Windows Azure and Cloud Computing Posts for 3/29/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics, Big Data and OData
- Windows Azure Access Control, Identity and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
Denny Lee (@dennylee) posted A Primer on PowerPivot Topologies and Configurations on 3/29/2012:
For those who would like a quick primer on PowerPivot Topologies and Configurations [for Excel and SharePoint], check out the SlideShare below:

Avkash Chauhan (@avkashchahan) described How to wipe out the DFS in Hadoop? in a 3/28/2012 post:
If you format only Namenode, it will remove the metadata stored by the Namenode, however all the temporary storage and Datanode blocks will still be there. To remove temporary storage and all the Datanode blocks you would need to delete the main Hadoop storage directory from every node. This directory is defined by the hadoop.tmp.dir property in your hdfs-site.xml.
First you would need to stop all the Hadoop processes in your Namenode. This can be done by running the default stop-all script which will also stop DFS:
- On Linux - bin/stop-all.sh
- On Windows – C:\apps\dist\bin\StopHadoop.cmd
Now you would need to delete all files in your main Hadoop storage based on your Hadoop. The storage directory is defined using Hadoop.tmp.dir parameter in hdfs-site.xml file. Be sure to perform this action on every machine in your cluster i.e Namenodes, JobTrackers, Datanodes etc.:
- On Linux: hadoop dfs -rmr /
- On Windows: hadoop fs -rmr (At Hadoop Command Shell)
- #rmr (At Interactive JavaScript Shell)
At last you would need to reformat the namenode as below:
- hadoop namenode -format
Finally you start your cluster again by running the following command which will startup DFS again:
- On Linux: bin/start-all.sh
- On Windows: C:\apps\dist\bin\StartHadoop.cmd

The Microsoft Business Intelligence Team (@MicrosoftBI) created a Big Data Playlist on YouTube in 3/2012:
Click here to see the entire current list of big data video clips in one page.
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
No significant articles today.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
Derrick Harris (@DerrickHarris) rhapsodizes on How federal money will change the face of big data in a second 3/29/2012 post to GigaOm’s Structure blog (see below for the first post):
If you think Hadoop and the current ecosystem of big data tools are great, “you ain’t seen nothing yet,” to quote Bachman Turner Overdrive. By pumping hundreds of millions of dollars a year into big data research and development, the Obama administration thinks it can push the current state of the art well beyond what’s possible today, and into entirely new research areas.
It’s a noble goal, but also a necessary one. Big data does have the potential to change our lives, but to get there it’s going to take more than startups created to feed us better advertisements.
Consumer data is easy to get, and profitable
It’s not fair to call the current state of big data problematic, but it is somewhat focused on profit-centric technologies and techniques. That’s because as companies — especially those in the web world — realized the value they could derive from advanced data analytics, they began investing huge amounts of money in developing cutting-edge techniques for doing so. For the first time in a long time, industry is now leading the academic and scientific research communities when it comes to technological advances.
As Brenda Dietrich, IBM Fellow and vice president for business analytics for IBM Software (and former VP of IBM’s mathematical sciences division), explained to me, universities are still doing good research, but students are leaving to work at companies like Google and Facebook as soon as their graduate Ph.D. studies are complete, often times beforehand. Research begun in universities is continued in commercial settings, generally with commercial interests guiding its direction.
And this commercial focus isn’t ideal for everyone. For example, Sultan Meghji, vice president of product strategy at Appistry, told me that many of his company’s government- and intelligence-sector customers aren’t getting what they expected out of Hadoop, and they’re looking for alternative platforms. Hadoop might well be the platform of choice for large web and commercial applications — indeed, it’s where most of those companies’ big data investments are going — but it has its limitations.
Enter federal dollars for big data
However, as John Holdren, assistant to the president and director of White House Office of Science and Technology Policy, noted during a White House press conference on Thursday afternoon, the Obama administration realized several months ago that it was seriously under-investing in big data as a strategic differentiator for the United States. He was followed by leaders from six government agencies explaining how they intend to invest their considerable resources to remedy this under-investment. That means everything from the Department of Defense, DARPA and the Department of Energy developing new techniques for storage and management, to the U.S. Geological Survey and the National Science Foundation using big data to change the way we research everything from climate science to educational techniques.
How’s it going to do all this, apart from agencies simply ramping up their own efforts? Doling out money to researchers. As Zach Lemnios, Assistant Secretary of Defense for Research & Engineering for the Department of Defense, put it, “We need your ideas.”
IBM’s Deitrich thinks increased availability of government grants can play a major role in keeping researchers in academic and scientific settings rather than bolting for big companies and big paychecks. Grants can help steer research away from targeted advertising and toward areas that will “be good … for mankind at large,” she said.
The 1,000 Genomes Project data is now freely available to researchers on Amazon's cloud.
Additionally, she said, academic researchers have been somewhat limited in what they can do because they haven’t always had easy access to meaningful data sets. With the government now pushing to open its own data sets, and as well as for collaborative research among different scientific disciplines, she thinks there’s a real opportunity for researchers to do conduct better experiments.
During the press conference, Department of Energy Office of Science Director William Brinkman expressed his agency’s need for better personnel to program its fleet of supercomputers. “Our challenge is not high-performance computing,” he said, “it’s high-performance people.” As my colleague Stacey Higginbotham has noted in the past, the ranks of Silicon Valley companies are deep with people who might be able to bring their parallel-programming prowess to supercomputing centers if the right incentives were in place.
Self-learning systems, a storage revolution and a cure for cancer?
As anyone who follows the history of technology knows, government agencies have been responsible for a large percentage of innovation over the past half century, taking credit for no less than the Internet itself. “You can track every interesting technology in the last 25 years to government spending over the past 50 years,” Appistry’s Meghji said.
Now, the government wants to turn its brainpower and money to big data. As part of its new, roughly $100-million XDATA program, DARPA Deputy Director Kaigham “Ken” Gabriel said his agency “seek[s] the equivalent of radar and overhead imagery for big data” so it can locate a single byte among an ocean of data. The DOE’s Brinkman talked about the importance of being able to store and visualize the staggering amounts of data generated daily by supercomputers, or by the second from CERN’s Large Hadron Collider.
IBM’s Dietrich also has an idea for how DARPA and the DOE might spend their big data allocations. “When one is doing certain types of analytics,” she explained, “you’re not looking at single threads of data, you tend to be pulling in multiple threads.” This makes previous storage technologies designed to make the most-accessed data the easiest to access somewhat obsolete. Instead, she said, researchers should be looking into how to store data in a manner that takes into account the other data sets typically accessed and analyzed along with any given set. “To my knowledge,” she said, “no one is looking seriously at that.”
Not surprisingly given his company’s large focus on genetic analysis, Appistry’s Meghji is particularly excited about the government promising more money and resources in that field. For one, he said, the Chinese government’s Beijing Genomics Institute probably accounts for anywhere between 25 and 50 percent of the genetics innovation right now, and “to see the U.S. compete directly with the Chinese government is very gratifying.”
But he’s also excited about the possibility of seeing big data turned to areas in genetics other than cancer research — which is presently a very popular pastime — and generally toward advances in real-time data processing. He said the DoD and intelligence agencies are typically two to four years ahead of the rest of the world in terms of big data, and increased spending across government and science will help everyone else catch up. “It’s all about not just reacting to things you see,” he said, “but being proactive.”
Indeed, the DoD has some seriously ambitious plans in place. Assistant Secretary Lemnios explained during the press conference how previous defense research has led to technologies such as IBM’s Watson system and Apple’s Siri that are becoming part of our everyday lives. Its latest quest: utilize big data techniques to create autonomous systems that can adapt to and act on new data inputs in real time, but that know enough to know when they need to invite human input on decision-making. Scary, but cool.
Related research and analysis from GigaOM Pro:
Subscriber content. Sign up for a free trial.




