Windows Azure and Cloud Computing Posts for 4/10/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics, Big Data and OData
- Windows Azure Access Control, Identity and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
My (@rogerjenn) Using Excel 2010 and the Hive ODBC Driver to Visualize Hive Data Sources in Apache Hadoop on Windows Azure updated 4/12/2012 begins:
Introduction
Microsoft’s Apache Hadoop on Windows Azure Community Technical Preview (Hadoop on Azure CTP) includes a Hive ODBC driver and Excel add-in, which enable 32-bit or 64-bit Excel to issue HiveQL Queries against Hive data sources running in the Windows Azure cloud. Hadoop on Azure is a private CTP, which requires an invitation for its use. You can request an invitation by completing a Microsoft Connect survey here. Hadoop on Azure’s Elastic MapReduce (EMR) Console enables users to create and use Hadoop clusters in the following sizes at no charge:

The Apache Software Foundation’s Hive™ is a related data warehousing and ad hoc querying component of Apache Hadoop v1.0. According to the Hive Wiki:
Hive is a data warehouse system for Hadoop that facilitates easy data summarization, ad-hoc queries, and the analysis of large datasets stored in Hadoop compatible file systems. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.
The following two earlier OakLeaf blog posts provide an introduction to Hadoop on Azure in general and its Interactive Hive Console in particular:
- Introducing Apache Hadoop Services for Windows Azure (4/2/2012)
- Using Data from Windows Azure Blobs with Apache Hadoop on Windows Azure CTP (4/9/2012)
This demonstration requires creating a flightdata_asv Hive data source table from downloadable tab-delimited text files as described in the second article and the following section. You design and execute an aggregate query against the Hive table and then visualize the query result set with an Excel bar chart. …




and ends with the steps required to create this worksheet and bar chart:

Jo Maitland (@JoMaitlandSF) asserted Hadoop cloud services don’t go far enough in a 4/12/2012 research report for GigaOm Pro (requires registration for a free trial subscription):
GoGrid and Sungard join a long list of service providers offering Hadoop in the cloud, but these services are missing a key ingredient at the top of the stack that will appeal to the mainstream. …

Microsoft’s Hive ODBC driver and add-in are a candidate for Jo’s “key ingredient,” as noted in the preceding article.
Datanami (@Datanami) asked Half the World’s Data to Touch Hadoop by 2015? on 4/12/2012:
It’s no secret that Hortonworks has placed its bets on Apache Hadoop, but the company has extended its view of the long-term success of the open source goldmine.
According to Shaun Connolly, VP of the company’s corporate strategy, Hadoop with touch or process 50 percent of the world’s data by 2015, a staggering figure, especially if the multi-zettabyte prediction for world data volumes is true for that year.
Connolly says that the fundamental drivers leading the interest in Hadoop and the adoption of Hadoop really are rooted in estimates like those from analyst group IDC, which estimates that the amount of data that enterprise data centers will be processing will grow by 50x.
Beyond data volume, however, is an equally important issue. Connolly says that if you look at data flow and what enterprise data centers, there is a gap in terms of how data is being handled. He states that 80% of that data flowing through enterprise data centers will be required to touch in some form or fashion--users may not store it, but it will flow through the business.
What this means, says Connolly, is that volume, the velocity, and the variety of data flowing through enterprises are key elements. He notes that if one is to look at traditional key application architectures today, they’re really not set up for that challenge, and it’s a challenge that requires a fundamental rethink of architectures overall. This is where Hadoop comes in…
The Hortonworks business lead claims that Hadoop can address these weaknesses because it was purpose-built to address those three V’s of big data (volume and the variety and velocity). It can store unstructured data, semi-structured data very well across commodity hardware, but says Connolly, it’s able to do it in an economically viable way, which makes it a standout technology option.
Hortonworks says that to stay ahead of the curve and prepare the Hadoop era, broad availability to technologies is step one—a fact that they say is covered by their commitment to open source software.
The second element of the equation is creating a broad and vibrant ecosystem in and around that, and enabling that ecosystem. As Connolly says, “It sort of gives us hand and glove with the open source technology, providing open APIs around that platform, but really focusing at Hortonworks as a business. When enabling sort of the key vendors and solution providers and platform vendors up and down the data stack, to be able to integrate their solutions that may already be within the enterprise today. Integrate them very tightly with this next generation data platform, so they’re able to offer more value to their existing enterprise customers."
Related Stories
Hortonworks has a contract to assist Microsoft with implementing its Apache Hadoop on Windows Azure CTP.
Carl Nolan (@carl_nolan) described a Framework for Composing and Submitting .Net Hadoop MapReduce Jobs in a 4/10/2012 post:
If you have been following my blog you will see that I have been putting together samples for writing .Net Hadoop MapReduce jobs; using Hadoop Streaming. However one thing that became apparent is that the samples could be reconstructed in a composable framework to enable one to submit .Net based MapReduce jobs whilst only writing Mappers and Reducers types.
To this end I have put together a framework that allows one to submit MapReduce jobs using the following command line syntax:
MSDN.Hadoop.Submission.Console.exe -input "mobile/data/debug/sampledata.txt" -output "mobile/querytimes/debug"
-mapper "MSDN.Hadoop.MapReduceFSharp.MobilePhoneQueryMapper, MSDN.Hadoop.MapReduceFSharp"
-reducer "MSDN.Hadoop.MapReduceFSharp.MobilePhoneQueryReducer, MSDN.Hadoop.MapReduceFSharp"
-file "%HOMEPATH%\MSDN.Hadoop.MapReduce\bin\Release\MSDN.Hadoop.MapReduceFSharp.dll"Where the mapper and reducer parameters are .Net types that derive from a base Map and Reduce abstract classes. The input, output, and files options are analogous to the standard Hadoop streaming submissions. The mapper and reducer options (more on a combiner option later) allow one to define a .Net type derived from the appropriate abstract base classes.
Under the covers standard Hadoop Streaming is being used, where controlling executables are used to handle the StdIn and StdOut operations and activating the required .Net types. The “file” parameter is required to specify the DLL for the .Net type to be loaded at runtime, in addition to any other required files.
As an aside the framework and base classes are all written in F#; with sample Mappers and Reducers, and abstract base classes being provided both in C# and F#. The code is based off the F# Streaming samples in my previous blog posts. I will cover more of the semantics of the code in a later post, but I wanted to provide some usage samples of the code.
As always the source can be downloaded from:
http://code.msdn.microsoft.com/Framework-for-Composing-af656ef7
Mapper and Reducer Base Classes
The following definitions outline the abstract base classes from which one needs to derive.
C# Base
- public abstract class MapReduceBase
- {
- protected MapReduceBase();
- public override void Setup();
- }
C# Base Mapper
- public abstract class MapperBaseText : MapReduceBase
- {
- protected MapperBaseText();
- public override IEnumerable<Tuple<string, object>> Cleanup();
- public abstract override IEnumerable<Tuple<string, object>> Map(string value);
- }
C# Base Reducer
- public abstract class ReducerBase : MapReduceBase
- {
- protected ReducerBase();
- public override void Cleanup();
- public abstract override object Reduce(string value, IEnumerable<string> value);
- }
F# Base
- [<AbstractClass>]
- type MapReduceBase() =
- abstract member Setup: unit -> unit
- default this.Setup() = ()
F# Base Mapper
- [<AbstractClass>]
- type MapperBaseText() =
- inherit MapReduceBase()
- abstract member Map: string -> IEnumerable<string * obj>
- abstract member Cleanup: unit -> IEnumerable<string * obj>
- default this.Cleanup() = Seq.empty
F# Base Reducer
- [<AbstractClass>]
- type ReducerBase() =
- inherit MapReduceBase()
- abstract member Reduce: string -> IEnumerable<string> -> obj
- abstract member Cleanup: unit -> unit
- default this.Cleanup() = ()
The objective in defining these base classes was to not only support creating .Net Mapper and Reducers but also to provide a means for Setup and Cleanup operations to support In-Place Mapper optimizations, utilize IEnumerable and sequences for publishing data from the Mappers and Reducers, and finally provide a simple submission mechanism analogous to submitting Java based jobs.
For each class a Setup function is provided to allow one to perform tasks related to the instantiation of each Mapper and/or Reducer. The Mapper’s Map and Cleanup functions return an IEnumerable consisting of tuples with a a Key/Value pair. It is these tuples that represent the mappers output. Currently the types of the key and value’s are respectively a String and an Object. These are then converted to strings for the streaming output.
The Reducer takes in an IEnumerable of the Object String representations, created by the Mapper output, and reduces this into a single Object value.
Combiners
The support for Combiners is provided through one of two means. As is often the case, support is provided so one can reuse a Reducer as a Combiner. In addition explicit support is provided for a Combiner using the following abstract class definition:
C# Base Combiner
- [AbstractClass]
- public abstract class CombinerBase : MapReduceBase
- {
- protected CombinerBase();
- public override void Cleanup();
- public abstract override object Combine(string value, IEnumerable<string> value);
- }
F# Base Combiner
- [<AbstractClass>]
- type CombinerBase() =
- inherit MapReduceBase()
- abstract member Combine: string -> IEnumerable<string> -> obj
- abstract member Cleanup: unit -> unit
- default this.Cleanup() = ()
Using a Combiner follows exactly the same pattern for using mappers and reducers, as example being:
-combiner "MSDN.Hadoop.MapReduceCSharp.MobilePhoneMinCombiner, MSDN.Hadoop.MapReduceCSharp"
The prototype for the Combiner is essentially the same as that of the Reducer except the function called for each row of data is Combine, rather than Reduce.
Binary and XML Processing
In my previous posts on Hadoop Streaming I provided samples that allowed one to perform Binary and XML based Mappers. The composable framework also provides support for submitting jobs that support Binary and XML based Mappers. To support this the following additional abstract classes have been defined:
C# Base Binary Mapper
- [AbstractClass]
- public abstract class MapperBaseBinary : MapReduceBase
- {
- protected MapperBaseBinary();
- public override IEnumerable<Tuple<string, object>> Cleanup();
- public abstract override IEnumerable<Tuple<string, object>> Map(string value, Stream value);
- }
C# Base XML Mapper
- [AbstractClass]
- public abstract class MapperBaseXml : MapReduceBase
- {
- protected MapperBaseXml();
- public abstract override string MapNode { get; }
- public override IEnumerable<Tuple<string, object>> Cleanup();
- public abstract override IEnumerable<Tuple<string, object>> Map(XElement value);
- }
F# Base Binary Mapper
- [<AbstractClass>]
- type MapperBaseBinary() =
- inherit MapReduceBase()
- abstract member Map: string -> Stream -> IEnumerable<string * obj>
- abstract member Cleanup: unit -> IEnumerable<string * obj>
- default this.Cleanup() = Seq.empty
F# Base Binary Mapper
- [<AbstractClass>]
- type MapperBaseXml() =
- inherit MapReduceBase()
- abstract member MapNode: string with get
- abstract member Map: XElement -> IEnumerable<string * obj>
- abstract member Cleanup: unit -> IEnumerable<string * obj>
- default this.Cleanup() = Seq.empty
To support using Mappers and Reducers derived from these types a “format” submission parameter is required. Supported values being Text, Binary, and XML; the default value being “Text”.
To submit a binary streaming job one just has to use a Mapper derived from the MapperBaseBinary abstract class and use the binary format specification:
-format Binary
In this case the input into the Mapper will be a Stream object that represents a complete binary document instance.
To submit an XML streaming job one just has to use a Mapper derived from the MapperBaseXml abstract class and use the XML format specification, along with a node to be processed within the XML documents:
-format XML –nodename Node
In this case the input into the Mapper will be an XElement node derived from the XML document based on the nodename parameter.
Samples
To demonstrate the submission framework here are some sample Mappers and Reducers with the corresponding command line submissions:
C# Mobile Phone Range (with In-Mapper optimization)
- namespace MSDN.Hadoop.MapReduceCSharp
- {
- public class MobilePhoneRangeMapper : MapperBaseText
- {
- private Dictionary<string, Tuple<TimeSpan, TimeSpan>> ranges;
- private Tuple<string, TimeSpan> GetLineValue(string value)
- {
- try
- {
- string[] splits = value.Split('\t');
- string devicePlatform = splits[3];
- TimeSpan queryTime = TimeSpan.Parse(splits[1]);
- return new Tuple<string, TimeSpan>(devicePlatform, queryTime);
- }
- catch (Exception)
- {
- return null;
- }
- }
- /// <summary>
- /// Define a Dictionary to hold the (Min, Max) tuple for each device platform.
- /// </summary>
- public override void Setup()
- {
- this.ranges = new Dictionary<string, Tuple<TimeSpan, TimeSpan>>();
- }
- /// <summary>
- /// Build the Dictionary of the (Min, Max) tuple for each device platform.
- /// </summary>
- public override IEnumerable<Tuple<string, object>> Map(string value)
- {
- var range = GetLineValue(value);
- if (range != null)
- {
- if (ranges.ContainsKey(range.Item1))
- {
- var original = ranges[range.Item1];
- if (range.Item2 < original.Item1)
- {
- // Update Min amount
- ranges[range.Item1] = new Tuple<TimeSpan, TimeSpan>(range.Item2, original.Item2);
- }
- if (range.Item2 > original.Item2)
- {
- //Update Max amount
- ranges[range.Item1] = new Tuple<TimeSpan, TimeSpan>(original.Item1, range.Item2);
- }
- }
- else
- {
- ranges.Add(range.Item1, new Tuple<TimeSpan, TimeSpan>(range.Item2, range.Item2));
- }
- }
- return Enumerable.Empty<Tuple<string, object>>();
- }
- /// <summary>
- /// Return the Dictionary of the Min and Max values for each device platform.
- /// </summary>
- public override IEnumerable<Tuple<string, object>> Cleanup()
- {
- foreach (var range in ranges)
- {
- yield return new Tuple<string, object>(range.Key, range.Value.Item1);
- yield return new Tuple<string, object>(range.Key, range.Value.Item2);
- }
- }
- }
- public class MobilePhoneRangeReducer : ReducerBase
- {
- public override object Reduce(string key, IEnumerable<string> value)
- {
- var baseRange = new Tuple<TimeSpan, TimeSpan>(TimeSpan.MaxValue, TimeSpan.MinValue);
- return value.Select(stringspan => TimeSpan.Parse(stringspan)).Aggregate(baseRange, (accSpan, timespan) =>
- new Tuple<TimeSpan, TimeSpan>((timespan < accSpan.Item1) ? timespan : accSpan.Item1, (timespan > accSpan.Item2) ? timespan : accSpan.Item2));
- }
- }
- }
MSDN.Hadoop.Submission.Console.exe -input "mobilecsharp/data" -output "mobilecsharp/querytimes"
-mapper "MSDN.Hadoop.MapReduceCSharp.MobilePhoneRangeMapper, MSDN.Hadoop.MapReduceCSharp"
-reducer "MSDN.Hadoop.MapReduceCSharp.MobilePhoneRangeReducer, MSDN.Hadoop.MapReduceCSharp"
-file "%HOMEPATH%\MSDN.Hadoop.MapReduceCSharp\bin\Release\MSDN.Hadoop.MapReduceCSharp.dll"C# Mobile Min (with Mapper, Combiner, Reducer)
- namespace MSDN.Hadoop.MapReduceCSharp
- {
- public class MobilePhoneMinMapper : MapperBaseText
- {
- private Tuple<string, object> GetLineValue(string value)
- {
- try
- {
- string[] splits = value.Split('\t');
- string devicePlatform = splits[3];
- TimeSpan queryTime = TimeSpan.Parse(splits[1]);
- return new Tuple<string, object>(devicePlatform, queryTime);
- }
- catch (Exception)
- {
- return null;
- }
- }
- public override IEnumerable<Tuple<string, object>> Map(string value)
- {
- var returnVal = GetLineValue(value);
- if (returnVal != null) yield return returnVal;
- }
- }
- public class MobilePhoneMinCombiner : CombinerBase
- {
- public override object Combine(string key, IEnumerable<string> value)
- {
- return value.Select(timespan => TimeSpan.Parse(timespan)).Min();
- }
- }
- public class MobilePhoneMinReducer : ReducerBase
- {
- public override object Reduce(string key, IEnumerable<string> value)
- {
- return value.Select(timespan => TimeSpan.Parse(timespan)).Min();
- }
- }
- }
MSDN.Hadoop.Submission.Console.exe -input "mobilecsharp/data" -output "mobilecsharp/querytimes"
-mapper "MSDN.Hadoop.MapReduceCSharp.MobilePhoneMinMapper, MSDN.Hadoop.MapReduceCSharp"
-reducer "MSDN.Hadoop.MapReduceCSharp.MobilePhoneMinReducer, MSDN.Hadoop.MapReduceCSharp"
-combiner "MSDN.Hadoop.MapReduceCSharp.MobilePhoneMinCombiner, MSDN.Hadoop.MapReduceCSharp"
-file "%HOMEPATH%\MSDN.Hadoop.MapReduceCSharp\bin\Release\MSDN.Hadoop.MapReduceCSharp.dll"F# Mobile Phone Query
- // Extracts the QueryTime for each Platform Device
- type MobilePhoneQueryMapper() =
- inherit MapperBaseText()
- // Performs the split into key/value
- let splitInput (value:string) =
- try
- let splits = value.Split('\t')
- let devicePlatform = splits.[3]
- let queryTime = TimeSpan.Parse(splits.[1])
- Some(devicePlatform, box queryTime)
- with
- | :? System.ArgumentException -> None
- // Map the data from input name/value to output name/value
- override self.Map (value:string) =
- seq {
- let result = splitInput value
- if result.IsSome then
- yield result.Value
- }
- // Calculates the (Min, Avg, Max) of the input stream query time (based on Platform Device)
- type MobilePhoneQueryReducer() =
- inherit ReducerBase()
- override self.Reduce (key:string) (values:seq<string>) =
- let initState = (TimeSpan.MaxValue, TimeSpan.MinValue, 0L, 0L)
- let (minValue, maxValue, totalValue, totalCount) =
- values |>
- Seq.fold (fun (minValue, maxValue, totalValue, totalCount) value ->
- (min minValue (TimeSpan.Parse(value)), max maxValue (TimeSpan.Parse(value)), totalValue + (int64)(TimeSpan.Parse(value).TotalSeconds), totalCount + 1L) ) initState
- box (minValue, TimeSpan.FromSeconds((float)(totalValue/totalCount)), maxValue)
MSDN.Hadoop.Submission.Console.exe -input "mobile/data" -output "mobile/querytimes"
-mapper "MSDN.Hadoop.MapReduceFSharp.MobilePhoneQueryMapper, MSDN.Hadoop.MapReduceFSharp"
-reducer "MSDN.Hadoop.MapReduceFSharp.MobilePhoneQueryReducer, MSDN.Hadoop.MapReduceFSharp"
-file "%HOMEPATH%\MSDN.Hadoop.MapReduceFSharp\bin\Release\MSDN.Hadoop.MapReduceFSharp.dll"F# Store XML (XML in Samples)
- // Extracts the QueryTime for each Platform Device
- type StoreXmlElementMapper() =
- inherit MapperBaseXml()
- override self.MapNode = "Store"
- override self.Map (element:XElement) =
- let aw = "http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey"
- let demographics = element.Element(XName.Get("Demographics")).Element(XName.Get("StoreSurvey", aw))
- seq {
- if not(demographics = null) then
- let business = demographics.Element(XName.Get("BusinessType", aw)).Value
- let sales = Decimal.Parse(demographics.Element(XName.Get("AnnualSales", aw)).Value) |> box
- yield (business, sales)
- }
- // Calculates the Total Revenue of the store demographics
- type StoreXmlElementReducer() =
- inherit ReducerBase()
- override self.Reduce (key:string) (values:seq<string>) =
- let totalRevenue =
- values |>
- Seq.fold (fun revenue value -> revenue + Int32.Parse(value)) 0
- box totalRevenue
MSDN.Hadoop.Submission.Console.exe -input "stores/demographics" -output "stores/banking"
-mapper "MSDN.Hadoop.MapReduceFSharp.StoreXmlElementMapper, MSDN.Hadoop.MapReduceFSharp"
-reducer "MSDN.Hadoop.MapReduceFSharp.StoreXmlElementReducer, MSDN.Hadoop.MapReduceFSharp"
-file "%HOMEPATH%\MSDN.Hadoop.MapReduceFSharp\bin\Release\MSDN.Hadoop.MapReduceFSharp.dll"
-nodename Store -format XmlF# Binary Document (Word and PDF Documents)
- // Calculates the pages per author for a Word document
- type OfficePageMapper() =
- inherit MapperBaseBinary()
- let (|WordDocument|PdfDocument|UnsupportedDocument|) extension =
- if String.Equals(extension, ".docx", StringComparison.InvariantCultureIgnoreCase) then
- WordDocument
- else if String.Equals(extension, ".pdf", StringComparison.InvariantCultureIgnoreCase) then
- PdfDocument
- else
- UnsupportedDocument
- let dc = XNamespace.Get("http://purl.org/dc/elements/1.1/")
- let cp = XNamespace.Get("http://schemas.openxmlformats.org/package/2006/metadata/core-properties")
- let unknownAuthor = "unknown author"
- let authorKey = "Author"
- let getAuthorsWord (document:WordprocessingDocument) =
- let coreFilePropertiesXDoc = XElement.Load(document.CoreFilePropertiesPart.GetStream())
- // Take the first dc:creator element and split based on a ";"
- let creators = coreFilePropertiesXDoc.Elements(dc + "creator")
- if Seq.isEmpty creators then
- [| unknownAuthor |]
- else
- let creator = (Seq.head creators).Value
- if String.IsNullOrWhiteSpace(creator) then
- [| unknownAuthor |]
- else
- creator.Split(';')
- let getPagesWord (document:WordprocessingDocument) =
- // return page count
- Int32.Parse(document.ExtendedFilePropertiesPart.Properties.Pages.Text)
- let getAuthorsPdf (document:PdfReader) =
- // For PDF documents perform the split on a ","
- if document.Info.ContainsKey(authorKey) then
- let creators = document.Info.[authorKey]
- if String.IsNullOrWhiteSpace(creators) then
- [| unknownAuthor |]
- else
- creators.Split(',')
- else
- [| unknownAuthor |]
- let getPagesPdf (document:PdfReader) =
- // return page count
- document.NumberOfPages
- // Map the data from input name/value to output name/value
- override self.Map (filename:string) (document:Stream) =
- let result =
- match Path.GetExtension(filename) with
- | WordDocument ->
- // Get access to the word processing document from the input stream
- use document = WordprocessingDocument.Open(document, false)
- // Process the word document with the mapper
- let pages = getPagesWord document
- let authors = (getAuthorsWord document)
- // close document
- document.Close()
- Some(pages, authors)
- | PdfDocument ->
- // Get access to the pdf processing document from the input stream
- let document = new PdfReader(document)
- // Process the pdf document with the mapper
- let pages = getPagesPdf document
- let authors = (getAuthorsPdf document)
- // close document
- document.Close()
- Some(pages, authors)
- | UnsupportedDocument ->
- None
- if result.IsSome then
- snd result.Value
- |> Seq.map (fun author -> (author, (box << fst) result.Value))
- else
- Seq.empty
- // Calculates the total pages per author
- type OfficePageReducer() =
- inherit ReducerBase()
- override self.Reduce (key:string) (values:seq<string>) =
- let totalPages =
- values |>
- Seq.fold (fun pages value -> pages + Int32.Parse(value)) 0
- box totalPages
MSDN.Hadoop.Submission.Console.exe -input "office/documents" -output "office/authors"
-mapper "MSDN.Hadoop.MapReduceFSharp.OfficePageMapper, MSDN.Hadoop.MapReduceFSharp"
-reducer "MSDN.Hadoop.MapReduceFSharp.OfficePageReducer, MSDN.Hadoop.MapReduceFSharp"
-combiner "MSDN.Hadoop.MapReduceFSharp.OfficePageReducer, MSDN.Hadoop.MapReduceFSharp"
-file "%HOMEPATH%\MSDN.Hadoop.MapReduceFSharp\bin\Release\MSDN.Hadoop.MapReduceFSharp.dll"
-file "C:\Reference Assemblies\itextsharp.dll" -format BinaryOptional Parameters
To support some additional Hadoop Streaming options a few optional parameters are supported.
-numberReducers X
As expected this specifies the maximum number of reducers to use.
-debug
The option turns on verbose mode and specifies a job configuration to keep failed task outputs.
To view the the supported options one can use a help parameters, displaying:
Command Arguments:
-input (Required=true) : Input Directory or Files
-output (Required=true) : Output Directory
-mapper (Required=true) : Mapper Class
-reducer (Required=true) : Reducer Class
-combiner (Required=false) : Combiner Class (Optional)
-format (Required=false) : Input Format |Text(Default)|Binary|Xml|
-numberReducers (Required=false) : Number of Reduce Tasks (Optional)
-file (Required=true) : Processing Files (Must include Map and Reduce Class files)
-nodename (Required=false) : XML Processing Nodename (Optional)
-debug (Required=false) : Turns on Debugging OptionsUI Submission
The provided submission framework works from a command-line. However there is nothing to stop one submitting the job using a UI; albeit a command console is opened. To this end I have put together a simple UI that supports submitting Hadoop jobs.
This simple UI supports all the necessary options for submitting jobs.
Code Download
As mentioned the actual Executables and Source code can be downloaded from:
http://code.msdn.microsoft.com/Framework-for-Composing-af656ef7
The source includes, not only the .Net submission framework, but also all necessary Java classes for supporting the Binary and XML job submissions. This relies on a custom Streaming JAR which should be copied to the Hadoop lib directory.
To use the code one just needs to reference the EXE’s in the Release directory. This folder also contains the MSDN.Hadoop.MapReduceBase.dll that contains the abstract base class definitions.
Moving Forward
Moving forward there a few considerations for the code, that I will be looking at over time:
Currently the abstract interfaces are all based on Object return types. Moving forward it would be beneficial if the types were based on Generics. This would allow a better serialization process. Currently value serialization is based on string representation of an objects value and the key is restricted to s string. Better serialization processes, such as Protocol Buffers, or .Net Serialization, would improve performance.
Currently the code only supports a single key value, although the multiple keys are supported by the streaming interface. Various options are available for dealing with multiple keys which will next be on my investigation list.
In a separate post I will cover what is actually happening under the covers.
If you find the code useful and/or use this for your MapReduce jobs, or just have some comments, please do let me know.


