Windows Azure and Cloud Computing Posts for 5/21/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI,Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

•• Updated 5/24/2012 for Steve Martin’s report on South Central US Data Center deployments, Pablo Castro’s and Alex James’ OData submission to OASIS report and Jeff Price’s Windows Azure Workshop announcement.
• Updated 5/23/2012 for IBM SmartCloud Application Services (SCAS), Wade Wegner’s contribution to Mary Jo Foley’s All About Microsoft blog, Avkash Chauhan’s debugging advice, Will Perry on Windows 8 and Service Bus, Beth Massi on Office Integration for LightSwitch and John Shewchuk on Windows Azure Active Directory.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics, Big Data and OData
- Windows Azure Service Bus, Access Control, Identity and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
Jo Maitland (@JoMaitlandSF) reported Microsoft breaks big data sorting record in a 5/21/2012 post to the GigaOm Pro blog:
It’s rare to hear Microsoft breaking any kind of record these days, which is why I thought this one in the big data arena was worth noting. The Redmond software behemoth just beat the MinuteSort benchmark, or the amount of data that can be sorted in 60 seconds or less. The Microsoft team sorted almost three times the amount of data (1,401 gigabytes vs. 500 gigabytes) with about one-sixth the hardware resources (1,033 disks across 250 machines versus 5,624 disks across 1,406 machines) used by the previous record holder, a team from Yahoo! that set the mark in 2009. Microsoft expects to use the research to power its bing search engine, but says its breakthrough technology and approach to the sorting challenge would be applicable to any big data application that required high performance.

Follow the technology and approach link to learn the details of this feat.
Full disclosure: I’m a registered GigaOm analyst.

No significant articles today.
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
No significant articles today.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
•• Alex James (@adjames) and Pablo Castro (@pmc) reported OData submitted to OASIS for standardization in a 5/24/2012 post to the OData.org blog:
I’m happy to announce that Citrix, IBM, Microsoft, Progress Software, SAP and WSO2 are jointly submitting a proposal for the standardization of OData to OASIS.
While the OASIS OData Technical Committee will standardize OData, the great collaboration will continue in the odata.org community to grow the library of producers and consumers and, share implementation and Interop experiences, etc.
The starting point for the proposal is the current OData v3 specification plus a number of proposed extensions that use the protocol extensibility points to add functionality without having to increase the footprint of the core specification.
We often have discussions within the team, with developers out there and the community about what OData can and cannot do and whether we should add this or that feature. In that context we always come back to the same few principles that guide the design of OData: the main value of this technology is not any particular design choice but the fact that enough people agree to the same pattern, thus removing friction from sharing data across independent producers and consumers. For that to work the protocol must remain simple for simple cases, cover more sophisticated cases reasonably well and avoid inventing stuff as much as possible.
With interoperability front and center in OData we saw more and more technology stacks that started to work with it. Now there are a number of companies that use OData in their products to ensure the data they manage is easily accessible beyond the boundaries of their applications. Many of these companies regularly collaborate on the ongoing design effort for OData. While so far we’ve run the OData design process as transparently as we could (sharing designs, taking feedback through the odata.org blog and distribution list, etc.), we are at a point where the level of adoption and the scale at which organizations are betting on OData require a more formal commitment to shared ownership of the design of this protocol.
We have a good amount of work ahead of us in the OASIS TC, but this is the first step. We’ll keep posting to this blog with updates as things progress.
We encourage others to get involved to learn more about the protocol and design decisions that were made in developing the protocol. Go to odata.org, check out the OData blog and join the OData mailing list (the instructions are on odata.org). Join the OASIS OData TC and help us standardize the protocol!
We’re happy to see OData take this important step on the journey towards standardization. Thanks to all the folks out there that helped get OData this far.


My (@rogerjenn) Using the Windows Azure Marketplace DataMarket (and Codename “Data Hub”) Add-In for Excel (CTP3) post of 5/21/2012 begins:
The Windows Azure Marketplace DataMarket and SQL Labs’ Codename “Data Hub” Preview promote Microsoft PowerPivot for Excel 2010 on each dataset’s summary page and offer a direct Export to Excel PowerPivot option on the Build Query page. PowerPivot’s business intelligence (BI) features often are overkill for simple analytical activities, such as browsing datasets, or might intimidate potential DataSet users.
The Windows Azure Marketplace DataMarket Add-In for Excel (CTP3) provides a simple alternative to exporting data as Excel *.csv files from DataMarket or Data Hub and opening them in Excel. According to the download page’s “Overview” section:
Microsoft Windows Azure Marketplace DataMarket Add-in for Excel (CTP 3) provides a simple experience allowing you to discover datasets published on the Windows Azure Marketplace DataMarket or in your instance of Microsoft Codename "Data Hub" right within Excel. Users can browse and search for a rich set of datasets within a tool they already use.
With only a couple of clicks, the user can query their datasets and import the data as a table into Excel. Once in the workbook, the data can be visualized, joined with other data sources (including owned/on premise data) or exported to be used in other applications.
Prerequisites: Installation of the Windows Azure Marketplace DataMarket Add-In for Excel (CTP3) is required. (See step 1 below.)
This tutorial assumes (but doesn’t require) that you have accounts for the Windows Azure Marketplace Datamarket and the OakLeaf Public Data Hub and have subscribed to (Datamarket) or added the Air Carrier Flight Delays dataset to your collection (Data Hub). See Accessing the US Air Carrier Flight Delay DataSet on Windows Azure Marketplace DataMarket and “DataHub” for details.
The following steps apply to both DataMarket and Data Hub datasets unless prefixed with [DataMarket] or [Data Hub]:
1. Download the Windows Azure Marketplace DataMarket Add-In for Excel (CTP3) from here, extract the files from the DataMarketExcelAddInSetupCTP3.zip, and run Setup.exe to install the add-in and its prerequisites.
Note: The following steps are more detailed than the Getting started with Windows Azure™ Marketplace DataMarket Add-In for Excel (CTP3) file, which displays when installation completes.
2. Launch Excel 2010, click the Data tab, which now sports an Import Data from DataMarket button:
3. Click the button to open a Subscribed Datasets taskpane:
4. If you’re not familiar with the public DataMarket, click its Learn More link to open the DataMarket’s About page. Alternatively, click the private DataHub’s Learn More link to open the SQL Azure Lab’s Welcome page for Codename “Data Hub,” and sign in with a Live ID.
5A. [DataMarket] Click the Sign In or Create Account button to open the sign-in page:
5B. [Data Hub] Type the HubName.clouddatahub.net URL for your organization’s Data Hub in the text box:
5C.[Data Hub] Click the link to find your account key (sign in, if requested):
5D. [Data Hub] Select and copy the Account Key to the Clipboard, close the Data Hub page to return to Excel, paste the Account Key to the text box and, optionally, mark the Remember Me checkbox. (Refer to step 5B’s screen capture.)
6A. [DataMarket] Click Sign In to open an Allow Access form:
6B. [DataMarket] Click Allow Access to display a list of the Datamarket datasets to which you’ve subscribed:
6C. [Data Hub] Click Sign In to display a list of Data Hub data sets in your collection:
7. Click the US Air Carrier Flight Delays Import Data link to open the Query Builder dialog:
Note: It isn’t clear how to enable the Group and Ungroup buttons.
8. Click the Add Filter button to add the first filter builder, select Month and type 2 as the value; click +, select Year and type 2012 as the value; and click +, select Dest and type OAK as the value to restrict the number of rows to a reasonable number:
Note: It isn’t clear how to return to where you were before clicking the Preview Data button, so clicking it isn’t recommended.
10. Click the Sort Results tab, click the Add Sort Order button to add the first sort builder, select FlightDate, click + and select Carrier to order by date and carrier:
11. Click the specify Returned Fields tab and clear the DayOfMonth, Month, RowId and Year check boxes:
12. Click Import Data to fill the worksheet, which has 3,462 rows and includes empty columns for the fields you omitted in step 11:
Tip: You can get help for the DataMarket add-in by searching online Office help for DataMarket.
13. Click the Insert tab, open the PivotTable gallery and choose PivotChart to open the Create PivotTable with PivotChart dialog, accept the default Table/Range value and click OK to open a PivotTable and PivotChart with a PivotTable Filed List taskpane.
14. Mark the Carrier and DepDelayMinutes field check boxes, open the Sum of DepDelayMinutes list in the Values area, select Value Field Settings, choose Summarize Values by Average, delete the legend and edit the chart title:
















Andrew Brust @AndrewBrust reported Cloudant makes NoSQL as a service bigger in a 5/22/2012 article for ZDNet’s Big Data blog:
The worlds of Big Data and NoSQL overlap and coincide quite a bit. For instance Hbase, a Wide Column Store NoSQL database is often used with Hadoop, and vice-versa. Meanwhile, beyond the Wide Column Store realm, NoSQL Document Stores are growing ever more popular with developers. One of the most popular Document Store NoSQL databases is CouchDB which, like HBase and Hadoop itself, is a top-level Apache Software Foundation project.
And now the news: Boston-based Cloudant uses CouchDB’s API and technology, combined with its own query and sharding (partitioning) code to offer the open source “BigCouch” database and a hosted “data layer” as a service offering that is effectively a super-charged CouchDB in the cloud. Today, Cloudant is announcing an expansion of the infrastructure upon which its cloud service is offered, by adding a new data center in Amsterdam, giving it points of presence across Europe, Asia and North America. That’s important for a hosted data service’s customers, especially with a distributed database like Cloudant’s flavor of CouchDB: it allows data to reside on the edges of the network, close to a variety of customers, which minimizes latency. Put another way: customers’ apps will go faster for a variety of their users, around the world.
So what’s the Big Data angle here? To start with, Cloudant’s query and sharding technology is the productization of particle physics research work done at MIT, where data loads of up to 100 Petabytes per second had to be accommodated. That sounds like Big Data to me, despite the fact that Cloudant’s data layer is designed for operational database use rather than for dedicated analysis work. Plus, Cloudant’s layer offers “chainable” MapReduce, making it more Big Data-friendly still.
Another Big Data tie-in is that no less than three former members of the product team from Vertica (an in-memory database appliance acquired by HP) now serve on Cloudant’s leadership team. Specifically, CEO Derek Schoettle, VP of Marketing Andy Ellicott and Board of Directors member Andy Palmer all come from Vertica. Ellicott also did a stint at VoltDB, another scale-out, in-memory database company. (This is getting to be a bit of a trend in the industry. As I reported earlier this month, another Vertica alumnus, former CEO Christopher Lynch, recently joined Hadapt’s Board as Chairman).
Technology start-ups (and their funders) are continuing their preference for NoSQL database architectures, and NoSQL databases are getting better at handling huge volumes of data, whether on-premise or in the cloud. With all that in mind, every student of Big Data needs to monitor the NoSQL world very carefully.

