Windows Azure and Cloud Computing Posts for 10/8/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI,Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

•• Updated 10/11/2012 8:30 AM PDT with new articles marked ••.
• Updated 10/10/2012 10:45 AM PDT with new articles marked •.
Tip: Copy bullet(s), press Ctrl+f, paste it/them to the Find textbox and click Next to locate updated articles:
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, Hadoop and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Marketplace DataMarket, Cloud Numerics, Big Data and OData
- Windows Azure Service Bus, Access Control, Caching, Active Directory, and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hosting, Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue, Hadoop and Media Services
•• Guarav Mantri (@gmantri) continued his series with Windows Azure Media Services-Part IV (Managing Access Policies via REST API) on 10/11/2012:
In the last post about Windows Azure Media Service (Media Service), I talked about how you can manage assets using REST API. You can read that post here: http://gauravmantri.com/2012/10/10/windows-azure-media-service-part-iii-managing-assets-via-rest-api/.
In this post, I’m going to take this further and talk about how to manage access policies using REST API. This post makes extensive use of concepts covered in earlier posts so I would recommend you go through them first.
Let’s get cracking!!!
Definition
Simply put, an access policy defines the permissions and duration of access to an asset. To explain, you could create an access policy which would grant say read permission on an asset for a duration of 60 minutes.
From the definition, it may seem like you create an access policy for an asset i.e. one-to-one kind of relationship, however that’s not the case. Access policies and assets share a many-to-many kind of relationship. What that means is that you can define an access policy and apply that access policy to one or more assets. Similarly an asset can have one or more access policies. The association between them is facilitated through what is called as “Locators”. We’ll cover locators in one of the next posts but for now let’s just define it: A locator is a URI which provides time-based access to a specific asset. …


Guarav continues with tables and source code for Access Policy Entity, Operations, and the complete source code for his project so far.
…
Summary
That’s it for this post. In the next post, we will deal with more REST API functionality and expand this library. I hope you have found this information useful. As always, if you find some issues with this blog post please let me know immediately and I will fix them ASAP.
•• Denny Lee (@dennylee) described HiveODBC error message “..expected data length is 334…” in a 10/11/2012 post:
One of the odd HiveODBC error messages that I recently encountered on a project is that when I am extracting data from my Hive/Hadoop cluster using the HiveODBC driver, I end up getting an error message similar to:
OLE DB provider ‘MSDASQL’ for linked server ‘[MyHadoopCluster]‘ returned data that does not match expected data length for column ‘[MSDASQL].error_message’. The (maximum) expected data length is 334, while the returned data length is 387.
In this case, the error message was generated from connecting my SQL Server to a Mac OSX Hadoop 1.0.1 cluster running Hive 0.8.1 using the HiveODBC driver (why I insist on experimenting on my Macbook Air is a blog post for another time!). This is similar to the design as called by the SQL Server Analysis Services to Hive- A Klout Case Study. The first I thought that was curious was that if I had created a HiveODBC linked server connection from my sql server, and then ran a select * into statement,
select * from openquery(‘MyHadoopCluster’,
select * from hive_weblogs
)
then all the string columns were automatically set to varchar(334).
Digging into the data, I had in fact
hada string column where a bunch of rows had a length much greater than 334 characters. In my case, I had error messages that were potentially thousands of characters long. As reminded to me by Dave Mariani (@dmariani) and some colleagues over at Platon (thanks Stig Torngaard Hammeken and Morten Post), this in fact is a bug noted in jira Hive-3382: Strings truncated to length 334 when hive data is accessed through hive ODBC driver.So until this is fixed, what can you do about it?
- You could always using the substring function to shorten it such as substring(errormessage, 1, 334)
- When exporting data out of HiveODBC, instead of exporting out all of the columns, just export out the columns you need. Using the above sql_hive_weblogs example, I only needed the errormessage column when I needed to dig into the data, so what I did was export out the server, eventtime, ipaddress, and errorcode columns into my PowerPivot workbook/ SSAS cube / SQL database via the HiveODBC driver. When I needed the actual error message, I had the errorcode handy and then I ran a Hive query to get the actual error message.
- Related to the above approach, use SQOOP or export the table (or just the errorcode and errormessage columns) out as CSV to ultimately load that data into your final destination.
- If you do not have an errorcode handy, perhaps build a hash of the errormessage field so you can do the above two tricks. Examples of hashes in Hive include (but are not limited to) Hive MD5 UDF, Hive-1262 patch to add security/checksum UDFs, etc.
A tad frustrating at times, but in many BI-related cases, the full string isn’t required so the workarounds suggested above work fine.
Hopefully this can help you too!



• Carl Nolan (@carl_nolan) reported availability of the Framework for .Net Hadoop MapReduce Job Submission V1.0 Release in a 10/10/2012 post:
It has been a few months since I have made a change to the “Generics based Framework for .Net Hadoop MapReduce Job Submission” code. However I was going to put together a sample for a Reduce side join and came across a issue around the usage of partitioners. As such I decided to add support for custom partitioners and comparators, before stamping the release as a version 1.0.
The submission options to be added will be -partitionerOption (for partitioning the data) and -comparatorOption (for sorting). Before talking about these options lets cover a little of the Hadoop Streaming Documentation.
A Useful Partitioner Class
Hadoop has a library class, KeyFieldBasedPartitioner, that allows the MapReduce framework to partition the map outputs on key segments rather than the whole key. Consider the following job submission options:
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner -Dstream.num.map.output.key.fields=4 -Dmapred.text.key.partitioner.options=-k1,2The -Dstream.num.map.output.key.fields=4 option specifies that the map output keys will have 4 fields. In this case the the -Dmapred.text.key.partitioner.options=-k1,2 option tells the MapReduce framework to partition the map outputs by the first two fields of the key; rather than the full set of four keys.This guarantees that all the key/value pairs with the same first two fields in the keys will be partitioned to the same reducer.
To simplify this specification the submission framework supports the following command line options:
-numberKeys 4 -partitionerOption ”-k1,2”When writing Streaming applications one normally has to do the partition processing in the Reducer. However with these options the framework will correctly send the appropriate data to the Reducer. This was the biggest change that needed to be made to the Framework.
This partition processing is important for handling Reduce side joins; the topic of my next blog post.
A Useful Comparator Class
Hadoop also has a library class, KeyFieldBasedComparator, that provides sorting the key data. Consider the following job submission options:
-D mapred.output.key.comparator.class=org.apache.hadoop.mapred.lib.KeyFieldBasedComparator -D mapred.text.key.comparator.options=-k2,2nrHere the MapReduce framework will sort the outputs on the second key field; the -Dmapred.text.key.comparator.options=-k2,2nr option. The -n specifies that the sorting is numerical and the -r specifies that the result should be reversed. The sort options are similar to a Unix sort, but here are some simple examples:
Reverse ordering:
-Dmapred.text.key.comparator.options=-rNumeric ordering:
-Dmapred.text.key.comparator.options=-nSpecific sort specification:
-Dmapred.text.key.comparator.options=-kx,yFor the general sort specification the -k flag is used, which allows you to specify the sorting key using the the x, y values; as in the sample above.
To simplify this specification the submission framework supports the following command line option:
-comparatorOption ”-k2,2nr”The framework then takes care of setting the appropriate job configuration values.
Summary
Although one could define the Partitioner and Comparator options using the job configuration parameters hopefully these new options make the process a lot simpler. In the case of the Partitioner options it also allows the framework to easily identity the difference in the number of sorting and partitioner keys. This allows the correct data to be sent to each Reducer.
As mentioned, using these options, in my next post I will cover how to use the Framework for doing a Reduce side join.


Denny Lee (@dennylee) recommended Padding zero-length string data with HiveODBC to avoid an “esoteric error” in a 10/9/2012 post:
One of the more esoteric error messages that you may receive from the HiveODBC driver connection is:
SQL_ERROR Failed to get data for column zu
When connecting to Hive using the HiveODBC driver using a linked server connection, the full error message looks something like:
OLE DB provider “MSDASQL” for linked server “MySQLHive” returned message “SQL_ERROR Failed to get data for column zu”.
OLE DB provider “MSDASQL” for linked server “MySQLHive” returned message “SQL_ERROR get signed long int data failed for column 9. Column index out of bounds.”.
OLE DB provider “MSDASQL” for linked server “MySQLHive” returned message “Option value changed”.
Msg 7330, Level 16, State 2, Line 1
Cannot fetch a row from OLE DB provider “MSDASQL” for linked server “MySQLHive”.
Thanks to some digging by James Baker and Dave Mariani (@dmariani, VP Engineering at Klout), we realized that the ODBC Provider for Hive might not correctly handle zero-length string data returned from Hive.
As noted in the SQL Server Analysis Services to Hive case study, to avoid these issues, avoid returning empty strings from Hive. For more information, please reference page 12 of the case study.



Maarten Balliauw (@maartenballiauw) explained What PartitionKey and RowKey are for in Windows Azure Table Storage in a 10/8/2012 post:
For the past few months, I’ve been coaching a “Microsoft Student Partner” (who has a great blog on Kinect for Windows by the way!) on Windows Azure. One of the questions he recently had was around PartitionKey and RowKey in Windows Azure Table Storage. What are these for? Do I have to specify them manually? Let’s explain…
Windows Azure storage partitions
All Windows Azure storage abstractions (Blob, Table, Queue) are built upon the same stack (whitepaper here). While there’s much more to tell about it, the reason why it scales is because of its partitioning logic. Whenever you store something on Windows Azure storage, it is located on some partition in the system. Partitions are used for scale out in the system. Imagine that there’s only 3 physical machines that are used for storing data in Windows Azure storage:
Based on the size and load of a partition, partitions are fanned out across these machines. Whenever a partition gets a high load or grows in size, the Windows Azure storage management can kick in and move a partition to another machine:
By doing this, Windows Azure can ensure a high throughput as well as its storage guarantees. If a partition gets busy, it’s moved to a server which can support the higher load. If it gets large, it’s moved to a location where there’s enough disk space available.
Partitions are different for every storage mechanism:
- In blob storage, each blob is in a separate partition. This means that every blob can get the maximal throughput guaranteed by the system.
- In queues, every queue is a separate partition.
- In tables, it’s different: you decide how data is co-located in the system.
PartitionKey in Table Storage
In Table Storage, you have to decide on the PartitionKey yourself. In essence, you are responsible for the throughput you’ll get on your system. If you put every entity in the same partition (by using the same partition key), you’ll be limited to the size of the storage machines for the amount of storage you can use. Plus, you’ll be constraining the maximal throughput as there’s lots of entities in the same partition.
Should you set the PartitionKey to the same value for every entity stored? No. You’ll end up with scaling issues at some point.
Should you set the PartitionKey to a unique value for every entity stored? No. You can do this and every entity stored will end up in its own partition, but you’ll find that querying your data becomes more difficult. And that’s where our next concept kicks in…RowKey in Table Storage
A RowKey in Table Storage is a very simple thing: it’s your “primary key” within a partition. PartitionKey + RowKey form the composite unique identifier for an entity. Within one PartitionKey, you can only have unique RowKeys. If you use multiple partitions, the same RowKey can be reused in every partition.
So in essence, a RowKey is just the identifier of an entity within a partition.
PartitionKey and RowKey and performance
Before building your code, it’s a good idea to think about both properties. Don’t just assign them a guid or a random string as it does matter for performance.
The fastest way of querying? Specifying both PartitionKey and RowKey. By doing this, table storage will immediately know which partition to query and can simply do an ID lookup on RowKey within that partition.
Less fast but still fast enough will be querying by specifying PartitionKey: table storage will know which partition to query.
Less fast: querying on only RowKey. Doing this will give table storage no pointer on which partition to search in, resulting in a query that possibly spans multiple partitions, possibly multiple storage nodes as well. Wihtin a partition, searching on RowKey is still pretty fast as it’s a unique index.
Slow: searching on other properties (again, spans multiple partitions and properties).
Note that Windows Azure storage may decide to group partitions in so-called "Range partitions" - see http://msdn.microsoft.com/en-us/library/windowsazure/hh508997.aspx.
In order to improve query performance, think about your PartitionKey and RowKey upfront, as they are the fast way into your datasets.
Deciding on PartitionKey and RowKey
Here’s an exercise: say you want to store customers, orders and orderlines. What will you choose as the PartitionKey (PK) / RowKey (RK)?
Let’s use three tables: Customer, Order and Orderline.
An ideal setup may be this one, depending on how you want to query everything:
Customer (PK: sales region, RK: customer id) – it enables fast searches on region and on customer id
Order (PK: customer id, RK; order id) – it allows me to quickly fetch all orders for a specific customer (as they are colocated in one partition), it still allows fast querying on a specific order id as well)
Orderline (PK: order id, RK: order line id) – allows fast querying on both order id as well as order line id.Of course, depending on the system you are building, the following may be a better setup:
Customer (PK: customer id, RK: display name) – it enables fast searches on customer id and display name
Order (PK: customer id, RK; order id) – it allows me to quickly fetch all orders for a specific customer (as they are colocated in one partition), it still allows fast querying on a specific order id as well)
Orderline (PK: order id, RK: item id) – allows fast querying on both order id as well as the item bought, of course given that one order can only contain one order line for a specific item (PK + RK should be unique)You see? Choose them wisely, depending on your queries. And maybe an important sidenote: don’t be afraid of denormalizing your data and storing data twice in a different format, supporting more query variations.
There’s one additional “index”
That’s right! People have been asking Microsoft for a secondary index. And it’s already there… The table name itself! Take our customer – order – orderline sample again…
Having a Customer table containing all customers may be interesting to search within that data. But having an Orders table containing every order for every customer may not be the ideal solution. Maybe you want to create an order table per customer? Doing that, you can easily query the order id (it’s the table name) and within the order table, you can have more detail in PK and RK.
And there's one more: your account name. Split data over multiple storage accounts and you have yet another "partition".
Conclusion
In conclusion? Choose PartitionKey and RowKey wisely. The more meaningful to your application or business domain, the faster querying will be and the more efficient table storage will work in the long run




