Windows Azure and Cloud Computing Posts for 5/17/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI, Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics, Big Data and OData
- Windows Azure Access Control, Identity and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
Benjamin Guinebertière (@benjguin) posted Windows Azure tables: partitioning guid row keys on 5/18/2012. From the Engish version:
This post is about using a partition key while the rowkey is a GUID in Windows Azure Table Storage. You may read more on Windows Azure Tables partitioning in this MSDN article.
Here is some context on when this sample code comes from.
I’m currently developing some sample code that works as a canvas application in Facebook. As this type of app runs in a iFrame, it restricts the use of cookies. Still, I wanted to keep some authentication token from page to page (the Facebook signed_request) without displaying it explicitly in the URL (it may also be sent to HTTP referer headers to external sites). So i decided to store the signed_request in a session. ASP.NET sessions can have their ID stored in the URL instead of cookies but ASP.NET pipelines does not provide the session yet while authenticating. So I created my own storage for the authentication and authorization session (Auth Session for short). I did it in Windows Azure tables so that it can easily scale out.
The functional key is a GUID (I don’t want user X to guess user Y’s authSessionKey). The key is passed from page to page as a query parameter (typically, app urls look like this: https://myhost/somepath?authSessionKey=3479D7A2-5D1A-41A8-B8FF-4F62EB1A07BB.
Still, in order to have this scaling horizontally I need to have a partition key. Here is the code I used:
internal class AuthSessionDataSource { //... public const int nbPartitions = 15; // ... public static class AuthSessionState { //... private static string PartitionKeyForGuid(Guid guid) { int sumOfBytes = 0; foreach (var x in guid.ToByteArray()) { sumOfBytes += x; } int partitionNumber = sumOfBytes % AuthSessionDataSource.nbPartitions; return partitionNumber.ToString(); } //...The principle is to get the remainder of the sum of all bytes participating in the GUID divided by the number of partitions as the partition number.
In order to have a rough idea of what it provides, here is a small console application (code, then sample execution result).
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace ConsoleApplication2 { class Program { static void Main(string[] args) { for (int i = 0; i < 36; i++) { Guid g = Guid.NewGuid(); Console.WriteLine("{0}, {1}", g, PartitionKeyForGuid(g)); } Console.ReadLine(); } private static string PartitionKeyForGuid(Guid guid) { const int nbPartitions = 12; int sumOfBytes = 0; foreach (var x in guid.ToByteArray()) { sumOfBytes += x; } int partitionNumber = sumOfBytes % nbPartitions; return partitionNumber.ToString(); } } }
The advantage is that the partition numbers should be distributed quite regularly and that you can get calculate the partition from the rowkey as long as the number of partitions doesn’t change.
Should I change and have more partitions as the number of users grow, I could store new users’ sessions to a new table where the number of partitions is higher while keeping already active users to the old table. Auth sessions don’t live very long so changing the number of partitions can be quite simple.
public const int nbDaysForOldSessions = 3; //... internal void RemoveOldValues() { DateTime oldDate = DateTime.UtcNow.AddDays(-1 * nbDaysForOldSessions); for(int p=0; p<nbPartitions; p++) { string partitionKey = p.ToString(); var query = (from c in context.AuthSessionStateTable where c.PartitionKey == partitionKey && c.Timestamp <= oldDate select c) .AsTableServiceQuery<AuthSessionStateEntity>(); var result = query.Execute(); int i = 0; foreach (var x in result) { i++; this.context.DeleteObject(x); if (i >= 100) { this.context.SaveChangesWithRetries(); i = 0; } } this.context.SaveChangesWithRetries(); } }Why not using the rowkey as a partition key? Well having several rows in the same partition allows batching which is also good for performance. For instance, I have to remove old sessions. As batch can only happen in a same partition and as no more than 100 rows can be batched together, here is the code to purge old Auth sessions:
In my case, having this way of partitioning data, seems to be a good fit.
Dans mon cas, partitionner les données de cette façon semble assez adapté.


Derrick Harris (@derrickharris) posted The unsexy side of big data: 5 tools to manage your Hadoop cluster to GigaOm’s Structure blog on 5/18/2012:
Before you can get into the fun part of actually processing and analyzing big data with Hadoop, you have to configure, deploy and manage your cluster. It’s neither easy nor glamorous — data scientists get all the love — but it is necessary. Here are five tools (not from commercial distribution providers such as Cloudera or MapR) to help you do it.
Apache Ambari
Apache Ambari is an open source project for monitoring, administration and lifecycle management for Hadoop. It’s also the project that Hortonworks has chosen as the management component for the Hortonworks Data Platform. Ambari works with Hadoop MapReduce, HDFS, HBase, Pig, Hive, HCatalog and Zookeeper.
Apache Mesos
Apache Mesos is a cluster manager that lets users run multiple Hadoop jobs, or other high-performance applications, on the same cluster at the same time. According to Twitter Open Source Manager Chris Aniszczyk, Mesos “runs on hundreds of production machines and makes it easier to execute jobs that do everything from running services to handling our analytics workload.”
Platform MapReduce
Platform MapReduce is high-performance computing expert Platform Computing’s entre into the big data space. It’s a runtime environment that supports a variety of MapReduce applications and file systems, not just those directly associated with Hadoop, and is tuned for enterprise-class performance and reliability. Platform, now part of IBM, built a respectable business managing clusters for large financial services institutions.
StackIQ Rocks+ Big Data
StackIQ Rocks+ Big Data is a commercial distribution of the Rocks cluster management software that the company has beefed up to also support Apache Hadoop. Rocks+ supports the Apache, Cloudera, Hortonworks and MapR distributions, and handles the entire process from configuring bare metal servers to managing an operational Hadoop cluster.
Zettaset Orchestrator
Zettaset Orchestrator is an end-to-end Hadoop management product that supports multiple Hadoop distributions. Zettaset touts Orchestrator’s UI-based experience and its ability to handle what the company calls MAAPS — management, availability, automation, provisioning and security. At least one large company, Zions Bancorporation, is a Zettaset customer.
If there are more Hadoop management tools floating around, please let me know in the comments.
Feature image courtesy of Shutterstock user .shock.
Related research and analysis from GigaOM Pro:
Subscriber content. Sign up for a free trial.





Shaun Connolly posted 7 Key Drivers for the Big Data Market to the Hortonworks blog on 5/14/2012 (missed when posted):
I attended the Goldman Sachs Cloud Conference and participated on a panel focused on “Data: The New Competitive Advantage”. The panel covered a wide range of questions, but kicked off covering two basic questions:
“What is Big Data?” and “What are the drivers behind the Big Data market?”
While most definitions of Big Data focus on the new forms of unstructured data flowing through businesses with new levels of “volume, velocity, variety, and complexity”, I tend to answer the question using a simple equation:
Big Data = Transactions + Interactions + Observations
The following graphic illustrates what I mean:
ERP, SCM, CRM, and transactional Web applications are classic examples of systems processing Transactions. Highly structured data in these systems is typically stored in SQL databases.
Interactions are about how people and things interact with each other or with your business. Web Logs, User Click Streams, Social Interactions & Feeds, and User-Generated Content are classic places to find Interaction data.
Observational data tends to come from the “Internet of Things”. Sensors for heat, motion, pressure and RFID and GPS chips within such things as mobile devices, ATM machines, and even aircraft engines provide just some examples of “things” that output Observation data.
With that basic definition of Big Data as background, let’s answer the question:
What are the 7 Key Drivers Behind the Big Data Market?
Business
- Opportunity to enable innovative new business models
- Potential for new insights that drive competitive advantage
Technical
- Data collected and stored continues to grow exponentially
- Data is increasingly everywhere and in many formats
- Traditional solutions are failing under new requirements
Financial
- Cost of data systems, as a percentage of IT spend, continues to grow
- Cost advantages of commodity hardware & open source software
There’s a new generation of data management technologies, such as Apache Hadoop, that are providing an innovative and cost effective foundation for the emerging landscape of Big Data processing and analytics solutions. Needless to say, I’m excited to see how this market will mature and grow over the coming years.
Key Takeaway
Being able to dovetail the classic world of Transactions with the new(er) worlds of Interactions and Observations in ways that drives more business, enhances productivity, or discovers new and lucrative business opportunities is why Big Data is important.
One promise of Big Data is that companies who get good at collecting, aggregating, refining, analyzing, and maximizing the value derived from Transactions, Interactions, and Observations will put themselves in a position to answer such questions as:
What are the behaviors that lead to the transaction?
And even more interestingly:
How can I better encourage those behaviors and grow my business?
So ask yourself, what’s your Big Data strategy?


<Return to section navigation list>
SQL Azure Database, Federations and Reporting
Mike Benkovich (@mbenko) continued his series with CloudTip #14-How do I get SQL Profiler info from SQL Azure? on 5/18/2012:
Your application is running slow. You need to find out what’s going on. If you’ve used SQL Profiler on a local database you might be familiar with how you can capture a trace of database activity and use it to figure out where your resources are going. The visibility makes it MUCH easier to tune a database than sorting thru a bunch of code. The question is, what do you do when you’re moving an app to the cloud?
If you’ve wondered how you can get Profile information from SQL Azure, the new online management portal for SQL Azure has been updated with design, deployment, administration and tuning features built in. The Overview screen provides quick links to the different areas of the portal, as well as easy links to help information from msdn online. You can get to the portal either by going to the Windows Azure management portal on http://windows.azure.com and after signing in going to the database section and clicking Manage, or simply browsing to your database name – https://<myserver>.database.windows.net where you substitute your database server’s name for <myserver>.
When I log in I can see my databases and get information about size, usage as well as the ability dive into specific usage. From there I can go into designing the schema, functions and code around my database. If I swap over to the admin page though, I have visibility into not just database size and usage, but also a link to query performance. Clicking this takes me to where I can see profile data from queries.
I can sort and see which calls to the database are most frequent as well as most expensive in terms of resource usage. Further I can select one and dive even deeper to see the execution plan and statistics around the calls. This information is key to making decisions on indexes and design of a well performing database.
In the query plan I can look for table scans or other expensive operations and if it make sense determine whether additional indexes would be useful.
Nice!





Cihan Biyikoglu (@cihangirb) explained ID Generation in Federations in Azure SQL Database: Identity, Sequences, Timestamp and GUIDs (Uniqueidentifier) on 5/17/2012:
Identity and timestamp are important pieces of functionality for many existing apps for generating IDs. Federation impose some restrictions on identity and timestamp and clearly we need alternatives for federations that can scale to the targets of scale federations hits. So I’ll dive into alternatives and options in this post.
There are a number of options for distributed systems.
GUID/Uniqueidentifier as a unique id generation method: I strongly recommend using uniqueidentifier as a identifier. It is globally unique by definition and does not require funneling generation through some centralized logic. Unlike identity and timestamp, uniqueidentifiers can be generated at any tier of the app. With unique identifiers you give up on one property; ID generation is no longer sequential. So what If you’d like to understand the order in which a set of rows were inserted? Well that is easy to do in an atomic unit. You can use a date+time data type with high enough resolution to give you ordering: ex: datetime2 or datetimeoffset data types both have resolution to 1/1000000 fraction of a second. So these types have great precision for ordering events.
This is more of an academic topic and don’t expect many folks to try this but, I’ll still mention that I strongly trying ordering across atomic units. Here is the core of the issue; If you need to sort across AUs, datetimeoffset still may work. However it is easy to forget that there isn’t a centralized clock in a distributed system. Due to the random number of repartitioning operations that may have happened over time, the date+time value may be coming from many nodes and nodes are not guaranteed to have sync clocks (they can be a few mins apart). Given no centralized clock, across atomic units datetime value may not reflect the exact order in which things happened.
Well, how about the difficulty of partitioning over ranges of uniqueidentifiers? GUIDs are sortable so this is nothing new but their sort order may get confusing. However it is fairly easy to understand once you see the explanation. This one explains the issue well; How are GUIDs sorted by SQL Server. It is a mind stretching exercise but I expect we’ll have tooling to help out with some of this in future.
Last but not the least, many people have experiences that suggest GUIDs (uniqueidentifiers) are bad candidates for clustering keys given they will not be ordered and cause page splits, causing higher latencies and fragmentation? No so on SQL Azure. at least not to the degree you experience in on premise SQL Server. SQL Azure dbs give you 3 replicas and that means the characteristics of writes are very different compared to a single SQL DB without HA. In SQL Azure the write have to be confirmed by 2 out of the 3 copies thus are always a network level writes… A network write is much slower in latency compared to what a page split would cause. Page split makes a tiny amount of this latency and is not visible to naked eye. You do end up with some fragmentation with uniqueidentifier and that is true. However fragmentation is hard to completely get rid of and unordered inserts compared to deletes or expanding updates don’t cause as much fragmentation so my experience simply says clustering on uniqueidentifiers is no reason for worry. This is easy to try; simply run the following script and watch your latencies. Here is a quick test you can try: See if you can make an unordered insert like the case for GUIDs take longer over many inserts:
use federation root with reset go drop table t1 drop table t2 go create table t1(c1 int identity primary key, c2 uniqueidentifier default newid(), c3 char(200) default 'a') create table t2(c1 int identity, c2 uniqueidentifier default newid() primary key, c3 char(200) default 'a') go -- MEASURE T1 set nocount on declare @s datetime2 set @s=getdate() declare @i int set @i=0 begin tran while (@i<1000000) begin if (@i%1000=0) begin commit tran begin tran end insert into t2(C2, C3) values(default,default) set @i=@i+1 end commit tran select datediff(ss,@s, getdate()) 'total seconds for t1' go -- MEASURE T2 set nocount on declare @s datetime2 set @s=getdate() declare @i int set @i=0 begin tran while (@i<1000000) begin if (@i%1000=0) begin commit tran begin tran end insert into t2(C2, C3) values(default,default) set @i=@i+1 end commit tran select datediff(ss,@s, getdate()) 'total seconds for t2' go
- Datetime2 for optimistic concurrency: Timestamp replacement is much easier to talk about; I recommend using datetime2 with its 1/1000000 of a second resolution instead of timestamp. Simply ensure that you generate ever[y] time you update, you also update the modified_date and ensure to use that just like timestamp to compare before updates to detect update conflicts.
That said, we plan to enhance these functions to be meaningful for federations in future and will also remove some restrictions in members especially on reference tables. if you need any more details on these, you can always reach me through the blog.

