Windows Azure and Cloud Computing Posts for 3/7/2012
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure Access Control, Service Bus, and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Service
Robbin Cremers (@RobbinCremers) described Everything you need to know about Windows Azure queue storage to build disconnected and reliable systems in a lengthy 3/7/2012 post:
In my attempt to cover most of the features of the Microsoft Cloud Computing platform Windows Azure, I’ve been recently covering Windows Azure blob and table storage. Today I’m reviewing the Windows Azure queue storage, which is often used to build disconnected and reliable systems:
The information about Windows Azure Blob storage:
Everything you need to know about Windows Azure Blob Storage including permissions, signatures, concurrencyThe information about Windows Azure Table storage:
Everything you need to know about Windows Azure Table Storage to use a scalable non-relational structured data storeWhy using Windows Azure storage:
- Fault-tolerance: Windows Azure Blobs, Tables and Queues stored on Windows Azure are replicated three times in the same data center for resiliency against hardware failure. No matter which storage service you use, your data will be replicated across different fault domains to increase availability
- Geo-replication: Windows Azure Blobs and Tables are also geo-replicated between two data centers 100s of miles apart from each other on the same continent, to provide additional data durability in the case of a major disaster, at no additional cost.
- REST and availability: In addition to using Storage services for your applications running on Windows Azure, your data is accessible from virtually anywhere, anytime.
- Content Delivery Network: With one-click, the Windows Azure CDN (Content Delivery Network) dramatically boosts performance by automatically caching content near your customers or users.
- Price: It’s insanely cheap storage
The only reason you would not be interested in the Windows Azure storage platform would be if you’re called Chuck Norris …
Now if you are still reading this line it means you aren’t Chuck Norris, so let’s get on with it.Windows Azure Queue storage is a service for storing large numbers of messages that can be accessed from anywhere in the world via authenticated calls using HTTP or HTTPS. A single queue message can be up to 64KB in size, a queue can contain millions of messages, up to the 100TB total capacity limit of a storage account.
The concept behind the Windows Azure queue storage is as following:
There are 3 things you need to know about to use Windows Azure Queue storage:
- Account: All access to Windows Azure Storage is done through a storage account. The total size of blob, table, and queue contents in a storage account cannot exceed 100TB.
- Queue: A queue contains a set of messages. All messages must be in a queue.
- Message: A message, in any format, of up to 64KB max. You can serialize information into the message
1. Creating and using the Windows Azure Storage Account
To be able to store data in the Windows Azure platform, you will need a storage account. To create a storage account, log in the Windows Azure portal with your subscription and go to the Hosted Services, Storage Accounts & CDN service:
Select the Storage Accounts service and hit the Create button to create a new storage account:
Define a prefix for your storage account you want to create:
After the Windows Azure storage account is created, you can view the storage account properties by selecting the storage account:
The storage account can be used to store data in the blob storage, table storage or queue storage. In this post, we will only cover queue storage. One of the properties of the storage account is the primary and secondary access key. You will need one of these 2 keys to be able to execute operations on the storage account. Both the keys are valid and can be used as an access key.
When you have an active Windows Azure storage account in your subscription, you’ll have a few possible operations:
- Delete Storage: Delete the storage account, including all the related data to the storage account
- View Access Keys: Shows the primary and secondary access key
- Regenerate Access Keys: Allows you to regenerate one or both of your access keys. If one of your access keys is compromised, you can regenerate it to revoke access for the compromised access key
- Add Domain: Map a custom DNS name to the storage account blob storage. For example map the robbincremers.blob.core.windows.net to static.robbincremers.me domain. Can be interesting for storage accounts which directly expose data to customers through the web. The mapping is only available for blob storage, since only blob storage can be publicly exposed.
Now that we created our Windows Azure storage account, we can start by getting a reference to our storage account in our code. To do so, you will need to work with the CloudStorageAccount, which belongs to Microsoft.WindowsAzure namespace:
We create a CloudStorageAccount by parsing a connection string. The connection string takes the account name and key, which you can find in the Windows Azure portal. You can also create a CloudStorageAccount by passing the values as parameters instead of a connection string, which could be preferable. You need to create an instance of the StorageCredentialsAccountAndKey and pass it into the CloudStorageAccount constructor:
The boolean that the CloudStorageAccount takes is to define whether you want to use HTTPS or not. In our case we chose to use HTTPS for our operations on the storage account. The storage account only has a few operations, like exposing the storage endpoints, the storage account credentials and the storage specific clients:
The storage account exposes the endpoint of the blob, queue and table storage. It also exposes the storage credentials by the Credentials operation. Finally it also exposes 4 important operations:
- CreateCloudBlobClient: Creates a client to work on the blob storage
- CreateCloudDrive: Creates a client to work on the drive storage
- CreateCloudQueueClient: Creates a client to work on the queue storage
- CreateCloudTableClient: Creates a client to work on the table storage
You won’t be using the CloudStorageAccount much, except for creating the service client for a specific storage type.
2. Basic operations for managing Windows Azure queues
There are 2 levels to be working with the windows azure queue storage, which is the queue and the messages being passed on to the queue.
To manage the windows azure queues, you need to create an instance of the CloudQueueClient through the CreateCloudQueueClient operation on the CloudStorageAccount:
There are not many interesting operations exposed on the CloudQueueClient, except for these:
- GetQueueReference: Get a CloudQueue instance through the name or the absolute uri of the queue
- ListQueues: List all queues present in the storage account or list all queues present that match a defined prefix
We use the GetQueueReference operation on the CloudQueueClient to get a CloudQueue reference returned. The CloudQueue exposes all the operations we need to manage our Windows Azure queues and the queue messages we will be working with:
The CloudQueue exposes a few operations to manage the queue:
- Clear: Clear all messages from the queue
- Create: Create a Windows Azure storage queue. If the queue already exists, an exception will be thrown
- CreateIfNotExists: Create a Windows Azure storage queue if it does not exists yet. This does not throw any exception if the queue already exists
- Delete: Delete the queue from the storage account
- Exists: Check whether a queue exists in the storage account
- SetMetadata: Set the queue metadata. The queue metadata can be specified through the Metadata property
- FetchAttributes: Load the attributes and metadata to the CloudQueue
Creating a queue and setting metadata for the queue looks like this:
We get the CloudQueue through the GetQueueReference operation, which gets a CloudQueue instance for the queue with the name “orders”. Even if the queue does not exist, this is the default way of working with Windows Azure storage. It will create an object with the necessary information, which allows you to execute operations on. Since the CloudQueue object contains the needed information about the queue, it’s able to build the REST requests that are executed on the Windows Azure storage. We start by checking whether the queue exists and if it does not exist, we will create the queue through the Create or CreateIfNotExists operation.
We store a NameValueCollection in the metadata collection and we store the metadata changes to the storage service through the SetMetadata operation. Finally we fetch the attributes from storage to our local CloudQueue instance through the FetchAttributes. It’s highly advised to invoke the FetchAttributes operation before trying to retrieve attributes or metadata on the CloudQueue.
For almost every synchronous operation there is an asynchronous operation exposed. Asynchronous operations is exposed through the Begin/End operations:
You could achieve the same by using lambda expressions:
However we will not be covering the asynchronous operations anymore, but we’ll go by the synchronous operations throughout this post. However it is highly recommended to use the asynchronous operations to provide better a better user experience and better throughput / performance.
To explore my storage accounts, I use a free tool called Azure Storage Explorer which you can download on codeplex:
http://azurestorageexplorer.codeplex.com/After having created the Windows Azure queue, it should be visible in the storage explorer:
Managing messages on the queue through the CloudQueue:
- AddMessage: Add a message to the queue
- DeleteMessage: Delete a message from the queue
- GetMessage: Get the next message from the queue. The message is being pulled from the queue and will be invisible for some duration for other receivers
- GetMessages: Get a specified number of messages from the queue. The messages are being pulled from the queue in a single request and will be invisible for some duration for other receivers
- PeekMessage: Get the next message from the queue in peek mode, meaning the message will stay visible to other receivers
- PeekMessages: Get a specified number of messages from the queue, meaning the messages will stay visible to other receivers
- UpdateMessage: Update the content or visibility time of a message in the queue
Adding a message to the queue is done by creating a CloudQueueMessage and adding it with the AddMessage operation. For each order that is being made, we will post the order to the orders queue. A processing service will be picking the orders off the queue and process them. Our Order class looks like this:
Since we will be serializing the object instance to binary format, it has to be marked with the Serializable attribute. You could also serialize it to XML, but that would make the payload of the message bigger and considering the maximum message size is 64 KB, we want our payload to be as small as possible.
I also have some extension methods for the Order class to serialize it to binary:
If you do not know what extension methods are and what they are used for, you can find information here:
Implementing and executing C# extension methodsAdding a message to the queue is done like this:
We create a new CloudQueueMessage which either takes a binary array or a string as content. Adding the message to the Windows Azure queue is done by the AddMessage operation, which takes a few parameters in some operation overloads:
- Content: Take either a byte array or string as content
- TimeToLive: Allows you to define Timespan to define how long the image can stay on the queue before it expires. A message can only live for a maximum of 7 days on the Windows Azure queue
- InitialVisibilityDelay: Allows you to define how long the message will be invisible for receivers after the message has been added to the queue. If you do not pass this value, the message is immediately visible for the receivers. If you define a Timespan, the message can only be received by a receiver after the delay has expired. This is a great feature when you add a message to a queue but you want it to be processed somewhere in the future instead of immediately. You specify a visibility delay of 1 day for example, and the message will only be processed after 1 day.
After adding the message to the queue, it’ll be visible in the storage explorer:
The message expiration time is set to 5 min from now, which I specified in the AddMessage operation.
I also added an extension method to serialize a CloudQueueMessage content back to an Order instance:
Reading a Order message from the queue:
We use the GetMessage operation to get a message from the queue. Retrieving the message with the GetMessage operation will pull the message from the queue and set it invisible for other receivers, so that other receivers can not retrieve the message during that time. The GetMessage has one operation overload with a visibility timeout you can pass along:
- VisibilityTimeout: Allows you to define a Timespan to define how long the message will be invisible after you retrieved it from the queue. If you do not pass this parameter,the default visibility timeout is 30 seconds. The behavior allows you to keep the message from being processed by other receivers while you are processing it.
The default visibility timeout is 30 seconds, meaning that after you get the message through the GetMessage operation it will be invisible for 30 seconds to the other receivers. If the message has not been deleted through the DeleteMessage operation within that time span, it will reappear on the queue and the Dequeue Count will be updated:
It will stay on the queue until some receiver receives the message or the message expires. The Dequeue Count comes into play so that you can avoid retrieving and attempting to process the message unlimited. This behavior allows you to receive a message from the queue, attempt to process it and after processing it, deleting it from the queue. If an error would occur during the processing of the message, the deletion of the message will not be invoked and the message will reappear in the queue after the visibility timeout expires, with an increased dequeue count.
Receiving a message properly with the GetMessage and DeleteMessage operations:
PS: In forgot to check whether the cloudQueueMessage is not null before I access the DequeueCount. You might want to check that in your production code obviously.
We retrieve the message from the queue with an invisibility timeout of 5 minutes. Through the DequeueCount property on the CloudQueueMessage we check whether the dequeue count of the message is less or equal then 3. We do this to make sure we don’t keep endlessly processing the same message over and over. If we attempted to process the message 3 times and it has not been processed yet it would mean there is an issue, so we would have to notify the administrator about this message and remove the message from the queue so it does not keep getting processed.
If we processed the message, we delete the message from the queue through the DeleteMessage operation. If you do not do this, the message will reappear when the 5 minutes of the invisibility timeout are passed and the message would be processed again by some receiver.
The ToXML operation on the order is an extension method again:
Ideally you would write this operation in a generic extension method, to be working with a type T instead of a fixed type.
I set the check of the dequeue count to less or equal to 3, so the message at least gets 3 attempts to be processed. As soon as you retrieve the message from the queue, the dequeue count will immediately be set to 1. That means if you would want to check whether a message can only be processed once, even if it would fail, you would have to check whether the dequeue count is equal to 1 and not 0.
Using the GetMessages operation is pretty much equal to the GetMessage operation. The GetMessages operation takes an additional parameter, which is an integer defining how many messages you want to retrieve in a single operation. The concepts behind processing and deleting the messages are the same. For example if you retrieve 10 messages at once with the GetMessages operation and you do not pass an invisibility timeout, the 10 messages will be retrieved and will be invisible on the queue for 30 seconds after retrieval time. This means if you do not manage to process the 10 messages within the next 30 seconds, some messages will reappear on the queue and might get processed again by another receiver, which could result in duplicating the workflow. The invisibility timeout has to be properly considered when retrieving messages from the queue.
One of the possibilities is to peek messages on the queue. When you retrieve a message from the queue with PeekMessage, the message is not dequeued and the visibility of the message remains unchanged. The DequeueCount is also not increased when retrieving a message with PeekMessage or PeekMessages. Using Peek mode to retrieve messages results that you can not delete the message, because you are basically peeking and not retrieving. The message remains available to other clients until a client retrieves the message with a call to GetMessage.
Using PeekMessage or PeekMessages could be particularly interesting if you want to look or search for a message in the queue, without changing the messages dequeue count and popreceipt values.
3. Saving storage transaction costs by using smart queue polling
By default, when polling messages from a queue you’ll be writing some code like this:
You will write an endless loop where we queue for messages. If there is a message present, we will process it and loop again to get the next message. If there is no message present anymore, we will wait for some period of time to attempt to check the queue again for a message. You’ll be using Thead.Sleep or a Timer to build your interval to wait to query the queue again.
However one thing to keep in mind with Windows Azure storage is that you pay for each transaction to the storage. This means every transaction to the queue, to receive a message, is billed. This comes from the windows azure pricing information:
The price for the storage transactions is cheap, but it’s pointless to pay for something that is wasted. Let’s suppose you have 3 worker roles which are processing orders from the queue. Every worker role is attempting to retrieve a message from the queue every 1 second, which is a common scenario. In 1 day that are 86.400 storage transactions for 1 worker role to the queue, even if there isn’t a single message in the queue. For 3 worker roles that ends up at 259.200 storage transactions in 1 day, while there was nothing in the queue at all. After all this is only 0,25$ for those transactions, but why waste the money and the bandwith while it’s not necessary. Please note when processing messages the transactions amount might increase since you’ll be using more operations like PeekMessage, DeleteMessage and so forth.
One of the common scenario’s to solve this is using a polling mechanism which will gradually increase every time you poll the queue and no message is found, until it reaches the maximum polling interval:
You basically specify a maximum interval time to poll the queue. When we receive a message from the queue, the current interval polling time is set to 0 and there will be no wait used. Immediately after the message is retrieved from the queue, we will try to get the next message from the queue. If no message is retrieved, which means there are no messages on the queue, we will increase the current interval every time we poll until it’s equal to the max interval we specified. We will start by polling with a 1 second interval, then 2 seconds, then 3 seconds until we reach the maximum of 15 seconds on which it will keep polling as long there are no messages in the queue. If all day no orders would be put in the queue, the storage transactions would already be divided by 15. As soon a message is received, the interval is set to 0 again, meaning that on the next request no message is received, the next polling request will be after 1 second again and it’ll start building up again to the maximum interval.
The polling interval would look like this:
As soon as a message is received, it’ll start polling the queue again on a shorter interval, which will increase more over time as long no message is retrieved. You can use any interval and any interval increase you want, as long as you keep in mind that storage transactions are billed and saving money where possible is advisable. Cutting down on storage transactions with queue polling is an easy effort.
4. Handling messages that exceed the maximum 64 KB message size
At some point you might want to transfer messages over the queue that are larger then 64 KB, for example every time a user uploads an image on the website, we want to drop a message in the queue for this image, which a background worker will pick up and process the image to create a few different size thumbnails.
However adding the image binary into the message will pass the maximum message size, so it would fail. A solution to this is to store the image in blob storage and pass the blob name or blob uri in the message we sent in the queue. The receiver then has to retrieve the image from blob storage and process the image to create the thumbnails.
If you are working with structured data, like the Order class, you could easily store the order in Windows Azure table storage and pass the partition and row key in the message send over the queue. Then the background worker processing the orders would receive the order again from the table storage through the partition and row key.
If you do not know about table or blob storage, you can find all the information here:
Everything you need to know about Windows Azure Blob Storage including permissions, signatures, concurrency
Everything you need to know about Windows Azure Table Storage to use a scalable non-relational structured data storeA simple example to upload the image to blob storage and send a queue message. Imagine if we want to handle an image of 262 KB, which is too big to send within the message on the queue:
We upload the image to blob storage with a specified name, which in our case is a generated guid. Then we create a new CloudQueueMessage and send it on to the queue with as content the guid of the blob image we uploaded.
The code for the background worker which processed the messages:
We retrieve the CloudQueueMessage content, which is the blob name of the image that got uploaded. In the background worker we simply retrieve the image again from blob storage then to process it to create the thumbnails.
Executing these operations after each other:
5. Extending the invisibility timeout of a message on the queue
A scenario that could be is that you retrieve a message from the queue with an invisibility timeout of 1 minute. After you processed the information of the message, it appears this is a message that needs to take a few extra steps to be processed, compared to the default message. This message could take up to 5 or 10 min to process instead of the 20 or 30 seconds it takes to process a normal message.
However since we retrieved this message with an invisibility timeout of 1 minute, the message will reappear in the queue after 1 minute, even though it takes a lot longer to process the message. So during processing the message, it will reappear for the other receivers, which could retrieve and start processing the message as well, which would end up in duplicate workflow and a lot of issues.
This is where the ability to extend the invisibility timeout of a message on the queue comes in, which can be done by the UpdateMessage operation on the CloudQueue object:
The UpdateMessage operation takes 3 parameters:
- CloudQueueMessage: The message we want to update in the queue
- InvisibilityTimeout: Allows us to define a new timespan for how long the message should be invisible
- MessageUpdateFields: An enumeration with possible values of Visibility or Content. You always need to pass Visibility, but you can also pass Content together to also update the content of the message
We update the CloudQueueMessage and we set the invisibility timeout to 60 minutes from now, so our worker has enough time to process this message. That way the message would not become visible again on the queue while we are processing it.
6. Storage queues versus service bus queues
There is also a possibility to use Windows Azure service bus queues, which is also a queuing mechanism provided by the service bus. However there are some important differences between Windows Azure storage queues and Windows Azure service bus queues. I’ll cover only some of the more important differences between both to base your decision on for what type of queue to use.
You can find the differences in detail here:
http://msdn.microsoft.com/en-us/library/windowsazure/hh767287(v=vs.103).aspx
The service bus queue supports the following features the storage queue does not:
- It supports order delivery guarantee
- It supports duplicate detection, which is the At-Most-Once delivery guarantee
- It supports long polling requests for receiving a message
- It allows to send multiple messages in a single batch to the queue, saving on transaction costs
The service bus queue supports the following features the storage queue does not:
- It supports automatic dead lettering, which is very useful
- It supports to relate messages to each other through sessions
- It supports duplicate detection
- It supports WF and WCF integration
The storage queue has few features the service bus queue does not have:
- You can request storage metrics for the queue
- There is a function to clear the entire queue from all messages
This is where things get interesting. The storage queue supports a maximum message size of 64 KB while the service bus queue supports 256 KB. The storage queue can have a maximum queue size of 100 TB, while the service bus queue can only have a maximum queue size of 5 GB. However, the storage queue only allows messages to live for a maximum of 7 days, while this is unlimited for the service bus queue.
The service bus queue has a lot more possibility to authenticate users or applications against, while the storage queue does not.
Deciding between what queue you want to use is depending on the requirements of the application. But the Windows Azure service bus queue is a queue designed for messaging integration.
When to use the Windows Azure storage queue:
- Your application needs to store over 5 GB worth of messages in a queue, where the messages have a lifetime shorter than 7 days.
- Your application requires flexible leasing to process its messages. This allows messages to have a very short lease time, so that if a worker crashes, the message can be processed again quickly. It also allows a worker to extend the lease on a message if it needs more time to process it, which helps deal with non-deterministic processing time of messages.
- Your application wants to track progress for processing a message inside of the message. This is useful if the worker processing a message crashes. A subsequent worker can then use that information to continue where the prior worker left off.
- You require server side logs of all of the transactions executed against your queues.
However as soon as you need some features like messages with a lifetime longer then 7 days, duplicate detection or dead lettering, then service bus queues are the way to go. If you can manage with the storage queue, then use the storage queue. In general, using a service bus queue will be more expensive then using a storage queue, but it provides you with more features for reliable messaging and messaging integration.
You can find an example of Windows Azure topic/subscription queuing mechanism here:
Windows Azure service bus messaging with publish/subscribe pattern using topics and subscriptionsAny suggestions, remarks or improvements are always welcome.
If you found this information useful, make sure to support me by leaving a comment.






































