Windows Azure and Cloud Computing Posts for 10/1/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI, Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

• Updated 10/2/2012 12:00 PM PDT with new articles marked •.
Tip: Copy bullet, press Ctrl+f, paste it to the Find textbox and click Next to locate updated articles:
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, Hadoop and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Marketplace DataMarket, Cloud Numerics, Big Data and OData
- Windows Azure Service Bus, Access Control, Caching, Active Directory, and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue, Hadoop and Media Services
• Brad Sarsfield (@bradoop) posted a HadoopOnAzure REST API Wrapper Sample to the Windows Azure Developer Center on 9/24/2012 (missed when posted):
This sample provides a more easy-to-use wrapper over the HadoopOnAzure REST API. Originally developed by Brad Sarsfield and available on GitHub, the original HadoopOnAzure REST API allows to programmatically submit a MapReduce or Hive job through a Web service.
Download: C# (188.8 KB)


This sample provides a more easy-to-use wrapper over the HadoopOnAzure REST API. Originally developed by Brad Sarsfield and available on GitHub, the original HadoopOnAzure REST API allows to programmatically submit a MapReduce or Hive job through a Web service.
This library was initially developed for automation in SQL Server Integration Services (SSIS) purpose. Interestingly
enough, it is not limited to SSIS and is compatible with a large amount of project types. Beyond somehow simplifying the usage, the new library also adds new features such as the possibility to run PIG and SQOOP scripts on Hadoop.Building the Sample
- Open the solution HadoopOnAzureJobClient.sln in Visual Studio 2010
- Set HadoopOnAzureJobClientSimplified as Startup Project
- Press F6 to build the library from Visual Studio 2010
Description
In order to simplify interactions with the user, the sample allows running commands with a minimum amount of code as illustrated hereafter.
The following provides some examples of use:
Getting the Hadoop version
JobClientSimplified client = new JobClientSimplified("https://yourcluster.cloudapp.net", username, password); var version = client.GetVersion();Substitute in the above code your actual Hadoop Cluster name for yourcluster.
Running a Job on the Head node cluster
JobClientSimplified client = new JobClientSimplified("https://yourcluster.cloudapp.net", username, password); var jobId = client.Start("HelloWords", "C:\\Temp\\hellowords.jar", "wordcount asv://ssis/books/fr-fr/ booksTopWords");Substitute in the above code your actual Hadoop Cluster name for yourcluster.
Waiting for and monitoring a job
JobClientSimplified client = new JobClientSimplified("https://yourcluster.cloudapp.net", username, password); client.Wait( progress => { Console.WriteLine(progress); }, finishResult => { if (finishResult != 0) Console.WriteLine("Job Complete with errors"); else Console.WriteLine("Job Complete with success"); }, jobId, waitingTime);Substitute in the above code your actual Hadoop Cluster name for yourcluster
Running a Pig script
JobClientSimplified client = new JobClientSimplified("https://yourcluster.cloudapp.net", username, password); string jobId = client.PigQueryFromFile("C:\\Temp\\query.pig", "C:\\Temp\tutorial.jar");Substitute in the above code your actual Hadoop Cluster name for yourcluster


<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
Seth Brodeur (@SMBTechie77) reported AMD and BlueStacks team up to bring 500K Android apps to Windows 8 desktop in a 10/1/2012 story for Windows Phone Central:
One of the biggest knocks that critics like to sling against Windows Phone is that there aren't enough apps available when compared to Apple and Android. Well, a new deal between chip maker AMD and software developer BlueStacks will ensure that the same cannot be said for Windows 8. The two companies have agreed to work together on bringing around 500,000 Android apps to Microsoft's upcoming operating system for PCs and tablets using AMD's AppZone Player.
By updating code in their processors and graphics chips, AMD has made it possible for apps designed for mobiles devices to look good on the larger displays of PCs and tablets. They hope that this will lure consumers to AMD-powered devices, rather than those running Intel chips.
"This helps AMD leapfrog Intel by making Windows 8 more attractive on their tablets and PCs," BlueStacks CEO Rosen Sharma told Wired. "We've worked closely together to optimise the performance of the apps for AMD's unique 'graphics and computing on one chip' setup. The result is awesome -- mobile apps run beautifully on their machines."
Apps that run in AppZone will also allow users to save information between devices. So if you are playing a game on your PC, you can pick up where you last saved on your mobile device. All AMD-powered Windows 8 devices will come with the AppZone player pre-installed. And if that weren't good enough, consumers who currently have a Windows 7 device with an AMD processor under the hood can run AppZone player now.
This is a brilliant move on AMD's part to capitalize on Windows 8 before it's even released and could be a huge lift for Microsoft as well. If only we could magically bring all those apps over to the Windows Phone Store. SHAZAM!

It’s much more likely that these apps will be for Windows Store apps running under WindowsRT than Windows 8 Desktop.
Bert Craven (@bertcraven) described the role of of Windows Azure SQL Database in easyJet’s migration to allocated seating in his Your seat in the clouds awaits you article of 10/1/2012:
Back in November 2011 easyJet announced that starting in the spring of 2012 we would begin a trial of allocated seating and on April 12th we went live on five routes from London Luton and Glasgow. Since then we have gradually extended this trial and we are now offering allocated seating on almost all routes on our network and by the end of November we will be at 100% operational delivery. This is a huge change for easyJet. Free seating, referred to by many of our passengers as “the scrum”, was part of our DNA. It was how we had always operated. It had become part of the definition of easyJet. As our CEO Carolyn McCall said in the article above, the trial could only be deemed successful if it met all three of the following criteria:
- It had to increase customer satisfaction. We work hard to have happy customers. It’s another thing that’s part of our DNA. Allocated seating had to really make a difference to the passenger experience. Many people said that they wanted it but, once we gave it to them, would it really make the difference they thought?
- It had to work operationally. easyJet operates one of the quickest turn-around times in the industry. If boarding passengers into allocated seats was seen to have a negative effect on our On Time Performance (OTP) it would not have been considered viable.
- It had to work commercially. Allocated seating had to prove itself a commercial success as a revenue generating product.
Trial by fire
This highlights the fact that such a move was a calculated risk. We were not sure it would work but it required significant change and investment to find out. One of the major changes was to our reservation system. Our home-grown reservation system did not support allocated seating. The primary advantage of maintaining a bespoke system is that it can be tailored to your exact business needs. No extraneous functionality cluttering up the works. It does, on the other hand, support bookings from around 58 million passengers a year and take over £4 billion in revenue.
Changing the beating heart of our enterprise, our various sales channels like easyJet.com and our operational systems to support allocated seating was no small undertaking, quite apart from the changes to our operational processes. Making those changes to support a trial, an experiment? That called for a quite special approach.
Our first decision was that we definitely did not want to have to conduct open-heart surgery on our reservation system to add this functionality. The I/O load from selling 58 million non-specific seats a year is already a veritable fire-hose. Scaling and refactoring to support the tracking and locking of over 58 million specific seats on a system that can book up to 1500 seats a minute would be a huge project.
“Seat-allocation-as-a-service”
Would it be possible, we wondered, to buy “seat-allocation-as-a-service” (SaaaS?) from a third party? Get someone else to do the heavy lifting of tracking the availability of every single seat we have on sale while we just stored the output, a few bytes that represented the selections made for the seats we have actually sold?
Apparently not. However the idea of a separate “seat-allocation-as-a-service” solution attached via a very light-weight integration was too attractive to let go so we decided to build our own.
What this means, in summary, is that the tens of millions of seats we have available at any given time are tracked via partitioned SQL Azure databases and cached in the Azure AppFabric Cache. All the logic, business rules and data relating to …
selecting seats
handling contention for seats
aircraft types
seating layouts and configurations
price bands
which passengers can sit where
seating access for passengers with restricted mobility
algorithms for automatically allocating seats to passengers who chose not to make a selection
and the million-and-one other things that have to be taken into consideration when seating an aircraft
…all this is done in the cloud. Even the interactive UI that displays the graphical map of the aircraft is served from Azure and injected into the booking pages on easyJet.com.
The ingenious work to achieve this using JSONP, Ajax and Knockout.js (amongst other things) is a tribute to the fantastic development team at easyJet and may be the subject of a subsequent blog post.
The overall approach however has allowed us to implement an incredibly significant change to the way we operate and sell our flights and deliver it at massive scale without needing to implement much more than small refactorings in our core operational and retail systems. The low cost and massive scale of Azure has made the whole notion of experimenting with something so fundamental an achievable reality. This calculated risk has become a bet we can much more easily afford to make.
Most importantly it has massively reduced the cost of failure. We had to conduct a thorough trial. We couldn’t be sure that it would work. Whether it worked or not was primarily a business decision rather than a technical one.
Now that it has been successful we have delivered a solution that works technically, works operationally, works commercially, improves customer experience and transformed our enterprise. However, if it had not worked and we had needed to turn it all off and walk away, we could have done so without having incurred huge risk, technical debt or cost.





