Windows Azure and Cloud Computing Posts for 5/26/2011+
| A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

•• Updated 5/29/2011 re next SQL Azure service release will be “repowered with SQL Server Denali” and (presumably) include the new Sequence object for sharding with SQL Azure Federations and bigint identity primary keys. (See my comment at end of the Itzik Ben-Gan continued his series with SQL Server Denali’s Sequences, Part 2 in the June 2011 issue of SQL Server Magazine article in the SQL Azure Database and Reporting section.
• Updated 5/27/2011 with articles marked • by Michael Desmond, Paul Patterson, Sam Vanhoutte, Patriek van Dorp, O’Reilly Media, Windows Azure Team, First Floor Software,DevOpsDays, Tim Anderson, Brian Harry, Andriy Svyryd of the Entity Framework Team, Riccardo Becker, Steve Yi, Karandeep Anand, Jurgen Willis, and Wade Wegner.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework
- Windows Azure Infrastructur and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
David Linthicum posited “While cloud computing is going strong, there seems to be a lack of interest in leveraging its storage services” while he explained Why cloud storage could be the first real cloud failure in a 5/26/2011 post to InforWorld’s Cloud Computing blog:
According to a survey market research firm TheInfoPro, a mere 10 percent of large corporations are considering the public cloud as a place to store even their data -- even the lowest-tier info -- for archive purposes. I wasn't surprised to hear of these results.
Don't believe the survey? Look at recent news reports. Last year EMC announced it was shutting down its Atmos Online storage service because it was competing with its own resellers. Cloud storage provider Vaultscape also closed. Additionally, Iron Mountain said it had stopped accepting new customers for its Virtual File Store service and was doing a two-year glide to a complete shutdown. Finally, startup Cirtas Systems announced it was leaving the market to "regroup."
Of course, there is Amazon's S3 service, which by all accounts is going like gangbusters. However, Amazon provides a more holistic offering; thus, much of the on-demand storage sold has been in support of data and application processing. I suspect Amazon made the market seem lucrative, and the ease of entry of creating storage on-demand storage was tempting for players that wanted to release a cloud offering on the cheap.
It seems clear the emerging market was not ready for so many players, and the lack of demand quickly shut some doors. I predict cloud storage will gain ground, but it will require players who are willing to invest the time needed for the market to emerge. However, VC-backed companies are notoriously impatient, and larger companies want quick ROI in the face of internal politics. Moreover, you're not only competing with other cloud storage providers, but with sharply falling prices for local storage.
The on-demand storage market will eventually evolve, and acceptance will take years, as we've seen with other emerging technologies in the past. In the meantime, we could look at cloud storage services to be the first real cloud failure. However, we learn from what did not work and plug on. Eventually, the market will be there.
<Return to section navigation list>
SQL Azure Database and Reporting
Steve Yi reminded developers about SQL Azure Federations: Product Evaluation Program Now Open for Nominations! in a 5/26/2011 post to the SQL Azure Team blog:
Cihan Biyikoglu, Senior Program Manager of SQL Azure, has posted information on the Microsoft SQL Azure Federations Product Evaluation Program. Nominations for the Microsoft SQL Azure Federations Product Evaluation Program are now open.
To learn more and discover how you can get involved, I encourage you to visit his blog entry here.
If you’re getting up to speed on the concept of federations, you can find an overview of the technology here.
For more details about sharding SQL Azure databases, read my Build Big-Data Apps in SQL Azure with Federation cover story for Visual Studio Magazine’s March 2011 issue.
Itzik Ben-Gan continued his series with SQL Server Denali’s Sequences, Part 2 in the June 2011 issue of SQL Server Magazine:
Last month I introduced sequences, which are a new feature in the upcoming version of SQL Server (code-named Denali). I explained how to create and alter sequences, I discussed how to obtain new values using the NEXT VALUE FOR expression, and I compared sequences with the IDENTITY column property [see below]. This month I discuss caching of sequence values, obtaining a range of sequence values, and producing multiple unique sequence values in the same target row.
Caching
SQL Server supports defining a caching option for sequences, with the purpose of improved performance by minimizing disk access. The caching option is an extension to standard SQL. When you create or alter a sequence, you can indicate the CACHE option along with a cache value or NO CACHE if you want to prevent caching. The current default option (as of press time) is to use a cache value of 50; this default might change in the future. (For more information about cache values, see the sidebar “How to Determine the Default Cache Value in SQL Server Denali.”)
If you choose the NO CACHE option (remember, the default is CACHE 50), every time a new sequence value is generated, SQL Server has to write the change to the system tables on disk. This, of course, can have a negative performance effect. When using the CACHE <cache_value> option, SQL Server writes to the system tables only once every <cache_value> request. What SQL Server records on disk every time a new block of cached values is allocated is the first value to be used in the next block. In the meantime, SQL Server keeps in memory only two members with the same type as the sequence type, holding the current value and how many values are left in the current block of cached values before the next write to disk needs to occur. Every time a request for a new sequence value is made, SQL Server updates those two members in memory.
Compared with not caching values, you can observe significant performance improvements when caching with even fairly small blocks of values (e.g., 50); the bigger the cache value, the better the performance. So why not simply use as big a value as possible in the cache option? Because if SQL Server shuts down uncleanly (e.g., power failure), you basically lose the remaining range up to the value currently written to disk. Given the fact that new sequence values generated in a transaction that doesn’t commit are eventually lost anyway, sequences can’t guarantee no gaps to begin with.
Note that if SQL Server shuts down cleanly, it writes the current value plus one to disk; then upon restart, when the next request for a sequence value is made, the new sequence value starts from that point. As an example, suppose the cache size is 50. The stored value in the system tables is 151 (first noncached value), the current sequence value is 142, and the number of values remaining to use is 8 before the next request will cause a write to disk. So if you shut down the system cleanly at this point, SQL Server will write the number 143—the next value to be used—to the system tables. When you restart the system and a request for a new sequence value is made, SQL Server will allocate 50 values by writing to disk 193.
If you’re curious about whether SQL Server caches values for IDENTITY as well, it does. Currently (at press time), the cache size of IDENTITY is a hard-coded value of 10, but this size might change in the future. The internals of the IDENTITY property and sequences are quite similar—but because the default cache size is 50 for sequences and 10 for IDENTITY, you should see a small performance advantage of sequences compared with IDENTITY.
There’s another interesting difference in the handling of caching between the two features. As I mentioned, with sequences, if the system shuts down unexpectedly, you lose the remaining cached values in the current block and simply end up with a gap in your values. With IDENTITY, when SQL Server restarts, during recovery it scans the log records to determine the last used IDENTITY value, so you end up not losing the remaining cached values (except in certain scenarios with low likelihood because their time window is very small). If you’re wondering why SQL Server can’t recover the last used sequence value from the log in a similar manner, it’s because sequence values can be generated by SELECT queries without inserting them into a table—and therefore no record exists in the log for those values. So SQL Server simply doesn’t attempt to recover the lost cache values.
Let’s examine some performance numbers from a test I ran on my laptop. It’s not really a thorough or exhaustive test, but rather a fairly simple test just to get a general sense of performance. Use the code in Listing 1 to create the objects used in this performance test. …
Read More: 2, 3, 4, Next, Last
•• Updated 5/29/2011: SQL Server Denali’s new Sequence object or its equivalent will be required to successfully shard SQL Azure Federation members with bigint identity primary key ranges. Microsoft’s David Robinson announced in slide 10 of his COS310: Microsoft SQL Azure Overview: Tools, Demos and Walkthroughs of Key Features TechEd North America 2011 session that “RePowering SQL Azure with SQL Server Denali Engine” is “coming in Next [SQL Azure] Service Release.”
Itzik Ben-Gan began a series with SQL Server Denali’s Sequences, Part 1 in the May 2011 issue of SQL Server Magazine:
The next version of SQL Server, which is code-named Denali, introduces support for sequences. A sequence is an object used to auto-generate numbers for different purposes, such as keys. In previous versions of SQL Server, you could use the IDENTITY column property for similar purposes, but sequences are more flexible than IDENTITY in many ways. This article is the first in a two-part series about sequences, in which I define sequences, explain how to create and use them, and discuss their advantages over IDENTITY.
The Basics
To work with sequences, you need to be familiar with only a small set of language elements: the CREATE SEQUENCE, ALTER SEQUENCE, and DROP SEQUENCE commands, which are used to create, alter, and drop sequences, respectively; the NEXT VALUE FOR function, which is used to retrieve the next value from a sequence; the sp_sequence_get_range procedure, which is used to secure a consecutive range of sequence values; and the sys.sequences view, which is used to query information about existing sequences. I’ll start with the basics of sequences, then discuss the more advanced aspects later in the article.
A sequence is an independent object in the database, unlike IDENTITY, which is a property tied to a particular column in a particular table. A basic and typical form of a sequence definition is one in which you indicate the data type of the sequence, which value to start with, and which value to increment by, like so:
CREATE SEQUENCE dbo.Seq1 AS INT START WITH 1 INCREMENT BY 1;This command is pretty straightforward and self-explanatory. It creates a sequence called Seq1 in the dbo schema in the database to which you’re currently connected. The sequence is created with the INT data type and is defined to start with 1 and increment by 1.
To obtain a new sequence value, the application would normally invoke the NEXT VALUE FOR function; for example, run the following code multiple times and see how you get a new value every time:
SELECT NEXT VALUE FOR dbo.Seq1 AS newval;The fact that you use an expression leads to another advantage of sequences over IDENTITY, in addition to the fact that sequences aren’t tied to specific tables. You can obtain a new sequence value before using it, like so:
DECLARE @newval AS INT = NEXT VALUE FOR dbo.Seq1; SELECT @newval;Of course, you’d typically use the obtained value in an INSERT statement, but you can use it for other purposes as well.
Back to the CREATE SEQUENCE command: I mentioned that this command creates the sequence in the database you’re connected to. You can’t use the three-part name including the database name; instead, you have to make sure you’re connected to the database where you want to create the sequence. If you want to first check whether such a sequence already exists in the database and, for example, drop it in such a case before creating the new one, you can use the OBJECT_ID function and look for a non-NULL value. Here’s an example in which the code first sets the database context (in this case to AdventureWorks2008R2), drops the sequence object if it already exists, and creates a new one:
USE AdventureWorks2008R2;IF OBJECT_ID('dbo.Seq1', 'SO') IS NOT NULL DROP SEQUENCE dbo.Seq1;
CREATE SEQUENCE dbo.Seq1 AS INT START WITH 1 INCREMENT BY 1;
Note that I indicated the type INT; otherwise, SQL Server would have used BIGINT as the default. Also, I indicated to start with the value 1; otherwise, SQL Server would have used the lowest value in the type as the default (e.g., -2147483648 for INT). The default value to increment by is 1, which would often be correct; still, it feels more natural to specify the value explicitly—especially if you’re already specifying the start-with value. I therefore specify it in what I refer to as “the typical definition.
