Windows Azure and Cloud Computing Posts for 7/12/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI,Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

•• Updated 7/15/2012 5:00 PM PDT with new articles marked •• in the Live Windows Azure Apps, APIs, Tools and Test Harnesses, Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN, Windows Azure Blob, Drive, Table, Queue and Hadoop Services, Visual Studio LightSwitch and Entity Framework v4+ and SQL Azure Database, Federations and Reporting sections.
• Updated 7/13/2012 11:00 AM PDT with new articles marked •.
Posted prematurely on 7/12/2012 at 1:30 PM PDT to get the word out about the release of the Windows Azure Active Directory (WAAD) Preview. See the Windows Azure Service Bus, Caching, Active Directory, and Workflow section.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Cloud Numerics, Big Data and OData
- Windows Azure Service Bus, Caching, Active Directory, and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
•• Manu Cohen-Yashar (@ManuKahn) described how to Upload to Shared Access Signature blob using WebClient (REST API) in a 7/14/2012 post:
I wa[s] asked by a client how to upload a blob (Put blob) to a SAS (Shared Access Signature) blob using the REST API.
Here is a simple code snippet demonstrating that using WebClient.
class Program { private static CloudBlobContainer m_container; static void Main(string[] args) { try { var m_StorageAccount = CloudStorageAccount.DevelopmentStorageAccount; var m_BlobClient = m_StorageAccount.CreateCloudBlobClient(); m_container = m_BlobClient.GetContainerReference("myContainer"); m_container.CreateIfNotExist(); BlobContainerPermissions permissions = new BlobContainerPermissions(); // The container itself doesn't allow public access. permissions.PublicAccess = BlobContainerPublicAccessType.Off; // The container itself doesn't allow SAS access. var containerPolicy = new SharedAccessPolicy() { Permissions = SharedAccessPermissions.None }; permissions.SharedAccessPolicies.Clear(); permissions.SharedAccessPolicies.Add("TestPolicy", containerPolicy); m_container.SetPermissions(permissions); var uri = GetSharedAccessSignature("b1", DateTime.Now.AddDays(1)); var client = new WebClient(); client.UploadFile(uri,"PUT", "b1.txt"); Console.WriteLine("Done"); } catch (Exception ex) { Console.WriteLine(ex.ToString()); } Console.ReadLine(); } public static string GetSharedAccessSignature(string objId, DateTime expiryTime) { CloudBlob blob = m_container.GetBlobReference(objId); var blobAccess = new SharedAccessPolicy { Permissions = SharedAccessPermissions.Write, SharedAccessExpiryTime = expiryTime }; return blob.Uri + blob.GetSharedAccessSignature(blobAccess, "TestPolicy"); } }

• See Andrew Brust’s Microsoft’s Big Data Plans: Acknowledge, Embrace, Integrate article in the Marketplace DataMarket, Cloud Numerics, Big Data and OData section below.
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
Jialiang Ge (@jialge, pictured below) reported a new Sharing "SQL Server and SQL Azure Samples Blog" in a 7/11/2012 post to the Microsoft All-In-One Framework blog:
Derrick VanArnam and Susan Joly from the SQL Server Customer Experience team started an Agile Sample development process for connecting with customers and developing SQL Server and SQL Azure code samples.
http://blogs.msdn.com/b/derrick_vanarnams_blog/
The team has just released their first Outlook Data Sync sample developed based on the Agile process.
http://msftdbprodsamples.codeplex.com/wikipage?title=Outlook%20Contact%20Data%20Sync%20Iteration%203
The agile process looks promising for having more iterations and engagements with customers, and learning customers' needs. Microsoft All-In-One Code Framework Team is partnering with SQL Server Customer Experience team to adopt the Agile process in creating samples for other technologies.

<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
• Andrew Brust (@AndrewBrust) asserted “Microsoft had its Worldwide Partner Conference in Toronto this week, and over 16,000 people were there; so was Big Data” in a deck for his Microsoft’s Big Data Plans: Acknowledge, Embrace, Integrate post of 7/13/2012 to ZDNet’s Big on Data blog:
Microsoft held its annual Worldwide Partner Conference (WPC) in Toronto this week. Although the event is held in North America, it is the only such event all year, anywhere, and attendance is truly international. Microsoft said that this year, over 16,000 people from 156 countries attended WPC. It is by any measure a big show and this year Microsoft had a lot to say about Big Data. Whether in keynotes, breakout sessions or invite-only roundtables, the message was there.
First, the facts: Microsoft has been working with Hortonworks to build a distribution of Hadoop for Windows Azure, its cloud platform, and for Windows Server. Right now the service is available as a cloud service in a by-invitation beta that just entered its third release. The distribution includes Hadoop itself, Hive, Pig, HBase, Sqoop, Mahout and Carnegie Mellon’s “Pegasus” graph mining system.
The Hadoop bone’s connected to the SQL bone
What’s interesting about Microsoft’s Big Data approach is that the company sees Hadoop as a part of its overall data platform. Maybe that’s why Microsoft Chief Operating Officer, Kevin Turner, called out the company’s Big Data strategy during his keynote address, saying "we're going big in Big Data." Turner also mentioned that Microsoft’s SQL Server is now the leader in the relational database market, in terms of units sold, and continues to grow. And despite the many technological differences between relational databases and a distributed computation system like Hadoop, Microsoft sees the open source Big Data technology fitting right in to its enterprise data strategy.
There are components in Microsoft’s Hadoop distribution that help reconcile it with Enterprise technology. For example, the distribution includes a very powerful browser-based console, providing a GUI for running MapReduce jobs; a JavaScript-based command console that also accommodates Pig and HDFS commands; and an interactive Hive console as well. Microsoft’s distribution also allows MapReduce code itself to be written in JavaScript (rather than Java) and provides an ODBC driver for Hive, facilitating connectivity to Hadoop from Excel and most of the Microsoft Business Intelligence stack.
Stay on message
Where the tech goes, so goes the partner messaging. In a session on the opportunities brought to Independent Software Vendors (ISVs) by SQL Server, Microsoft’s Director, SQL Server Partner Marketing, Bob Baker, specifically mentioned Microsoft’s Hadoop efforts and those very tie-ins to the BI stack. And it’s not just about the data platform, either. In a roundtable discussion I attended a key member of Microsoft’s Big Data team, it became quite clear that Microsoft sees the technology fitting into its entire data center and cloud product strategy.Bing Data
Why would Microsoft be so bullish on technology that is open source, Java-based and largely Linux-facing in pedigree? Most likely it’s because Microsoft runs Bing. By some counts, Bing and Yahoo Search (which is Bing-powered) together have about 30% search market share and Turner announced in his keynote that Bing is now leading Google in search relevance.While I’m not exactly sure who’s measured that or how, the fact is that Bing is a Big Data hot bed. In fact, according to one Microsoft Big Data team member I spoke with, Bing’s data corpus is now 250 Petabytes (PB), and is growing at 8 PB/month. With that amount of data, it’s no wonder that Bing has used Hadoop to great advantage. And given that Microsoft’s President for the Server and Tools Business (STB), Satya Nadella, was previously vice president of R&D for Microsoft's Online Services Division (which includes Bing), and that SQL Server falls under the STB organization, the Hadoop-SQL Server friendship isn’t so strange after all.
The Big Data Tidal Wave
Microsoft is not a Big Data company per se. It’s not venture-funded, it’s not a startup and its main business model is certainly not built around open source. Microsoft is a software company, and Microsoft’s take is that Big Data and Hadoop are increasingly part of the Enterprise software landscape. As it did back in the 1990s with TCP/IP and the Internet itself, Microsoft is embracing Hadoop, integrating it and making it accessible to business users. That matter-of-fact approach to Hadoop and Big Data is likely to become the norm throughout the Enterprise world. For over 16,000 attendees of the Microsoft Worldwide Partner Conference, that approach is the norm in their world starting now.


For more details about Apache Hadoop for Windows Azure see my Recent Articles about SQL Azure Labs and Other Added-Value Windows Azure SaaS Previews: A Bibliography post, updated 6/30/2012.
• Carol Geyer reported an OASIS OData webinar and upcoming Lightning Round in an 7/12/2012 message to the OData Mailing List:
We had a great turn-out for last Wednesday's webinar on the OASIS OData TC.
Thanks to Mike Pizzo (Microsoft) and Barb Hartel (SAP) for leading the discussion. You can download the recorded version at https://www.oasis-open.org/events/webinars/.
Also, OData will be featured in the Cloud Standards Lightning Rounds at the OASIS Open House on 25 July in Burlington, MA. Sanjay Patil (SAP) will present. All are welcome to attend; please RSVP. Details are at http://oasis-cloud-lightning-2012.eventbrite.com/.
Glenn Gailey (@ggailey777) posted Recent Goings on in OData and WCF Data Services on 7/12/2012:
While I’ve not been so focused strictly on OData, it turns out that there has been a lot going on in the data services world, including:
OData Standardization Submitted to OASIS
Sweet!
WCF Data Services 5.0.1 Release
True to their planned new semantic versioning model, the OData team at Microsoft has already released WCF Data Services 5.0.1. While mostly containing bug fixes, this version removes v5.0 assemblies from the GAC. More info here. This is a new publishing model for the team, so I expect that things should settle into a nice rhythm after a few cycles.
Update to the OData Client T4 Template
As you may recall from my previous post New and Improved T4 Template for OData Client and Local Database, the OData team is developing their own T4 template that is used to codegen OData clients (using WCF Data Services 5.0). As I mentioned, I really prefer T4 for codegen because it’s very easy to modify, especially compared to the insanely difficult VS codegen APIs. Anyway, there is now an update to the prerelease OData Client T4 template. Sadly, I don’t think I will have the time to port these updates to my Windows Phone storage sample Using Local Storage with OData on Windows Phone To Reduce Network Bandwidth.
WCF Data Services 5.1.0 RC1 Released to NuGet
The RC1 release includes the first preview of JSON light—which will become the default JSON format for OData. This is also the first version of WCF Data Services client that supports JSON (which mobile device developers have been begging for). However, it’s not fully baked yet, so you may want to wait for the next release to try out the client JSON—unless you are OK with writing your own EDMx model resolver.

<Return to section navigation list>
Windows Azure Service Bus, Caching, Active Directory and Workflow
• Tim Anderson (@timanderson) reported Microsoft opens up Office 365 and Azure single sign-on for developers on 7/13/2012:
Remember Passport and Hailstorm? Well here it comes again, kind-of, but in corporate-friendly form. It is called Windows Azure Active Directory, and is currently in Developer Preview:
Windows Azure AD provides software developers with a user centric cloud service for storing and managing user identities, coupled with a world class, secure & standards based authorization and authentication system. With support for .Net, Java, & PHP it can be used on all the major devices and platforms software developers use today.
The Windows Azure Active Directory SSO capability can be used by any application, from Microsoft or a third party running on any technology base. So if a user is signed in to one application and moves to another, the user doesn’t have to sign in again.
Organisations with on-premise Active Directory can use federation and synchronisation (Shewchuk fudges the distinction) so that you can get a single point of management as well as single sign-on between cloud and internal network.
Is this really new? I posted about Single sign-on from Active Directory to Windows Azure back in December 2010, and in fact I even got this working using my own on-premise AD to sign into an Azure app.
It seems though that Microsoft is working on both simplifying the programming, and adding integration with social networks. Here is where it gets to sound even more Hailstorm-like:
… we will look at enhancements to Windows Azure Active Directory and the programming model that enable developers to more easily create applications that work with consumer-oriented identities, integrate with social networks, and incorporate information in the directory into new application experiences.
Hailstorm failed because few trusted Microsoft to be the identity provider for the Internet. It is curious though: I am not sure that Facebook or Google are more well-trusted today, yet they are both used as identity providers by many third parties, especially Facebook. Spotify, for example, requires Facebook sign-in to create an account (an ugly feature).
Perhaps the key lesson is this. Once people are already hooked into a service, it is relatively easy to get them to extend it to third-parties. It is harder to get people to sign up for an all-encompassing internet identity service from scratch.
This is why Azure Active Directory will work where Hailstorm failed, though within a more limited context since nobody expects Microsoft to dominate today in the way it might have done back in 2001.
Related posts:
- Single sign-on from Active Directory to Windows Azure: big feature, still challenging
- What will it take to get developers to try Windows Azure? Microsoft improves its trial offer
- ODF support in Microsoft Office: a sign of strength, or weakness?
- Appcelerator opens component marketplace for mobile developers
- The Microsoft Azure VM role and why you might not want to use it

