Windows Azure and Cloud Computing Posts for 5/14/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI, Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics, Big Data and OData
- Windows Azure Access Control, Identity and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
Manu Cohen-Yashar (@ManuKahn) described Blob Parallel Upload and Download in a 5/14/2012 post:
To gain the best performance from azure blob storage it is required to upload and download data in parallel. For very small files it is OK to use the simple blob API (UploadFile, UploadFromStream etc.) but for large chucks of data parallel upload is required.
To do parallel upload we'll use a block blob when working with streaming data (such as images or movies) and use the producer consumer design pattern. One thread read the stream, create blocks and put them into a queue. A collection of other threads read blocks from the queue and upload them to the cloud. Once all the threads finished the whole blob is committed.
Lets see the code:
public class PrallelBlobTransfer { // Async events and properties public event EventHandler TransferCompleted; private bool TaskIsRunning = false; private readonly object _sync = new object(); // Used to calculate download speeds Queue<long> timeQueue = new Queue<long>(100); Queue<long> bytesQueue = new Queue<long>(100); public CloudBlobContainer Container { get; set; } public PrallelBlobTransfer(CloudBlobContainer container) { Container = container; } public void UploadFileToBlobAsync(string fileToUpload, string blobName) { if (!File.Exists(fileToUpload)) throw new FileNotFoundException(fileToUpload); var worker = new Action<Stream,string>(ParallelUploadStream); lock (_sync) { if (TaskIsRunning) throw new InvalidOperationException("The control is currently busy."); AsyncOperation async = AsyncOperationManager.CreateOperation(null); var fs = File.OpenRead(fileToUpload); worker.BeginInvoke(fs,blobName, TaskCompletedCallback, async); TaskIsRunning = true; } } public void UploadDataToBlobAsync(byte[] dataToUpload, string blobName) { var worker = new Action<Stream, string>(ParallelUploadStream); lock (_sync) { if (TaskIsRunning) throw new InvalidOperationException("The control is currently busy."); AsyncOperation async = AsyncOperationManager.CreateOperation(null); var ms = new MemoryStream(dataToUpload); worker.BeginInvoke(ms, blobName, TaskCompletedCallback, async); TaskIsRunning = true; } } public void DownloadBlobToFileAsync(string filePath, string blobToDownload) { var worker = new Action<Stream,string>(ParallelDownloadFile); lock (_sync) { if (TaskIsRunning) throw new InvalidOperationException("The control is currently busy."); AsyncOperation async = AsyncOperationManager.CreateOperation(null); var fs = File.OpenWrite(filePath); worker.BeginInvoke(fs, blobToDownload, TaskCompletedCallback, async); TaskIsRunning = true; } } public void DownloadBlobToBufferAsync(byte[] buffer, string blobToDownload) { var worker = new Action<Stream, string>(ParallelDownloadFile); lock (_sync) { if (TaskIsRunning) throw new InvalidOperationException("The control is currently busy."); AsyncOperation async = AsyncOperationManager.CreateOperation(null); var ms = new MemoryStream(buffer); worker.BeginInvoke(ms, blobToDownload, TaskCompletedCallback, async); TaskIsRunning = true; } } public bool IsBusy { get { return TaskIsRunning; } } // Blob Upload Code // 200 GB max blob size // 50,000 max blocks // 4 MB max block size // Try to get close to 100k block size in order to offer good progress update response. private int GetBlockSize(long fileSize) { const long KB = 1024; const long MB = 1024 * KB; const long GB = 1024 * MB; const long MAXBLOCKS = 50000; const long MAXBLOBSIZE = 200 * GB; const long MAXBLOCKSIZE = 4 * MB; long blocksize = 100 * KB; //long blocksize = 4 * MB; long blockCount; blockCount = ((int)Math.Floor((double)(fileSize / blocksize))) + 1; while (blockCount > MAXBLOCKS - 1) { blocksize += 100 * KB; blockCount = ((int)Math.Floor((double)(fileSize / blocksize))) + 1; } if (blocksize > MAXBLOCKSIZE) { throw new ArgumentException("Blob too big to upload."); } return (int)blocksize; } /// <summary> /// Uploads content to a blob using multiple threads. /// </summary> /// <param name="inputStream"></param> /// <param name="blobName"></param> private void ParallelUploadStream(Stream inputStream,string blobName) { // the optimal number of transfer threads int numThreads = 10; long fileSize = inputStream.Length; int maxBlockSize = GetBlockSize(fileSize); long bytesUploaded = 0; // Prepare a queue of blocks to be uploaded. Each queue item is a key-value pair where // the 'key' is block id and 'value' is the block length. var queue = new Queue<KeyValuePair<int, int>>(); var blockList = new List<string>(); int blockId = 0; while (fileSize > 0) { int blockLength = (int)Math.Min(maxBlockSize, fileSize); string blockIdString = Convert.ToBase64String(ASCIIEncoding.ASCII.GetBytes(
string.Format("BlockId{0}", blockId.ToString("0000000")))); KeyValuePair<int, int> kvp = new KeyValuePair<int, int>(blockId++, blockLength); queue.Enqueue(kvp); blockList.Add(blockIdString); fileSize -= blockLength; } var blob = Container.GetBlockBlobReference(blobName); blob.DeleteIfExists(); BlobRequestOptions options = new BlobRequestOptions() { RetryPolicy = RetryPolicies.RetryExponential(
RetryPolicies.DefaultClientRetryCount, RetryPolicies.DefaultMaxBackoff), Timeout = TimeSpan.FromSeconds(90) }; // Launch threads to upload blocks. var tasks = new List<Task>(); for (int idxThread = 0; idxThread < numThreads; idxThread++) { tasks.Add(Task.Factory.StartNew(() => { KeyValuePair<int, int> blockIdAndLength; using (inputStream) { while (true) { // Dequeue block details. lock (queue) { if (queue.Count == 0) break; blockIdAndLength = queue.Dequeue(); } byte[] buff = new byte[blockIdAndLength.Value]; BinaryReader br = new BinaryReader(inputStream); // move the file system reader to the proper position inputStream.Seek(blockIdAndLength.Key * (long)maxBlockSize, SeekOrigin.Begin); br.Read(buff, 0, blockIdAndLength.Value); // Upload block. string blockName = Convert.ToBase64String(BitConverter.GetBytes( blockIdAndLength.Key)); using (MemoryStream ms = new MemoryStream(buff, 0, blockIdAndLength.Value)) { string blockIdString = Convert.ToBase64String(
ASCIIEncoding.ASCII.GetBytes(string.Format("BlockId{0}", blockIdAndLength.Key.ToString("0000000")))); string blockHash = GetMD5HashFromStream(buff); blob.PutBlock(blockIdString, ms, blockHash, options); } } } })); } // Wait for all threads to complete uploading data. Task.WaitAll(tasks.ToArray()); // Commit the blocklist. blob.PutBlockList(blockList, options); } /// <summary> /// Downloads content from a blob using multiple threads. /// </summary> /// <param name="outputStream"></param> /// <param name="blobToDownload"></param> private void ParallelDownloadFile(Stream outputStream, string blobToDownload) { int numThreads = 10; var blob = Container.GetBlockBlobReference(blobToDownload); blob.FetchAttributes(); long blobLength = blob.Properties.Length; int bufferLength = GetBlockSize(blobLength); // 4 * 1024 * 1024; long bytesDownloaded = 0; // Prepare a queue of chunks to be downloaded. Each queue item is a key-value pair // where the 'key' is start offset in the blob and 'value' is the chunk length. Queue<KeyValuePair<long, int>> queue = new Queue<KeyValuePair<long, int>>(); long offset = 0; while (blobLength > 0) { int chunkLength = (int)Math.Min(bufferLength, blobLength); queue.Enqueue(new KeyValuePair<long, int>(offset, chunkLength)); offset += chunkLength; blobLength -= chunkLength; } int exceptionCount = 0; using (outputStream) { // Launch threads to download chunks. var tasks = new List<Task>(); for (int idxThread = 0; idxThread < numThreads; idxThread++) { tasks.Add(Task.Factory.StartNew(() => { KeyValuePair<long, int> blockIdAndLength; // A buffer to fill per read request. byte[] buffer = new byte[bufferLength]; while (true) { // Dequeue block details. lock (queue) { if (queue.Count == 0) break; blockIdAndLength = queue.Dequeue(); } try { // Prepare the HttpWebRequest to download data from the chunk. HttpWebRequest blobGetRequest = BlobRequest.Get(blob.Uri, 60, null, null); // Add header to specify the range blobGetRequest.Headers.Add("x-ms-range",
string.Format(System.Globalization.CultureInfo.InvariantCulture, "bytes={0}-{1}",
blockIdAndLength.Key, blockIdAndLength.Key + blockIdAndLength.Value - 1)); // Sign request. StorageCredentials credentials = blob.ServiceClient.Credentials; credentials.SignRequest(blobGetRequest); // Read chunk. using (HttpWebResponse response = blobGetRequest.GetResponse() as HttpWebResponse) { using (Stream stream = response.GetResponseStream()) { int offsetInChunk = 0; int remaining = blockIdAndLength.Value; while (remaining > 0) { int read = stream.Read(buffer, offsetInChunk, remaining); lock (outputStream) { outputStream.Position = blockIdAndLength.Key + offsetInChunk; outputStream.Write(buffer, offsetInChunk, read); } offsetInChunk += read; remaining -= read; Interlocked.Add(ref bytesDownloaded, read); } } } } catch (Exception ex) { // Add block back to queue queue.Enqueue(blockIdAndLength); exceptionCount++; // If we have had more than 100 exceptions then break if (exceptionCount == 100) { throw new Exception("Received 100 exceptions while downloading." + ex.ToString()); } if (exceptionCount >= 100) { break; } } } })); } // Wait for all threads to complete downloading data. Task.WaitAll(tasks.ToArray()); } } private void TaskCompletedCallback(IAsyncResult ar) { // get the original worker delegate and the AsyncOperation instance Action<Stream, string> worker = (Action<Stream, string>)((AsyncResult)ar).AsyncDelegate; AsyncOperation async = (AsyncOperation)ar.AsyncState; // finish the asynchronous operation worker.EndInvoke(ar); // clear the running task flag lock (_sync) { TaskIsRunning = false; } // raise the completed event async.PostOperationCompleted(state => OnTaskCompleted((EventArgs)state), new EventArgs()); } protected virtual void OnTaskCompleted(EventArgs e) { if (TransferCompleted != null) TransferCompleted(this, e); } private string GetMD5HashFromStream(byte[] data) { MD5 md5 = new MD5CryptoServiceProvider(); byte[] blockHash = md5.ComputeHash(data); return Convert.ToBase64String(blockHash, 0, 16); } }

![image_thumb1[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEioUGv0_sm9r4f2GpoxqiiGYAnsQwTlaeLu3cXiyjtFKYsqSoZbHsVGo-0rZpGlLe_rrRFICfeE0WFsTq3nRASTypWpMUe4eHdDTj5N-nXkpm0LvcK5lzPRWRiPnkn6I1SJLJWG3yhF/s1600-h/image_thumb116.png "image_thumb1[1]")
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
Haishi Bai (@HaishiBai2010) described how to Deploy Adventure Works Database to SQL Azure using SSMS 2012 in a 5/13/2012 post:
First, get SSMS 2012. I’m using Microsoft SQL Server 2012 Express, which can be downloaded here.
- Then, get the sample database here. Extract the zip file to a folder.
- Open a command-line prompt. Go to the extracted folder\Adventureworks.
- Issue command CreateAdventureWorksForSQLAzure.cmd <servername> <username> <password>.
Now the database should have been created on your
local/SQL Azure instanceenvironment.- Go to SSMS, select master database of your server and use query
CREATE LOGIN demo WITH PASSWORD = '<your password>'to create a new login.- Use query against both master and AdventureWork2012 database to create users
create user demo from login demo;to create a user from the login.- Finally, make demo db_owner (or other privileges you’d like to assign to the user):
sp_addrolemember 'db_owner', demo;