Full disclosure: I’m a GigaOm registered analyst.
Derrick Harris (@DerrickHarris) reported Obama’s big data plans: Lots of cash and lots of open data in a 3/29/2012 post to GigaOm’s Structure Blog:
The White House on Thursday morning released the details of its new big data strategy, and they involve access to funding and data for researchers. It’s a big financial commitment in a time of tight budgets — well over $200 million a year — but the administration is banking on big data techniques having revolutionary effects on par with the Internet, which federal dollars financed decades ago.
Here’s where its efforts are headed, in a nutshell:
- Grants: About $73 million has been specifically laid out for research grants, with the National Science Foundation chipping in about $13 million across three projects, and the Department of Defense ponying up $60 million. The U.S. Geological Survey will also be announcing a list of grantees working on big data projects, although no specific monetary amounts are listed.
- Spending: If there’s one thing the DoD knows how to do, it’s spend, and it will be doing a lot of it on big data — $250 million a year. DARPA alone will be investing $25 million annually for four years to develop XDATA, a program that aims “to develop computational techniques and software tools for analyzing large volumes of data, both semi-structured (e.g., tabular, relational, categorical, meta-data) and unstructured (e.g., text documents, message traffic).” The Department of Energy is getting in on the big data frenzy, too, investing $25 million to develop Scalable Data Management, Analysis and Visualization Institute, which aims to develop techniques for visualizing the incredible amounts of data generated by the department’s team of supercomputers.
- Open data: The White House has also teamed with Amazon Web Services to make the 1,000 Genomes Project data freely available to genetic researchers. The data set weighs in at a whopping 200TB, and is a valuable source of data for researching gene-level causes and cures of certain diseases. Hosting it in the cloud is critical because without access to a super-high-speed network, you wouldn’t want to move 200TB of data across today’s broadband networks. While the data itself is free, though, researchers will have to pay for computing resources needed to analyze it.
Here’s how the White House summed up the rationale behind its efforts in the press release announcing the new programs:
“In the same way that past Federal investments in information-technology R&D led to dramatic advances in supercomputing and the creation of the Internet, the initiative we are launching today promises to transform our ability to use Big Data for scientific discovery, environmental and biomedical research, education, and national security,” said Dr. John P. Holdren, Assistant to the President and Director of the White House Office of Science and Technology Policy.
It’s worth noting, however, that the White House’s approaches to capitalizing on the big data opportunity aren’t entirely novel. Open source projects such as Hadoop — the linchpin of many big data efforts — and the projects surrounding have already revolutionized the way we think about storing and analyzing unstructured data. And researchers have already had cloud-based access to genetic databases and tools — DNAnexus is hosting the 400TB Short/Sequence Read Archive as part of its cloud-based genome-analysis service, and Microsoft is hosting the NCBI BLAST DNA-analysis tool on its Windows Azure cloud.
Related research and analysis from GigaOM Pro:
Subscriber content. Sign up for a free trial.

Full disclosure: I’m a GigaOm registered analyst.
No significant articles today.
<Return to section navigation list>
Windows Azure Service Bus, Access Control, Identity and Workflow
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Mary Jo Foley (@maryjofoley) reported Microsoft sheds more light on cloud backup service for Windows Server 8 in a 3/29/2012 post to ZDNet’s All About Microsoft blog:
Microsoft is testing a beta of an Azure-based online backup service for Windows Server 8. Here are a few more tidbits about it.
With Windows 8 client in the spotlight, it’s sometimes easy to forget that Windows Server 8 is just as big a release and also packs hundreds of new features (“more than 300,” to be precise).
But lately, over on the Windows Server blog, team members have started diving into some of those features in a series of posts that are similar to what the Windows 8 team is doing on “Building Windows 8″ (but with a little more word-count control).
On March 28, Microsoft officials offered a few more details about the new backup service feature via a post to the Windows Server blog from Gaurav Gupta, a Senior Program Manager on the Cloud Backup team.
Microsoft is limiting the pool of testers of the service to a select group. “Please note that there are a limited number of customers that we can support during the beta and we will grow our capacity over time. We have available slots right now so if you are willing to give us feedback, sign up now to try this great new service,” according to yesterday’s post. The beta of the service currently is limited to 10 GB of cloud storage, as well. …


Read more. If I can’t back up system state, I won’t be very interested in the service.
Benjamin Guinebertière (@benjguin) described Lab: Deploy an Azure App. and explore the deployment thru RDP in a 3/29/2012 bilingual post. From the English version:
In this post, we’ll see how a Windows Azure application can be packaged from within Visual Studio 2010, then, you’ll have a chance to deploy this package to your Windows Azure environment and discover how the application is deployed by connecting to the virtual machines.
The first video shows how the package was created from a machine where the development environment was installed (comments are in French).
Here are the resulting files that you can download locally so that you can use them in your own Windows Azure environment.
- The password that protects the certificate is: RNheysom07
- The default password for AdministrateurRD is: PSgjycom61
NB: The last video shows how to change the credentials once the application is deployed.
In order to get our own Windows Azure environment for free, you can use the trial version.
The following video shows how to deploy the package, change and explore the application deployment (comments are in French).
If you want to change the remote desktop username or password or disable remote desktop, here is how you can do that (comments are in French):


Mike Benkovich (@mbenko) posted Cloud Tip #1–How to set a connection string in Web.config programmatically at runtime in Windows Azure on 3/28/2012:
The scenario is I’m migrating an application to the cloud. I’ve got a database connection defined in my web.config file which uses an on-premise SQL Server database and what I’d like to do is to move it to a Web Role on Windows Azure and use a SQL Azure database. The basic process is to add a Windows Azure Deployment Project to the solution that contains my web application. Next I move my database to SQL Azure (using the SQL Azure Migration Wizard), and then I change the connection string to point to the cloud database. Except that after I’ve deployed the project I may need to change where the database lives.
Try Azure for free - Activate a 90 day trial at http://aka.ms/AzureTrialMB today!
I have posted before how you can encrypt information stored in the web.config file during a Session_Start event by adding code to the Global.asax file to examine a section and then call protect. If I can add some code to determine whether I’m running in Azure, and if I am to read the setting from the ServiceConfiguration file then we should be good. Like the example of encrypting settings an approach that works well is to add code to the Session_Start event. For my example I’ve created a setting in the Windows Azure Role for dbConnectionString and set it to the value I’d like to use.
Next I make sure I add a reference to the Microsoft.WindowsAzure.ServiceRuntime namespace added to the web project so I can access information about the role. If I don’t have one already I add a global.asax file to my web project. This would be where I can add code for the events that fire periodically throughout the lifecycle of my app. I choose to use the Session_Start because if I’ve made changes to my ServiceDefinition file they will get applied the next time someone browses to my site.
public string dbConnectionString { get; set; }void Session_Start(object sender, EventArgs e){// Are we running in Azure?if (RoleEnvironment.IsAvailable == true){dbConnectionString = RoleEnvironment.GetConfigurationSettingValue("dbConnectionString");// Do we have a value for the alternate dbConnectionString in the ServiceConfiguraiton file?if (dbConnectionString != null){Configuration myConfig = WebConfigurationManager.OpenWebConfiguration("~");ConnectionStringsSection mySection = myConfig.GetSection("connectionStrings") as ConnectionStringsSection;if (mySection != null){if (mySection.ConnectionStrings["myDBConnectionString"].ConnectionString != dbConnectionString){mySection.ConnectionStrings["myDBConnectionString"].ConnectionString = dbConnectionString;myConfig.Save(ConfigurationSaveMode.Modified, true);}}}}}I check to see whether the value in the Service Configuration file is different than the value in my web.config, and if it is then make the change and save it. Initially when I tested the code I got a “the configuration is read only” error, but by adding the option for the Save method it works. Now I am able to update the database connection string from the Service Configuration File and have it propagate to my web.config of the running application.
Credit goes where credit is due, and Bing pointed me to a few posts on the subject, including StackOverflow and DotNetCurry.


