoft should also participate to speed up things. I see Azure as the first big infrastructure step, we are just at the beginning!
One thing that developers might be afraid of is that if today you build an application specially for Azure, you're going to use the Azure tables, the Azure way of doing message queuing, and so on, making it very hard to move away from Azure.
Of course, today, Azure is only available through Microsoft, but I think it makes sense in the future to have the Azure platform also available in custom flavors through service providers that are competing with one another on innovation and pricing.
Of course, Microsoft probably doesn't want to give everything away, but there are a lot of partner models. It will be interesting to see how this will evolve in the future.
Robert: Very good. Thanks, Olivier.
Olivier: Thank you.

Richard Parker explained How to migrate your ASP.NET site to the Azure cloud in a 6/1/2011 post to the DeveloperFusion blog:
Cloud computing is one of the hot topics of 2011 with those willing to make the jump to a cloud-based solution finding financial savings in this new approach as well as, in many cases, better fault tolerance and a more responsive service turnaround in many cases. However, what many developers may not realise is just how straightforward it can be to migrate a web site from a local or hosted server into the cloud.
We will cover:
- The SDKs and tools to be installed on your machine before you can continue
- How to set up your Windows Azure instance in preparation for the application
- How to alter the application so that it will function in the cloud
- How to deploy the application to Windows Azure
I’m going to assume that you’re already familiar with the .NET framework, that you know what the Windows Azure platform is, and that you’re comfortable with Visual Studio 2010. If you’ve not looked into Windows Azure before, have a look as Neil Mackenzie’s article “An Introduction to Windows Azure – What You Should Know” before continuing.
Pre-requisites
Before we begin, let’s get our development environment in order:
- Back-up all your existing application code and data before you take another step! You can never be too careful.
- Download and install the Windows Azure SDK
- Download and install the Windows Azure Tools for Visual Studio 2010.
- If you intend to implement session state in your application, then I’d recommend evaluating the Azure AppFabric Caching provider and for this you’ll need the Windows Azure AppFabric SDK.
You’ll need to make sure you have a Windows Azure services account. If you haven’t set one up already, sign up for a free trial. Windows Azure is a pay-as-you-go service but the free trial should more than suffice for you to experiment and try out Azure before you’ll need to start paying. If you’re a Microsoft BizSpark programme member or have an MSDN subscription, log in to your respective programme portal for information on the free offers available to you.
Modifying Your Existing ASP.NET Web Application
For the most part, modifying your existing ASP.NET application to run on the Windows Azure platform is a three step process:
- Create a new Windows Azure project into which code from your existing web application will be migrated.
Alter the code in the new project to work in the cloud rather than on a ‘local’ web server. In particular, we’ll look at a. Moving configuration settings from web.config to the Azure RoleEnvironment b. Setting the number of instances of the site to be running in the cloud c. Options for handling session state in the cloud. In this article, we’ll see how to use Azure AppFabric for this purpose.
Deploy your newly cloud-enabled application to the cloud.
So let’s start. Launch your copy of Visual Studio 2010, or Visual Web Developer Express and proceed to step 1.
Create A New Windows Azure Project
To begin migrating your web application to the cloud, you’ll need to create a new Windows Azure project to house your code. With Visual Studio running and in focus, you’ll need to:
- Click File > New Project.
- In the New Project dialog, select Visual C# > Cloud > Windows Azure Project, as shown below.
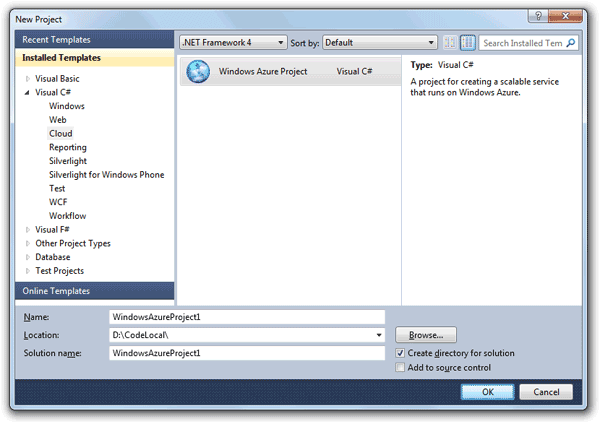
- Name your project, set its location, choose a solution name and click OK.
- In the New Windows Azure Project dialog box, as shown below, do not select any roles to add. Just click OK to have Visual Studio generate a blank Windows Azure project.
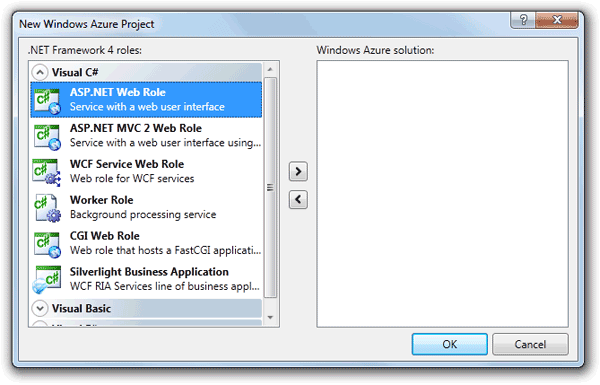
- When Visual Studio has finished generating your new project, click File > Add > Existing Project, browse to and select the .csproj file for the web application project you want to migrate and click Open. This will add your existing project to the new solution.
- Now right-click the Roles folder under the cloud project you added earlier, and choose Add > Web Role Project in solution as shown below.
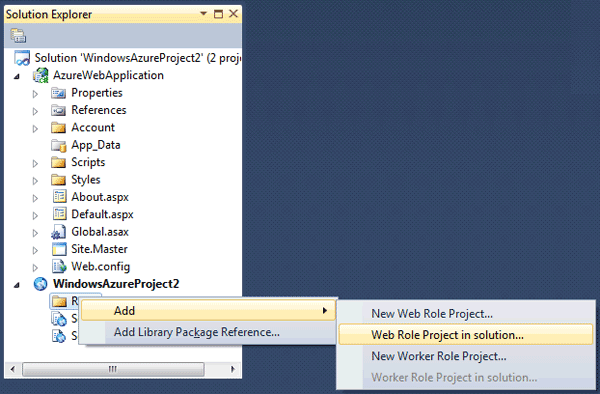
- In the Associate with Role Project dialog, choose your web application project and click OK.
You’ll see that it now appears under the Roles folder in Solution Explorer.
- Finally, you’ll need to add a reference to the Windows Azure service runtime to your Web Application project (not the Cloud project). Right click the References folder in that project and select Add > Reference.
- When the Add Reference dialog appears, switch to the .NET tab, find and select
Microsoft.WindowsAzure.ServiceRuntimeas shown below. Click OK.Your projects are now set up. The next step is to alter your web application’s code to run within and take advantage of the cloud.
Alter The Web Application To Run On Azure
For the most part, modifying your existing ASP.NET application to run on the Windows Azure platform will be a very simple process. However, you may run into some minor challenges depending on how your existing application is coded and there are some special considerations to make because your application can easily be scaled-up (and down, for that matter) to run multiple instances at the same time.
Move Configuration Settings Into The Cloud Project
The first thing that’s likely to trip you up is that calls to the ConfigurationManager class to get your application settings do not work in the Azure environment. You’ll need to redefine those settings within the cloud project in the solution and then use the Azure RoleEnvironment class to access them instead.
If you have a look at the cloud project in Solution Explorer, you’ll see it contains two files, ServiceConfiguration.cscfg and ServiceDefinition.csdef, as shown below. These two files are incredibly important. They store the configuration settings for your application, just like web.config does, as well as other important settings like how many roles you have in your solution, what type they are, and how many instances of them need to run.