Benjamin Guinebertière (@benjguin) posted HADOOP, HIVE, ODBC, SSIS, SQL Azure, SQL Azure Reporting on 3/6/2012:
In a previous post, I talked about analyzing 1 TB of IIS logs with JavaScript thru Hadoop Map/Reduce. In this post, let’s see how to copy and use the result of these jobs to SQL Azure.
First of all, from 1 TB of IIS logs, we had a result of less than 100 GB for the headers and details, so having this data in SQL Azure (or SQL
Server) will be more efficient than keeping it in Hadoop: Hadoop Map/Reduce is a world of batches that can handle bigger and bigger amounts of data linearly while SQL Azure is interactive (but requires SQL Azure federations to scale linearly).
The steps are the following:
- create a SQL Azure database
- create HIVE metadata
- open ODBC port
- install ODBC driver
- create SSIS package
- Run SSIS package
- Create and run a SQL Azure Report on top of databaseCreate a SQL Azure database
A SQL Azure database can be created as explained here.
Note that if one already has a SQL Azure database, he can reuse it but he might have to change its size. For instance to let a SQL Azure database grow from 1 GB to 150 GB, the following statement should be issued against the master database in the same SQL Azure server:
ALTER DATABASE demo MODIFY (MAXSIZE = 150 GB, EDITION='business')
Create HIVE metadata
HIVE can store its data in HDFS with a variety of format. It can also reference existing data without directly managing it. This king of storage is called external tables. In our case, we want to expose the iislogsH and iislogsD HDFS folders as HIVE tables. Here how the folders look in HDFS:
(…)
(…)
js> #tail iislogsH/part-m-00998
731g2x183 2012-01-25 19:01:05 2012-01-25 19:22:11 16
872410056 a34175aac900ed11ea95205e6c600d461adafbac test1833g4x659 2012-01-27 13:23:31 2012-01-27 13:39:28 4
872410676 a34182f009cea37ad87eb07e5024b825b0057fff test1651hGx209 2012-01-28 18:05:45 2012-01-28 18:41:37 7
872411200 a341afd002814dcf39f9837558ada25410a96669 test2250g4x61 2012-01-27 01:04:45 2012-01-27 01:23:19 5
872412076 a341b71e15a5ba5776ed77a924ddaf49d89bab54 test4458gAx34 2012-02-02 19:00:07 2012-02-02 19:09:12 10
872412288 a341c30edf95dfd0c43a591046eea9eebf35106e test2486g4x352 2012-01-27 17:05:52 2012-01-27 17:27:54 2
872412715 a341cb284b21e10e60d895b360de9b570bee9444 test3126g2x205 2012-01-25 13:07:47 2012-01-25 13:49:20 4
872413239 a341cc54e95d23240c4dfc4455f6c8af2a621008 test0765g7x99 2012-01-30 00:08:04 2012-01-30 00:43:17 5
872414168 a341d37eb48ae06c66169076f48860b1a3628d49 test0885g4x227 2012-01-27 18:02:40 2012-01-27 18:11:12 11
872414800 a341d8762f0d7e1e70ced16ce10786ea50ef3ca7 test2471hHx165 2012-01-29 20:00:58 2012-01-29 20:40:24 6js> #tail iislogsD/part-m-00998
9 a341d8762f0d7e1e70ced16ce10786ea50ef3ca7 20:40:24 /
872414323 a341d8762f0d7e1e70ced16ce10786ea50ef3ca7 20:07:49 /cuisine-francaise/huitres
872414402 a341d8762f0d7e1e70ced16ce10786ea50ef3ca7 20:00:58 /cuisine-francaise/gateau-au-chocolat-et-aux-framboises
872414510 a341d8762f0d7e1e70ced16ce10786ea50ef3ca7 20:29:52 /cuisine-francaise/gateau-au-chocolat-et-aux-framboises
872414618 a341d8762f0d7e1e70ced16ce10786ea50ef3ca7 20:39:51 /Users/Account/LogOff
872414692 a341d8762f0d7e1e70ced16ce10786ea50ef3ca7 20:09:52 /cuisine-francaise/gateau-au-chocolat-et-aux-framboises
872414900 a341db58e7be1b37828ed5591ba17c251c96a16a 03:00:23 /Modules/Orchard.Localization/Styles/orchard-localization-base.css
872415019 a341db58e7be1b37828ed5591ba17c251c96a16a 03:00:57 /Users/Account/LogOff
872415093 a341db58e7be1b37828ed5591ba17c251c96a16a 03:00:12 /Themes/Classic/Styles/Site.css
872415177 a341db58e7be1b37828ed5591ba17c251c96a16a 03:00:56 /
872415231 a341db58e7be1b37828ed5591ba17c251c96a16a 03:00:44 /Core/Shapes/scripts/html5.jsThe following statements will expose the folders as HIVE external tables:
CREATE EXTERNAL TABLE iisLogsHeader (rowID STRING, sessionID STRING, username STRING, startDateTime STRING, endDateTime STRING, nbUrls INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/user/cornac/iislogsH'CREATE EXTERNAL TABLE iisLogsDetail (rowID STRING, sessionID STRING, HitTime STRING, Url STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/user/cornac/iislogsD'These statements can be entered in the HadoopOnAzure portal
Ces requêtes peuvent être entrées dans le portail HadoopOnAzure
It is possible to check that data is exposed thru HIVE by issuing this kind of statement. Note that using SELECT * will not generate a map/reduce job because there is no need to change data before returning it.
SELECT * FROM iislogsheader LIMIT 20
SELECT * FROM iislogsdetail LIMIT 20
Open ODBC port
ouvrir le port ODBCFrom HadoopOnAzure portal, go to the Open Ports tile and make sure ODBC port 10000 is open
Install ODBC driver
On the server where SSIS will run, there must be the HIVE ODBC driver installed.
It can be installed from the HadoopOnAzure portal, by clicking the “Downloads” tile and choosing the right MSI:
Create an SSIS Package
A general guidance on how to create an SSIS package to fill SQL Azure is available here.
The user DSN (ODBC entry) can be created from Windows Control Panel.
In order to connect to HIVE thru ODBC, one should usein SSIS ODBC driver for ADO.NET
By default, the number of allowed errors is 1. You may want to change this value, by selecting the data flow, then the control flow and changing its MaximumErrorCount property.
One could also change timeouts.
While creating the package, you will get a chance to have the destination tables created automatically. Here are the resulting tables schemas in SQL Azure (as screenshots).
As Hadoop map/reduce may generate rowid duplicates in our case, the constraint on rowid will be removed by droping and recreating the tables with the code provided here (change is underlined). The principle is to leave original rowid on Hadoop cluster and create new ones in SQL.
DROP TABLE [dbo].[iislogsheader]
GOCREATE TABLE [dbo].[iislogsheader](
[rowid] bigint IDENTITY(1,1) NOT NULL,
[sessionid] [nvarchar](334) NULL,
[username] [nvarchar](334) NULL,
[startdatetime] [nvarchar](334) NULL,
[enddatetime] [nvarchar](334) NULL,
[nburls] [int] NULL,
PRIMARY KEY CLUSTERED
(
[rowid] ASC
)
)
DROP TABLE [dbo].[iislogsdetail]
GOCREATE TABLE [dbo].[iislogsdetail](
[rowid] bigint IDENTITY(1,1) NOT NULL,
[sessionid] [nvarchar](334) NULL,
[hittime] [nvarchar](334) NULL,
[url] [nvarchar](334) NULL,
PRIMARY KEY CLUSTERED
(
[rowid] ASC
)
)It will also be necessary to remove the link between source and destination rowid columns as they are independent.
Run SSIS Package
The SSIS package can be depoyed and run. In this sample, it is run from the debugger (F5 in Visual Studio).
Le package SSIS peut être déployé et exécuté. Dans cet exemple, on le lance depuis le débogueur (F5 dans Visual Studio).
Create and run a SQL Azure Report
A report can be built on top of this SQL Azure database as explained here.
For instance, the report designer looks like this
and the report looks like this




























