Windows Azure and Cloud Computing Posts for 12/27/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control and Service Bus
- Windows Azure Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available at no charge from the book's Code Download page.
Tip: If you encounter articles from MSDN or TechNet blogs that are missing screen shots or other images, click the empty frame to generate an HTTP 404 (Not Found) error, and then click the back button to load the image.
Azure Blob, Drive, Table and Queue Services
Allesandro Del Sole updated his Azure Blob Studio 2011 CodePlex project on 12/27/2010:
Project Description
A WPF client for managing files on your Windows Azure Blob Storage account available as a stand-alone application and as an extension for Visual Studio 2010. Of course, in Visual Basic 2010Azure Blob Studio 2011 is a WPF application written in Visual Basic 2010 which allows developers to easily manage files on their Blob Storage service on Windows Azure, for both the local Developer Account and your own account on the Internet.
Settings for your account are stored within My.Settings instead of the configuration file (see notices in the code about using App.config instead).
The application is available in two versions:
- stand-alone WPF client
- extension for Visual Studio 2010
You can:
- Work with both the developer and on-line accounts
- Create containers (folders)
- Upload multiple blobs (files)
- Remove containers
- Remove multiple blobs
- Retrieve URI for each blob
- Copy the blob's URI to the clipboard right-clicking the Blob's name
- Retrieve metadata
- Open blobs via URI
Screenshots:
Stand-alone:
Visual Studio extension:
Future plans: in future versions we should be able to syncronize the Developer Account with the on-line service.
Full Visual Basic 2010 source code provided
You can visit my Italian language blog or my English language blog
Rob Olmos reported Simple Cloud – Error Handling Not Portable between PHP storage adapters in a 12/27/2010 post:
In my previous article about the lack of exceptions in PHP libraries, I came across an inconsistency with Simple Cloud‘s API between file storage adapters.
The issue is that Windows Azure and Nirvanix storage adapters will always throw an exception on an unsuccessful attempt (checked against the API response) whereas Amazon S3 adapter will return true/false (checked against API response) or an exception (some other underlying client error) therefore breaking portability. You could add an explicit check for false but that isn’t obvious. There’s also no use of the @throws tag in the docblock making this even less obvious.
I’ve only checked this against the file storage part of Simple Cloud but I seem to remember the same no-exception issue being in the Amazon SQS API as well.
Zend\Service\Amazon\S3.php – putObject()
$response=$this->_makeRequest('PUT',$object, null,$headers,$data);
// Check the MD5 Etag returned by S3 against and MD5 of the buffer
if($response->getStatus() == 200) {
// It is escaped by double quotes for some reason
$etag=str_replace('"','',$response->getHeader('Etag'));
if(is_resource($data) ||$etag== md5($data)) {
returntrue;
}
}
returnfalse;Zend\Service\WindowsAzure\Storage\Blob.php – putBlob() to putBlobData()
// Perform request
$response=$this->_performRequest($resourceName,'', Zend_Http_Client::PUT,$headers, false,$data, Zend_Service_WindowsAzure_Storage::RESOURCE_BLOB, Zend_Service_WindowsAzure_Credentials_CredentialsAbstract::PERMISSION_WRITE);
if($response->isSuccessful()) {
//isSuccessful checks for 2xx or 1xx status code
returnnewZend_Service_WindowsAzure_Storage_BlobInstance();
//stripped code for blog article
}else{
thrownewZend_Service_WindowsAzure_Exception($this->_getErrorMessage($response,'Resource could not be accessed.'));
}Another issue is that the docblock for Zend\Cloud\StorageService\Adapter\S3.php storeItem() has “@return void” which isn’t the case (most of the other methods appear to be this way as well).
Related bug report without attention: http://framework.zend.com/issues/browse/ZF-9436