If you open ServiceDefinition.csdef, you’ll see it is an XML file just like web.config. You need to insert a
<ConfigurationSettings>element beneath<ServiceDefinition>\<WebRole>to describe any application settings that already exist in your existing ASP.NET web application. Edit your ServiceDefinition.csdef file so that it looks like this:<?xml version="1.0" encoding="utf-8"?> <ServiceDefinition name="MigratingToTheCloud" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceDefinition"> <WebRole name="LegacyWebApplication1"> <ConfigurationSettings> <!-- Add your configuration settings here --> </ConfigurationSettings> <Sites> <Site name="Web"> <Bindings> <Binding name="Endpoint1" endpointName="Endpoint1" /> </Bindings> </Site> </Sites> <Endpoints> <InputEndpoint name="Endpoint1" protocol="http" port="80" /> </Endpoints> <Imports> <Import moduleName="Diagnostics" /> </Imports> </WebRole> </ServiceDefinition>Where I’ve placed the comment, you’ll insert one of the following lines for each of the settings present in your existing ASP.NET web application’s .config file:
<Setting name="OldSettingName"/>When you’re done, your
<ConfigurationSettings>element in the ServiceDefinition.csdef file should look a little like this:<ConfigurationSettings> <Setting name="OldSettingName1"/> <Setting name="OldSettingName2"/> <Setting name="OldSettingName3"/> <Setting name="OldSettingName4"/> <Setting name="OldSettingName5"/> </ConfigurationSettings>Note how there are no value attributes. That’s because you define the values within ServiceConfiguration.cscfg, which is our next task.
Open ServiceConfiguration.csfg. It should already contain a
<ConfigurationSettings>element. Go ahead and cut and paste each of the<Setting>elements you added to ServiceDefinition.csdef under the first<Setting>element within ServiceConfiguration.cscfg. Then, add the “value” attribute to each of the elements you’ve added accordingly. When you’re done, you should end up with a file that looks similar to this:<?xml version="1.0" encoding="utf-8"?> <ServiceConfiguration serviceName="MigratingToTheCloud" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration" osFamily="1" osVersion="*"> <Role name="LegacyWebApplication1"> <Instances count="1" /> <ConfigurationSettings> <Setting name="Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString" value="UseDevelopmentStorage=true" /> <Setting name="OldSettingName1" value="foo"/> <Setting name="OldSettingName2" value="bar"/> <Setting name="OldSettingName3" value="abc"/> <Setting name="OldSettingName4" value="123"/> <Setting name="OldSettingName5" value="xyz"/> </ConfigurationSettings> </Role> </ServiceConfiguration>That takes care of our configuration files, now we just need to make sure that we replace the calls to ConfigurationManager in our existing code base to access the setting values from their new location if possible. To do this, we need to:
- Determine whether your application can ‘see’ the role environment by checking the value of
RoleEnvironment.IsAvailable. This returns true if it is running on the compute platform (either for real, or locally on an emulator.If true, return the setting value needed by calling
RoleEnvironment.GetConfigurationSettingValue(“configurationKey”).If false, try and retrieve the setting value from web.config with
ConfigurationManager.AppSettings[“configurationKey”].In effect, your code should now look like
String oldSettingValue = RoleEnvironment.IsAvailable ? RoleEnvironment.GetConfigurationSettingValue("OldSettingName1") : ConfigurationManager.AppSettings["OldSettingName1"];We’d recommend refactoring this into a helper class if you haven’t already done so to keep these changes and any new additions in a single, easy to locate place. You might want to implement them as either public properties or as methods, as demonstrated below.
using System.Configuration; using Microsoft.WindowsAzure.ServiceRuntime; namespace AzureWebApplication { public class ConfigHelper { /// <summary> /// Returns the value of the configuration setting called "OldSettingName1" /// from either web.config, or the Azure Role Environment. /// </summary> public static string OldSettingName1 { get { return RoleEnvironment.IsAvailable ? RoleEnvironment.GetConfigurationSettingValue("OldSettingName1") : ConfigurationManager.AppSettings["OldSettingName1"]; } } /// <summary> /// Returns the value of the configuration setting called ”settingName” /// from either web.config, or the Azure Role Environment. /// </summary> public static string GetSettingAsString(string settingName) { return RoleEnvironment.IsAvailable ? RoleEnvironment.GetConfigurationSettingValue(settingName) : ConfigurationManager.AppSettings[settingName]; } } }Using a simple ConfigHelper class such as this then, any existing calls to
ConfigurationManager.AppSettings[“OldKey”]are replaced with calls toConfigHelper.OldKey if you prefer using properties orConfigHelper.GetSettingAsString(“OldKey”)` if you prefer methods so you can do a simple Find/Replace to update your code.Set the Number of Site Instances to Run In the Cloud
The new cloud version of your web application can run on a number of instances. Think of instances as horizontal scaling for your application. You can control how many instances of your application are deployed by right-clicking the web role in the cloud project, and clicking “Properties”. You’ll see the following window appear in the main area of Visual Studio.

You’ll need to set the instance count to a number greater than one for the Azure SLA to apply to your web application.
Taking Care of Session State
If you are only planning to run one instance of your application (which is not recommended, by the way), or you don’t intend to make use of session state, then skip this section and go straight to deployment. If your application does make use of session state however, you will probably need to modify the way your application manages session state.
If your application currently uses “in-proc” session state and you intend to stick with only one instance running, again that’s fine. However - if you then ask Azure to scale-up and run it on two instances (which you should really consider if you want to avail of the Azure SLA), it will automatically load-balance between the two and suddenly session state will stop working as successive requests bounce from one instance to the other. This would be the same with two or more physical servers, too.
Your options for session state storage at this point are limited to three:
- SQL Azure
- Table Storage
- Azure AppFabric Caching.
Which you choose depends on your circumstances and you are strongly encouraged you to learn more about the differences between these (or at least enough to be able to work out which will save you more money and be most appropriate for your deployment, since everything on Azure is chargeable!)
The Windows Azure Platform Training Kit contains sample code for both SQL Azure and Table Storage session providers which are both easily implemented but for the purposes of this article, we’ll look at using AppFabric Caching for session state.
AppFabric Caching is “the elastic memory that your application needs for increasing its performance and throughput by offloading the pressure from the data tier and the distributed state so that your application is able to easily scale out the compute tier”, according to MSDN magazine. In a nutshell then, it’s a bit like “in-proc” session state, but non-resident to any one instance of your application. This means that all your instances can collectively use the same cache by referencing that centralised ‘pool’.
To get a cache up and running for use by your web application, go to your Azure Portal at http://windows.azure.com and sign in. Once there:
- Click Service Bus, Access Control & Caching from the left-hand menu and then AppFabric > Cache from the submenu that appears.
- Click New Namespace from the top menu.
- When the Create a new Service Namespace dialog appears, check the Cache service on the left hand menu and then fill out the form on the right hand side. Don’t forget to check the availability of the namespace you want to use. Note also that 128MB should be plenty for this demonstration.
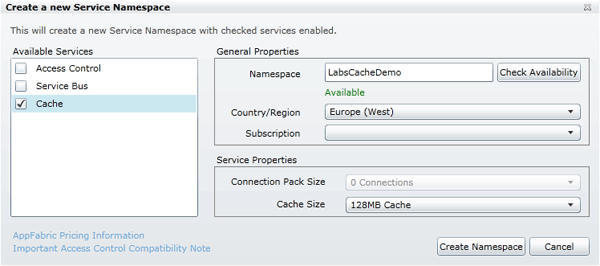
- Click Create Namespace when you are done.
It will take a little while for your cache to be set up. Once its Status is marked as Active, select its entry and make a note of its Management Endpoint and Authentication Token from the right hand side Properties panel, as shown below.
Finally, click View Client Configuration in the portal’s top menu bar and copy the resulting XML (all of it) to Notepad as we will need that in a minute.
With the cache ready and waiting, we need to set up our existing ASP.NET web application to use it. Head back in to Visual Studio, and add a reference to all the assemblies that came with the AppFabric SDK within your web application:
- Microsoft.ApplicationServer.Caching.Client
- Microsoft.ApplicationServer.Caching.Core
- Microsoft.Web.DistributedCache
- Microsoft.WindowsFabric.Common
- Microsoft.WindowsFabric.Data.Common
These assemblies are located in the
%Program files%\Windows Azure AppFabric SDK\V2.0\Assemblies\Cachefolder.Note: Ensure that “Copy Local” is set to true on each of these assemblies.
