Windows Azure and Cloud Computing Posts for 12/6/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI, Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |
‡ Updated 12/9/2012 11:00 AM PST with new articles marked ‡.
•• Updated 12/8/2012 12:00 PM PST with new articles marked ••.
• Updated 12/7/2012 5:00 PM PST with new articles marked •.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Marketplace DataMarket, Cloud Numerics, Big Data and OData
- Windows Azure Service Bus, Caching, Access Control, Active Directory, Identity and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue, HDInsight and Media Services
‡ Sergey Klimov and Andrei Paleyes wrote Hadoop on Windows Azure: Hive vs. JavaScript for processing big data and Network World published it on 12/6/2012 to its Data Center blog:
For some time Microsoft didn't offer a solution for processing big data in cloud environments. SQL Server is good for storage, but its ability to analyze terabytes of data is limited. Hadoop, which was designed for this purpose, is written in Java and was not available to .NET developers. So, Microsoft launched the Hadoop on Windows Azure service to make it possible to distribute the load and speed up big data computations.
But it is hard to find guides explaining how to work with Hadoop on Windows Azure, so here we present an overview of two out-of-the-box ways of processing big data with Hadoop on Windows Azure[, recently renamed HDInsight,] and compare their performance.
When the R&D department at Altoros Systems Inc. started this research, we only had access to a community technology preview (CTP) release of Apache Hadoop-based Service on Windows Azure. To connect to the service, Microsoft provides a Web panel and Remote Desktop Connection. We analyzed two ways of querying with Hadoop that were available from the Web panel: HiveQL querying and a JavaScript implementation of MapReduce jobs.
We created eight types of queries in both languages and measured how fast they were processed.
A data set was generated based on US Air Carrier Flight Delays information downloaded from Windows Azure Marketplace. It was used to test how the system would handle big data. Here, we present the results of the following four queries:
- Count the number of flight delays by year
- Count the number of flight delays and display information by year, month, and day of month
- Calculate the average flight delay time by year
- Calculate the average flight delay time and display information by year, month, and day of month
From this analysis you will see performance results tests and observe how the throughput varies depending on the block size. The research contains a table and three diagrams that demonstrate the findings.
Testing environment
As a testing environment we used a Windows Azure cluster. The capacities of its physical CPU were divided among three virtual machines that served as nodes. Obviously, this could introduce some errors into performance measurements. Therefore we launched each query several times and used the average value for our benchmark. The cluster consisted of three nodes (a small cluster). The data we used for the tests consisted of five CSV files of 1.83GB each. In total, we processed 9.15GB of data. The replication factor was equal to three. This means that each data set had a synchronized replica on each node in the cluster.
The speed of data processing varied depending on the block size -- therefore, we compared results achieved with 8MB, 64MB and 256MB blocks.
The results of the research
The table below contains test results for the four queries. (The information on processing other queries depending on the size of HDFS block is available in the full version of the research.)



Brief summary
As you can see, it took us seven minutes to process the first query created with Hive, while processing the same query based on JavaScript took 50 minutes and 29 seconds. The rest of the Hive queries were also processed several times faster than queries based on JavaScript. …
Sergey and Andrei are senior R&D engineers at Altoros Systems Inc. You can read more about the US Air Carrier Flight Delays dataset and my tests with Windows Azure in the following OakLeaf Systems blog posts:
- Recent Articles about SQL Azure Labs and Other Added-Value Windows Azure SaaS Previews: A Bibliography, 11/1/2012
- Introducing Apache Hadoop Services for Windows Azure, updated 8/23/2012
- Using the Windows Azure Marketplace DataMarket (and Codename “Data Hub”) Add-In for Excel (CTP3), 5/21/2012
- Accessing the US Air Carrier Flight Delay DataSet on Windows Azure Marketplace DataMarket and “DataHub”. 5/15/2012
- Creating An Incremental SQL Azure Data Source for OakLeaf’s U.S. Air Carrier Flight Delays Dataset, 5/11/2012
- Five Months of U.S. Air Carrier Flight Delay Data Available on the Windows Azure Marketplace DataMarket, 5/4/2012
- Creating a Private Data Marketplace with Microsoft Codename “Data Hub” 4/27/2012
- Analyzing Air Carrier Arrival Delays with Microsoft Codename “Cloud Numerics”, 3/26/2012
Jim O’Neil (@jimoneil) continued his series with Practical Azure #5: Windows Azure Table Storage on 12/6/2012:
Windows Azure Table Storage provides massively scalable, durable storage in the cloud with NoSQL and RESTful semantics... and as of yesterday, it's up to 28% cheaper, so you can't afford not to try it out at this point! In my fifth installment of DevRadio Practical Azure, I'll give you some insight into how it all works and point out some of the notable differences from the more traditional notion of a database 'table.'
Download: MP3 MP4
(iPod, Zune HD)High Quality MP4
(iPad, PC)Mid Quality MP4
(WP7, HTML5)High Quality WMV
(PC, Xbox, MCE)And here are the Handy Links for this episode:


Mary Jo Foley (@maryjofoley) asserted “Microsoft has chopped prices on its Windows Azure cloud storage for the second time this year” in a deck for her Microsoft cuts Windows Azure cloud storage prices article of 12/6/2012 for ZDNet’s All About Microsoft blog:
The cloud-storage pricing wars just keep going and going.
The latest to trim prices is Microsoft, following similar back-to-back moves by Amazon and Google.
On December 5, Microsoft announced its second Azure Storage price cut of this year. Effective December 12, Microsoft is cutting prices of both geo-redundant and locally-redundant storage by up to 28 percent, according to a post on the Windows Azure blog.
(As the Softies explain in the post, "Windows Azure Storage accounts have geo-replication on by default to provide the greatest durability. Customers can turn geo-replication off to use what we call Locally Redundant Storage, which results in a discounted price relative to Geo Redundant.")
Here's the new post-cut price list, courtesy of Microsoft:
So with this cut, which service is cheapest of them all, when it comes to storage? It's hard to say.
"Since pricing for both of these services are changing quite frequently and depended upon a number of factors, it was not possible for me to pinpoint exactly which service is cheaper," acknowledged Guarav Mantri, founder of Cerbrata and a Microsoft Most Valuable Professional (MVP) in a blog post on the topic. [See below post.]
Mantri created a simple calculator to try to help users determine whether Microsoft or Amazon was the low-cost winner. He noted that transaction costs (costs incurred based on number of transactions performed against each service); storage costs (costs of data stored in each service calculated in GB); and bandwidth costs (costs incurred based on data sent from the datacenter) all needed to be factored in.
Speaking of price cuts, the Azure team also recently posted about cutting the prices of two key Windows Azure Active Directory (WAAD) components -- access control and core directory and authentication -- to zero. The post never mentioned the original cost of these components or the amount by which the pricing was cut.
One reader mentioned to me in an e-mail exchangethat ACS (access control services) was officially priced at $1.99 per 100,000 identity transactions. He said it has been available for free as part of a promotion for for more than a year.
WAAD is Microsoft's Active Directory directory service for the cloud. A number of Microsoft cloud properties already are using WAAD, including the Windows Azure Online Backup, Windows Azure, Office 365, Dynamics CRM Online and Windows InTune.
In case you're looking for a one-stop Azure pricing page, try this.



Gaurav Mantri (@gmantri) updated his Simple Calculator for Comparing Windows Azure Blob Storage and Amazon S3 Pricing for the latest Windows Azure blob price reduction on 12/6/2012:
I originally wrote this post in September 2012. Recently at their re:Invent event, Amazon announced reduction in their storage prices by 24-28% (http://aws.typepad.com/aws/2012/11/amazon-s3-price-reduction-december-1-2012.html). Yesterday Microsoft announced similar price reduction (http://blogs.msdn.com/b/windowsazure/archive/2012/12/05/announcing-reduced-pricing-for-windows-azure-storage.aspx).
I have updated this blog post taking these price reductions into consideration and including them in my calculator below. Please note that both Amazon and Windows Azure have reduced only the storage charges. They have not changed the transaction charges or the bandwidth (Egress) charges. The new prices for Amazon became effective as of 01-December-2012 while that for Windows Azure will become effective on 12-December-2012.
Few months back, I wrote a few blog posts comparing Windows Azure Blob Storage and Amazon S3 services. You can read those blog posts here:
- http://gauravmantri.com/2012/05/09/comparing-windows-azure-blob-storage-and-amazon-simple-storage-service-s3part-i/
- http://gauravmantri.com/2012/05/11/comparing-windows-azure-blob-storage-and-amazon-simple-storage-service-s3part-ii/
- http://gauravmantri.com/2012/05/13/comparing-windows-azure-blob-storage-and-amazon-simple-storage-service-s3summary/
Since pricing for both of these services are changing quite frequently and depended upon a number of factors, it was not possible for me to pinpoint exactly which service is cheaper. I created a simple calculator where you can input appropriate values and compare the cost of both of these services to you.
As mentioned in my other blog posts, the pricing depends on 3 factors in both services:
- Transaction costs i.e. cost incurred based on number of transactions performed against each service. These include various REST based operations performed against the two services.
- Storage costs i.e. cost incurred based on the amount of data stored in each service. These are usually calculated based on Giga bytes of data stored per month.
- Bandwidth costs i.e. cost incurred based on the data sent out of the data center in each service. Please note that at the time of writing of this blog, all incoming traffic is free in both service as well as the data transferred between an application and storage service in same data center is also free.
In this simple calculator, I took only first two factors into consideration. Again when it comes to storage costs, both services offered a tiered pricing scheme, which I have not considered.
[See the original post for operable calculator version.]
A few comments:
- At the time of writing this blog post, the pricing is taken from respective services pages (https://www.windowsazure.com/en-us/pricing/details/ and http://aws.amazon.com/s3/pricing/). I will try an keep this post updated with the default pricing however I would strongly recommend that you check the pricing page for respective services to get most current pricing.
- While pricing is an important criteria, it should not be the sole criteria for deciding which service to choose. One must also consider the features offered by each service. You can check http://gauravmantri.com/2012/05/13/comparing-windows-azure-blob-storage-and-amazon-simple-storage-service-s3summary/ for a feature by feature comparison as of 11th of May 2012. Since then both services have offered some new features (e.g. Asynchronous copy blob support in Windows Azure and CORS support in Amazon S3 etc.) which should also be taken into consideration.
- For storage costs, I have taken very simple scenario though both services offer tiered pricing as well. One should take that into consideration as well.
- Lastly, I must emphasize that it is a very simple calculator with no in-built error checking or data validation. If you find any issues with this calculator (especially around incorrect calculations), please let me know ASAP and I will fix them.





<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
•• David Magar wrote and Craig Kittleman posted 3 best practices for Windows Azure SQL Reporting development to the Windows Azure Team blog on 12/7/2012:
Although it’s tempting to take an existing Reporting Services project and push it out to the cloud as-is, you really shouldn’t. A report that runs great on a local server might not be quite as performant after you deploy it on a SQL Reporting report server.
Fortunately, there are 3 simple modifications that almost always result in a faster running report. This blog post explains each one in detail.
Best Practice #1: Reconfigure the ReportViewer Control
If you are using the ReportViewer Control (RVC) in an ASP.Net page or Windows forms applications, you need to make the following configuration changes:
- Disable the default proxy in the initialization of your application by calling: WebRequest.DefaultWebProxy = null
- Set all your Windows Azure SQL Reporting report parameters at once by calling SetParameters and not SetParameter. Setting parameters results in calls to the Windows Azure SQL Reporting data tier, located in Windows Azure SQL Database. Reducing the read\write cycles by issuing one call instead of several can help a great deal.
- Configure your application’s RVC to use cookies for authentication instead of making log-on calls. This will force your users or application to login once and then return a cookie later on for faster rendering. Keep in mind that the Report Server only allows for cookies that were created within the last 60 minutes so you must take this fact into account when designing your application
Best Practice #2: Co-locate Web applications and databases in the same data center.
The ReportViewer control communicates frequently with the report server. You can’t eliminate this behavior, but you can minimize its cost by deploying your Windows Azure application and report server in the same data center.
The same considerations apply when choosing where to deploy your Windows Azure SQL database. Each query sent to a SQL Database comes with a certain amount of overhead. Authentication, authorization, handling requests, etc. are all actions that contribute to delays between the initial connection and when the page renders. Putting the database in the same data center as the other application components reduces the amount of time these actions take, saving significant rendering time and yielding better performance.
You can detect the location of your database, application, and report server as well as understand exactly how much time it takes to bring in the data for each report rendering, by reading this blog post by David Bahat from our team.
Best Practice #3: Write efficient queries
When authoring the report, set the query to bring only the data required by a report visualization (in particular, avoid “Select *” type of SQL Statements when designing a query). This best practice ensures your reports are optimized for the fastest rendering possible.
In conclusion, I hope these 3 suggestions will help resolve some of the performance issues you might be having with applications that work with SQL Reporting. I look forward to your feedback and comments below.