Bud Aaron posted Writing a small application to manipulate the [Windows Azure] SQL Database [a.k.a., SQL Azure] firewall on 5/18/2012:
Arg – it’s no longer SQL Azure, it’s now SQL Database! This article started out as a simple discussion of how to manipulate the SQL Database (was SQL Azure) firewall through REST calls, but on the way Microsoft threw me under the bus by completely changing branding names for what was Azure. To crawl out from under the bus I decided to use the new naming conventions which are listed below for all the world to see.


Now I know just enough about firewalls to be dangerous. I know they’re designed to help prevent uninvited guests from messing with my data, and that you can poke holes in them to allow invited guests into the database. I call it poking holes in the firewall, here’s a walkthrough on getting through a firewall to allow sqlserver.exe remote access.
Doing it the easy way
The Windows Azure Portal provides a way to Add, Edit and Delete firewall rules. First Select Database in the portal and navigate to the SQL database you’ve set up.
Windows Azure Portal
Select the Firewall Rules: button under Server Information to get this:
Firewall Information
Notice that the button says Firewall Rules followed by “: 2” indicating that 2 rules are in place. Click the Add button to get this:
Add new firewall rule
Fill in a new firewall rule:
Fill in firewall rule information
And click OK to get this:
Firewall rule overview
You can also Update or Delete the rules here. This is truly the simplest way to poke holes in the firewall as needed but now let’s do it by writing a program in Visual Studio 11 using Visual Basic.
First Things First
In order to get this done you will need to create a self-signed certificate. In order to make the certificate easily findable just make a temp folder on the C: drive. It’s a very short navigation trip when you need to point to files such as the certificate we’re going to generate.
Creating a certificate
In order to do many of the things we’re planning to, we’ll need an encryption certificate. In a production environment you will want to get your certificate from one of the many companies that who issue certificates but for development you can use the makecert command to generate a self-signed certificate. To do this I suggest you create a C:\temp folder making it easy to retrieve. In the Start menu under Visual Studio 2010 Tools you will find a command prompt. Click this to bring up the VS 2010 command prompt and navigate to your newly created temp folder.
It may be that I’m the only person in the world who just recently learned how to ‘paste’ in a command window but I’m so proud. On the off chance that you’ve never used it, I’m going to explain how it’s done. Clicking the little C:\ icon in the upper left corner of the command window brings up the following menu.
Now you can copy the makecert command shown below into the command window and press return to execute the command. Better yet copy it into notepad and edit it to suit your needs, then copy and paste to execute the command.
makecert -sky exchange -r -n "CN=dnccert.cer" -pe -a sha1 -len 2048 -ss My "dnccert.cer"I tell you this because I HATE trying to type long commands into the command window because I invariably mistype at least a half dozen times and then frequently get an error. So now I compose the command in notepad and then copy and paste it. I wish I’d known about this years ago. You’ll get the following message when your certificate has been successfully created in the C:\temp folder.
You can find more detailed information about the makecert command here:http://msdn.microsoft.com/en-US/library/bfsktky3(v=VS.80).aspxAdd the certificate to your portalOpen your Windows Azure management portal and select Hosted Services, Storage Accounts & CDN. Then select Management Certificates. You should see this screen:Hosted Services, Storage Accounts & CDN
Click the Add Certificate icon in the top left corner. In the dialog box, browse for the certificate in the C:\temp folder if that’s where you saved the certificate.
Add Management Certificate
Click OK to import the certificate and then make a copy of the Thumbprint in the text file you should be using to save things you need for this project.
Managing the Azure Firewall
The app we’re building is named SQLAzureFirewallManagement. The main form will be named FirewallDetails. I will use the capture below to give you layout details for the main form. I’ve given each of the controls a number and the table following the dialog will show that number followed by the control type, its name and text, followed by its left and top position, and finally its height and width.
Now the code:
Imports System.Collections.Generic Imports System.ComponentModel Imports System.Data Imports System.Drawing Imports System.Linq Imports System.Text Imports System.Threading.Tasks Imports System.Windows.Forms Imports System.Xml.Linq Imports System.Security.Cryptography.X509Certificates Imports System.IO Imports System.Net Public Class FirewallDetails Private Sub btnBrowse_Click(sender As Object, e As EventArgs) Handles btnBrowse.Click Dim input As String = String.Empty Dim ofd As New OpenFileDialog() ofd.Filter = "cer files (*.cer | *.cer" ofd.InitialDirectory = "C:\temp" ofd.Title = "Select a certificate" If ofd.ShowDialog() = System.Windows.Forms.DialogResult.OK Then txtCertPath.Text = ofd.FileName End If End Sub Private Sub btnOK_Click(sender As Object, e As EventArgs) Handles btnOK.Click Dim certfile As String Dim subscriptionID As String Dim servername As String certfile = txtCertPath.Text subscriptionID = txtSubID.Text servername = txtServerName.Text firewallList.Items.Clear() GetServerFirewallRules(certfile, subscriptionID, servername) End Sub Private Sub GetServerFirewallRules(certfile As String, subscriptionID As String, server As String) Try Dim url As String = String.Format("https://management.database .windows.net:8443/{0}/servers/{1}/firewallrules", subscriptionID, server) Dim webRequest As HttpWebRequest = TryCast(HttpWebRequest.Create(url), HttpWebRequest) webRequest.ClientCertificates.Add(New X509Certificate(certfile, "private key password")) webRequest.Headers("x-ms-version") = "1.0" webRequest.Method = "GET" comboList.Items.Clear() Using webresponse As WebResponse = webRequest.GetResponse() Using stream As Stream = webresponse.GetResponseStream() Using sr As New StreamReader(stream) Dim xml As String = sr.ReadToEnd() Dim doc As XDocument = XDocument.Parse(xml) Dim sc As XNamespace = "http://schemas.microsoft.com /sqlazure/2010/12/" Dim query = From s In doc.Elements(sc + "FirewallRules") .Elements(sc + "FirewallRule") Select s firewallList.Items.Add("=========================") For Each elm As XElement In query firewallList.Items.Add(elm.Element(sc + "Name") .Value.ToString()) comboList.Items.Add(elm.Element(sc + "Name") .Value.ToString()) firewallList.Items.Add(elm.Element(sc + "StartIpAddress").Value.ToString()) firewallList.Items.Add(elm.Element(sc + "EndIpAddress").Value.ToString()) firewallList.Items.Add("=========================") Next End Using End Using End Using Catch webEx As WebException Dim errorResponse As HttpWebResponse = DirectCast(webEx.Response, HttpWebResponse) Try Using errrs As Stream = errorResponse.GetResponseStream() Using sr As New StreamReader(errrs) MessageBox.Show(sr.ReadToEnd().ToString()) End Using End Using Catch innerex As Exception MessageBox.Show(innerex.ToString()) End Try Catch ex As Exception MessageBox.Show(ex.ToString() + vbLf) End Try End Sub Private Sub btnAdd_Click(sender As Object, e As EventArgs) Handles btnAdd.Click Dim certfile As String Dim subscriptionID As String Dim servername As String Dim ruleName As String Dim startIP As String Dim endIP As String certfile = txtCertPath.Text subscriptionID = txtSubID.Text servername = txtServerName.Text ruleName = txtRuleName.Text startIP = txtStartIP.Text endIP = txtEndIP.Text SetServerFirewallRule(certfile, subscriptionID, servername, ruleName, startIP, endIP) End Sub Private Sub SetServerFirewallRule(certfile As String, subscriptionID As String, server As String, ruleName As String, startIP As String, endIP As String) Try Dim url As String = String.Format("https://management.database .windows.net:8443/{0}/servers/{1}/firewallrules/{2}", subscriptionID, server, ruleName) Dim webRequest As HttpWebRequest = TryCast(HttpWebRequest.Create(url), HttpWebRequest) webRequest.ClientCertificates.Add(New X509Certificate(certfile, "private key password")) webRequest.Headers("x-ms-version") = "1.0" webRequest.Method = "PUT" Dim xmlbody As String = "<?xml version=""1.0"" encoding=""utf-8""? >" + vbLf + "<FirewallRule " + vbLf + " xmlns=""http://schemas.microsoft.com/sqlazure/2010/12/"" " + vbLf + " xmlns:xsi=""http://www.w3.org/2001/XMLSchema-instance"" " + vbLf + " xsi:schemaLocation=""http://schemas.microsoft.com/sqlazure/2010/12/ FirewallRule.xsd""> " + vbLf + " <StartIpAddress>" + startIP.ToString() + "</StartIpAddress>" + vbLf + " <EndIpAddress>" + endIP.ToString() + "</EndIpAddress" + vbLf + ">" + "</FirewallRule>" Dim bytes As Byte() = Encoding.UTF8.GetBytes(xmlbody) webRequest.ContentLength = bytes.Length webRequest.ContentType = "application/xml;charset=uft-8" Using requestStream As Stream = webRequest.GetRequestStream() requestStream.Write(bytes, 0, bytes.Length) End Using Using response As WebResponse = webRequest.GetResponse() MessageBox.Show("Rule Added") End Using Catch webEx As WebException Dim errorResponse As HttpWebResponse = DirectCast(webEx.Response, HttpWebResponse) Try Using errrs As Stream = errorResponse.GetResponseStream() Using sr As New StreamReader(errrs) MessageBox.Show(sr.ReadToEnd().ToString()) End Using End Using Catch innerex As Exception MessageBox.Show(innerex.ToString()) End Try Catch ex As Exception MessageBox.Show(ex.ToString() + vbLf) End Try End Sub Private Sub btnDelete_Click(sender As Object, e As EventArgs) Handles btnDelete.Click Dim certfile As String Dim subscriptionID As String Dim servername As String Dim ruleName As String certfile = txtCertPath.Text subscriptionID = txtSubID.Text servername = txtServerName.Text ruleName = comboList.SelectedItem.ToString() DeleteServerFirewallRule(certfile, subscriptionID, servername, ruleName) End Sub Private Sub DeleteServerFirewallRule(certfile As String, subscriptionID As String, server As String, ruleName As String) Try Dim url As String = String.Format("https://management.database.windows .net:8443/{0}/servers/{1}/firewallrules/{2}", subscriptionID, server, ruleName) Dim webRequest As HttpWebRequest = TryCast(HttpWebRequest.Create(url), HttpWebRequest) webRequest.ClientCertificates.Add(New X509Certificate(certfile, "private key password")) webRequest.Headers("x-ms-version") = "1.0" webRequest.Method = "DELETE" Using wr As WebResponse = webRequest.GetResponse() Using stream As Stream = wr.GetResponseStream() Using sr As New StreamReader(stream) MessageBox.Show("Rule Deleted") firewallList.Items.Clear() End Using End Using End Using Catch webEx As WebException Dim errorResponse As HttpWebResponse = DirectCast(webEx.Response, HttpWebResponse) Try Using errrs As Stream = errorResponse.GetResponseStream() Using sr As New StreamReader(errrs) MessageBox.Show(sr.ReadToEnd().ToString()) End Using End Using Catch innerex As Exception MessageBox.Show(innerex.ToString()) End Try Catch ex As Exception MessageBox.Show(ex.ToString() & vbLf) End Try End Sub End Class










<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
My (@rogerjenn) Updated Accessing US Air Carrier Flight Delay DataSets on Windows Azure Marketplace DataMarket and “DataHub” post gained a Visualizing Flight Delay Data with Tableau Software section on 5/19/2012:
Visualizing Flight Delay Data with the Tableau Public Application
Tableau Software (@Tableau) publishes data visualization software with an emphasis on big data. According to the Tableau blurb on OakLeaf’s US Air Carrier Flight Delays offering on the Windows Azure Marketplace DataMarket:
Tableau provides drag-and-drop data visualization based on best practices and patented technology from Stanford University. Tableau allows you to publish dashboards to the web with one click. It’s rapid-fire business intelligence that anyone can use.
According to the publisher:
Tableau Public is a free service that lets you create and share data visualizations on the web. Thousands use it to share data on websites and blogs and through social media like Facebook and Twitter. Tableau Public allows you to see data efficiently and powerfully without any programming.
Easy drag & drop interface:
- No programming language
- No plug-ins
- No Flash, so it shows up on the iPad …
How it works:
Tableau Public visualizations and data are always public. Anyone can interact with your visualizations, see your data, download it, and create their own visualizations from it.
When you save your visualizations, it will be to the publically accessible Tableau Public web servers -- nothing is saved locally on your computer. You can then embed your visualization on your blog or website or share it through social media or email.
Tableau Public can connect to several data sources, including Microsoft Excel, Microsoft Access, and multiple text file formats. It has a limit of 100,000 rows of data allowed in any single file and there is a 50 megabyte limit on storage space for data. …


Warning: As noted in the preceding quotation, Tableau Public works with a maximum of 100,000 data rows, which you won’t discover until you attempt to use a query that returns more than that amount of data.