Avkash Chauhan (@avkashchauhan) explained Programmatically retrieving Task ID and Unique Reducer ID in MapReduce in a 4/10/2012 post:
For each Mapper and Reducer you can get [both] Task attempt id and Task ID. This can be done when you set up your map using the Context object. You may also know that when setting a Reducer, an unique reduce ID is used inside reducer class setup method. You can get this ID as well.
There are multiple ways you can get this info:
1. Using JobConf Class.
- JobConf.get("mapred.task.id") will provide most of the info related with Map and Reduce task along with attempt id.
2. You can use Context Class and use as below:
- To get task attempt ID - context.getTaskAttemptID()
- Reducer Task ID - Context.getTaskAttemptID().getTaskID()
- Reducer Number - Context.getTaskAttemptID().getTaskID().getId()

<Return to section navigation list>
SQL Azure Database, Federations and Reporting
Wayne Berry returns to the Windows Azure blog with his SQL Azure Database Query Usage (CPU) Graph in the Management Portal post of 4/10/2012:
Within the SQL Azure Management Portal, customers can check their service usage with the help of various graphs. One of these graphs is the SQL Azure Database Query Usage (CPU) graph, which provides information on the amount of execution time for all queries running on a SQL Azure database over a trailing three month period.
In some cases, this graph was not rendering properly for customers, displaying an error message instead. This error was purely an issue with the portal and not with the underlying SQL Azure databases. We have removed the graph from the management portal, and are looking for alternative ways to surface the same data in a reliable and stable manner. We do apologize for any inconvenience this change has caused.
To learn more about the SQL Azure Management Portal, you can view this video.


Cihan Biyikoglu (@cihangirb) described AzureWatch for Monitoring Federated Databases in SQL Azure in a 4/9/2012 post:
AzureWatch has a great new experience now for watching Federations.
With AzureWatch it gets easier to monitor the whole deployment in an aggregate view for the following resource dimensions;
- Number of open transactions
- Number of open connections
- Number of blocking queries
- Number of federated members (root database only)
Igor writes about the support in-depth here;

<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
Mary Jo Foley (@maryjofoley) asserted “Microsoft is moving its Bing Search programming interface to the Windows Azure Marketplace and turning it into a paid subscription service” in a deck for her Microsoft's answer to Amazon's CloudSearch: Bing on Azure Marketplace post of 4/12/2012 to ZDNet’s All About Microsoft blog:
The same day that Amazon announced the beta of its new CloudSearch technology, Microsoft announed its counterstrike: Moving the Bing Search application programming interface (API) to the Windows Azure Marketplace.
The Windows Azure Marketplace is the site where Microsoft and third party vendors can sell (or offer for free) their data, apps and services.
Microsoft officials said the Bing API Marketplace transition will “begin in several weeks and take a few months to complete.” Via a post to the Bing Developer blog on April 12, officials did say that Microsoft plans to make the API available on a monthly subscription basis.
“Developers can expect subscription pricing to start at approximately $40 (USD) per month for up to 20,000 queries each month,” according to the post. However, “(d)uring the transition period, developers will be encouraged to try the Bing Search API for free on the Windows Azure Marketplace, before we begin charging for the service.”
In the interim, Microsoft is advising developers that they can continue to use the Bing Search API 2.0 for free. After the transition, it will no longer be free for public use and will be available from the Azure Marketplace only.
“We understand that many of you are using the API as an important element in your websites and applications, and we will continue to share details with you through the Bing Developer Blog as we approach the transition,” the Softies added.
Amazon CloudSearch, which went to beta today, is Amazon’s new managed search service in the cloud designed to allow developers to add search to their applications. Amazon officials blogged today that customers can set it up and start processing queries in less than an hour for less than $100 per month. The service relies on a set of CloudSearch APIs that can be managed through the Amazon Web Services console.

Alex James (@adjames) concluded his WCF Actions series with Actions in WCF Data Services – Part 3: A sample provider for the Entity Framework on 4/12/2012:
This post is the last in a series on Actions in WCF Data Services. The series was started with an example experience for defining actions (Part 1) and how IDataServiceActionProvider works (Part 2). In this post we’ll go ahead and walk through a sample action provider implementation that delivers the experience outlined in part 1 for the Entity Framework.
If you want to walk through the code while reading this you’ll find the code here: http://efactionprovider.codeplex.com.
Implementation Strategy
The center of the implementation is the EntityFrameworkActionProvider class that derives from ActionProvider. The EntityFrameworkActionProvider is specific to EF, whereas the ActionProvider provides a generic starting point for an implementation of IDataServiceActionProvider that enables the experience outlined in Part 1.
There is quite a bit going on in the sample code, so I can’t walk through all of it in a single blog post, instead I’ll focus on the most interesting bits of the code:Finding Actions
Data Service providers can be completely dynamic, producing a completely different model for each request. However with the built-in Entity Framework provider the model is static, basically because the EF model is static, also the actions are static too, because they are defined in code using methods with attributes on them. This all means one thing – our implementation can do a single reflection pass to establish what actions are in the model and cache that for all requests.
So every time the EntityFrameActionProvider is constructed, it first checks a cache of actions defined on our data source, which in our case is a class derived from EF’s DBContext. If a cache look up it successful great, if not it uses the ActionFactory class to go an construct ServiceActions for every action declared on the DBContext.
The algorithm for the ActionFactory is relatively simple:
- It is given the Type of the class that defines all the Actions. For us that is the T passed to DataService<T>, which is a class derived from EF’s DBContext.
- It them looks for methods with one of these attributes [Action], [NonBindableAction] or [OccasionallyBindableAction], all of which represent different types of actions.
- For each method it finds it then uses the IDataServiceMetadataProvider it was with constructed with to convert the parameters and return types into ResourceTypes.
- At this point it can construct a ServiceAction for each.
Parameter Marshaling
When an action is actually invoked we need to convert any parameters from WCF Data Services internal representation into objects that the end users methods can actually handle. It is likely that marshaling will be quite different for different underlying providers (EF, Reflection, Custom etc), so the ActionProvider uses an interface IParameterMarshaller, whenever it needs to convert parameters. The EF’s parameter marshaled looks like this:
public class EntityFrameworkParameterMarshaller: IParameterMarshaller
{
static MethodInfo CastMethodGeneric = typeof(Enumerable).GetMethod("Cast");
static MethodInfo ToListMethodGeneric = typeof(Enumerable).GetMethod("ToList");public object[] Marshall(DataServiceOperationContext operationContext, ServiceAction action, object[] parameters)
{
var pvalues = action.Parameters.Zip(parameters, (parameter, parameterValue) => new { Parameter = parameter, Value = parameterValue });
var marshalled = pvalues.Select(pvalue => GetMarshalledParameter(operationContext, pvalue.Parameter, pvalue.Value)).ToArray();return marshalled;
}
private object GetMarshalledParameter(DataServiceOperationContext operationContext, ServiceActionParameter serviceActionParameter, object value)
{
var parameterKind = serviceActionParameter.ParameterType.ResourceTypeKind;
// Need to Marshall MultiValues i.e. Collection(Primitive) & Collection(ComplexType)
if (parameterKind == ResourceTypeKind.EntityType)
{// This entity is UNATTACHED. But people are likely to want to edit this...
IDataServiceUpdateProvider2 updateProvider = operationContext.GetService(typeof(IDataServiceUpdateProvider2)) as IDataServiceUpdateProvider2;
value = updateProvider.GetResource(value as IQueryable, serviceActionParameter.ParameterType.InstanceType.FullName);
value = updateProvider.ResolveResource(value); // This will attach the entity.
}
else if (parameterKind == ResourceTypeKind.EntityCollection)
{
// WCF Data Services constructs an IQueryable that is NoTracking...
// but that means people can't just edit the entities they pull from the Query.
var query = value as ObjectQuery;
query.MergeOption = MergeOption.AppendOnly;
}
else if (parameterKind == ResourceTypeKind.Collection)
{
// need to coerce into a List<> for dispatch
var enumerable = value as IEnumerable;
// the <T> in List<T> is the Instance type of the ItemType
var elementType = (serviceActionParameter.ParameterType as CollectionResourceType).ItemType.InstanceType;
// call IEnumerable.Cast<T>();
var castMethod = CastMethodGeneric.MakeGenericMethod(elementType);
object marshalledValue = castMethod.Invoke(null, new[] { enumerable });
// call IEnumerable<T>.ToList();
var toListMethod = ToListMethodGeneric.MakeGenericMethod(elementType);
value = toListMethod.Invoke(null, new[] { marshalledValue });
}
return value;
}
}This is probably the hardest part of the whole sample because it involves understanding what is necessary to make the parameters you pass to the service authors action methods updatable (remembers Actions generally have side-effects).
For example when Data Services see’s something like this: POST http://server/service/Movies(1)/Checkout
It builds a query to represent the Movie parameter to the Checkout action, however when Data Services is building queries, it doesn’t need the Entity Framework to track the results – because all it is doing is serializing the entities and then discarding them. However in this example, we need to take the query and actually retrieve the object in such as way that it is tracked by EF, so that if it gets modified inside the action EF will notice and push changes back to the Database during SaveChanges.
Delaying invocation
As discussed in Part 2, we need to delay actual invocation of the action until SaveChanges(), to do this we return an implementation of an interface called IDataServiceInvokable:
public class ActionInvokable : IDataServiceInvokable
{
ServiceAction _serviceAction;
Action _action;
bool _hasRun = false;
object _result;public ActionInvokable(DataServiceOperationContext operationContext, ServiceAction serviceAction, object site, object[] parameters, IParameterMarshaller marshaller)
{
_serviceAction = serviceAction;
ActionInfo info = serviceAction.CustomState as ActionInfo;
var marshalled = marshaller.Marshall(operationContext,serviceAction,parameters);info.AssertAvailable(site,marshalled[0], true);
_action = () => CaptureResult(info.ActionMethod.Invoke(site, marshalled));
}
public void CaptureResult(object o)
{
if (_hasRun) throw new Exception("Invoke not available. This invokable has already been Invoked.");
_hasRun = true;
_result = o;
}
public object GetResult()
{
if (!_hasRun) throw new Exception("Results not available. This invokable hasn't been Invoked.");
return _result;
}
public void Invoke()
{
try
{
_action();
}
catch {
throw new DataServiceException(
500,
string.Format("Exception executing action {0}", _serviceAction.Name)
);
}
}
}As you can see this does a couple of things, it creates an Action (this time a CLR one - just to confuse the situation i.e. a delegate that returns void), that actually calls the method on your DBContext via reflection passing the marshaled parameters. It also has a few guards, one to insure that Invoke() is only called once, and another to make sure GetResult() is only called after Invoke().
Actions that are bound *sometimes*
Part 1 and 2 introduce the concept of occasionally bindable actions, but basically an action might not always be available in all states, for example you might not always be able to checkout a movie (perhaps you already have it checked out).
The ActionInfo class has an IsAvailable(…) method which is used by the ActionProvider whenever WCF Data Services need to know if an Action should be advertised or not. The implementation of this will call the method specified in the [OccasionallyBindableAction] attribute. The code is complicated because it supports always return true without actually checking if the actual availability method is too expensive to call repeatedly. This is indicated using the [SkipCheckForFeeds] attribute.
Getting the Sample Code
The sample is on codeplex made up of two projects:
- ActionProviderImplementation – the actual implementation of the Entity Framework action provider.
- MoviesWebsite – a sample MVC3 website that exposes a simple OData Service
Summary
For most of you downloading the samples and using them to create a OData Service with Actions over the Entity Framework is all you’ll need.
However if you are actually considering tweaking the example or building your own from scratch hopefully you now have enough context.