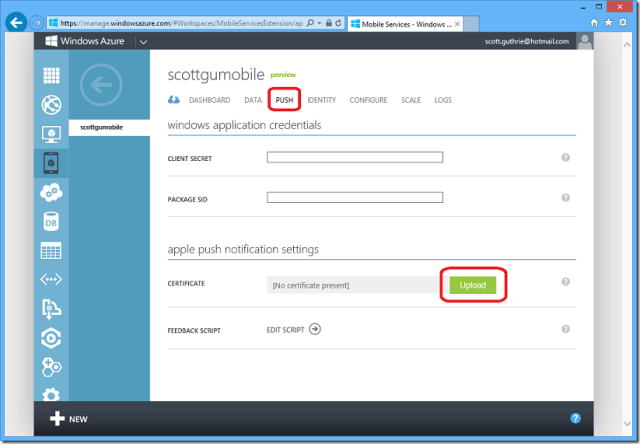
Alex Williams reported A Sign Of More Openness: Windows Azure Mobile Services Adds Push Notification For iOS in a 12/6/2012 post to the TechCrunch blog:
Windows Azure Mobile Services has added push notification for developers so they can fire off updates that may include sounds, badges or SMS messages.
Scott Guthrie, a corporate vice president in the Microsoft Tools and Servers group, writes that the new push notification, using Apple Push Notification Services (APNS), is one of a series of updates Microsoft has made to accommodate developers who build apps for the iOS platform. APNS is one of the more popular features for developers on the iOS platform.
Microsoft has recently shown a more open approach to third-party platforms. Guthrie notes that a few weeks ago he wrote about a number of updates to iOS and other services that I think highlight Microsoft’s more open philosophy:
- OS support – enabling you to connect iPhone and iPad apps to Mobile Services
- Facebook, Twitter, and Google authentication support with Mobile Services
- Blob, Table, Queue, and Service Bus support from within your Mobile Service
- Sending emails from your Mobile Service (in partnership with SendGrid)
- Sending SMS messages from your Mobile Service (in partnership with Twilio)
- Ability to deploy mobile services in the West US region
In tonight’s post, Guthrie specifically points to the recent addition of an “Objective-C client SDK that allows iOS developers to easily use Mobile Services for data and authentication.” Today’s news of the push notification is the next step in what we can expect will be a continuous development cycle to add more iOS features into Windows Mobile Services.
Note for developers: On his personal blog, Guthrie has a more detailed demonstration for how to configure applications for push notifications.
There is something more here. Earlier today, Microsoft announced a new set of features for Windows Azure Storage and a significant price drop. One developer commented on the blog post I wrote that the only Microsoft service he likes is Windows Azure. Making it easier to use Windows Azure Mobile Services for iOS push notifications will attract developers as well.
I wonder here about Apple in all of this. Apple makes beautiful mobile devices and the iOS development environment is a favorite. But Apple has not shown much in terms of providing a serious infrastructure that developers can as they do with other services. Microsoft has Azure. Google now has Google Compute Engine and Amazon has AWS. Where does that leave Apple? Any theories?


<Return to section navigation list>
Marketplace DataMarket, Cloud Numerics, Big Data and OData
•• Denny Lee (@dennylee) announced the availability of a Yahoo! 24TB SSAS Big Data Case Study + Slides in a 12/8/2012 post:
In my post from last year, I had asked the rhetorical question What’s so BIG about “Big Data”. I had the honor of announcing the largest known Analysis Services cube – at 24TB – in which the source of this cube is 2PB from a huge Hadoop cluster.
For those whom had attended the PASS 2011 session Tier-1 BI in the world of Big Data, Thomas Kejser, myself, and Kenneth Lieu were honored to discuss the details surrounding this uber-cube. At that time, I had promised the case study would only be months away…
Alas, it took a little while longer to get the case study out – 13 months – but nevertheless, I am proud to re-announce (I did tweet it last week) that the Yahoo! 24TB Analysis Services / Big Data case study has been published: Yahoo! Improves Campaign Effectiveness, Boosts Ad Revenue with Big Data Solution.
For those whom like a graphical view of this case study, embedded below is an excerpt of the Yahoo! TAO Case Study from the above mentioned PASS 2011 session.


•• Mark Stafford (@markdstafford) described the WCF Data Services 5.2.0-rc1 Prerelease in a 12/7/2012 post to the WCF Data Services Team blog:
A couple of days ago we posted a new set of NuGet packages and today we posted a new tools installer for WCF Data Services 5.2.0-rc1. This prerelease integrates the UriParser from ODataLib Contrib and fixes a few bugs.
What is in the prerelease
This prerelease contains the following noteworthy bug fixes:
- Fixes an issue where code gen for exceedingly large models would cause VS to crash
- Provides a better error message when the service model exposes enum properties
- Fixes an issue where IgnoreMissingProperties did not work properly with the new JSON format
- Fixes an issue where an Atom response is unable to be read if the client is set to use the new JSON format
URI Parser
In this release ODataLib now provides a way to parse filter and orderby expressions into a metadata-bound abstract syntax tree (AST). This functionality is typically intended to be consumed by higher level libraries such as WCF Data Services and Web API.
To parse a filter expression, use the following method on the new class ODataUriParser:
public static FilterClause ParseFilter(
string filter,
IEdmModel model,
IEdmType elementType,
IEdmEntitySet entitySet)The ParseFilter method returns a FilterClause object. The Expression property on the FilterClause contains the root node of the AST that represents the filter expression. In order to walk the AST, use the Visitor pattern to handle an arbitrary QueryNode by examining the Kind property, and then casting accordingly. For instance:
switch (node.Kind)
{
case QueryNodeKind.BinaryOperator:
return Visit((BinaryOperatorNode)node);
case QueryNodeKind.UnaryOperator:
return Visit((UnaryOperatorNode)node);
case QueryNodeKind.SingleValuePropertyAccess:
return Visit((SingleValuePropertyAccessNode)node);
// And so on...
}Let’s say the filter string was "Name eq 'Bob'", and Name is a property on the elementType provided to ParseFilter. This expression is represented by a BinaryOperatorNode. The BinaryOperatorNode has a Left expression, which is a SingleValuePropertyAccessNode, capturing the Name property, and a Right expression, which is a ConstantNode, capturing the string literal 'Bob'.
To parse an orderby expression, use ODataUriParser.ParseOrderBy. This method is very similar to ParseFilter. The resulting OrderByClause also has an Expression property, which is an AST just like FilterClause. Since an $orderby system query option can specify more than one ordering expression, there is a ThenBy property on OrderByClause that points to the next OrderByClause. So in essence, you get a linked list of OrderByClause objects. For example, the string "Name asc, ShoeSize desc" would result in an OrderByClause with an Expression capturing the Name property, and a ThenBy property pointing to another OrderByClause capturing the intent to order by the ShoeSize in descending order.
For a more detailed write-up on filter and orderby parsing, read this blog post. [See this post below.]
Feedback Please
We’d love to hear how well this release works for your service. Even if you don’t need the URI Parser functionality, please consider trying these new bits and providing us with feedback whether everything goes perfectly or you run into problems. As always, please feel free to leave a comment below or e-mail me directly at mastaffo@microsoft.com.

•• Steve Peschka posted Using OData and ECTs in SharePoint 2013 to his Share-n-dipity blog on 12/6/2012:
One of the nice enhancements in SharePoint 2013 BCS world is that SharePoint can now consume OData in BDC applications. There are a couple of gaps I ran across recently though when going through this process so I thought I'd cover them here in case anyone else gets similarly stuck. To start with, I recommend starting with this document to walk you through the basics of creating an application for OData: http://msdn.microsoft.com/en-us/library/sharepoint/jj163967.aspx. The main takeaway here is that you can NOT create a BDC application in SharePoint Designer that connects to an OData source - to do that you need to create an External Content Type (ECT) using a tool like Visual Studio.
The document I linked to above walks you through the process of creating the ECT. It follows that by showing how to use those ECTs in a SharePoint App and deploying it in that manner, but it does NOT show what you do if you want to add it to the BDC catalog so that it can be used many site collections, and that's where this post comes in. The first thing to understand is that when you go through the process described in the article above, it will create one ECT for each entity (like a table). The reason why that's important to know is because they will use a shared name in the ECT file, which will prevent you from uploading more than one to the BDC catalog. In order to use each of these entities in SharePoint here's what you need to do:
- Right-click on the ECT file in Visual Studio and select Open With... then select XML (Text) Editor. At the top of the document in the Model element you will see a Name attribute. This value has to be unique between all the ECTs that you upload to the BDC, so you should change each one to a descriptive value for that entity, like "Customers Table".
- You can, but don't have to, change the Namespace of the Entity element, which is about 20 lines down in the document. I changed mine to be consistent with the model name, but that's just a style choice, it's not required.
- Once you've made the changes and saved the file, you can upload the .ect file directly to the BDC. Just use the default options - it's a model - then click the OK button and you're good to go.
- Once you've imported the models, don't forget to grant permissions to folks to use them; kind of pointless without that.
One final thing worth noting here - out of the box you don't get OData metadata endpoints over things like SQL databases, Azure Table Storage, etc. Adding it for SQL is fortunately relatively easy. In a nutshell you:
- Create a new Empty ASP.NET web application
- Add an ADO.NET Entity Data Model
- Add a WCF Data Service
- In your WCF Data Service you need to set the Type in the class constructor; this may be a litle confusing at first. What you want to do is look for a file (that should be in the App_Code folder) that is named something like myDataConnection.Context.tt. If you expand that, underneath you should see a myDataConnection.Context.cs class. If you open that up you will see the two pieces of information you need for your WCF Data Service: 1) the class name, which you will use as the Type for the WCF Data Service class constructor. 2) The names of the entities it is supporting, implemented like get; set; properties. You will need the entity names in the WCF Data Service as well, because at a minimum you need to create "SetEntitySetAccessRules" for each entity you want to expose. This is explained in more detail in the comments when you add a WCF Data Service - I'm just trying to tell you where you go find the entity name to use when you create one of those rules.
• Alex James (@ADJames) announced the pending availability of OData in WebAPI – RC release in a 12/7/2012 post:
Next week we will release an official RC of the Microsoft ASP.NET WebAPI OData assembly. This marks the third release on our way to RTM.
Although this post talks about code that hasn’t been officially release yet, since all development is happening in public, if you can’t wait till next week, you can always go and get one of the nightly builds or for a more bare metal experience build it yourself from our code repository.
In this post I will cover what is new since the Alpha, if you need a more complete view of what we is currently supported I recommend you read about the August Release and the Alpha release as well.
Simplified OData support
To make it easy to support full OData we’ve added a simple extension method HttpConfiguration.EnableOData(IEdmModel) that allows you to easily configure your service to support OData, simply by providing an IEdmModel and optionally supplying an OData route prefix (i.e. ~/api or similar). The method does a number of key tasks for you, each of which you can do manually if necessary:

- Registers an OData wild card route. Which will have a prefix if you specified a prefix when you called EnableOData(..). For example this:
- HttpConfiguration.EnableOData(model, “api”) will position your OData service under the ~/api url prefix.
-
Registers the various ODataMediaTypeFormatters.
- Note today this will stomp on application/json for your whole service. By RTM we aim to make this much more selective, so you get the OData version of application/json only if your request addresses an OData resource.
- Stashes the IEdmModel on the configuration
- Stashes the DefaultODataPathHandler on the configuration.
- Registers the ODataControllerSelector and ODataActionSelectors and configures them to use default OData routing conventions. These selectors only do OData routing when the request is recognized as an OData request, otherwise they delegate to the previously registered selectors.
First class OData routing
In the alpha release to get everything (OData Actions, OData casts, OData navigations etc) working together I updated the sample to do custom routing. This routing was based on a component that understood OData Paths and dispatched to actions based on custom routing conventions. At the time we knew this was a merely a stop gap.
That code has now been refactored, improved and moved into the core code base.
The code consists of:
- A class called ODataPath that represents the path part of an OData Url. An ODataPath is made up of a list of ODataPathSegments, these semantically represent the OData operations you compose to address a resource. For example something like this: ~/Customers(10)/Orders, semantically has 3 instructions that are encoded as ODataPathSegments in an ODataPath:
- Start in the Customers EntitySet
- Then find a single customer with the key 10
- Then Navigate to the related Orders.
- An interface called IODataPathHandler that has two methods:
- ODataPath Parse(string odataPath) –> to take a Url and parse it into an ODataPath
- string Link(ODataPath) –> to take an ODataPath and generate a Url.
- A default implementation of IODataPathHandler called DefaultODataPathHandler, that implements these methods using the OData V3’s built-in conventions.
- A way to register and retrieve a IODataPathHandler on your HttpConfiguration. Two things worth calling out here:
- Normally you don’t have to worry about this, because calling HttpConfiguration.EnableOData(…) registers the DefaultODataPathHandler for you.
- This design means that you don’t like the way OData puts keys in parenthesis (i.e.~/Customers(1)) and would prefer to put keys in their own segments (i.e. ~/Customer/1) then all you need to do is override the DefaultODataPathHandler so that it recognizes this syntax. I’ve tried this personally and doing targeted overloads like this is pretty easy.
- All OData link generation conventions (for example for EditLinks or links to invoke actions) now build an ODataPath to represent the link and then ask the registered IODataPathHandler to convert that to a url using the IODataPathHandler.Link(..) method.
- An ODataControllerSelector and an ODataActionSelector that route OData requests based on a configurable set of IODataRoutingConventions. Out the box EnableOData(..) will register these routing conventions:
- EntitySetRoutingConvention –> for routing request to manipulate and query an EntitySet, for example:
- GET ~/Customers
- GET ~/Customers/Namespace.VIP
- POST ~/Customers
- EntityRoutingConvention –> for routing request to retrieve or manipulate an Entity, for example:
- GET ~/Customer(1)
- GET ~/Customers(1)/Namespace.VIP
- PUT ~/Customer(1)
- PATCH ~/Customers(1)
- DELETE ~/Customers(1)
- NavigationRoutingConvention –> for routing requests to retrieve related items, for example:
- GET ~/Customers(1)/Orders
- GET ~/Customers(1)/Namespace.VIP/Benefits
- MetadataRoutingConvention –> for routing request to retrieve $metadata or the service document
- GET ~/$metadata
- GET ~
- LinksRoutingConvention –> for routing requests to manipulate relationship, for example:
- DELETE ~/Customers(1)/$links/Orders(1)
- POST ~/Customers(1)/$links/Orders
- PUT ~/Customers(1)/$links/RelationshipManager
- ActionRoutingConvention –> for routing requests to invoke an OData Action
- POST ~/Customers(1)/ConvertToVIP
- UnmappedRequestRoutingConvention –> for routing requests that match no other convention to a fall back method, for example:
- GET ~/Customers(1)/RelationshipManager/Customers
- POST ~/Customers(1)/Orders
- A new ODataPathRouteConstraint class that implements IHttpRouteConstraint an makes sure the ‘wildcard route’ that captures every request against your OData service only matches if the Url is in fact an OData url.
- An EntitySetController<TEntity,TKey> class that provides a convenient starting point for creating controllers for your OData EntitySets. This class provides stub methods that follow the default IODataRoutingConventions will route requests too. Your job is simply to handle the request.
For a complete example of how to use all this new goodness check out the sample OData service which you can find at http://aspnet.codeplex.com in the source tree under: /Samples/Net4/CS/WebApi/ODataService.
Query validation
One of the most exciting new features is the ability to specify validation rules to be applied to a query. Essentially this allows you to constrain what query options you allow against your [Queryable]. Under the hood this is all implemented via the virtual ODataQueryOptions.Validate(ODataValidationSettings) method, which you can use if you need to.
That said the 90-99% scenario is simply to specify additional parameters to the [Queryable] attribute that the control what is allowed in a query, and then before the query is processed, Web API converts those settings into an ODataValidationSettings object and calls ODataQueryOptions.Validate(..). If anything not supported is found in the AST a validation error results, and your backend Queryable never gets called.
Here are some examples:
[Queryable(AllowedQueryParameters = ODataQueryParameters.Skip| ODataQueryParameters.Top)]This means only Skip and Top are allowed, i.e. a $filter or $orderby would result in a validation error. By default every thing is allowed, until you mention a particular setting, then only the things you list are supported.
Another example is:
[Queryable(AllowedLogicalOperators=ODataLogicalOperators.Equal)]This says the $filter only supports the Equal operator, so for example this:
~/Customer?$filter=Name eq ‘Bob’
will pass validation but this:
~/Customers?$filter=Name ne ‘Bob’
will fail.
Checkout the new [Queryable] attribute to find out more.
Delta<T> improvements
This now supports patching classes that derive from the T too. This is useful if you want both these requests:
PATCH ~/Customers(1)
PATCH ~/Customers(1)/Namespace.VIP
to be dispatched to the same method, for example:
public virtual HttpResponseMessage Patch([FromODataUri] TKey key, Delta<Customer> patch)
{
…
}
Now because Delta<Customer> can also hold changes made to a VIP (i.e. a class the derives from Customer) you can route to the same method, and deal with a whole inheritance hierarchy in one action.Another thing to notice is the new [FromODataUri] attribute, this tells Web API the key parameter is in the URL encoded as an OData Uri Literal.
$filter improvements
We now handle DateTime or DateTimeOffset literals or properties for the first time, and we allow you to specify casts in your filter too, for example:
~/Customers?$filter=Name eq ‘Bob’ or Namespace.VIP/RelationshipManager/Name eq ‘Bob’
At this point the only thing that we don’t support (and won’t support for RTM either) is spatial types and custom OData functions inside the filter. These will come later when support for them is added to ODataLib’s ODataUriParser.
Partial support for OData’s new JSON format
This release also includes a little support for the new OData v3 JSON format, and of course by RTM time we will have full support. This OData V3 JSON format is more efficient than our older V1/V2 JSON format (which incidentally the OData team has started calling ‘JSON verbose’, to make sure you know we don’t like it any more :)
The new JSON format has sub types, which allow clients to specify how much metadata they want, ranging from FullMetadata, through MinimalMetadata to NoMetadata. The RC supports the new OData JSON format only for write scenarios (i.e. responding to requests), it doesn’t currently handle read scenarios at all (i.e. request payloads that are in the new JSON format). It supports the most common payload kinds, feeds, entries, errors and service documents, and by RTM we will flesh this out to include other payloads like properties, links etc.
In the RC we don’t support NoMetadata at all, and we treat MinimalMetadata as if it is FullMetadata. We do this because MinimalMetadata means only send metadata and links that the client can’t deduce them by convention, and in the RC we don’t have anyway to tell the formatter that you are indeed following conventions. This forces us to always emit links. By RTM we will add a way to say you are following convention, and that will allow us to support MinimalMetadata properly.
Read What is JSON Light and Enabling JSON Light from WCF DS to learn more about the new OData JSON format.
Summary
As you can see we’ve been really busy making Web API a first class stack for creating and exposing OData services, ranging from supporting just the OData query syntax, through supporting the majority of the OData protocol, all the way up to supporting extra things not in OData but enabled by Web API, like for example new formats.
As always please let us know what you think.
Alex James (@ADJames) described Parsing $filter and $orderby using the ODataUriParser in a 12/6/2012 post:
Background and Plans
For a while now we’ve been shipping an early pre-release version of an ODataUriParser in ODataLib Contrib. The idea is to have code that converts a Uri used to interact with an OData Service into a Semantically bound Abstract Syntax Tree (AST) which represents the request in terms of the OData concepts used.
The ODataUriParser is currently an alpha at best, with many known functionality gaps and bugs. However the ASP.NET Web API OData library has a dependency on the parser and is RTMing soon, so we need to bring the quality up quickly.
Our plan is to move Uri Parser out of ODataLib Contrib into a fully supported ODataLib release.
Currently ASP.NET Web API only needs support for parsing $filter and $orderby: because today Web API doesn’t support $select and $expand, has it’s own parser for the PATH part of the Uri and all the other OData query options which are very simple to parse. This scoped set of requirements and tight time constraints means the ODataUriParser support we ship in ODataLib will initially be a subset, albeit a better tested and more complete subset, of the ODataUriParser currently in ODataLib Contrib.
So what will the API look like?
Parsing $filter
To parse a $filter you need at least two things: an IEdmModel, and an IEdmType to use as your collection element type. Optionally you can provide an IEdmEntitySet too.
For example imagine this request:
GET /Service/Customers?$filter=Name eq ‘ACME’
To parse the $filter query option, you would need an IEdmModel for the service hosted at ~/Service, and you need to provide the element type of the collection being filtered, in this case Customer.
To create the model, you can use EdmLib code directly:
var model= new EdmModel();
var customer = new EdmEntityType("TestModel", "Customer");
bool isNullable = false;
var idProperty = customer.AddStructuralProperty("Id", EdmCoreModel.Instance.GetInt32(isNullable);
customer.AddKeys(idProperty);
customer.AddStructuralProperty("Name", EdmCoreModel.Instance.GetString(isNullable));
edmModel.AddElement(customer);var container= new EdmEntityContainer("TestModel", "DefaultContainer");
container.AddEntitySet(“Customers”, customer);
model.AddElement(container);This code, builds a model with a single EntityType called customer (with Id and Name properties) an exposes customer instances via an EntitySet called Customers in the default container. Working with EdmLib directly like this, is however quite low-level, another simpler option is to use the ODataConventionModelBuilder from the Web API OData package, which provide a nice higher level API for building models. If you go the WebAPI route, be sure to checkout these blog posts:
- OData Support in ASP.NET Web API (August 2012)
- OData in Web API – Microsoft ASP.NET Web API OData 0.2.0-alpha release (November 2012)
In the above example working out the type of the collection is pretty simple, but of course OData paths (i.e. the bit before the ?) can be quite complicated. To help in the long run this functionality will be provided by the Uri Parser, but for now you have to work this out for the OData Uri Parser. That said, you are not alone, the WebAPI team had the same problem and has create a class called the DefaultODataPathParser that will work out the type (and EntitySet if appropriate) of any OData path.
Once you have the IEdmModel and IEdmType you need, you can parse the $filter like this:
FilterNode filter = ODataUriParser.ParseFilter(“Name eq ‘ACME’”, model, customer);
If you start exploring this filter which is an AST, you will notice it looks like this:
You could easily visit this to produce some sort alternate query syntax, perhaps SQL or CLR expressions. In fact this is what the ASP.NET Web API does, to support the [Queryable] attribute, it first parses the $filter and then it converts the AST into a LINQ expression. You don’t need to do this though, you could for example convert from this AST directly to SQL, which is very useful if you don’t have a LINQ provider, because creating a LINQ provider is a significant undertaking.
Parsing $OrderBy
To parse a $orderby you again need an IEdmModel and an IEdmType for the element type of the collection you want to order. For example:
To handle this:
GET /Service/Customers?$orderby=Name desc,Id
Which orders first by Name descending and then by Id ascending, you would make this call:
OrderByNode orderby = ODataUriParser.ParseOrderBy(“Name desc, Id”, model, customer);
Again if you visit you will see something like this:
If you are familiar with ASTs this will seem pretty simple.
The Node type hierarchy
The root of the type hierarchy is QueryNode. Beyond that the node hierarchy has been organized to prioritize two key pieces of information, namely:
- Whether the node represents a Collection or a Single value
- Whether the node represents an Entity or another type.
The first level down from the root of the type hierarchy indicates whether you are dealing with a Single value (SingleValueNode) or a Collection (CollectionNode). Then the second level down is used to distinguish between Entities and other types, so for example there is a node called SingleEntityNode that derives from SingleValueNode and a EntityCollectionNode that derives from CollectionNode.
Then the most derived node types distinguish between the various ways of getting to a Collection or Single instance of an Entity or Nonentity. For example the various ways you can get a single entity, one possible way is by following a navigation property with target multiplicity of 0..1 or 1 (SingleNavigationNode), and so on, each of these ways are represented as nodes that derive from SingleEntityNode.
This approach yields a hierarchy that (when simplified) looks a little like this:
Amongst the leaf nodes, a few deserve a special mention:
- BinaryOperatorNode which represents a Binary operator like for example: Name eq ‘Bob’
- UnaryOperatorNode which represents a Unary operator like for example: not True
- AnyNode which represents OData any filter expression, for example: collection/any(a: a/Age gt 100)
- AllNode which represents an OData all filter expression, for example: collection/all(a: a/Age gt 10)
From a type system perspective these all represent a boolean value, so then all derive from the natural place in the type hierarchy SingleValueNode.
To help recognize which kind of node you are dealing with at any time, all nodes have a Kind property which in the RC return one of the constants defined on the static NodeKind class. For example if you given a QueryNode and you want to write a visitor, you should visit the appropriate derived nodes, first by checking the QueryNode.Kind and then casting as appropriate. For RTM we’ll convert Kind to an Enum.
All nodes are held in the Expressions held by classes like FilterClause and OrderByClause, In the future new classes will be introduced to support ODataPath, $select, $expand, etc. Then finally we’ll add a class to represent the full url once we have full coverage of OData urls.
Conclusion
The ODataUriParser is on the road to RTM quality now, but it is not happening in one big step, we will start with $filter and $orderby and overtime cover the rest of OData including paths, $expand and $select.
If you are interested in the latest code I invite you to try out the latest version of ODataLib.




<Return to section navigation list>
Windows Azure Service Bus, Caching, Access Control, Active Directory, Identity and Workflow
•• Clemens Vasters (@clemensv) continued his Subscribe! video series on Channel9 with a Push vs. Pull episode on 12/7/2012:
Here’s from my Channel 9 Subscribe blog, an ad-hoc, single-take whiteboard discussion on "push" and "pull" communication patterns. There's a lot of talk in the industry on push (see push notifications) and pulling/polling (long polling vs. web sockets and messaging), so I'm dissecting that space a bit and explore push vs. pull and various pattern nuances from UDP upwards.
If you missed it, click here for: Part One Getting Started with Windows Azure Virtual Machines

<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
‡ David Baliles (@davidbaliles) described tips for Azure VMs - Managing, Resizing & Interacting with VHDs! in a 12/8/2012 post:
If you're a developer, consultant or simply want to build Proof of Concepts...it's most likely that you're playing around with Azure VMs for a reason. One might be...we want to turn my POC into a real product...I might be building this for a client, and now I need to switch it from my MSDN to their Pay-as-You-Go Subscription...the list goes on. If you're new to Windows Azure, or specifically to Windows Azure Virtual Machine Preview Feature, there are a number of things you'll unfortunately be learning the hard way. The goal of this entry is to bring together some of those Gotchas in the hopes it saves you some time, trouble and frustration. Everything you see in this may and most likely will change by the time the services rolls out of Preview and into Release...so take it as a moment in time.
Landmines to Avoid (a.k.a. Best Practices to Follow when Creating & Using Azure Virtual Machines)
Issue: There are Limits to MSDN-based Azure Benefits:
There are differences between creating a VM under your MSDN Subscription's Azure Virtual Machine Preview Subscription vs. a Trial or Pay-As-You-Go...just know this and read the differences!
Issue: Don't Create a VM under an MSDN Azure Account if you want to "Move It" to a Paid Account later on!
There is a way to "move" virtual machines after the fact, which I will cover, but you will save yourself a lot of work and definitely a lot of time if you follow this simple tip. It is better to "play around" with Virtual Machines on your local machine, and once you have something that is somewhat ready to use (i.e., everything's installed....NOW I want to start developing against it; or we've been developing and NOW we want to move it into the Azure management umbrella etc., etc.), then upload the VHD as a Page Blob to Windows Azure. I'll cover the workaround below if you've already found yourself in the dilemma of waking up and being out of hard drive space on the OS disk, drive C, and are trying to figure out how to make it bigger so you can actually start using it productively :-)
Resolution: if you already have a VM in Subscription #1 and want to move it to Subscription #2
If you already have a VM in either your MSDN or Trial Subscription and for some reason you want to move it to another one, I've compiled the steps in this document.
Issue: Want more than a 30 GB C drive? Create your own VHD offline, prepare & copy it to Windows Azure instead of using the Wizard
If you want the VM's OS Drive (Root C Drive) to be larger than 30GB (which is pretty much always) it is best to create the VM in your own environment, prepare it for Windows Azure, and upload it as a PAGE BLOB to your Azure Storage account. If you weren't warned or just dove in head first and already woke up to a useless VM because the C drive is full...don't bother asking if you can resize it using your Azure Management Tools...the answer will be no. Simply bite the bullet and refer to the Resolution listed below and PDF that I've attached.
Resolution: if you're already out of HD space on the OS C Drive: If you've already created a VM, discovered some of the limits, like running out of hard drive space on drive C, attached in the PDF file are the steps to get out of the situation. You can also download the same file here.
Issue: Want to connect to your Windows Azure Subscription using Third Party tools like Cloud Xplorer or Cloud Storage Studio 2?
These tools will ask you for a Management Certificate, and if this is the first time you're encountering this, you'll be wondering what the heck to do. It's pretty simple and you can follow the instructions below to make it happen. Basically, you do the following:
- Generate a Certificate on your local machine
- Upload the Certificate to the Windows Azure Subscription you want to manage
- Add the Subscription to the Cloud Management Tool using the Certificate you just uploaded to Azure
For the full walk-through of how to do this, click here to be taken to the detailed step-by-step. Once you've created the Certificate locally, click here to be taken to the instructions for how to then associate that Certificate with the Azure Subscription you're wanting to manage through the Cloud Management Tool.
Hopefully the above tips & tricks will prove useful to many of you who would have otherwise had to find all of this via many random forums and groups. Thanks to the many others who pioneer these tricks and created the foundation for this entry!


