Windows Azure and Cloud Computing Posts for 9/7/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

• Updated 9/7/2011 4:30 PM with articles marked • by Walter Myers III, the Windows Azure Platform Appliance Team, Windows Azure Team and Avkash Chauhan.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Apps, WF, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table and Queue Services
Steve Marx (@smarx) described Building a Task Scheduler in Windows Azure in a 6/7/2011 post:
In my last blog post (“Managing Concurrency in Windows Azure with Leases”), I showed how blob leases can be used as a general concurrency control mechanism. In this post, I’ll show how we can use that to build a commonly-requested pattern in Windows Azure: task scheduling.
Let’s set some requirements:
- We should be able to add tasks in any order and set arbitrary times for each.
- When it’s time, tasks should be processed in parallel. (If lots of tasks are ready to be completed, we should be able to scale out the work by running more instances.)
- There should be no single point of failure in the system.
- Each task should be processed at least once, and ideally exactly once.
Note the wording of that last requirement. In a distributed system, it’s often impossible to get “exactly once” semantics, so we need to choose between “at least once” and “no more than once.” We’ll choose the former. These semantics mean that our tasks still need to be idempotent, just like any task you use a queue for.
Representing the Schedule
Tackling requirement #1, we’ll use a table to store the list of tasks and when they’re due. We’ll store a simple entity called a
ScheduleItem:public class ScheduledItem : TableServiceEntity { public string Message { get; set; } public DateTime Time { get; set; } public ScheduledItem(string message, DateTime time) : base(string.Empty, time.Ticks.ToString("d19")) { Message = message; Time = time; } public ScheduledItem() { } }Note that we’re using a timestamp for the partition key, meaning that the natural sort order of the table will put the tasks in chronological order, with the next task to complete at the top. As we’ll see, this sort order makes it easy to query for which tasks are due.
Managing Concurrency
We could at this point write code that polls the table, looking for work that’s ready to complete, but we have a concurrency problem. If all instances did this in a naïve way, we would end up processing tasks more than once when multiple instances saw the tasks at the same time (violating requirement #4). We could have just a single instance of the role that does the work, but that would violate requirements #2 (parallel processing) and #3 (no single point of failure).
Part of the solution is to use a queue. A queue could distribute the work in parallel to multiple worker instances. However, we’ve just pushed the concurrency problem elsewhere. We still need a way to move items from the task list onto the queue in a way that avoids duplication.
Now, we have a fairly easy concurrency problem to solve with leases. We just need to make sure that only one instance at a time looks at the schedule and moves ready tasks onto the queue. Here’s code that does exactly that:
using (var arl = new AutoRenewLease(leaseBlob)) { if (arl.HasLease) { // inside here, this instance has exclusive access var ctx = tables.GetDataServiceContext(); foreach (var item in ctx.CreateQuery<ScheduledItem>("ScheduledItems").Where(s => s.PartitionKey == string.Empty && s.RowKey.CompareTo(DateTime.UtcNow.Ticks.ToString("d19")) <= 0) .AsTableServiceQuery()) { q.AddMessage(new CloudQueueMessage(item.Message)); // potential timing issue here: If we crash between enqueueing the message and removing it // from the table, we'll end up processing this item again next time. This is unavoidable. // As always, work needs to be idempotent. ctx.DeleteObject(item); ctx.SaveChangesWithRetries(); } } } // lease is released hereWe can safely run this code on all of our instances, knowing that the lease will protect us from having more than one instance doing this simultaneously.
Once the messages are on a queue, all the instances can work on the available tasks in parallel. (Nothing about this changes.)
All Together
Putting this all together, we have http://scheduleditems.cloudapp.net, which consists of:
- A web role inserting entities into the
ScheduledItemstable. Each entity has a string message and a time when it’s ready to be processed. These are maintained in sorted order by time.- A worker role that loops forever. One instance at a time (guarded by a lease) transfers due tasks from the table to a queue, and all instances process work from that queue.
This scheme meets all of our original requirements:
- Tasks can be added in any order, since they’re always maintained in chronological sort order.
- Tasks are executed in parallel, because they’re being distributed by a queue.
- There’s no single point of failure, because any worker instance can manage the schedule.
- Because tasks aren’t removed from the table until they’re on a queue, every task will be processed at least once. In the case of failures, it’s possible for a message to be processed multiple times (if an instance fails between enqueuing a message and deleting it from the table, or if an instance fails between dequeuing a message and deleting it).
The mechanism presented here could certainly be improved. For example, rescheduling a task is possible by performing an insert and a delete as a batch transaction. Recurring tasks could be supported by rescheduling a task instead of deleting it once it’s been inserted onto the queue.
Feedback
The snippets of code above are really all you need to implement task scheduling, but I wonder if a reusable library would be useful for this, or if it might make sense to integrate with some existing library. Let me know on Twitter (@smarx) what you think.
[UPDATE 11:12PM PDT] I had meant to include (but forgot) a note that Windows Azure AppFabric Service Bus Queues have a built-in way to schedule when the message appears on the queue: http://msdn.microsoft.com/en-us/library/microsoft.servicebus.messaging.brokeredmessage.scheduledenqueuetimeutc.aspx

Steve Marx (@smarx) explained Managing Concurrency in Windows Azure with Leases in a 9/6/2011 post:
Concurrency is a concept many developers struggle with, both in the world of multi-threaded applications and in distributed systems such as Windows Azure. Fortunately, Windows Azure provides a number of mechanisms to help developers deal with concurrency around storage:
- Blobs and tables use optimistic concurrency (via ETags) to ensure that two concurrent changes won’t clobber each other.
- Queues help manage concurrency by distributing messages such that (under normal circumstances), each message is processed by only one consumer.
- Blob leases allow a process to gain exclusive write access to a blob on a renewable basis. Windows Azure Drives use blob leases to ensure that only a single VM has a VHD mounted read/write.
Sometimes, however, an application needs to control concurrency around a different resource (one not in storage). For example, I see a somewhat regular stream of questions from customers about how to ensure that some initialization routine is performed only once. (Perhaps every time your application is deployed to Windows Azure, you need to download some initial data from a web service and load it into a table.)
Leases for concurrency control
Of the concurrency primitives available in Windows Azure, blob leases are the most general and can be used in much the same way that an object is used for locking in a multi-threaded application. A lease is the distributed equivalent of a lock. Locks are rarely, if ever, used in distributed systems, because when components or networks fail in a distributed system, it’s easy to leave the entire system in a deadlock situation. Leases alleviate that problem, since there’s a built-in timeout, after which resources will be accessible again.
Returning to our initialization example, we might create a blob named “initialize” and use a lease on that blob to ensure that only one Windows Azure role instance is performing the initialization.
This pattern of using leases for concurrency control is so powerful that I included a special class called
AutoRenewLeasein my storage extensions NuGet package (smarx.WazStorageExtensions).AutoRenewLeasehelps you write these parts of your code similarly to how you might use alockblock in C#. Here’s the basic usage:using (var arl = new AutoRenewLease(leaseBlob)) { if (arl.HasLease) { // inside here, this instance has exclusive access } } // lease is released here
AutoRenewLeasewill automatically create the blob if it doesn’t already exist. Note that unlike C#’slock, this is a non-blocking operation. If the lease can’t be acquired (because the blob has already been leased), execution will continue (with aHasLeasevalue offalse).As the name indicates,
AutoRenewLeasetakes care of renewing the lease, so you can spend as much time inside theusingblock without worrying about the lease expiring. (Blob leases expire after 60 seconds.AutoRenewLeaserenews the lease every 40 seconds to be safe.)Revisiting our initialization example once again, we might write a method like this to perform our initialization only once (and have all instances block until initialization is complete):
// blob.Exists has the side effect of calling blob.FetchAttributes, which populates the metadata collection while (!blob.Exists() || blob.Metadata["progress"] != "done") { using (var arl = new AutoRenewLease(blob)) { if (arl.HasLease) { // do our initialization here, and then blob.Metadata["progress"] = "done"; blob.SetMetadata(arl.leaseId); } else { Thread.Sleep(TimeSpan.FromSeconds(5)); } } }Here, we’re using the blob for leasing purposes, but we’re also using its metadata to track progress. This gives us a way to have all the instances wait until initialization is actually complete before moving on.
I found this pattern useful enough that I made a convenience method for it and included that in my storage extensions too. Here’s its basic usage:
AutoRenewLease.DoOnce(blob, () => { // do initialization here });To make sure something is done on every new deployment, you might use the deployment ID as the blob name:
AutoRenewLease.DoOnce(container.GetBlobReference(RoleEnvironment.DeploymentId), () => { // do initialization here });Download
The classes and methods mentioned above are all part of smarx.WazStorageExtensions (NuGet package, GitHub repository).
Next Steps
Leases are incredibly useful for managing all sorts of concurrency challenges. In upcoming blog posts, I’ll cover using leases to help with task scheduling and general leader election. Stay tuned!

<Return to section navigation list>
SQL Azure Database and Reporting
• Walter Myers III (@WalterMyersIII) wrote Field Note: Using Certificate-Based Encryption in Windows Azure Applications for the new Windows Azure Field Notes Group on 9/7/2011:
This is the first in a series of articles focused on sharing “real-world” technical information from the Windows Azure community. This article was written by Walter Myers III, Principal Consultant, Microsoft Consulting Services.
Problem
I have seen various Windows Azure-related posts where developers have chosen to use symmetric key schemes for the encryption and decryption of data. An important scenario is when a developer needs to store encrypted data in SQL Azure, which will then be decrypted in a Windows Azure application for presenting to the user. Another is a data synchronization scenario where on-premises data must be kept synchronized with data in SQL Azure, with the data encrypted while off-premises in Windows Azure. [Emphasis added.]
A developer might store the encryption key in Windows Azure storage as a blob, which will be secure as long as the storage key that references the Windows Azure storage is safe; but this is not a best practice, as the developer must have access to the symmetric key and may unknowingly compromise the symmetric key on premises. Additionally, if the Windows Azure application is compromised, then it is possible the key will become compromised as well. This article provides a model and code for certificate-based encryption/decryption of data for Windows Azure applications.
Solution
First, let me provide some background. With a certificate-based (asymmetric key) approach, a best practice is to follow a “separation of concerns” protocol in order to protect the private key. Thus, IT would be responsible for any certificates with private keys that are uploaded to the Windows Azure Management Portal as service certificates for use by Windows Azure applications (service certificates available to Windows Azure applications must be uploaded to the corresponding hosted service). Developers will be provided with the public key only for use on their development machines at the time of application deployment. When testing in the development fabric, the developer must use a certificate that they have created through self-certification using IIS7. When deploying, they would simply replace the thumbprint in their encrypt/decrypt code with that of the service certificate uploaded to Windows Azure and also deploy the public key of the service certificate with their application.
The developer must deploy the public key with their application so that, when Windows Azure spins up role instances, it will match up the thumbprint in the service definition with the uploaded service certificate and deploy the private key to the role instance. The private key is intentionally non-exportable to the .pfx format, so you won’t be able to grab the private key through an RDC connection into a role instance.
Implementation of Solution
Now that we have tackled a little theory, let’s walk through this to see the concepts demonstrated concretely. Note that this solution uses the Visual Studio-provided functionality for certificate management.
If you haven’t already, go ahead and install the public key certificate into your personal certificate store. Use Local Computer instead of the Current User store, so your code will be consistent with where Windows Azure will deploy your certificate. Note that in order to see the certificate, you can’t just launch certmgr.msc, because it will take you to the Current User store. You will have to launch mmc.exe and select the File | Add/Remove Snap-In… menu item, add the Certificates snap-in, and select Computer Account in order to see the Local Computer Certificates, as seen in the snapshot below.
So your certificate console should now look something like below:
Now let’s take a look at how things will look in Visual Studio 2010 before you deploy your application, and then we will look at how the certificate console looks in an Windows Azure role instance. Below is a screen shot where I selected the Properties page for my web role, and selected the Certificates tab. I added the certificate highlighted in the above screenshot and renamed it EncryptDecrypt. Note that the store location is LocalMachine, and the Store Name is My, which is what we want.
Once you have added your certificate here, you can now go to the ServiceDefinition.csdef file and yours should look similar to below. You will also find an entry along with the thumbprint in the ServiceConfiguration.cscfg file.
After you have deployed your application, you can then establish a Remote Desktop Connection (RDC) to any instance (presuming you have configured RDC when you published your application). In the same manner as above, launch mmc.exe and add the Certificates snap-ins for both Local Computer and Current User. Your RDC window should look similar to below.
Notice that certificates are installed into the Local Computer personal certificates store, but none have been installed in the Current User personal store. It was the combination of uploading the service certificate to your hosted service and configuring the certificate for your role that caused Windows Azure to install the certificate in your certificate store. Now if you right-click on the certificate and attempt to export, as discussed above, you will see that the private key is not exportable, which is what we would expect, as seen below.
So now we know how the certificate we will use for encrypt/decrypt of our data is handled. Let’s next take a look at the encrypt/decrypt routine that will do the work for us.
public static class X509CertificateHelper { public static X509Certificate2 LoadCertificate(StoreName storeName, StoreLocation storeLocation, string thumbprint) { // The following code gets the cert from the keystore X509Store store = new X509Store(storeName, storeLocation); store.Open(OpenFlags.ReadOnly); X509Certificate2Collection certCollection = store.Certificates.Find(X509FindType.FindByThumbprint, thumbprint, false); X509Certificate2Enumerator enumerator = certCollection.GetEnumerator(); X509Certificate2 cert = null; while (enumerator.MoveNext()) { cert = enumerator.Current; } return cert; } public static byte[] Encrypt(byte[] plainData, bool fOAEP, X509Certificate2 certificate) { if (plainData == null) { throw new ArgumentNullException("plainData"); } if (certificate == null) { throw new ArgumentNullException("certificate"); } using (RSACryptoServiceProvider provider = new RSACryptoServiceProvider()) { provider.FromXmlString(GetPublicKey(certificate)); // We use the public key to encrypt. return provider.Encrypt(plainData, fOAEP); } } public static byte[] Decrypt(byte[] encryptedData, bool fOAEP, X509Certificate2 certificate) { if (encryptedData == null) { throw new ArgumentNullException("encryptedData"); } if (certificate == null) { throw new ArgumentNullException("certificate"); } using (RSACryptoServiceProvider provider = (RSACryptoServiceProvider) certificate.PrivateKey) { // We use the private key to decrypt. return provider.Decrypt(encryptedData, fOAEP); } } public static string GetPublicKey(X509Certificate2 certificate) { if (certificate == null) { throw new ArgumentNullException("certificate"); } return certificate.PublicKey.Key.ToXmlString(false); } public static string GetXmlKeyPair(X509Certificate2 certificate) { if (certificate == null) { throw new ArgumentNullException("certificate"); } if (!certificate.HasPrivateKey) { throw new ArgumentException("certificate does not have a PK"); } else { return certificate.PrivateKey.ToXmlString(true); } } }Note that in the Encrypt and Decrypt routines above, we have to get the public key for the encryption but must get the private key for the decryption. This makes sense, because Public Key Infrastructure (PKI) allows us to perform encryption by anyone who has the public key, but only the person with the private key has the privilege of decrypting the encrypted string. A notable difference is when we get the key, we can export the public key to XML as seen in the Encrypt routine, but we can’t export the private key to XML in the Decrypt routine, since certificates are deployed with the private key set as non-exportable on Windows Azure, which we learned earlier.
Let’s now take a look at some code I wrote to simply encrypt a string and decrypt a string using the X509 encrypt/decrypt helper class from above:
string myText = "Encrypt me."; X509Certificate2 certificate = X509CertificateHelper.LoadCertificate( StoreName.My, StoreLocation.LocalMachine, "D3E6F7F969546ED620A255794CAB31D8C07E9F31"); if (certificate == null) { Response.Write("Certificate is null."); return; } byte[] encoded = System.Text.UTF8Encoding.UTF8.GetBytes(myText) byte[] encrypted; byte[] decrypted; try { encrypted = X509CertificateHelper.Encrypt(encoded, true, certificate); } catch (Exception ee) { Response.Write("Encrypt failed with error: " + ee.Message + "<br>"); return; } try { decrypted = X509CertificateHelper.Decrypt(encrypted, true, certificate); } catch (Exception ed) { Response.Write("Decrypt failed with error: " + ed.Message + "<br>"); return; }So in the code above I loaded my certificate, using the personal store on the local machine. The last parameter in the LoadCertificate method of my X509 encrypt/decrypt class holds the thumbprint that I grabbed from the Certificates tab in the property page for the role. As an exercise, you can write some code to retrieve this string from the ServiceConfiguration.cscfg file.
References: http://www.josefcobonnin.com/post/2007/02/20/Encrypting-with-Certificates.aspx







