Windows Azure and Cloud Computing Posts for 8/13/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI,Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

•• Updated 8/17/2012 with new articles marked ••.
• Updated 8/16/2012 with new articles marked •.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Cloud Numerics, Big Data and OData
- Windows Azure Service Bus, Access Control, Caching, Active Directory, and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure, Media Services and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
•• The Datanami Staff (@datanami) posted Marching Hadoop to Windows on 8/17/2012:
Bringing Hadoop to Windows and the two-year development of Hadoop 2.0 are two of the more exciting developments brought up by Hortonworks’s Cofounder and CTO, Eric Baldeschwieler, in a talk before a panel at the Cloud 2012 Conference in Honolulu.
The panel, which was also attended by Baldeschwieler’s Cloudera counterpart Amr Awadallah, focused on insights into the big data world, a subject Baldeschwieler tackled almost entirely with Hadoop. The eighteen-minute discussion also featured a brief history of Hadoop’s rise to prominence, improvements to be made to Hadoop, and a few tips to enterprising researchers wishing to contribute to Hadoop.
“Bringing Hadoop to Windows,” says Baldeschwieler “turns out to be a very exciting initiative because there are a huge number of users in Windows operating system.” In particular, the Excel spreadsheet program is a popular one for business analysts, something analysts would like to see integrated with Hadoop’s database. That will not be possible until, as Baldeschwieler notes, Windows is integrated into Hadoop later this year, a move that will also considerably expand Hadoop’s reach.
However, that announcement pales in comparison to the possibilities provided by the impending Hadoop 2.0. “Hadoop 2.0 is a pretty major re-write of Hadoop that’s been in the works for two years. It’s now in usable alpha form…The real focus in Hadoop 2.0 is scale and opening it up for more innovation.” Baldeschwieler notes that Hadoop’s rise has been result of what he calls “a happy accident” where it was being developed by his Yahoo team for a specific use case: classifying, sorting, and indexing each of the URLs that were under Yahoo’s scope.
What ended up happening was that other Yahoo teams requested use of the Hadoop nodes and found success with it, leading to a much more significant investment from Yahoo. “Yahoo took this (Hadoop) prototype and then built an internal service that now runs on 42,000 computers with roughly 200 petabytes of raw storage involved and it took about 300 person-years of investment and open source software to make this thing work.” From there, folks like Baldeschwieler and Awadallah went off and formed other projects like Hortonworks and Cloudera to further add to Hadoop.
While Hadoop’s rise makes for a fun success story, its status as somewhat of a happy accident has led to some inefficiencies and limitations, such that a new version entirely was necessary to continue its growth. “The existing Hadoop 1.0 base runs on about 4,000 computers whereas the target design is about 10,000 and that takes Moore’s law forward a few years. Our current target computer has about 12 TB of disk, the new one would have 36.”
Hadoop 2.0 is more than about improving its scale, however. Baldeschwieler would like to see programmers and data scientists able to work with more than MapReduce, in essence making it more ‘pluggable.’ He would also like to see new varieties of files introduced to Hadoop through version 2.0.
Making 2.0 more pluggable may also solve another Hadoop problem businesses are having. Baldeschwieler mentioned that every Fortune 500 company has Hadoop running in some form but many businesses are slow to make full use of it. Making Hadoop more pluggable will not help the businesses that hear of Hadoop, want to get into big data, and end up buying several nodes to accomplish that end without much thought.
It will however assist those with competent technology departments that have analytics tools but are unable to integrate them with Hadoop for whatever reason. “We need to make sure that there’s the right APIs for everyone who’s building data products to plug into Hadoop in various ways.”
Finally, someone has to be doing all this research into the advancement of Hadoop into its second version. Baldeschwieler notes that while the Hadoop community welcomes good ideas and contributions, one should build a reputation in the community by doing interesting research with Hadoop before trying to add to it.

Microsoft’s Apache Hadoop on Windows Azure service integrates Excel PowerPivot with a Hive ODBC provider to deliver effective “BI for the masses.”
Matt Asay (@mjasay) asserted “In a world of tissue when you're Kleenex, you've won” in a deck for his Becoming Red Hat: Cloudera and Hortonworks' Big-Data death match article of 8/17/2012 for The Register:
Open ... and Shut In the Big Data market, Hadoop is clearly the team to beat. What is less clear is which of the Hadoop vendors will claim the spoils of that victory.
Because open source tends to be winner-take-all, we are almost certainly going to see a "Red Hat" of Hadoop, with the second place vendor left to clean up the crumbs.
As ever with open source, this means the Hadoop market ultimately comes down to a race for community support because, as Redmonk analyst Stephen O'Grady argues, the biggest community wins.
In community and other areas, Linux is a great analogue for Hadoop. I've suggested recently that Hadoop market observers could learn a lot from the indomitable rise of Linux, including from how it overcame technical shortcomings over time through communal development. But perhaps a more fundamental observation is that, as with Linux, there's no room for two major Hadoop vendors.
Yes, there will be truckloads of cash earned by EMC, IBM and others who use Hadoop as a complement to drive the sale of proprietary hardware and software, just as we have in the Linux market with IBM, Oracle, Hewlett-Packard and others.
But for those companies aspiring to be the Red Hat of Hadoop - that primary committer of code and provider of associated support services - there's only room for one such company, and it's Cloudera or Hortonworks. I don't feel MapR has the ability to move Hadoop development, given that it doesn't employ key Hadoop developers as Cloudera and Hortonworks do, so it has no chance of being a dominant Hadoop vendor.
Cash kings
Cloudera and Hortonworks recognise this, which is why both have raised mountains of cash. The size of the Big Data pie is huge, but it's not going to be split evenly. Only one company gets to be the center of the Hadoop ecosystem. Not two.
In enterprise Linux, that "one company" is Red Hat. SUSE (then Novell then just SUSE again) initially took Red Hat on and had a real chance to be the leader, but Red Hat persevered and became the billion-dollar open-source company while SUSE-Novell-SUSE did not.
Why did Red Hat win? Community.
No, not the kind of community we sometimes associate with open source, ie, individual hackers staying up late for the love of coding, though that demographic matters. Red Hat contributes more to the Linux kernel than any single individual or company.
This, in turn, led Red Hat to attract the second type of community: the "professional developer," or third-party application developer. Red Hat managed to amass an unassailable third-party application ecosystem lead. Ultimately, in the Hadoop battle the community to be won is this community of developers building around the Hadoop ecosystem, because it's this ecosystem that leads to customer adoption, which fuels revenues which fuel the hiring of more code committers.
Call it the virtuous cycle of commercial open-source community development.
From 2002 until 2005, I worked at Novell and after the SUSE acquisition saw first-hand how Red Hat used its third-party application ecosystem to crush SUSE. SUSE was always second choice with customers because the applications they wanted ran on Red Hat first, which in turn made SUSE second-best with partners, too. By the time Novell/SUSE finally caught up in terms of sheer number of applications (and now exceeds Red Hat), Red Hat had already cemented its brand and Novell's Linux business languished.
As Linux Foundation executive director Jim Zemlin is fond of saying: "In a world of tissue when you're Kleenex, you've won." When Red Hat became "Kleenex," the game was over.
In the Hadoop world, the race to be "Kleenex" is on, and it involves attracting the biggest ISV community. Between the two dominant Hadoop distributions, it's still a somewhat even race, even if Cloudera took the early lead with customer traction. Hortonworks has been playing up its open source purity, arguing that it's "true" open source while Cloudera offers a freemium/open core model. It's very similar to the argument that Red Hat used to use against Novell/SUSE.
But in this case, I don't think it applies.
Both Cloudera and Hortonworks contribute to and distribute 100 per cent open-source Hadoop platforms. The difference comes from the management and other tools each offers alongside Hadoop. Hortonworks believes even this area should be open source, which is why its rival to Cloudera Manager is open-source Ambari. …


Read more.
•• Brad Sarsfield (@bradoop) reported availability of a new Hadoop on Azure REST API preview in a 6/13/2012 thread in the Hadoop on Azure Yahoo! Group, which Ganeshan Iyer updated on 8/13/2012 (missed when originally posted):
One of the top pieces of feedback that we’ve heard from those using the Hadoop on Azure preview to build proof of concepts and prototypes is the need for the ability to programmatically submit a Map Reduce or Hive job to the cluster from outside RDP on head node or www.hadooponazure.com web page.
To facilitate this we’d like to share a prototype .Net library that uses a REST API to submit jobs against the Hadoop on Azure free preview. This provides the ability to submit JAR and Hive jobs to the cluster and monitor status of those jobs.
While it's highly likely the REST API will change and evolve over time, we would like to share this now as a proof of concept to iterate and get your feedback as we continue to iterate.
Download:
- Zip: http://bit.ly/hoaRESTzip
- GitHub: http://bit.ly/hoaRESTgit
Example:
// Start a Map Reduce job
var package = new JobPackageBuilder().WithJar("hadoop-examples-0.20.203.1-SNAPSHOT.jar").AsHadoopJar("pi", "10 100");
var jarJob = jobClient.StartJob(package.ToStream());
// Issue a Hive query
var hivePackage = new JobPackageBuilder().WithJar(jarPath).AsHiveQuery("show tables;");
var hiveJob = jobClient.StartJob(hivePackage.ToStream());


The source code, which includes a .NET test project and is released under an Apache v2.0 license, is dated 7/16/2012.
• Denny Lee (@dennylee) posted a Power View Tip: Scatter Chart over Time on the X-Axis and Play Axis on 7/24/2012 (missed when posted):
As you have seen in many Power View demos, you can run the Scatter Chart over time by placing date/time onto the Play Axis. This is pretty cool and it allows you to see trends over time on multiple dimensions. But how about if you want to see time also on the x-axis?
For example, let’s take the Hive Mobile Sample data as noted in my post: Connecting Power View to Hadoop on Azure. As noted in Office 2013 Power View, Bing Maps, Hive, and Hadoop on Azure … oh my!, you can quickly create Power View reports right out of Office 2013.
Scenario
In this scenario, I’d like to see the number of devices on the y-axis, date on the x-axis, broken out by device make. This can be easily achieved using a column bar chart.
Yet, if I wanted to add another dimension to this, such as the number of calls (QueryTime), the only way to do this without tiling is to use the Scatter Chart. Yet, this will not yield the results you may like seeing either.
It does have a Play Axis of Date, but while the y-axis has count of devices (count of ClientID), the x-axis is the count of QueryTime – it’s a pretty lackluster chart. Moving Count of QueryTime to the Bubble Size makes it more colorful but now all the data is stuck near the y-axis. When you click on the play-axis, the bubbles only move up and down the y-axis.
Date on X-Axis and Play Axis
So to solve the problem, the solution is to put the date on both the x-axis and the play axis. Yet, the x-axis only allows numeric values – i.e. you cannot put a date into it. So how do you around this limitation?
What you can do is create a new calculated column:
DaysToZero = -1*(max([date]) – [date])
What this does is to calculate the number of days differing between the max([date]) within the [date] column as noted below.
As you can see, the max([date]) is 7/30/2012 and the [DaysToZero] column has the value of datediff(dd, [Date], max([Date]))
Once you have created the [DaysToZero] column, you can then place this column onto the x-axis of your Scatter Chart. Below is the scatter chart configuration.
With this configuration, you can see events occur over time when running the play axis as noted in the screenshots below.










• Denny Lee (@dennylee) posted a Office 2013 Power View, Bing Maps, Hive, and Hadoop on Azure … on my! on 7/23/2012 (missed when posted):
With all the excitement surrounding Office 2013 (here’s a nice Engadget Review) and energized by Andrew Brust’s tweets (@andrewbrust) and post Office 2013 brings BI, Big Data to Windows 8 tablets, I thought I would expand on my posts:
- Connecting Power View to Hadoop on Azure
- Connecting PowerPivot to Hadoop on Azure – Self Service BI to Big Data in the Cloud
For us involved in BI, the excitement surrounding Office 2013 is because Power View is now embedded directly in Excel. But in addition to that, now I can include maps! Yay!
So to make my Power View to Hive / Hadoop on Azure even more compelling, I downloaded Office 2013, installed the Hive ODBC driver, connected to Hadoop on Azure (instructions on how to do this are in the above bulleted blog posts)and charged ahead with Power View within Excel 2013.
Seriously cool, now I can click on the bars within my Power View report and it changes the bubbles in the maps depicting (in this case) the number of Apple devices (blue bar on the left chart) throughout the world (light blue bubbles indicate no devices in that part). The source of this data is from my Hadoop on Azure cluster, eh?!
Have fun and start downloading, eh?!



Arun Murthy (@acmurthy) posted Apache Hadoop YARN – Background and an Overview to the Hortonworks Blog on 8/7/2012:
Celebrating the significant milestone that was Apache Hadoop YARN being promoted to a full-fledged sub-project of Apache Hadoop in the ASF we present the first blog in a multi-part series on Apache Hadoop YARN – a general-purpose, distributed, application management framework that supersedes the classic Apache Hadoop MapReduce framework for processing data in Hadoop clusters.
MapReduce – The Paradigm
Essentially, the MapReduce model consists of a first, embarrassingly parallel, map phase where input data is split into discreet chunks to be processed. It is followed by the second and final reduce phase where the output of the map phase is aggregated to produce the desired result. The simple, and fairly restricted, nature of the programming model lends itself to very efficient and extremely large-scale implementations across thousands of cheap, commodity nodes.
Apache Hadoop MapReduce is the most popular open-source implementation of the MapReduce model.
In particular, when MapReduce is paired with a distributed file-system such as Apache Hadoop HDFS, which can provide very high aggregate I/O bandwidth across a large cluster, the economics of the system are extremely compelling – a key factor in the popularity of Hadoop.
One of the keys to this is the lack of data motion i.e. move compute to data and do not move data to the compute node via the network. Specifically, the MapReduce tasks can be scheduled on the same physical nodes on which data is resident in HDFS, which exposes the underlying storage layout across the cluster. This significantly reduces the network I/O patterns and keeps most of the I/O on the local disk or within the same rack – a core advantage.
Apache Hadoop MapReduce, circa 2011 – A Recap
Apache Hadoop MapReduce is an open-source, Apache Software Foundation project, which is an implementation of the MapReduce programming paradigm described above. Now, as someone who has spent over six years working full-time on Apache Hadoop, I normally like to point out that the Apache Hadoop MapReduce project itself can be broken down into the following major facets:
- The end-user MapReduce API for programming the desired MapReduce application.
- The MapReduce framework, which is the runtime implementation of various phases such as the map phase, the sort/shuffle/merge aggregation and the reduce phase.
- The MapReduce system, which is the backend infrastructure required to run the user’s MapReduce application, manage cluster resources, schedule thousands of concurrent jobs etc.
This separation of concerns has significant benefits, particularly for the end-users – they can completely focus on the application via the API and allow the combination of the MapReduce Framework and the MapReduce System to deal with the ugly details such as resource management, fault-tolerance, scheduling etc.
The current Apache Hadoop MapReduce System is composed of the JobTracker, which is the master, and the per-node slaves called TaskTrackers.
The JobTracker is responsible for resource management (managing the worker nodes i.e. TaskTrackers), tracking resource consumption/availability and also job life-cycle management (scheduling individual tasks of the job, tracking progress, providing fault-tolerance for tasks etc).
The TaskTracker has simple responsibilities – launch/teardown tasks on orders from the JobTracker and provide task-status information to the JobTracker periodically.
For a while, we have understood that the Apache Hadoop MapReduce framework needed an overhaul. In particular, with regards to the JobTracker, we needed to address several aspects regarding scalability, cluster utilization, ability for customers to control upgrades to the stack i.e. customer agility and equally importantly, supporting workloads other than MapReduce itself.
We’ve done running repairs over time, including recent support for JobTracker availability and resiliency to HDFS issues (both of which are available in Hortonworks Data Platform v1 i.e. HDP1) but lately they’ve come at an ever-increasing maintenance cost and yet, did not address core issues such as support for non-MapReduce and customer agility.
Why support non-MapReduce workloads?
MapReduce is great for many applications, but not everything; other programming models better serve requirements such as graph processing (Google Pregel / Apache Giraph) and iterative modeling (MPI). When all the data in the enterprise is already available in Hadoop HDFS having multiple paths for processing is critical.
Furthermore, since MapReduce is essentially batch-oriented, support for real-time and near real-time processing such as stream processing and CEPFresil are emerging requirements from our customer base.
Providing these within Hadoop enables organizations to see an increased return on the Hadoop investments by lowering operational costs for administrators, reducing the need to move data between Hadoop HDFS and other storage systems etc.
Why improve scalability?
Moore’s Law… Essentially, at the same price-point, the processing power available in data-centers continues to increase rapidly. As an example, consider the following definitions of commodity servers:
- 2009 – 8 cores, 16GB of RAM, 4x1TB disk
- 2012 – 16+ cores, 48-96GB of RAM, 12x2TB or 12x3TB of disk.
Generally, at the same price-point, servers are twice as capable today as they were 2-3 years ago – on every single dimension. Apache Hadoop MapReduce is known to scale to production deployments of ~5000 nodes of hardware of 2009 vintage. Thus, ongoing scalability needs are ever present given the above hardware trends.
What are the common scenarios for low cluster utilization?
In the current system, JobTracker views the cluster as composed of nodes (managed by individual TaskTrackers) with distinct map slots and reduce slots, which are not fungible. Utilization issues occur because maps slots might be ‘full’ while reduce slots are empty (and vice-versa). Fixing this was necessary to ensure the entire system could be used to its maximum capacity for high utilization.
What is the notion of customer agility?
In real-world deployments, Hadoop is very commonly deployed as a shared, multi-tenant system. As a result, changes to the Hadoop software stack affect a large cross-section if not the entire enterprise. Against that backdrop, customers are very keen on controlling upgrades to the software stack as it has a direct impact on their applications. Thus, allowing multiple, if limited, versions of the MapReduce framework is critical for Hadoop.
Enter Apache Hadoop YARN
The fundamental idea of YARN is to split up the two major responsibilities of the JobTracker i.e. resource management and job scheduling/monitoring, into separate daemons: a global ResourceManager and per-application ApplicationMaster (AM).
The ResourceManager and per-node slave, the NodeManager (NM), form the new, and generic, system for managing applications in a distributed manner.
The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system. The per-application ApplicationMaster is, in effect, a framework specific entity and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the component tasks.
The ResourceManager has a pluggable Scheduler, which is responsible for allocating resources to the various running applications subject to familiar constraints of capacities, queues etc. The Scheduler is a pure scheduler in the sense that it performs no monitoring or tracking of status for the application, offering no guarantees on restarting failed tasks either due to application failure or hardware failures. The Scheduler performs its scheduling function based on the resource requirements of the applications; it does so based on the abstract notion of a Resource Container which incorporates resource elements such as memory, cpu, disk, network etc.
The NodeManager is the per-machine slave, which is responsible for launching the applications’ containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager.
The per-application ApplicationMaster has the responsibility of negotiating appropriate resource containers from the Scheduler, tracking their status and monitoring for progress. From the system perspective, the ApplicationMaster itself runs as a normal container.
Here is an architectural view of YARN:
One of the crucial implementation details for MapReduce within the new YARN system that I’d like to point out is that we have reused the existing MapReduce framework without any major surgery. This was very important to ensure compatibility for existing MapReduce applications and users. More on this later.
The next post will dive further into the intricacies of the architecture and its benefits such as significantly better scaling, support for multiple data processing frameworks (MapReduce, MPI etc.) and cluster utilization.




Matt Winkler wrote the following on 5/29/2012 in a [HadoopOnAzureCTP] Re: Daytona support Yahoo! group thread:
In the hadoop 2.0 timeframe, there are interesting capabilities that YARN brings to the table. We are evaluating those now but don't have any concrete plans. As YARN evolves we will see other parts of the stack (like pig and hive) evolve to take advantage of the new model.
We are working closely to understand how this evolve[s] and what opportunities exist.

It’s a good bet that YARN will be part of the Apache Hadoop on Windows Azure picture in the future because Hortonworks is a Microsoft partner, but not the near future.
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
•• Cihan Biyikoglu (@cihangirb, pictured below) reported on 8/15/2012 Intergen’s Chris Auld talking about Federations & Fan-out Queries at TechEd 2012 New Zealand in early September:
If you are in town between Sept 4 and 7i n Auckland, here is a fantastic talk to attend!
http://newzealand.msteched.com/topic/details/AZR304#fbid=qwdA5tTXqJW
Windows Azure SQL Database Deep Dive
Track: Windows Azure Level: 300 By: Chris Auld – CTO Intergen
Most developers are familiar with the concept of scaling out their application tier; with SQL Azure Federations it is now possible to scale out the data tier as well. In this session we will deep dive on building large scale solutions on SQL Azure. In this session we will cover patterns and techniques for building scalability into your relational databases. SQL Azure Federations allow databases to be spread over 100s of nodes in the Azure data centre with databases paid for by the day. This presents a unique avenue for dealing with particularly massive volumes of data, of user load, or both. This session will discuss how to design a schema for federation scale-out while still maintaining the value afforded by a true relational (SQL) database. We’ll look at approaches for minimizing cross federation queries and as well as approaches to fan-out queries when necessary. We will examine approaches for dealing with elastically scaling applications and other high load scenarios.
Don’t miss it!

Repeated in the Cloud Computing Events section below.
Himanshu Singh (@himanshuks) posted Data Series: Control Database Access Using Windows Azure SQL Database Firewall Rules to the Windows Azure blog on 8/14/2012:
Editor's Note: Today's post comes from Kumar Vivek [pictured at right], Technical Writer in our Customer Experience team. This post provides an overview of the newly-introduced database-level firewall rules in Windows Azure SQL Database.
Well, now you can! Introducing database-level firewall rules in Windows Azure SQL Database! In addition to the server-level firewall rules, you can now define firewall rules for each database in your SQL Database server to restrict access to selective clients. To do so, you must create a database-level firewall rule for the required database with an IP address range that is beyond the IP address range specified in the server-level firewall rule, and ensure that the IP address of the client falls in the range specified in the database-level firewall rule.
This is how the connection attempt from a client passes through the firewall rules in Windows Azure SQL Database:
- If the IP address of the request is within one of the ranges specified in the server-level firewall rules, the connection is granted to your SQL Database server.
- If the IP address of the request is not within one of the ranges specified in the server-level firewall rule, the database-level firewall rules are checked. If the IP address of the request is within one of the ranges specified in the database-level firewall rules, the connection is granted only to the database that has a matching database-level rule.
- If the IP address of the request is not within the ranges specified in any of the server-level or database-level firewall rules, the connection request fails.
For detailed information, see the full article Windows Azure SQL Database Firewall.
Managing Database-Level Firewall Rules
Unlike server-level firewall rules, the database-level firewall rules are created per database and are stored in the individual databases (including master). The sys.database_firewall_rules view in each database displays the current database-level firewall rules. Further, you can use the sp_set_database_firewall_rule and sp_delete_database_firewall_rule stored procedures in each database to create and delete the database-level firewall rules for the database.
For detailed information about managing database-level firewall rules, see the complete article How to: Configure the Database-Level Firewall Settings.