Andrew Brust @AndrewBrust asserted Web Data is Big Data in a 5/19/2012 article for ZDNet’s Big Data blog:
In the world of Big Data, there’s a lot of talk about unstructured data — after all, “variety” is one of the three Vs. Often these discussions dwell on log file data, sensor output or media content. But what about data on the Web itself — not data from Web APIs, but data on Web pages that were designed more for eyeballing than machine-driven query and storage? How can this data be read, especially at scale? Recently, I had a chat with the CTO and Founder of Kapow Software, Stefan Andreasen, who showed me how the company’s Katalyst product tames data-rich Web sites not designed for machine-readability.
Scraping the Web
If you’re a programmer, you know that Web pages are simply visualizations of HTML markup — in effect every visible Web page is really just a rendering of a big string of text. And because of that, the data you may want out of a Web page can usually be extracted by looking for occurrences of certain text immediately preceding and following that data, and taking what’s in between.
Code that performs data extraction through this sort of string manipulation is sometimes said to be performing Web “scraping.” This term that pays homage to “screen scraping,” a similar, though much older, technique used to extract data from mainframe terminal screen text. Web scraping has significant relevance to Big Data. Even in cases where the bulk of a Big Data set comes from flat files or databases, augmenting that with up-to-date- reference data from the Web can be very attractive, if not outright required.
Unlocking Important Data
But not all data is available through downloads, feeds or APIs. This is especially true of government data, various Open Data initiatives notwithstanding. Agencies like the US Patent and Trademark Office (USPTO) and the Federal Securities and Exchange Commission (SEC) have tons of data available online, but API access may require subscriptions from third parties.Similarly, there’s lots of commercial data available online that may not be neatly packaged in code-friendly formats either. Consider airline and hotel frequent flyer/loyalty program promotions. You can log into your account and read about them, but just try getting a list of all such promotions that may apply to a specific property or geographic area, and keeping the list up-to-date. If you’re an industry analyst wanting to perform ad hoc analytical queries across such offers, you may be really stuck.
Downside Risk
So it’s Web scraping to the rescue, right? Not exactly, because Web scraping code can be brittle. If the layout of a data-containing Web page changes — even by just a little — the text patterns being searched may be rendered incorrect, and a mission critical process may completely break down. Fixing the broken code may involve manual inspection of the page’s new markup, then updating the delimiting text fragments, which would hopefully be stored in a database, but might even be in the code itself.Such an approach is neither reliable, nor scalable. Writing the code is expensive and updating it is too. What is really needed for this kind of work is a scripting engine which determines the URLs it needs to visit, the data it needs to extract and the processing it must subsequently perform on the data. What’s more, allowing the data desired for extraction, and the delimiters around it, to be identified visually, would allow for far faster authoring and updating than would manual inspection of HTML markup.
An engine like this has really been needed for years, but the rise of Big Data has increased the urgency. Because this data is no longer needed just for simple and quick updates. In the era of Big Data, we need to collect lots of this data and analyze it.
Making it Real
Kapow Software’s Katalyst product meets the spec, and then some. It provides all the wish list items above: visual and interactive declaration of desired URLs, data to extract and delimiting entities in the page. So far, so good. But Katalyst doesn’t just build a black box that grabs the data for you. Instead, it actually exposes an API around its extraction processes, thus enabling other code and other tools to extract the data directly.That’s great for public Web sites that you wish to extract data from, but it’s also good for adding an API to your own internal Web applications without having to write any code. In effect, Katalyst builds data services around existing Web sites and Web applications, does so without required coding, and makes any breaking layout changes in those products minimally disruptive.
Maybe the nicest thing about Katalyst is that it’s designed with data extraction and analysis in mind, and it provides a manageability layer atop all of its data integration processes, making it perfect for Big Data applications where repeatability, manageability, maintainability and scalability are all essential.
Web Data is BI, and Big Data
Katalyst isn’t just a tweaky programmer’s toolkit. It’s a real, live data integration tool. Maybe that’s why Informatica, a big name in BI which just put out its 9.5 release this week, announced a strategic partnership with Kapow Software. As a result, Informatica PowerExchange for Kapow Katalyst will be made available as part of Informatica 9.5. Version 9.5 is the Big Data release of Informatica, with the ability to treat Hadoop as a standard data source and destination. Integrating with this version of Informatica makes the utility of Katalyst in Big Data applications not merely a provable idea, but a product reality.

<Return to section navigation list>
Windows Azure Service Bus, Access Control, Identity and Workflow
• John Shewchuk posted Reimagining Active Directory for the Social Enterprise (Part 1) to the Windows Azure blog on 5/23/2012:
After working pretty quietly for the last several years on Windows Azure Active Directory—the Microsoft identity management service for organizations—we are excited about the opportunity to start sharing more information about what our team has been up to.
As Kim Cameron, distinguished engineer on the Active Directory team, described on his blog today, we think that identity management as a service has the potential to profoundly alter the landscape of identity. In this post, I want to share how Microsoft is reimagining the Active Directory service to operate in this new world.
Identity management solutions like Active Directory, a feature of the Windows Server operating system, have been in use for a long time. Active Directory is most often used by midsize and large organizations where the substantial effort and cost necessary to build and keep an identity management system running have brought many benefits, including:
- Single sign on (SSO) and access control across a wide range of applications and resources.
- Sharing of information between applications—for example, information about people, groups, reporting relationships, roles, contact information, printer locations, and service addresses.
- Information protection that enables encryption and controlled access to documents.
- Discovery of computers, printers, files, applications, and other resources.
- Tools to manage users, groups, and roles; reset passwords; and configure and distribute cryptographic keys, certificates, access policies, and device settings.
Organizations have built on these capabilities to create a range of solutions. One of the most important uses of Active Directory, often deployed in conjunction with identity products from other software vendors, is to provide a solid foundation to manage access to information, helping ensure that only approved users can access sensitive information. Similarly, Active Directory is often used as a basis to enable secure collaboration between people within the organization and, with Active Directory Federation Services or similar offerings, between organizations.
But for many smaller organizations, building and maintaining an identity management system and the associated application integration has been too hard and too costly to consider. Even organizations that have successfully deployed identity management solutions are looking for ways to make identity management easier and to broaden its reach.
Here in part 1 of a two-part posting, we will look at how the use of cloud architectures and cloud economies of scale is enabling us to offer Active Directory as a turnkey service at a cost that puts this powerful collection of capabilities within reach of essentially everyone—even small organizations without an IT staff. We see this as very important. It opens the door to “democratizing” identity management so it becomes a foundational capability that every organization and every software developer can count on—no matter what platform or technology base they are building from.
In part 2, we will look at how offering Active Directory in the cloud as turnkey services provides an opportunity to reimagine the way that directories can be used to enable the social enterprise—and how it enables developers to easily create applications that connect the directory to other software-as-a-service (SaaS) applications, cloud platforms, an organization’s customers, and social networks.
In evolving a powerful and widely deployed solution like Active Directory, we have to be very careful that we don’t create new issues while we’re addressing these new opportunities. In this overview, we provide some background on how we are reimagining Active Directory and highlight some of the key ideas driving this work.
What is Windows Azure Active Directory?
We have taken Active Directory, a widely deployed, enterprise-grade identity management solution, and made it operate in the cloud as a multitenant service with Internet scale, high availability, and integrated disaster recovery. Since we first talked about it in November 2011, Windows Azure Active Directory has shown itself to be a robust identity and access management service for both Microsoft Office 365 and Windows Azure–based applications.
In the interim, we have been working to enhance Windows Azure Active Directory by adding new, Internet-focused connectivity, mobility, and collaboration capabilities that offer value to applications running anywhere and on any platform. This includes applications running on mobile devices like iPhone, cloud platforms like Amazon Web Services, and technologies like Java.
The easiest way to think about Windows Azure Active Directory is that Microsoft is enabling an organization’s Active Directory to operate in the cloud. Just like the Active Directory feature in the Windows Server operating system that operates within your organization, the Active Directory service that is available through Windows Azure is your organization’s Active Directory. Because it is your organization’s directory, you decide who your users are, what information you keep in your directory, who can use the information and manage it, and what applications are allowed to access that information. And if you already have on-premises Active Directory, this isn’t an additional, separate copy of your directory that you have to manage independently; it is the same directory you already own that has been extended to the cloud.
Meanwhile, it is Microsoft’s responsibility to keep Active Directory running in the cloud with high scale, high availability, and integrated disaster recovery, while fully respecting your requirements for the privacy and security of your information.
Sounds straightforward, right? In practice, it really is easy to use Windows Azure Active Directory. To illustrate this, let us take a look at how a directory gets created and used when an organization signs up for Microsoft Office 365.
Windows Azure Active Directory and Office 365
Today Microsoft Office 365, Microsoft Dynamics CRM, Windows Intune software and services, and many third-party applications created by enterprises, established software vendors, and enterprise-focused startups are working with Windows Azure Active Directory. Here we focus on Office 365 and look at how Windows Azure Active Directory helps enable Office 365.
Each time a new organization signs up for Office 365, Microsoft automatically create a new Windows Azure Active Directory that is associated with the Office 365 account. No action is required on the part of the individual signing up.
With an Active Directory in place, the owner of the Office 365 account is able to easily add users to the directory. The figure below shows how I would add a new user to my personal Office 365 account.
The owner of the account is also able to manage passwords for the users, determine what roles they are in and which applications they can access, and so on. An example of this type of setting is shown in the figure below.
Now note several interesting aspects of the experience that the owner has when signing up for Office 365:
- Ease of use. As the previous example illustrates, it is incredibly easy to use Windows Azure Active Directory. In my case, I just signed up for Office 365—and, like magic, I got a high-scale, high-availability, disaster-tolerant Active Directory. My Active Directory was up and running in a flash, and I didn’t need to do anything to make this happen. In fact, most Office 365 customers aren’t even aware that they have an Active Directory working for them behind the scenes.
- Single sign on across applications. Even though they may not realize Windows Azure Active Directory is there, organizations and users quickly get a lot of value from the common user experiences that the directory enables. All the applications in Office 365—Microsoft Exchange Online, SharePoint Online, Lync Online, and Office Web Apps—work with Windows Azure Active Directory, so users get single sign on. Moreover, advanced Active Directory capabilities like information protection are available using this common identity. The Windows Azure Active Directory SSO capability can be used by any application, from Microsoft or a third party running on any technology base. So if a user is signed in to one application and moves to another, the user doesn’t have to sign in again.
- Shared context. Once an application establishes SSO with Windows Azure Active Directory, the application can use information in the directory, including information about people, groups, security roles, and so on. This makes an application more current and relevant, and it can save users a lot of time and energy because they don’t need to re-create, sync, or otherwise manage this information for each application that they use.
- Efficient, highly available operations. Office 365 customers don’t get a separate bill for their use of Windows Azure Active Directory; the costs of using Windows Azure and Windows Azure Active Directory are incorporated in the overall cost of the Office 365 solution. One of the key reasons that we are able to offer this rich set of identity management capabilities at reasonable cost is that we built Windows Azure Active Directory using cloud architecture and getting cloud economies of scale. We will talk more about this in a moment.
The ease of use; great common experiences like SSO; shared context between applications, including information about the people in an organization, their relationships, and roles; and efficient, highly available operations makes Windows Azure Active Directory a great foundation for many applications and services.
Working with Existing Active Directory Deployments
As the example above shows, for new organizations, it is very easy to get started with Windows Azure Active Directory. But what if an organization is already using Active Directory for on-premises identity management? To support this, Microsoft makes it easy to “connect” Windows Azure Active Directory with an existing directory. At the technical level, organizations can enable identity federation and directory synchronization between an existing Active Directory deployment and Windows Azure Active Directory.
When an organization does this, its Active Directory is, in a sense, stretching over both an on-premises and a cloud deployment. The ability for Active Directory to operate across both on-premises and cloud deployments in a hybrid mode enables an organization to easily take advantage of new cloud-based platforms and SaaS applications, while all of its existing identity management processes and application integration can continue unaffected.
In addition, being able to operate in this hybrid mode is critical for some organizations because of business or regulatory requirements that mandate that certain critical information, such as passwords, be maintained in on-premises servers.
Running Today at Internet Scale and With High Availability
To make Active Directory available as a service, you might think all we had to do was take a copy of the Windows Server Active Directory software and run it in the cloud—that is, use Windows Azure to create a new virtual machine for each customer and then run Active Directory on this virtual machine. But that kind of approach wouldn’t give us the efficient operations or high availability that we are able to provide with Windows Azure Active Directory.
To make the Active Directory service operate at extremely high scale and with very high availability (including the ability to do incremental servicing) and provide integrated disaster recovery, we made significant changes to the internal architecture of Active Directory and moved from a server-based system to a scale-out, cloud-based system. For example, instead of having an individual server operate as the Active Directory store and issue credentials, we split these capabilities into independent roles. We made issuing tokens a scale-out role in Windows Azure, and we partitioned the Active Directory store to operate across many servers and between data centers.
Beyond these architectural changes, it was also clear that we needed to reimagine how Active Directory would operate in the cloud. In talking with many developers, customers, and partners, we heard that they wanted us to enhance the ability for Active Directory to “connect”—to the new Internet-based identities from Google, Facebook, and other social networks; to new SaaS applications; and to other cloud platforms.
All this work involved efforts by many people and teams across Microsoft. To get everything operating at Internet scale has been a substantial undertaking, which has taken several years.
We have made good progress. Today we have hundreds of thousands of paying organizations using Windows Azure Active Directory as part of applications such as Office 365, Windows Intune, and many third-party applications. For example, organizations using Office 365 and the underlying Windows Azure Active Directory include Hickory Farms and Patagonia. Similarly organizations are building custom applications using Windows Azure Active Directory; for example, easyJet in Europe is using Windows Azure Active Directory Access Control and the Windows Azure Service Bus to enable flight check-in and other tasks for airport gate agents.
Coming in Part 2
In this first post, we focused on how we are reimagining Active Directory as a cloud service. We discussed how the application of cloud architecture and economics is making it possible to bring the power of organizational identity management to organizations of any size and IT sophistication, with great ease of use, low cost, and high availability.
Hopefully this post conveyed that Active Directory as a service is here now and that it is very easy for organizations to obtain and use. Many applications are already integrating with Windows Azure Active Directory, including SaaS applications such as Office 365 and many custom applications built on Windows Azure and other platforms.
For IT professionals and users within organizations, these integrations provide many benefits, including common experiences like SSO; shared context between applications, including information about the people in an organization, their relationships, and roles; consistent management; the ability to seamlessly extend existing directory deployments and identity management processes to the cloud; and efficient, highly available operations.
In my next post, I will cover what this reimagined Active Directory can mean for developers and how moving to the cloud is enabling Microsoft and software developers to work together to reimagine the role of Active Directory. We will focus on how we are making it easier for developers to integrate with Windows Azure Active Directory and look at how Windows Azure Active Directory can be used as a platform to enable the social enterprise.
In particular, we will look at enhancements to Windows Azure Active Directory and the programming model that enable developers to more easily create applications that work with consumer-oriented identities, integrate with social networks, and incorporate information in the directory into new application experiences. And we will talk about how developers can use Windows Azure Active Directory to support new scenarios that go well beyond the “behind the firewall” role that identity management has historically played. We are excited to work with developers and help them build these next-generation experiences and capabilities for organizations and users.