<Return to section navigation list>
MarketPlace DataMarket and OData
Shayne Burgess (@shayneburgess) wrote Build Great Experiences on Any Device with OData for the 9/2011 issue of MSDN Magazine:
In this article, I’ll show you what I believe is a serious data challenge facing many organizations today, and then I’ll show you how the Open Data Protocol (OData) and its ecosystem can help to alleviate that challenge. I’ll then go further and show how OData can be used to build a great experience on Windows Phone 7 using the new OData library for Windows Phone 7.1 beta (code-named “Mango”).
The Data Reach Challenge
An interesting thing happened at the end of 2010: for the first time in history, the number of smartphone shipments surpassed the number of PC shipments. A key thing to note is that this isn’t a one-horse race. There are many players (Apple Inc., Google Inc., Microsoft, Research In Motion Ltd. and so on) and platforms (desktop, Web, phones, tablets and more coming all the time). Many organizations want to target client experiences on all or most of these devices. And many organizations also have a variety of data and services that they want to make available to client devices. These may be on-premises, available through traditional Web services or built in the cloud.
The combination of a large and ever-expanding variety of client platforms with a large and ever-expanding variety of services creates a significant cost and complexity problem. When support for a new client platform is added, the data and services often have to be updated and modified to support that platform. And when a new service is added, all of the existing client platforms need to be modified to support that service. This is what I consider to be the data reach problem. How can we define a service that’s flexible enough to suit the needs of all the existing client experiences—and new client experiences that haven’t been invented yet? How can we define client libraries and applications that can work with a variety of services and data sources? These are some of the key questions that I hope to show can be partly addressed with OData.
The Open Data Protocol
OData is a Web protocol for querying and updating data that provides a uniform way to unlock your data. Simply put, OData provides a standard format for transferring data and a uniform interface for accessing that data. It’s based on ATOM and JSON feeds and the interface uses standard HTTP (REST) interfaces for exposing querying and updating capabilities. OData is a key component in bridging the data reach problem because, being a uniform, flexible interface, the API can be created once and used from a variety of client experiences.
The OData Ecosystem
The flexible OData interface that can be used from a variety of clients is most powerful when there are a variety of client experiences that can be built using existing OData-enabled clients. The OData client ecosystem has evolved over the last few years to the point where there are client libraries for the majority of client devices and platforms, with more coming all the time. Figure 1 lists just a sampling of the client and server platforms available at the time this article was written (a much more complete list of existing OData services is at odata.org/producers).
Figure 1 A Sampling of the OData Ecosystem
Clients .NET Silverlight Windows Phone WebOS iPhone DataJS Excel Tableau Services Windows Azure SQL Azure DataMarket SharePoint SAP Netflix eBay Wine.com

I can generally target any of the listed services in Figure 1 with any client. To help demonstrate this in practice, I’ll give examples of OData flexibility using a couple of different clients.
I’ll use the Northwind OData (read-only) sample service available on odata.org at http://services.odata.org/Northwind/Northwind.svc/. If you’re familiar with the Northwind database, the Northwind service shown in Figure 2 simply exposes the Northwind model as an OData service directly. Figure 2 shows the service document in the Northwind service from the browser; the service document exposes the entity sets in the service that are basically just the tables from the Northwind database.
.png "The Northwind Service")
Figure 2 The Northwind ServiceLet’s look at a couple of examples of using the client libraries to consume and build experiences using the Northwind OData service. For the first example, let’s consider a client experience that doesn’t require any code to build. The PowerPivot add-in for Excel provides an in-memory analysis engine that can be used directly from within the Excel interface and supports importing data directly from an OData feed. The PowerPivot add-in also includes support for importing data directly from the Windows Azure Marketplace DataMarket, as well as a number of other data sources.
Figure 3 shows a pivot chart created by importing the Products and Orders data from the Northwind OData service and joining the result. The price-per-unit and quantity fields of the order details are combined to produce a total value for each order, and then the average total value for each order is shown, grouped by product and then displayed on a simple pivot chart for analysis. All of this is done using the built-in interface and tools in PowerPivot and Excel.
.png "PowerPivot Add-In")
Figure 3 PowerPivot Add-InLet’s look next at another example of how to build an OData client experience on a different platform: iOS. The OData client library for iOS lets you build apps on that platform (such as for the iPad and iPhone) that consume existing OData services. The iOS library for OData includes a code-generation tool, odatagen, which will generate a set of proxy classes from the metadata on the service. The proxy classes provide facilities for generating OData URIs, deserializing a response into client-side objects and issuing create, read, update and delete (CRUD) operations against the service. The following code snippet shows an example of executing a request for the set of customers from the OData service:
- // Create the client side proxy and specify the service URL.
- NorthwindCatalog *proxy =
- [[NorthwindCatalog alloc]initWithUri:@http://host/Northwind.svc];
- // Create a query.
- DataServiceQuery *query = [proxy Customers];
- QueryOperationResponse *response = [query execute];
- customers = [query getResults];
The DataServiceQuery and QueryOperationResponse are used to execute a query by generating a URI and executing it against the service.
The Windows Phone 7 Library
Next, I’ll demonstrate another example of an OData library on a third platform. I did a quick overview of building on OData on other platforms, but for this one I’ll do a detailed walk-through to give insight into what it takes to build an app. To do this, I’ll show you the basic steps needed to write a data-driven experience on Windows Phone 7 using the new Windows Phone 7.1 (Mango) tools. For the rest of the article, I’ll walk through the key considerations when building a Windows Phone 7 app and show how the OData library is used. The app I build will target the same Northwind sample I used in the previous two examples (the Excel PowerPivot add-in and the iOS library).
The latest release of the Windows Phone 7.1 (Mango) beta tools features a significant upgrade in the SDK support for OData. The new library supports a set of new features that makes creating OData-enabled Windows Phone 7 apps easier. The Visual Studio Tools for Windows Phone 7 were updated to support the generation of a custom client proxy based on a target OData service. For those familiar with the existing Microsoft .NET Framework and Silverlight OData clients, this, too, will be familiar. To use the Visual Studio tools to automatically generate the proxy in a Windows Phone 7 project, right-click the Service References node in the project tree and select Add Service Reference (note that this is only available if the new Mango tools are installed). Once the Add Service Reference dialog appears, enter the URI of the OData service you’re targeting and select Go. The dialog will display the entity sets exposed by the service; you can then enter a namespace for the service and select OK. The first time the code generation is performed using Add Service Reference, it will use default options, but it’s possible to further configure the code generation by clicking the Show All Files option in the solution explorer, opening the .datasvcmap file in the service reference and configuring the parameters. Figure 4 shows the completed Add Service Reference dialog with the list of entity sets available.
.png "Using the Add Service Reference Dialog")
Figure 4 Using the Add Service Reference DialogA command-line tool is also included in the Visual Studio Tools for Windows Phone 7 that’s able to perform the same code-generation step. In either case, the code generation will create a client proxy class (DataServiceContext) for interacting with the service, and a set of proxy classes that reflect the shape of the service. …
Shane continues with details of LINQ support, tombstoning and credentials. He concludes:
Learning More
This article gives a summary of OData, the ecosystem that has been built around it and a walk-through using the OData client for Windows Phone 7.1 (Mango) beta to build great mobile app experiences. For more information on OData, visit odata.org. To get more information on WCF Data Services, see bit.ly/pX86x6 or the WCF Data Services blog at blogs.msdn.com/astoriateam.
Shayne is a program manager in the Business Platform Division at Microsoft, working specifically on WCF Data Services and the Open Data Protocol.
<Return to section navigation list>
Windows Azure AppFabric: Apps, WF, Access Control, WIF and Service Bus
• The Windows Azure Platform Team (@WindowAzure) sent the following e-mail on 9/7/2011:
Dear Customer,
Today we are excited to announce an update to the Windows Azure AppFabric Service Bus. This release introduces enhancements to Service Bus that improve pub/sub messaging through features like Queues, Topics and Subscriptions, and enables new scenarios on the Windows Azure platform, such as:
- Async Cloud Eventing - Distribute event notifications to occasionally connected clients (e.g. phones, remote workers, kiosks, etc.)
- Event-driven Service Oriented Architecture (SOA) - Building loosely coupled systems that can easily evolve over time
- Advanced Intra-App Messaging - Load leveling and load balancing for building highly scalable and resilient applications
These capabilities have been available for several months as a preview in our LABS/Previews environment as part of the Windows Azure AppFabric May 2011 CTP. More details on this can be found here: Introducing the Windows Azure AppFabric Service Bus May 2011 CTP.
To help you understand your use of the updated Service Bus and optimize your usage, we have implemented the following two new meters in addition to the current Connections meter:
- Entity Hours - A Service Bus "Entity" can be any of: Queue, Topic, Subscription, Relay or Message Buffer. This meter counts the time from creation to deletion of an Entity, totaled across all Entities used during the period.
- Message Operations - This meter counts the number of messages sent to, or received from, the Service Bus during the period. This includes message receive requests that return empty (i.e. no data available).
These two new meters are provided to best capture and report your use of the new features of Service Bus. You will continue to only be charged for the relay capabilities of Service Bus using the existing Connections meter. Your bill will display your usage of these new meters but you will not be charged for these new capabilities.
We continue to add additional capabilities and increase the value of Windows Azure to our customers and are excited to share these new enhancements to our platform. For any questions related to Service Bus, please visit the Connectivity and Messaging - Windows Azure Platform forum.
Windows Azure Platform Team
Eric Nelson (@ericnel) claimed Are you using Workflow Foundation? And Azure? Then you need the CTP of the Activity Pack in a 9/7/2011 post:
In September we released the first CTP of the Workflow Foundation Activity Pack for Windows Azure. It includes activities which you can “call” from your Workflows in Workflow Foundation 4.0. It can be found on the CodePlex page and is also available via NuGet, you can type “Install-Package WFAzureActivityPack” in your package manager console to install the activity pack.
For Windows Azure Storage Service – Blob
- PutBlob creates a new block blob, or replace an existing block blob.
- GetBlob downloads the binary content of a blob.
- DeleteBlob deletes a blob if it exists.
- CopyBlob copies a blob to a destination within the storage account.
- ListBlobs enumerates the list of blobs under the specified container or a hierarchical blob folder.
For Windows Azure Storage Service – Table
- InsertEntity<T> inserts a new entity into the specified table.
- QueryEntities<T> queries entities in a table according to the specified query options.
- UpdateEntity<T> updates an existing entity in a table.
- DeleteEntity<T> deletes an existing entity in a table using the specified entity object.
- DeleteEntity deletes an existing entity in a table using partition and row keys.
For Windows Azure AppFabric Caching Service
- AddCacheItem adds an object to the cache, or updates an existing object in the cache.
- GetCacheItem gets an object from the cache as well as its expiration time.
- RemoveCacheItem removes an object from the cache.
Related Links