You can specify several additional options in the sequence definition. Here’s the full syntax as it appears in SQL Server Books Online:
CREATE SEQUENCE [schema_name . ] sequence_name [ <sequence_property_assignment> [ ...n ] ] [ ; <sequence_property_assignment>::= { [ AS { built_in_integer_type | user-defined_integer_type } ] | START WITH <constant> | INCREMENT BY <constant> | { MINVALUE <constant> | NO MINVALUE } | { MAXVALUE <constant> | NO MAXVALUE } | { CYCLE | NO CYCLE } | { CACHE [<constant> ] | NO CACHE } }As you can see, you can define minimum and maximum values in case you want them to be different from the minimum and maximum that the type supports. Also, you can indicate whether you want the sequence to automatically cycle after reaching a boundary value, as opposed to throwing an exception in such a case, which is the default behavior. CACHE is a more advanced option related to performance; I cover this option next month. …
<Return to section navigation list>
MarketPlace DataMarket and OData
• Steve Yi (pictured below) posted Introducing OData: Data Access for the Web, Cloud, Devices, and More on 5/27/2011:
David Chappell recently completed a whitepaper on OData that I encourage you to take a look at. You can view it here, or download a PDF version. David does an outstanding job providing an overview of OData, the problems it solves, practical usage scenarios, and a look at the protocol itself. If you’re quitting work for the day, stop here and read David’s whitepaper. If you have a few more minutes to spare, then continue reading. :)

Many of our partners have started using OData in their commercial releases. Two notable recent ones are SAP, who are making it an integral part of their Netweaver offering to extend SAP data to devices and social applications. You can read more about it here.
EastBanc is also utilizing OData and SQL Azure to share real-time data from Washington metro area transit systems to share up to date schedules for trains and buses. A case study on that is here.
If you’re not already familiar with the Open Data Protocol (OData), it’s a Web protocol for querying and updating data that provides a way to unlock your data and free it from silos that exist in applications today. OData does this by applying and building upon Web technologies such as HTTP, Atom Publishing Protocol (AtomPub) and JSON to provide access to information from a variety of applications, services, and stores. The protocol emerged from experiences implementing AtomPub clients and servers in a variety of products over the past several years. OData is being used to expose and access information from a variety of sources including, but not limited to, relational databases, file systems, content management systems and traditional Web sites.
At this point you may be asking – why talk about OData on the SQL Azure blog? Because OData is an open protocol and what I like to call “the language of data on the web”. Let’s take an example of a web service that does a lookup of an employee. The tricky thing here is that this turns into multiple service calls, or methods with multiple input parameters to get results with different input and output criteria, like:
- GetEmployeeByLastName
- GetEmployeeByID
- GetEmployeeStartingWith
…and so on, making a simple lookup pretty complicated with multiple options based on different search criteria, and if multiple results are returned – having to factor in paging or selecting the top 50 results if there happen to be thousands. OData reduces this complexity by being able to accomplish all these queries and also allow updates to data in one service method. If you visit the OData SDK page, there are libraries for utilizing OData in PHP, Java & Android, Ruby, Windows Phone 7, iOS, Silverlight, and .NET (of course!). There’s also a library to interact with OData via JavaScript and jQuery, called DataJS.
One Service Powering Multiple Experiences
In addition to powering mobile experiences, the openness of the OData protocol can power multiple user experiences. In the videos below we show how to utilize OData to access SQL Azure cloud data on both Android and Windows Phone 7 devices. OData is also natively supported in PowerPivot, making complex BI attainable today with SQL Azure cloud databases – again using the same OData service that can power an Android, iOS, Windows Phone, and web experience.
Things get even more interesting for BI when you consider Windows Azure DataMarket, our one-stop shop for accessing public domain and commercial data-sets – all consistently accessible via OData. Joining that data with your application’s data can create some interesting new insights. Is there a relationship between retail sales and weather? Hmm … DataMarket has weather data available from WeatherBug.
- View this video as a WMV
 : Sharing Data with Android and SQL Azure via OData
: Sharing Data with Android and SQL Azure via OData - View this video as a WMV: Sharing Data with Windows Phone and SQL Azure via OData
Is it Hard?
No. And more partners are using it, like SAP and EastBanc I mentioned at the top. As I mentioned earlier there are libraries for most platforms. Here are some links to get started with SQL Azure:
- SQL Azure Labs has an OData service you can get started with today that will create an OData endpoint for your SQL Azure database.
- For .NET developers, you can also create your own in about 5 lines of code utilizing WCF Data Services that you can deploy locally, or in a web role in Windows Azure. These libraries are already included in the .NET Framework.
Hope this has whetted your appetite just a bit to get started. For all of you in the U.S., have a great Memorial Day weekend!
According to a message from Nick Randolph in today’s OData Mailing List feed:
The [Windows 7] Mango version doesn't support compression or the JSON form of OData.
Joydip Kanjilal described Using OData Services in ASP.NET Applications in a 5/25/2011 post to the DevX.com blog:
The official website for Open Data Protocol states: "The Open Data Protocol (OData) is a Web protocol for querying and updating data that provides a way to unlock your data and free it from silos that exist in applications today. OData does this by applying and building upon Web technologies such as HTTP, Atom Publishing Protocol (AtomPub) and JSON to provide access to information from a variety of applications, services, and stores."
This article presents an overview of the Open Data Protocol and discusses how you can work with it in your .NET applications.
Prerequisites
To work with the code examples listed in this article, you need to have Visual Studio 2008 or 2010 installed in your system.
What Is the OData Protocol?
OData is a REST-based protocol that uses HTTP, JSON and ATOM and supports any platform that has support for HTTP, XML or JSON. You can use it to expose data retrieved from relational databases, file systems or data services. OData enables you to perform CRUD operations on top of a data model or a data service. In essence, it is an HTTP-based, platform-independent protocol that supports REST. In OData, data is provided through the usage URIs and common HTTP verbs, like GET, PUT, POST, MERGE and DELETE. Note that WCF Data Services (previously known as ADO.NET Data Services) is the implementation of Open Data Protocol in .NET applications.
MSDN states: "OData defines operations on resources using HTTP verbs (PUT, POST, UPDATE and DELETE), and it identifies those resources using a standard URI syntax. Data is transferred over HTTP using the AtomPub or JSON standards. For AtomPub, the OData protocol defines some conventions on the standard to support the exchange of query and schema information."
Representation State Transfer (commonly known as REST) is an architectural paradigm that is based on the stateless HTTP protocol and is used for designing applications that can inter-communicate. In REST, Resources are used to represent state and functionality and these resources are in turn represented using user friendly URLs.
The official website of OData Protocol exposes data as an OData Service. Here is the service url: http://services.odata.org/website/odata.svc.
When you open the page in a browser, here is how the XML markup looks:
<service xml:base="http://services.odata.org/Website/odata.svc/"> <workspace> <atom:title>Default</atom:title> <collection href="ODataConsumers"> <atom:title>ODataConsumers</atom:title> </collection> <collection href="ODataProducerApplications"> <atom:title>ODataProducerApplications</atom:title> </collection> <collection href="ODataProducerLiveServices"> <atom:title>ODataProducerLiveServices</atom:title> </collection> </workspace> </service>Note that a collection of entity sets or feeds is referred to as workspace.
Read More: Next Page: OData Services in ASP.NET ![]()
<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
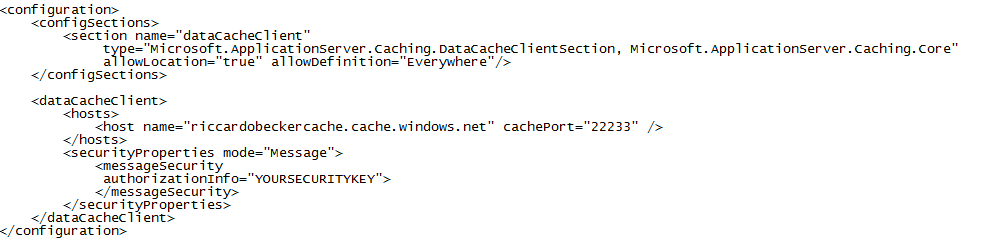
• Riccardo Becker (@riccardobecker) offered a Windows Azure Azure AppFabric Cache Introduction in a 5/27/2011 post:
Windows Azure now offers a caching service. It's a cloud scaled caching mechanism that helps you speed up your cloudapps. It does exactly what a cache is supposed to do: offer high-speed access (and high availability & scalability, it's cloud after all) to all your application data.
How to setup caching?
Click your Service Bus, Access Control & Caching tab on the left side of the Windows Azure portal. Click New Namespace from the toolbar and create the one you like and choose the appropriate size. See below.

After creation everything is arranged by the platform. Security, scalability, availability, access tokens etc.After you created the Caching Namespace you are able to start using it. First of all add the correct references to the assemblies involved in Caching. You can find them in the Program Files\Windows Azure AppFabric SDK\V1.0\Assemblies\NET4.0\Cache folder. Select the Caching.Client and Caching.Core assemblies and voila. ASP.NET project also need the Microsoft.Web.DistributedCache assembly.
The easiest way to create access to your cache is to copy the configuration to you app.config (or web.config). Click the namespace of the cache in Azure Portal. Then click in the toolbar on View Client Configuration on copy the settings and paste them in your config file in visual studio. The settings look like this.
Create a console app and copy code as below and voila, your scalable, highly available, cloudy cache is actually up and running!
using System; using System.Collections.Generic; using System.Linq; using System.Text; using Microsoft.ApplicationServer.Caching; using Microsoft.ApplicationServer; namespace ConsoleApplication1 { class Program { static void Main(string[] args) { // Cache client configured by settings in application configuration file. DataCacheFactory cacheFactory = new DataCacheFactory(); DataCache defaultCache = cacheFactory.GetDefaultCache(); // Add and retrieve a test object from the default cache. defaultCache.Add("myuniquekey", "testobject"); string strObject = (string)defaultCache.Get("testkey"); } } }What can you store in Cache? Actually everything as long as it's serializable.
Have fun with it and use the features of the Windows Azure platform!
• Sam Vanhoutte described Azure AppFabric Service Bus enhancements: Windows Azure User Group NL in a 5/27/2011 post:
Yesterday, I gave a presentation at Amstelveen, NL, on the messaging enhancements in the AppFabric Service Bus. This CTP was released last week and I did the following demos:
- Service Bus Tracer (using a client side WPF application that listens on trace information that gets broadcasted from Azure roles over the service bus eventrelaybinding)
- AppFabric queues & transactions: sending a batch of messages in one transaction to a queue.
- Sessions: splitting large messages in portions and send them in a session-enabled queue.
- Duplicate checks: preventing delivery of duplicate items, using deduplication on queues.
- Pub/sub demo: showing the usage of advanced filters and ad-hoc subscriptions on topics.
I uploaded the slide deck on SlideShare and the source code can be downloaded here.
View more presentations from Sam Vanhoutte.
• Patriek van Dorp (@pvandorp) explained Forging LinkedIn Authentication into WS-Federation in a 5/27/2011 post to his Cloudy Thoughts blog:
In my previous post about creating a custom STS using Windows Identity Foundation (WIF) I explained the WS-Federation protocol and showed how the ASP.NET Security Token Service Web Site project template was implemented to facilitate this protocol. I explained how the sign in process works and were the authentication should take place. I intentionally skipped the authentication part, because Windows Live Writer is limited in the number of lines that you can write in one blog post (and I reached that limit, so I’ll try to keep this post shorter).
In this post I’d like to explain how you can integrate the LinkedIn authentication process into our custom WIF STS. In a future post we’ll see how to host our STS in Windows Azure.