1. Download Tableau Public 7.0 from its download page. The download requires entering your email address.
Tip: The Thank You for Downloading … page appears immediately, but you must wait for a few minutes for the Do You Want to Run or Save TableauDesktop.msi … ? message to appear before taking additional actions.
2. Click Run to install the software, accept the license agreement, and click Install. Watch the Getting Started video, if you want. Close the Book 1 page.
3. Open the US Air Carrier Flight Delays dataset, sign into the DataMarket with an account that has a subscription to the dataset, click the Explore This Dataset link, and specify LAX as the optional parameter, which returns 86.940 rows with the current dataset. Click the Export button to open the Export pane, and mark the Tableau option in the Export to Program section:
4. Click the lower Download button and click Open when presented with the following message:
5. Click the Show button (see step 3’s screen capture) to display your Primary Account Key, copy it to the Clipboard and paste it in Tableau Public’s Login dialog:
6. Click OK to download the data and open Tableau Public’s main page and drag the Carrier dimension to the top Drop Field Here region, as shown here:
7. Select the DepDelayMinutes measure and drag it to the Rows shelf; select the Carrier dimension and drag it to the Columns shelf to enable appropriate chart styles in the Show Me gallery.
8. Open the Rows menu, select Measure (Sum) and choose Average in the submenu:
9. Here’s the basic column chart from the preceding steps.
You can edit the chart and axis titles, but due to the limited number of rows accommodated, further work usually isn’t warranted.
I have recommended that the DataMarket team add notice of the limitation in the number of rows supported by Tableau Public.
![image_thumb[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi-nBSIVCJPwo8dL48OVvgsrXAp5ZoYvzlurBgE5YWUVKGmUQZCQyIAVQjECU03EHAh_T36zG73SXdOQmuhPWgc_0dai6c9QkWhC7h0hm9j9jcRffJzJKHdiwDNltopXYzMKvLae5LN/s1600-h/image_thumb%25255B1%25255D%25255B2%25255D.png "image_thumb[1]")
![image_thumb[10]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhZ-vXZGgWqJ3XySQ058ntxUUB6okcs5oxzwOG7zVVIAA_RHju2WzfC6ww6D9z8-jNhZyd1CK0vi85U5AhbzJUU2VTpXnwUW9SEZfTci6wKMEQtjaS_C53VDXWvxfPlY2VAmRy069Dj/s1600-h/image_thumb%25255B10%25255D%25255B3%25255D.png "image_thumb[10]")
![image_thumb[12]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiTOzLoMD59zd3v9_NI7WK4QhdLGvQqJp2iea6lOcyxPdlHIHvO1hlKuB8gx9FANXbBMmjq96KdYGkc2GEN8DSaJef3dXg-nNU3U6Nt__jV2mt5X7AY12BhLfciA-7XrH_NS00j2Hdo/s1600-h/image_thumb%25255B12%25255D%25255B2%25255D.png "image_thumb[12]")
![image_thumb[19]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEinW_6u8SU-n_5nopzKqhUFhMtRiU9zLBRVhc9PZmeFqzBnecWvnVvl19lz9auLWg6D4XPGrPLHrQ9n5NG94UAcBlcca1Y8XFpTfRz_ZmmtpJ1FCpIdgf5YuVQ1SacPS2kCsdO_A5wF/s1600-h/image_thumb%25255B19%25255D%25255B3%25255D.png "image_thumb[19]")
![image_thumb[21]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjf32c1Kpy7BDZ_6N3dk3puzYkSof8ROzc6HSuBIQJHdZrguAe4P6eZchG4ufYGsU_QQSELR_XnJ4eOseFGcEeMe4gI99JOvKcIcL7a0XvTiBqKEOat_NDoSAoNtcogt1bW-TSeLgBG/s1600-h/image_thumb%25255B21%25255D%25255B3%25255D.png "image_thumb[21]")
![image_thumb[23]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjzAP8xP4IsLTyHJU-MWwIu7QQiKW7ZLfQEJQrW3KzXEUMWi2BqTMA1blFl_wi3gass01Oq-stXm1Dfc5fiZw-N2X3ccI3jBHO4Yttx9zjZVlzOZeDxf9jOR9RidecNd28kUCilf6w9/s1600-h/image_thumb%25255B23%25255D%25255B3%25255D.png "image_thumb[23]")
The Astoria (WCF Data Services) Team announced WCF Data Services 5.0.1 Released on 5/18/2012:
We have just pushed the official bits for 5.0.1 to NuGet and should be releasing an updated MSI sometime within the next week. Thanks to feedback from the community we found and fixed several bugs, detailed below.
NuGet Links
- http://www.nuget.org/packages/Microsoft.Data.Services
- http://www.nuget.org/packages/Microsoft.Data.Services.Client
- http://www.nuget.org/packages/Microsoft.Data.OData
- http://www.nuget.org/packages/Microsoft.Data.Edm
- http://www.nuget.org/packages/System.Spatial
Release Notes
- Added configuration setting to ODataLib to allow users to intercept the XML reader before ODataLib processes the payload
- Fixes bug where DateTime values do not roundtrip properly in JSON verbose
- Fixes bug where $metadata requests fail on services with both actions and service operations
- Fixes bug where $expand requests fail on Oracle providers
- Fixes bug where vocabulary annotations in an external annotations file fail to resolve the target
What does the MSI do?
All of the fixes detailed above are in the NuGet bits. There is one additional fix in the MSI for code generation against services that have multiple overloads for a function import. One important nuance of the MSI is that it removes the WCF Data Services DLLs from the GAC. (The 5.0.1 MSI is an upgrade to the 5.0 MSI, which means that the 5.0 MSI gets uninstalled and its install actions – including the GACing of the DLLs – are reversed.) We have blogged previously about leaving the GAC.
Where should the MSI be installed?
The MSI should only be installed on development machines as it solely contains tooling fixes. If the MSI is installed on a production Web server running a WCF Data Services 5.0.0 service that was not bin deployed, the service may stop functioning.
Feedback Please
As we begin to release more quickly and issue more prereleases, your feedback is critical to the process.
David Linthicum (@DavidLinthicum) asserted “Big data is not data warehousing or BI, so there are no proven paths --which is why you need data scientists” in a deck for his Big data in the cloud: It's time to experiment post of 5/18/2012 to InfoWorld’s Cloud Computing blog:
The lure of big data has many people in enterprise IT moving quickly to consolidate and mash up their data assets with other relevant information. The tools are here right now, including big data engines based on Hadoop, public clouds that provide rental access to a huge number of servers, and external cloud-delivered data resources to make better sense of your info.
Take, for example, a manufacturing company that can -- thanks to the use of cloud-based big data -- not only establish the output of its factories for the last 10 years but determine how that output compared with others in its industry, as well as the effects of the weather and other external factors. Moreover, it can predict future factory output through the use of proven algorithms and other relevant data models applied to that big data.
Big data is good. The cloud is good. Now, how do we actually make the whole thing work?
The truth is not many best practices have emerged on how to move to big data. We have the migration to data warehousing and business intelligence as an existing model, but as I look at what big data really is, it's clear that big data adoption is a different type of problem. Much of that experience in data warehousing and BI isn't relevant, and it may even lead to some dead ends.
The art of big data is that it consolidates many types of data resources with different structures and data models, all in a massive, distributed storage system. Big data systems may not enforce a structure, though structure can be layered into the data after the migration. But there are trade-offs in going this route, including migrating unneeded and redundant data that takes up space in the big data system.
For now, the proper path is more through trial and error than following proven concepts. The answer to how to best do big data is the classic consultant's response: It depends on what you're trying to do.
The bottom line is that you have to experiment. But you need not do so blindly. The emerging role of data scientist can help direct those experiments within an appropriate framework, in the manner of research scientists in any field. Data scientists can get you the answers to big data, as long as you understand that a scientist must run a lot of experiments.
At this point, experimentation is the best practice in moving to big data. Get a data scientist or two to design and run these trials.