<Return to section navigation list>
Marketplace DataMarket, Cloud Numerics, Big Data and OData
• Stuart Brorson, Alan Edelman and Ben Moskowitz wrote Testing Math Functions in Microsoft Cloud Numerics for the 10/2012 issue of MSDN Magazine. From the introduction:
Suppose you need to perform a mathematical calculation. For example, suppose you need to know the sine of 34°. What do you do? You probably turn to a calculator, computer or some other smart device. On your device, you type in “sin(34)” and you get an answer, often with 16 decimal digits of precision. But how do you know your answer is correct?
We’re so accustomed to getting mathematical answers from our electronic gizmos that nobody thinks about whether the answers are correct! Just about everybody takes it for granted that our machines give us the right answers. However, for a small set of software quality engineers, correctness can’t be taken for granted; the job is all about getting the right answer. This article explains how the math functions in the new Microsoft Cloud Numerics math library are tested.
Most scientific and engineering computations use floating-point arithmetic. The IEEE standardized the basic workings of floating-point math in 1985. A key feature of the standard is that it acknowledges not all numbers can be represented on a computer. While the set of real numbers is infinite and uncountable, the set of IEEE floating-point numbers is necessarily finite and countable because the numeric representation of floating-point numbers uses a fixed number of bits. The construction of IEEE floating-point numbers implies that they’re also rational, so commonly used numbers such as π aren’t expressed exactly, and operations using them, such as sin(x), aren’t exact, either.
Moreover, unlike with integers, the spacing between IEEE floating-point numbers is locally uniform, but it increases logarithmically with the magnitude of the number itself. This logarithmic aspect is depicted in Figure 1, which shows schematically the locations of uniform chunks of IEEE floating-point numbers on the real number line. In the figure, valid chunks of floating-point numbers (embedded in the real number line) are indicated by vertical lines. Note that the distance between valid floating-point numbers increases logarithmically as the magnitude of x increases. The distance between two adjacent floating-point numbers is often called the Unit of Least Precision or Unit in Last Place (ULP), and is provided as a built-in function called eps(x) in many common math programs. A consequence of the variation in spacing is that a small number close to 0 has no effect when added to a relatively larger number such as 1.
.png "The Floating-Point Number Grid Depicted Schematically")
Figure 1 The Floating-Point Number Grid Depicted SchematicallyBesides codifying formats for floating-point numbers, the IEEE standard provides strict guidance about how accurate the returns from the most fundamental math operations must be. For example, the IEEE standard specifies that the returns from the four arithmetic operations (+, -, * and /) must be “best rounded,” meaning that the answer returned must be closest to the “mathematically correct” result. Although this requirement was originally met with some resistance, returning the best-rounded result now takes place in hardware, showing how commonplace it has become. More interestingly, the IEEE floating-point spec also requires that the square root function return the best-rounded result. This is interesting because it opens the door to two questions: “How accurately can an irrational function be computed using the IEEE floating-point representation?” and “How should you test the accuracy of a function implementation?” …
• Sean Ianuzzi wrote OData, the Entity Framework and Windows Azure Access Control for the 10/2012 issue of MSDN Magazine. From the introduction:
In this article I’ll show how to implement the Open Data Protocol (OData) with the Entity Framework exposed with Windows Communication Foundation (WCF) RESTful services and secured with the Windows Azure Access Control Service (ACS).
Like most developers, I often find myself trying to leverage a combination of technologies in new and various ways to complete my project as efficiently as possible while also providing a flexible, easy-to-maintain solution. This can be difficult, particularly when the project requires data to be exposed quickly and securely.
Recently I was asked to create a secure Web service for an existing database and Web application. I really didn’t want to implement all of the create, read, update and delete (CRUD) code. It was tempting to just create custom service contracts, operation contracts and data contracts that would drive exactly how the data could be exposed and how someone else could potentially consume this data via services. But I knew there had to be a more advantageous route to take. I started researching various ways that this could be accomplished and saw potential with OData (or “Ohhhh Data,” as I like to call it). The problem was that OData by itself was not secured in a way that I felt was acceptable, and I needed to add an additional layer of security on top of the OData service in order to feel confident it would be secured properly. As I started to piece this together, I found ACS, which is great for implementing a cloud-based federated authentication and authorization service—exactly what I needed. Then I had my “aha!” moment. I realized that if I wired up ACS with OData, I’d have my solution.
Now, I did consider implementing custom service contracts, and there is a place for this approach, especially where a layer of abstraction is needed in front of a data model and where it’s required to protect the database entities from being directly exposed to consumers of a service. However, given how time-consuming this is—creating the appropriate document regarding how to consume the service, and adding in the additional effort required to set up the security (“MessageCredential” and “TransportWithMessageCredentials”)—the project could quickly spiral of control. I was also concerned that additional methods would be needed or requested for one reason or another to support how the services were being consumed, which, again, would add more time, maintenance and customization. Even if my implementation of the service used the Entity Framework versus ADO.NET directly, creating all of the CRUD code might still be required to keep the data layer in sync. Assuming there are a few dozen tables, this effort could be extremely tedious. Plus, creating and maintaining any additional documentation and implementation details required for end users to consume my service made this a much more complicated proposition to manage.
An Easier Way
Once I had identified the primary technologies, I looked for others to fill gaps and help build a cohesive solution. The goal was to limit the amount of code that needed to be written or maintained while securely exposing my OData WCF RESTful services. The technologies I linked together are: ACS, OData, Entity Data Models, WCF Data Services with Entity permissions and a custom Windows Azure security implementation. Each of these technologies already provides significant value on its own, but when combined, their value increases exponentially. Figure 1 demonstrates a high-level overview of how some of these technologies will work when implemented.
.jpg "High-Level Overview of ACS with a Security Intercept")
Figure 1 High-Level Overview of ACS with a Security InterceptBefore I tried to combine all of these technologies, I had to take a step back and really understand each one and how they could impact this project. I then gained a good perspective on how to combine them all and what would be required from someone else using other technologies to consume my services.
What Is ACS?
ACS is provided as a component of the Windows Azure platform. ACS allows me to set up my own cloud-based federated authentication and authorization provider that I use to secure my OData WCF services, but ACS can also be used for securing any app. ACS is a cloud-based service that helps bridge the security gap when there’s a need to implement single sign-on (SSO) in multiple applications, services or products—either cross-platform or cross-domain—supporting various SSO implementations. A Windows Azure account provides access to much more information. You can sign up for a free trial at windowsazure.com. To read more about ACS, see bit.ly/zLpIbw.
What Is OData and Why Would I Use It?
OData is a Web-based protocol for querying and updating data, and exposing the data using a standardized syntax. OData leverages technologies such as HTTP, XML, JSON and the Atom Publishing Protocol to provide access to data differently. Implementing OData with the Entity Framework and WCF Data Services provides many great benefits.
I started to wonder why I would use this versus custom WCF contracts. The answer was straightforward. The most practical reason was to leverage service documentation that’s already available and use a standardized syntax supporting how to access data from my service. Having written dozens of services, it seems that I always need to add an additional method as a result of providing custom services. And consumers of custom services tend to ask for more and more features.
For more information on OData and OData URI conventions, visit the following sites:
- OData main site: odata.org
- OData URI conventions: bit.ly/NRalFb
- Netflix OData example service: bit.ly/9UZjRd …
Read more.
Glenn Gailey (@ggailey777) reported A Few New OData Things of Interest on 10/1/2012:
There are a couple of interesting news items re. OData and WCF Data Services:
WCF Data Services 5.1.0-RC2 is released
The WCF Data Services team continues to work towards shoring-up support for the OData v3 spec, especially on a simplified JSON format.
Highlights of this RC release include the following:
- In-the-box support for $format and $callback. This is great news for JSON-P folks.
(In Getting JSON Out of WCF Data Services, I discussed to enable JSON-P because WCF Data Services didn’t support the $format query option out-of-the-box.)- Both a NuGet package and a standalone installer.
For the full list of new functionality in this preview release, see Mark’s post WCF Data Service 5.1.0-rc2 Released.
New public AdventureWorks sample OData feed
Since nearly the beginning, the OData team has hosted a sample, read-only Northwind feed—exposing the venerable Northwind database to the Web as OData. Now, there is a new read-only sample feed….Derrick VanArnam has published a portion of the (massive) AdventureWorks schema as OData. You can read more about how this sample project was planned and executed on Derrick’s blog Customer Feedback SQL Server Samples, starting with the post AdventureWorks2012 OData service sample – Introduction.

<Return to section navigation list>
Windows Azure Service Bus, Access Control Services, Caching, Active Directory and Workflow
• Joseph Fultz wrote Windows Azure In-Role Caching for MSDN Magazine’s 10/2012 issue. From the introduction:
The old notion that luck favors the prepared is meant to convey the idea that no matter how lucky you are, you need to be prepared in order to capitalize on the lucky occurrence. I’ve often thought this statement describes caching pretty accurately. If you’re lucky enough for the universe to align in such a way as to drive high use of your site and services, you’d better be prepared to serve the content quickly.
Back in January I covered some concepts related to caching that focused rather tactically on some coding approaches (msdn.microsoft.com/magazine/hh708748). With the addition of the dedicated and co-located roles for caching in the Windows Azure Caching (Preview), which I’ll refer to here as simply Caching Preview, I felt it would be useful to consider how to use these roles as part of the overall solution architecture. This won’t be an exhaustive coverage of caching features; instead, it’s intended to be a designer’s view of what to do with the big blocks.
A Cache by Any Other Name …
… is not the same. Sure, the back-end implementation is pretty similar and, like its forerunner Windows Azure Shared Caching, Caching Preview will move the data you fetch into the local cache client. More important, though, Caching Preview introduces some capabilities missing from the Shared Cache, so switching to role-based caching not only expands the available feature set, it also gives you better control over the deployment architecture. To start, let’s clarify the primary difference between the dedicated and co-located roles: configuration.
When configuring the cache nodes, you have the option of dedicating the entire role to the cache or setting aside just a percentage of the role. Just as a way to quickly consider the implications of reserving RAM for the co-located cache, take a look at Figure 1, which shows remaining usable RAM after the cache reservation. (Note that the co-located option isn’t available in the X-Small instance.)
Figure 1 Remaining RAM
Often the first thought is to simply choose some medium or small size and allocate some amount of memory. As long as the amount of memory allocated is sufficient for its intended use and within the boundary of the available RAM, this is a fine approach. However, if the number of objects is high and there’s a reasonable expectation that the cache client on each machine might be holding its maximum number of objects, the result could be unexpected memory pressure. Moreover, too little cache RAM could lead to unwanted cache evictions, reducing the overall effectiveness of the cache.
Figure 2 shows the percentage of RAM use based on virtual machine (VM) size. The chart is based on the one at msdn.microsoft.com/library/hh914152, which shows the amount of RAM available for caching in dedicated mode.
Figure 2 Cache Use for Dedicated Role
In my co-located grid (Figure 1), I didn’t go beyond 40 percent allocation for the co-located type because I assumed I’d need a majority of the RAM for the application. In comparison, the dedicated version usually provides more RAM, but appears to hit maximum efficiency of RAM allocation at the large VM size. In that sense, two medium VMs are less useful than one large. Of course, one large instance can’t help with options such as high availability (HA), which duplicates your data, that you might want in your caching infrastructure. Still, it’s worth weighing the needs of space against the need for redundancy and choosing a configuration that not only meets technical needs, but also optimizes cost.




Read more.

<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
• Sanjeev Bannerjee explained Setting up a Sharepoint farm as an extension to Enterprise Network in a 10/2/2012 post:
In my previous blog I had talked about how to create a SharePoint Foundation VM on Windows Azure as standalone server. That was pretty easy and simple stuff. I also tried doing the same in cloudshare and that was pretty neat and impressive. I am also thinking about comparing cloudshare with Azure from price point of view but that I am keeping it for some other post.
As a sequel to my previous blog post, here I am going to talk about what it takes for an organization to build a sharePoint Farm which will be nothing but an extension to their corporate network. There are plenty of great "how to" articles available but my effort over here is to consolidate and put in one place all that you need to know if you are considering going this route.
As a part of Windows Azure's cross premise connectivity, Microsoft has come up with something call Windows Azure Virtual Network which is currently in preview stage and provides secure private IPv4 network which enables an organization to extend their enterprise network to Windows Azure securely over S2S VPN. With Azure Virtual Network lot of new scenarios can be enabled like hybrid apps that span across cloud and their premise, Enterprise Identity and Access Control etc.
Now coming back to the topic of what are the steps one need to take to have a SharePoint farm work as extension to corporate network. Other than that there are other issues to that we need to be thinking about like how to configure load balancing for WFEs and how to implement high availability for SQL Server.So, first thing first, let us start with how to create an extended Virtual Network. Following are the steps:
a) Create a Virtual Network for cross premise connectivity
b) Add a virtual machine to the virtual network
c) Install a Replica AD Domain controller on the VM ( please note in this link there are few steps which you may not need to do if you are having your AD and DNS setup in your environment)
d) Provision other VMs to the DomainNow coming on to other concern about load balancing the WFEs we have on our Azure SharePoint Farm. For load balancing the WFEs, we can use the Azure Load Balancer. Following are the steps for configuring the Load Balancer:
a) Create the first SharePoint WFE VM as standalone

b) Configure the HTTP endpoint for the first VM
One point to notice here is that the endpoints are opened at the loadbalancer level, so even if we have one VM but that is also placed behind the load balancer, this makes the configuration of adding VMs to loadbalancer all that more simpler.
Install SharePoint on the VM.c) Add other WFEs and connect to the previously created VM

d) Now add the VM to the previously created loadbalancer
And that's it we are done!!! Thats pretty Simple...No?
Another concern people have is how can we setup high availability on SQL Server VMs on Windows Azure because Windows Azure doesn't allow SQL Server Clustering. So here we have two options either to go with SQL Server mirroring or Log shipping. For Automatic failover we can configure the SQL Server mirroring with witness which will have one primary server, secondary server and witness server.
One important thing to remember is that don't forget to add the WFEs and your SQL Servers (all three Principal,Mirro and Witness) on the their own availability set so that when Microsoft updates its OS, it won't take down all the server.