Packt Publishing announced the availability of David Burela’s (@DavidBurela) Microsoft Silverlight 5 and Windows Azure Enterprise Integration in eBook and printed versions in late 3/2012:
Overview of Microsoft Silverlight 5 and Windows Azure Enterprise Integration
- This book and e-book details how enterprise Silverlight applications can be written to take advantage of the key features of Windows Azure to create scalable applications
- Provides an overview of the Windows Azure platform and how the different technologies can be integrated within your enterprise application
- Examines ways that distributed asynchronous systems can be created to allow scalable processing
- Learn from a distinguished author with tips, tricks, and hands on experience to create scalable enterprise Silverlight applications that run on the Windows Azure platform
Language : English
Detailed Information
Paperback : 304 pages [ 235mm x 191mm ]
Release Date : March 2012
ISBN : 1849683123
ISBN 13 : 978-1-84968-312-8
Author(s) : David Burela
Topics and Technologies : All Books, Microsoft Servers, Cloud, Enterprise, Microsoft, Microsoft SilverlightBook Links
Microsoft Silverlight is a powerful development platform for creating rich media applications and line of business applications for the web and desktop.
Microsoft Windows Azure is a cloud services operating system that serves as the development, service hosting, and service management environment for the Windows Azure platform.
Silverlight allows you to integrate with Windows Azure and create and run Silverlight Enterprise Applications on Windows Azure.
This book shows you how to create and run Silverlight Enterprise Applications on Windows Azure.
Integrating Silverlight and Windows Azure can be difficult without guidance. This book will take you through all the steps to create and run Silverlight Enterprise Applications on the Windows Azure platform. The book starts by providing the steps required to set up the development environment, providing an overview of Azure. The book then dives deep into topics such as hosting Silverlight applications in Azure, using Azure Queues in Silverlight, storing data in Azure table storage from Silverlight, accessing Azure blob storage from Silverlight, relational data with SQL Azure and RIA, and manipulating data with RIA services amongst others.
What you will learn from this book :
- Understand federated authentication and how it can be used with your enterprise’s on premise Active Directory, or integrated to allow logins through Google, Yahoo, LiveId, or Facebook
- Learn the components that make up the Azure platform and know which components to use in each of your applications
- Understand how to partition your relational database into shards to improve scalability and performance
- Discover how to use frameworks such as WCF RIA Services to speed up the development of your line of business applications
- Learn how to configure your development environment quickly by using the Microsoft Web Platform Installer
- Deploy your enterprise applications onto Windows Azure servers
- Use AppFabric caching to improve the performance of your applications
- Understand what Azure Storage is, how it compares to SQL Azure, and when to choose one over the other
- Expose your data via OData to allow Silverlight, javascript, and other web enabled technologies to access and query your data
ApproachThis book is a step-by-step tutorial that shows you how to obtain the necessary toolset to create and run Silverlight Enterprise Applications on Azure. The book also covers techniques, practical tips, hints, and tricks for Silverlight interactions with Azure. Each topic is written in an easy-to-read style, with a detailed explanation given and then practical step-by-step exercises with a strong emphasis on real-world relevance.
Who this book is written for
If you are an application developer who wants to build and run Silverlight Enterprise applications using Azure storage, WCF Services, and ASP providers, then this book is for you. You should have a working knowledge of Silverlight and Expression Blend. However, knowledge of Azure is not required since the book covers how to integrate the two technologies in detail.





<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Beth Massi (@bethmassi) described LightSwitch IIS Deployment Enhancements in Visual Studio 11 in a 3/29/2012 post:
Note: This information applies to LightSwitch in Visual Studio 11 Beta ONLY (LightSwitch V2). For information on deploying LightSwitch applications built with Visual Studio 2010 (LightSwitch V1), please see: Deployment Guide: How to Configure a Web Server to Host LightSwitch Applications
In my last post on deployment I mentioned I’d point out some LightSwitch deployment goodies you get in Visual Studio 11 Beta. Last week I was knee deep in IIS6 and 7 deployment and I discovered some nice improvements in Visual Studio 11 that I’d like to discuss. First off, I want to mention that this is a Beta so details may change. However, I think it’s important to point out some of the changes that you see when you deploy your LightSwitch V2 applications to your own web servers. I’m not going to discuss Azure deployment (yet) as we’re still making improvements in this area. This post will focus on IIS deployment only.
Setting up IIS
For the most part, deployment is the same as it was before, albeit with a few nice new features I’ll discuss below. So you can set up your web and SQL servers exactly the same as before. For information on setting up your web servers see:
For IIS7: Deployment Guide: How to Configure a Web Server to Host LightSwitch Applications
For IIS6: Deploying LightSwitch Applications to IIS6 & Automating Deployment Packages
What’s really nice is that you can deploy LightSwitch V2 applications (built with Visual Studio 11 Beta) to any web server you set up using the V1 LightSwitch 2011 Server Runtime prerequisites. Additionally, when we release the final (RTM) version of LightSwitch V2, you will no longer need the LightSwitch server prerequisites or any LightSwitch specific tools. The same Web Platform Installer feed used by the rest of Visual Studio web applications will also work for LightSwitch applications. This reduces the numbers of steps to provision a server and should make deployment a lot more predictable. Read on to see what else we improved…
Import Settings
The first new feature you will notice on the publishing wizard is a button which allows you to import a .PublishSettings file to configure the deployment. Webmatrix and Web Application projects in Visual Studio also have this feature. Some ISPs/hosters will give you this file to make it easy to deploy to their systems. For more information on creating these files yourself see: IIS.NET: Generate a Profile XML File.
Your Choice: Publish Database Schema
Another new feature is the ability to choose whether you want to publish the database schema when you do a direct deployment (on the Publish Output step you select “Remotely publish to server now”). When you configure your database connections you will now see a checkbox that indicates whether LightSwitch should attempt to update the schema too. So if you are updating your application but you didn’t make any schema changes in the data designer, then you can uncheck this box to speed up the deployment. However, be careful – if you are unsure leave this box checked.
Additionally, if you are generating a package on disk (on the Publish Output step you select “Generate a package on disk”) you can also choose whether you want to generate the SQL database script as part of the package.
Generating and Installing Deployment Packages
When you choose to create a deployment package on disk instead of direct deployment, a package .ZIP file is created for you that you can import into IIS. In IIS7 you can import this package using IIS Manager, right-clicking on the Default Web Site and then selecting Deploy –> Import Application as detailed in the deployment guide. This process will prompt you for all the required parameters to install the package and set up the database. However in IIS6 you need to use the command line to import these, as I showed in my last deployment post.
In LightSwitch V2 there are now also a set of files that you can use to automate the importing of the package and specifying parameters via the command line. These are starting points and should be modified as necessary depending on your settings. Administrators can use these to get the right settings together quickly instead of having to manually create these files.
If you open up the readme it will detail the prerequisites and how to use the batch file. It is similar to the settings I detailed in the previous deployment post (which only dealt with V1 applications). Here are the V2 specific settings in the .SetParameters.xml. (Note that there is a Beta bug where you will see three additional internal parameters, “dbFullSql_Path”, “Update web.config connection string”, and “LightSwitchApplication_Path” so you will need to remove these lines if you see them).
Modify the following settings in bold to your specific values:
<?xml version="1.0" encoding="utf-8"?> <parameters> <setParameter name="DatabaseAdministratorConnectionString" value="Data Source=servername\SQLEXPRESS;Initial Catalog=Application1; User ID=admin;Password=adminPassword" /> <setParameter name="DatabaseServer" value="servername\SQLEXPRESS" /> <setParameter name="DatabaseName" value="Application1" /> <setParameter name="DatabaseUserName" value="dbuser" /> <setParameter name="DatabaseUserPassword" value="dbpassword" /> <setParameter name="Application1_IisWebApplication" value="Default Web Site/Application1" /> </parameters>Note that the DatabaseAdministratorConnectionString is only used to create/update the database. The DatabaseUserName and DatabaseUserPassword values are used to construct the connection string in the web.config and is the credential used by the LightSwitch middle-tier when your app is running.
If your application is using Windows authentication you will need to specify one additional parameter:
<setParameter name="Application Administrator User Name" value="DOMAIN\UserName" />If your application is using Forms authentication you will need to specify three additional parameters:
<setParameter name="Application Administrator User Name" value="UserName" /> <setParameter name="Application Administrator Full Name" value="Full Name" /> <setParameter name="Application Administrator Password" value="strongPassword" />Once you configure the .SetParameters.xml file, copy the .zip, .cmd and .xml files to the web server where you are the administrator and run the .Deploy.cmd. To install the package and the database run:
>Application1.Deploy.cmd /Y
See the readme for details on more options.
Setting up the System Administrator User
In LightSwitch V1 when you select to use either Forms or Windows authentication, the deployment wizard would ask for the credentials of the System Administrator that should be in the database initially and then after it deployed the database it would call Microsoft.LightSwitch.SecurityAdmin.exe (which is installed with the runtime prerequisites) to insert the corresponding records into the database at that time.
Now the System Administrator credentials you enter in the wizard are stamped in web.config. So now when your application starts the first time, LightSwitch looks to see if that user exists in the database and if it doesn’t, it will be created. This strategy works even when the LightSwitch runtime prerequisites are not installed. So now if you ever need to “reset” the admin password, you can modify web.config – either directly or via re-publish. If you look in the published web.config you will see these new keys:
<!-- If no admin user exists, create an admin user with this user name --> <add key="Microsoft.LightSwitch.Admin.UserName" value="UserName" /> <!-- When creating an admin user with Forms auth, use this as the full name --> <add key="Microsoft.LightSwitch.Admin.FullName" value="Full Name" /> <!-- When creating an admin user with Forms auth, use this as the pasword --> <add key="Microsoft.LightSwitch.Admin.Password" value="strongPassword" />Once your application runs for the first time and the System Administrator is added, you can remove these settings to avoid storing the password in your web.config indefinitely.
Wrap Up
Most of these are the more advanced IIS deployment settings that should help IT administrators with hosting/deploying LightSwitch applications. And it’s definitely nice that you can host V2 applications without changing your V1 servers. Most users will not need to wade through these settings and will instead deploy directly, hand off a package to an administrator to install, or use the user interface in IIS Manager to import the package manually. However, if you want the power of automated install of packages, and more control over your deployments then these new features should help.