OAuth 1.0a
First let me explain a little about the authentication protocol LinkedIn follows, OAuth 1.0a.
Figure 1: OAuth 1.0a
Figure 1 shows the steps of the OAuth 1.0a protocol. Let’s take a closer look:
- First you need to obtain an API key (in this case from the developers’ section of LinkedIn). This is called a Consumer Key in OAuth terms.
- You make a call to LinkedIn to ask to use their authentication system. This is called getting a Request Token. (A in figure 1)
- LinkedIn responds with an OAuth Token indicating that you can use their authentication system. (B in figure 1)
- You send the user to a LinkedIn URL. This URL includes the OAuth RequestToken you got and a few other parameters such as a URL for LinkedIn to return the user to after granting access. (C in figure 1)
- The user now needs to login to LinkedIn using the page that was returned by the LinkedIn URL.
- When the user successfully logs on, LinkedIn will redirect the user to the URL you provide in step 4. (D in figure 1)
- Next, you need to request an Access Token from LinkedIn. (E in figure 1)
- LinkedIn responds with the Access Token for that user. (F in figure 1)
- With every subsequent call to the LinkedIn API, you provide the Access Token for the user on whose behalf you’re making the call. (G in figure 1)
This whole process is described in detail in the Developer section of the LinkedIn website.
LinkedIn Developer Toolkit
All these calls I talked about are just plain HTTP requests and responses. This makes it incredibly ‘open’, but also very tedious and error-prone to implement. Lucky for us there is a LinkedIn Developer Toolkit designed to encapsulate these calls and relief us developers from all the hardship. This toolkit is based on an open source project for dealing with OAuth using .NET called DotNetOpenAuth.
The Solution
Now that we know a little bit more about OAuth, let’s look at how we can integrate the OAuth authentication process into a custom Security Token Service using WS-Federation. As we’ve seen in my previous post, the Custom ASP.NET Security Token Service Website project uses FormsAuthentication as it’s authentication method. This means that the FormsAuthenticationModule intercepts unauthenticated request and redirects them to the Login.aspx page. The project template implements a simple username/password page where users can enter their credentials. This would be the perfect place to implement the authentication process used by LinkedIn.
While investigating the samples that come with the LinkedIn Developer Toolkit, I figured I would need a LinkedInBasePage and some kind of TokenManager. The LinkedInBasePage is only needed to implement logic that can be re-used later in Default.aspx and to keep my code clean. The TokenManager is needed by the DotNetOpenAuth API to keep track of RequestTokens and TokenSecrets.
LinkedInBasePage
As example 1 shows, the LinkedInBasePage consists of three properties; AccessToken, TokenManager and Authorization.
protected string AccessToken { get; set; } protected XmlTokenManager TokenManager { get { var tokenManager = (XmlTokenManager)Application["TokenManager"]; if (tokenManager == null) { string consumerKey = ConfigurationManager.AppSettings["LinkedInConsumerKey"]; string consumerSecret = ConfigurationManager.AppSettings["LinkedInConsumerSecret"]; if (string.IsNullOrEmpty(consumerKey) == false) { string cookieUserData = string.Empty; if (User != null && User.Identity.IsAuthenticated) { cookieUserData = ((LinkedInIdentity) User.Identity).Ticket.UserData; } tokenManager = new XmlTokenManager(consumerKey, consumerSecret, cookieUserData); Application["TokenManager"] = tokenManager; } } return tokenManager; } } protected WebOAuthAuthorization Authorization { get; set; }Example 1: LinkedInBasePage
The Authorization property of type WebOAuthAuthorization is used for authenticating and authorizing each LinkedIn API call as we will see later on.
I chose storing the tokens and secrets in the userdata of the authentication ticket in the authentication cookie in the form of XML. I did this in anticipation of one day hosting my custom STS in Windows Azure and thus taking into account a load balanced environment. This is not all that has to be done to host the STS in Windows Azure, but I figured that changing this later on would cause me more trouble.
XmlTokenManager
The XmlTokenManager is really where the DotNetOpenAuth API will keep track of the various tokens and their secrets. The XmlTokenManager implements the IConsumerTokenManager interface which in turn implements the ITokenManager interface as shown in figures 2 and 3.
Figure 2: IConsumerTokenManager
Figure 3: ITokenManager
Login.aspx
As I said earlier Login.aspx seems like the perfect place to implement the LinkedIn authentication logic. Example 2 shows the implementation of the Login.aspx page.
public partial class Login : LinkedInBasePage { protected void Page_PreRender(object sender, EventArgs e) { if (AccessToken == null) { Authorization.BeginAuthorize(); } } protected void Page_Load(object sender, EventArgs e) { Authorization = new WebOAuthAuthorization(TokenManager, AccessToken); if (!IsPostBack) { string accessToken = Authorization.CompleteAuthorize(); if (accessToken != null) { AccessToken = accessToken; LinkedInService liService = new LinkedInService(Authorization); Person person = liService.GetCurrentUser(ProfileType.Standard, new List<ProfileField> {ProfileField.FirstName, ProfileField.LastName}); TokenManager.AddUserNameWithToken(accessToken, person.Name); var ticket = new FormsAuthenticationTicket(1, person.Name, DateTime.Now, DateTime.Now.Add(FormsAuthentication.Timeout), false, TokenManager.GetCookieUserData(person.Name)); var hashCookies = FormsAuthentication.Encrypt(ticket); var cookie = new HttpCookie(FormsAuthentication.FormsCookieName, hashCookies); Response.SetCookie(cookie); Response.Redirect(Request.QueryString["ReturnUrl"]); } } } }Example 2: Login.aspx
Here we just treat the STS website as a normal website using FormsAuthentication. So, the request to Default.aspx is redirected to Login.aspx. Her we see two event handlers that hook into the ASP.NET processing pipeline.
- First Page_Load is called. It will create a new WebOAuthAuthorization object which must contain a TokenManager and an AccessToken. As described earlier the AccessToken (together with the TokenSecret that belongs to it) is needed to authenticate every LinkedIn API call.
- The CompleteAuthorize() method is called on the WebOAuthAuthorization object. When the TokenManager does not contain a RequestToken, CompleteAuthorize() returns null.
- Because this is the first time around and CompleteAuthorize() returns null, the rest of the event handler is skipped for the moment.
- Next Page_PreRender will fire. It checks to see if there is no AccessToken and calls BeginAuthorize() on the WebOAuthAuthorization object.
- The BeginAuthorize() method walks through steps 2 – 5 of the OAuth protocol as described with figure 1. So this means that a RequestToken is requested and provisioned and saved in the TokenManager along with it’s TokenSecret. And the user is redirected to the login page of LinkedIn as depicted in figure 4.
- When the user successfully logs in and allows your application to make LinkedIn API calls the user is redirected to Default.aspx of the custom STS again.
- Because of FormsAuthentication the user gets redirected to Login.aspx again and Page_Load is called first.
- Now, because the TokenManager has the RequestToken and it’s TokenSecret, CompleteAuthorize() will return an AccessToken, meaning that we can now make API calls to LinkedIn.
- For the sake of this sample I only get the first name and the last name of my profile to provide a Name to the IIdentity that will be created when placing a cookie.
- Finally, I store the AccessToken and it’s TokenSecret in the userdata of the cookie ticket. This way, even if the TokenManager (which is stored in the Application object for this sample) gets lost, it can (and will) be created from the userdata in the cookie.
Figure 4: LinkedIn Login page
Global.asax
After the above sequence, FormsAuthentication redirects us to Default.aspx of the custom STS. Here we must create the output ClaimsIdentity with claims that are derived from data stored in LinkedIn. To do this we must first get the AccessToken and it’s TokenSecret from the userdata in the authentication cookie. For this I wrote a LinkedInIdentity that takes a FormsIdentity as input and parses the XML in the FormsIdentity.Ticket.UserData and saves the values in properties. In the Global.asax we intercept the request and convert the FormsIdentity to a LinkedInIdentity as shown in example 3.
protected void Application_AuthenticateRequest(object sender, EventArgs e) { // look if any security information exists for this request if (HttpContext.Current.User != null) { // see if this user is authenticated, any authenticated cookie (ticket) exists for this user if (HttpContext.Current.User.Identity.IsAuthenticated) { // see if the authentication is done using FormsAuthentication if (HttpContext.Current.User.Identity is FormsIdentity) { // Get the roles stored for this request from the ticket // get the identity of the user LinkedInIdentity identity = new LinkedInIdentity((FormsIdentity)User.Identity); // create generic principal and assign it to the current request HttpContext.Current.User = new LinkedInPrincipal(identity); } } } }Example 3: Global.asax
Default.aspx
In Default.aspx, when we have determined that the user is authenticated, we assign the Authorization property of the LinkedInBasePage (Default.aspx also inherits from LinkedInBasePage) taking the AccessToken from the User.Identity (which is now a LinkedInIdentity). Then we pass the WebOAuthAuthorization object in the Authorization property to the constructor of the CustomSecurityTokenService as shown in example 4.
SignInRequestMessage requestMessage = (SignInRequestMessage)WSFederationMessage.CreateFromUri(Request.Url); if (User != null && User.Identity != null && User.Identity.IsAuthenticated) { Authorization = new WebOAuthAuthorization(TokenManager, ((LinkedInPrincipal)User).AccessToken); SecurityTokenService sts = new CustomSecurityTokenService(CustomSecurityTokenServiceConfiguration.Current, Authorization); SignInResponseMessage responseMessage = FederatedPassiveSecurityTokenServiceOperations.ProcessSignInRequest(requestMessage, User, sts); try { FederatedPassiveSecurityTokenServiceOperations.ProcessSignInResponse(responseMessage, Response); } catch { //The ProcessSignInResponse executes Response.End() which throws a ThreadAbortedException. It's save to ignore this. } }Example 4: Default.aspx
CustomSecurityTokenService
From here on up, it’s just a matter of making a LinkedIn API call to get my profile and transforming the values into Claims and adding the Claims to an output ClaimsIdentity that will be wrapped in a SecurityToken.
Sample Code
Now, this is just a sample project to show how it’s possible to leverage the LinkedIn authentication process and forge it into our custom STS based on WS-Federation. The code in this sample is in no way secure. I didn’t use certificates or SSL and the implementation of the custom STS does not check whether or not a Relying Party is trusted. But it does give you an idea of how you can mix different protocols to extend Windows Identity Foundation.
In a future post I’ll show how to use this custom STS as an Identity Provider in Windows Azure AppFabric Access Control Service. And finally I’ll host this STS in Windows Azure.




• Karandeep Anand and Jurgen Willis presented an Introduction to Windows Azure AppFabric Composite Applications session at TechEd North America 2011 on 5/18/2011 at 1:30 to 2:45 PM. From Channel9’s description of the video:
The Windows Azure AppFabric Composite Application service lets you easily build,deploy,run and manage applications that span application tiers and technologies.
