Windows Azure and Cloud Computing Posts for 10/22/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI,Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

‡ Updated 10/27/2012 with new articles marked ‡.
•• Updated 10/25/2012 with new articles marked ••.
• Updated 10/24/2012 with new articles marked •.
Tip: Copy bullet(s) or dagger(s), press Ctrl+f, paste it/them to the Find textbox and click Next to locate updated articles:
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, Hadoop and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Marketplace DataMarket, Cloud Numerics, Big Data and OData
- Windows Azure Service Bus, Caching, Access & Identity Control, Active Directory, and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Windows Azure Blob, Drive, Table, Queue, Hadoop and Media Services
•• Yogeeta Kumari Yadav described Best Practices: Azure Storage Analytics in a 10/25/2012 post to the Aditi Technologies blog:
Windows Azure Storage Analytics feature helps users to identify usage patterns for all services available within an Azure storage account. This feature provides a trace of the executed requests against your storage account (Blobs, Tables and Queues).
Azure Storage Analytics allows you to:
- monitor requests to your storage account
- understand performance of individual requests
- analyse usage of specific containers and blobs
- debug storage APIs at a request level.
Storage Analytics Log Format
Each version 1.0 log entry adheres to the following format:

Sample Log
1.0;2012-09-05T09:22:27.2477320Z;ListContainers;Success;200;4;4;authenticated;mediavideos;mediavideos;blob;"http://mediavideos.blob.core.windows.net/?comp=list&timeout=90";"/mediavideos";fac965bb-c481-49bf-ae80-7920d49449c6;0;121.244.158.2:15621;2011-08-18;306;0;152;1859;0;;;;;;"WA-Storage/1.7.0";;
As you can see logs presented in this manner are not in a human readable format. To find out which entry represents the request packet size, you have to count the fields from the first entry and then get to the required field. This is no easy task.
I have now come across some tools that will simplify things and present the logs in a readable format.
Let us now look at some of these tools:
Azure Storage Explorer 5 Preview 1 - This tool helps to view the logs created after enabling storage analytics against a storage account. The logs seen with help of this tool are in same format as described above.
CloudBerry Explorer for Azure blob storage - This tool provides support for viewing Windows Azure Storage Analytics log in readable format. I have added here sample log information retrieved with the help of this tool.
Figure 1: Sample log information from CloudBerry Explorer

Isn't it easy to read the log in the screen shot than in the sample log?
Azure-Storage-Analytics Viewer – This is a visual tool that you can use to download Azure Storage Metrics and Log data, and display them the form of a chart. You can download this tool from the github website.
Figure 2: Azure-Storage-Analytics Viewer

To use this tool, enter the storage account information in the Azure-Storage-Analytics Viewer window and click the Load Metrics button.
You can see the various metrics represented in the form of a chart. To add metrics to the chart, right-click on a chart and select any option from the pop-up menu.
Figure 3: Azure-Storage-Analytics Viewer

You can select the period for which you wish to analyse the log information and save it to a csv file. Following is a sample snapshot of the csv file which contains storage analytics information for the period between 9 AM on 5th September 2012 and 9 AM on 6th September 2012.
Figure 4: Log information saved in an Excel file

This is the best way to analyse the usage patterns for a storage account and make decisions for effective utilization of storage account.
References

• David Campbell (@SQLServer) posted Simplifying Big Data for the Enterprise to the SQL Server blog on 10/24/2012:
Earlier this year we announced partnerships with key players in the Apache Hadoop community to ensure customers have all the necessary solutions to connect with, manage and analyze big data. Today we’re excited to provide an update on how we’re working to broaden adoption of Hadoop with the simplicity and manageability of Windows.
First, we’re releasing new previews of our Hadoop-based solutions for Windows Server and Windows Azure, now called Microsoft HDInsight Server for Windows and Windows Azure HDInsight Service. Today, customers can access the first community technology preview of Microsoft HDInsight Server and a new preview of Windows Azure HDInsight Service at Microsoft.com/BigData [see below.] Both of these new previews make it easier to configure and deploy Hadoop on the Windows platform, and enable customers to apply rich business intelligence tools such as Microsoft Excel, PowerPivot for Excel and Power View to pull actionable insights from big data.
Second, we are expanding our partnership with Hortonworks, a pioneer in the Hadoop community and a leading contributor to the Apache Hadoop project. This expanded partnership will enable us to provide customers access to an enterprise-ready version of Hadoop that is fully compatible with Windows Server and Windows Azure.
To download Microsoft HDInsight Server or Windows Azure HDInsight Service, or for more information about our expanded partnership with Hortonworks, visit Microsoft.com/BigData today.



Click the Sign Up for HDInsight Service button on the Big Data page, type your Windows Account (nee Live Id) name and password, and click Submit. If you’ve signed up for the Apache Hadoop on Windows Azure preview, you’ll be invited to request a new cluster:

Provisioning a new free five-day cluster takes about 30 minutes. When provisioning is complete, click the Go To Cluster link to open the HDInsight Dashboard, which is almost identical to that for Hadoop on Azure. According to a message of 10/23/2012 from Brad Sarsfield (@bradoop) on the Apache Hadoop on Azure CTP Yahoo! Group:
Based on usage patterns and feedback we have removed the FTP, S3 and Data Market functionality from the web based Hadoop portal. We strongly recommend leveraging Azure storage as the primary long term persistent data store for Hadoop on Azure. This allows the Hadoop cluster to be transient and size independent from the amount of data stored, and represents a significant $/GB savings over the long run.

Note: The Hadoop on Azure Yahoo! Group has moved to the HDInsight (Windows and Windows Azure) forum on MSDN, effective 10/24/2012.
Following are links to my earlier posts about HDInsight’s predecessor, Apache Hadoop on Windows Azure:
- Using Data from Windows Azure Blobs with Apache Hadoop on Windows Azure CTP (4/6/2012)
- Using Excel 2010 and the Hive ODBC Driver to Visualize Hive Data Sources in Apache Hadoop on Windows Azure (4/14/2012)
- Big data buzz gets louder with Apache Hadoop and Hive (5/1/2012 for TechTarget’s SearchCloudComputing.com)
- Creating an Interactive Hadoop on Azure Hive Table from an Amazon Elastic MapReduce Hive Output File (6/2/2012)
- Executing an Elastic MapReduce Hive Workflow from the AWS Management Console (6/2/2012)
- Introducing Apache Hadoop Services for Windows Azure (8/23/2012)
- Analyze Big Data with Apache Hadoop on Windows Azure Preview Service Update 3 (9/5/2012 for Red Gate Software’s ACloudyPlace blog)

• Himanshu Singh (@himanshuks) posted Matt Winkler’s Getting Started with Windows Azure HDInsight Service on 10/24/2012:
Editor's Note: This post comes from Matt Winkler (pictured below), Principal Program Manager at Microsoft.
This morning we made some big announcements about delivering Hadoop for Windows Azure users. Windows Azure HDInsight Service is the easiest way to deploy, manage and scale Hadoop based solutions. This release includes:
Hadoop updates that ensure the latest stable versions of:
- HDFS and Map/Reduce
- Pig
- Hive
- Sqoop
- Increased availability of the preview service
- A local, developer installation of Microsoft HDInsight Server
- An SDK for writing Hadoop jobs using .NET and Visual Studio
Community Contributions
Getting Access to the HDInsight Service
In order to get started, head to http://www.hadooponazure.com and submit the invitation form. We are sending out invitation codes as capacity allows. Once in the preview, you can provision a cluster, for free, for 5 days. We’ve made it super easy to leverage Windows Azure Blob storage, so that you can store your data permanently in Blob storage, and bring your Hadoop cluster online only when you need to process data. In this way, you only use the compute you need, when you need it, and take advantage of the great features of Windows Azure storage, such as geo-replication of data and using that data from any application.
Simplifying Development
Hadoop has been built to allow a rich developer ecosystem, and we’re taking advantage of that in order to make it easier to get started writing Hadoop jobs using the languages you’re familiar with. In this release, you can use JavaScript to build Map/Reduce jobs, as well as compose Pig and Hive queries using the JavaScript console hosted on the cluster dashboard. The JavaScript console also provides the ability to explore data and refine your jobs in an easy syntax, directly from a web browser.

For .NET developers, we’ve built an API on top of Hadoop streaming that allows for writing Map/Reduce jobs using .NET. This is available in NuGet, and the code is hosted on CodePlex. Some of the features include:
- Choice of loose or strong typing
- In memory debugging
- Submission of jobs directly to a Hadoop cluster
- Samples in C# and F#
Get Started
- Sign up for the Windows Azure HDInsight Service Preview.
- Download the Microsoft HDInsight Server community technology preview.
- Get started with the .NET SDK For Hadoop.



•• Thor Olavsrud (@ThorOlavsrud), a senior writer for CIO.com, provides a third-party view of HDInsight in an article for NetworkWorld of 10/24/2012:
Microsoft this week is focused on the launch of its converged Windows 8 operating system, which a number of pundits and industry watchers have declared a make-or-break release for the company, but in the meantime Microsoft is setting its sights on the nascent but much-hyped big data market by giving organizations the capability to deploy and manage Hadoop in a familiar Windows context.
Two days ahead of the Windows 8 launch, Microsoft used the platform provided by the O'Reilly Strata Conference + Hadoop World here in New York to announce an expanded partnership with Hortonworks-provider of a Hadoop distribution and one of the companies that has taken a leading role in the open source Apache Hadoop project- and to unveil new previews of a cloud-based solution and an on-premise solution for deploying and managing Hadoop. The previews also give customers the capability to use Excel, PowerPivot for Excel and Power View for business intelligence (BI) and data visualization on the data in Hadoop.
IN DEPTH: Hadoop wins over enterprise IT, spurs talent crunch
"Microsoft's entry expands the potential market dramatically and connects Hadoop directly to the largest population of business analysts: users of Microsoft's BI tools," says Merv Adrian, research vice president, Information Management, at Gartner. "If used effectively, Microsoft HDInsight will enable a significant expansion of the scope of data available to analysts without introducing substantial new complexity to them."
Microsoft Promises to Reduce Big Data Complexity
"This provides a unique set of offerings in the marketplace," says Doug Leland, general manager of SQL Server Marketing at Microsoft. "For the first time, customers will have the enterprise characteristics of a Windows offering-the simplicity and manageability of Hadoop on Windows-wrapped up with the security of the Windows infrastructure in an offering that is available both on-premise and in the cloud. This will ultimately take out some of the complexity that customers have experienced with some of their earlier investigations of big data technologies."
"Big data should provide answers for business, not complexity for IT," says David Campbell, technical fellow, Microsoft. "Providing Hadoop compatibility on Windows Server and Azure dramatically lowers the barriers to setup and deployment and enables customers to pull insights from any data, any size, on-premises or in the cloud."
One of the pain points experienced by just about any organization that seeks to deploy Hadoop is the shortage of Hadoop skills among the IT staff. Engineers and developers with Hadoop chops are difficult to come by. Gartner's Adrian is quick to note that HDInsight in either flavor won't eliminate that issue, but it will allow more people in the organization to benefit from big data faster.
"The shortage of skills continues to be a major impediment to adoption," Adrian says. "Microsoft's entry does not relieve the shortage of experienced Hadoop staff, but it does amplify their ability to deliver their solutions to a broad audience when their key foundation work has been done." …


<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
‡‡ Han, MSFT of the Sync Team answered Where in the world is SQL Data Sync? in a 10/28/2012 post:
During this past weekend, the new Windows Azure portal was officially released. Windows Azure subscribers are now directed to the new portal once they log in. Now, you may have noticed that SQL Data Sync is not in the new Windows Azure portal. Don't worry, SQL Data Sync still exists. We are working to port SQL Data Sync onto the new portal soon. In the mean time, SQL Data Sync users can continue to access SQL Data Sync via the old portal. To access the old portal, you will need to click on your user name on the top right corner. A context menu will appear. Click on the Previous portal link to redirect to the old portal (see below).


“Old portal” = Silverlight portal:

‡‡ Ralph Squillace described Data Paging using the Windows Azure Mobile Services iOS client SDK in a 10/28/2012 post:
As another follow up to an earlier post, I'm walking through the Windows Azure Mobile Services Tutorials to add in the iOS client version of handling data validation. This tutorial (like the earlier one), will appear on windowsazure.com soon, builds up from either the Getting Started With Data or the Using Scripts to Authorize Users iOS tutorials, in that you can use a running application and service from either of those tutorials to get service validation working and handled properly on the client. Then we'll walk through data paging and continue on the tour.
The steps are as follows. You must have either the Getting Started With Data or the Using Scripts to Authorize Users iOS tutorials completed and running.
- Open the project of one of the preceding iOS tutorial applications.
- Run the application, and enter at least four (4) items.
- Open the TodoService.m file, and locate the - (void) refreshDataOnSuccess:(CompletionBlock)completion method. Replace the body of the entire method with the following code. This query returns the top three items that are not marked as completed. (Note: To perform more interesting queries, you use the MSQuery instance directly.)
// Create a predicate that finds active items in which complete is false
NSPredicate * predicate = [NSPredicate predicateWithFormat:@"complete == NO"];
// Retrieve the MSTable's MSQuery instance with the predicate you just created.
MSQuery * query = [self.table queryWhere:predicate];
query.includeTotalCount = TRUE; // Request the total item count
// Start with the first item, and retrieve only three items
query.fetchOffset = 0;
query.fetchLimit = 3;
// Invoke the MSQuery instance directly, rather than using the MSTable helper methods.
[query readWithCompletion:^(NSArray *results, NSInteger totalCount, NSError *error) {
[self logErrorIfNotNil:error];
if (!error)
{
// Log total count.
NSLog(@"Total item count: %@",[NSString stringWithFormat:@"%zd", (ssize_t) totalCount]);
}
items = [results mutableCopy];
// Let the caller know that we finished
completion();
}];4. Press Command + R to run the application in the iPhone or iPad simulator. You should see only the first three results listed in the application.
5. (Optional) View the URI of the request sent to the mobile service by using message inspection software, such as browser developer tools or Fiddler. Notice that the Take(3) method was translated into the query option $top=3 in the query URI.
6. Update the RefreshTodoItems method once more by locating the query.fetchOffset = 0; line and setting the query.fetchOffset value to 3. This will take the next three items after the first three.
These modified query properties:
query.includeTotalCount = TRUE; // Request the total item count
// Start with the first item, and retrieve only three items
query.fetchOffset = 0;
query.fetchLimit = 3;
skips the first three results and returns the next three after that (in addition to returning the total number of items available for your use). This is effectively the second "page" of data, where the page size is three items.
7. (Optional) Again view the URI of the request sent to the mobile service. Notice that the Skip(3) method was translated into the query option $skip=3 in the query URI.
8. Finally, if you want to note the total number of possible Todo items that can be returned, we wrote that to the output window in Xcode. Mine looked like this:
2012-10-28 00:02:34.182 Quickstart[1863:11303] Total item count: 8
but my application looked like this:

With that, and the total count, and you can implement any paging you might like, including infinite lazy scrolling.



‡ Gregory Leake posted Announcing the Windows Azure SQL Data Sync October Update to the Window Azure blog on 10/26/2012:
We are happy to announce the new October update for the SQL Data Sync service is now operational in all Windows Azure data centers.
In this update, users can now create multiple Sync Servers under a single Windows Azure subscription. With this feature, users intending to create multiple sync groups with sync group hubs in different regions will enjoy performance improvements in data synchronization by provisioning the corresponding Sync Server in the same region where the synchronization hub is provisioned.
Further information on SQL Data Sync
SQL Data Sync enables creating and scheduling regular synchronizations between Windows Azure SQL Database and either SQL Server or other SQL Databases. You can read more about SQL Data Sync on MSDN. We have also published SQL Data Sync Best Practices on MSDN.
The team is hard at work on future updates as we march towards General Availability, and we really appreciate your feedback to date! Please keep the feedback coming and use the Windows Azure SQL Database Forum to ask questions or get assistance with issues. Have a feature you’d like to see in SQL Data Sync? Be sure to vote on features you’d like to see added or updated using the Feature Voting Forum.

‡ Nick Harris (@cloudnick) and Nate Totten (@ntotten) posted Episode 92 - iOS SDK for Windows Azure Mobile Services of the CloudCover show on 10/27/2012:
In this episode Nick and Nate are joined by Chris Risner who is a Technical Evangelist on the team focusing on iOS and Android development and Windows Azure. Chris shows us the latest addition to Windows Azure Mobile Services, the iOS SDK. Chris demonstrates, from his Mac, how easy it is to get started using Windows Azure and build a cloud connected iOS app using the new Mobile Services SDK.
In the News:

•• Carlos Figuera explained Getting user information on Azure Mobile Services in a 10/24/2012 post:
With the introduction of the server-side authentication flow (which I mentioned in my last post), it’s now a lot simpler to authenticate users with Windows Azure Mobile Services. Once the LoginAsync / login / loginViewControllerWithProvider:completion: method / selector completes, the user is authenticated, the MobileServiceClient / MSClient object will hold a token that is used for authenticating requests, and it can now be used to access authentication-protected tables. But there’s more to authentication than just getting a unique identifier for a user – we can also get more information about the user from the providers we used to authenticate, or even act on their behalf if they allowed the application to do so.
With Azure Mobile Services you can still do this. However, the property is not available at the user object stored at the client – the only property it exposes is the user id, which doesn’t give the information that the user authorized the providers to give. This post will show, for the supported providers, how to get access to some of their properties, using their specific APIs.
User identities
The client objects doesn’t expose any of that information to the application, but at the server side, we can get what we need. The User object which is passed to all scripts has now a new function, getIdentities(), which returns an object with provider-specific data which can be used to query their user information. For example, for a user authenticated with a Facebook credential in my app, this is the object returned by calling user.getIdentities():
{
"facebook":{
"userId":"Facebook:my-actual-user-id",
"accessToken":"the-actual-access-token"
}
}And for Twitter:
{
"twitter":{
"userId":"Twitter:my-actual-user-id",
"accessToken":"the-actual-access-token",
"accessTokenSecret":"the-actual-access-token-secret"
}
}Microsoft:

