Windows Azure and Cloud Computing Posts for 3/30/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

••• Updated 4/1/2012 at 2:00 PM PDT for new articles marked ••• by Toni Petrina, Avkash Chauhan, Mick Benkovich and Me.
•• Updated 3/31/2012 at 9:00 AM PDT for new articles marked •• by Jamie Thomson, Avkash Chauhan, Abishek Lal, Gavin Casimir, Mike Benkovich and Microsoft Operator Channels
• Updated 3/30/2012 at 4:30 PM PDT for new articles marked • by Beth Massi and Jonathan Rozenblit.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics, Big Data and OData
- Windows Azure Access Control, Identity and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
••• Avkash Chauhan (@avkashchauhan) explained Listing current running Hadoop Jobs and Killing running Jobs in a 4/1/2012 post:
When you have jobs running in Hadoop, you can use the map/reduce web view to list the current running jobs however what if you would need to kill any current running job because the submitted jobs started malfunctioning or in worst case scenario, the job is stuck in infinite loops. I have seen several scenarios when a submitted job got stuck in problematic states due to code defect in map/reduce job or the Hadoop cluster itself. In any of such situation, you would need to manually kill the job which is already started.
To kill a currently running Hadoop job first you need Job ID and then Kill the job using the as following commands:
- Hadoop job -list
- Hadoop job –kill <JobID>
To list current running job in Hadoop Command shell please use below command:
On Linux: $ bin/hadoop job –list
On Windows: HADOOP_HOME = C:\Apps\Dist\
HADOOP_HOME\bin\Hadoop job listAbove command will return job details as below:
[Linux]
1 jobs currently running
JobId State StartTime UserName
job_201203293423_0001 1 1334506474312 avkash[Windows]c:\apps\dist>hadoop job -list
1 jobs currently running
JobId State StartTime UserName Priority SchedulingInfo
job_201204011859_0002 1 1333307249654 avkash NORMAL NAOnce you have the JobID you can use the following command to kill the job:On Linux: $ bin/hadoop job -kill jobidOn Windows: HADOOP_HOME = C:\Apps\Dist\
HADOOP_HOME\bin\Hadoop job –kill <Job_ID>
[Windows]
c:\apps\dist>hadoop job -kill job_201204011859_0002
Killed job job_201204011859_0002

•• Avkash Chauhan (@avkashchauhan) described How to troubleshoot MapReduce jobs in Hadoop in a 3/30/2012 post:
When writing MapReduce programs you definitely going to hit problems in your programs such as infinite loops, crash in MapReduce, Incomplete jobs etc. Here are a few things which will help you to isolate these problems:
Map/Reduce Logs Files:
All MapReduce jobs activities are logged by default in Hadoop. By default, log files are stored in the logs/ subdirectory of the HADOOP_HOME main directory. Thee Log file format is based on HADOOP-username-service-hostname.log. The most recent data is in the .log file; older logs have their date appended to them.
Log File Format:
HADOOP-username-service-hostname.log
- The username in the log filename refers to the username account in which Hadoop was started. In Windows the Hadoop service is started with different user name however you can logon to the machine with different user name. So the user name is not necessarily the same username you are using to run programs.
- The service name belong to several Hadoop programs are writing the logm such as below which are important for debugging a whole Hadoop installation:
- Jobtracker
- Namenode
- Datanode
- Secondarynamenode
- tasktracker.
For Map/Reduce process, the tasktraker logs provide details about individual programs ran on datanote. Any exceptions thrown by your MapReduce program will be logged in tasktracker logs.
Subdirectory Userlogs:
Inside the HADOOP_HOME\logs folder you will also find a subdirectory name userlogs. In this directory you will find another subdirectory for every MapREduce task running in your Hadoop cluster. Each task records its stdout and stderr to two files in this subdirectory. If you are running a multi-node Hadoop cluster, then the logs you will find here are not centrally aggregated. To collect correct logs you would need to check and verify each TaskNode's logs/userlogs/ directory for their output and then create the full log history to understand what went wrong.

Andrew Brust (@andrewbrust) asserted “Hadoop Streaming allows developers to use virtually any programming language to create MapReduce jobs, but it’s a bit of a kludge. The MapReduce programming environment needs to be pluggable” in a deck for his MapReduce, streaming beyond Java article of 3/30/2012 for ZDNet’s Big Data blog:
I gave an introductory talk on Hadoop yesterday at the Visual Studio Live! conference in Las Vegas. During the talk, I discussed how Hadoop Streaming, a utility which allows arbitrary executables to be used as the Hadoop’s mappers and reducers, enables languages other than Java to be used to develop MapReduce jobs. For attendees at the conference, the take-away was that they could use C#, the prominent language of Microsoft’s .NET platform, to work with Hadoop. Cool stuff. Or is it?
I likened Hadoop Streaming to the CGI (Common Gateway Interface) facility on Web servers. In the pioneering days of the Web, CGI was frequently used to create Web applications with any programming language whose code could be compiled to an executable program. While not the most elegant way to do Web development, CGI opened up that world to developers working with common business programming languages. CGI still works; in fact, we now have FastCGI and, to this day, the PHP programming language can still work within Web servers’ CGI frameworks.
Likewise, Hadoop Streaming allows developers to use virtually any programming language to create MapReduce jobs. And just like CGI, it’s a bit of a kludge. It works, but it ain’t pretty. Writing MapReduce code in C# means creating two separate “console applications” (i.e. those that run from what is essentially the modern equivalent of a DOS prompt) with the mapper code in the main() function of one, and the reducer code in that of the other. There’s no Hadoop context as a developer writes the code, and the two executables have to be compiled, then uploaded to the Hadoop server. When you’re done with all that, you can get the job to run. It’s impressive, but when you’re done with it, you feel like you need to wash your hands.
If Hadoop is to go truly mainstream, if it’s going to take over the enterprise, if it’s going to capture the hearts and minds of today’s line of business application developers, then it will need to host non-Java execution environments more explicitly and simply. MapReduce needs to be pluggable, just like Web servers are now. Web applications can be easily developed in C# (and other languages), which is why the Web became mainstream as a platform, even inside the firewall. Now the same must happen with MapReduce.
In my discussion with Pervasive Software’s Mike Hoskins last week, he told me that such a pluggable framework is on its way. As far as I’m concerned, it can’t come soon enough. The market has already proven that Java-only isn’t good enough. First class status for other programming languages, and other programmers, is the way to go.


Microsoft Codename “Data Analytics” enables aggregating distributed numeric arrays with the Windows Azure HPC Scheduler and C# code, much like Hadoop Streaming’s -reduce aggregate option. You configure the HPC cluster locally, upload it to a hosted Azure service, and then submit a locally compiled C# executable as a job. A Visual Studio 2010 Microsoft Numerics Application template automates the process. For more information, see my Analyzing Air Carrier Arrival Delays with Microsoft Codename “Cloud Numerics” post updated 3/26/2012.
David Pallman announced the availability of Blob Drop: Sync Local Files to Windows Azure Blob Storage on 3/30/2012:
I'm pleased to announce a new community donation, Blob Drop. Blob Drop is a Windows Service that monitors a file folder and pushes file changes up to a blob container in Windows Azure Storage. Currently, this sync is only in one direction, up to the cloud.
Here's how Blob Drop works:
- Configuration: the folder to watch, blob storage account to use, and blob container are specified in the config file for the service.
- Initial Sync: upon initializing, blob drop will scan the folder it is configured to watch and see if any files in it are missing in the blob container - if there are, it queues upload tasks for itself.
- Ongoing Sync: Blob Drop watches for file events on the drop folder (file creates, updates, renames, deletes) and queues corresponding upload or delete tasks for itself.
- A pool of background worker threads handle queued tasks, such as uploading a file or deleting a blob.
Blob Drop Service
Blob Drop Command
There is also a console command edition of Blob Drop. It can do what the service does, with the added benefit that you can see activity on the console (see below). You can also run the console command with an option to just do an initial sync and exit. With the command line edition, you can use config-based parameters or specify them on the command line.BlobDrop -r
BlobDrop -r <folder> <storageAccountName> <storageAccountKey>BlobDrop -r runs the service as a console app, with visible display of activity. If parameters are specified on the command line, they are used in place of configuration settings.
As files are added, changed, or deleted from the drop folder, file events are detected and blob actions are triggered.
If BlobDrop encounters file system errors, blob storage errors, or file-in-use errors, it will dutifully retry the operation a number of times before giving up.
BlobDrop -s
BlobDrop -s <folder> <storageAccountName> <storageAccountKey>BlobDrop -s runs an initial sync and then exits.
BlobDrop -h
BlobDrop -h or -? displays help.
You can verify your files have made it into blob storage using an explorer tool such as Cloud Storage Studio or Azure Storage Explorer.
This is the initial drop of Blob Drop. As Blob Drop is new and has not yet been heavily tested, please treat this as prototype code and protect your data.
Blob Drop is another community donation from Neudesic. For support or inquiries, contact me through this blog.






