Windows Azure and Cloud Computing Posts for 5/5/2011+
| A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Updated 5/7/2011 with new articles marked • by Beth Massi, Michael Washington, Richard Waddell, Bill Zack, Yung Chow, Marcelo Lopez Ruiz, Doug Rehnstrom, Chris Hoff, Wall Street & Technology, Avkash Chauhan, James Hamilton, Neil MacKenzie, Rob Tiffany, Max Uritsky, the Windows Azure Connect Team, and the Windows Azure AppFabric Labs Team.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructur and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
• Marcelo Lopez Ruiz reported tracking down a Windows Azure Storage Emulator returning 503 - Service Unavailable problem in a 5/6/2011 post:
Today's post is the result of about four hours of tracking down a tricky problem, so hopefully this will help others.
My problem began when I was testing an Azure project with the storage emulator. The code that was supposed to work with the blob service would fail any request with a "503 - Service Unavailable" error. All other services seemed to be working correctly.
Looking at the headers in the Response object of the exception, I could see that this was produced by the HTTP Server library by the telling Server header (Microsoft-HTTPAPI/2.0 in my case). So this wasn't really a problem with the storage emulator - something was failing earlier on.
Looking at the error log at %SystemRoot%\System32\LogFiles\HTTPERR\httperr1.log in an Administrator command prompt, there almost no details, so I had to look around more to figure out what was wrong.
Turns out that some time ago I had configure port 10000 on my machine to self-host WCF services according to the instructions on Configuring HTTP and HTTPS, using http://+:10000. The storage emulator currently sets itself up as http://127.0.0.1:10000/. According to the precedence rules, "+" trumps an explicit host name, so that was routed to first, but there was no service registered for "+" at the moment, so http.sys was correctly returning 503 - Service Unavailable.
To verify, I can simply run this command from an Aministrator command prompt:
C:\Windows\system32>netsh http show urlacl
URL Reservations:
-----------------Reserved URL : http://*:2869/
User: NT AUTHORITY\LOCAL SERVICE
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;LS)Reserved URL : http://+:80/Temporary_Listen_Addresses/
User: \Everyone
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;WD)... (an entry for http://+:10000/ was among these!) ...
The first was a simple one-liner, again from an Administrator command prompt, to delete that bit of configuration I didn't need anymore, and the storage server is up and running again.
netsh http delete urlacl url=http://+:10000/
<Return to section navigation list>
SQL Azure Database and Reporting
Steve Yi recommended Andrew Brust’s Whitepaper on NoSQL and the Windows Azure Platform in a 5/4/2011 post to the SQL Azure Team blog:
I wanted to bring to your attention a great whitepaper on “NoSQL and the Windows Azure platform” written by Andrew Brust, a frequently quoted technology commentator and consultant.
This paper is important because there is a renewed interest in certain non-relational data stores which are sometimes collectively referred to as “NoSQL” technologies and this is a category which certainly has its niche of avid supporters. NoSQL databases often inherently use approaches like distributed horizontal scale-out and do away with some of the ACID characteristics of traditional relational databases in favor of flexibility and performance especially for certain workloads like scalable web applications. This in turn provokes a number of questions as to which scenarios NoSQL is appropriate for, whether it is a favored technology for the cloud and how it relates to cloud offerings like the Windows Azure platform.
I really enjoyed reading Andrew’s whitepaper because it does a great job of educating users on NoSQL and its major subcategories; understanding the NoSQL technologies already available in the Windows Azure platform; and on evaluating NoSQL and relational database approaches.
We have long believed that SQL Azure is unique because it has proven relational database technologies but is architected from the ground up for the scale, simplicity and ease of use of the cloud. But whether you are using SQL Azure or not, if you are working on cloud technologies you will likely at some point be confronted with decisions that relate to NoSQL and Andrew’s perspectives on this topic help to bring greater clarity to a topic which can be quite confusing at first.
<Return to section navigation list>
MarketPlace DataMarket, WCF and OData
Wes Yanaga posted Windows Azure Marketplace–DataMarket News on 5/5/2011:
Highlights
ISV Applications: Does your application leverage DataMarket data feeds? We are very intersted in helping to promote the many applications that use data from DataMarket. If you have built an application using 1 or more DataMarket feeds please send an email with the details of your applciation and which feeds you use to datamarketisv@microsoft.com. Your application could be featured on our blogs, in this newsletter and on our website.
World Dashboards by ComponentArt: ComponentArt's mission is to deliver the world's most sophisticated data presentation technology. ComponentArt has built a set of amazing World Data Digital Dashboards to show developers how they can build rich visualizations based on DataMarket data. Check out the dashboards at http://azure.componentart.com/.
Content Update
World Life Networks: The Social Archive - Micro-Blog Data (200+ Sources) by Keyword, Date, Location, Service—The Social Archive provides data from 200+ microblogs based on keyword, date, location, and/or service. UTF8 worldwide data on Entertainment, Geography, History, Lifestyle, Music, News, Science, Shopping, Technology, Transportation, etc. Updated every 60 seconds.
United Nations:
Indian Stock Market information available free on DataMarket:
ParcelAtlas Data from Boundary Solutions Inc available for purchase on DataMarket:
UPC Datasets from Gregg London Consulting available for building rich apps on various platforms:
- U.P.C. Data—Ingredients for Food—U.P.C. Data for Food includes Full Ingredient Information.
ISV Partners
DataMarket powers Presto, JackBe's flagship Real-Time Intelligent (RTI) Solution: Hear Dan Malks, Vice President for App Platform Engineering at JackBe, talk about how his company is taking advantage of DataMarket to power Presto, the company's flagship Real-Time Intelligence (RTI) solution. He adds, DataMarket speeds the decision-making process by providing a central place where they can find whatever data they need for different purposes, saving time and increasing efficiency.
Tableau uses DataMarket to add premium content as a data source option in its data visualization software: Ellie Fields, Director of Product Marketing at Tableau Software, talks about using DataMarket, to tame the Wild West of data. She adds, "Now, when customers use Tableau, they see DataMarket as a data source option. They simply provide their DataMarket account key for authentication and then find the data sets they want to use. Customers can import the data into Tableau and combine that information with their own corporate data for deep business intelligence."
Resources
- Marketplace: http://datamarket.azure.com/
- Developer Documentation: http://msdn.microsoft.com/en-us/library/gg315539.aspx
There was very little, if anything, new in the preceding post. However, the Windows Azure Marketplace DataMarket hasn’t received much attention recently.
• Marcelo Lopez Ruiz asserted Anecdotally, datajs delivers quiet success in a 5/4/2011 post:
So far it seems that the simple API resonates well with developers, and we're hitting the right level of simplicity with control, but I'm interested in hearing more of course. If you've tried datajs, what was your experience like? Good things, bad things, difficult things? If you haven't, is there something that's getting in your way or something that could change that would make the library more appealing to you?
If you want to be heard, just comment on this post or drop me a message - thanks in advance for your time!
Marcelo also described What we're up to with datajs in a 5/3/2011 post:
It's been a while since I last blogged about datajs, so in the interest of transparency I thought I'd give a quick update on what we're up to.
There are three things that we're working on.
- Cache implementation. Alex is doing some awesome work here, but the changes are pretty deep, which is why we haven't uploaded code for a while; we want to make sure that the codebase gets more stable over time at this moment.
- Bug fixes. A few minor things here and there, nothing too serious has come up so far.
- Responding to feedback. There are a couple of tweaks in design that we're considering to help with some scenarios. This is a great time to contribute ideas, so if you're interested, just go over to the Discussions page and post - we're listening.
Pedro Ardila described Spatial Types in the Entity Framework as a precursor to their incorporation in OData feeds in a 5/4/2011 post to the Entity Framework Design blog:
- The basics of SQL Server’s spatial support
- Design goals
- Walkthrough of design: CLR types, Metadata, Usage, WCF Serialization, Limitations
- Questions (we want to hear from you!)
This entry will not cover the tools experience as we want to focus on what is happening under the hood. We will blog about the tools design at a later time. For now, be sure that we plan on shipping Spatial with Tools support.
The Basics of Spatial
For those of you that are new to Spatial, let’s briefly describe what it’s all about: There are two basic spatial types called Geometry and Geography which allow you to perform geospatial calculations. An example of a geospatial calculation is figuring out the distance between Seattle and New York, or calculating the size (i.e. area) of a state, where the state has been described as a polygon.Geometry and Geography are a bit different. Geometry deals with planar data. Geometry is well documented under the Open Geospatial Consortium (OGC) Specification. Geography deals with ellipsoidal data, taking in mind the curvature of the earth when performing any calculations. SQL introduced spatial support for these two types in SQL Server 2008. The SQL implementation supports all of the standard functions outlined in the OGC spec.
Programming Experience in SQL
The query below returns all the stores within half a mile of the address of a person whose ID is equal to 2. In the where clause we multiply the result of STDistance by 0.00062 to convert meters to miles.DECLARE @dist sys.geography SET @dist = (SELECT p.Address FROM dbo.People as p WHERE p.PersonID = 2) SELECT [Store].[Name], [Store].[Location].Lat, [Store].[Location].Long FROM [dbo].[Stores] AS [Store] WHERE (([Store].[Location].STDistance(@dist)) * cast(0.00062 as float(53))) <= .5In the sample below, we change the person’s address to a different coordinate. Note that STGeomFromText takes two parameters: the point, and a Spatial Reference Identifier (SRID). The value of 4326 maps to the WGS 84 which is the standard coordinate system for the Earth.
update [dbo].[People] set [Address] = geography::STGeomFromText('POINT(-122.206834 57.611421)', 4326) where [PersonID] = 2Note that when listing a point, the longitude is listed before the latitude.
Design
Goals
The goals for spatial are the following:
- To provide a first class support for spatial in EDM
- Rich Programming experience in LINQ and Entity SQL against Spatial types
- Code-first, Model-first, and Database-first support
- Tooling (not covered in this blog)
We have introduced two new primitive EDM Types called Geometry and Geography. This allows us to have spatial-typed properties in our Entities and Complex Types. As with every other primitive type in EDM, Geometry and Geography will be associated with CLR types. In this case, we have created two new types named DBGeometry and DBGeography which allows us to provide a first-class programming experience against these types in LINQ and Entity SQL.
One can describe these types in the CSDL in a straightforward fashion:
<EntityType Name="Store"> <Key> <PropertyRef Name="StoreId" /> </Key> <Property Name="StoreId" Type="Int32" Nullable="false" /> <Property Name="Name" Type="String" Nullable="false" /> <Property Name="Location" Type="Geometry" Nullable="false" /> </EntityType>Representing in SSDL is very simple as well:
<EntityType Name="Stores"> <Key> <PropertyRef Name="StoreId" /> </Key> <Property Name="StoreId" Type="int" Nullable="false" /> <Property Name="Name" Type="nvarchar" Nullable="false" MaxLength="50" /> <Property Name="Location" Type="geometry" Nullable="false" /> </EntityType>Be aware that spatial types cannot be used as entity keys, cannot be used in relationships, and cannot be used as discriminators.
Usage
Here are some scenarios and corresponding queries showing how simple it is to write spatial queries in LINQ:

Have in mind that spatial types are immutable, so they can’t be modified after creation. Here is how to create a new location of type DbGeography:
s.Location = DbGeography.Parse("POINT(-122.206834 47.611421)"); db.SaveChanges();Spatial Functions
Our Spatial implementation relies on the underlying database implementation of any of the spatial functions such as Distance, Intersects, and others. To make this work, we have created the most common functions as canonical functions on EDM. As a result, Entity Framework will defer the execution of the function to the server.
Client-side Behavior
DbGeometry and DbGeography internally use one of two implementations of DbSpatialServices for client side behavior which we will make available:One implementation relies on Microsoft.SQLServer.Types.SQLGeography and Microsoft.SQLServer.Types.SQLGeometry being available to the client. If these two namespaces are available, then we delegate all spatial operations down to the SQL assemblies. Note that this implementation introduces a dependency.
Another implementation provides limited services such as serialization and deserialization, but does not allow performing non-trivial spatial operations. We create these whenever you explicitly create a spatial value or deserialize one from a web service.
DataContract Serialization
Our implementation provides a simple wrapper that is serializable, which allows spatial types to be used in multi-tier applications. To provide maximum interoperability, we have created a class called DbWellKnownSpatialValue which contains the SRID, WellKnownText (WKT), and WellKnownBinary (WKB) values. We will serialize SRID, WKT and WKB.
Questions
We want to hear from you. As we work through this design, it is vital to hear what you think about our decisions, and that you chime in with your own ideas. Here are a few questions, please take some time to answer them in the comments:
- In order to have client-side spatial functionality, EF relies on a spatial implementation supplied by the provider. As a default, EF uses the SQL Spatial implementation. Do you foresee this being a problematic for Hosted applications which may or may not have access to a spatial implementation?
- Do you feel as though you will need richer capabilities on the client side?
- In addition to Geometry and Geography types, do you need to have constrained types like Point, Polygon?
- Do you foresee using heterogeneous columns of spatial values in your application?
Spatial data is ubiquitous now thanks to the widespread use of GPS-enabled mobile devices. We are very excited about bringing spatial type support to the Entity Framework. We encourage you to leave your thoughts on this design below.
Be sure to read the comments.
Arlo Belshee posted Geospatial data support in OData to the OData blog on 5/3/2011:
OData supports geospatial data types as a new set of primitives. They can be used just like any other primitives - passed in URLs as literals, as types and values for properties, projected in $select, and so on. Like other primitives, there is a set of canonical functions that can be used with them.
Why are we leaning towards this design?
Boxes like these question the design and provide the reasoning behind the choices so far.
This is currently a living document. As we continue to make decisions, we will adjust this document. We will also record our new reasons for our new decisions.
The only restriction, as compared to other primitives, is that geospatial types may not be used as entity keys (see below).
The rest of this spec goes into more detail about the geospatial type system that we support, how geospatial types are represented in $metadata, how their values are represented in Atom and JSON payloads, how they are represented in URLs, and what canonical functions are defined for them.
Modeling
Primitive Types
Our type system is firmly rooted in the OGC Simple Features geometry type system. We diverge from their type system in only four ways.