Return to section navigation list>
Windows Azure Infrastructure and DevOps
Patrick Hynds wrote Digging into Azure and SD Times on the Web published it on 3/29/2012:
Cloud computing has become perhaps the most overblown and overused buzzword since Service Oriented Architecture (SOA). However, that does not mean that it is not still going to have a huge impact on how we build solutions. Most organizations are trying to find their way with this new, must-have technology just like they did with SOA a few years back.
Like all tools, Azure has its place, and helping in defining that place is what this article is all about. I have been impressed that Microsoft has been flexible over the first few years of Azure’s existence, and has responded to feedback and criticisms with tools and offerings to round out the platform. Digging into the details of where Azure stands today is the best way to determine if your solution will benefit from leveraging Microsoft’s cloud offering.
Conversely, Infrastructure-as-a-Service has been with us as a viable choice for even longer, and it is taken as a proven model in most circles. With IaaS, you basically rent a server, whether it is a VM on Amazon’s Elastic Compute Cloud (EC2) system or a hosted server at an Internet service provider. IaaS does not inherently remove the requirement to support the underlying platform with patches and configuration. It also leaves all the disaster recovery requirements in your hands.
PaaS is the next step in the progression. Brian Goldfarb, director for Windows Azure product management, described it this way: “With Windows Azure, Microsoft provides the industry’s most robust platform for developers to create applications optimized for the cloud, using the tools and languages they choose. With support for languages and frameworks that developers already know, including .NET, Java, Node.js and PHP, Windows Azure enables an open and flexible developer experience.”
The idea is to provide everything the developer needs except the code. Microsoft provides the hardware, the operating system, the patches, the connections, the bandwidth, health monitoring with automated server instance recovery, and even the tools for deploying. Smaller software companies can skip the need for an IT staff provided they can navigate the tools, which are tailored for developers. For larger companies, PaaS gets them to a point where they can achieve economies of scale that can only be had through provisioning many thousands of servers.
Microsoft is a prolific company when it comes to providing offerings and expanding solutions; over the years, it has not tended to err on the side of limited options for customers. Figure 1 shows a diagram of Microsoft’s Cloud offerings that span SaaS, IaaS and PaaS. …
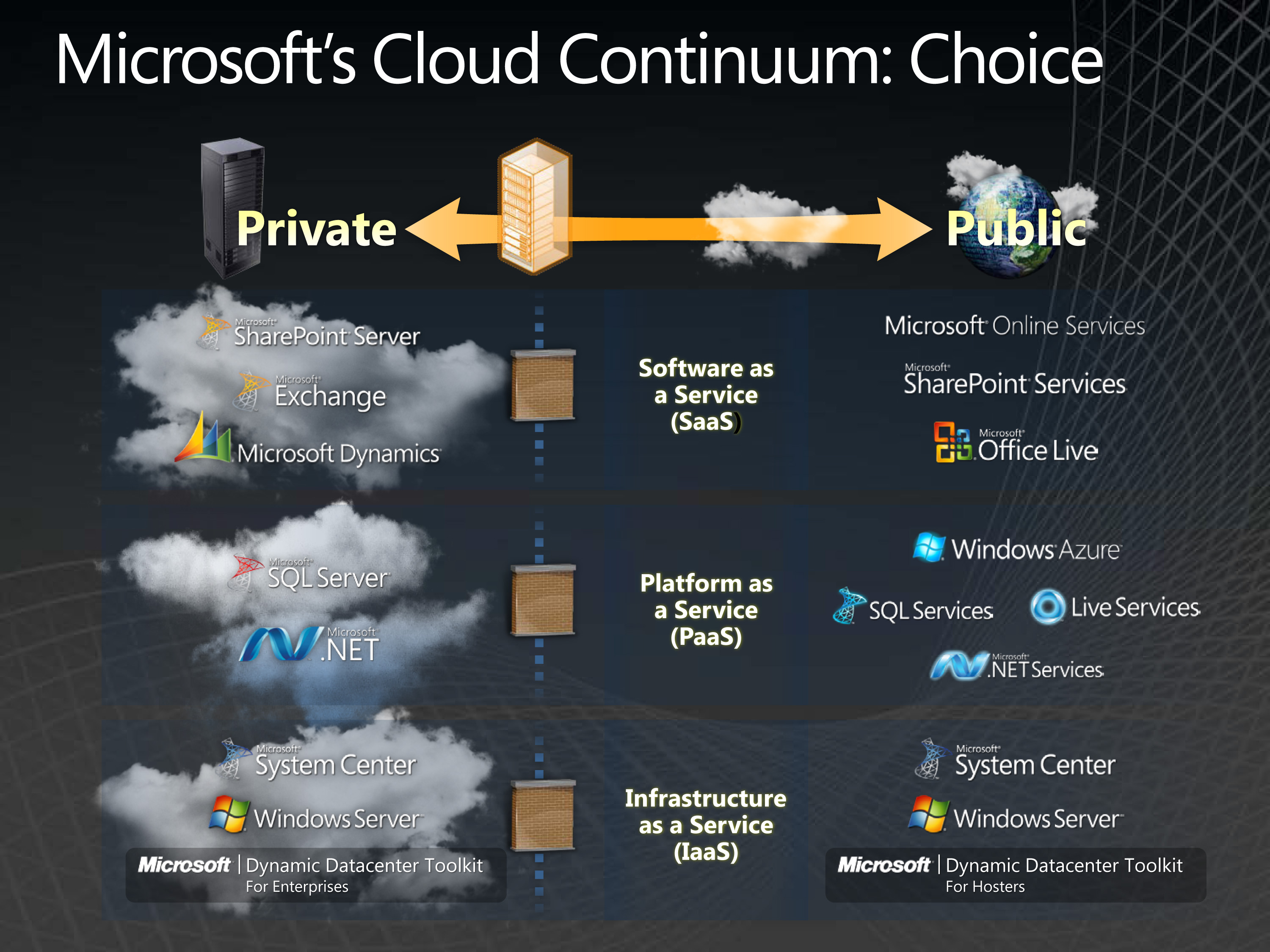
Figure 1
Charlie Satterfield described Using System Center 2012 to Monitor the Infrastructure & Application Layers for Private, Public and Traditional Environments in a 3/29/2012 post to the Microsoft Server and Cloud Platform blog:
Hi, I’m Charlie Satterfield, a Sr. Program Manager in the Management & Monitoring team here at Microsoft. A bit of background on the team – we run a management and monitoring service for 5,000 servers and receive about 20,000 alerts on a weekly basis. Our team provides this monitoring service to eight internal customers across Microsoft, including some of the more major global online properties at Microsoft, such as www.microsoft.com, TechNet, Windows update, and MSDN. The purpose of this blog today is to share at a high level our overall monitoring strategy.
First off, to level set, if you talked with me a year ago, I’d say that our management and monitoring service was built mostly on System Center Operations Manager 2007 R2 and Service Manager 2010. But, we were running that stack on physical hardware with minimal redundancy and failover capabilities – a legacy limitation we introduced purely from decisions around our architecture implementation. Today I can say we’re in the process of upgrading both our monitoring service and our ticketing service to System Center 2012 and we’re also moving much of our infrastructure to virtual machines and adding full redundancy in the stack. We’re able to design an infrastructure that’s highly available with System Center 2012 thanks to the removal of the RMS role and the concept of management pools in Operations Manager. And finally, one of the changes we’re seeing in our Microsoft customers is the move from traditional application hosting models to leveraging private and public clouds as well as hybrid’s combining all three. The applications we now monitor are across the board. So through this evolution, our monitoring implementation has changed a bit to accommodate this evolution. We’ll go through how we approach monitoring, the changes we make to adjust to monitoring an application regardless of where it resides, and I’ll include more details on how we’re using System Center 2012.
Before we begin looking at the way we monitor traditional, public cloud, and hybrid applications I want to provide some information on our overall monitoring strategy. Our monitoring strategy consists of two separate approaches:
- Service perspective application monitoring (Inside – Out)
- Monitoring the actual code that is executed and delivered by the application –through Custom MP’s leveraging application events, instrumentation, and performance counters, as well as the performance of the underlying platform subsystems. Monitoring from the service perspective allows the application owner to track leading indicators that can predict future issues or the need to increase capacity. Now, new in System Center 2012 is our ability to expand our service to offer APM to our customers which will enable detailed application performance monitoring and exception tracking without instrumentation.
- Client perspective application monitoring (Outside – In)
- End-user experiences related to application availability, response times, and page load times derived from web application availability monitors and Synthetic Transaction testing using both simple and more complex user experiences. Client perspective monitoring is the ultimate validation of application availability and performance as seen by the end user.
As we approach implementing this strategy some of the areas we are concerned about are:
- Monitoring at the hardware level
- Monitoring at the OS health/Subsystem level health
- Monitoring at the application components on premise
- Monitoring the application components in the cloud
As we move from network to cloud, and as we implement monitoring application components, we focus more on the application and less on the network/hardware layer. The scope of monitoring decreases in the cloud, from an implementation standpoint, and we become more of a consumer of the cloud service and monitors. The slide below shows how the monitoring priority shifts as we move across the application platforms.
For the traditional hosted application monitors, we have to take into consideration the entire scope of the application and the infrastructure. The infrastructure monitoring includes the Hardware, Operating System, SQL monitors, and IIS. For this we leverage the base management packs with a few exceptions. To monitor the application that runs on these traditional platforms we leverage custom MP’s, synthetic transactions to be able to test websites, and HTTP probes to test web services ensuring that the outside-in functionality of the application is available. What I mean by HTTP probes is a synthetic transaction that interrogates a test webpage for status codes. The test web page is actually exercising the functionality of the web service itself and returning success or error codes depending on the results.
For hybrid application monitoring, the scope of monitoring includes aspects of both traditional and public cloud based application monitoring. We leverage the same models of the traditional application monitoring including the base hardware, operating system, and IIS management packs. We also continue to rely on synthetic transactions and http probes to monitor the availability of the application from the end user’s perspective. In addition, the Azure and SQL Azure MP’s are used to monitor the public cloud specific portion of the application. You might wonder how we’re able to understand the overall health of an application stretched across these platforms. We’re able to get a single view of the health of these types of applications using the Operations Manager Distributed Application Model. Leveraging the Distributed Application Model, we’re able to diagram out the subservices and roles of the application and assign unique health aggregations for each portion of the model. For example, one of the many applications we monitor for our customers includes Windows Azure based web and web service roles, but the database for the application is located on premise on traditional hosting. In this case we would create a Distributed Application Model with three subservices. Two of the subservices would include monitors specific to Azure MP monitoring, Synthetic Transactions, and HTTP probes. The third subservice would include monitors focused on not only SQL Server but also the underlying Operating System and Hardware.
Additional Monitoring Features We are Starting to Leverage in System Center 2012
In System Center 2012 we get a number of additional capabilities that give us the flexibility to monitor at the infrastructure and application layer without compromising the service or the subservice layers. One of the most valuable additional capabilities in our business is the ability to use APM to monitor .NET applications running on IIS 7 for performance and capture exceptions without having to instrument the code. APM provides the ability to view graphical representations of the performance of the application including a breakdown of performance events based on duration. In addition, APM provides the ability to highlight the top failures in the application including the ability to drill into each failure and display the stack trace down to the method call if symbols are available. This functionality reduces the need for the application development team to reproduce the issue to generate similar data to triage and fix the issue. It is because of this functionality that all of our internal Microsoft customers are eager to get their hands on APM for their applications.
On top of all the architecture and monitoring improvements we’re taking advantage of in System Center 2012, the new dashboard capabilities are allowing us to more easily create dashboards in a few clicks of the mouse that were much more difficult to create in Operations Manager 2007 R2. We plan on creating dashboards initially to view the availability and health of our own servers before offering dashboards to our internal customers.
We hope you’ve found this blog posting helpful when you look at monitoring in the world of 2012.
Charlie Satterfield
Sr. Program Manager
Management & Monitoring