• Richard Conway (@azurecoder) described The issues you may have with the Azure co-located cache 1.7 and other caching gems on 7/12/2012:
On Tuesday 10th July I did a talk for the UKWAUG on using the new co-located cache. Since we’ve been working caching into our HPC implementation successfully I’ve become a dabhand on the dos and donts which I wanted to publish.
When the cache starts up it leaves four marker files in the storage account you set up in your configuration at compile time. The files have names like this f83f8073469549e1ba858d719238700f__Elastaweb__ConfigBlob and the four present means that cache configuration is complete and it now has an awareness of where the nodes in the cache cluster are.
These blobs are in a well-known storage container called cacheclusterconfig. The cache will reference the latest files in this container which are order dependent by time so if the settings are overwritten by something else then don’t expect the health of your cache to be good! Each node has Base64 config data associated with it in this file so the cluster won’t effectively exist you’re using the same account for multiple cache clusters from different deployments. Be aware, don’t reuse in this way for staging, production and as in my case the devfabric!
A small factor you should be aware of is the time it takes to install the cache. I’ve run several hundred tests now and generally it takes an additional 9 minutes to install the cache services when you include the plugin. Be aware of this because if you have time dependent deployments it will impact them. Using diagnostics with the cache is not that clearcut. In the spirit of including some code in this blogpost here is my RoleEntryPoint.OnStart method.
public override bool OnStart() { CloudStorageAccount.SetConfigurationSettingPublisher((configName, configSetter) => { // Provide the configSetter with the initial value configSetter(RoleEnvironment.GetConfigurationSettingValue(configName)); RoleEnvironment.Changed += (sender, arg) => { if (arg.Changes.OfType().Any((change) => (change.ConfigurationSettingName == configName))) { // The corresponding configuration setting has changed, so propagate the value if (!configSetter(RoleEnvironment.GetConfigurationSettingValue(configName))) { // In this case, the change to the storage account credentials in the // service configuration is significant enough that the role needs to be // recycled in order to use the latest settings (for example, the // endpoint may have changed) RoleEnvironment.RequestRecycle(); } } }; }); // tracing for the caching provider DiagnosticMonitorConfiguration diagConfig = DiagnosticMonitor.GetDefaultInitialConfiguration(); diagConfig = CacheDiagnostics.ConfigureDiagnostics(diagConfig); //// tracing for asp.net caching diagnosticssink diagConfig.Logs.ScheduledTransferLogLevelFilter = LogLevel.Warning; diagConfig.Logs.ScheduledTransferPeriod = TimeSpan.FromMinutes(2); // performance counters for caching diagConfig.PerformanceCounters.ScheduledTransferPeriod = TimeSpan.FromMinutes(2); diagConfig.PerformanceCounters.BufferQuotaInMB = 100; TimeSpan perfSampleRate = TimeSpan.FromSeconds(30); diagConfig.PerformanceCounters.DataSources.Add(new PerformanceCounterConfiguration() { CounterSpecifier = @"\AppFabric Caching:Cache(azurecoder)\Total Object Count", SampleRate = perfSampleRate }); diagConfig.PerformanceCounters.DataSources.Add(new PerformanceCounterConfiguration() { CounterSpecifier = @"\AppFabric Caching:Cache(default)\Total Object Count", SampleRate = perfSampleRate }); DiagnosticMonitor.Start("Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString", diagConfig); return base.OnStart(); }The first important line here is this:
CacheDiagnostics.ConfigureDiagnostics(diagConfig);You’ll want to configure diagnostics for the cache to find out what’s going on. Unfortunately with the default settings in place this will fail with a quota exception. There is a default size of 4000 MB set on the log limit and this call violates it by 200MB. Unfortunately the quota property cannot be increased, only decreased, so the fix for this is to change the default setting in the ServiceDefinition.csdef from:
<LocalResources> <LocalStorage name="Microsoft.WindowsAzure.Plugins.Caching.FileStore" sizeInMB="1000" cleanOnRoleRecycle="false" /> </LocalResources>to:
<LocalResources> <LocalStorage name="Microsoft.WindowsAzure.Plugins.Caching.FileStore" sizeInMB="10000" cleanOnRoleRecycle="false" /> </LocalResources>Notice also the addition of the performance counters. There are 3 sets but I’ve illustrated the most basic but also most important metrics for us which show the numbers of cache objects. The counters are well-documented on MSDN. Anyway, hope yo found this helpful. I’ll be publishing something else on memcache interop shortly based on testing I’ve done in Java and .NET.

Vittorio Bertocci (@vibronet) posted Single Sign On with Windows Azure Active Directory: a Deep Dive at 9:00 AM on 7/12/2012:
Are you excited about the Developer Preview of Windows Azure Active Directory? I sure am! [See the post below for the official announcement at noon.]
In this post I am going to give a pretty deep look at the machinery that’s behind the Web Single Sign On capabilities in AAD in this Preview, demonstrated by the samples we released as part of the Preview.
THIS IS A PREVIEW. The Windows Azure Active Directory Developer Preview is, to channel my tautological self, a preview. As such:
- It still has rough edges, things that are not as simple to use as they will be once we’ll get to general availability time. We already know about some of those; we fully expect to find various others thanks to your feedback.
My here goal is to help you to experiment with the preview: in this post I describe things as they are today, in the Developer Preview. If you want to know what is their intended final state please refer to John’s and Kim’s posts.- Given that you are willing to work with a preview, with rough edges and all (pioneers! Oh pioneers!) , I assume that both your thirst for fine grained details and your tolerance for complexity are higher than the norm. Most of what I am going to describe here is NOT necessary for you to operate the service: if you just want to see the SSO flow work, skip the tome here and go straight to the step-by-step samples’ manual. Read on if instead you are interested in understanding a bit more of how AAD operates and how things relate to what you already know about Web SSO.
SSO for a LoB App in the Cloud
Let’s start with a pretty simple scenario, which also happens to be extremely common in my experience.
Say that you have one line of business app that you want to run in the cloud, for one of the many reasons that make it a good idea. You already have one Windows Azure Active Directory tenant - perhaps you are an O365 subscriber – and you want your users to sign in the LoB app in the same way as they do for your SharePoint online instance.
Implementing the scenario entails two steps:
- Provision the application in your directory tenant
- Establish trust between the app and the SSO endpoint of the directory
Anybody surprised? This is precisely what we’ve been doing for a good 1/2 decade by now: in ADFS2/WIF terms you could say that #1 corresponds to establishing a “relying party trust” (for the record I always hated the term, but I have to admit that it gives the idea) and #2 corresponds to running the WIF tools on the app against ADFS2. Pick any federation based products, on any platform, and I am sure you’ll be able to come up with concrete ways of making those abstract steps happen.
Windows Azure Active Directory is no exception, although you’ll notice some extra provisions here and there due to the multi-tenant nature of the service. Let’s examine those two steps in details, and use the opportunity to explore how the directory works.
Provision the Application in the Directory Tenant
Quick, how do you identify a service within a realm in Kerberos?
That’s right: you use a Service Principal Name. In line with the tradition, Windows Azure Active Directory does the same with just a couple of multi-tenancy twists. Provisioning one application to enable Web single sign on is just a matter of creating the proper ServicePrincipal object for it, and AAD will take care of the rest.If you fully understood the last couple of paragraphs, chances are that you are a system administrator (or you have been at a certain point in your career).
If you didn’t, don’t feel bad: if you are a developer you likely never had a lot of exposure to the innards of a directory, given that you leverage it though contracts which abstract away the details. Think ADFS2 endpoints: you can happily set up Web SSO with it from your web app without the need to know anything about forests, LDAP attributes, schemas and whatnot.With Windows Azure Active Directory you are still not strictly required to learn about how a directory works, however in this preview there are a number of places in which directory-specific concepts are surfaced all the way to the Web SSO layer. Although it is perfectly possible to manipulate those without knowing what they mean (even without invoking Searle
) I think you’ll appreciate a tad of context-setting here (pioneers!).
The Directory in Windows Azure Active Directory
Let’s take a look at the main artifact we’ll have to work with: the directory itself.
As of today, the best way of experiencing the directory is to get an Office 365 tenant. All of the walkthroughs and samples in the Developer Preview instruct you to get one, as the very first step. In the future this step won’t be required given that you can get a directory with your Windows Azure subscription.Again as of today, you’ll find the most detailed technical information about the directory in the Office 365 documentation. You’ll have to be a bit careful as you read the Office365 docs to find information about Developer Preview scenario, as the terminology and the goals of the two are not 100% the same. For example: as an application developer, with “single sign on” you probably refer to the ability of users to sign in YOUR application by using their directory account; OTOH the O365 documentation talks to IT admins setting up the service for their companies, hence it refers to “single sign on” as the ability of signing in O365 applications using your local AD accounts. Both definitions are perfectly legit, they simply happen to refer to different scenarios which leverage different features. Keep that in the back of your mind as you read the docs, and you’ll find the info you need.
Here I’ll give you a super-concise mini-intro of what’s in the directory, hopefully that will help you to navigate the proper docs once you’ll decide to dig deeper. I’ll favor simplicity over strict correctness, hence please take this with a grain of salt.
In extreme synthesis, a directory is a collection of the following entities:
- Users
Users, passwords, password policies and the like- Groups
Security groups- Roles memberships
Who belongs to what. Note, only users (as opposed to groups) can be a role member- Service Principals
We’ll talk about those later- Domains
If you own one or more domains (in the DNS sense of the word) and you want to use it in O365 you can managed them via this collection- Subscriptions & licenses
- Company info
- Other stuff (often O365-specific)
The last 3 are what their names suggest: not super-relevant for the web SSO discussion anyway.If you are watching closely the Windows Azure Active Directory news, you might have recognized the above list as a super-set of the entities you can query with the Graph API.
Every directory tenant gets these collections and the infrastructure which handles them. In our parlance, there are two main flavors of directory tenants:
- Federated. A federated tenant is connected to a local ADFS2 instance.
- The content of Users and Groups in the directory comes straight from the users and groups from the local AD instance.
The first time you establish the connection between local directory and your Windows Azure Active Directory tenant, a utility (the Directory Synchronization tool, DirSync for friends) makes a copy and configures itself to perform updates every 3 hours. Note that as of today DirSync will propagate to the cloud changes taking place on premises, but it won’t do anything in the opposite direction: DirSync is unidirectional.- All authentication flows will rely on federation: the local ADFS2 instance is responsible for authenticating credentials. No user password is replicated to the cloud.
- Managed. A managed tenant does not have any footprint on-premises. Users, groups and everything else are cloud-native: they are created in the cloud, and in the cloud they live. That includes the user credentials, which will be verified by leveraging suitable could-only authentication endpoints.
For the purposes of the Web SSO discussion, the two tenant types are equivalent: the user experience at authentication time will differ (namely, the credentials will be gathered in different places) but the scenario setup is exactly the same in both cases.
How do you get stuff in and out of those collections? There are four main routes, as shown below.
Here there’s the rundown, counterclockwise from the bottom.
- DirSync. As described, for federated tenants it’s the way in which your users and groups collections are first populated from your local AD. Nothing else is copied up. You can ignore this route for managed tenants, where there’s no on-premises collections to sync from. As you can see in the diagram, today the arrow goes only in one direction.
- Graph API. In the Developer Preview, the Graph API allows you to read a subset of the entities in the directory: namely Users, Groups, Roles, Subscriptions, TenantDetails and some of the relationships which tie those together. As the interaction is read-only, the arrow reflects it by pointing only outward. For more details on the Graph, what it can do today and what it will be allow you to do in the future please refer to Ed’s session here.
- Office 365 Service Administration Portal. The management and subscriptions sections of the Office 365 management portal allow you to manage users, groups and licenses. The arrow goes both ways, given that you can use the portal to both read and write the selected subset of directory entities it is designed to manage today.
- PowerShell cmdlets for Office 365. As of today, the most powerful tool for manipulating the directory is the collection of PowerShell cmdlets which come with Office 365. Via the cmdlets you can pretty much read and write anything you need for the development scenarios in the Preview
From that list you can clearly get the sense that Windows Azure Active Directory is already a shipping product, powering Office 365 since its GA back in 2011. It’s important to remember that the Preview is about the new developer-oriented capabilities of AAD (SSO and Graph) but the service in itself is already being used in production by many, many customers.
Now that we got some terminology to play with, let’s get back to our main task: we want to provision our Web application in the directory. …