The <servername> <username> <password> values are those for your SQL Azure server instance. SQL Azure exists only in Microsoft data centers and isn’t supported by local instances.
The original version of this walkthrough is AdventureWorks Community Samples Databases for SQL Azure February 14, 2012 on CodePlex.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
My (@rogerjenn) Accessing US Air Carrier Flight Delay DataSets on Windows Azure Marketplace DataMarket and “DataHub” post of 5/14/2012 begins:
Contents:
Windows Azure Marketplace DataMarket
- Microsoft Codename “Data Hub”
- Building an OData URL Query and Displaying Data
- Coming Soon
The initial five months (October 2011 through February of US Air Carrier Flight Delays data curated from the U.S. Federal Aviation Administration’s (FAA) On_Time_On_Time_Performance.csv (sic) files is publicly available free of charge in OData and *.csv formats from OakLeaf Systems’ Windows Azure Marketplace DataMarket and Codename “Data Hub” preview sites.
And continues with detailed, illustrated tutorials for registering for and querying the US Air Carrier Flight Delays datasets to return tabular and OData streams.
Chris Woodruff (@cwoodruff) asserted “Microsoft’s newest version of the Open Data Protocol (OData) is something both developers and IT managers should check out” in a deck for his stand-in Why Microsoft’s Open Data Protocol matters article for Mary Jo Foley on 5/14/2012:
With the newest version of the Open Data Protocol (OData), Microsoft is bringing a richer data experience for developers, information workers and data journalists to consume and analyze data from any source publishing with the OData protocol. The goal is not to hide your data and keep it locked away, but to curate the data you provide to your partners, customers and/or the general public. By allowing a curated data experience, you will generate more revenue and allow your data more widespread adoption.
To gain a clearer picture of how this new forum will work, it’s key to understand what the Open Data Protocol is and where it originated. There’s more information about OData at my 31 Days of OData blog series, but the official statement for Open Data Protocol (OData) is that it is a Web protocol for querying and updating data that provides a way to unlock your data and free it from silos that exist in applications today. Really what that means is that we can select, save, delete and update data from our applications just like we have been against relational SQL databases for years. The benefit is the ease of setting up the OData feeds to be utilized from libraries which Microsoft has created for us developers.
An additional benefit comes from the fact that OData has a standard that allows a clear understanding of the data due to the metadata from the feed. Behind the scenes, we send OData requests to a web server which has the OData feed through HTTP calls using the protocol for OData.
OData started back in 2007 at the second Microsoft Mix conference. The announcement was an incubation project codenamed Astoria. The purpose of Project Astoria was to find a way to transport data across HTTP in order to architect and develop web based solutions more efficiently. Not until after the project had time to incubate, did the OData team see patterns occurring which led them to see the vision of the Open Data Protocol. The next big milestone was the 2010 Microsoft Mix Conference where OData was officially announced and proclaimed to the world as a new way to handle data. The rest is history.
Recently, a third version of the OData protocol was announced which will allow developers to produce and consume data, not only to their own desktop applications, web sites and mobile apps, but also open their data up for solutions they may never have intended when creating the OData service, better known as a feed. The next version will include a number of new feature additions for both the server side which hosts the OData feeds, as well as the client side which developers will use to consume the data in their architected solutions.
Here are just a few of the new features:
- Vocabularies that convey more meaning and extra information to enable richer client experiences.
- Actions that provide a way to inject behaviors into an otherwise data-centric model without confusing the data aspects of the model.
- OData version 3 supports Geospatial data and comes with 16 new spatial primitives and some corresponding operations.
An example is my own Baseball Statistics OData feed located here and publicly open to anyone to consume the data. The feed contains the entire 138 years of statistics for Major League Baseball including team, player and post-season stats. My baseball statistics OData feed will be updated to OData v3 very soon and will use many of the new features that were recently announced.
There are many libraries to consume and understand OData for developers to use in their solutions. You can find many of the libraries for your mobile, web and CMS solutions at the OData home site here.
What about the business aspects of OData for organizations that have valuable data they wish to share and wish to generate revenue from? By having data that is easy to consume and understand organizations can allow their customers and partners (via the developers that build the solutions using one or more of the available OData libraries) to leverage the value of curated data that the organization owns. Business customers can either host the data they own and control the consumer experience and subsequent revenue collection, or they can set up your OData feed inside Microsoft’s Windows Azure Marketplace and have Microsoft do the heavy lifting for them, in terms of offering subscriptions to theirr data and collection of subscription fees.
Think of the Windows Azure Datamarket as an App store for data. It’s a great place to generate that needed revenue without having to create the infrastructure beyond the OData feed which surfaces your proprietary data.
In the end, maintaining valuable data in an organization should not solely consist of utilizing databases which are hidden from those outside corporate walls. The data should be curated and allowed to be consumed and even generate revenue for an organization. If you are a developer looking at either producing a method to get data to your applications, or you wish to consume the rich data you see others using in their applications, dig into OData. You will find that it is a great way to become an expert in Data Experience. Furthermore, if you are a manager who is looking for new ways to get your data to the public either for free or to generate additional revenue for your company, explore the exciting world of OData. You just might find some unexpected benefits waiting for you.

Mary Jo is taking a couple of weeks off prior to the “busiest part of Microsoft’s 2012.”
You can check out the OData feed of my free US Air Carrier Flight Delays offering by signing up in the Windows Azure Marketplace DataMarket or adding it to your collection in OakLeaf Systems’s Data Hub sample. Run a query and choose DataExplorer’s XML option to display the raw OData content:

<Return to section navigation list>
Windows Azure Service Bus, Access Control, Identity and Workflow
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
Maarten Balliauw (@maartenballiauw) reminded me that the Windows Azure Content Delivery Network (CDN) has dynamic content capabilities similar to those announced by Amazon Web Services today (see the Other Cloud Computing Platforms and Services section below.) He described them in the “Serving dynamic content through the CDN” section of his Using the Windows Azure Content Delivery Network article of 4/5/2012 for the ACloudyPlace blog:
… Serving dynamic content through the CDN
Some dynamic content is static in a sense. For example, generating an image on the server or generating a PDF report based on the same inputs. Why would you generate those files over and over again? This kind of content is a perfect candidate to cache on the CDN as well!
As an example, we’ll be using this action method in a view to display the page title as an image. Here’s the view’s Razor code:
@{ ViewBag.Title = "Home Page"; } <h2><img src="/Home/GenerateImage/@ViewBag.Message" alt="@ViewBag.Message" /></h2> <p> To learn more about ASP.NET MVC visit <a href="http://asp.net/mvc" title="ASP.NET MVC Website">http://asp.net/mvc</a>. </p>In the previous section, we’ve seen how an IIS rewrite rule can map all incoming requests from the CDN. The same rule can be applied here: if the CDN requests /cdn/Home/GenerateImage/Welcome, IIS will rewrite this to /Home/GenerateImage/Welcome and render the image once and cache it on the CDN from then on.
As mentioned earlier, a best practice is to specify the Cache-Control HTTP header. This can be done in your action method by using the [OutputCache] attribute, specifying the time-to-live in seconds:
[OutputCache(VaryByParam = "*", Duration = 3600, Location = OutputCacheLocation.Downstream)] public ActionResult GenerateImage(string id) { // ... generate image ... return File(image, "image/png"); }We would now only have to generate this image once for every different string requested. The Windows Azure CDN will take care of all intermediate caching.
Note that if you’re using some dynamic bundling of CSS and JavaScript like ASP.NET MVC4’s new “bundling and minification”, those minified bundles can also be cached on the CDN using a similar approach.
Conclusion
The Windows Azure CDN is one of the building blocks to create fault-tolerant, reliable, and fast applications running on Windows Azure. By caching static content on the CDN, the web server has more resources available to process other requests, and users will experience faster loading of your applications because content is delivered from a server closer to their location.