Figure 1: The OGC Simple Features Type HierarchyWhy a subset?
Our primary goal with OData is to get everyone into the ecosystem. Thus, we want to make it easy for people to start. Reducing the number of types and operations makes it easier for people to get started. There are extensibility points for those with more complex needs.
First, we expose a subset of the type system and a subset of the operations. For details, see the sections below.
Second, the OGC type system is defined for only 2-dimensional geospatial data. We extend the definition of a position to be able to handle a larger number of dimensions. In particular, we handle 2d, 3dz, 3dm, and 4d geospatial data. See the section on Coordinate Reference Systems (CRS) for more information.
Why separate Geometrical and Geographical types?
They actually behave differently. Assume that you are writing an application to track airplanes and identify when their flight paths intersect, to make sure planes don't crash into each other.
Assume you have two flight plans. One flies North, from (0, 0) to (0, 60). The other flies East, from (-50, 58) to (50, 58). Do they intersect?
In geometric coordinates they clearly do. In geographic coordinates, assuming these are latitude and longitude, they do not.
That's because geographic coordinates are on a sphere. Airplanes actually travel in arcs. The eastward-flying plane actually takes a path that bends up above the flight path of the northward plane. These planes miss each other by hundreds of miles.
Obviously, we want our crash detector to know that these planes are safe.
The two types may have the same functions, but they can have very different implementations. Splitting these into two types makes it easier for function implementers. They don't need to check the CRS in order to pick their algorithm.
Third, the OGC type system ised for flat-earth geospatial data (termed geometrical data hereafter). OGC does not define a system that handles round-earth geospatial data (termed geographical data). Thus, we duplicate the OGC type system to make a parallel set of types for geographic data.
We refer to the geographical vs geometrical distinction as the topology of the type. It describes the shape of the space that includes that value.
Some minor changes in representation are necessary because geographic data is in a bounded surface (the spheroid), while geometric data is in an infinite surface (the plane). This shows up, for example, in the definition of a Polygon. We make as few changes as possible; see below for details. Even when we make changes, we follow prior art wherever possible.
Finally, like other primitives in OData, the geospatial primitives do not use inheritance and are immutable. The lack of inheritance, and the subsetting of the OGC type system, give us a difficulty with representing some data. We resolve this with a union type that behaves much like the OGC's base class. See the Union types section below for more details.
Coordinate Reference Systems
Although we support many Coordinate Reference Systems (CRS), there are several limitations (as compared to the OGC standard):
- We only support named CRSated by an SRID. This should be an official SRID. In particular, we don't support custom CRS defined in the metadata, as does GML.
- Thus, some data will be inexpressible. For example, there are hydrodynamics readings data represented in a coordinate system where each point has coordinates [lat, long, depth, time, pressure, temperature]. This lets them do all sorts of cool analysis (eg, spatial queries across a surface defined in terms of the temperature and time axes), but is beyond the scope of OData.
- There are also some standard coordinate systems that don't have codes. So we couldn't represent those. Ex: some common systems in New Zealand & northern Europe.
- The CRS is part of the static type of a property. Even if that property is of the base type, that property is always in the same CRS for all instances.
- The CRS is static under projection. The above holds even between results of a projection.
- There is a single "undefined" SRID value. This allows a service to explicitly state that the CRS varies on a per-instance basis.
- Geometric primitives with different CRS are not type-compatible under filter, group, sort, any action, or in any other way. If you want to filter an entity by a point defined in Stateplane, you have to send us literals in Stateplane. We will not transform WGS84 to Stateplane for you.
- There are client-side libraries that can do some coordinate transforms for you.
- Servers could expose coordinate transform functions as non-OGC canonical function extensions. See below for details.
Nominally, the Geometry/Geography type distinction is redundant with the CRS. Each CRS is inherently either round-earth or flat-earth. However, we are not going to automatically resolve this. Our implementation will not know which CRS match which model type. The modeler will have to specify both the type & the CRS.
There is a useful default CRS for Geography (round earth) data: WGS84. We will use that default if none is provided.
The default CRS for Geometry (flat earth) data is SRID 0. This represents an arbitrary flat plane with unit-less dimensions.
The Point types - Edm.Point and Edm.GeometricPoint
Why the bias towards the geographic types?
Mobile devices are happening now. A tremendous amount of new data and new applications will be based on the prevalence of these devices. They all use WGS84 for their spatial data.
Mobile devide developers also tend to be more likely to try to copy some code from a blog or just follow intellisense until something works. Hard-core developers are more likely to read the docs and think things through. So we want to make the obvious path match the mobile developers.
"Point" is defined as per the OGC. Roughly, it consists of a single position in the underlying topology and CRS. Edm.Point is used for points in the round-earth (geographic) topology. Edm.GeometricPoint is a point in a flat-earth (geometric) topology.
These primitives are used for properties with a static point type. All entities of this type will have a point value for this property.
Example properties that would be of type point or geometric point include a user's current location or the location of a bus stop.
The LineString types - Edm.LineString and Edm.GeometricLineString
"LineString" is defined as per the OGC. Roughly, it consists of a set of positions with linear interpolation between those positions, all in the same topology and CRS, and represents a path. Edm.LineString is used for geographic LineStrings; Edm.GeometricLineString is used for geometric ones.
These primitives are used for properties with a static path type. Example properties would be the path for a bus route entity, or the path that I followed on my jog this morning (stored in a Run entity).
The Polygon types - Edm.Polygon and Edm.GeometricPolygon
"Polygon" is defined as per the OGC. Roughly, it consists of a single bounded area which may contain holes. It is represented using a set of LineStrings that follow specific rules. These rules differ for geometric and geographic topologies.
These primitives are used for properties with a static single-polygon type. Examples include the area enclosed in a single census tract, or the area reachable by driving for a given amount of time from a given initial point.
Some things that people think of as polygons, such as the boundaries of states, are not actually polygons. For example, the state of Hawaii includes several islands, each of which is a full bounded polygon. Thus, the state as a whole cannot be represented as a single polygon. It is a Multipolygon, and can be represented in OData only with the base types.
The base types - Edm.Geography and Edm.Geometry
The base type represents geospatial data of an undefined type. It might vary per entity. For example, one entity might hold a point, while another holds a multi-linestring. It can hold any of the types in the OGC hierarchy that have the correct topology and CRS.
Although core OData does not support any functions on the base type, a particular implementation can support operations via extensions (see below). In core OData, you can read & write properties that have the base types, though you cannot usefully filter or order by them.
The base type is also used for dynamic properties on open types. Because these properties lack metadata, the server cannot state a more specific type. The representation for a dynamic property MUST contain the CRS and topology for that instance, so that the client knows how to use it.
Therefore, spatial dynamic properties cannot be used in $filter, $orderby, and the like without extensions. The base type does not expose any canonical functions, and spatial dynamic properties are always the base type.
Edm.Geography represents any value in a geographic topology and given CRS. Edm.Geometry represents any value in a geometric topology and given CRS.
Each instance of the base type has a specific type that matches an instantiable type from the OGC hierarchy. The representation for an instance makes clear the actual type of that instance.
Thus, there are no instances of the base type. It is simply a way for the $metadata to state that the actual data can vary per entity, and the client should look there.
Spatial Properties on Entities
Zero or more properties in an entity can have a spatial type. The spatial types are regular primitives. All the standard rules apply. In particular, they cannot be shredded under projection. This means that you cannot, for example, use $select to try to pull out the first control position of a LineString as a Point.
For open types, the dynamic properties will all effectively be of the union type. You can tell the specific type for any given instance, just as for the union type. However, there is no static type info available. This means that dynamic properties need to include the CRS & topology.
Spatial-Primary Entities (Features)
This is a non-goal. We do not think we need these as an intrinsic. We believe that we can model this with a pass-through service using vocabularies.
Communicating
Metadata
We define new types: Edm.Geography, Edm.Geometry, Edm.Point, Edm.GeometricPoint, Edm.Polygon, Edm.GeometricPolygon. Each of them has a facet that is the CRS, called "coordinate_system".
Entities in Atom
What should we use?
Unknown.
To spark discussion, and because it is perhaps the best of a bad lot, the strawman proposal is to use the same GML profile as Sql Server uses. This is an admittedly hacked-down simplification of full GML, but seems to match the domain reasonably well.
Here are several other options, and some of the problems with each:
GeoRSS only supports some of the types.
Full GML supports way too much - and is complex because of it.
KML ised for spatial data that may contain embedded non-spatial data. This allows creating data that you can't then use OData to easily query. We would prefer that people use full OData entities to express this metadata, so that it can be used by clients that do not support geospatial data.
Another option would be an extended WKT. This isn't XML. This isn't a problem for us, but may annoy other implementers(?). More critically, WKT doesn't support 3d or 4d positions. We need those in order to support full save & load for existing data. The various extensions all disagree on how to extend for additional dimensions. I'd prefer not to bet on any one WKT implementation, so that we can wait for another standards body to pick the right one.
PostGIS does not seem to have a native XML format. They use their EWKT.
Finally, there's the SqlServer GML profile. It is a valid GML profile, and isn't quite as much more than we need as is full GML. I resist it mostly because it is a Microsoft format. Of course, if there is no universal format, then perhaps a Microsoft one is as good as we can get.
Entities in JSON
Why GeoJSON?
It flows well in a JSON entity, and is reasonably parsimonious. It is also capable of supporting all of our types and coordinate systems.
It is, however, not an official standard. Thus, we may have to include it by copy, rather than by reference, in our official standard.
Another option is to use ESRI's standard for geospatial data in JSON. Both are open standards with existing ecosystems. Both seem sufficient to our needs. Anyone have a good reason to choose one over the other?
We will use GeoJSON. Technically, since GeoJSON ised to support entire geometry trees, we are only using a subset of GeoJSON. We do not allow the use of types "Feature" or "FeatureCollection." Use entities to correlate a geospatial type with metadata.
Why the ordering constraint?
This lets us distinguish a GeoJSON primitive from a complex type without using metadata. That allows clients to parse a JSON entity even if they do not have access to the metadata.
This is still not completely unambiguous. Another option would be to recommend an "__type" member as well as a "type" member. The primitive would still be valid GeoJSON, but could be uniquely distinguished during parsing.
We believe the ordering constraint is lower impact.
Furthermore, "type" SHOULD be ordered first in the GeoJSON object, followed by coordinates, then the optional properties.
This looks like:
{ "d" : { "results": [ { "__metadata": { "uri": "http://services.odata.org/Foursquare.svc/Users('Neco447')", "type": "Foursquare.User" }, "ID": "Neco447", "Name": "Neco Fogworthy", "FavoriteLocation": { "type": "Point", "coordinates": [-127.892345987345, 45.598345897] }, "LastKnownLocation": { "type": "Point", "coordinates": [-127.892345987345, 45.598345897], "crs": { "type": "name", "properties": { "name": "urn:ogc:def:crs:OGC:1.3:CRS84" } }, "bbox": [-180.0, -90.0, 180.0, 90.0] } }, { /* another User Entry */ } ], "__count": "2", } }Dynamic Properties
Geospatial values in dynamic properties are represented exactly as they would be for static properties, with one exception: the CRS is required. The client will not be able to examine metadata to find this value, so the value must specify it.
Querying
Geospatial Literals in URIs
Why only 2d?
Because OGC only standardized 2d, different implementations differ on how they extended to support 3dz, 3dm, and 4d. We may add support for higher dimensions when they stabilize. As an example, here are three different representations for the same 3dm point:
- PostGIS: POINTM(1, 2, 3)
- Sql Server: POINT(1, 2, NULL, 3)
- ESRI: POINT M (1, 2, 3)
The standard will probably eventually settle near the PostGIS or ESRI version, but it makes sense to wait and see. The cost of choosing the wrong one is very high: we would split our ecosystem in two, or be non-standard.
There are at least 3 common extensions to WKT (PostGIS, ESRI, and Sql Server), but all use the same extension to include an SRID. As such, they all use the same representation for values with 2d coordinates. Here are some examples:
/Stores$filter=Category/Name eq "coffee" and distanceto(Location, POINT(-127.89734578345 45.234534534)) lt 900.0/Stores$filter=Category/Name eq "coffee" and intersects(Location, SRID=12345;POLYGON((-127.89734578345 45.234534534,-127.89734578345 45.234534534,-127.89734578345 45.234534534,-127.89734578345 45.234534534)))/Me/Friends$filter=distance_to(PlannedLocations, SRID=12345;POINT(-127.89734578345 45.234534534) lt 900.0 and PlannedTime eq datetime'2011-12-12T13:36:00'If OData were to support 3dm, then that last one could be exposed and used something like one of (depending on which standard we go with):
PostGIS:/Me/Friends$filter=distance_to(PlannedLocations, SRID=12345;POINTM(-127.89734578345 45.234534534 2011.98453) lt 900.0ESRI:/Me/Friends$filter=distance_to(PlannedLocations, SRID=12345;POINT M (-127.89734578345 45.234534534 2011.98453) lt 900.0Sql Server:/Me/Friends$filter=distance_to(PlannedLocations, SRID=12345;POINT(-127.89734578345 45.234534534 NULL 2011.98453) lt 900.0Why not GeoJSON?
GeoJSON actually makes a lot of sense. It would reduce the number of formats used in the standard by 1, making it easier for people to add geospatial support to service endpoints. We are also considering using JSON to represent entity literals used with Functions. Finally, it would enable support for more than 2 dimensions.
However, JSON has a lot of nesting brackets, and they are prominent in GeoJSON. This is fine in document bodies, where you can use linebreaks to make them readable. However, it is a problem in URLs. Observe the following example (EWKT representation is above, for comparison):
/Stores$filter=Category/Name eq "coffee" and intersects(Location, {"type":"polygon", "coordinates":[[[-127.892345987345, 45.598345897], -127.892345987345, 45.598345897], [-127.892345987345, 45.598345897], [-127.892345987345, 45.598345897]]]})Not usable everywhere
Why not?
Geospatial values are neither equality comparable nor partially-ordered. Therefore, the results of these operations would be undefined.
Furthermore, geospatial types have very long literal representations. This would make it difficult to read a simple URL that navigates along a series of entities with geospatial keys.
If your entity concurrency control needs to incorporate changes to geospatial properties, then you should probably use some sort of Entity-level version tracking.
Geospatial primitives MAY NOT be compared using
lt,eq, or similar comparison operators.Geospatial primitives MAY NOT be used as keys.
Geospatial primitives MAY NOT be used as part of an entity's ETag.
Distance Literals in URLs
Some queries, such as the coffee shop search above, need to represent a distance.
Distance is represented the same in the two topologies, but interpreted differently. In each case, it is represented as a float scalar. The units are interpreted by the topology and coordinate system for the property with which it is compared or calculated.
Because a plane is uniform, we can simply define distances in geometric coordinates to be in terms of that coordinate system's units. This works as long as each axis uses the same unit for its coordinates, which is the general case.
Geographic topologies are not necessarily uniform. The distance between longitude -125 and -124 is not the same at all points on the globe. It goes to 0 at the poles. Similarly, the distance between 30 and 31 degrees of latitude is not the same as the distance between 30 and 31 degrees of longitude (at least, not everywhere). Thus, the underlying coordinate system measures position well, but does not work for describing a distance.
For this reason, each geographic CRS also defines a unit that will be used for distances. For most CRSs, this is meters. However, some use US feet, Indian feet, German meters, or other units. In order to determine the meaning of a distance scalar, the developer must read the reference for the CRS involved.
New Canonical Functions
Each of these canonical functions is defined on certain geospatial types. Thus, each geospatial primitive type has a set of corresponding canonical functions. An OData implementation that supports a given geospatial primitive type SHOULD support using the corresponding canonical functions in $filter. It MAY support using the corresponding canonical functions in $orderby.
Are these the right names?
We might consider defining these canonical functions as Geo.distance, etc. That way, individual server extensions for standard OGC functions would feel like core OData. This works as long as we explicitly state (or reference) the set of functions allowed in Geo.
distance
Distance is a canonical function defined between points. It returns a distance, as defined above. The two arguments must use the same topology & CRS. The distance is measured in that topology. Distance is one of the corresponding functions for points. Distance is defined as equivalent to the OGC ST_Distance method for their overlapping domain, with equivalent semantics for geographical points.
intersects
Intersects identifies whether a point is contained within the enclosed space of a polygon. Both arguments must be of the same topology & CRS. It returns a Boolean value. Intersects is a corresponding function for any implementation that includes both points and polygons. Intersects is equivalent to OGC's ST_Intersects in their area of overlap, extended with the same semantics for geographic data.
length
Length returns the total path length of a linestring. It returns a distance, as defined above. Length is a corresponding function for linestrings. Length is equivalent to the OGC ST_Length operation for geometric linestrings, and is extended with equivalent semantics to geographic data.
Why this subset?
It matches the two most common scenarios: find all the interesting entities near me, and find all the interesting entities within a particular region (such as a viewport or an area a use draws on a map).
Technically, linestrings and length are not needed for these scenarios. We kept them because the spec felt jagged without them.
All other OGC functions
We don't support these, because we want to make it easier to stand up a server that is not backed by a database. Some are very hard to implement, especially in geographic coordinates.
A provider that is capable of handling OGC Simple Features functions MAY expose those as Functions on the appropriate geospatial primitives (using the new Function support).
We are reserving a namespace, "
Geo," for these standard functions. If the function matches a function specified in Simple Features, you SHOULD place it in this namespace. If the function does not meet the OGC spec, you MUST NOT place it in this namespace. Future versions of the OData spec may define more canonical functions in this namespace. The namespace is reserved to allow exactly these types of extensions without breaking existing implementations.In the SQL version of the Simple Features standard, the function names all start with ST_ as a way to provide namespacing. Because OData has real namespaces, it does not need this pseudo-namespace. Thus, the name SHOULD NOT include the ST_ when placed in the
Geonamespace. Similarly, the name SHOULD be translated to lowercase, to match other canonical functions in OData. For example, OGC'sST_Bufferwould be exposed in OData asGeo.buffer. This is similar to the Simple Features implementation on CORBA.All other geospatial functions
Any other geospatial operations MAY be exposed by using Functions. These functions are not defined in any way by this portion of the spec. See the section on Functions for more information, including namespacing issues.
Examples
Find coffee shops near me
/Stores$filter=/Category/Name eq "coffee" and distanceto(/Location, POINT(-127.89734578345 45.234534534)) lt 0.5&$orderby=distanceto(/Location, POINT-127.89734578345 45.234534534)&$top=3Find the nearest 3 coffee shops, by drive time
This is not directly supported by OData. However, it can be handled by an extension. For example:
/Stores$filter=/Category/Name eq "coffee"&$orderby=MyNamespace.driving_time_to(POINT(-127.89734578345 45.234534534, Location)&$top=3Note that while
distancetois symmetric in its args,MyNamespace.driving_time_tomight not be. For example, it might take one-way streets into account. This would be up to the data service that is defining the function.Compute distance along routes
/Me/Runs$orderby=length(Route) desc&$top=15Find all houses close enough to work
For this example, let's assume that there's one OData service that can tell you the drive time polygons around a point (via a service operation). There's another OData service that can search for houses. You want to mash them up to find you houses in your price range from which you can get to work in 15 minutes.
First,
/DriveTime(to=POINT(-127.89734578345 45.234534534), maximum_duration=time'0:15:00')returns
{ "d" : { "results": [ { "__metadata": { "uri": "http://services.odata.org/DriveTime(to=POINT(-127.89734578345 45.234534534), maximum_duration=time'0:15:00')", "type": "Edm.Polygon" }, "type": "Polygon", "coordinates": [[[-127.0234534534, 45.089734578345], [-127.0234534534, 45.389734578345], [-127.3234534534, 45.389734578345], [-127.3234534534, 45.089734578345], [-127.0234534534, 45.089734578345]], [[-127.1234534534, 45.189734578345], [-127.1234534534, 45.289734578345], [-127.2234534534, 45.289734578345], [-127.2234534534, 45.189734578345], [-127.1234534534, 45.289734578345]]] } ], "__count": "1", } }Then, you'd send the actual search query to the second endpoint:
/Houses$filter=Price gt 50000 and Price lt 250000 and intersects(Location, POLYGON((-127.0234534534 45.089734578345,-127.0234534534 45.389734578345,-127.3234534534 45.389734578345,-127.3234534534 45.089734578345,-127.0234534534 45.089734578345),(-127.1234534534 45.189734578345,-127.1234534534 45.289734578345,-127.2234534534 45.289734578345,-127.2234534534 45.189734578345,-127.1234534534 45.289734578345)))Is there any way to make that URL shorter? And perhaps do this in one query?
This is actually an overly-simple polygon for a case like this. This is just a square with a single hole in it. A real driving polygon would contain multiple holes and a lot more boundary points. So that polygon in the final query would realistically be 3-5 times as long in the URL.
It would be really nice to support reference arguments in URLs (with cross-domain support). Then you could represent the entire example in a single query:
/Houses$filter=Price gt 50000 and Price lt 250000 and intersects(Location, Ref("http://drivetime.services.odata.org/DriveTime(to=POINT(-127.89734578345 45.234534534), maximum_duration=time'0:15:00')"))However, this is not supported in OData today.
OK, but isn't there some other way to make the URL shorter? Some servers can't handle this length!
We are looking at options. The goal is to maintain GET-ability and cache-ability. A change in the parameters should be visible in the URI, so that caching works correctly.
The current front-runner idea is to allow the client to place parameter values into a header. That header contains a JSON dictionary of name/value pairs. If it does so, then it must place the hashcode for that dictionary in the query string. The resulting request looks like:
GET /Houses?$filter=Price gt 50000 and Price lt 250000 and intersects(Location, @drive_time_polygon)&orderby=distanceto(@microsoft)&$hash=HASHCODE Host: www.example.com X-ODATA-QUERY: { "microsoft": SRID=1234;POINT(-127.2034534534 45.209734578345), "drive_time_polygon": POLYGON((-127.0234534534 45.089734578345,-127.0234534534 45.389734578345,-127.3234534534 45.389734578345,-127.3234534534 45.089734578345,-127.0234534534 45.089734578345),(-127.1234534534 45.189734578345,-127.1234534534 45.289734578345,-127.2234534534 45.289734578345,-127.2234534534 45.189734578345,-127.1234534534 45.289734578345)), }Of course, nothing about this format is at all decided. For example, should that header value be fully in JSON (using the same formatting as in a JSON payload)? Should it be form encoded instead of JSON? Perhaps the entire query string should go in the header, with only a $query=HASHCODE in the URL? And there are a lot more options.
This entry was written by Arlo Belshee, posted on Tuesday, May 03, 2011 Bookmark the permalink. Follow any comments here with the Atom feed for this post.
Related posts
Justin Metzgar described a workaround for the WCF scales up slowly with bursts of work problem in a 5/4/2011 post to the .NET Endpoint blog:
A few customers have noticed an issue with WCF scaling up when handling a burst of requests. Fortunately, there is a very simple workaround for this problem that is covered in KB2538826 (thanks to David Lamb for the investigation and write up). The KB article provides a lot of good information about when this would apply to your application and what to do to fix it. In this post, I want to explore exactly what's happening.
The best part is that there is an easy way to reproduce the problem. To do this, create a new WCF service application with the .NET 4 framework:
Then trim the default service contract down to only the GetData method:
using System.ServiceModel; [ServiceContract] public interface IService1 { [OperationContract] string GetData(int value); }And fill out the GetData method in the service code:
using System; using System.Threading; public class Service1 : IService1 { public string GetData(int value) { Thread.Sleep(TimeSpan.FromSeconds(2)); return string.Format("You entered: {0}", value); } }The two second sleep is the most important part of this repro. We'll explore why after we create the client and observe the effects. But first, make sure to set the throttle in the web.config:
<configuration> <system.web> <compilation debug="true" targetFramework="4.0" /> </system.web> <system.serviceModel> <behaviors> <serviceBehaviors> <behavior> <serviceMetadata httpGetEnabled="true"/> <serviceDebug includeExceptionDetailInFaults="false"/> <serviceThrottling maxConcurrentCalls="100"/> </behavior> </serviceBehaviors> </behaviors> <serviceHostingEnvironment multipleSiteBindingsEnabled="true" /> </system.serviceModel> <system.webServer> <modules runAllManagedModulesForAllRequests="true"/> </system.webServer> </configuration>The Visual Studio web server would probably suffice, but I changed my web project to use IIS instead. This makes it more of a realistic situation. To do this go to the project properties, select the Web tab, and switch to IIS.
Be sure to hit the Create Virtual Directory button. In my case, I have SharePoint installed and it's taking up port 80, so I put the default web server on port 8080. Once this is done, build all and browse to the service to make sure it's working correctly.
To create the test client, add a new command prompt executable to the solution and add a service reference to Service1. Change the client code to the following:
using System; using System.Threading; using ServiceReference1; class Program { private const int numThreads = 100; private static CountdownEvent countdown; private static ManualResetEvent mre = new ManualResetEvent(false); static void Main(string[] args) { string s = null; Console.WriteLine("Press enter to start test."); while ((s = Console.ReadLine()) == string.Empty) { RunTest(); Console.WriteLine("Allow a few seconds for threads to die."); Console.WriteLine("Press enter to run again."); Console.WriteLine(); } } static void RunTest() { mre.Reset(); Console.WriteLine("Starting {0} threads.", numThreads); countdown = new CountdownEvent(numThreads); for (int i = 0; i < numThreads; i++) { Thread t = new Thread(ThreadProc); t.Name = "Thread_" + i; t.Start(); } // Wait for all threads to signal. countdown.Wait(); Console.Write("Press enter to release threads."); Console.ReadLine(); Console.WriteLine("Releasing threads."); DateTime startTime = DateTime.Now; countdown = new CountdownEvent(numThreads); // Release all the threads. mre.Set(); // Wait for all the threads to finish. countdown.Wait(); TimeSpan ts = DateTime.Now - startTime; Console.WriteLine("Total time to run threads: {0}.{1:0}s.", ts.Seconds, ts.Milliseconds / 100); } private static void ThreadProc() { Service1Client client = new Service1Client(); client.Open(); // Signal that this thread is ready. countdown.Signal(); // Wait for all the other threads before making service call. mre.WaitOne(); client.GetData(1337); // Signal that this thread is finished. countdown.Signal(); client.Close(); } }The code above uses a combination of a ManualResetEvent and a CountdownEvent to coordinate the calls to all happen at the same time. It then waits for all the calls to finish and determines how long it took. When I run this on a dual core machine, I get the following:
Press enter to start test. Starting 100 threads. Releasing threads. Total time to run threads: 14.0s. Allow a few seconds for threads to die. Press enter to run again.If each individual request only sleeps for 2 seconds, why would it take 100 simultaneous requests 14 seconds to complete? It should only take 2 seconds if they're all executing at the same time. To understand what's happening, let's look at the thread count in perfmon. First, open Administrative Tools -> Performance Monitor. In the tree view on the left, pick Monitoring Tools -> Performance Monitor. It should have the % Processor counter in there by default. We don't need that counter so select it in the bottom and press the delete key. Now click the add button to add a new counter:
In the Add Counters dialog, expand the Process node:
Under this locate the Thread Count counter and then find the w3wp instance and press the Add >> button.
If you don't see the w3wp instance, it is most likely because it wasn't running when you opened the Add Counters dialog. To correct this, close the dialog, ping the Service1.svc service, and then click the Add button again in perfmon.
Now you can run the test and you should see results similar to the following:
In this test, I had pinged the service to get the metadata to warm everything up. When the test ran, you can see it took several seconds to add another 21 threads. The reason these threads are added is because when WCF runs your service code, it uses a thread from the IO thread pool. Your service code is then expected to do some work that is either quick or CPU intensive or takes up a database connection. But in the case of the test, the Thread.Sleep means that no work is being done and the thread is being held. A real world scenario where this pattern could occur is if you have a WCF middle tier that has to make calls into lower layers and then return the results.
For the most part, server load is assumed to change slowly. This means you would have a fairly constant load and the thread pool manager would pick the appropriate size for the thread pool to keep the CPU load high but without too much context switching. However, in the case of a sudden burst of requests with long-running, non-CPU-intensive work like this, the thread pool adapts too slowly. You can see in the graph above that the number of threads drops back down to 30 after some time. The thread pool has recognized that a thread has not been used for 15 seconds and therefore kills it because it is not needed.
To understand the thread pool a bit more, you can profile this and see what's happening. To get a profile, go to the Performance Explorer, usually pinned on the left side in Visual Studio, and click the button to create a new performance session:
Right click on the new performance session and select properties. In the properties window change the profiling type to Concurrency and uncheck the "Collect resource contention data" option.
Before we start profiling, let's first go to the Tools->Options menu in Visual Studio. Under Debugging, enable the Microsoft public symbol server.
Also, turn off the Just My Code option under Performance Tools:
The next step is to make the test client the startup project. You may need to ping the Service1.svc service again to make sure the w3wp process is running. Now, attach to the w3wp process with the profiler. There is an attach button at the top of the performance explorer window or you can right click on the performance session and choose attach.
Give the profiler a few seconds to warmup and then hit ctrl+F5 to execute the test client. After the test client finishes a single run pause and detach the profiler from the w3wp process. You can also hit the "Stop profiling" option but it will kill the process.
After you've finished profiling, it will take some time to process the data. Once it's up, switch to the thread view. In the figure below, I've rearranged the threads to make it easier to see the relationships:
Blue represents sleep time. This matches what we expect to see, which is a lot of new threads all sleeping for 2 seconds. At the top of the sleeping threads is the gate thread. It checks every 500ms to see if the number of threads in the thread pool is appropriate to handle the outstanding work. If not, it creates a new thread. You can see in the beginning that it creates 2 threads and then 1 thread at a time in 500ms increments. This is why it takes 14 seconds to process all 100 requests. So why are there two threads that look like they're created at the same time? If you look more closely, that's actually not the case. Let's zoom in on that part:
Here again the highlighted thread is the gate thread. Before it finishes its 500ms sleep, a new thread is created to handle one of the WCF service calls which sleeps for 2 seconds. Then when the gate thread does its check, it realizes that there is a lot of work currently backed up and creates another new thread. On a dual core machine like this, the default minimum IO thread pool setting is 2: 1 per core. One of those threads is always taken up by WCF and functions as the timer thread. You can see that there are other threads created up top. This is most likely ASP.Net creating some worker threads to handle the incoming requests. You can see that they don't sleep because they're passing off work to WCF and getting ready to handle the next batch of work.
The most obvious thing to do then would be to increase the minimum number of IO threads. You can do this in two ways: use ThreadPool.SetMinThreads or use the <processModel> tag in the machine.config. Here is how to do the latter:
<system.web> <!--<processModel autoConfig="true"/>--> <processModel autoConfig="false" minIoThreads="101" minWorkerThreads="2" maxIoThreads="200" maxWorkerThreads="40" />Be sure to turn off the autoConfig setting or the other options will be ignored. If we run this test again, we get a much better result. Compare the previous snapshot of permon with this one:
And the resulting output of the run is:
Starting 100 threads. Press enter to release threads. Releasing threads. Total time to run threads: 2.2s. Allow a few seconds for threads to die. Press enter to run again.This is an excellent result. It is exactly what you would want to happen if a sudden burst of work comes in. But customers were saying that this wasn't happening for them. David Lamb told me that if you run this for a long time, like 2 hours, it would eventually stop quickly adding threads and behave as if the min IO threads was not set.
One of the things we can do is modify the test code to give enough time for the threads to have their 15 second timeout and just take out all the Console.ReadLine calls:
using System; using System.Threading; using ServiceReference1; class Program { private const int numThreads = 100; private static CountdownEvent countdown; private static ManualResetEvent mre = new ManualResetEvent(false); static void Main(string[] args) { while (true) { RunTest(); Thread.Sleep(TimeSpan.FromSeconds(25)); Console.WriteLine(); } } static void RunTest() { mre.Reset(); Console.WriteLine("Starting {0} threads.", numThreads); countdown = new CountdownEvent(numThreads); for (int i = 0; i < numThreads; i++) { Thread t = new Thread(ThreadProc); t.Name = "Thread_" + i; t.Start(); } // Wait for all threads to signal. countdown.Wait(); Console.WriteLine("Releasing threads."); DateTime startTime = DateTime.Now; countdown = new CountdownEvent(numThreads); // Release all the threads. mre.Set(); // Wait for all the threads to finish. countdown.Wait(); TimeSpan ts = DateTime.Now - startTime; Console.WriteLine("Total time to run threads: {0}.{1:0}s.", ts.Seconds, ts.Milliseconds / 100); } private static void ThreadProc() { Service1Client client = new Service1Client(); client.Open(); // Signal that this thread is ready. countdown.Signal(); // Wait for all the other threads before making service call. mre.WaitOne(); client.GetData(1337); // Signal that this thread is finished. countdown.Signal(); client.Close(); } }Then just let it run for a couple hours and see what happens. Luckily, it doesn't take 2 hours and we can reproduce the weird behavior pretty quickly. Here is a perfmon graph showing several runs:
You can see that the first two bursts had quick scale up with the thread count. After that, it went back to being slow. After working with the CLR team, they determined that there is a bug in the IO thread pool. This bug causes the internal count of IO threads to get out-of-sync with reality. Some of you may be asking the question as to what min really means in terms of the thread pool. Because if you specify you want a minimum of 100 threads, why wouldn't there just always be 100 threads? For the purposes of the thread pool, the min is supposed to be the threshold that the pool can scale up to before it starts to be metered. The default working set cost for one thread is a half MB. So that is one reason to keep the thread count down.
Some customers have found that Juval Lowy's thread pool doesn't have the same problem and handles these bursts of work much better. Here is a link to his article: http://msdn.microsoft.com/en-us/magazine/cc163321.aspx
Notice that Juval has created a custom thread pool and relies on the SynchronizationContext to switch from the IO thread that WCF uses to the custom thread pool. Using a custom thread pool in your production environment is not advisable. Most developers do not have the resources to properly test a custom thread pool for their applications. Thankfully, there is an alternative and that is the recommendation made in the KB article. The alternative is to use the worker thread pool. Juval has some code for a custom attribute that you can put on your service to set the SynchronizationContext to use his custom thread pool and we can just modify that to put the work into the worker thread pool. The code for this change is all in the KB article, but I'll reiterate here along with with the changes to the service itself.
using System; using System.Threading; using System.ServiceModel.Description; using System.ServiceModel.Channels; using System.ServiceModel.Dispatcher; [WorkerThreadPoolBehavior] public class Service1 : IService1 { public string GetData(int value) { Thread.Sleep(TimeSpan.FromSeconds(2)); return string.Format("You entered: {0}", value); } } public class WorkerThreadPoolSynchronizer : SynchronizationContext { public override void Post(SendOrPostCallback d, object state) { // WCF almost always uses Post ThreadPool.QueueUserWorkItem(new WaitCallback(d), state); } public override void Send(SendOrPostCallback d, object state) { // Only the peer channel in WCF uses Send d(state); } } [AttributeUsage(AttributeTargets.Class)] public class WorkerThreadPoolBehaviorAttribute : Attribute, IContractBehavior { private static WorkerThreadPoolSynchronizer synchronizer = new WorkerThreadPoolSynchronizer(); void IContractBehavior.AddBindingParameters( ContractDescription contractDescription, ServiceEndpoint endpoint, BindingParameterCollection bindingParameters) { } void IContractBehavior.ApplyClientBehavior( ContractDescription contractDescription, ServiceEndpoint endpoint, ClientRuntime clientRuntime) { } void IContractBehavior.ApplyDispatchBehavior( ContractDescription contractDescription, ServiceEndpoint endpoint, DispatchRuntime dispatchRuntime) { dispatchRuntime.SynchronizationContext = synchronizer; } void IContractBehavior.Validate( ContractDescription contractDescription, ServiceEndpoint endpoint) { } }The areas highlighted above show the most important bits for this change. There really isn't that much code to this. With this change essentially what is happening is that WCF recognizes that when it's time to execute the service code, there is an ambient SynchronizationContext. That context then pushes the work into the worker thread pool with QueueUserWorkItem. The only other change to make is to the <processModel> node in the machine.config to configure the worker thread pool for a higher min and max.
<system.web> <!--<processModel autoConfig="true"/>--> <processModel autoConfig="false" minWorkerThreads="100" maxWorkerThreads="200" />Running the test again, you will see a much better result:
All … test runs finished in under 2.5 seconds.
We cannot make a recommendation on this alone though. There are other questions like how does this affect performance and does it continue to work this way for hours, days, weeks, etc. Our testing showed that for at least 72 hours, this worked without a problem. The performance runs showed some caveats though. These are also pointed out in the KB article. There is a cost for switching from one thread to another. This would be the same with the worker thread pool or a custom thread pool. That overhead can be negligible for large amounts of work. In the case that applies here with 2 seconds of blocking work, the context switch is definitely not a factor. But if you've got small messages and fast work, then it's likely to hurt your performance.
The test project is included with this post.
