Vittorio continues with the details of:
- Creating the ServicePrincipal
- The Developer Preview STS Endpoint
- Establish Trust Between the App and the Developer Preview STS Endpoint
- Running the LoB App
- Handling Multi-Tenancy
and concludes with:
Next Steps
Well, I hope that this long post satisfied your thirst for details about the developer preview of Windows Azure Active Directory! Next in my pipeline are a couple of posts giving some more details on how we structured the Java and PHP examples: I won’t go nearly as deep as I have done here, but I’ll see how – module intrinsic differences between platforms – in the end claims-based identity is claims-based identity everywhere, and what you learn on one is easily transferable to the others.
And how about your pipeline? Hopefully A TON of feedback for us! I hope you’ll enjoy experimenting with our developer preview, and I cannot wait to see what you’ll achieve with it. In the meanwhile, if you have questions do not hesitate to drop us a line in the forums.
Alex Simons posted Announcing the Developer Preview of Windows Azure Active Directory to the Windows Azure Team blog at 12:02 on 7/12/2012:
Today we are excited to announce the Developer Preview of Windows Azure Active Directory.
As John Shewchuk discussed in his blog post Reimagining Active Directory for the Social Enterprise, Windows Azure Active Directory (AD) is a cloud identity management service for application developers, businesses and organizations. Today, Windows Azure AD is already the identity system that powers Office 365, Dynamics CRM Online and Windows Intune. Over 250,000 companies and organizations use Windows Azure AD today to authenticate billions of times a week. With this Developer Preview we begin the process of opening Windows Azure AD to third parties and turning it into a true Identity Management as a Service.
Just as important, Windows Azure AD gives businesses and organizations their own cloud based directory for managing access to their cloud based applications and resources. And Windows Azure AD synchronizes and federates with their on-premise Active Directory extending the benefits of Windows Server Active Directory into the cloud.
Today’s Developer Preview release is the first step in realizing that vision. We’re excited to be able to share our work here with you and we’re looking forward to your feedback and suggestions!
The Windows Azure AD Developer Preview provides two new capabilities for developers to preview:
- Graph API
- Web Single Sign-On
This Preview gives developers early access to new REST APIs, a set of demonstration applications, a way to get a trial Windows Azure AD tenant and the documentation needed to get started. With this preview, you can build cloud applications that integrate with Windows Azure AD providing a Single Sign-on experience across Office 365, your application and other applications integrated with the directory. These applications can also access Office 365 user data stored in Windows Azure AD (assuming the app has the IT admin and/or user’s permission to do so).
Graph API
As John Shewchuk discussed in his last blog post, the Graph API brings the enterprise social graph contained in Windows Azure AD and Office 365 (and thus Windows Server AD as well) to the Internet and creates an opportunity for a breadth of new collaborative applications to be created.
In this Preview we have released the following features:
- Graph API REST interface (and metadata endpoints) that provide a large set of API to read the data in Windows Azure AD (for a detailed list of data available in the Preview, click on the documentation below)
- PowerShell cmdlets to grant an application read access to a tenant’s Windows Azure AD
- OData support for quick integration with Visual Studio and other Microsoft technologies
- Detailed code walkthroughs for .Net that demonstrate how to add Graph APIs in your application
You can get started using the Graph API here:
- Windows Azure AD Graph Explorer (hosted in Windows Azure)
- Windows Azure AD People Picker Source Code
For more detailed information on the Windows Azure AD Graph API, visit our MSDN page on the topic here.
Please note that this is a preview release. The API’s and features will certainly change between now and our official release. Today the Graph API offers read-only capabilities and only a subset of the Windows Azure AD data is available at this time. Over the coming months, we’ll deliver additional updates which will add more data, additional OData filters, role based access control, and support for write operations.
Web Single-Sign On
To support this preview release of the Graph API we are also releasing a preview of the SSO capabilities of Windows Azure AD. This set of capabilities make it easy to build cloud applications that deliver a Single Sign-On (SSO) experience for users logging-on to their domain joined PCs, on-premises servers and other cloud applications like Office 365. With SSO in Windows Azure AD, businesses and organizations can easily manage user access to cloud applications without the additional cost and hassle of having to acquire and manage new user credentials.
For this Preview release, we provide the following features:
- STS metadata endpoints to integrate Windows Azure AD in to your application
- Support for the WS-Federation protocol with SAML 2.0 tokens
- PowerShell cmdlets to configure a Windows Azure AD tenant to do SSO with your application
- Detailed code walkthroughs for PHP, Java, and .Net that demonstrate SSO capability to your application
Over the coming months we will release updates which broaden our protocol coverage to support authentication protocols commonly used on the internet including SAML 2.0.
You can access code samples and demonstration applications from the following links:
Putting It All Together: The Windows Azure AD Expense Demo App
To provide an example of the power of Windows Azure AD, we have developed a sample expense reporting application that uses Web SSO and the Graph API to provide a seamless sign-on and management experience for Office 365 customers.
This application will be updated as the platform improves, so feel free to download the sample application and provide feedback and updates on the progress.
- Windows Azure AD QuickStart Application (hosted in Windows Azure)
- Windows Azure AD QuickStart Application source
Get Started and Get Involved
Your feedback and input is critical to us and will help us make sure we’re delivering the right capabilities and the right developer experience as we build out the Windows Azure AD platform.
Today we are releasing some great material to get you started on using the Developer Preview of Windows Azure AD:
- Technical details about the Graph API platform, visit the MSDN articles here.
- Java, PHP, and .Net code samples on GitHub.
- A sample application built in Windows Azure that demonstrates what’s possible using Azure Active Directory using all of these technologies, available for download from GitHub here.
- Vittorio Bertocci’s blog post with a deep dive into creating a Windows n Azure AD integrated application.
- Brandon Werner’s blog post on the Windows Azure AD Expense Demo Application.
These are all great resources to understand how to access the Windows Azure AD using the new APIs, learn about the capabilities they offer, and how to enable SSO in your web based applications.
Some Things We Know We Need To Work On
Again, this is a very early preview so as you use the demo application and code samples and you will experience a few issues we are already working on fixing. I wanted to call them out so that you can get up to speed faster.
Tenant Admins Must Use PowerShell to Authorize an Application
During this Preview release, we rely on the Microsoft Online Services Module for Windows PowerShell (updated for this Preview release) as the tool for administrators to enable applications to work with their Windows Azure AD tenant. We have created a PowerShell script that automates much of this work for the admin in our documentation samples, but we are aware of the limitation of this approach and are working to provide a graphical authorization interface in a future release.
Audience URI Varies Based on Tenant and is in spn: Format
When the Developer Preview of Windows Azure AD issues a SAML 2.0 token for an application, the audience URI in the token includes the identifier of the application and the identifier of the tenant, instead of just the identifier of the application. For a Windows Identity Foundation-based application to handle this tenant-varying audience URI, extension code to WIF is required, and has been supplied in the web SSO samples. In addition, the audience URI is in spn: format instead of being the more familiar URL of the application. We are working to simplify this format in a future update.
Example:
SAML Token has no AuthenticationStatement
SAML 2.0 tokens issued by the preview do not include an AuthenticationStatement. Some federation software implementations may require the AuthenticationStatement to be present in the token, and may not interoperate with the preview release.
We're far from done, and have a lot of work left to do. Your feedback and suggestions will play a big role in helping us figure out what the right work to do is. We’re looking forward to hearing from you and sharing additional updates with you in the coming months as we continue to evolve Windows Azure AD!
Best Regards,
Alex Simons
Director of Program Management
Active Directory Division


Kim Cameron (@Kim_Cameron) posted Yes to SCIM. Yes to Graph about Simple Cloud Identity Management and the Windows Azure Active Directory Preview’s Graph API on 7/12/2012:
The Windows Azure Active Directory Developer Preview is live. How does its new Graph API relate to the SCIM provisioning protocol?
Today Alex Simmons, Director of Program Management for Active Directory, posted the links to the Developer Preview of Windows Azure Active Directory. Another milestone.
I’ll write about the release in my next post. Today, since the Developer Preview focuses a lot of attention on our Graph API, I thought it would be a good idea to respond first to the discussion that has been taking place on Twitter about the relationship between the Graph API and SCIM (Simple Cloud Identity Management).
Since the River of Tweets flows without beginning or end, I’ll share some of the conversation for those who had other things to do:
@NishantK: @travisspencer IMO, @johnshew’s posts talk about SaaS connecting to WAAD using Graph API (read, not prov) @IdentityMonk @JohnFontana
@travisspencer: @NishantK Check out @vibronet’s TechEd Europe talk on @ch9. It really sounded like provisioning /cc @johnshew @IdentityMonk @JohnFontana
@travisspencer: @NishantK But if it’s SaaS reading and/or writing, then I agree, it’s not provisioning /cc @johnshew @IdentityMonk @JohnFontana
@travisspencer: @NishantK But even read/write access by SaaS *could* be done w/ SCIM if it did everything MS needs /cc @johnshew @IdentityMonk @JohnFontana
@NishantK: @travisspencer That part I agree with. I previously asked about conflict/overlap of Graph API with SCIM @johnshew @IdentityMonk @JohnFontana
@IdentityMonk: @travisspencer @NishantK @johnshew @JohnFontana check slide 33 of SIA322 it is really creating new users
@IdentityMonk: @NishantK @travisspencer @johnshew @JohnFontana it is JSON vs XML over HTTP… as often, MS is doing the same as standards with its own
@travisspencer: @IdentityMonk They had to ship, so it’s NP. Now, bring those ideas & reqs to IETF & let’s get 1 std for all @NishantK @johnshew @JohnFontana
@NishantK: @IdentityMonk But isn’t that slide talking about creating users in WAAD (not prov to SF or Webex)? @travisspencer @johnshew @JohnFontana
@IdentityMonk: @NishantK @travisspencer @johnshew @JohnFontana indeed. But its like they re one step of 2nd phase. What are your partners position on that?
@IdentityMonk: @travisspencer @NishantK @johnshew @JohnFontana I hope SCIM will not face a #LetTheWookieWin situation
@NishantK: @johnshew @IdentityMonk @travisspencer @JohnFontana Not assuming anything about WAAD. Wondering about overlap between SCIM & Open Graph API
Given these concerns, let me explain what I see as the relationship between SCIM and the Graph API.
What is SCIM?
All the SCIM documents begin with a commendably unambiguous statement of what it is:
The Simple Cloud Identity Management (SCIM) specification is designed to make managing user identity in cloud based applications and services easier. The specification suite seeks to build upon experience with existing schemas and deployments, placing specific emphasis on simplicity of development and integration, while applying existing authentication, authorization and privacy models. Its intent is to reduce the cost and complexity of user management operations by providing a common user schema and extension model, as well as binding documents to provide patterns of exchanging this schema using standard protocols. In essence, make it fast, cheap and easy to move users in to, out of and around the cloud. [Kim: emphasis is mine]
I support this goal. Further, I like the concept of spec writers being crisp about the essence of what they are doing: “Make it fast, cheap and easy to move users in to, out of and around the cloud”. For this type of spec to be useful we need it to be as widely adopted as possible, and that means keeping it constrained, focussed and simple enough that everyone chooses to implement it.
I think the SCIM authors have done important work to date. I have no comments on the specifics of the protocol or schema at this point - I assume those will continue to be worked out in accordance with the spec’s “essence statement” and be vetted by a broad group of players now that SCIM is on a track towards standardization. Microsoft will try to help move this forward: Tony Nadalin will be attending the next SCIM meeting in Vancouver on our behalf.
Meanwhile, what is ”the Graph”?
Given that SCIM’s role is clear, let’s turn to the question of how it relates to a “Graph API”.
Why does our thinking focus on a Graph API in addition to a provisioning protocol like SCIM? There are two answers.
Let’s start with the theoretical one. It is because of the central importance of graph technology in being able to manage connectedness - something that is at the core of the digital universe. Treating the world as a graph allows us to have a unified approach to querying and manipulating interconnected objects of many different kinds that exist in many different relationships to each other.
But theory only appeals to some… So let’s add a second answer that is more… practical. A directory has emerged that by August is projected to contain one billion users. True, it’s only one directory in a world with many directories (most agree too many). But beyond the importance it achieves through its scale, it fundamentally changes what it means to be a directory: it is a directory that surfaces a multi-dimensional network.
This network isn’t simply a network of devices or people. It’s a network of people and the actions they perform, the things they use and create, the things that are important to them and the places they go. It’s a network of relationships between many meaningful things. And the challenge is now for all directories, in all domains, to meet a new bar it has set.
Readers who come out of a computer science background are no doubt familiar with what a graph is. But I recommend taking the time to come up to speed on the current work on connectedness, much of which is summarized in Networks, Crowds and Markets: Reasoning About a Highly Connected World (by Easley and Kleinberg). The thesis is straightforward: the world of technology is one where everything is connected with everything else in a great many dimensions, and by refocusing on the graph in all its diversity we can begin to grasp it.
In early directories we had objects that represented “organizations”, “people”, “groups” and so on. We saw organizations as “containing” people, and saw groups as “containing” people and other groups in a hierarchical and recursive fashion. The hierarchy was a particularly rigid kind of network or graph that modeled the rigid social structures (governments, companies) being described by technology at the time.
But in today’s flatter, more interconnected world, the things we called “objects” in the days of X.500 and LDAP are better expressed as “nodes” with different kinds of “edges” leading to many possible kinds of other “nodes”. Those who know my work from around 2000 may remember I used to call this polyarchy and contrast it with the hierarchical limitations of LDAP directory technology.
From a graph perspective we can see ”person nodes” having “membership edges” to “group nodes”. Or “person nodes” having “friend edges” to other “person nodes”. Or “person nodes” having “service edges” to a “mail service node”. In other words the edges are typed relationships between nodes that may possibly contain other properties. Starting from a given node we can “navigate the graph” across different relationships (I think of them as dimensions), and reason in many new ways.
For example, we can reason about the strength of the relationships between nodes, and perform analysis, understand why things cluster together in different dimensions, and so on.
From this vantage point, directory is a repository of nodes that serve as points of entry into a vast graph, some of which are present in the same repository, and others of which can only be reached by following edges that point to resources in different repositories. We already have forerunners of this in today’s directories - for example, if the URL of my blog is contained in my directory entry it represents an edge leading to another object. But with conventional technology, there is a veil over that distant part of the graph (my blog). We can read it in a browser but not access the entities it contains as structured objects. The graph paradigm invites us to take off the veil, making it possible to navigate nodes across many dimensions.
The real power of directory in this kind of interconnected world is its ability to serve as the launch pad for getting from one node to a myriad of others by virtue of different relationships.
This requires a Graph Protocol
To achieve this we need a simple, RESTful protocol that allows use of these launch pads to enter a multitude of different dimensions.
We already know we can build a graph with just HTTP REST operations. After all, the web started as a graph of pages… The pages contained URLs (edges) to other pages. It is a pretty simple graph but that’s what made it so powerful.
With JSON (or XML) the web can return objects. And those objects can also contain URLs. So with just JSON and HTTP you can have a graph of things. The things can be of different kinds. It’s all very simple and very profound.
No technology ghetto
Here I’m going to put a stake in the ground. When I was back at ZOOMIT we built the first commercial implementation of LDAP while Tim Howes was still at University of Michigan. It was a dramatic simplification relative to X.500 (a huge and complicated standard that ZOOMIT had also implemented) and we were all very excited at how much Tim had simplified things. Yet in retrospect, I think the origins of LDAP in X.500 condemned directory people to life in a technology ghetto. Much more dramatic simplifications were coming down the pike all around us in the form of HTML, latter day SQL and XML. For every 100 application programmers familiar with these technologies, there might have been - on a good day - one who knew something about LDAP. I absolutely respect and am proud of all the GOOD that came from LDAP, but I am also convinced that our “technology isolation” was an important factor that kept (and keeps) directory from being used to its potential.
So one of the things that I personally want to see as we reimagine directory is that every application programmer will know how to program to it. We know this is possible because of the popularity of the Facebook Graph API. If you haven’t seen it close up and you have enough patience to watch a stream of consciousness demo you will get the idea by watching this little walkthrough of the Facebook Graph Explorer. Or better still just go here and try with your own account data. [See first screen capture below.]
You have to agree it is dead simple and yet does a lot of what is necessary to navigate the kind of graph we are talking about. There are many other similar explorers available out there - including ours. I chose Facebook’s simply because it shows that this approach is already being used at colossal scale. For this reason it reveals the power of the graph as an easily understood model that will work across pretty much any entity domain - i.e. a model that is not technologically isolated from programming in general.
A pluggable namespace with any kind of entity plugging in
In fact, the Graph API approach taken by Facebook follows a series of discussions by people now scattered across the industry where the key concept was one of creating a uniform pluggable namespace with “any” kind of entity plugging in (ideas came from many sources including the design of the Azure Service Bus).
Nishant and others have posed the question as to whether such a multidimensional protocol could do what SCIM does. And my intuition is that if it really is multidimensional it should be able to provide the necessary functionality. Yet I don’t think that diminishes in any way the importance of or the need for SCIM as a specialized protocol. Paradoxically it is the very importance of the multidimensional approach that explains this.
Let’s have a thought experiment.
Let’s begin with the assumption that a multidimensional protocol is one of the great requirements of our time. It then seems inevitable to me that we will continue to see the emergence of a number of different proposals for what it should be. Human nature and the angels of competition dictate that different players in the cloud will align themselves with different proposals. Ultimately we will see convergence - but that will take a while. Question: How are we do cloud provisioning in the meantime? Does everyone have to implement every multidimensional protocol proposal? Fail!
So pragmatism calls for us to have a widely accepted and extremely focused way of doing provisioning that “makes it fast, cheap and easy to move users in to, out of and around the cloud”.
Meanwhile, allow developers to combine identity information with information about machines, services, web sites, databases, file systems, and line of business applications through multidimensional protocols and APIs like the Facebook and the Windows Azure Active Directory Graph APIs. For those who are interested, you can begin exploring our Graph API here: Windows Azure AD Graph Explorer (hosted in Windows Azure) (Select ‘Use Demo Company’ unless you have your own Azure directory and have gone through the steps to give the explorer permission to see it…) [See the second screen capture below/]
To me, the goals of SCIM and the goals of the Graph API are entirely complementary and the protocols should coexist peacefully. We can even try to find synergy and ways to make things like schema elements align so as to make it as easy as possible to move between one and the other.