• Adam Hoffman (@stratospher_es) asked “Want to support my.fancy.app.can.serve.up.anything.mybrand.com in your Windows Azure application?” in a deck for his Wildcard Subdomains in Windows Azure article of 10/2/2012:
I was meeting with a small company today that has developed a SaaS solution around task and project management. It's a very cool application, and as is the fashion these days, uses subdomains to determine the end user's company as requests come to the browser. So, if I were to sign up for the application, my home url would be http://adamhoffman.getdonedone.com, whereas if you signed up (and had the unlikely name of Bill Ion), your home page would be http://billion.getdonedone.com. This is handled in ASP.NET application code on their Win2K8 servers hosted at Rackspace. The question quickly became "hey, we can do something similar in Azure, right?"
My instant assumption was "yes", and ultimately, it is true that you can accomplish this behavior. It does, however, require that wherever you host your DNS that points to your application supports the concept of "wildcard DNS records", and more specifically, supports "wildcard CNAMEs". As it turns out, Go Daddy's DNS services don't support this, so we'll have to look elsewhere to get this functionality.
The next question you might be asking yourself now is why do we care about wildcard CNAME versus just wildcard DNS? Specifically, the answer lies in the way that Azure provides you high reliability. As a very quick DNS primer, you need to understand the difference between A records and CNAME records. Go read the link if you want the details, but the short answer is "A records point to IP addresses, CNAME records are aliases of other domain name records. OK, but why does this matter?
Well, as it turns out, when you want to put your fancy brand on your Azure based website, you can only do that by way of a CNAME record. The reason that you can't use an A record to point to your site is that your site doesn't have an IP address. Well, it does, but it's not something that you can get access to, and even if you could, it's not persistent, and will likely change. In order to avoid this problem, what you get is really a domain name that is a part of "cloudapp.net". For example, the website that I'm about to demo for you that supports wildcard subdomains is addressable by way of "wildcardsubdomain.cloudapp.net", but not by IP address. Well, OK, yes, smarty pants. It is addressable by IP as well. For example, at this moment I can also get to the same site at http://65.52.208.222, but I shouldn't rely on it. Who knows - by the time you read this, it might not work at all. If you want to know how I figured that out, check out nslookup.
The reason that's all true is that Azure relies on CNAME so that it can switch your IP around, but keep your site addressable. Why does it do it? It's mad network stuff related to load balancers, and the Azure Fabric controller, and it's done to ensure that your site has the maximum stability and uptime.
Okay, back to the problem at hand - getting our dynamic subdomains passed through to our application code to allow for multitenant applications split by the third level domain. How will we handle it? Here we go.
- First, we'll find a DNS service that supports wildcard CNAMEs.
- Next we'll configure that DNS service to point to our application.
- Finally, we'll write the application code that understands the incoming requests so that we can fork our clients appropriately.
- After finally, we'll take a look at the URL Routing features of ASP.NET and see if we can extend our example to integrate nicely with it.
On the first count, it's not actually as straightforward as you might think. For example, I've used GoDaddy to procure several of my domains (yes, I am aware of the SOPA thing, and won't get political here). As the link here reveals, wildcard CNAMEs aren't an option in GoDaddy's DNS servers, so we'll need to look elsewhere. I won't attempt to put together an exhaustive list here, but one DNS service that does support this concept is Amazon's Route 53 DNS service. Another nice feature of this is that it has an API, which actually opens up another possibility if we so chose. Our solution here to route all subdomains to a single hosted web site. An alternative to our multi-tenant single application approach would be to actually specifically provision subdomains and point them to different hosted web sites. So, instead of
*.adamhoffman.net CNAME wildcardsubdomain.cloudapp.net (which has application code that sorts it out)we could, instead go with
customer1.adamhoffman.net CNAME customer1.cloudapp.net (which is for the customer1 domain), andcustomer2.adamhoffman.net CNAME customer2.cloudapp.net (which is for the customer2 domain), andso on...Yes, we could do that, and with the Route 53 API, we could even provision those new CNAME records as necessary. But that's not the route we're going to use. We'd like to use the former option, and have a single wildcard CNAME record that just routes everything to our super smart application.
OK, so next, we'll get ourselves an Amazon account to set up our DNS services on Route 53. Once you've signed up, create, in Amazon's terminology, a hosted zone for the domain that we'll support wildcards on. Of course, you need to own this domain.

Take a look now at the "delegation set" that Route 53 has assigned you. There are 4 DNS servers listed here, and these are the DNS servers that you need to tell your domain registrar about so that it makes sure that requests for your domain are handed off to these Route 53 DNS servers. In my case, my registrar for adamhoffman.net is Go Daddy, so I'll use the Go Daddy tools to point to these DNS servers.

With all of this done, there's only one final step. We need to tell the DNS servers that handle adamhoffman.net that the canonical name (CNAME) for *.adamhoffman.net is really wildcardsubdomain.cloudapp.net. Look at the CNAME record for *.adamhoffman.net in the following picture. That's the secret sauce.





Read more.
• Doug Mahugh (@dmahugh) announced New open source options for Windows Azure web sites: MediaWiki and phpBB in a 10/2/2012 post to the Interoperability @ Microsoft blog:
Need to set up a powerful wiki quickly? Looking for an open source bulletin board solution for your Windows Azure Web Site? Today, we are announcing the availability of MediaWiki and phpBB in the Windows Azure Web Applications gallery. MediaWiki is the open source software that powers WikiPedia and other large-scale wiki projects, and phpBB is the most widely used open source bulletin board system in the world.
You can deploy a free Windows Azure Web Site running MediaWiki or phpBB with just a few mouse clicks. Sign up for the free trial if you don’t already have a Windows Azure subscription, and then select the option to create a new web site from the gallery.
This will take you to a screen where you can select from a list of applications to be automatically installed by Windows Azure on the new web site you’re creating. You’ll see many popular open source packages there, including MediaWiki and phpBB. Select the option you’d like, and then you’ll be prompted for a few configuration details such as the URL for your web site and database settings for the application:
Fill in the required fields, click the Next button, and you’ll soon have a running ready-to-use web site that is hosting your selected application.
The Windows Web App Gallery also includes MediaWiki and phpBB, so you can deploy either of them on-premises as well. See the MediaWiki and phpBB entries in the gallery.
The MediaWiki project now includes the Windows Azure Storage extensions that allow you to story media files on Windows Azure. You can use this functionality for MediaWiki sites deploy to Windows Azure Web Sites, or for other deployments as well. More information can be found on the MediaWiki wiki.
A big thanks to everyone who helped to make MediaWiki and phpBB work so well on Windows Azure! Markus Glazer, volunteer developer at Wikimedia Foundation, submitted the MediaWiki package to the Windows Azure Web Sites Gallery and integrated MediaWiki with Windows Azure Storage. Nils Adermann from the phpBB community submitted the updated phpBB 3.0.11 package to the Windows Azure Web Sites Gallery with the necessary changes for integration with Windows Azure.
The addition of phpBB and MediaWiki is a great example of Windows Azure’s support for open source software applications, frameworks, and tools. We’re continuing to work with these and other communities to make Windows Azure a great place to host open source applications. What other open source technologies would you like to be able to use on Windows Azure?
Doug Mahugh
Senior Technical Evangelist
Microsoft Open Technologies, Inc.





<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Himanshu Singh (@himanshuks, pictured below) posted a Real World Windows Azure: h.e.t. software Cuts Costs by 50% with Windows Azure case study on 10/2/2012:
As part of the Real World Windows Azure series, I connected Paul Patarou, Sales Director at h.e.t. software to learn more about how the company redeveloped its field worker application on Windows Azure to reduce client IT overhead, speed time to market, and scale to accommodate large volumes of data. Read h.e.t. software’s success story here. Read on to find out what he had to say.
Himanshu Kumar Singh: Tell me about h.e.t. software.
Paul Patarou: h.e.t. software develops specialist solutions for social care providers in the United Kingdom and Australia. Based in Haverhill, near Cambridge, we are considered a leader in the sector, with 550 clients that deliver care across home care, residential and nursing homes, and supported living services.
HKS: Where did the idea for your field worker application originate?
PP: We have an excellent knowledge of our social care services clients and continually evolve our solutions to meet their needs. We recognized that recording the care and contractual details of thousands of care service support visits was a large overhead for these organizations. For example, processing timesheets and mileage claim forms, and creating schedules can take many hours of administrative time. Being able to gather information in the field is essential for delivering quality services efficiently.
In 2008, with mobile devices playing an increasing role in the delivery of care, we saw an opportunity to expand our services. There are 7,000 home care providers in the U.K. alone, but until recently there were no applications that supported carers to capture site information in real time. Our clients relied on staff to fill in sheets about visits, and then processed them at an office. Administration and labor costs are big concerns for our clients.
HKS: So you developed a field worker solution. How did it perform?
PP: We moved quickly to develop a system that responded to these challenges. The solution was a success, but we needed a hosting platform that could cope with the large spikes in data transmission throughout our 24 hours a day, seven days a week service. We realized that the platform we had was not going to be as scalable as we needed it to be. Our clients have to record all visit data because they’re required to show it to the Government agencies that fund the care. Millions of transactions take place every day, and volumes tend to peak at certain times. For example, carers will make more visits at breakfast, lunch, and dinner times, so they capture more data during these periods.
HKS: Tell me about CareManagerMobile.
PP: CareManagerMobile is an application delivered as a service on a mobile device through Windows Azure. The secure web application can be accessed on multiple smartphone platforms through an HTML 5 browser. It uses GPS location-based tracking to record real time visit information, including arrival and departure times. When a carer arrives at a service user’s location, confirmation of both the visit and tasks are updated automatically. New schedules and requests can be sent to the mobile device, while details around proof of care are recorded for both the care provider and the funding agency.
HKS: What are some of the developer benefits with Windows Azure?
HKS: What about customer benefits?
PP: With Windows Azure, CareManagerMobile can quickly scale up and down to meet customers’ data requirements and application resources are cost-effectively allocated through specialized web and worker roles. Network load balancing is automatically managed to provide continuous availability and customers are protected by a 99.95 percent uptime availability service level agreement.
And we charge for CareManagerMobile as an annual subscription, per-user so we can scale the application up and down according to data volumes. This way, our clients can significantly reduce the operations and maintenance cost of their IT while allowing them to scale without performance issues.
HKS: And the business benefits to h.e.t. software?
PP: Our solutions are used by around nine percent of the potential market in the U.K. Following a strategic marketing push in 2012, we predict that the number of customers using CareManagerMobile will grow rapidly. We’ve got the scalability to manage expansion without having to factor in new staff or resources.
Additionally, Windows Azure features allow us to develop software services we couldn’t have provided ourselves. For example, we can configure test solutions in minutes. This helps us deliver competitive products and new releases to market quickly.
Care is also enhanced. In the past we didn’t have the data to plan resources as effectively as we wanted to. Now, if a client asks a carer to complete additional tasks that cause the appointment to take longer than allocated, we can let the next person know. And, if this happens frequently with a particular client, we know we need to allocate more time to that client in future.
HKS: What are your future plans with Windows Azure?
PP: We plan to begin moving our entire care solution portfolio onto Windows in 2012. It makes sense for us to extend the cost and performance benefits of Windows Azure to all our clients.
Read how others are using Windows Azure.