Avkash Chauhan (@avkashchauhan) explained How to chain multiple MapReduce jobs in Hadoop in a 3/29/2012 post:
When running MapReduce jobs it is possible to have several MapReduce steps with overall job scenarios means the last reduce output will be used as input for the next map job.
Map1 -> Reduce1 -> Map2 -> Reduce2 -> Map3...
While searching for an answer to my MapReduce job, I stumbled upon several cool new ways to achieve my objective. Here are some of the ways:
Using Map/Reduce JobClient.runJob() Library to chain jobs: http://developer.yahoo.com/hadoop/tutorial/module4.html#chaining
Method 1:
- First create the JobConf object "job1" for the first job and set all the parameters with "input" as inputdirectory and "temp" as output directory. Execute this job: JobClient.run(job1).
- Immediately below it, create the JobConf object "job2" for the second job and set all the parameters with "temp" as inputdirectory and "output" as output directory. Finally execute second job: JobClient.run(job2).
Method 2:
- Create two JobConf objects and set all the parameters in them just like (1) except that you don't use JobClient.run.
- Then create two Job objects with jobconfs as parameters: Job job1=new Job(jobconf1); Job job2=new Job(jobconf2);
- Using the jobControl object, you specify the job dependencies and then run the jobs: JobControl jbcntrl=new JobControl("jbcntrl"); jbcntrl.addJob(job1); jbcntrl.addJob(job2); job2.addDependingJob(job1); jbcntrl.run();
Using Oozie which is Hadoop Workflow Service described as below: https://issues.apache.org/jira/secure/attachment/12400686/hws-v1_0_2009FEB22.pdf
3.1.5 Fork and Join Control Nodes
A fork node splits one path of execution into multiple concurrent paths of execution. A join node waits until every concurrent execution path of a previous fork node arrives to it. fork and join nodes must be used in pairs. The join node assumes concurrent execution paths are children of the same fork node.
The name attribute in the fork node is the name of the workflow fork node. The to attribute in the transition elements in the fork node indicate the name of the workflow node that will be part of the concurrent execution. The name attribute in the join node is the name of the workflow join node. The to attribute in the transition element in the join node indicates the name of the workflow node that will executed after all 3.1.5 Fork and Join Control Nodes 5concurrent execution paths of the corresponding fork arrive to the join node.
Example:
<hadoop−workflow name="sample−wf"> ... <fork name="forking"> <transition to="firstparalleljob"/> <transition to="secondparalleljob"/> </fork> <hadoop name="firstparalleljob"> <job−xml>job1.xml</job−xml> <transition name="OK" to="joining"/> <transition name="ERROR" to="fail"/> </hadoop> <hadoop name="secondparalleljob"> <job−xml>job2.xml</job−xml> <transition name="OK" to="joining"/> <transition name="ERROR" to="fail"/> </hadoop> <join name="joining"> <transition to="nextaction"/> </join> ... </hadoop−workflow>Using Cascading Library (GPL):
Cascading is a Data Processing API, Process Planner, and Process Scheduler used for defining and executing complex, scale-free, and fault tolerant data processing workflows on an Apache Hadoop cluster. All without having to 'think' in MapReduce.
Using Apache Mahout Recommender Job Sample:
Apache Mahout project has a sample call RecommenderJob.java which chains together multiple MapReduce jobs. You can find the sample here:
Using a simple java library name “Hadoop-orchestration” at GitHub:
This library, enables execution of multiple Hadoop jobs as a workflow. The job configuration and workflow defining inter job dependency is configured in a JSON file. Everything is externally configurable and does not require any change in existing map reduce implementation to be part of a workflow. Details can be found here. Source code and jar is available in github.
http://pkghosh.wordpress.com/2011/05/22/hadoop-orchestration/

<Return to section navigation list>
SQL Azure Database, Federations and Reporting
•• Jamie Thomson (@jamiet) posted AdventureWorks2012 now available for all on SQL Azure to his SSIS Junkie blog on 3/27/2012:
Three days ago I tweeted this:
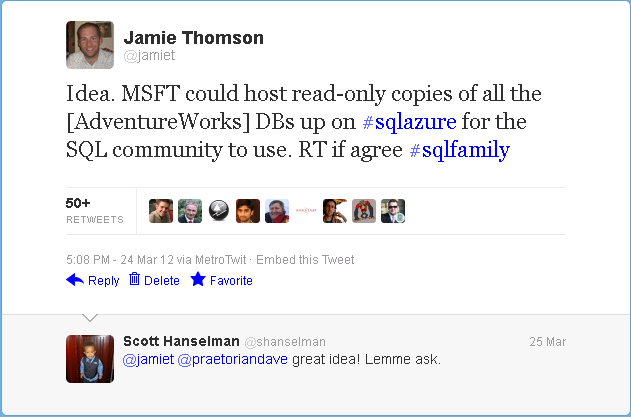
Idea. MSFT could host read-only copies of all the [AdventureWorks] DBs up on #sqlazure for the SQL community to use. RT if agree #sqlfamily
— Jamie Thomson (@jamiet) March 24, 2012
Evidently I wasn't the only one that thought this was a good idea because as you can see from the screenshot that tweet has, so far, been retweeted more than fifty times. Clearly there is a desire to see the AdventureWorks databases made available for the community to noodle around on so I am pleased to announce that as of today you can do just that - [AdventureWorks2012] now resides on SQL Azure and is available for anyone, absolutely anyone, to connect to and use* for their own means.
*By use I mean "issue some SELECT statements". You don't have permission to issue INSERTs, UPDATEs, DELETEs or EXECUTEs I'm afraid - if you want to do that then you can get the bits and host it yourself.
This database is free for you to use but SQL Azure is of course not free so before I give you the credentials please lend me your
earseyes for a short while longer. AdventureWorks on Azure is being provided for the SQL Server community to use and so I am hoping that that same community will rally around to support this effort by making a voluntary donation to support the upkeep which, going on current pricing, is going to be $119.88 per year. If you would like to contribute to keep AdventureWorks on Azure up and running for that full year please donate via PayPal to adventureworksazure@hotmail.co.uk. …

Read more: Jamie continues with details for PayPal donations to keep the database up, as well as log on name and password. I think it’s a great idea and Microsoft should support it with a free subscription.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
••• Tony Petrina (@to_pe) described Consuming OData for TFS using C# from Windows Phone 7 application in a 3/25/2012 post (missed when published):
This entry is part of a series, OData Service for TFS» Entries in this series:
- Installing and configuring OData Service for TFS 11
- Consuming OData for TFS using C#
- Consuming OData for TFS using C# from Windows Phone 7 application
*UPDATED 26.3.2012 Added code for OData Service Authorization and Fixed ExecuteAsync wrapper*
In the earlier post we saw how to consume the OData service from console application. The same code applies for any desktop application, whether it is Windows Forms or WPF application. Since there is no support for developing WP7 applications in the Visual Studio 11 Beta, the code is written in the Visual Studio 2010 Express for Windows Phone.
Add the reference to the OData service using the instructions from the last post.
Authorization
Authorization is slightly different here, here is a complete code:
// context is a valid instance of the TFSData class context.SendingRequest += (s, e) => { var credentials = string.Format(@"{0}\{1}:{2}", "DOMAIN", "USERNAME", "PASSWORD"); e.RequestHeaders["Authorization"] = string.Format(CultureInfo.InvariantCulture, "Basic {0}", Convert.ToBase64String(System.Text.Encoding.UTF8.GetBytes(credentials))); };Resource access problem
Even though you could use the same code for accessing the service’s resources on the desktop regardless of the application type, some parts of the code cannot be used on the Windows Phone 7.
For example, the following code will not work out of the box:
class TFSServiceHelper { public IEnumerable<string> GetProjectNames() { // TFSService is a valid instance of the TFSData class return this.TFSService.Projects.Select(item => item.Name); } } // somewhere else, helper is an instance of the TFSServiceHelper class foreach (var projectName in helper.GetProjectNames) _projects.Add(projectName);

