Windows Azure and Cloud Computing Posts for 4/2/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

Updated 4/5/2012 at 2:15 PM PST: See new Windows Azure Security documentation in the Cloud Security and Governance section and the official locations of two new Windows Azure data centers in the Windows Azure Infrastructure and DevOps section.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics, Big Data and OData
- Windows Azure Access Control, Identity and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
Avkash Chauhan (@avkashchauhan) explained Why it is important to set proper content-type HTTP header for blobs in Azure Storage in a 4/4/2012 post:
When you try to consume a content from Windows Azure blob storage you might see that sometime the content does not render correctly to browser or played correctly by the plugin used. After a few issues I worked on, I found this is mostly because the proper content-type HTTP header is not set with the blob content itself. Most of the browser Tag and plugin depends on HTTP header types and adding content-type becomes important in this regard.
For example, when you upload an audio MP3 blob to Windows Azure storage you must have the content-type header set to the blob otherwise the content will not be played correctly by the HTML5 audio element. Here is how you can do it correctly:
First I have uploaded a Kalimba.mp3 at my Windows Azure Blob Storage which is in publicly accessible container name “mp3”:
Let’s check the HTTP header type for the http://happybuddha.blob.core.windows.net/mp3/Kalimba.mp3 blob:
Now create a very simple video.html as below to play the MP3 content in HTML5 supported browser using “Audio” tag:
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head id="Head1" runat="server"> <head> <body> <audio ID="audio" controls="controls" autoplay="autoplay" src="http://happybuddha.blob.core.windows.net/mp3/Kalimba.mp3"></audio> </body> </html>Now play the video on Chrome or IE9 browser (which supports HTML5 Audio Tag):
Now let’s change the blob HTTP header type to include “Content-Type=<the_correct_content_type>”:
Finally open the Video.html in HTML5 supported browser and you can see the results:
So when you are bulk uploading your blobs, you can add proper content-type HTTP header programmatically to resolve such issues.





Avkash Chauhan (@avkashchauhan) explained Processing already sorted data with Hadoop Map/Reduce jobs without performance overhead in a 4/3/2012 post:
While working with Map/Reduce jobs in Hadoop, it is very much possible that you have got “sorted data” stored in HDFS. As you may know the “Sort function” exists not only after map process in map task but also with merge process during reduce task, so having sorted data to sort again would be a big performance overhead. In this situation you may want to have your Map/Reduce job not to sort the data.
Note: If you have tried changing map.sort.class to no-op, it would haven’t work as well.
So the question comes:
- if it is possible to force Map/Reduce to not to sort the data again (as it is already sorted) after map phase?
- Or “how to run Map/Reduce jobs in a way that you can control how do you want to results, sorted or unsorted”?
So if you do not need result be sorted the following Hadoop patch would be great place to start:
- Support no sort dataflow in map output and reduce merge phrase :https://issues.apache.org/jira/browse/MAPREDUCE-3397
Note: Before using above Patch the I would suggest reading the following comment from Robert about this patch:
- Combiners are not compatible with mapred.map.output.sort. Is there a reason why we could not make combiners work with this, so long as they must follow the same assumption that they will not get sorted input? If the algorithms you are thinking about would never get any benefit from a combiner, could you also add the check in the client. I would much rather have the client blow up with an error instead of waiting for my map tasks to launch and then blow up 4+ times before I get the error.
- In your test you never validate that the output is what you expected it to be. That may be hard as it may not be deterministic because there is no sorting, but it would be nice to have something verify that the code did work as expected. Not just that it did not crash.
- mapred-default.xml Please add mapred.map.output.sort to mapred-default.xml. Include with it a brief explanation of what it does.
- There is no documentation or examples. This is a new feature that could be very useful to lots of people, but if they never know it is there it will not be used. Could you include in your patch updates to the documentation about how to use this, and some useful examples, preferably simple. Perhaps an example computing CTR would be nice.
- Performance. The entire reason for this change is to improve performance, but I have not seen any numbers showing a performance improvement. No numbers at all in fact. It would be great if you could include here some numbers along with the code you used for your benchmark and a description of your setup. I have spent time on different performance teams, and performance improvement efforts from a huge search engine to an OS on a cell phone and the one thing I have learned is that you have to go off of the numbers because well at least for me my intuition is often wrong and what I thought would make it faster slowed it down instead.
- Trunk. This patch is specific to 0.20/1.0 line. Before this can get merged into the 0.20/1.0 lines we really need an equivalent patch for trunk, and possibly 0.21, 0.22, and 0.23. This is so there are no regressions. It may be a while off after you get the 1.0 patch cleaned up though.

![image_thumb1[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjyJ83j2NugRwr0UzcX9sMKBo3ag4-AnkgxY4fItTROY8iR91OHTbBA6Rr8BZXAzqXqHjVoB0zL-cE8Qf-YxjA69D-sUTxuiU1MYutwPcLZfDyH2alZMMML6vPuRp2kpXZEIBtK7PyB/s1600-h/image_thumb1%25255B1%25255D%25255B2%25255D.png "image_thumb1[1]")
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
SearchSQLServer.com published My (@rogerjenn) Manage, query SQL Azure Federations using T-SQL on 4/5/2012. It begins:
SQL Azure Federations is Microsoft’s new cloud-based scalability feature. It enhances traditional partitioning by enabling database administrators (DBAs) and developers to use their Transact-SQL (T-SQL) management skills with “big data” and the new fan-out query tool to emulate MapReduce summarization and aggregation features.
Highly scalable NoSQL databases for big data analytics is a hot topic these days, but organizations can scale out and scale up traditional relational databases by horizontally partitioning rows to run on multiple server instances, a process also known as sharding. SQL Azure is a cloud-based implementation of customized SQL Server 2008 R2 clusters that run in Microsoft’s worldwide data center network. SQL Azure offers high availability with a 99.9% service-level agreement provided by triple data replication and eliminates capital investment in server hardware required to handle peak operational loads.
The SQL Azure service released Dec. 12 increased the maximum size of SQL Azure databases from 50 GB to 150 GB, introduced an enhanced sharding technology called SQL Azure Federations and signaled monthly operating cost reductions ranging from 45% to 95%, depending on database size. Federations makes it easier to redistribute and repartition your data and provides a routing layer that can handle these operations without application downtime.
How can DBAs and developers leverage their T-SQL management skills with SQL Azure and eliminate the routine provisioning and maintenance costs of on-premises database servers? The source of the data to be federated is a subset of close to 8 million Windows Azure table rows of diagnostic data from the six default event counters: Network Interface Bytes Sent/Sec and Bytes Received/Sec, ASP.NET Applications Requests/Sec, TCPv4 Connections Established, Memory Available Bytes and % Processor Time. The SQL Server 2008 R2 Service Pack 1 source table (WADPerfCounters) has a composite, clustered primary key consisting of PartitionKey and RowKey values. The SQL Azure destination tables are federated on an added CounterID value of 1 through 6, representing the six event counters. These tables add CounterID to their primary key because Federation Distribution Key values must be included.
T-SQL for creating federations, adding tables
SQL Server Management Studio (SSMS) 2012 supports writing queries with the new T-SQL [CREATE | ALTER | DROP | USE] federations keywords. You can download a trial version of SQL Server 2012 and the Express version of SSMS 2012 only here.To create a new SQL Azure Federation in the database that contains the table you want to federate, select it in SSMS’ Available Databases list, open a new Query Editor window and whereDataType is int, bigint, uniqueidentifier or varbinary(n) type, the following:
CREATE FEDERATION FederationName (DistributionKeyName DataType RANGE)
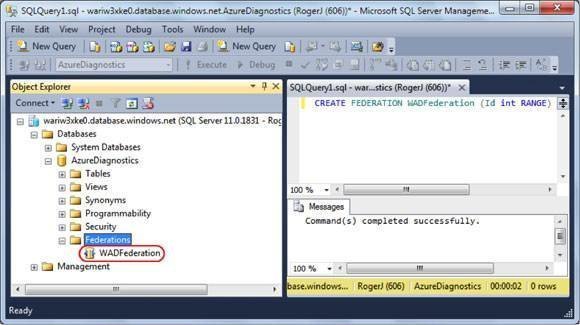
Then click Execute. For example, to create a Federation named WADDiagnostics with Id (from CounterId) as the Distribution Key Name, type this:
CREATE FEDERATION WADFederation (ID int RANGE)
GOThe RANGE keyword indicates that the initial table will contain all ID values.
When you refresh the Federations node, the new WADFederation node appears, as shown in Figure 1.
Figure 1. SQL Server Management Studio 2012 Express and higher editions support writing T-SQL queries against SQL Azure Federations.
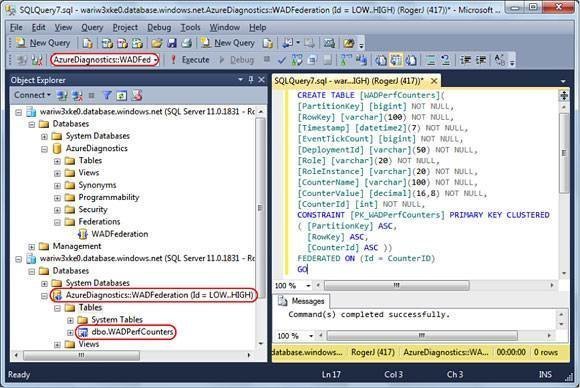
Adding a table to a Federation requires appending the FEDERATED ON(DistributionKeyName = SourceColumnName) clause to the CREATE TABLEstatement. For example, to create an initial WADPerfCounters table into which you can load data, double-click the WADFederation node to add the AzureDiagnostics::WADFederation federated database node, select it in the Available Databases list, open a new query and type the following:
CREATE TABLE [WADPerfCounters](
[PartitionKey] [bigint] NOT NULL,
[RowKey] [varchar](100) NOT NULL,
[Timestamp] [datetime2](7) NOT NULL,
[EventTickCount] [bigint] NOT NULL,
[DeploymentId] [varchar](50) NOT NULL,
[Role] [varchar](20) NOT NULL,
[RoleInstance] [varchar](20) NOT NULL,
[CounterName] [varchar](100) NOT NULL,
[CounterValue] [decimal](16,8) NOT NULL,
[CounterId] [int] NOT NULL,
CONSTRAINT [PK_WADPerfCounters] PRIMARY KEY CLUSTERED
( [PartitionKey] ASC,
[RowKey] ASC,
[CounterId] ASC ))
FEDERATED ON (Id = CounterID)
GOThen execute. Refresh the lower Tables list to display the first federated table (see Figure 2).
Figure 2. The CREATE TABLE instruction for SQL Azure Federations requires use of the FEDERATED ON keywords. …

Read more in the Adding Rows with Data Migration Wizard section.
Gregory Leake posted Announcing SQL Azure Data Sync Preview Update on 4/3/2012:
Today we are pleased to announce that the SQL Azure Data Sync preview release has been upgraded to Service Update 4 (SU4) within the Windows Azure data centers. SU4 is now running live. This update adds the most -requested feature: users can edit an existing Sync Group to accommodate changes they have made to their database schemas, without having to re-create the Sync Group. In order to use the new Edit Sync Group feature, you must install the latest release of the local agent software, available here. Existing Sync Groups do not need to be re-created, they will work with the new features automatically.
- Users can now modify a sync group without having to recreate it. See the MSDN topicEdit a Sync Group for details.
- New information in the portal helps customers more easily manage sync groups:
- The portal displays the upgrade and support status of the user’s local agent software: the local agent version is shown with a recommendation to upgrade if your client agent is not the latest, a warning if support for your agent version expires soon and an error if your agent is no longer supported.
- The portal displays a warning for sync groups that may become out-of-date if changes fail to apply for 60 or more days.
- The update fixes issues that affected ORM (Object Relational Model) frameworks such as Entity Framework and NHibernate working with Data Sync.
- The service provides better error and status messages.
If you are using SQL Azure and are not familiar with SQL Azure Data Sync, you can watch this online video demonstration.
The ability to edit an existing Sync Group enables some common customer scenarios, and we have listed some of these below as examples.
Scenario 1: User adds a table and a column to a sync group
- William uses Data Sync to keep the products databases in his branch offices up to date.
- He decides to add a new Material attribute to his products to indicate whether the product is made from Animal, Vegetable or Mineral.
- He adds a Material column to his Products table and a Material table to contain the range of material values.
- He modifies his sync group to include the new Material table and the new Material column in the Product table.
- The Data Sync service adjusts the sync configuration in William’s databases and begins synchronizing the new data.
- William categorizes his products using a Category ID in his Products table, which references records in a Category table in his database.
- He decides to discontinue the use of the Category attribute in favor of a set of descriptive tags which apply to each product.
- He modifies his application to use the descriptive tags in place of the Category attribute.
- William modifies the Sync Group to exclude the Category attribute for his Products table.
- He modifies the Sync Group to exclude the Category table.
- The Data Sync service adjusts the sync configuration in William’s databases and no longer synchronizes the Category data.
- William maintains a set of attributes for his products that include Notes and Thumbnail images.
- William decides to increase the length of the columns he uses to store these attributes:
- He changes the Notes column from CHAR(32) to CHAR(128) to accommodate more verbose notes.
- He changes the Thumbnail column from BINARY(1000) to BINARY(MAX) to hold higher resolution thumbnail images.
- William modifies his application to use the expanded attributes.
- William modifies his database by altering the Notes and Thumbnail columns to the larger sizes.
- He updates his Sync Group with the new column lengths for the Notes and Thumbnail columns.
- The Data Sync service adjusts the sync configuration in William’s databases and synchronizes the expanded columns.
Scenario 2: User removes a table and a column from a sync group
- William categorizes his products using a Category ID in his Products table, which references records in a Category table in his database.
- He decides to discontinue the use of the Category attribute in favor of a set of descriptive tags which apply to each product.
- He modifies his application to use the descriptive tags in place of the Category attribute.
- William modifies the Sync Group to exclude the Category attribute for his Products table.
- He modifies the Sync Group to exclude the Category table.
- The Data Sync service adjusts the sync configuration in William’s databases and no longer synchronizes the Category data.
Scenario 3: User changes the length of a column in a sync group
- William maintains a set of attributes for his products that include Notes and Thumbnail images.
- William decides to increase the length of the columns he uses to store these attributes:
- He changes the Notes column from CHAR(32) to CHAR(128) to accommodate more verbose notes.
- He changes the Thumbnail column from BINARY(1000) to BINARY(MAX) to hold higher resolution thumbnail images.
- William modifies his application to use the expanded attributes.
- William modifies his database by altering the Notes and Thumbnail columns to the larger sizes.
- He updates his Sync Group with the new column lengths for the Notes and Thumbnail columns.
- The Data Sync service adjusts the sync configuration in William’s databases and synchronizes the expanded columns.
Sharing Your Feedback
For community-based support, post a question to the SQL Azure MSDN forums. The product team will do its best to answer any questions posted there.
To suggest new SQL Azure Data Sync features or vote on existing suggestions, click here.
To log a bug in this release, use the following steps:
- Navigate to https://connect.microsoft.com/SQLServer/Feedback.
- You will be prompted to search our existing feedback to verify your issue has not already been submitted.
- Once you verify that your issue has not been submitted, scroll down the page and click on the orange Submit Feedback button in the left-hand navigation bar.
- On the Select Feedback form, click SQL Server Bug Form.
- On the bug form, select Version = SQL Azure Data Sync Preview
- On the bug form, select Category = SQL Azure Data Sync
- Complete your request.
- Click Submit to send the form to Microsoft.
If you have any questions about the feedback submission process or about accessing the new SQL Azure Data Sync preview, please send us an email message: sqlconne@microsoft.com.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
My (@rogerjenn) Importing Windows Azure Marketplace DataMarket DataSets to Apache Hadoop on Windows Azure’s Hive Databases article of 4/3/2012 begins:
Introduction
From the Apache Hive documentation:
The Apache HiveTM data warehouse software facilitates querying and managing large datasets residing in distributed storage. Built on top of Apache HadoopTM, it provides
Tools to enable easy data extract/transform/load (ETL)
- A mechanism to impose structure on a variety of data formats
- Access to files stored either directly in Apache HDFSTM or in other data storage systems such as Apache HBaseTM
- Query execution via MapReduce
Hive defines a simple SQL-like query language, called QL, that enables users familiar with SQL to query the data. At the same time, this language also allows programmers who are familiar with the MapReduce framework to be able to plug in their custom mappers and reducers to perform more sophisticated analysis that may not be supported by the built-in capabilities of the language. QL can also be extended with custom scalar functions (UDF's), aggregations (UDAF's), and table functions (UDTF's).
Hive does not mandate read or written data be in the "Hive format"---there is no such thing. Hive works equally well on Thrift, control delimited, or your specialized data formats. Please see File Format and SerDe in the Developer Guide for details.
Hive is not designed for OLTP workloads and does not offer real-time queries or row-level updates. It is best used for batch jobs over large sets of append-only data (like web logs). What Hive values most are scalability (scale out with more machines added dynamically to the Hadoop cluster), extensibility (with MapReduce framework and UDF/UDAF/UDTF), fault-tolerance, and loose-coupling with its input formats.
TechNet’s How to Import Data to Hadoop on Windows Azure from Windows Azure Marketplace wiki article of 1/18/2012, last revised 1/19/2012, appears to be out of date and doesn’t conform to the current Apache Hadoop on Windows Azure and MarketPlace DataMarket portal implementations. This tutorial is valid for the designs as of 4/3/2012 and will be updated for significant changes thereafter.
Prerequisites
The following demonstration of the Interactive Hive console with datasets from the DataMarket requires an invitation code to gain access to the portal. If you don’t have access, complete this Microsoft Connect survey to obtain an invitation code and follow the instructions in the welcoming email to gain access to the portal. Read the Windows Azure Deployment of Hadoop-based services on the Elastic Map Reduce (EMR) Portal for a detailed description of the signup process (as of 2/23/2012).
You also need an Windows Azure Marketplace Data Market account with subscriptions for one or more (preferably free) OData datasets, such as Microsoft’s Utility Rate Service. To subscribe to this service:
1. Navigate to the DataMarket home page, log in with your Windows Live ID and click the My Account link to confirm your User Name (email address) and obtain your Primary Account Key:

2. Open Notepad, copy the Primary Account Key to the clipboard, and paste it to Notepad’s window for use in step ? below.
3. Search for utility, which displays the following screen:

4. Click the Utility Rate Service to open its Data page:

5. Click the Sign Up button to open the Subscription page, mark the Accept the Offer Terms and Privacy Policy check box:

6. Click the Sign Up button to display the Purchase page:

Obtaining Values Required by the Interactive Hive Console
The Interactive Hive Console requires your DataMarket User ID, Primary Account Key, and text of the OData query.
1. If you’re returning to the DataMarket, confirm your User ID and save your Primary Account Key as described in step 1 of the preceding section.
2. If you’re returning to the DataMarket, click the My Data link under the My Account link to display the page of the same name and click the Use button to open the interactive DataMarket Service Explorer.

