Windows Azure and Cloud Computing Posts for 4/18/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

• Updated 4/19/2012 at 11:30 AM PDT with new articles marked • by Klint Finley, Beth Pariseau, Rob Collie, Jo Maitland, Barb Darrow, Manish Malhotra, Peeyush Toshi, Devopsdays Organizers, Andrew Lader, Mike Benkovich, Jeff Barr, Werner Vogels, Simon Munro and Richard Mitchell.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics, Big Data and OData
- Windows Azure Access Control, Identity and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
• Jo Maitland (@JoMaitlandSF) asserted “On the big data front, the Hadoop players realized very few companies have teams of systems engineers to learn MapReduce” in her Infrastructure Q1: Cloud and big data woo the enterprise research report for GigaOm Pro (trial or paid subscription required). From the Summary:
Cloud and big data providers spent the first quarter of 2012 adding services to their product lines that they hope will appeal to the enterprise market.
With enterprises now open to hybrid clouds, Amazon Web Services finally relaxed its rigid public-cloud-only stance and launched services to support hybrid-cloud deployments.
On the big data front, the Hadoop players realized very few companies have teams of systems engineers to learn MapReduce. This has meant adding support for SQL and integrating Hadoop with existing data-management tools and systems. In other words, Hadoop has grown up and is now being taken seriously by companies like Oracle and Microsoft.
This quarterly report examines these trends as well the exciting M&A and IPO news in this arena. It also includes a near-term outlook for the next 12–18 months.

Apache Hive provides the “support for SQL” and Hive support for SQL Azure blob storage enables “integrating Hadoop with existing data-management tools and systems” in Microsoft’s Apache Hadoop on Windows Azure CTP.
• Manish Malhotra and Peeyush Toshi asserted “Apache Hadoop and Pig provide excellent tools for extracting and analyzing data from very large Web logs” and described Hadoop and Pig for Large-Scale Web Log Analysis in a 4/18/2012 article for DevX:
The World Wide Web has an estimated 2 billion users and contains anywhere from 15 to 45 billion Web pages, with around 10 million pages added each day. With such large numbers, almost every website owner and developer who has a decent presence on the Internet faces a complex problem: how to make sense of their web pages and all the users who visit their websites.
Every Web server worth its salt logs the user activities for the websites it supports and the Web pages it serves up to the virtual world. These Web logs are mostly used for debugging issues or to get insight into the details, which are interesting from a business or performance point of view. Over time, the size of the logs keeps increasing until it becomes very difficult to manually extract any important information out of them, particularly for busy websites. The Hadoop framework does a good job at tackling this challenge in a timely, reliable, and cost-efficient manner.
This article explains the formidable task of Web log analysis using the Hadoop framework and Pig scripting language, which are well suited to handle large amounts of unstructured data. We propose a solution based on the Pig framework that aggregates data at an hourly, daily or yearly granularity. The proposed architecture features a data-collection and a database layer as an end-to-end solution, but in this article we focus on the analysis layer, which is implemented in the Pig Latin language.
Figure 1 shows an illustration of the layered architecture.

Click here for larger image
Figure 1. Log Analysis Solution ArchitectureAnalyzing Logs Generated by Web Servers
The challenge for the proposed solution is to analyze Web logs generated by Apache Web Server. Apache Web logs follow a standard pattern that is customizable. Their description and sample Web logs can be found easily on the Web. These logs contain information in various fields, such as timestamp, IP address, page visited, referrer, and browser, among others. Each row in the Web log corresponds to a visit or event on a Web page.
The size of Web logs can range anywhere from a few KB to hundreds of GB. We have to design solutions that based on different dimensions such as timestamp, browser and country can extract patterns and information out of these logs and provide us vital bits of information, such as the number of hits for a particular website or Web page, the number of unique users, and so on. Each potential problem can be divided into a particular use case and can then be solved. For our purpose here, we will take two use cases:
- Find number of hits and number of unique users for Year dimension.
- Find number of hits and number of unique users for Time, Country, and City dimensions.
These use cases will demonstrate the basic approach and steps required to solve these problems. Other problems can be tackled easily by making slight modifications to the implementations and/or approach used in solving the above-mentioned use cases.
The technologies used are the Apache Hadoop framework, Apache Pig, the Java programming language, and regular expressions (regex). Although this article focuses on Apache Web logs, the approach is generic enough so that it can be implemented to logs generated by any other server or system.
Hadoop Solution Architecture
The proposed architecture is a layered architecture, and each layer has components. It scales according to the number of logs generated by your Web servers, enables you to harness the data to get key insights, and is based on an economical, scalable platform. You can continue adding and retaining data for longer periods to enrich your knowledge base.
The Log Analysis Software Stack
- Hadoop is an open source framework that allows users to process very large data in parallel. It's based on the framework that supports Google search engine. The Hadoop core is mainly divided into two modules:
- HDFS is the Hadoop Distributed File System. It allows you to store large amounts of data using multiple commodity servers connected in a cluster.
- Map-Reduce (MR) is a framework for parallel processing of large data sets. The default implementation is bonded with HDFS.
The database can be a NoSQL database such as HBase. The advantage of a NoSQL database is that it provides scalability for the reporting module as well, as we can keep historical processed data for reporting purposes. HBase is an open source columnar DB or NoSQL DB, which uses HDFS. It can also use MR jobs to process data. It gives real-time, random read/write access to very large data sets -- HBase can save very large tables having million of rows. It's a distributed database and can also keep multiple versions of a single row.
The Pig framework is an open source platform for analyzing large data sets and is implemented as a layered language over the Hadoop Map-Reduce framework. It is built to ease the work of developers who write code in the Map-Reduce format, since code in Map-Reduce format needs to be written in Java. In contrast, Pig enables users to write code in a scripting language.
Flume is a distributed, reliable and available service for collecting, aggregating and moving a large amount of log data (src flume-wiki). It was built to push large logs into Hadoop-HDFS for further processing. It's a data flow solution, where there is an originator and destination for each node and is divided into Agent and Collector tiers for collecting logs and pushing them to destination storage.
Data Flow and Components
Content will be created by multiple Web servers and logged in local hard discs. This content will then be pushed to HDFS using FLUME framework. FLUME has agents running on Web servers; these are machines that collect data intermediately using collectors and finally push that data to HDFS.
Pig Scripts are scheduled to run using a job scheduler (could be cron or any sophisticated batch job solution). These scripts actually analyze the logs on various dimensions and extract the results. Results from Pig are by default inserted into HDFS, but we can use storage implementation for other repositories also such as HBase, MongoDB, etc. We have also tried the solution with HBase (please see the implementation section). Pig Scripts can either push this data to HDFS and then MR jobs will be required to read and push this data into HBase, or Pig scripts can push this data into HBase directly. In this article, we use scripts to push data onto HDFS, as we are showcasing the Pig framework applicability for log analysis at large scale.
The database HBase will have the data processed by Pig scripts ready for reporting and further slicing and dicing.
The data-access Web service is a REST-based service that eases the access and integrations with data clients. The client can be in any language to access REST-based API. These clients could be BI- or UI-based clients. …
Read more: Next Page: Hadoop Pig Implementation ![]()
Microsoft’s Apache Hadoop on Windows Azure CTP implements Pig.
Avkash Chauhan (@avkashchauhan) posted MapReduce in Cloud on 4/18/2012:
When someone is looking at cloud to find MapReduce to process your large amount of data, I think this is what you are looking for:
- A collection of machines which are Hadoop/MapReduce ready and instant available
- You just don’t want to build Hadoop(HDFS/MapReduce) instances from scratch because there are several IaaS service available give you hundreds of machines in cloud however building a Hadoop cluster will be nightmare.
- It means you just need to hook your data and push MapReduce jobs immediately
- Being in cloud, means you just want to harvest the power of thousands of machines available in cloud “instantly” and want to pay the cost of CPU usage per hour you will consume.
Here are a few options which are available now, which I tried before writing here:
Apache Hadoop on Windows Azure:
Microsoft also has Hadoop/MapReduce running on Windows Azure but it is under limited CTP, however you can provide your information and request for CTP access at link below:
https://www.hadooponazure.com/The Developer Preview for the Apache Hadoop- based Services for Windows Azure is available by invitation.
Amazon: Elastic Map Reduce
Amazon Elastic MapReduce (Amazon EMR) is a web service that enables businesses, researchers, data analysts, and developers to easily and cost-effectively process vast amounts of data. It utilizes a hosted Hadoop framework running on the web-scale infrastructure of Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Simple Storage Service (Amazon S3).
http://aws.amazon.com/elasticmapreduce/Google Big Query:
Besides that you can also try Google BigQuery in which you will have to move your data to Google propitiatory Storage first and then run BigQuery on it. Remember BigQuery is based on Dremel which is similar to MapReduce however faster due to column based search processing.
Google BigQuery is invitation only however you sure can request for access:
https://developers.google.com/bigquery/Mortar Data:
There is another option is to use Mortar Data, as they have used python and pig, intelligently to write jobs easily and visualize the results. I found it very interesting, please have a look:
http://mortardata.com/#!/how_it_works