The Microsoft PR Team asserted “New Microsoft research finds SMBs leveraging cloud services to expand geographic reach and identifies opportunities for local service providers” in an introduction to their Study: Cloud Usage Surging, Leveling Playing Field for Small and Midsize Businesses press release of 3/28/2012:
REDMOND, Wash. — March 28, 2012 — Microsoft Corp. today announced new research predicting a significant increase in paid cloud services over the next five years among small and midsize businesses (SMBs). The research conducted by Edge Strategies includes survey responses from IT decision-makers or influencers at more than 3,000 SMBs in 13 countries. According to survey results, paid cloud services are expected to double in five years, while the number of the world’s smallest companies using at least one paid cloud service will triple in the next three years.
The move to the cloud represents a major opportunity for service providers, and partnering with Microsoft offers the most complete set of cloud-based solutions to meet SMB needs.
“Gone are the days of large enterprises holding the keys to enterprise-class IT and services,” said Marco Limena, vice president, Operator Channels, Microsoft. “The cloud levels the playing field for SMBs, helping them compete in today’s quickly changing business environment, by spending less time and money on IT and more time focused on their most important priority — growing their businesses.”
Cloud computing is able to deliver more of what small and midsize businesses need — cheaper operations and faster, better fusion of vital information to virtually any device. In fact, the research finds 59 percent of companies currently using cloud services report significant productivity benefits from information technology, compared with just 30 percent of SMBs not yet using the cloud.
Moreover, despite a sluggish global economy, 63 percent of SMBs using cloud services today expect to grow in sales in the next 12 to 18 months while 55 percent believe technology will power their growth. SMBs worldwide are embracing cloud services to reap those benefits and stay ahead of competitors — 50 percent of SMBs say cloud computing is going to become more important for their operations, and 58 percent believe working in the cloud can make companies more competitive.
More Options, Fewer Concerns
- Cloud adopters want to do more with devices. Mobility is essential to current cloud users. They want mobile devices for more than email, including productivity and business apps.
- Security is a priority but no longer a main concern. Only about 20 percent of SMBs believe that data is less secure in the cloud than it is in their on-premise systems. Thirty-six percent overall and 49 percent of larger SMBs actually think that data is as secure in the cloud as in their own systems.
- Local is better when it comes to service providers. Most SMBs feel it is important to buy services from a provider with a local presence, and 31 percent feel this is critical.
Opportunities for Microsoft Partners
Although many SMBs are interested in the benefits that the cloud can deliver, many are unable to identify which services would be most valuable for them to implement and select a service provider. More than 60 percent of SMBs indicate they do not have the resources necessary to implement new technologies and services, and 52 percent do not have the resources to get their employees trained. For the large ecosystem of cloud service providers, this represents significant opportunity to bridge the knowledge and implementation gap and gain new customers — 56 percent of SMBs report a preference toward buying IT and cloud services from a single source.
“Trust development is critical to our work with SMBs,” said Aaron Hollobaugh, vice president of Marketing, Hostway. “Increasingly, clients tell us they work with Hostway because our global datacenter network often provides local support. Client trust is earned because we view every business – regardless of size – as an enterprise. We combine enterprise-class technologies and cost-effective service with the Microsoft brand to deliver cloud solutions that address the enterprise needs of SMBs.”
About the Research
The Microsoft SMB Business in the Cloud 2012 research report was designed and conducted in conjunction with Edge Strategies Inc. (http://www.edgestrategies.com) in December 2011. The research questioned 3,000 SMBs that employ 2 to 250 employees across 13 countries worldwide: Australia, Brazil, China, Denmark, France, Germany, Japan, Russia, South Korea, Spain, Turkey, the U.K. and the U.S. A copy of the survey results can be downloaded at http://www.microsoft.com/presspass/presskits/telecom/docs/SMBCloud.pdf