I wasn’t able to find a link to the test project and left Dustin a comment to that effect.
John Spurlock posted a downloadable odata4j v0.4 complete archive to Google Code on 4/18/2011 (missed when posted):
There is a vast amount of data available today and data is now being collected and stored at a rate never seen before. Much of this data is managed by Java server applications and difficult to access or integrate into new uses.
Project Info
odata4j is a new open-source toolkit for building first-class OData producers and first-class OData consumers in Java.
Goals and Guidelines
- Build on top of existing Java standards (e.g. JAX-RS, JPA, StAX) and use top shelf Java open-source components (jersey, Joda Time)
- OData consumers should run equally well under constrained Java client environments, specifically Android
- OData producers should run equally well under constrained Java server environments, specifically Google AppEngine
Consumers - Getting Started
- Download the latest archive zip
- Add odata4j-bundle-x.x.jar to your build path (or odata4j-clientbundle-x.x.jar for a smaller client-only bundle)
- Create an new consumer using ODataConsumer.create("http://pathto/service.svc/") and use the consumer for client scenarios
Consumers - Examples
(All of these examples work on Android as well)
- Basic consumer query & modification example using the OData Read/Write Test service: ODataTestServiceReadWriteExample.java
- Simple Netflix example: NetflixConsumerExample.java
- List all entities for a given service: ServiceListingConsumerExample.java
- Use the Dallas data service to query AP news stories (requires Dallas credentials): DallasConsumerExampleAP.java
- Use the Dallas data service to query UNESCO data (requires Dallas credentials): DallasConsumerExampleUnescoUIS.java
- Basic Azure table-service table/entity manipulation example (requires Azure storage credentials): AzureTableStorageConsumerExample.java
- Test against the sample odata4j service hosted on Google AppEngine: AppEngineConsumerExample.java
Producers - Getting Started
- Download the latest archive zip
- Add odata4j-bundle-x.x.jar to your build path (or odata4j-nojpabundle-x.x.jar for a smaller bundle with no JPA support)
- Choose or implement an ODataProducer
- Use InMemoryProducer to expose POJOs as OData entities using bean properties. Example: InMemoryProducerExample.java
- Use JPAProducer to expose an existing JPA 2.0 entity model: JPAProducerExample.java
- Implement ODataProducer directly
- Take a look at odata4j-appengine for an example of how to expose AppEngine's Datastore as an OData endpoint
- Hosting in Tomcat: http://code.google.com/p/odata4j/wiki/Tomcat
Status
odata4j is still early days, a quick summary of what's implemented
- Fairly complete expression parser (pretty much everything except complex navigation property literals)
- URI parser for producers
- Complete EDM metadata parser (and model)
- Dynamic entity/property model (OEntity/OProperty)
- Consumer api: ODataConsumer
- Producer api: ODataProducer
- ATOM transport
- Non standard behavior (e.g. Azure authentication, Dallas paging) via client extension api)
- Transparent server-driven paging Consumers
- Cross domain policy files for silverlight clients
- Free WADL for your OData producer thanks to jersey. e.g. odata4j-sample application.wadl
- Tested with current OData client set (.NET ,Silverlight, LinqPad, PowerPivot)
Todo list, in a rough priority order
- DataServiceVersion negotiation
- Better error responses
- gzip compression
- Access control
- Authentication
- Flesh out InMemory producer
- Flesh out JPA producer: map filters to query api, support complex types, etc
- Bring expression model to 100%, query by expression via consumer
- Producer model: expose functions
Disregard Google’s self-serving and untrue “Your version of Internet Explorer is not supported. Try a browser that contributes to open source, …” message. It appears to me that this message disqualifies Google Code as “open source.”
<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
• The Windows AppFabric Team announced Windows Azure AppFabric LABS Scheduled Maintenance and Breaking Changes Notification (5/12/2011) pm 5/6/2011:
Due to upgrades and enhancements we are making to Windows Azure AppFabric LABS environment, scheduled for 5/12/2011, users will have NO access to the AppFabric LABS portal and services during the scheduled maintenance downtime. [Emphasis added.]
When:
- START: May 12, 2011, 10am PST
- END: May 12, 2011, 5pm PST
- Service Bus will be impacted until May 16, 2011, 10am PST
Impact Alert:
- AppFabric LABS Service Bus, Access Control and Caching services, and the portal, will be unavailable during this period.
Additional impacts are described below.Action Required:
- Access to portal, Access Control and Caching will be available after the maintenance window and all existing accounts/namespaces for these services will be preserved.
- However, Service Bus will not be available until May 16, 2011, 10am PST. Furthermore, Service Bus namespaces will be preserved following the maintenance, BUT existing connection points and durable queues will not be preserved. [Emphasis added.]
- Users should back up Service Bus configuration in order to be able to restore following the maintenance. [Emphasis added.]
Thanks for working in LABS and providing us valuable feedback.
For any questions or to provide feedback please use our Windows Azure AppFabric CTP Forum.Once the maintenance is over we will post more details on the blog.
Steve Peschka continued his Federated SAML Authentication with SharePoint 2010 and Azure Access Control Service Part 2 series with a 5/6/2011 post:
In the first post in this series (http://blogs.technet.com/b/speschka/archive/2011/05/05/federated-saml-authentication-with-sharepoint-2010-and-azure-access-control-service-part-1.aspx) [see below] I described how to configure SharePoint to establish a trust directly with the Azure Access Control (ACS) service and use it to federate authentication between ADFS, Yahoo, Google and Windows Live for you and then use that to get into SharePoint. In part 2 I’m going to take a similar scenario, but one which is really implemented almost backwards to part 1 – we’re going to set up a typical trust between SharePoint and ADFS, but we’re going to configure ACS as an identity provider in ADFS and then use that to get redirected to login, and then come back in again to SharePoint. This type of trust, at least between SharePoint and ADFS, is one that I think more SharePoint folks are familiar with and I think for today plugs nicely into a more common scenario that many companies are using.
As I did in part 1, I’m not going to describe the nuts and bolts of setting up and configuring ACS – I’ll leave that to the teams that are responsible for it. So, for part 2, here are the steps to get connected:
1. Set up your SharePoint web application and site collection, configured with ADFS.
- First and foremost you should create your SPTrustedIdentityTokenIssuer, a relying party in ADFS, and a SharePoint web application and site collection. Make sure you can log into the site using your ADFS credentials. Extreme details on how this can be done is described in one of my previous postings at http://blogs.technet.com/b/speschka/archive/2010/07/30/configuring-sharepoint-2010-and-adfs-v2-end-to-end.aspx.
2. Open the Access Control Management Page
- Log into your Windows Azure management portal. Click on the Service Bus, Access Control and Caching menu in the left pane. Click on Access Control at the top of the left pane (under AppFabric), click on your namespace in the right pane, and click on the Access Control Service button in the Manage portion of the ribbon. That will bring up the Access Control Management page.
3. Create a Trust Between ADFS and ACS
- This step is where we will configure ACS as an identity provider in ADFS. To begin, go to your ADFS server and open up the AD FS 2.0 Management console
- Go into the AD FS 2.0…Trust Relationships…Claims Provider Trusts node and click on the Add Claims Provider Trust… link in the right pane
- Click the Start button to begin the wizard
- Use the default option to import data about the relying party published online. The Url you need to use is in the ACS management portal. Go back to your browser that has the portal open, and click on the Application Integration link under the Trust relationships menu in the left pane
- Copy the Url it shows for the WS-Federation Metadata, and paste that into the Federation metadata address (host name or URL): edit box in the ADFS wizard, then click the Next button
- Type in a Display name and optionally some Notes then click the Next button
- Leave the default option of permitting all users to access the identity provider and click the Next button.
- Click the Next button so it creates the identity provider, and leave the box checked to open up the rules editor dialog. The rest of this section is going to be very similar to what I described in this post http://blogs.technet.com/b/speschka/archive/2010/11/24/configuring-adfs-trusts-for-multiple-identity-providers-with-sharepoint-2010.aspx about setting up a trust between two ADFS servers:
You need to create rules to pass through all of the claims that you get from the IP ADFS server. So in the rules dialog, for each claim you want to send to SharePoint you're going to do the following:
- Click on Add Rule.
- Select the Pass Through or Filter an Incoming Claim in the Claim Rule Template drop down and click the Next button.
- Give it a Claim Name - probably including the name of the claim being passed through would be useful. For the Incoming Claim Type drop down, select the claim type you want to pass through, for example E-Mail Address. I usually leave the default option for Pass through all claim values selected, but if you have different business rules then select whatever's appropriate and click the Finish button. Note that if you choose to pass through all claim values ADFS will give you a warning dialog.
Once you've added pass through claims for each claim you need in SharePoint you can close the rules dialog. Now, for the last part of the ADFS configuration, you need to find the SharePoint relying party. Click on the Edit Claim Rules dialog, and for each Pass Through claim rule you made in the previous step, you ALSO need to add a Pass Through claim rule for the SharePoint relying party. That will allow the claims to flow from ACS, to ADFS through the trusted claim provider, and out to SharePoint through the trusted relying party.
Your ADFS configuration is now complete.
4. Add ADFS as a Relying Party in ACS
- Go back to your browser that has the portal open, and click on the Relying party applications link under the Trust relationships menu in the left pane
- Click on the Add link
- Fill out the Relying Party Application Settings section
- Enter a display name, like “ADFS to ACS”
- Use the default Mode of Enter settings manually
- In the Realm edit box you need to enter the realm that ADFS will be sending with the request. As it turns out, ADFS has a specific list of realms that it sends when redirecting to another identity provider, so you DO NOT use the realm that was used when creating the SPTrustedIdentityTokenIssuer in SharePoint. Instead, I recommend you use http://yourFullyQualifiedAdfsServerName/adfs/services/trust.
- For the return Url use https:// yourFullyQualifiedAdfsServerName /adfs/ls/.
- The Token format drop down can be SAML 2.0 or 1.1. Since the token is getting sent to ADFS and not SharePoint, and ADFS supports SAML 2.0 tokens, you don’t need to drop down to SAML 1.1 like you would if connecting directly to SharePoint
- You can set the Token lifetime (secs) to whatever you want. It’s 10 minutes by default; I set mine to 3600 which means 1 hour.
- Fill out the Authentication Settings section
- For the identity providers you can select them all, except and unless you have added your same ADFS server previously as an identity provider (as you would have if you followed the steps in the first posting in this series). If you did do that, then you can check everything except for the identity provider that points back to your same ADFS server that you are now setting up as the relying party.
- Under Rule groups, in the interest of time, I’m going to suggest you either follow the guidance for rule groups that I explained in part 1, or if you completed part 1 then just select that rule group from the list.
- In the Token Signing Settings you can leave the default option selected, which is Use service namespace certificate (standard).
Click the Save button to save your changes and create the relying party.
You should be able to login into your SharePoint site now using ADFS or ACS. One thing to remember though is that ADFS will write a cookie to remember what identity provider you last used. From that point forward it won’t prompt you for the identity provider unless you use something like an InPrivate browsing window in IE (I highlight this in extra big font because it is so commonly forgotten and a source of confusion). For example, here’s what it looks like the first time you are redirected to the ADFS server or if you are using an InPrivate browser session:

The rest of it works just as described in part 1 of this series (including the caveat about using an email address for Windows Live ID), so I won’t both posting screenshots again since they look almost identical. With this series complete now you should be able to successfully integrate ADFS, ACS, and all of the identity providers ACS supports into your SharePoint 2010 environment.
Attachment:
Federated Auth with SharePoint and ACS Part 2.docx
Steve Peschka started a Federated SAML Authentication with SharePoint 2010 and Azure Access Control Service Part 1 series with a 5/5/2011 post:
NOTE: As usual the formatting on this site sucks. I recommend you download the Word document attachment with this posting for better reading.
I had been looking at Windows Azure Access Control Service (ACS) with an interesting eye recently, thinking about some of the different integration options. There’s always lots of chatter about claims authentication with SharePoint 2010, and how to integrate ADFS, Windows Live, Facebook, etc. ACS (also known as AppFabric ACS to you Azure purists / marketing people) is rather cool because it includes “connectors” for these common identity providers out of the box. When you set up an ACS namespace (think of it like an account with connectors and configuration settings), you have simplified and streamlined connectivity to ADFS 2.0, Windows Live, Yahoo, Google and Facebook. The lazy programmer in me thinks hey, there must be something goin’ on there so I decided to look into it from a couple of different angles. I’m going to describe the first one in this post.
For this scenario I really just wanted to establish a trust directly between SharePoint 2010 and ACS. I wanted to be able to use ADFS, Windows Live, Yahoo and Google accounts to authenticate and get into my SharePoint site. I didn’t include Facebook because social computing is really not my thing (this blog’s as close as I get) so I don’t have a Facebook or Twitter account because I’m really not interested in frequently sharing pointless information with the world at large (“Puffy just had 3 kittens – Adorable!!”). I will NOT be explaining how to get a Windows Azure account, create an Access Control Service namespace, how to manage ACS, etc. – there should be reams of info out there from the Windows Azure folks so I’m not going to try and reinvent that.
What I am going to describe is the process of setting up the various trusts, certificates, and configuration necessary to get all this stuff working together. At the end I’ll include some screenshots of me logged in with identities from each of those providers. Here are the steps to get connected:
- Open the Access Control Management Page
- Log into your Windows Azure management portal. Click on the Service Bus, Access Control and Caching menu in the left pane. Click on Access Control at the top of the left pane (under AppFabric), click on your namespace in the right pane, and click on the Access Control Service button in the Manage portion of the ribbon. That will bring up the Access Control Management page.
Add An Identity Provider for ADFS
- Click on Identity providers in the Trust relationships menu in the left pane.
- Click on the Add link
- The WS-Federation identity provider radio button should be selected by default; check it if it is not. It is what’s used for ADFS 2.0. Click the Next button.
- Fill out the Identity Provider Settings section
- Fill out the Display name, such as “My ADFS Server”
- For the WS-Federation metadata, if your ADFS server is exposed via the Internet then you just put in the Url to the federation metadata endpoint. By default it’s at https://yourAdfsServer.com/FederationMetadata/2007-06/FederationMetadata.xml. If your ADFS server is not exposed to the Internet, then open the Url to the endpoint in your local browser. Go to your browser and save the page to the local file system as an .XML file. Then in the Identity Provider Settings in ACS click the radio button next to the File edit box and use the Browse button to find the federation metadata xml file you just saved.
That’s pretty much all you need to do to create your Identity Provider in ACS.
3. Add A Relying Party for SharePoint
- Now you need to add SharePoint as a relying party of ACS, just like you do when you configure SharePoint and ADFS together. Start by clicking the Relying party applications link under the Trust relationships menu in the left pane
- Click on the Add link.
- Fill out the Relying Party Application Settings section
- Enter a display name, like “SharePoint 2010”
- Use the default Mode of Enter settings manually
- In the Realm edit box enter a realm, and save that because you will use it again when you create your SPTrustedIdentityTokenIssuer in SharePoint. For purposes of this example let’s say the realm is “urn:sharepoint:acs”.
- For the return Url use the same format as you do when setting up SharePoint as a relying party in ADFS: https://yourSiteName/_trust/.
- The Token format drop down should be SAML 1.1
- You can set the Token lifetime (secs) to whatever you want. It’s 10 minutes by default; I set mine to 3600 which means 1 hour.
- Fill out the Authentication Settings section
- Check every box under the Identity providers; it should show you the ADFS identity provider you created in the previous step
- Under Rule groups leave the default checked, which is Create new rule group.
- In the Token Signing Settings you can leave the default option selected, which is Use service namespace certificate (standard).
- Click the Save button to save your changes and create the relying party
4. Create the rules for the Relying Party
- I’m assuming here that you have not already created a set of rules in ACS before so we’re creating a new group of them. If you had a group you wanted to reuse then in the previous step you would have just placed a check next to the group(s) you want to use with the relying party instead of taking the default of Create new rule group. But since we’re creating a new one, click on the Rule groups link under the Trust relationships menu in the left pane
- You should see a rule group that has a name like “Default Rule Group for whatever your relying party name was”. Click on that link for that rule group name
- Really the easiest thing to do at this point is just to click on the Generate link. It will automatically create a set of rules for you that basically enumerates all of the claims you’ll be getting from each identity provider, and then creates a rule for each one that passes through that claim value with the same claim type to the relying party
- On the Generate Rules page, just check the box next to each identity provider and click the Generate button. This creates the rules as I’ve described previously. When it’s complete you are redirected to the Edit Rule Group page, where you will see all the rules listed. In many cases this would be enough, but we have one anomaly here that we need to account for. In SharePoint, we’re going to use the email address as the identity claim. Ironically, all the identity providers send the email address along (and have rules created for them to do so) except for Windows Live. So for now, for this example, I am faking the Windows Live piece of it. What I mean by that is that I am going to take the one claim it does provide – nameidentifier – and I’m going to create a rule that passes that back, but it’s going to pass it back as an email claim. This is not the time to hate on Steve, this is just a way to get this demo environment running with the fewest moving parts (and there are several already). Now we’ll add this final rule
- Click on the Add link
- In the Identity Provider drop down, select Windows Live I
- In the Input claim type section, click the radio button next to Select type:. There’s only one claim type that Windows Live ID supports so it is already selected (nameidentifier)
- Scroll down to the Output claim type section and click the radio button next to Select type:
- In the drop down list find http://schemas.xmlsoap.org/ws/2005/05/identity/claims/emailaddress and select it
- Enter a description if you’d like, then click the Save button to save your changes and create the rule
- You’ll be redirected to the Edit Rule Group page, then click the Save button to save all your changes. You’re now done with the ACS configuration, but don’t close the browser yet because you will need to get some additional information from there when you create and configure the other components.
5. Create a Relying Party for ACS in ADFS
- While ADFS is an identity provider to ACS, ACS is a relying party to ADFS. That means we need to configure a relying party in ADFS so that when ACS redirects an authentication request to ADFS a trust has been established that allows ADFS to respond. Begin by going to your ADFS server and opening up the AD FS 2.0 Management console
- Go into the AD FS 2.0…Trust Relationships…Relying Party Trusts node and click on the Add Relying Party Trust… link in the right pane
- Click the Start button to begin the wizard
- Use the default option to import data about the relying party published online. The Url you need to use is in the ACS management portal. Go back to your browser that has the portal open, and click on the Application Integration link under the Trust relationships menu in the left pane
- Copy the Url it shows for the WS-Federation Metadata, and paste that into the Federation metadata address (host name or URL): edit box in the ADFS wizard, then click the Next button
- Type in a Display name and optionally some Notes then click the Next button
- Leave the default option of permitting all users to access the relying party and click the Next button
- Click the Next button so it creates the relying party
- Once the relying party is created, you and open the Rules Editor in ADFS to create new rules for passing claim values to ACS
- With the Issuance Transform Rules tab selected, click on the Add Rule… button
- Leave the default template of Send LDAP Attributes as Claims selected and click the Next button.
- Fill out the rest of the rule details:
- Type in a claim rule name
- From the Attribute store: drop down select Active Director
- In the Mapping of LDAP attributes section, map
- LDAP attribute E-Mail-Addresses to Outgoing Claim Type E-Mail Address
- LDAP attribute Token-Groups – Unqualified Names to Outgoing Claim Type Role
- Click the Finish button to save your rule. ADFS configuration is now complete.
6. Configure the SharePoint Trust with ACS
- This is a multi-step process that begins with getting the token signing certificate from ACS. Fortunately the certificate is included in the FederationMetadata.xml file, so we will retrieve it from there and save it locally to the SharePoint server. On the SharePoint Server, open a browser and open the Access Control Management page as described above
- Click on the Application Integration link under the Trust relationships menu in the left pane, copy the Url it shows for the WS-Federation Metadata and paste it into your browser. The ACS FederationMetadata.xml file will be displayed in the browser.
- Find the section that looks like this (it's about the second major section down from the top of the page):
<RoleDescriptor xsi:type="fed:SecurityTokenServiceType" protocolSupportEnumeration="http://docs.oasis-open.org/wsfed/federation/200706" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:fed="http://docs.oasis-open.org/wsfed/federation/200706">
<KeyDescriptor use="signing">
<KeyInfo xmlns="http://www.w3.org/2000/09/xmldsig#">
<X509Data>
<X509Certificate>MIIDEDCCAfiblahblahblah</X509Certificate>
</X509Data>
Copy the data out of the X509Certificate element and paste it into notepad. Save it with a .CER file extension (the encoding should be ANSI); for purposes of this post let’s assume you call the file C:\AcsTokenSigning.cer. This is the token signing certificate for ACS.
- Add the ACS token signing certificate to the list of trusted root authorities in SharePoint. You can do that as described at http://blogs.technet.com/b/speschka/archive/2010/07/07/managing-trusted-root-authorities-for-claims-authentication-in-sharepoint-2010-central-admin.aspx or you can add it with PowerShell like this:
$cert = New-Object System.Security.Cryptography.X509Certificates.X509Certificate2("c:\AcsTokenSigning.cer")
New-SPTrustedRootAuthority -Name "ACS Token Signing" -Certificate $cert
- The next step is to create your new SPTrustedIdentityTokenIssuer. I've described this in various places; you can use http://blogs.technet.com/b/speschka/archive/2010/07/30/configuring-sharepoint-2010-and-adfs-v2-end-to-end.aspx as a starting point (just scroll down to the information that comes AFTER setting up ADFS). Some things to remember:
- Both name and nameidentifier are reserved claim types in SharePoint, so even though nameidentifier is the only common claim across the standard identity providers in ACS it isn't an option for your identity claim. Instead I recommend for now just falling back on email address and adding the appropriate rules in ACS as I’ve described above
- The SignInUrl parameter for the New-SPTrustedIdentityTokenIssuer should point to your ACS instance. For example, https://myAcsNamespace.accesscontrol.windows.net:443/v2/wsfederation. You can find this by looking at the Relying Party you set up in ADFS for ACS. Open up the Relying Party properties dialog, click on the Endpoints tab, and use the Url it displays for the WS-Federation Passive Endpoint for the POST binding (it should be the only one there).
- The last step is just to create your web application, configure it to use claims authentication and the SPTrustedIdentityTokenIssuer you created for ACS, and finally create a site collection in the web application and begin testing.
At this point you should be ready to hit the site and give it a try. Remember that you’ll need to configure the site collection administrator to be one of the email addresses that one of the identity providers will return so you can log into the site. Once in there you can add email addresses or role claims from providers to SharePoint groups just as you would normally expect to do.
The one caveat to remember again, for now, is Windows Live ID. As stated previously in this post, you won’t really have a valid email address for Windows Live so you will need to add what they call the PUID to your SharePoint group. For testing purposes, the easiest way to get this is to log in using Windows Live ID, and then you will reach the page in SharePoint that says you are logged in as “foo” and access is denied. From there you can copy the PUID, login as an admin user, add the PUID to a SharePoint group and you should be good to go. I haven’t even looked at what kind of directory options, if any, are available for Windows Live ID (I’m guessing probably none). But it’s a start so we can move this proof of concept along. Now that we’ve done that, here’s what it looks like logging into my site using each of these identity providers:
Login Page
ADFS
Yahoo
Windows Live ID
Attachment:





The Windows Azure AppFabric Team announced New Caching Videos And Code Samples Available in a 5/5/2011 post:
These videos and code samples are part of the Windows Azure AppFabric Learning Series available on CodePlex.
We will be adding more resources to the learning series from time-to-time, so be sure to save this link!The following videos and code samples are currently available:
Name Link to Sample Code Link to Video Introduction to the Windows Azure AppFabric Cache N/A
Windows Azure AppFabric Cache - How to Set Up and Deploy a Simple Cache Click here Click here Windows Azure AppFabric Cache - Caching SQL Azure Data Click here Click here Windows Azure AppFabric Cache - Caching Session State Click here Click here Just as a reminder, we have a promotion period in which we will not be charging for the Caching service for billing periods prior to August 1st, 2011, so be sure to take advantage of this promotion period to start using the Caching service.
For questions and feedback on the Caching service please visit the Windows Azure Storage Forum.
If you haven’t signed up for Windows Azure AppFabric and would like to start using the Caching service, you can take advantage of our free trial offer. Just click on the image below and get started today!
Vittorio Bertocci (@vibronet) described Fun with FabrikamShipping SaaS III: Programmatic Use of the Enterprise Edition via OData, OAuth2 in a 5/4/2011 post:
Welcome to the last installment of the “Fun with FabrikamShipping SaaS” series. The “fun” blogs are meant to help you walking through the demo; once we are done with that, I’ll finally start to talk about what makes the demo tick: architecture, code and all those nice things.
The walkthrough I am discussing here is in fact a sub-scenario of the Enterprise Edition subscription: if you didn’t read the post which described it, you should really go through it and follow the steps it describes before getting into this post.
Last time Joe successfully subscribed to FabrikamShipping SaaS on behalf of its company, AdventureWorks, and obtained a dedicated Enterprise Edition instance: a dedicated web application running in Windows Azure (at https://fs-adventureworks1.cloudapp.net/) that AdventureWorks employees can SSO into, which authorizes them according to their role at AdventureWorks and the rules Joe established at sign-up time, etc etc.
Delivering the application functionality via web application is the most classic delivery vehicle for a SaaS solution, however it is not the only one. Let’s say that AdventureWorks would like to embed shipping capabilities in their existing LoB applications, rather than having their employees switch between the LoB app UI and the FabrikamShipping UI. In other words, Joe would like to be able to access FabrikamShipping via APIs, too. And being Joe a very trendy guy, he wants to access those APIs in REST style.
Few years ago, delivering on that requirement would have been a messy, sticky business: bridging enterprise and REST has always been less than straightforward, especially where access control plays an important part. luckily today it is much clearer what a solution should look like. I’ll get to the architecture in a later post, here I will just describe the solution from Joe’s perspective.
Wen Joe got his FabrikamShipping instance provisioned, he got a web application listening at https://fs-adventureworks1.cloudapp.net/ for AdventureWorks users to interact with the app. The web application is secured via WS-Federation, configured to trust the AdventureWorks STS via ACS at onboarding time (the magic which enables SSO).
Joe also got a programmatic OData endpoint, https://fs-adventureworks1.cloudapp.net/FabrikamShippingDataService, to exclusive use for AdventureWorks as well. This endpoint is secured using OAuth2. Thanks to the fact that FabrikamShipping is using ACS, the same trust relationship can be piggybacked for enabling AdventureWorks employees to securely invoke the OData service without having to provision extra credentials just to call the service. Once again, the details will come in a later post: just to whet your appetite, let’s say that the client consuming the OData service can acquire a SAML token via WS-Trust from the local active directory and trade it in at the ACS with a REST-friendly token which can be used to secure calls to the OData service via OAuth2.
So many words for describing what in the end is a very simple and straightforward user experience. Want to experience that yourself? The Enterprise Companion once again comes to the rescue. The SelfSTS provided with the companion includes the necessary endpoint to enable this scenario, and it includes a test client which uses it for invoking the OData endpoint form the pre-provisioned AdventureWorks instance.
Turn on the companion’s SelfSTS as described in the “Accessing the AdventureWorks Instance with the Enterprise Companion” section in the former post.
Once you’ve done that, open the test client solution (C:\FabrikamShippingSaaS_Companion\assets\OAuthSample\TestClient.sln) and hit F5.
The test client advertises the endpoints that will be involved in the call. The identity provider is the local AdventureWorks SelfSTS, the endpoint we are going to get the REST-friendly token is the OAuth2 (draft 13) endpoint on ACS, and the OData service is the one exposed by FabrikamShipping from the AdventureWorks instance. Hit enter and watch closely what happens.
After few seconds, the test client announces that it successfully requested & received a SAML token :
right after that, the test client trades that SAML token for a REST-friendly token from ACS:
Note that the token from ACS already contains the result of the rules which map claims from AdventureWorks into the roles specific to FabrikamShipping.
At this point we are ready to invoke the OData service:
The test client made a big deal out of all the intermediary steps, but that’s of course just for didactic purposes: in a real solution all those steps would take place in the blink of an eye, and completely transparently.
There you have it! Joe was able to invoke an OData service by using his active directory identity and piggybacking the settings already in place for the web SSO. What’s more, this service endpoint was dynamically provisioned as part of the SaaS solution, just like the web application: that’s handy for AdventureWorks, and good business for Fabrikam.
Alrighty, at this point you are able to walk though the main paths of the FabrikamShipping SaaS demo: creating and accessing a small business subscription, creating and accessing an enterprise subscription, and accessing the enterprise subscription programmatically via REST. Now we can finally start to chat about what’s inside the solution.




<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
• The Windows Azure Connect Team suggested that you Choose Relays Close to You in a 5/5/2011 post:
To change the relay location, click on “Relay Region” (the new button added in CTP refresh) and pick the relay location you desire, by default USA is chosen for you.
Please be aware that if you change your relay location, there will be a transition period of up to 5 minutes while your existing endpoints refresh their policy (which contains the relay location information), close their existing relay connections, and re-establish connections with the new relay location. During this time period, endpoints may not be able to communicate with each other until they have completed the transition to the new relay location.

• Avkash Chauhan described a workaround for When you RDP to your Web or Worker Role, you might see AzureAgentIntegrator.exe process consuming 70-80% CPU on 5/6/2011:
I was recently working on a problem in which Windows Azure user reported the following issue:
When Windows Azure user RDP to their Web Role they found that, AzureAgentIntegrator.exe process consuming 70-80% CPU which cause a significant amount of performance degradation.
- To enable "Windows Azure Connect" to your Web or Worker Role, you do the following:
- Once you enable "Windows Azure Connect" with Worker or Web Role, it adds up these following settings in your ServiceConfiguration.cscfg
<ConfigurationSettings>
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.ActivationToken" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.Refresh" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.Diagnostics" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.WaitForConnectivity" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.Upgrade" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.EnableDomainJoin" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.DomainFQDN" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.DomainControllerFQDN" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.DomainAccountName" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.DomainPassword" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.DomainOU" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.DNSServers" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.Administrators" value="" />
<Setting name="Microsoft.WindowsAzure.Plugins.Connect.DomainSiteName" value="" />
</ConfigurationSettings>Possible reason for this problem and Solution:
If you leave above fields empty and deploy your project to Windows Azure Cloud, that will cause AzureAgentIntegrator.exe process to start when the Role Starts. Now because most of these Windows Azure Connect settings are empty, that will cause AzureAgentIntegrator.exe process to try to configure empty content that will result excessive CPU consumption by AzureAgentIntegrator.exe process.
In our case these Windows Azure Connect settings were included in Service Configuration and even when the final Application Solution did not have "Windows Azure Connect" enabled. So it is best to check the Service Configuration file before deploying the package for any last minute inconsistencies. After removing all the empty settings in Service Configuration, and redeploying the configuration fixed the problem.

• Doug Rehnstrom described “Exploring an Azure Instance with RDP” in his A Look Inside a Windows Azure Instance post of 5/4/2011o the Learning Tree blog:
A Windows Azure instance may seem like a mysterious black box, but it is really just Windows Server running in a virtual machine. Using remote desktop, I accessed an instance that I had previously deployed.
The instance I accessed was a “Small Instance”, which according to Microsoft, has a 1.67Gh CPU, 1.75 GB of memory and 225 GB of storage. This computer would cost about $80 per month.
Let’s hunt around a bit. A look at Computer properties shows I have Windows Server 2008 Enterprise edition with service pack 2. I can also verify that I have 1.75 GB of RAM and one CPU.
A look at Windows Explorer shows I have three drives, and sure enough 225 GB of instance storage.
The instance I deployed was a Web role. That’s just a fancy way of saying IIS is running and the ASP.NET application that I deployed is set up. See the screen shot below.
A look at my Web application’s Advanced Settings shows the application I deployed was uploaded into the computer’s E drive.
I was also curious about what versions of the .NET Framework were installed. It turns out they all are.
Conclusion
If you are already a Windows administrator or .NET developer you can take advantage of cloud computing and Azure’s benefits, while leveraging your existing knowledge. Those benefits include, reduced administration, simplified deployment, massive scalability and fault tolerance. If you’d like to learn more about Azure, come to Learning Tree’s Windows Azure training course.
If you want to use Windows Azure, but don’t know .NET programming, come to Learning Tree’s Introduction to .NET training course.






• Bill Zack provides additional details about New Windows Azure Connect Features Released in a 5/6/2011 post to the Ignition Showcase blog:
Windows Azure Connect provides a simple and easy-to-manage mechanism to setup IP-based network connectivity between on-premises and Windows Azure resources. This capability makes it easier for an organization to migrate their existing applications to the cloud by enabling direct IP-based network connectivity with their existing on-premises infrastructure.
We have just announced the availability of several new features of Windows Azure Connect, including the addition of new relay locations in Europe and Asia that will allow customers in those regions to choose a relay location closer to their geo-location.
Other new features include:
- Certificate-based endpoint activation for local machines to enable customers to leverage existing on-premises PKI infrastructures to activate on-premises endpoints securely.
- Multiple enhancements in Admin UI including a re-organized ribbon and additional display of endpoint version and support status.
- An updated endpoint UI with more diagnostics checks.
For additional details visit the Windows Azure Team Blog [and Yung Chow’s Cloud Computing of PaaS with Windows Azure Connect (1/2) of 5/3/2011, below.]

• Yung Chow started a Cloud Computing of PaaS with Windows Azure Connect (1/2) series on 5/3/2011:
- Part 1: Concept
- Part 2: Application Integration/Migration Model

What It Is
To simply put, Windows Azure Connect offers IPSec connectivity between Windows Azure role instances in public cloud and computers and virtual machines deployed in a private network as shown below.

Why It Matters
The IPSec connectivity provided by Windows Azure Connect enables enterprise IT to relatively easily establish trust between on-premises resources and Windows Azure role instances. A Windows Azure role instance can now join and be part of an Active Directory domain. In other words, a domain-joined role instance will then be part of a defense-in-depth strategy, included in a domain isolation, and subjected to the same name resolution, authentication scheme, and domain policies with other domain members as depicted in the following schematic.

In Windows Azure Platform AppFabric (AppFabric), there is also the so-called Service Bus offering connectivity options for Windows Communication Foundation (WCF) and other service endpoints. Both Windows Azure Connect and AppFabric are very exciting features and different approaches for distributed applications to establish connectivity with intended resources. In a simplistic view, Windows Azure Connect is set at a box-level and more relevant to sys-admin operations and settings, while Service Bus is a programmatic approach in a Windows Azure application and with more control on what and how to connect.
A Clear Cloudy Day Ahead
Ultimately, Windows Azure Connect offers a cloud application a secure integration point with private network resources. At the same time, for on-premises computing Windows Azure Connect extends resources securely to public cloud. Both introduce many opportunities and interesting scenarios in a hybrid model where cloud computing and on-premises deployment together form an enterprise IT. The infrastructure significance and operation complexities at various levels in a hybrid model enabled by Windows Azure Connect bring excitements and many challenges to IT pros. …

The Windows Azure Team reported New Windows Azure Connect Features Add New Locations, Enhance Interface in a 5/5/2011 post:
Today we’re happy to announce the availability of several new features of Windows Azure Connect, including the addition of new relay locations in Europe and Asia that will allow customers in those regions to choose a relay location closer to their geo-location.
Other new features include:
- Certificate-based endpoint activation for local machines to enable customers to leverage existing on-premises PKI infrastructures to activate on-premises endpoints securely.
- Multiple enhancements in Admin UI including a re-organized ribbon and additional display of endpoint version and support status.
- An updated endpoint UI with more diagnostics checks.
Windows Azure Connect is available as a CTP. During the CTP period, Windows Azure Connect is free of charge, and invitation-only. To request an invitation, please visit the Beta Programs section of the Windows Azure Portal.
Click here to read an overview Windows Azure Connect.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Neil MacKenzie posted Windows Azure Diagnostics Sample Code to the MSDN Code Samples Gallery on 5/4/2011:
I uploaded a Windows Azure Diagnostics sample to the MSDN Code Samples Gallery. The sample demonstrates how to use the parts of the Windows Azure Diagnostics API I covered in earlier posts on Windows Azure Diagnostics and its management.
The sample can be downloaded from here. Its description is:
Windows Azure Diagnostics provides a coherent method of capturing log information, from various sources, in a Windows Azure instance and then transferring it to Windows Azure Storage. Various types of information can be captured including Windows Event Logs, Performance Counters, Trace logs, and custom logs. This information remains on the instance with a consequent risk of loss until it is transferred to Windows Azure Storage. WAD therefore provides for the scheduled and on-demand transfer of the captured information to Windows Azure Storage. Event-based logs are transferred to table storage while file-based logs are transferred to blog storage.
WAD is started automatically on all instances of a role for which the ServiceDefinition.csdef file contains an import specification for the Diagnostics module. WAD is configured at instance startup by retrieving the default initial configuration and modifying it to specify which logs to capture and the schedule with which they should be transferred. In the sample, this is performed in WebRole.cs.
The configuration for WAD is stored in instance-specific XML documents in blob storage. In the sample, the WAD configuration for each instance is retrieved from blob storage and displayed in the Configuration page. The Logs page in the sample displays the last five minutes of performance counter data transferred to table storage.
The WAD API supports remote configuration. This is useful when a change is required in the captured information such as adding one or more performance counters or changing the periodicity of the scheduled transfers. Another use is the request of an on-demand transfer when there is an immediate need to access the captured logs without waiting for the next scheduled transfer. In the sample, the Configuration page associates two buttons with the configuration of each instance. One button adds the capture of an additional performance counter while the other requests an on-demand transfer. These requests are then reflected in the instance configuration displayed on the page.
Once an on-demand transfer has been requested for an instance it is not possible to modify the WAD configuration again until the on-demand transfer has been formally ended. This cleanup removes the configuration of the on-demand transfer from the WAD configuration. The cleanup should also remove the message from the notification queue used to indicate completion of the transfer. In the sample, the OnDemandTransfer page demonstrates this cleanup.
• Information Week :: Analytics published their Wall Street & Technology Digital Issue: May 2011 on 5/4/2011:
It's amazing how quickly Wall Street firms have shifted their position on cloud computing. After several years of shunning the cloud for a lack of security, capital markets firms now acknowledge that they are aggressively pursuing cloud deployments. But the cloud isn't without its dangers. To help you optimize your cloud strategy, the May digital edition of Wall Street & Technology analyzes the latest cloud developments and best practices, and examines how cloud computing is transforming the Street.
Table of Contents
THE GREAT BUSINESS CASE IN THE SKY: The cloud promises lower costs, increased flexibility and improved performance. How can Wall Street resist?
CLOUD REGULATION ON THE HORIZON: As cloud computing gains steam in the capital markets, regulators are certain to take action.
BEWARE THE CLOUD: The cloud is the future, according to Larry Tabb. But as Amazon's recent cloud crash showed, it's not always safe.
PLUS:
Why You Should Adopt Cloud
IT Spending Soars on Cloud Investments
Transformative Powers: The Cloud Spawns New Business Models
Easing the Compliance Burden With Cloud SolutionsAbout the Author

Wall Street & Technology's mission is to deliver accurate, thought-provoking and targeted content to the capital markets industry's top business and technology executives. The brand's coverage derives from two main drivers: the experience and knowledge of the industry's most senior staff of editors, and our close work with our reader advisory board and other leading securities industry experts. WS&T's content helps business and technology executives gain a deeper understanding of the trends and technology that are shaping the market, including low-latency demands, back-office processing, data center efficiency, regulatory reporting, high-frequency trading, data and risk management strategy, and data security. The brand's content spans multiple media platforms -- digital publications, print publications, Web content, electronic newsletters, live events, virtual events, webcasts, video, blogs and more -- so executives can access information in the methods they prefer.