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Avkash Chauhan described an Experiment with Role.Instances Collection and creating all Role Instances Order in a 9/7/2011 post:
When there are multiple instance in a web role, I was trying to check if Role.Instances collection ordered consistently on all endpoints. I also wanted to be sure when instance count is increased by modifying service configuration, the new instances be added to the end of the collection or will it be random.
public override bool OnStart()
{
foreach (RoleInstance roleInst in RoleEnvironment.CurrentRoleInstance.Role.Instances){
Trace.WriteLine("Current Time: " + DateTime.Now.TimeOfDay);
Trace.WriteLine("Instance ID: " + roleInst.Id);
Trace.WriteLine("Instance Role Name: " + roleInst.Role.Name);
Trace.WriteLine("Instance Count: " + roleInst.Role.Instances.Count);
Trace.WriteLine("Instance EndPoint Count: " + roleInst.InstanceEndpoints.Values.Count);
Trace.WriteLine("IP : " + RoleEnvironment.CurrentRoleInstance.InstanceEndpoints["EndPoint1"].IPEndpoint.Address);
int port = RoleEnvironment.CurrentRoleInstance.InstanceEndpoints["EndPoint1"].IPEndpoint.Port;
Trace.WriteLine("Port: " + port);
}
return base.OnStart();
}
I started application in the Compute Emulator so I can look the start time for each instance in my Web Role:

I wanted to check the start time of each instance so I collected the following info for each instance:
Role[#]
Role.Instance.ID
Start Order
Role[0]
- Current Time: 15:07:05.9445984
- Instance ID: deployment(341).WebRoleTest.ASPWebRole.0
- IP : 127.0.0.1
- Port: 5145
2
Role[1]
- Current Time: 15:07:06.3676226
- Instance ID: deployment(341).WebRoleTest.ASPWebRole.1
- IP : 127.0.0.1
- Port: 5146
5
Role[2]
- Current Time: 15:07:06.4216257
- Instance ID: deployment(341).WebRoleTest.ASPWebRole.2
- IP : 127.0.0.1
- Port: 5147
7
Role[3]
- Current Time: 15:07:06.2376152
- Instance ID: deployment(341).WebRoleTest.ASPWebRole.3
- IP : 127.0.0.1
- Port: 5148
4
Role[4]
- Current Time: 15:07:05.9345979
- Instance ID: deployment(341).WebRoleTest.ASPWebRole.4
- IP : 127.0.0.1
- Port: 5149
1
Role[5]
- Current Time: 15:07:06.5746345
- Instance ID: deployment(341).WebRoleTest.ASPWebRole.5
- IP : 127.0.0.1
- Port: 5150
9
Role[6]
- Current Time: 15:07:06.2106137
- Instance ID: deployment(341).WebRoleTest.ASPWebRole.6
- IP : 127.0.0.1
- Port: 5151
3
Role[7]
- Current Time: 15:07:06.3846236
- Instance ID: deployment(341).WebRoleTest.ASPWebRole.7
- IP : 127.0.0.1
- Port: 5152
6
Role[8]
- Current Time: 15:07:06.5906354
- Instance ID: deployment(341).WebRoleTest.ASPWebRole.8
- IP : 127.0.0.1
- Port: 5153
10
Role[9]
- Current Time: 15:07:06.4746288
- Instance ID: deployment(341).WebRoleTest.ASPWebRole.9
- IP : 127.0.0.1
- Port: 5154
8
Based on above I could create the following Instance order:
- 1 deployment(341).WebRoleTest.ASPWebRole.4
- 2 deployment(341).WebRoleTest.ASPWebRole.0
- 3 deployment(341).WebRoleTest.ASPWebRole.6
- 4 deployment(341).WebRoleTest.ASPWebRole.3
- 5 deployment(341).WebRoleTest.ASPWebRole.1
- 6 deployment(341).WebRoleTest.ASPWebRole.7
- 7 deployment(341).WebRoleTest.ASPWebRole.2
- 8 deployment(341).WebRoleTest.ASPWebRole.9
- 9 deployment(341).WebRoleTest.ASPWebRole.5
- 10 deployment(341).WebRoleTest.ASPWebRole.8
When I ran the same application a few times, the order was not consistent. Adding new instances was also changing the order. So you can see the current role instance is always first in the list however the ordering is very different.
So If you would need to create instance order list, the best would be to have each instance write an entity to a table when it starts up (with a timestamp or a row key that represents the current time). Then you’ll be able to construct an ordered list.


Herve Roggero (@hroggero) claimed Spotlight (R) on Azure: Cool Tool in a 9/7/2011 post:
While testing the performance characteristics of the SQL Azure backup tool I am building (called Enzo Backup for SQL Azure), I decided to try Spotlight
(R)on Azure in order to obtain specific performance metrics from a virtual machine (VM) running on Microsoft's data center. Indeed, my backup solution comes with a cloud agent (running as a worker role in Azure) that performs backup and restore operations entirely in the cloud. Due to the nature of this application, I needed to have an understanding of possible memory and CPU pressures. [Emphasis added.]
When it comes to small companies with few operational capabilities, Spotlight
(R)on Azure delivers (from Quest). The installation is extremely simple and the tool comes with many metrics out of box. In my tests, I was able to obtain a quick read on my virtual machine and review performance graphs showing CPU Utilization, CPU Queue Length, Memory Utilization and Network Traffic. The tool shows by default the last 15 minutes or data, which is very handy. If you have a large farm of virtual machines, you can also view metrics rolled up across your virtual machines. Finally the tool allows you to declare Alerts if you cross performance thresholds (the thresholds values can be changed to your needs).All in all, this is a simple, yet powerful performance monitoring tool for your Azure virtual machines. Here is a link that shows the tool in action: http://www.youtube.com/watch?v=FDJjytW-VFI and here is a link where you can download the tool for a test drive: http://communities.quest.com/docs/DOC-9906

Not only is the Monitoring Pack for Windows Azure Applications difficult to install (it takes 60 steps - see my Installing the Systems Center Monitoring Pack for Windows Azure Applications on SCOM 2012 Beta of 9/5/2011). What’s worse is that % Processor Time Total (Azure) and Memory Available Megabytes (Azure) metrics are disabled by default (see my Configuring the Systems Center Monitoring Pack for Windows Azure Applications on SCOM 2012 Beta of 9/6/2011).
Linda Rosencrance (@Reporter1035) reported Microsoft Dynamics NAV ISVs Gearing Up for NAV 7 in Windows Azure in a 9/6/2011 post to the MSDynamicsWorld.com blog:
Microsoft's director of US ISV strategy, Mark Albrecht, told a group of Dynamics partners at a recent GP Partner Connections event that the company is actively focusing on cloud readiness of Dynamics NAV ISV partners to accelerate their development of Azure-friendly version of their solutions in conjunction with the NAV 7 release on Azure. Microsoft understands, Albrecht says, that having enough ISV solutions available in conjunction with a multi-tenant, Azure-based NAV solution will be a key differentiator.
"Our initial efforts in moving ISVs to the cloud will be [focused on] verticals and industries that have the biggest impact on the customer's purchase decision," Albrecht added. "We're working to make sure that both product and business model are making the shift to the cloud in the right time frame for that partner."
ISVs prepare
To-Increaseis one of those ISVs getting its solutions ready for the Azure-ready release of NAV 7. To-Increase develops Dynamics NAV solutions for the industrial equipment manufacturing industry.
"To-Increase is an ISV so we are always preparing for the next release of Microsoft [Dynamics products]," said Adri Cardol, Product Manager Microsoft Dynamics NAV, To-Increase. "We have the information Microsoft is making available on the new release. We're studying what the impact is on our solution and how we can best modify the design, adjust the design or redevelop the product to meet the requirements of the new Azure platform. So what we are doing is getting ready, but the available information is coming to us in bits and pieces."
Cardol said To-Increase is studying the information step-by-step and trying to estimate the impact of every piece of information that it gets so it can be ready when NAV 7 is rolled out. As part of Microsoft's early access beta program, they know what NAV 7 is all about. However, he said currently To-Increase is studying the new functionality of the newest build from Microsoft to determine how it will affect the company's solutions.
"Since NAV will be running on the Azure platform, we sort of assume that any new functionality that we develop will also run on that platform, simply as a hosted solution that will not be specific for the Azure platform," he said.
RMI Corp. is also working to get an Azure-hosted version of ADVANTAGE, the company's Dynamics NAV-based system for companies that rent, sell and service equipment, ready for the NAV 7 launch, according to Paul Chapdelaine, RMI's owner.
"We're a Dynamics NAV ISV and about four years ago we started offering a SaaS offering-at Microsoft's request-and about a year and a half ago we actually stopped offering the on-premise and went ‘all in' the cloud," he said. "The way I view this is that Microsoft will start offering another layer. Right now, we're hosting the software on SQL Server and we're combining other functional elements so we deliver to the end user a completely integrated Office environment."
"We're not looking to host individual installations on a box some place, we need true multi-tenancy," he said. "We've accomplished that where we are now, but we did it through a lot of hard work because NAV doesn't lend itself to that environment natively."
However, Chapdelaine declined to offer specifics on exactly how RMI accomplished that feat because "we've done it and no one else has. It's a competitive advantage and it took a lot of effort."
But Chapdelaine said he has some questions about how the Azure version of NAV 7 will work with his company's other offerings.
"As long as Microsoft Azure is a SQL database, a data storage device, that may work very well," he said. "But we want to see how it evolves with our other offerings. [And we want to know] who's going to control the end user experience. We want to make sure we can continue to control the end user's experience with the software. I need to be able to configure it to meet their needs with ancillary products."
Finding new ways to tailor a NAV solution
Going to cloud-based or hosted solutions also opens new opportunities but it also creates restrictions for ISVs, which is why it's important to estimate what the impact will be on your solution, Cardol said.
"If you want to fully use the possibility of hosted solutions you have to go to a much more templated type solution for an ERP application than we are used to in the ERP world," said Cardol of To-Increase. "The ERP world has a basic solution with which you go on-premise and, together with the customer, you implement, you customize, you tailor it to the specific needs of that customer. So that is an area that has to change in the sense that to fully use the benefit of hosted you have to come up with much more templated solutions that are much more standardized toward certain business areas."
That's exactly what To-Increase is working on, he said.
And although Dynamics NAV is the main attraction for RMI's customers, they also find themselves tailoring their solution for customers by offering other ISV add-ons to round out its offering like Commerce Clearing House sales tax updates, Matrix Documents, and Jet Reports, Chapdelaine said.
"How are we going to control how all of that works together?" he asked. "We're not concerned, we just don't know. We've talked to some folks within Microsoft and they have assured us that as soon as Dynamics NAV is ready to go at 7, they'll let us play in that sandbox first and do some pilots so we can figure out how to do it."
Planning for the NAV 7 release
Cardol said when his company's solutions will be ready depends on the actual release date of Dynamics NAV 7.
"We know it will be mid-2012 and we have a release schedule that's more or less in sync with that," he said. "We have our releases in May and November so ideally we will still catch it in the May release, maybe even delay it a month or so to meet the NAV 7 release. But if the NAV 7 release is going be in August or September 2012, then we might want to postpone our releases until November."
Microsoft is expected to release an initial beta version of NAV 7 at the beginning of 2012 with an announcement at the NAV Directions conference.
"They're going to show it at Directions for the first time," he said. "We haven't even got a copy of it," says RMI's Chapdelaine. "It's at that point, we'll start moving to Azure."

