Windows Azure and Cloud Computing Posts for 3/22/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

• Updated 3/25/2012 10:00 AM PST with new articles marked • by David Linthicum, Juan Carlos Perez, James Staten, Jay Heiser, SQL Azure Federations Team, Kostas Christodoulou, and Julian Paulozzi.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics, Big Data and OData
- Windows Azure Access Control, Identity and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
• David Linthicum asserted “Though data transfer performance is important to selecting cloud computing tools, it requires different thinking” in a deck for his All you need to know about cloud data transfers article of 3/23/2012 for InfoWorld’s Cloud Computing blog:
What is it with data-transfer cloud computing performance? Some people think cloud services provide great performance, and some think they don't perform well at all. The reality is that both beliefs are true, depending on how you use cloud services and the cloud providers themselves.
There are a few basic, core patterns that define data-transfer performance:
- Enterprise to cloud
- Mobile to cloud
- Cloud to cloud
Enterprise-to-cloud seems to be where the problems exist. Information is transferred, typically over the open Internet, from servers in the enterprise to public cloud computing providers. If you've ever checked out the speed difference in downloading data from a remote website versus an intranet site, you already know what the issues are in this arena. As a rule, try to avoid transfer of large chunks of data from the enterprise to the public cloud computing provider.
Mobile-to-cloud is not that big of a deal in the larger scheme. Businesses don't like to store data on mobile devices (smartphones, tablets, netbooks, and so on), and they pretty much leave most of the data in the cloud. Only data required for an operation is typically transferred to the mobile device. Thus, data-transfer performance is usually not an issue. Come to think of it, it's not a bad model to replicate when using cloud systems in any pattern.
Finally, cloud-to-cloud can be either intracloud (such as within Amazon Web Services) or intercloud transfer of data (such as between AWS and Rackspace). Intracloud data-transfer performance is directly related to the size of the pipe within the cloud service, as well as to performance-enhancing services such as cache services that might be in use. Typically, intracloud data transfer is between tenants, virtual machines, or applications and data stores. The approaches and technology vary greatly, so you should run your own benchmarks to duplicate the scenario you plan to implement. (For more information on an actual benchmarks, check out "Amazon comes out on top in cloud data transfer speed test.")
Intercloud data transfer is even more complex, having to deal with cloud services that may not like each other exchanging data. Moreover, the open Internet is the typical mode of transport, so the same issues arise here as with cloud-to-enterprise. I suspect that cloud providers will get better at this in the future, for the sake of their mutual clients. For now, you need to model, model, model, and test, test, test.

Andrew Brust (@andrewbrust) reported Microsoft does Hadoop, and JavaScript’s the glue in a 3/23/2012 post to ZDNet’s Big Data blog:
Microsoft’s getting into the Hadoop game, and people are skeptical. Can Microsoft really embrace open source technology? And if it can, will it end up co-opting it somehow, or will it truly play nice? Would you even want to run Hadoop on the Windows operating system? Why bother? Why care?
Based on what’s in Microsoft’s Hadoop distro and its cloud spin on things, I would say that you should care, and quite a lot. Microsoft is not dumbing Hadoop down. Instead, it is making it almost trivial to get a Hadoop cluster up-and-running. If that’s not enough for you then I think this should be: a browser-based console where you can work with Hadoop using a very friendly programming language. That language isn’t Visual Basic, Microsoft’s 20-year stalwart for business application development. And it’s not C#, the favored language for the company’s .NET platform. Actually, it’s not a Microsoft language at all. Rather it’s the language that runs the Web these days: JavaScript. While the console lacks many of the niceties of modern relational database tooling, it’s still very useful and convenient. And when Microsoft’s Hadoop distro becomes generally available (it’s still in an invitation-only Beta phase right now) I think it may bring many more people into the Hadoop ranks, regardless of their preferred platform and persuasion.
Microsoft’s Hadoop distribution, which it is building in partnership with Hortonworks, includes the core HDFS and MapReduce, plus a bunch more. Microsoft’s also throwing in Hive, Pig, Mahout, Sqoop, HedWig, Pegasus and HBase. (The last of these is no small feat for the creator of SQL Server). The distribution can be installed on-premises on Windows Server or in the cloud on customers’ Windows Azure “roles” (virtual machines).
Perhaps the best option, though, is a Web browser-provisioning interface for standing up an entire Hadoop cluster in just a few clicks of the mouse. Once the cluster is up and running, you can use Microsoft’s Remote Desktop software to connect directly to the head node, and then go to a command prompt and hack around with Hadoop and all those components. But the interactive console offers an even better way. It’s a command line interface that gives you, all in one place, access to:
- HDFS commands
- JAR file-based MapReduce jobs
- JavaScript expression evaluation
- Pig
- Hive
- Basic charting (bar, pie and line graphs)
- The pièce de résistance: a framework to execute MapReduce jobs written in JavaScript
Having one command line for all of this , and being able to mix and match it, is almost magical. For instance, you can author MapReduce code in JavaScript and then from the browser-based console, you can upload the code, run it, write a Pig expression to extract some data from the results, convert the output file content to a JavaScript array and then display it in a bar chart. That’s very empowering: it allows you to get your feet wet with MapReduce, HDFS, Pig and some light data visualization in just five interactive lines of code. And none of it uses any Microsoft technology, except of course Windows Server, which is cloud-based anyway, and therefore abstracted away.
There’s more too. Like an ODBC driver for Hive that effectively attaches Excel and most of the Microsoft Business Intelligence stack to Hadoop. But that’s fodder for a separate post…or seven.
Microsoft’s Hadoop offering should become generally available before too long. But if you’d like to apply for an invite to the beta, create an account on “Connect” and then fill out the special survey.



<Return to section navigation list>
SQL Azure Database, Federations and Reporting
• The SQL Azure Federations Team made available a SQL Azure Federation Poster on 3/13/2012 (missed when published):
Poster showing SQL Azure Federation features, process, and key terms:
Click image for 21.5% view.
Overview
The poster explains the federation process, including creating the federation root database, creating the scheme, and then using the split operation to partition the federation member into two partition members by row. It also explains the database infrastructure and includes sample T-SQL statements.

Don’t worry about changing the Adobe Reader’s settings for PDF files. Just save it to your Downloads folder.
Cihan Biyikoglu (@cihangirb) posted Inside SQL Azure – Self-healing, Self-governing, Massively Scalable Database service in the Cloud on 3/24/2012:
This is talk I did a few weeks ago that will take you under the hood of SQL Azure. I cover the gateway to SQL Azure that manager billing, connectivity and some parts of T-SQL as well as Engine and surrounding services like load balancing and node governance and the fabric of SQL Azure that manages node health, replication and failover.
Why is this all important to know you may ask... Well understanding all this allows you to build apps that are better citizens in the new cloud world. At the end I tie it all together with what you need to think about in your own apps when working with the service and talk about differences in app characteristics between SQL Server and SQL Azure.Even if you are not building an app on SQL Azure, today, If you want to get a deep understanding of services we built around SQL Server that make SQL Azure so unique, this is the talk to watch:


<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
My (@rogerjenn) Examining the state of PaaS in the year of ‘big data’ post of 3/23/2012 begins:
This year has already been marked as the year of “big data” in the cloud, with major PaaS players, such as Amazon, Google, Heroku, IBM and Microsoft, getting a lot of publicity. But which providers actually offer the most complete Apache Hadoop implementations in the public cloud?
It’s becoming clear that Apache Hadoop, along with HDFS, MapReduce, Hive, Pig and other subcomponents, are gaining momentum for big data analytics as enterprises increasingly adopt Platform as a Service (PaaS) cloud models for enterprise data warehousing. To indicate Hadoop has matured and is ready for use in production analytics cloud environments, the Apache Foundation upgraded to Hadoop v1.0.
The capability to create highly scalable, pay-as-you-go Hadoop clusters in providers’ data centers for batch processing with hosted MapReduce processing allows enterprise IT departments to avoid capital expenses for on-premises servers that are used sporadically. As a result, Hadoop has become de rigueur for deep-pocketed PaaS providers -- Amazon, Google, IBM and Microsoft --to package Hadoop, MapReduce or both as prebuilt services.
AWS Elastic MapReduce
Amazon Web Services (AWS) was first out of the gate with Elastic MapReduce (EMR) in April 2009. EMR handles Hadoop cluster provisioning, runs and terminates jobs and transfers data between Amazon EC2 and Amazon S3 (Simple Storage Service). EMR also offers Apache Hive, which is built on Hadoop for data warehousing services.
Figure 1 (Click to enlarge.)
Sample CloudWatch job workflow metrics for Amazon Web Services’ ElasticMapReduce feature. (Image courtesy of AWS.)EMR is fault tolerant for slave failures; Amazon recommends running only the Task Instance Group on spot instances to take advantage of the lower cost while still maintaining availability. However, AWS didn’t add support for spot instances until August 2011.
Amazon applies surcharges of $0.015 per hour to $0.50 per hour for EMR to its rates for Small to Cluster Compute Eight Extra Large EC2 instances. According to AWS: Once you start a job flow, Amazon Elastic MapReduce handles Amazon EC2 instance provisioning, security settings, Hadoop configuration and set-up, log collection, health monitoring and other hardware-related complexities, such as automatically removing faulty instances from your running job flow. AWS recently announced free CloudWatch metrics for EMR instances (Figure 1).
Google AppEngine-MapReduce
According to Google developer Mike Aizatskyi, all Google teams use MapReduce, which it first introduced in 2004. Google released an AppEngine-MapReduce API as an “early experimental release of the MapReduce API” to support running Hadoop 0.20 programs on Google App Engine. The team later released low-level files API v1.4.3 in March 2011 to provide a file-like system for intermediate results for storage in Blobs and improved open-source User-Space Shuffler functionality (Figure 2).
Figure 2 (Click to enlarge.)
Google AppEngine-MapReduce’s Shuffle process in an I/O 2012 session.The Google AppEngine-MapReduce API orchestrates the Map, Shuffle and Reduce operations via a Google Pipeline API. The company decribed AppEngine-MapReduce’s current status in a video presentation for I/O 2012. However, Google hadn’t changed the “early experimental release” description as of Spring 2012. AppEngine-MapReduce is targeted at Java and Python coders, rather than big data scientists and analytics specialists. Shuffler is limited to approximately 100 MB data sets, which doesn’t qualify as big data. You can request access to Google’s BigShuffler for larger data sets.
Heroku Treasure Data Hadoop add-on
Heroku’s Treasure Data Hadoop add-on enables DevOps workers to use Hadoop and Hive to analyze hosted application logs and events, which is one of the primary functions for the technology. Other Heroku big data add-ons include Cloudant’s implementation of Apache CouchBase, MongoDB from MongoLab and MongoHQ, Redis To Go, Neo4j (public beta of a graph database for Java) and RESTful Metrics. AppHarbor, called by some “Heroku for .NET,” offers a similar add-on lineup with Cloudant, MongoLab, MongoHQ and Redis To Go, plus RavenHQ NoSQL database add-ins. Neither Heroku nor AppHarbor host general-purpose Hadoop implementations.
IBM Apache Hadoop in SmartCloud
IBM began offering Hadoop-based data analytics in the form of InfoSphere BigInsights Basic on IBM SmartCloud Enterprise in October 2011. BigInsights Basic, which can manage up to 10 TB of data, is also available as a free download for Linux systems; BigInsights Enterprise is a fee-based download. Both downloadable versions offer Apache Hadoop, HDFS and the MapReduce framework, as well as a complete set of Hadoop subprojects. The downloadable Enterprise edition includes an Eclipse-based plug-in for writing text-based analytics, spreadsheet-like data discovery and exploration tools as well as JDBC connectivity to Netezza and DB2. Both editions provide integrated installation and administration tools (Figure 3).
IBM’s platform and vision for big data. (Image courtesy of IBM.)My Test-Driving IBM’s SmartCloud Enterprise Infrastructure as a Service: Part 1 and Part 2 tutorials describe the administrative features of a free SmartCloud Enterprise trial version offered in Spring 2011. It’s not clear from IBM’s technical publications what features from downloadable BigInsight versions are available in the public cloud. Their Cloud Computing: Community resources for IT professionals page lists only one BigInsights Basic 1.1: Hadoop Master and Data Nodes software image; an IBM representative confirmed the SmartCloud version doesn’t include MapReduce or other Hadoop subprojects. Available Hadoop tutorials for SmartCloud explain how to provision and test a three-node cluster on SmartCloud Enterprise. It appears IBM is missing elements critical for data analytics in its current BigInsights cloud version.
Microsoft Apache Hadoop on Windows AzureBefore joining the Hadoop bandwagon, Microsoft relied on Dryad, a graph database developed by Microsoft Research, and a High-Performance Computing add-in (LINQ to HPC) to handle big data analytics. The Hadoop on Azure CTP offers a choice of predefined Hadoop clusters ranging from Small (four computing nodes with 4 TB of storage) to Extra Large (32 nodes with 16 TB), simplifing MapReduce operations. There’s no charge to join the CTP for prerelease compute nodes or storage.
Figure 4 (Click to enlarge.)
Microsoft offers four sample Hadoop/MapReduce projects: Calculating the value of pi, performing Terasort and WordCount benchmarks, and demonstrating how to use C# to write a MapReduce program for streaming data. (Pegasus, Mahout and Sqoop added 3/25/2012.)Microsoft also provides new JavaScript libraries to make JavaScript a first-class programming language in Hadoop. This means JavaScript programmers can write MapReduce programs in JavaScript and run these jobs from Web browsers, which reduces the barrier to Hadoop/MapReduce entry. The CTP also includes a Hive add-in for Excel that lets users interact with data in Hadoop. Users can issue Hive queries from the add-in to analyze unstructured data from Hadoop in the familiar Excel user interface. The preview also includes a Hive ODBC Driver that integrates Hadoop with other Microsoft BI tools. In a recent blog post on Apache Hadoop Services for Windows Azure, I explain how to run the Terasort benchmark, one of seven
foursample MapReduce jobs (Figure 4).HoA is due for an upgrade in the “Spring Wave” of new and improved features scheduled for Windows Azure in mid-2012. The upgrade will enable the HoA team to admit more testers to the CTP and probably include a promised Apache Hadoop on Windows Server 2008 R2 for on-premises or private cloud and hybrid cloud implementations. Microsoft has aggressively reduced charges for Windows Azure compute instances and storage during late 2011 and early 2012; pricing for Hadoop on Azure’s release version probably will be competitive with Amazon Elastic MapReduce.
Big data will mean more than Hadoop and MapReduce
I agree with Forrester Research analyst James Kobielus, who blogged, “Within the big data cosmos, Hadoop/MapReduce will be a key development framework, but not the only one.” Microsoft also offers its Codename“Cloud Numerics” CTP for the .NET Framework, which allows DevOps teams to perform numerically intensive computations on large distributed data sets in Windows Azure.Microsoft Research has posted source code for implementing Excel cloud data analysis in Windows Azure with its Project “Daytona” iterative MapReduce implementation. However, it appears open source Apache Hadoop and related subprojects will dominate cloud-hosted scenarios for the foreseeable future.
PaaS providers who offer the most automated Hadoop, MapReduce and Hive implementations will gain the greatest following of big data scientists and data analytics practitioners. Microsoft provisioning the Excel front end for business intelligence (BI) applications gives the company’s big data offerings a head start among the growing number of self-service BI users. Amazon and Microsoft currently provide the most complete and automated cloud-based Hadoop big data analytics services.






See also Matthew Weinberg (@M_Wein) reported Google BigQuery: The Googleplex Takes On Big Data in the Cloud in a 3/24/2012 post to the SiliconANGLE blog in the Other Cloud Computing Platforms and Services section at the end of this post.
Brian T. Horowitz @bthorowitz asserted “Practice Fusion, an EHR vendor, has launched a new research site to provide clinical data to fuel health discoveries” in a deck for his New Practice Fusion Site Offers Big Data for Public Health Research report of 3/23/2012 for eWeek.com:
The research division of electronic health record (EHR) vendor Practice Fusion launched a new Web database March 20 that allows researchers to uncover patterns in public health. Researchers will analyze big data to study adverse health conditions and adverse drug reactions, according to the company.
"Big data holds the key to understanding health care today and improving it in the future," Dr. Robert Rowley, medical director at Practice Fusion, said in a statement. "Putting this knowledge in the hands of doctors will save lives and enable patients to make informed decisions about their health."
Big data can also be the key to personalized medicine, as more and more data is made available in the cloud.
The research site will allow health care professionals to access data previously "siloed" in major academic centers, according to Jake Marcus, a data scientist at Practice Fusion. "Practice Fusion's [data search] model unifies clinical data, allowing researchers to compare health trends in practices across the country," Marcus wrote in an email to eWEEK.
Practice Fusion also stores data outside of academic centers in small primary-care provider practices, said Marcus.
"The site will combine Practice Fusion's research dataset with other data, like air-quality data or weather patterns, to uncover interesting health patterns across domains," he said. It also will enable health care researchers to uncover facts, such as a 46 percent rate for late arrivals to doctors' appointments.
The company's clinical dataset provides information on patients' diagnoses, medication, allergies, immunizations, vital signs and medical histories.
Using the data on the site, medical researchers will be able to predict outbreaks of illnesses, Practice Fusion reported.
"To predict outbreaks, researchers and public health practitioners need reliable information on the geographical distribution and incidence of disease as quickly as possible," Marcus explained. "By looking at the number of patient visits related to different diseases recorded in the EHR, we can provide data much faster than surveillance systems that rely on patients or doctors voluntarily submitting reports."
A community of 150,000 medical professionals will be able to spot health trends that should be investigated. Doctors can also use the site to solicit input from colleagues and seek ideas for new studies or collaboration, said Marcus.
A syndromic-surveillance tool on the site allows researchers to spot trends in respiratory and gastrointestinal disease in various metropolitan areas, according to Marcus.
The company's anonymized health data also links up with Microsoft's Windows Azure cloud platform through a data portal called DataMarket.
Practice Fusion offers a free Web-based EHR application and plans to launch native versions of its EHR software in Apple iOS and on Google Android later this year. At its research site, the company will provide 15,000 de-identified EHRs to data scientists for their research on health care trends.
"This sample of 15,000 de-identified patient data includes diagnoses, prescriptions, allergies, immunizations, blood pressure, weight and height, and is available for download on the site," said Marcus.
Practice Fusion's EHR database comprises more than 30 million records.
By de-identifying EHRs, the research site complies with the Health Insurance Portability and Accountability Act (HIPAA) rule cfr 164.514, Practice Fusion reported. According to the rule, people with experience studying statistics and scientific principles should be unable to identify an individual by examining the data. In addition, all identifying info such as health plan ID numbers and Social Security numbers must be removed.