• Rob Tiffany described Windows Phone 7 Line of Business App Dev :: Uploading Data back to Azure in a 5/3/2011 post:
Looking back over the last 6 months of this series of articles, you’ve created wireless-efficient WCF REST + JSON Web Services in Azure to download data from SQL Azure tables to Windows Phone. You’ve maintained in-memory collections of objects in your own local NoSQL object cache. You’ve used LINQ to query those collections and bind results to various Silverlight UI elements. You’ve even serialized those collections to Isolated Storage using memory-efficient JSON. So what’s left to do?
Oh yeah, I guess you might want to know how to upload an object full to data back to a WCF Web Service in Azure. In order to keep this article simple and to-the-point, I’m going to work with a basic Submarine object and show you how to fill it with data and upload it from a Windows Phone or Slate to a WCF REST + JSON Web Service. Let’s take a look at this object:
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Runtime.Serialization; namespace Models { [DataContract()] public class Submarine { [DataMember()] public int Id { get; set; } [DataMember()] public string Name { get; set; } } }It includes just an integer data type called Id, and a string called Name. As in previous articles before, its decorated with a [DataContract()] and two [DataMember()]s to allow .NET serialization to do its thing. So the next thing we need to do is create and populate this Submarine object with data, serialize it as JSON, and send it on its way using WebClient.
Below is the method and its callback that accomplishes this:
using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Windows; using Microsoft.Phone.Controls; using System.IO; using System.Runtime.Serialization.Json; using System.Text; private void AddSubmarine() { Uri uri = new Uri(“http://127.0.0.1:81/SubService.svc/AddSubmarine”); Models.Submarine submarine = new Models.Submarine() { Id = 3, Name = “Seawolf” }; DataContractJsonSerializer ser = new DataContractJsonSerializer(typeof(Models.Submarine)); MemoryStream mem = new MemoryStream(); ser.WriteObject(mem, submarine); string data = Encoding.UTF8.GetString(mem.ToArray(), 0, (int)mem.Length); WebClient webClient = new WebClient(); webClient.UploadStringCompleted += new UploadStringCompletedEventHandler(webClient _UploadStringCompleted); webClient.Headers["Content-type"] = “application/json”; webClient.Encoding = Encoding.UTF8; webClient.UploadStringAsync(uri, “POST”, data); } void webClient_UploadStringCompleted(object sender, UploadStringCompletedEventArgs e) { var x = e.Result; }As you can see above, I point the URI at a WCF Service called SubService.svc/AddSubmarine. How RESTful. Next, I create an instance of the Submarine object, give it an Id of 3 and the Name Seawolf. I then use the same DataContractJsonSerializer I’ve been using in all the other articles to serialize the Submarine object to a JSON representation. Using the MemoryStream, I write the JSON to a stream and then artfully turn it into a string. Last but not least, I instantiate a new WebClient object, create an event handler for a callback, and upload the stringified Submarine object to the WCF Service.
So where did I upload the Submarine object to?
It takes two to Mango, so let’s take a look. For starters, it goes without saying that every WCF Service starts with an Interface. This one is called ISubService.cs:
using System; using System.Collections.Generic; using System.Linq; using System.Runtime.Serialization; using System.ServiceModel; using System.ServiceModel.Web; using System.Text; namespace DataSync { [ServiceContract] public interface ISubService { [OperationContract] [WebInvoke(UriTemplate = "/AddSubmarine", BodyStyle = WebMessageBodyStyle.Bare, RequestFormat = WebMessageFormat.Json, ResponseFormat = WebMessageFormat.Json, Method = "POST")] bool AddSubmarine(Models.Submarine sub); } }Unlike previous articles where I had you download data with WebGet, this time I’m using WebInvoke to denote that a PUT, POST, or DELETE HTTP Verb is being used with our REST service. The UriTemplate gives you the RESTful /AddSubmarine, and I added the Method = “POST” for good measure. Keep in mind that you’ll need the exact same Submarine class on the server that you had on your Windows Phone to make all this work.
Let’s see what we get when we Implement this Interface:
using System; using System.Collections.Generic; using System.Linq; using System.Runtime.Serialization; using System.ServiceModel; using System.ServiceModel.Web; using System.Text; using Microsoft.WindowsAzure; using Microsoft.WindowsAzure.Diagnostics; using Microsoft.WindowsAzure.ServiceRuntime; using Microsoft.WindowsAzure.StorageClient; using System.Configuration; using System.Xml.Serialization; using System.IO; namespace DataSync { public class SubService : ISubService { public SubService() { } public bool AddSubmarine(Models.Submarine submarine) { try { if (submarine != null) { //Do something with your Deserialized .NET Submarine Object //… = submarine.Id //… = submarine.Name return true; } else { return false; } } catch { return false; } } } }Here we end up with SubService.svc with the simple AddSubmarine method where you pass in a Submarine object as a parameter. What you do with this object, I’ll leave to you. Some might be tempted to INSERT it into SQL Azure. I’d prefer that you drop it into an Azure Queue and have a Worker Role do the INSERTing later so you can stay loosely-coupled. Just in case you need a refresher on a REST-based Web.config file, here’s one below:
<?xml version=”1.0″?>
<configuration>
<!– To collect diagnostic traces, uncomment the section below.
To persist the traces to storage, update the DiagnosticsConnectionString setting with your storage credentials.
To avoid performance degradation, remember to disable tracing on production deployments.
<system.diagnostics>
<sharedListeners>
<add name=”AzureLocalStorage” type=”DataSync.AzureLocalStorageTraceListener, DataSync”/>
</sharedListeners>
<sources>
<source name=”System.ServiceModel” switchValue=”Verbose, ActivityTracing”>
<listeners>
<add name=”AzureLocalStorage”/>
</listeners>
</source>
<source name=”System.ServiceModel.MessageLogging” switchValue=”Verbose”>
<listeners>
<add name=”AzureLocalStorage”/>
</listeners>
</source>
</sources>
</system.diagnostics> –>
<system.diagnostics>
<trace>
<listeners>
<add type=”Microsoft.WindowsAzure.Diagnostics.DiagnosticMonitorTraceListener, Microsoft.WindowsAzure.Diagnostics, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35″
name=”AzureDiagnostics”>
<filter type=”" />
</add>
</listeners>
</trace>
</system.diagnostics>
<system.web>
<compilation debug=”true” targetFramework=”4.0″ /></system.web>
<!–Add Connection Strings–>
<connectionStrings></connectionStrings>
<system.serviceModel>
<behaviors>
<serviceBehaviors>
<behavior>
<!– To avoid disclosing metadata information, set the value below to false and remove the metadata endpoint above before deployment –>
<serviceMetadata httpGetEnabled=”true”/>
<!– To receive exception details in faults for debugging purposes, set the value below to true. Set to false before deployment to avoid disclosing exception information –>
<serviceDebug includeExceptionDetailInFaults=”false”/>
</behavior>
</serviceBehaviors><!–Add REST Endpoint Behavior–>
<endpointBehaviors>
<behavior name=”REST”>
<webHttp />
</behavior>
</endpointBehaviors></behaviors>
<!–Add Service with webHttpBinding–>
<services>
<service name=”DataSync.SubService”>
<endpoint address=”" behaviorConfiguration=”REST” binding=”webHttpBinding”
contract=”DataSync.ISubService” />
</service>
</services><serviceHostingEnvironment aspNetCompatibilityEnabled=”true” multipleSiteBindingsEnabled=”true” />
<!–<serviceHostingEnvironment multipleSiteBindingsEnabled=”true” />–>
</system.serviceModel>
<system.webServer>
<modules runAllManagedModulesForAllRequests=”true”/>
</system.webServer>
</configuration>This Web.Config gives you the webHttpBinding you’re looking for to do a REST service. I even left you a spot to add your own database or Azure storage connection strings.
This article wraps up the Windows Phone 7 Line of Business App Dev series that I’ve been delivering to you since last September. Who knew I would make fun of OData or have you create your own NoSQL database to run on your phone along the way? I think I actually wrote the first article in this series from a hotel room in Nantes, France.
But have no fear, this isn’t the end.
In preparation for Tech Ed 2010 North America coming up on May 16th in Atlanta, I’ve been building the next-gen, super-fast, super-scalable Azure architecture designed for mobile devices roaming on wireless data networks. I’ve spent the last decade building the world’s largest and most scalable mobile infrastructures for Microsoft’s wonderful global customers. Now it’s time to make the jump from supporting enterprise-level scalability to the much bigger consumer-level scalability.
Yes, I’m talking millions of devices.
No, you won’t have to recreate Facebook’s servers, NoSQL, Memcache, or Hadoop infrastructure to make it happen. I’m going to show you how to make it happen with Azure in just two weeks so I’m looking forward to seeing everyone in Atlanta in two weeks.

• Marcelo Lopez Ruiz described a Must-have resource for Azure developers in a 5/3/2011 post:
Lately I've been looking into writing Azure applications. I already know the .NET platform, so it's a very familiar development experience for me: all the libraries I know and love are there.
There are two aspects however that are new to me.
- The first is how to build systems that can scale up and be always on. There is a lot of support from Windows Azure in terms of runtime environment, libraries and services, and I think I've got a fair grip on them, but I'm still building the muscle of thinking about building highly scalable, highly reliable systems.
- The second is how to engineer the development environment and runtime operations. In other words, how to set up my environment correctly, design things to be able to run unit tests quickly and with flexibility, and how to maintain enough information flowing and stored in the system to be able to keep the thing going when it's deployed. It turns out that building in flexiblity and diagnostics can help in both cases.
If you're in a similar situation as I am, I can't recomment the Windows Azure How-To Index enough. It's a densely packed page with lots of information to get you going with practical tasks, and it's refreshed quite frequently.
The Windows Azure Team posted a Real World Example of Cloud Elasticity With Windows Azure on 5/6/2011:
One of the promises of Windows Azure and cloud computing in general is the ability to quickly and easily expand and contract computing resources based on demand. Microsoft Cloud Architect Bart Robertson shares a great real-world example of how this feature works in a new blog post, “Cloud Elasticity – A Real-World Example” that’s worth a read if you’re interested in learning more about Windows Azure and elasticity.
In this case, Robertson explains, the web traffic spikes were due to ads, which typically ran for a day or two. Compared to March’s average daily traffic, SXP’s traffic spiked to over 700%. Traditionally, the only way to handle such spikes was to over-purchase capacity in advance of the ads running, but the SXP team decided instead to double their Windows Azure compute capacity to ensure they could handle the load.
They went from 3 servers to 6 servers on their web tier within an hour of making the decision. The total human time to accomplish this was a couple of minutes and a change to one value in an XML file - Windows Azure took care of the rest. Within half an hour, they validated via the logs they had doubled our capacity and all web servers were taking traffic. Full-retail cost for the burst capacity was $70 plus about 5 minutes of operations time.
It’s a great real-world example of how Windows Azure can seamlessly and cost-effectively enable elasticity; click here to read Bart’s post and learn more about this story. To learn more about SXP's experience using Windows Azure, read the related post, "Windows Azure and Microsoft SXP Serve Up to Two Million Media Rich Experiences Daily on Microsoft Showcase."
Yves Goeleven (@yvesgoeleven) started a Building Global Web Applications With the Windows Azure Platform – Introduction blog series on 5/5/2011:
I don’t know if you noticed, probably not, but I’ve put some content again on http://www.goeleven.com. This content will serve as a starting point to a new series that I’m writing. In this series I will discuss, step by step, what it takes to build global, highly scalable, highly available, high density and cheap web applications with the windows azure platform.
The general idea behind this series is to build on top of this basic sample, with more functionality and more windows azure features, and try out how the application will behave in the real world, in terms of performance, scalability, availability and so on. In order to achieve this we need to be able to simulate some real life load on our application, so I signed up at http://loadimpact.com which allows me to setup load tests with up to 5000 simulated users.
In a very first test I will ramp up to 50 concurrent users and see if this miniature application can handle it. 50 concurrent users means about a 1000 visits per hour (given that the average stay time is about 3 minutes), or 24000 visitors per day, this should definitly do for my simple site at this stage…
Note: If you want to derive the average number of concurrent users currently on your site, you can use the following formula: concurrent_users = (hourly_visits * time_on_site_in_seconds) / 3600
Now let’s have a look at the results:
As you can see, the site survived the onslaught, albeit barely. There is a significant decline in performance when the number of concurrent users increases over 30, and an almost 300% increase in response time once we reach 50 concurrent users. I’m quite sure the site would actually break down if we increased the numbers only a bit more.
Breaking down is a subjective concept on the web, it does not mean that the webserver actually crashes, it means that the users go away from the page they were intending to visit. This graph shows the average load times for all of the users. Average really means that 50% of the requests took more than the amount of time displayed in the graph. Personally I consider a site broken if it’s requests take more than 3 seconds to load on average, which means 50% of it’s users had to wait more than 3 seconds before they got a response (which they won’t do anymore).
So what can we do to handle this problem? How can we serve more people? We either scale up or scale out, right?
If this is your first reaction, you didn’t get the utility model yet…
Utilities, like windows azure, are all about optimal use of capacity. Windows azure roles offer an array of different kinds of capacity (compute, memory, bandwidth) and I bet that not all of these are optimally used yet and only one of them is the bottleneck…
Next time we will look into this capacity topic a bit further and see how we can get some more juice out of this instance without having to pay a lot more…
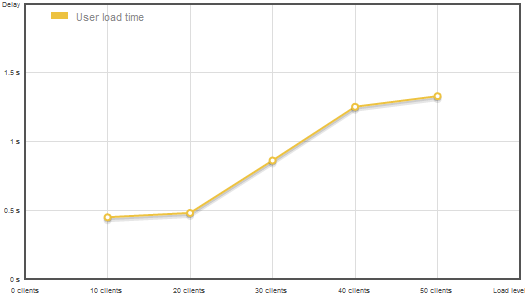
Vishwas Lele (@vlele) described SharePoint and Azure Integration Opportunities in a 5/5/2011 post:
There is a lot of talk about the use of SharePoint, and other Office products, in the upcoming cloud offering Office365. Office 365 is SaaS (Software as a Service) style of cloud computing wherein one can subscribe and use the SharePoint functionality without worrying about the underlying hardware and software infrastructure. The entire underlying infrastructure is owned, built and administered by Microsoft. In addition, the continued management of the infrastructure – including application of patches, upgrades, backups and recovery operations, etc. – is also Microsoft’s responsibility. Subscribers pay one fixed monthly amount for Office 365’s services. Microsoft is able to offer a reasonable price point for a monthly subscription because Office365 is based on a shared, multi-tenant infrastructure. Of course, while the software and hardware is shared, data belonging to each subscriber is appropriately sequestered
While a multitenant offering built on a shared infrastructure can be a cost effective option, there are scenarios where it may not completely meet the needs. Here are some examples:
- Regulatory Compliance: A specific regulatory or compliance requirement may prohibit hosting documents in a shared or public cloud environment. (For example, Canadian privacy laws may restrict data that can be stored in a cloud data center located outside Canada). SharePoint Customization: Since the underlying infrastructure is shared across all subscribers, there is limited flexibility in installing custom modules. Customizations are generated limited to the constraints imposed by SharePoint sandbox solutions (Sandbox solutions run in a separate process and can only access a limited subset of the SharePoint OM).
One possible alternative to the above limitations is to obtain a dedicated SharePoint instance in the cloud. This is possible in two ways today: i) For customers with a user base of 5000 of more users can take advantage of the dedicated level of service wherein the hardware is dedicated for the customer ii) For U.S. government organizations, Microsoft offers BPOS Federal, in which all data is stored in a secure facility dedicated to the customer. It is interesting to note that BPOS-Federal just achieved the FISMA (Federal Information Security Management Act) certification and accreditation.
- Other Platform Releases: There may be a need to run a previous version of SharePoint, such as Sharepoint 2007, and Office365 is based on SharePoint 2010. Conversely, there may be a need to tap into the functionality offered by a newer release of the .Net framework beyond the version that SharePoint is based on today (for instance, Windows Workflow 4.0).
The key points above represent dilemmas that customers face today. As shown in the diagram below, while SharePoint as a Service via Office365.com provides benefits such as lower costs and elasticity of resources, the flexibility to customize is limited, and there are potential compliance concerns. On the other hand, while setting up SharePoint on-premise addresses these issues , it also comes with the added responsibility of configuring and managing the underlying infrastructure.
i) On-premise installations can scale out easily by relying on the virtually infinite storage and computing resources available on the Windows Azure platform. The key benefit, of course, is that massive scalability is available without undertaking a huge capital investment upfront. Instead, customers are able to dynamically scale up and down while only paying for what they use.
ii) Online installations can take advantage of the Windows Azure platform to run customizations. For instance, a custom-built workflow may be hosted within a Windows Azure role. Since the workflow is hosted on Windows Azure, there is minimal administrative overhead for ensuring that the workflow is up and running, OS patches are applied etc.
To better understand this concept let us briefly look at a few scenarios:
Scenario #1: Connecting to Cloud-based databases
This scenario is about leveraging SQL Azure-based databases within an on-premise SharePoint instance. SQL Azure is a database-as-a-service offering that is part of Windows Azure. It makes it easy to provision any number of databases that are easy to administer and come bundled with a highly availability setup.
As depicted in the diagram below, Business Connectivity Services (BCS) can be used to connect data contained within a SQL Azure database to an external list in SharePoint. You can choose to connect to the SQL Azure instance directly or via a Web or Worker role.
For detailed steps on connecting to SQL Azure using BCS please refer to this toolkit.
Scenario #2: Taking advantage of the data marketplace
This scenario is about leveraging the Windows Azure DataMarket to author SharePoint-based dashboards and mashups. The Windows Azure DataMarket provides a marketplace for data where content publishers can make their datasets available to consumers. This includes datasets such as Health and Wellness data, location-based services, demographics, etc. All of the data available on DataMarket is curated and highly available. It is also consumable via a consistent set of REST-based ODATA APIs. This makes it possible to consume the DataMarket data via PowerPivot add-in in Excel. Once an Excel workbook containing PowerPivot data has been authored, it can then be published to SharePoint. This allows SharePoint users to view and collaborate around the Power Pivot application. For a brief demo of PowerPivot with a Windows Azure DataMarket datasource, please refer to this brief video I recorded a while back.
Scenario #3: Scalable routing of notifications
This scenario is about leveraging the Windows Azure-based infrastructure to route SharePoint notifications. The Windows Azure AppFabric Service Bus provides an infrastructure for large-scale event distribution. As shown in the diagram below, SharePoint notification such as the item added events (for instance adding a new announcement to a list) can be routed over the Windows Azure App Fabric Service Bus to a large number of listeners.
For detailed discussion on building custom SharePoint Service Application that can act as conduit to the Windows Azure AppFabric Service Bus, please refer to my earlier blog post.
Scenario #4: Dynamic Scaling
This scenario is about leveraging the elastic computational resources available on the Windows Azure platform. Windows Azure VM role allows customers to bring their own pre-created OS image to the cloud. Recently, as a proof of concept, we hosted an Excel Services instance via the VM Role. As shown in the diagram below, the benefit of such an approach is that number of VM role instances can be dynamically changed based on the load. This means that the customer doesn’t need to have a large setup on-premise to handle expected and un-expected peaks. Instead, they can “burst out” to the cloud
For more information on setting up Excel Services in VM role please refer to a blog post by Harin Sandhoo from AIS.
Before I close, I would like to refer the readers to Steve Fox’s blog. Steve Fox has been a thought leader on this topic of integrating Windows Azure with SharePoint.