Alex James (@adjames) concluded his WCF Actions series with Actions in WCF Data Services – Part 2: How IDataServiceActionProvider works on 4/11/2012:
In this post we will explorer the IDataServiceActionProvider interface, which must be implemented to add Actions to a WCF Data Service.
However if you are simply creating an OData Service and you can find an implementation of IDataServiceActionProvider that works for you (I’ll post sample code with Part 3) then you can probably skip this post.
IDataServiceActionProvider
Okay so lets take a look at the actions interface:
public interface IDataServiceActionProvider
{
bool AdvertiseServiceAction(
DataServiceOperationContext operationContext,
ServiceAction serviceAction,
object resourceInstance,
bool resourceInstanceInFeed,
ref ODataAction actionToSerialize);
IDataServiceInvokable CreateInvokable(
DataServiceOperationContext operationContext,
ServiceAction serviceAction,
object[] parameterTokens);
IEnumerable<ServiceAction> GetServiceActions(
DataServiceOperationContext operationContext);
IEnumerable<ServiceAction> GetServiceActionsByBindingParameterType(
DataServiceOperationContext operationContext,
ResourceType bindingParameterType);
bool TryResolveServiceAction(
DataServiceOperationContext operationContext,
string serviceActionName,
out ServiceAction serviceAction);
}
You’ll notice that every method either takes or returns a ServiceAction. ServiceAction is the metadata representation of an Action, that includes information like the Action name, its parameters, its ReturnType etc.When you implement IDataServiceActionProvider you are augmenting the metadata for your service which is defined by your services implementation of IDataServiceMetadataProvider with Actions and handling dispatch to those actions as appropriate.
We added this new interface rather than creating a new version of IDataServiceMetadataProvider because we didn’t have time to add an Action implementation for the built-in Entity Framework and Reflection provider, but we still wanted you be able to add actions when using those providers. This separation of concerns allows you to use the built-in providers and layer in support for Actions on the side.
However one problem remains: to create a new Action you will need access to the ResourceTypes in the your service, so you can create Action parameters and specify Action ReturnTypes. Previously you couldn’t get at the ResourceTypes unless you created a completely custom provider. So to give you access to the ResourceTypes we added an implementation of IServiceProvider to the DataServiceOperationContext class which is passed to every one of the above methods.
Now anywhere you have one of these operationContexts you can get the current implementation of IDataServiceMetadataProvider (and thus the ResourceTypes) like this:
var metadata = operationContext.GetService(typeof(IDataServiceMetadataProvider)) as IDataServiceMetadataProvider;
Exposing ServiceActions
There are 3 methods that the Data Services Server uses to learn about actions:
- GetServiceActions(DataServiceOperationContext) – returns every ServiceAction in the service, and is used when we need all the metadata, i.e. if someone goes to $metadata
- GetServiceActionsByBindingParameterType(DataServiceOperationContext,ResourceType) – returns every ServiceAction that can be bound to the ResourceType specified. This is used when we are returning an entity and we want to include information about Actions that can be invoked against that entity. The contract here is you should only include Actions that take the specified ResourceType exactly (i.e. no derived types) as the binding parameter to the action. We will call this method once for each ResourceType we encounter during serialization.
- TryResolveServiceAction(DataServiceOperationContext,serviceActionName,out serviceAction) – return true if a ServiceAction with the specified name is found.
Now you could clearly implement both GetServiceActionsByBindingParameterType(..) and TryResolveServiceAction(..) by calling GetServiceActions(..), but Data Services tries to avoid loading all the metadata at once wherever possible, so you get the opportunity to provide more efficient targeted implementations.
Basically 99% of the time Data Services doesn’t need every ServiceAction, so it won’t ask for all of them most of the time.
To expose an Action you simply create a ServiceAction and return it from these methods as appropriate. For example to create a ServiceAction that corresponds to this C# signature (where Movie is an entity):
void Rate(Movie movie, int rating)
You would do something like this:
ServiceAction movieRateAction = new ServiceAction(
“Rate”, // name of the action
null, // no return type i.e. void
null, // no return type means we don’t need to know the ResourceSet so use null.
OperationParameterBindingKind.Always, // i.e this action is always bound to an Movie entities
// other options are Never and Always.
new [] {
new ServiceActionParameter(“movie”, movieResourceType),
new ServiceActionParameter(“rating”, ResourceType.GetPrimitiveType(typeof(int)))
}
);As you can see nothing too tricky here.
Advertizing ServiceActions
If you looked at the first post you’ll remember that some Actions are available only in certain states. This is configured when you create your the ServiceAction, something like this:
ServiceAction checkoutMovieAction = new ServiceAction(
“Checkout”, // name of the action
ResourceType.GetPrimitiveType(typeof(bool)), // Edm.Boolean is the returnType
null, // the returnType is a bool, so it doesn’t have a ResourceSet
OperationParameterBindingKind.Sometimes, // You can’t always checkout a movie
new [] { new ServiceActionParameter(“Movie”, movieResourceType) }
);Notice in this example the OperationParameterBindingKind is set to Sometimes which means the Checkout Action is not available for every Movie. So when DataServices returns a Movie it will check with the ActionProvider to see if the Action is currently available. Which it does by calling:
bool AdvertiseServiceAction(
DataServiceOperationContext operationContext,
ServiceAction serviceAction, // the action that the server knows MAY be bound.
object resourceInstance, // the entity which MAY allow the action to be bound.
bool resourceInstanceInFeed, // whether the server is serializing a single entity or a feed (expect multiple calls).
ref ODataAction actionToSerialize); // modifying this parameter allows you to do customize things like the URL
// the client will POST to to invoke the action.For example you might check if the current user (i.e. HttpContext.Current.User) has a Movie checked out already, to decide whether they can Checkout that Movie or not.
The resourceInstanceInFeed parameter needs a special mention. Sometimes working out whether an Action is available is time or resource intensive, for example if you have to do a separate database query. Generally this isn’t a problem if you are returning just one Entity, but if you are returning a whole feed of entities it is clearly undesirable. The OData protocol says that in situations like this you should err by exposing actions that aren’t actually available (and fail later if they are invoked). WCF Data Services doesn’t know if it is expensive to establish action availability, so to help you decide whether to do the check it lets you know whether you are in a feed or not. This way your Action provider can just return true, it if knows it is costly to calculate and it is in a feed.
Invoking ServiceActions
When an action is invoked, your implementation of this is called:
IDataServiceInvokable CreateInvokable(
DataServiceOperationContext operationContext,
ServiceAction serviceAction,
object[] parameterTokens);Notice you don’t actually invoke the action immediately instead you return an implementation of IDataServiceInvokable, which looks like this:
public interface IDataServiceInvokable
{
object GetResult();
void Invoke();
}As you can see this is a simple interface, but why do we delay calling the action?
Well actions generally have side-effects so they need to work in conjunction with the UpdateProvider (or IDataServiceUpdateProvider2), to actually save those changes to disk. To support Actions you need an Update Provider like the built-in Entity Framework provider that implements the new IDataServiceUpdateProvider2 interface:
public interface IDataServiceUpdateProvider2 : IDataServiceUpdateProvider, IUpdatable
{
void ScheduleInvokable(IDataServiceInvokable invokable);
}This allows WCF Data Services to schedule arbitrary work to happen during IDataServiceUpdateProvider.SaveChanges(..), which allows update providers and action providers to be written independently. Which is great because if you are using the Entity Framework you really don’t want to have to write an update provider from scratch.
Now when you implement IDataServiceInvokable you are responsible for 3 things:
- Capturing and potentially marshaling the parameters.
- Dispatching the parameters to the code that actually implements the Action when Invoke() is called.
- Storing any results from Invoke() so they can be retrieved using GetResult()
The parameters themselves are passed as tokens. This is because it is possible to write a Data Service Provider that works with tokens that represent resources, if this is the case you may need to convert these token into actual resources before dispatching to the actual action. What is required depends 100% on the rest of the provider code, so it is impossible to say exactly what you need to do here. However in part 3 well explore doing this for the Entity Framework.
If the first parameter to the action is a binding parameter (i.e. an EntityType or a Collection of EntityTypes) it will be passed as an un-enumerated IQueryable. Most of the time this isn’t too interesting but it does mean you can do nifty tricks like write an action that doesn’t actually retrieve the entities from the database if appropriate.
Summary
This post walked you through the design of IDataServiceActionProvider and the expectations for people implementing this interface. While this is quite a tricky interface to implement, it is low level code and hopefully you will be able to find an existing implementation that works for you. Indeed in Part 3 we will share and walk through an sample implementation for the Entity Framework designed to deliver the Service Author Experience we introduced in Part 1.

Andrew Brust (@andrewbrust, pictured below) asked “A Technical Fellow at Microsoft says we’re headed for an in-memory database tipping point. What does this mean for Big Data?” in a deck for his In-memory databases at Microsoft and elsewhere post of 4/11/2012:
Yesterday, Microsoft’s Dave Campbell, a Technical Fellow on the SQL Server team, posted to the SQL Server team blog on the subject of in-memory database technology. Mary Jo Foley, our “All About Microsoft” blogger here at ZDNet, provided some analysis on Campbell’s thoughts in a post of her own. I read both, and realized there’s an important Big Data side to this story.
In a nutshell
In his post, Campbell says in-memory is about to hit a tipping point and, rather than leaving that assertion unsubstantiated, he provided a really helpful explanation as to why.
Campbell points out that there’s been an interesting confluence in the database and computing space:
- Huge advances in transistor density (and, thereby, in memory capacity and multi-core ubiquity)
- As-yet untranscended limits in disk seek times (and access latency in general)
This combination of factors is leading — and in some cases pushing — the database industry to in-memory technology. Campbell says that keeping things closer to the CPU, and avoiding random fetches from electromechanical hard disk drives, are the priorities now. That means bringing entire databases, or huge chunks of them, into memory, where they can be addressed quickly by processors.
Compression and column stores
Compression is a big part of this and, in the Business Intelligence world, so are column stores. Column stores keep all values for a column (field) next to each other, rather than doing so with all the values in a row (record). In the BI world, this allows for fast aggregation (since all the values you’re aggregating are typically right next to each other) and high compression rates.
Microsoft’s xVelocity technology (branded as “VertiPaq” until quite recently) uses in-memory column store technology. The technology manifested itself a few years ago as the engine behind PowerPivot, a self-service BI add-in for Excel and SharePoint. With the release of SQL Server 2012, this same engine has been implemented inside Microsoft’s full SQL Server Analysis Services component, and had been adapted for use as a special columnstore index type in the SQL Server relational database as well.
The BD Angle
How does this affect Big Data? I can think of a few ways:
- As I’ve said in a few posts here, Massively Parallel Processing (MPP) data warehouse appliances are Big Data products. A few of them use columnar, in-memory technology. Campbell even said that columnstore indexes will be added to Microsoft’s MPP product soon. So MPP has already started to go in-memory.
- Some tools that can connect to Hadoop and can provide analysis and data visualization services for its data, may use in-memory technology as well. Tableau is one example of a product that does this.
- Databases used with Hadoop, like HBase, Cassandra and HyperTable, fall into the “wide column store” category of NoSQL databases. While NoSQL wide column stores and BI column store databases are not identical, their technologies are related. That creates certain in-memory potential for HBase and other wide column stores, as their data is subject to high rates of compression.
Keeping Hadoop in memory
Hadoop’s MapReduce approach to query processing, to some extent, combats disk latency though parallel computation. This seems ripe for optimization though. Making better use of multi-core processing within a node in the Hadoop cluster is one way to optimize. I’ve examined that in a recent post as well.
- Also Read: Making Hadoop optimizations Pervasive
Perhaps using in-memory technology in place of disk-based processing is another way to optimize Hadoop. Perhaps we could even combine the approaches: Campbell points out in his post that the low latency of in-memory technology allows for better utilization of multi-cores.
Campbell also says in-memory will soon work its way into transactional databases and their workloads. That’s neat, and I’m interested in seeing it. But I’m also interested in seeing how in-memory can take on Big Data workloads.
Perhaps the Hadoop Distributed File System (HDFS) might allow in-memory storage to be substituted in for disk-based storage. Or maybe specially optimized solid state disks will be built that have performance on par with RAM (Random Access Memory). Such disks could then be deployed to nodes in a Hadoop cluster.
No matter what, MapReduce, powerful though it is, leaves some low hanging fruit for the picking. The implementation of in-memory technology might be one such piece of fruit. And since Microsoft has embraced Hadoop, maybe it will take a run at making it happen.
Addendum
For an approach to Big Data that does use in-memory technology but does not use Hadoop, check out JustOneDB. I haven’t done much due diligence on them, but I’ve talked to their CTO, Duncan Pauly, about the product. He and the company seem very smart and have some fairly breakthrough ideas about databases today and how they need to change.