<Return to section navigation list>
SQL Azure Database, Federations and Reporting
R. Syam Kumar described Moving SQL Azure Servers Between Subscriptions in a 3/7/2012 post to the Windows Azure blog:
This feature has been requested by many customers and fulfills multiple scenarios. For example, customers can now move their SQL Azure servers and databases in that server from a trial or introductory subscription to a different subscription that hosts their production services and resources. Another example use case is when a monetary or resource usage cap has been reached for a subscription and the customer wants to move the SQL Azure server and database resources to another subscription. Yet another example is when customers want to consolidate different SQL Azure servers and databases under a single subscription. With this new feature, customers can now easily accomplish this task using the Windows Azure Management Portal.
Who can use the Move Server Feature?
To move SQL Azure servers between subscriptions you need to be an account administrator, service administrator or a co-Administrator for both the source and target subscriptions. Please refer to the MSDN documentation to understand more about subscription management in Windows Azure.
How to Use the Move Server Feature
Once you login to the Windows Azure Management Portal and navigate to the “Database” section, you will see a new “Move Server” button in the Server Information pane. See Figure (1) below. As you can see in the Figure (1) below, you can see the various subscriptions for which you are a service administrator in the top left pane where the subscriptions, SQL Azure servers and the databases are listed.
Figure (1) – The Move Server button in the Server Information pane
Clicking on the button brings up a dialog that has a drop down selector which enables you to select the target subscription from all of your available, active subscriptions for which you are a service administrator. Select the subscription that you want the server moved to and click “OK”. See Figure (2).
Figure (2) – Move Server dialog
In a few seconds the portal will refresh and you will see the SQL Azure server you moved now listed under the target subscription. See Figure (3) where subscription “Azure Sandbox2 User 0389” has the SQL Azure server and the database that was moved.
Figure (3) – Server moved to new subscription
Moving a SQL Azure server does not involve a physical move of your SQL Azure server or databases (remember that a SQL Azure “server” is always a logical server which contains your databases that have multiple replicas for high availability). The SQL Azure server and the databases continue to be hosted within the same region/data center, and applications that use the databases on the moved server will continue to operate as normal since connection information remains the same. The move only changes the association of the SQL Azure server from one subscription to another. Please be aware of the impact to your bill as different subscriptions may be billed based on different offers that they are associated with.



