Windows Azure and Cloud Computing Posts for 10/18/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Update 10/19/2010: Articles marked •
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA)
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Tip: If you encounter articles from MSDN or TechNet blogs that are missing screen shots or other images, click the empty frame to generate an HTTP 404 (Not Found) error, and then click the back button to load the image.
Azure Blob, Drive, Table and Queue Services
• Bill Wilder posted An HTTP header that’s mandatory for this request is not specified: One Cause for Azure Error Message on 10/18/2010:
I recently posted sample code that shows copying a file up to Azure Blob Storage in One Page Of Code. In repurposing the code that deals with Azure Queues, I encountered a perplexing error message in using the Azure CloudQueue class from the SDK. I was able to figure it out, and the actual solution may actually be less interesting than how the solution was discovered, so here it is…
The story of ”an HTTP header that’s mandatory for this request is not specified”
First of all, my call to get a queue reference had completed without incident:
queue = queueStorage.GetQueueReference(“myqueue”);
Next I executed this line of seemingly innocuous code:
queue.CreateIfNotExist();
An Exception was raised – a “Microsoft.WindowsAzure.StorageClient.StorageClientException” to be exact – with the following message:
Exception Message: “An HTTP header that’s mandatory for this request is not specified”
“An HTTP header that’s mandatory for this request is not specified.”
That didn’t help, so I then checked the Inner Exception:
Inner Exception Message: “The remote server returned an error: (400) Bad Request.”
That didn’t help either. So I fired up Fiddler and looked at the http Request and Response (Raw views shown here):
If you look carefully in the Response, you will see there are two references to Blobs:
Blobs? Yes, blobs.
Blobs… That was my problem. This was supposed to be code to create a queue. A quick check back to my code immediately revealed a cut and paste error on my part. Two actually, as I tried this both against Development Storage and against live Cloud Storage with the same error.
This was the problem – the culpret – the issue – the bug:
var clientStorageAccount = CloudStorageAccount.DevelopmentStorageAccount;
CloudQueueClient queueStorage = new CloudQueueClient(clientStorageAccount.BlobEndpoint.AbsoluteUri,clientStorageAccount.Credentials);As was this:
CloudQueueClient queueStorage = new CloudQueueClient(String.Format(“http://{0}.blob.core.windows.net”, accountName), creds);
Replacing “Blob” with “Queue” did the trick for both snippets.
Pay the Fiddler
The error message was tricky, requiring that I fire up Fiddler to see the error of my ways. So.. Be careful out there when you Cut & Paste. Or don’t hack at 9:30 in the night. Or check out a Fiddler http trace, which may have additional information. Or all three..

 Bad Request.\"")


• Nati Shalom posted a NoCAP (No Consistency, Availability, Partition Tolerance) essay on 10/16/2010:
In the past few months i was involved in many of the NoSQL discussions. I must admit that i really enjoyed those discussions as it felt that we finally started to break away from the “one size fit it all” dogma and look at the data management solutions in a more pragmatic manner. That in itself sparks lots of interesting and innovative ideas that can revolutionize the entire database market such as the introduction of document model, map-reduce and new query semantics that comes with it. As with any new movement we seem to be going through the classic hype cycle. Right now it seems to me that were getting close to the peak of that hype. One of the challenges that i see when a technology reaches its peak of the hype is that people stop questioning the reason for doing things and jump on new technology just because X did that. NoSQL is no different on that regard.
In this post i wanted to spend sometime on the CAP theorem
and clarify some of the confusion that i often see when people associate CAP with scalability without fully understanding the implications that comes with it and the alternative approaches.
I chose to name this post NoCAP specifically to illustrate the idea that you can achieve scalability without compromising on consistency at least not at the degree that many of the disk based NoSQL implementations imposes.
Recap on CAP
Quoting the definition on wikipedia:
The CAP theorem, also known as Brewer's theorem, states that it is impossible for a distributed computer system
- Consistency
- Availability
- Partition Tolerance
CAP and NoSQL
Many of the disk based NoSQL implementations was originated from the need to deal with write scalability. This was largely due to the changes in traffic behavior that was mainly a result of the social networking in which most of the content is generated by the users and not by the site owner.
In a traditional database approach achieving data consistency requires synchronous write to disk and distributed transactions (known as the ACID properties).
It was clear that the demand for write scalability would conflict with the traditional approaches for achieving consistency (synchronous write to a central disk and distributed transactions).
The solution to that was: 1) Breaking the centralized disk access through partitioning of the data into distributed nodes. 2) Achieve high availability through redundancy (replication of the data into multiple nodes) 3) Use asynchronous replication to reduce the write latency.
The assumptions behind point 3 above is going to be the center in this specific post.
Graphical representation of the Cap Theorem. (Source
The Consistency Challenge
One of the common assumptions behind many of the NoSQL implementations is that to achieve write scalability we need to push as many operations on the write-path to a background process in order that we could minimize the time in which a user transaction is blocked on write.
The implication is that with asynchronous write we loose consistency between write and read operations i.e. read operation can return older version then that of write.
There are different algorithms that were developed to address this type of inconsistency challenges, often referred to as Eventual Consistency
For those interested in more information on that regard i would recommend looking at Jeremiah Peschka
Do we really need Eventual Consistency to achieve write scalability?
Before I'll dive into this topic i wanted to start with quick introduction to the term “Scalability” which is often used interchangeably with throughput. Quoting
The terms “performance” and “scalability” are commonly used interchangeably, but the two are distinct: performance measures the speed with which a single request can be executed, while scalability measures the ability of a request to maintain its performance under increasing load
(See previous post on that regard: The true meaning of linear scalability)
In our specific case that means that write scalability can be delivered primarily through point 1 and 2 above ( 1-Break the centralized disk access through partitioning of the data into distributed nodes. 2-Achieve high availability through redundancy and replication of the data into multiple nodes) where point 3 ( Use asynchronous replication to those replica’s to avoid the replication overhead on write) is mostly related with write throughput and latency and not scalability. Which bring me to the point behind this post:
Eventual consistency have little or no direct impact on write scalability .
To be more specific my argument is that it is quite often enough to break our data model into partitions (a.k.a shards) and break out from the centralized disk model to achieve write scalability. In many cases we may find that we can achieve sufficient throughput and latency just by doing that.
We should consider the use of asynchronous write algorithms to optimize the write performance and latency but due to the inherited complexity that comes with it we should consider that only after we tried simpler alternative such as using db-shards, FLASH disk or memory based devices.
Achieving write throughput without compromising consistency or scalability
The diagram below illustrates one of the examples by which we could achieve write scalability and throughput without compromising on consistency.

As with the previous examples we break our data into partitions to handle our write scaling between nodes. To achieve high throughput we use in-memory storage instead of disk. As in-memory device tend to be significantly faster and concurrent then disk and since network speed is no longer a bottleneck we can achieve high throughput and low latency even when we use synchronous write to the replica.
The only place in which we’ll use asynchronous write is the write to the long-term-storage (disk). As the user transaction doesn’t access the long-term storage directly through the read or write path, they are not exposed to the potential inconsistency between the memory storage and the long-term storage. The long-term storage can be any of the disk based alternatives starting from a standard SQL databases ending with any of the existing disk based NoSQL engines.
The other benefit behind this approach is that it is significantly simpler. Simpler not just in terms of development but simpler to maintain compared with the Eventual Consistency alternatives. In case of distributed system simplicity often correlate with reliability and deterministic behavior.
Final words
It is important to note that in this post [I] was referring mostly to the C in CAP and not CAP in its broad definition. My points was not to say don’t use solution[s] that are based on CAP/EventualConsistency model but rather to say don’t jump on Eventual Consistency based solutions before you considered the implications and alternative approaches. There are potentially simpler approaches to deal with write scalability such as using database shards, or [i]n-memory-data-grids.
As we[‘]re reaching the age of Terra-Scale devices such as Cisco UCS where we can achieve huge capacity of memory, network and compute power in a single box the area’s in which we can consider to put our entire data in-memory get significantly broader as we can easily store Terra bytes of data in just few boxes. The case of Foursquare's MongoDB Outage
For various reasons the entire DB is accessed frequently so the working set is basically its entire size Because of this, the memory requirements for this database were the total size of data in the database. If the database size exceeded the RAM on the machine, the machine would thrash, generating more I/O requests than the four disks could service.
It is a common misconception to think that putting part of the data in LRU based cache ontop of a disk based storage could yeild better performance as noted in the sanford research The Case for RAM Cloud
..even a 1% miss ratio for a DRAM cache costs a factor of 10x in performance. A caching approach makes the deceptive suggestion that “a few cache misses are OK” and lures programmers into con-figurations where system performance is poor..
In that case using pure In-Memory-Data-Grid as a front end and disk based storage as long term storage could potentially work better and with significantly lower maintenance overhead and higher determinism. The capacity of data in this specific case ( <100GB) shouldn't be hard to fit into single UCS box or few of the EC2 boxes.
References
- Lessons from Pat Helland: Life Beyond Distributed Transactions
- The true meaning of linear scalability
- Consistency models in nonrelational dbs
- Foursquare's MongoDB Outage
- CAP theorem
- Why Existing Databases (RAC) are So Breakable!
- Problems with CAP, and Yahoo’s little known NoSQL system
- CAP Confusion: Problems with ‘partition tolerance’

See also the Eric Brewer (@eric_brewer), pictured at the right, tweeted on 10/8/2010 (missed when posted) entry in my Windows Azure and Cloud Computing Posts for 10/11/2010+ post’s Azure Blob, Drive, Table and Queue Services section (scroll down).
Alex Smith explained Azure Applications: 3D Animation Rendering using Azure Worker Roles for ray tracing in a 00:18:48 webcast posted 10/15/2010:

This webcast demonstrates the use of Azure worker roles to render a 3D animation. The animation is rendered in the cloud by 16 worker roles running a legacy DOS text-based ray tracer.
Queues, blobs and tables in Azure storage are used to manage the render job and on premise applications used to upload the job details, monitor the job, and download the animation files.
Alex’s earlier Azure in Action: Large File Transfer using Azure Storage Webcast of 9/16/2010 carries this description:
This webcast is based on a real world scenario using Windows Azure Storage Blobs and Queues to transfer 15 GB of files between two laptops located behind firewalls. The use of Queues and Blobs resulted in a simple but very effective solution that supported load balancing on the download clients and automatic recovery from file transfer errors. The two client applications took about 30 minutes to develop, the transfer took a total of three hours, and the total cost for bandwidth was under $4.00.
Bill McColl claimed “The one area where MapReduce/Hadoop wins today is that it's freely available to anyone” as a deck for his NoHadoop: Big Data Requires Not Only Hadoop post of 10/18/2010:
Over the past few years, Hadoop has become something of a poster child for the NoSQL movement. Whether it's interpreted as "No SQL" or "Not Only SQL", the message has been clear, if you have big data challenges, then your programming tool of choice should be Hadoop. Sure, continue to use SQL for your ancient legacy stuff, but when you need cutting edge performance and scalability, it's time to go Hadoop.
The only problem with this story is that the people who really do have cutting edge performance and scalability requirements today have already moved on from the Hadoop model. A few have moved back to SQL, but the much more significant trend is that, having come to realize the capabilities and limitations of MapReduce and Hadoop, a whole raft of new post-Hadoop architectures are now being developed that are, in most cases, orders of magnitude faster at scale than Hadoop.
The problem with simple batch processing tools like MapReduce and Hadoop is that they are just not powerful enough in any one of the dimensions of the big data space that really matters. If you need complex joins or ACID requirements, SQL beats Hadoop easily. If you have realtime requirements, Cloudscale beats Hadoop by three or four orders of magnitude. If you have supercomputing requirements, MPI or BSP beat Hadoop easily. If you have graph computing requirements, Google's Pregel beats Hadoop by orders of magnitude. If you need interactive analysis of web-scale data sets, then Google's Dremel architecture beats Hadoop by orders of magnitude. If you need to incrementally update the analytics on a massive data set continuously, as Google now have to do on their index of the web, then an architecture like Percolator beats Hadoop easily.
The one area where MapReduce/Hadoop wins today is that it's freely available to anyone, but for those that have reasonably challenging big data requirements, that simple type of architecture is nowhere near enough.