Another attempt to placate partners’ concerns about competition from the “senior partner.”
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Reuven Cohen (@ruv) asserted Yes, Professional Services are Important for Cloud Providers in a 3/29/2012 post:
I keep reading these stories about how various cloud service providers are building up their consulting practices around cloud computing mostly to address the enterprise market (see my previous post for some thoughts on that subject). These articles mostly read like it's a surprising realization. Today's post comes via our friends at GigaOM, I'm actually a little surprised to see this type of marketing piece from them, but that's besides the point.
Let me get to the point. Of course professional services are important. These services are in many cases the most important part of the the decision process for businesses looking at utilizing cloud products. If you're going to implement an SAP platform (as a traditional example) you're most likely going to hire consultants and integrators to assist with the heavy lifting. The cloud is no different. Yes, you're going to hire a cloud consultant, expert, guru, whatever you call them, this is a certainty. The real question is whether that consultant is part of your providers organization or external. But to say this is a surprising realization, is absurd. Unless you of course have all the answers to all the questions.
So my word to wise, your cloud deployment is only as good as those (the people) who are going to implement. Do your homework.


Jonathan Gershater (@jgershater) recommended Where to store cloud encryption keys? Adhere to compliance guidance in a 3/28/2012 post to the Trend Cloud Security blog:
I recently read a blog post outlining how a customer should evaluate where they should store their encryption keys when encrypting data in the cloud. The post outlines the various options for storing keys and concludes, “Enterprises must assess their risk tolerance and audit requirements before they can select a solution that best meets their encryption key management needs.“
I completely agree with the post. Risk tolerance assessments and adherence to audit standards are essential elements of any quality data security program. I would argue though, that if the customer is following compliance and audit requirements then there is only one place keys should be stored: physically separate from the storage or infrastructure provider and under the direct control of the data owner.
A closer examination of four key compliance guidelines reveals:
1. COBIT : “COBIT is an IT governance framework and supporting toolset that allows managers to bridge the gap between control requirements, technical issues and business risks.” For management of encryption keys, COBIT states:
Verify that written procedures/policies exist,…. transporting, storage; recovery; retirement/destruction; theft and frequency of required use. Included with these procedures should be requirements over securing the key and controlling the elevation of the key…. Keys should be maintained on a computer that is not accessible by any programmers or users, such as router controls for logical access and strong physical controls with an air gap in a secured area/room.
2. PCI
The Payment Card Industry guidelines only specify that appropriate procedures should be documented, little guidance is provided for where keys should be stored.
Encryption keys used for encryption of cardholder data must be protected against both disclosure and misuse. All key management processes and procedures for keys used for encryption of cardholder data must be fully documented and implemented.
However, PCI DSS 2.0 states in section 3.6 defers to NIST
3.6 Fully document and implement all key-management processes and procedures for cryptographic keys used for encryption of cardholder data…. Note: Numerous industry standards for key management are available from various resources including NIST, which can be found at http://csrc.nist.gov.
3. HIPAA The Health Insurance Portability and Accountability Act in their breach notification rule calls out
“Protected health information (PHI) is rendered unusable, unreadable, or indecipherable to unauthorized individuals if one or more of the following applies:
1. Electronic PHI has been encrypted as specified in the HIPAA Security …… To avoid a breach of the confidential process or key, these decryption tools should be stored on a device or at a location separate from the data they are used to encrypt or decrypt. The encryption processes identified …. have been tested by the National Institute of Standards and Technology (NIST) and judged to meet this standard.“
4. SOX Sarbanes Oxley adheres to COBIT in section DS 5.7:
“Accepted frameworks for use with SOX are COSO and CobiT“ accepts the COBIT framework above for security technology”
and section DS 5.8 requires
“Dedicated key storage devices and application.
There is a very good reason for this physical division between the key server and the location of secure data stores. In audit parlance it’s called “separation of duties.” Separation of Duties, or “SoD”, is an important internal control concept that helps prevent mischief by ensuring an adequate system of checks and balances exists. More specific to this topic, SoD makes sure that only the data owner can access sensitive information. The encrypted volumes live with your cloud provider, your keys stay somewhere else and only you have all the credentials to join the pieces. Whether your key management solution resides in your data center or with a trusted third party, only you control the credentials required to access all the necessary elements necessary to unlock encrypted data. And control is critical for operating safely in any cloud environment.
In summary four compliance requirements call for storing encryption keys securely and separately from the data, under the control of the cloud consumer.



This is why Microsoft Codename “Trust Services” puts the user, not Microsoft, in possession and control of your encryption private key.
<Return to section navigation list>
Cloud Computing Events
Rick Garibay (@rickggaribay) posted Building Speedy Azure Applications with HTML5 and Web Sockets Today on 3/29/2012:
I had the pleasure of presenting at Spring DevConnections today in Las Vegas and as promised, below are the samples for each of my demos.
To recap. WebSocket brings full-duplex, bi-directional TCP sockets to web, desktop and mobile applications, introducing an alternative to XHR and long-polling, particularly when latency is a primary focus. What makes WebSocket so significant to developers in addition to providing a direct, socket-based connection is that it is standardized by both the IETF Hybi working group and W3C which has brought wide industry support across both browser vendors implementing the client support and platform vendors providing support for building WebSocket servers.
Microsoft has been an early champion of the WebSocket protocol, sharing some early investments via HTML5 Interoperability Labs website and maintaining that investment with support for the WebSocket protocol announced at //Build 11 which introduced WebSocket support to Windows 8, Windows Server 8. .NET 4.5 and IE 10 Developer Preview based on the hybi-10 specification.
With the release of .NET 4.5 Beta 1, all of the above have been updated to RFC 6455, which is the latest specification and expected to be final.
Along with broad native support for WebSockets in modern browsers like Chrome, IE 10, Safari and FireFox, the standardization dust has settled making this the right time to jump in.
In my talk, we took a lap around the WebSocket support in .NET 4.5, highlighting the APIs that Microsoft has made available in the Microsoft.WebSocket namespace that ships as a package on NuGet. While you can go as deep as you want in the new System.Net.WebSockets namespace that forms the core of Microsoft’s investment in the protocol, the Microsoft.WebSocket package provides higher level abstractions for developing WebSocket solutions today with WCF using WebSocketService and ASP.NET using WebSocketHandler.
Since .NET 4.5 and Window 8/Server 8 have not yet been released, it is currently not possible to deploy your .NET 4.5 applications to Windows Azure. That said, while Windows Azure will certainly be updated to support these key technologies following RTM, Azure supports a variety of non-Microsoft programming languages and platforms including Node.js.
Demonstrating the latest Azure SDK for Node.js, we got a fully RFC 6455 complain WebSocket service up and running on Windows Azure in a worker role running Node.js and using the WebSocket.IO module to integrate with Twitter’s Streaming API which provides a one-way firehose for tapping into Twitter’s event stream which proved to be a great example of using these capabilities together while having a little fun with HTML 5 JQuery and CSS 3.
Demo
Summary
Artifacts
Demo 1 Live chat sample of Silverlight-based client and WCF Service running on Windows Azure.
Please note that this implementation is deprecated and will not be carried forward.
Instead, please use .NET 4.5 WebSocket support in WCF and ASP.NET.
http://html5labs.cloudapp.net/WebSockets/ChatDemo/wsdemo.html
Demo 2
Simple “Hello World” example of ASP.NET ASHX handler using WebSocketHandler and HTML 5 client demonstrating a trivial “echo” service that displays the date/time each second.
Also included in the Demo 2 folder is a WCF version of the same implementation (which I did not demo during my talk).
Projects:
SimpleEventingSample
SimpleEventingService
Requires Visual Studio 11 Beta 1 & Windows 8/Windows 8 Server
Demo 3
Example of using the Twitter Search API as an event stream with WCF using WebSocketService, Linq to Twitter and HTML 5 with some nice JQuery and CSS animation.
http://sdrv.ms/HofK53
Projects:
StatusStreamClient
StatusStreamService
StatusStreamServiceTests
Requires Visual Studio 11 Beta 1 & Windows 8/Windows 8 Server
Demo 4
Another event streaming example, this time using the Twitter Streaming API, Node.js and WebSocket.IO in Windows Azure and HTML 5 animations with CSS 3 box shadow and rotate.
As opposed to the Twitter Search API used in Demo 3, you can see that events are immediately captured and the Streaming API is much more reliable than the Search API.
Use any text editor or your favorite JavaScript IDE.
Deck
http://sdrv.ms/Hf5oZB