Mike West posted slides and their transcript on 12/14/2010 for his Intro to IndexedDB presentation of 12/23/2010 (missed when posted):
Yesterday at the Silicon Valley GTUG meetup, I gave a presentation introducing the IndexedDB API. I've thrown the slides on Slideshare, but the transcription there is absolutely miserable. I’ll reproduce it here in a readable format, and add a few notes where appropriate.
I believe someone was recording the session, so if that becomes available online somewhere, I’ll post a link here.
Embedded Slides
Intro to IndexedDB (Beta) [Slideshare]
Slide Transcript
IndexedDB: Mike West, @mikewest, mkwst@google.com, SV GTUG, 2010.12.14
Beta: The IndexedDB API is incredibly beta. It’s only implemented in Firefox 4 and Chrome dev channel, so it’s not anything that can be used for production projects in the near future. Microsoft and Opera are contributing to the spec, however, and Google is working on pushing the code upstream to Webkit itself, so this looks like something that will be more and more relevant going forward.
Since the spec’s not finished, and everything’s in dev mode, this is a great time to examine the API, and experiment. We need to play around with this code, and feed our experience back into the standards bodies and browser vendors: that’s the best way to ensure that things work the way we want them to when everything’s solidified.
Offline: One of the most exciting recent realizations in web development is that the offline bits of the HTML5 suite of specifications are really ready for widespread use. It’s possible to store arbitrary amounts of information on a user’s computer without resorting to opaque hacks like Flash storage, while at the same time making that information available in useful ways to your program’s code. This opens up a whole new world of sites and applications which we’re only just beginning to appreciate. Offline’s important, and not just because of the Web Store.
Storage Options: What I'd like to do here is take a very brief survey of the landscape for context, and then dive into one particular feature that I think will become important in the near future: IndexedDB.
Cookies: These aren’t offline at all, but they’re relevant to the general context of how web applications store data at the moment. The image on this slide is Luigi Anzivino’s “Molasses-Spice cookies” (which look delicious).
Cookies
Simple, key-value pairs, “shared' between server and client.
Excellent for maintaining state, poor for anything else, as they are unstructured, and incur a significant overhead for each HTTP request.
Local Storage: The image on this slide is Evan Leeson’s “Toasters”.
Local Storage
The simplicity of cookies, tuned for higher-capacity, client-side-only storage.
Dead simple API:
localStorage.setItem( ‘key’, ‘value’ ); localStorage.getItem( ‘key’ ); // ‘value’Values are unstructured strings:
Filtering and search are O(n), unless you layer some indexing on top.
Structure requires
JSON.stringify&JSON.parseWebSQL: The image on this slide is Nick P’s “file cabinet to heaven”, which is a pretty accurate representation of life with WebSQL. Stacking file cabinets on top of each other certainly provides you with the possibility of well organized storage, but that doesn’t mean it’s a good idea.
WebSQL
- A real, relational database\n implementation on the client (SQLite)
- Data can be highly structured, and
JOINenables quick, ad-hoc access- Big conceptual overhead (
SQL), no finely grained locking- Not very JavaScripty, browser support is poor (IE and Firefox won’t implement it), and the spec has been more or less abandoned.
File API: The image on this slide is Davide Tullio’s “Hard Disk in B&W.
File API: I know nothing about the File API, but Seth does! And his presentation is right after mine, so I’ll be all ears. :)
IndexedDB: The image on this slide is Robin Riat’s “Kanuga library card catalog”
IndexedDB:
- Sits somewhere between full-on SQL and unstructured key-value pairs in localStorage.
- Values are stored as structured JavaScript objects, and an indexing system facilitates filtering and lookup.
- Asynchronous, with moderately granular locking
- Joining normalized data is a completely manual process.
IndexedDB Concepts
Practically everything is asynchronous. Callbacks are your friends.
Databases are named, and contain one or more named Object Stores
A diagram of how a database might look, containing a single object store and a set of objects.
Object stores define a property (similar to a primary key) which every stored object must contain, explicitly or implicitly (autoincremented).
The same diagram as #18, with IDs added.
Values in an Object Store are structured, but don’t have a rigidly defined schema. Think document database, CouchDB. Not MySQL.
The same diagram as #20, with differing data added for various objects.
Object Stores can contain one or more Indexes that make filtering and lookup possible via arbitrary properties.
The same diagram as #22, with a subset highlighted (as though they were filtered out).
IndexedDB API: Now we’ll dive into some JavaScript. Lovely, lovely JavaScript.
It’s beta. Again. This is a reminder. :)
Vendor Prefixes:
webkitIndexedDB&moz_indexedDBCode:
// Deal with vendor prefixes if ( "webkitIndexedDB" in window ) { window.indexedDB = window.webkitIndexedDB; window.IDBTransaction = window.webkitIDBTransaction; window.IDBKeyRange = window.webkitIDBKeyRange; // ... } else if ( "moz_indexedDB" in window ) { window.indexedDB = window.moz_indexedDB; } if ( !window.indexedDB ) { // Browser doesn’t support indexedDB, do something // clever, and then exit early. }Database Creation
Code:
var dbRequest = window.indexedDB.open( “AddressBook”, // Database ID “All my friends ever” // Database Description ); // The result of `open` is _not_ the database. // It’s a reference to the request to open // the database. Listen for its `success` and // `error` events, and respond appropriately. dbRequest.onsuccess = function ( e ) { ... }; dbRequest.onerror = function ( e ) { ... };Databases are versioned…
Code:
// The `result` attribute of the `success` event // holds the communication channel to the database dbRequest.onsuccess = function ( e ) { var db = e.result; // Bootstrapping: if the user is hitting the page // for the first time, she won’t have a database. // We can detect this by inspecting the database’s // `version` attribute: if ( db.version === “” ) { // Empty string means the database hasn’t been versioned. // Set up the database by creating any necessary // Object Stores, and populating them with data // for the first run experience. } else if ( db.version === “1.0” ) { // 1.0 is old! Let’s make changes! } else if ( db.version === “1.1” ) { // We’re good to go! } // ... };… and versioning is asychronous.
Code:
};dbRequest.onsuccess = function ( e ) { var db = e.result; if ( db.version === “” ) { // We’re dealing with an unversioned DB. Versioning is, of // course, asynchronous: var versionRequest = db.setVersion( “1.0” ); versionRequest.onsuccess = function ( e ) { // Here’s where we’ll set up the Object Stores // and Indexes. }; } // ...Creating Object Stores and Indexes
Code:
};dbRequest.onsuccess = function ( e ) { var db = e.result; if ( db.version === “” ) { var versionRequest = db.setVersion( “1.0” ); // Setting a version creates an implicit Transaction, meaning // that either _everything_ in the callback succeeds, or // _everything_ in the callback fails. versionRequest.onsuccess = function ( e ) { // Object Store creation is atomic, but can only take // place inside version-changing transaction. var store = db.createObjectStore( "contacts", // The Object Store’s name "id", // The name of the property to use as a key true // Is the key auto-incrementing? ); // ... }; } // ...More code:
dbRequest.onsuccess = function ( e ) { var db = e.result; if ( db.version === “” ) { var versionRequest = db.setVersion( “1.0” ); versionRequest.onsuccess = function ( e ) { var store = db.createObjectStore( "contacts", "id", true ); store.createIndex( “CellPhone”, // The index’s name “cell”, // The property to be indexed false // Is this index a unique constraint? ); }; } // ... };Writing Data (is asynchronous)
Code:
// Assuming that `db` has been set somewhere in the current // scope, we use it to create a transaction: var writeTransaction = db.transaction( [ “contacts” ], // The Object Stores to lock IDBTransation.READ_WRITE // Lock type (READ_ONLY, READ_WRITE) ); // Open a contact store... var store = writeTransaction.objectStore( “contacts” ); // ... and generate a write request: var writeRequest = store.add( { “name”: “Mike West”, “email”: “mkwst@google.com” } ); writeRequest.onerror = function ( e ) { writeTransaction.abort(); }; // Transactions are “complete” (not “committed”?) either when // they fall out of scope, or when all activities in the // transaction have finished (whichever happens last) writeTransaction.oncomplete = function ( e ) { ... };Reading Data (is asynchronous)
Code:
// Assuming that `db` has been set somewhere in the current // scope, we use it to create a transaction: var readTransaction = db.transaction( [ “contacts” ], // The Object Stores to lock IDBTransation.READ_ONLY // Lock type (READ_ONLY, READ_WRITE) ); // Open the `contact` store... var store = readTransaction.objectStore( “contacts” ); // ... and generate a cursor to walk the complete list: var readCursor = store.openCursor(); // Setup a handler for the cursor’s `success` event: readCursor.onsuccess = function ( e ) { if ( e.result ) { // You now have access to the key via `e.result.key`, and // the stored object via `e.result.value`. For example: console.log( e.result.value.email ); // mkwst@google.com } else { // If the `success` event’s `result` is null, you’ve reached // the end of the cursor’s list. } };Querying (is asynchronous)
Code:
var t = db.transaction( [ “contacts” ], IDBTransation.READ_ONLY ); var s = t.objectStore( “contacts” ); // ... and generate a cursor to walk a bounded list, for example // only those names between M and P (inclusive) var bounds = new IDBKeyRange.bound( “M”, // Lower bound “Q”, // Upper bound true, // Include lower bound? false // Include upper bound? ); var readCursor = store.openCursor( bounds ); // Setup a handler for the cursor’s `success` event: readCursor.onsuccess = function ( e ) { // process `e.result` };Further Reading:
Questions?, Mike West, @mikewest, mkwst@google.com, http://mikewest.org/
<Return to section navigation list>
SQL Azure Database and Reporting
Mitch Wheat posted SQL Server Migration Assistant supports MySQL and Access to SQL Azure on 12/27/2010 with links to four current versions:
Old news, but the SQL Server Migration Assistant now supports migrating from MySQL and Access to SQL Azure. The latest SQL Server Migration Assistant is available for free download here:
MSCerts.net explained Migrating Databases and Data to SQL Azure (part 1) - Generate and Publish Scripts Wizard on 12/25/2010:
So you want to move one or more of your applications and their databases to the cloud. It's a noble idea. More than likely, you're in the same category as countless others who are looking into moving applications into the cloud: you don't want to start from scratch. You'd rather migrate an existing application to the cloud, but you aren't sure about the steps necessary to do so, or the technologies available to help in the process. This section discusses three tools from Microsoft and come with SQL Server:
Generate and Publish Scripts Wizard
SQL Server Integration Services
Bcp utility
In addition to these three tools, we will also briefly mention a free utility found on CodePlex called the SQL Azure Migration Wizard which provides a wizard-driven interface to walk you through migrating your database and data to SQL Azure.
The examples in this article use SQL Server 2008 R2 Community Technology Preview (CTP), which at the time of this writing is available from Microsoft's MSDN site. These examples also work with SQL Server 2008, although some the screens may be a bit different.
You may wonder why the SQL Server Import and Export Wizard isn't listed here. The answer is that the SQL Server Import and Export Wizard isn't supported for SQL Azure yet. Microsoft is working on it. No timeframe has been given as to when the Import/Export Wizard will support SQL Azure, but support is definitely in the works.
The database you use in these examples is TechBio, which you can download from the Apress web site for this book. This sample database is a mini version of the TechBio database that is behind the TechBio application found in the download for this book.
1. Generate and Publish Scripts Wizard
The Generate and Publish Scripts Wizard is used to create T-SQL scripts for SQL Server databases and/or related objects within the selected database. You have probably used this wizard, so this section doesn't walk through it step by step; instead, the section briefly highlights a few steps in the wizard and points out the options necessary to effectively work with SQL Azure.
SQL Server 2008 R2 comes with the ability to script an on-premises database for the SQL Azure environment. Because many haven't moved to SQL Server 2008 R2, the examples in this section use the version prior to R2, which is the original release of SQL Server 2008.
One of the differences between SQL Server 2008 R2 and SQL Server 2008 (pertaining to object scripting) is a setting in the Advanced Scripting Options dialog as you go through the wizard. This dialog includes two properties you can set regarding the version of SQL Server for which you're scripting database objects: Script for Server Version and "Script for the database engine type." The Script for Server Version option lists the version of SQL Server that the Generate and Publish Scripts wizard supports, which ranges from SQL Server 2000 to SQL Server 2008 R2.
The "Script for the database engine type" property has two options you can choose from: "Stand-alone instance" and "SQL Azure database." The "SQL Azure database" option only works with the SQL Server 2008 R2 Server version. For example, if you set the Script for Server version to SQL Server 2008 (non R2) and then set the "Script for the database engine type" property to "SQL Azure database," the Script for Server version property value automatically changes to SQL Server 2008 R2.
The Generate and Publish Scripts Wizard does a really nice job of appropriately scripting objects for SQL Azure. The wizard checks for unsupported syntax and data types, and checks for primary keys on each table. Thus, the following example sets SQL for Server Version to SQL Server 2008 (non R2) for several reasons. First, many people aren't using SQL Server 2008 R2 and therefore don't have the option to script for SQL Azure. Second, this exercise shows you what steps are needed to get a script ready to run in SQL Azure.
1.1. Starting the Wizard
To start the Generate and Publish Scripts Wizard in SQL Server Management Studio (SSMS), open Object Explorer and expand the Databases node. Select a database, right-click it, and then select Generate Scripts from the context menu.
On the wizard's Introduction page for SQL Server 2008 R2, you're informed that you must follow four steps to complete this wizard:
Specify scripting or publishing objects.
Review selections.
Generate scripts.
The following sections work through these steps.
1.2. Choosing Target Objects
To select your target database objects, follow these steps:
On the Introduction page of the Generate and Publish Scripts Wizard, click Next.
On the Choose Objects page (see Figure 5-1), select the "Select specific database objects" option, because for the purposes of this example, you simply want to select a few objects to migrate.
Figure 1. Choosing objects to migrate into script form