•• Michael Washam (@MWashamMS) continued his series with a Windows Azure IaaS Webcast Series: Part Four Creating Virtual Machines with PowerShell episode on 12/7/2012:
In part four of the IaaS Webcast Series I show how using PowerShell you can quickly provision virtual machines that are completely configured with disks and endpoints.
View the video on Channel9 here. [Embed doesn’t appear to work.]
Other webcasts in the series:

•• Maarten Balliauw (@maartenballiauw) described Configuring IIS methods for ASP.NET Web API on Windows Azure Websites and elsewhere in a 12/6/2012 post:
That’s a pretty long title, I agree. When working on my implementation of RFC2324, also known as the HyperText Coffee Pot Control Protocol, I’ve been struggling with something that you will struggle with as well in your ASP.NET Web API’s: supporting additional HTTP methods like HEAD, PATCH or PROPFIND. ASP.NET Web API has no issue with those, but when hosting them on IIS you’ll find yourself in Yellow-screen-of-death heaven.
The reason why IIS blocks these methods (or fails to route them to ASP.NET) is because it may happen that your IIS installation has some configuration leftovers from another API: WebDAV. WebDAV allows you to work with a virtual filesystem (and others) using a HTTP API. IIS of course supports this (because flagship product “SharePoint” uses it, probably) and gets in the way of your API.
Bottom line of the story: if you need those methods or want to provide your own HTTP methods, here’s the bit of configuration to add to your Web.config file:
<?xml version="1.0" encoding="utf-8"?> <configuration> <!-- ... --> <system.webServer> <validation validateIntegratedModeConfiguration="false" /> <modules runAllManagedModulesForAllRequests="true"> <remove name="WebDAVModule" /> </modules> <security> <requestFiltering> <verbs applyToWebDAV="false"> <add verb="XYZ" allowed="true" /> </verbs> </requestFiltering> </security> <handlers> <remove name="ExtensionlessUrlHandler-ISAPI-4.0_32bit" /> <remove name="ExtensionlessUrlHandler-ISAPI-4.0_64bit" /> <remove name="ExtensionlessUrlHandler-Integrated-4.0" /> <add name="ExtensionlessUrlHandler-ISAPI-4.0_32bit" path="*." verb="GET,HEAD,POST,DEBUG,PUT,DELETE,PATCH,OPTIONS,XYZ" modules="IsapiModule" scriptProcessor="%windir%\Microsoft.NET\Framework\v4.0.30319\aspnet_isapi.dll" preCondition="classicMode,runtimeVersionv4.0,bitness32" responseBufferLimit="0" /> <add name="ExtensionlessUrlHandler-ISAPI-4.0_64bit" path="*." verb="GET,HEAD,POST,DEBUG,PUT,DELETE,PATCH,OPTIONS,XYZ" modules="IsapiModule" scriptProcessor="%windir%\Microsoft.NET\Framework64\v4.0.30319\aspnet_isapi.dll" preCondition="classicMode,runtimeVersionv4.0,bitness64" responseBufferLimit="0" /> <add name="ExtensionlessUrlHandler-Integrated-4.0" path="*." verb="GET,HEAD,POST,DEBUG,PUT,DELETE,PATCH,OPTIONS,XYZ" type="System.Web.Handlers.TransferRequestHandler" preCondition="integratedMode,runtimeVersionv4.0" /> </handlers> </system.webServer> <!-- ... --> </configuration>
Here’s what each part does:
- Under modules, the WebDAVModule is being removed. Just to make sure that it’s not going to get in our way ever again.
- The security/requestFiltering element I’ve added only applies if you want to define your own HTTP methods. So unless you need the XYZ method I’ve defined here, don’t add it to your config.
- Under handlers, I’m removing the default handlers that route into ASP.NET. Then, I’m adding them again. The important part? The "verb attribute. You can provide a list of comma-separated methods that you want to route into ASP.NET. Again, I’ve added my XYZ methodbut you probably don’t need it.
This will work on any IIS server as well as on Windows Azure Websites. It will make your API… happy.



<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
•• Erik Meijer (@headinthebox, pictured below) and Claudio Caldato described Lowering the barrier of entry to the cloud: announcing the first release of Actor Framework [for Windows Azure] from MS Open Tech (Act I) in a 12/7/2012 post:
There is much more to cloud computing than running isolated virtual machines, yet writing distributed systems is still too hard. Today we are making progress towards easier cloud computing as ActorFX joins the Microsoft Open Technologies Hub and announces its first, open source release. The goal for ActorFx is to provide a non-prescriptive, language-independent model of dynamic distributed objects, delivering a framework and infrastructure atop which highly available data structures and other logical entities can be implemented.
ActorFx is based on the idea of the Actor Model developed by Carl Hewitt, and further contextualized to managing data in the cloud by Erik Meijer in his paper that is the basis for the ActorFx project − you can also watch Erik and Carl discussing the Actor model in this Channel9 video.
What follows is a quick high-level overview of some of the basic ideas behind ActorFx. Follow our project on CodePlex to learn where we are heading and how it will help when writing the new generation of cloud applications.
ActorFx high-level Architecture
At a high level, an actor is simply a stateful service implemented via the IActor interface. That service maintains some durable state, and that state is accessible to actor logic via an IActorState interface, which is essentially a key-value store.
There are a couple of unique advantages to this simple design:
- Anything can be stored as a value, including delegates. This allows us to blur the distinction between state and behavior – behavior is just state. That means that actor behavior can be easily tweaked “on-the-fly” without recycling the service representing the actor, similar to dynamic languages such as JavaScript, Ruby, and Python.
- By abstracting the IActorState interface to the durable store, ActorFx makes it possible to “mix and match” back ends while keeping the actor logic the same. (We will show some actor logic examples later in this document.)
ActorFx Basics
The essence of the ActorFx model is captured in two interfaces: IActor and IActorState.
IActorState is the interface through which actor logic accesses the persistent data associated with an actor, it is the interface implemented by the “this” pointer.
public interface IActorState { void Set(string key, object value); object Get(string key); bool TryGet(string key, out object value); void Remove(string key); Task Flush(); // "Commit" }By design, the interface is an abstract key-value store. The Set, Get, TryGet and Remove methods are all similar to what you might find in any Dictionary-type class, or a JavaScript object. The Flush() method allows for transaction-like semantics in the actor logic; by convention, all side-effecting IActorState operations (i.e., Set and Remove) are stored in a local side-effect buffer until Flush() is called, at which time they are committed to the durable store (if the implementation of IActorState implements that).
The IActor interface
An ActorFx actor can be thought of as a highly available service, and IActor serves as the computational interface for that service. In its purest form, IActor would have a single “eval” method:
public interface IActor { object Eval(Func<IActorState, object[],
object> function, object[] parameters); }That is, the caller requests that the actor evaluate a delegate, accompanied by caller-specified parameters represented as .NET objects, against an IActorState object representing a persistent data store. The Eval call eventually returns an object representing the result of the evaluation.
Those familiar with object-oriented programming should be able to see a parallel here. In OOP, an instance method call is equivalent to a static method call into which you pass the “this” pointer. In the C# sample below, for example, Method1 and Method2 are equivalent in terms of functionality:
class SomeClass { int _someMemberField; public void Method1(int num) { _someMemberField += num; } public static void Method2(SomeClass thisPtr, int num) { thisPtr._someMemberField += num; } }Similarly, the function passed to the IActor.Eval method takes an IActorState argument that can conceptually be thought of as the “this” pointer for the actor. So actor methods (described below) can be thought of as instance methods for the actor.
Actor Methods
In practice, passing delegates to actors can be tedious and error-prone. Therefore, the IActor interface calls methods using reflection, and allows for transmitting assemblies to the actor:
public interface IActor { string CallMethod(string methodName, string[] parameters); bool AddAssembly(string assemblyName, byte[] assemblyBytes); }Though the Eval method is still an integral part of the actor implementation, it is no longer part of the actor interface (at least for our initial release). Instead, it has been replaced in the interface by two methods:
- The CallMethod method allows the user to call an actor method; it is translated internally to an Eval() call that looks up the method in the actor’s state, calls it with the given parameters, and then returns the result.
- The AddAssembly method allows the user to transport an assembly containing actor methods to the actor.
There are two ways to define actor methods:
(1) Define the methods directly in the actor service, “baking them in” to the service.
myStateProvider.Set(
"SayHello",
(Func<IActorState, object[], object>)
delegate(IActorState astate, object[] parameters)
{
return "Hello!";
});(2) Define the methods on the client side.
[ActorMethod] public static object SayHello(IActorState state, object[] parameters) { return "Hello!"; }You would then transport them to the actor “on-the-fly” via the actor’s AddAssembly call.
All actor methods must have identical signatures (except for the method name):
- They must return an object.
- They must take two parameters:
- An IActorState object to represent the “this” pointer for the actor, and
- An object[] array representing the parameters passed into the method.
Additionally, actor methods defined on the client side and transported to the actor via AddAssembly must be decorated with the “ActorMethod” attribute, and must be declared as public and static.
Publication/Subscription Support
We wanted to be able to provide subscription and publication support for actors, so we added these methods to the IActor interface:
public interface IActor { string CallMethod(string clientId, int clientSequenceNumber,
string methodName, string[] parameters); bool AddAssembly(string assemblyName, byte[] assemblyBytes); void Subscribe(string eventType); void Unsubscribe(string eventType); void UnsubscribeAll(); }As can be seen, event types are coded as strings. An event type might be something like “Collection.ElementAdded” or “Service.Shutdown”. Event notifications are received through the FabricActorClient.
Each actor can define its own events, event names and event payload formats. And the pub/sub feature is opt-in; it is perfectly fine for an actor to not support any events.
A simple example: Counter
If you wanted your actor to support counter semantics, you could implement an actor method as follows:
[ActorMethod] public static object IncrementCounter(IActorState state,
object[] parameters) { // Grab the parameter var amountToIncrement = (int)parameters[0]; // Grab the current counter value int count = 0; // default on first call object temp; if (state.TryGet("_count", out temp)) count = (int)temp; // Increment the counter count += amountToIncrement; // Store and return the new value state.Set("_count", count); return count; }Initially, the state for the actor would be empty.
After an IncrementCounter call with parameters[0] set to 5, the actor’s state would look like this:
Key
Value
“_count”
5
After another IncrementCounter call with parameters[0] set to -2, the actor’s state would look like this:
Key
Value
“_count”
3
Pretty simple, right? Let’s try something a little more complicated.
Example: Stack
For a slightly more complicated example, let’s consider how we would implement a stack in terms of actor methods. The code would be as follows:
[ActorMethod] public static object Push(IActorState state, object[] parameters) { // Grab the object to push var pushObj = parameters[0]; // Grab the current size of the stack int stackSize = 0; // default on first call object temp; if (state.TryGet("_stackSize", out temp)) stackSize = (int)temp; // Store the newly pushed value var newKeyName = "_item" + stackSize; var newStackSize = stackSize + 1; state.Set(newKeyName, pushObj); state.Set("_stackSize", newStackSize); // Return the new stack size return newStackSize; } [ActorMethod] public static object Pop(IActorState state, object[] parameters) { // No parameters to grab // Grab the current size of the stack int stackSize = 0; // default on first call object temp; if (state.TryGet("_stackSize", out temp)) stackSize = (int)temp; // Throw on attempt to pop from empty stack if (stackSize == 0) throw new InvalidOperationException(
"Attempted to pop from an empty stack"); // Remove the popped value, update the stack size int newStackSize = stackSize - 1; var targetKeyName = "_item" + newStackSize; var retrievedObject = state.Get(targetKeyName); state.Remove(targetKeyName); state.Set("_stackSize", newStackSize); // Return the popped object return retrievedObject; } [ActorMethod] public static object Size(IActorState state, object[] parameters) { // Grab the current size of the stack, return it int stackSize = 0; // default on first call object temp; if (state.TryGet("_stackSize", out temp)) stackSize = (int)temp; return stackSize; }To summarize, the actor would contain the following items in its state:
- The key “_stackSize” whose value is the current size of the stack.
- One key “_itemXXX” corresponding to each value pushed onto the stack.
After the items “foo”, “bar” and “spam” had been pushed onto the stack, in that order, the actor’s state would look like this:
Key
Value
“_stackSize”
3
“_item0”
“foo”
“_item1”
“bar”
“_item2”
“spam”
A pop operation would yield the string “spam”, and leave the actor’s state looking like this:
Key
Value
“_stackSize”
2
“_item0”
“foo”
“_item1”
“bar”
The Actor Runtime Client
Once you have actors up and running in the Actor Runtime, you can connect to those actors and manipulate them via use of the FabricActorClient. This is the FabricActorClient’s interface:
public class FabricActorClient { public FabricActorClient(Uri fabricUri, Uri actorUri, bool useGateway); public bool AddAssembly(string assemblyName, byte[] assemblyBytes,
bool replaceAllVersions = true); public Object CallMethod(string methodName, object[] parameters); public IDisposable Subscribe(string eventType,
IObserver<string> eventObserver); }When constructing a FabricActorClient, you need to provide three parameters:
fabricUri: This is the URI associated with the Actor Runtime cluster on which your actor is running. When in a local development environment, this is typically “net.tcp://127.0.0.1:9000”. When in an Azure environment, this would be something like “net.tcp://<yourDeployment>.cloudapp.net:9000”. [Emphasis added.]
- actorUri: This is the URI, within the ActorRuntime, that is associated with your actor. This would be something like “fabric:/actor/list/list1” or “fabric:/actor/adhoc/myFirstActor”.
- useGateway: Set this to false when connecting to an actor in a local development environment, true when connecting to an Azure-hosted actor.
The AddAssembly method allows you to transport an assembly to the actor. Typically that assembly would contain actor methods, effectively add behavior to or changing the existing behavior of the actor. Take note that the “replaceAllVersions” parameter is ignored.
What’s next?
This is only the beginning of a journey. The code we are releasing today is an initial basic framework that can be used to build a richer set of functionalities that will make ActorFx a valuable solution for storing and processing data on the cloud. For now, we are starting with a playground for developers who want to explore how this new approach to data storage and management on the cloud can become a new way to see old problems. We will keep you posted on this blog and you are of course more than welcome to follow our Open Source projects on our MSOpenTech CodePlex page. See you there!