The current Apache Hadoop on Windows Azure CTP requires all data used by Hadoop clusters to be held in memory.
The WCF Data Services Team explained What happened to application/json in WCF DS 5.0? in a 4/11/2012 post:
The roadmap for serialization formats
You may notice that when you upgrade to WCF DS 5.0, requesting the old JSON format is a bit different. To get the old JSON format, you must now explicitly request application/json;odata=verbose or set the MaxDataServiceVersion header to 2.0.
When will I get a 415 response and what can I do about it?
WCF Data Services 5.0 will return a 415 in response to a request for application/json if the service configuration allows a v3 response and if the client does not specify a MaxDataServiceVersion header or specifies a MaxDataServiceVersion header of 3.0. Clients should always send a value for the MaxDataServiceVersion header to ensure forward compatibility.
There are two ways to get a response formatted with JSON verbose:
1. Set the MaxDataServiceVersion header to 2.0 or less. For instance:
GET http://odata.example.org/Items?$top=5 HTTP/1.1
Host: odata.example.org
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.152 Safari/535.19
Accept: application/json
Accept-Encoding: gzip,deflate,sdch
Accept-Language: en-US,en;q=0.8
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
MaxDataServiceVersion: 2.0
2. Request a content type of application/json;odata=verbose. For instance:
GET http://odata.example.org/Items?$top=5 HTTP/1.1
Host: odata.example.org
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.152 Safari/535.19
Accept: application/json;odata=verbose
Accept-Encoding: gzip,deflate,sdch
Accept-Language: en-US,en;q=0.8
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.3
MaxDataServiceVersion: 3.0
It’s possible to modify the headers with jQuery as follows:
$.ajax(url, {
dataType: "json", // this tells jquery that you are expcting a json object and so it will parse the data for you.
beforeSend: function (xhr) {
xhr.setRequestHeader("Accept", "application/json;odata=verbose");
xhr.setRequestHeader("MaxDataServiceVersion", "3.0");
},
success: function (data) {
// do something interesting with the data you get back.
}
});
Why did WCF DS 5.0 ship before JSON light?
We had a set of features that were ready to be released as part of WCF DS 5.0. The more efficient JSON implementation is currently in progress and will be released sometime later this year.
I would have rather seen the resources devoted to WCF Actions be concentrated on JSON formatting.
Rob Collie (@PowerPivotPro) posted DataMarket Revisited: The Truth is Out There on 4/10/2012:
How many discoveries are right under our noses,
if only we cross-referenced the right data sets?Convergence of Multiple “Thought Streams”
Yeah, I love quoting movies. And tv shows. And song lyrics. But it’s not the quoting that I enjoy – it’s the connection. Taking something technical, for instance, and spotting an intrinsic similarity in something completely unrelated like a movie – I get a huge kick out of that.
That tendency to make connections kinda flows through my whole life – sometimes, it’s even productive and not just entertaining.
Anyway, I think I am approaching one of those aha/convergence moments. It’s actually a convergence moment “squared,” because it’s a convergence moment about… convergence. Here are the streams that are coming together in my head:
1) “Expert” thinking is too often Narrow thinking
I’ve read a number of compelling articles and anecdotes about this in my life, most recently this one in the New York Times. Particularly in science and medicine, you have to develop so many credentials just to get in the door that it tends to breed a rigid and less creative environment.
And the tragedy is this: a conundrum that stumps a molecular cancer scientist might be solvable, at a glance, by the epidemiologist or the mathematician in the building next door. Similarly, the molecular scientist might breeze over a crucial clue that would literally leap off the page at a graph theorist like my former professor Jeremy Spinrad.
2) Community cross-referencing of data/problems is a longstanding need
Flowing straight out of problem #1 above is this, need #2. And it’s been a recognized need for a long time, by many people.
Swivel and ManyEyes Both Were Attempts at this Problem
I remember being captivated, back in 2006-2007, with a website called Swivel.com. It’s gone now – and I highly recommend reading this “postmortem” interview with its two founders – but the idea was solid: provide a place for various data sets to “meet,” and to harness the power of community to spot trends and relationships that would never be found otherwise. (Apparently IBM did something similar with a project called ManyEyes, but it’s gone now, too).
There is, of course, even a more mundane use than “community research mashups” – our normal business data would benefit a lot by being “mashed up” with demographics and weather data (just to point out the two most obvious).
I’ve been wanting something like this forever. As far back as 2001, when we were working on Office 2003, I was trying to launch a “data market” type of service for Office users. (An idea that never really got off the drawing board – our VP killed it. And, at the time, I think that was the right call).
3) Mistake: Swivel was a BI tool and not just a data marketplace
When I discovered that Swivel was gone, before I read the postmortem, I forced myself to think of reasons why they might have failed. And my first thought was this: Swivel forced you to use THEIR analysis tools. They weren’t just a place where data met. They were also a BI tool.
And as we know, BI tools take a lot of work. They are not something that you just casually add to your business model.
In the interview, the founders acknowledge this, but their choice of words is almost completely wrong in my opinion:
- Check out the two sections I highlighted. The interface is not that important. And people prefer to use what they already have. That gets me leaning forward in my chair.
- YES! People prefer to use the analysis/mashup toolset they already use. They didn’t want to learn Swivel’s new tools, or compensate for the features it lacked. I agree 100%.
- But to then utter the words “the interface is not that important” seems completely wrong to me. The interface, the toolset, is CRITICAL! What they should have said in this interview, I think, is “we should not have tried to introduce a new interface, because interface is critical and the users already made up their mind.”
4) PowerPivot is SCARY good at mashups
I’m still surprised at how simple and magical it feels to cross-reference one data set against another in PowerPivot. I never anticipated this when I was working on PowerPivot v1 back at Microsoft. The features that “power” mashups – relationships and formulas – are pretty… mundane. But in practice there’s just something about it. It’s simple enough that you just DO it. You WANT to do it.
Remember this?
OK, it’s pretty funny. But it IS real data. And it DOES tell us something surprising – I did NOT know, going in, that I would find anything when I mashed up UFO sightings with drug use. And it was super, super, super easy to do.
When you can test theories easily, you actually test them. If it was even, say, 50% more work to mash this up than it actually was, I probably never would have done it. And I think that’s the important point…
PowerPivot’s mashup capability passes the critical human threshold test of “quick enough that I invest the time,” whereas other tools, even if just a little bit harder, do not. Humans prioritize it off the list if it’s even just slightly too time consuming.
Which, in my experience, is basically the same difference as HAVING a capability versus having NO CAPABILITY whatsoever. I honestly think PowerPivot might be the only data mashup tool worth talking about. Yeah, in the entire world. Not kidding.
5) “Export to Excel” is not to be ignored
Another thing favoring PowerPivot as the world’s only practically-useful mashup tool: it’s Excel.
I recently posted about how every data application in the world has an Export to Excel button, and why that’s telling.
Let’s go back to that quote from one of the Swivel founders, and examine one more portion that I think reflects a mistake:
Can I get a “WTF” from the congregation??? R and SAS but NO mention of Excel! Even just taking the Excel Pro, pivot-using subset of the Excel audience (the people who are reading this blog), Excel CRUSHES those two tools, combined, in audience. Crushes them.
Yeah, the mundane little spreadsheet gets no respect. But PowerPivot closes that last critical gap, in a way that continues to surprise even me. Better at business than anything else. Heck, better at science too. Ignore it at your peril.
6) But Getting the Data Needs to be Just as Simple!
So here we go. Even in the UFO example, I had to be handed the data. Literally. Our CEO already HAD the datasets, both the UFO sightings and the drug use data. He gave them to me and said “see if you can do something with this.”
There is no way I EVER would have scoured the web for these data sets, but once they were conveniently available to me, I fired up my convenient mashup tool and found something interesting.
7) DataMarket will “soon” close that last gap
In a post last year I said that Azure DataMarket was falling well short of its potential, and I meant it. That was, and is, a function of its vast potential much more so than the “falling short” part. Just a few usability problems that need to be plugged before it really lights things up, essentially.
On one of my recent trips to Redmond, I had the opportunity to meet with some of the folks behind the scenes.
Without giving away any secrets, let me say this: these folks are very impressive. I love, love, LOVE the directions in which they are thinking. I’m not sure how long it’s going to take for us to see the results of their current thinking.
But when we do, yet another “last mile” problem will be solved, and the network effect of combining “simple access to vast arrays of useful data sets” with “simple mashup tool” will be transformative. (Note that I am not prone to hyperbole except when I am saying negative things, so statements like this are rare from me.)
In the meantime…
While we wait for the DataMarket team’s brainstorms to reach fruition, I am doing a few things.
- I’ve added a new category to the blog for Real-World Data Mashups. Just click here.
- I’m going to do share some workbooks that make consumption of DataMarket simple. Starting Thursday I will be providing some workbooks that are pre-configured to grab interesting data sets from Data Market. Stay tuned.
- I’m likely to run some contests and/or solicit guest posts on DataMarket mashups.
- I’m toying with the idea of Pivotstream offering some free access to certain DataMarket data sets in our Hosted PowerPivot offering.





Rob is CTO of Pivotstream, former co-founder of the PowerPivot team and leader of Excel BI team at MS.
Alex James (@adjames) started a series with Actions in WCF Data Services – Part 1: Service Author Code on 4/10/2012:
If you read our last post on Actions you’ll know that Actions are now in both OData and WCF Data Services and that they are cool:
“Actions will provide a way to inject behaviors into an otherwise data-centric model without confusing the data aspects of the model, while still staying true to the resource oriented underpinnings of OData."
This post is the first of a series that will in turn introduce:
- The Experience we want to enable, i.e. the code the service author writes.
- The Action Provider API and why it is structured as it is.
- A sample implementation of an Action Provider for the Entity Framework
Remember if you are an OData Service author, happy to use an Action Provider written by someone else, all you need worry about is (1), and that is what this post will cover.
Scenario
Imagine that you have the following Entity Framework model
public class MoviesModel: DbContext
{
public DbSet<Actor> Actors { get; set; }
public DbSet<Director> Directors { get; set; }
public DbSet<Genre> Genres { get; set; }
public DbSet<Movie> Movies { get; set; }
public DbSet<UserRental> Rentals { get; set; }
public DbSet<Tag> Tags { get; set; }
public DbSet<User> Users { get; set; }
public DbSet<UserRating> Ratings { get; set; }
}Which you expose as using WCF Data Services configured like this:
config.SetEntitySetAccessRule("*", EntitySetRights.AllRead);
config.SetEntitySetAccessRule("EdmMetadatas", EntitySetRights.None);
config.SetEntitySetAccessRule("Users", EntitySetRights.None);
config.SetEntitySetAccessRule("Rentals", EntitySetRights.None);
config.SetEntitySetAccessRule("Ratings", EntitySetRights.None);
Notice that some of the Entity Framework data is completely hidden (Users,Rentals,Ratings and of course EdmMetadatas) and the rest is marked as ReadOnly. This means in this service people can see information about Movies, Genres, Actors, Directors and Tags, but they currently can’t edit this data through the service. Essentially some of the database is an implementation detail you don’t want the world to see. With Action for the first time it is easy to create a real distinction between your Data Model and your Service Model.Now imagine you have a method on your DbContext that looks something like this:
public void Rate(Movie movie, int rating)
{
var userName = GetUsername();
var movieID = movie.ID;// Retrieve the existing rating by this user (or null if not found).
var existingRating = this.Ratings.SingleOrDefault(r =>
r.UserUsername == userName &&
r.MovieID == movieID
);if (existingRating == null)
{
this.Ratings.Add(new UserRating { MovieID = movieID, Rating = rating, UserUsername = userName });
}
else
{
existingRating.Rating = rating;
}
}This code allows a user to rate a movie, simply by providing a rating and a movie. It uses ambient context to establish who is making the request (i.e. HttpContext.Current.User.Identity.Name), and looks for a rating by that User for that Movie (a user can only rate a movie once), if it finds one it gets modified otherwise a new rating is created.
Target Experience
Now imagine you want to expose this as an action. The first step would be to make your Data Service implement IServiceProvider like this:
public class MoviesService : DataService<MoviesModel>, IServiceProvider
{
public object GetService(Type serviceType)
{
if (typeof(IDataServiceActionProvider) == serviceType)
{
return new EntityFrameworkActionProvider(CurrentDataSource);
}
return null;
}
…
}Where EntityFrameworkActionProvider is the custom action provider you want to use, in this case a sample provider that we’ll put up on codeplex when Part 3 of this series is released (sorry to tease).
Next configure your service to expose Actions, in the InitializeService method:
config.SetServiceActionAccessRule("*", ServiceActionRights.Invoke);
config.DataServiceBehavior.MaxProtocolVersion = DataServiceProtocolVersion.V3;As per usual * means all Actions, but you could just as easy expose just the actions you want by name.
Finally with that groundwork done, expose your action by adding the [Action] attribute:
[Action]
public void Rate(Movie movie, int rating)
{With this done the action will show up in $metadata, like this:
<FunctionImport Name="Rate" IsBindable="true">
<Parameter Name="movie" Type="MoviesWebsite.Models.Movie" />
<Parameter Name="rating" Type="Edm.Int32" />
</FunctionImport>
And it will be advertised in Movie entities like this (in JSON format):
{
"d": {
"__metadata": {
…
"actions": {
"http://localhost:15238/MoviesService.svc/$metadata#MoviesModel.Rate": [
{
"title": "Rate",
"target": "http://localhost:15238/MoviesService.svc/Movies(1)/Rate"
}
]
}
},
…
"ID": 1,
"Name": "Avatar"
}
}This action can be invoked using the WCF Data Services Client like this:
ctx.Invoke(
new Uri(“http://localhost:15238/MoviesService.svc/Movies(1)/Rate”),
new BodyParameter(“rating”,4)
);or, if you prefer being closer to the metal, more directly like this:
POST http://localhost:15238/MoviesService.svc/Movies(1)/Rate HTTP/1.1
Content-Type: application/json
Content-Length: 20
Host: localhost:15238{
"rating": 4
}All very easy don’t you think?
Actions whose availability depends upon Entity State
You may also remember that whether an action is available can depend on the state of the entity or service. For example you can’t Checkout a movie that you already have Checked out. To address this requirement we need a way to support this through attributes too.
Excuse the terrible attribute name (it is only a sample) but perhaps something like this:
[OccasionallyBindableAction("CanCheckout")]
public void Checkout(Movie movie)
{
var userName = GetUsername();
var movieID = movie.ID;var alreadyCheckedOut = this.Rentals.Any(r =>
r.UserUsername == userName &&
r.MovieID == movieID &&
r.CheckedIn == null
);if (!alreadyCheckedOut)
{
// add a new rental
this.Rentals.Add(
new UserRental {
MovieID = movieID,
CheckedOut = DateTime.Now,
UserUsername = userName
}
);
}
}Notice instead of the [Action] attribute this has an [OccasionallyBindableAction] attribute which takes the name of a method to call to see if this action is available. This method must take one parameter, the same type as the binding parameter of the action (so in this case a Movie) and return a boolean to indicate whether the action should be advertised.
[SkipCheckForFeeds]
public bool CanCheckout(Movie movie)
{
var username = GetUsername();
var rental = this.Rentals.SingleOrDefault(
r => r.UserUsername == username && r.MovieID == movie.ID && r.CheckedIn == null
);
if (rental == null) return true;
else return false;
}Notice that this method runs a separate query to see if an unreturned rental exists for the current user and movie, if yes then the movie can’t be checked out, if no then the movie can be checked out.
The alert amongst you will have noticed the [SkipCheckForFeeds] attribute. This is here for performance reasons. Why?
Imagine that you retrieve a Feed of Movies, in theory we should call this ‘availability check’ method for every Movie in the feed. Now if the method only needs information in the Movie (i.e. imagine if the Movie has a CanCheckout property) this is not a problem, but in our example we actually issue a separate database query. Clearly running one query to get a feed of items and then a new query for each action in that feed of items is undesirable from a performance perspective.
We foresaw this problem and added some rules to the protocol to address this problem, namely if it is expensive to calculate the availability of an Action, it is okay to advertise the action whether it is available or not. So [SkipCheckForFeed] is used to indicate to our custom Actions Provider that this method is expensive and shouldn’t be called for all the Movies in a feed but should be advertised anyway.
Summary
As you can see our goal is to enable 3rd party Action Provider to provide a highly intuitive way of adding Actions to your OData Service, the above code examples illustrate one possible set of experiences. As you experiment I’m confident that you will find Actions to be a very powerful way to add behaviors to your OData Service.
In Part 2 we will look at the IDataServiceActionProvider interface in detail, and then in Part 3 we’ll walk through an implementation for the Entity Framework (and I’ll post the sample Entity Framework Action Provider sample code).
As always I’m super keen to hear what you think.

<Return to section navigation list>
Windows Azure Service Bus, Access Control, Identity and Workflow
Mike Benkovich (@mbenko) continued his series with Cloud Tip #9-Add Microsoft.IdentityModel to the GAC with a Startup Task on 4/7/2012 (missed when posted):
Access Control Services is one of the many services that are part of the Windows Azure Platform which handles an authentication conversation for you, allowing you an easy way to integrate cloud identity from providers like Yahoo, Google, Facebook and Live ID with your application. You need an active Azure Subscription (click here to try the 90 day Free Trial), add an ACS service namespace, then add a Secure Token Service (STS) reference to your application (you’ll need the Windows Identity SDK and tools for Visual Studio to add the Federation Utility that does that last part – download here).
If you’ve seen an error that says ‘Unable to find assembly Microsoft.IdentityModel’ and wondered what’s the deal? In the documentation for working with a Secure Token Service (STS) you might have seen that this assembly is not part of the default deployment of your Windows Azure package, and that you’ll need to add the reference to your project and set the deployment behavior to deploy a local copy with the application…all good, right?
So you follow the instructions and still get the error. One reason for this is that you might be seeing an error caused by calling methods from the serviceRuntime which changes the appdomain of your webrole. In that case you should consider adding a Startup Task to load the WIF assembly in the Global Assembly Cache.
The basic logic is that in the startup of the web role you’ll need to inject a startup task to run the gacutil executable to do the installation. I created a startup folder in my web project to contain the scripts and files necessary, including a copy of gacutil.exe, a configuration file for it, and a batch file “IdentityGac.cmd” to contain the script commands needed.
I copied the gactuil.exe and config files from my C:\Program Files (x86)\Microsoft SDKs\Windows\v7.0A\Bin\x64 directory, and put them in the Startup folder. Next I created a cmd file (in notepad) with the commands to install the assembly into the GAC. I found a post that discusses how to create a script to do the installation on http://blogs.infosupport.com/adding-assemblies-to-the-gac-in-windows-azure/ where it installs the Windows Identity files and then sets the windows update service to on demand, installs the SDK, then runs gacutil.
@echo off sc config wuauserv start= demand wusa.exe "%~dp0Windows6.1-KB974405-x64.msu" /quiet /norestart sc config wuauserv start= disabled e:\approot\bin\startup\gacutil /if e:\Approot\bin\Microsoft.IdentityModel.dllI add these files to the Startup folder, and then open the properties for the 3 files and set the build action to none and “Copy to Output Directory” to Copy Always. This ensures that these files will be present in the deployed instance for my startup task. Next we edit the startup tasks in the Service Definition file, adding a section for <Startup>, and a <Task… to run our script file.
<?xml version="1.0" encoding="utf-8"?> <ServiceDefinition name="MplsKickSite.Azure" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceDefinition"> <WebRole name="MplsKickSite" vmsize="ExtraSmall"> <Sites> <Site name="Web"> <Bindings> <Binding name="Endpoint1" endpointName="Endpoint1" /> </Bindings> </Site> </Sites> <Endpoints> <InputEndpoint name="Endpoint1" protocol="http" port="80" /> </Endpoints> <Startup> <Task commandLine="Startup\IdentityGac.cmd" executionContext="elevated" taskType="simple"> </Task> </Startup> <Imports> <Import moduleName="Diagnostics" /> <Import moduleName="RemoteAccess" /> <Import moduleName="RemoteForwarder" /> </Imports> </WebRole> </ServiceDefinition>In Steve Marx’s post on Startup Task Tips & Tricks he suggests that when debugging a new startup task to set the taskType to background instead of simple so that it won’t prevent Remote Desktop from getting configured. If you’re interested to download the Startup folder I used I’ve uploaded a zip archive file with the files here.