John Rivard (@johnrivard) described LightSwitch Architecture: OData in a 3/22/2012 post:
In Visual Studio 11 Beta, LightSwitch data services publish OData feeds and LightSwitch clients consume the OData feeds. This is an implementation change from LightSwitch 2011 where we used WCF RIA Services as the data protocol between client and server.
What is OData?
OData is an open REST-ful protocol for exposing and consuming data on the web. It attempts to break down the silos of data that are common across the web by standardizing on the way that data is accessed. Instead of requiring application-specific APIs to access data specific to each application’s web service, OData provides a common way to query and update data via REST. Beth Massi has already published a good introduction to OData and LightSwitch:
Enhance Your LightSwitch Applications with OData
Creating and Consuming LightSwitch OData ServicesWhy OData?
By moving the LightSwitch middle-tier services to OData we open up the LightSwitch to a growing ecosystem of OData producers and consumers. A LightSwitch application no longer lives in a silo.
This adds more value to your LightSwitch investment. In addition to the LightSwitch client, you can also connect to your LightSwitch data feeds from applications like Microsoft PowerPivot, or from a Browser or Windows 8 JavaScript client using the open-source datajs library.
OData allows LightSwitch applications to consume more data sources. There is a growing list of live services and systems support the OData protocol. Some interesting producers for business applications include SAP NetWeaver Gateway and SQL Server Reporting Services.
OData Basics
OData is a a REST protocol based on existing internet standards including HTTP, AtomPub, JSON, and hyper-media design patterns. A main feature of REST APIs is the use of existing HTTP verbs against addressable resources identified in the URI. Conceptually, OData is a way of performing database-style CRUD using HTTP verbs:
Create : POST
Read: GET
Update: PUT
Delete: DELETEThe URI specifies the resource (entity set or entity) and the body of the request or response encodes the entity data in AtomPub or JSON format. The top level resource in an OData feed is an entity container. The entity container has one or more entity sets. An entity set contains instances of entities of a given entity type. Entity sets are analogous to Lists or Tables. Entities within the entity set can be addressed individually via key values, or as collections via query options.
OData specifies URI conventions for addressing entity sets, individual entities, and paths to linked entities via navigation properties. It also specifies a simple query language that allows a client to request arbitrary filtering, sorting, and paging. The entity data is encoded in the body of the request or response using uniform AtomPub or JSON formats.
OData is strongly typed. It uses the Entity Data Model (EDM) to describe the entity types, entity sets, and entity relationships in the entity container. The data schema is typically referred to as the metadata. A live OData feed can return a metadata document so that any consumer can discover the resources available and can use the protocol’s URI conventions to address them.
Examples:
- Get the feed metadata
HTTP GET http://services.odata.org/OData/OData.svc/$metadata- Get all products
HTTP GET http://services.odata.org/OData/OData.svc/Products- Get a specific product
HTTP GET http://services.odata.org/OData/OData.svc/Products(1)- Get the category related to a product
HTTP GET http://services.odata.org/OData/OData.svc/Products(1)/Category- Get all products where the Rating is >= 3 sorted by Price
HTTP GET http://services.odata.org/OData/OData.svc/Products?$filter=Rating ge 3&$orderby=Price- Delete a product
HTTP DELETE http://services.odata.org/OData/OData.svc/Products(1)(TIP: Your browser might have formatted feed reading enabled. To see the XML formatting for these links, turn off feed reading in your browser options.)
You can learn a lot more about OData at www.odata.org.
Producing OData Feeds with LightSwitch
LightSwitch automatically publishes one OData feed per data source that you create or attach to in your LightSwitch project. There is no additional configuration or coding required. LightSwitch exposes the same data model that you define using the LightSwitch entity designer.
Mapping the LightSwitch data model to OData is trivial because both LightSwitch and OData are based on the EDM type system. The entity types, relationships, entity sets and queries that you define in LightSwitch are exposed as resources in the OData feed.
LightSwitch Element
OData ElementProduct entity
Product entity typeProduct.Category navigation property
Product.Category navigation propertyProducts table
Products entity setAvailableProducts query
AvailableProducts function importAs you can see, there is a fairly direct correspondence between the LightSwitch elements and the corresponding OData elements.
When you publish your LightSwitch application, LightSwitch uses the data source name to construct the base feed URL. By default the “intrinsic” data source is called “ApplicationData”. This is created when you define hew tables in the LightSwitch Data Designer. LightSwitch will use “/ApplicationData.svc” as the feed URL. If you attach to an external SQL database and call the data source “NorthwindData”, LightSwitch will use “/NorthwindData.svc” as the feed URL. To access the Products table in the NorthwindData data source, you’d construct the URL using your web-sites base address.
http://www.contoso.com/NorthwindData.svc/Products
During F5, these services are addressable via http://localhost at port number selected by the project. This port number will be visible in the Browser URL and in the Windows tray icon. Say the port number is 1234. You can view the OData metadata for your ApplicationData at the following URL.
http://localhost:1234/ApplicationData.svc/$metadata
Securing LightSwitch OData Feeds
Opening your application data via OData raises the obvious question: How do I secure access to my application data?
You can turn on access control for LightSwitch applications using the project settings. LightSwitch supports three authentication settings: None, Forms, and Windows.
When you select Forms, LightSwitch enables two modes of authentication. One is a custom protocol used by the LightSwitch clients Login dialog. This uses a custom web service API to pass credentials and obtain a forms-authentication cookie. If a request for data doesn’t have a valid forms-authentication cookie, LightSwitch will respond with an HTTP Basic challenge. This allows non-LightSwitch clients to pass credentials via a standard HTTP protocol.
If you choose Windows authentication, LightSwitch will require an authenticated Windows user. This works great for in-house applications. LightSwitch doesn’t currently support this option for Azure-hosted services, although you can configure ADFS manually outside of LightSwitch.
Whatever authentication mechanism you use, you should considering transport-level security, via HTTPS, to secure any credentials, tokens, and data that pass on the wire. Without HTTPS, forms and basic credentials will pass in clear text, as will forms-authentication tokens. Windows authentication is more secure, but without HTTPS, any data flowing between client and server will still be clear text. To mitigate this, LightSwitch has a publish setting that causes the runtime to require a secure connection.
With this setting On, LightSwitch will redirect requests from HTTP to HTTPS. But you still need to obtain and configure the HTTPS certificate on your web site.
This version of LightSwitch doesn’t provide a direct mechanism for hiding or excluding entity sets or entity properties from the OData endpoint. Whatever you connect to on the back-end will be visible on the front-end of your service. You can control access to those resources by using the
CanXxxaccess control methods in your data service code. We have also added true row-level filtering in this release using theentity_Filterquery method, so you can filter out any or all entities from escaping the service interface. Unfortunately, we have no column-level filtering, so a client will either get all or none of the entity.Here is an example of how to prevent all Update, Delete and Insert from the Animals table.
Consuming LightSwitch OData Feeds from Non-LightSwitch Clients
The OData protocol isn’t specific to .NET or Microsoft. OData feeds published by LightSwitch can be consumed by any OData client on a variety of platforms. By using HTTP Basic authentication, most existing clients will be able to attach to your feed securely.
The two main opportunities this opens up for LightSwitch developers are generic OData clients and custom OData clients.
Many new products like Microsoft PowerPivot and Microsoft Codename “Data Explorer” are generic OData consumers. They are designed for ad-hoc query and analysis of OData feeds. You’ll find several more from on the OData ecosystem web site.
You can also author your own custom clients for whatever platforms and devices your solution requires. The OData SDK has client libraries for a variety of popular platforms including JavaScript, PHP, Java, Ruby, and Objective-C.
Attaching to External OData Feeds
You can attach to external OData feeds as data sources in your LightSwitch projects. When you attach to another OData feed, LightSwitch fetches the $metadata and imports the external data schema into your LightSwitch project. LightSwitch will list any unsupported data elements at attach time and will not import these into the LightSwitch project. Unfortunately, these data elements will be unavailable to your LightSwitch application. (See Protocol Support below.)
Some OData producers are known to work well with LightSwitch. These are SharePoint 2010 (using the SharePoint option at in the Attach dialog), most feeds produced in Visual Studio with WCF Data Services and Entity Framework, and of course feeds produced by LightSwitch.
Not all OData feeds in the wild support the same level of functionality. Some don’t support pagination, or sorting, or certain kinds of query filters, features that screens use by default. We are still working out the best way to give a great experience using these feeds. Our current thinking is to disable a lot of the built-in query functionality for unknown OData feeds. The developer can progressively turn these features back on after experimenting with the feed and determining what works and what doesn’t.
In the meantime, the LightSwitch team is working with the OData community to find better ways for arbitrary consumers to negotiate capabilities with arbitrary feeds. We are big fans of OData and we want to improve the experience for LightSwitch customers and for other products that adopt OData.
Upgrading from LightSwitch 2011
It was a design principle in LightSwitch 2011 to hide the data-access implementation details, to avoid lock-in to any one data access technology. That decision as paid off. The LightSwitch engineers were able to re-plumb both the LightSwitch client and server using OData and to maintain an extremely high degree of compatibility with earlier APIs and runtime semantics. We replaced our earlier dependency on WCF RIA Services with WCF Data Services (the .NET implementation of OData). We considered the prior WCF RIA Service endpoints to be private, so they no longer exist, but that shouldn’t break anyone. On the server, they are replaced with public OData endpoints.
When you upgrade to Visual Studio 11, your data model remains the same and any entity and data service pipeline code you wrote stays the same. LightSwitch simply changes the code-generation for the underlying plumbing to use OData instead of WCF RIA Services, as well as updating the LightSwitch runtime libraries.
You might be wondering about custom data sources. Did these go the way of the dodo when we took out WCF RIA Services as our service endpoint? No, we still support using the WCF RIA Services DomainService as a back-end data adapter. These will upgrade and continue to work as-is.
Implementation Details
If you’re interested in some low-level details, I’m going to look at the features of the OData protocol that LightSwitch supports, the general runtime architecture, and some client-side optimizations that enhance our use of OData.
OData Protocol Support
OData has published v2.0 of the protocol and has recently announced OData v3.0. The v3.0 protocol isn’t yet finalized and LightSwitch isn’t taking advantage of any v3.0 capabilities.
LightSwitch supports a broad set of the OData 2.0 capabilities:
- Data Types: Most primitive EDM data types, entity types
- Relationships: Associations, navigation properties, links
- Feed Formats: atom, json
- Query Options: Filtering, sorting, paging, count, selection, expansion
- Query Expressions: OData comparison operators; OData string, date, and math functions
- Update and Batch: http put, patch, delete, post
- Concurrency Control: ETags and If-Match headers
There are certain OData v1.0 and v2.0 features that LightSwitch doesn’t support. These include the DataTimeOffset data type, complex types, inheritance, many-many relationships, media resources, open types, and custom service operations. Each of these has value in certain scenarios. We haven’t excluded any of these on principle or merits. It is just a matter of resources and investment to get new scenarios lit up.
Runtime Architecture
The overall architecture of the LightSwitch client and server doesn’t change too much from LightSwitch 2011. The simplified architecture stacks for client (presentation) and server (logic) tiers now look like the following:
Note that for LightSwitch 2011 you would have seen WCF RIA Services playing a prominent role in both the client and the server. You’ll see that these are simply replaced by WCF Data Services.
Client Optimizations
Under the hood, we did a lot to ensure that our use of OData maintained compatibility and is as efficient as possible. The OData protocol allows a client to request which related entities should be included in a query by using the $expand option. To avoid server round trips when loading screens, LightSwitch automatically expands screen queries to include related entities that are used in the screen—for example, including the customer and the order lines with the order record. The screen designer has advanced options where you can explicitly control this.
Another optimization we made is to include a RowVersion property for LightSwitch entities. OData uses ETags to handle data concurrency. These ETags can get large if they include original values from all of the entity properties—sometimes too large to fit in the request headers. By using RowVersion, we shrink the ETag to just one property value, while maintaining full support for concurrency checking and resolution. The introduction of a RowVersion also makes concurrency more robust because all properties are considered whereas in the past we excluded potentially large values like text, binary, and images. (Note: The RowVersion feature isn't yet available in the beta.)
Summary
The OData protocol is great for cross-platform data interoperability—whether inside your corporate network or on the internet. LightSwitch allows you to consume OData feeds and mash them up together with SQL Server data, SharePoint data and other OData feeds. LightSwitch applications automatically expose application data as OData feeds, so even non-LightSwitch clients can consume your application data. This opens up the opportunity of connecting your LightSwitch application with a variety of devices—HTML/JavaScript, iOS, and Windows 8 just name a few.
The LightSwitch data pipeline lets you publish OData safely. You can secure your feeds via HTTPS and use LightSwitch access control mechanisms like Basic and Windows authentication and permissions-based authorization. You can use the LightSwitch query and update pipelines to control access to data, keep the data clean, and manage business rules—regardless of which client is using the data.
Feedback
How will you use OData with LightSwitch in your business applications? What new scenarios can you accomplish? What else do you need in OData in specific and data access in general?
Download the beta and give it a try, and let us know what you think!