Tony Baer (@TonyBaer) added “Searching for data scientists as a service” as an introduction to his Big Data Brings Big Changes article of 5/18/2012:
It’s no secret that rocket .. err … data scientists are in short supply. The explosion of data and the corresponding explosion of tools, and the knock-on impacts of Moore’s and Metcalfe’s laws, is that there is more data, more connections, and more technology to process it than ever. At last year’s Hadoop World, there was a feeding frenzy for data scientists, which only barely dwarfed demand for the more technically oriented data architects. In English, that means:
- Potential MacArthur Grant recipients who have a passion and insight for data, the mathematical and statistical prowess for ginning up the algorithms, and the artistry for painting the picture that all that data leads to. That’s what we mean by data scientists.
- People who understand the platform side of Big Data, a.k.a., data architect or data engineer.
The data architect side will be the more straightforward nut to crack. Understanding big data platforms (Hadoop, MongoDB, Riak) and emerging Advanced SQL offerings (Exadata, Netezza, Greenplum, Vertica, and a bunch of recent upstarts like Calpont) is a technical skill that can be taught with well-defined courses. The laws of supply and demand will solve this one – just as they did when the dot com bubble created demand for Java programmers back in 1999.
Behind all the noise for Hadoop programmers, there’s a similar, but quieter desperate rush to recruit data scientists. While some data scientists call data scientist a buzzword, the need is real.
It’s all about connecting the dots, not as easy as it sounds.
However, data science will be a tougher number to crack. It’s all about connecting the dots, not as easy as it sounds. The V’s of big data – volume, variety, velocity, and value — require someone who discovers insights from data; traditionally, that role was performed by the data miner. But data miners dealt with better-bounded problems and well-bounded (and known) data sets that made the problem more 2-dimensional.
The variety of Big Data – in form and in sources – introduces an element of the unknown. Deciphering Big Data requires a mix of investigative savvy, communications skills, creativity/artistry, and the ability to think counter-intuitively. And don’t forget it all comes atop a foundation of a solid statistical and machine learning background plus technical knowledge of the tools and programming languages of the trade.
Sometimes it seems like we’re looking for Albert Einstein or somebody smarter.
Nature abhors a vacuum
As nature abhors a vacuum, there’s also a rush to not only define what a data scientist is, but develop programs that could somehow teach it, software packages that to some extent package it, and otherwise throw them into a meat … err, the free market. EMC and other vendors are stepping up to the plate to offer training, not just on platforms, but for data science. Kaggle offers an innovative cloud-based, crowdsourced approach to data science, making available a predictive modeling platform and then staging sponsored 24-hour competitions for moonlighting data scientists to devise the best solutions to particular problems (redolent of the Netflix $1 million prize to devise a smarter algorithm for predicting viewer preferences).
With data science talent scarce, we’d expect that consulting firms would buy up talent that could then be “rented’ to multiple clients. Excluding a few offshore firms, few systems integrators (SIs) have yet stepped up to the plate to roll out formal big data practices (the logical place where data scientists would reside), but we expect that to change soon.
Opera Solutions, which has been in the game of predictive analytics consulting since 2004, is taking the next step down the packaging route. having raised $84 million in Series A funding last year, the company has staffed up to nearly 200 data scientists, making it one of the largest assemblages of genius this side of Google. Opera’s predictive analytics solutions are designed for a variety of platforms, SQL and Hadoop, and today they join the SAP Sapphire announcement stream with a release of their offering on the HANA in-memory database. Andrew Brust provides a good drilldown on the details on this announcement.
With market demand, there will inevitably be a watering down of the definition of data scientists so that more companies can claim they’ve got one… or many.
From SAP’s standpoint, Opera’s predictive analytics solutions are a logical fit for HANA as they involve the kinds of complex problems (e.g., a computation triggers other computations) that their new in-memory database platform was designed for.
There’s too much value at stake to expect that Opera will remain the only large aggregation of data scientists for hire. But ironically, the barriers to entry will keep the competition narrow and highly concentrated. Of course, with market demand, there will inevitably be a watering down of the definition of data scientists so that more companies can claim they’ve got one… or many.
The laws of supply and demand will kick in for data scientists, but the ramp up of supply won’t be as quick as that for the more platform-oriented data architect or engineer. Of necessity, that supply of data scientists will have to be augmented by software that automates the interpretation of machine learning, but there’s only so far that you can program creativity and counter-intuitive insight into a machine.
You may also be interested in:
- Fast data hits the big data fast lane
- EMC's Hadoop strategy cuts to the chase
- Big data consolidation race enters home stretch, as Teradata buys Aster Data
- Oracle fills another gap in its big data offering
- VMforce: Cloud mates with Java marriage of necessity for VMware and Salesforce.com
- HP buys Fortify, and it's about time
See Apigee (@Apigee) announced on 5/18/2012 a Live Webcast: OData Introduction and Impact on API Design scheduled for 5/24/2012 at 11:00 AM PDT in the Cloud Computing Events section below.
Mike Gualtieri (@mgualtieri) explained how to answer What's Your Big Data Score? in a 5/17/2012 post to his Forrester blog:
If you think the term "Big Data" is wishy washy waste, then you are not alone. Many struggle to find a definition of Big Data that is anything more than awe inspiring hugeness. But, Big Data is real if you have an actionable definition that you can use to answer the question: "Does my organization have Big Data?" Proposed is a definition that takes into account both the measure of data and the activities performed with the data. Be sure to scroll down to calculate your Big Data Score.
Big Data Can Be Measured
Big Data exhibits extremity across one or many of these three alliterate measures:
- Volume. Metric prefixes rule the day when it comes to defining Big Data volume. In order of ascending magnitude: kilobyte, megabyte, gigabyte, terabyte, petabyte, exabyte, zettabyte, and yottabyte. A yottabyte is 1,000,000,000,000,000,000,000,000 bytes = 10 to the 24th power bytes. Wow! The first hard disk drive from IBM stored 3.75MB in 1956. That’s chump change compared to the 3TB Seagate harddrive I can buy at amazon for $165.86. And, that’s just personal storage, IBM, Oracle, Teradata, and others have huge, fast storage capabilities for files and databases.
- Velocity. Big data can come fast. Imagine dealing with 5TB per second as Akamai does on its content delivery and acceleration network. Or, algorithmic trading engines that must detect trade buy/sell patterns in which complex event processing platforms such as Progress Apama have 100 microseconds to detect trades coming in at 5,000 orders per second. RFID, GPS, and many other data can arrive so fast that technologies such as SAP Hana and Rainstor to capture it fast enough.
- Variety. There are thirty flavors of Pop-Tarts. Flavors of data can be just as shocking because combinations of relational data, unstructured data such as text, images, video, and every other variations can cause complexity in storing, processing, and querying that data. NoSQL databases such as MongoDB and Apache Cassandra are key-value stores can store unstructured data with ease. Distributed processing engines like Hadoop can be used to process variety and volume (but, not velocity). Distributed in-memory caching platforms like VMWare vFabric GemFire can store a variety of objects and is fast to boot because of in-memory.
Volume, velocity, and variety are fine measures of Big Data, but they are open-ended.There is no specific volume, velocity, or variety of data that constitutes big. If a yottabyte is Big Data then that doesn’t mean a petabyte is not? So, how do you know if your organization has Big Data?
The Big Data Theory of Relativity
Big Data is relative. One organization’s Big Data is another organization’s peanut. It all comes down to how well you can handle these three Big Data activities:
- Store. Can you store all the data whether it is persistent or transient.
- Process. Can you cleanse, enrich, calculate, translate, or run algorithms, analytics or otherwise against the data?
- Query. Can you search the data?
Calculate Your Big Data Score
For each combination of Big Data measures (volume, velocity, variety) and activities (store, process, query) in the table below enter a score:
- 5 = Handled perfectly or not required
- 3 = Handled ok but could be improved
- 1 = Handled poorly and frequently results in negative business impact
- 0 = Need exists but not handled.
Add up your scores in the points column and then sum at the bottom to get your Big Data score.
Once you have tallied your score, look in the table below to find out what it means.
I hope this helps and by all means, let me know how to improve this.



David Ramel (@dramel) asserted “Microsoft released demos of both to get them in front of developers; already there's a wishlist of features from developers. Here's some of my initial thoughts and experiments with them” in a deck for his Trying Out the OData/WCF Data Services Upgrades article of 5/17/2012 for Microsoft Certified Professional Magazine Online’s SQL Advisor column:
Microsoft recently updated the Open Data Protocol (OData) and WCF Data Services framework and just last week provided some demo services so data developers can try out the new features.
The WCF Data Services 5.0 release offers libraries for .NET 4 and Silverlight 4 and a slew of new client and server features, including support for actions, vocabularies, geospatial data, serialization/deserialization of OData payloads, "any" and "all" functions in queries and more (including a new JSON format).
The three new V3 demo services include simple read-only and read-write models for Products, Categories and Suppliers, and a read-only service that exposes the trusty Northwind database.
The new support for actions looks promising, providing for example, a Discount action for Products that takes a discountPercentage integer as a parameter and decreases the price of the product by that percentage, as shown on the demo services page.
But I decided to quickly try out something a little simpler just as a proof of concept: the new "any" and "all" operators. They allow tacking onto URLs filters such as this example shown on the demo services page:
http://services.odata.org/V3/OData/OData.svc/Categories?$filter=Products/any(p: p/Rating ge 4)
As WCF Data Services supports LINQ, I experimented with the "any" and "all" operators in a LINQ query via a Visual Studio project, using the MSDN Library Quickstart here.
I changed this query:
var ordersQuery = from o in context.Orders.Expand("Order_Details")
where o.Customer.CustomerID == customerId
select o;to this query (note the use of the "All" operator):
var ordersQuery = context.Orders.Expand("Order_Details")
.Where(c =>
c.Order_Details.All (p =>
p.Quantity > 50));Sure enough, this query didn't work with the old Northwind service, but it worked after simply inserting "V3" into the service URL so it looks like:
http://services.odata.org/V3/Northwind/Northwind.svc/
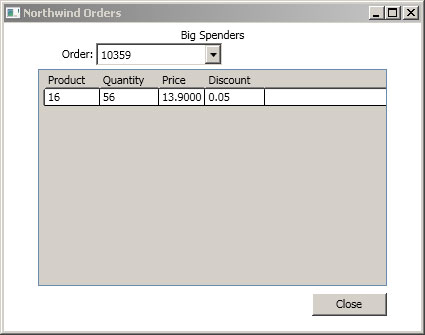
Fig. 1 shows the result of my efforts, in a WPF application showing customer orders with a quantity of more than 50.
Figure 1. A WPF app successfully pulls Northwind orders via a LINQ query using the new "Any" operator. (Click image to view larger version. [In the original article])
Without the "V3" in the service URL, though, you get an error message (see Fig. 2).
Figure 2. Not using the new V3 OData service results in an error. (Click image to view larger version.)
I recommend the Quickstart as an easy way to experiment with the new OData features, but you have to plug them in yourself because it doesn't use them, though it does require WCF Data Services 5. The completed project files are available if you don't want to go through the whole process of creating each project and just plug new feature functionality into them, as I did.
More improvements may be coming soon, as WCF Data Services, as the team is now using "semantic versioning" and NuGet, as have other products, such as Entity Framework. One reader asked about support for "Join," while Microsoft's Glenn Gailey has a list of improvements he'd like to see, including support for enums, client JSON support, functions and more (note that this wish list is included in a post of his favorite things that did make it into the new versions).


The Astoria Team announced the availability of NuGet and Bin Deploy on 5/17/2012:
Managing dependencies with NuGet
If you’re already familiar with NuGet, you probably understand its value proposition and can skip ahead to bin deploying applications. If you haven’t used NuGet before, this section will provide you with a quick introduction. The NuGet site has a great documentation section that provides significantly more detail.
What is NuGet?
Languages such as Ruby and Python have package management systems that make it trivial to take a dependency on a centrally published package. NuGet provides similar functionality for .NET. With a few clicks or a simple command a developer can take a dependency on Microsoft.Data.Services.Client, the assembly that provides WCF Data Services client functionality. Taking a dependency on that package adds three other packages to your project: Microsoft.Data.OData, Microsoft.Data.Edm and System.Spatial.
Getting a specific version of WCF Data Services is also very easy: issuing the command
Install-Package Microsoft.Data.Services.Client –Version 5.0.1will install version 5.0.1 of the client, even if there is a more recent version of the client published. (Issuing the commandInstall-Package Microsoft.Data.Services.Clientor installing the package with the explorer will always get the most recent version of the client.)Installation experience with Manage NuGet Packages dialog:



Installation experience with Package Manager Console:

Sample installation commands:
Install-Package Microsoft.Data.Services.Client: Installs the most recent released version of the WCF Data Services client.Install-Package Microsoft.Data.Services.Client –Pre: Installs the most recent version of the WCF Data Services client (including prereleases).Install-Package Microsoft.Data.Services.Client –Version 5.0.0.50403: Installs an explicit version of WCF Data Services client, ignoring more recent versions.Updating Packages with NuGet
In addition to the simple installation process, NuGet makes it easy to update packages.
Update experience with Manage NuGet Packages dialog:

Update experience with Package Manager Console:

Sample update commands:
Update-Package: Updates all packages to their most recently released version.Update-Package –Pre: Updates all packages to their most recent versions (including prereleases).Update-Package Microsoft.Data.Services.Client: Updates the Microsoft.Data.Services.Client package to its most recently released version, including any dependency updates required by the Microsoft.Data.Services.Client package.Simplified Dependency Management
In summary, NuGet greatly simplifies the process of locating, downloading, and adding references to the most recent version of WCF Data Services. Developers no longer need to search the Download Center for a version of WCF Data Services, sort by date, download and install an MSI, manually copy the DLLs and add a reference to them, etc. With NuGet developers simply use the Manage NuGet Packages dialog or the Package Manager Console to easily take a dependency on WCF Data Services.
Bin Deploying Applications
Bin deployment is a term commonly used for a deployment process wherein the contents of the bin folder (potentially with a few other files) are copied to a server using a very simple file copy or similar process. In other words, bin deploy scenarios do not require an MSI to be run on the server that will host the application. This is especially key in scenarios where the server is not controlled by the developer (e.g., Web hosting). However, bin deploy is also beneficial in many other scenarios. Some of the benefits of bin deploy are as follows:
- Simple file copy deployment using SMB, FTP, or some similar alternative.
- Assemblies can be configured to run in medium trust (GACed assemblies always run in full trust).
- No need to have an operations team run an MSI to get the latest version of an assembly.
- Easier to automate deployments.
Bin deployment is also a natural companion for NuGet, semantic versioning, and our amended EULA for the imminent 5.0.1 version of WCF Data Services, which will include a redistribution clause.
A Glimpse Into the Future
Down the road, we will be taking a much deeper dependency on NuGet – we are currently revamping our tooling to install NuGet packages when you add a WCF Data Service or a reference to an OData service to your application.






<Return to section navigation list>
Windows Azure Service Bus, Access Control, Identity and Workflow
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Richard Conway (@azurecoder) posted Some updates to [Windows Azure] fluent management on 5/19/2012:
It’s been a while since I’ve done any posts on fluent management. This is taking place in the background and I’m using one of our projects to drive the development of this. I’ve back in a lot of changes and I realise now that if I’m going to get people to use this then I need to set up a wiki!
There have been a whole heap of changes which allow config to be injected in prior to deployment and that wrap up .cscfg files so have a nice way to add and remove settings. This proved mandatory for us on the current project we’re undertaking which needs the use config-driven settings for plugins we’re writing at runtime.
One of the key aspects which will be added in the next release is the idea of workflow. I want to be able to add a storage account, do something with it, add a database, add a hosted service, create a service bus namespace and queue etc. in a single transaction and rollback if this fails at any point. I’ve added some context interfaces to the lib which should enable this fairly easily now.
Someone recently asked whether the lib was published under an open source license. Yes, it is under a GNU lesser license. Currently it’s in beta so we won’t take repsonsibility for it if you use it in production and it fails. We’re going to offer a manadatory support contract going forward if you turnover more than $5m/year. This is mainly because a lot of consultancies that we’ve worked with don’t put anything back in the ecosystem and we don’t want them to profit from our labour and maintenance if they’re not helping the community. This has been our general experience with the user group – not a lot of support from the “partner” “community” – two terms I use very loosely.