Kim Cameron was the Chief Architect of Identity in the Identity and Access Division at Microsoft until he resigned in June 2011 to become an independent consultant to the firm.
Facebook graph of my public data at https://graph.facebook.com/roger.jennings.10:

Graph Explorer of “Demo Company” Office 365 directory entry:

<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
•• Michael Washam (@MWashamMS) explained Connecting Windows Azure Virtual Machines with PowerShell in a 7/13/2012 post:
In my post on automating virtual machines I showed the basics for getting around and managing aspects of Windows Azure VMs. In this post I want to cover a few of the more complex scenarios such as connectivity between VMs, deploying into a virtual network and finally deploying a virtual machine automatically domain joined into an Active Directory Domain.
Connecting Virtual Machines
So how do you add two virtual machines to the same cloud service? When you create the first virtual machine using New-AzureVM or New-AzureQuickVM you are required to specify the -Location or -AffinityGroup parameter. When you specify either parameter it tells the cmdlets that you wish to create the cloud service at that time because the data center location can only be set on initial creation. To tell the cmdlets to create the VM in an existing cloud service you just omit the -Location/-AffinityGroup parameter.
Create a VM and a New Cloud Service (specify -Location/-AffinityGroup)New-AzureVMConfig -ImageName $img -Name $vmn -InstanceSize Small | Add-AzureProvisioningConfig -Windows -Password $PWD | New-AzureVM -ServiceName $svc -Location $loc
Create a VM and Adds to an Existing Cloud Service by (omit -Location/-AffinityGroup)New-AzureVMConfig -ImageName $img -Name $vmn -InstanceSize Small | Add-AzureProvisioningConfig -Windows -Password $PWD | New-AzureVM -ServiceName $svcConnecting Virtual Machines with Windows Azure Virtual Networks
The second way of provisioning connected virtual machines is by using a Windows Azure Virtual Network. With a Windows Azure Virtual Network the network can span cloud services. This enables scenarios such as virtual machines (or web and worker roles) in different cloud services to be fully connected in the cloud.
How do you provision VMs into a VNET with PowerShell?
Just like the -Location parameter a VNET can only be specified when creating the first VM in a cloud service (note that the subnet for each VM can be set per VM on provisioning). Additionally, VNETs require that the cloud service be deployed into the same affinity group as the VNET was created in. The New-AzureVM cmdlet requires -AffinityGroup instead of -Location when deploying to a VNET.
Joining a Virtual Network at Provision TimeNew-AzureVMConfig -ImageName $img -Name $vmn -InstanceSize Small | Add-AzureProvisioningConfig -Windows -Password $PWD | Set-AzureSubnet 'subnet' | New-AzureVM -ServiceName $svc -AffinityGroup 'myag' -VNetName 'VNET'Specifying DNS
One of the significant differences between deploying a virtual machine outside of a VNET and one within is inside of a VNET there is no Windows Azure Provided DNS for VM to VM name resolution. To provide for this you are allowed to specify DNS servers inside of the Virtual Network configuration. When deploying with PowerShell you also have the ability to specify DNS settings when you create the first VM. This is a very flexible approach because it allows you the ability to specify DNS at deployment time without the need to modify the underlying virtual network configuration.
Specifying DNS Server on ProvisioningIn this example I am creating a DNS object that references a DNS server (10.1.1.4) and I specify it with New-AzureVM. All VMs created in this cloud service will inherit this DNS setting on boot.
$dns = New-AzureDns -Name 'onprem-dns' -IPAddress '10.1.1.4' New-AzureVMConfig -ImageName $img -Name $vmn -InstanceSize Small | Add-AzureProvisioningConfig -Windows -Password $PWD | Set-AzureSubnet 'subnet' | New-AzureVM -ServiceName $svc -AffinityGroup 'myag' -VNetName 'VNET' -DnsSettings $dnsDeploying a Virtual Machine into an Active Directory Domain
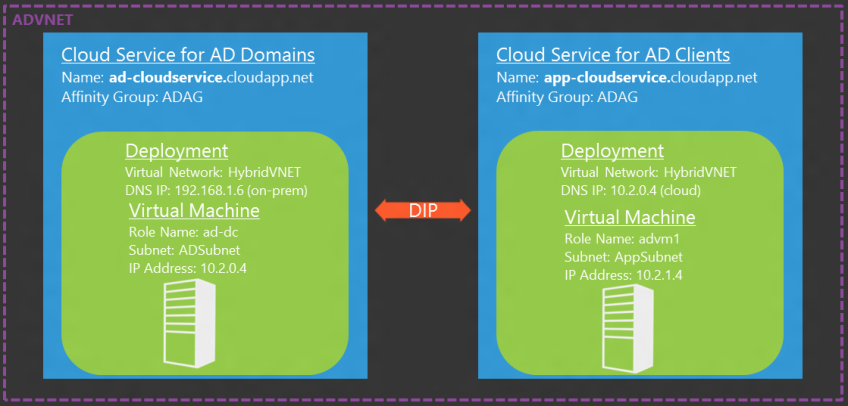
With Windows Azure Virtual Machines it is entirely possible to have a full Active Directory environment in the cloud. AD can either be hosted on-premises with connectivity provided by a site-to-site VPN tunnel using Windows Azure Virtual Networks OR you can host an AD domain directly in the cloud.
Once AD connectivity is in place you can use the PowerShell cmdlets to automatically join a Windows Virtual Machine directly to an Active Directory domain at provision time. For AD domain join to work you must specify the DNS server IP address for your Active Directory domain.
In this example New-AzureDNS is used to specify the DNS for the VM to point to an AD DNS Server in the cloud (10.2.0.4) which itself has been configured to point to an on-premise AD server (192.168.1.6) in a previous deployment. Setting DNS at this level is also useful because any future VMs added to this cloud service will inherit the DNS setting.$subnet = 'APPSubnet' $ou = 'OU=AzureVMs,DC=fabrikam,DC=com' $dom = 'fabrikam' $domjoin = 'fabrikam.com' $domuser = 'administrator' $domVM = New-AzureVMConfig -Name 'advm1' -InstanceSize Small -ImageName $image | Add-AzureProvisioningConfig -WindowsDomain -JoinDomain $domjoin -Domain $dom -DomainPassword $pass -Password $pass -DomainUserName $domuser -MachineObjectOU $ou | Set-AzureSubnet -SubnetNames $subnet $dns = New-AzureDns -Name 'clouddc-ad' -IPAddress '10.2.0.4' New-AzureVM -ServiceName 'app-cloudservice' -AffinityGroup 'ADAG' -VNetName 'HybridVNET' -DnsSettings $dns -VMs $domVM
If you would like to try some of this out on your own I highly suggest the Windows Azure Training Kit as a starting point. There are many hands on labs including deploying Active Directory and connecting multiple virtual machines.

•• Jesper Christiansen (@JesperMLC) described Creating a Windows Azure virtual network with site-to-site VPN to SonicWALL in a 7/2/2012 post (missed when published):
One of the great new features of Windows Azure is the ability to create a site-to-site VPN connection to your local network.
Microsoft delivers configuration instructions for Cisco and Juniper and currently only deliver information and step-by-step configuration details for these devices.
Creating a Local Network
For establishing the connection to a local network you can define your local network before actual creating a new Virtual Network in Windows Azure. This will give you the possibility to create a site-to-site connection in the “New Virtual Network” configuration wizard.
Access the network configuration section in the Windows Azure web portal.
Click the tab called “Local Networks”
Here you click “+ Create” button on the bottom of the page.
Fill out the Name and the public IP address of the VPN gateway.
Then click the next-arrow to proceed to step 2.
You will fill out the subnet(s) and click the checkmark button to create this entry.
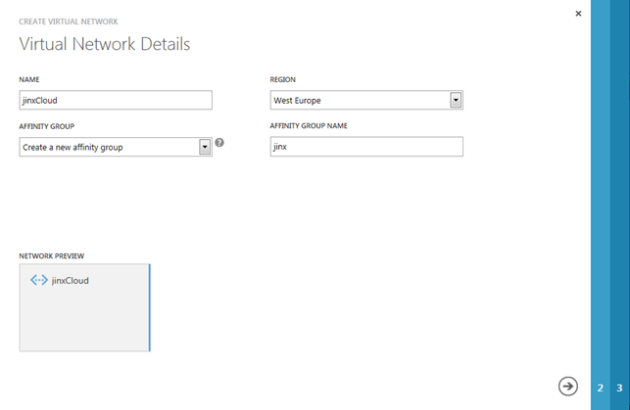
Creating a new Virtual Network and the gateway connection in Windows Azure
It is vital that you create the virtual network before you create the virtual machines in Windows Azure as it is not easy to change to another network for the machines (at the moment).
You will access your portal and click the “+ NEW” button and select “Network” and “Custom Create”
Here you will fill in details regarding the network such as Name, Region to be used and select or create an affinity group.
Then click the next-arrow to proceed to step 2.
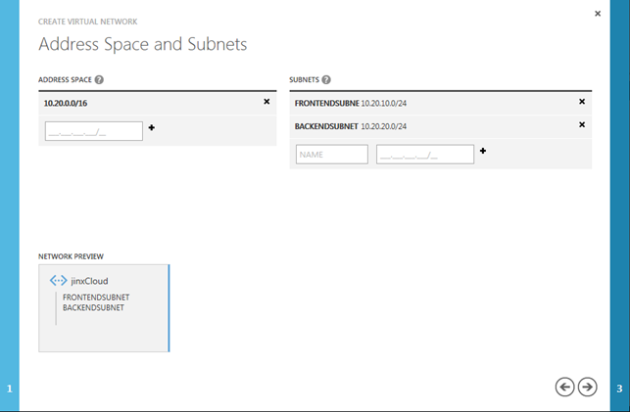
Here you will create your address space and subnets. It is important that you know a bit about subnetting as the address space must include all the subnets you create. The address space is used for “grouping” the addresses and will be used for routing and the VPN tunnel. The network is virtualized and do not conflict with any other networks in Windows Azure.
I create two subnets as the screenshot shows.
Then click the next-arrow to proceed to step 3.
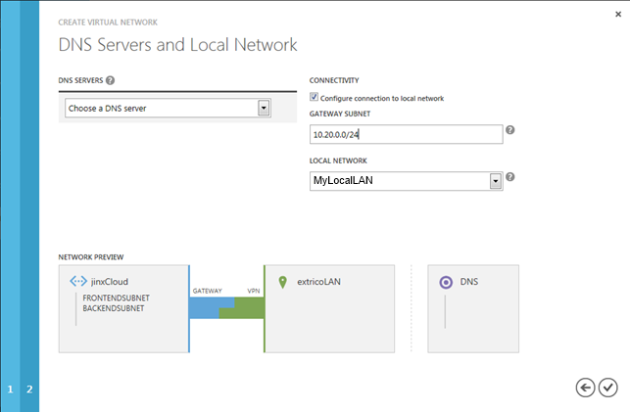
On this configuration screen you will choose a DNS (if any, the default is a Windows Azure default). If you need to create additional domain controllers for an existing domain from your local network it could be a good idea to fill this out.
This is also the page where you configure the actual connection to the local network. You will type in the subnet of the Windows Azure network that is available for the local network. In this example I will provide access to all my Windows Azure subnets.
Click the checkmark button to create the new Virtual Network and configure the Windows Azure VPN connection.
Note: You cannot change the VPN connection details without deleting the gateway. This takes a while and will delete the Windows Azure VPN entry. Afterwards you can create a new gateway and VPN connection again for this Virtual Network.
Configuring the SonicWALL for the VPN connection to the Windows Azure gateway
This example is made from a SonicWALL with an enhanced firmware installed. The enhanced firmware is not required for this to work and just use the same configuration details for a standard firmware.
Log on to your SonicWALL as an admin and go to the “Network” and “Address Objects” menu.
Create a new Address Object (and possibly an Address Group also for future reconfigurations) that defines the Windows Azure network used in the VPN tunnel.
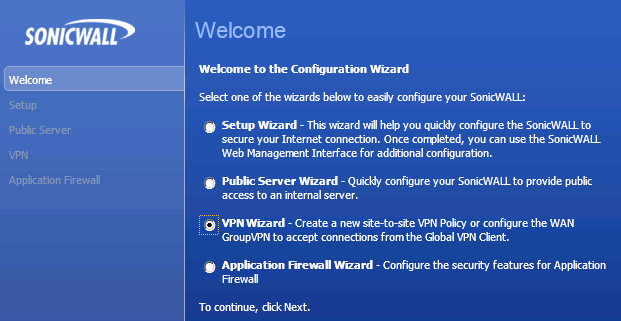
Now you will start the VPN configuration wizard from the button in the upper right corner of the SonicWALL – click Wizards and choose “VPN Wizard”
Choose Site-to-Site
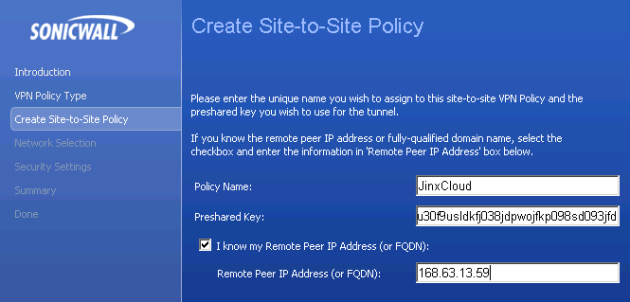
Fill in a name, the preshared key and the Remote Peer IP Address. You can find this by accessing the Windows Azure web portal, go to the “Networks” area and clicking your Virtual Network. On this dashboard you can see the “Gateway IP address” which you will use. The preshared key can be found by clicking the “View Key” on the same page.
Select which subnets you want the Windows Azure networks to access internally and the Windows Azure networks created before
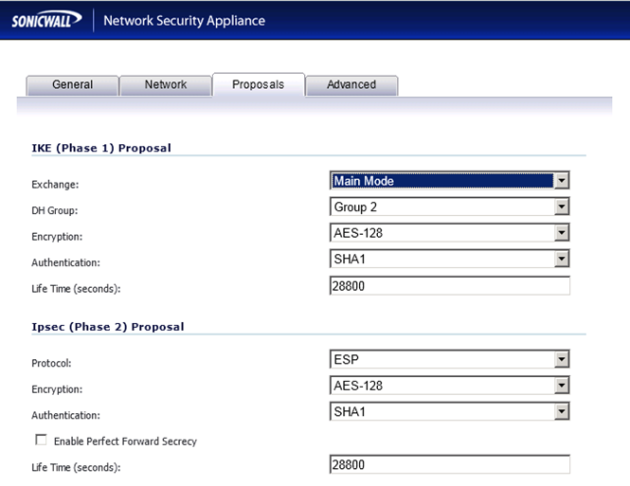
Now select the security settings for this tunnel. This can be different in your configuration or future Windows Azure standards and can be found in the configuration script generated by the Windows Azure Virtual Network Download-wizard. Download the file and check the content.
Now you can complete your wizard and both NAT entries and the VPN tunnel will be created.
Edit the VPN tunnel and configure the ID’s for this tunnel to match the public IP of the SonicWALL and the internal Windows Azure gateway IP (you can see this in the SonicWALL log in an error message. Microsoft could change the settings to support other VPN vendors that do not support their auto-IP-ID configuration):
Also check the proposals section for this – The exchange method must be set to “Main mode”
To active this you can try pinging an address on the remote subnet and you should be able to reach this after the VPN tunnel has initialized. Alternatively you can enable the “Keep alive” on the “Advanced” tab of the VPN tunnel configuration on the SonicWALL.
Note: All Windows Azure Windows Servers has activated the Windows Firewall and you need to either disable the firewall (not recommended!) or add an allow-entry for ICMPv4 traffic in this.
You can check the status of the site-to-site connection on the Windows Azure web portal “Networks” area and clicking your Virtual Network.