<Return to section navigation list>
Windows Azure Service Bus, Access Control, Identity and Workflow
Wade Wegner (@WadeWegner) produced Episode 73 - Nick Harris on Push Notifications for Windows 8 as his swansong at Microsoft on 3/24/2012:
Join Wade and David each week as they cover Windows Azure. You can follow and interact with the show at @CloudCoverShow.
In this episode, Wade is joined by Nick Harris—Technical Evangelist for Windows Azure—who shows us the Consumer Preview update of the Windows Azure Toolkit for Windows 8. Nick goes into depth regarding the Windows Push Notification Service and how to best leverage Windows Azure.
In the news:
- Leaving Microsoft
- Small to Extra Small Compute Ratio Details
- SAL Real World Migration from LAMP to Windows Azure
- Manual Steps for Installing the Windows Azure SDK on Windows 8
Here are the NuGet packages mentioned on the show:
Alan Smith described a Windows Azure Service Bus Resequencer in a 3/23/2012 post:
Introduction
As a long-time BizTalk developer I have seen many scenarios where the order of messages sent to a destination system needs is critical to business operations. Updating orders is a good example, if the first update to an order is sent after the second update then data may well be corrupted. Many BizTalk adapters, such as the file and FTP adapters have the potential to shuffle the sequence of messages as they enter BizTalk server, and message channels must be developed to resequence these messages.
The Enterprise Integration Patterns website provides a description of the Resequencer pattern here.
There are also scenarios where the sequence of messages can get mixed up when working with Service Bus brokered messaging. When sending a stream of messages using the asynchronous send method there is a good chance that the messages will be placed on the queue out of sequence. The following scenario will use this as an example, and a resequencer will be implemented to restore the order of the messages.
Resequencer Scenario
The scenario used for the resequencer implementation is the transfer of a photo over a Service Bus queue. The photo is broken down into 64 tiles (8 x 8), with each tile being sent in a separate message. When the tiles are received from the queue they are reassembled to form the original image.
I’ve have used this scenario previously when demoing resequencer patterns in BizTalk Server after seeing Shy Cohen use a similar scenario to demo reliable messaging in WCF. It’s great to use for presentations, and the use of an image makes it easy to see when messages are out of sequence.
The application that sends and receives the messages is built using Windows Presentation Foundation (WPF), with a basic user interface to show the original image, and the reassembled image after it has been sent and received on the queue. The application has the option to send messages using the synchronous or asynchronous send methods.
A screenshot of the application after sending the messages synchronously is shown below.
The received image has been assembled correctly from the sequence of message tiles, indicating that there was not a disturbance in the order of the messages. The sending of the messages, however, was not optimal. As they were sent synchronously, with the send operation on one having to complete before the next message can be sent, it took almost 7 seconds to send all 64 messages, at about 9.5 messages per second.
Sending messages asynchronously will provide much better throughput for the sending application. The results of this are shown below.
Using asynchronous send the 64 messages were sent in under half a second, at a rate of over 150 messages per second. In this test, sending messages asynchronously provides better than 15 times the throughput. Sending the messages asynchronously, however, has affected the order in which the messages were received. While most of the messages are in order, the first four messages containing the first half of the book title were the last four messages to be received.
In some scenarios the order of messages is not important, we are only concerned with throughput and reliability, but in this scenario it affects the display of the image. For these kinds of scenarios we need to implement a resequencer.
Resequencer Implementation
In this scenario the resequencer will be implemented as in intermediary service between the source system and the target system. I am using the Image Transfer WPF application to act as the source and target system, but the principle is the same.
The pseudo-code for a possible resequencer is shown below.
while (true) { ReceiveMessage; if (message is in sequence) { ForwardMessage; Forward any stored in sequence messages; } else { Store message; } }The design decisions we have to make when implementing a resequencer are as follows:
- How is the sequence of messages determined?
- How should the message store be implemented?
Determining the Sequence of Messages
In order for a resequencer to work it must have a means of determining the correct sequence of messages. The BrokeredMessage class provides a SequenceNumber property, which is set by the queue or topic when the message is enqueued, starting with 1 for the first message enqueued.
In some scenarios the messages could have been enqueued in the correct order, and then the sequence changed by a multi-threaded receive. In those scenarios the SequenceNumber could be used to resequencer the messages.
In this scenario the messages are enqueued out of sequence by the multi-threaded asynchronous sending operations. This means that the SequenceNumber property of the dequeued messages will not reflect correct order of the messages. This means that the message sender will have to provide some means of identifying the sequence of each message.
The following code shows the code used to create messages from the encoded image streams and assign an incrementing send session ID value to the Label property of the message header. The message is then sent synchronously or asynchronously depending on the selection made by the user.
for (int y = 0; y < ImageTiles; y++) { for (int x = 0; x < ImageTiles; x++) { MemoryStream ms = new MemoryStream(); // Use a delegate as we are accessing UI elements in a different thread. SimpleDelegate getImageCrop = delegate() { // Create a cropped bitmap of the image tile. CroppedBitmap cb = null; cb = new CroppedBitmap(FileBitmapImage, new Int32Rect (x * blockWidth, y * blockHeight, blockWidth, blockHeight)); // Encode the bitmap to the memory stream. PngBitmapEncoder encoder = new PngBitmapEncoder(); encoder.Frames.Add(BitmapFrame.Create(cb)); encoder.Save(ms); }; this.Dispatcher.Invoke(DispatcherPriority.Send, getImageCrop); // Create a brokered message using the stream. ms.Seek(0, SeekOrigin.Begin); BrokeredMessage blockMsg = new BrokeredMessage(ms, true); // Set the send sequence ID to the message lable. blockMsg.Label = sendSequenceId.ToString(); // Send the message using either sync or async. if (SendAsync == true) { queueClient.BeginSend(blockMsg, OnSendComplete, new Tuple<QueueClient, string>(queueClient, blockMsg.MessageId)); } else { queueClient.Send(blockMsg); } // Increment the send sequence ID sendSequenceId++; // Update the progress bar. SimpleDelegate updateBar = delegate() { prgTransfer.Value++; }; this.Dispatcher.BeginInvoke(DispatcherPriority.Send, updateBar); } }Delegates have been used here as the code is running on a background worker thread and needs to access the UI elements in the WPF application.
Storing Messages
Any messages that are received out of sequence will need to be stored, and then forwarded to the target system once the previous message in the sequence has been received and forwarded. The message deferral functionality available when receiving messages from queues and subscriptions provides a nice way to store messages that are out of sequence. Provided the messages are received using the peek-lock receive mode the messages can be deferred, and then received again by specifying the appropriate SessionId in the receive method.
Implementing the Resequencer Loop
The resequencer is implemented as a separate WPF application. It receives messages from an inbound queue, resequences them, and sends them, and then sends them on an outbound queue. The code for the main loop of the resequencer is shown below. The receiveSequenceId variable is used to keep track of the sequence of received messages. If the sendSequenceId, which is retrieved from the Label property of the message matches the receiveSequenceId the message is cloned and forwarded and receiveSequenceId is incremented.
When a message has been forwarded, the next message in the sequence may have been received earlier and been deferred. The deferred messages are checked using the dictionary to see if the next message is present. If so it is received, copied, and forwarded, and the process repeated.
If the receiveSequenceId does not match sendSequenceId then the message is out of sequence. When this happens the message is deferred, and the SequenceNumber of the message added to a dictionary with the sendSequenceId used as a key. The SequenceNumber is required to receive the deferred message.
// Initialize the receive sequence ID. long receiveSequenceId = 1; while (true) { BrokeredMessage msg = inbloudQueueClient.Receive(TimeSpan.FromSeconds(3)); if (msg != null) { long sendSequenceId = long.Parse(msg.Label); // Is the message in sequence? if (sendSequenceId == receiveSequenceId) { // Clone the message and forward it. Debug.WriteLine("Forwarding: " + sendSequenceId); BrokeredMessage outMsg = CloneBrokeredMessage(msg); outboundQueueClient.Send(outMsg); msg.Complete(); // Increment the receive sequence ID. receiveSequenceId++; // Check for deferred messages in sequence. while (true) { if (deferredMessageSequenceNumbers.ContainsKey(receiveSequenceId)) { Console.WriteLine("Sending deferred message: " + receiveSequenceId); // Receive the deferred message from the queue using the sequence ID // retrieved from the dictionary. long deferredMessageSequenceNumber = deferredMessageSequenceNumbers[receiveSequenceId]; BrokeredMessage msgDeferred = inbloudQueueClient.Receive(deferredMessageSequenceNumber); // Clone the deferred message and send it. BrokeredMessage outMsgDeferred = CloneBrokeredMessage(msgDeferred); outboundQueueClient.Send(outMsgDeferred); msgDeferred.Complete(); receiveSequenceId++; } else { // The next message in the sequence is not deferred. break; } } } else { // Add the message sequence ID to the dictionary using the send sequence ID // then defer the message. We will need the sequence id to receive it. deferredMessageSequenceNumbers.Add(sendSequenceId, msg.SequenceNumber); msg.Defer(); } } }Testing the Implementation
In order to test the resequencer the image transfer application will send messages to the inbound queue, and receive them from the outbound queue. The results of testing with the application sending messages asynchronously is shown below.
When the application was tested with 16 tiles (4 x 4) with tracing added the forwarding and deferring of the messages can clearly be seen.
Deferring: 3 Deferring: 4 Deferring: 5 Deferring: 6 Deferring: 7 Deferring: 8 Deferring: 9 Deferring: 10 Deferring: 11 Deferring: 12 Deferring: 13 Deferring: 14 Deferring: 15 Deferring: 16 Forwarding: 1 Forwarding: 2 Sending deferred message: 3 Sending deferred message: 4 Sending deferred message: 5 Sending deferred message: 6 Sending deferred message: 7 Sending deferred message: 8 Sending deferred message: 9 Sending deferred message: 10 Sending deferred message: 11 Sending deferred message: 12 Sending deferred message: 13 Sending deferred message: 14 Sending deferred message: 15 Sending deferred message: 16Issues with Cloning Messages
When receiving messages from one messaging entity and forwarding them to another the following code should not be used.
// Receive a message from the inbound queue. BrokeredMessage msg = inbloudQueueClient.Receive(TimeSpan.FromSeconds(3)); // Forward the message to the outbound queue. outboundQueueClient.Send(outMsg);It will result in an InvalidOperationException being thrown with the message “A received message cannot be directly sent to another entity. Construct a new message object instead.”.
The resequencer uses a quick and dirty message clone method, the code for this is shown below.
private BrokeredMessage CloneBrokeredMessage (BrokeredMessage msg) { Stream stream = msg.GetBody<Stream>(); BrokeredMessage clonedMsg = new BrokeredMessage(stream, true); clonedMsg.Label = msg.Label; return clonedMsg; }The code seems to work fine in this scenario, but care must be taken to ensure that the appropriate message properties are copied from the header of the source message to that of the destination message.
Alternative Resequencer Implementations
The implementation in the previous section has been developed to demonstrate the principles of a resequencer in a presentation. For this reason it is hosted in a WPF application, and no error handling code has been added. In a real world scenario the resequencer would be either hosted in a service, or alternatively in the target system. Using a worker role in Windows Azure would allow for a cloud-based solution, but the hourly costs may make this prohibitive.
Handling Errors
As well as the standard error handling on sending and receiving messages a resequencer should also handle a scenario when one of the messages in the sequence is missing. If this happens in my scenario all subsequent messages will be deferred, and the system will never recover. There are a number of ways that this could be handled better.
One option would be to set a threshold of a specific number of deferred messages or a specific time interval that would indicate that the missing message is probably lost. When this threshold is reached, an error or warning could be raised, and the sequence could be resumed. This could either be by an administrative action, or automatically. In either case, if the missing message does eventually arrive at the resequencer it can be dead-lettered and another error or warning raised.
Storing State of Deferred Messages
One of the disadvantages of the message deferral design is that the resequencer needs to hold the state of the SequenceNumber values for the deferred messages. If this is lost there is no way to receive these messages from the queue. In my demo scenario I use an in-memory dictionary for this. In a real-world implementation the resequencer should store the SequenceNumber values in a durable store.
Using SessionId for Send Sequence Id
An alternative to using message deferral to store messages the resequencer could be implemented using message sessions. Each session would contain one message, and the SessionId would be set to the sending sequence id. The resequencer (or the receiving application) could then use a session receiver and receive the message from the session by incrementing the value of the session it is listening for to receive the messages in order. The disadvantage of this design is that it would not be possible to use sessions for another purpose in the implementation.




<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Himanshu Singh (@himanshuks) posted Windows Azure Community News Roundup (Edition #11) on 3/23/2012:
Welcome to the latest edition of our weekly roundup of the latest community-driven news, content and conversations about cloud computing and Windows Azure. Let me know what you think about these posts via comments below, or on Twitter @WindowsAzure. Here are the highlights from last week.
- The Differences Between Development on Windows Azure and Windows Server by Rachel Appel (posted Mar. 22)
- The Beauty of Moving SQL Azure Servers between Subscriptions by Prabhakar Krishnakumar, Aditi Blog (posted Mar. 22)
- Node.js on (Windows) Azure Calling SAP Gateway by Luc Stakenborg (posted Mar. 21)
- Windows Azure PowerShell for Node.js by Shiju Varghese (posted Mar. 20)
- Programmatically finding Deployment Slot from Code Running in Windows Azure by Gaurav Mantri (posted Mar. 16)
Upcoming Events, and User Group Meetings
- March 26: Windows Azure Service Bus – Stockholm, Sweden
- March 27: I Gotta Get Me Some of That! (Windows Azure Event) – Charlotte, NC
- March 28: Hands on: Windows Azure Diagnostics - Online
- March 29: Boston (Windows) Azure Cloud User Meeting – Boston, MA
- March 30: (Windows) Azure Discovery Event – Dublin, Ireland
- March 30: Windows Azure Kick Start – Minneapolis, MN
- April 4: CloudCamp Vienna – Vienna, Austria
- April 4: Houston Cloud Tech Symposium – Houston, TX
- April 4: Windows Azure UK User Group – Manchester, UK
- April 28: Vancouver TechFest 2012 – Burnaby, BC, Canada
- Ongoing: Cloud Computing Soup to Nuts - Online
Recent Windows Azure Forums Discussion Threads
- Accessibility of Web role instances – 442 views, 4 replies
- How to test the TableStorage locally using DevFabric – 599 views, 10 replies
- (SQL) Azure Sync with Windows Server 2003 and SQL 2005 – 434 views, 4 replies
- Reliable inter-datacenter connectivity? – 602 views, 9 replies
Send us articles that you’d like us to highlight, or content of your own that you’d like to share. And let us know about any local events, groups or activities that you think we should tell the rest of the Windows Azure community about. You can use the comments section below, or talk to us on Twitter @WindowsAzure.

Himanshu Singh (@himanshuks) reported Movideo Undertakes a Large Scale Java Transition to Windows Azure in a 3/22/2012 post:
Movideo, a global online video platform, has announced it has chosen to transition its Java based platform to Windows Azure. Created by Australian media business, MCM Entertainment Group, Movideo is the only end-to-end SaaS online video platform business based in the Asia Pacific region.
According to research by Accustream, the online video market is expected to grow from US$4.4B in 2011 to over US$10B by the end of 2014. As Movideo works to take full advantage of the booming global online video market, the move to Windows Azure will help to drive business growth across Asia Pacific and beyond.
To learn more about how Movideo is betting on Windows Azure, you can read the full release on Microsoft News Center.

Craig Resnick reported Invensys’ Alliance with Microsoft to Help Accelerate Windows Azure Development to the ARC Advisory Group blog on 3/22/2012:
Invensys Operations Management, a global provider of technology systems, software solutions and consulting services to the manufacturing and infrastructure operations industries, announced an alliance with Microsoft Corp. for migrating some Invensys applications to the Windows Azure cloud. The alliance expands the company's continuing relationship with Microsoft and will afford end users cloud-based offerings in the manufacturing and infrastructure operations space.
Liam Cavanagh (@liamca) continued his series with What I Learned Building a Startup on Microsoft Cloud Services: Part 10 – Choosing a Billing System on 3/21/2012:
I am the founder of a startup called Cotega and also a Microsoft employee within the SQL Azure group where I work as a Program Manager. This is a series of posts where I talk about my experience building a startup outside of Microsoft. I do my best to take my Microsoft hat off and tell both the good parts and the bad parts I experienced using Azure.
Stripe is a really interesting company. They are one of the many companies that have come out of the Y Combinator startup program. Their prices seemed to be very similar to what you would get from PayPal which is 2.9% + $0.30 / charge. But what I really liked about Stripe was their support. Although they have the typical support where you can email questions, they also have a Campfire based chatroom where you can go to ask questions in real-time. I have logged on a few times and each time there were always a large number of people online to answer my questions. But what was really surprising was that most of the questions were not in fact answered by Stripe customer support but rather by Stripe customers. Imagine having the support of customers who would take the time to help out other customers?
The other great part about Stripe were the API’s. Not only did Stripe offer their own API Library to integrate with languages like Python, Ruby, PHP and Java, but they also had a really extensive set of 3rd party libraries for even more languages (including two for .NET that both work really well).
Dwolla, was also really interesting. I still don’t completely understand how they keep pricing so outrageously low. Their pricing is also pretty simple. If you charge your customers less than $10 you do not pay anything for that transaction. If you charge anything more than $10, you pay a flat $0.25 / transaction. For this unique business model, they were ranked by “Fast Company” as one of the 50 most innovative companies.
Just as an aside. When I signed up for a business credit card from my bank they kept calling me to see if I wanted to use their credit card processing system. If I remember correctly, they wanted to charge me something like $100 to setup, plus $30 / month usage fee, plus 2.9% + $0.30 / transaction. When I told them about Dwolla’s pricing they stopped calling me.
In the end, I chose to use Stripe. I had just read so many awesome things about them and their support was just so great that it tipped the scales for me over Dwolla’s amazing pricing.
After spending a lot of time with Stripe and getting my first paid customers, I am still very happy that I chose to use them. Their administrative dashboard is very extensive and really easy to use. I also love how easy it is to switch from “live” and “test” mode which allowed me to fully test Cotega with simulated credit cards and subscription plans before going live. I am still not sure if customers will demand to be able to use PayPal, but Stripe has seemed to give me everything I need for now.

If you need a credit card to sign up for a Windows Azure trial account, you might as require a credit card for billings of a service that monitors your SQL Azure databases.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Julian Paulozzi described his Paulozzi Co. Metro Shell [Extension for LightSwitch 2011] in a Visual Studio Gallery entry of 3/20/2011 (missed when posted):

Note: this version does not run properly in Visual Studio 11 Beta.
Requirements: The following prerequisite is required in order to use LightSwitch extensions.
Installing the Extension
- Download the LightSwitch PaulozziCo.MetroShell.vsix file to your local machine.
- Double-click the PaulozziCo.MetroShell.vsix file.
- Launch Visual Studio and open a LightSwitch project.
- Open Application designer.
- In the Extensions tab, enable the PaulozziCo.MetroShell extension.
- In the General Properties tab, expand the Shell drop-down list and select MetroShell, expand the Theme drop-down list and select MetroTheme.