• Larry Franks (@larry_franks) described Node.js specific diagnostics for Windows Azure in a 10/2/2012 post to the [Windows Azure’s] Silver Lining blog:
I've been researching how to troubleshoot Node.js applications hosted on Windows Azure recently, and while I'm don't have a complete story yet I wanted to share what I do have. So here's a brain dump of diagnostics information that Node.js developers might find useful.
Also, don't be depressed/upset about some of the problems I call out with things like logging on Cloud Services. We know that we need to improve this story. The Windows Azure developers are working on it, but if you have thoughts on how we can improve troubleshooting for Node.js applications on Windows Azure, let me know.
Web Sites and Cloud Services
This doesn't mean that you should never use Worker Roles, just that if you do use one and need to troubleshoot your application that you'll have to fall back on standard works-for-every-node-application troubleshooting steps.
Here's the breakdown of what is and isn't available for troubleshooting Node.js applications hosted as a Web Site or Cloud Service (Web Role only):
IISNode basics
Since most of the troubleshooting functionality is implemented through IISNode, it's important to understand how it works. Basically, IISNode is a layer that sits between IIS and Node.exe, and routes requests that arrive at IIS to Node.exe. This lets IIS handle things like spinning up multiple node instances (1 per core by default) and lifecycle management tasks.
IISNode has a bunch of configuration options, which can be controlled by adding an iisnode.yml file to the root of your application. A full listing of switches can be found at https://github.com/tjanczuk/iisnode/blob/master/src/samples/configuration/iisnode.yml.
So here's one of the gotcha's with IISNode - Windows Azure doesn't use the full version. Instead it uses a 'core' version that only implements some of the functionality of the full version. I don't have a complete list of what is/isn't in the core version, but the things I mention in this article should work (unless I call out specifically why they don't.)
IISNode logging
IISNode can capture stdout/stderr streams and save them to a log file. This is currently enabled by default for Windows Azure Web Sites and Cloud Service Web Roles. By default, the logs are stored in a subdirectory named iisnode. If you want to disable logging, you can create an iisnode.yml file and add
loggingEnabled: falseto it.For Windows Azure Web Sites, the log files can be pulled down by visiting the FTP link for your web site, or by using the Command-line tools command of
azure site log downloadcommand. The download command will pull down a Zip archive containing not only the IISNode logs, but any other logging you may have enabled in the portal.Windows Azure Web Sites have one other nice feature; the logs from all instances of your web site are aggregated, so there's just the one directory containing logs of the stdout/stderr output for all instances of the application.
The story for Windows Azure Cloud Services isn't as good currently. The log files are stored into the iisnode subdirectory, but there's no centralized aggregation of the log files and there's no functionality to easily get to them. The logs are stored on a per role instance basis, and you need to either remotely connect to each instance to retrieve them or set up a process that periodically copies them off the instance.
HTTP access to logs
If you read through the iisnode.yml example linked above, you may be thinking "But I can just access the log files via HTTP, why do I have to remote into the instances or download the logs?" Well, this functionality is disabled for Web Sites and Cloud Services by default. You can make it work by modifying the IIS URL Rewrite rules in the web.config for your application, however consider this; how useful is it to enable HTTP access to the logs when you can't easily determine which hosting instance you'll connect to?
For example, if you're hosting the application on a Cloud Service you might have it scaled out to 2 instances. Those are load balanced behind the virtual IP assigned to the service, so hitting that URL is going to take you to one of the instances, but you can't really direct it to one or the other.
So for a production, scaled out application, HTTP logs are sort of not that useful. It's far more useful to have some sort of centralized aggregation of the logs, such as that done by Windows Azure Web Sites.
Development errors
Ever browsed your application after deploying it and received an HTTP 500 response? Not very helpful. When development errors are enabled, you'll get an HTTP 200 response instead, along with the last few lines of information sent to stderr.
Development errors can be controlled by adding
devErrorsEnabled: trueorfalseto your iisnode.yml file. Currently the default seems to be true. For a production application, I'd recommend disabling this setting, as most end users don't want to see your code's error spew and would appreciate a custom friendly error instead.Windows Azure Portal
IISNode isn't the only thing available in Windows Azure that can help diagnose problems; since IISNode runs under IIS, and on Windows, there are additional logs for those pieces of the infrastructure that can be enabled in the diagnostics section of the CONFIGURATION settings for your Web Site or Cloud Service. For more information on working with these settings and the information logged by them, see How to Monitor Cloud Services and How to Monitor Web Sites.
Anything I've missed?
I hope the above information is useful to those of you hosting Node.js applications on Windows Azure, and if you have any additional diagnostic/troubleshooting tips you'd like to share feel free to send them my way.


• Brady Gaster (@bradygaster) introduced The CloudMonitR Sample for Windows Azure in a 10/1/2012 post:
The next Windows Azure code sample released by the Windows Azure Evangelism Team is the CloudMonitR sample. This code sample demonstrates how Windows Azure Cloud Services can be instrumented and their performance analyzed in real time using a SignalR Hub residing in a web site hosted with Windows Azure Web Sites. Using Twitter Bootstrap and Highcharts JavaScript charting components, the web site provides a real-time view of performance counter data and trace output. This blog post will introduce the CloudMonitR sample and give you some links to obtain it.
Overview
Below, you’ll see a screen shot of CloudMonitR in action, charting and tracing away on a running Windows Azure Worker Role.
The architecture of the CloudMonitR sample is similar to a previous sample I recently blogged about, the SiteMonitR sample. Both samples demonstrate how SignalR can be used to connect Windows Azure Cloud Services to web sites (and back again), and both sites use Twitter Bootstrap on the client to make the GUI simple to develop and customizable via CSS.
The point of CloudMonitR, however, is to allow for simplistic performance analysis of single- or multiple-instance Cloud Services. The slide below is from the CloudBurst presentation deck, and shows a very high-level overview of the architecture.
As each instance of the Worker (or Web) Role you wish to analyze comes online, it makes an outbound connection to the SignalR Hub running in a Windows Azure Web Site. Roles communicate with the Hub to send up tracing information and performance counter data to be charted using the Highcharts JavaScript API. Likewise, user interaction initiated on the Windows Azure Web Sites-hosted dashboard to do things like add additional performance counters to observe (or to delete ones no longer needed on the dashboard) is communicated back to SignalR Hub. Performance counters selected for observation are stored in a Windows Azure Table Storage table, and retrieved as the dashboard is loaded into a browser.
Available via NuGet, Too!
The CloudMonitR solution is also available as a pair of NuGet packages. The first of these packages, the simply-named CloudMonitR package, is the one you’d want to pull down to reference from a Web or Worker Role for which you need the metrics and trace reporting functionality. Referencing this package will give you everything you need to start reporting the performance counter and tracing data from within your Roles.
The CloudMonitR.Web package, on the other hand, won’t bring down a ton of binaries, but will instead provide you with the CSS, HTML, JavaScript, and a few image files required to run the CloudMonitR dashboard in any ASP.NET web site.

![35[1]](http://www.bradygaster.com/Media/Default/WindowsLiveWriter/TheCloudMonitRSample_DF44/35%5b1%5d_3.png "35[1]")

• Adron Hall (@adron) offers opinions about TypeScript in his The #TypeScript Bomb Went off With a BANG Today! article of 6/1/2012:
First thing in the morning today the east coast was talking about Mary Jo Foley’s article about the TypeScript release. Later in the day Matt Baxter-Reynolds (@mbrit) released a bit of write up titled “Microsoft TypeScript: Can the father of C# save us from the tyranny of JavaScript?“. My first reactions went something like this:
- TypeScript sounds interesting. Anders is on it, so that’s a big plus. It’s a “superset” & “syntactic sugar” which is also interesting.
- TypeScript is a lousy name. I wish MS could find people to name things with something entertaining. It just seems disconnected.
After a little bit more review and an explosion on twitter I came to a few other conclusions.
- The whole large applications notion just doesn’t cut it for me. Writing big applications well is about a good team, not about your language taking up the slack of a bad team.
- I get that this makes things easier in Visual Studio and other IDEs to do certain “easy button” and F5 type development for coders that use those tools. There’s big plusses and really big negatives to this.
- If you check out the site http://www.typescriptlang.org/ you’ll see open source with the code available. I’m stoked to see that Microsoft isn’t just playing lip service to this. They’re walking the walk these days, there’s even a pull requests section albeit no requests yet, and it is indeed using Git. Just (git clone https://git01.codeplex.com/typescript)
- A huge cool factor too, are the tons of plugins available already.
- Sublime 2 [download] (which I hear from my buddy Jerry Sievert (@jerrysievert) will work with TextMate)
- Emacs [download]
- Vi [download]
- Visual Studio [download]
- There’s a tutorial, which I plundered through real quick at lunch amid the plethora of pictures I took. Working through this tutorial I found the thing I’m happiest about, more so than the plugins, is that there is indeed an npm package (npm install -g typescript). Remember when installing, you’ll probably need to do a sudo.
- The TypeScript Playground is a cool feature. Kind of like jsbin, except for toying around with TypeScript. However change the following snippet of code:
class Greeter { greeting: string; constructor (message: string) { this.greeting = message; } greet() { return "Hello, " + this.greeting; } } var greeter = new Greeter("world"); var button = document.createElement('button') button.innerText = "Say Hello" button.onclick = function() { alert(greeter.greet()) } document.body.appendChild(button)…and change the instantiation of…
var greeter = new Greeter("world", 123);
…or change it to…
var greeter = new Greeter("world", "WTF");
…and then think about it for a second. I thought the point was to do strong typing, but it seems that isn’t strong typing the bits in the parameter list of the object instantiation. Beyond little nuances like that, I’m generally ok with the enhancements they’ve added with TypeScript. Not sure people that know how to write JavaScript really need to have this. It seems there is a strong case that this is created to make it easier for C# (and by proxy Java) coders to grok and write JavaScript code. That’s fine by me too. The sooner people can stop whining about how horrible the language is (which I also will admit I’m totally fine with the language, just learn it, it isn’t hard).
Summary
In the end, I’m fine with TypeScript. I think Anders & team have put this together in a responsible, positive way and inclusive of prospective community feedback and interaction. After so many years of the opposite, I’m still always impressed when things are done in good faith with the community. Do I think they need to work on how they put these efforts together? Yes. Do I think the approach of bombing the community with this new thing with a whole pre-built MS community around it pre-existing? Yes. But I digress, overall all looks good, and nothing truly negative about it (unless one is personally perturbed). So I’d suggest to try it out, it can definitely make things easier in a number of ways. I might even have some examples cropped up over the next few days.