The SonicWALL Tz100 Network Security Appliance is available for $227.85 from Amazon.com.
The Windows Azure Virtual Network team should provide a similar walkthrough for non-Network Admins to configure the Cisco ASA 5505 with its Wizard. See my Configuring a Windows Azure Virtual Network with a Cisco ASA 5505-BUN-K9 Adaptive Security Appliance of 6/21/2012 for details.
• Doug Hamilton asked Does Microsoft Windows Azure Threaten vCloud[?] in a 7/13/2012 post to the CloudTweaks blog:
It appears like Microsoft is desperate to become the OS for cloud computing. At Microsoft’s Worldwide Partner Conference on July 10th, the company has announced its Windows Azure’s white-label version which is targeted at the web hosts currently based on Windows Server. This can be viewed as a challenge for VMware, which is trying to push its vCloud agenda. In recent years, VMware is spanning cloud-based and on-premise deployments.
According to Sinclair Schuller, the CEO & founder of Microsoft Partner Apprenda, Microsoft’s this move is smart and the company has tried to develop its cloud-computing footprint. He said,” As Microsoft is expanding their toolkit they’re trying to make sure it’s not a disjointed experience.” Users might wish to use multiple cloud services, but they want a single interface to interact with them. [Link added.]
Apprenda provides an on-premise platform for .NET applications and is now a partner to Microsoft’s latest offering. If a web host performs an internal deployment of an Apprenda instance & plugs it into the portal, the auto-scaling & PaaS capabilities of Apprenda can be deployed directly from the Service Management Portal by the customers.
The Service Management Portal may prove to be the most prominent weapon for Microsoft in its war against virtualization king VMware to become cloud’s operating system. The vCloud-Datacenter-Services program & the vCloud-Director-Management software have provided the head start to VMware, but now Microsoft has got the answers to both. Microsoft, although, still needs to mature a lot, particularly if it wishes to contend for the enterprise-workloads.
Microsoft did something similar few years back with the introduction of Windows Azure Appliance, but it never worked. This strategy was confined to few big partners including Dell, Fujitsu, and HP. Apparently, Fujitsu is the only partner that followed through this strategy.
Microsoft is adding insult to the injury by planning to grow a service-provider-partners ecosystem with a latest program. This will assist them to shift from VMware’s hypervisor to Microsoft’s Hyper-V.
• Edu Lorenzo (@edulorenzo) described Creating and Opening a Windows Azure [Orchard] Website in a 7/12/2012 post:
Microsoft announced the addition of the capability to create new websites straight off the Windows Azure portal. This is a great development but was not able to try it out immediately.
So, late as it is, here goes my attempt.
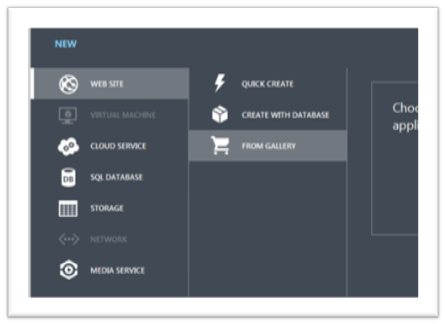
Just hit that, and
I go the way of creating a new website based on a template.
There are several templates on line, I choose Orchard as it is close to my heart J
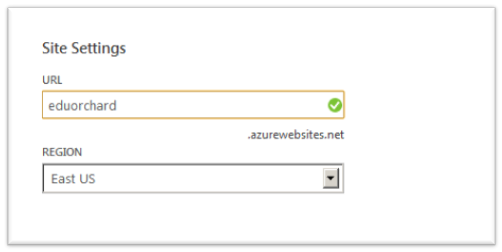
It asks me for a name, fair enough
Then I finish it.
It takes several minutes to deploy. But once you have it started, you have an Orchard CMS up and running on the cloud!
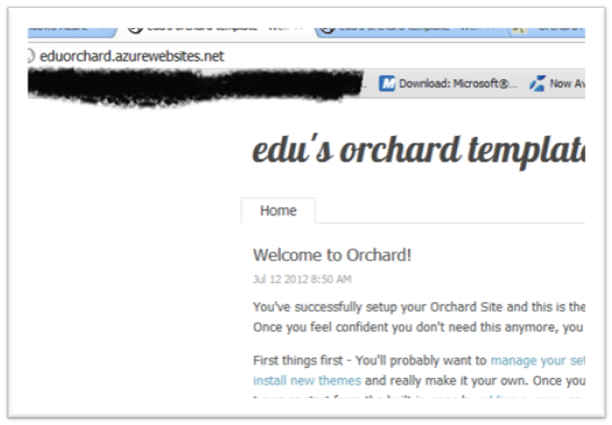
Now all is well and good, I try it out by clicking the url (or clicking the “Browse” button at the lower part of the page).. so that brings me to my brand spanking new Orchard powered CMS.
Configuring, editing and using the CMS will be the same is if it was hosted somewhere else. Nothing fancy to learn
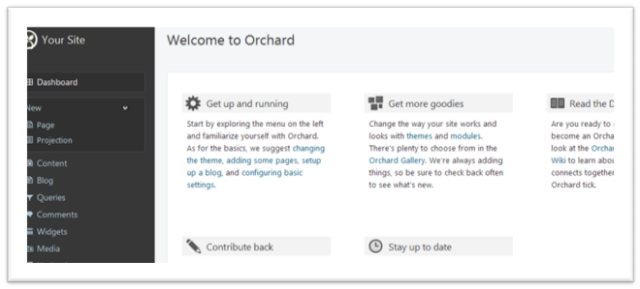
Then you will have your 100% running Orchard CMS Website in minutes!
Of course complete with the dashboard
This blog will not include HOW to maintain an Orchard Website, that can be found in Orchard’s own website.
I was asked, what to do if one wants to download an offline copy of the website from windows azure to edit in his/her machine. Well the new Azure supports FTP and GIT, but an easy way is to find the “WebMatrix” button at the bottom of the page and clicking it. That will either download a fresh install of webmatrix (if not yet done) or fire up an instance of WebMatrix, already connected to your existing Orchard app on Azure.
It might take a few minutes depending on your connection speed.
But after that, it will start downloading all the needed files to your machine.
And afterwards, you have a working local copy of your Orchard powered CMS site!
So there it is! Creating an Orchard CMS through the Windows Azure Portal.





Kristian Nese (@KristianNese) posted Introducing Network Virtualization with Virtual Machine Manager on 7/12/2012:
One of my favorite features for Hyper-V in Windows Server 2012 is Network Virtualization.
In a nutshell: You can virtualize any network and run them all on a single physical network fabric.
How is that even possible? We`ll get to that after we’ve gone through some information and explained the scenarios behind this new capability in Microsoft`s virtualization stack.
I’ve been working a lot with hosters in my career and a common challenge is a secure and scalable solution for multi-tenancy. First thing that you might think of in relation to network is to use VLAN`s. Fair enough, that`s a wide adopted technology to separate networks, but it is also complex and not suited to scale. When I say scale, I am thinking of big time scale, for those major hosters.
In these days when cloud computing is all over the place, we are expecting our service providers to provision infrastructure, platform and software as a Service quite rapidly, working together with anything else and without making any changes to our environment. Unfortunately this is very challenging and not practically realistic.One additional challenge to VLANs is that when you need to scale your Fabric with new virtualization hosts, storage and networking, you are in some ways limited to one physical location.
VLAN can’t span multiple logical subnets and will therefore restrict the placement of virtual machines. So how can you get a solution that works for your customers – even when they have already existing solutions that they want to move to the cloud?
Note: When cloud is mentioned in this blog post, we are thinking of private clouds, public clouds and service provider clouds – which is related to hosters.
By using traditional networking and VLAN`s you will have to reassign IP addresses when moving to the cloud, since mostly of the configuration is relying on the IP configuration on those machines. This will include policies, applications, services and everything else that is used for layer 3 network communications. With the limitations of VLAN`s, the physical location will determine the virtual machine`s IP addresses.
This is where Network Virtualization in Windows Server 2012 – Hyper-V comes to the rescue.
It removes the challenges related to IaaS adoption for customers, and will provide the datacenter administrator an easy an effective way to scale their network fabric for virtual machines.
Network Virtualization will let you run several virtual machines – even with the same identical IP assigned, without letting them see each other, which sounds like the solution for multi-tenancy.
How does it work?
Network Virtualization is policy-based and will use a CA – Customer Address (for the virtual machines, this is the IP that each VM can see and know of) and a PA – Provider Address (this is the IP that the hypervisor will see, letting the VM be visible on the physical network only)
You have two options when it comes to Network Virtualization.
IP rewrite will modify the customer IP address of the packets on the virtual machine before they are transferred on the physical network fabric. One of the pros with IP rewrite is that it will provide better performance since VMQ (Virtual Machine Queue) will continue to operate.
IP encapsulation will encapsulate all the VM packets with a new header before they are sent on the physical network. If we are thinking of scalability, IP encapsulation is the best option since this will allow all of the VMs on a host to share the same provider IP address. The different tenants will be identified by checking the header of the encapsulated packet that will contain a tenant network ID. So since all of the VMs are sharing the provider IP address, the switches in the infrastructure will be smiling since they only need to know the IP address and MAC address for the provider address.
With Network Virtualization in Windows Server 2012 – Hyper-V, any VM can run with any IP configuration and be reachable by the customer, without altering the existing IP configuration. This will ease the transformation to the cloud.
If you want to play around with Network Virtualization in Windows Server 2012 – Hyper-V, you have to brush of your PowerShell skills, as there is no GUI to apply, manage or tweak around the settings.
This work quite well, in small environments, and I would recommend you to follow a fellow MVP blog posts on this subject. Brian Ehlert has just started a series of blog posts about Network Virtualization and it’s PowerShell all the way: http://itproctology.blogspot.com
Management with System Center 2012 SP1 – Virtual Machine Manager
But to manage this in large environments, you would appreciate a world class premium cloud management solution as Virtual Machine Manager.
With the upcoming release of Service Pack 1 for System Center 2012 – Virtual Machine Manager, you will be able to take this a step further and almost do everything without touching PowerShell.
First thing first, you’ll have to prepare the Network Fabric in VMM prior to implement Network Virtualization.
If you are not familiar with Network Fabric in VMM, I’ll suggest that you read this blog post http://kristiannese.blogspot.no/2011/05/create-networks-with-vmm-2012.html for a guidance on how to setup Logical Networks, Virtual Networks, IP Pools and more. This is related to PA – Provider Addresses – which is the IP addresses that the Hyper-V hosts will be able to see and use.
Once this is done, we can move further and configure Network Virtualization.
You’ll find ‘VM Networks’ in the VMs and Services workspace in VMM. VMM uses the IP pools associated with a VM network to assign CA – Customer Addresses to virtual machines that use network virtualization. Remember that the CA is only visible to the VMs and is used by customers to communicate with those VMs.
Default when you configure Network Virtualization in VMM, VMM uses IP rewrite, but you will be able to use IP encapsulation (with Generic Routing Encapsulation (NVGRE) by using PowerShell.
We will create two VM Networks in the following procedure, and using both IP rewrite and IP encapsulation.
If you followed the blog post explaining how to set up the Network Fabric, you should at least have a single logical network containing IP pools, subnets and maybe VLANs. In addition, it’s important that you have associated the logical network with your Hyper-V hosts or/and clusters. If using a cluster, make sure that the virtual networks are associated with the correct interface on each node, and the logical network.
Overview
We will create two VM networks (Blue_VMNet and Red_VMNet). Both associated with the logical network (PA) in Network Fabric.
We will create two VM subnets (IP rewrite) for Blue_VMNet, and one VM subnet (IP encapsulation) for Red_VMNet.
Last, we will create IP address pools for each VM subnet in each VM network (Blue VMSubnet1 IPPool, Blue VMSubnet2 IPPool and Red VMSubnet1 IPPool).
To create a VM network and VM subnets with IP rewrite
- Open the VMs and Services workspace.
- Click Create VM Network. Name the VM network as Blue_VMNet, type a description and click the logical network you created earlier for PA.
- On the VM Subnets page, click Add, and add a VM subnet for Blue_VMSubnet1 (192.168.1.0/24). Repeat the process and create a VM subnet for Blue_VMSubnet2 (192.168.2.0/24)
To create a VM network and VM subnet with IP encapsulation
- 1. Open the VMs and Services workspace
- 2. Click Create VM Network. Name the VM network as Red_VMNet, type a description and click the logical network you created earlier for PA.
- 3. Instead of creating a VM subnet here, we will finish the wizard and start the Powershell module within VMM.
[Detailed instructions]
- Open the VMs and Services workspace.
- On the Home tab, in the Create group, click Create VM Network.
- The Create VM Network Wizard opens.
- On the Name page, do the following, and then click Next.
- Enter a name and optional description for the VM network, for example, enter Green_VMNet.
- In the Logical network list, click the logical network that you created for provider addresses, For example, click PA_Net.
- On the VM Subnets page, click Next, and then on the Summary page, click Finish.
- To configure a VM subnet to use NVGRE, you must create the VM subnet by using the VMM command shell instead of the user interface (UI). Use the New-SCVMSubnet cmdlet with the VMSubnetType parameter. For example, create a VM subnet that is named Green_VMSubnet1, with an IP subnet of 192.168.1.0/24, as shown in the following commands:
PS C:\> $SubNetVLan = New-SCSubnetVLan -Subnet "192.168.1.0/24"
PS C:\> $VMNetwork = Get-SCVMNetwork -Name "Red_VMNet"
PS C:\> New-SCVMSubnet -Name "Red_VMSubnet1" -SubnetVLan $SubnetVLan -VMNetwork $VMNetwork -VMSubNetType "IPEncapsulationWindowsNetworkVirtualization"
Verify that the subnets are created in the console afterwards.
The last thing to do before you are done is to create IP address pool for each subnet in each VM network.
- Open the VMs and Services workspace.
- Click VM Networks.
- In the VM Networks and IP Pools pane, right-click the VM network where you want to create the IP address pool, and then click Create IP Pool.
- Enter a name (Blue VMSubnet1 IPPool), and configure the IP range and settings.
- Repeat this process for each VM subnet.
Congratulations! You have now enabled Network Virtualization with VMM.
During VM creation, you`ll have a couple of new options for the vNIC, connecting to a logical network and VM network.