Be sure to read Kim Cameron’s Identity Management As A Service post of 5/23/2012 (linked in John’s second paragraph.
• Will Perry (@willpe) described Getting Started with the Service Bus Samples for Windows 8 in a 5/22/2012 post:
As part of the Windows Azure Toolkit for Windows 8, we recently released a sample library for accessing Service Bus from Windows 8 metro style applications and a sample metro app demonstrating how to use some basic Service Bus functionality. In this post, we'll take a quick tour around the sample app, get an introduction to the sample library and examine in detail how the sample library works.
Service Bus Sample Browser for Windows 8
In every sample, bringing up the AppBar in the sample browser (Right Click with a Mouse, or swipe up from the bottom bezel with touch) will allow you to Copy Source Code from the sample to the clipboard for use in Visual Studio.
When you launch the sample browser, you'll find 3 simple samples included:
Simple Queues
Service Bus Queues are durable First In, First Out message queues that permit communication between distributed applications or components. You can learn more about Service Bus queues on WindowsAzure.com. The pattern for using queues is straightforward: someone sends a message to the queue, someone else receives the message later.
In the Simple Queues sample, you can follow a simple example of how to use this messaging pattern within a Windows 8 metro style application.
Simple Topics
Topics and Subscriptions in Service Bus support a publish/subscribe communication model - messages are Sent to a single topic and can then be Received by multiple subscribers. You can learn more about Service Bus Topics on WindowsAzure.com. Using topics is as simple as using queues - someone sends a message to the topic and each subscriber is able to receive a copy of that message later.
In the Simple Topics sample you'll create a Topic, add one or more subscribers to it then send and receive messages.
Peek Lock, Abandon and Complete
Both Queues and Subscriptions support to different ways to receive messages. The first, Receive and Delete, removes the message from the queue or subscription when it is received - if the receiver fails to process the message, then its content is lost. The second, Peek Lock, makes the Receive and Delete operations two separate operations - first a messages is Peeked from the queue by the receiver, later the receiver can Complete the message (deleting it from the queue or subscription and marking it as processed) or Abandon the message (marking it as not completed or unprocessed). A message is returned to the queue or subscription if it is abandoned of its peek-lock times out (by default, the peek lock timeout is 30 seconds).In the Peek Lock Sample, you try out peek locking yourself. Click each of the shapes to send it to a queue and then try receiving. When you've received a shape, select it to Complete or Abandon the message - Completed messages do not return to the Queue, while abandoned ones do. If you neither complete or abandon a message, you'll observe that it's lock expires and it is automatically returned to the queue.
Sample Service Bus Library for Windows 8 - Microsoft.Samples.ServiceBus
To get started download the Windows Azure Toolkit for Windows 8.
To make it easier to consume the Service Bus REST API, we've built a sample library for Windows 8 which wraps common Service Bus primitives like Queue, Topic and Subscription - let's dive straight into some code to illustrate creating a queue, sending a message, receiving the message and deleting the queue. If you are new to the Service Bus, take a look at these how-to articles on Service Bus Queues and Service Bus Topics.
Since we'll be calling Service Bus over HTTP, we need to consider a couple of things:
- Request the Internet (Client) capability in your package manifest: Service Bus is on the internet, so you'll need to make sure your application has permissions to access the network.
- Calls to the network should always be asynchronous: since a network call could take a little time to complete, you'll always want to use asynchronous IO. The Sample Service Bus Library helps out by exposing simple asynchronous methods for every operation.
First up, we need a Token Provider. Token Providers are used by the library to request an authorization token from the Access Control Service (ACS) and attach that token to requests made to Service Bus. You can think of the Token Provider like a set of credentials - it specifies 'who' is trying to perform an action on a service bus resource:
TokenProvider tokenProvider = TokenProvider.CreateSharedSecretTokenProvider(
serviceNamespace: "Your Service Bus Namespace Name, e.g. contoso",
issuerName: "owner",
issuerSecret: "Your Service Bus Issuer Secret, e.g. b66Gxx...");Next we'll create a queue - this super-simple call specifies the path of the queue to create and uses the default queue description. If you want to tweak the settings on the queue you're creating, you'll find a helpful overload accepting a Queue Description as a parameter:
Queue myQueue = await Queue.CreateAsync("MyQueue", tokenProvider);
With the queue created in Service Bus, we can go ahead and send a message. The samples library makes it simple to send plain text messages or messages whose body is a JSON formatted object. Here, we're just going to asynchronously send a plain text string as the body of the message:
await myQueue.SendAsync("Hello World!");
Receiving a message is just a simple - we'll attempt to receive from the queue using Receive and Delete semantics. If you want to use Peek Lock semantics, you'll find the PeekLockAsync method nearby. Having received the message, we'll extract the plain-text body:
BrokeredMessage message = await myQueue.ReceiveAndDeleteAsync();
string greeting = message.GetBody<string>();Finally, we're going to clean up after ourselves and delete the queue:
await Queue.DeleteAsync("MyQueue", tokenProvider);
So, there we go - just a few lines of code to create, send, receive and delete entities in Service Bus. In the Sample Service Bus Library for Windows 8, we've tried to ensure you have a simple API surface area to get started with and the full power of our REST API surface available when you want it. We're shipping this library as an open source licensed sample to give you the freedom and flexibility to dive deep into the code if you want to and tweak to your heart's content!
We're hopeful that the simplified API surface in the Sample Service Bus Library for Windows 8 makes it easy to get started building great Metro Style Apps that are connected with Service Bus - we've tried to reduce the total number of concepts you need to become familiar with to achieve typical scenarios and make it easier to learn about our advanced features as you need them - we're always keen to hear your feedback on how useful this sample library is to you, please let us know you thoughts on the discussion list for Windows Azure Toolkit for Windows 8.
Going Deep: How the Sample Service Bus Library for Windows 8 Works
Service bus operations fall into one of two classes: Management or Runtime. Management operations are used to Create, Enumerate, Get and Delete service bus entities like Queues, Topics and Subscriptions; Runtime operations are used to Send and Receive messages. Firstly we'll dive deep into how the Sample Service Bus Library for Windows 8 implements Management Operations, and then we'll take a look at how Runtime Operations are implemented.
Management Operations: Create, Get, Enumerate and Delete
The service bus namespace can be thought of as a set of ATOM Feeds, each describing entities that exist at paths beneath it. For example, if a Queue called 'Foo' exists at the Uri: https://contoso.servicebus.windows.net/Foo then we would find an atom entry like this at that address:
Quickly looking over the markup, you'll notice the address of the queue (line 3), the name of the queue (line 4) and the description of the queue that exists here (line 12-25). This pattern is true throughout the namespace - all entities are represented as an XML Entity Description wrapped in an Atom Entry.
Managing service bus entities is achieved by performing RESTful operations on these feeds within a service bus namespace over HTTPS: To create an entity we issue an HTTP PUT, to get an entity we issue an HTTP GET and to delete an entity we issue an HTTP DELETE. Enumeration is performed by issuing an HTTP GET within the reserved $Resources collection at the root of the namespace (for example, /$Resources/Queues).
Each type of entity and sub entity that you can create is represented in a hierarchy of Resource Descriptions. These include the familiar Queue, Topic and Subscription Descriptions and more advanced entities like Rule Description, Rule Filter and Rule Action:
The Resource Description types encapsulate the Content of an Atom entry that represents a service bus entity - when serialized to XML (using the DataContractSerializer) and wrapped in an Atom entry, these types can be used to create, delete, list and represent entities in service bus.
Within the Sample Service Bus Library for Windows 8, a Resource Description can be expressed as an Atom Entry by calling the AsSyndicationItem() method; the SyndicationItem type is within System.ServiceModel.Syndication namespace which provides classes to work with both RSS and ATOM feeds. Similarly, a Resource Description can be extracted from an Atom Entry by using the static ResourceDescription.Create<T>(SyndicationItem) method and specifying the expected resource type as the type parameter, T (for example, T could be QueueDescription).
Understanding how we model the descriptions of various service bus entities (as ResourceDescriptions) and how we convert those descriptions to and from Atom (using the ResourceDescription.AsSyndicationItem() and ResourceDescription.Create<T>(SyndicationItem item) methods) we're well prepared to see how the Create, Get, List and Delete operations are implemented. We'll use Queues to examine how management operations are implemented, but the logic for Topics, Subscriptions and Rules is extremely similar.
Let's take a look at creating a Queue:
Queue myQueue = await Queue.CreateAsync("Foo", tokenProvider);
When we call Queue.CreateAsync, we're going to perform the following operations:
- Create an instance of QueueDescription and specify "Foo" as the path;
- Create a NamespaceManager for the service bus namespace specified in the tokenProvider;
- Request that the NamespaceManager create a new Queue with the specified QueueDescription;
- Within the NamespaceManager, wrap the QueueDescription in Atom by calling AsSyndicationItem();
- Request that a SyndicationClient create a new resource with the specified SyndicationItem;
- The SyndicationClient requests an Authorization Token with the TokenProvider;
- The SyndicationClient issues an HTTP PUT with the SyndicationItem as its body and the Authorization Token as a header;
- The HTTP Response is read and loaded into a SyndicationItem by the SyndicationClient;
- The SyndicationItem is returned to the NamespaceManager;
- The NamespaceManager extracts the Content of the SyndicationItem as a QueueDescription;
- The QueueDescription is returned to the calling Queue.CreateAsync method;
- An instance of a Queue is created to encapsulate the newly created QueueDescription.
You can visualize the Queue, NamespaceManager and SyndicationClient as each adding a layer of information to the original intent to create a queue called foo before handing the request off to service bus:
The Queue is a convenience class that encapsulates a Queue's description and also operations like Send/Receive in one place. The Queue type uses a NamespaceManager to Create, List, Get and Delete entities in a Service Bus namespace. The NamespaceManager is responsible for figuring out the full URI that an HTTP Request should be issued against (using the ServiceBusEnvironment) and wrapping Resource Descriptions in Atom (using the AsSyndicationItem method) before using a SyndicationClient to create HTTP Calls. The SyndicationClient is responsible for getting an authorization token (using a TokenProvider) and making HTTP calls (using HTTPClient).
All management operations happen the same way - they're first issued against a high-level abstraction like Queue, Topic or Subscription, passed down to a Namespace Manager for addressing and conversion to Atom then handled by a Syndication Client to perform the actual raw HTTP Request against service bus.
Runtime Operations: Send, Receive, Peek Lock, Abandon and Complete
Sending and receiving messages over HTTP is really simple. To send a message you issue an HTTP POST to the 'messages' collection of a Queue or Topic and to Receive (in receive and delete mode) you issue an HTTP DELETE to the head of the 'messages' collection of a Queue or Subscription. Peek locking is similarly achieved by issuing an HTTP POST to the head of the messages collection to create the peek lock; issuing an HTTP PUT to the lock location to abandon the message and issuing an HTTP DELETE to the lock location.Service Bus Messages have Headers (like Sent Time, Message Id and Time-to-Live); user-specified message Properties and a body. Over HTTP, Headers are encapsulated as a JSON formatted structure in a reserved HTTP Header named BrokerProperties; user-specified message properties are encapsulated as plain HTTP Headers and the body of the service bus message is - you guessed it - the body of the HTTP Message. Sending a message to a queue is as simple as invoking SendAsync on that queue:
await myQueue.SendAsync("Hello, World!");
Let's take a look at a the HTTP trace for sending this message to get a better idea of what it looks like:
POST https://contoso.servicebus.windows.net/Foo/Messages HTTP/1.1
Host: contoso.servicebus.windows.net
Authorization: WRAP access_token="..."
Content-Type: text/plain
Content-Length: 13Hello, World!
Receiving a message is similarly straightforward - this time we'll Receive and Delete from the head of the Queue:
BrokeredMessage message = await myQueue.ReceiveAndDeleteAsync();
And here's the corresponsing HTTP request and response traces:
DELETE https://contoso.servicebus.windows.net/Foo/Messages/Head?timeout=30 HTTP/1.1
Host: contoso.servicebus.windows.net
Authorization: WRAP access_token="..."
Content-Length: 0-
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: text/plain
Server: Microsoft-HTTPAPI/2.0
BrokerProperties: {"DeliveryCount":1,"MessageId":"62a7eceab7eb4d52ac741af5f44393ce","SequenceNumber":1,"TimeToLive":922337203685.47754}
Date: Mon, 04 Aug 2015 16:23:42 GMTHello, World!
You can see here the simple format of a service bus message over HTTP and start to identify some of the metadata available in the BrokerProperties header. Within the Sample Service Bus Library for Windows 8, the type BrokeredMessage is used as an encapsulation for a service bus message, its headers, properties and body. Let's walk through how the call to SendAsync actually works:
- SendAsync(string …) is called indicating that a plain-text service bus message should be sent;
- A new BrokeredMessage is constructed and writes the body of the message to a Stream;
- The Queue calls SendAsync(BrokeredMessage) on a MessageSender with the newly constructed message;
- The MessageSender requests an Authorization Token with the TokenProvider;
- The MessageSender issues an HTTP POST specifying the BrokeredMessage's BodyStream as its body;
- HTTP Headers, including any BrokerProperties, user-specified message properties and the Authorization Header are appended to the request.
- The HTTP Response is checked for an OK (200) status code.
The message sender also supports sending more complex types as the body of a message by serializing them to JSON. A MessageReceiver is used in a similar fashion to receive messages from a Queue or Subscription.
Hopefully this quick whirlwind-tour of the Sample Service Bus Library for Windows 8 gives you some pointers to get started. We're really excited to hear your feedback on the library and see the awesome connected apps you build with it - lets us know what you're up to on the discussion list for Windows Azure Toolkit for Windows 8.