If you’ve continuing from the preceding section, click the Explore This DataSet link to open the interactive DataMarket Service Explorer.
3. In the DataMarket Service Explorer, accept the default CustomerPlans query and click Run Query to display the first 100 records:

4. Click the Develop button to display the OData query URL to retrieve the first 100 records to a text box:

5. Copy the query text and paste it to the Notepad window with your Primary Account Key.
Loading the Hive Table with Data from the Utility Rate Service
1. Navigate to the Apache Hadoop on Windows Azure portal, log in with the Windows Live ID you used in your application for an invitation code, and scroll to the bottom of the Welcome Back page:

Note: By default, your cluster’s lifespan is 48 hours. You can extend it’s life when 6 hours or fewer remain by clicking the Extend Cluster button.
2. Click the Manage Cluster tile to open that page:

3. Click the DataMarket button to open the Import from DataMarket page. Fill in the first three text boxes with your Live ID and the data you saved in the preceding section; remove the $top=100 parameter from the query to return all rows, and type UtilityRateService as the Hive Table Name:

4. Click the Import Data button to start the import process and wait until import completes, as indicated by the DataLoader progress = 100[%] message:

The text of the generated data import Command with its eight required arguments is:
c:\apps\dist\bin\dataloader.exe
-s datamarket
-d ftp
-u "roger_jennings@compuserve.com"
-k "2ZPQEl2CouvtQw+..............................Qud0E="
-q "https://api.datamarket.azure.com/Data.ashx/Microsoft/UtilityRateService/ Prices?"
-f "ftp://d5061cb5f84c9ea089bfa052f1a0a3f2:da835ebe965c87b428923032057014f7@
localhost:2222/uploads/UtilityRateService/UtilityRateService"
-h "UtilityRateService" …










![image_thumb1[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgubO1NmQ5i5-0pJCCHoHe4vQvWFr0ni5RuZoBvzkxXbLpXqK6P7ZjUrISRv-8ZZhqk9hbsWtE1biYCI_8UQROdlTTqIIzN_bveGcb59WH_tPE1HrZFSau-usJtv1LWjn_WrLekS1-x/s1600-h/image_thumb1%25255B1%25255D%25255B6%25255D.png "image_thumb1[1]")




The post continues with “Querying the UtilityRateService Hive Database”, “Viewing Job History”, and “Attempting to Load ContentItem Records from the Microsoft Codename ‘Social Analytics’ DataSet” sections and concludes:
Conclusion
Data import from the Windows Azure Marketplace DataMarket to user-specified Hive tables is one of three prebuilt data import options for Hadoop on Azure. The other two on the Manage Cluster page are:
- ASV (Windows Azure blob storage)
- S3 (Amazon Simple Storage Service)
Import of simple DataMarket datasets is a relatively simple process. As demonstrated by the problems with the VancouverWindows8 dataset’s ContentItems table, more complex datasets might fail for unknown reasons.
Writing Java code for MapReduce jobs isn’t for novices or faint-hearted code jockeys. The interactive Hive console and the HiveQL syntax simplify the query process greatly.
My (@rogerjenn) Analyze Years of Air Carrier Flight Arrival Delays in Minutes with the Windows Azure HPC Scheduler article of 4/3/2012 for Red Gate Software’s ACloudyPlace blog begins:
The Microsoft Codename “Cloud Numerics” Lab from SQL Azure Labs provides a Visual Studio template to enable configuring, deploying and running numeric computing SaaS applications on High Performance Computing (HPC) clusters in Microsoft data centers.

Figure 1: The Microsoft “Cloud Numerics” components
The Microsoft “Cloud Numerics” Lab provides a Visual Studio 2010 C# project template and deployment utility, .NET 4 runtime, and .NET native and system libraries for numeric analysis in a single downloadable package. (Diagram based on Microsoft’s The “Cloud Numerics” Programming and runtime execution model documentation.)
Why Use the “Cloud Numerics” Lab and Windows HPC Scheduler?
The “Cloud Numerics” Lab is designed for developers of computationally intensive applications that involve large datasets. It specifically targets projects that benefit from “bursting” computational work from desktop PCs to small-scale supercomputers running Windows HPC Server 2008 R2 in Microsoft data centers. Few small businesses or medium-size enterprises can afford the capital investment or administrative and operating costs of dedicated, on-premises HPC clusters that might be used for only a few hours or minutes per week. Although Microsoft’s new Apache Hadoop on Windows Azure developer preview offers similar advantages, Hadoop and its subcomponents are Java-centric. This means Microsoft shops can incur substantial training costs to bring their .NET developers up-to-speed with Hadoop, HDFS, MapReduce, Hive, Pig, Sqoop, and other open-source software.
Installing the “Cloud Numerics” package from Connect.Microsoft.com adds a customizable Microsoft Cloud Numerics Application C# template to Visual Studio 2010 that most .NET developers will be able to use out-of-the-box without a significant learning curve. The template generates a solution with these projects automatically:
- AppConfigure – Publishes a fully-configured Windows HPC Server cluster to Windows Azure aided by a graphical Cloud Numerics Deployment Utility
- HeadNode – Provides failover and mediates access to the cluster resources as the single point of management and job scheduling for the cluster (see Figure 2)
- ComputeNode – Carries out the computation tasks assigned to it by the Scheduler
- FrontEnd – Provides a Web-accessible endpoint and UI for the Windows Azure HPC Schedule Web Portal, which display job status and diagnostic messages
- AzureSampleService – Defines roles for and number of HeadNode, ComputeNode, and FrontEnd instances; generates ServiceConfiguration.Local.csfg, ServiceConfigure.Cloud.csfg, and ServiceDefinition.csdef files
- MSCloudNumericsApp – Provides replaceable C# code stubs for specifying and reading data sources, defining computational functions, and determining output format and destination (usually a blob in Windows Azure storage)

Figure 2: The Microsoft Cloud Numerics Application template generates and deploys these components to local Windows HPC Server 2008 R2 runtime instances or Windows Azure HPC hosted services.
The template includes a simple MSCloudNumericsApp project for random-number arrays that developers can run locally to verify correct installation and, optionally, deploy with a Windows Azure HPC Scheduler to a service hosted in a Microsoft data center. My initial Introducing Microsoft Codename “Cloud Numerics” from SQL Azure Labs and Deploying “Cloud Numerics” Sample Applications to Windows Azure HPC Clusters tutorials describe these operations in detail.
Like Hadoop/MapReduce projects, “Cloud Numerics” apps are batch processes. They split data into chunks, run operations on the chunks in parallel and then combine the results when computation completes. “Cloud Numerics” apps operate on distributed numeric arrays, also called matrices. They primarily deliver aggregate numeric values, not documents, and aren’t intended to perform “selects” or other relational data operations. .NET developers without a background in statistics, linear algebra, or matrix operations probably will need some assistance from their more mathematically inclined colleagues to select and apply appropriate analytic functions. On the other hand, math majors will require minimal programming guidance to modify the MSCloudNumericsApp code to define their own jobs and deploy them to Windows Azure independently. …