See how to build an application that composes multiple Azure services such as web roles, storage, Caching, SQL Azure, and ServiceBus, while leveraging familiarMicrosoft .NET developer experiences in Microsoft ASP.NET, Microsoft Silverlight, Windows Communication Foundation (WCF), and Windows Workflow Foundation (WF). Leverage the Composite Application service to easily provision, deploy, monitor, scale and manage this application as a cohesive unit throughout its lifecycle.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
Jason Chen posted on 5/26/2011 the slides for his COS303 Connecting Cloud and On-Premises Applications Using Windows Azure Virtual Network session at TechEd North America 2011:
Windows Azure Virtual Network is a component of Windows Azure that enables customers to setup secure, IP-level network connectivity between their Windows Azure compute services and existing, on-premise resources. This eases enterprise adoption by allowing Windows Azure applications to leverage and integrate with a customer’s current infrastructure investments. For example, using the Windows Azure Virtual Network a customer can migrate a line-of-business application to Windows Azure that requires connectivity to an on-premise SQL Server database which is secured using Active Directory-based Windows Integrated Authentication.
In this session, we will give an overview of Windows Azure Virtual Network's functionality, discuss usage scenarios, and walk through the steps involved in setting up and managing a Virtual Network.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Wade Wegner (@wadewegner) announced RELEASED: Windows Azure Toolkit for iOS V1.0.1 in a 3/27/2011 post:
Last night we released an update to the Windows Azure Toolkit for iOS. This release is a minor update that includes the refactoring of code for better conformance to standards, some bug updates, and a few additions to the sample application. You can take a look at the updates in each of the three repositories:
https://github.com/microsoft-dpe/watoolkitios-lib
- https://github.com/microsoft-dpe/watoolkitios-samples
- https://github.com/microsoft-dpe/watoolkitios-doc
One of the important updates is guidance—via the sample application—on how to use Windows Azure Queues.
Here’s an exhaustive list of the updates.
- Refactored the classes for better conformance with a Cocoa framework: http://developer.apple.com/library/mac/documentation/Cocoa/Conceptual/CodingGuidelines/CodingGuidelines.html
- Renamed TableEntity valueForKey and setValue:forKey to objectForKey and setObject:forKey
- Renamed Block methods to CompletionHandler
- Renamed "get" methods to "fetch" methods for better conformance
- Converted Base64 helper methods to proper categories on NSString and NSData
- Refactored sample client to support above library changes
- Included example of queue support in the sample client
- Fixed bug in queue class when sending messages containing non-escaped characters (<, >, &, ‘)
- Fixed bug in queue class with delegate not firing on message completion
- Updated walkthrough documentation for above class refactoring
- Updated compile HTML class documentation for above class refactoring
What’s nice about this release is that some of these updates came from the community and some of them came from us – a model I hope to continue as we move forward with these toolkits.
When you visit the GitHub repositories, be sure to look for and download v1.0.1.zip or the v1.0.1 tag.
We have more updates in the pipeline, so expect to hear more soon.



• The Windows Azure Team reminded US Developers: Get $250 for Your First Windows Azure Application in a 5/27/2011 post:
Only the first Windows Azure-compatible application registered by an organization is eligible for this offer. Windows Azure applications completed prior to Apr 15, 2011 do not qualify for this promotion. Review the offer terms and conditions here.
This promotion is available US developers only.
• Tim Anderson (@timanderson) asked Would you consider running PHP on Azure? Microsoft faces uphill battle to convince customers in a 3/27/2011 post:
Yesterday Microsoft announced Windows Azure SDK for PHP version 3.0, an update to its open source SDK for PHP on Windows Azure. The SDK wraps Azure storage, diagnostics and management services with a PHP API.
It is good to see Microsoft making an effort to support this important open source platform, and I am sure it has been welcomed by Microsoft-platform organisations who want to run WordPress, say, on their existing infrastructure.
Attracting PHP developers to Azure may be harder though. I asked Nick Hines, CTO for Innovation at Thoughtworks, a global IT consultancy and developer, what he thought of the idea.
I’d struggle to see any reason. Even if you had it in your datacentre, I certainly wouldn’t advise a client, unless there was some corporate mandate to the contrary, and especially if they wanted scale, to be running a Java or a PHP application on Windows.
Microsoft’s scaling and availability story around windows hasn’t had the penetration of the datacentre that Java and Linux has. If you look at some of the heavy users of all kinds of technology that we come across , such as some of the investment banks, what they’re tending to do is to build front and middle tier applications using C# and taking advantage of things like Silverlight to get the fancy front ends that they want, but the back end services and heavy lifting and number crunching predominantly is Java or some sort of Java variant running on Linux.
Hine also said that he had not realised running PHP on Azure was something Microsoft was promoting, and voiced his suspicion that PHP would be at a disadvantage to C# and .NET when it came to calling Azure APIs.
His remarks do not surprise me, and Microsoft will have to work hard to persuade a broad range of customers that Azure is as good a platform for PHP as Linux and Apache – even leaving aside the question of whether that is the case.
The new PHP SDK is on Codeplex and developed partly by a third-party, ReadDolmen, sponsored by Microsoft. While I understand why Microsoft is using a third-party, this kind of approach troubles me in that you have to ask, what will happen to the project if Microsoft stops sponsoring it? It is not an organic open source project driven by its users, and there are examples of similar exercises that have turned out to be more to do with PR than with real commitment.
I was trying to think of important open source projects from Microsoft and the best I could come up with is ASP.NET MVC. This is also made available on CodePlex, and is clearly a critical and popular project.
However the two are not really comparable. The SDK for PHP is licensed under the New BSD License; whereas ASP.NET MVC has the restrictive Microsoft Source License for ASP.NET Pre-Release Components (even though it is now RTM – Released to manufacturing). ASP.NET MVC 1.0 was licensed under the Microsoft Public License, but I do not know if this will eventually also be the case for ASP.NET MVC 3.0.
Further, ASP.NET MVC is developed by Microsoft itself, and has its own web site as part of the official ASP.NET site. Many users may not realise that the source is published.
My reasoning, then, is that if Microsoft really want to make PHP a first-class citizen on Azure, it should hire a crack PHP team and develop its own supporting libraries; as well as coming up with some solid evidence for its merits versus, say, Linux on Amazon EC2, that might persuade someone like Nick Hine that it is worth a look.
Related posts:
Brian Swan also chimed in with New Version of Windows Azure SDK for PHP (v 3.0) Available on 5/27/2011:
The Interoperability Team at Microsoft announced today that the production-ready 3.0 version of the Windows Azure SDK is now available. You can read about the details of the release here: http://blogs.msdn.com/b/interoperability/archive/2011/05/26/new-sdk-shows-how-to-leverage-the-scalability-of-windows-azure-with-php.aspx, but I wanted to share what I consider the highlights of the release in this post.
Second, it’s exciting to see real PHP applications leveraging the Azure platform in production. One example is Hotelpeeps, a Facebook application that leverages the Azure platform to help you find great hotel rates. And (what I think is equally exiting), we are starting to see community contributions to the SDK. The code is available on CodePlex here, http://phpazure.codeplex.com/releases/view/64047 (note that it is also available as a PEAR package).
Lastly (and this isn’t part of the official release announcement), I took some time to play with the SDK while it was still in beta. I looked at some ASP.NET application tutorials on the TechNet Wiki and wondered how easy it would be to implement the same functionality using PHP and the Windows Azure SDK for PHP. The result of my investigation produced three beginner-level tutorials:
- Using the Windows Azure Web Role and Windows Azure Table Service with PHP
- Using the Windows Azure Web Role and SQL Azure with PHP
- Using the Windows Azure Web Role and Windows Azure Blob Service with PHP
If you read/use those tutorials, please edit/improve them…it’s a wiki!
Craig Kitterman (@craigkitterman) posted New SDK and Sample Kit demonstrates how to leverage the scalability of Windows Azure with PHP on 5/26/2011 to the Interoperability @ Microsoft blog:
From the floor of the PHP Tek Conference in Chicago, with my colleague Peter Laudati, we’re excited to announce the availability of the Windows Azure SDK for PHP version 3.0. This Open Source SDK gives PHP developers a “speed dial” library to take full advantage of Windows Azure’s coolest features. On top of many improvements and bug fixes for this version (see the list from Maarten Balliauw’s preview), we’re particularly excited about the new service management possibilities and the new logging infrastructure.
The most compute intensive part of Facebook app www.hotelpeeps.com is powered by PHP on Windows Azure
My colleague Todi Pruteanu from Microsoft Romania worked with Lucian Daia and Alexandru Lapusan from Zitec to help them get started with PHP on Windows Azure. The result is impressive. The most compute intensive part of the Hotel Peeps Facebook application is now running on Windows Azure, using the SDK for PHP, as well as SQL Azure. Read the interview of Alexandru to get the details on what and how they did it (you can also check out the case study here). I like this quote from the interview: “HotelPeeps Trends running on the Windows Azure platform is the epitome of interoperability. Some people think that a PHP application running on Microsoft infrastructure is science fiction, but that’s not the case.”
Another interesting aspect is also the subsequent contribution by Zitec of an advanced “logging” component to the Windows Azure SDK for PHP. This new component provides the possibility of storing logs from multiple instances in a centralized location, namely Azure Tables.More contributions from the community
As the SDK gets more widely adopted, there is an exciting trend toward more community involvement. For example, Damien Tournoud from the CommerceGuys who is working on developing the Drupal integration module for Windows Azure, recently contributed a patch fixing bugs related to inconsistencies in URL-encoding of parameters in the HTTP_Client library. As we continue to improve the SDK to ensure great interoperability with popular applications like WordPress, Drupal and Joomla! we look forward to engagement more deeply with those communities to make the experience even better.
New! Windows Azure Sample Kit for PHP
Today we are also announcing the Windows Azure Sample Kit for PHP. It is a new project hosted on github that will be the primary repository for all sample php code / apps that developers can use to learn how to take advantage of the various features of Windows Azure in php. Today we are releasing two samples to the repository: the Guestbook application (example of how to use the Windows Azure storage objects – blobs, queues and tables as well as a simple web/worker pattern) and “Deal of the Day” (more on this one later). We look forward to feedback on the samples and I am also hoping to see some forks and new samples coming from the community!
New features to easily manage auto-scaling of applications on Windows Azure
As I mentioned the version 3.0 of the Windows Azure SDK for PHP includes a new “service management” library, which provides easy ways to monitor the activity of your running instances (Windows Azure web roles & workers roles virtual machines), and to start/stop automatically instances based on usage. Then it becomes easy for you to decide which parameters (CPU, bandwidth, # of connections, etc.) and thresholds to use to scale up and down, and maintain the optimum quality of service for your web applications.
The scenario is simple: let’s say you are running an e-commerce site and you want to run daily promotions to get rid of overstocked items. So you’re going to offer crazy deals every day starting at 8am, each deal being advertised to your subscribers by an email blast. You will have to be ready ready to absorb a major spike in traffic, but the exact time is difficult to predict as the news of the deal may take some time to travel through twitter. When the traffic does materialize, you want the site to run & scale independently – providing service assurance but also minimizing your costs (by shutting down unnecessary capacity as loads go down). This is the scenario for the “Deal of the Day” sample application.
What’s the “Deal of the Day” (DotD) sample app and what to expect?
Deal of the Day (DotD) is a sample application written in PHP to show how to utilize Windows Azure’s scalability features from within PHP. We’ve kept is simple and built it in a way that’s easy to deconstruct and learn from.