![image_thumb1[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjFpmq4pYq6_7Uj-eB-P-iKikGK0U9ATgZ5l87JtNvgx0xucMUX9NQUxaqwh_KrnpqG8qOW-u5B95wiu9ET79cuORIzyxukqduVKjkQoFwSr_et0euA5HKIeJnLm2JMsbZmoCBUNyD5/s1600-h/image_thumb1%25255B1%25255D%25255B6%25255D.png "image_thumb1[1]")
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
• Richard Mitchell (@richard_j_m) described Red Gate Cloud Services – something new in a 4/19/2012 post to the ACloudPlace blog:
For the past several months I’ve been working on something new. This is a hosted service for maintaining cloud applications cunningly named Red Gate Cloud Services. It’s been live since the beginning of the year and it’s free to try out too.
Schedule SQL Azure Backups
Simply put, you can schedule backups of your SQL Azure database to be performed really easily, I’ve been driving to keep the UI as clean and modern as I can and with the help of tools like twitter bootstrap and MVC3 I feel I’ve achieved something quite special.
Not skimping on the features, this allows you to set a retention policy, get a transactionally consistent backup and recieve e-mail alerts for success and failures.
Backup your Azure blobs to Amazon S3
The next full scale tool feature that is available is that you can just as easily schedule a backup of your Azure blobs to Amazon S3. It really is this simple to use. In fact a few customers (yes people really do pay $10 a month for this) have said they’d like the option to synchronise whole storage accounts – so I’ll make that happen.
Community
There is an active community forming around the tool to help guide the development, after all in order for this tool to be truly useful I need input of what you’d like to get from it. This is being developed as a lean startup within the fold of Red Gate so I don’t have to worry about paying my mortgage while developing it, which is nice. If you’re not familiar with the term lean startup you should really read Eric Ries’ book
Did I mention it’s free to try it out yet? Also, you can check out its development history by looking at the development announcements blog



Full disclosure: I’m a paid contributor to Red Gate Software’s ACloudyPlace blog.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
• Rob Collie (@powerpivotpro) posted a Datamarket: Quick Followup on 4/19/2012:
“There are people out there whose jobs force them to be the place where two sources of data meet, and they are the ones who integrate and cross-reference that data to form conclusions…
…I think a lot of the world is like that.”
-Bill Gates circa 2002
People are always asking me if I know Tyler Durden
I mean, I’m often asked if I ever met Bill Gates during my time at Microsoft. I did, once, in 2002, when he wanted to review the XML features we were introducing in Excel 2003.
A few things from that meeting lodged in my head, and the quote above is one of them. The first sentence is paraphrasing on my part as I don’t precisely remember. But the last sentence, in italics, I remember word for word because I found it so validating of some of my own personal views and experience.
And I just realized, today, that quote should have been attached to one of the previous posts on DataMarket.
Real Reason for the Post: People with V2 Don’t See the Same Thing?
Last week I posted a workbook that lets you download weather data from basically anywhere in the world, accompanied with instructions on how to customize it for your needs.
The workbook I provided was produced in PowerPivot V1 (SQL 2008 R2, versions 10.xx).
I received reports from a few people that when you got to the step of editing the connection in the workbook, you saw a different dialog than I saw.
Is This What You See When You Edit Connection In The Workbook I Provided?
What I See
From the previous post, here’s what I see, with the two things you need to change highlighted:
What I See
How To Make Required Changes If You Are Seeing the “Alternate” Dialog
Click Advanced
Fill In Required Info in These Three Places
That Should Do It
Let me know, again, if you have problems. I am channeling feedback to Microsoft on this stuff so they can address any snags we hit.
Why is Microsoft paying such close attention to us in particular?
Because WE are those people where the data sources come together.






Lori MacVittie (@lmacvittie) asserted “‘Big data’ focuses almost entirely on data at rest. But before it was at rest – it was transmitted over the network. That ultimately means trouble for application performance” in an introduction to her The Four V’s of Big Data of 4/18/2012 to F5’s DevCentral blog:
The problem of “big data” is highly dependent upon to whom you are speaking. It could be an issue of security, of scale, of processing, of transferring from one place to another.
What’s rarely discussed as a problem is that all that data got where it is in the same way: over a network and via an application. What’s also rarely discussed is how it was generated: by users.

If the amount of data at rest is mind-boggling, consider the number of transactions and users that must be involved to create that data in the first place – and how that must impact the network. Which in turn, of course, impacts the users and applications creating it.
It’s a vicious cycle, when you stop and think about it.
This cycle shows no end in sight. The amount of data being transferred over networks, according to Cisco, is only going to grow at a staggering rate – right along with the number of users and variety of devices generating that data. The impact on the network will be increasing amounts of congestion and latency, leading to poorer application performance and greater user frustration.
MITIGATING the RISKS of BIG DATA SIDE EFFECTS
Addressing that frustration and improving performance is critical to maintaining a vibrant and increasingly fickle user community. A Yotta blog detailing the business impact of site performance (compiled from a variety of sources) indicates a serious risk to the business. According to its compilation, a delay of 1 second in page load time results in:
- 7% Loss in Conversions
11% Fewer Pages Viewed
16% Decrease in Customer SatisfactionThis delay is particularly noticeable on mobile networks, where latency is high and bandwidth is low – a deadly combination for those trying to maintain service level agreements with respect to application performance. But users accessing sites over the LAN or Internet are hardly immune from the impact; the increasing pressure on networks inside and outside the data center inevitably result in failures to perform – and frustrated users who are as likely to abandon and never return as are mobile users.
Thus, the importance of optimizing the delivery of applications amidst potentially difficult network conditions is rapidly growing. The definition of “available” is broadening and now includes performance as a key component. A user considers a site or application “available” if it responds within a specific time interval – and that time interval is steadily decreasing. Optimizing the delivery of applications while taking into consideration the network type and conditions is no easy task, and requires a level of intelligence (to apply the right optimization at the right time) that can only be achieved by a solution positioned in a strategic point of control – at the application delivery tier.
Application Delivery Optimization (ADO)
Application delivery optimization (ADO) is a comprehensive, strategic approach to addressing performance issues, period. It is not a focus on mobile, or on cloud, or on wireless networks. It is a strategy that employs visibility and intelligence at a strategic point of control in the data path that enables solutions to apply the right type of optimization at the right time to ensure individual users are assured the best performance possible given their unique set of circumstances.
The technological underpinnings of ADO are both technological and topological, leveraging location along with technologies like load balancing, caching, and protocols to improve performance on a per-session basis. The difficulties in executing on an overarching, comprehensive ADO strategy is addressing variables of myriad environments, networks, devices, and applications with the fewest number of components possible, so as not to compound the problems by introducing more latency due to additional processing and network traversal. A unified platform approach to ADO is necessary to ensure minimal impact from the solution on the results.
ADO must therefore support topology and technology in such a way as to ensure the flexible application of any combination as may be required to mitigate performance problems on demand.
Topologies
- Symmetric Acceleration
- Front-End Optimization (Asymmetric Acceleration)
Lengthy debate has surrounded the advantages and disadvantages of symmetric and asymmetric optimization techniques. The reality is that both are beneficial to optimization efforts. Each approach has varying benefits in specific scenarios, as each approach focuses on specific problem areas within application delivery chain. Neither is necessarily appropriate for every situation, nor will either one necessarily resolve performance issues in which the root cause lies outside the approach's intended domain expertise. A successful application delivery optimization strategy is to leverage both techniques when appropriate.
Technologies
- Protocol Optimization
- Load Balancing
- Offload
- Location
Whether the technology is new – SPDY – or old – hundreds of RFC standards improving on TCP – it is undeniable that technology implementation plays a significant role in improving application performance across a broad spectrum of networks, clients, and applications. From improving upon the way in which existing protocols behave to implementing emerging protocols, from offloading computationally expensive processing to choosing the best location from which to serve a user, the technologies of ADO achieve the best results when applied intelligently and dynamically, taking into consideration real-time conditions across the user-network-server spectrum.
ADO cannot effectively scale as a solution if it focuses on one or two comprising solutions. It must necessarily address what is a polyvariable problem with a polyvariable solution: one that can apply the right set of technological and topological solutions to the problem at hand. That requires a level of collaboration across ADO solutions that is almost impossible to achieve unless the solutions are tightly integrated.
A holistic approach to ADO is the most operationally efficient and effective means of realizing performance gains in the face of increasingly hostile network conditions.