You will get a
NotSupportedExceptionwith the following details:Silverlight does not enable you to directly enumerate over a data service query. This is because enumeration automatically sends a synchronous request to the data service. Because Silverlight only supports asynchronous operations, you must instead call the
BeginExecuteandEndExecutemethods to obtain a query result that supports enumeration.Asynchronous version
Since it is expected of WP7 apps to never block the UI, you are forced to write the same code asynchronously using the
BeginExecute/EndExecutemethods. While this is not such a hard task, it is cumbersome to write all that boilerplate code for something that is essentially a one liner. Correct version of the above code is:// async version of GetProjectNamespublic IAsyncResult GetProjectNamesAsync(Action<IEnumerable<string>> callback){ return this.TFSService.Projects.BeginExecute((ar) => { var results = this.TFSService.Projects.EndExecute(ar); Deployment.Current.Dispatcher.BeginInvoke(() => callback(results.Select(item => item.Name))); }, null);} // usagehelper.GetProjectNamesAsync((names) =>{ foreach (var projectName in names) _projects.Add(projectName); });Our very simple application as it appears in the emulator:
Using C# 5 style asynchrony
The above code is correct, but it breaks the code flow. We want both the power and necessity of the asynchronous version while at the same time the elegance of the synchronous version. In the previous post we saw how to use the new feature in the VS11 for streamlined asynchronous syntax. However, we cannot do the same in WP7 since Visual Studio 2010 Express for Windows Phone does not use the same C# compiler the VS11 is using.
Luckily, the solution is simple: download and install Visual Studio Async CTP (Version 3) and you will be able to use
async/awaitin the WP7 applications. Simply add the reference to the AsyncCtpLibrary_Phone assembly (you can find it in the \Documents\Microsoft Visual Studio Async CTP\Samples folder) and write code using it.Asynchronous version of the
GetProjectNamesfunction:public async Task<IEnumerable<string>> GetProjectNamesTaskAsync() { return (await this.TFSService.Projects.ExecuteAsync(null)).Select(item => item.Name); }

You can use the above function by adding minimum amount of code to the first, and erroneous, sample at the beginning of this post:
foreach (var projectName in await helper.GetProjectNamesTaskAsync()) _projects.Add(projectName)However, this will not immediately compile, we must add the same extension method from the previous post.Conclusion
That is it, you can now write your OData client for Windows Phone 7. If you are lucky and you can use Async CTP, the code will be pleasant to write while the UI will remain fluent and responsive.
In the next post we will see how to create and update resources using OData Service for TFS.
<Return to section navigation list>
Windows Azure Service Bus, Access Control, Identity and Workflow
•• Abishek Lal described Formatting the content for Service Bus messages in a 3/30/2012 post:
A message broker has to deal with scenarios where clients are using different protocol and client library versions to send and receive messages. In addition different platforms and protocols have varying support for serialization. For Windows Azure Service Bus, following are some examples of using different methods to create messages to send to Topics and Queues, and the corresponding approaches that can be used to receive the messages from Queues and Subscriptions.
Stream bodyStream = receiveMessage.GetBody<Stream>();
The following examples apply when using the .NET API to send and receive messages.
Example 1: Using string
When creating a BrokeredMessage with a string and the default (DataContract + Binary) serializer:
BrokeredMessage stringDefaultMessage = new BrokeredMessage("default string");
You can receive this message as:
string s = receiveMessage.GetBody<string>();
Example 2: Using Text instead of Binary XML in DataContractSerializer
When creating a BrokeredMessage with a string and a DataContractSerializer and use Text instead of Binary Xml:
BrokeredMessage stringDataContractMessage = new BrokeredMessage("DataContract string", new DataContractSerializer(typeof(string)));
You can receive this message as:
string s = receiveMessage.GetBody<string>(new DataContractSerializer(typeof(string)))
Example 3: Using raw UTF8 string
When creating a BrokeredMessage with just a raw UTF 8 string:
string utf8String = "raw UTF8 string";
BrokeredMessage utf8StringMessage = new BrokeredMessage(new MemoryStream(Encoding.UTF8.GetBytes(utf8String)), true);
You can receive this message as:
string s = new StreamReader(receiveMessage.GetBody<Stream>(), Encoding.UTF8).ReadToEnd();
Example 4: Using raw UTF16
When creating a BrokeredMessage with just a raw UTF16 (“Unicode”) string:
string utf16String = "raw UTF16 string";
BrokeredMessage utf16StringMessage = new BrokeredMessage(new MemoryStream(Encoding.Unicode.GetBytes(utf16String)), true);
You can receive this message as:
string s = new StreamReader(receiveMessage.GetBody<Stream>(), Encoding.Unicode).ReadToEnd();
Example 5: Using a custom DataContract
When creating a BrokeredMessage using custom DataContract type and using default serializer (DataContract + Binary Xml):
[DataContract(Namespace = "")] class Record { [DataMember] public string Id { get; set; } } [...] Record recordDefault = new Record { Id = "default Record" }; BrokeredMessage recordDefaultMessage = new BrokeredMessage(recordDefault);You can receive this message as:
Record r = receiveMessage.GetBody<Record>();
Example 6: Using custom DataContract and Text
When creating a BrokeredMessage using custom DataContract type and using DataContractSerializer (will use Text Xml instead of Binary):
Record recordDataContract = new Record { Id = "DataContract Record" };
BrokeredMessage recordDataContractMessage = new BrokeredMessage(recordDataContract, new DataContractSerializer(typeof(Record)));
You can receive this message as:
Record r = receiveMessage.GetBody<Record>(new DataContractSerializer(typeof(Record)));