Now we need to edit web.config:
- Go back to your Notepad document that contains your XML. There are actually two sections (defined by comments) in the XML you copied.
- Append the
<configSections>element to your existing web.config. If you don’t already have a<configSections>element, add it to the top of the file, directly below the<configuration>element.- Next, grab the
<dataCacheClient>element from Notepad and add that directly below the<configSections>element (this is important – you’ll receive an error if<configSections>and<dataCacheClient>aren’t right at the top of the document).- Now, create a
<sessionState>element and add it to web.config. If you already have a<sessionState>element, delete it and replace it with the relevant section from the code you copied into Notepad.When you’re done, you should end up with a web.config that looks a little like this:
<configuration> <configSections> <section name="dataCacheClient" type="Microsoft.ApplicationServer.Caching.DataCacheClientSection, Microsoft.ApplicationServer.Caching.Core" allowLocation="true" allowDefinition="Everywhere"/> </configSections> <dataCacheClient deployment="Simple"> <hosts> <host name="LabsCacheDemo.cache.appfabriclabs.com" cachePort="22233"/> </hosts> <securityProperties mode="Message"> <messageSecurity authorizationInfo="--- YOUR APP FABRIC LABS AUTHORIZATION INFO HERE ----"/> </securityProperties> </dataCacheClient> <system.web> <sessionState mode="Custom" customProvider="AppFabricCacheSessionStoreProvider"> <providers> <add name="AppFabricCacheSessionStoreProvider" type="Microsoft.Web.DistributedCache.DistributedCacheSessionStateStoreProvider, Microsoft.Web.DistributedCache" cacheName="MyApplicationCache1" sharedId="SharedApp" /> </providers> </sessionState> </system.web> </configuration>Your application is now configured to use distributed cache, which means you can scale your application up (or down) to as many or as few instances as you like, and session state will be maintained for you across all instances.
Deploying your Application to Windows Azure
Now, with all the preparation done, we’re ready to deploy our application out to the cloud. The first thing we need to do is create a package for our new deployment. To do this, right-click on the cloud project in your solution, and click “Publish” (make sure you select the cloud project, and not your existing ASP.NET project).
- Click “Create service package only”:
- In a few moments, Windows will open a folder that contains your new package. Copy the location to the clipboard as we’ll need that in a moment.
Now, open and sign in to the Windows Azure portal at http://windows.azure.com if you haven’t already done so:
- Click New Hosted Service from the top menu. You’ll see the Create a New Hosted Service dialog appear, as shown below.
- Ensure the correct subscription is selected (if you have only one, it is selected by default).
- Enter a name for your service, for example “Acme Website”.
- Choose a URL prefix for your application. This will, initially, be the only way you can access your cloud application but you can assign a CNAME to it later. For now, choose something unique to your deployment. The portal will let you know if you can use the name you’ve chosen.
- Now, choose a region. It is sensible to decide at this stage where you think most of your traffic will come from and locate your application within that region.
- Ensure that Deploy to stage environment is selected, and that the checkbox marked Start after successful deployment is checked.
- Enter a name for your deployment, for example, “Acme Website V1”.
- Now, click Browse Locally… next to the “Package location” box and browse to the location of your publish in Visual Studio (if you copied the location of the folder to the clipboard, CTRL+V to paste, press ENTER, and then your file will appear).
- Repeat this step for the “Configuration file” box underneath.
- Now, click “OK”.
The next step may take anywhere from 15 minutes to an hour to complete, but in general shouldn’t take longer. During this time, your package is being uploaded to Windows Azure and instances are being allocated within the region you chose to host your application.
The portal will keep you up to date with the progress, and when you see “Ready” in the status you’re good to go. Click on the instance and over to the right you’ll see your service URL where you can browse to verify everything’s working as expected. You’ll note at this time that your URL isn’t the one that you chose earlier.
That’s because Windows Azure is running your application in the stage environment, to give you a chance to test things out and rollback if necessary. When you’re satisfied everything is working as expected, just click “Swap VIP” (swap virtual IP) on your deployment and Windows Azure will migrate your application across to the production system and your new URL will become active.
Congratulations! You’ve now upgraded your very first existing ASP.NET application to run in the cloud and you’ve left your physical infrastructure behind forever!
Summary
In this article, we looked at the core steps required to update a web application project so that it works in the cloud. In particular, we saw how to configure the cloud for your application, a few of the basic coding issues you’ll need to resolve in order to base your application in the cloud, and finally how to deploy it.
<Return to section navigation list>
Visual Studio LightSwitch
• Jervis from ASPHostPortal described Visual Studio LightSwitch Hosting - ASPHostPortal :: The Powerfull of LightSwitch Application[s] in a 5/31/2011 post:
Visual Studio LightSwitch is built on two basic concepts; data and screens which are used to create typical business applications.
Obviously, there is more to it than that but generally when developing a business application, you start with a piece of data. This can take the form of local data or a connection to an external data source of some description. You describe this data in your application and then build your application in order to manipulate the data as required. The second step involves providing a mechanism to interact with that data. This is generally accomplished by designing screens which allow users to perform standard CRUD (create/read/update/delete) operations on the data. Ultimately, a combination of screens makes a business application.
Business application developers should immediately see the benefits of LightSwitch once they start to get their hands dirty with it. However, in general, Business Intelligence (BI) projects are not really about building business applications, rather they provide the means to analyse the data being produced by such business applications. However, many BI projects face the same challenge, namely how to manage master data or some other data. Commonly, BI solutions require that a number of tables in the database require content which needs to be managed by the users. More often than not, database tools are used to manage these tables but this is not an ideal solution as generally users expect a more user-friendly way to do this and database tools such as Management Studio are far too powerful for managing this sort of data.So how have we solved this problem in the past? I cannot speak for all BI solution providers, but at Altius we’ve been solving this problem by writing custom applications to let users to manage data. Such custom applications have been written in such languages as VB 6, ASP.NET, C# and WPF. More importantly, most have been created from scratch which has created additional overhead to the project.
By using LightSwitch, instead of writing all those applications, can we very quickly create an application for the users to manage their master data such as user permissions or dimension data. The beauty of LightSwitch is that you can leverage the data regardless of where it is. Your data can come from SQL Server (local and remote), SharePoint, Azure, or even .NET WCF Services.LightSwitch also provides some really powerful integration functionality with common business tools. For example, you can export any list to Excel with no coding whatsoever or with some minor custom code create reports in Word or PowerPoint.
Another powerful feature is that while creating your LightSwitch application you don’t need to think about it how you are ultimately going to deploy it. LightSwitch applications can be deployed as web-based applications or desktop applications.
One word of warning however. LightSwitch relies on the use of SilverLight. This allows the decision around deployment to be made late during development. This could obviously cause issues if the organisation you are working in does not have SilverLight installed on the client machines. Generally, such applications for managing BI data would only be available to a small set of users so some concessions could be made for these users.There are many powerful features of LightSwitch application. We have launched our new LightSwitch hosting. Please visit our site for more information about our new product.
Reasons why you must trust ASPHostPortal.com
Every provider will tell you how they treat their support, uptime, expertise, guarantees, etc., are. Take a close look. What they’re really offering you is nothing close to what ASPHostPortal does. You will be treated with respect and provided the courtesy and service you would expect from a world-class web hosting business.You’ll have highly trained, skilled professional technical support people ready, willing, and wanting to help you 24 hours a day. Your web hosting account servers are monitored from three monitoring points, with two alert points, every minute, 24 hours a day, 7 days a week, 365 days a year.


Jarvis continued with a list of ASPHostPortal capabilties. I believe most LightSwitch users will deploy their projects to Windows Azure with Visual Studio.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
Shaun Xu described Assemblies Installed on Windows Azure in a 5/1/2011 post:
When we build an application that will be deployed on Windows Azure, one thing we should keep in mind is that the assemblies installed on the virtual machines on Windows Azure are very limited. It only contains the default assemblies in .NET 3.5 SP1 and .NET 4.0. For those references not included on Windows Azure, we should set their Copy Local = True.