Chirag Mehta (@chirag_mehta) continued his series with 4 Big Data Myths - Part II on 4/18/2012:
This is the second and the last part of this two-post series blog post on Big Data myths. If you haven't read the first part, check it out here.
Myth # 2: Big Data is an old wine in new bottle
I hear people say, "Oh, that Big Data, we used to call it BI." One of the main challenges with legacy BI has been that you pretty much have to know what you're looking for based on a limited set of data sources that are available to you. The so called "intelligence" is people going around gathering, cleaning, staging, and analyzing data to create pre-canned "reports and dashboards" to answer a few very specific narrow questions. By the time the question is answered its value has been diluted. These restrictions manifested from the fact that the computational power was still scarce and the industry lacked sophisticated frameworks and algorithms to actually make sense out of data. Traditional BI introduced redundancies at many levels such as staging, cubes etc. This in turn reduced the the actual data size available to analyze. On top of that there were no self-service tools to do anything meaningful with this data. IT has always been a gatekeeper and they were always resource-constrained. A lot of you can relate to this. If you asked the IT to analyze traditional clickstream data you became a laughing stroke.What is different about Big Data is not only that there's no real need to throw away any kind of data, but the "enterprise data", which always got a VIP treatment in the old BI world while everyone else waited, has lost that elite status. In the world of Big Data, you don't know which data is valuable and which data is not until you actually look at it and do something about it. Every few years the industry reaches some sort of an inflection point. In this case, the inflection point is the combination of cheap computing — cloud as well as on-premise appliances — and emergence of several open computing data-centric software frameworks that can leverage this cheap computing.
Traditional BI is a symptom of all the hardware restrictions and legacy architecture unable to use relatively newer data frameworks such as Hadoop and plenty of others in the current landscape. Unfortunately, retrofitting existing technology stack may not be that easy if an organization truly wants to reap the benefits of Big Data. In many cases, buying some disruptive technology is nothing more than a line item in many CIOs' wish-list. I would urge them to think differently. This is not BI 2.0. This is not a BI at all as you have known it.
Myth # 1: Data scientist is a glorified data analyst
The role of a data scientist has exponentially grown in its popularity. Recently, DJ Patil, a data scientist in-residence at Greylock, was featured on Generation Flux by Fast Company. He is the kind of a guy you want on your team. I know of a quite a few companies that are unable to hire good data scientists despite of their willingness to offer above-market compensation. This is also a controversial role where people argue that a data scientist is just a glorified data analyst. This is not true. Data scientist is the human side of Big Data and it's real.If you closely examine the skill set of people in the traditional BI ecosystem you'll recognize that they fall into two main categories: database experts and reporting experts. Either people specialize in complicated ETL processes, database schemas, vendor-specific data warehousing tools, SQL etc. or people specialize in reporting tools, working with the "business" and delivering dashboards, reports etc. This is a broad generalization, but you get the point. There are two challenges with this set-up: a) the people are hired based on vendor-specific skills such as database, reporting tools etc. b) they have a shallow mandate of getting things done with the restrictions that typically lead to silos and lack of a bigger picture.
The role of a data scientist is not to replace any existing BI people but to complement them. You could expect the data scientists to have the following skills:
- Deep understanding of data and data sources to explore and discover the patterns at which data is being generated.
- Theoretical as well practical (tool) level understanding of advanced statistical algorithms and machine learning.
- Strategically connected with the business at all the levels to understand broader as well deeper business challenges and being able to translate them into designing experiments with data.
- Design and instrument the environment and applications to generate and gather new data and establish an enterprise-wide data strategy since one of the promises of Big Data is to leave no data behind and not to have any silos.
I have seen some enterprises that have a few people with some of these skills but they are scattered around the company and typically lack high level visibility and an executive buy-in.
Whether data scientists should be domain experts or not is still being debated. I would strongly argue that the primary skill to look for while hiring a data scientist should be how they deal with data with great curiosity and asking a lot of whys and not what kind of data they are dealing with. In my opinion if you ask a domain expert to be a data expert, preconceived biases and assumptions — knowledge curse — would hinder the discovery. Being naive and curious about a specific domain actually works better since they have no pre-conceived biases and they are open to look for insights in unusual places. Also, when they look at data in different domains it actually helps them to connect the dots and apply the insights gained in one domain to solve problems in a different domain.
No company would ever confess that their decisions are not based on hard facts derived from extensive data analysis and discovery. But, as I have often seen, most companies don't even know that many of their decisions could prove to be completely wrong had they have access to right data and insights. It's scary, but that's the truth. You don't know what you don't know. BI never had one human face that we all could point to. Now, in the new world of Big Data, we can. And it's called a data scientist.