TypeScript might be the incentive I’ve needed for several years to write JavaScript.
Mary Jo Foley (@maryjofoley) asserted “Microsoft is launching a preview of a new programming language known as TypeScript, which aims to make JavaScript development scale beyond the client” in a deck for her Microsoft takes the wraps off TypeScript, a superset of JavaScript in a 10/1/2012 post to ZDNet’s All About Microsoft blog:
As of today, we now know more about the formerly secret Microsoft JavaScript effort upon which Technical Fellow and father of C# Anders Hejlsberg has been working.
On October 1, Microsoft took the wraps off TypeScript, a new programming language that is aimed at making JavaScript development scale beyond the client.
Microsoft has made available to those interested via its CodePlex site a preview of the TypeScript bits; the TypeScript language specification; and the source code for the TypeScript compiler. TypeScript is available under an Apache 2.0 open-source license. In addition to the new TypeScript language and compiler, Microsoft also plans to make available a TypeScript for Visual Studio 2012 plug-in, providing JavaScript developers with Visual Studio features like code navigation, refactoring, static error messages and IntelliSense.
A Microsoft Channel 9 video of Hejlsberg discussing TypeScript is available on Microsoft's Web site:
Soma Somasegar, Corporate Vice President of Microsoft' Developer Division, outlined the problem space that Microsoft believes it can solve with TypeScript in an October 1 blog post:
"With HTML5, the standards web platform has become significantly more compelling for delivering rich user experiences. At the same time, the reach of JavaScript has continued to expand, going beyond the browser to include native device apps (e.g. Windows Store apps for Windows 8), applications in the cloud (e.g., node.js running on Windows Azure), and more. With these developments, we’re starting to see applications of unprecedented size written with JavaScript, despite the fact that creating large-scale JavaScript applications is hard. TypeScript makes it easier."
Microsoft is building the TypeScript "superset" of JavaScript to provide the "syntactic sugar" needed to build large applications and support large teams, Somasegar blogged. TypeScript will provide better JavaScript tooling to users writing client-side apps or server/cloud-side ones, Somasegar said. The kinds of tools that typically have been available only for statically-typed languages will be available for JavaScript via TypeScript, he said.
I got a couple of tips about Hejlsberg & Co.'s JavaScript effort leading up to today's announcement. One of them posited that that Microsoft's new JavaScript project (which this person said was codenamed "Strada" internally -- a name upon which Microsoft officials wouldn't comment) -- was yet another example of Microsoft's good old "embrace and extend" philosophy.
Hejlsberg and the others working on TypeScript disagreed with that characterization. Microsoft is building TypeScript so that JavaScript code already developed can easily be brought into the TypeScript world because, as Somasegar claimed on his blog, "all JavaScript code is already TypeScript code."
Microsoft's official site for TypeScript is http://www.typescriptlang.org/.
What are your initial thoughts on what the Softies are doing, any of you developer-readers out there?
Update: In spite of the Somasegar quote above regarding the Windows Store -- if you still were unsure whether you can build Windows Store apps for Windows 8 and Windows RT using TypeScript, the answer is yes.

Tim Anderson (@timanderson, pictured below) climbs on the TypeScript bandwagon with his Here comes TypeScript: Microsoft’s superset of JavaScript article of 10/1/2012:
Microsoft’s Anders Hejlsberg has introduced TypeScript, a programming language which is a superset of JavaScript and which compiles to JavaScript code.
The thinking behind TypeScript is that JavaScript is unsuitable for large projects.
“JavaScript was never designed to be a programming language for big applications,” says Microsoft’s Anders Hejlsberg, inventor of C#. “It’s a scripting language.”
The ubiquity of JavaScript makes it remarkably useful though, with that now extending to the server thanks to projects like node.js. Microsoft is using node.js for its Azure Mobile Services.
TypeScript therefore lets you use features including type annotations, classes, modules and interfaces to make large projects more robust and maintainable.
Variable names are preserved when TypeScript is compiled. Further, since TypeScript is a superset, any JavaScript code can be pasted into a TypeScript project. The compiler is open source and you can download an early version here.
Microsoft is also trying to stay close to the specification for Ecmascript 6, the proposed next iteration of the official JavaScript standard, where relevant.
There is tooling for Visual Studio including a language service to provide code hinting, syntax highlighting and the like.
TypeScript differs from projects like Google Web Toolkit or Script#, both of which also emit JavaScript, in that it does not compile from one language into another; rather, it compiles into a reduced version of itself.
Why is Microsoft doing this? That is the interesting question. I would conjecture that it is partly self-interest. Microsoft itself has to write increasing amounts of JavaScript, for things like Office Web Apps (apparently written in Script#) and the new Azure portals. Azure Mobile Services uses JavaScript as mentioned above. JavaScript is also one of the options for coding apps for Windows 8. Better tools will help Microsoft itself to be more productive.
That said, the arrival of TypeScript will re-ignite the debate about whether Microsoft, while not anywhere close to abandoning .NET, is nevertheless drifting away from it, towards both native code in Windows and now JavaScript in the managed code space.
More information from Microsoft’s S Somasegar here.

Olivier Bloch (@obloch) reported Sublime Text, Vi, Emacs: TypeScript enabled! in a 10/1/2012 post:
TypeScript is a new open and interoperable language for application scale JavaScript development created by Microsoft and released as open source on CodePlex. You can learn about this typed superset of JavaScript that compiles to plain JavaScript reading Soma’s blog.
At Microsoft Open Technologies, Inc. we are thrilled that the discussion is now open with the community on the language specification: you can play (or even better start developing with TypeScript) with the bits, read the specification and provide your feedback on the discussion forum. We also wanted to make it possible for developers to use their favorite editor to write TypeScript code, in addition to the TypeScript online playground and the Visual Studio plugin.
Below you will find sample syntax files for Sublime Text, Vi and Emacs that will add syntax highlighting to the files with a .ts extension. We want to hear from you on where you think we should post these files for you to be able to optimize them and help us make your TypeScript programming an even greater experience, so please comment on this post or send us a message.

TypeScript support for
Sublime Text
TypeScript support for
Emacs
TypeScript support for
VimOlivier Bloch
Senior Technical Evangelist
Microsoft Open Technologies, Inc.

Xignite announced clearTREND Delivers Professional Analytics tools to Investors’ Laptops and Windows 8 Tablets in a 10/1/2012 press release:
Xignite, Inc., the leading market data cloud solutions provider, and Appleton Group Wealth Management, LLC, today announced that they have partnered with each other, Skyline Technologies, and Microsoft (MSFT) Windows Azure/Windows 8 to develop clearTREND™, a new mobile investment research app that helps manage investment portfolios. clearTREND is the first investment trend calculator publicly available. It solves a fundamental problem in investing by accurately calculating past price trends for any security, then generating real-time buy and sell recommendations.
“Xignite is a leader in delivering market data to fast-running apps by harnessing the power of the cloud,” said Stephane Dubois, CEO and founder of Xignite. “We are proud to be in the company of industry leaders such as Microsoft, Skyline Technologies, and Appleton Wealth Management.”
“clearTREND represents a significant leap forward in the field of investment and economic research,” said Mark C. Scheffler, Founder and Sr. Portfolio Manager for Appleton Group. “This app is a ‘must‐have’ for any individual investor or professional advisor, but it’s especially useful for 401(k) participants working to make their retirement plans more profitable, less risky and more predictable.”
For information on features, benefits, pricing and availability, please go to: http://www.cleartrendresearch.com/?page_id=2072.
About Xignite
Xignite is the leading provider of market data cloud solutions. The Xignite Market Data Cloud fulfills more than 5 billion requests per month and offers more than 50 financial web services APIs providing real-time, historical, and reference data across all asset classes. Xignite APIs power mobile financial applications, websites, and front-, middle- and back-office functions for more than 1000 clients worldwide, including Wells Fargo, GE, Computershare, BNY Mellon, Natixis, Forbes.com, SeekingAlpha, ExxonMobil, Starbucks, and Barrick Gold. The company’s award-winning XigniteOnDemand market data cloud platform also powers data distribution solutions for exchanges and data vendors, as well as Enterprise Data Distribution (EDD) solutions for financial institutions. Companies using XigniteOnDemand for market data distribution include the CME Group, NASDAQ OMX, NYSE Euronext and Direct Edge.
About Appleton Wealth Management
Appleton Group Wealth Management LLC is an independent Registered Investment Advisor (RIA), offering objective and unbiased wealth management services to all investment management clients. The firm is compensated solely for the advisory services it provides to its clients, and is in no way compensated by commissions of any kind. As a small privately held firm, Appleton Group is solely focused on providing investment advisory and management services and helping the investment community build and manage more consistent and profitable portfolios.
Jim O’Neil (@jimoneil) posted Sample Browser–The Next Visual Studio Extension You’ll Install on 10/1/2012:
The one software design pattern that I have used in just about every application I’ve written is “cut-and-paste,” so the new “Sample Browser” – read sample as a noun not an adjective – is a great boon to my productivity.
Once you’ve installed the extension (if you’re running Visual Studio Express you can use the standalone version), you’ll be able to browse samples by category (HTML 5, Windows 8, Windows Azure, etc.), search by term or description, and even put in a request to have a sample built by Microsoft engineers if there is a gap in the current offerings.
The really cool feature, in my opinion, is that you can trigger a contextual search in the Visual Studio editor for other samples that might reference a specific method, like OnNavigagedTo as seen to the right.
And consider subscribing to the Sample of the Day RSS feed right from the Visual Studio Start screen, it’s a great way to learn something new each day!

Installed on VS 2011 and 2012.
Mary Jo Foley (@maryjofoley) asserted “Microsoft' Dynamics NAV 2013 ERP release is generally available. But it won't be hosted on Windows Azure until the first quarter of 2013, instead of this month, as originally planned” in a deck for her Microsoft Dynamics NAV 2013 debuts, minus promised Azure hosting article of 10/1/2012 for ZDNet’s All About Microsoft blog:
On October 1, Microsoft announced general availability of its small/mid-size-business-targeted Dynamics NAV 2013 ERP release.
Dynamics NAV 2013, which is one of four ERP products offered by Microsoft, was slated to be the first of the four to be hosted on Microsoft's Windows Azure cloud operating system. But it turns out NAV 2013 won't be hosted on Microsoft's cloud right out of the gate, after all.
Microsoft's new plan is to make NAV 2013 available on Azure some time in the first quarter of calendar 2013, a spokesperson confirmed. Once it is hosted on Azure, the product still will be sold through NAV 2013 partners, as per Microsoft's original plan, the spokesperson said. There's no date or official commitment as to when/whether Microsoft also might offer NAV 2013 hosted on Azure directly to customers itself, the spokesperson added.
Microsoft officials are not sharing details as to what led to the Azure-hosting delay with NAV 2013. When I asked for more background on this, I received the following statement from the spokesperson:
“Microsoft Dynamics NAV 2013 is available to customers both on-premises and in the cloud via partner-hosted offerings. With the new version we have made significant investments in the 'hostability' of the product to ensure a great customer and partner experience deploying and using NAV in the cloud. We are currently fine-tuning deployment scenarios and creating prescriptive guidance for deploying NAV on Windows Azure and expect to make deployment of Microsoft Dynamics NAV on Windows Azure broadly available in Q1 of CY2013.“
Improvements to "hostability" is just one of a number of new features in the NAV 2013 release. The latest release also includes improvements to querying and charting; more granular role-tailored capabilities; increased general-ledger flexibility; integration with Microsoft's SharePoint and OneNote note-taking products; and expanded Web Client/broser support.
Microsoft's grand ERP plan is to follow the same model on the ERP side of the house that it's already pursuing on the CRM side of its Dynamics business. This year, Microsoft is rolling out simultaneously on-premises and in the cloud its NAV 2013 release. After this year, future Dynamics ERP releases will be cloud-first. As is the case with Dynamics CRM, Microsoft will be making two major updates a year to its ERP platforms once they're available both on-premises and in the cloud, officials have said.