The Windows Azure Team posted The Appleton Compassion Project on Windows Azure Teaches the Art of Compassion to Local Students on 5/4/2011:
How would you depict the idea ‘compassion’ on a piece of canvas? To see how local art students would respond to that question, the Trout Museum of Art, in partnership with the Appleton, WI Area School District and the Appleton Education Foundation, last year announced The Appleton Compassion Project. The project organizers asked 10,436 Appleton Area School District K-12 art students to draw or paint their idea of compassion on a 6-inch-by-6-inch art panel, along with a written statement about their work.
To help museum and virtual visitors view the artwork, Appleton-based Skyline Technologies built a viewer on Windows Azure to enable visitors to search for art by student name, grade, school, teacher or art teacher, as well as provide a manageable way look at selected pieces from the larger exhibit.
The inspiration behind the project came from Richard Davidson, PhD, a University of Wisconsin-Madison brain researcher who has found that those who practice compassion have measurably healthier brains. Davidson’s research also shows that compassion can be learned, and should be practiced, as a skill. “A little more joy might be within everyone’s reach,” says Davidson.
* The virtual exhibit page requires Silverlight to be installed on your computer. You can install Silverlight here or it will install automatically the first time you visit the page. Please be patient, it may take several minutes to load.
Bruno Aziza interviewed Joannes Vermorel on 5/4/2011 in a 00:10:07 Forecasting Sales In The Cloud Business Intelligence TV video segment on You Tube:
The Windows Azure Team described how Windows Azure Helps Microsoft Groups Deliver Flexibility, Value, and Competitive Advantages for Consumers, Enterprises, and Partners in a 5/3/2011 post:
Many groups at Microsoft—from product and service groups to partner support programs—are taking advantage of the Windows Azure platform to develop and host their own applications and services. Here are summaries of how the Microsoft Live@edu team, the Microsoft Office Product Development Group, and the Microsoft Partner Network used Windows Azure to promote and enhance Microsoft solutions and help support consumers, enterprise customers, educational institutions, and Microsoft technology partners.
Microsoft Live@edu: Help Educational Institutions Introduce and Promote New Services
Microsoft Live@edu services helps educational institutions provide more than 15 million students worldwide with free* hosted email, communication, and collaboration services. Schools use Live@edu to connect students to Microsoft Outlook Live and Microsoft Office Web Apps—online versions of Microsoft Word, Excel, PowerPoint, and OneNote.
Institutions that adopt Live@edu need to promote the service to students, staff, and alumni, so the Microsoft Live@edu team used Windows Azure to package and host the Live@edu “Promote on Campus” online tool. The tool uses Microsoft SQL Azure to store localized file information and Windows Azure Storage to house promotional materials. With Promote on Campus, educational institutions can easily download customizable marketing materials and kits they can use to introduce Live@edu, and help students activate and make the most of their accounts.
The Promote on Campus page is localized in 16 languages and available in 130 countries. It includes nearly 2,000 pieces of marketing content and offers features such as content filtering and high-fidelity preview images to enhance usability. In the three months after Promote on Campus was launched, schools used the tool to download material more than 1,000 times, and visits to the “Promote” page on the Live@edu website increased 63 percent over the previous year.
With Windows Azure, Live@edu is helping schools quickly and inexpensively promote their Live@edu services so they can successfully drive adoption and usage of tools that students can use to create, edit, and share work, while developing the skills they will need in their future careers.
Office POSA: Introduce More Choice and Flexibility for Consumers
The Microsoft Office Product Development Group wanted to provide consumers with more choice and flexibility in how they purchase Microsoft Office 2010 and other Microsoft solutions. Microsoft worked with PC manufacturers and retail outlets to introduce point of sale activation (POSA) Product Key Cards that consumers can buy and use to download versions of Office 2010 over the Internet or activate Office 2010 software that has been preloaded onto new PCs.
The POSA card is activated with the purchase value and the consumer can then use the card to unlock Office Home and Student 2010, Office Home and Business 2010, or Office Professional 2010 on their new PC. To build and host a web page where consumers can validate their POSA card and retrieve a Product Key that they can use to activate and register their software, the Office Product Development Group used the Digital Distribution Services engineered and operated by the Manufacturing and Supply Chain Information Solutions (MSCIS) group. The MSCIS Digital Distribution Services are powered with Windows Azure and Microsoft SQL Azure.
The team used the MSCIS Digital Distribution Services to power additional Windows Azure portals that validate Product Key Cards for Microsoft Office 2010 for Mac and Windows Anytime Upgrade. The Product Key Card sites have provided service for more than 100,000 users. By delivering software with POSA Product Key Cards and online validation, Microsoft offers consumers a fast, simple way to purchase and install Microsoft solutions on new PCs, uses fewer resources for packaging and media, and reduces overhead costs for both itself and its retail partners.
Microsoft Platform Ready: Help ISVs, Microsoft Partners, and Other Developers Plan and Build Applications That are Compatible with Microsoft Technologies
The Microsoft Partner Network wanted to make it easier for independent software vendors (ISVs), solutions integrators, and developers to plan and build software, web, and mobile applications that are compatible with the latest Microsoft platform technologies. So the Microsoft Partner Network launched the Microsoft Platform Ready web portal that provides training, development, testing and marketing resources for Microsoft partners and all application developers. Microsoft Platform Ready resources are available to the public and there are no costs to join or to use the service.
Microsoft Platform Ready is built on and powered by Windows Azure and the Microsoft SQL Azure database management service. The website team integrated Live ID in the Windows Azure environment to authenticate users by connecting the logon process to the Microsoft Partner Network databases. The global site supports 17 languages and includes features such as automatic email reminders for participants in Microsoft Platform Ready programs.
Over 23,000 companies worldwide have registered and profiled applications on the website, and Microsoft Platform Ready receives an average of 28,000 visitors every month. By avoiding the cost of supporting the website with an on-premises infrastructure, the Microsoft Partner Network could invest more funds in marketing the Microsoft Platform Ready program. The website helps ISVs and other application developers streamline their development processes and accelerate their time-to-market, while providing a successful example for Microsoft partners who want to begin building applications with the Windows Azure platform.
For information about how other groups at Microsoft are using the Windows Azure platform to enhance services and respond to the business needs of their customers, visit:
* Access to and use of the Internet may require payment of a separate fee to an Internet service provider. Local and/or long-distance telephone charges may apply.
Avkash Chauhan described Microsoft Platform Ready Certification for Windows Azure Application Part 2 - Using Microsoft Platform Ready Test Tool in a 5/3/2011 post:
Previous [see below]: Microsoft Platform Ready Certification for Windows Azure Application Part 1 - Application Submission and Microsoft Platform Ready Test Tool Download & Installation
In the above windows please select "Start New Test":
In the above window, please enter the test name suitable for your application, and also choose appropriate "Microsoft Platforms and Technologies" with regard to your application. After it select "Next":
Now in the above windows Click on "Edit" Link to enter the application related credentials as below:
Once above data is completed, click Close. You will be back to previous windows however you will have status "Pass" as below:
Once you will select "Next" and follow the dialog details:
Once you selected "Next" above you will see that the test execution has been completed. In this screen you will also need to accept that you have manually tested your Windows Azure application for primary functionalities.
Once you confirm the checkbox and then select "Next", you will see test results as "pass" if there are no issues and at this windows, you can see the test report as well.
Select "Next" to almost finish the test and view the test reports:
Now to view the reports, please select "Reports" button above you will see the test results as below:
Note: Please contact mprsupport@microsoft.com for questions about the program, about the certification, or about the tool itself.











As reported in the preceding OakLeaf post, I went through this process a few months ago to earn the Powered By Window Azure logo for my OakLeaf Systems Azure Table Services Sample Project - Paging and Batch Updates Demo.
Avkash Chauhan posted Microsoft Platform Ready Certification for Windows Azure Application Part 1 - Application Submission and Microsoft Platform Ready Test Tool Download & Installation on 5/3/2011:
Microsoft Platform Ready (MPR) is designed to give you what you need to plan, build, test and take your solution to market. We’ve brought a range of platform development tools together in one place, including technical, support and marketing resources, as well as exclusive offers. Please visit Microsoft Platform Ready site and signup your application using Windows Live Account:
Once your application is signed up it will be listed as below:
Please be sure to setup appropriate “Microsoft Platform” used by your application as below, you can do that by editing the application properties later or setup correctly when you registered your application:
Once your application is selected in proper Microsoft Platform category it will listed as below and a download link to the test tool will be made available:
Once you click “Download tool” above you will get download link to “Microsoft Platform Ready Test Tool x86.msi” as below:
Download and Install - Microsoft Platform Ready Test Tool x86.msi properly.
Once Application is installed in your machine it is time to run the Microsoft Platform Ready test.
Note: Please contact mprsupport@microsoft.com for questions about the program, about the certification, or about the tool itself.






<Return to section navigation list>
Visual Studio LightSwitch
• Beth Massi (@bethmassi) reported on 5/6/2011 the availability of a 1:15:54 Channel9 Video: Introducing Visual Studio LightSwitch from her DevDays Netherlands session:
Last week I spoke at DevDays in the Netherlands and what a fun show! They just posted my session Introduction to Visual Studio LightSwitch on Channel 9 so check it out when you have a chance, I think it went really well. The room was about 500 people so there was a lot of interest from professional developers at the conference in LightSwitch.
I’ll write up a full recap of all my sessions (along with the promised code samples and resources!) soon but for now enjoy the Beth Massi show. :-)
Watch: Introduction to Visual Studio LightSwitch
(Tip, download the the High Quality WMV if you can, it’s a lot smoother)
Beth’s Visual Studio LightSwitch - Beyond the Basics is another 1:13:42 Channel9 video from DevDays Netherlands:
You’ll see how to extend LightSwitch applications with your own Silverlight custom controls and RIA services
• Michael Washington (@adefwebserver) described The Three Concepts of LightSwitch in a 3/6/2011 post to his Visual Studio LightSwitch Help blog:
I was surprised when I was chosen to present at Visual Studio Live in Las Vegas early this year. I had sent in 3 proposed topics months before, and the one chosen was Advanced LightSwitch Programming. After being informed of my selection to speak at the conference, I sat down to create the presentation and ran into a huge problem. There is just too much to cover about advanced LightSwitch programming to cram into 75 minutes.
These are presented in order of importance.
Concept #1 - LightSwitch requires you to only write the code that only you can write
Examples of the concept:
- A calculated field that shows the course and the teacher for the enrollment
- Validation to prevent an Enrollment from starting before the Section it belongs to starts
- Pre-process query to only show a teacher their classes when taking attendance
What it means:
- If there is no way for LightSwitch to figure this out it’s self, then yes you must write the code, but if it can (for example if the Order table is related to the Customer table, it will know the Orders for the Customer), then there is usually a non-code way for you to achieve the objective.
Let’s ignore the Concept:
- You will become frustrated trying to write code to explicitly update the sample calculated value, when a user updates the enrollment to assign it to another Teacher.
How to obey the concept:
- When you wire up a method you will be asked a question (for example, return a bool or return a result). “Just answer the question”
- Yes you can go off and perhaps call a web service to query an external system for the students StateID number, but if you find yourself creating records and updating records when the question was “tell me what you want displayed for this field”, you are fighting the concept
- Try this “thought process”
- First look to see if I should click on a field in a table and write some code?
- Next, look to see if I should click on the table and write some code?
- Next, should I create a Query and write some code? (for example, only allow teachers to see students enrolled in their class) Can I use a PreProcess query?
- Next, should I create an external data source that will help?
- Only last, should I add a button to a screen and write some code.
Concept #2 - When creating a Silverlight Custom Control, you only create custom UI, LightSwitch still handles everything else
Examples of the concept:
- Creating an School Attendance control that uses radio buttons to allow the user to take attendance (LightSwitch does not provide a mechanism for using radio buttons without making a Silverlight Custom Control).
What it means:
- We are not dropping into our own custom Attendance Module. The code that will process the Attendance will still be written inside the LightSwitch framework according to the LightSwitch rules.
Let’s ignore the Concept:
- You really can’t. LightSwitch enforces the MVVM design and then only allows you to insert a custom Silverlight control on the “V”
How to obey the concept:
- If LightSwitch will allow you to do it, then you’re not doing anything wrong
Concept #3 - Even when you implement advanced code, stay within the Framework
Examples of the concept:
- Creating an in-memory record so the Attendance form shows a record for each student enrolled that day
What it means:
- Even though we are creating in-memory records, we still are only filling the normal collection the screen is bound to
Let’s ignore the Concept:
- We could try to bypass the normal collection and manually bind to the controls on the LightSwitch screen
How to obey the concept:
- Try to only do one thing when implementing custom code in a LightSwitch method.
• Michael Washington (@adefwebserver) asserted LightSwitch: 10 Times As Many Silverlight Developers As Today in a 5/4/2011 post to the OpenLightGroup blog:
The number one problem is the “you’re not doing it right”. This scares people away, who needs the fighting? MVVM is very time consuming, and confusing. I have watched developers spend hours trying to learn how to fill a drop down properly. You may say “well these developers are lame”. Perhaps, but, the Silverlight adoption among developers is low.
Get Ready For A Flood Of Silverlight Programmers
With all the negativity of the preceding paragraph, why do I now feel that the number of Silverlight programmers will explode?
LightSwitch IS Silverlight.
My presentation was on LightSwitch for the professional programmer. As I demonstrated the LightSwitch projects covered in my LightSwitch Student Information System project, I challenged the audience to “voice your concerns, your fears, your criticism… bring it on!”. I received questions like:
- “I want to make a UI like the airline web sites, where the calendar control blocks out certain dates” (fine, create a Silverlight Custom Control)
- “I need the drop down to be complex and display pictures with dynamic text” (fine, create a Silverlight Custom Control)
- “I need a wizard that walks the user through a process” (fine, create a Silverlight Custom Control)
The answer to most questions was to create a Silverlight Custom Control. A large number of LightSwitch programmers, means there will now be a large number of Silverlight programmers. LightSwitch uses MVVM,however, it gives you easy to use tools to create the “M” (Model) , and the “VM” (View Model). You only need to create the “V” (View) manually, using Silverlight Custom Controls.
LightSwitch Is Inclusive
I recently looked at my speaking engagements over the past few years, and I have presented about so many Silverlight applications and techniques I have learned, however, I know that the majority of the attendees did not fully understand, and 95% never tried any of it themselves.
However, at my presentation tonight I could tell that everyone in the room, FULLY, understood and followed my presentation. I fully expect that a year from now, 95% will have used LightSwitch for at least one project.
I challenged the audience to “use LightSwitch for that project that you would otherwise not do”. Sometimes I feel we programmers are like doctors who wont fix that cleft lip on a child because any operation will cost at least $10,000. A simple web page that gathers data into a single database table can take a programmer a day to code, test, and deploy. If the application has any business rules, it could take days. If you don’t have $3-4k don’t even bother asking for any help from a professional programmer.
People matter, and their work matters. As programmers we should help, but time is money, and if the project is going to take 30 hours, I need someone to come up with $3,000. However, with LightSwitch I can do the project in 2 hours.
LightSwitch IS Silverlight
LightSwitch is powerful, but it is easy to use and understand. Most importantly, it is blazingly fast to develop an application with it. Time is money, and it can cut the time by 80%+. LightSwitch is here to stay and it’s adoption is going to be big. However, to have it display the user interface exactly how you desire, you will want to make Silverlight Custom Controls.
Yes, now, you’re using Silverlight. Good old fashion 100% Silverlight. Congratulations, you’re now a “Silverlight Programmer”… I am glad you made it.
• Richard Waddell posted Creating a Relationship on the UserRegistrations Table to the Visual Studio LightSwitch Help blog on 5/5/2011:
Often we don’t care who the logged-in User is because we can control what they can do through Roles and Permissions. But if the User is a member of some group, it would be handy to place the Users table in a many-to-one relationship with that group. In this example the groups are SalesTeams made up of SalesPersons. All Sales made by a particular team are accessible only by members of that team.
Start by adding a SalesTeam entity:
A SalesTeam is composed of SalesPersons:
We’re going to associate each SalesPerson with a User. Let’s make sure we’re agreed on what I mean by ‘User’. Under Solution Explorer / Properties / Access Control select ‘User Forms authentication’ and check ‘Granted for debug’ next to SecurityAdministration.
Press F5 to run the application, expand the Administration menu, and click on ‘Users’.
As you can see, there are no Users defined. In the lower-right corner we see that we are logged in as the special user TestUser by virtue of running under Visual Studio. If this were a deployed application it would prompt for user and password on startup. Instead we are automatically logged-in for convenience during development. The upshot is that in a deployed application the current User, which can be determined through Application.Current.User.Name, will always be one of the Users you see on the Administration/Users page shown above. Under Visual Studio it will always be TestUser, which isn’t necessarily one of the Users you see above.
First of all, we need a property to bind User to SalesPerson. As I said, User.Name is actually UserRegistration.UserName, so we’ll add a UserName property to SalesPerson. We can use the Name property for the person’s actual name.
Before we can add SalesPersons we need SalesTeams. Add a SalesTeam Editable Grid Screen:
Add some SalesTeams:
Save them and create a SalesPerson Editable Grid Screen where we find we can select the Sales Team when we create a Sales Person:
The point of SalesPersons.UserName is to map to UserRegistration.UserName so at run time we can tell which SalesPerson we are dealing with by matching Application.User.Name to SalesPerson.UserName. This in effect gives us the ability to create relationships between User and other tables; In this case a many-to-one relationship to SalesTeam. You could also create one-to-many relationships, such as a scenario where a SalesPerson got an individualized commission on each Sale made by the team requiring a one-to-many relationship between SalesPerson and Commissions.
When we create a new SalesPerson…
…if necessary we also create a new UserRegistration. We don’t want to deal with passwords, so we set it to some default value the user should change the first time they log on:
namespace LightSwitchApplication{public partial class ApplicationDataService{partial void SalesPersons_Inserting(SalesPerson entity){var reg = (from regs in this.DataWorkspace.SecurityData.UserRegistrationswhere regs.UserName == entity.UserNameselect regs).FirstOrDefault();if (reg == null){var newUser = this.DataWorkspace.SecurityData.UserRegistrations.AddNew();newUser.UserName = entity.UserName;newUser.FullName = entity.Name;newUser.Password = "changeme/123";this.DataWorkspace.SecurityData.SaveChanges();}}}}If we now go to Administration/Users we find the new User there.
When launched from Visual Studio, the logged-on user is always TestUser, so we’ll create add a SalesPerson to Red Team with that UserName.
Now we need something to test. The point of belonging to a SalesTeam is that you have access to whatever the SalesTeam has access to. So we’ll create a Sale entity with a many-to-one relationship to SalesTeam.
Create an Editable Grid Screen for Sales and add some:
Now you can see I’ve added Sales for both teams. For obvious reasons, team members would not be allowed access to this screen. So we’ll add another Editable Grid Screen and filter it by the SalesTeam of the logged-in User. There’s a couple of ways we could do this. We could go ahead and create the screen and then modify the query, but I’m going to go ahead and create the query and then generate a screen based on the query.
Right-Click the Sales Data Source and select Add Query.
And there are a couple of ways to write the query to restrict Sales to only those belonging to the same SalesTeam as the logged-on SalesPerson / User.
- A ‘pre-process’ query that runs before the query we’re modifying
- A Global Variable that we can add as a filter.
The Pre-Process Query
To add the pre-process query,
In the query we find the SalesPerson associated with the logged on User. This gives us the SalesTeam and thereby a means to select only Sales linked to the same SalesTeam as the SalesPerson / User.:
partial void UserSalesTeamSales_PreprocessQuery(ref IQueryable<Sale> query){SalesPerson person = (from persons in this.DataWorkspace.ApplicationData.SalesPersonswhere persons.UserName == Application.Current.User.Nameselect persons).FirstOrDefault();int salesTeamId = person == null ? -1 : person.SalesTeam.Id;query = from theSales in querywhere theSales.SalesTeam.Id == salesTeamIdselect theSales;}Now we create the screen:
The first thing I see is that when logged-in as TestUser I can only see Red Team Sales:
If I go to the Editable Sales Persons Grid I find that TestUser should be restricted to Red Team sales. So far so good:
If I change the Sales Team to Blue Team, click Save, go back to Editable User Sales Team Sales Grid and click Refresh:
I find that TestUser now is restricted to Blue Team Sales.
The Global Variable Query Parameter
The scary thing about creating a Global Variable is that you have to modify an lsml file, which can disable the designer and lead to strange error messages if mishandled, so we have to proceed with care. First, switch to file view:
We’re going to edit Common/ ApplicationDefinition.lsml. You may want to back up the file first.
You may get a Catastrophic failure when you try to edit this file. I discovered that if I first opened this one under data, then closed it I was able to edit the one under Common. If you look at properties you’ll find they both map to the same file, the one under data.
Insert the following GlobalValueContainerDefinition element after the initial ModelFragment element tag as shown below:
<ModelFragment xmlns="http://schemas.microsoft.com/LightSwitch/2010/xaml/model"xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"><GlobalValueContainerDefinition Name="GlobalSalesTeamInfo"><GlobalValueDefinition Name="UserSalesTeamId" ReturnType=":Int32"><GlobalValueDefinition.Attributes><DisplayName Value="User SalesTeam ID" /><Description Value ="Gets the logged on User's SalesTeam ID." /></GlobalValueDefinition.Attributes></GlobalValueDefinition></GlobalValueContainerDefinition>Now you have to provide the code behind the variable. Create a new class in the Common folder named GlobalSalesTeamInfo. When created there will be a bunch of using statements at the top that show errors. Replace everything with this:
using System;using System.Collections.Generic;using System.Linq;using System.Text;using Microsoft.LightSwitch;namespace LightSwitchApplication{public class GlobalSalesTeamInfo{public static int UserSalesTeamId(){SalesPerson person = (from persons in Application.Current.CreateDataWorkspace().ApplicationData.SalesPersonswhere persons.UserName == Application.Current.User.Nameselect persons).FirstOrDefault();return person != null ? person.SalesTeam.Id : -1;}}}Now we need to switch to logical view so we can modify the query to use this new variable. But when we do the designer will throw a hissy and tell you that you must reload. Once upon a time you could right-click in Solution Explorer and reload from there. Now, if you’re lucky, BindingToUsersTable Designer will be in a tab at the top. Click on that tab and you’ll get a page with a Reload button. If you can’t get to that tab the only other way I know is to reload the solution. In other words, you need for the screen designer to be open in a tab when you edit the .lsml file. That way, when you need to reload, the tab will be there to select. In my experience once you change the .lsml file the Solution Explorer is hosed as far as the logical view, so you can’t get to the designer. Actually I didn’t think of the View menu. Anyway, don’t panic when you start getting all the incomprehensible messages. At best you have to exit and restart. At worst you have to exit, restore the .lsml file, and restart.
Back in logical view, open the UserSalesTeamSales query:
We can now filter on User Sales Team ID. (LightSwitch insists on breaking the name up into words).
Get rid of the pre-process query:
//partial void UserSalesTeamSales_PreprocessQuery(ref IQueryable<Sale> query)//{// SalesPerson person = (from persons in this.DataWorkspace.ApplicationData.SalesPersons// where persons.UserName == Application.Current.User.Name// select persons).FirstOrDefault();// int salesTeamId = person == null ? -1 : person.SalesTeam.Id;// query = from theSales in query// where theSales.SalesTeam.Id == salesTeamId// select theSales;//}And sure enough I get the same results when I switch TestUser’s team membership.
The advantage of the Global Variable approach is that it’s simpler to add the filter to each query that needs it, as you can see above, than it is to write a custom pre-process query for every query that needs to filter on SalesTeam membership as you can see in the now commented-out code immediately above.
Testing Other Users
To really test, we need to deploy the application so we can log in as different Users. When you do, you’ll find that all your Users and data have disappeared, so we’ll have to create new SalesTeams, SalesPersons, and Sales.
We’ll log in as a Blue Team Member:
And we only see Blue Team Sales:
Now we log in as a Red Team Member:
And we’re restricted to Red Team Sales:
So there you have it. In a less restricted application you’d want to make the Entity associated with User a little more generic, such as Person, so they could participate in a variety of scenarios but always be identifiable as an individual User. Which means a more succinct example would be a Global Variable that identifies the User/Person. Here I use the example of SalesPerson. I’ve added the UserSalesPersonID GlobalValueDefinition to ApplicationDefinition.lsml.
<GlobalValueContainerDefinition Name="GlobalSalesTeamInfo"><GlobalValueDefinition Name="UserSalesTeamId" ReturnType=":Int32"><GlobalValueDefinition.Attributes><DisplayName Value="User SalesTeam ID" /><Description Value ="Gets the logged on User's SalesTeam ID." /></GlobalValueDefinition.Attributes></GlobalValueDefinition><GlobalValueDefinition Name="UserSalesPersonId" ReturnType=":Int32"><GlobalValueDefinition.Attributes><DisplayName Value="User SalesPerson ID" /><Description Value ="Gets the logged on User's SalesPerson ID." /></GlobalValueDefinition.Attributes></GlobalValueDefinition></GlobalValueContainerDefinition>Visual Studio was particularly cranky about these changes. I had to reload the solution twice, once because I made a mistake and it wouldn’t recognize that I had fixed it. The second time I don’t know why. The change was what you see above and I could reload in the designer, but Logical View would not come up. After I reloaded the solution, there it was. So don’t assume you’ve made a mistake when Logical View won’t come up, even if you hit the designer reload button.
Here’s the code behind UserSalesPersonId. I’ve kept UserSalesTeamId because it’s still what I really need, but you can see that you could spin off Global Variables for every relationship that the logged-on user is involved from the one core method LoggedOnPerson() .
namespace LightSwitchApplication{public class GlobalSalesTeamInfo{public static int UserSalesPersonId(){SalesPerson person = LoggedOnPerson();return person != null ? person.Id : -1;}public static int UserSalesTeamId(){SalesPerson person = LoggedOnPerson();return person != null ? person.SalesTeam.Id : -1;}private static SalesPerson LoggedOnPerson(){return (from persons in Application.Current.CreateDataWorkspace().ApplicationData.SalesPersonswhere persons.UserName == Application.Current.User.Nameselect persons).FirstOrDefault();}}}




