No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Jialiang Ge (@jialge) posted [Sample of Apr 12nd] Enable static compression in Azure to the Microsoft All-In-One Code Framework blog on 4/12/2012:
Sample Download: http://code.msdn.microsoft.com/CSAzureEnableCompression-9f4d9b73
Today’s code sample demonstrates how to add new mime types for static compression in Windows Azure. It is written by Microsoft Escalation Engineer - Narahari Dogiparthi.
You can find more code samples that demonstrate the most typical programming scenarios by using Microsoft All-In-One Code Framework Sample Browser or Sample Browser Visual Studio extension. They give you the flexibility to search samples, download samples on demand, manage the downloaded samples in a centralized place, and automatically be notified about sample updates. If it is the first time that you hear about Microsoft All-In-One Code Framework, please watch the introduction video on Microsoft Showcase, or read the introduction on our homepage http://1code.codeplex.com/.
Introduction
Static compression is the feature that is shipped out of the box in IIS. Using static compression, developers/administrators can enable faster downloads of their web site static content like javascripts, text files, Microsoft office documents, html/htm files, cs files, etc. So, how can we make use of this feature when hosting the web application in Windows Azure? By default static compression is enabled in Windows Azure, however, there are only few mime types that will be compressed. This sample demonstrates adding new mime types for static compression.
Building the Sample
This sample can be run as-is without making any changes to it.
Running the Sample
- Open the sample on the machine where VS 2010, Windows Azure SDK 1.6 are installed
- Right click on the cloud service project i.e. CSAzureEnableCompression and choose Publish
- Follow the steps in publish Wizard and choose subscription details, deployment slots, etc. and enable remote desktop for all roles
- After successful publish, browse to a page that has javascript files and then login to Azure VM and verify that the cache directory has the compressed files.
Using the Code
To customize static compression settings in Windows Azure, you can use startup tasks. Below are the steps I have followed to successfully enable static compression for few of the mime types my application needed.
1. Configure following tag in Application’s web.config @Configuration/System.WebServer
<urlCompression doStaticCompression="true"/>2. Create iisconfigchanges.cmd file with required commands to customize ApplicationHost.config configuration of IIS
iisconfigchanges.cmd
%windir%\system32\inetsrv\appcmd.exe set config -section:system.webServer/httpCompression /+"staticTypes.[mimeType='application/x-javascript',enabled='True']" /commit:apphost
%windir%\system32\inetsrv\appcmd.exe set config -section:system.webServer/httpCompression /+"staticTypes.[mimeType='text/javascript',enabled='True']" /commit:apphost
%windir%\system32\inetsrv\appcmd.exe set config -section:system.webServer/httpCompression /+"staticTypes.[mimeType='application/vnd.openxmlformats-officedocument.wordprocessingml.document',enabled='True']" /commit:apphost
%windir%\system32\inetsrv\appcmd.exe set config -section:system.webServer/httpCompression /+"staticTypes.[mimeType='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet',enabled='True']" /commit:apphost
%windir%\system32\inetsrv\appcmd.exe set config -section:system.webServer/httpCompression /+"staticTypes.[mimeType='application/vnd.openxmlformats-officedocument.presentationml.presentation',enabled='True']" /commit:apphost
%windir%\system32\inetsrv\appcmd.exe set config -section:serverruntime /frequentHitThreshold:1 /commit:APPHOST
exit /b 0Above commands configures MIME types for javascripts, word documents (docx), Excel documents(xlsx), Powerpoint documents(pptx). If you need to compress any specific files other than mentioned above, find out the MIME types per your requirement and add similar commands to the file.
Note: I have changed frequentHitThreshold parameter since I could not see compression happening without explicitly specifying this parameter.
3. Add below startup task that will execute iisconfigchanges.cmd during startup of the rule. This configuration should be added in ServiceConfiguration.csdef under webrole/workerrole tag.<Startup> <Task commandLine="iisconfigchanges.cmd" executionContext="elevated" taskType="simple" /> </Startup>4. Add iisconfigchanges.cmd file to webrole/workerrole project
5. Configure below file properties for iisconfigchanges.cmd file , so that it will be copied to bin directory
Build Action : Content
Copy To Output Directory : Copy AlwaysMore Information
Caution: Compression settings should be tweaked carefully, It might result in undesired performance too if not configured properly. For example, images like png are already compressed and compressing these types again, will cause additional CPU on the system without any significant gain in the bandwidth. I recommend you to research and thoroughly test your application with the compression settings before you apply the changes to production. I recommend below blog entry for further reading on IIS7 compression.
IIS 7 Compression. Good? Bad? How much? http://weblogs.asp.net/owscott/archive/2009/02/22/iis-7-compression-good-bad-how-much.aspx

Jialiang Ge (@jialge) also posted [Sample of Apr 11st] Add registry entries to VMs running in Windows Azure programmatically to the Microsoft All-In-One Code Framework blog on 4/12/2011:
Sample download: http://code.msdn.microsoft.com/CSAzureAddRegistryKeysToVMs-75edd269
Today’s code sample demonstrates how to add registry entries to VMs running in Windows Azure programmatically. One of the common asks from developers is the ability to write to registry in Windows Azure. Startup tasks in Windows Azure can help you write to registry. This sample code will add the registry keys to Azure VM's.
The sample is written by Microsoft Escalation Engineer - Narahari Dogiparthi.
Introduction
One of the common asks from developers is the ability to write to registry in Windows Azure. Startup tasks in Windows Azure can help you write to registry. This sample code will add the registry keys to Azure VM's.
Building the Sample
This sample can be run as-is without making any changes to it.
Running the Sample
Open the sample on the machine where VS 2010, Windows Azure SDK 1.6 are installed.
Right click on the cloud service project i.e. CSAzureAddRegistryKeysToVMs and choose Publish.
Follow the steps in publish Wizard and choose subscription details, deployment slots, etc. and enable remote desktop for all roles.
After successful publish, login to Azure VM and verify that 3 registry keys(One for string, One for binary value, One for DWORD value) are created under HKEY_LOCAL_MACHINE\System\Test\Test1Using the Code
1) Create sample.reg file with required registry entries. For testing purposes, I’m using sample.reg file with below entries. In real world scenarios, you can create the registry file simply by exporting the section of registry settings you would like to add to Azure VM’s.
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\System\Test\Test1]
"New Binary Setting"=hex:42,69,6e,61,72,79,20,56,61,6c,75,65
"New DWORD Setting"=dword:00000001
"New String Setting"="Something"
This sample file adds values settings named “New Binary Setting”, “New DWORD Setting”, “New String Setting” and configures with above specified values.2) Add the sample.reg file to web role / worker role project as required.
3) Configure below file properties for sample.reg file , so that it will be copied to bin directory.
Build Action : Content
Copy To Output Directory : Copy Always4) Create addreg.cmd file with below code.
regedit /s sample.reg
exit /b 05) Add the addreg.cmd file to Web Role / Worker role as required.
6) Configure below file properties for addreg.cmd file, so that it will be copied to bin directory.
Build Action : Content
Copy To Output Directory : Copy Always7) Finally, define startup task in ServiceDefinition.csdef file by adding following block of configuration under <Webrole> / <WorkerRole> tag
<Startup> <Task commandLine="addreg.cmd" executionContext="elevated" taskType="simple"> </Task> </Startup>8) Deploy the application to cloud and you should have “New Binary Setting”, “New DWORD Setting”, “New String Setting” under HKEY_LOCAL_MACHINE\System\Test\Test1 path.
More Information
Below articles gives you additional details regarding adding, modifying, deleting registry sub keys, .reg file syntax http://en.wikipedia.org/wiki/.reg
How to add, modify, or delete registry subkeys and values by using a registration entries (.reg) file http://support.microsoft.com/kb/310516
Note: If you want to verify that settings are added properly, enable remote desktop connection and connect to VM to verify the settings. Below article can help you enable remote desktop option to your Windows Azure VM’s
How to connect to VM using Remote Desktop(RDP) on Windows Azure (Cloud) http://blogs.msdn.com/b/narahari/archive/2010/12/01/how-to-connect-to-vm-on-windows-azure.aspx
Himanshu Singh (@himanshuks, pictured below) posted ISV Blog Series: Guest Post by Founder and CEO of Fielding Systems on 4/11/2012:
The purpose of the Windows Azure ISV blog series is to highlight some of the accomplishments from the ISVs we’ve worked with during their Windows Azure application development and deployment. Today’s post, written by Fielding Systems Founder and CEO Shawn Cutter, describes how the company uses Windows Azure to power and deliver its web-based services for its Oil and Gas industry customers.
Fielding Systems provides two powerful web-based services for midstream and upstream oil and gas companies of all sizes that help operators streamline production activities and increase production output with field operations management, remote monitoring, and production analysis. Each application includes a fully-featured mobile version allowing all users access to their data and operations from any modern smartphone including iPhone, Android & Windows Phone.
FieldVisor is a field automation and data capture application that can be used to track everything that takes place in an oil and gas production operation. Users can track production, equipment, service, treatment history, tasks and many other facets of a production operation. FieldVisor is more heavily focused on manual data input to replace pen and paper field operations and providing robust analysis and reporting on that data. ScadaVisor monitors remote devices such as flow meters, pump-off controllers, tanks, compressors, PLC's, artificial lifts, and various other SCADA devices in real time. It is the only truly cloud-based service of its kind since it is supported by our own cloud-based communication and polling engine called VisorBridge. This gives Fielding Systems a definitive competitive advantage over all other hosted SCADA service providers.
The initial migration to Windows Azure resulted in minimal savings over the existing data center costs for rack space, power, backups, and secondary hot site colocation. However, since the migration, the costs continue to go down as we have been expanding our offerings and customer base.
Architecture
FieldVisor, FieldVisor Mobile, ScadaVisor, and ScadaVisor Mobile exist in Windows Azure as separate multi-tenant web applications with single-tenant SQL Azure databases for each of our customers. These applications are supported by a Central SSO Administration Application to manage all users, roles, security and some other application configuration along with a multi-threaded worker role for purposes of processing alarms and notifications, maintaining customer databases, and performing the remote data collection from field devices.
We currently utilize nearly every aspect of the Windows Azure cloud including:
- Compute Instances: multiple web and worker roles
- Blob Storage: Blob storage is used for site incremental upgrades and automated SQL Azure database backups using BacPac.
- Table Storage: Tables are used for centralized data reprocessing and performance counter data for complete system logging.
- Queue Storage: Queues are used for event scheduling, real time device data requests, automated notifications, and worker role management.
- SQL Azure: All customer application data is stored in single-tenant databases along with a few central core management databases that are multi-tenant.
- SQL Azure Reporting: Reporting in FieldVisor and ScadaVisor is supported by SQL Azure Reporting. Reports are run on-demand by users using the Report View ASP.NET control and also on user-defined schedules controlled by a worker role process that manages all scheduled reports.
- Caching: Caching is used for the session provider in each application along with cache support for each of the web applications. Caching is also utilized heavily to limit the load on each SQL Azure database.
We considered Table Storage for a number of processes while upgrading each application. Due to the complexity of data and the required existence of SQL Databases, we decided to utilize databases for all central processes but chose to adhere to a pub/sub model for background processing, database inserts, automated imports/exports, and remote device polling.
SSO / Central Multi-Threaded Worker Roles
Our custom Single Sign On (SSO) service along with all worker roles that process scheduled tasks, notifications, automated imports/exports, and anything else we need done reside on a few Small instances. Most of the actual work and processing that is done is performed as small units of work in SQL Azure, so the overhead required on these compute instances is low.
Applications
FieldVisor and ScadaVisor, along with their mobile versions, supporting web and OData services, are all housed on two Medium compute instances. Our multi-tenancy deployment process handles the rollouts and manages IIS to spin up new sites and services. The diagram depicts the single tenant databases for each application.
SQL Azure Reporting
Upon initial production deployment to Windows Azure, we were required to keep our own instance of SQL Server 2008 R2 Reporting Services running that handled the processing all reports for both FieldVisor and ScadaVisor. We have since moved all report processing over to SQL Azure Reporting and were one of the first companies to go to production with SQL Azure Reporting.
Worker Roles
All worker roles instances are designed to run in a multi-threaded environment where each task processor has its own thread with a single master thread on each instance that maintains all the other threads. The single master thread also functions as an enterprise master thread on one of the compute instances to ensure that there is one and only one decision maker that will determine what processes need to run and when. This worker role architecture was built to fill the void of a limitation of Windows Azure not providing SQL Agent or additional task scheduler to handle these types of scheduled tasks. The processes running on these worker roles provide both internal management functions and also customer facing services. Some examples of these processes include:
- Critical device alarm processing
- Running customer scheduled reports
- Internal health checks and reports
- Sending email/SMS notifications
- Database maintenance including re-indexing and blob backups
- Automated imports and exports for customers
The master scheduler utilizes Windows Azure Queues to submit each task or group of tasks to the queue for processing. The worker threads, running on multiple compute instances, monitor the various queues and pick up the tasks for processing. The multi-threaded nature of each instance allows us to maximize all resources on each instance and also allows for nearly infinite scalability on task processing going into the future. The Windows Azure Queues enable the worker roles to be resilient in the event of an instance going offline; those tasks are then placed back on a queue where they will be picked up and processed by another instance. Every single unit of work has been designed with idempotency in mind so that as each message is processed from a queue, the unit of work itself contains all of the data needed for each thread to process and if one of the workers should disappear, the unit of work can be picked up by any other worker instance without risk of data corruption.
Multi-Tenancy
During the migration to Windows Azure, we decided to convert each application to run in multi-tenant application mode rather than provisioning separate applications for each customers and each application. This decision was based on two key factors:
Increased maintenance and rollout times for each application for all customers
- Large amount of server resources required for each customer
Each application, during heavy usage, can consume a great deal of memory that would effectively consume all memory on even a Large instance if each customer essentially had its own IIS application for each service. We handle multi-tenancy through an additional data access layer that maps SQL Azure connections to appropriate databases based on the services available to a particular customer and based on the identity of the user. We currently host the core customer-facing services on two Medium instances and as the load increases during heavy use, additional instances can be brought up to share the services of processing during peak hours of the day. We monitor the performance using performance counters and leverage the Compute API to manage our services. For our services, we watch two key counters: CPU and memory usage.
We also created our own multi-application host deployment process and management layer that uses a worker role to monitor for changes in zip files on blob storage, and update applications when changes are detected. The process drastically reduced the administration and maintenance overhead of rolling out updates.
Windows Azure Worker and Web Role Sizing
We load-tested each application individually for diagnostic, performance, and compute instance sizing considerations prior to the complete application migration to Windows Azure. The Central SSO service and a handful of worker processes had already been running on two Small Compute instances with no issue or performance concerns. These processes were to be left alone since the number of requests per second on these instances is minimal and the majority of the processing involved simple, short bursts resulting in low IO and memory usage even at peak times. As more resources are needed, additional instances could be added in order to scale out the throughput.
For the application instances, several different configurations were tested to assess the correct configuration. The tests consisted of recording the user request patterns in each application and replaying those in Test Studio. The main configurations tested were 2-6 Small Compute Instances as compared 2-3 Medium Compute Instances. While Medium instances obviously contain more memory, there are also differences in network and IO capacity:
- Small: 100Mbps
- Medium: 200Mbps
These differences were reflected exponentially during heavy load testing. When generating 30-50 requests/second against a configuration with 6 Small Compute instances, requests would eventually get queued and timeouts would result. The Medium sized instances easily withstood heavy load testing and we feel that in the future, we can continue to scale out rather than up to Large instances. We also can break the Medium instances out so that they are handling separate services meaning we go from having four compute instances sharing the load of all services to having two sets of Medium instances with 50% of the services being hosted each set.
Conclusion
For Fielding Systems, nearly the entire Windows Azure stack is being utilized in our drive to focus entirely on building incredibly scalable oil and gas software services rather than worry about server capacity, backups, and administration. Before choosing to upgrade and move everything to Windows Azure, we looked at other cloud offerings. We saw the long term benefits of a Platform as the Service (PaaS) design and understood the clear advantage it had over simply adding and managing virtual machines in some remote data center. While our competition spends time and resources on managing their cost centers, we focus on improving our core technology: software. We are constantly looking at ways to further improve scale by leveraging Windows Azure more with increased use of Windows Azure Caching and Windows Azure Service Bus. The cloud is not just something we sell to our customers; we also use it internally for everything we can with services like Office 365 and Dynamics CRM. We are on the bleeding edge of technology and loving it.