<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
•• Mike Volodarski (@leanserver) suggested that you Deploy LeanSentry to your Azure application in seconds with our Nuget package! on 7/11/2012 (missed when published):
You can now deploy LeanSentry to your Windows Azure project in just a few keystrokes, by using our Nuget package! This makes deploying to Azure a snap.
Install with:
PM> Install-Package LeanSentryAzureDeployment
As soon as you re-publish your project to Azure normally, LeanSentry will be installed and will begin monitoring the performance and health of your Azure application.
This can make a huge difference, since Azure apps can be so notoriously hard to diagnose when they fail. Esp. when your role keeps recycling due to an unhandled exception or a startup task error – you may not be able to log into your instance, but LeanSentry is running on it and is capturing errors and other interesting events. You can then log into your www.leansentry.com dashboard and troubleshoot from there!
See more here: https://www.nuget.org/packages/LeanSentryAzureDeployment
We are excited to see our users trying LeanSentry out over the last few weeks, and have been getting great feedback that make features like this possible. Keep it coming!


Brian Swan (@brian_swan) described Service Management with the Windows Azure SDK for PHP in a 7/12/2012 post:
Since the June 7th release of the “new” Windows Azure SDK for PHP, the Azure team has been working hard to add functionality that will (eventually) wrap the complete Windows Azure REST API. One area that they have been working on (and that may have slipped under your radar) is Service Management. The ServiceManagementRestProxy class currently provides programmatic access to much of the storage services-related functionality that is available in the management portal (such as creating storage services, creating affinity groups, accessing storage service properties, etc). While this is just a subset of what can be done via the Service Management REST API, the available functionality can be useful in building applications that need programmatic access to storage services.
In this post, I’ll try to give you enough information to get started with service management via PHP (I’ll assume you have already created a Windows Azure account and a storage account). Of course, to dig into the details yourself, you can always check out the Service Management classes on Github.
Get the PHP Client Libraries for Windows Azure
All the details for getting the PHP Client Libraries for Windows Azure (and other components of the Windows Azure SDK for PHP) can be found here: Download the Windows Azure SDK for PHP. Note that for the code snippets in this article, I followed the instructions for using Composer to install the client libraries (hence, the snippets reference the ‘vendor\autoload.php’ autoloader file).
Set up your connection
Connecting to the Service Management endpoint is handled via the Configuration class. To create a configuration object, you need three ServiceManagementSettings: your subscription ID, the path to your management certificate, and the management endpoint URI (which is https://management.core.windows.net). You can obtain your subscription ID through the management portal, and you can create management certificates in a number of ways – I’ll use OpenSSL, which you can download for Windows and run in a console.
You actually need to create two certificates, one for the server (a .cer file) and one for the client (a .pem file). To create the .pem file, execute this:
openssl req -x509 -nodes -days 365 -newkey rsa:1024 -keyout mycert.pem -out mycert.pemTo create the .cer certificate, execute this:
openssl x509 -inform pem -in mycert.pem -outform der -out mycert.cer(For more information about Windows Azure certificates, see Overview of Certificates in Windows Azure. For a complete description of OpenSSL parameters, see the documentation at http://www.openssl.org/docs/apps/openssl.html.)
After you have created these files, you will need to upload the .cer file via the management portal, and you will need to make note of where you saved the .pem file (you’ll need the path to this file to create a Configuration object).
After you have obtained your subscription ID and created a certificate, you can create a Configuration object like this (where $subscription_id is your subscription ID and $cert_path is the path to your .pem file):
require_once 'vendor\autoload.php';use WindowsAzure\Common\Configuration;use WindowsAzure\ServiceManagement\ServiceManagementSettings;$config = new Configuration();$config->setProperty(ServiceManagementSettings::SUBSCRIPTION_ID, $subscription_id);$config->setProperty(ServiceManagementSettings::CERTIFICATE_PATH, $cert_path);$config->setProperty(ServiceManagementSettings::URI, "https://management.core.windows.net");Create a ServiceManagementRestProxy object
Most of service management will be done through the ServiceManagementRestProxy class. To create a ServiceManagementRestProxy object, you simply pass a configuration object to the ServiceManagementService::create factory method:
require_once 'vendor\autoload.php';use WindowsAzure\ServiceManagement\ServiceManagementService;$svc_mgmt_rest_proxy = ServiceManagementService::create($config);List available locations
The Windows Azure team has added some new data center locations recently, and I have trouble remembering the location names anyway, so the ServiceManagementRestProxy->listLocations method I find very helpful:
$svc_mgmt_rest_proxy->listLocations();$locations = $result->getLocations();foreach($locations as $location){echo $location->getName()."<br />";}Currently, the available locations are…
Anywhere US
Anywhere Europe
West Europe
Anywhere Asia
Southeast Asia
East Asia
North Central US
North Europe
South Central US
West US
East USYou will need to know what locations are available when you create a storage service or an affinity group.
Create a storage service
A storage service gives you access to Windows Azure Blobs, Tables, and Queues. To create a storage service, you need a name for the service (between 3 and 24 lowercase characters and unique within Windows Azure), a label (a base-64 encoded name for the service, up to 100 characters), and either a location or an affinity group. Providing a description for the service is optional. The location, affinity group, and description are set in a CreateStorageServiceOptions object, which is passed to the ServiceManagementRestProxy->createStorageService method. The following snippet shows you how to create a storage service by specifying a location. If you want to use an affinity group, you’ll need to create one first (see the section below) and set it with the CreateStorageServiceOptions->setAffinityGroup method.
require_once 'vendor\autoload.php';use WindowsAzure\ServiceManagement\ServiceManagementService;use WindowsAzure\ServiceManagement\Models\CreateStorageServiceOptions;$svc_mgmt_rest_proxy = ServiceManagementService::create($config);$name = "mystorageservice";$label = base64_encode($name);$options = new CreateStorageServiceOptions();$options->setLocation('West US');$result = $svc_mgmt_rest_proxy->createStorageService($name, $label, $options);Once you have several storage services, you may need to list them and inspect their properties:
$get_storage_services_result = $svc_mgmt_rest_proxy->listStorageServices();$storage_services_properties = $get_storage_services_result->getStorageServices();foreach($storage_services_properties as $storage_service_properties){$name = $storage_service_properties->getServiceName();echo "Service name: ".$name."<br />";echo "Service URL: ".$storage_service_properties->getUrl()."<br />";$properties = $svc_mgmt_rest_proxy->getStorageServiceProperties($name);echo "Affinity group: ".$properties->getStorageService()->getAffinityGroup()."<br />";echo "Location: ".$properties->getStorageService()->getLocation()."<br />";echo "------<br />";}Note: The development team is working on making this scenario smoother, since it seems strange that the affinity group and location aren’t available on the ServiceProperties objects returned by getStorageServices().
Finally, you can delete a storage service by passing the service name to the deleteStorageService method:
$svc_mgmt_rest_proxy->deleteStorageService("mystorageservice");Create an affinity group
An affinity group is a logical grouping of Azure services that tells Windows Azure to locate the services for optimized performance. For example, you might create an affinity group in the “West US” location, then create a Cloud Service in that affinity group. If you then create a storage service in the same affinity group, Windows Azure knows to put it in the “West US” location and optimize within the data center for the best performance with the Cloud Services in the same affinity group.
To create an affinity group, you need a name, label, and location. You can optionally provide a description:
use WindowsAzure\ServiceManagement\ServiceManagementService;use WindowsAzure\ServiceManagement\Models\CreateAffinityGroupOptions;$svc_mgmt_rest_proxy = ServiceManagementService::create($config);$name = "myAffinityGroup";$label = base64_encode($name);$location = "West US";$options = new CreateAffinityGroupOptions();$options->setDescription = "My affinity group description.";$svc_mgmt_rest_proxy->createAffinityGroup($name, $label, $location, $options);As mentioned earlier, after you have created an affinity group, you can specify the group (instead of a location) when creating a storage service.
You can also list affinity groups and inspect their properties by calling listAffinityGroups, then calling appropriate methods on the AffinityGroup object:
$result = $svc_mgmt_rest_proxy->listAffinityGroups();$groups = $result->getAffinityGroups();foreach($groups as $group){echo "Name: ".$group->getName()."<br />";echo "Description: ".$group->getDescription()."<br />";echo "Location: ".$group->getLocation()."<br />";echo "------<br />";}Lastly, you can delete an affinity group by passing the group name to the deleteAffinityGroup method:
$svc_mgmt_rest_proxy->deleteAffinityGroup("myAffinityGroup");That’s it for now…hopefully enough to get you started with using the Service Management API to manage storage services. As always, if you have feedback, we’d love to hear it.

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
•• Beth Massi (@bethmassi) described New Features Explained – LightSwitch in Visual Studio 2012 in a 7/13/2012 post:
The team has been cranking out a lot of great content over on the LightSwitch Team blog and a lot of that stuff is related to all the new features in Visual Studio 2012. The Release Candidate (RC) has been available since late May. So if you haven’t done so already, I encourage you to download and play with it and notify us in the LightSwitch RC forum of any issues you encounter. We’re working hard to lock down the release.
With all the (well deserved) hype over the HTML Client Preview lately, I thought it would be helpful to bring some focus back and tally the list of articles on the major new features that are ready to ship that are available in Visual Studio 2012. Just in case you missed them:
OData Services Support
- Creating and Consuming LightSwitch OData Services
- Enhance Your LightSwitch Applications with OData
- LightSwitch Architecture: OData
- Using LightSwitch OData Services in a Windows 8 Metro Style Application
- Creating a LightSwitch Application Using the Commuter OData Service (Part 1, Part 2, Part 3)
- LightSwitch OData Consumption Validation in Visual Studio 2012
- Finding Your LightSwitch Produced OData Services in Visual Studio 2012
New Data Features
- LightSwitch Concurrency Enhancements in Visual Studio 2012
- User Defined Relationships within Attached Database Data Sources
- Filtering Data using Entity Set Filters
Security Enhancements
UI Design Improvements
- New Business Types: Percent & Web Address
- How to Add Images and Text to your LightSwitch Applications
- How to Use the New LightSwitch Group Box
- How to Format Values in LightSwitch
Deployment Enhancements
- LightSwitch IIS Deployment Enhancements in Visual Studio 2012
- Publishing LightSwitch Apps to Azure with Visual Studio 2012
The team is continuing to publish articles on more features so make sure you check the LightSwitch team blog weekly and follow @VSLightSwitch on Twitter. And to see all the great stuff the community has been producing check out my LightSwitch Community & Content Rollups.