The article continues with “Creating and Running the Air Carrier Flight Arrival Delays Solution” and “Test-Drive Microsoft Codename ‘Data Numerics’” sections.
For more details about the Microsoft Codename “Data Numerics” PaaS Lab, see my two tutorials linked above.
<Return to section navigation list>
Windows Azure Service Bus, Access Control, Identity and Workflow
Vittorio Bertocci (@vibronet) described Authenticating Users from Passive IPs in Rich Client Apps – via ACS in a 4/4/2012 post:
It’s been a couple of years that we released the first samples showing how to take advantage of ACS from Windows Phone 7 applications; the iOS samples, released in the Summer, and the Windows8 Metro sample app last Fall demonstrated that the pattern applies to just any type of rich clients.
I am currently crammed in a small seat in cattle class, inclusive of crying babies and high-pitch barking dogs (yes, plural), on a Seattle-Paris flight that is bringing me to a 1-week vacation at home. It’s hardly the best situation to type a lengthy post, but if I don’t do it I know this will but me for the entire week and I don’t want it to distract me from the mega family reunion and the 20th anniversary party of my alma mater so my dear readers, wear confortable clothes and gather around, because in the next few hours (for the writer, at least) we are going to shove our hands deep into the guts of this pattern and shine our bright spotlight pretty much in every fold. Thank you Ping Identity for the noise-cancelling headset you got me during last Cloud Identity Summit, without which this post would not have been possible.
The General Idea
Rich clients. How do they handle authentication? Let’s indulge our example bias and pick some notable case from the traditional world.
Take an email client, like Outlook: in the most general case, Outlook won’t play games and will simply ask you for your credentials. The same goes for SQL Management Studio, Live Writer, FileZilla, Messenger. That’s because your mail server, SQL engine, blog engine, FTP server and Live ID all have programmatic endpoints that accept raw credentials.
A slightly less visible case is the use of Office apps within the context of your domain, in which you are silently authenticated and authorized: however I assure that you are not using your midichlorians to submit that file share to your will. It’s simply that you are operating in one environment fully handled by your network software, where there is an obvious, implicit authority (the KDC) which is automatically consulted whenever you do anything that requires some privilege. There is an unbroken chain of authentication which starts when you sign in the workstation and unfolds all the way to your latest request, and it is all supported by programmatic authentication endpoints.
All this has worked pretty well for few decades, and still enjoys very wide application: however it does not cover all the authentication needs of today’s scenarios. Here there’s a short list of situations in which the approach falls short:
- No endpoints for non-interactive authentication
Nowadays some of the most interesting user populations can be found among the users of social networks, web applications and similar. Those guys built a business on people navigating with their browsers to their pages, or on people navigating with their browsers to others’ pages which end up calling their API. Although the meteoric rise of the mobile app is shifting things around, the basic premises are sound. Those applications and web sites might provide endpoints accepting raw credentials, but more often than not they will expose their authentication capabilities via browser-based flows: that works well when you are integrating with them from a web application, as the uses would consume it from a browser. Things get less clear when the calling application is a rich client.:Manufacturing web requests and scraping the responses is technically feasible, but extremely brittle and above all a very likely a glaring violation of the terms and conditions of the target IP. My advice is, don’t even try it. There are other solutions.- Changing or hard requirements on authentication mechanics
When you drive authentication with raw credentials from a rich client, you bear the burden of making things happen: creating the credential gathering experience, dispatching the credentials t the IP according to the protocol of choice & interpret the response, and so on. If you just hurl passwords from A to B, or you take advantage of an underlying Kerberos infrastructure, that’s not that bad: but if you need to do more complicated stuff, things get tougher. Say that your industry regulations impose you to use, in addition to username and password, a one-time key sent to the user’s mobile phone": now you need to create the appropriate UI elements, drive the challenge/response experience, and adapt the protocol bits accordingly. What happens if in 1 month the law changes, and now your IP imposes you to use a hard token or a smart card as well? That means writing new infra code, and redeploy it to all your clients. Not the happiest place to be.- Consent experiences
More and more often, the authentication experience is compounded with some kind of consent experience: not only the user needs to authenticate with the IP, he or she also needs to decide what information and resources should be made available to the application triggering the authentication flow.
Needless to say, each IP can have completely different needs here: for example, different resource types require different privileges. Icing on the cake, those things are as fluid as mercury and will change several times per year. Creating a general-purpose rich UI to accommodate for all that is perhaps not impossible, but would require a gargantuan all-up effort for which there’s simply no pressure for. Why bother, when a browser can easily render your latest consent experience no matter how often you change it?- Chaining authorities
This is subtler. Say that the service you want to call from your rich client trusts A; however your users do not have an account with A. They do have an account with B, and A trusts B. Great! The transitive closure of trust relationship will pull you out of trouble, right? B can act as federation provider, A as identity provider, and the user gets to access the service. Only, with rich clients it’s not that simple. In the passive case, you can take the user to a rise and redirect him/her as many times as needed, each leg rendering its own UI, gathering its own specific set of info using whatever protocol flavor it deems appropriate, without requiring changes in the browser or in the service. In the rich client you have to muscle through every leg: every call to an STS entails knowing exactly the protocol options they use, every new credential type must be accounted for in the client code: doing dynamic stuff is possible (some of the oldest readers know what I am talking about) but certainly non-trivial.Ready for some good news? All of the above can be solved, or at least mitigated, by a bit of inventiveness. Rich clients render their UI with their own code, rather than feeding it to a browser: but if the browser works so well for the authentication scenarios depicted above, why not opening one just when needed for driving he authentication phase?
The idea is sound, but as usual the devil is in the details. With some exceptions, the protocols used for browser based authentication aim at delivering a token (or equivalent) to one application on a server; if we want this impromptu browser trick to work, we need to find a way of “hijacking” the token toward the rich client app before it gets sent to the server.
The good news keep coming. ACS offers a way for you to use it from within a browser driven by a rich client, and faithfully deliver tokens to the calling client app while still maintaining the usual advantages it offers: outsourcing of trust relationships, support for many identity provider types, claims transformation rules, lightweight token formats suitable for REST calls, and so on.
If all you care is knowing that such method exists, and you are fine with using the samples we provide without tweaking them, you should stop reading now.
If you decide to push farther, here there’s what to expect. The way in which you use ACS from a browser in a rich client is based on a relatively minor tweak on how we handle WS-Federation and home realm discovery. Since I can’t assume that you are all familiar with the innards of WS-Federation (which you would, if you would have taken advantage of yesterday’s 50% off promotion from O’Reilly) I am going to give you a refresher of the relevant details. Done then, I’ll explain how the method works in term of the delta in respect to traditional ws-fed.
An ACS & WS-Federation Refresher
The figure below depicts what append during a classic browser-based authentication flow taking advantage of ACS.
In order to keep things manageable I omitted the initial phase, in which an unauthenticated request to the web app results in a redirect to the home realm discovery page: I start the flow directly from there. Furthermore, instead of showing a proper HTML HRD page I use a JSON feed, assuming that the browser would somehow render it for the user so that its corresponding entries will be clickable. Hopefully things will get clearer once I get in the details.
Home Realm Discovery
Let’s say that you want to help the user to authenticate with a given web application, protected by ACS. ACS knows which identity providers the application is willing to accept users from, and knows how to integrate with those. How do you take advantage of that knowledge? You have two easy ways:
- you can rely on one page that ACS automatically generates for you, which presents to the user a list of the acceptable identity providers. That’s super-easy, and that’s also what I show in the diagram above in step 1. However it is not exactly the absolute best in term of experience; ACS renders the bare minimum for the user to make a choice, and the visuals are – how should I put it? – a bit rough. And that’s by design.
- Another alternative is to obtain the list of identity providers programmatically. ACS offers a special endpoint you can use to obtain a JSON feed of identity providers trusted for a given relying party, inclusive of all the coordinates required for engaging each of them in one authentication flow. Once you have that list, you can use that info to create whatever authentication experience and/or look&feel you deem appropriate.
The second alternative is actually pretty clever! Let’s take a deeper look. How do you obtain the JSON feed for a given RP? You just GET the following:
https://w8kitacs.accesscontrol.windows.net:443/v2/metadata/IdentityProviders.js?protocol=wsfederation&realm=http%3a%2f%2flocalhost%3a7777%2f&reply_to=http%3a%2f%2flocalhost%3a7777%2f&context=&request_id=&version=1.0&callback=
The first part is the resource itself, the IP feed; it follows the customary rule for constructing ACS endpoints, the namespace identifier (bold) followed by the ACS URL structure. The green part specifies that we want to integrate ACS and our app using WS-Federation. The last highlighted section identifies which specific RP (among the ones described in the target namespace) we want to deal with. What do we get back? The following:
[
{
"Name": "Windows Live™ ID",
"LoginUrl": "https://login.live.com/login.srf?wa=wsignin1.0&wtrealm=https%3a%2f%2faccesscontrol.windows.net%2f&wreply=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fwsfederation&wp=MBI_FED_SSL&wctx=pr%3dwsfederation%26rm%3dhttp%253a%252f%252flocalhost%253a7777%252f%26ry%3dhttp%253a%252f%252flocalhost%253a7777%252f",
"LogoutUrl": "https://login.live.com/login.srf?wa=wsignout1.0",
"ImageUrl": "", "EmailAddressSuffixes": []
},
{
"Name": "Yahoo!",
"LoginUrl": "https://open.login.yahooapis.com/openid/op/auth?openid.ns=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0&openid.mode=checkid_setup&openid.claimed_id=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0%2fidentifier_select&openid.identity=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0%2fidentifier_select&openid.realm=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fopenid&openid.return_to=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fopenid%3fcontext%3dpr%253dwsfederation%2526rm%253dhttp%25253a%25252f%25252flocalhost%25253a7777%25252f%2526ry%253dhttp%25253a%25252f%25252flocalhost%25253a7777%25252f%26provider%3dYahoo!&openid.ns.ax=http%3a%2f%2fopenid.net%2fsrv%2fax%2f1.0&openid.ax.mode=fetch_request&openid.ax.required=email%2cfullname%2cfirstname%2clastname&openid.ax.type.email=http%3a%2f%2faxschema.org%2fcontact%2femail&openid.ax.type.fullname=http%3a%2f%2faxschema.org%2fnamePerson&openid.ax.type.firstname=http%3a%2f%2faxschema.org%2fnamePerson%2ffirst&openid.ax.type.lastname=http%3a%2f%2faxschema.org%2fnamePerson%2flast",
"LogoutUrl": "",
"ImageUrl": "",
"EmailAddressSuffixes": []
},
{
"Name": "Google",
"LoginUrl": "https://www.google.com/accounts/o8/ud?openid.ns=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0&openid.mode=checkid_setup&openid.claimed_id=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0%2fidentifier_select&openid.identity=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0%2fidentifier_select&openid.realm=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fopenid&openid.return_to=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fopenid%3fcontext%3dpr%253dwsfederation%2526rm%253dhttp%25253a%25252f%25252flocalhost%25253a7777%25252f%2526ry%253dhttp%25253a%25252f%25252flocalhost%25253a7777%25252f%26provider%3dGoogle&openid.ns.ax=http%3a%2f%2fopenid.net%2fsrv%2fax%2f1.0&openid.ax.mode=fetch_request&openid.ax.required=email%2cfullname%2cfirstname%2clastname&openid.ax.type.email=http%3a%2f%2faxschema.org%2fcontact%2femail&openid.ax.type.fullname=http%3a%2f%2faxschema.org%2fnamePerson&openid.ax.type.firstname=http%3a%2f%2faxschema.org%2fnamePerson%2ffirst&openid.ax.type.lastname=http%3a%2f%2faxschema.org%2fnamePerson%2flast",
"LogoutUrl": "",
"ImageUrl": "",
"EmailAddressSuffixes": []
},
{
"Name": "Facebook",
"LoginUrl": "https://www.facebook.com/dialog/oauth?client_id=194667703936106&redirect_uri=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%2fv2%2ffacebook%3fcx%3dcHI9d3NmZWRlcmF0aW9uJnJtPWh0dHAlM2ElMmYlMmZsb2NhbGhvc3QlM2E3Nzc3JTJmJnJ5PWh0dHAlM2ElMmYlMmZsb2NhbGhvc3QlM2E3Nzc3JTJm0%26ip%3dFacebook&scope=email",
"LogoutUrl": "",
"ImageUrl": "",
"EmailAddressSuffixes": []
}
]Well, that’s clearly meant to be consumed by machines: however JSON is clear enough for us to take this guy apart and understand what’s there.
First of all, the structure: every IP gets a name (useful for presentation purposes), a login URL (more about that later), a rarely populated logout URL, the URL of one image (again useful for presentation purposes) and a list of email suffixes (longer conversation, however: useful if you know the email of your user and you want to use it to automatically pair him/her to the corresponding IP, instead of showing all the list).
The login URL is the most interesting property. Let’s take the first one:
https://login.live.com/login.srf?wa=wsignin1.0&wtrealm=https%3a%2f%2faccesscontrol.windows.net%2f&wreply=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fwsfederation&wp=MBI_FED_SSL&wctx=pr%3dwsfederation%26rm%3dhttp%253a%252f%252flocalhost%253a7777%252f%26ry%3dhttp%253a%252f%252flocalhost%253a7777%252f
This is the URL used to sign in using Live. The yellow part, together with various other hints (wreply, wctx, etc) suggests that the integration with Live is also based on WS-Federation. This is what is often referred to as a deep link: it contains all the info required to go to the IP and then get back to the ACS address that will take care of processing the incoming token and issue a new token for the application. The part highlighted green shows such endpoint. Note the wsfederation entry in the wctx context parameter, it will come in useful later. You don’t need to grok al the details here: suffice to say that if the user clicks on this link he’ll be transported in a flow where he will authenticate with live id, will be bounced back to ACS and will eventually receive the token needed to authenticate with the application. Al with a simple click on a link.
Want to try another one? let’s take a look at the URL for Yahoo:
https://open.login.yahooapis.com/openid/op/auth?openid.ns=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0&openid.mode=checkid_setup&openid.claimed_id=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0%2fidentifier_select&openid.identity=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0%2fidentifier_select&openid.realm=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fopenid&openid.return_to=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fopenid%3fcontext%3dpr%253dwsfederation%2526rm%253dhttp%25253a%25252f%25252flocalhost%25253a7777%25252f%2526ry%253dhttp%25253a%25252f%25252flocalhost%25253a7777%25252f%26provider%3dYahoo!&openid.ns.ax=http%3a%2f%2fopenid.net%2fsrv%2fax%2f1.0&openid.ax.mode=fetch_request&openid.ax.required=email%2cfullname%2cfirstname%2clastname&openid.ax.type.email=http%3a%2f%2faxschema.org%2fcontact%2femail&openid.ax.type.fullname=http%3a%2f%2faxschema.org%2fnamePerson&openid.ax.type.firstname=http%3a%2f%2faxschema.org%2fnamePerson%2ffirst&openid.ax.type.lastname=http%3a%2f%2faxschema.org%2fnamePerson%2flast
Now that’s a much longer one! I am sure that many of you will recognize the OpenID/attribute exchange syntax, which happens to be the redirect-based protocol that ACS uses to integrate with Yahoo. The value of the return_to parameter hints at how ACS processes the flow: once again, notice the wsfederation string; and once again, all it takes to authenticate is a simple click on the link.
Google also integrates with ACS via OpenID, hence we can skip it. How about Facebook, though?
https://www.facebook.com/dialog/oauth?client_id=194667703936106&redirect_uri=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%2fv2%2ffacebook%3fcx%3dcHI9d3NmZWRlcmF0aW9uJnJtPWh0dHAlM2ElMmYlMmZsb2NhbGhvc3QlM2E3Nzc3JTJmJnJ5PWh0dHAlM2ElMmYlMmZsb2NhbGhvc3QlM2E3Nzc3JTJm0%26ip%3dFacebook&scope=email
Yet another integration protocol: this time it’s OAuth2. The flow leverages one Facebook app I created for the occasion, as it’s standard procedure with ACS. Another link type, same behavior: for the user, but also for the web app developer, it’s just a matter of following a link and eventually an ACS-issued token comes back.
Getting Back a Token
Alrighty, let’s say that the user clicks on one of the login URL links. In the diagram that’s step 2. In this case I am showing a generic IP1. As you know by now, the IP can use whatever protocol ACS and the IP agreed upon. In the diagram I am using WS-Federation, which is what you’d see if IP1 would be an ADFS2 or Live ID.
WS-Federation uses an interesting way of returning a token upon successful authentication. It basically sends back a form, containing the token and various ancillary parameters; it also sends a Javascript fragment that will auto-post that form to the requesting RP. That’s what happens in step 2 (IP to ACS) and 3 (ACS to the web application). Let’s take a closer look to the response returned by ACS:
1: <![CDATA[2: <html><head><title>Working...</title></head><body>3: <form method="POST" name="hiddenform" action="http://localhost:7777/">4: <input type="hidden" name="wa" value="wsignin1.0" />5: <input type="hidden" name="wresult" value="&lt;t:RequestSecurityTokenResponse6: Context=&quot;rm=0&amp;amp;7: id=passive&amp;amp;ru=%2fdefault.aspx%3f&quot;8: xmlns:t=&quot;http://schemas.xmlsoap.org/ws/2005/02/trust&quot;><t:Lifetime>9: <wsu:Created xmlns:wsu="http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-wssecurity-utility-1.0.xsd">10: 2012-03-28T19:19:56.488Z</wsu:Created>11: <wsu:Expires xmlns:wsu="http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-wssecurity-utility-1.0.xsd">2012-03-28T19:29:56.488Z</wsu:Expires>12: </t:Lifetime>13: <wsp:AppliesTo xmlns:wsp="http://schemas.xmlsoap.org/ws/2004/09/policy"><EndpointReference xmlns="http://www.w3.org/2005/08/addressing"><Address>http://localhost:7777/</Address></EndpointReference>14: </wsp:AppliesTo>15: <t:RequestedSecurityToken>16: <Assertion ID="_906f33bd-11ca-4d32-837b-71f8a3a1569c"17: IssueInstant="2012-03-28T19:19:56.504Z"18: Version="2.0" xmlns="urn:oasis:names:tc:SAML:2.0:assertion">19: <Issuer>https://w8kitacs.accesscontrol.windows.net/</Issuer>20: <ds:Signature [...]21: lt;/Assertion></t:RequestedSecurityToken>22: [....]23: lt;/t:RequestSecurityTokenResponse>" />24: <input type="hidden" name="wctx" value="rm=0&id=passive&ru=%2fdefault.aspx%3f" />25: <noscript><p>Script is disabled. Click Submit to continue.</p><input type="submit" value="Submit" />26: </noscript>27: </form>28: <script language="javascript">29: window.setTimeout('document.forms[0].submit()', 0);30: </script></body></html>31: ]]>Now THAT’s definitely not meant to be read by humans. I did warn you at the beginning of the post, didn’t I.
Come on, it’s not that bad: let me be your Virgil here. As I said above, in WS-Federation tokens are returned to the target RP by sending back a form with autopost: and that’s exactly what we have here. Lines 3-27 contain a form, which features a number of input fields used to do things such as signaling to the RP the nature of the operation (line 4: we are signing in) and transmitting the actual bits of the requested token (line 5 onward).
Lines 28-30 contain the by-now-famous autoposter script. And that’s it! The browser will receive the above, sheepishly (as in passively) execute the script and POST the content as appropriate.
The RP will likely have interceptors like WIF which will recognize the POST for what it is (a signin message), find the token, mangle it as appropriate and authenticate (or not) the user. All as described in countless introductions to claims-based identity.
Congratulations, you now know much more about how ACS implements HRD and how WS-Fed works than you’ll ever actually need. Unless, of course, you want to understand in depth how you can pervert that flow into something that can help with rich clients. …not from a Jedi
The Javascriptnotify Flow
Let’s get back to the rich client problem. We already said that we can pop out a browser from our rich client when we need to – that is to say when we have to authenticate the user - and close it once we are done. The flow we have just examined seems almost what we need, both for what concerns the HRD (more about that later) and the authentication flow. The only thing that does not work here is the last step.
Whereas in the ws-fed flow the ultimate recipient of the token issuance process is the entity that requires it for authentication purposes, that is to say the web site, in the rich client case it is the client itself that should obtain the token and store it for later use (securing calls to a web service). It is a bit if in the WS-Federation case the token would stop at the browser, instead of being posted to the web site. Here, let me steal my own thunder: we make that happen by providing in ACS an endpoint which is almost WS-Federation, but in fact provides a mechanism for getting the token where/when we need it in a rich client flow. We call it javascriptnotify. Take a look at the diagram below.
That looks pretty similar to the other one, with some important differences:
- there is a new actor, the rich client application. Although the app is active before and after the authentication phase, here we represent things only form the moment in which the browser pops out (identified in the diagram by the browser control entry, which can be embedded or popped out as dialog according to the style of the apps in the target platform) to the moment in which the authentication flow terminates
- the diagram does not show the intended audience of the token, the web service. Here we focus just on the token acquisition rather than use (which comes later in the app flow), whereas in the passive case the two are inextricably entangled.
Here I did in step 1 the same HRD feed/page simplification I did above; I’ll get back to it at the end of the post. The URl we use for getting the feed, though, has an important difference:
https://w8kitacs.accesscontrol.windows.net/v2/metadata/IdentityProviders.js?protocol=javascriptnotify&realm=urn:testservice&version=1.0
The URI of the resource is the same, and the realm of the target service is obviously different; the interesting bit here is the protocol parameter, which now says “javascriptnotify” instead of “wsfederation”. Let’s see if that yields to differences in the actual feed:
{
"Name": "Windows Live™ ID",
"LoginUrl": "https://login.live.com/login.srf?wa=wsignin1.0&wtrealm=https%3a%2f%2faccesscontrol.windows.net%2f&wreply=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fwsfederation&wp=MBI_FED_SSL&wctx=pr%3djavascriptnotify%26rm%3durn%253atestservice",
"LogoutUrl": "https://login.live.com/login.srf?wa=wsignout1.0",
"ImageUrl": "",
"EmailAddressSuffixes": []
},
{
"Name": "Yahoo!",
"LoginUrl": "https://open.login.yahooapis.com/openid/op/auth?openid.ns=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0&openid.mode=checkid_setup&openid.claimed_id=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0%2fidentifier_select&openid.identity=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0%2fidentifier_select&openid.realm=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fopenid&openid.return_to=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fopenid%3fcontext%3dpr%253djavascriptnotify%2526rm%253durn%25253atestservice%26provider%3dYahoo!&openid.ns.ax=http%3a%2f%2fopenid.net%2fsrv%2fax%2f1.0&openid.ax.mode=fetch_request&openid.ax.required=email%2cfullname%2cfirstname%2clastname&openid.ax.type.email=http%3a%2f%2faxschema.org%2fcontact%2femail&openid.ax.type.fullname=http%3a%2f%2faxschema.org%2fnamePerson&openid.ax.type.firstname=http%3a%2f%2faxschema.org%2fnamePerson%2ffirst&openid.ax.type.lastname=http%3a%2f%2faxschema.org%2fnamePerson%2flast",
"LogoutUrl": "",
"ImageUrl": "",
"EmailAddressSuffixes": []
},
{
"Name": "Google",
"LoginUrl": "https://www.google.com/accounts/o8/ud?openid.ns=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0&openid.mode=checkid_setup&openid.claimed_id=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0%2fidentifier_select&openid.identity=http%3a%2f%2fspecs.openid.net%2fauth%2f2.0%2fidentifier_select&openid.realm=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fopenid&openid.return_to=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%3a443%2fv2%2fopenid%3fcontext%3dpr%253djavascriptnotify%2526rm%253durn%25253atestservice%26provider%3dGoogle&openid.ns.ax=http%3a%2f%2fopenid.net%2fsrv%2fax%2f1.0&openid.ax.mode=fetch_request&openid.ax.required=email%2cfullname%2cfirstname%2clastname&openid.ax.type.email=http%3a%2f%2faxschema.org%2fcontact%2femail&openid.ax.type.fullname=http%3a%2f%2faxschema.org%2fnamePerson&openid.ax.type.firstname=http%3a%2f%2faxschema.org%2fnamePerson%2ffirst&openid.ax.type.lastname=http%3a%2f%2faxschema.org%2fnamePerson%2flast",
"LogoutUrl": "",
"ImageUrl": "",
"EmailAddressSuffixes": []
},
{
"Name": "Facebook",
"LoginUrl": "https://www.facebook.com/dialog/oauth?client_id=194667703936106&redirect_uri=https%3a%2f%2fw8kitacs.accesscontrol.windows.net%2fv2%2ffacebook%3fcx%3dcHI9amF2YXNjcmlwdG5vdGlmeSZybT11cm4lM2F0ZXN0c2VydmljZQ2%26ip%3dFacebook&scope=email",
"LogoutUrl": "",
"ImageUrl": "",
"EmailAddressSuffixes": []
}
]The battery is starting to suffer, so I have to accelerate a bit. I am not extracting the Login URLs of the various IPs, but I highlighted the places where ws-federation has been substituted by javascriptnotify (facebook follows a different approach, more about is some other time: but you can see that the two redirect_uri are different).
The integration between the IP and ACS – step 2 - goes as usual, modulo a different value in some context parameter; I didn’t show it in details earlier, I won’t show it now. What is different, though, is that coming back from the IP there’s something in the URL which tells ACS that the token should not be issued via WS-Federation, but using Javascriptnotify. That will influence how ACS sends back a token, that is to say the return portion of leg 3. Earlier we got a form containing the token, and an autoposter script; let’s see what we get now.
1: <html xmlns="http://www.w3.org/1999/xhtml">2: <head>3: <title>Loading </title>4: <script type="text/javascript">1:2: try {3: window.external.notify(4: '{5: "appliesTo":"urn:testservice",6: "context":null,7: "created":1332868436,8: "expires":1332869036,9: "securityToken":"<?xml version="1.0" encoding="utf-16"?\u003e<wsse:BinarySecurityToken wsu:Id="uuid:0ebe45bb-c8f5-4b58-b6fd-20cc54667721" ValueType="http://schemas.xmlsoap.org/ws/2009/11/swt-token-profile-1.0" EncodingType="http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-soap-message-security-1.0#Base64Binary" xmlns:wsu="http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-wssecurity-utility-1.0.xsd" xmlns:wsse="http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-wssecurity-secext-1.0.xsd"\u003eaHR0cCUzYSUyZiUyZnNjaGVtYXMueG1sc29hcC5vcmclMmZ3cyUyZjIwMDUlMmYwNSUyZmlkZW50aXR5JTJmY2xhaW1zJTJmbmFtZWlkZW50aWZpZXI9MWJOdnROc2c5cmolMmIxdTVwTFlwTkE5VndveFFVUEx4TmtMNGJnMmZYWk13JTNkJmh0dHAlM2ElMmYlMmZzY2hlbWFzLm1pY3Jvc29mdC5jb20lMmZhY2Nlc3Njb250cm9sc2VydmljZSUyZjIwMTAlMmYwNyUyZmNsYWltcyUyZmlkZW50aXR5cHJvdmlkZXI9dXJpJTNhV2luZG93c0xpdmVJRCZBdWRpZW5jZT11cm4lM2F0ZXN0c2VydmljZSZFeHBpcmVzT249MTMzMjg2OTAzNiZJc3N1ZXI9aHR0cHMlM2ElMmYlMmZ3OGtpdGFjcy5hY2Nlc3Njb250cm9sLndpbmRvd3MubmV0JTJmJkhNQUNTSEEyNTY9blpPWE1pN3k2VkE4QlEyVXJWQWlpTDZXSkQ4OHJjb3ZvanBVb2t3dmklMmY4JTNk</wsse:BinarySecurityToken\u003e",10: "tokenType":"http://schemas.xmlsoap.org/ws/2009/11/swt-token-profile-1.0"}');11: }12: catch (err) {13: alert("Error ACS50021: windows.external.Notify is not registered.");14: }15:</script>16: </head>17: <body>18: </body>19: </html>I hope you’ll find in you to forgive the atrocious formatting I am using, hopefully that does not get in the way of making my point.
As you can see above, the response from ACS is completely different; it’s a script which substantially passes a string to whomever in the container implements a handler for the notify event. And the string contains.. surprise surprise, the token we requested. If our rich client provided a handler for the notify event, it will now receive the token bits for storage and future use. Mission accomplished: the browser control can now be closed and the rich native experience can resume, ready to securely invoke services with the newfound token.
The notifi-ed string also contains some parameter about the token itself (audience, validity interval, type, etc). Those parameters can come in handy to know what the token is good for, without the need for the client to actually parse and understand the token format (which can be stored and used as amorphous blob, nicely decoupling the client from future updates in the format or changes in policy).
A bit more on token formats. ACS allows you to define which token format should be used for which RP, regardless of the protocol. When obtaining tokens for REST services, you normally want to get tokens in a lightweight format (as you’ll likely need to use them in places – like the HTTP headers - where long tokens risk being clipped). In this example, in fact, I decided to use SWT tokens for my service urn: testservice. However ACS would have allowed me to send back a SAML token just as well. One more point in favor of keeping the client format-agnostic, given that the service might change policy at any moment.
That’s it for the flow! I might be biased, but IMHO it’s not that hard; in any case, I am glad that the vast majority of developers will never have to know things at this level of detail.
If you are interested in taking a look at code that handles the notify, I’d suggest getting the ACS2+WP7 lab and taking a look at Labs\ACS2andWP7\Source\Assets\SL.Phone.Federation\Controls\AccessControlServiceSignIn.xaml.cs, and specifically to SignInWebBrowserControl_ScriptNotify.Now that you know what it’s supposed to do, I am sure you’ll find it straightforward.
A Note About HRD on Rich Clients
Before closing and getting some sleep, here there’s a short digression on home realm discovery and rich clients.
At the beginning of the WS-Federation refresher I mentioned that web site developers have the option of relying on the precooked HRD page, provided by ACS for development purposes, or take the matter in their own hands and use the HRD JSON feed to acquire the IPs coordinates programmatically and integrate tem in their web site’s experience.
A rich client developer has even more options, which can be summarized in the following;
- Provide a native HRD experience. This is what we demonstrate in all of our rich client +ACS samples such as the WP7 and the Windows8 Metro ones: we acquire the JSON IP feed and we use it to display the possible IPs using the style and controls afforded by the target platform. When the user makes a choice, we open a browser (or conceptual equivalents, let’s not get too fiscal here) and point it to the LoginUrl associated to the IP of choice.
There are many nice things to be said about this approach, the main one being that you have the chance of leveraging the strengths of your platform of choice. The other side of the coin is that you might need to write quite a lot of code. Also: if you are writing multiple versions of your client, targeting multiple platforms, you’ll have to rethink the code of the HRD experience just as many times.- Drive the HRD experience from the browser. Of course you can always decide to just follow the passive case more closely, and handle the HRD experience in the browser as well. There are multiple ways of doing so, from driving it with a page served from some hosted location to generating the HTML from the JSON IPs feed directly on the client side. The advantage is that the structure of your app can be significantly simplified, with all the authentication code nicely ring-fenced in the browser control sub-system. The down side is that you’ll likely not blend with the target platform as well as you could if you’d use its visual elements & primitives directly.
Well folks, I have a confession to make. Right now I am still writing from a plane, and there are still babies crying around, but this time it’s the Paris-Seattle: the vacation is over and I am coming back. I didn’t finish this post on my way in, the magic noise cancelling headset fought bravely but in the end the babies-dogs combined attack could not be contained. Believe it or not, I actually managed to enjoy my vacation without thinking about this: however as soon as I got on the return plane I ALT-TABbed my way to Live Writer (left open for the whole week) and finalized. Good, because I caught few bugs that eluded [m]y stressed self of one week ago but were super-evident (“risplenda come un croco in polveroso prato” – from memory! No internet on transatlantic flights) to the rested self of time present.
I am not sure how generally useful this post is going to be. Once again, to be sure; this is NOT for the general-purpose developer. However I do know that this will provide some answers to very specific questions I got; and If you got this far, however, something tells me that “general-purpose” is not the right label for you.
As usual: if you have questions, write away!