• The LightSwitch Team posted source code for a Filter Control for Visual Studio LightSwitch to MSDN’s Source Code Library on 4/26/2011 (missed when posted):
Introduction
Getting Started
To install and use the extension in your LightSwitch applications, unzip the LightSwitchFilter zip file into your Visual Studio Projects directory (My Documents\Visual Studio 2010\Projects) and double-click on the LightSwitchFilter.vsix package located in the Binaries folder. You only need LightSwitch installed to use the Excel Importer.
In order to build the extension sample code, Visual Studio 2010 Professional, Service Pack 1, the Visual Studio SDK and LightSwitch are required. Unzip the LightSwitchFilter.zip file into your Visual Studio Projects directory (My Documents\Visual Studio 2010\Projects) and open the LightSwitchFilter.sln solution.
Building the Sample
To build the sample, make sure that the LightSwitchFilter solution is open and then use the Build | Build Solution menu command.
Running the Sample
To run the sample, navigate to the Vsix\Bin\Debug or the Vsix\Bin\Release folder. Double click the LightSwitchFilter.Vsix package. This will install the extension on your machine.
Create a new LightSwitch application. Double click on the Properties node underneath the application in Solution Explorer. Select Extensions and check off LightSwitch Utilities. This will enable the extension for your application.
Using the LightSwitch Filter
In your application, define the data you'd like to filter. For example, create a Table called Customer with a single String property called Name. Right click on the table in solution explorer and select Add Query. Name the query FilterCustomers. Add a single string parameter called FilterTerm.
Select the Write Code dropdown for the query and select PreprocessQuery. Add the following code to the method.
Edit Script
query = LightSwitchFilter.Server.FilterExtensions.Filter(query, FilterTerm, this.Application);query = LightSwitchFilter.Server.Filter(query, FilterTerm, Me.Application)Add a screen based on the query you've defined. Change the control type for the Customer Filter Term control to Advanced Filter Builder. Additionally, change the label position of the parameter to "None".
Run the application. The filter builder control should be displayed. Once you have defined the filter, the Go button will execute it against the server.
How it Works
The filter control will generate an XML representation of the designed filter. This is then passed to the query as a string. On the server, the query code will parse the XML and generate appropriate filter clauses.
For more information on how to develop your own extensions for the community please see the Extensibility Cookbook. And please ask questions in the LightSwitch Extensibility forum.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
• James Hamilton analyzed Open Compute UPS & Power Supply in a 5/4/2011 post:
This note looks at the Open Compute Project distributed Uninterruptable Power Supply (UPS) and server Power Supply Unit (PSU). This is the last in a series of notes looking at the Open Compute Project. Previous articles include:
The open compute uses a semi-distributed uninterruptable power supply (UPS) system. Most data centers use central UPS systems where large the UPS is part of the central power distribution system. In this design, the UPS is in the 480 3 phase part of the central power distribution system prior to the step down to 208VAC. Typical capacities range from 750kVA to 1,000kVA. An alternative approach is a distributed UPS like that used by a previous generation Google server design.
In a distributed UPS, each server has its own 12VDC battery to serve as backup power. This design has the advantage of being very reliable with the batter directly connected to the server 12V rail. Another important advantage is the small fault containment zone (small “blast radius”) where a UPS failure will only impact a single server. With a central UPS, a failure could drop the load on 100 racks of servers or more. But, there are some downsides of distributed UPS. The first is that batteries are stored with the servers. Batteries take up considerable space, can emit corrosive gasses, don’t operate well at high temperature, and require chargers and battery monitoring circuits. As much as I like aspects of the distributed UPS design, it’s hard to cost effectively and, consequently, is very uncommon.
The Open Compute UPS design is a semi-distributed approach where each UPS is on the floor with servers but rather than having 1 UPS per server (distributed UPS) or 1 UPS per order 100 racks (central UPS with roughly 4,000 servers), they have 1 UPS per 6 racks (180 servers).
In this design the battery rack is the central rack flanked by two triple racks of servers. Like the server racks, the UPS is delivered 480VAC 3 phase directly. At the top of the battery rack, they have control circuitry, circuit breakers, and rectifiers to charge the battery banks.
What’s somewhat unusual in the output stage of the UPS doesn’t include inverters to convert the direct current back to the alternating current required by a standard server PSU. Instead the UPS output is 48V direct current which is delivered directly to the three racks on either side of the UPS. This has the upside of avoiding the final invert stage which increases efficiency. There is a cost to avoiding converting back to AC. The most important downside is they need to effectively have two server power supplies where one accepts 277VAC and the other accepts 48VDC from the UPS. The second disadvantage is using 48V distribution is inefficient over longer distances due to conductor losses at high amperage.
The problem with power distribution efficiency is partially mitigated by keeping the UPS close to servers where the 6 racks its feeds are on either side of the UPS so the distances are actually quite short. And, since the UPS is only used during short periods of time between the start of a power failure and the generators taking over, the efficiency of distribution is actually not that important a factor. The second issue remains, each server power supply is effectively two independent PSUs.
The server PSU looks fairly conventional in that it’s a single box. But, included in the single box, is two independent PSUs and some control circuitry. This has the downside of forcing the use of a custom, non-commodity power supply. Lower volume components tend to cost more. However, the power supply is a small part of the cost of a server so this additional cost won’t have a substantially negative impact. And, it’s a nice, reliable design with a small fault containment zone which I really like.
The Open Compute UPS and power distribution system avoids one level of power conversion common in most data centers, delivers somewhat higher voltages (277VAC rather than 208VAC) close to the load, and has the advantage of a small fault zone.


David Linthicum (@DavidLinthicum) asserted “Although many companies start with private clouds, public clouds may be the best way to start your cloud computing journey” as a deck for his The case for public-first cloud computing post to InfoWorld’s Cloud Computing blog:
I've previously talked about the move to private cloud computing as corporate America's first-generation cloud attempt. After all, you control it completely, you don't have to worry about security, and you can laugh at all those cloud outages.
However, private clouds are very much like traditional computing: You have to purchase your own hardware and software, configure all elements, and pay employees to watch over it as they would a data center or any other IT infrastructure. Thus, the core benefit of cloud computing -- shared resources -- can be lost when creating and maintaining a private cloud.
Considering the relative costs and benefits of a private cloud, many enterprises start with public clouds instead. The reasons are obvious: You can be up and running in a short amount of time, you pay for only the resources you consume, and you don't have to push yet another server into the data center. Good initial uses of the public cloud include prototyping noncritical applications on a PaaS cloud or providing simple storage via IaaS.
A significant benefit is that you get real cloud computing experience, not more data center exercises under a new name. From there, you can take the lessons learned to get better usage of more public clouds, to deploy a private cloud that leverages cloud principles, and/or to take strong advantage of a mix of public and private clouds (a hybrid cloud).
Ironically, starting with the public cloud removes much of the risk of moving to the cloud; you're not making the large capital and labor investments and nervously awaiting the expected benefit. The costs of using the public cloud are low, and the payoff (especially the learning aspect) is high.
Of course, many Global 2000 enterprises are still wary about using public clouds. Negative perceptions regarding cloud security, performance, and reliability can be daunting obstacles, but those fears are quickly overcome when you take into account the real costs and the real value private clouds versus public clouds. The latter wins every time -- as long as you're willing to share.
Brian Gracely asked if you’re Confused about Cloud Computing? You should be... in a 5/5/2011 post to his Clouds of Change blog:
You [may] or may not believe this, but I think we've reached a point with Cloud Computing where the discussions centered around "definitions" are almost over and we'll quickly be moving into a stage of people/companies wanting to do stuff. I know what you're thinking...thank goodness we can finally stop having every presentation begin with a NIST definition, or a stack showing *aaS this and *aaS that.
That's the good news.
The bad news? The number of available Cloud Computing options in the market today is mind-blowing. Let's take a basic inventory (in no particular order):
Before you dive into these lists, keep this quote from 'The Wire' in mind:
Cutty: "The game done changed."
Slim Charles: "Game's the same, just got more fierce."
IaaS Platforms and Services
- Amazon EC2
- Rackspace Cloud Servers
- GoGrid
- Terremark IaaS
- VCE Vblock
- FlexPod
- VMware vCloud Director
- HP Converged Infrastructure / Blade Matrix
- Dell vStart
- OpenStack (open-source)
- Eucalyptus (open-source)
- Nimbula
- Cloud.com (open-source)
- Open Nebula (open-source)
- [IBM SmartCloud Enterprise] [added]
PaaS Platforms and Services
- Google App Engine
- AWS Elastic Beanstalk
- Salesforce.com / Heroku
- Salesforce.com / VMforce (w/ VMware)
- Cloud Foundry (open-source)
- Microsoft Azure
- Joyent SmartDataCenter
- RedHat Openshift (open-source)
- CloudBees
- Bungee Connect
IBM PaaS[deleted in favor of Iaas]SaaS Platforms and Services
- Google Apps
- Salesforce.com
- Mozy, Crashplan, DropBox, Box.net, Carbonite, BackBlaze
- Skype, WebEx, GoToMeeting
- Microsoft BPOS, Microsoft 365
- <1001 others than I've left off the list, so add your favorites here...>
Open-Source Projects
- Server Hardware - Open Compute
- Hypervisor - Xen and KVM
- Compute/Storage Stack (IaaS) - OpenStack, Eucalyptus, Cloud.com, Open Nebula
- Infrastructure - OpenFlow
- Application Platforms - Cloud Foundry, OpenShift
These lists alone aren't what makes Cloud Computing so complicated. Huh?!? That's a lot of choices, but choice isn't a terrible thing. Where it gets complicated is thinking about the options about vendor selection, commercial products vs. open-source, intelligence in infrastructure vs. intelligence in software, portability of applications between clouds, etc. This is where your heads starts to spin.
So let's start looking at what changes for various people in the Cloud Computing value-chain:
CIO: Your job has probably never been more complicated than it is today. Your vendors/partners are engaging in coopetition like never before. The technology is changing incredibly fast and you're struggling to keep/grow internal talent. Plus your internal users are getting much smarter and may be looking for ways to avoid your services. External services are now available with completely new consumption models, but they also bring a new forms of risk that aren't very well understood yet. And all your colleagues are talking about "cloud projects" and you may not know exactly where to start, or expand. And the start-ups in your industry don't have the existing IT legacy to deal with, so they are approaching the use of IT in strategic ways that you've probably never dealt with before.
IT Operations: If you're like most IT organizations, you're spending 70-80% of your time and budget keeping the internal systems operational. That doesn't leave much time to deal with the pace of change coming from all these cloud offerings, but the CIO is still pushing you for it. So how do you find the funding? How do you find the right skills (internally, retrain, cross-train, externally)? If you're considering a Private Cloud, this might be worth a listen. The key is to start looking at the best practices of the Public Cloud operators (here, here, here and here) and see what best-practices you can bring in-house (where it makes sense) and where external services might make more sense.
Server, Storage, Network teams: In the past, your world was challenging enough keeping up with all the technology, protocols, architectures, etc. Now the divisions between your groups are breaking down as virtualization technologies provide integration within platforms. Or maybe the emerging cloud stacks are abstracting functionality out of your hardware and moving it to application software. Some people look at this as an opportunity to broaden your skills and take a broader role as an "infrastructure specialist" (or "cloud architect"), while others believe that proliferating IT generalists is a bad idea.
Application Developers: Open-Source frameworks; the momentum of DevOps; infrastructure you can obtain with a credit-card and avoid IT bottlenecks. On the surface your world is looking pretty good because many of the barriers from your previous life (software licenses, IT operations, procurement delays, etc.) seem to be coming down. But not everything may be rosy. You've got to potentially design for external/public cloud infrastructure that may not be well understood. And maybe you'll design your applications to be portable between clouds? But you also have to consider new ways to audit applications and data, and potentially new ways to secure it and make applications highly-available.
Systems Integrators: Being able to integrate these complex systems, on-premise or off-premise, may become an even more valuable skill moving forward, especially if you're able to harness some of the open-source projects that allow you to add value. But is that currently your strength? Were you previously focused on solutions based on commercial vendor offerings? Are those vendors still using you as a primary channel, or are they looking to take customer business direct through their own clouds (here, here, here, or here)? Or should you be looking to partner with some of the existing Cloud providers for technology scale, and focus on localized relationships with customers?
Cloud Providers: We've already seen this space consolidating and changing quickly (Terremark/Verizon, CenturyLink/Savvis, TimeWarner/Navisite) as well as outages that have customers questioning if they will deploy to public clouds. But they are moving quickly to roll-out new services and address demands from Enterprise and Government customers. Some are even pushing frameworks that could open up new innovation or undermine operational advantages. Each of them will need to decide if they want to provide commodity services, differentiated services, and which *aaS frameworks they need to support to drive customer demand.
Application "Stores" and Cloud Ecosystems: We're all familiar with App Stores like iTunes or Android, but will independent Application Stores begin to emerge for applications built on open frameworks such as Cloud Foundry? Will we see greater expansion of the services available from existing Cloud providers such as Salesforce.com, Google Apps or others to entice customers not to make themselves overly portable?
IT Vendors: Software stacks and open-source projects are knocking at your door, threatening to disrupt the foundation of businesses built on hardware platforms and commercial software offerings. Will these macro-level trends simply create downward pressure on margins vs. open-source alternatives, or does this spur a new wave of innovation that interacts with these new models in ways to balance the flexibility with stability and investment? Do your customers want solutions based on these newer models, which also changes their internal skills and buying models? Should you hedge your bets by setting up Cloud services directly, or do you continue your existing go-to-market approaches? How do you manage coopetition in partnerships where every vendor appears to be moving into 2 or more adjacent technology markets than they were in a few years ago?
As you can see, the potential for significant change in the overall value chain between technology providers, technology delivery mechanisms and technology consumers is extremely high. It has the potential to significantly change existing business models, but it's also highly dependent on a new set of skills emerging for operators, architectures and people in between.
But out of confusion comes opportunity if you're open to change and new ideas. We're just at the beginning of a significant change in our industry and how it effects business on many levels. How companies (vendors, providers, integrators and business consumers) navigate these changes and confusion will determine the winners and losers of the next 5-to-10-to-20 years in the IT space.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
• Chris Hoff (@Beaker) posted More On Cloud and Hardware Root Of Trust: Trusting Cloud Services with Intel® TXT on 5/6/2011:
Whilst at CloudConnect I filmed some comments with Intel, RSA, Terremark and HyTrust on Intel’s Trusted Execution Technology (TXT) and its implications in the Cloud Computing space specific to “trusted cloud” and using the underlying TPM present in many of today’s compute platforms.
The 30 minute session got cut down into more consumable sound bites, but combined with the other speakers, it does a good job setting the stage for more discussions regarding this important technology.
I’ve written previously on cloud and TXT with respect to measured launch environments and work done by RSA, Intel and VMware: More On High Assurance (via TPM) Cloud Environments. Hopefully we’ll see more adoption soon.
Related articles
- Video: Intel’s Cloud Computing Vision (insidehpc.com)
Chris Hoff (@Beaker) asked Hacking The Cloud – Popular Science!? in a 5/6/2011 post:
In the April 2011 “How It Works” issue of Popular Science, a magazine I’ve loved since I was a kid, Marie Pacella wrote a great story on security and cloud computing.
I was thrilled to be included in several sections and for once I’m not bashful about tooting my own horn — this is so cool to me personally!
The sections that went through editing got cut down quite bit, but originally the drafts included some heavier details on the mechanics and some more meaty sections on technical elements (and theoretical stuff,) but I think Marie and the editors did a great job. The graphics were awesome, also.
At any rate, if you subscribe to the magazine or better yet have the iPad application (which is awesome,) you can check it out:

Jay Heiser posted Butterfly Wings and Nuclear Bombs to his Gartner blog on 5/6/2011:
Both Google and Amazon have recently experienced software failures that led to prolonged downtime. This downtime wasn’t due to a hardware failure, it wasn’t due to natural disasters, or terrorist bombs. It was because staff at the cloud service providers shot their customers in the foot.
This is somewhat surprising, given that one of the beauties of the cloud computing model is that we can almost take fault tolerance for granted. I’m fully prepared to believe that a growing number of cloud service providers are fully insulating their customers from the impact of a hard drive failure, a crashed host, and even the total loss of a data center. What a marvelous and inexpensive form of high availability.
The irony of this new physical fault hyper-tolerance is that it also increases the potential for and the damage from a logical failure. No single terrorist attack could do as much damage as a poorly-tested software upgrade. It is easier to build a nuclear bomb shelter than it is to anticipate every stroke of the software butterfly’s wing that might cascade into a cloud data storm.
To the extent that commercial cloud computing does change the disaster scenario, it requires revised or even new IT contingency practices. What exactly does it mean when a CSP talks about recovery time objectives (RTO)? Recovery from what? How is a potential customer supposed to conceptualize the potential for data loss, and how can they gain a useful assessment of a provider’s ability to restore data? Google and Amazon both took 4 days to restore service after relatively limited failures. Is there a linear relationship between recovery time and the amount of data that is lost? How long does it take to restore a cloud? How often does a cloud need to be rebooted, and how long does that take? Personally, I’m not convinced that traditional BCP/DR practices and terminology will fully apply to cloud computing–at least not without some adaptation. What hasn’t changed is the benefit of maintaining offline backups. In the recent Google and Amazon failures, data was completely lost from within the active cloud. Some of that lost data was subsequently recovered from tape, and some was not.
The best practices for commercial cloud continuity and recovery are ambiguous and incomplete, and it is yet another area where buyers should demand more transparency from service providers. Watch out for the head fake. If you ask a CSP about their ability to recover from a data loss incident, and they reply that they have a High level of Availability, its probably a head fake. Fault tolerance is a wonderful thing, but no system, especially a highly complex and distributed one, can be fully resistant to all forms of accidental faults, let alone deliberate attack. Its nice to know that a provider can continue to provide service even if a bomb or flood takes a data center offline, but what’s their contingency plan for a data-eating software upgrade? Simple and mundane failures represent a bigger potential for service and data loss than do dramatic events.
For cloud computing, the scary disaster movie plot starts with a poorly-tested patch.
Graphic: Eastern Tailed-Blue by Jay Heiser
<Return to section navigation list>
Cloud Computing Events
• Max Uritsky reported on 5/6/2011 a Leveraging DataMarket to Create Cloud-Powered Digital Dashboards Webcast scheduled for 5/24/2011 at 8:00 AM PDT:
On May 24 at 8 am PST, join our upcoming MSDN webcast “Leveraging DataMarket to create Cloud-Powered Digital Dashboards. Milos Glisic, Director of Development, ComponentArt Inc., and Christian Liensberger, Program Manager, Microsoft Corporation will showcase ComponentArt’s Data Visualization technology to create interactive, web-based digital dashboards in Microsoft Silverlight 4 and mobile dashboards on Windows Phone 7 using Windows Azure DataMarket.
Click here to register
Jonathan Rozenblit announced on 5/6/2011 a Developer Lunch and Learn Webinar: Windows Azure series starting 5/19/2011:
I’ve been talking a lot about AzureFest recently as we’re travelling around the country introducing developers to the concepts of Cloud computing, and more specifically, what’s possible with Windows Azure. Many of you have told me that with a schedule defined by the constraints of application build, test cycle, and deployment milestones, taking the time out of your day to come out to an in-person training event is difficult. You also told me that short 1 hour training “sprints” squeezed in during the day are a great way to get your training done while not interfering with your project commitments.
As a result, I’ve designed a 3-part lunch and learn live webinar series where we can get together for three Thursdays and explore how to build solutions for the Cloud. You’ll see how developing and deploying applications to Windows Azure is fast and easy, leveraging the skills you already have (.NET, Java, PHP, or Ruby) and the tools you already know (Visual Studio, Eclipse, etc.), all in the comfort of your own chair, at the office, or at home.
We’ll go through an overview of Windows Azure, making sure that you learn everything to you need to know to get up and running with Windows Azure. We’ll cover the Windows Azure platform itself, the Windows Azure SDK, and the Windows Azure Tools for Visual Studio 2010. We’ll then apply the concepts as we migrate a traditional on-premise ASP.NET MVC application to Windows and SQL Azure.
Unlike other webinars, this is a hands-on event. This means that you will be following along in your own environment and, by the end of the webinar, your application will be running on Windows Azure!
Click here for the webinar details.
I look forward to spending Thursday lunches with you learning about the Cloud!
Cory Fowler (@SyntaxC4) announced AzureFest: [Now an] Open Source Presentation in a 5/6/2011 post:
Undoubtedly by now you have heard of AzureFest, with any luck you have been out to one of the events [if you live in the GTA]. For the rest of you, that haven’t been able to experience the event, I wanted to take the opportunity to introduce you to what AzureFest is and why you might be interested in the event itself.
What is AzureFest?
At it’s core AzureFest is a talk that focuses on a few barriers to Windows Azure Adoption including Pricing, Registration, Platform Confusion and Coding/Deployment. This is not your Grandma’s Windows Azure Presentation, It includes both a lecture and a hands on component which is rare for a Community Event.
Why Talk Pricing?
Simple, pricing is the first question that I get asked at the end of every presentation that I’ve done to date, so why not talk about it first? Pricing goes hand-in-hand with the Platform, which means not only do you get to understand what the Windows Azure Platform consists of, but you also get an understanding of what it will cost as well. Finally, It would be rather irresponsible not to talk about the costs of Windows Azure when the first Hands-on-Lab is a walkthrough of the registration process.
What Will I Learn?
Besides the Overview of the Platform and the Pricing Strategies, each attendee who participates in the Labs will learn:
How to Register for a Windows Azure Platform Subscription
How to Create, Manage, Configure and Leverage a SQL Azure Database
How to Create and Configure a Windows Azure Storage Service Account
How to Create & Deploy a Project to Windows Azure Compute
How to use the Windows Azure Platform Portal
Attendees will also learn some of the gotcha’s around the Tool Installation/Configuration Process and some strategies on how to debug your cloud based solutions both on premise [using the Compute Emulator] and “In The Cloud”.
Bonus… We’re giving it away!
In the spirit of growing adoption of the Windows Azure Platform within Canada [or any country for that matter], ObjectSharp is releasing the content as an Open Source Presentation. This means it is FREE for anyone to download, learn and/or deliver.
If you are interested in doing an AzureFest presentation in your area, download the Resources for AzureFest. The resources include:
- An AzureFest Slide Deck
- Hands-on-Lab Kit [Ready to deploy cspkg and cscfg files]
- Modified NerdDinner Source Code for Hands-on-Lab
If you have specific questions about delivering an AzureFest presentation, or need clarification on the content, please direct your questions to me via twitter.