Gaurav Mantri (@gmantri) continued his series with Windows Azure Media Service-Part II (Setup, API and Access Token) on 10/8/2012:
In the previous post about Windows Azure Media Service (WAMS), I provided an introduction to the service as to how I understood it. I also explained some key terms associated with WAMS. You can read this post here: http://gauravmantri.com/2012/10/05/windows-azure-media-service-part-i-introduction/
In this post, we’ll talk about creating a media service through Windows Azure Portal, explore a bit of API & SDK and what options are available to you when it comes to develop and manage media applications using WAMS. We’ll also talk briefly about authentication/authorization and finally we’ll wrap this post with some code for writing our own library for managing WAMS.
Setup
Before you start building media applications using WAMS, first thing you would need to do is create a media service. You can create a new media service through Windows Azure Portal. Following screenshots demonstrate the steps for the same.
1. Provide media service name & choose a storage account
First thing you would need to do is provide a media service name and choose a storage account where files related to various assets will be stored.
2. Manage access keys
Once media service has been created successfully, next thing you would want is to get hold of the access keys. If you have used Windows Azure Storage Service, you would be familiar with the concept of access keys. Essentially these are the keys required for securely communicating with WAMS. Anybody with access to these keys (and your service name) has complete access to your media service thus extreme care must be taken to protect these keys.
Another thing to notice here is the “Storage key configuration” section. While creating a media service, you specified which storage account you wish to use to store files. By choosing between “sync primary key” and “sync secondary key”, you are telling WAMS to use that particular key when communicating with the storage account. Also if you end up regenerating your storage account key (for whatever reason), by doing this you’re ensuring that your media service keeps working. I believe what it does is that it constantly polls storage service and fetches the storage account key you chose to keep in sync (total guess!!!)
Based on my testing if I don’t click on any of these “sync primary key” and “sync secondary key” buttons by default WAMS make use of storage account primary key. If I change my primary key, any operation I perform which involves WAMS to interact with this storage account will fail.
API & SDK
At the core of it, WAMS exposes management functionality through a REST API. It also provides a .Net SDK which essentially is a wrapper around REST API.
One may ask the question as to which route to go: REST API or .Net SDK? In my opinion, the answer depends on a number of factors, such as:
- Flexibility: Usually in my experience, consuming REST API gives you more flexibility as you are not bound by only the functionality exposed through SDK.
- Convenience: Obviously SDK provides you more convenience as most of the work as far as implementing REST API has already been done for you. Plus it includes some helper functionality (like moving files into blob storage) which is not there in REST API for WAMS.
- Platform Feature Compatibility: In my experience, SDK comes a bit after (sometimes long after) REST API. If we take Windows Azure Storage for example, there are still some things you could not do with SDK (version 1.7 at the time of writing) while they are available in the system and are exposed via REST API. If we look at WAMS in particular, the ability to create Job Templates and Task Templates are still not available through SDK at the time of writing this blog. Thus if you need these functionality, you would have to go REST API route.
- SDK Unavailability: Sometimes you don’t have a choice. For example, if you’re building functionality in say PHP and we know that currently there’s no SDK available for PHP. In that case you would need to use REST API. Having said this thing and given the way things are going in other parts of Windows Azure, I would not be surprised if the SDK for many common platforms (PHP, Java, node.js) arrive pretty soon.
REST API
A few things about REST API:
- Get an access token first: Before using REST API, you would need to get an access token first from Windows Azure Access Control Service (ACS). This is described in detail later in this blog post.
- Know about various request/response headers: Again when using REST API, understand about various headers you would need to pass in your request and the headers returned in response. You can find more information about this here: http://msdn.microsoft.com/en-us/library/windowsazure/hh973616.aspx.
.Net SDK
A thing or two I noticed about .Net SDK:
- Windows Azure Storage Client Library Version: Please note that at the time of writing this blog, the SDK has a dependency on Windows Azure Storage Client Library for SDK version 1.6 (library version 1.1) while the most latest SDK version is 1.7. Please make a note of that.
Authenticating (or is it Authorizing) REST API Requests
As mentioned above, before you could invoke WAMS REST API functionality you would need to get an access token from Windows Azure Access Control Service (ACS). In order to do so, a few things to keep in mind:
Endpoint:
Endpoint for getting an access token is: https://wamsprodglobal001acs.accesscontrol.windows.net/v2/OAuth2-13
HTTP Method:
HTTP Method for this request is POST.
Request Body:
Request body should be in this format:
grant_type=client_credentials&client_id=[client id value]&client_secret=[URL-encoded client secret value]&scope=urn%3aWindowsAzureMediaServicesFor example, if we take the values from above, the request body will be:
grant_type=client_credentials&client_id=gauravdemomediaservice&client_secret=RlT8voLHr6aHNYyxNOxS%2f1MkRsgT5Tb8m9guPMucsfw%3d&scope=urn%3aWindowsAzureMediaServicesResponse Body:
Response is returned in JSON format. Here’s how typical response looks like:
{ "token_type":"http://schemas.xmlsoap.org/ws/2009/11/swt-token-profile-1.0", "access_token":"http%3a%2f%2fschemas.xmlsoap.org%2fws%2f2005%2f05%2fidentity%2fclaims%2fnameidentifier=gauravdemomediaservice&urn%3aSubscriptionId=35d2de3b-a2cd-4160-aee5-f55d799962c4&http%3a%2f%2fschemas.microsoft.com%2faccesscontrolservice%2f2010%2f07%2fclaims%2fidentityprovider=https%3a%2f%2fwamsprodglobal001acs.accesscontrol.windows.net%2f&Audience=urn%3aWindowsAzureMediaServices&ExpiresOn=1349691469&Issuer=https%3a%2f%2fwamsprodglobal001acs.accesscontrol.windows.net%2f&HMACSHA256=LrliUJEEfUlBPTJJVlp35%1fS2XEX7xwWUQRN%2fb1NkJkM%3d", "expires_in":"5999", "scope":"urn:WindowsAzureMediaServices" }A few things to keep in mind here:
- access_token: This is the access token you would need when working with WAMS REST API. It must be included in every request.
- expires_in: This indicates the number of seconds for which the access token is valid. One must keep an eye on this value and ensure that the access token has not expired. One needs to get the access token again if the access token has expired.
Sample Project
Now what we will do is create a simple class library project which would be the wrapper around REST API much like .Net SDK. Then we’ll start consuming this library in another project. We’ll use VS 2010 to create this project and make use of .Net framework version 4.0. For the sake of simplicity, we’ll call this project as “WAMSRestWrapper”. Also because this REST API sends and receives the data in JSON format, we’ll make use of Json.Net library.
Since I’ll also be learning the REST API, the code would not be the best quality code and would desire a lot of improvements. Please feel free to make improvements as you see fit.
In this blog post, only thing we will do is get the access token and store it with our application.
To do so, let’s first create a class called AcsToken. Members of this class will map to the JSON data returned by ACS.
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace WAMSRestWrapper { public class AcsToken { public string token_type { get; set; } public string access_token { get; set; } public int expires_in { get; set; } public string scope { get; set; } } }Next let’s create a class for fetching this ACS token. Since this class will be doing a lot of stuff in the days to come, let’s call it “MediaServiceContext” (inspired by MediaContextBase in .Net SDK).
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Net; using System.Web; using Newtonsoft.Json; using System.Globalization; using System.IO; namespace WAMSRestWrapper { public class MediaServiceContext { private const string acsEndpoint = "https://wamsprodglobal001acs.accesscontrol.windows.net/v2/OAuth2-13"; private const string acsRequestBodyFormat = "grant_type=client_credentials&client_id={0}&client_secret={1}&scope=urn%3aWindowsAzureMediaServices"; private string _accountName; private string _accountKey; private string _accessToken; private DateTime _accessTokenExpiry; /// <summary> /// Creates a new instance of <see cref="MediaServiceContext"/> /// </summary> /// <param name="accountName"> /// Media service account name. /// </param> /// <param name="accountKey"> /// Media service account key. /// </param> public MediaServiceContext(string accountName, string accountKey) { this._accountName = accountName; this._accountKey = accountKey; } /// <summary> /// Gets the access token. If access token is not yet fetched or the access token has expired, /// it gets a new access token. /// </summary> public string AccessToken { get { if (string.IsNullOrWhiteSpace(_accessToken) || _accessTokenExpiry < DateTime.UtcNow) { var tuple = FetchAccessToken(); _accessToken = tuple.Item1; _accessTokenExpiry = tuple.Item2; } return _accessToken; } } /// <summary> /// This function makes the web request and gets the access token. /// </summary> /// <returns> /// <see cref="System.Tuple"/> containing 2 items - /// 1. The access token. /// 2. Token expiry date/time. /// </returns> private Tuple<string, DateTime> FetchAccessToken() { HttpWebRequest request = (HttpWebRequest)WebRequest.Create(acsEndpoint); request.Method = "POST"; string requestBody = string.Format(CultureInfo.InvariantCulture, acsRequestBodyFormat, _accountName, HttpUtility.UrlEncode(_accountKey)); request.ContentLength = Encoding.UTF8.GetByteCount(requestBody); request.ContentType = "application/x-www-form-urlencoded"; using (StreamWriter streamWriter = new StreamWriter(request.GetRequestStream())) { streamWriter.Write(requestBody); } using (var response = (HttpWebResponse)request.GetResponse()) { using (StreamReader streamReader = new StreamReader(response.GetResponseStream(), true)) { var returnBody = streamReader.ReadToEnd(); var acsToken = JsonConvert.DeserializeObject<AcsToken>(returnBody); return new Tuple<string, DateTime>(acsToken.access_token, DateTime.UtcNow.AddSeconds(acsToken.expires_in)); } } } } }The code is pretty straight forward. The constructor takes 2 parameters – account name and key and it exposes a public property called AccessToken. If an access token has never been fetched in this object’s lifecycle or has expired, a web request is made to ACS and token is fetched.
Now let’s write a simple console application which makes use of this library and all it does is prints out the access token on the console.
using System; using System.Collections.Generic; using System.Linq; using System.Text; using WAMSRestWrapper; using Microsoft.WindowsAzure.MediaServices.Client; namespace WAMSSampleApplication { class Program { static string accountName = "<your media service account name>"; static string accountKey = "<your media service account key>"; static MediaServiceContext context; static void Main(string[] args) { context = GetContext(); var accessToken = context.AccessToken; Console.WriteLine("Acces token fetched: " + accessToken); Console.WriteLine(); Console.WriteLine(); Console.WriteLine("Press any key to terminate the application!"); Console.ReadLine(); } static MediaServiceContext GetContext() { return new MediaServiceContext(accountName, accountKey); } } }Once we run this program, this is what we see on the console.
Now when invoking the WAMS REST API, we will make use of this access token.
Summary
That’s it for this post. In the next post, we will deal with more REST API functionality and expand this library. I hope you have found this information useful. As always, if you find some issues with this blog post please let me know immediately and I will fix them ASAP.








<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
Matteo Pagani (@qmatteoq) posted Having fun with Azure Mobile Services – The Windows Phone application on 10/9/2012:
Did you have fun using your Azure Mobile Service with your Windows 8 app? Good, because now the fun will continue! We will do the same operations using a Windows Phone application. As I already anticipated in the previous posts, actually there isn’t a Windows Phone SDK and the reason is very simple: Microsoft is probably waiting for the Windows Phone 8 SDK to be released, in order to proper support both its old and new mobile platform.
But we don’t have to worry: our service is a REST service that supports the OData protocol, so we can interact with it starting from now by using simple HTTP requests and by parsing the HTTP response.
To help us in our work we’ll use two popular libraries:
- RestSharp, that is a wrapper around the HttpWebRequest class that simplifies the code needed to communicate with a REST service. Sometimes RestSharp tries to be “too smart” for my taste, as we’ll see later, but it’s still a perfect candidate for our scenario.
- JSON.NET, that is a library that provides many useful features when you work with JSON data, like serialization, deserialization, plus a manipulation language based on LINQ called LINQ to JSON.
Let’s start! First you have to open Visual Studio 2010 (the 2012 release isn’t supported yet by the current Windows Phone SDK) and create a new Windows Phone project. Then, using NuGet, we’re going to install the two library: right click on the project, choose Manage NuGet Packages and look for the two needed libraries using the keywords RestSharp and JSON.NET.
The UI of the application will be very similar to the one we’ve used for the Windows 8 app, I’ve just replaced the ListView with a ListBox.
<StackPanel>
<ButtonContent="Insert data"Click="OnAddNewComicButtonClicked"/>
<ButtonContent="Show data"Click="OnGetItemButtonClicked"/>
<ListBoxx:Name="ComicsList">
<ListBox.ItemTemplate>
<DataTemplate>
<StackPanelMargin="0, 20, 0, 0">
<TextBlockText="{Binding Title}"/>
<TextBlockText="{Binding Author}"/>
</StackPanel>
</DataTemplate>
</ListBox.ItemTemplate>
</ListBox>
</StackPanel>Insert some data
To insert the data we’ll have to send a HTTP request to the service, using the POST method; the body of the request will be the JSON that represent our Comic object. Let’s see the code first:
privatevoidOnAddNewComicButtonClicked(objectsender, RoutedEventArgs e)
{
RestRequest request =newRestRequest("https://myService.azure-mobile.net/tables/Comics");
request.Method = Method.POST;
request.AddHeader("X-ZUMO-APPLICATION","your-application-key");
Comic comic =newComic
{
Title ="300",
Author ="Frank Miller"
};
stringjsonComic = JsonConvert.SerializeObject(comic,newJsonSerializerSettings
{
NullValueHandling = NullValueHandling.Ignore
});
request.AddParameter("application/json", jsonComic, ParameterType.RequestBody);
RestClient client =newRestClient();
client.ExecuteAsync(request, response =>
{
MessageBox.Show(response.StatusCode.ToString());
});
}The first thing we do is to create a RestRequest, which is the RestSharp class that represents a web request: the URL of the request (which is passed as parameter of the constructor) is the URL of our service.
Then we set the HTTP method we’re going to use (POST, in this case, since we’re going to add some data do the table) and we set the application’s secret key: thanks to Fiddler, by intercepting the traffic of our previous Windows 8 application, I’ve found that the key that in our Windows Store app was passed as a parameter of the constructor of the MobileService class is added as a request’s header, which name is X-ZUMO-APPLICATION. We do the same by using the AddHeader method provided by RestSharp.
The next step is to create the Comic object we’re going to insert in the table: for this task please welcome Json.net, that we’re going to use to serialize our Comic object, that means converting it into a plain JSON string. What does it mean? That if you put a breakpoint in this method and you take a look at the content of the jsonComic variable, you’ll find a plain text representation of our complex object, like the following one:
{
"Author" : "Frank Miller",
"Title" : "300"
}We perform this task using the SerializeObject method of the JsonConvert class: other than passing the Comic object to the method, we also pass a JsonSerializerSettings object, that we can use to customize the serialization process. In this case, we’re telling to the the serializer not to include object’s properties that have a null value. This step is very important: do you remember that the Comic object has an Id property that acts as primary key and that is automatically generated every time we insert a new item in the table? Without this setting, the serializer would add the Id property to the Json with the value “0”. In this case, the request to the service would fail, since it isn’t a valid value: the Id property shouldn’t be specified since it’s the database that takes care of generating it.
Once we have the json we can add it to the body of our request: here comes a little trick, to avoid that RestSharp tries to be too smart for us. In fact, if you use the AddBody method of the RestRequest object you don’t have a way to specify which is the content type of the request. RestSharp will try to guess it and will apply it: the problem is that, sometimes, RestSharp fails to correctly recognize the content type and this is one of these cases. In my tests, every time I’ve tried to add a json in the request’s body, RestSharp set the content type to text/xml, that it’s not only wrong, but actively refused by the Azure mobile service, since the only accepted content type is application/json.
By using the AddParameter method and by manually specifying the content type, the body’s content and the parameter’s type (ParameterType.RequestBody) we are able to apply a workaround to this behavior. In the end we can execute the request by creating a new instance of the RestClient class and by calling the ExecuteAsync method, that accepts as parameters the request and the callback that is executed when we receive the response from our service. Just to trace what’s going on, in the callback we simply display using a MessageBox the status code: if everything we did is correct, the status code we receive should be Created.
To test it, simply go to the Azure management portal, access to your service’s dashboard and go into the data tab: you should see the new item in the table.
Play with the data
Getting back the data for display purposes is a little bit simpler: it’s just a GET request, with the same features of the POST request. The difference is that, this time, we’re going to use deserialization, which is the process to convert the JSON we receive from the service into C# objects.
privatevoidOnGetItemButtonClicked(objectsender, RoutedEventArgs e)
{
RestRequest request =newRestRequest("https://myService.azure-mobile.net/tables/Comics");
request.AddHeader("X-ZUMO-APPLICATION","my-application-key");
request.Method = Method.GET;
RestClient client =newRestClient();
client.ExecuteAsync(request, result =>
{
stringjson = result.Content;
IEnumerable<Comic> comics = JsonConvert.DeserializeObject<IEnumerable<Comic>>(json);
ComicList.ItemsSource = comics;
});
}The first part of the code should be easy to understand, since it’s the same we wrote to insert the data: we create a RestRequest object, we add the header with the application key and we execute asynchronously the request using the RestClient object.
This time in the response and, to be more precisely, in the Content property we get the JSON with the list of all the comics that are stored in our table. It’s time to use Json.Net again: this time we’re going to use the DeserializeObject<T> method of the JsonConvert class, where T is the type of the object we expect to have back after the deserialization process. In this case, the return type is IEnumerable<Comic>, since our request returns a collection of all the comics stored in the table.
Some advanced scenarios for playing with the data
In the next posts we’ll see some more operations we can do with the data: the mobile service we’ve created with Azure supports the OData protocol; this means that we can perform additional operations (like filtering the results) directly with the HTTP request, without having to get the whole content of the table first. We’ll see how to do it, in the meantime… happy coding!



<Return to section navigation list>
Marketplace DataMarket, Cloud Numerics, Big Data and OData
•• Vagif Abilov (@ooobject) announced MongoDB OData provider now supports arrays and nested collections on 10/11/2012:
It’s been a while since I blogged about MongOData – a MongoDB OData provider that I wrote to cross MongoDB and OData protocol. Even though the provider has not reached it’s “Version 1.0” state, the response was quite encouraging: I received suggestions and bug reports, and this was indeed a good motivation factor. One of requests was to add support for collections. Property collections haven’t been supported by OData until the most recent protocol version (version 3), and such late attention to this topic is partly explained by the fact that property collections are not currently supported by Entity Framework which is often used to create OData services using WCF Data Services classes. But this should not be a limiting factor for document databases where arrays are used instead of relations in traditional SQL databases. To fill the gap I have upgraded OData protocol used by MongOData to version 3 and added creation of metadata for BsonArray properties.
Let me show how it works using a simple example. Imagine we have a JSON document with a root element colorsArray that consists of a collection of pairs (colorName,hexValue). Here’s the sample document:
How will MongOData expose it if we create a MongoDB collection “Colors” and import there the document above? Let’s have a look at generated metadata for entity and complex type:
Note the type name assigned to a property colorsArray. It’s a collection of items of a type Mongo.Colors__colorsArray – MongOData generates it’s type definition when it reads the first element. It is assumed that all array elements have the same structure – a reasonable assumption if we expect to generate the collection’s metadata.
Now let’s see how data exposed by this OData service can be consumed from the client. On a client side I am using Simple.Data OData adapter – a library that I also happened to maintain.
MongOData can be downloaded as an MSI installer or as a NuGet package.