I [and many others] call Erik the “Father of LINQ.”
Craig Kitterman (@craigkitterman) posted Cross-Post: Fast-LMM and Windows Azure Put Genetics Research on a Faster Track on 12/6/2012:
In the video below, David Heckerman, Distinguished Scientist, Microsoft Research, talks about the work he and his team conducted using data from the genome-wide association study (GWAS). Their goal is to find associations between genetics, disease and responsiveness to drugs.
As David explains, “With Windows Azure, we have the infrastructure to do the computations that would normally take years in just a few hours.” His team conducted a 27,000-core run on Windows Azure to crunch data from this study. With the nodes busy for 72 hours, 1 million tasks were consumed—the equivalent of approximately 1.9 million compute hours. If the same computation had been run on an 8-core system, it would have taken 25 years to complete.
Here are links to the original blog post and case study for a more in-depth description of the project


<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
‡ Michael Washington (@ADefWebserver) described Implementing The Wijmo Radial Gauge In The LightSwitch HTML Client in a 12/8/2012 post to his Visual Studio LightSwitch Help Website:
ComponentOne provides a set of free and commercial controls called Wijmo that can be consumed in the Visual Studio LightSwitch HTML Client.
For this tutorial, I am using the LightSwitch HTML Client Preview 2.
The Sample Application
Select File then New Project.
Create a LightSwitch HTML Application.
The application will be created.
Select Add Table.
Create the table and save it.
Add a Screen.
Create a Browse Data Screen.
Add another Screen.
Create a Add/Edit Details Screen.
Now, we need to make a Button to allow a user to Add records.
Open the Browse screen and add a New Button.
Select addAndEditNew for the Method.
Then select the Add/Edit Detail Screen for Navigate To.
Click OK.
The Button will show.
Now, we need to allow a user to Edit an existing record.
Click on the List control, and in Properties click on the link next to Item Tap.
Select editSelected for the Method.
Then select the Add/Edit Detail Screen for Navigate To.
Click OK.
Press F5 to run the application.
You will be able to Add students.
You will be able to Edit existing records.
Download Code
The LightSwitch project is available at [the bottom of the]http://lightswitchhelpwebsite.com/Downloads.aspx [list.]
(You must have HTML Client Preview 2 or higher installed to run the code [and have an account to open the downloads list.])






















Note the similarity to layout of the HTML UI generated by the LightSwitch HTML Client Preview 2: OakLeaf Contoso Survey Application Demo on Office 365 SharePoint Site of 11/20/2012.
‡ Michael Washington (@ADefWebserver) continued Implementing The Wijmo Radial Gauge In The LightSwitch HTML Client in a 12/8/2012 with instructions for installing the full set of Wijmo controls:
When we go to this link, we can find documentation on the Wijmo Radial Gauge. You can get the full documentation at this link.
Using that documentation, I created this reusable JavaScript class (right-click on the link and select Save Target As and save it as GuageControl.js (yes I used ‘creative spelling’ for the name of the JavaScript file) and put it in the Scripts folder of the Client project).
Add a reference to the file in the default.htm page.
Switch back to Logical View.
Open the Add/Edit Detail Screen.
We want to bind the control to the value of the Test Score.
Add a second instance of Test Score.
Change the second instance of Test Score to a Custom Control.
In the Properties of the control:
- Set Label Position to Hidden
- Set Height to Fixed Size
- Set Pixels to 240
In the Properties for the control, select Edit Render Code.
A method will be created for you to enter custom JavaScript code.
Change the code to the following:
myapp.WijmoStudentDetail.TestScore1_render = function (element, contentItem) {// Write code here.var radialContrl = $('<div id="gaugeDIV"></div>');radialContrl.appendTo($(element));// Create the controlCreateRadialContrl(radialContrl, contentItem.value);};
When you run the application, the Gauge will display and match the value entered for Test Score.
However, when you change the Test Score, you have to save the record and return to it to see the Gauge change.
If we close the web browser and return to the JavaScript method and add the following code to the method, the Gauge will automatically update:
contentItem.dataBind("value", function (newValue) {UpdateRadialContrl(radialContrl, newValue);});
LightSwitch Help Website Articles
- Writing JavaScript In LightSwitch HTML Client Preview
- Creating JavaScript Using TypeScript in Visual Studio LightSwitch
- Theming Your LightSwitch Website Using JQuery ThemeRoller
- Using Toastr with Visual Studio LightSwitch HTML Client (Preview)
LightSwitch Team HTML and JavaScript Articles
- Custom Controls and Data Binding in the LightSwitch HTML Client (Joe Binder)
- Creating Screens with the LightSwitch HTML Client (Joe Binder)
- The LightSwitch HTML Client: An Architectural Overview (Stephen Provine)
- Writing JavaScript Code in LightSwitch (Joe Binder)
- New LightSwitch HTML Client APIs (Stephen Provine)
- A New API for LightSwitch Server Interaction: The ServerApplicationContext
- Building a LightSwitch HTML Client: eBay Daily Deals (Andy Kung)
Special Thanks
A special thanks to LightSwitch team members Joe Binder and Stephen Provine for their valuable assistance.












Joe Binder described Custom Controls and Data Binding in the LightSwitch HTML Client in a 12/6/2012 post to the Visual Studio LightSwitch Team Blog:
Custom JavaScript controls allow you to create user experiences that are tailored to specific use cases and business needs. Given the wealth of code samples, control frameworks, and partner control offerings available today, we wanted to ensure that existing controls could be used as-is within the LightSwitch HTML client.
Having heard some great feedback through the forums and individually, I thought it’d be useful to provide an overview of LightSwitch’s custom control support and share a few tips-and-tricks that have proven useful in my own development.
You can download the LightSwitch HTML Client Preview 2 here.
If you’re new to LightSwitch or the HTML client, you might want to check the following articles before reading through this article:
- Announcing LightSwitch HTML Client Preview 2! Provides an overview of the LightSwitch HTML client preview 2.
- Building a LightSwitch HTML Client: eBay Daily Deals (Andy Kung) If you haven’t had a chance to use the LightSwitch HTML client, Andy’s walkthrough is a great way to get started.
- New LightSwitch HTML Client APIs (Stephen Provine) Stephen’s article offers an in-depth look at all of the programmatic entry points in the HTML client. We’ll be drilling into more detail on a few of the APIs he describes in this article.
An Overview of UI Customization Events
UI Customization in the LightSwitch HTML client is accomplished through the render and postRender events. Here’s a basic set of guidelines to help you decide which event to use for a given scenario:
- If you need to insert new elements into the DOM, use the render event. The render event allows you to programmatically create and insert an arbitrary set of DOM elements. For example, if you want to use a control from jQuery UI, use the render event to instantiate the control and insert it into the DOM.
- If you need to augment or otherwise modify DOM elements created by LightSwitch, use the postRender event. The postRender event is commonly used to add a CSS class or DOM attribute to existing DOM elements: for example, you may want to add a jQuery Mobile class to a DOM element created by LightSwitch. We’ll also use the postRender event to change the screen header dynamically later in this article.
A First Step
Let’s jump in and create a simple example to demonstrate how the render event works.
Connect to existing data
We’ll be using the Northwind database for all of the examples in this article. If you don’t have the Northwind database installed, you can download it here.
1. Create a new HTML Client Project (VB or C#)
2. Select “Attach to external data source”
3. Select “Database”
4. Enter the connection information for your Northwind database.
5. Select all entities and click Finish.
Build some basic screens
1. Right-click on the HTML Client node in the Solution Explorer and select “New Screen”
2. Select the “Browse Data Screen” template, using the “Order” entity as a Data Source
Inserting a Custom Control and Handling postRender
With the screen created, the first thing you’ll notice that each control created on the screen has an associated postRender event in the “Write Code” dropdown.
If you need to change or add CSS classes or other DOM attributes on any of the content items shown in the designer, use the postRender event. We’re going to focus on the render event today, though, as it’s the most effective means of creating customized UI in LightSwitch and seems to generate the most interest in the forums.
The render event is only available for custom controls, so we need to add a custom control to the screen before we can use it.
1. Change the default Summary control for the order item to a custom control:
2. Now open the “Write Code” dropdown and select the “RowTemplate_Render” event.
The code stub for the render event includes two parameters, element and contentItem.
myapp.BrowseOrders.RowTemplate_render = function (element, contentItem) { // Write code here. };The element represents the DOM element-- the <div>-- into which our custom UI will be generated. The contentItem represents the view model to which our custom control will be bound. In this example, the content item represents a single order item in the list. Let’s start by generating our list items to show the order date.
myapp.BrowseOrders.RowTemplate_render = function (element, contentItem) { var orderDate = $("<p>" + contentItem.value.OrderDate + "</p>"); orderDate.appendTo($(element)); };On the first line, we’re using jQuery to create a paragraph element that contains the order date. Since this custom control is hosted inside a list, the content item represents a single Order. “contentItem.value” returns the order instance, and contentItem.value.OrderDate returns the order’s date. Once our custom HTML is created, we use jQuery to append it to the placeholder <div> element encapsulated in the element parameter. We can now run the application and see the list items displaying the respective order date.
Displaying Navigation Properties
Displaying the order date was a good first step, but it probably makes more sense to display the Customer for a given order. Since the Order has a “Customer” navigation property, we can probably just update our code to display the Customer’s CompanyName instead of the date:
myapp.BrowseOrders.RowTemplate_render = function (element, contentItem) { var orderDate = $("<p>" + contentItem.value.Customer.CompanyName + "</p>"); orderDate.appendTo($(element)); };Unfortunately, this doesn’t work; a list of empty list items is displayed:
Let’s set a breakpoint in our code and use the Watch Window to see what’s going on:
Our list items are blank because contentItem.value.Customer is “undefined”. Typically “undefined” errors are rooted in typos in one form or another, but in this case the binding path is correct. In fact, the problem is that the Order.Customer property is not loaded. We need to understand a bit more of the LightSwitch view model to understand why the property isn’t loaded and how we can fix the problem.
When we build LightSwitch UI using the designer, LightSwitch figures out the data elements that should be loaded on the screen based on the controls in the layout tree. For example, if we were to manually drag the Order.Customer property onto the screen, LightSwitch would make sure that the Customer is fetched when the screen is loaded. But in this instance, we’re building custom UI and LightSwitch has no way of knowing what data should be loaded; we have to explicitly tell it to load the customer. This is pretty easy to do using the designer:
1. Click the “Edit Query” link for the Orders collection in the designer.
2. Now find the “Managed included data” link in the property sheet for the query.
3. Change “Customer: Excluded (Auto)” to “Customer: Included”
Changing this setting to “Included” tells LightSwitch to fetch the Customer for each order that’s queried; it is effectively the span of the query. Now we can run our application again and see that the Company name is properly displayed.
Render function Tips
1. When referring to the screen’s view model (e.g., contentItem.value.OrderDate), make sure that the casing of view model properties in code matches the casing used in the screen designer exactly.
var orderDate = $("<p>" + contentItem.value.OrderDate + "</p>");
3. If you would like to use jQuery to interact with the container div—the element parameter—make sure to wrap it in $(element). The element passed in is not a jQuery object, so you need to create one.
orderDate.appendTo($(element));4. If you see “undefined” errors, inspect the “undefined” element under the debugger to ensure that the code does not include a typo. The Visual Studio Watch window is a great tool for this purpose.
5. Whenever a custom control is displaying navigation properties, always include the navigation property in the parent query’s span by using the “Manage included data” feature.
An Introduction to Data Binding
Thus far we’ve been adding custom UI inside list items, but many scenarios will call for custom UI on a standalone screen. It’s possible to replace any UI on a LightSwitch screen with the exception of the header/title using the render event described above, but we have some new challenges to deal with when working outside the context of the list. In particular, it’s much more likely that the data we’re displaying in our custom control will change over the lifetime of the screen.
For example, consider a scenario where we’re displaying the order’s ShippedDate on the OrderDetail screen:
1. The user gestures to “Ship It” on the order detail screen.
2. The “Ship It” button sets the order’s ShippedDate to the current date.
If we use the above approach, our UI will not reflect the new ShippedDate because the render function is only called when the control is created. LightSwitch’s databinding APIs are a much better option for this scenario. In fact, it’s best to always use data binding when displaying LightSwitch data to guard against scenarios where data is loaded or changed asynchronously.
Add a detail screen
1. Add a new screen to the application
2. Select the “Add/Edit” screen template and choose “Order” as the data source
3. Switch back to the BrowseOrders screen and select the OrdersList
4. Click the “Tap” action link in the property sheet
5. Configure the tap action to launch our “EditOrder” screen as follows:
6. Now switch back to the Edit Order screen and select the top-level RowsLayout and gesture to handle the postRender event
Set the screen title dynamically
As our first introduction into LightSwitch databinding, we’re going to set the title of the screen dynamically. We could grovel through the DOM to find the element that contains the screen title, but it’s much easier to update the underlying view model property to which the screen title is bound: “screen.details.displayName”
Add the following to the postRender function:
myapp.EditOrder.Details_postRender = function (element, contentItem) { contentItem.dataBind("screen.Order.ShipAddress", function (newValue) { contentItem.screen.details.displayName = newValue; }); };The dataBind(…) function accepts a binding path as a string and a function that will be called when the corresponding value is loaded or changed. However simple, the dataBind method saves us from manually hooking up change listeners to the view model. If we run the application, we’ll see the screen title change in accordance with the ShipAddress.
Databinding a scalar field
We can extend the above example to add a new data-bound custom control to the screen.
1. Add a new custom control to the Details tab of the EditOrder Screen
2. Set the binding path for the control to the ShippedDate
3. Open the Write Code dropdown and select “Order_ShippedDate_Render”
4. Add the following code to the render function.
myapp.EditOrder.Order_ShippedDate_render = function (element, contentItem) { var shippedDate = $('<p id="shippedDate"></p>'); shippedDate.appendTo($(element)); contentItem.dataBind("stringValue", function (newValue) { shippedDate.text(newValue); }); };There are a few subtle differences between this code and the earlier example that set the screen title:
1- contentItem in this example represents the ShippedDate property, so the binding path is relative to the ShippedDate.
2- We’re binding to the “stringValue”. As its name implies, the string value is a formatted string representation of the underlying property value. Binding to “stringValue” instead of “value” is advantageous when using a text control, because “stringValue” will give us a properly formatted string; whereas simply displaying the JavaScript Date object in this case does nothing—setting the “text” attribute of a <p> to something other than a string will throw an error.
Two-way data binding
Two-way data binding works is just an extension of the above example. We’ll just change the paragraph element to an <input> and listen for its change events:
myapp.EditOrder.Order_ShippedDate_render = function (element, contentItem) { var shippedDate = $('<input id="shippedDate" type="datetime"/>'); shippedDate.appendTo($(element)); // Listen for changes made via the custom control and update the content // item whenever it changes shippedDate.change(function () { if (contentItem.value != shippedDate.val()) { contentItem.value = new Date(shippedDate.val()); } }); // Listen for changes made in the view model and update our custom control contentItem.dataBind("stringValue", function (newValue) { shippedDate.val(newValue); }); };When the input value changes, we set the underlying content item’s value. In this example, the content item maps to a date field, so we need to assign it a date object.
Databinding Tips
Although data binding in LightSwitch only entails a single API, there are a number of things to keep in mind when you’re using it. Let’s recap:
- Always use data binding when displaying LightSwitch data. There is no guarantee that the data you’re trying to display in a render event will be loaded when your render event is fired; databinding allows you to guard against cases where data isn’t loaded when your control is created or when that data changes elsewhere in the application.
- Bind to the stringValue property on the contentItem when displaying data as text. The stringValue gives you the formatted string representation of whatever type you’re displaying.
- When setting view model values, make sure the source and target property values are the same type; otherwise the assignment will fail silently. (See our two-way databinding example above.)
- Whenever possible, set the binding path of your control in the designer and use relative binding in code. Setting the binding path in the designer has several advantages: (1) it tells LightSwitch the data you’re using so it can be loaded automatically; (2) it allows your custom control code to be more generalized and re-used more easily—you aren’t hard-coding the binding to a particular screen; (3) relative binding allows you to easily access relevant content item properties, such as the stringValue and displayName.
Interacting with “live” DOM elements
jQueryMobile and LightSwitch do most of the heavy lifting required to manipulate the DOM, but you may run into scenarios that require you to interact with the “live” DOM. The good news is that the full extent of frameworks like jQuery are at your disposal within LightSwitch. It is important to keep in mind, however, that the DOM that we see inside our _render and postRender methods is not, strictly speaking, the “live” DOM—it’s the DOM as it exists before jQueryMobile expands it. While this is generally a good thing—it enables us to use jQueryMobile classes and other DOM annotations in our code—it does mean that we have to wait for jQueryMobile to complete its expansion before the DOM is live.
Let’s walk through a simple example that popped up on the forums to illustrate the problem. Consider that you want to set focus on our ShippedDate custom control from above. Easy, right? There’s a jQuery focus event we can probably just call…
myapp.EditOrder.Order_ShippedDate_render = function (element, contentItem) { var shippedDate = $('<input id="shippedDate" type="datetime"/>'); shippedDate.appendTo($(element)); // Listen for changes made via the custom control and update the content // item whenever it changes shippedDate.change(function () { if (contentItem.value != shippedDate.val()) { contentItem.value = new Date(shippedDate.val()); } }); // Listen for changes made in the view model and update our custom control contentItem.dataBind("stringValue", function (newValue) { shippedDate.val(newValue); }); shippedDate.focus(); };If we run the application, you’ll notice that our custom control doesn’t receive focus as expected. The problem is that the control isn’t visible and/or “live” yet so the browser can’t set focus on it. We can work around this by wrapping the call—and any other similar types of operations—in setTimeout(…).
myapp.EditOrder.Order_ShippedDate_render = function (element, contentItem) { var shippedDate = $('<input id="shippedDate" type="datetime"/>'); shippedDate.appendTo($(element)); // Listen for changes made via the custom control and update the content // item whenever it changes shippedDate.change(function () { if (contentItem.value != shippedDate.val()) { contentItem.value = new Date(shippedDate.val()); } }); // Listen for changes made in the view model and update our custom control contentItem.dataBind("stringValue", function (newValue) { shippedDate.val(newValue); }); setTimeout(function () { if (shippedDate.is(':visible')) { shippedDate.focus(); } }, 1000); };While this might seem arbitrary, it’s the simplest way to workaround issues of this sort; keep it in mind if you need to interact with the live DOM.
Wrapping Up
Custom controls and databinding are powerful capabilities within LightSwitch; they are the escape hatch that allow you to create differentiated user experiences atop the default LightSwitch client. It’s our hope that you find the entry points described here useful in your application development. If you run into any issues, head on over to the forums and we’d be more than happy to help you.
As a follow-up to this post, we’ll dive into the CSS side of UI customization and show how to use custom CSS in conjunction with the code you’ve seen today.
Thanks for your support and taking the time to try out Preview 2!


