As a sample application, DotD did not undergo extensive testing, nor does the code include all the required error catching, security verifications and so on, that an application designed for real production would require. So, do expect glitches. And if you do witness issues, send us a screenshot showing error messages with a description. I’ll get a prize to the first 100 bug trackers!
However, to give you an opportunity to see the sample application working, we’ve decided to deploy a live version on Windows Azure to let you test it for real and give the chance to win actual fun prizes! (and sorry for our friends outside of USA, but prizes can be shipped only to a US address
)
Wanna play? Just go this way: http://dealoftheday.cloudapp.net/
Looking for the code, just get it on GitHub here: http://bit.ly/iPddwxArchitecture of the DotD sample app
The DotD sample app is comprised of several pieces which fit together to create the overall experience:
- Storage –responsible for containing all business data (product information & images, comments) and monitoring data (diagnostic information). All data is stored in Windows Azure Tables, Queues, and Blobs.
- Web Roles – Point of interaction of the application with visitors. Number of active Web Roles varies depending on the load. They are all the same, running the core of the applications logic, producing the user interface (HTML) and handling user inputs. All Web Roles share the storage elements described above.
- Worker Roles – Worker roles sit in the background processing events, managing data, and provide load balancing for scale out. The diagram shows two Worker Roles, one for managing the applications “scalability” (adding/removing Web roles) and one for asynchronously processing some of the applications tasks in the background (another way to achieve scalability)
- Content Delivery Network (CDN) – Global content distribution that provides fast content delivery based on visitor location.
Each of these parts is essential to the performance and scalability of DotD and for more details I invite you to read this introduction article, and then to dig deeper by reading part I (Performance Metrics) and Part II (Role Management) of our “Scaling PHP applications on Windows Azure” series. We will expand the series with additional in depth articles, the next one will be around monitoring the performance of your app.
We look forward to your feedback on the SDK and the Sample Kit. Once again the URL is https://github.com/Interop-Bridges/Windows-Azure-Sample-Kit-4-PHP



Maarten Balliauw reported Windows Azure SDK for PHP v3.0 released in a 5/26/2011 post:
Microsoft and RealDolmen are very proud to announce the availability of the Windows Azure SDK for PHP v3.0 on CodePlex! (here's the official Microsoft post) This open source SDK gives PHP developers a speed dial library to fully take advantage of Windows Azure’s cool features. Version 3.0 of this SDK marks an important milestone because we’re not only starting to witness real world deployment, but also we’re seeing more people joining the project and contributing.
A comment we received a lot for previous versions was the fact that for table storage, datetime values were returned as strings and parsing of them was something you as a developer should do. In this release, we’ve broken that: table storage entities now return native PHP DateTime objects instead of strings for Edm.DateTime properties.
Here’s the official changelog:
- Breaking change: Table storage entities now return DateTime objects instead of strings for Edm.DateTime properties
- New feature: Service Management API in the form of Microsoft_WindowsAzure_Management_Client
- New feature: logging infrastructure on top of table storage
- Session provider now works on table storage for small sessions, larger sessions can be persisted to blob storage
- Queue storage client: new hasMessages() method
- Introduction of an autoloader class, increasing speed for class resolving
- Several minor bugfixes and performance tweaks
Find the current download at http://phpazure.codeplex.com/releases/view/66558. Do you prefer PEAR? Well... pear channel-discover pear.pearplex.net & pear install pearplex/PHPAzure should do the trick. Make sure you allow BETA stability packages in order to get the fresh bits.
Bruce Kyle described a New Feature -- Migrate Your Free App From Free to Active Paying Account on Windows Azure in a 5/26/2011 to the ISV Developer Community blog:
Once you have tried out Windows Azure on a 30-day Pass, no credit card, free accounts, you can now migrate your work into a paid account. Move your Azure application, SQL Azure, and Windows Azure AppFabric to a Azure account without losing all that hard work.
Your free Azure account is, with your permission, moved to your paying Azure account.
- Get a free pass. Promo code DPWE01. No credit card required.
- Build your Windows Azure applications, SQL Azure databases and proof-of-concepts.
- Migrate your account to a full, paying Azure subscription.
The links to migrate your apps will be in the introductory email that you receive once you sign up for the 30-day Pass.
Getting Started with Windows Azure
See the Getting Started with Windows Azure site for links to videos, developer training kit, software developer kit and more. Get free developer tools too.
See Tips on How to Earn the ‘Powered by Windows Azure’ Logo.
For free technical help in your Windows Azure applications, join Microsoft Platform Ready.
Also Available for Limited time
Get $250 USD when you complete your FIRST Windows Azure Application via Microsoft Platform Ready
Learn What Other ISVs Are Doing on Windows Azure
For other videos about independent software vendors (ISVs) on Windows Azure, see:
- Accumulus Makes Subscription Billing Easy for Windows Azure
- Azure Email-Enables Lists, Low-Cost Storage for SharePoint
- Crowd-Sourcing Public Sector App for Windows Phone, Azure<
- Food Buster Game Achieves Scalability with Windows Azure
- BI Solutions Join On-Premises To Windows Azure Using Star Analytics Command Center
- NewsGator Moves 3 Million Blog Posts Per Day on Azure
- How Quark Promote Hosts Multiple Tenants on Windows Azure
The Windows Azure Team reported Real World Windows Azure: Interview with Dano DeBroux, Dir. of Disruptive Business Technologies, ONR in a 5/26/2011 post:
MSDN: Tell us about the Office of Naval Research and the Disruptive Business Technologies division.
DeBroux: The ONR is an executive branch agency within the United States Department of Defense that supports innovative military operations for the Navy and Marine Corps. The Disruptive Business Technologies department supports the ONR by finding innovative technology solutions that integrate commercially available and emerging technologies as a way to address business and military operations.
MSDN: What were some of the challenges that you faced prior to implementing Windows Azure?
DeBroux: This industry is dominated by highly customized and specialized technologies and implementing new solutions typically involves lengthy research and development processes that are grounded in science. That means, it can take up to 20 years to develop new capabilities to a level of maturity that they can be deployed to active military personnel. Plus, with years of development work, the process is usually expensive.
MSDN: Why did you choose Windows Azure?
DeBroux: We wanted to use an open and innovative framework and take advantage of disruptive technologies—ones that were built on open standards and commercially-available—as a way to solve complex military problems. We want to move away from the idea that we have to force ourselves to start from a blank canvas and instead use off-the-shelf technology that we can package together to enable military capabilities and, in theory, reduce costs and the timeline associated with delivering those capabilities to the field. We had to look for commercially-available and mature technologies, pull them together rapidly, and hope there was little to no learning curve, because there simply wouldn’t be time to do anything else. Windows Azure was the best choice to enable us to do that.
MSDN: Can you describe the solution you built with the Windows Azure platform to address your need openness and interoperability?
DeBroux: We started a proof-of-concept project to test several off-the-shelf technologies to address three military scenarios: command and control, information sharing, and event reconstruction. At the heart of the solution is Inca X software, which runs on Windows Azure with global positioning systems, geocasting, data broadcast, and rich media capabilities. Then, because Windows Azure supports open standards and multiple programming languages, such as PHP and JavaScript, we added telecommunications components and smartphones running Windows Mobile 6.1. We also used Bing Maps platform for geographic and location-based information, Windows Live Mesh for synchronizing and sharing information across devices, and a web-based user interface based on Microsoft Silverlight 3 browser technology.
MSDN: What makes this solution unique?
DeBroux: We took Windows Azure and combined it with smart devices and other off-the-shelf technologies and ended up with a platform for creativity. With that platform, we can build very powerful business and military capabilities.
MSDN: What kinds of benefits have you realized with the Windows Azure platform?
DeBroux: When we started the project, we deliberately gave ourselves a compressed timeline of only two weeks in order to prove how rapidly we could develop new capabilities. We were able to easily meet that goal. Plus, once the solution was deployed, we could quickly gather feedback from the field, make changes, and deploy new capabilities in a matter of minutes or hours. In addition, the pay-as-you-go model helps us to reduce costs by only paying for the resources we use. We could peak at 200 users and then be down to zero users until the next training exercise starts. If we had to rely on an on-premises infrastructure, or any other traditional client-server model, we’d be paying for resources even when they’re sitting idle.
Read the full story at: http://www.microsoft.com/casestudies/casestudy.aspx?casestudyid=4000009462
To read more Windows Azure customer success stories, visit: www.windowsazure.com/evidence
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework
• Andriy Svyryd of the Entity Framework Team described EF 4.1 Validation in a 5/27/2011 post:
Validation is a feature added in CTP5 and we already have a blog post describing it. But since then we received a lot of feedback and made a number of changes for 4.1 RTW. Before proceeding please read the CTP5 validation blog post, as it introduces a number of useful concepts.
Validation changes in 4.1 RTW since CTP5:
Here is a list of the design changes we made. We will look into each of them in detail in this post:
Database First and Model First are now supported in addition to Code First
MaxLength and Required validation is now performed automatically on scalar properties if the corresponding facets are set.
LazyLoading is turned off during validation.
Validation of transient properties is now supported.
Validation attributes on overridden properties are now discovered.
DetectChanges is no longer called twice in SaveChanges.
Exceptions thrown during validation are now wrapped in a DbUnexpectedValidationException.
All type-level validators are treated equally and all are invoked even if one or more fail.
Database First and Model First
We were planning to release this in CTP5, but there were still design issues that needed to be resolved.
To use validation with the more traditional Database First and Model First approaches you will need to create a class derived from DbContext for your model, you can read how to do this in the Model & Database First Walkthrough.
You can enable validation in two ways – for Required and MaxLength validation you can modify corresponding facets accordingly (read on for more details). Another option is to decorate properties on the generated entity or complex type classes with validation attributes. Unfortunately this approach does not really work for generated code – the changes will be overwritten every time the code is regenerated. You can avoid this by adding validation attributes by using an Associated Metadata class as described in this blog post.
Facet validation
There are two property facets in EDM that contain information that can be validated: IsNullable and MaxLength. These facets are now validated by default:
- IsNullable = false is equivalent to [Required(AllowEmptyStrings = true)]
- MaxLength = 10 is equivalent to [MaxLength(10)]
If you need different validation behavior you can place one of the above attributes (or StringLength) on the property to override the default.
Since the MaxLength facet is now more important you need to ensure that it’s set to an appropriate value in your model. Also read about the EF 4.1 RTW Change to Default MaxLength in Code First
There are however certain properties that are excluded from facet validation:
- Store generated properties, as the value might not be set at the moment when validation runs
- Complex properties, as they should never be null
- Navigation properties, as you could set the associated FK value and the navigation property would be set on SaveChanges()
- Foreign key properties, for the inverse of the above
Lazy Loading
Lazy loading is now disabled during validation. The reason this change was made is because when validating a lot of entities at once the lazily loaded properties would get loaded one by one potentially causing a lot of unexpected database round-trips and crippling performance.
To avoid receiving validation errors due to navigation properties not being loaded you need to explicitly load all properties to be validated by using .Include(), you can read more on how to do this here: Using DbContext in EF 4.1 Part 6: Loading Related Entities.
Transient Properties
Transient properties are properties on your CLR types that aren’t mapped to a property in the corresponding entity type in the model. Entity Framework ignores these properties for persistence purposes. Now validation attributes placed on them will be picked up. However unlike complex properties we don’t drill down into the transient properties that are not of scalar type.