Brian Hitney (@bhitney) described Getting Started with the Windows Azure Cache in a 4/4/2012 post to the US Cloud Connection blog:
Windows Azure has a great caching service that allows applications (whether or not they are hosted in Azure) to share in-memory cache as a middle tier service. If you’ve followed the ol’ Velocity project, then you’re likely aware this was a distributed cache service you could install on Windows Server to build out a middle tier cache. This was ultimately rolled into the Windows Server AppFabric, and is (with a few exceptions) the same that is offered in Windows Azure.
On the flip side, the problem with building a middle tier cache is the maintenance and hardware overhead, and it introduces another point of failure in an application. Offering the cache as a service alleviates the maintenance and scalability concerns.
The Windows Azure cache offers the best of both worlds by providing the in-memory cache as a service, without the maintenance overhead. Out of the box, there are providers for both the cache and session state (the session state provider, though, requires .NET 4.0). To get started using the Windows Azure cache, we’ll configure a namespace via the Azure portal. This is done the same way as setting up a namespace for Access Control and the Service Bus:
Selecting new (upper left) allows you to configure a new namespace – in this case, we’ll do it just for caching:
Just like setting up a hosted service, we’ll pick a namespace (in this case, ‘evangelism’) and a location. Obviously, you’d pick a region closest to your application. We also need to select a cache size. The cache will manage its size by flushing the least used objects when under memory pressure.
To make setting up the application easier, there’s a “View Client Configuration” button that creates cut and paste settings for the web.config:
In the web application, you’ll need to add a reference to Microsoft.ApplicationServer.Caching.Client and Microsoft.ApplicationServer.Caching.Core. If you’re using the cache for session state, you’ll also need to reference Microsoft.Web.DistributedCache (requires .NET 4.0), and no additional changes (outside of the web.config) need to be done. For using the cache, it’s straightforward:
using (DataCacheFactory dataCacheFactory =
new DataCacheFactory())
{
DataCache dataCache = dataCacheFactory.GetDefaultCache();
dataCache.Add("somekey", "someobject", TimeSpan.FromMinutes(10));
}If you look at some of the overloads, you’ll see that some features aren’t supported in Azure:
That’s it! Of course, the big question is: what does it cost? The pricing, at the time of this writing, is:






One additional tip: if you’re using the session state provider locally in the development emulator with multiple instances of the application, be sure to add an applicationName to the session state provider:
<sessionState mode="Custom" customProvider="AppFabricCacheSessionStoreProvider">
<providers>
<add name="AppFabricCacheSessionStoreProvider"
type="Microsoft.Web.DistributedCache.DistributedCacheSessionStateStoreProvider,
Microsoft.Web.DistributedCache"
cacheName="default" useBlobMode="true" dataCacheClientName="default"
applicationName="SessionApp"/>
</providers>
</sessionState>The reason is because each website, when running locally in IIS, generates a separate session identifier for each site. Adding the applicationName ensures the session state is shared across all instances.
Alan Smith continued his Service Bus series with Transactional Messaging in the Windows Azure Service Bus with a 4/2/2012 post:
Introduction
I’m currently working on broadening the content in the Windows Azure Service Bus Developer Guide. One of the features I have been looking at over the past week is the support for transactional messaging. When using the direct programming model and the WCF interface some, but not all, messaging operations can participate in transactions. This allows developers to improve the reliability of messaging systems. There are some limitations in the transactional model, transactions can only include one top level messaging entity (such as a queue or topic, subscriptions are no top level entities), and transactions cannot include other systems, such as databases.
Transactional Messaging
Messaging entities in the Windows Azure Service Bus provide support for participation in transactions. This allows developers to perform several messaging operations within a transactional scope, and ensure that all the actions are committed or, if there is a failure, none of the actions are committed. There are a number of scenarios where the use of transactions can increase the reliability of messaging systems.
Using TransactionScope
In .NET the TransactionScope class can be used to perform a series of actions in a transaction. The using declaration is typically used de define the scope of the transaction. Any transactional operations that are contained within the scope can be committed by calling the Complete method. If the Complete method is not called, any transactional methods in the scope will not commit.
// Create a transactional scope. using (TransactionScope scope = new TransactionScope()) { // Do something. // Do something else. // Commit the transaction. scope.Complete(); }In order for methods to participate in the transaction, they must provide support for transactional operations. Database and message queue operations typically provide support for transactions.
Transactions in Brokered Messaging
Transaction support in Service Bus Brokered Messaging allows message operations to be performed within a transactional scope; however there are some limitations around what operations can be performed within the transaction.
In the current release, only one top level messaging entity, such as a queue or topic can participate in a transaction, and the transaction cannot include any other transaction resource managers, making transactions spanning a messaging entity and a database not possible.
When sending messages, the send operations can participate in a transaction allowing multiple messages to be sent within a transactional scope. This allows for “all or nothing” delivery of a series of messages to a single queue or topic.
When receiving messages, messages that are received in the peek-lock receive mode can be completed, deadlettered or deferred within a transactional scope. In the current release the Abandon method will not participate in a transaction. The same restrictions of only one top level messaging entity applies here, so the Complete method can be called transitionally on messages received from the same queue, or messages received from one or more subscriptions in the same topic.
Sending Multiple Messages in a Transaction
A transactional scope can be used to send multiple messages to a queue or topic. This will ensure that all the messages will be enqueued or, if the transaction fails to commit, no messages will be enqueued.
An example of the code used to send 10 messages to a queue as a single transaction from a console application is shown below.
QueueClient queueClient = messagingFactory.CreateQueueClient(Queue1); Console.Write("Sending"); // Create a transaction scope. using (TransactionScope scope = new TransactionScope()) { for (int i = 0; i < 10; i++) { // Send a message BrokeredMessage msg = new BrokeredMessage("Message: " + i); queueClient.Send(msg); Console.Write("."); } Console.WriteLine("Done!"); Console.WriteLine(); // Should we commit the transaction? Console.WriteLine("Commit send 10 messages? (yes or no)"); string reply = Console.ReadLine(); if (reply.ToLower().Equals("yes")) { // Commit the transaction. scope.Complete(); } } Console.WriteLine(); messagingFactory.Close();The transaction scope is used to wrap the sending of 10 messages. Once the messages have been sent the user has the option to either commit the transaction or abandon the transaction. If the user enters “yes”, the Complete method is called on the scope, which will commit the transaction and result in the messages being enqueued. If the user enters anything other than “yes”, the transaction will not commit, and the messages will not be enqueued.
Receiving Multiple Messages in a Transaction
The receiving of multiple messages is another scenario where the use of transactions can improve reliability. When receiving a group of messages that are related together, maybe in the same message session, it is possible to receive the messages in the peek-lock receive mode, and then complete, defer, or deadletter the messages in one transaction. (In the current version of Service Bus, abandon is not transactional.)
The following code shows how this can be achieved.
using (TransactionScope scope = new TransactionScope()) { while (true) { // Receive a message. BrokeredMessage msg = q1Client.Receive(TimeSpan.FromSeconds(1)); if (msg != null) { // Wrote message body and complete message. string text = msg.GetBody<string>(); Console.WriteLine("Received: " + text); msg.Complete(); } else { break; } } Console.WriteLine(); // Should we commit? Console.WriteLine("Commit receive? (yes or no)"); string reply = Console.ReadLine(); if (reply.ToLower().Equals("yes")) { // Commit the transaction. scope.Complete(); } Console.WriteLine(); }Note that if there are a large number of messages to be received, there will be a chance that the transaction may time out before it can be committed. It is possible to specify a longer timeout when the transaction is created, but It may be better to receive and commit smaller amounts of messages within the transaction.
It is also possible to complete, defer, or deadletter messages received from more than one subscription, as long as all the subscriptions are contained in the same topic. As subscriptions are not top level messaging entities this scenarios will work.
The following code shows how this can be achieved.
try { using (TransactionScope scope = new TransactionScope()) { // Receive one message from each subscription. BrokeredMessage msg1 = subscriptionClient1.Receive(); BrokeredMessage msg2 = subscriptionClient2.Receive(); // Complete the message receives. msg1.Complete(); msg2.Complete(); Console.WriteLine("Msg1: " + msg1.GetBody<string>()); Console.WriteLine("Msg2: " + msg2.GetBody<string>()); // Commit the transaction. scope.Complete(); } } catch (Exception ex) { Console.WriteLine(ex.Message); }Unsupported Scenarios
The restriction of only one top level messaging entity being able to participate in a transaction makes some useful scenarios unsupported. As the Windows Azure Service Bus is under continuous development and new releases are expected to be frequent it is possible that this restriction may not be present in future releases.
The first is the scenario where messages are to be routed to two different systems.
The following code attempts to do this.
try { // Create a transaction scope. using (TransactionScope scope = new TransactionScope()) { BrokeredMessage msg1 = new BrokeredMessage("Message1"); BrokeredMessage msg2 = new BrokeredMessage("Message2"); // Send a message to Queue1 Console.WriteLine("Sending Message1"); queue1Client.Send(msg1); // Send a message to Queue2 Console.WriteLine("Sending Message2"); queue2Client.Send(msg2); // Commit the transaction. Console.WriteLine("Committing transaction..."); scope.Complete(); } } catch (Exception ex) { Console.WriteLine(ex.Message); }The results of running the code are shown below.
When attempting to send a message to the second queue the following exception is thrown:
No active Transaction was found for ID '35ad2495-ee8a-4956-bbad-eb4fedf4a96e:1'. The Transaction may have timed out or attempted to span multiple top-level entities such as Queue or Topic. The server Transaction timeout is: 00:01:00..TrackingId:947b8c4b-7754-4044-b91b-4a959c3f9192_3_3,TimeStamp:3/29/2012 7:47:32 AM.
Another scenario where transactional support could be useful is when forwarding messages from one queue to another queue. This would also involve more than one top level messaging entity, and is therefore not supported.
Another scenario that developers may wish to implement is performing transactions across messaging entities and other transactional systems, such as an on-premise database. In the current release this is not supported.
Workarounds for Unsupported Scenarios
There are some techniques that developers can use to work around the one top level entity limitation of transactions. When sending two messages to two systems, topics and subscriptions can be used. If the same message is to be sent to two destinations then the subscriptions would have the default subscriptions, and the client would only send one message. If two different messages are to be sent, then filters on the subscriptions can route the messages to the appropriate destination. The client can then send the two messages to the topic in the same transaction.
In scenarios where a message needs to be received and then forwarded to another system within the same transaction topics and subscriptions can also be used. A message can be received from a subscription, and then sent to a topic within the same transaction. As a topic is a top level messaging entity, and a subscription is not, this scenario will work.









Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
The ACloudyPlace blog posted Maarten Balliauw’s (@maartenballiauw) Using the Windows Azure Content Delivery Network article on 4/5/2012:
Windows Azure is a very rich platform. Next to compute and storage, it offers a series of building blocks that simplify your life as a cloud developer. One of these building blocks is the content delivery network (CDN), which can be used for offloading content to a globally distributed network of servers, ensuring faster throughput to your end users.
Reasons for using a CDN
Another reason for using the CDN is throughput. If you look at a typical webpage, about 20% of it is HTML which was dynamically rendered based on the user’s request. The other 80% goes to static files like images, CSS, JavaScript, and so forth. Your server has to read those static files from disk and write them on the response stream, both actions which take away some of the resources available on your virtual machine. By moving static content to the CDN, your virtual machine will have more capacity available for generating dynamic content.
Enabling the Windows Azure CDN
The Windows Azure CDN is built for two services that are available in your subscription: storage and compute. The easiest way to get started with the CDN is by using the Windows Azure Management Portal at http://windows.azure.com. If you have a storage account or a hosted service on Windows Azure, you can navigate to the “Hosted Services, Storage Accounts & CDN” pane and click the “CDN” node. After selecting a storage account or hosted service, click the “New Endpoint” button in the toolbar, which will show you the following screen:
If required, you can enable HTTPS on the CDN edge nodes. Unfortunately, this is done using a certificate that Microsoft provides and there’s currently no option to use your own. A second option available is to enable caching based on query string parameters. When enabled, the CDN will keep different cached versions of files hosted on your storage account, based on the exact URL (including query string) for that file.
After clicking OK, the CDN will be initialized. This may take up to 60 minutes because the settings you’ve just applied may take that long to propagate to all CDN edge locations, globally. Your CDN will be assigned a URL in the form of http://<id>.vo.msecnd.net. You can also assign a custom domain name to the CDN by clicking the “Add Domain” button in the toolbar.
Serving blob storage content through the CDN
Let’s start and offload our static content (CSS, images, JavaScript) to the Windows Azure CDN using a storage account as the source for CDN content. In an ASP.NET MVC 3 project, edit the _Layout.cshtml view and change the URLs to all referenced scripts and CSS to a URL hosted on your newly created CDN:
<!DOCTYPE html> <html> <head> <title>@ViewBag.Title</title> <link href="http://az172665.vo.msecnd.net/static/Content/Site.css" rel="stylesheet" type="text/css" /> <script src="http://az172665.vo.msecnd.net/static/Scripts/jquery-1.5.1.min.js" type="text/javascript"></script> </head> <!-- more HTML --> </html>Note that the CDN URL includes a reference to a blob container names “static”.
If you now run this application, you’ll find no CSS or JavaScript applied, as you can see in the picture below. The reason for this is obvious: we have specified the URL to our CDN but haven’t uploaded any files to our storage account backing the CDN.
Uploading files to the CDN is easy. All you need is a public blob container and some blobs hosted in there. You can use tools like Cerebrata’s Cloud Storage Studio or upload the files from code. For example, I’ve created an action method taking care of uploading static content for me:
[HttpPost, ActionName("Synchronize")] public ActionResult Synchronize_Post() { var account = CloudStorageAccount.Parse (ConfigurationManager.AppSettings["StorageConnectionString"]); var client = account.CreateCloudBlobClient(); var container = client.GetContainerReference("static"); container.CreateIfNotExist(); container.SetPermissions( newBlobContainerPermissions { PublicAccess = BlobContainerPublicAccessType.Blob }); var approot = HostingEnvironment.MapPath("~/"); var files = new List<string>(); files.AddRange(Directory.EnumerateFiles( HostingEnvironment.MapPath("~/Content"), "*", SearchOption.AllDirectories)); files.AddRange(Directory.EnumerateFiles( HostingEnvironment.MapPath("~/Scripts"), "*", SearchOption.AllDirectories)); foreach (var file in files) { var contentType = "application/octet-stream"; switch (Path.GetExtension(file)) { case "png": contentType = "image/png"; break; case "css": contentType = "text/css"; break; case "js": contentType = "text/javascript"; break; } var blob = container.GetBlobReference(file.Replace(approot, "")); blob.Properties.ContentType = contentType; blob.Properties.CacheControl = "public, max-age=3600"; blob.UploadFile(file); blob.SetProperties(); } ViewBag.Message = "Contents have been synchronized with the CDN."; return View(); }Note the lines of code marked in red. The first one, container.SetPermissions, ensures that the blob storage container we’re uploading to allows public access. The Windows Azure CDN can only cache blobs stored in public containers.
The second red line of code, blob.Properties.CacheControl, is more interesting. How does the Windows azure CDN know how long a blob should be cached on each edge node? By default, each blob will be cached for 72 hours. This has some important consequences. First, you cannot invalidate the cache and you have to wait for content expiration to occur. Second, the CDN will possibly refresh your blob every 72 hours.
As a general best practice, make sure that you specify the Cache-Control HTTP header for every blob you want to have cached on the CDN. If you want to have the option to update content every hour, make sure you specify a low TTL of, say, 3600 seconds. If you want less traffic to occur between the CDN and your storage account, specify a longer TTL of a few days or even a few weeks.
Another best practice is to address CDN URLs using a version number. Since the CDN can, when enabled, create a separate cache of a blob based on the query string, appending a version number to the URL may make it easier to refresh contents in the CDN based on the version of your application. For example, main.css?v1 and main.css?v2 may return different versions of main.css cached on the CDN edge node. Here’s a quick code snippet which appends the AssemblyVersion to the CDN URLs:
@{ var version = System.Reflection.Assembly.GetAssembly( typeof(WindowsAzureCdn.Web.Controllers.HomeController)) .GetName().Version.ToString(); } <!DOCTYPE html> <html> <head> <title>@ViewBag.Title</title> <link href="http://az172729.vo.msecnd.net/static/Content/Site.css?@version" rel="stylesheet" type="text/css" /> <script src="http://az172729.vo.msecnd.net/static/Scripts/jquery-1.5.1.min.js?@version" type="text/javascript"></script> </head> <!-- more HTML --> </html>Using hosted services with the CDN
So far we’ve seen how you can offload static content to the Windows Azure CDN. We can upload blobs to a storage account and have them cached on different edge nodes around the globe. Did you know you can also use your hosted service as a source for files cached on the CDN? The only thing to do is, again, go to the Windows Azure Management Portal and ensure the CDN is enabled for the hosted service you want to use.
Serving static content through the CDN
The main difference with using a storage account as the source for the CDN is that the CDN will look into the /cdn/* folder on your hosted service to retrieve its contents. There are two options for doing this: either move static content to the /cdn folder, or use IIS URL rewriting to “fake” a /cdn folder.
Using both approaches, you’ll have to modify the _Layout.cshtml file to reflect your CDN URL:
@{ var version = System.Reflection.Assembly.GetAssembly( typeof(WindowsAzureCdn.Web.Controllers.HomeController)) .GetName().Version.ToString(); } <!DOCTYPE html> <html> <head> <title>@ViewBag.Title</title> <link href="http://az170459.vo.msecnd.net/Content/Site.css?@version" rel="stylesheet" type="text/css" /> <script src="http://az170459.vo.msecnd.net/Scripts/jquery-1.5.1.min.js?@version" type="text/javascript"></script> </head> <!-- more HTML --> </html>Note that this time the CDN URL does not include any reference to a blob container.
Moving static content into a /cdn folder
The Windows Azure CDN only looks at the /cdn folder as a source of files to cache. This means that if you simply copy your static content into the /cdn folder as seen in the below image, you’re finished. Your web application and the CDN will play happily together.
Using IIS URL rewriting to expose static content to the CDN
An alternative to copying static content to a /cdn folder explicitly is to use IIS URL rewriting. IIS URL rewriting is enabled on Windows Azure by default and can be configured to translate a /cdn URL to a /URL. For example, if the CDN requests the /cdn/styles/main.css file, IIS URL rewriting will simply serve the /styles/main.css file leaving you with no additional work.
To configure IIS URL rewriting, add a <rewrite> section under the <system.webServer> section in Web.config:
<system.webServer> <!-- More settings --> <rewrite> <rules> <rule name="RewriteIncomingCdnRequest" stopProcessing="true"> <match url="^cdn/(.*)$" /> <action type="Rewrite" url="{R:1}" /> </rule> </rules> </rewrite> </system.webServer>As a side note, you can also configure an outbound rule in IIS URL rewriting to automatically modify your HTML into using the Windows Azure CDN. Do know that this option is only supported when not using dynamic content compression and adds additional workload to your web server due to having to parse and modify your outgoing HTML.
Serving dynamic content through the CDN
Some dynamic content is static in a sense. For example, generating an image on the server or generating a PDF report based on the same inputs. Why would you generate those files over and over again? This kind of content is a perfect candidate to cache on the CDN as well!
Imagine you have an ASP.NET MVC action method which generates an image based on a given string. For every different string the output would be different, however if someone uses the same input string the image being generated would be exactly the same.
As an example, we’ll be using this action method in a view to display the page title as an image. Here’s the view’s Razor code:
@{ ViewBag.Title = "Home Page"; } <h2><img src="/Home/GenerateImage/@ViewBag.Message" alt="@ViewBag.Message" /></h2> <p> To learn more about ASP.NET MVC visit <a href="http://asp.net/mvc" title="ASP.NET MVC Website">http://asp.net/mvc</a>. </p>In the previous section, we’ve seen how an IIS rewrite rule can map all incoming requests from the CDN. The same rule can be applied here: if the CDN requests /cdn/Home/GenerateImage/Welcome, IIS will rewrite this to /Home/GenerateImage/Welcome and render the image once and cache it on the CDN from then on.
As mentioned earlier, a best practice is to specify the Cache-Control HTTP header. This can be done in your action method by using the [OutputCache] attribute, specifying the time-to-live in seconds:
[OutputCache(VaryByParam = "*", Duration = 3600, Location = OutputCacheLocation.Downstream)] public ActionResult GenerateImage(string id) { // ... generate image ... return File(image, "image/png"); }We would now only have to generate this image once for every different string requested. The Windows Azure CDN will take care of all intermediate caching.
Note that if you’re using some dynamic bundling of CSS and JavaScript like ASP.NET MVC4’s new “bundling and minification”, those minified bundles can also be cached on the CDN using a similar approach.
Conclusion
The Windows Azure CDN is one of the building blocks to create fault-tolerant, reliable, and fast applications running on Windows Azure. By caching static content on the CDN, the web server has more resources available to process other requests, and users will experience faster loading of your applications because content is delivered from a server closer to their location