{
"microsoft":{
"userId":"MicrosoftAccount:my-actual-user-id",
"accessToken":"the-actual-access-token"
}
}
Google:
{
"google":{
"userId":"Google:my-actual-user-id",
"accessToken":"the-actual-access-token"
}
}Each of those objects has the information that we need to talk to the providers API. So let’s see how we can talk to their APIs to get more information about the user which has logged in to our application. For the examples in this post, I’ll simply store the user name alongside the item which is being inserted
Talking to the Facebook Graph API
To interact with the Facebook world, you can either use one of their native SDKs, or you can talk to their REST-based Graph API. To talk to it, all we need is a HTTP client, and we do have the nice request module which we can import (require) on our server scripts. To get the user information, we can send a request to https://graph.facebook.com/me, passing the access token as a query string parameter. The code below does that. It checks whether the user is logged in via Facebook; if so, it will send a request to the Graph API, passing the token stored in the user identities object. If everything goes right, it will parse the result (which is a JSON object), and retrieve the user name (from its “name” property) and store in the item being added to the table.
- function insert(item, user, request) {
- item.UserName = "<unknown>"; // default
- var identities = user.getIdentities();
- var req = require('request');
- if (identities.facebook) {
- var fbAccessToken = identities.facebook.accessToken;
- var url = 'https://graph.facebook.com/me?access_token=' + fbAccessToken;
- req(url, function (err, resp, body) {
- if (err || resp.statusCode !== 200) {
- console.error('Error sending data to FB Graph API: ', err);
- request.respond(statusCodes.INTERNAL_SERVER_ERROR, body);
- } else {
- try {
- var userData = JSON.parse(body);
- item.UserName = userData.name;
- request.execute();
- } catch (ex) {
- console.error('Error parsing response from FB Graph API: ', ex);
- request.respond(statusCodes.INTERNAL_SERVER_ERROR, ex);
- }
- }
- });
- } else {
- // Insert with default user name
- request.execute();
- }
- }
With the access token you can also call other functions on the Graph API, depending on what the user allowed the application to access. But if all you want is the user name, there’s another way to get this information: the userId property of the User object, for users logged in via Facebook is in the format “Facebook:<graph unique id>”. You can use that as well, without needing the access token, to get the public information exposed by the user:
- function insert(item, user, request) {
- item.UserName = "<unknown>"; // default
- var providerId = user.userId.substring(user.userId.indexOf(':') + 1);
- var identities = user.getIdentities();
- var req = require('request');
- if (identities.facebook) {
- var url = 'https://graph.facebook.com/' + providerId;
- req(url, function (err, resp, body) {
- if (err || resp.statusCode !== 200) {
- console.error('Error sending data to FB Graph API: ', err);
- request.respond(statusCodes.INTERNAL_SERVER_ERROR, body);
- } else {
- try {
- var userData = JSON.parse(body);
- item.UserName = userData.name;
- request.execute();
- } catch (ex) {
- console.error('Error parsing response from FB Graph API: ', ex);
- request.respond(statusCodes.INTERNAL_SERVER_ERROR, ex);
- }
- }
- });
- } else {
- // Insert with default user name
- request.execute();
- }
- }
The main advantage of this last method is that it can not only be used in the client-side as well.
- private async void btnFacebookLogin_Click_1(object sender, RoutedEventArgs e)
- {
- await MobileService.LoginAsync(MobileServiceAuthenticationProvider.Facebook);
- var userId = MobileService.CurrentUser.UserId;
- var facebookId = userId.Substring(userId.IndexOf(':') + 1);
- var client = new HttpClient();
- var fbUser = await client.GetAsync("https://graph.facebook.com/" + facebookId);
- var response = await fbUser.Content.ReadAsStringAsync();
- var jo = JsonObject.Parse(response);
- var userName = jo["name"].GetString();
- this.lblTitle.Text = "Multi-auth Blog: " + userName;
- }
That’s it for Facebook; let’s move on to another provider.
Talking to the Google API
The code for the Google API is fairly similar to the one for Facebook. To get user information, we send a request to https://www.googleapis.com/oauth2/v1/userinfo, again passing the access token as a query string parameter.
- function insert(item, user, request) {
- item.UserName = "<unknown>"; // default
- var identities = user.getIdentities();
- var req = require('request');
- if (identities.google) {
- var googleAccessToken = identities.google.accessToken;
- var url = 'https://www.googleapis.com/oauth2/v1/userinfo?access_token=' + googleAccessToken;
- req(url, function (err, resp, body) {
- if (err || resp.statusCode !== 200) {
- console.error('Error sending data to Google API: ', err);
- request.respond(statusCodes.INTERNAL_SERVER_ERROR, body);
- } else {
- try {
- var userData = JSON.parse(body);
- item.UserName = userData.name;
- request.execute();
- } catch (ex) {
- console.error('Error parsing response from Google API: ', ex);
- request.respond(statusCodes.INTERNAL_SERVER_ERROR, ex);
- }
- }
- });
- } else {
- // Insert with default user name
- request.execute();
- }
- }
Notice that the code is so similar that we can just merge them into one:
- function insert(item, user, request) {
- item.UserName = "<unknown>"; // default
- var identities = user.getIdentities();
- var url;
- if (identities.google) {
- var googleAccessToken = identities.google.accessToken;
- url = 'https://www.googleapis.com/oauth2/v1/userinfo?access_token=' + googleAccessToken;
- } else if (identities.facebook) {
- var fbAccessToken = identities.facebook.accessToken;
- url = 'https://graph.facebook.com/me?access_token=' + fbAccessToken;
- }
- if (url) {
- var requestCallback = function (err, resp, body) {
- if (err || resp.statusCode !== 200) {
- console.error('Error sending data to the provider: ', err);
- request.respond(statusCodes.INTERNAL_SERVER_ERROR, body);
- } else {
- try {
- var userData = JSON.parse(body);
- item.UserName = userData.name;
- request.execute();
- } catch (ex) {
- console.error('Error parsing response from the provider API: ', ex);
- request.respond(statusCodes.INTERNAL_SERVER_ERROR, ex);
- }
- }
- }
- var req = require('request');
- var reqOptions = {
- uri: url,
- headers: { Accept: "application/json" }
- };
- req(reqOptions, requestCallback);
- } else {
- // Insert with default user name
- request.execute();
- }
- }
And with this generic framework we can add one more:
Talking to the Windows Live API
Very similar to the previous ones, just a different URL. Most of the code is the same, we just need to add a new else if branch:
- if (identities.google) {
- var googleAccessToken = identities.google.accessToken;
- url = 'https://www.googleapis.com/oauth2/v1/userinfo?access_token=' + googleAccessToken;
- } else if (identities.facebook) {
- var fbAccessToken = identities.facebook.accessToken;
- url = 'https://graph.facebook.com/me?access_token=' + fbAccessToken;
- } else if (identities.microsoft) {
- var liveAccessToken = identities.microsoft.accessToken;
- url = 'https://apis.live.net/v5.0/me/?method=GET&access_token=' + liveAccessToken;
- }
And the user name can be retrieved in the same way as the others – notice that this is true because all three providers seen so far return the user name in the “name” property, so we didn’t need to change the callback code.
Getting Twitter user data
Twitter is a little harder than the other providers, since it needs two things from the identity (access token and access token secret), and one of the request headers needs to be signed. For simplicity here I’ll just use the user id trick as we did for Facebook:
- if (identities.google) {
- var googleAccessToken = identities.google.accessToken;
- url = 'https://www.googleapis.com/oauth2/v1/userinfo?access_token=' + googleAccessToken;
- } else if (identities.facebook) {
- var fbAccessToken = identities.facebook.accessToken;
- url = 'https://graph.facebook.com/me?access_token=' + fbAccessToken;
- } else if (identities.microsoft) {
- var liveAccessToken = identities.microsoft.accessToken;
- url = 'https://apis.live.net/v5.0/me/?method=GET&access_token=' + liveAccessToken;
- } else if (identities.twitter) {
- var userId = user.userId;
- var twitterId = userId.substring(userId.indexOf(':') + 1);
- url = 'https://api.twitter.com/users/' + twitterId;
- }
And since the user name is also stored in the “name” property of the Twitter response, the callback doesn’t need to be modified.
Accessing provider APIs from the client
So far I’ve shown how you can get user information from the script, and some simplified version of it for the client side (for Facebook and Twitter). But what if we want the logic to access the provider APIs to live in the client, and just want to retrieve the access token which is stored in the server? Right now, there’s no clean way of doing that (no “non-CRUD operation” support on Azure Mobile Services), so what you can do is to create a “dummy” table that is just used for that purpose.
In the portal, create a new table for your application – for this example I’ll call it Identities, set the permissions for Insert / Delete and Update to “Only Scripts and Admins” (so that nobody will insert any data in this table), and for Read set to “Only Authenticated Users”

Now in the Read script, return the response as requested by the caller, with the user identities stored in a field of the response. For the response: if a specific item was requested, return only one element; otherwise return a collection with only that element:
- function read(query, user, request) {
- var result = {
- id: query.id,
- identities: user.getIdentities()
- };
- if (query.id) {
- request.respond(200, result);
- } else {
- request.respond(200, [result]);
- }
- }
And we can then get the identities on the client as a JsonObject by retrieving data from that “table”.
- var table = MobileService.GetTable("Identities");
- var response = await table.ReadAsync("");
- var identities = response.GetArray()[0].GetObject();
Notice that there’s no LookupAsync method on the “untyped” table, so the result is returned as an array; it’s possible that this will be added to the client SDK in the future, so we won’t need to get the object from the (single-element) array, receiving the object itself directly.
Wrapping up
The new multi-provider authentication support added in Azure Mobile Services made it quite easy to authenticate users to your mobile application, and it also gives you the power to access the provider APIs. If you have any comments or feedback, don’t hesitate to send either here on in the Azure Mobile Services forum.

Carlos Figuera posted Troubleshooting authentication issues in Azure Mobile Services on 10/22/2012:
With the announcement last week in ScottGu’s blog, Azure Mobile Service now supports different kinds of authentication in addition to authentication using the Windows Live SDK which was supported at first. You can now authenticate the users of your applications using Facebook, Google, Twitter and even Microsoft Accounts (formerly known as Live IDs) without any native SDK for those providers, just like on web applications. In fact, the authentication is done exactly by the application showing an embedded web browser control which talks to the authentication provider’s websites. In the example below, we see an app using Twitter to authenticate its user.


There are a number of issues which may be causing this problem, and the nature of authentication of connected mobile applications, with three distinct components (the mobile app itself, the Azure Mobile Service, and the identity provider) makes debugging it harder than simple applications.
There is, however, one nice trick which @tjanczuk (who actually implemented this feature) taught me and can make troubleshooting such problems a little easier. What we do essentially is to remove one component of the equation (the mobile application), to make debugging the issue simpler. The trick is simple: since the application is actually hosting a browser control to perform the authentication, we’ll simply use a real browser to do that. By talking to the authentication endpoints of the mobile service runtime directly, we can see what’s going on behind the scenes of the authentication protocol, and hopefully fix our application.
The authentication endpoint
Before we go into broken scenarios, let’s talk a about the authentication endpoint which we have in the Azure Mobile Services runtime. As of the writing of this post the REST API Reference for Windows Azure Mobile Services has yet to be updated for the server-side (web-based) authentication support, so I’ll cover it briefly here.
The authentication endpoint for an Azure Mobile Service responds to GET requests to https://<service-name>.azure-mobile.net/login/<providerName>, where <providerName> is one of the supported authentication providers (currently “facebook”, “google”, “microsoftaccount” or “twitter”). When a browser (or the embedded browser control) sends a request to that address, the Azure Mobile Service runtime will respond with a redirect (HTTP 302) response to the appropriate page on the authentication provider (for example, the twitter page shown in the first image of this post). Once the user enters valid credentials, the provider will redirect it back to the Azure Mobile Service runtime with its specific authentication token. At that time, the runtime will validate those credentials with the provider, and then issue its own token, which will be used by the client as the authentication token to communicate with the service.

The diagram above shows a rough picture of the authentication flow. Notice that the client may send more than one request to the authentication provider, as it’s often first asks the user to enter its credentials, then (at least once per application) asks the user to allow the application to use its credentials. What the browser control in the client does is to monitor the URL to where it’s navigating, and when it sees that it’s navigating to the /login/done endpoint, it will know that the whole authentication “dance” has finished. At that point, the client can dispose the browser control and store the token to authenticate future requests it sends.
This whole protocol is just a bunch of GET requests and redirect responses. That’s something that a “regular” browser can handle pretty well, so we can use that to make sure that the server is properly set up. So we’ll now see some scenarios where we can use a browser to troubleshoot the server-side authentication. For this scenario I prefer to use either Google Chrome or Mozilla Firefox, since they can display JSON payloads in the browser itself, without needing to go to the developer tools. With Internet Explorer you can also do that, but by default it asks you to save the JSON response in a file, which I personally find annoying. Let’s move on to some problems and how to identify them.
Missing configuration
Once the mobile service application is created, no identity provider credentials are set in the portal. If the authentication with a specific provider is not working, you can try browsing to it. In my application I haven’t set the authentication credentials for Google login, so I’ll get a response saying so in the browser.

To fix this, go to the portal, and enter the correct credentials. Notice that there was a bug in the portal until last week where the credentials were not being properly propagated to the mobile service runtime (it has since been fixed). If you added the credentials once this was released, you can try removing them, then adding them again, and it should go through.
Missing redirect URL
In all of the providers you need to set the redirect URL so that the provider knows to, after authenticating the user, redirect it back to the Azure Mobile Service login page. By using the browser we can check see that error clearer than when using an actual mobile application. For example, this is what we get when we forget to set the “Site URL” property on Facebook, after we browse to https://my-application-name.azure-mobile.net/login/facebook:

And for Windows Live (a.k.a. Microsoft Accounts), after browsing to https://my-application-name.azure-mobile/login/microsoftaccount:

Not as clear an error as the one from Facebook, but if you look at the URL in the browser (may need to copy/paste to a text editor to see better):
https://login.live.com/err.srf?lc=1033
#error=invalid_request&
error_description=The%20provided%20value%20for%20the%20input%20parameter%20'redirect_uri'%20is%20not%20valid.%20The%20expected%20value%20is%20'https://login.live.com/oauth20_desktop.srf'%20or%20a%20URL%20which%20matches%20the%20redirect%20URI%20registered%20for%20this%20client%20application.&
state=13cdf4b00313a8b4302f6It will have an error description saying that “The provided value for the input parameter 'redirect_uri' is not valid”.
For other providers the experience is similar.
Invalid credentials
Maybe when copying the credentials from the provider site to the Windows Azure Mobile Services portal, the authentication will also fail, but only after going through . In this case, most providers will just say that there is a problem in the request, so one spot to look for issues is on the credentials to see if the ones in the portal match the ones in the provider page. Here are some examples of what you’ll see in the browser when that problem happens. Twitter will mention a problem with the OAuth request (OAuth being the protocol used in the authentication):

Facebook, Microsoft and Google accounts have different errors depending on whether the error is at the client / app id or the client secret. If the error is at the client id, then the provider will display an error right away. For example, Microsoft accounts will show its common error page

But the error description parameter in the URL shows the actual problem: “The client does not exist. If you are the application developer, configure a new application through the application management site at https://manage.dev.live.com/.” Facebook isn’t as clear, with a generic error.

Google is clearer, showing the error right on the first page:

Now, when the client / app id is correct, but the problem is on the app secret, then all three providers (Microsoft, Facebook, Google) will show the correct authentication page, asking for the user credentials. Only when the authentication with the provider is complete, and it redirects it back to the Azure Mobile Service (step 5 in the authentication flow diagram above), and the runtime tries to validate the token with the provider is that it will show the error. Here are the errors which the browser will show in this case. First, Facebook:

Google:

Microsoft:

Other issues
I’ve shown the most common problems which we’ve seen here which we can control. But as usual, there may be times where things just don’t work – network connectivity issues, blackouts on the providers. As with all distributed systems, those issues can arise from time to time which are beyond the control of the Azure Mobile Services. For those cases, you should confirm that those components are working correctly as well.
When everything is fine
Hopefully some of the troubleshoots steps I’ve shown here you’ve been able to fix your server-side authentication with the Azure Mobile Services. If that’s the case, you should see this window.

And with that window (code: 200), you’ll know that, at least the server / provider portion of the authentication dance is ready. With the simple client API, hopefully that will be enough to get your application authentication support.
















<Return to section navigation list>
Marketplace DataMarket, Cloud Numerics, Big Data and OData
‡ Paul van Bladel (@paulbladel) described A cool OData hack in LightSwitch on 10/27/2012:
Introduction
Warning: this post is nerd-only.

We’ll try to add a record directly over the Odata service, even without making a service reference !
Our Setting
We simply start with an empty LightSwitch application in which we add:
- an entity type “Customer” with 2 fields: LastName and FirstName
- A completely empty screen (start with a new data screen and do not relate it to an entity type)
How?
using System; using System.Linq; using System.IO; using System.IO.IsolatedStorage; using System.Collections.Generic; using Microsoft.LightSwitch; using Microsoft.LightSwitch.Framework.Client; using Microsoft.LightSwitch.Presentation; using Microsoft.LightSwitch.Presentation.Extensions; using LightSwitchApplication.Implementation; using System.Data.Services.Client; namespace LightSwitchApplication { public partial class ODataUpdate { [global::System.Data.Services.Common.EntitySetAttribute("Customers")] [global::System.Data.Services.Common.DataServiceKeyAttribute("Id")] public class MyCustomer { public int Id { get; set; } public string LastName { get; set; } public string FirstName { get; set; } public byte[] RowVersion { get; set; } } partial void AddCustomer_Execute() { MyCustomer c = new MyCustomer(); c.FirstName = "paul"; c.LastName = "van bladel"; Microsoft.LightSwitch.Threading.Dispatchers.Main.BeginInvoke(() => { Uri uri = new Uri(System.Windows.Application.Current.Host.Source, "../ApplicationData.svc"); DataServiceContext _appService = new DataServiceContext(uri); _appService.AddObject("Customers", c); _appService.BeginSaveChanges(SaveChangesOptions.Batch, (IAsyncResult ac) => { _appService = ac.AsyncState as DataServiceContext; DataServiceResponse response = _appService.EndSaveChanges(ac); }, _appService); }); } } }I needed to introduce a separate MyCustomer class and decorate this with the EntitySet and DataServiceKey attributes. When I try to do the save with the Customer type instead I get, for unknown reasons, and error: “This operation requires the entity to be of an Entity Type, either mark its key properties, or attribute the class with DataServiceEntityAttribute”. Strange, because I would suspect the build-in LightSwitch type Customer having these attributes. The MyCustomer type needs to have as well the RowVersion field.
As you can see, it works with the good old BeginExecute and EndExecute async pattern.
Could this be useful?
For your daily LightSwitch work, the answer is: by and large no !
But… imagine you want to do inter-application communications without making explicit service references towards eachother… Just update the Uri variable and you are up speed