Full disclosure: I’m a paid contributor to Red Gate Software’s ACloudyPlace blog.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Brian Swan (@brian_swan, pictured below) posted Azure Real World: Optimizing PHP Applications for the Cloud authored by Ken Muse on 5/14/2012:
This is a guest-post written by Ken Muse, Vice President of Technology at ecoInsight. He has written an amazingly in-depth post about optimizing PHP applications for Windows Azure based on his experience in doing a mixed PHP (Joomla!) and .NET deployment. ecoInsight is using Joomla! running on Windows Azure to manage, maintain, and publish informative articles and industry news to its users. The Joomla! server is used by the company’s content teams to aggregate industry content and publish it to end users in several different vertical markets as AtomPub feeds. The advertisements displayed to users of the ecoInsight Energy Audit & Analysis desktop and mobile platforms are also published using Joomla! In the future, ecoInsight plans to utilize the Joomla! platform for building a collaborative social network and to provide content storage services.
Mr. Muse is responsible for the overall technical architecture of ecoInsight’s software solutions. Mr. Muse was a senior architect and team lead at SAP, focusing on security, globalization standards, and distributed systems integration. Mr. Muse has a breadth of software and hardware knowledge, including a broad skill set in enterprise and distributed network architecture and multi-platform software development. Mr. Muse is a member of MENSA and IEEE (Institute of Electrical and Electronics Engineers), and a full member of ASHRAE (American Society of Heating, Refrigerating and Air‐Conditioning Engineers).
Optimizing PHP Applications for the Cloud
PHP Configuration
The master configuration for the PHP runtime is the PHP.INI file. This file controls the numerous settings used by PHP when processing a request. It’s important to make sure you start with a file containing the proper configuration for an IIS deployment. If PHP is installed using the Web Platform Installer (WebPI), this will be automatically configured. If not, the Learn IIS web site provides all of the details here.
One improvement you can make in this file is to remove unnecessary extensions. Each referenced extension library is loaded by the PHP runtime when it is initializing. These libraries then have to register the various functions and constants that are available to the PHP runtime and perform any necessary initialization. By removing any extension which is not used, this additional overhead can be removed.
An important consideration with your PHP configuration is that these settings may need to change based on the PHP deployment. Settings for the server name, database connectivity, and external resources can change quite quickly in the cloud. The use of Windows Azure does not guarantee zero downtime.
On February 29, 2012, Windows Azure experienced a partial service outage, the “Leap-Day Outage”. The partial outage impacted a large number of servers. The Windows Azure team was incredibly transparent about the details of the scope, cause, and fixes involved in this outage. I highly recommend reading their blog article for more information. You can find it at http://blogs.msdn.com/b/windowsazure/archive/2012/03/09/summary-of-windows-azure-service-disruption-on-feb-29th-2012.aspx.
In order to account for this inevitability, your application must be fault tolerant and easily reconfigured. During the leap-day outage, we were able to recover and minimize the impact of the outage. We quickly redeployed our web roles and a read-only snapshot of our database instance to a different data center until the problem was resolved. While some portions of the application were forced to use this read-only database snapshot, users were still able to use the entire application with a minimal disruption. If settings are hard-coded into a PHP file, these kinds of redeployments are difficult. You would be forced to modify your application and rebuild the deployment package. Then, you would need to undo those changes if you needed to relocate your resources back to the original servers. If your settings are obtained dynamically, you can redeploy the package to another server with very little difficulty. There are several strategies which help improve the code in this particular area.
There are several strategies which an application can use for configuring its settings or to configure PHP.INI:
- The application can receive its settings externally from the csdef using the Windows Azure SDK for PHP. The current implementation of the Windows Azure SDK for PHP uses a command line tool in order to read the service definition settings from Windows Azure. It is therefore important to make sure to take advantage of the caching features in PHP to minimize the frequency of calls to those SDK functions if you use this approach.
- Rewrite the PHP and application configuration files using a startup task. Combined with the previous method, this can minimize the number of times the SDK is used to retrieve values. The most common way to perform this task is to use a batch file or Windows PowerShell script, although nothing prevents you from invoking the PHP command line.
- Configure the command-line parameters for the PHP process to pass additional “defines” on the command line. By scripting the FastCGI configuration to pass additional defines (-D) into the PHP runtime with these settings when the role is starting, it is possible to get the flexibility of using external configuration values without the overhead of executing the SDK tools each time a value is needed.
- Use the PHP Contrib extension, php_azure.dll. This provides a native method for retrieving configuration settings using the published Windows Azure native library APIs. The method azure_getconfig() is able to directly retrieve the configuration settings with minimal overhead; it is the equivalent of calling RoleEnvironment.GetConfigurationSettingValue() from the .NET runtime. It is important to be aware that calls to this function require the PHP runtime to have %RoleRoot%\base\x86 in the PATH. This is allows the native and diagnostics libraries to be loaded by the PHP runtime.
The extension and its documentation are available from http://phpazurecontrib.codeplex.com.Whenever possible, you should try to make sure your application can retrieve its configuration settings directly from the role. This provides you the greatest control over the configuration and minimizes any special handling that might be required to deal with restarts or redeployments. Since the machines are stateless, you are not guaranteed of a constant configuration between any two starts.
By using one or more of these techniques, the application can be dynamically pointed to appropriate Windows Azure resources with minimal effort.
Configuring the Web Role
As mentioned previously, the Windows Azure instances require some configuration. There are many ways to deploy PHP, including using the scaffolding framework or the Web Platform Installer (WebPI) command line. Both of these are covered in some detail in numerous blog articles. You can also manually install and configure PHP as part of your deployment.
In our case, we realized that we wanted to ensure that the version of the PHP runtime we were using was completely configured and under our control. By using a specific runtime version, we could adjust the settings more specifically to our needs. In addition, owning the installation would allow us to verify that the extensions we are using will each behave as expected. In more extreme circumstances, this would also allow us to patch the components for any discovered issues. We package the PHP runtime with the deployment and use startup scripts to configure the settings required by IIS, including configuring FastCGI and handlers for the *.php file extension.
There are two important things to remember in the configuration process:
- The configuration scripts must be idempotent. These startup scripts are not just executed when the Windows Azure instance is first deployed; they can be executed any time Windows Azure restarts or reconfigures the instance. This means that it is important to test the scripts and to make sure that the scripts can handle being run multiple times. Many sample startup scripts for configuring IIS forget this. This can lead to instances failing to launch or suddenly becoming unavailable and refusing to reload. If you are using appcmd to deploy settings to IIS, make sure that the script is either detecting an existing configuration or deleting the configuration section and recreating it.
- The configuration of the instance can change any time the instance is redeployed, and this configuration change can occur without the server rebooting. When deploying an upgrade, this is especially noticeable. Windows Azure can disconnect the drive hosting the current deployment and connect a new drive containing the upgraded deployment. When this occurs, the paths to the application and any CGI values may need to change in order for the instance to remain usable. This is why idempotent startup scripts are necessary – the scripts may be configuring the PHP runtime to a new location on a completely different drive letter from the previous location. Several early failures on our system could be traced to this particular situation.
Web.Config
Because we are running under IIS, we have to make sure that the application is properly configured. This involves making sure to include a valid web.config file with any additional definitions or settings required by the application. If you do not include a web.config with your application, one is automatically created. If you include a web.config, Windows Azure will modify the file slightly to include various settings used on the server. In some cases, these settings may also reflect changes made using the appcmd tool.
When hosting PHP under IIS – including with Windows Azure – you might find that your code occasionally fails with the generic 500 error message. This message makes it difficult to troubleshoot the issues. In these cases, adding the line <httpErrors errorMode="Detailed" /> can make the initial troubleshooting significantly easier. This will allow the error message returned by PHP to be displayed to the client. Important: It is not recommended that you leave this setting enabled in production since it can expose significant details about your application.
It’s important to remember that this is a base feature of IIS, so you can take advantage of this file to customize the behavior of your application on IIS. If you understand this file and the related configuration settings available on IIS you can further improve the application behavior. For example, in our deployments we commonly enable dynamic and static compression to reduce the bandwidth required by our application. Occasionally we enable the caching mechanisms to fine-tune the caching of documents and files hosted on IIS. These settings and more can be configured in one of two popular ways.
The first is to use the web.config packaged with your deployment. This will allow you to configure most of the common settings associated with your application. For example, one of the more important settings you can configure is the defaultDocument. If this is not properly configured, performance suffers whenever IIS attempts to resolve each request that does not specify a file. IIS is automatically configured with a default list which must be searched in order until either a match is made or a 404 occurs. By explicitly setting your defaultDocument – normally index.php – you can eliminate this search and improve the performance. For more details on configuring the default document, see http://www.iis.net/ConfigReference/system.webServer/defaultDocument.
The second method is to use the appcmd command line management tool for IIS. This is a powerful way to fine-tune your configuration. This method gives you the ability to configure the web application (web.config) as well as the IIS instance (applicationHost.config). Using appcmd allows you to configure logging, dynamic and static compression, FastCGI, and many other aspects of the web role. This is still a very common way to configure the FastCGI settings to host the PHP runtime. If you’re interested in understanding this tool, I would recommend reading http://support.microsoft.com/kb/930909, and http://learn.iis.net/page.aspx/114/getting-started-with-appcmdexe/. In addition, you can refer to http://www.iis.net/ConfigReference/system.webServer/fastCgi for details on configuring FastCGI for PHP.
There are two considerations when using appcmd in your startup script. First, the deployment process may have modified some settings of your web.config file during the configuration of the server. As an example, the deployment process will configure the <machineKey> element. For this reason, do not assume that you will know the exact state of the web.config file. Second, be aware that your startup tasks may be run multiple times. This means that you must make sure any scripts using appcmd are idempotent.
Debugging
When developing or testing in PHP, it’s common to use a debugger extension, such as XDebug. Make sure that you remove these extensions from the production PHP configuration. Debugging extensions can impair the performance of a production server, so they should be used with care.
One recommendation in this regards is to place a debug flag in the service configuration (cscfg) file. You can then use one of the methods described in Configuring the Web Role to modify the PHP.INI at startup to configure the debugging extensions if this flag has been set. This method can also be used to install, enable, and configure other debugging components such as WebGrind.
Don’t forget that it is also possible to use Remote Desktop to connect to an instance and enable debugging manually. If you do this, remember to remove the debugging extensions from PHP.ini or rebuild the instance when you are done!
Logging
Logging can make it much easier to understand the behavior of your application, but it can also slow down the execution of your program. Make sure that you minimize logging on your production instance unless you need it for diagnosing an issue. You can enable logging dynamically from the service configuration file using the same method described in Debugging PHP.
Session Management
In case I haven’t mentioned it – Windows Azure Compute instances are stateless. This means that you cannot guarantee that any two requests will be handled by the same server. In addition, this means that the state on the instance is not guaranteed to be consistent with the state of any other instance. Since a load balancer can direct requests to any instance, it would be ill-advised for an instance to use any form of in-memory session management.
By nature, sessions provide state. This state must be shared and consistent across multiple instances. In order to make this work, you need a consistent and reliable means of storing the shared state. At the moment, Windows Azure Caching does not yet have support for PHP. This means that it is not currently an option for session management with PHP. The current recommendation is to use Windows Azure Table Storage. I would highly recommend reading Brain Swan’s excellent article on this topic, http://blogs.msdn.com/b/silverlining/archive/2011/10/18/handling-php-sessions-in-windows-azure.aspx. Make sure to also read the follow-up article which explains the importance of batching the data being inserted, http://blogs.msdn.com/b/silverlining/archive/2012/01/25/improving-performance-by-batching-azure-table-storage-inserts.aspx. It’s also important to remember that when storing session data, you must account for transient failures. Since Windows Azure uses shared resources, it is possible that resources will be briefly unavailable for short periods of time.
Caching
There is not always a need to dynamically create content for the user. In many cases, resources change infrequently. Caching provides a way of quickly responding to a request with content that already exists. It also provides a way of storing content closer to the user; in some circumstances, the content can be stored in the user’s browser, reducing the number of server requests.
Static Content
If the files are not changing often, it’s a perfect candidate for caching. This type of content can be placed in Window Azure Blob Storage and served using the Windows Azure CDN. This reduces the load on the server and places the content closer to the user. By default, content on the Windows Azure CDN will be cached for 72 hours. If you are not familiar with using the Windows Azure CDN, a hands-on lab is available at http://msdn.microsoft.com/en-us/gg405416.
Output Caching
Output caching preserves dynamic content for a period of time. When the content is requested before the cache expires, IIS will automatically serve the cached content and will not execute the PHP script again. This reduces the number of times a script has to be executed, improving overall performance. This topic is covered in depth in a blog, http://www.microsoft.com/web/post/performance-tuning-php-apps-on-windowsiis-with-output-caching.
File-based Caching
Of course, caching sometimes requires more advanced control. One strategy which we have seen used is to generate content on the server (or directly to Azure Blob Storage). If this file is being presented directly to the user, the page can redirect the user’s browser to this cached content. If the data is one or more database objects, then PHP serialization can be used to store and retrieve the object. Until circumstances change that require the code to create new output, the application can continue to use this cached document.
A word of warning here – if you are using this method, make sure that you are not inadvertently exposing the data publicly. Also, keep in mind that unless you are using Windows Azure Blob Storage, these caches are local to the server. If you are using Windows Azure Blob Storage, remember that there is a change for transient issues, so you must have some form of retry logic to ensure the persistence. Finally, don’t cache anything which relies on synchronization between the instances of the role. Remember that each role is independent and stateless.
If all of this seems quite challenging and risky, that’s because it can be. Of course, this is PHP so there are always more options for caching this data. Two of the most common are Wincache and Memcached.
Wincache
Most PHP veterans with any experience using Windows are familiar with Wincache (and for everyone else, you are already most likely using something similar, APC). This extension increases the speed of PHP applications by caching the scripts and the resulting byte code in memory. This improves the overall performance and reduces the I/O overhead associated with reading the script files. Configuring the extension is quite simple:
- Copy php_wincache.dll to the PHP extensions folder
- Register the extension in the php.ini file: extension = php_wincache.dll
- Optionally, enable the WinCache Functions Reroutes as described here: http://www.php.net/manual/en/wincache.reroutes.php. This improves the performance of certain file-system related calls.
- Deploy the application with the new settings. For local testing, restart the Application Pool in IIS so that the change is applied.
You will observe the session.save_handler was not configured to use Wincache. This is one change for Azure that is quite easy to miss! Remember that Windows Azure instances are stateless. The Wincache session management relies on using local memory. As a result, the session state would not exist across multiple servers. For this reason, session management has to use one of the persistence mechanisms provided by the platform.
Memcached
Many PHP applications cache data using Memcached to minimize database access. On Windows Azure this is even more important. SQL Azure is a shared service which has limits on the overall resource utilization. In addition, SQL Azure throttles client connections.
Memcached can be deployed on both Web and Worker roles, and it can be accessed in cluster mode from PHP applications. Maarten Balliauw has made a scaffolder available use with the Windows Azure SDK for PHP at https://github.com/interop-Bridges/Windows-Azure-PHP-Scaffolders/tree/master/Memcached. This site includes details about the implementation and usage instructions.
PHP and SQL Azure
The performance of an application can be limited by the performance of the slowest operation. With our Joomla instance, we are taking advantage SQL Azure for the database support. The performance when using this resource – which is external to the application server – can directly impact the ability of the web role to perform its job. A poorly tuned query can quite easily make the difference between a sub-second response time and an activity time out when dealing with large amounts of data. When a PHP application is performing slowly, in many cases the database queries can be the root of the problem. In a distributed system, this is even more likely to be true since there is more latency. To get the best performance out of your application, you must ensure that any database access is performed as efficiently as possible.
The Driver
If you need to access a database, you need to use drivers. In the past, you might have used the bundled extension to access the mssql functions. Starting with PHP version 5.3, these functions are no longer included with the PHP installation for Microsoft Windows. These functions have been replaced by a new driver from Microsoft which is open-source and available at http://sqlsrvphp.codeplex.com. The new sqlsrv functions are more efficient and vendor-supported. This driver supports both SQL Server and SQL Azure. In general, I recommend trying to keep your drivers up to date so that you can take advantage of bug fixes and platform enhancements. Like any other extension, you will need to place the non-thread safe (NTS) version of the files in your extensions folder and include any required configuration in the PHP.INI file. Full instructions are included with the Getting Started guide. Be aware that version 3.0 of the drivers does not include support for PHP 5.2 and earlier. For that, you will require the older version 2.0 drivers.
We found it quite simple to port legacy code to the new driver; the APIs are nearly identical with the exception of changing the prefix from mssql to sqlsrv. The biggest difference tends to be improved error handling methods in the new APIs: you will need to replace mssql_get_last_message (which returns a single result) with the method sqlsrv_errors (which returns an array of arrays).