• Kostas Christodoulou reported CLASS Extensions Version 2 Released on 3/23/2012:
CLASS Extensions version 2 is now available. All the features demonstrated in the demo videos are included plus the AttachmentsListEx collection control that is demostrated in the sample application but was not mentioned in the previous post.
Features
Color Business type and Controls. This business type is used to represent color values. The underlying CLR type is integer. After a request the change from the previous free version is that by default the pop-up window color picker control is used both for details and collections. Boolean property called “Drop Down” was added in the Appearance category which is false by default. When checked the drop-down/expander color picker control is used instead. This property is ignored in collections (grids/lists etc.) and pop-up is used. The color-picker control (as mentioned in the first version also) is contained in SilverlightContrib Codeplex project under Ms-PL.
Boolean Checkbox & Boolean Viewer controls. These controls handle bool and bool? (Nullable<bool>) values. No changes made from the previous – free – version. 
Rating Business type and Controls. This business type is used to represent rating values. The underlying CLR type is integer. The control is using the Mark Heath’s Silverlight Star Rating Control from CodePlex under Ms-PL. 
Percentage Business type and Controls. This business type is used to represent percentages. The underlying CLR type is decimal. In read-only mode a progress bar is displayed which is green for percentages <= 100% and red otherwise. It’s ideal for representing progress. 
ImageURI Business type and Controls. This business type is used to display an image from a URI location. The underlying CLR type is string. You can define a thumbnail view and size and also choose if the URI should be visible (editable if not read-only). Stretch Image property applies Uniform stretch to the image.
AudioFile Business type and Controls.This business type is used to store and reproduce audio files from a URI location. The underlying CLR type is string. You can choose if the URI should be visible (editable if not read-only). Play, Pause, Stop, Volume Control are available. Progress is also displayed. 
VideoFile Business type and Controls. This business type is used to store and reproduce video files from a URI location. The underlying CLR type is string. You can choose if the URI should be visible (editable if not read-only). Play, Pause, Stop, Volume Control are available. Progress is also displayed.
DrawingFile type and Control. This business type is used to store drawings. The underlying CLR type is string. The background of the drawing is defined as an image URI (not binary). Using the control you can draw lines, polygons and texts on a layer over the image store and edit afterwards to delete drawings, move edit or delete texts, change fonts and colors e.t.c. The control can also operate in local mode, where all drawings are saved in application’s Isolated Storage. Every time a drawing is saved a png image snapshot of the drawing is also generated and can be easily (with 2 lines of code) saved in traditional Image (byte[]) fields. 
AttachmentsListEx Collection Control. This is a special use collection control used to represent collections of entities implementing CLASSExtensions.Contracts.IAttachment. 
FileServer Datasource Extension. A very important RIA Service datasource provided to smoothly integrate all the URI-based features. This Datasource exports two entity types: ServerFile and ServerFileType. Also provides methods to retrieve ServerFile entities representing the content files (Image, Audio, Video, Document, In the current version these are the ServerFileTypes supported) stored at your application server. Also you can delete ServerFile entities. Upload (insert/update) is not implemented in this version as depending on Whether your application is running out of browser or not it has to be done a different way. Maybe in an update. The idea for this datasource was based on this article of Michael Washington. A good numbered (30+) collection of ValueConverters and Extension Classes. You can reuse in your applications either to create your own custom controls and extensions or application code in general.
Pricing
The price is $50 for the package without the code. Depending on demand, a code inclusive version and pricing may become available. The payment is done through PayPal and if invoice is required will be sent by post. After payment you will receive a zip file containing the vsix file the sample application used for the demonstration videos.Remarks
- Regarding Rating business type the Maximum and Default rating properties have to be set on the control. Although I found I way to add attributes to the business type, I couldn’t find a way to retrieve in the control so that these parameters could be set once on the entity’s property.
- The reason DrawingFile is using URI as image background and not a binary image was a result of my intention to create a lightweight drawing type which is also portable. As long as the image URI is public the drawings can be ported to any other application using the extension copying just a few KBs.
For the FileServer Datasource to work you must create a folder hierarchy in your web application’s folder. You have to create a Content (see also ContentDirectory appSetting below) sub-folder in the root folder of your application and a hierarchy like shown below. If the folders are not there, an attempt will be made by code to be created, but to avoid extra permissions issues you can create in advance. Also if you want to be able to delete files you have to take care of file permissions so that the account can delete files.
Also, as you can see in the sample application you will receive along with the extensions, in ServerGenerated\web.config there are 2 appSettings entries:
<add key="VirtualDirectory" value="" />
<add key="ContentDirectory" value="Content" />
The first one VirtualDirectory is compulsory and if your application is not running at the root of the publishing site the value should be the name of the virtual directory under which your application is running. In the sample the value is null.
The second one ContentDirectory is optional and if omitted then Content is assumed as the folder to look for files.- For AudioFile and VideoFile controls: The total duration of the media file is not always available so many times in the rightmost digital time display the value will be zero.
- For all URI based types: If you are using the FileServer Datasource while debugging you will have issues regarding the validity of the URIs. As between builds and runs the host’s port can change, a URI provided from the FileServer Datasource (containing the current port) during one debug session, may be invalid in a next session if the port changes. Of course after deployment this will never be an issue unless you somehow change your application’s URL.







Beth Massi (@bethmassi) described Deploying LightSwitch Applications to IIS6 & Automating Deployment Packages in a 3/23/2012 post:
A lot of folks have asked me for information on how to publish a LightSwitch application to IIS6. With the help of a couple team members we finally got the steps written down. This is a follow up to the detailed IIS7 on Windows Server 2008 deployment guide which you should familiarize yourself with first. There is a lot more information there on how deployment actually works:
Deployment Guide: How to Configure a Web Server to Host LightSwitch Applications
In this post I’m just going to show you the basic steps necessary to configure a Windows 2003 Server with IIS6 installed. I’ll also show you the MSDeploy commands you need to automate a deployment package created with Visual Studio LightSwitch.
Setup IIS6 on Windows 2003 Server with Web Platform Installer
Step 1: Install Web Platform Installer
You can use the Web Platform Installer (WPI) to set up a Windows web server fast. This makes it super easy to set up a machine with all the stuff you need. Although you can do this all manually, I highly recommend you set up your LightSwitch server this way. This will install IIS & Web Deploy for you (if you don’t have it installed already) and configure them properly.
To get started, select the Products link at the top then select Tools on the left. There you will see two options for LightSwitch Server Runtime. One option is to install SQL Server Express called “Visual Studio LightSwitch 2011 Server Runtime and Local SQL“ and the other is “without Local SQL”. If you already have an edition of SQL Server installed on the machine or if you are hosting the database on another machine you can choose the “without Local SQL” option
Select the option you want and then click Install and off you go. During the install you will need to reboot a few times.
Step 2: Start Web Deployment Agent
Next we need to verify the Web Deployment Agent Service is started. Open up Services and right-click on Web Deployment Agent Service and select Start if it’s not already started.
Step 3: Configure Your Web Site and Database for Network Access
In order for other computers to access your server’s websites via HTTP on a Windows 2003 machine, you need to configure the Windows Firewall. Click on the Advanced tab, select the network connection and click the Settings… button. On the Services tab check off the “Web Server (HTTP)” and verify the name of your web server, then click OK.
Now computers on your network will be able to navigate to the server via http://SERVERNAME. Next thing you need to verify is that your database server is also accessible. This configuration is the same as I describe in the Deployment Guide using SQL Configuration Manager so refer to that post.
Step 4: Deploy from Visual Studio LightSwitch
Now that your server is set up, you can deploy directly from Visual Studio LightSwitch. Keep in mind that when you deploy directly to IIS6 that the service URL should use http, not https. Https web deployment it is not supported on IIS6. See the Deployment Guide for step-by-step instructions on how to walk through the deployment wizard.
If you are not deploying directly from Visual Studio LightSwitch to your server but instead create a deployment package on disk, see the bottom of this post on how to install the package on IIS6.
Setup IIS6 on Windows 2003 Server without Web Platform Installer
Step 1: Install IIS6
First you will need to install IIS6 on your Windows 2003 box. You can take a look at this article for options on how to do this: Installing IIS (IIS 6.0)
Step 2: Install .NET Framework 4.0
Next you will need to install the .NET Framework 4.0 in order to get ASP.NET on the box.
Step 3: Install Web Deploy 1.1
In order to publish deployment packages you need to install Web Deploy 1.1. Install the appropriate package based on your server architecture and refer to this documentation for installation details: Web Deployment Tool Installation
Step 4: Install Visual Studio LightSwitch 2011 Server Runtime
Step 5: Start Web Deployment Agent
Open up Services and right-click on Web Deployment Agent Service and select Start if it’s not already started. See Step 2 in above section.
Step 6: Configure Your Web Site and Database for Network Access
In order for other computers to access your server’s websites via HTTP on a Windows 2003 machine, you need to configure the Windows Firewall. See step 3 in the above section on how to do this.
Step 7: Set .XAP file MIME type
In IIS Manager, verify the mime type for the .xap file extension. Right-click on the Default Web Site and select Properties then select the HTTP Headers tab. Click MIME Types… and map the .xap extension to application/x-silverlight-app as shown:
Step 8: Deploy from Visual Studio LightSwitch
Now that your server is set up, you can deploy directly from Visual Studio LightSwitch. Keep in mind that when you deploy directly to IIS6 that the service URL should use http, not https. Https web deployment it is not supported on IIS6. See the Deployment Guide for step-by-step instructions on how to walk through the deployment wizard.
If you are not deploying directly from Visual Studio LightSwitch to your server but instead create a deployment package on disk, see below for steps on how to install the package on IIS6.
Importing a LightSwitch Deployment Package into IIS
Note: These instructions will only work for the RTM (version 1) Release of Visual Studio LightSwitch (not LightSwitch in Visual Studio 11 Beta). These instructions will work for both IIS6 and 7+
Instead of using direct deployment from the LightSwitch deployment wizard, you can choose to create a deployment package on disk. (See the Deployment Guide for step-by-step on how to walk through the deployment wizard to create a package and deploy it to IIS7).
In order to deploy to IIS6 you need to use the MSDeploy command line tool. If you are going to be creating or updating a remote database you will also need SQL Server Management Objects installed on this machine. You can get these through the Web Platform Installer referenced above and selecting SQL Server Management Studio 2008 R2 Express or the Visual Studio LightSwitch 2011 Server Runtime with Local SQL. You can also obtain them directly from here. If you already have SQL or SQL Express installed then you can skip this prerequisite.
1. Make sure you are logged in as an administrator of the machine.
2. Copy the deployment package (i.e. Application1.zip) to the IIS6 server machine.
3. Next create a file with the parameters you are going to need to pass to MSDeploy. You can obtain the parameters you need from the package by executing this command. Open a command prompt and assuming the path to the deployment package is C:\Publish\Application1.zip, type:
>"C:\Program Files\IIS\Microsoft Web Deploy\msdeploy.exe" -verb:getParameters -source:package=C:\Publish\Application1.zip
This will list out the parameters you need. Some of them will change based on the type of authentication you are using. For any LightSwitch application you will need to specify the following:
<?xml version="1.0" encoding="utf-8"?> <parameters> <setParameter name="DatabaseAdministratorConnectionString"
value="Data Source=servername\SQLEXPRESS;Initial Catalog=Application1;
User ID=admin;Password=adminPassword" /> <setParameter name="DatabaseServer" value="servername\SQLEXPRESS" /> <setParameter name="DatabaseName" value="Application1" /> <setParameter name="DatabaseUserName" value="dbuser" /> <setParameter name="DatabaseUserPassword" value="dbpassword" /> <setParameter name="Application1_IisWebApplication" value="Default Web Site/Application1" /> </parameters>Note that the DatabaseAdministratorConnectionString is only used by this process to create/update the database. The DatabaseUserName and DatabaseUserPassword values are used to construct the connection string in the web.config and is the credential used by the LightSwitch middle-tier when your app is running.
If you are using Windows authentication you will need to specify one additional parameter:
<setParameter name="Application Administrator User Name" value="DOMAIN\UserName" />If you are using Forms authentication you will need to specify three additional parameters:
<setParameter name="Application Administrator User Name" value="UserName" /> <setParameter name="Application Administrator Full Name" value="Full Name" /> <setParameter name="Application Administrator Full Password" value="strongPassword" />4. Save the parameters XML file in the same location as the deployment package (i.e. Application1.Parameters.xml)
5. Run the following command to import the package, replacing the ServerName below with the name of the IIS server:
>"C:\Program Files\IIS\Microsoft Web Deploy\msdeploy.exe" -verb:sync -source:package=c:\Publish\Application1.zip –dest:auto,computerName=http://ServerName/MSDEPLOYAGENTSERVICE -setParamFile:c:\Publish\Application1.Parameters.xml
If you get any errors connecting to the deployment service then double-check the service is running (as shown above) and verify that you are logged in as an administrator of the machine.
6. If your application is using Forms or Windows authentication then you need to also run the following command to set up the Admin user in the database so you can log in the first time. You need to specify the location of the web.config to do this.
For Windows authentication, run:
>”C:\Program Files\Microsoft Visual Studio 10.0\LightSwitch\1.0\Tools\Microsoft.LightSwitch.SecurityAdmin.exe” /createadmin
/config:"c:\inetpub\wwwroot\Application1\web.config" /user:"DOMAIN\UserName"For Forms authentication run:
>”C:\Program Files\Microsoft Visual Studio 10.0\LightSwitch\1.0\Tools\Microsoft.LightSwitch.SecurityAdmin.exe” /createadmin
/config:"c:\inetpub\wwwroot\Application1\web.config" /user:"UserName" /fullname:"Full Name" /password:"strongPassword"You can perform the same steps on either an IIS6 or IIS7 machine.
Wrap Up
Direct deployment is a lot less work if you can allow it. The LightSwitch publishing wizard performs all the necessary steps for you directly from the LightSwitch development environment. However, often times you do not have (nor want) access to deployment servers. This is why LightSwitch can produce deployment packages on disk instead. With IIS7, you can import these packages using the GUI in IIS manager, however in IIS6 you need to use the MSDeply command line as shown above.
We’re making improvements to the deployment in LightSwitch in Visual Studio 11 and in my next post on deployment I’ll walk through some of the enhancements. In particular, now when you create a package, the parameters and command files are automatically generated for you alongside the deployment package. This makes it really easy to just add your settings and go. Until next time…






The Entity Framework Team reported EF5 Beta 2 Available on NuGet in a 3/22/2012 post:
A few weeks ago we released EF5 Beta 1, since then we’ve been working to improve quality and polish up the release. Today we are making EF5 Beta 2 available on NuGet.
This release is licensed for use in production applications. Because it is a pre-release version of EF5 there are some limitations, see the license for more details.
What Changed Since Beta 1?
Beta 2 is mainly about improving quality, here are the more notable changes since Beta 1:
- Migrations commands now work in Visual Studio 2010. There was a bug in Beta 1 that caused them to only work in Visual Studio 11 Beta.
- Moved database related Data Annotations to System.ComponentModel.DataAnnotations.Schema namespace. The annotations that originally shipped in EntityFramework.dll have moved into System.ComponentModel.dll in .NET 4.5. As part of this move, the database related annotations were moved into a .Schema sub-namespace. In EF 5 we made the same namespace change for applications targeting .NET 4.0.
- Fixed the ‘Sequence contains no elements’ bug that several users reported on Beta 1.
- Simplified the web.config/app.config settings to register SQLEXPRESS or LocalDb as the default. We added a LocalDbConnectionFactory which makes the config that is created while installing the NuGet package much simpler. See the ‘Visual Studio 11 includes LocalDb rather than SQLEXPRESS.’ point in the next section for more details on how the default database is selected.
- LocalDb database now created in App_Data directory of ASP.NET applications by default. The new LocalDbConnectionFactory will add LocalDb database files to the App_Data directory when used in ASP.NET applications.
EF Power Tools Beta 2 is Coming
Entity Framework has progressed a lot in the last 6 months and we’ve let the Power Tools fall behind. We are working on an updated version at the moment and we’re aiming to have it available in the next couple of weeks.
Simplified msdn.com/data/ef
We’ve been doing some work to simplify the main Entity Framework to make it a better starting point for our product. There is still plenty of room for improvement but you should find the site much more useful already.
What’s New in EF5?
EF 5 includes bug fixes to the 4.3.1 release and a number of new features. Most of the new features are only available in applications targeting .NET 4.5, see the Compatibility section for more details.
- Enum support allows you to have enum properties in your entity classes. This new feature is available for Model, Database and Code First.
- Table-Valued functions in your database can now be used with Database First.
- Spatial data types can now be exposed in your model using the DbGeography and DbGeometry types. Spatial data is supported in Model, Database and Code First.
- The Performance enhancements that we recently blogged about are included in EF 5 Beta 1.
- Visual Studio 11 includes LocalDb database server rather than SQLEXPRESS. During installation, the EntityFramework NuGet package checks which database server is available. The NuGet package will then update the configuration file by setting the default database server that Code First uses when creating a connection by convention. If SQLEXPRESS is running, it will be used. If SQLEXPRESS is not available then LocalDb will be registered as the default instead. No changes are made to the configuration file if it already contains a setting for the default connection factory.
The following new features are also available in the Entity Model Designer in Visual Studio 11 Beta:
- Multiple-diagrams per model allows you to have several diagrams that visualize subsections of your overall model.
- Shapes on the design surface can now have coloring applied.
- Batch import of stored procedures allows multiple stored procedures to be added to the model during model creation.
Getting Started
You can get EF 5 Beta 2 by installing the latest pre-release version of the EntityFramework NuGet package.
PM> Install-Package EntityFramework –Pre
These existing walkthroughs provide a good introduction to using the Code First, Model First & Database First workflows available in Entity Framework:
We have created walkthroughs for the new features in EF 5:
Compatibility
This version of the NuGet package is fully compatible with Visual Studio 2010 and Visual Studio 11 Beta and can be used for applications targeting .NET 4.0 and 4.5.
Some features are only available when writing an application that targets .NET 4.5. This includes enum support, spatial data types, table-valued functions and the performance improvements. If you are targeting .NET 4.0 you still get all the bug fixes and other minor improvements.
Support
We are seeing a lot of great Entity Framework questions (and answers) from the community on Stack Overflow. As a result, our team is going to spend more time reading and answering questions posted on Stack Overflow.
We would encourage you to post questions on Stack Overflow using the entity-framework tag. We will also continue to monitor the Entity Framework forum.
No significant articles today.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
No significant articles today.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Simon Munro (@simonmunro) riffs on the Eucalyptus Systems partnership in his Finally, AWS is Cloud Computing is AWS post of 3/22/2012:
The news that AWS is partnering with Eucalyptus to provide some sort of API compatible migration between private clouds and AWS is interesting. But not for the reasons you would expect. Yes, at some level it is interesting that AWS is acknowledging private-public cloud portability. It is also somewhat interesting that Eucalyptus providers now have an extra arrow in their quiver. But all of that will be minor in the bigger AWS scheme of things anyway — after all, those partnerships seldom mount to much (as @swardley asks, “Is ”AWS partnering with Eucalyptus = MS partnering with Novell“ a sensible analogy or the argument of those hanging on by their fingernails?”). But still it is a good move by Eucalyptus nonetheless.
What is interesting is the API compatibility. Eucalyptus is AWS API compatible and OpenStack is not. The OpenStack community has been arguing for months on whether or not they should make their API compatible with AWS. I haven’t followed the argument in detail (yawn) and think that currently they are still um and ah-ing over AWS API compatibility. Feel free to correct me in the comments if necessary. Have a read through Innovation and OpenStack: Lessons from HTTP by Mark Shuttleworth for his opinion on the matter (as of September 2011).
One of the questions about API compatibility is whether or not AWS would get upset and it seems that the Eucalyptus agreement has given explicit rights to use the AWS API. The legal rights around using the same API may be grey, but the right to brag about it has to be given by the original authors, surely? This bragging right is going to give Eucalyptus a lot of credibility and a head start over Openstack.
What about CloudFoundry, OpenShift and other cloud platforms? I have always avoided trying to define AWS in the context of cloud taxonomies, using the IaaS/PaaS/SaaS or any other taxonomy (see Amazon Web Services is not IaaS) and the reason is quite simple. AWS is pretty much the definition of cloud computing and all definitions have to bow down to AWSs dominance. After all, what’s the point of drawing little definition boxes if the gorilla doesn’t fit comfortably into any of them?
So what is really interesting about the Eucalyptus announcement is that it lends credibility to AWS as the definition of cloud computing (not just the market leader or early adopter). Using AWS as the definition and getting rid of all of the IaaS/PaaS crap makes it pretty easy for AWS to talk to the enterprise – far more than talking on-prem does.