Liam Cavanagh (@liamca) continued his Cotega series with What I Learned Building a Startup on Microsoft Cloud Services: Part 8 – I failed to plan for failure on 3/7/2012:
I am the founder of a startup called Cotega and also a Microsoft employee within the SQL Azure group where I work as a Program Manager. This is a series of posts where I talk about my experience building a startup outside of Microsoft. I do my best to take my Microsoft hat off and tell both the good parts and the bad parts I experienced using Azure.
What I did not plan for, was the case when Windows Azure itself became unavailable. When I first learned of the outage, my first thought was that maybe it was a bad idea to rely so heavily on the cloud for my service. But soon after I realized that this was really just a failure on my part, not on the cloud. All services will have issues at some point in time. This is true regardless of whether they are in the cloud or on premises. I had not considered all critical failure scenarios. Not only did I not have a solution to handle failures like this, I did not even know about the failure until I read about it in the news. In the back of my mind I had always thought either Windows Azure or a customer would notify me if there was an issue like this, but even if they had, this would not have helped me automatically handle the failure. What I took away from this is that I needed to automate the failover of the monitoring service. To do this I would need to set up a separate application to watch my worker roles. Since pinging worker roles is disabled by default and I prefer to avoid opening up this port, the next best thing seems to be to check the logging table from a machine outside of the Windows Azure data centers. If there were no entries in the log table in last 5 minutes, then there must be an issue and it would then:
- Send me an email and SMS notification of the failure
- Start running the monitoring from a separate location
Then once Windows Azure was back up and running, I could reset this tool back to the state of pinging the worker roles and disable monitoring from this separate location. Luckily, the monitoring service is built to handle multiple instances of the monitoring service running at the same time, so when Windows Azure comes back up, the separate monitoring service will just work in parallel to it until I shut it down. The only problem I still need to handle is the case where Windows Azure queues becomes unavailable as this is a central service that is needed by my service. I’ll have to think about how to handle this failure a little more. In any case, this was a really good test for me to learn from a major service failure and I think this will ultimately make the final service more more solid.

<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
Jake McTigue wrote Predictive IT Analytics for InformationWeek::Reports, who published it on 3/7/2012:
Manufacturing, financial, retail, and pharmaceutical companies have long used predictive analytics for everything from anticipating parts shortages to calculating credit scores. But across industries, the software can also warn IT organizations about potential system failures before they affect the business.
For enterprise IT, we’re not advocating all-purpose analytic workbenches that demand deep, and expensive, data mining and statistics expertise. Rather, we’re recommending that organizations consider a focused analytics suite, such as Hewlett-Packard’s Service Health Analyzer, IBM’s SPSSpowered Tivoli product, Netuitive’s eponymous offering, and systems from the likes of CA and EMC. All these products come with ready-made dashboards, reports, alerts, and key performance indicators set up for IT system and application measurement and prediction.
About the Author
Jake McTigue is the IT manager for Carwild Corp. and a senior consulting network engineer for NSI. He is responsible for IT infrastructure and has worked on numerous customer projects as well as ongoing network management and support throughout his 10-year consulting career.
Ted Kummert posted The Data Explosion – Making Sense of it All to the Official Microsoft Blog on 3/6/2012:
The rapid growth of data volume presents a real opportunity. It’s also a challenge that most organizations are either wrestling with now, or soon will be. As the cost of storing data continues to fall and cloud-hosted storage is increasingly adopted, more IT organizations are transitioning to a “save everything” or ”save more” approach. Accordingly, the question of what to do with all this “big data” comes up frequently in IT conversations.
However, big data by itself glosses over the real story. While most industry talk today focuses on the mechanics of data collection and storage, the opportunity lies in deriving actionable insights from the data you have. Data is an incredibly valuable asset whose value grows and grows as you’re able to gain insight from it.
To obtain actionable insights from data of every type and size – including unstructured data such as video files, social media streams and Web logs – you need a data platform that can store, manage and analyze all of your information. This includes business-critical relational databases and data warehouses, as well as data from inside the organization and in the cloud. But a modern data platform goes a step beyond, offering a set of tools to analyze both structured and unstructured data and deliver insights that everyone can easily interpret and act upon.
Infographic: In 2011, an estimated 1.8 zettabytes (1.8 trillion gigabytes) of information was created and replicated: See larger version.
Today, that modern platform is here, with our release to manufacturing of SQL Server 2012. It’s more scalable, more reliable and delivers greater performance than ever before. It also includes Power View, our industry-leading business intelligence functionality. Power View provides users with a powerful interactive capability that transforms the exploration of any data, anywhere, into a more natural, immersive experience. Ultimately this encourages better decision-making – a significant benefit, with massive implications in today’s era of big data. Take a look at the numbers: Microsoft customers are already working with vast amounts of complex data to create insights that drive business value.
With today's release of SQL Server 2012, now more than ever Microsoft is helping customers manage any data, any size, anywhere, with a data platform and tools that can extract valuable insights that lead to action. To learn more about SQL Server 2012, including the new features and benefits that are delivered in this release, visit our virtual launch event that kicks off tomorrow at www.SQLServerLaunch.com.
Ted Kummert is corporate vice president of the Business Platform Division (BPD) within the Microsoft Server and Tools Business at Microsoft Corp. Kummert leads the product strategy for products such as Microsoft SQL Server, Microsoft SQL Azure, Microsoft BizTalk Server, Windows Server AppFabric and Windows Azure platform AppFabric, Windows Communication Foundation and Windows Workflow Foundation.

PRWeb asserted DMTI (@DMTI_Spatial) solution hand-selected for DataMarket due to proven expertise in Canadian Location Intelligence in a deck for a DMTI Announces Location Hub® for Microsoft SQL Server Data Quality Services press release of 3/6/2012:
DMTI Spatial Inc. (DMTI), Canada’s leading provider of Location Intelligence solutions, has announced the release of Location Hub® for Microsoft SQL Server Data Quality Services, which is a part of the Windows Azure Marketplace Data Quality Services (DQS). Microsoft hand-selected solution providers with proven domain expertise for the DataMarket, with DMTI being only one of six initial providers and the only Canadian-based company. DMTI was chosen due to its strong reputation for excellence in the field of Location Intelligence and address management. The DMTI solution will aid SQL Server 2012 users by allowing them to clean, validate and enrich their Canadian address data.
Microsoft SQL Server 2012 Data Quality Services is a user-driven, computer-assisted solution to identify incorrect or incomplete data and modify, remove, or enrich that data to resolve data quality issues. DQS embraces the expert business knowledge of users, and rather than attempting to replace business users, DQS assists users' data cleansing operations enabling them to become data stewards.
“SQL Server 2012 gives customers the tools they need to quickly unlock breakthrough insights with managed self-service data discovery across structured, unstructured, and cloud data sources,” said Jim Karkanias, Partner Director PM, Information Services, Microsoft. “Now, through the Windows Azure Marketplace Data Quality Services, customers can access DMTI’s data quality software solution to take advantage of proven Canadian Location Intelligence.”
“Being selected product of choice for SQL Server 2012 Data Quality Services once again demonstrates DMTI’s reputation as a leading provider in the Location Intelligence market with respect to data quality,” said John Fisher, CEO, DMTI. “Some of the largest companies in the world utilize SQL Server for their most important business. We are proud to now offer access to DMTI’s Location Hub via the DQS to help customers gain more insight from their Canadian address data and make key business decisions.”
On March 22, 2012, DMTI and Microsoft will be hosting a complimentary webinar to provide an overview of Location Hub for Microsoft SQL Server Data Quality Services. The webinar will feature speakers from DMTI and Microsoft and will feature a question and answer session. To register for this webinar, visit http://offers.dmtispatial.com/MicrosoftSQLServerDQS_lp.html
For more information regarding DMTI Location Intelligence solutions please visit http://www.dmtispatial.com

