Windows Azure and Cloud Computing Posts for 10/9/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Updated 10/10/2010 with articles marked • Tip: Paste the bullet to the Ctrl+F search box.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA)
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Supergadgets rated my Cloud Computing with the Windows Azure Platform among the Best Windows Azure Books in a recent HubPages post:
… Cloud Computing with the Windows Azure Platform
I prefer Wrox's IT books much as well because they are mostly written by very experienced authors. Cloud computing with Azure book is an excellent work with the best code samples I have seen for Azure platform. Although the book is a bit old and some Azure concepts evolved in a different way, still it is one of the best about Azure. Starting with the concept of cloud computing, the author takes the reader to a progressive journey into the depths of Azure: Data center architecture, Azure product fabric, upgrade & failure domains, hypervisor (in which some books neglect the details), Azure application lifecycle, EAV tables usage, blobs. Plus, we learn how to use C# in .Net 3.5 for Azure programming. Cryptography, AES topics in security section are also well-explained. Chapter 6 is also important to learn about Azure Worker management issues.
Overall, another good reference on Windows Azure which I can suggest reading to the end.
p.s: Yes, the author had written over 30 books on different MS technologies.
Book Highlights from Amazon
- Handles numerous difficulties you might come across when relocating from on-premise to cloud-based apps (for example security, privacy, regulatory compliance, as well as back-up and data recovery)
- Displays how you can conform to ASP.NET validation and role administration to Azure web roles
- Discloses the advantages of offloading computing solutions to more than one WorkerRoles when moving to Windows Azure
- Shows you how to pick the ideal mixture of PartitionKey and RowKey values for sharding Azure tables
- Talks about methods to enhance the scalability and overall performance of Azure tables …
Azure Blob, Drive, Table and Queue Services
• Clemens Vasters (@clemensv) released Blobber– A trivial little [command-line] tool for uploading/listing/deleting Windows Azure Blob Storage files on 10/9/2010:
There must be dozens of these things, but I didn’t find one online last week and I needed a tool like this to prep a part of my keynote demo in Poland last week – and thus I wrote one. It’s a simple file management utility that works with the Windows Azure Blob store. No whistles, no bells, 344 lines of code if you care to look, both exe and source downloads below, MS-PL license.
Examples:
List all files from the 'images' container:
Blobber.exe -o list -c images -a MyAcct -k <key>
List all files matching *.jpg from the 'images' container:
Blobber.exe -o list -c images -a MyAcct -k <key> *.jpg
List all files matching *.jpg from the 'images' container (case-insensitive):
Blobber.exe -o list -l -c images -a MyAcct -k <key> *.jpg
Delete all files matching *.jpg from the 'images' container:
Blobber.exe -o deletefile -l -c images -a MyAcct -k <key> *.jpg
Delete 'images' container:
Blobber.exe -o deletectr -c images -a MyAcct -k <key>
Upload all files from the c:\pictures directory into 'images' container:
Blobber.exe -o upload -c images -a MyAcct -k <key> c:\pictures\*.jpg
Upload like above and include all subdirectories:
Blobber.exe -o upload -s -c images -a MyAcct -k <key> c:\pictures\*.*
Upload like above and convert all file names to lower case:
Blobber.exe -o upload -l -s -c images -a MyAcct -k <key> c:\pictures\*.*
Upload all files from the c:\pictures directory into 'images' container on dev storage:
Blobber.exe -o upload -l -s -c images -d c:\pictures\*.*
Arguments:
-o <operation> upload, deletectr, deletefile, list (optional, default:'list')
-o list [options] -c <container> <relative-uri-suffix-pattern> (* and ? wildcards)
-o upload [options] [-s] -c <container> <local-path-file-pattern>
-o deletefile [options] -c <container> <relative-uri-suffix-pattern> (* and ? wildcards)
-o deletectr [options] -c <container>
-c <container> Container (optional, default:'files')
-s Include local file subdirectories (optional, upload only)
-p Make container public (optional)
-l Convert all paths and file names to lower case (optional)
-d Use the local Windows Azure SDK Developer Storage (optional)
-b <baseUri> Base URI (optional override)
-a <accountName> Account Name (optional if specified in config)
-k <key> Account Key (optional if specified in config)You can also specify your account infomation in blobber.exe.config and omit the -a/-k arguments.
Executable: Blobber-exe.zip (133.4 KB)
Source: Blobber-src.zip (5.41 KB)[Update: I just found that I unintentionally used the same name as a similar utility from Codeplex: http://blobber.codeplex.com/. Sorry.]
Neil MacKenzie posted Performance in Windows Azure and Azure Storage on 10/9/2010 to his new WordPress blog:
Azure Storage Team
The Azure Storage Team blog – obligatory reading for anyone working with Azure Storage – has a number of posts about performance.
The Windows Azure Storage Abstractions and their Scalability Targets post documents limits for storage capacity and performance targets for Azure blobs, queues and tables. The post describes a scalability target of 500 operations per second for a single partition in an Azure Table and a single Azure Queue. There is an additional scalability target of a “few thousand requests per second” for each Azure storage account. The scalability target for a single blob is “up to 60 MBytes/sec.”
The Nagle’s Algorithm is Not Friendly towards Small Requests post describes issues pertaining to how TCP/IP handles small messages < 1460 bytes). It transpires that Azure Storage performance may be improved by turning Nagle off. The post shows how to do this.
Rob Gillen
Rob Gillen (@argodev) has done a lot of testing of Azure Storage performance and, in particular, on maximizing throughput for uploading and downloading of Azure Blobs. He has documented this in a series of posts: Part 1, Part 2, Part 3. The most surprising observation is that it while operating completely inside Windows Azure it is not worth doing parallel downloads of a blob because the overhead of reconstructing the blob is too high.
He has another post, External File Upload Optimizations for Windows Azure, that documents his testing of using various block sizes for uploads of blobs from outside an Azure datacenter. He suggests that choosing a 1MB block size may be an appropriate rule-of-thumb choice. These uploads can, of course, be performed in parallel.
University of Virginia
A research group at the University of Virginia presented the results of its investigations into the performance of Windows Azure at the 2010 ACM International Symposium on High Performance Distributed Computing. The document is downloadable from the ACM Library or (somewhat cheaper) from the webpage of one of the researchers. There is also a PowerPoint version for those with a short attention span.
The paper covers both Windows Azure and Azure Storage. The researchers used up to 192 instances at a time to investigate both the times taken for instance-management tasks and the maximum storage throughput as the number of instances varied. There is a wealth of performance information which deserves the attention of anyone developing scalable services in Windows Azure. Who would have guessed, for example, that inserting a 1KB entity into an Azure Table is 26 times faster than updating the same entity while inserting a 64KB entity is only 4 times faster.
This work is credited to: Zach Hill, Jie Li, Ming Mao, Arkaitz Ruiz-Alvarez, and Marty Humphrey – all of the University of Virginia.
Microsoft eXtreme Computing Group
The Microsoft eXtreme Computing Group has a website, Azurescope, that documents benchmarking and guidance for Windows Azure. The Azurescope website has a page describing Best Practices for Developing on Window Azure and a set of pages with code samples demonstrating various optimal techniques for using Windows Azure Storage services. Note that Rob Gillen and the University of Virginia group are also involved in the Azurescope project.
Bill Wilder asked Why Don't Windows Azure Libraries Show Up In Add Reference Dialog when Using .NET Framework Client Profile? on 10/9/2010:
You are writing an application for Windows – perhaps a Console App or a WPF Application – or maybe an old-school Windows Forms app. Every is humming along. Then you want to interact with Windows Azure storage. Easy, right? So you Right-Click on the References list in Visual Studio, pop up the trusty old Add Reference dialog box, and search for Microsoft.WindowsAzure.StorageClient in the list of assemblies.
But it isn’t there!
You already know you can’t use the .NET Managed Libraries for Windows Azure in a Silverlight app, but you just know it is okay in a desktop application.
You double-check that you have installed Windows Azure Tools for Microsoft Visual Studio 1.2 (June 2010) (or at least Windows Azure SDK 1.2 (last refreshed from June in Sept 2010 with a couple of bug-fixes)).
You sort the list by Component Name, then leveraging your absolute mastery of the alphabet, you find the spot in the list where the assemblies ought to be, but they are not there. You see the one before in the alphabet, the one after it in the alphabet, but no Microsoft.WindowsAzure.StorageClient assembly in sight. What gives?
Look familiar? Where is the Microsoft.WindowsAzure.StorageClient assembly?
Azure Managed Libraries Not Included in .NET Framework 4 Client Profile
If your eyes move a little higher in the Add Reference dialog box, you will see the problem. You are using the .NET Framework 4 Client Profile. Nothing wrong with the Client Profile – it can be a friend if you want a lighter-weight version of the .NET framework for deployment to desktops where you can’t be sure your .NET platform bits are already there – but Windows Azure Managed Libraries are not included with the Client Profile.
Bottom line: Windows Azure Managed Libraries are simply not supported in the .NET Framework 4 Client Profile
How Did This Happen?
It turns out that in Visual Studio 2010, the default behavior for many common project types is to use the .NET Framework 4 Client Profile. There are some good reasons behind this, but it is something you need to know about. It is very easy to create a project that uses the Client Profile because it is neither visible – and with not apparent option for adjustment – on the Add Project dialog box – all you see is .NET Framework 4.0:
The “Work-around” is Simple: Do Not Use .NET Framework 4 Client Profile
While you are not completely out of luck, you just can’t use the Client Profile in this case. And, as the .NET Framework 4 Client Profile documentation states:
If you are targeting the .NET Framework 4 Client Profile, you cannot reference an assembly that is not in the .NET Framework 4 Client Profile. Instead you must target the .NET Framework 4.
So let’s use the (full) .NET Framework 4.
Changing from .NET Client Profile to Full .NET Framework
To move your project from Client Profile to Full Framework, right-click on your project in Solution Explorer (my project here is called “SnippetUploader”):
From the bottom of the pop-up list, choose Properties.
This will bring up the Properties window for your application. It will look something like this:
Of course, by now you probably see the culprit in the screen shot: change the “Target framework:” from “.NET Framework 4 Client Profile” to “.NET Framework 4” (or an earlier version) and you have one final step:
Now you should be good to go, provided you have Windows Azure Tools for Microsoft Visual Studio 1.2 (June 2010) installed. Note, incidentally, that the Windows Azure tools for VS mention support for
…targeting either the .NET 3.5 or .NET 4 framework.
with no mention of support the .NET Client Profile. So stop expecting it to be there!






Bill Wilder reported You can't add a reference to Microsoft.WindowsAzure.StorageClient.dll as it was not build against the Silverlight runtime on 10/8/2010:
Are you developing Silverlight apps that would like to talk directly to Windows Azure APIs? That is perfectly legal, using the REST API. But if you want to use the handy-dandy Windows Azure Managed Libraries – such as Microsoft.WindowsAzure.StorageClient.dll to talk to Windows Azure Storage – then that’s not available in Silverlight.
As you may know, Silverlight assembly format is a bit different than straight-up .NET, and attempting to use Add Reference from a Silverlight project to a plain-old-.NET assembly just won’t work. Instead, you’ll see something like this:
If you pick a class from the StorageClient assembly – let’s say, CloudBlobClient – and check the documentation, it will tell you where this class is supported:
Okay – so maybe it doesn’t exactly – the Target Platforms list is empty – presumably an error of omission. But going by the Development Platforms list, you wouldn’t expect it to work in Silverlight.
There’s Always REST
As mentioned, you are always free to directly do battle with the Azure REST APIs for Storage or Management. This is a workable approach. Or, even better, expose the operations of interest as Azure services – abstracting them as higher level activities. You have heard of SOA, haven’t you?


<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
• David Ebbo (@DavidEbbo) tweeted on 10/9/2010:
We have a preliminary #nupack feed using oData at http://bit.ly/dkczL7. You'll need to build newest client to use it.
Here’s what the first entry looks like:

See Kelly Fiveash’s Microsoft lovingly open sources .NET package manager Register article of 10/7/2010 for more information about NuPack.
• See Microsoft’s Campbell Gunn announced “no plans in Version 1 to support/extend oData” in a 10/9/2010 reply to apacifico’s Lightswitch dataprovider support and odata question of 10/9/2010 in the LightSwitch Extensibility forum in the Visual Studio LightSwitch section below.
• Nikos Makris explained Transforming Latitude and Longitude into Geography SQL Server Type in this brief post of 10/9/2010:
SQL Server 2008 provides support for spatial data and many accompanying functions. SQL Server Reporting Services 2008 R2 has a built in support for maps (SHD files or even bing maps). There is a handy wizard in Report Builder 3.0 that will guide you through through the report creation process with map. If you want to use Bing Maps you have to have a Geography type in your SQL datasource somewhere.
I recently faced a situation where the customer had the Lat & Long coordinates of the spots which should be plotted in a map. In order to convert lat & long in Geography type use the following T-SQL:
geography::STPointFromText('POINT(' + CAST([Longitude] AS VARCHAR(10)) + ' ' +
CAST([Latitude] AS VARCHAR(10)) + ')', 4326)Then you have the option of using the Bing maps in your SSRS reports.
4326 refers to the EPSG:4326 Geographic longitude-latitude projection. You can learn more about EPSG:4326 here and read Microsoft Research’s Adding the EPSG:4326 Geographic Longitude-Latitude Projection to TerraServer publication by Siddharth Jain and Tom Barclay of August 2003. The latter might tell you more than you want to know about EPSG:4326.
My (@rogerjenn) Patrick Wood Requests Votes for Access 2010 ADO Connections to SQL Azure post to the AccessInDepth blog of 10/9/2010 follows up on an earlier post:
In his You Can Vote to Get ADO for Microsoft Access® to Connect to SQL Azure™ post of 10/9/2010, Patrick Wood wrote:
Microsoft has put much more emphasis lately on listening to developers and users when they ask for Features to be added to Microsoft Software. This has led to many improvements in new software releases and updates. Microsoft is really listening to us but you have to know where to give them your requests.
On Friday Roger Jennings posted about this on his Roger Jennings’ Access Blog, “I agreed and added three votes.” He also wrote about it on his software consulting organization blog, OakLeaf Systems and added a link to the The #sqlazure Daily which I have found to be a great place to keep up with the very latest tweets, articles, and news about SQL Azure. Roger Jennings has written numerous books about programming with Microsoft Software, a number of which have been about Microsoft Access. His books are among the very best about Access and contain a wealth of helpful detailed information. I have never had a conversation or any correspondence with before now but I greatly appreciate his support in this matter.
Why do we need ADO (this is not ADO.Net) when we have ODBC to link tables and queries to SQL Azure? If you are just planning to use SQL Azure for your own use you can get by fine without it. But if you distribute Access Databases that use SQL Azure as a back end then you have to be very careful because an ODBC DSN is a plain text file that contains your server web address, your user name, and your password. If you use DSN-less linked tables and queries another programmer can easily read all your connection information through the TableDef.Connect or QueryDef.Connect properties even if you save your database as an accde or mde file.
ADO allows you to use code to connect to SQL Server and if we had the same capability with SQL Azure this would allow us to keep all of our connection information in code. Then using accde or mde files will provide us with better security. ADO also provides additional functionality which can make developing with SQL Azure easier.
We have already picked up a few votes for ADO but we need a lot more to let Microsoft know there are enough of us developers who want ADO to make it worthy of their attention.
You can vote for ADO here. You can use 3 votes at a time and your support is greatly appreciated.
You can read more about SQL Azure and Microsoft Access at my Gaining Access website.
Happy computing,
Patrick (Pat) Wood
Gaining Access
Dan Jones explains Moving Databases Between SQL Azure Servers with a .dacpac in a 10/9/2010 post:
This week I had to move a couple of databases between two SQL Azure accounts. I needed to decommission one account and thus get the important stuff out before nuking it. My goal was straight forward: move two databases from one SQL Azure server (and account) to another SQL Azure server (and account). The applications have a fairly high tolerance for downtime which meant I didn’t have to concern myself with maintaining continuity.
I opted to go the .dacpac route for two simple reasons: first, I wanted to get the schema moved over first and validate it before moving the data and second, I wanted to have the schema in a portable format that wasn’t easily altered. Think of this as a way of preserving the integrity of the schema. Transact-SQL scripts are too easy to change without warning.
I connected Management Studio to the server being decommissioned and from each database I created a .dacpac – I did this by right-clicking the database in Object Explorer, selecting Tasks –> Extract Data-tier Application… I followed the prompts in the wizard, accepting all of the defaults. Neither of my schema are very complex so the process was extremely fast for both.
Once I had the two .dacpacs on my local machine I connected Management Studio to the new server. I expanded the Management node, right-clicked on Data-tier Applications and selected Deploy Data-tier Application. This launched the deployment wizard. I followed the wizard, accepting the defaults. I repeated this for the second database.
Now that I had the schema moved over, and since I used the Data-tier Application functionality I had confidence everything moved correctly – because I didn’t receive any errors! It’s time to move the data.
I opted to use the Import/Export wizard for this. It was a simple and straight forward. I launched the wizard, pointed to the original database, pointed to the new database, selected my tables and let ‘er rip! It was fast (neither database is very big) and painless. One thing to keep in mind when doing this is it’s not performing a server to server copy; it brings the data locally and then pushes it back up to the cloud.
The final step was to re-enable the logins. For security reasons passwords are not stored in the .dacpac. When SQL logins are created during deployment, each SQL login is created as a disabled login with a strong random password and the MUST_CHANGE clause. Thereafter, users must enable and change the password for each new SQL login (using the ALTER LOGIN command, for example). I quick little Transact-SQL and my logins are back in business.
The entire process took me about 15 minutes to complete (remember my databases are relatively small) – it was awesome!
Every time I use SQL Azure I walk away with a smile on my face. It’s extremely cool that I have all this capability at my finger tips and I don’t have to worry about managing a service, applying patches, etc.
Dan is a Principal Program Manager at Microsoft on the SQL Server Manageability team.
Pablo M. Cibraro (@cibrax) explained ASP.NET MVC, WCF REST and Data Services – When to use what for RESTful services on 10/8/2010:
Disclaimer: This post only contains personal opinions about this subject
In the way I see it, REST mainly comes in for two scenarios, when you need to expose some AJAX endpoints for your web application or when you need to expose an API to external applications through well defined services.
For AJAX endpoints, the scenario is clear, you want to expose some data for being consumed by different web pages with client scripts. At this point, what you expose is either HTML, text, plain XML, or JSON, which is the most common, compact and efficient format for dealing with data in javascript. Different client libraries like JQuery or MooTools already come with built-in support for JSON. This data is not intended for being consumed by other clients rather than the pages running in the same web domain. In fact, some companies add custom logic in these endpoints for responding only to requests originated in the same domain.
For RESTful services, the scenario is completely different, you want to expose data or business logic to many different client applications through a well know API. Good examples of REST services are twitter, the Windows Azure storage services or the Amazon S3 services to name a few.
Smart client applications implemented with Silverlight, Flex or Adobe Air also represent client applications that can be included in this category with some restrictions, as they can not make cross domain call to HTTP services by default unless you override the cross-domain policies.
A common misconception is to think that REST services only mean CRUD for data, which is one of the most common scenarios, but business workflows can also be exposed through this kind of service as it is shown in this article “How to GET a cup of coffee”
When it comes to the .NET world, you have three options for implementing REST services (I am not considering third party framework or OS projects in this post),
- ASP.NET MVC
- WCF REST
- WCF Data Services (OData)
ASP.NET MVC
This framework represents the implementation of the popular model-view-controller (MVC) pattern for building web applications in the .NET space. The reason for moving traditional web application development toward this pattern is to produce more testable components by having a clean separation of concerns. The three components in this architecture are the model, which only represents data that is shared between the view and the controller, the view, which knows how to render output results for different web agents (i.e. a web browser), and finally the controller, which coordinates the execution of an use case and the place where all the main logic associated to the application lives on. Testing ASP.NET Forms applications was pretty hard, as the implementation of a page usually mixed business logic with rendering details, the view and the controller were tied together, and therefore you did not have a way to focus testing efforts on the business logic only. You could prepare your asp.net forms application to use MVC or MVP (Model-View-Presenter) patterns to have all that logic separated, but the framework itself did not enforce that.
On the other hand, in ASP.NET MVC, the framework itself drives the design of the web application to follow an MVC pattern. Although it is not common, developers can still make terrible mistakes by putting business logic in the views, but in general, the main logic for the application will be in the controllers, and those are the ones you will want to test.
In addition, controllers are TDD friendly, and the ASP.NET MVC team has made a great work by making sure that all the ASP.NET intrinsic objects like the Http Context, Sessions, Request or Response can be mocked in an unit test.
While this framework represents a great addition for building web applications on top of ASP.NET, the API or some components in the framework (like view engines) not necessarily make a lot of sense when building stand alone services. I am not saying that you could not build REST services with ASP.NET MVC, but you will have to leverage some of the framework extensibility points to support some of the scenarios you might want to use with this kind of services.
Content negotiation is a good example of an scenario not supported by default in the framework, but something you can implement on your own using some of the available extensions. For example, if you do not want to tie your controller method implementation to an specific content type, you should return an specific ActionResult implementation that would know how to handle and serialize the response in all the supported content types. Same thing for request messages, you might need to implement model binders for mapping different content types to the objects actually expected by the controller.
The public API for the controller also exposes methods that are more oriented to build web applications rather than services. For instance, you have methods for rendering javascript content, or for storing temporary data for the views.
If you are already developing a website with ASP.NET MVC, and you need to expose some AJAX endpoints (which actually represents UI driven services) for being consumed in the views, probably the best thing you can do is to implement them with MVC too as operations in the controller. It does not make sense at this point to bring WCF to implement those, as it would only complicate the overall architecture of the application. WCF would only make sense if you need to implement some business driven services that need to be consumed by your MVC application and some other possible clients applications as well.
This framework also introduced a new routing mechanism for mapping URLs to controller actions in ASP.NET, making possible to have friendly and nice URLS for exposing the different resources in the API.
As this framework is layered on top of ASP.NET, one thing you might find complicated to implement is security. Security in ASP.NET is commonly tied to a web application, so it is hard to support schemes where you need different authentication mechanisms for your services. For example, if you have basic authentication enabled for the web application hosting the services, it would be complicated to support other authentication mechanism like OAuth. You can develop custom modules for handling these scenarios, but that is something else you need to implement.
WCF REST
The WCF Web Http programming model was first introduced as part of the .NET framework 3.5 SP1 for building non-SOAP http services that might follow or not the different REST architectural constraint. This new model brought to the scene some new capabilities for WCF by adding new attributes in the service model ([WebGet] and [WebInvoke]) for routing messages to service operations through URIs and Http methods, behaviors for doing same basic content negotiation and exception handling, a new WebOperationContext static object for getting access and controlling different http header and messages, and finally a new binding WebHttpBinding for handling some underline details related to the http protocol.
The WCF team later released an REST starter kit in codeplex with new features on top of this web programming model to help developers to produce more RESTful services. This starter kit also included a combination of examples and Visual Studio templates for showing how some of the REST constraints could be implemented in WCF, and also a couple of interesting features to support help pages, output caching, intercepting request messages and a very useful Http client library for consuming existing services (HttpClient)
Many of those features were finally included in the latest WCF release, 4.0, and also the ability of routing messages to the services with friendly URLs using the same ASP.NET routing mechanism that ASP.NET MVC uses.
As services are first citizens in WCF, you have exclusive control over security, message size quotas and throttling for every individual services and not for all services running in a host as it would happen with ASP.NET. In addition, WCF provides its own hosting infrastructure, which is not dependant of ASP.NET so it is possible to self hosting services in any regular .NET application like a windows service for example.
In the case of hosting services in ASP.NET with IIS, previous versions of WCF (3.0 and 3.5) relied on a file with “svc” extension to activate the service host when a new message arrived. WCF 4.0 now supports file-less activation for services hosted in ASP.NET, which relies on a configuration setting, and also a mechanism based on Http routing equivalent to what ASP.NET MVC provides, making possible to support friendly URLs. However, there is an slight difference in the way this last one works compared to ASP.NET MVC. In ASP.NET MVC, a route specifies the controller and also the operation or method that should handle a message. In WCF, the route is associated to a factory that knows how to create new instances of the service host associated to the service, and URI templates attached to [WebGet] and [WebInkoke] attributes in the operations take care of the final routing. This approach works much better in the way I see it, as you can create an URI schema more oriented to resources, and route messages based on Http Verbs as well without needing to redefine additional routes.
The support for doing TDD at this point is somehow limited fore the fact that services rely on the static context class for getting and setting http headers, making very difficult to initialize that one in a test or mock it for setting some expectations.
The content negotiation story was improved in WCF 4.0, but it still needs some twists to make it complete as you might need to extend the default WebContentTypeMapper class for supporting custom media types other than the standard “application/xml” for xml and “application/json” for JSON.
The WCF team is seriously considering to improve these last two aspects and adding some other capabilities to the stack for a next version.
WCF Data Services
WCF Data Services, formerly called ADO.NET Data Services, was introduced in the .NET stack as way of making any IQueryable data source public to the world through a REST API. Although a WCF Data Service sits on top of the WCF Web programming model, and therefore is a regular WCF service, I wanted to make a distinction here for the fact that this kind of service exposes metadata for the consumers, and also adds some restrictions for the URIs and the types that can be exposed in the service. All these features and restrictions have been documented and published as a separate specification known as OData.
The framework includes a set of providers or extensibility points that you can customize to make your model writable, extend the available metadata, intercepting messages or supporting different paging and querying schemas.
A WCF Data Service basically uses URI segments as mechanism for expressing queries that can be translated to an underline linq provider, making possible to execute the queries on the data source itself, and not something that happens in memory. The result of executing those queries is what finally got returned as response from the service. Therefore, WCF Data services use URI segments to express many of supported linq operators, and the entities that need to be retrieved. This capability of course is what limit the URI space that you can use on your service, as any URI that does not follow the OData standard will result in an error.
Content negotiation is also limited to two media types, JSON and Xml Atom, and the content payload itself is restricted to specific types that you can find as part of the OData specification.
Besides of those two limitations, WCF Data Service is still extremely useful for exposing a complete data set with query capabilities through a REST interface with just a few lines of code. JSON and Atom are two very accepted formats nowadays, making this technology very appealing for exposing data that can easily be consumed by any existing client platform, and even web browsers.
Also, for Web applications with ajax and smart client applications, you do not need to reinvent the wheel and create a complete set of services for just exposing data with a CRUD interface. You get your existing data model, configure some views or filters for the data you want to expose in the model in the data service itself, and that is all.
Steve Yi posted Model First For SQL Azure to the SQL Azure Team blog on 9/30/2010 (missed when posted)
One of the great uses for ADO.NET Entity Framework 4.0 that ships with .NET Framework 4.0 is to use the model first approach to design your SQL Azure database. Model first means that the first thing you design is the entity model using Visual Studio and the Entity framework designer, then the designer creates the Transact-SQL for you that will generate your SQL Azure database schema. The part I really like is the Entity framework designer gives me a great WYSIWYG experience for the design of my tables and their inter-relationships. Plus as a huge bonus, you get a middle tier object layer to call from your application code that matches the model and the database on SQL Azure.
Visual Studio 2010
Data Layer Assembly
At this point you should have a good idea of what your data model is, however you might not know what type of application you want to make; ASP.NET MVC, ASP.NET WebForms, Silverlight, etc.. So let’s put the entity model and the objects that it creates in a class library. This will allow us to reference the class library, as an assembly, for a variety of different applications. For now, create a new Visual Studio 2010 solution with a single class library project.
Here is how:
- Open Visual Studio 2010.
- On the File menu, click New Project.
- Choose either Visual Basic or Visual C# in the Project Types pane.
- Select Class Library in the Templates pane.
- Enter ModelFirst for the project name, and then click OK.
The next set is to add an ADO.NET Entity Data Model item to the project, here is how:
- Right click on the project and choose Add then New Item.
- Choose Data and then ADO.NET Entity Data Model
- Click on the Add Button.
- Choose Empty Model and press the Finish button.
Now you have an empty model view to add entities (I still think of them as tables).
Designing You Data Structure
The Entity Framework designer lets you drag and drop items from the toolbox directly into the designer pane to build out your data structure. For this blog post I am going to drag and drop an Entity from the toolbox into the designer. Immediately I am curious about how the Transact-SQL will look from just the default entity.
To generate the Transact-SQL to create a SQL Azure schema, right click in the designer pane and choose Generate Database From Model. Since the Entity Framework needs to know what the data source is to generate the schema with the right syntax and semantics we are asked by Entity Framework to enter connection information in a set of wizard steps.
Since I need a New Connection to I press the Add Connection button on the first wizard page. Here I enter connection information for a new database I created on SQL Azure called ModelFirst; which you can do from the SQL Azure Portal. The portal also gives me other information I need for the Connection Properties dialog, like my Administrator account name.
Now that I have the connection created in Visual Studio’s Server Explorer, I can continue on with the Generate Database Wizard. I want to uncheck that box that saves my connection string in the app.config file. Because this is a Class Library the app.config isn’t relevant -- .config files go in the assembly that calls the class library.
The Generate Database Wizard creates an Entity Framework connection string that is then passed to the Entity Framework provider to generate the Transact-SQL. The connection string isn’t stored anywhere, however it is needed to connect to the SQL Azure to find out the database version.
Finally, I get the Transact-SQL to generate the table in SQL Azure that represents the Transact-SQL.
-- -------------------------------------------------- -- Creating all tables -- -------------------------------------------------- -- Creating table 'Entity1' CREATE TABLE [dbo].[Entity1] ( [Id] int IDENTITY(1,1) NOT NULL ); GO -- -------------------------------------------------- -- Creating all PRIMARY KEY constraints -- -------------------------------------------------- -- Creating primary key on [Id] in table 'Entity1' ALTER TABLE [dbo].[Entity1] ADD CONSTRAINT [PK_Entity1] PRIMARY KEY CLUSTERED ([Id] ASC); GOThis Transact-SQL is saved to a .sql file which is included in my project. The full project looks like this:
I am not going to run this Transact-SQL on a connection to SQL Azure; I just wanted to see what it looked like. The table looks much like I expected it to, and Entity Framework was smart enough to create a clustered index which is a requirement for SQL Azure.
Summary
Watch for our upcoming video and interview with Faisal Mohamood of the Entity Framework team to demonstrate a start-to-finish example of Model First. From modeling the entities, generating the SQL Azure database, and all the way to inserting and querying data utilizing Entity Framework.
Make sure to check back, or subscribe to the RSS feed to be alerted as we post more information. Do you have questions, concerns, comments? Post them below and we will try to address them.





C|Net Download posted a link to Kreuger Systems, Inc.’s OData Browser 1.0 for iPhone recently:
OData Browser enables you to query and browse any OData source. Whether you're a developer or an uber geek who wants access to raw data, this app is for you. It comes with the following sources already configured:
- Netflix - A huge database of movies and TV shows
- Open Government Initiative - Access to tons of data published by various US government branches
- Vancouver Data Service - Huge database that lists everything from parking lots to drinking fountains
- Nerd Dinner - A social site to meet other nerds
- Stack Overflow, Super User, and Server Fault - Expert answers for your IT needs Anything else!
If you use Sharepoint 2010, IBM WebSphere, Microsoft Azure, then you can use this app to browse that data. The app features:
- Support for data relationship following
- Built-in map if any of the data specifies a longitude and latitude
- Built-in browser to navigate URLs and view HTML
- Query editor that lists all properties for feeds
Use this app to query your own data or to learn about OData. There is a vast amount of data available today and data is now being collected and stored at a rate never seen before. Much, if not most, of this data however is locked into specific applications or formats and difficult to access or to integrate into new uses. The Open Data Protocol (OData) is a Web protocol for querying and updating data that provides a way to unlock your data and free it from silos that exist in applications today.
Preconfigured sources are the usual suspects.
Hilton Giesenow produced an undated 00:12:26 Use SQL Azure to build a cloud application with data access video segment for MSDN:

Microsoft SQL Azure provide for a suite of great relational-database-in-the-cloud features. In this video, join Hilton Giesenow, host of The Moss Show SharePoint Podcast, as he explores how to sign up and get started creating a Microsoft SQL Azure database. In this video we also look at how to connect to the SQL Azure database using the latest release of Microsoft SQL Server Management Studio Express (R2) as well as how to configure an existing on-premises ASP.NET application to speak to SQL Azure.
<Return to section navigation list>
AppFabric: Access Control and Service Bus
Juval Lovey wrote AppFabric Service Bus Discovery for MSDN Magazine’s October 2010 issue:
In my January 2010 article, “Discover a New WCF with Discovery” (msdn.microsoft.com/magazine/ee335779), I presented the valuable discovery facility of Windows Communication Foundation (WCF) 4. WCF Discovery is fundamentally an intranet-oriented technique, as there’s no way to broadcast address information across the Internet.
Yet the benefits of dynamic addresses and decoupling clients and services on the address axis would apply just as well to services that rely on the service bus to receive client calls.
Fortunately, you can use events relay binding to substitute User Datagram Protocol (UDP) multicast requests and provide for discovery and announcements. This enables you to combine the benefit of easy deployment of discoverable services with the unhindered connectivity of the service bus. This article walks through a small framework I wrote to support discovery over the service bus—bringing it on par with the built-in support for discovery in WCF—along with my set of helper classes. It also serves as an example of rolling your own discovery mechanism.
AppFabric Service Bus Background
If you’re unfamiliar with the AppFabric Service Bus, you can read these past articles:
- “Working With the .NET Service Bus,” April 2009
msdn.microsoft.com/magazine/dd569756- “Service Bus Buffers,” May 2010
msdn.microsoft.com/magazine/ee336313Solution Architecture
For the built-in discovery of WCF, there are standard contracts for the discovery exchange. Unfortunately, these contracts are defined as internal. The first step in a custom discovery mechanism is to define the contracts used for discovery request and callbacks. I defined the IServiceBusDiscovery contract as follows:
- [ServiceContract]
- public interface IServiceBusDiscovery
- {
- [OperationContract(IsOneWay = true)]
- void OnDiscoveryRequest(string contractName,string contractNamespace,
- Uri[] scopesToMatch,Uri replayAddress);
- }
The single-operation IServiceBusDiscovery is supported by the discovery endpoint. OnDiscoveryRequest allows the clients to discover service endpoints that support a particular contract, as with regular WCF. The clients can also pass in an optional set of scopes to match.
Services should support the discovery endpoint over the events relay binding. A client fires requests at services that support the discovery endpoint, requesting the services call back to the client’s provided reply address.
The services call back to the client using the IServiceBusDiscoveryCallback, defined as:
- [ServiceContract]
- public interface IServiceBusDiscoveryCallback
- {
- [OperationContract(IsOneWay = true)]
- void DiscoveryResponse(Uri address,string contractName,
- string contractNamespace, Uri[] scopes);
- }
The client provides an endpoint supporting IServiceBusDiscoveryCallback whose address is the replayAddress parameter of OnDiscoveryRequest. The binding used should be the one-way relay binding to approximate unicast as much as possible. Figure 1 depicts the discovery sequence.
Figure 1 Discovery over the Service Bus
The first step in Figure 1 is a client firing an event of discovery request at the discovery endpoint supporting IServiceBusDiscovery. Thanks to the events binding, this event is received by all discoverable services. If a service supports the requested contract, it calls back to the client through the service bus (step 2 in Figure 1). Once the client receives the service endpoint (or endpoints) addresses, it proceeds to call the service as with a regular service bus call (step 3 in Figure 1).
Discoverable Host
Obviously a lot of work is involved in supporting such a discovery mechanism, especially for the service. I was able to encapsulate that with my DiscoverableServiceHost, defined as:
.png "Discovery over the Service Bus")
See article for longer C# source code examples.
Besides discovery, DiscoverableServiceHost always publishes the service endpoints to the service bus registry. To enable discovery, just as with regular WCF discovery, you must add a discovery behavior and a WCF discovery endpoint. This is deliberate, so as to both avoid adding yet another control switch and to have in one place a single consistent configuration where you turn on or off all modes of discovery.
You use DiscoverableServiceHost like any other service relying on the service bus:
See article for longer C# source code examples.
Note that when using discovery, the service address can be completely dynamic.
Figure 2 provides the partial implementation of pertinent elements of DiscoverableServiceHost.
Figure 2 Implementing DiscoverableServiceHost (Partial)
See article for longer C# source code examples.
The helper property IsDiscoverable of DiscoverableServiceHost returns true only if the service has a discovery behavior and at least one discovery endpoint. DiscoverableServiceHost overrides the OnOpening method of ServiceHost. If the service is to be discoverable, OnOpening calls the EnableDiscovery method.
EnableDiscovery is the heart of DiscoverableServiceHost. It creates an internal host for a private singleton class called DiscoveryRequestService (see Figure 3).
Figure 3 The DiscoveryRequestService Class (Partial)
See article for longer C# source code examples.
The constructor of DiscoveryRequestService accepts the service endpoints for which it needs to monitor discovery requests (these are basically the endpoints of DiscoverableServiceHost).
EnableDiscovery then adds to the host an endpoint implementing IServiceBusDiscovery, because DiscoveryRequestService actually responds to the discovery requests from the clients. The address of the discovery endpoint defaults to the URI “DiscoveryRequests” under the service namespace. However, you can change that before opening DiscoverableServiceHost to any other URI using the DiscoveryAddress property. Closing DiscoverableServiceHost also closes the host for the discovery endpoint.
Figure 3 lists the implementation of DiscoveryRequestService.
See article for longer C# source code examples.
OnDiscoveryRequest first creates a proxy to call back the discovering client. The binding used is a plain NetOnewayRelayBinding, but you can control that by setting the DiscoveryResponseBinding property. Note that DiscoverableServiceHost has a corresponding property just for that purpose. OnDiscoveryRequest then iterates over the collection of endpoints provided to the constructor. For each endpoint, it checks that the contract matches the requested contract in the discovery request. If the contract matches, OnDiscoveryRequest looks up the scopes associated with the endpoint and verifies that those scopes match the optional scopes in the discovery request. Finally, OnDiscoveryRequest calls back the client with the address, contract and scope of the endpoint.
Discovery Client
For the client, I wrote the helper class ServiceBusDiscoveryClient, defined as:
I modeled ServiceBusDiscoveryClient after the WCF DiscoveryClient, and it’s used much the same way, as shown in Figure 4.
Figure 4 Using ServiceBusDiscoveryClient
See article for longer C# source code examples.
ServiceBusDiscoveryClient is a proxy for the IServiceBusDiscovery discovery events endpoint. Clients use it to fire the discovery request at the discoverable services. The discovery endpoint address defaults to “DiscoveryRequests,” but you can specify a different address using any of the constructors that take an endpoint name or an endpoint address. It will use a plain instance of NetOnewayRelayBinding for the discovery endpoint, but you can specify a different binding using any of the constructors that take an endpoint name or a binding instance. ServiceBusDiscoveryClient supports cardinality and discovery timeouts, just like DiscoveryClient.
Figure 5 shows partial implementation of ServiceBusDiscoveryClient.
Figure 5 Implementing ServiceBusDiscoveryClient (Partial)
See article for longer C# source code examples.
The Find method needs to have a way of receiving callbacks from the discovered services. To that end, every time it’s called, Find opens and closes a host for an internal synchronized singleton class called DiscoveryResponseCallback. Find adds to the host an endpoint supporting IServiceBusDiscoveryCallback. The constructor of DiscoveryResponseCallback accepts a delegate of the type Action<Uri,Uri[]>. Every time a service responds back, the implementation of DiscoveryResponse invokes that delegate, providing it with the discovered address and scope. The Find method uses a lambda expression to aggregate the responses in an instance of FindResponse. Unfortunately, there’s no public constructor for FindResponse, so Find uses the CreateFindResponse method of DiscoveryHelper, which in turn uses reflection to instantiate it. Find also creates a waitable event handle. The lambda expression signals that handle when the cardinality is met. After calling DiscoveryRequest, Find waits for the handle to be signaled, or for the discovery duration to expire, and then it aborts the host to stop processing any discovery responses in progress.
More Client-Side Helper Classes
Although I wrote ServiceBusDiscoveryClient to be functionally identical to DiscoveryClient, it would benefit from a streamlined discovery experience offered by my ServiceBusDiscoveryHelper:
- public static class ServiceBusDiscoveryHelper
- {
- public static EndpointAddress DiscoverAddress<T>(
- string serviceNamespace,string secret,Uri scope = null);
- public static EndpointAddress[] DiscoverAddresses<T>(
- string serviceNamespace,string secret,Uri scope = null);
- public static Binding DiscoverBinding<T>(
- string serviceNamespace,string secret,Uri scope = null);
- }
DiscoverAddress<T> discovers a service with a cardinality of one, DiscoverAddresses<T> discovers all available service endpoints (cardinality of all) and DiscoverBinding<T> uses the service metadata endpoint to discover the endpoint binding. Much the same way, I defined the class ServiceBusDiscoveryFactory:
- public static class ServiceBusDiscoveryFactory
- {
- public static T CreateChannel<T>(string serviceNamespace,string secret,
- Uri scope = null) where T : class;
- public static T[] CreateChannels<T>(string serviceNamespace,string secret,
- Uri scope = null) where T : class;
- }
CreateChannel<T> assumes cardinality of one, and it uses the metadata endpoint to obtain the service’s address and binding used to create the proxy. CreateChannels<T> creates proxies to all discovered services, using all discovered metadata endpoints.
Announcements
To support announcements, you can again use the events relay binding to substitute UDP multicast. First, I defined the IServiceBusAnnouncements announcement contract:
- [ServiceContract]
- public interface IServiceBusAnnouncements
- {
- [OperationContract(IsOneWay = true)]
- void OnHello(Uri address, string contractName,
- string contractNamespace, Uri[] scopes);
- [OperationContract(IsOneWay = true)]
- void OnBye(Uri address, string contractName,
- string contractNamespace, Uri[] scopes);
- }
As shown in Figure 6, this time, it’s up to the clients to expose an event binding endpoint and monitor the announcements.
Figure 6 Availability Announcements over the Service Bus
The services will announce their availability (over the one-way relay binding) providing their address (step 1 in Figure 6), and the clients will proceed to invoke them (step 2 in Figure 6).
Service-Side Announcements
My DiscoveryRequestService supports announcements:
- public class DiscoverableServiceHost : ServiceHost,...
- {
- public const string AnnouncementsPath = "AvailabilityAnnouncements";
- public Uri AnnouncementsAddress
- {get;set;}
- public NetOnewayRelayBinding AnnouncementsBinding
- {get;set;}
- // More members
- }
However, on par with the built-in WCF announcements, by default it won’t announce its availability. To enable announcements, you need to configure an announcement endpoint with the discovery behavior. In most cases, this is all you’ll need to do. DiscoveryRequestService will fire its availability events on the “AvailabilityAnnouncements” URI under the service namespace. You can change that default by setting the AnnouncementsAddress property before opening the host. The events will be fired by default using a plain one-way relay binding, but you can provide an alternative using the AnnouncementsBinding property before opening the host. DiscoveryRequestService will fire its availability events asynchronously to avoid blocking operations during opening and closing of the host. Figure 7 shows the announcement-support elements of DiscoveryRequestService.
Figure 7 Supporting Announcements with DiscoveryRequestService
.png "Availability Announcements over the Service Bus")
See article for longer C# source code examples.
The CreateAvailabilityAnnouncementsClient helper method uses a channel factory to create a proxy to the IServiceBusAnnouncements announcements events endpoint. After opening and before closing DiscoveryRequestService, it fires the notifications. DiscoveryRequestService overrides both the OnOpened and OnClosed methods of ServiceHost. If the host is configured to announce, OnOpened and OnClosed call CreateAvailabilityAnnouncementsClient to create a proxy and pass it to the PublishAvailabilityEvent method to fire the event asynchronously. Because the act of firing the event is identical for both the hello and bye announcements, and the only difference is which method of IServiceBusAnnouncements to call, PublishAvailabilityEvent accepts a delegate for the target method. For each endpoint of DiscoveryRequestService, PublishAvailabilityEvent looks up the scopes associated with that endpoint and queues up the announcement to the Microsoft .NET Framework thread pool using a WaitCallback anonymous method. The anonymous method invokes the provided delegate and then closes the underlying target proxy.
Receiving Announcements
I could have mimicked the WCF-provided AnnouncementService, as described in my January article, but there’s a long list of things I’ve improved upon with my AnnouncementSink<T>, and I didn’t see a case where you would prefer to use AnnouncementService in favor of AnnouncementSink<T>. I also wanted to leverage and reuse the behavior of AnnouncementSink<T> and its base class.
Therefore, for the client, I wrote ServiceBusAnnouncementSink<T>, defined as:
- [ServiceBehavior(UseSynchronizationContext = false,
- InstanceContextMode = InstanceContextMode.Single)]
- public class ServiceBusAnnouncementSink<T> : AnnouncementSink<T>,
- IServiceBusAnnouncements, where T : class
- {
- public ServiceBusAnnouncementSink(string serviceNamespace,string secret);
- public ServiceBusAnnouncementSink(string serviceNamespace,string owner,
- string secret);
- public Uri AnnouncementsAddress get;set;}
- public NetEventRelayBinding AnnouncementsBinding {get;set;}
- }
The constructors of ServiceBusAnnouncementSink<T> require the service namespace.
ServiceBusAnnouncementSink<T> supports IServiceBusAnnouncements as a self-hosted singleton. ServiceBusAnnouncementSink<T> also publishes itself to the service bus registry. ServiceBusAnnouncementSink<T> subscribes by default to the availability announcements on the “AvailabilityAnnouncements” URI under the service namespace. You can change that (before opening it) by setting the AnnouncementsAddress property. ServiceBusAnnouncementSink<T> uses (by default) a plain NetEventRelayBinding to receive the notifications, but you can change that by setting the AnnouncementsBinding before opening ServiceBusAnnouncementSink<T>. The clients of ServiceBusAnnouncementSink<T> can subscribe to the delegates of AnnouncementSink<T> to receive the announcements, or they can just access the address in the base address container. For an example, see Figure 8.
Figure 8 Receiving Announcements
See article for longer C# source code examples.
Figure 9 shows the partial implementation of ServiceBusAnnouncementSink<T> without some of the error handling.
Figure 9 Implementing ServiceBusAnnouncementSink<T> (Partial)
See article for longer C# source code examples.
The constructor of ServiceBusAnnouncementSink<T> hosts itself as a singleton and saves the service namespace. When you open ServiceBusAnnouncementSink<T>, it adds to its own host an endpoint supporting IServiceBusAnnouncements. The implementation of the event handling methods of IServiceBusAnnouncements creates an AnnouncementEventArgs instance, populating it with the announced service address, contract and scopes, and then calls the base class implementation of the respective announcement methods, as if it was called using regular WCF discovery. This both populates the base class of the AddressesContainer<T> and fires the appropriate events of AnnouncementSink<T>. Note that to create an instance of AnnouncementEventArgs, you must use reflection due to the lack of a public constructor.
The Metadata Explorer
Using my support for discovery for the service bus, I extended the discovery feature of the Metadata Explorer tool (presented in previous articles) to support the service bus. If you click the Discover button (see Figure 10), for every service namespace you have already provided credentials for, the Metadata Explorer will try to discover metadata exchange endpoints of discoverable services and display the discovered endpoints in the tree.
Figure 10 Configuring Discovery over the Service Bus
The Metadata Explorer will default to using the URI “DiscoveryRequests” under the service namespace. You can change that path by selecting Service Bus from the menu, then Discovery, to bring up the Configure AppFabric Service Bus Discovery dialog (see Figure 10).
For each service namespace of interest, the dialog lets you configure the desired relative path of the discovery events endpoint in the Discovery Path text box.
The Metadata Explorer also supports announcements of service bus metadata exchange endpoints. To enable receiving the availability notification, bring up the discovery configuration dialog box and check the Enable checkbox under Availability Announcements. The Metadata Explorer will default to using the “AvailabilityAnnouncements” URI under the specified service namespace, but you can configure for each service namespace any other desired path for the announcements endpoint.
The support in the Metadata Explorer for announcements makes it a simple, practical and useful service bus monitoring tool.
Juval Lowy is a software architect with IDesign providing .NET and architecture training and consulting. This article contains excerpts from his recent book, “Programming WCF Services 3rd Edition” (O’Reilly, 2010). He’s also the Microsoft regional director for the Silicon Valley. Contact Lowy at idesign.net.
Thanks to the following technical expert for reviewing this article: Wade Wegner
.png "Configuring Discovery over the Service Bus")
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Steve Evans (@scevans) posted Windows Azure Staging Model on 10/10/2010:
One of my favorite features of Windows Azure is their Production/Staging model. I think the best way to explain why I think this is so well implemented is to walk you through the processes.
Here we have Test1 running in Production and Test2 running in Staging. Clients that go to your production URL are routed to your production code. Clients that go to your staging URL are routed to your staging code. This allows you to have your customers use your production code, while you can test your new code running in staging.
Now we have updated our code again and have pushed up Test3 to our staging area. We now have Test2 still running in production, and can do testing on Test3 in staging.
Now that we have tested our Test3 code and are ready to move it to production we hit the swap button again and Test3 becomes production and Test2 is moved to staging ready to be moved back into production on a moments notice.
One thing to take note of is that the Web Site URL’s for Production and Staging never changed. Unfortunately neither of them are URL’s you want your customers to see or you would want work with. What you want to do is create to DNS CNAME records. In the example case I’m using here you would create two DNS records:
serktools-stagetest.clodapp.net CNAME test.serktools.com
e7e3f38589d04635a6d0d0aee22bd842.cloudapp.net CNAME stage.test.serktools.com




• The VAR Guy interviewed Allison Watson in a 00:04:03 Microsoft’s Allison Watson: SaaS and Cloud, Part 2 video segment on 3/10/2010:
The VAR Guy FastChat Video interviews Microsoft Channel Chief Allison Watson about cloud opportunities for partners. This is part II, covering how VARs can embrace Windows Azure and Business Productivity Online Suite (BPOS), plus SaaS pricing questions.