Cyrielle Simeone (@cyriellesimeone, pictured below) posted Thomas Mechelke’s Using a Windows Azure SQL Database with Autohosted apps for SharePoint on 8/13/2012:
This article is brought to you by Thomas Mechelke, Program Manager for SharePoint Developer Experience team. Thomas has been monitoring our new apps for Office and SharePoint forums and providing help on various topics. In today's post, Thomas will walk you through how to use a Windows Azure SQL Database with autohosted apps for SharePoint, as it is one of the most active thread on the forum. Thanks for reading !
Getting started
In a previous post, Jay described the experience of creating a new autohosted app for SharePoint. That will be our starting point.
If you haven't already, create a new app for SharePoint 2013 project and accept all the defaults. Change the app name if you like. I called mine "Autohosted App with DB". Accepting the defaults creates a solution with two projects: the SharePoint project with a default icon and app manifest, and a web project with some basic boilerplate code.
Configuring the SQL Server project
Autohosted apps for SharePoint support the design and deployment of a data tier application (DACPAC for short) to Windows Azure SQL Database. There are several ways to create a DACPAC file. The premier tools for creating a DACPAC are the SQL Server Data Tools, which are part of Visual Studio 2012.
Let's add a SQL Server Database Project to our autohosted app:
- Right-click the solution node in Solution Explorer, and then choose Add New Project.
- Under the SQL Server node, find the SQL Server Database Project.
- Name the project (I called it AutohostedAppDB), and then choose OK.
A few steps are necessary to set up the relationship between the SQL Server project and the app for SharePoint, and to make sure the database we design will run both on the local machine for debugging and in Windows Azure SQL Database.
First, we need to set the target platform for the SQL Server Database project. To do that, right-click the database project node, and then select SQL Azure as the target platform.
Next, we need to ensure that the database project will update the local instance of the database every time we debug our app. To do that, right-click the solution, and then choose Set Startup Projects. Then, choose Start as the action for your database project.
Now, build the app (right-click Solution Node and then choose Build). This generates a DACPAC file in the database output folder. In my case, the file is at /bin/Debug/projectname.dacpac.
Now we can link the DACPAC file with the app for SharePoint project by setting the SQL Package property.
Setting the SQL Package property ensures that whenever the SharePoint app is packaged for deployment to a SharePoint site, the DACPAC file is included and deployed to Windows Azure SQL Database, which is connected to the SharePoint farm.
This was the hard part. Now we can move into building the actual database and data access code.
Building the database
SQL Server Data Tools adds a new view to Visual Studio called SQL Server Object Explorer. If this view doesn't show up in your Visual Studio layout (usually as a tab next to Solution Explorer), you can activate it from the View menu. The view shows the local database generated from your SQL Server project under the node for (localdb)\YourProjectName.
This view is very helpful during debugging because it provides a simple way to get at the properties of various database objects and provides access to the data in tables.
Adding a table
For the purposes of this walkthrough, we'll keep it simple and just add one table:
- Right-click the database project, and then add a table named Messages.
- Add a column of type nvarchar(50) to hold messages.
- Select the Id column, and then change the Is Identity property to be true.
After this is done, the table should look like this:
Great. Now we have a database and a table. Let's add some data.
To do that, we'll use a feature of data-tier applications called Post Deployment Scripts. These scripts are executed after the schema of the data-tier application has been deployed. They can be used to populate look up tables and sample data. So that's what we'll do.
Add a script to the database project. That brings up a dialog box with several script options. Select Post Deployment Script, and then choose Add.
Use the script editor to add the following two lines:
delete from Messages
insert into Messages values ('Hello World!')
The delete ensures the table is empty whenever the script is run. For a production app, you'll want to be careful not to wipe out data that may have been entered by the end user.
Then we add the "Hello World!" message. That's it.
Configuring the web app for data access
After all this work, when we run the app we still see the same behavior as when we first created the project. Let's change that. The app for SharePoint knows about the database and will deploy it when required. The web app, however, does not yet know the database exists.
To change that we need to add a line to the web.config file to hold the connection string. For that we are using a property in the <appSettings> section named SqlAzureConnectionString.
To add the property, create a key value pair in the <appSettings> section of the web.config file in your web app:
<add key="SqlAzureConnectionString" value="Data Source=(localdb)\YourDBProjectName;Initial Catalog=AutohostedAppDB;Integrated Security=True;Connect Timeout=30;Encrypt=False;TrustServerCertificate=False" />
The SqlAzureConnectionString property is special in that its value is set by SharePoint during app installation. So, as long as your web app always gets its connections string from this property, it will work whether it's installed on a local machine or in Office 365.
You may wonder why the connection string for the app is not stored in the <connectionStrings> section. We implemented it that way in the preview because we already know the implementation will change for the final release, to support geo-distributed disaster recovery (GeoDR) for app databases. In GeoDR, there will always be two synchronized copies of the database in different geographies. This requires the management of two connection strings, one for the active database and one for the backup. Managing those two strings is non-trivial and we don't want to require every app to implement the correct logic to deal with failovers. So, in the final design, SharePoint will provide an API to retrieve the current connection string and hide most of the complexity of GeoDR from the app.
I'll structure the sample code for the web app in such a way that it should be very easy to switch to the new approach when the GeoDR API is ready.
Writing the data access code
At last, the app is ready to work with the database. Let's write some data access code.
First let's write a few helper functions that set up the pattern to prepare for GeoDR in the future.
GetActiveSqlConnection()
GetActiveSqlConnection is the method to use anywhere in the app where you need a SqlConnection to the app database. When the GeoDR API becomes available, it will wrap it. For now, it will just get the current connection string from web.config and create a SqlConnection object:
// Create SqlConnection.
protected SqlConnection GetActiveSqlConnection()
{
return new SqlConnection(GetCurrentConnectionString());
}
GetCurrentConnectionString()
GetCurrentConnectionString retrieves the connection string from web.config and returns it as a string.
// Retrieve authoritative connection string.
protected string GetCurrentConnectionString()
{
return WebConfigurationManager.AppSettings["SqlAzureConnectionString"];
}
As with all statements about the future, things are subject to change—but this approach can help to protect you from making false assumptions about the reliability of the connection string in web.config.
With that, we are squarely in the realm of standard ADO.NET data access programming.
Add this code to the Page_Load() event to retrieve and display data from the app database:
// Display the current connection string (don't do this in production).
Response.Write("<h2>Database Server</h2>");
Response.Write("<p>" + GetDBServer() + "</p>");
// Display the query results.
Response.Write("<h2>SQL Data</h2>");
using (SqlConnection conn = GetActiveSqlConnection())
{
using (SqlCommand cmd = conn.CreateCommand())
{
conn.Open();
cmd.CommandText = "select * from Messages";
using (SqlDataReader reader = cmd.ExecuteReader())
{
while (reader.Read())
{
Response.Write("<p>" + reader["Message"].ToString() + "</p>");
}
}
}
}
We are done. This should run. Let's hit F5 to see what happens.
It should look something like this. Note that the Database Server name should match your connection string in web.config.
Now for the real test. Right-click the SharePoint project and choose Deploy. Your results should be similar to the following image.
The Database Server name will vary, but the output from the app should not.
Using Entity Framework
If you prefer working with the Entity Framework, you can generate an entity model from the database and easily create an Entity Framework connection string from the one provided by GetCurrentConnectionString(). Use code like this:
// Get Entity Framework connection string.
protected string GetEntityFrameworkConnectionString()
{
EntityConnectionStringBuilder efBuilder =
new EntityConnectionStringBuilder(GetCurrentConnectionString());
return efBuilder.ConnectionString;
}
We need your feedback
I hope this post helps you get working on the next cool app with SharePoint, ASP.NET, and SQL. We'd love to hear your feedback about where you want us to take the platform and the tools to enable you to build great apps for SharePoint and Office.











Han reported SQL Data Sync Preview 6 is now live! in an 8/13/2012 post to the Sync Team blog:
- Enhance overall performance on initial provision and sync tasks
- Enhance sync performance between on-promise databases and Windows Azure SQL databases
Please download the new Agent from http://www.microsoft.com/en-us/download/details.aspx?id=27693
Also, for now on, we will be calling all subsequent preview releases Preview instead of the usual Service Update.
In another episode of Microsoft’s recent branding frenzy, SQL Azure Data Sync has become simply SQL Data Sync, similar to SQL Azure -> Windows Azure SQL Database, but (strangely) missing the Window Azure prefix.
Cihan Biyikoglu (@cihangirb) described Setting up Azure Data Sync Service with Federations in Windows Azure SQL Database For Reference Data Replication in an 8/12/2012 post:
In a previous post, I talked about the ability to use Data Sync Service with Federation Members. In this post, like to walk you through the details.
The scenario here is to sync a reference table called language_codes_tbl across federation members. The table represents language codes for the blogs_federation in my BlogsRUs_DB.
1. Create a “sync server” and a “sync group” called sync_codes
2. Add the root database as the hub database; blogsrus_db with conflict resolution set to “Hub Wins” and schedule set to every 5 mins.
3. Define the Sync dataset as the dbo.language_code_tbl

4. Add federation member databases into the sync_codes sync group and “deploy” the changes.

With this setup, replication happens bi-directionally. This means, I can update any one of the federation member dbs and the changes will first get replicated to the root db copy of my reference table and then will be replicated to all other federation member dbs automatically by SQL Data Sync. SQL Data Sync provides powerful control over the direction of data flow and conflict resolution to create the desired topology for syncing reference data in federation members.
Handling Federation Repartitioning Operations
This will work as long as you don’t reconfigure these members with an operation like ALTER FEDERATION … SPLIT. With SPLIT we drop the existing member database and create 2 new member databases that contain the redistributed data based on the new split point of the federation. Lets assume we issue the following statement to split the existing range 350000-400000.
alter federation blogs_federation split at (id=355000)
With that, you will notice that the sync group will start reporting an error on the member is impacted by the split operation – see the red error indicator marked below the database icon.
1. Given this database no longer exists, you need to deprovision the database from the sync group. To do this first remove the database with the “remove database” button above the topology area. You finalize the operation by deploying the change using the “deploy” button above. Since the database is dropped, you will need to do a forced removal after the deploy.
2. Next you need to add in the 2 new member names that are created by the SPLIT operation. we do this by running the following script. Once you have the new database names for the members covering the new ranges 350000-355000 and 355000 – 400000, you can follow step #4 above to add the names to the sync group.
Limitations with Azure Data Sync Service:
There are a few limitation to be aware of SQL Data Sync however; First the service has 5 min as its lowest latency for replication. There is no scripting support for set up of the data sync relationships. This means you will need to populate all the db names through the UI by hand. SQL Data sync also does not allow synchronization between more than 30 databases in sync groups in a single sync server at the moment. You can only create a single sync server with DSS today. SQL Data Sync is currently in preview mode and is continuously collecting feedback. Vote for your favorite request or add a new one at SQL Data Sync Feature Voting website!





<Return to section navigation list>
Marketplace DataMarket, Cloud Numerics, Big Data and OData
•• Doug Mahugh (@dmahugh) described Using the Cloudant Data Layer for Windows Azure in an 8/16/2012 post to the Interoperability @ Microsoft blog:
If you need a highly scalable data layer for your cloud service or application running on Windows Azure, the Cloudant Data Layer for Windows Azure may be a great fit. This service, which was announced in preview mode in June and is now in beta, delivers Cloudant’s “database as a service” offering on Windows Azure.
From Cloudant’s data layer you’ll get rich support for data replication and synchronization scenarios such as online/offline data access for mobile device support, a RESTful Apache CouchDB-compatible API, and powerful features including full-text search, geo-location, federated analytics, schema-less document collections, and many others. And perhaps the greatest benefit of all is what you don’t get with Cloudant’s approach: you’ll have no responsibility for provisioning, deploying, or managing your data layer. The experts at Cloudant take care of those details, while you stay focused on building applications and cloud services that use the data layer.
You can do your development in any of the many languages supported on Windows Azure, such as .NET, Node.JS, Java, PHP, or Python. In addition, you’ll get the benefits of Windows Azure’s CDN (Content Delivery Network) for low-latency data access in diverse locations. Cloudant pushes your data to data centers all around the globe, keeping it close to the people and services who need to consume it.
For a free trial of the Cloudant Data Layer for Windows Azure, create a new account on the signup page and select “Lagoon” as your data center location.
For an example of how to use the Cloudant Data Layer, see the tutorial “Using the Cloudant Data Layer for Windows Azure,” which takes you through the steps needed to set up an account, create a database, configure access permissions, and develop a simple PHP-based photo album application that uses the database to store text and images:
The sample app uses the SAG for CouchDB library for simple data access. SAG works against any Apache CouchDB database, as well as Cloudant’s CouchDB-compatible API for the data layer.
My colleague Olivier Bloch has provided another great example of using existing CouchDB libraries to simplify development when using the Cloudant Data Layer. In this video, he demonstrates how to put a nice Windows 8 design front end on top of the photo album demo app:
This example takes advantage of the couch.js library available from the Apache CouchDB project, as well as the GridApp template that comes with Visual Studio 2012. Olivier shows how to quickly create the app running against a local CouchDB installation, then by simply changing the connection string the app is running live against the Cloudant data layer running on Windows Azure.
The Cloudant data layer is a great example of the new types of capabilities – and developer opportunities – that have been created by Windows Azure’s support for Linux virtual machines. As Sam Bisbee noted in Cloudant’s announcement of the service, “The addition of Linux-based virtual machines made it possible for us to offer the Cloudant Data Layer service on Azure.”
If you’re looking for a way to quickly build apps and services on top of a scalable high-performance data layer, check out what the Cloudant Data Layer for Windows Azure has to offer!



•• Alex James (@adjames) described OData support in ASP.NET Web API in an 8/15/2012 post updated 8/16/2012:
UPDATE 2 @1:21 pm on 16th August (PST):
There is an updated version of the nuget package that resolves the previous dependency issues. Oh and my comments are now working again.UPDATE 1 @10:00 am on 16th August (PST):
If you’ve tried using the preview nuget package and had problems, rest assured we are working on the issue (which is a dependency version issue). Essentially the preview and one of its dependencies have conflicting dependencies on specific versions of packages. The ETA for a fix that resolves this nuget issue is later today.
Also if you’ve made a comment and it isn’t showing up, don’t worry it will. I’m currently having technical problems approving comments.
Earlier versions ASP.NET Web API included basic support for the OData, allowing you to use the OData Query Options $filter, $orderby, $top and $skip to shape the results of controller actions annotated with the [Queryable] attribute. This was very useful and worked across formats. That said true support for the OData format was rather limited. In fact we barely scratched the surface of OData, for example there was no support for creates, updates, deletes, $metadata and code generation etc.
To address this we’ve create a preview of a new nuget package (and codeplex project) for building OData services that:
- Continues to support the [Queryable] attribute, but also allows you to drop down to an Abstract Syntax Tree (or AST) representing $filter & $orderby.
- Adds ways to infer a model by convention or explicitly customize a model that will be familiar to anyone who’s used Entity Framework Code First.
- Adds support for service documents and $metadata so you can generate clients (in .NET, Windows Phone, Metro etc) for your Web API.
- Adds support for creating, updating, partially updating and deleting entities.
- Adds support for querying and manipulating relationships between entities.
- Adds the ability to create relationship links that wire up to your routes.
- Adds support for complex types.
- Adds support for Any/All in $filter.
- Adds the ability to control null propagation if needed (for example to avoid null refs working about LINQ to Objects).
- Refactors everything to build upon the same foundation as WCF Data Services, namely ODataLib.
In fact this is an early preview of a new OData Server stack built to take advantage of Web APIs inherent flexibility and power which compliments WCF Data Services.
This preview ships with a companion OData sample service built using Web API. The sample includes three controllers, that each expose an OData EntitySet with varying capabilities. One is rudimentary supporting just query and create, the other two are more complete, supporting Query, Create, Update, Patch, Delete and Relationships. The first complete example does everything by hand, the second derives from a sample base controller called EntitySetController that takes care of a lot of the plumbing for you and allows you to focus on the business logic.
The rest of this blog post will introduce you to the components that make up this preview and how to stitch them together to create an OData service, using the code from this sample from the ASP.NET Web Stack Sample repository if you want to follow along.
[Queryable] aka supporting OData Query
If you want to support OData Query options, without necessarily supporting the OData Formats, all you need to do it put the [Queryable] attribute on an action that returns either IQueryable<> or IEnumerable<>, like this:
[Queryable]
public IQueryable<Supplier> GetSuppliers()
{
return _db.Suppliers;
}Here _db is an EntityFramework DBContext. If this action is routed to say ~/Suppliers then any OData Query options applied to that URI will be applied by an Action Filter before the result is sent to the client.
For example this: ~/Suppliers?$filter=Name eq ‘Microsoft’
Will pass the result of GetSuppliers().Where(s => s.Name == “Microsoft”) to the formatter.
This all works as it did in earlier previews, although there are a couple of, hopefully temporary, caveats:
- The element type can’t be primitive (for example IQueryable<string>).
- Somehow the [Queryable] attribute must find a key property. This happens automatically if your element type has an ID property, if not you might need to manually configure the model (see setting up your model).
Doing more OData
If you want to support more of OData, for example, the official OData formats or allow for more than just reads, you need to configure a few things.
The ODataService.Sample shows all of this working end to end, and the remainder of this post will talk you through what that code is doing.
Setting up your model
The first thing you need is a model. The way you do this is very similar to the Entity Framework Code First approach, but with a few OData specific tweaks:
- The ability to configure how EditLinks, SelfLinks and Ids are generated.
- The ability to configure how links to related entities are generated.
- Support for multiple entity sets with the same type.
If you use the ODataConventionModelBuilder most of this is done automatically for you, all you need to do is tell the builder what sets you want, for example this code:
ODataModelBuilder modelBuilder = new ODataConventionModelBuilder();
modelBuilder.EntitySet<Product>("Products");
modelBuilder.EntitySet<ProductFamily>("ProductFamilies");
modelBuilder.EntitySet<Supplier>("Suppliers");
IEdmModel model = modelBuilder.GetEdmModel();Builds a model with 3 EntitySets (Products, ProductFamilies and Suppliers) where the EntityTypes of those sets are inferred from the CLR types (Product, ProductFamily and Supplier) automatically, and where EditLinks, SelfLinks and IdLinks are all configured to use the default OData routes.
You can also take full control of the model by using the ODataModelBuilder class, here you explicitly add EntityTypes, Properties, Keys, NavigationProperties and how to route Links by hand. For example this code:
var products = modelBuilder.EntitySet<Product>("Products");
products.HasEditLink(entityContext => entityContext.UrlHelper.Link(
ODataRouteNames.GetById,
new { controller = "Products", id = entityContext.EntityInstance.ID }
));
var product = products.EntityType;
product.HasKey(p => p.ID);
product.Property(p => p.Name);
product.Property(p => p.ReleaseDate);
product.Property(p => p.SupportedUntil);Explicitly adds a EntitySet called Products to the model, configures the EditLink (and unless overridden the SelfLink and IdLink) generation so that if uses the ODataRouteNames.GetById route, and then as you can see the code needed to configure the Key and Properties is very similar to the Code First.
For a more complete example take a look at the GetExplicitEdmModel() method in the sample it builds the exact same model as the ODataConventionModelBuilding by hand.
Setting up the formatters, routes and built-in controllers
To use the OData formats you first need to register an ODataMediaTypeFormatter, which will need the model you built previously:
// Create the OData formatter and give it the model
ODataMediaTypeFormatter odataFormatter = new ODataMediaTypeFormatter(model);// Register the OData formatter
configuration.Formatters.Insert(0, odataFormatter);Next you need to setup some routes to handle common OData requests, below are the routes required for a Read/Write OData model built using the OData Routing conventions that also supports client side code-generation (vital if you want a WCF DS client application to talk to your service).
// Metadata routes to support $metadata and code generation in the WCF Data Service client.
configuration.Routes.MapHttpRoute(
ODataRouteNames.Metadata,
"$metadata",
new { Controller = "ODataMetadata", Action = "GetMetadata" }
);
configuration.Routes.MapHttpRoute(
ODataRouteNames.ServiceDocument,
"",
new { Controller = "ODataMetadata", Action = "GetServiceDocument" }
);// Relationship routes (notice the parameters is {type}Id not id, this avoids colliding with GetById(id)).
// This code handles requests like ~/ProductFamilies(1)/Products
configuration.Routes.MapHttpRoute(ODataRouteNames.PropertyNavigation, "{controller}({parentId})/{navigationProperty}");// Route for manipulating links, the code allows people to create and delete relationships between entities
configuration.Routes.MapHttpRoute(ODataRouteNames.Link, "{controller}({id})/$links/{navigationProperty}");// Routes for urls both producing and handling urls like ~/Product(1), ~/Products() and ~/Products
configuration.Routes.MapHttpRoute(ODataRouteNames.GetById, "{controller}({id})");
configuration.Routes.MapHttpRoute(ODataRouteNames.DefaultWithParentheses, "{controller}()");
configuration.Routes.MapHttpRoute(ODataRouteNames.Default, "{controller}");
One thing to note is the way that the ODataRouteNames.PropertyNavigation route attempts to handle requests to urls like ~/ProductFamilies(1)/Products and ~/Products(1)/Family etc. Essentially a single route for all Navigations. For this to work without requiring a single Action for all navigation properties, we register a custom action selector that will build the Action name using the {navigationProperty} parameter of the PropertyNavigation route:// Register an Action selector that can include template parameters in the name
configuration.Services.Replace(typeof(IHttpActionSelector), new ODataActionSelector());This custom action selector will dispatch a request to GET ~/ProductFamilies(1)/Products, to an action called the GetProducts(int parentId) on the ProductFamilies controller.
At this point our previous GetSupplier action can return OData formats. However it will still produce links that won’t work when dereferenced. To fix this we need to start creating our controllers.
Adding Support for OData requests
In our model we added 3 entitysets: Products, ProductFamilies and Suppliers. So first we create 3 controllers, called ProductController, ProductFamiliesController and SuppliersController respectively.
Queries
By convention your controllers should have a method called Getxxx() that returns IQueryable<T>. Here the T is the CLR type backing your EntitySet, so for example on the ProductsController which is for the Products entityset the T should be Product, and the action should look something like this:
[Queryable]
public IQueryable<Product> GetProducts()
{
return _db.Products;
}As you can see this is the same as before, but now it is participating in a ‘compliant’ OData service. Inside this method you can do all sorts of things, you can add additional filters based on the identity of the caller, you do auditing, you can do logging, you can aggregate data from multiple sources.
There is even a way to drop down a layer so you get to the see the OData query that has been received. Doing this allows you to process the query yourself in whatever way is appropriate for your data sources. For example you might not have an IQueryable you can use. See ODataQueryOptions for more on this.
At this point because you’ve registered a model and you’ve setup routes for $metadata and the OData Service Document, you should be able to use Visual Studio’s Add Service Reference to generate a set of client proxy classes that you could use like this:
foreach(var product in ctx.Products.Where(p => p.Name.StartsWith(“MS”))
{
Console.WriteLine(product.Name);
}WCF DS client will then translate this into a GET request like this:
~/Products$filter=startswith(Name,’MS’)
And everything should just work.
Get by Key
To retrieve an individual item using it’s key in OData you send a GET request to a url like this: ~/Products(1). The ODataRouteNames.GetById route handles requests like this:
public HttpResponseMessage GetById(int id)
{
Supplier supplier = _db.Suppliers.SingleOrDefault(s => s.ID == id);
if (supplier == null)
{
return Request.CreateResponse(HttpStatusCode.NotFound);
}
else
{
return Request.CreateResponse(HttpStatusCode.OK, supplier);
}
}As you can see the code simply attempts to retrieve an item by ID, and then return it with a 200 OK response or return 404 Not Found.
If you have WCF DS proxy classes on the client a request like this:
ctx.Products.Where(p => p.ID == 5).FirstOrDefault();
Should now hit this action.
Inserts (POST requests)
To create a new Entity in OData you POST a new Entity directly to the url that represents the EntitySet, this means that insert requests just like queries end up matching the ODataRouteNames.Default route, however Web API’s action selector picks actions prefixed with Post for POST requests to distinguish from GET requests for Queries:
public HttpResponseMessage PostProduct(Product product)
{
product.Family = null;Product addedProduct = _db.Products.Add(product);
_db.SaveChanges();
var response = Request.CreateResponse(HttpStatusCode.Created, addedProduct);
response.Headers.Location = new Uri(
Url.Link(ODataRouteNames.GetById, new { Controller = "Products", Id = addedProduct.ID })
);
return response;
}Here we simply add the product to our Entity Framework context and then call SaveChanges(). The only interesting bit way we set the location header using the ODataRouteNames.GetById route (i.e. the default OData route for Self/Edit links).
Updates (PUT requests)
To replace an Entity in OData you PUT the updated version of the entity to the uri specified in the EditLink of the entity. This will match the GetById route, but because it is a PUT request it will look for an Action name prefixed with Put.
This example shows how to do this:
public HttpResponseMessage Put(int id, Product update)
{
if (!_db.Products.Any(p => p.ID == id))
{
throw ODataErrors.EntityNotFound(Request);
}
update.ID = id; // ignore the ID in the entity use the ID in the URL.
_db.Products.Attach(update);
_db.Entry(update).State = System.Data.EntityState.Modified;
_db.SaveChanges();
return Request.CreateResponse(HttpStatusCode.NoContent);
}The code is pretty simple, first we verify the entity the client is trying to update actually exists, then we ignore the ID in the entity and instead use the id extracted from the uri of the request, this stops clients updating one entity using the editlink of another entity.
Once all that validation is out of the way we attach the updated entity and tell EF it has been modified before calling save changes and finally returning a No Content response.
As you can see this leverages a helper class called ODataErrors, its job is simply to raise OData compliant errors. The sample uses the EntityNotFound method quite frequently, and it follows the general pattern for failing in an OData compliant way so lets take a peak at its implementation:
public static HttpResponseException EntityNotFound(this HttpRequestMessage request)
{
return new HttpResponseException(
request.CreateResponse(
HttpStatusCode.NotFound,
new ODataError
{
Message = "The entity was not found.",
MessageLanguage = "en-US",
ErrorCode = "Entity Not Found."
}
)
);
}We create a HttpResponseException with a nested Not Found response, the body of which contains an ODataError. By putting an ODataError in the body we get the ODataMediaTypeFormatter to format the body as a valid OData error message as per the content-type requested by the client.
NOTE: Over time we will try to teach the ODataMediaTypeFormatter to handle HttpError as well by using a default translation from HttpError to ODataError.
Partial Updates (PATCH requests)
PUT request have replace semantics which makes updates all or nothing, meaning you have to send all the properties even if only a subset have changed.This is where PATCH comes in, PATCH allows clients to send just the modified properties on the wire, essentially allowing for partial updates.
This example shows an implementation of Patch for Products:
public HttpResponseMessage PatchProduct(int id, Delta<Product> product)
{
Product dbProduct = _db.Products.SingleOrDefault(p => p.ID == id);
if (dbProduct == null)
{
throw new HttpResponseException(HttpStatusCode.NotFound);
}
product.Patch(dbProduct);
_db.SaveChanges();return Request.CreateResponse(HttpStatusCode.NoContent);
}Notice that the method receives a Delta<Product> rather than a Product.
We do this because, if we use a Product directly and set the properties that came on the wire as part of the patch request, we would not be able to tell why a property has a default value. It could be because the request set the property to its default value or it could be because the property hasn’t been set yet. This could lead to mistakenly resetting properties the client doesn’t want reset. Can anyone say ‘data corruption’?
The Delta<Product> class is a dynamic class that acts as a lightweight proxy for a Product. It allows you to set any Product property, but it also remembers which properties you have set. It uses this knowledge when you call .Patch(..) to copy across only properties that have been set.
Given this we simply retrieve the product from the database and then we call Patch to apply the changes requested to the entity in the database. Once that is done we call SaveChanges to push the changes to the database.
Deletes (DELETE requests)
To delete an entity you send a DELETE request to it’s editlink, so this is similar to GetById, Put and Patch, except this time Web API will look for an action prefixed with Delete, something like this:
public HttpResponseMessage DeleteProduct(int id)
{
Product toDelete = _db.Products.FirstOrDefault(p => p.ID == id);
if (toDelete == null)
{
throw ODataErrors.EntityNotFound(Request);
}
_db.Products.Remove(toDelete);
_db.SaveChanges();
return Request.CreateResponse(HttpStatusCode.Accepted);
}As you can see if the entity is found it is simply deleted and we return an Acccepted response.
Following Navigations
To address related entities in OData you typically start with the Uri of a particular entity and then append the name of the navigationProperty. For example to retrieve the Family for Product 15 you do a GET request here: ~/Products(15)/Family.
Implementing this is pretty simple:
public ProductFamily GetFamily(int parentId)
{
return _db.Products.Where(p => p.ID == parentId).Select(p => p.Family).SingleOrDefault();
}This matches the ODataRouteNames.PropertyNavigation which you’ll notices uses {parentId} rather than {id}, if it was id, this method would also be a match for the ODataRouteNames.GetById route, which would cause problems in the action selector infrastructure. By using parentId we sidestep this issue.
Creating and Deleting links
The OData protocol allows you to get and modify links between entities as first class resources. In the preview however we only support modifications.
To create links you POST or PUT a uri (specified in the request body) to a url something like this: ~/Products(1)/$links/Family.
The uri in the body points to the resource you wish to assign to the relationship. So in this case it would be the uri of a ProductFamily you wish to assign to Product.Family (i.e. setting Product 1’s Family).
Whether you POST or PUT depends on the cardinality of the relationship, if it is a Collection you POST, if it is a single item (as Family is) you PUT. Both are mapped through the ODataRouteNames.Link route, which is set up to handle creating links for any relationship. Unlike following Navigations it feels okay to use a single method because the return type always the same, i.e. a No Content response:
public HttpResponseMessage PutLink(int id, string navigationProperty, [FromBody] Uri link)
{
Product product = _db.Products.SingleOrDefault(p => p.ID == id);switch (navigationProperty)
{
case "Family":
// The utility method uses routing (ODataRoutes.GetById should match) to get the value of {id} parameter
// which is the id of the ProductFamily.
int relatedId = Configuration.GetKeyValue<int>(link);
ProductFamily family = _db.ProductFamilies.SingleOrDefault(f => f.ID == relatedId);
product.Family = family;
break;default:
throw ODataErrors.CreatingLinkNotSupported(Request, navigationProperty);
}
_db.SaveChanges();return Request.CreateResponse(HttpStatusCode.NoContent);
}The {navigationProperty} parameter from the route is used to decide what relationship to create, also notice the [FromBody] attribute on the Uri link parameter it is vital otherwise the link will always be null.
If you want to remove a relationship between entities you send a DELETE request to the same URL, the code for that looks like this:
public HttpResponseMessage DeleteLink(int id, string navigationProperty, [FromBody] Uri link)
{
Product product = _db.Products.SingleOrDefault(p => p.ID == id);
switch (navigationProperty)
{
case "Family":
product.Family = null;
break;default:
throw ODataErrors.DeletingLinkNotSupported(Request, navigationProperty);
}
_db.SaveChanges();
return Request.CreateResponse(HttpStatusCode.NoContent);
}Conclusion
If you implement all these methods for each of your OData EntitySets you should have a compliant OData service. Of course this code is only at preview quality so is likely to have bugs, that said I hope you’ll agree this provides a good foundation for creating OData services.
We are currently thinking about adding support for: inheritance, OData actions & functions, etags and JSON Light etc. And of course we want to hear your thoughts so we can incorporate your feedback!
Next up
This blog post doesn’t cover everything you can do with the Preview, you can use:
- ODataQueryOptions rather than [Queryable] to take full control of handling the query.
- ODataResult<> to implement OData features like Server Driven Paging and $inlinecount.
- EntitySetController<,> to simplify creating fully compliant OData entitysets.
I’ll be blogging more about these soon.