From version 2.0 onwards, the drivers include support for PHP Data Objects (PDO). PDO provides an abstraction layer for calling database driver functions. You can read more about PDO in the PHP Manual. While a discussion of PDO is outside the scope of this article, the principals discussed here apply equally whether you are using PDO or not.
Understanding SQL Cursors
To understand how to optimize the PHP code, you must first understand a bit about the cursor types you see in PHP. Each type is optimized for specific uses and has certain performance tradeoffs. Selecting the right type for the job is therefore very important. In most cases, the default cursor type (SQLSRV_CURSOR_FORWARD) is the preferred choice. For more details on these cursor types, I recommend reading the MSDN article: http://msdn.microsoft.com/en-US/library/ee376927(v=SQL90).aspx.
Static
A static cursor (SQLSRV_CURSOR_STATIC) will generally make a copy of the data that will be returned. This is done by creating a work table to store the rows used by the cursor in a special database called tempdb. If there is enough data, it also starts an asynchronous process to populate the work table to improve the performance. This process has performance cost since the database server must retrieve and copy the records.
Dynamic
By comparison, a dynamic cursor (SQLSRV_CURSOR_DYNAMIC) works directly from the tables, avoiding the overhead of copying the data but having an increase in the time it takes to find the data for a single row. Dynamic cursors do not ‘snapshot’ the data typically, meaning it is possible for the underlying data to change between the time the cursor is created and the time the values are read.
Forward Only
The forward-only cursor (SQLSRV_CURSOR_FORWARD) is a specialized type of dynamic cursor which improves the performance by eliminating the need for the cursor to be able to navigate both forwards and backwards through a result set. As a result, a forward-only cursor can only read the current row of data and the rows after it. Once the cursor has moved passed a row, that row is no longer accessible. This is the default cursor type and is ideal for presenting grids or lists of data. Because the results are materialized and sent to the client dynamically, dynamic and forward-only cursors cannot use the sqlsrv_num_rows function.
Keyset
A keyset cursor (SQLSRV_CURSOR_KEYSET) behaves similar to a static cursor, but it only copies the keys for the rows into a keyset in tempdb. This improves performance, but it also allows the non-key values to be updated. Those changes are visible when moving through the data set, similar to a dynamic cursor. If one or more tables lack a unique index, a keyset cursor will automatically become a static cursor. Both keyset and static cursors can use sqlsrv_num_rows to retrieve the number of records in the result set. This means that when calling sqlsrv_num_rows, the database server will be working with a copy of the data stored in tempdb.
Using the Right Cursor
In one of the third-party software components we utilize, the application needed to count the total number of records on the server to implement a paged display. A second query would then requests the current page of data for display. Paging was being used to limit how many records were returned since the dataset could be quite large. This is a fairly common scenario for displaying results in a grid. Both of these queries were originally configured to use a static cursor so that sqlsrv_num_rows could be called. This pattern is quite common in many PHP scripts. Unfortunately, this pattern has a serious flaw.
When the query was invoked to determine the total number of records was invoked, this resulted in the large dataset being copied into tempdb. As the number of records grew, the time required for this processing also increased. This query was not used to generate the actual data view, so none of the data copied into tempdb was used by the client. Before long, this query was taking several seconds to process. It didn’t take long before users began to complain about the time required to view each page.
Fixing this issue is surprisingly simple. First, we converted both queries to use a forward-only cursor. This allowed us to work with the dataset more efficiently since we were no longer copying the records into tempdb. This was also the ideal cursor type for returning the paged results since the grid view was rendering each row in order. For the query which determined the total number of records, the call to sqlsrv_num_rows was replaced by a standard SELECT COUNT query. The modified queries took only a few milliseconds to return their results.
Prepared Statements
Another way to improve your PHP code is to take advantage of prepared statements. Prepared statements basically provide the database server a cacheable template of your query which can then be executed multiple times with different parameters. This reduces the time it takes for the database server to parse the query since the server can reuse the cached query plan. More importantly, prepared statements automatically escape the query parameters. By eliminating string concatenation and the need to escaping the query parameters manually, prepared statements can significantly reduce the risk of a SQL injection attack if used correctly. A final benefit is that prepared statements separate the query template from actual parameters. This can improve the maintainability if the code. It can also be very beneficial if you are trying to support multiple databases!
This feature is more than just a best practice recommendation. It is considered to be so important that it is the only feature PDO drivers are required to emulate if it is not actually supported by the database. You can view a complete example of how to use prepared statements with the SQL Server driver here.
The Tools of the Trade
The Microsoft SQL Server platform provides several tools which can be helpful for maintaining and optimizing your code when dealing with SQL Azure. You can download the current set of tools from http://www.microsoft.com/sqlserver/en/us/get-sql-server/try-it.aspx.
SQL Server Data Tools (SSDT)
SQL Server Data Tools is an integrated collection of tools for managing, maintaining, and debugging SQL scripts. It provides a GUI editor for table definitions, enhanced query debugging, and system for managing and maintaining your scripts in source control. In addition, SSDT has the ability to create a data-tier application (DAC). A DAC provides a way of managing, packaging, and deploying schema changes to SQL Azure. When a DAC is deployed to SQL Azure, it can perform most of the common schema migration tasks for you automatically, drastically reducing the effort required to update your application. In addition, a DAC project can make managing scripts for SQL Azure easier; it provides Intellisense and identifies invalid SQL statements. A hands-on lab is available which walks through creating, managing, and deploying schema changes to SQL Azure using this tool. You can find it at http://msdn.microsoft.com/en-us/hh532119.
You can learn more about SSDT from http://msdn.microsoft.com/en-us/data/gg427686.
SQL Server Profiler
The SQL Server profiler provides a way of capturing and analyzing the queries being sent to a SQL Server instance. By capturing the queries being sent and examining the execution times for each query, you can more easily identify the queries that are taking the most time. Not only that, you can identify additional issues such as repetitive calls and excessive cursor usage.
Using this tool, we noticed that one particular application made a database call for each row that was going to be displayed on the screen. Looking more closely, we noticed that that this query was being used to return a single value from another table. This was accounting for almost 80% of the time required to render that page. By modifying the original query to include a JOIN, we were able to eliminate this overhead and reduce the number of calls to the database.
SQL Server Query Analyzer
Once you’ve identified a query that is taking an excessive amount of time, you need to learn why. The Query Analyzer provides the tools for executing and debugging SQL queries and analyzing the results. This tool also provides a graphical visualization of the query plan to enable you to more effectively find the bottlenecks in your query. This tool is now part of SSDT.
Database Engine Tuning Advisor
If you’ve taken the time to profile your application, you might be interested in learning about optimizations you can make to your schema which might improve the overall performance. The Database Engine Tuning Advisor (DTA) examines your queries and suggests indexes, views, and statistics which can potentially improve the overall performance of your application. Of course you still need to examine whether the proposed changes provide real improvement, but this can be a great help in identifying changes which can improve the overall performance of the application.
Because both SQL Server and SQL Azure have the ability to identify optimal query execution plans, you may find some surprising suggestions. SQL Server can use indexes for schema structures that are not part of the actual query, so this can open up the potential for unexpected optimizations. In our case, a particularly slow query was able to be optimized by creating an indexed view. Because this index provided coverage for the query, SQL Azure was able to use the index and view when retrieving the requested data.
A tutorial for the 2008 R2 edition is available at http://technet.microsoft.com/en-us/library/ms166575(v=sql.105).aspx.
SQL Azure Federations
Federations are the newest addition to the SQL Azure platform. Federated databases provide a way to achieve greater scalability and performance from the database tier of your application. If you’ve done any large scale development on PHP, you will be familiar with the concept of “sharding” the databases. Basically, one or more tables within the database are distributed across multiple databases (referred to as federation members). By separating the data across multiple databases, you can potentially improve the overall performance of your database system. Using SQL Azure Federations via PHP covers this topic in greater detail.
For users that are more familiar with the SQL Server platform and tools, it is worth mentioning that the current tools – Microsoft Visual Studio and SQL Server Data Tools – do not yet support this feature if you are deploying the database as a data-tier application (DAC). As a result, federations must be managed manually at the current time.
Resiliency
The SQL Azure database is a shared resource which can be throttled or restricted based on how it is being used. Because it is a shared resource, it can also be unavailable for short periods of time. While this is not always the case, it is the reality of the cloud. For that reason, your code must not blindly assume that every connection will be successful or that every query will succeed. Two strategies will help you in this regards.
The first strategy is to use a retry policy with effective error handling. That is, if the connection or query fails due to a transient condition, you may create a new connection and attempt to perform the SQL query again. Don’t forget that SQL Azure can become unavailable during a query (closing the connection with an error) or between two queries. Poor error handling can lead to data corruption very easily in a distributed environment.
The other strategy is to isolate your read logic and write logic as much as possible. By separating these two concerns, it becomes possible to continue using your application even if there is a major service outage. In many applications, a large portion of the code is devoted to allowing the user to review stored information. It tends to be a smaller portion of the code which is involved in modifying the data. In these types of applications, a clean separation makes it possible to allow reading to continue independently from write operations. This allows users to continue to use your application, although possibly at a reduced capacity.
During the leap day outage, the SQL Azure instance responsible for serving news feeds to our users had availability issues. During this time, we reconfigured the compute instances which were hosting these services. The new configuration retrieved the data from a copy of the database in a different datacenter and did not allow updating or storing new data. Although we could not create new content or modify existing feeds during this time, our users were able to continue receiving the news feeds.
Sizing the Servers
When deploying to Windows Azure one of the first considerations you have to make is the server size. Windows Azure is not a one-size-fits-all solution. It is a highly configurable set of many different types of services and servers. One of those configuration options is the size of the virtual machine instances that will host the web role. The size of the instance controls the availability of resources such as memory, CPU cores, drive space, and I/O bandwidth; you can read more on the configurations of the available virtual machine sizes at http://msdn.microsoft.com/en-us/library/windowsazure/ee814754.aspx.
This is an important decision for optimizing the performance of your PHP application. The various sizes each have limitations on the available resources – CPU, RAM, disk space, bandwidth, and overall performance – which have to be balanced with the application’s needs. For example, if the application requires extensive network bandwidth, a large server instance may be necessary in order to keep up with the system’s demands. On the other extreme, if the application requires mostly CPU resources and spends significant time in small, blocking operations, it may be advantageous to use multiple small instances so that Windows Azure can load-balance the incoming requests. In each case, the performance is very dependent on how the system is being used.
We have observed that an application running on 2 medium instances can behave very differently from the same application on 4 small instances. In at least one case, the small instances were able to more effectively balance the loads. This appears to be due to more effective load balancing for the application. The load balancer would send each request to the next available instance, preventing the CPU from any one instance from becoming saturated. I would caution that this was a specific case and that you should examine how the resources are being used by your application to understand the most efficient size for your web role. If you are unsure, start with a small instance and work up from there.
Our Stateless World
Remember that the Windows Azure servers are currently designed to be stateless. This means that any changes made locally on the server are not guaranteed to be available. The only way to have persistent storage is to commit the storage to one of the available persistence stores such as a Windows Azure drive, SQL Azure, or blob storage. Windows Azure servers can be reallocated and restarted at any time, so any manual configuration adjustments or changes can be lost unless they are part of your deployment package. For this reason, you cannot make any assumptions about how long local changes will persist. This can be confusing for new developers who might assume that changes made through a Remote Desktop session will continue to work. We have seen cases in which a server suddenly stopped working because a manual change was made to one or more files, and those changes were lost when the instance was redeployed suddenly by the Windows Azure controller in the middle of the night. The same thing can be said for any log files or other persisted content which does not use the proper Windows Azure storage mechanisms – you can’t guarantee the content will not be removed. The servers are stateless.
In one case, we discovered a component of our Joomla installation which was storing image content in a local folder on the server. This had two immediate side effects. First, not all of the servers had copies of this content. This meant that any time we increased the instance count of our Windows Azure deployment, customers would begin to receive 404 errors in the event they were routed to an instance which did not contain the physical file. Since local folders are not synchronized between instances, only the server which initially received the image would be able to serve that content. Second, we observed that the content was permanently lost if the Windows Azure instance was recreated, upgraded, or restarted. The fix to both problems was to make sure that any user provided content was stored directly and subsequently retrieved from Windows Azure’s blob storage. By making this adjustment, we also noticed a substantial performance change when accessing the content. The content was no longer using bandwidth on the server and we could now serve it using the Windows Azure CDN. One additional benefit – the content was now protected by the redundancy built-in to Windows Azure Storage.
Replacing local content storage with remote storage does not come without some cost. It can take longer to transfer a file to remote storage than to the local file system, especially if the server is acting as a gateway to the resources. This can require changes to the end-user experience, or configuring the code to allow the content to be directly uploaded into blob storage. This tradeoff is minor compared to the benefits you can gain. It is also a minor tradeoff compared to the risk of data loss from incorrectly assuming that your content will continue to persist.
Other Windows Azure Features
There are a number of other services available in Windows Azure which can greatly benefit your application. Taking some time to understand these other features can help you to get more out of Windows Azure.
Worker Role
Up until this point, we’ve discussed compute instances using the Web Role almost exclusively. For more advanced development, a Worker Role is also available. The Worker Role allows you to create processes and services which are continuously running and can provide additional features. Worker Roles can be used for calculations, asynchronous processing, notification, scheduling, and numerous other tasks. In short, if you need the equivalent of a background process or daemon, then the Worker Role is ideally suited for performing that job. Worker Roles are a type of compute instance, so they are billed the same way as a Web Role. This means that you still have to consider the related costs.
Windows Azure Blob Storage and CDN
As discussed earlier, one of the first considerations on Windows Azure is the server sizing. Part of sizing the server correctly is to understand the way the server is being used. A server which provides exclusively dynamic content has completely different usage than a server which is mostly static content. The smaller instances of Windows Azure offer much lower bandwidth that the larger instances. One approach is to use a larger server instance if you find you need more bandwidth. This certainly solves the problem, but you are now left with an under-utilized (and rather expensive!) server. A more scalable solution is to move the static content to the Windows Azure Blob storage and enable the CDN. This places the content closer to the end-user, improving the delivery characteristics. It also reduces the amount of network and I/O bandwidth required by the Role. Images, style sheets, static HTML pages, JavaScript, Silverlight XAP files, and other static content types can be placed onto blob storage to allow significantly larger scale at a lower total cost. For applications which are mostly static content, it is possible to use Extra Small instances and effectively host your web role.
Integrated Technologies (Advanced)
Remember that you’re running on platform based on the Windows 2008 server technology. This means that any of the technologies available on that platform are available to you on Windows Azure. From within a compute instance, it is possible to leverage the platform to take advantage of additional features. Be forewarned that if you’re using some of these additional technologies that you must account for the stateless nature of the server, the need for idempotent scripts, and the fact that redeployments can result in your resources moving to a different drive or location.
Some of the features available to you:
- ASP.NET. If you need a lightweight integration into Windows Azure or have components that run using the .NET runtime, you can use that technology side-by-side with PHP without any issue. For users comfortable with .NET, you can even create startup tasks and handle Role events through event handlers. You’ll likely want the Windows Azure SDK for .NET.
- Background Startup Tasks. If you don’t need the resiliency and restarting features of a service, but you do need a simple background (daemon) task, then you can use a background startup task in Windows Azure to run a script or executable in the background of your deployment. Background startup tasks are started with the instance and (especially .NET based tasks) can respond to the RoleChange and RoleChanging events. This is the basis of several of the plugins provided with the Windows Azure SDKs.
- Windows Azure Entry Point. By default, an entry point exists for every Web Role and Worker Role. You are allowed to provide a .NET based DLL containing a customized entry point based on the RoleEntryPoint class in your deployment and to include an <EntryPoint> element in your Service Definition (csdef) which provides the details required by Azure to use the entry point. This allows you to respond to the RoleChanged/RoleChanging events and to control the state of your role. For a VM role, this is not available and the recommendation in the Azure SDK is to use a Windows Service. For more advanced cases, you can even override the Run() method to run background tasks. When the Run() method ends, the Role is restarted. This provides you another mechanism for executing background tasks from a Web Role.
- IIS. This technology is at the heart of every Web Role and provides the web hosting environment. As a result, all of the features of this platform (including Smooth Streaming support) are available to you. To really make the most of this feature, you’ll want to become intimately familiar with the appcmd tool described in Configuring the Web Role. You’ll also want to make sure to explore WebPI