•• Gavin Casimir explained A very simple Windows Azure AppFabric Cache Class in a 3/27/2012 post:
I have an application on Windows Azure which has both a worker and a Web role. I needed a way to send basic throw away info to the Web role from the worker role, so I decided to use Windows Azure cache. I created this very simple class which allows you to initialize a connection to the cache and use it for basic adding and reading of data.
[SDK Install Path]\V1.5\Assemblies\NET4.0\Cache\Microsoft.ApplicationServer.Caching.Client.dllSetup your azure cache instance then insert your access key and azure cache url in the code below:using System; using System.Collections.Generic; using Microsoft.ApplicationServer.Caching; using System.Security; namespace Yoursite.Azure.Wrappers { public static class CacheStore { private static DataCache _cache; static CacheStore() { // Declare array for cache host. DataCacheServerEndpoint[] servers = new DataCacheServerEndpoint[1]; servers[0] = new DataCacheServerEndpoint("[YOUR-NAME-SPACE].cache.windows.net", 22243); // Setup DataCacheSecurity configuration. string strACSKey = "[INSERT KEY HERE]"; var secureACSKey = new SecureString(); foreach (char a in strACSKey) { secureACSKey.AppendChar(a); } secureACSKey.MakeReadOnly(); DataCacheSecurity factorySecurity = new DataCacheSecurity(secureACSKey,true); // Setup the DataCacheFactory configuration. DataCacheFactoryConfiguration factoryConfig = new DataCacheFactoryConfiguration(); factoryConfig.Servers = servers; factoryConfig.SecurityProperties = factorySecurity; // Create a configured DataCacheFactory object. DataCacheFactory cacheFactory = new DataCacheFactory(factoryConfig); // Get a cache client for the default cache. _cache = cacheFactory.GetDefaultCache(); } public static void SetValue(string key,object value) { _cache[key] = value; } public static T GetValue<T>(string key) { return (T)_cache[key]; } } }Usage:
var saveme = 856; //Store value CacheStore.SaveValue("savemekey",saveme); //Retrieve value var readme = CacheStore.GetValue<int>("savemekey");Enjoy! Don’t forget to catch exceptions. My error logs show exceptions while attempting to communicate with the azure caching server every now and then.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
••• My (@rogerjenn) Back Up and Restore Windows 8 Server Beta Files to/from Windows Azure Storage with Microsoft Online Backup post of 4/1/2012 begins:
Overview and Signup Details from TechNet
Guarav Gupta announced availability of the Microsoft Online Backup Service in a 3/28/2012 post to TechNet’s Windows Server blog:
Getting started
Getting started with Microsoft Online Backup service on Windows Server “8” Beta is a simple two-step process:
- Get a free beta Online Backup Service account (with 10 GB of cloud storage). In order to request access, please sign up to get an invitation to the service at http://connect.microsoft.com/onlinebackup. Please note that there are a limited number of customers that we can support during the beta and we will grow our capacity over time. We have available slots right now so if you are willing to give us feedback, sign up now to try this great new service.
- Download and install the Microsoft Online Backup Agent. The agent installer download is located on the Microsoft Connect Site indicated above.
Key features
Below are some of the key features we’re delivering in Windows Server “8” using Microsoft Online Backup service:
Simple configuration and management. Microsoft Online Backup Service integrates with the familiar Windows Server Backup utility in order to provide a seamless backup and recovery experience to a local disk, or to the cloud.
- Simple user interface to configure and monitor the backups.
- Integrated recovery experience to transparently recover files and folders from local disk or from cloud.
- Easily recover any data that was backed up onto any server of your choice.
- Windows PowerShell command-line interface scripting capability.
Figure 1: Microsoft Online Backup User Interface
- Block level incremental backups. The Microsoft Online Backup Agent performs incremental backups by tracking file and block level changes and only transferring the changed blocks, hence reducing the storage and bandwidth utilization. Different point-in-time versions of the backups use storage efficiently by only storing the changes blocks between these versions.
- Data compression, encryption and throttling. The Microsoft Online Backup Agent ensures that data is compressed and encrypted on the server before being sent to the Microsoft Online Backup Service over the network. As a result, the Microsoft Online Backup Service only stores encrypted data in the cloud storage. The encryption passphrase is not available to the Microsoft Online Backup Service, and as a result the data is never decrypted in the service. Also, users can setup throttling and configure how the Microsoft Online Backup service utilizes the network bandwidth when backing up or restoring information.
- Data integrity is verified in the cloud. In addition to the secure backups, the backed up data is also automatically checked for integrity once the backup is done. As a result, any corruptions which may arise due to data transfer can be easily identified and they are fixed in next backup automatically.
- Configurable retention policies for storing data in the cloud. The Microsoft Online Backup Service accepts and implements retention policies to recycle backups that exceed the desired retention range, thereby meeting business policies and managing backup costs.
The Microsoft Online Backup Service only supports the Windows Server “8” operating system. It does not support Windows 8 Consumer Preview client operating systems or any Windows operating systems released prior to Windows Server “8”. …


Continues with illustrated “Overview and Signup Details from TechNet, Installing the Online Backup Agent and Registering Your Server”, “Scheduling Backups and and Running Them Now” and “Restoring Files from Backups” sections, and ends with:
Conclusion
Microsoft Online Backup appears to be a well thought-out, feature-complete offering that takes advantage of Windows Azure’s high-availability blog storage with a master and two replica copies, as well as georeplication to data centers at least 100 miles apart within the same region.
There’s no indication so far of pricing for the service. If standard Windows Azure storage prices were to apply:
- Backup upload bandwidth and storage transactions would be free
- Data storage would be US$0.125 per GB per month
- Restore transaction charges would be $0.01 per 10,000 transactions
- Restore download bandwidth charges would be US$0.12 per GB in North American and European regions; US$0.19/GB in the Asia Pacific region
It’s not immediately clear what would constitute a storage transaction; probably a single file.
OnlineBackupDeals.com provides a handy Online Backup [Price] Comparison page, which shows considerable variation in pricing, but a popular price point for personal backup appears to be US$5.00/month for 100 GB.
Following are links to pricing examples for popular online backup services:
- Carbonite charges $5.00 per month ($59.00 per year) for unlimited personal storage.
- Jungle Disk charges $4.00 per month plus US$0.15/GB for storage > 10 GB for their Workgroup edition; the Server Edition is $5.00 per month.
- Mozy charges $6.95 per month for a server or $3.95 per month for a desktop license and $0.50/GB per month for storage.
The preceding services don’t have published bandwidth charges and don’t indicate whether they support block-level incremental backup or data encryption/compression features.
After Microsoft finalizes their pricing, I’ll post a comparison with other online backup vendors.
••• Mike Benkovich (@mbenko) posted Cloud Tip #4-How to migrate an existing ASP.NET App to the Cloud on 4/1/2012:
Suppose you have an existing application that you want to migrate to the cloud. There are many things to look at, from the data to the architecture to considering how you plan to scale beyond one instance. For simple web sites which don’t use a lot of data or stateful information the migration to the cloud can be pretty easy with the installation of the Visual Studio Tools for Windows Azure.
The current release of the tools (as of March 2012) is v1.6 which adds a command to the context menu when you right click on a web project. The SDK is installed using the Web Platform Installer (aka WebPI) which checks for previous versions of the tools and any other prerequisites and the consolidates the install into a single step.
After installing the tools when you open a Web Project, whether ASP.NET Web Forms, MVC, or similar, right clicking the project file gives you the command to add an Azure Deployment Project. You could achieve something similar by simply adding a Cloud Project to your solution and then right clicking on the “Roles” folder and adding the existing site to the project.
This adds a Cloud project to the solution and then adds the current Web project as a standard Web Role in the deployment. The key assets added include a Service Definition file and a couple Service Configuration files (one for running locally and one for running in the cloud).
The Service Definition file includes markup which describes how the Cloud Service will be deployed, including the public ports that are enrolled in the load balancer, any startup tasks and plugins that you want to run, as well as any other custom configuration that should be part of the deployment.
For example the Service Definition we created for the Kick Start event in Minneapolis looked like this:
<?xml version="1.0" encoding="utf-8"?> <ServiceDefinition name="MplsKickSite.Azure" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceDefinition"> <WebRole name="MplsKickSite" vmsize="Small"> <Sites> <Site name="Web"> <Bindings> <Binding name="Endpoint1" endpointName="Endpoint1" /> </Bindings> </Site> </Sites> <Endpoints> <InputEndpoint name="Endpoint1" protocol="http" port="80" /> </Endpoints> <Imports> <Import moduleName="Diagnostics" /> </Imports> </WebRole> </ServiceDefinition>
<?xml version="1.0" encoding="utf-8"?> <ServiceConfiguration serviceName="MplsKickSite.Azure" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration"
osFamily="2" osVersion="*"> <Role name="MplsKickSite"> <Instances count="3" /> <ConfigurationSettings> <Setting name="Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString" value="UseDevelopmentStorage=true" /> <Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.Enabled" value="true" /> <Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.AccountUsername" value="... <Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.AccountEncryptedPassword" value="...
<Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.AccountExpiration" value="... <Setting name="Microsoft.WindowsAzure.Plugins.RemoteForwarder.Enabled" value="true" /> <Setting name="QueueName" value="createthumbnail" /> <Setting name="myStorageAcct" value="UseDevelopmentStorage=true" /> </ConfigurationSettings> <Certificates> <Certificate name="Microsoft.WindowsAzure.Plugins.RemoteAccess.PasswordEncryption" thumbprint="... </Certificates> </Role> </ServiceConfiguration>Pressing F5 will run the Cloud Service in the local emulator (assuming we’re running Visual Studio as Administrator so it can communication cross process to the running services…an error message tells you if you’re not). The nice thing about this approach is it supports attaching to the local debugger and using the rich set of features such as breakpoints, local and watch variables, and all the rest of the goodness we’ve come to expect in Visual Studio debugging.
Once we’re satisfied that the application works and we are ready to go to the Cloud, you can right click on the Azure Deployment project and either click “Package” to create a deployment package which you can manually upload the the Windows Azure Management portal, or you can select Publish to automate it directly from Visual Studio. This runs a wizard with 3 basic steps to collect the necessary information and complete the deployment. You select the subscription you want to use, name the hosted service, optionally enable remote desktop and web deploy, and then click complete.