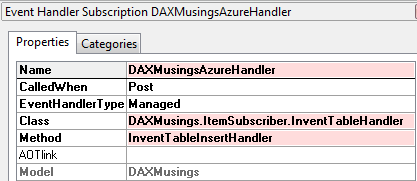
Joris de Gruyter (@jorisdg) described a 10-Minute AX 2012 App: Windows Azure (Cloud) in a 9/6/2011 post:
Powerfully simple put to the test. If you missed the first article, I showed you how to create a quick WPF app that reads data from AX 2012 queries and displays the results in a grid. In this article, I will continue showing you how easy it is to make use of AX 2012 technology in conjunction with other hot Microsoft technologies. Today, we will create a Windows Azure hosted web service (WCF), to which we'll have AX 2012 publish product (item) data. Again, this will take 10 minutes of coding or less. Granted, it was a struggle to strip this one down to the basics to keep it a 10-minute project.
So, we'll build an Azure WCF service using Table storage (as opposed to BLOB storage or SQL Azure storage). Make sure to evaluate SQL Azure if you want to take this to the next level. So, our ingredients for today will require you to install something you may not have already...
Ingredients:
- Visual Studio 2010
- Windows Azure SDK (download here)
- Access to an AX 2012 AOS
Now, the Azure SDK has some requirements of its own. I have it using my local SQL server (I did not install SQL Express) and my local IIS (I did not install IIS express).
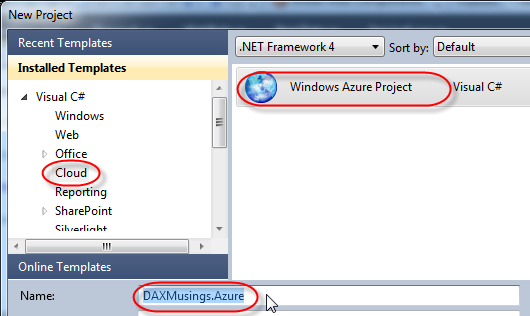
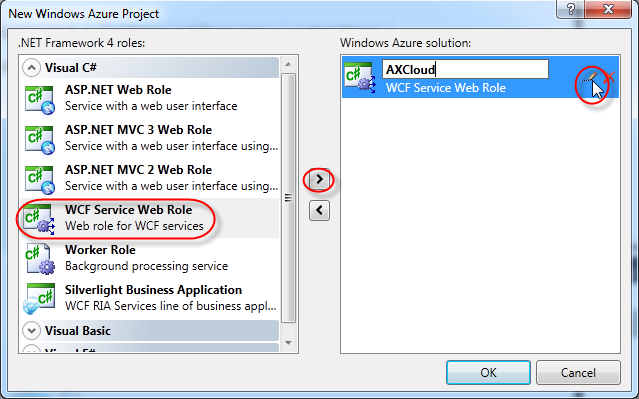
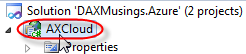
Ok, everything installed and ready? Start the timer! You need to start Visual Studio 2010 as administrator. So right-click Visual Studio in your start menu and select "Run as Administrator". This is needed to be able to run the Windows Azure storage emulators. We'll start a new project and select Cloud > Windows Azure Project. I've named this project "DAXMusings.Azure". Once you click OK, Visual Studio will ask you for the azure role and type of project. I've select "WCF Service Web Role". Click the little button to add the role to your solution. Also, click the edit icon (which won't appear until your mouse hovers over it) to change the name to "AXCloud".
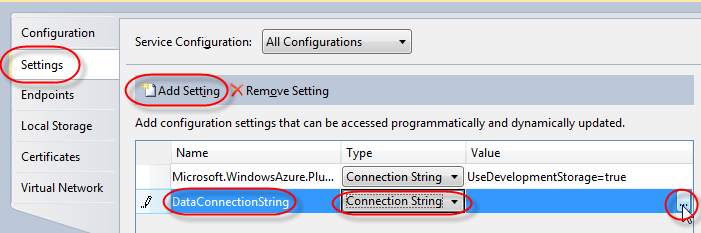
Ok, first things first, setup the data connection for the table storage. Right-click on the "AXCloud" under "Roles" and select properties.
Under settings, click the "Add Setting" button, name it "DataConnectionString", set the drop down to... "Connection String", and click the ellipsis. On that dialog screen, just select the "Use the Windows Azure storage emulator" and click OK.
Hit the save button and close the properties screen. So, what we will be storing, and communicating over the webservice, is item data. So, let's add a new class and call it ItemData. To do this, we right-click on the AXCloud project, and select Add > New Item. On the dialog, select Class and call it "ItemData".
So, here's the deal. For WCF to be able to use this, we need to declare this class as a data contract. For Azure table storage to be able to use it, we need three properties: RowKey (string), Timestamp (DateTime) and PartitionKey (string). For item data, we will get an ITEMID from AX, but we'll store it in the RowKey property since that is the unique key. We'll just add a Name property as well, to have something more meaningful to look at. To support the data contract attribute, you'll need to add the namespace "System.Runtime.Serialization" and for the DataServiceKey you need to add the namespace "System.Data.Services.Common". The PartitionKey we'll set to a fixed value of "AX" (this property has to do with scalability and where the data lives in the cloud; also, the RowKey+PartitionKey technically make up the primary key of the data...). We'll also initialize the Timestamp to the current DateTime, and provide a constructor accepting the row and partition key.
Click here for screenshot or copy the code below:namespace AXCloud { [DataContract] [DataServiceKey(new[] { "PartitionKey", "RowKey" })] public class ItemData { [DataMember] public string RowKey { get; set; } [DataMember] public String Name { get; set; } [DataMember] public string PartitionKey { get; set; } [DataMember] public DateTime Timestamp { get; set; } public ItemData() { PartitionKey = "AX"; Timestamp = DateTime.Now; } public ItemData(string partitionKey, string rowKey) { PartitionKey = partitionKey; RowKey = rowKey; } } }
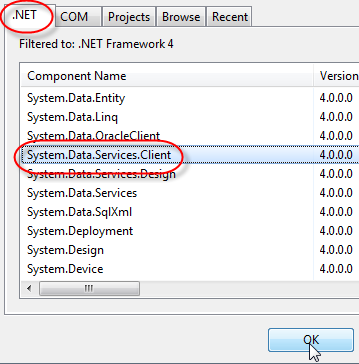
Next, we'll need a TableServiceContext class. We'll need to add a reference to "System.Data.Services.Client" in our project. Just right-click on the "References" node of the AXCloud project and select "Add Reference". On the .NET tab, find the "System.Data.Services.Client" assembly and click OK.
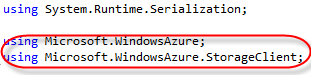
For easy coding, let's add another using statement at the top as well, for the Azure storage assemblies.
And we'll add the Context class. This will provide a property that's Queryable, and an easy way to add an item through an AddItem() method.
Click here for screenshot or copy the code below:public class ItemDataServiceContext : TableServiceContext { public ItemDataServiceContext(string baseAddress, StorageCredentials credentials) : base(baseAddress, credentials) { } public IQueryable Items { get { return this.CreateQuery("Items"); } } public void AddItem(string itemId, string name) { ItemData item = new ItemData(); item.RowKey = itemId; item.Name = name; this.AddObject("Items", item); this.SaveChanges(); } }
So, first time we use this app (or any time you restart your storage emulator), the table needs to be created before we can use it. In a normal scenario this would not be part of your application code, but we'll just add it in here for easy measure. Open the "WebRole.cs" file in your project, which contains a method called "OnStart()". At the top, add the using statements for the Windows Azure assemblies. Inside the onstart() method, we'll add code that creates the table on the storage account if it doesn't exist.
Click here for a full screenshot or copy the below code to add before the return statement:CloudStorageAccount.SetConfigurationSettingPublisher((configName, configSettingPublisher) => { var connectionString = Microsoft.WindowsAzure.ServiceRuntime.RoleEnvironment.GetConfigurationSettingValue(configName); configSettingPublisher(connectionString); } ); CloudStorageAccount storageAccount = CloudStorageAccount.FromConfigurationSetting("DataConnectionString"); storageAccount.CreateCloudTableClient().CreateTableIfNotExist("Items");
Next, we'll create a new operation on the WCF service to actually add an item. Since we already have all the ingredients, we just need to add a method to the interface and its implementation. First, in the IService.cs file, we'll add a method where the TODO is located. You probably want to remove all the standard stuff there, but to keep down the time needed and to make it easier for you to see where I'm adding code, I've left it in these screenshots.
Now, into the Service1.svc.cs we'll add the implementation of the method, for which we'll need to add the Windows Azure using statements again:
Click here for a full screenshot or copy the code below:public void AddItem(ItemData item) { CloudStorageAccount.SetConfigurationSettingPublisher((configName, configSettingPublisher) => { var connectionString = Microsoft.WindowsAzure.ServiceRuntime.RoleEnvironment.GetConfigurationSettingValue(configName); configSettingPublisher(connectionString); }); CloudStorageAccount storageAccount = CloudStorageAccount.FromConfigurationSetting("DataConnectionString"); new ItemDataServiceContext(storageAccount.TableEndpoint.ToString(), storageAccount.Credentials).AddItem(item.RowKey, item.Name); }
So now the last thing to do is create a class the consumes this service, which we can use as a post event handler for the insert() method on the InventTable table in AX... I am skipping through some of the steps here, but basically, we create a new class library project in Visual Studio (open a second instance of Visual Studio, since we'll need to keep the Azure service running!), and "Add it to AOT". For a walkthrough on how to do this, check this blog article. We're calling this class libary "DAXMusings.ItemSubscriber".Alright, when you have the new project created and added to the AOT, we need to add a service reference to the Azure WCF service. Since we're running all of this locally, you'll need to make sure the Azure service is started (F5 on the Azure project). This will open internet explorer to your service page (on mine it's http://127.0.0.1:81/Service1.svc). If Azure opens your web site but not the .svc file (you probably will get a 403 forbidden error then), just add "Service1.svc" behind the URL it did open. If you renamed the WCF service in the project, you'll have to use whatever name you gave it.
So, we'll add that URL as a service reference to our subscriber project, and I'm giving it namespace "AzureItems":
Now that we have the reference, we will make a static method to use as an event handler in AX. First, we need to add references to XppPrePostArgs and InventTable by opening the Application Explorer, navigating to Classes\XppPrePostArgs and Data Dictionary\Tables\InventTable respectively. For each one, right-click on the object and select "Add to project" (for more information on the why and how, check this blog post on managed handlers).
Next, there's one ugly part I will have you add. Since the reference to the service is in a class library, which will then be used in an application (AX), the service reference configuration (bindings.. the endpoint etc) which gets stored in the App.config for your class library, will not be available to the AX executables. Technically, we should copy/paste these values into the Ax32Serv.exe.config (or the client one, depending where your code will run). However, this would require a restart of the AOS server, etc. So (.NET gurus will kill me here, but just remember: this is supposed to be up and running in 10 minutes!) for the sake of moving along, we will just hardcode a quick endpoint into the code...
Click here for full screenshot of the class.public static void InventTableInsertHandler(XppPrePostArgs args) { InventTable inventTable = new InventTable((Microsoft.Dynamics.AX.ManagedInterop.Record)args.getThis()); AzureItems.ItemData itemData = new AzureItems.ItemData(); itemData.RowKey = inventTable.ItemId; itemData.Name = inventTable.NameAlias; System.ServiceModel.BasicHttpBinding binding = new System.ServiceModel.BasicHttpBinding(); binding.Name = "BasicHttpBinding_IService1"; System.ServiceModel.EndpointAddress address = new System.ServiceModel.EndpointAddress("http://127.0.0.1:83/Service1.svc"); AzureItems.Service1Client client = new AzureItems.Service1Client(binding, address); client.AddItem(itemData); }
Notice how the URL is hardcoded in here (this is stuff that should go into that config file). One thing I've noticed, with the Azure project running emulated on my local machine, that it seems to change ports every now and then (I started and stopped it a few times). So you may need to tweak this while you're testing this stuff out.So last thing to do is add this as a Post-Handler on the InventTable insert() method... (for more information and walkthrough on adding managed post-handlers on X++ objects, check this blog post)
Time to add an item and test! If you wish to debug this to see what's going on, remember the insert method will be running on the AX server tier so you need to attach the debugger to the AOS service.
How do you now know your item was actually added in the Azure table storage? Well, I will post some extra code tomorrow (a quick and dirty ASP page that lists all items in the table).
I am expecting you will run into quite a few issues trying to get through this exercise. I know I have, some of them were minor things but took me hours to figure out what I was missing. Feel free to contact me or leave a comment, and I'll try to look into each issue.