Opstera (@Opstera) asserted their “… Cloud-Based AzureOps Provides the Industry's Most Comprehensive View of Cloud Application Operations; Monitors More Than 100 Million Windows Azure Metrics per Month” in an introduction to an Opstera Optimizes Cloud Application Performance for 100 Customers on Windows Azure press release of 4/11/2012:
Today, Opstera -- the only cloud-based Windows Azure operations management provider -- announced it has more than 100 customers using its AzureOps solution. The company reached this major milestone just three months after its inception in January 2012, demonstrating strong market demand for a new approach to health management and capacity optimization for cloud applications. Opstera's AzureOps solution monitors more than 100 million Windows Azure metrics per month and provides customers with the most comprehensive view of their entire cloud solution, including the underlying platform, the application, and the dependent third party cloud services. Executives from cloud services provider Cumulux founded Opstera based on real-world feedback from customers who needed better visibility into their cloud applications.
"Today, the cloud is a black box for many customers, so there is a growing need for better methods of monitoring the health of these applications to optimize operations and minimize downtime," said Opstera CEO Paddy Srinivasan. "Opstera's growth is evidence that customers want a cloud based management solution to give them more control over their Windows Azure applications."
Since AzureOps is a cloud-based management solution, customers can realize the benefits of increased visibility and control of their Windows Azure application immediately without installing or maintaining any software. This approach allows small and medium-sized organizations to have a deep level of insight over their application that was previously available to only large enterprises. The solution also provides automatic provisioning of servers, scaling up to meet increased demands during busy periods and scaling down again at off-peak times. This allows customers to benefit from the elastic nature of the cloud and save operational costs. In addition, AzureOps offers smart default settings based on workloads, so each customer can easily identify and monitor the parameters that are most relevant for their specific application.
Opstera co-founders Paddy Srinivansan and Ranjith Ramakrishnan have a proven track record of building a leading cloud company based on Microsoft Corp.'s Windows Azure. Their previous company, Cumulux, helped customers realize the benefits of SaaS computing by moving on-premises solutions into the cloud. Cumulux was twice recognized as Microsoft's "Cloud Partner of the Year" before the company was sold in 2011.
Opstera's AzureOps solution is available in five SKUs including Starter, Standard, Plus, Corporate, and Enterprise, starting at $50 per month. For more information, visit www.opstera.com.
About Opstera
Opstera is the only cloud-based operations management provider for Windows Azure. Opstera's AzureOps provides the industry's most comprehensive view of health management and capacity optimization, monitoring the underlying Windows Azure platform, the application itself, and the dependent cloud services. AzureOps provides enterprise grade functionality for optimizing application performance including auto-scaling, smart analytics, and proactive alerts and notifications. For more information, go to www.opstera.com, visit Facebook, or follow Opstera or on Twitter at @opstera.
<Return to section navigation list>
David Pallman described WorldSheet: A Shared Spreadsheet in the Cloud based on SignalR and Windows Azure in a 4/8/2012 post (missed when published):
WorldSheet (http://worldsheet.net)is a new sample I developed today that showcases SignalR combined with WindowsAzure. It’s a shared spreadsheet in the cloud that multiple people can connectto and edit in real-time. It can be used on desktop browsers as well as modern tabletsand smartphones.
To use worldsheet, simply browse to it (along with a few otherpeople, or on several browsers/devices) and start editing: everyone should beseeing the same view. Cell value changes are passed on when you move off thecell via the tab key, an arrow key, or clicking elsewhere in the spreadsheet.
SignalR
SignalR is an async signaling library that can be called by .NETclients as well as JavaScript clients. For web applications, it’s very useful forpushing out notifications to web clients in a multi-user setting. Although itisn’t finished yet and has some limitations today, it’s powerful, reliable, andeasy to use. Since real-time notifications are becoming more and more common inweb work, a first-class library for handling them in ASP.NET is a welcomeaddition.
To get started with SignalR, I read Scott Hanselman’s introductorypost on SignalR and was able to create an MVC4 application by following theinstructions without too much trouble. SignalR is out on GitHub but you can install itspieces in Visual Studio using the Library Package Manager (nuget).
From what I’ve been reading, SignalR is coming along wellbut isn’t completed yet and has some limitations. It doesn’t appear it’s readyto work in a scale-out (farm) scenario yet but that’s coming.
In a web client, you can get SignalR initialized with just alittle bit of JavaScript that also specifies a message processing function.$(function () {
// Proxy created on the fly
var chat = $.connection.chat;
// Declare a function on the chat hub so the server can invoke it
chat.addMessage = function (message) {
...process received message...
};
$("#broadcast").click(function () {
// Call the chat method on the server
});
// Start the connection
$.connection.hub.start();
});To send a message, you use code like this:
var chat = $.connection.chat;
chat.send("my message");As you can see, SignalRis short and simple to use.
SignalR on WindowsAzure
Having been able to see SignalR work I was eager to get itworking on Windows Azure. It won’t do so out of the box, but Clemens Vasters ofMicrosoft has created a module that makes SignalR work via the Windows AzureService Bus. Clemens’article is essential reading to make this work and theSignalR.WindowsAzureServiceBus module is also on GitHub.Again, my understanding is that this isn’t working well yet in a multiple serverinstance configuration so I confined my experimentation to a single Windows Azureinstance for the time being. That means, WorldSheet might occasionally not be available due to data center maintenance operations such as patching.
To use SignalR on Windows Azure, you need to add the SignalR.WindowsAzureServiceBusmodule to your solution, create a Service Bus namespace in the Windows Azureportal, and add some initialization code in your global.asax file’sApplication_Start method.
protected void Application_Start()
{
AreaRegistration.RegisterAllAreas();
RegisterGlobalFilters(GlobalFilters.Filters);
RegisterRoutes(RouteTable.Routes);
BundleTable.Bundles.RegisterTemplateBundles();
var config = AspNetHost.DependencyResolver.Resolve<IConfigurationManager>();
config.ReconnectionTimeout = TimeSpan.FromSeconds(25);
// TODO: specify your Serivce Bus access
AspNetHost.DependencyResolver.UseWindowsAzureServiceBus("{namespace}","{account}", "{key}", "{appname}", 2);
}My first attempts to get SignalR working on Windows Azure(working locally via the Windows Azure Simulation Environment) were disappointing:about one time in twenty the code would work, but most of the time I received TypeLoadExceptionson start-up that were difficult to make sense out of. The fact that itsometimes worked smacked of a race condition but I was having a hard timetracking it down. Success came when I realized that the application needs to referencethe SignalR library in the SignalR.WindowsAzureServiceBus module, not theversion of the library that nuget provides. Once that was in place, I hadsuccess every time I ran.
WorldSheet
Having gotten SignalR to be happy on Windows Azure, it wastime to build something. Chat programs seem to be really overdone, so I wantedto come up with something else. I came up with the idea of a shared Excel-likespreadsheet experience that multiple people could use simultaneously. I spentmost of today and tonight creating WorldSheet and it’s now live at http://worldsheet.net.
WorldSheet is wide open to anyone to use; if you want some semblanceof privacy to a smaller group, you can change the tab name (initially ‘default’)to something else only your parties would know.
WorldSheet on theClient
When a user moves off of a cell, it causes an onBlur eventthat causes a JavaScript function to run that sends out the update via SignalRto other connected parties. The MVC server app is also notified with an Ajaxcall and updates the copy of the spreadsheet in the Windows Azure CacheService. When a new user connects, they call the server to load the latest copyof the spreadsheet out of the cache.
function Cell_Changed(e) {
if (e === undefined) return;
var chat = $.connection.chat;
var tab = $('#tabname').val();
var id = e.id;
var value = $('#' + id).val();
chat.send(tab + "~" + id + '|' + value);
Update(id, value);
}To load a spreadsheet, the web client makes an Ajax call to the serverspecifying the tab name to load:
// Load a spreadsheet.
function Load() {
var name = $('#tabname').val();
if (name === '') {
name = "default";
$('#tabname').val(name);
}
var url = '/Home/Load/' + name + "/";
var request = {
name: name
};
$.ajax({
type: "POST",
url: url,
cache: false,
dataType: "json",
data: JSON.stringify(request),
contentType: "application/json; charset=utf-8",
success: function (result) {
if (result !== undefined && result !== null && result.status === "success") {
ClearSheet();
var chat = $.connection.chat;
var tab = $('#tabname').val();
chat.send(tab + "~*|" + result.data);
var id;
var value;
var values = result.data.split('|');
for (var i = 0; i < values.length; i += 2) {
id = values[i];
value = values[i + 1];
$('#' + id).val(value);
}
}
else {
alert('Sorry, the spreadsheet could not be retrieved from cloud cache');
}
},
error: function (error) {
alert("Sorry, communication with the server failed.");
}
});
}To pass on a cell update, this function is called:
// Update cell in spreadsheet.
function Update(id, value) {
var name = $('#tabname').val();
if (name === '') {
name = "default";
$('#tabname').val(name);
}
var url = '/Home/Update/' + name + "/";
var request = {
name: name,
cellId: id,
cellValue: value
};
$.ajax({
type: "POST",
url: url,
cache: false,
dataType: "json",
data: JSON.stringify(request),
contentType: "application/json; charset=utf-8",
success: function (result) {
if (result !== undefined && result !== null && result.status === "success") {
//alert('The cell has been updated.');
}
else {
alert("Sorry, the cell could not be updated in cloud cache"); // : " + error.responseText);
alert(error.status);
alert(error.error);
}
},
error: function (error) {
alert("Sorry, communication with the server failed.");
}
});
}WorldSheet on theServer
On the server, the HomeController of the MVC applicationuses the Windows Azure Cache Service to hold the spreadsheet data. It’s initializedwith this code and config:
static DataCacheFactory dataCacheFactory = new DataCacheFactory();
static DataCache dataCache = dataCacheFactory.GetDefaultCache();<dataCacheClients>
<dataCacheClient name="default">
<hosts>
<host name="worldsheet.cache.windows.net" cachePort="22233" />
</hosts>
<securityProperties mode="Message">
<messageSecurity
authorizationInfo="YWNzOmh0dHBzOi8vd29ybGR...WhOQXJ1UXVBPSZodHRwOi8vd29ybGRzaGVldC5jYWNoZS53aW5kb3dzLm5ldA==">
</messageSecurity>
</securityProperties>
</dataCacheClient>
</dataCacheClients>Putting the spreadsheet to or from the cache is easy thanksto the simple nature of the Windows Azure Cache Service API. Here’s thefunction to load a spreadsheet out of cache:
// Load a worksheet from storage.
[HttpPost]
public JsonResult Load(LoadRequestModel request)
{
LoadResponseModel response = new LoadResponseModel();
try
{
Document doc = dataCache.Get(request.name) as Document;
if (doc == null)
{
doc = new Document();
}
response.status = "success";
response.data = doc.DataString;
return Json(response);
}
catch (Exception ex)
{
response.status = "error";
response.error = ex.ToString();
}
return Json(response);
}And here’s the server method to update a cell of thespreadsheet whose value has changed:
// Update a cell.
[HttpPost]
public JsonResult Update(UpdateRequestModel request)
{
UpdateResponseModel response = new UpdateResponseModel();
try
{
Document doc = dataCache.Get(request.name) as Document;
if (doc == null)
{
doc = new Document();
}
if (request.cellId == "*")
{
doc.Clear();
}
else
{
doc.Add(request.cellId, request.cellValue);
}
dataCache.Put(request.name, doc);
response.status = "success";
}
catch (Exception ex)
{
response.status = "error";
response.error = ex.ToString();
}
return Json(response);
}The source code to WorldSheet can be downloaded here. When I havesome more time, I plan to make the application more robust and do some refactoringand clean-up of the code and put it up on CodePlex -- but for now, I’m satisfied with these results for a one-dayeffort.


Visual Studio LightSwitch and Entity Framework 4.1+
Beth Massi (@bethmassi) announced on 4/11/2012 an MSDN Webcast: What's New with LightSwitch in Visual Studio 11 on 5/11/2012 at 1:00 PM PDT:
Join me next month as I take you on a tour of the new features of LightSwitch in Visual Studio 11.
What's New with LightSwitch in Visual Studio 11
Friday, May 11, 2012 1:00 PM Pacific Time
Microsoft Visual Studio LightSwitch is the simplest way to build business applications and data services for the desktop and the cloud. LightSwitch contains several new features and enhanced capabilities in Visual Studio 11. In this demonstration-heavy webcast, we walk through the major new features, such as creating and consuming OData services, new controls and formatting, new features with the security system and deployment, and much more.
Hope you can join this webcast, it should be a lot of fun! In the meantime, enjoy some of these LightSwitch in Visual Studio 11 resources.
Articles:
- Enhance Your LightSwitch Applications with OData
- Creating and Consuming LightSwitch OData Services
- LightSwitch Architecture: OData
- New Business Types: Percent & Web Address
- New Formatting Support in LightSwitch
- Active Directory Group Support
- LightSwitch IIS Deployment Enhancements in Visual Studio 11
- Tips on Upgrading Your LightSwitch Applications to Visual Studio 11 Beta
- More articles coming out every week on the LightSwitch Team Blog!
Featured Extensions:
- LightSwitch Cosmopolitan Shell and Theme
- LightSwitch Extensibility Toolkit for Visual Studio 11 Beta
- More here
Featured Samples:
- Vision Clinic Walkthrough & Sample
- Contoso Construction - LightSwitch Advanced Sample (Visual Studio 11 Beta)
- More here
Community:
- LightSwitch in Visual Studio 11 Beta Forum
- LightSwitch Product Feedback
- LightSwitch Team Blog
- LightSwitch on Facebook
- LightSwitch on Twitter
You can find all of this plus more on the LightSwitch Developer Center.
That should keep you busy until the webcast next month
.


Return to section navigation list>
Windows Azure Infrastructure and DevOps
David Linthicum (@DavidLinthicum) asserted “While a service-oriented architectural approach could save you millions, the term's baggage almost guarantees a no” in a deck for his Perfect fit: The cloud and SOA -- but don't call it that post of 4/11/2012 to InfoWorld’s Cloud Computing blog:
The phone rings. "We're looking for a path to cloud computing for our enterprise that will reduce risks and cost, but also raise our ability to be flexible and agile," the voice on the phone pleads.
"How about using SOA as an architectural pattern to drive the movement to cloud computing?" I respond.
"Isn't SOA outdated?" the person immediately asks. "I thought somebody declared it dead."
There's a long pause. Then I respond: "OK, how about the ability to break up your existing enterprise assets as sets of logical services that can be formed and/or reformed into business solutions? That will provide us with a foundation to evaluate each service as something that may benefit from new cloud-based platforms and determine the best path for migration. This approach will also provide better access to your core information and critical business services, no matter where they reside."
"Wow, that sounds like exactly what we should be doing."
I make a note to myself: Remove "SOA" from any statement of work, but make sure we use a service-oriented architecture.
The fact of the matter is that the best and most effective way to move to the cloud for an enterprise whose technology platforms reflect decades of enterprise IT neglect is to use SOA as an approach and process. Just don't call it "SOA."
The problem is that SOA is a daunting and complex topic. There are only about 5,000 people on this planet (as best I can figure) who understand SOA at a functional level. That compares to about 500,000 to 1 million people (again, as best I can figure) who are charged with migrating core enterprise systems to cloud computing.
The benefits of usng service-oriented patterns are well known -- but not well understood. The ability to deal with systems as sets of services better prepares you for migration to both public and private cloud computing platforms. Indeed, it saves you millions of dollars in terms of avoiding costly mistakes that occur when you jump feet first into cloud computing technology without understanding the true requirements, and the correct path to change, for efficiency and agility.
In other words, it requires SOA. Just don't call it that.

Brent Stineman (@BrentCodeMonkey) posted Exceeding the SLA–Its about resilience on 4/10/2012:
Last week I was in Miami presenting at Sogeti’s Windows Azure Privilege Club summit. Had a great time, talked with some smart, brave, and generally great people about cloud computing and Windows Azure. But what really struck me was how little was out there about how to properly architect solutions so that they can take advantage of the promise of cloud computing.
What is an SLA?
So when folks start thinking about uptime, the first thing that generally pops to mind is the vendor service level agreements, or SLA’s.
An SLA, for lack of a better definition is a contract or agreement that provides financial penalties if specific metrics are not met. For cloud, these metrics are generally expressed as a percentage of service availability/accessibility during a given period. What this isn’t, is a promise that things will be “up”, only that when they aren’t, the vendor/provider has some type of penalty they will pay. This penalty is usually a reimbursement of fees you paid.
Notice I wrote that as “when” things fail, not if. Failure is inevitable. And we need to start by recognizing this.
What are after?
With that out of the way, we need to look at what we’re after. We’re not after “the nines”. What we’re wanting is to protect ourselves from any potential losses that we could incur if our solutions are not available.
We are looking for protection from:
- Hardware failures
- Data corruption (malicious & accidental)
- Failure of connectivity/networking
- Loss of Facilities
- <insert names of any of 10,000 faceless demons here>
And since these types of issues are inevitable, we need to make sure our solution can handle them gracefully. In other words, we need to design our solutions to be resilient.
What is resilience?
To take a quote from the Bing dictionary:
Namely we need solutions that can self recovery from problems. This ability to flex and handle outages and easily return to full functionality when the underlying outages are resolved are what make your solution a success. Not the SLA your vendor gave you.
If you were Netflix, you test this with their appropriately named “chaos monkey”.
How do we create resilient systems?
Now that is an overloaded question and possibly a good topic for someone doctoral thesis. So I’m not going to answer that in today’s blog post. What I’d like to do instead of explore some concepts in future posts. Yes, I know I still need to finish my PHP series. But for now, I can at least set things up.
First off, assume everything can fail. Because at some point or another it will.
Next up, handle errors gracefully. “We’re having technical difficulties, please come back later” can be considered an approach to resilience. Its certainly better then a generic 404 or 500 http error.
Lastly, determine what resilience is worth for you. While creating a system that will NEVER go down is conceivably possible, it will likely be cost prohibitive. So you need to clear understand what you need and what you’re willing to pay for.
For now, that’s all I really wanted to get off my chest. I’ll publish some posts over the next few weeks that focus on some 10,000 foot high options for achieving resilience. Maybe after that, we’ can look at how these apply to Windows Azure specifically.