Note that if you enable Web Deploy, because this is only supported for a single instance development environment where you require the ability to publish changes to a web site quickly, the publishing process will change your configured number of instances to 1 despite having set it to 3 in the configuration files. That’s because if you have more than 1 instance deployed the load balancer will distribute the incoming web requests round robin, and if you change one of the instances with a web deploy you’ll have an inconsistent state. You can always change the number of instances from the management portal, but you should be aware of what you’re doing.
What happens next is the deployment process takes place. This includes validating that the hosted service is provisioned for you, uploading certificates if needed, then uploading your deployment package and configuration files to Windows Azure storage, and then deploying and starting your instances. It will also add the service deployment to the Server Explorer window (CTRL + ALT + S). From there you can see the status of your service instances, download the profile or intellitrace files if you’ve enabled that option (under advanced features during the publish).
For more information on how to do this, or if you’d like to see a webcast on how this is done, check out the first webcast in the Cloud Computing Soup to Nuts series (http://bit.ly/s2nCloud).









Wade Wegner (@WadeWegner) posted what is probably his Cloud Cover swansong as Episode 74 - Autoscaling and Endpoint Protection in Windows Azure on 3/30/3012:
Join Wade and David each week as they cover Windows Azure. You can follow and interact with the show at @CloudCoverShow.
In the news:
- The Differences Between Development on Windows Azure and Windows Server
- The Beauty of Moving SQL Azure Servers between Subscriptions
- Programmatically finding Deployment Slot from code running in Windows Azure
In the Tip of the Week, Wade demonstrates how to use the Microsoft Endpoint Protection support in Windows Azure and shows it in action.
Wade announced a few days ago that he’s leaving Microsoft for a new gig in the Windows Azure arena.
Larry Franks (@larry_franks) listed Azure-related links in his Pie in the Sky (March 30, 2012) post to the Silver Lining blog:
Sorry for the lack of posts recently; both Brian and I are heads down on work for future updates to the Windows Azure platform. Here's a few links for your Friday reading:
- Developing for Windows Azure in WordPress: This is a good mix of guidance and resources for developing and deploying WordPress on Windows Azure (via Ben Lobaugh.
- Real World Azure: Migrating a Drupal Site from LAMP to Windows Azure: A behind-the-scenes look at what it took to move the SAG Awards Drupal website from a LAMP stack to Windows Azure.
- ASP.NET MVC, Web API, Razor and Open Source: Scott Guthrie blogs about open sourcing MVC, Web API, and Razor.
- The future of CodePlex is bright: Codeplex now supports Git.
- Node.js on Azure calling SAP Gateway: Walks through the process of creating a Node.js application in Cloud9IDE that talks to SAP.
- Azure User Management Console: This project provides a GUI for managing users and logins in your SQL Azure database.

Greg Oliver (@GoLiveMSFT, pictured below) reported Go Live Partners Series: Wealth Habit, Inc. chose Windows Azure in a 3/29/2012 post to the Go Live blog:
Angel-funded startup and Bizspark member Wealth Habit (https://wealthhabit.com/) is a Cloud Services company located in Portland, Oregon. Led by CEO James Werner, and CTO Brian Gambs, Wealth Habit provides enterprise-level B2B financial services. It adds value by reducing or removing financial stress on employees by providing up to the minute feedback on purchasing and savings decisions - either via a web browser or on the user's mobile phone. Based on the latest research in behavioral economics, their products help to reduce employee financial distress by clearly framing the spending and savings decisions of users.
Wealth Habit chose Windows Azure as their deployment platform because the costs are very low and the platform adds value over and above simply providing compute and storage capabilities.
For example, their SQL Azure database just runs, without any intervention on their part due to the massively scaled infrastructure of the Windows Azure cloud. While periodic backups are always recommended, failures due to hardware fault are all but unheard of due to replication-in-triplicate built in at a very low level to the Azure storage services.
Wealth Habit is a great example of the benefits that can accrue to folks that embrace the cloud.

The VAR Guy (@thevarguy) posted Microsoft Online Backup Service for Windows 8: New Details on 3/28/2012:
Microsoft (MSFT) is developing a cloud-based backup service for Windows Server 8. New details about the Microsoft Online Backup Service surfaced on the Microsoft Windows Server blog earlier today. On the one hand, the Microsoft cloud service could potentially compete with established online backup companies. But on the other hand, Microsoft is opening up the Online Backup Service to partners. Here’s some timely perspective from The VAR Guy.
Microsoft is offering Windows Server 8 testers a free beta of the Online Backup Service with up to 10 GB of storage. But Microsoft offers this caveat:
Please note that there are a limited number of customers that we can support during the beta and we will grow our capacity over time. We have available slots right now so if you are willing to give us feedback, sign up now to try this great new service.
Approved testers can download and install the Microsoft Online Backup Agent and get started.
- How much will the Microsoft Online Backup Service actually cost?
- Will the Microsoft Online Backup Service ever address non-Windows servers?
- What type of fees, if any, can partners earn for reselling the Microsoft Online Backup Service?
- How fast can the Microsoft Online Backup Service restore customer data?
- The Microsoft Online Backup Service is based on Windows Azure, which suffered a major leap year cloud outage.
Those are Big Questions. And so far: There are not clear answers. For most VARs, that means the logical choice is to continue using established cloud-based backup services that offer cross-platform support and clear SLA (service level agreement) terms.
Still, Microsoft offered this intriguing side note: The Microsoft Online Backup Service has an API that allows partners to offer their own backup solution.
Hmmm… That’s fascinating…
Read More About This Topic

Accepted a 10-foot EULA, signed up for the beta, and received my Windows Online Services ID. Stay tuned for more details.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Beth Massi (@bethmassi) posted Tips on Upgrading Your LightSwitch Applications to Visual Studio 11 Beta (Beth Massi) on 3/30/2012:
We’ve seen some questions in the forum about upgrading your current Visual Studio LightSwitch applications (LightSwitch V1) to Visual Studio 11 Beta (LightSwitch V2) so I thought I’d post some quick tips here on how to make the upgrade process a smooth as possible.
After you install Visual Studio 11 Beta:
1. Install any extensions you are using in your V1 project onto the machine where you installed Visual Studio 11 Beta
Extensions need to be installed first into VS11 before you upgrade because of the way .VSIX packages work – they are installed per instance of Visual Studio. Many extensions will install and work in both versions, however some do not at this time. Depending on the vendor, you will have to contact them if they are supporting VS 11 Beta yet.
These LightSwitch team extensions were tested and we released updates if necessary.
- LightSwitch Metro Theme Extension Sample (Updated for VS 11)
- Filter Control for LightSwitch (Updated for VS 11)
- Excel Importer (VSIX located in binaries folder works with VS 11)
- Many to Many Control (VSIX located in binaries folder works in VS 11)
I also personally tested the Office Integration Pack and that works correctly as well. If you are looking for an upgrade of the Bing Map Control that was included in the original Training Kit, an update is included in this sample: Contoso Construction - LightSwitch Advanced Sample (Visual Studio 11 Beta)
I also encourage you to check out the new LightSwitch Cosmopolitan Shell and Theme for Visual Studio 11. This extension is only supported in VS11 projects.
2. Disable any Extensions that are not supported in Visual Studio 11 Beta
If you have an extension that will not install in VS 11 then you will need to open the V1 project in VS 2010 and disable the extension first. From the Project Properties, select the Extensions tab and uncheck the extension in the list.
3. Open your project in Visual Studio 11 Beta to start the conversion process
Now you are ready to open your project in Visual Studio 11 Beta. The conversion process will make a backup of your original source and then start the conversion.
4. Re-enable your extensions and build your project
Once the conversion is done you should see your project in the Solution Explorer. (If you don’t, try closing VS and restarting). Now you can go to the Project Properties –> Extension tab, and re-enable your extensions by checking them off in the list. Finally build your project and make sure there are no errors.
Note: If you have Visual Studio 11 Beta installed on the same machine as Visual Studio 2010 then you do not need to go through this process of re-installing extensions. The upgrade process will tell you if any extensions are not compatible.
Wrap Up
Hopefully this will help you avoid any upgrade pain. However, we’re still investigating upgrade issues so if you have any problems please report them in the forum. There are a lot of team members there to help: LightSwitch in Visual Studio 11 Beta Forum