Roger Strukhoff (@strukhoff) asserted “SNIA's CSI Integrates Cloud Data Management Interface (CDMI)” in a preface to his Cloud Storage Initiative Seeks Holy Grail of Portable Data of 10/18/2010:
The promise of vendor lock-in is a promise that most IT buyers avoid, particularly smaller businesses and enterprises in developing countries. It's unavoidable to a great degree when it comes to hardware infrastructure, operating environments, and major software applications. One of the promises of Cloud Computing is to avoid vendor lock-in, with computing services being provided by a third-party that is responsible for acquiring the IT infrastructure. But how do you avoid third-party vendor lock-in?
The Storage Networking Industry Association (SNIA) is attacking this problem through its Cloud Storage Initiative (CSI), and particularly through the Cloud Data Management Interface (CDMI) contained within the initiative. In SNIA's words, "by implementing a standard interface such as CDMI, you are free to move your data from cloud vendor to cloud vendor without the pain of recoding to different interfaces."
Portable data is a Holy Grail of sorts for the industry. It adds a final flexibility and elasticity to Cloud that is lacking when data is locked into a particular provider's environment.
Marc Farley, a well-known storage guru who now works for 3Par (which was recently acquired by HP), is very enthusiastic about it. "This is a huge deal because it promises to alleviate one of the largest concerns about cloud storage, which is portability of data among different cloud storage service and IAAS providers," he writes at his very informative and highly entertaining website, www.storagerap.com.
Marc recently posted a very informative and highly entertaining video at his site as well about CDMI.
You don't have to be a SNIA member to join the CSI/CDMI conversation at the SNIA website.
SNIA's quest is a complex one, and one that I would imagine will involve some passive-aggressive or even actively aggressive pushback from vendors who would love to have a standard of their own, but who are not likely in favor of universal data portability. The seriousness of the issue again points out the empty-vessel nature of hype cycles and other such ephemeral claptrap. Onward!

<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
• Fabrice Marguerie reported the availability of OData feeds for Proagora.com
There's a new OData kid on the block: The data from Proagora.com is now available as OData.
+
As on the website, data published as OData is about jobs, companies, and experts.
Two feeds are available, one for each of the languages supported by Proagora at the moment:
- English: http://proagora.com/en/odata/
- French: http://proagora.com/fr/odata/
Of course, you can use your favorite OData explorer to browse these feeds:
These OData feeds exhibit several interesting features of Sesame Data Browser, such as:
- Rich and easy navigation in data


- Pictures and Web hyperlinks

Known issue: Columns/properties selection ($select) fails with an error. I haven't found a solution yet.
Please give this a go and send me your feedback.
Gentle reminder: have you published your profile on Proagora.com? ;-)

Here’s the list of collections:

And part of the first six job entries in Fabrice’s Sesame Data Browser [Beta]:

• Lynn Langit published the slide deck for her What’s New in SQL Azure – from Tech Ed Africa 2010 session on 10/19/2010:
Here’s the deck from my talk in Durban this morning – enjoy!

Lynn published Migrating data to SQL Azure – from TechEd Africa later on the same day:
Here’s the deck from my talk on migrating relational data to SQL Azure – enjoy!

View more presentations from Lynn Langit.
• Alex James (@adjames) announced Support for Http PATCH in a 10/18/2010 post to the Open Data Protocol blog:
OData has supported two types of updates for a while now:
Replace Semantics via a standard PUT: this updates the whole entry with what has been provided on the wire, so any properties missing from the wire will be reset to their default values.
Merge Semantics via a MERGE tunneled through POST using the X-Http-Method header: this updates only the properties on the wire, so any properties missing will be left unchanged.
However PATCH is now a standard, and is semantically equivalent to OData's MERGE.
So we think - given our principle of adopting HTTP and ATOM standards wherever possible - that the next version of OData should support both PATCH and MERGE, and treat PATCH requests like MERGE requests.
• Alex James (@adjames) described Enhancing OData support for streams in another 10/18/2010 post to the OData blog:
A Media Resource is a unstructured piece of data or stream, something like a Document, Image or Video. And the way that you access or learn about a Media Resource is via the associated Media Link Entry, which is just a special type of Entry which links to a Media Resource and includes additional metadata about it.
So using something like this to retrieve a particular MLE:
GET ~/Service/Videos(123123)
Might return something like this:
<entry m:etag="UVWXYZ">
<id>http://server/Service/Videos(123)</id>
<title>OData Named Resource Streams</title>
<summary>A short video about Named Resource Streams...<summary>
<updated>2010-08-21T08:27:16Z</updated>
<author>
<name />
</author>
<link m:etag="ABCDEF" rel="edit-media" title="Title" href="Videos(123)/$value" />
<content src="... uri to a picture to represent the video ..." />
<m:properties xmlns:m=" http://schemas.microsoft.com/ado/2007/08/dataservices/metadata" xmlns:d="http://schemas.microsoft.com/ado/2007/08/dataservices">
<d:Id>123</d:Id>
<d:Synopsis> A short video about Named Resource Streams...</d:Synopsis>
<d:Name>OData Named Resource Streams </d:Name>
</m:properties>
</entry>
In this example the actual video (or Media Resource) can be found in the 'edit-media' link's href.So far OData is just using standard ATOM support for media-resource.
Named Resource Streams
But what happens though if you need multiple versions of that video?
For example High and Low bandwidth versions.Today you could model this with multiple MLEs, but doing so implies you have different metadata for each stream, if note you end up with copies of the same metadata for each version of the stream. Clearly this is not desirable when you have multiple versions of essentially the same video, image or document.
It turns out that this is a very common scenario, common enough that we thought it needed to be supported without forcing people to use multiple MLEs.
Ideally you should be able to have something like this:
<entry m:etag="UVWXYZ">
<id>http://server/Service/Videos(123)</id>
<title>OData Named Resource Streams</title>
<summary>A short video about Named Resource Streams...<summary>
<updated>2010-08-21T08:27:16Z</updated>
<author>
<name />
</author>
<link m:etag="ABCDEF" rel="edit-media" title="Title" href="Videos(123)/$value" />
<link
rel=" http://schemas.microsoft.com/ado/2007/08/dataservices/edit-media/ HighBandwidth"
title="HighBandwidth"
href="Videos(123)/ HighBandwidth/$value" />
<link
rel=" http://schemas.microsoft.com/ado/2007/08/dataservices/edit-media/ LowBandwidth"
title="LowBandwidth"
href="Videos(123)/LowBandwidth/$value" />
<content src="... uri to a picture to represent the video ..." />
<m:properties xmlns:m=" http://schemas.microsoft.com/ado/2007/08/dataservices/metadata" xmlns:d="http://schemas.microsoft.com/ado/2007/08/dataservices">
<d:Id>123</d:Id>
<d:Synopsis> A short video about Named Resource Streams...</d:Synopsis>
<d:Name>OData Named Resource Streams </d:Name>
</m:properties>
</entry>This says there is some default representation of the video that can be downloaded from Videos(123)/$value (i.e. the standard Media Resource), and there are also High and LowBandwidth streams too.
Note: In the above example the URI's for the Named Resource Streams simply use the URI conventions, i.e. the uri that identifies the Named Stream property with $value appended. However the clients should be payload driven here, so a server should be able to return any uri they want.
To achieve this the metadata would need to look like this:
<EntityType Name="Video" m:HasStream="true">
<Key>
<PropertyRef Name="ID" />
</Key>
<Property Name="ID" Type="Edm.Int32" Nullable="false" />
<Property Name="Name" Type="Edm.String" Nullable="true" />
<Property Name="Synopsis" Type="Edm.String" Nullable="true" />
<Property Name="HighBandwidth" Type="Edm.Stream" />
<Property Name="LowBandwidth" Type="Edm.Stream" />
</EntityType>Notice the extra streams are just extra properties on the item of type Edm.Stream. Here Edm.Stream is simply a new built-in complex type, with some explicit structure (MimeType) and an implicit stream.
I think this is a natural next step for OData's stream support.
What do you think?
Rob Tiffany explained Windows Phone 7 Line of Business App Dev :: Moving your WCF REST + JSON Service to Windows Azure on 10/18/2010:
Ever since my last blog post where I demonstrated how to create lightweight WCF REST + JSON services for consumption by Windows Phone 7, I’ve received many requests from folks wanting to know how to do the same thing from Windows Azure. Using Visual Studio 2010, the Azure Development Fabric and SQL Server, I will show you how to move this code to the cloud.
Select WCF Service Web Role and move it over to your Cloud Service Solution. Rename it to AzureRestService and click OK.
You’ll then be presented with the default Service1.svc.cs SOAP web service that implements the IService1.cs Interface. Needless to say, you’ll need to makes some modifications to these two files as well as Web.config if you want to be a true RESTafarian.
In Service1.svc.cs, delete the GetDataUsingDataContract method but leave the GetData method since you’ll use it to perform an initial test.
Next, open IService1.cs and delete the GetDataUsingDataContract [OperationContract] as well as the CompositeType [DataContract]. You should be left with the simple GetData [OperationContract].
Open Web.config. You’ll notice that it’s already pretty full of configuration items. After the closing </serviceBehaviors> tag, tap on your Enter key a few times to give you some room to insert some new stuff. Insert the following just below the closing </serviceBehaviors> tag and just above the closing </behaviors> tag as shown:
<endpointBehaviors>
<behavior name="REST">
<webHttp />
</behavior>
</endpointBehaviors>This provides you with the all-important webHttp behavior that enables lean REST calls using HTTP Verbs.
Below the closing </behaviors> tag and above <serviceHostingEnvironment multipleSiteBindingsEnabled="true" />, insert the following as shown:
<services>
<service name="AzureRestService.Service1">
<endpoint address="" behaviorConfiguration="REST" binding="webHttpBinding" contract="AzureRestService.IService1" />
</service>
</services>Here is where we define our service name and contract. It’s also where we point our behaviorConfiguration at the webHttp behavior you named “REST” and set the binding to webHttpBinding.
Now it’s time to decorate your interface’s [OperationContract] with a WebGet attribute and utilize a UriTemplate to give the Windows Phone 7 caller a web-friendly Uri to call. So beneath [OperationContract] and above string GetData(int value);, squeeze in the following:
[WebGet(UriTemplate = "/getdata?number={value}", BodyStyle = WebMessageBodyStyle.Bare)]
Since we want to call the GetData method via a GET request, we use WebGet and then we set our UriTemplate to something that anyone could access via their browser. Lastly, we strip out all unnecessary junk by setting WebMessageBodyStyle.Bare.
It’s convenient that I mentioned using a browser to access this new REST service because that’s exactly how we’re going to test it. Hit F5 in Visual Studio to fire up the Azure Development Fabric and start your Web Role. Internet Explorer will come up and you’ll probably see an Error page because it points to the Root of your Role Site. This is expected behavior. In order to test the service, type the following in the IE address bar:
http://127.0.0.1:81/service1.svc/getdata?number=5
This points to a loopback address on your computer with a port number of 81. If your environment uses a different port, then just change what you pasted in as appropriate. After the port number and “/”, you type in the name of the service you created which is service1.svc. After the next “/”, you type the format you described in the UriTemplate. You can type any Integer you wish and if everything works, the browser will display the following result:
<string xmlns="http://schemas.microsoft.com/2003/10/Serialization/">You entered: 5</string>
With your test REST service working from your local Azure Development Fabric, it’s time to bring over the business logic from my last blog post where I showed you how to return Customer information from an on-premise WCF Service connected to SQL Server. I don’t necessarily expect you to have a SQL Azure account so you’ll add a connection string to Web.config that points to a local SQL Server Express instance. Don’t worry, you can swap this connection string out later to point to our awesome cloud database. Beneath the closing </system.web> tag and above the <system.serviceModel> tag, insert the following:
<connectionStrings>
<add name="ContosoBottlingConnectionString" connectionString="Data Source=RTIFFANY2\SQLEXPRESS;Initial Catalog=ContosoBottling;Integrated Security=True" providerName="System.Data.SqlClient" />
</connectionStrings>This is the same connection string from the last blog post and you’ll definitely need to modify it to work with both your local SQL Server instance and SQL Azure when you’re ready to deploy. Bear with me as the rest of this blog post will be a large Copy and Paste effort.
Open IService1.cs and add the following:
using System.Collections.ObjectModel;
and
[OperationContract]
[WebGet(UriTemplate = "/Customers", BodyStyle = WebMessageBodyStyle.Bare, ResponseFormat = WebMessageFormat.Json)]
ObservableCollection<Customer> GetCustomers();Open Service1.svc.cs and add the following:
using System.Web.Configuration;
using System.Collections.ObjectModel;
using System.Data.SqlClient;and
//Get the Database Connection string
private string _connectionString = WebConfigurationManager.ConnectionStrings["ContosoBottlingConnectionString"].ConnectionString;and
public ObservableCollection<Customer> GetCustomers()
{
SqlConnection _cn = new SqlConnection(_connectionString);
SqlCommand _cmd = new SqlCommand();
_cmd.CommandText = "SELECT CustomerId, DistributionCenterId, RouteId, Name, StreetAddress, City, StateProvince, PostalCode FROM Customer";try
{
_cn.Open();
_cmd.Connection = _cn;ObservableCollection<Customer> _customerList = new ObservableCollection<Customer>();
SqlDataReader _dr = _cmd.ExecuteReader();
while (_dr.Read())
{
Customer _customer = new Customer();
_customer.CustomerId = Convert.ToInt32(_dr["CustomerId"]);
_customer.DistributionCenterId = Convert.ToInt32(_dr["DistributionCenterId"]);
_customer.RouteId = Convert.ToInt32(_dr["RouteId"]);
_customer.Name = Convert.ToString(_dr["Name"]);
_customer.StreetAddress = Convert.ToString(_dr["StreetAddress"]);
_customer.City = Convert.ToString(_dr["City"]);
_customer.StateProvince = Convert.ToString(_dr["StateProvince"]);
_customer.PostalCode = Convert.ToString(_dr["PostalCode"]);//Add to List
_customerList.Add(_customer);
}
return _customerList;
}
finally
{
_cmd.Dispose();
_cn.Close();
}
}As you can see, the only remaining error squigglies refer to the lack of the Customer class I discussed in the on-premise WCF project from the last blog post. To add it, I want you to right-click on your AzureRestService project and select Add | Class and name the class Customer.
Now I want you to paste the code below into this new class:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Runtime.Serialization;
using System.ComponentModel;namespace AzureRestService
{
[DataContract()]
public class Customer : INotifyPropertyChanged
{
public Customer() { }private int customerId;
private int distributionCenterId;
private int routeId;
private string name;
private string streetAddress;
private string city;
private string stateProvince;
private string postalCode;[DataMember()]
public int CustomerId
{
get { return customerId; }
set
{
customerId = value;
NotifyPropertyChanged("CustomerId");
}
}[DataMember()]
public int DistributionCenterId
{
get { return distributionCenterId; }
set
{
distributionCenterId = value;
NotifyPropertyChanged("DistributionCenterId");
}
}[DataMember()]
public int RouteId
{
get { return routeId; }
set
{
routeId = value;
NotifyPropertyChanged("RouteId");
}
}[DataMember()]
public string Name
{
get { return name; }
set
{
name = value;
NotifyPropertyChanged("Name");
}
}[DataMember()]
public string StreetAddress
{
get { return streetAddress; }
set
{
streetAddress = value;
NotifyPropertyChanged("StreetAddress");
}
}[DataMember()]
public string City
{
get { return city; }
set
{
city = value;
NotifyPropertyChanged("City");
}
}[DataMember()]
public string StateProvince
{
get { return stateProvince; }
set
{
stateProvince = value;
NotifyPropertyChanged("StateProvince");
}
}[DataMember()]
public string PostalCode
{
get { return postalCode; }
set
{
postalCode = value;
NotifyPropertyChanged("PostalCode");
}
}public event PropertyChangedEventHandler PropertyChanged;
private void NotifyPropertyChanged(String propertyName)
{
if (null != PropertyChanged)
{
PropertyChanged(this, new PropertyChangedEventArgs(propertyName));
}
}}
}As I mentioned in the last article, this class is a little overkill since it inherits from INotifyPropertyChanged and adds all the code associated with firing NotifyPropertyChanged events. I only do this because you will use this same class in your Windows Phone 7 project to support two-way data binding.
The Customer table you’ll be pulling data from is shown in SQL Server Management Studio below:
We’re now ready to roll so hit F5 in Visual Studio to debug this new cloud solution in the Azure Development Fabric. When Internet Explorer comes up, type the following in the IE address bar: http://127.0.0.1:81/service1.svc/customers
You might be surprised to see the following dialog pop up instead of XML rendered in the browser:
The reason you see this is because you’re returning the data objects in wireless-friendly JSON format. Notice that the dialog say the Unknown file type is only 671 bytes. This is a good thing. Click the Save button and save this file to your desktop.
Now find the customer file on your desktop and rename it to customer.txt so you can view it in Notepad. Double-click on this text box to reveal the tiny, JSON-encoded data in Notepad that you just looked at in the previous SQL Server Management Studio picture.
Conclusion
If you followed me through this example and all the code executed properly, you now know how to build Windows Azure REST + JSON services designed to conquer those slow, unreliable, and highly-latent wireless data networks we all deal with all over the world. When combined with my last article, both your on-premise and Windows Azure bases are covered with WCF. The only thing left to do is sign up for an Windows Azure Platform account and move this Web Role and SQL Azure database to cloud. In my next article, I’ll show you how to use the WebClient object from Silverlight in Windows Phone 7 to call these services. [Emphasis added.]
Keep coding.