<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+

Return to section navigation list>
Windows Azure Infrastructure and DevOps
Bruno Terkaly (@brunoterkaly) posted Essential Windows Azure (Microsoft Cloud) Knowledge : Part 1: Web roles, Worker Roles on 5/13/2012:
Globally distributed data centers

In all seriousness, this post is directed to developers, architects and technical decision makers. Maybe in a future post I'll lower the technical barriers and explain things even more simply. I would argue this post covers the spectrum - from basic to fairly sophisticated.
I assume that you understand the Windows Azure Platform is a cloud-based computing technology from Microsoft, built upon a highly evolved programming environment and hosted in mega-data centers throughout the world.
 Note: It appears to me that the illustration is a bit out of date with only four Windows Azure data centers indicated by the dark circle border. (Amsterdam isn’t included in the Green Energy list, so it appears as if the dark circle borders don’t specify greenness.) East and West US and the two Asian Windows Azure data centers are missing dark borders.
Note: It appears to me that the illustration is a bit out of date with only four Windows Azure data centers indicated by the dark circle border. (Amsterdam isn’t included in the Green Energy list, so it appears as if the dark circle borders don’t specify greenness.) East and West US and the two Asian Windows Azure data centers are missing dark borders.
This post is very visual. I want to convey as much as I can with as many diagrams as possible. You obviously can't pull up PowerPoint during Thanksgiving, but if someone asks you for an explanation, having a visual in your head really helps.
I've been doing lectures about cloud computing for a few years now. Along the way I have constructed 100's of slides that explain the Microsoft cloud, the Windows Azure platform. I want to present some of them to you here. It should help you understanding the massive capabilities of the platform as well as explain how some things work.
The basics - hosting web sites and web services
The point of the diagram below is to think about hosting your web-based content and services. It also addresses running background processes.

- You can think of Compute as being a container for web roles and worker roles.
- Compute enables you to run application code in the cloud and allows you to quickly scale your applications. Each Compute instance is a virtual machine that isolates you from other customers
- Compute runs a Virtual Machine (VM) role
- Compute automatically includes network load balancing and failover to provide continuous availability.
- Windows Azure provides a 99.95% monthly SLA for Compute services
- Web roles are simply front-end web applications and content hosted inside of IIS in a Microsoft data center.
- What is IIS?
- Internet Information Services (IIS) is a web server application and set of feature extension modules that support HTTP, HTTPS, FTP, FTPS, SMTP and NNTP.
- IIS can host ASP.NET, PHP, HTML5, and Node.js.
Note that you are not limited to ASP.NET, or MVC. You can also use PHP, Node.js, and HTML5.
- You can quickly and easily deploy web applications to Web Roles and then scale your Compute capabilities up or down to meet demand.
- Web roles can host WCF Services.
- The Windows Communication Foundation (or WCF), is an application programming interface (API) in the .NET Framework for building connected, service-oriented applications.
- WCF unifies most distributed systems technologies that developers have successfully used to build distributed applications on the Windows platform over the past decade.
- WCF supports sending messages using not only HTTP, but also TCP and other network protocols.
- WCF has built-in support for the latest Web services standards (SOAP 1.2 and WS-*) and the ability to easily support new ones.
- WCF supports security, transactions and reliability.
- WCF supports sending messages using formats other than SOAP, such as Representational State Transfer (REST).
ASP.NET Web Forms versus MVC
ASP.NET Web Forms has been around for a while and is a mature technology that runs small and large scale websites alike. MVC is the newer technology that promises many advantages.
- Web Forms is built around the Windows Form construction model
- Web Forms have a declarative syntax with an event driven model.
- Web Forms allow visual designers can use a drag and drop, WYSIWYG, interface.
- Web Forms make it possible for you drop controls onto the ASP.NET page and then wire up the events
- Microsoft basically extended the Visual Basic programming model to the Web
- Web Form disadvantages include:
- Display logic coupled with code, through code-behind files
- Difficult unit testing because of coupling
- ViewState and PostBack model
- State management of controls leads to very large and often unnecessary page sizes
MVC
The ASP.NET MVC Framework is a web application framework that implements the model-view-controller (MVC) pattern.
- At the expense of drag and drop, MVC gives you a very granular control over the output of the HTML that is generated.
- MVC supports a ‘closer to the metal’ experience to the developers that program with it, by providing full control and testability over the output that is returned to the browser
- Clear separation of concerns
- Results in strong support for unit testing
- MVC easily integrates with JavaScript frameworks like jQuery or Yahoo UI frameworks
- MVC allows you to map URLs logically and dynamically, depending on your use
- MVC provides RESTful interfaces are used by default (this helps out with SEO)
Worker roles are part of compute but are not hosted in IIS.
Applications hosted within Worker roles can run asynchronous, long-running or perpetual tasks independent of user interaction or input.
- Worker roles let you host any type of application, including Apache Tomcat and Java Virtual Machines (JVM).
- Applications are commonly composed of both Web and Worker roles.
- A common implementation in Windows Azure takes input from a Web role, sends those requests through a Queue to a Worker role, then processes the requests and stores the output.
Sample Implementation
Imagine that you are Microsoft and that you want to offer video encoding services to customers. That means that someone like me can take my home videos, upload them to the Microsoft Cloud, specifically Windows Azure Media Services. Next, I can use a management API that Microsoft provides, and programmatically encode my videos so they can run well on other devices. This simply means I want to take my vacation.mpg video and convert it to a native QuickTime format, like .mov files. Many of you blog readers know that there are many video formats, such as WMV, AVI, MP4, MOV - just to name a few.
The diagram below illustrates how such an offering might exist. Let's walk through it.
A sample scenario
Imagine the user wants to upload their video so they can get it encoded in multiple formats, so the video will look good across a spectrum of devices.
Let's walk through a scenario.
The portal that user's interact with is a web role
- Note that the web role is the portal. It interacts with the user who wants to user Microsoft's video services.
- Microsoft could have built the portal using ASP.NET Web Forms, MVC, PHP, HTML5, Node.js. Microsoft probably would choose MVC because of it's testability, and fine-grained control over the rendered HTML to the user.
- The portal runs inside of IIS and inside a VM that is running Windows Server 2008 R2.
- You may have multiple instances running that Azure will automatically load balance requests for.
- The web role can interact with the worker role using queues.
- The web role takes the user's video and stores inside of Azure Storage, it sends the worker role some instructions about where the .mov files are and what the desired
- It does so using the Windows Azure Queues.
Background Process - Worker Role
- Like a Windows Service
- The Worker Role is similar to a windows service.
- Long Running
- It starts up and is running all the time.
- No timer
- Instead of a timer, it uses a simple while(true) loop and a sleep statement.
- Background processing
- This is great for background processing.
- Data Required
- Worker roles usually need some data to work with.
- The Queue is the data bridge
- You can communicate between a worker and a web role via the use of a queue.

- Worker role simple reads from queue
- The worker role doesn’t care how stuff got into the queue
- First in First out
- The worker role processes items in the queue using FIFO.
- The user interacts with the web role, not the worker role
- Generally speaking it is the web role that is user driven and causes data to go into the queue.
- The worker role interacts with storage.

- The worker role knows there is two types of storage containers
- There are 3 main categories of storage - 2 Azure Blob Containers and one Azure Table
- BlobContainer = Movies to Encode
- Movies that still need to be processed and encoded.
- BlobContainer = Encoded movies
- The finished product, multiple movie formats, one for each device type
- Azure Tables
- Stores the meta data about the Azure blobs.
- It records the location of the Azure blobs so the worker role knows where to read and write video content
- It knows because of the two types of Azure blob containers

Notes for the diagram above
Here is some details about he diagram above.
- The web role interacts with the user
- The user may download or upload files.
- The user may upload a video because they want it encoded
- The web role would be the portal where the user does that
- But the user may also wish to download the finished product (the encoded video performed by the worker role)
- The portal must allow downloads from BlobContainer = EncodedMovies
- The web role could read/write Azure Tables. But we may choose to let the worker role do that.
- The web role writes Azure blob locations as text strings to queues and forgets about them.