The Windows Azure Team asserted It’s Not Too Late to Attend – or Host - A Windows Azure Boot Camp Near You! in a 5/5/2011 post:
If you’re looking for some deep-dive training on Windows Azure, you may still be able attend a Windows Azure Boot Camp near you. Boot Camps have been going on since late last year but there are still a handful of upcoming classes.
Upcoming classes* are:
- May 9-10, 2011: Bloomington, IN
- June 14-15, 2011: San Francisco
- June 15-16, 2011: Las Vegas, NV
- September 23-24, 2011: Salt Lake City, UT
Each Boot Camp is a FREE two-day deep dive class to get you up to speed on developing for Windows Azure. The class includes a trainer with deep real world experience with Windows Azure, as well as a series of labs so you can practice what you just learned. For most boot camps, you will need to bring your own laptop and have it preloaded with the software listed here.
If you don’t see a class in your area, don’t worry - throw one of your own! Windows Azure Boot Camp organizers will provide all of the materials and training you need to host your own class. This can be for your company, your customers, your friends, or even your family. Click here to send a note to ask for more information.
*Schedules are subject to change; click here to see the latest list of Windows Azure Boot Camps.

Troy Angrignon announced on 5/5/2011 Private Cloud Webinar with CloudTP to be held 5/12/2011 at 10:15 AM PDT:
Next Thursday, we’re joining with our partner CloudTP to deliver a webinar on effective development and deployment of private cloud. We’ll talk about:
- The state of the private cloud market
- The business case for implementing private clouds
- The architecture of a well-structured private cloud initiative
- The essential technical components of private clouds
- The application strategy and its critical role
Date: Thursday, May 12, 2011
Time: 9:30 until 10:15 PDT
Should be a useful 45 minutes. Register, and help us spread the word.
The Mobile Tech Association of Michigan posted Mobile and the Cloud - a Perfect Match; Learn Why at MoMoDetroit on May 9th on 5/3/2011:
As more and more companies support more and more complex mobile scenarios, the need for a reliable and cost-effective back-end solution is paramount. Users expect access to personal and corporate data from whatever devices they choose to carry, blurring the traditional boundaries of corporate firewalls. Development timelines for mobile applications are usually measured in days or weeks, not months or years, so they need to provision resources quickly, and a successful mobile app may need to scale very rapidly as well.
With his presentation, ‘Mobile and The Cloud – A Perfect Match’, Microsoft’s Patrick Foley will explain how cloud technologies match these needs of mobile software development perfectly. The cloud is cheap, reliable, secure, ubiquitous, and easy to scale. His presentation gives an overview of what “the cloud” is, who the major players are, and how mobile developers can take advantage of cloud technologies today.
Patrick Foley is an ISV Architect Evangelist with Microsoft. His responsibilities include helping software companies, including mobile software companies, to build on top of the Microsoft platform, particularly in the areas of Windows Phone and Windows Azure.
Also presenting will be Jim Jakary, Senior Regional Sales Manager with Fiberlink Communications. Fiberlink designed, built, markets and maintains MaaS360, the only true cloud-based wireless solution for managing worldwide mobile devices and life cycle for smartphones, tablets, and laptop computers.
Jim’s presentation will focus on the realities of enterprise remote device management using a cloud-based utility solution. He will share mobile industry trends and best practices seen while working with Fortune 1000 companies, discuss core attributes that define cloud-based services for mobility, and provide insights to help attendees see and manage smartphones, tablets, and laptops that connect to corporate systems. Further, he will contrast SaaS offerings with “hosted” mobility solutions, and talk to key IT considerations for each delivery model regarding on-premise hardware and software, maintenance, updates, network configuration, licensing, and life-cycle.
Once again Mobile Monday Detroit will be meeting at the Compuware Building located at 1 Campus Martius in Detroit.
Please note that the networking portion of our meeting begins at 5:30 p.m., presentations begin at 6:00 p.m. and advance registration is required. You may register to attend the event at http://meetup.com/Mobile-Monday-Detroit. Refreshments will be provided, and free parking is available in Compuware’s conveniently-located parking deck.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Carl Brooks (@eekygeeky) described Red Hat's halfhearted attempt at cloud in a 5/5/2011 post to SearchCloudComputing.com:
Red Hat announced the fruits of its cloud computing labor at the Red Hat Summit user conference in Boston this week. Frankly, it seemed a little out of sorts in the sunlight, like a Linux geek who's left the basement during normal business hours.
CloudForms is the company's Infrastructure as a Service, an outgrowth of the Deltacloud project, and then there's OpenShift, a PaaS stack whose tagline is "push git and go." There's also a JBoss thing called Enterprise Data Grid 6 that's being touted as a "cloud-ready, scalable distributed data cache."
CloudForms is a beta signup; we know it incorporates the Deltacloud application programming interfaces (APIs), which means it includes the ability to provision on outside public cloud services, and it's touted as heavy on "application management," so we can assume there's a service catalog and templator of some kind (it's called Image Factory in the white paper).
It's using Condor and something called Katello, as well as "the messaging component of Red Hat Enterprise MRG" and a version of Gluster called, what else, "CloudFS" for blob storage. Identity management contains components from Red Hat Enterprise Identity, and so on. Basically, they've gathered enough bits and pieces from the sum total of RHEL to add up to the definable characteristics of a cloud infrastructure, when you use it with KVM or a "Red Hat Certified Cloud Provider."
A closer look at Red Hat's new cloud pieces
To be fair, RHEL does a lot of very complicated stuff, and I'm picking out only the bits that can make cloud a pain. OpenShift looks a bit more promising; the company claims that it's "free, leading-edge cloud services that enable developers to deploy applications." Sign up for a subscription, download the client-side bits and make an app. Push the code onto your new application thingie and away you go.Does it work? Probably; somebody will give it a try fairly soon. But exactly how "free" is it? Can I run a business on it; what's going to happen if I try? What's going to happen when Russian spammers try? Chances are, if it takes off, Red Hat will clarify what it means to be "free" with extreme vigor, but for now they do seem to have the "online, self-serve, easy" part of cloud down.
Nobody knows why JBoss Enterprise Data Grid 6 is cloud, but it was on the list. It must be tough being Red Hat these days, probably a little bit like IBM: you've been at the front end of enterprise IT for a long time, doing things your own way, and all of a sudden some jerks with an online bookstore come along and roll out a smashing success based on open source and automation. They call it cloud computing, and now you're all alone at the party and can't figure out why everyone's so keen on that guy. You can do everything he does…well, you could've…
Anyway, it's nice that Red Hat recognizes the cloud trend. But how is this going to play out when cloud platforms like Eucalyptus and Abiquo, ones that have been around for years at this point, work out the kinks and build a user base at telecoms and other early cloud adopters? Where is Red Hat going to get an ecosystem of "Red Hat Certified Cloud Providers" when, between them, Rackspace Cloud and Amazon Web Services (AWS) have 300,000 users (based on Rackspace disclosures and an educated guess about AWS usage) and show no signs of slowing down?
OpenShift seems to have taken the lessons of Google App Engine, Engine Yard and Heroku to heart, but those platforms, again, have years of problem-solving, wrinkle-smoothing and outage-surviving under their belts. It's one thing to be an enterprise leader and say cloud is the future; it's another when the future is already here.

More on Red Hat and the cloud:
Rosalie Marshall reported SAP blames Amazon outage for difficulties selling SaaS products in a 5/5/2011 post to the v3.co.uk blog:
SAP is blaming cloud computing giant Amazon Web Services (AWS) for difficulties it says the industry is experiencing selling software-as-a-service.
Sanjay Poonen, head of SAP’s global solutions business, told Bloomberg that the Amazon outage, which occurred over a week ago, has made it harder to convince customers of the benefits of cloud computing.
"It was a tough week,” he reportedly said of the incident. “We’ll have to work harder to make people comfortable with where cloud computing is.”
The outage left many AWS customers' web services crippled or inaccessible for a period of several days.
Industry analysts have said the outage should serve as a lesson for all enterprises considering moving to cloud platforms. Meanwhile, IDC analyst David Bradshaw said he had sympathy with SAP’s point of view.
“If a major service outage occurs, people will be worried about the availability of the services depending on it. People don’t want to find that business-dependent services cannot be accessed because of an outage,” he told V3.co.uk.
Bradshaw argued that the extent to which the outage affects other cloud computing vendors will depend on how businesses interpret Amazon’s explanation of the outage.
AWS said that it was caused by a misdirected software upgrade, which shifted large amounts of traffic onto systems not configured to handle the load. This triggered further outages before the problem was resolved.
“If this is proved an exceptional event that is not necessarily going to be duplicated by other service providers, there will be less damage to the cloud computing industry than if the outage is seen as a problem in the general cloud infrastructure,” said Bradshaw.
SAP has previously admitted that it is encountering problems selling its Business ByDesign software-as-a-service offering. The product was launched in 2007 but, because of technical problems with its architecture, it was ready for widespread deployment only last year.
Jeff Barr (@jeffbarr) announced AWS Elastic Beanstalk Now Supports Tomcat 7 in a 5/5/2011 post:
We've added a second container type to AWS Elastic Beanstalk. Version 7 of Apache Tomcat is now available for use and is the default for all new environments (you can still choose version 6 if you'd like).
Tomcat 7 includes functional improvements such as support for the latest versions of a number of standards including Servlet 3.0 (JSR 315), JSP 2.2 (JSR 245), and JSP-EL 2.2. It also includes some security improvements such as CSRF request prevention using a nonce and a memory leak detection and prevention mechanism. For more information, check out the Apache Tomcat 7 documentation.
The AWS Toolkit for Eclipse also supports a new server type called "AWS Elastic Beanstalk for Tomcat 7." You will need to update your AWS Toolkit plugin using the Software Updates… menu item in the Eclipse Help menu.
If your application can run on Tomcat 7 and you would like to migrate your environment, here is how you can do it with minimal downtime:
- In the AWS Management Console, make sure the application you’d like to migrate is selected.
- Click on Launch New Environment in the top right corner.
- From the Select an existing application version drop down, choose the application version that you’d like to run on Tomcat 7.
- From the Container Type drop-down, select the Tomcat 7 container that best fits your application and complete the rest of the wizard with the settings that work for your application.
- Once the environment has launched, test your application and make sure that it works as expected
- Move your existing domain name to point to the new environment’s URL.
- Once you’ve verified that the domain name is pointing to the new environment, use the Actions menu for the old environment, to Terminate this Environment.
James Urquhart (@jamesurquhart) posted Outages, complexity, and the stronger cloud on 5/4/2011 to his The Wisdom of Clouds blog on C|Net News:
The extended outage of Amazon Web Services' EBS storage services in one of their service "regions" the week of April 21st has triggered so much analysis--emotional and otherwise--that I chose to listen rather than speak until now. Events like this are tremendously important, not because they validate or invalidate cloud services, but because they let us see how a complex system responds to negative events.
You see, for almost four years now, I've believed that cloud computing is evolving into a complex adaptive system. Individual services and infrastructure elements within a cloud provider's portfolio are acting as "agents" that have various feedback mechanisms with various other services and infrastructure. A change in any one element triggers automation that likely changes the condition of other elements in the system.
It's similar to the behavior of other systems, such as automated trading on the stock market (an example I've used before).
The thing is, science shows us that in complex adaptive systems tiny changes to the system can result in extreme behaviors. Events like this will happen again. I don't panic when there is a cloud outage--I embrace it, because the other aspect of complex adaptive systems is that they adapt; they get better and better at handling various conditions over time.
I'll bet this week's VMware Cloud Foundry outage will be an excellent microcosm in which to see this behavior play out. That outage was also triggered by human error. The result will be corrections to the processes that were violated, but also evolution of the service itself to be more resilient to such errors. Cloud services can't afford only to attempt to ban mistaken behavior; they have to find what it takes to remain viable when faced with one of those mistakes.
Outages are inevitable. We all know that's true. We don't have to like it, but we have to live with it. But thinking that good design can eliminate failure outright is naive. Demanding that our providers adapt their services to eliminate specific failures is where the rubber meets the road.
How does one improve the resiliency of a complex adaptive system? By changing its behavior in the face of negative events. We can plan as humans for a fairly wide swath of those events, but we can't protect against everything. So, when faced with a major failure, we have to fix the automation that failed us. Change an algorithm. Insert new checks and balances. Remove the offending element for good.
There is, however, no guarantee that one fix won't create another negative behavior elsewhere.
Which brings me to my final point: many AWS customers felt let down by Amazon as a result of this outage. I think they had the right to feel that way, but not to the extent that they could claim Amazon was negligent in how it either built EBS or handled the outage. Amazon was, however, guilty of not giving customers enough guidance on how to develop resilient applications in AWS.
Graphic Credit: CNET/Tom Krazit
Judith Hurwitz (@jhurwitz) asked Can IBM Build a Strong Cloud Partner Ecosystem? in a 5/3/2011 post to her Cloud-Centric blog:
Despite all of the hand wringing surrounding Amazon.com’s service outages last week, it is clear to me that cloud computing is dramatically changing the delivery models of computing forever. We simply will not return to a model where organizations assume that they will consume primarily their own data center resources. The traditional data center certainly isn’t going away but its role and its underlying technology will change forever. One of the ramifications of this transition is the role of cloud infrastructure leaders in determining the direction of the partnership models.
Traditionally, System vendors have relied on partners to expand the coverage of their platforms. With the cloud, the requirement to have a strong partner ecosystem will not change. If anything, partners will be even more important in the cloud than they have been in traditional computing delivery models. This is because with cloud computing, the barriers to leveraging different cloud-based software offerings – platform as a service and Software as a Service are very low. Any employee with a credit card can try out just about anything. I think that the Amazon.com issues will be seen in the future as a tipping point for cloud computing. It, in fact, will not be the end to cloud but it will change the way companies view the way they select cloud partners. Service management, scalability, and reliability will become the selection standard – not just for the end customer but for partners as well.
So, I was thinking about the cloud partnership model and how it is evolving. I expect that the major systems vendors will be in a perfect position to begin to reassert their power in the era of the cloud. So, I decided to take a look at how IBM is approaching its partnership model in light of cloud computing. Over the past several months, IBM has been revealing a new partnership model for the cloud computing market. It has been difficult for most platform vendors to get noticed above the noise of cloud pioneers like Amazon and Google. But this is starting to change. It is not hard to figure out why. IBM believes that cloud is a $181 billion business opportunity and it would like to grab a chunk of that opportunity.
Having followed IBM’s partnering initiatives for several decades I was not surprised to see a revamped cloud partnering program emerge this year. The new program is interesting for several different reasons. First, it is focused on bringing together all of IBM’s cloud offerings across software, developer relations, hardware, and services into a single program. This is important because it can be intimidating for an ISV, a Value Added Reseller, or a systems integrator to navigate the complexity of IBM’s offerings without some assistance. In addition, IBM has to contend with a new breed of partners that are focused on public, private, and hybrid cloud offerings.
The new program is called the Cloud Specialty program and targeted to cover the entire cloud ecosystem including cloud builders (hardware and software resellers and systems integrators), Service Solution Providers (software and service resellers), Infrastructure Providers (telecom providers, hosting companies, Managed Service Providers, and distributors), Application Providers (ISVs and systems integrators), and Technology Providers (tools providers, and appliance vendors).
The focus of the cloud specialty program is not different than other partnering programs at IBM. It is focused on issues such as expanding the skills of partners, building revenue for both IBM and partners, and providing go to market programs to support its partners. IBM is the first to admit that the complexity of the company and its offerings can be intimidating for partners. Therefore, one of the objectives of the cloud specialty program is to clarify the requirements and benefits for partners. IBM is creating a tiered program based on the different types of cloud partners. The level of partner investment and benefits differ based on the value of the type of partner and the expectation of those partners. But there are some common offerings for all partners. All get early access to IBM’s cloud roadmap, use of the Partnerworld Cloud Specialty Mark, confidential updates on IBM’s cloud strategy and roadmap, internal use of LotusLive, networking opportunities. In addition, all these partners are entitled to up to $25,000 in business development funds. There are some differences. They include:
- Cloud builders gain access to business leads, and access to IBM’s lab resources. In exchange these partners are expected to have IBM Cloud Reference architecture skills as well as cloud solutions provider and technical certification. They must also demonstrate ability to generate revenue. Revenue amounts vary based on the mix of hardware, software, and services that they resell. They must also have two verified cloud references for the previous calendar year.
- Service Solution Providers are provided with a named relationship manager and access to networking opportunities. In exchange, partners are expected to use IBM cloud products or services, demonstrate knowledge and skills in use of IBM cloud offerings, and the ability to generate $300,000 in revenue from the partnership.
- Infrastructure Providers are given access to named IBM alliance manager, and access to business development workshops. In exchange, these partners are expected to use IBM’s cloud infrastructure products or services, demonstrate skills in IBM technology. Like service solution providers they must use and skills in IBM cloud offerings, have at least $300,000 a year in client references based on two cloud client references
- Application Providers are given access to a named IBM alliance manager, and access to business development workshops. They are expected to use IBM cloud products or services, have skills in these technologies or services, and a minimum of $100,000 a year in revenue plus two cloud client references.
- Technology Providers get access to networking opportunites, and IBM’s cloud and services assessment tools. In exchange, these partners are required to demonstrate knowledge of IBM Cloud Reference architecture, have skills related to IBM’s cloud services. Like application providers, these partners must have at least $100,000 in IBM revenue and two client references.
What does IBM want? IBM’s goals with the cloud specialty program is to make it as attractive as possible for prospective partners to chose its platform. It is hoping that by offering financial and technical incentives that it can make inroads with cloud focused companies. For example, it is openings its labs and providing assistance to help partners define their offerings. IBM is also taking the unusual step of allowing partners to white label its products. On the business development side, IBM is teaming with business partners on calls with prospective customers. IBM anticipates that the impact on these partners could be significant – potentially generating as much as 30% gross margin growth.
Will the effort work? It is indeed an ambitious program. IBM will have to do a good job in explaining its huge portfolio of offerings to the prospective partners. For example, it has a range of services including CastIron for cloud integration, analytics services, collaboration services (based on LotusLive), middleware services, and Tivoli service management offerings. In addition, IBM is encouraging partners to leverage its extensive security services offerings. It is also trying to encourage partners to leverage its hardware systems. One example of how IBM is trying to be more attractive to cloud-based companies like Software as a Service vendors to to price offerings attractively. Therefore, it is offering a subscription-based model for partners so that they can pay based on usage – the common model for most cloud platform vendors.
IBM is on the right track with this cloud focused partner initiative. It is a sweeping program that is focused on provides a broad set of benefits for partners. It is pricing its services so that ISVs can rent a service (including IBM’s test and development cloud) by the month — an important issue in this emerging market. It is also expecting partners to make a major investment in learning IBM’s software, hardware, and services offerings. It is also expecting partners to expand their knowledge of the markets they focus on.
See my Test-Driving IBM’s SmartCloud Enterprise Infrastructure as a Service: Part 2 - Spring 2011 Promotion Free Trial (updated 5/6/2011) and Test-Driving IBM’s SmartCloud Enterprise Infrastructure as a Service: Part 1 (updated 4/6/2011) for a first take on IBM’s SmartCloud Enterprise offering.
<Return to section navigation list>

















0 comments:
Post a Comment