The WCF Data Services Team explained How to use WCF DS 5.0 in a Web Site project in a 4/17/2012 post:
The WCF Data Services 5.0 RTM release includes an update to the Add Service Reference behavior in Visual Studio. For most project types that target .NET Framework 4.0, this means that when you add a new service reference, you will automatically get assembly references to the new client assemblies, and your client will be able to communicate with servers that support v3 of the OData protocol.
This does not happen by default for Web Site Projects, but there are some manual steps you can take to update these projects to use the new functionality. This applies to Web Site Projects only, not Web Application Projects or any other type of project with support for WCF Data Services.
Configuring a Web Site Project to work with WCF Data Services 5.0:
Add a Service Reference in the Web Site project.
How to: Add, Update, or Remove a Service Reference
This will add the service reference with assembly references to the WCF Data Services client that is included with .NET Framework 4.0, and not the updated version that is included with the 5.0 RTM release.
Update the project’s assembly references to point to the new client.
There are three ways to do this:
(Recommended) Use NuGet to install the
Microsoft.Data.Services.Clientpackage. Click the Tools menu, then Library Package Manager, then Package Manager Console. In the console, typeInstall-Package Microsoft.Data.Services.Client. You will still need to remove the reference toSystem.Data.Services.Clientusing one of the methods below.Right-click the project name in Solution Explorer, select Property Pages, then choose the References tab. Remove the reference to
System.Data.Services.Client, then add references toMicrosoft.Data.Services.Client,Microsoft.Data.OData,Microsoft.Data.EdmandSystem.Spatialthat were installed with WCF Data Services 5.0.Edit the <assemblies> section in the project’s web.config file.
Remove the reference to System.Data.Services.Client:
<compilation> <assemblies> <add assembly="System.Data.Services.Client, Version=4.0.0.0, Culture=neutral, PublicKeyToken=B77A5C561934E089" /> </assemblies> </compilation>Add references to the new client assemblies:
<compilation> <assemblies> <add assembly="System.Spatial, Version=5.0.0.0, Culture=neutral, PublicKeyToken=31BF3856AD364E35"/> <add assembly="Microsoft.Data.Services.Client, Version=5.0.0.0, Culture=neutral, PublicKeyToken=31BF3856AD364E35"/> <add assembly="Microsoft.Data.OData, Version=5.0.0.0, Culture=neutral, PublicKeyToken=31BF3856AD364E35"/> <add assembly="Microsoft.Data.Edm, Version=5.0.0.0, Culture=neutral, PublicKeyToken=31BF3856AD364E35"/> </assemblies> </compilation>Configure the project to use the new build provider for WCF Data Services.
Edit the
web.configfile to override the defaultDataServiceBuildProviderthat is specified in the rootweb.configthat is installed with the .NET Framework.<compilation> <folderLevelBuildProviders> <remove name="DataServiceBuildProvider"/> <add name="DataServiceBuildProvider" type="System.Data.Services.BuildProvider.DataServiceBuildProvider, Microsoft.Data.Services.Design, Version=5.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35"/> </folderLevelBuildProviders> </compilation>This step only needs to be done once per project and does not need to be repeated if additional service references are added. All other steps need to be done for each service reference.
Update the
Reference.datasvcmapfile for the service reference.The
Reference.datasvcmapfile contains parameters that control how the code is generated for the service reference. The following parameters are the default for other project types and will allow your types to be used with data binding and will allow the client to communicate with services that support v3 of the OData protocol.<ReferenceGroup> <Parameters> <Parameter Name="UseDataServiceCollection" Value="true" /> <Parameter Name="Version" Value="3.0" /> </Parameters> </ReferenceGroup>
No significant articles today.
<Return to section navigation list>
Windows Azure Service Bus, Access Control, Identity and Workflow
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Himanshu Singh (@himanshuks) posted Video: Pariveda Solutions Helps Clients Grow Their Business with Windows Azure on 4/18/2012:
Dallas, Texas based IT Consultancy, Pariveda Solutions, is a provider of custom cloud deployments to Fortune 500 companies using Windows Azure. One of the company's most recent projects has involved creation of a web application to help a large media organization manage subscription models and provide digital users the ability to view premium content, a service, which is especially valuable during peak news cycles in which media sites experience high volumes of traffic.
In this video, Pariveda talks about the solution they created on Windows Azure, which helped them meet the scalability needs of the solution, while helping reduce infrastructure cost in parallel. As a result of the deployment in the cloud, the company says it was able to duplicate staging environments for faster and more reliable testing.
Learn more about Pariveda Solutions. Learn how others are using Windows Azure.
Hovannes Avoyan asserted “There are three types of scalable compute instances which you can run in the cloud” in an introduction to his description of a Windows Azure Custom Monitor in C# of 4/18/2012:
In this article we’ll describe the Windows Azure monitor written in C#. Windows Azure has a set of different services, but we’ll limit our article to only those services that we use for capturing performance counters. If you’re new to Windows Azure and want more information you can visit the Microsoft Azure website.
Windows Azure Compute
- Web Role – provide a dedicated Internet Information Services (IIS) web-server used for hosting front-end web applications.
- Worker Role – can run asynchronous, long-running or perpetual tasks independent of user interaction or input.
- VM Role – Virtual Machine (VM) roles, now in Beta, enable you to deploy a custom Windows Server 2008 R2 (Enterprise or Standard) image to Windows Azure.
The current version of our Azure Monitor supports capturing performance counters for the Web Role or the Worker Role. For a complete overview of available metrics, click here. In addition to the standard performance counters, Windows Azure allows for custom performance counters.
In our custom monitor, the performance counters are configured by calling the SetupCounters method in project HostWorkerRole. The sample code is of the Worker Role which is deployed to the Azure Compute Service.
Windows Azure Storage.
Windows Azure Storage provides secure and scalable storage services that are highly available and durable. The Storage service supports virtually all types of storage needs, from structured to unstructured data, NoSQL databases, and queues. You can find more information about this service here. Some of the most practical uses of Azure Storage are:
- BLOB (Binary Large Object) storage. BLOB Storage is the simplest way to store large amounts of unstructured text or binary data such as video, audio and images.
- Table storage is used by applications requiring storing large amounts of data storage that need additional structure. While a table stores structured data, it does not provide any way to represent relationships between the data, sometimes called a NoSQL database. You can use SQL Azure for relational database service on Windows Azure.
- Queue used for reliable, persistent messaging between applications. You can use Queues to transfer messages between applications or services in Windows Azure.
- Windows Azure Drive allows applications to mount a Blob formatted as a single volume NTFS VHD. You can move your VHDs between private and public clouds using Windows Azure Drive.
All of these storage types related to a Storage Account, which is created in the Windows Azure dashboard.
Windows Azure Storage Analytics performs logging and provides metrics data for a storage account. You can use this data to trace requests, analyze usage trends, and diagnose issues with your storage account. A detailed overview is available on MSDN.
Storage Analytics Metrics can report transaction statistics and capacity data for a storage account. All metrics data is stored in two tables per service: one table for transaction information, and another table for capacity information. Transaction information consists of request and response data. Capacity information consists of storage usage data. As of version 1.0 of Storage Analytics, capacity data will only be reported for the Blob service. The current implementation of our monitor application supports analytics for the Table service. In the future it can be expanded to support Blobs and Queues.
Azure Pricing Information
Windows Azure Diagnostic collects diagnostic data from instances and copies it to a Window Azure Storage account (either on blob and table storage). Those diagnostic data (such as log) can indeed help developer for the purpose of monitoring performance and tracing source of failure if exception occurs.
We’ll need to define what kind of log (IIS Logs, Crash Dumps, FREB Logs, Arbitrary log files, Performance Counters, Event Logs, etc.) to be collected and send to Windows Azure Storage either on-schedule-basis or on-demand.
However, if you are not careful defining your needs for diagnostic information, you could end up paying an unexpected high bill. At the time of this writing, the cost is as follows:
- $0.14 per GB stored per month based on the daily average
- $0.01 per 10,000 storage transactions
Some Figures for Illustration
Assuming the following figures:
- You have a few applications that require high processing power of 100 instances
- You apply five performance counter logs (Processor% Processor Time, MemoryAvailable Bytes, PhysicalDisk% Disk Time, Network Interface Connection: Bytes Total/sec, Processor Interrupts/sec)
- Perform a scheduled transfer with an interval of 5 seconds
- The instance will run 24 hours per day, 30 days per month
Given the above scenario, the total number of transactions comes to 259,200,000 each month (5 counters X 12 times X 60 min X 24 hours X 30 days X 100 instances), or $259/month.
Now what if you don’t really need that many counters every 5 seconds and reduce them to 3 counters and monitor it every 20 seconds? In this case it would be 3 counters X 3 times X 60 min X 24 hours X 30 days X 100 instances = 3,8880,000 transactions, or $38/month. Windows Azure Diagnostic is needed but using it improperly may be more expensive than you bargained for.
Storage Analytics is enabled by a storage account owner; it is not enabled by default. All metrics data is written by the services of a storage account. As a result, each write operation performed by Storage Analytics is billable. Additionally, the amount of storage used by metrics data is also billable.
The following actions performed by Storage Analytics are billable:
- Requests to create blobs for logging
- Requests to create table entities for metrics
If you have configured a data retention policy, you are not charged for delete transactions when Storage Analytics deletes old logging and metrics data. However, delete transactions from a client are billable.
Mediator Project
The Mediator application makes it possible to retrieve performance counter values and Storage Account Table metrics Windows Azure. The following performance counters are included:
- \Processor(_Total)\% Processor Time
- \Memory\Available Bytes
Table metrics:
- TotalRequests – the number of requests made to a storage service or the specified API operation. This number includes successful and failed requests, as well as requests which produced errors.
- TotalBillableRequests – the number of billable requests.
- Availability – the percentage of availability for the storage service or the specified API operation. Availability is calculated by taking the TotalBillableRequests value and dividing it by the number of applicable requests,including those that produced unexpected errors. All unexpected errors result in reduced availability for the storage service or the specified API operation.
Each metric or performance counter gets its own monitor on the Dashboard at www.monitis.com.
Windows Azure Storage Metrics allows you to track your aggregated storage usage for Blobs, Tables and Queues. The details include capacity, per service request summary, and per API level aggregates. The metrics information is useful to see an aggregate view of how a given storage account’s blobs, tables or queues are doing over time. It makes it very easy to see the types of errors that are occurring to help tune your system and diagnose problems and the ability to see daily trends of its usage. For example, the metrics data can be used to understand the request breakdown (by hour).
Mediator Workflow
The application performs the role of Mediator between the Windows Azure Table Service and public API of monitis.com. To get started, the first step is to specify the API key to access REST service on www.monitis.com.
After logging in the Mediator will check if all required monitors are already created on the Monitis Dashboard. If they are not, you can use the create button to create all the required monitors.
Once the monitors have been created, the “Next” button will enabled and you will see all the monitors created be Mediator on the dashboard.
Next, Mediator needs your account information for Windows Azure Storage Account so we can access the performance and metrics data for monitor. If you don’t have it the account information, you can check “Use Default” and all values will fill with test credentials.
Click on “Apply” to check the credentials and test the connection to the Windows Azure Table Service. The applications will also check the existence of the table PerformanceCounter data. This table will automatically be created when the installation configures capturing of performance counters. For example, the table name for performance counters is “WADPerformanceCountersTable”.
After this is done, you will see a screen where you can configure the interval period in seconds used synchronize the data to the Monitis monitor. If there is actual data in the performance counters table, you should see a chart like this:
The optimal value for the current performance counters configuration is 180 seconds.
For the Storage Account Analytics you will see a section that allows you to specify the time period you want to synchronize between Azure and Monitis.
Select the time period and click “Sync”. After this is completed you’ll see the result of Storage Analytics and performance counters:
Performance counters and analytics metrics can work together. This means that you can start the Mediation process for performance counters and at the same time use the “Sync” button for the Storage Account Analytics.
Here are some links with more information:









Andreas Grabner asked “Is it going to be HTML5, Flash or Silverlight for your rich end-user interface?” in a deck for his Best Practices on APM in Windows Azure and Silverlight post of 1/28/2012:
Are you the one to decide on implementing your next project based on public cloud platforms such as Windows Azure? Is it going to be HTML5, Flash or Silverlight for your rich end-user interface? Have you thought about the costs running on cloud services that seem cheaper than hosting on your own hardware? What other open questions and second thoughts do you have that keep you from making a decision?
Getting End-to-End Visibility in Windows Azure
- How to get visibility into every end user and automate the collection of client-side performance and functional problems?
- How to best prioritize and reduce mean time to repair identified problems?
- What are the best practices to analyze and optimize application performance on these new sets of technologies and platforms?
Leveraging Compuware dynaTrace's User Experience Management (UEM), Application Performance Management (APM) for Windows Azure and the early access support for Silverlight allows them to:
- Automatically and centrally track all user actions, client- and server-side performance and functional problems 24/7 to answer: What exceptions are thrown in Silverlight and impact the end user? Are errors related with the used browser or Silverlight version? Are errors caused by the application deployed on Windows Azure?
- Easily perform an impact analysis of identified problems to answer: Was this a problem due to a user error or an application error? Does this happen to a specific user or for everybody? What's the severity of this error?
- Analyze and correlate runtime cost of Windows Azure to user interactions to answer business questions such as: How much does it cost to provide the service for a user? How much money do we need to charge to break even? How can we optimize cost by optimizing our implementation?
The following image shows a Compuware dynaTrace end-to-end PurePath starting in Silverlight tracing all the way through their ASP.NET application hosted on Windows Azure into SQL Azure. The client side error logging (such as exceptions that impact the end user experience) and the connection with server side transactions gives them visibility they haven't had before:
Analyzing every End User Action from Silverlight all the way back to SQL Azure including Client-Side Errors, SQL Statements and Exceptions
Join the Best Practices Webinar
Real End User Experience Management was one of the open questions ‘software architects' had to answer when moving their application to Windows Azure and deciding to use Silverlight as one of their client technologies. Managing cost, optimizing application performance and leveraging the scalability options of Windows Azure are additional challenges they are dealing with.If you are in the progress of moving to a public cloud platform such as Windows Azure or want to learn more about the best practices from ‘software architects' then join us for the upcoming webinar on April 25th with Alexander Huber and Simon Opelt, and Daniel Kaar from Compuware.
Register here: How time cockpit make Azure work for them
If you are a Compuware dynaTrace Community Member you can access our Azure Best Practices.