•• The WCF Data Services Team reported the availability of a WCF Data Services 5.0.2-rc Prerelease on 8/15/2012:
What is in the prerelease
This prerelease contains a number of bug fixes:
- Fixes NuGet packages to have explicit version dependencies
- Fixes a bug where WCF Data Services client did not send the correct DataServiceVersion header when following a nextlink
- Fixes a bug where projections involving more than eight columns would fail if the EF Oracle provider was being used
- Fixes a bug where a DateTimeOffset could not be materialized from a v2 JSON Verbose value
- Fixes a bug where the message quotas set in the client and server were not being propagated to ODataLib
- Fixes a bug where WCF Data Services client binaries did not work correctly on Silverlight hosted in Chrome
- Allows "True" and "False" to be recognized Boolean values in ATOM (note that this is more relaxed than the OData spec, but there were known cases where servers were serializing "True" and "False")
- Fixes a bug where nullable action parameters were still required to be in the payload
- Fixes a bug where EdmLib would fail validation for attribute names that are not SimpleIdentifiers
- Fixes a bug where the FeedAtomMetadata annotation wasn't being attached to the feed even when EnableAtomMetadataReading was set to true
- Fixes a race condition in the WCF Data Services server bits when using reflection to get property values
- Fixes an error message that wasn't getting localized correctly
Getting the prerelease
The prerelease is only available on NuGet. To install this prerelease NuGet package, you will need to use one of the following commands from the Package Manager Console:
- Install-Package <PackageId> –Pre –Version 5.0.2-r
- Update-Package <PackageId> –Pre –Version 5.0.2-r
Our NuGet package ids are:
- Microsoft.Data.Services.Client (WCF Data Services Client)
- Microsoft.Data.Services (WCF Data Services Server)
- Microsoft.Data.OData (ODataLib)
- Microsoft.Data.Edm (EdmLib)
- System.Spatial (System.Spatial)
Call to action
If you have experienced one of the bugs mentioned above, we encourage you to try out the prerelease bits in a preproduction environment. As always, we’d love to hear any feedback you have!
<Return to section navigation list>
Windows Azure Service Bus, Access Control Services, Caching, Active Directory and Workflow
• Dan Plastina posted AD RMS under the hood: Client bootstrapping (Part 2 of 2) on 8/10/2012 (missed when published):
Although this blog normally features content updates and product announcements from the members who work with me within the Information Protection team here at Microsoft, we do occasionally have the opportunity to feature guest bloggers from AD RMS [Active Directory Rights Management Services] community whose expertise we think you will really enjoy and benefit from hearing.
In this case, I'm pleased to offer you Part 2 in the story on AD RMS bootstrapping that Alexey Goldbergs of Crypto-Pro first presented on our team blog a little while ago. It gives a lot of great insight to what is happening at a deeper level at the AD RMS client as users access rights-protected content.
Though we like to pride ourselves on making AD RMS something you shouldn't have to know all the "under the hood" workings of to make great use of it, for those who enjoy knowing more of that sort of thing, Alexey can and will provide you all the intimate technical details.
Enjoy!
- Dan
Hey, what's up? After a very looooong delay it's Alexey Goldbergs of Crypto-Pro here with you once again to give you the rest of a deeper look into the AD RMS client bootstrapping process.
As I mentioned in my previous post, AD RMS under the hood: Server bootstrapping (Part 1 of 2), this is the second part of my discussion on how the bootstrapping process occurs, from the client perspective, which consists of acquiring user certificates, including the Rights Account Certificate (RAC). In some materials you might also see the term Group Identity Certificate (GIC) but keep in mind if you do that it is referring to the same thing. (You can check out this post by Enrique Saggese to learn more about what the RAC is and how it is related to other AD RMS entities.)
RAC acquisition starts right after the SPC creation. This is the first time when an AD RMS client communicates with the AD RMS Server and the RAC is the first certificate that isn’t self-signed but is signed by AD RMS Server certificate (SLC) which was created during the AD RMS Server bootstrapping process described in Part 1.
But before the client can receive the RAC it should find the "right" AD RMS Certification Server. So this is how the service discovery process looks like in a typical scenario (Note that this is the sequence for a client trying to protect content for the first time. The process is slightly different for a client that’s consuming content before it is activated for the first time):
- Client checks if it has been manually configured with registry settings for activation.
○ For x86 clients: HKEY_LOCAL_MACHINE\Software\Microsoft\MSDRM\ServiceLocation.
○ For 64 bit clients running 32 bit applications: HKEY_LOCAL_MACHINE\Software\Wow6432Node\Microsoft\MSDRM\ServiceLocation.
You can find more details about key values for registry overrides in this relatedTechNetarticle, AD RMS Client Requirements.
If these registry keys are empty then the client sends the request for RMS Service Connection Point (SCP) to Active Directory, which returns the URL for the Intranet Certification URL configured by AD RMS.
After the client has used this URL to acquire a RAC, the client communicates with the AD RMS Certification "ServiceLocator" service to ask for the AD RMS Licensing Service URL. This service will be used for getting the next certificate - the Client Licensor Certificate (CLC). This URL could also be manually configured in the client with registry keys instead of using automatic discovery.
Going back to RAC acquisition, as soon as the client finds the certification server it goes through the following sequence:
- Client sends request for the RAC and it includes its Secure Process Certificate (SPC) to the AD RMS Certification Server (<http/https>://<AD_RMS_cluster_name>/_wmcs/certification/certification.asmx).
- The server extracts machine public key from the SPC sent by the client.
- The user has already authenticated against the web service, so the server users the user information to query the users email address from Active Directory.
- The server checks if the user already has a RAC in the AD RMS database (as you will see it the next steps the RAC is stored there as an encrypted blob) and if so gets it from this database.
- If the user doesn’t have a RAC in AD RMS database then the server generates the key pair which could be up to RSA 2048-bit if the cluster is configured to use CryptographicMode 2 instead of default RSA 1024-bit.
- The server encrypts the key pair using its public key.
- The server submit created blob to its database for the next time this user will request RAC from another device.
- The server creates a Rights Account Certificate that includes user’s RAC public key.
- The server signs this RAC with its private key.
- The server encrypts the user’s RAC private key using machine’s public key (extracted from received SPC in step 1).
- The server sends encrypted private key and RAC back to the client.
Properties of the RAC will vary depending on the client situation and authentication mechanism. There are five types of RACs AD RMS will issue, used for different scenarios and with different validity period:
Type of RAC
Decsription
Default Validity Period
Standard RAC
Domain joined computer
**365 days
Temporary RAC
Stand-alone computer or computer belonging to another domain
15 minutes
AD FS RAC
Used for federated users
7 days
Windows Live ID RAC Private
Used for Windows Live ID on a private computer
6 months
Windows Live ID RAC Public
Uses for Windows Live ID on a public computer
Until you log off


After acquiring the RAC, the client uses the service discovery process discussed above to find the Licensing URL, which it will use to acquire a Client Licensor Certificate, the final certificate that is used to protect content.
CLC issuance is very similar to RAC issuance, with the only difference (besides being done by calling Publish.asmx in the Licensing pipeline instead of Certification.asmx in the Certification pipeline) that CLCs are not stored at the server, so every time you request a new one (e.g. because you are using a new client machine) the server will generate it from scratch. This is not a problem since the CLC is only used for signing Publishing Licenses for protecting content and not for encryption.
After creation at the server, the CLC private key is encrypted with the users RAC public key and sent to the client along with the Client Licensor Certificate, so the client will be able to decrypt the private key when needed to create protected content.
Once the client has received the RAC and CLC, the client is fully bootstrapped and ready to protect new content.
Author: Alexey Goldbergs, Deputy Chief Technical Officer at Crypto-Pro.
Contributor: Enrique Saggese, Sr. Program Manager, Information Protection team, Microsoft.
Sheik Uduman Ali (@udooz) described Azure ServiceBus Message Payload Serialization using protobuf in an 8/7/2012 post:
Choices are between ready made coffee maker and make it ourselves available in Windows Azure kitchen. As long as we want cappuccino, Windows Azure .NET libraries are good to go in terms of productivity and maintainability. Sometimes, we may need to prepare blended iced cappuccino. REST API (the actual service interface to Windows Azure services) is the way for that. Here, I am talking about Windows Azure ServiceBus queue and how to use custom serialization on message payload (or body).
My Blended Iced Cappuccino
This is not the common case in the messaging world. A queue may be designated for receiving document type message or command type message. For command type messages, DataContractSerializer is fine. When the message type is document, both sender and receiver can agreed upon specific content-type of the message payload. For this, REST is the best friend.
Solution
To send a message, Windows Azure ServiceBus REST API requires the following:
- URI – http{s}://{serviceNamespace}.servicebus.Windows.net/{queue path}/messages
- Method – POST
- Header – Authorization header with WRAP token as value
- Request Body – could be anything
If everything going well, this web request returns 201.
To receive the message,
- URI – https://{serviceNamespace}.servicebus.Windows.net/{queue path}/messages/head?timeout={seconds}
- Method – POST (peek n lock) or DELETE (destructive)
- Header – Authorization header with WRAP token as value
This would returns message properties (for destructive nothing will be returned) and payload with response code 200.
In this case, there is no restriction on which serialization to be used on message payload. So, we can use protobuf. The main reason is content size. When a sender sends the message with HTTP content-type as application/protobuf, the receive always gets the message with the same content-type. …

Udooz continues with source code samples.
<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
•• Haishi Bai (@HaishiBai2010) announced BlobShare is now on Windows Azure Web Sites on 8/17/2012:
BlobShare is a great Windows Azure sample built by my DPE colleagues last year. It’s a comprehensive, end-to-end scenario showcasing Windows Azure storages as well as claim-based service of ACS. You can find the original source repository on CodePlex. You can also read the nice blog article by Vittorio Bertocci on MSDN blog. Or, if you prefer videos, you can watch this Cloud Cover episode on Channel 9 for a detailed introduction.

• Brian Swan (@brian_swan) described Migrating Drupal to Windows Azure Web Sites in an 8/16/2012 post:
DrupalCon Munich is next week, and I am lucky enough to be going. As part of preparing for the conference, I thought it would be worthwhile to see just how easy (or difficult) it would be to migrate an existing Drupal site to Windows Azure Web Sites. So, in this post, I’ll do just that. Fortunately, because Windows Azure Web Sites supports both PHP and MySQL, the migration process is relatively straightforward. And, because Drupal and PHP run on any platform, the process I’ll describe should work for moving Drupal to Windows Azure Web Sites regardless of what platform you are moving from. Of course, Drupal installations can vary widely, so YMMV.
Before getting started, it’s worth noting that Windows Azure Websites lets you run up to 10 Web Sites for free in a multitenant environment. And, you can seamlessly upgrade to private, reserved VM instances as your traffic grows. To sign up, try the Windows Azure 90-day free trial.
1. Create a Windows Azure Web Site and MySQL database
There is a step-by-step tutorial on http://www.windowsazure.com that walks you through creating a new website and a MySQL database, so I’ll refer you there to get started: Create a PHP-MySQL Windows Azure web site and deploy using Git. If you intend to use Git to publish your Drupal site, then go ahead and follow the instructions for setting up a Git repository. Make sure to follow the instructions in the Get remote MySQL connection information section as you will need that information later. You can ignore the remainder of the tutorial for the purposes of deploying your Drupal site, but if you are new to Windows Azure Web Sites (and to Git), you might find the additional reading informative.
<Pause while you complete the tutorial.>
Ok, now you have a new website with a MySQL database, your have your MySQL database connection information, and you have (optionally) created a remote Git repository and made note of the Git deployment instructions. Now you are ready to copy your database to MySQL in Windows Azure Web Sites.
2. Copy database to MySQL in Windows Azure Web Sites
I’m sure there is more than one way to copy your Drupal database, but I found the mysqldump tool to be effective and easy to use. To copy from a local machine to Windows Azure Web Sites, here’s the command I used:
mysqldump -u local_username --password=local_password drupal | mysql -h remote_host -u remote_username --password=remote_password remote_db_nameYou will, of course, have to provide the username and password for your existing Drupal database, and you will have to provide the hostname, username, password, and database name for the MySQL database you created in step 1. This information is available in the connection string information that you should have noted in step 1. i.e. You should have a connection string that looks something like this:
Database=remote_db_name;Data Source=remote_host;User Id=remote_username;Password=remote_passwordDepending on the size of your database, the copying process could take several minutes.
<Pause while database is copied to MySQL in Windows Azure Websites.>
Now your Drupal database is live in Windows Azure Websites. Before you deploy your Drupal code, you need to modify it so it can connect to the new database.
3. Modify database connection info in settings.php
Here, you will again need your new database connection information. Open the /drupal/sites/default/setting.php file in your favorite text editor, and replace the values of ‘database’, ‘username’, ‘password’, and ‘host’ in the $databases array with the correct values for your new database. When you are finished, you should have something similar to this:
$databases = array ('default' =>array ('default' =>array ('database' => 'remote_db_name','username' => 'remote_username','password' => 'remote_password','host' => 'remote_host','port' => '','driver' => 'mysql','prefix' => '',),),);Be sure to save the settings.phpfile, then you are ready to deploy.
4. Deploy Drupal code using Git or FTP
The last step is to deploy your code to Windows Azure Web Sites using Git or FTP.
If you are using FTP, you can get the FTP hostname and username from you website’s dashboard. Then, use your favorite FTP client to upload your Drupal files to the /site/wwwroot folder of the remote site.
If you are using Git, you need to set up a Git repository in Windows Azure Web Sites (steps for this are in the tutorial mentioned earlier). And, you will need Git installed on your local machine. Then, just follow the instructions provided after you created the repository:
One note about using Git here: depending on your Git settings, your .gitignore file (a hidden file and a sibling to the .git folder created in your local root directory after you executed git commit), some files in your Drupal application may be ignored. In my case, all the files in the sites directory were ignored. If this happens, you will want to edit the .gitignore file so that these files aren’t ignored and redeploy.
After you have deployed Drupal to Windows Azure Web Sites, you can continue to deploy updates via Git or FTP.
Related information
If you are looking for more information about Windows Azure Web Sites, these posts might be helpful:
- Windows Azure Websites- A PHP Perspective
- Windows Azure Websites, Web Roles, and VMs- When to use which-
- Configuring PHP in Windows Azure Websites with .user.ini Files
One last thing you might consider, depending on your site, is using the Windows Azure Integration Module to store and serve your site’s media files.
If you have any comments or questions, please leave them in the comments for this post.


Michael Washam (@MWashamMS) described Publishing and Synchronizing Web Farms using Windows Azure Virtual Machines in an 8/13/2012 post:
Deploying new web applications is pretty painless with Windows Azure Web Sites and “fairly” painless using Windows Azure PaaS style cloud services. However, for existing web apps that are being migrated to the cloud both solutions can require significant rewriting/re-architecture. That is where Windows Azure Infrastructure as a Service comes in. Running Virtual Machines allows you to have the economies of scale of using a cloud based solution and have full access to cloud services such as storage, service bus etc.. while not requiring you to re-architect your application to take advantage of these services.
In this post I will walk through how to use Windows Azure Virtual Machines to create a web farm that you can directly publish to using Visual Studio Web Deploy. In addition to simple publishing I will also show how you can automatically synchronize web content across multiple virtual machines in your service to make web farm content synchronization simple and painless.
Step #1 – Image Preparation
Create a new virtual machine using either Windows Server 2008 R2 or Server 2012. On this machine install the Application Server and Web Server roles and enable ASP.NET).