<Return to section navigation list>
Windows Azure Access Control, Service Bus and Workflow
Scott Densmore (@scottdensmore) reported Thinktecture.IdentityModel.* on GitHub in a 3/6/2012 post:
Thinktecture.IdentityModel.* on GitHub: "
I uploaded Thinkecture.IdentityModel (core) and Thinktecture.IdentityModel.Web (WCF Web Programing Model) to github.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
The Data Explorer Team (@DataExplorer) described Consuming “Data Explorer” published data feeds in Visual Studio primer (Part 2: Consuming an authenticated feed) in a 3/7/2012:
In Part 1, we discussed the basics of creating a simple, unsecured data feed consumable by Visual Studio (VS). A possibly more interesting and realistic scenario could be to consume feeds that have been secured via a feed key, so that only intended users can access the published data. The experience of publishing and programmatically consuming data from Microsoft Codename “Data Explorer” continues to be a work in progress, but in this post we will take on a way to allow such consumption of protected feeds.
1. Ensuring the published mashup is set up to be consumable
Note that the same data type restrictions from our previous example apply:
- Resources with Time, Duration, DateTimeOffset, and Geospatial data types are not yet importable.
- Exposed service operations returning keyed-table types will import correctly but the service operations will be ignored.
- Exposed service operations returning tables without keys, or that require parameters, will fail the VS import.
- Currently tables with navigation properties will fail the import, but a fix for this is forthcoming.
After saving the mashup, and publishing it, we now choose to have only our workspace consumers to the publish page.
The publish page will now feature a feed key as well as a feed link. We will use both of these to add a service reference and consume the data programmatically in VS.
2. Consuming a secured feed in Visual Studio
Just as in our previous post consuming an open feed in VS, you will need to be sure that the Microsoft WCF Data Services October 2011 CTP (link to http://www.microsoft.com/download/en/details.aspx?id=27728) is installed.
2.a. Adding an authenticated service reference in Visual Studio
In your VS project, right-click on Service References to Add Service Reference in much the same way as for an unauthenticated feed. Enter the feed link from the Data Explorer publish page into the Address box (make sure they match exactly) and click Go. When prompted, agree to authenticate the request and send the credentials. In the user name and password pop-up dialog, enter any non-blank, non-empty string (no whitespaces… “foo” works well J) as the user name and the feed key as the password. Make sure you enter the feed key without any extra spaces or other characters.
You should then see that the service was successfully added.
Note that even though you provided credentials (the feed key) when adding the service reference, the code you write will also need to provide credentials when it wishes to query data from the secured feed.
2.b. Using the secured service reference in a console application
In addition to the classes and “using” statements we employed in the code to access an unsecured feed, providing authentication information will require a couple of additional .NET Framework C# classes:
- System.Net.NetworkCredential (link to http://msdn.microsoft.com/en-us/library/system.net.networkcredential.aspx) to provide the credential information to the feed; and
- System.Security.SecureString (link to http://msdn.microsoft.com/en-us/library/system.security.securestring.aspx) to provide the actual feed key to the NetworkCredential constructor.
Here is a very simple console program to consume the above feed (VS project can be downloaded here):
Remember that, as with the unauthenticated feed consumption sample code, the “EntityCatalog”and “EntityType0” references can be resolved via the “Resolve” context menu option. Note also that the new column names (“DateOfBirth” and “TaxID”) are now available to access those columns from each element. These can be seen in the corresponding feed metadata (accessible by adding “/$metadata” to the feed link).
The above code, when compiled and run, will output the data in the table from our simple mashup.
This pattern can again be extended to extract data from more complex data feeds.
Support for programmatic consumption using VS is still a work in progress, and we welcome feedback on your experience of unlocking and consuming the data generated in Microsoft Codename “Data Explorer”. Let us know your thoughts and continue to check in as we make it easier to publish and make the most of your data.
3. Some additional troubleshooting FAQs
The above steps should allow you to create a service reference and pull data from your feed-key secured feed. Here are a couple of additional issues that may come up; have a look to see if they help, or post a reply with more specific issues you find.
3.a. Why am I sometimes asked for credentials when navigating to the feed link or metadata link?
Bear in mind that unlike the “available to everyone” feeds in our previous example, a protected feed’s link and metadata link will require credentials even when navigating to it when using a Web browser unless you are already logged into “Data Explorer”. Keep this in mind when pointing others to use your feed: they will need to provide the feed key even to access the metadata (which may be necessary to understand the underlying structure of the data and to properly query the feed). Remember: any non-blank, non-empty string will suffice for the user name, and the feed key is the password.
3.b. Why do I get an unhandled DataServiceQueryException when running the sample program?
This particular unhandled exception could be tied to not creating a NetworkCredentials object to authenticate against a secured feed. Try double-checking that the credentials are being set in the code as well as when adding the service reference.
4. Resources used in this post
* Because this feed is protected, there is no publicly available publish page.
* The protected feed link used for this post is available at https://ws32842467.dataexplorer.sqlazurelabs.com/Published/Protected%20publish%20to%20VS%20test/Feed
* The feed key is: “eq3hCprmxKRbBF0yGgBowT/2FApv7I7jExA2gEHUBexd” (without the quotes)
* The sample project can be found here.











For details about my experiences with Codename “Data Explorer,” see:
- Microsoft cloud service lets citizen developers crunch big data (1/24/2012)
- Problems with Microsoft Codename “Data Explorer” - Aggregate Values and Merging Tables - Solved (12/30/2012)
- Mashup Big Data with Microsoft Codename “Data Explorer” - An Illustrated Tutorial (12/27/2012)
Ben Martens (@benmartens) recommended that you Learn about the Data Explorer weekly release process in a 3/6/2012 post to the Data Explorer Team blog:
My name is Ben Martens and I’m a test lead on the “Data Explorer” project. I thought I’d take you behind the scenes and talk a little bit about our engineering process.
First, let’s go through the process for fixing a bug. When a user sends feedback, it gets sent in an email to the team. Let’s assume that we decide to fix the bug immediately and get it out in the next release. The developer, program manager and tester responsible for that feature will investigate the bug, create a fix, test it and then check it into our code base. The following Tuesday, we take the current build, which now includes the fix, and we do more thorough testing on it. We run all of our tests against the local client on a variety of platforms, run all our tests against the cloud service, and the whole team has dedicated time each week to bash on the release candidate before it ships. We also run perf and stress on the release candidate. If all of those steps come back green, we deploy the build on the following Tuesday. That’s why if you try to use the site on Tuesday, you might see that it’s down for scheduled maintenance. Come back in a few hours and try out the new version! You can keep track of our upgrades by looking at the build number located in the lower right of the editor page.
There was (and still is) a lot to be learned about releasing a new version every week. The biggest decision we made was keeping our main code branch at a very high quality level and not allowing it to slip. The goal is to have the main branch in such a clean state that we could theoretically release it every single day if we wanted to.
But obviously when you’re developing features or fixing bugs, things will break. We have code branches off of the main branch to deal with this type of work. Feature teams can “check out” a branch for their use for a week or two. The quality of that branch can dip down very low, but it must come back to a fully-tested, clean state with no functional, perf or stress regressions before it can be integrated back into the main branch. Some branches are only out for a couple days while others might last 2 or 3 weeks. Branch owners are required to provide regular status to avoid branches wandering off and never returning.
All of this process doesn’t mean that you’ll never hit a bug on our site, but it has allowed us to release more often without big swings in the quality level. That instability is pushed down into branches and only affects small feature teams. We can now take a few team members and dedicate them to either adding new features or fixing existing bugs. How we make that decision is best left to another blog post.



<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Beth Massi (@bethmassi) posted LightSwitch Community & Content Rollup–February 2012 on 3/7/2012:
Well I know I’m a little late getting this one out but I’ve been busy travelling all over the world and trying to sell and move out of my house so I apologize, it’s been a busy month! If you missed the previous rollups you can view them here.
The big news last week of course was the release of Visual Studio 11 Beta which includes LightSwitch in the box! Very exciting to be on the Dev11 train.
Download Visual Studio 11 Beta
You can read about the major new features of LightSwitch in Visual Studio 11 beta on the team blog:
Announcing LightSwitch in Visual Studio 11 Beta
We’ll be releasing more content weekly on all the new features so keep tuned into the LightSwitch team blog and the LightSwitch in Visual Studio 11 Beta page on the Developer Center. And please visit the LightSwitch in Visual Studio 11 Beta forum to ask the team questions.
Of course a lot of other things happened in February…
LightSwitch Star Contest – Grand Prize Winners & Mini Case Studies
The LightSwitch Star Contest has come to a close over on Code Project and all the prizes have been announced. However, even though the contest is over, CodeProject has created a dedicated LightSwitch section of their site to host the submissions as well as any new tutorials that people want to contribute. Check out all the submissions, particularly ones that have been deployed to Azure, to give you an idea of the types of applications you can create quickly with LightSwitch.
In early February they announced the grand prize winners. Here are all the winners of the contest. Congrats to all!
Most Efficient Business Application
- 1st prize November: App name: Security Central – winner name: Keith Craigo
- 2nd prize November: App name: PTA LightSwitch – winner name: Matt Milner
- 1st prize December: App name: Patient Tracker – winner name: Netsuper
- 2nd prize December: App name: Instant Assets – winner name: Delordson Kallon
- 1st prize January: app name: LightSwitch Job Hunter Application - winner name: stuxstu
- 2nd prize January: app name: Orion – winner name: TheRegan
- Grand Prize: app name: Security Central - winner name: Keith Craigo
Most Ground-breaking Business Application
- 1st prize November: app name: Church+ - winner name: Ihesie Peter Onyebuchi
- 2nd prize November: app name: Engineering App – winner name: Laurentz Tonniau
- 1st prize December: app name: Health and Safety Management System - winner name: PaulSPatterson
- 2nd prize December: app name: Orion – winner name: Julio Iglesias Vázquez
- 1st prize January: app name: MyBizz Portal - winner name: Jan Van der Haegen
- 2nd prize January: app name: Light Enterprise Solution – winner name: Chun Te
- Grand Prize: app name: MyBizz Portal - winner name: Jan Van der Haegen
LightSwitch at TechDays Netherlands
A couple weeks ago I had the pleasure of returning to one of my favorite countries, The Netherlands, to speak at TechDays. I delivered two LightSwitch talks, one intro and one advanced. Read my trip report on the fun adventures and check out the videos of my sessions:
- Video Presentation: Introduction to Visual Studio LightSwitch
- Video Presentation: Advanced Development & Customization Techniques
LightSwitch at MVP Summit
Last week over 1500 Most Valuable Professionals visited Microsoft for a week of meetings with the product teams. It’s always great to see folks helping drive our developer communities face-to-face. I saw a lot of friends and the team got a lot of great feedback on LightSwitch (as well as Azure, Office & SharePoint development). While I was there, Jay Schmelzer and myself chatted with MVPs Andrew Brust and Michael Washington about LightSwitch in Visual Studio 11 Beta. Jay and Andrew talked about what developers can look forward to in the next release of LightSwitch and me and Michael chat about the community (of course!). Check out these short videos:
LightSwitch Unleashed – Book Released!
One of the things
me andMichael and I spoke about in the interview is Alessandro Del Sole’s book released last week. Congrats Ale!! I know it was a long road but you did it! I was the technical reviewer for the book and I know how much work it was to get it right.Book: Visual Studio LightSwitch Unleashed
Michael Washington also interviewed Alessandro on his website: An Interview With Alessandro Del Sole.
And Alessandro also made chapter 3 available to download for free! Thanks!
More Notable Content this Month
LightSwitch in Visual Studio 11 Beta
- Announcing LightSwitch in Visual Studio 11 Beta
- Enhance Your LightSwitch Applications with OData
- LightSwitch Filter Control For Visual Studio 11 Beta
- LightSwitch Team Chats with MVPs about Visual Studio 11 Beta
- Microsoft LightSwitch – A First Class Citizen to Visual Studio 11
- What’s new in Visual Studio LightSwitch 11 (LS VS vNext Beta) – a hacker’s view
- Visual Studio 11 Beta Released!
- Sample: Vision Clinic Walkthrough & Sample (Visual Studio 11 Beta)
- Sample: Contoso Construction - LightSwitch Advanced Sample (Visual Studio 11 Beta)
Visual Studio LightSwitch - RTM
- Calling Your Custom WCF RIA Services Using OData
- Creating a LightSwitch Business Type Extension
- Creating A LightSwitch Collection Control Extension
- Creating A LightSwitch Group Extension
- Creating a very dynamic LightSwitch shell extension in 15 minutes or less
- Enhancing A LightSwitch Detail Control Extension
- Integrating LightSwitch Into An ASPNET Application To Provide Single Sign On
- LightSwitch Screen Tips: Scrollbars and Splitters
- Making integers searchable in LightSwitch
- Microsoft LightSwitch – Add Granularity to Reference Data
- Microsoft LightSwitch – Data First and Breaking Some
- Microsoft LightSwitch – A Little Productivity
- MyBizz Portal: The “smallest” LightSwitch application you have ever seen (Thank you!)
- The DELORDSON LightSwitch OutlookBar Shell
- Trip Report–Techdays 2012 Netherlands
LightSwitch Team Community Sites
Become a fan of Visual Studio LightSwitch on Facebook. Have fun and interact with us on our wall. Check out the cool stories and resources. Also here are some other places you can find the LightSwitch team:
LightSwitch MSDN Forums
LightSwitch Developer Center
LightSwitch Team Blog
LightSwitch on Twitter (@VSLightSwitch, #VisualStudio #LightSwitch)