The WCF Data Services Team posted Important: Security Advisory 2749655 affects WCF DS on 10/9/2012:
What is the advisory?
Microsoft just released Security Advisory 2749655, which addresses “an issue involving specific digital certificates that were generated by Microsoft without the proper timestamp attributes.” If you are using WCF Data Services 5.0.1 or have previously installed the WCF Data Services MSI from the download center, you may run into this issue.
Does this issue create a security vulnerability?
The advisory notes that “this is not a security issue”, meaning that this issue is not creating a vulnerability. However, there could be a combination of factors which might cause a WCF Data Service to stop working, or cause our installer to fail to install. Microsoft recommends that you “apply the KB 2749655 update and any rereleased updates addressing this issue immediately”.
I installed WCF Data Services 5.0 or 5.0.1. What do I need to do?
There are up to three actions WCF Data Services customers should take:
- We recommend that you install the KB referenced above
- If you installed the WCF Data Services 5.0 MSI before Sept 26, 2012, you should download and install the replacement version of this MSI
- If you have a dependency on the WCF Data Services NuGet package, we recommend that you upgrade to 5.0.2; this should not make any functional difference since we only expect people will run into problems on install/uninstall, however updating these DLLs would ensure that you have validly signed DLLs
Our NuGet packages are:
- Microsoft.Data.Services.Client (WCF Data Services Client)
- Microsoft.Data.Services (WCF Data Services Server)
- Microsoft.Data.OData (ODataLib)
- Microsoft.Data.Edm (EdmLib)
- System.Spatial (System.Spatial)
<Return to section navigation list>
Windows Azure Service Bus, Access Control Services, Caching, Active Directory and Workflow
Richard Seroter (@rseroter, pictured below) recounted Trying Out the New Windows Azure Portal Support for Relay Services in a 10/8/2012 post:
Scott Guthrie announced a handful of changes to the Windows Azure Portal, and among them, was the long-awaited migration of Service Bus resources from the old-and-busted Silverlight Portal to the new HTML hotness portal. You’ll find some really nice additions to the Service Bus Queues and Topics. In addition to creating new queues/topics, you can also monitor them pretty well. You still can’t submit test messages (ala Amazon Web Services and their Management Portal), but it’s going in the right direction.
One thing that caught my eye was the “Relays” portion of this. In the “add” wizard, you see that you can “quick create” a Service Bus relay.
However, all this does is create the namespace, not a relay service itself, as can be confirmed by viewing the message on the Relays portion of the Portal.
So, this portal is just for the *management* of relays. Fair enough. Let’s see what sort of management I get! I created a very simple REST service that listens to the Windows Azure Service Bus. I pulled in the proper NuGet package so that I had all the Service Bus configuration values and assembly references. Then, I proceeded to configure this service using the webHttpRelayBinding.
I started up the service and invoked it a few times. I was hoping that I’d see performance metrics like those found with Service Bus Queues/Topics.
However, when I returned to the Windows Azure Portal, all I saw was the name of my Relay service and confirmation of a single listener. This is still an improvement from the old portal where you really couldn’t see what you had deployed. So, it’s progress!
You can see the Service Bus load balancing feature represented here. I started up a second instance of my “hello service” listener and pumped through a few more messages. I could see that messages were being sent to either of my two listeners.
Back in the Windows Azure Portal, I immediately saw that I now had two listeners.
Good stuff. I’d still like to see monitoring/throughput information added here for the Relay services. But, this is still more useful than the last version of the Portal. And for those looking to use Topics/Queues, this is a significant upgrade in overall user experience.









Brian Swan (@brian_swan) described Using Memcache to access a Windows Azure Dedicated Cache in a 10/9/2012 post to the [Windows Azure’s] Silver Lining blog:
[A] few weeks ago, Larry and I wrote a couple of post about how to set up co-located caching using Windows Azure Caching (Preview) and access it from Ruby and PHP: Windows Azure Caching (Preview) and Ruby Cloud Services and PHP, Memcache, and Windows Azure Caching. What we didn’t cover in those posts was how to set up a role as a dedicated cache and then access it using the Memcache protocol. (In the co-located scenario, you dedicated a portion of a role’s memory to caching and access from the same role.) So, in this post I’ll cover how to set up a Node.js worker role that serves as a dedicated cache and a PHP web role that accesses the cache using the php_memcache extension. To follow the steps below, you’ll need a Windows Azure account (you can sign up for the free trial) and a Windows Azure Storage account.
- The steps in this tutorial assume that you are working on a Windows machine. The Windows Azure team is working on expanding Cloud Services development to other platforms.
- Windows Azure Caching (Preview) is not currently available in Windows Azure Web Sites.
- As you will see in the details below, all of the steps to enable this scenario are configuration steps. You can expect tooling support in the future that makes this work much easier.
- I have chosen to use a Node.js worker role as the dedicated cache simply because I wanted to. You could choose to use a worker role with any runtime of your choice. The same is true for the web role.
With those things in mind, here’s how to set things up:
1. Make sure you have the Windows Azure SDK 1.7 installed: download.
2. Install the Windows Azure PowerShell cmdlets: install. (For information about using the cmdlets, see How to use Windows Azure PowerShell.)
3. Create a new Windows Azure project with this command: New-AzureServiceProject <project name>. This will create a new directory (with the same name as <project name>). From within that directory, add a PHP web role and a Node.js worker role with the following commands: Add-AzurePHPWebRole and Add-AzureNodeWorkerRole. By default, the role names will be WebRole1 and WorkerRole1. Optionally, you can enable remote desktop access to these roles by running this command: Enable-AzureServiceProjectRemoteDesktop.
4. Locate the CachingPreview folder in the .NET SDK. (This is typically found here: C:\Program Files\Microsoft SDKs\Windows Azure\.NET SDK\2012-06\ref. ) Copy that folder and paste it in the bin folder of your web role (<project name>/WebRole1/bin). Finally, rename the pasted folder WindowsAzure.Caching.MemcacheShim. (The shim will be installed in a start up task that is defined in the next step.)
5. Open the project’s ServiceDefinition.csdef file (in the <project name> folder) and locate the <WebRole> element. Add the highlight element (below) as a child to the <Startup> element. This defines the task that will install the Memcache shim upon role start up.
<Startup>
<Task commandLine="setup_web.cmd > log.txt" executionContext="elevated">
<Environment>
<Variable name="EMULATED">
< RoleInstanceValue xpath="/RoleEnvironment/Deployment/@emulated" />
</Variable>
<Variable name="VERSION" value="5.3.13" />
<Variable name="DATACENTER" value="" />
<Variable name="RUNTIMEURL" value="" />
<Variable name="MANIFESTURL" value="http://azurertscu.blob.core.windows.net/php/runtimemanifest.xml" />
</Environment>
</Task>
<Task commandLine="WindowsAzure.Caching.MemcacheShim\MemcacheShimInstaller.exe" executionContext="elevated" />
< /Startup>6. Still in the <WebRole> element of the .csdef file, add the highlighted element (below) to the <Endpoints> element. This sets up an internal port for Memcache protocol communication. We’ll configure it to communicate with the dedicated cache later.
<Endpoints>
< InputEndpoint name="Endpoint1" protocol="http" port="80" />
<InternalEndpoint name="memcache_default" protocol="tcp">
< FixedPort port="11211" />
</InternalEndpoint>
< /Endpoints>7. Moving now to the <WorkerRole> element of the .csdef file, add the following element (below) as a child of the <WorkerRole> element. This will import the module that allows the worker role to serve as the dedicated cache.
<Imports>
<Import moduleName="Caching" />
< /Imports>8. Also as a child of the <WorkerRole> element, add the element below. This sets up a resource for collecting logs and dumps.
<LocalResources>
< LocalStorage name="Microsoft.WindowsAzure.Plugins.Caching.FileStore" sizeInMB="1000" cleanOnRoleRecycle="false" />
< /LocalResources>9. Now open the ServiceConfiguration.cscfg file (in the <project name> folder). Add the highlighted elements (below) to the <ServiceConfiguration> element for WorkerRole1. Note that you will also need to fill in your storage account name and key.
<Role name="WorkerRole1">
< ConfigurationSettings>
<Setting name="Microsoft.WindowsAzure.Plugins.Caching.NamedCaches" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Caching.Loglevel" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Caching.CacheSizePercentage" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Caching.ConfigStoreConnectionString" value="DefaultEndpointsProtocol=https;AccountName=Your storage account name;AccountKey=Your storage account key" />
</ConfigurationSettings>
<Instances count="1" />
< /Role>In the next few steps, we’ll enable the memcache shim (on the PHP web role) to communicate with the dedicated cache on the worker role).
10. From the WebRole1 folder, delete the Web.cloud.config file. The shim will look for the Web.config file.
11. Open the Web.config file and delete the following element. If you plan to run your project in the Windows Azure Emulators, leave this element for now, but delete it before you publish your project to Windows Azure.
<appSettings>
<add key="EMULATED" value="true" />
< /appSettings>12. Still in the Web.config file, add the following element as the first child of the <configuration> element:
<configSections>
<section name="dataCacheClients"
type="Microsoft.ApplicationServer.Caching.DataCacheClientsSection, Microsoft.ApplicationServer.Caching.Core"
allowLocation="true"
allowDefinition="Everywhere" />
< /configSections>13. Again in the Web.config file, add the following element as a child of the <configuration> element (just not the first child). Make sure that the value of the identifier element is the name of the worker role (WorkerRole1 is the default name).
<dataCacheClients>
<tracing sinkType="DiagnosticSink" traceLevel="Error" />
< dataCacheClient name="DefaultShimConfig" useLegacyProtocol="false">
< autoDiscover isEnabled="true" identifier="WorkerRole1" />
</dataCacheClient>
< /dataCacheClients>14. Finally, you need to add the PHP memcache extension to the web role (it isn’t included by default). Do this by adding a php folder to the bin directory of your web role. In the php folder add a php.ini file with one line (this will be added to the role’s PHP configuration: extension=php_memcache.dll. Also, add an ext directory to the php folder and put the php_memcache.dll there (make sure it is the php 5.3, nts, VC9 version of the dll, which you can find here).
That’s all there is to the configuration.
Like I mentioned earlier, look for tooling soon that will make this work easier.
At this point, your application is ready for deployment, but we should add some PHP code that tests that the cache is working. To do this, I suggest adding a PHP file (cachetest.php) to the root of your web role with the following code:
<?php$memcache = new Memcache;$memcache->connect('localhost_WebRole1', 11211) or die ("Could not connect");$version = $memcache->getVersion();echo "Server's version: ".$version."<br/>\n";$tmp_object = new stdClass;$tmp_object->str_attr = 'test';$tmp_object->int_attr = 123;$memcache->set('key', $tmp_object, false, 10) or die ("Failed to save data at the server");echo "Store data in the cache (data will expire in 10 seconds)<br/>\n";$get_result = $memcache->get('key');echo "Data from the cache:<br/>\n";var_dump($get_result);?>Note the connection code (the server name is ‘localhost_<name of web role>’):
$memcache->connect('localhost_WebRole1', 11211) or die ("Could not connect");
After you deploy your project (Publish-AzureServiceProject), you should be able to browse to cachetest.php and see the output of the code above.
As always, we’d love feedback on this if you try it out.



<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
•• Tyler Doerksen (@tyler_gd) described Website Pricing, Shared or Reserved in a 10/11/2012 post:
Less than a month ago (Sept 17), there was an update to Windows Azure Websites. This update added a third option for hosting websites, the Free option.
Previously all Shared hosted sites were free but now you can choose between Free, Shared, or Reserved. Here is a brief summary of the functionality of each.
Free: You know what they say “Free is the new Shared” well in this case that’s right. Free is like shared in that your site could be hosted on the same VM as other sites but you cannot assign a different domain name to the site. With Free the site will always be <something>.azurewebsites.net
Shared: The same hosting as free in that the site is not on a dedicated VM, however with this option you pay for the ability to assign your own domain to the site, even without a subdomain or what is called a “naked domain”.
Reserved: With this option you can assign the domain like shared but all of your sites in that datacenter are hosted on a reserved instance. The key point here is that all your websites are hosted by the same reserved instance. So if you have a high traffic site that requires 2 VMs and another small site, both will gain the 2nd VM if they are in the same datacenter.
Pricing
Also before this change the only option that would show up on your bill was the reserved instance but now that there is a cost for the Shared instance, you may need to make some decisions on how you are hosting your sites.
Since all of your Reserved instance sites share one cost for the machine, you may want to go to reserved if you have a number of small traffic sites to host. However, at what point would you switch from Shared to Reserved? Take a look at these screenshots from the Azure pricing calculator.



•• Yochay Kiriaty (@yochayk) started a WAWS Preview to support .NET Framework 4.5 thread in the Windows Azure Web Sites Preview forum on 10/9/2012:
The Windows Azure Web Sites (WAWS) team is committed to listening to customer feedback, introducing new functionality and improving performance and user experience. In few days, we will update WAWS Preview to support.NET Framework 4.5, which has been one of the top asks from our customers.
With this update, all of WAWS web servers will run .NET Framework 4.5. This update is affecting all our web servers since our environment is fully managed. Also, .NET Framework 4.5 is an in place upgrade, running .NET Framework 4.5 and .NET Framework 4.0 side by side is not supported. Note that Web applications built with .NET Framework 4.0 will still work without any changes.
In preparation for this change, we have answered few questions that we think you might have.
Q: Why was my site upgraded to .NET Framework 4.5?
Windows Azure Web Sites has been upgraded to .NET Framework 4.5 due to popular demand in a strategic move to enable access to latest technology for our customers. As WAWS is a managed hosted environment all WAWS web servers are now running .NET 4.5
New features available in .NET Framework 4.5 are described at http://msdn.microsoft.com/en-us/library/vstudio/ms171868.aspx. New features available for ASP in .NET Framework 4.5 are described at http://msdn.microsoft.com/en-us/library/vstudio/hh420390.aspx and in more detail at http://www.asp.net/vnext/overview/whitepapers/whats-new
Q: How do I migrate my ASP.NET application to enable features in ASP.NET 4.5?
In order to provide the best backwards compatibility ASP.NET requires developers to target the .NET Framework 4.5. The Migration Guide to the .NET Framework 4.5 is a great place to start.
Q: What should I do if my app stops working?
We have worked very hard to make sure .NET Framework 4.0 applications work seamlessly with .NET 4.5. However, some changes in the .NET Framework may require changes to your web application code. Upgrading from earlier versions of .NET framework to 4.5 is easily achieved once you open your project in VS 2012. For more information about upgrading a project, see How to: Troubleshoot Unsuccessful Visual Studio Project Upgrades and follow the notes in the The Migration Guide to the .NET Framework 4.5.
Q: Can I configure my website to continue using .NET Framework 4.0 instead of upgrading to .NET Framework 4.5?
No .NET Framework 4.5 is an in-place upgrade that replaces .NET Framework 4, rather than a side-by-side installation.
Q: Why is .NET 4.5 not offered side-by-side with 4.0?
The .NET Framework 4.5 was designed as if it were a service pack to .NET 4.0 that also adds additional features to .NET 4.0. The .NET Framework 4.5 simply replaces previous assemblies during installation.
Q: Are HTML 5 Web Sockets available in Windows Azure Web Sites?
HTML 5 Web Socket support requires both .NET Framework 4.5 and Windows Server 2012. Today Windows Azure Web Sites is running on Windows Server 2008 R2, therefore HTML 5 Web Sockets are not supported on WAWS. Support for Windows Server 2012 is coming soon. [Emphasis added.]
Q: Why is the Configure tab in the Azure Portal showing .NET 4.0 as an option?
This feature is being deployed in multiple stages and the .NET framework options in the Configure tab are still pending an update to align with the naming convention for .NET 4.5.
If you discover any compatibility issues with your ASP.NET application running on Windows Azure Web Sites, we want to hear about them via Forums Feedback or Windows Azure Support.


• Manu Yashar-Cohen (@ManuKahn) commented about Connecting Cloud Services to Azure Virtual Network in a 10/10/2012 post:
A customer asked me if it is possible to connect cloud services to azure virtual network.
When creating a new virtual machine we specify the network to be used but when creating a new cloud service the portal does not provide a method to connect the new cloud service to an existing virtual network.
Well It is possible !!!
Michael Washam wrote a nice blog about it. [See post below.]The Idea is to put NetWorkConfiguration in the config file (.cscfg) of your deployment.