TIP: Don’t forget to install the .NET Framework 4.0 if you are using Server 2008 R2.
For this solution you will also need the Windows Azure PowerShell Cmdlets on the web server. See this article for configuring your publish settings with the PS cmdlets.
I will use the cmdlets to discover the VM names in my web farm without having to manually keep track of them. This helps if you need the ability to grow and shrink your web farm at will without updating your synchronization scripts.The tool I will use for content sync is Web Deploy 3.0. Download but do not install Web Deploy 3.0.
Web Deploy works by a starting a remote agent that listens for commands from either Visual Studio or the MSDeploy.exe client. By default it will listen on port 80. This default port configuration will not work in a load balanced environment.
To install on an alternate external port such as 8080:
C:\WebDeployInstall>msiexec /I webdeploy_amd64_en-us.msi /passive ADDLOCAL=ALL LISTENURL=http://+:8080/Once installed you will need to configure a firewall rule to allow traffic in on port 8080 for publishing and synchronization.
Now that the image is configured you will sysprep the vm to remove any unique characteristics like machine names etc. Ensure you have Enter System-Out-Of-Box Experience, Generalize and Shutdown all selected.
Once the VM status is shown as shut down in the Windows Azure Management portal highlight the VM and click capture. This will be the customized image you can use to quickly provision new VMs for your web farm using the management portal or powershell.
Ensure you check I have sysprepped this VM and name the image WebAppImg and click the check mark button to capture the image.
Step #2 – Virtual Machine Deployment
Once the image has been created you can use the portal or the Windows Azure PowerShell cmdlets to provision the web farm.
Here is a PowerShell example of using the new image as the basis for a three VM web farm.
A few things to note: I have created a load balanced endpoint for port 80 but for 8080 I’m only selecting a single server.
This server will be the target server for publishing from Visual Studio that will then be used as the source server for publishing to the other nodes in the web farm.$imgname = 'WebAppImg' $cloudsvc = 'MyWebFarm123' $pass = 'your password' $iisvm1 = New-AzureVMConfig -Name 'iis1' -InstanceSize Small -ImageName $imgname | Add-AzureEndpoint -Name web -LocalPort 80 -PublicPort 80 -Protocol tcp -LBSetName web -ProbePath '/' -ProbeProtocol http -ProbePort 80 | Add-AzureEndpoint -Name webdeploy -LocalPort 8080 -PublicPort 8080 -Protocol tcp | Add-AzureProvisioningConfig -Windows -Password $pass $iisvm2 = New-AzureVMConfig -Name 'iis2' -InstanceSize Small -ImageName $imgname | Add-AzureEndpoint -Name web -LocalPort 80 -PublicPort 80 -Protocol tcp -LBSetName web -ProbePath '/' -ProbeProtocol http -ProbePort 80 | Add-AzureProvisioningConfig -Windows -Password $pass $iisvm3 = New-AzureVMConfig -Name 'iis3' -InstanceSize Small -ImageName $imgname | Add-AzureEndpoint -Name web -LocalPort 80 -PublicPort 80 -Protocol tcp -LBSetName web -ProbePath '/' -ProbeProtocol http -ProbePort 80 | Add-AzureProvisioningConfig -Windows -Password $pass New-AzureVM -ServiceName $cloudsvc -VMs $iisvm1,$iisvm2,$iisvm3 -Location 'West US'Once the VMs are provisioned RDP into iis1 by clicking connect in the management portal. This is where you will configure a PowerShell script that will run MSDeploy to synchronize content across the other servers.
Inside of the iis1 virtual machine create a new text file named sync.ps1 in a directory off of your root such as C:\SynchScript and paste the following in (ensuring that you update $serviceName with your cloud service name).
Import-Module 'C:\Program Files (x86)\Microsoft SDKs\Windows Azure\PowerShell\Azure\Azure.psd1' $publishingServer = (gc env:computername).toLower() $serviceName = 'REPLACE WITH YOUR CLOUD SERVICE' Get-AzureVM -ServiceName $serviceName | foreach { if ($_.Name.toLower() -ne $publishingServer) { $target = $_.Name + ":8080" $source = $publishingServer + ":8080" $exe = "C:\Program Files\IIS\Microsoft Web Deploy V3\msdeploy.exe" [Array]$params = "-verb:sync", "-source:contentPath=C:\Inetpub\wwwroot,computerName=$source", "-dest:contentPath=C:\Inetpub\wwwroot,computerName=$target"; & $exe $params; } }This script enumerates all of the virtual machines in your cloud service and attempts to run a web deploy sync job on them. If you have other servers in your cloud service like database etc.. you could exclude them by filtering on the VM name. Note: Web Deploy supports MANY more operations other than just synchronizing directories. Click here to find more information.
To enable content synchronization you will need to create a new scheduled task by going into Control Panel -> Administrative Tools -> Scheduled Tasks -> Create a new Task.
Accept the defaults for everything except when it gets to the action screen.
Program/Script: powershell.exe
Parameters: -File C:\WebDeployInstall\sync.ps1Open the properties of the new task and you’ll need to modify the schedule to synchronize content fairly often so content isn’t out of sync during a publish.
Ensure you select Run Whether User Is Logged on or Not. You will need to provide an account for the task to run as. I’m choosing the administrator account because I am lazy. However, you could create new duplicate accounts on each of the VMs to use for synchronization.
Step #3 – Publishing with Visual Studio
Finally, to test the configuration create a new MVC app and tweak the code slightly to show the computer name.
Now right click on the project and select publish. In the drop down select new profile.
- In the settings page add your cloud app url and append :8080 to it for the service URL.
- Set the site/app name to Default Web Site
- Set the Destination URL to your cloud app url (without :8080)
Finish the wizard and let Visual Studio publish.
When the web app first launches you may or may not see the new content. It may show the default IIS8 content. As soon as the scheduled task runs the content should sync across all of the servers.
Once it has synchronized press CTRL F5 a few times and you should see the content with the individual machine names to verify the load balancing is working.

In this post you have seen how you can configure a custom OS image that can be used to provision virtual machines for a web farm. You have then seen how you can use Web Deploy along with PowerShell to synchronize content published from Visual Studio across all of the servers in your farm.

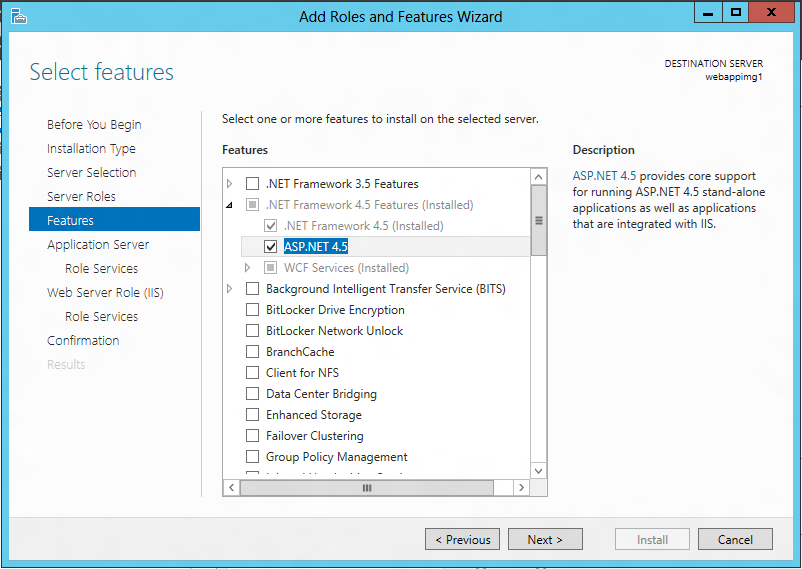

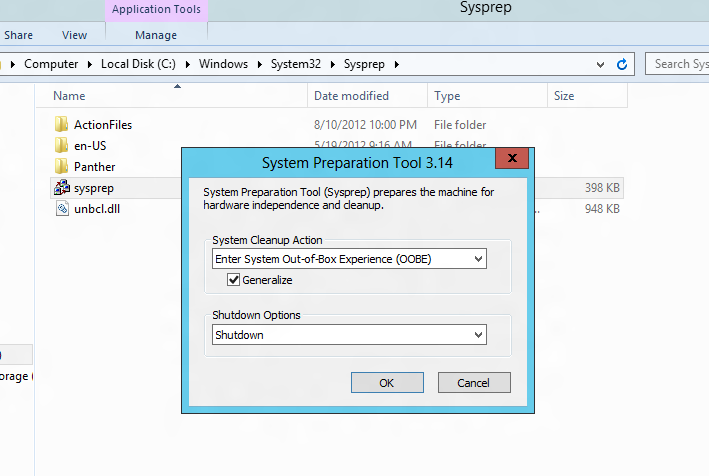

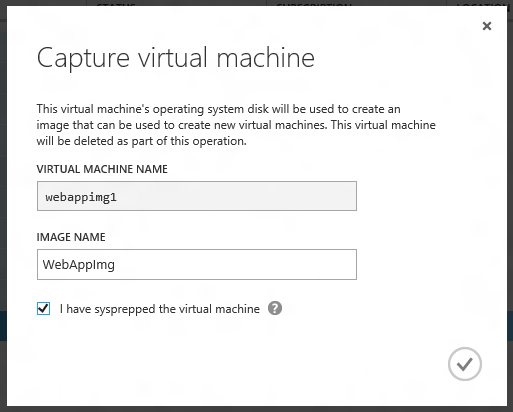



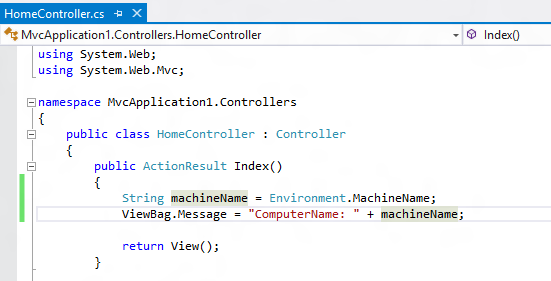


<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Steve Marx (@smarx) described Calling the Windows Azure Service Management API from Python in an 8/14/2012 post:
Written as a response to a Stack Overflow question about how to do it, below is a little Python command-line tool that takes a .publishsettings file as an argument and calls the List Storage Accounts method of the Windows Azure Service Management API.
import argparse import base64 import os from OpenSSL.crypto import * import requests import tempfile import xml.etree.ElementTree parser = argparse.ArgumentParser() parser.add_argument('file', metavar='file', type=str, help='Your .publishsettings file.') args = parser.parse_args() tree = xml.etree.ElementTree.parse(args.file) pp = tree.find('PublishProfile') cert = load_pkcs12(base64.decodestring(pp.get('ManagementCertificate'))) subscription_id = pp.find('Subscription').get('Id') with tempfile.NamedTemporaryFile(mode='w', delete=False) as f: f.file.write(dump_certificate(FILETYPE_PEM, cert.get_certificate())) f.file.write(dump_privatekey(FILETYPE_PEM, cert.get_privatekey())) name = f.name response = requests.get( 'https://management.core.windows.net/%s/services/storageservices' % subscription_id, headers={'x-ms-version': '2011-02-25'}, cert=f.name).text os.remove(name) tree = xml.etree.ElementTree.fromstring(response) for e in tree.iterfind('.//{http://schemas.microsoft.com/windowsazure}ServiceName'): print e.textTo run it, you'll need a .publishsettings file. For a bit more information about what that is and how to get one, see my earlier blog post "Calling the Windows Azure Service Management API with the New .publishsettings File."
You'll also need to install two prerequisite Python modules. pip install pyopenssl requests should do the trick.
There are two things I don't really like about this code:
- It assumes a .publishsettings file that contains only one subscription. I haven't tested it, but I think in the presence of multiple subscriptions, this will just use the first subscription ID it finds. This is just me being lazy.
- It writes the certificate out to a temporary file. It seems that Python's ssl module insists on certificates being passed around via file names. If anyone knows of a nicer way to do this, please let me know!

• Brian Swan (@brian_swan) described Customizing a Windows Azure PHP Worker Role in an 8/14/2012 post:
I was recently asked if it is possible to run PHP 5.4 in a Windows Azure Worker Role. (The default scaffold for a PHP worker role currently installs a version of PHP 5.3.) This got me to wondering how you might use any custom PHP installation in a worker role. The short answer is, yes, you can use ay custom PHP installation in a worker role – in this post I’ll walk you through the steps for doing so. However, a disclaimer first: my investigations here raised a few questions I haven’t answered yet, so depending on what you want to do, this post may/or may not be helpful.
Anyway, here’s what I did to get my local installation of PHP 5.4 running in a worker role…
1. I used the Windows Azure Powershell cmdlets to create a new Windows Azure Service, add a PHP worker role, and enable remote desktop access:
2. I added my local PHP 5.4 installation to the WorkerRole1 directory. I also edited the php.ini file to make sure all paths referenced in the file were relative, not absolute (e.g. include_path=".\ext\" instead of "C\:\php54\ext\").
Note: Here is where some questions arise. Some PHP extensions may require dependencies that aren’t installed by default. For example, the sqlsrv extension requires SQL Server Native Client. In this case, I could install the dependency using the Web Platform Installer, but other dependencies may require other methods.
3. I deleted all other files from the WorkerRole1 directory except for the setup_worker.cmd file. This script is called when the role is started, and I changed it so that it will add my PHP installation to the Path environment variable.
@echo offecho Granting permissions for Network Service to the deployment directory...icacls . /grant "Users":(OI)(CI)Fif %ERRORLEVEL% neq 0 goto errorecho OKecho SUCCESSsetx Path "%PATH%;%~dp0php54" /Mexit /b 0:errorecho FAILEDexit /b -14. I added two files to the WorkerRole1 folder: php_entry.cmd and entry.php. The first file (php_entry.cmd) will be the program entry point for the role (I’ll configure this in a later step). The only thing that this file does is call the entry.php script. It’s contents are simply this:
php entry.phpThe entry.php script is just an example of some long-running script that might actually do something interesting in a “real” scenario. In my case this is just a proof of concept, so I just open and write to a file once every minute:
<?php$h = fopen("output.txt", "a+");while(true){fwrite($h, "Hello world!");sleep(60);}?>My WorkerRole1 directory now looks like this:
5. Finally, publish the project with the Powershell cmdlets: Publish-AzureServiceProject
It will take a few minutes to publish the project, but when it is ready, you should be able to login to it via remote desktop…
…and find your way to the approot directory to see that your long-running php script is writing to the file as expected. (Of course, your project will do something interesting.)
One last thing to consider: By default, port 80 is open on a PHP Worker Role. Here’s the entry in the ServiceDefinition.csdef file:
<Endpoints><InputEndpoint name="HttpIn" protocol="tcp" port="80" /></Endpoints>Depending on what your worker role does, you may want to close this endpoint. To allow other Azure services to communicate with your worker role, you may want to open other endpoints. For more information, see How to: Enable Role Communication.
The approach to using a custom PHP installation for a web role is similar to that for a worker role. The steps are basically…
1. Use the Powershell tools to create a new project and PHP Web Role.
2. Add your PHP installation to the WebRole/bin directory.
3. Modify the startup script (setup_web.cmd) to configure IIS (this configures IIS to run PHP from my php54 directory):
SET PHP_FULL_PATH=%~dp0php54\php-cgi.exeSET NEW_PATH=%PATH%;%RoleRoot%\base\x86%WINDIR%\system32\inetsrv\appcmd.exe set config -section:system.webServer/fastCgi /+"[fullPath='%PHP_FULL_PATH%',maxInstances='12',idleTimeout='60000',activityTimeout='3600',requestTimeout='60000',instanceMaxRequests='10000',protocol='NamedPipe',flushNamedPipe='False']" /commit:apphost%WINDIR%\system32\inetsrv\appcmd.exe set config -section:system.webServer/fastCgi /+"[fullPath='%PHP_FULL_PATH%'].environmentVariables.[name='PATH',value='%NEW_PATH%']" /commit:apphost%WINDIR%\system32\inetsrv\appcmd.exe set config -section:system.webServer/fastCgi /+"[fullPath='%PHP_FULL_PATH%'].environmentVariables.[name='PHP_FCGI_MAX_REQUESTS',value='10000']" /commit:apphost%WINDIR%\system32\inetsrv\appcmd.exe set config -section:system.webServer/handlers /+"[name='PHP',path='*.php',verb='GET,HEAD,POST',modules='FastCgiModule',scriptProcessor='%PHP_FULL_PATH%',resourceType='Either',requireAccess='Script']" /commit:apphost%WINDIR%\system32\inetsrv\appcmd.exe set config -section:system.webServer/fastCgi /"[fullPath='%PHP_FULL_PATH%'].queueLength:50000"In this case, you will likely want to leave port 80 open.
That’s it. As usual, feedback in the comments is appreciated.




• Edu Lorenzo (@edulorenzo) described How to use Windows Azure Profiling Tools in Visual Studio in an 8/13/2012 post:
Just recently, I have been looking for a tool to profile my Windows Azure application when it runs on Azure. Yeah most browsers have that F12 dev tools, but they just won’t cut it for what I want. What I didn’t know, is that I didn’t look very far. As it so happens, the Windows Azure SDK includes a profiler that will profile your app (including code) when it runs on Windows Azure.
Was a bit hesitant so I decided to test it myself.
Steps would be:
- Create an azure worker role with two functions, one is okay, and the other is really bad (performance hog)
- Deploy it and have it profiled
- Hopefully the profiler will be able to identify which function is better, or which one needs improvement
Sounds sensible enough J
So I fire up Visual Studio and create a worker role.
So, what to put.. friend of mine Jon Limjap pointed me here and here is what I have now:
///
<summary>/// Function I got from Stackoverflow
///
</summary>///
<param name=”stringLength”></param>///
<returns></returns>private
string RandomStringGood(int size){
System.Text.StringBuilder builder = new
StringBuilder();Random random = new
Random();char ch;
for (int i = 0; i < size; i++)
{
ch = Convert.ToChar(Convert.ToInt32(Math.Floor(26 * random.NextDouble() + 65)));
builder.Append(ch);
}
return builder.ToString();
}
///
<summary>/// modified it to be a bad function (my specialty hahaha)
///
</summary>///
<param name=”size”></param>///
<returns></returns>private
string RandomStringBad(int size){
String builder = string.Empty;
Random random = new
Random();char ch;
for (int i = 0; i < size; i++)
{
ch = Convert.ToChar(Convert.ToInt32(Math.Floor(26 * random.NextDouble() + 65)));
builder += ch;
}
return builder.ToString();
}
Then I call them
public
override
void Run(){
// This is a sample worker implementation. Replace with your logic.
Trace.WriteLine(“$projectname$ entry point called”, “Information”);
while (true)
{
RandomStringBad(1);
RandomStringGood(1);
Thread.Sleep(10000);
Trace.WriteLine(“Working”, “Information”);
}
}
Short, simple and should do the job (fingers crossed)
So, then I use the profiling tool.. I deploy this to my Azure Subscription using Visual Studio
With these settings
I checked Enable Profiling then published it.
Some waiting involved..
Took a while but when it is ready..
You can start profiling the workerrole
Again some waiting
Then I saw something that caught my attention
So I guess there is something that will need to be done with the symbols. But my test app is just a barebones app so I guess there is no need to worry about that just now.
I tried visiting the browser version of the Azure management portal.. and it showed activity
Annndddddd… here are the results!
The profiler indicates that RandomStringBad uses more resources than RandomStringGood!
And clicking on that item on the list takes me to the code
So I guess it works!