There are some requirements that the transient properties must meet in order to be validated – they must not be static or an indexer and should have a public getter.
You could use transient properties for some simple custom validation:
public class Client { public int Id { get; set; } public string HomePhone { get; set; } public string WorkPhone { get; set; } public string CellPhone { get; set; } [MinLength(1)] public string[] Phones { get { var phones = new List<string>(); if (!string.IsNullOrEmpty(HomePhone)) phones.Add(HomePhone); if (!string.IsNullOrEmpty(WorkPhone)) phones.Add(WorkPhone); if (!string.IsNullOrEmpty(CellPhone)) phones.Add(CellPhone); return phones.ToArray(); } } }This will validate that at least one phone number was supplied.
Overridden Properties
Validation attributes defined on properties of a parent class that were overridden or hidden are now preserved as well as the validation attributes on the parent class itself, even if they aren’t mapped in the model.
Note: the validation attributes on properties defined in interfaces aren’t preserved as that would lead to conflicts that can’t be reliably resolved.
SaveChanges
In CTP5 by default SaveChanges called DetectChanges, then validated the modified entities and then called DetectChanges again to detect any changes to entities made during validation. DetectChanges is potentially an expensive operation and the built-in validation attributes will not make any changes. For this reason we decided to change validation to stop invoking DetectChanges for a second time after validation.
If you have custom validation logic that can cause property values to change, you can still invoke DetectChanges explicitly as part of your validation logic.
Exceptions
By contract validators indicate validation error by returning a ValidationResult and not by throwing an exception. The built-in validation attributes will not throw exceptions unless they can’t validate a property because either the attribute was not used correctly (vide InvalidCastException when MaxLength attribute is put on DateTime property) or potentially because there is a bug in the attribute implementation. If it does happen it may become difficult to find out which validation attribute is causing the exception from the stack trace. To alleviate this we are now wrapping exceptions thrown during validation in a DbUnexpectedValidationException that contains additional information in the error message to help you find the root cause.
Validator Execution Order
An often overseen behavior is that some validators will short-circuit on a failure to avoid exceptions or redundant error messages. In general property level validation is performed before type level validation. But type-level validation doesn’t run if property validation returns errors as commonly type-level validation checks the relationship between properties and assumes that property-level validation succeeded. If the property-level validation for a complex property returns errors complex type validation won’t run as usually this means that the property value is null.
This is the order in which validators are run. In each step all matching validators are executed, but the execution stops at the first step that returns errors:
- Property-level validation on the entity and the base classes. If a property is complex its validation would also include:
- Property-level validation on the complex type and its base types
- Type level validation on the complex type and its base types, including IValidatableObject validation on the complex type
- Type-level validation on the entity and the base entity types, including IValidatableObject validation
Note: you shouldn’t assume any particular order for same-level validation. For example if a property has a Required attribute and a CustomValidation attribute you still need to handle the null case in the custom validation implementation as it may be the first to be invoked:
public class Person { public int ID { get; set; } [Required] [CustomValidation(typeof(Person), "ValidateName")] public string FirstName { get; set; } [Required] [CustomValidation(typeof(Person), "ValidateName")] public string FirstName { get; set; } public static ValidationResult ValidateName(string value) { if (value == null) { return ValidationResult.Success; } if (value.Contains(" ")) { return new ValidationResult("Names shouldn't contain spaces."); } return ValidationResult.Success; } }Custom validation sample: Uniqueness
One of the most requested validation features is uniqueness validation. In the general case to verify that a property value is unique the store needs to be queried. EF validation avoids store queries by design that’s why we didn’t ship a uniqueness validation attribute. However the upcoming Unique Constraints feature will allow you to enforce uniqueness in the store. But before it is shipped you could just use this simple custom validator that might be enough depending on your scenario.
You need the context to validate uniqueness, so it should be added to the “items” custom dictionary used by validators:
public class StoreContext : DbContext { public DbSet<Category> Categories { get; set; } public DbSet<Product> Products { get; set; } protected override DbEntityValidationResult ValidateEntity( DbEntityEntry entityEntry, IDictionary<object, object> items) { var myItems = new Dictionary<object, object>(); myItems.Add("Context", this); return base.ValidateEntity(entityEntry, myItems); } }Having the context the rest is fairly straightforward:
public class Category : IValidatableObject { public int CategoryID { get; set; } public string CategoryName { get; set; } public string Description { get; set; } public IEnumerable<ValidationResult> Validate(ValidationContext validationContext) { var storeContext = (StoreContext)validationContext.Items["Context"]; if (storeContext.Categories.Any( c => c.CategoryName == CategoryName && c.CategoryID != CategoryID)) { yield return new ValidationResult("A category with the same name already exists!", new[] { "CategoryName" }); } yield break; } }Summary
In this post we looked at the new validation features and changes introduced in EF 4.1 RTW. We explored some of the reasoning behind the changes and saw a few applications of validation.
Feedback and support
We appreciate any feedback you may have on validation or EF 4.1 in general.
For support please use the Entity Framework Forum.
• Paul Patterson explained Microsoft LightSwitch – Sending Emails From the Client in a 5/26/2011 post:
Most of you may have already read an earlier post on how to send emails from LightSwitch (seen here). This post extends what was learned in that previous post, and shows how to wire up a button to send an email on demand.That previous post showed a specific function that would send out an email when an entity was added to the database. A helper class was created in the Server project of the LightSwitch solution. Then, when the new record was created in the database, that server code was called and an email went out.
The whole process was pretty simple to implement, however it was a good exercise that helped me better understand how LightSwitch separates concerns. It was this knowledge and understanding that helped me implement a solution for another email challenge.
The challenge I have is this; I want functionality that will let me send an email on demand, via a button on a screen, and I don’t want to code some fancy WCF service or custom extension to do the job.
Here is the thing – you can’t call server code from the client. It is in the server code that the email processing occurs. Why? Because the client and common projects are Silverlight based projects and I can’t add the necessary System.Net reference to those projects – otherwise I would have used the System.Net.Mail namespace directly from the client.
But hey, the Server project is a .Net 4 class library project, and I can add the System.Net reference to that project. That is why the actual email processing has to occur in the Server project. Following me so far?
So, here is what I did…
For the sake of this post and your reference, I created a simple project named “SendEmail”.
In the Solution Explorer of my LightSwitch project, I switched to File View so that I can get at the Server project…
Knowing that I need to use an external (SMTP) email service to actually send out the email, I decided to store some static information that my email processing can use to process the email; such as stuff for the email service authentication. To do this, I opened the Server project settings.
Next, I added some Application scoped configuration settings…
…come on, you didn’t actually think that I would post my own credentials did ya…I learned from that mistake already
I made sure to save the updates.
Next, a folder is created within the Server project, and named the folder “UserCode”. Within that folder I created a new Class file and named it “EmailHelper.vb”.
This is the code I added to this file…
Imports System.Net Imports System.Net.Mail Namespace LightSwitchApplication Public Class MailHelper Private Property SMTPServer As String = My.Settings.SMTPServer Private Property SMTPUserId As String = My.Settings.SMTPUserID Private Property SMTPPassword As String = My.Settings.SMTPPassword Private Property SMTPPort As Integer = My.Settings.SMTPPort Private Property MailFrom As String Private Property MailFromName As String Private Property MailTo As String Private Property MailToName As String Private Property MailSubject As String Private Property MailBody As String Sub New(ByVal SendFrom As String, ByVal SendFromName As String, _ ByVal SendTo As String, _ ByVal SendToName As String, _ ByVal Subject As String, _ ByVal Body As String) _MailFrom = SendFrom _MailFromName = SendFromName _MailTo = SendTo _MailToName = SendToName _MailSubject = Subject _MailBody = Body End Sub Public Sub SendMail() Dim SMTPUserAddress = New MailAddress(_SMTPUserId) Dim mail As New MailMessage Dim mailFrom As New Mail.MailAddress(_MailFrom, _MailFromName) Dim mailTo As New Mail.MailAddress(_MailTo, _MailToName) With mail .From = mailFrom .To.Add(mailTo) .Subject = _MailSubject .Body = _MailBody End With Dim smtp As New SmtpClient(_SMTPServer, _SMTPPort) smtp.EnableSsl = True smtp.Credentials = New NetworkCredential(SMTPUserAddress.Address, _SMTPPassword) smtp.Send(mail) End Sub End Class End NamespaceSo, this class contains some pretty simple code. Instantiating the class requires a bunch of parameters that are later used by the SendMail() method. The SendMail() methid is where the mail message gets created, configured, and sent using the a SmtpClient. As you can see, some class properties are defaulted to the values that are stored in the App.Config file of the Server project (which were added earlier).
Next, I go back into the logical view of the solution.
In the logical view, a new table is created. The table name is “ProxyEmail”, and it looks like this…
Now, with this table, I have essentially created a “Model” that I can use in my workaround. Remember, my challenge is to do all this with native LightSwitch features and functionality. I don’t want to create a fancy-smancy WCF service or custom extension for this. I just want to get the job done. By creating this entity, I have, in essence, created a business object that I am going to use to do what I want to do.
Here is the fun part! I can’t call the Server code directly from any screens, however I know that my “entity” can access the server code via its dependencies. For example, my ProxyEmail entity has a method called ProxyEmails_Inserted(), which runs on the server when an entity as added to the table (add to the collection of ProxyEmail entities).
So, I add some code to this method…
…and here is the code if you want…
Private Sub ProxyEmails_Inserted(entity As ProxyEmail) ' Write your code here. Dim sSubject = "Test Email." Dim carRtn = Environment.NewLine & Environment.NewLine Dim sMessage = "The following email has come from a button on LightSwitch..." & carRtn sMessage += "Testing 1, 2, 3!!" ' Create the MailHelper class created in the Server project. Dim mailHelper As New MailHelper(entity.SenderEmailAddress, _ entity.RecipientName, _ entity.RecipientEmailAddress, _ entity.RecipientName, _ sSubject, _ sMessage) ' Let 'er rip! mailHelper.SendMail() End SubSo, this is pretty much the same as the last post. Right, but here is how this similar stuff is used to create a feature that will allow you to send an email on demand, rather than relying only on updates to entities.
I create a new Screen and, using the New Data Screen template, name it “SendAnEmail”, but don’t assign any screen data to it…
In the screen designer for the new SendAnEmail screen, I click Add Data Item… and create a Method with a name of “SendMyEmailOnDemand”…
Back in the screen designer, I expand the Screen Command Bar, and drag and drop the SendMyEmailOnCommand method to the command bar.
I right click the newly added button, and select to Edit Execute Code.
I edit the method to this…
…and here is the actual code you can use…
Private Sub SendEmailOnCommand_Execute() Dim newEmail = DataWorkspace.ApplicationData.ProxyEmails.AddNew() With newEmail .RecipientEmailAddress = "paulspatterson@hotmail.com" .RecipientName = "Paul Patterson" .SenderEmailAddress = "paul@selectsystems.ca" .SenderName = "Paul Patterson (Select Systems)" End With DataWorkspace.ApplicationData.SaveChanges() newEmail.Delete() DataWorkspace.ApplicationData.SaveChanges() End SubWhat this is doing is simply creating a new ProxyEmail entity, settings it’s properties, the committing the insert to the system. The SaveChanges after the setting the properties will cause the ProxyEmails collection to fire that ProxyEmails_Inserted() method that was wired up earlier, which then sends the email from the server code. After that, the newly added entity is deleted because I don’t need it any more.