‡ Andrew Brust (@andrewbrust) asserted “Strata + Hadoop World NYC is done, but cataloging the Big Data announcements isn't. This post aims to remedy that” in a deck for his NYC Data Week News Wraps-Up post for ZDNet’s Big Data blog:
With NYC Data Week and the Starta + Hadoop World NYC event, lots of Big Data news annoucements have been made, many of which I've covered.
- Also read: NYC Data Week, Day 1: IBM, Tervela, Cisco and SiSense announce
- Also read: More Big Data news: Datameer, Nominum/IBM, Actuate/Quiterian
- Also read: Strata + Hadoop World opens, brings Big Data announcements
After a full day at the show and series of vendor briefings this week, I wanted to report back on the additional Big Data news coming out with the events' conclusion.
Cloudera Impala
Cloudera announced a new Hadoop component, Impala, that elevates SQL to peer level with MapReduce as a query tool for Hadoop. Although API-compatible with Hive, Impala is a native SQL engine that runs on the Hadoop cluster and can query data in the Hadoop Distributed File System (HDFS) and HBase. (Hive merely translates the SQL-like HiveQL language to Java code and then runs a standard batch-mode Hadoop MapReduce job.)
- Also read: Cloudera’s Impala brings Hadoop to SQL and BI
- Also read: Cloudera aims to bring real-time queries to Hadoop, big data
Impala, currently in Beta, is part of Cloudera’s Distribution including Apache Hadoop (CDH) 4.1, but is not currently included with other Hadoop distributions. Impala is open source, and it’s Apache-licensed, but it is not an Apache Software Foundation project, as most Hadoop components are. Keep in mind, though, that Sqoop, the import-export framework that moves data between Hadoop and Data Warehouses/relational databases, also began as a Cloudera-managed open source project and is now an Apache project. The same may happen with Impala.
MapR optimizes HBase, sets new Terasort record
MapR, makers of a Hadoop distribution which replaces HDFS with an API-compatible layer over standard network file systems, and which is offered as a cloud service via Amazon Elastic Map Reduce and soon on Google Compute Engine, introduced a new Hadoop Distribution at Strata+ Hadoop World. Dubbed M7, the new distribution includes a customized version of HBase, the Wide Column Store NoSQL database included with most Hadoop distributions.For this special version of HBase in M7, MapR has integrated HBase directly into the MapR distribution. And since MapR’s file system is not write-once as is HDFS, MapR’s HBase can avoid buffered writes and compactions, making for faster operation and largely eliminating limits on the number of tables in the database. Additionally, various HBase components have been rewritten in C++, eliminating the Java Virtual Machine as a layer in the database operations, and further boosting performance.
And a postscript: MapR announced that its distribution (ostensibly M3 or M5) running on the Google Compute Engine cloud platform, has broken the time record for the Big Data Terasort benchmark, coming in at under one minute -- a first. The cloud cluster employed 1,003 servers, 4,012 cores and 1,003 disks. The previous Terasort record, 62 seconds, was set by Yahoo running vanilla Apache Hadoop on 1,460 servers, 11,680 cores and 5,840 disks.
SAP Big Data Bundle
While SAP has interesting Big Data/analytics offerings, including the SAP HANA in-memory database, the Sybase IQ columnar database, the Business Objects business intelligence suite, and its Data Integrator Extract Transform and Load (ETL) product, it doesn’t have its own Hadoop distro. Neither do a lot of companies. Instead, they partner with Cloudera or Hortonworks shipping one of their distributions instead.SAP has joined this club, and then some. The German software giant announced its Big Data Bundle, which can include all of the aforementioned Big Data/analytics products of its own, optionally in combination with Cloudera’s or Hortonworks' Hadoop distributions. Moreover, the company is partnering with IBM, HP and Hitachi to make the Big Data Bundle available as a hardware-integrated appliance. Big stuff.
EMC/Greenplum open sources Chorus
The Greenplum division of EMC announced the open source release of its Chorus collaboration platform for Big Data. Chorus is a Yammer-like tool for various Big Project team members to communicate and collaborate in their various roles. Chorus is both Greenplum database- and Hadoop-aware.On Chorus, data scientists might communicate their data modeling work, Hadoop specialists might mention the data they have amassed and analyzed, BI specialists might chime in about the refinement of that data they have performed in loading it into Greenplum, and business users might convey their success in using the Green plum data and articulate new requirements, iteratively. The source code for this platform is now in an open source repository on GitHub.
Greenplum also announced a partnership with Kaggle, a firm that runs data science competitions, which will now use the Chrous platform.
Pentaho partners
Pentaho, a leading open source business intelligence provider announced its close collaboration with Cloudera on the Impala project, and a partnership with Greenplum on Chorus. Because of these partnerships, Pentaho’s Interactive Report Writer integrates tightly with Impala and the company’s stack is compatible with Chorus. …

‡ Andrew Lavshinsky posted First Look: Querying Project Server 2013 OData with LINQPad on 10/21/2012 (missed when published):
As I gradually immerse myself into the world of Project Server 2013, one of the major changes I’ve been forced to come to grips with is the new method of querying Project Server data through OData. OData is now the preferred mechanism to surface cloud based data, and is designed to replace direct access to the SQL database.
To access Project Server OData feeds, simply add this to your PWA URL:
…//_api/ProjectData/
…meaning that the PWA site at http://demo/pwa would have an OData feed at http://demo/PWA//_api/ProjectData/.
The results look something like this, i.e. pretty much like an RSS feed:

In fact, one of the tricks you’ll pick up after working with OData is turning off the default Internet Explorer RSS interface, which tends to get in the way of viewing OData feeds. Access that via the Internet Explorer > Internet Options page.

I can also consume OData feeds directly in Office applications such as Excel. In Excel 2013, I now have the option to connect to OData directly…

That yields the table selection which I may then use to develop my reports.

More on that topic in later posts. In this post, I want to talk about writing queries against OData using LINQ a querying language that some of you are probably familiar with. I would hardly call myself an expert, but I’ve found the easiest way to get up to speed is to download and install LINQPad, a free query writing tool.
With LINQPad, I can teach myself LINQ, following a simple step by step tutorial.

…and then point LINQPad at a hyper-V image of Project Server to test my queries.

…even better, LINQPad generates the URL that I’ll need to customize the OData feed from Project Server:

I.e. the query above to select the Project Name and Project Start from all projects starting after 1/1/2013 yields a URL of:
http://demo/PWA//_api/ProjectData/Projects()?$filter=ProjectStartDate ge datetime’2013-01-01T00:00:00′&$select=ProjectName,ProjectStartDate
Minor caveat to this approach: out of the box, LINQPad doesn’t authenticate to Office 365 tenants. It looks like other folks have already figured out a solution to this, which I haven’t gotten around to deciphering on my own. In the meantime, LINQPad works fine against on-premises installations. For now, I’ll probably be developing my queries against an on-prem data set, then applying the URLs to my Office 365 tenant.
For example, using my online tenant, I can parse the following URL:
https://lavinsky4.sharepoint.com/sites/pwa//_api/ProjectData/Projects()?$filter=ProjectStartDate ge datetime’2012-01-01T00:00:00′&$select=ProjectName,ProjectStartDate
…and get the correct results. Here’s what it looks like in Excel:

Coming up….porting some of my previous report queries into LINQ.









•• Gianugo Rabellino (@gianugo) described Simplifying Big Data Interop – Apache Hadoop on Windows Server & Windows Azure in a 10/23/2012 post to the Interoperability @ Microsoft blog:
As a proud member of the Apache Software Foundation, it’s always great to see the growth and adoption of Apache community projects. The Apache Hadoop project is a prime example. Last year I blogged about how Microsoft was engaging with this vibrant community, Microsoft, Hadoop and Big Data. Today, I’m pleased to relay the news about increased interoperability capabilities for Apache Hadoop on the Windows Server and Windows Azure platforms and an expanded Microsoft partnership with Hortonworks.
Here’s what Dave had to say in the official news about how this partnership is simplifying big data in the enterprise.
“Big Data should provide answers for business, not complexity for IT. Providing Hadoop compatibility on Windows Server and Azure dramatically lowers the barriers to setup and deployment and enables customers to pull insights from any data, any size, on-premises or in the cloud.”
Dave also outlined how the Hortonworks partnership will give customers access to an enterprise-ready distribution of Hadoop with the newly released solutions.
And here’s what Hortonworks CEO Rob Bearden said about this expanded Microsoft collaboration.
“Hortonworks is the only provider of Apache Hadoop that ensures a 100% open source platform. Our expanded partnership with Microsoft empowers customers to build and deploy on platforms that are fully compatible with Apache Hadoop.”
An interesting part of my open source community role at MS Open Tech is meeting with customers and trying to better understand their needs for interoperable solutions. Enhancing our products with new Interop capabilities helps reduce the cost and complexity of running mixed IT environments. Today’s news helps simplify deployment of Hadoop-based solutions and allows customers to use Microsoft business intelligence tools to extract insights from big data.

Peter Horsman posted Here’s What’s New with the Windows Azure Marketplace on 10/23/2012:
Making things easier and more efficient while helping you improve productivity, is the name of the game at the Windows Azure Marketplace. In this month’s release, the addition of Windows Azure Active Directory simplifies the user experience, while access to new content expands your capabilities.
Improved Experience
Now you can use your Windows Azure Active Directory ID (your Office 365 login) to access the Windows Azure Marketplace. We heard your feedback about improving efficiency. With just a single identity to manage, publishing and promoting—even purchasing--offerings becomes easier. And the process of updating, organizing and managing contact and ecommerce details becomes more secure and streamlined too.
In addition, the marketplace has lots of new content from great providers who are committed to expanding the power of the Windows Azure platform.
New Data Sources
Check out new data offerings from RegioData Research GmbH, including RegioData Purchasing Power Austria 2012 and RegioData Purchasing Power United Kingdom 2012. Purchasing Power refers to the ability of one person or one household to buy goods, services or rights with a given amount of money within a certain period of time. These indices clearly represent the regional prosperity levels and disposable incomes (including primary and transfer income) in Austria and the UK respectively. You can browse the full list of data sources available in the Marketplace here.
New Apps
In the realm of apps, we have new content from High 5 Software, ClearTrend Research, QuickTracPlus, and multiple providers out of Barcelona including Santin e Associati S.r.l. (Tempestive). You’ll find everything from web content management tools to document generation to staff auditing and management apps. Take a look:
- SME: Service Management Enterprise
- KERN4CLOUD (Spanish version)
- MeasureBox
- clearTREND
- Service Delivery Broker
- Tempestive GhostWriter on the Cloud
- PushLocker
- Cloud-FTP
- Smartsite iXperion for Azure - Dynamic Web Content Management
- Cherrystaff
- QuickTracPlus
You can check out the complete list of apps available in the Marketplace here.
We’ve got more exciting features in coming releases, so stay tuned for more updates!
<Return to section navigation list>
Windows Azure Service Bus, Caching, Access Control & Identity Services, Active Directory and Workflow
•• Mick Badran (@mickba) announced Azure: Windows Workflow Manager 1.0 RTMed on 10/24/2012:
Great news – Jurgen Willis and his team have worked hard to bring Microsoft’s first V1.0 WF Workflow Hosting Manager.
It runs both as part of Windows Server and within Azure VMs also. It also is used by the SharePoint team in 2013, so learn it once and you’ll get great mileage out of it.
(I’m yet to put it through serious paces)
The following main areas for WF improvements in .NET 4.5: (great MSDN magazine article)
- Workflow Designer enhancements
- C# expressions
- Contract-first authoring of WCF Workflow Services
- Workflow versioning
- Dynamic update
- Partial trust
- Performance enhancements
Specifically for WorkflowManager there’s integration with:
1. Windows Azure Service Bus.
So all in all a major improvement and we’ve now got somewhere serious to host our WF Services. If you’ve ever gone through the process of creating your own WF host, you’ll appreciate it’s not a trivial task especially if you want some deeper functionality such as restartability and fault tolerance.
but…. if you want to kick off a quick WF to be part of an install script, evaluate an Excel spreadsheet and set results, then hosting within the app, spreadsheet is fine.
Let’s go through installation:
Download from here

Workflow_Manager_BPA.msi = Best Practices Analyser.
WorfklowClient = Client APIs, install on machines that want to communicate to WF Manager.
WorkflowManager = the Server/Service Component.
WorkflowTools = VS2012 plugin tools – project types etc.
And we’ll grab the 4 or you can you the Web Platform Installer

The Workflow Client should install fine on it’s own (mine didn’t as I had to remove some of the beta bits that were previously installed).
Installing the Workflow Manager – create a farm, I went for a Custom Setting install below, just to show you the options.


As you scroll down on this page, you’ll notice a HTTP Port – check the check box to enable HTTP communications to the Workflow Manager.
This just makes it easier if we need to debug anything across the wire.Select NEXT or the cool little Arrow->
On Prem Service Bus is rolled into this install now – accepting defaults.

Plugin your Service Accounts and passphrase (for Farm membership and an encryption seed).
Click Next –> to reveal….

As with the latest set of MS Products a cool cool feature is the ‘Get PowerShell Commands’ so you can see the script behind your UI choices (VMM manager, SCCM 2012 has all this right through). BTW – passwords don’t get exported in the script, you’ll need to add.
Script Sample:
# To be run in Workflow Manager PowerShell console that has both Workflow Manager and Service Bus installed.
# Create new SB Farm
$SBCertificateAutoGenerationKey = ConvertTo-SecureString -AsPlainText -Force -String '***** Replace with Service Bus Certificate Auto-generation key ******' -Verbose;New-SBFarm -SBFarmDBConnectionString 'Data Source=BTS2012DEV;Initial Catalog=SbManagementDB;Integrated Security=True;Encrypt=False' -InternalPortRangeStart 9000 -TcpPort 9354 -MessageBrokerPort 9356 -RunAsAccount 'administrator' -AdminGroup 'BUILTIN\Administrators' -GatewayDBConnectionString 'Data Source=BTS2012DEV;Initial Catalog=SbGatewayDatabase;Integrated Security=True;Encrypt=False' -CertificateAutoGenerationKey $SBCertificateAutoGenerationKey -MessageContainerDBConnectionString 'Data Source=BTS2012DEV;Initial Catalog=SBMessageContainer01;Integrated Security=True;Encrypt=False' -Verbose;
# To be run in Workflow Manager PowerShell console that has both Workflow Manager and Service Bus installed.
# Create new WF Farm
$WFCertAutoGenerationKey = ConvertTo-SecureString -AsPlainText -Force -String '***** Replace with Workflow Manager Certificate Auto-generation key ******' -Verbose;New-WFFarm -WFFarmDBConnectionString 'Data Source=BTS2012DEV;Initial Catalog=BreezeWFManagementDB;Integrated Security=True;Encrypt=False' -RunAsAccount 'administrator' -AdminGroup 'BUILTIN\Administrators' -HttpsPort 12290 -HttpPort 12291 -InstanceDBConnectionString 'Data Source=BTS2012DEV;Initial Catalog=WFInstanceManagementDB;Integrated Security=True;Encrypt=False' -ResourceDBConnectionString 'Data Source=BTS2012DEV;Initial Catalog=WFResourceManagementDB;Integrated Security=True;Encrypt=False' -CertificateAutoGenerationKey $WFCertAutoGenerationKey -Verbose;
# Add SB Host
$SBRunAsPassword = ConvertTo-SecureString -AsPlainText -Force -String '***** Replace with RunAs Password for Service Bus ******' -Verbose;Add-SBHost -SBFarmDBConnectionString 'Data Source=BTS2012DEV;Initial Catalog=SbManagementDB;Integrated Security=True;Encrypt=False' -RunAsPassword $SBRunAsPassword -EnableFirewallRules $true -CertificateAutoGenerationKey $SBCertificateAutoGenerationKey -Verbose;
Try
{
# Create new SB Namespace
New-SBNamespace -Name 'WorkflowDefaultNamespace' -AddressingScheme 'Path' -ManageUsers 'administrator','mickb' -Verbose;Start-Sleep -s 90
}
Catch [system.InvalidOperationException]
{
}# Get SB Client Configuration
$SBClientConfiguration = Get-SBClientConfiguration -Namespaces 'WorkflowDefaultNamespace' -Verbose;# Add WF Host
$WFRunAsPassword = ConvertTo-SecureString -AsPlainText -Force -String '***** Replace with RunAs Password for Workflow Manager ******' -Verbose;Add-WFHost -WFFarmDBConnectionString 'Data Source=BTS2012DEV;Initial Catalog=BreezeWFManagementDB;Integrated Security=True;Encrypt=False' -RunAsPassword $WFRunAsPassword -EnableFirewallRules $true -SBClientConfiguration $SBClientConfiguration -EnableHttpPort -CertificateAutoGenerationKey $WFCertAutoGenerationKey -Verbose;
Upon completion you should see a new IIS Site…. with the ‘management ports’ of in my case HTTPS

Let’s Play
Go and grab the samples and have a play – make sure you run the samples as the user you’ve nominated as ‘Admin’ during the setup – for now.