Brian Swan (@brian_swan) posted an Overview of Command Line Deployment and Management with the Windows Azure SDK for PHP on 9/6/2011:
I’ve been exploring the Windows Azure SDK for PHP command line tools that allow you to create, deploy, and manage new hosted services and web roles. In this post, I’ll walk you through a the basics of using the tools, but first I want to point out a couple of the benefits that come to mind when using these tools:
- The tools are platform-independent (with the exception of the package tool). The service, certificate, and deployment tools essentially wrap the REST-based Windows Azure management API. (If you look at the files in the SDK, you’ll notice that there are .bat and .sh files for these tools.) So, you can manage your Windows Azure services and deployments from the platform of your choice. (Note that because the management API is REST-based, you can use it via the language of your choice, not just PHP. In fact, tools based on languages other than PHP already exist - See this Ruby example on github.)
- The tools allow you to programmatically manage your Windows Azure services and deployments.This series of articles, Building Scalable Applications for Windows Azure, demonstrates how to programmatically scale an application using the PHP classes in the SDK. The same type of management is possible with the command line tools.
Overview of service, certificate, and deployment tools
The operations exposed by the service, certificate and deployment tools should give you a good idea of what you can do with them. The following tables list the operations that are available. For more information (such as short operation names and parameter information), type the tool name at the command line.
service


Note: The list operation returns two properties: ServiceName and Url. The value of the Url property is the management API endpoint, not the service URL. If you want the service URL, you can create it from the ServiceName property: http://ServiceName.cloudapp.net.
certificate

deployment

Note: The getproperties operation returns 5 properties: Name, DeploymentSlot, Label, Url, and Status. The value of the Name property is the deployment ID.
Using the service, certificate, and deployment tools
Creating and uploading a service management API certificate
Before you can use the command line management tools, you need to create certificates for both the server (a .cer file)and the client (a .pem file). Both files can be created using OpenSSL, which you can download for Windows and run in a console.
To create the .pem certificate, execute this:
openssl req -x509 -nodes -days 365 -newkey rsa:1024 -keyout mycert.pem -out mycert.pemTo create the .cer certificate, execute this:
openssl x509 -inform pem -in mycert.pem -outform der -out mycert.cer(For a complete description of OpenSSL parameters, see the documentation at http://www.openssl.org/docs/apps/openssl.html.)
Next, you’ll need to upload the .cer certificate to your Windows Azure account. To do this, go to the Windows Azure portal, select Hosted Services, Storage Accounts & CDN, choose Management Certificates, and click Add Certificate.
Now you are ready to use the service, certificate, and deployment tools.
Create a configuration file
The command line tools in the the Windows Azure SDK for PHP support using a configuration file for commonly used parameters. Here’s what I put into my config.ini file:
-sid="my_subscription_id"-cert="path\to\my\certificate.pem"This makes it possible to use the –F option on any operation to include my SID and certificate.
List hosted services
The following command will list all hosted services:
service list -F="C:\config.ini"This operation will return two properties ServiceName and Url. As mentioned above, the Url property is the management URL, not the service URL. You can create the service URL from the value of the ServiceName property: http://ServiceName.cloudapp.net.
Create a new hosted service
The following command will create a new hosted service:
service create -F="C:\config.ini" --Name="unique_dns_prefix" --Location="North Central US" --Label="your_service_label"Note that the value of the Name parameter must be your unique DNS prefix. This is the value that will prefix cloudapp.net to create your service URL (e.g. http://your_dns_prefix.cloudapp.net). When this operation completes successfully, it will return your unique DNS prefix.
Add a certificate
The command below will add a certificate to a hosted service. Note that this isn’t a management certificate, but one that might be used to enable RDP, for example.
certificate addcertificate -F="C:\config.ini" --ServiceName="dns_prefix" --CertificateLocation="path\to\your\certificate.cer" --CertificatePassword=your_certificate_passwordNote that the ServiceName parameter takes the DNS prefix of your service. When this operation completes successfully, it returns the DNS prefix of the targeted service.
Create a staging deployment from a local package
Next, to create a new deployment from a local package (.cspkg file) and service configuration file (.cscfg)…
deployment createfromlocal -F="C:\config.ini" --Name="dns_prefix" --DeploymentName="deployment_name" --Label="deployment_label" --Staging --PackageLocation="path\to\your.cspkg" --ServiceConfigLocation="path\to\ServiceConfiguration.cscfg" --StorageAccount="your_storage_account_name"Again, the Name parameter is the DNS prefix of your hosted service. When this operation completes successfully, it returns the request ID of the request. (Look for future posts on using this request ID with the getasynchronousoperation tool in the SDK.)
Get deployment properties
Once a deployment has been created, you can get its properties:
deployment getproperties -F="C:\config.ini" --Name="dns_prefix" --BySlot=StagingNote that you get get deployment properties BySlot (staging or production) or ByName (the name of the deployment).
Move staging deployment to production
To move a deployment from staging to production…
deployment swap -F="C:\config.ini" --Name="dns_endpoint"When this operation completes successfully, it returns the request ID of the request.
Add an instance
And lastly, to change the number of instances for a deployment…
deployment editinstancenumber -F="C:\config.ini" --Name="dns_prefix" --BySlot=production --RoleName="role_name" --NewInstanceNumber=2Wrap Up
Hopefully, those examples are enough to give you the idea. In future posts, I’ll take a look at how to create scripts using these commands to make deployment and management quick and easy. In the meantime, we would love to hear your thoughts on these command line tools. How usable are they for you? What’s missing? Etc.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
The ADO.NET Entity Framework Team reported Code First Migrations: Alpha 2 Released in a 6/6/2011 post:
Six weeks back we released the first preview of Code First Migrations. This preview was called ‘Code First Migrations August 2011 CTP’. However, after some changes to how we name our releases it is best to think of that release as ‘Code First Migrations Alpha 1’. Today we are happy to announce that ‘Code First Migrations Alpha 2’ is available.
Alpha 2 is still is primarily focused on the developer experience inside of Visual Studio. We realize this isn’t the only area in which migrations is important and our team is also working on scenarios including team build, deployment and invoking migrations from outside of Visual Studio as well as from custom code.
What Changed
The short answer… a lot! You gave us a lot of feedback on our first alpha and we summarized it in the 'Code First Migrations: Your Feedback' blog post. The changes are pretty widespread so we would recommend reading the Code First Migrations Alpha 2 Walkthrough to get an overview of the new functionality. Here are some of the more notable changes:
- We did a lot of work to improve the ‘no-magic’ workflow, including a code based format for expressing migrations. Our walkthrough also starts with the no-magic approach and then shows how to transition to a more-magic approach for folks who want to use it.
- A provider model is now available. Providers need to inherit from the System.Data.Entity.Migrations.Providers.DbMigrationSqlGenerator base class and are registered in a new Settings class that is added when you install the NuGet package. Alpha 2 includes a provider for SQL Server (including SQL Azure) and SQL Compact.
- We’ve taken a NuGet package name change. Alpha 1 was released as EntityFramework.SqlMigrations, but given the design changes that name makes less sense. We have now dropped the ‘Sql’ and are now just EntityFramework.Migrations.
- We’ve improved how we do type resolution to find your context etc. In the first preview there were a number of issues around how we discovered your context, especially in solutions with multiple projects. This would result in various errors when trying to run either of the migration commands. We’ve done some work to make this more robust in Alpha 2.
Feedback
We really want your feedback on this work so please download it, use it and let us know what you like and what you would like to see change. You can provide feedback by commenting on this blog post.
The key areas we really want your feedback on are:
- Shape of the API for expressing migrations. The API for migrations isn’t complete yet but Alpha 2 contains a large part of what we expect the final API to look like. We’d love your feedback on whether we are heading down the right path.
- Will you use the automatic migrations functionality? We support a purely imperative workflow where all changes are explicitly expressed in code. A lot of folks have told us that is how they want to work. We want to know if we should continue to invest in the option of having sections of the migrations process handled automatically.
Getting Started
The Code First Migrations Alpha 2 Walkthrough gives an overview of migrations and how to it for development.
Code First Migrations Alpha 2 is available via NuGet as the EntityFramework.Migrations package.
Known Issues & Limitations
We really wanted to get your feedback on these design changes so Alpha 2 hasn’t been polished and isn’t a complete set of the features we intend to ship.
Some known issues, limitations and ‘yet to be implemented’ features include:
- You must start using migrations targeting an empty database that contains no tables or targeting a database that does not yet exist. Code First Migrations assumes that it is starting against an empty database. If you target a database that already contains some/all of the tables for your model then you will get an error when migrations tries to recreate the same tables. We are currently working on a boot strapping feature that will allow you to start using migrations against an existing schema.
- VB.Net is not yet supported. Migrations can currently only be scaffolded in C#, we are adding VB.Net code generation at the moment and will release another Alpha shortly that includes VB.Net support. You can, however, use a C# project to work with migrations that reference a domain model and context that are defined in a separate VB.Net project(s).
- There is an issue with using Code First Migrations in a team environment that we are currently working through. Code First Migrations generates some additional metadata alongside each migration that captures the source and target model for the migration. The metadata is used to replicate any automatic migrations between each code-based migration. If the source model of a migration matches the target model of the previous migration then the automatic pipeline is skipped. The issue arises when two developers add migrations locally and then check-in. Because the metadata of their migrations are captured during scaffolding they don’t reflect the model changes made by the other developer, even if the second developer to check-in sync’s before committing their changes. This can cause the automatic pipeline to kick in when the migrations are run. We realize this is the key team development scenario and are working to resolve it at the moment.
- No outside-of-Visual-Studio experience. Alpha 2 only includes the Visual Studio integrated experience. We also plan to deliver a command line tool and an MSDeploy provider for Code First Migrations.
- Downgrade is currently not supported. When generating migrations you will notice that the Down method is empty, we will support down migration soon.
- Migrate to a specific version is not supported. You can currently only migrate to the latest version, we will support migrations up/down to any version soon.
Prerequisites & Incompatibilities
Migrations is dependent on EF 4.1 Update 1, this updated release of EF 4.1 will be automatically installed when you install the EntityFramework.Migrations package.
Important: If you have previously run the EF 4.1 stand alone installer you will need to upgrade or remove the installation before using migrations. This is required because the installer adds the EF 4.1 assembly to the Global Assembly Cache (GAC) causing the original RTM version to be used at runtime rather than Update 1.
This release is incompatible with “Microsoft Data Services, Entity Framework, and SQL Server Tools for Data Framework June 2011 CTP”.
Support
This is a preview of features that will be available in future releases and is designed to allow you to provide feedback on the design of these features. It is not intended or licensed for use in production. If you need assistance we have an Entity Framework Pre-Release Forum.
Rowan Miller of the ADO.NET Entity Framework Team posted Code First Migrations: Alpha 2 Walkthrough on 9/6/2011:
We have released the second preview of our migrations story for Code First development; Code First Migrations Alpha 2. This release includes a preview of the developer experience for incrementally evolving a database as your Code First model evolves over time.
This post will provide an overview of the functionality that is available inside of Visual Studio for interacting with migrations. This post assumes you have a basic understanding of the Code First functionality that was included in EF 4.1, if you are not familiar with Code First then please complete the Code First Walkthrough.
Building an Initial Model
Before we start using migrations we need a project and a Code First model to work with. For this walkthrough we are going to use the canonical Blog and Post model.
- Create a new ‘Demo’ Console application
.- Add the EntityFrameworkNuGet package to the project
- Tools –> Library Package Manager –> Package Manager Console
- Run the ‘Install-Package EntityFramework’ command
.- Add a Model.cs class with the code shown below. This code defines a single Blog class that makes up our domain model and a BlogContext class that is our EF Code First context.
Note that we are removing the IncludeMetadataConvention to get rid of that EdmMetadata table that Code First adds to our database. The EdmMetadata table is used by Code First to check if the current model is compatible with the database, which is redundant now that we have the ability to migrate our schema. It isn’t mandatory to remove this convention when using migrations, but one less magic table in our database is a good thing right!
using System.Data.Entity;
using System.Collections.Generic; using System.ComponentModel.DataAnnotations; using System.Data.Entity.Infrastructure; namespace Demo { public class BlogContext : DbContext { public DbSet<Blog> Blogs { get; set; } protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Conventions.Remove<IncludeMetadataConvention>(); } } public class Blog { public int BlogId { get; set; } public string Name { get; set; } } }Installing Migrations
Now that we have a Code First model let’s get Code First Migrations and configure it to work with our context.
- Add the EntityFramework.MigrationsNuGet package to the project
- Run the ‘Install-Package EntityFramework.Migrations’ command in Package Manager Console
.- The EntityFramework.Migrations package has added a Migrations folder to our project. At the moment this folder just contains a single Settings class, this class has also been opened for you to edit. This class allows you to configure how migrations behaves for your context. The Settings class also exposes the provider model for code generation and SQL generation. We’ll come back to these settings a little later on, for the moment we’ll just make edit the setting class to specify our BlogContext (highlighted below).
using System.Data.Entity.Migrations; using System.Data.Entity.Migrations.Providers; using System.Data.SqlClient; namespace Demo.Migrations { public class Settings : DbMigrationContext<BlogContext> { public Settings() { AutomaticMigrationsEnabled = false; SetCodeGenerator<CSharpMigrationCodeGenerator>(); AddSqlGenerator<SqlConnection, SqlServerMigrationSqlGenerator>(); // Uncomment the following line if you are using SQL Server Compact // SQL Server Compact is available as the SqlServerComapact NuGet package // AddSqlGenerator<System.Data.SqlServerCe.SqlCeConnection, SqlCeMigrationSqlGenerator>(); } } }Scaffolding & Running Migrations
We’re going to start by looking at the purely imperative workflow (that’s where every migration operation is explicitly defined in code). This workflow gives you the most control over the migration process and involves the least magic.
Code First Migrations has two commands that you are going to become familiar with. Add-Migration will scaffold the next migration based on changes you have made to your model. Update-Database will apply any pending changes to the database. Update-Database currently only support migrating your database ‘up’ to the latest version. Migrating ‘up’ and ‘down’ to any version will be supported in the future.
- We haven’t generated any migrations yet so this will be our initial migration that creates the first set of tables (in our case that’s just the Blogs table). We can call the Add-Migration command and Code First Migrations will scaffold a migration for us with it’s best guess at what we should do to being the database up-to-date with the current model. Once it has calculated what needs to change in the database, Code First Migrations will use the CSharpMigrationCodeGenerator that was configured in our Settings class to create the migration. The Add-Migrationcommand allows us to give these migrations a name, let’s just call ours ‘MyFirstMigration’.
- Run the ‘Add-Migration MyFirstMigration’ command in Package Manager Console
.- In the Migrations folder we now have a new MyFirstMigration migration. The migration is pre-fixed with a timestamp to help with ordering. There is also a code behind file that stores some metadata about the migration, we won’t cover that just yet but you can take a look if you want. Let’s turn our attention to the code that Code First Migrations has scaffolded and opened for us.
namespace Demo.Migrations { using System.Data.Entity.Migrations; public partial class MyFirstMigration : DbMigration { public override void Up() { CreateTable( "Blogs", c => new { BlogId = c.Int(nullable: false, identity: true), Name = c.String(), }) .PrimaryKey(t => t.BlogId); } public override void Down() { // This preview of Code First Migrations does not support downgrade functionality. } } } .- We could now edit or add to this migration but in this case everything looks pretty good. Let’s use Update-Databaseto apply this migration to the database.
- Run the ‘Update-Database’ command in Package Manager Console
.- Code First Migrations has now created a Demo.BlogContext database on our local SQL Express instance. We could now write code that uses our BlogContext to perform data access against this database.