Notes for the diagram above.
Notice many worker and web roles in many racks.
There are several instances of Fabric Controller instances running in various racks in data centers.
- One is elected to act as the primary controller.
- If it fails, another picks up the slack.
- There fabric controllers are redundant.
- If you start a service on Azure, the FC can fall over entirely and your service is not shut down.
- The Fabric Controller uses the Preboot eXecution Environment
- PXE, also known as Pre-Execution Environment; sometimes pronounced "pixie"
- PXE is an environment to boot computers using a network interface independently of data storage devices (like hard disks) or installed operating systems
- PXE leverages the Internet Protocol (IP), User Datagram Protocol (UDP), Dynamic Host Configuration Protocol (DHCP) and Trivial File Transfer Protocol (TFTP) to support boostrapping a computer
- The Fabric Controller runs Sysprep, the system is rebooted as a unique machine
Understanding the Fabric Controller









Nice diagrams, Bruno!
Joseph Fultz wrote 5 Reasons to Start Working with Windows Azure for the May 2012 issue of MSDN Magazine’s Forecast Cloudy column:
Everywhere you turn nowadays, you hear about the cloud—that it’s a major step in the evolution of the Web and will change the way you develop, deploy and manage applications. But not everyone has figured out how the cloud really applies to them. This is especially true for those with medium-to-large infrastructures and relatively flat usage consumption—where the capitalized cost is beneficial compared to the operational cost of the cloud. However, if your infrastructure is on the small side or you have a dynamic consumption model, the cloud—Windows Azure—is a no-brainer. Moreover, for shops heavy in process, where standing up a development environment is like sending a bill to Capitol Hill, Windows Azure can provide a great platform for rapid prototyping.

Joseph continues with detailed descriptions of the following five reasons:
- Great Tools Integration
- Performance and Scale
- Manageable Infrastructure
- You’re Writing the Code Already
- It’s the Future
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Peter Lubanski described Self-Service in System Center 2012 in a 5/14/2012 to Thomas Schinder, MD’s Private Cloud Architecture blog:
“Self-Service” is one of the core features of a Private Cloud. Self-Service gives the user the ability to request computing resources for his/her use with minimal or no interaction with their IT staff. In some cases, it may be as simple as browsing to a website, entering some information, such as the number and type of resources needed, then poof the resources are built and ready for use in a few minutes, without anyone on the IT staff having to manually build new machines.
And while you might think the idea of requesting and getting IT resources without a long wait and lots of human interaction sounds too good to be true, with System Center 2012 it’s not only is it true, but quite easy to setup and make a reality.
System Center 2012 comes with 3 options for Self-Service. For the purposes of this article, I’ll classify them into good – better – best and explain why in each section to help you decide on the best approach for your needs.
Good
Virtual Machine Manager 2012 Self-Server Portal. This in-box solution is nearly identical to the VMM 2008 R2 Self-Service Portal. The main difference is that it prompts the user for what cloud they want to deploy their virtual machine to, based on what they have permissions to use. Note that This is a basic, simple portal that is not easily customized.
It can be setup in 4 simple steps:
- Install it from the Virtual Machine Manager setup menu
- Add user accounts to the self-service user role in VMM
- Grant users access to a cloud
- Grant users access to deploy a template
That will give users access to the self-service portal and the ability to create and manage new machines based on the templates they have access to. This “good” solution is easy and fast to setup, but is limited in its ability to customize its experience.
Better
AppController 2012 – A new option in System Center 2012 is AppController 2012. This is the new portal that is designed to provide a common self-service experience across private and public clouds that can help you easily configure, deploy, and manage virtual machines and services in both environments.
Best
Service Manager 2012 Self-Service Portal – A full deployment of System Center 2012 would include Service Manager 2012 and the new Cloud Services Process Pack. Service Manager provides an integrated platform for automating and adapting your organization’s IT service management best practices, such as those found in Microsoft Operations Framework (MOF) and Information Technology Infrastructure Library (ITIL). It provides built-in processes for incident and problem resolution, change control, and asset lifecycle management.
Service Manager is designed to provide a full IT Service Catalog that can be beyond just virtual machine provisioning. Service Manager has Orchestrator integration to launch runbooks in other System Center components such as Virtual Machine Manager, Data Protection Manager, Operations Manager or Configuration Manager. It is more of a toolkit to build out Service Offerings and Request Offerings that can offer a wide range of self-service options for users – Active Directory requests, security access requests, capacity requests, change requests and more. The possibilities are plentiful given the Orchestrator integration.
Likewise, the Cloud Services Process Pack is Microsoft’s infrastructure as a service solution built on the System Center platform. With the System Center Cloud Services Process Pack, enterprises can realize the benefits of infrastructure as a service while simultaneously leveraging their existing investments in the Service Manager, Orchestrator, Virtual Machine Manager, and Operations Manager platforms. In a nutshell, the Cloud Services Process Pack gives you a great first step toward realizing the reality of Infrastructure as a Service providing Service Manager components and Orchestrator runbooks. It provides a startup IaaS solution and building blocks to further expand those offerings.
This “best” solution has the potential to be a rich self-service experience for your entire service catalog. It also includes the capabilities for different approaches to approvals and notifications.
Summary
As always, your individual needs will determine what is the best solution for you. Do you need to manage your public clouds? Do you need to customize the experience for your users? Do you need a workflow of approvals and notifications? Fortunately, System Center 2012 provides options to meet your needs no matter where you land and they are all easy to setup and configure. With System Center 2012, you can provide Self Service of IT resources to your users !!
Also, it is important to note that all 3 components (VMM, AppController and Service Manager) can be controlled through scripts and automation using PowerShell modules or cmdlets. Here are links to that info:
- Scripting in Virtual Machine Manager - link
- Using AppController cmdlets - link
- Cmdlets in System Center 2012 - Service Manager - link
Thanks!
Michael Lubanski
Americas Private Cloud Center of Excellence Lead
Microsoft Services
mlubansk@microsoft.com


<Return to section navigation list>
Cloud Security and Governance
Himanshu Singh (@himanshuks) asserted Research Shows Cloud Computing Reduces Time and Money Spent Managing Security in a 5/14/2012 post to the Windows Azure and SQL Azure blogs:
Security is often reported as one of the top concerns or barriers to cloud adoption for businesses. To help dispel this perception, today Microsoft released research that shows that small and medium sized businesses (SMB) are gaining significant IT security benefits from using the cloud.
The U.S. findings show benefits in three main areas:
- Time Savings: 32 percent of U.S. companies say they spend less time worrying about the threat of cyber-attacks.
- Money Savings: SMBs that use the cloud are nearly 6x more likely to have decreased the total amount spent on security than SMBs not using the cloud.
- Improved Security: 35 percent of U.S. companies have experienced noticeably higher levels of security since moving to the cloud.
Time and money spent managing security prior to using cloud services is being re-invested by SMBs to grow their business and be more competitive.
You can read more about the study on Microsoft News Center and the Trustworthy Computing Blog.

Ed Moyle (@securitycurve) described Leveraging Microsoft Azure security features for PaaS security in a 5/14/2012 article for SearchCloudSecurity.com:
As I discussed in my previous article, application security expertise is critical for PaaS security. Investments in developer education and software development lifecycle processes are imperative for an enterprise using PaaS environments. However, organizations on the whole have been slow to invest in application security.
There are two things that shops in that position should know: First, the Azure environment itself provides some pretty robust security features to protect applications that live there, including measures like network-level controls, physical security, host hardening, etc. But those protections only tell half the story; any environment, no matter how well protected, can still be attacked through application-level issues that aren't addressed. Fortunately, there are a few features that we can layer on once the application is developed that add some measure of protection at the application layer.
These stopgaps aren’t the only application security measures available (not by a long shot) --they don’t include things you should be doing anyway (like SSL), and they’re not universally applicable to every use case. But these Microsoft Azure security features are useful for security pros to know about because they’re relatively quick to implement, require mostly minor code changes, and can many times get bolted on to an existing application without requiring extensive retesting of business logic.
Microsoft Azure security: Partial trust
Windows Azure out-of-the-box provides some level of insulation against attacks of that subvert the application by running user-supplied code as a non-administrator user on the native OS (this is almost entirely transparent from a caller standpoint). However, organizations can further restrict access permissions available to a role by restricting it to “partial” instead of “full trust.”
Folks familiar with the security model in a traditional .NET context will recognize the concept, but the idea is to restrict the impact of a security failure in the application itself by limiting what the application itself can do. Much like some Web servers and applications employ a “jailed” file system or restricted privilege model, the concept of partial trust is similar. Microsoft provides a full list of functionality available under partial trust and instructions on how to enable it in Visual Studio.
There is a caveat though. While using partial trust can be a useful avenue to pursue in smaller applications/services, larger or more complicated ones (for example in a direct port from a legacy .NET application) are likely to require the permissions of full trust in order to function.
Microsoft Azure security: AntiXSS
Many of the issues that arise within an application context (and more specifically, a Web application context) occur as a result of malicious input; in other words, user-supplied input is a common avenue of attack unless input is constrained or validated as part of application processing. This isn’t easy to do; it generally takes quite a bit of effort (and training) to get developers of business logic to understand what to filter, why, and how to test that filtering is comprehensive.
Because of this, Microsoft has made freely available the Web Protection Library (WPL) which provides a canned library of input validation that developers can use to help offset some of these issues. The AntiXSS library within the WPL provides capabilities that developers can integrate to encode user input, thereby reducing the likelihood that an attacker could subvert the input field to negatively influence application behavior.
Microsoft Azure security: Leveraging diagnostics
The next best thing to being able to prevent an attack is to have some way to know that it happened. In a traditional on-premise application deployment scenario, security professionals might implement enhanced logging and detection controls to offset application-level security risks. This same strategy can be applied to Azure. Specifically, the diagnostics capability of Azure can be configured to provide additional security relevant information beyond just the instrumentation that might already exist within the application itself. IIS logs, infrastructure logs and other logging can be a way to keep an eye on the application once it’s live without the need for extensive planning, coding, and retesting.
Obviously, these measures aren’t a comprehensive answer for PaaS security. Ideally, the goal for organizations is a long-term sophisticated lifecycle-focused methodology that includes baking in security to the application through SDLC and process changes. But short-term, when it’s hard to get traction for code changes and there’s pressure to get something out the door in a hurry, these quick steps might help.

Full disclosure: I’m a paid contributor to SearchCloudSecurity.com’s sister publication, SearchCloudComputing.com.
“Researcher” posted to the Clean-Cloud blog on 5/12/2012 (missed when published):
United States Health Insurance Portability and Accountability Act of 1996 were intended to protect individuals’ privileges to privacy and confidentiality and security of electronic transfer of personal information.
1.1.1 Challenges:
- Physically and logically secure environment
- Encryption of the data / Mitigation control
- Auditing, Back-Ups, & Disaster Recovery
- Access Controls
- CSP: An ISO/IEC 27001-certificated ISMS will ensure that you are in compliance with the whole range of information-related legislation, including (as applicable) HIPAA, GLBA, SB 1386 and other State breach laws, PIPEDA, FISMA, EU Safe Harbor regulations
- CSP: SAS 70 is an operational certification to help satisfy HIPAA requirements. SAS 70 checks a lot of things on the HIPAA list.
1.1.2 Solution / Control Objectives in Cloud
1.1.3 Example
Amazon Web Services (AWS) provides a reliable, scalable, and inexpensive computing platform “in the cloud” that can be used to facilitate healthcare customers’ HIPAA-compliant applications.


“Researcher” described Cloud Computing and ISO/IEC 27001 in a 5/11/2012 post to the Clean-Cloud blog (missed when published):
ISO/IEC 27001 is an Information Security Management System (ISMS) standard published in October 2005 by the International Organization for Standardization (ISO) and the International Electro technical Commission (IEC).
1.1.1 Challenges:
ISO/IEC 27001 requires that management:
- Establish Information Security Management System
- Design and implement information security controls and
- Adopt monitoring and management process to ensure that the information security controls meet the organization’s information security needs
- Manage identified risks.
- The 27001 standard does not mandate specific information security controls, but it provides a checklist of controls that should be considered in the accompanying code of practice, ISO/IEC 27002:2005. This second standard describes a comprehensive set of information security control objectives and a set of generally accepted good practice security controls.
- CSP & Customer: Establish policies for Data Confidentiality, Data Integrity, Availability, Backup & Archive, ownership, classification, decommissioning, and location awareness.
- CSP & Customer: Use of Cloud monitoring and management products
- CSP: ISO 27001 auditors may request a SAS 70 Type II report in order to complete their evaluations for customers
1.1.2 Solution / Control Objectives in Cloud
1.1.3 Example
AWS has achieved ISO 27001 certification of our Information Security Management System (ISMS) covering AWS infrastructure, data centers, and services including Amazon EC2, Amazon S3 and Amazon VPC.