Full disclosure: I’m a paid contributor to Red Gate Software’s ACloudyPlace blog.
Mike Benkovitch (@mbenko) continued his series with Cloud Tip #7-Configuring your firewall at work for cloud development on 4/5/2012:
I had a question after a Windows Azure Camp about what ports need to be opened and enabled at my work environment to enable working with Windows Azure. While the services work with REST there are a couple services that will benefit from adjusting the firewall to allow traffic between on-premise and the cloud. I found settings for Service Bus and SQL Server, and the settings are below…
- -Minimal: Enable outbound http on port 80 and 443, authenticated against proxy server if any
- Optimal: Allow outbound on port 9350 to 9353, can limit to well known IP range
- 9350 unsecured TCP one-way client
- 9351 Secured TCB one-way (all listeners, secured clients)
- 9352 Secured TCP Rendezvous (all except one way)
- 9353 Direct Connect Probing Protocol (TCB listeners with direct connect)
SQL on-Premise via Windows Azure Connect
- In SSMS - Enable Remote Connections on SQL Server properties window
- In SQL Server Configuration Manager
- Disable or stop SQL Server Browser
- Enable TCP/IP in the SQL Server Network Configuration | Protocols for server
- Edit TCP/IP protocol properties and set TCP Dynamic Ports to Blank, and then specify TCP Port to 1433
- Restart SQL Service
- In Windows Firewall add the following rules
- Inbound Port 1433 (TCP) Allow the connection
- Apply to all profiles (Domain, Private and Public)
- Name the rule something significant

<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
The Windows Azure Team (@WindowsAzure) published details for Installing the Windows Azure SDK on Windows 8 on 4/5/2012:
You can develop Windows Azure applications on Windows 8 by manually installing and configuring your development environment. The Windows Azure all-in-one installer is not yet supported on Windows 8. The steps below describe how to set up your Windows 8 system for Windows Azure development.
Please check back for updates, or subscribe to the Windows Azure newsletter for notification when an update becomes available.
Installation on Windows 8
These steps will prepare a development environment for Windows 8. If you have previouslly followed the manual install steps on the download center page for Windows Azure SDK - November 2011, you will notice that the install steps for Windows 8 closely resemble these steps. It's important to follow the steps in order and pay attention to differences around IIS and the .NET Framework.
Follow these steps to install the tools and configure the environment:
Install Windows 8.
Open the Windows Feature configuration settings.
- Press the Windows logo key to show the Start area in the Windows shell.
- Type Windows Feature to show search results.
- Select Settings.
- Select Turn Windows features on or off.
Enable the following features:

Install SQL Server 2008 R2 Express with SP1.
- It is helpful to install the server with tools. This installer is identified by the WT suffix.
- Choose SQLEXPRWT_x64_ENU.exe or SQLEXPRWT_x86_ENU.exe.
- Choose New Installation or Add Features.
- Use the default install options.
Uninstall any existing versions of the Windows Azure SDK for .NET on the machine.
Download and install the Windows Azure SDK for .NET - November 2011 individual components from the download center page for Windows Azure SDK - November 2011. (Note that the all-in-one installer available from the Windows Azure .NET Developer will not work in this scenario.) Choose the correct list below based on your platform, and install the components in the order listed:
- 32-bit:
- WindowsAzureEmulator-x86.exe
- WindowsAzureSDK-x86.exe
- WindowsAzureLibsForNet-x86.msi
- WindowsAzureTools.VS100.exe
- 64-bit:
- WindowsAzureEmulator-x64.exe
- WindowsAzureSDK-x64.exe
- WindowsAzureLibsForNet-x64.msi
- WindowsAzureTools.VS100.exe
Known Limitations and Issues
Windows Azure .NET applications must only target the .NET Framework 3.5 or 4.0. .NET Framework 4.5 development is currently unsupported for Windows Azure applications.
The all-in-one Web Platform Installer will not install the Windows Azure SDK on Windows 8.
You will need to install and leverage SQL Server Express to enable your project to run on the Windows Azure compute emulator. Install SQL Server R2 Express with SP1 as described in the steps above. If SQL Server Express is already installed, run DSINIT from an elevated Windows Azure command prompt to reinitialize the emulator on SQL Server Express.
Support
For support and questions about the Windows Azure SDK, visit the Windows Azure online forums.
Steve Morgan began a series with an Identifying the Tenant in Multi-Tenant Azure Applications - Part 1 post of 4/4/2012 to the BusinessCloud9 blog:
In this short series of articles, I will refer to a number of fictitious organisations; CloudStruck (www.cloudstruck.com) , Little Pay (www.littlepay.co.uk) and HasToBe.Net (www.hastobe.net).
There are a number of key characteristics that I’m looking to satisfy when designing a multi-tenant application:
- Users of the application should not know that it is supporting multiple tenants
- Customers should be able to brand and customise the application to their own requirements
- The application should strive to maximise resource utilisation by sharing wherever possible…
- Yet allow data to be isolated wherever necessary
- The on-boarding process for new customers should be automated as much as possible
- On-boarding a new customer must not result in downtime for existing customers
In my previous posts (the first and the second), I discussed some approaches to the hosting of data in SQL Azure; shared where possible, isolated where necessary. This time, I’m going to explore a design issue that is important to providing all of these key characteristics: when a user accesses my multi-tenant application, how do I identify the right tenant? Until I identify the tenant, I can’t apply any of the customer-specific customisations or branding and can’t determine what data is the right data for that user.
Here are a number of approaches you may consider along with some pros and cons of each.
Identify the Tenant from the User’s Profile
OK, let’s get this one out of the way quickly, because I hate it.
If each user is associated with a single tenant, you can create them a profile within the application and hold a tenant identifier within profile. When they reach your application, you can force them to login with their credentials. Once they’ve logged in, you have identified the tenant from their account information.
Did I mention that I hate this approach?
The problems are obvious and fundamental.
The first is that the application, up until the user has logged in, must be generic and unbranded. It fails to satisfy a number of my essential characteristics comprehensively:
- It’s blindingly obvious that the user is access a multi-tenant application
- Until the user is logged in, the application can’t apply any branding or customisation
I can think of a few more issues, though:
- It won’t work for anonymous users; they have no user account and consequently, no relationship with a tenant
- A user can’t have a relationship with more than one tenant unless they have different credentials
- It’s difficult to have more than one identity provider. You may want to allow tenants to specify their own identity provider (such as Windows Live ID or their own Active Directory). But in this scenario, you need to know the identity provider before you find out who the tenant is.
So, this model is all wrong (in my opinion). We want to know who the tenant is before we present the application to the user.
Identify the Tenant with an Identifier in the URL
If we include the tenant identifier in the URL, we can solve a lot of those issues easily enough:
http://www.littlepay.co.uk/cloudstruck
http://www.littlepay.co.uk?t=cloudstruck
OK, so this has a number of distinct advantages. The application now knows who the tenant is, so we can customise the application straight away. We can also choose an appropriate identity provider so that we know where to authenticate the user when they login. It will also work with anonymous users. Users can have accounts with more than one tenant, because their access is scoped by tenant.
This is all a distinct improvement. But there remain a couple of issues.
- It’s still blindingly obvious that this is a multi-tenant application, because the URL specifies a host that means nothing to the user: www.littlepay.co.uk
- Users aren’t going to find the application using the common technique of ‘URL surfing’, where you type into the address bar of your browser an educated guess. For example, if I’m ‘URL surfing’ for Cloudstruck.com’s payroll system, I may guess at (or even vaguely remember) http://www.cloudstruck.com/payroll or http://payroll.cloudstruck.com/ I’m never going to guess that it’s at http://www.littlepay.co.uk?t=cloudstruck
The URL is an important part of a company’s brand; using someone else’s host name in a URL for a site that you’re trying to present as your own only weakens the brand.
The URL of the site is obviously an important factor, so let’s explore some further refinements.
Let's break there, because we're going to go deeper (and we get to look at some real code) when we consider how to identify our tenants using sub-domains.

Steve is Principal Customer Solution Architect / Windows Azure Centre of Excellence Lead Architect at Fujitsu UK&I.
Himanshu Singh (@himanshuks) posted Real World Windows Azure: Interview with Florin Anton, Advanced eLearning Department Manager at SIVECO Romania on 4/4/2012:
As part of the Real World Windows Azure series, I spoke with Florin Anton, Advanced eLearning Department Manager at SIVECO Romania about how they tapped Windows Azure and SQL Azure to run the Romanian Ministry of Education’s exams website. Read the customer success story. Here’s what he had to say:
Himanshu Kumar Singh: What is SIVECO?
Florin Anton: SIVECO Romania is a Bucharest-based software vendor and integrator, active in Central and Eastern Europe, the Middle East, the Commonwealth of Independent States, and North Africa. We’re also a member of the Microsoft Partner Network.
HKS: Tell me about the exams website you created.
FA: We’re a longtime technology partner to the Romanian Ministry of Education. Every year, approximately 200,000 Romanian eighth-graders submit their high school choices and automatic distribution is made based on student preferences and school capacities. To make it easier for students to check for their high school assignments, we developed a high school admission application, ADLIC, and the distribution results are posted on the ADLIC website each July.
HKS: How well did the website meet demand from students and parents?
FA: Every July, when up to 200,000 students and their parents rushed to the site to check the high school they will go to, the site had difficulty responding. Anxious candidates had to revisit the site repeatedly, in order to see their results. The ministry did not have sufficient hardware infrastructure to properly support peak traffic loads. It’s extremely important to the ministry that this site functions properly and stays available during the distribution results publishing period; it is the fastest way of transmitting the results to waiting students and is proof of ministry’s capacity to completely automate the distribution process.
HKS: Were there also technical issues you faced?
FA: Yes, the ministry had experienced denial-of-service and other malicious attacks on the site, which meant that our staff had to monitor the servers around the clock to safeguard them. Adding to the server workload, the exam results site used static webpages, which required significant compute power and implied a time-consuming deployment process.
HKS: What was the solution?
FA: We wanted to convert the ADLIC website to use dynamic webpages, but a dynamic architecture would require more powerful and expensive servers, for which the ministry had no budget. Even using static pages, the ministry had to pay for fairly powerful servers used just one or two months a year.
HKS: When did you find out about Windows Azure?
FA: We learned about Windows Azure in October 2010 and immediately saw it as a way to solve the ADLIC website challenges. With the Ministry of Education’s approval, we moved the ADLIC website to Windows Azure for its cloud compute resources, using SQL Azure as the cloud database service. This was scheduled for the busy summer months only, and the website would run in the ministry’s data center the rest of the year.
HKS: How did Windows Azure help address your technical issues?
FA: With the virtually unlimited compute power made available by using Windows Azure, we were able to upgrade the site from a static to a dynamic architecture. This enabled the ministry to offer new capabilities, such as a better search interface and richer data presentation, leading to a better user experience. Student test scores are still maintained in an on-premises database running SQL Server. But the web servers run in Windows Azure, and public data sets for the website are delivered through SQL Azure.
HKS: How did the website perform after the move to Windows Azure?
FA: In July 2011, the first year that the ministry delivered the high school distribution results using Windows Azure, we deployed 10 Windows Azure instances, with a total of 80 processor cores, and loaded about 400 megabytes of data into SQL Azure. We adjust Windows Azure resources as needed and pay only for the resources that we use.
By moving the ADLIC public website to Windows Azure during peak traffic periods, we’re able to give the Ministry of Education the performance and availability it needs, when needed, at a very attractive cost.
HKS: What are some of the other benefits you’ve experienced?
FA: By using Windows Azure, we can quickly scale up the ADLIC web infrastructure when necessary without paying all year for expensive unused infrastructure. With this critical web application running on Windows Azure, students can get their distribution results immediately without the anxiety of waiting for hours or days on a slow website. They also enjoy improved functionality because of the site’s ability to offer dynamic webpages. To create a comparable infrastructure on premises, I estimate that the ministry would have had to spend US$100,000 on servers, software, communications and management resources.
Its also worth noting that, during the first summer that the ADLIC website was run on Windows Azure, the ministry experienced zero downtime for the first time. Every year previously, we’ve had downtime to contend with, so this was a huge improvement. For the first time in years, our staff enjoyed a good night’s sleep every night. This peace of mind came from not having to watch ADLIC servers around the clock for a month to defend against denial-of-service attacks. This also reduced our costs by approximately $10,000.
HKS: What’s next for SIVECO and Windows Azure?
FA: We’re eager to present the possibilities of Windows Azure to more customers. By using Windows Azure, we have the ability to create more flexible solutions for our customers. With it, we can now serve customers that we could not serve before because they could not justify expensive on-premises IT models.
Richard Conway (@azurecoder) announced the v0.2 release of Azure Fluent Management including Sql Azure management on 4/1/2012:
Okay. So we’re back for installment number 2! This release of v0.2 represents a much more resilient version of the Azure Fluent Management library. I noticed that I had introduced a bug into the lib (or reintroduced) so many of you who have downloaded this wouldn’t be able to get this to work without Fiddler. Fiddler is great for debugging HTTP trace information and working out issues but if you leave it on always it can mask other errors. In this case I introduced a bug into the library which stopped the SSL mutual authentication working without fiddler running in the background. What a bind! Anyway, it’s all sorted now so feel free to download v0.2 and test properly. Since I got this out in a rush I forgot to make the interfaces explicit which sort of made the fluent part redundant. I’ve updated this too now.
Anyway, apart from getting the service management deployments working we’ve just added the ability to create a Sql Azure server, set all types of firewall rules – auto detect, for azure hosted services or a remote range, add a new database, add database admin users (as well as a server admin user) and execute a local script directory against the newly created database.
One caveat is the dependency on SQL Server Management Objects (SMO). The speed at which you can execute scripts against the azure database is astounding so this was a no-brained instead of trying to parse the file and slice on GO statements.
var sqlAzure = new SqlAzureManager("6xxxxxxxxxxxx-xxxx-xxxx-xxxxxxxxxxxa"); sqlAzure.AddNewServer(DeploymentManager.LocationWestEurope) .AddCertificateFromStore("AAxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx") .AddNewFirewallRule("myofficeip", "10.27.27.253", "10.27.27.254") .AddNewFirewallRule("anotherip", "10.27.28.11", "10.27.28.254") .AddNewFirewallRuleForWindowsAzureHostedService() .AddNewFirewallRuleWithMyIp("myhomeip") .WithSqlAzureCredentials("ukwaug", "M@cc0mputer") .AddNewDatabase("test") .AddNewDatabaseAdminUser("ukwaugdb", "M@cc0mputer") .ExecuteScripts(@"C:\Projects\Tech Projects\Elastacloud") .Go();v0.2 should be up on nuget now. Have fun and send us any feedback, bugs or requests.
BTW – Ensure you that you add the following into your App.Config or web.config (we plan on updating our nuget install to make this default during the week).
<configuration> <startup useLegacyV2RuntimeActivationPolicy="true"> <supportedRuntime version="v4.0"/> </startup> </configuration>