As the image shown above I set the unity reference as Copy Local = True as I pretty know that in Windows Azure the assemblies of Enterprise Library will not be installed by default. But the problem is that, which references are not on Windows Azure.
I had to mark all suspicious references to copy local until I found this website, http://gacviewer.cloudapp.net.

It lists all assemblies that installed on Windows Azure machine in the default page. And additionally, it allows us to upload our project file (web role or worker role) and verifies which references should be copy local. Now it supports C# and VB.NET projects.

After I uploaded the project file the website verified the references are not present on Windows Azure which need to be set Copy Local = True. It also lists the ones were installed already.
If we forget to set the references not installed on Windows Azure to Copy Local our application will be in trouble while deployed and initialized. The role status loops between start … initializing … busy … stop … start which is very strange. To figure out what’s wrong with it we have to enable the IntelliTrace and Copy Local the reference we forgot and have another try which is very time-consuming. But if we checked our project though this website things will become much simpler.



Jay Fry (@jayfry3) posted Looking forward or backward? Cloud makes you decide what IT wants to be known for to his Data Center Dialog blog on 6/1/2011:
Cloud computing is all about choice. I’ve heard that a lot. What most people mean when they say this is that there are suddenly a whole bunch of places to run your IT workloads. At Amazon using EC2 or at Rackspace? At ScaleMatrix or Layered Tech? Or inside your own data center on a private cloud you’ve created yourself?
But there are some more fundamental choices that cloud seems to present as well. These choices are about what IT is going to be when it grows up. Or at least what it’s going to morph into next.
Here are 3 big decisions that I see that cloud computing forces IT to make, all of which add up to one, big, fundamental question: will IT define itself as an organization that looks toward the future or back into the past? Before you scoff, read on: the answer, even for those eagerly embracing the cloud, may not be as clear as you think.
The business folks’ litmus test for IT: Cloud v. No Clouds
First off, the business people in big organizations are using the rise of cloud computing, even after setbacks like the recent Amazon outage, to test whether IT departments are about looking forward or backward. When the business folks come to IT and describe what they are looking for, they now expect cloud-type reaction times, flexibility, infinite options, and pay-as-you-go approaches. At that point, IT is forced to pick sides. Will they acknowledge that cloud is an option? Will IT help make that option possible, if that’s the right choice for the business? Or will they desperately hold onto the past?
Embracing cloud options in some way, shape, or form puts IT on the path to being known as the forward-looking masters of the latest and greatest way of delivering on what the business needs. Rejecting consideration of the cloud paints IT as a cabal of stodgy naysayers who are trying their darnedest to keep from having to do anything differently.
John Treadway tweeted a great quote from Cloud Connect guru Alistair Croll on this same topic: "The cloud genie is out of the bottle. Stop looking for the cork and start thinking [about] what to wish for."
The business folks know this. They will use IT’s initial reaction to these options as a guide for future interactions. Pick incorrectly, and the business isn’t likely to ask again. They’ll do their own thing. That path leads to less and less of IT work being run by IT.
OK. Say IT decides to embrace the cloud as an option. The hard choices don’t stop there.
A decision about the IT role: Factory Manager v. Supply Chain Orchestrator
Starting to make use of cloud computing in real, live situations puts IT on a path to evaluate what the role of IT actually evolves into. Existing IT is about running the “IT factory,” making the technology work, doing what one CIO I heard recently called “making sure the lights don’t flicker.” This is IT’s current comfort zone.However, as you start using software, platforms, and infrastructure as-a-service, IT finds itself doing less of the day-to-day techie work. IT becomes more of an overseer and less of the people on the ground wiring things together.
I’ve talked about this role before as a supply chain orchestrator, directing and composing how the business receives its IT service, and not necessarily providing all that service from a company’s own data centers. You can make a good case that this evolution of IT will give it a more strategic seat at the table with the business users.
But, even if you decide you want to consider cloud-based options and you’re all in favor of changing the role of IT itself, there’s still another question that will have a big effect on the perception – and eventual responsibilities – of IT.
The problem with sending the new stuff cloud: Building IT expertise in Legacy v. Cutting Edge
Everyone who has made the choice to use cloud computing is next faced with the logical follow-on question: so, what do I move to the cloud? And, then, what do I keep in-house to run myself?And that’s where I think things get tricky. In many cases, the easiest thing to do is to consider using the cloud for new applications – the latest and greatest. This lets you keep the legacy systems that are already working as they are – running undisturbed as the Golden Rules of IT and a certain 110-year-old light bulb suggest (“if it’s working, don’t touch it!”).
But that choice might have the unintended effect of pigeonholing your IT staff as the caretakers of creaky technology that is not at the forefront of innovation. You push the new, more interesting apps off elsewhere – into the cloud. In trying to make a smart move and leverage the cloud, IT misses its chance to show itself as a team that is at (and can handle) the leading edge.
Maybe I’m painting this too black and white, especially in IT shops where they are working to build up a private cloud internally. And maybe I’m glossing over situations where IT actually does choose to embrace change in its own role. In those situations, there will be a “factory” role, alongside an “orchestrator” role. But that “factory” manager role will be trimmed back to crucial, core applications – and though they are important, they are also the ones least in need of modernization.
Either way, isn’t the result still this?: IT’s innovation skills get lost over time if they don’t take a more fundamental look at how they are running all of their IT systems, environment, and how they look at their own roles.
The problem I see is that big enterprises aren’t going to suddenly reassess everything they have on the first day they begin to venture into the cloud. However, maybe they should. For the good of the skills and capability and success of their IT teams, a broader view should be on the table.
Short-term and long-term answers
So, as you approach each of these questions, be sure to look not only at the immediate answer, but also at the message you’re sending to those doing the asking. Your answers today will have a big impact on all future questions.
All of this, I think, points out how much of a serious, fundamental shift cloud computing brings. The cloud is going to affect who IT is and how it’s viewed from now on. Take the opportunity to be the one proactively making that decision in your organization. And if you send things outside your four walls, or in a private cloud internally, make sure you know why – and the impact these decisions will have on IT’s perception with your users.Since cloud computing is all about choice, it’s probably a smart idea to make sure you’re the one doing the choosing.

Jay is marketing & strategy VP for CA Technologies' cloud business. He joined CA via its Cassatt acquisition (private cloud software).
Tim Wieman of the AppFabricCAT Team reported Windows 2008/2008 R2 default Power Plan of "Balanced" can increase latency and reduce throughput in a 6/2/2011 post:
Windows Server 2008 and 2008 R2 use a default “Power Plan” of “Balanced“. While this can save on energy and cooling costs by allowing Windows to control a number of motherboard and processor settings for reduced power consumption, it can also lead to increased latency and possible decreased throughput in your applications.
Results
By changing the Power Plan to “High Performance“, they were able to decrease the latency and increase the overall throughput by 15%. Of course, your results may vary depending on how constant your load is, for example. If you are producing constant load on the server, then the processor will stay at a higher clock speed on the “Balanced” power plan.
NOTE:
In order to take advantage of this in virtualized environments, you need to change the Power Plan on both the Host and Guest operating systems.
Unfortunately, we did not include this bit of guidance in the recently-released BizTalk Server 2010 Performance Optimization Guide. Our doc team is currently working on an update to the perf. guide, in which this guidance will be included in the section “General Guidelines for Improving Operating System Performance“.
Background
We actually document this in the little-known KB article 2207548. Superficially, it’s easy to see why we might see increased latency and degraded performance using the “Balanced” power plan, because this setting allows the CPU clock speed to go down to “5%” of maximum. The “Balanced” power plan allows for 100% CPU maximum, but initial requests coming in will be at a lower clock speed. The “Performance Tuning Guidelines for Windows Server 2008” says it very well on Page 10:
However, Balanced might not be appropriate for all customers. For example, some applications require very low response times or very high throughput at high load. Other applications might have sensitive timing or synchronization requirements that cannot tolerate changes in processor clock frequency. In such cases, changing the power plan to High Performance might help you to achieve your business goals. Note that the power consumption and operating cost of your server might increase significantly if you select the High Performance plan.