Please remember that demos 2 and 3 require .NET 4.5 Consumer Preview and either Windows 8 or Windows 8 server.
Since the Microsoft.WebSockets NuGet package is the easiest way to get started with WebSocketHandler and WebSocketService, I’d recommend starting with Demo 2 and Demo 3.
For demo 4, you will need an Azure account which you can sign up for free (really, free) at http://azure.com
As we discussed during my talk, even though .NET 4.5 and Windows 8 are not yet RTM:
- Now is the time to dive into WebSockets in .NET 4.5!
- Consider how WebSockets can improve existing near real-time messaging scenarios.
- Start building WebSocket apps on Windows 8 and Windows Server 8 today.
- .NET 4.5 support in Windows Azure is coming soon. In the meantime, consider alternate frameworks like Node.js which is supported today!
- Last but not least, here are the resources I provided on my last slide for easy access:
- Microsoft.Web.WebSockets NuGet Package: http://nuget.org/packages/Microsoft.WebSockets
- Paul Batum’s blog: http://www.paulbatum.com/2011/09/getting-started-with-websockets-in.html
- Damir Dobric’s blog on WCF WebSockets: http://developers.de/blogs/damir_dobric/archive/2011/11/26/wcf-duplex-via-websocket.aspx
- ASP.NET Documentation:
- http://msdn.microsoft.com/en-us/library/system.web.websockets%28v=vs.110%29.aspx
- http://msdn.microsoft.com/en-us/library/system.net.websockets%28v=vs.110%29.aspx
- WebSocket.IO: https://github.com/learnboost/websocket.io
- Nice CSS & JQuery scripts/samples: http://marcofolio.net
Last but not least, I’d like to thank @paulbatum, PM at Microsoft working on the WCF and ASP.NET WebSocket features for helping me grok WebSockets in .NET 4.5. His guidance and thought leadership around WebSocket are invaluable to the community, so if you run into Paul, thank him or better yet, buy him a beer.

Nuno Filipe Godinho (@NunoGodinho) described Visual Studio Live @ Las Vegas Presentations – Tips and Tricks on Architecting Windows Azure for Costs in a 3/29/2012 post:
Unfortunately I wasn’t able to go and speak in Visual Studio Live @ Las Vegas as it was scheduled, due to an illness that made it impossible for me to travel, and stay in bed for a few days.
But even if I wasn’t there I would like to share with you some of the points on this topic “Tips and Tricks on Architecting Windows Azure for Costs”.
Tips & Tricks On Architecting Windows Azure For Costs
View more presentations from Nuno Godinho
- Cloud pricing isn’t more complex than on-premises, it’s just different
- Every component has it’s own characteristics, adjust them to your needs
- Always remember that Requirements impact costs, choose the ones that are really important
- Always remember that Developers and the way things are developed impact costs, so plan, learn and then code.
- Windows Azure pricing model can improve code quality, because you pay what you use and very early can discover where things are going out of plan
- But don’t over-analyze! Don’t just block because things have impacts, because even today the same things are impacting you, the difference is that normally you don’t see them that quickly and transparently, so “GO FOR IT”, you’ll find it’s really worth it.
In some next posts I’ll go in-depth into each one of those.
Special thanks for Maarten Balliauw for providing a presentation he did previously that I could work on.

Mike Benkovich (@mbenko) posted Cloud Tip #2–Finding Cloud Content that works for You on 3/29/2012:
There are many ways to learn a new technology. Some of us prefer to read books, others like videos or screencasts, still others will choose to go to a training style event. In any case you need to have a reason to want to learn, whether it’s a new project, something to put on the resume or just the challenge because it sounds cool. For me I learn best when I’ve got a real project that will stretch my knowledge to apply it in a new way. It also helps to have a deadline.
I’ve been working for the last several years now for Microsoft in a role that allows me to help people explore what’s new and possible with the new releases of technology coming out at a rapid pace from client and web technologies like ASP.NET and Phone to user interface techniques like Silverlight and Ajax, to server and cloud platforms like SQL Server and Azure. The job has forced me to be abreast of how the technologies work, what you can do with them, and understanding how to explain the reasons for why and how they might fit into a project.
In this post I’d like to provide a quick tour of where you can find content and events on Cloud Computing that should help you get started and find answers along the way.
4/3 : Part 7 - Get Started with Windows Azure Caching Services with Brian Hitney (http://bit.ly/btlod-77)
How can you get the most performance and scalability from platform as a service? In this webcast, we take a look at caching and how you can integrate it in your application. Caching provides a distributed, in-memory application cache service for Windows Azure that provides performance by reducing the work needed to return a requested page.4/10 : Part 8 - Get Started with SQL Azure Reporting Services with Mike Benkovich (http://bit.ly/btlod-78)
Microsoft SQL Azure Reporting lets you easily build reporting capabilities into your Windows Azure application. The reports can be accessed easily from the Windows Azure portal, through a web browser, or directly from applications. With the cloud at your service, there's no need to manage or maintain your own reporting infrastructure. Join us as we dive into SQL Azure Reporting and the tools that are available to design connected reports that operate against disparate data sources. We look at what's provided from Windows Azure to support reporting and the available deployment options. We also see how to use this technology to build scalable reporting applications4/17 : Part 9 – Get Started working with Service Bus with Jim O’Neil (http://bit.ly/btlod-79)
No man is an island, and no cloud application stands alone! Now that you've conquered the core services of web roles, worker roles, storage, and Microsoft SQL Azure, it's time to learn how to bridge applications within the cloud and between the cloud and on premises. This is where the Service Bus comes in—providing connectivity for Windows Communication Foundation and other endpoints even behind firewalls. With both relay and brokered messaging capabilities, you can provide application-to-application communication as well as durable, asynchronous publication/subscription semantics. Come to this webcast ready to participate from your own computer to see how this technology all comes together in real time.If you’re looking for a conversational 30 minute show that covers Cloud topics I suggest checking out Cloud Cover on Channel9. This show features Azure experts including Ryan Dunn, Steve Marx, Wade Wegner, David Aiken and others who work closely with the product teams at Microsoft to learn how to use the latest releases.
Live events are a moving target depending on when you read this post, but we try to keep a list of upcoming Microsoft Events for developers on http://msdnevents.com. As we schedule them we add the events to this hub and you can find them by date and by location with a map of upcoming events. Another place to check is the demo page I’ve created on BenkoTips which shows not only upcoming events (aggregated from Community Megaphone, if you add it there it should show up on the map) but also User Group locations and links to their sites. That’s on http://benkotips.com/ug, then use the pan and zoom to focus the map on your city. Pins get added with the links. If your User Group data is out of date, send me an email & we’ll get it fixed.
We’ve got a series scheduled to run in thru May 2012 for Cloud Computing called Kick Start, which are a 1 day focused event that takes you thru the content from Soup to Nuts. The current schedule includes:
- 3/30 - Microsoft Edina Office
- 4/3 - Microsoft Independence Office
- 4/5 - Microsoft Columbus Office
- 4/10 - Microsoft Overland Park Office
- 4/12 - Microsoft Omaha Office
- 4/13 - Microsoft Mason Office
- 4/19 - Microsoft Southfield Office
- 4/25 - Microsoft Houston Office
- 5/1 - Microsoft Creve Coeur Office
- 5/1 - Microsoft Downers Grove Office
- 5/2 - Microsoft Franklin Office
- 5/3 - Microsoft Chicago Office
- 5/8 - Microsoft Edina Office
As to books I’d suggest checking out Sriram Krishnan’s book Programming Windows Azure: Programming the Microsoft Cloud, or Brian Prince’s book Azure in Action. If it’s SQL Azure that you’re after then Scott Klein has a great book called Pro SQL Azure (Expert’s Voice in .NET). I am also partial to the Patterns and Practices team’s book on Moving Applications to the Cloud on the Microsoft Azure Platform.
Finally you need an active Azure Subscription to get started. You can activate a 90 Free Trial by going to http://aka.ms/AzureTrialMB and get the tools at http://aka.ms/AzureMB.