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Matt Thalman described Active Directory Group Support (Matt Thalman) by LightSwitch in a 4/3/2012 post:
In Visual Studio 11 Beta, LightSwitch has introduced the ability to use Active Directory security groups to control access to the application. In the first release of LightSwitch, it was only possible to control access by registering each individual Windows user in the application. Application administrators can now register security groups as well. By adding a security group, all authentication and authorization rights associated with that group apply to the members of that group. Note that only security groups are supported – not distribution groups.
The following screenshot shows adding a security group with an account name of "CONTOSO\BuildingA" to the list of registered accounts, giving all members of that group access to this application.
Nested Groups
LightSwitch also supports nested groups. For example, let's say the Contoso company has the following groups and users in their Active Directory:
- Kim Abercrombie
- Account name: CONTOSO\kim
- Member of: CONTOSO\BuildingA_2ndFlr
- Building A - 2nd Floor (security group)
- Account name: CONTOSO\BuildingA_2ndFlr
- Member of: CONTOSO\BuildingA
- Building A (security group)
- Account name: CONTOSO\BuildingA
When an administrator adds "CONTOSO\BuildingA" as a registered account in the application, this grants all member of that group to have access to the application, even if that membership occurs as a result of nested groups. Thus, Kim would have access to the application because she belongs to the “CONTOSO\BuildingA_2ndFlr” group, which is a member of the “CONTOSO\BuildingA” group.
Role Inheritance
Role inheritance applies the roles assigned to a registered security group to all members of that group—the members of the group inherit any roles assigned to the group. Using the Contoso example, let's say that "Building A" and "Kim Abercrombie" are both listed as registered accounts in the application. If the "Sales Person" role is assigned to the "Building A" security group, then when Kim is selected in the Users screen, the "Sales Person" role appears in her list of assigned roles. The role assignment also indicates that the "Sales Person" role is inherited from the "Building A" security group, as illustrated in the following screenshot.
If a user belongs to multiple groups, the user inherits all of the roles assigned to those groups, in addition to any roles explicitly assigned to that user. Inherited roles are treated as read-only so it is not possible to remove a role that is inherited. For example, you wouldn’t be able to remove the SalesPerson role just for Kim.
Beta Note:
One thing that is not yet implemented in the Beta release is support for checking role membership or whether a user has a permission in server-side code. That is, if you write code that executes on the server and calls User.IsInRole or User.HasPermission, those methods will not take into account group membership. This will be supported in the final release.
Administrator Account
When publishing a LightSwitch app configured to use authentication you are prompted to define an administrator account, which can now be a security group.
Conclusion
Active Directory group support greatly simplifies the administration of user access to your LightSwitch applications. No longer will you need to add each user individually. Just add a group and you're done.
For more information see: How to Create a Role-based Application




Beth Massi (@bethmassi) posted LightSwitch Community & Content Rollup–March 2012 on 4/3/2012:
Last Fall I started posting a rollup of interesting community happenings, content, samples and extensions popping up around Visual Studio LightSwitch. If you missed those rollups you can check them all out here: LightSwitch Community & Content Rollups
March was filled with a flurry of content around Visual Studio 11 Beta since it was released on February 29th. If you haven’t done so already, I encourage you to download it and give it a spin.
Download Visual Studio 11 Beta
You can provide general feedback using the Visual Studio UserVoice site and LightSwitch-specific feedback on the LightSwitch UserVoice site. There are also a handful of Beta forums you can use to ask questions in particular areas, including the LightSwitch in Visual Studio 11 Beta Forum.
LightSwitch Beta Resources on the Developer Center
If you haven’t noticed the LightSwitch team has been releasing a lot of good content around the next version of LightSwitch in Visual Studio 11. We’ve created a page on the LightSwitch Developer Center with a list of key Beta resources for you. Check back to the page often as we add more content each week! Here’s the easy-to-remember URL:
http://bit.ly/LightSwitchDev11
New Cosmopolitan Shell & Theme
In March the team released the beta version of the LightSwitch Cosmopolitan Shell and Theme extension for Visual Studio 11 Beta.
We drew inspiration from the Silverlight Cosmopolitan theme in designing the extension. The shell and theme provide a modern UI to achieve a more immersive feel, simple and clean styling for the controls, corporate/product branding, as well as many other improvements. This shell will become the default shell for new LightSwitch projects developed with Visual Studio 11. Check out these screen shots and give it a spin! (click to enlarge). You can provide feedback and report issues with the shell in the Beta forum or directly on the LightSwitch Team blog post.

New Extensibility Toolkit & Samples Released
An updated version of the LightSwitch Extensibility Toolkit for Visual Studio 11 Beta was also released in March. This toolkit refresh provides project types for creating new LightSwitch Extension Libraries using Visual Studio 11 beta and includes templates for creating all the different types of supported LightSwitch extensions. If you’re building LightSwitch extensions then you’ll want to check out this release.
Along with this release are updated versions of all the extensibility samples.
- LightSwitch Value Control Extension Sample for Visual Studio 11
- LightSwitch Stack Panel Control Extension Sample for Visual Studio 11
- LightSwitch Metro Theme Extension Sample for Visual Studio 11
- LightSwitch Smart Layout Control Extension Sample for Visual Studio 11
- LightSwitch Business Type Extension Sample for Visual Studio 11
- LightSwitch Screen Template Extension Sample for Visual Studio 11
- LightSwitch Shell Extension Sample for Visual Studio 11
- LightSwitch Detail Control Extension Sample for Visual Studio 11
LightSwitch Community Rock Stars
If you’ve been spending any time developing LightSwitch applications and listening to the #LightSwitch hash tag on twitter, hanging out in the forums, or searching the internet for LightSwitch content, then you probably have run across these people at one time or another. These folks constantly pop up in our community channels – some have been helping the LightSwitch community since the early betas and some are emerging recently. These are just a few of the LightSwitch rock stars to definitely keep an eye on.
- Alessandro Del Sole
- Jan Van der Haegen
- Jewel Lambert
- Keith Craigo
- Michael Washington
- Paul Patterson
- PlusOrMinus
- Spaso Lazarevic
- Yann Duran
Have more folks to recommend? Post a comment below!
New LightSwitch MSDN Magazine Column: Leading LightSwitch
One of our LightSwitch rock stars has started a new column on MSDN Magazine! Jan van der Haegen released his first “Leading LightSwitch” column in the March issue. I’m really looking forward to the great stuff Jan will teach us!
Consume a LightSwitch OData Service from a Windows Phone Application
Jan Van der Haegen's first LightSwitch column explores one of the key features added in the beta release of the tool--the ability to create and consume OData services, which can in turn be consumed from any client, including custom Windows Phone applications.Notable Content this Month
Lots of content has been streaming out from folks all over the internet. I’m also excited by the number of extensions the community released this month, nice! Here’s some more notable resources I found.
Extensions (see all 81 of them here!):
- ComponentOne FlexGrid for LightSwitch
- DockShell - LightSwitch Shell Extension
- Excel Data Provider for LightSwitch
- LightSwitch Filter Control For Visual Studio 11 Beta
- LightSwitch Cosmopolitan Shell and Theme
- MicroApplications LightSwitch Business Types
- PaulozziCo.MetroShell
- SAP ADO.NET Data Provider
More Samples (see all of them here):
- Vision Clinic Walkthrough & Sample (Visual Studio 11 Beta)
- Contoso Construction - LightSwitch Advanced Sample (Visual Studio 11 Beta)
Team Articles:
Visual Studio 11 Beta (LightSwitch V2)
- Creating and Consuming LightSwitch OData Services
- Creating a LightSwitch Application Using the Commuter OData Service
- Enhance Your LightSwitch Applications with OData
- LightSwitch Architecture: OData
- LightSwitch IIS Deployment Enhancements in Visual Studio 11
- New Business Types: Percent & Web Address
- Tips on Upgrading Your LightSwitch Applications to Visual Studio 11 Beta
- Using LightSwitch OData Services in a Windows 8 Metro Style Application
Visual Studio LightSwitch (LightSwitch V1)
- Deploying LightSwitch Applications to IIS6 & Automating Deployment Packages
- Using the SecurityData service in LightSwitch
Community Content:
- Accessing Your Visual Studio 2011 LightSwitch Application Using OData
- An Interview With Alessandro Del Sole (Author of LightSwitch Unleashed)
- Calling LightSwitch 2011 OData Using Server Side Code
- Changing the Numeric Keypad Period to a Comma
- CLASS Extensions Version 2 Released
- Fix: Installing Extensions In LightSwitch When You Also Have LightSwitch Beta 2011
- How Can I Display the Version Number of the Currently Running LightSwitch Application?
- How Do I Prevent a Column in a Grid From Gaining Focus?
- How To Add an Application Logo Background Similar To the Feature Dropped After Beta
- How to use previously Out-of-Browser-only features in LightSwitch for In-Browser Apps with VS11 Beta
- I’m speaking at MS NetWork 2.0
- Installing LightSwitch Themes and Shells built for LightSwitch v1 into the LightSwitch in Visual Studio 11 Beta (LightSwitch v2)
- Learn How To Make OData Calls In LightSwitch 2011
- LightSwitch: reading threads from StackOverflow with OData
- Microsoft LightSwitch – 8 Ways to Reporting and Printing Success
- Microsoft LightSwitch – Consuming OData
- Monthly LightSwitch column in MSDN Magazine, and other “all things LightSwitch”…
- Notification “Toast” For In-Browser LightSwitch Apps Using Growl For Windows
- Rise of the Citizen Developer – Slide Deck and Speaker Notes
- switchtory – turn on the innovation
LightSwitch Team Community Sites
Become a fan of Visual Studio LightSwitch on Facebook. Have fun and interact with us on our wall. Check out the cool stories and resources. Here are some other places you can find the LightSwitch team:
LightSwitch MSDN Forums
LightSwitch Developer Center
LightSwitch Team Blog
LightSwitch on Twitter (@VSLightSwitch, #VisualStudio #LightSwitch)




Matt Sampson posted OData Apps In LightSwitch, Part 2 on 4/2/2012:
I wanted to continue making some improvements to the OData Application we started in my last post OData Apps in LightSwitch, Part 1 (which also has the sample project uploaded in VB.NET now).
At the end of the last post we had: attached to a public OData feed and pulled in data for the DC Metro, we showed off some new data types, and we utilized caching on our computed fields to improve performance. We also added queries to narrow down our data.
There are still a few things we should wrap up on before finishing up:
- Add some automatic refreshing to our Arrivals screen
- Customize the “Stops” screen so that it can provide us with a map of the Stops location
- Hook up the Incidents entity so that we can pull in data regarding all the busted escalators (and DC has a lot of them)
Let’s kick this off first by adding some automatic refreshing to our Arrivals List and Details screen.
Adding Auto Refresh
We should have an Arrivals screen that looks something like this:
This data is updated in real time, but our screen is not updated real time. It’d be nice to not have to hit the “refresh” button every time we want to see new train information.
We can add our own Auto Refresh functionality pretty easily as you will see.
- Open up the Arrivals screen in the screen designer (should be called MetroByArrivalTimeListDetail)
- Right click the screen in the Solution Explorer, and select select “View Screen Code”
- We should now be in the code editor
- Add a using statement for the System.Threading since we will need to use some classes from that namespace
- Copy and paste the below code into your screen’s class
Code Snippet
- private Timer myTimer;
- partial void MetroByArrivalTimeListDetail_Closing(ref bool cancel)
- {
- this.myTimer.Dispose();
- }
- partial void MetroByArrivalTimeListDetail_Created()
- {
- TimerCallback tcb = MyCallBack;
- this.myTimer = new Timer(tcb);
- myTimer.Change(120000, 120000);
- }
- public void MyCallBack(Object stateInfo)
- {
- this.Details.Dispatcher.BeginInvoke(() =>
- {
- this.Refresh();
- }
- );
- }
Let’s go through what we’re doing with this code.
When our Arrival List and Details screen is created for the first time the Created() method gets invoked. Inside of this method we start a Timer. When we construct the Timer object we pass in a TimerCallBack object which specifies the method to be invoked by the timer – in this case the method is “MyCallBack”. The MyCallback method does the actual call to “Refresh” the screen. Keep in mind that we have to switch to the logic dispatcher before we invoke the Refresh() method. This is because Refresh() can only be invoked from the logic dispatcher, so we are simply making sure here that we are indeed on the logic dispatcher by doing a this.Details.Dispatcher.BeginInvoke() call.
Our Timer is set to be invoked after 120,000 milliseconds (which is = 2 minutes). And then will be invoked again every 2 minutes after that, for as long as this screen is open. When the screen is closed we will invoke the Closing() method which will make sure we are cleaning up after ourselves and will dispose of our object.
If you F5 now, open up the Arrivals List and Details screen and wait 2 minutes you will see the auto refresh in action.
Adding Bing Maps
For our next trick we are going to do something with the latitude and longitude properties that are displayed on the Stops List and Details screen. We can beautify this a bit and show a map instead.
Beth Massi has an awesome demo of her own on consuming OData, using the Bing Maps extension, and a dozen other things. She also reminds us that if we are going to be using Bing Maps in our project we need to get a Bing Maps Key first. As Beth says:
Getting the key is a free and straightforward process you can complete by following these steps:
- Go to the Bing Maps Account Center at https://www.bingmapsportal.com.
- Click Sign In, to sign in using your Windows Live ID credentials.
- If you haven’t got an account, you will be prompted to create one.
- Enter the requested information and then click Save.
- Click the "Create or View Keys" link on the left navigation bar.
- Fill in the requested information and click "Create Key" to generate a Bing Maps Key.
Hang onto your Bing Maps Key, we’ll use it later.
The Bing Maps extension is a VSIX which you can find in the zip file here.
Double click the VSIX file after you download the zip file to install the extension. After installing the VSIX open up the Properties designer for our application and go to the “Extensions” tab. We need to enable the Bing Maps extension now like this:
Let’s go back to our Stops entity now in the entitiy designer.
Add a new string property to the Stops entity which will be a computed property. Call it “Location”.
The Stops entity should look something like this now:
In the Properties for Location, click the “Edit Method” button. We should now be in the generated computed property method. Copy the below code into the method:
Code Snippet
- partial void Location_Compute(ref string result)
- {
- result = this.Lat + " " + this.Lon;
- }
In this method we are setting up our Location computed property so that it’s value is the Latitude and Longitude coordinates of our Metro stop. The value has to be Latitude followed by Longitude (if you invert it and make it Longitude followed by Latitude you will end up in Antarctica and will completely miss your train).
Now open up our StopsDCMetroListDetail screen. We’ll add in the Location property now to this screen. (I dragged and dropped it onto the screen). And then click on the drop down arrow for the property and switch it to “Bing Map Control”.
On the property sheet for the Location field you should see an option for the Bing Maps Keys. You’ll need to paste in the value here that you got from the http://www.bingmapsportal.com site.
At this point we should be ready to F5.
Check it out
We should now have an Arrivals List and Details screen that auto refreshes every couple minutes, and a Stops List and Details screen that shows us a map of where our Metro stop is located.
Our Stops List and Details screen now:
I still want to pull in information for the “Incidents” entity so that we can keep track of all the busted escalators.
To do this will involve a blog post just by itself, since we will need to do some low level technical things to pull in all that information. But after we do that I think we’ll be able to navigate the DC Metro system with confidence.
Thanks for reading and let me know if you have any questions.







Return to section navigation list>
Windows Azure Infrastructure and DevOps
David Cameron of the Windows Azure Team (@WindowsAzure) posted Announcing New Datacenter Options for Windows Azure in a 4/5/2012 post:
To keep pace with growing demand, we are announcing two new datacenter options for Windows Azure. Effective immediately, compute and storage resources are now available in “West US” and “East US”, with SQL Azure coming online in the coming months. These new options add to our worldwide presence and significantly expand our US footprint.
Pricing for Windows Azure Compute and Storage remains consistent across all datacenters worldwide. As always, the best way to get started with Windows Azure is with a 90 day free trial.

Updated 4/5/2012 2:15 PM PDT: The official location of the two new Windows Azure data centers are US West (California) and US East (Virginia).
- US East and West are paired together for Windows Azure Storage geo-replication
- US North and South are paired together for Windows Azure Storage geo-replication
Updated 4/5/2012 12:00 PM PDT: Press reports over the past two years located the West US data center in Quincy, WA, and the East US data center in Boydton, VA. As of 12:30 PM PDT on 4/5/2012, both data centers appeared in the Windows Azure Portal’s regions list for Hosted Services, but not SQL Azure databases.
Stevan Vidich expanded on David Cameron’s Announcement above in his Windows Azure Trust Center Launched post of 4/5/2012 to the Windows Azure Team blog:
In Dec 2011, we announced that Windows Azure obtained ISO 27001 certification for its core features. Today, we are launching Windows Azure Trust Center with the goal of providing customers and partners with easier access to regulatory compliance information.
We are also announcing additional contractual commitments to volume licensing (Enterprise Agreement) customers:
- A Data Processing Agreement that details our compliance with the E.U. Data Protection Directive and related security requirements for Windows Azure core features within ISO/IEC 27001:2005 scope.
- E.U. Model Contractual Clauses that provide additional contractual guarantees around transfers of personal data for Windows Azure core features within ISO 27001 scope.
Please contact your Microsoft account manager or Microsoft Volume Licensing for details.
Windows Azure has completed another important milestone for its core features: a submission to the Cloud Security Alliance STAR registry. STAR is a free, publically accessible registry that documents the security controls provided by various cloud computing offerings. The Cloud Security Alliance published the Cloud Control Matrix (CCM) to support customers in the evaluation of cloud services. In response to this publication, Microsoft has created a white paper to outline how Windows Azure security controls map to the CCM controls framework, providing customers with in-depth information on Windows Azure security policies and procedures.
Windows Azure Trust Center will be updated on a regular basis with announcements of additional compliance programs that Windows Azure is pursuing.
See The Windows Azure Team (@WindowsAzure) submitted Microsoft Windows Azure to the Cloud Security Alliance’s Security, Trust and Assurance Registry (STAR) on 3/30/2012 article in the Cloud Security and Governance section below for more details.
My (@rogerjenn) Uptime Report for my Live OakLeaf Systems Azure Table Services Sample Project: March 2012 of 4/3/2012 reported 99.96% availability:
My live OakLeaf Systems Azure Table Services Sample Project demo runs two small Windows Azure Web role instances from Microsoft’s South Central US (San Antonio, TX) data center. Here’s its uptime report from Pingdom.com for March 2012:
Following is detailed Pingdom response time data for the month of March 2012:
This is the tenth uptime report for the two-Web role version of the sample project. Reports will continue on a monthly basis.