Steve Yi points to a wiki article about obtaining Billing Numbers Directly From Transact-SQL in this 10/18/2010 post:
SQL Azure exposes two Dynamic Managed Views called sys.database_usage and sys.bandwidth_usage that show you the activity for your account. This wiki article shows you how to use them to understand your account usage from a billing perspective.
Stephen Forte posted DevReach Day 1 from Sofia, Bulgaria on 10/18/2010:
Today I spoke at DevReach in Sofia, Bulgaria and spoke on:
- Added a Silverlight Business Application
- Changed the Title to DevReaCH (I accidently hit cap locks in the session)
- Mapped an EF model to Northwind
- Created a Domain Service
- Wrote a business rule in said service
- Made fun of Canada
- Showed the client site generated code
- Added a DataGrid and wrote code to fill it
- Asked the audience if they thought the code would work
- Fixed the bug I introduced in my code
- Dragged and dropped a Data Source to datagrid with automatic binding
- Added a data pager with no code
- Added a filter with no code
- Added a “Save” button with no code
- Added Steve Jobs as a customer (and told the audience how much I hate him)
- Went into the metadata class and added validation
- Viewed the validation
- Exposed the RIA Service as an OData feed
- Told everyone about OData in <5 minutes (and said they were excused from my OData talk later in the day) [Emphasis added.]
The OData talk did more of the same, same as my TechEd talk, so you can download the slides and demos here.
I also recorded an episode of .NET Rocks with Richard and Carl.
Tomorrow is a Scrum talk with Joel.
Good times.
FlexWeb asked What is in Store for Developers in WCF RIA Services framework? on 10/18/2010:
The release of WCF RIA services framework a big part of the latest RIA development pulpit Silverlight 4 has released a huge storm in the industry of rich internet application development with its extra ordinary features. A notable feature found in WCF which offers aristocratic abstraction of raw socket programming is that it allows the developer to write services as included in terms of the service contract as well as offers some platform that builds up encoding, transport, security options etc. Developer on the client side uses metadata offered by WCF RIA services so that they are able to use tools to build up proxy classes which will allow them to access the service.
New things found in the WCF RIA services are sure to boost RIA development and erodes the thought that client and RIA services are two different entities working on a project. It in fact brings them together on one single platform to work together on the project. RIA services application found in WCF provide tooling and framework support for sharing artifacts between service and client. A significant change seen in WCF Rich Internet Application services is the changed names for applications and namespaces for example previously used System.Web.DomainServices namespaces becomes System.ServiceModel.DomainServices.Server in WCF RIA services. Many other features can be found in WCF an advanced rich internet development platform.
Jason Jarrett (@ElegantCode) continues removing “magic strings” from OData with code described in OData’s DataServiceQuery and removing the .Expand(“MagicStrings”) –Part II of 10/17/2010:
In a previous post I elaborated on the problem of magic strings in OData service queries, and gave a quick (but lacking in depth) statically typed helper solution.
A commenter mynkow left a note stating that my solution would not work with nested objects. I initially replied asking if he could give an example (as I hadn’t run into that scenario yet being a noob to OData). He didn’t get back to me, but it wasn’t long before I ran into the problem he was talking about.
(from x in People.Expand("TitlesDirected/ScreenFormats")
select x).Take(5)If you tried to take the above and translate it to my “no magic string” fix from the previous post you would get something like.
(from x in People.Expand(p => p.TitlesDirected /* Now what? dead end. /ScreenFormats*/ )
select x).Take(5)Now that the problem in my solution was apparent, and using his example as a quick guide (It wasn’t quite what I was looking for, but had the general theme). The solution became more than a few lines of code and I wanted to wrap some tests around the whole thing just to verify it was all working correctly…
ODataMuscle was born:
http://github.com/Staxmanade/ODataMuscle
Sorry for the name. Just think of “Strong Typing” your OData queries and giving them a little Muscle. I threw this little project up on github since this blog is not the best place to version code and if anyone felt inclined to extend it they could easily fork it and do so.
I hacked the initial version together, and once a co-worker of mine was done with it I think he cleaned it up nicely.
This new version now supports expanding not only child properties, but grandchild properties and grandchild properties of collections. (That doesn’t seem to translate well…)
EX: our little Netflix example from above would now look like
(from x in People.Expand(p => p.TitlesDirected.Expand(p2 => p2.ScreenFormats))
select x).Take(5)Which would translate into the following query
http://odata.netflix.com/catalog/People()?$top=5&$expand=TitlesDirected/ScreenFormats
Thanks to mynkow for the initial feedback and I hope this helps someone else…
Sebastien Lambla claimed “the NuPack project will shift to the horrendous OData protocol” at the end of his Using NuPack as a package repository in OpenWrap post of 10/17/2010 to CodeBetter.com:
NuPack came out a short while ago. While NuPack is only a subset of what OpenWrap was built to solve, a lot of libraries have already been added to their repositories, probably for the sole reason that it’s Microsoft and some people get excited about them doing anything having to do with Visual Studio.
But in the OpenWrap team, we think that packages are good, that’s why we’ve worked hard on our system for so many months. And we think you should, as a dedicated OpenWrap users, be able to import those packages until such a time the world adopt OpenWrap as the main way to deliver dependencies to you.
So you can do this now. At a command line, add nupack as a repository through the usual remote command.
PS C:\src\demo> o add-remote nu nupack://go.microsoft.com/fwlink/?LinkID=199193
# OpenWrap v1.0.0.0 ['C:\src\demo\wraps\_cache\openwrap-1.0.0.18871048\bin-net35\OpenWrap.dll'] Remote repository 'nu' added.From now on, any nupack will be downloaded and converted to the OpenWrap native format and be usable as usual in OpenWrap. Note that we only support things that do not have dependencies on PowerShell, so while you get command support out of the box with OpenWrap packages, we will do nothing with the PowerShell scripts at all.
You can query packages on that new server using the list-wrap –query command.
PS C:\src\demo> o list-wrap -query *castle* -remote nu
# OpenWrap v1.0.0.0 ['C:\src\demo\wraps\_cache\openwrap-1.0.0.18871048\bin-net35\OpenWrap.dll'] - Castle.Components.Validator Versions: 1.1.0 - Castle.Core-log4net Versions: 2.5.1 - Castle.Core-NLog Versions: 2.5.1 - Castle.Core Versions: 1.1.0, 1.2.0, 2.5.1 - Castle.DynamicProxy Versions: 2.1.0, 2.2.0 - Castle.Windsor-log4net Versions: 2.5.1 - Castle.Windsor-NLog Versions: 2.5.1 - Castle.Windsor Versions: 2.1.1, 2.5.1 - SNAP.CastleWindsor Versions: 1.0And add one to the package, say the latest castle.core version:
PS C:\src\demo> o add-wrap castle.core
# OpenWrap v1.0.0.0 ['C:\src\demo\wraps\_cache\openwrap-1.0.0.18871048\bin-net35\OpenWrap.dll'] Wrap descriptor found. Project repository present. Dependency added to descriptor. Copying 'Castle.Core-2.5.1' from 'nu' to 'System repository' Copying 'Castle.Core-2.5.1' from 'nu' to 'Project repository' Making sure the cache is up-to-date...
That’s Sebastien’s description, not mine.
<Return to section navigation list>
AppFabric: Access Control and Service Bus
• See the VCL01: Introducing the Azure AppFabric Service Bus Visual Studio Connections session by Juval Lowy in the AppFabric: Access Control and Service Bus section below.
• See the VCL02: Rocking AppFabric Access Control: Practical Scenarios, Killer Code and Wicked Tools Visual Studio Connections session by Michele Leroux Bustamante in the AppFabric: Access Control and Service Bus section below.
Sebastian W posted MS CRM 2011 and AppFabric (part 1) on 10/17/2010:
Welcome in part 1. Let’s try to that OOB functionality which allows us to easy create connection to Appfabric Service Bus .
What we need
-Visual Studio 2010 preferable
-Plugin registraion tool – DIY job (We need to build that from sources).
How to build “Plugin registration tool” !//if you know how to do that skip next paragraph.
To build Plugin registraion tool download Microsoft Dynamics CRM 2011 Software Development Kit (SDK) from http://go.microsoft.com/fwlink/?LinkID=200082 then install it. Find directory Tools\PluginRegistration click PluginRegistrationTool.sln, this will open solution in Visual Studio, all what you need to do press F6 or Build. This will build new “plugin registraion tool” for us. Output files will be placed in \Tools\PluginRegistration\bin\Debug (or Release depends which configuration you’ve used).
OK we need to test that tool so run plugin registration tool (PluginRegistration.exe) and connect to you environment.
Now it’s a bit of challenge to do that for online I hope this is because of beta version .
I’ve put https://myorganization.crm4.dynamics.com/ as discovery URL and empty user name.
You will be will asked about credentials after you press “connect” and if you are lucky you will see screen like bellow:
If you have problems. Try to do following.
For Exception Unhandled Exception: System.ServiceModel.Security.MessageSecurityException: …..
1) Try Delete %userprofile%\LiveDeviceID
2) Try to use diffrent Discovery Web Service URL.
North America: https://dev.crm.dynamics.com/XRMServices/2011/Discovery.svc
EMEA: https://dev.crm4.dynamics.com/XRMServices/2011/Discovery.svc
APAC: https://dev.crm5.dynamics.com/XRMServices/2011/Discovery.svcPre-beta version showed “Microsoft.Crm.ServiceBus” on the plugin list , current version of plugin registration tools doesn’t do that, but this funcionality still exists. Instead of doing that in conventional was assembly->plugin->step, we will just create endpoint and then register sdkmessageprocessingstep. Credits to person from MSFT for that explanation. I was a bit confused where OOB “Microsoft.Crm.ServiceBus” has gone but they made it clear.
More in [the] next part. If you haven’t seen part 0, have a look .