Return to section navigation list>
Windows Azure Infrastructure and DevOps
Joe Panettieri (@joepanettieri) asked Microsoft: The World’s Biggest Cloud Software Company? in a 3/7/2012 post to the TalkinCloud blog:
Within the halls of Microsoft, a cordial but strategic debate is emerging. Some leaders within the company want Microsoft to describe itself as the world’s biggest cloud software provider. But other Microsoft insiders are being a bit more cautious and conservative, preferring to hold off on making such a statement to the masses, Talkin’ Cloud has heard.
Is Microsoft the world’s largest provider of cloud software — right now? Channel Chief Jon Roskill (pictured [at right]) made a pretty compelling case during an interview with Talkin’ Cloud and The VAR Guy last week. Roskill’s extensive views on Microsoft’s partner ecosystem will surface on The VAR Guy in the next few days. In the meantime, let’s take a look at Roskill’s cloud perceptions.
Microsoft vs. Google, Salesforce.com
Roskill concedes that some pundits consider Google and Salesforce.com the leaders in cloud computing. But he notes: Google really isn’t a software company, and Google Apps doesn’t generate much revenue for the search company. And while Salesforce.com is a pure-play cloud company, Roskill still thinks Microsoft has the upper hand when it comes to cloud revenues.
That’s an intriguing point. Many independent cloud service providers and telecom companies now offer hosted Exchange. And hosted SharePoint seems to be coming on strong. One indication: Rackspace recently acquired a hosted SharePoint specialist to push into that market.
Meanwhile, Microsoft hasn’t said much about overall Office 365 cloud deployments, but Roskill remains upbeat. “Today we see a fair amount of Office 365 on our enterprise agreements,” said Roskill. “I don’t know what the timeframe is — the next year or two — but I fully believe [people will realize] we’ve got these amazing cloudified businesses like Exchange, SharePoint, Lync and Dynamics. They’re all doing extremely well.”
In other words, Roskill is predicting that Microsoft will likely declare itself as the cloud industry’s largest software provider by 2013 or 2014 — if not sooner.
Microsoft’s Cloud Partner Program
Roskill reiterated that Microsoft has about 42,000 cloud partners reselling Office 365 and other Microsoft online services. But Talkin’ Cloud asked: How many of those partners are really active and engaged with Microsoft on the cloud front? “If you dig into the numbers, I think you’ll find the 80-20 rule holds true,” said Roskill. “About 20 percent of the partners are driving a large portion of the seats. Others are engaging opportunistically.”
Roskill continues to evangelize two opportunities — Cloud Essentials and Cloud Accelerate — to channel partners. Cloud Essentials represents a low friction, low barrier to entry for channel partners. Cloud Accelerate is designed for partners that have dome three-plus deals and over 150 seats. Roskill says “thousands” of partners are now in the Cloud Accelerate camp, though he didn’t offer an exact number.
About 80 percent of Microsoft’s cloud partners are now managed partners, Roskills estimates, meaning that the partners are working closely with Microsoft’s channel account managers to drive more business.
Office 365: Improving Reliability?
To Microsoft’s credit, the Office 365 cloud suite seems to have gotten more and more reliable since launching in June 2011. Initially, Office 365 — the successor to BPOS (Business Productivity Online Suite) suffered multiple outages. But more recently, chatter about Office 365 reliability concerns seems to have quieted down in the IT channel.
Also to Microsoft’s credit, more than 40 percent of the world’s top MSPs say they are testing and/or deploying Office 365 for end-customers, according to the fifth-annual MSPmentor 100 report, published by our sister site in February 2012.
Competitive Landscape
Still, Microsoft faces fierce competition against Google, Salesforce, Amazon and other cloud giants. Indeed…
- Google Apps does seem to be gaining momentum with channel partners.
- Oracle is quick to note that the vast majority of public SaaS platforms — from NetSuite to Salesforce.com — run Oracle.
- And a range of open source options — Linux, Apache, MySQL — are widely popular in the cloud, though it’s difficult to pinpoint how much revenue they generate from commercial software companies.
Meanwhile, some partners remain wary of Office 365 because Microsoft controls pricing and end-customer billing. But it’s safe to expect Roskill to offer more momentum updates during Microsoft Worldwide Partner Conference 2012 (July 8-12, Toronto).
In the meantime, keep an eye on our sister site — The VAR Guy — for a more comprehensive update and interview with Roskill, who covered a range of partner topics during last week’s conversation.
Read More About This Topic

Simon Munro (@simonmunro) described Availability outcomes and influencers to his Cloud Comments blog on 3/7/2012:
Often, in cloud computing, we talk about availability. After all, we use the cloud to build high availability applications, right? When pressed to explain exactly what is meant by availability, people seem to be stuck at an answer. “A system that is not ‘down’, er, I mean ‘Up” is not good enough, but very common. So I had a crack at my own definition, starting of by describing availability outcomes and influencers. Have a look at Defining application availability and let me know what you think.

Simon Munro (@simonmunro) posted Defining application availability on 3/7/2012:
As part of an availability model that I am working on, I got stuck right at the beginning when trying to find a definition that fits. So I went back to base principles to try and decompose what is meant by availability. This is a conceptual view, and separate from the measurement of availability (‘nines’ malarky). Have a look at it and give me some input so that I can refine it further.
Simon Munro
@simonmunroAvailability is simplistically viewed as binary — the application is either available at a point in time, or it is not. This leads to a misunderstanding of availability targets (the ‘nines of availability’), the approaches to improving availability and the ability of salespeople to sell availability snake oil off the shelf (see 100% availability offered by Rackspace).
Application availability is influenced by something and has a visible outcome for the consumer, as discussed below.
Availability outcomes
The outcome, or end result, of availability is more than just ‘the site is down’. What does ‘down’ mean? Is it really ‘down’ or is that just the (possibly valid) opinion a frustrated user (that is trying to capture an online claim after arriving late to work because they crashed their car)? The outcomes of availability are those behaviours that are perceived by the end users, as listed below.
Failure
The obvious visible indication of an unavailable application is one that indicates to the end user that something has failed and no amount of retrying on the users’ part makes it work. The phrase ‘is down’ is commonly used to describe this situation, which is an obvious statement about the users’ perception and understanding of the term ‘down’, rather than a reasonable indication of failure. The types of failure include,
- Errors — where the application consistently gives errors. This is often seen on web applications where the chrome all works but the content has an error, or garbage.
- Timeouts – an application that takes too long to respond may be seen as being ‘down’ by the user or even the browser or service that is calling it.
- Missing resources – a ‘404 – Not found’ response code can have devastating effects on applications beyond missing image placeholders, missing scripts or style sheets can ‘down’ an application.
- Not addressable – a DNS lookup error, a ‘destination host unreachable’ error and other network errors can create the perception that an application is unavailable regardless of its addressability from other points. This is particularly common for applications that don’t use http ports and network traffic gets refused by firewalls.
Responsiveness
While it may be easy to determine that an application that is switched off is unavailable, what about one that performs badly? If, for example, a user executes a search and it takes a minute to respond, would the user consider the application to be available? Would the operators share the same view? Apdex (Application Performance Index) incorporates this concept and has an index that classifies application responsiveness into three categories, namely: Satisfied, Tolerating, and Frustrated. This can form a basis for developing a performance metric that can be understood, and also serves as a basis to acknowledge that in some cases we will experience degraded performance, but should not have too many frustrated users for long or critical periods.
Reliability
In addition to features being snappy and responsive, users also expect that features can be used when they are needed and perform the actions that they expect. If, for example, an update on a social media platform posts immediately (it is responsive), but is not available for friends to see within a reasonable time, it may be considered unreliable.
Availability influencers
While the availability outcomes receive focus, simply focussing on outcomes, by saying “Don’t let the application go down”, fails to focus effort and energy on the parts of the application that ultimately influence availability. Some of these availability influencers are discussed below.
Quality
The most important, and often unconsidered, influence on availability is the quality of the underlying components of the system. Beyond buggy (or not) code, there is the quality of the network (including the users’ own device), the quality of the architecture, the quality of the testing, the quality of the development and operational processes, the quality of the data and many others. Applications that have a high level of quality, across all aspects of the system, will have higher availability — without availability being specifically addressed. An application hosted in a cheap data centre, with jumble of cheap hardware, running a website off a single php script thrown together by copying and pasting off forums by a part time student developer will have low availability — guaranteed.
Fault tolerance
Considering that any system is going to have failures at some point, the degree to which an application can handle faults determines its availability. For example, an application that handles database faults by failing over to another data source and retrying will be more available than one that reports an error.
Scalability
If a frustratingly slow and unresponsive application can be considered to be unavailable (not responsive or reliable) and this responsiveness is due to high load on the application, then the ability to scale is an important part of keeping an application available. For example, a web server that is under such high load that it takes 20 seconds to return a result (unavailable) may be easily addressed by adding a bunch of web servers.
Maintainability
If a fault occurs and an application needs to be fixed, the time to recovery is an important part of availability. The maintainability of the application, primarily the code base, is a big part of the time that it takes to find, fix, test and redeploy a fixed defect. For example, applications that have no unit tests and large chunks of code that has not been touched in years wouldn’t be able to fix a problem quickly. This is because a large code base needs to be understood, impacts need to be understood and regression tests performed — turning a single line code change into days of delays in getting an important fix deployed.
Serviceability
Modern web based applications don’t have the luxury of downtime windows for planned maintenance that exist in internal enterprise applications (where planned maintenance frequently occurs on weekends). The ability of an application to have updates and enhancements deployed while the application is live and under load is an important aspect of availability. A robust and high quality application will have low availability if the entire system needs to be brought down for a few hours in order to roll out updates.
Recoverability
Assuming that things break, the speed at which they can be fixed is a key influencer of availability. The degree of recoverability in an application is largely up to the operational team (including support/maintenance developers and testers) to get things going again. The ability to diagnose the root cause of a problem in a panic free environment in order to take corrective action that is right the first time is a sign of a high level of operational maturity and hence recoverability.
Detectability
If availability is measured in seconds of permissible downtime, only knowing that the application is unavailable because a user has complained takes valuable chunks out of the availability targets. There is the need not only for immediate detection of critical errors, but for the proactive monitoring of health in order to take corrective action before a potential problem takes down the application.