Bruno Terkaly (@brunoterkaly) described Simplifying Synchronization-Challenges of a multi-device, highly-connected world in a 4/3/2012 post:
Simplifying Synchronization Complexities
Synchronizing data is more important than ever. Never has there been more device types and never has the world of distributed systems been more common. I’m getting a lot of questions about keeping phones, browsers, and databases synchronized.
Things get difficult right away.


There a many scenarios the modern developer faces. Moving forward, as the lines separating between desktop, tablet, and mobile become increasingly blurred, the synchronizing challenge will increase. Consumers will switch between devices and expect to be able to continue where they left off. They also expect to get the latest information from applications.
Developers must support cloud, on-premise and mobile. I present you three challenges and three solutions.

The Big Picture
Figure 1: A Visual Picture of Synchronization Challenges The various players in the world of synch.
How do you keep this stuff synchronized?
The 3 challenges I will address here are:
(1)Synchronizing Mobile and Web
(2)Relational data base in the cloud and hosted on-premise
(3)Browser and Web
Challenge #1: Web user needing latest information from an on-premise web site
This situation is very common. The goal is to have real-time persistent long-running connections between the on-premise web site and the remotely connected web user.
Imagine the web user wants real time stock price information.
There are many situations where you want as near real time as possible to synchronize the web server and the browser.
Figure 2: A user of a web browser needs the latest from the ASP.NET Web Site (doesn’t have to be a browser, could be a .NET Client as well)
Keeping the web user synchronized with up to the second weather, travel or financial information. Note that the web site/service could be hosted on-premise or in the cloud.Solution to Challenge #1 - SignalR
Scott Hanselman describes SignalR succinctly as "Asynchronous scalable web applications with real-time persistent long-running connections."
There are two pieces to SignalR, a client piece and a server piece. The client piece comes in two forms: (1) Javascript for browsers; (2) .NET for web apps or for thick client (WPF, WinForms, etc).




Where to get SignalR
https://github.com/SignalR/SignalR
Challenge #2: Synchronizing databases (SQL Azure and On-Premise SQL Server)
The challenge is having multiple copies of databases in different locations. There is a need to synchronize multiple copies of a database globally dispersed. You can even think of the scenario as needing to sync two different web sites. Often times and efficient way to pass messages from the cloud to an on-premise web site/service is to have some type of an Messages table that is kept in synch between op-premise and cloud-hosted databases.

Figure 3: Synchronizing geographically dispersed databases.
Using SQL Azure Data Sync to keep databases properly synchronized
Image hereSolution to Challenge #2: Microsoft SQL Azure Data Sync
Microsoft SQL Azure Data Sync is a cloud-hosted data synchronization service which provides uni-directional and bi-directional data sync. Data Sync allows data to be easily shared between SQL Azure and on-premises SQL Server databases, as well as between multiple SQL Azure databases.
Benefits of Microsoft SQL Azure Data Sync

Where to get Microsoft SQL Azure Data Sync
http://msdn.microsoft.com/en-us/library/hh667316.aspx
Challenge #3: Sending data to mobile devices from the cloud for from on-premise web sites
The challenge is not having mobile devices “poll” for new data. This is also known as the “pull” model, where by the mobile application needs to constantly ask the web server if there is newer data. This is considered too chatty, meaning that it wastes bandwidth, doesn’t scale well, and drains battery life.
In a practical sense, it doesn’t work well, since most mobile frameworks don’t allow applications to constantly poll web services, because of the limited power of batteries.Figure 4: Sending data to mobile devices
From on-premise or cloud-hosted web sites
Solution to Challenge #3: Push Notifications services
The solution is to leverage the native notification frameworks available in today’s modern devices. There are third party vendors, such as Urban Airship, as well as implementations by Apple and Microsoft.
Microsoft offers a powerful service hosted in Windows Azure. The diagram illustrates the major pieces. As you can see, the Microsoft Push Notification Service brokers or proxies the messaging interactions. Notice that there is a push client service built into the Windows Phone 7 frameworks and operating systems.
Figure 5: Windows Push Notification Services Diagram
How the pieces fit together
Two Types of Notification



Here is an example relevant for Windows Phone 7 developers.
Figure 6: A Cloud Hosted Notification Server sending messages to a Windows Phone 7 Device
Developers can easily create scalable, cloud-hosted push notifications services with the Windows Azure SDK and Visual Studio web sitesBenefits to Solution #3
The definitive way to send data from a web server/service to a mobile device. The primary driver is enabling updates to the mobile device but not requiring the an application to always be running. This approach saves on battery life.
Where to get more information on Push Notification Services
How it works can be found here: http://msdn.microsoft.com/en-us/library/ff402558%28v=VS.92%29.aspx
There is also an extensive lab in the Windows Phone Training Kit
Conclusion
I presented 3 technologies that will help you stay synchronized. There is more to discuss in a future post. Here are some additional synchronization technologies that offer additional capabilities.


Ernest Mueller (@ernestmueller) asserted DevOps: It’s Not Chef And Puppet in a 4/2/2012 post:
There’s a discussion on the devops Google group about how people are increasingly defining DevOps as “chef and/or puppet users” and that all DevOps is, is using one of these tools. This is both incorrect and ignorant.
Chef and puppet are individual tools that you can use to implement specific parts of an overall DevOps strategy if you want to use them – but that’s it. They are fine tools, but do not “solve DevOps” for you, nor are they even the only correct thing to do within their provisioning niche. (One recent poster got raked over the coals for insisting that he wanted to do things a different way than use these tools…)
This confusion isn’t unexpected, people often don’t want to think too deeply about a new idea and just want the silver bullet. Let’s take a relevant analogy.
Agile: I see a lot of people implement Scrum blindly with no real understanding of anything in the Agile Manifesto, and then religiously defend every one of Scrum’s default implementation details regardless of its suitability to their environment. Although that’s better than those that even half ass it more and just say “we’ve gone to our devs coding in sprints now, we must be agile, woot!” Of course they didn’t set up any of the guard rails, and use it as an exclude to eliminate architecture, design, and project planning, and are confused when colossal failure results.
DevOps: “You must use chef or puppet, that is DevOps, now let’s spend the rest of our time fighting over which is better!” That’s really equivalent to the lowest level of sophistication there in Agile. It’s human nature, there are people that can’t/don’t want to engage in higher order thought about problems, they want to grab and go. I kinda wish we could come up with a little bit more of a playbook, like Scrum is for Agile, where at least someone who doesn’t like to think will have a little more guidance about what a bundle of best practices *might* look like, at least it gives hints about what to do outside the world of yum repos. Maybe Gene Kim/John Willis/etc’s new DevOps Cookbook coming out soon(?) will help with that.
My own personal stab at “What is DevOps” tries to divide up principles, methods, and practices and uses agile as the analogy to show how you have to treat it. Understand the principles, establish a method, choose practices. If you start by grabbing a single practice, it might make something better – but it also might make something worse.
Back at NI, the UNIX group established cfengine management of our Web boxes. But they didn’t want us, the Web Ops group, to use it, on the grounds that it would be work and a hassle. But then if we installed software that needed, say, an init script (or really anything outside of /opt) they would freak out because their lovely configurations were out of sync and yell at us. Our response was of course “these servers are here to, you know, run software, not just happily hum along in silence.” Automation tools can make things much worse, not just better.
At this week’s Agile Austin DevOps SIG, we had ~30 folks doing openspaces, and I saw some of this. “I have this problem.” “You can do that in chef or puppet!” “Really?” “Well… I mean, you could implement it yourself… Kinda using data bags or something…” “So when you say I can implement it in chef, you’re saying that in the same sense as ‘I could implement it in Java?’” “Uh… yeah.” “Thanks kid, you’ve been a big help.”
If someone has a systems problem, and you say that the answer to that problem is “chef” or “puppet,” you understand neither the problem nor the tools. It’s “when you have a hammer, everything looks like a nail – and beyond that, every part of a construction job should be solved by nailing shit together.”
We also do need to circle back up and do a better job of defining DevOps. We backed off that early on, and as a result we have people as notable as Adrian Cockroft saying “What’s DevOps? I see a bunch of conflicting blog posts, whatever, I’ll coin my own *Ops term.” That’s on us for not getting our act together. I have yet to see a good concise DevOps definition that is unique if you remove the word DevOps and insert something else (“DevOps helps you bring value to software! DevOps is about delivering a service to a customer!” s/DevOps/100 other things/).
At DevOpsDays, some folks contended that some folks “get” DevOps and others don’t and we should leave them to their shame and just do our work. But I feel like we have some responsibility to the industry in general, so it’s not just “the elite people doing the elite things.” But everyone agreed the tool focus is getting too much – John Willis even proposed a moratorium on chef/puppet/tooling talks at DevOpsDays Mountain View because people are deviating from the real point of DevOps in favor of the knickknacks too much.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Gartner licensed Thomas A. Bittman’s (@tombitt) Top Five Trends for Private Cloud Computing of 2/14/2012 for distribution in 4/2012:

Private cloud computing is moving from the drawing board to deployments in 2012. We present the five major trends for private cloud that enterprises should be aware of for planning purposes.
Overview
Through year-end 2012, a significant number of pilot and production deployments of private cloud services will emerge, and hybrid cloud capability will become a major requirement. The market for cloud management platforms will expand greatly, but a number of vendors will be acquired or will exit the market. Outsourcing will become a mainstream alternative to internally deployed private clouds.
Key Findings
- New private cloud pilots and many production rollouts will occur during 2012.
- While use of hybrid cloud computing is minor today, interest for the future is very high.
- The number of vendors for cloud management platforms is already large, but will evolve and shakeout in 2012.
- Internal private clouds will remain predominant, but outsourced deployments are growing.
- Agility and speed will be the most important drivers of successful private cloud projects.
Recommendations
- Deploy early private clouds in a focused, stepwise manner, demand references from private cloud consultants and ensure the consultants assigned to you have experience.
- Evaluate future interoperability (for hybrid cloud computing) when deploying pilots. Technology and vendor choices matter.
- Expand your shortlist of cloud management platform vendors beyond just virtualization platform vendors, and consider heterogeneity (physical and virtual, various virtualization platforms) as a requirement.
- Consider outsourced offerings, and match up their varying levels of privacy with your service requirements to optimize cost and security.
- Work with end users to establish a business case and a successful, early private cloud pilot, based more on agility and speed than cost.
Analysis
The private cloud computing trend has been gaining traction since the term was introduced in 2008. Virtualization has been a major catalyst in enterprise IT, transforming server, network and storage assets into more flexible pools of resources. Since early 2012, roughly 50% of x86 architecture servers have been virtualized, and many enterprises are planning to create standardized, automated, self-service capability for specific service offerings based on their virtualized infrastructure. Private cloud is at the Peak of Inflated Expectations on the 2011 Hype Cycle (see "Hype Cycle for Cloud Computing, 2011"), and 2012 will be all about real production deployments, real products and real enterprise experience. Users will learn what's valuable (agility), and what's harder to attain (cost reduction) with private cloud computing.
Much of Gartner's research on private cloud computing for 2012 will focus on five trends. (1) In terms of real deployments, Gartner will produce case studies and best practices research. (2) For hybrid cloud, Gartner will analyze technologies and service provider offerings that enable hybrid. (3) We will further analyze the architecture of private cloud services, and the maturing market for cloud management platform (CMP) offerings. (4) As sourcing alternatives for private cloud expand, we will publish research evaluating the privacy enabled by each, and considerations for the selection. (5) Finally, Gartner will publish more research on how to measure and evaluate agility for business enabled by private cloud services.
Real Deployments
Based on discussions with hundreds of clients, 2012 will be the year that a significant number of private cloud pilots are initiated, and a large number of 2011's pilots move into production. Last year, 2011, was the first big year of private cloud deployments, with hundreds of pilots and some production rollouts. The number of deployments throughout 2012 will be at least 10 times higher. Polls (see Figure 1) continue to show that enterprise interest in private cloud computing remains high. Gartner's research on private cloud computing was among the most-read during 2011 — another indication of the trend. In many cases, early deployments that were called "private clouds" were shared services or just virtualized servers. Few included self-service, automated provisioning and management, or metered usage. However, technologies are maturing and the majority of the clients we speak with today have richer, real private cloud projects in progress.
Figure 1. Gartner Data Center Conference Poll (December 2011): Will your enterprise be pursuing a private cloud computing strategy by 2014? (n = 150)
Source: Gartner (February 2012)
What you need to do: There is very little end-user experience with private cloud computing in the market today. This is changing. Clients should deploy small pilots first, and be cautious about rushing into production with private cloud computing. Any private cloud project should be initiated as part of a broader cloud computing and infrastructure modernization strategy. Consulting skills with private cloud experience will be rare; therefore, demand references. During 2012, there will be a significant amount of best practice (and bad practice) information available to leverage, and Gartner will publish feedback from our clients.
Hybrid Plans
Client interest in building the capability to leverage external cloud services interoperably with a private and/or on-premises cloud (in a hybrid mode) is growing. A poll conducted during Gartner's U.S. Data Center Conference held in December 2011 proves the point: 47% of the respondents to one question said that, by 2015, they wanted the ability to manage both on-premises and off-premises virtual machines centrally. Service providers (notably VMware's vCloud data center partners, but others are emerging) are adding hybrid capability, and technologies for cloud interoperability are being delivered.
What you need to do: While hybrid cloud computing may not be a requirement today for many organizations, pilot projects should be deployed with interoperability in mind. Answer the following questions: What technologies are being used for the private cloud architecture? What interoperability do those technologies enable today? More importantly, what interoperability will they enable in the future? Recognize that vendors such as HP, IBM, Microsoft, Oracle and VMware have very different plans for hybrid cloud computing, so choices matter.
Choices Expand
The number of vendor offerings is growing. CMP can be categorized into at least four distinct categories: virtualization platforms expanding up (e.g., VMware, Citrix, Microsoft), traditional management vendors expanding into virtualization and cloud management (e.g., BMC Software, CA Technologies, HP, IBM), open-source initiatives (most importantly, OpenStack) and startups (such as Abiquo, DynamicOps, Eucalyptus Systems and ManageIQ). Most of the smaller companies will likely need to be acquired in the midterm to survive; however, they have the most innovative technologies in the short term. Already, a significant number of smaller CMP-enabling vendors have been acquired (notably 3Tera and Hyperformix by CA Technologies, Cloud.com and VMlogix by Citrix Systems, newScale by Cisco Systems and Platform Computing by IBM). Clearly, there will be a shakeout in the marketplace. Given the huge interest in projects beginning in 2012, the winners and losers will likely be decided in the next two to three years.
What you need to do: Choices matter, but the market will be in flux through acquisitions and changing competitive positioning. While avoiding vendor lock-in may be impossible, be cautious about locking in too early, or leveraging unique vendor functionality early. Compare and contrast alternatives. Do not necessarily expect your server virtualization vendor to be your CMP vendor. Consider the value of heterogeneity under the CMP, be mindful that a CMP vendor might change its strategy through acquisition or competitive pressure, and also consider the hybrid cloud connections the CMP might or might not enable.
Sourcing Alternatives
While many private clouds may be deployed on-premises (within an enterprise), there is a growing interest in the potential of service-provider-managed private clouds. These can come in many different forms with varying levels of privacy. For example, Amazon Virtual Private Cloud provides privacy through a private virtual network topology (not physically separated), while a solution like Savvis Symphony Dedicated provides a private cloud in a dedicated hardware environment. Likewise, many enterprises that already have outsourcing relationships are struggling to evolve those relationships to include private cloud computing capabilities. While outsourcers are expanding their cloud offerings, they aren't anxious to migrate traditionally outsourced customers to cloud services. Gartner believes the majority of private clouds will be internal and on-premises; however, as some enterprises struggle with the changes necessary internally (political, cultural, process, skills) or with relationships with traditional outsourcers, there will be a growing trend to build net new private cloud services with service providers.
What you need to do: While often presented under the moniker "virtual private cloud," the amount of sharing and true security/privacy will vary greatly among solutions. Likewise, enterprise requirements for different services may vary greatly. Match up your privacy requirements with the appropriate offering; consider multiple providers for disparate, unrelated services with different privacy requirements; and consider service providers that offer a range of privacy capabilities for different requirements. A stepwise hybrid cloud relationship with these providers might be the right approach when an internal private cloud is already in place. One size will not fit all.
Value Is Shifting
In the early days of private cloud computing (2008 to 2009), most clients considered the primary benefit would be reduced IT costs. Many saw private cloud computing as the natural next step for the virtualized infrastructure, and virtualization vendors promoted that idea. The market has matured, and the conversation is shifting. While virtualization can reduce capital expenses significantly, additional investments for private cloud focus primarily on operational expenses — and the cost of automation software often makes the cost savings minor. According to a Gartner poll conducted in late 2011, agility and speed were considered the primary benefits over cost in almost a three-to-one margin. In addition, according to the 2012 Gartner survey of thousands of CIOs published in January 2012 (see "Executive Summary: Amplifying the Enterprise: The 2012 CIO Agenda"), CIOs continue to rank "increasing enterprise growth" as their top business priority. More enterprises are focusing on private cloud computing as a style of computing to employ only for services that are standardized and in high demand, and require speed of deployment. Also, more enterprises are engaging their business unit customers in the plans to deploy private cloud services.
What you need to do: Working with the service customers early is critical to identifying the right standards that will meet their needs, and to help the service customers understand how speed might change their service usage and processes. Rather than focusing on building a massive, all-encompassing private cloud, focus on building a laser-focused and successful first service with a willing and engaged customer, learn from it and expand from there, but keep it in the context of the larger cloud computing and IT modernization strategy. Create metrics for agility, and ensure that the business case for private cloud efforts focus on agility, speed and business value. The ROI of private cloud services will often be measured more in business agility (reducing business costs and increasing business opportunity) than in IT cost reduction.
Bottom Line
This is the year that private cloud moves from market hype to many pilot and mainstream deployments. The choices are evolving and growing for internally developed private cloud architectures and outsourced private clouds, and the markets for both will look very different by year-end 2012 (through acquisitions and technology choices). While hybrid cloud computing is mostly aspirational today, service providers and visionary enterprises are choosing technologies and building on-ramps. During 2012, we will start to determine vendor winners, and best and bad enterprise practices will emerge. Private cloud will find its appropriate niche in many companies, and successful deployments will be based on business requirements where agility and speed help the business grow.