Digging deeper into Windows 2008 R2 and processor power management in the Windows 2008 R2 version of the performance tuning guide, you will find some other new energy efficiency features as well. One of these is processor “core parking”. Another interesting one is the ability to control “Intel Turbo Boost Technology” through the power plan. From page 15 of the Windows 2008 R2 perf tuning guide:
Intel Turbo Boost Technology is a feature that allows Intel processors to achieve additional performance when it is most useful (that is, at high system loads). However, this feature increases CPU core energy consumption, so we configure Turbo Boost based on the power policy that is in use and the specific processor implementation. Turbo Boost is enabled for High Performance power plans on all Intel processors and it is disabled for Power Saver power plans on all Intel processors. TurboBoost is disabled on Balanced power plans for some Intel processors. For future processors, this default setting might change depending on the energy efficiency of such features. To enable or disable the Turbo Boost feature, you must configure the Processor Performance Boost Policy parameter.
From this, we see that the “Balanced” power plan can also disable Intel Turbo Boost. The guide actually shows you how to enable it for Balanced (and other) power plans, so that is always an option as well.
What does the community have to say?
This has also been brought to attention in some blog entries:
- Power Plans and Windows Server 2008 R2: https://www.sqlservercentral.com/blogs/glennberry/archive/2010/02/22/power-plans-and-windows-server-2008-r2.aspx
- Databases and power management, not a perfect fit: http://www.anandtech.com/show/3602
and forums:
- Does CPU power management affect server performance? http://serverfault.com/questions/94212/does-cpu-power-management-affect-server-performance
The consensus seems to be the same as we’ve seen.
Recap
Keeping the default Power Plan as “Balanced” on your Windows 2008 or Windows 2008 R2 SQL Servers, BizTalk Servers, IIS Servers, or any application server can cause increased latency and decreased throughput. During your performance and functional testing, test your servers with the “High Performance” power plan and weigh any increased performance with the energy costs of your data center.
My team has seen several customer environments where the “High Performance” power plan helped with overall performance, and the customer thought the energy efficiency trade-off was worth the change.
Authored by: Tim Wieman
Reviewed by: Paolo Salvatori, James Podgorski
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
• Gavin Clarke (@gavin_clarke) asked “Azure to run Linux?!” as he reported Microsoft eyes Ubuntu and Debian love on Hyper-V in a 6/2/2011 article for The Register:
Microsoft says that its Hyper-V virtualization stack may soon support the Ubuntu and Debian Linux distros as well as CentOS, Red Hat, and SuSE.
The proprietary software shop has told The Register that after adding CentOS support last month, it's looking to support other Linux distros on both the Hyper-V stack and its management software. It's also considering giving Ubuntu and Debian penguins a phone number they can call if things go wrong.
"One request that has come to us time and again is Ubuntu and Debian," Sandy Gupta, general manager for marketing strategy for Microsoft's Open Solutions Group, told The Reg during a recent interview. "We haven't seen a lot of requests, but what we have found is when somebody wants Ubuntu, they want Ubuntu.
"If we were to do look at those two [Debian and Ubuntu], and we are looking, Ubuntu would be the next big popular thing for us to look at." Requests are primarily coming from web hosters in Europe.
Microsoft's love for Linux is designed to stop VMware from becoming the default virtualization and management standard for Linux in the cloud. Several Linux distros currently install on VMware hypervisors.
Gerry Car, director of communications at Ubuntu sponsor Canonical, told us there were no specific conversations taking place with Microsoft, although company reps had spoken to Gupta at various events.
Car added that while Microsoft is a closed-source-centric company – and opposed to the open-source Linux philosophy of Ubuntu – it makes sense for the two companies to partner with each other. "We obviously recognize their place in the market and spend a lot of time working on technologies to better integrate with them; so if there is work that will make out users' lives easier then that's very welcome."
Historically, Microsoft has been aggressively anti-Linux and anti-open source at a corporate level, but those in its Server and Tools biz are pragmatic. They know that they need to work better with Linux and open source or risk losing operating system, virtualization, and management money to VMware. The Server and Tools group is home to both Windows Server 2008 and Hyper-V.
Gupta said that Microsoft is moving into Linux support for one simple reason. "VMware is competition for us. VMware has similar support on ESX." If Microsoft doesn't act, it will lose potential customers to VMware forever, as those running Linux and Windows standardize on ESX as their virtualization layer. "We have more differentiation in systems than just virtualization, across other aspects of management," he said.
This all goes back to a massive re-organization of the Microsoft's Server and Tools unit last year. During that re-org, VMware was identified in a leaked internal memo seen by The Reg as a potential threat to Microsoft in the cloud.
Supporting Linux on Hyper V also means that Microsoft can equip itself with the technical knowledge and driver-level support needed to run the open source OS on the company's own Windows Azure cloud.
Sounds crazy? The Reg has learned from a source familiar with the situation that the company already has a version of Linux working on its Azure compute fabric in the lab. This work was done by Microsoft's Windows Azure engineering labs, which sits inside the Server and Tools group. According to our source, the work is at a very early stage. It will be at least 10 months, he says, before Microsoft is ready to announce anything.
Presumably, this will involve running Linux on Azure's "VM roles", raw instances akin to what you get on Amazon EC2. Originally, Azure was a pure platform-as-a-service, meaning it didn't offer access to raw VMs, but this is changing.
Currently, Microsoft's Azure compute fabric uses a modified version of Windows Server 2008 R2. And while it runs its own hypervisor – the Windows Azure Hypervisor – features from that hypervisor are moving into the main Hyper-V software. The Fabric controller handles high-speed connections, load balancing, and switching between servers used in Azure.
While Linux on any sort of Windows might be anathema to the Microsoft old guard and anybody outside Microsoft's Server and Tools unit, Linux on Azure would be a big win for the company's customers.
Many of Microsoft's biggest users of Windows, Hyper-V, and other Redmond products also run Linux in their data centers. These are precisely the companies Microsoft is trying to push towards the Azure cloud.
For Microsoft, it would also mean Azure becomes more like Amazon's EC2, which offers a choice of operating systems - including Window. It fits with Microsoft's strategy of giving customers the choice of running non-Microsoft languages such as Java and PHP on top of Azure.
There's a long way to go before that.
Read more: Microsoft's Linux heartbeat monitor (next page)
<Return to section navigation list>
Cloud Security and Governance
• Chris Hoff (@Beaker) posted Clouds, WAFs, Messaging Buses and API Security… to his Rational Survivability blog on 6/2/2011:
In my Commode Computing talk, I highlighted the need for security automation through the enablement of APIs. APIs are centric in architectural requirements for the provisioning, orchestration and (ultimately) security of cloud environments.
So there’s a “dark side” with the emergence of APIs as the prominent method by which one now interacts with stacks — and it’s highlighted in VMware’s vCloud Director Hardening Guide wherein beyond the normal de rigueur deployment of stateful packet filtering firewalls, the deployment of a Web Application Firewall is recommended.
Why? According to VMware’s hardening guide:
In summary, a WAF is an extremely valuable security solution because Web applications are too sophisticated for an IDS or IPS to protect. The simple fact that each Web application is unique makes it too complex for a static pattern-matching solution. A WAF is a unique security component because it has the capability to understand what characters are allowed within the context of the many pieces and parts of a Web page.
I don’t disagree that web applications/web services are complex. I further don’t disagree that protecting the web services and messaging buses that make up the majority of the exposed interfaces in vCloud Director don’t require sophisticated protection.
This, however, brings up an interesting skill-set challenge.
How many infrastructure security folks do you know that are experts in protecting, monitoring and managing MBeans, JMS/JMX messaging and APIs? More specifically, how many shops do you know that have WAFs deployed (in-line, actively protecting applications not passively monitoring) that did not in some way blow up every app they sit in front of as well as add potentially significant performance degradation due to SSL/TLS termination?