Louis Columbus (@LouisColumbus) posted Sizing the Data Center Services Market, 2012 on 3/5/2012 (missed when published):
The Data Center Services (DCS) market is at a turning point today, with both Infrastructure-as-a-Service (IaaS) and Platform-as-a-Service (PaaS) strategies potentially playing a pivotal role.
Traditionally data centers generate the majority of their business from colocation, data center outsourcing, and hosting. The current and future impact of IaaS and PaaS is small but growing rapidly in this market. Gartner estimates the global DCS market generated $150B globally as of 2011, projected to grow to $200B in 2012.
IaaS and PaaS Will Define The Future of the DCS Market
With IaaS generating $4B in global revenues in 2011 and PaaS is generating $1.4B, together they contributed 3.6% of the total DCS revenues last year. The future direction of the DCS market, including the nature and trajectory of IaaS and PaaS, will be determined over the next three to five years by enterprise adoption of these platforms and the increasing move of enterprise applications to the cloud. In sizing the DCS market, it’s useful to take a look at the forecasts from Gartner of cloud application infrastructure and cloud applications as a proportion of enterprise application software. The following tables provide this analysis.
Cloud Application Infrastructure, Cloud Systems Infrastructure as a Proportion of Core ITO and Traditional Web Hosting (Dollars in Billions)
Source: Forecast: Public Cloud Services, Worldwide and Regions, Industry Sectors, 2010-2015, 2011 Update
Cloud Applications as a Proportion of Enterprise Application Software (Dollars in Billions)
Source: Forecast: Public Cloud Services, Worldwide and Regions, Industry Sectors, 2010-2015, 2011 Update
Mapping the Data Center Services Market – A First Approach
Gartner has proposed a Data Center Services Map and Market Compass for Enterprise Data Center Services, both of which are shown below. Taken as taxonomies for organizing the market, they are effective, resembling value chains in their structure. The Garter Data Center Services Map is shown below:
The Gartner Data Center Services Map
Source: Data Center Services: Regional Differences in the Move Toward the Cloud, 2012
Gartner’s Market Compass for Enterprise Data Center Services takes into account size, scope and management of data center (DC) applications by the use of sharing, pricing models and elasticity (Time to Provision Change) to create a market grid. These are considered to be the six most differentiating factors in DC performance in this model. The foundation of the Market Compass are shown below:
Gartner’s Market Compass for Enterprise Data Center Services
Source:Data Center Outsourcing, Hosting or Cloud? Use Gartner’s Market Map and Compass to Decide
The Garter Market Compass can further be used to define which solution sets in the DCS market best align with a given business’ strategic and IT needs. Elasticity of infrastructure utility and cloud computing are, according to the analysis, the strongest growth factors in the DCS market today.
Analyzing the Six Main Segments of the Data Center Services Market with the Gartner Market Compass
Source: Data Center Outsourcing, Hosting or Cloud? Use Gartner’s Market Map and Compass to Decide
Bottom line: As more enterprise applications migrate to the cloud, DCS providers will be forced to rapidly improve the elasticity and time provisioning options their platforms provide. All these changes will re-order the economics of cloud computing forcing DCS providers to greater level of flexibility that many have attained in the past.



<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Bruce Kyle posted Windows Azure Security Best Practices -- Part 1: The Challenges, Defense in Depth to the US ISV Evangelists blog on 3/7/2012:
Every conversation I have with developers about moving their application to the cloud revolve around two main issues.
- One is business. What are the economies of scale around moving your app to the cloud?
- And close on its heals, come the questions around security. “How secure is the cloud, especially Windows Azure? What benefits does Windows Azure provide? What do I need to do to secure my application?”
And also, often unstated, “How do I make my user experience as easy as for users as it is for on-premise applications?”
As ISVs we want to provide authorized users, clients and systems access to the data they require at any time, from any technology, in any location, while meeting basic security requirements for confidentiality, availability and integrity.
And equally important, we want to keep bad guys from getting to this same data.
This is the first of several posts about the challenges in designing your software and what you can do in your software to insure access to those who should have access and prevent access those who do not.
The intent of this series is to provide a context for you to learn more and empower you to write great applications for the public cloud.
Threats
I’ll begin with a brief summary of the challenges. The threats to your application are in many ways, similar to the threats that you think of for on premises applications. However with on premises applications, some of the key points are mitigated because your application runs behind the firewall.
When moving to the Windows Azure cloud, the some of those threats are heightened, some reduced. And mitigating those threats becomes a deeper partnership than when you host your own application. When you host your application on your own servers, you control the physical access to the server, the operating system, the patching, how users access it, and more. And with that comes the added responsibility for maintaining the infrastructure, insuring backups are performed, load balancers are configured.
But when you partner with Microsoft, the Global Foundation Services team handles many customer requirements and is responsible for some of your application’s security.
In the same way you think of the differences between Infrastructure as a Service (IaaS) where you are responsible for the infrastructure and and Platform as a Service (PaaS) where you share the infrastructure with Microsoft.
In either environment, you can think of seven vectors for attacks.
- Customer admin where you administer the application. How is your application deployed, updated, and data accessed? Who has access and how is that authenticated?
- Central administration of the hosting service. How, when, where, who has access and what monitors the hoster administrators?
- How do you physically access the server? Is it under a desk? Under armed guard? Who can touch the server and who has physical access to the devices?
- What can users access and how is data presented to those users? What are they authorized to see?
- How can a customer attack Windows Azure from inside an application? How can they jailbreak and compromize the system?
- And what happens when a customer uses Azure to attack other Web sites?
Traditional threats still exist, even though you are moving your application to the Cloud. For example, you’ll still need to consider cross site scripting attacks (XSS), code injection attacks. And providers need to account for DNS attacks, network flooding.
Some threats are expanded such as data privacy that you need to consider. You’ll need to be aware of the location of the data and segregation of data, especially in multi-tenant environments. You’ll also need to handed privileged access.
New threats are introduced by the nature of the cloud service provider. For example:
- New Privilege Escalation Attacks (VM to host or VM to VM)
- Jailbreaking the VM boundary
- Hyperjacking (rootkitting the host or VM)
And yet certain old threats are mitigated due to patching being automated and instances are moved to secure systems. In addition, cloud resiliency improves failover.
Through the next several posts in this series, I’ll describe what you can do to protect your data. And I’ll explain what Windows Azure provides. I’ll also provide the basic references that you can view for more details.
Defense in Depth
The Online Services Security and Compliance (OSSC) team manages the manages security for the Microsoft cloud infrastructure and is a part of the Global Foundation Services division. Securing The Microsoft Cloud shows how the coordinated and strategic application of people, processes, technologies, and experience results in continuous improvements to the security of the Microsoft cloud environment.
Having a defense-in-depth approach is a fundamental element in how Microsoft provides a trustworthy cloud infrastructure. Applying controls at multiple layers involves employing protection mechanisms, developing risk mitigation strategies, and being capable of responding to attacks when they occur.
Physical security
Use of technical systems to automate authorization for access and authentication for certain safeguards is one way that physical security has changed as security technology advances.
OSSC manages the physical security of all of Microsoft’s data centers, which is critical to keeping the facilities operational as well as to protecting customer data. Established, precise procedures in security design and operations are used in each facility. Microsoft ensures the establishment of outer and inner perimeters with increasing controls through each perimeter layer.
Data Security
Microsoft applies many layers of security as appropriate to data center devices and network connections. For example, security controls are used on both the control and management planes. Specialized hardware such as load balancers, firewalls, and intrusion prevention devices, is in place to manage volume-based denial of service (DoS) attacks. The network management teams apply tiered access control lists (ACLs) to segmented virtual local area networks (VLANs) and applications as needed. Through network hardware, Microsoft uses application gateway functions to perform deep packet inspection and take actions such as sending alerts based on—or blocking—suspicious network traffic.
A globally redundant internal and external DNS infrastructure is in place for the Microsoft cloud environment. Redundancy provides for fault tolerance and is achieved through clustering of DNS servers.
Identity and Access Management
Microsoft uses a need-to-know and least-privilege model to manage access to assets. Where feasible, role-based access controls are used to allocate logical access to specific job functions or areas of responsibility, rather than to an individual. These policies dictate that access that has not been explicitly granted by the asset owner based upon an identified business requirement is denied by default.
Application Security
The rigorous security practices employed by development teams at Microsoft were formalized into a process called the Security Development Lifecycle (SDL) in 2004.
References
Learn more at Global Foundation Services Online Security. The Global Foundation Services team delivers trustworthy, available online services that create a competitive advantage for you and for Microsoft’s Windows Azure.
Next Up
In Windows Azure Security Best Practices -- Part 2: What Azure Provides Out-of-the-Box. I explain that security with Windows Azure is a shared responsibility, and Windows Azure provides your application with security features that go beyond those that you need to consider in your on premises application. But then, it also exposes other vulnerabilities that you should consider. In addition, I’ll explore the compliance.
In other upcoming parts, I’ll describe the steps you can take to embrace security in your overall application design, development, and deployment.