So, I F5 to test it…
… and I click the Send Email On Demand button. Then I go and check my email, and presto…
Yes!
This may not be the super cool software code monkey way of doing things, but who cares! It does the job, and I did [it] in no time at all.















• First Floor Software posted Announcing Document Toolkit for LightSwitch (Beta) on 5/18/2011 (missed when posted):
As of today Document Toolkit, a document viewer for Silverlight, is now available as LightSwitch Extension. Document Toolkit for LightSwitch adds document viewing capabilities to your LightSwitch application. Documents of type XPS, PDF *), and Microsoft Office documents such as Word, Excel and PowerPoint are supported.
Learn more
The following tutorials provide step-by-step instructions on installing and using Document Toolkit for LightSwitch.
- Tutorial: Installing Document Toolkit for LightSwitch
- Tutorial: Using the Document Viewer
- Tutorial: How To Create And Use A Table of Documents
For more details about Document Toolkit see http://firstfloorsoftware.com/DocumentToolkit
About Visual Studio LightSwitch
Microsoft Visual Studio LightSwitch is the simplest way for developers of all skill levels to develop business applications for the desktop and cloud. See http://msdn.com/lightswitch for more details.
About Document Toolkit
Document Toolkit for Silverlight is a fast, feature-rich and 100% client-only document viewer library for Silverlight. Document Toolkit offers a range of features that enables easy document access and document display in Silverlight applications.
*) PDF support is experimental and may not be used in production environments.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
• Michael Desmond (@michaeldesmond, pictured below) described my cover article for the June 2011 issue of Visual Studio Magazine in his VSM June Issue Preview post of 5/26/2011 to his Desmond File blog:
…
On the cover is Roger Jennings' in-depth look at Microsoft's efforts to enable application migration to Windows Azure on- and off-premise cloud infrastructure. Jennings looks at the progress the Windows Azure team has made since PDC 10, and the impact Scott Guthrie, incoming corporate vice president of the Azure Application Platform, might have on Microsoft's cloud making efforts. …
Click here to read the entire story.
Full disclosure: Michael is editor-in-chief of Visual Studio Magazine, for which I’m a contributing editor.
• Brian Harry described the CTP of the System Center Operations Manager and VS 2010 TFS in a 5/17/2011 post (missed when posted):
For the last year or so I’ve been giving talks about trends in software development and particularly ALM. I’ve described one of the big upcoming trends as the need for better collaboration between development and operations. The state of that collaboration today is not great even given our current technology stacks. However, as cloud architectures become more and more common and the need for being “up to date” with short release cycles continue to accelerate, we are going to see ever increasing demand for the development and operations teams to work closely together. In some orgs we’ll even see some blurring of the line between the two – there’s recently been a lot of talk about a new pedigree called DevOps.
VS ALM has always been about connecting people involved in the software lifecycle. When we launched VS 2010 and introduced a slew of new testing tools, we talked a great deal about the vacuum between Dev and Test – the lack of consistent tooling, organizational barriers, poor communication, lots of wasted time, energy and frustration. One of the pillars of our VS 2010 release was to tackle this problem.
In the next VS release, we are tackling the problem of Stakeholder <-> Development team collaboration. You can read more about the announcements we’ve made around that here: http://blogs.msdn.com/b/jasonz/archive/2011/05/16/announcing-alm-roadmap-in-visual-studio-vnext-at-teched.aspx. And I’ll be writing more about that in the coming weeks.
I’ve generally been describing the Operations <-> Development team collaboration problem as the next problem to tackle in Visual Studio V.NextNext. I’ve had a few conversations with the System Center team about what that might look like but it had all been pretty low key because we’ve been so focused on our current deliverables. Then, to my surprise, a month or so ago, I got invited to a demo by the System Center team where they showed connectivity between System Center and TFS. I was so excited I was drooling the whole time I think. Yesterday Jason, announced a CTP of this new technology at TechEd. What I fear may not have been entirely clear is that this is NOT a VS V.Next feature. This feature works with TFS 2010 TODAY! It’s only in CTP form now and we’ve got some work to do finishing it off – but it’s a workable solution TODAY! I don’t yet know what the ultimate release schedule for this will look like but I’ll let you know more as we figure it out.
Let me expand a bit on how this works (beyond what is in the whitepaper I referenced above):
First, the SCOM-TFS Connector is a set of services that run on your SCOM Root Management Server (RMS) that synchronize data between System Center and Team Foundation Server. It enables the operations team to work as they always do inside Operations Manager and yet collaborate easily with the development team. Let’s walk through a scenario …
An operator gets an alert of an operations issue in production and opens Operations Manager to review the alert.
The operations engineer reviews the knowledge base associated with the alert and sees that this particular class of issue can’t be addressed with configuration but needs to be escalated to the development team.
The operator can right click on the alert and set the state to “Assigned to Engineering” (yes ignore that this is missing from the menu in the screenshot – it will be there if you install the connector. Sorry for the broken screenshot).
Every alert in System Center is associated with some deployed component. When you configure the Connector, you map each component to a TFS project. The connector will notice the state change in System Center and seamlessly and automatically open a new work item in TFS in the associated Team Project. The new work item will be of type “Operational Issue” (which will need to be added to the process template for every Team Project mapped to a System Center component). The Operational Issue captures all of the information from the System Center alert and implements a simplified operational workflow.
Now, that new Operational Issue will magically appear in TFS project in your development environment. You can query for them, assign them, etc the same way you do any other work item in TFS. Further, you can navigate links in the work item back to information stored in System Center.
Ultimately, the operational issue is likely handled in one of 3 ways:
- The developer diagnosed the alert and recommends a work around to the operations team. He/she can do this by simply updating the operations issue in TFS with the appropriate work around steps and the TFS-SCOM connector will automatically pick up those comment and replicate them into the System Center alert for the operator to see and take action on.
- The developer can file a new bug and link it to the operations issue. The bug can then be prioritized and scheduled to be addresses as is appropriate within the team’s schedule.
- The developer can ignore the issue by just closing it – OK, your operations team will be cursing you, but you can do it :)
I’m really thrilled to see this incredibly important scenario enabled by the TFS-SCOM connector. It’s the first step of many in the journey to connect the development and operations teams together to build, deploy and operation first class services for their organizations.
Please try it out if you have the chance and let me know what you think!




Bruce Guptill and Bill McNee cowrote Switched-on: Cloud IT is Now About Business Velocity and posted it to the Saugatuck Technology Web site of 5/26/2011. From the “What Is Happening Section” (site registration required):
For the past several years, the emphasis on most Cloud IT (i.e., SaaS, IaaS) acquisition and deployment by user enterprises has focused primarily on reducing costs and internal process improvement. One of the key selling points for enterprises of all sizes has been the ability to rapidly deploy without significantly affecting IT capital outlays. These factors alone could account for the vast majority of Cloud acquisition and deployment by user enterprises.
Within the past 12-18 months, however, Saugatuck has seen a dramatic and compelling surge in enterprise Cloud adoption and use by large enterprises – not only at the “fringes” of the business solution portfolio, but increasingly at its “core.” In many ways, this is being driven by factors beyond those that drove first-generation growth. The rapid, almost rampant, adoption and use of Cloud IT today is driven by an accelerating desire and demand by business executives to transform and improve their abilities to do business. Saugatuck has used the term “IT velocity” to help articulate the infrastructure and services aspects of this trend (874CLS, Can the Cloud Help Enterprises Achieve “IT Velocity?”, 14Apr2011). Based on analysis of our most recent research among enterprise and SMB executives and managers, we are adding the term “business velocity” to the Cloud lexicon as well.
Leading-edge Cloud buyers and users today seek something well beyond the traditional business benefits of Cloud noted above. Leaders are strategizing on, and investing in, Cloud to achieve business and IT transformation.
The net for Cloud buyers and providers is this: The Cloud opportunity is not just about the consumption of SaaS business solutions or IaaS storage or compute services. Cloud is about the transformation of enterprise business, and the increasing speed of that transformation. …
The authors continue with the usual “Why Is It Happening” and “Market Impact” sections.
Jason Bloomberg asserted “There are different degrees of multitenancy, with different advantages and disadvantages” as a deck for his Cloud Multitenancy: More Than Meets the Eye article of 5/26/2011:
One of the most important characteristics of Public Clouds is multitenancy. Put multiple customers on the same physical infrastructure, sharing the same application. Establish appropriate security measures so that they can't interfere with each other, or snoop on the other's data. Presto! Cost savings, efficiency, and scalability are yours!
The good news is, multitenancy is one of the key enablers of the Public Cloud value proposition. But of course, there's more to multitenancy than meets the eye. There are actually different degrees of multitenancy, with different advantages and disadvantages. And as you might expect, there's plenty of vendor hype as well. As a result, understanding the various degrees of multitenancy is essential for understanding what you're paying for when you use a Public Cloud.
First Degree Multitenancy: Shared Schema Approach
With the shared schema approach, all customers share all tiers of the Software-as-a-Service (SaaS) application: presentation, processing tier, and the underlying database. In fact, each table of the underlying database would typically contain data for each SaaS customer. The app keeps these data separate via a customer number or other unique identifier that every table would have to contain.The advantages of the shared schema approach include:
- Simple updates - since there is essentially only the single SaaS application, any application updates automatically apply to every customer at the same time. No configuration differences, no branching code.
- Supports social capabilities, analysis, targeted marketing, etc. - the app vendor can easily support any application capabilities that require queries across multiple customers, since all customer data are in the same tables. As a result, building any kind of cross-customer capability, like collaboration or social networking, is straightforward. It's also simple for the app vendor to analyze information across their customer base.
- Simple to manage - simple to update means simple to manage, as there will only be one version in production at any time.
- Simple integration with back-end infrastructure - identity management, backups, and other back-end capabilities are straightforward to implement.
The disadvantages of the shared schema approach include:
- The vendor must architect the application for multitenancy. Moving a single-tenant app to the Cloud won't give you first degree multitenancy without a lot of rework.
- Relatively vulnerable to certain attacks like SQL injection, etc. - since your data are in the same tables as everyone else's, any attack that exposes other rows in the tables you can access have a chance of succeeding. Make sure your SaaS provider has addressed these isssues.
Requirements for scaling out a shared schema-based application:
- Some vendors deploy duplicate stacks - essentially, they run identical application instances (including all tiers) for different customer segments. As long as the vendor is careful to insure that each application instance is identical, they are still able to achieve the benefits of the shared schema approach. However, this approach does not improve the app's fault tolerance; if one stack goes down, then all customers on that stack are affected.
- Segment the database by customer - instead of every customer putting their data into every table, segment or "shard" the database into multiple database instances, each supporting a different customer segment. Scale out the other tiers as well. This approach provides the greatest fault tolerance but is more difficult to manage than the duplicate stack approach.
- Individual infrastructure elements (processors, storage, etc.) can take advantage of the elastic provisioning capabilities of the Cloud.