Whether you’re deploying vCloud or some other cloud stack (I just happen to be reading these docs at the moment,) the scope of exposed API interfaces ought to have you re-evaluating your teams’ skillsets when it comes to how you’re going to deal with the spotlight that’s now shining directly on the infrastructure stacks (hardware and software) their private and public clouds.
Many of us have had to get schooled on web services security with the emergence of SOA/Web Services application deployments. But that was at the application layer. Now it’s exposed at the “code as infrastructure” layer.
Think about it.
/Hoff
Related articles
- I love WAFs and so should you. (jarrodloidl.blogspot.com)
- AWS’ New Networking Capabilities – Sucking Less (rationalsurvivability.com)
- Should We Be Limiting Developers API Usage? (programmableweb.com)
- Glass House Syndrome and the Security Industry (ashimmy.com)

[Upper] image via Wikipedia
Bernard Golden (@bernardgolden) posted Cloud CIO: The Two Biggest Lies About Cloud Security to NetworkWorld’s Security blog on 5/27/2011:
Survey after survey note that security is the biggest concern potential users have with respect to public cloud computing. Here, for example, is a survey from April 2010, indicating that 45 percent of respondents felt the risks of cloud computing outweigh its benefits. CA and the Ponemon Institute conducted a survey and found similar concerns. But they also found that deployment had occurred despite these worries. And similar surveys and results continue to be published, indicating the mistrust about security persists.
Most of the concerns voiced about cloud computing relate to the public variant, of course. IT practitioners throughout the world consistently raise the same issues about using a public cloud service provider (CSP). For example, this week I am in Taiwan and yesterday gave an address to the Taiwan Cloud SIG. Over 250 people attended, and, predictably enough, the first question addressed to me was, "Is public cloud computing secure enough, and shouldn't I use a private cloud to avoid any security concerns?" People everywhere, it seems, feel that public CSPs are not to be trusted.
However, framing the cloud security discussion as a "public cloud insecure, private cloud secure" formula indicates an overly simplistic characterization. Put simply there are two big lies (or, more charitably, two fundamental misapprehensions) in this viewpoint, both rooted in the radical changes this new mode of computing forces on security products and practices.
Cloud Security Lie #1
- Related Content
- IRS: Top 10 things every taxpayer should know about identity theft
- Checklist for a successful security assessment
- Lesson from SecurID breach: Don't trust your security vendor
- Sony to restore Thursday all PlayStation Network services
View more related content
- Facebook video scam puts malware on Mac and Windows
- Cyberattacks fuel concerns about RSA SecurID breach
- Mac scareware gang evades Apple's new anti-malware defenses
- Security still a concern for those considering cloud move
The first big lie is that private cloud computing is, by definition, secure merely by way of the fact that it is deployed within the boundaries of a company's own data center. This misunderstanding arises from the fact that cloud computing contains two key differences from traditional computing: virtualization and dynamism.
The first difference is that cloud computing's technological foundation is based on the presence of a hypervisor, which has the effect of insulating computing (and the accompanying security threats) from one of the traditional tools of security: examining network traffic for inappropriate or malicious packets. Because virtual machines residing on the same server can communicate completely via traffic within the hypervisor, packets can be sent from one machine to another without ever hitting a physical network, which is where security appliances are typically installed to examine traffic.
Crucially, this means that if one virtual machine is compromised, it can send dangerous traffic to another without the typical organizational protective measures even being involved. In other words, one insecure application can communicate attacks to another without the organization's security measures ever having a chance to come into play. Just because an organization's apps reside inside a private cloud does not protect it against this security issue.
Of course, one might point out that this issue is present with vanilla virtualization, without any aspect of cloud computing being involved. That observation is correct. Cloud computing represents the marriage of virtualization with automation, and it's in this second element that another security shortcoming of private clouds emerges. …
<Return to section navigation list>
Cloud Computing Events
• Joe Panettieri (@joepanettieri) listed themes from Ingram Micro Summit: Top 10 Keynote Highlights… in a 6/2/2011 post to the TalkinCloud blog:
Nearly 300 VARs and MSPs are attending this week’s Ingram Micro Cloud Summit in Phoenix, Ariz. Today’s cloud computing keynotes — including executives from Amazon.com, Broadcom, Hewlett-Packard, Ingram, Microsoft, Salesforce.com, Symantec and VMware — just wrapped up. Here’s a recap of the key themes raised.
1. Social Business Media Meets the Cloud: Find a recap of Salesforce.com VP Peter Coffee’s keynote here.
2. Sticking With Standards: Broadcom CTO Nick Ilyadis described why good old Ethernet — modernized for the cloud age — will gain a bigger and bigger footprint in data centers.
3. Don’t Abandon Best Practices: Ingram CIO Mario Leone mentioned that NetFlix remained online even while Amazon’s cloud failed. The reason: NetFlix designed its service with redundancy with failure in mind.
4. Big Threats, Big Opportunities: In April Alone, Symantec scanned 6.6 billion emails and found 73,000 new web sites with spyware and malware, according to Stephen Banbury, senior director of Symantec.cloud. Symantec CEO Enrique Salem has previously stated that he expects roughly 10 percent of Symantec annual revenues to involve the cloud within a few years. That amounts to a $1 billion annual SaaS and cloud revenue target.
5. Why the Cloud Matters: Best-selling Author and former Oracle On Demand Leader Timothy Chou offered the following question:
- What if you could have one PC for 3.5 years?
- Or what if you could pay the same price to have 10,000 computers for 30 minutes?
Option two is far more compelling. What would you do with those 10,000 computers? The possibilities are endless, highlighting the power of the cloud, said Chou.
6. Scalability: Google has 50 servers per employee and Facebook has 30 servers per employee, Chou said.
7. Big Bet: Microsoft‘s Matt Thompson said Windows Azure now has 10,000 customers and is the biggest technology bet Microsoft has ever made. Thompson added that virtually all of Microsoft’s on-premise software now has an equivalent cloud offering.
8. That’s a Yotta Data: So what comes after Petabytes, Exabytes and Zettabytes? The answer is Yotta bytes, noted Daniel A. Powers, VP, Amazon Web Services. The cloud managed 2.9 billion objects in 2006, and now manages 339 billion objects. And the Amazon storage service manages more than 200,000 transactions per second. Amazon has hundreds of thousands of cloud customers in 190 countries, Powers said.
9. Networking Plus Cloud: Hewlett-Packard VP Paul Miller shared the company’s cloud vision. But before he started Miller noted HP’s continued acceleration in the networking market. On the cloud front, Miller promised that HP would enable partners with training, equip partners with sales and technical marketing documents, and empower the channel. He also mentioned 3Par and Opsware as cloud opportunities. And he zeroed in on the HP CloudSystem as built for the channel.
10. Where VMware Fits In: Julie Eades, VP of Americas marketing at VMware, showed how quickly the cloud noise has gotten louder. In 2008, it wasn’t a CIO priority.
- By 2009 it was priority number 16;
- By 2010 it was number 2; and
- by 2011 it was priority No. 1.
I think Eades’ source was either Gartner or CIO.com.
Eades said cloud computing isn’t a destination. Rather, it’s an approach to computing. Eades reinforced some points that the company made a few months ago at the VMware Exchange partner conference. At that time, VMware painted Microsoft, Amazon and Oracle as cloud pretenders. But this time around — in the presence of some rivals — VMware softened its statements but still painted Microsoft, Amazon and Oracle as closed cloud systems.
Bottom Line
The keynotes are over. What are my key takeaways? I’ll be sure to share them later today.
Depending on when Joe posts them, I’ll add his takeaways to this or tomorrow’s issue.
Mary Jo Foley (@maryjofoley) posted Microsoft: If we 'Build' a new developers conference, will they come? to her All About Microsoft blog on 6/1/2011:
Microsoft execs told developers earlier this year that there would be a new developers conference happening in mid-September 2011. But until this evening, details about this until-now-unnamed event were relatively few.
On June 1, in conjunction with Windows President Steven Sinofsky’s Windows 8 demo at the AllThingsD conference, Microsoft shared the new name of the conference — “Build/Windows.” (I’m guessing the name could be inspired by the Maker Faire brand.)