• Michael Washam (@MWashamMS) posted Connecting Web or Worker Roles to a Simple Virtual Network in Windows Azure on 8/6/2012 (missed when published):
In this post I’m going to show you how simple it is to connect cloud services to a virtual network.
Before I do that let me explain a couple of reason of why you would want to do this.
There are a few use cases for this.
Web or Worker Roles that need to:
- Communicate with a Virtual Machine(s)
- Communicate with other web or worker roles in a separate cloud service (same subscription and region though)
- Communicate to an on-premises network over a site to site VPN tunnel (not covered in this post)
In at least the first two cases you could accomplish the connectivity by opening up public endpoints on the cloud services and connecting using the public IP address. However, this method introduces latency because you are making multiple hops over each cloud service load balancer. Not to mention that there is a good chance that the endpoint you are trying to connect to would be more secure if it wasn’t exposed as a public endpoint. Connecting through a VNET is much faster and much more secure.
For this example I’m going to walk through a simple VNET that will accomplish the goal of connecting cloud services.
Step 1: Create an affinity group for your virtual network in the region where your cloud services will be hosted.
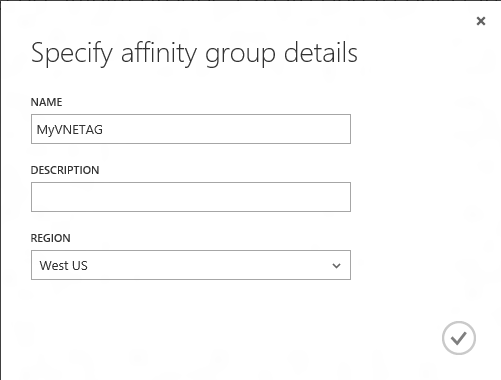
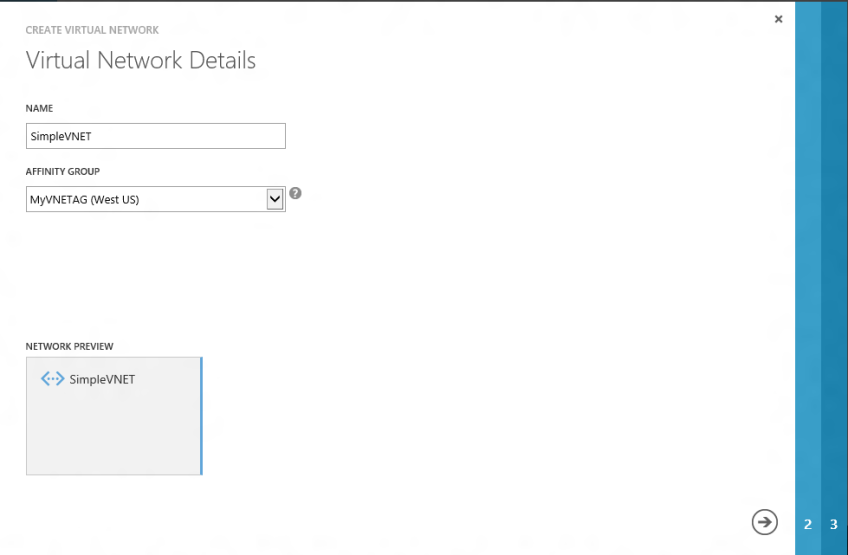
Step 2: Create a simple virtual network and specify the previously created affinity group along with a single subnet network configuration.
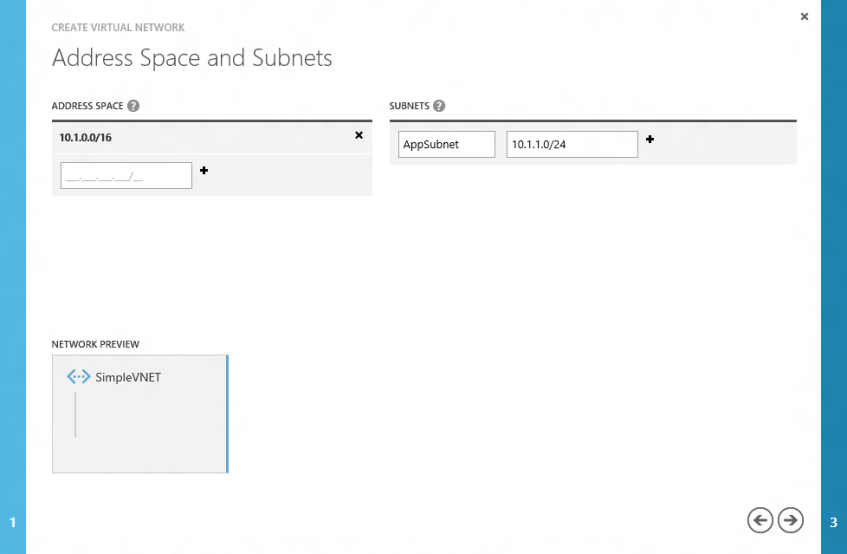
For the subnet details I am specifying 10.1.0.0/16 which is a class B address space. I’m only carving one subnet (10.1.1.0/24) out of the address space to keep things simple. Unless you need connectivity back to on-premises or are planning to lock down traffic between subnets when Windows Azure supports ACLs this will likely be a sufficient solution for simple connectivity.
Step 3: Deploy a Cloud Service to the VNET.
Unlike deploying a Virtual Machine you cannot specify virtual network settings on provisioning through the portal. The networking configuration goes inside of the .cscfg file of your Windows Azure deployment package.
To connect to this virtual network all you would need to do is paste the following below the last Role tag in your service configuration file (.cscfg) and deploy.
<NetworkConfiguration> <VirtualNetworkSite name="SimpleVNET" /> <AddressAssignments> <InstanceAddress roleName="MyWebRole"> <Subnets> <Subnet name="AppSubnet" /> </Subnets> </InstanceAddress> </AddressAssignments> </NetworkConfiguration>A few things to note about this configuration. If you have multiple roles in your deployment package you will need to add additional InstanceAddress elements to compensate. Another thing to point out is the purpose behind multiple subnets for each role. The idea is if you have an elastic service that has instances added/removed you could conceivably run out of addresses in the subnet you specify. If you specify multiple subnets to the role Windows Azure will automatically pull an address out of the next available subnet when the instance is provisioned if you run out of addresses from the first subnet.
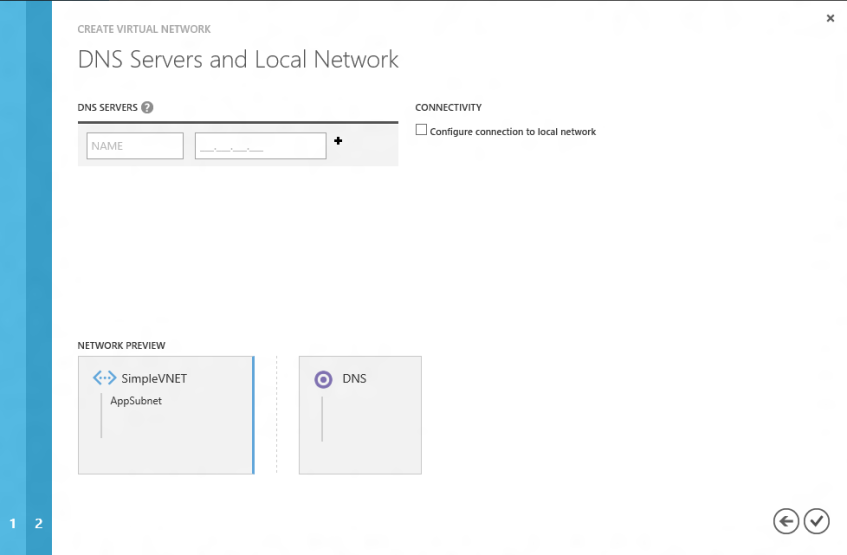
Name resolution is another area to address. When deployed inside of a virtual network there is no default name resolution between instances. So if you are deploying a web role that will connect to a SQL Server running on a virtual machine you will need to specify the IP address of the SQL server in your web.config. For that specific scenario it would make sense to deploy the SQL VM first so you can actually get the internal IP address for your web app. It is of course possible to deploy your own DNS server in this environment. If you do you can specify the DNS server for your web/worker role instances with an additional XML configuration.
This would go right below the NetworkConfiguration element start tag:
<Dns> <DnsServers> <DnsServer name="mydns" IPAddress="10.1.1.4"/> </DnsServers> </Dns>Finally, to make a truly connected solution you would want to deploy additional services such as VM or other cloud service/web worker roles to the VNET. The beauty of this configuration is every application deployed into this VNET will be on the same virtual network and have direct low latency and secure connectivity.
P.S. Virtual Network and Subnet Names are case sensitive in the configuration file.


Alan Le Marquand reported Overview of Windows Azure Virtual Machines (IaaS) MVA Course now released on 10/8/2012:
The MVA team is pleased to announce the release of the new Overview of Windows Azure Virtual Machines (IaaS) course
About the Course
This course offers an overview of the features that make up the new Windows Azure Virtual Machines and Virtual Networks offerings. This course explains the Virtual Machine storage architecture and demonstrates how to provision and customize virtual machines, configure network connectivity between virtual machines, and configure site-to-site networks that enable true applications that span from on-premises to Windows Azure. This course also demonstrates features that enable you to create highly available Virtual Machine-based services.


Kristian Nese (@KristianNese) posted System Center 2012 SP1 - Virtual Machine Manager - The Review on 10/8/2012:
When I was so honored to receive the MVP award in 2010, it was in the Virtual Machine Manager expertise. This component lays close to my passion for virtualization and cloud computing in general, and it’s a core component in Microsoft's cloud solutions.
I have been using Virtual Machine Manager since the 2008 version and watched the development with big enthusiasm. The launch of System Center 2012 was beyond impressive, and Service Pack 1 – that will support Windows Server 2012 (Hyper-V) will be even more stunning.
Virtual Machine Manager 2012 SP1 – what value does it bring to your business?
System Center 2012 SP1 – Virtual Machine Manager is the management layer for your infrastructure like virtualization hosts, storage, networking (pooled resources) so you can deliver cloud services to your business and customers. I believe that there’s no need to dive into all the features in Hyper-V in Windows Server 2012, because you have most likely heard a lot of them by now. The bottom line is that many organizations, independent of the size of their businesses, are looking towards Microsoft’s premium hypervisor in these days. All the known challenges and limitations from earlier versions are now addressed in this release. Multi-tenancy, VM mobility, optimization in the entire stack, and simplified management, licensing and disaster recovery to mention a few, will automatically give your ROI a solid burst.
Virtual Machine Manager is an abstraction layer above your infrastructure and you can manage those components completely from a single pane of glass.
Investments made in storage will let customers benefit from JBOD and commodity hardware in their environment by using file storage(SMB 3.0) as an alternative to block storage (iSCSI, FC) which is often associated with expensive SAN’s, switches and cables.
Virtual Machine Manager will leverage SMB and file shares (also scale-out file servers) and take care of the required configuration (no need to map permissions on individually shares and folders).
Of course, if you have invested in a SAN solution, you can leverage this from VMM as well with the support for SMI-S protocol.To summarize the value of VMM for your fabric, VMM will support the lifecycle of your resources. All the way from bare-metal deployment of virtualization hosts by using PXE, creation of clusters, servicing and maintenance through the integration with WSUS. Needless to say, the bigger environment you got, it’s more likely that VMM will be a good friend of you.
Complexity and simplification
Network virtualization is a key feature in Hyper-V to support multi-tenancy. It’s a very powerful technique to scale your network as well, by using IP encapsulation – which is default in VMM (requires only one PA from the physical network fabric, instead of one PA for each CA if you are using IP rewrite). To configure network virtualization in Hyper-V without VMM, you must polish your kung-fu skills in Powershell. With all the respect to powershell, it’s great to configure and automate every single process in your system, but with network virtualization, it’s hard to manage a dynamic environment. And especially large environments with multiple hosts and clusters. This is where VMM comes to the playground and takes care of every bit, acting like a policy server controlling IP pools, VM networks and also routing within your environment, and also outside your network.
Beyond virtualization – and beyond private cloud
For those of you who have already played with the Beta, VMM introduces tenants in this build.
A tenant administrator can create and manage self-service users and VM networks. They can create and deploy their own VMs and services using the VMM console and a web portal.
To see the big reasons for this, we must first see the big Picture.
System Center 2012 SP1 – Orchestrator will include SPF – which is Service Provider Foundation.
This will let customers use VMM, OpsMgr and Orchestrator together in a multi-tenancy environment.
To explain this as simple as possible, you can use the SPF-activities in Orchestrator to create runbooks that will communicate with the VMM web service through OData, and use REST.
You can connect to SPF by using your own existing portal, Windows Azure Services for Windows Server and also System Center App Controller.
An interesting scenario here is when you have reached your capacity in your own private cloud, you can connect to a SPF-cloud (which could be a partner, or another cloud vendor) to increase capacity and scale to meet your needs. There might be reasons why you can’t use, or won’t use IaaS in Windows Azure for this, and that’s when this is really handy. Needless to say, App Controller will of course manage IaaS in Azure so that you can deploy virtual machines both on-premise and to the big blue cloud.So you are interested in the best management tool for your cloud infrastructure?
- Guess what!
System Center 2012 SP1 – Virtual Machine Manager will be the ultimate solution for you. Not only embracing the components in your own datacenter, and integrates with the other components of System Center, but it is also a framework to deliver automated and effective cloud solutions to your customers.



Liam Cavanagh (@liamca) described How to Host a Website on Azure and Link it to a Domain like .IO in a 10/6/2012 post:
.COM addresses are becoming harder and hard to come by. It seems each time you look, it is harder to get the name you want. Many startups have become creative in the way they name their site, for example if you wanted to create a site called score.com, you might try calling it scorable.com or scorability.com. Another option that seems to be getting more and more popular is to use non .COM domains such as instant.ly or ordr.in or ginger.io. Many of these domains are easier to get, but the downside for many is that they are typically more expensive and the process of configuring them is often harder. I want to talk about how I managed to create URL using the io domain which used a site hosted on Windows Azure (where all the html pages are hosted). I am going to assume you already know how to create a web site on Windows Azure.
Getting the Domain Name
In the past, I have used GoDaddy as the place that I set up most of my domains. For .COM’s this is incredibly cheap (most of the time you can find a promo code for just about anything) and I have found them to be extremely supportive and easy to work with. However, in this case I wanted to get a .IO domain which is actually a Indian Ocean domain because the .COM was owned by someone else trying to sell it. To do this, I used http://nic.io where it cost ~$93 for the year (as opposed to ~$8 for a .COM domain).
DNS Server Configuration
After I purchased the .io domain from nic.io, I learned that they needed to be provided with DNS settings requiring a Primary and Secondary DNS Server. This was kind of frustrating since GoDaddy provided me with this whenever I created a .COM address. So after looking a little more I learned that I could just use GoDaddy for this. In my case, I could just log into my existing GoDaddy account and configure this for no extra charge. For you, you could either look at another DNS Server provider or create an account with GoDaddy to do this.
GoDaddy DNS Configuration
Within my GoDaddy account, I launched the DNS Manager and chose to create a new Offsite Domain. This was pretty hidden which is why I am adding a screen shot of where I went.
In the Domain Name text box I entered my .IO domain name, clicked Next and copied the 2 DNS servers that were provided. Copy these as you will need them in a minute.
Create A Record
The next step is to configure the GoDaddy DNS servers so that when a request for my domain .io is requested, it know where to point the user to. In my case it is a Windows Azure website with a .cloudapp.net name. To do this config, in the GoDaddy DNS Dashboard you click on “Edit Zone” under the domain you just added. In the A Host section, choose “Add Record” and for “Host” use @, and for “Points To” add the IP address to your Azure hosted site.
Choose Save
Add DNS Servers to NIC.io.
The final step is to configure NIC.io so that it knows to use the GoDaddy domain servers you just configured. Log in to the admin panel for NIC.io and choose to Manage the DNS Settings. In the “DNS Servers or Mail & Web Forwarding Details”, for the primary server enter the first DNS server you copied from the previous steps and in the Secondary Server enter the second. If you only have one DNS server, I think that is probably ok. At the bottom choose “Modify Domain”.
Give it an hour or two
It usually takes an hour or two for these configurations to fully get updated. However, after that you should be all set to go.