For background about the Windows Azure Fluent Management library, see Release of Azure Fluent Management v0.1 library of 3/26/2012 and Richard’s later posts.
Wely Lau (@wely_live) answered Managing session state in Windows Azure: What are the options? on 5/18/2012:
One of the most common questions in developing ASP.NET applications on Windows Azure is how to manage session state. The intention of this article is to discuss several options to manage session state for ASP.NET applications in Windows Azure.
What is session state?
Session state is usually used to store and retrieve values for a user across ASP.NET pages in a web application. There are four available modes to store session values in ASP.NET:
- In-Proc, which stores session state in the individual web server’s memory. This is the default option if a particular mode is not explicitly specified.
- State Server, which stores session state in another process, called ASP.NET state service.
- SQL Server, which stores session state in a SQL Server database
- Custom, which lets you choose a custom storage provider.
You can get more information about ASP.NET session state here.
In-Proc session mode does not work in Windows Azure
The In-Proc option, which uses an individual web server’s memory, does not work well in Windows Azure. This may be applicable for those of you who host your application in a multi-instance web-farm environment; Windows Azure load balancer uses round-robin allocation across multi-instances.
For example: you have three instances (A, B, and C) of a Web Role. The first time a page is requested, the load balancer will allocate instance A to handle your request. However, there’s no guarantee that instance A will always handle subsequent requests. Similarly,the value that you set in instance A’s memory can’t be accessed by other instances.
The following picture illustrates how session state works in multi-instances behind the load balancer.
Figure 1 – WAPTK BuildingASP.NETApps.pptx Slide 10
The other options
1. Table Storage
Table Storage Provider is a subset of the Windows Azure ASP.NET Providers written by the Windows Azure team. The Table Storage Session Provider is,in fact, a custom provider that is compiled into a class library (.dll file), enabling developers to store session state inside Windows Azure Table Storage.
The way it actually works is to store each session as a record in Table Storage. Each record will have an expired column that describe the expired time of each session if there’s no interaction from the user.
The advantage of Table Storage Session Provider is its relatively low cost: $0.14 per GB per month for storage capacity and $0.01 per 10,000 storage transactions. Nonetheless, according to my own experience, one of the notable disadvantages of Table Storage Session Provider is that it may not perform as fast as the other options discussed below.
The following code snippet should be applied in web.config when using Table Storage Session Provider.
<sessionState mode="Custom" customProvider="TableStorageSessionStateProvider">
<providers>
<clear/>
<add name="TableStorageSessionStateProvider" type="Microsoft.Samples.ServiceHosting.AspProviders.TableStorageSessionStateProvider" />
</providers> </sessionState>You can get more detail on using Table Storage Session Provider step-by-step here.
2. SQL Azure
As SQL Azure is essentially a subset of SQL Server, SQL Azure can also be used as storage for session state. With just a few modifications, SQL Azure Session Provider can be derived from SQL Server Session Provider.
You will need to apply the following code snippet in web.config when using SQL Azure Session Provider:
<sessionState mode="SQLServer" sqlConnectionString="Server=tcp:[serverName].database.windows.net;Database=myDataBase;User ID=[LoginForDb]@[serverName];Password=[password];Trusted_Connection=False;Encrypt=True;" cookieless="false" timeout="20" allowCustomSqlDatabase="true" />For the detail on how to use SQL Azure Session Provider, you can either:
- Follow the walkthrough from this post.
- Or use ASP.NET Universal Providers via Nuget.
The advantage of using SQL Azure as session provider is that it’s cost effective, especially when you have an existing SQL Azure database. Although it performs better than Table Storage Session Provider in most cases, it requires you to clean the expired session manually by calling the DeleteExpiredSessions stored procedure. Another drawback of using SQL Azure as session provider is that Microsoft does not provide any official support for this.
3. Windows Azure Caching
Windows Azure Caching is probably the most preferable option available today. It provides a high-performance, in-memory, distributed caching service. The Windows Azure session state provider is an out-of-process storage mechanism for ASP.NET applications. As we all know, accessing RAM is very much faster than accessing disk, so Windows Azure Caching obviously provides the highest performance access of all the available options.
Windows Azure Caching also comes with a .NET API that enables developers to easily interact with the Caching Service. You should apply the following code snippet in web.config when using Cache Session Provider:
<sessionState mode="Custom" customProvider="AzureCacheSessionStoreProvider"> <providers> <add name="AzureCacheSessionStoreProvider" type="Microsoft.Web.DistributedCache.DistributedCacheSessionStateStoreProvider, Microsoft.Web.DistributedCache" cacheName="default" useBlobMode="true" dataCacheClientName="default" /> </providers> </sessionState>A step-by-step tutorial for using Caching Service as session provider can be found here.
Other than providing high performance access, another advantage about Windows Azure Caching is that it’s officially supported by Microsoft. Despite its advantages, the charge of Windows Azure Caching is relatively high, starting from $45 per month for 128 MB, all the way up to $325 per month for 4 GB.
Conclusion
I haven’t discussed all the available options for managing session state in Windows Azure, but the three I have discussed are the most popular options out there, and the ones that most people are considering using.
Windows Azure Caching remains the recommended option, despite its cons but developers and architects shouldn’t be afraid to decide on a different option, if it’s more suitable for them in a given scenario.
This post was also published at A Cloud[y] Place blog.


Full disclosure: I’m a paid contributor to the ACloudyPlace blog.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Jay Schmelzer posted Visual Studio 11 Product Line-up Announced on 5/18/2012:
Today the Visual Studio 11 product line-up was announced on the Visual Studio Team blog. Part of this announcement was information on what editions will support LightSwitch development.
Launched last year as an out-of-band release, I’m excited to announce that LightSwitch is now a core part of the Visual Studio product line! LightSwitch will be available through Visual Studio 11 Professional, Premium and Ultimate. With this integration, Visual Studio now provides a comprehensive solution for developers of all skill levels to build line-of-business applications and data services quickly and easily for the desktop and cloud.
I am particularly excited about the additional tools for data application development that will be available to you. In addition, with the new data services (OData) support in LightSwitch, you will be able to build additional clients using the broad set of project templates now included in these editions including Windows 8 Metro style apps.
LightSwitch will be retired from sale as a standalone product with the release of Visual Studio 11. If you acquire Visual Studio Professional, Premium, or Ultimate you will also get the LightSwitch development experience included in the box. We previously announced a price reduction for Visual Studio 2010 Professional to align it with the planned pricing for Visual Studio 11 making this an even more exciting offer. For more information on Visual Studio pricing please see: http://www.microsoft.com/visualstudio/11/en-us/products/pricing. [Emphasis added.]
Bringing LightSwitch and Visual Studio closer together was a natural choice. LightSwitch is a valuable tool offering a wide variety of developers the ability to quickly and easily build line of business applications. By including LightSwitch into the core Visual Studio 11 product line we are able to more fully integrate the products, making both stronger and offering additional value to developers of all skill levels.


Jay is Principal Director Program Manager of the LightSwitch Team.
Keith Craigo described Visual Studio LightSwitch Deployment GOTCHA's in a 5/18/2012 post:
Over the past several days I've been deploying two Visual Studio LightSwitch 2011 applications to my company's intranet server. I may revise this for Visual Studio 11 at a later time.
The 1st application was a packaged application, meaning I developed it on my personal computer zipped it and then gave it to my employers admin to install (namely Me, I'm the admin)
The 2nd application was deployed directly to the server from my work laptop. Needless to say neither went as smooth as I had hoped but I did learn some valuable lessons along the way.
NOTE: In this article I'm going to talk about what I did to deploy the 2nd application, a "WEB application", directly to the server, I'll be pointing out some issues I came across. The environment is restricted access to the application using Windows Authentication on my company's Intranet server. I'll talk about deploying a package at a little later time.
Disclaimer: Every scenario will not be discussed here, I can only comment on what worked best for me. I'm not a server administrator so please keep reading with that in mind.
I hope you find what I've learned useful.
Guides
First and foremost keep these two references handy:
- Beth Massi's Deployment Guide: How to Configure a Web Server to Host LightSwitch ApplicationsShe goes over in detail on how to setup your server.
- Eric Erhardt's Diagnosing Problems in a Deployed 3-Tier LightSwitch Application (Eric Erhardt)
Also I highly recommend installing Fiddler2 to debug your browsers traffic. It's proved to be valuable resource for me.
If using DevExpress XtraReports
The DevExpress XtraReports Suite is fantastic, but I've come across some GOTCHAS when it comes to deploying.
1st you need to ensure that under the Server and Server Generated - References folders that all the DevExpress libraries property Copy Local is set to true. Thank you Supreet Tare for this tip.
One of the things that kept happening to me was that for some reason when I did a Release build some of the libraries were changing back to false (will troubleshoot that later).
If you receive the error message "Load operation failed for query 'GetAuthenticationInfo'" on your deployed application, this message is really misleading a lot of times so check that the libraries have not been set to false.
GOTCHA Update 5/18/12 - XtraReports running under Authentication mode ASP.Net Impersonation is not supported at this time, this prevents XtraReports from accessing the database.
DevExpress has provided a workaround on their Support Forum (90% down the page) http://www.devexpress.com/Support/Center/Question/Details/Q385592
Deployment Checklist
ON THE APPLICATION HOST
I followed Beth Massi's Deployment Guide: How to Configure a Web Server to Host LightSwitch Applications to install all the LightSwitch pre requisites on the server.
Ask your server admin to assist with these if you don't have access:
- Install the Windows Platform Installer on the server as well as on your development machine - makes life a lot easier, trust me.
- Install the Web Deployment tool on both the server and development machine I used version 1.1
- Get the credentials of an account that can connect to the server and has appropriate permissions to install your app - i.e. server admin.
- Get the credentials of the SQL Server user that will perform read / write functions to the database on the behalf of your users -Publishing Wizard-Database Connection-Specify the user connection: is where this goes. Or you can click the Create Database Login button and LightSwitch will take care of this.
- Get the credentials of the SQL Server Application Administrator - this is the user that will be allowed to create roles, assign privileges to roles, create user accounts and assign users to roles for your application. Or you can select the Yes, create the Application Administrator at this time radio button, fill in the details and LightSwitch will take care of this.
- I created ahead of time an APPPOOL with .NET 4.0 and Integrated management. I'm going to assign my application to this APPPOOL.
- If supporting multiple users a maintenance time saver is to create a host server group and add all your users to this group, Once the application database is created, add the group to the database server logins and assign db_dataread and db_datawrite privileges for your applications database to this group. Now everyone is updated in one place Woo!Hoo!
NOTE: I will update this once I get into controlling access through Active Directory groups.ON THE DEVELOPMENT MACHINE
Manually Copy your database files to the server.
Open SQL Server Express Management Studio right click your database and select Tasks-Generate Scripts
Then make sure that the radio button for "Script entire database and all database objects" is selected. PLEASE NOTE: This tool does not script any Triggers - this was a GOTCHA. But we can remedy this by copying and pasting the trigger into the appropriate location on the production server.
Save the output to a convenient location then copy the zip file over to the production server.
Switch to the Production Server
Open the zip file you just copied in the SQL Server Management Studio and execute the scripts to create the production database, then create the appropriate triggers on your tables.
Once the database is set up go to the SQL Server Security folder and right click the user you created in step 4 above and select properties
Select User Mappings and then the database you just created
Assign aspnet_Memebership_BasicAccess, aspnet_Memebership_FullAccess, aspnet_Memebership_ReportingAccess, aspnet_Roles_BasicAccess, aspnet_Roles_FullAccess, aspnet_Roles_ReportingAccess, db_datareader, and db_datawriter to this account. Public is selected by default. Click OK
Open the database Security-Users folder and you will see that this user has been added.
Switch back to your development machine
Publishing: In the Publishing Wizard Dialog Box under DataBase Connections and Other Connections, change the Data Source to the Server that will be hosting the application and the user credentials to the appropriate users you specified above.
In Other Connections, for DevEpress.XtraReports and my WCFRia Services I put bin for location.Switch to the Production Server
Open IIS Manager, if icon is not available, click Start and in Search Programs and files box, type in inetmgr.
Select your new virtual directory then in the Actions panel Select Basic Settings...
In the dialog box select the Select Button and then choose the APPPOOL you created in step 6 above. Click OK and OK again.Make sure you’re on the /project Home page.
NOTE: If you need to Trace the application please refer to
Eric Erhardt's Diagnosing Problems in a Deployed 3-Tier LightSwitch Application (Eric Erhardt).Under IIS select Authentication, again you can just double click this icon or in the Actions panel select Open Feature.
I enabled Windows Authentication and ASP.NET Impersonation, all other settings are disabled.
Ok this is one other GOTCHA I ran across.
Revision 5/17/12 - You can set these settings before deploying, in Visual Studio - Select your projects top node and click File View then select All Files, navigate to the ServerGenerated folder and open the Web.config file and make your changes.
With the project selected, in the Actions panel select Explore open your web.config file by right clicking and choosing Edit(you may have to give yourself read / write privs first).
Scroll down to your connection strings, make sure that all of the data sources are set to the production server and not the development machine, I had an issue where one of my WCFRia Services still pointed to my development machine.
Save your changes and close this file, you may even want to revoke the write privs for your account.
Now if you have Fiddler installed you may want to run this first, but it's not required.
If you enabled Tracing, just navigate to http://{your server}/{your project}/trace.axd
Back on the /project Home page, in the Actions pane under Manage Application click Browse *.80(http) or Browse *.443(https) if your running under SSL.
I chose the Browse *.80(http) link, run your application step through your screens, give it a thorough thrashing to make sure everything is working as it should from the server.
Now all I have to do is troubleshoot an issue with one of my WCFRia Services, hopefully by the end of today I'll have that resolved.
Once resolved I can re-publish to the server and I'll invite my co-workers to test out my application and once everything has been tested, debugged and if necessary fixed and tested again. I'll be ready to release it to my users.