Liam Cavanagh (@liamca) continued his series with What I Learned Building a Startup on Microsoft Cloud Services: Part 11 – Vacation Time, Profitability and Listening to the Customers on 4/17/2012:
I am the founder of a startup called Cotega and also a Microsoft employee within the SQL Azure group where I work as a Program Manager. This is a series of posts where I talk about my experience building a startup outside of Microsoft. I do my best to take my Microsoft hat off and tell both the good parts and the bad parts I experienced using Azure.
Vacation Time
Profitability
Since I last posted, I started charging for the service and I am happy to say that Cotega is now officially profitable. Yeah!… Well, let me be more clear about that. By profitable, I mean I am officially making enough money to cover the costs of operating the service (including those costs that will come when my BizSpark program ends). I am still a long way from taking any major salary. But for me this is a big step because it was one of the main goals of starting Cotega. If you are reading this and are thinking of doing a startup, I have to tell you that one of the most exciting things to see are those first transactions coming in to your account. Even the small transactions are incredibly exciting. I think it has to do with the realization that there are in fact customers out there that are interested in what you are doing and are willing to pay for it.
New Features and Customer Suggestions
The other big reason why I have not posted is because I have been focusing on some new features for the service. Yesterday I deployed an update that allows for monitoring of blocked and poor performing queries. Each of these new features have come from existing customers I have been working with. I keep the suggestions in the Github issue repository where I can track the features that are most commonly requested and start working on those first. The other great source of ideas has been from people I have contacted that are not customers at all. For example, Microsoft has some amazing MVP’s who work closely with different Microsoft technologies and are absolute experts in these products. Every MVP I have ever worked with has gone way out of their way to help me and some of the best ideas (that are still in the works) have come from these people.
If any of you have not yet tried the service but are interested in seeing the service, I created this code that you can use to try any of the plans for 30 days free: 30dayfree

Mike Benkovich (@mbenko) continued his series with Cloud Tip#10-Use the Windows Azure Toolkit for Windows 8 to add interaction to your Metro Applications on 4/17/2012:
Yesterday in Bangalore at the GIDS conferences I did a session on working with Windows 8 and Notification Services. In it we talked about the live tiles that make up the new start screen in Windows 8 and how as a developer you have new ways to interact with your users thru the use of Toast, Tile, Badge and Raw notifications. We explored the 2 pieces of the puzzle that as developers we need to build, and showed how to make it all work.
The tools and technologies you need include 2 versions of Visual Studio, including Visual Studio 2010 with the Windows Azure SDK 1.6 installed, and Dev11 to build the Metro style client application on Windows 8. This Starting from scratch there are NuGet packages you could use, but a MUCH easier path is to use the Windows Azure Toolkit for Windows 8 hosted on http://watwindows8.codeplex.com. Nick Harris has a great blog post that talks thru the contents of the kit and details for installing, but the basic premise is that on a 32 GB developer tablet (small disk) I was able to install all the parts I needed to be able to make it work and still had 10 GB left over after installing everything.



<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Andrew Lader described How to Use the New LightSwitch Group Box in a 4/19/2012 post:
Note: This article applies to LightSwitch in Visual Studio 11 (LightSwitch V2)
When building a LightSwitch application, organizing the content is an important aspect of screen design. The layout system in LightSwitch has allowed you to use columns, rows, tabs and tables to great effect. And to give you even more options, the upcoming release of LightSwitch in Visual Studio 11 allows you to leverage a new grouping control, the Group Box. Using this control, you can create boundaries in your screens, grouping similar elements together to help users focus on input fields that belong together.
Using the Group Box Control
Let’s get right to it. The Group Box control is leveraged through the screen designer. In the content tree, a Group Box can be added in the same way you would add a new group. Click on the Add button, and from the drop down menu, select New Group. This will add a Rows Layout to the tree (unless you add it under a Table Layout, which will add a TableColumn Layout).
Now, click on the down arrow of the Rows Layout, and the drop down menu will contain a new item: Group Box:
Choose this option, and the Rows Layout will switch to a Group Box:
This group behaves exactly like a Rows Layout. Adding elements beneath it creates new row elements within the Group Box organized vertically.
Two Flavors
But unlike a Rows Layout, the Group Box has a couple of additional properties. First, the Group Box control can be displayed one of two ways: with all four borders (the default), or with just the top border displayed. With the Group Box selected, examine the Properties window. In the Appearance section, you will see a new option called Border Mode. By default it is set to All Borders. Click on the drop down, to see the other mode options:
The first mode displays all four borders of the Group Box with rounded corners. Choosing this option (or leaving it as the default) gives you the typical look and feel of a Group Box control:
Choosing the second mode, Top Border, displays only the top border of the Group Box; this is also a typical way to group fields together. It consists of a single line that stretches across horizontally.
This mode is great for delineating portions of content that are organized vertically.
Labels
In both of the examples above, the Group Box displayed the label associated with it. In the Properties window, right below Border Mode is a property called Show Display Name. This option is used to suppress the label. By default, it is checked, which means the label will be displayed.
Likewise, unchecking it hides the label. So for a Group Box with All Borders chosen, it will look like this:
And a Group Box with Top Border selected and no label, you will see this:
Nested Group Boxes
The Group Box can be nested within other layouts, including other Group Boxes. Since it behaves like a Rows Layout, you can place a Group Box anywhere in the content tree that you can a Rows Layout.
The Group Box in Action
To make the screen shots above, I used two entities and one screen. The first entity is Person which has a first name, a last name, a computed field for the full name, and a one-to-many relationship to the second entity, Address. The Address entity has a type, which is a choice list of address types, and then typical address fields like street, city, state and zip code. The screen was created using the List Details screen template. With both entities created, I added another computed field on the Person entity called HomeAddress that displays a summarized address of the first address in the list.
Once I had my entities set up, and my screen created, I set about to adding some Group Boxes:
- Under the top-level Columns Layout, I changed the right column (the details column) from Rows Layouts to Group Boxes.
- Under the right column, I changed the Person Details Rows Layout to a Group Box. I set its Border Mode property value to Top Border.
- I added a new group above the Addresses Data Grid, and then moved the data grid so it was a child under this new group.
- I then changed this new group from a Rows Layout to a Group Box, and set the Border Mode property value to Top Border.
When I was done, my content tree looked like this:
And when I pressed F5 and added some data, my application looked like this (note the nested Group Boxes in the Details Column):
Wrapping Up
I have demonstrated the new Group Box control, and the various ways you can use it in your screens to create boundaries and organize your fields to help users focus on related input. You can use this new control in the screen designer in exactly the same way as the Rows Layout. This flexibility allows you to nest Group Boxes under other layouts, including other Group Boxes. The Group Box allows you to display all four borders of the control, or just the top border. And it allows you to choose whether or not you want to display the associated Group Box label. I hope you enjoy using it in your applications!








Beth Massi (@bethmassi) posted LightSwitch Companion Client Examples using OData on 4/18/2012:
One of the biggest features with LightSwitch in Visual Studio 11 is the Open Data Protocol (OData) support. OData is a standard Web protocol for exchanging data on the web which provides easy, secure access into data stores. Not only can you consume OData services in LightSwitch, the middle-tier services are also now exposed as OData service endpoints reachable by other clients. For instance, I showed how power users can easily perform analytics and reporting on your LightSwitch data using Excel PowerPivot.
However, this also allows you to create a different UI for your LightSwitch application so that you can expose it to other platforms that aren’t supported out of the box. Furthermore, all your business rules and access control logic is preserved when calling these services. Your data models, business logic, and access control logic is where you spend the bulk of your time when building a LightSwitch application and all this work is preserved.
- LightSwitch Architecture: OData
- Enhance Your LightSwitch Applications with OData
- Creating and Consuming LightSwitch OData Services
- OData Apps in LightSwitch
- Using LightSwitch OData Services in a Windows 8 Metro Style Application
The community has taken these examples even further. I’d like to call out Michael Washington who runs the www.LightSwitchHelpWebsite.com where he’s been on fire recently posting examples of companion clients. Check these out!
- A Full CRUD DataJs and KnockoutJs LightSwitch Example Using Only An .Html Page
- A Full CRUD LightSwitch JQuery Mobile Application
- Communicating With LightSwitch Using Android App Inventor
Jan van der Haegen also wrote a great MSDN Article last month using a WIndows Phone 7 client:
Consume a LightSwitch OData Service from a Windows Phone application
Opening up the middle-tier services was a major goal for LightSwitch and you can see why – it allows you to exchange data easily with other systems and clients over the Web. I’m excited to see what the community comes up with next!