.- It’s time to make some more changes to our model. Let’s change Blog.Name to have a maximum length of 100 and add in a Blog.Rating property. We’re also going to introduce the Post class at this time.
public classBlog { public int BlogId { get; set; } [MaxLength(100)] public string Name { get; set; }
public int Rating { get; set; } public List<Post> Posts { get; set; } } public class Post { public int PostId { get; set; } [MaxLength(200)] public string Title { get; set; } public string Content { get; set; } public int BlogId { get; set; } public Blog Blog { get; set; } }
.- Let’s use the Add-Migrationcommand to let Code First Migrations scaffold it’s best guess at the migration for us. We’re going to call this migration ‘MySecondSetOfChanges’.
- Run the ‘Add-Migration MySecondSetOfChanges’ command in Package Manager Console
.- Code First Migrations did a pretty good job of scaffolding these changes, but there are some things we might want to change:
- First up, let’s add a unique index to Posts.Title column, we can do this inline with the CreateTable call.
- We’re also adding a non-nullable Blogs.Rating column, if there is any existing data in the table this will fail because it will try to use null for the value of this new column. Let’s specify a default value of 3 so that existing rows in the Blogs table will get assigned a value.
- Finally, let’s also add a non-unique index to the Blogs.Name column.
These changes to the scaffolded migration are highlighted below:
namespace Demo.Migrations
{
using System.Data.Entity.Migrations;
public partial class MySecondSetOfChanges :DbMigration
{
public override void Up()
{
CreateTable(
"Posts",
c =>new
{
PostId = c.Int(nullable: false, identity: true),
Title = c.String(maxLength: 200),
Content = c.String(),
BlogId = c.Int(nullable: false),
})
.PrimaryKey(t => t.PostId)
.ForeignKey("Blogs", t => t.BlogId)
.Index(p => p.Title, unique: true);
AddColumn("Blogs", "Rating", c => c.Int(nullable: false, defaultValue: 3));
ChangeColumn("Blogs", "Name", c => c.String(maxLength: 100));
CreateIndex("Blogs", new[] { "Name" });
}
public override void Down()
{
// This preview of Code First Migrations does not support downgrade functionality.
}
}
}
.- Our edited migration is looking pretty good, so let’s use Update-Database to bring the database up-to-date. This time let’s specify the –Verboseflag so that you can see the SQL that Code First Migrations is running.
- Run the ‘Update-Database –Verbose’ command in Package Manager Console
.- Code First Migrations has now updated the schema of our Demo.BlogContext database.

Automatic Migrations
So far you have seen how to scaffold, customize and run migrations. For a lot of folks this will be the complete workflow you use with Code First Migrations. There is another piece that you can opt into though, and that is to have some parts of the migration process happen without needing to have a migration file in your project. This is known as automatic migrations.
Automatic migrations can be combined with the imperative workflow we looked at in the last section. Code First Migrations uses that metadata it stored in the code behind file of each migration to replicate any automatic migrations you performed in-between each code-based migration.
- Let’s go ahead and add a Blog.Url property:
public classBlog { public int BlogId { get; set; } [MaxLength(100)] public string Name { get; set; } public int Rating { get; set; } public string Url { get; set; } public List<Post> Posts { get; set; } }
.- We could write this change to a migration file and then execute it, but at this stage we might be feeling pretty comfortable with how Code First Migrations handles column additions. Let’s just try and issue an Update-Databasecommand.
- Run the ‘Update-Database’ command in Package Manager Console
.- The update process gives us a warning letting us know that there are pending model changes that could not be applied to the database:
There are pending model changes but automatic migration is disabled. Either write these changes to a migration script or enable automatic migration.
To add a migration script with the pending changes use the Add-Migration command. To use automatic migrations edit the settings class in the Migrations directory to enable automatic migrations then re-run the Update-Database command.- Let’s go ahead and enable automatic migrations in the Settings class:
public class Settings : DbMigrationContext<BlogContext> { public Settings() { AutomaticMigrationsEnabled = true; SetCodeGenerator<CSharpMigrationCodeGenerator>(); AddSqlGenerator<SqlConnection, SqlServerMigrationSqlGenerator>(); // Uncomment the following line if you are using SQL Server Compact // SQL Server Compact is available as the SqlServerComapact NuGet package // AddSqlGenerator<System.Data.SqlServerCe.SqlCeConnection, SqlCeMigrationSqlGenerator>(); } }
.- Now let’s try and re-run the update process with automatic migrations enabled.
- Run the ‘Update-Database’ command in Package Manager Console
.- This time the update process succeeds and the Url column is added to the Blogs table. If we now made additional changes we could either continue to use automatic migrations or write those changes out to a code-based migration file. If we opt to use a code-based migration for the next set of changes then Code First Migrations will still replicate this same automatic addition of the Url column between the two code-based migrations when upgrading another database instance. It uses the metadata from the code behind files either side of the automatic addition to ensure the automatic changes are applied in the correct order.

Getting a SQL Script
Now that we have performed a few iterations on our local database let’s look at applying those same changes to another database.
If another developer wants these changes on their machine they can just sync once we check our changes into source control. Once they have our new migrations they can just run the Update-Database command to have the changes applied locally.
However if we want to push these changes out to a test server, and eventually production, we probably want a SQL script we can hand off to our DBA. In this preview we need to generate a script by pointing to a database to migrate, but in the future you will be able to generate a script between two named versions without pointing to a database.
Getting a script is also an easy way to preview what Code First Migrations is going to do. This is especially useful when using automatic migrations.
- We’re just going to simulate deploying to a second database on the local SQL Express instance. We can change the database that migrations is targeting in the Settings class. We’re still working through how to handle multiple target databases, so this is an area that will change in future releases.
public class Settings : DbMigrationContext<BlogContext> { public Settings() { AutomaticMigrationsEnabled = true; SetCodeGenerator<CSharpMigrationCodeGenerator>(); AddSqlGenerator<SqlConnection, SqlServerMigrationSqlGenerator>(); TargetDatabase(@"Server=.\SQLEXPRESS;Database=BloggingTest;Trusted_Connection=True"); // Uncomment the following line if you are using SQL Server Compact // SQL Server Compact is available as the SqlServerComapact NuGet package // AddSqlGenerator<System.Data.SqlServerCe.SqlCeConnection, SqlCeMigrationSqlGenerator>(); } }- Now let’s run the Update-Database command but this time we’ll specify the –Scriptflag so that changes are written to a script rather than just applied.
- Run the ‘Update-Database –Script’ command in Package Manager Console
.- Code First Migrations will run the update database pipeline but instead of actually applying the changes it will write them out to a .sql file for you. Once the script is generated, it is opened for you in Visual Studio, ready for you to view or save.
Summary
In this walkthrough you saw how to scaffold and run code-based migrations. You saw that parts of the migration process can be left up to automatic migrations and that code-based and automatic migrations can be intermingled. You also saw how to get a SQL script that represents the pending changes to a database.
As always, we really want your feedback on what we have so far, so please try it out and let us know what you like and what needs improving.
Rowan Miller
Program Manager
ADO.NET Entity Framework




Return to section navigation list>
Windows Azure Infrastructure and DevOps
The Windows Azure Information Experience Team reported Content Update: New Web Pages Available for Finding Technical Content on Windows Azure in a 9/7/2011 post to the Windows Azure blog:
The technical subject pages (such as the one shown below) are designed to
- Highlight featured tutorials and articles.
- Provide catalogs of available self-paced tutorials and deep-dive technical content from a variety of reliable and authoritative sources.
- List additional resources such as blogs, forums, and references.
- Present a way to navigate between subjects.
As always, we welcome your comments. Let us know what you think by using the Give us Feedback link at the bottom of any Windows Azure web site page or by emailing azuresitefeedback@microsoft.com.

J P Morganthal claimed There Is No ROI in Cloud Computing in a 9/7/2011 post:
Return-on-Investment (ROI), perhaps the biggest crock-of-$%@& metric ever applied to the information technology industry. How does one measure return? If we use monetary return, then the question, “how much money did I make on my investment in a $10K server,” is relatively impossible to answer. One must consider the software run on that server, what role it’s playing in servicing customer value, etc. The answer is arbitrary; it’s a minute subcomponent of a complete capital expenditure plan directed at delivering a business service. Using an intangible metric is even more obtuse. “Gee, after we made that additional $10K investment in that server hardware the number of calls into the help desk seemingly decreased,” is bad Freakonomics at best.
ROI was created by management consultants to illustrate the relationship between investments and expenses on revenue. Then one of these quacks decided, “hey, vendors will love this tool as a means of explaining why IT management has to use their latest doohickey.” ROI is now a plague on the IT industry being used to show how spending more money now will save you money in the long run. To me this is akin to the US government paying citizens to shuck perfectly good working cars that were paid off for new working cars and additional consumer debt.
Okay, I’ll get to the point. Cloud computing is about an effective use of compute resources that provides agility and flexibility to my business in a cost-effective manner. I’m not investing in cloud computing, I’m consuming a service. Do you discuss the ROI on eating at McDonalds or having your car washed? Of course not, because there’s no ROI in using a service since using a service is not an investment. Using services is about effective use of cash flow relative as an alternative to using your own resources and assets.
You may ask, “but I’m investing in acquiring my own cloud computing infrastructure, and I’m expecting an ROI on that.” My answer, if you’re not a cloud service provider, good luck with that. Call the sales representative that sold that bill of goods to you and tell him Christmas gift will be paid for with the ROI on your new cloud infrastructure. I imagine you’ll break even on that investment just in time to need a technology refresh on those blades. If you’re investing in your own cloud infrastructure, I hope it’s because it will effectively allow you to scale certain processes that are not scaling well today and would be cost-ineffective to acquire dedicated hardware to support. Moreover, I would hope this investment is because you have some very rigid requirement that would not allow you to burst to an existing cloud service provider for that additional compute power when required.
Sorry Virginia, there is no ROI in cloud computing. If you want to compute the value of using cash to acquire a service versus doing it in-house, that would be a risk/reward or opportunity cost analysis, not an ROI. The only thing you are investing in with cloud computing is lining your cloud computing service provider’s pockets, which is okay as long as you applied the same resources and assets to an endeavor that will generate more revenue than you are spending on the service.