Prior to assuming her current role in 2010, Watson spent eight years as head of the Worldwide Partner Group, directing Microsoft's worldwide strategy for the diverse ecosystem of more than 640,000 independently owned-and-operated partner companies that support Microsoft and its customers in 170 countries.
• The VAR Guy interviewed Allison Watson on 3/10/2010 in a 00:04:19 Microsoft’s Allison Watson: SaaS and Cloud, Part 1 video segment:
The VAR Guy FastChat Video interviews Microsoft Channel Chief Allison Watson about Microsoft's cloud strategy for partners; SaaS competition with Google and Salesforce.com; plus Microsoft Business Productivity Online Suite (BPOS) and Windows Azure.
These interviews might be dated, but they express Microsoft’s marketing approach to Windows Azure and BPOS at about the time of the Microsoft Worldwide Partners Conference in the Spring of 2010.
On Windows claimed “Descartes' Global Logistics Network (the GLN) is being extended using Windows Azure, Microsoft’s cloud computing platform for Descartes' software-as-a-service (SaaS) 3.0 solutions” as a lead-in to its Microsoft, Descartes use Azure cloud article of 10/8/2010:
Descartes unveiled its new SaaS 3.0 strategy to extend its GLN SaaS technology platform with cloud-computing capabilities
"We're excited to work with Microsoft, one of the leaders in cloud-computing technology, to federate with our GLN. This gives our customers increased enterprise agility by providing component based solutions in the cloud," said Frank Hamerlinck, senior vice president of research and development at Descartes.
"Descartes is moving ahead with a well thought out hybrid approach to cloud computing. Windows Azure will allow Descartes to quickly extend its GLN based on customer demand, while keeping costs low," said Nicole Denil, Director of Americas for the Windows Azure Platform at Microsoft.
The two companies are scheduled to discuss the details of this relationship and the Descartes technology vision and research and development methodology at its Global User Group Conference in Florida on 5-7 October.
Dan Tohatan (@pavethemoon) evaluates the cost of cloud hosting for his SaaS project in a Cloud Computing Adoption: Slow, but Why? post of 10/8/2010:
It is a fairly well-established fact that cloud computing as been in a very niche market so far. Certainly, no company that I've worked at - and I've worked at more than 3 companies in the last 4 years, has implemented cloud computing. They are all talking about it. But they have yet to turn words into actions.
The Pros
Here are some uses that I believe are legitimate for cloud computing:
1. Part-time server, for prototyping and demos
Say you want to spin up a server for 20 hours to demonstrate an app to your clients. Would you go and get a hosting account, pre-pay 3 months, and end up spending around $50? Or, would you prefer spending $2 on a cloud server with a greater degree of performance and flexibility? I would certainly opt for the latter.2. Large-scale data center for public data
Suppose I have a Digg-like site that gets millions of views per day and I need a large-scale data center to host that on. Would I be inclined to build a data center myself, or outsource that work to a third-party provider? At that scale, it's likely that from a cost perspective the outsourcing option makes more sense.Notice one thing - there is no middle ground. You either have to have a requirement for a large, Facebook-size data center, or for a part-time server for demo and prototyping use.
The Cons
The main concerns with cloud computing seem to be as follows:
1. What if I want to run my server full time?
You can, but you won't get much bang for the buck out of it. In fact, you'll be spending more than you need on hardware that you probably don't need that is more expensive than either VPS or shared hosting which is more than enough for 99% of sites out there. I mean, VPS starts at $20/month. You get the same flexibility and almost the same performance as cloud computing, for a quarter of the cost. This comes about because it turns out that all cloud computing providers charge by CPU-hour. For a month consisting of 720 hours, that usually adds up to at least $80/month.2. What about security?
The question you have to ask yourself is, is your data sensitive enough that you can't trust a third-party provider (be it Microsoft, Godaddy, or whatever) with it? There is an argument to be made that smaller, more local providers are more trustworthy from a security standpoint because even if the data leaks internally, not a lot of eyeballs will see it or be likely to leak it. Whereas with a provider like Microsoft, with thousands of employees, it's much easier to find a rogue hacker within the company who would love to expose your data to the public. Now, even beyond that, if you can't trust anyone but insiders with your data, then really your only option is to build an internal data center.Conclusions
Any good article has to have some conclusions. So here we go. I think the security issue is not really a concern because hosting providers have roughly the same level of security as cloud computing providers. However, the cost issue is a clear barrier to entry. Why should I pay $80 for the exact same service that I can go next door and pay $20 for? I think where cloud computing has gone wrong is in the idea that users would be willing to pay retail markup for essential back-end services. At this point, you can bet your bottom dollar Microsoft is paying only $0.01 per hour of CPU time internally to provide Windows Azure to you at $0.12 per hour.
At this time, unless I'm looking to build an Amazon-like site or need a prototyping server with root access, I would not consider cloud computing. I would much rather go with VPS or shared hosting. This is probably what millions of other people are thinking as well.
<Return to section navigation list>
Visual Studio LightSwitch
• Microsoft’s Campbell Gunn announced “no plans in Version 1 to support/extend oData” in a 10/9/2010 reply to apacifico’s Lightswitch dataprovider support and odata question of 10/9/2010 in the LightSwitch Extensibility forum:

A very bad decision, which needs revisiting.
• Peter Kellner explained Building [a] Job Ads Management Module With LightSwitch Beta 1 For Silicon Valley Code Camp in a 9/30/2010 post (missed when posted):
The End Result
Motivation
As you can imagine, The Silicon Valley Code Camp web site has lots of “back end” functions that need to be done. That is, things like doing mailings, assigning roles to users, making schedules, allocating rooms and times and literally hundreds of other tasks like that. Over the 5 years of code camp, I’ve always built simple protected ASP.NET web pages to do this. I’ve always used the simplest ASP.NET control I could find, such as GridView, DetailsView, DropDownList, and SqlDataSource. The interfaces usually basically work but are very clumsy and lacking in both functionality and aesthetics.
Why Now
I’ve seen lots of short demos on LightSwitch for Visual Studio and recently read on someone else’s blog that they are now building all their simple applications using LIghtSwitch. Also, my friend Beth Massi has been running around the world espousing the greatness of this product and I knew if I ran into any dumb issues that she’d bail me out (I’m the king of running into dumb issues. I’ve found that given two choices that seem right, I always pick the wrong one which is what actually happened here along the way, and Beth did bail me out).
First Blood
First thing to do (after installing LightSwitch) is to say “File/New/Project”. My plan is to add this project right off my SV Codecamp solution. So, here goes.
So far so good. Next step is to choose attach to an external database
Continuing, but don’t get tripped up here like I did. You will use WCF RIA Services under the covers but you don’t want to select that choice. You want to say that you want to connect to a database and let LightSwitch do the work for you.
PIck your database and connection strings.
Now, pick the tables you plan on working with. If this were Linq2sql, I’d be choosing them all, but now that I’m in RIA Services land, I’m hoping I can have separate “Domains” and not have to reference all the tables all the time. Jury is still out on that one but for now, I’m following the advice of the team and just picking the tables I want to manage now.
And, I’m going to name the Data Source “svcodecampDataJobs”. I’ll have to see how this goes and report later. I’m doing this live so I really don’t know where I’ll end up.
Click finish, then rebuild all and it all works. It comes up with this screen showing me my relationship between the tables. It is showing me a Company table with a link to a JobListing table which is what I have. Here is what LightSwitch shows me.
The reality of my database is that I also have a JobListingDates table that is now shown here. Taking a step backwards to explain my database, I have a simple company table, the company has a detail table associated with it called JobListings, and the JobListings table has a details file associated with it called JobListingsDates. That is, a company may run an ad for 30 days, take it down for 30,and bring it back up again.
Here is what that schema actually looks like in SqlManager from EMS.
One thing I like about great software is that it has things that are discoverable. So, just now, I double clicked on the little table called JobListings and the view changed to having JobListing as primary and if you look on the bottom right, it shows JobListingDate. Very cool. I have no idea where this is all going but I’m starting to get excited. Here is what I’m looking at now.
Building a Screen
So now, let’s push the “Screen” button and see what happens (while looking at the Company View).
This is nice, I get a list of sample screens. How about if we build an Editable Grid Screen with the hope of editing and adding new Companies. Notice that I’m naming it EditableGridCompany and choosing the Company for the data in the dropdown.
You now get a screen that is a little scary looking so rather than actually try and understand it, I thought “maybe I’m done, maybe this will just run”. So, here goes, Debug/Start Without Debug. Here is the scary screen, followed by what happens after the run.
And the Run:
Wow! Paging, Fancy editing including date pickers, exporting to Excel, Inserts, Updates and Deletes on the company table. This is amazing. Let me add another Grid so that I can add JobListings to the company. To do that, go back to the solution explorer and choose add screen.
Then again, I have choices.
I choose Details Screen and check Company in the dropdown, Company Details and Company JobListings for the additional data.
Another intimidating screen, but simply do Debug/Debug Start.
Well, that’s it for now. Code Camp is 4 days away and I don’t really have time to take this to the next level. You can see from the screen at the top of the post that this is pretty amazing for the effort! I’m sure I’ll be back to this.
















Dan Seefeldt explains How Do I: Import and Export Data to/from a CSV file [with LightSwitch]in this 8/10/2010 post to the Visual Studio LightSwitch team blog:
LightSwitch provides weakly-typed data access APIs which allow you to add general purpose code to perform common tasks. In this example, these APIs are used to implement a simple general purpose import/export. The import/export will read and write CSV files. Export will write the names of the properties as the first line of the output file. Import will read this line to get the correct column into the right property. It is designed to be called on the client from screen code. This general purpose code can be placed in its own class file in the Client/UserCode folder of your project so it can be called from any screen. In the following examples, it is used on two buttons on a Customer screen, one to perform an import and one to perform an export.
The export button first gets a list of the properties to export. In this case, I’m only exporting storage properties. Storage properties are simple, scalar properties that are stored in the database. They do not include calculated or navigation properties. The call to PromptAndExportEntities() takes an enumerable list of entities to export and the list of properties to export.

The import button prompts the user first and then deletes all existing customers in the database. Next, it calls PromptAndImportEntities() to import new customers into the entity set specified, in this case, the Customers entity set.

Export
The start of the export process prompts for a file to save the exported data to. This is accomplished by opening the SaveFileDialog() and getting the file stream that is the result. Then, this information is passed to the export function.
Note: This method of opening a save file dialog is currently a Beta1 limitation. Launching a UI control needs to happen on the UI thread, which is what the Dispatchers.Main.Invoke() is doing. We’re looking at ways of making this easier in the future.
The export function takes a stream on which to write the output, the list of entities to export and a list of the properties to export. The first step is to setup the export by initializing the stream writer and writing a header containing the property names to the file. Then, it continues by looping over each entity and passing it to the single line exporter.

The single line exporter takes an entity to export and loops through its properties to add the values of its properties to a string array. It uses the Properties on the Details member of the entity to get the value of each entity property. The last step is to write the string array to the output as a comma separated list.
Import
Import starts with the PromptAndImportEnties() method. It takes an entity set in which to create the new entities. The start of the import process is to prompt for a file to import. The OpenFileDialog() is used for this purpose.
Note: Again, this method of opening a dialog is a Beta1 limitation for LightSwitch.

The Import function does pretty much the opposite of the export function. It takes in the file to read and the entity set in which to create the entities. The first step is to open the file and read the header line to get the property names. Then, it continues by looping over all data rows in the file, passing the data to the single line importer. Once all lines are imported into entities, SaveChanges() is called to save the data.

The single line importer creates the new entity by calling AddNew() on the entity set. It then loops through all property names read in the import function and gets the desired property from the new entity by name, again, using the Details.Properties on the entity. It then converts the data for the property to the correct type based on the type information from the entity property. Lastly, it sets the value of the property.

Hopefully this example gives you an idea of how the weakly-typed API can be used to create general purpose solutions to common problems. There are many possibilities for extending this example including enhancing it to support relationships, using it to create a general purpose entity archiver, or modifying it to export data to Excel using LINQ to XML. I attached the sample code to the bottom of this post.
Try it out and have fun! Download the sample code here.
Return to section navigation list>
Windows Azure Infrastructure
• Daniel Wong dispelled the exaggerated reports of Microsoft’s imminent demise and finds “an upside worth considering” in his A Closer Look at Microsoft: Undervalued or Unsustainable? article of 10/9/2010 for the Seeking Alpha blog:
For over 25 years, Microsoft (MSFT) has been a dominant force in the computer software market – from DOS in the 80’s, Windows and Office in the 90’s, to Internet Explorer at the turn of the century. With each successive wave of emerging technologies, Microsoft has demonstrated the ability to outlast its competitors.
Curiously, Microsoft has never been the innovator or first to market in any of the areas in which it dominates today. It has, however, been a master of network effects – generating the critical mass that makes their software so indispensable.
In the last five years, Microsoft has appeared less than superhuman. Missteps with Windows Vista and poor adoption of Zune and Windows Mobile have tarnished its reputation of technological leadership. Meanwhile, the emergence of Google (GOOG) and the resurgence of Apple (AAPL) have stolen the spotlight and captured the hearts of the consumers. As they set the standard for what is now new and innovative, internet services and ultra-mobile devices have become all the rage. Suddenly, Microsoft has become the underdog, bombarded with criticism for its lack of imagination and old-world thinking.
This is all great news for a value investor. Companies that have fallen out of favour present great buying opportunities; and Microsoft is certainly unloved in today’s market. But not every cheap stock is a bargain. Sometimes they are discounted for good reason – a company with a failed business model will never make you any money. Let’s examine Microsoft closer to see what kind of animal it is.
Financial Overview
Microsoft is a hugely profitable company. It enjoys an 80% gross margin, a 30% net margin, and a 40% return on capital. Few companies can claim such lofty ratios. In terms of sustainability, Microsoft spends over $8B annually on R&D (Research and Development) and holds a cash reserve of over $36B to capitalize on future opportunities. Furthermore, it now pays a dividend of 16 cents per quarter, which at yesterday’s closing price of $24.53 (10/7/2010) provides a dividend yield of 2.6%.
Building Intuition around Value
Like any good value investor, we first look at book value to gain a feel for economic reality. Since assets and liabilities are far more concrete than discounted cash flows, a stock that trades at a low price-to-book (P/B) ratio is typically more defensible and thus more resilient in uncertain economic times. Book value can also give us an idea of what a company is worth at a minimum.
Microsoft’s reported book value per share last June was $5.17. Capitalizing a few years worth of R&D and marketing expenses easily bring this figure up to $14. This adjusted book value is our back-of-the-envelope estimate of reproduction cost. Finally, substituting reproduction cost for book value, we get a P/B ratio of 1.75 and the implication that 43% of Microsoft’s stock price is attributable to a sustainable competitive advantage. How reasonable is this?
I’d say it is quite reasonable. Microsoft’s sustainable competitive advantage is nothing to scoff at. It has been able to generate sizeable switching costs for its consumers who are helplessly attached to its Windows and Office franchises. The large number of other people utilizing Microsoft products makes collaboration difficult with anything but Microsoft products. This is what we referred to earlier as the network effect – a phenomenon so cunningly perpetuated by Microsoft’s OEM (Original Equipment Manufacturer) distribution channel strategy.
The Last Decade
To get a good sense of where Microsoft might be headed in the future, I’ve plotted some key performance metrics over the last decade. Microsoft’s chart (below) paints the picture of a solid company – all measures of revenue, earnings, and cash flow have been growing strongly and steadily for an extended period of time.
Overlaid on the plots are exponential curves that I’ve fitted using Excel’s “trend line” feature. The useful characteristic of equations in exponential form is that I can isolate from it the continuously compounded rate of interest. (For those less quantitatively-inclined, the annual rate of interest is approximately the power to which the “e” is raised to.) Revenue and net income have been growing on average at 10.5% y/y, while operating cash flow has been growing at 5.5% and FCF (Free Cash Flow) has been growing at 4.5%.
From here we take a look at FCF over the last decade. This gives us a good sense of what a “normal” cash flow should look like for Microsoft today. The details of my calculation can be seen in the figure below, but the end result is a normalized cash flow of $18.6B. This is in comparison to the $22.1B in actual cash flow reported last June, and thus incorporates a reasonable discount for the cyclical surge in earnings due to both the business PC (Personal Computer) and Windows 7 refresh cycles.
Discounted Cash Flow Analysis – No Growth ScenarioFor my DCF (Discounted Cash Flow) analysis, I have opted to keep things simple. Sometimes it’s best to focus on the basics so as not to obfuscate the conclusions with more speculative elements. Using only my normalized cash flow estimate, a 0% growth rate, and a 10% cost of capital, I have calculated an intrinsic value of $24.28 per share. (My 10% cost of capital is based on the value found in Trefis and Bloomberg.)
The calculated intrinsic value is essentially Microsoft’s stock price today. In other words, Microsoft is priced in the market for no growth whatsoever from now until eternity – not one ounce of growth while still spending billions of dollars on R&D each year. Despite all the naysayers who say growth is dead at Microsoft, I have to say that this is an unlikely scenario. Recall the unmistakable upward sloping trends we saw earlier. Even companies in mature markets exhibit some kind of growth.
Discounted Cash Flow Analysis – Status Quo Scenario
From another angle, it can be argued that Microsoft will continue to grow as per usual by shifting its portfolio of businesses from declining markets to new growth markets. One promising area of new growth for Microsoft is in the area of cloud computing. To this end, Microsoft has been pouring billions of R&D dollars into datacentres and evolving Windows and Office for connected scenarios.
To model what I have called the status quo scenario, I have assumed 5 years of 4.5% FCF growth y/y (based on the trend analysis we looked at earlier), which drops off to 2% in the long run. Note that 4.5% is not exactly a high-flying growth figure – it fits a company with one foot in a maturing market. Recall furthermore that historical net income growth was 10% y/y. Since, theoretically, cash flow and earnings must eventually converge, 4.5% FCF growth is potentially an underestimate.
For my DCF calculation, I am projecting free cash flow only. Greyed-out values show implied values for other line items, but are only present for illustrative purposes. The result of the calculation is a substantial $32.97 per share.
Discounted Cash Flow Analysis – Declining Margins ScenarioTo take into account impending shifts in the computing landscape, I’ve attempted to generate a convincing scenario that effectively captures the downside risk for Microsoft. It is commonly publicized in the press that the two major threats to Microsoft’s dominance are cloud computing and the tablet PC.
Cloud computing, in my opinion, is the lesser of the threats. Despite being dubbed as “The Two Words Bill Gates Doesn’t Want You to Hear” (one year ago by the Motley Fool), cloud computing has actually become an area that Microsoft stands to compete strongly in. Microsoft’s Windows Azure can easily become the preferred cloud platform for large enterprises whose IT (Information Technology) personnel are already knowledgeable in Microsoft Server technologies and whose developers are already experienced in .NET programming. What I expect to see is another example of Microsoft’s network effect in action. The downside, of course, is that cloud computing cannibalizes on Microsoft’s core desktop offerings, such as its very profitable cash cows: Windows and Office. [Emphasis added.]
Tablets, on the other hand, are an area in which Microsoft currently has no presence in. The rise of the iPad has really shaken things up in the laptop PC market, as it has substantially cannibalized the tail-end netbook category. iPad and iPad-inspired tablets are based on the ARM architecture, which is incompatible with Windows 7. This means that for every netbook substituted with a tablet, one less Windows licence is sold. Fortunately for Microsoft, the types of computers that are vulnerable to cannibalization from the tablet are limited to those designed to primarily surf the internet – my best estimate is 12% of the overall PC market. Moreover, Steve Ballmer, Chief Executive of Microsoft, remains hopeful that his own version of the tablet PC, scheduled to be released this Christmas, will recapture its lost Windows market.
For the sake of argument, let’s assume for a moment that the PC market does decline significantly; that the use of cloud computing does become widespread; that tablets do supersede laptop computers. This is basically Google’s vision of the future. Computers that are no more than web browsers with all computing capability reassigned to the internet. The loser here would be Microsoft’s traditional Windows platform. Gone are the complexities of managing local computing devices. In its place would arise Windows Azure or an equivalent – a virtualized computing platform better known as PaaS (Platform-as-a-Service). Taking it a step further, we realize that computing resources haven’t really disappeared after all. They have just been outsourced to data centres, where Microsoft Sever technologies have the opportunity to take center stage. The likely scenario would see a substitution of platforms: Traditional Windows to Windows Azure. The irreversible downside, however, is a decline in pricing power for Microsoft. The cloud computing market is a busy space and if all current incumbents survive, there will be plenty of choice for consumers. The inevitable is thus a substitution from high margin revenue to low margin revenue. [Emphasis added.]
In contrast, on the Microsoft Office front, Microsoft actually stands a good chance of preserving its valuable franchise despite the advent of these disruptive technologies. Unlike Windows, Office is not tied to the survival of the PC market. Office as a web application is as valuable as Office as a PC application. The switching cost, the network effect – everything that forms Office’s sustainable competitive advantage – is preserved. Currently, the only credible competitor to Microsoft Office is Google Apps. But think about the entrenchment of Microsoft Office in large enterprises. The productivity penalty for switching from Office is far too high. Google Apps has been selling well with small and medium-sized businesses, but Microsoft has already begun to respond with Office Web Apps. Ultimately, it is of my opinion that the familiar look and feel of Office Web Apps will win over long-time Office users. Finally, the most telling sign that Office is probably here to stay is the fact that 80% of Office revenues are from sales to business – a segment where switching costs are highest.
The scenario I have depicted is captured in the DCF calculation below. I have carried over the revenue numbers from the status quo scenario, but have decreased Microsoft’s net margin from 28% to 21% over the next 3 years. The degree of margin shrinkage was determined as follows. First, Microsoft’s Windows Division contributed to 40% of total operating income; Its Business Division (including Office) contributed to another 40%. Next, the gross margin of both these divisions is 68%; Microsoft’s Services Division (including Azure) has a gross margin of only 34%. Therefore the simplifying assumption would be a 50% reduction of margins in 50% of Microsoft’s total operating income, or equivalently a 25% reduction in overall margins. This is consistent with a decline in net margin from 28% to 21%.
Intrinsic value under these circumstances comes out to $26.19 per share.
An Upside Worth Considering
At this point, let’s review our intrinsic value estimates. Adjusted book value is $14 per share, and in a world where Microsoft is incapable of growing, it is still worth $24.28 per share. Both of these estimates define lower bounds albeit with varying levels of substance. Nevertheless, with yesterday’s close at $24.53, they give us confidence that Microsoft's true intrinsic value is north of its price in the market. Our final two intrinsic value estimates revolve around the longevity and resilience of the PC industry. If the PC industry is relatively untouched, then Microsoft is worth $32.97 per share. On the other hand, if the PC industry is completely overhauled, then Microsoft is worth $26.19 per share. The important take-away is not which way the PC industry is evolving, but that Microsoft is undervalued in either case. Depending on how it plays out, you are looking at a 7% to 34% upside.
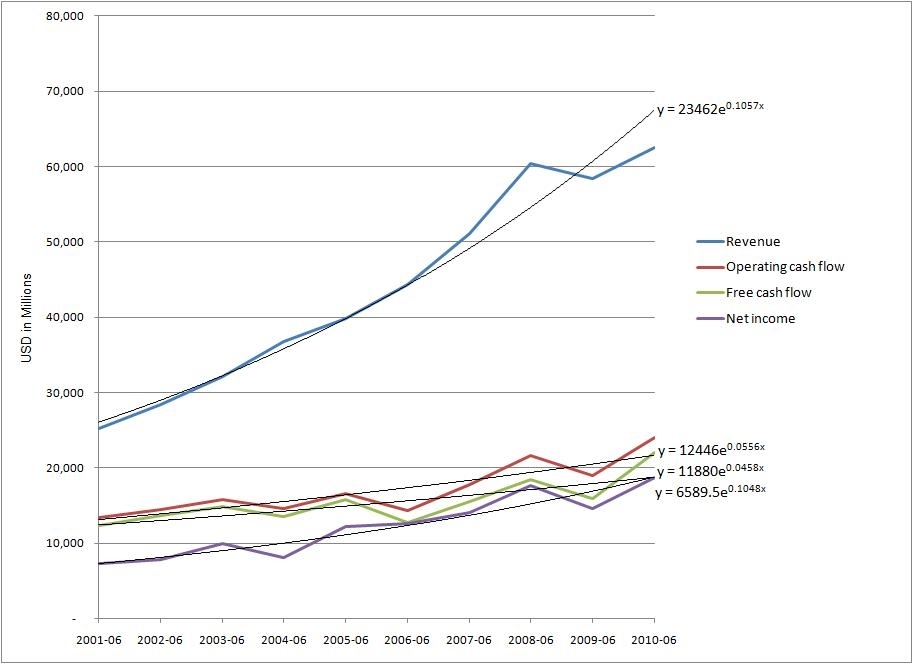