Return to section navigation list>
Windows Azure Infrastructure and DevOps
• Simon Munro (@simonmunro) muses over Cloud sales channels and Microsoft Partners in a 4/19/2012 post:
When Windows Azure first launched I thought that their well established sales channel and partner network would give them the edge – where loyal partners would sell the next big thing from Redmond, as they have done in the past. A few years down the line and Microsoft has been unable to turn that well-oiled machine into increased adoption of Windows Azure. Indeed, the reverse seems true where partners are corralling back to traditional enterprise IT and barely giving Windows Azure any attention. On the other hand Amazon Web Services has never had a sales channel and is, if you look at the broader Amazon philosophy, the epitome of disintermediation — where authors can sell to readers with no publishing or distribution intermediaries in between. Disintermediation is not a good brand when trying to attract ‘partners’.
Perhaps the existing Microsoft model harks back to days when software had to be shipped out of a distribution centre with manuals and media that had to be fed, one by one, into a carefully built server. That is no longer necessary and the customer can use their credit card and go directly to the source and they believe, perhaps wrongly, that going directly to the supplier is the best thing. This direct-from-source model means that the traditional channel, where SIs pass the product along after adding some margin, is non-existent. Despite the direct sales model, there are still ‘partners’, even Amazon Web Services appears to have them (with a newly announced ‘network’), but it is not what it used to be. It has gone from “We’ll market this product and you make money selling and supporting it” to “We’ll market, sell and (sort of) support this product and you make money by selling additional services to the customer (that you have just handed over to us)”. It is little wonder that the existing partners are struggling to see how this works for them.
Of course, those reading this post will be thinking that having a direct sales model is as it should be. The public cloud, it can be argued, is about breaking of traditional IT models — if planning, provisioning, development, operation and architectures have changed, then why should the sales channel and acquisition be built on outdated practices? There are potentially two reasons why a well established sales channel may be necessary, or at least useful.
Firstly, people do need help getting their cloud stuff running. Being able to rent an instance using a credit card is not the only skill that is required to use the cloud and a lot of potential buyers are left out of the cloud revolution because they don’t know what to do with cloud technology once they have their hands on it. For cloud computing to truly break into the mainstream it cannot remain within the hacker community and needs to be able to be consumed by those organisations without the full breadth of skills. Someone from the channel to help them choose, architect and configure seems logical. Unfortunately though, in their attempt to make the cloud seem easy to use and consume, cloud providers do not want to mention that a partner is advised in order to get it working properly.
Secondly, there is a lot of non-cloud IT still happening. Part of the reason for this is not technical and is related to the huge investment that the incumbents have in traditional IT and their desire to keep their market under their control. There are also a lot of talented, well connected and wealthy salespeople selling traditional kit and would never sell public cloud offerings because it makes no financial sense to them. How much commission would a salesperson get selling a one petabyte multi-datacentre SAN versus the salesperson who sells Amazon S3 as the best solution? (The answer — a lot, lot more). For every cloud ‘win’ there are thousands of traditional IT purchases simply because of the sheer number of vendors sweet talking the CTO — and the CTO has made time for them, their campaigns, their presentations and sales pitches. So while cloud providers are creating channel conflict, competing with their existing channels or simply don’t have one, Oracle, EMC and other enterprise vendors are making money hand over fist selling as much as they possibly can. And, just to rub salt in it, are branding their products as ‘private cloud’ — ensuring that the CTO can report back to the steering committee that they do have a cloud strategy and locking out the public cloud for a few more years.
I think that there is still a lot of development and maturing that has to take place with the channel strategies that get public clouds into the hands of the people who will pay every month. It may not be as complex as traditional IT where tin has to be physically put in place, but it is a lot more complicated than getting someone to read a book on a kindle. Microsoft hasn’t been able to work their channel to Azure’s advantage and is probably dismantling the channel that took them twenty years to build. Amazon has direct sales in its DNA and are dipping their toes into partnerships — while potential partners are fearful of Amazon stomping all over them if they turn their backs. There is a middle ground that needs to be found and while the big providers take their time to sort it out, old school IT (branded as private cloud) continues to rake in the cash. Perhaps it is time to start thinking less about technologies and features and focus on building sustainable ecosystems that allow big cloud providers to work in harmony with their customers and providers of specialised skills, products and services.

See also the Jeff Barr announced The AWS Marketplace - Find, Buy, Compare, and Launch Cloud Software, a competitor to the Windows Azure Marketplace and Brian Taylor asked OpenStack Counterstroke? Amazon Launches New Partner Program articles in the Other Cloud Computing Platforms and Services section below.
Full disclosure: OakLeaf Systems is a registered Microsoft Partner.
• The Devopsdays MountainView Organizers team (@devopsdays) reported in a 4/19/2012 email that registration is now open:
The event will happen on Thursday 28 and Friday 29 of June, right after Velocity and is hosted by Google.
Registrations are currently going at 1 registration/minute. Only 250 tickets will be issued, so be quick to register at:
http://devopsdays.org/events/2012-mountainview/registration/.We are also still looking for talk proposals and ignites at http://devopsdays.org/events/2012-mountainview/proposals/.
See you all in MountainView.

• Klint Finley (@klintron) asked Are We Too Concerned with Vendor Lock-In? in a 4/18/2012 post to the SiliconANGLE blog:
I’ve written frequently about vendor lock-in and how to avoid it, but Matt Asay suggests that lock-in might be the least of a CIO’s worries. No one wants to get stuck being price gauged by a mega-vendor, but the truth is being locked into something that works is better than freely using something doesn’t.
Earlier this week, VMware’s Matthew Lodge wrote: “Openness is not about how you write software, it’s about what you allow your customers to be able to do.” Asay quotes Red Hat’s Gordon Haff:
The key is that phrase “you *allow* your customers to do.” IOW the vendor, in this case VMware, calls the shots.
I agree with Haff, but Asay has a point in saying this is an ineffective strategy. He cites Red Hat’s past marketing efforts as an example: “Red Hat for years has emphasized value, not fluffy intangibles in its field marketing. Yes, the company will talk about vendor lock-in for its high-level marketing messages, but the salespeople walking in to talk with a CIO? They’re talking about performance-to-cost ratios over competitors like IBM and HP.”
Actually, Red Hat CEO Jim Whitehurst told me in an interview recently that the company doesn’t even focus that much on cost. Whitehurst said that when the Red Hat team went back and asked customers why they chose RHEL, customers almost always emphasized performance and flexibility – not cost.
As we start to look at the next round of debate – VMware vs. OpenStack, Heroku vs. Cloud Foundry, etc. – advocates of open source software and open standards would do well to keep in mind the real value of software: performance, agility, stability, and so on.

• Mike Benkovitch (@mbenko) continued his series with Cloud Tip #11-Activate your MSDN Benefits on 4/19/2012:
If you have an MSDN Subscription you get Azure benefits which you can use to develop in the cloud. In this post I’d like to share what’s involved in activating these.
After you select the MSDN Subscription you’re working with, click the link to Activate Windows Azure. It will navigate to the Azure account management page and begin the process of activation. Depending on the level of subscription you have you’ll see details on the amount of resources that are included with your benefits. All that will be required to activate them is a credit card.
Next enter your credit card info, and click to continue…Note that although the credit card is required for activation, a cap is applied to the account and your subscription will be suspended if your reach any of the usage limits for the duration of the billing cycle (month).

After validating the credit card your account is provisioned. To see information about your active subscriptions click on the Account link to see details. As the third screen shows my account has a $0 spending limit attached to it, so I will not be billed for the duration of my subscription unless I remove the cap. More on that in another post.







Full disclosure: I have a complimentary MSDN Ultimate subscription and use it to run the OakLeaf Table
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Thomas W. Shinder (@tshinder) announced The Private Cloud Solution Hub Gets a Refresh on 4/16/2012 (missed when published):
Hey private cloud fans! I want to check in with you this week to let you know that the Private Cloud Solutions Hub over on TechNet received a refresh this week.
Our vision of the Private Cloud Solutions Hub is to provide a place where anyone interested in private cloud computing will be able to find the information they need. The information is now categorized in sections named:
Explore
- Plan
- Deliver
- Operate
If you want more details on the Private Cloud Solution Hub and a nice video overview of how it works, then please take a chance to watch this video done by my colleague and teammate Jim Dial.
Let us know what you think of the Private Cloud Solution Hub and what we can do it make it better and more useful for you.


No significant articles today.
<Return to section navigation list>
Cloud Security and Governance

<Return to section navigation list>
Cloud Computing Events
Brian Loesgen (@BrianLoesgen) reported DevCamp Irvine is this Friday April 20th on 4/16/2012:
I’ll be at DevCamp:Cloud this Friday at the UC Irvine campus. The L.A. event was sold out, and most stayed all day. Lots of good info.