“Researcher” also published Cloud Computing and SAS 70 TYPE-II (5/10/2012)
<Return to section navigation list>
Cloud Computing Events
Sarah Lamb (@MrsActionLamb, @girlygeekdom) reported on 5/14/2012 Scott Guthrie to speak at UK Windows Azure Conference on 6/22/2012 in London, UK:
For those of you who haven’t yet heard. The Windows Azure conference is coming up and if you building or considering building applications for the cloud, then the 22nd June is a date for your diary.
Not to be missed is the keynote speaker Scott Guthrie, the Microsoft Corporate Vice President in charge of the development platform for Windows Azure. [Emphasis added.]
Tickets are free until 20th May so get them whilst you can.
Register for the conference here: http://azureconference2012.eventbrite.com/

HBaseCon reported HBase Conference 2012 will take place on 5/22/2012 at the InterContinental hotel in San Francisco CA:
Real-Time Your Hadoop
Join us for HBaseCon 2012, the first industry conference for Apache HBase users, contributors, administrators and application developers.
Network. Share ideas with colleagues and others in the the rapidly growing HBase community. See who is speaking ›
Learn. Attend sessions and lightning talks about what’s new in HBase, how to contribute, best practices on running HBase in production, use cases and applications. View the agenda ›
Train. Make the most of your week and attend Cloudera training for Apache HBase, in the 2 days following the conference. Sign up ›
Date & Location
May 22, 2012
InterContinental San Francisco Hotel
888 Howard Street
San Francisco, CA 94103Attend and Receive a Free Ebook
Courtesy of O’Reilly Media, all attendees will receive a voucher for a free ebook of HBase: The Definitive Guide, by author Lars George.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Joe Brockmeier (@jzb) reported Google Prices its Cloud SQL Offering, Solidifies Cloud Database Market in a 5/14/2012 post to the ReadWriteCloud:
The cloud database market continues to solidify as Google puts a price tag on its Cloud SQL offering. With actual charges to begin on June 12th, the move finally gives developers a way to see what they'll be spending on Cloud SQL, but comparing Google's offering to Amazon, Microsoft and others might still be a bit tricky.
Google's Cloud SQL is MySQL-based and is intended to be used with Google App Engine (GAE). Google's pricing structure is very simple, though not as comprehensive or as expandable as Amazon or others.
Google has two billing plans: a package plan and a per-use plan. The package plan has four tiers, each of which includes a set amount of RAM, storage and I/O per day. For instance, Google charges $1.46 per day for the D1 tier, which has .5GB of RAM, 1GB of storage and 850,000 I/O requests. The top package (D8) includes 4GB of RAM, 10GB storage and 8 million I/O requests for $11.71 per day.
The same instances are available on an on-demand basis, starting at $0.10 per hour, with storage and I/O extra.
The cheapest package from Google, then, runs about $45 a month and the most expensive runs about $357. That doesn't count any overages for I/O or storage.
Sizing Up Google's Pricing
Trying to compare Google pricing with Amazon, Azure or databases offered with PaaS services such as Heroku and Engine Yard is tricky, at best. Heroku's database offerings start at $50 per month, but the specs for its database differ considerably from the other providers. For example, Heroku features data clips for developers, and the hstore extension for key/value data storage.
Amazon's DB instances seem to be a bit more powerful than Google Cloud SQL instances, and Amazon has features that Google Cloud SQL doesn't. For instance, Amazon's Small DB instance has 1.7 GB of RAM and has the equivalent of a single CPU. You're also limited to Google App Engine supported languages, Python and Java.
Developers can choose between 5GB and 1TB of storage (the max for Google is 10GB storage). The Small DB instance runs about $77 a month, if it's on-demand. But, choosing a one-year reserved instance brings that down to about $45 a month. The pricing, then, seems to line up for the "small" instances for Amazon RDS and Google Cloud SQL, but Google has fewer features and what looks to be less compute power.
But if you're using GAE, then Cloud SQL is the natural choice - so it's nice to see Google finally getting this into developers' hands. If you're using GAE and Cloud SQL, we'd love to hear what you think.

Google’s pricing doesn’t appear to me to be competitive with SQL Azure.
Lydia Leong (@cloudpundit) offers the view of a Gartner Research VP in her Amazon CloudFront gets whole site delivery and acceleration of 5/14/2012:
For months, there have been an abundance of rumors that Amazon was intending to enter the dynamic site acceleration market; it was the logical next step for its CloudFront CDN. Today, Amazon released a set of features oriented towards dynamic content, described in blog posts from Amazon’s Jeff Barr and Werner Vogels.
When CloudFront introduced custom origins (as opposed to the original CloudFront, which required you to use S3 as the origin), and dropped minimum TTLs down to zero, it effectively edged into the “whole site delivery” feature set that’s become mainstream for the major CDNs.
With this latest release, whole site delivery is much more of a reality — you can have multiple origins so you can mix static and dynamic content (which are often served from different hostnames, i.e., you might have images.mycompany.com serving your static content, but www.mycompany.com serving your dynamic content), and you’ve got pattern-matching rules that let you define what the cache behavior should be for content whose URL matches a particular pattern.
The “whole site delivery” feature set is important, because it hugely simplifies CDN configuration. Rather than having to go through your site and change its URL references to the CDN (long-time CDN watchers may remember that Akamai in the early days would have customers “Akamaize” their site using a tool that did these URL rewrites), the CDN is smart — it just goes to the origin and pulls things, and it can do so dynamically (so, for instance, you don’t have to explicitly publish to the CDN when you add a new page, image, etc. to your website). It gets you closer to simply being able to repoint the URL of your website to the CDN and having magic happen.
The dynamic site acceleration features — the actual network optimization features — that are being introduced are much more limited. They basically amount to TCP connection multiplexing, TCP connection peristency/pooling, and TCP window size optimization, much like Cotendo in its very first version. At this current stage, it’s not going to be seriously competing against Akamai’s DSA offering (or CDNetworks’s similar DWA offering), but it might have appeal against EdgeCast’s ADN offering.
However, I would expect that like everything else that Amazon releases, there will be frequent updates that introduce new features. The acceleration techniques are well known at this point, and Amazon would presumably logically add bidirectional (symmetric POP-to-POP) acceleration as the next big feature, in addition to implementing the common other optimizations (dynamic congestion control, TCP “FastRamp”, etc.).
What’s important here: CloudFront dynamic acceleration costs the same as static delivery. For US delivery, that starts at about $0.12/GB and goes down to below $0.02/GB for high volumes. That’s easily somewhere between one-half and one-tenth of the going rate for dynamic delivery. The delta is even greater if you look at a dynamic product like Akamai WAA (or its next generation, Terra Alta), where enterprise applications that might do all of a TB of delivery a month typically cost $6000 per app per month — whereas a TB of CloudFront delivery is $120. Akamai is pushing the envelope forward in feature development, and arguably those price points are so divergent that you’re talking about different markets, but low price points also expand a market to where lots of people can decide to do things, because it’s a totally different level of decision — to an enterprise, at that kind of price point, it might as well be free.
Give CloudFront another year of development, and there’s a high probability that it can become a seriously disruptive force in the dynamic acceleration market. The price points change the game, making it much more likely that companies, especially SaaS providers (many of whom use EC2, and AWS in general), who have been previously reluctant to adopt dynamic acceleration due to the cost, will simply get it as an easy add-on.
There is, by the way, a tremendous market opportunity out there for a company that delivers value-added services on top of CloudFront — which is to say, the professional services to help customers integrate with it, the ongoing expert technical support on a day to day basis, and a great user portal that provides industry-competitive reporting and analytics. CloudFront has reached the point where enterprises, large mainstream media companies, and other users of Akamai, Limelight, and Level 3 who feel they need ongoing support of complex implementations and a great toolset that helps them intelligently operate those CDN implementations, are genuinely interested in taking a serious look at CloudFront as an alternative, but there’s no company that I know of that provides the services and software that would bridge the gap between CloudFront and a traditional CDN implementation.


Barb Darrow (@gigabarb) provided a third-party slant on Amazon updates CDN for dynamic content in a 5/14/2012 post to GigaOm’s Structure blog:
Amazon is updating its Cloudfront content delivery network (CDN) to handle dynamic, interactive web content.
CDNs help web sites ensure that users get the web pages they want faster, typically by caching popular pages closer to likely users. Over the years, CDN providers like market leader Akamai have moved on from static pages — collections of text and photos — to streamed video. Now the battle is all about dynamic or interactive sites — online games for example, that require bursts of traffic flowing back and forth.
Amazon’s CDN has for some time delivered static and streaming content for business customers but relied on partners including Akamai for much more bandwidth intensive dynamic content. (Check out CDN Planet for a good overview of the major CDN players.) According to the Amazon Web Services blog, several changes to Cloudfront should speed up that delivery.
For example, Cloudfront will now let customers serve content from multiple sources — from Amazon’s own S3 storage service, dynamic content from Amazon EC2, as well as from third-party sites — from a single domain name. That, the company said, simplifies implementation.
By adding more dynamic delivery capabilities to Cloudfront, Amazon is starting to encroach more on turf of its CDN partners, including Akamai.
In response to another Cloudfront update, an Akamai source earlier this year told me that he clearly had to watch what Amazon is doing in CDNs but that to date, Cloudfront only dealt with static content — leaving the heavy lifting on dynamic content to Akamai. That is clearly starting to change. Akamai remains the dominant CDN power with more than 1,700 CDN sites on its network, compared to 30 locations for Cloudfront, but it’s clear that Amazon is not content to rest on its laurels. …