•• Jesus Rodriguez posted NodeJS and Windows Azure: Using Service Bus Queues on 10/24/2012:
I have been doing a lot of work with NodeJS and Windows Azure lately. I am planning to write a series of blog post about the techniques required build NodeJS applications that leverage different Windows Azure components. I am also planning on deep diving into the different elements of the NodeJS modules to integrate with Windows Azure.
Getting Started
The initial step to use Azure Service Bus queues from a NodeJS application is to instantiate the ServiceBusService object as illustrated in the following code:
1: process.env.AZURE_SERVICEBUS_NAMESPACE= "MY NAMESPACE...";2: process.env.AZURE_SERVICEBUS_ACCESS_KEY= "MY ACCESS KEY....;3: var sb= require('azure');4: var serviceBusService = sb.createServiceBusService();Creating a Queue
Create a service bus queue using NodeJS is accomplished by invoking a createQueueIfNotExists operation of the ServiceBusService object. The operation can take similar several parameters to customize the settings of the queue. The following code illustrates this process.
1: function createQueueTest(queuename)2: {3: serviceBusService.createQueueIfNotExists(queuename, function(error){4: if(!error){5: console.log('queue created...');6:7: }8: })9: }Sending a Message
Placing a message in a service bus queue from NodeJS can be accomplished using the sendQueueMessage operation of the ServiceBusService object. In addition to the message payload, we can include additional properties that describe metadata associated with the message. The following NodeJS code illustrates the process of enqueueing a message in an Azure Service Bus queue using NodeJS.
1: function sendMessageTest(queue)2: {3: var message = {4: body: 'Test message',5: customProperties: {6: testproperty: 'TestValue'7: }}8:9: serviceBusService.sendQueueMessage(queue, message, function(error){10: if(!error){11: console.log('Message sent....');12: }})13: }Receiving a Message
Similarly, to the process of enqueuing a message, we can dequeue a message from a service bus queue by invoking the ReceiveMessage operation from the ServiceBusService object. By default, messages are deleted from the queue as they are read; however, you can read (peek) and lock the message without deleting it from the queue by setting the optional parameter isPeekLock to true. The following NodeJS code illustrates this technique.
1: function receiveMessageTest(queue)2: {3: serviceBusService.receiveQueueMessage(queue, function(error, receivedMessage){4: if(!error){5: console.log(receivedMessage);6: }7: })8: }Putting it all together
The following code offers a very simple way to test the different operations we explored in this blog post using simple URL patterns such as http://<server>/SEND, http://<server>/RECEIVE and http://<server>/CREATE. Now go have some fun testing Windows Azure Service Bus Queues from NodeJS.
1: function azureQueueTest(request, response)2: {3:4: var test= url.parse(request.url).path;5:6: console.log(test);7:8: var queuename= 'myqueue';9:10:11: if(test='CREATE')12: {13: createQueueTest(queu
Vittorio Bertocci (@vibronet) announced the availability of Windows Identity Foundation Tools for Visual Studio 2012 RTM in a 10/23/2012 post:
The wait is finally over! This morning we are making available the RTM version of the Identity and Access Tools for Visual Studio 2012.
Together with it, we refreshed all the WIF project samples in the code gallery to take advantage of the latest bits. All the descriptions and links to the samples remain the same as the beta.
Release Notes
- Existing code using the localSTS from the RC will need to be updated.
The localSTS changed version for RTM. As a result, all existing code taking advantage of it (RC or even Beta) will have to be updated. If you need a reference on how to do that, take a look at the code of our refreshed samples: this change is the main update we did on them, as they remain pretty much the same.- Moving apps from IIS Express to IIS will require manual adjustments.
If you create one web application targeted at IIS Express, we’ll generate the right return URLs and the like. If you create it against full IIS, we will also generate the right configs. What we won't do is proactively adjusting those values if you move your app from one environment to the other.
The tool help you to emit the config corresponding to the settings you apply in its UI, but once you’ve done that it leaves your code alone. If you want to change the realm or the return URL you should be able to do so without us undoing the change. That holds also in the case in which the change might lead to broken code: you might have very good reasons for doing so (for example: you are generating a package to the deployed elsewhere, and the settings you are putting in are the ones of the target system hence they won't work on the current one)- In order to connect to ADFS2 your app must be on HTTPS.
Biore won't stick to a dry nose, and ADFS2 won’t issue tokens to a relying party (application) that is not hosted on HTTPS: that’s just the way it works. That means that in order to use with ADFS2 the “Use a business identity provider” option in the Providers tab you’ll need to ensure that your app uses SSL. For full IIS that’s pretty straightforward; for IIS Express it’s even easier, just select the project in solution explorer and in the properties are you’ll find all the necessary settings.- Not all Identity Providers and Project Templates combinations will work.
The tool facilitates establishing trust relationships and tweaking the most common options to drive claims-based authentication; however it won't prevent requirements mismatches from happening. For example, a project template might expect claims that your identity provider won't provide (e.g. if you choose ACS+Live ID for authenticating against an MVC4 mobile template the combination won't work as the IdP will not provide all the claims the project needs)Pretty straightforward stuff, but we wanted to make sure we cover those points.
Automatic Generation of the HRD Experience
…and now for something completely different! :-)
You might recall that one of the settings we introduced in the Config tab had to do with the redirection strategy at authentication time (described here). You can read more about this here, but in a nutshell: the idea is that
- here are times in which you don't want to blindly redirect every unauthenticated request to your identity provider of choice, but you’d rather have some parts of the web app to offer content to unauthenticated users, and opt in for authentication for the areas you do want to protect. The <authorization> element and the [authorize] attribute are there for that, after all.
- there are times in which before sending the user off site to authenticate, you want the chance to steer the experience: formatting options, providing text that describes what’s going on, or whatever else you’d like to do in your authentication experience
The option we introduced did make it simpler to emit the WIF and ASP.NET configuration for 1, but it didn't do anything for 2. And while it’s not impossibly hard to write the code that takes care of that, as shown here, we kind of felt bad that you’d end up in a situation where you can’t simply F5 and see your choice in action.
Here there’s what we did about it: we added a code generation feature that will automatically generate a home realm discovery page for you.
Allow me to demonstrate.
Open Visual Studio 2012, ensure that you have the latest Identity and Access Tool, and create a new MVC4 project (internet template).
Right click on the project in solution explorer, choose Identity and Access, and pick ACS (as explained here).
Now, move to the Configuration tab. You’ll notice that the first option in “Choose how to handle unauthenticated requests” got quite longer than in the RC.

The option recites “Generate a controller in your project to handle the authentication experience at the following address”, and the textbox displays a default value for it. Hit OK. The tool will cook for a moment and return to VS.
Open HomeControllers.cs and add an [Authorize] on top of About() – then hit F5.

You’ll notice that you are not being shipped off to ACS right away, as it would usually happen; instead, you can access the home page as usual. However, let’s see what happens if you click on About:

That’s right, you are still in the application! The home realm discovery experience is rendered directly within the app, and the list of identity providers comes straight from ACS. If I click on the Google link and go through the IdP’s authentication flow, I’ll get authenticate as usual. Handy, right? :-)
Now, say that I want to rechange the identity provider of choice and I go back to the tool to move the selection from ACS to the local STS. As soon as I hit OK, I get the following:

Substantially; the tool detects that your choice would require re-generating some of the code, however it does not want to interfere with your work hence it offers you the chance of keeping your code as-is if you know what you are doing. Ah, for the record: the home realm discovery page for the local STS or ADFS2 would simply be a single link to the STS.
That’s pretty cool right? Time for some disclaimers, then :-)
This feature is meant to give you a starting point if the authentication experience you are targeting is different than the blanket redirection, but you don't want to spend an evening grokking all this. We fully expect you to get on the generated code and enhance it, which is why we display only the essential to get though the experience and we kept the generated code to an absolute minimum.
Also: we won't delete any of your existing code, which likely means that the existing login machinery from the default template wills till be there; and we’ll do our best not to ever lose anything, which means that repeated runs of this feature on the same project will lead to a lot of commented code and backups :-)Any use beyond the above will likely lead to broken code. If you apply this feature to a project which delved too far from the starting template, or if you heavily modify the code, you might end up with non-functioning authentication code. Even without invoking the halting problem, which would make impossible a perfect solution, that would be simply out of scope.
This is the first time we venture in heavier code generation: for our first foray, we scoped things down to MVC4. We believe that - provided that the scope of action of the feature is well understood – this functionality can really give more control over the authentication experience also to developers that don't want to get too deep in the nitty-gritty details or HRD generation and the like. We are looking forward to hear what you think of it!
The RTM of the Identity and Access tool for VS2012 marks an important milestone in the trajectory to democratize claims-based identity.
We are far from done yet! From making our cloud services drop-dead simple to develop against, to integrating with REST protocols and devices, to offering better integration across all of Microsoft’s development platform, the road is still long; the team is super-charged, and we can’t wait to tell you what’s next :-)







Clemens Vasters (@clemensv) posted Service Bus: BeginSend is no magic async pixie dust on 10/18/2012 (missed when published):
I just got off the call with a customer and had a bit of a déjà vu from a meeting at the beginning of the week, so it looks like the misconception I'll explain here is a bit more common than I expected.
In both cases, the folks I talked to, had the about equivalent of the following code in their app:
var qc = factory.CreateQueueClient(…);
for( int i = 0; i < 1000; i++ )
{
… create message …
qc.BeginSend( msg, null, null );
}
qc.Close();
In both cases, the complaint was that messages were lost and strange exceptions occurred in the logs – which is because, well, this doesn't do what they thought it does.
BeginSend in the Service Bus APIs or other networking APIs as much as BeginWrite on the file system isn't really doing the work that is requested. It is putting a job into a job queue – the job queue of the I/O thread scheduler.
That means that once the code reaches qc.Close() and you have also been mighty lucky, a few messages may indeed have been sent, but the remaining messages will now still sit in that job queue and scheduled for an object that the code just forced to close. With the result that every subsequent send operation that is queued but hasn't been scheduled yet will throw as you're trying to send on a disposed object. Those messages will fail out and be lost inside the sender's process.
So how should you do it? Don't throw messages blindly into the job queue. It's ok to queue up a few to make sure there's a job in the queue as another one completes (which is just slightly trickier than what I want to illustrate here), but generally you should make subsequent sends depend on previous sends completing. In .NET 4.5 with async/await that's a lot easier now:
var qc = factory.CreateQueueClient(…);
for( int i = 0; i < 1000; i++ )
{
… create message …
await task.Factory.FromAsync(qc.BeginSend, qc.EndSend, msg, null );
}
qc.Close();Keep in mind that the primary goal of async I/O is to not waste threads and lose time through excessive thread switching as threads hang on I/O operations. It's not making the I/O magically faster per-se. We achieve that in the above example as the compiler will break up that code into distinct methods where the loop continues on an I/O thread callback once the Send operation has completed.
Summary:
- Don't stuff the I/O scheduler queue with loads of blind calls to BeginXXX without consideration for how the work gets done and completed and that it can actually fail
- Always call End and think about how many operations you want to have in flight and what happens to the objects that are attached to the in-flight jobs


<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
‡‡ Sandrino Di Mattia (@sandrinodm) described Continuous Deployment with Windows Azure Websites and Bitbucket in a 10/28/2012 post:
A little over a month ago Scott Guthrie announced support for continuous deployment in Windows Azure Web Sites with GitHub and CodePlex. Yesterday while I was browsing the azure tag on StackOverflow, I noticed a very interesting answer by David Ebbo:
Update (10/27/2012): as it turns out, the Bitbucket support for public git repros just became available today, so give it a try!
Currently this is only supported for Github and Codeplex, but the Bitbucket support is around the corner. Initially, it will only support public repos, but the private repo support won’t be too far behind. Can’t give exact dates, but normally it should all happen before the end of the year.
Let’s see how easy it is to set up continuous deployment in your Windows Azure Web Site with Bitbucket.
Setup
First we’ll start by setting up our Bitbucket repository. At the moment only public repositories are supported, but as you can see in David’s answer, private repositories are on the roadmap. I’m going to create a new repository called SampleAzureWebSite, choose Git as repository type and set the language to C#.

That’s it for the Bitbucket part! Now, in the Windows Azure Portal I’ve created a new Web Site called Bitbucketwebsite and I’m going to set up Git publishing (you can find the option under quick glance):

If you’re familiar with the Git publishing screen you’ll see a new option available here: Deploy from my Bitbucket repository

By clicking the Authorize Windows Azure link you’ll grant access to your public and private repositories.

After granting access, Windows Azure will be able to show your repositories (only the public ones at the moment) in the portal. Select the repository you want to link to your Web Site:

That’s it, your repository has been linked to your Windows Azure Web Site!

Our first commit
Now that everything has been setup we can start doing some actual work. I’ve created a new ASP.NET MVC4 project and saved it under D:\Repositories\Bitbucket\SampleAzureWebSite. This will be the root of my repository. I’ve only made a small change in the HomeController:
And now I’m ready to commit (I’m using Git Bash for this). I’m simply going to initialize the repository, add all items in the local repository and commit/push all changes:

This push will trigger the continuous deployment process in Windows Azure. Go back to the Windows Azure Portal, open your Web Site and navigate to the Deployments tab. You’ll see that your changes have been picked up (notice the Initial commit comment) which triggered a build and publish to your Web Site:

That’s it! Now, each time it push something to my repository I’ll see the change on http://Bitbucketwebsite.azurewebsites.net

Again a job well done by the Windows Azure team to make deployments a walk in the park!


‡ Scott Guthrie (@scottgu) followed up with a .NET 4.5 now supported with Windows Azure Web Sites post on 10/25/2012:
This week we finished rolling out .NET 4.5 to all of our Windows Azure Web Site clusters. This means that you can now publish and run ASP.NET 4.5 based apps, and use .NET 4.5 libraries and features (for example: async and the new spatial data-type support in EF), with Windows Azure Web Sites. This enables a ton of really great capabilities - check out Scott Hanselman’s great post of videos that highlight a few of them.
Visual Studio 2012 includes built-in publishing support to Windows Azure, which makes it really easy to publish and deploy .NET 4.5 based sites within Visual Studio (you can deploy both apps + databases). With the Migrations feature of EF Code First you can also do incremental database schema updates as part of publishing (which enables a really slick automated deployment workflow).
Each Windows Azure account is eligible to host 10 free web-sites using our free-tier. If you don’t already have a Windows Azure account, you can sign-up for a free trial and start using them today.
In the next few days we’ll also be releasing support for .NET 4.5 and Windows Server 2012 with Windows Azure Cloud Services (Web and Worker Roles) – together with some great new Azure SDK enhancements. Keep an eye out on my blog for details about these soon.


•• Larry Franks (@larry_franks) described Exporting and Importing VM settings with the Azure Command-Line Tools in a 10/25/2012 post:
We've talked previously about the Windows Azure command-line tools, and have used them in a few posts such as Brian's Migrating Drupal to a Windows Azure VM. While the tools are generally useful for tons of stuff, one of the things that's been painful to do with the command-line is export the settings for a VM, and then recreate the VM from those settings.
You might be wondering why you'd want to export a VM and then recreate it. For me, cost is the first thing that comes to mind. It costs more to keep a VM running than it does to just keep the disk in storage. So if I had something in a VM that I'm only using a few hours a day, I'd delete the VM when I'm not using it and recreate it when I need it again. Another potential reason is that you want to create a copy of the disk so that you can create a duplicate virtual machine.
The export process used to be pretty arcane stuff; using the
azure vm showcommand with a--jsonparameter and piping the output to file. Then hacking the .json file to fix it up so it could be used with theazure vm create-fromcommand. It was bad. It was so bad, the developers added a newexportcommand to create the .json file for you.Here's the basic process:
Create a VM
VM creation has been covered multiple ways already; you're either going to use the portal or command line tools, and you're either going to select an image from the library or upload a VHD. In my case, I used the following command:
azure vm create larryubuntu CANONICAL__Canonical-Ubuntu-12-04-amd64-server-20120528.1.3-en-us-30GB.vhd larry NotaRealPassword --ssh 22 --location "East US"This command creates a new VM in the East US data center, enables SSH on port 22 and then stores a disk image for this VM in a blob. You can see the new disk image in blob storage by running:
azure vm disk listThe results should return something like:
info: Executing command vm disk list + Fetching disk images data: Name OS data: ---------------------------------------- ------- data: larryubuntu-larryubuntu-0-20121019170709 Linux info: vm disk list command OKThat's the actual disk image that is mounted by the VM.
Export and Delete the VM
Alright, I've done my work and it's the weekend. I need to export the VM settings so I can recreate it on Monday, then delete the VM so I won't get charged for the next 48 hours of not working. To export the settings for the VM, I use the following command:
azure vm export larryubuntu c:\stuff\vminfo.jsonThis tells Windows Azure to find the VM named larryubuntu and export its settings to c:\stuff\vminfo.json. The .json file will contain something like this:
{ "RoleName":"larryubuntu", "RoleType":"PersistentVMRole", "ConfigurationSets": [ { "ConfigurationSetType":"NetworkConfiguration", "InputEndpoints": [ { "LocalPort":"22", "Name":"ssh", "Port":"22", "Protocol":"tcp", "Vip":"168.62.177.227" } ], "SubnetNames":[] } ], "DataVirtualHardDisks":[], "OSVirtualHardDisk": { "HostCaching":"ReadWrite", "DiskName":"larryubuntu-larryubuntu-0-20121024155441", "OS":"Linux" }, "RoleSize":"Small" }If you're like me, you'll immediately start thinking "Hrmmm, I wonder if I can mess around with things like RoleSize." And yes, you can. If you wanted to bump this up to medium, you'd just change that parameter to medium. If you want to play around more with the various settings, it looks like the schema is maintained at https://github.com/WindowsAzure/azure-sdk-for-node/blob/master/lib/services/serviceManagement/models/roleschema.json.
Once I've got the file, I can safely delete the VM by using the following command.
azure vm delete larryubuntuIt spins a bit and then no more VM.
Recreate the VM
Ugh, Monday. Time to go back to work, and I need my VM back up and running. So I run the following command:
azure vm create-from larryubuntu c:\stuff\vminfo.json --location "East US"It takes only a minute or two to spin up the VM and it's ready for work.
That's it - fast, simple, and far easier than the old process of generating the .json settings file. Note that I haven't played around much with the various settings described in the schema for the json file that I linked above. If you find anything useful or interesting that can be accomplished by hacking around with the .json, leave a comment about it.


•• Nathan Totten (@ntotten) announced ASP.NET 4.5 on Windows Azure Web Sites on 10/24/2012:
As of today Windows Azure Web Sites now supports .Net Framework 4.5. This gives you the ability to use all kinds of new features with your web app. The most important feature for web developers with .Net 4.5 is the new asynchronous methods available in ASP.NET. This asynchronous support enables developers to easily build high scale and high performance web applications without all the hassle normally associated with asynchronous programming. In this post I will walk you through how to build a simple ASP.NET MVC 4 web application using .Net 4.5 and how to deploy that application to Windows Azure Web Sites.
If you don’t already have it you should install Visual Studio 2012. You can download Visual Studio Express 2012 for Web using the Web Platform installer. This version of Visual Studio is completely free.
After you are setup with Visual Studio create a new MVC 4 web app and use the internet template.
After you create the project, add a new Controller to the project that to serve our results asynchronously Change the controller to inherit from AsyncController rather than Controller. Below you will see this controller along with a simple method that utilizes async to server content asynchronously.You can see this controller returns a Task<ActionResult> rather than just the ActionResult object. The beauty of all this is that with just a few changes to how you write your controllers you can easily build services and actions that are non-blocking. This will increase the capacity of your services and improve overall performance of your application.
In addition to the new asynchronous features, another cool feature that .Net 4.5 allows is the use of spacial data types in Entity Framework. Spacial data types allow you to store data such as longitude and latitude coordinates of an object and query them in geographically appropriate ways. To use this feature with Entity Framework code-first you simply need to create an object like the one shown below that has a property of type DbGeography. You can see an example of a location object below.
You can read more about how geospatial data works in this blog post.
In order to deploy your application to Windows Azure Web Sites you simply need to download the publish profile from the portal and publish using WebDeploy. You can read more about how to create and deploy a web site to Windows Azure here.
After the site is deployed you can see how the AsyncController serves the “Hello” content after waiting for 3 seconds.

And that’s all we need to do in order to publish a .Net 4.5 site to Windows Azure.




• 
Folks, the bits have been deployed.
I expect a Microsoft blog post on the topic and will update this article when I find it.
Brian Swan (@brian_swan) described Getting Database Connection Information in Windows Azure Web Sites in a 10/23/2012 post to the [Windows Azure’s] Silver Lining blog:
A few weeks ago, I wrote a post that suggested you use app settings in Windows Azure Web Sites to store your database connection information. This approach allowed you to access database connection information as environment variables in PHP and Node.js applications.
Sql Server: SQLCONNSTR_
- MySql: MYSQLCONNSTR_
- Sql Azure: SQLAZURECONNSTR_
- Custom: CUSTOMCONNSTR_
So let’s say you create a PHP website with a MySQL database and you name the connection string connectionString1 (which is the default name):
The connection string will be accessible as an environment variable with the name MYSQLCONNSTR_connectionString1. So in PHP, you can access the connection string with the getenv function like this:
$conn_str = getenv("MYSQLCONNSTR_connectionString1");In one way, this is nicer than storing values in app settings: the connection string will be hidden by default on the site’s CONFIGURE tab in the portal:
And, if you need a properly formatted MySQL connection string you’ve got it. If however, you need the various parts of a MySQL connection string, you may want a function that breaks them out. Here is such a function, though I’m not sure this is the best such function:
function connStrToArray($conn_str){// Initialize array.$conn_array = array();// Split conn string on semicolons. Results in array of "parts".$parts = explode(";", $conn_str);// Loop through array of parts. (Each part is a string.)foreach($parts as $part){// Separate each string on equals sign. Results in array of 2 items.$temp = explode("=", $part);// Make items key=>value pairs in returned array.$conn_array[$temp[0]] = $temp[1];}return $conn_array;}So suppose you access a MySQL connection string with the getenv function as shown above, and suppose it looks something like this:
Database=bswandb;Data Source=us-cdbr-azure-east-b.cloudapp.net;User Id=b43c7d64f33b47;Password=e6e050a0If you pass this connection string to the function above, the function will return an array that looks like this:
Array ( [Database] => bswandb [Data Source] => us-cdbr-azure-east-b.cloudapp.net [User Id] => b43c7d64f33b47 [Password] => e6e050a0 )Hopefully, you can use that array when connecting to a MySQL database. Let us know what you think.
Note: We’re updating the Windows Azure Web Sites documentation to make sure it’s clear that you can access DB connection strings as environment variables with the prefixes I mentioned earlier.