<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Adron Hall (@adronbh) points to his new CodePlex project in #wp7/#wp7dev + Amazon Web Services (AWS) and Windows Azure of 10/19/2010:
I got to mess around with the Windows Phone 7 SDK finally over the last few weeks (Twitter hashtags #wp7 and #wp7dev). The first few things I noticed was that there are a lot of missing parts to it. Namely the calendar control I fussed about well over a month ago in Windows Phone 7 Calendar Control. Even with the missing elements I kept wondering what I could build that would be useful and might be a good open source project? I finally stumbled on the idea that I’d roll a few of my points of study together into one; Windows Azure, Amazon Web Services, and Windows Phone 7. With that stumbling notion I navigated straight over to Codeplex and rolled a new project!
Here are my first few user stories just to get things started. If you think of other functionality, please feel free to add that to the comments below or to the tracking section on the Codeplex Project: http://wp7cloudadmin.codeplex.com/.
• The Windows Azure Team posted Windows Azure Helps Drive New Interactive Game and Search Experience For JAY-Z's Book DECODED on 10/19/2010:
Over the next month, fans will come together as a community to compile DECODED online before it hits bookshelves. The contest will challenge players to find all 300 pages of JAY-Z's book, which will be located via 600 unique traditional, non-traditional and digital advertising placements in 15 locations around the world and in Bing Maps. Players of the game, produced by creative agency Droga5, can play at Bing.com/jay-z, or in-person by locating the clues in New York City, London and beyond. Any player who locates a page online, or in-person (by texting unique game codes from the page) is entered into a drawing for a prize: the specific page they've located, signed by JAY-Z. All participants will be entered for a grand prize: two tickets to JAY-Z and Coldplay in concert in Las Vegas on New Year's Eve.
DECODED is on sale November 16 from Spiegel & Grau, an imprint of the Random House Publishing Group.
You can read more about this in a blog post by the BING team here.

See Aashish Dhamdhere (@dhamdhere) claimed The hunt for Jay-Z's memoir is powered by Windows Azure and Bing in a 10/18/2010 tweet. Very cool! Here’s the NYTimes’ Find Jay-Z’s Memoir at a Bookstore, or on a Billboard story by Andrew Adam Newman below (in this section).
• Datacastle claimed its “RED version 4 addresses enterprise concerns about data backup security in the cloud” in a Datacastle RED Version 4 with Mac OS X and Enhanced Microsoft Windows Azure Platform Support Launched at Gartner SYMPOSIUM ITxpo 2010 press release of 10/19/2010:
Datacastle, a market leader for business resiliency solutions for the mobile workforce, today announced the release of Datacastle RED version 4, the latest version of the company's single-agent, policy controlled backup and endpoint data protection solution for laptops, tablets and desktops in the enterprise. Datacastle RED version 4 includes support for Mac OS X and addresses the concerns many enterprises have about data backup security in the cloud with enhanced support for the Microsoft Windows Azure platform. Datacastle will debut Datacastle RED version 4 at the Gartner SYMPOSIUM ITxpo 2010 taking place in Orlando, Florida October 17-21.
"It is of paramount importance that our customers know that their high impact data can be securely stored whether on premise or in the cloud," said Ron Faith, president and CEO of Datacastle. "Since the initial roll-out of Datacastle RED on the Microsoft Windows Azure platform in the spring of 2010, we have been focused on more fully leveraging the Microsoft Windows Azure platform to optimize scalability, security and administration for our customers and partners."
With Datacastle RED running as a cloud service over Windows Azure, enterprises can rest assured that their data is secure and protected at all times. Datacastle RED operates as a native cloud service on the Windows Azure platform, leveraging Windows Azure, Microsoft SQL Azure and Azure storage tables. In addition to Datacastle RED's unique encryption policies with keys for every device and every block of data within a single file that can only be retrieved by customers, all encrypted data and metadata is stored in Windows Azure at Microsoft data centers, which are ISO 27001:2005 accredited with SAS 70 Type I and Type II attestations.
Additional enhancements in the new version further demonstrate Datacastle's commitment to a "friction-free" experience for end users and IT, including performance enhancements for silent deployments and operations, administrative enhancements for support staff to know what is happening to each device at any given time, and self-management enhancements for end users to improve control over files that are backed up.
Datacastle RED version 4 is now available from Datacastle or one of its partners in the United States, Canada, Europe or Australia. For more information call 425.996.9684 or email sales@datacastlecorp.com.
About Datacastle
Datacastle makes an organization's mobile workforce resilient to the unexpected. Listed in Gartner's Hype Cycle for Storage Technologies, 2010, Datacastle RED turns vulnerable business information into a resilient, managed business asset. Datacastle empowers IT to enforce data policies and exceed compliance requirements. To learn more about Datacastle RED, visit our website or follow us on Twitter.
Jim O’Neill continued his At Home series with Azure@home Part 9: Worker Role Run method on 10/18/2010:
In my last post, I covered the initialization of the WorkerRole in Azure@home – namely the implementation of the OnStart method via which we set up the role to collect a few performance statistics as well as to log system and application errors. The next stage in a worker role’s lifecycle is the Run method, typically implemented as an infinite loop – in fact if the Run method terminates, the role will be recycled and started again, so even if you don’t implement an infinite loop in Run directly, the Windows Azure fabric pretty much enforces one on you (granted in a more disruptive fashion).
Revisiting the architecture diagram (see [right]), each instance of the WorkerRole is responsible for starting the Folding@home process (FAH.EXE – Step 4) and reporting the progress of the simulation (Steps 5 and 6) via an Azure table (workunit – Step 7) as well as a web service call (Step 8) to the main distributed.cloudapp.net application. When a single simulation run – known as a work unit – completes, the WorkerRole simply starts another Folding@home console application process and the cycle repeats. …
Jim continues with source code.
Marius Oiaga described WikiBhasha Crowdsourcing Multilingual Content on Wikipedia in a 10/18/2010 post to the Softpedia blog:

A new free and open source tool from Microsoft Research is designed to leverage crowdsourcing in order to build multilingual content on Wikipedia.
WikiBhasha Beta is currently available for download from the Redmond company, and can be used in order to expand the number of languages in which Wikipedia content is available.
According to the software giant, WikiBhasha is based on the work done with WikiBABEL, a Microsoft Research project set up to take advantage of a language community in order to collaboratively create linguistic parallel data.
“WikiBhasha beta enables Wikipedia users and contributors to explore and source content from English Wikipedia articles, to translate the content into a set of target languages, and to use the content with user additions and corrections for contribution to the target language Wikipedia,” Microsoft stated.
“The content creation workflow is flexible enough to accommodate new content creation, at the same time preserving reusable information, such as references and templates.”
WikiBhasha is designed to work in tandem with Microsoft’s machine translation technology, but with one limitation.
Users will not be able to perform translations between all the language pairs supported by Microsoft Translator, but only between English as a source language and any of the other languages featured by the technology.
All the content that is translated by contributors will be submitted to the appropriate Wikipedias, the software giant informs.
Users interested in contributing will need to install the WikiBhasha beta, which is designed as a browser application that will be brought to life by Wikipedia articles.
“It features an intuitive and simple UI layer that stays on the target language Wikipedia for the entire content creation process,” the company stated.“This UI layer integrates content discovery, linguistic and collaborative services, focusing the user primarily on content creation in the target Wikipedia.
“A simple 3-step process guides the user in the content discovery and sourcing from English Wikipedia articles, composing target language Wikipedia article and, finally, publication in target Wikipedia. While a typical session may be to enhance a target language Wikipedia article, new articles may also be created following similar process.”
The WikiBhasha label has been coined through a combination of “Wiki” and “Bhasha” (language in Hindi or Sanskrit).
Aashish Dhamdhere (@dhamdhere) claimed The hunt for Jay-Z's memoir is powered by Windows Azure and Bing in a 10/18/2010 tweet. Very cool! Here’s the NYTimes’ Find Jay-Z’s Memoir at a Bookstore, or on a Billboard story by Andrew Adam Newman:
PRINT advertising by publishing houses tends to boast about books that are being bold and original, but that can seldom be said of the ads themselves, which generally consist of ho-hum photographs of the book and author, a brief description of the subject matter and laudatory blurbs.
“If in certain pages Jay-Z is talking about something related to Times Square, then those pages might be on billboards in Times Square,” said David Droga, creative chairman Droga5, the New York agency heading the campaign. Mr. Droga declined to reveal locations beforehand (including the veracity of the Times Square example), but did describe the campaign in oblique terms.
While about half of the pages will be displayed in traditional outdoor advertising like billboards, the rest will be offbeat, printed in one instance on the bottom of a hotel swimming pool, in another on the lining of jackets in a store display window, and in another on the felt of pool tables in a pool hall, said Mr. Droga.
Along with New York, the pages will appear in cities including Los Angeles, New Orleans, Miami and London, and will continue to pop up until Nov. 16, when “Decoded” will be published by Spiegel & Grau, an imprint of Random House, with a list price of $35.
The best way to search for the pages will be, appropriately enough, through a search engine. Microsoft will host a Web page, Bing.com/Jay-Z, that will function as an online scavenger hunt. That site, and the Bing logo, will be featured prominently in the outdoor ads.
The scavenger hunt, also scheduled to start Monday, showcases a regular Bing feature, a 3-D map based on photographs (like Google Street View), which enables users to click on a spot on a map, then amble around at street level and look anywhere, as a pedestrian might. Although streetscapes in Bing are based on photographs from before the billboards went up, visitors will see the “Decoded” billboards superimposed in the 3-D map. Players will follow clues to bring them in the general vicinity of pages, while a “proximity meter” on the screen will indicate when they are getting closer.
Players who are the first to discover the pages will be eligible to win a signed copy of the book and the grand prize, a trip to Las Vegas to see Jay-Z and Coldplay in a New Year’s Eve concert.
Pages may end up first being discovered either inside the Bing game or in the real world. Clues about page locations will be given on Bing, as well as by Jay-Z on Facebook, where his official page has more than 4.4 million followers, and through Twitter, where he has more than 256,000. …
Read more here.
FICO claimed it “enhances business rules management leveraging the cloud computing power of Windows Azure Platform” in its FICO Delivers Decision Services in the Cloud press release of 10/18/2010:
Using FICO's business rules management software and Microsoft Corp.'s complementary cloud technologies allows companies in any industry to execute their operational business decisions in an agile and scalable manner. FICO(TM) Blaze Advisor(R) enables the creation of reusable decision services that can be leveraged across the organization to drive more effective and consistent business results.
"Business rules are an essential tool for companies to make better decisions," said Kim Akers, general manager for global partners at Microsoft Corp. "With solutions based on the Windows Azure platform, companies can have access to a more scalable, cost-effective platform from which to make automated decisions."
"FICO is the leader in helping companies deliver better decisions wherever they are needed, and the cloud is increasingly becoming an important part of how companies do business," said David Lightfoot, vice president of Product Management at FICO. "By taking advantage of the Windows Azure platform, our clients can advance their decision management while taking full advantage of the enterprise access and collaboration made possible with the cloud."
FICO(TM) Blaze Advisor(R) is the world's leading business rules management system (BRMS), delivering unparalleled speed and agility in the deployment and management of high-volume, automated decisions. FICO Blaze Advisor enables business users to easily design, deploy, execute and maintain business rules and policies as part of an automated business application.
About FICO: FICO transforms business by making every decision count. FICO's Decision Management solutions combine trusted advice, world-class analytics and innovative applications to give organizations the power to automate, improve and connect decisions across their business. Clients in 80 countries work with FICO to increase customer loyalty and profitability, cut fraud losses, manage credit risk, meet regulatory and competitive demands, and rapidly build market share. FICO also helps millions of individuals manage their credit health through the www.myFICO.com website. Learn more about FICO at www.fico.com.
Morebits posted Starting With Windows Azure to his or her MSDN blog on 10/17/2010:
Cloud Computing
Windows Azure Platform is Microsoft implementation of cloud computing. The National Institute of Standards and Technology defines cloud computing as follows:
Cloud computing is a model for enabling convenient on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction. This cloud model promotes availability and is composed of five essential characteristics, three service models and four deployment models.
For more information see NIST Cloud Computing.
Fig. 1 Accessing Cloud Computing Resources
Cloud Characteristics
- On demand-self-service is one of the cloud characteristics. It enables a consumer to provision computing resources as needed automatically, without intervention on the part of the cloud solution provider. From now on we will use the term cloud to mean cloud computing.
- Also a broad network access allows for computing resources to be available through standard mechanisms such as HTTP and SOAP protocols. This is to enable access by a variety of clients such as laptops, mobile phones and other devices.
- Another important characteristic is resource pooling. The cloud resources are pooled to serve multiple consumers using a multi-tenant model where resources are assigned based on consumer demand.
Cloud Service Models
- The software as a service (SaaS) enables the consumer to use the provider applications that run in the cloud. The applications are accessible from various client devices through a thin interface such as a web browser. An example is a web-based e-mail application.
- The consumer has the ability to deploy her own applications in the cloud as supported by the platform as a service (PaaS) model. These applications are created using programming languages and tools supported by the provider.
- Finally, the infrastructure as a service (IaaS) enables the consumer to provision processing, storage, networks and other computing resources to deploy and run applications. The consumer cannot control the underlying physical infrastructure, though.
Fig.2 Cloud Service Models
Deployment Models
- In the private cloud model the cloud is dedicated solely to an organization. It could be managed by the organization or a third party and may be located on premise or outside.
- A community cloud model enables several organizations to share a cloud that supports a specific community with shared needs such as security requirements, policy and compliance considerations.
- In the public cloud model the cloud is made available to the general public or a to a large industry group.
Cloud Ecosystem
The following community categories are involved in the cloud computing ecosystem:
- Cloud Providers. They provide the hosting platform and cloud infrastructure services.
- Cloud Consumers. They utilize the cloud platform and create applications and services for the users.
- Cloud Users. They use the applications and services provided by the cloud consumers.
Fig. 3 Cloud Computing Ecosystem
Cloud Architecture
The cloud architecture is structured in layers. Each layer abstracts the one below it and exposes interfaces that layers above can build upon. The layers are loosely coupled and provide horizontal scalability (they can expand) if needed.
Fig. 4 Cloud Architecture
As shown in the previous illustration, the cloud architecture contains several subsystems that are described next.
- Hosting Platform. This platform provides the physical, virtual and software components. These components include servers, operating system, network, storage devices and power control and virtualization software. All these resources are abstracted as virtual resources to the layer above.
- Cloud Infrastructure Services. The important function of this layer is to abstract the hosting platform as a set of virtual resources and to manage them based on scalability and availability. The layer provides three types of abstract resources: compute, storage and network. It also exposes a set of APIs to access and manage these resources. This enables a user to gain access to the physical resources without knowing the details of the underlying hardware and software and to control these systems through configuration. Services provided by this layer are known as Infrastructure as a Service (IaaS).
- Cloud Platform Services. This layer provides a set of services to help integrating on-premise software with services hosted in the cloud. For example in Windows Azure, Microsoft .NET Service Bus helps with discovery and access. Services provided by this layer are known as Platform as a Service (PaaS).
- Cloud Applications. This layer contains applications built for cloud computing. They expose web interfaces and services and enable multitenant hosting. Services provided by this layer are known as Software as a Service (SaaS).
Windows Azure Platform
Windows Azure platform is the Microsoft implementation of cloud computing. The core of this platform is the Windows Azure operating system. The following illustration maps the Windows Azure platform to the cloud computing layers.
Fig. 5 Windows Azure Platform Architecture
From now on we will use the name Windows Azure to indicate the entire platform unless we want to specifically refer to the operating system. Windows Azure provides resources and services for consumers. For example, hardware is abstracted and exposed as compute resources. Physical storage is abstracted as storage resources and exposed through very well defined interfaces. A common Windows Fabric abstracts the hardware and the software and exposes virtual compute and storage resources. Each instance of an application is automatically managed and monitored for availability and scalability. If an application goes down, the Fabric is notified and a new instance of the application is created. Because virtualization is a key element in cloud computing, no assumption must be made on the state of the underlying hardware hosting the application. As matter of a fact Windows Azure follows a computing model where the Fabric controller maps service declarative specifications to available resources.





Rinat Abdullin announced the Release of Lokad-CQRS for Windows Azure, Community Credits on 10/15/2010:
First release of Lokad.CQRS for Windows Azure is out!
Lokad.CQRS for Windows Azure is a guidance and framework on efficiently building solutions for the cloud. It fits distributed and scalable enterprise scenarios as well as small and cost-effective solutions.
Lokad.CQRS is based on cloud experience and R&D investments of Lokad (winner of Windows Azure Partner Award 2010 by Microsoft), a lot of existing theory (i.e.: Efficient Development series, CQRS, etc) and numerous production-proven .NET building blocks.
First release manifests an important milestone for us and development of this project. It includes Azure Starter binaries (available in the downloads), tutorials with samples (1-4) and a large list of reference materials.
Credits
Before going any further I would like to thank people that made such a project possible and helped us to move forward (I'm sorry if the paragraph below will sound a bit like the Oscar nomination show, but this is really important):
- Udi Dahan - for clarifying CQRS; without his blog I wouldn't know where to start.
- Greg Young - for wonderful and inspiring ideas about taking CQRS/DDD/ES to the edge; they serve as constant inspiration to move forward and help to reduce complexity of existing code.
- Marc Gravell - for his wonderful ProtoBuf-net framework and community help in C#; without ProtoBuf we would still be struggling over evolving messages and keeping performance-high.
- Nicholas Blumhardt - for Autofac, of course; Lokad.CQRS infrastructure and configuration DSLs are a breeze to write and evolve thanks to this elegant, powerful and lean IoC container for .NET. Thanks again, man!
- CQRS/DDD community and especially Jonathan Oliver, Jérémie Chassaing, Yves Reynhout, Mark Nijhof, Szymon Pobiega and many others commenting on my Journal, providing encouraging feedback, valuable critics and sharing experience.
- All the readers of this Journal. There is nothing as motivating to move forward as hitting "1000 subscribers" point.
- Lokad team. You know for what.
Lokad.CQRS Recap
In the first place Lokad.CQRS project is a guidance on building scalable applications with Windows Azure. As such it packs in some samples, tutorials and reference materials.
In addition to that, there is an Open Source .NET Framework that handles core complexities and intricacies of building scalable enterprise solution with Windows Azure (there are still a lot of issues with this young platform; we hit them and do not want you to experience the same).
Lokad.CQRS framework for Azure could be reused in the binary form or as a reference implementation (esp. to save you some time or demonstrate some approach). Everything (articles, tutorials and source code) is open-source and you can use it without any commercial restrictions (OSI-compatible New BSD License).
Here's a quick overview of the primary links:
BTW, out of sheer curiosity you can also check the full list of Lokad projects that we share with the community as open source.
Used in Production at Lokad
This first release is far from being perfect. There is so much more what we've learned since starting Lokad.CQRS. There is even more that we want to add to this project down the road (i.e.: just to handle higher requirements on scalability, simplicity and reduced development and maintenance friction).
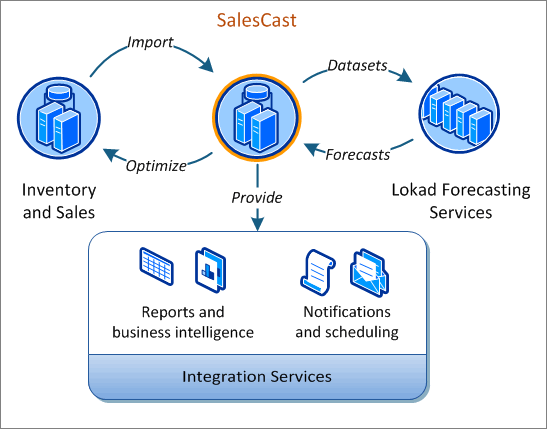
Yet Lokad.CQRS is what we actually use in the production: Lokad Salescast is currently running on the latest version of the codebase (and latest Windows Azure Guest OS with .NET 4.0) without any problems (if there were any I would be fixing them instead of writing this blog post).
Salescast is an integration platform between Lokad Forecasting services and our customers. It was started as a small Windows Azure application to be developed and maintained by 1-2 people.
Yet right now it:
- features auto-detection and integration with more than 10 ERP data formats, custom workflows, report and integration intelligence;
- can reliably and automatically handle integration with MS SQL, MySQL and Oracle databases frequently hosted in unreliable environments;
- has "pumped through" over 9.5 millions of products, 66 millions of order lines and delivered 3.6 millions of forecasts. The numbers are steadily growing;
- is capable of being scaled out to handle even higher loads (at least 100x higher with a modest improvements in Lokad.CQRS core, that are planned);
- has a lot of features to reduce development, maintenance and support friction and has not shown any signs of complexity barrier yet.
At the same time the project is still fun and still requires less than 1 person full time to keep on development and adding new features (maintenance and partial customer support included).
Most of that was achieved thanks to Windows Azure, Lokad.CQRS and ideas liberally borrowed from the development community. And this is the reason why we put so much effort to give Lokad.CQRS to the community back.
BTW, while using ask.lokad.com community for posting questions about our technologies, guidance and frameworks, please use separate topics (instead of comments) to post questions and express your feedback which we really appreciate! I especially loved this one:
Rinat, thank you so much for the detailed answer and invaluable code snippets! I love you , man! From your first snippet I see that until now I've had completely wrong understanding about the pub/sub functionality of Lokad.CQRS. That aside, the approach you propose will fit perfectly in my scenario. Thank you once again!
Well, thank you all! There is more coming to CQRS (for the small and cloud solutions alike). Stay tuned!
MSDevCon announced on 10/13/2010 seven new Windows Azure Fall 2010 introductory training videos by Bill Lodin:
This series updates materials already available on MSDev to reflect the latest developments in the Windows Azure platform, and adds material covering new features of the Windows Azure platform as of Fall, 2010:
- Windows Azure: : Storing Blobs in Windows Azure Storage: This short video shows how to store data as blobs in Windows Azure storage. It explains how to use the storage API to create containers for data, and how to store, retrieve, and manage that data.
- Windows Azure: Leveraging Queues in Windows Azure: This video introduces the viewer to the use of queues to facilitate communication between Web and Worker roles in Windows Azure.
- Windows Azure: Storing Data in Windows Azure Tables: This screencast will show you how to get started with Windows Azure tables, including how to create tables and add, edit, or delete data.
- Windows Azure: Debugging Tips for Windows Azure Applications: This presentation covers how to use the local desktop version of Windows Azure to debug your Windows Azure applications before moving them into the cloud.
Windows Azure: Getting Started with AppFabric?: This video shows you how to get started using the Windows Azure AppFabric, including setting up a project and a service namespace, downloading the SDK, and using the built-in samples.
Mikkel Høy Sørensen presented Enterprise Level Applications on Windows Azure to the JAOO Conference in Aarhus, Denmark on 10/5/2010 (posted to Channel 9 on 10/15/2010):
[A] Website is probably one of the most obvious usage example’s for the cloud computing. But what did it take to convert one of the biggest Web Content Management Systems (WCMS) in the world? You will be given an insight look to the challenges that Sitecore has meet, when they converted there WCMS to Windows Azure and how they have used the cloud to solved and ease problems like deployment, elasticity and multiple geo location setups.
There are multiple Windows Azure Hosting centers placed in the different regions of the world. And you can use this to greatly reduce the latency between our Azure application and the end user. We will be showing how Windows Azure makes it easy to deploy Sitecore installations all over the world.
Biography: Mikkel Høy Sørensen is a Program Manager at Sitecore. He has held multiple architectural an[d] development positions. But since 2004 his focus has been on Web Content Management. For the last four year Mikkel has worked closely with Multiple Product Teams at Microsoft Redmond, like .Net [and] Visual Studio teams. He is currently working closely with the Windows Azure and SQL Azure groups. Through the years he has be[en] working on several project[s] to create systems to automate website purchase, setup and deployment on hosting server farms. And with his latest project the Sitecore Azure, Mikkel is the first to create a full automated purchase, setup and deployment system for Windows Azure
<Return to section navigation list>
Visual Studio LightSwitch
• Jack Vaughan reviewed Light-weight apps and the LightSwitch development kit on 10/18/2010 for SearchSOA.com’s SOA Talk blog:
Enterprise-scale applications – by that we mean big banger ”let’s-change-the-way-we-do-things-around-here” enterprise applications – are what we want to do, right? Of course. It is in human nature to want to make a strong impact.
But sometimes enterprise applications can be overdone. Grand ambition has its place, but it also invites a lot of risk, especially the risk of a failed project.
In a manner, we have seen scaled down ambitions transform the Java space. Spring and Seam and the latest version of Java EE are all about building smaller, simpler Web applications more quickly, and not trying to boil the ocean. Now, Microsoft is going the simpler-is-better route with its LightSwitch tool set, intended to rapidly build tactical applications.
This is somewhat ironic, because this is the company that wrote the book on this approach. Microsoft developer tools initially rose to prominence on the back of Visual Basic tools that were very much associated with rapid client-server application development. The application might not effectively scale, but it would prove the concept. PowerBuilder, another tool associated with that era - while kind of leaving some Visual Basic developers in the lurch. Maybe, in a way, LightSwitch is filling a gap that the .NET movement inadvertently created.
We recently spoke with Patrick Emmons, director of professional services at Adage Technologies, which builds custom software using ASP.NET for a variety of businesses. Emmons is very clear in stating that enterprise-ready is not for every situation and every person. He indicates that sometimes in a line-of-business within a large organization you have to move forward very quickly, and that, for a very young boot-strapping organization the expense of an enterprise-ready application is just overkill. As an add-in to Visual Studio, Emmons advises, LightSwitch works just as if you were creating a project. It is a project template, but with an entirely different modeling tool for picking data sources.
It is just in beta now, and a link to Microsoft’s Azure cloud platform is in the works. This may help in scaling up future LightSwitch applications. In any case, the LightSwitch idea seems to play both to the trends of the day and to historical ones.
• Beth Massi (@BethMassi) was interviewed at Silicon Valley Code Camp by Dice’s David Sparks in this 00:02:37 Build custom apps fast with LightSwitch video:

Return to section navigation list>
Windows Azure Infrastructure
• Tim Anderson (@timanderson, pictured below) asserted “Ray out redeployed - MS execs go pale” as he asked Was Ozzie's head in the clouds as rivals stole his role? in this 10/19/2010 article for The Register:
Ray Ozzie's unexpected departure from his role as chief software architect does not look good for Microsoft, not least because it follows a series of other high-level departures.
It follows Microsoft Business Division president Stephen Elop's move to become CEO of Nokia last month, and the retirement of entertainment and devices execs Robbie Bach and J Allard announced earlier this year.
Are rattled execs smelling the coffee?
Ozzie's case is different, especially as he is not leaving Microsoft just yet. Microsoft CEO Steve Ballmer says, oddly, that Ozzie will now be "focusing his efforts in the broader area of entertainment". This is a bizarre move for someone who was supposedly guiding the entire company's software architecture.
Ray Ozzie announced Azure at the company's PDC 2008 conference, but it remained a lacklustre and confusing project for some time. Muglia's expanded division has done a better job of positioning what now seems to be a solid cloud platform.
Another project closely associated with Ozzie is Live Mesh, launched in April 2008. Live Mesh was not just a synchronisation service, but a development platform with an API. In a widely leaked memo, Ozzie described the Web as "the hub of our social mesh and our device mesh", with the device mesh central to his vision of connected productivity. Mesh proved to be a poor development platform, and the API was later withdrawn. Live Mesh was scaled down, and is now folded into Windows Live Essentials, an internet services add-on for Windows.
The positive spin on this would be that, having nurtured Azure and passed it into good hands, there was little more for Ozzie to do. The negative spin would be that Ozzie's vision of synchronisation at the heart of Microsoft's cloud has failed to capture hearts and minds either within or outside the company. If that is the case, then Ozzie's demotion merely formalises what was happening anyway - that execs other than Ozzie were shaping the company's software architecture, if there is such a thing.
That makes this a healthy change for Microsoft, though it raises the question of who is the person of vision who can guide this huge company's strategy? Judging by his public appearances, CEO Steve Ballmer is no more the right person for the task than Ozzie proved to be.
• Tim posted Ray Ozzie no longer to be Microsoft’s Chief Software Architect to his blog a day earlier:
A press release, in the form of a memo from CEO Steve Ballmer, tells us that Ray Ozzie is to step down from his role as Chief Software Architect. He is not leaving the company:
Ray and I are announcing today Ray’s intention to step down from his role as chief software architect. He will remain with the company as he transitions the teams and ongoing strategic projects within his organization … Ray will be focusing his efforts in the broader area of entertainment where Microsoft has many ongoing investments.
Ozzie may have done great work out of public view; but my impression is that Microsoft lacks the ability to articulate its strategy effectively, with neither Ozzie nor Ballmer succeeding in this. Admittedly it is a difficult task for such a diffuse company; but it is a critical one. Ballmer says he won’t refill the CSA role, which is a shame in some ways. A gifted strategist and communicator in that role could bring the company considerable benefit.
Related posts:
• Mini-Microsoft takes another tack in Mr. Ray Ozzie and Microsoft's Chief Software Architect - So long, farewell, auf wiedersehen, adieu, adieu, adieu of 10/19/2010:
…
I feel with Ray Ozzie's departure that Steve Ballmer has finally asserted his complete control over the company. We've had some house cleaning this year, ranging from Mr. Ozzie to Mr. Bach & Mr. Allard to Technical Fellows to continued targeted layoffs. Perhaps this is due to the big, contemplative review Mr. Ballmer had with the Microsoft Board this year. Mr. Ballmer has hit the reset button. Do we have a Hail Mary pass, or is this Ballmer 2.0?
We'll see how that goes. In the meantime, here's hoping that the technical Presidents reporting to Mr. Ballmer can take up the custom of intellectual rigor. Because that is one custom we can't let decline anymore.
• Buck Woody posted a description of Windows Azure Components for newbies on 10/19/2010:
In a previous post I explained an overview of the storage options you have for Windows Azure. I’d like to pull back a bit today – because Windows Azure is often used as a single term, you might not be aware it actually is composed of three components. These components work together, but can also be used separately.
The first is Windows Azure “Compute”. This is made up of two kinds of “Roles”. The first is a “Web Role”, which basically means ASP.NET. That’s just the delivery mechanism – within that you can write in languages like C#. The point is, a Web Role is the front end code, screens and so on that you expose to your users. The other Role is a “Worker Role”. This can use various languages as well, and is basically like the Windows Services or DLL’s you use today in typical .NET programming. Worker Roles are the programs that don’t have a front end to the user.
The second component (or feature) in Windows Azure is the Storage – which I explained in my earlier post. You have three types here – Blobs, which are like files, Tables, which are key-value-pair type storage, and Queues, which let Web Roles and Worker Roles communicate to each other.
The third component in Windows Azure is the Application Fabric. From a wide view, this component handles authentication (lots of options here) and transport – not only between Windows Azure applications, but even from servers in your four walls. In other words, you could take that large SQL Server or Oracle system and expose that to an Azure application, and you wouldn’t have to allow the users of the application into your network.
I’ll point back to this post from time to time as I explore each of these areas in more depth.
Mary Jo Foley observed Microsoft starts moving more of its own services onto Windows Azure in a 10/18/2010 post to her All About Microsoft blog for ZDNet:
Some of Live Mesh was on it. The Holm energy-tracking app was an Azure-hosted service. Pieces of its HealthVault solution were on Azure. But Hotmail, CRM Online, the Business Productivity Online Suite (BPOS) of hosted enterprise apps? Nope, nope and nope.
I asked the Softies earlier this year if the lack of internal divisions hosting on top of Azure could be read as a lack of faith in Microsoft’s cloud OS. Was it just too untried and unproven for “real” apps and services?
The Azure leaders told me to watch for new and next-generation apps for both internal Microsoft use and external customer use to debut on Azure in the not-too-distant future. It looks like that’s gradually starting to happen.
Microsoft Research announced on October 18 a beta version of WikiBhasha, “a multilingual content creation tool for Wikipedia, codeveloped by WikiPedia and Microsoft. The beta is an open-source MediaWiki extension, available under the Apache License 2.0, as well as in user-gadget and bookmarklet form. It’s the bookmarklet version that is hosted on Azure. [See article in the Live Windows Azure Apps, APIs, Tools and Test Harnesses section above
Gaming is another area where Microsoft has started relying on Azure. According to a case study Microsoft published last week, the “Windows Gaming Experience” team built social extensions into Bing Games on Azure, enabling that team to create in five months a handful of new hosting and gaming services. (It’s not the games themselves hosted on Azure; it’s complementary services like secure tokens, leaderboard scores, gamer-preferences settings, etc.) The team made use of Azure’s hosting, compute and storage elements to build these services that could be accessed by nearly two million concurrent gamers at launch in June — and that can scale up to “support five times the amount of users,” the Softies claim.
Microsoft also is looking to Azure as it builds its next-generation IntelliMirror product/service, according to an article Microsoft posted to its download center. Currently, IntelliMirror is a set of management features built into Windows Server. In the future (around the time of Windows 8, as the original version of the article said), some of these services may actually be hosted in the cloud.
An except from the edited, October 15 version of the IntelliMirror article:
The “IntelliMirror service management team, like many of commercial customers of Microsoft, is evaluating the Windows Azure cloud platform to establish whether it can offer an alternative solution for the DPM (data protection manager) requirements in IntelliMirror. The IntelliMirror service management team sees the flexibility of Windows Azure as an opportunity to meet growing user demand for the service by making the right resources available when and where they are needed.
“The first stage of the move toward the cloud is already underway. Initially, IntelliMirror service management team plans to set up a pilot on selective IntelliMirror and DPM client servers by early 2011, to evaluate the benefits of on-premises versus the cloud for certain parts of the service.”
There’s still no definitive timeframe as to when — or even if — Microsoft plans to move things like Hotmail, Bing or BPOS onto Azure. For now, these services run in Microsoft’s datacenters but not on servers running Azure.
Audrey Watters reported Gartner Hype Cycle 2010: Cloud Computing at the Peak of Inflated Expectations on 10/18/2010:
Analyst firm Gartner has released its 2010 Hype Cycle Report, identifying those technologies it thinks have reached the "Peak of Inflated Expectations" as well as those languishing in the "Trough of Disillusionment."
Activity streams, cloud computing, and 3D flat-panel TVs and displays are among those at that peak. Gartner defines this as a "phrase of overenthusiasm and unrealistic projections." And although according to Gartner's map, it means these technologies may be on their way to mainstream, the next stop is one of disillusionment because those technologies failed to live up to expectations.
And at that low point of disillusionment currently stands public virtual worlds, according to Gartner.
Gartner's report examines 1800 technologies as well as trends in 75 industry and topic areas. These reports are meant to provide a snapshot into emerging technologies. as well as estimates in the time until these technologies become mainstream. Cloud computing and e-readers, according to the report will be mainstream in less than 5 years, but we have to look beyond the five year mark for mainstream 3D printing and robots.
Gartner identifies several themes from the Hype Cycle report, including the importance of UI, data-driven decision-making, and cloud computing.