Patrick Thibodeau (@DCgov) asserted “Forrester Research forecast sees hardware spending lagging; IT hiring outlook mixed” in a deck for his Emerging software tools help boost IT spending projections article of 4/6/2012 for ComputerWorld (missed when published):
Overall U.S. tech spending is forecast to grow by 7.1% this year and then by 7.4% in 2013, according to Forrester Research.
The strongest growth area will be software management tools, and much of that growth will come from cloud-based products.
Overall financial management, human resources management, ePurchasing, CRM and business intelligence software will collectively grow by 11.4% through 2011, and 12% next year, Forrester said.
Some hot new software categories are emerging from these broad software management areas.
These include case management tools, automated spend analysis, services procurement, supplier risk and performance management, services procurement, as well as talent and recruitment management software tools, according to Forrester.
Software in these categories will grow by 15% to 20% both this year and next, with most purchases for software as a service products, the researcher projected.
"The problems that technology is being expected to solve are expanding," said Andrew Bartels, an analyst at Forrester. The emerging tools are used to manage areas that, in the past, lacked strong technical solutions.
Case management software is used to manage a social service case or an insurance case. The tools are designed to bring together all relevant information a user needs to manage a case. They also analytical capabilities and the ability to work with other people.
"The technology that's available has a better fit against the unsolved business problems," said Bartels.
Supplier risk management tools allow a purchasing department, or line of business, to have in one place all the information, such as orders and history of business, about any of its suppliers.
The risk management systems draw on third parties to check the financial condition of a supplier, and can even provide data on non-financial risk factors, such as environmental or social responsibility ratings, said Bartels.
Computer equipment spending growth this year will be 4.5%, less than half of what it was last year, said Forrester. Strong hardware spending over the last two years has given most firms the capacity they need.
Hardware spending will rebound in 2013, rising to 8.4%, Forrester predicts.
Overall IT spending next year will be $1,266 billion on all goods, services and staff.
The largest categories are IT salaries accounting for $241 billion, and software at $232 billion. Computer equipment spending will be $92 billion.
What isn't growing fast is IT hiring.
Forrester estimates that IT staffs grew by only 0.3% last year, although salary and benefit increases brought up spending on staff to more than 4%.
Hiring should grow by 2% this year and then to 4% in 2013. Competition for workers will cause compensation to rise, which will increase staff spending to 7.2% next year.
The IT job market growth is either strong or weak, depending on what government data is used. Differences in IT job estimates are based on the decisions analysts make on what labor categories to include or not include in the estimate.
TechServe Alliance, which tracks government data monthly says that 15,000 IT jobs were added in March out of the 120,000 new jobs reported by the government. TechServe estimates the IT workforce now stands at 4.14 million.
Janco Associates, a research firm that tracks IT employment, looks a narrower segment of IT jobs, and reported a net increase of 4,900 seasonally adjusted jobs IT jobs in March.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Accenture (@accenture)/Avenade “Signs agreement with Microsoft Corp. to provide comprehensive Windows Azure design, delivery and management services in collaboration with Microsoft-specialist, Avanade” introduces a Accenture to Become First Global Technology Services Provider to Deliver End-to-End Public Cloud Solution on Windows Azure press release of 4/10/2012:
Accenture and Microsoft Corp. have signed an agreement that enables Accenture to provide clients with an end-to-end public cloud solution on the Windows Azure platform, marking the first time clients can contract for design, delivery and ongoing management services of applications hosted in the cloud on Windows Azure from a single global technology services provider.
The agreement extends to Avanade, a provider of business technology solutions and managed services, and enables both Accenture and Avanade to sell, host and deliver Windows Azure services to clients. Avanade is a majority-owned subsidiary of Accenture.
Under the agreement, Accenture will expand its infrastructure outsourcing options to include Platform-as-a-Service (PaaS) services (and Infrastructure-as-a-Service (IaaS) as it becomes available) from Windows Azure. Accenture and Avanade clients are now able to sign a single contract for the delivery and running of cloud services on Windows Azure to receive one-stop provisioning and monitoring through Accenture. The goal is to help make it quicker and easier to adopt the Windows Azure platform and drive benefits such as increased speed-to-market and agility, better collaboration across organizational boundaries, more modernized application portfolios, and a greater ability to manage variable demand capacity needs.
Doug Hauger, general manager, Windows Azure Business Development, at Microsoft Corporation, said, “Accenture and Avanade are key Microsoft global services providers for the Windows Azure platform in the enterprise. They offer clients a combination of market-leading cloud vision, industry insight, business acumen and delivery skills. Microsoft’s long-standing relationship with Accenture and Avanade creates a powerful team that can help customers advance their cloud strategy with Windows Azure.”
Adam Warby, Avanade CEO, said, “This agreement provides us with the unprecedented ability to deliver a full-range of services and solutions that reinforce the value of Windows Azure as the leading enterprise cloud platform. With more certified Windows Azure architects than any other Microsoft partner, coupled with our unique insights and innovation and integrated global delivery capabilities, we are able to help organizations quickly migrate to Windows Azure and realize business results faster.”
Accenture and Avanade have collaborated for more than two years to provide solutions for enterprise-ready public and private cloud solutions on the Windows Azure platform, and integrate them within the hybrid cloud environments used by clients. The companies have the largest number of certified Windows Azure professionals(1)dedicated to the platform and have spent more than 170,000 hours in the development of projects, delivering more than 40 Windows Azure projects for clients in 2011.
The agreement to deliver end-to-end public cloud solutions with Windows Azure is one in a series of recent strategic efforts between Microsoft and Accenture/Avanade. For example, Avanade and Microsoft are driving innovation in areas such as mobile enterprise and SQL Server solutions. Initiatives like these reinforce the unique relationship Accenture and Avanade have with Microsoft to deliver enterprise-class solutions powered by Microsoft technology.
(1)According to Microsoft official certification records, as of September 1, 2011, Accenture and Avanade combined have certified the largest number of individuals across all Worldwide Enterprise Partner Alliances in the following capabilities and technologies: Application Development on the Windows Azure Platform
About Accenture
Accenture is a global management consulting, technology services and outsourcing company, with more than 246,000 people serving clients in more than 120 countries. Combining unparalleled experience, comprehensive capabilities across all industries and business functions, and extensive research on the world’s most successful companies, Accenture collaborates with clients to help them become high-performance businesses and governments. The company generated net revenues of US$25.5 billion for the fiscal year ended Aug. 31, 2011. Its home page is www.accenture.com .
SOURCE: Accenture


There’s no definitive mention of Accenture/Avenade installing WAPAs in their data centers, but it certainly sounds like a repetition of Microsoft’s previous agreement with Fujitsu. See article below.
Gavin Clarke (@gavin_clarke) posted Microsoft-Accenture venture to fluff Azure clouds to The Channel Register on 4/10/2012:
Hope finally floats for Redmond
Microsoft’s Windows Azure cloud is leaking out of Redmond through a joint venture with Accenture.
Windows' desktop and server cloud computing outfit has signed an agreement for Accenture and its Avanade subsidiary to become just the second and third companies to sell, host and deliver Windows Azure services to customers.
Accenture will initially expand its IT outsourcing options to include Platform-as-a-Service (PaaS) on Windows Azure followed by the Amazon-like Infrastructure-as-a-Service (IaaS) “as it becomes available", Tuesday’s announcement said.
“Accenture and Avanade clients are now able to sign a single contract for the delivery and running of cloud services on Windows Azure to receive one-stop provisioning and monitoring through Accenture,” the companies said.
Accenture and Avanade will provide design, delivery and ongoing management services.
Microsoft finally picked a strategy by the middle of 2010 when it grandly announced plans at its prestigious partner conference that summer for the development of a Windows Azure appliance by the end of that year – with Dell, Hewlett-Packard, Fujitsu and eBay as early adopters. Dell said it would have appliances running in its data centres by January 2011.
The plan was to sell servers loaded with the Windows Azure elastic computing and storage software, to be installed in customer’s data centres, as well as to sell hosted services from PC makers and Windows Azure consulting services.
But the appliances and services missed their deadlines. And while Microsoft tried to convince the world that Windows Azure appliances really did exist by conducting a series of trials, Dell and HP embraced the open-source OpenStack and the VMware alternatives. Dell last month announced the European availability of its OpenStack PowerEdge bundle, running Ubuntu Linux, in Europe.
In 2011, HP’s ex-chief executive Leo Apotheker actually backed away from his company’s commitment to Windows Azure. When asked by The Reg whether HP’s still forthcoming cloud would float on Azure, per the announcement of 2010, he declined to comment.
OpenStack has attracted a huge industry following, with nearly 120 corporate contributors since it was unveiled by Nasa and Rackspace also in summer 2010. US telco giant AT&T became the latest sign-up in January this year as an OpenStack contributor.
So far, it seems just Fujitsu has delivered on that original 2010 announcement by Microsoft. The server-and-services part of the company launched its Global Cloud Platform on Windows Azure running in its Japan data centre in August 2011.
Now, Microsoft’s consulting partner Accenture and its subsidiary Avanade – a joint venture formed between the two companies in 2000 – joins Fujitsu in the Azure cloud.
Adam Warby, Avanade chief executive, said in a statement about the Windows Azure agreement: “With more certified Windows Azure architects than any other Microsoft partner, coupled with our unique insights and innovation and integrated global delivery capabilities, we are able to help organisations quickly migrate to Windows Azure and realise business results faster.”



<Return to section navigation list>
Cloud Security and Governance

<Return to section navigation list>
Cloud Computing Events
Richard Conway (@azurecoder) announced Agile, Continuous Integration and Windows Azure on 4/22/2012:
Recently our friends at Blush Packages raised the bar with a great implementation of TeamCity build for an Azure project they’re consulting on. We will be running an intermediate day course on Azure for the Enterprise which will comprise of how to make an enterprise ready application. The course will be delivered at the behest of Microsoft who are sponsors. It will probably take place within the next four weeks and we will have the following agenda:
- Introduction to TFS Preview: Using TFS Preview to build an agile project in Azure
- Development of a sample application using web/worker roles
- Adding security using SQL Azure and Membership
- Integration of Diagnostics capture for trace, exceptions and logs
- Resilience and autoscaling with Enterprise Application Blocks
- Automating common deployment tasks with Cerebrata Powershell CmdLets
- Using mstest, msbuild and TFS to make a CI server
Feel free to leave a comment here if you’re interested in attending. For updates on this follow @ukwaug or @azurecoder

<Return to section navigation list>
Other Cloud Computing Platforms and Services
Simon Munro (@simonmunro) asserted AWS leads in PaaS v.Next in a 4/12/2012 post:
One of the most popular posts on CloudComments is the year old Amazon Web Services is not IaaS, mainly because people search for AWS IaaS and it comes up first. It does illustrate the pervasiveness of the IaaS/PaaS/SaaS taxonomy despite it’s lack of clear and agreed definition — people are, after all, searching for AWS in the context of IaaS.
Amazon, despite being continually referred to by analysts and the media as IaaS has avoided classifying itself as ‘just’ IaaS and specifically avoids trying to be placed in the PaaS box. This is understandable as many platforms that identify themselves as PaaS, such as Heroku, run on AWS and the inferred competition with their own customers is best avoided. As covered by ZDnet earlier this year,
“We want 1,000 platforms to bloom,” said Vogels, echoing comments he made at Cloud Connect in March, before explaining Amazon has “no desire to go and really build a [PaaS].”
(which sort of avoids directly talking about AWS as PaaS).
As an individual with no affiliation with analysts, standards organisations and ‘leaders’ who spend their days putting various bits of the cloud in neat little boxes, I have no influence (or desire to influence) the generally accepted definition of IaaS or PaaS. It is, after all, meaningless and tiresome, but the market is still led by these definitions and understanding AWSs position within these definitions is necessary for people still trying to figure things out.
To avoid running foul of some or other specific definition of what a PaaS is, I’ll go ahead and call AWS PaaS v.Next. This (hopefully) implies that AWS is the definition for what PaaS needs to be and, due to their rapid innovation, are the ones to look at for what it will become. Some of my observations,
- AWS is releasing services that are not only necessary for a good application platform, but nobody else seems to have (or seem to be building). Look at Amazon DynamoDB and Amazon CloudSearch for examples of services that are definitely not traditional infrastructure but are fundamental building blocks of modern web applications.
- AWS CloudFormation is the closest thing to a traditional PaaS application stack and although it has some gaps, they continue to innovate and add to the product.
- Surely it is possible to build an application platform using another application platform? Amazon Web Services (the clue being in the ‘Web Services’ part of the name) provides services that, in the context of modern application architectures, are loosely coupled, REST based and fit in perfectly well with whatever you want to build on it. It doesn’t make it infrastructure (there is no abstraction from tin), it makes it platform services which are engineered into the rest of the application. Heroku, for example, is a type of PaaS running on the AWS application platform and will/should embrace services such as DynamoDB and CloudSearch — architecturally I see no problem with that.
- The recent alignment of Eucalyptus and CloudStack to the AWS API indicates that AWS all but owns the definition of cloud computing. The API coverage that those cloud stacks have supports more of the infrastructure component for now and I would expect that over time (as say Eucalyptus adds a search engine) that they would continue to adopt the AWS API and therefore the AWS definition of what makes a platform.
What of the other major PaaS players (as put into neat little boxes) such as Windows Azure and Google App Engine? Well it is obvious that they are lagging and are happy (relieved?), for now, that AWS is not trying to call itself PaaS. But the services that are being added at such a rapid rate to AWS make them look like less and less attractive platforms. Azure has distinct advantages as a purer PaaS platform, such as how it handles deployments and upgrades, and Azure has a far better RDBMS in SQL Azure. But how do application developers on Azure do something simple like search? You would think that the people who built Bing would be able to rustle up some sort of search service — it is embarrassing to them that AWS built a search application platform first. (The answer to the question, by the way, is ‘Not easily’ — Azure developers have to mess around with running SOLR on Java in Azure). How many really useful platform services does AWS have to release before Microsoft realises that AWS has completely pwned their PaaS lunch?
I don’t know what the next platform service is that AWS will release, but I do know two three things about it. Firsty, it will be soon. Secondly it will be really useful, and lastly, it won’t even be in their competitors’ product roadmap. While there is still a lot to be done on AWS and many shortcomings in their services to application developers, to me it is clear that AWS is taking the lead as a provider of application platform services in the cloud. They are the leaders in what PaaS is evolving into — I’ll just call it PaaS v.Next