I, too “am at a complete loss at explaining why, after more than two years this is still the case.” See the Mårten Mickos (@martenmickos) asserted “AWS and Eucalyptus to Make it Easier for Customers to Migrate Applications Between On-premises Environments and the Cloud” in the deck for an Amazon Web Services (AWS) and Eucalyptus Partner to Bring Additional Compatibility Between AWS and On-premises IT Environments press release of 3/22/2012 post in the Other Cloud Computing Platforms and Services section below.
Erik Lofstrand described the pros and cons of DHCP in a Cloud Enabled World by Erik Lofstrand in a 3/22/2012 post to Microsoft’s Private Cloud Architecture blog:
In a surprising number of our private cloud engagements we have run into an unexpected roadblock: Lack of DHCP. Having spent a previous life in the dotcom days as a network engineer, I was really surprised to see today, as organizations and networks have matured, automation of IP assignment has not.
Now, the first caveat to this post is that ultimately the decision is up to the customer. Our best practices might not be suitable for your organization. The second caveat is that automation in a cloud, means automation across the board. You can’t deploy a cloud architecture with manual dependencies. Particularly in something as critical, and central as network connectivity.
This article is going to address the major resistance points customers have regarding DHCP and how a cloud focused organization can address them. We will also provide the key configuration aspects of a healthy DHCP environment that address the concerns raised and provide a win-win scenario for the cloud endeavor.
The issue:
Overwhelmingly, the push back against DHCP falls into one of two main areas. If there are others that you are faced with, we’d certainly like to hear about them. There could certainly be cases where DHCP just doesn’t fit, but as you’ll see, there are ways to address them. If DHCP is a complete show stopper in an organization, it could also be a telltale sign that your IO (infrastructure optimization) maturity is not ready to accommodate a cloud architecture.
This is not a bad thing, Core IO maturity takes a lot of effort and an organization dedicated to its success. Moving to a private cloud is also a process that challenges what IT organizations are used to doing. If you’re not familiar with the Microsoft Core IO model, or for more information click here.
Issue 1
The vast majority of customers we work with who have a policy against DHCP usually have this response when asked why: “We tried to leverage DHCP… There were lots of problems… It never worked properly… It made the entire environment (read their job security) less stable”
Issue 2
In a close second place is IP address management (IPAM). Particularly in large organizations, IP address assignment is a different team’s, if not an entirely different organization’s from the infrastructure ownership that would be responsible for the DHCP service. There are tools out there that handle IP Address Management, including a new feature in the upcoming release of Windows. The reality we’ve seen, all too often, is that there just isn’t a workable solution for IPAM. The really good ones are expensive, so companies don’t often buy them. The main tool used in a lot of organizations for IPAM is Excel. This highlights why DHCP would be blocked from being used. Organizations that have to rely on tools like a spreadsheet for IPAM, can’t have DHCP running around handing out addresses for them.So what’s the solution? We’ll get to that in a minute, but in the interest of full disclosure we should point out the pros and cons of DHCP. If you are facing this dilemma, this information should allow you to make an informed decision either way.
DHCP Pros:
So in searching for reliable sources to compile this list, maybe the most pertinent piece of information for you is that there really weren’t any. Most of the information compiled here was found in various forums and other places around the web, so take it all with a grain of salt. The goal here is to understand the necessity of DHCP in a cloud enabled environment, so pros and cons are presented to make that case with your internal teams.
The one source that I will give the most credit to is TechNet. Not that Microsoft said it, but that someone actually sat down to provide something other than opinion. From here the main benefits of DHCP are :
- Reliable IP address configuration. DHCP minimizes configuration errors caused by manual IP address configuration, such as typographical errors, or address conflicts caused by the assignment of an IP address to more than one computer at the same time.
- Reduced network administration. DHCP includes the following features to reduce network administration:
- Centralized and automated TCP/IP configuration.
- The ability to define TCP/IP configurations from a central location.
- The ability to assign a full range of additional TCP/IP configuration values by means of DHCP options.
- The efficient handling of IP address changes for clients that must be updated frequently, such as those for portable computers that move to different locations on a wireless network.
- The forwarding of initial DHCP messages by using a DHCP relay agent, which eliminates the need for a DHCP server on every subnet.
Some other benefits pulled from elsewhere:
- IT Automation requires IP automation.
DHCP is a straightforward way to dynamically provision machines with an IP address.
Other automation tools, like PXE, leverage DHCP- Better DNS Integration.
One of the caveats to assigning static IPs addresses in the datacenter was DNS. If I need to reach a server by name, the DNS record and IP address could be different. Fortunately, dynamic DNS has matured along with DHCP and the two, particularly in a Windows environment work very well and maintaining the correct information. In practice, we don’t see issues here today.- Enables Flexibility.
As pointed out above, dynamic addressing creates portability of machines across subnets. This can be particularly important in clouds that serve dev and test functions that need to be moved between different subnets.- Potential Cost Savings.
By eliminating the manual task of managing, assigning, and troubleshooting IP conflicts, overburdened IT shops can focus their time on other priorities.- Baseline for the Future of IPv6.
With IPv6 around the corner, managing a static IPv6 infrastructure will be daunting for even the brightest IP Gurus in the business. I could probably still recount the entire IP nomenclature I managed back in the day. Ask me to scale that by 4 times (32 bit IPv4 vs 128bit IPv6 addresses) and I give up. Building and managing a DHCP infrastructure today will prepare you for the evolution to IPv6 in the future.DHCP Cons:
There is always a downside to any technology. Here are some for DHCP, mostly compiled from talking with customers, but also found the same in various forum sites.
- DHCP is not secure.
So the argument is this, if I allow any device to connect to my network to receive an IP address my network security is compromised. While this is a true statement, my personal opinion is that your network security was compromised before the IP address was assigned by allowing an unauthorized user to connect in the first place. But security is a flag often raised, so you need to understand the concern.- DHCP adds network complexity.
Building and maintaining a resilient DHCP infrastructure requires planning, testing, maintenance and support. All of these things add costs to the network both in hard dollars and IT resources.- DHCP creates an additional failure point in the datacenter.
If a server does not receive an IP address, critical services could become unavailable.
DHCP becomes a critical service, and must be restored immediately in a DR / Business Continuity scenario.- DHCP becomes an IP black box.
By allowing dynamic IP addresses, how am I supposed to keep my memorized list of server addresses intact?
The networks I managed all had static addresses, at least partly for this reason.The Solution:
So if DHCP is so necessary in building a cloud, and we are more comfortable, in theory, with static IP addresses, how do we solve this problem? The answer is to do both. Leverage DHCP in your environments that have a need for it. We already do this on most desktops. For critical services like DHCP, DNS and Active Directory, use static addresses to protect the key components of the environment. For the same reason, there are a lot of best practices around keeping a portion of these services running on physical hardware as well.
And for the other services, particularly those running in your cloud? Leverage DHCP, with IP address reservations. So the key in every conversation with customers that overwhelmingly addresses issue number 2 above is that they now can leverage better tools than Excel to manage IP addresses and still have 100% control over which server gets what address. This fits perfectly into automation scenarios as well.
A common OS deployment from bare metal would follow this path:
The figure shows the following process flow: request submitted with MAC address from vendor manifest >> Routed to IPAM team for address assignment and approval >> orchestration engine provisions DHCP reservation >> Orchestration engine provisions machine
Additionally, the IPAM team can get reservation data via Powershell from Windows DHCP servers. While there is not native module prior to the next release of Windows, scripts like this show how it can be done. This can also be integrated in the orchestration so that the workflow reports back to the IPAM team on a regular basis reservation data like when an address was last used. This will give them the ability to proactively manage their IP pools better than before and could still even use Excel as their interface. Decommissioning of IP Addresses would work just as easily, by reversing the workflow logic.
Once a machine is deprovisioned, the orchestration engine would remove the reservation from DHCP and report back to the IPAM Team that it is now available. Some additional steps might include DNS updates, leveraging static MAC addresses in a virtualized environment, and any network device provisioning such as firewall rules or router table entries. All-in-all, DHCP with reservations gives the stability and control of static addresses but in an automated fashion that is conducive to cloud deployment strategies.
One more key part of this solution is the resiliency of the DHCP infrastructure. The majority of reasons behind issue #1 above boiled down to DHCP not being a first class network citizen. Poor architecture, poor infrastructure, poor maintenance all were the root causes for instability in DHCP environments. First, DCHP needs to be designed and implemented properly. This includes designing for failure scenarios to minimize risk to the environment.
It also means that the infrastructure teams and the network teams must collaborate to ensure that the network devices are set to forward DHCP packets around the network. Unless there is a DHCP server in each and every subnet in an organization, you will need to enable IP helpers on your routers. This is a must have for a healthy DHCP environment.
Below are a few best practices pulled from an older TechNet article for Windows 2003, but nonetheless still relevant:
- Use the 80/20 design rule for balancing scope distribution of addresses where multiple DHCP servers are deployed to service the same scope.
Using more than one DHCP server on the same subnet provides increased fault tolerance for servicing DHCP clients located on it. With two DHCP servers, if one server is unavailable, the other server can take its place and continue to lease new addresses or renew existing clients.
A common practice when balancing a single network and scope range of addresses between two DHCP servers is to have 80 percent of the addresses distributed by one DHCP server and the remaining 20 percent provided by a second. For more information and an example of this concept, see Configuring scopes.- Use superscopes for multiple DHCP servers on each subnet in a LAN environment.
When started, each DHCP client broadcasts a DHCP discover message (DHCPDISCOVER) to its local subnet to attempt to find a DHCP server. Because DHCP clients use broadcasts during their initial startup, you cannot predict which server will respond to the DHCP discover request of a client if more than one DHCP server is active on the same subnet.
For example, if two DHCP servers service the same subnet and its clients, clients can be leased at either server. Actual leases distributed to clients can depend on which server responds first to any given client. Later, the server first selected by the client to obtain its lease might be unavailable when the client attempts to renew.
If renewal fails, the client then delays trying to renew its lease until it enters the rebinding state. In this state, the client broadcasts to the subnet to locate a valid IP configuration and continue without interruption on the network. At this point, a different DHCP server might respond to the client request. If this occurs, the responding server might send a DHCP negative acknowledgement message (DHCPNAK) in reply. This can occur even if the original server that first leased the client is available on the network.
To avoid these problems when using more than one DHCP server on the same subnet, use a new superscope configured similarly at all servers. The superscope should include all valid scopes for the subnet as member scopes. For configuring member scopes at each server, addresses must only be made available at one of the DHCP servers used on the subnet. For all other servers in the subnet, use exclusion ranges for the same scope ranges of addresses when configuring the corresponding scopes.
For more information, see Using superscopes.- Deactivate scopes only when removing a scope permanently from service.
Once you activate a scope, it should not be deactivated until you are ready to retire the scope and its included range of addresses from use on your network.
Once a scope is deactivated, the DHCP server no longer accepts those scope addresses as valid addresses. This is only useful when the intention is to permanently retire a scope from use. Otherwise, deactivating a scope causes undesired DHCP negative acknowledgement messages (DHCPNAKs) to be sent to clients.
If the intent is only to affect temporary deactivation of scope addresses, editing or modifying exclusion ranges in an active scope achieves the intended result without undesired results.
For more information, see Manage Scopes.- Use server-side conflict detection on DHCP servers only when it is needed.
Conflict detection can be used by either DHCP servers or clients to determine whether an IP address is already in use on the network before leasing or using the address.
DHCP client computers running Windows 2000 or Windows XP that obtain an IP address use a gratuitous ARP request to perform client-based conflict detection before completing configuration and use of a server offered IP address. If the DHCP client detects a conflict, it will send a DHCP decline message (DHCPDECLINE) to the server.
If your network includes legacy DHCP clients (clients running a version of Windows earlier than Windows 2000), you can use server-side conflict detection provided by the DHCP Server service under specific circumstances. For example, this feature might be useful during failure recovery when scopes are deleted and recreated. For more information, see DHCP Troubleshooting.
By default, the DHCP service does not perform any conflict detection. To enable conflict detection, increase the number of ping attempts that the DHCP service performs for each address before leasing that address to a client. Note that for each additional conflict detection attempt that the DHCP service performs, additional seconds are added to the time needed to negotiate leases for DHCP clients.
Typically, if DHCP server-side conflict detection is used, you should set the number of conflict detection attempts made by the server to use one or two pings at most. This provides the intended benefits of this feature without decreasing DHCP server performance.
For more information, see Enable address conflict detection.- Reservations should be created on all DHCP servers that can potentially service the reserved client.
You can use a client reservation to ensure that a DHCP client computer always receives the same IP address lease at startup. If you have more than one DHCP server reachable by a reserved client, add the reservation at each of your other DHCP servers.
This allows the other DHCP servers to honor the client IP address reservation made for the reserved client. Although the client reservation is only acted upon by the DHCP server where the reserved address is part of the available address pool, you can create the same reservation on other DHCP servers that exclude this address.
For more information, see Add a client reservation.- For server performance, note that DHCP is disk-intensive and purchase hardware with optimal disk performance characteristics.
DHCP causes frequent and intensive activity on server hard disks. To provide the best performance, consider RAID solutions when purchasing hardware for your server
computer that improves disk access time.
When evaluating performance of your DHCP servers, you should evaluate DHCP as part of making a full performance evaluation of the entire server. By monitoring system hardware performance in the most demanding areas of utilization (CPU, memory, disk input/output), you obtain the best assessment of when a DHCP server is overloaded or in need of an upgrade.
Note that the DHCP service includes several System Monitor counters that can be used to monitor service. For more information, see Monitoring DHCP server performance.- Keep audit logging enabled for use in troubleshooting.
By default, the DHCP service enables audit logging of service-related events. Audit logging provides a long-term service monitoring tool that makes limited and safe use of server disk resources. For more information, see Audit logging.
For more information on interpreting server audit log files, see Analyzing server log files.- Reduce lease times for DHCP clients that use Routing and Remote Access service for remote access.
If Routing and Remote Access service is used on your network to support dial-up clients, you can adjust the lease time on scopes that service these clients to less than the default of eight days. One recommended way to support remote access clients in your scopes is to add and configure the built-in Microsoft vendor class provided for the purpose of client identification.- Increase the duration of scope leases for large, stable, fixed networks if available address space is plentiful.
For small networks (for example, one physical LAN not using routers), the default lease duration of eight days is a typical period. For larger routed networks, consider increasing the length of scope leases to a longer period of time, such as 16-24 days. This can reduce DHCP-related network broadcast traffic, particularly if client computers generally remain in fixed locations and scope addresses are plentiful (at least 20 percent or more of the addresses are still available).- Integrate DHCP with other services, such as WINS and DNS.
WINS and DNS can both be used for registering dynamic name-to-address mappings on your network. To provide name resolution services, you must plan for interoperability of DHCP with these services. Most network administrators implementing DHCP also plan a strategy for implementing DNS and WINS servers.- For routed networks, either use relay agents or set appropriate timers to prevent undesired forwarding and relay of BOOTP and DHCP message traffic.
If you have multiple physical networks connected through routers, and you do not have a DHCP server on each network segment, the routers must be capable of relaying BOOTP and DHCP traffic. If you do not have such routers, you can set up the DHCP Relay Agent component on at least one server running Windows Server 2003 in each routed subnet. The relay agent relays DHCP and BOOTP message traffic between the DHCP-enabled clients on a local physical network and a remote DHCP server located on another physical network.
When using relay agents, be sure to set the initial time delay in seconds that relay agents wait before relaying messages on to remote servers. For more information on DHCP relay agents, see DHCP/BOOTP Relay Agents.- Use the appropriate number of DHCP servers for the number of DHCP-enabled clients on your network.
In a small LAN (for example, one physical subnet not using routers), a single DHCP server can serve all DHCP-enabled clients. For routed networks, the number of servers needed increases, depending on several factors, including the number of DHCP-enabled clients, the transmission speed between network segments, the speed of network links, whether DHCP service is used throughout your enterprise network or only on selected physical networks, and the IP address class of the network. For more information on determining how many DHCP servers to set up, see Planning DHCP networks.- For DNS dynamic updates performed by the DHCP service, use the default client preference settings.
The Windows Server 2003 DHCP service can be configured to perform DNS dynamic updates for DHCP clients based on how clients request these updates to be done. This setting provides the best use of the DHCP service to perform dynamic updates on behalf of its clients as follows:
- DHCP client computers running Windows 2000, Windows XP, or a Windows Server 2003 operating system explicitly request that the DHCP server only update pointer (PTR) resource records used in DNS for the reverse lookup and resolution of the client's IP address to its name. These clients update their address (A) resource records for themselves.
- Clients running earlier versions of Windows cannot make an explicit request for DNS dynamic update protocol preference. For these clients, the DHCP service updates both the PTR and the A resource records when the service is configured to do so.
For more information, see Using DNS servers with DHCP, Enable DNS dynamic updates for clients, and Configure DNS dynamic update credentials.
- Use the manual backup and restore methods in the DHCP server console.
Use the Backup command on the Action menu of the DHCP console to perform full backup of the DHCP service at an interval that protects you from significant data loss. When you use the manual backup method, all DHCP server data is included in the backup, including all scope information, log files, registry keys, and DHCP server configuration information (except DNS dynamic update credentials). Do not store these backups on the same hard drive upon which the DHCP service is installed, and make sure that the access control list (ACL) for the backup folder only contains the Administrators group and DHCP Administrator groups as members. In addition to performing manual backups, backup to other locations, such as a tape drive, and make sure unauthorized persons do not have access to your backup copies. You can use Windows Backup for this purpose. For more information, see Best practices for Backup.
When restoring the DHCP service, use a backup created with the manual Backup command or a copy of the database created with synchronous backup by the DHCP service. In addition, use the Restore command on the Action menu in the DHCP console to restore a DHCP server.
For more information, see Backing up the DHCP database and Restoring server data.- Follow the recommended process for moving a DHCP server database from old server computer hardware to new hardware.
Moving a DHCP server database can be problematic. To manage moving the server database more easily, choose and follow a process tried and used by Microsoft Product Support Services such as the following:
- For restoring server data at the same server computer, see Restoring server data.
- For moving DHCP server data to another server computer, such as in the case of hardware failure or data recovery, see Move a DHCP database to another server.
- Before you install a DHCP server, identify the following:
- The hardware and storage requirements for the DHCP server.
For more information, see Planning DHCP networks.- Which computers you can immediately configure as DHCP clients for dynamic TCP/IP configuration and which computers you should manually configure with static TCP/IP configuration parameters, including static IP addresses.
For more information, see Checklist: Configuring TCP/IP.- The DHCP option types and their values to be predefined for DHCP clients.
The DHCP Design guide should also be leveraged in the planning. To maintain a healthy DHCP environment, Microsoft has a Best Practices Analyzer along with a Management Pack for System Center Operations Manager. With the same attention paid towards DHCP that is given to any other critical service of an organization, you will find that DHCP can provide many benefits and a considerable amount of consistency in our cloud enabled worlds.
Conclusion:
For its detractors, DHCP is not perfect, but as part of the overall solution, it can provide a stable addressing infrastructure and leave IPAM teams in control of the organization’s address space. If security is a concern for an organization, address the access vulnerability to your network access points with 802.1x or other controls, but DHCP is not the risk, and static IP addresses are not any more secure. As the services that an IT organization provides become increasingly more dynamic, and deploying clouds in your organization becomes a reality, we need to make sure that the infrastructure evolves as well. Dynamic IP addressing is a key component of this, and a well built, well managed DHCP environment will be a benefit to the organization.
Erik Lofstrand
US Private Cloud CoE Lead
eriklof@microsoft.com