BusinessWire announced Quest Software Debuts Foglight for Windows Azure Applications in an 8/13/2012 press release:
Building on its 20-year heritage as an industry leader in application performance monitoring, Quest Software today introduced Foglight® for Windows Azure Applications, an application performance monitoring (APM) solution available via software-as-a-service (SaaS). Available immediately as a beta, the newest addition to the industry-leading Foglight APM portfolio enables IT administrators to monitor performance and understand what end users are experiencing with Windows Azure-based applications.
News Facts:
- Enterprises recognize that end users have high expectations from applications. The success or failure of an application often is determined by the end user’s experience with that application; however, IT administrators sometimes struggle to understand the end user experience, particularly within cloud-based applications.
- Foglight for Windows Azure Applications enables enterprises to leverage cloud-based performance monitoring technology for applications built on the Windows Azure platform, and allows IT administrators to gain critical insight as to how end users interact with these applications.
- Foglight for Windows Azure Applications gives application owners and operators confidence that their users are getting the service expected, and the applications and infrastructure are performing optimally. Specifically, the product provides:
- Insight at a glance into the current and historical availability, as well as the health of the application and its supporting infrastructure
- The ability to drill down into problems to understand both their impact and probable cause
- Insight into the quality of service experienced by the application’s users, combined with an at-a-glance view of response time, showing normal behavior and drawing attention to anomalies
- A geographical view of performance and user location, drawing attention to problems affecting particular geographies rather than all users
- A true understanding of performance issues related to browser types, mobile device and other user agents, identifying compatibility issues and showing how users access the application
- Alarms that are reserved for truly important matters. In addition to appearing in the product, these can be forwarded to email clients so that IT staff are notified when critical issues arise, enabling them to take action when needed
- To access the beta version of Foglight for Windows Azure Applications, please visit http://www.foglight-on-demand.com/content/en/appPerformance/guided-tour.html?Azure
Quest’s Foglight Products Continue to Simplify APM:
- For more than 20 years, Quest Software’s industry-leading Foglight application performance monitoring solution has provided unparalleled monitoring capabilities for enterprises worldwide.
- Quest’s longstanding leadership in the performance monitoring of Windows applications and deep-dive monitoring of multivendor databases is ideally suited for helping large enterprises maximize operational efficiencies while reducing the cost, complexity and administrative overhead of managing application performance.
- Unique user experience management capabilities, real-time session capture, replay and analysis offer a 360-degree view from business, IT and end user perspectives to expedite the resolution of performance problems and improve transaction conversion rates. …
The press release continues with supporting quotes, etc.
Richard Conway (@azurecoder) described Building a virus scanning gateway in Windows Azure with Endpoint Protection in an 8/12/2012 post to the Elastacloud blog:
I remember being on a project some 9 years ago and having to build one of these. To build a realtime gateway is not as easy as you would think. In my project there were accountants uploading invoices of various types and formats that we had to translate into text using an OCR software package. We built a workflow using a TIBCO workflow designer solution (which I wouldn’t hesitate now to replace with WF!)
At a certain point people from outside the organisation had the ability to upload a file and this file had to be intercepted by a gateway before being persisted and operated on the through the workflow. You would think that this was an easy and common solution to implement. However, at the time it wasn’t. We used a Symantec gateway product and its C API which allowed us to use the ICAP protocol and thus do real time scanning.
Begin everything with a web role
For the last 6 months I’ve wanted to talk about Microsoft Endpoint Protection (http://www.microsoft.com/en-us/download/details.aspx?id=29209) which is still in CTP as a I write this. It’s a lesser known plugin which exists for Windows Azure. For anybody that receives uploaded content, this should be a commonplace part of the design. In this piece I want to look at a pattern for rolling your gateway with Endpoint Protection. It’s not ideal because it literally is a virus scanner, enabling real time protection and certain other aspects but uses Diagnostics to show issues that have taken place.
The files which are part of the endpoint protection plugin
So initially we’ll enable the imports:
<Imports> <Import moduleName="Diagnostics" /> <Import moduleName="Antimalware" /> <Import moduleName="RemoteAccess" /> <Import moduleName="RemoteForwarder" /> </Imports>You can see the addition of Antimalware here.
Correspondingly, our service configuration gives us the following new settings:
<Setting name="Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString" value="<my connection string>" /> <Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.ServiceLocation" value="North Europe" /> <Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.EnableAntimalware" value="true" /> <Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.EnableRealtimeProtection" value="true" /> <Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.EnableWeeklyScheduledScans" value="false" /> <Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.DayForWeeklyScheduledScans" value="7" /> <Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.TimeForWeeklyScheduledScans" value="120" /> <Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.ExcludedExtensions" value="txt|rtf|jpg" /> <Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.ExcludedPaths" value="" /> <Setting name="Microsoft.WindowsAzure.Plugins.Antimalware.ExcludedProcesses" value="" />The settings are using Endpoint Protection for real time protection and scheduled scan. It’s obviously highly configurable like most virus scanners and in the background will update all malware definitions securely from a Microsoft source.
Endpoint protection installed on our webrole
First thing we’ll do is download a free virus test file from http://www.eicar.org/85-0-Download.html. Eicar has ensured that this definition is picked by most of the common virus scanning so Endpoint Protection should recognise this immediately. I’ve tested this with the .zip file but any of them are fine.
The first port of call is setting up diagnostics to proliferate the event log entries. We can do this within our RoleEntryPoint.OnStart method for our web role.
var config = DiagnosticMonitor.GetDefaultInitialConfiguration(); //exclude informational and verbose event log entries config.WindowsEventLog.DataSources.Add("System!*[System[Provider[@Name='Microsoft Antimalware'] and (Level=1 or Level=2 or Level=3 or Level=4)]]"); //write to persisted storage every 1 minute config.WindowsEventLog.ScheduledTransferPeriod = System.TimeSpan.FromMinutes(1.0); DiagnosticMonitor.Start("Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString", config);
Diagnostics info in Azure Management Studio
Okay, so in testing it looks like the whole process of cutting and pasting the file onto the desktop or another location takes about 10 seconds for the Endpoint Protection to pick this up and quarante the file. Given this we’ll set the bar at 20 seconds.
Endpoint protection discovers malware
I created a very simple ASP.NET web forms application with a file upload control. There are two ways to detect whether the file has been flagged as malware:
- Check to see whether the file is still around or has been removed and placed in quarantine
- Check the eventlog entry to see whether this has been flagged as malware.
We’re going to focus on No.2 so I’ve created a simple button click event which will persist the file. Endpoint protection will kick in within the short period so we’ll write the file to disk and then pause for 20 seconds. After our wait we’ll then check the eventlog and in the message string we’ll have a wealth of information about the file which has been quarantined.
bool hasFile = fuEndpointProtection.HasFile; string path = ""; if(hasFile) { path = Path.Combine(Server.MapPath("."), fuEndpointProtection.FileName); fuEndpointProtection.SaveAs(path); } // block here until we check endpoint protection to see whether the file has been delivered okay! Thread.Sleep(20000); var log = new EventLog("System", Environment.MachineName, "Microsoft Antimalware"); foreach(EventLogEntry entry in log.Entries) { if(entry.InstanceId == 1116 && entry.TimeWritten > DateTime.Now.Subtract(new TimeSpan(0, 2, 0))) { if(entry.Message.Contains(value: fuEndpointProtection.FileName.ToLower())) { Label1.Text = "File has been found to be malware and quarantined!"; return; } } } Label1.Text = path;
When I upload a normal file
When I upload the Eicar test file
The eventlog entry should look like this, which contains details on the affected process, the fact that it is a virus and also some indication on where to get some more information by providing a threat URL.%%860 4.0.1521.0 {872DA7D0-383A-4A18-A447-DC4C7E71785F} 2012-08-12T09:31:18.362Z 2147519003 Virus:DOS/EICAR_Test_File 5 Severe 42 Virus http://go.microsoft.com/fwlink/?linkid=37020&name=Virus:DOS/EICAR_Test_File&threatid=2147519003 3 2 3 %%818 D:\Windows\System32\inetsrv\w3wp.exe NT AUTHORITY\NETWORK SERVICE containerfile:_F:\sitesroot\0\eicar_com.zip;file:_F:\sitesroot\0\eicar_com.zip->(Zip);file:_F:\sitesroot\0\eicar_com.zip->eicar.com 1 %%845 1 %%813 0 %%822 0 2 %%809 0x00000000 The operation completed successfully. 0 0 No additional actions required NT AUTHORITY\SYSTEM AV: 1.131.1864.0, AS: 1.131.1864.0, NIS: 0.0.0.0 AM: 1.1.8601.0, NIS: 0.0.0.0Okay, so this is very tamed example but it does prove the concept. In the real world you may even want to have a proper gateway which acts as a proxy and then forwards the file onto a "checked" store if it succeeds. We looked at the two ways you can check to see whether the file has been treated as malware. The first, checking to see whether the file has been deleted from it's location is too non-deterministic because although "real time" means real time we don't want to block and wait and timeout on this. The second is better because we will get a report if it's detected. This being the case, a more hardened version of this example will entail building a class which may treat the file write as a task and asynchronously ping back the user if the file has been treated as malware - something like this could be written as an HttpModule or ISASPI filter pursue the test and either continue with the request or end the request and return an HTTP error code to the user with a description of the problems with the file.






<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
•• Beth Massi (@bethmassi) explained Getting Started with LightSwitch in Visual Studio 2012 in an 8/15/2012 post:
Awesome! This morning we released Visual Studio 2012 which has a ton of new LightSwitch enhancements like the ability to access data from any OData source as well as create OData services, a new theme, and a whole lot more. For a good rollup of content to get you up to speed on all our new features see my post:
New Features Explained – LightSwitch in Visual Studio 2012
Also now that LightSwitch is a core part of the Visual Studio product line, we wanted to also align the LightSwitch and Visual Studio web sites including a new integrated Developer Center and User Voice sites. The Developer Center is still your one-stop-shop for learning all about Visual Studio and building business applications with LightSwitch. From here you can explore LightSwitch Architecture, watch the How Do I videos, build and install extensions, download samples and a whole lot more.
LightSwitch on the Visual Studio Developer Center —> http://msdn.com/lightswitch
I’ve also been busy preparing some special treats for you to help you get started learning all about LightSwitch development. If you’re completely new to LightSwitch or even software development itself, get started with this beginning LightSwitch article series and samples.
Get Started Building LightSwitch Apps with Visual Studio 2012
- Part 1: What’s in a Table? Describing Your Data
- Part 2: Feel the Love. Defining Data Relationships
- Part 3: Screen Templates, Which One Do I Choose?
- Part 4: Too much information! Sorting and Filtering Data with Queries
- Part 5: May I? Controlling Access with User Permissions
- Part 6: Go beyond the box. Customizing LightSwitch Apps with Extensions
- Download the Competed Sample App
Also if you want a super-quick way to get an application started, check out the LightSwitch starter kits for Visual Studio 2012. There’s currently six available for you to choose from and are full working applications you can use.
New LightSwitch Starter Kits for Visual Studio 2012
You can also use these right from within Visual Studio 2012. File –> New Project then select the “Online” node. Under Templates –> Other, select LightSwitch and you will see all of them listed there.
More on the way!
I’ll be releasing more How Do I videos in the coming weeks and some of the team members have planned on some great content to roll out on the LightSwitch Team blog very soon so stay tuned for a whole lot more. Thanks to everyone in this amazing LightSwitch developer community who helped make LightSwitch in Visual Studio 2012 the very best it could be!



•• MSDN (@MSDN) published How to: Deploy a LightSwitch OData Service with Visual Studio 2012 on 7/15/2012:
By publishing a Visual Studio LightSwitch application as a service, you can use it as the middle tier to provide data to other applications. You can host services on Windows Azure or Internet Information Services (IIS). For more information about how to deploy a service to Windows Azure, see How to: Host an Application on Windows Azure.
You can use the LightSwitch Publish Application Wizard to deploy a service by either publishing or packaging it.
If you publish a service, client computers can access it immediately after you complete the wizard. The installation automatically deploys the database schema to SQL Server. To publish a service, you must have administrative access to both the web server and the database server, and you must provision the web server for LightSwitch. For more information, see How to: Configure a Server to Host LightSwitch-Based Applications.
If you package an application, you must compress (zip) everything that’s required to run the service in a folder. The server must also install the service and make it available. For more information, see How to: Install a LightSwitch Application on a Server.
To publish a service
On the menu bar, choose Build, Publish ApplicationName.
The LightSwitch Publish Application Wizard appears.
On the Application Type page, choose the Service only option button, and then choose the Next button.
On the Application Server Configuration page, choose the IIS Server option button.
If you aren’t sure whether the server that’s running IIS has the necessary prerequisites installed, clear the IIS Server has the LightSwitch Server Prerequisites installed check box; otherwise, leave it selected.
Note: If you have a publish settings file (.publishsettings or .pubxml) that was created for another service, you can use that file to provide the rest of the information that you need for deployment. Choose the Import Settings button to specify a publish settings file.
Choose the Next button, and then, on the Publish Output page, choose the Remotely publish to a server now option button.
The Details section appears.
In the Service URL text box, enter the Uniform Resource Locater (URL) for the server that’s running IIS.
In the Site/Application text box, enter a path for the webpage that’s used to host the application manifest.
This path is typically Default Web Site/ServiceName, where ServiceName is the name of your application.
In the User Name and Password text boxes, enter your IIS credentials, and then choose the Next button.
On the Security Settings page, choose the On option button if your application requires a secure HTTPS connection; otherwise, choose the Off option button.
For more information about security, see Security Considerations for LightSwitch.
Choose the Next button to open the Database Connections page of the wizard.
Enter the administrator and user connection strings for the database server where you want to publish the application database, and then choose the Next button.
The database server must be running a compatible version of SQL Server, such as SQL Server 2005 or SQL Server 2005 Express. You don’t need to publish the application to the database server.
If the Authentication page appears, enter a valid User Name, Full Name, and Password for the user who will be the initial application administrator, and then choose the Next button on the Authentication page.
On the Other Connections page, update the connection strings for any additional connections as needed, choose the Next button, and then choose the Publish button.
When the service is published, other applications can access it from the website specified by the Site/Application name plus ServiceName.svc, where ServiceName is the name of a data source that your service exposes.
To package a service
On the menu bar, choose Build, Publish ApplicationName.
The LightSwitch Publish Application Wizard appears.
On the Application Type page, choose the Service only option button, and then choose the Next button.
On the Application Server Configuration page, choose the IIS Server option button.
If you aren’t sure whether the server that’s running IIS has the necessary prerequisites installed, clear the IIS Server has the LightSwitch Server Prerequisites installed check box; otherwise, leave it selected.
Choose the Next button, and then, on the Publish Output page, choose the Create a package on disk option button.
In the What should the website be named? text box, enter a name for the website that will host the service.
By default, the name of the website is the application name.
In the Where should the package be created? text box, enter the UNC path for the location where you want the output to be published.
By default, the output is published in the Publish subdirectory under your project directory.
On the Security Settings page, choose the On option button if your application requires a secure HTTPS connection; otherwise, choose the Off option button.
For more information about security, see Security Considerations for LightSwitch.
Choose the Next button, and then, on the Database Configuration page of the wizard, select the Generate a new database called option button, and enter a name for the database.
You must specify the same name that you entered for the Application Name property in the Application Designer.
Select the Yes, create an Application Administrator check box if the Authentication page appears when you’re packaging an application for the first time. Select the No, an Application Administrator already exists check box if the page appears when you’re packaging an update.
On the Other Connection Information page, update the connection strings for any additional connections as needed, choose the Next button, and then choose the Publish button.
When the service is published, a .zip file that contains the package is placed in the directory that you specified for the publish output. After this package has been created, a server administrator can use the MSDeploy tool to deploy the service to servers that are running IIS and SQL Server. For more information, see How to: Install a LightSwitch Application on a Server.
When the service is deployed, other applications can access it from the website specified by the Site/Application name plus ServiceName.svc, where ServiceName is the name of a data source that your service exposes.
Concepts: Deploying LightSwitch Applications
Other Resources:

•• The Entity Framework Team announced EF5 Released on 8/15/2012:
We are very pleased to announce the release of Entity Framework 5. EF5 is available as the Entity Framework NuGet package and is also included in Visual Studio 2012.
What’s New in EF5
EF 5 includes a number of new features and bug fixes to the EF4.3 release. Most of the new features are only available in applications targeting .NET 4.5, see the Compatibility section for more details.
- Enum support allows you to have enum properties in your entity classes.
- Spatial data types can now be exposed in your model using the DbGeography and DbGeometry types.
- The Performance enhancements that we recently blogged about.
- Code First will now detect if you have LocalDb or SQL Express available for creating new databases. Visual Studio 2012 includes LocalDb, whereas Visual Studio 2010 includes SQL Express.
- Code First will add tables to existing database if the target database doesn’t contain any of the tables from the model.
The EF Designer in Visual Studio 2012 also has some new features:
- DbContext code generation for new models means that any new models created using the EF Designer will generate a derived DbContext and POCO classes by default. You can always revert to ObjectContext code generation if needed. Existing models will not automatically change to DbContext code generation.
- Multiple-diagrams per model allows you to have several diagrams that visualize subsections of your overall model. Shapes on the design surface can also have coloring applied.
- Table-Valued functions in an existing database can now be added to your model.
- Batch import of stored procedures allows multiple stored procedures to be added to the model during model creation.
Get Started @ msdn.com/data/ef
The updated EF MSDN site includes a bunch of walkthroughs and videos to get you started with Entity Framework, including the new features in EF5.
What Changed Since the Release Candidate
You can see a list of bugs that we fixed since the EF5 RC on the EF CodePlex site.
The most notable change since RC is that new models created using the EF Designer in Visual Studio 2012 will now generate a derived DbContext and POCO classes by default. You can always revert to ObjectContext code generation if needed.
Compatibility
This version of the NuGet package is fully compatible with Visual Studio 2010 and Visual Studio 2012 and can be used for applications targeting .NET 4.0 and 4.5.
Some features are only available when writing an application that targets .NET 4.5. This includes enum support, spatial data types, table-valued functions and the performance improvements.
Need Help?
Head to the EF MSDN site to find out how to get help with Entity Framework.
Paul van Bladel (@paulbladel) described Saving data async with cancellation support in an 8/13/2012 post:
Introduction
I can’t get enough from the async calls in LightSwitch. Today I’m discovering a well known feature in WCF Ria Services: cancellation support, which is perfectly supported in LightSwitch as well.
Please read first my previous post on loading data async with cancellation support: http://blog.pragmaswitch.com/?p=394.
This post is quite analogue and focuses on the save pipeline.
The setup
I have a command table and a fictious table called CommandSideEffect. When a command is inserted, I create 1000 records in the CommandSideEffect table :
partial void Commands_Inserting(Command entity) { ApplicationData appData = this.Application.CreateDataWorkspace().ApplicationData; foreach (CommandSideEffect item in appData.CommandSideEffects) { item.Delete(); } appData.SaveChanges(); int totalRecords = 1000; DateTime timeStamp = DateTime.Now; for (int i = 0; i < totalRecords; i++) { CommandSideEffect sideEffectRecord = appData.CommandSideEffects.AddNew(); sideEffectRecord.Effect = i.ToString() + " " + timeStamp; } appData.SaveChanges(); }The user has 2 buttons on the command listdetail screen: Execute command async and Cancel Command.
The client side code
public partial class CommandsListDetail { ISubmitOperationInvocation _saveChangesInvocation; partial void ExecuteCommandAsync_Execute() { Command command = this.Commands.AddNew(); command.Verb = "RunCommand"; _saveChangesInvocation.ExecuteAsync(); } partial void ExecuteCommandAsync_CanExecute(ref bool result) { result = _saveChangesInvocation != null && _saveChangesInvocation.CanExecute; } partial void CommandsListDetail_InitializeDataWorkspace(List<IDataService> saveChangesTo) { _saveChangesInvocation = this.DataWorkspace.ApplicationData.Details.Methods.SaveChanges.CreateInvocation(new object[] { }); _saveChangesInvocation.ExecuteCompleted += new EventHandler<ExecuteCompletedEventArgs>((s1, e1) => { this.Details.Dispatcher.BeginInvoke(() => { switch (_saveChangesInvocation.ExecutionState) { case ExecutionState.Cancelled: this.DataWorkspace.ApplicationData.Details.DiscardChanges(); break; case ExecutionState.Executed: break; case ExecutionState.Executing: break; case ExecutionState.HasError: break; case ExecutionState.NotExecuted: break; default: break; } this.ShowMessageBox(GetStateMessage(_saveChangesInvocation.ExecutionState)); }); }); } private string GetStateMessage(ExecutionState state) { return "Save : " + state.ToString(); } partial void CancelCommandExecution_Execute() { if (_saveChangesInvocation != null) { _saveChangesInvocation.ExecuteAsyncCancel(); } } partial void CancelCommandExecution_CanExecute(ref bool result) { result = _saveChangesInvocation != null && _saveChangesInvocation.CanExecuteAsyncCancel; } }Disclaimer
As for cancellation in the query pipeline, the cancellation is only a client side matter: when a save is cancelled, the command execution will continue server side but the client will no longer wait for the result. In the query pipeline this normally does not lead to collateral damage, but this is not true for the save pipeline. In case you want to undo also the effects of the server side processing as a result of the command triggering you will need to do some more steps: you should implement a “compensating transaction” mechanism, which you will trigger probably also via the command mechanism, but that story is a bit more involved


Paul van Bladel (@paulbladel) described Loading data in LightSwich async with cancellation support. in an 8/13/2012 post:
Introduction
I’m showing in the blog post a technique which is completely useless in the context of my simplified example but which could be useful in other circumstances.
WCF Ria services has out-of-the-box support for client side cancellation. This means that you can decide to cancel client side the load operation which has been started asynchronously.
A UI prototype
Since I’m focusing here rather on a technique than a practical solution, we simply stick to a very rudimentary UI. We have customer search screen with 2 buttons: “Load Customers Async” and “Cancel Load”.
Our MVVM mind wants of course that the buttons are enabled appropriately: when a load operation is busy, the load button should be disabled and the Cancel Load button should be enabled. When no load operation is taking place, the cancel load button should be disabled.
How?
The trick is to cast the loader of the ScreenCollection to an IScreenCollectionPropertyLoader, which derives from IExecutable.
The cool thing is that an IExecutable supports async cancellation.
public interface IExecutable { bool CanExecute { get; } bool CanExecuteAsync { get; } bool CanExecuteAsyncCancel { get; } Exception ExecutionError { get; } ExecutionState ExecutionState { get; } event EventHandler<ExecuteCompletedEventArgs> ExecuteCompleted; void Execute(); void ExecuteAsync(); void ExecuteAsyncCancel(); }Take a look at the implementation:
partial void SearchCustomers_InitializeDataWorkspace(List<IDataService> saveChangesTo) { _loader = this.Details.Properties.Customers.Loader as IScreenCollectionPropertyLoader; _loader.ExecuteCompleted += new EventHandler<ExecuteCompletedEventArgs>((s, e) => { this.Details.Dispatcher.BeginInvoke(() => { string message = "all records successfully loaded"; if (!_loader.IsLoaded) { message = "opeation canceled by user"; } this.ShowMessageBox(message); }); }); } partial void CancelLoad_Execute() { _loader.ExecuteAsyncCancel(); } partial void CancelLoad_CanExecute(ref bool result) { result = _loader != null && _loader.CanExecuteAsyncCancel; } partial void LoadCustomersAsync_Execute() { _loader.ExecuteAsync(); } partial void LoadCustomersAsync_CanExecute(ref bool result) { result = _loader != null && _loader.CanExecuteAsync; }What’s happening?
It is very important to have a clear understanding what is happening here: client side cancellation means that you are no longer interested in the result of the load operation, but this does not mean that the server is informed about this cancellation. So, the server will still process the request as if there was no cancellation, it will return the response, but the client will not use it because it’s no longer waiting for it. You can verify easily with fiddler that, for a cancelled load operation, the response is still going over the wire. In case you want simulate a long running load operation, put a Thread.Sleep(5000) in the PreProcessQuery method.



Return to section navigation list>
Windows Azure Infrastructure, Media Services and DevOps
•• David Linthicum (@DavidLinthicum) asserted “Though corporate IT fights against unauthorized use of cloud-based resources, this user-pull approach is actually helpful” in a deck for his 'Shadow IT' can be the cloud's best friend article of 8/17/2012 for InfoWorld’s Cloud Computing blog:
"Shadow IT" -- where users acquire and manage IT resources outside the control of corporate IT -- is the bane of many IT organizations. We've seen numerous instances of this over the years, including the use of PCs, the Web, the iPhone, and now cloud computing resources without a formal policy and support from corporate IT.
It's easy to see why users resort to shadow IT: Employees charged with running profit centers see a need for a specific type of technology. Rather than fight through IT's red tape and endless meetings, they go out and get what they need. Indeed, a PricewaterhouseCoopers study finds as much as 30 percent of IT spending coming from business units outside the official IT budget.
Although this is akin to anarchy for many in IT, shadow IT in reality pulls the company in more productive directions, which today includes the use of the cloud. We saw that same user-driven benefit in the 1980s with the PC, in the 1990s with the Web, and in the last few years with mobile devices. Now users are bringing in cloud services such as file and document sharing, enterprise applications, mass storage, and even on-demand data analytics.
I do not advocate that IT give up control and allow business units to adopt any old technology they want. However, IT needs to face reality: For the past three decades or so, corporate IT has been slow on the uptake around the use of productive new technologies.
When the business units move forward, they force the hand of corporate IT. Often, IT will stomp out the use of unauthorized cloud-based resources and thus reduce the productivity of that business unit. A better approach would be for IT to get ahead of that technology on behalf of the company, leading versus following those business units into the cloud.
The end result is a new and hotter fire under corporate IT to lead the way in evaluating new technologies, such as cloud computing, and bringing value to the business. The days of IT automatically saying no are quickly coming to a close. If IT doesn't add value, then business units will work around them, and that would lead to a much smaller and less impactful corporate IT resource. I'm not sure anybody wants or needs that now.