Lori MacVittie (@lmacvittie) asserted Need it you do, even if know it you do not. But you will…heh. You will as a preface to her What is Network-based Application Virtualization and Why Do You Need It? post of 10/18/2010 to F5’s DevCentral blog:
With all the attention being paid these days to VDI (virtual desktop infrastructure) and application virtualization and server virtualization and <insert type> virtualization it’s easy to forget about network-based application virtualization. But it’s the one virtualization technique you shouldn’t forget because it is a foundational technology upon which myriad other solutions will be enabled.
WHAT IS NETWORK-BASED APPLICATION VIRTUALIZATION?
This term may not be familiar to you but that’s because since its inception, oh, more than a decade ago, it’s always just been called “server virtualization”. After the turn of the century (I love saying that, by the way) it was always referred to as service virtualization in SOA and XML circles. With the rise of the likes of VMware and Citrix and Microsoft server virtualization solutions, it’s become impossible to just use the term “server virtualization” and “service virtualization” is just as ambiguous so it seems appropriate to give it a few more modifiers to make it clear that we’re talking about the network-based virtualization (aggregation) of applications.
That “aggregation” piece is important because unlike server virtualization that bifurcates servers, network-based application virtualization abstracts applications, making many instances appear to be one.
Network-based application virtualization resides in the network, in the application delivery “tier” of an architecture. This tier is normally physically deployed somewhere near the edge of the data center (the perimeter) and acts as the endpoint for user requests. In other words, a client request to http://www.example.com is answered by an application delivery controller (load balancer) which in turn communicates internally with applications that may be virtualized or not, local or in a public cloud.
Many, many, many organizations take advantage of this type of virtualization as a means to implement a scalable, load balancing based infrastructure for high-volume, high-availability applications.
Many, many, many organizations do not take advantage of network-based application virtualization for applications that are not high-volume, high-availability applications.
They should.
FOUR REASONS to USE NETWORK-BASED APPLICATION VIRTUALIZATION for EVERY APPLICATION
There are many reasons to use network-based application virtualization for every application but these four are at the top of the list.
- FUTURE-PROOF SCALABILITY. Right now that application may not need to be scaled but it may in the future. If it’s deployed on its own, without network-based application virtualization, you’ll have a dickens of a time rearranging your network later to enable it. Leveraging network-based application virtualization for all applications ensures that if an application ever needs to be scaled it can be done so without disruption – no downtime for it or for other applications that may be impacted by moving things around.
This creates a scalability domain that enables the opportunity to more easily implement infrastructure scalability patterns even for applications that don’t need to scale beyond a single server/instance yet.- IMPROVES PERFORMANCE. Even for a single-instance application, an application delivery controller provides value – including aiding in availability. It can offload computationally intense functions, optimize connection management, and apply acceleration policies that make even a single instance application more pleasant to use.
An architecture that leverages network-based application virtualization for every application also the architect to employ client-side and server-side techniques for improving performance, tweaking policies on both sides of “the stack” for optimal delivery of the application to users regardless of the device from which they access the application. The increasing demand for enterprise applications to be accessible from myriad mobile devices – iPad, Blackberry, and smart phones – can create problems with performance when application servers are optimized for LAN delivery to browsers. The ability to intelligently apply the appropriate delivery policies based on client device (part of its context-aware capabilities) can improve the performance of even a single-instance application for all users, regardless of device.- STRATEGIC POINT of CONTROL. Using network-based application virtualization allows you to architect strategic points of control through which security and other policies can be applied. This include authentication, authorization, and virtual patching through web application firewall capabilities. As these policies change, they can be applied at the point of control rather than in the application. This removes the need to cycle applications through the implementation-test-deploy cycle as often as vulnerabilities and security policies change and provides flexibility in scheduling.
Applications that may be deployed in a virtualized environment and that may “move” around the data center because they are not a priority and therefore are subject to being migrated to whatever resources may be available can do so without concern for being “lost”. Because the application delivery controller is the end-point, no matter where the application migrates it can always be accessed in the same way by end-users. Business continuity is an important challenge for organizations to address and as infrastructure continues to be virtualization and highly mobile the ability to maintain its interfaces becomes imperative in reducing the disruption to the network and applications as components are migrating around.- IMPROVES VISIBILITY. One of the keys to a healthy data center is keeping an eye on things. You can’t do anything about a crashed application if you don’t know it’s crashed, and the use of network-based application virtualization allows you to implement health monitoring that can notify you before you get that desperate 2am call. In a highly virtualized or cloud computing environment, this also provides critical feedback to automation systems that may be able to take action immediately upon learning an application is unavailable for any reason. Such action might be as simple as spinning up a new instance of the application elsewhere while taking the “downed” instance off-line, making it invaluable for maintaining availability of even single instance-applications.
When the application delivery infrastructure is the “access point” for all applications, it also becomes a collection point for performance-related data and usage patterns, better enabling operations to plan for increases in capacity based on actual use or as a means to improve performance.
To summarize, four key reasons to leverage network-based application virtualization are: visibility, performance, control, and flexibility.
APPLICATION DELIVERY INFRASTRUCTURE is a PART OF ENTERPRISE ARCHITECTURE
The inclusion of an architecture of an application delivery network as a part of a larger, holistic enterprise architecture is increasingly a “must” rather than a “should”. Organizations must move beyond viewing application delivery as simple load balancing in order to take full advantage of the architectural strategic advantages of using network-based application virtualization for every application. The additional control and visibility alone are worth a second look at that application delivery controller that’s been distilled down to little more than a Load balancer in the data center.
The whole is greater than the sum of its parts, and load balancing is just one of the “parts” of an application delivery controller. Architects and devops should view such data center components with an eye toward how to leverage its many infrastructure services to achieve the flexibility and control necessary to move the enterprise architecture along the path of maturity toward a truly automated data center.
Your applications - even the lonely, single-instance ones – will thank you for it.



<Return to section navigation list>
Windows Azure Platform Appliance (WAPA)
Thomas Bittman noted an increased interest in private coulds in his Virtualization Then & Now: Symposium 2009-2010 post to the Gartner blogs on 10/18/2010:
My first presentation at Symposium 2010 was “Server Virtualization: From Virtual Machines to Private Clouds.” Attendance was crazy – the large room was packed, people were standing at the back, and apparently a few dozen were turned away at the door. This proves that server virtualization is not only a hot topic, it’s getting hotter right now (one stat I mentioned was that more virtual machines would be deployed during 2011 than 2001 through 2009 combined).
I started the presentation with some fundamental changes in server virtualization since I presented a year ago.
1) Virtual machine penetration has increased 50% in the last year. We believe that nearly 30% of all workloads running on x86 architecture servers are now running on virtual machines.
2) Midsized enterprises rule. For the first time, the penetration of virtualization in midsized enterprises (100-999 employees) now exceeds that of the global 1000 (or it will before year-end). There has been a HUGE uptake in the last year. Also, unlike large enterprises, midsized enterprises tend to deploy all at once – with outside help.
3) Hyper-V is under-performing. Maybe my expectations were too high, but Hyper-V has not grabbed as much market share as I was predicting. I especially thought that Microsoft would be the big beneficiary of midmarket virtualization. Surveys show otherwise – VMware is doing pretty well there. Here’s a theory. Clients repeatedly told us that live migration was a big hole in Microsoft’s offering – even for midmarket customers (to reduce planned downtime managing the parent OS). Microsoft’s Hyper-V R2 (with live migration) came out 8/2009. Was that too late? Did the economy put pressure on midsized enterprises to virtualize early, before Hyper-V R2 was proven in the market? Or did VMware just have too much mindshare?
VMware’s competition is growing (especially Microsoft, Citrix and Oracle), but VMware is still capturing plenty of new customers.
4) Private clouds are the buzz. Every major vendor on the planet who sells infrastructure stuff has a private cloud story today. In the last year, the marketing, product announcements and acquisitions have been mind-numbing. Some of this is clearly cloudwashing (“old stuff, new name”), but we’ve seen a number of smart start-ups captured by big vendors, and important product rollouts (notably VMware’s vCloud Director). Now the question is – what will the market buy?
5) IaaS Providers Shifting to Commercial VMs. IaaS (infrastructure as a service) providers have focused on open source and internal technologies to deliver solutions at the lowest possible cost. But that’s changing. In the past year, there’s been a rapidly growing trend for IaaS providers to add support for major commercial VM formats – especially VMware, but also Hyper-V and XenServer. The reason? To create an easy on-ramp for enterprises. As enteprises virtualize (and in many cases, build private clouds), the IaaS providers know that they need to make interoperability, hybrid, overdrafting, migration as easy as possible. The question is whether that will require commercial offerings (such as VMware’s vCloud Datacenter Services, or Microsoft Dynamic Datacenter Alliance), or if conversion tools will be good enough. I tend to think that service providers better make the off-premises experience as identical to the on-premises experience as possible – and I’m not sure conversion will get them there.
Thomas published The Buzz at Gartner’s Symposium 2010: Cloud! the same day:
Because of presentations, roundtables and so forth, I only had 35 one-on-one slots available. 11 of those are on virtualization (mostly VMware and Microsoft). 9 are about cloud computing (mainly what’s ready, which services, which providers, customer experiences). 14 are about private cloud (how do I start, VMware’s vCloud, etc.). [Emphasis added.]
The sense I get so far is the interest in cloud computing continues to grow, but there is more real activity and near-term spending on private cloud solutions. A lot of interest in VMware’s vCloud – but attendees want some proof first.
At the end of the week, I’ll summarize what I learned. Should be a great week!
<Return to section navigation list>
Cloud Security and Governance
• Tanya Forsheit published Legal Implications of Cloud Computing -- Part Five (Ethics or Why All Lawyers-Not Just Technogeek Lawyers Like Me-Should Care About Data Security) to the InfoLaw Group blog on 10/19/2010:
So, you thought our cloud series was over? Wishful thinking. It is time to talk about ethics. Yes, ethics. Historically, lawyers and technologists lived in different worlds. The lawyers were over here, and IT was over there. Well, maybe not just historically. As recently as last year, I attended an ediscovery CLE where a trial lawyer announced to the audience of litigators, with great emphasis, that they would have to start talking to the "geeks" and understanding technology in order to competently handle ediscovery in almost any commercial litigation. This made the audience laugh. I have found myself on conference calls with seasoned litigators who claim that ediscovery is not their area of practice. As a more general matter, I find that lawyers believe that they do not need to concern themselves with security controls for protecting sensitive information because they are already subject to existing ethics rules and standards governing the protection of privileged information. In the meantime, lawyers everywhere, particularly solo practitioners, are singing the virtues of cloud computing solutions for case management and are casually storing client data - often unencrypted - with a third party.
Here's the reality: Technology - whether we are talking cloud computing, ediscovery or data security generally - IS very much the business of lawyers. This is true both from a legal ethics point of view and from a best practices data security point of view. The issue of ethics and the use of cloud by lawyers is not new - I recommend this piece by Jeremy Feinberg and Maura Grossman and this blog post by E. Michael Power. A few State Bar associations have opined on the subject of lawyer use of cloud computing and other technologies. This blog post does not purport to cover that entire universe. Instead, this post focuses on three recent documents, ranging from formal opinions to draft issue papers, issued by three very prominent Bar associations -- the American Bar Association (ABA), the New York State Bar Association (NYSBA), and the State Bar of California (CA Bar). These opinions and papers all drive home the following points: as succinctly stated by the ABA, "[l]awyers must take reasonable precautions to ensure that their clients’ confidential information remains secure"; AND lawyers must keep themselves educated on changes in technology and in the law relating to technology. The question, as always, is what is "reasonable"? Also, what role should Bar associations play in providing guidelines/best practices and/or mandating compliance with particular data security rules? Technology, and lawyer use of technology, is evolving at a pace that no Bar association can hope to meet. At the end of the day, do the realities of the modern business world render moot any effort by the Bar(s) to provide guidance or impose restrictions? Read on and tell us - and the ABA - what you think.
Tanya continues with a detailed analysis of the The ABA Issues Paper Concerning Client Confidentiality and Lawyers’ Use of Technology, The New York State Bar Association Formal Opinion and related qtopics.
Chris Hoff (@Beaker) asserted What’s The Problem With Cloud Security? There’s Too Much Of It… in a 10/17/2010 post:
Here’s the biggest challenge I see in Cloud deployment as the topic of security inevitably occurs in conversation:
There’s too much of it.
Huh?
More specifically, much like my points regarding networking in highly-virtualized multi-tenant environments — it’s everywhere – we’ve got the same problem with security. Security is shot-gunned across the cloud landscape in a haphazard fashion…and the buck (pun intended) most definitely does not stop here.
The reality is that if you’re using IaaS, the lines of demarcation for the responsibility surrounding security may in one take seemed blurred but are in fact extremely well-delineated, and that’s the problem. I’ve seen quite a few validated design documents outlining how to deploy “secure multi-tentant virtualized environments.” One of them is 800 pages long.
Check out the diagram below.
I quickly mocked up an IaaS stack wherein you have the Cloud provider supplying, operating, managing and securing the underlying cloud hardware and software layers whilst the applications and information (contained within VM boundaries) are maintained by the consumer of these services. The list of controls isn’t complete, but it gives you a rough idea of what gets focused on. Do you see some interesting overlaps? How about gaps?
This is the issue; each one of those layers has security controls in it. There is lots of duplication and there is lots of opportunity for things to be obscured or simply not accounted for at each layer.
Each of these layers and functional solutions is generally managed by different groups of people. Each of them is generally managed by different methods and mechanisms. In the case of IaaS, none of the controls at the hardware and software layers generally intercommunicate and given the abstraction provided as part of the service offering, all those security functions are made invisible to the things running in the VMs.
A practical issue is that the FW, VPN, IPS and LB functions at the hardware layer are completely separate from the FW, VPN, IPS and LB functions at the software layer which are in turn completely separate from the FW, VPN, IPS and LB functions which might be built into the VM’s (or virtual appliances) which sit stop them.
The security in the hardware is isolated from the security in the software which is isolated from the security in the workload. You can, today, quite literally install the same capabilities up and down the stack without ever meeting in the middle.
That’s not only wasteful in terms of resources but incredibly prone to error in both construction, management and implementation (since at the core it’s all software, and software has defects.)
Keep in mind that at the provider level the majority of these security controls are focused on protecting the infrastructure, NOT the stuff atop it. By design, these systems are blind to the workloads running atop them (which are often encrypted both at rest and in transit.) In many cases this is why a provider may not be able to detect an “attack” beyond data such as flows/traffic.
To make things more interesting, in some cases the layer responsible for all that abstraction is now the most significant layer involved in securing the system as a whole and the fundamental security elements associated with the trust model we rely upon.
The hypervisor is an enormous liability; there’s no defense in depth when your primary security controls are provided by the (*ahem*) operating system provider. How does one provide a compensating control when visibility/transparency [detective] are limited by design and there’s no easy way to provide preventative controls aside from the hooks the thing you’re trying to secure grants access to?
“Trust me” ain’t an appropriate answer. We need better visibility and capabilities to robustly address this issue. Unfortunately, there’s no standard for security ecosystem interoperability from a management, provisioning, orchestration or monitoring perspective even within a single stack layer. There certainly isn’t across them.
In the case of Cloud providers who use commodity hardware with big, flat networks with little or no context for anything other than the flows/IP mappings running over them (thus the hardware layer is portrayed as truly commoditized,) how much better/worse do you think the overall security posture is of a consumer’s workload running atop this stack. No, that’s not a rhetorical question. I think the case could be argued either side of the line in the sand given the points I’ve made above.
This is the big suck. Cloud security suffers from the exact same siloed security telemetry problems as legacy operational models…except now it does it at scale. This is why I’ve always made the case that one can’t “secure the Cloud” — at least not holistically — given this lego brick problem. Everyone wants to make the claim that they’re technology is that which will be the first to solve this problem. It ain’t going to happen. Not with the IaaS (or even PaaS) model, it won’t.
However, there is a big opportunity to move forward here. How? I’ll give you a hint. It exists toward the left side of the diagram.
/Hoff
Related articles
- Hoff’s 5 Rules Of Cloud Security… (rationalsurvivability.com)
- Hack The Stack Or Go On a Bender With a Vendor? (rationalsurvivability.com)
- The Missing Piece of Cloud Security? (pcworld.com)
- Cloud Adoption Still Struggles With Security Issues in CSO Survey (securecloudreview.com)
- VMware’s (New) vShield: The (Almost) Bottom Line (rationalsurvivability.com)
- If You Could Have One Resource For Cloud Security… (rationalsurvivability.com)