<Return to section navigation list>
Cloud Computing Events
No significant articles today.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Jeff Barr (@jeffbarr) reported DynamoDB Expands to Japan and Europe in a 3/7/2012 post:
We launched Amazon DynamoDB in the US East (Northern Virginia) Region less than two months ago. At that time we committed to making it available in additional Regions as quickly as possible.
I was in Japan last week for the first JAWS-UG (Japan AWS User Group) Summit Meeting. At that meeting we celebrated the one year anniversary of the launch of our Tokyo Region. I was also able to inform the attendees that DynamoDB was now available in their Region.
Today we are expanding again, bringing DynamoDB to the EU (Ireland) Region. You can access DynamoDB in all three Regions via the AWS SDKs and the AWS Management Console. You can also consult our Regions and Endpoints list for a complete list of service endpoints in each of the AWS Region.
Bringing a couple of threads together, the creator of Ruby (Yukihiro "matz" Matsumoto) was a special guest (via remote video) at one of the sessions of the JAWS-UG Summit. I felt inspired to spend some time brushing up on Ruby with the AWS SDK for Ruby and DynamoDB. It turns out to be really easy to use the SDK to insert data into a DynamoDB table.
The first step is to include the SDK and create a DynamoDB object:
require 'aws-sdk'
dynamo_db = AWS::DynamoDB.new(:access_key_id => ACCESS_KEY, :secret_access_key => SECRET_KEY)Next, reference the table and tell the SDK about its key:
table = dynamo_db.tables['my_table']
table.hash_key = [:id, :string]And then insert the data:
item - table.items.create('id' => key,
'first_name' => first_name,
'last_name' => last_name)That's all it takes. With DynamoDB, the table can be provisioned to handle hundreds, thousands or even hundreds of thousands of inserts (writes) per second. This provisioning can also be done programmatically. Here's all it takes to double the amount of provisioned write throughput:
writes = table.write_capacity_units * 2
table.provision_throughput :write_capacity_units => writesThis is a lot easier than calling your IT department and asking them to double the I/O capacity of a database! Writes to the table continue to run at the full provisioned speed while the re-provisioning process is underway.
You can verify that the provisioning process has completed by checking the table status:
if table.status != :updating then
puts "Table throughput updated"
endWe'll be holding a DynamoDB webinar on March 20th. Everyone is welcome to attend, but the time (10:00 AM GMT) was chosen so as to be amenable to our customers (and potential customers) in Europe.
Finally, my friend Jeffrey McManus is running an online DynamoDB training course later this month. Check it out!


Ed Scannell reported IBM gives SmartCloud Foundation shops more control in a 3/7/2012 post to SearchCloudComputing.com:
IBM filled in some missing pieces to its SmartCloud Foundation strategy on Tuesday, rolling out a handful of new offerings it hopes will give IT shops more control over things such as unplanned incidents and the ability to better manage and secure mobile devices.
IBM SmartCloud Control Desk will help large IT shops maintain configuration integrity when planned changes and unplanned problems occur anywhere across the enterprise, thereby avoiding a discontinuation of service. The new offering will also improve management efficiencies.
More on IBM cloud
A second offering, IBM Endpoint Manager for Mobile Devices, reportedly helps administrators both manage and bolster the security of mobile environments. The product reportedly takes only a few minutes to install; IT professionals can then remotely set policies, track and monitor devices to identify data that potentially has been compromised. It also lets IT remotely wipe data from lost or stolen devices.
”We think [IBM Smart Cloud Control Desk] will let users take a much more holistic approach to controlling more complex service management processes,” said Scott Hebner, vice president, marketing with IBM’s Tivoli Software Group, speaking here before 8,000 attendees at the IBM Pulse conference.
IBM’s cloud strategy hasn’t been very clear. One attendee said some of the new cloud services, such as SmartCloud Control Desk, gave him a bit more confidence in IBM’s cloud strategy.
Other attendees also liked what they saw of the new SmartCloud products, although some said the announcements were overdue.
I wish [IBM] would deliver some of these pieces quicker. I would hate to see them lose momentum they have built up since last year.
Donny Harrison, purchasing agent with a large shipping company in Las Vegas
“I wish [IBM] would deliver some of these pieces quicker,” said Donny Harrison, a purchasing agent with a large shipping company in Las Vegas. “They have been relatively quiet about the whole SmartCloud thing since last fall. I would hate to see them lose momentum they have built up since last year.”
IBM complimented these two new offerings with two more cloud services: SmartCloud Monitoring, which lets administrators maximize cloud availability by closely watching virtual infrastructures and applying analytics to optimize workloads, and SmartCloud Virtual Storage Center, which improves flexibility and use of storage with a series of automated administration, management and provisioning controls.
Separately, IBM officials said it plans to release new features and functions in IBM SmartCloud Continuous Delivery. The suite, which is a set of best practice patterns for enabling integrated lifecycle management of cloud services, blends Rational Collaborative Lifecycle Management tools with IBM’s SmartCloud Provisioning.
Company officials said IBM’s recent acquisition of Green Hat will further extend these capabilities, thereby reducing development lifecycle times.
Ed Scannell is Senior Executive Editor for SearchCloudComputing.com and SearchWindowsServer.com. He can be contacted at escannell@techtarget.com.


Full disclosure: I’m a paid contributor to SearchCloudComputing.com.
Tim Anderson (@timanderson) explained How Amazon Web Services dominate infrastructure as a service in a 3/7/2012 post:
During Mobile World Congress I met with some folk from Twilio, the cloud telephony company, who said something that interested me. Twilio uses Amazon Web Service (AWS) for its infrastructure and told me that essentially there is no choice, AWS is the only cloud provider which can scale on demand quickly and smoothly as required.
Today at QCon London I met a guy from another major cloud-based company, which is also built on Amazon, and I put the same point to him. Not only did he agree, he said that Amazon is increasing its lead over the competition. Amazon is less visible than some, he said, because of its approach to PR. It concentrates on marketing directly to developers rather than chasing press stories or running big advertising campaigns.
Amazon has also just reduced its prices.
This is mixed news for the industry. In general developers I speak to like working with AWS, and its scalability is a huge benefit when, for example, you are entering a new market. You can do so without having to invest in IT infrastructure.
On the other hand, stronger competition would be healthy. My contact said that he reckoned his company could move away from Amazon in 12 weeks or so if necessary, so it is not an absolute lock-in.
Related posts:


Saad Ladki (@saadladki) described a new Resource Level IAM for Elastic Beanstalk in a 3/6/2012 post:
We are excited to announce that AWS Elastic Beanstalk now supports resource permissions through AWS Identity and Access Management (IAM). AWS Elastic Beanstalk provides a quick way to deploy and manage applications in the AWS cloud. IAM enables you to manage permissions for multiple users within your AWS account.
In this blog post, we will walk you through an example of how you can leverage resource permissions for Elastic Beanstalk. Let’s assume that a consulting firm is developing multiple applications for different customers and that Jack is one of the developers working on an Elastic Beanstalk application “App1”. Jill tests the changes for “App1” and for a second application “App2”. John is the manager overseeing the two applications and owns the AWS resources. John helps out with development and testing, and only he can update their production environments for “App1” and “App2”. The following matrix describes the different levels of access needed for Jack, Jill, and John:



To create the IAM users and assign policies, do the following:
- Log into the IAM tab of the AWS Management Console.
- In the Navigation pane, click Users.
- Click Create new Users. You can also create groups of users if you have multiple users with the same permissions.
- In the Create User page, type the name of the user(s) and click Create.
- In the Create User confirmation page, click Download Credentials to store the credentials for each user.
- In the user list, select the user John, and then click the Permissions tab.
- In the Permissions tab, click Attach User Policy.
- Click Custom Policy, and then click Select.
- In the Manage User Permissions page, type a name for each policy and then copy/paste the policies below. Notice that Jack has permissions to perform all “Describe” operations on application “App1”, and he can update only the “app1-staging” environment. This prevents him from being able to deploy to the production environment, “app1-prod”. Jack has three associated policies. Replace with your AWS account ID.
- Follow steps 7 through 10 to assign policies to John and Jill using policies modeled after the following:
If Jack attempts to deploy an application version to the “app1-prod” environment, he will receive the following error:
To learn more about AWS Elastic Beanstalk or to get started setting up resource permissions for AWS Elastic Beanstalk, go to the Creating Policies to Control Access to Specific AWS Elastic Beanstalk Resources in the AWS Elastic Beanstalk Developer Guide.
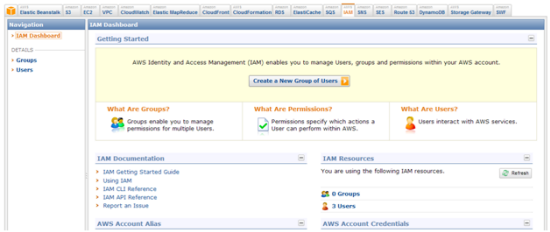
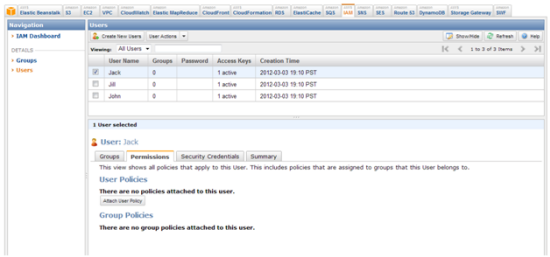
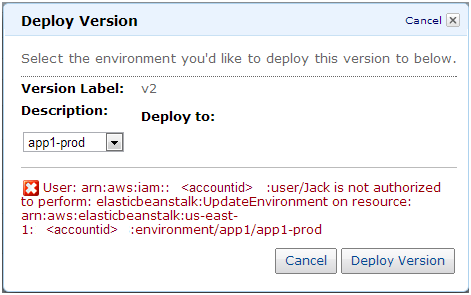
<Return to section navigation list>

















0 comments:
Post a Comment