In the list of objects in Figure 1, expand the Tables and Stored Procedures nodes, and select the following objects:
Tables: Docs, UserDoc, and Users
Stored procedures: proc_CreateProfile, proc_GetDocument, and proc_UpdateDocFile
On the Set Scripting Objects page, select the "Save to new query window" option shown in Figure 2, and then click the Advanced button.
Figure 2. Scripting options

<Return to section navigation list>
MarketPlace DataMarket and OData
The MSDN Library Team posted an OData + Sync: Operations topic in 12/2010:
Sync Framework 2.1
[This topic is pre-release documentation and is subject to change in future releases. Blank topics are included as placeholders.]
This section describes the operation model for OData + Sync, which specifies the interactions between clients and service for performing incremental synchronization.
Operations Basics
Representation formats and content type negotiations
OData + Sync supports two formats for representing requests and responses:
OData + Sync: Atom
OData + Sync: JSON
A synchronization service MUST implement at least one of these formats. It must use the same format as that of client request in its response. The OData + Sync protocol does not define how OData + Sync clients and synchronization service negotiate the representation format. If the service does not support the representation format that is used in the client request, an error response MUST be sent. The protocol does not define specific error responses. However, OData + Sync: HTTP defines a recommended approach ($format service options) that OData + Sync clients and services MAY use to perform format negotiation.
Error conditions
OData + Sync protocol is based on a request, response message exchange pattern. The protocol is defined in such a way that synchronization works correctly despite messages being lost.
When processing a request, a synchronization service may encounter errors at two levels: errors occurred while processing the whole request, or errors occurred while processing some operations in a request.
The service MUST respond with an error response when it encounters errors processing the whole request. OData: Operations does not define a set of standard error responses. OData + Sync: HTTP defines a set of error messages that OData + Sync: HTTP based synchronization service MAY use.
When synchronization service encounters an error processing any individual operation it MUST make sure that the response includes a compensating change, and when the OData + Sync client applies the compensating change it will be in sync with the service.
Metadata Retrieval Operations
The OData + Sync protocol defines two operations that MAY be implemented by a synchronization service for metadata retrieval.
GetSyncScopes
GetSyncScopeSchema
These operations help clients with discovery and initialization.
GetSyncScopes
A synchronization service MAY support GetSyncScopes operation to expose a metadata document that lists all the available synchronization scopes from the service. A successful response to a GetSyncScopes operation MUST list all the scopes that are available for synchronization from the synchronization service. The metadata document MAY be formatted in either Atom or JSON as described in OData + Sync: Atom or OData + Sync: JSON.
GetScopeSchema
A synchronization service MAY support the GetSyncScopeSchema operation to expose a metadata document that describes the scope. The scope metadata document defines the name of scope, types of any parameters, names of collections in the scope, and the types of the entities in the collection. This metadata document is described in EDM terms using an XML language for describing models called the Conceptual Schema Definition Language (CSDL). CSDL is fully described in [CSDL Specification]. When exposed by an OData service as a Service Metadata Document, the CSDL document is packed using the format described in [EDMX Specification].
Synchronization Operations
The OData + Sync: Operations defines two operations that are the foundation for clients and service to perform synchronization. They are as follows: DownloadChanges, and UploadChanges.
UploadChanges
The UploadChanges operation MUST be supported by all synchronization services. An OData + Sync client’s change is considered to be successfully incorporated by a synchronization service, when a success response is returned after the service performs an UploadChanges operation. OData + Sync clients SHOULD only include new changes that have not been successfully incorporated by the synchronization service. If a change already incorporated by the synchronization service is included in an UploadChanges request, the service MUST assume it is a new change. The synchronization service MUST process the UploadChanges request immediately and respond with the results of applying that change. The synchronization service MUST also send an updated anchor binary large object (blob) as part of the response notifying the OData + Sync client of the reception and processing of the UploadChanges operation. The OData + Sync clients MUST wait for a response from the OData + Sync server and then process the response. Upon successful processing of the UploadChanges response, clients MUST persist the new anchor blob locally.
Synchronization Conflicts
A synchronization service MAY encounter conflicts when incorporating changes from an OData + Sync client. The synchronization service has two options when it encounters a conflict:
Resolve the conflict
Notify the OData + Sync client of the conflict
If the synchronization service resolves the conflict then it MUST send the information about conflict, along with the resolution, back to the OData + Sync client in the UploadChanges response.
If the synchronization service chooses to report the conflict back to the OData + Sync client without resolving it then it MUST send the current state of the item as part of the response so that the OData + Sync client can perform additional processing on the conflicts.
Synchronization Errors
A synchronization service MAY encounter an unrecoverable error when incorporating a change from an OData + Sync client. In such cases the synchronization service MUST create a response that describes what caused the error. The response MUST also contain a compensating action that can be used to fix the error. For example if an OData + Sync client tried to insert an item that could not be incorporated by the synchronization service, the synchronization service MAY decide to send a compensating action that equates to deleting the Item. As another example, an error could have been caused by an invalid value being specified for a field by the OData + Sync client. In this case, the synchronization service may choose to respond with a compensating action that equates to replacing the local copy with the OData + Sync server’s version.
DownloadChanges
The DownloadChanges operation MUST be implemented by all synchronization services. New clients perform the DownloadChanges operation with a null value for ServerBlob when synchronizing for the first time or when all the local data has to be replaced, which will return all current data. Performing the DownloadChanges operation with a non-null value for ServerBlob will return all the data changes that have occurred after the ServerBlob value was set (i.e., incremental changes). For each DownloadChanges operation processed by a synchronization service, the service responds with unincorporated changes and a new anchor blob for OData + Sync client to persist. If OData + Sync client processes the DownloadChanges response then it MUST persist the associated anchor blob locally.
Incremental Change Payloads
When performing the UploadChanges operation, the payload MAY include incremental changes. The same is true when you perform a DownloadChanges operation. An UploadChanges response also includes changes due to conflicts, and errors occurred while processing the UploadChanges request.
Entity Data Model (EDM) Overview
The central concepts in the EDM are entities and associations. Entities are instances of Entity Types (for example, Customer, Employee, and so on) which are structured records that consist of named and typed properties and with a key. The Entity Key (for example, CustomerId or OrderId) is a fundamental concept for uniquely identifying instances of entity types and enabling these instances to participate in relationships. Entities are grouped in Entity Sets (for example, Customers is a set of instances of Customer entity type). Multiple entity sets are grouped together to form a single synchronization scope. For example CustomersScope could be a synchronization scope for a collection of Customers, Orders and OrderDetails entity sets.
Rules
OData + Sync clients and servers MUST produce incremental change payloads that conform to the following rules:
Each entity is uniquely identified by an ID element that is an IRI as per [RFC4287] and not by the EDM’s entity keys
ID elements are always issued by a synchronization service.
When an OData + Sync client creates one or more entities, and then performs the UploadChanges operation, the synchronization service MUST provide a response that includes those new entities, where each entity will have an ID element.
Each entity MAY only have only one change specified in a payload. This is excluding any conflict changes, which are sub-elements for a change.
Response for the UploadChanges operation MAY NOT include changes to entities not specified in the UploadChanges request.
Incremental change payload elements
The following table lists the elements defined by the OData + Sync protocol to be used in an incremental payload.

<Return to section navigation list>
Windows Azure AppFabric: Access Control and Service Bus
Pluralsight released their online Windows Azure AppFabric training course on 12/26/2010:
From the Description:
The Windows Azure AppFabric contains three services meant to improve developer productivity in the cloud: Cache, Access Control, and Service Bus. This course covers all areas of these services. The services themselves offer a lot of functionality: high performance caching of frequently used data, an STS that can make single sign-on a breeze from corporate accounts, and a mechanism to expose services from your local infrastructure out to the Internet. Inside, you'll find gems like a pub sub system, short-lifetime queues, and full authentication integration with Google, Yahoo!, Facebook, and Windows Live.
From the Table of Contents (collapsed):

About the author, Scott Seeley:
Scott Seely is the president of Friseton, LLC, www.friseton.com. From 2002 to 2006, Scott was a developer on the WCF/Indigo team at Microsoft. Today, he is an active member of the .NET community in the Chicago area, helping lead the Lake County .NET Users’ Group, organize Code Camps, and speaking at user groups throughout the region. Scott has focused on distributed systems since 1995.
<Return to section navigation list>
Windows Azure Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Jon Skeet is up to #9 in his LINQ to Objects series with Reimplementing LINQ to Objects: Part 9 – SelectMany of 12/27/2010:
The next operator we'll implement is actually the most important in the whole of LINQ. Most (all?) of the other operators returning sequences can be implemented via SelectMany. We'll have a look at that at the end of this post, but let's implement it first.
What is it?
SelectMany has 4 overloads, which look gradually more and more scary:

In every case, we start with an input sequence. We generate a subsequence from each element in the input sequence using a delegate which can optionally take a parameter with the index of the element within the original collection.
Now, we either return each element from each subsequence directly, or we apply another delegate which takes the original element in the input sequence and the element within the subsequence.
In my experience, uses of the overloads where the original selector delegate uses the index are pretty rare - but the others (the first and the third in the list above) are fairly common. In particular, the C# compiler uses the third overload whenever it comes across a "from" clause in a query expression, other than the very first "from" clause.
It helps to put this into a bit more context. Suppose we have a query expression like this:

That would be converted into a "normal" call like this:

In this case the compiler has used our final "select" clause as the projection; if the query expression had continued with "where" clauses etc, it would have created a projection to just pass along "file" and "line" in an anonymous type. This is probably the most confusing bit of the query translation process, involving transparent identifiers. For the moment we'll stick with the simple version above.
So, the SelectMany call above has three arguments really:
- The source, which is a list of strings (the filenames returned from Directory.GetFiles)
- An initial projection which converts from a single filename to a list of the lines of text within that file
- A final projection which converts a (file, line) pair into a single string, just by separating them with ": ".
The result is a single sequence of strings - every line of every log file, prefixed with the filename in which it appeared. So writing out the results of the query might give output like this:
It can take a little while to get your head round SelectMany - at least it did for me - but it's a really important one to understand.
A few more details of the behaviour before we go into testing:
- The arguments are validated eagerly - everything has to be non-null.
- Everything is streamed. So only one element of the input is read at a time, and then a subsequence is produced from that. Only one element is then read from the subsequence at a time, yielding the results as we go, before we move onto the next input element and thus the next subsequence etc.
- Every iterator is closed when it's finished with, just as you'd expect by now.
What are we going to test?
I'm afraid I've become lazy by this point. I can't face writing yet more tests for null arguments. I've written a single test for each of the overloads. I found it hard to come up with a clear way of writing the tests, but here's one example, for the most complicated overload:


So, to give a bit more explanation to this:
- Each number is summed with its index (3+0, 5+1, 20+2, 15+3)
- Each sum is turned into a string, and then converted into a char array. (We don't really need to ToCharArray call as string implements IEnumerable<char> already, but I thought it made it clearer.)
- We combine each subsequence character with the original element it came from, in the form: "original value: subsequence character"
The comment shows the eventual results from each input, and the final test shows the complete result sequence.
Clear as mud? Hopefully it's not to bad when you look at each step in turn. Okay, now let's make it pass...
Let's implement it!
We could implement the first three overloads in terms of calls to the final one - or more likely, a single "Impl" method without argument validation, called by all four public methods. For example, the simplest method could be implemented like this:

However, I've decided to implement each of the methods separately - splitting them into the public extension method and a "SelectManyImpl" method with the same signature each time. I think that would make it simpler to step through the code if there were ever any problems... and it allows us to see the differences between the simplest and most complicated versions, too:

The correspondence between the two methods is pretty clear... but I find it helpful to have the first form, so that if I ever get confused about the fundamental point of SelectMany, it's really easy to understand it based on the simple overload. It's then not too big a jump to apply the two extra "optional" complications, and end up with the final method. The simple overload acts as a conceptual stepping stone, in a way.
Two minor points to note:
- The first method could have been implemented with a "yield foreach selector(item)" if such an expression existed in C#. Using a similar construct in the more complicated form would be harder, and involve another call to Select, I suspect... probably more hassle than it would be worth.
- I'm not explicitly using a "checked" block in the second form, even though "index" could overflow. I haven't looked to see what the BCL does in this situation, to be honest - I think it unlikely that it will come up. For consistency I should probably use a checked block on every method which uses an index like this... or just turn arithmetic checking on for the whole assembly.
Reimplementing operators using SelectMany
I mentioned early on in this post that many of the LINQ operators can be implemented via SelectMany. Just as a quick example of this, here are alternative implementations of Select, Where and Concat:

Explaining LINQ’s SelectMany operator was one of my most difficult tasks when I wrote Professional ADO.NET 3.5 with LINQ and the Entity Framework in early 2009.
<Return to section navigation list>
Visual Studio LightSwitch
Johannes Kebeck’s Bing Maps Developer's Guide: Building Mapping Applications for Mobile, Silverlight, SharePoint, Desktops, and the Web carries the following Editorial Review from the Amazon.com site:
Product Description
Delve into the Bing Maps platform -- and build interactive Web mapping applications for the cloud, desktop, and mobile devices such as Windows® Phone 7. Led by a Microsoft Technology Specialist for Bing Maps, you'll gain a thorough introduction to Bing Maps APIs, best practices, and performance optimization -- ideal whether you're an application developer, IT architect, or technical decision maker.
Discover how to:
- Embed Bing Maps into your Web site without writing code
- Use the AJAX and Microsoft® Silverlight® APIs to build interactive applications
- Add tracking and location-based functionality with SOAP or REST Web services
- Publish Bing Maps applications in the cloud using Windows Azure™
- Build mobile apps for Windows Phone 7, the iPhone, and other devices
- Develop spatial analysis applications using Microsoft SQL Server®
- Combine Bing Maps with Microsoft SharePoint®
Create desktop and rich-client applications with Microsoft Visual Studio LightSwitch® [Emphasis added.]
About the Author
Johannes Kebeck is a Technology Specialist for Microsoft's Bing Maps, supporting customers and partners in Europe, the Middle East and Africa. He is currently based in Reading, UK and has over 14 years of experience in the GI/GIS market. In October 2004 Johannes joined Microsoft in Germany working within the Enterprise & Partner Group, and in 2005 he joined the Bing Maps team. Before specializing on Microsoft’s geospatial products and services, he had experience with various GIS, spatial databases, relational database management systems, workflow management, collaboration products, and IT security.
Ayende Rahien (@ayende, a.k.a. Oren Eini) dealt with n+1 queries in his Analyzing LightSwitch data access behavior post of 8/25/2010 (missed when published):

I thought it would be a good idea to see what sort of data access behavior LightSwitch applications have. So I hook it up with the EntityFramework Profiler and took it for a spin.
It is interesting to note that it seems that every operation that is running is running in the context of a distributed transaction:
There is a time & place to use DTC, but in general, you should avoid them until you really need them. I assume that this is something that is actually being triggered by WCF behavior, not intentional.
Now, let us look at what a simple search looks like:
This search results in:
That sound? Yes, the one that you just heard. That is the sound of a DBA somewhere expiring. The presentation about LightSwitch touted how you can search every field. And you certainly can. You can also swim across the English channel, but I found that taking the train seems to be an easier way to go about doing this.
Doing this sort of searching is going to be:
- Very expensive once you have any reasonable amount of data.
- Prevent usage of indexes to optimize performance.
In other words, this is an extremely brute force approach for this, and it is going to be pretty bad from performance perspective.
Interestingly, it seems that LS is using optimistic concurrency by default.
I wonder why they use the slowest method possible for this, instead of using version numbers.
Now, let see how it handles references. I think that I run into something which is a problem, consider:
Which generates:
This make sense only if you can think of the underlying data model. It certainly seems backward to me.
I fixed that, and created four animals, each as the parent of the other:
Which is nice, except that here is the SQL required to generate this screen:
-- statement #1 SELECT [GroupBy1].[A1] AS [C1] FROM (SELECT COUNT(1) AS [A1] FROM [dbo].[AnimalsSet] AS [Extent1]) AS [GroupBy1] -- statement #2 SELECT TOP ( 45 ) [Extent1].[Id] AS [Id], [Extent1].[Name] AS [Name], [Extent1].[DateOfBirth] AS [DateOfBirth], [Extent1].[Species] AS [Species], [Extent1].[Color] AS [Color], [Extent1].[Pic] AS [Pic], [Extent1].[Animals_Animals] AS [Animals_Animals] FROM (SELECT [Extent1].[Id] AS [Id], [Extent1].[Name] AS [Name], [Extent1].[DateOfBirth] AS [DateOfBirth], [Extent1].[Species] AS [Species], [Extent1].[Color] AS [Color], [Extent1].[Pic] AS [Pic], [Extent1].[Animals_Animals] AS [Animals_Animals], row_number() OVER(ORDER BY [Extent1].[Id] ASC) AS [row_number] FROM [dbo].[AnimalsSet] AS [Extent1]) AS [Extent1] WHERE [Extent1].[row_number] > 0 ORDER BY [Extent1].[Id] ASC -- statement #3 SELECT [Extent1].[Id] AS [Id], [Extent1].[Name] AS [Name], [Extent1].[DateOfBirth] AS [DateOfBirth], [Extent1].[Species] AS [Species], [Extent1].[Color] AS [Color], [Extent1].[Pic] AS [Pic], [Extent1].[Animals_Animals] AS [Animals_Animals] FROM [dbo].[AnimalsSet] AS [Extent1] WHERE 1 = [Extent1].[Id] -- statement #4 SELECT [Extent1].[Id] AS [Id], [Extent1].[Name] AS [Name], [Extent1].[DateOfBirth] AS [DateOfBirth], [Extent1].[Species] AS [Species], [Extent1].[Color] AS [Color], [Extent1].[Pic] AS [Pic], [Extent1].[Animals_Animals] AS [Animals_Animals] FROM [dbo].[AnimalsSet] AS [Extent1] WHERE 2 = [Extent1].[Id] -- statement #5 SELECT [Extent1].[Id] AS [Id], [Extent1].[Name] AS [Name], [Extent1].[DateOfBirth] AS [DateOfBirth], [Extent1].[Species] AS [Species], [Extent1].[Color] AS [Color], [Extent1].[Pic] AS [Pic], [Extent1].[Animals_Animals] AS [Animals_Animals] FROM [dbo].[AnimalsSet] AS [Extent1] WHERE 3 = [Extent1].[Id]I told you that there is a select n+1 builtin into the product, now didn’t I?
Now, to make things just that much worse, it isn’t actually a Select N+1 that you’ll easily recognize. because this doesn’t happen on a single request. Instead, we have a multi tier Select N+1.
What is actually happening is that in this case, we make the first request to get the data, then we make an additional web request per returned result to get the data about the parent.
And I think that you’ll have to admit that a Parent->>Children association isn’t something that is out of the ordinary. In typical system, where you may have many associations, this “feature” alone is going to slow the system to a crawl.