Return to section navigation list>
Windows Azure Infrastructure and DevOps
John Treadway (@CloudBzz) recommended RACI and PaaS – A Change in Operations in a 5/18/2012 post:
I have been having a great debate with one of my colleagues about the changing role of the IT operations (aka “I&O”) function in the context of PaaS. Nobody debates that I&O is responsible and accountable for infrastructure operations.
Application developers (with or without the blessing of Enterprise Architecture) select platform components such as application servers, middleware etc. I&O keeps the servers running – probably up to the operating system. The app owners then manage their apps and the platform components. I&O has no SLAs on the platform, etc.
In the PaaS era, I think this needs to change. IT Operations (I&O) needs to have full accountability and responsibility for the OPERATION of the PaaS layer. PaaS is no longer a part of the application, but is now really part of the core platform operated by IT. It’s about 24×7 monitoring, support, etc. and generally this is a task that I&O is ultimately best able to handle.
Both teams need to be accountable and responsible for the definition of the PaaS layer to ensure it meets the right business and operational needs. But when it comes to operations, I&O now takes charge.
The implication of this will be a need for PaaS operations and administration skills in the I&O business. It also means that the developers and application ownership teams need only worry about the application itself – and not the standard plumbing that supports it.
Result? Better reliability of the application AND better agility and productivity in development. That’s a win, right?



Michael D. Dunn described Running Mission Critical Solutions on Windows Azure in a 5/17/2012 post to his MSDN blog:
I wanted to follow up on my previous post for Common Tip and post something that covers how Upgrades work, how to achieve maximum availability and scale along with deployment and monitoring recommendations.
Understanding Updates & Upgrades
There are three types of Update events that can occur on the Windows Azure Platform.
- · Application Upgrade
- · Guest OS Update
- · Host OS Update
An Application Upgrade occurs when you do an in-place upgrade on your application, options for this is covered in the Deployment section.
The Guest OS Version is controlled via the Azure Service Configuration by setting osFamily and the osVersion attributes. The osFamily attribute currently can be a 1, Windows Server 2008, or a 2, Windows Server 2008 R2. The osVersion controls a group of OS patches and updates for a given time, by setting the osVersion to “*” instead of an explicit version, this will install OS patches automatically. For Mission Critical applications you will have to determine if having the latest patches, including security vulnerabilities installed automatically is more of risk to your solution, than manually performing the upgrade. There are two ways to perform this update manually either through the Service Configuration or through “Configure OS” within the Management Portal.
The Host OS Update occurs one the Host system. Windows Azure tenants have no control as to when this update happens. To ensure the 99.95% SLA, Windows Azure will not update all hosts at once but perform host updates on host on different Fault domains, which is why you must have at least 2 instances for each role for the guaranteed 99.95% SLA. The Scalability & Elasticity section goes into more detail on how you can ensure capacity during these updates.
Increasing Scalability & Elasticity
A lot of times it is easy to choose the largest instance possible, surely adding more memory or CPU will increase the performance of your application? The problem is that most application are not written specifically to leverage multiple CPU cores and I have yet see an application that actually needed 14 GB of memory that the Extra Large VM provides.
Which is better: 4 Mediums or 2 large instances?
I would argue that 4 Mediums would be “better” as it would give you elasticity to increase OR decrease the number of instances based on my load at any given time, yet reducing cost by not over provisioning resources. For example if you have 2 Large Instances – You couldn’t scale down without sacrificing the 99.95% SLA provided for roles that have at least 2 instances and you couldn’t scale up without paying for an entire new Extra Large VM.
Also by choosing the medium instances over the large instances, it would allow you to increase the number update domains from 2 to 4, this allows you to have higher capacity availability during Host OS updates, Guest OS updates and Application updates. For example if a Host OS update occurs, which you cannot control when it happens, and you were using 2 Large instances, during this time frame your solution could only handle 50% of your maximum capacity. On the other hand if you had used 4 Medium instances you could choose to create 4 update domains, one for each instance, which means during any update your solution, would be able to handle 75% of your maximum capacity.
What is your solutions tolerance for reduced capacity? Maybe 25%-50% reduced capacity for a short period is acceptable, if not what are your options?
The simplest option is to create an additional update domain that runs the same number of instances as all your other domains. In the example above of using 4 Mediums instances, this would mean running a 5th update domain with 1 additional medium instance.
Another option would be to consider auto scaling or reducing feature availability for features that are CPU and/or memory intensive. The Enterprise Library Integration pack for Windows Azure includes WASABi , Windows Azure Autoscaling Application Block. This application block allows you to create rules to scale up/down and to reduce resource intensive features on the fly. Developers can download this application block from: http://www.microsoft.com/en-us/download/details.aspx?id=28189
Increasing Availability with Geo-Redundancy
With two fault domains in a single datacenter and multiple upgrade domains, you are setup nicely in the event of an inner data center failure. What about a complete datacenter failure? As with an inner datacenter failure, you have to decide what is your tolerance for a complete datacenter failure? If your tolerance is low, then you should consider deploying your application into two data center and if you are not using auto scaling type features – this means running a complete duplicate of all of your instances in a secondary data center to run at 100% capacity you had prior to the failure. Once you have your solution deployed into two data centers, you can leverage the Traffic Manager feature to create a new ‘Failover’ policy for your secondary deployment.
It sounds simple right? Well there are other considerations when planning to have a complete failover, such as are you leveraging any other Windows Azure features, such as storage, Service Bus, Cache or Access Control? Since these services are datacenter dependent in the event of a failure, these services may not be available.
This is not a simple task and will take additional development and planning. While I’ve geared this section to be towards for a complete data center failure, this could be leveraged for a specific service failure. For example, if your solution leverages Table Storage, if the storage service for the data center your application has a failure, your Windows Azure Compute instances will be running, but any features leveraging storage will not be available and depending on the feature this could be a critical feature of the application.
Deployment Process Recommendations
With Windows Azure there are multiple options for deploying applications. You can use Visual Studio, the management portal, or something custom using the Management Service API. There isn’t one way that is better than the other, but you should deploy your application in a consistent method across multiple environments: Development, Testing, Staging and Production.
If it is possible within your team or organization, you should consider automated deployments. This option takes additional time, but allows you to deploy consistently. Automated deployments can be achieved in various ways, but currently require a custom development effort. The largest benefit to automated deployments is for operations teams to be able to rapidly re-deploy services in other data centers in of a catastrophic data center failure. For thoughts around how an automated deployment could be implemented, read the “Automating Deployment and using Windows Azure Storage” in the Moving Applications to the Cloud, written by Microsoft’s Patterns and Practices team. http://msdn.microsoft.com/en-us/library/ff803365
If automate deployment isn’t feasible, you should consider leveraging Windows Azure PowerShell Cmdlets, available for download here: http://wappowershell.codeplex.com/
These PowerShell Cmdlets provides consistent management accessibility that conforms to other Microsoft products that are leveraging PowerShell as a management interface.
Another common question is “Should I use a VIP Swap or leverage the In Place Upgrade?” With the 1.5 Windows Azure SDK – In Place upgrades features are on-par with a VIP Swap. So what is the advantage of using a VIP Swap? The advantage is the ability to follow a process, to smoke test your application prior to it being published “live”. IF you were to use an in-place upgrade, once complete the application is “live”. Mistakes happen in IT, what if someone published the wrong version? If you used VIP swap, you could smoke test the application first and even after you perform the VIP swap, you could revert back to the previous version instantaneously!
Solution Monitoring
Even if you are using an auto scaling framework such as WASABi – Monitoring is an important aspect. Monitoring will assist in diagnosing issues within your application and knowing important key metrics about your application performance, errors and load. While Windows Azure can log Windows Events, Performance Counters and Logs to your storage accounts there is no “Out of the Box” Solution to view this data in a user friendly, graphical format.
System Center Operations Manager offers a Windows Azure management pack, which allows you to view alerts for Events and Performance metrics of your applications in a friendly manner.
The Windows Azure Management pack is available for download: http://www.microsoft.com/en-us/download/details.aspx?id=11324
Disaster Recovery
While it is true that Windows Azure does backup your Storage and SQL Azure data in triplicate, however this isn’t for you to leverage to restore your data on-demand. These backups are used by the Windows Azure teams in case of a catastrophic failure so they can restore an entire datacenter and not necessarily recover data for individual Windows Azure tenants. While this provides some relief, it is best to have backups of your application, configurations and data so that you can restore onto another Azure datacenter manually. While creating backups of Storage data would be a custom development effort, relational data stored on SQL Azure can be backed up and restored to a file using the Import/Export feature in the Windows Azure.

Mike Benkovich (@mbenko) continued his series with CloudTip #13-What do you need to know to get started? on 5/17/2012:
There are many ways to learn a new technology. Some of us prefer to read books, others like videos or screencasts, still others will choose to go to a training style event. In any case you need to have a reason to want to learn, whether it's a new project, something to put on the resume or just the challenge because it sounds cool. For me I learn best when I've got a real project that will stretch my knowledge to apply it in a new way. It also helps to have a deadline.
I've been working for a while now for Microsoft in a role that allows me to help people explore what's new and possible with the new releases of technology coming out at a rapid pace from client and web technologies like ASP.NET and Phone to user interface techniques like Silverlight and Ajax, to server and cloud platforms like SQL Server and Azure. The job has forced me to be abreast of how the technologies work, what you can do with them, and understanding how to explain the reasons for why and how they might fit into a project.
In this post I'd like to provide a quick tour of where you can find content and events on Cloud Computing that should help you get started and find answers along the way.
Part 1 - Get Started with Cloud Computing and Windows Azure.
You've heard the buzz, your boss might even have talked about it. In this first webcast of the Soup to Nuts series we'll get started with Windows Azure and Cloud Computing. In it we will explore what Azure is and isn't and get started by building our first Cloud application. Fasten your seatbelts, we're ready to get started with Cloud Computing and Windows Azure.
Video; WMVMP4 Audio; WMA Slides: PPTXPart 2 - Windows Azure Compute Services
The Cloud provides us with a number of services including storage, compute, networking and more. In this second session we take a look at how roles define what a service is. Beyond the different flavors of roles we show the RoleEntryPoint interface, and how we can plug code in the startup operations to make it easy to scale up instances. We will show how the Service Definition defines the role and provides hooks for customizing it to run the way we need it to.
Video; WMVMP4 Audio; WMA Slides: PPTXPart 3 - Windows Azure Storage Options
The Cloud provides a scalable environment for compute but it needs somewhere common to store data. In this webcast we look at Windows Azure Storage and explore how to use the various types available to us including Blobs, Tables and Queues. We look at how it is durable, highly available and secured so that we can build applications that are able to leverage its strengths.
Video; WMVMP4 Audio; WMA Slides: PPTXPart 4 - Intro to SQL Azure
While Windows Azure Storage provides basic storage often we need to work with Relational Data. In this weeks webcast we dive into SQL Azure and see how it is similar and different from on-premise SQL Server. From connecting from rich client as well as web apps to the management tools available for creating schema and moving data between instances in the cloud and on site we show you how it's done.
Video; WMVMP4 Audio; WMA Slides: PPTXPart 5 - Access Control Services and Cloud Identity
Who are you? How do we know? Can you prove it? Identity in the cloud presents us with the same and different challenges from identity in person. Access Control Services is a modern identity selector service that makes it easy to work with existing islands of identity such as Facebook, Yahoo and Google. It is based on standards and works with claims to provide your application with the information it needs to make informed authorization decisions. Join this webcast to see ACS in action and learn how to put it to work in your application today.
Slides: PPTXPart 6 - Diagnostics & Troubleshootingx
So you've built your Cloud application and now something goes wrong. What now? This weeks webcast is focused on looking at the options available for gaining insight to be able to find and solve problems. From working with Intellitrace to capture a run history to profiling options to configuring the diagnostics agent we will show you how to diagnose and troubleshoot your application.Part 7 - Get Started with Windows Azure Caching Services with Brian Hitney (http://bit.ly/btlod-77)
How can you get the most performance and scalability from platform as a service? In this webcast, we take a look at caching and how you can integrate it in your application. Caching provides a distributed, in-memory application cache service for Windows Azure that provides performance by reducing the work needed to return a requested page.Part 8 - Get Started with SQL Azure Reporting Services with Mike Benkovich (http://bit.ly/btlod-78)
Microsoft SQL Azure Reporting lets you easily build reporting capabilities into your Windows Azure application. The reports can be accessed easily from the Windows Azure portal, through a web browser, or directly from applications. With the cloud at your service, there's no need to manage or maintain your own reporting infrastructure. Join us as we dive into SQL Azure Reporting and the tools that are available to design connected reports that operate against disparate data sources. We look at what's provided from Windows Azure to support reporting and the available deployment options. We also see how to use this technology to build scalable reporting applicationsPart 9 - Get Started working with Service Bus with Jim O'Neil (http://bit.ly/btlod-79)
No man is an island, and no cloud application stands alone! Now that you've conquered the core services of web roles, worker roles, storage, and Microsoft SQL Azure, it's time to learn how to bridge applications within the cloud and between the cloud and on premises. This is where the Service Bus comes in-providing connectivity for Windows Communication Foundation and other endpoints even behind firewalls. With both relay and brokered messaging capabilities, you can provide application-to-application communication as well as durable, asynchronous publication/subscription semantics. Come to this webcast ready to participate from your own computer to see how this technology all comes together in real time.