See you there?
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Jeff Barr (@jeffbarr) announced The AWS Marketplace - Find, Buy, Compare, and Launch Cloud Software, a competitor to the Windows Azure Marketplace, on 4/19/2012:
Using the new AWS Marketplace, you can easily find, compare, and start using an array of software systems and products. We've streamlined the discovery, deployment, and billing steps to make the entire process of finding and buying software quick, painless, and worthwhile for application consumers and producers.
Here's what it looks like:
We are launching the AWS Marketplace with many categories of development and IT software. They are grouped into 3 categories:
- Software Infrastructure - Application Development, Application Stacks, Application Servers, Databases & Caching, Network Infrastructure, Operating Systems, and Security.
- Developer Tools - Issue & Bug Tracking, Monitoring, Source Control, and Testing.
- Business Software - Business Intelligence, Collaboration, Content Management, CRM, eCommerce, High Performance Computing, Media, Project Management, and Storage & Backup.
The AWS Marketplace includes pay-as-you-go products that are available in Amazon Machine Image (AMI) form and hosted software with a variety of pricing models. When you launch an AMI, the product will run on your own private EC2 instance and the usage charges (monthly and/or hourly) will be itemized on your AWS Account Activity report. Hosted software is run by the seller and accessed through a web browser.
The Details
Each product in the marketplace is described by a detail page. The page contains the information you'll need to make an informed decision including an overview, a rating, versioning data, details on the support model for the product, a link to the EULA (End User License Agreement), and pricing for each AWS Region.For this example, I will focus on the Zend Server. I can find it by browsing or by searching:
I can then choose from among a list of matching products:
I can read all about the product, and I can check on the pricing. I'll pay for the software and for the AWS resources separately:
The software pricing can vary by EC2 instance type:
1-Click Launch
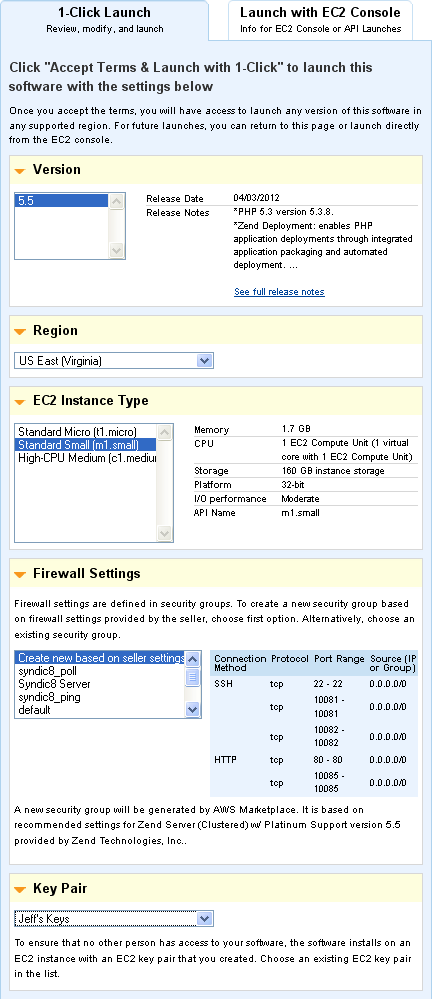
When I am ready to go I click the Continue button. I then have two launch options: 1-click and EC2 Console:
The 1-click launch process starts with sensible default values (as recommended by the software provider) that I can customize as desired by expanding the section of interest:
As you can see from the screen shot above, the Marketplace can use an existing EC2 security group or it can create a new one that's custom tailored to the application's requirements. Once everything is as I like it, I need only click on the Accept Terms and Launch button:
I can visit the Your Software section of the AWS Marketplace to see all of my subscriptions and all of the EC2 instances that they are running on:
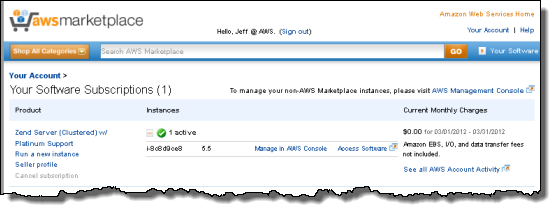
The Access Software link routes directly to the admin page for the Zend Server. After accepting the license agreement and entering a password, I can proceed to the Zend Server console:


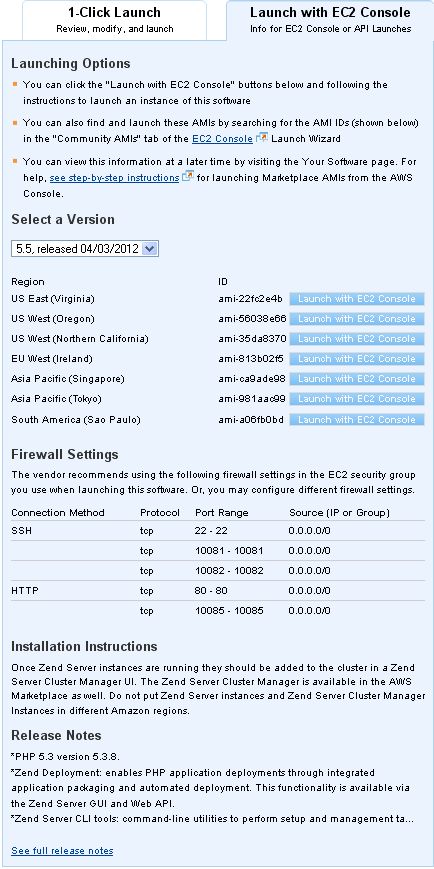
EC2 Console Launch
I can also choose to launch the Zend Server AMI through the EC2 console. You can do this if you want to launch multiple instances at the same time, exercise additional control over the security groups, launch the software within a VPC or on Spot Instances, or perform other types of customization:
The AWS Marketplace distributes and then tracks AMIs for each product across Regions. These AMIs are versioned and the versions are tracked; you have the ability to select the version of your choice when launching a product.
Selling on the AWS Marketplace
If you are an ISV (Independent Software Vendor) and you want to list your products in the AWS Marketplace, start here! Check out our listing guidelines and best practices guides, and then get in touch with us via the email address on that page. Products that fit within one of the existing categories will be given the highest priority. As I noted earlier, we'll add additional categories over time.











Here’s the first few Microsoft items in the AWS Marketplace:

• Werner Vogels (@werner) seconded the motion with Expanding the Cloud – Introducing AWS Marketplace on 4/19/2012:
Today Amazon Web Services launched AWS Marketplace, an online store that makes it easy for you to find, buy, and immediately start using software and services that run on the AWS Cloud. You can use AWS Marketplace’s 1-Click deployment to quickly launch pre-configured software on your own Amazon EC2 instances and pay only for what you use, by the hour or month. AWS handles billing and payments, and software charges appear on your AWS bill.
Marketplace has software listings from well-known vendors including 10gen, CA, Canonical, Couchbase, Check Point Software, IBM, Microsoft, SAP, Zend, and others, as well as many widely used open source offerings including Wordpress, Drupal, and MediaWiki.
AWS Marketplace brings the same simple and trusted online shopping experience that customers enjoy on Amazon.com to software built for the AWS platform, streamlining the process of doing research and purchasing software. It features a wide selection of development and business software, including software infrastructure, developer tools, and business applications. Product prices are clearly stated and appear on the same bill as your other AWS services.
AWS Marketplace also simplifies many of the challenges software companies face, such as acquiring customers, developing distribution channels, and billing for their software.
Why shop here?
The way businesses are buying applications is changing. There is a new generation of leaders that have very different expectations about how they can select the products and tools they need to be successful. Last week I met with a CIO for a discussion about how her IT department can use AWS to help make their business units be more agile and move faster. One of the stumbling blocks she mentioned was how to select the best software running on AWS, in a way that was completely in line with the “Cloud Experience”: no software to install, no sales cycle, no procurement delays, and a selection of licensing models to choose from. She jokingly asked for an “Amazon 1-Click” experience for software. I am sure she will be a very happy CIO today.
AWS Marketplace features a wide selection of commercial and free IT and business software. AWS Marketplace enables you to compare options, read reviews, and quickly find the software you want.
We wanted to shrink the time between finding what you want and getting it up and running. Once you find software you like, you can deploy that software to your own EC2 instance with 1-Click -- like the CIO suggested -- or using popular management tools like the AWS Console.
In addition, for most products, software prices are clearly posted on the website so you can purchase software immediately, with the payment instrument you already have on file with Amazon Web Services. Software charges appear on the same monthly bill as your AWS infrastructure charges.
Why sell here?
The Amazon Web Services have helped to create great ecosystem of ISVs that are selling software and services to other customers running in the cloud. It has had a true democratization effect: no longer does the dominant vendor in a market automatically get chosen. I have many IT decision makers ask me who are the young and exciting companies they should be paying attention to. Who are the companies that have a native cloud product, who are the ones that have innovative new licensing models, who are the young and hungry companies that break with the old style of enterprise software vending and are truly customer-centric. At the same time the up-and-coming companies often ask me how we can help them get in front of more customers such that they can compete in an open and honest way. And they also often ask whether we can help them with what Amazon.com does so well for its sellers: handle billing and charging.
AWS Marketplace includes both large, well known companies as well as exciting up and coming companies. If you’re a software provider with an offering that runs on the AWS cloud, you can gain new customers, enable usage-based billing without much additional work, and ensure that customers have a fast and easy deployment experience with their software.
AWS Marketplace helps software and SaaS providers find new customers by exposing their products to some of the hundreds of thousands of AWS customers, ranging from individual software developers to large enterprises.
Additionally, if you are interested in adding hourly billing to your software, AWS Marketplace can help. Simply upload an Amazon Machine Image to AWS and provide the hourly cost. Billing is managed by AWS Marketplace, relieving sellers of the responsibility of metering usage, managing customer accounts, and processing payments, leaving software developers more time to focus on building great software.
Summary
At Amazon we have a long experience with buyers and sellers in a marketplace. We know that something great happens when you solve problems for both the people selling things and those buying things – the market becomes more and more vibrant. We know that for buyers it is important to have very convenient ways of discovering and buying products. For sellers it is important to get their products in front of as many relevant customers as possible and make the sales process as painless as possible.
But more important that anything else for both parties is trust: easy to understand product information, high quality, relevant reviews by other customers, that the seller is reputable and has a history of delivery, and that the buyer will only be charged for his exact usage. For the seller it removes the burden of having to manage customers, measuring their usage and collecting payments for it.
The AWS Marketplace is a great step forward in making easier to buy and deploy software. It also makes it dead simple for ISVs for add hourly billing to their offerings and get their software in from of hundreds of thousands of active AWS customers.
For more information see the announcement at the AWS website, the "Introducing AWS Marketplace" video, the posting on the AWS blog and off course visit the AWS Marketplace for a test drive.