Be sure to read the comments. Steve Anonsen (Microsoft) mentioned that LightSwitch Beta2 will correct several problems:
On navigation properties, Beta 2 will provide spans (aka include, $expand) that by default are autocalculated based on the UI contents and can be tuned to n-levels of depth. It works great, is very flexible, and is fully declarative. If you think that sounds insufficient, engage with the team on the beta site--they're very interested in feedback.
For pictures, the default behavior is right for product catalog sized photos (i.e. a few K) , but it isn't right for 2MB photos. Without partial entity load, big pics will need to be handled differently (e.g. put on a secondary table, etc). Again, the beta forum is a good place to discuss this with the product community. Ditto on search behavior and options.
…
The default behavior in LightSwitch beta 2 does not use "cartesian products and 10 table joins per each form." It does not blindly include everything. I think it does what people want--take a look at it in beta 2 and give your feedback.
Return to section navigation list>
Windows Azure Infrastructure
Jeremy Geelan reported “The Founder & VP Products at CloudSwitch shares her thoughts” in his My Top Five Cloud Predictions for 2011: Ellen Rubin post of 12/27/2010:
"When you’re building a new company within a new industry and evolving market," says Ellen Rubin (pictured), the Founder & VP Products at CloudSwitch, "it’s never dull."
"Many things you envision and dream about turn out to be false starts or take a while to appear," she continues, "while others match your original plans on a white board exactly as you sketched them. The thrill is to watch the market unfold in sometimes unforeseen ways and enjoy being part of the early ride."
So as we head into 2011, how does the cloud look from where she sits at CloudSwitch, Cloud Computing Journal asked Rubin. Here are her thoughts.
1. Movement of applications between cloud environments will emerge as a critical requirement: Hybrid cloud, accepted as a new paradigm for enterprise cloud computing in 2010, requires the integration of data centers, private clouds and public clouds. To make this work, enterprises are just starting to realize the importance of VM mobility to be able to run workloads in the environment that best meets their specific needs (at a particular point in time, or on an ongoing basis). This is frequently cross-hypervisor (especially VMware to Xen), and always cross technology platforms.2. Networking bandwidth will become the new bottleneck: We’ve been tracking network optimization as a key issue this past year, and in 2011, this will begin to edge out security as the key area that enterprises consider as they evaluate the risks of running larger and more production-oriented workloads in the cloud. There will also be many new requirements for network configurability and scaling within the cloud to match customers’ internal network topologies. See my blog post for more on this topic.
3. Security will remain a key concern, but no longer a show-stopper: We still discuss security requirements as part of every customer engagement, and the bar remains extremely high. However, since we’ve been able to address these requirements for some of the most security- conscious companies in the world, we’ve learned that there is a willingness to put specific types of workloads outside the firewall. The ability to span internal and external clouds also has alleviated some of the concerns, since sensitive or compliant data can stay inside while the “spiky” tiers of the application move out.
4. True “bang for the buck” analyses of the cloud will be conducted: Many of the TCO (total cost of ownership) analyses done in 2010 were back-of-the-envelope calculations. Many were done to justify either the initiation or prevention of cloud evaluations. Many lacked thorough assessments of current, internal costs (hint: it’s not just the cost of buying a new server). We’re starting to see customers want to analyze a range of cloud options based on $ spent per unit of compute performance. This is a much more meaningful way to assess cloud and helps determine which offerings should be used for which workloads, and when.
5. More clouds, more fun: Like those Six Flags commercials, I keep thinking about how much more exciting it will be with more viable cloud options out there. We’re working with several new offerings that will be coming online in 2011, providing more choice, flexibility, geographic locations and architectures. More competition is good for the industry, pushing providers to innovate and continue to drive cloud costs down. Of course, this will also lead to still more heterogeneity in the cloud provider market and the need to orchestrate across multiple
"The outlook for 2011 will certainly include many bumps and surprises along the way as enterprises make cloud a more serious part of their business," notes Rubin in conclusion."
"But that’s a sign of the market maturing, moving beyond the past few years of hype into a more rational, pragmatic phase," she says.
By the end of 2011, according to Rubin, we can expect to see many large, well-known enterprises sharing their best practices and case studies of cloud deployments and presenting cloud providers and enablement vendors with lists of must-have features.
"We wouldn’t have it any other way," adds Rubin.
Jeremy is President & COO of Cloud Expo, Inc.
Brian Prince published Microsoft and the Cloud: Year in Review on 12/22/2010 to Internet.com’s CodeGuru blog (missed when posted):
Introduction
Wow, what a year. Cloud computing seems to have come out of no where, and is moving fast. Of course, like all overnight successes, this one took twenty years to really happen. But when Microsoft gets behind something, you can really see the momentum. The various cloud computing and product teams at Microsoft have been on overdrive, delivering features in a continual pace since the initial Microsoft Azure release. This isn't your mothers Windows. This isn't a new version every three years. This is the twitter of software, with new features, and options every few months. Just try to keep up.
Microsoft Azure was released to production and available for customers to use and pay for in February of 2010, and at that time they shipped version 1.1 of the SDK (version 1.0 was shipped at PDC 2009 in November, 2009). It was a solid release, and followed on a whole year long beta process. It had all the basic features, and was for all intents and purposes the first real Platform as a Service offering that customers could really buy and rely on. There have been other smaller PaaS offerings, but none of them had the legs or scale that Azure had.
Many customers had already adopted version 1.0 of the SDK that was released at Microsoft PDC in November, 2009. The 1.1 release added support for Windows Azure Drives. This feature allows a role instance to mount a VHD that is stored in BLOB storage as a real local drive. This was a move to make it easier to migrate legacy applications to the cloud without having to rewrite all of the underlying file I/O code.
Version 1.1 also released the idea of Windows Azure Role Image support. When you deploy a role to Windows Azure, those instances of that role are running some form of Windows, but you don't pick which version of Windows. Instances are also not patched. Instead you deploy your instances with a Windows Azure OS image. This image is a prepacked specialized version of Windows, along with patches, and other software the Windows Azure environment needs to run. This includes the device drivers needed for Microsoft Azure Drive and the local agent that works with the Fabric Controller. When a new patch comes out, the Windows Azure team creates a new image, and makes that available to customers.