Microsoft’s hope is to convince Windows, Windows Azure, Windows Phone and Web developers to attend the September 13 to 16 Build show in Anaheim to learn what’s going on across all of Microsoft’s platforms. (Microsoft also is postponing and relocating its annual Financial Analyst Meeting from its typical late July in Redmond venue to September 14 to Anaheim, Calif., this year.)
Build supersedes the Microsoft Professional Developers Conference (PDC), Microsoft’s near-annual gathering of developers interested in the company’s developer tools and platform futures. Like other Microsoft watchers, I’m expecting Microsoft to deliver a test build of Windows 8, as well as a possible test build of Visual Studio 2012, in conjunction with the conference. And maybe Microsoft will finally raise the curtain on “Jupiter,” its new XAML-based app model for Windows 8 there, too….
Microsoft is opening registration for the Build conference on June 1.
I intend to wait until I see the session list before I commit to driving to and from Anaheim.
Paul Thurott (@thurrott) suggested that you Learn About Windows 8 at the BUILD Conference in September in a 6/1/2011 post to his WinSuperSite blogs:
As part of its Windows 8 revelations this week, Microsoft also said that its developer-oriented BUILD event will happen in September. This was previously expected to be called PDC 2011 and then WDC (“Windows Developer Conference”). Not sure what the name change is all about, but here’s what the company has to say about the event:
Registration is now open for Microsoft’s new developer conference, BUILD. The conference takes place September 13-16, 2011 in Anaheim, CA. BUILD is where the full spectrum of developers – from startups and entrepreneurs to those who work for the world’s biggest brands – will come together to get a deeper understanding of Microsoft’s product roadmap. In addition to providing the industry’s first deep dive on the next version of Windows, attendees can expect to see new capabilities for Windows Azure, Microsoft’s tools emphasis for HTML5 support, new development opportunities on Windows Phone and our commitment to interoperable environments. [Emphasis added.]
For more info, please visit the BUILD Web site and check out Somasegar’s Weblog:
Today, Steven Sinofsky and Julie Larson-Green announced that we’ll be starting a dialog with developers about the next generation of Windows, internally codenamed “Windows 8". We’re very excited to invite you to be a part of the conversation at BUILD, our new developer conference taking place September 13-16 in Anaheim, California. Registration is now open at buildwindows.com.
BUILD is the event for developers who want a front row seat at the industry’s first deep dive on Windows 8. It is where the full spectrum of developers - from startups and entrepreneurs to those who work for the world’s biggest enterprises – will come together to get a deeper understanding of Microsoft’s roadmap. At BUILD, Microsoft will show off the new app model that enables the creation of web-connected and services-powered apps that have access to the full power of the PC.
The conference name, BUILD, reflects a call to action for the more than one hundred million developers driving the pace of technology: build experiences with the next version of Windows that will transform the computing experience for billions of people across the globe.
I’ve already RSVP’d for the event. I can’t wait!
I’m not as enthusiastic as Paul about the subject matter of the BUILD conference that replaces PDC 2011 or the erstwhile WDC 2011. Nor am I partial to hokey DisneyLand or DisneyWorld suburbs as locations for developer conferences.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Carl Brooks (@eekygeeky) posted NYSE launches community cloud for financial traders to the SearchCloudComputing.com blog on 6/2/2011:
The technology arm of international stock exchange corporation NYSE Euronext has launched what it calls the "financial industry's first cloud platform." It's in beta and amounts to a proof-of-concept for what NYSE Technologies calls the Capital Markets Community Platform. It has two customers at the moment and runs at NYSE's data centers in Mahwah, N.J.
NYSE Technologies announced the platform in conjunction with VMware and EMC. It runs on vCloud Director and integrates a great deal of NYSE Technologies' trading services; users can tap into virtual machines and IT services and pay for it on demand.
Jarrod Yuster, CEO of Pico Quantitative Trading, said the new service essentially gives him more of the infrastructure setup he currently runs for real-time trading. He said Pico had begun moving over virtual infrastructure used for test, development and other non-critical systems, and it was fairly seamless.
"That's how it exists in [our] other data centers as well," he said, noting that he was already a heavy consumer of NYSE Technologies' historical stock data.
This essentially puts his systems closer to services he already used and lets him off the hook for infrastructure management, a common cloud computing benefit. Yuster noted that he's not yet ready to move his actual trading systems into the Community Platform; they require dedicated physical servers and communications to perform at the speeds necessary. Advantages in real-time trading can involve thousands upon thousands of trades every day, and margins for profit are measured in microseconds.
A community cloud for financials
NYSE Technologies CEO Stanley Young said that the idea was to create a "community cloud" specific to the financial industry that would absorb risk and lower investment costs for investors and trading firms. He added, however, that it was not a true infrastructure cloud like Amazon Web Services (AWS) and so comparisons, especially on pricing, would not be fair."We're caging [servers] for a different need," he said.
Price and subscription details were not fully announced. The service should be coming out of beta July 1.
The Capital Markets Community Platform is, at heart, a set of custom OS images and application stacks tightly integrated with NYSE's other IT services, such as the Superfeed data service, the Risk Management Gateway (RMG), Managed Services Hub and the global Liquidity Center Network, all of which run on the Secure Financial Transaction Infrastructure (STFI). Customers buy packages of CPU, storage, bandwidth and services.
While adamant that this is a true cloud computing platform, Young said it is intended to be consumed more like managed hosting, with NYSE Technologies doing all the actual provisioning and server management. He didn't, however, rule out self-service.
"It's holistic in what it's offering…the intention is to make this a managed service that customers can use as a self-service if they want," he said.
Young said that NYSE Euronext is expecting rapid intake of users and building infrastructure to support this in London, Basel and, later in the year, Tokyo. He said demand was in part driven by larger firms unwilling to invest capital in IT and uninterested in using pure-play cloud environments like AWS. He said the Volcker Rule had created a gold rush of financial startups that would also buy into the platform.
So it's not a true self-service cloud and it only delivers what the NYSE wants traders to have, but it can be had on-demand and pay-as-you-go. It remains to be seen whether the cloud-hungry will come; NYSE Technologies may have some cachet with the high-tech finance world but it has a steep uphill climb against established, enterprise-class hosters to deliver infrastructure at a competitive level.
Carl Brooks is the Senior Technology Writer for SearchCloudComputing.com.
Full disclosure: I’m a paid contributor to SearchCloudComputing.com.
• Bruce Guptil (@bguptil) asserted VMware + SocialCast Make Business More Social in a 6/2/2011 Research Alert for Saugatuck Technology (Site registration required):
What Is Happening?
In a deal that almost perfectly illustrates the interwoven, Cloud-driven nature and approaches of business software and workflow in the 21st century, IT virtualization and management Master Brand VMware announced on Tuesday May 31 its acquisition of collaborative / social business software and service provider Socialcast.
Socialcast is described on its website as “an enterprise collaboration platform built on activity streams that unites people, data and applications in real-time.” The company provides microblogging services tailored to workgroups and process management within enterprise business applications.
Socialcast’s role within the VMware portfolio will be to enable and expand collaborative business communication environments, whether as part of user IT environments or as part of Cloud services providers’ workflow management/collaborative offering portfolios. A worker’s or workgroup “social graph” will be virtualized, enabling communication, task management, performance monitoring and other workflow/group tasks and activities to be more easily shared within or between individuals, groups, and enterprises. Collaborators will be able to see activity, tasks, progress, and other information in real-time, including following and contributing to comment streams. The virtualized web service already works within customer SAP ERP applications and Oracle finance applications. According to Socialcast CEO Tim Young, the company will continue operating as an independent business unit with existing staff intact. …
Bruce continues with the usual “Why Is It Happening” and “Market Impact” sections.
Amit Naik (@suprgeek) explained an Open Source Engine Powering the Next Gen. Cloud Stack – Part 1 in a 6/2/2011 post to BMC’s Flying with the Jet Stream blog:
Recently there have been a flood of announcements in the Cloud Computing space that have heartened the Open Source community. This is particularly important to ensure large adoption of some of the guts of the cloud computing stack. This post will examine some of these announcements in the light of building an entire stack of open source cloud.