Jim O’Neil (@jimoneil) continued his series with Fun with the Service Bus (Part 2) on 5/21/2012:
In Part 1, we looked at a scenario using the Service Bus as a WCF relay endpoint that allowed clients on the web to communicate with a WCF service hosted on my local machine. The workflow looks something like below, where a publically available endpoint (a simple ASP.NET application on Windows Azure) made calls to my service, self-hosted in a WPF application and running on my local machine, behind a firewall but attached to a relay endpoint in the Service Bus.
All that works fine, but there is a significant drawback in the approach: both sides have to be “up” at the same time or the communication fails. Sure that happens on-premises too, and you can build retry logic in, but wouldn’t it be easier if all that were just done for you? That’s where Service Bus queues come in. A queue provides a place for the messages to sit in case there are no clients available to process them, perhaps because the client is down or too busy. As an direct result of this ‘temporal decoupling,’ it’s possible now for senders and receivers to operate at different rates; furthermore, multiple consumers that work off the same queue can process messages at their independent own rates. It’s the same type of “competing consumer” model as a queue in a bank where you’re waiting to be served by the next available teller.
As the focus of this post, I’ll take the existing sample I walked through in the previous blog post and modify it to work with Service Bus queues. As with that previous sample, you can download the full source code from GitHub, although you will need to modify the application settings (in App.config and web.config) to use the Service Bus identities and keys you set up for the previous sample.
Creating a Queue
The first step is to create a Service Bus queue. You can do that programmatically or via the Windows Azure Portal directly under the Service Bus namespace you created in part 1. Here I’ve created a queue named thequeue and left all of the properties at their default settings:
- Default message time to live (TTL) indicates how long the message will sit on the queue before it is deleted. That curious default number there is just over 29000 years, by the way! If you also check the Enable Dead Lettering on Message Expiration box, the message will be moved to a special dead letter queue with an endpoint in this case of
sb://heyjim.servicebus.windows.net/thequeue/$DeadLetterQueue- Queues also support duplicate message detection where a message’s uniqueness is defined by the MessageId property. To detect duplicates, you’d check the Requires Duplicate Detection checkbox and set the time window during which you want duplicates to be detected (Duplicate Detection History Time Window). The default is 10 minutes, which means that a second message with the same MessageId that arrives within 10 minutes of the first occurrence of that message will automatically be deleted.
- Lock Duration specifies the length of time (with a max of five minutes) that a message is hidden to other consumers when the queue is accessed in PeekLock mode (versus ReceiveAndDelete mode).
- The Maximum Queue Size can be specified in increments of 1GB up to a maximum of 5GB; each message can be up to 256KB in size.
- If Requires Session is checked, messages that must be processed together by the same consumer can be accommodated. A session is defined at message creation time using the SessionId property. Setting this property requires that clients use a SessionReceiver to consume messages from the queue.
All of these properties can be set when you programmatically create a queue as well (using the CreateQueue method via a Service Bus identity that has the Manage claim). In fact there are two additional (QueueDescription) properties that don’t seem settable via the portal:
- EnableBatchedOperations indicates that Send and Complete requests to the queue can be batched (only when using asynchronous methods of the .NET managed client), which can increase efficiency; by default batched operations are enabled.
- MaxDeliveryCount (default value: 10) indicates the maximum number of times a message can be read from the queue. This setting applies only when the MessageReceiver is in PeekLock mode, in which a message is locked for a period of time (LockDuration) during which it must be marked complete, or it will again be available for processing. MaxDeliveryCount then figures into strategies for poison message processing, since a doomed message would never be marked complete and would otherwise reappear on the queue ad infinitum.
Windows Azure Storage also includes queues, how do they differ? In general, Service Bus queues have more capabilities and features, but they can have higher latency and are capped at 5GB. Service Bus queues are a great option for hybrid applications and those requiring “at-most-once” or “first-in-first-out” delivery. Windows Azure Storage queues have a simpler programming model and are well suited for inter-role communication, like between a Web Role and Worker Role within a cloud service. That said there are a host of other distinctions that could push your decision one way or the other. Check out Windows Azure Queues and Windows Azure Service Bus Queues - Compared and Contrasted for a detailed analysis.
Coding the Consumer
In our example, the message queue consumer is the WPF client application. In the on-premises scenario covered by my previous post, the WPF application self-hosted a WCF service endpoint through the Service Bus using BasicHttpRelayBinding. With queues you can also use WCF semantics via a new binding, NetMessagingBinding, and Tom Hollander covers this approach in his blog. Alternatively, you can use the REST API from any HTTP client, or as I’ll cover here the .NET API.
The code for processing the messages is launched on a separate thread from the simple UI of the WPF window. The complete code appears below, with the more salient portions highlighted and explained below.
1: internal void ProcessMessages()2: {3: try4: {5: MessagingFactory factory = MessagingFactory.Create(6: ServiceBusEnvironment.CreateServiceUri("sb",7: Properties.Settings.Default.SBNamespace,8: String.Empty),9: TokenProvider.CreateSharedSecretTokenProvider("wpfsample",10: Properties.Settings.Default.SBListenerCredentials));11: MessageReceiver theQueue = factory.CreateMessageReceiver("thequeue");12:13: while (isProcessing)14: {15: BrokeredMessage message = theQueue.Receive(new TimeSpan(0, 0, 0, 5));16: if (message != null)17: {18: Dispatcher.Invoke((System.Action)(()19: =>20:21: {22: NotificationWindow w;23: try24: {25: w = new NotificationWindow(26: message.Properties["Sender"].ToString(),27: message.GetBody<String>(),28: message.Properties["Color"].ToString());29: }30: catch (KeyNotFoundException)31: {32: w = new NotificationWindow(33: "system",34: String.Format("Invalid message:\n{0}",
message.GetBody<String>()),35: "Red"36: );37: }38: WindowRegistry.Add(w);39: w.Show();40: message.Complete();41: }));42: }43: }44: }45:46: catch (Exception ex)47: {48: Dispatcher.Invoke((System.Action)(()49: =>50: {51: btnServiceControl.Content = "Start Responding";52: this.Background = new SolidColorBrush(Colors.Orange);53: this.isProcessing = false;54: }));55: MessageBox.Show(ex.Message, "Processing halted",
MessageBoxButton.OK, MessageBoxImage.Stop);56: }57: }Lines 5-10 set up the MessagingFactory which establishes the Service Bus endpoint and the credentials for access (the wpfsample user is assumed to present the Send claim as set up in my prior blog post). In Line 11, a MessageReceiver is instantiated pointing to the queue that we explicitly created earlier via the Windows Azure portal.
The call to Receive in Line 15 yields the next message on the queue or times out after five seconds. If no message appears on the queue within that time period, the resulting message in Line 16 is null. The enclosing while loop will then iterate and continue to await the next message. (The isProcessing flag is a class level variable that enables the WPF application user to stop and start listening on the queue; it’s set via the command button on the user interface).
The message returned is of type BrokeredServiceMessage, through which you can access header information in a Properties bag and obtain the message payload itself via the GetBody method (Lines 25-28). If the message doesn’t contain the expected content, for instance the headers aren’t set, some action needs to be taken. Here the remediation (Lines 30ff) is to simply display a error message via the same method as for a legitimate notification, but we could have taken another approach and moved it to the dead letter queue, via the aptly named DeadLetter method, where some other process could inspect and forward messages for human intervention or diagnosis.
With the message processed, the last step is to mark it complete (Line 40). That should be a cue that I’m using the (default) PeekLock semantics on the queue. If I’d set
theQueue.Mode = ReceiveMode.ReceiveAndDelete;the message would automatically be deleted; however, I would have run the risk of losing that message had there been a service outage or error between retrieving the message and completing the processing of the message.Other possibilities for handling the message include:
abandoning it, in which case the peek lock on the message is immediately released and the message become visible again for another consumer,
moving it to the dead letter queue as mentioned earlier, or
deferring the message and moving on to the next one in the queue. Here you must retain the SequenceNumber and call the overloaded Receive method passing that number at the point when you do wish to process the message.
Coding the Producer
The message producer in this case is the ASP.NET web application. It could be hosted anywhere, like say Windows Azure, but if you’re just testing it out, you can run it from the Azure emulator on your local machine or even just via the development web server (Cassini) from within Visual Studio. The code follows:
1: protected void btnSend_Click(object sender, EventArgs e)2: {3: if (txtMessage.Text.Trim().Length == 0) return;4: String userName = (txtUser.Text.Trim().Length == 0) ? "guest" : txtUser.Text;5:6: // create and format the message7: BrokeredMessage message = new BrokeredMessage(txtMessage.Text);8: message.Properties["Sender"] = txtUser.Text;9: message.Properties["Color"] = ddlColors.SelectedItem.Text;10:11: // send the message12: MessagingFactory factory = MessagingFactory.Create(13: ServiceBusEnvironment.CreateServiceUri("sb",14: ConfigurationManager.AppSettings["SBNamespace"],15: String.Empty),16: TokenProvider.CreateSharedSecretTokenProvider(17: userName,18: ConfigurationManager.AppSettings["SBGuestCredentials"]));19: factory.CreateMessageSender("thequeue").Send(message);20: }In Lines 7-9, a new message is created from the text provided in the Web form, and two properties set, one corresponding to the name of the sender and the other corresponding to the selected color.
Then in Lines 12-18, a MessagingFactory is likewise instantiated; however, here the Service Bus identity (guest, by default) needs the Send versus the Listen claim.
In Line 19, the message is sent via a MessageSender instance. It’s done synchronously here, but asynchronous versions of Send and other operations on the complementary MessageReceiver class are also available (and preferred in most cases for scalability and user experience reasons).
Grab the Code!
I’ve added the code for the brokered messaging sample to the relay sample code already on GitHub (MS-LPL license) so you can experiment on your own. Next time we’ll look at a more advanced publication/subscription scenario leveraging Service Bus topics and subscriptions.