<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
‡ Greg Duncan described The Windows Kinect, Ray-Tracing and Windows Azure in a 10/26/2012 post to Channel 9’s Coding for Fun/Kinect blog:
Today's cutting edge demo provides an example of how the cloud and the Kinect can be used together to create a very interesting demo...
256 Windows Azure Worker Roles, Windows Kinect and a 90's Text-Based Ray-Tracer
The “$2 demo” was great for presenting at user groups and conferences in that it could be deployed to Azure, used to render an animation, and then removed in a one hour session. I have always had the idea of doing something a bit more impressive with the demo, and scaling it from a “$2 demo” to a “$30 demo”. The challenge was to create a visually appealing animation in high definition format and keep the demo time down to one hour. This article will take a run through how I achieved this.

...
The challenge now was to make a cool animation. The Azure Logo is fine, but it is static. Using a normal video to animate the pins would not work; the colors in the video would not be the same as the depth of the objects from the camera. In order to simulate the pin board accurately a series of frames from a depth camera could be used.
Windows Kinect
The Kenect controllers for the X-Box 360 and Windows feature a depth camera. The Kinect SDK for Windows provides a programming interface for Kenect, providing easy access for .NET developers to the Kinect sensors. The Kinect Explorer provided with the Kinect SDK is a great starting point for exploring Kinect from a developers perspective. Both the X-Box 360 Kinect and the Windows Kinect will work with the Kinect SDK, the Windows Kinect is required for commercial applications, but the X-Box Kinect can be used for hobby projects. The Windows Kinect has the advantage of providing a mode to allow depth capture with objects closer to the camera, which makes for a more accurate depth image for setting the pin positions.
Creating a Depth Field Animation
The depth field animation used to set the positions of the pin in the pin board was created using a modified version of the Kinect Explorer sample application. In order to simulate the pin board accurately, a small section of the depth range from the depth sensor will be used. Any part of the object in front of the depth range will result in a white pixel; anything behind the depth range will be black. Within the depth range the pixels in the image will be set to RGB values from 0,0,0 to 255,255,255.
...

...
The render farm is a hybrid application with the following components:
On-Premise
- Windows Kinect – Used combined with the Kinect Explorer to create a stream of depth images.
- Animation Creator – This application uses the depth images from the Kinect sensor to create scene description files for PolyRay. These files are then uploaded to the jobs blob container, and job messages added to the jobs queue.
- Process Monitor – This application queries the role instance lifecycle table and displays statistics about the render farm environment and render process.
- Image Downloader – This application polls the image queue and downloads the rendered animation files once they are complete.
Windows Azure
- Azure Storage – Queues and blobs are used for the scene description files and completed frames. A table is used to store the statistics about the rendering environment.
...
Effective Use of Resources
According to the CloudRay monitor statistics the animation took 6 days, 7 hours and 22 minutes CPU to render, this works out at 152 hours of compute time, rounded up to the nearest hour. As the usage for the worker role instances are billed for the full hour, it may have been possible to render the animation using fewer than 256 worker roles. When deciding the optimal usage of resources, the time required to provision and start the worker roles must also be considered. In the demo I started with 16 worker roles, and then scaled the application to 256 worker roles. It would have been more optimal to start the application with maybe 200 worker roles, and utilized the full hour that I was being billed for. This would, however, have prevented showing the ease of scalability of the application.
The new management portal displays the CPU usage across the worker roles in the deployment.
The average CPU usage across all instances is 93.27%, with over 99% used when all the instances are up and running. This shows that the worker role resources are being used very effectively.
Grid Computing Scenarios
Although I am using this scenario for a hobby project, there are many scenarios where a large amount of compute power is required for a short period of time. Windows Azure provides a great platform for developing these types of grid computing applications, and can work out very cost effective.
- Windows Azure can provide massive compute power, on demand, in a matter of minutes.
- The use of queues to manage the load balancing of jobs between role instances is a simple and effective solution.
- Using a cloud-computing platform like Windows Azure allows proof-of-concept scenarios to be tested and evaluated on a very low budget.
- No charges for inbound data transfer makes the uploading of large data sets to Windows Azure Storage services cost effective. (Transaction charges still apply.)
Project Information URL: http://geekswithblogs.net/asmith/archive/2012/06/25/150043.aspx



•• Himanshu Singh (@himanshuks) posted Rick Anderson’s Using Trace in Windows Azure Cloud Applications article to the Windows Azure blog on 10/25/2012:
Editors Note: Today's post comes from Rick Anderson, ASP.NET MVC Programmer/Writer. He discusses using Trace in Windows Azure cloud apps.
Trace.WriteLine("Working", "Information");
The Windows Azure template generated code has the trace diagnostics listener partially configured, this post will show you how to fully configure tracing.
Persisting Trace
I like to use Trace.TraceError for errors and Trace.TraceInformation for information.
But calling the Trace API is not enough to actually persist the data in Azure. You need to configure the diagnostic monitor. I use the following code to do that:
private void ConfigDiagnostics()
{
DiagnosticMonitorConfiguration config =
DiagnosticMonitor.GetDefaultInitialConfiguration();
config.ConfigurationChangePollInterval = TimeSpan.FromMinutes(1d);
config.Logs.BufferQuotaInMB = 500;
config.Logs.ScheduledTransferLogLevelFilter = LogLevel.Verbose;
config.Logs.ScheduledTransferPeriod = TimeSpan.FromMinutes(1d);
DiagnosticMonitor.Start(
"Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString",
config);
}
In the code above, the transfer rate is set to one minute (which is the minimum, anything lower will be rounded up to one minute). If you application generates trace data very slowly, say one event per minute, only one row will be uploaded from each agent each minute in a separate transaction. By setting the upload rate to 60 minutes, then 60 rows could be packaged into a single batch and uploaded in one transaction -- you would be saving on transaction costs. The downside of using a large transfer period:
A large delay in data showing up in storage.
If there is a lot of data (dozens of thousands, or hundreds of thousands) of rows, then the upload will be bursty (as opposed to smoothed over) and hence can cause throttling.
The sample sets the ScheduledTransferLogLevelFilter to Verbose, so all trace messages are captured.
To use the code, in the OnStart() method of each web role and worker role, I call ConfigDiagnostics as shown in the following code:
public override bool OnStart()
{
ConfigDiagnostics();
Trace.TraceInformation("Initializing storage account")
// Code removed for clarity.
}
Note: The above code works only in Windows Azure Cloud Applications, it won’t work in Windows Azure Web Sites.
Warning: Storing Trace information my incur a charge. See the Windows Azure Pricing Calculator for details. You can view trace data with Azure Storage Explorer under the WADLogsTable.

A best practice is to use a separate storage account for trace data and production data. The following XML from my ServiceConfiguration.Cloud.cscfg file shows the Trace configuration.
<?xml version="1.0" encoding="utf-8"?>
<ServiceConfiguration serviceName="AzureEmailService" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration" osFamily="1" osVersion="*" schemaVersion="2012-05.1.7">
<Role name="MvcWebRole">
<Instances count="1" />
<ConfigurationSettings>
<Setting name="Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString"
value="DefaultEndpointsProtocol=https;
AccountName=[TraceAccount];
AccountKey=[Key]" />
<Setting name="StorageConnectionString"
value="DefaultEndpointsProtocol=https;
AccountName=[DataAccount];
AccountKey=[Key2]" />
</ConfigurationSettings>
</Role>
<Role name="WorkerRoleA">
<Instances count="1" />
<ConfigurationSettings>
<Setting name="Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString"
value="DefaultEndpointsProtocol=https;
AccountName=[TraceAccount];
AccountKey=[Key]" />
<Setting name="StorageConnectionString"
value="DefaultEndpointsProtocol=https;
AccountName=[DataAccount];
AccountKey=[Key2]" />
</ConfigurationSettings>
</Role>
</ServiceConfiguration>
Tracing provides a great way to monitor your Windows Azure application and provide rich information to help debug problems.
For more information on Tracing in Windows Azure, see the following:

Business Wire reported emotive Announces Launch of Ground Breaking Cloud Mobile Platform Built on Windows Azure in a 10/23/2012 press release:
emotive today announced the general availability of their integrated end-to-end SaaS platform for mobile application development and deployment. The announcement addresses the increasing demand for robust, contextual mobile applications using multiple devices and business applications.
“To address the significant gaps in current mobile application development products and technologies, we have delivered a comprehensive platform that enables developers to rapidly build, deploy and manage mobile applications,” said CEO John Hubinger. “Developers can now create and deliver rich, compelling value based mobile applications to users and customers using their existing web development skills,” John explained.
emotive’s main capabilities are:
- Integrated mobile SaaS platform to develop and deploy applications
- Hybrid development model - JavaScript, JQuery, CSS3 and HTML5
- Web based designer tools
- Write once, deploy instantly on multiple device types
- Push notification delivers applications and rich media
- Maximum response time through leading edge data caching
- Open API’s (REST) for effective and efficient connectivity
- SAML2/OATH security
- User and application management
“With the rise of apps and the explosion of devices, businesses are facing a proliferation of management and performance challenges,” said Kim Akers, General Manager, Microsoft (NASDAQ: MSFT). “Cloud solutions like emotive built on Windows Azure help developers rapidly deploy and manage mobile applications.”
The combination of this unique platform and reliability and reach of Windows Azure provides customers a unique value proposition that extends the scope of their enterprise applications beyond the desktop.
About emotive
emotive is the next generation, mobile cloud platform that delivers everything application developers need to build fast, secure, scalable enterprise mobile apps. Only emotive allows developers to create and deploy intuitive, content-rich mobile applications using HTML5,CSS3,JavaScript,JQuery and JQuery mobile. Our customers and partners leverage cloud processing, integrate with existing enterprise systems and use native device features. emotive based solutions solve the hardest mobility problems such as cross platform support, push notifications, offline access and federated identity management.
By reusing existing skills, web assets and an open standards based development approach, developers slash development time over traditional and native mobile application approaches, drive down development and deployment costs and avoid vendor lock-in.
emotive is the first end-to-end, integrated solution, built by enterprise developers for enterprise developers. emotive is a private company headquartered in Oakland, California.
Alan Smith described his 256 Worker Role 3D Rendering Demo is now a Lab on my Azure Course in a 10/21/2012 post:
Ever since I came up with the crazy idea of creating an Azure application that would spin up 256 worker roles (please vote if you like it) to render a 3D animation created using the Kinect depth camera I have been trying to think of something useful to do with it.
I have also been busy working on developing training materials for a Windows Azure course that I will be delivering through a training partner in Stockholm, and for customers wanting to learn Windows Azure. I hit on the idea of combining the render demo and a course lab and creating a lab where the students would create and deploy their own mini render farms, which would participate in a single render job, consisting of 2,000 frames.

As students would be creating and deploying their own applications, I thought it would be fun to introduce some competitiveness into the lab. In the 256 worker role demo I capture the rendering statistics for each role, so it was fairly simple to include the students name in these statistics. This allowed the process monitor application to capture the number of frames each student had rendered and display a high-score table.
When I demoed the application I deployed one instance that started rendering a frame every few minutes, and the challenge for the students was to deploy and scale their applications, and then overtake my single role instance by the end of the lab time. I had the process monitor running on the projector during the lab so the class could see the progress of their deployments, and how they were performing against my implementation and their classmates.
When I tested the lab for the first time in Oslo last week it was a great success, the students were keen to be the first to build and deploy their solution and then watch the frames appear. As the students mostly had MSDN suspicions they were able to scale to the full 20 worker role instances and before long we had over 100 worker roles working on the animation.
There were, however, a few issues who the couple of issues caused by the competitive nature of the lab. The first student to scale the application to 20 instances would render the most frames and win; there was no way for others to catch up. Also, as they were competing against each other, there was no incentive to help others on the course get their application up and running.
I have now re-written the lab to divide the student into teams that will compete to render the most frames. This means that if one developer on the team can deploy and scale quickly, the other team still has a chance to catch up. It also means that if a student finishes quickly and puts their team in the lead they will have an incentive to help the other developers on their team get up and running.
As I was using “Sharks with Lasers” for a lot of my demos, and reserved the sharkswithfreakinlasers namespaces for some of the Azure services (well somebody had to do it), the students came up with some creative alternatives, like “Camels with Cannons” and “Honey Badgers with Homing Missiles”. That gave me the idea for the teams having to choose a creative name involving animals and weapons.
The team rendering architecture diagram is shown below.

Render Challenge Rules
In order to ensure fair play a number of rules are imposed on the lab.
- The class will be divided into teams, each team choses a name.
- The team name must consist of a ferocious animal combined with a hazardous weapon.
- Teams can allocate as many worker roles as they can muster to the render job.
- Frame processing statistics and rendered frames will be vigilantly monitored; any cheating, tampering, and other foul play will result in penalties.
The screenshot below shows an example of the team render farm in action, Badgers with Bombs have taken a lead over Camels with Cannons, and both are leaving the Sharks with Lasers standing.

If you are interested in attending a scheduled delivery of my Windows Azure or Windows Azure Service bus courses, or would like on-site training, more details are here.





<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
‡‡ Luke Chung (@LukeChung) published a Microsoft Visual Studio LightSwitch for Microsoft Access, SQL Server, and Visual Studio .NET Database Developers to the FMS, Inc. blog:
The Visual Studio team has introduced a development platform called LightSwitch which simplifies the creation of database applications in Visual Studio. This rapid application development environment lets you create solutions that can be easily deployed on Windows or Mac platforms from a public web site or Intranet.
This article provides an overview of the benefits and limitations of the LightSwitch platform for the Microsoft Access community.
Sample Screens
Here are some examples of what can be created in LightSwitch.
Sample LightSwitch User Interface
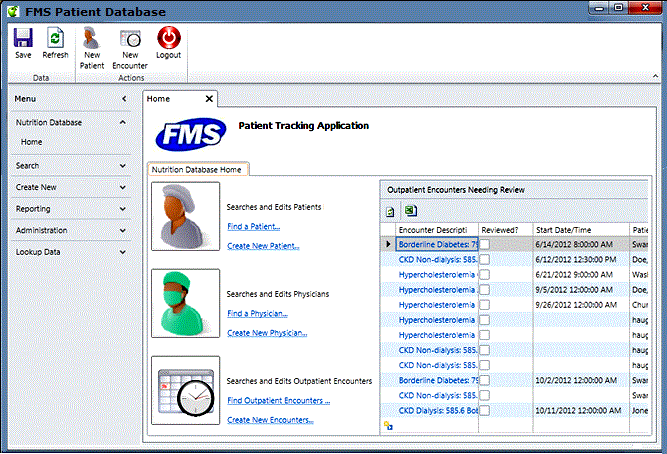
Dashboards Built in LightSwitch
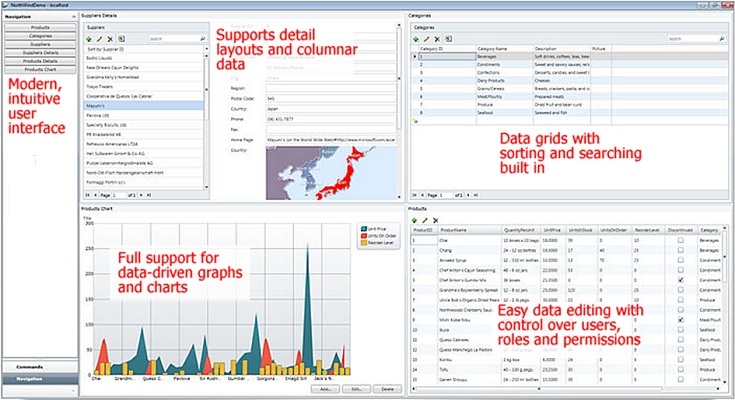
LightSwitch Integration with Other Programs
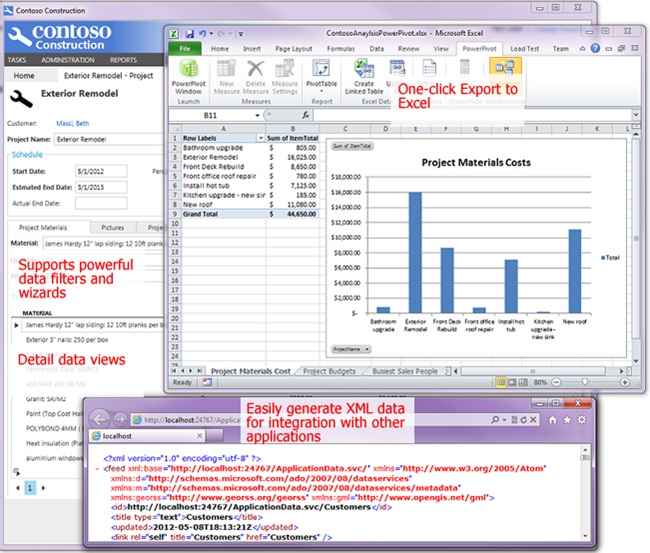
Customization Using Visual Studio .NET
While LightSwitch can be used to create database applications with limited coding, as part of the Microsoft Visual Studio .NET family, LightSwitch supports customization using C# and VB.NET programming languages. This offers all the benefits of managed code and the latest programming features.
LightSwitch does not support Office/Access VBA.
Direct Support for Microsoft SQL Server
LightSwitch works directly against SQL Server databases. It understands table structures, referential integrity, one-to-many relationships, and other database architecture so that it can bind directly to your table, fields, and records. It requires your database to be properly designed with primary keys and other basic requirements, so having a good database design helps (and should be done anyway).
It also supports databases hosted on SQL Azure, Microsoft's cloud provider.
Dramatically Reduced Development Time
LightSwitch provides the ability to deliver incredibly rich, intuitive and easy to use applications, all within a Windows, Mac or Browser client. It offers affordable, reliable, and scalable custom solutions with user-friendly views of your data. It dramatically decreases the time it takes to build and deliver the custom application compared to traditional Visual Studio .NET approaches.
LightSwitch allows the use of extensible application shells to provide users with the familiar feel of popular Microsoft software, significantly reducing learning curve and application adoption time.
Built-in authentication models simplify the management of users with varying degrees of access and authorization, especially when integrated with existing Active Directory implementations.
Requires Silverlight on the Client Machine
Visual Studio .NET and LightSwitch are used by the developer and are not installed on the users' machines.
However, LightSwitch applications require installing the free Microsoft’s Silverlight on each user's machine. This is a one time installation similar to installing Adobe Flash to watch videos or Adobe Acrobat Reader to open PDF files. Silverlight allows applications to be easily run on desktops and browsers through a one-click deployment, thereby dramatically reducing distribution and maintenance efforts. The Silverlight requirement makes a LightSwitch application inappropriate for general Internet solutions.
Unlike Microsoft Access database applications, you don't need to worry about what the user has installed on their Windows desktop, the version of Office/Access, and version conflicts on their machine. Unlike installing Office which usually requires physically updating each machine, Silverlight can be installed by the user from their browser.
Platforms Supported by LightSwitch
LightSwitch runs as a Windows or Mac client application, and supports multiple web browsers, including:
- Internet Explorer versions 7, 8, and 9 on Windows Vista and Windows 7
- Google Chrome version 12 or greater
- Mozilla Firefox version 3.6 or higher
- Apple Safari on Macintosh OS 10.5.7 (Intel-based) or higher
These browsers can run on 32 or 64-bit operating systems.
Silverlight Limitations
Does not Support iPad, iPhone, Android and Windows Phones
Silverlight is not supported on mobile platforms such as the iPad/iPhone, Android or Windows phone.
Silverlight Requirement Limits its Use for Public Websites
By requiring the installation of Silverlight, LightSwitch applications are not suited for public web sites where visitors may not have it installed on their machines (sites face the similar issue when using Flash). However, for internal users and close external contacts, this requirement may be perfectly acceptable.
Does not Support 64-bit Browsers
Silverlight is currently a 32-bit program that does not run in 64-bit browsers. This should not be an issue for most users. By default, on 64-bit PCs, the 32-bit version of Internet Explorer is installed and extra steps are required to intentionally install the 64-bit version, which will have problems supporting other common 32-bit components as well.
Additional Limitations
Limited User Interface Options
The LightSwitch architecture limits the user interface to its structure. We find the structure suitable for most database solutions but many Visual Studio .NET developers find the constraints (or potential constraints) too restrictive and uncomfortable in the long-term. There is definitely a tradeoff here, so it's important everyone understands the style of solution LightSwitch offers and are comfortable with it.
No Reports
LightSwitch doesn't offer reporting. You can display data in a list, but you can't get the nice reports with groupings, summaries, sub-reports, etc. that exist in Microsoft Access. With SQL Server, you can use its Reporting Services feature, but integrating it into a .NET application is not the same as Access where you can share the same variable space as the application. There are third party controls that can be added for reporting.
Future Directions
Microsoft has a preview version of an HTML5-based client that replaces Silverlight and offers true browser-based operation of LightSwitch applications (Microsoft announcement). We expect the HTML5 client to be available from Microsoft in 2013 to support mobile clients. However, the features are not the identical to the Silverlight platform which provides a richer end user environment and is simpler to develop.
Summary
With our experience building Microsoft Access and SQL Server solutions, we are very excited by the functionality and productivity LightSwitch offers for database application developers. LightSwitch fills a niche that allows the creation of web deployable SQL Server database solutions with .NET extensibility. It's ideal for solutions where the users are known either inside your organization or over the web. Microsoft Access remains a viable solution for end users, information workers, and applications that work on Windows.
Database Evolution
Visual Studio LightSwitch offers the Microsoft Access community the opportunity to extend their platform beyond the Windows desktop. It is the natural evolution of solutions which start in Excel, evolve to Microsoft Access, grow into SQL Server, and now to the Intranet and web. Compared to traditional Visual Studio .NET applications, the learning curve for LightSwitch is considerably shorter which means solutions that were either too expensive or took too long to build, can now be created profitably.
If you're interested in learning how our Professional Solutions Group can help you with Microsoft Access, LightSwitch, SQL Server, and/or Visual Studio .NET, please visit our LightSwitch Consulting page.