Tom Bittman (@tombitt) posted Top Five Private Cloud Computing Trends, 2012 to his Gartner blog on 3/22/2012:
Private cloud computing continues to heat up, and there are several key trends defining private cloud computing in 2012:
1) Real Deployments: We’ll see about a 10X increase in private cloud deployments in 2012. Enterprises will find where private cloud makes sense, and where it’s completely over-hyped. We’ll see successes – and there will also be a number of failures (we’ve seen some already).
2) Hybrid Plans: According to polls, enterprises are already looking beyond private cloud to hybrid cloud computing (not cloud bursting, per se, but resource pool expansion). Interest in hybrid is affecting architecture plans and vendor selection today – but actual hybrid cloud usage is really rare right now.
3) Choices Expand: The cloud management platform market is very immature, but there are choices, and four distinct categories are forming up: a) virtualization platforms expanding “up”, b) traditional management vendors expanding “down”, c) open source-centered initiatives (most notably OpenStack), and d) start-ups often focused on Amazon interoperability (and note that Amazon just announced a tighter relationship with Eucalyptus Systems for exactly this).
4) Sourcing Alternatives: While on-premises private clouds are becoming the most common, there’s a growing interest in private clouds managed by service providers – but with varying levels of “privacy”, and understanding that is critical.
5) Value is Shifting: Many enterprises have assumed that the primary benefit of private cloud is lower costs. That’s changing. According to recent polls, the majority of large enterprises consider speed and agility to be the primary benefit. This is making private cloud decisions more sophisticated, based more on understanding business requirements. Enterprises engaged in private cloud projects to reduce their costs will usually fail to meet objectives, as well as miss the mark on potential business benefits.
2012 will be the year that private cloud moves from market hype to many pilot and mainstream deployments. So much will be happening in 2012 that winners and losers in the vendor sweepstakes will probably be pretty clear by year-end 2012, and certainly by year-end 2013. Also, enterprises are rushing so fast that there will be casualties along the way. Staying on top of best practices and learning from early adopters is a must.

<Return to section navigation list>
Cloud Security and Governance
• Jay Heiser (pictured below) reported a New Academic Paper on Melting Clouds in a 3/23/2012 post to his Gartner blog:
Bryan Ford, a researcher at Yale, has just released a very interesting 5-page paper, “Icebergs in the Clouds: the Other Risks of Cloud Computing”, which provides a compelling technical and historical explanation of the potential for emergent chain reaction failures in commercial cloud computing offerings.
He takes a nuanced approach, explaining that this is speculative and forward-looking, but given the increasing reliance on public cloud computing, this is an area that deserves research attention now.
To quote selectively from the synopsis linked to above: “As diverse, independently developed cloud services share ever more fluidly and aggressively multiplexed hardware resource pools, unpredictable interactions between load-balancing and other reactive mechanisms could lead to dynamic instabilities or “meltdowns.” Non-transparent layering structures, where alternative cloud services may appear independent but share deep, hidden resource dependencies, may create unexpected and potentially catastrophic failure correlations, reminiscent of financial industry crashes. ”
When cloud computing buyers do have a concern about risk, it tends to be narrowly focused on data confidentiality. Many security practitioners are unfortunately encouraging a simplistic belief that if we just deal with data secrecy, then we can use cloud services for everything. The types of failures that have already occured suggest a greater need to look at the broader risk issues, especially reliability and data loss.
In his introduction, Ford explains that “Non-transparent layering structures, where alternative cloud services may appear independent but share deep, hidden resource dependencies, may create unexpected and potentially catastrophic failure correlations, reminiscent of financial industry crashes.” In a 2010 blog entry, ‘Toxic Clouds’, I drew multiple parallels between the runup to the financial services meltdown, and the willingness of cloud buyers to accept complex but non-transparent offerings. In both cases, the mechanisms that allow the leveraging of a relatively small set of resources to provide high levels of value for a huge number of customers means that a single failure can have widespread impact. In both cases, complexity inevitably leads to brittleness, unless explicit measures are taken to anticipate and prevent the emergence of destabilizing behaviors. In the case of the financial markets, greed won out over governance. It remains to be seen what will happen with public cloud computing.

Windows Azure compute apparently fell victim to a “meltdown” of this type in late February 2012.
Jon Udell (@judell) posted The Translucent Cloud: Balancing Privacy, Convenience to the Wired Cloudline blog on 3/23/2011:
As we migrate personal data to the cloud, it seems that we trade convenience for privacy. It’s convenient, for example, to access my address book from any connected device I happen to use. But when I park my address book in the cloud in order to gain this benefit, I expose my data to the provider of that cloud service.
When the service is offered for free, supported by ads that use my personal info to profile me, this exposure is the price I pay for convenient access to my own data. The provider may promise not to use the data in ways I don’t like, but I can’t be sure that promise will be kept.
Is this a reasonable trade-off?
For many people, in many cases, it appears to be. Of course we haven’t, so far, been given other choices. And other choices can exist. Storing your data in the cloud doesn’t necessarily mean, for example, that the cloud operator can read all the data you put there. There are ways to transform it so that it’s useful only to you, or to you and designated others, or to the service provider but only in restricted ways.
Early Unix systems kept users’ passwords in an unprotected system file,
/etc/passwd, that anyone could read. This seemed crazy when I first learned about it many years ago. But there was a method to the madness. The file was readable, so anyone could see the usernames. But the passwords were transformed, using a cryptographic hash function, into gibberish. The system didn’t need to remember your cleartext password. It only needed to verify that when you typed your cleartext password at logon, the operation that originally encoded its/etc/passwdequivalent would, when repeated, yield a matching result.Everything old is new again. When it was recently discovered that some iPhone apps were uploading users’ contacts to the cloud, one proposed remedy was to modify iOS to require explicit user approval. But in one typical scenario that’s not a choice a user should have to make. A social service that uses contacts to find which of a new user’s friends are already members doesn’t need cleartext email addresses. If I upload hashes of my contacts, and you upload hashes of yours, the service can match hashes without knowing the email addresses from which they’re derived.
In the post Hashing for privacy in social apps, Matt Gemmell shows how it can be done. Why wasn’t it? Not for nefarious reasons, Gemmell says, but rather because developers simply weren’t aware of the option to uses hashes as a proxy for email addresses.
The best general treatise I’ve read on this topic is Peter Wayner’s Translucent Databases. I reviewed the first edition a decade ago; the revised and expanded second edition came out in 2009. A translucent system, Peter says, “lets some light escape while still providing a layer of secrecy.”
Here’s my favorite example from Peter’s book. Consider a social app that enables parents to find available babysitters. A conventional implementation would store sensitive data — identities and addresses of parents, identities and schedules of babysitters — as cleartext. If evildoers break into the service, there will be another round of headlines and unsatisfying apologies.
A translucent solution encrypts the sensitive data so that it is hidden even from the operator of the service, while yet enabling the two parties (parents, babysitters) to rendezvous.
How many applications can benefit from translucency? We won’t know until we start looking. The translucent approach doesn’t lie along the path of least resistance, though. It takes creative thinking and hard work to craft applications that don’t unnecessarily require users to disclose, or services to store, personal data. But if you can solve a problem in a translucent way, you should. We can all live without more of those headlines and apologies.



Brian Hitney described Antimalware in the Windows Azure [What?] in a 3/21/2012 post:
On most (or perhaps even all?) of the production servers I’ve worked on, antivirus/antimalware detection apps are often not installed for a variety of reasons – performance, risk of false positives or certain processes getting closed down unexpectedly, or the simple fact most production machines are under strict access control and deployment restrictions.
Still, it’s a nice option to have, and it’s now possible to set this up easily in Windows Azure roles. Somewhat quietly, the team released a CTP of Microsoft Endpoint Protection for Windows Azure, a plug in that makes it straightforward to configure your Azure roles to automatically install and configure the Microsoft Endpoint Protection (MEP) software.
The download includes the necessary APIs to make it simple to configure. Upon initial startup of the VM, the Microsoft Endpoint Protection software is installed and configured, downloading the binaries from Windows Azure storage from a datacenter of your choosing. Note: *you* don’t have store anything in Windows Azure Storage; rather, the binaries are kept at each datacenter so the download time is fast and bandwidth-free, provided you pick the datacenter your app resides in.
So, to get started, I’ve downloaded and installed the MSI package from the site. Next, I’ve added the antimalware module to the ServiceDefinition file like so:
<?xml version="1.0" encoding="utf-8"?>
<ServiceDefinition name="MEP" xmlns="http://schemas.microsoft.com/ServiceHosting
/2008/10/ServiceDefinition">
<WebRole name="WebRole1" vmsize="ExtraSmall">
<Sites>
<Site name="Web">
<Bindings>
<Binding name="Endpoint1" endpointName="Endpoint1" />
</Bindings>
</Site>
</Sites>
<Endpoints>
<InputEndpoint name="Endpoint1" protocol="http" port="80" />
</Endpoints>
<Imports>
<Import moduleName="Antimalware" />
<Import moduleName="Diagnostics" />
<Import moduleName="RemoteAccess" />
<Import moduleName="RemoteForwarder" />
</Imports>
</WebRole>
</ServiceDefinition>
Specifically, I added Antimalware to the <imports> section. The other modules are for diagnostics (not needed necessarily but useful, as you’ll see in a bit) and remote access, so we can log into the server via RDP.Next, the ServiceConfiguration will configure a bunch of options. Each setting is spelled out in the document on the download page:
<?xml version="1.0" encoding="utf-8"?>
<ServiceConfiguration serviceName="MEP" xmlns="http://schemas.microsoft.com/
ServiceHosting/2008/10/ServiceConfiguration" osFamily="1" osVersion="*">
<Role name="WebRole1">
<Instances count="1" />
<ConfigurationSettings>
<Setting name="Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString"
value="xxx" />
<Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.ServiceLocation"
value="North Central US" />
<Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.EnableAntimalware"
value="true" />
<Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.EnableRealtimeProtection"
value="true" />
<Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.EnableWeeklyScheduledScans"
value="true" />
<Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.DayForWeeklyScheduledScans"
value="1" />
<Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.TimeForWeeklyScheduledScans"
value="120" />
<Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.ExcludedExtensions"
value="txt|log" />
<Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.ExcludedPaths"
value="e:\approot\custom" />
<Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.ExcludedProcesses"
value="d:\program files\app.exe" />
<Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.Enabled"
value="true" />
<Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.AccountUsername"
value="xxx" />
<Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.AccountEncryptedPassword"
value="xxx" />
<Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.AccountExpiration"
value="2013-03-21T23:59:59.000-04:00" />
<Setting name="Microsoft.WindowsAzure.Plugins.RemoteForwarder.Enabled"
value="true" />
</ConfigurationSettings>
<Certificates>
<Certificate name="Microsoft.WindowsAzure.Plugins.RemoteAccess.PasswordEncryption"
thumbprint="xxx" thumbprintAlgorithm="sha1" />
</Certificates>
</Role>
</ServiceConfiguration>Many of these settings are self-explanatory, but essentially, we’re setting up weekly scans at 2am on Sunday, excluding app.exe, and everything in e:\approot\custom. We’re also skipping txt and log files. Also, the MEP bits will be pulled from the North Central US datacenter. It’s not a big deal if your app is outside of North Central– it’s just that the install takes a few moments longer (the default is South Central). (And, technically, since bandwidth going into the datacenter is currently free, the bandwidth isn’t an issue.)
If we log into the box (the role must be RDP enabled to do this) we’ll see these settings reflected in MEP.
Weekly scans:
Excluding app.exe:
And skipping txt and log files:
Finally, we can also set up the Windows Azure Diagnostics agent to transfer relevant event log entries to storage – in this example, we’re just adding the antimalware entries explicitly, though getting verbose information like this is probably not desirable:
private void ConfigureDiagnosticMonitor()
{
DiagnosticMonitorConfiguration diagnosticMonitorConfiguration =
DiagnosticMonitor.GetDefaultInitialConfiguration();
diagnosticMonitorConfiguration.Directories.ScheduledTransferPeriod =
TimeSpan.FromMinutes(1d);
diagnosticMonitorConfiguration.Directories.BufferQuotaInMB = 100;
diagnosticMonitorConfiguration.Logs.ScheduledTransferPeriod = TimeSpan.FromMinutes(1d);
diagnosticMonitorConfiguration.Logs.ScheduledTransferLogLevelFilter = LogLevel.Verbose;
diagnosticMonitorConfiguration.WindowsEventLog.DataSources.Add("Application!*");
diagnosticMonitorConfiguration.WindowsEventLog.DataSources.Add("System!*");
diagnosticMonitorConfiguration.WindowsEventLog.ScheduledTransferPeriod =
TimeSpan.FromMinutes(1d);
//Antimalware settings:
diagnosticMonitorConfiguration.WindowsEventLog.DataSources.Add(
"System!*[System[Provider[@Name='Microsoft Antimalware']]]");
diagnosticMonitorConfiguration.WindowsEventLog.ScheduledTransferPeriod =
System.TimeSpan.FromMinutes(1d);
PerformanceCounterConfiguration performanceCounterConfiguration =
new PerformanceCounterConfiguration();
performanceCounterConfiguration.CounterSpecifier = @"\Processor(_Total)\% Processor Time";
performanceCounterConfiguration.SampleRate = System.TimeSpan.FromSeconds(10d);
diagnosticMonitorConfiguration.PerformanceCounters.DataSources.Add(
performanceCounterConfiguration);
diagnosticMonitorConfiguration.PerformanceCounters.ScheduledTransferPeriod =
TimeSpan.FromMinutes(1d);
DiagnosticMonitor.Start(wadConnectionString, diagnosticMonitorConfiguration);
}To filter the event logs from MEP, we can add some filtering like so (adding the Level 1, 2, and 3 to the filter so we’re skipping the verbose level 4 stuff):
diagnosticMonitorConfiguration.WindowsEventLog.DataSources
.Add("System!*[System[Provider[@Name='Microsoft Antimalware'] and
(Level=1 or Level=2 or Level=3)]]");After deploying the role and waiting a few minutes, the entries are written into Azure table storage, in the WADWindowsEventLogsTable. In this case, I’m looking at them using Cloud Storage Studio (although, for diagnostics and performance counters, their Azure Diagnostics Manager product is fantastic for this kind of thing):
While not everyone needs or desires this functionality, it’s a great option to have (particularly if the system is part of a file intake or distribution system).