Return to section navigation list>
Windows Azure Infrastructure and DevOps
• Jonathan Rozenblit (@jrozenblit) described Tossed Salad Served With an Azure Dressing in a 3/30/2012 post to MSDN’s Canadian Developer Connection blog:
Earlier this week, I blogged about taking your Cloud like you do your coffee – half and half. Might as well continue the food theme with this post.
Think of the kinds of solutions you put together these days. It is unlikely that your solution is a homogenous solution, as in all of its different components written using one language or one technology – say .NET – like a Caesar salad. More likely, especially in more complex solutions, different components are written in the language/technology that best suites the type of work being performed by the component. For example, you might have an ASP.NET front end calling a Java-based web service that reads from a MySQL-based database. A tossed technology salad.
You might think to yourself that a solution like that is destined to stay on-premises for it's entire lifecycle. Moving it to the Cloud would be too complicated and may involve using multiple Cloud platforms or a Cloud platform that does IaaS (infrastructure-as-a-service), allowing you to deploy different machines that will handle each of the different technologies. If that’s what you’d be thinking, the good news is that you’d be wrong!
Allow me to add some Windows Azure dressing to your tossed technology salad.
In his blog post Openness Update for Windows Azure, Gianugo Rabellino, Senior Director, Open Source Communities at Microsoft, said:
We understand that there are many different technologies that developers may want to use to build applications in the cloud. Developers want to use the tools that best fit their experience, skills, and application requirements, and our goal is to enable that choice.
How So
One of the main design principles behind Windows Azure is to be open and interoperable – to give you, the developer, the choice of languages, runtimes, frameworks, and other technologies. But it’s one thing to say open and interoperable and have the platform be a hack job just to say that the platform supports non-.NET technologies, it’s completely something else to say open and interoperable and have actual support for the other technologies. Here’s how the principle manifests itself:
Languages
- .NET – this one is obvious, given that it is a Microsoft platform. You can write .NET based applications and have the .NET runtime run applications and have IIS run websites. Feature-rich tools for Visual Studio support your building, testing, and deploying efforts.
- Node.js – If you’re not familiar with Node.js, it is a “platform built on Chrome's JavaScript runtime for easily building fast, scalable network applications. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient, perfect for data-intensive real-time applications that run across distributed devices.” according to the node.js project home page. You can write Node.js applications and have IIS, with an automatically installed IISNode native module installed, run your Node.js applications. Check out Larry Franks’ post on Node.js learning resources.
- Java – Java developers writing applications that use Windows Azure get extra love! Not only is there support for Java on Windows Azure (via the Windows Azure SDK for Java), there’s also a Windows Azure Plugin for Eclipse that provides templates and functionality that allows you to easily create, develop, test, and deploy Windows Azure applications using the Eclipse development environment. Buck Woody has put together a list of Java on Windows Azure resources.
- PHP – Write PHP applications in your editor of choice using the community-supported Windows Azure SDK for PHP. This will give you access into the pre-created objects for the runtime, storage services, etc. Once done, you can use the tools in the SDK to take care of packaging your application and readying it for deployment. Interoperability Bridges has an entire section dedicated to Windows Azure for PHP.
- Ruby and Python – though there is no specific SDK for these two, they do in fact work with Windows Azure. Larry Franks details how.
Technologies
- SQL Azure – For those that use SQL Server today, SQL Azure is the Cloud equivalent. Take your existing SQL Server database, script it, and then execute it against SQL Azure to get it going in the Cloud. Granted there are some limitations to SQL Azure (over SQL Server), but those will go away in time, I’m sure.
- Apache Hadoop – Access Hadoop’s JavaScript libraries to enable powerful insights on data through an ODBC driver and/or Excel plugin.
- MongoDB – For developers who prefer a NoSQL alternative to SQL Azure, MongoDB is a scalable, high performance, open source NoSQL database and is supported on Windows Azure.
- Memcached – The popular open-source caching server that can be used to improve the performance of dynamic web applications.
- Solr – the popular, blazing fast open source enterprise search platform from the Apache Lucene project. There’s a set of code tools and configuration guidelines to get the most out of Solr running on Windows Azure.
That’s Definitely Tossed
When you combine many different ingredients together, a whole universe of taste is possible. Similarly, when you throw many different technology capabilities together, there’s no limit to the types of solutions you can have running in the Cloud, including one’s you would’ve never thought possible. The Windows Azure dressing makes it possible.
So next time you’re looking at a menu and decide that you’re not going to have a salad because you can’t mix and match the ingredients to your liking, at least you’ll know that it is possible when you order the tossed technology salad with Azure dressing.
Bon appetite.
Original picture by Anushruti RK

•• Microsoft Operator Channels posted a 25-page Drivers & Inhibitors to Cloud Adoption for Small and Midsize Business research report (PDF) that was the subject of Bob Kazarian’s breakout presentation of 3/29/2012 to the Microsoft Hosting Summit 2012:

Source: Edge Strategies survey commissioned by Microsoft Corp., “SMB Business in the Cloud 2012,” Feb. 8, 2012
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
David Linthicum (@DavidLinthicum) asserted “Naysayers need to understand that private clouds have a place in the enterprise, so get over it” in a deck for his Private cloud-public cloud schism is a meaningless distraction article of 3/30/2012 for InfoWorld’s Cloud Computing blog:
I've heard it all about private clouds over the last few years. "Private clouds are not true clouds," say the public cloud computing purists. "Private clouds are the best way to move toward cloud computing," say those who typically sell older technology in need of a quick cloud rebranding to become relevant.
The focus needs to be on the architecture and the right-fitting enabling technology, including both private and public cloud technology, and not gratuitous opinions. There should be no limits on the technology solution patterns you can apply. If that means private, public, or a mix of both, that's fine as long as you do your requirements homework and can validate that you have chosen the right solution.
All -- and I mean all -- public cloud computing providers have some private cloud offering. No matter if it's a loosely coupled partnership with a private cloud provider or a private cloud computing version of its public cloud offering that it sells as -- gulp -- software. Many of these providers were dragged into the world of the private cloud kicking and screaming, but realized they needed to provide a solution that the market -- that is, their customers -- demands.
The downside is that those who put together cloud computing requirements and define cloud computing solutions in enterprises have a tendency to jump to private clouds when public clouds are a much better fit. This is the "I want to hug my server" aspect that keeps getting in the way of progress.
The hard truth is that private clouds are often too expensive and add complexity. They increase -- not reduce -- the amount of hardware and software you maintain, and they can become new information silos that make things more -- not less -- complex. In many instances, they reduce the value of cloud computing and raise the risks.
However, there are times when you need the advantage of cloud-based computing, such as auto-provisioning of resources, and you have a requirement to keep the processes and data in house. Private clouds work just fine for those requirements, as long as you focus on fit, function, and the value to the business, and not on some dumb argument that has gone on for too long.