This is why I’m lobbying for a version of the Service Management Portal that doesn’t require a Service Provider Licensing Agreement (SPLA) for deploying enterprise private clouds with do-it-yourself provisioning for business units. See my recent Will a version of the Management Portal and API be available for Enterprise Users? thread in the Web Sites and Virtual Machines on Windows Server for Hosting Service Providers for more details. (Repeated later.
•• Werner Vogels (@werner) analyzed Total Cost of Ownership and the Return on Agility in an 8/16/2012 post:
In the many meetings with customers in which I have done a deep dive on their architecture and applications to help them create an accurate cost picture, I have observed two common patterns: 1) It is hard for customers to come to an accurate Total Cost of Ownership (TCO) calculation of an on-premise installation and 2) they struggle with how to account for the “Return on Agility”; the fact that they are now able to pursue business opportunities much faster at much lower costs points than before. Both of these are important as they help customer accurately gauge the economic benefits of running their applications in the cloud. The best practices that we are collecting in the AWS Economics Center are there to help our customers get a total view on their IT cost such that they can accurately compare on-premise and cloud.
Total Cost of Ownership
An apples to apples comparison of the costs associated with running various usage patterns on-premises and with AWS requires more than a simple comparison of hardware expense versus always-on utility pricing for compute and storage. The cost of acquiring and operating your own data center or leasing collocated equipment needs to factor in related costs for what needs to be done to run even the most basic datacenter. This starts with procuring the datacenter space, arranging power, cooling and physical security, then buying the servers, wiring them up, connecting them to the storage and backup devices, building a network infrastructure, and making sure all of the hardware is imaged with right software, provisioned and managed, and that ongoing maintenance is performed, and problems fixed in a reasonable timeframe.
Owning your own hardware is extremely inflexible, you have to over-scale and plan for peak demand and if you make a mistake with the type of hardware you are stuck with it. AWS on the other hand is extremely flexible, not only in what you want to run when you want to run it, but also in a variety of pricing models that allow you to really drive cost down for your use case. As such when calculating the cost of using AWS, you need to go beyond simply multiplying on-demand pricing for all the services and multiplying hourly usage assuming it will be running 24*7 all the time.
There are several ways we enable our customers to take advantage of our price structure, whether they are small or large, running variable or predictable workloads. The AWS Economics Center now features the TCO of Web Applications whitepaper
This white paper provides a detailed view of the comparable costs of running various workloads on-premises and in the AWS Cloud and offers guidance on how to work out an apples-to-apples comparison of the TCO of running web applications in the AWS Cloud versus running them on-premises.Below are some highlights of the Web Applications white paper. Best practices show that there are substantial savings to be had with each of the three types of usage patterns: steady state, spiky predictable and uncertain predictable. Here’s a summary chart of the TCO analysis.
What this chart summarizes is that
If you have a web application for which you expect uniform steady state traffic, the most cost-effective option is to use Heavy Utilization Reserved Instances (RIs). This option offers 68% savings over the on-premises option. 3-Year Heavy Utilization Reserved Instances offer the maximum savings over equivalent servers deployed in an on-premises environment.
When you expect your web application to have spiky usage patterns, the most cost-effective option is to use Reserved Instances for your baseline servers and On-Demand instances to handle spikes of your traffic. This option offers 72% savings over the on-premises option. The significant savings is because you are using your resources efficiently, only when you need them, stopping them after your peak traffic subsides, and not paying anything when you don’t need them.
If you are dealing with a new web application and are unsure about its traffic pattern, the most cost-effective option is to use On-Demand Instances because there is no upfront commitment, and the overall cost is a tiny compared to what you would pay in the on-premises option. With AWS, customers can start-out with minimal risks and no upfront commitment using on-demand pricing. If their projects are successful, customers often shift into some combination of reserved and on-demand instances to lock in additional price savings as their usage patterns become more predictable. Making predictions about web traffic is a very difficult endeavor. The odds of guessing wrong are very high, as are the costs. This is also a good illustration of one of the really exciting benefits of Cloud Computing – lowering the cost of failure. When you lower the cost of failing with new web application projects, you have an opportunity to change the dynamics of decision-making in your company towards encouraging more innovation. With Cloud Computing, you can experiment often, fail quickly at very low cost and likely end up with more innovation, as more of your company’s ideas are tested in the market.
Some of our customers are even more adventurous and also include capacity from the spot market to even drive their cost down further. Below are two charts that Ryan Parker of Pinterest shared with us at the AWS Summit in NYC. The left one shows the hourly cost of autoscaling his web servers with only on-demand instances while at the right are his costs with his always needs met by Reserved Instances and his variable needs by a combination of On-Demand and Spot.
Another issue that I have heard complicates their TCO calculations is the continuous price reduction. AWS has lowered it prices more than 20 times in the past 6 years, and is likely to continue to do so in the future. A customer I recently met had executed a consolidation project for 20 types of invoice processing on AWS with the calculation that the project would pay back for itself in 2 years. However during development and the year of business AWS lowered it prices a number of times such that the project paid back for itself in 8 months. The customer complained a bit that she had to redo the projections several times but she was very happy with the results :-). …

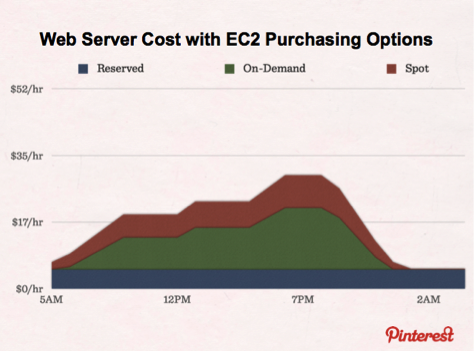
Werner continues with “Return on Agility” and “Saving Money” topics.
Jinesh Varia (@jinman) wrote a related People And Patterns: Getting Cloud TCO Right article published by TechCrunch on 8/16/2012.
• Mike Neil announced Windows Server 2012 Now Available in the Windows Azure Virtual Machine Gallery in an 8/16/2012 post:
Windows Server 2012 brings hundreds of new capabilities to customers, and is drawing high praise from product reviewers and industry analysts, such as this CIO Magazine article that outlines what it sees as the top 10 features. Perhaps most exciting are the hybrid cloud scenarios enabled by Windows Server 2012, when used in combination with our newest System Center management solutions. You’ll be able to deploy and manage applications and workloads both in your own datacenter and on Windows Azure.
For in-depth insights about all that Windows Server 2012 has to offer, be sure to visit the Windows Server blog, where the product’s engineering team describes what they’ve built. Also, on September 4th, Microsoft will host an online launch event where our executives, engineers, customers and partners will share more about how Windows Server 2012 and Windows Azure can help organizations of all sizes realize the benefits of what we call the Cloud OS. In the meantime, you can be up and running with Windows Server 2012 in less than 15 minutes using Virtual Machines on Windows Azure. Sign-up for a free trial and take it for a spin!
- Mike Neil, General Manager, Windows Azure
Lori MacVittie (@lmacvittie) asserted “Maintaining Consistent Performance of Elastic Applications in the Cloud Requires the Right Mix of Services” in an introduction to her Curing the Cloud Performance Arrhythmia post of 7/13/2012 to F5’s DevCenter blog:
Arrhythmias are most often associated with the human heart. The heart beats in a specific, known and measurable rhythm to deliver oxygen to the entire body in a predictable fashion. Arrhythmias occur when the heart beats irregularly. Some arrhythmias are little more than annoying, such as PVCs, but others can be life-threatening, such as ventricular fibrillation. All arrhythmias should be actively managed.
Inconsistent application performance is much like a cardiac arrhythmia. Users may experience a sudden interruption in performance at any time, with no real rhyme or reason. In cloud computing environments, this is more likely, because there are relatively few, if any, means of managing these incidents.
A 2011 global study on cloud conducted on behalf of Alcatel-Lucent showed that while security is still top of mind for IT decision makers considering cloud computing, performance – in particular reliable performance – ranks higher on the list of demands than security or costs.
THE PERFORMANCE PRESCRIPTION
One of the underlying reasons for performance arrhythmias in the cloud is a lack of attention paid to TCP management at the load balancing layer. TCP has not gotten any lighter during our migration to cloud computing and while most enterprise implementations have long since taken advantage of TCP management capabilities in the data center to redress inconsistent performance, these techniques are either not available or simply not enabled in cloud computing environments.
Two capabilities critical to managing performance arrhythmias of web applications are caching and TCP multiplexing. These two technologies, enabled at the load balancing layer, reduce the burden of delivering content on web and application servers by offloading to a service specifically designed to perform these tasks – and do so fast and reliably.
In doing so, the Load balancer is able to process the 10,000th connection with the same vim and verve as the first. This is not true of servers, whose ability to process connections degrades as load increases, which in turn necessarily raises latency in response times that manifests as degrading performance to the end-user. Test
Failure to cache HTTP objects outside the web or application server has a similar negative impact due to the need to repetitively serve up the same static content to every user, chewing up valuable resources that eventually burdens the server and degrades performance.
Caching such objects at the load balancing layer offloads the burden of processing and delivering these objects, enabling servers to more efficiently process those requests that require business logic and data.
FAILURE in the CLOUD
Interestingly, customers are very aware of the disparity between cloud computing and data center environments in terms of services available.
In a recent article on this topic from Shamus McGillicuddy, "Tom Hollingsworth, a senior network engineer with United Systems, an Oklahoma City-based value-added reseller (VAR). "I want to replicate [in the cloud with] as much functionality [customers] have for load balancers, firewalls and things like that."
So why are cloud providers resistant to offering such services?
Shamus offered some insight in the aforementioned article, citing maintenance and scalability as inhibitors to cloud provider offerings in the L4-7 service space. Additionally, the reality is that such offload technologies, while improving and making more consistent performance of applications also have a side effect of making more efficient the use of resources available to the application. This ultimately means a single virtual instance can scale more efficiently, which means the customer needs fewer instances to support the same user base. This translates into fewer instances for the provider, which negatively impacts their ARPU (Annual Revenue Per User) – one of the key metrics used to evaluate the health and growth of providers today.
But the reality is that providers will need to start addressing these concerns if they are to woo enterprise customers and convince them the cloud is where it's at. Enabling consistent performance is a requirement, and a decade of experience has shown customers that consistent performance in a scalable environment requires more than simple load balancing – it requires the very L4-7 services that today do not exist in provider environments.



Lori MacVittie (@lmacvittie) asserted “Cloud Integrating environments occurs in layers …” in an introduction to her The Cloud Integration Stack article of 8/8/2012 for F5’s DevCentral blog:
We use the term “hybrid cloud” to indicate a joining together of two disparate environments. We often simplify the “cloud” to encompass public IaaS, PaaS, SaaS and private cloud. But even though the adoption of such hybrid architectures may be a foregone conclusion, the devil is, as they say, in the details and how that adoption will be executed is not so easily concluded.
At its core, cloud is about integrating infrastructure. We integrate infrastructure from the application and networking domains to enable elasticity and scalability. We integrate infrastructure from security and delivery realms to ensure a comprehensive, secure delivery chain that promises performance and reliability. We integrate infrastructure to manage these disparate worlds in a unified way, to reduce the burden on operations imposed by necessarily disconnected systems created by integrating environments.
How these integrations are realized can be broken down into a fairly simple stack comprised of the network, resources, elasticity, and control.
The NETWORK INTEGRATION LAYER
At the network layer, the goal is normalize connectivity and provide optimization of network traffic between two disconnected environments. This is generally applicable only to the integration of IaaS environments, where connectivity today is achieved primarily through the use of secured network tunnels. This enables secure communications over which data and applications may be transferred between environments (and why optimization for performance sake may be desired) and over which management can occur. The most basic of network integration enabling a hybrid cloud environment is often referred to as bridging, after the common networking term.
Bridging does not necessarily imply layer 3 normalization, however, and some sort of overlay networking technology will be required to achieve that normalization (and is often cited as a use of emerging technology like SDN).
Look for solutions in this layer to be included in cloud “bridges” or “bridging” offerings.
The RESOURCE INTEGRATION LAYER
At the resource layer, integration occurs at the virtualization layer. Resources such as compute and storage are integrated with data center residing systems in such a way as to be included in provisioning processes. This integration enables visibility into the health and performance of said resources, providing the means to collect actionable performance and status related metrics for everything from capacity planning to redistribution of clients to the provisioning of performance-related services such as acceleration and optimization.
This layer of integration is also heavily invested in the notion of maintaining operational consistency. One way this is achieved is by integrating remote resources into existing delivery network architectures that allow the enforcement of policy to ensure compliance with operational and business requirements.
Another means of achieving operational consistency through resource integration is to integrate remotely deployed infrastructure solutions providing application delivery services. Such resources can be integrated with data center deployed management systems in such a way as to enforce operational consistency through synchronization of policies across all managed environments, cloud or otherwise.
Look for solutions in this layer to be included in cloud “gateway” offerings.
The ELASTICITY INTEGRATION LAYER
Elasticity integration is closely related to resource integration but not wholly dependent upon it. Elasticity is the notion of expanding or contracting capacity of resources (whether storage, network, or compute) to meet demand. That elasticity requires visibility into demand (not as easy as it sounds, by the way) as well as integration with the broader systems that provision and de-provision resources.
Consider a hybrid cloud in which there is no network or resource integration, but rather systems are in place to aggregate demand metrics from both cloud and data center deployed applications. When some defined threshold is met, a trigger occurs that instructs the system to interact with the appropriate control-plane API to provision or de-provision resources. Elasticity requires not only the elasticity of compute capacity, but may also require network or storage capacity be adjusted as well. This is the primary reason why simple “launch a VM” or “stop a VM” responses to changes in demand are wholly inadequate to achieve true elasticity – such simple responses do not take into consideration the ecosystem that is cloud, regardless of its confines to a single public provider or its spread across multiple public/private locations.
True elasticity requires integration of the broader application delivery ecosystem to ensure consistent performance and security across all related applications.
Look for solutions in this layer to be included in cloud “gateway” offerings.
The CONTROL INTEGRATION LAYER
Finally, the control integration layer is particularly useful when attempting to integrate SaaS with private cloud or traditional data center models. This is primarily because integration at other layers is virtually non-existent (this is also true of PaaS environments, which are often highly self-contained and only truly enable integration and control over the application layer).
The control layer is focused on integrating processes, such as access and authentication, for purposes of maintaining control over security and delivery policies. This often involves some system under the organization’s control (i.e. in the data center) brokering specific functions as part of a larger process. Currently the most common control integration solution is the brokering of access to cloud hosted resources such as SaaS. The initial authentication and authorization steps of a broader log-in process occur in the data center, with the enterprise-controlled systems then providing assurance in the form of tokens or assertions (SAML, specifically crafted encrypted tokens, one time passwords, etc…) to the resource that the user is authorized to access the system.
Control integration layers are also used to manage disconnected instances of services across environments for purposes of operational consistency. This control enables the replication and synchronization of policies across environments to ensure security policy enforcement as well as consistent performance.
Look for solutions in this layer to be included in cloud “broker” offerings.
Eventually, the entire integration stack will be leveraged to manage hybrid clouds with confidence, eliminating many of the obstacles still cited by even excited prospective customers as reasons they are not fully invested in cloud computing.


Steve Fox (@redmondhockey) described SharePoint 2013 and Windows Azure Media Services in an 8/4/2012 post (missed when published):
One of the cool new kids on the block for Windows Azure is Media Services. Windows Azure Media Services (WAMS) is currently in Beta, and as I dig in more I personally feel there’s a ton of potential here—especially when it comes to SharePoint. For those that don’t know what WAMS is all about, it’s a slick set of services and APIs within the Azure platform that enable you to do things like upload videos, encode into new file formats/codecs, save to BLOB storage, set permissions for consumption, stream BLOBs with global cache, and so on. Here’s the thing: you can do this all through a set of cloud-based APIs, which when compared to previous media management workflows and processes buys you quite a bit. Using WAMS, you can not only optimize your multimedia processing and management, but you can build some pretty darn compelling apps in the process.
Windows Azure Media Services
So, why should you give a rip, right? Well, what’s interesting is that there’s been a relative constant when it comes to the adoption of SharePoint: in many organizations it’s being used as a multimedia learning platform (or even a corporate communications platform). That is, the document libraries, lists and ability to manage sites and media within those sites give you the ability to build out multimedia solutions that are built on SharePoint. It’s just easy to integrate multimedia with the ability to manage sites, documents, and permissions against those artifacts. However, what’s been tricky has been the ability to process and manage the multimedia that sits behind those solutions. Think creating and projecting a WMV format across 3-4 different other codecs; think having a common streaming point where we can assess permissions using the native SharePoint security authentication; and think about having a set of services and APIs that can now allow you to not only publish to SharePoint, but also project cross-device.
Some interesting scenarios that bring these two technologies together are:
- Organizational Web sites
- Learning solutions built on SharePoint
- Corporate communications
- Digital marketing campaigns in SharePoint FIS
- Multimedia publishing platform
- Social networking/community web sites
- …
In short, there’s lots of potential here.
WAMS & SharePoint
Now for readers of this blog, you know I’ve focused a lot on the Azure and SharePoint kick; albeit I’ve focused a lot on SharePoint 2010. However, with the veil lifting on what SharePoint 2013 has to offer, all of a sudden not only is the integration of SharePoint and Windows Azure native, but it also is very compelling (and know that I’ll be focusing some energy on this moving forward). For example, for those of you who are in the SharePoint community, I’m sure you’re now up to speed on the fact that the future direction for SharePoint app development is the cloud; it’s the guidepost for future app design and deployment and is somewhat of a shift from what we’ve come to understand in SharePoint 2010. That is, within SharePoint 2013, there exist a couple of ways to build and deploy apps within a cloud-hosted app model: the first is the autohosted app; and the second is the provider-hosted app. The autohosted app model is an inclusive cloud model, where you build an app where configuration information lives in SharePoint and the core server-side code lives in Windows Azure (but through deployment they are registered and live as one). The provider-hosted app model is much more flexible. You can deploy code to any web platform, including Windows Azure, and then register that app with SharePoint.
So, the question becomes how we begin to mesh this interesting world of WAMS with the (new and existing) world of SharePoint—thus, the integration of media and SharePoint. To help illustrate, let’s walk through an example. And in this walkthrough, we’ll do two things:
1. Build out an HTML5 cloud-based app that leverages a video streamed from Azure Media Services; and
2. Create a simple SharePoint 2013 “Client App” that surfaces the media within SharePoint.
Yes, there is an assumption here about managing and consuming media from WAMS. What about the upload? What about the transcode? What about the management of media? Well, it’s all here. Using the SDK and How-to’s, you can build yourself a handy-dandy app that moves your apps into your Azure account and then makes them available for use within other solutions or platforms like SharePoint. And it’s within these how-to’s and the SDK that you’ll hopefully begin to see the power of WAMS. But this is a blog, and we must scopeth that which we delivereth. Thus, the assumption with this walkthrough is that you’ve followed the aforementioned tutorials and have created a WMV, uploaded and encoded it as a MP4, and have then saved it to Blob storage so you can stream it from Azure. So, we start from a video that is ready to be streamed from WAMS, e.g. http://myvidsite.cloudapp.net/home/default.html.
Building an HTML-based Media App
You can create a Windows Azure app using the .NET 4.0 framework and all the latest and greatest Azure tools/SDK (v. 1.7). To do this:
- Open Visual Studio 2012.
- Click File, New Project.
- Select Cloud and then select Windows Azure Cloud Service.
- Provide a name for the project and click OK.
- When prompted, select the ASP.NET MVC 4 Web Role, and then edit the name of your role to make it more intuitive.
- Click OK.
- At this point, Visual Studio creates the project structure and default code spit for you.
At this point, I removed a bunch of the default project goo—such as the ASPX pages, App_Data folder, etc. You’ll note that I added a set of supplement libraries/resources for my HTML video player, e.g. a CSS folder with a playerframework.min.css file (and debug file), a JS file added to the Scripts folder called playerframework.min.js (and again a debug file), and then focused on the heart of the Azure app by creating the default.html page—which will load the BLOB from Azure (or WAMS). (You could probably trim even more if you wanted from the default project, but I chose to stop here.)
- To hit the default.html page when you’re debugging, right-click and select Set as Start Page.
- Within the default.html page, add code that resembles the following snippet of code. (What will vary in your code will be the bolded URI that points to your video.)
<html xmlns="http://www.w3.org/1999/xhtml">
<head runat="server">
<title>HTML5 Video Player</title>
<link rel="stylesheet" href="../CSS/playerframework.min.css"/>
<script type="text/javascript" src="../Scripts/playerframework.min.js"></script>
</head>
<body>
<form id="form1" runat="server">
<div>
<video id="myVideo" class="pf-video" width="480" height="320" controls="controls">
<source src=http://myblobstore.blob.core.windows.net/html/BigBuckBunnyMP4.mp4?sr=c&si=new&sig=5CxDGrmtYndAm8bhdwITw7tlABlZFTxtsL%2BfR051Ngg%3D
type='video/mp4;
codecs="avc1.42E01E, mp4a.40.2"' />
</video>
<script type="text/javascript">
var myPlayer = new PlayerFramework.Player("myVideo");
</script>
</div>
</form>
</body>
</html>Now there’s a couple of things of interest here. The first is that we’re using HTML5 and the <video> tag to load and play our Azure-hosted video. (If you’re looking for a good primer on the video tag, check this blog-post out.) The second is that you can see that we’re not only referencing the MP4 file (http://myblobstore.blob.core.windows.net/html/BigBuckBunnyMP4.mp4) but we’ve also got some strange GUID thingy (sr=c&si=new&sig=5CxDGrmtYndAm8bhdwITw7tlABlZFTxtsL%2BfR051Ngg%3D) at the end of the URL: this is the access signature that you create programmatically using the WAMS API—or you can use the Cloud Storage Explorer to do some of this manually (also known as an Access Policy ID). This indicates the level of access you can set for consumers for a specific video asset. For example, if you click on an MP4 asset in your Cloud Explorer view, and then click Security, you’ll have the ability to manually set the shared access permissions options.
If you then click the Shared Access Signatures tab, you’ll be able to leverage a Shared Access Policy that you’ve created for your BLOB, and you can click the Generate Signature button, which creates a full BLOB URL for your video. You can then Copy to Clipboard and then paste in a browser to load the video and stream from Azure. (As per this post, ensure you have the correct MIME type; else, this will cause a failure for your video to load properly.)
You can see that when you click the Shared Access Policies tab you can create new policies with specific access rights and start and expiration times—all of which are enforced against your video BLOB.
While not complete, the below excerpt from the WAMS SDK gives you a sense for how you can do some of the above programmatically:
static String GetAssetSasUrl(IAsset asset, TimeSpan accessPolicyTimeout)
{
IAccessPolicy readPolicy = _context.AccessPolicies.Create("My Test Policy", accessPolicyTimeout, AccessPermissions.Read);
ILocator locator = _context.Locators.CreateSasLocator(asset, readPolicy, DateTime.UtcNow.AddMinutes(-5));
…
var theOutputFile = from f in asset.Files
where f.Name.EndsWith(".mp4")
select f;
IFileInfo theFile = theOutputFile.FirstOrDefault();
string fileName = theFile.Name;
var uriBuilder = new UriBuilder(locator.Path);
uriBuilder.Path += "/" + fileName;
…
return uriBuilder.Uri.AbsoluteUri;
}
- When you’re done adding the HTML and required resources, hit F5 to debug. You should see something similar to the below: your video being streamed from WAMS within your HTML5 video player.
- The next step is to publish your app to Windows Azure. To do this, right-click your Cloud project and select Publish. Then, publish the application to your Windows Azure subscription/account. This will then make the app accessible from the wider Web, hosted on Windows Azure.
- Once you’ve published your HTML5 video player app that consumes the video being streamed from WAMS, you are now ready to move onto the next step: creating a simple SharePoint 2013 app that surfaces the Azure app.
Integrating the Azure App with SharePoint 2013
In the first exercise, you created and deployed an HTML5-based video player that was hosted on Windows Azure and leveraged the core WAMS features to upload, transcode, store, and stream a video (although this WAMS-specific functionality was a pointer to the SDK). Where you should have left off was having a deployed app where the HTML5-based video loaded for you from Windows Azure. In essence, a URL not unlike the following: http://myvidsite.cloudapp.net/home/default.html. Now, you’ll use the new SharePoint 2013 app model to integrate the Azure app to SharePoint. You’ll use the autohosted Client App template to do this. (Note: to get started with Office 2013 development, visit the MSDN Developer page.)
- Open Visual Studio 2012, and click File, New Project.
- Select Office/SharePoint, and then select Apps and App for SharePoint 2013.
- Provide a name and click OK.
- In the next dialog in the wizard, select the SharePoint site you’ll be deploying the app to, and then select Autohosted in the drop-down list.
- Visual Studio will create a project comprising two parts: one part configuration and another part web app code. Delete the “..Web” part of the project.
- Right-click the project, and then select Add and then New Item. Select “Client Web Part (Host Web),” provide a name for the new Client Web Part and click Add. You can see below, I added one called “MyAzureVidPlayer” to the project.
- Now you’ll want to copy the URL to the Azure video player page and configure two parts of the project.
- First, open the Elements.xml file and amend the Content element, as per the bolded XML code within the snippet below.
<?xml version="1.0" encoding="utf-8"?>
<Elements xmlns="http://schemas.microsoft.com/sharepoint/">
<ClientWebPart Name="MyAzureVidPlayer" Title="MyAzureVidPlayer Title" Description="MyAzureVidPlayer Description" DefaultWidth="300" DefaultHeight="200">
<Content Type="html" Src="http://myvidsite.cloudapp.net/home/default.html" /></ClientWebPart>
</Elements>
- Second, right-click the AppManifest.xml file and click View Code. Amend the XML file as per the bolded code so it looks like the below:
<?xml version="1.0" encoding="utf-8" ?>
<App xmlns="http://schemas.microsoft.com/sharepoint/2012/app/manifest"
Name="MyFirstAzureVidPlayer"
ProductID="{70e24eec-9734-4b8d-b084-5851ff7be7c4}"
Version="1.0.0.0"
SharePointMinVersion="15.0.0.0">
<Properties>
<Title>MyFirstAzureVidPlayer</Title>
<StartPage>http://myvidsite.cloudapp.net/home/default.html</StartPage>
</Properties><AppPrincipal>
<AutoDeployedWebApplication/>
</AppPrincipal><AppPrerequisites>
<AppPrerequisite Type="AutoProvisioning" ID="RemoteWebHost" />
</AppPrerequisites>
<AppPermissionRequests><AppPermissionRequest Scope="http://sharepoint/content/sitecollection/web" Right="Read" /></AppPermissionRequests></App>
- Now you can hit F6 to build, and then right-click the project and select Publish. Publishing the app will build an autohosted cloud app that you can deploy to your SharePoint site. When the project is done building, copy the auto-opened Windows Explorer path for use in the next step.
- Now, navigate to your SharePoint site. In this case, I’m using SharePoint Online, so I clicked Apps in Testing and then selected new app to deploy, which enables me to upload the .app I just built (you can now click Browse and paste in the folder path from the previous step).
- Once you’ve uploaded the .app, click Deploy and then hit the Trust It button to trust the app. This deploys the Azure app to SharePoint but integrates them natively using the new SharePoint 2013 (autohosted) cloud model.
- To get your app onto a page, click Page, Edit, Insert, and then select App Part and then choose the app part you just deployed. And voila, your WAMS video player app (hosted in Azure) now shows up as an integrated app in SharePoint.