Chris Hoff (@Beaker) posted Security As A Service: “The Cloud” & Why It’s a Net Security Win on 3/19/2012 (missed when published)
If you’ve been paying attention to the rash of security startups entering the market today, you will no doubt notice the theme wherein the majority of them are, from the get-go, organizing around deployment models which operate from “The Cloud.”
We can argue that “Security as a service” usually refers to security services provided by a third party using the SaaS (software as a service) model, but there’s a compelling set of capabilities that enables companies large and small to be both effective, efficient and cost-manageable as we embrace the “new” world of highly distributed applications, content and communications (cloud and mobility combined.)
As with virtualization, when one discusses “security” and “cloud computing,” any of the three perspectives often are conflated (from my post “Security: In the Cloud, For the Cloud & By the Cloud…“):
In the same way that I differentiated “Virtualizing Security, Securing Virtualization and Security via Virtualization” in my Four Horsemen presentation, I ask people to consider these three models when discussing security and Cloud:
- In the Cloud: Security (products, solutions, technology) instantiated as an operational capability deployed within Cloud Computing environments (up/down the stack.) Think virtualized firewalls, IDP, AV, DLP, DoS/DDoS, IAM, etc.
- For the Cloud: Security services that are specifically targeted toward securing OTHER Cloud Computing services, delivered by Cloud Computing providers (see next entry) . Think cloud-based Anti-spam, DDoS, DLP, WAF, etc.
- By the Cloud: Security services delivered by Cloud Computing services which are used by providers in option #2 which often rely on those features described in option #1. Think, well…basically any service these days that brand themselves as Cloud…

What I’m talking about here is really item #3; security “by the cloud,” wherein these services utilize any cloud-based platform (SaaS, PaaS or IaaS) to delivery security capabilities on behalf of the provider or ultimate consumer of services.
For the SMB/SME/Branch, one can expect a hybrid model of on-premises physical (multi-function) devices that also incorporate some sort of redirect or offload to these cloud-based services. Frankly, the same model works for the larger enterprise but in many cases regulatory issues of privacy/IP concerns arise. This is where the capability of both “private” (or dedicated) versions of these services are requested (either on-premises or off, but dedicated.)
Service providers see a large opportunity to finally deliver value-added, scaleable and revenue-generating security services atop what they offer today. This is the realized vision of the long-awaited “clean pipes” and “secure hosting” capabilities. See this post from 2007 “Clean Pipes – Less Sewerage or More Potable Water?”
If you haven’t noticed your service providers dipping their toes here, you certainly have seen startups (and larger security players) do so. Here are just a few examples:
- Qualys
- Trend Micro
- Symantec
- Cisco (Ironport/ScanSafe)
- Juniper
- CloudFlare
- ZScaler
- Incapsula
- Dome9
- CloudPassage
- Porticor
- …and many more
As many vendors “virtualize” their offers and start to realize that through basic networking, APIs, service chaining, traffic steering and security intelligence/analytics, these solutions become more scaleable, leveragable and interoperable, the services you’ll be able to consume will also increase…and they will become more application and information-centric in nature.
Again, this doesn’t mean the disappearance of on-premises or host-based security capabilities, but you should expect the cloud (and it’s derivative offshoots like Big Data) to deliver some really awesome hybrid security capabilities that make your life easier. Rich Mogull (@rmogull) and I gave about 20 examples of this in our “Grilling Cloudicorns: Mythical CloudSec Tools You Can Use Today” at RSA last month.
Get ready because while security folks often eye “The Cloud” suspiciously, it also offers up a set of emerging solutions that will undoubtedly allow for more efficient, effective and affordable security capabilities that will allow us to focus more on the things that matter.
/Hoff
Cloud Computing Image (Photo credit: Wikipedia)
Related articles by Zemanta
- [Webinar] Cloud Based Security Services: Saving Cloud Computing Users From Evil-Doers (rationalsurvivability.com)
- The Four Horsemen Of the Virtualization (and Cloud) Security Apocalypse… (rationalsurvivability.com)
- DDoS – A Moose On Cloud’s Table Or A Pea Under The Mattress? (rationalsurvivability.com)
- Six Year Old Rationalizes the Cloud (rationalsurvivability.com)
- Cloud Computing Security: (Orchestral) Maneuvers In the Dark? (rationalsurvivability.com)
- Cloudifornication: Indiscriminate Information Intercourse Involving Internet Infrastructure (rationalsurvivability.com)
- You Can’t Secure The Cloud… (rationalsurvivability.com)
- Security and the Cloud – What Does That Even Mean? (rationalsurvivability.com)
- Building/Bolting Security In/On – A Pox On the Audit Paradox! (rationalsurvivability.com)
- Security As A Service: Virtual Patching for Cloud Environments (canadacloud.biz)
- Security As A Service Is More Than A Virtual Security Gateway (securecloudreview.com)
- The Inevitability of Security-as-a-Service (securecloudreview.com)




<Return to section navigation list>
Cloud Computing Events
Brent Stineman (@BrentCodeMonkey) posted Detroit Day of Azure Keynote on 3/24/2012:
Keynote is a fancy way of saying “gets to go first”. But when my buddy David Giard asked me if I would come Detroit to support his Day of Azure, I couldn’t say no. So we talked a bit, tossed around some ideas.. and I settled on a presetion idea I had been calling “When? Where? Why? Cloud?”. This presentation isn’t technical, its about helping educate both developers and decision makers on what cloud computing is, how you can use it, what opportunities, etc…. Its a way to start the conversation on cloud.

David Strom (@dstrom) anounced BigDataWeek Plans Lots of Meetings in April Around the World in a 3/22/2012 post to the ReadWriteCloud blog:
If you are interested in Big Data you might want to keep your calendar open in late April for some interesting meetups. Every day starting with Monday April 23 will have at least one meeting going on in cities around the world on various Big Data topics including data science, data visualization and specific software development tool-related user groups around data-related businesses. There are activities scheduled in New York and San Francisco as well as Sydney Australia and London. And they have a cool logo, too.
The London events look the most organized so far, in keeping with that it is Europe's largest community of professionals exploring commercial big data opportunities, at least according to the site organizers. There will be the "first ever" Data Science Hackathon that will cover 24 hours starting on Saturday morning April 28. Unlike other marathon coding sessions, it promises to have better food than the standard Jolt-plus-pizza that you find at others. (Ironic that the Brits actually are advertising their food!) Another London event will be a Hadoop Day on Wednesday April 25. And if you are in London you will have a chance to spend some time with our favorite Big Data geek Hilary Mason from Bit.ly.
She told me: "It's great to see people come together around the data theme! Most data scientists are the only person in their organization who thinks about data from that perspective, and so Big Data week will be a great opportunity for them to meet their peers and learn new things." She makes a very good point: sometimes it is nice to network with peers in person, and these events would be a great way to do that and break out of your IRC chat shell and into some quality f2f time. If you can stand doing so.
The BigDataWeek website is somewhat spare and sketchy at this point but it looks like the various events could be a lot of fun and certainly something to check out if you are near one of the venues and interested in learning more about the topics.


Andy Cross (@AndyBareWeb) reported the availability of a Video: UK Tech.days online Azure Conference in a 3/21/2012 post:
Elastacloud today provided the talk for the UK MSDN Tech.days online conference. The topic was advanced Windows Azure techniques and we decided to broach this rather broad topic by focussing on 10 key challenges that a developer may face in Windows Azure and discussing 10 accelerating tools that empower the user to rapidly achieve success in these fields.
Anyone [who] wants to see the slides with a higher fidelity, here they are: 10 tools in 10 minutesv1.

<Return to section navigation list>
Other Cloud Computing Platforms and Services
• James Staten (@staten7) asked Has Amazon Solved Its Private Cloud Dilemma? in a 3/23/2012 post to his Forrester Research blog:
Amazon Web Services (AWS) is great, but many of our enterprise clients want those cloud services and values delivered on premise, behind their firewall, which may feel more comfortable for protecting their intellectual property (even if it isn't). AWS isn't very interested in providing an on-premise version of its solution (and I don't blame them). Today's partnership announcement with Eucalyptus Systems doesn't address this customer demand but does give some degree of assurance that your private cloud can be AWS compatible.
This partnership is a key value for organizations who have already seen significant adoption of AWS by their developers, as those empowered employees have established programmatic best practices for using these cloud services — procedures that call AWS' APIs directly. Getting them to switch to your private cloud (or use both) would mean a significant change for them. And winning over your developers to use your cloud is key to a successful private cloud strategy. It also could double your work to design and deploy cloud management solutions that span the two environments.
Eucalyptus, from the beginning, has pledged AWS API compatibility (or at least compatibility with the APIs for AWS' IaaS service, Elastic Compute Cloud, EC2) but that pledge was one-sided. There was no statement of assurance of this compatibility from AWS. This (and other reasons) have held back many enterprises from committing to this open source IaaS implementation. While the agreement doesn't contractually obligate AWS to ensuring this compatibility, it does provide a clear statement of commitment (and resources) to make best efforts at ensuring these solutions will work together well. That's a big deal given that AWS is by far the most commonly used public cloud by enterprise developers today (confirmed by our Forrsights surveys) and its API has become a de facto standard in the market. This is a significant shot in the arm for Eucalyptus. And it comes at an opportune time.
Next month the other major open-source IaaS project will hold its biannual conference. At The OpenStack Summit the Essex release will debut and is expected to be a major milestone showing that OpenStack IaaS clouds are ready for enterprise implementation. A variety of software vendors are counting on Essex for cloud fortunes in 2012 including Piston, Nebula, and HP. But the pressures of anticipation are on the OpenStack community for more than just this release — APIs are a hot topic in the community and the degree of commitment to AWS compatibility will be part of what enterprises will be listening for at the summit. All indications so far point to only limited AWS compatibility from this effort, which could give Eucalytpus a clear differentiator. Sort of.
There's yet another open-source IaaS implementation in the market that has also pledged AWS compatibility and is used in one of the biggest hybrid cloud implementations to date — the Zynga's Z Cloud. That solution is CloudStack. Citrix bought cloud.com in 2011, giving it ownership of this technology solution that powers a large number of public and private clouds today, including those from GoDaddy, Korea Telecom, and Tata. While Citrix is a member of the OpenStack community and has even marketed this heavily, it only incorporates the Swift storage services from OpenStack today. For many of Citrix's customers, AWS API compatibility is key. For Zynga it makes moving games back and forth between environments dead simple. For GoDaddy the value is competitive as it eases transitioning customers off of AWS.
AWS said the partnership with Eucalyptus is not exclusive, so a similar commitment to CloudStack could come right on the heels of this announcement. Eucalyptus better move quickly to capitalize on this differentiator.

The last article on the AWS-Eucalyptus partnership. I promise.
• Juan Carlos Perez (@JuanCPerezIDG) asserted “Google services like Cloud Storage will now be able to authenticate interaction with applications using certificate-based technology” in a deck for his Google boosts security of hosted developer services article of 3/22/2012 for ComputerWorld (missed when published):
Google has beefed up the security of its cloud hosted services for developers by making several of them able to authenticate interactions with applications using certificate-based Service Accounts.
These certificates offer a stronger authentication method than shared keys and passwords because they aren't "human-readable or guessable," wrote Google product manager Justin Smith in a blog post.
Cloud-hosted developer services that can now authenticate application requests through Service Accounts are Google Cloud Storage; Google Prediction API; Google URL Shortener; Google OAuth 2.0 Authorization Server; Google APIs Console; and Google APIs Client Libraries for Python, Java, and PHP.
Google plans to add more APIs and client libraries to that list. The feature is implemented as an OAuth 2.0 flow and is compliant with draft 25 of the OAuth 2.0 specification, according to Smith.
IDC analyst Stephen Hendrick said that security remains the main concern among users regarding cloud services, so Google has done well to focus on this initiative.
"Since the cloud is predicated on service enablement, security improvements specific to service invocation are likely to gain attention and garner praise. Initiatives like OAuth 2.0 and Google's decision to align their Service Account support with OAuth is an important step forward in improving cloud security," Hendrick said via email.


It’s about time. Windows Azure has offered certificate-based access control for a couple of years.
Matthew Weinberg (@M_Wein) reported Google BigQuery: The Googleplex Takes On Big Data in the Cloud in a 3/24/2012 post to the SiliconANGLE blog:
At this week’s Structure Data conference, Google discussed BigQuery, its forthcoming entrant into the emerging big data marketplace, leveraging Google’s computing power and algorithmic know-how as a cloud platform for business intelligence and analytics. The service has been available in a closed preview since 2010 and is available now in a closed beta.
Google BigQuery, as you may guess from the name, is designed to crunch huge amounts of data – the search giant isn’t ready to divulge case studies or even many customer names just yet, but Google indicates that it’s been field-tested with tens of terabytes of database entries. It doesn’t use SQL, per se, but it does support “SQL-like” queries from within Google Spreadsheets, but Google suggests that you use the existing Google Cloud SQL solution if you’re looking for a relational database. Google BigQuery is for, well, big queries.
On stage at Structure, Ju-Kay Kwek, product manager for the Google Cloud Platform Team, explained that Google BigQuery is a natural extension of the company’s internal tools, reports PCWorld. After all, you’d better believe Google applies analytics to usage of even its consumer services like Gmail. And with its scalable cloud infrastructure, Google is able to keep every scrap of data it generates for later analysis by engineers.
“The fine-grain data is key,” Kwek said. “The more questions you can quickly ask, the smarter those questions get.”
We Are Cloud , a service provider based in Montpellier, France, also took the stage to offer some perspectives on the value of using big data in the cloud to offer customers Bime, business intelligence, analytics and data visualization solution that uses Google BigQuery as its data management platform.
But while the cloud affords new opportunities, said We Are Cloud CEO Rachel Delacour during her time in the spotlight, on premises big data isn’t dead yet. On premises tools still offer superior speed and depth on data analysis, more flexible visualizations and performance across data sets. But the cloud already provides a cost, management and collaboration edge for big data applications, whether you’re using Google BigQuery or Hadoop.
Services Angle
Big data remains the trend to watch in 2012, no doubt. But it’s extremely interesting watching big data in the cloud develop as its own submarket, as businesses look for a way to take advantage that doesn’t involve deploying or maintaining their own clusters. Google entering this arena isn’t much of a surprise, and I suspect that the analytics industry is big enough for another cloud player.
Just as Foursquare tapped Amazon Elastic MapReduce to provide big data-driven analytics for its Amazon Web Services-hosted data, I’m expecting the majority of Google BigQuery’s customer base to already be using Google’s cloud platform to some extent, though it’s also available as a standalone offering.
I’m also glad that Google took the time to bring We Are Cloud into the conversation – service providers are increasingly taking a consultative role when it comes to big data, and while that’s not something that the search giant’s traditionally made a major play, putting a partner up there front and center shows that Google understands the need. The cloud already goes a long way towards closing the skills gap for small businesses, thanks to the lack of a need for management, and the service provider can go the rest of the way.
Google BigQuery: The Googleplex Takes On Big Data in the Cloud is a post from: SiliconANGLE
We're now available on the Kindle! Subscribe today.

Joe Brockmeier (@jzb) asked PaaS or Fail: Does Elastic Beanstalk Make the Grade as a PaaS? in a 3/23/2012 post to the ReadWriteCloud blog:
Earlier this week Amazon added PHP and Git support to Elastic Beanstalk. To me, this looks like Amazon encroaching on PaaS territory and offering features similar to Engine Yard, OpenShift, Heroku, and others. All of which, by the way, host on top of Amazon. But not everyone agrees that Elastic Beanstalk has the necessary ingredients for a PaaS, or that Amazon is trying to compete with existing PaaS providers.
After hearing a bit of discussion over whether Elastic Beanstalk really fit the PaaS bill, I touched base with some of the PaaS providers and colleagues that work with PaaS software. In particular, I spent a good deal of time talking with Dave McCrory, senior architect of Cloud Foundry.
Is Elastic Beanstalk a PaaS?
Let's start with the first item, does Elastic Beanstalk qualify as a PaaS in the first place?
My view is that it is a PaaS, if a rudimentary one when you line it up next to folks like Engine Yard or Heroku. It does provide a platform for running Java and PHP apps beyond the raw infrastructure. As Amazon's CTO Werner Vogels says on his post following the PHP/Git announcement, "AWS Elastic Beanstalk is another abstraction on top of the core AWS building blocks. It takes a different approach than most other development platforms by exposing the underlying resources. This approach provides the simplicity to quickly get started for application developers, but it also allows them to modify the stack to meet their goals."
Is it exactly analogous to other development platforms? No. Says Vogels, "So is there a "one-size-fits-all" in the development platform space? No, each platform fits the needs of different developers, applications, and use cases. Preference and familiarity also play a role in why some developers choose one over the other. Ultimately, we want developers to successfully run and manage reliable, highly scalable applications on AWS, irrespective of the abstraction that their development platform of choice offers."
McCrory says that he doesn't necessarily see Elastic Beanstalk as a PaaS. Instead, he describes it as more of a "configuration feature for IaaS, like InstallShield. It makes it easy to deploy and configure an application" but it doesn't do many of the other things automatically that developers have come to expect from a PaaS like Engine Yard or Heroku.
The problem with Elastic Beanstalk for McCrory, is pretty much the same thing that Vogels touts as a feature: It exposes the infrastructure and "expects the developer to fiddle with all of those things beneath." And this is true – while Amazon has the components like monitoring, message queuing, and so on it does expect developers to assemble the bits they need.
Bill Platt, VP of operations at Engine Yard, also brings up support. "If you want to have Ops people on staff or use your Dev resources to troubleshoot issues when your PaaS provider goes down, then AWS Elastic Beanstalk is an option. If you want to assign your Dev resources to building killer products, then Engine Yard provides you with a commercial grade platform, deep expertise and proactive support staff that have extensive experience deploying Ruby on Rails and PHP apps."
I would agree with Platt that, if you want to pay extra for hand-holding, you should look to one of the other PaaS providers. But when it comes to features, I wouldn't count on AWS being behind other PaaS offerings for long. The company has a history of innovating very quickly and it has far more engineers at its disposal than most of its competition (excepting Google and Microsoft). It may never be the best company for personal warm and fuzzies, but I expect its feature set will continue to evolve towards the more traditional PaaS offerings.
Competitive with Traditional PaaSes?
The other question is whether Amazon is competing with Engine Yard and other services, or means to. Vogels has said "Our goal is to ensure every developer's favorite platform is always available on AWS so they can stop worrying about deploying and operating scalable and fault-tolerant application and focus on application development. In a nutshell, we want to let a thousand platforms bloom on AWS."
Of course Amazon does. As I pointed out in the prior post, this is win/win for Amazon. If customers go directly to AWS, then Amazon benefits. If customers go to Engine Yard, Heroku, or OpenShift hosted on AWS... it also wins. The only way Amazon loses out is when customers pick PaaS offerings hosted elsewhere.
But if you're partnered with Amazon, that doesn't mean the company is going to stay out of your back yard. If you wonder whether Amazon is willing to go after its partners' business, you only need to look how Amazon is working with publishers. While Amazon is continually fighting with publishers, the company is not only squeezing them, it's also setting up shop as its own publishing imprint.
In short, I don't expect Amazon to come out and declare war on its partners in PaaS. That doesn't mean the company is going to be content to stay in the IaaS business for eternity, or even the next five years. If I was with Engine Yard or Heroku, I'd be operating under the assumption that Amazon will happily eat my lunch if PaaS looks like an attractive enough market.
So is Elastic Beanstalk a PaaS? You might disagree, but I'm still convinced it is. Granted, it's a rudimentary PaaS when compared with other offerings, but it still seems to fit the bill.