<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Himanshu Singh (@himanshuks) reported Riak is now available on Windows Azure on 10/9/2012:
As announced on the Basho blog today, Riak is now available on Windows Azure as a fully supported and tested NoSQL database option. Riak brings a master-less, distributed database option to Windows Azure, allowing unlimited scale, built-in replication and fast querying options. Please visit these links for more information, extensive documentation and packaging tools.
Over the coming weeks Basho will work with the Microsoft team to add tools that make creation and benchmarking of large clusters simple—Basho is currently in development to automate the creation of Riak clusters for benchmarks.
We are excited to have this new offering on Windows Azure, so stay tuned for updates.

Gregory Leake posted Announcing StockTrader 6 Reference Application: Cross-Device Mobile Applications with Windows Azure Cloud Services on 10/9/2012:
Today I am happy to announce the availability of StockTrader 6, a new end-to-end reference application for Windows Azure and Windows Azure SQL Database. The sample application with full source code and Visual Studio solutions can be downloaded and installed from MSDN here.
If you want to check the application out before downloading it yourself, you can:
a) Browse a live deployment of the sample application on Windows Azure via HTML5/MVC here.
b) Install and run the working mobile applications:
- Install the iOS application from the Apple App Store.
- Install the Android application from the Google Play Store.
- The Windows 8 and Windows Phone clients are included in the download.
Sharing Client Code across Device Types
One of the cool things about the sample is that each mobile client has a native user-interface for each device type, but via Xamarin mono roughly 60% of the client code (including REST service calls, data communication, security, etc.) is shared across all device types and written entirely in C#.
Sharing a Single Azure Cloud Service Backend across Device Types
Also, all clients across all devices work against the single, common Windows Azure Cloud Service backend. The backend is a Windows Azure RESTful service that scales out across as many middle-tier compute instances as you want. The data tier has also been specifically designed to optionally take advantage of Windows Azure SQL Database Federation for data tier scale out.
More Details
The focus of the sample is thus two-fold:
- Cloud-connected mobile applications: Illustrate how to adapt existing applications and services to extend the reach to all major mobile platforms, including Apple iPhone/iPad, Android devices, Windows 8, and HTML5, with shared client code across device types.
- Achieving backend scale: Illustrate the use of SQL Database Federation for data-tier scale-out, in conjunction with Windows Azure Cloud Services, including optional use of Windows Azure Service Bus for durable, asynchronous messaging.
View Technical Presentation and Documents Online
I highly encourage developers to also check out the following materials that cover the application itself, and the core technologies used:
- StockTrader 6 online technical presentation (1 hour)
- StockTrader 6 Technical Whitepaper
- SQL Database Federations Deep-dive presentation (1 hour)
You can post questions and discuss the StockTrader 6 sample application via the discussion forum on MSDN, which is easily accessed on the MSDN landing page.
The Windows Azure Marketing Team (#AzureFast) announced a new Windows Azure Fast contest featuring rapper NoClue (@NoClueOfficial):

PRNewswire reported Hyland Software Makes Implementing Mobile Solutions Easier by Utilizing Windows Azure in a 10/9/2012 news release:
CLEVELAND, Oct. 9, 2012 /PRNewswire/ -- Hyland Software released its latest deployment innovation, Mobile Broker for Microsoft Corp.'s Windows Azure, to help customers more easily implement mobile solutions. Windows Azure is Microsoft's cloud computing platform used to build, deploy and manage applications through its global network of datacenters. Hyland's Mobile Broker for Windows Azure provides customers of its enterprise content management solution, OnBase, with an alternative implementation option for mobile solutions without the upfront investment in hardware.
Mobile Broker for Windows Azure allows customers using a Windows Phone, iPhone, iPad, Android or Blackberry to securely connect to OnBase through the Windows Azure platform. This reduces the need for IT departments to manage secure access connections between mobile devices and their corporate networks. For customers with over-burdened IT departments, Mobile Broker for Windows Azure will allow them to swiftly implement their mobile solution without additional IT resources.
"Windows Azure provides a global, scalable cloud platform to help Hyland's customers implement secure mobile solutions," said Bill Hamilton, director, Windows Azure product marketing, at Microsoft. "Hyland is making it easier for all of its customers, regardless of their IT sophistication level, to offer mobile access to their users."
Hyland is a member of the Microsoft Partner Network with an ISV Gold Competency. Since its inception, more than 20 years ago, Hyland has worked closely with Microsoft. OnBase uses numerous Microsoft technologies including .NET, Windows Azure, SQL Database and BizTalk Server and seamlessly integrates with many Microsoft products including Microsoft Office, Microsoft SharePoint and Microsoft Outlook.
For more information on Hyland's Mobile Broker for Windows Azure and relationship with Microsoft, visit Hyland.com.
About Hyland Software
For over 20 years, Hyland Software has helped our more than 11,000 lifetime customers by providing real-world solutions to everyday business challenges. That dedication is why Hyland realizes double-digit growth year after year, and why 98 percent of our customer base continues to renew its annual maintenance. Our customers see the ongoing value of partnering with Hyland and continue to work with us year after year.
Hyland's enterprise content management (ECM) solution, OnBase, is one of the most flexible and comprehensive ECM products on the market today. OnBase empowers users to grow their solutions as needs change and business evolves. It is tailored for departments, but comprehensive for the enterprise, designed to give you what you need today and evolve with you over time. For more information about Hyland Software's ECM solutions, please visit Hyland.com.



<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
•• Beth Massi (@bethmassi) posted Trip Report–DevReach Bulgaria & Silicon Valley Code Camp on 10/10/2012:
Last week I had the pleasure of speaking at DevReach in Sofia Bulgaria. I’ve spoken at DevReach before and it’s always a great conference organized by Telerik. What I like most about it is that there tends to be more women at this conference than I am used to seeing in the states -- very encouraging! :-) It’s held the Arena Cinema Mladost, a large movie theater, where more than 40 speakers from 10 countries came to speak this year. The conference content is delivered in 60+ sessions in 6 parallel tracks covering a broad range of topics.
This year I presented LightSwitch in two different tracks, cloud and web. LightSwitch in Visual Studio 2012 is the easiest way to build modern line of business applications that are scalable, n-tier web applications and OData services. These applications (and services) can be easily deployed to the cloud, including Azure websites. So LightSwitch is appropriate for multiple conference tracks :-)
I also spoke at Silicon Valley Code Camp last weekend so I unfortunately could only spend one day in Bulgaria this year (and I was a lot more jet lagged with the short turn-around). SVCC is one of the largest free code camps around and I’ve been speaking at SVCC since it started 7 years ago -- it just keeps getting bigger and bigger. There was a great line-up of sessions in so many different technology areas. The one and only Scott Guthrie also made an appearance on Sunday with a couple Azure sessions. I delivered the same sessions at both conferences.
Building Business Applications for Mobile Devices
This talk focused on the LightSwitch HTML Client preview that was made available back in late June. I encourage you to check it out for yourself:
Download the LightSwitch HTML Client Preview
The HTML client focuses on touch-oriented mobile device apps. In many business today you see mobile companion apps to line-of-business systems. The LightSwitch team is focusing on bringing its rapid development experience to HTML/JavaScript clients. So you will be able to not only build rich desktop applications optimized for mouse and keyboard, but also be able to build companion applications optimized for touch and mobile scenarios.
This talk was very well attended at both conferences. Most people had heard of LightSwitch but didn't realize that this is the direction we are going. It was very encouraging to see folks interested in this so much. There are a lot of developers out there that are being asked to build these mobile solutions as an extension to their core business applications and are struggling with where to start. LightSwitch is positioned to make this type of development easy and I think I conveyed that to the audience. The demo I did was very similar to the walkthrough that is provided with the preview. (See below for the slides)
Building Open Data (OData) Cloud Services with LightSwitch
This session was a total blast for me. I started from scratch to build an application that tracks job candidates & open positions using one of our Starter Kits and incorporated an OData service that provides development experts called Proagora. You can actually see how I did that in this video: How Do I Consume OData Services in a LightSwitch App?
I also show how LightSwitch creates OData services automatically for us so that you can interoperate with other business systems and clients easily. LightSwitch is all about data. When you design a LightSwitch app, you are modeling your data and writing business rules around that data. What LightSwitch in Visual Studio 2012 does for you is it takes that model (business rules, permissions and all) and exposes it as a service endpoint so that it can interoperate with other systems easily. You can see how that works in this video: How Do I Create OData Services with LightSwitch?
You can then deploy these services to Azure. I showed how to deploy to the new Azure websites offering and it took about two minutes to get our application and services running. Pretty slick. Andrew wrote up a good post on the LightSwitch team blog on how to deploy to Azure: Publishing LightSwitch Apps to Azure with Visual Studio 2012
Session Slides & More Resources
Slides: Building Business Applications for Mobile Devices
Slides: Building Open Data (OData) Cloud Services with LightSwitch
Articles:
- Getting Started with LightSwitch in Visual Studio 2012
- Creating and Consuming LightSwitch OData Services
- LightSwitch Architecture: OData
- Publishing LightSwitch Apps to Azure with Visual Studio 2012
- New Features Explained – LightSwitch in Visual Studio 2012
- The LightSwitch HTML Client: An Architectural Overview
Downloads:
Thanks to all of you who came to my sessions on both continents! Enjoy!



My A Visual Studio 2012 LightSwitch “Course Manager” Application Clone with Real-World Data: Part 1 of 10/9/2012 begins:
Application Clone with Real-World Data: Part 1
- Course Manager VS 2012 Sample Part 1 – Introduction
- Course Manager VS 2012 Sample Part 2 – Setting up Data
- Course Manager VS 2012 Sample Part 3 – User Permissions & Admin Screens
- Course Manager VS 2012 Sample Part 4 – Implementing the Workflow
- Course Manager VS 2012 Sample Part 5 – Detail Screens
- Course Manager VS 2012 Sample Part 6 – Home Screen
Downloadable VB and C# source code for Andy’s tutorial is available here: LightSwitch Course Manager End-to-End Application (Visual Studio 2012).
While the Course Manager tutorial is useful in demonstrating LightSwitch basics, its underlying database has only a few records in each table.
In preparation for a consulting project in which I plan to use LightSwitch as a forms-over-data front end, I wanted to demonstrate to my client the user experience with a database having tables containing more realistic numbers of records. I also wanted a real-world comparison of performance with an on-premises instance of SQL Server Express versus that for a Windows Azure SQL Database back-end. Thus this project.
Contents, Part 1:
- The Oakmont University Sample Database
- Setting Up the OakmontSQL Data Source
- Starting a LightSwitch Project from the OakmontSQL Data Source
- Adding Summary Properties and Computed Values
- Adding Queries as Data Sources
The Oakmont University Sample Database
Oakmont University is a fictitious, private four-year institution located in Navasota, TX*. The OakmontSQL database is designed to serve both students and registrars. The original version was created by Steven Gray and Rick Lievano for Roger Jennings' Database Workshop; Microsoft Transaction Server 2.0, which published in late 1997. Versions with updated dates and faculty members assigned to departments were later included in multiple editions of my Special Edition Using Microsoft Access, Introducing Microsoft Office InfoPath 2003, and Microsoft Access 2010 In Depth for QUE Books.
Following is the OakmontSQL database diagram displayed by SQL Server Management Studio 2012:
The only significant changes from the preceding version is movement of the Capacity field from the Courses to Sections table (to correct a long-term error) and advancing the current date to 2012’s fall semester.
The following table lists the number of records in each of the eight database tables:
All tables have clustered primary-key indexes. Windows Azure SQL Database (SQL Azure) doesn’t support (heap) tables with non-clustered indexes.
You can download OakmontSQL.mdf (50 MB) and OakmontSQL_log.ldf (3.5 MB) from my Skydrive account as OakmontSQL.zip (9.7 MB).
*According to Wikipedia:
Navasota is a city in Grimes County, Texas, United States. The population was 6,789 at the 2000 census. In 2005, the Texas Legislature named the city "The Blues Capital of Texas," in honor of the late Mance Lipscomb, a Navasota native and blues musician.
For more about Mance Lipscomb, see my The Southeast Texas – East Bay Music Connection Window Azure Web Site page.
Setting Up the OakmontSQL Data Source
1. Install SQL Server 2012 Express with Tools (ENU\x64\SQLEXPRWT_x64_ENU.exe or ENU\x86\SQLEXPRWT_x86_ENU.exe) to create a local server instance (named SQLEXPRESS) and SQL Server Mangement Studio (SSMS) 2012 to manage it from the download page.
2. Download OakmontSQL.zip from my Skydrive account and extract its files to your C:\Program Files\Microsoft SQL Sever\MSSQL11.SQLEXPRESS\MSSQL\DATA folder.
3. Launch SSMS 2012, which displays the Connect to Server dialog. Open the Server Name list, select your local computer’s name, and add the \SQLEXPRESS suffix:
4. Click Connect to open SSMS, right-click Object Explorer’s Databases node, choose Attach to open the Attach Databases dialog, and click the Add button to open the Locate Database Files dialog, and select OakmontSQL.mdf in the list:
5. Click OK to close the dialog, open the Owner list, and choose sa as the database owner (dbo):
6. Click OK to close the dialog, expand Object Explorer’s Databases, OakmontSQL and Database Diagrams nodes, and select dbo.Relationships to display the diagram shown earlier:
7. Optionally, close SSMS.






… And continues with these sections:
- Starting a LightSwitch Project from the OakmontSQL Data Source
- Adding Summary Properties and Computed Values
- Adding Queries as Data Sources
The “Adding Queries as Data Sources” section was under construction when this article was posted.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
• David Linthicum (@DavidLinthicum) wrote a Sector RoadMap: Platform as a Service in 2012 Research Briefing, which GigaOm Pro published on 10/9/2012 (requires trial or paid subscription):
Summary: The Platform-as-a-Service (PaaS) market is predicted to reach $20.1 billion in 2014. Huge brands occupy this emerging space, including Microsoft, Amazon, Google, and Salesforce.com. Many newer startups enter the market each month, too.
The recent trend is that more features and functions win the day, especially those with the ability to instantly provision resources for PaaS-built applications, such as elastic storage, compute, and database services. This report examines the key disruptive trends that shape the emerging PaaS market and where companies will position themselves to gain share and increase revenue.

Full disclosure: I’m a registered GigaOm Analyst.
David Linthicum (@DavidLinthicum) asserted “Many enterprises cite the number of applications and databases that exist in the cloud, but that's only half of the story” in a deck for his Services hold key to cloud computing success article of 10/9/2012 for InfoWorld’s Cloud Computing blog:
Cloud computing is, at its core, a new take on an old model (timesharing) for consuming IT resources, but for many enterprises, it requires a new architecture based on services rather than apps. As cloud computing evolves, we'll become more accustomed to viewing our tech needs through the prism of services, but right now, it's a departure for many in enterprise IT as they move from single monolithic applications to collections of widely distributed services, cloud and otherwise.
Most cloud-based systems are sets of services hosted in remote sites, mixed and matched with internal systems to form a business application. Thus, the best way to measure utilization of cloud computing resources is to count services, not applications.
Take a simple inventory application: It may reside on a traditional database (such as Oracle) within the enterprise, while the services that process the data exist within Amazon EC2. Moreover, the user interface may live on a PaaS provider such as Google App Engine.
While this may seem complex, it's normal for cloud-based applications to be spread across internal resources and a public cloud or even several public clouds. The key, then, to understanding utilization is to look at the number of cloud-based services leveraged by the application.
As enterprises migrate to cloud computing, bits and pieces of an application will make the move, rather than the complete application. For instance, a company could leverage a service from a public cloud provider to provide stock price data for an application or for storage purposes.
Over time, other application services will find their way in public clouds, which often provide the best value as a platform. While many enterprises will talk about whole system migration, most will take service-by-service baby steps. That's the way we should measure the movement to cloud computing.