<Return to section navigation list>
 Cloud Security and Governance
Cloud Security and Governance

No significant articles today.
<Return to section navigation list>
Cloud Computing Events
•• Mike Benkovich (@mbenko) posted Cloud Tip #3–Find good examples on 3/31/2012:
Yesterday in Minneapolis we delivered the first Windows Azure Kick Start event of the series we’re running this spring to help developers learn and understand how to use the new tools and techniques for building cloud based applications. As part of that event we wrote a lot of code as a demonstration of how this stuff comes together and I’ve uploaded it to www.benkotips.com in case you’re interested in the download. The solution includes several projects including:
- MplsKickSite - An existing ASP.NET web site that we migrated to Windows Azure, implementing the RoleEntryPoint interface and adding references to the Microsoft.WindowsAzure.StorageClient for working with storage, and Microsoft.WindowsAzure.ServiceRuntime to give us instance information. We also added cloud identity to the site using Access Control Services to secure a data entry page with data hosted in a SQL Azure database
- WPFUpload which is a Windows application which includes logic to support drag and drop to upload files into Windows Azure Blob Storage, and if they are images to add work to a queue to create thumbnail images
- UploadDataLib which is a class library that implements Windows Azure Table Storage logic for working with the images uploaded by WPFUpload and the ThumbMaker worker role projects.
- ThumbMaker which is a worker role class that demonstrated working with Tables and Queues and the System.Drawing library to create thumbnail images and brand them with a custom logo message
- PhoneApp1 which demonstrates how to use a Windows Phone Silverlight user control to handle the login conversation with ACS
- NugetPhone which is a second example of ACS in use with devices, except that instead of spending 10 minutes to write the code like we did with PhoneApp1 we use the Nuget package manager to include a package (Install-Package Phone.Identity.AccessControl.BasePage) to perform the authentication for us and make the 4 code changes to implement the logic…2 minutes to demo

Steve Plank (@plankytronixx) reported Event: Red Gate/Cerebrata Cloud Tools’ designer at UK Windows Azure User Group on Tuesday 3rd April in a 3/30/2012 post:
Anybody who has got involved in developing on Windows Azure will almost certainly have used at least one of the tools in the Red Gate/Cerebrata line-up. Cloud Storage Studio, Diagnostics Manager or Azure Management Cmdlets.
Gaurav Mantri, CEO of Cerebrata Software will be speaking to the UK Windows Azure Group about Cerebrata tools, how they are used and how they were built using underlying REST APIs provided by the Windows Azure Fabric. Gauriv is here for a short time from India so this is a rare opportunity to catch him speaking. Redgate will be at the meeting to offer some free product licenses to a few attendees.

Himanshu Singh (@himanshuks) posted Windows Azure Community News Roundup (Edition #12) on 3/30/2012:
Welcome to the latest edition of our weekly roundup of the latest community-driven news, content and conversations about cloud computing and Windows Azure. Let me know what you think about these posts via comments below, or on Twitter @WindowsAzure. Here are the highlights from last week.
- (Windows) #Azure Action Community Newsletter 28th March 2012 by @drmcghee (posted Mar. 28)
- Best Practices for Building Windows Azure Service by Qingsong Yao (posted Mar. 28)
- A Primer on Hadoop (from the Microsoft SQL Community Perspective) by @dennylee (posted Mar. 27)
- Developing for Windows Azure in WordPress by @benlobaugh (posted Mar. 26)
- Windows Azure Service Bus Resequencer by @alansmith (posted Mar. 23)
Upcoming Events, and User Group Meetings
- April 3: UK Windows Azure User Group – London, UK
- April 4: CloudCamp Vienna – Vienna, Austria
- April 4: Houston Cloud Tech Symposium – Houston, TX
- April 4: Windows Azure UK User Group – Manchester, UK
- April 26: Sales@night: (Windows) Azure - Brussels, Belgium
- April 28: Vancouver TechFest 2012 – Burnaby, BC, Canada
- May 11: Windows Azure Bootcamp – London, UK
- May 18: Windows Azure Bootcamp – Liverpool, UK
- Ongoing: Cloud Computing Soup to Nuts - Online
Recent Windows Azure Forums Discussion Threads
- Windows Azure REST API – 255 views, 6 replies
- Increasing role count takes site offline? – 707 views, 10 replies
- (SQL) Azure: problem with ‘Test Connectivity’ – 1,031 views, 9 replies
- Delete entities in (Windows) Azure Table Storage – 623 views, 6 replies
Send us articles that you’d like us to highlight, or content of your own that you’d like to share. And let us know about any local events, groups or activities that you think we should tell the rest of the Windows Azure community about. You can use the comments section below, or talk to us on Twitter @WindowsAzure.

<Return to section navigation list>
Other Cloud Computing Platforms and Services
Barb Darrow (@gigabarb) asserted Google: AppEngine is here to stay in a 3/30/2012 post to GigaOM’s Structure blog:
Software developers in search of a platform still wonder whether Google is serious about Google AppEngine. As in serious enough not to pull the plug on the platform as a service in six months, next year, or the year after.
Google’s problem is that many developers simply think GAE and other development tools are a sideline to Google’s advertising-fueled search engine and are thus expendable in the fluctuating line of services that Google launches, tests and either keeps or discards. That’s why Google, despite its formidable infrastructure, doesn’t get much respect from developers.
Greg D’Alesandre, AppEngine product manager, understands their angst, since he worked on Google Wave, the collaboration service launched with fanfare in 2009 and folded the following year. He acknowledged that Google sometimes launches services before a business model is cooked.
But, he insists that Google AppEngine is different. “We have support all the way up to Larry [Page, Google CEO]. AppEngine is here to stay, there is no plan to re-evaluate. We are sticking around, increasing the investment,” D’Alesandre said in an interview on Thursday. “AppEngine is no longer a beta or a preview product.”
Doubt about Google’s focus
Those words may reassure current GAE users but the lingering perception that third-party developers are not really a priority for Google was fed by a recent blog post by James Whitaker. He was a Google tech evangelist and engineering director, who returned to Microsoft because he felt Google had lost its tech edge. Whitaker’s bottom line:
The Google I was passionate about was a technology company that empowered its employees to innovate. The Google I left was an advertising company with a single corporate-mandated focus.
D’Alesandre would not comment on that personnel move but reiterated that Google is fully behind developers. Current GAE developers fall into three categories — mobile developers like Pulse; consumer web applications; and internal business applications “like Lotus Notes,” he said.
Other applications running on GAE are Webfilings, Best Buy’s Giftag gift registry, parts of Evite, and Cloudlock.
Victor Sanchez, CEO of Mashme.tv, a Madrid-based online collaboration and video conferencing service, does not have to be sold.
Sanchez went with GAE because it takes care of all the infrastructural heavy lifting. “Google is my sysadmin. I cannot say how big this is for us as a startup,” he said via email. Although the Mashme.tv team is very technical, they wanted to focus entirely on product development, not plumbing and plumbing management.
Second, Google has made progress with its platform support and now offers attractive service level agreements, in his view. The adoption of those SLAs convinced Sanchez that Google was serious about GAE.
His platform choice was influenced by bad experiences with Amazon. When his last company experienced an EC2 bug, it took Amazon five days to respond while Google responds within two or three hours if he has an issue. Then, if the problem persists, they call. That is “really hard to beat,” he said.
What developers want: consistency, no surprises
He and others acknowledged that Google shot itself in the foot when it raised GAE prices last year, sparking outrage among some GAE shops. But Jeff Bayer, backend systems engineer for Pulse.me, said Google worked with his company to tune its workloads and mitigate the impact of the changes. And some maintained at the time, that the fact that Google is pricing GAE as a bona fide business platform, means GAE really is a business.
Still, Google needs to bring more developers aboard, and to do that it must persuade them that developers can rely on GAE and related services well into the future as well as provide a consistent, predictable roadmap with no more unpleasant pricing surprises .
Toward that end, developers would like to see Page, who assumed the CEO title last year, make an appearance at the Google I/O conference in June. The presence of Google’s top exec at its developer-focused event could go a long way to show that Google really is all-in with developers. A Google spokeswoman would not comment on the speaker lineup for the show.
Say what you will about Microsoft CEO Steve Ballmer: He has always been clear that developers are absolutely critical to Microsoft. Page needs to convince them that they are also crucial to Google.