Congratulations! You’ve now build your first WAMS and SharePoint 2013 integrated app using the new cloud app model.
Final Thoughts
In this blog-post, I showed you separately how to create the Azure app and how to create the SharePoint app; although, breaking them apart wasn’t for naught. Hopefully, you now can see that while there may be separate pieces to the cloud puzzle, they are increasingly coming together as a united front—whether it be through concerted templates/functionality or by integrating Azure and SharePoint natively. (Note that by using the Provider hosted template in SharePoint 2013, you’ll be able to pull the above exercise together within one Visual Studio deployment.) And what’s interesting is that while here we talked about Windows Azure and WAMS, it’s about the wider web being your play-ground; it’s about being able to not only create a great Azure media app, but also integrate a great HTML5 or PhP app with SharePoint as well. But, WAMS is hugely compelling; especially from the process and workflow perspective. Again, within this blog I pointed to the SDK as an example of this, which makes the after-integration of WAMS and SharePoint look easy—which is where I focused.
I encourage you to play around with the WAMS SDK. When thinking about SharePoint, there are some interesting integrations you can accomplish with both 2010 and 2013. Expect to see more here.















Dan Turkenkopf (@dturkenk) posted East Coast vs. West Coast PaaS Psychology. And Why it Matters to the Apprenda blog on 7/31/2012 (missed when published)
The first time I heard someone differentiate between East Coast and West Coast Platform as a Service (PaaS), something clicked. Over the past year or so, I’ve had more than one “polite discussion” about what organizations should be looking for in a platform. It usually seems like we are talking past each other rather than to each other.
James Urquhart of EnStratus, Master of Ceremonies at DeployCon, was the first thought leader I’ve heard suggest the theory that distinct cultural viewpoints might be the cause of so much controversy in the PaaS ecosystem. While external manifestations of different approaches were argued in great detail that day, the underlying divide wasn’t.
On the heels of that talk, Rodrigo Flores of Cisco explored a similar divide between “Silicon Valley” PaaS and “Enterprise” PaaS. To Flores, Silicon Valley PaaS consists of a “black-box” application hosting platform. Enterprise PaaS, he theorizes, is more a managed set of composable application stack components that consumers can select to assemble whatever application hosting stack needed.
I definitely appreciate the attempt to identify two different approaches to PaaS, I still suspect that this dichotomy misses the mark slightly.The biggest issue with Flores’ split is that his Enterprise PaaS, while being valuable in many circumstances, doesn’t provide the core values to look for in a platform as a service.
The two biggest requirements – which is the essential essence of a PaaS – are to treat the application as the unit of abstraction, and to hide the underlying infrastructure from the consumer.
Making the application THE first-class citizen acknowledges that the business value delivered by the application is the true goal of IT, and puts the developer in control of ensuring that value is realized.
The second requirement follows from the first. If all consumer interaction with the platform occurs within the scope of the application, then there really is no need to understand what’s beneath the application. The conversation is raised to capabilities and capacity, rather than servers and setup.
This is why you’ll see the same set of basic functionality in just about every platform as a service you look at. Nearly all of them provide developers self-service application management and deployment and the ability to leverage value-adding services offered by the platform or by third parties. None of them require the developer to access the underlying virtual machine or operating system to perform her task. And most offer some level of health monitoring and application resiliency simply by running on the platform.
Once these basic needs are met, you start to see the West/East divide form; the most apparent manifestation being public PaaS versus private PaaS.
The West Coast mindset (to use Urquhart’s term and expand out of just Silicon Valley to Seattle and Portland) predicts a much more rapid transition to a fully public cloud where IT operations are essentially outsourced to cloud providers.
The East Coast mentality recognizes there are some use cases where running in the public cloud makes sense, but is hesitant to give up the control of their IT; whether for regulatory/security concerns (be they real or imagined), or because of large existing investments in infrastructure and staff, or due to large amounts of business critical data.
I’m not going to explore the underlying psychology behind the split beyond suggesting it has something to do with where technology supports the business versus where technology IS the business.
If your goal in life as a PaaS vendor is to become a service provider and take over IT operations for companies, gaining economies of scale is probably the most important thing you can do. And to get economies of scales, you need to draw as many developers as you possibly can. Make the barriers of entry low, and offer support for a wide variety of languages and frameworks. But, because you need to support so many different flavors of technology to gain the mass audience you need, you can only offer fairly limited support for each of them. It might not be truly the lowest common denominator, but it’s not far off. Trying to do much more will likely lead to product fragmentation.
That means that most, if not all, the West Coast PaaS flavors, provide the definitional capabilities of self-service deployment and location transparency, but can’t go much deeper than that. And there can be lots of value in that, especially for start ups and individual developers. But there’s also a limit to that value.
East Coast PaaS, on the other hand, tries to support the entire organization – of which developers are the most important piece. It’s often delivered in a private or hybrid form factor, and relies on the existing organizational capabilities of the IT staff to manage and maintain a robust delivery infrastructure. There’s no need to build up economies of scale just for the PaaS – because they’re already built into the traditional enterprise offerings.
What East Coast PaaS offers is a renewed focus on developers, giving the same self-service application management and location transparency that West Coast PaaS provides. But, almost paradoxically, because East Coast PaaS providers recognize and support the IT operations for enterprises, they can provide deeper value to the developer. Enterprises generally have standardized a few stacks (Java and .NET for the most part), which means the PaaS providers can remain intensely focused on those technologies and leverage their advanced capabilities to enhance the developer experience. For example, by augmenting capabilities in the .NET stack, Apprenda can dynamically transform an application into a SaaS application at deployment time, saving upwards of a year of effort. It’s unlikely you’ll ever see those sorts of capabilities evolve in a polyglot world. …

Dan continues with an analysis of the polyglot developer world.
I’m definitely a member of the West Coast PaaS camp.
Kristian Nese (@KristianNese) described Cloud Services in Windows Azure in an 8/11/2012 post:
As a part of the new offerings in Windows Azure, Hosted Services are now replaced with Cloud Services in the new Windows Azure portal.
A hosted service was previously a service in Azure that could contain Web Roles, Worker Roles and VM Roles.With the new Virtual Machine (persistent) in Azure, you can also add them to a cloud service so that they can communicate in their private network.
This is important to know if you’re planning to extend your infrastructure and create connectivity between resources on-premise and in Windows Azure. Instead of going through the external IP/DNS name, you can take advantage of this private network.
So let’s repeat the PaaS service model in Windows Azure
A hosted service in Windows Azure was basically a combination of code and configuration. This does still apply for the cloud service.
A cloud service represents the PaaS service model in Azure, where you can deploy your multi-tier applications, using multiple roles and have a flexible model to scale your stateless applications.
Each role (Web or/and Worker Role) has its own code and configuration file.
So from a developer’s perspective, they only need to concentrate on their code, and let Windows Azure’s eco-system take care of the underlying architecture for the infrastructure and maintain performance, patching of the operating system and general maintenance in case of a failure.
Based on the SLA’s available in Azure, you must specify at least two instances of each role to assure you meat a satisfied SLA. This will apply to both failures and when you’re servicing your service.
This is to guarantee external connectivity to your internet-facing roles 99.95% of the time.
If you have worked with System Center 2012 – Virtual Machine Manager, you may be aware of the service concept where you can deploy distributed applications, use load balancing and scale out the stateless instances, and specify upgrade domains. Windows Azure has something similar, and provides you with two environments.
The staging environment is where you can test your cloud service before you put it into your production environment. When you are satisfied with your service, you can easily do a VIP swap (swapping the virtual IP address that’s associated with the two environments).
I’ll blog more about Azure over the next weeks.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
My Configuring Windows Azure Services for Windows Server post of 8/14/2012 begins:
Contents:
Introduction
The Microsoft Hosting site describes a new multi-tenanted IaaS offering for hosting service providers that the Windows Server team announced at the Worldwide Partners Conference (WPC) 2012, held in Houston, TX on 7/8 through 7/12/2012:
The new elements of Windows Azure Services for Windows Server 2008 R2 or 2012 (WAS4WS) are the Service Management Portal and API (SMPA); Web Sites and Virtual Machines are features of Windows Azure Virtual Machines (WAVM), the IaaS service that the Windows Azure team announced at the MEET Windows Azure event held in San Francisco, CA on 6/7/2012.
Licensing Requirements
Although Hosting Service Providers are the target demographic for WAS4WS, large enterprises should consider the service for on-site, self-service deployment of development and production computing resources to business units in a private or hybrid cloud. SMPA emulates the new Windows Azure Management Portal Preview, which also emerged on 6/7/2012.
When this post was written, WAS4WS required a Service Provider Licensing Agreement:
Licensing links:
Any Microsoft partner can join the Microsoft Hosting Community (I’ve tried to join but don’t receive the promised email response.):
More details are available on the Microsoft partner-hosted services page.
Full disclosure: OakLeaf Systems is a Microsoft Partner.
Memo to Microsoft: Provide licensing for organizations that aren’t commercial hosting services to use WAS4WS for creating internal (private) or hybrid clouds for business units without the SPLA requirement. This version should support Active Directory and, optionally, Windows Azure Active Directory (WAAD), as well as Remote Desktop Services (RDS) and Remote Web Access (RWA). Presumably, RDS and RWA would require purchasing Windows Server Azure 2008 R2 Remote Desktop Services (5-User Client Access License) CALs, US$749.00 from the Microsoft Store
Note: WAS4WS isn’t related to the elusive Windows Azure Platform Appliance (WAPA), which Microsoft introduced in July, 2010 and later renamed the Windows Azure Appliance (see Windows Azure Platform Appliance (WAPA) Announced at Microsoft Worldwide Partner Conference 2010 of 6/7/2010 for more details.) To date, only Fujitsu has deployed WAPA to a data center (see Windows Azure Platform Appliance (WAPA) Finally Emerges from the Skunk Works of 6/7/2011.) WAS4WS doesn’t implement Windows Azure Storage (high-availability tables and blobs) or other features provided by the former Windows Azure App Fabric, but is likely to be compatible with the recently announced Service Bus for Windows Server (Service Bus 1.0 Beta.)
Prerequisites
System Requirements
From the 43-page Getting started Guide: Web Sites, Virtual Machines, Service Management Portal and Service Management API July 2012 Technical Preview (PDF):
The Technical preview is intended to run on a single Hyper-V host with 7 virtual machines. In addition to the virtual machines required for the software, it is expected that there will be a separate server (or servers) in the datacenter running Microsoft SQL Server, MySQL Server, and a File Server (Windows UNC) or NAS device hosting web content.
Hyper-V Host server for Service Management Portal and Web Sites VMs:
- Dual Processor Quad Core
- Operating System: Windows Server 2008 R2 SP1 Datacenter Edition With Hyper-V (64bit) / Windows Server 2012 with Hyper-V (64 bit)
- RAM: 48 GB
- 2 Volumes:
First Volume: 40GB or greater (host OS).
Second Volume: 100GB or greater (VHDs).- Separate SQL server(s) for Web Sites configuration databases and users/web sites databases running Microsoft SQL Server 2008 R2.
- Separate MySQL server version 5.1 for users/web sites databases.
- Either a Windows UNC share or a NAS device acting as a File server to host web site content.
Note: The SQL Server, MySQL Server, and File Server can coexist with each other, and the Hyper-V host machine, but should not be installed in the same VMs as other Web Sites roles. Use separate SQL Server computers, or separate SQL instances, on the same SQL Server computer to isolate the Web Sites configuration databases from user/web sites databases.
A system meeting the preceding requirements is required to meet the high-end (three Web workers and two load balancers) of the following architecture:
Service Management Portal and Web Sites-specific server role descriptions:
- Web Workers – Web Sites-specific version of IIS web server which processes client’s web requests.
- Load Balancer(s) – IIS web server with Web Sites-specific version of ARR which accepts web requests from clients, routes requests to Web Workers and returns web worker responses to clients.
- Publisher – The public version of WebDeploy and an Web Sites-specific version of FTP which provide transparent content publishing for WebMatrix, Visual Studio and FTP clients.
- Service Management Portal / Web Sites Controller – server which hosts several functions:
o Management Service - Admin Site: where administrators can create
Web Sites clouds, author plans and manage user subscriptions.
o Management Service - Tenant Site: where users can signup and
create web sites, virtual machineand databases.
o Web Farm Framework to provision and manage server Roles.
o Resource Metering service to monitor webservers and site resource
usage.- Public DNS Mappings. (DNS management support for the software is coming in a future release. The recommended configuration for this technical preview is to use a single domain. All user-created sites would have unique host names on the same domain.)
Software Requirements
- Download (as 1 *.exe and 19 *.rar files), extract to a 20+ GB VHD, and install System Center 2012 Service Pack 1 CTP2 – Virtual Machine Manager – Evaluation (VHD) on a Windows Server 2008 R2 (64-bit) or Windows Server 2012 host with the Hyper-V role enabled.
- Download and install System Center 2012 Service Pack 1 Community Technology Preview 2 - Service Provider Foundation Update for Service Management API to the VM created from the preceding VHD.
- Download and run the Web Platform Installer (WebPI, Single-Machine Mode) for the 60 additional components required to complete the VM configuration.
Note: This preview doesn’t support Active Directory for VMs; leave the VMs you create as Workgroup members.
Tip: Before downloading and running the WebPI, click the Configure SQL Server (do this first) button on the desktop (see below) and install SQL Server 2008 R2 Evaluation Edition with mixed-mode (Windows and SQL Server authentication) by giving the sa account a password. Logging in to SQL Server as sa is required later in the installation process (see step 1 in the next section).





The post continues with a detailed, illustrated Configuring the Service Management Portal/Web Sites Controller section.
I’m lobbying for a version of the Service Management Portal that doesn’t require a Service Provider Licensing Agreement (SPLA) for deploying enterprise private clouds with do-it-yourself provisioning for business units. See my recent Will a version of the Management Portal and API be available for Enterprise Users? thread in the Web Sites and Virtual Machines on Windows Server for Hosting Service Providers for more details.
Kevin Kell described Learning Tree’s Implementing a Private Cloud Solution courseware for AWS and Windows Server/System Center in an 8/7/2012 post:
Last week I attended Learning Tree’s “Implementing a Private Cloud Solution” course at our Reston Education Center. It is a great course for anyone seeking in-depth technical details on how to build their own on-premises private cloud. The course also covers using a hosted private cloud solution and building secure connections to your own data center.
This course is not for the faint of heart! It is also not for the technically challenged! When you show up Tuesday morning you need to be prepared to work very hard for the next four days. The course author, Boleslav Sykora, has put together a fast paced session that gives you as much technical detail as you would ever want on the subject. It is the type of course where you will want to come early and stay late each and every day so you can work through all the extensive bonus exercises that are offered. I loved it and I think you will too!
We feature building two private clouds, one using Eucalyptus and another using Microsoft System Center, completely from scratch. There is a lot of Linux command line stuff and quite a bit of detailed networking configuration. This is exactly the reality of what is involved if you want to build your own private cloud. Over the four days you come to understand that private cloud computing is not some mystical, magical hype but is an evolution of solid fundamental concepts that have been around for some time. This course will appeal to technical professionals who want to gain real experience implementing solutions that will define the future of the on-premises data center.
For those who would prefer not to bother with the complexity of an internal private cloud implementation there are many hosted solutions to choose from. Probably the best known is Amazon’s Virtual Private Cloud (VPC). Once you use VPC on Amazon you will likely never go back to using EC2 without it.
In fact as I write this blog I am on a train heading to New York. There I will teach Learning Tree’s “Cloud Computing with Amazon Web Services” course. That, also, is a great course!
Because there are many private cloud implementations based on the Amazon EC2 model and API (particularly Eucalyptus) Amazon has kind of become the de facto standard for how Infrastructure as a Service (IaaS) is done. Even if you believe you would never use a public cloud for a production system there is much to be learned about cloud computing from Amazon. Beyond that the public cloud is a great place to do testing, development and proof-of-concept before investing the time and capital required to build your own private cloud. Public clouds such as Amazon can also become part of a hybrid solution that features the best of what private clouds and public clouds have to offer. Learning Tree’s Amazon Web Services course gives you hands-on experience with many aspects of Amazon’s cloud and shows you how to build solutions using the various services offered there.
So if you are a hardcore techie who wants to have end-to-end control over all aspects of a cloud solution come to Learning Tree’s private cloud course. If you would like to understand how to leverage the Amazon public cloud or to understand the service models of arguably the most dominant cloud provider in the world then come to Learning Tree’s Amazon Web Services course. Either way I hope to see you soon!



<Return to section navigation list>
Cloud Security and Governance
•• Chris Hoff (@Beaker) posted an Incomplete Thought: Virtual/Cloud Security and The Potemkin Village Syndrome on 8/16/2012:
A “Potemkin village” is a Russian expression derived from folklore from the 1700′s. The story goes something like this: Grigory Potemkin, a military leader and statesman, erected attractive but completely fake settlements constructed only of facades to impress Catherine the Great (empress of Russia) during a state visit in order to gain favor and otherwise hype the value of recently subjugated territories.
I’ll get to that (and probably irate comments from actual Russians who will chide me for my hatchet job on their culture…)
Innovation over the last decade in technology in general has brought fundamental shifts in the way in which we work, live, and play. In the last 4 years, the manner in which technology products and services that enabled by this “digital supply chain,” and the manner in which they are designed, built and brought to market have also pivoted.
Virtualization and Cloud computing — the technologies and operational models — have contributed greatly to this.
Interestingly enough, the faster technology evolves, the more lethargic, fragile and fractured security seems to be.
This can be explained in a few ways.
First, the trust models, architecture and operational models surrounding how we’ve “done” security simply are not designed to absorb this much disruption so quickly. The fact that we’ve relied on physical segregation, static policies that combine locality and service definition, mobility and the (now) highly dynamic application deployment options means that we’re simply disconnected.
Secondly, fragmentation and specialization within security means that we have no cohesive, integrated or consistent approach in terms of how we define or instantiate “security,” and so customers are left to integrate disparate solutions at multiple layers (think physical and/or virtual firewalls, IDP, DLP, WAF, AppSec, etc.) What services and “hooks” the operating systems, networks and provisioning/orchestration layers offers largely dictates what we can do using the skills and “best practices” we already have.
Lastly, the (un)natural market consolidation behavior wherein aspiring technology startups are acquired and absorbed into larger behemoth organizations means that innovation cycles in security quickly become victims of stunted periodicity, reduced focus on solving specific problems, cultural subduction and artificially constrained scope based on P&L models which are detached from reality, customers and out of step with trends that end up driving more disruption.
I’ve talked about this process as part of the “Security Hamster Sine Wave of Pain.” It’s not a malicious or evil plan on behalf of vendors to conspire to not solve your problems, it’s an artifact of the way in which the market functions — and is allowed to function.
What this yields is that when new threat models, evolving vulnerabilities and advanced adversarial skill sets are paired with massively disruptive approaches and technology “conquests,” the security industry basically erects facades of solutions, obscuring the fact that in many cases, there’s not only a lacking foundation for the house of cards we’ve built, but interestingly there’s not much more to it than that.
Again, this isn’t a plan masterminded by a consortium of industry “Dr. Evils.” Actually, it’s quite simple: It’s inertial…if you keep buying it, they’ll keep making it.
We are suffering then from the security equivalent of the Potemkin Village syndrome; our efforts are largely built to impress people who are mesmerized by pretty facades but don’t take the time to recognize that there’s really nothing there. Those building it, while complicit, find it quite hard to change.
Until the revolution comes.
To wit, we have hardworking members of the proletariat, toiling away behind the scenes struggling to add substance and drive change in the way in which we do what we do.
Adding to this is the good news that those two aforementioned “movements” — virtualization and cloud computing — are exposing the facades for what they are and we’re now busy shining the light on unstable foundations, knocking over walls and starting to build platforms that are fundamentally better suited to support security capabilities rather than simply “patching holes.”
Most virtualization and IaaS cloud platforms are still woefully lacking the native capabilities or interfaces to build security in, but that’s the beauty of platforms (as a service,) as you can encourage more “universally” the focus on the things that matter most: building resilient and survivable systems, deploying secure applications, and identifying and protecting information across its lifecycle.
Realistically this is a long view and it is going to take a few more cycles on the Hamster Wheel to drive true results. It’s frankly less about technology and rather largely a generational concern with the current ruling party who governs operational security awaiting deposition, retirement or beheading.
I’m looking forward to more disruption, innovation and reconstruction. Let’s fix the foundation and deal with hanging pictures later. Redecorating security is for the birds…or dead Russian royalty.
/Hoff
Related articles






<Return to section navigation list>
Cloud Computing Events
•• Cihan Biyikoglu (@cihangirb, pictured below) reported on 8/15/2012 Intergen’s Chris Auld talking about Federations & Fan-out Queries at TechEd 2012 New Zealand in early September:
If you are in town between Sept 4 and 7i n Auckland, here is a fantastic talk to attend!
http://newzealand.msteched.com/topic/details/AZR304#fbid=qwdA5tTXqJW
Windows Azure SQL Database Deep Dive
Track: Windows Azure Level: 300 By: Chris Auld – CTO Intergen
Don’t miss it!