<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Thomas Shinder, MD posted Private Cloud Architecture Sessions at TechEd North America 2012 to the Private Cloud architecture blog on 5/18/2012:
This is a big year for Microsoft! We’re going to see the release a Windows Server 2012 and a slew of other fantastic products – and you’re going to want to learn about them all. The big thing about Windows Server 2012 is that it’s all about the cloud. Private cloud, public cloud, hybrid cloud and more. TechEd North America 2012 is going to be heavy into the cloud and so you want to get up to speed on all things cloud.
This is where the Private Cloud Architecture track sessions come in. Before you start to envision and design your private cloud, you’ll need to make sure it’s built on a firm architectural foundation. A solid grounding in private cloud architecture will enable you to consider all the key design decisions that make the difference between a private cloud that propels your business to unprecedented levels of efficiency and productivity versus just another virtualized infrastructure.
So here I present to you a list of private cloud architecture sessions. We’ve worked hard to make sure that each session builds on the previous – so that your journey to an exemplary private cloud goes right from the start and succeeds by design. I will be delivering several of these sessions and I hope to see you there. As an added incentive, I’ll be bringing a pile of books to give away! Come to one of my sessions and you’ll have the opportunity to win one of the books I’ve written – and I’ll autograph them at no additional charge (in case you want to put them on eBay).
You can find all of these sessions by going to your MyTechEd and searching for Architecture & Practices.
AAP304: Private Cloud Principles, Concepts, and Patterns
Speaker(s): Tom Shinder
Monday, June 11 at 3:00 PM - 4:15 PM in S230E (663)
Architecture & Practices | Breakout Session | 300 - AdvancedSo you've heard a lot about the Private Cloud—but, what exactly is a Private Cloud? What are the principles, patterns, and concepts that drive a private cloud infrastructure? Attend this session to learn about business value, perception if infinite capacity, predictability, fabric management, fault domains, and many more private cloud architectural components that enable you to realize the true benefits of the private cloud. This is a cornerstone session that you must attend to understand how the private cloud differs from a traditional datacenter and how to architect the private cloud correctly.
AAP315: Optimize the Business with Microsoft Datacenter Services 2.0
Speaker(s): Ulrich Homann
Monday, June 11 at 4:45 PM - 6:00 PM in S331 (350)
Architecture & Practices | Breakout Session | 300 - AdvancedLearn all you need to know about the Microsoft Datacenter Services Solution (DCS) IaaS scenario in a private cloud deployment mode. Find out the new scenarios delivered by the Data Center Services Reference Implementation v2.0, how MCS and Premier can deliver an end-to-end solution including Microsoft Services architecture and implementation. Learn how DCS improves operational efficiency by implementing tools for provisioning, managing, monitoring, and optimizing data center hardware and virtual resources through integrated consoles to reduce the strain on IT staff.
AAP203: Private Cloud Design and Management: Speeding the Transition to a Responsive, Virtualized Storage Infrastructure
Speaker(s): Rob Griffin
Tuesday, June 12 at 10:15 AM - 11:30 AM in S210A (387)
Architecture & Practices | Breakout Session | 200 - IntermediateLearn key principles to quickly transform your IT operations into a robust, private cloud. Return home with recommendations for achieving performance, availability, and flexibility through the virtualization of your storage infrastructure. Experience how IT organizations incorporate storage hypervisor functions to rapidly provision resources, dynamically distribute workloads across multiple tiers and types of storage, non-disruptively refresh hardware to expand capacity, while tapping into the latest and most cost-effective disk technologies. Learn how you can leverage and optimize Hyper-V, Clustered Shared Volumes, and Microsoft System Center in your virtualized storage environment. You’ll take away concrete and actionable steps considered standard practice by seasoned colleagues in the IT industry to help you build and enhance your private cloud infrastructure. The session includes a live demonstration and a discussion of various real-world customer scenarios.
AAP306: Private Cloud Security Architecture: A Solution for Private Cloud Security
Speaker(s): Tom Shinder, Yuri Diogenes
Tuesday, June 12 at 1:30 PM - 2:45 PM in N320C (600) T-TH
Architecture & Practices | Breakout Session | 300 - AdvancedCloud computing introduces new opportunities and new challenges. One of those challenges is how security is approached in the private cloud. While private cloud can share a lot of security issues with traditional datacenters, there are a number of key issues that set private cloud security apart from how security is done in the traditional datacenter. In this session, Dr. Tom Shinder and Yuri Diogenes discusses these issues and wrap them in to a comprehensive discussion on private cloud security architecture. By taking an architectural approach to private cloud security, you will be able to understand the critical concepts, principles and patterns that drive a successful security implementation of private cloud.
AAP201: Hybrid Computing Is the New Net Norm
Speaker(s): Heath Aubin
Wednesday, June 13 at 1:30 PM - 2:45 PM in S331 (350)
Architecture & Practices | Breakout Session | 200 - IntermediateMicrosoft Service recently gathered subject matter experts and architects actively consulting in the field to research the problem space of Hybrid IT. Hybrid IT is defined as the composition of two or more data center environments (traditional IT, private cloud, or public/host cloud) which are individually unique but are bound together to share or provide services and data. The team discovered that organizations do not set out with a goal of having a “Hybrid” environment. Rather, they are tasked with either going to the public cloud to take advantage of perceived cost reduction or they are looking to centralize services within a disconnected environment thus providing their own private cloud. Come to this session to learn about Microsoft Services strategy, experience, and best practices within this focus area and new term we call Hybrid IT.
AAP305: Modern Application Design: Cloud Patterns for Application Architects
Speaker(s): Ulrich Homann
Wednesday, June 13 at 3:15 PM - 4:30 PM in N320E (576)
Architecture & Practices | Breakout Session | 300 - AdvancedHow does one build a “modern” application? In this session, learn about the key design patterns ranging from adaptive and insight-driven applications to 'Social'-enabled and aware application design, to Big Data: why HPC is coming to you…Architecture patterns and practices ranging from Enterprise Architecture to design and delivery.
AAP302: The Four Pillars of Identity: A Solution for Online Success
Speaker(s): Heath Aubin
Thursday, June 14 at 10:15 AM - 11:30 AM in S320C (628)
Architecture & Practices | Breakout Session | 300 - AdvancedInternet and cloud computing have revolutionized the way people expect to access and share information. To be successful, organizations need to develop a comprehensive identity and access strategy for providing services to diverse groups of people while assuring secure online access, respecting privacy, and complying with regulatory mandates. Today, there is no shortage of standards, products, or solutions which claim to solve all sorts of identity and security challenges. This session is about framing the Four Pillars of Identity (Administration, Authentication, Authorization, and Audit) as guiding principles when designing a robust and effective identity solution. In this session, we cover key industry trends within the identity space, discuss key aspects of an identity strategy and provide you with guidance and Microsoft Services solution examples which will help you as you begin planning your identity architecture.
AAP307: The Private Cloud: Building up a Self-Service Catalog
Speaker(s): Mike Resseler
Thursday, June 14 at 10:15 AM - 11:30 AM in S320E (280/556)
Architecture & Practices | Breakout Session | 300 - AdvancedSelf-Service is one of the key components in the Private Cloud concept. But how do you start with this? What are you going to offer? Who needs to be involved in such a project? This session is all about the Self-Service layer and guides you through the creating of real-life examples to offer services to your customers.
AAP303: Sustainability in Infrastructure Design
Speaker(s): Jeff Stokes
Thursday, June 14 at 1:00 PM - 2:15 PM in N210 (848)
Architecture & Practices | Breakout Session | 300 - AdvancedThis session discusses the importance of considering sustainability and supportability needs in IT Architecture projects. Topics to be explored include monitoring, scaling for performance and stability, management of servicing machines en masse in the data center and beyond.


Edwin Yuen (@edwinyuen) posted Top 5 Reasons to Choose Hyper-V for your Virtualization and Private Cloud Infrastructure on 5/17/2012:
In my last post, I provided some facts related to Microsoft’s virtualization and private cloud offerings to help ensure that our customers and partners have accurate information as they’re exploring technology options and making investments in their infrastructure. Some of these facts are related to providing customers with a scalable and economical private cloud solution that will grow with them and their businesses without imposing taxes on that growth. Other aspects of the post touch on the technical capabilities Microsoft offers, such as deep physical and virtual application insight and the broad extensibility of System Center to work with third party and custom solutions.
Today I wanted to explore some of the top reasons for choosing Windows Server 2008 R2 SP1 with Hyper-V, which we’ve also compiled into a brief whitepaper you can find at this link. These top reasons include:
1. Tremendous Industry Recognition & Strong Adoption by Customers
Hyper-V has experienced strong market growth since its introduction with market share expanding 409% (from 4.9% to 24.8%) from calendar Q3 2008 to Q3 2011, as noted in the IDC WW Quarterly Server Virtualization Tracker from December 2011. Hyper-v also been positioned by top industry analysts as a Leader in x86 Server Virtualization Infrastructure.
Customers, including Target, CH2M HILL and many others, are running their businesses on Hyper-V. You can find details on these customers and more through the broad portfolio of case studies available at this link.
2. Built-in Virtualization & Familiarity with Windows
Hyper-V exists in 2 variations; as a free standalone product called Microsoft Hyper-V Server 2008 R2 SP1, and as an installable role in Windows Server 2008 R2 SP1. Since Hyper-V is an integral part of Windows Server 2008 R2 SP1, it provides great value by enabling IT Professionals to continue to utilize their familiarity with Windows while minimizing the learning curve.
Since its launch in 2008, we have continued to evolve Hyper-V to deliver even more capabilities, increase scalability and enhance performance. Recent feature additions include Dynamic Memory, so customers can better utilize the memory resources of Hyper-V hosts by balancing how memory is distributed between running virtual machines. Another is Live Migration so customers with multiple Hyper-V physical hosts in their datacenters can easily and rapidly move running
virtual machines, VMs, to the best physical computer for performance, scaling, or optimal consolidation without affecting users; thereby reducing costs and increasing productivity.With the upcoming release of Windows Server 2012 Hyper-V there are even more improvements to performance and scalability to help customers transform their organization’s cloud computing environment.
3. Hyper-V as the Best Choice for Virtualizing Microsoft Workloads
Microsoft has published third-party validated lab results that prove best-in-class performance for Microsoft workloads, including SharePoint 2010, Exchange Server 2010, and SQL Server 2008. Also available is recent data highlighting SQL Server 2012 running on Hyper-V with performance within 88% of a physical server and scaling to 2,090 OLTP transactions per second.
The results demonstrate that Hyper-V can provide enterprise ready support for tier-1 datacenter applications, while maintain high levels of scalability and performance.
4. Comprehensive Management Capabilities with System Center 2012
With System Center 2012, customers don’t have to settle for a cobbled together collection of management offerings (see the video in item #1 of this post), but instead have a highly integrated solution for managing across their entire environment including their physical, virtual, private and public cloud environments.
Some of the System Center 2012 differentiated capabilities include:
- Support for multi-hypervisor management
- Support for third party integration and process automation
- Ability to manage applications via a single view across private clouds and Windows Azure
- Deep application diagnostics and insight for Windows and .NET based environments
- Technologies like Server Application Virtualization, which enable you to abstract your applications from the underlying private cloud infrastructure.
All of this is delivered in a unified solution which is available in the Datacenter edition license which covers unlimited virtual machines.
5. Per Physical Processor Pricing with Unlimited Virtualization Rights
The licensing advantages of the Microsoft virtualization and private cloud offerings over the competition were covered fairly extensively in my previous blog post. The simple way to understand the situation is that Microsoft private cloud solutions are licensed on a per processor basis with unlimited virtualization rights. Microsoft’s licensing allows you to get the cloud computing benefits of scale with unlimited virtualization and lower costs – consistently and predictably over time. The private cloud solutions from VMware charge you more as you grow and are licensed by either the number of VMs or the virtual memory allocated to those VMs.
You can find the details in this whitepaper as well as running server virtualization and private cloud calculations for yourself with these tools.
I hope the above information has provided you with some useful facts to help you while you’re investigating virtualization and private cloud infrastructures.