‡ Paul van Bladel (@paulbladel) described Applying server-side caching via a Ria Service in a 10/26/2012 post:
Introduction
Caching data is a quite popular in regular web technology (e.g. asp.net). Although LightSwitch has no native support for caching, it can be easily accomplished via a dedicated Ria Service.
When to use caching
There is no clear rule of thump for using caching and for when using no caching. Personally, I would only use it,
- for data which is updated infrequently and
- for read-only data.
If you apply these simple rules, you will love caching. Otherwise.. you’ll hate it
How?
I presume here that you are familiar with setting up a RIA service in a LightSwitch project.
I have in LightSwitch a Customer entity with a firstname and lastname field. I create in the RiaService a DTO (data transfer object) called “MyCacheDTO” which is doing nothing more than projecting the two customer fields to this new DTO.
This is the code for the Ria Service:
using System; using System.Collections.Generic; using System.ComponentModel.DataAnnotations; using System.Linq; using System.ServiceModel.DomainServices.Hosting; using System.ServiceModel.DomainServices.Server; using System.Text; using System.Web; using System.Web.Caching; namespace Ria { public class MyCacheDTO { [Key] public int ID { get; set; } public string MyName { get; set; } } [EnableClientAccess] public class CachService : LightSwitchDomainServiceBase { [Query(IsDefault = true)] public IQueryable<MyCacheDTO> GetCustomers() { return GetData().AsQueryable(); } private IQueryable<MyCacheDTO> GetData() { IQueryable<MyCacheDTO> result; string cacheKey = "Customers"; if (HttpContext.Current.Cache.Get(cacheKey) == null) { string timeStamp = DateTime.Now.ToString(); result = from c in this.Context.Customers select new MyCacheDTO { ID = c.Id, MyName = c.LastName + " " + timeStamp }; HttpContext.Current.Cache.Add(cacheKey, result, null, DateTime.Now.AddMinutes(1), Cache.NoSlidingExpiration, CacheItemPriority.Default, null); } else { result = (IQueryable<MyCacheDTO>)HttpContext.Current.Cache[cacheKey]; } return result; } } }I apply a little trick so that you can easily verify that the caching is actually working correctly. When I project the data to the DTO I add a time stamp to the lastName field. This allows you to verify if the cache was “hit”‘.
Also for testing purposes, I have set the cache expiration to one minute, but this is probably you want to change when using it in production.
I’m in the habit of letting my RIA services derive from a base class “LightSwitchDomainServiceBase”, which I add over here for completeness:
using ApplicationData.Implementation; using System; using System.Collections.Generic; using System.Data.EntityClient; using System.Linq; using System.ServiceModel.DomainServices.Server; using System.Text; namespace Ria { public class LightSwitchDomainServiceBase : DomainService { #region Database connection private ApplicationDataObjectContext m_context; public ApplicationDataObjectContext Context { get { if (this.m_context == null) { string connString = System.Web.Configuration.WebConfigurationManager .ConnectionStrings["_IntrinsicData"].ConnectionString; EntityConnectionStringBuilder builder = new EntityConnectionStringBuilder(); builder.Metadata = "res://*/ApplicationData.csdl|res://*/ApplicationData.ssdl|res://*/ApplicationData.msl"; builder.Provider = "System.Data.SqlClient"; builder.ProviderConnectionString = connString; this.m_context = new ApplicationDataObjectContext(builder.ConnectionString); } return this.m_context; } } #endregion // Override the Count method in order for paging to work correctly protected override int Count<T>(IQueryable<T> query) { return query.Count(); } } }Create now a new screen for the cacheDTO and enjoy the server cache !


Paul Van Bladel (@paulbladel) continued his series with LightSwitch Treeview on demand loading with direct OData connection – part 3 on 10/21/2012:
Introduction
First read my previous posts on treeviews with on demand loading in LightSwitch. [See below posts.]
In this post I present a slight variation: we retrieve the root data not via binding to the viewmodel of the hosting LightSwitch screen, but rather via a direct OData connection.
How?
Our xaml stays pretty the same, except that there is no binding code :
<UserControl xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" xmlns:d="http://schemas.microsoft.com/expression/blend/2008" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:telerik="http://schemas.telerik.com/2008/xaml/presentation" x:Class="SilverlightClassLibrary.TelerikTreeWithOdataBinding" mc:Ignorable="d" d:DesignHeight="300" d:DesignWidth="400"> <UserControl.Resources> <telerik:HierarchicalDataTemplate x:Name="ItemTemplate"> <TextBlock Text="{Binding DepartmentName}" /> </telerik:HierarchicalDataTemplate> </UserControl.Resources> <Grid x:Name="LayoutRoot" Background="White"> <telerik:RadTreeView x:Name="MyRadTreeView" IsLoadOnDemandEnabled="True" IsExpandOnSingleClickEnabled="True" ItemPrepared="MyRadTreeView_ItemPrepared" LoadOnDemand="MyRadTreeView_LoadOnDemand" ItemTemplate="{StaticResource ItemTemplate}" > </telerik:RadTreeView> </Grid> </UserControl>Since we retrieve the data now via the Odata service, we need to setup a connection to this service and store the root elements in a DataServiceCollection:
using SilverlightClassLibrary.DepartmentDataServiceReference; using System; using System.Collections.Generic; using System.Data.Services.Client; using System.Linq; using System.Net; using System.Windows; using System.Windows.Controls; using System.Windows.Documents; using System.Windows.Input; using System.Windows.Media; using System.Windows.Media.Animation; using System.Windows.Shapes; using Telerik.Windows.Controls; namespace SilverlightClassLibrary { public partial class TelerikTreeWithOdataBinding : UserControl { private DepartmentDataServiceReference.DepartmentServiceData _service; public TelerikTreeWithOdataBinding() { InitializeComponent(); Uri uri = new Uri(Application.Current.Host.Source, "../DepartmentServiceData.svc"); _service = new DepartmentDataServiceReference.DepartmentServiceData(uri); var query = _service.DepartmentDTOes.Where(d => d.ParentID == null); var coll = new DataServiceCollection<DepartmentDTO>(); coll.LoadAsync(query); MyRadTreeView.ItemsSource = coll; } private void MyRadTreeView_LoadOnDemand(object sender, Telerik.Windows.RadRoutedEventArgs e) { RadTreeViewItem clickedItem = e.OriginalSource as RadTreeViewItem; DepartmentDTO dataItem = clickedItem.Item as DepartmentDTO; var query = _service.DepartmentDTOes.Where(d => d.ParentDepartment.ID == dataItem.ID); var childCollection = new DataServiceCollection<DepartmentDTO>(); childCollection.LoadCompleted += (s, e2) => { clickedItem.IsLoadOnDemandEnabled = true; clickedItem.ItemsSource = childCollection; clickedItem.IsExpanded = true; clickedItem.IsLoadingOnDemand = false; }; childCollection.LoadAsync(query); } private void MyRadTreeView_ItemPrepared(object sender, Telerik.Windows.Controls.RadTreeViewItemPreparedEventArgs e) { var treeViewItem = e.PreparedItem; var dataItem = treeViewItem.Item as DepartmentDTO; if (dataItem.ChildrenCount <= 0) { treeViewItem.IsLoadOnDemandEnabled = false; } else { treeViewItem.IsLoadOnDemandEnabled = true; } } } }The most striking difference is that our user control has no reference at all to LightSwitch Dlls !
So, you could perfectly port the above code to another non-LightSwitch silverlight application.
Conclusion
Another way of retrieving the data. For me, it’s not yet clear which approach is the best: this one or via the LightSwitch binding.
In a next post (but not for today) I will introduce searching and filtering in the treeview control.


Paul Van Bladel (@paulbladel) continued his series with Introducing on demand loading in the LightSwitch treeview user control – part 2 10/21/2012:
Introduction
As explained in my previous post, a decent treeview solution for LightSwitch needs on demand loading.
I have search intensively to achieve this with the silverlight treeview control, but without success. So, I had to look into the direction of Telerik to get what I want. No doubt that other vendors have similar functionality. Of course, I’m very curious if a pure silverlight treeview solution would be überhaupt possible.
Nonetheless, it’s not because we opt here for a third party control, that it all works out of the box. We still need to integrate it with the LightSwitch way of thinking and the way we use Odata.
Understanding “load on demand”.
We will start from the setup in my previous post and basically replace the silverlight treeview with the Telerik RadTreeView control. The most important difference will be that we will not use any longer the ValueConverter for fetching the Child departments. The Telerik treeview has 2 important events which we will use for the “load on demand” functionality:
private void MyRadTreeView_LoadOnDemand(object s1, Telerik.Windows.RadRoutedEventArgs e1) { } private void MyRadTreeView_ItemPrepared(object sender, Telerik.Windows.Controls.RadTreeViewItemPreparedEventArgs e) { }The LoadOnDemand event will be used to load the child data and the ItemPrepared event will be used to tell the control that there are children present. This is done by setting the IsLoadOnDemandEnabled property of the current treeViewItem:
private void MyRadTreeView_ItemPrepared(object sender, Telerik.Windows.Controls.RadTreeViewItemPreparedEventArgs e) { var treeViewItem = e.PreparedItem; var dataItem = treeViewItem.Item as IEntityObject; // if the dataItem has children { // treeViewItem.IsLoadOnDemandEnabled = false; } //else { //treeViewItem.IsLoadOnDemandEnabled = true; } }The problem is of course: how can we find out if the current item has children?
The problem is that an odata feed has no notion of a count on the number of records in a navigation property. So, that’s something we first need to solve.
Of course, you can easily calculate client side the amount of child records by simply retrieving them… but remember… that’s what we wanted to avoid. We want to load the children on demand.
Create a RIA service for a Department DTO with children count
So, it’s clear so far that we can not directly bind our Telerik treeview to the GetRoot query of Departments. We need a data transfer object (DTO) which carries as well a ChildrenCount method which we will eventually use in the ItemPrepared event.
By doing so, the xaml of the custom control will be:
<UserControl x:Class="SilverlightClassLibrary.TelerikTreeWihtLightSwitchBinding" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" xmlns:d="http://schemas.microsoft.com/expression/blend/2008" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" mc:Ignorable="d" xmlns:telerik="http://schemas.telerik.com/2008/xaml/presentation" d:DesignHeight="300" d:DesignWidth="400"> <UserControl.Resources> <telerik:HierarchicalDataTemplate x:Name="ItemTemplate"> <TextBlock Text="{Binding DepartmentName}" /> </telerik:HierarchicalDataTemplate> </UserControl.Resources> <Grid x:Name="LayoutRoot" Background="White"> <telerik:RadTreeView x:Name="MyRadTreeView" LoadOnDemand="MyRadTreeView_LoadOnDemand" IsVirtualizing="True" ItemPrepared="MyRadTreeView_ItemPrepared" IsLoadOnDemandEnabled="True" IsExpandOnSingleClickEnabled="True" IsRootLinesEnabled="True" IsLineEnabled="True" IsTextSearchEnabled="True" ItemTemplate="{StaticResource ItemTemplate}" ItemsSource="{Binding Screen.GetRoot}"> </telerik:RadTreeView> </Grid> </UserControl>Note that the xaml is quite similar to the previous implementation, but there is no ValueConverter any longer in the HierarchicalDateTemplate. In the TreeView, we also hook up the 2 aforementioned events ( LoadOnDemand=”MyRadTreeView_LoadOnDemand” ItemPrepared=”MyRadTreeView_ItemPrepared”). We still bind to Screen.GetRoot, but this query is now operating on our DepartmentDTO:

The underlying RIA service looks as follows:
using System; using System.Collections.Generic; using System.ComponentModel.DataAnnotations; using System.Linq; using System.ServiceModel.DomainServices.Hosting; using System.ServiceModel.DomainServices.Server; using System.Text; namespace Ria { public class DepartmentDTO { [Key] public int ID { get; set; } public string DepartmentName { get; set; } public string Location { get; set; } public int? ParentID { get; set; } [Association("MyRef", "ParentID", "ID", IsForeignKey = true)] public DepartmentDTO ParentDepartment { get; set; } [Association("MyRef", "ID", "ParentID", IsForeignKey = false)] public IQueryable<DepartmentDTO> ChildDepartments { get; set; } public int ChildrenCount { get; set; } } [EnableClientAccess()] public class DepartmentService : LightSwitchDomainServiceBase { [Query(IsDefault = true)] public IQueryable<DepartmentDTO> GetOrders() { return from d in this.Context.Departments select new DepartmentDTO { ID = d.Id, ParentID = d.Department_Department, DepartmentName = d.DepartmentName, Location = d.Location, ChildrenCount = d.ChildDepartments.Count() }; } } }As you can see, the DTO has a ChildrenCount property, which counts the children server side and includes the property in the DepartmentDTO object.
Note also that the DepartmentDTO class needs the correct attributes (the [Association] attribute) for setting up the hierarchical relationship !
The RIA service is consumed by the GetRoot query in LightSwitch:
public partial class DepartmentServiceDataService { partial void GetRoot_PreprocessQuery(ref IQueryable<DepartmentDTO> query) { query = query.Where(d => d.ParentDepartment.ID == null); } }We can use now this ChildrenCount property in our ItemPrepared event:
private void MyRadTreeView_ItemPrepared(object sender, Telerik.Windows.Controls.RadTreeViewItemPreparedEventArgs e) { var treeViewItem = e.PreparedItem; var dataItem = treeViewItem.Item as IEntityObject; if ((int)dataItem.Details.Properties["ChildrenCount"].Value <= 0) { treeViewItem.IsLoadOnDemandEnabled = false; } else { treeViewItem.IsLoadOnDemandEnabled = true; } }Now, only the most important thing is left now: implementing the LoadOnDemand event:
private void MyRadTreeView_LoadOnDemand(object s1, Telerik.Windows.RadRoutedEventArgs e1) { RadTreeViewItem clickedItem = e1.OriginalSource as RadTreeViewItem; var dataItem = clickedItem.Item as IEntityObject; IEntityCollectionProperty entityNavigationProp = dataItem.Details.Properties["ChildDepartments"] as IEntityCollectionProperty; IExecutableWithResult query = entityNavigationProp.Loader as IExecutableWithResult; query.ExecuteCompleted += new EventHandler<ExecuteCompletedEventArgs>((s2, e2) => { clickedItem.IsLoadOnDemandEnabled = true; clickedItem.ItemsSource = query.Result as IEnumerable; clickedItem.IsExpanded = true; clickedItem.IsLoadingOnDemand = false; }); query.ExecuteAsync(); }In fact the LoadOnDemand event is doing more or less the same as in our previous implementation (that from part 1), but in a much more transparant way. There is no fuzz anylonger with doing things on the right thread, enumerating the collection, storing it in an ObservableCollection, etc. …
We simply retrieve the child collection in an async way and set the ItemSource (and a few other properties) of the clicked treeviewItem to the retrieve child records.
The proof of the pudding is in the eating
Let’s verify now that indeed we have not a much more responsive UI and that data is actually loaded on demand.