<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+

Return to section navigation list>
Windows Azure Infrastructure and DevOps
• David Linthicum (@DavidLinthicum) asserted “A recent survey shows that lack of innovation and maturity cause many businesses to avoid the cloud -- for now” in a deck for his Buyers say the cloud is already tired out article of 10/2/2012 for InfoWorld’s Cloud Computing blog:
Why is there not larger adoption of cloud computing? A joint survey by the CSA (Cloud Security Alliance) and ISACA (previously known as the Information Systems Audit and Control Association) tries to answer that question.
Of course, government regulations and international data privacy rules are on the list of concerns that hurt confidence in cloud computing, the survey shows. However, a lack of innovation and maturity in cloud computing itself are larger concerns, slowing widespread cloud adoption. In fact, 24 percent of respondents said there is little to no innovation in the cloud market. Meanwhile, only 33 percent who say the level of innovation is significant.
I've previously pointed out the cloud's problem of "little boxes all the same" due to the lack of innovation in cloud computing, and this survey appears to validate that observation. The perception that cloud computing has both low innovation and low maturity is very scary when you consider just how young the cloud is.
The core problem is that most cloud technology providers believe what they do is innovative. To them, that means adopting the strategies of the market leaders, replicating their features and APIs (call for call), and hyping the market.
While such a "fast follower" strategy have worked a few years ago, it falls flat today with IT organizations that are much more savvy -- and cautious -- about the cloud. They understand that, for cloud computing to have value, it must bring something new to the table. Lacking those innovations, and thus that value, they understandably take a wait-and-see approach.
It's not good for the cloud industry to seem so old and tired at such a young age.

Lori MacVittie (lmacvittie) answered “Why active-active is not best practice in the data center, and shouldn't be in the cloud either” in her Load Balancing 101: Active-Active In the Cloud article of 10/1/2012 for F5’s DevCentral blog:
Last time we dove into a "Load Balancing 101" discussion we looked at the difference between architected for scale and architected for fail. The question that usually pops up after such a discussion is "why can't I just provision an extra server and use it. If one fails, the other picks up the load"?
We call such a model N+1 – where N is the number of servers necessary to handle load plus one extra, just in case. The assumption is that all N+1 servers are active, so no resources are just hanging out idle and wasting money. This is also sometimes referred to as "active-active" when such architectures include a redundant pair of X (firewalls, load balancers, servers, etc… ) because both the primary and backup are active at the same time.
So it sounds good, this utilization of all resources and when everything is running rosy it can benefit in terms of improving performance, because utilization remains lower across all N+1 devices.
The problem comes when one of those devices fails.
HERE COMES the MATH
In the simplest case of two devices – one acting as backup to the other – everything is just peachy keen until utilization is greater than 50%.
Assume we have two servers, each with a maximum capacity of 100 connections. Let's assume clients are generating 150 connections and a load balancing service distributes this evenly, giving each server 75 connections for a utilization rate of 75%.
Now let's assume one server fails.
The remaining server must try to handle all 150 connections, which puts its utilization at … 150%. Which it cannot handle. Performance degrades, connections time out, and end-users become very, very angry.
Which is why, if you consider the resulting impact of performance and downtime on business revenue and productivity, redundancy is considering a best practice for architecting data center networks. N+1 works in the scenario in which only 1 device fails (because the idle one can take over) but the larger the pool of resources, the more likely it is that more than one device will fail at relatively the same time. Making it necessary to take more of an N+"a couple or three spares" approach.
Yes, resources stand idle. Wasted. Money down the drain.
Until they're needed. Desperately.
They're insurance, they always have been, against failure. The cost of downtime and/or performance degradation was considered far greater than the operational and capital costs associated with a secondary, idle device.
The ability of a load balancing service to designate a backup server/resource that remains idle is paramount to enabling architectures built to fail. The ability of a load balancing service in the cloud to do this should be considered a basic requirement. In fact, much like leveraging cloud as a secondary "backup" data center for disaster recovery/business continuity strategies, having a "spare" resource waiting to assure availability should be a no-brainer from a cost perspective, given the much lower cost of ownership in the cloud.
Referenced blogs & articles:
Related blogs & articles:


No significant articles today
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds

<Return to section navigation list>
Cloud Security and Governance
Walt Lapinsky asked and answered PCI in the Cloud? in a 9/30/2012 post:
I have written about PCI compliance on several occasions over the past two years. The Payment Card Industry (PCI) Data Security Standard (DSS) is the worldwide information security standard for organizations that handle cardholder information for debit, credit, prepaid, e-purse, ATM and point-of-sale (POS) cards. The sole purpose of these standards is to reduce credit card fraud due to the exposure of the sensitive information contained on the card. This information is printed, encoded in the magnetic stripe, or in some active or passive embedded device (e.g., RFID chip) on the card. This information is necessary to complete the financial transaction, and when stolen can be used to commit that fraud. Based on the volume of such transactions, organizations must have an annual audit by an external Qualified Security Assessor (QSA) or by a Self-Assessment Questionnaire.
Each card has a 16-digit number on the front called the PAN (primary account number). If your organization stores, processes or transmits the PAN, then you must be 100% PCI compliant 100% of the time. Failure to be compliant can be expensive, with an average cost to your organization of over $200 per lost record, plus the potential of significant fines and lost good will.
Because of the nature of the DSS requirements, I have been counseling organizations subject to PCI compliance to either eliminate their requirement to be PCI compliant, or ignore the Cloud as an opportunity for that processing.
It turns out that many companies handle the PAN for no good reason. In many cases, it is because of history: when they started out they were handling the order screens themselves and thus had the PAN at least moving through their systems and therefore were required to be PCI compliant, even though they never actually stored the PAN. Other companies have stored the PAN either to make recurring payments easier for them, or with the really bad idea of using the PAN to identify a customer. Never use any identifier created by a government or financial entity as your internal customer id. It exposes you to far more security risk than you can afford to deal with. Even small companies can accept credit cards for on-line payments with no PCI exposure through companies like PayPal, and several companies (including PayPal) offer credit card readers and software for smart phones that are PCI-DSS compliant.
Note that using one of these smart phone credit card payments options does not remove your PCI compliance requirement – you are still handling the PAN. Your employee is holding and can see the card, and the PAN is transmitted through your device. However, unless you are the size of Apple with over 300 stores each averaging 75 employees and doing over US$30M per year, you should be OK with a relatively simple self-assessment questionnaire. Your primary security issues are training your staff on the security requirements and procedures to handle the card, and confirming the certification status of the reader and software you are using with the device vendor(s).
Even though I have been preaching that the Cloud is constantly evolving, and what should not go in the Cloud six months ago might be OK today, I was surprised to see a webinar by Phil Cox sponsored by RightScale that talked about being PCI-DSS compliant in the IaaS (Infrastructure as a Service) Public Cloud.
Phil is currently the Director, Security and Compliance, at RightScale. He has been on all sides of the PCI compliance issue, with years of experience as a QSA and as a merchant, as a contributor to the PCI virtualization supplement, and as a member of the PCI Cloud SIG (special interest group).
Why would you want to go to a Public Cloud in the first place?
- To save a lot of money, and only pay for what you use.
- To gain significant agility, the ability to grow or shrink your infrastructure to almost any level in minutes to match your current requirements.
- To get rid of some of the aggravation of running an IT infrastructure securely and reliably. Often, companies get a significant security boost by moving to the Cloud because most Cloud Service Providers are really good at managing IT – it is their core competency.
Importantly, there is no guidance from the PCI Security Standards Council as to how their requirements and controls are to be met and validated in a Cloud environment. Many PCI-DSS experts that I have talked to believe that almost by definition you are not compliant if you are using the Cloud. Yet there is actually no mention of the Cloud in the PCC-DSS.
There are many important steps to moving your PCI processing to the Public IaaS Cloud. Here are four to think about initially.
- A good rule for designing a system involving PCI data is to keep it simple, independent of the environment. The fewer parts, the better. If your cardholder data is scattered in multiple applications on multiple servers in multiple physical locations, you will have a very difficult time proving you are PCI compliant. In general, you want your cardholder data only in one place. When you move to the Cloud, put all of your cardholder data in your Cloud provider, don’t leave any “at home.” Part of achieving simplicity is to completely separate your development and test (dev/test) environment from your production system and include absolutely no real cardholder data in your dev/test environment. This means your dev/test environment is completely outside of the area that needs to be compliant, and you only need to worry about your production system. It also means that your test cardholder data is manufactured, not simply a transformation of some real cardholder data. It must be impossible to recreate any actual data from your test data.
- Choose your Cloud Service Provider carefully. Ideally, they will be on the “Approved Service Providers” list for one of the major card brands. If they are not listed but have done a Level 2 assessment and will share their Report on Compliance they may be acceptable. Check with your QSA. Alternatively, have them sign a contract that they will protect cardholder data according to the PCI DSS to the extent that it applies to them. Again, let your QSA guide you.
- Choose your QSA carefully. If they do not understand the Cloud in general and Public Cloud IaaS in particular, they will likely fail you in one of two ways: either by simply saying “no” to the Cloud, or certifying you when you really do not have everything in place to be compliant.
- Keep your stakeholders informed. Many Cloud implementations fail not because they were badly implemented, but because someone with a title in the organization stopped it. The way to prevent that, or at least determine you are trouble before you have spent a lot of effort, is to get your stakeholders involved early, listen to their concerns, address the issues, and keep the stakeholders informed throughout the journey. At a minimum, your stakeholders are your CEO, CFO, CIO, the head of information security, the person in charge of internal audits, your QSA if you have one, and your legal department.
A few years ago I attended a Cloud Symposium sponsored by a major player in the Cloud space. One question from the audience was, “What about Amazon as a Cloud Service Provider?” The Cloud expert on the panel responded with, “Would you trust your business to a bookseller?” That generated a laugh. But, think about it. The Amazon IT infrastructure is designed to routinely handle up to 500,000 transactions per second, and has peaked at close to a million transactions per second. Their 2011 revenue was about the same as eBay plus Google, and more than twice TJX, which includes the TJ Max, Marshalls, and Home Goods in the US. That is essentially the infrastructure you are running on when you use AWS, the Amazon Cloud. Not surprisingly, AWS has achieved PCI DSS Level 1 Compliance. This is the highest level, applying to merchants processing over six million transactions per year.
For more information, I suggest you read Phil’s “How I Did It” blog.
Compliance, unfortunately, does not equal security. Every year we hear about companies that had just passed their internal or external PCI audit and were still hacked. But companies seem to be getting much better at being secure as well as being compliant. Last year only 4% of organizations that lost PCI-protected information to cybercriminals were certified, down from 21% just two years earlier.
We are only considering PCI compliance in this post. Even if you do not handle the PAN and are not responsible for PCI-DSS compliance, you may still have information that subjects you to government privacy and other compliance requirements.
No matter how you handle it, security is your responsibility. If something goes wrong, it is your problem to fix, your fines to pay, and your customer relationships that are damaged. Your CSP will likely help to investigate the problem, but the CSP will not take responsibility nor accept any liability. Make sure you and your own security and compliance team are satisfied with your total PCI-DSS compliance status, including your partners.
The last word:
I will be giving a free one-hour Cloud Security webinar as part of the Arrow ECS – IBM Business Partner webinar series at 2PM EDT on Tuesday, 9 October. You may register if interested.
Comments solicited.