Haishi Bai (@HaishiBai2010) recommended Window Azure Service Bus: Use read-only credentials for your Service Bus clients in a 5/21/2012 post:
Your Service Bus namespace “owner” is a very privileged account as to the namespace. You should never, ever share your “owner” key (either explicitly or to embed in your source code) to anybody, including your business partners. Why? Because they can do very bad things to your Service Bus namespaces such as deleting your queues or topics. But that’s not all. They can do other damages to your business without taking down your service. This should be obvious, but just in case that you are still not convinced, here’s an example for you – Let’s say you have two business partners, partner “Joker Bob” and partner “Serious Sam” (which coincidentally has the same name as one of my favorite FPS games). You trust Sam to handle your high-valued orders, while you give low-valued orders to Joker. So you implement content-based routing using Service Bus topics and subscriptions:
nsm.CreateSubscription("orders", "low_value", new SqlFilter("value <= 100")); nsm.CreateSubscription("orders", "high_value", new SqlFilter("value > 100"));var qc = mf.CreateSubscriptionClient("topic","low_value", ReceiveMode.PeekLock); var rules = nsm.GetRules("topic", "low_value"); foreach (var rule in rules) qc.RemoveRule(rule.Name); qc.AddRule("all orders", new SqlFilter("value >=0"));Guess what, now he’s competing with Sam for high-valued orders. What’s worse is that in Management Portal you can’t tell if the filter on a subscription has been rigged. It’s hard to find this out unless you are monitoring your services very closely.So, when you release a Service Bus client to your users, make sure that they can be associated only with read-only accounts. The good news is, this is fairly easy to do - here’s how. Let’s say you want to create a reader user that can only listen to messages, what you need to do is to create a separate server identifier that only has Listen access to your namespace. Actually, because Service Bus is integrated with ACS, you can set up such users with any trusted identity providers. Here, for simplicity, we’ll just use Service identifiers provided by ACS out-of-box:
- Login to Management Portal. Click on the Service Bus namespace you want to manage, and then click on Access Control Service icon on the top pane.
- Click on Service identifiers link. You’ll see your owner user listed. This is the default owner account of your namespace. Guard it safe!
- Click on Add link to create a new identifier.
- Enter reader as Name. Then click on Generate button to generate a shared secret for the user. Finally, click Save.
- Click on Relying party applications link in the left pane. You’ll see a ServiceBus application listed (because your Service Bus service configured as a relying party of ACS).
- Click on ServiceBus. Then, in the relying party page, scroll down and click on Default Rule Group for ServiceBus link.
- In this group you’ll see three rules are already created. These three rules grant owner user Listen, Send, as well as Manage accesses.
- Click on Add link to add a rule for reader:

- Use this identifier in your client code. Now the client won’t be able to call administrative methods such as GetRules() and RemoveRule() anymore


<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Avkash Chauhan (@avkashchauhan) described Debugging Windows Azure Web Role Application_Start() method in Global.asax.cs on 5/22/2012:
I am writing the detail below on how you can hit BP at Application_Start() in Global.asax.cs:
First you can write Debugger.Break() code in your Application_Start() as below:
Now please open your Role Properties > Web and select
1.Use Visual Studio Development Server settings (I have chosen as shown in image below)
2.Use Local IIS Web Server
Now debug your application and you will see a message as below to debug W3WP.EXE process:

Select Debug option above and then you will see BS JIT Debugger Windows as below:

Once you accept VS JIT debugger launch process, you will see the PB hit in your Applicaton_start() as below:

That's it!!





My (@rogerjenn) Recent Articles about SQL Azure Labs and Other Added-Value Windows Azure SaaS Previews: A Bibliography article of 5/20/2012 begins:
I’ve been concentrating my original articles for the past six months or so on SQL Azure Labs, Apache Hadoop on Windows Azure and SQL Azure Federations previews, which I call added-value offerings. I use the term added-value because Microsoft doesn’t charge for their use, other than Windows Azure compute, storage and bandwidth costs or SQL Azure monthly charges and bandwidth costs for some of the applications, such as Codename “Cloud Numerics” and SQL Azure Federations.
Windows Azure Marketplace DataMarket plus Codenames “Data Hub” and “Data Transfer” from SQL Azure Labs
Apache Hadoop on Windows Azure from the SQL Server Team
Codename “Cloud Numerics” from SQL Azure Labs
Codename “Social Analytics from SQL Azure Labs
Codename “Data Explorer” from SQL Azure Labs
SQL Azure Federations from the SQL Azure Team

Kathleen Richards (@RichardsKath) reported Microsoft Reveals Visual Studio 11 Product Lineup, Adds Windows Phone in a 5/21/2012 post to the Visual Studio Magazine blog:
Visual Studio 11 Express for Windows Phone is slated for release with the next version of Windows Phone, the company announced on Friday.
Microsoft has unveiled its final Visual Studio 11 product lineup and specifications, and the SKUs and hardware requirements are largely unchanged from Visual Studio 2010.
Visual Studio 11 Ultimate is still the company's all-in-one Application Lifecycle Management platform. It integrates all of the tools (including the higher end testing functionality and design tools) with Visual Studio Team Foundation Server for team collaboration. Visual Studio 11 Premium offers most of the diagnostic and testing tools without the high level architecture and modeling support. Visual Studio 11 Professional is the entry-level developer product. Visual Studio LightSwitch, previously a standalone product, is now available in all three editions. All of the Visual Studio 11 products require Windows 7 or higher.
On Friday, Microsoft announced that it has added Visual Studio 11 Express for Windows Phone to the lineup. The free tooling is slated for release with the next version of Windows Phone. The Visual Studio 11 previews (including the current beta product) have not supported phone development or out of band Windows Azure upgrades.
Express tooling for Windows Azure is expected with the next update of Microsoft's cloud platform, according to the Visual Studio team blog. In addition to the Windows Phone and cloud tooling, Microsoft is offering Visual Studio 11 Express for Windows 8, Visual Studio 11 Express for the Web and Visual Studio 11 Team Foundation Server Express. All three products are currently in beta and available for download.
The Visual Studio 11 default target for managed applications, running on Windows Vista or higher, is .NET Framework 4.5 or the VC11 tooling for native apps. Developers can use the IDE's multi-targeting support to run managed applications on Windows XP and Windows Server 2003 with .NET 4 and earlier versions of the framework, according to Microsoft. However, multi-targeting for C++ requires a side-by-side installation of Visual Studio 2010.
The company is working on solving this issue, according to the Visual Studio Team blog:
"[W]e are evaluating options for C++ that would enable developers to directly target XP without requiring a side-by-side installation of Visual Studio 2010 and intend to deliver this update post-RTM."Pricing Preview
Microsoft offered developers a preview of its estimated retail pricing for the Visual Studio 11 products earlier this year. The company is planning to offer Visual Studio Ultimate with a 12 month MSDN subscription ($13,299), Visual Studio Premium with MSDN ($6,119), Visual Studio Professional with MSDN ($1,199) and Test Professional with MSDN ($2,169). Visual Studio Professional is also available as a standalone product without an MSDN subscription ($499). Full featured Team Foundation Server is $499, with the same ERP for a CAL (user or device). Outside of the entry-level Professional product without MSDN, Visual Studio 11 pricing is generally higher than Visual Studio 2010, which debuted in April 2010.Upgrades for existing customers with MSDN subscriptions are considerably less, and Microsoft is encouraging developers to buy or upgrade to Visual Studio 2010 with MSDN to take advantage of the renewal pricing for the Visual Studio 11 lineup.
The pricing on Visual Studio 2010 Professional with MSDN ($799) remains unchanged. However, the company is offering various incentives including a bundle with a discounted Samsung Series 7 Slate ($2,198). Microsoft is also reducing the pricing on Visual Studio 2010 Professional from $799 to $499 U.S. (Pricing outside of the U.S. may vary by region.)
In April, Microsoft expanded its licensing terms for Visual Studio Team Foundation Server 2010 to enable access to Server Reports and System Center Operations Manager, without a CAL purchase. In March, the company started to offer Visual Studio Team Explorer Everywhere 2010 as a free download.
Visual Studio LightSwitch, which offers templates for building data-driven line of business apps, was released out of band last summer. It's availability as a standalone tool is ending when Visual Studio 11 is released, according to a blog posted by Jay Schmelzer, principal director program manager of the LightSwitch team at Microsoft. Visual Studio 11 is integrated with LightSwitch Version 2, which offers project templates for Windows 8 Metro style apps. LightSwitch also adds support for the OData protocol, which can be used for querying and integrating data services (HTTP, ATOM and JSON) into applications.
Full disclosure: I’m a contributing editor for Visual Studio Magazine.
Joseph Fultz wrote Azure Performance Tips, Part 2: Cloud Checks as an “In Depth” column and Visual Studio Magazine posted it online on 5/17/2012:
Visual Studio test tools, profiling, performance counters, and the SQL Azure Management Console provide a snapshot as to how the app performs.
Now I'm ready to put a little stress on my deployed code and collect some information. I'll make use of Visual Studio test tools, profiling, performance counters, and the SQL Azure Management Console to get a picture of how the app performs.
Setting Up the Test Harness
First, a warning: do not do this for a full-scale test. A full-scale load test would have potentially thousands of virtual users connecting from the same location and thus cause the security infrastructure to suspect that your cloud app is the victim of a DoS attack.Setting off the DoS protection for your app could result in significant hits to time and cost. The goal here is to set up a local test and re-point it to the cloud with sufficient load to make any hotspots light up.
To get started, I've added a Test Project to my solution and added a couple of test methods to a unit test, as shown in Listing 1.
With a reference added to the service, I want to add a couple of test methods. One retrieves a specific transaction by the specific ID. I randomly picked the test ID to minimize the impact of any caching on the test execution. This is shown in Figure 1.
The second test method asks for a couple of days of data from a randomly picked store. In this case, I don't want the test method to retrieve too much data as that's unrealistic; but I do want it to be enough to potentially bring to light latency caused by serialization, marshaling types, and transferring data across machine boundaries.
I'll set up the load test by running it against the local dev fabric. The local test won't represent true performance (neither will the cloud test since profiling will be on), but what I'm really after is relative performance to catch outliers. I'm going to wave my hands over the local run since the focus here is on the cloud.

[Click on image for larger view.]
Figure 1. Load distribution.Having added a load test to my Test Project, I'm going to adjust the settings a bit. I want to get about two detail requests for every search request, so I've adjusted it appropriately in the load Test Mix. Additionally, I need to set up the overall test scenario.

[Click on image for larger view.]
Figure 2. Load test settings.I don't want to set off any warning alarms, nor do I want to take out any new loans to support my cloud habit, so this isn't the means by which I want to accomplish my actual load tests.
I do want to stress the site with more than one user, and I want to know how things might look in the cloud vs. the local tests I've run. So I set up a maximum of 25 concurrent users with no wait time on a test that will run for five minutes (Figure 2).
Finally, I'll need to modify the URI used by the proxy; that's easily accomplished by editing the endpoint address in the Unit Test project app.config, as shown here:
<endpoint address="http://jofultzazure.cloudapp.net/TestDataService.svc" binding="wsHttpBinding" bindingConfiguration="WSHttpBinding_ITestDataService" contract="CloudPerf.ITestDataService" name="WSHttpBinding_ITestDataService" />In this case, I'm not making use of Visual Studio's ability to collect performance data. This would require more setup than I want to take time to do at this stage. As a different part of the overall development effort, I'll want a full test rig to exercise the application for performance and soak. That setup will leverage Visual Studio's testing features and require a little more complexity, including Azure Connect and deploying agents into the cloud. Once ready for that scenario, you can find the fully detailed steps here.
Collecting Data from the WebRole
Since I'm not collecting that data performance data in the normal Visual Studio way, I'm going to need to instrument my app to collect the primary items I'm for which I'm looking. Items that interest me the most are Test Time, CPU, GC Heap Size, Call Duration and Call Failures. There is a bounty of other metrics that I want to collect and review for a full load test, but for this purpose this information will do. The great news is that between Profiling and the Load Test information, I'll have everything except for the GC Heap information.To collect the extra data I want I'll need to have an Azure Storage location for the performance counter logs; I also have to modify my WebRole's OnStart() method and set up the collection for the performance counters, as shown in Listing 2.
As you can see in Figure 5, I've added a setting to the WebRole (DevLoadTesting) to indicate whether or not I should load the counters I'm interested in. Additionally, since I'm running a short test I've set the collection time at five seconds.
With that bit of work, the setup is done and I can deploy the role, run the test and collect the data.
Testing and Information
When deploying the application for my quick test, I make sure to enable Profiling for the deployment, as shown in Figure 3.