Scott Guthrie (@scottgu) posted Announcing: Improvements to the Windows Azure Portal late at night on 10/7/2012:
Earlier today we released a number of enhancements to the new Windows Azure Management Portal. These new capabilities include:
- Service Bus Management and Monitoring
- Support for Managing Co-administrators
- Import/Export support for SQL Databases
- Virtual Machine Experience Enhancements
- Improved Cloud Service Status Notifications
- Media Services Monitoring Support
- Storage Container Creation and Access Control Support
Service Bus Management and Monitoring
The new Windows Azure Management Portal now supports Service Bus management and monitoring. Service Bus provides rich messaging infrastructure that can sit between applications (or between cloud and on-premise environments) and allow them to communicate in a loosely coupled way for improved scale and resiliency. With the new Service Bus experience, you can now create and manage Service Bus Namespaces, Queues, Topics, Relays and Subscriptions. You can also get rich monitoring for Service Bus Queues, Topics and Subscriptions.
To create a Service Bus namespace, you can now select the “Service Bus” tab in the Windows Azure portal and then simply select the CREATE command:
Doing so will bring up a new “Create a Namespace” dialog that allows you to name and create a new Service Bus Namespace:
Once created, you can obtain security credentials associated with the Namespace via the ACCESS KEY command. This gives you the ability to obtain the connection string associated with the service namespace. You can copy and paste these values into any application that requires these credentials:
It is also now easy to create Service Bus Queues and Topics via the NEW experience in the portal drawer. Simply click the NEW command and navigate to the “App Services” category to create a new Service Bus entity:
Once you provision a new Queue or Topic it can be managed in the portal. Clicking on a namespace will display all queues and topics within it:
Clicking on an item in the list will allow you to drill down into a dashboard view that allows you to monitor the activity and traffic within it, as well as perform operations on it. For example, below is a view of an “orders” queue – note how we now surface both the incoming and outgoing message flow rate, as well as the total queue length and queue size:
To monitor pub/sub subscriptions you can use the ADD METRICS command within a topic and select a specific subscription to monitor.
Support for Managing Co-Administrators
You can now add co-administrators for your Windows Azure subscription using the new Windows Azure Portal. This allows you to share management of your Windows Azure services with other users. Subscription co-administrators share the same administrative rights and permissions that service administrator have - except a co-administrator cannot change or view billing details about the account, nor remove the service administrator from a subscription.
In the SETTINGS section, click on the ADMINISTRATORS tab, and select the ADD button to add a co-administrator to your subscription:
To add a co-administrator, you specify the email address for a Microsoft account (formerly Windows Live ID) or an organizational account, and choose the subscription you want to add them to:
You can later update the subscriptions that the co-administrator has access to by clicking on the EDIT button, and then select or deselect the subscriptions to which they belong.
Import/Export Support for SQL Databases
The Windows Azure administration portal now supports importing and exporting SQL Databases to/from Blob Storage. Databases can be imported/exported to blob storage using the same BACPAC file format that is supported with SQL Server 2012. Among other benefits, this makes it easy to copy and migrate databases between on-premise and cloud environments.
SQL Databases now have an EXPORT command in the bottom drawer that when pressed will prompt you to save your database to a Windows Azure storage container:
The UI allows you to choose an existing storage account or create a new one, as well as the name of the BACPAC file to persist in blob storage:
You can also now import and create a new SQL Database by using the NEW command. This will prompt you to select the storage container and file to import the database from:
The Windows Azure Portal enables you to monitor the progress of import and export operations. If you choose to log out of the portal, you can come back later and check on the status of all of the operations in the new history tab of the SQL Database server – this shows your entire import and export history and the status (success/fail) of each:
Enhancements to the Virtual Machine Experience
One of the common pain-points we have heard from customers using the preview of our new Virtual Machine support has been the inability to delete the associated VHDs when a VM instance (or VM drive) gets deleted. Prior to today’s release the VHDs would continue to be in your storage account and accumulate storage charges.
You can now navigate to the Disks tab within the Virtual Machine extension, select a VM disk to delete, and click the DELETE DISK command:
When you click the DELETE DISK button you have the option to delete the disk + associated .VHD file (completely clearing it from storage). Alternatively you can delete the disk but still retain a .VHD copy of it in storage.
Improved Cloud Service Status Notifications
The Windows Azure portal now exposes more information of the health status of role instances. If any of the instances are in a non-running state, the status at the top of the dashboard will summarize the status (and update automatically as the role health changes):
Clicking the instance hyperlink within this status summary view will navigate you to a detailed role instance view, and allow you to get more detailed health status of each of the instances. The portal has been updated to provide more specific status information within this detailed view – giving you better visibility into the health of your app:
Monitoring Support for Media Services
Windows Azure Media Services allows you to create media processing jobs (for example: encoding media files) in your Windows Azure Media Services account. In the Windows Azure Portal, you can now monitor the number of encoding jobs that are queued up for processing as well as active, failed and queued tasks for encoding jobs. On your media services account dashboard, you can visualize the monitoring data for last 6 hours, 24 hours or 7 days.
Storage Container Creation and Access Control Support
You can now create Windows Azure Storage storage containers from within the Windows Azure Portal. After selecting a storage account, you can navigate to the CONTAINERS tab and click the ADD CONTAINER command:
This will display a dialog that lets you name the new container and control access to it:
You can also update the access setting as well as container metadata of existing containers by selecting one and then using the new EDIT CONTAINER command:
This will then bring up the edit container dialog that allows you to change and save its settings:
In addition to creating and editing containers, you can click on them within the portal to drill-in and view blobs within them.
Summary
The above features are all now live in production and available to use immediately. If you don’t already have a Windows Azure account, you can sign-up for a free trial and start using them today. Visit the Windows Azure Developer Center to learn more about how to build apps with it.
We’ll have even more new features and enhancements coming later this month – including support for the recent Windows Server 2012 and .NET 4.5 releases (we will enable new web and worker role images with Windows Server 2012 and .NET 4.5, and support .NET 4.5 with Websites). Keep an eye out on my blog for details as these new features become available.





















<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hosting, Hyper-V and Private/Hybrid Clouds
Mary Jo Foley (@maryjofoley) asserted “Microsoft plans to deliver to hosters the fully released version of its Windows Azure cloud services for Windows Server 2012 by early 2013” in her Microsoft delivers beta of Azure services for Windows Server article of 10/8/2012 for ZD Net’s All About Microsoft blog:
Microsoft is moving ahead with plans to add some of its new Windows Azure services to Windows Server 2012, announcing the beta release of those services on October 8. [See post below.]
Microsoft's plan is to deliver the final versions of these services, which include virtual machine hosting and Web-site hosting for Windows Server, by early 2013, officials said in a new Server and Cloud Blog post today.
Microsoft delivered a Community Technology Preview (CTP) test build of these Azure services for Windows Server in July at the Worldwide Partner Conference. The coming services are aimed at service providers and hosting partners. At some point Microsoft might expand the target audience to other customers, but for now, that's the core audience, officials said. [Emphasis added.]
The CTPs are versions of four of the same new services that Microsoft announced in June as part of its Azure spring updates:
- Hosted virtual machines
- High-density Web Sites (the complement of Windows Azure Web Sites, codenamed "Antares")
- Service Management Portal
- Service Management application programming interface (codenamed Katal)
I asked Microsoft last week whether the persistent VM services allowing Linux and Windows Server to be hosted on Azure have yet moved beyond preview/testing. A spokesperson told me they are still considered preview at this time and declined to offer a timeframe as to when they'll be fully released.
On the server side, these new services will be fully released along with System Center 2012 Service Pack 1, which is due in early 2013, according to today's blog post.

As I noted in my Windows Azure preview enables multi-tenant IaaS hosting article of 9/13/2012:
It's understandable that Microsoft's Server and Tools Business doesn't want to sacrifice current licensing revenue by enabling enterprises to pay-as-you-go on a monthly basis using an SPLA. Regardless, Microsoft should provide the Service Management Portal and API as a package to enterprises that require more granular deployment and chargeback features than those offered out of the box by Windows Server and Systems Center 2012 with App Controller. IT admins can make a case for these features in the Web Sites and Virtual Machines on Windows Server for Hosting Service Providers forum.
See also Mike Schultz’s July 12, 2012 TechNet blog post, which stated:
One question I received yesterday after my presentation was how enterprise customers should think about this release and whether it's something they should adopt as well. This is a great question and one on which I wanted to provide a little more clarity. This release was specifically designed to benefit service providers and not the typical enterprise customer. Hosting service providers will use these technologies to provide out-of-the-box web site and Infrastructure as a Service (IaaS) offerings to their breadth customer community.
For enterprise customers, the right solution for a dynamic datacenter and private cloud environment is Windows Server plus System Center. Here you'll find all the capabilities needed to aggregate resources and delegate them within the organization to allow for self-service provisioning and management of your VMs and applications, whether in your datacenter or through a Windows Azure subscription. Plus, with the upcoming Service Pack 1 release of System Center 2012, we'll enable customers to see and utilize capacity they've provisioned from service providers in the very same way as they consume their own resources or those in Windows Azure.
Mike is general manager of Windows Server and Management marketing.
Chris Van Wesep posted Bringing Windows Azure Services to Windows Server – Beta Release to Microsoft’s Server and Cloud Blog on 10/8/2012:
As part of the product management team for Windows Server & System Center, it’s been very energizing to see the excitement in the community around the 2012 releases of Windows Server and System Center. I just came back last week from conducting launch events in Southeast Asia for Windows Server 2012 and, while people were very interested in many of the individual technologies, there was a real sense that they also find the broader vision Microsoft has laid out highly compelling. Specifically I’m talking about the notion that as datacenter computing continues to evolve, customers should ultimately have full flexibility to decide where their datacenter resources are deployed (in their datacenter, a service provider’s datacenter, or Microsoft’s datacenter) and not have to worry about increased management burden or costs. These are the fundamentals of the vision we call the Cloud OS.
A big part of this vision is making sure we provide innovative technologies to our hosting service provider partners to allow them to easily deploy more solutions and drive down their overall cost structure. In July, Mike Schutz announced the Community Technology Preview of the ability for hosters to deliver cloud capabilities on Windows Server & System Center that were previously found only in Windows Azure. Today, I’m happy to announce that we’ve moved to the next engineering milestone and are releasing the beta version of these technologies. Please check back shortly if you encounter any problems tracking down the beta.
Service Management Portal & API
- Distributed install
- of the Service Management Portal and API (datacenter readiness)
- of the Web Sites controller separate from the Service Management Portal and API
- Users are now able to sign up for multiple plans
Web Sites
- HTTPS/SSL support – tenants are now able to upload custom certificates and use them for programmatic access
- Distributed installation with High Availability and Live Upgrade
- Generic FastCGI and custom stack support
Virtual Machines
- Custom create from VM Template with a rich wizard experience
- Create VM from VHD using hardware profile
- Tenants are now VMM Tenant Admins and utilize the new VMM On-behalf Of features
As a reminder, these technologies are not something incremental that needs to be purchased by hosters. This is simply part of the broad solution you tap into when you deploy Windows Server 2012 and System Center 2012. We’re now moving in the final phase of testing and bug fixes to make sure these technologies will be fully released along with the System Center 2012 Service Pack 1, which is scheduled for early 2013.
We’re really excited about how this solution is coming together and it’s great to see the momentum already in the partner ecosystem. Please check out the beta and provide feedback!
Chris Van Wesep
Sr. Product Manager
Haishi Bai (@HaishiBai2010) described Recipes for Multi-tenant Cloud Service Design – Recipe 2: Centralized SSL Certificate Management in a 10/8/2012 post:
This is the second part of my blog series on multi-tenant Cloud service design. Each of the posts has two parts – discussions on Multi-tenancy and recipes to address specific challenges. When I first planned for the series the discussion parts were merely around particular problems, but somehow they grew into full-sized beasts by themselves. So, if you want to get to the recipes directly, you can safely do so. And if you just want to read higher-level discussions, you can skip the recipe parts without getting disconnected from post to post. On the other hand, if you want to get both the big picture as well as practical tactics to make the picture reality along the way, read through all texts :). Here’s the first part:
Recipe 1: Throttling by Tenants Using Multi-site Cloud Services and IIS 8 CPU Throttling
More about Multi-tenancy
In the previous article I listed some of the challenges an ISV has to face when designing for multi-tenant Cloud Services. Before we jump into any specifics again, I’d like to share some thoughts on different strategies of getting customers to the cloud. Many ISVs realize the benefits of IaaS and want to migrate their customers to the low cost, highly reliable hosting environment. One intuitive strategy to do so is to have dedicated resource(s) for each customer. This design is also referred as single-tenant, multi-instance architecture. At the surface this strategy has some very tempting benefits, among which code reuse is probably the dominating one. Because customers are still isolated to dedicated resources, the existing software should work as-it-is, shouldn’t it? Well, the bad news is, it’s rarely the case. As I mentioned in the last post, moving to the cloud is a major shift in business model and should not been taken lightly. Business aspects aside, such strategy is not immune to many of the technical challenges I mentioned in previous post such as authentication, authorization and performance. Managing a multi-instance environment can be challenging as well. Because the instances are independent from each other, chances are software updates and database patches need to be applied individually. This increased complexity makes service management and upgrades difficult. In addition, isolated resources make re-purposing of resources harder, causing unnecessary waste of capacities. For example, an ISV have to anticipate and allocate sufficient disk space for each customer. On one hand, the unused disk space is wasted (or could have been at least utilized better – remember resources are not free). On the other hand, when the customer exceeds allocated resources, addition resources have to be provisioned. Again this increases management complexity.
What becomes more interesting is when centralized features, such as administrative features and BI capabilities, are developed. Some annoying problems may jump out on you here and here. For instance, how a new feature reliably identifies individual tenants when the tenants don’t have such identifiers built in themselves? This sounds like a very small problem and there seems to be a very easy solution – a global lookup table. Technically a lookup table would have worked fine, but throughout my previous projects I’ve observed such lookup tables going out of sync pretty easily. One major reason is that the operation teams who stand up new tenants consider maintaining this global table as an additional burden – this is something they didn’t have to do and doing so doesn’t contribute or affect their deliverables. Of course in an ideal world everybody will do the right thing, but in reality the new features are often victims of such neglects and behave miserably - they try to query a system that don’t exist, they miss new systems that are coming online, and so on and so forth. Another similar problem is to open up effective communication channels to existing systems while owner of existing systems are not willing to cooperate. Such resistance is actually not that surprising - after all the initial motivation of using multi-instance architecture is to reuse existing code! The point is, again, going to multi-tenancy is a business model shift and need company-wide commitments. Many of such projects failed not merely because of technical reasons. As the discussion here is already going out of the technical scope, I shall stop here.
The multi-instance architecture is not all bad. In addition to reuse of existing implementations, it provides very good tenant isolation across all system layers; It allows uneven topologies – meaning it allows different customers to run different versions of software on different hardware. I know I just mentioned such things as downsides, but in some particular situations they are actually desirable. For example, I used to have a customer who made a major update to the software and wanted its customers to pay to upgrade. However at the same time it would like existing customers to keep using the older versions as long as they renew maintenance contracts. In another example, an ISV would like to allocated a small number of servers that were dedicated to student users while keep other paid users on the main cluster.
Enough said on multi-instance architecture for now. The other architecture choice is actually also obvious – to refactor the single-tenant system into a multi-tenant system. There’s no way to sugarcoat it – the refactoring will be a big project. And without doubts some system are harder to be refactored than others. Here are several characteristics that I’ve observed make such refactoring harder:
- Stateful services. It’s not unusual to see long-living components who assume they have global knowledge of the system, or have global control over the system. Such components are often named as “managers”, “dispatchers”, “schedulers” and such. These components are dangerous because they often maintain heavy states, and they often assume they live throughout the lifetime of the service. In a multi-tenant environment, especially a cloud-hosted multi-tenant environment, no components live forever. For example, an server instance may be brought down by the hosting environment for maintenance at certain intervals (such as quarterly). Will these components be ready to persist and rehydrate their states? What happens when this happens? Those are the exact hard questions that lead people to stateless services. The greater danger, however, is the temptation to promote such components to the global level. And you might be surprised by how often that happens! Prompting such components creates single points of failures (SPOF), and failures of such components are often catastrophic.
- Resources hogs. In the previous post we examined how to guard one type of resource hogs by throttling CPU usage. There are several other resources at play, such as storage, memory, and bandwidth. Because resource pressures build up much quicker on a multi-tenant system than on a single-tenant system, excessive resource consumption can easily create bottlenecks here and there. And if such problems are not corrected early, you may find yourself in a very unpleasant position of redesigning in very late phases of the project.
- Tightly-coupled components. The single-tenant to multi-tenant migration is mostly a long process for any sizable projects. Chances are you’ll need to swap out old parts piece by piece. Tightly-coupled components make such swapping very hard – I guess I don’t need to say more on that.
Recipe 2: Centralized SSL management
Problem
When an ISV needs to host a large number of secured sites that use SSL certificates, certificate management may become problematic in terms of increasing site density, ensuring manageability, as well as improving performance. If you have a large number of SSL certificates on an IIS server, you may run into serious performance issues when you handle HTTPS traffics. This is because ALL certificates are loaded in memory when HTTPS traffics come in. This not only consumes memory, but also slows down the response time. In addition, it’s often desirable to remove certificate management tasks from developers’ responsibilities. For Cloud Services running on Windows Azure, certificate management is mostly separated from service management. However, there are three small catches:
- The certificate thumbprints are included in .cscfg file. Although this file can be uploaded and modified without redeploying the service, changes in this file may cause the service to be redeployed anyway. For instance, when you renew a certificate with a new thumbprint, IIS configurations on the instance virtual machines have to be updated, causing service interruptions. This is a big problem when you have many certificates to renew.
- There could be a disconnection between the system administrator and the developers – the administrator may have updated the .cscfg file while the developers are still building/deploying services with older .cscfg file, causing more fictions.
- Cloud Service .csdef file doesn’t allow you to specify multiple certificates for HTTPS endpoints on the same port. The workarounds include using different ports, which is usually very undesirable, or use wildcard certificate or a SAN certificate.
What I’d like to achieve here are the following:
- Complete separation of concern. The developers should not care about what certificates are used and when they are changed or renewed. I don’t want any references to certificate thumbprints anywhere in the code, including .cscfg file.
- I want to enable IIS 8 centralized certificate management so certificate management can be greatly simplified.
- I can use other certificates other than wildcard certs and SAN certs to secure my web sites.
Solution
In a nutshell, the idea of centralized SSL certificate management is simple – instead of installing certificates on each individual machines, certificates are kept on a network share as (.pfx) files. When IIS is configured to use centralized certificate management, it will look up in this location to find correctly certificate to resolve binding by matching host headers with certificate file names. When a system administrator needs to renew a certificate, all he needs to do is to xcopy the renewed certificate over the old one and the job is done. In addition to significant improvement in manageability, centralized SSL certificates also provide a very noticeable performance boost especially when you have many certificates. When IIS is configured to use SSL certificates, ALL certificates are loaded into memory when it handles a HTTPS request. The CPU and memory cost is ignorable when you have only a few certificates, but it becomes huge when you have hundreds and thousands of certificates to load. With centralized SSL certificates, certificates are loaded on-demand, which greatly reduces the processing time and memory consumption.
Sample walkthrough
As usual, the following is a walkthrough of creating the sample scenario from scratch. I do assume you are familiar with Windows Azure Cloud Service, IIS manager and ASP.NET MVC in general, so some of the steps won’t be as details as for beginners.
Prerequisites
- Visual Studio 2012
- Windows 8 with IIS 8.0
- Windows Azure SDK
Step 1: Enable secured connection for a Cloud Service with multiple sites
- Follow Step 1 of recipe 1 to create the baseline application. You can skip step 3 to 5 because you won’t need the CPUThrottleController in this case. You can also directly use the result solution of previous exercise as well.
- Make a wildcard self-issued cert for testing:
makecert.exe -r -pe -n "CN=*.haishibai.com" -b 01/01/2010 -e 01/01/2050 -eku 1.3.6.1.5.5.7.3.1 -ss my -sr localMachine -sky exchange -sp "Microsoft RSA SChannel Cryptographic Provider" -sy 12The above command installs a wildcard certificate to Local Computer personal store.- Open the certificate in mmc, export the certificate to a .pfx file. Name the file as _.haishibai.com.pfx. When you deploy the Cloud Service to Azure, this is the certificate you, or your system administrator, needs to upload.
- Copy the thumbprint of the certificate. This is the thumbprint (with spaces removed) you need to enter to .cscfg file.
- Import the .pfx file to Trusted Root Certification Authorities of Local Computer store. This is to avoid certificate warnings during our tests.
- Go back to Visual Studio. Double-click the Web Role in the Cloud Service project to bring up property page.
- Go to Certificates tab. Click on Add Certificate link.
- Set the name of the certificate to WildcardCert, and pick the certificate from Local Computer store:

- Go to Endpoints tab. Add an endpoint with https protocol. Pick the SSL certificate we just added:

- Make sure all sites in the .csdef file refer to the new endpoint:
... <Sites> <Site name="gold" physicalDirectory="..\..\..\IIS8Features.Web"> <Bindings> <Binding name="Endpoint1" endpointName="Endpoint1" hostHeader="gold.haishibai.com" /> <Binding name="Https" endpointName="HttpsIn" hostHeader="gold.haishibai.com" /> </Bindings> </Site> <Site name="silver" physicalDirectory="..\..\..\IIS8Features.Web"> <Bindings> <Binding name="Endpoint1" endpointName="Endpoint1" hostHeader="silver.haishibai.com" /> <Binding name="Https" endpointName="HttpsIn" hostHeader="silver.haishibai.com" /> </Bindings> </Site> </Sites> ...- Press F5 to run the application. Ignore the errors and certificate warnings you see in the browser. Type in https://gold.haishibai.com:444 or https://silver.haishibai.com:444 in address bar. The site should be loaded correctly without certificate warnings. Note on your machine you may have to use a different port – see recipe 1 part 1 for details on how to get the correct port number.
There’s nothing new so far – this is what you typically do when you enable SSL for multi-site Cloud Service. Note that there’s no reference to actual certificate in the .csdef file. However, you can see the thumbprint in .cscfg file:
<Role name="IIS8Features.Web"> ... <Certificates> <Certificate name="WildcardCert" thumbprint="55B5D291B7B56BDD4C6C38CE93CA3E3DCD49E7BD" thumbprintAlgorithm="sha1" /> </Certificates> ... </Role>Step 2: Enable centralized SSL certificate management
- Create a new network share, and copy the _.haishibai.com.pfx file into the folder. This shared folder will be the centralized certificate store.
- Make sure Centralized SSL Certificate Support has been enabled. If not, enable the feature from Control Panel –> Turn Windows Features On or Off:
- Open IIS manager. Select the server node. You’ll see the new Centralized Certificates icon. Double-click the icon to open the feature:

- In action pane, click Edit Feature Settings…
- In Edit Centralized Certificates Settings dialog, enter credential to the network share. Note that in current version, all certificates under the folder have to have the same private key password:

- Click OK to update the settings.
- Now we can remove references to certificates in our code. First, remove <Certificates> element from both .cscfg and .csdef.
- Then, remove the certificate attribute from <InputEndpoint> element as well:
<Endpoints> <InputEndpoint name="Endpoint1" protocol="http" port="80" /> <InputEndpoint name="HttpsIn" protocol="https" port="443"certificate="WildcardCert"/> </Endpoints>- Press F5 to launch the application.
- Open IIS manager. Select the gold site. Then click Bindings… link in action pane.
- In Site Bindings dialog, select the https binding, and then click Edit… button.
- In Edit Site Binding dialog, check Use Centralized Certificate Store, then click OK.

- Repeat step 10 to 12 for silver.haishibai.com.
- Now navigate to https://gold.haishibai.com or https://silver.haishibai.com. The sites should load without certificate warnings. IIS looks under the shared folder for matching certificate. Because wildcard certificate is supported, IIS picks up _.haishibai.com (we use _ instead of * because * is an invalid character for file names) in this case. Of course, now you are free to use any number of domain specific certificates as well – simply copy the certs to the shared folder following the naming convention, for example gold.haishibai.com.pfx for gold.haishibai.com domain and so on.
Some additional notes
At this point I don’t have everything automated. The major problem I’m facing is to auto-configure the centralized certificate store. This configuration is (rightfully) not saved in any configuration files, so digging that up is kind of hard. However, the following are some of the other pieces of puzzle that may become useful when you try to automate the process:
- Use WebPI command line tool (v4 preview) in a startup task to install required IIS components. For example, to enable Centralized SSL Certificate Support, use command:
webpicmdline /Install /Products:CertProvider- Here are some of the other IIS components you can install by WebPI (to get a complete list, use webpicmdline /List /ListOption:Available):
ID
TitleAppWarmUp
IIS: Application InitializationIPSecurity
IIS: IP and Domain RestrictionsRequestMonitor
IIS: Request Monitor- I *think*you should be able to use appcmd to change default site settings to enable centralized SSL certificate for newly created sites. However I haven’t tried it myself.
Recipe 2 Summary
In this post we enabled IIS8 Centralized SSL Certificate Support and configured our web site to use HTTPS endpoints without having any references to any certificates in our .csdef or .cscfg files.







<Return to section navigation list>
Cloud Security and Governance
Dinesh Sharma posted Top 8 security hazards on Windows Azure - Part 2 to the Aditi Technologies blog on 10/8/2012:
In my previous post, I discussed threats to security on Windows Azure - physical security, hardware security, eavesdropping/packet sniffing and DoS and DDoS attack.
Here are four more - privilege elevation, man in the middle attack, network spoofing and unauthorized access to the configuration store.
Privilege Elevation
This reduces the potential impact and increases the necessary sophistication of any attack, requiring privilege elevation in addition to other exploits. It also protects the customer’s service from attacks by its own end-users.
Man in the middle attack
The internal communications provided by Windows Azure are protected using SSL encryption.
Customers can opt for the Windows Azure SDK which extends the core .NET libraries to allow developers to integrate the .NET Cryptographic Service Providers (CSPs) within Windows Azure.
Network spoofing
Windows Azure uses Network Packet Filters (NPF) to prevent spoofing. Network Packet Filters ensure that untrusted VMs do not generate spoofed traffic. Network packet filtering is done by the hypervisor and the root operating system.
An NPF blocks inappropriate sending or receiving of traffic. Furthermore, the channel used by the root OS to communicate with the Fabric Controller is encrypted and mutually authenticated over an HTTPS connection. This provides a secure transfer path for configuration and certificate information that cannot be intercepted.
Unauthorized access to configuration store
Windows Azure configuration store is completely secure as it is only accessible by hosted services on the management portal or by Service Management API.
So, by the inherent design of Windows Azure, the integrity of the customer configuration is protected, maintained, and persisted constantly during an application’s lifetime.
In my next post I will discuss other security threats and security measures provided by Windows Azure to tackle these threats. Stay tuned.


<Return to section navigation list>
Cloud Computing Events
Steve Plank (@plankytronixx) reported on 10/9/2012 Event: UK announces Six Steps to Windows Azure on 8th/9th November. Register Now:
Six Steps to Windows Azure programme which offers a series of free technical events and online sessions on the Windows Azure Platform. The programme aims to guide those currently building apps or considering the cloud on how to take full advantage of Windows Azure. Our upcoming events will cover both the technical and commercial aspects of adopting Windows Azure.
Here are the kick off events; register now.
Windows Azure in the Real World - 8th November 2012
Get started with Windows Azure by seeing how companies have implemented real world solutions for different types of Azure workload. Join us if you currently building applications, considering moving to the Cloud and want to understand how to take full advantage of the Windows Azure Platform.
Advanced Topics in Windows Azure - 9th November 2012:
Join us to tour the latest features of Windows Azure from Media and Mobile services to Windows Azure Active Directory. The day will explore the opportunities Windows Azure offers with Windows 8 and the latest Phone Toolkits (iOS, Android and Windows Phone).
What’s next? Here are the upcoming themes. Registration will open shortly.
- Step 2: Architecture and Design (13 November)
- Step 3: Integration with Mobile and the New World of Apps (3 December)
- Step 4: Open Source Development (14 January)
- Step 5: HPC (4 February)
- Step 6: Big Data (24 February)
If you have any questions please email ukmsdn@microsoft.com or keep an eye on this blog for the next update.

Jim O’Neil (@jimoneil) reported on 10/8/2012 a Building Your First Windows 8 App in Albany, NY–Oct 9th meeting:
I’ll be the guest of the Tech Valley User Group at their October meeting, tomorrow October 9th, at Tyler Technologies, and presenting on Windows 8 – specifically walking through building your first application on the new platform. If you have Windows 8 and Visual Studio 2012 installed, feel free to bring your laptop and follow along, but it’s definitely not a requirement.
We won’t be building the next killer app, but hopefully you'll gain enough insight and get pointers to resource like Generation App, that will enable you to get your app into the Windows Store and start reaching hundreds of millions of users when Windows 8 officially launches on Oct. 26th.
I’ll be in town early as well, so if you’re working on a app know or just want to chat about potential ideas, how to get going, etc., feel free to stop by the Daily Grind in Troy – I’ll be hanging out there from about 3:45 to 5:15 or so.

<Return to section navigation list>
Other Cloud Computing Platforms and Services
•• Peter Wayner asserted “HP's OpenStack-based IaaS cloud blends openness and portability with nice proprietary extras and welcome hand-holding” in a deck for his Review: HP Cloud challenges Amazon and Google of 10/10/2012 for InfoWorld’s Cloud Computing blog:
Hewlett-Packard may be best known for its ubiquitous printers and laptops, but in the enterprise world, it is just as recognized for its servers. Now that the idea of the cloud is taking over, HP is joining the marketplace and renting some of its servers in the HP Cloud.
The servers are priced by the hour just like everyone else's, but though these machines may be commodities like hamburgers, there are differences, just as there are differences between Burger King and McDonald's.
For instance, HP offers a longer list of Linux distributions for your new server slice than some of the others. You can get the classics such as Ubuntu, Debian, and CentOS in many of the best-known versions. If you know what you're going to do with the machine, you can start right up with a Bitnami distribution sporting a number of pre-installed applications like Drupal.
Not everything is on the list. Windows Server and Red Hat Enterprise Server, two operating systems offered for a bit more money by Rackspace and other clouds, aren't anywhere to be seen. This promises to be temporary. Marc Padovani, HP Cloud Services director of product management, suggests that Windows will arrive sooner rather than later. And a long list of solution partners shows that HP Cloud is embracing a broad commercial ecosystem along with the open source software.
The HP Cloud is built on OpenStack, which should be attractive for any enterprise manager worried about being locked into a cloud. Sure, all of the cloud vendors talk as if the machines are really commodities, but if it takes you several months to recode your scripts, mobility is extremely limited. HP's embrace of OpenStack is clearly a push to attract managers who want the flexibility to outgrow the HP Cloud or just move on. The wide range of Linux distributions feels like a part of that plan.
As with the other clouds, the price list for HP Cloud machines largely follows the amount of RAM. The smallest offering delivers 1GB of RAM for 4 cents per hour. This price is cut in half now during a special "public beta" promotion. By comparison, Rackspace charges 6 cents per hour for a 1GB machine.
HP starts tossing in additional virtual CPUs with more RAM. A 2GB machine comes with two virtual CPUs, not one. Some cloud providers don't speak about the number of CPUs, but this may be an advantage for certain applications.
There isn't a lockstep connection between the amount of RAM and the number of CPUs as you march down the price list, but it's roughly correlated. By the time you reach a 32GB machine, you also get eight virtual CPUs at a price of $1.28 per hour (or 64 cents during the private beta sale). …

Like the Ford Model T, the HP cloud is short on customization features. You can have any operating system image you want, as long as it’s Linux.
•• Jeff Barr (@jeffbarr) announced Amazon RDS - SQL Server SSL Support in a 10/10/2012 post:
As you can probably tell from the pace of releases on this blog, the Amazon RDS team has been designing, implementing, and deploying new features at a very rapid clip. They've added a number of data protection and security features to create a product that's a great match for enterprise deployments.
Today, we're announcing SSL support for RDS for SQL Server.
With this change, you can now protect and secure your data both in transit and at rest:
- Enable SQL Server SSL to protect data as it travels from your application server to your RDS database instance and back again.
- Use SQL Server's column level encryption to protect data at rest.
- Launch your RDS database instance running SQL Server in a Virtual Private Cloud for network isolation.
Enabling SSL Support
Here's all you need to do to enable SSL Support:
- Download a public certificate key from RDS at https://rds.amazonaws.com/doc/rds-ssl-ca-cert.pem
- Use the Microsoft Management Console (MMC) to import the certificate into Windows:
Making SSL Connections
You can establish an SSL connection to your RDB database instance running SQL Server in a number of ways. Here are two of the most common.If you are making a programmatic connection to RDS, add "encrypt=true" to your connection string. For example:
Server=##.##.##.##;Database=dbname;uid=username;pwd=password;encrypt=true
If you use SQL Server Management Studio, select the "Encrypt connection" option:
Your Turn
I believe that the combination of these three features makes RDS for SQL Server a perfect fit for just about any enterprise. What do you think?-- Jeff;
PS - Before you ask, you can also establish SSL connections to an RDS database instance running MySQL (see my blog post for more information).