Full disclosure: I’m a registered GigaOm analyst.
Jeff Barr (@jeffbarr) reported Amazon CloudFront - Support for Dynamic Content in a 5/14/2012 post:
Introduction
Amazon CloudFront's network of edge locations (currently 30, with more in the works) gives you the ability to distribute static and streaming content to your users at high speed with low latency.
Today we are introducing a set of features that, taken together, allow you to use CloudFront to serve dynamic, personalized content more quickly.
What is Dynamic Personalized Content?
As you know, content on the web is identified by a URL, or Uniform Resource Locator such as http://media.amazonwebservices.com/blog/console_cw_est_charge_service_2.png . A URL like this always identifies a unique piece of content.
A URL can also contain a query string. This takes the form of a question mark ("?") and additional information that the server can use to personalize the request. Suppose that we had a server at www.example.com, and that can return information about a particular user by invoking a PHP script that accepts a user name as an argument, with URLs like http://www.example.com/userinfo.php?jeff or http://www.example.com/userinfo.php?tina.
Up until now, CloudFront did not use the query string as part of the key that it uses to identify the data that it stores in its edge locations.
We're changing that today, and you can now use CloudFront to speed access to your dynamic data at our current low rates, making your applications faster and more responsive, regardless of where your users are located.
With this change (and the others that I'll tell you about in a minute), Amazon CloudFront will become an even better component of your global applications. We've put together a long list of optimizations that will each increase the performance of your application on their own, but will work even better when you use them in conjunction with other AWS services such as Route 53, Amazon S3, and Amazon EC2.
Tell Me More
Ok, so here's what we've done:Persistent TCP Connections - Establishing a TCP connection takes some time because each new connection requires a three-way handshake between the server and the client. Amazon CloudFront makes use of persistent connections to each origin for dynamic content. This obviates the connection setup time that would otherwise slow down each request. Reusing these "long-haul" connections back to the server can eliminate hundreds of milliseconds of connection setup time. The connection from the client to the CloudFront edge location is also kept open whenever possible.
Support for Multiple Origins - You can now reference multiple origins (sources of content) from a single CloudFront distribution. This means that you could, for example, serve images from Amazon S3, dynamic content from EC2, and other content from third-party sites, all from a single domain name. Being able to serve your entire site from a single domain will simplify implementation, allow the use of more relative URLs within the application, and can even get you past some cross-site scripting limitations.
Support for Query Strings - CloudFront now uses the query string as part of its cache key. This optional feature gives you the ability to cache content at the edge that is specific to a particular user, city (e.g. weather or traffic), and so forth. You can enable query string support for your entire website or for selected portions, as needed.
Variable Time-To-Live (TTL) - In many cases, dynamic content is either not cacheable or cacheable for a very short period of time, perhaps just a few seconds. In the past, CloudFront's minimum TTL was 60 minutes since all content was considered static. The new minimum TTL value is 0 seconds. If you set the TTL for a particular origin to 0, CloudFront will still cache the content from that origin. It will then make a GET request with an If-Modified-Since header, thereby giving the origin a chance to signal that CloudFront can continue to use the cached content if it hasn't changed at the origin.
Large TCP Window - We increased the initial size of CloudFront's TCP window to 10 back in February, but we didn't say anything at the time. This enhancement allows more data to be "in flight" across the wire at a given time, without the usual waiting time as the window grows from the older value of 2.
API and Management Console Support - All of the features listed above are accessible from the CloudFront APIs and the CloudFront tab of the AWS Management Console. You can now use URL patterns to exercise fine-grained control over the caching and delivery rules for different parts of your site.
Of course, all of CloudFront's existing static content delivery features will continue to work as expected. GET and HEAD requests, default root object, invalidation, private content, access logs, IAM integration, and delivery of objects compressed by the origin.
Working Together
Let's take a look at the ways that various AWS services work together to make delivery of static and dynamic content as fast, reliable, and efficient and possible (click on the diagram at right for an even better illustration):
- From Application / Client to CloudFront - CloudFront’s request routing technology ensures that each client is connected to the nearest edge location as determined by latency measurements that CloudFront continuously takes from internet users around the world. Route 53 may be optionally used as a DNS service to create a CNAME from your custom domain name to your CloudFront distribution. Persistent connections expedite data transfer.
- Within the CloudFront Edge Locations - Multiple levels of caching at each edge location speed access to the most frequently viewed content and reduce the need to go to your origin servers for cacheable content.
- From Edge Location to Origin - The nature of dynamic content requires repeated back and forth calls to the origin server. CloudFront edge locations collapse multiple concurrent requests for the same object into a single request. They also maintain persistent connections to the origins (with the large window size). Connections to other parts of AWS are made over high-quality networks that are monitored by Amazon for both availability and performance. This monitoring has the beneficial side effect of keeping error rates low and window sizes high.
Cache Behaviors
In order to give you full control over query string support, TTL values, and origins you can now associate a set of Cache Behaviors with each of your CloudFront distributions. Each behavior includes the following elements:
- Path Pattern - A pattern (e.g. "*.jpg") that identifies the content subject to this behavior.
- Origin Identifier -The identifier for the origin where CloudFront should forward user requests that match this path pattern.
- Query String - A flag to enable support for query string processing for URLs that match the path pattern.
- Trusted Signers - Information to enable other AWS accounts to create signed URLs for this URL path pattern.
- Protocol Policy - Either allow-all or https-only, also applied only to this path pattern.
- MinTTL - The minimum time-to-live for content subject to this behavior.
Tool Support
Andy from CloudBerry Lab sent me a note to let me know that they have added dynamic content support to the newest free version of the CloudBerry Explorer for Amazon S3. In Andy's words:I'd like to let you know that CloudBerry Explorer is ready to support new CloudFront features by the time of release. We have added the ability to manage multiple origins for a distribution, configure cache behavior for each origin based on URL path patterns and configure CloudFront to include query string parameters.
He also sent some screen shots to show us how it works. The first step is to specify the Origins and CNAMEs associated with the distribution:
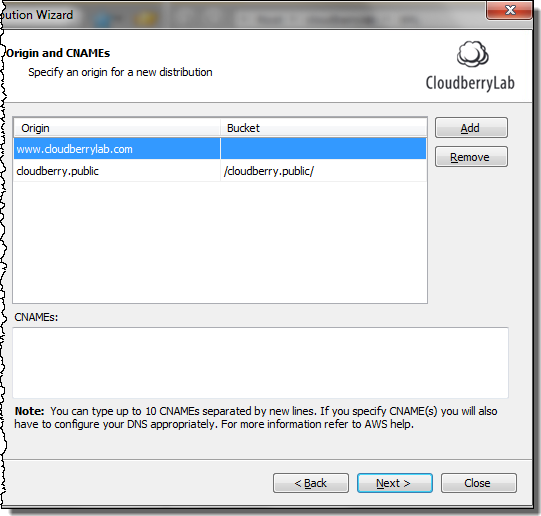
The next step is to specify the Path Patterns:
With the Origins and Path Patterns established, the final step is to configure the Path Patterns:
And Here You Go
Together with CloudFront's cost-effectiveness (no minimum commits or long-term contracts), these features add up to a content distribution system that is fast, powerful, and easy to use.So, what do you think? What kinds of applications can you build with these powerful new features?


Werner Vogels (@werner) described Dynamic Content Support in Amazon CloudFront on 5/13/2012:
In the past three and a half years, Amazon CloudFront has changed the content delivery landscape. It has demonstrated that a CDN does not have to be complex to use with expensive contracts, minimum commits, or upfront fees, such that you are forcibly locked into a single vendor for a long time. CloudFront is simple, fast and reliable with the usual pay-as-you-go model. With just one click you can enable content to be distributed to the customer with low latency and high-reliability.
Today Amazon CloudFront has taken another major step forward in ease of use. It now supports delivery of entire websites containing both static objects and dynamic content. With these features CloudFront makes it as simple as possible for customers to use CloudFront to speed up delivery of their entire dynamic website running in Amazon EC2/ELB (or third-party origins), without needing to worry about which URLs should point to CloudFront and which ones should go directly to the origin.
Dynamic Content Support
Recall that last month the CloudFront team announced lowering the minTTL customers can set on their objects, down to as low as 0 seconds to support delivery of dynamic content. In addition to the TTLs, customers also need some other features to deliver dynamic websites through CloudFront. The first set of features that CloudFront is launching today include:
Multiple Origin Servers: the ability to specify multiple origin servers, including a default origin, for a CloudFront download distribution. This is useful when customers want to use different origin servers for different types of content. For example, an Amazon S3 bucket can be used as the origin for static objects and an Amazon EC2 instance as the origin for dynamic content, all fronted by the same CloudFront distribution domain name. Of course non-AWS origins are also permitted.
Query String based Caching: the ability to include query string parameters as part of the object's cache key. Customers will have a switch to turn query strings 'on' or 'off'. When turned off, CloudFront's behavior will be the same as today - i.e., CloudFront will not pass the query string to the origin server nor include query string parameters as a part of the object's cache key. And when query strings are turned on, CloudFront will pass the full URL (including the query string) to the origin server and also use the full URL to uniquely identify an object in the cache.
URL based configuration: the ability to configure cache behaviors based on URL path patterns. Each URL path pattern will include a set of cache behaviors associated with it. These cache behaviors include the target origin, a switch for query strings to be on/off, a list of trusted signers for private content, the viewer protocol policy, and the minTTL that CloudFront should apply for that URL path pattern. See the graphic at the end of this post for an example configuration.
More new features
In addition to these features, there are other things the CloudFront team has achieved to speed up delivery of content, but all customer will get these benefits by default without additional configuration. These performance optimizations are available for all types of content (static and dynamic) delivered via CloudFront. Specifically:
Optimal TCP Windows. The TCP initcwnd has been increased for all CloudFront hosts to maximize the available bandwidth between the edge and the viewer. This is in addition to the existing optimizations of routing viewers to the edge location with lowest latency for that user, and also persistent connections with the clients.
Persistent Connection to Origins. Connections are improved from CloudFront edge locations to the origins by maintaining long-lived persistent connections. This helps by reducing the connection set-up time from the edge to the origin for each new viewer. When the viewer is far away from the origin, this is even more helpful in minimizing total latency between the viewer and the origin.
Selecting the best AWS region for Origin Fetch. When customers run their origins in AWS, we expect that our network paths from each CloudFront edge to the various AWS Regions will perform better with less packet loss given that we monitor and optimize these network paths for availability and performance. In addition, we have shown an optional configuration in the architecture diagram how developers can use Route 53’s LBR (Latency Based Routing) to run their origin servers in different AWS Regions. Each CloudFront edge location will then go to the “best” AWS Region for the origin fetch. And Route 53 already understands very well which CloudFront host is in which edge location (this is integration we’ve built between the two services). This helps improve performance even further.
Amazon CloudFront is expanding it functionality and feature set at an incredible pace. I am particularly excited about these features that help customers deliver both static and dynamic content through one distribution. CloudFront stays true to its mission in making a Content Delivery Network dead simple to use, and now they also do this for dynamic content.
For more details, see the CloudFront detail page and the posting on the AWS developer blog.


Joe Panettieri (@joepanettieri) asked Red Hat OpenShift PaaS: Will Cloud Developers Climb Aboard? in a 5/13/2012 post to the TalkinCloud blog:
When Red Hat (NYSE: RHT) recently announced its long-term strategy for OpenShift, I began to think about potential implications for cloud-focused application developers and emerging cloud consultants. Already, cloud developers are seeking to understand cloud platforms like OpenStack, CloudStack, Microsoft Windows Azure and VMware Cloud Foundry. Amid all that noise, can Red Hat attract developers to OpenShift? And equally important: Can cloud consultants explain OpenShift and its alternatives to business customers?
So far, Red Hat is positioning OpenShift, a platform as a service (PaaS), mostly for enterprise customers and developers. There isn’t much — if any — chatter about OpenShift for SMB (small and midsize business) use.
Red Hat unveiled OpenShift in May 2011. By April 2012, Red Hat open sourced OpenShift through a project called OpenShift Origin. And in May 2012, Red Hat offered updates regarding the OpenShift road map. That roadmap explains how OpenShift is built atop Red Hat’s core technologies. According to Red Hat:
“Combining the core enterprise technologies that power OpenShift PaaS– including Red Hat Enterprise Linux, Red Hat Storage, JBoss Enterprise Middleware and OpenShift’s integrated programming languages, frameworks and developer tools – Red Hat plans to deliver the OpenShift cloud application platform available as a PaaS for enterprises in an open and hybrid cloud.”
Potential OpenShift Opportunities
No doubt, Red Hat will try to convince existing Red Hat Enterprise Linux ISVs (independent software vendors), JBoss integrators and other channel partners to embrace OpenShift. And it sounds like there will be three ways for enterprise customers to use OpenShift, including:
- As a service. A fee-based version of OpenShift.RedHat.com is expected to launch in late 2012.
- As a private PaaS offering. Where enterprises run OpenShift on their own.
- On a third-party cloud or via a third-party virtualization provider — though it’s unclear to me at this time which third parties might be options for Red Hat customers.
Rival PaaS Offerings
In some ways, OpenShift sounds most similar to VMware’s Cloud Foundry, another emerging PaaS platform. A safe guess:
- Red Hat will likely assert that OpenShift coupled with Red Hat Enterprise Virtualization (RHEV) will offer a lower-cost, more open approach forward vs. VMware Cloud Foundry and vSphere virtualization.
- VMware (NYSE: VMW), on the flip side, will likely assert that its virtualization software remains the most scalable, most reliable, easiest-to-manage foundation for cloud services.
Meanwhile, Microsoft (NASDAQ: MSFT) continues to march forward with its own PaaS play — Windows Azure. Microsoft hasn’t said much about Windows Azure’s revenue base so far, and there have been rumors that Microsoft may rebrand Windows Azure amid a slow market start (personally, I doubt the rumors). [Emphasis added.]
In recent weeks, a growing list of ISVs (independent software vendors) have launched applications in the Windows Azure cloud. One example is CA Technologies’ ARCserve, a backup and recovery software platform that started out as an on-premises solution. But in some cases, Microsoft is paying third-party ISVs to support Windows Azure, Talkin’ Cloud has confirmed with multiple sources. That could be a sign that Microsoft is struggling to make Azure a mainstream success.
Talkin’ Cloud will seek an update during Microsoft Worldwide Partner Conference 2012 (WPC12, July 8-12, Toronto).
PaaS vs. IaaS
Elsewhere, some folks are comparing OpenShift, Cloud Foundry and Windows Azure to OpenStack and CloudStack. But that’s not exactly an apples-to-apples comparison.
- OpenStack (originally promoted by Rackspace) and CloudStack (originally promoted by Citrix) are IaaS. Here, cloud providers typically offer virtual machines, raw block storage, firewalls and other basic network infrastructure.
- OpenShift, Cloud Foundry and Windows Azure are PaaS. Here, cloud providers typically offer a solution stack (operating systems, databases and web serviers) to application developers.
Time to Educate Your Customers
Cloud developers certainly understand all the jargon above. But it’s a safe bet most CIOs (chief information officers) and corporate executives don’t know the differences between OpenShift, Cloud Foundry and other emerging PaaS options.
That’s where cloud consultants and cloud integrators enter the picture. And so far, I don’t think Red Hat and its rivals have done enough to educate consultants and integrators about the cloud opportunities ahead.
Read More About This Topic

<Return to section navigation list>

















0 comments:
Post a Comment