This mechanism is important to understand. This is how you KNOW that your code, and the instance it is running on, won't be changed or patched without your permission. You set the version of the Microsoft Azure OS you want to run, and it stays that way. You also have the option of choosing 'auto upgrade.' When you do this any new Microsoft Azure OS version will get copied down to your server, and it will get restarted with the new OS version. In this way Microsoft can release new features without breaking existing customers. This gives them the flexibility to release at a very rapid pace.
Four months passed, and in June of 2010 Microsoft released version 1.2. This version was more focused on the tooling developers needed and on what they call platform alignment. This was the first version that was compatible with the RTM version of Microsoft Visual Studio 2010, which had just shipped, as well as including .NET Framework 4 support.
One of the most popular features was the support for using IntelliTrace in Microsoft Azure. IntelliTrace was a feature that shipped with Microsoft Visual Studio 2010 Ultimate Edition, and allows for historical debugging. Think of it as the black box running on the server tracking your code. By attaching this black box to Microsoft Visual Studio you can replay what your code did, much like watching a show on a DVR. This became the first real way you could debug applications that were truly running in the cloud. Up until now you could only debug when running in the local cloud simulator, and could only trouble shoot in the cloud using tracing and log files.
The Microsoft Visual Studio tooling was upgraded to allow you to explore your cloud storage (in a read-only mode) from within the IDE, as well as be able to see the status of your running instances. The biggest new feature with tooling was the option to be able to deploy from within Visual Studio by configuring and using the publishing feature. This reduced the deployment barrier to almost nothing. This saved developers time from having to jump out of VS and login through the portal or other tools.
They also shipped a new feature for SQL Azure called Database Copy. This allows you to make a transactionally complete copy of your SQL Azure database. You can do this from the portal, or through SQL commands. This is an important feature for backup and recovery operations. The SQL Azure team also raised the maximum database size several times, eventually resting at 50GB per database.
We also saw the release of Windows Azure CDN, a global network of cache servers to make it easier for your users to access the files in your BLOB storage. I have talked with customers that just don't believe how fast and how cheap the CDN offering is compared to the entrenched competitors. Microsoft has had this network for internal use only for years. They just repackaged it and started letting customers use it. Until now CDNs were the prevue of expensive, super big scale operations like game developers trying to let the world download the latest demo. And it showed in the pricing where you would spend thousands of dollars in setup fees, pay $5/GB for storage, and high charges for bandwidth. Windows Azure CDN doesn't have contracts, and costs $0.15/GB for storage, plus a much more sane charge for bandwidth. There aren't any setup or monthly service fees.
Microsoft also wanted to make it easy for developers to try the cloud, and launched two offerings. The first is that MSDN subscribers could receive lots of free Microsoft Azure resources just by signing up. The second is something called the introductory account. These let any developer sign up for an account, and receive 25 hours of compute time, plus other free resources, per month. This is the perfect amount of free time to kick the tires and try things out.
There has been a lot of marketing in the industry around Private Clouds. This is the concept that you would get all of the benefits of the cloud, but not sharing those resources by running them for yourself. Microsoft sees a future in this market, and released into beta a product called Windows Azure Appliance. This is in partnership with HP, Dell, Fujitsu and eBay. The Appliance will be a ready to go package with the servers, networking and power hardware, and the Windows Azure software to turn key your own private cloud. Microsoft expects a lot of hosting providers will invest in the Appliance to build their own clouds to sell to customers. Perhaps these different clouds will offer specialties, for example special features for the healthcare or finance industry.
About this time Microsoft launched a massive 'We're all in' campaign, telling the world that they made a big bet on cloud computing. They talked about how they invested $2.5 billion dollars building out the data centers, and that every product team is focusing on how to leverage the cloud with their product.
This change reminded me of when Microsoft woke up to the Internet. They definitely missed the start of the Internet, and Bill Gates worked hard (with a famous internal memo) to turn the ship, and get the whole company thinking about the Internet. This time Microsoft didn't miss the boat, and they engaged the whole company on cloud computing before it was too late.
Then four months later, in October, at the PDC 2010, Microsoft released version 1.3. This was a major release, and was big enough to get a 2.0 version number in my opinion. Briefly, here are some of the features that they either released or announced would be released shortly:
- VM Role: Microsoft announced a new role (to be added to the existing web and worker roles). The VM Role lets you build your own image and run it in Microsoft Azure. This was a move to make it easier to migrate legacy applications that aren't exactly cloud friendly.
- Remote Desktop: Normally you could not directly access the servers running your code in Microsoft Azure, and in a pure Platform-as-a-Service this is the way. Microsoft released this feature to make it easier to troubleshoot issues during migrations, and should only be used in a development/testing scenario, and not in a production scenario.
- Extra Small Instances: The small instance size is one dedicated CPU core with about 2GB of RAM. The new extra small instance gives you about half of a small instance, running on a shared core and is charged at $.05 per hour. This is great for low load scenarios, or just plain testing.
- Brand new portal: The new portal is based on Silverlight and brings together all of the admin portals into one tool. It is much easier to navigate and work with your cloud resources. I do miss the giant cubes of jelly that visualized your service containers though.
- Co-Admins: You can now have additional Live IDs identified as co-admins, giving them access to your resources through the new portal. This bypassed the limit of one technical admin account in the past.
- Support for Windows Server 2008 R2 and IIS 7.5 (with full IIS support)
- Startup tasks and admin mode: This feature lets you define tasks that must be run during the startup phase of the server giving you a chance to customize the server image before you code is wired up and launched.
- Windows Azure AppFabric Caching: This makes a distributed cache available to your role instances running in Microsoft Azure. This helps with sharing server state across your instances (perhaps ASP.NET session state) and for sharing cached data in a highly available way.