[Click on image for larger view.]
Figure 3. Configuring the Profiling settings.Note in Figure 6 that I've selected Instrumentation. As with any testing, the more precise the measurement the more the measurement will impact the test. I'm not immune to this affect, but I'm more concerned with relative performance than accurate run-time performance. So, while this will have an impact on the overall execution of the code, it's a cost worth paying, as it will net me a wealth of information. Other than that change, I deploy the application as usual.
Once the application is up and running, I give it a quick check to make sure it's working as expected. In my case, this is a Web service deployment so I just make a quick pass with WCFTestClient (SOAPUI is also an excellent tool for this). Satisfied that it's running properly, I open my load test and start the run, as shown in Figure 4.

[Click on image for larger view.]
Figure 4. Load Test Running.I like to see the execution times while the test is running, but it's also important to watch the Errors/Sec. If I start receiving errors, I'll want to stop the test and investigate to figure out if the error is in the test or in the service code. With everything looking pretty good here, I can just wait out the full test execution and then get to the good stuff.
Right-clicking on the running Instance allows me to view the Profiling report. Visual Studio retrieves all the collected information, and presents a nice graph (Figure 5) showing time, CPU utilization and the hot functions listed at the bottom.

[Click on image for larger view.]
Figure 5. The Profiling report.This is the same information presented by running a local Performance Analysis (Alt+F2) from the Debug menu. By clicking on the Call Tree link at the bottom, I get to see the top-level functions and metrics related to their executions. More importantly, I can drill into the execution and see where I might be experiencing some trouble, as shown in Figure 6.

[Click on image for larger view.]
Figure 6. Drill-down data on performance issues.Obviously, my data look-up method is running a bit long and it looks like my call to AddRange() is where the bulk of the effort is. I'll need to look at ways to optimize that bit of code, maybe through not using AddRange() or even List<>. In addition to, or in lieu of, changing that I should look at caching the return.
Until Next Time
In this installment I got the app out into the cloud and ran a test against it to generate some profiling information. In the next and final installment I'll do three things:
- Review the other supporting information from SQL Azure and the counters collected on my own
- Make a couple of adjustments to improve performance
- Run the test again and look at the delta







Full disclosure: I’m a contributing editor for Visual Studio Magazine.
Joseph Fultz wrote Azure Performance Tips, Part 1: Prepping and Testing the Local Development Machine as an “In Depth” column and Visual Studio Magazine posted it online on 4/11/2012 (missed when published):
In this multi-part series, Joseph Fultz will walk you through exactly what you need to know to make sure your Azure deployment performs optimally. First up, the steps you need to take on your local development machine.
In this series I'm going to go through the things I check and the way I check them in an attempt to assure good performance in a Windows Azure deployment. My focus won't be on covering the full optimization of each layer, but rather the way I check locally and then translate into the cloud to check the performance in deployment. Note that I consider this effort less than full testing, but the goal here is to ensure a solid product leaving the development team and arriving fully ready for the test assault. In this installment my focus is on the local development machine, while subsequent articles will focus more on the cloud side of the performance check.
The Application
The first activity in testing the application is understanding how it's constructed and how it operates. To that end I've created a rather simple application that consists of a service layer in front of a 5GB database in both my local SQL Server Developer Edition and in SQL Azure. While there are a lot of rows, they're not very wide and the schema isn't particularly complex (see Figure 1).
Figure 1. The SQL Server database schema.
What I've done within this database is leave off any indexes that might benefit me for the purpose of finding them along the way. The service interface against which I'll be doing my initial testing is shown in Listing 1.
Obviously this isn't a complete interface, but it will do for my purposes here. In each function I'll use LINQ to allow it to generate the SQL to fetch the data. Between my length of data, lack of indexes, lack of prepared statements and lack of optimizing data types -- especially as they relate to crossing boundaries -- I should have plenty of chances to make these bits of code better.
Test Approach and Concepts
I'll take a top-down approach, testing from the primary interface through to the back-end. For a full test, I suggest the layers and components be tested more granularly/individually and then within a full integration. But right now, I'm mainly focused on some aspects of performance testing. Generally, as a developer working on a feature, you have a pretty good idea of the performance of a piece of code in isolation and under low stress. In fact, you might have some standards around performance for checking. However, I want to do a little more than just test in isolation. For some of you, this will require a special environment to which you can deploy code and get a more realistic test, but in many cases you can run a small but integrated test right from your machine to spot check it. This is what I want to do to have the confidence that the code I'm checking in and passing on to the test team has a good chance of performing well.Visual Studio has full testing capabilities that I'll use locally prior to pushing my solution to the cloud. Then I'll cover running the tests in the cloud against the Staging deployment slot. One of the keys to identifying and making adjustments is to have an idea of the types of things you're looking for in each layer, as well as in the spaces between.
Figure 2 illustrates the various levels of detail that I spot-check and drill into if needed when I'm checking my work in my dev environment. Visual Studio provides most of the testing tools I need by providing functionality for Unit Testing, Load Testing, test metrics collection and performance counter collection. In addition, I'll use SQL Server Query Profiler to take a look at execution plans in SQL Server. Using these together in addition to some SQL Server built-in reports, I should be able to get a deployment that I can fine-tune for the cloud environment once there.

[Click on image for larger view.]Figure 2. The various levels and layers to spot-check while testing your work in your dev environment.
Setting up the Test Harness
While I've been doing a little more REST than SOAP for services lately, for this pass I'll work with the SOAP interfaces within the test project while also using the Windows Communication Foundation Test Client (WcfTestClient.exe).With my service project set as the default project, I press Ctrl+F5 to start without debugging. Once the tools have the Windows Azure emulator running and my package is deployed, I add a reference to the running project so I can use the generated proxies to code my tests against (see Figure 3).



Full disclosure: I’m a contributing editor for Visual Studio Magazine.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Beth Massi (@bethmassi) of the Visual Studio LightSwitch team announced New Office Integration Pack Extension Released to CodePlex on 5/22/2012:
If you haven’t noticed, Grid Logic has been working on a new version of the Office Integration Pack and has opened up source code for community contributions on CodePlex!
http://officeintegration.codeplex.com/
Released last year, the Office Integration Pack is a LightSwitch extension that makes it easy to manipulate the 2010 versions of Excel, Word and Outlook in a variety of ways common in desktop business applications. You can create documents, PDFs, spreadsheets, email and appointments using data from your LightSwitch applications. With the release to CodePlex they “are actively developing new features and welcome the community to help!” (see their website).
This new version expands upon the export APIs so that you can export any collection to Excel or Word. Collections can come from queries on your screens, or queries executed directly against the DataWorkspace. They can even be in-memory collections or LINQ queries and projections. They also have added the ability to format data as it is being exported.
Visit the Downloads tab to download the Office Integration Pack Extension and the Sample App. Visit the Documentation tab for an explanation on how to use the APIs. And if you have questions or issues please visit their CodePlex site and click on the Discussions or Issue Tracker tabs.
Thank you Grid Logic!



Beth Massi (@bethmassi) reported .NET Rocks! Podcast: Beth Massi Builds Apps with LightSwitch in Studio 11 on 5/22/2012:
Check it out, I’ve got another podcast with Richard and Carl this time talking about the new features in LightSwitch in Visual Studio 11. I always have a ton of fun talking with these guys and you can tell I’m super excited about the next version of LightSwitch.
Show #769: Beth Massi Builds Apps with LightSwitch in Studio 11
Carl and Richard talk to Beth Massi about the latest incarnation of LightSwitch. In 2011 LightSwitch shipped as a separate install, but the upcoming version of LightSwitch is part of every SKU of Studio 11. Beth talks about how LightSwitch has evolved to be an awesome consumer and creator of data, making it simple to create oData interfaces over anything. The conversation also digs into the role of Silverlight, the evolution of the client and how LightSwitch makes apps in the cloud much simpler.


Return to section navigation list>
Windows Azure Infrastructure and DevOps
•• Steve Martin (@stevemar_msft) posted Datacenter Expansion and Capacity Planning to the Windows Azure blog on 5/24/2012:
People’s ears usually perk-up when they hear Windows Azure uses more server compute capacity than was used on the planet in 1999. We are excited and humbled by the number of new customers signing up for Windows Azure each week and the growth from existing customers who continue to expand their usage. Given the needs of both new and existing customers, we continue to add capacity to existing datacenters and expand our global footprint to new locations across the globe.
As we announced in a recent blog post, two new US datacenter options (“West US” and “East US”) are available to Windows Azure customers. Today we are announcing the availability of SQL Azure in the “East US” Region to complement existing compute and storage services.
We appreciate the incredible interest our customers are showing in Windows Azure, and will communicate future news around our growing footprint of global datacenters as new options come online. As always, the best way to try Windows Azure is with the free 90-day trial.