<Return to section navigation list>
Cloud Security and Governance
Dave Asprey (@daveasprey) posted Data in Motion: The Other side of the Cloud Encryption Coin to the Trend [Micro] Security Blog on 5/17/2012:
You’ve probably seen some of my blog posts about the importance of encrypting data stored in the cloud and on servers in traditional data centers, but I write less about encrypting data in motion because most of us are probably thinking “That’s because we have SSL/TLS and IPSec; the problem is solved. “ The truth is that the problem is only kind of solved; using these things for clouds is a bit of a kluge because these technologies typically only protect network traffic to the edge of the cloud network, leaving traffic between servers within the cloud network unprotected.
Tunnel-based solutions don’t really work that well in cloud networks due their point-to-point nature. Since “points” move around very quickly in clouds, point-to-point technologies can easily cause problems with scalability, management and performance in clouds.
I am intrigued at how Certes Networks approaches this problem. They just announced vCEP (Virtual Certes Enforcement Point). According to the release “the vCEP is a virtual appliance that allows organizations to protect sensitive network traffic among virtual servers and between clouds without using tunnels. It encrypts network traffic from IaaS cloud infrastructures to data centers across the WAN and from server to server within the cloud.”
Huh? Encrypting network traffic without tunnels? The OSI model must be quaking in its boots.
Although they’re not a household name, Certes Networks is a pioneer in network encryption, having deployed the first group encryption solution years ago. Group based encryption removes the need for point-to-point key negotiations, which in turn eliminates tunnels and makes data in motion encryption scalable and transparent to the infrastructure. Since cloud infrastructure is always shifting its configuration, transparent encryption is really important.
The other interesting thing here is that the Certes policy and key management system allows IaaS clients to maintain control of their own policies and keys. This really matters for regulated or sensitive workloads. It should also be a welcome development to cloud providers who can address client concerns about security without bearing the legal and administrative burden of owing (or having access to) their client policies and keys).
The availability of cloud security for data in transit fills the security gap between the client’s trusted network and the data protection offered by Trend Micro’s SecureCloud data-at-rest encryption. This doesn’t exactly spell the end of IPsec, but it does make it easier to cryptographically isolate your data and traffic from other cloud clients. And that’s a good thing!


<Return to section navigation list>
Cloud Computing Events
Goutama Bachtiar (@goudotmobi, pictured below) reported on 5/19/2012 Microsoft Corporate VP Hadba urges app designers to think of cloud design before anything else during his 5/15/2012 presentation to Indonesian startups:
A session held on the 15 May for Indonesian local startups, “Microsoft BizSpark Startup Night” witnessed the presence of a special guest speaker, Walid Abu-Hadba.
The Palestinian-born tech executive, who was also the main presenter, is the Redmond-based corporate vice president, developer and platform evangelism group at Microsoft.
In his 40-minute talk, [Hadba, pictured at right,] shared about Microsoft Cloud Computing Platform“Windows Azure” and how he leads efforts in building vibrant solutions ecosystems through technical evangelism, community engagement and audience marketing.
Hadba[, pictured at right,] invoked a new perspective into audiences when he challenged app designers to think about cloud design first amongst other things during app design. Afterwhich, think about how and where to deploy.
“Design the app and cloud as if it will scale up unlimitedly. Never limit yourself or you will suffer. Microsoft offers public, private and hybrid cloud services because it sees the Asian market as very appealing due to its highest 67 percent adoption rates for cloud computing, which is comparatively higher to 61 percent and 57 percent adoption rate in the US and Europe respectively,” says Hadba.
Another program introduced is BizSpark Plus. Targeting small and promising firms, it provides full hosting worth US$ 60,000 Windows Azure for free, instead of tech access, software (such as MS SQL Server, Visual Studio .NET), training and publication as mentioned earlier under the BizSpark program. Azure, an open and flexible cloud platform, proffers unlimited servers and storage so one can scale their applications to any size based on the needs.
Hadba also mentioned Windows Azure Store where developers can build, submit, and share their codes and apps with other developers. Another store is the Windows 8 Store (widely known as Windows Store) which is currently designed for Windows 8 Beta (also known as Consumer Preview.)
Although the long-awaited Windows Phone store will be available for Indonesians soon, no exact date as given as Microsoft Indonesia declined to disclose the information.
Combining developer platform, tools and ecosystems of the respective developer-centric company, the store which was first announced in September last year offers up to 80 percent revenue share for apps sold. Set the price in local currency and our piece will be available in more than 100 languages. The currency conversions and local tax laws will be handled by the store. Pricing model is flexible and rewards popular apps with a better percentage of the net receipts while delivery options include in-app purchases, trial versions, in-app adv, and third-party transaction services.
Lastly, Hadba highlighted Windows9.com as a site where one can find everything – videos, samples, design, codes, guides, roadmaps and tutorials – in order to develop a Windows 8 app.
The 3-hour event was wrapped up with showcases from Mobile Game Development Studio Nightspade, KOMPAS app for foodie SajianSedap, City lifestyle directory Urbanesia and a presentation by Agate Studio – all lead by Microsoft Indonesia Developer Evangelist Norman Sasono.


Himanshu Singh (@himanshuks) posted Windows Azure Community News Roundup (Edition #19) on 5/18/2012:
Welcome to the latest edition of our weekly roundup of the latest community-driven news, content and conversations about cloud computing and Windows Azure. Here are the highlights from this week.
Articles and Blog Posts
- Windows Azure SDK for Node.js 0.5.4 is Out by @digthepony (posted May 11)
- Essential Windows Azure Knowledge Part 1: Web Roles, Worker Roles by @brunoterkaly (posted May 13)
- Tuning (Windows) Azure Performance by @hakaneren (posted May 12)
- The VM Role by @tyler_gd (posted May 12)
- Why Can’t I Connect to My SQL Azure Database? by @clinted (posted May 15)
Upcoming Events, and User Group Meetings
North America
- NEW! – June 7: MEET Windows Azure (Register here)– San Francisco, CA & Live Streaming
- May 30: Cloud Camp – Reston, VA
- May 30: Windows Azure Meetup - Vancouver, Canada
- June 11-14: Microsoft TechEd North America 2012 – Orlando, FL
- June 13: (SELA) Windows Azure Workshop for Developers – Toronto, Canada
Europe
- May 23: Sweden Windows Azure User Group – Stockholm, Sweden
- May 23-24: DevCon 12 – Moscow, Russia
- May 26: Node.js in the Cloud with Windows Azure – Oslo, Norway
- June 20: Windows Azure Dev Camp – Paris, France
- June 22: Microsoft Cloud Day – London, UK
- June 26-29: Microsoft TechEd Europe 2012 – Amsterdam, Netherlands
Other
- May 21-25: Windows Azure UK Bootcamps – Online
- May 22: Architectural Patterns for the Cloud - Online
- May 22-24: Integration Master Class with Richard Seroter – Australia (3 cities)
- May 29: Windows Azure Sydney User Group – Sydney, Australia
- May 31: Melbourne Windows Azure Meetup Group – Melbourne, Australia
Recent Windows Azure Forums Discussion Threads
- Diagnostic Monitor/Transferring Logs to Storage – 922 views, 12 replies
- Unable to Connect to SQL Azure from Management Studio 2008 R2 – 9,044 views, 12 replies
- How do I Select a (Windows) Azure Database from a Local SQL Management Studio – 781 views, 5 replies
Send us articles that you’d like us to highlight, or content of your own that you’d like to share. And let us know about any local events, groups or activities that you think we should tell the rest of the Windows Azure community about. You can use the comments section below, or talk to us on Twitter @WindowsAzure.

Brian Hitney reported Windows Azure Dev Camps Soon! in a 5/18/2012 post:
It’s that time – Windows Azure Dev Camps are coming really soon. Here’s the schedule:
- May 24th, 2012, Alpharetta, GA: Register
- May 30th, 2012, Reston, VA: Register
- May 31st, 2012, Iselin, NJ: Register
We’re pretty excited to mix up the format a little, with some time to jump into some new areas we haven’t typically talked about in our previous shows:
1. The Azure Platform – An Overview (60 minutes)
Let’s start off the day with a dive into Windows Azure. We’ll talk about what Windows Azure offers, from hosting applications to durable storage. We’ll look at Windows Azure roles types, hosting web applications and worker processes. We’ll also cover durable storage options, both traditional relational database that is offered as SQL Azure, or more cloud-centric offerings in Windows Azure Storage for files, semi-structured data, and queues.
2. Hands on @home with Azure (120 minutes)
For this hands-on portion of the day, we’ll work on the @home with Windows Azure project. The @home project will give you a solid understanding of using Windows Azure in a project that contributes back to Stanford’s Folding@home distributed computing project. We’ll walk through the code, provisioning an account, and getting the application deployed and running.3. Caching – A Scalable Middle Tier (45 minutes)
Creating a stateless application is a difficult but fundamental aspect of building a scalable application in the cloud. In this session, we’ll talk about the Windows Azure Cache service and using it as a middle tier to maintain state and cache objects that can be shared by multiple instances.4. SQL Azure, Data Sync, and Reporting (45 minutes)
SQL Azure offers a scalable database as a service without having to configure and maintain hardware. We’ll look at the subtle differences between on premises SQL Server databases and SQL Azure, and how Data Sync can be used to synchronize data between multiple databases both in the cloud and on premises. We’ll also look at SQL Azure Reporting.5. Windows 8 and Azure – Better Together (60 minutes)
The consumer preview of Windows 8 is out, and it’s the perfect time to ramp up on developing native Metro-style applications. In this session, we’ll give an overview of Windows 8, and delivering a richer user experience by leveraging a cloud backend.
Apigee (@Apigee) announced on 5/18/2012 a Live Webcast: OData Introduction and Impact on API Design scheduled for 5/24/2012 at 11:00 AM PDT:
When: Thursday, May 24th, 11:00am PT / 2:00pm ET
We're in a data-driven economy. Web API designers need to define what and how to expose data from a variety of apps, services, and stores. What are challenges of unlocking data and opening up access in a straightforward and standards-compliant manner? Is OData the right tool for the job?
Join Anant, Brian, and Greg for a discussion of OData, its API design implications, and the pros and cons of OData as an enabler of data integration and interoperability across Data APIs.
If you can't make the live webcast, register and we'll send you a video recording with slides.
- OData, SQL, and the "RESTification" of data - providing a uniform way to expose, structure, query and manipulate data using REST principles.
- Opportunity and challenges for OData.
- The questions of Web standards and proprietary versus open tools and protocols.



Greg BrailAnant Jhingran

Brian Pagano
Bruce Kyle suggested that you Join in the ‘Meet Windows Azure’ Event Online June 7 in a 5/18/2012 post:
The Windows Azure team has announced a new event, MEET Windows Azure. Whether you’re just getting started or are a long time customer, you’ll definitely want to tune-in.
For details, see the announcement at Mark Your Calendar—MEET Windows Azure Event Streamed Online June 7th.
Hear from Scott Guthrie and other technology leaders about the latest cloud-based development technologies from Windows Azure.
Sign-up today at meetwindowsazure.com.

For more details, see my recent Social meet up on Twitter for Meet Windows Azure on June 7th and “Meet Windows Azure” Event Scheduled for 6/7/2012 in San Francisco posts.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Jeff Barr (@jeffbarr) reported Elastic Load Balancer - Console Updates and IPv6 Support for 2 Additional Regions in a 5/18/2012 post:
You can now manage the listeners, SSL certificates, and SSL ciphers for an existing Elastic Load Balancer from within the AWS Management Console. This enhancement makes it even easier to get started with Elastic Load Balancing and simpler to maintain a highly available application using Elastic Load Balancing.
While this functionality has been available via the API and command line tools, many customers told us that it was critical to be able to use the AWS Console to manage these settings on an existing load balancer.
With this update, you can add a new listener with a front-end protocol/port and back-end protocol/port:
If the listener uses encryption (HTTPS or SSL listeners), then you can create or select the SSL certificate:
In addition to selecting or creating the certificate, you can now update the SSL protocols and ciphers presented to clients:
We have also expanded IPv6 support for Elastic Load Balancing to include the US West (Northern California) and US West (Oregon) regions.



Not sure if this rises to the level of “feature of the week,” but it’s close.
Jeff Barr (@jeffbarr) posted RDS Read Replicas in the Virtual Private Cloud on 5/17/2012:
You can now launch Amazon Relational Database Service (RDS) MySQL Read Replicas inside of a Virtual Private Cloud (VPC).
Amazon RDS removes the headaches of running a relational database reliably at scale, allowing Amazon RDS customers to focus on innovation for their customers. Read Replicas enables you to elastically scale out beyond the capacity constraints of a single DB Instance for read-heavy database workloads.
You can now create one or more replicas of a given “source” DB Instance and serve incoming read traffic from multiple copies of your data within a VPC environment. You can create a Read Replica with a few clicks of the AWS Management Console or using the CreateDBInstanceReadReplica API.
Amazon VPC allows you to customize the network configuration to closely resemble a traditional network that you might operate in your own datacenter. I described the process of launching a DB Instance inside of a VPC in an earlier post.
Amazon RDS in VPC enables you to have a DB instance within a private network powering a public web application. The DB instance is on a private subnet, which does not have a public IP address. You can also use Amazon RDS + VPC to run corporate applications that are not intended to be accessed from the Internet


<Return to section navigation list>

















0 comments:
Post a Comment