<Return to section navigation list>
Cloud Security and Governance
The Windows Azure Team (@WindowsAzure) posted a new Windows Azure Trust Center Web site on 4/4/2012. From the landing page:
Windows Azure Trust Center
Last Updated: March 2012
As a Windows Azure customer, you have entrusted Microsoft to help protect your data. Microsoft values this trust, and the privacy and security of your data is one of our top concerns. Microsoft strives to take a leadership role when it comes to security, privacy, and compliance practices.
- Relentless on Security: Excellence in cutting edge security practices
- Your Privacy Matters: We respect the privacy of your data
- Independently Verified: Compliance with world class industry standards verified by third parties
- FAQs: Frequently Asked Questions
For more information on our legal agreements, please see Windows Azure Legal Information.
Shared Responsibility
Our customers around the world are subject to many different laws and regulations. Legal requirements in one country or industry may be inconsistent with legal requirements applicable elsewhere. As a provider of global cloud services, we must run our services with common operational practices and features across multiple geographies and jurisdictions. To help our customers comply with their own requirements, we build our services with common privacy and security requirements in mind. However, it is ultimately up to our customers to evaluate our offerings against their own requirements, so they can determine if our services satisfy their regulatory needs. We are committed to providing our customers with detailed information about our cloud services to help them make their own regulatory assessments.
It is also important to note that a cloud platform like Windows Azure requires shared responsibility between the customer and Microsoft. Microsoft is responsible for the platform, and seeks to provide a cloud service that can meet the security, privacy, and compliance needs of our customers. Customers are responsible for their environment once the service has been provisioned, including their applications, data content, virtual machines, access credentials, and compliance with regulatory requirements applicable to their particular industry and locale.
Updates
The information presented in the Windows Azure Trust Center is current as of the “last updated” date at top but is subject to change without notice. We encourage you to review the Trust Center periodically to be informed of new security, privacy and compliance developments.

The Windows Azure Team (@WindowsAzure) submitted Microsoft Windows Azure to the Cloud Security Alliance’s Security, Trust and Assurance Registry (STAR) on 3/30/2012:
Computing in the cloud raises questions about security, data protection, privacy, and data ownership. Windows Azure is hosted in Microsoft data centers around the world, and it is designed to offer the performance, scalability, security, and service levels business customers expect. We have applied state-of-the-art technology and processes to maintain consistent and reliable access, security, and privacy for every user. Windows Azure has built-in capabilities for compliance with a wide range of regulations and privacy mandates.
In this document, we provide our customers with a detailed overview of how Windows Azure core services fulfill the security, privacy, compliance, and risk management requirements as defined in the Cloud Security Alliance (CSA) Cloud Control Matrix (CCM). Note that this document is intended to provide information on how Windows Azure operates. Customers have a responsibility to control and maintain their environment once the service has been provisioned (i.e., user access management and appropriate policies and procedures in accordance with their regulatory requirements).


You can download the 50-page Self-Assessment CAI submission document in PDF and DOCX formats here.
Brandon Butler (@BrandonButler1) asserted “Microsoft is one of the few companies that has joined the Cloud Security Alliance's registry” in a deck for his Microsoft details Azure security features Network World article of 4/4/2012:
Microsoft has added its Azure cloud platform to the Cloud Security Alliance's STAR security registry, which is a listing where cloud service providers post information about their security features.
The Security, Trust and Assurance Registry (STAR) began last year but almost six months after its launch only three companies had filled out the 170-question form that makes up STAR. Microsoft was one of the early adopters when it submitted security information for Microsoft Office 365, with cloud service providers Mimecast and Solutionary being the others. In the last month, though, there have been two additions, including Microsoft Azure and IT and cloud manager SHI International.
- BACKGROUND: Cloud security registry slow to catch on
- EDITORIAL: Push your cloud supplier to participate in CSA STAR
Some cloud watchers have expressed optimism for STAR to be a place where customers can easily compare and contrast security features from providers they may consider working with. But, to fully realize that potential, Kyle Hilgendorf, a Gartner analyst, says more companies need to sign on. CSA officials say that some big name companies, such as Google, McAfee, Verizon and Intel, have said they will contribute to STAR, but they haven't yet.
"Our customers are able to go to the STAR registry and they're able to pick up our specific security controls, they're able to dive into what we do at the data center level, all the way up through the platform level," says Kellie Ann Chainier, a cloud business manager for Microsoft, in a video posting the company released about the news.

Brandon’s and other reporters’ stories would have been more complete if they had included a link to Microsoft’s submission (see above item).
<Return to section navigation list>
Cloud Computing Events
Richard Conway (@azurecoder) reported about Redgate (Cerebrata) tools and UKWAUG in a 4/4/2012 post:
Last night we had the pleasure of hosting Gaurav Mantri, CEO and founder of Cerebrata Software, recently purchased by Redgate. Gaurav turned up with a small entourage from Cambridge and India to speak about Cerebrata products. What we got was a tour of Windows Azure unparalleled. I had high expectations of listening to Gaurav given that he’d already solved a lot of the problems I’ve had and publicised solutions on the MSFT social forums. A true hero with clearer answers to rest api problems than anyone else.
The Cerebrata team have a wealth of features on their roadmap and we discussed new UI adaptations to make access to config easier as well as codegen and the exposing of an underlying SDK which would enable extensibility that would add a new wealth of quick code development patterns.
We’ll be working closely with the Cerebrata team going forward to ensure that we push the idea of using their Powershell CmdLets product as the pivotal component in a CI build. Many people have asked us now at bootcamps and other places how they can build a wholly agile project in Windows Azure. Last month at the user group we looked at the Blush Packages project which used a great application stack. Today in Manchester Blush will be speaking for about an hour which will give us license to fully understand their stack in minute details: TeamCity, NUnit, Watin and key to all of this Cerebrata Powershell CmdLets. As a first point of priciple we’ll be running an advanced bootcamp which will discuss many of these issues and possibly take a look at how to begin writing a project in Windows Azure in an agile friendly manner. It will be another Microsof-sponsored event in London. Comment back if you’re interested in attending and we’ll send an email around nearer the time.
Conference registration has opened up at: http://azureconference2012.eventbrite.co.uk
Feel free to register – there will be a lot of surprises at this conference so not one to miss.
Redgate have been very supportive to our user group and we’d like to extend them a big thank you for all of their support and effort. In addition if you’ve got your own user group then contact me and I’ll put you in touch with Luke Jefferson from Redgate and you may be able to get some free tools from group members which you can raffle or have prize draws on.

Full disclosure: I’m a paid contributor to Red Gate Software’s ACloudyPlace blog.
Christian Weyer (@christianweyer) reported the availability of Slides for my sessions at DevWeek 2012 on 4/4/2012:
And here we go – as promised to all of you nice people attending one of my sessions last week in London.
- Light-weight web-based architectures with Web APIs
- Real world experiences with Windows Azure (the slides do not make a lot of sense without the demos, which I cannot publish – sorry)
- Loosely coupled messaging with Windows Azure Service Bus
See you next year at DevWeek.

Brian Hitney (@bhitney) announced Debugging and Troubleshooting in the Cloud in a 4/4/2012 post:
Thursday, April 5th, at noon, we’ll be having our second from the last @home webcast, this time focusing on debugging and diagnostics in the cloud. While a lot of what we show is in the context of our @home app…
… much of what we’ll be doing is fairly general in nature, especially some of the diagnostics material we’ll be covering this week. From this week’s abstract:
We’ll talk with you then!


This post is a bit late. However, you can still register and watch the Webcast at the above link.
Steve Marx (@smarx) suggested on 4/3/2012 that you Join Me for “An Evening on Azure” in Bellevue, WA on 4/25/2012:
Microsoft and Aditi are holding an “Evening on Azure” dinner series. Please register and join us on April 25th at 5:30pm at Purple Café and Wine Bar for dinner and conversation. In my new role as Chief Windows Azure Architect for Aditi, I’m going to be leading a discussion about best practices in the cloud (and Windows Azure specifically).
The evening’s discussion will be around the following:
- Windows Azure monetization strategies
- Best practices around cloud fit analysis and application selection
- Windows Azure in general, and Microsoft’s cloud roadmap
Go here to register for the event: http://pages.aditi.com/l/3172/2012-03-22/bfdvx. I hope to see you there!


<Return to section navigation list>
Other Cloud Computing Platforms and Services
SearchCloudComputing.com posted their Top 10 cloud computing providers of 2011 slideshow on 4/5/2012. From the advert on LinkedIn’s Cloud Computing Trends group:
As cloud has quickly become one of (if not THE) hottest technologies in the IT world in the last few years, both new and established vendors have jumped on board to try to ride the waves of the trend. Unfortunately, many of these offerings (even from your most trusted vendors) are either not fully formed or falsely labeled as "cloud" in an attempt to boost marketing and sales success.
With the rapid growth of the trend and the massive influx of cloud services, how can you know which are the "real deal" and will be around for the long haul?
Find out which cloud providers kept on top of their cloud efforts (or just joined the game) in 2011 and why you need to pay attention to them in 2012: http://bit.ly/I0TVeq.This expert breakdown of the best cloud providers in the marketplace today provides insight into:
- Why there's still hope for Microsoft after Azure's lackluster performance
- How CSC and BlueLock broke into the space and bumped off 2010 winners
- Which reigning giant held onto the #1 spot for the second year in a row, and how, in spite of a public SLA debacle
- Plus, the top 10 (plus one runner up) cloud providers of 2011 list
Uncover who made the cut this year so you can effortlessly navigate the cloud vendor marketplace
From the first slide:

Spring is here (in San Francisco, at least), and that means it's time to blow the cobwebs off our list of the top 10 cloud computing service providers. Much has happened since last year's top 10, and we're proud to introduce the best of the best for 2011. Our rankings are based on customer traction, solid technical innovation and management track record.
For a video version of the list, watch Jo Maitland and Carl Brooks run down the top 10 on their new weekly TV show at CloudCoverTV.com.
Here’s the Windows Azure Slide:

How Nephoscale got on the list is a mystery to me.
Lydia Leong (@cloudpundit) analyzed Citrix, CloudStack, OpenStack, and the war for open-source clouds in a 4/3/2012 post:
There are dozens upon dozens of cloud management platforms (CMPs), sometimes known as “cloud stacks” or “cloud operating systems”, out in the wild, both commercial and open source. Two have been in the news recently — Eucalyptus and CloudStack — with implications for the third, OpenStack.
Last week, Eucalyptus licensed Amazon’s API, and just yesterday, Wired extolled the promise of OpenStack.
Now, today, Citrix has dropped a bombshell into the open-source CMP world by announcing that it is contributing CloudStack (the Amazon-API-compatible CMP it acquired via its staggeringly expensive Cloud.com acquisition) to the Apache Software Foundation (ASF). This includes not just the core components, which are already open-source, but also all of the currently closed-source commercial components (except any third-party things that were licensed from other technology companies under non-Apache-compatible licenses).
I have historically considered CloudStack a commercial CMP that happens to have a token open-source core, simply because anyone considering a real deployment of CloudStack buys the commercial version to get all the features — you just don’t really see people adopting the non-commercial version, which I consider a litmus test of whether or not an open-core approach is really viable. This did change with Citrix, and the ASF move truly puts the whole thing out there as open source, so adopters have a genuine choice about whether or not they want to pay for commercial support, and it should spur more contributions from people and organizations that were opposed to the open-core model.
What makes this big news is the fact that OpenStack is a highly immature platform (it’s unstable and buggy and still far from feature-complete, and people who work with it politely characterize it as “challenging”), but CloudStack is, at this point in its evolution, a solid product — it’s production-stable and relatively turnkey, comparable to VMware’s vCloud Director (some providers who have lab-tested both even claim stability and ease of implementation are better than vCD). Taking a stable, featureful base, and adding onto it, is far easier for an open-source community to do than trying to build complex software from scratch.
Also, by simply giving CloudStack to the ASF, Citrix explicitly embraces a wholly-open, committer-driven governance model for an open-source CMP. Eucalyptus has already wrangled with its community over its open-core closed-extensions approach, and Rackspace is still strugging with governance issues even though it’s promised to put OpenStack into a foundation, because of the proposed commercial sponsorship of board seats. CloudStack is also changing from GPLv3 to the Apache license, which should remove some concerns about contributing. (OpenStack also uses the Apache license.)
Citrix, of course, stands to benefit indirectly — most people who choose to use CloudStack also choose to use Xen, and often purchase XenServer, plus Citrix will continue to provide commercial support for CloudStack. (It will just be a commercial distribution and support, though, without any additional closed-soure code.) And they rightfully see VMware as the enemy, so explicitly embracing the Amazon ecosystem makes a lot of sense. (Randy Bias has more thoughts on Citrix; read James Urquhart’s comment, too.)
Citrix has also explicitly emphasized Amazon compatibility with this announcement. OpenStack’s community has been waffling about whether or not they want to continue to support an Amazon-compatible API; at the moment, OpenStack has its own API but also secondarily supports Amazon compatibility. It’s an ecosystem question, as well as potentially an intellectual property issue if Amazon ever decides to get tetchy about its rights. (Presumably Citrix isn’t being this loud about compatibility without Amazon quietly telling them, “No, we’re not going to sue you.”)
I think this move is going to cause a lot of near-term soul-searching amongst the major commercial contributors to OpenStack. While clearly there’s value in working on multiple projects, each of the vendors still needs to place bets on where their engineering time and budgets are best spent. Momentum is with OpenStack, but it’s also got a long way to go.
HP has effectively recently doubled down on OpenStack; it’s not too late for them to change their mind, but for the moment, they’re committed in an OpenStack direction both for their public developer-centric cloud IaaS, and where they’re going with their hybrid cloud and management software strategy. No doubt they’ll end up supporting every major CMP that sees significant success, but HP is typically a slow mover, and it’s taken them this long to get aligned on a strategy; I’m not personally expecting them to shift anytime soon.
But the other vendors are largely free to choose — likely to support both for the time being, but there may be a strong argument for primarily backing an ASF project that’s already got a decent core codebase and is ready for mainstream production use, over spending the next year to two years (depending on who you talk to) trying to get OpenStack to the point where it’s a real commercial product (defined as meeting enterprise expectations for stable, relatively maintenance-free software).
The absence of major supporting vendor announcements along with the Citrix announcement is notable, though. Most of the big vendors have made loud commitments to OpenStack, commitments that I don’t expect anyone to back down on, in public, even if I expect that there could be quiet repositioning of resources in the background. I’ve certainly had plenty of confidential conversations with a broad array of technology vendors around their concerns for the future of OpenStack, and in particular, when it will reach commercial readiness; I expect that many of them would prefer to put their efforts behind something that’s commercially ready right now.
There will undoubtedly be some people who say that Citrix’s move basically indicates that CloudStack has failed to compete against OpenStack. I don’t think that’s true. I think that CloudStack is gaining better “real world” adoption than OpenStack, because it’s actually usable in its current form without special effort (i.e., compared to other commercial software) — but the Rackspace marketing machine has done an outstanding job with hyping OpenStack, and they’ve done a terrific job building a vendor community, whereas CloudStack’s primary committers have been, to date, almost solely Cloud.com/Citrix.
Both OpenStack and CloudStack can co-exist in the market, but if Citrix wants to speed up the creation of Amazon-compatible clouds that can be used in large-scale production by enterprises trying to do Amazon hybrid clouds (or more precisely, who want freedom to easily choose where to place their workloads), it needs to persuade other vendors to devote their efforts to enhancing CloudStack rather than pouring more time into OpenStack.
Note that with this announcement, Citrix also cancels Project Olympus, its planned OpenStack commercial distribution, although it intends to continue contributing to OpenStack. (Certainly they need to, if they’re going to support folks like Rackspace who are trying to do XenServer with OpenStack; the OpenStack deployments to date have been KVM for stability reasons.)
But it’s certainly going to be interesting out there. At this stage of the CMP evolution, I think that the war is much more for corporate commitment and backing with engineers paid to work on the projects, than it is for individual committers from the broader world — although certainly individual engineers (the open-source talent, so to speak) will choose to join the companies who work on their preferred projects.



Nihir Bihani described Live Smooth Streaming With CloudFront and Windows IIS Media Services in a 4/1/2012 post:
Flexibility is one of the key benefits you get with AWS – you can use our services either stand-alone or together in a building-block fashion, you choose which operating system to use with Amazon EC2, the type of origin you want to use with CloudFront, and there are even multiple ways to launch, configure, and manage your AWS resources. To add to this list, we’ve created another option for you to distribute your live media with CloudFront – Live Smooth Streaming using a Windows IIS Media Services AMI for delivery to Smooth Streaming clients, such as Microsoft Silverlight.
You use a familiar set-up to create this Live Smooth Streaming stack – a CloudFormation template which configures and launches the AWS resources you’ll need, including an Amazon EC2 instance running Windows Media Services and an Amazon CloudFront HTTP download distribution.
The flexibility doesn’t stop there; you have full access to your live streaming origin server running on Amazon EC2, so you can customize it to your needs with advanced IIS or Live Smooth Streaming configurations. And you still only pay for the AWS resources you consume during your live event.
Live Smooth Streaming offers adaptive bit rate streaming of live content over HTTP. Your live content is delivered to clients as a series of MPEG-4 (MP4) fragments encoded in different bit rates, with each individual fragment cached by CloudFront edge servers. As clients play these video fragments, network conditions may change (for example, increased congestion in the viewer’s local network) or streaming may be affected by other applications that are running on the client. Smooth Streaming compatible clients use heuristics to dynamically monitor current local network and PC conditions. As a result, clients can seamlessly switch the video quality by requesting CloudFront to deliver the next fragment from a stream encoded at a different bit rate. This helps provide your viewers with the best playback experience possible based on their local network conditions.
Let’s talk about how your live content flows through AWS. You first encode a live broadcast to the Smooth Streaming format using Microsoft Expression Encoder 4 Pro or another encoder that supports Smooth Streaming. Next, you publish the encoded live stream to an Amazon EC2 instance running Windows IIS Media Services. When viewers request your live stream, CloudFront pulls the Live Smooth Streaming fragments and manifest file from the Amazon EC2 instance, caches these files at its edge locations, and serves them to Smooth Streaming-compatible clients, such as Microsoft Silverlight. You can also use the same set-up to deliver your live media to Apple iOS devices using the Apple HTTP Live Streaming (HLS) format. The CloudFront Live Smooth Streaming tutorial walks you through this entire set-up.
With multiple options for live streaming using CloudFront, we hope that you will enjoy the flexibility you get and choose the solution that best meets your needs. And with either option, you take advantage of the performance and scalability offered by Amazon CloudFront, so you can easily and cost-effectively deliver a great live streaming experience to your audience.



<Return to section navigation list>

















0 comments:
Post a Comment