Second Degree Multitenancy: The Clustered Shared Schema Approach
With the clustered shared schema approach, the SaaS vendor intentionally segments customers onto different application instances running on separate stacks, where the instances are generally not identical to each other.The advantages of the clustered shared schema approach:
- More customer choice - the vendor configures each cluster according to customer requirements, instead of the "one size fits all" limitation of the shared schema approach.
- Allows for round robin updates - instead of updating every app instance at once, the vendor can rotate their updates, which requires a smaller administration team.
The disadvantages of the clustered shared schema approach:
- Increased maintenance complexity - the vendor may have multiple different versions of their app in production at once, with different release cycles or the potential of branching code. As a result, management is more complicated than the shared schema approach.
- Collaboration and analysis across clusters is problematic - any capability that requires data from multiple clusters requires data integration that can deal with the different application versions in each cluster.
Requirements for scaling out the clustered shared schema approach:
- Add new clusters - essentially, scalability is built in, because adding new clusters is straightforward.
- Individual infrastructure elements (processors, storage, etc.) can take advantage of the elastic provisioning of the Cloud, as with the shared schema approach.
Isolated tenancy approach (sometimes called megatenancy)
Every customer has their own application instance, as though they were running the app on their internal infrastructure. But since the applications are running in the Cloud, the customer is none the wiser-at least in theory.The advantages of the isolated tenancy approach include:
- Maximum customer choice - every customer gets the configuration they want, and the vendor can apply new releases or customizations on the schedule each customer desires.
- Minimal rearchitecting of the original app - if the vendor is trying to take an existing application they designed for on-premise installations and move it to the cloud, the isolated tenancy approach requires minimal changes to the internal architecture of the app.
The disadvantages of the isolated tenancy approach include:
- Highest management complexity - since every customer has unique configuration, the vendor must manage every application instance as a separate, distinct application, since after all, that's what they are.
- Most expensive - management, integration, updates, customer support, etc. all cost more. With isolated tenancy you lose any cost savings benefits the Cloud might have provided.
- Lack of vendor commitment - vendors typically offer isolated tenancy because they're rushing to offer a SaaS version of their app, and they don't have the time, money, or will to rearchitect it for the Cloud. But since it's such a hassle to support, as soon as one of the other approaches is viable, they'll want to move their customers to it. Then again, they may not wait. They may simply change their mind about supporting the app altogether, leaving customers in the lurch.
Requirements for scaling out the isolated tenancy approach:
- Add more application instances - in other words, add more stacks, each of which supports an application instance.
- Individual infrastructure elements (processors, storage, etc.) may or may not be able to take advantage of the elastic provisioning of the Cloud, depending on the architecture of the application. In other words, the isolated tenancy approach may not really be SaaS at all. It may simply be a hosted provider model masquerading as SaaS.
The ZapThink Take
The moral of this story, of course, is caveat emptor: let the buyer beware. Not all SaaS offerings have the same type of multitenancy, and each approach has its advantages and disadvantages. And as with all IT decisions, do your homework to make sure your vendor isn't trying to pull the wool over your eyes.It's also important to take the lessons of this ZapFlash to heart when you are planning a Private Cloud. You might think that since Private Clouds are inherently single tenant that you don't need to worry about multitenancy. Architecturally speaking, however, there may be advantages to a multitenant approach even in a Private Cloud, where instead of multiple customers, you consider multiple users or user types.
Taking a shared schema approach to a Private Cloud can reduce your costs relative to the other approaches, but will give you more of a "one size fits all" set of applications. Ignore the best practices of multitenancy, however, at your peril, as you may not achieve the cost savings and efficiency benefits that led you to consider a Private Cloud in the first place.

Jason is Managing Partner and Senior Analyst at Enterprise Architecture advisory firm ZapThink LLC.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Eric Nelson (@ericnel) mentioned WAPA in his Windows Azure Platform Roadmap from Microsoft UK TechDays May 23rd and 24th post of 5/26/2011:
Several attendees asked me to share the roadmap slide from the developer track at Tech.Days 2011 this week.
This is my summary as of May 23rd 2011:
[Emphasis added.]
Beta
- Extra Small compute instance
- Windows Azure VM Role
CTP
- Windows Azure Connect
- Windows Azure Traffic Manager
- SQL Azure OData Service (labs)
- SQL Azure Reporting (Limited CTP)
- SQL Azure Data Sync (labs)
- AppFabric Service Bus enhancements (labs)
Announced
- SQL Azure Backup and Restore
- SQL Azure Federations
- SQL Azure codename “Austin”
- AppFabric Developer Tools
- AppFabric Application Manager
- AppFabric Composition Model
- Windows Azure Platform Appliance [Emphasis added.]
- VM Role Support for Windows Server 2003
- VM Role Support for Windows Server 2008 SP2
- Constructing VM role images in the cloud
- Improved support for Java
The slides and videos from the day will be available on the Tech.Days site in due course but for now you can download my two decks from Slides for Windows Azure Developer Track on Monday 23rd.
Related Links
- Connect with my team if you are an ISV (or similar) in the UK – http://bit.ly/ukisvfirststop (Including our blog, LinkedIn group and Microsoft Platform Ready assistance for Windows Azure)
- http://www.azure.com/offers
- http://www.azure.com/getstarted
- Attend a one day FREE event for Application LifeCycle Management with Visual Studio 2010 on June 27th in Reading
It’s nice to see a Microsoft evangelist mention WAPA in a public post. The only other info about WAPA that’s been available lately is the occasional job posting by the Venice and other teams.
<Return to section navigation list>
Cloud Security and Governance
James Staten (@staten7) asserted A Key Decision Is Often Clouded By Emotion in a 5/26/2011 post to his Forrester blog:
What is one of the most important decisions infrastructure & operations (I&O) professionals face today? It's not whether to leverage the cloud or build a private cloud or even which cloud to use. The more important decision is which applications to place in the cloud, and sadly this decision isn't often made objectively. Application development & delivery professionals often decide on their own by bypassing IT. When the decision is made in the open with all parts of IT and the business invited to collaborate, emotion and bravado often rule the day. "SAP's a total pain and a bloated beast, let's move that to the cloud," one CIO said to his staff recently. His belief was if we can do that in the cloud it will prove to the organization that we can move anything to the cloud. Sadly, while a big bang certainly would garner a lot of attention, the likelihood that this transition would be successful is extremely low, and a big bang effort that becomes a big disaster could sour your organization on the cloud and destroy IT's credibility. Instead, organizations should start with low risk applications that let you learn safely how to best leverage the cloud — whether public or private.
But how do you get the emotion, conjecture and bravado out of the process?
This requires a methodology and tool for framing the discussion and grounding it in best practices. And by the way, this decision process isn't unique to the cloud decision.
The overall decision is one of getting outsourcing right because some applications should move to true cloud solutions while others are a better fit for traditional hosting, colocation and other deployment methods. Getting this right is what Forrester calls "strategic rightsourcing." This methodology we debuted in 2009 is based on best practice efforts from over 200 customers. Now we have boiled this methodology down into a single tool that can be used to drive your internal discussions. Through a structured set of questions your organization can break down your application and IT service catalogs into not only candidates for the cloud but also phases of consideration that let you achieve measurable and meaningful wins while gaining the experience necessary to move up from non-critical applications toward mission critical ones with the knowledge and confidence they will succeed. Download it today. But this is just a decision making tool. You also have to get management of the new outsourcing model right. Marrying strategic rightsourcing with a multisourcing management model by your sourcing & vendor management colleagues.
This collaboration will be the topic of my session Friday here at Forrester IT Forum. Getting this right is critical to achieving outsourcing and cloud-sourcing success. Come join us.
<Return to section navigation list>
Cloud Computing Events
• O’Reilly Media announced that its Velocity Conference 2011 will take place at the Santa Clara Conference Center in Santa Clara, CA on 6/14 through 6/16/2011:
Web performance and operations, once the secret sauce of elite Web companies, are now essential ingredients in every company's online strategy. The business value of "fast and reliable" has been established, and stakeholders are demanding more and better results now. Get the skills and tools you need to master this ever-shifting, increasingly complex domain at Velocity.
New for Velocity 2011: Mobile Performance. The ubiquity of mobile devices has made small screen optimization critical, so in addition to tracks for Operations, Web Performance, and Velocity Culture, we've added a fourth focus on Mobile Performance.
Velocity 2011 Topics and Themes
- Automation strategies
- Optimizing mobile performance
- Cloud computing: the good bits [Emphasis added.]
- JavaScript speedups
- Storing and managing big data: NoSQL, Hadoop
- Metrics and monitoring
- Building and supporting the business case
O'Reilly Velocity happens June 14-16, 2011 at the Santa Clara Convention Center in Santa Clara, CA. Join us for three days of intensely practical training, illuminating case studies, and strategies for building a culture of high performance and reliability, delivered by the best in the business. Velocity 2010 sold out, so sign up now to reserve your place at the premier event for web performance and operations education.
Stay Sharp Year-round with the
Velocity All Access PassRegister for the Velocity All Access Pass and keep your web ops and performance skills honed even after the conference ends. In addition to a full conference pass including workshops, you'll receive six essential O'Reilly ebooks, access to the recorded video archive, and enrollment in three half-day online conferences.
• The DevOpsDays 2011 conference will follow Velocity 2011 on 6/17 and 6/18/2011 at Linked In’s campus in Mountain View, CA:
Devopsdays Mountain View 2011 will be a two day event for discussing all topics around improving the interaction between what is traditionally considered development activity and that which is traditionally considered operations activity.
Devopsdays is an open event for discussing all topics around improving the interaction between what is traditionally considered development activity and that which is traditionally considered operations activity. As we put together an agenda, we are looking to *YOU* to help shape the event. The best way to ensure that you get the most out of this event is to make a proposal or suggestion about a topic in which you are interested!
It will happen on 17 and 18 June 2011 in Mountain View, California. It will be two day event, with a mixture of talks and openspace.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Klint Finley (@klintron) reported Citrix Launching New IaaS [Technology] Based on OpenStack (Updated) in a 5/26/2011 post to the ReadWriteCloud blog:
Update: A spokesperson for Citrix has clarified that what Citrix is releasing is not actually an IaaS: "The company is launching a product that public and private clouds can build their IaaS services on (they won't competing with established IaaS providers)."
Today Citrix announced that it will launch a new infrastructure-as-a-service based on the OpenStack platform. The new service is called Project Olympus and will be available for as both a public cloud and as a platform for private clouds. The first offering, which will include a "cloud-optimized" version of Xen Server, should be ready later this year.
The selection of OpenStack is important as various initiatives vie to become the standard for cloud computing. OpenStack is the open source initiative started by Rackspace and NASA and now supported by over 60 companies, including AMD, Canonical, Cisco, Dell, Intel and Citrix. Other potential cloud standards include Red Hat's Deltacloud and the NRE Alliance's proposal.
Citrix will be taking on established IaaS providers like Amazon Web Services, Joyent and Rackspace. Dell and HP are expected to launch public and private IaaS solutions as well. It might be worth noting though that both Dell and Rackspace gave positive supporting quotes in the announcement.
Also, a few IaaS providers have been acquired by telcos this year, meaning that much of the competition has very deep pockets.
<Return to section navigation list>

















0 comments:
Post a Comment