As a result, only one call with only the data we need. Let’s click now on a certain root node:

Only the direct childs are retrieved and let’s verify what’s in such a child:

It contains exactly what we want, the child record with the ChildrenCount property. Nothing more, nothing less !
Conclusion
Setting up load on demand is not that complicated, when using a control that supports it.
In a next post I will demonstrate that the binding of the treeview to the LightSwitch data could be done also directly to the odata service rather than via the typical binding mechanism used between LightSwitch and a custom control.





Paul Van Bladel (@paulbladel) started a series with In search for an improved treeview solution – part 1 on 10/21/2012:
Introduction
This post is the first in a series:
- Introducing on demand loading in the LightSwitch treeview user control – part 2
- LightSwitch Treeview on demand loading with direct OData connection – part 3
There are a few LightSwitch treeview solutions around, based on the silverlight treeview control. There is even a LightSwitch treeview extension. In this first “treeview post”, I will analyse how this treeview solution works and draw your attention to a kind of drawback of this solution when it comes to data loading. It’s not my intention to criticize this solution, but just to share with your the room for improvement.
How does the mainstream LightSwitch treeview solution looks?
I’ll use as example structure, a treeview depicting the different departments of an organization. A department structure is inherently hierarchical.

Important to setup the self-relationship correctly:

Following silverlight usercontrol can be consumed in a LightSwitch screen:
<UserControl xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" xmlns:d="http://schemas.microsoft.com/expression/blend/2008" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:sdk="http://schemas.microsoft.com/winfx/2006/xaml/presentation/sdk" x:Class="SilverlightClassLibrary.SilverlightTreeWithLightSwitchBinding" mc:Ignorable="d" xmlns:local="clr-namespace:SilverlightClassLibrary" d:DesignHeight="300" d:DesignWidth="400"> <UserControl.Resources> <local:EntityCollectionValueConverter x:Key="EntityCollectionValueConverter" /> <sdk:HierarchicalDataTemplate x:Name="TreeDataTemplate" ItemsSource="{Binding Converter={StaticResource EntityCollectionValueConverter}, ConverterParameter=ChildDepartments}"> <TextBlock Text="{Binding DepartmentName}" /> </sdk:HierarchicalDataTemplate> </UserControl.Resources> <Grid x:Name="LayoutRoot" Background="White"> <sdk:TreeView ItemTemplate="{StaticResource TreeDataTemplate}" ItemsSource="{Binding Screen.GetRoot}" > </sdk:TreeView> </Grid> </UserControl>As you can see, the TreeView binds to Screen.GetRoot:
The GetRoot query goes as follows:
partial void GetRoot_PreprocessQuery(ref IQueryable<Department> query) { query = query.Where(d => d.ParentDepartment == null); }and the query is bound to the datacontext of the silverlight user control:The most interesting part in the user control is the treeview’s itemtemplate which is an hierarchical data template:
<sdk:HierarchicalDataTemplate x:Name="TreeDataTemplate" ItemsSource="{Binding Converter={StaticResource EntityCollectionValueConverter}, ConverterParameter=ChildDepartments}"> <TextBlock Text="{Binding DepartmentName}" /> </sdk:HierarchicalDataTemplate>The data template his no direct binding, but binds the ChildDepartments via a ValueConverter:
public class EntityCollectionValueConverter : IValueConverter { public object Convert(object value, Type targetType, object parameter, System.Globalization.CultureInfo culture) { string strErrorMessage = "Converter parameter should be set to the property name that will serve as source of data"; IEntityObject entity = value as IEntityObject; if (entity == null) throw new ArgumentException("The converter should be using an entity object"); string sourcePropertyName = parameter as string; if (string.IsNullOrWhiteSpace(sourcePropertyName)) throw new ArgumentException(strErrorMessage); var entities = new ObservableCollection<IEntityObject>(); var temporaryEntites = new List<IEntityObject>(); entity.Details.Dispatcher.BeginInvoke(delegate { IEntityCollection eCollection = entity.Details.Properties[sourcePropertyName].Value as IEntityCollection; if (eCollection == null) { Debug.Assert(false, "The property " + sourcePropertyName + " is not an entity collection"); return; } foreach (IEntityObject e in eCollection) { temporaryEntites.Add(e); } Microsoft.LightSwitch.Threading.Dispatchers.Main.BeginInvoke(delegate { foreach (IEntityObject e in temporaryEntites) { entities.Add(e); } }); }); return entities; } public object ConvertBack(object value, Type targetType, object parameter, System.Globalization.CultureInfo culture) { throw new NotImplementedException(); } }Basically, this valueconverter will make sure the ChildDepartments are added in an observable collection in such a way the binding system can pick up it’s values and all this should be done on the right thread. Although it’s not quite sure if the above is reflecting the main intention of the idea of a “value converter”‘, it’s clear that this is a very clever solution. It works great for small trees. Nonetheless, there is a problem…
What’s the problem?
In essence, the problem with the above solution is that the valueconverter causes a very chatty communication pattern which is causing for large trees a lot of delays in the screen rendering.

We are simply loading the tree which has some 25 root elements, but the value converter is sending out 25 requests instead of just one request.
You could use fiddler here, but the trace handler (trace.axd) will reveal enough information as well:

Hmm… no good. Fidller will learn us that also the children of all root elements are already loaded. That’s crazy, because maybe we only want to go to the details of let’s say root element 5. When you open consecutive child elements, you will notice that loading becomes very slow.
What do we need?
Well… we want that when we click on a tree node
- only the immediate children are loaded
- the data are loaded in one request.
This is called on demand loading. I prefer in the context of a treeview “on demand loading” above “lazy loading”, because it expresses clearly what it does: loading only data when they are needed or demanded when the user clicks on a node.
How can we achieve this?
That will be the topic of my next treeview post



Return to section navigation list>
Windows Azure Infrastructure and DevOps
‡‡ The Windows Azure Team updated the HTML Windows Azure Management Portal on 10/28/2012 with a new Store feature for third-party Windows Azure Add-ons and reclassification of features into Compute, Data Services, App Services, Networks and Store groups:

The first time you log into the upgraded portal, you’re invited to take a tour of the new features:

I recommend giving it a try.
Clicking the New panel’s Store item opens this page that lets you purchase third-party Add-ons for Windows Azure from the Windows Store:

Service Bus options dominate the App Services category:

You’ll need to use the original (Silverlight) portal for features not yet supported by the HTML version, such as Windows Azure SQL Data Sync (formerly SQL Azure Data Sync) and the Content Delivery Network (CDN).
You can expect more details about the upgraded portal in the Windows Azure team’s posts from the //BUILD/ conference this coming week.
Guess it’s time for me to revamp the graphic in this blog’s header.
•• David Linthicum (@DavidLinthicum) wrote “If cloud services were layered architecturally, providers would be able to better contain the effects of failure on the critical services” in a deck for his The lesson from the Amazon outage: It's time to layer the cloud of 10/25/2012 for InfoWorld’s Cloud Computing blog:
The recent Amazon Web Services outage reminded us once again that cloud computing is not yet a perfect science. That said, perhaps it's also time we define formal methods, models, and approaches to make cloud computing easier to understand -- and more reliable.
Most organizations that implement cloud computing view clouds as a simple collection of services or APIs; they use the cloud functions, such as storage and compute, through these services. When they implement cloud computing services, they see it as just a matter of mixing and matching these services in an application or process to form the solution.
The trouble with that approach? There is a single layer of services that most cloud users see that exposes the cloud computing functions. Thus, all types of services exist at this layer, from primitive to high level, from coarse to fine grained.
Although it's not at all a new concept, in many instances it's helpful to define cloud services using a layered approach that works up from the most primitive to the highest-level services, with the higher-level services depending on those at the lower levels. Many IaaS clouds already work this way internally. However, all exposed services, primitive or not, are pretty much treated the same: as one layer.
A better approach would be for each layer to have a common definition from cloud provider to cloud provider. Each layer would provide a specific set of predefined levels of support. For example:
- Layer 0: Hardware services
- Layer 1: Virtualization service (if required)
- Layer 2: Storage
- Layer 3: Compute
- Layer 4: Data
- Layer 5: Tenant management
- Layer 6: Application
- Layer 7: Process
- Layer 8: Management
Of course, this is just a concept. I suspect the layers will change to represent the purpose and functions of each cloud.

•• Kristian Nese (@KristianNese) posted SQL 2012 AlwaysOn + IP for Azure in Orchestrator 2012 SP1 on 10/24/2012:
Just a quick heads up for something interesting in this blog post.
1. Learn how to configure SQL 2012 AlwaysOn for your VMM 2012 SP1 database
2. Download and test the Integration Pack for Orchestrator 2012 SP1 that let you manage your virtual machines, services etc in Windows Azure.
http://www.microsoft.com/en-us/download/details.aspx?id=35399
Overview
Feature Summary
The Integration Pack includes the following activities:
- Azure Certificates- the Azure Certificates activity is used in a runbook to add, delete, and list management and service certificates
- Azure Deployments- the Azure Deployments activity is used in a runbook to create, delete, get, and swap deployments, change deployment configurations, update deployment statuses, rollback an update or upgrade, get and change deployment operating systems, upgrade deployments, walk upgrade domains, and reboot and reimage role instances
- Azure Cloud Services- the Azure Cloud Services activity is used in a runbook to create, delete, and get cloud services, check cloud service name availability, and create affinity groups
- Azure Storage- The Azure Storage activity is used in a runbook to create, delete, update, and list storage accounts, get storage account properties, get and regenerate storage account keys, create, list, and delete containers, and put, copy, delete, list, snapshot, and download blobs
- Azure Virtual Machine Disks- the Azure Virtual Machine Disks activity is used in a runbook to add, delete, update, and list virtual machine disks and virtual machine data disks
- Azure Virtual Machine Images- the Azure Virtual Machine Images activity is used in a runbook to add, delete, update, and list virtual machine operating system images
- Azure Virtual Machines- the Azure Virtual Machines activity is used in a runbook to create virtual machine deployments, download virtual machine remote desktop files, as well as get, delete, start, restart, shutdown, capture, and update virtual machine roles

•• Lori MacVittie (@lmacvittie) claimed “Automating incomplete or ineffective processes will only enable you to make mistakes faster – and more often” in an introduction to her To Err is Human… post of 10/24/2012 to F5’s DevCentral blog:
Most folks probably remember the play on "to err is human…" proverb when computers first began to take over, well, everything.
The saying was only partially tongue-in-cheek, because as we've long since learned the reality is that computers allow us to make mistakes faster and more often and with greater reach.
One of the statistics used to justify a devops initiative is the rate at which human error contributes to a variety of operational badness: downtime, performance, and deployment life-cycle time.
Human error is a non-trivial cause of downtime and other operational interruptions. A recent Paragon Software survey found that human error was cited as a cause of downtime by 13.2% of respondents. Other surveys have indicated rates much higher. Gartner analysts Ronni J. Colville and George Spafford in "Configuration Management for Virtual and Cloud Infrastructures" predict as much as 80% of outages through 2015 impacting mission-critical services will be caused by "people and process" issues.
Regardless of the actual rates at which human error causes downtime or other operational disruptions, reality is that it is a factor. One of the ways in which we hope to remediate the problem is through automation and devops.
While certainly an appropriate course of action, adopters need to exercise caution when embarking on such an initiative, lest they codify incomplete or inefficient processes that simply promulgate errors faster and more often.
DISCOVER, REMEDIATE, REFINE, DEPLOY
Something that all too often seems to be falling by the wayside is the relationship between agile development and agile operations. Agile isn't just about fast(er) development cycles, it's about employing a rapid, iterative process to the development cycle. Similarly, operations must remember that it is unlikely they will "get it right" the first time and, following agile methodology, are not expected to. Process iteration assists in discovering errors, missing steps, and other potential sources of misconfiguration that are ultimately the source of outages or operational disruption.
An organization that has experienced outages due to human error are practically assured that they will codify those errors into automation frameworks if they do not take the time to iteratively execute on those processes to find out where errors or missing steps may lie.
It is process that drives continuous delivery in development and process that must drive continuous delivery in devops. Process that must be perfected first through practice, through the application of iterative models of development on devops automation and orchestration.
What may appear as a tedious repetition is also an opportunity to refine the process. To discover and eliminate inefficiencies that streamline the deployment process and enable faster time to market. Inefficiencies that are generally only discovered when someone takes the time to clearly document all steps in the process – from beginning (build) to end (production). Cross-functional responsibilities are often the source of such inefficiencies, because of the overlap between development, operations, and administration.
The outage of Microsoft’s cloud service for some customers in Western Europe on 26 July happened because the company’s engineers had expanded capacity of one compute cluster but forgot to make all the necessary configuration adjustments in the network infrastructure.
-- Microsoft: error during capacity expansion led to Azure cloud outage
Applying an agile methodology to the process of defining and refining devops processes around continuous delivery automation enables discovery of the errors and missing steps and duplicated tasks that bog down or disrupt the entire chain of deployment tasks.
We all know that automation is a boon for operations, particularly in organizations employing virtualization and cloud computing to enable elasticity and improved provisioning. But what we need to remember is that if that automation simply encodes poor processes or errors, then automation just enables to make mistakes a whole lot faster.
Take care to pay attention to process and to test early, test often.



David Linthicum (@DavidLinthicum) asserted “In the Halloween season, not all scares are in good fun, but you can escape these cloud computing frights” in a deck for his It came from the cloud! 3 terrors lurking in wait article of 10/23/2012 for InfoWorld’s Cloud Computing blog:
It's that time of the year again: Ghost shows and monster movies are constantly on TV, there's plenty of candy in the office, and memos are issued on appropriate costumes for the workplace. I love Halloween.
Not much scares me this time of year -- except in the world of cloud computing. In fact, certain developments in cloud computing strike fear in my heart. Be afraid -- very afraid -- of these three things.
1. The lack of security planning in cloud deployments. You'd think security is at the top of the list for those who deploy systems on public clouds. Sadly, I've noticed that security is typically an afterthought, very much like in internal deployments.
When dealing with public clouds, security comes down to understanding the type of data set to be stored and how that data will move in and out of the cloud. Once you have done modeling, selecting the right security technology and approaches is relatively easy. But few people do this fundamental work. As a result, in the cloud deployments that I see, there is either too much or too little security.
2. The absence of service governance for distributed cloud services. When you're managing hundreds of services, they quickly get away from you. Who's consuming the services from public clouds, and how they are being combined into working systems? Lacking a good service governance approach and technology, you'll find you're quickly crushed under the weight of managing these services.
3. The dearth of understanding of the performance issues to account for when deploying on public clouds. The design of a cloud system has a lot to do with how it will perform when in production. Although clouds are very good and fast when asked to process within the clouds, talking to other clouds or to internal enterprise systems is still problematic -- in fact, they can kill your cloud migration project. You need to model and understand the issues up front, then work through them.
Although these are all big issues, they are also very fixable. Dealing with these issues is of the learning process when moving to cloud computing. Sometimes you just have to let people touch the hot stove -- even if it is scary. …