Bruce Kyle explained How to Install Drivers, Services, or Configure Windows on a Windows Azure Instance by a link to a Greg Oliver post in a 9/7/2011 post to the US ISV Evangelism blog:
In my day to day discussions with ISVs who are moving their applications to Windows Azure, they often express the need to install drivers or services. Many think that they need a VM Role. But it turns out that most all of the configurations, drivers, and services can be installed using elevated privileges
When Windows Azure creates a new instance, it will hand control to a PowerShell script, let you raise the permissions, do your settings, then return the permissions. Greg’s post points you to the experts and samples that walk you through how to do this, without needing the VM Role.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
• The Windows Azure Platform Appliance team posted a new Principal Program Manager Lead Job opening to LinkedIn on 9/7/2011:
Job Description
Job Category: Hardware Engineering
Location: Redmond, WA, US
Job ID: 746495-53059
Division: Server & Tools Business
The Windows Azure Platform Appliance (WAPA) team is creating server, network, rack and infrastructure designs to take the power of Azure to on-premise enterprise data-center environments. We are searching for a Principal Hardware Program Manager to take the lead in defining planning and release models that incorporate innovative new approaches and then to put them into action for the appliance.At the center of Microsoft's cloud strategy, Azure and the Azure Appliance provide our customers with an industry-leading cloud platform that can be hosted by Microsoft at global scale as well as offered to our customers/partners to be operated on-premise in their own datacenters, on their hardware (specified by us) and in service of their own business needs, public and private. The Windows Azure Platform comprises complicated technology developed by multiple teams around Microsoft and spans all layers of the stack, from the metal to the app/service. A key element of the WAPA value proposition is the careful definition of the appliance hardware architecture - across compute, storage, network and datacenter requirements - which will enable excellent price-per-performance of each component and precedent-setting operational efficiency.
This person will work with multiple teams across organizations to plan, execute and ship. This role also includes standard program management duties such as schedule management, risk and issue management, driving triage and release criteria management and communicating project status to broad audiences within the Server and Tools Business.
The successful candidate should have the following attributes and experience:
- Knowledge of current server, storage and datacenter technologies and trends for large-scale operations
- Experience working with semiconductor, server and infrastructure vendors/partners in the specification of hardware components
- Experience with hardware partner development lifecycles and support operations is beneficial
- Exceptional communication and cross-team/partner collaboration is a must.
- Networking knowledge is a plus
- Experience connecting with customers and partners in support of our team's mission and representing their interests through the course of our work with them, product development and support
Company Description
AMAZING THINGS HAPPEN HERE! At Microsoft, we're about helping customers realize their potential. From gamers to governments, moms to mega-corporations, we serve just about every kind of customer, all over the globe.
Many people think Microsoft = software. We do do software-but we also do hardware, services, research, and more. We work on PC operating systems and applications-like Windows and Windows Live. Products for IT professionals and developers-like Windows Server and Visual Studio. Online services such as Bing and MSN. Business solutions like Office and Exchange. And devices like Xbox, keyboards, webcams, and mice. We're passionate about what we do.
What this means if you come to work here is opportunity-to do things that make a real difference in millions, even billions, of lives. To reach your potential. So why not take a closer look at Microsoft? We think you'll find that amazing things really do happen here.
Additional Information
- Posted: August 29, 2011
- Type: Full-time
- Experience: Not Applicable
- Functions: Engineering
- Industries: Computer Hardware, Computer Software, Information Technology and Services
- Employer Job ID: 746495-53059
- Job ID: 1908902
- Apply on Company Website
Despite the paucity of customers, Microsoft continues to staff up the WAPA project.
Is HP’s announcement of … cloud services with an OpenStack flavor another nail in WAPA’s coffin? See the Other Cloud Computing Platforms and Services section below.
Steven Sinofsky reported that he’s Bringing Hyper-V to “Windows 8” in a 9/7/2011 post to the Building Windows 8 blog:
In this post we talk about how we will support virtualization on the Windows "client" OS. Originally released for Windows Server where the technology has proven very popular and successful, we wanted to bring virtualization to a core set of scenarios for professionals using Windows. The two most common scenarios we focused on are for software developers working across multiple platforms and clients and servers, and IT professionals looking to manage virtualized clients and servers in a seamless manner. Mathew John is a program manager on our Hyper-V team and authored this post. One note is that, as with all features, we're discussing the engineering of the work and not the ultimate packaging, as those choices are made much later in the project. --Steven PS: We didn't plan on doing so many posts in a row so we'll return to more sustainable pace -- sorry if we inadvertantly set expectations a bit too high. We're getting ready for BUILD full time right now!!
Whether you are a software developer, an IT administrator, or simply an enthusiast, many of you need to run multiple operating systems, usually on many different machines. Not all of us have access to a full suite of labs to house all these machines, and so virtualization can be a space and time saver.
In building Windows 8 we worked to enable Hyper-V, the machine virtualization technology that has been part of the last 2 releases of Windows Server, to function on the client OS as well. In brief, Hyper-V lets you run more than one 32-bit or 64-bit x86 operating system at the same time on the same computer. Instead of working directly with the computer’s hardware, the operating systems run inside of a virtual machine (VM).
Hyper-V enables developers to easily maintain multiple test environments and provides a simple mechanism to quickly switch between these environments without incurring additional hardware costs. For example, we release pre-configured virtual machines containing old versions of Internet Explorer to support web developers. The IT administrator gets the additional benefit of virtual machine parity and a common management experience across Hyper-V in Windows Server and Windows Client. We also know that many of you use virtualization to try out new things without risking changes to the PC you are actively using.
An introduction to Hyper-V
Hyper-V requires a 64-bit system that has Second Level Address Translation (SLAT). SLAT is a feature present in the current generation of 64-bit processors by Intel & AMD. You’ll also need a 64-bit version of Windows 8, and at least 4GB of RAM. Hyper-V does support creation of both 32-bit and 64-bit operating systems in the VMs.
Hyper-V’s dynamic memory allows memory needed by the VM to be allocated and de-allocated dynamically (you specify a minimum and maximum) and share unused memory between VMs. You can run 3 or 4 VMs on a machine that has 4GB of RAM but you will need more RAM for 5 or more VMs. On the other end of the spectrum, you can also create large VMs with 32 processors and 512GB RAM.
As for user experience with VMs, Windows provides two mechanisms to peek into the Virtual Machine: the VM Console and the Remote Desktop Connection.
The VM Console (also known as VMConnect) is a console view of the VM. It provides a single monitor view of the VM with resolution up to 1600x1200 in 32-bit color. This console provides you with the ability to view the VM’s booting process.
For a richer experience, you can connect to the VM using the Remote Desktop Connection (RDC). With RDC, the VM takes advantage of capabilities present on your physical PC. For example, if you have multiple monitors, then the VM can show its graphics on all these monitors. Similarly, if you have a multipoint touch-enabled interface on your PC, then the VM can use this interface to give you a touch experience. The VM also has full multimedia capability by leveraging the physical system’s speakers and microphone. The Root OS (i.e. the main Windows OS that’s managing the VMs) can also share its clipboard and folders with the VMs. And finally, with RDC, you can also attach any USB device directly to the VM.
For storage, you can add multiple hard disks to the IDE or SCSI controllers available in the VM. You can use Virtual Hard Disks (.VHD or .VHDX files) or actual disks that you pass directly through to the virtual machine. VHDs can also reside on a remote file server, making it easy to maintain and share a common set of predefined VHDs across a team.
Hyper-V’s “Live Storage Move” capability helps your VMs to be fairly independent of the underlying storage. With this, you could move the VM’s storage from one local drive to another, to a USB stick, or to a remote file share without needing to stop your VM. I’ve found this feature to be quite handy for fast deployments: when I need a VM quickly, I start one from a VM library maintained on a file share and then move the VM’s storage to my local drive.
Another great feature of Hyper-V is the ability to take snapshots of a virtual machine while it is running. A snapshot saves everything about the virtual machine allowing you to go back to a previous point in time in the life of a VM, and is a great tool when trying to debug tricky problems. At the same time, Hyper-V virtual machines have all of the manageability benefits of Windows. Windows Update can patch Hyper-V components, so you don’t need to set up additional maintenance processes. And Windows has all the same inherent capabilities with Hyper-V installed.
Having said this, using virtualization has its limitations. Features or applications that depend on specific hardware will not work well in a VM. For example, Windows BitLocker and Measured Boot, which rely on TPM (Trusted Platform Module), might not function properly in a VM, and games or applications that require processing with GPUs (without providing software fallback) might not work well either. Also, applications relying on sub 10ms timers, i.e. latency-sensitive high-precision apps such as live music mixing apps, etc. could have issues running in a VM. The root OS is also running on top of the Hyper-V virtualization layer, but it is special in that it has direct access to all the hardware. This is why applications with special hardware requirements continue to work unhindered in the root OS but latency-sensitive, high-precision apps could still have issues running in the root OS.
As a reminder, you will still need to license any operating systems you use in the VMs.
Here’s a quick run-through of how the Hyper-V works in Windows 8.
Your browser doesn't support HTML5 video.
Download this video to view it in your favorite media player:
High quality MP4 | Lower quality MP4Supporting VM communication through wireless NICs
As you saw in the demo, creating an external network switch is as simple as selecting a physical network adapter (NIC) from a drop-down list and clicking OK. This already worked well for Windows Server Hyper-V, but to have similar results in Windows 8, we needed to get it working with wireless NICs, a new challenge.
The problem
The virtual switch in Hyper-V is a “layer-2 switch,” which means that it switches (i.e. determines the route a certain Ethernet packet takes) using the MAC addresses that uniquely identify each (physical and virtual) network adapter card. The MAC address of the source and destination machines are sent in each Ethernet packet and a layer-2 switch uses this to determine where it should send the incoming packet. An external virtual switch is connected to the external world through the physical NIC. Ethernet packets from a VM destined for a machine in the external world are sent out through this physical NIC. This means that the physical NIC must be able to carry the traffic from all the VMs connected to this virtual switch, thus implying that the packets flowing through the physical NIC will contain multiple MAC addresses (one for each VM’s virtual NIC). This is supported on wired physical NICs (by putting the NIC in promiscuous mode), but not supported on wireless NICs since the wireless channel established by the WiFi NIC and its access point only allows Ethernet packets with the WiFi NIC’s MAC address and nothing else. In other words, Hyper-V couldn’t use WiFi NICs for an external switch if we continued to use the current virtual switch architecture.
Figure 1: Networking between VM and external machine using wired connection
The solution
To work around this limitation, we used the Microsoft Bridging solution, which implements ARP proxying (for IPv4) and Neighbor Discovery proxying (for IPv6) to replace the virtual NICs’ MAC address with the WiFi adapter’s MAC address for outgoing packets. The bridge maintains an internal mapping between the virtual NIC’s IP address and its MAC address to ensure that the packets coming from the external world are sent to the appropriate virtual NIC.
Hyper-V integrates the bridge as part of creating the virtual switch such that when you create an external virtual switch using a WiFi adapter, Hyper-V will:
- Create a single adapter bridge connected to the WiFi adapter
- Create the external virtual switch
- Bind the external virtual switch to use the bridge, instead of the WiFi adapter directly
In this model, Ethernet switching still happens in the virtual switch, and MAC translation occurs in the bridge. For the end user who is creating an external network, the workflow is the same whether you select a wired or a wireless NIC.

Figure 2: Networking between VM and external machine using WiFi connectionIn conclusion, by bringing Hyper-V from Windows Server to Windows Client, we were able to provide a robust virtualization technology designed for the scalability, security, reliability, and performance needs of most data centers. With Hyper-V, developers and IT professionals can now build a more efficient and cost-effective environment for using and testing across multiple machines.
--Mathew John


kranthineo92 asked Microsoft Berates VMware, Outlines Cloud Strategy? in a 9/4/2011 post to the Cloudy News blog:
Earlier in the week, Microsoft talked up a storm about its Dynamics CRM Online as well as cash incentives to take it up. But the tough talk was only part of a wider piece from Microsoft about its cloud strategy. Could it be that Microsoft is finally nailing down the nuts and bolts of what it wants to do in the cloud?
Well, if not a complete strategy, it certainly gives room for reflection over the Labor Day weekend (if you haven’t been invited anywhere) and contains some nuggets that should be of interest.
In particular, Microsoft pitches itself as the White Knight of business and price efficiency, opposing the Dark Forces of virtualization and additional virtual boxes, epitomized by VMware.
Cloud Computing Market
The piece in question appears in the Microsoft News Center and focuses on Microsoft and cloud computing in a market that is expected to grow from $40.7 billion in 2011 to more than $241 billion by 2020.
And these are not Microsoft figures, either; they appear in the Microsoft article courtesy of Forrester, which published them in the report from April this year entitled Sizing the Cloud by Stefan Ried and Holger Kisker.
The article consists of an interview with corporate vice presidents Brad Anderson and Michael Park, from the Management and Security Division and Business Solutions Division, and they used the occasion to showcase their offerings at a time when both VMware and Salesforce were having their annual shindigs.
Microsoft, Virtualization
In answer to the question of why Microsoft is launching a new advertising campaign and incentives around Dynamics CRM, Anderson said that now “is the time to provide the information businesses need to make informed decisions about where to invest.”
He didn’t mention the Salesforce or VMware conferences, but he did say that he wanted to help prospective clients understand the difference between Microsoft’s private cloud and VMware’’s version of it.
He then outlined what Microsoft sees as “post-virtualization.” He says for Microsoft, virtualization does not mean cloud computing; virtualization is only a step on the way to private clouds.
The post-virtualization stage, using cloud investments to date, is an era of “… quickly deployed solutions without having to worry about hardware, economics of scale… and the ability to focus on applications that drive business value — instead of the underlying technology.”
Microsoft, the Cloud
The key to Microsoft’s approach, Anderson says, is that it provides a comprehensive cloud strategy. In other words, Microsoft his focusing on providing public cloud, private cloud, SaaS singly or in combination.
The difference with a virtualization strategy — notably VMware’s strategy — is that it is focused on the deployment and consolidation of virtual boxes. But then VMware can focus on this because its mothership, in the shape of EMC, can provide the rest.
Microsoft’s solutions, he adds, are also considerably easier to use and at a considerable price difference over VMware, is some cases by as much as 10 times cheaper.
This, he says is based on the fact that VMware’s private cloud solution, Cloud Infrastructure Suite, appears to be priced by adding either virtual machines or memory to run mission-critical applications, charging you more as you grow.
<Return to section navigation list>
Cloud Security and Governance
The Cloud Journal staff asked Are Security Concerns About the Cloud Dropping? in an 9/7/2011 post:
By Gary Flood (from Business Cloud 9.)
“Now here’s a thing. Remember that old frequently aired chestnut about how security fears are holding back the adoption of Cloud Computing?
Well according to a new study from Cisco – Cloud Watch – at least one in four ICT decision makers reckon that the Cloud offers higher levels of security than in-house ICT or outsourcing.
The study – which quizzed 250 UK IT decision makers across government, retail, healthcare, finance and service providers – found that just over half (56%) of businesses believe responsibility for Cloud security should be shared between end user organisations, Cloud service providers and application providers. Cloud is on the IT agenda for just over half of all companies (52%) but is only considered critical by 7% of them.
For those who do have Cloud on the agenda, 74% are planning to invest in the next 12 months with the most used Cloud services currently being web conferencing, video-conferencing and unified communications (72%, 71% and 68% respectively).”
The rest of this article may be found here.
Gilad Parann-Nissany asserted “Data in a public cloud is more vulnerable to some attacks compared with data stored in a data center” in a deck for his Cloud Encryption and Security Tips post of 9/7/2011 to the Porticor Cloud Secuity blog:
One of these days your company will start shifting compute resources to the cloud, and as you probably know, the many advantages cloud computing has to offer still leave the responsibility for data security and data compliance on you and your security team.
Cloud Security tip #1: START FROM THE DATA when considering the cloud provider. You should ask your cloud provider what mechanisms he has in place to secure your data, ask about data security best practice and which security vendors are supporting his cloud and can provide security and encryption services for you out of the gate.
Data in a public cloud is more vulnerable to some attacks compared with data stored in a data center. New risk vectors exploiting the shared infrastructure and resources, the insider threat, or cloud-account hijacking exist. These are either new threats, or old threats that are qualitatively different for data in the cloud. Data encryption in the cloud mitigates many of these, and is therefore top priority. But encryption doesn’t come easy in a cloud infrastructure. Encryption in the cloud could be cost intensive and timely if not done effectively.
Cloud Security tip #2: Choose the data encryption strategy wisely. Understand how you would like to approach data encryption: Will you implement encryption using the tools provided by your cloud provider, or will you use a third party vendor? In order to do so you need to get to the details of your cloud technology, and your technical team capabilities. If you’re implementing a small server project in the cloud and have great security skills in-house, you might want to secure your virtual server yourself; but if the plan is to aggressively grow in the cloud, adding many servers and applications, a security vendor approach would prove to be more effective. (And if you’re a software vendor developing your application in the cloud – you’ll find my previous blog regarding cloud encryption and key management for software vendors relevant)
Now that you’ve chosen your cloud provider, and have a concrete encryption strategy in place, let’s talk about the encryption keys. How will you keep your encryption keys private in a public cloud? The common approach recommended by most security vendors is to keep your keys away from the cloud for security reasons. This approach is a result of migrating the traditional PKI infrastructure to the cloud as-is, and will force you to use a third party SaaS vendor to manage your keys, or to install a key management server back in your datacenter. But there’s a third option for key-management in the cloud:
Cloud Security tip #3: Be the master of your (cloud) domain. As mentioned above, the current approach is to store the encryption keys as far as possible from your cloud, meaning you will need to invest additional resources and manage yet another system in or outside your datacenter. You should know that there are alternatives. Companies such as Porticor have developed a unique key management platform tailored for the cloud, enabling you to store your encryption keys in your cloud, without compromising the security of your keys. For additional reading you can download the Porticor Key Management white paper
Summary
Many companies are shifting (or will do so very soon) compute resources to the cloud. When moving to the cloud, the security manager should be involved as early as possible and understand who the cloud provider is, what are the provided security tools, and what vendors are supporting the cloud infrastructure. Data encryption in the cloud is a must have due to the new attack vectors, therefore the data encryption strategy is critical, alongside the key management strategy which should be cloud enabled and flexible as the cloud itself.