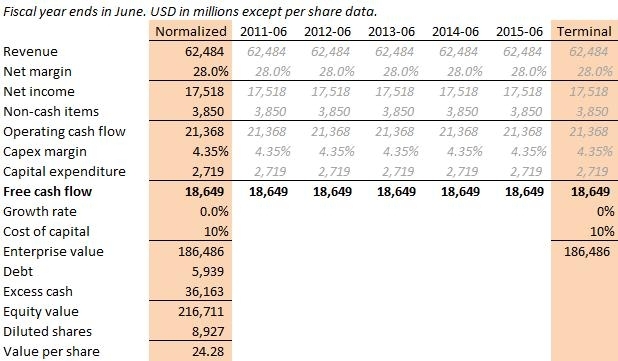
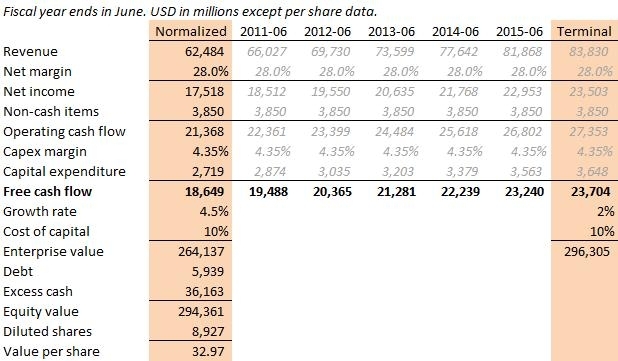
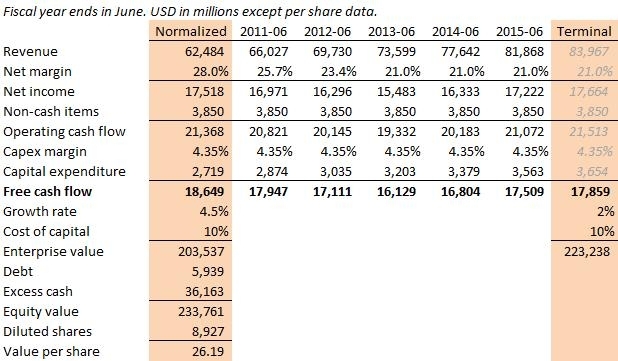
Dan is an MBA grad and Technology enthusiast. His expertise is in the IT and software space.
John Gallant and Eric Knorr published an extraordinarily lengthy Q&A: Microsoft's Bob Muglia details cloud strategy to the ComputerWorld Norway site on 10/8/2010:
Microsoft's Bob Muglia [pictured at right], head of the company's Server and Tools Division, is gung-ho on cloud computing and on Microsoft's efforts to make it easier for customers to embrace the technology. He talked about what Microsoft is doing in an interview with IDG Enterprise Chief Content Officer John Gallant and and InfoWorld.com Editor in Chief Eric Knorr.
In this interview with IDG Enterprise Chief Content Officer John Gallant and InfoWorld.com Editor in Chief Eric Knorr, Muglia talked about how customers are making the move to cloud and what they need to be doing right now. He also staked Microsoft's claim to leadership in the emerging cloud market, talked about the Windows Azure private-cloud appliance and explained what customers can learn from the City of Los Angeles' challenges using Google Apps.
How do you envision customers making the transition to the cloud? The thing about the cloud is that it really is the delivery of IT as a service and customers being able to adopt services to run their business. It's happening at somewhat different paces based on the workload. We see some workloads like e-mail collaboration that are moving very, very rapidly towards the cloud. [Question emphasis added throughout.]
Virtually every customer that we're working with on e-mail is having a conversation about [whether it] is time for them to move those workloads into a cloud service. Many are choosing yes. We're being very successful with our business productivity online services and helping customers make that transition with those workloads. Some are saying, 'Well, maybe it isn't really the time for me. Maybe I have some regulatory issues. Maybe I feel like I run the operation efficiently myself and it's not my business issue at the moment.' But it is a conversation that is happening almost everywhere, and it is a set of workloads that is moving very, very rapidly. We see other workloads like CRM probably moving pretty quickly because of the distributed -- geographic -- nature of the force of people that work with CRM. There are other business applications that are very well suited for the cloud. I think about an application that requires significant amounts of computing horsepower for a period of time, but then may not require it all the time, like high-performance applications, simulations, modeling, things like that. Or they're areas where you're reaching out and connecting to your supply chain or to your partners -- your sales partners and distributors. Those are also good examples of business applications that need to be built. They're not standardized apps like e-mail, but they are business applications that are well suited to the cloud.
How are you helping customers make the transition? We're helping customers across virtually all of these workloads in the sense that we're providing world-class messaging and collaborative services that we deliver with our SharePoint Online and our Exchange Online. We're able to move customers that are on premises [into] those products, but also effectively move customers from other environments. Some legacy customers are coming from, say, a Notes environment, [where] the cost of ownership in running that is a bit higher -- significantly higher, actually -- than, say, an Exchange installation is. The economic case for moving from an existing on-premises Notes installation to a cloud-provided Exchange and SharePoint is a very easy business case to justify. That's one set of examples.
In the creation of business applications, we're working to make it simple for people to take their existing applications that they've written, many of which are running on Windows Server today, and help move them into cloud environments -- whether it be a private cloud or a public cloud like Windows Azure.
How do you define private cloud? The definitions of cloud have been something the industry has really struggled with. I think, first of all, it's helpful that the industry is really clarifying itself, saying that cloud is IT as a service, providing IT as a service. That by itself is a fairly big step in getting clarity. Then, I think the real question is where is the cloud running and is it dedicated to an individual customer? I think of a private cloud as something that is running inside a customer data center and is dedicated to their own business applications. Then you have public clouds, which are shared across multiple organizations. Windows Azure is an example of that. We have shared examples of our Exchange and SharePoint Online services, but we are also offering dedicated SharePoint and Exchange where we run it and, yet, it's dedicated to a customer.
What do you think IT leaders should be doing differently or better in the way that they're moving toward or viewing cloud? The most important thing is that customers begin to understand how cloud could be used to solve their business needs. Again, we are having that conversation with virtually every customer with workloads like messaging and collaboration. That's relatively universal. I'm not going to say to every customer, 'You should all move to the cloud right now,' because it may not meet their business needs. But I do recommend that every customer evaluate it for those sets of workloads.
When it comes to business applications, customers are in a different state of adoption. Some are really aggressively looking at applications that they can move into a cloud environment. Some are relatively aggressively looking at how they can build their own private clouds. And there are a number of organizations that are still more nascent there. What I would recommend that every organization do is take a look at their business applications pick at least one to move to Windows Azure in a public cloud. I was talking to a large financial services organization not that long ago that has about 4,500 applications. And my feedback to them was, 'Choose. I know you've got all these regulatory issues. You're global, all these things. [But] there's one of those applications that you could move to a public cloud. Choose it and really begin and start working on that.
How can customers expect licensing to change in the cloud model? The biggest change as we move to the cloud model is it's a subscription-based model. It's an ongoing payment structure, because, obviously, you're running the service for the customer. If it is a well-defined service, like messaging or collaboration or CRM, it will typically be a per-user fee of some form that's paid, which is fairly consistent with the way they buy today, although they typically don't buy it by subscription. They buy it as a one-time purchase, but they, again, pay a per-user fee.
For business applications, the cloud model is based on instances or capacity-based, so it's based on the usage of the application. The model changes somewhat. Obviously, one of the implications is that, particularly if you're moving to a public cloud environment, there's a transition from having upfront cap-ex costs associated with purchasing hardware. That is not a software licensing issue, but it's very significant [change] to the customer, to an op-ex and ongoing charge.
But probably the most dramatic change that affects the customer in terms of the costs associated with this has nothing to do with licensing. It really has to do with their overall cost of operations. The promise of the cloud is that by running these things at very high scale, by using software to standardize and deliver a consistent set of services to customers, we can reduce the cost of running that operation very substantially. We know that the majority of cost in IT is the people cost associated with operations. That's where the cloud really brings the advantages. The main advantage in terms of getting better business value at a lower cost is because the cloud standardizes the way operations is done and really dramatically reduces that.
If you look at most of our customers, they will have a ratio of somewhere between 50 to 100 servers per administrator. A world-class IT shop might get that up to 300, 400 servers per administrator. When we run these cloud services, we run them at 2,000 to 4,000 servers per administrator internally. By running it ourselves, we are also able to really engineer the software to continue to drive out that cost of operations in a way that I don't think the industry's ever seen before.
So, two questions on the shift to that kind of pricing. One, do you think customers are prepared for that? Do they have a good handle on a budget that goes from projects and cyclical upgrades to a subscription flow like that and are they understanding the long-term implications of that shift? I think they love it. I think they're not just prepared, they're demanding it. This came home to me when I was at a CIO event -- it was large companies, top 100 U.S. companies. It was one of those vendor events where you're kind of getting beat up by about 20 guys. It's like dental work without any Novocain, basically, for an hour. One of the CIOs said to me, 'Bob, you don't get it. We never want another software update from Microsoft again. We want the features. But you put all the burden on us. You put all the operations costs on us. You make us do all the work. I want you to handle that. I don't want to take care of it.' That's really the key to software as a service and the cloud all around: how we can provide the services to our customers and then keep them up-to-date. We can keep the value associated with the new technology flowing into the IT organization, into the company, and, thus, generate the business value. But they don't have to pay all the cost and have all the training and everything.
Do you think there's the potential for any surprise or risk for them? Could cloud end up costing them more over time? Well, there's always [that] potential. I'm sure there will be cases. But I think, in general, it will really be transformative to enabling businesses to focus more on what they can add value to. That's part of the promise of the cloud, that the customer can focus on their business and adding value through IT and things that make a difference to the business versus the things that they have to do now that are not differentiating. Customers are able to achieve a larger focus on the things that enable them to differentiate.
There will be problems. There will be failures. There have always been those things. Throughout all of the history of IT, whatever promising new technology comes in brings with it some set of challenges, but it also advances things. Because of the focus on the business and business results [with cloud], the net benefit will be substantial.
Going back to the licensing, how does Microsoft navigate that change? The model has been that you gather together a bunch of new features and new capabilities into a new release, which has big revenue associated with it. Now people are going to expect these features to just become part of the product to which they subscribe. Well, it's actually great for us, because our biggest competition with our new product releases is always our old product releases. We still have a lot of XP. XP is pretty much still ruling the world and we're seeing people now move to Windows 7. There's Office 2003 and Office 2007, and we've shipped Office 2010. That's always been our biggest challenge, the complexity customers have associated with moving forward is an impediment to our being able to license them new software. The cloud will eliminate that because it's our job to move them forward. We'll deliver a service to a customer that is evergreen. It's always up-to-date with the latest set of features. We need to provide customers with some level of control. I mean we don't want to update a retail customer from just before Thanksgiving until after Christmas. But we will commit to keeping and maintaining the software for the customers, one of the main differentiators. That's a huge advantage to us, because our sales force today spends a lot of time explaining the advantages of the new release and why a customer should go through the upgrade themselves.
When we talk to readers about cloud, management is always an issue; security's always an issue. Can you talk about what Microsoft is doing to address those big worries about cloud computing? We've invested very heavily in both of those areas for quite a number of years. Let me take them separately because I think the issues are somewhat different.
In the case of management, the advantages and benefits that accrue from the cloud largely have to do with changes in the operational environment and the way things are managed. So, there are some natural advantages from a management perspective. One of the things we are doing is enabling customers to use their existing management tools, like System Center, to help bridge the gap from where they are today into the cloud environment. And so they'll have a consistent set of management facilities and tools and one pane of glass, so to speak, that they can look across both of these environments. In contrast, security is different because you're moving into, in many cases -- particularly a public cloud -- a shared environment. There's a need for an incremental set of security capabilities to be added. Those are things that we are rapidly advancing. This environment still is nascent. There are still definitely areas where the cloud is not ready to take on all of the applications and services that customers want. I don't recommend [that] a banking customer move their core banking system to the cloud right now. I would not tell any bank to do that at this point, because the underlying facilities and services in the public cloud to handle the regulatory concerns, the security concerns, are simply not there. Five years from now, 10 years from now, I think they probably will be.
Most of the areas where you look at a focused or a finished application, like messaging, for example, we are able to work through and provide the security that's necessary, the regulatory requirements that are necessary to handle just about every industry right now. So, in most countries around the world -- every country is somewhat different -- we are able to handle the needs of financial services organizations, pharmaceuticals, I mean the more regulated industries. We have examples of customers in all of those industries that are using our cloud services.
The cloud is kind of a misnomer. It's more like multiple clouds. What is Microsoft doing to drive interoperability and standardization across different cloud platforms to make it easier for customers to bridge them? There's obviously a number of emerging standards that are going to be important here. They're still emerging, so knowing which ones are important and which ones are not [is difficult]. We're involved in that. I think, in the end, people will say, 'The most important characteristic is that I need the cloud services that I have to fully interoperate. And then I also need to have choice of vendor." Those are probably the two main things. In both areas, we're investing significantly.
All of the services that we're delivering in our clouds are based on Internet standards, either Web services or REST-based protocols, pretty much exclusively. We've used those standardized protocols as we've been building out our clouds. The only things that I would say probably don't fit in that nature are areas like messaging and collaboration, where there are no standard protocols that have really emerged. If there is a standard, it turns out to be something like ActiveSync, which Microsoft has now fully licensed. That's what everybody uses now to synchronize their e-mail. That's how an iPhone synchronizes, a Google, an Android. Also, there are protocols that we built and have now made available to people. We've built these proprietary systems, but have now fully published our protocols and everyone else is adopting them in the industry.
In the case of Windows Azure, it's all Web services and REST-based stuff and everything is done that way, so it's interoperable.
The other thing that's important is that the customers say, 'I don't want only one cloud provider. I don't want to be locked into Microsoft or Google, anyone else.' We're in a very strong position because we're running the cloud ourselves with Windows Azure. And we're working to offer this Azure appliance that allows service providers, telcos and hosters, to also run cloud. So customers will be able to choose, from a number of different providers to run their sets of services. That's good, because there are a million reasons why customers might want to choose to use a given service provider.
Talking about Google in particular, what do you think people should have learned from the City of Los Angeles' experience with Google apps? That it's not so easy. The City of Los Angeles is an indicator of how complicated an enterprise and a business environment is. It speaks to one of the most fundamental differentiators that Microsoft has in this space, which is that we are the only company in the industry that has 20 years of experience working with enterprise customers and really understanding their needs, and 15 years of experience building massive scale consumer services. Go through the industry. You can't find anyone that has both of those. IBM has more than 20 years' enterprise experience. I'll give them that. But, really no consumer experience. Google has big consumer services, no industry experience in terms of the business.
I think what the City of Los Angeles found out was really some of the issues that come about when a provider doesn't have that experience of working with enterprise customers and understanding the complexity of that environment. One thing I think is really important -- if you look at the classic enterprise competitors, you know, the Oracles, the IBMs, the VMWares -- is that you gotta run this stuff yourself. And, you know what? Your engineering team has to run it. IBM says they're running these clouds, but it's their services organization that's running these things and building these things. That's really an outsourcing. It's a hosting sort of circumstance and an arm's length thing. It's my own engineering teams that are running the clouds. It's my engineering teams that are getting called when there's a problem. It's my engineering teams that are dealing with and understanding what happens when you're running a service, day-in, day-out for a customer. I can't even imagine how a provider can deliver a cloud service unless they're operating that way. To be fair, Google operates that way, an Amazon would operate that way. The consumer service companies have that experience. They know that. But they don't know the enterprise. They don't understand the needs that the enterprise has in terms of the complexity of their environments, the lifecycle associated with their applications. You see things with these consumer services guys. They release something and customers build apps and they say, 'Oh, we're going to change that API in the next version completely.' And customers have built and made investments. We've come to learn what sort of expectations an enterprise customer has. It's that balance of understanding what it means to run these services at scale and actually have your engineering teams live with it, and understand the complexity and the expectations in the enterprise.
What other big shifts is Microsoft focused on with major corporate customers around collaboration, mobility, business intelligence? There are some great things that are happening. We see a strong emergence of a wide variety of devices and connecting those sets of devices. Obviously, we're highly engaged in building those things. We're excited to see Windows Phone 7 launching this fall. That's really a huge step and I think we'll start to see a lot of success there.
You mentioned business intelligence. I think that's an example of one of the major opportunities that emerges in this sort of this crunch time where we have this combination of business systems and sensors that are being deployed. I was just in China not that long ago and the utility companies are going to have smart meters sending this massive amount of data back associated with the usage of electricity. There's a massive amount of information that's coming into these systems. How can we actually make use of that and put it in a form that people can digest and actually make better business decisions?
Our view is that [BI] is something that needs to be democratized and made available to everyone, every person who is working with information. Other folks are building these complicated, high-priced tools where there's a lot of training required. Our tool for business intelligence is called Excel. It's a tool that people really know. We took a massive step forward this spring with Excel 2010 and the power pivot capabilities that we put in there for people to analyze and work with business data. So now Excel can work with, essentially, information of any size, data sheets of any size, hundreds of millions of rows, with some very, very strong visualization technologies. People can view the data and pivot it in different ways. The path of innovation on that stuff is unbelievably exciting.
One of the things that excites me in general about this time is I that feel like the speed of innovation and our ability to bring technology to market is really increasing. I very much see that in the BI space. We have a SQL conference coming up at the end of this year and there's a whole new round of interesting stuff that we'll be talking about.
Do you have any interest in NoSQL, the "big data" solutions? Absolutely. Let's make sure it's all clear. NoSQL has really become SQL and other ways of working with data. The only provocative thing about NoSQL is the name, right? People have been working with non-relational data sets since the beginning of time. Columnar databases, flat files. SQL relational databases are not the way to analyze Web logs. Nobody analyzes Web logs with a relational database. They may sometimes take information out and put it in a data warehouse, but it's an example of a data set that's not naturally suited to the relational model. There's a new capability in SQL Server that we deliver called StreamInsight that's designed to do real time analysis of business information that's not relational. And, for example, our Bing team is using that now to do ad serving based on what a user is actively doing. If you don't have any profile information about a user, you can, based on seeing what sites they're going to, use that information in real time to do better ad serving. That's an example of a NoSQL scenario. It came out of our research and it's used broadly in our Web services. There's a technology called Dryad that essentially does a sophisticated MapReduce on associated Web logs or, again, non-relational data. We're incorporating that into our high-performance computing products, making that available broadly to everyone. This is new in the sense that it enables you to work with this massive amount of data. The idea that you had relational and non-relational data is not new.
Going back to cloud, how do you see this shaking out with your ecosystem of all the companies that build around Microsoft? Do you see in the future that they'd even be able to build into the core applications, the Exchanges, the SharePoints, the Office products? The cloud very much will take existing applications forward. But the really exciting thing is the new applications that can be created and the way these things can be brought together or mashed up, to use that term. As we move services like Exchange to the cloud, the ability for people to build applications around that increases, because you'll have standard protocols that are available for people to work with and pull information in and out of those things. The impediment of having to build up the infrastructure associated with deploying these business applications is just gone.
If a customer is using our online services, our Exchange-hosted services, and an application wants to work with contact management information, as an example, for an application that's a logical extension of Exchange, they'll be able to deploy that in a cloud service like Windows Azure and interoperate and work with the data with Exchange, and then simply sell that service to the customer without having to go through the process of talking about the infrastructure.... I mean, very literally, a customer that's operating with, say, Exchange-hosted services could very rapidly trial one of these applications, and begin to get it up and running, with virtually no cost to them. The issue of selling that and actually going through the deployment, all of those things go away.
COO Kevin Turner said in July that leading with cloud helps better position Microsoft to sell on-premise products. What did he mean by that? Well, I think what he means is that by explaining the future and helping our customers to know where they're going in the future, they have confidence in what they're doing today. There's a path. No customer is going to cut over immediately to the cloud. That's impossible for any substantive customer to do. They may move their messaging system to the cloud, or they may move a given application to the cloud, but any large customer has hundreds, thousands of applications. The complexity of their environment is very high. But by helping our customers see where they can drive themselves into the future, where they can focus on their business advantage and not need to worry about these infrastructure components, it provides them with a level of security knowing what they're doing today can be brought forward. It's a good balance.
But what about the knock on Microsoft in the sense that you're not pure-play cloud? Some competitors can say: 'Hey, we're all cloud. We're fully committed.' This reflects the benefit that I was talking about a few minutes ago where Microsoft has 20 years of experience of working with our enterprise customers and providing them with the services and capabilities they need, and 15 years of experience writing consumer services. If we just had that consumer services experience, I mean if all we had was a hammer, everything would look like a nail to us, too.
But that's not the world our customers live in. Our customers live in a world that's very heterogeneous. There is no significant customer where everything they do is in the cloud today. The fact that we're able to meet the customers' needs with on-premises software, while providing them with these amazing new services that the cloud brings and allowing customers to move at their own speed is actually a huge advantage. It turns out all of our customers see that. Our engagements with customers about where they're going in the future, what they want to do as they roll out a new messaging collaboration service, they're very positive. And, in fact, we're winning the vast, vast majority of all those engagements.
Customers don't think your approach is defensive toward the cloud? No, it's not defensive at all. In fact, we've been so focused on investing in the cloud and driving new sets of value there, that customers see Microsoft taking very much a leadership role in terms of providing a set of services that really no one else can match. I think that's very true today. If you look at what we have with our Exchange Online services, our SharePoint Online services, if you look at what we're doing with Windows Azure and a new service we'll be bringing out next year, Windows Intune, nobody on the planet has services like that for business customers. They're highly differentiated.
At the 2010 Hosting Summit you used a reference to cloud being like rock climbing. It's exciting and scary at the same time. What scares you about the cloud? The thing that's interesting about the cloud is you're running everything yourself. We are responsible for what our customers are experiencing. If we have a problem, it's a problem that's visible to our customers. We have to make sure we are world-class. We need to continue to improve every day. Anybody who runs an operations system has some moments anywhere from concern to terror. That's one thing.
But the reference I made at the time was really to the hosting partners about how the business model is transitioning here and how Microsoft has decided to jump in with both feet and embrace the change. That change will affect the partner ecosystem as well and certainly affects our hosting partners. I was encouraging them to embrace it and to drive their business forward, because it is where the future is going. We've embraced the future and are driving it forward.
So, from a business perspective, how do you smoothly make the transition from the big upgrade cycles, the big surges of revenue, to the subscription model? The first thing to realize is that we don't really see that surge of revenue at the time of an upgrade anymore because the majority of our customers are buying on multi-year annuities anyway. We have to provide incentives for our customers to upgrade. One of the great things about the cloud is that it's a good business for us because it's a continuation of that annuity cycle. We're very confident that the cloud will drive down the cost of [customer] operations substantially and, thus, enable our customers to save money and, at the same time, actually be able to build a good business for ourselves.
Talk about the Azure appliance. What's the goal with that and what has the uptake been? I've got to back up to Windows Azure before I talk about the Azure appliance. What is the benefit that we can see for moving to a cloud environment? We learned this ourselves as we deployed consumer services. Our initial consumer services, our initial MSN services, were deployed largely the same way that any enterprise would build an internal application. They used standard servers, standard operational practices. As we built a large number of these services and they started scaling at large numbers, the cost of operations associated with that just got out of whack for us. It wasn't a sustainable business model. [Emphasis added.]
And when we created Bing, we knew we were going to create a massive -- we needed to create a massive scale service because that's what an internet search system is. I mean it's a service that's measured in hundreds of thousands of servers, you know, not even tens of thousands. If we ran that in a traditional way, it was going to be non-viable. So, we built a system with Bing that was a proprietary system designed to enable us to roll out thousands and thousands of servers with very low operations costs. And it worked. It was not general purpose, however. It was not something we could take and offer to our customers or even, frankly, apply broadly within Microsoft.
[Windows Azure Compute] [South Central US] posted an update on 10/8/2010 about [Yellow] Compute Service Degradation in South Central US of the same date:
- Oct 8 2010 1:03PM Management operations are not possible on hosted services in one of the clusters in the South Central US region. Applications already running in that cluster are not impacted. The other compute clusters in this region, and all other regions are not impacted. Storage is not impacted.
- Oct 8 2010 7:07PM The root cause has been identified and the repair steps are being implemented.
- Oct 8 2010 9:16PM The repair steps have been successfully implemented and validated, and the impacted cluster is back online in the South Central US region.
I wonder if the Windows Azure Compute SLA applies to management operations outages. Obviously, instances running in the affected cluster could not be scaled up or down for more than eight hours last Friday.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA)
See near end of John Gallant and Eric Knorr published an extraordinarlily lenghthy Q&A: Microsoft's Bob Muglia details cloud strategy to the ComputerWorld Norway site on 10/8/2010 in the Windows Azure Infrastructure section above.
<Return to section navigation list>
Cloud Security and Governance
• Alessio Marziali’s Transparent Data Encryption Explained post of 10/10/2010 to his Cyphersec.com blog describes a feature most cloud-oriented developers (including me) would like to see implemented as an SQL Azure option:

As noted in the previous post, TDE's specific purpose is to protect data at rest by encrypting the physical files of the databased rather than the data itself. Transparent Data Encryption was introduced in SQL Server 2008, as a feature of the Enterprise Edition. The Developer edition of SQL Server 2008 also offered TDE but its license limits its use to development and testing only.
These physical files include
- Transaction log .ldf
- Backup file .bak
The protection of the database files is accomplished through an encryption key hierarchy that exists externally from the database in which TDE has been enabled
Transparent data encryption performs all of the cryptographic operations at the database level which is quite useful considering that removes any need for application developers to create custom code to encrypt and decrypt data. With TDE data is encrypted as it is written to disk, and decrypted as it is read from disk. Apple users can consider TDE as similar to the cryptographic utility FileVault.
TDE is designed to protect data at rest by encrypting the physical data files rather than the data itself. This level of protection prevents the data and backup files from being opened in a text editor to expose the file's content.
TDE encryption occurs prior to writing data to disk, and the data is decrypted when it is queries and recalled into memory. This encryption and decryption occurs without any additional coding or data type modifications; thus it's transparency. Once the data is recalled from disk, into memory, it is no longer considered to be at rest. It becomes data in motion, which is beyond the scope of this feature. As such, alongside TDE, software security people should consider applying additional supporting layers of protection to sensitive data, to ensure complete protection from unauthorised disclosure. For example, you may wish to implement, in addition to TDE, encrypted database connections, cell-level encryption, or one-way encryption.
As many encryption features are present in SQL Server 2008 Enterprise many software people get easily confused by topics as Cell Encryption vs Transparent Data Encryption and which one they should leverage in their architecture. I will cover Cell Encryption in the future but for the moment let's focus on benefits and disadvantages of TDE.
TDE is best suited in conjunction with other encryption and obfuscation methods, for a layered approach to protection.
When dealing with Sensitive Data consider the following benefits and disadvantages.
Benefits
- Implementation of TDE does not require any schema modification.
- Since the physical data files and not the data itself are encrypted, the primary keys and indexes on the data are unaffected, and so optimal query execution can be maintained.
- The performance impact on the database is minimal. In "Database Encryption in SQL Server 2008 Enterprise Edition" Microsoft itself estimate the performance degradation for TDE to be 3-5%, while cell-level encryption is estimated to be 20-28%.
- The decryption process is invisible to the end user.
Disadvantages
- Use of TDE renders negligible any benefits to be gained from backup compression, as the backup files will be only minimally compressed. It is not recommended to use these two features together on the same database.
- TDE does not provide the same granular control, specific to a user or database role, as is offered by cell-level encryption.
- TDE is available only with SQL Server 2008, Enterprise Edition and so will probably will not be available to all installations within your environment
Performance impact on TempDB
When TDE is initially implemented, the physical file of the TempDB system database is also encrypted. Since the TempDB database contains temporary data from the TDE-enabled database, its encryption is required to maintain full protection by this feature; otherwise the information that is temporarily stored in the TempDB database from the TDE enabled databases would be exposed through the physical files of TempDB.
The TempDB database is used by all users and system database in the instance to store temporary objects, such as temporary tables, cursors and work tables for spooling. It also provides row versioning and the ability to rollback transactions.
Once the TempDB database is encrypted, any reference and use of this database by other databases, regardless of whether they have TDE enabled or not, will require encryption and decryption. While this encryption and decryption of the TempDB database files remains transparent to the users, it does have a minimal performance impact on the entire instance. Microsoft has estimated the entire impact of TDE on a SQL Server instance to be 3-5% depending on the server environment and data volume.
Backup and Recovery
Another cool feature of TDE is that it also limits the recovery of the database backup file to the instance that holds the encryption key hierarchy that was in existence at the time the backup was created.
With TDE enabled, backup files of databases are encrypted using a key hierarchy that includes the service master key of the SQL Server instance, the database master key and certificate for the Master database.
Despite this dependency, none of these keys are included with the standard database backup, and must be backed up separately via the following commands
- BACKUP SERVICE MASTER KEY to backup of the service master key
- BACKUP MASTER KEY to backup of a database master key
- BACKUP CERTIFICATE to backup the certificate
This behaviour is one of the security benefits of TDE. In order to restore the encrypted data to another instance of SQL Server, a user needs to recover the service master key backup file, the Master database master key backup file and the Master database certificate private key, prior to recovering the database backup file.
The database encryption key that is created in the user database, in which TDE has been implemented, is included in the standard database backup. It is stored in the boot record of the database file so that it can be accessed and used to decrypt the user database.
When the service master key and database master key are backed up, it is recommended to store their backup files in a separate location from the database file. This separation will ensure continued protection of the encrypted data in the event that the database media is stolen or compromised.
Using Replication? Read this
There is one thing that you should be aware of. If you are using Replication keep in mind that the subscribing database MUST also have TDE implemented. The data that is travelling between the databases (Data-In-Motion) will be in plain text and is vulnerable to unauthorised disclosure.
Alessio (@alessiomarziali) is a Security Consultant with Cigital, a software security and quality consulting firm. He has 10 years of experience developing and securing applications in a variety of sectors in different countries. You might enjoy his earlier Difference Between Data-At-Rest and Data-In-Motion post.
• David Kolle [pictured below] reported “Despite running a successful trial of Microsoft Azure earlier this year, Computershare chief information officer Stuart Irving still has reservations over data security” in a preface to his Computershare CIO has concerns over Cloud post of 10/10/2010 to the InformativeReport.com site:
“It went fairly well,” he said of the pilot. “We architected the application slightly so that it could work in the cloud. We re-engineered some of our apps to be more cloud appealing and it was a success. We could scale up and down at a fraction of the cost,” Irving said.
“My concerns in the cloud centre around security and a little term called ‘data patriation’, which is the need to keep local data in several, local private clouds,” Irving said.
He added that customer data that originated in the UK needs to be kept in a European Union datacentre as per the Data Protection Act, for example.
As a result of the company’s global operations, Computershare is required to keep data within national boundaries, making the process of consolidating multiple datacentres into the one large cloud almost impossible.
“We run regional datacentres as it stands, and the appeal to collapse that into two or three mega datacentres using the cloud is [high], but the privacy rules of data patriation means you have to think again … which is a little bit frustrating.”
Even if it were legal to store data across country borders, Irving’s concerns around the cloud would not be assuaged.
“When you outsource [data] into a public cloud, [security is] no longer in your control. When it’s an internal cloud, you can attest to the [security], but when it’s in a cold, dark datacentre somewhere, you have to take on due diligence yourself,” Irving said.
“Our customers are public companies who like to know that we have certain standards on who gets to see and access data, whether things are encrypted or unencrypted and if we’ve deployed technology in Computershare to prevent data leakage.
“There’s still a long way to go before I would commit a lot of our applications to [a cloud] environment,” he said.
“We’re still looking at a way for Computershare to best harness the cloud. We trial to make sure we’re comfortable with the secured, regional private cloud but still have the ability to ramp up and ramp down when we need to.”
David is an Account Manager for Pitney Bowes Business Insight (PBBI) a software & data organization. Computershare Investor Services provides comprehensive, transfer agent services for more than 2,700 public corporations and closed-end funds, and their 17 million active shareholder accounts.
Paul Krill (@pjkrill) asserted “Cloud vendors are implementing better security measures, but potential clients still need to be reassured” in a deck for his Security still an issue for cloud customers post of 10/8/2010 to InfoWorld’s Cloud Computing blog:
Cloud computing may offer a quick and inexpensive way to build an online business, but customer fears about security still must be allayed.
Representatives of three cloud-based application companies touted their efforts Friday afternoon during an event at Google offices in San Francisco. Two of the companies, WebFilings and Simperium, were using Google's App Engine cloud while the third, Rypple, leveraged Rackspace cloud services but used Google technologies like Google Web Toolkit.
"We have several Fortune 100 and Fortune 500 companies that are storing their financial information with us and on Google App Engine, " said Daniel Murray, managing director of WebFilings, which provides an application to assist companies with filling out U.S. Securities and Exchange Commission reports. WebFilings just signed up a Fortune 30 company also, Murray said.
WebFilings, though, still has to sell the cloud concept itself, Murray acknowledged. But a lot of issues as far as security are starting to fall away, he said. Both WebFilings and Google implement layers of security, said Murray.
"You have to make [sure] you can educate your customers and help them understand how [cloud computing] can be secure and how it can be a benefit to them," Murray said.
At Rypple, which furnishes Web-based team feedback software, the company uses Rackspace instead of App Engine because Racksapce made it easier to address concerns about security and privacy, said Tihomir Bajić, Rypple software developer. Customers, however, were more concerned about privacy of data, he said.
Simperium's Simplenote application, meanwhile, provides a way to keep notes on the Web, a mobile device or a computer.
"Simplenote actually started as a mobile app. We built it for iPhones originally and it's been around for over a year now," said Fred Cheng, Simperium founder.
<Return to section navigation list>
Cloud Computing Events
• Following is a brief retrospective of five Azure-related sessions from Code Camp Silicon Valley 2010, which took place on 10/9 and 10/10/2010 at the Foothill College campus in Los Altos Hills, CA:
- Speaker: Beth Massi
- Level: Intermediate | Room: 1401 | 3:30 PM Saturday
The Open Data Protocol (OData) is a REST-ful protocol for exposing and consuming data on the web and is becoming the new standard for data-based services. In this session you will learn how to easily create these services using WCF Data Services in Visual Studio 2010 and will gain a firm understanding of how they work as well as what new features are available in .NET 4 Framework. You’ll also see how to consume these services and connect them to other public data sources in the cloud to create powerful BI data analysis in Excel 2010 using the PowerPivot add-in. Finally, we will build our own Excel and Outlook add-ins that consume OData services exposed by SharePoint 2010.
Creating and Migrating MVC/WebForm apps to the Cloud
- Speaker: Bruno Terkaly
- Level: Intermediate | Room: 4218 | 11:15 AM Saturday
If scalability and reliability are important to your web applications, this session will help you achieve both. This session is heavy on hands-on development and will take you from the very beginning all the way to a finished application running in the cloud. What makes this session interesting is that builds everything from scratch, including the database. But a web application by itself is not scalable if the data cannot be scaled as well. That’s why both the MVC application and the database get migrated to Windows Azure and SQL Azure, respectively. By the time you leave this session, you will have created an on-premise database and MVC application and you will have migrated both the data and the app to the cloud. This session was delivered live to 1,000s with exceptional audience satisfaction.
Cross Platform Push Notifications in the Cloud
- Speaker: John Waters
- Level: Advanced | Room: 3403 | 2:45 PM Sunday
In this session, I will show you how to send Push Notification from an Azure Worker Role both to Windows Phone 7 clients, using MS Push Notifications, AND iPhone clients, using Apple Push Notifications.
Microsoft Azure for Beginners
- Speaker: Robin Shahan
- Level: Beginner | Room: 1401 | 1:45 PM Saturday
What the heck is Azure other than a nice shade of blue? How do you pronounce it? Why would you want to use it? How would you use it? What would you use it for? What does the programming look like? This session is for enquiring minds who want to know the answers to these questions, and more. I will also show how to create and run a WCF service in a web role, talk about deployment, and show how to convert an existing Silverlight application to run on Azure.
Windows Phone 7 Meets Cloud Computing - Supplying Mobile Devices with the Power of the Cloud
- Speaker: Bruno Terkaly
- Level: Intermediate | Room: 3106 | 9:45 AM Saturday | Windows Phone 7 Track
No phone application is an island. Mobile applications are hungry for a couple of things. First, they need data. Second, they need computing power to process the data. The obvious solution to computing power and connected data is the 'cloud.' If you plan to connect mobile applications to the cloud, then this session is for you. We will start by migrating on-premise data to the cloud, specifically SQL Azure. Next, we will need to create web services to expose that data and make it available to Windows Phone 7 applications. Rather than just show you how to connect to some 'already created' data source, I show you how to build your own infrastructure to expose cloud based data to the world. This is a soup to nuts session that builds everything from scratch and gives you a limitless ability to consume data from Windows Phone 7 applications. I presented this session to 1000's during the Visual Studio 2010 launch and it was very well received. Join me in what I consider to be absolutely essential Windows Phone 7 development skills.
Check in to the speakers’ blogs next week or Twitter #svcc for availability of slide decks and sample code.
Lydia Leong (@CoudPundit) listed the three Upcoming Gartner conferences of 2011 in which she will participate:
I will be at three Gartner conferences during the remainder of this year.
I will be at Symposium ITxpo Orlando. My main session here will be The Great Debate: Shared-Hardware vs. Shared-Everything Multitenancy, or Amazon’s Apples vs. Force.com’s Oranges. (Or for those of you who heard Larry Ellison’s OpenWorld keynote, Oracle ExaLogic vs. Salesforce.com…) The debate will be moderated by my colleague Ray Valdes, I’ll be taking the shared-hardware side while my colleague Eric Knipp takes the shared-everything side. I’m also likely to be running some end-user roundtables, but mostly, I’ll be available to take questions in 1-on-1 sessions.
If you go to Symposium, I highly encourage you to attend a session by one of my colleagues, Neil MacDonald. It’s called Why Cloud-Based Computing Will Be More Secure Than What You Have Today, and it’s what we call a “maverick pitch”, which means that it’s follows an idea that’s not a common consensus opinion at Gartner. But it’s also the foundation of some really, really interesting work that we’re doing on the future of the cloud, and it follows an incredibly important tenet that we’re talking about a lot: that control is not a substitute for trust, and the historical model that enterprises have had of equating the two is fundamentally broken.
I will be at the Application Architecture, Development, and Integration Summit (ala, our Web and Cloud conference) in November. I’m giving two presentations there. The first will be Controlling the Cloud: How to Leverage Cloud Computing Without Losing Control of Your IT Processes. The second is Infrastructure as a Service: Providing Data Center Services in the Cloud. I’ll also be running an end-user roundtable on building private clouds, and be available to take 1-on-1 questions.
Finally, I will be at the Data Center Conference in December. I’m giving two presentations there. The first will be Is Amazon, Not VMware, the Future of Your Data Center? The second is Getting Real With Cloud Infrastructure Services. I’ll also be in one of our “town hall” meetings on cloud, running an end-user roundtable on cloud IaaS, and be available to take 1-on-1 questions.
Randy Bias (@randybias) included a list of upcoming cloud-computing events in his Cloudscaling CEO Speaking in Europe and NYC post of 10/9/2010:
I’m off on a whirl-wind speaking tour this October. Would be great to meet more cloud folks and I would definitely appreciate your support at these venues. If you want to connect, please reach out via Twitter, LinkedIn, or TripIt.
Here’s my list of upcoming speaking engagements this month:
- Panel – October 14th, 10:30AM CET: VMworld Europe 2010, Copenhagen Denmark- Opportunities and Challenges with Platform as a Service (PC8533)
- Presentation – October 18th, 9:20AM EST: Interop 2010, NYC - From Bare Metal to Private Clouds
- Panel – October 19th, 1:30PM EST: Interop 2010, NYC - Public Cloud End Users: Enterprises
- Panel – October 20th, 11:30AM EST: Interop 2010, NYC – Measuring Cloud Performance
- Presentation – October 28th, 2:30PM CET: ISC Cloud 2010, Frankfurt Germany – A Painful Transition Private Cloud Implementations for Large Enterprises
- Panel – October 29th, 12:30PM DST: ISC Cloud 2010, Frankfurt Germany - Developing Your Organization’s Cloud: Where to Start What to Do, What to Avoid
For those who missed VMworld 2010 in San Francisco, you can listen to the panel I was on at the VMware website. You may have to register and login. Also be sure to check out my VMworld Video Panel, which I received a lot of positive feedback for.
Channel9’s The Knowledge Chamber released a 00:19:59 PDC10 and the new Online Experience video segment on 10/6/2010 (missed when posted):