• Brian Taylor (@BT_TalkinCloud) asked OpenStack Counterstroke? Amazon Launches New Partner Program in a 4/19/2012 post to the TalkinCloud blog:
Amazon Web Services (AWS) announced the beta version of its new AWS Partner Network (APN), which it touts as a “global program that provides partners with the technical information and sales and marketing support they need to accelerate their business on AWS.”
With the partner program in beta, Amazon for now is simply signing up new partners and offering existing partners to join APN. The new AWS program has two elements: Technology Partners and Consulting Partners. Commercial software or Internet services companies doing work on platforms that run on, or are complimentary to, AWS, can sign on to APN as a tech partner. Consulting partners, on the other hand, comprise professional services firms that assist customers to design, migrate and build new applications on AWS, and include system integrators, strategic consultancies, resellers and VARs.
While having partners is nothing new for Amazon, the acknowledged public cloud leader is seeing enhanced competition from open source cloud platform OpenStack, which is hosting its Design Summit in the Bay Area this week, and recently happily (we assume) announced $4 million in annual support from a veritable Who’s Who list of 19 technology companies.
Given the sharper competitive climate now facing AWS, and the timing of the news — arriving during the OpenStack Design Summit — is it too far-fetched to ask whether this is Amazon’s countermeasure to OpenStack’s momentum? It is fair to ask the question—for-profit entities do not operate in a vacuum—but only time will tell whether either of these cloud contenders will come to dominate the market. Right now that’s anyone’s guess, if indeed it happens at all. We still don’t know whether any one platform can dominate in the cloud era, as has happened with technology in ages past (think Microsoft in the PC era).
In her post on GigaOm, Barb Darrow adroitly noted that as they grow bigger, tech companies — she cites Amazon as well as Microsoft in this instance — often add services that bring them into competition (oops!) with their partners. Which means Amazon is now simply charting the same “tricky waters” that other large tech firms already have had to navigate.
Before I sign off, here’s another nugget of information about Amazon Web Services: We all know it’s big. But how big? Cloud intelligence firm DeepField Networks posted an interesting answer to that question on same day AWS made its partner announcement. (Coincidence? I think not.)
It turns out that a full one-third of Internet users visit a site based on Amazon infrastructure every day. That includes all users and all web activities, no matter how limited. Also, as of April 2012, Amazon contributes more than 1 percent of all consumer traffic in North America. This is a “huge” volume of traffic in DeepField’s view, since Amazon does not host video content like YouTube, which accounted for 6 percent of Internet traffic in 2010. Again, DeepField says it speaks to the magnitude of Amazon’s infrastructure.
Talkin’ Cloud readers who want to investigate the AWS Partner Network can click here to go to its site.
Read More About This Topic


• Barb Darrow (@gigabarb) reported Cycle Computing spins up 50K core Amazon cluster in a 4/19/2012 post to GigaOm’s Cloud (formerly Structure) blog:
For those who doubt that public cloud infrastructure can handle the toughest high-performance computing (HPC) jobs, Cycle Computing and Shrödinger have some news for you. The two companies used a 50,000-core Amazon cluster to run a complex screening process to locate compounds that could pay off in new cancer drugs.
The problem for computational chemists and biologists is there’s a trade-off between accuracy and speed. This ”Naga” compute environment built by Cycle atop the Amazon cloud eased that tradeoff, said Ramy Farid, president of New York-based Schrödinger, which specializes in computational drug design.
“We’ve got these really accurate methods but they would take months on a normal cluster. The problem is we want to do the best possible science fast,” Farid said in an interview this week.
That’s where Cycle Computing comes in. The company has made its name building high-performance computing atop AWS infrastructure and has previously deployed 10,000 and 30,000 core clusters on the cloud. For Schrödinger, it upped the ante to 50,000 cores. The alternative in this case would be for Schrödinger to build its own 50,000-core cluster or log time on a supercomputer, said Cycle Computing CEO Jason Stowe.
HPC for rent
“Practically speaking, the latter is impractical for a for-profit company and is generally restrictive. If you’re an academic wanting time on the San Diego Super Computer, for example, you’ll have months of wait time to get approved and even then you get a limited-time window — so if something with your software is not working at that time, you’re out of luck.” And, big supercomputers don’t tend to run the kinds of software these companies want to run. “The beauty of the cloud is it runs your flavor of Linux and other software,” Farid said.
On the other hand, building a 50,000 core cluster could easily cost $20 million to $30 million, he said. The Schrödinger project, by contrast, cost about $4,850 per hour to run.
For this trial, the cluster had access to all regions of AWS and used all of them in some capacity. The application used the various EC2 APIs to provision the resources.
“All the compound data for analysis was uploaded into S3 [Amazon's Simple Storage System]. The cluster was provisioned along side it and grabbed data from S3 to run the calculations and then pushed it back into S3,” said Crowe, who will be talking about the implementation Thursday at an Amazon event in New York. The application also took advantage of some Amazon IP address and DNS capabilities. …






Full disclosure: I’m a registered GigaOm Analyst.
• Beth Pariseau (@bethpariseau) asserted OpenStack gains appeal with Puppet Labs integration in a 4/19/2012 post to the SearchCloudComputing.com blog:
IT pros are still kicking the tires on OpenStack and its rivals, but Puppet Labs throwing its weight behind OpenStack give some cloud shops more reason to choose the open source platform.
OpenStack’s most recent iteration, codenamed Essex, was released last Thursday with the hope of attracting bigger fish in the cloud computing and enterprise markets. Meanwhile, Citrix Systems split from OpenStack in favor of its CloudStackplatform, causing a schism in the market. The two also compete with Eucalyptus in the open source cloud world, and more broadly, with Amazon Web Services (AWS) and VMware for dominance.
Puppet Labs, an IT automation software company, jumped into the fray with OpenStack because it is now a mature product its customers use, company executives said.
“More companies are not just talking about OpenStack, they’re deploying it in actual production implementations, including Rackspace’s public cloud based on Puppet,” said Puppet Labs CEO Luke Kanies.
Early adopters say Puppet’s integration will enhance OpenStack’s appeal. “I was going to implement OpenStack anyway, because I knew that I could write a Puppet module around the API,” wrote Joe Julian, senior systems administrator for Ed Wyse Beauty Supply in Seattle, Wash., in an email. “The integration does make it much more appealing because it will save me implementation time and money.”
The integration between Puppet and OpenStack caught the eye of one service provider who had already begun testing CloudStack.
“I’ve always been a fan of automated configuration,” said Doug Granzow, senior systems administrator for a small education services provider in the Washington, D.C. area. “Even at small scale, we like it because we know servers are built the same way every time.”
Granzow, who uses Puppet to manage about 100 production servers today, said Puppet’s involvement will earn OpenStack a second look from him, though it’s too soon to tell which way he will go.
How Granzow and others like him make up their minds in the coming year is the hottest topic in the IT market right now, analysts say. As IT pros evaluate their options, tools like Puppet can help, according to Jonathan Eunice, analyst with Illuminata, Inc. in Nashua, N.H.
“If, in the future, OpenStack isn’t cutting it and you want to re-host on CloudStack, Amazon or another environment that hasn’t emerged yet, a tool like Puppet can … help you move,” said Eunice. Conversely, “your options can be limited by not having a high level of build automation.” …


Full disclosure: I’m a paid contributor to SearchCloudComputing.com.
Jinesh Varia (@jinman) posted Announcing the AWS Partner Network on 4/17/2012:
When I joined AWS almost six years ago, I had the opportunity to work with one of the partners who built S3Fox Organizer - the cool Firefox plugin for Amazon S3. Back then, we had just launched Amazon S3 and Amazon SQS. S3Fox Organizer was not only easy to install but also extremely easy to use. It is still being used by thousands of users to store and retrieve files. The partner built the tool over the weekend and enhanced the value of Amazon S3 and made it even simpler and easier for customers to use the service. In fact, several people came to know about Amazon S3 because of this cool plugin. I remember, every now and then, I hear statements like, “I know about Amazon S3, I use S3Fox and it’s cool!”
That's the power of partners and the ecosystem!
Partners are an integral part of the AWS ecosystem as they enable customers and help them scale their business globally. Some of our greatest wins, particularly with enterprises, have been influenced by our Partners.
With that context, we are pleased to announce the Public Beta launch of the new AWS Partner Network (APN). This new global program is focused on providing members of the AWS partner ecosystem with the technical information, and sales and marketing support they need to accelerate their AWS-based businesses.
![Apn_logo_beta_4_12[1]](http://aws.typepad.com/.a/6a00d8341c534853ef0168ea4655bc970c-800wi "Apn_logo_beta_4_12[1]")
APN membership is available for both Technology-based partners (including ISVs, SaaS, tools providers, platform providers, and others) and Consulting-based partners (including SIs, agencies, consultancies, MSPs, and others).Within each of these two partner types, partners can qualify for one of three tiers (Advanced, Standard, and Registered) based on a common, published set of requirements. Partners that qualify for the Standard and Advanced tiers will receive a number of valuable benefits including:
- a logo publicly designating the partner as either Standard or Advanced
- a listing in the new AWS Partner Directory
- $1,000 in AWS Services credits
- $1,000 in AWS Premium Support credits
Although APN will not be fully activated until later this year, we encouraging all existing AWS partners to pre-qualify for the Standard and Advanced tiers via the new APN Upgrade Form as soon as possible so that they can get the above benefits quickly.
If you have any questions regarding the new APN program or wish to talk with the AWS partner team for any reason, feel free to reach out to your account manager or contact the APN Partner Support.
To learn more about APN, feel free to access the APN Overview section of the AWS site.

<Return to section navigation list>

















{kind=link}
0 comments:
Post a Comment