Gianugo Rabellino (@gianugo) posted Interoperability Elements of a Cloud Platform: Technical Examples to the Interoperability @ Microsoft blog on 10/19/2012:
Two years ago we shared our view on Interoperability Elements of a Cloud Platform. Back then we talked to customers and developers and came out with an overview of an open and interoperable cloud, based on four distinct elements: Data Portability, Standards, Ease of Migration and Deployment, and Developer Choice. Since then, we have been laser focused on the quest for an interoperable and flexible cloud platform that would enable heterogeneous workloads.
Windows Azure is committed to openness across the entire application stack, with service APIs and service management APIs exposed as RESTful endpoints that can be used from any language or runtime, key services such as Caching, Service Bus, and Identity that can be hosted either on-premises or in the cloud, and open source SDKs for popular languages that give developers a choice of tools for building cloud-based applications and services.
In this blog post I’ll recap some of the most important news of the last year in each of these areas. As I mentioned in a blog postearlier this year, when a journey reaches an important milestone it’s good to look back and think about the road so far. We’ve come even farther down that road now, and here are many technical examples of what has been accomplished.
Data Portability
When customers create data in an on-premises application, they have a high level of confidence that they have control over the data stored in the on-premise environment. Customers should have a comparable level of control over their data when they are using cloud platforms. Here are some examples of how Windows Azure supports Data Portability:
- Interoperability Surface for Data Portability
- Support for Open Data Protocol (OData) in Windows Azure
- Migrating SQL Server Data to Hadoop with Sqoop
- Mount a Durable Hard Drive Volume in the Cloud with Windows Azure Drives
- Moving Data in and out of Windows Azure SQL Databases and Blob Storage
Standards
Cloud platforms should reuse existing and commonly used standards when it makes sense to do so. If existing standards are not sufficient, new standards may be created. Here are some of the ways we’re working to support standards for cloud computing:
- Microsoft Engagement with Standards Organizations
- Standards Based Interoperability Surfaces in Windows Azure
- Support for Open Data Protocol (OData) in Windows Azure
- Standards Based Messaging in Windows Azure
Ease of Migration and Deployment
Cloud platforms should provide a secure migration path that preserves existing investments and enable co-existence between on-premise software and cloud services. Here are some examples of ease of migration and deployment on Windows Azure:
- Deploy Linux Applications on Windows Azure
- Migrate MySQL Apps and Data to Windows Azure
- Moving Data in and out of Windows Azure SQL Databases and Blob Storage
- Deploying memcache Applications on Windows Azure
- Use Your Favorite Management Tools on Windows Azure
- Third Party Identity Providers
- Standards Based Messaging in Windows Azure
- Mount a Durable Hard Drive Volume in the Cloud with Windows Azure Drives
- Crossing Boundaries with Windows Azure Service Bus
Developer Choice
Cloud platforms should enable developer choice in tools, languages and runtimes to facilitate the development of interoperable customer solutions. This approach will also broaden the community of developers that write for a given cloud platform and therefore enhance the quality of services that the platform will offer to customers. Here are some of the ways that Windows Azure is delivering on developer choice:
- Developer Choice in Languages and Runtimes with Windows Azure
- Windows Azure Plugin for Eclipse with Java
- Windows Azure Web Sites Gallery
It’s exciting to see how far we’ve come, and we still have much to do as well. The Interoperability Elements of a Cloud Platform originally came out of discussions with customers, partners, and developers about what they need from an interoperable cloud, and we’re continuing those discussions going forward, and we will continue to deliver on these important elements!
Gianugo Rabellino
Senior Director, Open Source Communities
Microsoft Open Technologies, Inc.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Thomas W. Shinder, MD (@tshinder) posted What is Automation? by Michael Lubanski on 10/22/2012:
Automation is "the use of machines or technologies to optimize productivity in the production of goods and delivery of services. The correct incentive for applying automation is to increase productivity, and/or quality beyond that possible with current human labor levels so as to realize economies of scale, and/or realize predictable quality levels.[1] “
Automation in the private cloud is no different. Its purpose is to optimize productivity in the delivery of Infrastructure-as-a-Service beyond what human labor can provide. It seeks to use the technology in a private cloud (virtualization, monitoring, orchestration, etc.) to provide virtual resources faster than a human can at a predictable level. This, in turn, improves the economies of scale for a private cloud.
Why is automation needed in a private cloud?
Automation is needed in the private cloud because it improves the bottom line (through a reduction of costly human labor) and improves customer satisfaction (through a reduction in the amount of time it takes to complete requests).
Without automation, you do not have self-service and providing self-service is one of the most compelling and cited reasons for a private cloud. Self-service does not refer to entering information in a portal that in turn creates a work ticket or assignment for an administrator to create virtual machines for the requestor. Self-service must be driven by automation to meet the requestors' needs without any further human interaction. The speed by which the request is satisfied is merely limited to the speed of the physical resources, e.g., how fast the disks spin and how fast the bits move across the network. Even on the oldest hard drives and the slowest network, it will still produce the desired result faster than any human interaction in the process.
Without automation, you do not have a cloud. Why? The NIST definition of a cloud lists five essential characteristics of cloud computing:
- on-demand self-service,
- broad network access,
- resource pooling,
- rapid elasticity or expansion,
- and measured service.[2]
Although virtualization optimizes resource pooling and elasticity, and the network configuration provides broad network access, automation is what will enable self-service and measured service.
Besides self-service, automation also opens the door for even more capabilities of the private cloud. Examples of automation in a private cloud:
- Self-service virtual machine provisioning - creating a new virtual machine based on the criteria entered in the request. Think of deploying a virtual machine without human interaction.
- Self-healing - defined as taking a corrective action when an incident occurs, without human interaction. Think how loss of a service may cause an automatic recycling (or rebooting) of resources to bring the service back online.
- Application resiliency and availability - burst an application to a new server or a public cloud based on defined thresholds of application usage and performance. Think how the usage of www.nfl.com increases on a Sunday. Automation can be used to automatically increase the resources available to the app, thus improving performance.
- Power management - reduce the use of computing resources when they are not needed and bringing them back online when they are. Think of a thermostat – the air conditioner turns on when it gets hot, then turns off when it gets cool, all without someone physically turning the power to the AC unit on or off.
- Chargeback or showback - collect data and report on the usage of the physical infrastructure to help with cost allocation or awareness. Think of a monthly credit card statement to show how much you are spending every month on datacenter resources.
Automating the private cloud has big potential for OpEx savings and CapEx optimization. At the very least, automation should be used to enable or improve redundancy and recovery of private cloud resources to ensure the lights stay on and the applications stay running. It can reduce the outage time of applications (OpEx) and make more efficient use of datacenter resources (CapEx).
OK, I understand the value of automation. How do I enable it?
At a basic level, automation can be enabled with runbooks. Runbooks can take a series of pre-assembled actions (like scripts) and execute them when a trigger occurs. The automation is able to detect the trigger, activate the runbooks, run the scripts in the defined order, and then report the result of the runbooks.
A basic example:
- Trigger - server goes offline and cannot be pinged.
- Runbook – detects the trigger has been fired and activates a series of scripts, in a specific order, to perform.
- Scripts (examples):
a. remove server from the load balancer so it cannot respond to any application requests
b. e-mail the application administrator of the outage
c. attempt a forced reboot the server to attempt to bring it back online- Results - did the scripts succeed? did a forced reboot of the server bring it back online? or did it still fail? If server is online, e-mail admin again. If server is offline, open an incident in the IT service management system.
In essence, the automation eliminated manual (human) triage steps and quickly brought the issue to an admin for either notification that the problem was automatically fixed or raised an incident for an admin or engineer to begin troubleshooting.
At a more advanced level, you can enable policy-based automation that can perform certain tasks based on the identity of the user (requestor). For example, when requesting virtual machines, the user is limited to only 5 VMs, because of membership in the testing group.
How do I ensure my automation efforts are successful?
There are several recommendations when automating a private cloud:
- Determine the goal of automation and what's important to you. Is it to reduce human action in certain situations? Is it to increase availability and performance of applications? Is it to enable faster outage triage? Is it to meet service level agreements? what do you want to achieve with automation?
- Include automation from the beginning. Do not build a private cloud, and then try to retrofit it with automation at a later time.
- Automation efforts must include computing, storage and network resources for it to be effective. Including 1 or 2 out of the 3 will not yield the more optimum results.
- To increase the value of automation in the private cloud, it should interface with existing business systems, such as license management, IT Service Desk, escalation procedures, etc. to provide a more holistic lifecycle around the automation touch points.
Summary
No product provides the runbooks necessary to automate your environment. This is the investment needed to realize the benefits of automation - making it real in your environment. Use the automation toolkits to define business or IT processes and specifically, the triggers, scripts and results reporting.
One product that delivers the tools to enable private cloud automation is Microsoft System Center. Automation is built into each component of System Center, with Orchestrator acting as the runbook automation engine. Each System Center component is instrumented with a PowerShell interface and an Orchestrator Integration Pack. These go a long way in helping you develop and test your automation. There are also Integration Packs for popular components from HP, IBM, BMC, VMware, EMC, NetApp and much more. This will ensure that the automation can reach out across the IT infrastructure for a more comprehensive solution.
For more information on System Center automation capabilities, click here.
Michael Lubanski
Americas Private Cloud Center of Excellence Lead
Microsoft Services
mlubansk@microsoft.com

<Return to section navigation list>
Cloud Security and Governance
‡ Sreenivasa Rao Pilla listed Top 5 tips to block a DoS attack against Windows Azure in a 10/25/2012 post to the Aditi Technologies blog:

Denial of Service (DoS) is an attempt to make the resources unavailable for the intended audience by generating heavy traffic continuously to exhaust the target resources. DoS attack usually originates from one machine (IP).
A more powerful and destructive form of DoS attack is Distributed DoS (DDoS). This kind of attack generates high traffic from different source-machines across the geography. This makes detection and mitigation more difficult.
Before going further, let me list the three areas which [are] at risk of being under a possible DoS attack:
Infrastructure Level
- Platform Level (PaaS)
- Application Level
The good news is that Azure provides maximum protection for DoS attacks at the infrastructure level and platform level. Azure detects and stops the DoS attacks at the infrastructure or platform level even before it reaches to your application that is deployed on the Azure platform.
However, if the traffic looks legitimate (for example, the traffic originates from a valid source IP and [includes] the accurate request parameters/headers), then Azure allows these requests to come to your application. It now becomes your responsibility to prevent these DoS attacks. Any infrastructure or platform providers shouldn't block the requests, even if
aheavy traffic originates from a single IP. The feature to allow more traffic from a single IP is really required to perform a load test on your application.Tips for blocking DoS attack:
- Allow access only to specific IPs. You can specify the IP list which your role can have access to. This linkgives you more details.
- You can look at using some tools such as “Dynamic IP Restrictions” at IIS level. With this, you can specify the IP blocking pattern such as “Any IP should be blocked if it has concurrent requests of 10 or more”. Read herefor more details.
- Create an independent VM role to periodically detect the usage patterns and the originating IP addresses. The IPs can be dynamically moved to the Azure Firewall settings to prevent any further traffic coming from these IP’s.
- Be extra cautious when you setup a maximum role instance count (rules) if you use Autoscaler to ramp-up your application instances to match the traffic.
- Be smart while setting a maximum Azure usage limit (on your credit card) based on the availability requirements of your application.
Azure completely blocks the DoS attacks that come from other tenant applications within Azure.
Subscription charges for usage during a DoS attack:
Who takes care of your Azure subscription charges? Will you end up shelling out money for all the heavy usage due to [a] DoS attack? To answer these questions here are some key points:
- Remember that in Azure, all the in-bound traffic (bytes) is free of charge except for CDN
- Microsoft would review and may discard the Azure usage charges during DoS attack. However, the onus of supporting your claim (with proper logs) is on you.
DoS attackers are getting smarter every day and continue to challenge the platform providers and application developers. Application developers should keep an eye on the DoS attack patterns worldwide and re-sharpen their DoS attack strategies.
Windows Azure team has been working closely with Microsoft Global Foundation Services (GFS) to continuously improvise and strengthen Azure platform from DoS attacks.
To know more about Azure’s security, read here.
Have you come across with any DoS attacks on any cloud platforms or applications deployed on cloud? Feel free to share your experiences here.

No significant articles today
<Return to section navigation list>
Cloud Computing Events
‡ Jim O’Neil (@jimoneil) posted MongoDB Boston Resources on 10/24/2012:
Thanks to all that came out to my “MongoDB and Windows Azure” presentation at MongoDB Boston. It was great to be invited back to present on two of my passions – Cloud and NoSQL. It’s also been fun watching the evolution of the Microsoft and 10gen partnership over the past year as the technical implementation of the MongoDB on Windows Azure solution has matured and expanded – now to encompass not only Platform-as-a-Service but also Infrastructure-as-a-Service.
We covered a lot of ground in a short time, so I wanted to establish this blog post as a landing point for the myriad of references touched upon in the session. Please leverage the great resources that both 10gen and Microsoft have to offer, and if you have any questions on the session or need additional pointers on these materials, please send me a note via the comment option at the bottom of this post. I do make it a point to respond to every comment or question.
MongoDB and Windows Azure presentation (on SlideShare)
Windows Azure
- Windows Azure features overview
- Access to free, 90-day trial account for Windows Azure
- Windows Azure Training Kit (download | GitHub)
- OSS on Azure tutorials
- MongoDB Experts Video Series
Azure and MongoDB resources
- MongoDB on Azure Overview (on mongodb.org)
- MongoDB on Azure Worker Roles installation guide
- MongoDB installer for Windows VMs in Windows Azure (guide)
- MongoDB on CentOS VM in Windows Azure (walkthrough)
- Node.js on Windows Azure with MongoLab (tutorial)
- Node.js and MongoDB on Windows Azure (tutorial)

•• Brian Hitney announced Microsoft DevRadio: (Part 2) Windows Azure Web Sites Explained in a 10/23/2012 post:
Watch Part 1
After watching this video, follow these next steps:
Step #1 – Start Your Free 90 Day Trial of Windows Azure
Step #2 – Download the Tools for Windows 8 App Development
Step #3 – Start building your own Apps for Windows 8
Subscribe to our podcast via iTunes, Zune, or RSS
If you're interested in learning more about the products or solutions discussed in this episode, click on any of the below links for free, in-depth information:
Websites:
Blogs:
Virtual Labs:
Download
- MP3 (Audio only)
- MP4 (iPod, Zune HD)
- High Quality MP4 (iPad, PC)
- Mid Quality MP4 (WP7, HTML5)
- High Quality WMV (PC, Xbox, MCE)
Brian H. Prince (@brianhprince) posted Gen Appathon announcement on 10/23/2012:
I try not to just copy and paste stuff to my blog, but for event announcements there really isn’t much to add. I do feel that this is the start to a new computing era, and 10 years from now you will look back and see that you were a part of it.
Build your one-of-a-kind Windows app at the free Gen Appathon event on November 9th.
Join thousands of developers just like you on November 9, 2012 for the world’s largest code fest – Gen Appathon. Here’s your chance to get down to business and start building your dream app, or polish up the last lines of code on that app you’ve already started. This event is an open hackathon, where you’ll put all your coding skills into practice. Code to your heart’s content, with experts available for one-on-one consultation to guide you through every step of the process. And did we mention that it’s free?
There’s never been a better time to build apps.
Windows 8 is set to launch, hardware manufacturers are readying new devices, and millions of consumers are expected to upgrade. We can’t guarantee your success, but releasing a first-of-its-kind app in the Windows Store can’t hurt your reputation – or your bottom line.
This full-day event will be filled with coding, sharing, plenty of food, and the occasional Lightning Talk on topics determined by your apps and questions. Bring your own laptop (for recommended system specs, click on the city nearest you), your apps and your best ideas, and get ready to create!
FREE EVENTS
Seating is limited, so register today.

For more information or to register, visit > www.msdnevents.com
OR CALL 1-877-MSEVENT


<Return to section navigation list>
Other Cloud Computing Platforms and Services
‡ Barb Darrow (@gigabarb) reported Google puts App Engine back online in a 10/26/2012 post to Giga Om’s Cloud blog:
TGIF, they must be saying at Google, which just put Google App Engine back online after a rough day of outages.
In a statement released at around 12:45 p.m. PDT, the company said the service had been restored and that it continued to look into the root cause.

According to Google, an event this morning caused its load balancing servers to fail. To restore service, Google shut down traffic and slowly brought the service back up. This was the “first major high replication datastore outage we’ve had since moving to database infrastructure“ almost two years ago.
Users of the GAE Platform as a Service can go to this site for updates, including an incident report.
Friday was indeed a tough morning for the interwebs. Tumblr, Dropbox and GAE all experienced outages, leading some to surmise that there was a broader issue around large packet losses in North America and Asia. It is unclear if all these outages are related. Amazon Web Services suffered a serious outage early this week



‡ Emil Protalinsky (@EmilProtalinski) observed Major sites and platforms experiencing outages today, including Dropbox and Google App Engine in a 10/26/2012 post to the TNW Insider blog. From the Google App Engine content:
Following the Amazon Web Services outage earlier this week, major sites and platforms are experiencing outages today, including at least Dropbox and Google App Engine. …
Update at 12:05PM EST: Dropbox appears to be coming back. Google App Engine is still down and out, and the search giant has classified the issue as an “Anomaly” (talk about understatement) over at Google App Engine’s System Status page. “App Engine is currently experiencing serving issues. The team is actively working on restoring the service to full strength.” We are told to keep an eye on this Google Groups thread for more information.
Update at 12:35PM EST: Cedexis has posted Google App Engine traffic details for today, which show things may be starting to return to normal:

Update at 1:15PM EST: Google has posted an explanation.
At approximately 7:30am Pacific time this morning, Google began experiencing slow performance and dropped connections from one of the components of App Engine. The symptoms that service users would experience include slow response and an inability to connect to services. We currently show that a majority of App Engine users and services are affected. Google engineering teams are investigating a number of options for restoring service as quickly as possible, and we will provide another update as information changes, or within 60 minutes.
Update at 1:50PM EST: Google App Engine is starting to come back.
Update at 2:10PM EST: It’s down again. Google has more.
We are continuing work to correct the ongoing issues with App Engine. Operation has been restored for some services, while others continue to see slow response times and elevated error rates. The malfunction appears to be limited to a single component which routes requests from users to the application instance they are using, and does not affect the application instances themselves. We’ll post another status update as more information becomes available, and/or no later than one hour from now.
Update at 3:45PM EST: All systems are go.
At this point, we have stabilized service to App Engine applications. App Engine is now successfully serving at our normal daily traffic level, and we are closely monitoring the situation and working to prevent recurrence of this incident.
This morning around 7:30AM US/Pacific time, a large percentage of App Engine’s load balancing infrastructure began failing. As the system recovered, individual jobs became overloaded with backed-up traffic, resulting in cascading failures. Affected applications experienced increased latencies and error rates. Once we confirmed this cycle, we temporarily shut down all traffic and then slowly ramped it back up to avoid overloading the load balancing infrastructure as it recovered. This restored normal serving behavior for all applications.
We’ll be posting a more detailed analysis of this incident once we have fully investigated and analyzed the root cause.
Google has sent over an apologetic statement.
Google App Engine has now been restored and users should see service returning to normal. Our team is still continuing to investigate and determine the root cause of the issue. We know that many of our customers rely on App Engine for their mission critical applications. We apologize for the inconvenience caused by this outage and we appreciate our customers’ patience.
Update at 4:15PM EST: Now it’s Facebook’s turn.
Update at 9:00PM EST: Google has more information on the outage today over on its App Engine blog.


Barb Darrow (@gigabarb) suggested Why Amazon customers might think twice about going east in a 10/23/2012 post to Giga Om’s Cloud blog:
Why do tech-savvy companies like Heroku, Pinterest, AirBNB, Instagram, Reddit, Flipboard, and FourSquare keep so much of their computing horsepower running on Amazon’s aging US-East infrastructure given its problematic track record? US-East experienced big problems again Monday, impacting those sites and more. The latest snafu comes after other outages in June and earlier.
Why they’re sticking with US-East — especially since Amazon itself preaches distribution of loads across availability zones and geographic regions — is the multimillion dollar question that no one at these companies is addressing publicly. But there are pretty safe bets as to their reasons. For one thing, Ashburn, VA-based US-East came online in 2006 and is Amazon’s oldest and biggest data center (or set of data centers).That’s why lot of big, legacy accounts run there. Moving applications and workloads is complicated and expensive given data transfer fees. Face it, inertia hits us all — take a look at your own closets and you’ll probably agree. Moving is just not easy. Or fun.
Stop putting crap in us-east-1, m’kay? The other regions are very nice.—
George Reese (@GeorgeReese) October 22, 2012Data gravity is one issue. “If you’ve been in US-East for a while, chances are you’ve built up a substantial amount of data in that region. It’s not always easy to move data around depending on how the applications are constructed,” said an industry exec who’s put a lot of workloads in Amazon and did not want to be identified.
In addition, the dirty little secret to the world at large is that many applications running on AWS “are really built with traditional data center architectures, so moving them around is akin to a data center migration — never an easy task in the best of circumstances,” he added. While most companies want to run applications and services in multiple venues, the complexity of doing so can be daunting, he said. He pointed to a post-mortem of an April 2011 Heroku outage as an example.
US-East by default
Vittaly Tavor, founder and vice president of products for Cloudyn, a company that helps customers best utilize Amazon services, said the deck is still stacked in US-East’s favor nine months after the company’s new Oregon data center was activated. For one thing, the AWS console directs customers to US-East by default. So if you don’t know better, your stuff is going to go there, he said.
@gigabarb @eekygeeky @GeorgeReese Simple. US-East-1 is cheaper than US-West-1. US-West-2 missing some instance types.—
Lydia Leong (@cloudpundit) October 23, 2012The US-West 2 data center, in Oregon, is newer but also smaller than US-East. Tavor suspects that Amazon may tell very large customers not to move there. “Oregon is much smaller than US East so if you’re a company of Heroku’s size and need to suddenly launch lots of instances, Oregon might be too small,” he said. and, US West 1, in California, is more expensive than either of the other two because of the region’s higher energy and other costs.
@gigabarb US-East gets new features first and among the lowest cost. By IP range, US-East is 58% of the total worldwide AWS capacity.—
adrian cockcroft (@adrianco) October 23, 2012

For the record, as of Tuesday morning, Amazon was still sorting out residual issues from the problem — which surfaced there at 10:30 a.m. PDT — according to its status page:
4:21 AM PDT We are continuing to work on restoring IO for the remainder of affected volumes. This will take effect over the next few hours. While this process continues, customers may notice increased volume IO latency. The re-mirroring will proceed through the rest of today.
I have reached out to several of the affected companies and to Amazon itself and will update this if and when they respond. Of course, Amazon competitors are having a field day. Check out Joyent’s mash note to Reddit .


<Return to section navigation list>

















0 comments:
Post a Comment