Return to section navigation list>
Windows Azure Infrastructure and DevOps
•• David Linthicum (@DavidLinthicum) asserted “Real issues and problems will slow migration to this useful cloud technology, but less so if you're prepared” in a deck for his The unpleasant truths about database-as-a-service article of 12/7/2012 for InfoWorld’s Cloud Computing blog:
The recent announcement of Amazon.com's Redshift -- and other cloud-delivered databases, for that matter -- makes it clear we're moving to a future where some or even most of our data will exist in public clouds. Although the cost savings are compelling, I believe this migration will happen much more slowly than cloud providers predict. Indeed, for the Global 2000, cloud-based data stores will initially be a very hard sell, though the poorer small businesses won't have any other choice, economically speaking.
That said, there are a few problems you need to consider before you load your data onto USB drives and ship it to a cloud computing data center. First and foremost, you're dumping your data onto USB drives, when are then dropped off at UPS. No kidding -- it's too much data to upload.
There are other problems to consider as well.
Ongoing data integration with on-premise data stores is a problem. Although a one-time movement of data is a pain, it's not an ongoing issue. But cloud-based data stores aren't static repositories, so enterprises that need to migrate data weekly, daily, hourly, or even in real time will have their work cut out for them. They must figure out data-integration mechanisms that work consistently. In some cases, when there is too much data to move, it will be impractical to use cloud-based databases.
Data security remains an ongoing concern. The ability to encrypt information, both in motion and at rest, is a solvable problem. However, there needs to be a holistic approach to cloud-based data security that does not exist in most implementations I've seen. This means securing data at the record and table levels, with links to data-governance systems, and an identity-based security infrastructure. In other words, encryption will only get you so far when you place data in public clouds.
Data rules and regulations still get in the way. In many instances, the data you place in the cloud is regulated, such as health and financial info. You need to be diligent in understanding the regulations and the laws that govern the use of that data, including if or when the data can be moved out of a political jurisdiction and how the data should be secured. Many organizations that move data into the cloud often overstate the impact of these regulations, and they push back on the use of the cloud without good reason. But some don't understand the regulations and end up with compliance issues that can result in fines -- or worse.
None of this should scare you away from using cloud-based databases. But you need to understand that nothing is truly free. There are problems that must be understood and solved -- as is the case with any shift in technology. Cloud-based databases are no different.

Most cloud database providers, such as Microsoft with Windows Azure SQL Database (a.k.a., SQL Azure) don’t charge for data ingress (upload) bandwidth. However, all charge for data storage.
Erik Enger explained Why I love PowerShell…and so should you in a 12/6/2012 post to Perficient’s Microsoft Enterprise Technologies blog:
This blog post is meant for both the PowerShell newbie and scripter out there looking for a reason why they should start learning aptly named PowerShell or push themselves to learn a new aspect of PowerShell they’ve been meaning to try.
It’s been a few years now since PowerShell first came to be. Remember those Monad days when we first got a glimpse at what Microsoft had up their sleeve? I’ll admit I was one of the skeptical ones, deeply entrenched in VBScript, DOS batch files, AutoIT, VB.Net, etc. I thought to myself, “Great, another programming language. This will never catch on. Microsoft did what to the administrative interface?!” I just didn’t get it at first.
When Exchange 2007 hit the market I knew they were serious. Microsoft cleverly led me (although initially it felt more like ‘forced me’) to learn this new scripting language by including helpful syntax examples whenever I would use the Exchange Management Console to do simple and sometimes complex tasks:
For example, moving a mailbox:
‘contoso.com/Test/Test Account1′ | move-mailbox -TargetDatabase ‘E2K7SVR1\First Storage Group\Exchange2007DB2′
Ok. That was simple enough and looking at the code, somewhat easy to follow the logic although at the time I didn’t have any clue what the syntax rules were yet or how to do anything I was used to doing with VBScript. Ah, my cherished VBScript. Not anymore! Fast-forward a few years later.
I can barely recall any scripts I wrote in VBScript let alone how to even write a simple one anymore. I can barely spell it nowadays. I look at scripts I’ve used and wonder how I got anything done. So many lines of code for what seemed like an easy thing to do. After my first go around with Exchange 2007 and PowerShell, I haven’t looked back. I scoured the web for any material and examples I could find on PowerShell. From sample code to concepts, from simple loops to functions, from standard console scripts to GUI-interfaces. Pretty soon I had a fairly solid understanding of just how (pardon the pun) powerful PowerShell really is.
The seemingly endless lines of VBScript quickly turned into one-liners. How awesome is that? As a former Exchange admin it was a blessing for sure. You could now take those seemingly daunting tasks your boss or HR would throw at you and knock them out in a matter of minutes.
So, what have I done with PowerShell since way back when? Well, I use it practically every day. I’m always looking for new and interesting ways to code with it. I am, however, very practical and spend the most time coding with PowerShell when I have a clear goal in mind, something I’m trying to solve for myself or my clients. For me it always stems from a problem I’m trying to solve for a client or developing new tools for my teammates. There is a lot of information out there today as compared to a few years ago. There’s tons of blogs, books, editors, and snap-ins you can sometimes download for free. The Quest ActiveRoles Management Shell for Active Directory is/was one of my favorites. I used that one in my job a lot for making bulk operations on AD objects a breeze.
Since I’m an Exchange and migration guy I am always looking for ways to make migrations easier. PowerShell helps me do that very easily. A few years back when BPOS (Business Productivity Online Suite) first came out there were literally only 5 PowerShell cmdlets you could use to manipulate cloud objects. Yeah, I know. Not a lot to work with. Well, a client was looking for an easy way to manage their cloud objects from resetting passwords (pre-ADFS and O365), reporting on their licensing, activating accounts and setting mailbox permissions. Of course my first inclination was to give them some PowerShell scripts but then realized I needed to make it easier. I really wanted a graphical interface for them. After hunting around I found the Sapien PrimalForms product (now known as PowerShell Studio). I literally spent weeks teaching myself how to use the product but I was able to give the client what they wanted, a simple graphical interface to help their support staff fend off the support calls after their migration to the cloud.
From there I did some custom updates to the product and we used it at different clients. Everyone loved it. But then Office 365 came around and offered a lot more cmdlets plus a decent web portal so I left my app on the shelf for a while, just providing support for those that still used it until their transition to O365 was complete. I did get a call to update the version to support O365 so I did. Here’s what it looks like now. There’s not a lot of features simply because I feel most of the benefits are already available in the portals and cmdlets. Nevertheless, it still has some useful things it can do to make someone’s job a little easier. Sure, the interface could be improved upon, more features could be added, and more “fill in the blank” could be done.
Here are some examples of what I’ve been doing with PowerShell:
Office 365 Admin Utility
Exchange 2010 Pre-Audit Checklist
Exchange 2010 Post-Installation Tests
CSV Utility for separating and combining CSV files
My point is that you too can and should be creating some really cool scripts of your own. Even if they are for your own use, learning everything that PowerShell can do can be exciting and rewarding. There are so many facets to PowerShell and with version 3.0 and Windows Server 2012 there are thousands of new cmdlets and features to take advantage of. Windows Server 2012 is said to be one of the most automatable versions of Windows Server yet. PowerShell has even found its way into other MS products like SharePoint and Lync plus 3rd party vendors are including modules and snap-ins to work with their products. The PowerShell 3.0 feature I’m trying to get my head around now are the workflows and running processes in parallel.
So, now I get it, Microsoft. Thanks.
Until next time.
$me=New-PSHappyCamper





Packt Publishing published Riccardo Becker’s (@riccardobecker) Windows Azure programming patterns for Start-ups book in October 2012. From the Overview page:
Overview
Explore the different features of Windows Azure and its unique concepts.
- Get to know the Windows Azure platform by code snippets and samples by a single start-up scenario throughout the whole book.
- A clean example scenario demonstrates the different Windows Azure features.
What you will learn from this book
Understand all the concepts and features of Windows Azure
- Prepare your Visual Studio environment for building Windows Azure services
- Learn to use Windows Azure storage like Blobs, Tables and Queues
- Integrate your services with popular identity providers like Facebook
- Leverage the power of Service Bus technology into your own service
- Implement common scenarios such as supporting existing user stores, user sign up, and supporting AJAX requests
- Learn the billing principles behind the different features of Windows Azure and how to keep track of the bill
- Understand SQL Database and bring the power of a relational database to the cloud


The Windows Azure Online Backup (WAOB) team reminds Windows Server 2012 users to sign up for the Windows Azure Online Backup preview release:
Peace of mind—your server backups in the cloud
Help protect your important server data with easily accessible backups stored in the cloud.
Simple to manage
Manage cloud backups from the familiar backup tools in Windows Server 2012, Windows Server 2012 Essentials, and the System Center 2012 Data Protection Manager component to provide a consistent experience configuring, monitoring, and recovering backups across local disk and cloud storage. After data is backed up to the cloud, authorized users can easily recover backups to any server.
Efficient and flexible
With incremental backups, only changes to files are transferred to the cloud. This helps ensure efficient use of storage, reduced bandwidth usage, and offers point-in-time recovery of multiple versions of data. Configurable data retention policies, data compression and data transfer throttling also offer you added flexibility and help boost efficiency.
Next steps:
- Privacy
- View the Windows Azure Online Backup privacy statement. (Please note that the privacy statement at the Privacy and Cookies link below is for Windows Azure, a different group of services.)
- Get started
I had forgotten to give WAOB a try now that I’m running Windows Server 2012 on my test and development machine.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Lori MacVittie (@lmacvittie) asserted “Presenters asked, attendees responded, I compiled” in an introduction to her Completely Unscientific Hybrid Cloud Survey Results from Gartner DC 2012 article of 12/6/2012 for F5’s DevCentral blog:
Of COURSE you know I have something to say about these results, particularly with respect to the definition of "cloud bridges" comprising a variety of features that are more properly distributed across cloud brokers and cloud gateways, but we'll leave that for another day. Today, enjoy the data.