Jinesh Varia (@jinman) announced New Whitepaper: The Total Cost of (Non) Ownership of a NoSQL Database Service in a 3/30/2012 post to the Amazon Web Services blog:
We have received tremendous positive feedback from customers and partners since we launched Amazon DynamoDB two months ago. Amazon DynamoDB enables customers to offload the administrative burden of operating and scaling a highly available distributed database cluster while only paying for the actual system resources they consume. We also received a ton of great feedback about how simple it is get started and how easy it is to scale the database. Since Amazon DynamoDB introduced the new concept of a provisioned throughput pricing model, we also received several questions around how to think about its Total Cost of Ownership (TCO).
We are very excited to publish our new TCO whitepaper: The Total Cost of (Non) Ownership of a NoSQL Database service. Download PDF.
In this whitepaper, we attempt to explain the TCO of Amazon DynamoDB and highlight the different cost factors involved in deploying and managing a scalable NoSQL database whether on-premise in the Cloud.
When calculating TCO, we recommend that you start with a specific use case or application that you plan to deploy in the cloud instead of relying on generic comparison analysis. Hence, in this whitepaper, we walk through an example scenario (a social game to support the launch of a new movie) and highlight the total costs for three different deployment options over three different usage patterns. The graph below summarizes the results of our white paper.
When determining the TCO of a cloud-based service, it’s easy to overlook several cost factors such as administration and redundancy costs, which can lead to inaccurate and incomplete comparisons. Additionally, in the case of a NoSQL database solution, people often forget to include database administration costs. Hence, in the paper, we are providing a detailed breakdown of costs for the lifecycle of an application.
It’s challenging to do the right apples-to-apples comparison between on-premises software and a Cloud service, especially since some costs are up-front capital expenditure while others are on-going operating expenditure. In order to simplify the calculations and cost comparison between options, we have amortized the costs over a 3 year period for the on-premises option. We have clearly stated our assumptions in each option so you can adjust them based on your own research or quotes from your hardware vendors and co-location providers.
Amazon DynamoDB frees you from the headaches of provisioning hardware and systems software, setting up and configuring a distributed database cluster, and managing ongoing cluster operations. There are no hardware administration costs since there is no hardware to maintain. There are no NoSQL database administration costs such as patching the OS and managing and scaling the NoSQL cluster, since there is no software to maintain. This is an important point because NoSQL database admins are not that easy to find these days.
We hope that the whitepaper provides you with the necessary TCO information you need so you can make the right decision when it comes to deploying and running a NoSQL database solution. If you have any questions, comments, suggestions and/or feedback, feel free to reach out to us.


Nihar Bihani described Live Streaming with Amazon CloudFront & Flash Media Server 4.5 in a 3/29/2012 post to the Amazon Web Services blog:
Today, I’d like to tell you about two different ways we’ve improved our live streaming solution. But before I dive into what’s changing, I want to start by calling out some things that are staying the same. Our live streaming solution still uses the standard HTTP protocol to deliver your live video. The set-up is still simple and straightforward; an Amazon CloudFormation template helps you create your live streaming stack on AWS. You continue to have full control over the live streaming origin server – Adobe’s Flash Media Server running on Amazon EC2. And you still only pay for what you use. You told us you liked these things, so we left them alone. So, then, what’s changing? How is this better?
The first change is that our new solution now supports live streaming to Apple iOS devices by streaming in Apple’s HTTP Live Streaming (HLS) format. Our customers told us that their audience is increasingly using iOS devices to access live content. Apple’s HLS format works by breaking the overall stream into a sequence of small HTTP-based file downloads. With support for HTTP caching already available with CloudFront, what was required is an origin server that can produce your live stream in the Apple HLS format. That’s where Flash Media Server 4.5 comes in. In FMS 4.5, Adobe has added support for streaming on-demand and live content to Apple iOS devices using the HLS format. You only need to encode your live video once, and publish it to FMS’s live packager application on your origin server. Then, your origin server takes care of creating the live content fragments (.f4f and .ts) and the manifest files (.f4m and .m3u8) in real-time, so you can use CloudFront to deliver your live content to both Flash-based and Apple iOS devices from a single source.
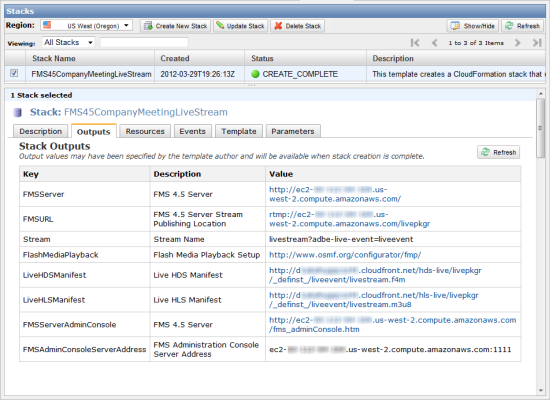
While this may seem complex to set-up, we’ve made it super simple for you with the use of a CloudFormation template which asks you for a few basic parameters about your live event to get a live streaming stack set-up on AWS. After the stack is created, CloudFormation hands out all the URLs you’ll need to publish, stream, and manage (using the Adobe FMS Admin Console) your live event:
Our live streaming tutorial that walks you through the steps you’ll need to get this going in no time. Plus, if you are already familiar and comfortable with Adobe’s Flash Media Server, or wish to configure multi-bitrate live streaming, DVR functionality, or other features of FMS 4.5, you already have full access to your live streaming origin server (FMS 4.5 running on Amazon EC2). You can also modify the CloudFormation template to make it easier for you to reproduce your live event with your custom configuration settings.
The second change is that we’ve made it easier for you to deliver your live event to a world-wide audience without the need to scale your origin infrastructure. Our improved live streaming solution uses a feature CloudFront recently announced – lower minimum expiration period for files cached by our HTTP network. With this feature, you can set the expiration period on your frequently updated live manifest files (.f4m, .m3u8, etc.) to a short amount of time, e.g., 2 seconds, by setting the cache control header on your files in the origin. This way, clients do not need to go to the origin EC2 instance directly every few seconds to retrieve the updated manifest files. The good news is that your FMS origin server already sets the cache control header with a low expiration period on these manifest files, so there is no additional work needed on your part. The CloudFormation template is configured to hand out a CloudFront domain name for you to access both the live manifest files and the live video fragments directly from CloudFront.
Adobe’s Flash Media Server 4.5 is now available in all current AWS regions, so you can launch you CloudFormation stack in the region closest to your live event location for best possible performance when uploading your encoded live video to the FMS origin server running on Amazon EC2. And with CloudFront’s global edge location network (now in 28 locations), your viewers can get the best possible performance while viewing your live event.
We hope that our improved live streaming solution helps you offer your audience more choice in accessing your content, including access via multiple mobile platforms. We’d love to hear what types of live event you use this solution for and other cool things you do with full access to your Flash Media Server 4.5 origin server!
For another perspective on this launch, check out the new post by Adobe's Kevin Towes: Announcing Flash Media Server 4.5 on Amazon Web Services.
Finally, we’ll also be hosting a webinar on May 04, 2012 from 10am–11am PDT with speakers from both Amazon CloudFront and Adobe to explain how you can use this solution for your live streaming needs. Please register for this webinar here.



Pavel Safronov posted Amazon DynamoDB and the AWS SDK for .NET to the Amazon Web Services blog on 3/29/2012:
The AWS SDK for .NET provides a simple client for our new service, Amazon DynamoDB. This client gives you a straight-forward way to interface with this Internet-scale NoSQL database service. But what you might not know is that the SDK also provides an object persistence framework for Amazon DynamoDB.
The object persistence framework enables you to define and use .NET classes like the one shown below to represent and manage data in Amazon DynamoDB. The framework—specifically the DynamoDBContext object—takes care of all the nitty-gritty details of marshalling and unmarshalling your data from .NET objects to Amazon DynamoDB attributes. All you need to do is define the classes and treat them like any other .NET data types.
[DynamoDBTable("Movies")] public class Movie { [DynamoDBHashKey] public string Title { get; set; } [DynamoDBRangeKey(AttributeName="Released")] public DateTime ReleaseDate { get; set; } public List<string> Genres { get; set; } [DynamoDBProperty("Actors")] public List<string> ActorNames { get; set; } [DynamoDBIgnore] public string Comment { get; set; } }As you can see, the class has a few attributes marking it up. These attributes specify the table to store the data in, the keys for the table, and which properties should either not be stored or be stored using a different name than in the class. These attributes are all you need to add to your code to seamlessly interact with Amazon DynamoDB.
The sample below shows basic CRUD (Create, Read, Update, Delete) operations that can be performed on these objects. Using the object persistence framework is as simple as making a Save or a Load call!
Actor actor = new Actor("John Doe"); context.Save(actor); actor = context.Load<Actor>("John Doe"); actor.Email = "john.doe@example.net"; context.Save(actor); context.Delete(actor);This article provides an in-depth walkthrough of using the object persistence framework to design a sample movie-tracking application. The article discusses the data structure aspects of the application, provides a sample schema, and shows the various interactions with Amazon DynamoDB.


<Return to section navigation list>

















0 comments:
Post a Comment