PDC10 is fast approaching, and if you’ve been paying attention, you know that things are different this year. While you might know that for the first time we will be holding it at our own conference facility on the Microsoft Campus, and you might also know that we sold out early due to the smaller size of the venue. What you may not realize however, is that we’ve been working hard to make the online experience as exciting as possible.
For this episode, I’ve invited Eric Schmidt to talk to us about the brand new “viewer” he’s been working on for PDC10 which is being specifically designed to make sure those developers who couldn’t attend in person, will still be able to get a lot of value from the material being presented. Like always, we’ll be streaming the Keynote live, but we will also be streaming all of the in-person seminars live as well! We will also be preparing a great collection of pre-recorded seminars specifically for the PDC, and all of those sessions will be available online as soon as the PDC starts. Our media player is being built with the specific needs of our online audience in mind, with some very exciting features and capabilities.
Watch the segment:
- High Quality WMV (PC, XBox, MCE)
- MP3 (Audio only)
- MP4 (iPod, Zune HD)
- Medium Quality WMV (Lo-band, Mobile)
Oh, and don't be concerned about Eric's mention of the PDC starting on Oct 29th near the end of this episode... he hadn't had his morning coffee yet, and really intended to say "Oct 28th".
Here are some additional links you may find useful:
- http://www.MicrosoftPDC.com
For the latest details and information on the PDC.
- http://www.MicrosoftPDC.com/local
For information on special viewing events in your area.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• James Hamilton [pictured at right below] described Netflix Migration to the [Amazon] Cloud in a 10/10/2010 post:
This morning I came across an article written by Sid Anand, an architect at Netflix that is super interesting. I liked it for two reasons: 1) it talks about the move of substantial portions of a high-scale web site to the cloud, some of how it was done, and why it was done, and 2) its gives best practices on AWS SimpleDB usage.
I love articles about how high scale systems work. Some past postings:
- FriendFeed use of MySQL
- Facebook Cassandra Architecture and Design
- Wikipedia Architecture
- MySpace Architecture and .Net
- Flickr DB Architecture
- Geo-Replication at Facebook
- Scaling at LucasFilms
- Facebook: Needle in a Haystack: Efficient Storage of Billions of Photos
- Scaling LinkedIn
- Scaling at MySpace
The article starts off by explaining why Netflix decided to move their infrastructure to the cloud:
Circa late 2008, Netflix had a single data center. This single data center raised a few concerns. As a single-point-of-failure, it represented a liability – data center outages meant interruptions to service and negative customer impact. Additionally, with growth in both streaming adoption and subscription levels, Netflix would soon outgrow this data center – we foresaw an imminent need for more power, better cooling, more space, and more hardware.
Our option was to build more data centers. Aside from high upfront costs, this endeavor would likely tie up key engineering resources in data center scale out activities, making them unavailable for new product initiatives. Additionally, we recognized the management of multiple data centers to be a complex task. Building out and managing multiple data centers seemed a risky distraction.
Rather than embarking on this path, we chose a more radical one. We decided to leverage one of the leading IAAS offerings at the time, Amazon Web Services. With multiple, large data centers already in operation and multiple levels of redundancy in various web services (e.g. S3 and SimpleDB), AWS promised better availability and scalability in a relatively short amount of time.
By migrating various network and back-end operations to a 3rd party cloud provider, Netflix chose to focus on its core competency: to deliver movies and TV shows.
I’ve read considerable speculation over the years on the difficulty of moving to cloud services. Some I agree with – these migrations do take engineering investment – while other reports seem to less well thought through focusing mostly on repeating concerns speculated upon by others. Often, the information content is light.
I know the move to the cloud can be done and is done frequently because, where I work, I’m lucky enough to see it happen every day. But the Netflix example is particularly interesting in that 1) Netflix is a fairly big enterprise with a market capitalization of $7.83B – moving this infrastructure is substantial and represents considerable complexity. It is a great example of what can be done; 2) Netflix is profitable and has no economic need to make the change – they made the decision to avoid distraction and stay focused on the innovation that made the company as successful as it is; and 3) they are willing to contribute their experiences back to the community. Thanks to Sid and Netflix for the later.
For more detail, check out the more detailed document that Sid Anand has posted: Netflix’s Transition to High-Availability Storage Systems.
For those SimpleDB readers, here’s a set of SimpleDB best practices from Sid’s write-up:
- Partial or no SQL support. Loosely-speaking, SimpleDB supports a subset of SQL: Do GROUP BY and JOIN operations in the application layer; one way to avoid the need for JOINs is to denormalize multiple Oracle tables into a single logical SimpleDB domain
- No relations between domains: Compose relations in the application layer
- No transactions: Use SimpleDB’s Optimistic Concurrency Control API: ConditionalPut and ConditionalDelete
- No Triggers: Do without
- No PL/SQL: Do without
- No schema - This is non-obvious. A query for a misspelled attribute name will not fail with an error: Implement a schema validator in a common data access layer
- No sequences: Sequences are often used as primary keys: In this case, use a naturally occurring unique key. For example, in a Customer Contacts domain, use the customer’s mobile phone number as the item key; If no naturally occurring unique key exists, use a UUID
- Sequences are also often used for ordering: Use a distributed sequence generator
- No clock operations: Do without
- No constraints. Specifically, no uniqueness, no foreign key, no referential & no integrity constraints: Application can check constraints on read and repair data as a side effect. This is known as read-repair. Read repair should use the CondtionalPut or ConditionalDelete API to make atomic changes
If you are interested high sale web sites or cloud computing in general, this one is worth a read: Netflix’s Transition to High-Availability Storage Systems.