Surprisingly, Microsoft is missing from Lori’s graphic.
<Return to section navigation list>
Cloud Security and Governance

<Return to section navigation list>
Cloud Computing Events
•• Craig Kittleman posted Windows Azure Community Roundup (Edition #48) to the Windows Azure Team site on 12/7/2012:
Welcome to the latest edition of our weekly roundup of the latest community-driven news, content and conversations about cloud computing and Windows Azure.
I would like to take this opportunity to introduce Mark Brown, the Windows Azure community manager. Starting next week, Mark will be taking over the weekly roundup. Mark's focus will be to curate and highlight the most interesting and impactful content directly from members of the global Windows Azure community, as well as the latest info on global events, discussions, and even code! If you have comments or suggestions for the weekly roundup, or would like to get more involved in a Windows Azure community, drop him a line on twitter @markjbrown
Here is what we pulled together this week based on your feedback:
Articles, Videos and Blog Posts
- Blog: Simple Calculator for Comparing Windows Azure Blob Storage and Amazon S3 Pricing by @gmantri (posted Sep.3)
- Blog: Configuring IIS methods for ASP.NET Web API on Windows Azure Websites and elsewhere by @maartenballiauw (posted Dec. 7)
- Blog: Understanding Windows Identity Foundation (WIF) 4.5 by @mohamadhalabi (posted Dec. 5)
- Blog: Securing access to your Windows Azure Virtual Machines by @sandrinodm (posted Dec. 5)
- Blog: MVP Monday - Connected Apps Made Wicked Easy with Windows Azure Mobile Services by @sseely (posted Dec. 3)
- Blog: HDInsight, Finally by @GFritchey (posted Dec. 3)
- Blog: Engineering for Disaster Recovery in the Cloud (Avoiding Data Loss) by @codingoutloud (posted Dec. 1)
Upcoming Events and User Group Meetings
North America
- October - June, 2013: Windows Azure Developer Camp – Various (50+ cities)
- December 11: Hands on Hacknight – Charlotte, NC
Europe
- December 10: Windows Azure Camp – Brussels, Belgium
- December 11: Clemens Vasters Unplugged - Azure UG – Zaventem, Belgium
Rest of World/Virtual
- Ongoing: Windows Azure Virtual Labs – On-demand
Interesting Recent Windows Azure Discussions on Stack Overflow
- Azure - Preparing content for Smooth Streaming – 2 answers, 1 vote
- What's the recommended way to deploy a Django app on IIS? – 1 answers, 0 votes
- Microsoft Windows Azure Storage vs. Microsoft Windows Azure Storage Client – 1 answer, 5 votes
Grigori Melnik (@gmelnik) suggested on 6/12/2012 that you Join us at the patterns & practices symposium 2013 to be held in Redmond, WA 1/15 through 1/17/2013:
Join my team for our flagship event – the patterns & practices symposium 2013. It will take place on Microsoft campus, Jan 15-17, 2013.
Don’t miss the opportunity to see my colleagues and I speak on the latest projects coming from p&p and industry experts discussing the latest trends in software engineering. We have a fantastic roundup of speakers. Where else would you get to meet in person and hear ScottGu, Scott Hanselman, Greg Young, Adam Steltzner and Felicity Aston – all at one event?
The symposium agenda includes three tracks: The Cloud, The Client and The Engineering. Check out the details and register now. We look forward to seeing you and interacting with you over these three exciting days.
Register at http://aka.ms/pnpsym


Gregg Ness (@archimedius) summarized the Amazon re:Invent and Gartner Data Center conferences in his Two Weeks in Vegas post of 12/6/2012:
A rant from the 23rd floor as I remove my lanyard and decompress:
Two weeks of recirculated casino air passing through two great cloud computing-themed conferences driven by fresh outlooks. The contrast between stale casino smoke and fresh ideas was at times overpowering. IT is bold and strategic again, with less control and yet more options than ever. Welcome to consumerism on steroids.
I’m wrapping up the Gartner Data Center Conference week tonight, after last week at Amazon AWS re:INvent. One conference focused on public cloud and the other on hybrid cloud; it was clear that IT is experiencing the beginning of the end of a kind of feudalism, one driven by vendors and various forms of hardware and channel lock-in.
IMHO channels are going to become more service-driven than ever. Buyers will have more choices than ever.
Agility will be the mantra of this new age; risk taking will be more commonplace.
Both conferences were monumental. It was Amazon AWS’ first show and it was exquisitely managed; it was perhaps Gartner’s most visionary, most aggressive conference, at least in my memory. Gartner has been hiring and bringing in some brilliant provocateurs, the kind of minds every company wants in this new age.
Beyond Gartner and Amazon and the lights of Las Vegas a cultural shift is underway in organizations of all sizes, public and private. Fortune may indeed go to the bold.
Amazon’s greatest risk may be in becoming a kind of Novell-like public cloud purist while the likes of VMware, Microsoft, Cisco, etc. keep expanding from their base in private clouds to the emergent hybrid cloud, along with OpenStack and a new generation of hungry startups. [Emphasis added.]
Next week our stealth team plans to announce another big step, a kind of crossing of the hybrid cloud process barrier. Stay tuned.


<Return to section navigation list>
Other Cloud Computing Platforms and Services
•• Lydia Leong (@cloudpundit) posted Some clarifications on HP’s SLA [to her earlier post at the end of this blog] on 12/7/2012:
I corresponded with some members of the HP cloud team in email, and then colleagues and I spoke with HP on the phone, after my last blog post called, “Cloud IaaS SLAs can be Meaningless“. HP provided some useful clarifications, which I’ll detail below, but I haven’t changed my fundamental opinion, although arguably the nuances make the HP SLA slightly better than the AWS SLA.
The most significant difference between the SLAs is that the HP’s SLA is intended to cover a single-instance failure, where you can’t replace that single instance; AWS requires that all of your instances in at least two AZs be unavailable. HP requires that you try to re-launch that instance in a different AZ, but a failure of that launch attempt in any of the other AZs in the region will be considered downtime. You do not need to be running in two AZs all the time in order to get the SLA; for the purposes of the SLA clause requiring two AZs, the launch attempt into a second AZ counts.
HP begins counting downtime when, post-instance-failure, you make the launch API call that is destined to fail — downtime begins to accrue 6 minutes after you make that unsuccessful API call. (To be clear, the clock starts when you issue the API call, not when the call has actually failed, from what I understand.) When the downtime clock stops is unclear, though — it stops when the customer has managed to successfully re-launch a replacement instance, but there’s no clarity regarding the customer’s responsibility for retry intervals.
(In discussion with HP, I raised the issue of this potentially resulting in customers hammering the control plane with requests in mass outages, along with intervals when the control plane might have degraded response and some calls succeed while others fail, etc. — i.e., the unclear determination of when downtime ends, and whether customers trying to fulfill SLA responsibilities contribute to making an outage worse. HP was unable to provide a clear answer to this, other than to discuss future plans for greater monitoring transparency, and automation.)
I’ve read an awful lot of SLAs over the years — cloud IaaS SLAs, as well as SLAs for a whole bunch of other types of services, cloud and non-cloud. The best SLAs are plain-language comprehensible. The best don’t even need examples for illustration, although it can be useful to illustrate anything more complicated. Both HP and AWS sin in this regard, and frankly, many providers who have good SLAs still force you through a tangle of verbiage to figure out what they intend. Moreover, most customers are fundamentally interested in solution SLAs — “is my stuff working”, regardless of what elements have failed. Even in the world of cloud-native architecture, this matters — one just has to look at the impact of EBS and ELB issues in previous AWS outages to see why.


•• Jeff Barr (@jeffbarr) reported an AWS Expansion in Brazil - Elastic Beanstalk, Provisioned IOPS for EBS and RDS in a 12/7/2012 post:
We launched an AWS Region in Brazil almost a year ago, along with Portuguese and Spanish versions of the AWS Blog.
Today we are adding the following new AWS functionality in the Region:
AWS Elastic Beanstalk - You can now deploy and manage .NET, PHP, Python, Ruby, and Java applications in the AWS Cloud using AWS Elastic Beanstalk. With this new addition to our lineup in Brazil, you can get your application online more quickly and allow Elastic Beanstalk to handle system updates, scaling, monitoring, and lots more.
EBS Provisioned IOPS - You can now create EBS Provisioned IOPS volumes in Brazil, with up to 2000 IOPS per EBS volume. This will give you more control and the ability to create fast, responsive applications on AWS.
RDS Provisioned IOPS - You can now create RDS Database Instances with up to 10,000 Provisioned IOPS (for MySQL and Oracle) or 7,000 (SQL Server). This gives you the power to create fast, responsive database-driven applications on AWS. As part of today's launch, this is also available in the Asia Pacific (Singapore) Region.
-- Jeff;
PS[0] - Check out the AWS Products and Services by Region to find out which services are available in each AWS Region.
PS[1] - This post is also available in [Brazilian?] Portuguese and Spanish.


Microsoft hasn’t yet added a Windows Azure data center in South America. Amazon doesn’t explain the reason for the reduced Provisioned IOPS limit with SQL Server.
Brandon Butler (@BButlerNWW) asserted “Amazon Web Services is doing well with startups and midsize businesses, but pricing structure, security, and privacy issues are holding it back from gaining traction with enterprises” in a deck for his What's Amazon's enterprise strategy for the cloud? article for InfoWorld’s Cloud Computing blog:
Roaming the floor of Amazon Web Services' first user conference last week, it didn't look like a traditional tech show. Many of the 6,000 attendees at AWS re:Invent were with startups or mid-size businesses looking to learn more about AWS services or the public cloud.
Light on attendance were major enterprise IT shops. …
AWS has been making moves in recent months targeting the enterprise market, with the release of services such its Glacier storage service, its Redshift data warehousing product and others. But it raises the question: What is Amazon's enterprise play right now?
- CLOUD WARS: Amazon vs. Rackspace (OpenStack) vs. Google vs. Microsoft
- MORE AWS RE: INVENT: Google, Microsoft watching Amazon's cloud moves
Amazon wants you to leave this conference thinking that anything can be done on its cloud, says Gordon Haff, a cloud evangelist for Red Hat who attended the show. "Public cloud will be a part of enterprise IT, it will not be all of enterprise IT," he says. CIOs are still trying to figure out what workloads make sense for running in the cloud and which still are best for on-premise applications. Many specialized applications, he says, are still best to run yourself in your own data center.
James Staten, a Forrester analyst, predicts that 30 to 50 percent of enterprise workloads and applications could one day run in the public cloud. "It's rare I talk to an enterprise today that isn't doing something in AWS's cloud," he says. The biggest factor holding the industry back, Staten says, is culture.
Customers are used to running their systems on-premise. The cloud is a completely new model with a new pricing structure of PAYG (pay as you go), new operations management, and new use cases. "Enterprises aren't used to the PAYG model," says Michael Wasserman, of cloud cost management startup Apptio. "They want to know how much they'll pay and they want the bulk discounts. That hasn't seemed to be AWS's sales model so far."
In fact, at the conference, AWS Senior Vice President Andy Jassy highlighted the opposite point: The public cloud, he says, is ideal for businesses because there are no upfront costs and businesses only pay for what they use. …