<Return to section navigation list>
Cloud Computing Events
My (@rogerjenn) Windows Azure and SQL Azure Sessions from TechEd Australia 2011 post of 9/7/2011 lists cloud-computing sessions:
Following are links to videos and full descriptions of sessions in TechEd Australia 2011’s Cloud Computing and Online Services track as of 9/7/2011:
To The Cloud! A lap around the entire Windows Azure platform
Steven Nagy
- COS211
- Microsoft offers a variety of services under the Windows Azure Platform umbrella. This session will go through them all at a high level to help you catch up with what's happening outside your organisational boundaries. Be you IT Pro, Developer, or pointy haired boss, this session is not to be missed if you need to ramp up on Microsoft's premium cloud offering.
Ward Britton
- COS202
- HPC and Azure are both emerging technologies which integrate together to provide a scalable, cost effective and on-demand compute power capability. This session covers using Excel to distrbute analytics to HPC, to provide significant compute power to the desktop and then goes on to describe the next evolution... Bursting to the cloud from HPC, to provide virtually unlimited, cost effective compute capacity to the desktop. This session is fact based. Drawn from a project that has recently been completed in a major Australian bank and covers refers to learnings gained from that initiative.
Chris HewittCloud Computing and Online Services (COS)
- COS212
- SQL Azure provides sophisticated data storage options for your cloud applications. We will explore the patterns and practices that help you develop and deploy applications that can exploit the full power of the elastic, highly available, and scalable SQL Azure Database service. The session details scalable application design techniques such as sharding and horizontal partitioning and dives into future enhancements to SQL Azure Databases. The term ‘NoSQL’ may be mentioned, and we will look at how SQL Azure Federations can benefit specific real world applications.
Lynn Langit
- COS203
- This session will be filled with hands-on demonstrations using SQL Azure with new and existing tools. First I'll show how to get started with a SQL Azure account (database and object), then I'll walk through the tools such as SQL Server Management Studio, to view or modify those objects. Next I'll show Visual Studio to connect to .NET applications with Entity Framework, OData, and SQL Server Developer Tools (Codename "Juneau").
Surprisingly slim pickings for such an important new product category. The absence of sessions on new Window Azure AppFabric and Windows Azure diagnostics features is surprising. Hope //BUILD/ is better in this respect.

<Return to section navigation list>
Other Cloud Computing Platforms and Services
Derrick Harris (@derrickharris) reported HP unveils cloud services with an OpenStack flavor in a 9/7/2011 post to Giga Om’s Structure blog:
On Wednesday HP released its first two public cloud computing services for private beta, and they’re based in part on the open-source OpenStack code. The services, some details of which were leaked in the spring, are HP Cloud Compute and HP Cloud Object Storage. The news certainly helps validate the OpenStack project, but it’s too early to tell whether HP can make it as a public cloud provider. [Private beta link added.]
As HP VP of Cloud Solutions Patrick Harr told me in June, the new services aim to compete directly with other developer-focused cloud services such as Amazon Web Services and Rackspace, which leads the OpenStack project. HP announced its OpenStack membership in late July, but it would seem the company has been working with the code since before that time.
As sexy as the OpenStack angle is, though — HP is the first major provider other than Rackspace to publicly use OpenStack code in an availabIe offering — it appears a stretch to call the new cloud services “OpenStack-based.” HP’s Emil Sayegh wrote on his blog announcing HP’s official entrée into public cloud computing, saying, “Both offerings are based on HP’s world class hardware and software with key elements of HP Converged Infrastructure and HP Software combined with a developer friendly, integration of OpenStack through our easy to use, web-based User Interface (UI) along with open, RESTful APIs.”
Right now HP’s approach appears different from that of fellow server maker Dell, which launched its own Infrastructure-as-a-Service play last week. Whereas Dell is starting with a VMware vCloud-based offering and expanding to Microsoft Windows Azure and OpenStack-based clouds, HP looks to have settled on one service and to have written much of its own code.
I’m leery (and I’m not alone) that a new Infrastructure-as-a-Service provider can compete with market leader AWS, but if anyone can match AWS on economies of scale and overall investment, it’s a giant like HP (or perhaps Dell). Rackspace has neither HP’s revenue nor its software expertise, and IBM’s SmartCloud service appears more focused on risk-averse enterprise developers than on mainstream programmers.
Assuming HP has tweaked the OpenStack code to make it ready for prime time beyond object storage (that part is based on the Rackspace Cloud Files code), the next question is whether these new services can help polish HP’s tarnished image. With the private beta just starting, it’s too early to tell on the technical side, but I’d say HP handled this launch eloquently.
The company is declining further comment at this time, but that might be for the best. Just launching the services is enough to generate buzz, and integrating with OpenStack is sure to garner some intrigue, as well.
When beta users start talking and when HP opens the doors on its cloud services to the public, then we’ll see how HP really stacks up as a cloud computing provider.


I’ve applied for a trial account. HP’s Scaling the Cloud blog provides more details.
Matthew Weinberger (@MattNLM) offered Dreamforce ’11: Some Final Cloud Thoughts in a 9/7/2011 post to the TalkinCloud blog:
Your humble correspondent is over his cold, sitting over a cup of coffee at home and trying to unwind after Salesforce.com‘s Dreamforce ’11. It was, without a doubt, the strangest cloud computing industry event I’ve ever covered. Here are some of my final stray observations from the Dreamforce ’11 show floor.
It’s not that Salesforce’s partners weren’t represented at Dreamforce ’11: In addition to the partner welcome keynote I attended on day one, there were multiple channel success workshops over the course of the event. But Salesforce.com CEO Marc Benioff’s keynotes and the overall focus of Dreamforce were squarely on customers and developers, not resellers and service providers. Rest assured, I’ll be attempting to track down Salesforce.com channel executives for more insights on the week’s big announcements.
- There seemed to be a huge contingent of Japanese cloud pros and press present — Dreamforce was even offering interpretation services to its Japanese attendees, and Salesforce.com’s so-called campground on the show floor had an information desk just for that same contingent. It seems Salesforce.com is serious about expanding its market share in the Asia Pacific region, and systems integrators can potentially benefit greatly.
- On the subject of the show floor, the Salesforce.com ISV solutions on display were impressive just in terms of the scope and scale. Just walking around, I saw solutions for a thousand different use cases. It speaks well for the company’s developer rapport that so many were showing off Salesforce.com-specific products.
- As for why Dreamforce was so strange: We cover a lot of industry events. But this was the first time a company has prefaced a keynote with a man serenading the crowd with a ukelele. And the first time I’ve had the chance to take a picture with the company’s mascot, which is just its “No Software” logo with arms and logo. Also, I’m not used to having to navigate through a party involving Elvis impersonators on stilts, Marilyn Monroe and Jimi Hendrix look-alikes and Vegas showgirls just to get dinner.
All in all, Dreamforce ’11 was a worthy celebration of the cloud computing industry, with an obvious focus on Salesforce.com. But it would still have been nice to see some more partner engagement.
Read More About This Topic

Todd Hoff explained What Google App Engine Price Changes Say About the Future of Web Architecture in a 9/7/2011 post to his High Scalability blog:
When I was a child, I spake as a child, I understood as a child, I thought as a child: but when I became a man, I put away childish things. -- Corinthians
With this new pricing, developments will be driven by the costs. I like to optimize my apps to make them better or faster, but to optimize them just to make them cheaper is a waste of time. -- Sylvain on Google Groups
The dream is dead. Google App Engine's bold pay for what you use dream dies as it leaves childish things behind and becomes a real product. Pricing will change. Architectures will change. Customers will change. Hearts and minds will change. But Google App Engine will survive.
Google is shutting down many of its projects. GAE is not among them. Do we have GAE's pricing change to thank for it surving the more wood behind more deadly arrows push? Without a radical and quick shift towards profitably GAE would no doubt be a historical footnote in the long scroll of good ideas. The urgency involved is clearly reflected in GAE's offering a 50% pricing discount and moving to the new pricing scheme before the multi-threaded version of Python has been rolled out.
The dream was beautiful: pay for what you use and make it dead easy to use. Now that's an easy vision to understand. It's fair and compelling. GAE had 3 years of a trial run to live the dream, and for the bottom line, it was apparently a nightmare. That's the shame of it. Google was bold. They created something new. They worked hard. GAE revolutionised the development of scalable applications and has extended PaaS in original and interesting ways. They did an amazing job. And the result was well liked, even loved by many. But the economics failed them and they've had to pivot. Hard. What is the result of that change?
<Return to section navigation list>

















{kind=link}
{kind=link}
{kind=link}
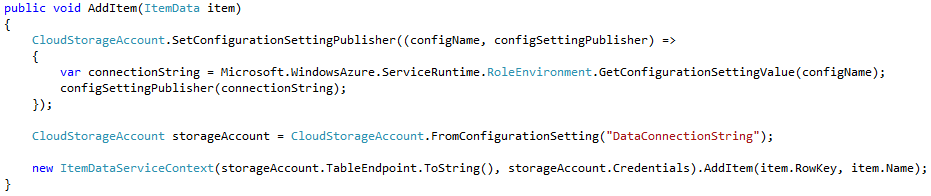{kind=link}
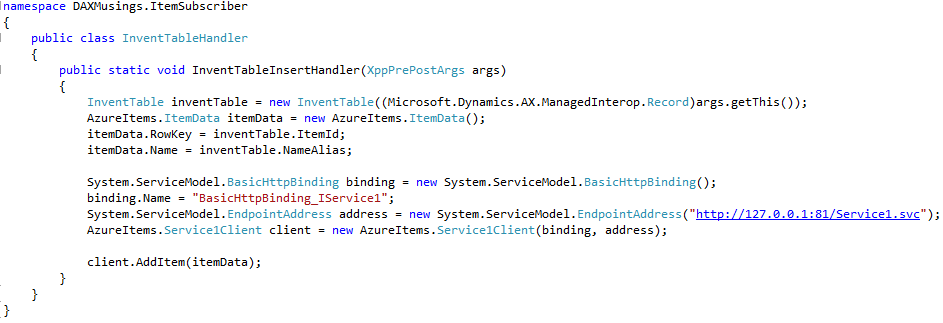{kind=link}
0 comments:
Post a Comment