• Kostas Christodoulou (@kchristo71) posted Just Visiting or (not so) Simple Extension Methods (part 4) on 7/13/2012:
One of my favorite design patterns since the age of c++ is the Visitor Pattern. I will not explain here what the visitor pattern is. But, if you know how to use the design pattern this is a post worth reading.
One may ask what the visitor pattern has to do with LightSwitch. Well, it doesn’t! I mean not exclusively. But the code below provides a full visitor pattern implementation background that can also be used in LS. Also, a part of the implementation is ideal for LS, since one of the challenges I had to face, when trying to widely use the visitor pattern, was make it work for “sealed” classes, classes that were not written by me and could not easily fit to my –reflection based- visitor pattern implementation. To solve this the best thing I could think of was “wrapping”. And working with LS, most of the classes (apart from the ones that belong to the domain/datasource) are actually “sealed” in the way described above.(I have to note here that this reflection-based implementation is a revision of an implementation I found (if I recall correctly) in CodeProject).
First the two basic interfaces that have to be defined:
The IVisitor interface that has to be implemented by the “worker” (or helper to follow the VB-oriented naming of the LS Team) class.public interface IVisitor { void VisitDefault(IVisitorTarget source); }Then the IVisitorTarget interface (implied above) that has to be implemented by the class to be “consumed/visited” by the Visitor.public interface IVisitorTarget { void Accept(IVisitor visitor); }Ok, I know, nothing much up to now. But as I say “The longest journey starts with the first step”…(yes I am an old Chinese philosopher)
To have your visitor pattern in place you need an extension method to do the trick:public static bool ConcreteVisit(this IVisitorTarget target, IVisitor visitor) { Type[] types = new Type[] { target.GetType() }; MethodInfo mi = visitor.GetType().GetMethod("Visit", types); if (mi == null) return false; mi.Invoke(visitor, new object[] { target }); return true; }Now that these pieces are in place let’s say we have a class called DisplayNameBuilder that implements the IVisitor interface. Also, let’s say we have a Customer entity in our datasource and we want it to implement the IVisitorTarget interface. All we have to do is open Customer entity in the designer, click Write Code and change the class declaration to:public partial class Model : IVisitorTargetmake sure you are using the namespace of the class where the above extension method is implemented and implement the IVisitorTarget interface like this:#region IVisitorTarget Members public void Accept(IVisitor visitor) { if (!this.ConcreteVisit(visitor)) visitor.VisitDefault(this); } #endregionAlso this is a sample implementation of the DisplayNameBuilder class:public class DisplayNameBuilder : IVisitor { public string Name{ get; private set; } public void VisitDefault(IVisitorTarget visitorTarget){ Name = visitorTarget.ToString(); } public void Visit(Customer visitorTarget){ Name = string.Format("{0}{1}{2}", visitorTarget.FirstName, string.IsNullOrWhiteSpace(visitorTarget.FirstName) ? "", " ", visitorTarget.LastName); } }In the above code please note these:Now lets say you create a calculated string field in Customer entity called hmmmmm… DisplayName (surprised? It’s a gift I have regarding giving original names
- The code was written in Live Writer as it’s demo code, so maybe it does not compile as is.
- The customer is implied to have a nullable FirstName property and a not nullable LastName (which I believe it’s a fair assumption and I agree with me).
- The implementation, as obvious, is domain aware as it knows what Customer is. This implies that the ideal place for this class to live is in the Common project.
). This would be the code that would implement the calculation of DisplayName property:
partial void DisplayName_Compute(ref string result) { DisplayNameBuilder builder = new DisplayNameBuilder(); this.Accept(builder); result = builder.Name; }I HAVE to stress one more time that the code is for demonstration purposes only. It’s not just you, it IS too much fuss for nothing.
Ok, now it should be easier to understand the problem of using the visitor pattern with pre-defined classes. You cannot add the IVisitorTarget behavior to most of the classes, automatically generated by LS.
So this is the solution to the problem.public class IVisitorWrapper<TObjectType> : IVisitorTarget { public TObjectType Content { get; set; } #region IVisitorTarget Members public void Accept(IVisitor visitor) { if (!this.ConcreteVisit(this, visitor)) if (!this.VisitWrapper(this, visitor)) visitor.VisitDefault(this); } #endregion }This is a wrapper class (one could say it is an IVisitorTarget decorator). If you are still with me and you keep on reading the code you have already noticed that VisitWrapper extension method is not yet defined, so this is it:public static bool VisitWrapper<TObjectType>(this IVisitorWrapper<TObjectType> wrapper, IVisitor visitor) { Type[] types = new Type[] { typeof(TObjectType) }; MethodInfo mi = visitor.GetType().GetMethod("Visit", types); if (mi == null) return false; mi.Invoke(visitor, new object[] { wrapper.Content }); return true; }
Now you can wrap any type of object and use the DisplayNameBuilder to build it’s display name. Also (as –I hope- you guessed) you have to implement the respective Visit method in DisplayNameBuilder in order not go get the type name back as Name.


Matt Sampson described Finding Your LightSwitch Produced OData Services (Visual Studio 2012) in a 6/13/2012 post (missed when published):
With the latest version of LightSwitch in Visual Studio 2012 you can now consume as well as produce OData services from the data sources managed by the LightSwitch middle-tier. But if we want to interact with the OData services that LightSwitch produces we need to know how to reference them directly.
We’re going to learn how to do this today with a custom Silverlight control for our LightSwitch applications to help us easily view the OData service that LightSwitch produces for each data source on our application.
(If you want some more detailed info on how LightSwitch makes and uses OData services, then John Rivard has a good article on just how LightSwitch uses OData services - LightSwitch Architecture: OData).
Where is my OData Service?
If I make a LightSwitch application with a couple of data sources, like NorthwindData and ApplicationData, and build then we will have two OData services that will be automatically created for us. These OData services will be named: NorthwindData.svc and ApplicationData.svc. This is the important bit - each data source gets its own OData service. The diagram below illustrates this well:
These OData services are used by the LightSwitch client to communicate with the LightSwitch server. But maybe you want to query these OData services directly yourself with your own OData client (like Power Pivot for example), or maybe you’re just curious what these services look like.
If you launch a published LightSwitch web application you will see the url look something like: http://MyServer/MyLightSwitchApplication/. And if you wanted to directly query the OData service for the Northwind data source directly you could just modify the url like so: http://MyServer/MyLightSwitchApplication/NorthwindData.svc/.
As you can see, the format for referencing the OData service is http:// + server name + application name + OData service name:
To know what the OData service name is however, you would need to know the data source names. You probably don’t have this knowledge unless you were the developer of the data model, and even then perhaps you’ve published your LightSwitch application several months ago and now you no longer recall the data source names.
Find it with a custom control
We can simplify finding the LightSwitch produced OData service by creating a custom Silverlight control, adding it to our screen, then clicking a button to launch our OData service.
Our custom Silverlight control will utilize the LightSwitch API to determine what the name of our OData service is, and then it will launch a new browser window with the OData service as the URL.
If you haven’t used custom controls before, it just takes a few steps to add it to your screen.
- Follow the basic steps over on my Code Gallery post, Custom Silverlight Control to find LightSwitch OData Services, to build the custom Silverlight Control into a .dll that we will use later
- Create a LightSwitch Web application, add some data and add a screen (I created a table called “MyBook” to the ApplicationData data source)
- Add a screen
- Add a custom control to the screen like so:
Step 1 – Select Add –> New Custom Control-
Step 2 – A dialog pops up asking where the custom control is. Click “Add Reference”.
Step 3 – Click the “Browse” button and find the .dll for the custom Silverlight control that you made in the beginning. Hit OK.
Step 4 – Expand the reference that was added to select the actual custom control name. Hit OK.
Step 5 – You can modify the control’s properties to give it a name like “OData Service:” as I did below:
Step 6 – F5 it! You’ll see the control at runtime on your screen. Click the drop down arrow to see a list of your OData services that are available to you.
And viola! A new browser window opens up with your OData service.
Quick look at the code
Let’s take a look at the Silverlight custom control code.
In the constructor code below, which is invoked when the control is created, we are doing a few things:
- We are looking through the list of Modules available to the client. The one we want specifically is called LightSwitchCommonModule
- We get all the EntityContainers off of the LightSwitchCommonModule and store them in a List object which we wil use later. An EntityContainer will be our data source (e.g. ApplicationData, NorthwindData, etc.)
- The List object we populated with Data Source names is bound to the custom Silverlight control. That is the data the user will see at runtime available as a drop down list.
Control Constructor
- public ODataFinder()
- {
- InitializeComponent();
- try
- {
- IModuleDefinition module = ClientApplicationProvider.Current.Details.GetModules().Where(i => i.Name.Contains("LightSwitchCommonModule")).First();
- // EntityContainer objects will be things such as ApplicationData, NorthwindData,...
- foreach (LightSwitch.EntityContainer globalItem in module.GlobalItems.OfType<LightSwitch.EntityContainer>())
- {
- ServicesDropDownList.Items.Add(globalItem.Name);
- }
- }
- catch (Exception)
- {
- // if we fail then we just won't populate any data sources
- }
- }
Our custom control is a drop down list. When the drop down is closed we will try to launch the OData service URL in a browser.
This method below does that in the following way:
- Get the URI of the Host machine, which will be something like “http://myServer/myApp/App.xap”
- We parse off the name of the Host machine, and the name of the application
- We combine the host name + the application name + the data source name selected by the user to form a URL. Something like http://myServer/myApp/ApplicationData.svc/.
- We launch the URL in a web browser (the way we launch it in a web browser varies a bit on whether or not we are in a Desktop client or a Web client)
Control Closed Method
- private void ServicesDropDownList_DropDownClosed(object sender, EventArgs e)
- {
- try
- {
- string absoluteUri = Application.Current.Host.Source.AbsoluteUri;
- System.UriBuilder appUri = new UriBuilder(absoluteUri);
- string host = Application.Current.Host.Source.Host;
- int indexOfHost = absoluteUri.IndexOf(host);
- int indexOfEndOfHost = absoluteUri.IndexOf("/", indexOfHost + host.Length);
- string dataServiceUri = absoluteUri.Substring(0, indexOfEndOfHost);
- if (host.Contains("localhost"))
- {
- dataServiceUri = dataServiceUri + "/" + ServicesDropDownList.SelectedItem.ToString() + ".svc" + "/";
- }
- else
- {
- //Example format: http://IISMachine/AppName/Web/Application18.Client.xap?v=1.0.2.0?v=1.0.2.0
- int indexOfEndOfAppName = absoluteUri.IndexOf("/", indexOfEndOfHost + 2);
- int lengthOfAppName = indexOfEndOfAppName - indexOfEndOfHost;
- string appName = absoluteUri.Substring(indexOfEndOfHost, lengthOfAppName);
- dataServiceUri = dataServiceUri + appName + "/" + ServicesDropDownList.SelectedItem.ToString() + ".svc" + "/";
- }
- // Check to see if we are running in the Desktop
- if (AutomationFactory.IsAvailable)
- {
- var shell = AutomationFactory.CreateObject("Shell.Application");
- shell.ShellExecute(dataServiceUri);
- }
- // Else we are running in a web client
- else
- {
- //Open up the OData service in a new web page
- System.Windows.Browser.HtmlPage.Window.Navigate(new Uri(dataServiceUri), "_blank");
- }
- }
- catch (Exception)
- {
- // if we fail then just don't display anything
- }
- }
Bring it all together
We’ve covered a couple things here:
a) How you can go about manually finding your OData services that LightSwitch produces for each data source
b) How you can make this a bit easier by adding a custom Silverlight control your LightSwitch applications to find and display the OData service for you.
Check out my Ccode Gallery post, Custom Silverlight Control to find LightSwitch OData Services, for the code and for some more details on how to make this custom SL control.
Thanks all, and please let me know if you have any feedback.










Return to section navigation list>
Windows Azure Infrastructure and DevOps
• John Furrier (@furrier) asked Devops – Art? Science? Hype? Can DevOps Deliver on Business Needs[?] in a 7/13/2012 post to SiliconANGLE’s DevOpsANGLE blog:
Talking about DevOps can be quite conceptual in many cases. How we integrate the Devops concept into the architecture of a company can quite literally be a blend of arts, discipline and the science of technology. Where that line is drawn is really variable and it depends on a number of factors.
At the intersection of Development and Operations is a genetically embedded business agenda that begins with some issue, followed by a root cause analysis, and the production of an answer or solution. The solutions that have come to meet this have formed into this DevOps movement.
Hard-core statisticians out there may be inclined to point to algorithmic deductions and target those types of gains and advantages that can be identified. With no shortage of statistical information from logging information, performance collections, and the sort, it is quite easy to fixate and become reactive to the analysis of information that is gleaned from these resources. Indeed, sometimes that may actually be the desired focus. Others may rely heavily on features and technical benefits of one technology over others, such as scripting ability and compatibility. Other times it may be a talent analysis of the personnel that drives the focus on a technology. It is very important though to either turn on the filter and extract real value from these technical capabilities or better yet focus on the solutions aspect from the outset.
In a conceptual state, the introduction of DevOps into the enterprise should approach this solution focused balance throughout integration and early during design when possible. Clearly there are cost factors and technical realities in any functional environment, but from the outset, the approach must remain consistent and that is what the underlying balance must maintain.
Infrastructure
Let’s reflect on infrastructure. Modern datacenters feature a range of network, server, and cloud technologies. Whether the cloud environment is internal (private cloud), external (public), or hybrid cloud, the environment calls for tools that feature management, automation, and consistency in the technology that drives it. In many scenarios the problem may consist of a need to boost reliability in infrastructure by making it reproducible and preset. This is common in development environments where leading tools such as Puppet and Chef work to ensure the automated configuration of systems and services in the infrastructure by utilizing their powerful features. Further, the environment may then rely on monitoring and performance metric information that also can implement automated integration strategy.
If an organization starts out in the midst of minutiae of technical elements from the outset, the path can become blurred or delayed, or at least needs to get back on track. A consistent approach to DevOps is one that embraces the underlying business value, being that it addresses the issue and solution, in respect to the technical realities and capabilities of the organization.
In the example above, DevOps may serve as a solution to create the complex and interconnected elements of a sustainable, automated and reliable infrastructure that must be implemented at each stage of design, implementation, and ultimately production.
Looking at scenario after scenario in the wild, the infrastructure, the operations elements are becoming more critical parts of the application. Infrastructure is essentially becoming a code, particularly as many if not all resources are more than likely virtual. The goal, the solution to solve – is visible in many scenarios that hit the news.
Anytime there is a major outage, such as Amazon Web Services, Netflix, and others – in these production instances, uptime, flexibility, and reliability are the keys to customer expectations and successful business for these companies.
If by DevOps from its basic approach one can deliver value to the organization, then DevOps wins and often saves the day. It is always about solving the problem as efficiently as possible. DevOps solutions must meet and deliver on the goals of the business and the ability of that solution to meet the expectations of success. More power to the organization and better value to the customer are being unleashed, be it better development or sustained, reliable operations, or infrastructure for BigData – whatever it is a leading practice on into the future of computing.
Devops – Art? Science? Hype? Can DevOps Deliver on Business Needs is a post from: SiliconANGLE. We're now available on the Kindle! Subscribe today.