<Return to section navigation list>
Cloud Computing Events
No significant articles today
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Barb Darrow (@gigabarb) rang in with Tit for tat: Amazon offers free taste of Oracle database on 10/2/2012:
On Monday, Amazon added its Relational Database Service (RDS) to its Free Usage Tier, according to the AWS blog. That means new customers can try out MySQL, the Oracle database or Microsoft SQL Server for free. Usage is restricted to a small “MicroDB” instance and one really important caveat is that Oracle database users have to bring their already bought-and-paid-for licence to the table. But the underlying Amazon infrastructure usage is free. More details are here.
The timing can’t be a coincidence coming as it does just after Oracle CEO Larry Ellison took to the stage Sunday night to outline the company’s all-Oracle-all-the-time Infrastructure-as-a-Service (IaaS) offering.
While Oracle’s cloud targets big existing Oracle shops and AWS is seen as services for lean startups, that perception is simplistic and misleading. Developers at Oracle shops also use Amazon IaaS services. And Amazon is building enterprise credibility through higher-end services and alliances with such enterprise players as SAP ( a huge Oracle rival, by the way) and integrators like Capgemini. Another factor: Timing and pricing of Oracle’s upcoming cloud services is hazy at best — Ellison said the underlying Oracle 12C database is due sometime next year. Meanwhile, users can run Oracle database instances on Amazon infrastructure right now.
Anyone who doesn’t see Oracle cloud and AWS as potential competitors should look again.

Jeff Barr (@jeffbarr) reported Amazon RDS - Now Available in the AWS Free Usage Tier on 10/1/2012:
I'm a big fan of the Amazon Relational Database Service (RDS). I enjoy showing people just how easy it is to create, scale, and backup a DB Instance running MySQL, SQL Server, or Oracle Database with just a few clicks in the AWS Management Console. Our customers appreciate the fact that they can launch DB Instances on demand at very affordable hourly rates, with the option to purchase Reserved DB Instances to reduce their costs even more. Here's a video (featuring Biswaroop Palit of the Amazon RDS team) with more information about what RDS is and how it will simplify your life:

See original post for video.
We are now adding RDS to the AWS Free Usage Tier. New AWS customers (see the AWS Free Usage Tier FAQ for eligibility details) can use the MySQL, Oracle (BYOL licensing model), or SQL Server database engines on a Micro DB Instance for up to 750 hours per month, along with 20 GB of database storage, 10 million I/Os and 20 GB of backup storage. When you combine this new capability with the existing EC2 usage available on the Free Usage Tier, you may be to build and run a complete multi-tiered web application without spending a penny. Here's another video with more information on this important new development:

See original post for video.
In order to help you to get the most from Amazon RDS on Oracle, we'll be hosting a free RDS webinar at 10:00 AM (PT) on October 18th. Attend the webinar to learn how RDS lets you focus on your business by addressing the key pain points that come with Oracle database administration.
Ju-Kay Kwek (@jukaykwek) reported Google BigQuery updates: Faster, easier and more data formats in a 10/1/2012 post to the Official Google Enterprise Blog:
We know you have a lot of data to work with within your organization, which can present big challenges. Your data can be large in volume and complex in structure. For example, large-scale web applications have millions of users, documents and events to manage. As a result, many engineering teams choose highly scalable NoSQL databases over relational databases. Though this approach is effective in storing and retrieving data, it poses challenges for interactive data analysis.
Today’s release of Google BigQuery tackles these hurdles with several new features:
- Support for JSON: JSON is used to power most modern websites, is a native format for many NoSQL databases hosting large scale web applications, and is used as the primary data format in many REST APIs. With this update, it’s now possible to import data formatted in JSON directly to BigQuery without the hassle of writing extra code to convert the data format.
- Nested and Repeated Fields: If you’re using App Engine Datastore or other NoSQL databases, it’s likely you’re taking advantage of nested and repeated data in your data model. For example, a customer data entity might have multiple accounts, each storing a list of invoices. Now, instead of having to flatten that data, you can keep your data in a hierarchical format when you import to BigQuery.
- Additional improvements:
- Increased import quotas from 1000 jobs per day to 1000 jobs per table per day, and boosted the file size limit from 4GB to 100GB
- Faster data exports from BigQuery to Google Cloud Storage, by enabling large tables to be exported as multiple files in parallel
- Permanently save common queries in the BigQuery interface
To learn more about how Google BigQuery can help you gain insights from your data in the cloud, click here to sign up.


Lydia Leong (@cloudpundit) described The meta-info of my OpenStack note in a 10/1/2012 post:
I’ve been reading the social media reactions to my recent note on OpenStack, “Don’t Let OpenStack Hype Distort Your Selection of a Cloud Management Platform in 2012” (that’s a client link; a free public reprint without the executive summary is also available), and wanted to respond to some comments that are more centered on the research process and publication process than on the report itself. So, here are a number of general assertions:
Gartner doesn’t do commissioned research. Ever. Repeat: Gartner, unlike almost every other analyst firm, doesn’t do commissioned resesarch — ever. Most analyst firms will do “joint research” or “commissioned whitepapers” or the like — research where a vendor is paying for the note to be written. About a decade ago, Gartner stopped this practice, because management felt it could be seen as compromising neutrality. No vendor paid for that OpenStack note to be written, directly or indirectly. Considering that most of the world’s largest IT vendors are significant participants in OpenStack, and plenty of small ones are as well, and a bunch of them are undoubtedly unhappy about the publication of that note, if Gartner’s interests were oriented around vendors, we certainly wouldn’t have published research practically guaranteed to upset a lot of vendors.
Gartner earns the overwhelming majority of its revenue from IT buyers. About 80% of Gartner’s revenues come from our IT buyer clients (we call them “end-users”). We don’t shill for vendors, ever, because our bread-and-butter comes from IT buyers, who trust us for neutral advice. Analysts are interested in helping our end-user clients make the technology decisions that are best for their business. We also want to help vendors (including those who are involved with free or commercial open-source) succeed in better serving end-users — which often means that we will be critical of vendor efforts. Our clients are asking about OpenStack, and every example of hype in that note comes directly from client interactions. I wrote that note because the volume of OpenStack queries from clients was ramping up, and we needed written research to address it.
Gartner analysts are not compensated on commissions of any sort. Many other analyst firms have incentives for analysts that are tied to revenue or publicity — be quoted in the press X times, sell reports, sell consulting, sell strategy days with vendors, etc. Gartner doesn’t do any of that, and hasn’t for about a decade. Our job, as Gartner analysts, is to try to offer the best advice we can to our clients. Sometimes, of course, we will be wrong, but we try hard. It’s not an academic exercise; our end-user clients have business outcomes that ride on their technology decisions.
Gartner doesn’t dislike open source. As a collective entity, Gartner tends to be cautious in its stances, as our end-user clients tend to be mid-market and enterprise IT executives who are fairly risk-averse; our analysis of all solutions, including OSS, tends to be from that perspective. But we write extensively about open source; we have analysts devoted to the topic, plus everyone covers the OSS relevant to their own coverage. We consider OSS a business strategy like anything else. In fact, we’ve been particularly vocal about how we feel that cloud is driving OSS adoption across a broad spectrum of solutions, and advocates that an IT organization’s adoption of cloud is a great time to consider replacing proprietary tech with OSS. (You’ll note that a whole section of the report predicts OpenStack’s eventual success, by the way, so it’s not like this a prediction of gloom, just an observation of present stumbling-blocks on the road to maturity.)
Gartner research notes are Gartner opinion, not an individual analyst’s opinion. Everything that Gartner publishes as a research note (excluding things like blog posts, which we consider off-the-clock, personal time and not a corporate activity) undergoes a peer review process. While notes do slip through the cracks (i.e., get published without sufficiently broad or deep review), our internal processes require analysts to get review from everyone who touches a coverage area. My OpenStack note was very broadly peer reviewed — by other analysts who cover cloud infrastructure, cloud management platforms, and open source software, as well as a bunch of related areas that OpenStack touches. (As a result of that review, the original note almost quadrupled in size, split into one note on OSS CMPs in general, and one note on OpenStack itself.) I also asked for our Ombudsman’s office, which deals with vendor complaints, to review the note to make sure that it seemed fair, balanced, and free of inflammatory language, and they (and my manager) also asked questions about potentially controversial sections, in order to ensure they were backed by facts. Among other things, these processes are intended to ensure that individual analyst bias is eliminated to as large an extent as possible. That process is part of why Gartner’s opinions often sound highly conservative, but when we take a stance, it is usually neither casual nor one analyst’s opinion.
The publication of this note was not a shock to the vendors involved. Most of the vendors were aware that this note was coming; it was a work in progress over the summer. Rackspace, as the owner of OpenStack at the time that this was placed in the publication pipeline, was entitled to a formal review and discussion prior to its publication (as we do for any research that covers a vendor’s product in a substantive way). I had spoken to many of the other vendors in advance of its publication, letting them know it was coming (although since it was pre-Foundation they did not have advance review). The evolving OpenStack opinions of myself and other Gartner analysts have long been known to the vendors.
It would have been easier not to write anything. I have been closely following OpenStack since its inception, and I have worked with many of the OpenStack vendors since the early days of the project. I have a genuine interest in seeing them, and OpenStack, succeed, and I hope that the people that I and other analysts have dealt with know that. Many individuals have confided in me, and other Gartner analysts, about the difficulties they were having with the OpenStack effort. We value these relationships, and the trust they represent, and we want to see these people and their companies succeed. I was acutely careful to not betray any individual confidences when writing that report, ensuring that any concerns surfaced by the vendors had been said by multiple people and organizations, so that there would be no tracebacks. I am aware, however, that I aired everyone’s collective dirty laundry in public. I hope that making the conversation public will help the community rally around some collective goals that will make OpenStack mainstream adoption possible. (I think Rackspace’s open letter implicitly acknowledges the issues that I raised, and I highly encourage paying attention to its principles.)
You will see other Gartner analysts be more active in OpenStack coverage. I originally picked up OpenStack coverage because I have covered Rackspace for the last decade, and in its early days it was mostly a CMP for service providers. Enterprise adoption has begun, and so its primary home for coverage is going to be our CMP analysts (folks like Alessandro Perilli, Donna Scott, and Ronni Colville), although those of us who cover cloud IaaS (especially myself, Kyle Hilgendorf, and Doug Toombs) will continue to provide coverage from a service provider perspective. Indeed, our coverage of OSS CMPs (CloudStack, Eucalyptus, OpenNebula, etc.) has been ramping up substantially of late. We’re early in the market, and you can expect to see us track the maturation of these solutions.