Repeated in the SQL Azure Database, Federations and Reporting section above.
Brian Gracely (@bgracely) said he’s Looking Forward to VMworld 2012 in a 7/12/2012 post:
It's that time again - VMworld. For the 2011 event in the US, I wrote some before and after thoughts on the state of technology, new trends and the event.
Given the actions that VMware has taken recently (new CEO, Software Defined Data Center vision, Nicira acquisition, DynamicOps acquisition, Cetas acquisition, CloudFoundry + OpenStack), I'm going to go out on a limb and say that VMworld 2012 will be one of the most highly watched events that IT has seen for a long time (all Apple announcements not withstanding). It's not a reach to say that every aspect of VMware will be questioned:
New Leadership - Pat Gelsinger (CEO) takes over a business that must learn how to regain it's technology leadership in a space that will face intense commoditization (hypervisor). His Intel experience should be an excellent fit for this task. It must also determine what role it will play in Public and Hybrid clouds, with speculation growing that it may launch public services.
- New Technology - From VMware's perspective, in order to not only deliver great Enterprise services but also compete with Amazon, Google, Microsoft and Rackspace (or other OpenStack SPs), it needed to be able to control the automation and management of every aspect that impacted a VM. The acquisition of Nicira was the next logical step, as existing networks were never designed for the mobility and dynamic nature of today's environments.
- Evolving Technology - Considering the possibility that more and more customers would adopt a Hybrid Cloud model (private/public, or multi-public), it's interesting to see VMware finally acknowledge heterogenous environments with both the DynamicOps and Nicira acquisitions. Support for multiple hypervisors, multiple Cloud providers and various elements of open-source are all potentially in play. It'll be interesting to see how VMware plans to blend in the different elements.
- New Revenue Sources - CloudFoundry seems to be gaining momentum with the announcements by several Cloud providers to launch services on top of this open-source PaaS platform (Tier 3, Uhuru, etc.), but how will VMware monetize beyond the ESX hypervisor and vSphere tools? vFabric is making progress and has some very interesting functionality, but is the knowledge getting out to the market? Where are the vFabric evangelists like there are for vSphere?
Simon Wardley (@swardley) had some interesting perspectives on VMware in his blog today. As you can see, he highlights many of the questions that people have about VMware's future strategies, partnerships and technology direction. Some of the insight may seem extreme at first glance, but given Simon's open-source background and incredible ability to analyze strategic models, I wouldn't discard anything he says. [Disclosure - I am currently employed by EMC, but none of my comments should be interpreted to have insider knowledge of VMware strategy or plans.]
For me, these are the key areas that I'd like to see greater clarity:
- How does the vCloud Director (vCD) and DynamicOps integration come together? Unlike vCenter, which did an excellent job of opening up the ability for ecosystem integration (network, storage, management, virtual-appliances), vCD has always been very closed. Networking - closed. Security - closed. Storage - limited. Multi-Cloud choice - limited. So will DynamicOps be used to allow hybrid cloud management, or just used to manage 3rd-party hypervisors? Or will it eventually replace vCD?
- VMware has historically always shown technology previews at VMworld, typically 12-18 months out, which signals where they expect to embed functionality that currently resides in 3rd-party HW/SW into VMware platforms. With their new vision of Software Defined Data Center, I'd expect to see this included an expanding list of functionality. It will be very interesting to see how this impacts their partner ecosystem, or if they signal a greater level of participation in open-source efforts. vFabric has had this for a while with SpringSource integration. They inherit some from Nicira (OpenStack Quantum, Open vSwitch) and DynamicOps (XenServer management) but also via work with Puppet Labs + Razor, CloudFoundry, and CloudFoundry + OpenStack.
- While Software Defined Networking (SDN) is a cool concept, networking is very difficult to get right. The early buzz is that Nicira customers are pleased with the technology, but how SDN fits into non-greenfield environments will be the more interesting question. Understanding about SDN is still in the early stages, and many networking-gurus still aren't sure what the killer use-cases are. VM Mobility is an immediate need in the Enterprise, but will it be a compelling enough use-case for companies to change their networking model vs. existing (and semi-new) overlay models such as VXLAN? How quickly will Enterprise networking teams be able to deal with SDN, or will this be the tipping point for Server teams to take back greater control over the connectivity of applications?
- The vision of Software Defined Data Center is a powerful concept, and one that I believe has many of the pieces in place to succeed with today. It's the next evolution of intelligent software delivering IT differentiation on consistent hardware. It'll drive a new set of integration rules for software elements, and it'll open up new opportunities for hardware to deliver greater speed and capacity to move the massive amounts of data being generated by users and applications.
- VMware has started building their Big Data story with the Cetas acquisition, open-source Project Serengeti and new elements of vFabric / GemFire / SQLFire. Unlike CloudFoundry, which seems to have a clear Cloud vision, it's not immediately obvious how VMware is trying to shape this segment of the market. They are showing that virtualization can play a role in Big Data (easier setup of environments; self-service consumption), but is there a bigger play they will attempt to capture with a more unified vision? Software Defined Data Center plays a role in infrastructure setup and operations, but how does it play in the Big Data middleware stack that is being created? And how does it tie into CloudFoundry, which also supports MongoDB, MySQL, Redis.
In the past, VMworld was often perceived to be an infrastructure show. Now they have the attention of application developers, DBAs, OpenStack, networking teams, cloud providers and a breadth of partners trying to figure out their role in the new world VMware is trying to build. How many of these questions are answered will determine not only the future of VMware, but have far reaching impact on many segments of the IT ecosystem. And I didn't even speculate on what might happen if some of the other rumors turn out to be even partially true. It's a fun time to be involved with aspects of VMware and VMworld.


Microsoft’s Servers and Tools Business (@stbtalent) will hold a Cloud Computing Hiring Event – September 27 & 28th, according to an 8/13/2012 post:
Microsoft’s Server & Tools Business (STB) is a place where brilliant minds can collaborate with other brilliant minds. Where your work environment gives you the flexibility determine your own career path. Microsoft Server & Tool Business is the place where talent and determination win. Where industry leaders lead and legends are born. It’s a place where every day is an opportunity to make the extraordinary happen because Ordinary Doesn’t Work Here. #ODWH
The SQL Azure team will be interviewing for full-time Software Developer Engineer roles on September 27th & 28th. Required skills needed for consideration:
- Completed Degree (Bachelors or Masters or PhD) prior to 2011* in Computer Science or related field *we are unable to consider full-time students*
- 4+ years coding with C, or C++, or C# and systems development experience
- 1+ years’ experience with one or more of the following areas: computer architecture, distributed systems, enterprise server development, query processing, query, cloud computing, operating systems
- Travel assistance is available for those selected for onsite interviews – Microsoft schedules and pays for your trip!
- Apply for event consideration!


Apparently, the Talent Team didn’t receive the SQL Azure -> Windows Azure SQL Database memo.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
•• Brian Gracely (@bgracely) reported on An Evening with OpenStack and the DevOps Community in a 8/16/2012 to his Clouds of Change blog:
I had the chance to attend the Triangle DevOps meetup, along with my podcast co-host Aaron Delp (@aarondelp), which was being held at the Teradata offices and lead by their DevOps person (Felix Maldonado) responsible for their OpenStack environment. It was an interesting event for a few reasons:
- We've had a few guests (here, here, here) on the podcast to talk about OpenStack, but our hands-on exposure had been limited in comparison to years of VMware environments.
- Most of the people we had spoken with were deeply involved with the OpenStack development, or worked directly at Rackspace, so their viewpoints were slightly skewed to the positive.
- Aaron had just written a blog about his experience with the new Rackspace Private Cloud edition. We had compared it to another write-up from Cody Bunch (@cody_bunch), noting that Aaron's experience seemed much simpler. Another experience here.
The presenter was very transparent about his experience with OpenStack. They had work that needed to be done, but they were short on budget, so they decided to spend their money on new server hardware instead of software licenses. They were a development group, but their output needed to go into a production environment, so the system ultimately needed to work. He was tasked with getting a small "cloud" up and running (3 servers, hosting about 80 VMs of various sizes).
[I'll stop here and clarify that I don't intend this to be a commentary on OpenStack, but rather a set of observations from both the audience ("DevOps crowd") and myself, somewhat in the context of experience with other systems.]
While he made it clear that he had the environment working, and was happy with it's performance, he did highlight a number of challenges. He highlighted these for the audience, who were there to learn about OpenStack (most had never tested it in any way).
- Getting things to work took quite a bit of trial and error. He had to rebuild the system several times before it worked as expected. [Note: All done using community distro, not any of the new pre-built distros from Rackspace, Redhat, Piston Cloud, Nebula)
- The documentation is terrible. It makes many assumptions that people know about OpenStack architecture or concepts, and then mixes many scripted and manual configurations together.
- No built in management or monitoring tools (capacity, performance, etc.)
- No way to move VMs dynamically from controller to controller (manually copy config files)
- No native load-balancing function
- No way to have HA-like functionality of VMs
- Not clear where KVM or Xen tools go once OpenStack is managing via Nova-Controller
- Making changes to the system has all sorts of unexpected side-effects, often times causing a crash.
- Updates only come out every six months, which he believed to be too short, especially when bugs were reported through various channels.
[NOTE: Please let us know where there is incorrect information above]
He pointed out that he uses customized Nagios as his primary means of monitoring performance, and was exploring other tools like Zenoss. He also explained that having to go through the setup trial and error allowed him to learn quite a bit about the underlying OpenStack architecture. Having used AWS EC2 before, he made many comparisons between the functionality of the two systems (EBS <-> Snapshots; Instance Sizes <-> Flavors, etc.)I walked away from the event with several thoughts:
For me, it's always good to see technology outside of the high-profile events, away from the headlines and with people that are only focused on making things work. This group walked away moderately interested in OpenStack, but not overwhelmed. OpenStack has a ways to go, but it has come a long way in just a few years. Time will tell...
- It's been two years, but OpenStack still feels like it's very early days. One person in attendance compared it to ESX 2.0, back before vCenter and all the tools became commonplace.
- The installation process should get considerably easier, with all the pre-buit distros coming into the market.
- There are still plenty of unanswered questions about how to architect the system; when it makes sense to deploy OpenStack vs. using native hypervisor tools; and which types of applications make the most sense in this architecture.
- At one point, I thought it was impressive that OpenStack releases had shipped consistently every six months. But the audience seem quite surprised that bug updates weren't made available more often. Either way, it's a much more rapid development cycle than some commercial implementations.
- OpenStack already has support for many configuration tools, such as Puppet, Chef, enStratus, RightScale, so some of the "it's not included" comments are covered through external tools.


•• Paul Guth (@pgutheb) reported on his Presentation to OpenStack Los Angeles Meetup in an 8/9/2012 post (missed when published):
(This is an edited version of a post that originally appeared at my personal blog, constructolution.)
Last week I took a trip down to L.A. to attend the #OSLAX meetup and presented my talk on “Openstack IRL,” which seemed to be very well received.
The video of my talk is up on Vimeo if you’re interested in hearing the actual presentation, or you can see the slides on Slideshare. The message was the same as when I presented to #lspe earlier this year: You *can* build a production cloud using Openstack. Cloudscaling has done it. This time around I was able to provide a little more detail about some of the specifics of what we at Cloudscaling are doing in our Open Cloud System, especially around resiliency for internal OpenStack components, networking and AWS compatibility.
Enjoy, and let me know what you think in the comments.
Openstack In Real Life from Paul Guth
OpenStack LA Meetup Jul 26 – Paul Guth from DreamHost on Vimeo.


•• Jeff Barr (@jeffbarr) and Jinesh Varia (@jinman) described Additional RDS for Oracle Features - VPC Support, Oracle Application Express (APEX) and Oracle XML DB in an 8/16/2012 post:
We have added three new features to Amazon RDS for Oracle Database to enable you to use it for more of your use cases:
- You can use Amazon RDS for Oracle in Amazon Virtual Private Cloud (VPC)
You can use Oracle XML DB to store, retrieve, navigate, and query XML documents.
- You can use Oracle Application Express (APEX) to rapidly build web applications.
Judging from the number of requests that I have received for these features, I expect them to be very popular.
Amazon RDS for Oracle in Amazon VPC
You can now launch Amazon RDS DB Instances running Oracle Database within a Virtual Private Cloud (VPC). Within a VPC, you can define a virtual network topology and customize the network configuration as desired. You can use subnets, routers, and access control lists to create the same type of network that you would find in a traditional data center. Amazon RDS for Oracle makes it easy to set up, operate, and scale Oracle Database deployments in the cloud. You can not only create Multi-AZ Oracle Database deployments with automated failure detection and recovery but also leverage Oracle Enterprise Manager to manage your databases. In addition, all of the other Amazon RDS for Oracle Database functionality is available including backup management, software patching, and easy scaling of compute and storage resources to meet changing needs.Oracle APEX
Oracle APEX is a rapid web development tool for Oracle database and enables you to create and deploy rich web applications using a web browser and limited programming experience. Both the Runtime and Development environments are available and you can switch between them using our Option Groups functionality.To start using APEX, you will need to create an RDS for Oracle DB instance (this is the APEX repository). You can also use an existing one if it is running engine version 11.2.0.2.v4 (or newer) of the RDS for Oracle Database. Apply the XMLDB, APEX, and APEX_DEV options via a RDS option group:
You will have to set the password of the APEX_PUBLIC_USER account and then unlock it.
You will also need to install and run the APEX listener (the HTTP server) on your own host or on an Amazon EC2 instance. As part of the configuration process, you will point the listener at your RDS instance.
Oracle XMLDB
Oracle XML DB is a feature of Oracle database that provides native XML storage and retrieval capabilities. It fully supports the W3C XML data model and provides new standard access methods for navigating and querying XML. With Oracle XML DB you get the advantages of relational database technology and the benefits of XML.In addition to these new updates, we have also included support for Oracle Time Zone so you can change the time zone of your Oracle database. This enables you to consistently store timestamp information when you have users in multiple time zones by setting the time zone datatype TIMESTAMP WITH LOCAL TIMEZONE.
These features are all available at no additional charge in all Regions where Amazon RDS for Oracle is available.



Matthew Lodge (@mathewlodge) invited users to Try Your Own vCloud in Minutes on 8/15/2012:
Today, we’re announcing that we’re introducing a new service that allows you to get your own vCloud IaaS service in minutes, called vCloud Service Evaluation. We heard from many customers that they came to vcloud.vmware.com to learn more about vCloud services, but that it wasn’t easy to sign up with a credit card, kick the tires, and learn by doing. vCloud Service Evaluation will provide a quick, easy and low-cost way for you to learn about the advantages of a vCloud through hands-on testing and experimentation.
You can sign up for the beta here: www.vmware.com/go/vcloudbeta. We’ll be sending out invites to those who sign up the week of August 27th, and those of you who are going to VMworld in San Francisco can see and try the service at the cloud services pod within the VMware booth.
You’ll need a credit card to use the service. It makes the service self-funding, and we can keep things simple, avoiding complex “service quotas” and other artificial restrictions – and also offer Windows VMs. We learned that customers have widely differing requirements for tests and proofs of concept. So, instead of annoying restrictions, you pay a small amount for what you use – a 1Gb Linux VM with one vCPU is $0.04/hour – and you are free to run the VMs you need until you are done. Once you have entered your card details, you’ll get your credentials within 15 minutes. If we need to verify anything, you’ll get a call.
To keep costs down, we commissioned a VMware vCloud service provider to build and operate the service on our behalf. We’re giving you a vanilla example of how a vCloud Powered service – delivered by a VMware vCloud service provider – would work. It’s worth pointing out that vCloud service providers offer significantly more in terms of cloud functionality. vCloud Service Evaluation has all the basics like a catalog of useful VM templates, virtual networking, persistent storage, external IP addresses, firewalls, load balancers, the vCloud API etc., but you’ll get a lot more in a production vCloud service.
To find that production vCloud service, head to vcloud.vmware.com: the gateway to the world’s largest network of certified compatible public cloud services, including more than 145 vClouds in 28 countries.
To get you started quickly, vCloud Service Evaluation offers a variety of pre-built content templates (at no charge) including Wordpress, Joomla!, Sugar CRM, LAMP stack, Windows Server and a mix of web and application stacks and OSes. You can also Bring Your Own VM (BYOVM). That’s right, you can BYOVM and put it into your own private catalog for deployment. You can do that either by uploading it directly into vCloud Director, or you can run the vCloud Connector VMs into your account (they’re in the public catalog) and use that to transfer your VMs from vSphere or any other vCloud.
Here’s what the main console looks like:
The service evaluation also allows you to run the VMware vCloud Director® interface.

We also learned that while we had some great information on vmware.com, but that it was hard to find stuff relevant to vCloud – and it wasn’t clear where to ask questions. So we put all the “how to” guides in one place, added some new ones, and also provided a Community site (message boards) where you can ask questions and get answers from experts at VMware and our partners.
Finally, email, chat and telephone support is available Monday through Friday for billing enquiries and to report any technical problems. “How do I…?” questions are best asked (and answered) on the Communities site.
We hope you find vCloud Service Evaluation a simple, low-cost way to learn about VMware vCloud, and look forward to getting your feedback on the service.

Chris Talbot reported Red Hat Unveils OpenStack Distribution in an 8/14/2012 post to the TalkinCloud blog:
Another open source vendor has tossed its hat into the OpenStack ring. A red hat, to be more precise. Now in preview release, Red Hat‘s (NYSE: RHT) own OpenStack distribution based on the open source OpenStack framework for building and management public, private and hybrid IaaS clouds.
The news that Red Hat was planning on launching its own OpenStack distribution broke back in April when a GigaOm report let the news slip. Red Hat joining the OpenStack community seems like a case of “if you can’t beat ‘em, join ‘em.” It’s no secret that the vendor was facing increasing competition from the OpenStack community, and now it really is official the company that helped build the Linux empire back in the good ol’ days has seen the OpenStack light.
Of course, Red Hat has had its share of contributions to the OpenStack community and was recognized as the third overall contributor to OpenStack at the OpenStack Summit 2012 in April.
The company is currently looking for feedback from its early customers and expects to launch a fully supported OpenStack release in 2013. That gives Red Hat at least several months to gather customer feedback, test and tweak its distribution.
“Our current productization efforts are focused around hardening an integrated solution of Red Hat Enterprise Linux and OpenStack to deliver an enterprise-ready solution that enables enterprises worldwide to realize infrastructure clouds,” said Brian Stevens, CTO and vice president of worldwide engineering at Red Hat, in a prepared statement.
It should be interesting to see what Red Hat has up its sleeve and how it plans to leverage the rest of its hybrid cloud portfolio of products, which include Red Hat Enterprise Linux, Red Hat Enterprise Virtualization, Red Hat CloudForms, Red Hat Storage and Red Hat OpenShift PaaS.
As partners and customers kick the tires of Red Hat’s OpenStack distribution, they should keep in mind it’s in its early stages and is currently unsupported by the vendor. Based on Red Hat Enterprise Linux 6, the preview version of the OpenStack distribution is available for download now.
Read More About This Topic

Jeff Barr (@jeffbarr) reported AWS Direct Connect - New Locations and Console Support in an 8/13/2012 post:
Did you know that you can use AWS Direct Connect to set up a dedicated 1 Gbps or 10 Gbps network connect from your existing data center or corporate office to AWS?
New Locations
Today we are adding two additional Direct Connect locations so that you have even more ways to reduce your network costs and increase network bandwidth throughput. You also have the potential for a more consistent experience. Here is the complete list of locations:
- CoreSite 32 Avenue of the Americas, New York - Connect to US East (Northern Virginia). New.
- Terremark NAP do Brasil - Connect to South America (Sao Paulo). New.
- CoreSite One Wilshire, Los Angeles, CA - Connect to US West (Northern California).
- Equinix DC1 – DC6 & DC10, Ashburn, VA - Connect to US East (Northern Virginia).
- Equinix SV1 & SV5, San Jose, CA - Connect to US West (Northern California).
- Equinix SG2, Singapore - Connect to Asia Pacific (Singapore).
- Equinix TY2, Tokyo - Connect to Asia Pacific (Tokyo).
- TelecityGroup Docklands, London - Connect to EU West (Ireland).
If you have your own equipment running at one of the locations listed above, you can use Direct Connect to optimize the connection to AWS. If your equipment is located somewhere else, you can work with one of our APN Partners supporting Direct Connect to establish a connection from your location to a Direct Connection Location, and from there on to AWS.
Console Support
Up until now, you needed to fill in a web form to initiate the process of setting up a connection. In order to make the process simpler and smoother, you can now start the ordering process and manage your Connections through the AWS Management Console.Here's a tour. You can establish a new connection by selecting the Direct Connect tab in the console:
After you confirm your choices you can place your order with one final click:
You can see all of your connections in a single (global) list:
You can inspect the details of each connection:
You can then create a Virtual Interface to your connection. The interface can connected to one of your Virtual Private Clouds or it can connect to the full set of AWS services:
You can even download a router configuration file tailored to the brand, model, and version of your router:
Get Connected
And there you have it! Learn more about AWS Direct Connect and get started today.


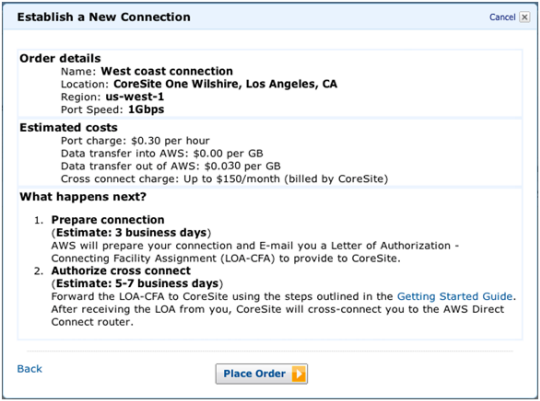
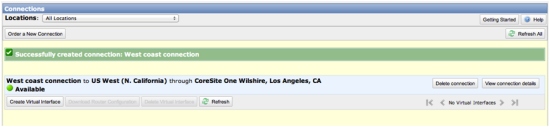
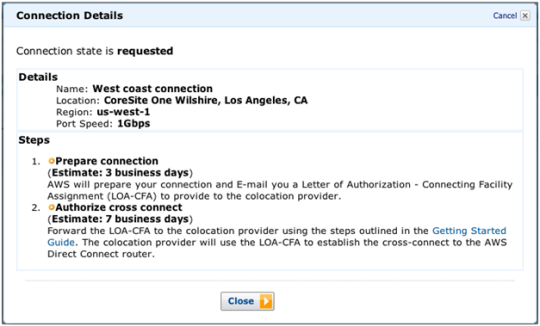
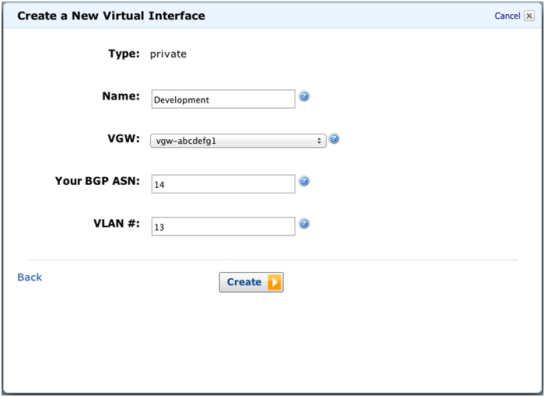
<Return to section navigation list>

















0 comments:
Post a Comment