Mårten Mickos (@martenmickos) asserted “AWS and Eucalyptus to Make it Easier for Customers to Migrate Applications Between On-premises Environments and the Cloud” in the deck for an Amazon Web Services (AWS) and Eucalyptus Partner to Bring Additional Compatibility Between AWS and On-premises IT Environments press release of 3/22/2012:
SEATTLE, WA. – March 22, 2012 – Amazon Web Services LLC (AWS), an Amazon.com company and the leader in cloud computing (NASDAQ: AMZN), and Eucalyptus Systems, a provider of on-premises Infrastructure as a Service (IaaS) software, today announced an agreement that enables customers to more efficiently migrate workloads between their existing data centers and AWS while using the same management tools and skills across both environments. As part of this agreement, AWS will support Eucalyptus as they continue to extend compatibility with AWS APIs and customer use cases. Customers can run applications in their existing datacenters that are compatible with popular Amazon Web Services such as Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Simple Storage Service (Amazon S3).
“We’re pleased to provide customers with the added flexibility to more freely move workloads between their existing IT environments and the AWS cloud,” said Terry Wise, Director of Amazon Web Services Partner Ecosystem. “Enterprises can now take advantage of a common set of APIs that work with both AWS and Eucalyptus, enabling the use of scripts and other management tools across both platforms without the need to rewrite or maintain environment-specific versions. Additionally, customers can leverage their existing skills and knowledge of the AWS platform by using the same, familiar AWS SDKs and command line tools in their existing data centers.”
“We’re excited to be working more closely with AWS,” said Marten Mickos, CEO of Eucalyptus. “The ability to develop against a common set of market-leading APIs, for both on-premise and cloud deployments, is a big benefit for our customers and software partners. This agreement is going to accelerate our roadmap, and help us maintain our compatibility with AWS as both companies continue to innovate.”
“The cloud is becoming an increasingly important foundation for our data center operations, which support more than 600,000 hotel rooms under seven brands,” said Scott Johnson, Vice President of Enterprise Engineering at InterContinental Hotel Group. “As a user of both Amazon Web Services and Eucalyptus, this agreement will provide us with even greater flexibility and scalability for our cloud deployments. We believe the ability to leverage a common set of APIs will significantly transform our operations and provide a business advantage in the competitive hospitality industry.”
About Eucalyptus Systems
Eucalyptus Systems provides IT organizations in enterprises, government agencies and Web and mobile businesses with the most widely deployed software platform for on-premises Infrastructure-as-a-Service (IaaS). Eucalyptus is specifically designed for enterprise use, and the software platform is uniquely suited for private or hybrid IaaS computing. Built as an open source product, Eucalyptus supports the industry-leading Amazon Web Services (AWS) cloud APIs, as well as all major virtualization platforms including Xen, KVM and VMware vSphere, ESX and ESXi. The company has an active and growing ecosystem of customers, partners, developers and researchers that benefit from Eucalyptus’ open, fast and standards-compliant approach. For more information about Eucalyptus, please visit www.eucalyptus.com.
Eucalyptus and Eucalyptus Systems are trademarks in the U.S. All other trademarks are property of their respective owners. Other product or company names mentioned may be trademarks or trade names of their respective companies.
About Amazon Web Services
Launched in 2006, Amazon Web Services (AWS) began exposing key infrastructure services to businesses in the form of web services -- now widely known as cloud computing. The ultimate benefit of cloud computing, and AWS, is the ability to leverage a new business model and turn capital infrastructure expenses into variable costs. Businesses no longer need to plan and procure servers and other IT resources weeks or months in advance. Using AWS, businesses can take advantage of Amazon's expertise and economies of scale to access resources when their business needs them, delivering results faster and at a lower cost. Today, Amazon Web Services provides a highly reliable, scalable, low-cost infrastructure platform in the cloud that powers hundreds of thousands of enterprise, government and startup customers businesses in 190 countries around the world. AWS offers over 28 different services, including Amazon Elastic Compute Cloud (Amazon EC2), Amazon Simple Storage Service (Amazon S3) and Amazon Relational Database Service (Amazon RDS). AWS services are available to customers from data center locations in the U.S., Brazil, Europe, Japan and Singapore.
Forward-Looking Statements
This announcement contains forward-looking statements within the meaning of Section 27A of the Securities Act of 1933 and Section 21E of the Securities Exchange Act of 1934. Actual results may differ significantly from management's expectations. These forward-looking statements involve risks and uncertainties that include, among others, risks related to competition, management of growth, new products, services and technologies, potential fluctuations in operating results, international expansion, outcomes of legal proceedings and claims, fulfillment center optimization, seasonality, commercial agreements, acquisitions and strategic transactions, foreign exchange rates, system interruption, inventory, government regulation and taxation, payments and fraud. More information about factors that potentially could affect Amazon.com's financial results is included in Amazon.com's filings with the Securities and Exchange Commission, including its most recent Annual Report on Form 10-K and subsequent filings.

See also the Simon Munro (@simonmunro) riffs on the Eucalyptus Systems partnership in his Finally, AWS is Cloud Computing is AWS post of 3/22/2012 post in the Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds section above.
Steve O’Grady (@sogrady) chimes in with a Eucalyptus Doubles Down on its Amazon Bet post of 3/22/2012 to his RedMonk blog:
Born as a research project in the computer science department at UCSB, Eucalyptus the company was founded in January of 2009. Originally intended to replicate a subset of the Amazon cloud’s featureset in software that could be run locally, one of the project’s primary differentiators was its compatibility with the Amazon API. Importantly, however, this support was unofficial: Amazon neither supported nor legally blessed this feature. Which meant that its appeal was throttled by the uncertainty of Eucalyptus’ legal footing. More than one large vendor has privately characterized the Amazon API as a “non-starter” because their legal departments could not be assured of Amazon’s intent with respect to the intellectual property issues involved.
Meanwhile, a year and a half after Eucalyptus was commercialized, NASA and Rackspace jointly launched their own cloud project, OpenStack. While the initial versions were closer to a set of tools than the stack the name implies, OpenStack had an impressive partner roster at launch. And industry skepticism of the level of commitment of those partners has been offset with sustained momentum. Due in part to its more permissive licensing – OpenStack is Apache licensed, while Eucalyptus is reciprocally licensed under version 3 of the GPL – the NASA/Rackspace effort has enjoyed wide corporate interest and support. From AT&T to Dell to HP, OpenStack’s traction has been such that even skeptics like IBM and Red Hat have lately appeared to be moving towards acceptance of the project.
For all of OpenStack’s momentum, however, Amazon remains the dominant player in public cloud, with one researcher estimating its datacenter size at just shy of a half a million servers. Amazon itself has validated external estimates of its growth trajectory, saying (PDF) “Every day Amazon Web Services adds enough new capacity to support all of Amazon.com’s global infrastructure through the company’s first 5 years, when it was a $2.76 billion annual revenue enterprise.”
The question facing Amazon was if, or perhaps when, interest in on premise functionality would become sufficient to incent its participation – whether through build or a partnership – in private cloud solutions. The answer to that question appears to be this year. In January, the retailer turned technology giant announced the availability of the Amazon Storage Gateway, a virtual machine run locally that bridges data to Amazon’s storage service, S3. And then this morning, Amazon announced a partnership with Eucalyptus. As Om Malik put it, “On paper it looks like one of those strategic agreements that large companies sign-up with small startups,” but the announcement belies the larger significance. Amazon is, for the first time, playing the intellectual property trump card it has been holding in reserve.
By strategically and selectively removing the uncertainty regarding its APIs, Amazon gains literally overnight a credible private cloud offering, minimizing that as an angle of attack for competitors who might otherwise attempt to sell against Amazon by emphasizing its public cloud-only technology story. Nor does it have to deviate from its public cloud orientation by creating a more traditional software organization. This deal instead effectively outsources that to Eucalyptus.
Eucalyptus, for its part, may now realize the full potential of its differentiated access to Amazon public clouds. As Amazon’s only approved platform, it can expect its attach rate within organizations consuming Amazon cloud resources to improve substantially. While the deal is apparently not exclusive, OpenStack is not likely to either ask for or receive the same blessing from Amazon that Eucalyptus received. Assuming that the API licensing would survive a transaction, Eucalyptus has with this announcement substantially increased its valuation. The success of one organization is the success of the other; wider Eucalyptus adoption poses no risk to Amazon’s growth, while its success would push Amazon’s APIs closer to becoming the de facto standards of the public cloud.
From a landscape perspective, this cements the perception that it’s Amazon and Eucalyptus versus OpenStack and everyone who’s not Amazon, with the notable exceptions of Joyent, Microsoft and VMware, each of whom owns and sells their own cloud stack. In general, betters would be best advised to take the field over any single vendor, but the cloud market is an exception: Amazon is that dominant. By virtue of being first to market as well as executing consistently for six years, Amazon made itself into the proverbial 600 pound gorilla in one of the most strategic markets in existence. If you’re going to pick sides, as Eucalyptus did more emphatically this morning, that’s not a bad choice to make.
Disclosure: Dell, Eucalyptus, Joyent, HP, IBM, Microsoft, Red Hat and VMware are RedMonk customers. Amazon is not a RedMonk customer.
Related posts:



Jeff Barr (@jeffbarr) reported Multi-Region Latency Based Routing now Available for AWS in a 3/21/2012 post:
The Amazon Web Services are now available in an ever-expanding series of locations. You've asked us to make it easier to build applications that span multiple AWS regions and we are happy to oblige.
Today I'm pleased to announce that Amazon Route 53 is making available the same latency based routing technology that powers Amazon CloudFront to users of Amazon EC2, Elastic Load Balancing, and more. With Amazon Route 53’s new Latency Based Routing (LBR) feature, you can now have instances in several AWS regions and have requests from your end-users automatically routed to the region with the lowest latency.
Configuring Latency Based Record Sets with Amazon Route 53
DNS record sets hosted on Amazon Route 53 can now be marked as latency based in both the Route 53 API, and the Route 53 tab of the AWS Management Console. If you enter an EC2 instance public IP, Elastic IP, or Elastic Load Balancer target in the Route 53 console it will suggest the correct region for you:
Once you have configured two or more latency based record sets with matching names and types, then the Route 53 nameservers will use network latency and DNS telemetry to choose the best record set to return for any given query.
Behind the scenes, we are constantly gathering anonymous internet latency measurements and storing them in a number of Relational Database Service instances for processing. These measurements help us build large tables of comparative network latency from each AWS region to almost every internet network out there. They also allow us to determine which DNS resolvers those end-users generally use.
Latency Based Routing is available for the "A", "AAAA", "CNAME", "TXT" DNS record types as well as the Route 53 specific "ALIAS to A" and "ALIAS to AAAA" record types.
Pricing
We're introducing Latency Based Routing pricing at $0.75 per million queries, for the first billion queries per month, and $0.375 per million queries for all additional queries in a given month. Queries to latency based Elastic Load Balancer "ALIAS" record sets are free of charge.A Smooth Transition to Latency Based Routing
Today, we're also unlocking another feature in Amazon Route 53. It is now possible to create "ALIAS" records that point to resource record sets within your own Route 53 hosted zone. These ALIAS records act as pointers or arrows in a decision tree, enabling you to compose latency based record sets, weighted record sets and multi-record record sets to address advanced or complex routing scenarios.By combining weighted resource record sets and an alias to a latency based record set, it's possible to have a simple "dial" determining how often latency based routing should be used at first. By starting with a small percentage and gradually increasing that percentage any risks of regional overload or poor user experience can be minimized.
For example, when migrating from a single-region configuration with an instance in the AWS US East (Northern Virginia) region to a latency based routing configuration with instances in both US East (Northern Virginia) and EU (Ireland), we might configure a series of record sets forming a decision tree that resembles the following diagram:
With this kind of configuration, approximately 99% of DNS queries will be unaffected by latency based routing, and users will be directed to the US East (Northern Virginia) answer (192.0.2.1). The other 1% of the time, Route 53 will choose where to send the user based on network latency - some users will be directed to eu-west-1, some to us-east-1 - based on our own global connectivity measurements between the origin of the request and the two AWS regions. Gradually, these percentages can be altered and over time we can transition to a fully latency based decision process.
Combining Latency Based Routing and Weighted Round Robin Record Sets
It is also possible to combine latency based record sets and weighted round robin record sets in the opposite order. For example, you may want to distribute load across several instances in the same region using weighted round robin DNS.In the example below, Route 53 can be configured to first use latency based routing to decide what region to direct a user to, and then if the EU (Dublin) region is selected, to apply a weighted round-robin policy with half of the answers returning 192.0.2.127 and the other half returning 192.0.2.128.
Bonus Scaling Feature: Weighting More Than 100 record Sets and Multi-record Answers
Amazon Route 53 is used by many large-scale web presences and in response to feedback from our customers we're now also enabling weighted round-robin DNS for even larger sets of answers. Until now, weighted resource record sets have been restricted to just one hundred record sets, each with just one record (e.g. IP address) each.Firstly, a weighted "ALIAS" record set is itself now also a valid target for a weighted "ALIAS" record set. This allows for recursive weighted trees of aliases to be created. We allow up to three levels of recursion, permitting up to one million distinct weighted record sets per DNS name.
Secondly, another way to weight more than one hundred records is to create record sets each containing multiple records. For example if you have twenty Elastic IPs hosting your service it may be useful to create five record sets, each containing four IP addresses. If the DNS clients support retries then it is particularly useful to ensure that each record set contains a mix of records from different availability zones. This way, alternatives are available for clients when an availability zone is unavailable.
These kinds of multi-record record sets may now be used with weighted round-robin DNS by again using "ALIAS" records. Multi-record record sets are completely valid as a target for weighted aliases.
You can learn more about Latency Based Routing, aliasing and WRR in the Route 53 documentation.
We are very interested in hearing about how you may use the new Latency Based Routing feature in your business or application. Please take a minute and provide us feedback on this one-question Route 53 survey.
You can also learn more about Amazon Route 53 and the Latency Based Routing feature by registering for our Route 53 webinar (coming up on April 26th at 10AM PST).


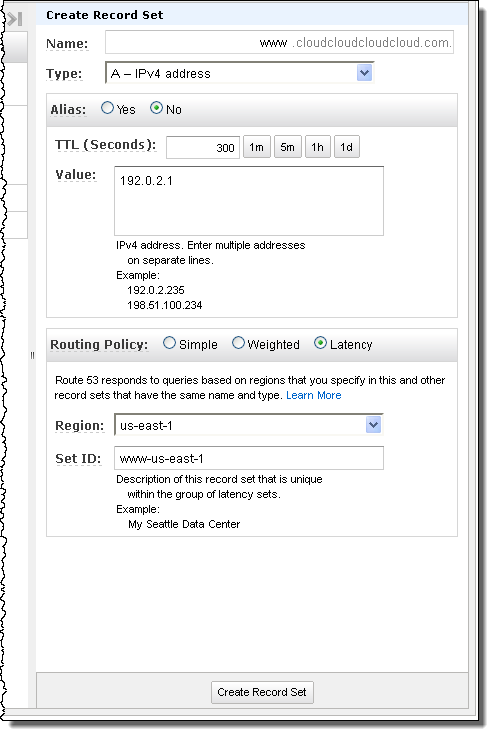
It’s about time. Windows Azure Traffic Manager, which performs the same service, was released as a CTP in April 2011 for MIX 11.
<Return to section navigation list>

















0 comments:
Post a Comment