• Edu Lorenzo (@edulorenzo) described Migrating a Data Centric Application to Windows Azure in a 7/11/2012 post:
My last blog entry was to illustrate some concerns that I have encountered when one is to develop an application to Windows Azure. So that comes as a bit of an oversight. I was looking at a world where there are no existing applications. So I backtracked a bit and will need to deliver a separate blog for Migrating or converting an existing web application to Windows Azure. Because 99% of the web applications out there are of course already existing. [Link added.]
First, the scope. Migration, as defined is the movement from one place to another. Not coexistence. As simple as that, we define what migration is. The existing web application will be MOVED from one location to another, with no turning back.
Then we define what is an application built for Windows Azure. It is very often that we hear people refer to an application on Windows Azure as a “Cloud Application”. Which is fair enough, as Windows Azure is, Microsoft’s cloud platform service. But I must state clearly, that not all applications running on Windows Azure were built for Windows Azure, hence, I would not consider them as cloud applications.
A cloud application, is one that was engineered and built in such a way that it will not run on any other platform other than the cloud. It will also take advantage of, and leverage everything that the cloud has to offer, such as Scaling, Multi-tenancy, CDNs, blob storage etc. If the application is not built as such, I will not call that said application as a Cloud Application or an application built for Windows Azure.
Simply put, an application must be deployed to Windows Azure, use the services offered (like Web Roles, Worker Roles, Cloud Storage etc) in the proper way, to be considered as a cloud application.
As I was writing this blog entry, I stumbled upon a webpage that illustrates everything I want to illustrate and more. J
So here it is.

• David Linthicum (@DavidLinthicum) asserted “Two sins are self-inflicted by the cloud providers, while the third is an evil spawned by regulators” in a deck for his 3 more evils that threaten cloud computing post of 7/13/2012 to InfoWorld’s Cloud Computing blog:
There's a lot of good in cloud adoption, which is why I've railed against problems that threaten to kill cloud computing. This summer, three more problems have surfaced that are raising my blood pressure -- and threatening the cloud.
1. The recent AWS outages. Amazon.com is the leader in the IaaS (infrastructure as a service) space, so it has a responsibility to set the standards for service. Lately, it has had too many outages, opening up cloud computing to criticism around the risks of using public cloud resources. The federal government is now looking into the outages, and the naysayers are coming out of the woodwork to toss mud at AWS -- and at cloud computing in general.
2. Vendor technology duels. As with any overheated technology space, the larger technology providers are sniping at each other's versions of the cloud. Each says its version is perfect, whereas their competitors' versions of cloud computing are proprietary and, of course, evil.
Organizations debating the use of cloud computing will continue to watch these vendor marketing battles, waiting to see who wins. But there won't be any winners any time soon, so hesitant enterprises will miss the benefit of cloud computing. It's a shame that cloud computing's benefit is obscured by the FUD that so many of the providers spin in their competitive insults -- it hurts everyone.
3. New European regulations around the use of cloud services. European privacy watchdogs are recommending the use of a new auditing system for vetting cloud providers in the United States and elsewhere. You can find this in Article 29 Working Party, which is a group representing the various E.U. member states' data protection bodies.
There's a ton of confusion around what it means to be compliant, so it's easy to surmise that many organizations are not compliant. However, there's little enforcement. That will change with the proposed auditing system -- and it will make the adoption of cloud computing in Europe a very painful experience.
I'm sure more such evils will surface later this year for me to call out!


• Wouter Belmans and Uwe Lambrette (@CiscoSP360) asserted 6 Battlefields Are Disrupting the Cloud Value Chain in a 7/10/2012 post to Cisco Systems’ Service Provider 360 (SP360) blog:
As cloud computing matures and hype becomes reality, uptake among small and medium-sized businesses (SMBs) and large enterprises is increasing. And although the cloud is still in its infancy, the Cisco Internet Business Solutions Group (IBSG) believes it is an appropriate time to ask: “How is the cloud value chain taking shape, and where are the battlefields I need to be concerned about?”
Cisco IBSG has found that major disruptions are taking place on six battlefields across the value chain:
1. SaaS Will Further Disrupt the Independent Software Vendor (ISV) Landscape
- Barriers to new entrants continue to decrease due to IaaS, PaaS, and cloud brokers.
- ISV incumbents are slowed down by cannibalization.
- The SaaS paradigm is already disruptive in approximately 25 percent of the software market.
- Mobile application access is accelerating SaaS adoption in additional software segments.
2. PaaS: Development Platforms Will Be at the Core of the Cloud
- The advantages of automation are increasing, while the drawbacks of lock-in are being addressed.
- PaaS is winning the hearts of web developers, with enterprise development close behind.
- In just five years, PaaS could be the cloud delivery model that generates the most revenues for cloud service providers. [Emphasis added.]
3. IaaS: Web-Grade and Enterprise-Grade Infrastructure Services Continue To Battle Each Other
- The battle of web- versus enterprise-grade services rages on across hosted and internal IaaS.
- Maturing web-grade cloud enablers will accelerate the entry of more than 30,000 hosting companies.
- Despite the head start of web-grade services, Cisco IBSG expects strong growth for enterprise-grade IaaS.
- The battle of data center (DC) architectures will continue with massively scalable DCs (web) versus vertically integrated DCs (enterprise) co-existing for the foreseeable future.
4. Facility and Infrastructure Strategies Are Often-Forgotten Fundamentals
- Two facility strategies are on the rise, and often compete with each other:
1) On-net cloud delivers the value of WAN / IT integration.
2) Mega-exchanges deliver the value of an ecosystem of players that host services together.
- Cloud computing enhances IT infrastructure buying power and sophistication. This means ICT infrastructure original equipment manufacturers (OEMs) must rapidly innovate to avoid commoditization.
5. Commercial Activity Channels Are Being Disrupted by Cloud Brokers
- Everybody wants to be a cloud broker, but only a few companies will attract the required ecosystem to succeed.
- Players that can grow from the core will be more successful in the cloud market.
6. Professional Services Require a Shift to Activities that Add More Business Value
- In the short term, cloud migration services are the main opportunity.
- Longer term, professional services companies must shift their focus to activities that add more business value.
- As the focus shifts to business value, deep industry expertise will become increasingly important.
Network service providers (NSPs) must be aware of these value-chain dynamics when determining their go-to-market strategies, which include:
- Commodity infrastructure services with PaaS support
- Enterprise-grade infrastructure services with developer enablement
- Telco-centric SaaS, including communications, collaboration, and security
- Vertical business process services, with a platform ready for business process as a service
- Network as a service (enriched network to better support the cloud)
- Cloud aggregation and brokerage linked to telco-centric managed services
Across the various go-to-market strategies, NSPs need to make a clear choice about how to address professional service requirements—either by building internally, partnering, or acquiring a company with the needed skill sets. Commercial success will often be greater and occur faster (with less risk) where new cloud business models can be layered on top of existing services. Companies that grow from the core can reuse existing capabilities, including customer relationships and sales channels. For telecommunications companies, it often makes sense to grow a cloud portfolio from a base of hosted communications and collaboration products.

Wouter Belmans is a Senior Manager and Uwe Lambrette is a Director of Cisco Systems’ Internet Business Solutions Group.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Maureen O’Gara (@MaureenOGara) asserted “A newfangled Service Management Portal built into Windows 8’s new Metro user interface can deliver Azure-like services” in a deck for her Windows Server Painted Azure article of 7/13/2012 for the Azure Cloud on Ulitzer blog:
Microsoft has colored Windows Server 2012 Azure and white-boxed it for service providers and hosting outfits disenfranchised by Amazon, creating in the process a cloud operating system that it can rattle under the nose of the vCloud-pushing VMware.
What it's done exactly is add Azure-y features to Windows Server so service providers can build Azure-like infrastructure clouds out of their Windows Server data centers and offer turnkey cloud services. They don't have to use Microsoft's infrastructure. They can have their own branded IaaS clouds.
A newfangled Service Management Portal built into Windows 8's new Metro user interface can deliver Azure-like services like automated web site hosting, high-scale web sites and Windows or Linux virtual machine hosting. The widgetry's extensible APIs let developers connect their hosted applications to other people's specialized services, their own on-premise resources and Windows Azure if they want.
Voilà, the beginnings of a hybrid cloud strategy.
Microsoft has the widgetry in a beta-y community technology preview (CTP) release that giant web hoster Go Daddy is already piloting.*
Taking it out for a spin requires at least four VMs running Windows Server 2012 or Windows Server 2008 R2 as well as a System Centre 2012 Service Pack 1 virtual hard drive image and .NET 3.5 and 4 frameworks on all virtual machines. No word on pricing of course.
[Truncated reference to GigaOm removed.]
In the grand scheme of things, Service Management Portal could go down as Microsoft's most-significant blow in its battle against virtualization market leader VMware to become the operating system for the cloud. VMware has a head start with its vCloud Datacenter Services program and vCloud Director management software, but Microsoft now essentially has an answer to both, although it still has plenty of maturing to do (especially if it wants to compete for enterprise workloads)."
Microsoft also kicked off a Switch to Hyper-V program at its Worldwide Partner Conference Tuesday offering partners tools and training to move customers to Windows Server and Hyper-V and dislodge VMware. The toolbox includes widgetry to convert a VMware image to Hyper-V's format.
Wired called Service Management Portal a "brilliant move by Microsoft that hits at several different markets to increase their own footprint especially in the virtualization battlefield.... The Microsoft ‘cloud' influence is quickly moving from obscurity to being everywhere."
ZDNet imagines Microsoft attracting telecommunications companies left out in the cold by Amazon.
"If Microsoft can get enough service providers using its technology," it said, "it will get the twin benefits of a massive R&D bonus from the ensuing feedback and the chance to supply ammunition to those keen to use their data centers, fiber networks and good company relations to take on Amazon. After all, big telecommunications companies like Cable & Wireless Worldwide, AT&T and Verizon all have major cloud offerings, vast data centers and great globe-spanning connectivity. It must be galling to see an online bookseller from Seattle overtake you in a market that, if one thinks about this objectively, you should own."
Windows Server 2012 is due out in September.


* Derrick Harris (@derrickharris) refuted Go Daddy’s use of Microsoft’s new hosted IaaS services in his updated Take that, vCloud: Microsoft opens Windows Azure to web hosts post of 7/10/2012 to GigaOm’s Structure blog:
Microsoft already has one big-name pilot customer for Service Management Portal in the form of web-hosting giant GoDaddy — whose involvement raises the question of just how disruptive Microsoft might be to the entire private-cloud software industry that has seen most of its traction thanks to service providers. Last year, GoDaddy announced a cloud offering based on Cloud.com’s (now Citrix’s) CloudStack software
, and I’m awaiting word from GoDaddy as to whether Microsoft’s new portal might replace that offering. According to an email responsed from GoDaddy Distinguised Engineer Brian Krouse:GoDaddy is always looking for ways to better serve our customers. We are currently exploring the new Microsoft Windows solution for our 4GH Web hosting, which is a scalable shared-hosting offering. GoDaddy is aware of Microsoft’s capabilities to run an IaaS solution and we are actively investigating the possibility. Currently, our Cloud Servers product is powered by Citrix for both Windows and Linux.

<Return to section navigation list>
 Cloud Security and Governance
Cloud Security and Governance

No significant articles today.
<Return to section navigation list>
Cloud Computing Events
• Michael Collier (@MichaelCollier) posted the following message on the Windows Insider distribution list on 7/13/2012:
Hello fellow Azure Insiders,
I'm one of the founders of a new cloud computing conference - CloudDevelop. I could really use your help with spreading the word about CloudDevelop.
What is CloudDevelop?
CloudDevelop will provide education, training and networking opportunities for the professional software development community focused on architecting, development and managing cloud applications. Sessions will be targeted to application developers, architects, dev-ops, technical decision makers, as well as those involved more with the business side of an organization.
If you're interested in cloud computing at all, then this is the event for you! Sessions at CloudDevelop include:
- Windows Azure
- AppHarbor
- Amazon AWS
- VMWare
- Cloud Foundry
- Windows Live services
- Heroku
- DevOps techniques
- Cloud security and legal issues
Tickets are now just $15!
To learn more, including registration details, please visit http://www.clouddevelop.org.
How Can You Help?
Everybody send a tweet about CloudDevelop! :) You can also forward this to your friends, neighbors, communities, user groups, or even your favorite barista.
Sample Tweets
- @CloudDevConf is coming to Columbus on Aug. 3rd. Learn about #cloudcomputing from some of the best! Register today: clouddevelop.org
- Learn about building great #cloudcomputing apps from several #WindowsAzure MVPs at @CloudDevConf. clouddevelop.org #mvpbuzz
- Are you #cloud ready? Learn from the best at @CloudDevConf on Aug. 3rd. Tix just $15. clouddevlop.org
- One day. One ticket. All the #cloud you can handle! Register for @CloudDevConf today for just $15. clouddevelop.org
Thanks,
Michael S. Collier
@MichaelCollier
http://www.MichaelSCollier.com

<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Charles Babcock (@babcockcw) wrote a Google Shakes Up IaaS Market research report, which Information Week published on 7/11/2012:
Building on its platform-as-a-service success, the company takes aim at Amazon with its Google Compute Engine, but privacy concerns, Microsoft's infrastructure-as-a-service initiative and Google's own inertia could derail its plans. We take a closer look and provide a hands-on review.
Table of Contents
3 Google Compute Engine Challenges Amazon
4 Why Open Source?
5 Driving a Hybrid
5 Rent the Spike
6 Google Compute Engine: Hands-On Review
6 Services
7 The Good Stuff
8 Impact on the IaaS Market
8 Final Thoughts
9 Google Compute Engine Is No Threat to Amazon, Microsoft, RackSpace
11 Google Compute Engine Ignores VMware, Microsoft Users
13 Google Compute Engine Leverages Third-Party Support
16 Related Reports


• Jeff Barr (@jeffbarr) reported the availability of Database Engine Tuning Advisor for Amazon RDS on 7/11/2012:
Ok folks, this one is a mouthful, so bear with me!
The Amazon Relational Database Service for SQL Server now supports the Microsoft SQL Server Database Engine Tuning Advisor. The Advisor will help you to select and create an optimal set of indexes, indexed views, and partitions even if you don't have an expert-level understanding of the structure of your database or the internals of SQL Server.
You will need to create a representative workload (a set of Transact-SQL statements) to run against the database or databases that you want to tune. The workload can be stored in a file or in a database table. Either way, the workload must be structured in such a way that the Advisor can execute or replay it multiple times. You can, if you'd like, generate the workload by performing a trace against your DB Instance while it is supporting a real or simulated version of your application.
To learn more about how to use the Tuning Advisor, please visit the Common DBA Tasks for Microsoft SQL Server section of the Amazon RDS documentation
<Return to section navigation list>

















0 comments:
Post a Comment