Jeff Barr (@jeffbarr) described Amazon CloudSearch - Start Searching in One Hour for Less Than $100 / Month in a 4/12/2012 post:
Continuing along in our quest to give you the tools that you need to build ridiculously powerful web sites and applications in no time flat at the lowest possible cost, I'd like to introduce you to Amazon CloudSearch. If you have ever searched Amazon.com, you've already used the technology that underlies CloudSearch. You can now have a very powerful and scalable search system (indexing and retrieval) up and running in less than an hour.
You, sitting in your corporate cubicle, your coffee shop, or your dorm room, now have access to search technology at a very affordable price. You can start to take advantage of many years of Amazon R&D in the search space for just $0.12 per hour (I'll talk about pricing in depth later).
What is Search?
Search plays a major role in many web sites and other types of online applications. The basic model is seemingly simple. Think of your set of documents or your data collection as a book or a catalog, composed of a number of pages. You know that you can find the desired content quickly and efficiently by simply consulting the index.Search does the same thing by indexing each document in a way that facilitates rapid retrieval. You enter some terms into a search box and the site responds (rather quickly if you use CloudSearch) with a list of pages that match the search terms.
As is the case with many things, this simple model masks a lot of complexity and might raise a lot of questions in your mind. For example:
- How efficient is the search? Did the search engine simply iterate through every page, looking for matches, or is there some sort of index?
- The search results were returned in the form of an ordered list. What factor(s) determined which documents were returned, and in what order (commonly known as ranking)? How are the results grouped?
- How forgiving or expansive was the search? Did a search for "dogs" return results for "dog?" Did it return results for "golden retriever," or "pet?"
- What kinds of complex searches or queries can be used? Does the result for "dog training" return the expected results. Can you search for "dog" in the Title field and "training" in the Description?
- How scalable is the search? What if there are millions or billions of pages? What if there are thousands of searches per hour? Is there enough storage space?
- What happens when new pages are added to the collection, or old pages are removed? How does this affect the search results?
- How can you efficiently navigate through and explore search results? Can you group and filter the search results in ways that take advantage of multiple named fields (often known as a faceted search).
Needless to say, things can get very complex very quickly. Even if you can write code to do some or all of this yourself, you still need to worry about the operational aspects. We know that scaling a search system is non-trivial. There are lots of moving parts, all of which must be designed, implemented, instantiated, scaled, monitored, and maintained. As you scale, algorithmic complexity often comes in to play; you soon learn that algorithms and techniques which were practical at the beginning aren't always practical at scale.
What is Amazon CloudSearch?
Amazon CloudSearch is a fully managed search service in the cloud. You can set it up and start processing queries in less than an hour, with automatic scaling for data and search traffic, all for less than $100 per month.CloudSearch hides all of the complexity and all of the search infrastructure from you. You simply provide it with a set of documents and decide how you would like to incorporate search into your application.
You don't have to write your own indexing, query parsing, query processing, results handling, or any of that other stuff. You don't need to worry about running out of disk space or processing power, and you don't need to keep rewriting your code to add more features.
With CloudSearch, you can focus on your application layer. You upload your documents, CloudSearch indexes them, and you can build a search experience that is custom-tailored to the needs of your customers.
How Does it Work?
The Amazon CloudSearch model is really simple, but don't confuse simple, with simplistic -- there's a lot going on behind the scenes!Here's all you need to do to get started (you can perform these operations from the AWS Management Console, the CloudSearch command line tools, or through the CloudSearch APIs):
- Create and configure a Search Domain. This is a data container and a related set of services. It exists within a particular Availability Zone of a single AWS Region (initially US East).
- Upload your documents. Documents can be uploaded as JSON or XML that conforms to our Search Document Format (SDF). Uploaded documents will typically be searchable within seconds. You can, if you'd like, send data over an HTTPS connection to protect it while it is transit.
- Perform searches.
There are plenty of options and goodies, but that's all it takes to get started.
Amazon CloudSearch applies data updates continuously, so newly changed data becomes searchable in near real-time. Your index is stored in RAM to keep throughput high and to speed up document updates. You can also tell CloudSearch to re-index your documents; you'll need to do this after changing certain configuration options, such as stemming (converting variations of a word to a base word, such as "dogs" to "dog") or stop words (very common words that you don't want to index).
Amazon CloudSearch has a number of advanced search capabilities including faceting and fielded search:
Faceting allows you to categorize your results into sub-groups, which can be used as the basis for another search. You could search for "umbrellas" and use a facet to group the results by price, such as $1-$10, $10-$20, $20-$50, and so forth. CloudSearch will even return document counts for each sub-group.
Fielded searching allows you to search on a particular attribute of a document. You could locate movies in a particular genre or actor, or products within a certain price range.
Search Scaling
Behind the scenes, CloudSearch stores data and processes searches using search instances. Each instance has a finite amount of CPU power and RAM. As your data expands, CloudSearch will automatically launch additional search instances and/or scale to larger instance types. As your search traffic expands beyond the capacity of a single instance, CloudSearch will automatically launch additional instances and replicate the data to the new instance. If you have a lot of data and a high request rate, CloudSearch will automatically scale in both dimensions for you.Amazon CloudSearch will automatically scale your search fleet up to a maximum of 50 search instances. We'll be increasing this limit over time; if you have an immediate need for more than 50 instances, please feel free to contact us and we'll be happy to help.
The net-net of all of this automation is that you don't need to worry about having enough storage capacity or processing power. CloudSearch will take care of it for you, and you'll pay only for what you use.
Pricing Model
The Amazon CloudSearch pricing model is straightforward:You'll be billed based on the number of running search instances. There are three search instance sizes (Small, Large, and Extra Large) at prices ranging from $0.12 to $0.68 per hour (these are US East Region prices, since that's where we are launching CloudSearch).
There's a modest charge for each batch of uploaded data. If you change configuration options and need to re-index your data, you will be billed $0.98 for each Gigabyte of data in the search domain.
There's no charge for in-bound data transfer, data transfer out is billed at the usual AWS rates, and you can transfer data to and from your Amazon EC2 instances in the Region at no charge.
Advanced Searching
Like the other Amazon Web Services, CloudSearch allows you to get started with a modest effort and to add richness and complexity over time. You can easily implement advanced features such as faceted search, free text search, Boolean search expressions, customized relevance ranking, field-based sorting and searching, and text processing options such as stopwords, synonyms, and stemming.
CloudSearch Programming
You can interact with CloudSearch through the AWS Management Console, a complete set of Amazon CloudSearch APIs, and a set of command line tools. You can easily create, configure, and populate a search domain through the AWS Management Console.Here's a tour, starting with the welcome screen:
You start by creating a new Search Domain:
You can then load some sample data. It can come from local files, an Amazon S3 bucket, or several other sources:
Here's how you choose an S3 bucket (and an optional prefix to limit which documents will be indexed):
You can also configure your initial set of index fields:
You can also create access policies for the CloudSeach APIs:
Your search domain will be initialized and ready to use within twenty minutes:
Processing your documents is the final step in the initialization process:
After your documents have been processed you can perform some test searches from the console:
The CloudSearch console also provides you with full control over a number of indexing options including stopwords, stemming, and synonyms:
CloudSearch in Action
Some of our early customers have already deployed some applications powered by CloudSearch. Here's a sampling:
- Search Technologies has used CloudSearch to index the Wikipedia (see the demo).
- NewsRight is using CloudSearch to deliver search for news content, usage and rights information to over 1,000 publications.
- ex.fm is using CloudSearch to power their social music discovery website.
- CarDomain is powering search on their social networking website for car enthusiasts.
- Sage Bionetworks is powering search on their data-driven collaborative biological research website.
- Smugmug is using CloudSearch to deliver search on their website for over a billion photos.
As you can see, these early applications represent a very diverse set of use cases. How do you plan to use Amazon CloudSearch? Leave me a comment and let us know!
Interested in learning more? To learn more, please visit the Amazon CloudSearch overview page and watch a video that shows how to build a search application using Amazon CloudSearch. You can also sign up for the Introduction To Amazon CloudSearch webinar on May 10.


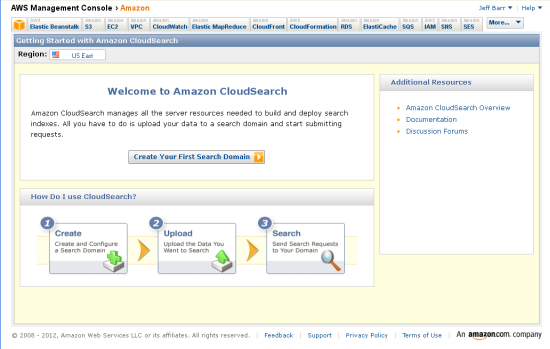
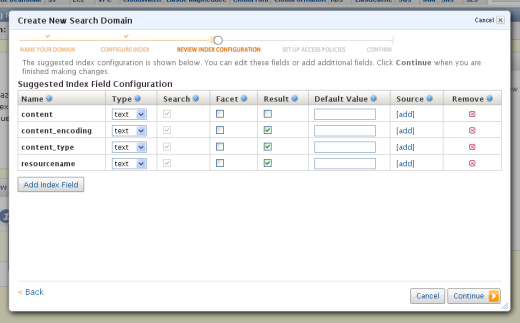
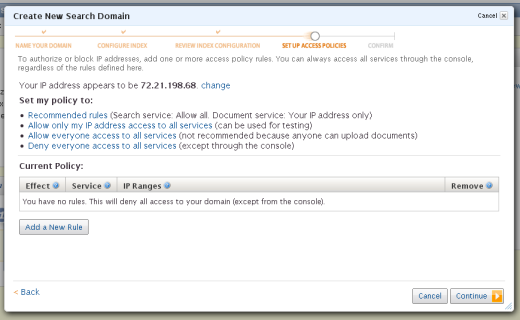


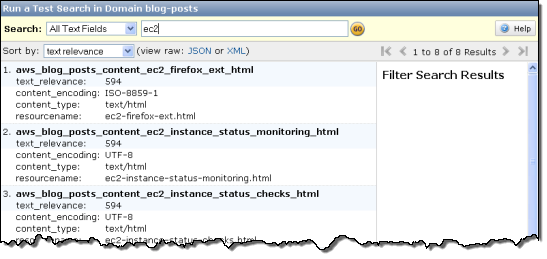
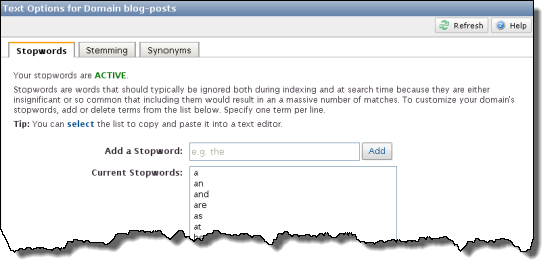
Werner Vogels (@werner) adds his spin with Expanding the Cloud – Introducing Amazon CloudSearch on 4/12/2012:
Today Amazon Web Services is introducing Amazon CloudSearch, a new web service that brings the power of the Amazon.com’s search technology to every developer. Amazon CloudSearch provides a fully-featured search engine that is easy to manage and scale. It offers full-text search with features like faceting and user-defined rank functions. And like most AWS services, Amazon CloudSearch scales automatically as your data and traffic grow, making it an easy choice for applications small to large. With Amazon CloudSearch, developers just create a Search Domain, upload data, and start querying.
Why Search?
Search is an essential part of many of today's cloud-centric applications. While in our daily lives we are mostly familiar with the search functionality offered by web search, there are in fact many more cases where search is a fundamental component of an application. Search is a much broader technology than just the indexing of large collections of web pages. Many organizations have large collections of documents, structured and unstructured, that can benefit from a specialized search service. With the rise of the App developer culture there is an increasing number of consumer data sources that cannot be simply queried with a web search engine. Using specialized ranking functions these apps can give their customers a highly specialized search experience.
And increasingly, search is applied to data that, though called a "document" for the purposes of search, is really just a record in a database or an object in a NoSQL system. On the query side, we are used to seeing search results as users, but search results are increasingly being used at the core of complex distributed systems where the results are consumed by machines, not people.
With these applications in mind, our customers have told us that a cloud-based managed search service is high on their wish lists. Their main motivation is that existing search technologies, both commercial and open source, have proven to be hard to manage and complex to configure.
Amazon CloudSearch will have democratization effect as it offers features that have been out of reach for many customers. With Amazon CloudSearch, a powerful search engine is now in the hands of every developer, at our familiar low prices, using a pay-as-you-go model. It will allow developers to improve functionality of their products, at lower costs with almost zero administration. It is very simple to get started; customers can create a Search Domain, upload their documents, and can immediately start querying.
How it Works
Developers set up a Search Domain -- a set of resources in AWS that will serve as the home for one collection of data. Developers then access their domain through two HTTP-based endpoints: a document upload endpoint and a query endpoint. As developers send documents to the upload endpoint they are quickly incorporated into the searchable index and become searchable.
Developers can upload data either through the AWS console, from the command-line tools, or by sending their own HTTP POST requests to the upload endpoint.
There are three features that make it easy to configure and customize the search results to meet exactly the needs of the application.
Filtering: Conceptually, this is using a match in a document field to restrict the match set. For example, if documents have a "color" field, you can filter the matches for the color "red".
Ranking: Search has at least two major phases: matching and ranking. The query specifies which documents match, generating a match set. After that, scores are computed (or direct sort criterion is applied) for each of the matching documents to rank them best to worst. Amazon CloudSearch provides the ability to have customized ranking functions to fine tune the search results.
Faceting: Faceting allows you to categorize your search results into refinements on which the user can further search. For example, a user might search for ‘umbrellas’, and facets allow you to group the results by price, such as $0-$10, $10-$20, $20-$40, etc. Amazon CloudSearch also allows for result counts to be included in facets, so that each refinement has a count of the number of documents in that group. The example could then be: $0-$10 (4 items), $10-$20 (123 items), $20-$40 (57 items), etc.
For more information on the different configuration possibilities visit the Amazon CloudSearch detail page.
Automatic Scaling
Amazon CloudSearch is itself built on AWS, which enables it to handle scale.

Amazon CloudSearch supports both horizontal and vertical scaling. The main search index is kept in memory to ensure that requests can be served at very high rates. As developers add data, CloudSearch increases either the size of your underlying node or it increases the number of nodes in the cluster. To handle growing request rates, the service autoscales the number of instances handling queries.
Amazon CloudSearch is based on more than a decade of developing high quality search technologies for Amazon.com. It has been developed by A9, the Amazon.com subsidiary that focuses on search technologies. The technology that is used at all the different places where you can search on Amazon.com is also at the core of at Amazon CloudSearch.
Summary
With the launch of Amazon CloudSearch the Amazon Web Services remove yet another pain point for developers. Almost every application these days needs some form of search and as such every developer has to spend significant time implementing it. With Amazon CloudSearch developers can now simply focus on their application and leave the management of search to the cloud.
For more information see the Amazon CloudSearch detail pages, the Amazon CloudSearch Developer Guide and the posting on the AWS developer blog.
You can sign up for the Introduction To Amazon CloudSearch webinar on May 10.


Adron Hall (@adron) reported Cloud Foundry 1 Year Anniversary & New Bits (Code Included) on 4/11/2012:
Today was the 1 year anniversary for the Cloud Foundry Open Source PaaS Project. For info on what PaaS is, especially related to open source and related to Cloud Foundry check out my 5 part series at New Relic’s Blog; Part 1, Part 2, Part 3.1, Part 3.14159265, Part 4, and Part 5 (which I know, it is really a 6 part series).
Updates, Updates, and More Updates!
Today was pretty cool and jam packed with code & information. There are a load of updates in the Cloud Foundry Repository now.
One of the big parts of the new features released today, isn’t so much a feature, but an entire open source project based around actually building & deploying an entire Cloud Foundry PaaS Environment called BOSH. Here’s my takeaway notes about this project, what it does, and how it can help Cloud Foundry usage.
BOSH (https://github.com/cloudfoundry/bosh.git)
The first thing to do, when learning about and using BOSH is to hit the groups:
- BOSH Users Group
- BOSH Developers
- and VCAP Dev if you want to follow the Cloud Foundry Development too.
What is it?
BOSH is a YAML based Cloud Foundry deployment tool. It provides a way to deploy a multiple image machine into a new Cloud Foundry environment. These images, just basic VMs, are referred to in the BOSH System as Stem Cells.
There is more to learn about BOSH, but for now suffice it to say there is some serious potential in what it enables for building out a Cloud Foundry Environment. Up until now this process was a manual installation effort which would take take a lot of energy and take an long time.
Cloud Foundry Additions?
There are a lot of Cloud Foundry changes that are in the works and a lot that went in. However, from an external point of view, there isn’t a lot of visible changes. No new user interface or anything like that. The biggest changes have been around stability, scaling, deployment, and other core capabilities.
For further information and news on the release, check out some of these write ups:
- http://siliconangle.com/blog/2012/04/11/cloud-foundry-team-announces-new-deployment-tool-called-bosh/
- http://www.marketwire.com/press-release/cloud-foundry-ecosystem-celebrates-first-anniversary-nyse-vmw-1642701.htm
- http://www.zdnet.com/blog/open-source/vmware-cloud-foundry-paas-will-be-the-linux-of-the-cloud/10754
- http://www.zdnet.com/blog/btl/vmware-cto-describes-cloud-foundry-as-linux-of-the-cloud/73865?tag=mantle_skin;content
- http://www.eweek.com/c/a/Application-Development/VMwares-Cloud-Foundry-Celebrates-First-Anniversary-651422/
Cloud 9 IDE ROCKS!
Outside of the Cloud Foundry Project there are other things working toward interoperability with Cloud Foundry and building in features that will help you work against Cloud Foundry. One of those companies is Cloud 9. They’ve enabled single-click deployment via their Cloud 9 IDE.
That’s it from me for now. I’ll have a lot more regarding Cloud Foundry, Iron Foundry, and other projects related to PaaS soon.


David Linthicum (@DavidLinthicum) asserted “An enterprise-out strategy is HP's only real cloud option, but it needs more than the beta Converged Cloud offering to succeed” in a deck for his HP's OpenStack bet to deliver what Amazon Web Services won't article of 4/10/2012 for InfoWorld’s Cloud Computing blog:
HP today announced its HP Converged Cloud, which when released in beta form in May will use a version of the open source OpenStack software. HP's betting that the OpenStack-fueled offering will get enterprises excited about the cloud in ways that Amazon Web Services (AWS) has not -- and overcome the objections in many IT organizations around using technology from public cloud vendors such as Amazon.com, whose private and hybrid cloud offerings are an afterthought handled by third parties.
HP says its Converged Cloud lets enterprises use cloud computing to deploy an internal architecture to interact with some external cloud service providers that leverage OpenStack. In turn, this could provide a private cloud approach that takes into account IT's fears and a more palatable path to extending into public and hybrid clouds.
HP is not picking a winner for the use of virtual machine hypervisors and other development platforms. Instead, its private cloud service hosts the major virtual machine offerings: EMC VMware's ESX Server, Microsoft's Hyper-V, and Red Hat's KVM. HP's approach is to not worry about customers' preferred VM technology but to provide an on-premise IaaS that works and plays well with other OpenStack-based cloud providers, whether inside or outside of the enterprise.
HP will also provide cloud maps, which are templates of preconfigured cloud services, so you don't have to build your cloud from scratch. Moreover, HP promises several new features such as service virtualization, which will let cloud developers test systems in protected domains. There are new networking and security services in HP's cloud cocktail as well.
Although HP is clearly looking to beat AWS as the premier enterprise cloud platform, Converged Cloud offers AWS compatibility; you can reach out to AWS services as needed. HP understands that if you don't work with AWS, you won't have much of a chance in this emerging market. No doubt HP hopes that such compatibility will provide a nice offramp from AWS for enterprises that want a private cloud strategy and will be happy to extend beyond -- or even replace -- AWS's focus on public IaaS and PaaS offerings. The fact that AWS leaves private cloud deployments to partners means HP's approach nicely complements AWS for enterprises that don't fear the public cloud.
HP's cloud vision is different than Amazon's. Where Amazon sees the public cloud as the endgame, HP sees cloud deployments moving from private to public to hybrid. HP'ss focus is on cross-compatibility and on development and deployment of software that can leverage public clouds, including the company's own.
From where I sit, this is exactly what HP should do -- in fact, it's HP's only option. If HP tries to battle it out with AWS in the public cloud space, it will quickly be handed its head. That's why it needs to focus on what AWS is not focusing on: the transformation of internal systems to private and hybrid clouds, with the vision of eventually moving to public clouds.
But HP needs to do more than roll out the beta Converged Cloud offering. It must also improve its thought leadership (rather than constantly searching for new CEOs) so that it can lead the conversation. Right now, IBM and Microsoft have more to say about this kind of enterprise-out migration than HP does. Second, HP needs to make its stuff work. Companies like HP have made many hard, complex promises like this one that end up as failures. HP can't afford that now.

<Return to section navigation list>

















0 comments:
Post a Comment