But not in the South Central US data center. I’m waiting for the West US data center to support SQL Azure before moving my sample projects closer to home (from South Central US.)
• Wade Wegner (@WadeWegner) posted How to calculate what to move to the Windows Azure cloud to Mary Jo Foley’s All About Microsoft ZDNet blog on 5/23/2012:
A former Microsoft Windows Azure evangelist offers some advice for what to move to the cloud and when.
I’m taking a couple weeks off before the busiest part of Microsoft’s 2012 kicks into full gear. But never fear: The Microsoft watching will go on while I’m gone. I’ve asked a few illustrious members of the worldwide Microsoft community to share their insights via guest posts on a variety of topics — from Windows Phone, to Hyper-V. Today’s entry is all about Windows Azure and is authored by Wade Wegner.
I spent the last four years of my career as a Technical Evangelist for Windows Azure at Microsoft. Not only did I focus on driving the adoption of Windows Azure through building developer training kits and tool kits, but I also got to work with hundreds of customers and partners making their first investments in Windows Azure. Some of these folks started small with either a few cores and some data up in the cloud, while others made huge bets on the platform and leveraged thousands of cores and stored petabytes of data.
When I joined Aditi Technologies a few months ago, it was a bit of a wake-up call for me to see just how much time is spent talking with customers about what to move to the cloud even before the question of how is brought up. I had thought that it was common knowledge what applications would be best served in the cloud and how easy this decision should be for customers. Yet, the more I worked with customers in the early stages, the less surprised I was that that so much time is spent in making this decision. Deciding which workload to move to the cloud is one of the most important decisions to make. Often times the future of other projects and initiatives is based on the outcome of this first project.
When taking a cloud platform approach, as you do with Windows Azure, there’s a very different set of considerations a customer needs to make than if they’re simply moving their infrastructure to a virtualized environment or taking a software-as-a-service approach.
Since the platform approach focuses on the application instead of the underlying hardware, network, or even operating system, customers need to think much more long term about their architecture holistically. They need to think short term: “what do I want to gain in the next three-to-six months?” as well as long term: “how will this decision impact my future technology investments and business goals?” Independently these questions can be fairly simple to answer. In combination they create something of a domino effect, and the answers become much more complex.
With this in mind, I’ve come up with the following three “tips” that should guide a customer’s thought process when contemplating a move to the cloud.
1. Always plan for the long-term. It’s easy to be tempted by solutions that promise immediate benefit and what looks like the quickest route to the cloud. While the PaaS (platform as a service) approach may appear more complex, the long-term benefits such as built-in elasticity, service healing, patch management, and so forth, make it a worthwhile investment that will pay dividends both on the technology and business sides of the house.
2. It’s okay to start with something simple. Many companies use smaller applications with fewer dependencies as a way kick start their Windows Azure journey. Rather than taking a “fork lift” approach and moving everything all at once you can think of hybrid scenarios where you tactically move individual pieces to the cloud – one at a time, but as part of a larger, interconnected architecture.
3. Know the outcomes you want to achieve. It could be cost savings or time to market; regardless, know what you want to achieve and design the solution accordingly.
With these “tips” in mind, I put together a series of questions for customers to keep in mind as they consider moving different workloads to Windows Azure. This is by no means exhaustive, but it helps set the context of how and what people should think about.
Are you building a new application or are you able to adapt an existing application to operate in the cloud?
You can certainly move existing applications into Windows Azure, but oftentimes you’ll have to make changes so that you can benefit from the elasticity of the platform. Consequently it is sometimes easier to target new applications when first moving to Windows Azure.
Do you have large amounts of data that you either have to store or process in your solution? Do you worry about running out of storage capacity on any apps with more users coming on board?
The low cost and durability of storage in the cloud make it extremely practical to start collecting and storing data that you otherwise would have thrown away. This opens up all kinds of opportunities to start mining your data for patterns and insights that you otherwise would have missed.
Do you have a predictable pattern of usage with your applications? Alternatively, do you have spikey and unpredictable usage patterns?
The ability to scale horizontally means you only need to allocate enough compute to satisfy the immediate needs of the application. When you need more servers, spin up more servers. When you’re doing with them, shut them down.
Is having a global presence for your application important?
Windows Azure has eight data centers worldwide – and a lot more content delivery networks for caching your static data – which makes it easy to target a worldwide audience. Additionally, there’s a service called Traffic Manager that lets you define a policy for routing your users to the closest datacenter to reduce latency.
Do you have solutions that require access to services that exist inside secure networks?
There are many ways to securely connect back into your on-premises assets – this can be especially important if you’re in a regulated industry or have information that you cannot move into the cloud. You can target specific services by using the Service Bus to relay messages through your firewall, benefiting from a service-oriented approach on-premises. Furthermore, you can also segregate your systems by using queuing technologies – e.g. drop a message into queue in the cloud and pick it up from a local machine.
While answering yes to any of these questions doesn’t necessarily mean your application is an ideal fit for moving into Windows Azure, but it at least suggests that you can explore the possibilities. Microsoft and many of its top partners offer assessments and design sessions that focus on identifying the best options when moving to Windows Azure. Take advantage of these options when you can, and also check out these two great resources to help get you started moving your apps to the cloud: Moving Applications to the Cloud, 2nd Edition and Get Started with your Cloud Journey.
I understand that your first inclination may be to immediately start building an application or service for the cloud – at least, as a developer, that’s my first inclination. If you can, try to take a few moments to think about which application to work on – often times this decision can be more difficult than the actual technical implementation.

David Linthicum (@DavidLinthicum) asserted “If you have no cloud computing plan, you've essentially decided to fail. Here's how to succeed” in a deck for his 3 easy steps to creating your cloud strategy article of 5/22/2012 for InfoWorld’s Cloud Computing blog:
You're in IT and have yet to create a cloud computing strategy for your business. Now what?
You can wing it, which is what most IT shops do. You can wait to see which way the wind blows, then create strategy around what works. But lack of planning means there will be a lot of expensive retrofitting and rework. Your risk of failure skyrockets.
For those of you who hate to plan, let me provide you with three easy steps to create a cloud computing strategy. It's less painful than you think.
Step 1: Define a high-level business case
In the past I've explained the metrics around creating a low-level business case for cloud computing. But if you don't have time to dig through the details, then focus on the high-level benefits of cloud computing. This includes increased business agility, preservation of capital, and use of business data. The points of value are very different from business to business, so make sure to understand your own needs.Step 2: Define core requirements
Think of the core requirements as more of a list than a document. This is where you write down what the business needs in terms of performance, security, governance, and growth. The idea is that you'll have a much better understanding of the enterprise requirements for cloud computing. You can then drill down on each, if you like. Or use this quick list as a jumping-off point to begin migration to the cloud.Step 3: Define core technology
Again, this is quick and dirty. Now that you've completed steps 1 and 2, ask yourself what are the likely cloud computing technologies that should be in play in your enterprise. I'd start with IaaS, PaaS, or SaaS, including any combination of the three. Also decide if you want private, public, or hybrid. Then move from the what to the whom. List the possible providers or technologies you'll likely use and, if there is time, further define their role.Easy, right? My objective here is to start you thinking about what needs to get done, without forcing you to create a detailed plan. In other words, it's cloud computing for those who hate doing the paperwork, which is most of you. Good luck.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant posts today.
<Return to section navigation list>
Cloud Security and Governance
Chris Hoff (@Beaker) posted Incomplete Thought: On Horseshoes & Hand Grenades – Security In Enterprise Virt/Cloud Stacks on 5/22/2012:
It’s not really *that* incomplete of a thought, but I figure I’d get it down on vPaper anyway…be forewarned, it’s massively over-simplified.
Over the last five years or so, I’ve spent my time working with enterprises who are building and deploying large scale (relative to an Enterprise’s requirements, that is) virtualized data centers and private cloud environments.
For the purpose of this discussion, I am referring to VMware-based deployments given the audience and solutions I will reference.
To this day, I’m often shocked with regard to how many of these organizations that seek to provide contextualized security for intra- and inter-VM traffic seem to position an either-or decision with respect to the use of physical or virtual security solutions.
For the sake of example, I’ll reference the architectural designs which were taken verbatim from my 2008 presentation “The Four Horsemen of the Virtualization Security Apocalypse.“
If you’ve seen/read the FHOTVA, you will recollect that there are many tradeoffs involved when considering the use of virtual security appliances and their integration with physical solutions. Notably, an all-virtual or all-physical approach will constrain you in one form or another from the perspective of efficacy, agility, and the impact architecturally, operationally, or economically.
The topic that has a bunch of hair on it is where I see many enterprises trending: obviating virtual solutions and using physical appliances only:
…the bit that’s missing in the picture is the external physical firewall connected to that physical switch. People are still, in this day and age, ONLY relying on horseshoeing all traffic between VMs (in the same or different VLANs) out of the physical cluster machine and to an external firewall.
Now, there are many physical firewalls that allow for virtualized contexts, zoning, etc., but that’s really dependent upon dumping trunked VLAN ports from the firewall/switches into the server and then “extending” virtual network contexts, policies, etc. upstream in an attempt to flatten the physical/virtual networks in order to force traffic through a physical firewall hop — sometimes at layer 2, sometimes at layer 3.
It’s important to realize that physical firewalls DO offer benefits over the virtual appliances in terms of functionality, performance, and some capabilities that depend on hardware acceleration, etc. but from an overall architectural positioning, they’re not sufficient, especially given the visibility and access to virtual networks that the physical firewalls often do not have if segregated.
Here’s a hint, physical-only firewall solutions alone will never scale with the agility required to service the virtualized workloads that they are designed to protect. Further, a physical-only solution won’t satisfy the needs to dynamically provision and orchestrate security as close to the workload as possible, when the workloads move the policies will generally break, and it will most certainly add latency and ultimately hamper network designs (both physical and virtual.)
Virtual security solutions — especially those which integrate with the virtualization/cloud stack (in VMware’s case, vCenter & vCloud Director) — offer the ability to do the following:
…which is to say that there exists the capability to utilize virtual solutions for “east-west” traffic and physical solutions for “north-south” traffic, regardless of whether these VMs are in the same or different VLAN boundaries or even across distributed virtual switches which exist across hypervisors on different physical cluster members.
For east-west traffic (and even north-south models depending upon network architecture) there’s no requirement to horseshoe traffic physically.
Interestingly, there also exists the capability to actually integrate policies and zoning from physical firewalls and have them “flow through” to the virtual appliances to provide “micro-perimeterization” within the virtual environment, preserving policy and topology.
There are at least three choices for hypervisor management-integrated solutions on the market for these solutions today:
- VMware vShield App,
- Cisco VSG+Nexus 1000v and
- Juniper vGW
Note that the solutions above can be thought of as “layer 2″ solutions — it’s a poor way of describing them, but think “inter-VM” introspection for workloads in VLAN buckets. All three vendors above also have, or are bringing to market, complementary “layer 3″ solutions that function as virtual “edge” devices and act as a multi-function “next-hop” gateway between groups of VMs/applications (nee vDC.) For the sake of brevity, I’m omitting those here (they are incredibly important, however.)
They (layer 2 solutions) are all reasonably mature and offer various performance, efficacy and feature set capabilities. There are also different methods for plumbing the solutions and steering traffic to them…and these have huge performance and scale implications.
It’s important to recognize that the lack of thinking about virtual solutions often seem to be based largely on ignorance of need and availability of solutions.
However, other reasons surface such as cost, operational concerns and compliance issues with security teams or assessors/auditors who don’t understand virtualized environments well enough.
From an engineering and architectural perspective, however, obviating them from design consideration is a disappointing concern.
Enterprises should consider a hybrid of the two models; virtual where you can, physical where you must.
If you’ve considered virtual solutions but chose not to deploy them, can you comment on why and share your thinking with us (even if it’s for the reasons above?)




<Return to section navigation list>
Cloud Computing Events
•• Jeff Price (@jeffreywprice) of Terrace Software announced on 5/24/2012 a Windows Azure Workshop on 6/1/2012 at Microsoft San Francisco:
Considering the cloud? Join us at Microsoft in San Francisco on June 1st for a Windows Azure workshop and we'll help you understand the impact. Register Now
At the workshop, a cloud expert from Terrace Software will explore how real-world application challenges can or cannot be solved in the cloud. A whiteboard session will show you how to architect truly elastic Azure applications. We'll also do a walk-through of the secret sauce of Azure design-cost based architecture.
At the workshop, you'll learn:
- How to "Azure-ize" your on-premises application.
- If you should move your entire application to Azure or just migrate key components?
- The best approach to decompose your architecture for optimal scalability.
- Methods to implement heterogeneous data storage (Tables, Blobs, SQL Azure, and Content Delivery Networks) in accordance with international privacy and data protection laws.
- A Primer to Azure-Cloud101:
- Scaling, queues and asynchronous processing
- Azure data storage, retry policies and OData
- Caching, session management and persistence
- Deployment, diagnostics and monitoring
- Integration with other systems, both on-premises and external
- Security, authentication and authorization, OpenID and OAuth
- Cost forecasting for a sample Azure application
Workshop Date, Time and Location
- Friday, June 1, 2012
- 9:15 a.m. - 11:45 a.m. (Registration at 9:00 a.m.)
- Microsoft Corporation
- 835 Market Street, Suite 700
- San Francisco, CA
Link for Registration and Details
- Register Now
- Please feel free to forward this invitation to interested colleagues.
- Terrace Software, Inc. Ask.Us@Terrace.com 888-269-6200

Roop Astala posted on 5/22/2012 Cloud Numerics at Progressive F# Tutorial in NYC on June 6th:
You may recall we posted about using Cloud Numerics and F# for distributed computing on Windows Azure a while back. In the tutorial we’ll give hands-on examples of using libraries for math, linear algebra and statistics, and present demos of data analysis using Cloud Numerics and F# on Azure.
This is a great opportunity to learn about Cloud Numerics; don’t worry if you’re not an Azure user yet. You can try out the hands-on examples with distributed arrays and libraries using your local development environment.
Mike Benkovich (@mbenko) continued his series on 5/21/2012 with CloudTip #15-MEET Windows Azure:
The Cloud comes in many flavors, types and shapes and the terminology can be daunting. You’ve got Public vs. Private. vs. Home grown. You’ve got compute, storage and database not to mention identity, caching, service bus and many more. Then there are the several players including Microsoft, Amazon, Rackspace, Force, and too many others to list them all.
That’s a lot to learn, but if you’re curious to see what’s been happening with the Microsoft Cloud and get a feel for the direction things are heading then you want to check out the recently announced Microsoft event “Meet Windows Azure” live in San Francisco on June 7, where the people who are in the drivers seat will take time to share their space.
While the details are sparse so far you can get more information on http://MeetWindowsAzure.com , as well as follow the happenings on twitter. It looks like an interesting event you won’t want to miss. With people like Scott Guthrie it’s sure to be full of great examples of what and how you can get started with Windows Azure and learn more about what you need to know to get started today.
Check it out today!