AWS appears to be on a roll with new services and features.
• Chris Talbot (@ajaxwriter) reported Red Hat, Zend Partner for PHP Developer PaaS on OpenShift in a 10/10/2012 post to the TalkinCloud blog:
A new partnership between Red Hat (NYSE: RHT) and Zend should give PHP developers more flexibility and ease of use when developing for the Red Hat OpenShift PaaS.
Zend, which specializes in PHP (it calls itself “the PHP company,” after all), has worked with Red Hat to launch a new server on OpenShift to provide developers with a professional-grade PHP development deployment and runtime environment where they can test out their applications for the cloud. To make application development as easy as possible, the companies have added built-in debugging, monitoring and application performance tuning capabilities to the new server.
Red Hat launched the OpenShift PaaS in May 2011 as a platform for developers to run and test cloud-based applications in their choice of programming language. Over the last year and a half, the company has expanded the capabilities of OpenShift, and this latest partnership with Zend now gives developers a focused PHP development server. Currently, the platform provides support for several different programming languages, including PHP, Node.js, Ruby, Python, Perl and Java. It also supports a variety of frameworks, including Zend, Java EE, Spring, Rails, Play and others.
As Ashesh Badani, general manager of the Red Hat Cloud Business Unit and OpenShift, noted in a prepared statement, the ecosystem for developers provided through the platform makes it simpler to deploy and manage applications written in a variety of languages.
“With millions of PHP developers in the world today, it is exciting to be able to collaborate on an offering that combines the power of Zend’s leading tools for PHP developers and our enterprise-grade application server with the flexibility and strong ecosystem of integrated partner solutions that Red Hat is building with the OpenShift platform,” said Andi Gutmans, Zend’s CEO, in a prepared statement.
The new server, available for free use to PHP developers, offers one-click deployment to OpenShift of a PHP runtime environment, a certified PHP stack, a job queue for improving application performance and reducing bottlenecks, and advance debugging in the cloud.
Read More About This Topic


• Jeff Barr (@jeffbarr) described Lots of New Features for AWS GovCloud (US) in a 10/10/2012 post:
AWS GovCloud (US) is a gated community cloud designed to support the compliance needs of customer workloads with direct or indirect ties to U.S. Government functions, services, or regulations. The AWS GovCloud (US) framework adheres to U.S. International Traffic in Arms Regulations (ITAR) requirements. Workloads that are appropriate for the AWS GovCloud (US) region include all categories of Controlled Unclassified Information (CUI), including ITAR, as well as Government oriented publicly available data. The customer community utilizing AWS GovCloud (US) includes U.S. Federal, State, and Local Government organizations as well as U.S. Corporate and Educational entities.
Today we are adding a number of important new features to AWS GovCloud (US) in order to open it up to even more types of workloads. Here's what's new:
- High Performance Computing - Support for EC2's Cluster Compute Eight Extra Large Instances (60.5 GB of RAM).
- Elastic Load Balancing - Automatically distribute traffic across multiple EC2 instances.
- Auto Scaling - Automatically scale EC2 capacity up or down based on user-defined conditions.
- CloudWatch Alarms - Receive notification when a CloudWatch metric falls beyond a configurable threshold.
- Simple Notification Service (SNS) - Cloud-based notifications using a topic-centric publish and subscribe model.
- Simple Queue Service (SQS) - Reliable, highly scalable hosted queues for building distributed applications.
The combination of Elastic Load Balancing, Auto Scaling, and CloudWatch alarms means that applications running in the AWS GovCloud can now meet stringent requirements for scalability and availability.
In general, GovCloud is functionally the same as our standard commercial regions, and customers used to AWS will feel right at home. The services in GovCloud have the same APIs and semantics, with very few exceptions. There are some important differences, however:
- GovCloud is the only region where customers are vetted by personal interaction with our sales organization before gaining access.
- For EC2 customers, GovCloud is a VPC-only region; traditional EC2 NAT networking is not available.
- GovCloud has a separate identity and access system; identities and credentials are not shared between GovCloud and other regions.
- There are a few technical enhancements for customers in the government ecosystem, specifically, the presence of FIPS 140-2 certified SSL termination endpoints for AWS APIs and for S3.
- There is as yet no web-based graphical console for GovCloud; that is coming soon, but in the meantime we have supported the creation of the ElasticWolf client-side application. ElasticWolf runs on both Windows and Mac and supports all of the new features listed above. It works with all of the AWS regions including GovCloud (US) and includes extensive VPC support. Of course our command-line tools and APIs work as usual. Here's a screen shot of the most recent version of ElasticWolf:


John Ribeiro (@Johnribeiro) asserted “The cloud service will use private networks rather than the public Internet” in his IBM, AT&T team on cloud services report of 10/9/2012 for InfoWorld’s Computing blog:
IBM has teamed with AT&T to offer secure shared cloud services to customers over private networks rather than the public Internet, the companies said Tuesday.
The service to be delivered from early next year is targeted at clients worldwide who are deploying clouds that demand high levels of security and availability, and who often cite security as a key inhibitor to cloud computing adoption, the companies said in a statement.
Customers will be connecting to IBM's cloud computing resources, using AT&T's virtual private network, with tightly integrated security protections.
As a result, customers will be able to shift information or applications between their own data centers in private clouds and the new cloud service, without the data leaving the security protections of the virtual private network, the companies said. The feature is expected to be particularly relevant for businesses that need to protect applications and data as they move between data centers and wired or wireless computing devices such as tablets and smartphones.
Spending on public IT cloud services will be more than $40 billion this year, and is expected to go up to nearly $100 billion in 2016, according to research firm IDC. The U.S. will remain the largest public cloud services market followed by Western Europe and Asia Pacific excluding Japan, IDC said in September, though it expects that the fastest growth in spending will be in emerging markets.
The service that will be offered jointly by IBM and AT&T next year combines AT&T's virtual private networking with IBM SmartCloud Enterprise+, an Infrastructure-as-a-Service designed for mission-critical, enterprise workloads. IBM has previously said that it aims to make $7 billion in total cloud revenue by 2015.
Technology developed by AT&T will dynamically allocate networking resources to computing resources, allowing both to scale or contract together when required, the companies said.
Other features of the new cloud service include customization options to meet customer needs, over 70 automated built-in security functions, and security extended to wired and wireless devices which are authenticated to the customer's virtual private network.
The financial terms of the agreement have not been disclosed.
IBM also announced Tuesday its PureData System which is optimized for analyzing big data in the cloud. The company unveiled three models of the system varying by the workload, including PureData System for Transactions, PureData System for Analytics, and PureData System for Operational Analytics.



James Staten (@staten7) asserted Oracle Continues to Make Cloud Progress in a 10/9/2012 to his Forrester Research blog:
Well if you're going to make a dramatic about face from total dismissal of cloud computing, this is a relatively credible way to do it. Following up on its announcement of a serious cloud future at Oracle Open World 2011, the company delivered new cloud services with some credibility at this last week's show. It's a strategy with laser focus on selling to Oracle's own installed base and all guns aimed at Salesforce.com. While the promise from last year was a homegrown cloud strategy, most of this year's execution has been bought. The strategy is essentially to deliver enterprise-class applications and middleware any way you want it - on-premise, hosted and managed or true cloud. A quick look at where they are and how they got here:
* A real Software as a Service portfolio now, but not Fusion - On the SaaS front, nearly all of Oracle's new announcements were the integration of its myriad SaaS acquisitions in 2011-2012 - social sites, business intelligence, marketing services, etc. The portfolio has been integrated with its much older acquisition of Siebel OnDemand (now Oracle CRM OnDemand). They are basically filling out a portfolio of SaaS services surrounding this core element just as Salesforce.com has done so with Chatter, SupportForce, MarketForce and its other services. However, very little of the promised Fusion apps have been delivered. Now that Oracle has a unified Fusion middleware platform that supports multitenancy, the company has claimed it would transition its full portfolio of applications over to the SaaS model so you can choose on-premise or delivered. That, so far, hasn't happened. And it's not clear if and when that will ever happen as many of those applications remain on legacy architectures. What this means for customers is that they shouldn't wait around for Oracle to migrate its on-premise applications to the cloud; there's not clear roadmap for that to happen. What Forrester clients should count on, are new generation SaaS applications that eventually will replace the on-premise predecessors. Oracle's fast path to SaaS is through M&A, so despite the remarks from Oracle's CFO Safra Catz last week, Oracle clearly isn't done buying its way into the cloud space. Not by a long shot.
* OnDemand has been cloudwashed as SaaS - You could have made a drinking game out of all the Oracle spokepeople's slipups when they talked about the portfolio of hosted managed services called OnDemand - oops, I mean Oracle Cloud Services. Frankly, as far as Oracle is concerned, if they are managing it for you - no matter how - it's SaaS. Don't be fooled by this. There are security, control, agility and most definitely cost differences between the three modes of hosting (see chart below). If Oracle sets up and manages an Oracle implementation specifically for you on isolated resources with a unique configuration, you're paying more for that and are likely locked in for multiple years. You won't get pay-per-use, auto-scaling, fast feature enhancements or self-service. But then again, many of you don't really want that. Ellison is right when he says that customers want the choice of SaaS versus managed hosting versus on-premise. And he's right that he can offer all three choices on the same common infrastructure layer. Just know going in that there are many, many differences between all the services under this now-expanded Cloud banner and you should know which deployment choice you want before talking with Oracle.
* Cloud Platform, Delivered - True to its word, Oracle took the "preview" tag off its Java Cloud Service and it appears to be a legitimately valuable offering. Nearly everything you would expect from a Java EE environment on-premises has been faithfully reproduced in a multitenant, virtualized cloud offering here. But don't think this is an Amazon Web Services or Microsoft Windows Azure competitor - it's aimed squarely at existing WebLogic customers. The Platform as a Service solution uses OracleVM (the Xen hypervisor atop ExaLogic hardware) as its basis for multitenancy and isolation but the instances provided are prepopulated with Oracle Linux and WebLogic as your only OS and middleware choices. And the packaging is best suited to non-elastic, traditional JavaEE applications. You get 1, 2 or 4 instances with requisite heap, storage and network at a fixed price per month (ala Salesforce.com's Java service on Heroku, non-coincidentally). No per-hour or per-resource pricing. Scaling is scheduled, and not automatic. And selected services are not there yet. The Oracle Java Cloud Service does not yet support JMS (a JMS service is coming in 2013), or identity federation, and Java EE 6 is not fully supported. EJBs, JSF, JSP, web and REST Svcs (JAX) are all supported and each instance gets its own database (isolated via schema from the Oracle Database Cloud Service) pre-integrated via JDBC and the Java persistence API. You can manage and monitor your Java workloads via Ant, Maven, the CLI or Oracle Enterprise Manager (the portal) but you can't monitor the underlying infrastructure and you can't programmatically control the environment via RESTful APIs. Oracle has done a nice job with IDE integration via plug-ins for Eclipse and their own JDeveloper and NetBeans solutions. It has a whitelisting feature for catching, while you are coding or publishing, commands and service requests that are not supported by its cloud. Bottom line: Oracle's Java Cloud Service is designed to service traditional, Systems of Record Java applications - not the new generation, elastic, componentized Systems of Engagement apps. Last year, Oracle positioned the Java Cloud Service as an extensibility platform for its SaaS offerings, similar to early positioning of Force.com from Salesforce.com. No announcements were made that built this positioning.
* The Promise of Private Clouds - Ellison, in his Sunday keynote also promised a bright future for the cloud portfolio of services hinting at what sounded to many as Infrastructure as a Service but what is really more PaaS and managed services. He spoke about the common infrastructure services that underlie the Java Cloud Service and their overall Cloud portfolio being made available to customers. What that really meant was:
1. A series of Oracle Cloud Services - Not IaaS but application services such as the JMS service mentioned above; and a Developer Service that would add pre-built test and development frameworks, source code repository and other team development tools. Both are in limited preview today. Oracle head of all-things-cloud, Sandeep Banerjie, was pretty clear that the company saw little value in providing a raw IaaS offering from its data centers. However that could be different on-premise...
2. An on-premise managed private cloud service - Want the virtualization and consolidation benefits of Oracle Cloud Services but in your own data center? Give Uncle Larry a few racks and he'll roll in the equipment and remotely manage it for you. This solution, expected sometime in 2013, will be a fully managed extension of the Oracle Cloud, Banderjie said, where Oracle owns the assets, manages the hardware and the software for the solution, and links it via secure network (probably VPN and MPLS) to your tenancy on the Oracle Cloud. This version may expose OracleVM directly for hosting non-WebLogic workloads in just the same way that the new ExaData appliance can do for fully isolated Oracle database instances. To be determined.
Roll it all up and you have a pretty well thought out and executed enterprise-centric cloud strategy. Oracle isn't looking to court non-Oracle customers with these offerings, nor the individual developers who helped pioneer the cloud movement but that has never really been their market. If anything, Oracle is hoping this strategy will keep their customers from developing a wandering eye. Every keynote, when talking about cloud, was clearly themed around matching and differentiating Oracle's solution against Salesforce.com who brings a disruptive , pure-play cloud story. Sadly the demos and rhetoric look like "me too" offerings rather than presenting new or better business value. And yes, for customers who want to go cloud at their own pace and keep a lot on premise, the Oracle approach preserves those choices.
And if they are wrong, they can always buy more cloud players.


Jeff Barr (@jeffbarr) described Identity and Access Management for the AWS Marketplace in a 10/7/2012 post:
AWS Marketplace now supports role-based permissions and management via AWS Identity and Access Management.
Let's review the key terms before diving in to the details:
- AWS Marketplace makes it easy to find, buy, and 1-click deploy software to the cloud, featuring hundreds of popular commercial and open-source software products for developers, IT admins, and business users.
- AWS Identity and Access Management (IAM) offers greater security, flexibility, and control when using AWS. For larger businesses, IAM enables identity federation between your corporate directory and AWS services.
What is Subscribing?
AWS Marketplace lets you browse through more than 25 categories of software, including the most popular developer tools; operating systems, application infrastructure, and middleware; and business applications. When you find software that you want to use, you "subscribe" to the software. AWS Marketplace then creates EC2 instances to run the software.
EC2 instances can be launched either immediately, as part of the subscription process, or later (e.g. during the development cycle). The software is delivered as an AMI, so when you’re ready to create an EC2 image with the AMI, you can do so through the Marketplace UI, or alternatively through the same EC2 API or command line statements that you use for any other AMI. Once you’ve subscribed to software, the Marketplace AMI looks to you just like any of your other AMIs.
As the AWS account owner, you now have fine-grained control over usage and software costs. Roles and permissions are created and managed through IAM, making it easy to get started, and easy to add controls for AWS Marketplace to new or existing IAM groups. You can now use Marketplace permissions to control access to Marketplace and to the EC2 instances that it launches, based on a user's role in the business. For example you can set up your account so that:
- Managers and employees of the Finance Department can manage subscriptions but can't run or terminate EC2 instances.
- Developers and IT personnel can inspect, run, and terminate EC2 instances, but cannot subscribe to applications.
Marketplace actions are now controlled by IAM permissions.
With the new IAM integration, we are providing three pre-made templates (these can be fully customized or changed, just like any other IAM template):
The permissons in the View Subscribed Software template are generally designed for administrators, staff concerned with technical standards, or anyone else interested in understanding usage and adoption of software, but who don't need to actually create or manage particular instances of software.
The Manage Subscriptions permissions let a user subscribe to software, but not start or manage particular EC2 that run the software. This is useful for technical standards, procurement, or admin staff who want to enable or approve software for use inside an organization, but who do not need to create particular instances of the software.
Finally, the permissions in the Full Control template combines the permissions from the previous templates while adding in administrative EC2 permission, thereby enabling a user to subscribe to new software, as well as create and manage EC2 images running that software.
Our goal with these templates is to make it very easy for a company to get started with AWS Marketplace without the worries of losing control over software costs or usage. For organizations that have a strong procurement and standards function, the Manage Subscriptions and Manage EC2 roles make it easy to support workflows and use cases where approving software for use is a separate responsibility from actual implementation. However, for more decentralized organizations, the Full Control permission duplicates the existing Marketplace experience, letting a single user find, buy, and deploy software in a matter of minutes. Meanwhile, the View Subscribed Software role can be used to oversee and audit usage.
Here's a walkthrough so that you can see how these features work together.
First, some new IAM users are created:
One of the users tries to launch an application in the AWS Marketplace. They are informed (via the message in the yellow box) that they do not have permission to do so:
They are then given the appropriate permissions via an IAM policy:
The users can log into AWS Marketplace using the IAM user name that they’ve been given. Then can then make changes to subscriptions in AWS Marketplace:

![image_thumb1[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEitDn7HaTzVll3fQA10rjkgDTycRfkXmUArayIg48jmwaa_k6Iyj498kQTKQOuc1tD6x4fa14oHZtPImqBWzizfJkM_sQKdY7yTw3fXfT5ycY19pTpCMqB2KVOaJ_rJdEspziMSpm3E/s1600-h/image_thumb1%25255B1%25255D%25255B7%25255D.png "image_thumb1[1]")
<Return to section navigation list>

















0 comments:
Post a Comment