Jeff Barr (@jeffbarr) suggested Get Started With Oracle Applications Now With Our New Test Drive Program on 10/1/2012:
One of the key advantages that customers and partners are telling us they really appreciate about AWS is its unique ability to cut down the time required to evaluate new software stacks. These "solution appliances" can now be easily deployed on AWS and evaluated by customers in hours or days, rather than in weeks or months, as is the norm with the previous generation of IT infrastructure.
With this in mind, AWS has teamed up with leading Oracle ecosystem partners on a new initiative called the Oracle Test Drive program.
Starting today, customers can experience firsthand a new way to evaluate and learn about advantaged new Oracle features and use cases, on AWS at no charge. In as little as one hour, customers can be guided step-by-step through the experience of:
- Backing up an Oracle database to Amazon S3.
- Creating a high available database solution using Oracle Data Guard.
- Use the business analytics capabilities of Oracle Business Intelligence Enterprise Edition.
- Evaluate PeopleSoft, E-Business Suite, Siebel, JD-Edwards and Hyperion analytics, human capital management, value chain management and financial management software.
While this may sound somewhat intimating to the non-initiated, all of these hands-on labs walk you through the process of logging into your own private AWS instance, and then use the pre-configured Oracle software. The simple step-by-step instructions enable you to experience firsthand the advanced capabilities of Oracle software on AWS at your own speed. The test drive labs are designed to provide you with instant insight into the capabilities and approaches that each of these Oracle solutions provide, and do so in as little as an hour.
For some people the cloud is still somewhat ethereal in nature, a non-tangible concept that is not quite concrete yet in their minds. The Oracle Test Drive labs may be able to make the cloud much more tangible, especially for customers that are familiar with the Oracle environment. Each lab includes up to 5 hours of complimentary AWS server time.
Let's say that I want to learn how to back up my Oracle database to AWS using the Oracle Secure Backup product. I visit the test drive page and find the appropriate test drive:
Then I fill out the form on the partner site:
The partner sends me an activation link via email, and I click it to get started:
And I sign in on the partner site:
This partner site allows me to choose one of three distinct test drives:
I selected Oracle Secure Backup. This launches a complete, self-contained test environment on an Amazon EC2 instance:
While the environment was setting up, I was able to tab through a preview of what I would see and learn:
When the environment is ready (this one launched in about five minutes), I received a second email, with complete signin details:
And from there I simply connected to the EC2 instance (the lab actually creates one Windows instance and one Linux instance, both within a Virtual Private Cloud):
After I gained access to the Windows instance, I followed the directions and opened up a pre-configured PuTTY session to the Linux instance (yes, this means that I am using a virtual desktop to access one virtual server to log in to a second virtual server):
I continued to follow the directions and verified that the expected database processes and tables were in place:
Per the directions, I installed the Oracle Secure Backup model (this took about 3 minutes) and then I ran an actual backup (the rman.sh script simply invokes the rman command with some parameters):
From there it was easy to verify my backup:
Next (still following the directions), I simulated a disaster by removing a database file and verifying that I could no longer operate on it. I then learned how to recover the data:
After this I brought the database back on line and verified that I could resize it. This concluded the lab, which ended with a nice summary of the benefits of backing up my Oracle database to Amazon S3:
And that's that! Note that I didn't have to do any of the following in order to learn how to use Oracle Secure Backup:
- Get permission from Corporate IT or my manager.
- Acquire, install, and configure a server.
- Install and configure Oracle Database 11G or Oracle Secure Backup.
- Spend any money.
- Leave a mess behind.
I was able to do the entire lab in 90 minutes. This included the time to complete the lab and to write and illustrate this blog post. If I can do it, so can you.
This is just one of nearly two dozen labs. Check them out today to learn more about Oracle and AWS, or to improve your skills.

![image_thumb1[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgAluC-i7Ws1qRxaj6uV5aZKXS7iWagxM8_xqyS0UMKbIn90011g1dmfLiZMbmp55YX2UYQ8pKbwqnx_wZrWbIXuvtTFVDDQfndkLHkFoWWjXVGADZpPGcum3R38kY4a3Zw_uab-vrp/s1600-h/image_thumb1%25255B1%25255D%25255B7%25255D.png "image_thumb1[1]")

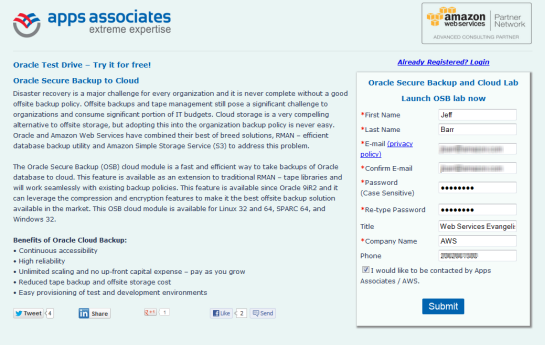
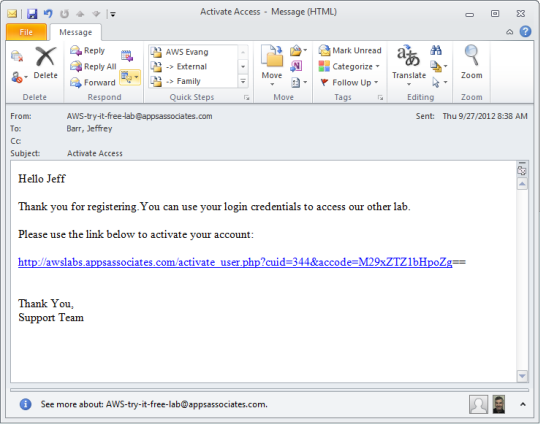
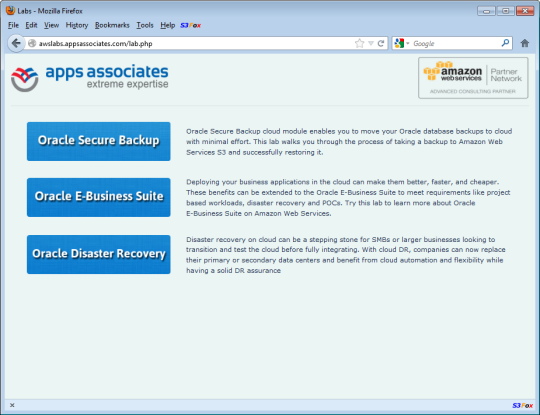


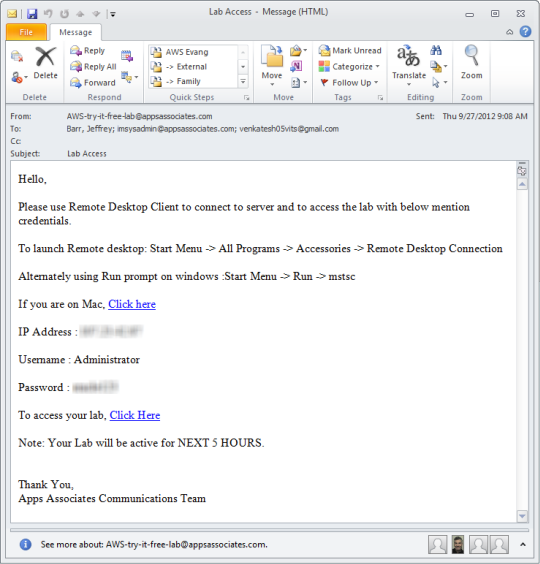

Barb Darrow (@gigabarb) reported Shocker! Oracle takes on Amazon with all-Oracle-all-the-time cloud in a 9/30/2012 article for GigaOm’s Cloud blog:
Updated: Oracle has found a market for its big, pricey engineered hardware systems — and it’s in new public and private Oracle clouds. Oracle CEO Larry Ellison laid out the company’s new all-red infrastructure-as-a-service cloud plan at Oracle OpenWorld on Sunday night.
Oracle is jumping into the public infrastructure as a service (IaaS) business — the market pioneered and dominated by Amazon Web Services — with infrastructure that is all about Oracle.
Oracle cloud will use “our OS, our VM, our compute services and storage services on the fastest most reliable systems in the world — our engineered systems, Exadata, Exalogic, Exalytics, all linked with Infiniband,” Ellison told thousands of Oracle customers, partners and others at San Francisco’s Moscone Center Sunday night. For banks and other companies with requirements to run infrastructure in house, Oracle will offer a private cloud based on the exact same technology and run and manage it customer data centers, Ellison said.
The promised Oracle 12c (the “c” stands for cloud) database will be the software foundation and Ellison said this iteration of the database will put multitenancy — the ability to securely keep separate sets of data in one place — at the database level where it belongs. The rough concept is that 12C is a database container that can run separate “pluggable” databases — one for ERP, another for CRM and so on.
“Back in 1998 and 1999 when NetSuite and Salesforce.com came out, the only way to do multitenancy was at the application layer,” Ellison said, adding that he had problems with that – he Ellison used to blast competitors’ user of multitenancy, calling it an aging technology. That apparently all changes now. (Ellison had stakes in NetSuite and Salesforce.com, both pioneering SaaS companies and still owns a big piece of NetSuite.)
By moving multitenancy into the database, software as a service (SaaS) and platform as a service (PaaS) providers can relinquish that workload to the database and use database query and business intelligence tools to work with them instead of having to come up with application-specific tools.
Ellison: Our SaaS customers want this
Ellison said SaaS and PaaS customers asked Oracle to supply this infrastructure so it will be interesting to see if either Salesforce.com or NetSuite — both SaaS companies which use Oracle databases — makes a move. That’s doubtful in Salesforce.com’s case since that company is competing more and more with Oracle. And, NetSuite CEO Zach Nelson will speak at OracleOpenWorld so stay tuned.
Update: Reached by email, NetSuite’s Nelson said: “NetSuite wouldn’t choose to run our application on anyone’s public cloud — Oracle’s, Microsoft’s, or Amazon’s. We need to manage every aspect of our infrastructure to ensure service level commitments we have made to our customers.” No word back yet from Salesforce.com’s Marc Benioff.
Update: Nelson wrote back in to clarify his statement: “I should have qualified this a bit to say we wouldn’t run our ‘production’ application on anyone’s cloud. However, the idea of doing pre-release testing and/or disaster recovery on Oracle’s cloud is interesting to us. And of course, we certainly believe Oracle’s technology is fantastic for cloud delivery as we (like salesforce.com) run a complete Oracle database and app server beneath the NetSuite application,” he wrote.
The hardware foundation for Oracle Cloud will be Exadata X3, a new “engineered system” which packs 26TB of memory — 4TB of DRAM and 22TB of Flash memory, Ellison said.
MyPOV: if Larry really wanted to impress the audience, he would announce 10 cloud providers adopting Oracle cloud DB #OOW #OOW12 @benkepes—
Frank Scavo (@fscavo) October 01, 2012Oracle’s problem in all this is that it has not made much of a case for its hardware to date. Oracle’s hardware business was off 24 percent year over year in its last quarter. It also has a bit of an ecosystem problem. Yes it has SaaS customers, but as several on Twitter commented, they would be more impressed if Oracle had trotted out a list of customers and/or partners that signed up for this cloud effort.
Playing catchup in cloud
And, Oracle’s entry into public cloud is late given that competitors including IBM, HP, and the OpenStack players are already there.
In addition, Oracle’s decision to use very high-end specialized hardware to power its cloud flies in the face of conventional wisdom espoused by web giants like Facebook, Google and Amazon that yoke together thousands of commodity servers in webscale data centers. Oracle’s take is definitely scale-up in what appears to be an increasingly scale-out world.
Oracle OpenWorld photo courtesy of Flickr user Oracle_Photos_Screenshots


If you can’t sell it, rent it. Sounds like the ultimate in pricey lock-in to me.
Full disclosure: I’m a registered GigaOm Analyst.
<Return to section navigation list>

















0 comments:
Post a Comment