Read more: next page ›, 2, 3
Brandon Butler (@BButlerNWW) asserted “Gartner analyst Lyida Leong says cloud market leader AWS also has one of the worst SLAs, but HP's new offering is giving it a run for its money” in his Gartner: Amazon, HP cloud SLAs are "practically useless" aticle of 12/6/2012 for NetworkWorld’s Cloud blog:
Amazon Web Services, which Gartner recently named a market-leader in infrastructure as a service cloud computing, has the "dubious status of 'worst SLA (service level agreement) of any major cloud provider'" analyst Lydia Leong blogged today [see below post] but HP's newly available public cloud service could be even worse..
HP launched the general availability of its HP Compute Cloud on Wednesday along with an SLA. Both AWS and HP impose strict guidelines in how users must architect their cloud systems for the SLAs to apply in the case of service disruptions, leading to increased costs for users.
AWS's, for example, requires customers to have their applications run across at least two availability zones (AZ), which are physically separate data centers that host the company's cloud services. Both AZs must be unavailable for the SLA to kick in. HP's SLA, Leong reports, only applies if customers cannot access any AZs. That means customers have to potentially architect their applications to span three or more AZs, each one imposing additional costs on the business. "Amazon's SLA gives enterprises heartburn. HP had the opportunity to do significantly better here, and hasn't. To me, it's a toss-up which SLA is worse," Leong writes. …
Cloud SLAs are an important topic, as recent outages from providers like AWS have shown. AWS has experienced three major outages in the past two years, including a recent one that took down sites such as Reddit, Imgur and AirBNB. Each of AWS's outages have been limited in scope, however, and have mostly centered around the company's Northern Virginia US-East region.
AWS's policy of requiring users to run services across multiple AZs costs users more money than if applications are running in a single AZ. "Every AZ that a customer chooses to run in effectively imposes a cost," Leong writes. HP's SLA, which requires all of the AZs to be down before the SLA applies leaves customers vulnerable, she says. "Most people are reasonably familiar with the architectural patterns for two data centers; once you add a third and more, you're further departing from people's comfort zones, and all HP has to do is to decide they want to add another AZ in order to essentially force you to do another bit of storage replication if you want to have an SLA."
The SLA requirements basically render the agreements useless. "Customers should expect that the likelihood of a meaningful giveback is basically nil," she says. If users are truly interested in protecting their systems and received financial compensation for downtime events, she recommends investigating cyber risk insurance, which will protect cloud-based assets. AWS has recently allowed insurance inspectors into its facilities to inspect its data centers for such insurance claims, she notes.
A strict requirement of service architecture isn't the only aspect of the SLAs Leong takes issue with. They're unnecessarily complex, calling them "word salads," and limited in scope. For example, both AWS and HP SLAs cover virtual machine instances, not block storage services, which are popular features used by enterprise customers. AWS's most recent outage impacted its Elastic Block Storage (EBS) service specifically, which is not covered by the SLA. "If the storage isn't available, it doesn't matter if the virtual machine is happily up and running — it can't do anything useful," Leong writes. …



Lydia Leong (@cloudpundit) asserted Cloud IaaS SLAs can be meaningless in a 12/5/2012 post:
In infrastructure services, the purpose of an SLA (or, for that matter, the liability clause in the contract) is not “give the customer back money to compensate for the customer’s losses that resulted from this downtime”. Rather, the monetary guarantees involved are an expression of shared risk. They represent a vote of confidence — how sure is the provider of its ability to deliver to the SLA, and how much money is the provider willing to bet on that? At scale, there are plenty of good, logical reasons to fear the financial impact of mass outages — the nature of many cloud IaaS architectures create a possibility of mass failure that only rarely occurs in other services like managed hosting or data center outsourcing. IaaS, like traditional infrastructure services, is vulnerable to catastrophes in a data center, but it is additionally vulnerable to logical and control-plane errors.
Unfortunately, cloud IaaS SLAs can readily be structured to make it unlikely that you’ll ever see a penny of money back — greatly reducing the provider’s financial risks in the event of an outage.
Amazon Web Services (AWS) is the poster-child for cloud IaaS, but the AWS SLA also has the dubious status of “worst SLA of any major cloud IaaS provider”. (It’s notable that, in several major outages, AWS did voluntary givebacks — for some outages, there were no applicable SLAs.)
HP has just launched its OpenStack-based Public Cloud Compute into general availability. HP’s SLA is unfortunately arguably even worse.
Both companies have chosen to express their SLAs in particularly complex terms. For the purposes of this post, I am simplifying all the nuances; I’ve linked to the actual SLA text above for the people who want to go through the actual word salad.
To understand why these SLAs are practically useless, you need to understand a couple of terms. Both providers divide their infrastructure into “regions”, a grouping of data centers that are geographically relatively close to one another. Within each region are multiple “availability zones” (AZs); each AZ is a physically distinct data center (although a “data center” may be comprised of multiple physical buildings). Customers obtain compute in the form of virtual machines known as “instances”. Each instance has ephemeral local storage; there is also a block storage service that provides persistent storage (typically used for databases and anything else you want to keep). A block storage volume resides within a specific AZ, and can only be attached to a compute instance in that same AZ.
AWS measures availability over the course of a year, rather than monthly, like other providers (including HP) do. This is AWS’s hedge against a single short outage in a month, especially since even a short availability-impacting event takes time to recover from. 99.95% monthly availability only permits about 21 minutes of downtime; 99.95% yearly availability permits nearly four and a half hours of downtime, cumulative over the course of the year.
However, AWS and HP both define their SLA not in terms of instance availability, or even AZ availability, but in terms of region availability. In the AWS case, a region is considered unavailable if you’re running instances in at least two AZs within that region, and in both of those AZs, your instances have no external network connectivity and you can’t launch instances in that AZ that do; this is metered in five-minute intervals. In the HP case, a region is considered unavailable if an instance within that region can’t respond to API or network requests, you are currently running in at least two AZs, and you cannot launch a replacement instance in any AZ within that region; the downtime clock doesn’t start ticking until there’s more than 6 minutes of unavailability.
Every AZ that a customer chooses to run in effectively imposes a cost. An AZ, from an application architecture point of view, is basically a data center, so running in multiple AZs within a region is basically like running in multiple data centers in the same metropolitan region. That’s close enough to do synchronous replication. But it’s still a pain to have to do this, and many apps don’t lend themselves well to a multi-data-center distributed architecture. Also, that means paying to store your data in every AZ that you need to run in. Being able to launch an instance doesn’t do you very much good if it doesn’t have the data it needs, after all. The AWS SLA essentially forces you to replicate your data in two AZs; the HP one makes you do this for all the AZs within a region. Most people are reasonably familiar with the architectural patterns for two data centers; once you add a third and more, you’re further departing from people’s comfort zones, and all HP has to do is to decide they want to add another AZ in order to essentially force you to do another bit of storage replication if you want to have an SLA.
(I should caveat the former by saying that this applies if you want to be able to usefully run workloads within the context of the SLA. Obviously you could just choose to put different workloads in different AZs, for instance, and not bother trying to replicate into other AZs at all. But HP’s “all AZs not available” is certainly worse than AWS’s “two AZs not available”.)
Amazon has a flat giveback of 10% of the customer’s monthly bill in the month in which the most recent outage occurred. HP starts its giveback at 5% and caps it at 30% (for less than 99% availability), but it covers strictly the compute portion of the month’s bill.
HP has a fairly nonspecific claim process; Amazon requires that you provide the instance IDs and logs proving the outage. (In practice, Amazon does not seem to have actually required detailed documentation of outages.)
Neither HP nor Amazon SLA their management consoles; the create-and-launch instance APIs are implicitly part of their compute SLAs. More importantly, though, neither HP nor Amazon SLA their block storage services. Many workloads are dependent upon block storage. If the storage isn’t available, it doesn’t matter if the virtual machine is happily up and running — it can’t do anything useful. For example of why this matters, you need look no further than the previous Amazon EBS outages, where the compute instances were running happily, but tons of sites were down because they were dependent on data stores on EBS (and used EBS-backed volumes to launch instances, etc.).
Contrast these messes to, say, the simplicity of the Dimension Data (OpSource) SLA. The compute SLA is calculated per-VM (i.e., per-instance). The availability SLA is 100%; credits start at 5% of monthly bill for the region, and go up to 100%, based on cumulative downtime over the course of the month (5% for every hour of downtime). One caveat: Maintenance windows are excluded (although in practice, maintenance windows seem to affect the management console, not impacting uptime for VMs). The norm in the IaaS competition is actually strong SLAs with decent givebacks, that don’t require you to run in multiple data centers.
Amazon’s SLA gives enterprises heartburn. HP had the opportunity to do significantly better here, and hasn’t. To me, it’s a toss-up which SLA is worse. HP has a monthly credit period and an easier claim process, but I think that’s totally offset by HP essentially defining an outage as something impacting every AZ in a region — something which can happen if there’s an AZ failure coupled with a massive control-plane failure in a region, but not otherwise likely.
Customers should expect that the likelihood of a meaningful giveback is basically nil. If a customer needs to, say, mitigate the fact he’s losing a million dollars an hour when his e-commerce site is down, he should be buying cyber-risk insurance. The provider absorbs a certain amount of contractual liability, as well as the compensation given by the SLA, but this is pretty trivial — everything else is really the domain of the insurance companies. (Probably little-known fact: Amazon has started letting cyber-risk insurers inspect the AWS operations so that they can estimate risk and write policies for AWS customers.)



Windows Azure Compute requires two or more instances to qualify for Microsoft’s standard SLA of 99.95% for network connectivity and 99.9% for detecting when a role instance’s process is not running and initiating corrective action. See my See my Republished My Live Azure Table Storage Paging Demo App with Two Small Instances and Connect, RDP post of 5/9/2011 for more details.
Tom Rizzo (@TheRealTomRizzo) posted Windows Wednesday - AWS Tools for Windows PowerShell on 12/5/2012:
Over the years, we have introduced a number of tools that make it easy for Windows customers to use Amazon Web Services. We provide an SDK for .NET, an Elastic Beanstalk container for hosting .NET applications, an integrated toolkit for Visual Studio, and a web-based management console. All of these allow Windows developers and administrators to manage their AWS services in a way that's natural to them.
With our continuing investment in making AWS the best place for Windows customers, we are announcing today the AWS Tools for Windows PowerShell. For Windows developers, administrators, and IT Pros alike, PowerShell is becoming the tool of choice to manage Windows environments. Now you can use PowerShell to manage your AWS services too. The AWS Tools for Windows PowerShell provides over 550 cmdlets that let you perform quick actions from the command line and craft rich automated scripts, all from within the PowerShell environment.
We've put together an introductory video where you can see the AWS Tools for PowerShell in action:
Download the AWS Tools for Windows PowerShell now and get started right away!


See also Erik Enger explained Why I love PowerShell…and so should you in a 12/6/2012 post to Perficient’s Microsoft Enterprise Technologies blog in the Other Cloud Computing Platforms and Services section above.
Full disclosure: Tom was the technical editor for my Expert One-on-One Visual Basic 2005 Database Programming book for Wiley/WROX.
Janakiram MSV asserted VMware’s Spin-off Poses a Potential Threat to Microsoft in a 12/5/2012 post:
The rumors and speculations turned true. VMware and EMC are committing their key assets and resources to form a new virtual organization called the Pivotal Initiative led by Paul Maritz. This will bring the developer, Cloud and Big Data offerings of these two companies under one roof.
For the last few years, VMware has been trying to transform itself into a platform company. To be a strong platform company, they need to own an operating system. But interestingly, VMware doesn’t have an OS but owns a product, which is more of a meta-OS in the form of vSphere. But that is not enough to position them as a strong contender. Realizing this, VMware went after building a strong developer platform through the acquisition of Spring, RabbitMQ, GemFire and SQLFire. Then came Cloud Foundry through which VMware made a strong statement that they are indeed serious about winning the developers.
Branded as vFabric, VMware has acquired all the layers to be qualified as a serious developer platform. At the bottom, there is Spring covering the language, runtime and framework layer. SQLFire, GemFire, tc Server and RabbitMQ form the application and the data services layer. And then on the top is the Cloud Foundry that encapsulates all the ingredients to form the Platform as a Service (PaaS).
On the other hand, EMC has been pushing the Big Data product called Greenplum. They also acquired a SFO based agile software development company called Pivotal Labs that is into Cloud, Social and Mobile. Pivotal Labs can integrate their analytics with Greenplum to offer a unified Big Data processing and analysis product. In April 2012, VMware acquired Cetas, a Palo Alto based Big Data analytics startup. EMC’s Pivotal Labs acquisition and VMware’s Cetas acquisition have the same goal of adding Big Data analytics to their product portfolio. Recently, VMware also announced an initiative called Project Serengeti with an aim of enabling Apache Hadoop to run on Private Cloud.
With the fragmented and overlapping investments, it only makes sense for both the companies to consolidate the efforts. Pivotal Initiative will bring all the developer and Big Data related assets under one roof.
So, how is this a threat to Microsoft? The new spin-off will be run by the veterans of Microsoft, who were involved in driving some key projects including Windows Azure. Paul Maritz led the Platform Strategy and Developer Group at Microsoft. He comes with a strong understanding of the developer needs and precisely knows what it takes to build a platform. The last four years that he spent at VMware gave him a different perspective of the business and he is now a seasoned leader ready to run the new business.
Then comes Mark Lucovsky who extensively worked on Windows NT, .NET and the initial set of Microsoft Cloud Services code named Hailstorm. After Microsoft, Mark worked at Google driving the Maps API business and helping the teams monetize it. In his current role at VMware, Mark is the VP, Engineering solely responsible for the architecture of Cloud Foundry. He is currently focused on moving CloudFoundry.com from beta to general availability.
Finally, this new entity will have another ex-Microsoft veteran in the form of Amitabh Srivasatava. [Emphasis added.] Amitabh is currently the President for the storage division at EMC. It is expected that Amitabh will spend his first year in EMC storage division to avoid the violation of the non-compete agreement with Microsoft that prevents him from working with a direct competitor. It is also expected that Amitabh will soon mover over to the Cloud business of VMware to contribute to the evolving PaaS strategy. Amitabh quit Microsoft only last year before which he was deeply involved in the Windows Azure business. Amitabh was one among the elite group of Distinguished Engineers at Microsoft. Distinguished Engineer is a coveted title at Microsoft that it is typically awarded to individuals who have the technical brilliance with the ability to significantly impact the product roadmap. In his last stint, Amitabh worked along with Ray Ozzie, Dave Cutler, Yusef Khalidi and other top-notch technologists to give shape to the Microsoft Cloud platform code named Red Dog that is now known as Windows Azure.
What is common in Paul Maritz, Mark Lucovsky and Amitabh Srivastava? They are the brains behind Microsoft’s successful platform offerings like Windows NT, .NET and Windows Azure. With some of their veterans on the other side, VMware’s Pivotal Initiative is certainly pivotal for the platform and Cloud business of Microsoft.
It is not just a threat to Microsoft but this announcement also sends a strong message to Red Hat, an archrival of VMware, which is in the same game of platform and Cloud.

<Return to section navigation list>

















0 comments:
Post a Comment