• Sankar reported Tata Communications debuts InstaCompute Cloud Service in India in a 10/10/2010 post to the Cloudshoring blog:

Tata Communications debuted its Cloud services in the Indian market on Thursday of last week as reported by ‘The Hindu’ .
InstaCompute, Tata Telecom’s Cloud computing service will provide organizations in India to leverage the flexible pay per use computing model for different capacities. InstaCompute’s pricing is very similar to the other Cloud service providers.
Details of the pricing along with the Price calculator (similar to Amazon AWS calculator) is available on their website. The interesting thing is that Payment options are available in Multiple currencies of Indian rupees, Singapore Dollar, USD and Euros.
You can actually try out a one week trial that comes with a INR 900 (USD 40) credit.
It took me 5 minutes to get signed and start using the Cloud services portal. When you login, you will be taken to the dashboard as shown below that provides the summary of the operational parameters.
You can then navigate to the “Instance” menu and launch a Virtual machine of specific capacity/config in seconds! As of now InstaCloud Provides a preset template for the following platforms and you can choose the template to launch the system needed.
- Ubuntu 10.04 LTS, x64 with 20 GB partition
- Cent OS 5.4 .X64 , 20 GB root partition
Windows 2003 X64 Datacenter Edition – 20GB primary disk
Windows 2003 X86 Datacenter Edition – 20GB primary disk
Windows 2008 R2 Datacenter Edition – 20GB primary disk
You can also add templates from templates library with various stacks of SuSe, Redhat, CentOS, Oracle enterprise Linux servers and Windows Servers
Cloud server instances started can be stopped, restarted, terminated flexibly
Multiple Storage disks from 50 GB to 1 TB can easily be added to the cloud through the Storage menu . The pricing for the storage is available in the rates section of their website
You can flexibly configure the network through the Network menu, you can acquire IP numbers, purchase additional IPs and configure firewalls, do port forwarding and load balancing
There is an events interface that provides you with a quick log history of the operations on the cloud which is a good utility for systems administrators.
There are a lot of other features to manage your account and in the support section to explore, although I didn’t have a chance to try in detail.
I was trying to find information on the support terms and the SLA’s . However, the SLA link in their website didn’t work during my trials.
Overall, my quick trial for a day on the Tata telecom’s InstaCompute cloud was pretty impressive, easy to setup and use without much IT knowledge and resource requirements. This is good for a lot of small and medium businesses looking at moving their IT to the cloud.
Tata’s InstaCompute seems to be a great opportunity for India based or Asia-pacific based compaies, especially the SMBs to leverage Cloud computing for their IT operations. Happy Cloudshoring to InstaCompute!
For Asia-Pacific customers, its relative technical, cost and support advantages against Amazon AWS, which has a hosting center in Singapore and other cloud providers like Voxel from Singapore needs to be explored.





Note: Windows instance licensing is a per-hour surcharge.
Marcelo Calbucci (@calbucci) wrote Another 10 Mistakes Made by API Providers as a guest author for the ReadWriteCloud blog:
There was a recent post on ReadWriteCloud about 10 common mistakes made by API providers. I think this is a very thoughtful post, but I think it's an inward look at the problem. In other words, they are looking at problems that developers face while implementing their own APIs.
I think biggest mistakes are not necessarily how to implement your API, but how API consumers will perceive, implement and use the API. So I came up with my own list based on nearly a decade of implementing APIs from the receiving end.
1) Naming Convention
Naming convention in the software world is a debate as old as the first programming language was invented. Independent of which convention you use, be consistent. It's very annoying to implement an API that uses lowercase for all XML elements and attributes, except for a couple of them. Any developer can tell you stories of countless hours chasing a bug because of case-mismatch. My preference is all lowercase because it helps with HTTP compression.
2) URL Consistencies
This is similar to naming convention, and it's just too common to see APIs where the URL stems and query string have not a strong logic to it. As in, to get users use api.mydomain.com/getusers.php, but to get pictures use api.mydomain.com/pictures/get.php. A little bit of thought goes a long way, even if you are starting with a single API. Thinking as "objects" and "actions" is a good start.
3) Authentication
I love APIs that just ask me to pass a single API-Key on the URL. It's much simpler than having to do some digest authentication (although digest is simple too), and a lot of heck simpler than having to do a separate call to get a session cookie to use on subsequent calls.
4) Simplicity
Some engineers over-think and over-engineer the problem. YouTube used to have a beautifully simple API where you could get meta-data from a YouTube video. Now they decided to normalize and use the Google standard ATOM response, which is pretty awful and bloated. Awful and bloated is one of the reasons SOAP has not caught up. Trying to create a common response for all APIs is silly. Getting user information is different from getting a video information, which is different from posting a comment, which is different from getting a list of followers. Keep it obvious. Keep it simple.
5) Object normalization
If you are going to return an object of type User on the XML element (or JSON) then make sure that every API that returns the element is consistent and returns similar fields. It's very hard when the same provider has three different APIs that might return a similar, but not the same object. It means I have to parse it three different ways. Making attributes/values optional is fine, but don't overload their meaning.
6) Documentation
This is the most awful part of implementing APIs, particularly for newly released APIs. Don't make me figure out how each call, each element and each attribute works. I spend way too much time looking into many responses to see what's optional, what's not, what's the date format, is it a string or an integer, is it long-lat or lat-long, etc. It doesn't have to be an extensive MSDN-like documentation, but clearly stating what are the call parameters, what values are valid, what are the default values, and on the response side giving an XML-response example and describing what each element/attribute is.
7) Be Forward and Backward Thoughtful
Don't break my code! There is nothing worse when using a third-party API to learn that your live production code stopped working because the provider changed how an API works. It can be as simple as a change on the format of an element or sometimes as bad as a new XML format that is completely different from the previous format. I know you wrote on your blog, told on your Twitter account and, maybe, emailed everyone you could about this change, but don't assume people pay attention to that. The best way is to make sure the URL itself has versioning, as in api.mydomain.com/1/myapi.xml. Be committed to keep old versions for at least six months after you release a new version and be very proactive at alerting consumers of your API.
8) Error Messages Are Important
There are two points I want to make: First, "Internal Error" is not a satisfactory error message, and, second, don't overload the meaning of HTTP response status codes. The best error messages have both an English description of what they are and a parser-friendly code, as in "783". I don't want to parse English-language error messages to figure out what I should tell my user. A standard error code to indicate the Full-Name field must be present is much better. Now, we might get into preferences now, but I prefer every HTTP call to respond with status code 200 and error messages to be embedded inside of the response body (or on an HTTP header), but using 401, 403, 500 to indicate success or error is just confusing. The HTTP status code is not supposed to understand the semantic inside of the response.
9) Mak[e] it Parsing Friendly
It's important to remember as an API provider, that the cost of generating the output might be different from the cost of receiving that output and converting into a usable data structure. This goes both for the computational cost and for the implementation (lines of code) cost. Stay clear of custom date-time formats, stay clear of creating custom data types (for example, multiple pieces of information concatenated into a single string, e.g. "374|Mike Wallace|yes"). It also means don't get too creative of embedding a CSV file inside a JSON inside an XML.
10) Allow for Subsets
I really like when APIs give me the ability of choosing a subset of data on the response. Amazon e-commerce API supports that and it's great because if you just need a few fields back why would you get a 30Kb response? Depending on how I'm using the API, the CPU, network and monetary costs can be significant for me. I might also have some of the data cached, so returning a "user-id" might be enough instead of returning a full "user" object.
I don't think this is an extensive list of best practices of implementing your own API for others to consume, but I think the more you wear the hat of the consumer side of things, the more adopted your API will be. Before you even start implementing your API think of three or four applications that would be built using it, and understand what the needs would be. Maybe you should go ahead and use a bit of test-driven development, on this case usage-driven development, and implement those applications first.
James Hamilton explained Scaling AWS Relational Database Service on 10/9/2010:
Another database scaling technique is to simply not use a relational database. For workloads that don’t need schema enforcement and complex query, NoSQL databases offer both a cheaper and a simpler approach to hosting the workload. SimpleDB is the AWS hosted NoSQL database with Netflix being one of the best known users (slide deck from Netflix’s Adrian Cockcroft: http://www.slideshare.net/adrianco/netflix-oncloudteaser). Cassandra is another common RDBMS alternative in heavy use by many high-scale sites including Facebook where it was originally conceived. Cassandra is also frequently run on AWS with the Cassandra Wiki offering scripts to make it easy install and configure on Amazon EC2.
For those workloads where a relational database is the chosen solution, MySQL read replication is a good technique to have in your scaling tool kit. Last week Amazon announced read replica support for the AWS Relational Database Service. The press release is at: Announcing Read Replicas, Lower High Memory DB Instance Price for Amazon AWS.
You can now create one or more replicas of a given “source” DB Instance and serve incoming read traffic from multiple copies of your data. This new database deployment option enables you to elastically scale out beyond the capacity constraints of a single DB Instance for read-heavy database workloads. You can use Read Replicas in conjunction with Multi-AZ replication for scalable, reliable, and highly available production database deployments.
If you are running MySQL and wish you had someone else to manage it for you, check out Amazon RDS. The combination of read replicas to scale read workloads and Mulit-AZ support for multi-data center, high availability make it a pretty interesting way to run MySQL.
Jeff Barr posted AWS Management Console Support for DB Engine Version Management on 10/8/2010:
We introduced the DB Engine Version Management feature earlier this year to give you control over the version of MySQL running in each of your DB Instances. You can now access this feature from the AWS Management Console. You can create a new DB Instance using any supported version of MySQL:
You can also upgrade a running instance to a newer version using the Modify Instance operation:
As you can see, you can update your DB Instances to a newer version of MySQL with a couple of clicks. Pretty easy, huh?
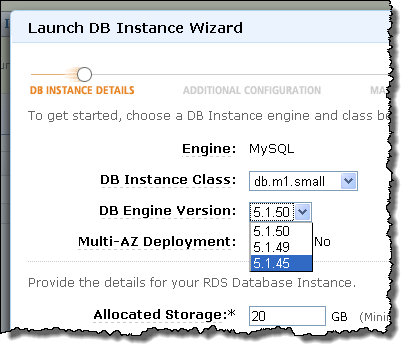
A nice feature.
Matt Asay reported MySQL price hikes reveal depth of Oracle's wallet love in a 10/8/2010 article for The Register:
Open...and Shut Oracle has repeatedly declared its intent to invest heavily in MySQL technology in its effort to up-end Microsoft's SQL Server business.
What it didn't say, but which should have been clear, given Oracle's treatment of its own database customers, is that MySQL customers were going to have to pay for those investments. Through the nose.
That's the cheery message MySQL customers are now getting from Oracle's MySQL sales team, one of whose emails was forwarded to me. These emails promise "changes to MySQL's pricing and possibly pricing model soon," with a further stealth price increase in the form of removal of MySQL's Basic and Silver support options.
Here is the Oracle letter in its entirety:
Hello Customer,
I am writing as way of introduction. My name is [removed] and I am your MySQL contact at Oracle. It is my understanding that you are the most appropriate person to speak with at your organization regarding MySQL. If you have any MySQL requirements, questions on the products, support, consulting or training we provide, please do not hesitate in contacting me.
I'm sure you are aware that Oracle purchased Sun and therefore MySQL last February. We're being told that there will be changes to MySQL's pricing and possibly pricing model soon and wanted to let you know. We have not had a price increase for over 6 years but there will be an increase in the next price list that will be available soon. We've been expecting the increase for the past couple of months but I'm told it the new price list will be released soon.
For those of you using Basic and Silver support we're being told those options will no longer be available. If you wish to continue with Basic or Silver you will need to sign a multi-year agreement and you would be able to keep using Basic or Silver for up to another 3 years.
If you are considering purchasing additional licenses for MySQL support subscription, please let me know, because you can save money if you do it before the changes take place, some time in the next month or two. You can also sign multi-year agreements and lock down current prices for up to 3 years.
You can receive up to a 30% discount for a 3 yr. commitments pre-pay but annual payments are available as well for multi-year agreements.
If you would like to speak to someone about MySQL Cluster, please let me know and I can arrange for an expert to call you within the next week.
Please let me know if you have any questions.
Thank you, [Name removed] Oracle
There is no clear guidance on how much of a price increase to expect, but people are beginning to make educated guesses.
If customers want to stay with MySQL, they're going to need to go Gold or better, and they're going to need to pay more than they're accustomed. Unless, of course, they act now and lock themselves into a long-term support contract. The generosity or Oracle chief executive Larry Ellison knows no bounds.
All's fair in love and software pricing, of course, and somebody has to pay for all the MySQL development Oracle has been doing. At its recent OpenWorld conference, Oracle chief corporate architect Edward Screven suggested: "Some folks thought when we'd acquire Sun [Microsystems], we'd deprecate MySQL, but it's quite the opposite... We are focused on making MySQL better."
And pricier, but that might well be a good thing. Former MySQL executives Marten Mickos and Zack Urlocker managed to build a very healthy $100m business, but undoubtedly wouldn't have minded customers paying a bit more. They simply lacked the pricing power, as perhaps reflected in the MySQL Unlimited program. This program gave customers the right to run unlimited instances of MySQL for an initial annual fee of $40,000, which program was adopted by Sun and bumped to a $65,000 entry fee.
It was a way to make it cheap to significantly deploy MySQL throughout an enterprise. Apparently, Oracle feels it's time to stop seeding the ground and begin reaping. As The Register's Gavin Clarke recently wrote of the MySQL team within Oracle:
[Robin] Hood's [MySQL] men are about to find the responsibility of running the castle is a lot less fun and more predictable and businesslike than ambushing the enemy in the woods...
MySQL was growing under Sun. In fact, it was Sun's fastest growing software business. It just wasn't growing fast enough, so Oracle's strapping a rocket on the database's business.
Clarke was speaking of enterprise-class technology upgrades to MySQL, but Oracle is apparently also thinking of enterprise-class pricing upgrades. Oracle, after all, is used to getting paid. This is the company that raised prices by 20 per cent in 2008 and another 40 per cent in 2009 as the economy stuttered to resurrect itself.
But Oracle just might be playing an overly aggressive hand.
MySQL rules the web database market, but as Oracle improves its viability in the transactional, enterprise market, open-source Postgres is waiting in the wings. Postgres has long been the unfortunately forgotten stepchild of open-source databases, but that may be changing.
In 2009, Red Hat invested in EnterpriseDB, a company backing the Postgres database, reportedly as a hedge against an Oracle/MySQL combination. More recently, my own conversations with EnterpriseDB sales executives indicate an acceleration of commercial interest in Postgres, including from MySQL customers who are anxious that Oracle may ruin MySQL for them.
On the other hand, a Jaspersoft survey finds "most respondents think Oracle is a better steward of Java and MySQL than Sun."
Whether they're willing to pay extra for such stewardship is an open question, one that Oracle must be believe customers will answer with a "Yes." In its own database business Oracle has generally been right: price increases have not caused a customer exodus. But then, Oracle was never dealing with freedom-loving, tight-fisted MySQL customers before.
This could get interesting.
Matt Asay is chief operating officer of Ubuntu commercial operation Canonical. With more than a decade spent in open source, Asay served as Alfreso's general manager for the Americas and vice president of business development, and he helped put Novell on its open-source track. Asay is an emeritus board member of the Open Source Initiative (OSI). His column, Open...and Shut, appears every Friday on The Register.
Dave Rosenberg explained Why relational databases make sense for big data in a 10/6/2010 article for CNet News’ Software, Interrupted blog:
In 2010, the talk about a "big data" trend has reached a fever pitch. "Big data" centers around the notion that organizations are now (or soon will be) dealing with managing and extracting information from databases that are growing into the multi-petabyte range.
This dramatic amount of data has caused developers to seek new approaches that tend to avoid SQL queries and instead process data in a distributed manner. These so-called "NoSQL," such as Cassandra and MongoDB databases, are built to scale easily and handle massive amounts of data in a highly fluid manner.
And while I am a staunch supporter of the NoSQL approach, there is often a point where all of this data needs to be aggregated and parsed for different reasons, in a more traditional SQL data model.
It occurred to me recently that I've heard very little from the relational database (RDBMS) side of the house when it comes to dealing with big data. To that end, I recently caught up via e-mail with EnterpriseDB CEO Ed Boyajian, whose company provides services, support, and training around the open-source relational database PostgreSQL.
Boyajian stressed four points:
1. Relational databases can process ad-hoc queries
Production applications sometimes require only primary key lookups, but reporting queries often need to filter or aggregate based on other columns. Document databases and distributed key value stores sometimes don't support this at all, or they may support it only if an index on the relevant column has been defined in advance.
2. SQL reduces development time and improves interoperability
SQL is, and will likely remain, one of the most popular and successful computer languages of all time. SQL-aware development tools, reporting tools, monitoring tools, and connectors are available for just about every combination of operating system, platform, and database under the sun, and nearly every programmer or IT professional has at least a passing familiarity with SQL syntax.
Even for the types of relatively simple queries that are likely to be practical on huge data stores, writing an SQL query is typically simpler and faster than writing an algorithm to compute the desired answer, as is often necessary for data stores that do not include a query language.
3. Relational databases are mature, battle-tested technology
Nearly all of the major relational databases on the market today have been around for 10 years or more and have very stable code bases. They are known to be relatively bug-free, and their failure modes are well understood. Experienced DBAs can use proven techniques to maximize uptime and be confident of successful recovery in case of failure.
4. Relational databases conform to widely accepted standards
Migrating between two relational databases isn't a walk in the park, but most of the systems available today offer broadly similar capabilities, so many applications can be migrated with fairly straightforward changes. When they can't, products and services to simplify the process are available from a variety of vendors.
Document databases and distributed key-value stores have different interfaces, offer different isolation and durability guarantees, and accept very different types of queries. Changing between such different systems promises to be challenging.
Ed also provided an amusing analogy that perhaps illustrates how the differing types of databases (RDBMS, NoSQL and everything in between) relate to each other. You be the judge.
"An RDBMS is like a car. Nearly everybody has one and you can get almost everywhere in it. A key-value store is like an Indy car. It's faster than a regular car, but it has some limitations that make it less than ideal for a trip to the grocery store. And a column-oriented database is a helicopter. It can do many of the same things that a car can do, but it's unwieldy for some things that a car can do easily, and on the flip side excels at some things that a car can't do at all."Ultimately, users care more about the data than they do about their database. Managing and manipulating the data to meet their specific needs should always trump any specific technology approach.
<Return to section navigation list>

















0 comments:
Post a Comment