Eric Nelson (@ericnel) reported Gaurav Mantri of Cerebrata Cloud Storage Studio fame is in London on April 3rd in a 3/29/2012 post:
Cerebrata (now owned UK company Red-Gate) make awesome tools for Windows Azure – thanks largely to the work of Gaurav Mantri.
And it just so happens that the UK Windows Azure User Group has Gaurav speaking on April 3rd in London. Definitely a session worth attending if you are in London that day.
Gaurav Mantri, CEO of Cerebrata Software (recently acquired by Redgate) will be speaking to the UK Windows Azure Group about Cerebrata tools, how they are used and how they were built using underlying REST APIs provided by the Windows Azure Fabric. Gauriv is here for a short duration from India so this is a rare opportunity to catch him speaking. If you’re already building a project in Windows Azure then you almost certainly use Cloud Storage Studio, Diagnostics Manager and CmdLets. If you don’t you will be soon! Redgate will be at the meeting to offer some free product licenses to a few attendees. Please register for this meeting @ http://www.ukwaug.net/.
Full disclosure: I’m a paid contributor to Red Gate Software’s ACloudyPlace blog.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Matt Wood (@mza) announced availability of 100 TB of data from The 1000 Genomes Project in a 3/29/2012 post:
We're very pleased to welcome the 1000 Genomes Project data to Amazon S3.
The original human genome project was a huge undertaking. It aimed to identify every letter of our genetic code, 3 billion DNA bases in total, to help guide our understanding of human biology. The project ran for over a decade, cost billions of dollars and became the corner stone of modern genomics. The techniques and tools developed for the human genome were also put into practice in sequencing other species, from the mouse to the gorilla, from the hedgehog to the platypus. By comparing the genetic code between species, researchers can identify biologically interesting genetic regions for all species, including us.
A few years ago there was a quantum leap in the technology for sequencing DNA, which drastically reduced the time and cost of identifying genetic code. This offered the promise of being able to compare full genomes from individuals, rather than entire species, leading to a much more detailed genetic map of where we, as individuals, have genetic similarities and differences. This will ultimately give us better insight into human health and disease.
The 1000 Genomes Project, initiated in 2008, is an international public-private consortium that aims to build the most detailed map of human genetic variation available, ultimately with data from the genomes of over 2,661 people from 26 populations around the world. The project began with three pilot studies that assessed strategies for producing a catalog of genetic variants that are present at one percent or greater in the populations studied. We were happy to host the initial pilot data on Amazon S3 in 2010, and today we're making the latest dataset available to all, including results from sequencing the DNA of approximately 1,700 people.
The data is vast (the current set weighs in at over 200Tb), so hosting the data on S3 which is closely located to the computational resources of EC2 means that anyone with an AWS account can start using it in their research, from anywhere with internet access, at any scale, whilst only paying for the compute power they need, as and when they use it. This enables researchers from laboratories of all sizes to start exploring and working with the data straight away. The Cloud BioLinux AMIs are ready to roll with the necessary tools and packages, and are a great place to get going.
Making the data available via a bucket in S3 also means that customers can crunch the information using Hadoop via Elastic MapReduce, and take advantage of the growing collection of tools for running bioinformatics job flows, such as CloudBurst and Crossbow.
You can find more information, the location of the data and how to get started using it on our 1000 Genomes web page, or from the project pages.


Microsoft hosts the NCBI BLAST DNA-analysis tool on Windows Azure.
Jeff Barr (@jeffbarr) reported an Updated Amazon Linux AMI (2012.03) Now Available on 3/28/2012:
We've just released version 2012.03 of the Amazon Linux AMI. Coming six months after our previous major release, this version of the AMI is loaded with new features that EC2 users will enjoy.
One of our goals for this release has been to make available multiple major versions of important packages. This allows code that relies on different versions of core languages, databases, or applications to migrate from older AMIs with minimal changes needed. For example:
- Tomcat 7: Support is included for both Tomcat 6 and Tomcat 7. Both are included in the package repository, and can be installed via yum install tomcat6 or yum install tomcat7.
- MySQL 5.5: New Amazon Linux AMI 2012.03 users who yum install mysql (or yum install mysql55) will get MySQL 5.5 by default, unless they explicitly choose to install the older MySQL 5.1. Users upgrading via yum from Amazon Linux AMI 2011.09 instances with the older MySQL 5.1 installed will stay with MySQL 5.1, which is still available as mysql51 in the package repository.
- PostgreSQL 9: Similar to MySQL, new Amazon Linux AMI 2012.03 users who yum install postgresql (or yum install postgresql9) will get PostgreSQL 9 by default, unless they explicitly choose to install the older PostgreSQL 8. Users upgrading via yum from Amazon Linux AMI 2011.09 instances with the older PostgreSQL 8.4.x installed will stay with PostgreSQL 8, which is still available as postgresql8 in the package repository.
- GCC 4.6: While GCC 4.4.6 remains the default, we have included GCC 4.6.2, specifically for use on EC2 instances that support Intel's new AVX instruction set. Run yum install gcc46 in order to get the packages. GCC 4.6 enables the Amazon Linux AMI to take advantage of the AVX support available on the Cluster Compute Eight Extra Large (cc2.8xlarge) instance type.
- Python 2.7: While Python 2.6 is still the default, you can yum install python27 to install version 2.7. We are constantly working on getting more modules built and available for the new Python version, and will be pushing those modules into the repository as they become available.
- Ruby 1.9.3: While Ruby 1.8.7 is still the default, you can yum install ruby19 to run version 1.9.3 of Ruby.
We have also upgraded the kernel to version 3.2, updated all the AWS command line tools, and refreshed many of the packages that are available in the Amazon Linux AMI to the latest upstream versions.
The Amazon Linux AMI 2012.03 is available for launch in all regions. The Amazon Linux AMI package repositories have also been updated in all regions. Users of 2011.09 or 2011.02 versions of the Amazon Linux AMI can easily upgrade using yum. Users who prefer to lock on the 2011.09 package set even after the release of 2012.03 should consult the instructions on the EC2 forum.
For more information, see the Amazon Linux 2012.03 release notes.


Updated competition to Windows Azure.
<Return to section navigation list>

















{kind=link}
0 comments:
Post a Comment