- SQL Azure Reporting: This provides SQL Server Reporting Services as a service to provide reports and report support in your Microsoft Azure applications.
- Windows Azure Connect: This was code-named Sydney, and provide a virtual private network between your cloud servers and your on-premises servers.
- Windows Azure Marketplace: The Marketplace has two stores. One is a listing of cloud ready applications, and the second is a data marketplace where you can buy and sell data in an easy to consume way.
- TFS in Microsoft Azure: They announced they are working on a version of Team Foundation Server that they will host in the cloud for customers. No timeline for RTW has been given.
- Significant enhancements to the ACS and Service Bus features of Windows Azure AppFabric
- SQL Azure Data Sync: Will provide a secure way for SQL Azure databases and SQL Server databases to be easily synced.
This is a long list, and these are just the major features that were released or announced. There were many, many more released on a smaller scale. This shows a huge effort from Microsoft to really move Microsoft Azure forward at a very fast pace, and to out innovate the other players in the market.
Brian is an Architect Evangelist with Microsoft focused on building and educating the architect community in his district.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
Wes Yanaga announced three January 2011 - Windows Azure Webinars in a 12/27/2010 post to the US ISV Evangelism blog:
This is a three part series covering the benefits, implications and best practices for adopting Windows Azure. The webinars are scheduled for three dates in January:
The Business Case for Azure (Part 1) - January 12, 2011
The objective of this session is to provide an understanding of why Software as a Service is a compelling business model for today's ISVs and how Windows Azure can be a key enabler for ISVs considering a move to the cloud.
Understanding Implications of the Cloud (Part 2) - January 19, 2011
The focus of this session will be on the implications for adopting cloud computing as a core pillar of a go to market strategy. This webinar will provide an understanding of what ISVs face relative to change management challenges and implications for their current business models.
Easing (Leaping) Into the Cloud (Part 3) - January 29, 2011
The objective of this third and final session will be to introduce a decision-making framework - based on real world experience - for rationally adopting Windows Azure as a core element of an application architecture.
If you would like to try the Windows Azure Platform for 30 days with no credit card required please visit this link: http://bit.ly/ihxFR7 and the promo code DPWE01
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Jeff Barr (@jeffbarr) announced AWS Portal Improvements - Search, Multiple Languages, and More! on 12/27/2010:
We've made some improvements to the AWS Portal to make it easier for you to find and access the information that you need to build even more AWS-powered applications. We've added content in several new languages, improved the search features, revamped the discussion forums, and added a number of features to the AWS resource catalogs for AMIs, source code, customer applications, and so forth.
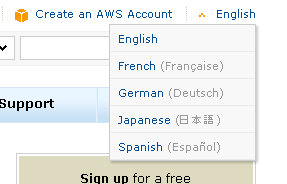
Most of the technical and marketing pages (including the AWS case studies) on the AWS Portal have been translated into French, German, Japanese, and Spanish. You can use the drop-down menu at the top right of each portal page to switch languages:
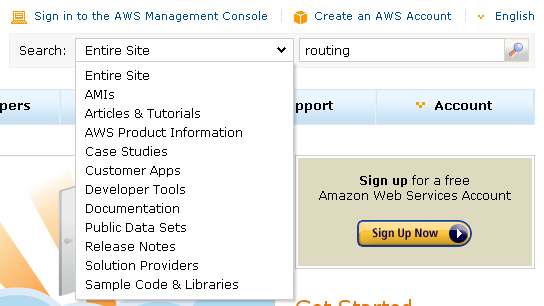
The portal's brand-new search function is contextual and faceted. You can choose to search the entire AWS site or you can limit your search to just one area using the Search menu:
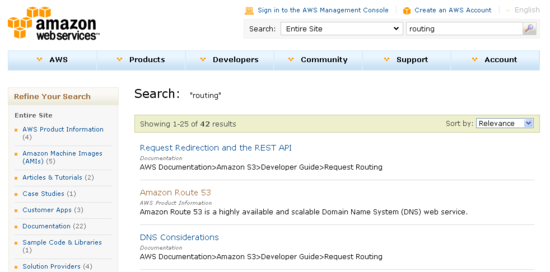
The search results now include information about where each match was found. You can use the box on the left to further refine your search (searching within results):
The AWS Discussion forum now includes a tag cloud and the editor now supports the use of markdown (simple text to HTML markup). Performance has been markedly improved as well.
The AWS resource catalogs (EC2 AMIs, Sample Code, Developer Tools and so forth) now make use of Amazon S3 and Amazon SimpleDB internally. This work was a prerequisite to some larger and more visible changes that are already on the drawing board:
We have a lot of plans for the AWS Portal in 2011 and beyond, so stay tuned to the blog (or better yet, subscribe to the RSS feed using the big icon at the top right corner).
Amazon Web Services won’t allow grass to grow under their feet.
Jerry Huang explained Backup Solutions for OpenStack Cloud Storage in a 12/25/2010 post:
OpenStack Object Storage is cloud storage services created by open source software.
For service providers that need a cloud storage service built on commodity hardware and open source software, OpenStack could be an option.
One of cloud storage’s primary use case is backup. If you are deploying OpenStack, very likely your first batch of customers will be looking for backup solutions that can take customer’s local data and backup to OpenStack.
Gladinet has a suite of products for backing up to OpenStack cloud storage.
Before we introduces the suite of products, first review the different backup use cases.
Mirror Backup
Mirror backup is the easiest form of backup. It mirrors a local folder into OpenStack cloud storage. Whenever you make changes to the local folder, the changes will be picked up and send over to OpenStack.
Snapshot Backup
Snapshot backup is more sophisticated and can work together with Volume Shadow Copy Service(VSS). Once it works with VSS, you can take snapshots with files and folders, SQL Servers and etc. If you schedule the snapshot to be taken on a daily basis, you can recover your files from daily snapshots. These snapshots can be stored on OpenStack cloud storage.
Existing Local/Tape Backup
Some may already have backup solutions deployed locally. In this case, connecting existing local backup to OpenStack cloud storage makes more sense so the local backup can backup to the OpenStack cloud storage.
Ad Hoc Backup
Sometimes you just need the ability to drag and drop stuff to an external USB drive for backup purpose. With OpenStack cloud storage, it can be like an external virtual drive for Ad Doc transfer.
Gladinet Cloud Desktop (GCD)
Gladinet Cloud Desktop is best fit for a personal user that has backup need. It mounts OpenStack cloud storage as virtual drive, so it supports Ad Hoc Backup. It also has mirror backup features. Optionally you can turn on the Snapshot features.
Gladinet Cloud Backup (GCB)
Gladinet Cloud Backup is best fit for taking snapshots of your folders and files, SQL Server and other VSS supported applications. You can use a stand-alone Cloud backup to connect to OpenStack, you can also use it from the other two products.
Gladinet CloudAFS (AFS)
Gladinet CloudAFS is best fit for a group of users. It has mirror backup feature so you can backup the file server. It integrates with the Gladinet Cloud Backup so you can take snapshots of the file server too. It is a file server for the cloud storage, so it interoperates with existing local backup and can turn them to cloud backup.
Feature Matrix

*1 – You can get snapshot backup from Gladinet Cloud Desktop and Gladinet CloudAFS because they integrate with the Cloud Backup, which can be activated with a Cloud Backup license.
Related Post
<Return to section navigation list>

















0 comments:
Post a Comment