Motivations for going Open Source
When you have one company that is innovating rapidly as Amazon has been in the cloud computing space, it is often hard for others to overcome the first mover advantage. Indeed, Amazon was first to the Cloud Computing party by offering its EC2 service way back in August 2006. Since then it has been innovating at a rapid pace and adding new services and features almost on a monthly basis.
The only way to compete with this kind of pace is for other companies to enlist the help of developers all over the world to help improve their cloud computing offerings. If the specs and code forming the cloud computing offering, are put on the Web for everybody to use and explore, it forms a powerful force for improving the core product. If your open source offering grabs more mind share than your competitors then you gain a tremendous competitive advantage.
Another key motivation is the building of the ecosystem. When a large enough user-base starts building around a product, the software community gets engaged around the product and starts building extensions and plug-ins that elevate the whole platform. Witness the explosive growth of the Eclipse platform. There are probably more than 1000 Eclipse plug-ins that are being actively maintained all thanks to its open source nature.
The final motivation has to do with Company Philosophy or Goodwill. Sometimes an organization is so well known for being a major player in the open source ecosystem that new products are, by default, expected to be Open Source (with a paid variant if need be). Famous examples of these are organizations such as Red Hat or Apache. The associated advantage is the goodwill that the company has earned amongst the developer community.
The Cloud Computing stack
The simplified cloud stack is depicted in the figure below:

Fig 1: The Simplified Cloud Stack
Let us look at each layer of the Stack and find out how Open Source can power the next gen. Cloud Stack.
Physical Hardware
This is the layer at which Racks and Servers are physically connected to Storage and Networking devices to form the guts of your cloud. Facebook created a stir recently when it decided to open source all the specs to its data centers. Their recent Open Compute Project puts detailed blueprints for Servers and Datacenters out on the web for everyone to analyze and (hopefully) emulate. The Facebook team presented a very compelling case for more vendors to use the specs that they have released – namely Power Savings from Efficiency. Facebook engineers claim their servers are 38 percent more efficient than the off-the-shelf ones they were buying previously. And that has meant a 24 percent cost savings. The hope is obviously that other High growth start-ups that need to build their own data centers (Twitter, Square, etc being the prime candidates) can embrace these specifications and actually improve on them.
This is in direct contrast to Google that is notoriously secretive when it comes to the exact specs of their enormous datacenters. They maintain such a super-secret tight control on the exact specifications that the Google data centers have been compared to Area 51 sometimes.
This is no small feat on Facebook’s part. Facebook is engaged in a fierce battle with other web scale companies such as Google and having a super-efficient data center could be a huge competitive advantage for them. However, Facebook is betting that by essentially commoditizing the “secret sauce” of the efficient data center, they are unleashing an innovation ecosystem that will allow all players to benefit.
Infrastructure as a Service (IaaS)
This is the core software layer that enables IaaS services such a Provisioning-on-demand, Configuration and Management of the Cloud infrastructure. This software is also known as the Cloud Orchestration software, IaaS enabler, Cloud Director, Cloud Manager, etc.
The open source IaaS space used to be dominated by Eucalyptus software until recently. Eucalyptus grew from an academic project at UCSB into one of the most widely downloaded open source Private and Hybrid cloud platforms. Eucalyptus claim to fame was the user-facing API that it exposed was compatible with the Amazon API. However last year it suffered many defections – the chief one being NASA who was one of the highest profile users of Eucalyptus.
NASA, reportedly unhappy with the scalability constraints of Eucalyptus, collaborated with Rackspace to found the OpenStack project. In a very short time, OpenStack has managed to attract a wide consortium of companies including Microsoft, Cisco, Dell, Citrix, Intel etc.Rackspace is one of the founding members of OpenStack and have publicly declared that they are going to shifting all of their existing cloud hosting to OpenStack very shortly. Recently Internap has become the second provider to publicly announce that they are building an OpenStack based cloud. This is all the more remarkable as Internap is a competitor to Rackspace. OpenStack has also been gaining tremendous momentum lately with many major announcements – Citrx recently announced that they will be selling a Citrix branded OpenStack edition with a cloud ready Xen Server edition.
At its heart, the OpenStack framework allows anyone to build three different flavors of IaaS services:
- OpenStack Compute (Nova) – designed to provision and manage large networks of virtual machines, backed by orchestration and management support.
- OpenStack Storage (Swift) – designed for creating redundant, scalable object storage using clusters of standardized servers.
- OpenStack Image Service (Glance) – designed to provide discovery, registration, and delivery services for virtual disk images.
All of these services are backed by extensive API support that allows programmatic manipulation of almost all the control interfaces to these services. Cisco is another heavyweight that has shown interest in OpenStack. They have actively begun to work on it by submitting their Networking as a Service (NaaS) proposal to the OpenStack group. In another interesting tie-in, OpenCompute and OpenStack are now also collaborating to ensure that OpenStack can run efficiently on top of the OpenCompute reference architectures.
Obviously OpenStack is not the only player in the open source IaaS space and neither is it the first. Take a look at some of the other notable open source projects for IaaS in addition to OpenStack and Eucalyptus:
- OpenNebula - One of the earliest entrants to the open source IaaS party and one of the most mature. OpenNebula bills itself as the “Industry Standard for on-premise IaaS cloud computing, offering a comprehensive solution for the management of virtualized data centers to enable private, public and hybrid (cloudbursting) clouds“. It has a number of clients using it including CERN and FermiLab. They are roughly equivalent to OpenStack Nova.
- Red Hat CloudForms - Along with OpenShift (which we will look at in more details in Part 2) this forms Red Hat’s foray into the cloud computing space. As of posting this (June 2011) the CloudForms service was still in closed beta. The promise of CloudForms is enticing as it claims to offer “..Application Lifecycle Management (ALM) functionality that enables management of an application deployed over a constellation of physical, virtualized and cloud-based environments.“
- CloudStack – A community offering from Cloud.com that enables users to build, manage and deploy compute cloud environments. Note that a commercial version of this is also available that has more cutting edge features.
- Puppet, Chef and the like are not full-fledged IaaS Solutions but do capture some of the more important functionalities in the IaaS enablement solution. With a little bit of work these utilities could form the backbone of a workable IaaS solution.
Check out this post for a comparison of some of the above mentioned open source solutions along with some Enterprise solutions in the IaaS space.
However, OpenStack has picked up a staggering velocity and has gone thru 3 major releases already in under a year.With the diverse nature of companies that are supporting OpenStack and large developer interest, it seems to be well on its way to becoming the dominant player in the open source IaaS space.Stay tuned for part 2 of this post, where we will examine the many interesting open source players in the PaaS, SaaS and the Cloud Client spaces and how they are playing a part in driving the next generation of the open and interoperable cloud. We will also look at some other open source plays such as Open Virtualization Alliance that are taking a different track on the cloud computing issue.

Sante Gennaro Rotondi reported VMware announces the acquisition of Socialcast in a 6/2/2011 post to the CloudComputing.info blog:
VMware CTO Steve Herrod announced on May 31 the acquisition of Socialcast. Socialcast is an enterprise social networking software vendor, such as Yammer, Salesforce and Jive.
The Socialcast acquisition is the last of a serie which included the cloud-based online presentation company Sliderocket and the groupware company Zimbra.
VMware recently added Single Sign On (SSO) support to VMware Horizon App Manager, which aims to be the keystone for enabling and managing the cloud applications nowadays commonly used by enterprise employees. Socialcast software is not yet integrated into Horizon App Manager, but surely will be supported soon.
All these moves, together with the two recent posts of VMware CTO Steve Harrod on the “post-PC era” (1, 2), bring new evidence on what is going to be the new role of VMware on the market, shifting from being a mere provider to becoming an enabler for virtualization and cloud technologies, as this article from Gartner analyst Chris Wolf points out.
<Return to section navigation list>

















0 comments:
Post a Comment