No significant articles today.
<Return to section navigation list>
Cloud Computing Events
• Penton Media will present Visual Studio Connections on 11/1 through 11/4/2010 at the Mandalay Bay Hotel in Las Vegas, NV. Following are LightSwitch and cloud-related sessions as of 10/19/2010:
VMS01: Building Business Applications with Visual Studio LightSwitch
Orville McDonald
Visual Studio LightSwitch is the simplest way to build business applications for the desktop and cloud. LightSwitch simplifies the development process by letting you concentrate on the business logic, while LightSwitch handles the common tasks for you. In this demo-heavy session, you will see, end-to-end, how to build and deploy a data-centric business application using LightSwitch. After that you will discover what is under the hood to better understand the architecture of a LightSwitch application. Finally you will learn how you can use Visual Studio 2010 Professional and Expression Blend 4 to customize and extend its UI and Data layers for when the application’s requirements grow beyond what is supported by default.VCL01: Introducing the Azure AppFabric Service Bus
Juval Lowy
The services bus is arguably the most accessible, ready to use, powerful, and needed piece of cloud computing. The service bus allows clients to connects to services across any machine, network, firewall, NAT, routers, load balancers, virtualization, IP and DNS as if they were part of the same local network, and doing all that without compromising on the programming model or security. The service bus also supports callbacks, event publishing, authentication and authorization and doing all that in a WCF-friendly manner. This session will present the service bus programming model, how to configure and administer service bus solutions, working with the dedicated relay bindings including the available communication modes, relying on authentication in the cloud for local services and the various authentication options, and how to provide for end-to-end security through the relay service. You will also see some advanced WCF programming techniques, original helper classes, productivity-enhancing utilities and tools, as well as discussion of design best practices and pitfalls.VCL02: Rocking AppFabric Access Control: Practical Scenarios, Killer Code and Wicked Tools
Michele Leroux Bustamante
AppFabric Access Control is a feature of the Windows Azure platform that makes it easy to secure web resources such as REST-based services using a simple set of standard protocols. In fact, AppFabric Access Control uniquely facilitates several scenarios not previously possible including a standards-based mechanism for securing web resources, identity federation for REST, and secure calls from Silverlight and AJAX clients to web resources including REST-based WCF services or REST-based MVC implementations. In this session, you will get a tour of the AppFabric Access Control feature set and learn how to implement these key security scenarios with the help of some custom tools that encapsulate common functionality, exposing a simple object model for working with the protocols underlying Access Control. In addition, you will learn how to integrate typical Windows Identity Foundation (WIF) authorization techniques such as ClaimsPrincipal to decouple the authentication and authorization mechanism from the business logic.
• Nicole Helmsoth described What's Missing From This Year's Cloud Circuit in a 10/19/2010 article for the HPC in the Cloud’s Behind the Cloud blog:
Conference season is upon us, folks, which for some of you means an endless series of flights and hotels and for others means anticipation officially begins now for SC ’10 in New Orleans.
There are a number of upcoming events that bridge the divide between HPC and cloud coming in the next year, one of the most notable of which will be taking place in Frankfurt, Germany at the end of this month, ISC Cloud.
While the program there will be highlighted in the coming weeks in advance of the event, a look at the events calendar is worthwhile if you have some frequent flyer miles and the desire to network and learn more about some of the bleeding edge innovations taking place in the cloud space for high-performance computing.
ISC Cloud is one of a handful of cloud events that is HPC-specific, whereas the majority of events taking place between now and spring are focused on mainstream cloud computing, or cloud for the SMEs. On the industry/academia front, however, ISC Cloud is a winner in terms of casting and conversations.
One other particular event that has caught my eye is covering a range of topics that we try to grant some exposure to here, this is the 11th annual CCGrid 2011 function—a three day HPC/Cloud/Grid fest with a rather interesting lineup of topics.
Among the host of issues to be tackled are those related to current paradigms and technologies (so most likely topics revolving around system architecture and design, old and new programming models, and of course, GPGPU computing). Additionally, the focus will be on emerging matters of green computing and the economic implications of utility computing.
Perhaps one of the more eye-catching topics is in the realm of applications and experiences, which as the event organizers explain will focus on “applications to real and complex problems in science, engineering, business and society” along with case studies based on large-scale deployments of systems or applications.
Bingo, CCGrid ’11 organizers—this is what’s missing from the conversations…real-world deployments, practical scenarios, and most importantly, balanced and truthful outcome reports.
The Missing Meat of Mainstream Cloud Conferences
It seems to me that some of the most successful conferences have some kind of focus on real-world applications versus simply discussion of abstract (albeit relevant) topics. Just as any publication devoted to covering a technological paradigm (ahem) that is still in its infancy owes its readers some keen delivery of practical examples or case studies of actual deployments, it seems that conference schedules should deliver that same relation to the real world as well.
As I prepare to embark on a journey to Cloud Expo, which is coming in the first week of November, I am forced to spend some time planning which sessions hold the most value, both for you guys and for my own personal enjoyment. However, I take a look at the session list and see a number of technical discussions and practical implementation sessions, but these are all aimed at teaching people how to use the cloud—what it is, how it works, and how the speaker’s own view/product (after all, most of the speakers are CTOs are major cloud companies) fits into the overall picture. What this event needs are two or three sessions that simply a “How X Left Behind its Legacy Systems” or “Details about How X Implemented a Private Cloud” led by, well, X himself.
I wonder how many of the speakers will talk about actual deployments, the challenges, the benefits—all of this in a way that is balanced and fair, revealing the good, the bad, and the ugly (because this cloud migration business is no picnic, at least according to some of the larger enterprise leaders I’ve talked to candidly about how long it took for them to get their solution up and running and the roadblocks along the way).
There is certainly nothing wrong with brainstorming and information-sharing sessions at any event and in fact, for academic conferences like ISC Cloud, this is ideal since guests get a broad range of deeper insights than might come from a mainstream, cloud-for-all conference. However, it seems to me that for users, even those who are coming to a mainstream cloud event, one of the most salient bits of information they could glean would be in the form of a few talks on the challenges and benefits of an actual deployment. No product solution chats (although I know they pay the bills for organizers) and no single-solution discussions about one, single-sided aspect of a cloud deployment (i.e., choosing and deploying an automation product)—just a straight-up, “this is my company, this is what we do, these were our IT challenges, this was our decision on the cloud front (public, hybrid, private, etc.) and here’s the skinny on how it went down.”
Why is this so difficult to find?
I have high hopes for the CCGrid’s focus on applications and implementations and will look for news about that as it happens.
Although May 2011 might seem to be a point in the inconceivably distant future, the 11th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid 2011) has announced its call for papers with a deadline of November 30 for the Newport Beach, California event sponsored by the IEEE Computer Society, Technical Committee on Scalable Computing and the ACM.
The Atlantic Canada Open Source Showcase (ACOSS) announced on 10/18/2010 CloudCamp Conference Taking Place In Halifax, November 1st 2010:
1st, 2010, A CloudCamp conference will be taking place at the World Trade and Convention Center in Halifax, Nova Scotia. CloudCamp is “an unconference where early adopters of Cloud Computing technologies exchange ideas.” The conference is not vendor specific and covers propriety and open source cloud computing related products. In particular, Shawn Duggan will be giving a talk on his experiences migrating an open source application into a cloud computing environment. Everyone from end users to IT professionals are invited to attend and participate.
Registration is currently open on the Halifax Cloud Camp webpage.
[The] CloudCamp logo is the property of the CloudCamp organization.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• James Hamilton [pictured below] described on 10/19/2010 a new Amazon Web Services Book by Jeff Barr:
Long time Amazon Web Services [evangelist]
AlumJeff Barr has written a book on AWS. Jeff’s been with AWS since the very early days and he knows the services well.
The new book Host Your Web Site in the Cloud: Amazon Web Services Made Easy, covers each of the major AWS services, how to write code against them, with code examples in PHP. It covers S3, EC2, SQS, EC2 Monitoring, Auto Scaling, Elastic Load Balancing, and SimpleDB. The table of contents:
Recommended if you are interested in Cloud Computing and AWS: http://www.amazon.com/Host-Your-Web-Site-Cloud/dp/0980576830.

Strictly speaking, Jeff is still an Amazon evangelist, so alumnus isn’t quite correct.
Amazon Web Services sent an Announcing Amazon SNS Management Console e-mail message on 10/18/2010:
Dear Amazon EC2 Customer,
The AWS Management Console is available free of charge at: aws.amazon.com/console.
Sincerely,
The Amazon SNS Team
<Return to section navigation list>
Technorati Tags: Windows Azure, Windows Azure Platform, Azure Services Platform, Azure Storage Services, Azure Table Services, Azure Blob Services, Azure Drive Services, Azure Queue Services, SQL Azure Database, SADB, Open Data Protocol, OData, Windows Azure AppFabric, Azure AppFabric, Windows Server AppFabric, Server AppFabric, Cloud Computing, Visual Studio LightSwitch, LightSwitch, Silverlight, Windows Phone 7, WP7, Amazon Web Services, AWS, Amazon Simple Notification Service, SNS, NuPack

















{kind=link}
0 comments:
Post a Comment