Alan Smith reported on 5/21/2012 Sweden Windows Azure Group Meeting - Migrating Applications to Windows Azure & Sharding And Scaling with RavenDB, with Shay Friedman & Oren Eini will occur on 5/23/2012 at 6:00 PM Stockholm time:
Wednesday, May 23, 6:00 PM, Stockholm
Migrating Applications to Windows Azure – Shay Friedman
Sharding And Scaling with RavenDB – Oren Eini
From the get go, RavenDB was designed with sharding in mind. But sharding was always a complex topic, and it scared people off. Following the same principles that guides us with the rest of RavenDB design, we have taken sharding to the next level, made it easier to work with, performant and self optimizing.
Come to this talk with Ayende Rahien to discover RavenDB sharding, discuss scaling scenarios and see how we can use RavenDB in a high traffic scenarios.
Shay Friedman
Shay Friedman is a Visual C#/IronRuby MVP and the author of IronRuby Unleashed. With more than 10 years of experience in the software industry, Friedman now works in CodeValue, a company he has co-founded, where he creates products for developers, consults and conducts courses around the world about web development and dynamic languages. You can visit his blog at http://IronShay.com.
Oren Eini (Ayende Rahien)
Oren Eini has over 15 years of experience in the development world with a strong focus on the Microsoft and .NET ecosystem and has been awarded the Microsoft’s Most Valuable Professional since 2007. An internationally known presenter, Oren has spoken at conferences such as DevTeach, JAOO, QCon, Oredev, NDC,...
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• IBM (@IBMcloud) announced the transition of its SmartCloud Application Services (SCAS) PaaS from beta to pilot scale on 5/15/2012 (missed when published):
Pilot services bulletin: IBM SmartCloud Application Services pilot program
Want to get a preview of the offering with early access to our platform services? You’re in luck, you can with our SmartCloud Application Services Pilot Services program.
What can I do with IBM SmartCloud Application Services?
SmartCloud Application Services is an IBM platform as a service offering that enables you to quickly and easily develop, test, deploy and manage applications within your IBM SmartCloud Enterprise Services (SCE).
Deploy a new web application during lunch (and still have time to eat lunch)
Application deployment—which usually takes weeks with a traditional environment—can now be completed in minutes on the cloud. With a true multi-tenant shared infrastructure, IBM SmartCloud Application Services reduces costs and accelerates time to value with maximum flexibility.
What is included in the SmartCloud Application Services pilot?
SCAS will provide access to the following Service Instances as described in the applicable Terms of Use.
- Application Workload Service allows you to create and deploy workload patterns in your SCE account.
- Web application pattern
- Transactional database pattern
- Data mart pattern
- Virtual System Patterns
- Collaborative Lifecycle Management Service (CLMS)
CLMS will enable you to coordinate software development activities throughout the lifecycle including requirements tracking, design, development, build, test and deployment.
For additional value, IBM developerWorks is providing an IBM Virtual Pattern Kit for developers. To get yours today, visit the developerWorks web site.
How long does the pilot last?
The SmartCloud Application Services pilot will begin May 15, 2012 and continue until IBM makes SCAS generally available. IBM reserves the right to withdraw this Pilot Service or not make SCAS generally available upon notice to participants of this Pilot Services program.
Will my work in the pilot be saved for use at general availability?
Yes, if you use persistent storage within your account you can retain that data for future use at general availability.
Are there any charges associated with the pilot?
Yes, clients will pay for the SmartCloud Enterprise computing resources as specified in the applicable Terms of Use for any ordered SCAS Pilot Services.
How are clients selected for the pilot?
IBM sales representatives nominate their clients for the program and an internal board determines which clients would most benefit from Pilot Services participation. The IBM sales rep will notify their client if they have been selected to participate – a limited number of clients will be allowed to participate in the Pilot Services program.
Additional Term for the Pilot Services
An IBM SmartCloud Enterprise Account is required for the SmartCloud Application Services Pilot Services. You understand that Pilot Services may not be at a level of performance or compatibility of the other Services options and may not have been fully tested. The availability of any of the Pilot Services does not guarantee or represent that IBM will make the Pilot Services or any similar services available, or if made available, that it will be the same as the Pilot Services. While IBM does not recommend that you use Pilot Services for commercial or production purposes, you may, at your sole risk, use these Pilot Services for any purpose.
This Pilot Services Bulletin provides the information and terms regarding the identified Pilot Services. Use of these Pilot Services are subject to the terms of this Pilot Services Bulletin, the IBM SmartCloud Agreement, and its attachments, including the applicable Terms of Use, and you agree to such terms by accessing and using the Pilot Services.

A link to the developerWorks’ IBM Virtual Pattern Kit page would have been a nice touch.
<Return to section navigation list>
Jeff Barr (@jeffbarr) described how to Explore Your DynamoDB Tables Using the AWS Management Console in a 5/22/2012 post:
You can now view and modify the contents of your DynamoDB tables from within the AWS Management Console. With the addition of this new feature, you can learn by doing -- trying out a number of DynamoDB features without even writing any code. You can create a table, add some items, and see them in the table, all through a very clean and simple user interface.
You can also use this feature to browse through your production data. You can access the data for reporting or analytic purposes, again without having to write any code.
Here's a tour to help you get started:
Select a table and click Explore Table:
You can scan through the table, ten items at a time, using the button controls:

You can also retrieve items by hash or range keys, as appropriate:
Last but not least, you can put new items. Since DynamoDB doesn't use a database schema, you have full control of the attributes associated with each item:
You can specify the type of each attribute:
Editing sets of strings or numbers is easy and straightforward:


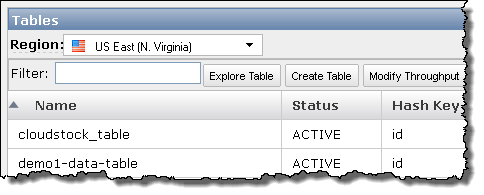

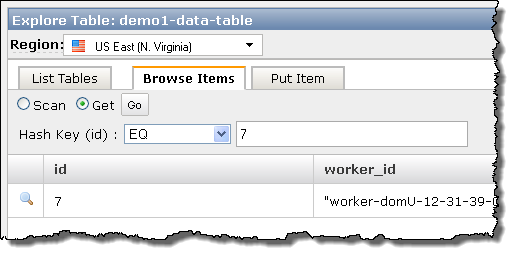
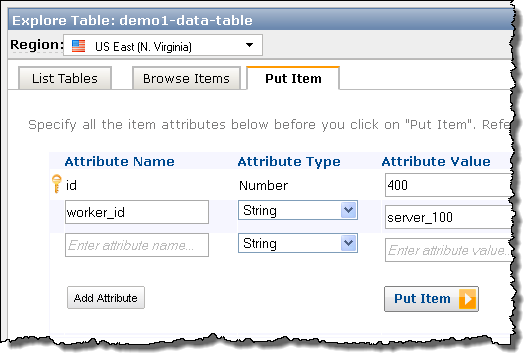


Barbara Darrow (@gigabarb) asked After Amazon, how many clouds do we need? in a 5/19/2012 post to GigaOm’s Structure blog:
With news that Google and Microsoft plan to take on the Amazon Web Services monolith with infrastructure services of their own, you have to ask: How many clouds do we need?
This Google-Microsoft news, broken this week by Derrick Harris [see article below], proves to anyone who didn’t already realize it that Amazon is the biggest cloud computing force (by far) and, as such, wears a big fat target on its back. With the success of Amazon cloud services, which started out as plain vanilla infrastructure but has evolved to include workflow and storage gateways to enterprise data centers, Amazon’s got everyone — including big enterprise players like Microsoft, IBM and HP — worried. Very worried.
Amazon as enterprise apps platform? Don’t laugh
Take the news late this week that IBM is working with Ogilvy and Mather to move the advertising giant’s SAP implementation from its current hosted environment to ”SmartCloud for SAP Applications hosted in IBM’s state-of-the-art, green Smarter Data Center.” (Note to IBM: brevity is beauty when it comes to branding.)
Don’t think that little tidbit is unrelated to last week’s announcement that SAP and Amazon together certified yet another SAP application — All-in-One — to run on Amazon’s EC2. This sort of news validates Amazon as an enterprise-class cloud platform, and that’s the last thing IBM or HP or Microsoft wants to see happen. So every one of these players — plus Google — are taking aim at Amazon.
Some hardware players, including HP, which is reportedly about to cut 30,000 jobs, see the cloud as a way to stay relevant, and oh, by the way, keep customers workloads running on their hardware and software. HP’s OpenStack-based public cloud went to public beta earlier this month.
Case in point: Along with the SAP migration news, IBM also said its SmartCloud Enterprise+, IBM’s managed enterprise cloud infrastructure offers:
“unprecedented support for both x86 and P-Series [servers] running … Windows, Linux and AIX on top of either VMware or PowerVM hypervisors….
and
SCE+ is designed to support different workloads and associated technology platforms including a new System z shared environment that will be available in the U.S. and U.K. later this year.
Hmmm. P-Series and System Z — not exactly the sort of commodity hardware that modern webscale cloud companies run, but they are integral to IBM’s well-being.
Vendor clouds to lock customers in
This illustrates what prospective buyers should know: Despite all the talk about openness and interoperability, a vendor’s cloud will be that vendor’s cloud. It represents a way to make sure customers run that company’s hardware and software as long as possible. But legacy IT vendors are not alone in trying to keep customers on the farm.
Amazon is making its own offerings stickier so that the more higher-value services a customer uses, the harder it will be to move to another cloud. As Amazon continues what one competitor calls its “Sherman’s march on Atlanta,” legacy IT vendors are building cloud services as fast as they can in hopes that they can keep their customers in-house. For them, there had better be demand for at least one more cloud.
There will doubtless be more discussion on this and other cloud topics at the GigaOM Structure conference in San Francisco next month.


Full disclosure: I’m a registered GigaOm analyst.
Derrick Harris (@derrickharris) reported Scoop: Google, Microsoft both targeting Amazon with new clouds on 5/17/2012:
Google is hard at work on a cloud computing offering that will compete directly with the popular Amazon EC2 cloud, according to a source familiar with Google’s plans. Not to be outdone, other sources have confirmed Microsoft is also building an Infrastructure as a Service platform, and that the Redmond cloud will be ready — or at least announced — before Google’s. According to my sources, Google should roll out its service for renting virtual server instances by the end of the year, while Microsoft is slating its big announcement for a June 7 event in San Francisco.
Although Google declined to comment on whether the offering is indeed on the way, an IaaS cloud would make a lot of sense for the company. It already has a popular platform-as-a-service offering in App Engine that is essentially a cloud-based application runtime, but renting virtual servers in an IaaS model is still where the money is in cloud-based computing. Google also has an API-accessible storage offering — the aptly named Google Cloud Storage — that would make for a nice complement to an IaaS cloud, like Amazon’s ridiculously popular S3 storage service is for EC2.
We’ll no doubt hear a lot more about Microsoft’s plans at our Structure conference next month, when I sit down to talk Azure with Microsoft Server and Tools Business President Satya Nadella.
Google and Microsoft are two cloud providers that should have Amazon Web Services shaking a bit, in a way Rackspace and the OpenStack haven’t yet been able to. Google and Microsoft both have the engineering chops to compete with AWS technically, and both have lots of experience dealing with both developers and large companies. More importantly, both seem willing and able to compete with AWS on price — a big advantage for AWS right now as its economies of scale allow it to regularly slash prices for its cloud computing services.
In terms of timing, this looks like a case of both companies realizing they got ahead of themselves and the market by centering their cloud computing plans around PaaS rather than IaaS. If Google really does roll out an IaaS offering, maybe it’s also a sign of its newfound maturity when it comes to rolling out new services that fit naturally into its existing business and that it can actually sell. Although AWS has a commanding lead in market share — estimates start at 50 percent and only go higher — there are still a lot of developers left to win over and even some opportunity to poach a few from AWS if Google and Microsoft can keep up in the innovation game.
Related research and analysis from GigaOM Pro:
Subscriber content. Sign up for a free trial.


Full disclosure: I’m a registered GigaOm analyst.

















0 comments:
Post a Comment